Κεφάλαιο 13Τυχαίοι Αλγόριθμοι
Οι πιθανότητες είναι μέρος της καθημερινότητάς μας. Για παράδειγμα, πόσο πιθανό είναι να υπάρχουν δύο άνθρωποι στη Νέα Υόρκη με τον ίδιο αριθμών τριχών; Με βάση την αρχή των περιστερώνων (pigeonhole principle)1111Αν τοποθετηθούν περιστέρια σε περιστερότρυπες, τότε υπάρχει τουλάχιστον μία περιστερότρυπα με περισσότερο από ένα περιστέρι. αποδεικνύεται ότι η πιθανότητα είναι μονάδα. Επίσης στο Κεφάλαιο 7.4 έχουμε μιλήσει για το παράδοξο των γενεθλίων. Αυτά είναι παραδείγματα όπου ένα γεγονός θα συμβεί με σημαντική πιθανότητα ή και βεβαιότητα. Αντιθέτως, η πιθανότητα να εκλεγεί πρόεδρος των ΗΠΑ με μία ψήφο διαφορά είναι 1 προς 10.000.000. Η πιθανότητα κατά τη διάρκεια ενός χρόνου κάποιος να σκοτωθεί από κεραυνό είναι 1 προς 2.500.000. Η πιθανότητα κατά τη διάρκεια ενός χρόνου ένας μεγάλος μετεωρίτης να πέσει στη γη είναι 1 προς 100.000. Αυτά είναι παραδείγματα, όπου η πιθανότητα να συμβεί ένα γεγονός είναι σχεδόν μηδενική. Σε τέτοιες περιπτώσεις θεωρούμε την πιθανότητα σαν να είναι πράγματι μηδενική. Στη λογική αυτή στηρίζονται οι λεγόμενοι τυχαίοι ή τυχαιοποιημένοι (randomized) αλγόριθμοι, των οποίων η συμπεριφορά δεν εξαρτάται μόνο από τα δεδομένα εισόδου αλλά και από τιμές που παράγονται από μία γεννήτρια τυχαίων αριθμών.
Στον αντίποδα των τυχαίων αλγορίθμων βρίσκονται οι λεγόμενοι αιτιοκρατικοί (deterministic) αλγόριθμοι, όπου η πολυπλοκότητα της χειρότερης περίπτωσης αποδεικνύεται με βεβαιότητα (δηλαδή πιθανότητα 1). Σε μία τέτοια περίπτωση, βέβαια, υπεισέρχεται η πιθανότητα το πρόγραμμα να έχει λάθος ή να συμβεί οποιοδήποτε άλλο αρνητικό γεγονός (όπως βλάβη του υλικού, πτώση ρεύματος, κλπ). Έτσι, είναι προτιμότερο το πρόγραμμά μας να είναι απλούστερο (άρα χωρίς λάθη) στηριζόμενοι με υπολογισμένο ρίσκο στο γεγονός ότι η χειρότερη περίπτωση θα συμβεί με ελάχιστη πιθανότητα.
13.1 Κατηγορίες Τυχαίων Αλγορίθμων
Διακρίνουμε τρεις κατηγορίες τυχαίων αλγορίθμων, τους αλγορίθμους τύπου Las Vegas, τύπου Monte Carlo και τύπου Sherwood. Οι αλγόριθμοι Las Vegas πάντοτε δίνουν την ίδια (σωστή) έξοδο για τα ίδια δεδομένα εισόδου, απλώς ο χρόνος εκτέλεσης εξαρτάται από την έξοδο της γεννήτριας των τυχαίων αριθμών. Απεναντίας οι αλγόριθμοι Monte Carlo απαιτούν το ίδιο χρόνο εκτέλεσης ανεξαρτήτως της εξόδου της γεννήτριας των τυχαίων αριθμών, αλλά δεν δίνουν πάντοτε την ίδια έξοδο για τα ίδια δεδομένα εισόδου. Προφανώς, η ιδιότητα αυτή δεν είναι επιθυμητή, γιατί άλλοτε ο αλγόριθμος θα δίνει τη σωστή λύση και άλλοτε κάποια λανθασμένη.
Λέγεται λοιπόν ότι ένα αλγόριθμος Las Vegas (Monte Carlo) αποτυγχάνει αν δεν τερματίζει εντός ενός συγκεκριμένου χρονικού διαστήματος (αν δεν δίνει τη σωστή απάντηση). Η απαίτησή μας είναι οι αντίστοιχοι αλγόριθμοι να αποτυγχάνουν με κάποια πολύ μικρή πιθανότητα, δηλαδή , για δεδομένη τιμή της παραμέτρου .
Τέλος, η κατηγορία αλγορίθμων Sherwood περιλαμβάνει αλγορίθμους που πάντοτε δίνουν απάντηση και η απάντηση αυτή είναι σωστή. Συχνά σε αιτιοκρατικούς αλγορίθμους η χειρότερη περίπτωση είναι σημαντικά χειρότερη από τη μέση περίπτωση. Ενσωματώνοντας, λοιπόν, την τυχαία επιλογή μίας γεννήτριας (με μηδαμινό κόστος) είναι δυνατόν να εξαλειφθεί η διαφορά μεταξύ της χειρότερης και της μέσης περίπτωσης. Καθώς μία τέτοια τεχνική βοηθά σε μία περισσότερο ομαλή εκτέλεση του αιτιοκρατικού αλγορίθμου, δεν τίθεται ζήτημα θεώρησης της κατανομής της πιθανότητας ο αλγόριθμος να μην τερματίσει ή να δώσει λανθασμένα αποτελέσματα.
Αυτή είναι η βάση των τυχαίων αλγορίθμων, των οποίων η ανάλυση είναι μία εναλλακτική οπτική γωνία στην ανάλυσης της μέσης περίπτωσης, όπου για την ευκολία μας μπορεί να υιοθετήσουμε περιοριστικές υποθέσεις. Οι τυχαίοι αλγόριθμοι έχουν καλύτερη και χειρότερη περίπτωση αλλά τα δεδομένα εισόδου που προκαλούν τις περιπτώσεις αυτές είναι άγνωστα και μπορεί να είναι οποιαδήποτε ακολουθία μεγέθους .
13.2 Εξακρίβωση Επαναλαμβανόμενου Στοιχείου
Έστω ότι ένας πίνακας με στοιχεία περιέχει διακριτά στοιχεία, όπου τα έχουν την ίδια τιμή. Το ζητούμενο είναι να βρούμε ποιά είναι η τιμή που εμφανίζεται φορές. Είναι εύκολο να σχεδιάσουμε έναν αιτιοκρατικό αλγόριθμο που να σαρώνει τον πίνακα και να διαπιστώνει ποιά είναι αυτή η τιμή μετά από βήματα στη χειρότερη περίπτωση. Αυτή η περίπτωση ανταποκρίνεται στην κατάσταση όπου οι πρώτες θέσεις του πίνακα καταλαμβάνονται από αντίστοιχες διακριτές τιμές, ενώ η (/2+2)-οστή είναι η πρώτη επανάληψη της πολλαπλής τιμής.
Τώρα θα εξετάσουμε έναν τυχαίο αλγόριθμο, δηλαδή έναν αλγόριθμο που στηρίζεται σε μία γεννήτρια τυχαίων αριθμών. Έστω, λοιπόν, ότι επιλέγουμε με τυχαίο τρόπο δύο διαφορετικές θέσεις του πίνακα και ελέγχουμε αν το περιεχόμενό τους είναι ίδιο. Αν πράγματι το περιεχόμενο είναι ίδιο, τότε αλγόριθμος τερματίζει, αλλιώς πρέπει το δειγματοληπτικό πείραμα να συνεχισθεί για όσο χρειασθεί. Προφανώς, ο αλγόριθμος αυτός ανήκει στην κατηγορία Las Vegas, δηλαδή ο αλγόριθμος είναι βέβαιο ότι τερματίζοντας δίνει τη σωστή απάντηση αλλά δεν είναι σταθερός ο απαιτούμενος χρόνος. Η επόμενη διαδικασία παρουσιάζει αυτήν την περιγραφή.
procedure repeatedelement
1. flag <-- true;
2. while flag do
3. i <-- random(1,n); j <-- random(1,n)
4. if (i<>j) and (A[i]=A[j]) then
5. flag <-- false; return A[i]
Η πιθανότητα ότι μία δοκιμή θα είναι επιτυχής, δηλαδή θα εξακριβώσει τη ζητούμενη τιμή ισούται με . Διαπιστώνεται, δηλαδή, ότι για , ισχύει , άρα σε μία τέτοια περίπτωση πρέπει να επαναλάβουμε τη δοκιμή με πιθανότητα 0.8. Η πιθανότητα ο αλγόριθμος να μην τερματίσει μετά από 10 δοκιμές είναι και, άρα, η πιθανότητα να τερματίσει είναι 0.89 περίπου. Αντίστοιχα, η πιθανότητα να μην τερματίσει μετά από 100 δοκιμές είναι .
Στη γενική περίπτωση, η πιθανότητα να μην τερματίσει ο αλγόριθμος μετά από βήματα (για κάποια σταθερά ) είναι
| (13.1) |
που δίνει , αν . Συνεπώς, με πιθανότητα μεγαλύτερη από , ο αλγόριθμος θα τερματίσει στη χειρότερη περίπτωση μετά από πειράματα. Έτσι, θεωρώντας ως βαρόμετρο την εντολή 5, προκύπτει ότι η πολυπλοκότητα του τυχαίου αυτού αλγορίθμου είναι Ο.
13.3 Εξακρίβωση Πλειοψηφικού Στοιχείου
Στην παράγραφο αυτή θα εξετάσουμε ένα παρεμφερές με το προηγούμενο πρόβλημα. Έστω ότι δίνεται ένας πίνακας με στοιχεία. Λέγεται ότι ο πίνακας αυτός έχει ένα πλειοψηφικό (majority) στοιχείο, αν ένα στοιχείο του εμφανίζεται περισσότερο από φορές. Είναι, όμως, ενδεχόμενο να μην υπάρχει πλειοψηφικό στοιχείο στον πίνακα. Ας μελετήσουμε τον επόμενο αλγόριθμο.
function maj
1. i <-- random(1,n); x <-- A[i]; k <-- 0;
2. for j <-- 1 to n do
3. if A[j]=x then k <-- k+1
4. return (k>n/2)
Αν ο πίνακας δεν έχει πλειοψηφικό στοιχείο, τότε ο αλγόριθμος maj ορθώς θα επιστρέψει false. Ωστόσο, αν ο πίνακας έχει πλειοψηφικό στοιχείο, τότε ο αλγόριθμος θα επιστρέψει true, αλλά το αποτέλεσμα θα είναι ορθό με πιθανότητα . Όμως λάθος ίσο με 50% δεν μπορεί να είναι αποδεκτό. Προχωρούμε σε μία δεύτερη εκδοχή.
function maj2
1. if maj then return true
2. else return maj
Αν ο πίνακας δεν έχει πλειοψηφικό στοιχείο, τότε ο αλγόριθμος maj2 ορθώς θα
επιστρέψει false, τιμή που ορθώς θα του περάσει ο αλγόριθμος maj. Από
την άλλη πλευρά, αν ο πίνακας πράγματι έχει πλειοψηφικό στοιχείο και ορθώς ο αλγόριθμος
maj επιστρέψει τιμή true, τότε και αλγόριθμος maj2 θα επιστρέψει
true. Αν όμως με πιθανότητα ο αλγόριθμος maj επιστρέψει τιμή
false, τότε o αλγόριθμος maj2 θα ξανακαλέσει τον αλγόριθμο maj που θα
επιστρέψει και πάλι true ή false πιθανότητα και αντίστοιχα.
Στην περίπτωση αυτή θα λάβουμε ορθό αποτέλεσμα με πιθανότητα . Επομένως,
επιτύχαμε σημαντική βελτίωση στην αξιοπιστία του αρχικού αλγορίθμου.
Η τελική μας εκδοχή είναι ο επόμενος αλγόριθμος Monte Carlo. Υποθέτουμε ότι είναι η μέγιστη ανοχή της πιθανότητας λάθους. Είναι προφανές ότι η πολυπλοκότητα του αλγορίθμου είναι Ο(). Ο αλγόριθμος αυτός έχει μόνο διδακτική σπουδαιότητα, καθώς είναι εύκολο να σχεδιάσουμε έναν αιτιοκρατικό αλγόριθμο με γραμμική πολυπλοκότητα.
function majMC
1. k <-- log(1/e)
2. for j <-- 1 to k do
3. if maj then return true
4. return false
13.4 Αναζήτηση σε Διατεταγμένη Λίστα
Γνωρίζουμε από το μάθημα των Δομών Δεδομένων ότι μπορούμε να αναπαραστήσουμε μία δυναμική λίστα με τη βοήθεια ενός πίνακα. Ας μελετήσουμε την τεχνική αυτή με ένα παράδειγμα. Στο Σχήμα 13.1 παρουσιάζεται ένας δισδιάστατος πίνακας A με τα γνωστά 9 κλειδιά 52, 12, 71, 56, 5, 10, 19, 90 και 45, τα οποία εμφανίζονται στην πρώτη γραμμή του πίνακα. Στη δεύτερη γραμμή παρουσιάζονται κάποιες τιμές που προσομοιώνουν τον κλασικό δείκτη των δυναμικών συνδεδεμένων λιστών. Ακολουθώντας αυτούς τους τεχνητούς δείκτες μπορούμε να πάρουμε τα στοιχεία σε αύξουσα διάταξη. Για να γίνει δυνατή η προσπέλαση και η επεξεργασία της δομής, είναι απαραίτητο να έχουμε και μία βοηθητική μεταβλητή header που να δίνει τη θέση του μικρότερου στοιχείου της δομής. Στην περίπτωση μας ισχύει header=5. Επίσης, παρατηρούμε ότι ο δείκτης του μεγαλύτερου στοιχείου είναι 0 ώστε να διευκολύνει το πέρας της προσπέλασης.
| 52 | 12 | 71 | 56 | 5 | 10 | 19 | 90 | 45 |
| 4 | 7 | 8 | 3 | 6 | 2 | 9 | 0 | 1 |
Η επόμενη διαδικασία αναζητά το κλειδί key που υπάρχει πράγματι στη δομή και επιστρέφει τη θέση του κλειδιού στη δομή. Είναι εύκολο να εξαχθεί η επίδοση της αναζήτησης στη δομή αυτή. Προφανώς στη μέση (χειρότερη) περίπτωση θα πρέπει να σαρωθεί ο μισός (ολόκληρος) ο πίνακας και, επομένως, η αναζήτηση είναι γραμμική Θ().
function search(key, header)
1. i <-- header
2. while key > A[1,i] do i <-- A[2,i]
3. return i
Μία τυχαιοποιημένη εκδοχή έχει ως εξής.
function searchrandom(key)
1. i <-- random(1,n); y <-- A[1,i]
2. if key<y then return search(key,header)
3. else if key>y then return search(key,A[2,i])
4. else return i
Εύκολα και πάλι προκύπτει ότι η νέα τυχαιοποιημένη συνάρτηση είναι γραμμικής πολυπλοκότητας. Ωστόσο, πληρώνοντας το αμελητέο κόστος της εντολής 1, η διαδικασία επιταχύνεται κατά 50% κατά μέσο όρο. Η συνάρτηση αυτή στηρίζεται στη φιλοσοφία Sherwood.
13.5 Διαγραφή σε Δυαδικό Δένδρο Αναζήτησης
Όπως είναι γνωστό από το μάθημα των Δομών Δεδομένων, η διαδικασία της διαγραφής σε δυαδικό δένδρο αναζήτησης είναι πιο σύνθετη από τη διαδικασία της εισαγωγής. Αν ο κόμβος που πρόκειται να διαγραφεί είναι τερματικός, τότε η περίπτωση είναι εύκολη. Επίσης σχετικά εύκολη είναι η περίπτωση που ο διαγραφόμενος κόμβος έχει μόνο έναν απόγονο. Η δυσκολία του προβλήματος παρουσιάζεται, όταν το στοιχείο που θα διαγραφεί έχει δύο απογόνους. Στην περίπτωση αυτή το διαγραφόμενο κλειδί αντικαθίσταται από το κλειδί του πιο δεξιού κόμβου του αριστερού υποδένδρου, ο οποίος (όπως μπορεί να αποδειχθεί) έχει το πολύ έναν απόγονο.
Στη συνέχεια, δίνεται η αναδρομική διαδικασία delete που καλεί την επίσης αναδρομική διαδικασία del, όταν o κόμβος με το κλειδί key έχει δύο απογόνους. Έτσι, ανιχνεύεται ο προηγούμενος λεξικογραφικά κόμβος, δηλαδή ο δεξιότερος κόμβος του αριστερού υποδένδρου του κόμβου q που πρόκειται να διαγραφεί. Αν ο κόμβος αυτός είναι ο r, τότε το περιεχόμενό του αντικαθιστά το περιεχόμενο του q και ο χώρος του r επιστρέφεται στο σύστημα. Για την κατανόηση αναφέρεται ότι θεωρείται κόμβος με τρία πεδία (data,left,right), ακέραιου τύπου και τύπου δείκτη.
procedure del(r)
1. if r.right<>nil then del(r.right)
2. else
3. q.data <-- r.data; q <-- r; r <-- r.left
procedure delete(key,p);
1. if p=nil then write('Το κλειδί ',key,'δεν υπάρχει')
2. else if key<p.data then delete(key,p.left)
3. else if key>p.data then delete(key,p.right)
4. else
5. q:=p;
6. if q.right=nil then p:=q.left
7. else if q.left=nil then p:=q.right
8. else del(q.left);
9. dispose(q)
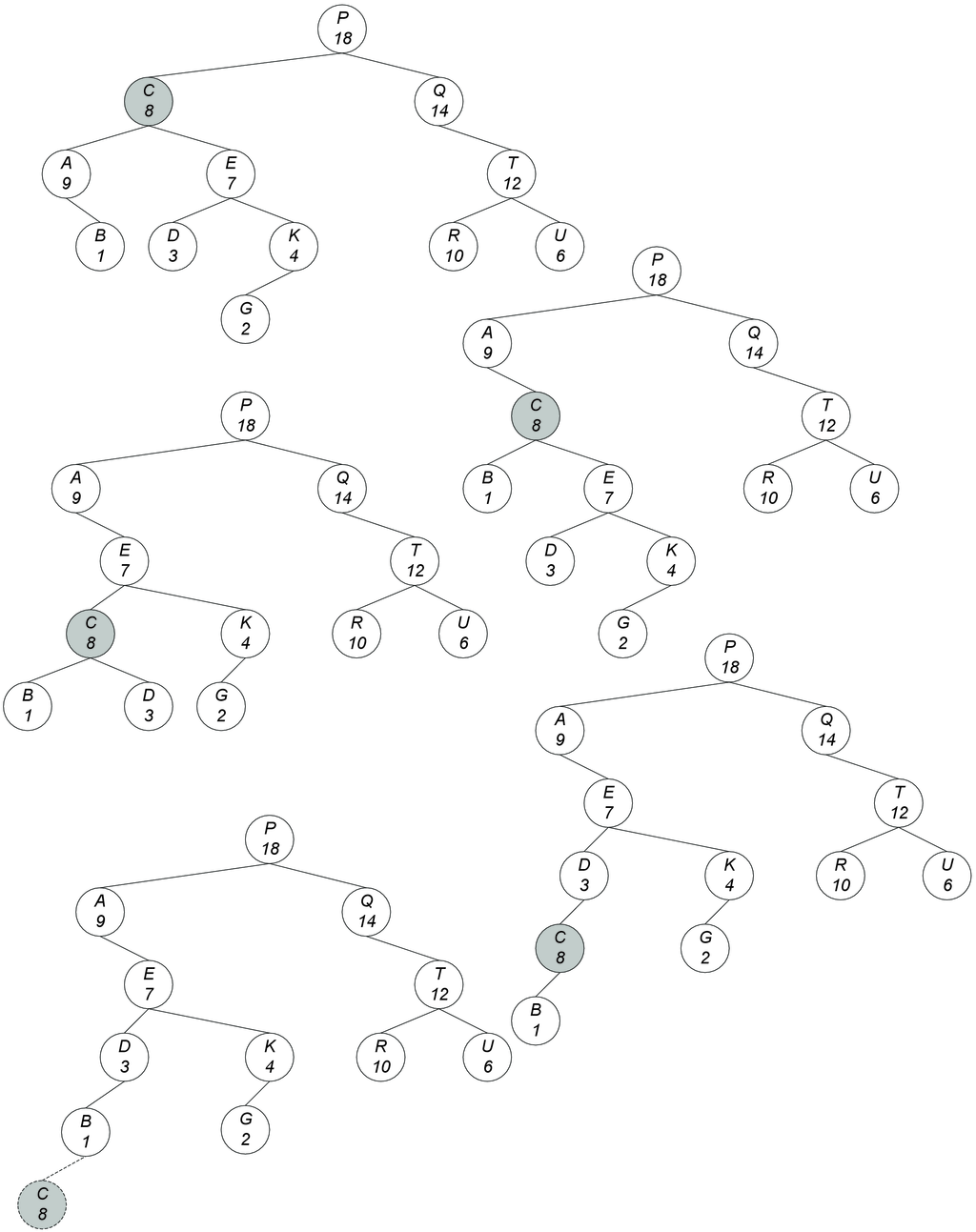
Για παράδειγμα στο επόμενο σχήμα δίνεται η διαδικασία της διαδοχικής διαγραφής των κλειδιών 19, 52, 5 και 12 από το αρχικό δένδρο.

Ο τρόπος υλοποίησης της διαδικασίας της διαγραφής δεν είναι ο μοναδικός. Για παράδειγμα, αν το υπό διαγραφή κλειδί έχει και αριστερό αλλά και δεξιό υποδένδρο, τότε αυτό ισοδύναμα θα μπορούσε να αντικατασταθεί από τον επόμενο λεξικογραφικά κόμβο, δηλαδή τον αριστερότερο κόμβο του δεξιού υποδένδρου. Αυτές οι δύο εναλλακτικές υλοποιήσεις ονομάζονται ασύμμετρες (asymmetric), σε αντίθεση με τη μέθοδο της συμμετρικής (symmetric) διαγραφής, σύμφωνα με την οποία το υπό διαγραφή κλειδί αντικαθίσταται με τον προηγούμενο ή τον επόμενο λεξικογραφικά κόμβο είτε εναλλάξ είτε με τυχαίο τρόπο (δηλαδή με 50%-50% πιθανότητα να χρησιμοποιηθεί ο αριστερός ή ο δεξιός υποψήφιος). Η υλοποίηση της συμμετρικής τυχαίας διαγραφής από δυαδικό δένδρο αναζήτησης είναι εύκολη υπόθεση για τον αναγνώστη.
Έχει αποδειχθεί ότι αν από τυχαίο δένδρο με κόμβους διαγραφεί ένα κλειδί με την ασύμμετρη μέθοδο, τότε δεν προκύπτει ένα τυχαίο δένδρο. Πιο συγκεκριμένα, το μήκος εσωτερικού μονοπατιού δεν παραμένει τάξης Ο() αλλά αυξάνει. Εμπειρικές μελέτες από τον Eppinger (1983) έδειξαν ότι αν χρησιμοποιηθεί η ασύμμετρη μέθοδος διαγραφής, τότε το μήκος εσωτερικού μονοπατιού γίνεται τάξης O(). Αντίθετα, αν χρησιμοποιηθεί η συμμετρική μέθοδος διαγραφών, τότε το μήκος εσωτερικού μονοπατιού πράγματι παραμένει O(). Συνεπώς, η τεχνική της τυχαιοποιημένης διαγραφής δεν είναι χωρίς επίπτωση στη συνολική επίδοση της δομής κατά τις αναζητήσεις.
Πίσω από την συμμετρική διαγραφή βρίσκεται η φιλοσοφία των αλγορίθμων Sherwood. Στα επόμενα δύο παραδείγματα θα ασχοληθούμε με κλασικότερα παράδειγμα τυχαίων αλγορίθμων που ανήκουν σε μία από τις δύο άλλες κατηγορίες που αναφέρθηκαν, δηλαδή τις κατηγορίες Las Vegas ή Monte Carlo.
13.6 Τυχαία Δυαδικά Δένδρα
Στο σημείο αυτό θα ασχοληθούμε με δυαδικά δένδρα αναζήτησης, τα οποία βασίζονται στις τυχαίες επιλογές που κάνει ο αλγόριθμος κατά την κατασκευή τους. Τα συγκεκριμένα τυχαία δένδρα ονομάζονται Δένδρα Αναζήτησης Σωρού (ΔΑΣ για συντομία - treaps) και παρουσιάζονται αναλυτικά στο [167].
Έστω ένα σύνολο με στοιχεία, όπου το καθένα απαρτίζεται από ένα κλειδί και μία προτεραιότητα. Ένα ΔΑΣ για το είναι ένα δυαδικό δένδρο με κόμβους, το οποίο είναι δομημένο με ενδοδιάταξη ως προς τα κλειδιά και με διάταξη σωρού ως προς τις προτεραιότητες (παρόμοιο με δομές που ονομάζονται Δένδρο Προτεραιότητας [121] και Καρτεσιανό Δένδρο [188]). Η ενδοδιάταξη σημαίνει ότι το κλειδί κάθε κόμβου είναι μεγαλύτερο από τα κλειδιά του αριστερού υποδένδρου του και μικρότερο από τα κλειδιά του δεξιού υποδένδρου του, ενώ η προτεραιότητα του είναι μεγαλύτερη από τις προτεραιότητες των κόμβων των δύο υποδένδρων του (δηλαδή είναι σωρός μεγίστων). Αν όλα τα κλειδιά, καθώς και οι προτεραιότητες, είναι διακριτά, τότε το ΔΑΣ είναι μοναδικό. Έτσι, το αντικείμενο με τη μεγαλύτερη προτεραιότητα θα είναι στην ρίζα, ενώ ο διαχωρισμός των υπόλοιπων κλειδιών στο αριστερό και δεξιό υποδένδρο θα γίνει με βάση την ενδοδιάταξη των κλειδιών.
Έστω το ΔΑΣ που αποθηκεύει το σύνολο . Δοθέντος του κλειδιού ενός στοιχείου , το στοιχείο μπορεί να ευρεθεί στο χρησιμοποιώντας τον κλασικό αλγόριθμο σε δυαδικά δένδρα αναζήτησης. Προφανώς, ο χρόνος εύρεσης ισούται με το βάθος του κόμβου, όπου βρίσκεται το στο δένδρο . Η εισαγωγή ενός νέου στοιχείου στο δένδρο επιτυγχάνεται σε δύο φάσεις. Αρχικά, με βάση την τιμή του κλειδιού του εισάγουμε το στο κατάλληλο φύλλο του και, συνεπώς, η ενδοδιάταξη του δένδρου διατηρείται. Σε μία δεύτερη φάση ελέγχεται αν ο πατέρας του έχει μικρότερη προτεραιότητα από τον , διότι τότε παραβιάζεται η διάταξη σωρού. Σε μία τέτοια περίπτωση, λοιπόν, για την αποκατάσταση της διάταξης σωρού μεταφέρεται το προς τα επάνω με απλές περιστροφές.
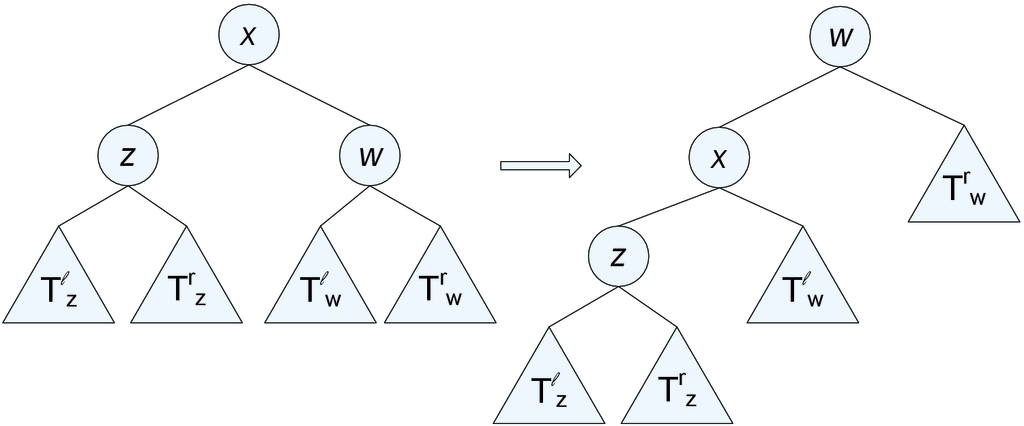
Η διαγραφή του γίνεται με αντίστοιχο τρόπο. Δηλαδή, πρώτα βρίσκουμε τον κόμβο που περιέχει το και έπειτα με απλές περιστροφές τον μεταφέρουμε προς τα κάτω μέχρι να γίνει φύλλο, ώστε να τον διαγράφουμε στη συνέχεια. Η απλή δεξιά περιστροφή ενός κόμβου με δεξιό παιδί τον και αριστερό τον και με δεξιό υποδένδρο του το και αριστερό υποδένδρο του το , είναι μία πράξη τοπικής μεταβολής της δομής, έτσι ώστε ο θα έχει δεξιό παιδί τον και ο αριστερό παιδί το υποδένδρο . Στο Σχήμα 13.2 φαίνεται μία αριστερή περιστροφή. Προσοχή, διότι οι απλές περιστροφές γίνονται έτσι ώστε να ισχύει η διάταξη σωρού ως προς τις προτεραιότητες. Στο Σχήμα 13.3 φαίνονται επακριβώς οι πράξεις εισαγωγής και διαγραφής. Σε κάθε κόμβο του σχήματος το επάνω μέρος είναι το κλειδί (λεξικογραφική σειρά) και το κάτω μέρος είναι η προτεραιότητα.
Οι προτεραιότητες στα ΔΑΣ εισάγουν την τυχαιότητα στην κατασκευή του δένδρου.
Πιο συγκεκριμένα, κάθε φορά που ένα στοιχείο με κλειδί εισάγεται στο ΔΑΣ ,
παράγεται ένας τυχαίος αριθμός και προσάπτεται στο στοιχείο ως προτεραιότητα.
Στη συνέχεια, θα αναλύσουμε ένα σύνολο από ενδιαφέροντα μεγέθη στα ΔΑΣ, τα οποία θα μας επιτρέψουν να βρούμε τη χρονική πολυπλοκότητα των βασικών πράξεων. Αυτά τα μεγέθη είναι τα εξής:
- :
-
το βάθος ενός κόμβου στο δένδρο και
- :
-
το μήκος της δεξιάς ράχης του αριστερού υποδένδρου του και το μήκος της αριστερής ράχης του δεξιού υποδένδρου του . Η αριστερή (δεξιά) ράχη ενός δένδρου είναι το μονοπάτι από τη ρίζα προς το αριστερότερο (αντιστοίχως, δεξιότερο) φύλλο.
Έστω, λοιπόν, ένα ΔΑΣ για το σύνολο με στοιχεία για , αριθμημένα με βάση το κλειδί κατά αύξουσα τάξη. Οι προτεραιότητες είναι τυχαίες μεταβλητές. Αφού για καθορισμένο σύνολο κλειδιών η μορφή του δένδρου εξαρτάται από τις προτεραιότητες, τα προηγούμενα μεγέθη θα είναι και αυτά τυχαίες μεταβλητές και, επομένως, θα πρέπει να υπολογίσουμε μέσες τιμές. Η ανάλυση είναι πολύ απλή δεδομένου ότι κάθε ένα από τα μεγέθη αυτά μπορεί να αναπαρασταθεί με τη βοήθεια των εξής δεικνυουσών μεταβλητών:
-
•
η είναι 1, αν το είναι πρόγονος του στο , αλλιώς είναι 0.
-
•
η είναι 1, αν το είναι κοινός πρόγονος των και , αλλιώς είναι 0.
Επίσης, θεωρούμε ότι κάθε κόμβος είναι πρόγονος του εαυτού του.
Λήμμα 13.1.
Έστω ότι . Τότε ισχύει:
-
1.
-
2.
-
3.
Απόδειξη. Η (1) είναι προφανής, αφού το βάθος ενός κόμβου είναι ίσο με τον αριθμό των προγόνων του. Για τις (2) και (3) αρκεί να ασχοληθούμε με μία από τις δύο, αφού είναι συμμετρικές (έστω τη (2)).
Αν η έχει αριστερό υποδένδρο, τότε ο χαμηλότερος κόμβος (ως προς το βάθος) στην δεξιά του υποδένδρου ράχη είναι το στοιχείο . Είναι σαφές ότι σε αυτή την περίπτωση η ράχη αποτελείται από όλους τους προγόνους του εξαιρουμένων των προγόνων του . Όμως οι πρόγονοι του είναι επίσης πρόγονοι του . Επίσης, δεν υπάρχει κάποιο , έτσι ώστε , το οποίο να βρίσκεται επάνω σε αυτή τη ράχη. Αν η δεν έχει αριστερό υποδένδρο, τότε είτε , και σε αυτή την περίπτωση η (2) σωστά δίνει , ή το είναι πρόγονος του οπότε κάθε πρόγονος του είναι κοινός πρόγονος των και και η (2) δίνει σωστά .
Έστω ότι =E[] (E υποδηλώνει μέση τιμή) και =
E[]. Τότε από τη γραμμικότητα της μέσης τιμής προκύπτει το εξής
συμπέρασμα.
Λήμμα 13.2.
Έστω ότι . Τότε ισχύει:
-
1.
E
-
2.
E
-
3.
E
Στην ουσία η ανάλυση της πολυπλοκότητας έχει αναχθεί στην εύρεση των μέσων τιμών των και . Αφού ασχολούμαστε με δεικνύουσες μεταβλητές έχουμε τα εξής:
| (13.2) |
| (13.3) |
Ο καθορισμός αυτών των πιθανοτήτων και κατ’ επέκταση των μέσων τιμών είναι δυνατός
χρησιμοποιώντας το επόμενο λήμμα προγόνων.
Λήμμα 13.3.
Έστω ότι είναι ένα ΔΑΣ στο και έστω . Αν οι προτεραιότητες είναι διακριτές μεταξύ τους, τότε το είναι πρόγονος του στο , αν και μόνο αν για όλα τα , όπου μεταξύ των και , το στοιχείο έχει τη μεγαλύτερη προτεραιότητα.
Απόδειξη. Έστω ότι είναι το στοιχείο με τη μεγαλύτερη προτεραιότητα στο και έστω ότι και . Από τον ορισμό του ΔΑΣ, το είναι η ρίζα του και τα αριστερό και δεξιό υποδένδρο της θα είναι ΔΑΣ για τα και αντιστοίχως.
Είναι προφανές ότι για οποιοδήποτε ζεύγος κόμβων που περιέχει τη ρίζα η σχέση ως προς το ποιός είναι πρόγονος είναι σωστή. Επιπλέον, η προγονική σχέση για οποιοδήποτε ζεύγος , και είναι προφανής, αφού είναι σε διαφορετικά υποδένδρα και δεν έχουν κάποια σχέση μεταξύ τους. Όμως, στην περίπτωση αυτή η μέγιστη προτεραιότητα μεταξύ των και ανήκει στη ρίζα . Το ίδιο αποδεικνύεται επαγωγικά για όλα τα ζεύγη που βρίσκονται εξ ολοκλήρου είτε στο είτε στο .
Μία άμεση συνέπεια αυτού του λήμματος είναι ένα ανάλογο λήμμα κοινών προγόνων.
Λήμμα 13.4.
Έστω ένα ΔΑΣ για το και έστω όπου . Έστω ότι είναι η προτεραιότητα του στοιχείου . Αν οι προτεραιότητες είναι διακριτές μεταξύ τους, τότε το είναι κοινός πρόγονος των και στο , αν και μόνο αν:
-
•
-
•
-
•
Τα δύο τελευταία λήμματα διευκολύνουν τον υπολογισμό των πιθανοτήτων και
.
Λήμμα 13.5.
Σε ένα ΔΑΣ, το είναι πρόγονος του με πιθανότητα , δηλαδή:
| (13.4) |
Απόδειξη. Σύμφωνα με το λήμμα των προγόνων θα πρέπει η προτεραιότητα του να είναι η μεγαλύτερη ανάμεσα σε όλα τα στοιχεία μεταξύ των και . Αφού αυτές οι προτεραιότητες είναι ανεξάρτητες και ίδιας κατανομής συνεχείς τυχαίες μεταβλητές, αυτό συμβαίνει με πιθανότητα .
Με αντίστοιχο τρόπο αποδεικνύεται το επόμενο συμπέρασμα.
Λήμμα 13.6.
Έστω ότι . Η μέση τιμή για κοινό πρόγονο είναι:
| (13.5) |
Από τη συζήτηση που προηγήθηκε μπορούμε να υπολογίσουμε τις μέσες τιμές των μεγεθών
που μας ενδιαφέρουν. Ο υπολογισμός αυτός εμπεριέχει αρμονικούς αριθμούς (δες Κεφάλαιο
2.1).
Λήμμα 13.7.
Έστω . Σε ένα ΔΑΣ ισχύουν τα εξής:
-
1.
E[
-
2.
E[
-
3.
E[
Απόδειξη. Η απόδειξη προκύπτει με απλή αντικατάσταση των τιμών από τα Λήμματα 13.5 και 13.6 στο Λήμμα 13.2.
Στη συνέχεια προχωρούμε στη ανάλυση των βασικών πράξεων σε ΔΑΣ. Μία επιτυχής αναζήτηση για το στοιχείο σε ένα ΔΑΣ ξεκινά από τη ρίζα του και χρησιμοποιώντας το κλειδί του ακολουθεί το μονοπάτι μέχρι τον κόμβο που περιέχει το . Ο απαιτούμενος χρόνος είναι ανάλογος του μήκους του μονοπατιού ή αλλιώς του βάθους του συγκεκριμένου κόμβου που περιέχει το . Επομένως, με βάση το Λήμμα 13.7 ο μέσος χρόνος για μία πράξη επιτυχούς αναζήτησης είναι O().
Σε περίπτωση ανεπιτυχούς αναζήτησης για ένα ανύπαρκτο κλειδί μεταξύ των κλειδιών των στοιχείων και , ο μέσος χρόνος είναι O() αφού αυτή η διαδικασία θα πρέπει να σταματήσει είτε στο είτε στο (θεωρούμε ότι τα και είναι υπαρκτά).
Ένα στοιχείο εισάγεται στο ΔΑΣ, αφού πρώτα το εισάγουμε σε ένα νέο κόμβο που προσάπτεται σε ένα φύλλο που βρέθηκε κατά την ανεπιτυχή αναζήτηση. Έπειτα το στοιχείο αυτό ανεβαίνει στο μονοπάτι προς τη ρίζα με απλές περιστροφές μέχρι να μην παραβιάζεται η διάταξη σωρού. Ο αριθμός των περιστροφών είναι το πολύ ίσος με το μήκος του μονοπατιού που διασχίσθηκε κατά την ανεπιτυχή αναζήτηση. Επομένως, ο χρόνος για την εισαγωγή είναι ίσος με το χρόνο μίας ανεπιτυχούς αναζήτησης, ο οποίος στη μέση περίπτωση είναι O().
Η πράξη της διαγραφής απαιτεί στην ουσία τον ίδιο χρόνο, αφού είναι η ακριβώς αντίστροφη διαδικασία της εισαγωγής. Κατ’αρχάς εντοπίζεται το προς διαγραφή στοιχείο με βάση το κλειδί του και έπειτα εκτελούνται απλές περιστροφές μέχρι αυτό το κλειδί να γίνει φύλλο, οπότε και το διαγράφουμε. Αν θα γίνει δεξιά ή αριστερή περιστροφή αποφασίζεται με βάση τις προτεραιότητες, αφού πάντα ο κόμβος με τη μεγαλύτερη προτεραιότητα θα περάσει προς τα επάνω.
Κάτι που είναι επίσης πολύ ενδιαφέρον είναι ο μέσος αριθμός περιστροφών ανά πράξη ενημέρωσης (εισαγωγής ή διαγραφής). Γενικώς, η περιστροφή είναι μία ακριβή πράξη σε σχέση με την προσπέλαση ενός κόμβου και θα επιθυμούσαμε το πλήθος τους να είναι κατά το δυνατόν μικρότερο. Αφού η διαγραφή είναι συμμετρική της εισαγωγής, θα μελετήσουμε μόνο την περίπτωση της διαγραφής. Έστω ένα στοιχείο του ΔΑΣ , το οποίο πρόκειται να διαγραφεί. Παρότι δεν μπορούμε να συμπεράνουμε από τη δομή του ποιές περιστροφές θα εκτελεσθούν, ωστόσο μπορούμε να συμπεράνουμε πόσες θα είναι αυτές. Πιο συγκεκριμένα, το πλήθος τους θα είναι ίσο με το άθροισμα των μηκών της δεξιάς ράχης του αριστερού υποδένδρου του και της αριστερής ράχης του δεξιού υποδένδρου του . Η ορθότητα του επιχειρήματος φαίνεται από το γεγονός ότι μία αριστερή περιστροφή του έχει το αποτέλεσμα της μείωσης κατά 1 του μήκους της αριστερής ράχης του δεξιού υποδένδρου, ενώ μία δεξιά περιστροφή του μειώνει το μήκος κατά 1 της δεξιάς ράχης του αριστερού υποδένδρου. Επομένως, από το Λήμμα 13.7 προκύπτει ότι ο μέσος αριθμός περιστροφών είναι μικρότερος από .
13.7 Φίλτρα Bloom
Ένα φίλτρο Bloom είναι μία δομή δεδομένων που χρησιμοποιείται για να απαντήσει προσεγγιστικά ερωτήματα συμμετοχής ενός αριθμού σε ένα σύνολο αριθμών . Ένα φίλτρο Bloom αποτελείται από έναν πίνακα με bits, που δεικτοδοτούνται από μέχρι , όπου αρχικά . Το φίλτρο χρησιμοποιεί διαφορετικές συναρτήσεις κατακερματισμού στο διάστημα , το οποίο αντιστοιχεί στις θέσεις του πίνακα. Υποθέτουμε ότι οι συναρτήσεις κατακερματισμού επιλέγουν κάθε κελί με ίδια πιθανότητα.
Η πρόσθεση ενός στοιχείου στο σύνολο επιτυγχάνεται εξάγοντας θέσεις στον πίνακα από τις διαφορετικές συναρτήσεις κατακερματισμού, οι οποίες εφαρμόζονται στο συγκεκριμένο στοιχείο . Έπειτα, θέτουμε σε τα κελιά που δεικτοδοτούνται από αυτούς τους αριθμούς. Η ερώτηση αν ένα στοιχείο συμμετέχει στο σύνολο που ήδη έχει αποθηκευτεί σε ένα Bloom φίλτρο γίνεται εφαρμόζοντας τις συναρτήσεις κατακερματισμού στο . Έπειτα ελέγχουμε τις θέσεις του πίνακα και αν όλες είναι τότε απαντάμε ότι το ανήκει στο αλλιώς, αν έστω και ένα κελί έχει τότε το στοιχείο δεν ανήκει στο .
Σε περίπτωση που η απάντηση συμμετοχής του στο σύνολο είναι αρνητική, τότε το σίγουρα δεν υπάρχει στο που αποθηκεύεται στο φίλτρο Bloom. Αυτό γιατί αν είχε εισαχθεί στο φίλτρο Bloom, τότε όλες οι αντίστοιχες θέσεις του πίνακα θα ήταν . Αν η απάντηση συμμετοχής είναι θετική, τότε υπάρχει η περίπτωση το στοιχείο να μην ανήκει στο , αλλά όλες οι θέσεις να έχουν γίνει εξαιτίας της εισαγωγής άλλων στοιχείων στο . Σε αυτή την περίπτωση έχουμε ψευδή θετική απόκριση στην ερώτηση για συμμετοχή του στοιχείου .
Αν και υπάρχει η πιθανότητα ψευδούς θετικής απόκρισης, τα φίλτρα Bloom έχουν ένα εξαιρετικό πλεονέκτημα ως προς τη χρησιμοποίηση χώρου σε σχέση με άλλες δομές δεδομένων (όπως δέντρα, λίστες κοκ). Όλες αυτές οι δομές απαιτούν την αποθήκευση ολόκληρου του στοιχείου που δεικτοδοτείται, το οποίο μπορεί να είναι από μερικά bits (ακέραιος) μέχρι αρκετές εκατοντάδες ψηφιακών λέξεων (αλφαριθμητικά). Τα φίλτρα Bloom από την άλλη πλευρά με πιθανότητα ψευδούς θετικής απόκρισης και βέλτιστη τιμή του , απαιτούν περίπου bits ανά στοιχείο ανεξαρτήτως μεγέθους του στοιχείου. Γενικά την πιθανότητα ψευδούς θετικής απόκρισης μπορούμε να την υποδεκαπλασιάζουμε απλώς αυξάνοντας το χώρο ανά στοιχείο κατά bits. Επιπλέον, το κόστος για ένθεση ενός στοιχείου είναι συνάρτηση μόνο του και όχι του μεγέθους του στοιχείου ή του μεγέθους του συνόλου. Όμως, ένα σημαντικό πρόβλημα που έχουν τα φίλτρα Bloom είναι ότι είναι δύσκολο να υποστηριχθεί η διαγραφή ενός στοιχείου.
Θεώρημα 13.1.
Η πιθανότητα ψευδούς θετικής απόκρισης είναι .
Απόδειξη. Έστω ότι η συνάρτηση κατακερματισμού επιλέγει κάθε θέση του πίνακα με ίδια πιθανότητα. Αν είναι ο αριθμός των bits στον πίνακα , η πιθανότητα ότι κάποιο συγκεκριμένο bit δεν θα γίνει ίσο με κατά την εισαγωγή ενός στοιχείου είναι:
Η πιθανότητα ότι δεν θα τεθεί από καμία από τις συναρτήσεις κατακερματισμού θα είναι:
Αν ενθέσουμε στοιχεία, τότε η πιθανότητα να είναι είναι:
και, άρα, η πιθανότητα αυτό να είναι είναι:
Έστω ότι ελέγχουμε την συμμετοχή στο ενός στοιχείου που δεν ανήκει σε αυτό. Τότε η πιθανότητα να έχουμε ψευδή θετική απόκριση είναι:
Έστω ότι . Η πιθανότητα ψευδούς θετικής απόκρισης μειώνεται, όταν αυξάνεται το και αυξάνεται καθώς το αυξάνει. Για δοσμένα και , η τιμή του που ελαχιστοποιεί αυτή την πιθανότητα προκύπτει από την ελαχιστοποίηση της συνάρτησης , ενώ ισχύει ότι . Άρα, η καλύτερη τιμή για το προκύπτει από την ελαχιστοποίηση της ως προς . Παίρνοντας την πρώτη παράγωγο της ως προς βρίσκουμε ότι η συνάρτηση ελαχιστοποιείται για . Αντικαθιστώντας το βρίσκουμε την πιθανότητα ψευδούς απόκρισης:
13.8 Λίστες Παράλειψης
Η μέθοδος των λιστών παράλειψης (skip lists) προτάθηκε από τον Pugh το 1990. Η δομή αυτή είναι πολύ αποτελεσματική σε όλες τις σχετικές λειτουργίες, δηλαδή αναζήτηση, εισαγωγή και διαγραφή. Για την επεξήγηση της δομής πρέπει να γίνει μία μικρή εισαγωγή με ένα παράδειγμα.
Ας θεωρηθεί κατ’αρχάς μία κλασική απλή λίστα που περιέχει ταξινομημένα κλειδιά, όπως φαίνεται στην πρώτη δομή του επόμενου σχήματος. Είναι γνωστό ότι στη χειρότερη περίπτωση για μία επιτυχή αναζήτηση θα διασχισθεί η λίστα μέχρι τέλους. Στη δεύτερη δομή του σχήματος κάθε δεύτερος κόμβος της λίστας περιέχει δύο δείκτες αντί ένα: ο πρώτος δείκτης δείχνει στον επόμενο κόμβο, ενώ ο δεύτερος δείχνει στο μεθεπόμενο κόμβο της λίστας. Φαίνεται διαισθητικά ότι στη χειρότερη περίπτωση για μία επιτυχή αναζήτηση θα προσπελασθούν κόμβοι, όπου είναι το μήκος της λίστας. Κατά παρόμοιο τρόπο στην τρίτη δομή του σχήματος, όπου κάθε τέταρτος κόμβος περιέχει τέσσερις δείκτες, μία επιτυχής αναζήτηση θα απαιτήσει στη χειρότερη περίπτωση την προσπέλαση κόμβων της λίστας.
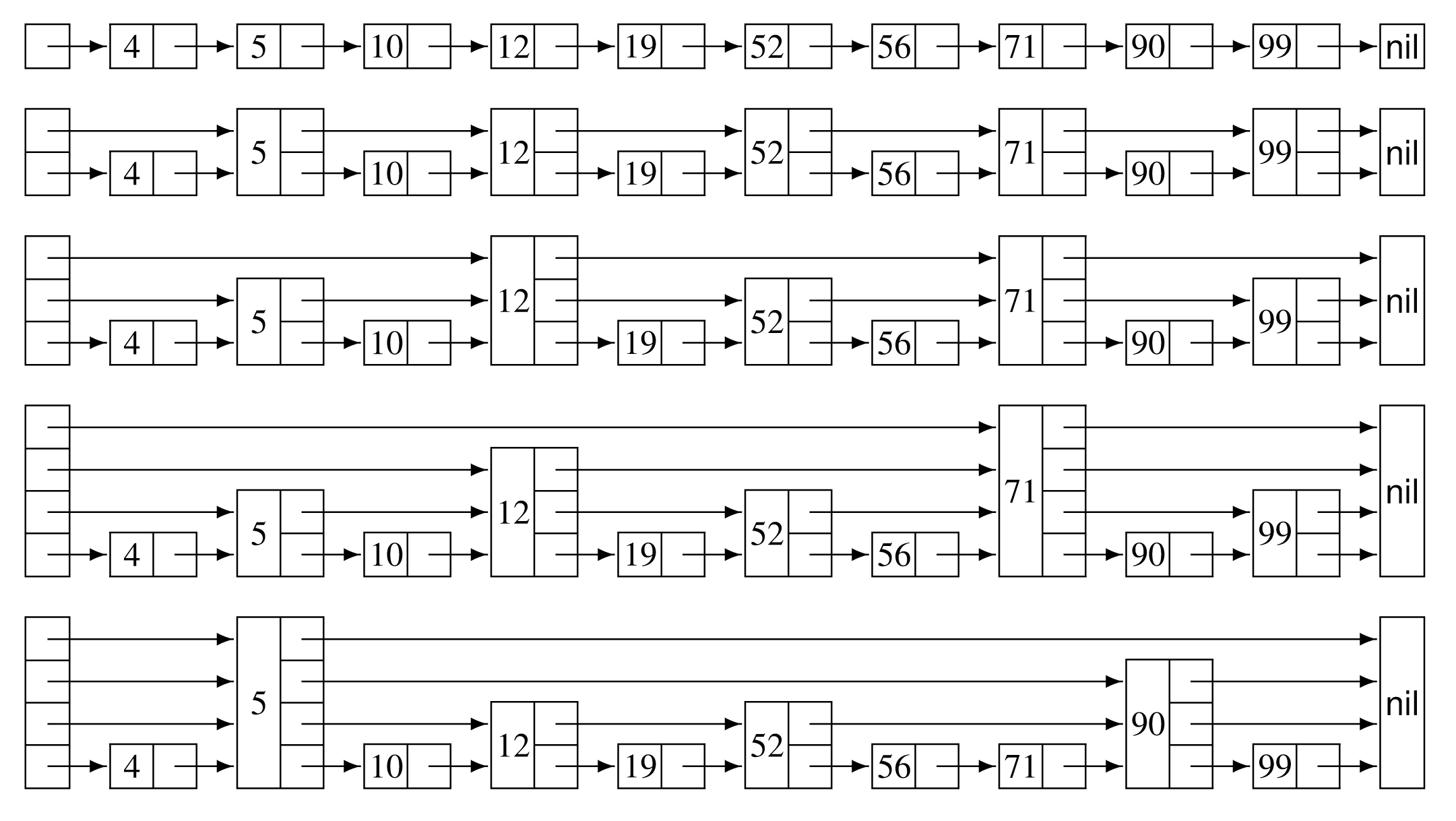
Στην τέταρτη δομή του σχήματος υπάρχουν κόμβοι με ένα δείκτη σε ποσοστό 50%, κόμβοι με δύο δείκτες σε ποσοστό 25%, κόμβοι με τρεις δείκτες σε ποσοστό 12,5% και, τέλος, κόμβοι με τέσσερις δείκτες σε ποσοστό 12,5%. Λέγεται ότι ο κόμβος με δείκτες βρίσκεται στο -οστό επίπεδο (level). Ακολουθώντας το σκεπτικό αυτό είναι πλέον ευνόητο τι κατανομή κόμβων υπάρχει σε μία λίστα με κόμβους μέχρι επίπεδα.
Σε μία λίστα παράλειψης με κόμβους σε επίπεδα η κατανομή των κόμβων ακολουθεί τη μέθοδο αυτή, αλλά η αλληλουχία τους είναι τυχαία. Δείγμα δομής λιστών παράλειψης είναι η τελευταία περίπτωση του προηγούμενου σχήματος. Στη δομή αυτή ένας πίνακας δεικτών παίζει το ρόλο του δείκτη header των κλασικών συνδεδεμένων λιστών. Όλοι οι δείκτες αρχικοποιούνται με τιμή nil. Η αναζήτηση ενός κλειδιού σε μία τέτοια δομή γίνεται αρχικά ακολουθώντας την αλυσίδα των δεικτών του μεγαλυτέρου επιπέδου, μέχρι να προσπελασθεί κόμβος με κλειδί ίσο ή μεγαλύτερο από το αναζητούμενο. Στην πρώτη περίπτωση η διαδικασία τερματίζεται, ενώ στη δεύτερη η διαδικασία συνεχίζεται ακολουθώντας την αλυσίδα των δεικτών του χαμηλότερου επιπέδου. Έτσι, η διαδικασία συνεχίζεται διαδοχικά θεωρώντας τις αλυσίδες των μικρότερων επιπέδων. Για παράδειγμα, κατά την αναζήτηση του κλειδιού 71 στην τελική δομή του σχήματος προσπελάζονται οι κόμβοι με κλειδιά 5, 90, 12, 52, 56 και τελικά 71.
Η επόμενη διαδικασία search περιγράφει την αναζήτηση σε μία λίστα παράλειψης του κλειδιού searchkey. Με τη μεταβλητή level συμβολίζεται το μέγιστο επίπεδο της λίστας παράλειψης, ενώ με forward συμβολίζονται οι δείκτες των διαδοχικών επιπέδων.
procedure search(searchkey)
1. x <-- header
2. for i <-- level downto 1 do
3. while x.forward[i].key < searchkey
4. do x <-- x.forward[i]
5. x <-- x.forward[1]
6. if x.key=searchkey then print(successful)
7. else print(unsuccessful)
Η διαδικασία εισαγωγής ενός κλειδιού αρχίζει σαν τη διαδικασία της αναζήτησης, ώστε να εντοπισθεί το σημείο, όπου θα πρέπει να δημιουργηθεί ο νέος κόμβος. Ο αριθμός των δεικτών του νέου κόμβου προσδιορίζεται με ένα ψευδοτυχαίο αριθμό που υπακούει την κατανομή των κόμβων ανά επίπεδο. Για την ολοκλήρωση της διαδικασίας απαιτείται η σύνδεση του νέου κόμβου με τους υπόλοιπους της δομής. Αυτό επιτυγχάνεται με τη χρήση ενός βοηθητικού πίνακα που περιέχει τους δεξιότερους δείκτες όλων των επιπέδων που βρίσκονται αριστερά από το σημείο όπου θα γίνει η εισαγωγή. Ανάλογη διαχείριση απαιτείται και κατά τη διαγραφή ενός κόμβου, ώστε να γίνει η σύνδεση των κόμβων της λίστας. Κατά την υλοποίηση απαιτείται κάποια προσοχή στη διαχείριση των δεικτών επειδή η εισαγωγή ή η διαγραφή μπορεί να αφορά σε κόμβο οποιουδήποτε επιπέδου. Η επόμενη διαδικασία insert αποτυπώνει αυτήν την περιγραφή. Ο πίνακας update χρειάζεται για τη σύνδεση των κόμβων της δομής. Πιο συγκεκριμένα, στη θέση update[i] τοποθετείται ο κατάλληλος δείκτης προς το δεξιότερο κόμβο επιπέδου ή υψηλότερου, ο οποίος κόμβος βρίσκεται στα αριστερά του σημείου όπου θα εισαχθεί ο νέος κόμβος μέσω της makenode. Οι μεταβλητές value και newvalue αναφέρονται σε ένα βοηθητικό πεδίο.
procedure insert(searchkey,newvalue)
1. x <-- header
2. for <-- level downto 1 do
3. while x.forward[i].key < searchkey
4. do x <-- x.forward[i]
5. update[i] <-- x
6. x <-- x.forward[1]
7. if x.key=searchkey then x.value <-- newvalue
8. else
9. newlevel <-- randomlevel
10. if newlevel>level then
11. for i <-- level+1 to newlevel do
12. update[i] <-- header
13. level <-- newlevel
14. x <-- makenode(newlevel,searchkey,value)
15. for i <-- 1 to newlevel do
16. x.forward[i] <-- update[i].forward[i]
17 update[i].forward[i] <-- x
Στην πρώτη δομή του επόμενου σχήματος παρουσιάζεται η διαδικασία αναζήτησης της θέσης όπου θα πρέπει να εισαχθεί το κλειδί 52, ενώ στο κάτω μέρος του σχήματος δίνεται η τελική κατάσταση της δομής.
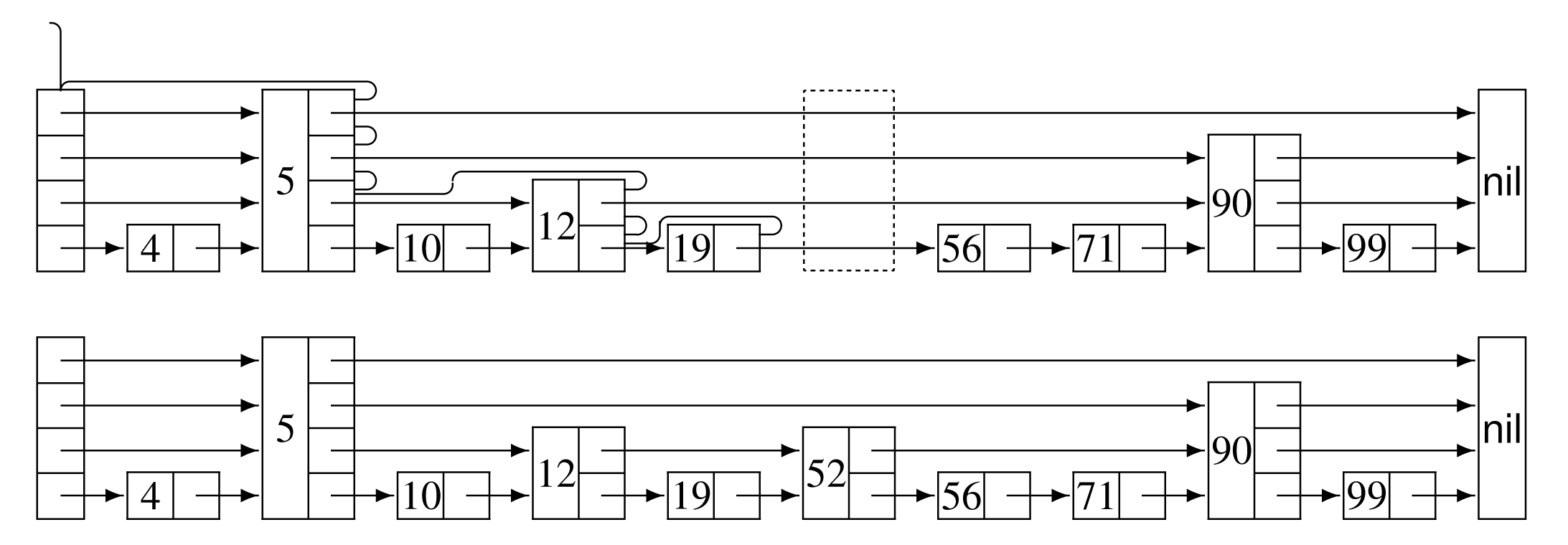
Στη διαδικασία insert σημαντικό ρόλο παίζει η διαδικασία randomlevel, που με μια λογική Las Vegas προσδιορίζει με τυχαίο τρόπο το επίπεδο του προς εισαγωγή κόμβου. Η διαδικασία randomlevel που δίνεται στη συνέχεια είναι γενική, καθώς με p συμβολίζεται το ποσοστό των κόμβων με δείκτες στο -οστό επίπεδο, οι οποίοι έχουν δείκτες και στο ()-οστό επίπεδο.
procedure randomlevel
1. newlevel <-- 1
2. while random()<p do newlevel <-- newlevel+1
3. return min(newlevel,maxlevel)
Για , η διαδικασία μοιάζει με τη συνεχή ρίψη κερμάτων μέχρι να έρθουν “γράμματα”. Η πιθανότητα ένα δεδομένο στοιχείο να αποθηκευθεί σε κόμβο του -οστού επιπέδου είναι ίση με την πιθανότητα ρίχνοντας το κέρμα να βγάλουμε φορές “κορώνα” και κατόπιν “γράμματα”. Αυτό μπορεί να συμβεί με πιθανότητα . Η πιθανότητα ένα στοιχείο να ξεπεράσει τα επίπεδα είναι . Άρα, η πιθανότητα οποιοδήποτε στοιχείο να βρίσκεται σε παραπάνω από επίπεδα δε θα είναι μεγαλύτερη από . Για παράδειγμα, το ύψος είναι μεγαλύτερο από με πιθανότητα:
| (13.6) |
Γενικώς, δοθείσης σταθεράς , το ύψος είναι μεγαλύτερο από με
πιθανότητα το πολύ . Συνεπώς, με πολύ μεγάλη πιθανότητα το ύψος είναι
Ο(). Ωστόσο, θεωρητικά η τιμή του ύψους μπορεί να γίνει οσοδήποτε μεγάλη.
Για το λόγο αυτό αποφασίζεται από την αρχή η μέγιστη τιμή του επιτρεπτού πλήθους
επιπέδων maxlevel να ισούται με , και, άρα, , .
Στη συνέχεια, θα ασχοληθούμε με την ανάλυση της πολυπλοκότητας της διαδικασίας της αναζήτησης. Η πολυπλοκότητα της διαδικασίας της εισαγωγής και της διαγραφής είναι παρόμοια, καθώς το επιπλέον κόστος είναι συνάρτηση του μέγιστου αριθμού των επιπέδων και όχι του πλήθους των στοιχείων της δομής. Για τους σκοπούς της ανάλυσης αυτής θα μελετήσουμε τα βήματα της αναζήτησης κατά την αντίστροφη φορά. Για παράδειγμα, έστω ότι στο Σχήμα 13.5 αναζητούμε το κλειδί 56. Ο Πίνακας 13.2 δείχνει τις εκτελούμενες ενέργειες κατά την αντίστροφη φορά.
| Κόμβος | Επίπεδο | Κίνηση |
|---|---|---|
| 56 | 0 | πίσω |
| 52 | 0 | επάνω |
| 52 | 1 | πίσω |
| 12 | 1 | πίσω |
| 5 | 1 | επάνω |
| 5 | 2 | επάνω |
| header | 3 | πίσω |
Πρόταση.
Η πολυπλοκότητα της αναζήτησης σε λίστα παράλειψης είναι λογαριθμική.
Απόδειξη
Η πολυπλοκότητα της αναζήτησης εξαρτάται από τον αριθμό των βημάτων προς τα επάνω και
προς τα πίσω. Εκ κατασκευής η πιθανότητα από κάποιο σημείο να κινηθούμε προς τα πίσω
είναι , ενώ η πιθανότητα να κινηθούμε προς τα επάνω είναι . Έστω ότι με
συμβολίζουμε τη μέση τιμή του μήκους του μονοπατιού αναζήτησης που ανεβαίνει επίπεδα
σε μία δομή με άπειρα επίπεδα. Ως αρχική συνθήκη ισχύει και γενικώς:
Με απλά λόγια, ένα μονοπάτι που ανεβαίνει επίπεδα έχει μήκος για .
Ο μέγιστος αριθμός επιπέδων είναι . Επομένως, η δομή έχει λογαριθμική
πολυπλοκότητα Ο().
Πρόταση.
Η χωρική πολυπλοκότητα της λίστας παράλειψης είναι γραμμική.
Απόδειξη
Ως προς τη χωρική πολυπλοκότητα παρατηρούμε τα εξής υποθέτοντας ότι . Με το
προηγούμενο σκεπτικό γνωρίζουμε ότι η πιθανότητα ένα στοιχείο να βρίσκεται στο -οστό
επίπεδο είναι ίση με την πιθανότητα ρίχνοντας το κέρμα να βγάλουμε φορές “κορώνα”
και κατόπιν “γράμματα”. Αυτό μπορεί να συμβεί με πιθανότητα . Επομένως, η μέση
τιμή των στοιχείων στο -οστό επίπεδο είναι . Άρα, η προσδοκητή τιμή του πλήθους
των δεικτών είναι:
| (13.7) |
όπου είναι ο αριθμός των επιπέδων της δομής. Συνεπώς, ασυμπτωτικά προκύπτει ότι η χωρική πολυπλοκότητα είναι Θ().
13.9 Γρήγορη Ταξινόμηση
Μελετήσαμε τη γρήγορη ταξινόμηση στο Κεφάλαιο 8.3. Η επίδοση της γρήγορης ταξινόμησης εξαρτάται από την επιλογή του άξονα (pivot). Στη κλασική έκδοση του αλγορίθμου ως άξονας επιλέγεται το πρώτο στοιχείο του πίνακα. Αν η τιμή του άξονα είναι το μεσαίο στοιχείο του τελικώς ταξινομημένου πίνακα, τότε ο αρχικός πίνακας χωρίζεται σε δύο ίσους υποπίνακες. Σε αντίθεση με αυτή την καλύτερη περίπτωση, στη χειρότερη περίπτωση η τιμή του άξονα μπορεί να είναι η μικρότερη ή η μεγαλύτερη τιμή των στοιχείων του πίνακα, οπότε ο πίνακας θα υποδιαιρεθεί σε δύο υποπίνακες μεγέθους 0 και .
Στη βιβλιογραφία έχουν προταθεί αρκετές παραλλαγές της γρήγορης ταξινόμησης με σκοπό την επιλογή ενός άξονα με τιμή που να οδηγεί σε καλύτερο διαμερισμό. Μία παραλλαγή είναι η λεγόμενη “μεσαίος των τριών”(median-of-three), όπου από το πρώτο, το τελευταίο και το μεσαίο στοιχείο του πίνακα επιλέγεται ως άξονας το στοιχείο με τη μεσαία τιμή μεταξύ των τριών. Μία άλλη παραλλαγή είναι η ταξινόμηση με τη μέση τιμή (meansort), όπου ως άξονας επιλέγεται η μέση τιμή των στοιχείων του πίνακα. Έχει αποδειχθεί ότι στη χειρότερη περίπτωση οι τεχνικές αυτές δεν αποφεύγουν την τετραγωνική πολυπλοκότητα Θ().
Σκοπός μας, λοιπόν, είναι ένας “δίκαιος” (δηλαδή αποτελεσματικός) διαμερισμός. Για το σκοπό αυτό προτείνεται η επιλογή ενός τυχαίου στοιχείου του πίνακα ως άξονα. Η επόμενη διαδικασία σκιαγραφεί την τεχνική αυτή τύπου Las Vegas.
procedure quicksortrand(left,right);
1. if left<right then
2. i <-- left; j <-- right+1;
3. k <-- random(left,right);
4. swap(A[k],A[left]); pivot <-- A[left];
5. repeat
6. repeat i <-- i+1 until A[i]>=pivot;
7. repeat j <-- j-1 until A[j]<=pivot;
8. if i<j then swap(A[i],A[j]);
9. until j<=i;
10. swap(A[left],A[j]);
11. quicksort(left,j-1);
12. quicksort(j+1,right)
Στη συνέχεια, θα προχωρήσουμε στην παρουσίαση δύο ανεξάρτητων αλλά ισοδύναμων αποδείξεων
σχετικά με την πολυπλοκότητα της τυχαίας γρήγορης ταξινόμησης. Η πρώτη έχει ως εξής:
Πρόταση.
Η πολυπλοκότητα της γρήγορης ταξινόμησης είναι Θ() στη μέση περίπτωση.
Απόδειξη 1η
Δεδομένου ενός συνόλου , με συμβολίζουμε τον -οστό μικρότερο αριθμό.
Ορίζουμε την τυχαία μεταβλητή , ώστε να έχει τιμή 1 (0) αν τα στοιχεία και
(δεν) συγκριθούν κατά την εκτέλεση της τυχαίας γρήγορης ταξινόμησης. Συνεπώς, για
την προσδοκητή τιμή του συνολικού αριθμού συγκρίσεων που εκτελούνται από τον αλγόριθμο ισχύει:
| (13.8) |
Καθώς η τυχαία μεταβλητή παίρνει τιμές 0 και 1, ουσιαστικά δηλώνει την πιθανότητα τα στοιχεία και να συγκριθούν. Έστω τα στοιχεία . Τα δύο στοιχεία και θα συγκριθούν, αν το ένα από τα δύο έχει επιλεγεί ως άξονας. Αν δεν έχει επιλεγεί το ένα από τα δύο ως άξονας, τότε θα έχει επιλεγεί ένα εκ των , γεγονός που θα στείλει τα δύο στοιχεία και σε διαφορετικούς υποπίνακες, οπότε δεν πρόκειται να συγκριθούν. Συνεπώς, η πιθανότητα τα δύο αυτά στοιχεία να συγκριθούν είναι . Άρα:
Απόδειξη 2η
Η δεύτερη εναλλακτική απόδειξη στηρίζεται στις αναδρομικές εξισώσεις και τον ορισμό
της πολυπλοκότητας. Για την ανάλυσή μας, για τη θέση του pivot θα θεωρήσουμε δύο
ισοπίθανες περιπτώσεις (δηλαδή πιθανότητα 1/2):
-
•
τον “καλό διαμερισμό” όπου ισχύει:
(13.9) -
•
τον “κακό διαμερισμό” όπου ισχύει:
(13.10) ή
(13.11)
Με απλά λόγια, καλός θεωρείται ο διαχωρισμός όταν ο τυχαία επιλεγόμενος άξονας οδηγεί σε διαμερισμό όπου ο μικρότερος υποπίνακας έχει μέγεθος το ελάχιστο , ενώ ο μεγαλύτερος υποπίνακας έχει μέγεθος το πολύ .
Από το Κεφάλαιο 8.3 γνωρίζουμε ότι γενικώς ισχύει η επόμενη αναδρομική εξίσωση για :
| (13.12) |
Αν με κάποιο τρόπο μπορούσαμε να εγγυηθούμε ότι κάθε διαμερισμός θα είναι καλός, τότε θα ίσχυε η επόμενη αναδρομική εξίσωση:
Στην ανωτέρω επεξεργασία χρησιμοποιήσαμε το γεγονός ότι η μέγιστη τιμή της ποσότητας στο διάστημα λαμβάνεται στα άκρα του διαστήματος1212Για λόγους ευκολίας τα όρια του αθροίσματος δεν ταυτίζονται με τα όρια που προσδιορίσθηκαν προηγουμένως στις περιπτώσεις του καλού και του κακού διαχωρισμού..
Τώρα θέλουμε να αποδείξουμε ότι . Θα το αποδείξουμε με επαγωγή. Η αλήθεια της πρότασης ισχύει για μικρά και για . Θα αποδείξουμε ότι ισχύει και για κάθε . Διαδοχικά έχουμε:
όπου η αλήθεια της τελευταίας ανισοϊσότητας προκύπτει για .
Από την άλλη πλευρά υπάρχει και ο κακός διαμερισμός για τον οποίο ισχύει:
Από την τελευταία σχέση καταλήγουμε ότι: . Όμως, με την όποια πιθανότητα θα συμβεί ένας κακός διαμερισμός με την ίδια πιθανότητα θα συμβεί και ένας καλός διαμερισμός. Άρα, στη γενική περίπτωση ισχύει:
Όπως και πριν, θα αποδείξουμε επαγωγικά ότι για κάποια σταθερά . Η αλήθεια της πρότασης ισχύει για μικρά και για . Θα αποδείξουμε ότι ισχύει και για . Διαδοχικά έχουμε:
όπου η αλήθεια της τελευταίας ανισοϊσότητας προκύπτει για .
Διαπιστώνουμε, λοιπόν, ότι και πάλι καταλήγουμε στο ίδιο συμπέρασμα σε σχέση με την επίδοση της μέσης περίπτωσης. Ωστόσο, ενώ στην ανάλυση της κλασικής γρήγορης ταξινόμησης θεωρούμε το σύνολο των διαφορετικών διατάξεων που μπορούν να εισαχθούν προς ταξινόμηση, στην παρούσα περίπτωση θεωρούμε το σύνολο των δυνατών αποτελεσμάτων της τυχαίας γεννήτριας. Στη συμβατική γρήγορη ταξινόμηση μπορούσαμε να ισχυρισθούμε ότι: Αν τα δεδομένα είναι τυχαία, τότε η πολυπλοκότητα της μέσης περίπτωσης της γρήγορης ταξινόμησης είναι Θ()’. Αντίθετα τώρα μπορούμε να ισχυρισθούμε ότι: “Με πολύ μεγάλη πιθανότητα η τυχαία γρήγορη ταξινόμηση εκτελείται σε χρόνο Θ()”.
13.10 Έλεγχος Πρώτων Αριθμών
Όπως γνωρίζουμε από την Άσκηση 1.12, πρώτος λέγεται ένας
ακέραιος αριθμός, αν διαιρείται μόνο από τη μονάδα και τον εαυτό του. Το 1 δεν θεωρείται
πρώτος, ενώ οι 5 μικρότεροι αριθμοί είναι οι 2, 3, 5, 7 και 11. Εκτός από τους αρχαίους
Έλληνες (όπως ο Ευκλείδης και ο Ερατοσθένης), με το πρόβλημα είχαν ασχοληθεί και οι
αρχαίοι Κινέζοι που πίστευαν ότι αν ο αριθμός διαρείται ακριβώς δια του ,
τότε ο είναι πρώτος. Ωστόσο, η εικασία αυτή δεν είναι ορθή. Αντιπαράδειγμα αποτελεί
ο αριθμός . Το πρόβλημα του ελέγχου αν ένας αριθμός είναι πρώτος ή σύνθετος
(primality testing), καθώς και το πρόβλημα της παραγοντοποίησης (factorization) βρίσκουν
σημαντική χρήση στην κρυπτογραφία, μία γνωστική περιοχή που βασίζεται στο γεγονός ότι
δεν υπάρχουν αποτελεσματικοί αλγόριθμοι για την παραγοντοποίηση μεγάλων αριθμών.
Σύμφωνα με την Άσκηση 1.12, αν είναι ένας θετικός σύνθετος ακέραιος, τότε ο έχει έναν πρώτο αριθμό που δεν ξεπερνά το . Επομένως, προκειμένου να διαπιστώσουμε αν ένας ακέραιος είναι πρώτος αρκεί να εκτελέσουμε δοκιμές στη χειρότερη περίπτωση και να απαντήσουμε με βεβαιότητα κατά πόσο ο αριθμός είναι πρώτος. Στην επόμενη διαδικασία prime1 υποθέτουμε ότι ο n είναι περιττός αριθμός.
procedure prime1(n)
1. for i <-- 3 to n step 2 do
2. if n mod i = 0 then return false;
3. return true
Λέγεται ότι ένας αλγόριθμος είναι αποτελεσματικός χρονο-πολυωνυμικά (poly-time
efficient) αν εκτελείται σε χρόνο πολυωνυμικό ως προς το μήκος του μεγέθους της
αναπαράστασης του αριθμού σε bits, δηλαδή να ισχύει Ο(), για κάποια
σταθερά . Προφανώς, η πολυπλοκότητα του ανωτέρω αιτιοκρατικού αλγορίθμου είναι
Ο()=Ο() και, επομένως, ο αλγόριθμος δεν είναι
αποτελεσματικός χρονο-πολυωνυμικά.
Στη συνέχεια, θα εξετάσουμε τυχαίους αλγορίθμους που ανήκουν στην κατηγορία Monte Carlo και θα καταλήξουμε σε έναν πολύ αποτελεσματικό τυχαίο αλγόριθμο. Για παράδειγμα, έστω ότι δίνεται ο αριθμός , που προφανώς δεν είναι πρώτος. Θα μπορούσαμε να ακολουθήσουμε τη λογική του προβλήματος των επαναλαμβανόμενων στοιχείων και να δοκιμάσουμε αν το 2773 διαιρείται με κάποιον ακέραιο που επιλέγεται τυχαία στο διάστημα . Επομένως, με πιθανότητα περίπου 2% θα επιλέγαμε το 47 και θα καταλήγαμε ότι το 2773 δεν είναι πρώτος αριθμός, όμως με περίπου 98% θα καταλήγαμε σε λάθος συμπέρασμα. Βέβαια κατά τον έλεγχο αριθμών με πολλά ψηφία (πράγμα που κατ’εξοχήν συμβαίνει στην κρυπτογραφία) η πιθανότητα για ορθή απάντηση θα είναι ακόμη μικρότερη. Θα μπορούσαμε να εκτελέσουμε το πείραμα αυτό περισσότερες φορές, ώστε να αυξήσουμε την πιθανότητα αποκλεισμού του λάθους, όπως φαίνεται στην επόμενη διαδικασία prime2. Η διαδικασία αυτή εκτελεί ένα μεγάλο αριθμό πειραμάτων (large), ώστε η πιθανότητα της ορθής απάντησης να είναι της τάξης , όπως πρέπει να συμβαίνει στους αλγορίθμους που στηρίζονται σε μία λογική Monte Carlo.
procedure prime2(n)
1. for k <-- 1 to large do
2. i <-- random(1,sqrt(n));
3. if (n mod i = 0) then return false;
3. return true
Στο αλγόριθμο αυτό οι αρνητικές απαντήσεις (δηλαδή ότι ο αριθμός δεν είναι πρώτος)
είναι με βεβαιότητα ορθές, ενώ οι θετικές απαντήσεις (δηλαδή ότι ο αριθμός είναι
πρώτος) είναι ορθές αλλά με μικρή πιθανότητα. Επίσης, η πιθανότητα του λάθους δεν είναι
τόσο συνάρτηση του ελεγχόμενου αριθμού αλλά του αποτελέσματος της γεννήτριας τυχαίων
αριθμών. Στη συνέχεια, θα εξετάσουμε έναν εναλλακτικό τυχαίο αλγόριθμο που στηρίζεται στο
επόμενο θεώρημα του Fermat, του οποίου την απόδειξη μπορούμε να βρούμε σε βιβλία Θεωρίας
Αριθμών.
Θεώρημα.
Αν ο αριθμός είναι πρώτος, τότε για ισχύει: .
Απόδειξη.
Μία πρώτη απόδειξη είναι επαγωγική ως προς και θα αποδείξει την ισοδύναμη πρόταση:
. Είναι προφανές ότι πάντοτε ισχύει η βασική συνθήκη για (ακόμη
και αν ο δεν είναι πρώτος). Δεχόμαστε ότι ισχύει . Θα αποδείξουμε
ότι . Έχουμε ότι:
| (13.13) |
Ο συντελεστής είναι διαιρετός δια εκτός από τις περιπτώσεις και . Επομένως, ισχύει:
| (13.14) |
Μία δεύτερη απόδειξη στηρίζεται στην εξής ιδέα. Έστω οι αριθμοί , , που τους πολλαπλασιάσουμε επί , οπότε προκύπτουν οι αριθμοί , . Οι αριθμοί αυτοί είναι διακριτοί ως προς mod και υπάρχουν τέτοιοι αριθμοί. Άρα, οι αριθμοί αυτοί είναι ίδιοι με τους προηγούμενους αλλά με μία άλλη σειρά. Άρα, ισχύει:
Συνεπώς, ισχύει η πρόταση.
Ας δοκιμάσουμε το θεώρημα για τον πρώτο αριθμό . Πράγματι ισχύει: , και . Ενώ για αντιπαράδειγμα, ο δεν είναι πρώτος αριθμός και ισχύει: και . Ωστόσο, το θεώρημα περιγράφει μία ικανή συνθήκη αλλά όχι και αναγκαία, δηλαδή δεν ισχύει και κατά την αντίστροφη σειρά. Έτσι, υπάρχουν μη πρώτοι αριθμοί για τους οποίους ισχύει η συνθήκη μερικές φορές. Για παράδειγμα, για το μη πρώτο αριθμό ισχύει: για , αλλά . Έτσι, το 9 λέγεται 8-ψευδοπρώτος (8-pseudoprime). Οι -ψευδοπρώτοι αριθμοί είναι πιο σπάνιοι αριθμοί από τους πρώτους. Για παράδειγμα, το 9 είναι ο μικρότερος ψευδοπρώτος ακέραιος, ενώ ο μικρότερος 2-ψευδοπρώτος είναι ο 341 (δηλαδή ισχύει: ).
Με βάση το θεώρημα μπορούμε να σχεδιάσουμε έναν τυχαίο αλγόριθμο, όπου για δεδομένο περιττό αριθμό , με τυχαίο τρόπο θα επιλέγουμε τιμές για το , ώστε να δοκιμάζουμε αρκετές φορές τη συνθήκη του θεωρήματος (και να μην πέσουμε εύκολα στην παγίδα των ψευδοπρώτων). Η επόμενη διαδικασία prime3 αποτυπώνει αυτή την περιγραφή. Παρατηρούμε ότι στην περίπτωση αυτή ο αλγόριθμος θα έχει την αντίστροφη λογική από τη λογική του αλγορίθμου prime2. Έτσι, οι αρνητικές απαντήσεις (δηλαδή ότι ο αριθμός δεν είναι πρώτος) είναι με βεβαιότητα ορθές, ενώ οι θετικές απαντήσεις (δηλαδή ότι ο αριθμός είναι πρώτος) είναι ορθές με μεγάλη πιθανότητα. Σημειώνεται, επίσης, ότι ο διπλός βρόχος while είναι μία ακόμη εκδοχή ύψωσης σε δύναμη (δες Κεφάλαιο 4.4).
procedure prime3(n)
1. q <-- n-1;
2. for i <-- 1 to large do
3. m <-- q; y <-- 1;
4. a <-- random(2,n-1); z <-- a;
5. while (m>0) do
6. while (m mod 2 = 0) do
7. z <-- (z*z) mod n; m <-- int(m/2);
8. m <-- m-1; y <-- (y*z) mod n;
9. if (y<>1) then rerurn false;
110. return true
Η διαδικασία prime3 είναι σημαντικά αποτελεσματικότερη σε σχέση με την
prime2 αλλά και πάλι δεν έχουμε λύσει το πρόβλημα καθ’ολοκληρία γιατί όπως
δείξαμε στο προηγούμενο παράδειγμα το θεώρημα ισχύει κατά τη μία μόνο κατεύθυνση.
Ωστόσο, όπως αναφέρεται στη βιβλιογραφία χειρότερη είναι η σύμπτωση των λεγόμενων
αριθμών Carmichael, οι οποίοι δεν είναι πρώτοι αλλά πάντοτε ικανοποιούν το
θεώρημα του Fermat. Αν και οι αριθμοί αυτοί είναι σπάνιοι, εντούτοις το σύνολό τους
είναι άπειρο. Για παράδειγμα, αναφέρεται ότι υπάρχουν 255 τέτοιοι αριθμοί μέχρι το
100.000.000, ενώ οι εννέα μικρότεροι αριθμοί Carmichael είναι οι 561, 1105, 1729, 2465,
2821, 6601, 8911, 10585 και 15841, που περνούν όλες τις συνθήκες για κάθε θετικό
μικρότερο του αντίστοιχου αριθμού.
Πρόταση.
Ο αριθμός είναι Carmichael, αν και μόνο αν ισχύει , όπου οι είναι πρώτοι αριθμοί και ισχύει:
για κάθε .
Για παράδειγμα, ισχύει: , ενώ
, και . Εν πάσει περιπτώσει,
η προσέγγιση της διαδικασίας prime3 απειλείται καθώς ο αλγόριθμος αυτός θα δίνει
(σπανίως βέβαια) λάθος συμπέρασμα, που θα ισχύει για τις ίδιες πάντοτε περιπτώσεις
(δηλαδή ανεξαρτήτως του αποτελέσματος της γεννήτριας τυχαίων αριθμών). Όμως, λύση
υπάρχει και στηρίζεται στην εξής πρόταση.
Πρόταση.
Αν ο είναι πρώτος αριθμός και ισχύει , τότε η εξίσωση
έχει μόνο 2 λύσεις, τις και .
Απόδειξη.
Η εξίσωση αυτή σημαίνει ότι .
Εφόσον το είναι πρώτος αριθμός και , έπεται ότι το πρέπει να
διαιρεί είτε το είτε το .
Από την πρόταση αυτή συνάγεται ότι αν υπάρχουν και άλλες ρίζες πλην των και , τότε ο αριθμός δεν είναι πρώτος. Πράγματι, σε σχέση με το 561, το μικρότερο αριθμό Carmichael, ισχύει ότι η εξίσωση: έχει τις δύο προφανείς λύσεις και καθώς και μερικές ακόμα, όπως , κοκ. Άρα, ο δεν είναι πρώτος. Στην πρόταση αυτή, λοιπόν, στηρίζεται η επόμενη διαδικασία prime4 που βελτιώνει τη διαδικασία prime3. Μάλιστα, η εντολή PrimeQ του Mathematica υλοποιεί αυτόν τον αλγόριθμο, που φέρει το όνομα των Miller-Rabin.
procedure prime2(n,alpha)
1. q <-- n-1;
2. for i <-- 1 to alpha*log(n) do
3. m <-- q; y <-- 1;
4. a <-- random(2,n-1); z <-- a;
5. while (m>0) do
6. while (m mod 2 = 0) do
7. x <-- z; z <-- (z*z) mod n;
8. if ((z=1) and (x<>1) and (x<>q)) then
9 . return false;
10. m <-- int(m/2);
11. m <-- m-1; y <-- (y*z) mod n;
12. if (y<>1) then rerurn false;
13. return true
Σύμφωνα, λοιπόν, με τη διαδικασία αυτή, αν το είναι πρώτος, τότε και θα
ικανοποιείται το θεώρημα του Fermat αλλά και δεν θα υπάρχει κάποια μη τετριμμένη λύση
σύμφωνα με το προηγούμενο θεώρημα. Έτσι, ο αλγόριθμος αυτός δίνει πάντοτε ορθή απάντηση
για τους πρώτους αριθμούς και τους αριθμούς Carmichael. Ωστόσο, μπορεί να δώσει λάθος
αποτέλεσμα αν πέσει στην παγίδα των ψευδοπρώτων αριθμών (δηλαδή ο αριθμός να μην είναι
πρώτος, αλλά στην έξοδο να δοθεί σαν πρώτος). Η αξιοπιστία του αλγορίθμου στην περίπτωση
αυτή εξαρτάται από τη γεννήτρια των τυχαίων αριθμών και τις τιμές της παραμέτρου a
(εντολή 4), οι οποίες θα επιλεγούν για τη δοκιμή. Ας ονομάσουμε μάρτυρα (witness)
την τιμή του , η οποία αποκαλύπτει τη συνθετότητα του . Η πιθανότητα επιλογής μίας
τιμής μάρτυρα για το δίνεται (χωρίς απόδειξη) από την επόμενη πρόταση, η οποία
αποτελεί τη βάση για να φθάσουμε στην πολυπλοκότητα της prime4.
Λήμμα 13.8.
Αν ο περιττός αριθμός δεν είναι πρώτος, τότε υπάρχουν τουλάχιστον τιμές του , οι οποίες είναι μάρτυρες.
Λήμμα 13.9.
Για κάθε μονό αριθμό και ακέραιο , η πιθανότητα λάθους της prime4 είναι .
Απόδειξη. Με βάση το Λήμμα 13.8 η εκτέλεση κάθε επανάληψης του αλγορίθμου δίνει μάρτυρα για την συνθετότητα του ακεραίου με πιθανότητα . Ο αλγόριθμος δεν θα ανακαλύψει ότι ο είναι σύνθετος αν είναι τόσο άτυχος, ώστε σε κάθε επανάληψη από τις συνολικά επαναλήψεις να μην βρίσκει μάρτυρα. Η πιθανότητα αυτή είναι τουλάχιστον .
Θεώρημα 13.2.
Η πολυπλοκότητα της prime4 είναι λογαριθμική.
Απόδειξη. Αν το είναι πρώτος, τότε πάντοτε λαμβάνουμε ορθή απάντηση, οπότε αυτή η περίπτωση δεν μας απασχολεί. Ας υποθέσουμε ότι το δεν είναι πρώτος. Από το Λήμμα 13.9 προκύπτει ότι η πιθανότητα κανείς από τους επιλεγόμενους τυχαίους αριθμούς να μην είναι μάρτυρας είναι . Δηλαδή, η διαδικασία prime4 θα δώσει λανθασμένη απάντηση με πιθανότητα , οπότε έτσι ικανοποιείται η απαίτηση των αλγορίθμων Monte Carlo για επιτυχία με μεγάλη πιθανότητα ίση με . Καθώς κάθε βρόχος while συνεπάγεται Ο() επαναλήψεις, έπεται ότι η πολυπλοκότητα του αλγορίθμου είναι Ο().
Μερικά επιλογικά σχόλια αναφορικά με το πρόβλημα του ελέγχου πρώτων αριθμών, για το οποίο μόλις μελετήσαμε μία αποτελεσματική λύση. Μέχρι πρόσφατα θεωρούνταν ότι το πρόβλημα αυτό δεν υπήρχε πολυωνυμικός αιτιοκρατικός αλγόριθμος. Στις 6 Αυγούστου του 2002, τρεις ερευνητές του Institute of Technology in Kampur, οι M. Agrawal, N. Kayal και N Saxena, δημοσίευσαν στο διαδίκτυο μία μελέτη που λύνει το πρόβλημα σε πολυωνυμικό χρόνο. Έτσι, ανοίγει μία νέα περίοδος στην έρευνα των γρήγορων μαθηματικών αλγορίθμων της Θεωρίας Αριθμών.
13.11 Στατιστικά Διάταξης
Στο Κεφάλαιο 8.4 είχαμε εξετάσει το πρόβλημα των στατιστικών
διάταξης σε συνδυασμό με τη γρήγορη ταξινόμηση. Με παρόμοιο τρόπο, μπορούμε να
διατυπώσουμε μία τυχαιοποιημένη εκδοχή της συνάρτησης για την επιλογή του -οστού
στοιχείου ενός αταξινόμητου πίνακα υιοθετώντας κάθε φορά μία τυχαία επιλογή του άξονα.
Με παρόμοιο, επίσης, τρόπο θα μπορούσαμε να διατυπώσουμε την αντίστοιχη ανάλυση, που
θα κατέληγε στο ίδιο συμπέρασμα, δηλαδή πολυπλοκότητα Ο(). Η προσέγγιση αυτή είναι
σχετικά εύκολη υπόθεση για τον αναγνώστη και για το λόγο αυτό στην παρούσα παράγραφο
θα ασχοληθούμε με ένα νέο πρόβλημα: την εύρεση του προσεγγιστικού μεσαίου
(approximate median). Τυπικά το πρόβλημα ορίζεται ως εξής:
Ορισμός.
Δεδομένου ενός πίνακα με αριθμούς, τότε -μεσαίος λέγεται ένας αριθμός
, τέτοιος ώστε και .
Για την ευκολία της επίλυσης του προβλήματος θεωρούμε ότι οι τιμές του πίνακα είναι οι αριθμοί , ενώ επίσης δεχόμαστε ότι το είναι δύναμη του 3, δηλαδή ισχύει . Θεωρούμε τη δομή ενός πλήρους τριαδικού δένδρου με φύλλα. Λαμβάνουμε μία τυχαία διάταξη από τις συνολικά και θεωρούμε ότι τα στοιχεία αυτής της διάταξης αποτελούν τα φύλλα του δένδρου. Συνεχίζουμε την κατασκευή του δένδρου από το επίπεδο των φύλλων προς το επίπεδο της ρίζας αντιστοιχώντας 3 φύλλα σε ένα κόμβο-πατέρα με περιεχόμενο ίσο προς το μεσαίο των 3 στοιχείων των κόμβων-παιδιών. Η διαδικασία συνεχίζεται αναδρομικά μέχρι το επίπεδο της ρίζας. Στο σημείο αυτό, μία πρώτη παρατήρηση είναι ότι η τάξη του στοιχείου της ρίζας θα είναι στη μέση περίπτωση. Το Σχήμα 13.6 απεικονίζει ένα παράδειγμα με .

Έστω ότι με συμβολίζουμε την πιθανότητα η έξοδος του αλγορίθμου να μην είναι μεγαλύτερη από , δεδομένου ενός δένδρου με ύψος . Για το επίπεδο των φύλλων ισχύει η βασική συνθήκη . Θα υπολογίσουμε την πιθανότητα με αναδρομικό τρόπο.
Έστω η ρίζα του δένδρου, η οποία έχει 3 παιδία με τιμές . Η μεσαία τιμή των τριών αυτών τιμών μπορεί να είναι λιγότερο από , αν και μόνον αν δύο από τις τιμές αυτές είναι μικρότερη από . Αυτό μπορεί να συμβεί σε δύο περιπτώσεις:
-
•
ακριβώς δύο από τις τιμές των παιδιών είναι λιγότερο από .
-
•
και οι τρεις τιμές είναι λιγότερο από .
Έτσι, προκύπτουν οι σχέσεις:
Με διαδοχικές αντικαταστάσεις έχουμε:
Έτσι, φθάνουμε στο συμπέρασμα ότι με ένα τυχαίο αλγόριθμο μπορούμε να βρούμε τον προσεγγιστικό μεσαίο με πολύ μεγάλη πιθανότητα.
13.12 Βιβλιογραφική Συζήτηση
Ο αλγόριθμος ελέγχου για το αν ένας αριθμός είναι πρώτος σχεδιάσθηκε από τον Rabin [150], ενώ όπως αναφέρθηκε και στο κυρίως κείμενο σε μία πρόσφατη δημοσίευση οι Agrawal, Kayal και Saxena [1] έδωσαν έναν αιτιοκρατικό αλγόριθμο αποδεικνύοντας ότι το συγκεκριμένο πρόβλημα τελικά ανήκει στη κλάση . Και τους δυο αλγορίθμους μπορείτε, επίσης, να τους βρείτε στο βιβλίο [173].
Μία αντιπροσωπευτική περιοχή εφαρμογής τυχαιοποιημένων αλγορίθμων στα οποία δεν αναφερθήκαμε είναι η μέθοδος της διασποράς (hashing). Αυτή η ιδέα της χρήσης της μεθόδου της διασποράς, ώστε να ξεπεράσουμε το λογαριθμικό όριο για την πράξη της αναζήτησης σε μία RAM τέθηκε για πρώτη φορά από τον Yao [201]. Από τότε έχει γίνει πολλή δουλειά όσον αφορά τον ορισμό συναρτήσεων διασποράς που περιλαμβάνει μεταξύ άλλων τις τέλειες συναρτήσεις διασποράς [180] και τις καθολικές συναρτήσεις διασποράς [190]. Μία πρόσφατη και απλή μέθοδος διασποράς είναι και η διασπορά του κούκου (cuckoo-hashing) [139].
13.13 Ασκήσεις
-
1.
Τα φίλτρα Bloom μπορούν να χρησιμοποιηθούν, για να υπολογίσουμε προσεγγιστικά τη διαφορά συνόλων. Έστω δύο σύνολα και καθένα από τα οποία έχει στοιχεία. Δημιουργούμε Bloom φίλτρα και για τα δύο σύνολα χρησιμοποιώντας τον ίδιο αριθμό από bits και πλήθος συναρτήσεων κατακερματισμού . Να καθορίσετε το αναμενόμενο πλήθος bits όπου τα δύο φίλτρα διαφέρουν μεταξύ τους σαν συνάρτηση των και .
-
2.
Να εισάγετε την παρακάτω ακολουθία αριθμών με την σειρά που εμφανίζεται σε (α) μία λίστα παράλειψης (), (β) σε ένα δέντρο αναζήτησης σωρού και (γ) σε ένα φίλτρο Bloom ( - επιλέξτε εσείς τις συναρτήσεις κατακερματισμού).
Έπειτα, διαγράψτε τα στοιχεία από τη λίστα παράλειψης και από το δέντρο αναζήτησης σωρού.
-
3.
Τα φίλτρα Bloom δεν έχουν την δυνατότητα διαγραφής ενός στοιχείου. Μπορείτε να αλλάξετε τα φίλτρα Bloom, ώστε να είναι σε θέση να υποστηρίζουν την πράξη της διαγραφής; Πόσος είναι ο χώρος που θα χρησιμοποιούν σε αυτή την περίπτωση;
-
4.
Έστω πραγματικοί αριθμοί, έτσι ώστε: . Έστω ένας τυχαίος αλγόριθμος που υπολογίζει μία συνάρτηση όπου:
και
Έστω ότι για κάθε , είναι ο τυχαίος αλγόριθμος, ώστε για κάθε είσοδο ο εκτελείται φορές στο . Η έξοδος του είναι αν και μόνο αν και οι εκτελέσεις του στο έδωσαν έξοδο (έξοδος σημαίνει ότι η έξοδος είναι λανθασμένη). Σε κάθε άλλη περίπτωση ο αλγόριθμος υπολογίζει το σωστό αποτέλεσμα . Να υπολογίσετε το μικρότερο , ώστε ώστε .
-
5.
Έστω ότι είναι ένας Monte Carlo αλγόριθμος, έτσι ώστε για κάθε είσοδο , υπολογίζει το σωστό αποτέλεσμα με πιθανότητα , όπου εξαρτάται από το μέγεθος του (αριθμός bits, έστω ). Έστω μία σταθερά, . Πόσες επαναλήψεις του στο πρέπει να γίνουν, έτσι ώστε να επιτύχουμε , αν .
-
6.
Έστω ότι είναι ένας τυχαίος αλγόριθμος που υπολογίζει μία συνάρτηση με για κάθε . Επίσης υποθέστε ότι ξέρετε ότι για κάθε λανθασμένο αποτελέσμα (η πιθανότητα υπολογισμού λανθασμένης τιμής είναι το πολύ 1/4). Μπορείτε να χρησιμοποιήσετε αυτή την πληροφορία, ώστε να σχεδιάσετε έναν χρήσιμο τυχαίο αλγόριθμο για τη συνάρτηση ;
-
7.
σφαίρες ρίχνονται σε κάδους σε μία επαναληπτική διαδικασία. Σε κάθε επανάληψη κάθε σφαίρα επιλέγει να πέσει σε ένα κάδο ισοπίθανα. Αν μία σφαίρα πέσει μόνη της σε έναν κάδο τότε η σφαίρα αυτή αφαιρείται και η διαδικασία επαναλαμβάνεται με τις υπόλοιπες σφαίρες (αυτό το παιχνίδι μοντελοποιεί ένα απλό σύστημα όπου διεργασίες χρησιμοποιούν τυχαία συσκευές επικοινωνίας και κάθε συσκευή εξυπηρετεί μόνο, αν της πέσει μία και μόνο μία διεργασία, αλλιώς τις απορρίπτει όλες).
Αν υπάρχουν σφαίρες στην αρχή της επανάληψης, ποιό είναι το αναμενόμενο πλήθος σφαιρών στο τέλος μίας επανάληψης;
-
8.
Δοθέντος ενός δικαίου νομίσματος (πιθανότητα για Γράμματα (Γ) ή Κορώνα (Κ) είναι ) να εξομοιώσετε ένα κίβδηλο νόμισμα όπου η πιθανότητα εμφάνισης Κ είναι και η πιθανότητα εμφάνισης Γ είναι . Προσπαθείστε να ελαχιστοποιήσετε το μέσο αριθμό πειραμάτων (στρίψιμο νομίσματος) του δικαίου νομίσματος.
-
9.
Θεωρείστε τον παρακάτω αλγόριθμο εύρεσης ελαχίστου στοιχείου σε έναν μη ταξινομημένο πίνακα:
procedure random(A[1,...,n]) 1. min=Infinity; 2. for i <-- 1 to n in random order do 3. if (A[i]<min) 4. min<--A[i]; 5. return min(α) Στη χειρότερη περίπτωση, πόσες φορές θα εκτελεστεί η γραμμή 4;
(β) Ποιά είναι η πιθανότητα η γραμμή 4 να εκτελεστεί κατά την -ιοστή επανάληψη;
(γ) Ποιος είναι ο ακριβής αναμενόμενος αριθμός εκτελέσεων της γραμμής 4;
-
10.
Έστω ένα σύνολο σημείων στο επίπεδο. Ένα σημείο στο καλείται Pareto-βέλτιστο αν δεν υπάρχει άλλο σημείο που να είναι πιο πάνω και δεξιά από το .
(α) Σχεδιάστε και περιγράψτε έναν αλγόριθμο που υπολογίζει τα Pareto-βέλτιστα σημεία του σε χρόνο .
(β) Έστω ότι κάθε σημείο του επιλέγεται ανεξάρτητα και ισοπίθανα από το μοναδιαίο τετράγωνο . Ποιο είναι το αναμενόμενο πλήθος Pareto-βέλτιστων σημείων στο ;
-
11.
Έστω ότι παρακολουθούμε μία ροή (stream) από δεδομένα τα οποία τα επεξεργαζομαστε ένα κάθε φορά. Από τη στιγμή που ένα στοιχείο της ροής επεξεργαστεί και έρθει το επόμενο του, το χάνεται. Θέλουμε να πάρουμε ένα τυχαίο δείγμα διαφορετικών στοιχείων από τη ροή με τους παρακάτω περιορισμούς:
-
–
Μπορούμε να αποθηκεύσουμε μόνο στοιχεία κάθε χρονική στιγμή (το μέγεθος της μνήμης χωράει στοιχεία).
-
–
Δεν γνωρίζουμε το συνολικό αριθμό πακέτων στη ροή.
-
–
Αν αποφασίσουμε να μην αποθηκεύσουμε ένα στοιχείο την στιγμή που φτάνει σε εμάς, τότε αυτό χάνεται για πάντα.
Σχεδιάστε έναν αλγόριθμο ώστε όταν η ροή τερματιστεί, θα έχουμε αποθηκεύσει ένα υποσύνολο της ροής με στοιχεία επιλεγμένα με ίση πιθανότητα από όλα τα στοιχεία της ροής. Αν ο συνολικός αριθμός στοιχείων της ροής είναι μικρότερος του , τότε θα πρέπει να αποθηκεύσετε όλα τα πακέτα.
-
–
-
12.
Μας δίνεται ένα κίβδηλο νόμισμα με πιθανότητα εμφάνισης Κορώνας (Κ) και Γραμμάτων (Γ) . Πως θα εξομοιώσετε ένα δίκαιο νόμισμα (πιθανότητα Κ και Γ είναι ) χρησιμοποιώντας το κίβδηλο νόμισμα;
-
13.
Έστω ότι ο είναι ένας πίνακας πραγματικών αριθμών (διαφορετικών μεταξύ τους), και έστω ένας πίνακας δεικτών για τον πίνακα με την εξής ιδιότητα: Αν το είναι το μεγαλύτερο στοιχείο του , τότε το είναι το μικρότερο στοιχείο του . Διαφορετικά το είναι το μικρότερο στοιχείο του μεγαλύτερο από το . Για παράδειγμα:
1 2 3 4 5 6 7 8 9 83 54 16 31 45 99 78 62 27 6 8 9 5 2 3 1 7 4 Περιγράψτε και αναλύστε έναν τυχαίο αλγόριθμο που αποφασίζει αν ένας αριθμός εμφανίζεται στον πίνακα σε αναμενόμενο χρόνο . Ο αλγόριθμος που θα προτείνετε δεν πρέπει να μεταβάλει τους πίνακες και .
-
14.
Ένα δέντρο πλειοψηφίας είναι ένα πλήρες δέντρο βάθους , όπου κάθε φύλλο έχει τιμή ή . Η τιμή ενός εσωτερικού κόμβου είναι η πλειοψηφούσα τιμή των παιδιών του. Θα ασχοληθούμε με το πρόβλημα εύρεσης της τιμής της ρίζας ενός τριαδικού πλειοψηφικού δέντρου δοθείσης της ακολουθίας των φύλλων σαν είσοδο. Για παράδειγμα, αν και τα φύλλα έχουν τιμή η ρίζα έχει τιμή (Σχήμα 13.7).
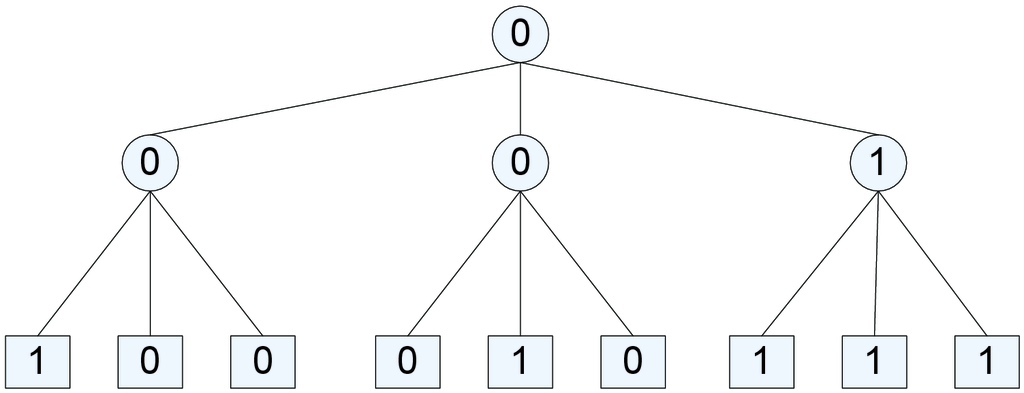
Σχήμα 13.7: Ένα τριαδικό δέντρο πλειοψηφίας με βάθος . Περιγράψτε και αναλύστε έναν τυχαίο αλγόριθμο που βρίσκει την τιμή της ρίζας σε αναμενόμενο χρόνο για κάποια σταθερά .
[Υπόδειξη: Κοιτάξτε την απλή περίπτωση . Έπειτα, εφαρμόστε αναδρομικά την διαδικασία αυτή.]
-
15.
Έστω ότι θέλουμε να φτιάξουμε ένα αλγόριθμο που βρίσκει μία αναδιάταξη των ακεραίων από , όπου κάθε δυνατή αναδιάταξη έχει ίδια πιθανότητα εμφάνισης. Ο παρακάτω αλγόριθμος είναι μία τέτοια υλοποίηση:
procedure RP(n) 1. for i <-- 1 to n 2. π[i]<--NULL; //Το π είναι ο πίνακας που θα περιέχει //την αναδιάταξη 3. for i <-- 1 to n 4. j<--Random(n); //Επιστρέφει ένα τυχαίο ακέραιο στο //διάστημα [1,n] ισοπίθανα 5. while(π[j]!=NULL) 6. j<--Random(n); 7. π[j]=i; 8. return(π);Απόδείξτε ότι ο αλγόριθμος είναι σωστός (να δείξετε δηλαδή ότι πράγματι παράγει μία αναδιάταξη ισοπίθανα). Ποιός είναι ο αναμενόμενος χρόνος εκτέλεσης του συγκεκριμένου αλγόριθμου;