Κεφάλαιο 8Αλγόριθμοι Ταξινόμησης
Η ταξινόμηση (sorting) τοποθετεί ένα σύνολο κόμβων ή εγγραφών σε μία ιδιαίτερη
σειρά (αύξουσα ή φθίνουσα) με βάση την τιμή του (πρωτεύοντος) κλειδιού της εγγραφής.
Σκοπός της ταξινόμησης είναι, στη συνέχεια, η διευκόλυνση της αναζήτησης των στοιχείων
του αντίστοιχου συνόλου. Για παράδειγμα, είναι γνωστό ότι η αναζήτηση ενός κλειδιού σε
μη ταξινομημένο πίνακα με εγγραφές γίνεται σειριακά με συγκρίσεις της τάξης Ο(),
ενώ σε ταξινομημένο πίνακα η δυαδική αναζήτηση απαιτεί κόστος της τάξης O().
Η χρησιμότητα της ταξινόμησης αποδεικνύεται στην πράξη σε περιπτώσεις αναζήτησης
αριθμητικών ή αλφαβητικών δεδομένων, όπως σε βιβλιοθηκονομικά συστήματα, λεξικά,
τηλεφωνικούς καταλόγους, καταλόγους φόρου εισοδήματος και γενικά παντού, όπου γίνεται
αναζήτηση αποθηκευμένων αντικείμενων. Στη συνέχεια, δίνεται ένας τυπικός ορισμός της
ταξινόμησης.
Ορισμός.
Δοθέντων των στοιχείων η ταξινόμηση συνίσταται στη
διάταξη (permutation) της θέσης των στοιχείων, ώστε να τοποθετηθούν σε μία σειρά
, , έτσι ώστε δοθείσης μίας συνάρτησης διάταξης
(ordering function), , να ισχύει:
| (8.1) |
Αξίζει να σημειωθεί ότι η προηγούμενη συνάρτηση διάταξης μπορεί να τροποποιηθεί, ώστε να καλύπτει και την περίπτωση, όπου η ταξινόμηση γίνεται με φθίνουσα τάξη (descending sequence) μεγέθους του κλειδιού. Στη γενικότερη περίπτωση μπορεί να θεωρηθεί ότι η ταξινόμηση στηρίζεται σε δύο ή περισσότερα κλειδιά της εγγραφής. Για παράδειγμα, σε πολλά παιχνίδια της τράπουλας οι παίκτες ταξινομούν τα χαρτιά τους με πρώτο κλειδί το χρώμα του φύλλου (πχ. μπαστούνια, σπαθιά, καρό και κούπες) και με δεύτερο κλειδί την αξία του φύλλου (πχ. Άσσος, Ρήγας, Ντάμα, Βαλές, 10, …, 2).
Όπως γνωρίζουμε από το μάθημα των Δομών Δεδομένων, το αντικείμενο της ταξινόμησης είναι πολύ πλούσιο, καθώς μπορεί να εφαρμοσθεί σε πολλά περιβάλλοντα (όπως εσωτερική (internal) ταξινόμηση στην κύρια μνήμη ή εξωτερική (external) ταξινόμηση στη δευτερεύουσα μνήμη) και υπό πολλές συνθήκες (όπως επιτοπίως (in situ, in place) ή με επιπλέον χώρο, ως προς τη στατιστική κατανομή των κλειδιών προς ταξινόμηση κλπ.). Στο κεφάλαιο αυτό θα εξετάσουμε εκ νέου τους γνωστούς αλγορίθμους εσωτερικής ταξινόμησης, ώστε να αποδείξουμε και τυπικά τις (γνωστές εξάλλου) εκφράσεις των πολυπλοκοτήτων τους. Αρχικά, θα εξετάσουμε μεθόδους ταξινόμησης που βασίζονται στη σύγκριση, ενώ στη συνέχεια θα μελετήσουμε άλλες μεθόδους. Επίσης, θα απαντήσουμε στο ενδιαφέρον ερώτημα: «Πόσο γρήγορα μπορεί να γίνει η ταξινόμηση», με σκοπό να αποδείξουμε το θεωρητικό όριο της πολυπλοκότητας των αλγορίθμων ταξινόμησης.
8.1 Ταξινόμηση με Εισαγωγή
Αρχικά, θα εξετάσουμε τον αλγόριθμο της ταξινόμησης με εισαγωγή και θα καταλάβουμε τη συμπεριφορά του σε δύο περιπτώσεις: δίνοντας στην είσοδο τους πίνακες Α1=[1,2,3,4,5,6] και Α2=[6,5,4,3,2,1], με στοιχεία που είναι ήδη ταξινομημένα ή αντίστροφη σειρά ταξινομημένα. Παρατηρούμε ότι οι περιπτώσεις αυτές είναι ακραίες και δεν μπορούν να χαρακτηρισθούν ως η μέση περίπτωση, η περίπτωση δηλαδή όπου τα στοιχεία του πίνακα εμφανίζονται με μία τυχαία σειρά. Με την ίδια προσέγγιση θα ασχοληθούμε με την ταξινόμηση με επιλογή στο αμέσως επόμενο Κεφάλαιο 8.2. Ακολουθεί ο ψευδοκώδικας για τον αλγόριθμό μας.
procedure insert
1. for i <-- 2 to n do
2. x <-- A[i];
3. j <-- i-1;
4. while j>0 and x<A[j] do
5. A[j+1] <-- A[j]
6. j <-- j-1
7. A[j+1] <-- x
Η μέθοδος αυτή διακρίνει τον πίνακα σε δύο τμήματα: την ακολουθία πηγής (source
sequence) και την ακολουθία προορισμού (destimation sequence). Δηλαδή, λαμβάνει στοιχεία
από την ακολουθία πηγής και τα κατευθύνει στη σωστή θέση στην ακολουθία προορισμού.
Έτσι, κάθε φορά το μέγεθος της ακολουθίας πηγής μειώνεται κατά ένα, ενώ το μέγεθος της
ακολουθίας προορισμού αυξάνεται κατά ένα. Το κάθε φορά λαμβανόμενο στοιχείο είναι πρώτο
της ακολουθίας πηγής (δες την εντολή 3). Το στοιχείο αυτό συγκρίνεται με τα στοιχεία
της ακολουθίας προορισμού αρχίζοντας από το τέλος και συνεχίζοντας προς την αρχή μέχρι
να εντοπίσει την κατάλληλη θέση. Ένα παράδειγμα του αλγορίθμου απεικονίζεται στο Σχήμα 8.1.

Πρόταση.
Η πολυπλοκότητα της ταξινόμησης με εισαγωγή για την καλύτερη, τη μέση και τη χειρότερη
περίπτωση είναι Θ(), Θ() και Θ(), αντιστοίχως.
Απόδειξη
Αν στην είσοδο θεωρηθεί ο πίνακας Α1, τότε η ταξινόμηση συμπεριφέρεται πολύ
αποτελεσματικά και δεν εισέρχεται μέσα στο σώμα της εντολής 4. Έτσι, ουσιαστικά το κάθε
φορά λαμβανόμενο στοιχείο από την ακολουθία πηγής συγκρίνεται με ένα μόνο στοιχείο (όπως
προκύπτει από τη συνθήκη ελέγχου 4). Θεωρώντας αυτή τη σύγκριση ως την πράξη βαρόμετρο,
καταλήγουμε ότι για ένα πίνακα μεγέθους στοιχείων, ο αντίστοιχος αριθμός συγκρίσεων
είναι . Επομένως, προκύπτει ότι στην καλύτερη περίπτωση η πολυπλοκότητα είναι
γραμμική Θ().
Τώρα ας θεωρήσουμε την περίπτωση όπου στην είσοδο δίνεται ο πίνακας Α2. Το κάθε φορά επιλεγόμενο στοιχείο είναι μικρότερο από τα ήδη τοποθετημένα στην ακολουθία προορισμού. Έτσι, εκτελείται ένας συγκεκριμένος αριθμός συγκρίσεων μέχρι να τοποθετηθεί το νέο στοιχείο στη σωστή θέση, δηλαδή στην πρώτη θέση της ακολουθίας προορισμού. Έτσι, η εντολή 5 εκτελείται φορές, όπου το μεταβάλλεται από 1 μέχρι . Συνεπώς και πάλι θεωρώντας την πράξη αυτή ως βαρόμετρο, καταλήγουμε ότι για ένα πίνακα μεγέθους στοιχείων, o αντίστοιχος αριθμός συγκρίσεων είναι . Επομένως, η πολυπλοκότητα στη χειρότερη περίπτωση είναι τετραγωνική Θ().
Το σημαντικότερο ερώτημα προκύπτει στην περίπτωση ταξινόμησης τυχαίων δεδομένων εισόδου, δηλαδή στην περίπτωση, όπου οποιαδήποτε από τις διατάξεις των δεδομένων εισόδου μπορεί να εμφανισθεί με ίση πιθανότητα . Η επίδοση αυτή μπορεί να προκύψει θεωρώντας ότι το στοιχείο που κάθε φορά λαμβάνεται από την ακολουθία πηγής θα διανύσει το μισό δρόμο μέχρι την αρχή της ακολουθίας προορισμού. Όπως προηγουμένως, και πάλι θα προκύψει ότι στη μέση αυτή περίπτωση η επίδοση περιγράφεται από μία τετραγωνική συνάρτηση, επομένως και στην περίπτωση αυτή η πολυπλοκότητα είναι Θ().
8.2 Ταξινόμηση με Επιλογή
Από το Κεφάλαιο 1.5 αντιγράφουμε τον ψευδοκώδικα της ταξινόμησης με επιλογή.
procedure select
1. for i <-- 1 to n-1 do
2. minj <-- i; minx <-- A[i];
3. for j <-- i+1 to n do
4. if A[j]<minx then
5. minj <-- j
6. minx <-- A[j]
7. A[minj] <-- A[i]
8. A[i] <-- minx
Πρόταση.
Η πολυπλοκότητα της ταξινόμησης με επιλογή είναι Θ() σε κάθε περίπτωση.
Απόδειξη
Όπως φαίνεται στον ψευδοκώδικα, ουσιαστικά ο αλγόριθμος της ταξινόμησης με
επιλογή σαρώνει τον πίνακα, ώστε να εντοπίσει το μικρότερο στοιχείο και να το τοποθετήσει
στην πρώτη θέση. Στη συνέχεια, περιορίζει την αναζήτηση στα υπόλοιπα στοιχεία,
ώστε να εντοπίσει το μικρότερο μεταξύ αυτών και να το τοποθετήσει στη δεύτερη θέση κοκ.
Επομένως, εύκολα προκύπτει ότι η εντολή 4 (δηλαδή, if A[j]<minx) θα εκτελεσθεί τον
ίδιο αριθμό επαναλήψεων ανεξαρτήτως του περιεχομένου του πίνακα εισόδου. Είτε, λοιπόν,
στην είσοδο δοθεί ο πίνακας Α1 είτε ο Α2, το αντίστοιχο πλήθος συγκρίσεων θα είναι:
. Επομένως, σε κάθε περίπτωση η πολυπλοκότητα είναι
τετραγωνική Θ().
Από το παράδειγμα αυτό εξάγεται το συμπέρασμα ότι η ταξινόμηση με επιλογή έχει την ίδια επίδοση (δηλαδή, τετραγωνική πολυπλοκότητα) ανεξαρτήτως των δεδομένων εισόδου. Έτσι, επιβεβαιώνουμε κάτι που αναφέραμε στο Κεφάλαιο 2, δηλαδή ότι ο αλγόριθμος αυτός είναι σταθερός (robust), επειδή έχει ταυτόσημες την καλύτερη, χειρότερη και μέση περίπτωση. Αντίθετα, δεν συμβαίνει το ίδιο με τον αλγόριθμο ταξινόμησης με εισαγωγή.
Καθώς η εξέταση του πλήθους των συγκρίσεων ήταν εύκολη υπόθεση, στη συνέχεια θα
εξετάσουμε τον αλγόριθμο αυτό, ώστε να προσδιορίσουμε το πλήθος των καταχωρήσεων. Καθώς
υπάρχουν αρκετές καταχωρήσεις στον αλγόριθμο, επιλέγουμε ως σημαντικότερη την καταχώρηση
minx <-- A[j] της εντολής 6 εντός του εσωτερικού βρόχου, παρά τις καταχωρήσεις που
εκτελούνται εκτός του εσωτερικού αλλά εντός του εξωτερικού βρόχου. Εξάλλου είναι εύκολο
να διαπιστωθεί ότι οι καταχωρήσεις στις εντολές minj <-- i; minx <-- A[i];
A[minj] <-- A[i] και A[i] <-- minx (εντολές 2, 7, 8) θα εκτελεσθούν συνολικά
φορές.
Πρόταση.
Η μέση τιμή του πλήθους των καταχωρήσεων κατά την ταξινόμηση με επιλογή είναι Θ().
Απόδειξη
Ας υποθέσουμε ότι τα στοιχεία του πίνακα είναι διακριτά και ότι κάθε μία από τις
διατάξεις είναι ισοπίθανες να συμβούν. Στην -οστή επανάληψη ο αλγόριθμος αναζητά
το μικρότερο μεταξύ των στοιχείων του πίνακα στα δεξιά της θέσης
(συμπεριλαμβανομένης της θέσης αυτής). Έστω ότι με συμβολίζουμε το πλήθος των
καταχωρήσεων που απαιτούνται για την επιλογή του ελάχιστου μεταξύ των στοιχείων,
οπότε για τη μέση τιμή του ισχύει:
| (8.2) |
όπου είναι το πλήθος των καταχωρήσεων που αθροίζονται κατά την εκτέλεση των διαφορετικών διατάξεων των στοιχείων.
Ας θεωρήσουμε τις περιπτώσεις, όπου το ελάχιστο στοιχείο εντοπίζεται στην τελευταία θέση του πίνακα. Στην περίπτωση αυτή το πλήθος των καταχωρήσεων είναι
| (8.3) |
καθώς ο αλγόριθμος συμπεριφέρεται σαν να υπήρχαν αρχικά μη επαναλαμβανόμενα στοιχεία, οπότε στη συνέχεια θα εκτελούνταν άλλη μία καταχώρηση για κάθε μία από τις διαφορετικές διατάξεις. Αν εξαιρεθεί η τελευταία περίπτωση (δηλαδή, το ελάχιστο βρίσκεται στην τελευταία θέση), τότε απομένουν προς εξέταση περιπτώσεις. Στις περιπτώσεις αυτές το ελάχιστο στοιχείο βρίσκεται από την πρώτη μέχρι την -οστή θέση, οπότε για κάθε ομάδα διατάξεων απαιτούνται καταχωρήσεις. Αυτό συνολικά δίνει άλλες
| (8.4) |
καταχωρήσεις. Έτσι, προκύπτει η αναδρομική εξίσωση:
| (8.5) |
με αρχική συνθήκη . Άρα, για τη μέση τιμή του ισχύει:
| (8.6) |
που επιλύεται εύκολα και δίνει τη λύση:
| (8.7) |
Λαμβάνοντας υπ’όψιν το σύνολο των επαναλήψεων του εξωτερικού βρόχου (εντολή 1) προκύπτει ότι η μέση τιμή του πλήθους των καταχωρήσεων είναι:
Άρα, προκύπτει ότι στη μέση περίπτωση το πλήθος των καταχωρήσεων είναι της τάξης
Θ(). Ακόμη και αν προσθέταμε τις καταχωρήσεις που εκτελούνται
εκτός του εσωτερικού βρόχου, και πάλι το αποτέλεσμα δε θα άλλαζε.
Ένα τελικό σχόλιο. Μία μέθοδος ταξινόμησης λέγεται ευσταθής (stable), αν διατηρεί τη σχετική θέση πριν και μετά τη διάταξη για τα στοιχεία με την ίδια τιμή. Σε αντίθετη περίπτωση λέγεται ασταθής. Στο Σχήμα 8.2 παρουσιάζεται μία περίπτωση ευσταθούς και μία περίπτωση ασταθούς αλγορίθμου. Η ταξινόμηση με εισαγωγή είναι ευσταθής, αν και η μέθοδος αυτή έχει κακή σταθερή πολυπλοκότητα Θ(). Για την περίπτωση της γρήγορης ταξινόμησης που θα μελετήσουμε στη συνέχεια, θα παρατηρήσουμε ότι η τελευταία αυτή μέθοδος δεν είναι ευσταθής, καθώς εκτελεί περιττές μετακινήσεις ίσων κλειδιών. Παρ’ όλ’ αυτά δεν παύει να θεωρείται μία πολύ αποτελεσματική μέθοδος.

8.3 Γρήγορη Ταξινόμηση
Η γρήγορη ταξινόμηση (quicksort), που αλλιώς ονομάζεται και ταξινόμηση με διαμερισμό και ανταλλαγή (partition exchange sort), θεωρείται ένας από τους top-10 αλγορίθμους ως προς την πρακτική χρησιμότητά και το ενδιαφέρον που προκάλεσε από τη θεωρητική σκοπιά. Η γρήγορη ταξινόμηση αποτελεί ένα κλασικό παράδειγμα αλγορίθμου της οικογενείας Διαίρει και Βασίλευε. Όπως δηλώνει το πρώτο όνομα του αλγορίθμου, πρόκειται για μία πολύ αποτελεσματική μέθοδο ταξινόμησης (πλην ελαχίστων εξαιρέσεων). Όπως δηλώνει το δεύτερο όνομά του, τα βασικά χαρακτηριστικά του είναι δύο: η ανταλλαγή και ο διαμερισμός. Πρώτον, δηλαδή, εκτελούνται ανταλλαγές μεταξύ των στοιχείων του πίνακα, έτσι ώστε τα στοιχεία με μικρότερες τιμές να μετακινηθούν προς τη μία πλευρά, ενώ τα στοιχεία με μεγαλύτερες τιμές να μετακινηθούν προς την άλλη πλευρά του πίνακα. Έτσι, επακολουθεί η εφαρμογή του δεύτερου χαρακτηριστικού, δηλαδή του διαμερισμού του πίνακα σε δύο μικρότερους που ταξινομούνται ανεξάρτητα μεταξύ τους. Είναι προφανές ότι στους δύο υποπίνακες επιφυλάσσεται η ίδια αντιμετώπιση: ανταλλαγή και διαμερισμός.
procedure quicksort(left,right);
1. if left<right then
2. i <-- left; j <-- right+1; pivot <-- A[left];
3. repeat
4. repeat i <-- i+1 until A[i]>=pivot;
5. repeat j <-- j-1 until A[j]<=pivot;
6. if i<j then swap(A[i],A[j]);
7. until j<=i;
8. swap(A[left],A[j]);
9. quicksort(left,j-1);
10. quicksort(j+1,right)
Η προηγούμενη διαδικασία quicksort υποθέτει ότι δίνεται προς ταξινόμηση ένας πίνακας A[1..n], που περιέχει ακεραίους αριθμούς. Ο pivot είναι ένα στοιχείο του πίνακα, το οποίο παίρνει την τελική του θέση στον πίνακα, ώστε κατόπιν να γίνει ο διαμερισμός (δηλαδή, να γίνουν οι κλήσεις της partition) σε δύο υποπίνακες με μικρότερα και μεγαλύτερα στοιχεία από τον pivot αντίστοιχα. Η επιλογή του pivot μπορεί να γίνει κατά πολλούς τρόπους. Στο σημείο αυτό δεχόμαστε ότι ως pivot λαμβάνεται το πρώτο στοιχείο του πίνακα. Έτσι, ο πίνακας σαρώνεται από τα αριστερά προς τα δεξιά αναζητώντας το πρώτο στοιχείο με τιμή μεγαλύτερη ή ίση με την τιμή του pivot. Ύστερα, ο πίνακας σαρώνεται από τα δεξιά προς τα αριστερά αναζητώντας το πρώτο στοιχείο με τιμή μικρότερη ή ίση με την τιμή του pivot. Όταν εντοπισθούν δύο τέτοια στοιχεία, τότε αυτά ανταλλάσσονται, ώστε κατά το δυνατόν να τείνουν να πλησιάσουν προς την τελική τους θέση. Κατόπιν, συνεχίζουμε τις σαρώσεις προσπαθώντας να εντοπίσουμε άλλα παρόμοια ζεύγη και να τα ανταλλάξουμε. Κάποια στιγμή οι δύο δείκτες σάρωσης διασταυρώνονται. Τότε η σάρωση σταματά και ο pivot λαμβάνει την τελική του θέση εκτελώντας άλλη μία ανταλλαγή μεταξύ του pivot και του στοιχείου όπου σταμάτησε ο δείκτης της σάρωσης από δεξιά. Έτσι, η διαδικασία μπορεί να συνεχίσει στους δύο υποπίνακες κατά τα γνωστά. Το επόμενο σχήμα δείχνει τα βήματα του κώδικα μέχρι τον πρώτο διαμερισμό.
| Αρχικά κλειδιά | 52 | 12 | 71 | 56 | 5 | 10 | 19 | 90 | 45 |
| 1η ανταλλαγή | 52 | 12 | 45 | 56 | 5 | 10 | 19 | 90 | 71 |
| 2η ανταλλαγή | 52 | 12 | 45 | 19 | 5 | 10 | 56 | 90 | 71 |
| Διασταύρωση δεικτών | |||||||||
| Ανταλλαγή και | [10 | 12 | 45 | 19 | 5] | 52 | [56 | 90 | 71] |
| διαμερισμός |
Τώρα ας προχωρήσουμε στην εύρεση της πολυπλοκότητας του αλγορίθμου. Κατ’αρχάς θα
εξετάσουμε τη χειρότερη περίπτωση που είναι ευκολότερη, και στη συνέχεια την καλύτερη
και τη μέση περιπτωση.
Πρόταση.
Η πολυπλοκότητα της γρήγορης ταξινόμησης είναι Θ() στη χειρότερη περίπτωση.
Απόδειξη
Η περίπτωση αυτή συμβαίνει όταν σε πίνακα μεγέθους , το επιλεγόμενο στοιχείο ως
pivot είναι το μικρότερο ή το μεγαλύτερο, ώστε τα μεγέθη των δύο υποπινάκων
που θα προκύψουν να είναι 0 και (αφού η μία θέση του συγκεκριμένου πίνακα θα
καταληφθεί από τον ίδιο τον pivot). Έτσι, εύκολα προκύπτει η ακόλουθη αναδρομική
εξίσωση:
| (8.8) |
Ο όρος του δεξιού σκέλους αντιστοιχεί στις συγκρίσεις που θα εκτελεσθούν κατά τη σάρωση του πίνακα (εντολές 4-5)11Στην πραγματικότητα είναι δυνατό να εκτελεσθούν περισσότερες από συγκρίσεις, αλλά σε κάθε περίπτωση ο αριθμός των συγκρίσεων είναι μικρότερος από , γεγονός που δεν αλλάζει το τελικό συμπέρασμα.. Η ανωτέρω αναδρομική εξίσωση είναι εύκολη υπόθεση, καθώς διαδοχικά ισχύει:
| (8.9) |
| (8.10) |
| (8.11) |
| (8.12) |
Αθροίζοντας τα αριστερά και δεξιά σκέλη αυτών των εξισώσεων και θεωρώντας ότι , προκύπτει ότι:
| (8.13) |
Πρόταση.
Η πολυπλοκότητα της γρήγορης ταξινόμησης είναι Θ() στην καλύτερη περίπτωση.
Απόδειξη
Για να αναλύσουμε την καλύτερη περίπτωση αρκεί να διαπιστώσουμε ότι αυτή συμβαίνει, όταν
κάθε φορά ως pivot επιλέγεται ένα στοιχείο που λαμβάνοντας την τελική του θέση
υποδιαιρεί τον πίνακα σε δύο υποπίνακες ίσου μεγέθους. Επομένως, ισχύει η αναδρομική εξίσωση:
| (8.14) |
με αρχικές συνθήκες . Για την ευκολία της ανάλυσης υποθέτουμε ότι , οπότε:
| (8.15) |
Η τελευταία αναδρομική εξίσωση είναι πλέον εύκολη υπόθεση, καθώς ισχύει διαδοχικά:
| (8.16) |
| (8.17) |
| (8.18) |
Αθροίζοντας τα αριστερά και δεξιά σκέλη αυτών των εξισώσεων προκύπτει ότι:
| (8.19) |
Πρόταση.
Η πολυπλοκότητα της γρήγορης ταξινόμησης είναι Θ() στη μέση περίπτωση.
Απόδειξη
Για να εξετάσουμε τη μέση περίπτωση θα υποθέσουμε ότι για στοιχεία, κάθε διάταξη
των στοιχείων αυτών (όπου είναι το πλήθος των διατάξεων) είναι ισοπίθανη. Επομένως,
ο κάθε φορά επιλεγόμενος pivot τελικά επιλέγεται με τυχαίο τρόπο. Θα χειρισθούμε
τη μέση περίπτωση με τη βοήθεια της επόμενης αναδρομικής εξίσωσης για :
| (8.20) |
με αρχικές συνθήκες . Λόγω συμμετρίας και των αρχικών συνθηκών, η προηγούμενη αναδρομική εξίσωση μετασχηματίζεται σε:
| (8.21) |
Τώρα, τη σχέση αυτή πολλαπλασιάζουμε επί και προκύπτει:
| (8.22) |
Επίσης, στην ίδια σχέση αντικαθιστούμε το με και πολλαπλασιάζουμε με , οπότε προκύπτει
| (8.23) |
Αφαιρώντας τα αντίστοιχα σκέλη των δύο τελευταίων εκφράσεων και εκτελώντας απλή άλγεβρα, προκύπτει:
| (8.24) |
| (8.25) |
Με διαδοχικές αντικαταστάσεις του με προκύπτει:
Αθροίζοντας αντίστοιχα τα αριστερά και τα δεξιά σκέλη και απλοποιώντας προκύπτει:
| (8.26) |
Επομένως, πρέπει να υπολογίσουμε το άθροισμα του δεξιού σκέλους:
| (8.27) |
Τελικώς, έχουμε:
| (8.28) |
| (8.29) |
Η γρήγορη ταξινόμηση δεν είναι επιτόπιος αλγόριθμος, δηλαδή δεν αρκείται στο χώρο του συγκεκριμένου πίνακα, αλλά χρειάζεται επιπλέον χώρο. Ο χώρος αυτός δεν φαίνεται καθαρά στον ανωτέρω κώδικα αλλά απαιτείται από το μεταγλωττιστή κατά την αναδρομή. Εύλογα προκύπτει η ερώτηση σχετικά με το μέγεθος αυτού του απαιτούμενου χώρου. Στη χειρότερη περίπτωση το μέγιστο βάθος της αναδρομής θα είναι κλήσεις, αριθμός υπερβολικός. Για το λόγο αυτό έχει σχεδιασθεί μία επαναληπτική εκδοχή της γρήγορης ταξινόμησης, δηλαδή μία εκδοχή που υλοποιεί την απαραίτητη στοίβα, όπου τοποθετούνται τα όρια του μικρότερου υποπίνακα, όπως φαίνεται στην επόμενη διαδικασία iterative_quicksort.
procedure iterative_quicksort(left,right);
1. repeat
2. while (left<right) do
3. i <-- left; j <-- r+1; pivot <-- A[left];
4. repeat
5. repeat i <-- i+1 until A[i]>=pivot;
6. repeat j <-- j-1 until A[j]<=pivot;
7. if i<j then swap(A[i],A[j]);
8. until j<=i;
9. swap(A[left],A[j]);
10. if ((j-p)<(q-j)) then
11. push(j+1); push(q); q <-- j-1
12. else
13. push(p); push(j-1); p <-- j+1
14. if stack is empry then return
15. pop(q); pop(p)
16. until (false)
Πρόταση.
Η χωρική πολυπλοκότητα της γρήγορης ταξινόμησης είναι Θ() στη μέση περίπτωση.
Απόδειξη
Ο απαιτούμενος χώρος εκφράζεται από την αναδρομική εξίσωση:
| (8.30) |
Επομένως, υποθέτοντας ότι , αρκεί να επιλύσουμε την εξίσωση:
8.4 Στατιστικά Διάταξης
Με τον όρο στατιστικά διάταξης (order statistics) εννοούμε την περίπτωση, όπου δεδομένου ενός πίνακα A με αταξινόμητα στοιχεία, πρέπει να αναζητήσουμε το μικρότερο, το μεγαλύτερο, το μεσαίο ή γενικά το -οστό στοιχείο του πίνακα με βάση την τιμή του κλειδιού του. Παρά το γεγονός ότι το αντικείμενο είναι πρόβλημα αναζήτησης και όχι ταξινόμησης, θα το εξετάσουμε στο σημείο αυτό για λόγους που θα φανούν στη συνέχεια.
Ας αρχίσουμε από τα εύκολα, δηλαδή έστω ότι θέλουμε να βρούμε ταυτόχρονα το μικρότερο και το μεγαλύτερο στοιχείο ενός πίνακα. Η προφανής λύση είναι να εκτελέσουμε δύο σαρώσεις, μία σάρωση για την εύρεση του μικρότερου και στη συνέχεια μία σάρωση για την εύρεση του μεγαλύτερου. Είναι ευνόητο ότι η πολυπλοκότητα αυτής της πρώτης προσέγγισης είναι Θ(). Με τη διαδικασία που ακολουθεί προσπαθούμε με μία μόνο σάρωση να επιτύχουμε την ταυτόχρονη εύρεση των δύο στοιχείων που μας ενδιαφέρουν.
procedure maxmin1
1. max <-- A[1]; min <-- A[1];
2. for i <-- 2 to n do
3. if A[i]>max then max <-- A[i]
4. if A[i]<min then min <-- A[i]
5. return max, min
Η διαδικασία αυτή δεν παύει να είναι μία απλοϊκή προσέγγιση. Αν και γίνεται μία σάρωση του πίνακα, κάθε στοιχείο υποβάλλεται σε δύο συγκρίσεις, που όπως είπαμε είναι ένα σύνηθες βαρόμετρο. Η κατάσταση θα μπορούσε να βελτιωθεί, αν αντικαθιστούσαμε τις εντολές 3-4 με τις εντολές:
3. if A[i]>max then max <-- A[i] 4. else if A[i]<min then min <-- A[i]
Ωστόσο, και αυτή η εκδοχή μπορεί να αποδειχθεί ότι δεν βοηθά στη χειρότερη περίπτωση. Η επόμενη διαδικασία, που προσπαθεί να εκμεταλλευθεί την τεχνική του Διαίρει και Βασίλευε, υποθέτει ότι με τα ορίσματα i,j δίνουμε τα όρια του πίνακα και με τα ορίσματα fmax,fmin μας επιστρέφονται οι τιμές που μας ενδιαφέρουν. Επίσης, υποθέτουμε ότι η συνάρτηση max επιστρέφει το μέγιστο μεταξύ δύο στοιχείων, ενώ η συνάρτηση min επιστρέφει το ελάχιστο μεταξύ των δύο στοιχείων.
procedure maxmin2(i,j,fmax,fmin)
1. if i=j then
2. max <-- A[i]; min <-- A[i];
3. else if i=j-1 then
4. if A[i]<A[j] then
5. fmax <-- A[j]; fmin <-- A[i];
6. else
7. fmax <-- A[i]; fmin <-- A[j];
8. else
9. middle <-- (i+j)/2;
10. maxmin2(i,mid,gmax,gmin);
11. maxmin2(mid+1,j,hmax,hmin);
11. fmax <-- max(gmax,hmax);
12. fmin <-- min(gmin,hmin);
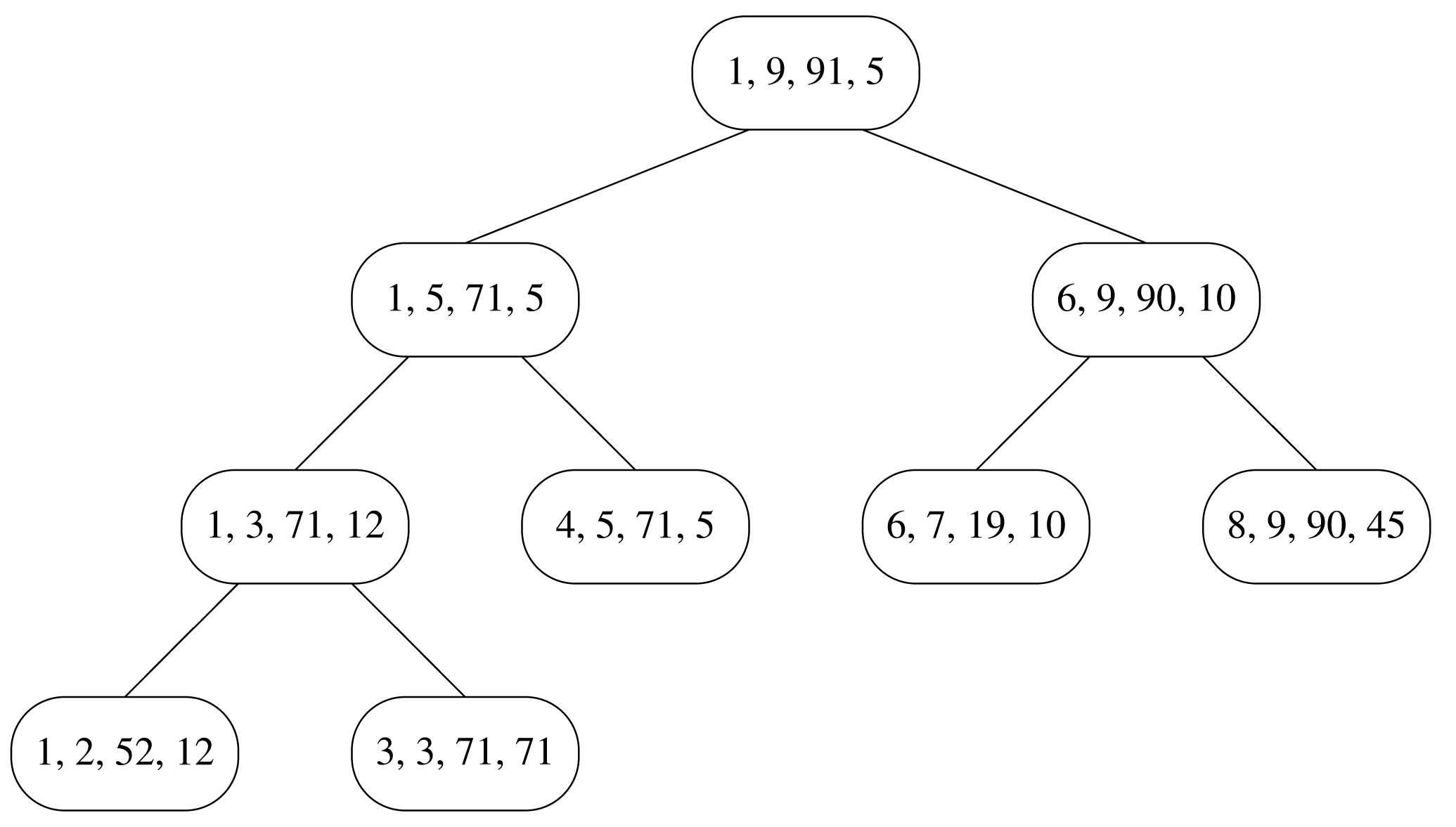
Έστω ότι το περιεχόμενο του πίνακα A είναι τα 9 στοιχεία 52, 12, 71, 56, 5, 10,
19, 90, 45. Στο επόμενο σχήμα απεικονίζεται ένα δένδρο με κόμβους που περιέχουν τα
ορίσματα των κλήσεων. Διασχίζοντας το δένδρο με προτεραιότητα κατά βάθος (dfs) μπορούμε
να αποτυπώσουμε την επακριβή σειρά των διαφόρων κλήσεων.
Πρόταση.
Η πολυπλοκότητα της maxmin2 είναι Θ() στη χειρότερη περίπτωση.
Απόδειξη
Η πολυπλοκότητα της διαδικασίας αυτής μπορεί να ευρεθεί επιλύοντας την αναδρομική εξίσωση:
| (8.31) |
όπου οι σταθεροί όροι εκφράζουν το κόστος των συγκρίσεων στις εντολές 4 και 11-12. Θεωρώντας τη χειρότερη περίπτωση και ότι διαδοχικά έχουμε:
Επομένως, παρότι ο τελευταίος αλγόριθμος είναι βελτιωμένος δεν μπορεί να υπερβεί το όριο
της γραμμικής πολυπλοκότητας Θ().
8.4.1 Στατιστικά σε Μέσο Γραμμικό Χρόνο
Έστω ότι επιθυμούμε να βρούμε το -οστό στοιχείο ενός αταξινόμητου πίνακα. Αυτό μπορεί να επιτευχθεί ταξινομώντας τον πίνακα και λαμβάνοντας το περιεχόμενο της αντίστοιχης θέσης του πίνακα. Γνωρίζουμε ήδη από το αντικείμενο των Δομών Δεδομένων ότι το κάτω όριο (που θα αποδειχθεί στη συνέχεια) των αλγορίθμων ταξινόμησης που στηρίζονται σε συγκρίσεις είναι Ο(). Επομένως, το όριο αυτό προσδιορίζει και την πολυπλοκότητα της μεθόδου που ανάγει το πρόβλημα της επιλογής σε πρόβλημα ταξινόμησης. Στη συνέχεια, θα επιλύσουμε το πρόβλημα της επιλογής του -οστού στοιχείου με μία μέθοδο που στηρίζεται στη γρήγορη ταξινόμηση, όπως φαίνεται από τον επόμενο αλγόριθμο. Ο αλγόριθμος αυτός σχεδιάστηκε από τον C.A.R. Hoare [75]. Σημειώνεται ότι πρέπει να ισχύει: .
procedure find(left,right,k);
1. if left=right then return A[left]
2. else
3. i <-- left; j <-- right+1; pivot <-- A[left];
4. repeat
5. repeat i <-- i+1 until A[i]>=pivot;
6. repeat j <-- j-1 until A[j]<=pivot;
7. if i<j then swap(A[i],A[j]);
8. until j<=i;
9. swap(A[left],A[j]);
10. if k=j then return A[j]
11. else if (k<j) then find(left,j-1,k)
12. else find(j+1,right,k-j);
Παρατηρούμε ότι η διαδικασία find είναι σχεδόν ταυτόσημη με τη διαδικασία
quicksort. Πιο συγκεκριμένα, οι εντολές 3-9 ταυτίζονται με αντίστοιχες εντολές της
quicksort, καθώς αφορούν στις διαδικασίες επιλογής του pivot και του
διαμερισμού. Στη συνέχεια, διαφοροποιούνται οι εντολές 10-12. Η ουσία είναι ότι καθώς
ο pivot τοποθετείται οριστικά στη θέση j του πίνακα, αποφασίζουμε αν θα
τερματίσουμε ή αν θα συνεχίσουμε την αναζήτηση του -οστού στοιχείου στον αριστερό
ή στο δεξιό υποπίνακα με αναδρομικό τρόπο. Η ανάλυση του αλγορίθμου είναι πλέον αρκετά
προφανής με βάση όλα τα προηγούμενα.
Πρόταση.
Η πολυπλοκότητα της find είναι Θ(), Θ() και Θ() στη χειρότερη,
τη μέση και την καλύτερη περίπτωση, αντιστοίχως.
Απόδειξη
Κατ’αρχάς η χειρότερη περίπτωση είναι Θ() και αυτό θα συμβεί, όταν συνεχώς ο
επιλεγόμενος pivot είναι το μικρότερο ή το μεγαλύτερο στοιχείο. Θα μελετήσουμε
τη μέση περίπτωση για την οποία ισχύει:
| (8.32) |
με αρχικές συνθήκες . Επομένως:
| (8.33) |
Τώρα, τη σχέση αυτή πολλαπλασιάζουμε επί και προκύπτει:
| (8.34) |
Επίσης, στην ίδια σχέση αντικαθιστούμε το με και πολλαπλασιάζουμε με , οπότε προκύπτει
| (8.35) |
Αφαιρώντας τα αντίστοιχα σκέλη των δύο τελευταίων εκφράσεων και εκτελώντας απλή άλγεβρα, προκύπτει:
Αθροίζοντας αντίστοιχα τα αριστερά και τα δεξιά σκέλη και απλοποιώντας, προκύπτει:
Καθώς για τον αρμονικό αριθμό ισχύει , έπεται ότι η πολυπλοκότητα της μέσης περίπτωσης της διαδικασίας find είναι Θ(). Ομοίως, γραμμική είναι και η πολυπλοκότητα της καλύτερης περίπτωσης.
8.4.2 Στατιστικά σε Γραμμικό Χρόνο Χειρότερης Περίπτωσης
Σε αυτή την ενότητα θα μελετήσουμε τον γραμμικό αλγόριθμο Select για την εύρεση του oστού μεγαλύτερου στοιχείου, ο οποίος αναπτύχθηκε από τους Blum et. al. [15]. Το πρόβλημα που είχε ο αλγόριθμος find ήταν ότι ο διαχωρισμός της αρχικής ακολουθίας δεν ήταν κατ’ ανάγκην καλός και μπορούσε να οδηγήσει σε μεγάλα μεγέθη υποπροβλημάτων.
Ο αλγόριθμος Select βασίζεται στην εξής ιδέα για τον καλύτερο διαχωρισμό:
Αυτό που χρειάζεται είναι να επιλέξουμε το στοιχείο διαχωρισμού βάσει ενός καλύτερου δείγματος. Αυτό το δείγμα μπορούμε να το χτίσουμε χωρίζοντας το σε ομάδες π.χ. των 5 στοιχείων, να λάβουμε τους μέσους για κάθε ομάδα και με τους μέσους να κατασκευάσουμε μια μεγαλύτερη ομάδα, η οποία αποτελεί δειγματισμό των στοιχείων του . Ο μέσος αυτής της ομάδας (μέσος των μέσων) είναι εγγυημένα καλό στοιχείο διαχωρισμού.
Η ιδέα αυτή παράγει σωστό διαχωρισμό, πέραν αυτού του βήματος όμως, ο αλγόριθμος λειτουργεί ακριβώς όπως ο find. O ψευδοκώδικας που παρουσιάζεται στη συνέχεια, υλοποιεί τον αλγόριθμο Select.
H διαδικασία που εκτελείται στις γραμμές 5-8 μπορεί να φανεί στο Σχήμα 8.5. Στη γραμμή 5, χωρίζουμε το σε ομάδες των 5 στοιχείων τις . Στη συνέχεια ταξινομούμε τις ομάδες (γραμμή 6) και βρίσκουμε τον μέσο κάθε ομάδας (έστω ο μέσος της ομάδας ). Κάθε ομάδα απεικονίζεται με μια στήλη και η τοποθέτηση των στοιχείων στη στήλη είναι τέτοια, ώστε οι τιμές να αυξάνουν καθώς κινούμαστε προς τα πάνω σε κάθε στήλη. Στη γραμμή 8, βρίσκουμε το στοιχείο , το οποίο είναι ο μέσος όλων των , δηλαδή ο μέσος των μέσων το στοιχείο που είναι εγγυημένα καλός διαχωριστής. Από το σημείο αυτό και έπειτα ο αλγόριθμος προχωρά, όπως ακριβώς και στο find.
Τα στοιχεία που περικλείονται από το γκρί ορθογώνιο στο Σχήμα 8.5 είναι αυτά τα οποία σίγουρα έχουν τιμή μικρότερη ίση από το και άρα σίγουρα ανήκουν στο . Αυτό μπορεί να φανεί, δεδομένου ότι τα στοιχεία του γκρίζου ορθογωνίου είναι μικρότερα από τον μέσο της στήλης στην οποία ανήκουν και ο μέσος καθεμίας από της στήλες είναι μικρότερος από τον μέσο των μέσων, . Με εντελώς όμοιο συλλογισμό, τα στοιχεία του διαφανούς ορθογωνίου, είναι όλα μεγαλύτερα ή ίσα του και ανήκουν στο . Τα δε , περιέχουν πιθανώς και άλλα στοιχεία, αλλά αυτά που περιβάλλονται από ορθογώνια, περιέχονται σίγουρα σε αυτά τα σύνολα.
Φράσσοντας τον μέγιστο αριθμό στοιχείων που μπορεί να έχει ένα τέτοιο σύνολο, δίνει την δυνατότητα φραγής του μέγιστου κόστους μιας αναδρομικής κλήσης της Select, κάτι που θα βοηθήσει στην απόδειξη της γραμμικότητάς της. Το παρακάτω Λήμμα προκύπτει εύκολα.

Λήμμα 8.1.
To ελάχιστο μέγεθος του ή του είναι
Απόδειξη. Από την παρατήρηση του Σχήματος 8.5, προκύπτει ότι καθένα από τα ορθογώνια περιέχει τουλάχιστον στοιχεία. Αυτό προκύπτει αφού δεν μετράμε την τελευταία πεντάδα που μπορεί να μην είναι γεμάτη καθώς και την πεντάδα που περιέχει το .
Από το Λήμμα 8.1 προκύπτει ότι το μέγιστο υποπρόβλημα αν λάβουμε σαν στοιχείο διαχωρισμού το , περιέχει στοιχεία. Έστω , ο μέγιστος χρόνος εκτέλεσης του αλγορίθμου για κάθε σύνολο που περιέχει στοιχεία και κάθε .
Λήμμα 8.2.
Η παρακάτω αναδρομική σχέση περιγράφει την πολυπλοκότητα του αλγορίθμου Select.
Απόδειξη. O αλγόριθμος θα εκτελεστεί μια φορά για τον μέσο των μέσων (γραμμή 8), δηλαδή για στοιχεία, οπότε προκύπτει ο όρος και μια φορά αναδρομικά, είτε για το (γραμμή 12) είτε για το (γραμμή 14), όπου ο χρόνος που ξοδεύεται είναι το πολύ , λόγω του Λήμματος 8.1. Επίσης, θα πρέπει . Ο όρος , αφού οι υπόλοιπες γραμμές του προγράμματος απαιτούν γραμμικό πλήθος βημάτων. Έστω λοιπόν σταθερά , έτσι ώστε , για κάθε μεγαλύτερο από μία σταθερά.
Θεώρημα 8.1.
O αλγόριθμος Select τρέχει σε χρόνο γραμμικό ως προς το πλήθος της εισόδου
Απόδειξη. Θα αποδείξουμε με επαγωγή ότι , όπου μία σταθερά εξαρτώμενη από τη σταθερά στον όρο της αναδρομικής σχέσης.
- Για :
-
Προφανές.
- Για :
-
Υποθέτουμε ότι ισχύει . Θα δείξουμε ότι ισχύει και για . Έχουμε
Συνολικά έχουμε
8.5 Ταξινόμηση με Συγχώνευση
Με τον όρο συγχώνευση (merging) εννοούμε την πράξη της δημιουργίας ενός νέου ταξινομημένου πίνακα που περιέχει όλα τα στοιχεία δύο (ή και περισσοτέρων) πινάκων, που είναι ήδη ταξινομημένοι. Η διαδικασία Merge που ακολουθεί υλοποιεί τη συγχώνευση δύο ταξινομημένων πινάκων A και B (με και ακεραίους αντίστοιχα) στον πίνακα C. Θεωρείται ότι οι δύο πίνακες έχουν και μία επιπλέον θέση που χρησιμεύει για την αποθήκευση ενός φρουρού (sentinel).
procedure merge;
1. i <-- 1; j <-- 1; A[n+1] <-- maxint; B[m+1] <-- maxint;
2. for k <-- 1 to n+m do
3. if A[i]<B[j] then
4. C[k] <-- A[i]; i <-- i+1
5. else
6. C[k] <-- B[j]; j <-- j+1
Στην ουσία η συγχώνευση γίνεται με τη βοήθεια δύο δεικτών i και j που σαρώνουν
τους δύο πίνακες και διαδοχικά συγκρίνουν στοιχεία από τους πίνακες A και B.
Έτσι, κάθε φορά το μικρότερο στοιχείο μεταφέρεται στον πίνακα εξόδου C. Ο αναγνώστης
μπορεί πολύ εύκολα να καταλάβει τη λειτουργία της διαδικασίας Merge και δεν χρειάζονται
περισσότερες επεξηγήσεις. Από το βρόχο της εντολής 2, είναι προφανές ότι η πολυπλοκότητα
της συγχώνευσης είναι Θ(), θεωρώντας φραγμένο από επάνω το κόστος της ερώτησης της
εντολής 3-6.
Στη φιλοσοφία της διαδικασίας αυτής βασίζεται μία σημαντικότατη μέθοδος ταξινόμησης, η ονομαζόμενη ταξινόμηση με ευθεία συγχώνευση (straight merge sort). Κατά καιρούς η μέθοδος αυτή έχει υλοποιηθεί με πλήθος τρόπων, όπως επαναληπτικά ή αναδρομικά, για λίστες ή πίνακες κοκ. Στη συνέχεια, ακολουθεί μία εκδοχή της για πίνακες, η οποία αποτελείται από δύο τμήματα: την αναδρομική merge_sort και τη merge. Στις εντολές 16-18 της merge_sort βρίσκεται το μεσαίο στοιχείο του πίνακα και εκτελούνται 2 κλήσεις στους δύο υποπίνακες που προκύπτουν. Από εδώ προκύπτει ότι η μέθοδος ανήκει στην οικογένεια των αλγορίθμων Διαίρει και Βασίλευε. Η διαδικασία merge που καλείται όταν προκύψουν στοιχειώδεις υπο-…-υπο-πίνακες αναλαμβάνει τις συγκρίσεις των στοιχείων και τα τακτοποιεί με τη βοήθεια ενός βοηθητικού πίνακα B.
procedure merge(left,middle,right);
1. first <-- left; second <-- middle+1; temp <-- left;
2. while (first<=middle) and (second<=right) do
3. if A[first]<=A[second] then
4. B[temp] <-- A[first]; first <-- first+1;
5. else
6. B[temp] <-- A[second]; second <-- second+1;
7. temp <-- temp+1
8. if first<=middle then
9. for k <-- first to middle do
10. B[temp] <-- A[k]; temp <-- temp+1
11. else
12. for k <-- second to right do
13. B[temp] <-- A[k]; temp <-- temp+1
14. for k <-- left to right do A[k] <-- B[k]
procedure merge_sort(left,right);
15. if left<right then
16. middle <-- (left+right) div 2;
17. merge_sort(left,middle);
18. merge_sort(middle+1,right);
19. merge(left,middle,right)

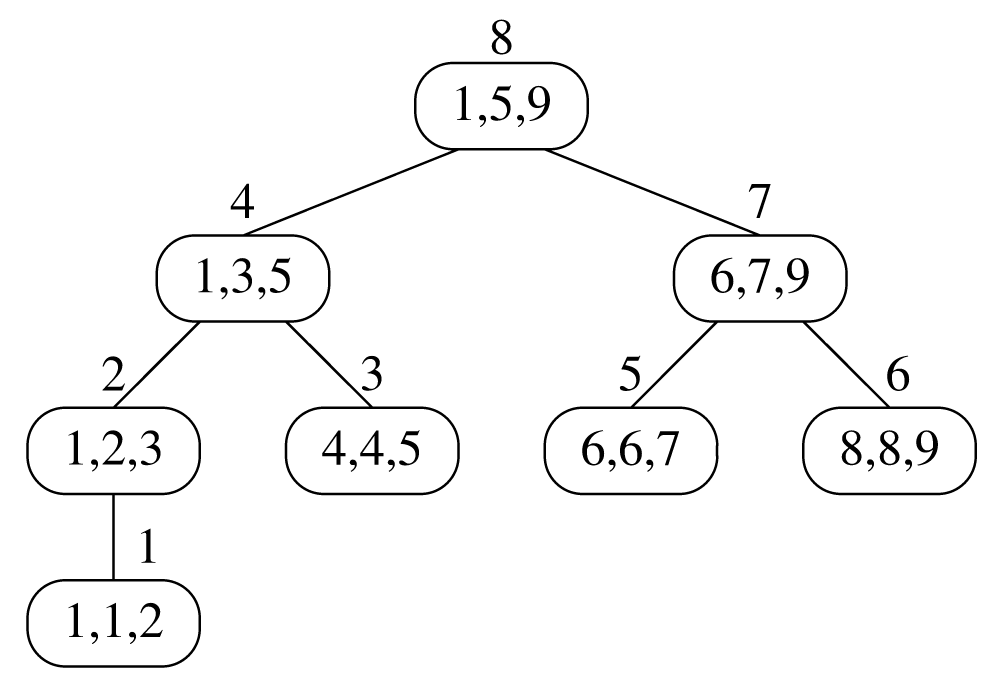
Αν εφαρμόσουμε τις ανωτέρω διαδικασίες σε πίνακα με τα 9 γνωστά κλειδιά, τότε η
mergesort θα κληθεί 17 φορές με τη σειρά που απεικονίζεται επάνω από κάθε κόμβο του επομένου
σχήματος, ενώ μέσα σε κάθε κόμβο φαίνονται τα ορίσματα της αντίστοιχης κλήσης. Στο
Σχήμα 8.7 φαίνονται 8 κλήσεις της merge, με την αντίστοιχη τάξη εκτός
του κόμβου και τα ορίσματα εντός του κόμβου. Και στις δύο περιπτώσεις η διάσχιση του
δένδρου ακολουθεί τη λογική της αναζήτησης με προτεραιότητα βάθους (dfs).
Πρόταση.
Η πολυπλοκότητα της merge_sort είναι Θ() στη χειρότερη περίπτωση.
Απόδειξη
Παρατηρώντας τη διαδικασία merge_sort εξάγουμε την επόμενη αναδρομική εξίσωση:
| (8.37) |
με αρχική συνθήκη , ενώ οι τρεις όροι του δεξιού σκέλους αντιστοιχούν στις εντολές 17-19. Συγκεκριμένα, το κόστος σε συγκρίσεις της εντολής 19 προκύπτει από όσα αναφέρθηκαν προηγουμένως για τη διαδικασία συγχώνευσης 2 πινάκων. Για την ευκολία της ανάλυσης υποθέτουμε ότι , οπότε η ανωτέρω αναδρομική εξίσωση είναι πλέον εύκολη υπόθεση καθώς ισχύει διαδοχικά:
Η μέθοδος ταξινόμησης με ευθεία συγχώνευση αξίζει την προσοχή μας γιατί είναι πολύ ευσταθής (stable) μέθοδος, δηλαδή ανεξάρτητα από τη φύση των δεδομένων θα εκτελέσει τον ίδιο αριθμό συγκρίσεων στη μέση και τη χειρότερη περίπτωση. Το χαρακτηριστικό αυτό έρχεται σε αντίθεση με το μειονέκτημα της γρήγορης ταξινόμησης, που διακρίνεται από πολυπλοκότητα O() για τη χειρότερη περίπτωση. Ωστόσο, το συμπέρασμα αυτό προκύπτει γιατί στην ανάλυση λάβαμε υπ’όψιν μας μόνο το πλήθος των εκτελούμενων συγκρίσεων. Σε μία πραγματική υλοποίηση, η χρήση του βοηθητικού πίνακα B και οι εκτελούμενες καταχωρήσεις είναι, επίσης, πράξεις μη αμελητέου χρονικού κόστους, οι οποίες επιβαρύνουν τη συνολική επίδοση. Τελικώς, αν και η ταξινόμηση με συγχώνευση δεν είναι ίσως η καλύτερη μέθοδος ταξινόμησης στην κύρια μνήμη, εν τούτοις αποτελεί τη βάση για μεθόδους εξωτερικής ταξινόμησης.
8.6 Ταξινόμηση του Shell
Η μέθοδος που προτάθηκε από τον Shell έχει βασικό χαρακτηριστικό ότι χρησιμοποιεί μία ακολουθία ακεραίων , όπου ισχύει: και γι’αυτό φέρει και την ονομασία ταξινόμηση με μειούμενες αυξήσεις (diminishing increment). Στην πράξη η μέθοδος λειτουργεί για οποιεσδήποτε τιμές της ακολουθίας , αλλά θα πρέπει να ισχύει .
Θα μπορούσε να υποστηριχθεί ότι η ταξινόμηση του Shell είναι μία παραλλαγή της ταξινόμησης με εισαγωγή. Ουσιαστικά, η μέθοδος αποτελείται από φάσεις, όπου στην -οστή φάση (για ) θεωρείται το βήμα , οπότε ακολουθώντας τη λογική της ταξινόμησης με εισαγωγή τίθενται σε σωστή διάταξη μεταξύ τους τα στοιχεία του πίνακα που απέχουν θέσεις. Προφανώς η -οστή και τελευταία φάση είναι ένα κλασικό πέρασμα της ταξινόμησης με εισαγωγή που ολοκληρώνει τη διαδικασία. Πρέπει να τονισθεί ότι αποδεδειγμένα, αν ο πίνακας είναι ταξινομημένος με βάση κάποιο βήμα, τότε παραμένει ταξινομημένος με βάση το ίδιο βήμα ακόμη και αν εφαρμοσθούν ένα η περισσότερα επόμενα βήματα στη συνέχεια. Επίσης, καθώς η μέθοδος αυτή στηρίζεται στην ταξινόμηση με εισαγωγή, είναι και αυτή ευσταθής, δηλαδή δεν ανταλλάσσει αμοιβαία στοιχεία με ίσα κλειδιά.
Το παράδειγμα του Σχήματος 8.8 δείχνει το περιεχόμενο του πίνακα με τα γνωστά 9 κλειδιά και τον τρόπο ανταλλαγής τους, καθώς ο πίνακας ταξινομείται σταδιακά με 3 βήματα μεγέθους 4, 2 και 1. Μεταξύ των γραμμών που δείχνουν το πέρας κάθε φάσης, παρουσιάζονται οι εκτελούμενες ανταλλαγές στοιχείων του πίνακα. Στο παράδειγμα αυτό, επίσης, παρατηρούμε χαρακτηριστικά πως ο πίνακας παραμένει ταξινομημένος με βήμα 4 ακόμη και μετά το πέρας της φάσης με βήμα 2.
| Αρχικά | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Κλειδιά | 52 | 12 | 71 | 56 | 5 | 10 | 19 | 90 | 45 |
| 5 | 52 | ||||||||
| 45 | 52 | ||||||||
| 10 | 12 | ||||||||
| 19 | 71 | ||||||||
| Βήμα 4 | 5 | 10 | 19 | 56 | 45 | 12 | 71 | 90 | 52 |
| 52 | 71 | ||||||||
| 12 | 56 | ||||||||
| Βήμα 2 | 5 | 10 | 19 | 12 | 45 | 56 | 52 | 90 | 71 |
| 12 | 19 | ||||||||
| 52 | 56 | ||||||||
| 71 | 90 | ||||||||
| Βήμα 1 | 5 | 10 | 12 | 19 | 45 | 52 | 56 | 71 | 90 |
Ο ψευδοκώδικας που ακολουθεί παρουσιάζει αλγοριθμικά το προηγούμενο σκεπτικό. Ο ψευδοκώδικας δεν είναι αρκετά γενικός, καθώς θεωρεί μία απλή ακολουθία με 3 βήματα μεγέθους 4, 2 και 1, ώστε να συμφωνεί με το παράδειγμα. Η δεύτερη παρατήρηση είναι ότι για επιπλέον λόγους ευκολίας θεωρεί ότι στα αριστερά του πίνακα υπάρχουν τρεις επιπλέον θέσεις, όπου τοποθετούνται κόμβοι φρουροί με τιμές ίσες προς τα βήματα, αντίστοιχα.
procedure shellsort;
1. h[1] <-- 4; h[2] <-- 2; h[3] <-- 1;
2. for m <-- 1 to 3 do
3. k <-- h[m]; s <-- -k
4. for i <-- k+1 to n do
5. x <-- A[i]; j <-- i-k;
6. if s=0 then s <-- -k;
7. s <-- s+1; A[s] <-- x;
8. while x<Α[j] do
9. A[j+k] <-- A[j]; j <-- j-k
10. A[j+k] <-- x
Η απλή αυτή λογική της μεθόδου του Shell πάσχει κατά το ότι η ακολουθία των ακεραίων
παραμένει μία παράμετρος προς βελτιστοποίηση. Δηλαδή, έχουν προταθεί και έχουν αναλυθεί
με περισσότερη ή λιγότερη δυσκολία αρκετές ακολουθίες, αλλά θα μπορούσε να προταθεί μία
νέα ακολουθία και να αποδειχθεί ότι αυτή είναι καλύτερη από κάθε προηγούμενη και πιθανώς
η βέλτιστη. Στη συνέχεια, θα παρουσιάσουμε την ανάλυση της χειρότερης περίπτωσης για την
ακολουθία που προτάθηκε από τον ίδιο τον Shell και δίνεται από τις σχέσεις:
και .
Πρόταση.
Η πολυπλοκότητα της shellsort είναι Θ() στη χειρότερη περίπτωση για την
ακολουθία του Shell, όπου και .
Απόδειξη
Για να αποδείξουμε ότι η πολυπλοκότητα της χειρότερης περίπτωσης για την ακολουθία του
Shell είναι Θ(), πρώτα θα αποδείξουμε ότι ισχύει το Ω() και μετά το Ο().
Έστω ότι , οπότε κάθε βήμα είναι άρτιος αριθμός εκτός από το τελευταίο βήμα που
ισούται με τη μονάδα. Έστω, επίσης, ότι αρχικά τα μεγαλύτερα στοιχεία
τοποθετούνται στις άρτιες θέσεις, ενώ τα μικρότερα στοιχεία τοποθετούνται στις
περιττές θέσεις. Μέχρι να φθάσουμε στο τελευταίο βήμα, όλα τα μεγαλύτερα στοιχεία
είναι ακόμη στις άρτιες θέσεις και όλα τα στοιχεία είναι στις μικρότερες θέσεις.
Επομένως, το -οστό μικρότερο στοιχείο (για ) βρίσκεται στην -οστή
θέση πριν αρχίσει το τελικό πέρασμα και πρέπει να εκτελεσθούν ανταλλαγές μέχρι
να φθάσει στην τελική του θέση. Άρα, για όλα τα μικρότερα στοιχεία θα απαιτηθούν
ανταλλαγές. Το Σχήμα
8.9 απεικονίζει το παράδειγμα που περιγράφηκε πριν.
| Αρχικά | 1 | 5 | 2 | 6 | 3 | 7 | 4 | 8 |
|---|---|---|---|---|---|---|---|---|
| Βήμα 4 | 1 | 5 | 2 | 6 | 3 | 7 | 4 | 8 |
| Βήμα 2 | 1 | 5 | 2 | 6 | 3 | 7 | 4 | 8 |
| Βήμα 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
Για να αποδείξουμε το δεύτερο σκέλος, αρκεί να θεωρήσουμε ότι κατά το πέρασμα με βήμα
, ουσιαστικά εκτελείται μία ταξινόμηση με εισαγωγή (τετραγωνικής πολυπλοκότητας)
για ένα σύνολο στοιχείων. Επομένως, για το σύνολο των περασμάτων με αυτό το
βήμα η πολυπλοκότητα είναι Ο = O. Επομένως για το σύνολο
των βημάτων προκύπτει η πολυπλοκότητα . Καθώς η ακολουθία των βημάτων είναι γεωμετρική, έπεται ότι
. Έτσι προκύπτει το ζητούμενο, δηλαδή ότι η πολυπλοκότητα
της ταξινόμησης του Shell για τη δεδομένη ακολουθία είναι Ο().
Στη βιβλιογραφία έχουν παρουσιασθεί πολλές εναλλακτικές προτάσεις για την ακολουθία των βημάτων και έχουν αναλυθεί. Για παράδειγμα, για την ακολουθία του Hibbard, αν και εικάζεται από πειραματικά αποτελέσματα ότι η πολυπλοκότητα είναι Ο(), το όριο που έχει αποδειχθεί είναι Θ().
8.7 Όρια Αλγορίθμων Ταξινόμησης
Μέχρι στιγμής εξετάσθηκαν μέθοδοι ταξινόμησης με πολυπλοκότητα της τάξης O() ή
Ο(). Τι εκφράζει η κάθε μία από αυτές τις τάξεις πολυπλοκότητας; Ο μέθοδος της
ταξινόμησης με εισαγωγή, της ταξινόμησης με επιλογή και της ταξινόμησης με ανταλλαγή
(bubblesort) είναι οι λεγόμενες ευθείες (straight) μέθοδοι που είναι απλές στην
κατανόηση, την κωδικοποίηση και την ανάλυση, αλλά αποτελούν μία οικογένεια αργών
αλγορίθμων ταξινόμησης. Για τις μεθόδους αυτές ισχύει η επόμενη θεώρηση.
Δοθέντος ενός πίνακα Α με διακριτά στοιχεία λέγεται ότι υπάρχει μία αντιστροφή
(inversion), αν ισχύει για κάποια . Με απλά λόγια, στην ακολουθία
οι αντιστροφές είναι (3,1), (14,1), (14,5) και(14,9).
Πρόταση.
Κάθε αλγόριθμος που σε κάθε βήμα απομακρύνει το πολύ μία αντιστροφή απαιτεί
βήματα στη χειρότερη περίπτωση και βήματα στη μέση περίπτωση.
Απόδειξη.
Αν υποθέσουμε ότι ο πίνακας Α περιέχει μία τυχαία διάταξη των τιμών από
το σύνολο των διατάξεων. Ορίζουμε ως ανεστραμμένο (reverse) του πίνακα Α,
τον πίνακα . Σημειώνεται ότι
, ενώ για δεν υπάρχει περίπτωση κάποιος πίνακας να αποτελεί
αντίστροφο του εαυτού του. Έτσι οι διατάξεις μπορούν να χωρισθούν σε ζεύγη,
όπου κάθε ζεύγος αποτελείται από μία διάταξη και την αντεστραμμένη της. Υπάρχουν
ζεύγη τιμών , όπου . Για κάθε τέτοιο ζεύγος τιμών
() και για κάθε ζεύγος διάταξης και της αντεστραμμένης της (),
θα υπάρχει μόνο μία αντιστροφή στη μία διάταξη από τις δύο του κάθε ζεύγους. Επομένως
ο συνολικός αριθμός αντιστροφών σε όλες τις διατάξεις είναι , ενώ η μέση τιμή
των αντιστροφών είναι .
Πρόταση.
Δεδομένου ενός πίνακα που περιέχει μία τυχαία διάταξη με στοιχεία, το άθροισμα των
αποστάσεων που διανύονται από τα στοιχεία κατά την ταξινόμησή τους είναι .
Απόδειξη.
Ας υποθέσουμε ότι ο πίνακας Α περιέχει μία τυχαία διάταξη των τιμών .
Δοθέντος ενός τυχαίου στοιχείου Α[], η απόσταση που θα διανύσει είναι .
Επομένως θεωρώντας το σύνολο των στοιχείων ισχύει ότι η μέση τιμή της απόστασης ισούται με:
Συνεπώς, η μέση διανυόμενη απόσταση είναι:
| (8.38) |
Οι όροι εντός του αθροίσματος είναι ίδιοι για συμπληρωματικές τιμές του και επομένως ισχύει:
| (8.39) |
Συνεπώς, ένας αλγόριθμος ταξινόμησης που μετακινεί τα στοιχεία κατά ένα σταθερό αριθμό θέσεων
σε κάθε βήμα απαιτεί Ο() βήματα.
Τελικά τίθεται το ερώτημα «Πόσο γρήγορα μπορεί μία μέθοδος να ταξινομήσει έναν πίνακα;». Θα αποδειχθεί ότι, όταν μία μέθοδος ταξινόμησης στηρίζεται μόνο σε συγκρίσεις και ανταλλαγές κλειδιών, τότε στη χειρότερη περίπτωση δεν μπορεί να ταξινομήσει σε χρόνο κατώτερο του Ο().
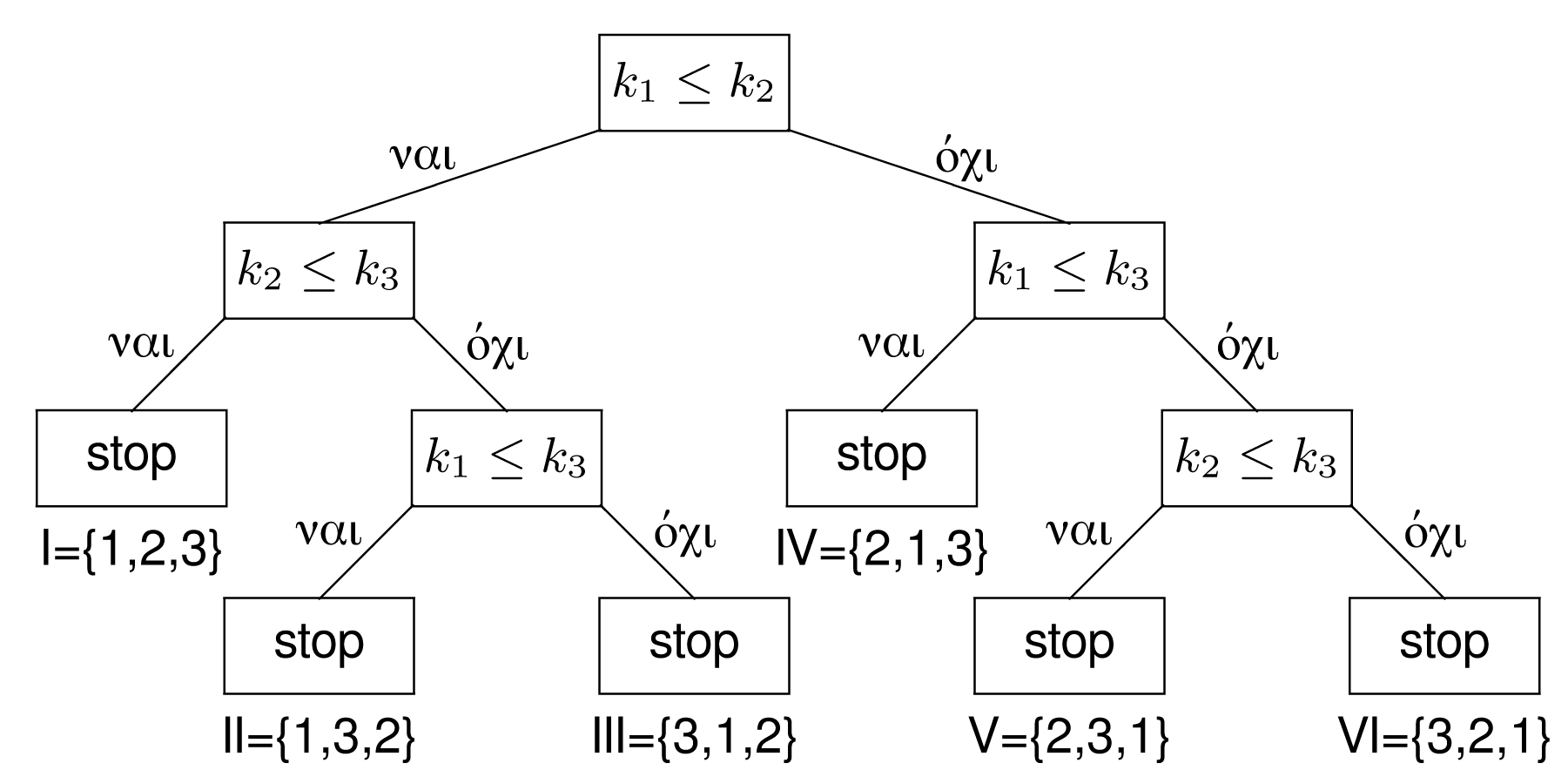
Πριν την απόδειξη της σχετική πρότασης είναι αναγκαίο να περιγραφεί η διαδικασία ταξινόμησης με ένα δένδρο αποφάσεων (decision tree). Ένα μονοπάτι του δένδρου δείχνει μία πιθανή διαδοχή από υπολογισμούς που ο αλγόριθμος πιθανώς να ακολουθήσει. Για παράδειγμα, ας υποτεθεί ότι πρέπει να ταξινομηθούν τρία κλειδιά: τα και αντίστοιχα. Η σειρά εισόδου των κλειδιών είναι και που φαίνεται στο δένδρο αποφάσεων ως (1,2,3). Αρχικά, συγκρίνονται τα κλειδιά και . Αν , τότε η σειρά (1,2,3) δεν αλλάζει, αλλιώς γίνεται (2,1,3).
Στο επόμενο σχήμα φαίνονται όλα τα πιθανά ενδεχόμενα που μπορούν να συμβούν σε έναν
αλγόριθμο ταξινόμησης ανάλογα με τη σειρά σύγκρισης των κλειδιών στο δένδρο. Από το
σχήμα αυτό φαίνεται ότι το δένδρο αποφάσεων είναι ένα δυαδικό δένδρο. Τα φύλλα του
δένδρου είναι αριθμημένα από Ι ως VI και αποτελούν τα μοναδικά σημεία τερματισμού κάθε
αλγορίθμου ταξινόμησης. Το δένδρο αυτό έχει 3!=6 φύλλα που εξασφαλίζει ότι ο αλγόριθμος
βρίσκει πάντοτε τη διάταξη εκείνη που αντιστοιχεί στην ταξινομημένη σειρά.
Πρόταση.
Κάθε δένδρο αποφάσεων που ταξινομεί διακεκριμένα κλειδιά έχει ύψος τουλάχιστον .
Απόδειξη.
Ένα δένδρο αποφάσεων έχει φύλλα που αντιστοιχούν σε κάθε μία από τις διατάξεις
των κλειδιών. Ας υποτεθεί ότι το δένδρο είναι πλήρες και ότι το ύψος του είναι .
Τότε ο αριθμός των φύλλων είναι , οπότε συνεπάγεται ότι .
Λογαριθμώντας και τα δύο μέλη της σχέσης προκύπτει:
| (8.40) |
Το δένδρο δεν είναι πλήρες και, άρα, η πρόταση ισχύει.
Πρόταση.
Κάθε αλγόριθμος που ταξινομεί κάνοντας μόνο συγκρίσεις και ανταλλαγές κλειδιών έχει στη
χειρότερη περίπτωση χρόνο τάξης Ο().
Απόδειξη.
Πρέπει να αποδειχθεί ότι σε κάθε δένδρο αποφάσεων με ! φύλλα υπάρχει ένα μονοπάτι μήκους
, όπου είναι μία σταθερά. Από την προηγούμενη πρόταση προκύπτει ότι κάθε
μονοπάτι είναι μήκους . Αντικαθιστώντας με βάση τον τύπο του Stirling προκύπτει:
| (8.41) |
8.8 Ταξινόμηση με Μέτρημα
Ας υποθέσουμε ότι δίνεται ένας πίνακας Α με στοιχεία, που λαμβάνουν τιμές από 1 μέχρι , όπου . Θα εκτελέσουμε μία ταξινόμηση με τη βοήθεια ενός βοηθητικού πίνακα C μεγέθους , ενώ το αποτέλεσμα θα αποθηκευθεί στον πίνακα B. Με απλά λόγια, η ταξινόμηση αυτή δεν είναι επιτόπια. Δίνεται ο επόμενος ψευδοκώδικας και θα σχολιασθεί στη συνέχεια με τη βοήθεια ενός παραδείγματος.
procedure countsort
1. for i <-- 1 to k do C[i] <-- 0;
2. for i <-- 1 to n do C[A[i]] <-- C[A[i]]+1;
3. for i <-- 2 to k do C[i] <-- C[i]+C[i-1]
4. for i <-- n downto 1 do
5. B[C[A[i]]] <-- A[i]; C[A[i]] <-- C[A[i]]-1
| 5 | 7 | 3 | 5 | 2 | 1 | 4 | 3 |
Έστω και ο πίνακας Α με το περιεχόμενο του Πίνακα 8.1. Με την εντολή 2 καταμετρώνται οι εμφανίσεις της κάθε τιμής (από τις ) και τοποθετούνται σε αντίστοιχες θέσεις του πίνακα C. Με την εντολή 3 σαρώνεται ο πίνακας C και προκύπτει η νέα μορφή του C, όπου κάθε θέση προκύπτει ως το άθροισμα των τιμών των δύο προηγούμενων θέσεων. Το περιεχόμενο του πίνακα C μετά το πέρας των εντολών 2-3 δίνονται στoν Πίνακα 8.2. Με το βρόχο της εντολής 4, στον πίνακα Β τοποθετείται η ζητούμενη ταξινομημένη ακολουθία και τερματίζει ο αλγόριθμος.
| 1 | 1 | 2 | 1 | 2 | 0 | 1 |
| 1 | 2 | 4 | 5 | 7 | 7 | 8 |
Παρατηρούμε ότι ο ψευδοκώδικας αποτελείται από τέσσερις διαδοχικούς βρόχους. Εξ αυτών
οι δύο εκτελούν επαναλήψεις, ενώ άλλοι δύο εκτελούν επαναλήψεις. Ευνόητο είναι
ότι η πολυπλοκότητα του αλγορίθμου είναι Θ(). Με την παραδοχή ότι , έπεται ότι
η πολυπλοκότητα είναι Θ(). Επιτύχαμε δηλαδή ένα γραμμικό αλγόριθμο ταξινόμησης
σε αντίθεση με τα προηγούμενα; Η ερώτηση είναι παγίδα γιατί στην παρούσα περίπτωση
(α) ο αλγόριθμος δεν στηρίζεται στις συγκρίσεις και (β) αν , τότε προφανώς δεν
ισχύει το τελικό συμπέρασμα.
Τώρα ας προσέξουμε τον επόμενο κώδικα. Οι πρώτες δύο εντολές είναι πανομοιότυπες με τις πρώτες δύο εντολές της διαδικασίας countsort, αλλά στη συνέχεια υπάρχει διαφορά. Πιο συγκεκριμένα, δεν υπάρχει ο βοηθητικός πίνακας Β και, επίσης παρατηρούμε ένα διπλό βρόχο στις εντολές 4-6. Αν εκτελέσουμε τον αλγόριθμο, έστω και με χαρτί και μολύβι, θα διαπιστώσουμε ότι ουσιαστικά εκτελεί την ίδια λειτουργία με την προηγούμενη διαδικασία.
procedure countsort2
1. for i <-- 1 to k do C[i] <-- 0;
2. for i <-- 1 to n do C[A[i]] <-- C[A[i]]+1;
3. i <-- 0;
4. for j <-- 1 to k do
5. for m <-- C[j] down to 1 do
6. i <-- i+1; A[i] <-- j
Πρόταση.
Η πολυπλοκότητα της countsort2 είναι Θ() στη χειρότερη περίπτωση.
Απόδειξη.
Η περίπτωση θυμίζει το παράδειγμα που είχαμε επιλύσει στο Κεφάλαιο 1.5
(όπου το άνω όριο του βρόχου δεν ήταν ένας κλασικός δείκτης αλλά το περιεχόμενο μίας θέσης
του πίνακα). Σύμφωνα, λοιπόν, με μία πρώτη προσέγγιση, με βάση τα όρια των βρόχων for
μπορούμε να φθάσουμε στο συμπέρασμα ότι η πολυπλοκότητα είναι Ο(), επειδή είναι η
τιμή του C[i] στην εντολή 5 στη χειρότερη περίπτωση. Ωστόσο, η ανάλυση αυτή δεν είναι σφικτή.
Ο εξωτερικός βρόχος for της εντολής 4 είναι συγκεκριμένος, δηλαδή έχουμε επαναλήψεις. Η εντολή 6 θα εκτελεσθεί ακριβώς φορές και όχι . Αυτό προκύπτει με βάση την εξής παρατήρηση: Ας θεωρήσουμε την -οστή επανάληψη του εξωτερικού βρόχου. Ο έλεγχος του εσωτερικού βρόχου for θα εκτελεσθεί C[j]+1 φορές. Επομένως, ο συνολικός αριθμός ελέγχων στο σημείο αυτό είναι:
| (8.42) |
Συνεπώς και πάλι καταλήγουμε στο ίδιο συμπέρασμα ως προς την πολυπλοκότητα της διαδικασίας.
8.9 Ταξινόμηση με Βάση τη Ρίζα
Η ταξινόμηση με βάση τη ρίζα (radix sort) είναι μία γενίκευση της ταξινόμησης με μέτρημα. Με απλά λόγια, έστω ότι δίνεται προς ταξινόμηση ένας πίνακας με ακεραίους μέγεθους ψηφίων. Εκτελούμε μία ταξινόμηση με μέτρημα ως προς το τελευταίο, δηλαδή το λιγότερο σημαντικό ψηφίο (least significant digit). Έτσι, προκύπτει μία νέα μορφή του πίνακα, που και πάλι ταξινομούμε με μέτρημα αλλά αυτή τη φορά ως προς το δεύτερο ψηφίο από το τέλος. Η διαδικασία αυτή συνεχίζεται και τελειώνει, όταν ο προκύπτων πίνακας ταξινομείται ως προς το πρώτο, δηλαδή το περισσότερο σημαντικό ψηφίο (most significant digit).
Σημειώνεται ότι στην ταξινόμηση με βάση τη ρίζα δεν υπάρχει περιορισμός ως προς το εύρος τιμών των κλειδιών, όπως υπάρχει στην ταξινόμηση με μέτρημα (η γνωστή παράμετρος ). Όμως, όταν λαμβάνεται σε κάθε κλήση το αντίστοιχο ψηφίο, τότε εκεί προφανώς τα ψηφία λαμβάνουν τιμές εντός του διαστήματος 1-9, και έτσι συνιστάται η χρήση της ταξινόμησης με μέτρημα. Η μέθοδος θα μπορούσε να εφαρμοσθεί και σε συμβολοσειρές, όπου κάθε χαρακτήρας θα λάμβανε τιμές στο διάστημα a-z ή α-ω (δηλαδή, 26 ή 24 διαφορετικές τιμές αντίστοιχα). Από το χρησιμοποιούμενο, λοιπόν, αριθμητικό σύστημα (δηλαδή το δεκαδικό, δυαδικό κλπ. σε περίπτωση αριθμών ή το διάστημα 1-24/26 σε περίπτωση χαρακτήρων) προκύπτει η ονομασία της μεθόδου (radix). Η επόμενη συνοπτικότατη διαδικασία καταγράφει αυτήν την περιγραφή.
procedure radixsort 1. for i <-- 1 to d do 2. countsort(d)
Έστω ότι δίνονται προς ταξινόμηση ο πίνακας A με τα γνωστά 9 κλειδιά 52, 12, 71, 56, 5, 10, 19, 90 και 45, όπως φαίνεται στοn Πίνακα 8.3. Αν καλέσουμε την countsort της εντολής 2 με όρισμα d=1 (θεωρούμε ότι η αρίθμηση των ψηφίων αρχίζει από το λιγότερο σημαντικό), τότε θα προκύπτει η δεύτερη μορφή του πίνακα, ενώ με τη δεύτερη κλήση της countsort και όρισμα d=2 θα προκύψει η τελική μορφή του πίνακα.
| 52 | 12 | 71 | 56 | 5 | 10 | 19 | 90 | 45 |
| 10 | 90 | 71 | 52 | 12 | 5 | 45 | 56 | 19 |
| 5 | 10 | 12 | 19 | 45 | 52 | 56 | 71 | 90 |
Η ανάλυση της πολυπλοκότητας της ταξινόμησης με βάση της ρίζα είναι εύκολη υπόθεση. Εφόσον η ταξινόμηση με μέτρημα έχει γραμμική πολυπλοκότητα Θ(), έπεται ότι η πολυπλοκότητα της ταξινόμησης με βάση τη ρίζα είναι Θ(). Θεωρώντας το σταθερά, προκύπτει και πάλι γραμμική πολυπλοκότητα.
8.10 Ταξινόμηση με Κάδους
Η ταξινόμηση με κάδους (bucket sort) στηρίζεται στην υπόθεση ότι δίνονται προς ταξινόμηση αριθμοί που ανήκουν στο διάστημα [0,1). Το διάστημα αυτό υποδιαιρείται σε ίσα υποδιαστήματα (τους λεγόμενους κάδους), όπου κατανέμονται τα ισάριθμα στοιχεία προς ταξινόμηση. Επειδή, θεωρούμε ότι τα στοιχεία υπακούουν σε μία ομοιόμορφη κατανομή, δεν αναμένουμε να ανήκουν πάρα πολλά στοιχεία σε ένα συγκεκριμένο υποδιάστημα. Η τελική ταξινομημένη ακολουθία προκύπτει ταξινομώντας τα στοιχεία του κάθε κάδου και κατόπιν λαμβάνοντας τους κάδους στη σειρά. Η επόμενη διαδικασία περιγράφει όσα αναφέραμε. Εκτός του πίνακα Α με τα στοιχεία, χρησιμοποιείται και ένας βοηθητικός πίνακας Β με επίσης θέσεις για τη δημιουργία συνδεδεμένων λιστών.
procedure bucketsort
1. for i <-- 1 to n do insert(A[i],B[floor(n*A[i])])
2. for i <-- 1 to n do insertsort(B[i])
3. return (B[1], B[2], ..., B[n])
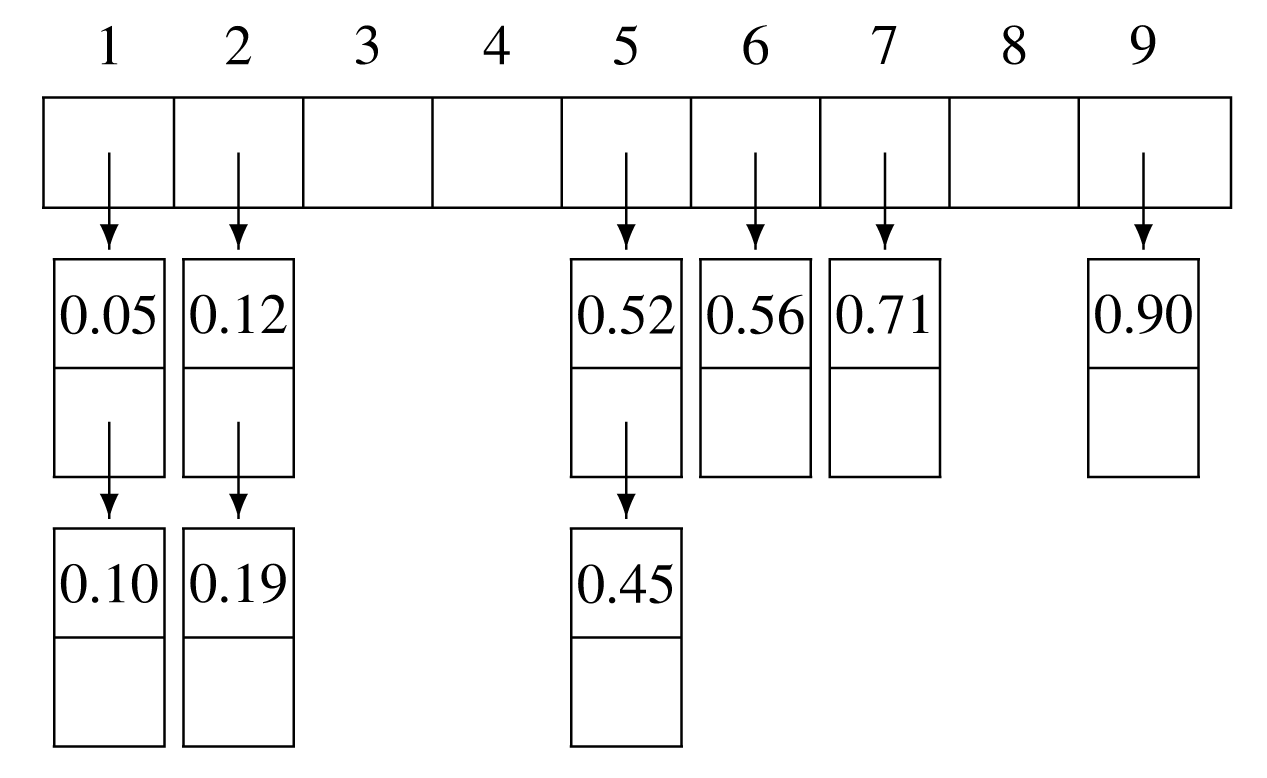
Για παράδειγμα, έστω ότι δίνεται ο πίνακας Α με τα γνωστά στοιχεία από τα
προηγούμενα παραδείγματα, διαιρεμένα δια 100. Θεωρούμε έναν πίνακα Β με 9 θέσεις, όποτε
τα υποδιαστήματα που αντιστοιχούν στις θέσεις του πίνακα Β είναι [0-0,11), [0,11-0,22),
[0,22-0,33), …, [0,88-1). Το Σχήμα 8.11 απεικονίζει την κατάσταση μετά το
πέρας της εντολής 1, οπότε έχουν εισαχθεί όλα τα στοιχεία στις αντίστοιχες συνδεδεμένες
λίστες. Εννοείται ότι στη συνέχεια τα στοιχεία κάθε λίστας πρέπει να ταξινομηθούν,
ώστε να δοθούν στην έξοδο.
Πρόταση.
Η πολυπλοκότητα της bucketsort είναι γραμμική στη μέση περίπτωση.
Απόδειξη.
Προκειμένου να βρούμε την πολυπλοκότητα της μεθόδου πρέπει να εστιάσουμε στην εντολή 2,
γιατί προφανώς η εντολή 1 έχει γραμμικό κόστος. Στην εντολή 2 ουσιαστικά εκτελούμε
ανεξάρτητες ταξινομήσεις με εισαγωγή με στοιχεία η κάθε μία, όπου το είναι
μία τυχαία μεταβλητή. Επομένως, το συνολικό κόστος των εντολών 1-2 είναι:
Ορίζουμε μία τυχαία μεταβλητή που ισούται με 1, αν το στοιχείο κατανέμεται στον -οστό κάδο, ενώ αλλιώς ισούται με 0 (όπου ). Άρα ισχύει και συνεπώς:
Θα επιλύσουμε τα δύο αθροίσματα ξεχωριστά. Η τυχαία μεταβλητή ισούται με 1 με πιθανότητα . Επομένως:
| (8.43) |
Σε σχέση με το δεύτερο άθροισμα ισχύει ότι και επομένως οι δύο τυχαίες μεταβλητές είναι ανεξάρτητες. Από το Κεφάλαιο 2.1 γνωρίζουμε ότι: . Συνεπώς:
| (8.44) |
Άρα, αντικαθιστώντας προκύπτει:
Επιστρέφοντας στην αρχική σχέση έχουμε:
| (8.45) |
Στη συνέχεια, ακολουθεί μία κομψότερη απόδειξη του προηγούμενου αποτελέσματος.
Πρόταση.
Η πολυπλοκότητα της bucketsort είναι γραμμική στη μέση περίπτωση.
Απόδειξη.
Η πιθανότητα ένα συγκεκριμένο στοιχείο να κατανεμηθεί στον -οστό κάδο είναι .
Η πιθανότητα υπακούει μία δυωνυμική κατανομή με προσδοκητή τιμή και
απόκλιση . Από το Κεφάλαιο 2.1 γνωρίζουμε
ότι για οποιαδήποτε τυχαία μεταβλητή ισχύει:
| (8.46) |
Συνεπώς, ισχύει:
| (8.47) |
Άρα, αντικαθιστώντας την τελευταία έκφραση στον αρχικό τύπο του , τελικώς προκύπτει ότι η ταξινόμηση με κάδους έχει γραμμική πολυπλοκότητα Θ() στη μέση περίπτωση. Στη χειρότερη περίπτωση η πολυπλοκότητα είναι τετραγωνική Θ().
8.11 Βιβλιογραφική Συζήτηση
Η ταξινόμηση είναι ένα εξαιρετικά τιμημένο αντικείμενο της Πληροφορικής, καθώς έχει απασχολήσει στο παρελθόν πλήθος ερευνητών λόγω της θεωρητικής και πρακτικής σπουδαιότητάς του. Οι αλγόριθμοι ταξινόμησης που παρουσιάσθηκαν προηγουμένως μπορούν να βρεθούν σε οποιοδήποτε διδακτικό εγχειρίδιο για δομές δεδομένων και αλγορίθμους. Ο 3ος τόμος του βιβλίου του Knuth είναι ίσως το πληρέστερο και βαθύτερο κείμενο [89]. Σύμφωνα με τον Knuth, κάθε αλγόριθμος ταξινόμησης κατατάσσεται σε μία από πέντε κατηγορίες αναλόγως με τη βασική λειτουργία του. Οι κατηγορίες είναι: με εισαγωγή, με ανταλλαγή, με επιλογή, με συγχώνευση και με κατανομή. Πλούσιο σε υλικό είναι επίσης και το βιβλίο των Gonnet-BaezaYates [60].
Καλές επισκοπήσεις μπορούν να βρεθούν στα βιβλία και άρθρα [44, 107, 114, 115, 126, 127]. Ιδιαιτέρως, στο άρθρο [127] οι αλγόριθμοι ταξινόμησης κατατάσσονται σε δύο κατηγορίες: αυτούς που έχουν εύκολο διαχωρισμό και δύσκολη σύνδεση (όπως ταξινόμηση με εισαγωγή, ταξινόμηση με συγχώνευση, ταξινόμηση με μειούμενες αυξήσεις) και σε αυτούς που έχουν δύσκολο διαχωρισμό και εύκολη σύνδεση (όπως ταξινόμηση φυσαλίδας, ταξινόμηση επιλογής, γρήγορη ταξινόμηση).
Η λεγόμενη ταξινόμηση φυσαλίδας ή ταξινόμηση με αντικατάσταση έχει υπερ-παρουσιασθεί σε διδακτικά εγχειρίδια, αν και είναι η χειρότερη τετραγωνική μέθοδος. Παρότι δεν εξετάσθηκε στα πλαίσια του παρόντος βιβλίου παρά μόνο στις Ασκήσεις 8-9, σχετικό υλικό μπορεί να βρεθεί στα άρθρα [38, 39, 191]. Από τις τετραγωνικές μεθόδους ξεχωρίζει η μέθοδος της ταξινόμησης με εισαγωγή, η οποία έχει μελετηθεί περισσότερο από τις άλλες αντίστοιχες μεθόδους [111, 184], θεωρείται μάλιστα ότι είναι η προσφορότερη όταν ο πίνακας είναι περίπου ταξινομημένος [33]. Η ανάλυση για την πολυπλοκότητα των μετακινήσεων στην ταξινόμηση με επιλογή αναφέρρεται στο άρθρο [47].
Η γρήγορη ταξινόμηση προτάθηκε από τον Hoare [76] και υπήρξε πολύ δημοφιλής, καθώς αποτέλεσε αφορμή για πλήθος παραλλαγών και αναλύσεων [26, 81, 106, 111, 133, 134, 132, 154, 160, 163, 162, 164, 186, 187, 189]. Βασική αναφορά για τη μέθοδο ταξινόμησης με συγχώνευση αποτελεί το άρθρο [22], ενώ παραλλαγές της μεθόδου προτείνονται στα άρθρα [145, 185]. H ταξινόμηση shellsort προτάθηκε από τον Shell [170], ενώ ο Hibbard βελτίωσε σημαντικά την αρχική μέθοδο στο άρθρο [74]. Απόδειξη για την πολυπλοκότητα της μέθοδου χρησιμοποιώντας την ακολουθία Hibbard αναφέρεται στο βιβλίο [195]. Περαιτέρω, η μέθοδος μελετήθηκε εκτενώς, όπως στα άρθρα [16, 20, Εrkio80, 43, 54, 80, 149, 165, 194, 192, 193, 202].
Η χρήση του δέντρου απόφασης για το κάτω όριο ταξινόμησης βάσει συγκρίσεων οφείλεται στους Ford-Johnson [49]. H παρουσίαση των ταξινομήσεων που δεν βασίζονται στις συγκρίσεις ακολουθεί την προσέγγιση του βιβλίου των Cormen-Leiserson-Rivest-Stein [34].
Η Άσκηση 8 βασίζεται στο άρθρο [45], η Άσκηση 14 στο βιβλίο [69], η Άσκηση 15 στα άρθρα [133, 134, 132], η Άσκηση 22 στο άρθρο [33], η Άσκηση 23 στο άρθρο [72], ενώ η Άσκηση 25 στο άρθρο [61].
Στα πλαίσια του βιβλίου αυτού δεν εξετάζονται αλγόριθμοι εξωτερικής ταξινόμησης (δηλαδή σε δευτερεύουσα μνήμη), καθώς περισσότερο ταιριάζουν στο αντικείμενο των Βάσεων Δεδομένων. Ωστόσο, ο ενδιαφερόμενος αναγνώστης παραπέμπεται στο βιβλίο της Salzberg [157]. Επίσης, ο αναγνώστης παραπέμπεται στο άρθρο [44], όπου εξετάζονται οι λεγόμενοι προσαρμοζόμενοι (adaptive) αλγόριθμοι ταξινόμησης, δηλαδή αλγόριθμοι των οποίων η πολυπλοκότητα εξαρτάται από την ποσότητα της αταξίας στον υπό ταξινόμηση πίνακα.
8.12 Ασκήσεις
-
1.
Ποιά από τις επόμενες πράξεις μπορούν να υλοποιηθούν καλύτερα, αν προηγουμένως ο αντίστοιχος πίνακας έχει ταξινομηθεί;
-
–
εύρεση της ελάχιστης τιμής,
-
–
εύρεση της μέγιστης τιμής,
-
–
εύρεση της μέσης τιμής,
-
–
εύρεση της μεσαίας τιμής, και
-
–
εύρεση της συχνότερης τιμής (mode).
-
–
-
2.
Ποιός είναι ο ελάχιστος αριθμός συγκρίσεων για την ταξινόμηση 5 διακριτών ακεραίων; Πόσες συγκρίσεις και μετακινήσεις απαιτούνται στην καλύτερη, μέση και χειρότερη περίπτωση. Να επιλυθεί η άσκηση θεωρώντας 8 διακριτούς αριθμούς.
-
3.
Επί ευθείας γραμμής τοποθετούνται δίσκοι, όπου εναλλάσσονται ένας μαύρος και ένας λευκός. Ας υποθέσουμε ότι οι δίσκοι περιττής (άρτιας) τάξης είναι μαύροι (λευκοί). Πρέπει να συγκεντρώσουμε όλους τους μαύρους στα αριστερά και όλους τους λευκούς στα δεξιά της ευθείας γραμμής. Η μοναδική επιτρεπόμενη κίνηση είναι να ανταλλάξουμε μεταξύ τους δύο γειτονικούς δίσκους. Ποιός είναι ο ελάχιστος αριθμός μετακινήσεων;
-
4.
Επί ευθείας γραμμής τοποθετούνται δίσκοι, όπου οι πρώτοι είναι μαύροι και επόμενοι είναι λευκοί. Ποιός είναι ο ελάχιστος αριθμός μετακινήσεων, ώστε στη γραμμή να εναλλάσσονται μαύροι και λευκοί (ο πρώτος δίσκος να είναι μαύρος);
-
5.
Να σχεδιασθεί και να αναλυθεί η μέθοδος εισαγωγής με δυαδική εισαγωγή (binary insertion sort), όπου χρησιμοποιείται η δυαδική αναζήτηση για την εύρεση της σωστής θέσης όπου θα γίνει η κάθε φορά εισαγωγή του επόμενου στοιχείου μέσα στην ακολουθία προορισμού. Η ανάλυση να θεωρήσει το πλήθος των συγκρίσεων και το πλήθος των μετακινήσεων.
-
6.
Να σχεδιασθεί και να αναλυθεί αλγόριθμος που να εντοπίζει τους 2 μεγαλύτερους αριθμούς σε ένα πίνακα με διαφορετικούς ακεραίους.
-
7.
Δίνεται ένας πίνακας με κλειδιά και ζητείται να βρεθούν τα μικρότερα κλειδιά, όπου , χωρίς όμως να ταξινομηθεί πρώτα ο πίνακας. Να σχεδιασθούν τουλάχιστον δύο τρόποι.
-
8.
Δίνεται αταξινόμητος πίνακας με στοιχεία και ζητείται το -οστό μεγαλύτερο. Να σχεδιασθεί λεπτομερώς αλγόριθμος που θα ταξινομεί τα πρώτα στοιχεία και κατόπιν θα εξετάζει τα επόμενα με τη βοήθεια της ταξινόμησης με εισαγωγή. Να βρεθεί η πολυπλοκότητα του προτεινόμενου αλγορίθμου.
-
9.
Σε ένα πίνακα Α[0..n-1] τα στοιχεία Α[0], Α[2], Α[4] κλπ είναι τα μικρότερα στοιχεία, ενώ τα Α[1], Α[3], Α[5] κλπ είναι τα μεγαλύτερα. Να βρεθεί ο συνολικός αριθμός των συγκρίσεων (ως συνάρτηση του ) που θα κάνει η μέθοδος ταξινόμησης με εισαγωγή και η μέθοδος του Shell με δύο μειούμενες αυξήσεις μεγέθους 2 και 1, αντιστοίχως.
-
10.
Ο πίνακας A[0..n-1] περιέχει τις διακριτές τιμές από 0 μέχρι . Τι εκτελεί ο επόμενος κώδικας; Τι πολυπλοκότητα έχει; Ο πίνακας B ορίζεται ομοίως.
for (i=0; i<n; i++) B[A[i]]=A[i]
-
11.
Δίνεται ο επόμενος κώδικας. Σε τι μοιάζει και σε τι διαφέρει με τον προηγούμενο κώδικα;
for (i=0; i<n; i++) while (A[i] != i) swap(i,A[i]) -
12.
Σε έναν πίνακα υπάρχουν διπλά κλειδιά που πρέπει να απομακρυνθούν. Ποιά μέθοδος ταξινόμησης αν τροποποιηθεί εκτελεί αυτήν τη λειτουργία πιο αποτελεσματικά;
-
13.
Έστω ότι πρέπει να ταξινομηθεί ένας πίνακας με κλειδιά, όπου τα πρώτα κλειδιά είναι ήδη ταξινομημένα, ενώ τα τελευταία δεν είναι. (Ισχύει βέβαια .) Ας θεωρηθεί διαδοχικά ότι: και ότι . Να σχεδιασθούν και να αναλυθούν εναλλακτικοί τρόποι για κάθε περίπτωση.
-
14.
Δίνεται ταξινομημένος πίνακας A[0..n-1]. Με βάση τα στοιχεία του πίνακα αυτού υπολογίζονται τα στοιχεία:
(8.48) Να σχεδιασθεί γραμμικός αλγόριθμος δημιουργίας ενός πίνακα B[0..2*n-2] που να περιέχει τα στοιχεία του πίνακα A και τα στοιχεία .
-
15.
Η ταξινόμηση με το μέσο όρο (meansort) είναι μία παραλλαγή της γρήγορης ταξινόμησης σύμφωνα με την οποία κατά το πρώτο πέρασμα λαμβάνεται ως άξονας το κλειδί της πρώτης θέσης, όπως δηλαδή και στη γρήγορη ταξινόμηση. Όμως κατά τη διάρκεια του πρώτου περάσματος υπολογίζοντα οι μέσες τιμές των στοιχείων των δύο υποπινάκων και στη συνέχεια χρησιμοποιούνται ως άξονες για τις περαιτέρω υποδιαιρέσεις των υποπινάκων. Να σχεδιασθεί λεπτομερώς ο αλγόριθμος. Να βρεθούν τα πλεονεκτήματα και τα μειονεκτήματα της μεθόδου σε σχέση με τη γρήγορη ταξινόμηση, ως προς το πλήθος των περασμάτων και των ανταλλαγών. Να αποδειχθεί ότι και η παραλλαγή αυτή είναι Ο(). (Hint: αρκεί να βρεθεί μία κατάλληλη διάταξη θεωρώντας ένα μικρό πίνακα).
-
16.
Να σχεδιασθούν και να αναλυθούν επαναληπτικοί και αναδρομικοί αλγόριθμοι ταξινόμησης με συγχώνευση 3 δρόμων (3-way merge). Δηλαδή, ένας πίνακας θέσεων θα πρέπει να διαιρεθεί σε τρία τμήματα μεγέθους , και , αυτά με τη σειρά τους να ταξινομηθούν και στη συνέχεια να γίνει η συγχώνευση.
-
17.
Δεδομένου πίνακα μεγέθους , γενικεύοντας την προηγούμενη άσκηση να σχεδιασθούν και να αναλυθούν επαναληπτικοί και αναδρομικοί αλγόριθμοι ταξινόμησης με συγχώνευση δρόμων.
-
18.
Ως γνωστό η απλή συγχώνευση δύο ταξινομημένων πινάκων A[0..n-1] και B[0..m-1] έχει πολυπλοκότητα Ο(). Η πολυπλοκότητα αυτή μπορεί να βελτιωθεί αν . Για παράδειγμα, αν =1, τότε το στοιχείο αυτό μπορεί να καταλάβει τη σωστή θέση μεταξύ των στοιχείων με δυαδική αναζήτηση. Για το λόγο αυτό, η επόμενη τεχνική ονομάζεται δυαδική συγχώνευση (binary merging).
Σύμφωνα, λοιπόν, με τη μέθοδο αυτή ο πίνακας A υποδιαιρείται σε +1 διαδοχικούς υποπίνακες. Αν το τελευταίο στοιχείο του πίνακα B είναι μικρότερο από το τελευταίο στοιχείο του προτελευταίου υποπίνακα του πίνακα A, τότε το στοιχείο αυτό μαζί με τα στοιχεία του τελευταίου υποπίνακα αποθηκεύονται στις τελευταίες θέσεις του πίνακα εξόδου. Σε αντίθετη περίπτωση βρίσκεται η θέση του -οστού στοιχείου μεταξύ των στοιχείων του τελευταίου υποπίνακα, οπότε και πάλι το αποτέλεσμα αποθηκεύεται στον πίνακα εξόδου. Έτσι, η μέθοδος συνεχίζει αναδρομικά μέχρι την εξάντληση και των δύο πινάκων A και B. Να σχεδιασθεί και να αναλυθεί η μέθοδος.
-
19.
Να σχεδιασθεί και να αναλυθεί η μέθοδος της ευθείας εισαγωγής δύο δρόμων (two way straight insertion), σύμφωνα με την οποία ένας πίνακας με κλειδιά ταξινομείται τοποθετώντας τα κλειδιά σε έναν άλλον πίνακα μεγέθους 2+1 θέσεων. Η μέθοδος τοποθετεί το πρώτο κλειδί ως μεσαίο στοιχείο του πίνακα εξόδου. Τα υπόλοιπα κλειδιά τοποθετούνται αριστερά ή δεξιά του μεσαίου στοιχείου ανάλογα με το μέγεθος του κλειδιού. Κατά τη διάρκεια της τοποθέτησης γίνονται οι απαραίτητες μετακινήσεις. Για παράδειγμα, αν τα κλειδιά είναι στον πίνακα εισόδου με τη σειρά 52, 12, 71, 56, 5, 10, 19, 90 και 45, τότε τοποθετούνται στον πίνακα εξόδου με τη μορφή παρουσιάζεται στον Πίνακα 8.4.
4 5 6 7 8 9 10 11 12 13 14 52 12 52 12 52 71 12 52 56 71 5 12 52 56 71 5 10 12 52 56 71 5 10 12 19 52 56 71 5 10 12 19 52 56 71 90 5 10 12 19 45 52 56 71 90 Table 8.4: Το πρόβλημα της ευθείας εισαγωγής δύο δρόμων. -
20.
Η μέθοδος της δυαδικής εισαγωγής δύο δρόμων (two way binary insertion) είναι παρόμοια προς την ευθεία εισαγωγή δύο δρόμων της Άσκησης 19, αλλά η παρεμβολή γίνεται με δυαδικό τρόπο. Να σχεδιασθεί και να αναλυθεί η μέθοδος.
-
21.
Σύμφωνα με τη μέθοδο της ταξινόμησης περιττής-άρτιας μετάθεσης (odd-even transposition sort) στα περάσματα περιττής (άρτιας) τάξης συγκρίνονται τα στοιχεία Α[i] και A[i+1], όπου το i είναι περιττός (αντίστοιχα, άρτιος) αριθμός. Αν ισχύει Α[i]Α[i+1], τότε τα στοιχεία ανταλλάσσονται. Τα περάσματα επαναλαμβάνονται μέχρις ότου δεν συμβούν άλλες ανταλλαγές. Να σχεδιασθεί και να αναλυθεί αντίστοιχος αλγόριθμος.
-
22.
Η ιδανικότερη μέθοδος για την ταξινόμηση πινάκων με στοιχεία που είναι περίπου ταξινομημένα είναι η εξής: Αρχικά, ελέγχονται τα στοιχεία του πίνακα εισόδου για τον εντοπισμό ζευγών διαδοχικών κλειδιών που δεν ακολουθούν τη σχέση διάταξης. Το ζεύγος αυτό διαγράφεται από τον πίνακα εισόδου και αποθηκεύεται σε έναν πίνακα εξόδου. Μετά την αφαίρεση κάποιου ζεύγους, η διαδικασία συνεχίζεται με τη σύγκριση του στοιχείου αμέσως πριν το πρώτο του ζεύγους με το στοιχείο αμέσως μετά το δεύτερο του ζεύγους. Μετά την απομάκρυνση κάποιων ζευγών ο πίνακας εισόδου είναι πλέον ταξινομημένος. Στη συνέχεια, ο πίνακας εξόδου ταξινομείται χρησιμοποιώντας τη γρήγορη ταξινόμηση, οπότε οι δύο ταξινομημένοι πίνακες συγχωνεύονται με μία απλή διαδικασία συγχώνευσης. Να σχεδιασθεί και να αναλυθεί η μέθοδος.
-
23.
Η ακόλουθη διαδικασία της κυκλικής ταξινόμησης (cycle sort) είναι μία παραλλαγή που εντάσσεται στις ταξινομήσεις με μέτρημα (δες Κεφάλαιο 8.8). Υποτίθεται ότι ένα ιστόγραμμα (πίνακας H) διατηρεί τις συχνότητες εμφάνισης όλων των τιμών των κλειδιών που βρίσκονται στο διάστημα 1... Ο αλγόριθμος να δοκιμασθεί για διαφορετικές τιμές του και να υπολογισθεί η πολυπλοκότητα χρόνου και χώρου. Πότε η μέθοδος είναι αποτελεσματική;
procedure cycle_sort; 1. H[1] <-- 0; 2. for k <-- 1 to m-1 do H[k+1] <-- H[k]+h[k]; 3. for i <-- 1 to n do 4. k <-- A[i]; j <-- H[k]+1; 5. if i>=j then 6. if i<>j then 7. temp <-- A[i]; 8. repeat 9. swap(A[j],temp); 10. H[k] <-- j; k <-- temp; j <-- H[k]+1; 11. until i=j; 12. A[i] <-- temp; 13. H[k] <-- I; -
24.
Η μέθοδος ταξινόμησης με ανταλλαγή ρίζας (radix exchange sort) εξετάζει τα ψηφία από τα αριστερά προς τα δεξιά. Η μέθοδος θυμίζει τη γρήγορη ταξινόμηση, επειδή αρχικά τα κλειδιά που έχουν ως πρώτο ψηφίο το Ο τοποθετούνται πριν τα κλειδιά που έχουν ως πρώτο ψηφίο το 1. Κατόπιν, η επεξεργασία συνεχίζεται σε κάθε ένα από τα δύο αυτά υποσύνολα αναδρομικά για τα επόμενα ψηφία κατά τον ίδιο τρόπο.
Η επόμενη διαδικασία radix_exchange θεωρεί ότι τα κλειδιά είναι θετικοί ακέραιοι. Ο πίνακας σαρώνεται από αριστερά και από δεξιά με τη βοήθεια δύο δεικτών, i και j, αναζητώντας κλειδιά που να αρχίζουν από 1 και 0, αντιστοίχως. Όταν τέτοια κλειδιά εντοπισθούν, τότε ανταλλάσσονται αμοιβαία. Η διαδικασία σάρωσης συνεχίζεται μέχρι να συναντηθούν οι δύο δείκτες. Η ταξινόμηση εκτελείται με την κλήση radix_exchange(1,n,15). Ο τελεστής shr εκτελεί διολίσθηση προς δεξιά, ενώ το όρισμα b χρησιμεύει για τον έλεγχο του αντίστοιχου ψηφίου ξεκινώντας από την τιμή 15 (για το αριστερότερο ψηφίο) και φθάνοντας μέχρι και την τιμή 0 (για το δεξιότερο ψηφίο).
procedure radix_exchange(left,right,b); if (right>left) and (b>=0) then i <-- left; j <-- right; repeat while (A[i] shr (b-1) mod 2=0) and (i<j) do i <-- i+1; while (A[j] shr (b-1) mod 2=1) and (i<j) do j <-- j-1; Swap(A[i],A[j]); until j <-- i; if (A[r] shr (b-1) mod 2=0) then j <-- j+1; radix_exchange(left,j-1,b-1); radix_exchange(j,right,b-1) -
25.
Η ταξινόμηση γραμμικής εξέτασης (linear probing sort) συνδυάζει στοιχεία της αναζήτησης παρεμβολής και του ταξινομημένου κατακερματισμού με γραμμική εξέταση. Εφαρμόζεται όταν είναι γνωστό το εύρος των τιμών m<n των κλειδιών του πίνακα A[0..n-1], ενώ επίσης θα πρέπει να θεωρηθεί ένας συμπληρωματικός πίνακας n+w θέσεων, όπου οι θέσεις χρησιμεύουν ως περιοχή υπερχείλισης. Κάθε στοιχείο του αρχικού πίνακα τοποθετείται σε κενή θέση του βοηθητικού πίνακα εφαρμόζοντας την αναζήτησης παρεμβολής. Αν η θέση του βοηθητικού πίνακα είναι κατειλημμένη από άλλο κλειδί, τότε η θέση αυτή καταλαμβάνεται τελικά από το μικρότερο κλειδί, ενώ το μεγαλύτερο τοποθετείται στην επόμενη θέση του βοηθητικού πίνακα. Μετά την εισαγωγή όλων των στοιχείων στο βοηθητικό πίνακα, με ένα απλό πέρασμα τα στοιχεία τοποθετούνται και πάλι στον αρχικό πίνακα. Να σχεδιασθεί η μέθοδος, να δοκιμασθεί πειραματικά και να αναλυθεί η επίδοσή της.
-
26.
Αν στον αλγόριθμο Select το δείγμα αλλάξει από 5 σε 7 ή 3 τότε ο αλγόριθμος θα συνεχίσει να έχει γραμμική πολυπλοκότητα στη χειρότερη περίπτωση;
-
27.
Να δείξετε πως ο αλγόριθμος ταξινόμησης Quicksort μπορεί να αλλάξει, ώστε η πολυπλοκότητά του να είναι στην χειρότερη περίπτωση.
-
28.
Έστω ότι και δύο ταξινομημένοι πίνακες. Να δώσετε έναν αλγόριθμο με πολυπλοκότητα για την εύρεση του μεσαίου στοιχείου των στοιχείων των πινάκων και .