Next: 7.4 Ισοδυναμία NFA και Up: 7. Τυπικές γλώσσες και Previous: 7.2 Ντετερμινιστικά Αυτόματα Contents Index
Θα δούμε όμως σύντομα ότι αυτό είναι μόνο φαινομενικό, και ότι τα δύο μοντέλα είναι απολύτως ισοδύναμα, όσον αφορά τουλάχιστον το ποιες γλώσσες αναγνωρίζουν. Με άλλα λόγια, θα δούμε μια μέθοδο που για κάθε NFA θα κατασκευάζει ένα ισοδύναμο DFA, ένα DFA δηλ. που θα αναγνωρίζει ακριβώς την ίδια γλώσσα με το δοθέν NFA. Παρ' όλα αυτα το να μελετούμε NFA προσφέρει μερικά πλεονεκτήματα σε σχέση με τα DFA σε ορισμένες περιπτώσεις, όπως θα δούμε στα παραδείγματα.
Ένα μη ντετερμινιστικό αυτόματο είναι σαν ένα DFA αλλά για
κάθε κορυφή και για κάθε γράμμα του αλφαβήτου μπορεί κανεις
να έχει οποιοδήποτε πεπερασμένο
πλήθος από ακμές που ξεκινούν από την κορυφή και έχουν
το γράμμα ως ετικέτα
Μπορεί ακόμη και να μην υπάρχει καμία ακμή από κάποια
κορυφή για κάποιο γράμμα.
(Αν
![]() είναι το κενό
σύνολο τότε δεν υπάρχει στο γράφημα καμία ακμή από την κορυφή
είναι το κενό
σύνολο τότε δεν υπάρχει στο γράφημα καμία ακμή από την κορυφή ![]() με ετικέτα
με ετικέτα ![]() .)
.)
Η σημαντική διαφορά με πριν είναι ότι, όταν διαβάζουμε μια λέξη,
δεν είναι πλέον μονοσήμαντα καθορισμένη η κίνησή μας πάνω στο γράφημα αφού
ενδέχεται να έχουμε περισσότερες από μία επιλογές μετάβασης όντας σε μία κορυφή
και διαβάζοντας ένα γράμμα.
Το σε ποιες καταστάσεις μπορούμε να πάμε από μια κατάσταση ![]() αφού διαβάσουμε
το γράμμα
αφού διαβάσουμε
το γράμμα ![]() μας το λέει η συνάρτηση μετάβασης.
Το σύνολο αυτών των δυνατών καταστάσεων είναι το
μας το λέει η συνάρτηση μετάβασης.
Το σύνολο αυτών των δυνατών καταστάσεων είναι το
![]() .
.
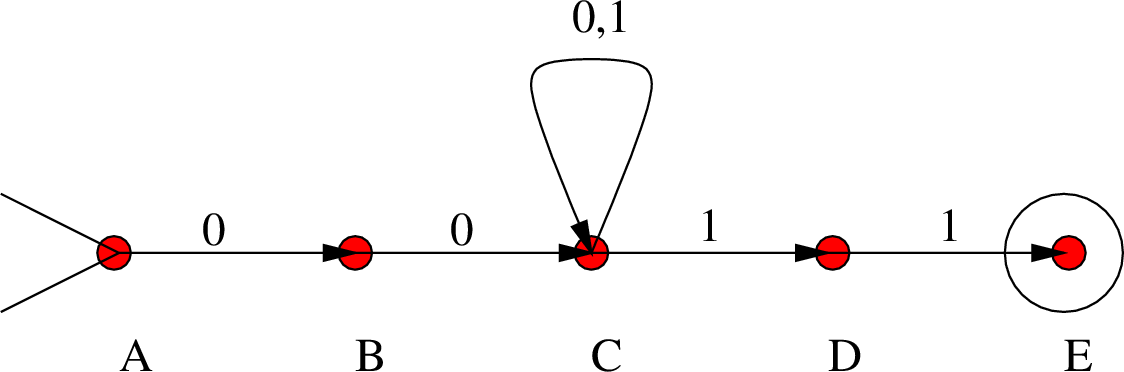
Πρόκειται για NFA και όχι για DFA μια και στη μεσαία κορυφή υπάρχουν δύο ακμές με ετικέτα 1. Παρατηρήστε τη συντομογραφία που επιλέξαμε εδώ: ο βρόχος (loop) από τη μεσαία κορυφή στον εαυτό της έχει δύο ετικέτες 0 και 1. Αυτό σημαίνει ότι επιτρέπεται να διανύσουμε την κορυφή αυτή όταν διαβάσουμε είτε 0 είτε 1. Θα μπορούσαμε να είχαμε το ίδιο αποτέλεσμα αν φτιάχναμε δύο βρόχους από την κορυφή αυτή στον εαυτό της, ένα με ετικέτα 0 κι ένα με ετικέτα 1. Επιλέγουμε τη συντομογραφία για καθαρότητα στο σχήμα και τίποτε άλλο.
Γιατί το NFA του σχήματος 7.6 αναγνωρίζει τη γλώσσα
![]() ;
Παρατηρήστε ότι η
;
Παρατηρήστε ότι η ![]() αποτελείται από εκείνες ακριβώς τις λέξεις που αρχίζουν
με
αποτελείται από εκείνες ακριβώς τις λέξεις που αρχίζουν
με ![]() και τελειώνουν με
και τελειώνουν με ![]() .
Κάθε τέτοια λέξη περνάει από το NFA ως εξής: με τα δύο πρώτα 0 μεταβαίνει
στη μεσαία κορυφή, στην οποία και παραμένει χρησιμοποιώντας το βρόχο μέχρι
να διαβάσει και το προπροτελευταίο γράμμα. Με τα δύο τελευταία 1 επιλέγει
να κινηθεί προς τα δεξιά για να καταλήξει στη μοναδική τελική κορυφή.
Θα μπορούσε να επιλέξει με τα δύο τελευταία 1 να κινηθεί πάνω στο
βρόχο της μεσαίας κορυφής, αλλά με αυτό τον τρόπο δεν καταλήγει σε
τελική κορυφή. Αρκεί όμως για την αποδοχή μιας λέξης να υπάρχει έστω και
ένας τρόπος να γίνει αποδεκτή.
.
Κάθε τέτοια λέξη περνάει από το NFA ως εξής: με τα δύο πρώτα 0 μεταβαίνει
στη μεσαία κορυφή, στην οποία και παραμένει χρησιμοποιώντας το βρόχο μέχρι
να διαβάσει και το προπροτελευταίο γράμμα. Με τα δύο τελευταία 1 επιλέγει
να κινηθεί προς τα δεξιά για να καταλήξει στη μοναδική τελική κορυφή.
Θα μπορούσε να επιλέξει με τα δύο τελευταία 1 να κινηθεί πάνω στο
βρόχο της μεσαίας κορυφής, αλλά με αυτό τον τρόπο δεν καταλήγει σε
τελική κορυφή. Αρκεί όμως για την αποδοχή μιας λέξης να υπάρχει έστω και
ένας τρόπος να γίνει αποδεκτή.
Αντίστροφα τώρα, αν η λέξη ![]() περνά από το NFA τότε υποχρεωτικά αρχίζει από
δύο 0 (αλλιώς δε μπορεί να πάει δεξιότερα
από τη δεύτερη κορυφή) και τελειώνει σε δύο 1 (αλλιώς δε μπορεί να καταλήξει
στην τελική κορυφή).
περνά από το NFA τότε υποχρεωτικά αρχίζει από
δύο 0 (αλλιώς δε μπορεί να πάει δεξιότερα
από τη δεύτερη κορυφή) και τελειώνει σε δύο 1 (αλλιώς δε μπορεί να καταλήξει
στην τελική κορυφή).
Ας δώσουμε τώρα και ένα DFA για την ίδια γλώσσα:
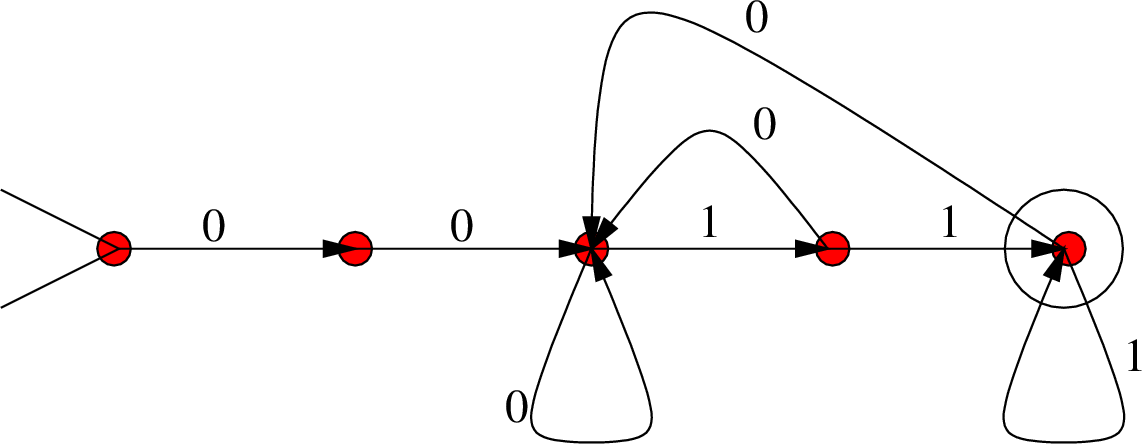
Είναι μια καλή άσκηση να να αποδείξετε ότι το άνω αυτόματο
αναγνωρίζει τη γλώσσα
![]() . Για να το κάνετε δώστε κάποιο
«νόημα» στις καταστάσεις, όπως κάναμε παραπάνω για να δείξουμε ότι το
DFA του σχήματος 7.5 δουλεύει.
. Για να το κάνετε δώστε κάποιο
«νόημα» στις καταστάσεις, όπως κάναμε παραπάνω για να δείξουμε ότι το
DFA του σχήματος 7.5 δουλεύει.