ΚΕΦΑΛΑΙΟ 7 - Επεξεργασία και Κατανόηση Φυσικής Γλώσσας
Σύνοψη
Η επεξεργασία φυσικής γλώσσας είναι μια από τις πιο δημοφιλείς εφαρμογές της ΤΝ. Η ιδέα του να επικοινωνεί κάποιος με τον υπολογιστή και να τον ελέγχει μιλώντας τη μητρική του γλώσσα ή κάποια ευρύτερα ομιλούμενη, όπως τα αγγλικά, είναι πολύ ελκυστική. Όμως, η φυσική γλώσσα έχει διττή φύση (ως προς τη σύνταξη και ως προς τη σημασιολογία), γεγονός που δεν εμποδίζει μεν την επεξεργασία της, αλλά δημιουργεί προβλήματα στην κατανόησή της, με αποτέλεσμα να καθίσταται το εγχείρημα της επεξεργασίας και παράλληλα της κατανόησής της ιδιαίτερα δύσκολο. Στο κεφάλαιο αυτό εξετάζουμε τα στάδια της επεξεργασίας φυσικής γλώσσας (: τη συντακτική, τη σημασιολογική και την πραγματολογική ανάλυση) και θίγουμε θέματα σχετικά με την πραγματολογική ανάλυση και τις τεχνικές που χρησιμοποιούνται για διευκρίνιση διφορούμενων προτάσεων και καθιστούν εφικτή την κατανόηση κειμένου.
Προαπαιτούμενη γνώση
Επεξεργασία γλωσσών προγραμματισμού, Μεταγλωττιστές
7.1 Εισαγωγή
Πριν κάνουμε επισκόπηση στο πώς μπορούμε να επιτύχουμε την επεξεργασία φυσικής γλώσσας (natural language processing-NLP) και την κατανόηση φυσικής γλώσσας (natural language understanding-NLU), θα παρουσιάσουμε τα οφέλη που μπορεί να επιφέρει η χρήση φυσικής γλώσσας κατά την επικοινωνία χρήστη-υπολογιστή. Πλήθος τομέων μπορούν να επωφεληθούν από τη χρήση της, με κυριότερο, καταρχάς, την επικοινωνία ανθρώπου-μηχανής (human-computer interaction). Στο χώρο αυτό, η χρήση φυσικής γλώσσας επιτρέπει στους χρήστες να χρησιμοποιούν το φυσικό τρόπο επικοινωνίας τους και όχι τεχνητές γλώσσες (προγραμματισμού, μηχανής, κ.ά.) ή δομημένα μενού. Μια τέτοια προσέγγιση έχει και προτερήματα και μειονεκτήματα. Ναι μεν δεν απαιτείται εκπαίδευση στη χρήση της γλώσσας, αλλά αυτό διευκολύνει περισσότερο τους περιστασιακούς χρήστες και λιγότερο τους εξειδικευμένους, όπως είναι για παράδειγμα οι προγραμματιστές ή οι υπάλληλοι γραφείου που εισάγουν στοιχεία σε φόρμες.
Μια δεύτερη περιοχή είναι αυτή της διαχείρισης πληροφορίας (information management), όπου η NLP θα μπορούσε να ενεργοποιήσει διαδικασίες αυτόματης διαχείρισης και επεξεργασίας της πληροφορίας με βάση τη διερμηνεία της. Αν, για παράδειγμα, ένα σύστημα μπορούσε να κατανοήσει το νόημα ενός εγγράφου, θα μπορούσε να το αρχειοθετήσει μαζί με τα άλλα αντίστοιχα έγγραφα.
Τρίτη περιοχή είναι αυτή της αναζήτησης σε βάσεις δεδομένων (database searching). Οι συνήθεις τρόποι έκφρασης μιας επιθυμητής πληροφορίας είναι μέσω επιλογής από λίστες, συμπλήρωσης μενού ή σύνταξης του αιτήματος σε τεχνητή γλώσσα (special query language-SQL). Η χρήση τεχνητής γλώσσας επιτρέπει μεν την ανάπτυξη απλών μηχανισμών αναζήτησης, αλλά και πάλι ο χρήστης πρέπει να έχει κάποια γνώση σχετικά με τη δομή της βάσης. Από την άλλη πλευρά, ο χρήστης είναι πιο εξοικειωμένος με το περιεχόμενο ή την περιοχή ενδιαφέροντος της βάσης παρά με τη δομή της. Με τη χρήση φυσικής γλώσσας, τα αιτήματα μπορεί να περιοριστούν σε όρους σχετικούς με το περιεχόμενο και την περιοχή ενδιαφέροντος.
7.2 Δυσκολίες στην Κατανόηση Φυσικής Γλώσσας
Η μεγαλύτερη δυσκολία στην επεξεργασία φυσικής γλώσσας είναι η διφορούμενη ερμηνεία που προκαλεί ασάφεια στη γλώσσα (ambiguity of language) σε πολλά επίπεδα: .
- καταρχάς, ασάφεια σε επίπεδο σύνταξης (ambiguity at syntactic level) της γλώσσας. Κάποιες συντακτικά ορθά προτάσεις επιδέχονται πάνω από μια διερμηνεία, ανάλογα με το πώς θα αναλυθούν συντακτικά, καθιστάμενες συντακτικά ασαφείς. Για παράδειγμα:
Χτύπησα τον κλέφτη με το τσεκούρι. Το τσεκούρι ήταν το όπλο με το οποίο χτύπησα τον κλέφτη ή χτύπησα τον κλέφτη που κρατούσε το τσεκούρι;
- Δευτερευόντως, ασάφεια σε επίπεδο λεξιλογικό (ambiguity at lexical level), όταν το νόημα μιας λέξης είναι διφορούμενο. Για παράδειγμα:
Το πρώτο γράμμα του Γιώργου. Εννοεί το πρώτο γράμμα που έγραψε ο Γιώργος ή το γράμμα του αλφαβήτου από το οποίο αρχίζει το όνομα «Γιώργος»; Η λέξη γράμμα έχει δυο έννοιες, της επιστολής και του γράμματος του αλφαβήτου.
- Τρίτον, ασάφεια σε αναφορικό επίπεδο (ambiguity at referential level), όταν δεν είναι ευκρινές το σε ποιον, πού ή σε τι η πρόταση αναφέρεται. Για παράδειγμα:
Ο Γιάννης χτύπησε τον Πέτρο, γιατί του αρέσει η Μαίρη. Σε ποιον αρέσει η Μαίρη, στο Γιάννη ή στον Πέτρο;
- Τέταρτον, ασάφεια σε σημασιολογικό επίπεδο (ambiguity at semantic level), όταν, με διατήρηση της ίδιας συντακτικής ανάλυσης, η πρόταση επιδέχεται τουλάχιστον δυο διαφορετικές ερμηνείες. Για παράδειγμα:
Τον άφησε στα κρύα του λουτρού. Η πρόταση κυριολεκτεί ότι κάποιος άφησε κάποιον άλλον στα κρύα ενός λουτρού ή παρουσιάζει μεταφορικά ότι τον παράτησε και έφυγε στη μέση κάποιας συνεργασίας;
- Τέλος, ασάφεια σε πραγματολογικό επίπεδο (pragmatic level), κατά τη διερμηνεία μιας πρότασης, όταν λαμβάνουμε υπόψη το πλαίσιο του κειμένου που την περιέχει. Στην παρακάτω πρόταση δεν είναι εύκολο να λυθεί η πραγματολογική ασάφεια:
Οι δεινόσαυροι έχουν εξαφανιστεί πολλά χρόνια. Πόσα χρόνια είναι τα πολλά χρόνια;
Οι επιμέρους ασάφειες μπορεί να συνδυαστούν σε μια μόνη πρόταση. Για παράδειγμα, η παρακάτω πρόταση περιέχει ασάφεια σε λεξιλογικό, αναφορικό και πραγματολογικό επίπεδο:
- Ο Νίκος ζήτησε από τον Ηλία να τον αντικαταστήσει στη δουλειά σήμερα, πριν φύγει ταξίδι. Υπάρχει αμφιβολία σχετικά με την απόδοση του χρονικού προσδιορισμού «σήμερα» σε ένα από τα δύο ρήματα, όπως και για το ποιος θα φύγει ταξίδι (πραγματολογικό και αναφορικό επίπεδο).
- Ο Γιάννης χτύπησε εχθές τον Πέτρο, που είναι γάιδαρος, επειδή του αρέσει η Μαίρη. Σε επίπεδο σημασιολογικής ασάφειας δεν ξέρουμε αν ο Πέτρος είναι ζώο γάιδαρος ή άνθρωπος που συμπεριφέρεται ως γάιδαρος. Από πλευράς αναφορικής δεν ξέρουμε σε ποιον αρέσει η Μαίρη και από πλευράς πραγματολογικής δεν ξέρουμε το πότε είναι το «χθες».
7.3 Ιστορική Αναδρομή
Από το 1950-1960, οπότε κατασκευάζονται οι πρώτοι υπολογιστές και επιτρέπουν το χειρισμό αριθμών και λέξεων, παρουσιάζονται και οι πρώτες δυνατότητες επεξεργασίας γλωσσικής γνώσης.
- Στα μέσα της δεκαετίας του 1960 , στο σύστημά του ELIZA ο Weizenbaum βασίζεται στα αυτόματα πεπερασμένων καταστάσεων (finite state automata, FSA) για την αναγνώριση λεκτικών οντοτήτων (π.χ., λέξεων και άλλων στοιχείων του λόγου). Τη ίδια δεκαετία , ο Schank με τη βοήθεια των σημασιολογικών δικτύων (semantic networks) εισάγει την έννοια των εννοιολογικών εξαρτήσεων (conceptual dependencies).
- Τα έτη 1968-1970, ο Winograd, με το σύστημά του SHRDLU, γραμμένο σε Lisp, προσφέρει το πρώτο σύστημα κατανόησης φυσικής γλώσσας.
- Στις αρχές της δεκαετίας του 1970 ο Montague εργάστηκε επί της αρχής της συνθετικότητας, για να αναλύσει προτάσεις της φυσικής γλώσσας με αρκετή επιτυχία. Ήδη στα τέλη του 19ου και στις αρχές του 20ου αιώνα, ο Frege είχε εισαγάγει την ιδέα πως η σημασία μιας πρότασης είναι συνθετική και απαρτίζεται από τις επιμέρους έννοιες των συνθετικών μερών της (compositional semantics).
- Το 1977 οι Schank και Abelson συνέβαλαν σημαντικά στην κατανόηση της φυσικής γλώσσας με την αναπαράσταση του κειμένου μέσω σεναρίων (scripts) που εξετάζουν την αιτιότητα και τη διαδοχή των γεγονότων μέσα σε αυτό.
Μπορεί σήμερα η επεξεργασία και κατανόηση φυσικής γλώσσας να επιφέρει εντυπωσιακά αποτελέσματα, αλλά στις απαρχές του κλάδου οι τεχνικές που χρησιμοποιούνταν και τα αποτελέσματα ήταν στοιχειώδη. Για παράδειγμα, στο πρόγραμμα ELIZA, το οποίο προσομοιώνει τη συνομιλία ενός ψυχιάτρου με μια ασθενή, γίνεται απλή αναγνώριση λεκτικών μονάδων που πυροδοτούν τυποποιημένες απαντήσεις του προγράμματος-ψυχίατρου. Ακολούθως, δίνεται ένας παραδειγματικός διάλογος:
ΟΙ ΑΝΘΡΩΠΟ ΕΙΝΑΙ ΟΛΟΙ ΙΔΙΟΙ : ασθενής
ΜΕ ΠΟΙΟ ΤΡΟΠΟ; : πρόγραμμα-ψυχίατρος
ΠΑΝΤΑ ΑΠΑΙΤΟΥΝ ΚΑΤΙ ΑΠΟ ΕΜΑΣ ΜΕ ΤΟΝ ΕΝΑ Η ΤΟΝ ΑΛΛΟ ΤΡΟΠΟ
ΜΠΟΡΕΙΣ ΝΑ ΣΚΕΦΤΕΙΣ ΕΝΑ ΣΥΓΚΕΚΡΙΜΕΝΟ ΠΑΡΑΔΕΙΓΜΑ;
ΝΑ, Ο ΦΙΛΟΣ ΜΟΥ ΜΕ ΕΚΑΝΕ ΝΑ ΕΡΘΩ ΕΔΩ
Ο ΦΙΛΟΣ ΣΟΥ ΣΕ ΕΚΑΝΕ ΝΑ ΕΡΘΕΙΣ ΕΔΩ;
ΛΕΕΙ ΟΤΙ ΕΊΜΑΙ ΣΕ ΚΑΤΑΘΛΙΞΗ ΤΟΝ ΠΕΡΙΣΣΟΤΕΡΟ ΧΡΟΝΟ
ΛΥΠΑΜΑΙ ΠΟΥ ΑΚΟΥΩ ΟΤΙ ΕΙΣΑΙ ΣΕ ΚΑΤΑΘΛΙΨΗ
ΕΙΝΑΙ ΑΛΗΘΕΙΑ, ΕΙΜΑ ΔΥΣΤΥΧΗΣ
ΝΟΜΙΖΕΙΣ ΟΤΙ ΕΡΧΟΜΕΝΗ ΕΔΩ ΘΑ ΠΑΨΕΙΣ ΝΑ ΕΙΣΑΙ ΔΥΣΤΥΧΗΣ;
ΧΡΕΙΑΖΟΜΑΙ ΚΑΠΟΙΑ ΒΟΗΘΕΙΑ, ΑΥΤΟ ΕΙΝΑΙ ΣΙΓΟΥΡΟ
ΤΙ ΘΑ ΣΗΜΑΙΝΕ ΓΙΑ ΣΕΝΑ ΝΑ ΠΑΡΕΙΣ ΚΑΠΟΙΑ ΒΟΗΘΕΙΑ;
ΙΣΩΣ ΘΑ ΜΕ ΒΟΗΘΟΥΣΕ ΝΑ ΤΑ ΒΓΑΛΩ ΠΕΡΑ ΜΕ ΤΗ ΜΗΤΕΡΑ ΜΟΥ
ΠΕΣ ΜΟΥ ΠΕΡΙΣΣΟΤΕΡΑ ΓΙΑ ΤΗΝ ΟΙΚΟΓΕΝΕΙΑ ΣΟΥ
Η ΜΗΤΕΡΑ ΜΟΥ ΜΕ ΦΡΟΝΤΙΖΕΙ
ΠΟΙΟΣ ΑΛΛΟΣ ΣΤΗΝ ΟΙΚΟΓΕΝΕΙΑ ΣΟΥ ΣΕ ΦΡΟΝΤΙΖΕΙ;
Ο ΠΕΑΤΕΡΑΣ ΜΟΥ
Ο ΠΑΤΕΡΑΣ ΣΟΥ;
ΜΟΙΑΖΕΙΣ ΜΕ ΤΟΝ ΠΑΤΕΡΑ ΜΟΥ ΚΑΤΑ ΚΑΠΟΙΟΝ ΤΡΟΠΟ
ΠΟΙΑ ΟΜΟΙΟΤΗΤΑ ΒΛΕΠΕΙΣ;
ΔΕΝ ΕΙΣΑΙ ΕΠΙΘΕΤΙΚΟΣ, ΑΛΛΑ ΝΟΜΙΖΩ ΟΤΙ ΔΕ ΘΕΛΕΙΣ ΝΑ ΣΤΟ ΣΗΜΕΙΩΣΩ
ΤΙ ΣΕ ΚΑΝΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ ΔΕΝ ΕΙΜΑΙ ΠΟΛΥ ΕΠΙΘΕΤΙΚΟΣ;
ΔΕ ΔΙΑΦΩΝΕΙΣ ΜΑΖΙ ΜΟΥ
ΤΙ ΣΕ ΚΑΝΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ ΔΕ ΔΙΑΦΩΝΩ ΜΑΖΙ ΣΟΥ;
ΜΕ ΦΟΒΑΣΑΙ
ΣΕ ΕΥΧΑΡΙΣΤΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ ΣΕ ΦΟΒΑΜΑΙ;
Ο ΠΑΤΕΡΑΣ ΜΟΥ ΤΟΥΣ ΦΟΒΑΤΑΙ ΟΛΟΥΣ
ΤΙ ΑΛΛΟ ΣΟΥ ΕΡΧΕΤΑΙ ΣΤΟ ΜΥΑΛΟ ΟΤΑΝ ΣΚΕΦΤΕΣΑΙ ΤΟΝ ΠΑΤΕΡΑ ΣΟΥ;
ΨΕΥΡΟΠΑΛΛΗΚΑΡΙΣΜΟΙ
ΕΧΕΙ ΑΥΤΟ ΚΑΠΟΙΑ ΣΧΕΣΗ ΜΕ ΤΟ ΓΕΓΟΝΟΣ ΟΤΙ Ο ΦΙΛΟΣ ΣΟΥ ΣΕ
ΕΚΑΝΕ ΝΑ ΕΡΘΕΙΣ ΕΔΩ;
Οι τεχνικές του ΕLΙΖΑ είναι οι ακόλουθες:
Α. Οι απαντήσεις συνθέτονται μέσω περιγραμμάτων (templates) ή σκελετών, π.χ.
Περίγραμμα 1:
- ΤΙ ΣΕ ΚΑΝΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ XXX ?
Περίγραμμα 2:
- ΠΕΣ ΜΟΥ ΠΕΡΙΣΣΟΤΕΡΑ ΓΙΑ XXX ?
Περίγραμμα 3:
- ΜΕ ΣΕ ΕΥΧΑΡΙΣΤΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ XXX ?
Β. Η πρόταση εισόδου εξετάζεται για την παρουσία λέξεων-κλειδιών ή μερών προτάσεων που αναγνωρίζονται από αυτόματα πεπερασμένων καταστάσεων, π.χ.:
- ΕΓΩ, ΕΣΥ, ΜΗΤΕΡΑ, ΜΙΣΩ, ...
Γ. Κάθε λέξη-κλειδί σχετίζεται με ένα σύνολο κανόνων που μετασχηματίζουν τη φράση εισόδου σε φράση εξόδου, π.χ.:
Κανόνας 1:
- ΕΣΥ ΔΕΝ ZZZ ΜΕ ΕΜΕΝΑ → XXX ΕΓΩ ΔΕΝ ZZZ ΜΕ ΕΣΕΝΑ;
Κανόνας 2:
Όπου ΧΧΧ:
- ΤΙ ΣΕ ΚΑΝΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ ή
- ΣΕ ΕΥΧΑΡΙΣΤΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ
Παράδειγμα εφαρμογής των κανόνων:
- ΔΕ ΔΙΑΦΩΝΕΙΣ ΜΑΖΙ ΜΟΥ
- ΤΙ ΣΕ ΚΑΝΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ ΔΕ ΔΙΑΦΩΝΩ ΜΑΖΙ ΣΟΥ;
- ΜΕ ΦΟΒΑΣΑΙ
- ΣΕ ΕΥΧΑΡΙΣΤΕΙ ΝΑ ΠΙΣΤΕΥΕΙΣ ΟΤΙ ΣΕ ΦΟΒΑΜΑΙ;
Όταν το σύστημα δεν βρίσκει λέξεις-κλειδιά, τότε αντιδρά με φράση από προηγούμενη συζήτηση.
Όταν, επίσης, βλέπει να δίνονται μονολεκτικές απαντήσεις, τότε αντιδρά με κάποια γενικής φύσης φράση, όπως είναι:
- ΔΕ ΦΑΙΝΕΣΑΙ ΠΟΛΥ ΟΜΙΛΗΤΙΚΟΣ ΣΗΜΕΡΑ
7.4 Πώς πραγματοποιείται η Επεξεργασία Φυσικής Γλώσσας σήμερα
Υπάρχουν τρία στάδια για την επεξεργασία φυσικής γλώσσας: συντακτική ανάλυση, σημασιολογική ανάλυση και η πραγματολογική ανάλυση. Οι προτάσεις μπορεί να είναι καλοσχηματισμένες (well formed) ή κακοσχηματισμένες (ill formed) σε επίπεδο σύνταξης, σημασιολογίας ή πραγματολογικής διαφάνειας. Για παράδειγμα, ας δούμε περιπτώσεις καλοσχηματισμένων και κακοσχηματισμένων απαντήσεων στο ερώτημα : ‘Ξέρετε πού είναι το σχολείο;’
- Το σχολείο είναι στο βάθος του δρόμου: καλοσχηματισμένη πρόταση από όλες τις απόψεις και θα μπορούσε να δοθεί κάλλιστα ως απάντηση στο ερώτημα.
- Το σχολείο είναι στο βάθος του ελέφαντα: συντακτικά καλοσχηματισμένη πρόταση, αλλά σημασιολογικά κακοσχηματισμένη. Ξέρουμε από τις γνώσεις μας σε σχέση με το τι σημαίνει σχολείο και τι ελέφαντας ότι από την πρόταση δεν βγαίνει νόημα.
- Το σχολείο βάθος δρόμου είναι: Αποτελεί μια συντακτικά κακοσχηματισμένη πρόταση.
- Ναι: Αποτελεί μια πραγματολογικά κακοσχηματισμένη πρόταση. Δεν απαντά στο ερώτημα.
Κατά τη διάρκεια της επεξεργασίας το σύστημα θα προσδιορίσει κατά πόσο η πρόταση είναι καλοσχηματισμένη. Τα τρία στάδια επεξεργασίας δεν είναι κατ’ ανάγκη διακριτά ή σειριακά, αλλά θα τα θεωρήσουμε ως τέτοια για τις ανάγκες μιας όσο γίνεται πιο κατανοητής παρουσίασης.
Για να μπορέσουν να λειτουργήσουν τα στάδια της επεξεργασίας, είναι απαραίτητη η ύπαρξη ενός λεξικού της φυσικής γλώσσας, όπου θα είναι αποτυπωμένη η έννοια κάθε λέξης και επιπλέον στοιχεία που είναι απαραίτητα κατά την ανάλυση.
7.4.1 Λεξικό
Το λεξικό μιας φυσικής γλώσσας περιέχει όλες τις λέξεις που χρησιμοποιούνται στη γλώσσα αυτή. Λόγω του μεγάλου αριθμού των λέξεων, αποθηκεύεται μόνο η βασική μορφή κάθε λέξης και οι άλλες μορφές προκύπτουν με κανόνες μορφολογικής ανάλυσης (morphological analysis):
- πρόσωπα, χρόνοι, πτώσεις, γένη, αριθμοί (μορφολογία κλίσεων - inflectional morphology).
- νέες λέξεις, με προσθήκη γνωστών προθεμάτων (π.χ. στερητικό α-) ή καταλήξεων (ετυμολογική μορφολογία - derivational morphology).
- σύνθετες λέξεις (σύνθεση λέξεων - compounding).
Επιπλέον, το λεξικό πρέπει να κατατάσσει σημασιολογικά όλες τις λέξεις ανάλογα με τον τρόπο χρήσης τους. Για παράδειγμα:
- Το κάθε ρήμα θα πρέπει να σχετίζεται με την κατηγορία στην οποία ανήκει το
- υποκείμενό του και το
- αντικείμενό του (όταν το ρήμα είναι μεταβατικό)
Η γνώση μιας τέτοιας πληροφορίας δε θα επιτρέψει να παραχθούν φράσεις όπως «Ο φοιτητής είναι Μαρία».
Τα λεξικά που οργανώνονται σημασιολογικά ονομάζονται οντολογίες (ontologies ).
7.5 Συντακτική Ανάλυση
Η συντακτική ανάλυση (syntactic analysis) εξετάζει τη δομή των προτάσεων προσπαθώντας να διαπιστώσει με διάφορους τρόπους αν αυτή είναι ορθή ή λανθασμένη.
Η πιο απλή προσέγγιση είναι η χρήση κάποιου τύπου ταιριάσματος προτύπου, οπότε απαιτείται να υπάρχουν αποθηκευμένα πρότυπα προτάσεων που περιέχουν μεταβλητές, ώστε να επιτρέπεται το ταίριασμα με συγκεκριμένες προτάσεις, Π.χ. το πρότυπο
<η ** πίνει **>
όπου ** ταιριάζει με οτιδήποτε, επιτρέπει την αναγνώριση ως συντακτικά καλοσχηματισμένων προτάσεων όπως: ο Γιώργος οδηγεί ένα ωραίο αυτοκίνητο, ο Πέτρος οδηγεί το τραίνο, κλπ. Παρά ταύτα, η προσέγγιση δε θεωρείται πολύ αποτελεσματική, γιατί δεν επιτρέπει την αναγνώριση προβληματικών σημασιολογικά προτάσεων, όπως, π.χ., ο τοίχος οδηγεί ένα σπίτι. Η μέθοδος του ταιριάσματος προτύπων θεωρείται κατάλληλη μόνο για πολύ στοιχειώδη περιβάλλοντα επικοινωνίας, όπου η χρήση της φυσικής γλώσσας πραγματοποιείται υπο περιορισμούς. Χρησιμοποιήθηκε αρχικά από το πρόγραμμα ELIZA (Weizenbaum, 1966) που, όπως αναφέραμε και στην προηγούμενη παράγραφο, δεν κατόρθωσε να εντοπίσει τις διφορούμενες προτάσεις και κατέληξε να αποδέχεται ως καλοσχηματισμένες προτάσεις ασυνάρτητες.
Πιο αποτελεσματική μέθοδος είναι η γραμματική ανάλυση μιας πρότασης (parsing), κατά την οποία η πρόταση μετατρέπεται σε μια ιεραρχική δομή που υποδεικνύει τα συστατικά της μέρη. Τα συστήματα γραμματικής ανάλυσης αποτελούνται από:
- μια γραμματική που προσφέρει μια δηλωτική αναπαράσταση των συντακτικών στοιχείων σχετικά με τη γλώσσα,
- έναν συντακτικό αναλυτή που συγκρίνει την πρόταση που εισάγεται με τη γραμματική.
Οι συντακτικοί αναλυτές μπορεί να είναι ανοδικοί, εάν αρχίζουν από τα σύμβολα εισόδου και προσπαθούν να ταιριάξουν κανόνες σε αυτά, ή καθοδικοί, οπότε αρχίζουν από τους γραμματικούς κανόνες και προσπαθούν να ταιριάξουν τα σύμβολα εισόδου σε αυτούς.
Άλλες μέθοδοι συντακτικής ανάλυσης περιλαμβάνουν διαγράμματα μετάβασης (transition networks) και επαυξημένα διαγράμματα μετάβασης (augmented transition networks) (ενδεικτικά).
Αν υπάρχει αμφισημία στις λέξεις, συνήθως δοκιμάζεται η συντακτική ανάλυση διαφόρων ερμηνειών των λέξεων μέσα από το λεξικό και επιλέγονται εκείνες που ταιριάζουν καλύτερα τόσο στη συντακτική όσο και στη σημασιολογική και πραγματολογική ανάλυση μιας πρότασης.
7.6 Γραμματική
Μια γραμματική (grammar) προσδιορίζει τις αποδεκτές δομές μιας γλώσσας. Αποτελείται από ένα σύνολο κανόνων του τύπου
Α → Β
που επιτρέπουν κάθε στοιχείο που ταιριάζει με το αριστερό μέρος τους να αντικαθίσταται από το δεξί μέρος. Για παράδειγμα, έστω ότι έχουμε δυο κανόνες:
1ος κανόνας: υποκείμενο → άρθρο ουσιαστικό
2ος κανόνας: πρόταση → υποκείμενο ρήμα αντικείμενο
τότε, στον 2ο κανόνα, εκεί όπου παρουσιάζεται το αριστερό μέρος του 1ου κανόνα, δηλαδή ό όρος ‘υποκείμενο’, μπορεί να αντικατασταθεί από το δεξί μέρος του, διαμορφώνοντας τον 2ο κανόνα ως εξής:
πρόταση → άρθρο ουσιαστικό ρήμα αντικείμενο
Μια γραμματική έχει τρία συστατικά μέρη:
- τερματικά σύμβολα,
- μη-τερματικά σύμβολα,
- κανόνες παραγωγής.
Τερματικά σύμβολα (terminals) είναι οι λέξεις που αποτελούν τη γλώσσα και διαμορφώνουν το λεξικό της (lexicon). Επιπλέον, για κάθε λέξη στο λεξικό προσδιορίζεται ο θεμελιώδης τύπος της.
Παράδειγμα, η πρόταση η γάτα πίνει γάλα, περιέχει 4 τερματικά σύμβολα ( "η", "γάτα", "πίνει", "γάλα"), τα οποία στο λεξικό θα έχουν καταχωρηθεί με τους προσδιορισμούς τους ως εξής:
[η]: άρθρο
[γάτα]: ουσιαστικό
[πίνει]: ρήμα
[γάλα]: αντικείμενο
Τα μη-τερματικά σύμβολα (non-terminals) είναι ειδικά σύμβολα που περιγράφουν δομές της γλώσσας και είναι τριών τύπων:
- λεκτικές κατηγορίες, που είναι γραμματικές κατηγορίες λέξεων (π.χ. ουσιαστικό, ρήμα),
- συντακτικές κατηγορίες, που είναι επιτρεπόμενοι συνδυασμοί λεκτικών κατηγοριών (π.χ. αντικειμενική-πρόταση, κατηγορηματική-πρόταση, υποκείμενο),
- αρχικό σύμβολο, ένα ειδικό σύμβολο που αντιπροσωπεύει την αρχική πρόταση που περιγράφεται γραμματικά.
Οι γραμματικοί κανόνες παραγωγής ή συντακτικοί κανόνες (production rules or syntax rules) ή, απλώς, κανόνες περιγράφουν τους έγκυρους συνδυασμούς των λέξεων της γλώσσας. Ένας κανόνας έχει συνήθως την εξής μορφή:
Α → ΟΦ ΡΦ
όπου, Α το αρχικό σύμβολο για μια ονοματική φράση ΟΦ (π.χ. η γάτα) και ΡΦ για μια ρηματική φράση (π.χ. πίνει γάλα)
Αν μια σωστή πρόταση δεν αναγνωρίζεται συντακτικά από τη γραμματική, τότε η γραμματική πρέπει να επεκτείνεται, ώστε να αναγνωρίζεται και η συγκεκριμένη πρόταση.
7.6.1 Γραμματικές Οριστικών Προτάσεων
Γραμματικές σαν την παραπάνω ονομάζονται Γραμματικές Οριστικών Προτάσεων-ΓΟΠ (Definite Clause Grammars-DCGs).
Τρία είναι τα κύρια προβλήματα που πρέπει να αντιμετωπιστούν, όταν γίνεται η χρήση τους από ένα σύστημα συντακτικής ανάλυσης:
- Η γραμματική μια φυσικής γλώσσας έχει πολλούς κανόνες και, άρα, χρειάζεται μεγάλη προσπάθεια για την αποτύπωσή τους.
- Κατά συνέπεια, η αναζήτηση της δομής μιας πρότασης καθίσταται πολύπλοκο πρόβλημα αναζήτησης.
- Είναι απαραίτητη η βοήθεια από σημασιολογική και πραγματολογική ανάλυση, για να εντοπίζονται σημεία μη εγκυρότητας μέσα σε συντακτικά ορθές προτάσεις.
Παράδειγμα γραμματικής με αποτύπωση μόνο συντακτικών κανόνων:
Γραμματική Γ1
- πρόταση → υποκείμενο ρήμα (αντικείμενο | κατηγορούμενο)
- υποκείμενο → άρθρο ουσιαστικό
- αντικείμενο → άρθρο ουσιαστικό | ουσιαστικό
- κατηγορούμενο → επίθετο | ουσιαστικό
Η γραμματική συνοδεύεται από το παρακάτω λεξικό:
- [είναι]: ρήμα
- [πίνει]: ρήμα
- [γάτα]: ουσιαστικό
- [έξυπνος]: επίθετο
- [Γιάννης]: ουσιαστικό
- [μαύρη]: επίθετο
- [νέος]: επίθετο
- [ο]: άρθρο
- [η]: άρθρο
Στην παραπάνω γραμματική Γ1, το αρχικό σύμβολο είναι το πρόταση, τερματικά σύμβολα είναι όλα τα σύμβολα μεταξύ ‘[‘ και ‘]’ που εμφανίζονται στο λεξικό, όλα δε τα υπόλοιπα είναι μη-τερματικά σύμβολα.
Βασικό πρόβλημα της παραπάνω γραμματικής είναι το ότι δεν μπορεί να αναγνωρίσει σημασιολογικά λάθη, όπως αυτά της πρότασης η Γιάννης πίνει γάτα. Η επίλυση του προβλήματος απαιτεί τον εμπλουτισμό της γραμματικής με επιπλέον κανόνες σημασιολογικής και πραγματολογικής μορφής. Άλλα πιθανά προβλήματα μπορεί να οφείλονται σε μη αναγνώριση λέξεων που είτε δεν υπάρχουν στο λεξικό είτε έχουν καταχωρηθεί λανθασμένα.
7.6.2 Συντακτικό Δένδρο
Η παραπάνω γραμματική Γ1 μπορεί να αναγνωρίσει συντακτικά οποιαδήποτε πρόταση είναι γραμμένη στη γλώσσα της. Ένας συντακτικός αναλυτής (parser) που κάνει καθοδική γραμματική ανάλυση (parsing) θα αρχίσει από το αρχικό σύμβολο της γραμματικής, στην περίπτωσή μας το πρόταση, το οποίο θα αποτελέσει τη ρίζα ενός δένδρου που καλείται συντακτικό δένδρο (parse tree). Ουσιαστικά, ένα συντακτικό δένδρο αντιπροσωπεύει την ιεραρχική διάσπαση μιας πρότασης στα συντακτικά μέρη της. Η ρίζα του είναι το αρχικό σύμβολο και κάθε ενδιάμεσος κόμβος του αντιπροσωπεύει ένα μη-τερματικό σύμβολο της γραμματικής. Τα φύλλα του δένδρου αντιπροσωπεύουν τερματικά σύμβολα.
Ο συντακτικός αναλυτής αναπτύσσει το συντακτικό δένδρο βήμα-βήμα με τη βοήθεια των παραγωγών της γραμματικής, έως ότου καταλήξει σε φύλλα, δηλαδή σε τερματικά σύμβολα. Σε κάθε βήμα ανάπτυξης, επιλέγεται ένας κόμβος που εκπροσωπεί ένα αριστερό μη-τερματικό σύμβολο ενός κανόνα και από κάτω διασπάται σε κόμβους που αντιπροσωπεύουν τα σύμβολα του δεξιού μέρους του κανόνα.
Το συντακτικό δένδρο που παράγει η συντακτική ανάλυση διερμηνεύεται
- από τη σημασιολογική ανάλυση ανάλογα με τα πιθανά νοήματα των δομικών της συστατικών,
- κατά την πραγματολογική ανάλυση, σύμφωνα με το περικείμενο (context) στο οποίο είναι ενταγμένη και τις προθέσεις που εκφράζονται μέσα σε αυτό.
Στο σχήμα 7.1 παρουσιάζεται το συντακτικό δένδρο που προκύπτει από την γραμματική ανάλυση της πρότασης ο Γιάννης είναι έξυπνος.

Σχήμα 7.1 Παράδειγμα συντακτικού δένδρου
Εντούτοις, η γραμματική που χρησιμοποιήθηκε είναι πολύ περιορισμένη. Για να την επεκτείνουμε, χρειαζόμαστε πολλούς ακόμα κανόνες και ένα πολύ μεγαλύτερο λεξικό. Θα επανέλθουμε στο θέμα αυτό αργότερα.
7.6.3 Διαγράμματα Μετάβασης
Ένα διάγραμμα μετάβασης (transition network) είναι μια μέθοδος συντακτικής ανάλυσης που αναπαριστά τη γραμματική ως ένα σύνολο μηχανών πεπερασμένων καταστάσεων. Μια μηχανή πεπερασμένων καταστάσεων, που καλείται επίσης αυτόματο πεπερασμένων καταστάσεων (finite state automaton-FSA), είναι ένα μοντέλο υπολογιστικής συμπεριφοράς, στο οποίο κάθε κόμβος αναπαριστά μια εσωτερική κατάσταση του συστήματος και οι ακμές παρουσιάζουν τον τρόπο μετάβασης από κατάσταση σε κατάσταση. Στην περίπτωση της επεξεργασίας φυσικής γλώσσας, οι ακμές αντιπροσωπεύουν είτε ένα τερματικό είτε ένα μη τερματικό σύμβολο. Οι γραμματικοί κανόνες αντιστοιχούν σε μια διαδρομή μέσα στο διάγραμμα. Για κάθε μη-τερματικό σύμβολο, υπάρχει και ένα διάγραμμα μετάβασης που το αναγνωρίζει.
Στο σχήμα 7.2 δίνεται ένα παράδειγμα χρήσης διαγραμμάτων μετάβασης για τη γραμματική Γ1.
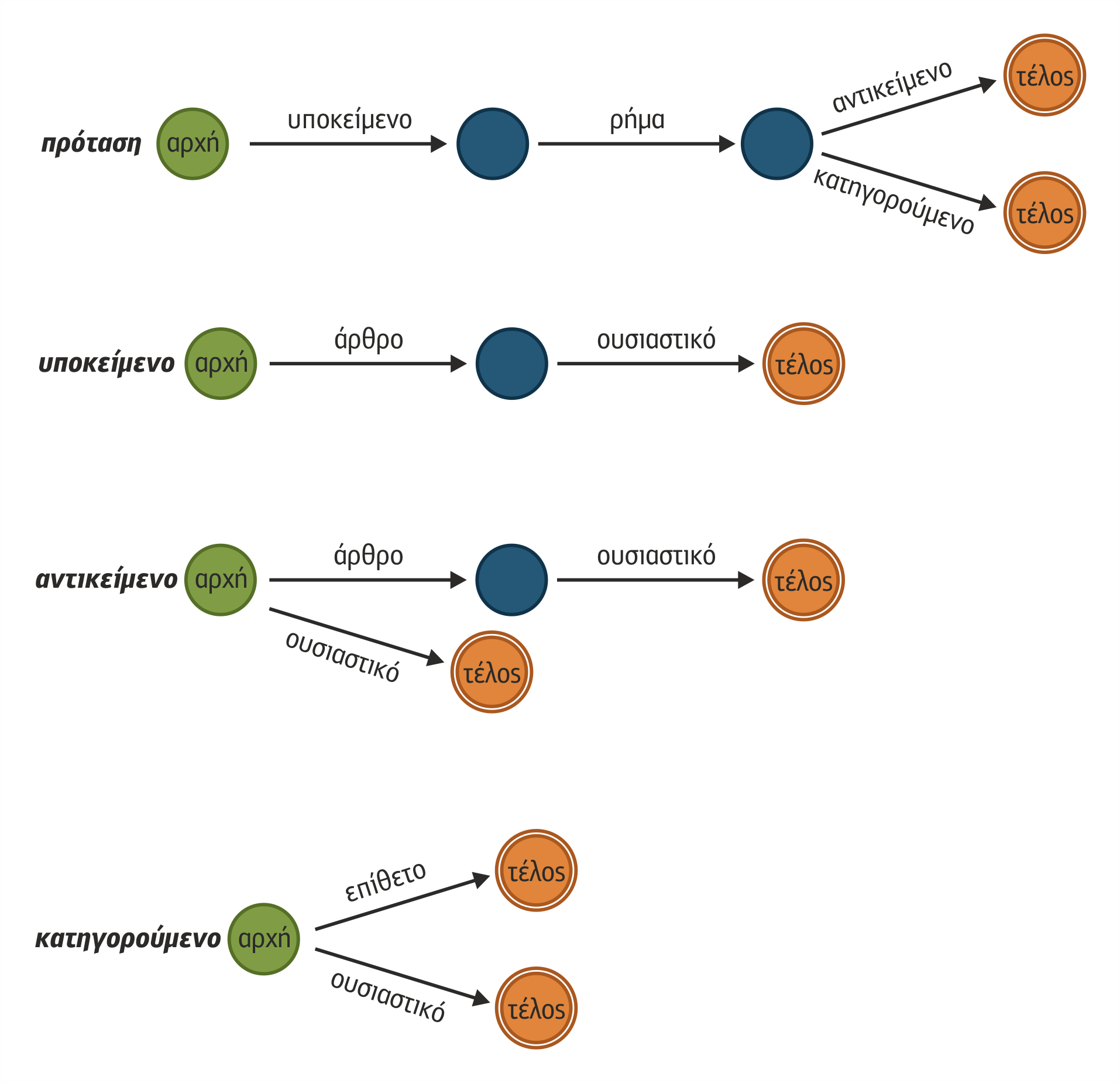
Σχήμα 7.2 Παράδειγμα διαγραμμάτων μετάβασης
Η αναγνώριση της πρότασης ο Γιάννης είναι έξυπνος θα γίνει ως ακολούθως: Καταρχάς, θα επιχειρηθεί η διάσχιση του διαγράμματος του αρχικού συμβόλου πρόταση. Για τη διάσχιση του διαγράμματος απαιτείται, πρώτον, η αναζήτηση ενός τερματικού συμβόλου τύπου άρθρου. Η λέξη ‘ο’ είναι ορισμένη στο λεξικό ως άρθρο, οπότε επιτρέπει τη διάσχιση προς τον επόμενο κόμβο που απαιτεί ένα τερματικό σύμβολο τύπου ουσιαστικού. Η λέξη Γιάννης είναι ορισμένη στο λεξικό ως ουσιαστικό, οπότε η διάσχιση του διαγράμματος για την αναγνώριση του υποκειμένου ολοκληρώνεται επιτυχώς και επιστρέφουμε στο αρχικό διάγραμμα για την συνέχιση της διάσχισης. Ακολουθεί η ανάγκη διάσχισης του διαγράμματος του μη-τερματικού συμβόλου ρήμα Για τη διάσχιση θα απαιτηθεί η αναζήτηση ενός τερματικού συμβόλου τύπου ρήματος. Η λέξη είναι που ακολουθεί είναι ορισμένη στο λεξικό ως ρήμα οπότε η διάσχιση είναι επιτυχής και προχωρούμε στην ανάγκη διάσχισης ή του διαγράμματος αντικείμενο ή του διαγράμματος κατηγορούμενο. Μετά από ανάλυση επιλέγεται το κατηγορούμενο, οπότε διασχίζοντας το διάγραμμά του απαιτείται η παρουσία ενός επιθέτου ή ενός ουσιαστικού. Δεδομένου ότι στην πρόταση ακολουθεί η λέξη έξυπνος που είναι καταχωρημένη ως επίθετο, η αναγνώριση ολοκληρώνεται επιτυχώς Η ολοκληρωμένη συντακτική ανάλυση για την αναγνώριση της πρότασης ο Γιάννης είναι έξυπνος δίνεται στο σχήμα 7.3.

Σχήμα 7.3 Διάσχιση διαγραμμάτων μετάβασης κατά τη συντακτική ανάλυση
7.7 Αλγόριθμοι Διόρθωσης Ορθογραφικών Λαθών
Τα πιο κοινά λάθη που παρουσιάζει μια πρόταση και εμποδίζουν την αναγνώρισή της είναι τα ορθογραφικά. Για να αντιμετωπιστούν, η επεξεργασία φυσικής γλώσσας χρησιμοποιεί αλγόριθμους διόρθωσης λαθών που συνήθως έχουν τις παρακάτω δυνατότητες:
- κατανόηση γραπτού κειμένου,
- αναγνώριση λέξεων σε προφορικό λόγο,
- προγράμματα ορθογραφίας.
Η λειτουργία των αλγορίθμων διόρθωσης λαθών στηρίζεται στην έννοια της εγγύτητας (closeness) μεταξύ λέξεων. Τρόποι ορισμού της εγγύτητας είναι οι παρακάτω:
- μοντέλο χαρακτήρων,
- ηχητικό μοντέλο.
7.7.1 Μοντέλο Χαρακτήρων Διόρθωσης Λαθών
Στο μοντέλο χαρακτήρων (letter-based model), ως λάθη θεωρούνται:
- η εισαγωγή / διαγραφή ενός μεμονωμένου χαρακτήρα,
- η αντιμετάθεση δύο γειτονικών χαρακτήρων,
- η αντικατάσταση ενός γράμματος από ένα άλλο.
Αν θεωρήσουμε ότι η γλώσσα μας διαθέτει ένα αλφάβητο 24 γραμμάτων και ότι έχει συμβεί μόνο ένα λάθος σε μια λέξη, μια λέξη με 8 γράμματα μπορεί να έχει σε επίπεδο χαρακτήρων 9x24 πιθανά λάθη εισαγωγής, 8 πιθανά λάθη διαγραφής, 8x23 πιθανά λάθη αντικατάστασης και 7 πιθανά λάθη αντιμετάθεσης∙ άρα, μπορεί να έχει συνολικά 415 διαφορετικά λάθη.
Η χρήση της εγγύτητας χαρακτήρων μπορεί να βοηθήσει στον περιορισμό της αναζήτησης του λάθους. Για παράδειγμα, έστω ότι έχει γραφεί λανθασμένα η έγκυρη λέξη "αυτοκίνητο". Γειτονικές λανθασμένες λέξεις αυτής της λέξης, σε σχέση με την εγγύτητα είναι οι ακόλουθες:
- με απόσταση 1 λάθος: "ατοκίνητο", "υατοκίνητο", "ααυτοκίνητο" κλπ,
- με απόσταση 2 λάθη: "αυτκοίνητο", "ατκίνητο", κλπ.
Όμως η διόρθωση λαθών βάσει εγγύτητας δε μπορεί να εφαρμοστεί σε όλες τις περιπτώσεις. Για παράδειγμα:
- Η λέξη "ατμοκίνητο" παρόλο που απέχει 2 λάθη από την έγκυρη "αυτοκίνητο" γίνεται εξαρχής αποδεκτή γιατί τα λάθη δε μπορούν να ανιχνευτούν εφόσον η λέξη "ατμοκίνητο" είναι επίσης έγκυρη!!!
- Η λανθασμένη λέξη "ατκίνητο" ισαπέχει από δύο έγκυρες λέξεις, τις "αυτοκίνητο" και "ατμοκίνητο" γεγονός που δημιουργεί πρόβλημα στη διόρθωση του λάθους.
7.7.2 Ηχητικό Μοντέλο Διόρθωσης Λαθών
Στο ηχητικό μοντέλο (sound-based model), οι λέξεις μεταφράζονται στο φωνητικό ισοδύναμο, στο οποίο διατηρείται όλη η πληροφορία που είναι απαραίτητη για την εκφώνηση της λέξης, χωρίς, ωστόσο, να διατηρείται και η ορθογραφία τους. Για παράδειγμα, γίνεται αντικατάσταση των «αι» από «ε», των «η» και «υ», από το «ι».
Αφού κατασκευαστεί το φωνητικό ισοδύναμο, μπορούν να εφαρμοστούν οι ίδιοι κανόνες αναζήτησης λαθών, όπως και στο μοντέλο χαρακτήρων. Όσο λιγότεροι είναι οι φθόγγοι, τόσο ευκολότερα μπορούν να ανιχνευθούν ‘κοντινές’ λέξεις.
7.8 Σημασιολογική ανάλυση
Κατά τη σημασιολογική ανάλυση (semantic analysis) πραγματοποιείται μετατροπή των προτάσεων σε εσωτερικές δομές αναπαράστασης γνώσης, χρησιμοποιώντας τη νοηματική σημασία των λέξεων. Για να επιτευχθεί κάτι τέτοιο, απαιτούνται οι λεγόμενες εξελιγμένες Γραμματικές Οριστικών Προτάσεων.
Σημαντικότερο πρόβλημα αποτελεί η ασάφεια σε επίπεδο λεκτικό που προκύπτει από την πολυσημία (ambiguity) των λέξεων. Ένας τρόπος αντιμετώπισης της ασάφειας αυτής είναι το να λαμβάνονται υπόψη χαρακτηριστικά της κλίσης των ουσιαστικών και ρημάτων: π.χ. γένος, αριθμός, πτώση των ουσιαστικών, πρόσωπα ρημάτων. Ακολουθεί ένα παράδειγμα εξελιγμένης γραμματικής που υποστηρίζει την παραπάνω προσέγγιση:
πρόταση ® υποκείμενο(Γένος,Αριθμός,ονομαστική)
ρήμα(Αριθμός)
αντικείμενο(Γένος,Αριθμός,αιτιατική)
πρόταση ® υποκείμενο(Γένος,Αριθμός,ονομαστική)
ρήμα(Αριθμός)
κατηγορούμενο(Γένος,Αριθμός,ονομαστική)
υποκείμενο ® άρθρο(Γένος,Αριθμός,Πτώση)
ουσιαστικό(Γένος,Αριθμός,Πτώση)
κατηγορούμενο® επίθερο(Γένος,Αριθμός,Πτώση)
Σε γραμματικές του παραπάνω τύπου, τα χαρακτηριστικά διαδίδονται από τους ειδικότερους στους γενικότερους κανόνες, ώστε να υπάρχει συμφωνία των χαρακτηριστικών αυτών μεταξύ διαφορετικών τμημάτων της πρότασης. Για παράδειγμα:
- Ο αριθμός του υποκειμένου πρέπει να συμφωνεί με την κατάληξη του ρήματος.
- Tο γένος, η πτώση και ο αριθμός του άρθρου του υποκειμένου πρέπει να συμφωνεί με τα αντίστοιχα χαρακτηριστικά της κλίσης του ουσιαστικού του υποκειμένου.
7.8.1 Αντιμετώπιση αμφιβολίας στην ερμηνεία
Η αμφιβολία στην ερμηνεία προκύπτει από την ασάφεια και σε σημασιολογικό και σε πραγματολογικό επίπεδο, όπως αναλύσαμε στην εισαγωγική παράγραφο του κεφαλαίου αυτού. Για παράδειγμα, στην παρακάτω πρόταση υπάρχει αμφιβολία σχετικά με την απόδοση του χρονικού προσδιορισμού «σήμερα» σε ένα από τα δύο ρήματα:
Ο Νίκος ζήτησε από τον Ηλία να τον αντικαταστήσει στη δουλειά σήμερα.
Τέτοιας μορφής ασάφεια μπορεί να αντιμετωπισθεί με συντακτικούς κανόνες, όπως, για παράδειγμα, ότι χρονικοί προσδιορισμοί συνδέονται με το κοντινότερο ρήμα. Όμως, οι κανόνες αυτοί δεν μπορούν να έχουν καθολική ισχύ.
Αμφιβολία στην ερμηνεία προκύπτει, επίσης, από την πολυσημία των λέξεων. Για παράδειγμα, στην παρακάτω πρόταση, η λέξη καιρός μπορεί να αναφέρεται και α) στα καιρικά φαινόμενα και β) στην έννοια του χρόνου:
Ο καιρός φταίει που οι ντομάτες δεν έχουν κοκκινίσει.
Η πιθανότητα χρήσης της λέξης με την πρώτη της σημασία είναι μεγαλύτερη και αυτή η πληροφορία πρέπει να αποτυπώνεται με κάποιο τρόπο στο λεξικό της γλώσσας. Η εξαγωγή των πιθανοτήτων υπό συνθήκη είναι εργασία των σταδίων της σημασιολογικής και της πραγματολογικής ανάλυσης.
7.9 Πραγματολογική ανάλυση
Σκοπός της πραγματολογικής ανάλυσης είναι η κατανόηση κειμένων και ο χειρισμός διαλόγων. Κατά την πραγματολογική ανάλυση επιχειρείται η ένταξη κάθε πρότασης μέσα στο γενικότερο νοηματικό πλαίσιο των συμφραζόμενων (context) της, λαμβανομένων υπόψη των συνθηκών μέσα στις οποίες αυτή λέχθηκε. Δυσκολίες προκύπτουν, όταν η πρόταση περιέχει αντωνυμίες, οι οποίες αναφέρονται σε ονόματα άλλων προτάσεων. Για παράδειγμα:
Τον αγαπάει.
Ως αίτια που οδηγούν ένα κείμενο να παρουσιάζει δυσκολίες στην κατανόησή του καταγράφονται:
- αντωνυμίες ως αντικείμενα, οι οποίες αναφέρονται σε ονόματα άλλων προτάσεων,
Ο Γιώργος είχε μια κόκκινη μπάλα. Ο Νίκος την ήθελε.
- τμήματα αντικειμένων που λείπουν,
Η Ελένη άνοιξε το βιβλίο που μόλις είχε αγοράσει. Η πρώτη σελίδα ήταν σκισμένη.
- τμήμα ενεργειών που λείπουν,
Ο Κώστας πήγε ταξίδι στην Κρήτη. Έφυγε με την πρωινή πτήση.
- οντότητες εμπλεκόμενες σε ενέργειες,
Την περασμένη εβδομάδα έγινε διάρρηξη στο σπίτι μου. Μου έκλεψαν την τηλεόραση.
- σχέσεις αιτίου – αιτιατού,
Χθες είχε φοβερή χιονοθύελλα. Τα σχολεία είναι κλειστά σήμερα.
- σειρές σχεδίων.
Η Μαρία θέλει να αγοράσει καινούριο αυτοκίνητο. Αποφάσισε να βρει δουλειά.
Για να λυθούν τα παραπάνω προβλήματα κατανόησης, πρέπει το σύστημα επεξεργασίας φυσικής γλώσσας να κατέχει τη γνώση για τον τρόπο με τον οποίο λειτουργεί ο κόσμος (το γενικότερο νοηματικό πλαίσιο) μέσα στον οποίο αναφέρεται η πρόταση, για τις πιθανότητες εμφάνισης κάποιων γεγονότων, για συνήθειες των ενεργούντων, πιθανά σενάρια (scripts) που μπορεί να διαδραματιστούν (ενδεικτικά).
Με βάση αυτήν τη γνώση και το περιεχόμενο των προτάσεων ενός κειμένου ή διαλόγου, το σύστημα μπορεί να κάνει πολλούς εύλογους συμπερασμούς, διευρύνοντας τη γνώση του για την τρέχουσα κατάσταση του κειμένου ή μιας συζήτησης. Χωρίς γενική γνώση του αντικειμένου που πραγματεύεται ένα κείμενο ή διάλογος είναι αδύνατο να γίνει πραγματολογική ανάλυση.
7.10 Παραγωγή Φυσικής Γλώσσας
Η δυνατότητα ενός συστήματος να απαντά στο χρήστη σε φυσική γλώσσα απαιτεί την παραγωγή φυσικής γλώσσας (natural language generation) από το σύστημα, αφού, φυσικά, κατανοήσει πρώτα το ερώτημα του χρήστη, όταν αυτό έχει επίσης εκφραστεί σε φυσική γλώσσα.
Η παραγωγή φυσικής γλώσσας πραγματοποιείται σε δύο στάδια:
- επιλογή του τι θα λεχθεί και
- επιλογή του πώς αυτό θα λεχθεί.
Το στάδιο της επιλογής του τι θα λεχθεί έχει να κάνει με το ποια πληροφορία επιλέγει το σύστημα να αναφέρει στο χρήστη. Το πρόβλημα της επιλογής της πληροφορίας αναφέρεται ως σχεδιασμός κειμένου (text planning) και σε εξελιγμένες περιπτώσεις δανείζεται τεχνικές από το σχεδιασμό ενεργειών (planning).
Για το στάδιο της επιλογής πώς θα λεχθεί μια πληροφορία, δηλαδή για τον τρόπο εμφάνισής της, η πληροφορία συνήθως ομαδοποιείται σε μικρές λογικές ενότητες, από τις οποίες δημιουργούνται προτάσεις με χρήση κανόνων γραμματικής.
Σε περίπτωση κατά την οποία η απάντηση πρέπει να εκφωνηθεί, υπάρχουν επίσης δύο προσεγγίσεις:
- να έχουν αποθηκευθεί ηχητικά όλες οι λέξεις, με όλες τις δυνατές παραλλαγές τους.
- να γίνεται σύνθεση φθόγγων από τα γράμματα των λέξεων.
Στην εκφώνηση μηχανικού προφορικού λόγου υπάρχει πάντα το πρόβλημα της διαφορετικής προφοράς μιας λέξης ανάλογα είτε με τις λέξεις που προηγούνται ή ακολουθούν είτε με τη θέση της στην πρόταση.
7.11 Αναγνώριση ομιλίας
Για να καταστεί δυνατή η αναγνώριση ομιλίας (speech recognition), πρέπει να υπάρχει σύστημα καταγραφής ηχητικών-ηλεκτρικών σημάτων με δυνατότητα μετατροπής τους σε φθόγγους και σύνθεσης των φθόγγων για την παραγωγή λέξεων και προτάσεων.
Τα βήματα αναγνώρισης ομιλίας είναι τρία:
- Παραγωγή φασματογραφήματος: δημιουργία του φασματογραφήματος (spectrogram) του ήχου που συλλαμβάνεται από ένα μικρόφωνο.
- Αναγνώριση φθόγγων: εξαγωγή των φθόγγων (phonemes) από το φασματογράφημα, βάσει μιας βιβλιοθήκης που περιέχει πρότυπα (templates) αυτών.
- Δημιουργία λέξεων: συνδυασμός των φθόγγων σε λέξεις που αναγνωρίζονται με τη βοήθεια του λεξικού της γλώσσας.
7.12 Πεδία εφαρμογής Επεξεργασίας Φυσικής Γλώσσας
Η επεξεργασία φυσικής γλώσσας έχει ένα πλήθος εφαρμογών σε διάφορους χώρους. Κατά την κρίση μας, σημαντικότεροι για παρουσίαση είναι οι παρακάτω:
- Ανάκτηση πληροφοριών (information retrieval): χαρακτηρισμός εγγράφων με λέξεις-κλειδιά ή, στην ιδανική περίπτωση, νοηματική επεξεργασία των εγγράφων, για να δοθεί απάντηση σε ερώτηση που διατυπώνεται σε φυσική γλώσσα.
- Ανάκτηση εγγράφων (document retrieval).
- Εξαγωγή πληροφορίας (information extraction).
- Εξόρυξη δεδομένων (Data Mining).
- Φωνητική προσπέλαση βάσεων δεδομένων: Η εφαρμογή αυτή αφορά την εισαγωγή ερωτημάτων σε βάσεις δεδομένων χρησιμοποιώντας φυσική γλώσσα.
- Κατηγοριοποίηση κειμένων (text categorization): ταξινόμηση κειμένων βάσει του περιεχομένου τους.
- Αυτόματη περίληψη (automated synopsis): εξαγωγή από ένα μεγάλο κείμενο ενός μικρότερου, με το βασικό/κεντρικό νόημα του πρώτου. Επιτρέπει την παραγωγή περιλήψεων από τα επιστρεφόμενα έγγραφα μιας μηχανής αναζήτησης.
- Αυτόματη μηχανική μετάφραση/διερμηνεία (machine translation).
- Αναγνώριση μερών του λόγου (part-of-speech tagging),
- Συντακτική ανάλυση (parsing),
- Εφαρμογές Επεξεργασίας Κειμένου (Word Processing Applications): έλεγχος ορθογραφίας, εισαγωγή κειμένου.
- Εκμάθηση γλώσσας υποβοηθούμενη από Η/Υ,
- Κατασκευή ηλεκτρονικών λεξικών: Επέκταση υπαρχόντων λεξικών π.χ λεξικό ιατρικής ορολογίας (Wolff, 1984).
Παρά την πληθώρα τους, οι εφαρμογές στις οποίες απαιτείται κατανόηση φυσικής γλώσσας συχνά αποτυγχάνουν στο να κατανοήσουν και να διατυπώσουν σύνθετες ερωτήσεις. Για να υπάρχει ικανοποιητικό αποτέλεσμα, ο χρήστης θα πρέπει να γνωρίζει το υποστηριζόμενο λεξιλόγιο και τις γραμματικές/συντακτικές δυνατότητες του συστήματος. Ίσως και για το λόγο αυτό δε γνώρισαν έως τώρα μεγάλη εμπορική επιτυχία.