Κεφάλαιο 7Αλγόριθμοι Αναζήτησης
Από το αντικείμενο των Δομών Δεδομένων είναι γνωστή η μεγάλη σημασία του προβλήματος της αναζήτησης καθώς εμφανίζεται σε πλήθος θεωρητικών και πρακτικών προβλημάτων. Στο παρόν κεφάλαιο συνοψίζονται δεδομένα αποτελέσματα, αλλά παρουσιάζονται κατά αναλυτικότερο τρόπο.
7.1 Σειριακή Αναζήτηση
Η απλούστερη μέθοδος αναζήτησης είναι η σειριακή (sequential) ή αλλιώς γραμμική (linear). Αν και η μέθοδος είναι απολύτως γνωστή από το αντικείμενο των Δομών Δεδομένων, επαναλαμβάνουμε ελάχιστα σημεία ως εισαγωγή στο παρόν κεφάλαιο. Η επόμενη διαδικασία Sequential1 υποθέτει ότι αναζητείται η τιμή key στον πίνακα που περιέχει αταξινόμητα στοιχεία και επιστρέφει τη θέση του κλειδιού στον πίνακα ή την τιμή , αν το κλειδί δεν υπάρχει (περίπτωση ανεπιτυχούς αναζήτησης).
Η διαδικασία αυτή μπορεί να βελτιωθεί υιοθετώντας την τεχνική του κόμβου φρουρού (sentinel), οπότε η μέθοδος θα υλοποιηθεί θεωρώντας μία ακόμη θέση στον πίνακα με τη μορφή . Αν και πρακτικά η διαδικασία θα βελτιωθεί, σε θεωρητικό επίπεδο σε κάθε περίπτωση θα ισχύουν οι επόμενες προτάσεις υποθέτοντας ότι η πιθανότητα αναζήτησης του κλειδιού είναι , για .
Πρόταση 7.1.
Η επιτυχής αναζήτηση σε πίνακα με αταξινόμητα κλειδιά έχει πολυπλοκότητα , και στην καλύτερη, στη χειρότερη και στη μέση περίπτωση, αντίστοιχα.
Απόδειξη. Η καλύτερη και η χειρότερη περίπτωση συμβαίνουν, όταν η αναζήτηση τερματίζεται με την εξέταση της πρώτης και της τελευταίας θέσης του πίνακα, αντίστοιχα. Για τη μέση περίπτωση ισχύει ότι:
από όπου προκύπτει η αλήθεια της πρότασης.
Πρόταση 7.2.
Η ανεπιτυχής αναζήτηση σε πίνακα με αταξινόμητα κλειδιά έχει πολυπλοκότητα στην καλύτερη, στη χειρότερη και στη μέση περίπτωση.
Απόδειξη. Σε κάθε περίπτωση θα σαρωθεί ολόκληρος ο πίνακας και, άρα, η πρόταση ισχύει.
Αν υποθέσουμε ότι ο πίνακας περιέχει ταξινομημένα στοιχεία, τότε για την επιτυχή αναζήτηση ισχύει η ανωτέρω πρόταση, αλλά για να επιταχύνουμε την ανεπιτυχή αναζήτηση πρέπει να μετατρέψουμε τη διαδικασία Sequential1 ως εξής:
Πρόταση 7.3.
Η ανεπιτυχής αναζήτηση σε πίνακα με ταξινομημένα κλειδιά έχει πολυπλοκότητα , και στην καλύτερη, στη χειρότερη και στη μέση περίπτωση, αντίστοιχα.
Απόδειξη. Όταν αναζητούμε ένα μη υπαρκτό κλειδί, τότε αυτό μπορεί να ανήκει σε ένα από μεσοδιαστήματα που (σχηματικά) δημιουργούνται από τις τιμές των στοιχείων του πίνακα επάνω στην ευθεία των ακεραίων. Η καλύτερη και η χειρότερη περίπτωση συμβαίνουν, όταν το αναζητούμενο είναι μικρότερο από το πρώτο στοιχείο και μεγαλύτερο από το τελευταίο στοιχείο του πίνακα, αντίστοιχα. Για τη μέση περίπτωση θα πρέπει να εξετάσουμε περιπτώσεις και να λάβουμε το μέσο όρο τους. Αν το είναι μικρότερο από το πρώτο στοιχείο, τότε αρκεί μία σύγκριση για να τερματισθεί η διαδικασία. Αν το είναι μεγαλύτερο από το -οστό και μικρότερο από το -οστό στοιχείο (για ), τότε αρκούν συγκρίσεις. Αν το είναι μεγαλύτερο από το -οστό στοιχείο, τότε αρκούν συγκρίσεις. Συνεπώς, ισχύει:
από όπου προκύπτει η αλήθεια της πρότασης.
7.2 Δυαδική Αναζήτηση
Κλασικό παράδειγμα των αλγορίθμων της οικογενείας Διαίρει και Βασίλευε είναι η δυαδική αναζήτηση (binary search). Όπως γνωρίζουμε, η αναζήτηση αυτή εφαρμόζεται σε πίνακες που περιέχουν ταξινομημένα στοιχεία. Υπενθυμίζοντας όσα τονίσθηκαν στο Κεφάλαιο 4.2 σχετικά με την αποτελεσματικότητα των αναδρομικών και των επαναληπτικών μεθόδων, στη συνέχεια παρουσιάζουμε την επαναληπτική διαδικασία Binary_Iterate και την αναδρομική διαδικασία Binary_Rec που δείχνουν την ίδια θεωρητική συμπεριφορά.
Μπορούμε να περιγράψουμε τη λογική των προηγούμενων διαδικασιών ως εξής: Έστω ότι αναζητούμε το ακέραιο κλειδί σε ένα πίνακα με ταξινομημένους ακεραίους αριθμούς. Συγκρίνουμε το κλειδί με το περιεχόμενο της μεσαίας θέσης του πίνακα , που είναι η θέση . Στο σημείο αυτό τρία ενδεχόμενα μπορεί να συμβούν:
-
1.
τα δύο στοιχεία είναι ίσα, οπότε ο σκοπός μας επιτεύχθηκε,
-
2.
το είναι μικρότερο από το , οπότε είμαστε βέβαιοι ότι το αποκλείεται να βρίσκεται στον υποπίνακα . Έτσι, συνεχίζουμε στον υποπίνακα εξετάζοντας το μεσαίο στοιχείο του,
-
3.
το είναι μεγαλύτερο του , οπότε το σαφώς δεν βρίσκεται στον υποπίνακα . Έτσι, συνεχίζουμε και πάλι εξετάζοντας το μεσαίο στοιχείο του υποπίνακα .
Οι ανωτέρω διαδικασίες επιστρέφουν τη θέση του μέσα στον πίνακα. Αν το βρίσκεται πράγματι μέσα στον , τότε επιστρέφει τη συγκεκριμένη θέση, ενώ στην αντίθετη περίπτωση επιστρέφει την τιμή . Ένα παράδειγμα εκτέλεσης του αλγορίθμου παρουσιάζεται στο Σχήμα 7.5.

Στη συνέχεια, θα εξετάσουμε αναλυτικά τη δυαδική αναζήτηση. Μία βασική υπόθεση που γίνεται στο σημείο αυτό είναι ότι η σύγκριση είναι τριών δρόμων (-way comparison). Δηλαδή, με μοναδιαίο κόστος αποφασίζουμε να επιλέξουμε ένα δρόμο μεταξύ τριών.
Πρόταση 7.4.
Η πολυπλοκότητα της δυαδικής αναζήτησης είναι λογαριθμική.
Απόδειξη. Κάθε φορά που η σύγκριση του με το μεσαίο στοιχείο του πίνακα δεν καταλήγει σε ισότητα, η σύγκριση επαναλαμβάνεται σε υποπίνακα μισού μεγέθους σε σχέση με το μέγεθος του αρχικού. Επομένως, εύκολα προκύπτει η αναδρομική εξίσωση:
Απλοποιούμε τη σχέση αυτή θεωρώντας τη χειρότερη περίπτωση (δηλαδή, αγνοούμε το δεύτερο σκέλος) και ότι για κάποιο ακέραιο αριθμό . Έτσι, προκύπτει:
με αρχική συνθήκη . Έτσι, διαδοχικά έχουμε:
Έτσι, λοιπόν, για προκύπτει ότι η πολυπλοκότητα της δυαδικής αναζήτησης είναι λογαριθμική. Εύκολα μπορεί να αποδειχθεί ότι η πολυπλοκότητα είναι .
Εναλλακτικά, μπορεί να διατυπωθεί η εξής πρόταση.
Πρόταση 7.5.
Η μέση τιμή του αριθμού των συγκρίσεων ή για μία επιτυχή ή μία ανεπιτυχή αναζήτηση δίνεται από τις σχέσεις:
όπου .
Απόδειξη. ‘Εστω ότι , όπου . Τότε ισχύει:
Η απόδειξη της περίπτωσης της ανεπιτυχούς αναζήτησης είναι προφανής.
7.3 Αναζήτηση Παρεμβολής
Η αναζήτηση παρεμβολής προσομοιάζει με τον τρόπο αναζήτησης σε ένα λεξικό ή σε έναν τηλεφωνικό κατάλογο. Κατά την αναζήτηση μίας λέξης, δεν ανοίγουμε το λεξικό αρχικά στη μέση και μετά στο ή στα , κοκ, δηλαδή δεν συνηθίζεται να κάνουμε δυαδική αναζήτηση. Για παράδειγμα, αν αναζητούμε μία λέξη που αρχίζει από Α, τότε ανοίγουμε το λεξικό προς την αρχή, αν αρχίζει από Ε πάλι ανοίγουμε προς την αρχή αλλά όχι τόσο κοντά στο Α, ενώ αν αρχίζει από Ω τότε ανοίγουμε προς το τέλος του λεξικού. Στη συνέχεια, αναλόγως αν η λέξη είναι λεξικογραφικά μεγαλύτερη ή μικρότερη, κινούμαστε προς το τέλος ή την αρχή του λεξικού παραλείποντας έναν αριθμό σελίδων, πριν λάβουμε την επόμενη απόφαση. Το πλήθος των παραλειπόμενων σελίδων είναι ανάλογο της αλφαβητικής απόστασης της σελίδας όπου βρισκόμαστε από τη ζητούμενη λέξη. Παραδείγματος χάριν, αν είμαστε στο Ε και η ζητούμενη λέξη αρχίζει από Η ή από Μ, τότε στην πρώτη περίπτωση θα μεταπηδήσουμε σε μικρότερη απόσταση σε σχέση με τη δεύτερη. Στην ουσία αυτή η τακτική, αρχικά, προσπαθεί να προσεγγίσει τη θέση όπου μπορεί να βρίσκεται το ζητούμενο στοιχείο και μετά να κινηθεί αναλόγως.
Έτσι, λοιπόν, στην αναζήτηση με παρεμβολή (interpolation search), όταν αναζητούμε το στοιχείο που βρίσκεται μεταξύ του και του ή γενικότερα μεταξύ του και του , τότε το στοιχείο που επιλέγεται για εξέταση είναι το στοιχείο που βρίσκεται στη θέση
| (7.1) |
Στην ουσία εξετάζοντας πόσο μεγαλύτερο είναι το ζητούμενο στοιχείο από το στοιχείο του αριστερού άκρου, καθώς και πόσο μεγαλύτερο είναι το στοιχείο του δεξιού από το στοιχείο του αριστερού άκρου, γίνεται εκτίμηση της θέσης του λαμβάνοντας το λόγο των δύο διαφορών. Ο επόμενος ψευδοκώδικας υλοποιεί τη μέθοδο.

Στο παράδειγμα του Σχήματος 7.7 παρατηρούμε ότι, όταν τα στοιχεία είναι ακέραιοι που διαφέρουν κατά μία μονάδα το ένα από το άλλο, τότε αυτή η εκτίμηση είναι ακριβής. Επίσης, αν τα στοιχεία διαφέρουν από τα γειτονικά τους κατά μία μικρή ποσότητα, και πάλι η εκτίμηση θα είναι σχετικά ακριβής. Όμως, όταν οι διαφορές μεταξύ των στοιχείων είναι σημαντικές, τότε οι εκτιμήσεις δεν θα είναι επαρκώς ακριβείς και θα χρειασθούν περισσότερες επαναλήψεις.
Ο χρόνος χειρότερης περίπτωσης για την αναζήτηση παρεμβολής είναι , ενώ ο μέσος χρόνος είναι . Στη μέση περίπτωση η αναζήτηση παρεμβολής φαίνεται να υπερισχύει της δυαδικής αναζήτησης και αυτό είναι λογικό αφού τα προς εξέταση διαστήματα δεν υποδιπλασιάζονται σε κάθε βήμα αλλά μπορεί να γίνουν πολύ μικρότερα. Παρόλα αυτά, πειραματικά αποτελέσματα έδειξαν ότι η αναζήτηση παρεμβολής δεν εκτελεί πολύ λιγότερες συγκρίσεις, έτσι ώστε να αποφεύγεται το αυξημένο υπολογιστικό κόστος εύρεσης του και να έχει καλύτερους χρόνους, εκτός και αν οι πίνακες είναι πολύ μεγάλοι. Για το λόγο αυτό, συχνά είναι προτιμότερο τα πρώτα βήματα να εκτελούν αναζήτηση παρεμβολής, έτσι ώστε το διάστημα να μειώνεται δραματικά και μετά να εκτελείται δυαδική αναζήτηση. Στη συνέχεια, θα μελετήσουμε αυτήν ακριβώς την παραλλαγή.
7.3.1 Δυαδική Αναζήτηση Παρεμβολής
Ακολουθεί ο ψευδοκώδικας της δυαδικής αναζήτησης παρεμβολής (binary interpolation search), ενώ στη συνέχεια θα σχολιασθεί και θα αναλυθεί η πολυπλοκότητα της μεθόδου.
Σχετικά με τον ανωτέρω κώδικα, που είναι ενδεικτικός περισσότερο και σε καμία περίπτωση δεσμευτικός, παρατηρούμε τα εξής:
-
•
Στην ουσία μετά το βήμα παρεμβολής (γραμμές και , έκφραση 7.1) αναζητούμε γραμμικά με άλματα μεγέθους , για να προσδιορισθεί το υποδιάστημα που περιέχει το . Στη συνέχεια, επαναλαμβάνεται η ίδια διαδικασία για το νέο διάστημα, όπως φαίνεται στο Σχήμα 7.9.
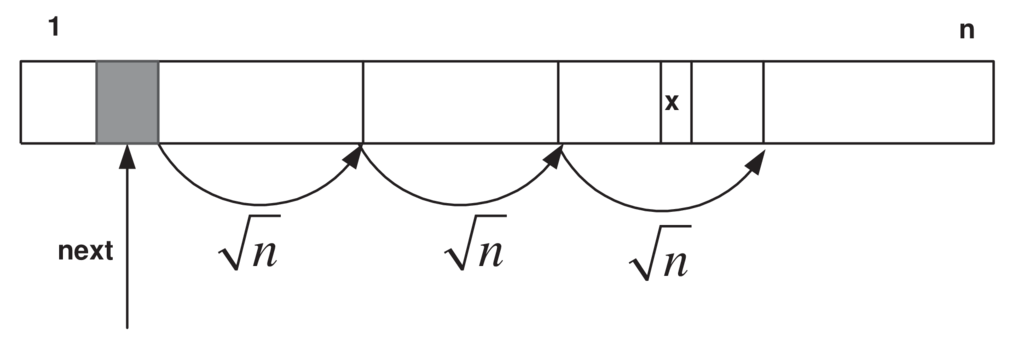
Σχήμα 7.9: Αναζήτηση δυαδικής παρεμβολής. -
•
Για να γίνει απλούστερος ο ψευδοκώδικας, στη γραμμή θεωρούμε ότι για σχετικά μικρά μεγέθη εκτελούμε γραμμική αναζήτηση, χωρίς αυτό να επηρεάζει την ασυμπτωτική συμπεριφορά του αλγορίθμου. Για παράδειγμα, κάλλιστα θα μπορούσε να εκτελεσθεί γραμμική αναζήτηση και για μικρότερο του 5.
-
•
Ο ανωτέρω ψευδοκώδικας δεν χειρίζεται κάποιες ακραίες περιπτώσεις, όπως όταν το αναζητούμενο στοιχείο είναι μεγαλύτερο από κάθε στοιχείο του πίνακα ή αν ενδεχομένως το βήμα μήκους υπερβεί το δεξιό άκρο του υποπίνακα. Η διαχείριση των προβλημάτων αυτών είναι απλή και αφήνεται ως άσκηση στον αναγνώστη.
Πρόταση 7.6.
Ο μέσος χρόνος της δυαδικής αναζήτησης παρεμβολής είναι .
Απόδειξη. Έστω ότι όλα τα στοιχεία του πίνακα επιλέγονται ισοπίθανα από το διάστημα . Επίσης, έστω ότι είναι το πλήθος των συγκρίσεων μέχρι να βρεθεί το κατάλληλο υποδιάστημα μεγέθους που περιέχει το κλειδί που ψάχνουμε. Έστω ότι το κλειδί θα βρίσκεται στη θέση . Αν το δεν είναι μέσα στον πίνακα, τότε το είναι το μεγαλύτερο στοιχείο στο πίνακα που είναι μικρότερο από το . Τέλος, έστω η πιθανότητα, ότι θα χρειασθούν τουλάχιστον συγκρίσεις για να προσδιορισθεί το επίμαχο υποδιάστημα. Είναι βέβαιο ότι θα χρειασθούν συγκρίσεις τουλάχιστον και, επομένως, ισχύει: . Τότε ο αριθμός συγκρίσεων θα είναι:
Για το ισχύει:
Θα χρησιμοποιήσουμε την ανισότητα του Chebyschev, για να φράξουμε από πάνω την πιθανότητα :
για τυχαία μεταβλητή με μέση τιμή και διασπορά και για κάποια ποσότητα .
Έστω, λοιπόν, η τυχαία μεταβλητή, που λαμβάνει τιμές το πλήθος των , όπου είναι τα στοιχεία του πίνακα . Η πιθανότητα , ώστε ένα να είναι μικρότερο του , είναι:
όπου είναι το κάτω όριο του διαστήματος που ψάχνουμε (στην αρχική κλήση της αναζήτησης παρεμβολής ) και είναι το πάνω όριο του διαστήματος που ψάχνουμε (ομοίως αρχικά είναι ). Η πιθανότητα είναι στην πραγματικότητα η πιθανότητα η θέση του να ισούται με . Δεδομένου ότι τα επιλέγονται ισοπίθανα αυτή η πιθανότητα θα ακολουθεί τη διωνυμική κατανομή:
Η ακολουθεί τη δυωνυμική κατανομή με μέση τιμή και διασπορά (αφού για η συνάρτηση μεγιστοποιείται όταν ). Παρατηρούμε ότι , δηλαδή ότι ο δείκτης παρεμβολής είναι ίσος με τη μέση τιμή της . Άρα, χρησιμοποιώντας την ανισότητα Chebyschev:
Συνεπώς, ισχύει:
Αν είναι το μέσο πλήθος των συγκρίσεων, τότε:
για και . Η αναδρομική αυτή περιγράφει τη διαδικασία εύρεσης με παρεμβολή, αφού έπειτα από κατά μέσο όρο συγκρίσεις το υποπρόβλημα που λύνεται στην 1η (και άρα στις επόμενες) αναδρομική κλήση έχει μέγεθος . Λύνοντας τη συγκεκριμένη αναδρομική διαδικασία προκύπτει:
Πρόταση 7.7.
Στην χειρότερη περίπτωση ο χρόνος της δυαδικής αναζήτησης παρεμβολής είναι .
Απόδειξη. Στην πρώτη εκτέλεση του βρόγχου while της εντολής εκτελούνται το πολύ συγκρίσεις, στη δεύτερη το πολύ , στην τρίτη κοκ. Δηλαδή ισχύει:
Ο χρόνος χειρότερης περίπτωσης μπορεί να βελτιωθεί από O() σε O() χωρίς να χειροτερεύει ο χρόνος μέσης περίπτωσης. Αντί το να αυξάνεται γραμμικά (δηλαδή, με την εντολή : μέσα στο βρόγχο while), αυτό να αυξάνεται εκθετικά (δηλαδή, με μία εντολή: ). Έτσι, τα άλματα γίνονται συνεχώς μεγαλύτερα κρατώντας το αριστερό άκρο σταθερό (όπως στο Σχήμα 7.10), με αποτέλεσμα το τελευταίο υποδιάστημα να είναι πολύ μεγαλύτερο από . Μόλις βρεθεί αυτό το υποδιάστημα εφαρμόζουμε δυαδική αναζήτηση στα στοιχεία μέσα σε αυτό που απέχουν κατά και έτσι προκύπτει το ζητούμενο υποδιάστημα μεγέθους . Πιο συγκεκριμένα:
-
1.
Με μεγάλα εκθετικά βήματα εξέτασε τα διαστήματα: , , μέχρι να βρεθεί τέτοιο ώστε:
-
2.
Αναζήτησε δυαδικά στα στοιχεία των θέσεων: . Δηλαδή, ψάξε δυαδικά στα στοιχεία που απέχουν απόσταση στο διάστημα που βρέθηκε από το Βήμα 1. Έτσι, προκύπτει τελικά ένα διάστημα μεγέθους .
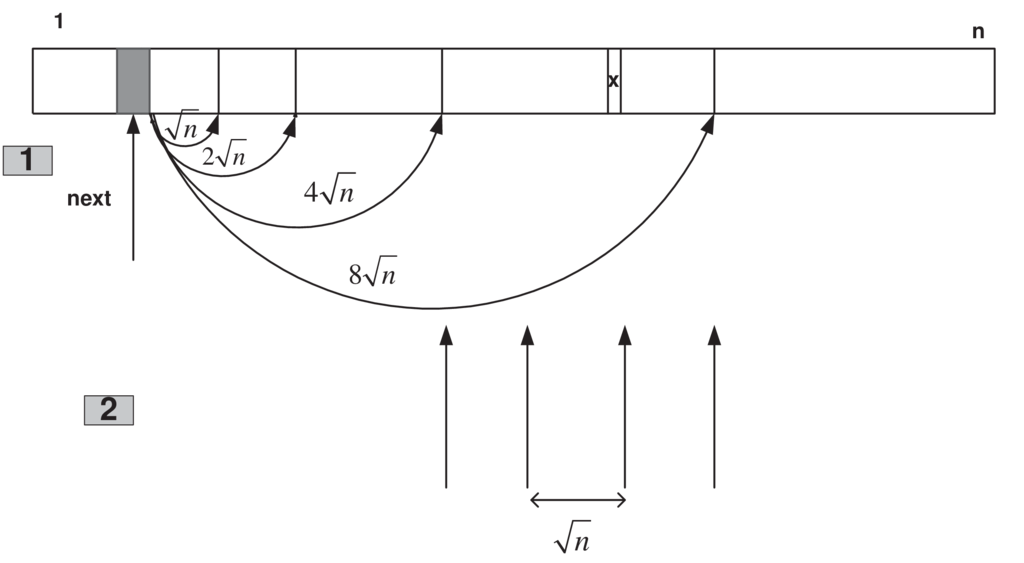
Έστω ότι για το πρώτο βήμα εκτελούμε στη χειρότερη περίπτωση συγκρίσεις. Αυτό σημαίνει ότι:
Συνεπώς, για το πρώτο βήμα χρειάζεται χρόνο , ενώ για το δεύτερο βήμα χρειάζεται χρόνος . Έτσι, προκύπτει ότι κάθε επανάληψη του while θα χρειάζεται χρόνο στη χειρότερη περίπτωση. Άρα, συνολικά θα χρειασθεί χρόνος:
Ο χρόνος μέσης περίπτωσης δεν αλλάζει, υπό την προϋπόθεση ότι όλα τα στοιχεία του πίνακα επιλέχθηκαν ισοπίθανα από το διάστημα . Αυτό συμβαίνει διότι σε κάθε επανάληψη της αναδρομικής σχέσης το κόστος είναι , συνεπώς συνολικά το αναμενόμενο κόστος θα είναι . Η περίπτωση τα στοιχεία του πίνακα να μην επιλέχθηκαν ισοπίθανα από το διάστημα εξετάζεται στη συνέχεια.
7.3.2 Γενίκευση της Μεθόδου Παρεμβολής
Κάθε μέθοδος αναζήτησης (δυαδική ή παρεμβολής) προσπαθεί να εντοπίσει το προς αναζήτηση στοιχείο περιορίζοντας σε κάθε επανάληψη το σχετικό διάστημα. Ο περιορισμός αυτός γίνεται με επιλογή ενός στοιχείου στο τρέχον διάστημα και με βάση αυτό το στοιχείο γίνεται ο διαχωρισμός του διαστήματος σε δύο υποδιαστήματα. Στη δυαδική αναζήτηση γίνεται διχοτόμηση επιλέγοντας το μεσαίο στοιχείο του διαστήματος σύμφωνα με τον τύπο:
ενώ στην αναζήτηση παρεμβολής επιλέγοντας το στοιχείο σύμφωνα με τον τύπο:
Στη βιβλιογραφία έχουν προταθεί συνθετότεροι αλλά και αποτελεσματικότεροι τρόποι, με συνεχείς εναλλαγές στον τρόπο επιλογής του στοιχείου .
- Μέθοδος Alternate.
-
Το στοιχείο διαχωρισμού υπολογίζεται στη μία επανάληψη με βάση τη δυαδική αναζήτηση, ενώ στην επόμενη με βάση την αναζήτηση παρεμβολής κοκ. Δηλαδή:
-
–
Αν , τότε , ενώ
-
–
Αν , τότε
-
–
- Μέθοδος Retrieve.
-
Σε κάθε -οστή επανάληψη της μεθόδου το στοιχείο διαχωρισμού επιλέγεται ως εξής:
-
–
Αν , τότε
-
–
Αν , τότε
-
–
Αν , τότε
όπου
ενώ τα και είναι παράμετροι της μεθόδου.
-
–
Πρόταση 7.8.
Όταν τα στοιχεία του πίνακα επιλέγονται από το διάστημα με ομαλή κατανομή, τότε ο μέσος χρόνος για την Alternate είναι , ενώ για την Retrieve είναι .
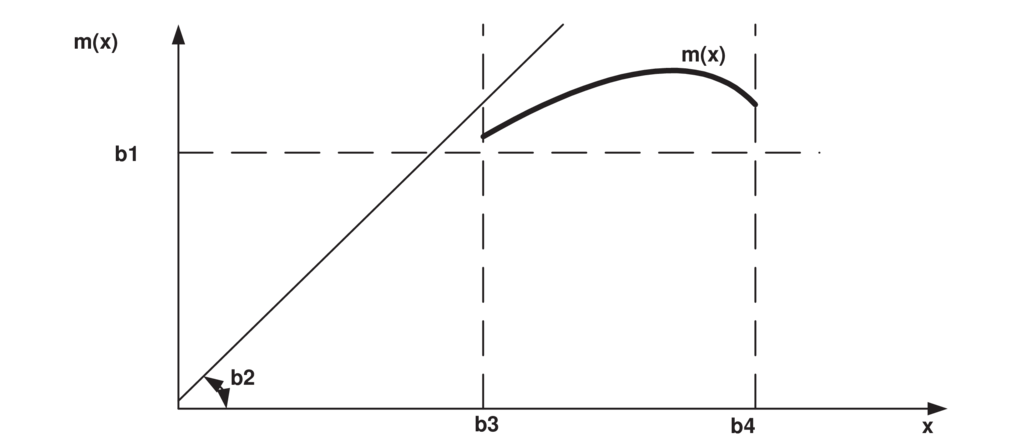
Ορισμός 7.1.
Μία κατανομή καλείται ομαλή, αν υπάρχουν για τα οποία ισχύει:
-
1.
όταν
-
2.
-
3.
όταν
όπως παρουσιάζεται στο παράδειγμα του Σχήματος 7.11.
7.4 Κατακερματισμός
Με τον όρο κατακερματισμός (hashing) δηλώνεται ένα πολύ ευρύ αντικείμενο, τόσο σε θεωρητικό επίπεδο όσο και σε πρακτικό. Το πρόβλημα του σχεδιασμού αποτελεσματικών τεχνικών κατακερματισμού προκύπτει λόγω των πολλών διαφορετικών περιβαλλόντων και εφαρμογών όπου μπορεί να εφαρμοσθεί, όπως σε περιπτώσεις μεταγλωττιστών, βάσεων δεδομένων, ανάκτησης πληροφοριών κλπ. Υπό προϋποθέσεις οι μέθοδοι του κατακερματισμού έχουν πολύ καλή και σταθερή επίδοση, που υπερτερεί της δυαδικής αναζήτησης που εξετάσαμε προηγουμένως.
Εναλλακτική ονομασία του κατακερματισμού είναι μετασχηματισμός κλειδιού σε διεύθυνση (key to address transfrmation). Ο μετασχηματισμός αυτός επιτυγχάνεται με τη βοήθεια της συνάρτησης κατακερματισμού (hashing function), η οποία όμως δεν είναι αμφιμονοσήμαντη. Δηλαδή, είναι δυνατόν δύο διαφορετικά κλειδιά να αντιστοιχίζονται στην ίδια διεύθυνση του πίνακα. Το φαινόμενο αυτό ονομάζεται σύγκρουση (collision) και αποτελεί το μειονέκτημα της μεθόδου. Ουσιαστικά, κάθε μέθοδος κατακερματισμού προτείνει και μία διαφορετική τεχνική επίλυσης των συγκρούσεων. Το ερώτημα που τίθεται είναι πόσο συχνά μπορεί να εμφανισθεί περίπτωση σύγκρουσης. Στο ερώτημα αυτό απαντά το επόμενο παράδειγμα του παραδόξου των γενεθλίων (birthday paradox).
Το παράδοξο των γενεθλίων
Έστω ότι επιλέγονται τυχαία άτομα από το πλήθος. Κάθε φορά ελέγχουμε αν το επιλεγόμενο άτομο έχει γενέθλια την ίδια ημέρα με τους ήδη επιλεγέντες. Η ερώτηση είναι πόσα άτομα πρέπει να επιλεγούν, ώστε η πιθανότητα δύο ή περισσότερα άτομα να έχουν την ίδια ημέρα γενέθλια να είναι περισσότερο από 50%. Κατ’αρχάς υποθέτουμε ότι όλες οι ημέρες του χρόνου είναι ισοπίθανο να είναι ημέρες γενεθλίων. Σε μία τέτοια περίπτωση, η πιθανότητα δύο άτομα να έχουν την ίδια ημέρα γενέθλια είναι , οπότε η πιθανότητα δύο άτομα να μην έχουν την ίδια ημέρα γενέθλια είναι . Ομοίως, η πιθανότητα το τρίτο επιλεγόμενο άτομο να μην έχει γενέθλια με τους δύο προηγούμενους επιλεγέντες είναι . Με τη λογική αυτή καταλήγουμε ότι πρέπει να προσδιορίσουμε το εκείνο για το οποίο ισχύει η σχέση:
| (7.2) |
Αξιοποιώντας τη σχέση (που ισχύει για κάθε όπως είδαμε στο Κεφάλαιο 2), προκύπτει η ισοδύναμη σχέση:
| (7.3) |
| (7.4) |
| (7.5) |
| (7.6) |
Με κατάλληλη άλγεβρα και λύνοντας την παραγόμενη τετραγωνική εξίσωση φθάνουμε στο συμπέρασμα ότι η ζητούμενη τιμή είναι . Το αποτέλεσμα αυτό θεωρείται παράδοξο, καθώς κάποιος θα ανέμενε ότι η συγκεκριμένη πιθανότητα (δηλαδή, δύο ή περισσότερα άτομα να έχουν την ίδια ημέρα γενέθλια να είναι περισσότερο από 50%) θα συνέβαινε για ένα μεγαλύτερο σύνολο ατόμων. Από το παράδοξο αυτό μπορούμε να σκεφτούμε την αναλογία σε σχέση με τον κατακερματισμό, δηλαδή ότι οι 365 ημέρες αντιστοιχούν σε θέσεις ενός πίνακα, ενώ τα άτομα αντιστοιχούν σε κλειδιά που εισάγονται στον πίνακα. Με βάση τη δυωνυμική κατανομή προκύπτει ότι η πιθανότητα κατά την εισαγωγή κλειδιών, από αυτά να συμπέσουν στην ίδια θέση είναι:
| (7.7) |
Για αρκετά μεγάλο η προηγούμενη σχέση προσεγγίζεται από 1/. Από την προηγούμενη δυωνυμική κατανομή συνάγεται ότι αν σε πίνακα 1000 θέσεων εισαχθούν κλειδιά, τότε η πιθανότητα σε μία θέση του πίνακα να αντιστοιχηθούν κλειδιά δίνεται από τον Πίνακα 7.1. Συνεπώς, η πιθανότητα να παρουσιασθούν συγκρούσεις είναι σημαντικότατη και για το λόγο αυτό έχουν προταθεί τόσες πολλές τεχνικές αντιμετώπισης του προβλήματος.
| πιθανότητα | |
|---|---|
| συγκρούσεων | |
| 0 | 37% |
| 1 | 37% |
| 2 | 18% |
| 3 | 6% |
| 4 | 1.5 % |
| 5 | 0.3% |
7.4.1 Γραμμικός Κατακερματισμός
Ο κλειστός κατακερματισμός (closed hashing) είναι μία οικογένεια αλγορίθμων που δεν χρησιμοποιούν δείκτες για το χειρισμό των πινάκων. Στην οικογένεια αυτή ανήκουν αρκετές τεχνικές, μεταξύ των οποίων η γραμμική αναζήτηση (linear probing), η τετραγωνική αναζήτηση (quadratic probing), και o διπλός κατακερματισμός (double hashing). Την απλούστερη τεχνική της γραμμικής αναζήτησης θα εξετάσουμε στη συνέχεια, ενώ στο Κεφάλαιο LABEL:section_quadratic θα εξετάσουμε την τετραγωνική αναζήτηση.
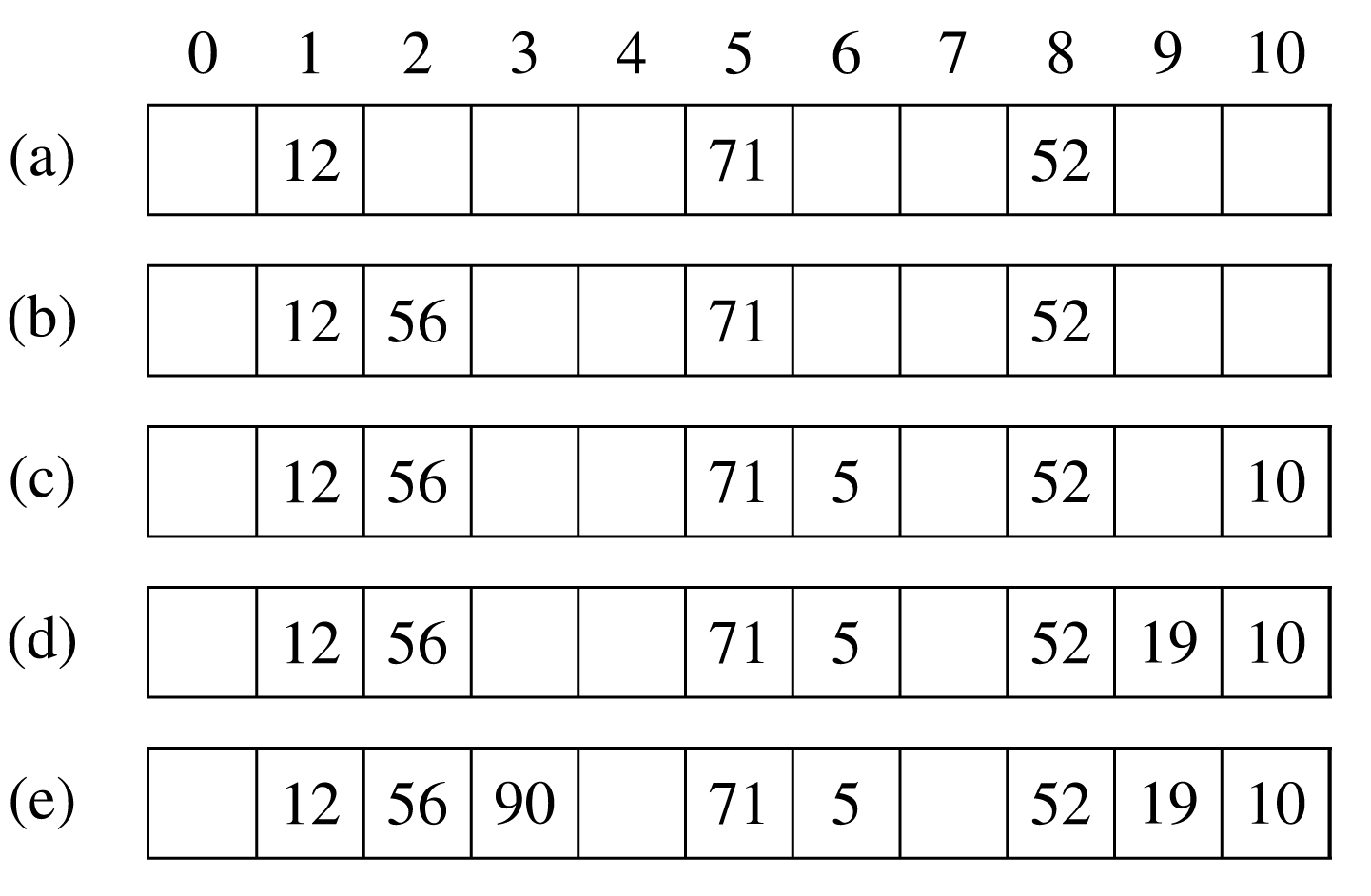
Η επόμενη διαδικασία insert παριστά τον αλγόριθμο εισαγωγής υποθέτοντας ότι ο πίνακας A έχει m θέσεις. Σύμφωνα με τη μέθοδο αυτή, κατά την εισαγωγή ενός κλειδιού καλείται η συνάρτηση κατακερματισμού που δίνει τη διεύθυνση του πίνακα όπου θα πρέπει να εισαχθεί το κλειδί. Αν η θέση δεν είναι κατειλημμένη, τότε το κλειδί εισάγεται και η διαδικασία τερματίζει. Αν η θέση είναι κατειλημμένη, τότε δοκιμάζεται η επόμενη θέση διαδοχικά μέχρι να τοποθετηθεί το κλειδί ή να γίνουν m προσπάθειες, γεγονός που δηλώνει ότι ο πίνακας είναι πλήρης.
Το επόμενο σχήμα δείχνει ένα παράδειγμα της δομής αυτής με και . Πιο συγκεκριμένα, εισάγονται με τη σειρά τα κλειδιά 52, 12, 71, 56, 5, 10, 19 και 90, ενώ η χρησιμοποιούμενη συνάρτηση κατακερματισμού είναι: hash(key) = key mod m.
Παρόμοιο είναι και το σκεπτικό του αλγορίθμου αναζήτησης, όπως φαίνεται στην επόμενη διαδικασία search, που επιστρέφει τη διεύθυνση του πίνακα όπου το κλειδί είναι αποθηκευμένο ή επιστρέφει την τιμή , αν το κλειδί δεν υπάρχει στον πίνακα.
Θα αναλύσουμε την επίδοση της μεθόδου για την περίπτωση της επιτυχούς και της
ανεπιτυχούς αναζήτησης, Ε και Α αντίστοιχα, δηλαδή όταν αναζητούμε ένα υπαρκτό ή
ανύπαρκτο κλειδί μέσα στον πίνακα. Υποθέτουμε ότι η συνάρτηση κατακερματισμού παράγει
μία τυχαία διάταξη των κλειδιών, οπότε οι θέσεις στον πίνακα εξετάζονται με τυχαίο
τρόπο. Αρχικά, θα ασχοληθούμε με την ανεπιτυχή αναζήτηση. Οι παράμετροι που υπεισέρχονται
στην ανάλυση της επίδοσης της μεθόδου είναι το μέγεθος του πίνακα, το πλήθος των
κλειδιών και ο παράγοντας φόρτωσης (load factor) .
Πρόταση 7.9.
Η μέση τιμή του αριθμού των συγκρίσεων κατά τη γραμμική αναζήτηση, σε περίπτωση επιτυχούς και ανεπιτυχούς αναζήτησης είναι αντιστοίχως:
και
Απόδειξη. Ας υποθέσουμε ότι μία ανεπιτυχής αναζήτηση απαιτεί προσπελάσεις () στον πίνακα. Στην περίπτωση αυτή θα γίνουν προσπελάσεις σε κατειλημμένες θέσεις του πίνακα, ενώ η -οστή θα προσπελάσει μία κενή θέση. Επομένως, αν εξαιρέσουμε αυτήν την ομάδα των συνεχόμενων θέσεων, μένουν θέσεις εκ των οποίων κατειλημμένες είναι οι θέσεις. Το πλήθος των τρόπων που μπορεί να εμφανισθεί αυτή η περίπτωση είναι , ενώ το σύνολο των περιπτώσεων είναι . Συνεπώς, η πιθανότητα να απαιτηθούν προσπελάσεις είναι:
| (7.8) |
Άρα ισχύει:
| (7.9) |
Για το τελευταίο άθροισμα ισχύει:
| (7.10) |
Επομένως, επιστρέφοντας στο A έχουμε:
| (7.11) |
Με βάση την ταυτότητα των συνδυασμών, την οποία γνωρίζουμε από το Κεφάλαιο 2, έχουμε διαδοχικά:
| (7.12) |
Το αποτέλεσμα αυτό εξηγείται και διαισθητικά. Το δηλώνει το ποσοστό των
κατειλημμένων θέσεων, οπότε το δηλώνει το ποσοστό των κενών θέσεων. Άρα,
αναμένουμε να εκτελέσουμε προσπελάσεις, πριν να εντοπίσουμε μία κενή θέση.
Για να φθάσουμε στην αντίστοιχη έκφραση για την επιτυχή αναζήτηση αρκεί να παρατηρήσουμε ότι το πλήθος των προσπελάσεων για την εύρεση ενός κλειδιού ισούται με το πλήθος των προσπελάσεων που είναι απαραίτητες για την εισαγωγή του (δηλαδή, προσπελάσεις σε κατειλημμένες θέσεις και μία προσπέλαση σε κενή θέση). Συνεπώς, καταλήγουμε ότι:
Στις ίδιες εκφράσεις για τα E και A μπορούμε να καταλήξουμε στηριζόμενοι σε ένα διαφορετικό σκεπτικό. Έστω ότι με συμβολίζουμε την πιθανότητα να απαιτηθούν ακριβώς προσπελάσεις για μία ανεπιτυχή αναζήτηση, οπότε ισχύει:
| (7.13) |
Έστω επίσης ότι με συμβολίζουμε την πιθανότητα να απαιτηθούν τουλάχιστον προσπελάσεις, οπότε ισχύει η σχέση:
| (7.14) |
Το πρόβλημα, λοιπόν, ανάγεται στον προσδιορισμό του . Προφανώς, ισχύει , , ενώ γενικώς ισχύει:
| (7.15) |
Επανερχόμενοι στη σχέση για το E έχουμε:
| (7.16) |
7.4.2 Τετραγωνική Αναζήτηση
Η επίδοση της γραμμικής αναζήτησης δεν είναι ιδιαίτερα ελκυστική και οφείλεται στο φαινόμενο της πρωτεύουσας συγκέντρωσης (primary clustering), δηλαδή της σύγκρουσης σε διάφορες περιοχές του πίνακα κλειδιών που προέρχονται από διαφορετικές αρχικές διευθύνσεις, δηλαδή δεν είναι συνώνυμα. Για τη μείωση της πρωτεύουσας συγκέντρωσης συχνά χρησιμοποιούνται μη γραμμικές μέθοδοι αναζήτησης της επόμενης διαθέσιμης θέσης. Μία τέτοια μέθοδος είναι η τετραγωνική αναζήτηση (quadratic search), που σκοπό έχει τη γρήγορη απομάκρυνση των κλειδιών από την αρχική περιοχή σύγκρουσης. Σύμφωνα με τη μέθοδο αυτή οι επόμενες θέσεις που θα εξετασθούν μπορούν να υπολογισθούν με βάση τη σχέση:
(
όπου είναι ο αύξων αριθμός της αναζήτησης (δηλαδή, ), ενώ τα και είναι αυθαίρετες σταθερές.
Στο Σχήμα 7.15 παρουσιάζεται η εισαγωγή της προηγούμενης ομάδας κλειδιών στον πίνακα των 11 θέσεων θεωρώντας ότι =1 και =2. Είναι εύκολη για τον αναγνώστη η κατανόηση του τρόπου που προκύπτουν οι διαδοχικές μορφές που παίρνει ο πίνακας μετά την αποθήκευση των κλειδιών 71, 56, 10 και 90, αντίστοιχα. Σημειώνεται ότι τα κλειδιά 56, 5 και 19 εισάγονται μετά από 2, 3, και 3 προσπάθειες, αντίστοιχα.
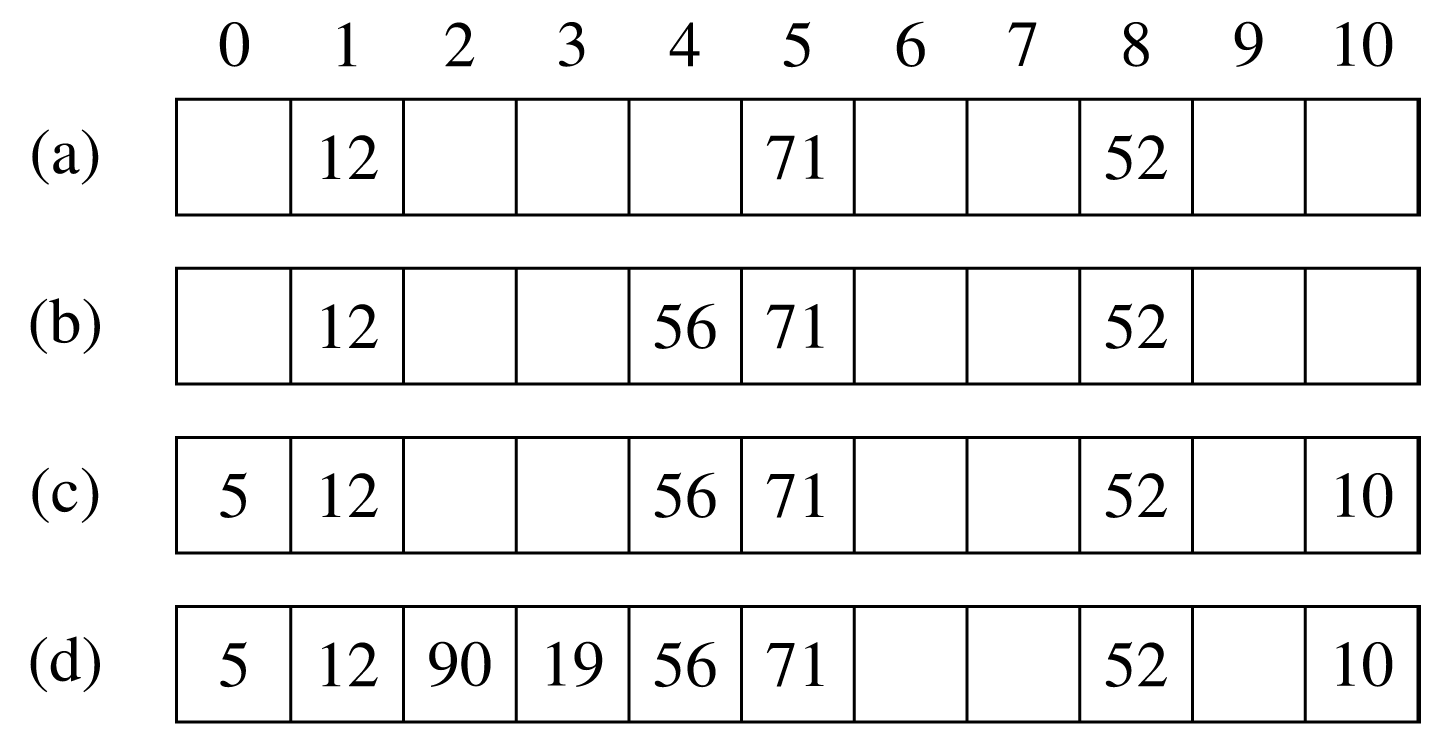
Επίσης, σημειώνεται ότι η προηγούμενη γενική σχέση μπορεί να απλοποιηθεί ως εξής:
| (7.17) |
Για την περίπτωση αυτή έχει αποδειχθεί ότι δεν είναι απαραίτητο να υπολογίζεται το τετράγωνο που είναι χρονοβόρα πράξη, αλλά η θέση όπου θα γίνει η -οστή σύγκριση μπορεί να προκύψει προσθέτοντας 2 μονάδες στο άλμα, που χρησιμοποιήθηκε στην ()-οστή σύγκριση. Αυτό φαίνεται από την επόμενη ταυτότητα, που μπορεί να αποδειχθεί με μαθηματική επαγωγή:
| (7.18) |
Στη συνέχεια δίνεται η διαδικασία εισαγωγής με την τετραγωνική εξέταση, που στηρίζεται στην αντίστοιχη διαδικασία της γραμμικής εξέτασης. Είναι εύκολο για τον αναγνώστη να μετατρέψει τη διαδικασία search της γραμμικής εξέτασης, ώστε να ισχύει για την τετραγωνική εξέταση.
Ένα μειονέκτημα της μεθόδου αυτής είναι ότι για μερικές τιμές του μεγέθους του πίνακα υπάρχει πιθανότητα να καταστεί αδύνατη η εισαγωγή ενός κλειδιού. Ειδικά αν , τότε μπορεί να προσπελασθούν πολύ λίγες θέσεις του πίνακα, ενώ διαφορετική είναι η περίπτωση όπου το είναι πρώτος αριθμός. Στην περίπτωση αυτή μπορεί η -οστή εξέταση να συμπίπτει με την ()-οστή εξέταση.
Πρόταση 7.10.
Αν το είναι πρώτος αριθμός, τότε κατά την τετραγωνική εξέταση μπορεί να προσπελασθούν μόνο οι μισές θέσεις του πίνακα.
Απόδειξη. Έστω ότι η -οστή και η -οστή προσπάθεια, όπου το είναι ο μικρότερος τέτοιος ακέραιος, συμπίπτουν στην ίδια θέση του πίνακα. Τότε ισχύει:
| (7.19) |
Συνεπώς, προκύπτει:
| (7.20) |
Επειδή τα και είναι άνισα, πρέπει να ισχύει:
| (7.21) |
Άρα, πρέπει ή το ή το είναι μεγαλύτερα από /2.
Επειδή ισχύει η προηγούμενη πρόταση ο πίνακας θεωρείται πλήρης, όταν ισχύει . (όπως φαίνεται στα όρια της εντολής ελέγχου until της εντολής 10.) Το πρόβλημα αυτό της τετραγωνικής εξέτασης επιλύεται μερικώς με την πρόσθεση διαδοχικά των όρων της ακολουθίας +1, –1, +4, –4, +9, –9 κλπ. επάνω στην αρχική ποσότητα της location (εντολή 1) και με κατάλληλη αναγωγή στο μέγεθος του πίνακα.
7.4.3 Διπλός Κατακερματισμός
Η τετραγωνική αναζήτηση αντιμετωπίζει το πρόβλημα της πρωτεύουσας συγκέντρωσης, υποφέρει όμως από τη λεγόμενη δευτερεύουσα συγκέντρωση (secondary clustering). Ο λόγος είναι είτε ο τρόπος επιλογής της επόμενης θέσης, ο οποίος είναι κοινός για όλα τα κλειδιά, είτε η εξάρτηση από την αρχική διεύθυνση, όπου κατευθύνεται ένα κλειδί προς αποθήκευση. Το πρόβλημα αυτό αντιμετωπίζεται με την τεχνική του διπλού κατακερματισμού (double hashing), που χρησιμοποιεί μία δεύτερη συνάρτηση μετασχηματισμού για να εντοπίσει την επόμενη διαθέσιμη θέση. Δηλαδή, έστω ότι χρησιμοποιείται η συνάρτηση της διαίρεσης:
| (7.22) |
για την εύρεση της αρχικής θέσης αποθήκευσης του κλειδιού. Σε περίπτωση σύγκρουσης χρησιμοποιείται μία άλλη συνάρτηση, για να δώσει την απόσταση σε θέσεις από την αρχική θέση. Σε περίπτωση νέας σύγκρουσης γίνεται δοκιμή σε θέση που απέχει την ίδια απόσταση από τη θέση της δεύτερης σύγκρουσης. Ένα συνηθισμένο παράδειγμα συνάρτησης επανα-κατακερματισμού είναι:
| (7.23) |
Δηλαδή, στη δεύτερη αυτή συνάρτηση πρώτα υπολογίζεται το πηλίκο του κλειδιού διαιρούμενου με το μήκος του πίνακα, κατόπιν υπολογίζεται το υπόλοιπο (κατά τα γνωστά) που προστίθεται στο αποτέλεσμα της (key). Σημειώνεται ότι αν το υπολογιζόμενο πηλίκο είναι ίσο με 0, τότε αυθαίρετα εξισώνεται με 1. Έτσι, με τον τρόπο αυτό τα συνώνυμα που συγκρούονται σε μία αρχική θέση δεν ακολουθούν την ίδια διαδρομή στον πίνακα για την εύρεση μίας διαθέσιμης θέσης. Πρέπει επίσης να προσεχθεί, ώστε το μέγεθος του πίνακα να είναι πρώτος αριθμός, γιατί αλλιώς για μερικά κλειδιά υπάρχει η δυνατότητα να μην προσπελασθούν όλες οι θέσεις του πίνακα για εξέταση. Από τα προηγούμενα γίνεται αντιληπτό γιατί η μέθοδος αυτή λέγεται και μέθοδος γραμμικού πηλίκου (linear quotient).
Ας εξετασθεί και πάλι το παράδειγμα εισαγωγής με τις γνωστές τιμές κλειδιών. Στο Σχήμα 7.17 φαίνεται διαδοχικά η μορφή του πίνακα μετά την εισαγωγή των κλειδιών 71, 56, 10 και 90, αντίστοιχα.
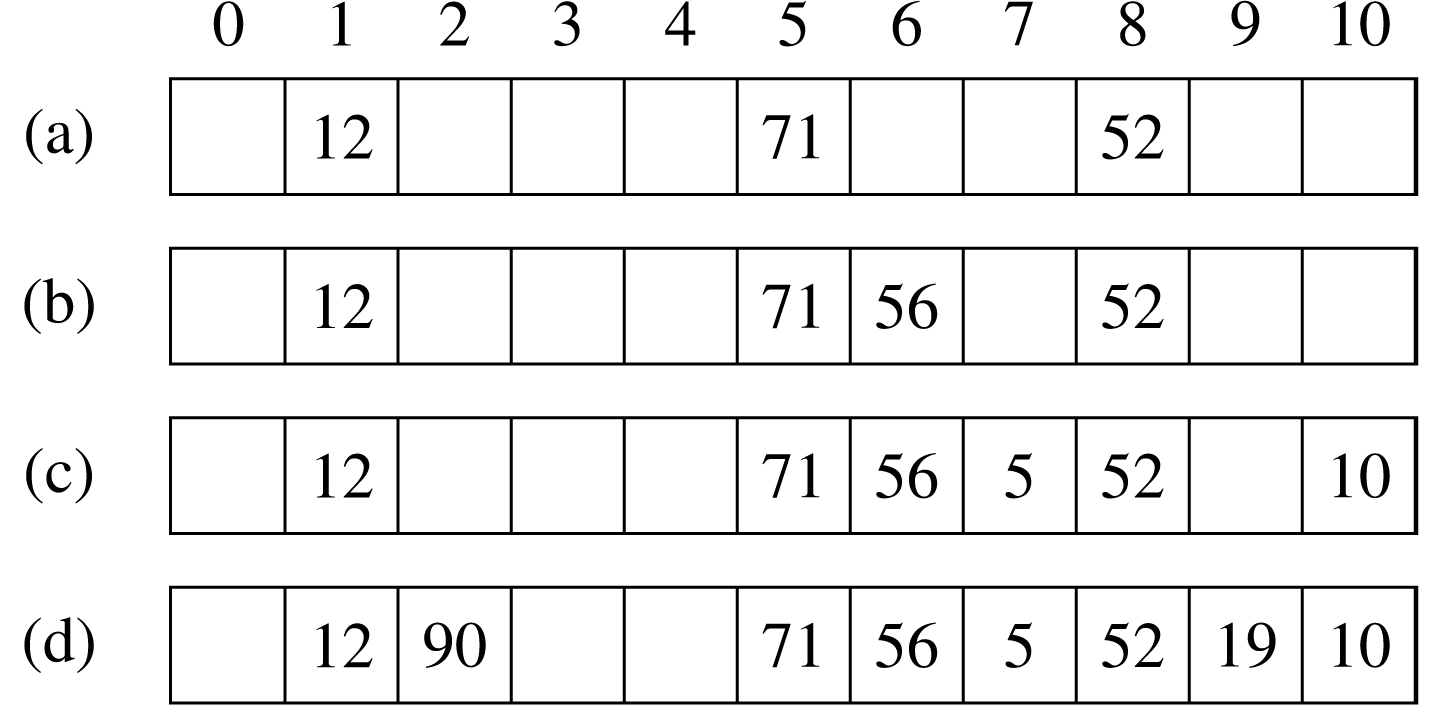
Στη συνέχεια, δίνεται η διαδικασία double_insert για την εισαγωγή στοιχείων σε πίνακα με τη μέθοδο του διπλού κατακερματισμού. Με hash1 και hash2 συμβολίζονται οι δύο συναρτήσεις κατακερματισμού που περιγράφηκαν προηγουμένως.
Πρόταση 7.11.
Η μέση τιμή του αριθμού των συγκρίσεων για την επιτυχή και την ανεπιτυχή αναζήτηση σύμφωνα με τη μέθοδο του διπλού κατακερματισμού είναι αντίστοιχα:
Απόδειξη. Η πιθανότητα κάποια θέση να είναι κατειλημμένη είναι . Επομένως, για την ανεπιτυχή αναζήτηση ισχύει:
Αν το είναι πολύ μεγάλο, τότε ο αφαιρετέος είναι πολύ μικρός, ενώ το άθροισμα μπορεί να θεωρηθεί ως άθροισμα απείρων όρων φθίνουσας ακολουθίας. Έτσι, προκύπτει η αλήθεια της πρότασης.
Ο αριθμός των συγκρίσεων για μία επιτυχή αναζήτηση ισούται με τον αριθμό των συγκρίσεων για την εισαγωγή του αντίστοιχου κλειδιού. Αν θεωρηθεί ότι ο πίνακας δημιουργείται εισάγοντας τα κλειδιά ένα-προς-ένα, τότε ο παράγοντας φόρτωσης αυξάνει κατά μικρά βήματα. Άρα, η τιμή του E ισούται με το μέσο όρο των τιμών του A, καθώς ο παράγοντας φόρτωσης αυξάνει από 0 ως . Συνεπώς:
| (7.24) |
από όπου προκύπτει η αντίστοιχη αλήθεια της πρότασης.
7.4.4 Κατακερματισμός με Αλυσίδες
Αναφέραμε ότι η οικογένεια των μεθόδων του κλειστού κατακερματισμού δεν χρησιμοποιεί επιπλέον χώρο πέραν του χώρου του συγκεκριμένου πίνακα. Μία άλλη μεγάλη οικογένεια μεθόδων κατακερματισμού, η οικογένεια της ανοικτής διεύθυνσης (open addressing), χρησιμοποιεί αλυσίδες που ξεκινούν από τις θέσεις του πίνακα και μπορούν να επεκταθούν δυναμικά. Σε επίπεδο τύπων υποθέτουμε ότι υπάρχει μία δομή record με δύο πεδία, όπου το πρώτο πεδίο data αφορά στα καθαρά δεδομένα, ενώ το δεύτερο πεδίο ptr παριστά το δείκτη προς τον επόμενο κόμβο της αλυσίδας. Το διπλανό σχήμα δείχνει ένα παράδειγμα της δομής αυτής με και (τα ίδια κλειδιά με το προηγούμενο παράδειγμα). Πιο συγκεκριμένα, πρέπει να έχουμε υπ’όψιν ότι η παραλλαγή αυτή λέγεται μέθοδος με ξεχωριστές αλυσίδες (separate chaining), καθώς υπάρχει και η μέθοδος των σύμφυτων αλυσίδων (coalesced chaining), η οποία όμως δεν θα μας απασχολήσει στη συνέχεια. Ο ψευδοκώδικας Chain_Search που ακολουθεί δείχνει τη διαδικασία επιτυχούς και ανεπιτυχούς αναζήτησης.
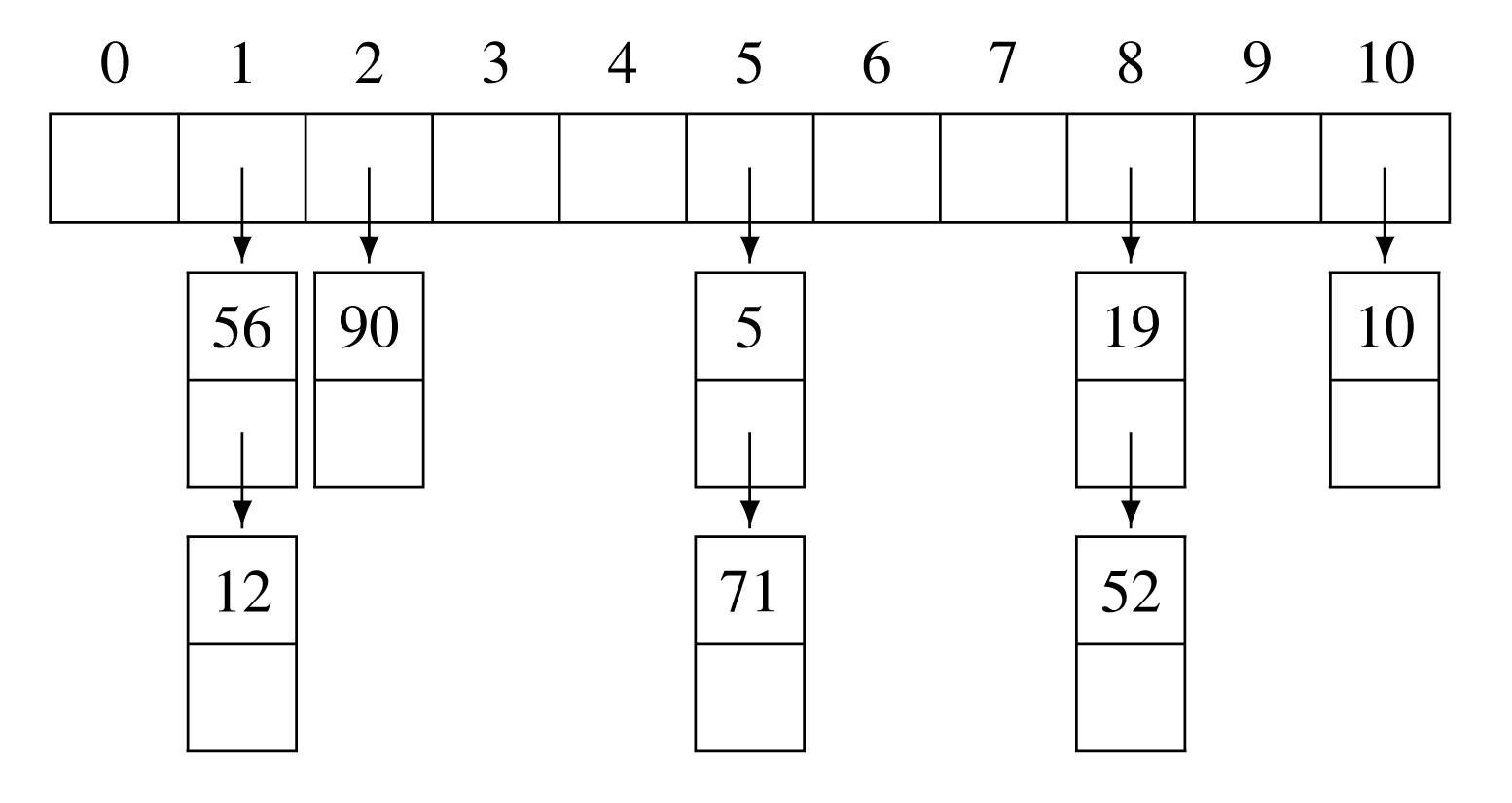
Πρόταση 7.12.
Η μέση τιμή του αριθμού των συγκρίσεων κατά την αναζήτηση σε κατρακερματισμό με αλυσίδες, σε περίπτωση επιτυχούς και ανεπιτυχούς αναζήτησης είναι αντιστοίχως:
| (7.25) |
και
| (7.26) |
Απόδειξη. Θα εξετάσουμε κατ’αρχάς την περίπτωση της ανεπιτυχούς αναζήτησης. Υποθέτοντας μία τυχαία συνάρτηση κατακερματισμού, αναμένουμε ότι κάθε κλειδί θα κατευθυνθεί σε οποιαδήποτε θέση από τις θέσεις του πίνακα με την ίδια πιθανότητα (εντολή 1). Στη συνέχεια, η αναζήτηση θα συνεχισθεί στην αντίστοιχη αλυσίδα (εντολές 3-5), που θα τη διασχίσει μέχρι το τέλος της, ώστε να επιστραφεί η ένδειξη false. Επομένως, η επίδοση εξαρτάται από το μήκος της αλυσίδας, και εφόσον συνολικά έχουν εισαχθεί κλειδιά σε όλες τις αλυσίδες, έπεται ότι το μέσος μήκος της αλυσίδας είναι . Άρα, η πολυπλοκότητα της ανεπιτυχούς αναζήτησης είναι Θ(1+) στη μέση περίπτωση.
Για να εξετάσουμε την περίπτωση της επιτυχούς αναζήτησης, θα υποθέσουμε ότι κάθε νέο κλειδί εισάγεται στο τέλος της αντίστοιχης αλυσίδας. Επομένως, το πλήθος των προσπελάσεων που θα πραγματοποιηθούν για μία επιτυχή αναζήτηση είναι μία μονάδα περισσότερο από το πλήθος που απαιτούνται για την εισαγωγή του αντίστοιχου κλειδιού. Όταν εισάγεται το -οστό κλειδί, το μήκος της αντίστοιχης αλυσίδας είναι . Επομένως, ισχύει:
Συνεπώς και πάλι προκύπτει ότι η πολυπλοκότητα είναι Θ() στη μέση περίπτωση.
Στο σημείο αυτό πρέπει να προσεχθεί ότι στην περίπτωση της ανοικτής διεύθυνσης ισχύει , αλλά στην περίπτωση των αλυσίδων δεν ισχύει αυτός ο περιορισμός. Επομένως, η επίδοση της επιτυχούς και της ανεπιτυχούς αναζήτησης είναι ικανοποιητική, όταν το είναι της τάξης του , επομένως το είναι της τάξης της μονάδας.
7.5 Βιβλιογραφική Συζήτηση
Η δυαδική αναζήτηση απασχόλησε τους ερευνητές της Πληροφορικής στις αρχές της δεκαετίας του 1970. Οι πρώτες αναλύσεις της μεθόδου αναφέρονται στα άρθρα [48, 83]. Την περίοδο εκείνη η μέθοδος ήταν δημοφιλής και εκδοχές της δημοσιεύονταν σε πλήθος βιβλίων και άρθρων. Ωστόσο, τότε δεν ήταν προφανές αυτό που είναι σήμερα. Στο άρθρο [98] παρουσιάζονται και αναλύονται τα λάθη που είχαν παρεισφρήσει σε 26 δημοσιεύσεις της εποχής σχετικά με το θέμα. Εξάλλου ο Bentley ισχυρίζεται ότι λίγοι προγραμματιστές μπορούν να κωδικοποιήσουν τη μέθοδο χωρίς λάθη μέσα σε δύο ώρες [13]. Γενικεύσεις της μεθόδου μπορούν να βρεθούν στα άρθρα [55, 97].
Δημοφιλής μέθοδος αναζήτησης υπήρξε και η αναζήτηση με παρεμβολή. Προτάθηκε το 1977 από τους Perl-Reingold [147] και εν συνεχεία μελετήθηκε στα άρθρα [25, 62, 100, 146], αυτή καθώς και οι παραλλαγές της με σειριακή αναζήτηση [63] και με δυαδική αναζήτηση [158]. Οι παραλλαγές Alternate και Retrieve διαπτυπώθηκαν από τον Willard [198].
Πέραν των δύο αυτών μεθόδων, στη βιβλιογραφία αναφέρονται και άλλες μέθοδοι, που όμως δεν άντεξαν στο χρόνο. Για παράδειγμα, αναφέρεται η Fibonaccian μέθοδος [46, 138], η αναζήτηση άλματος [172, 82] και η πολυωνυμική αναζήτηση [171].
Η μέθοδος του κατακερματισμού υπήρξε εξίσου δημοφιλής και ερευνήθηκε σε βάθος τις δεκαετίες του 1970 και 1980. Οι πρώτες βασικές εργασίες σχετικά με τον κατακερματισμό ήταν τα άρθρα [118, 148]. Σχετικά με την επιλογή της κατάλληλης συνάρτησης κατακερματισμού είναι τα άρθρα [87, 122]. Θεμελιωτές της τετραγωνικής μεθόδου ήταν οι Bell και Radke [10, 151], ενώ αντίστοιχα στο διπλό κατακερματισμό αναφέρονται τα άρθρα [71, 108]. Κατά καιρούς έχουν εμφανισθεί διάφορες επισκοπήσεις της περιοχής, όπως τα άρθρα [37, 103, 117, 168]. Το βιβλίο των Gonnet-BeazaYates συμπεριλαμβάνει σε συνοπτικό τρόπο πλήθος μεθόδων κατακερματισμού και αντίστοιχες αναλύσεις [60]. Τη δεκαετία του 1990 η έρευνα στράφηκε στη σχεδίαση δυναμικών μεθόδων κατακερματισμού για χρήση σε δευτερεύουσα μνήμη και προέκυψαν πολλές νέες μέθοδοι. Οι μέθοδοι αυτές δεν θα εξετασθούν στα πλαίσια του βιβλίου αυτού, καθώς ταιριάζουν περισσότερο στο αντικείμενο των Βάσεων Δεδομένων (Data Bases). Ωστόσο, ο ενδιαφερόμενος αναγνώστης παραπέμπεται στην επισκόπηση [41].
7.6 Ασκήσεις
-
1.
Να βρεθεί η μέση τιμή του αριθμού των αναζητήσεων για την περίπτωση της ανεπιτυχούς σειριακής αναζήτησης σε ταξινομημένο πίνακα. Να θεωρηθεί ότι η πιθανότητα αναζήτησης ενός ανύπαρκτου κλειδιού από τα δημιουργούμενα διαστήματα μεταξύ των κλειδιών είναι ίση για όλα τα διαστήματα.
-
2.
Δίνεται ταξινομημένος πίνακας με στοιχεία, όπου επιτρέπεται η ύπαρξη πολλαπλών τιμών. Να τροποποιηθεί ο αλγόριθμος της δυαδικής αναζήτησης, ώστε να βρίσκει την πρώτη εμφάνιση του αναζητούμενου κλειδιού σε χρόνο της τάξης Θ.
-
3.
Δίνεται ταξινομημένος πίνακας με στοιχεία, όπου επιτρέπεται η ύπαρξη πολλαπλών τιμών. Να τροποποιηθεί ο αλγόριθμος της δυαδικής αναζήτησης, ώστε να βρίσκει το μεγαλύτερο κλειδί που είναι μικρότερο από το αναζητούμενο κλειδί, το οποίο όμως δεν υπάρχει (ανεπιτυχής αναζήτηση). Αν το αναζητούμενο είναι το μικρότερο στοιχείο του πίνακα, τότε να επιστρέφεται μήνυμα λάθους.
-
4.
Η μέθοδος των παραγεμισμένων λιστών (padded lists) προσπαθεί να βελτιώσει τη δυαδική αναζήτηση χρησιμοποιώντας δύο πίνακες ίσου μεγέθους: ένα πίνακα για δεδομένα και ένα πίνακα για λογικές σημαίες. Αρχικά ο πίνακας δεδομένων περιέχει και κάποιες κενές θέσεις ομοιόμορφα διαμοιρασμένες μεταξύ των κατειλημμένων θέσεων. Στις κενές αυτές θέσεις αποθηκεύονται τυχαίες τιμές, έτσι ώστε ο πίνακας να παραμένει ταξινομημένος, ενώ οι αντίστοιχες θέσεις του πίνακα σημαιών παίρνουν τιμές false. Η αναζήτηση ενός κλειδιού γίνεται στον πίνακα δεδομένων κατά τα γνωστά, αλλά παράλληλα ελέγχεται αν η αντίστοιχη λογική σημαία είναι true. Σε περίπτωση διαγραφής η σημαία από true γίνεται false. Τέλος, αν σε περίπτωση εισαγωγής η θέση δεν είναι κατειλημμένη, τότε η σημαία από false γίνεται true, ενώ αν η θέση είναι κατειλημμένη, τότε ακολουθείται μία διαδικασία ολισθήσεων. Για μεγαλύτερη αποτελεσματικότητα περιοδικά απαιτείται η αναδιοργάνωση των πινάκων, έτσι ώστε οι κενές θέσεις να μοιράζονται και πάλι ομοιόμορφα μεταξύ των κατειλημμένων θέσεων. Να σχεδιασθούν και να αναλυθούν αλγόριθμοι υλοποίησης των διαφόρων λειτουργιών των παραγεμισμένων λιστών (δηλαδή, εισαγωγή, διαγραφή, αναζήτηση).
-
5.
Με βάση την δυαδική αναζήτηση να σχεδιασθεί και να αναλυθεί μέθοδος αναζήτησης σε ταξινομημένο πίνακα που να τον τριχοτομεί (αντί να τον διχοτομεί).
-
6.
Ποιά είναι η πιθανότητα 3 άτομα μεταξύ 100 τυχαίων ατόμων να έχουν γενέθλια την ίδια ημέρα;
-
7.
Έστω ένας πίνακας με ταξινομημένα στοιχεία, όπου . Έτσι, χωρίζουμε τον πίνακα σε υποπίνακες με στοιχεία ο καθένας. Προκειμένου να ψάξουμε ένα κλειδί πρώτα το συγκρίνουμε με σειριακό τρόπο με το τελευταίο κλειδί του κάθε υποπίνακα. Με τον τρόπο αυτό καταλαβαίνουμε σε ποιόν υποπίνακα πρέπει να συνεχισθεί η αναζήτηση. Σε περίπτωση επιτυχούς αναζήτησης, στη χειρότερη περίπτωση θα εκτελεσθούν συγκρίσεις, στη μέση περίπτωση θα εκτελεσθούν συγκρίσεις. Για ποιές τιμές των η επίδοση βελτιστοποιείται;
-
8.
Στη συνέχεια δίνεται η διαδικασία αναζήτησης Fibonacci. Υποτίθεται ότι αναζητείται το key στον ταξινομημένο πίνακα A[0..n-1]. Αν το κλειδί βρεθεί, τότε η μεταβλητή position επιστρέφει τη θέση του, αλλιώς επιστρέφει 0. Σημειώνεται, επίσης, ότι η εντολή while υπολογίζει τον αριθμό Fibonacci που είναι αμέσως μεγαλύτερος του n. Να αναλυθεί η πολυπλοκότητα του αλγορίθμου.
procedure Fibonacci(key,position) j<--1; while F(j)<n+1 do j<--j+1; done <-- false; mid <-- n-F(j-2)+1; f1 <-- F(j-2); f2 <-- F(j-3); while (not done) and (key<>A[mid]) do if (mid<=0) or (key>A[mid]) then if f1=1 then done <-- true; else mid <-- mid+f2; f1 <-- f1-f2; f2 <-- f2-f1; else if f2=0 then done <-- true; else mid <-- mid-f2; temp <-- f1-f2; f1 <-- f2; f2 <-- temp; if done then position <-- 0 else position <-- mid -
9.
Έστω ένας πύργος με ορόφους, ενώ επίσης μας δίνεται μία λάμπα και πρέπει να βρούμε το χαμηλότερο όροφο από τον οποίο θα σπάσει, αν την αφήσουμε σε ελεύθερη πτώση. Η πρώτη λύση είναι να αρχίσουμε από τον πρώτο όροφο και να συνεχίσουμε προς το δεύτερο, τρίτο κλπ μέχρι να βρούμε την απάντηση. Προφανώς η λύση αυτή έχει γραμμική πολυπλοκότητα. Να σχεδιασθούν δύο αλγόριθμοι μη γραμμικής πολυπλοκότητας για την εύρεση της αντοχής της λάμπας, ενώ μας διατίθενται δύο λάμπες για την εκτέλεση του πειράματος. Να αποδειχθεί η πολυπλοκότητα του κάθε αλγορίθμου.
-
10.
Συχνά παρουσιάζεται η ανάγκη αναζήτησης κλειδιών σε ένα ταξινομημένο πίνακα στοιχείων. Να σχεδιασθούν και να αναλυθούν τρεις αλγόριθμοι μαζικής αναζήτησης, όπου δηλαδή τα κλειδιά να αναζητούνται με μία κλήση του αλγορίθμου και όχι με διαδοχικές κλήσεις. Οι τρεις αλγόριθμοι να στηρίζονται στη σειριακή, τη δυαδική και την αναζήτηση παρεμβολής.
-
11.
Η γραμμική αναζήτηση με διαχωρισμό της ακολουθίας (split sequence linear search) λειτουργεί ως εξής. Έστω ότι κατά την εισαγωγή ενός κλειδιού key εφαρμόζεται η συνάρτηση κατακερματισμού hash(key) και προκύπτει μία θέση του πίνακα, η οποία όμως είναι κατειλημμένη. Αν το κλειδί που είναι αποθηκευμένο στη θέση είναι μεγαλύτερο (μικρότερο) από το αναζητούμενο κλειδί, τότε η επόμενη θέση όπου θα συνεχισθεί η σύγκριση δίνεται αντίστοιχα από τις σχέσεις:
(7.27) όπου τα και είναι δύο άνισες ακέραιες σταθερές. Έτσι, δημιουργούνται δύο ακολουθίες θέσεων, όπου θα κατευθυνθούν τα συνώνυμα και η πρωτεύουσα συγκέντρωση πράγματι μειώνεται. Να σχεδιασθεί η μέθοδος στις λεπτομέρειές της (δηλαδή, εισαγωγή, διαγραφή, αναζήτηση) και να αναλυθεί η χειρότερη περίπτωσή της.
-
12.
Ο ταξινομημένος κατακερματισμός (ordered hashing) μπορεί να εφαρμοσθεί τόσο με τη γραμμική και τη μη γραμμική αναζήτηση, όσο και με το διπλό κατακερματισμό. Σύμφωνα με τη μέθοδο αυτή όταν προκύπτει σύγκρουση κατά την εισαγωγή, τότε τη συγκεκριμένη θέση καταλαμβάνει το κλειδί με τη μικρότερη τιμή εκτοπίζοντας το κλειδί με τη μεγαλύτερη τιμή, το οποίο πρέπει να επανα-εισαχθεί. Να σχεδιασθούν οι αλγόριθμοι εισαγωγής, διαγραφής και αναζήτησης. Να αναλυθεί η επιτυχής και η ανεπιτυχής αναζήτηση για την περίπτωση του ταξινομημένου διπλού κατακερματισμού.
-
13.
Αν είναι γνωστή εκ των προτέρων η πιθανότητα αναζήτησης κάθε κλειδιού, τότε να σχεδιασθεί και να αναλυθεί η διαδικασία εισαγωγής, διαγραφής και αναζήτησης για μία παραλλαγή για τη μέθοδο κατακερματισμού με αλυσίδες, η οποία να εκμεταλλεύεται αυτό το γεγονός.