7.3 Γεννήτριες Τυχαίων Αριθμών
Από τα παραπάνω απλά παραδείγματα ολοκλήρωσης Monte Carlo παρατηρούμε ότι το κοινό στοιχείο των μεθόδων επίλυσής τους είναι η δημιουργία «τυχαίων αριθμών» από μια κατανομή, ή αλλιώς η δειγματοληψία της συγκεκριμένης κατανομής. Η σωστή δειγματοληψία, την οποία συχνά περιγράφουμε και ως προσομοίωση, είναι το πρώτο και σημαντικότερο βήμα σε κάθε αλγόριθμο Monte Carlo, καθώς το στοχαστικό μοντέλο θα επιλυθεί χρησιμοποιώντας τους τυχαίους αριθμούς, οι οποίοι έχουν προκύψει από την συγκεκριμένη δειγματοληψία. Οι τυχαίοι αριθμοί είναι μια πολύ σημαντική έννοια στη θεωρία πιθανοτήτων και γενικότερα στην στατιστική ανάλυση. Τι είναι όμως οι «τυχαίοι αριθμοί» και πως δημιουργούνται; Όπως είδαμε και στην εισαγωγή τυχαίοι αριθμοί είναι μια ακολουθία αριθμών, η οποία έχει τις παρακάτω ιδιότητες:
-
(α)
Οι τιμές των αριθμών κατανέμονται μέσα σε ένα διάστημα, ακολουθώντας κάποια συγκεκριμένη κατανομή (συνήθως την ομοιόμορφη), και
-
(β)
Δεν υπάρχει καμία συσχέτιση μεταξύ των αριθμών. Δηλαδή δεν μπορούμε να προβλέψουμε τις επόμενες (μελλοντικές) τιμές των αριθμών δεδομένων των προηγούμενων τιμών τους.
Οι τυχαίοι αριθμοί είναι μια πρωταρχική έννοια σε κάθε αλγόριθμο Monte Carlo και γενικότερα στοχαστικής μοντελοποίησης – προσομοίωσης. Συνδέονται δε άμεσα με την έννοια των τυχαίων μεταβλητών, που είδαμε παραπάνω.
Ορισμός.
Γεννήτρια Τυχαίων Αριθμών: Γεννήτρια τυχαίων αριθμών ονομάζουμε τον αλγόριθμο δημιουργίας τυχαίων αριθμών σε κάποιο διάστημα, ακολουθώντας κάποια συγκεκριμένη κατανομή. Συνήθως το διάστημα είναι το και οι αριθμοί δημιουργούνται έτσι ώστε να υπακούουν την Ομοιόμορφη Κατανομή (uniform distribution). Πιο συγκεκριμένα αν είναι μια σειρά τυχαίων αριθμών, η γεννήτρια:
-
•
Ξεκινώντας από μια αρχική τιμή u0 δημιουργεί, μέσω μιας σχέσης Di(u0), την σειρά (ui) στο διάστημα [0, 1].
-
•
Οι τιμές πρέπει να αναπαράγουν τη συμπεριφορά ομοιόμορφων τυχαίων μεταβλητών, δηλαδή να υπακούουν την κατανομή .
Παρατήρηση 7.2.
«Φιλοσοφικό Παράδοξο»: Προσέξτε ότι οι «τυχαίοι αριθμοί» δημιουργούνται από ένα ντετερμινιστικό αλγόριθμο. Για το λόγο αυτό ονομάζονται και ψεύδο-τυχαίοι. Λόγω ακριβώς της ντετερμινιστικής τους φύσης οι παραπάνω αλγόριθμοι επαναλαμβάνουν περιοδικά την ίδια ακολουθία τυχαίων αριθμώ, αν ξεκινήσουν από ακριβώς τις ίδιες αρχικές συνθήκες.
Ορισμός.
Περίοδος Γεννήτριας Τυχαίων Αριθμών: Περίοδος ενός αλγορίθμου δημιουργίας τυχαίων αριθμών είναι ο ακέραιος αριθμός για τον οποίο ισχύει:
Η επαναλαμβανόμενη σειρά τυχαίων αριθμών δεν είναι σημαντικό πρόβλημα όσο το μέγεθός της δεν ξεπερνά την περίοδο του αλγορίθμου. Αν όμως την ξεπεράσει μπορεί να δημιουργήσει πρόβλημα λόγω της ισχυρής συσχέτισης μεταξύ των δημιουργούμενων αριθμών. Παρακάτω θα δούμε αναλυτικά τρόπους – αλγορίθμους δημιουργίας «τυχαίων», ή καλύτερα ψευδό-τυχαίων αριθμών.
7.3.1 Ομοιόμορφη Κατανομή
Όπως είδαμε και παραπάνω, η πιο συνηθισμένη σειρά τυχαίων αριθμών αφορά μια ακολουθία αριθμών στο διάστημα , η οποία ακολουθεί την ομοιόμορφη κατανομή, δηλαδή την . Στο κεφάλαιο αυτό θα εξετάσουμε δύο διαφορετικούς αλγόριθμους δημιουργίας τυχαίων αριθμών από την ομοιόμορφη κατανομή.
Αλγόριθμος «Συμβατική Γεννήτρια»
Ο πρώτος αλγόριθμος που θα δούμε είναι η συμβατική γεννήτρια (congruential generator) τυχαίων αριθμών. Έστω μία σειρά n τυχαίων αριθμών. Η σειρά αναπαράγεται μέσω της σχέσης:
| (7.5) |
όπου είναι σταθερές (ακέραιοι φυσικοί αριθμοί). Το δεξί μέλος της παραπάνω σχέσης υποδηλώνει το υπόλοιπο της διαίρεσης των ακεραίων αριθμών και .
Πιο συγκεκριμένα, ο αλγόριθμος αποτελείται από τα παρακάτω βήματα:
-
(α)
Αρχικά επιλέγουμε τις τιμές των ακεραίων καθώς και μία αρχική τιμή (“seed”) .
-
(β)
Για υπολογίζουμε μέσω των παραπάνω σχέσεων την ακέραια μεταβλητή και την πραγματική .
Ο αλγόριθμος αυτός είναι αρκετά απλός και μια υλοποίηση του παρουσιάζεται στο Παράρτημα του κεφαλαίου σε γλώσσα MATLAB. Πώς ξέρουμε όμως ότι ο παραπάνω αλγόριθμος είναι μια «καλή» γεννήτρια τυχαίων αριθμών; Όπως αναφέραμε θα πρέπει να ελέγξουμε:
-
(α)
Αν αναπαράγει την ομοιόμορφη κατανομή στο διάστημα , και
-
(β)
Αν υπάρχει συσχέτιση μεταξύ των τυχαίων αριθμών που δημιουργεί.
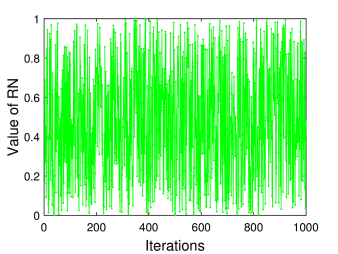
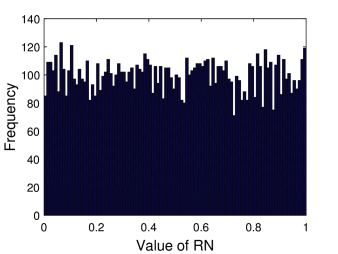
Κατόπιν υλοποιούμε τον παραπάνω αλγόριθμο για συγκεκριμένες τιμές των σταθερών. Αποτελέσματα φαίνονται στο παρακάτω διάγραμμα (Σχήμα 7.3). Πρώτα, στο Σχήμα 7.3α βλέπουμε ενδεικτικά μια σειρά τυχαίων αριθμών. Όπως παρατηρούμε όλοι οι αριθμοί βρίσκονται, όπως θα περιμέναμε, μέσα στο επιθυμητό διάστημα ενώ ακολουθούν μια αρκετά «ακανόνιστη» τροχιά.
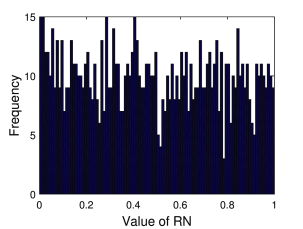
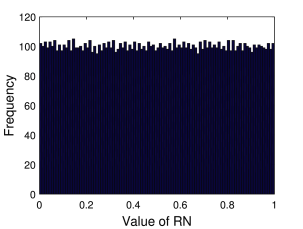
Στο Σχήμα 7.3β βλέπουμε την κατανομή αυτών, η οποία όπως βλέπουμε προσεγγίζει την ομοιόμορφη κατανομή. Ο συγκεκριμένος αριθμός όμως δεν είναι ακόμη αρκετά μεγάλος για να αναπαράγει με ακρίβεια την ομοιόμορφη κατανομή. Στο Σχήμα 7.3γ βλέπουμε την κατανομή ενός μεγαλύτερου αριθμού τυχαίων αριθμών . Όπως βλέπουμε η κατανομή αυτών είναι πολύ πιο «κοντά» στην ομοιόμορφη. Αυτό είναι κάτι που περιμένουμε καθώς όσο αυξάνει η δειγματοληψία από μια συγκεκριμένη κατανομή, τόσο περισσότερο θα πρέπει η κατανομή των δειγματοληπτούμενων Τ.Μ. θα πρέπει να προσεγγίζει τη κατανομή αυτή. Στο όριο που ο αριθμός αυτός φτάνει στο άπειρο θα πρέπει να αναπαράγεται ακριβώς η συγκεκριμένη κατανομή.
 |
 |
 |
Ερώτηση κατανόησης 7.3.
Για ποιο λόγο η κατανομή συχνοτήτων στο Σχήμα 7.3γ για έχει τιμές περίπου ίσες με 100; Θα άλλαζε αυτός ο αριθμός αν άλλαζε ο αριθμός των τυχαίων αριθμών ;
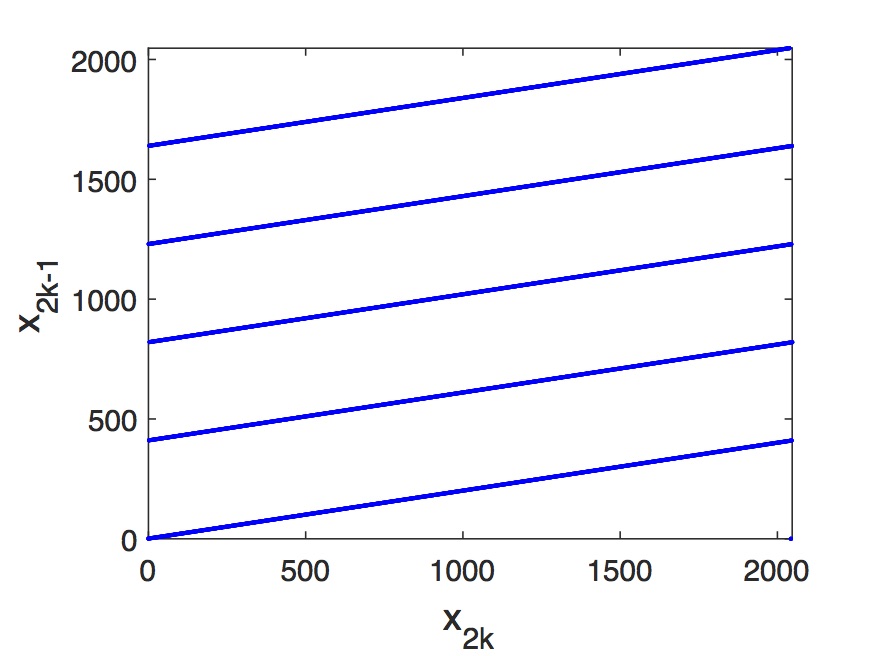
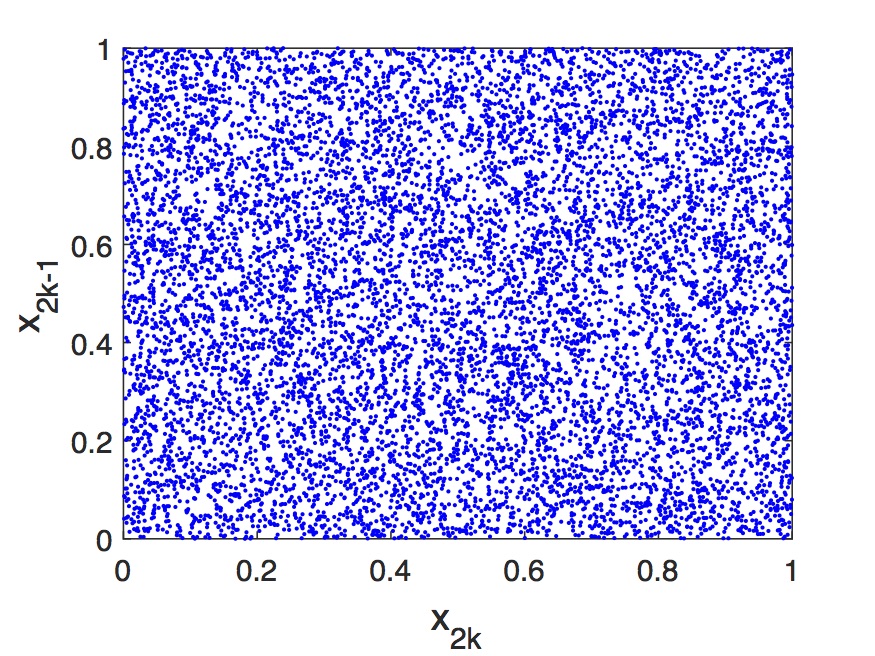
Σε δεύτερο στάδιο ελέγχουμε το αν υπάρχει συσχέτιση μεταξύ των διαφορετικών τυχαίων αριθμών. Αν υπάρχει θα περιμέναμε να είναι πιο ισχυρή μεταξύ διαδοχικών τυχαίων αριθμών. Για το λόγο αυτό ελέγχουμε τη συσχέτιση με διαγράμματα διαδοχικών αριθμών τύπου vs. όπου , δηλαδή άρτιων-περιττών. Αν δεν υπάρχει συσχέτιση τα ζευγάρια μπορούν να πάρουν κάθε τιμή στο [0-1, 0-1], ενώ αν υπάρχει συσχέτιση δεν είναι όλα τα ζευγάρια δυνατά και δημιουργούνται συγκεκριμένα «μοτίβα». Στο Σχήμα 7.4 παρουσιάζουμε τα ζευγάρια από την παραπάνω υλοποίηση. Βλέπουμε ότι, τουλάχιστον για τις συγκεκριμένες τιμές των σταθερών του αλγορίθμου, υπάρχει ισχυρή συσχέτιση μεταξύ διαδοχικών τυχαίων αριθμών. Συνεπώς ο συγκεκριμένος αλγόριθμος δεν είναι η καλύτερη δυνατή λύση.
Αλγόριθμος «Mersenne Twister»
Ο δεύτερος αλγόριθμος που θα δούμε είναι ο αλγόριθμος Mersenne Twister. Αυτός είναι ένας ιδιαίτερα πολύπλοκος αλγόριθμος που χρησιμοποιείται σε πολλά πακέτα μοντελοποίησης για την ακριβή δημιουργία τυχαίων αριθμών. Επίσης είναι ενσωματωμένη συνάρτηση και προεπιλεγμένη γεννήτρια τυχαίων αριθμών σε διάφορες γλώσσες προγραμματισμού, όπως η γλώσσα MATLAB (συνάρτηση rand). Τα αποτελέσματα από την εφαρμογή του αλγορίθμου Mersenne Twister φαίνονται παρακάτω στο Σχήμα 7.5. Αρχικά στο Σχήμα 7.5α βλέπουμε την κατανομή τυχαίων αριθμών η οποία όπως θα περιμέναμε προσεγγίζει πολύ καλά την ομοιόμορφη κατανομή. Κατόπιν στο Σχήμα 7.5β εξετάζουμε συσχέτιση μεταξύ διαδοχικών αριθμών μέσω γραφημάτων vs. όπως και παραπάνω. Είναι ξεκάθαρο ότι δεν υπάρχει καμία συσχέτιση μεταξύ διαδοχικών τυχαίων αριθμών.
 |
 |
Ερώτηση κατανόησης 7.4.
Συμπερασματικά μια καλή γεννήτρια τυχαίων αριθμών είναι ένας ντετερμινιστικός αλγόριθμος ο οποίος θα πρέπει:
-
(α)
να αναπαράγει την συγκεκριμένη κατανομή,
-
(β)
να μην υπάρχει συσχέτιση μεταξύ των τ.μ., και
-
(γ)
να έχει αρκετά μεγάλη περίοδο.
Σήμερα υπάρχουν πλέον αρκετά καλοί τέτοιοι αλγόριθμοι, οι οποίοι είναι ενσωματωμένοι ως εσωτερικές συναρτήσεις σε κάθε γλώσσα προγραμματισμού.
7.3.2 Αντίστροφη Μέθοδος
Όπως είδαμε παραπάνω η δειγματοληψία τυχαίων μεταβλητών από την ομοιόμορφη κατανομή μπορεί να γίνει με μεγάλη επιτυχία. Τι γίνεται όμως αν επιθυμούμε δειγματοληψία από μια διαφορετική κατανομή; Αυτό είναι ένα αρκετά δύσκολο πρόβλημα το οποίο δεν έχει λύση για οποιαδήποτε κατανομή.
Στην πραγματικότητα μπορούμε να πάρουμε απ’ευθειας δειγματοληψία, μόνο από ένα μικρό αριθμό κατανομών. Υπάρχει όμως ένα θεώρημα που μας επιτρέπει να πάρουμε από μία κατανομή αν ξέρουμε την αντίστροφη συνάρτηση κατανομής. Παρακάτω, πρώτα ορίζουμε την αντίστροφη συνάρτηση και μετά δίνουμε ένα παράδειγμα δειγματοληψίας από μια κατανομή, χρησιμοποιώντας την αντίστροφή της.
Ορισμός.
Αντίστροφη Συνάρτηση (Inverse Function): Για μια συνάρτηση η αντίστροφή της είναι η:
| (7.6) |
Λήμμα.
Έστω μια τυχαία μεταβλητή με και η προσθετική συνάρτηση κατανομής. Τότε η τ.μ. έχει κατανομή όπου .
Σύντομο πρόβλημα 7.1.
Αποδείξτε το παραπάνω Λήμμα.
Υπενθυμίζουμε εδώ τον ορισμό της προσθετικής συνάρτησης κατανομής.
Ορισμός.
Προσθετική Συνάρτηση Κατανομής (Cumulative Distribution Function) Έστω μια τυχαία μεταβλητή . Η συνάρτηση:
| (7.7) |
ονομάζεται προσθετική συνάρτηση κατανομής.
Παράδειγμα 7.1.
Εκθετική κατανομή. Η εκθετική κατανομή είναι μια οικογένεια κατανομών η οποία ορίζεται, για ένα δεδομένο φυσικό αριθμό , ως:
| (7.8) |
Έστω μια τυχαία μεταβλητή, , η οποία υπακούει την εκθετική κατανομή με , δηλαδή: . Η προσθετική συνάρτηση κατανομής είναι: . Υπολογίζοντας την αντίστροφη συνάρτηση, δηλαδή λύνοντας ως προς , έχουμε την: . Άρα, για η ακολουθεί την εκθετική κατανομή.
Παρατήρηση 7.3.
Προσέξτε ότι σε αυτό το παράδειγμα χρησιμοποιήσαμε την ιδιότητα ότι αν η είναι τ.μ. που ακολουθεί την ομοιόμορφη κατανομή στο τότε το ίδιο ισχύει και για την , δηλαδή αν και η .
Παρατήρηση 7.4.
Η εφαρμογή της παραπάνω μεθόδου απαιτεί ακριβής γνώση (υπολογισμό) της προσθετικής συνάρτησης κατανομής. Σε πολλές περιπτώσεις (κατανομές) αυτό δεν είναι εφικτό.
Ερώτηση κατανόησης 7.5.
Ποια είναι η προσθετική συνάρτησης κατανομής της κανονικής κατανομής;
7.3.3 Κανονική Κατανομή
Όπως είδαμε παραπάνω η δειγματοληψία τυχαίων μεταβλητών από την ομοιόμορφη κατανομή μπορεί να γίνει με μεγάλη επιτυχία. Τι γίνεται όμως αν επιθυμούμε δειγματοληψία από μια διαφορετική κατανομή; Αυτό είναι ένα αρκετά δύσκολο πρόβλημα το οποίο δεν έχει λύσει για οποιαδήποτε κατανομή.
Στην πραγματικότητα μπορούμε να πάρουμε απευθείας δειγματοληψία, μόνο από ένα μικρό αριθμό κατανομών. Από τις κατανομές αυτές πιο σημαντική είναι η κανονική κατανομή καθώς σε πολλά προβλήματα εμφανίζονται τυχαίες μεταβλητές οι οποίες υπακούουν την κανονική κατανομή. Παρακάτω περιγράφουμε ένα αλγόριθμο δημιουργίας τ.μ. από την κανονική κατανομή.
Αλγόριθμος Box – Muller
Θεωρήστε ζευγάρι τ.μ. και τις αντίστοιχες πολικές συντεταγμένες , όπου:
| (7.9) |
Αν οι έρχονται από την κανονική κατανομή με μέση τιμή 0 και διασπορά 1, τότε , η τ.μ. έρχεται από την ομοιόμορφη κατανομή στο , και η από την εκθετική κατανομή με .
Σύντομο πρόβλημα 7.2.
Αποδείξτε την παραπάνω ιδιότητα.
Συνεπώς ένας αλγόριθμος δημιουργίας τ.α. από την κανονική κατανομή είναι ο ακόλουθος:
-
(α)
Δημιουργία μιας τ.μ. («γωνίας») και μιας δεύτερης τ.μ. («ακτίνας») . Υπενθυμίζουμε ότι στα προηγούμενα υπο-κεφάλαια είδαμε τρόπους δημιουργίας τ.μ. τόσο από την ομοιόμορφη όσο και από την εκθετική κατανομή.
-
(β)
Μετατροπή των τ.μ. και στις καρτεσιανές συντεταγμένες από τις παραπάνω σχέσεις (7.9).
-
(γ)
Επιστροφή στο βήμα (α).
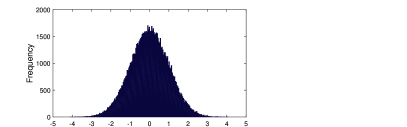
Στο Σχήμα 7.6 παρουσιάζεται η κατανομή που ακολουθούν τυχαίοι αριθμού που έχουν δημιουργηθεί από τον παραπάνω αλγόριθμο. Όπως βλέπουμε ότι προσεγγίζουν με μεγάλη ακρίβεια την κανονικά κατανομή.
7.3.4 Μέθοδοι Αποδοχής – Απόρριψης
Όπως αναφέραμε και παραπάνω στη γενική περίπτωση δεν μπορούμε να πάρουμε δειγματοληψία, για μια τ.μ. , από οποιαδήποτε πυκνότητα πιθανότητας . Μια εναλλακτική μέθοδο σε αυτή την περίπτωση είναι οι εφαρμογή μεθόδων αποδοχής-απόρριψης (accept-reject).
Βασική ιδέα των μεθόδων αποδοχής – απόρριψης: Δειγματοληπτούμε την τ.μ. από μια άλλη πυκνότητα η οποία είναι σχετικά παρόμοια της , και από την οποία μπορούμε να πάρουμε δειγματοληψία.
Η παραπάνω ιδέα βασίζεται στο παρακάτω θεώρημα:
Θεώρημα.
Πρωταρχικό Θεώρημα προσομοίωσης (Fundamental Theorem of Simulation). Η προσομοίωση της τ.μ. είναι ισοδύναμη με την προσομοίωση του ζευγαριού τ.μ. .
Το παραπάνω θεώρημα δεν μας βοηθά άμεσα καθώς η προσομοίωση του ζευγαριού είναι εξίσου δύσκολη με αυτή της αρχικής μεταβλητής. Αυτό όμως που μπορεί να γίνει είναι η προσομοίωση του ζευγαριού σε ένα μεγαλύτερο σύνολο και κατόπιν η τελική επιλογή του ζευγαριού που ικανοποιεί τον παραπάνω περιορισμό.
Αλγόριθμος Αποδοχής – Απόρριψης (Accept – Reject or Rejection Sampling Algorithm)
Έστω δύο πυκνότητες με για κάθε . Μπορούμε να δημιουργήσουμε δείγμα από την μέσω του παρακάτω αλγορίθμου:
-
(α)
Δημιουργία
-
(β)
Αποδοχή με πιθανότητα
-
(γ)
Επιστροφή στο βήμα (α).
Τελικά εύκολα δείχνουμε ότι για κάθε μετρήσιμο σύνολο οι τιμές της είναι από την κατανομή :
| (7.10) |
Με άλλα λόγια αν θεωρήσουμε ότι οι τ.μ. που θέλουμε να δημιουργήσουμε βρίσκονται μέσα σε ένα σύνολο τιμών και δημιουργήσουμε ομοιόμορφο δείγμα τ.μ. από ένα υπερσύνολό του , τότε κρατώντας μόνο τους όρους που είναι και μέσα στο μπορούμε τελικά να έχουμε ένα ομοιόμορφο δείγμα στο .