Κεφάλαιο 3Το Λογικό Μοντέλο
3.1 Εισαγωγή
Η Ανάκτηση Πληροφορίας, όπως έχουμε αναφέρει σε προηγούμενο κεφάλαιο, στοχεύει στην εξυπηρέτηση των πληροφοριακών αναγκών των χρηστών. Βασικό ρόλο για την επίτευξη του στόχου αυτού παίζει ο μηχανισμός που χρησιμοποιείται από ένα ΣΑΠ για τον προσδιορισμό των σχετικών εγγράφων ως προς κάποιο ερώτημα. Ο μηχανισμός αυτός καλείται εναλλακτικά και μοντέλο Ανάκτησης Πληροφορίας. Η περιγραφή του μοντέλου ανάκτησης προϋποθέτει ότι έχει καθοριστεί ο τρόπος αναπαράστασης των εγγράφων και των ερωτημάτων, καθώς επίσης και ο τρόπος προσδιορισμού της σχετικότητας ενός εγγράφου ως προς κάποιο ερώτημα.
Στο κεφάλαιο αυτό θα μελετήσουμε ένα από τα πρώτα και απλούστερα μοντέλα ανάκτησης που έχουν προταθεί. Το μοντέλο αυτό καλείται Λογικό ή Boolean μοντέλο, διότι όπως θα δούμε στη συνέχεια στηρίζεται σε λογικές εκφράσεις της άλγεβρας Boole για τον προσδιορισμό των ερωτημάτων. Το Λογικό μοντέλο μαζί με το Διανυσματικό μοντέλο και το Πιθανοτικό μοντέλο αποτελούν την οικογένεια των κλασσικών μοντέλων ανάκτησης. Επίσης θα περιγράψουμε τις επεκτάσεις που έχει υποστεί το Boolean μοντέλο έτσι ώστε να καλύψει πληρέστερα τις πληροφοριακές ανάγκες των χρηστών και, τέλος, θα συζητήσουμε τα πλεονεκτήματα και τα μειονεκτήματά του.
3.2 Το Απλό Λογικό Μοντέλο
Τόσο στο Λογικό μοντέλο όσο και στα άλλα δύο μοντέλα που απαρτίζουν την οικογένεια των κλασικών μοντέλων ανάκτησης τα έγγραφα της συλλογής αναπαρίστανται με όρους (terms) ή αλλιώς λέξεις-κλειδιά (key-words). Στη γενικότερη περίπτωση, χρησιμοποιούνται όλοι οι όροι των εγγράφων. Ωστόσο, λαμβάνοντας υπόψη ότι πολλοί από τους όρους ενός εγγράφου δεν προσφέρουν σημαντική πληροφορία (όπως για παράδειγμα τα άρθρα και τα επίθετα) σε πολλές περιπτώσεις πραγματοποιείται προ-επεξεργασία των εγγράφων με στόχο τη διατήρηση των λέξεων που περιέχουν σημαντική πληροφορία. Οι όροι με το περισσότερο πληροφοριακό περιεχόμενο είναι τα ουσιαστικά, ενώ άρθρα, ρήματα και επιρρήματα συνήθως δεν χρησιμοποιούνται για την αναπαράσταση των εγγράφων. Συνήθως, στις μηχανές αναζήτησης που χρησιμοποιούνται στον παγκόσμιο ιστό όπως και σε πολλά άλλα συστήματα χρησιμοποιούνται όλοι οι όροι για την αναπαράσταση των εγγράφων, οπότε στην περίπτωση αυτή έχουμε αναπαράσταση πλήρους κειμένου (full text). Για τις ανάγκες αυτού του κεφαλαίου θα χρησιμοποιήσουμε τη μικρή συλλογή εγγράφων του Κεφαλαίου 1, η οποία παρουσιάζεται εκ νέου στο Σχήμα 3.1 για τη διευκόλυνση του αναγνώστη.
| : | Ο κομήτης του Χάλλεϋ μας επισκέπτεται περίπου κάθε εβδομήντα έξι χρόνια. |
|---|---|
| : | Ο κομήτης του Χάλλεϋ ανακαλύφθηκε από τον αστρονόμο Έντμοντ Χάλλεϋ. |
| : | Ένας κομήτης διαγράφει ελλειπτική τροχιά. |
| : | Ο πλανήτης Άρης έχει δύο φυσικούς δορυφόρους, το Δείμο και το Φόβο. |
| : | Ο πλανήτης Δίας έχει εξήντα τρεις γνωστούς φυσικούς δορυφόρους. |
| : | Ο Ήλιος είναι ένας αστέρας. |
| : | Ο Άρης είναι ένας πλανήτης του ηλιακού μας συστήματος. |
3.2.1 Βασικές Έννοιες
Το απλό Λογικό μοντέλο ανάκτησης είναι από τα πρώτα μοντέλα που χρησιμοποιήθηκαν στα συστήματα ανάκτησης πληροφορίας κυρίως λόγω του ότι στηρίζεται στη θεωρία συνόλων και επομένως χαρακτηρίζεται από απλότητα. Τα ερωτήματα αναπαρίστανται με λογικές εκφράσεις της άλγεβρας Boole χρησιμοποιώντας τους τελεστές AND (σύζευξη), OR (διάζευξη) και NOT (άρνηση). Εναλλακτικά χρησιμοποιούμε τα σύμβολα για τον τελεστή AND, για τον τελεστή OR και για τον τελεστή NOT. Μεγαλύτερη προτεραιότητα έχει ο τελεστής NOT, στη συνέχεια ο τελεστής AND και τέλος ο τελεστής OR. Σε περιπτώσεις που θέλουμε να αλλάξουμε την προτεραιότητα των τελεστών σε μία λογική έκφραση χρησιμοποιούνται παρενθέσεις. Στο Σχήμα 3.2 δίνονται μερικές βασικές λογικές εκφράσεις με τη μορφή διαγραμμάτων Venn.

Το βασικό χαρακτηριστικό του Λογικού μοντέλου είναι ότι υποστηρίζει την επακριβή ταύτιση (exact match). Αυτό σημαίνει ότι τα έγγραφα του αποτελέσματος θα πρέπει να ικανοποιούν πλήρως τη λογική έκφραση του ερωτήματος, δηλαδή η λογική έκφραση θα πρέπει να είναι αληθής για κάθε έγγραφο. Στον Πίνακα 3.1 δίνονται μερικά ερωτήματα με τη μορφή λογικών εκφράσεων και οι αντίστοιχες επεξηγήσεις. Αν συμβολίσουμε με το σύνολο των εγγράφων που περιέχονται στην απάντηση του ερωτήματος τότε έχουμε: = , = , = , = και = .
| ερώτημα | λογική | αναζήτηση εγγράφων |
| έκφραση | που περιέχουν τους όρους: | |
| κομήτης | κομήτης | |
| κομήτης AND Χάλλεϋ | κομήτης και Χάλλεϋ | |
| πλανήτης AND NOT Άρης | πλανήτης αλλά όχι Άρης | |
| (κομήτης OR Χάλλεϋ) AND πλανήτης | πλανήτης και κομήτης | |
| ή πλανήτης και Χάλλεϋ | ||
| πλανήτης OR κομήτης | πλανήτης ή κομήτης |
Στη γενική περίπτωση, ένα ερώτημα προσδιορίζει έναν ή περισσότερους όρους που μαζί με τους λογικούς τελεστές σχηματίζουν τη λογική έκφραση του ερωτήματος. Σύμφωνα με το Λογικό μοντέλο, ένας όρος είτε θα βρίσκεται σε ένα έγγραφο είτε όχι. Αυτό σημαίνει ότι για κάθε έγγραφο και κάθε όρο του ερωτήματος μπορούμε να αντιστοιχήσουμε μία τιμή που μπορεί να λάβει μόνο τις τιμές 0 και 1. Αν =0 τότε ο όρος δεν βρίσκεται στο έγγραφο , ενώ αν =1 τότε ο όρος υπάρχει στο έγγραφο .
Εφόσον ένα ερώτημα ουσιαστικά αποτελεί μία λογική έκφραση, σύμφωνα με τη μεθοδολογία της άλγεβρας Boole μπορεί να κανονικοποιηθεί στη διαζευκτική κανονική μορφή (disjunctive normal form).
Ορισμός 3.1.
Η διαζευκτική κανονική μορφή ενός λογικού ερωτήματος συμβολίζεται με και έχει τη μορφή , όπου το κάθε ισούται είτε με είτε με , είναι το πλήθος των όρων του ερωτήματος και είναι το πλήθος των συζευκτικών συνιστωσών. Η -οστή συζευκτική συνιστώσα του ερωτήματος συμβολίζεται με .
Συνήθως, η διαζευκτική κανονική μορφή ενός ερωτήματος δίνεται με τη μορφή διανύσματος και συμβολίζεται με . Επίσης, μπορούμε να θεωρήσουμε ότι και κάθε συζευκτική συνιστώσα αναπαριστάται με ένα διάνυσμα που αποτελείται από 1 και 0 ανάλογα με την παρουσία ή απουσία του αντίστοιχου όρου. Για παράδειγμα, ας θεωρήσουμε ένα ερώτημα που χρησιμοποιεί τρεις όρους (, , ) και εκφράζεται με την εξής λογική έκφραση:
| (3.1) |
| διάνυσμα | έκφραση | απάντηση | |||
|---|---|---|---|---|---|
| 0 | 0 | 0 | (0, 0, 0) | 0 | |
| 0 | 0 | 1 | (0, 0, 1) | 0 | |
| 0 | 1 | 0 | (0, 1, 0) | 0 | |
| 0 | 1 | 1 | (0, 1, 1) | 1 | |
| 1 | 0 | 0 | (1, 0, 0) | 0 | |
| 1 | 0 | 1 | (1, 0, 1) | 1 | |
| 1 | 1 | 0 | (1, 1, 0) | 0 | |
| 1 | 1 | 1 | (1, 1, 1) | 1 |

Με βάση το ερώτημα τα έγγραφα που θα επιστραφούν ως απάντηση πρέπει οπωσδήποτε να περιέχουν τον όρο και τουλάχιστον έναν από τους όρους και . Στον Πίνακα 3.2 δίνεται ο πίνακας αληθείας (truth table) για το ερώτημα , από όπου φαίνεται ότι η λογική έκφραση του ερωτήματος γίνεται αληθής για τους συνδυασμούς: (0, 1, 1), (1, 0, 1) και (1, 1, 1), όπου στο κάθε διάνυσμα η πρώτη τιμή αφορά στον όρο , η δεύτερη στον όρο και η τρίτη στον όρο . Στο Σχήμα 3.3 δίνεται ένα ενδεικτικό διάγραμμα Venn μαζί με τα αντίστοιχα διανύσματα. Η περιοχή του διαγράμματος που αντιστοιχεί στο ερώτημα δίνεται από τα διανύσματα που επαληθεύουν τη λογική έκφραση του ερωτήματος. Με βάση τα προηγούμενα, η διαζευκτική κανονική μορφή του ερωτήματος έχει τη μορφή:
| (3.2) |
Το ερώτημα αποτελείται από τρεις συζευκτικές συνιστώσες , και , όπου = , = και = . Τα αντίστοιχα διανύσματα είναι: = , = και = . Επομένως, η διανυσματική αναπαράσταση της διαζευκτικής κανονικής μορφής είναι:
| (3.3) |
Ένα έγγραφο θα βρίσκεται στην απάντηση αν επαληθεύει έναν από τους όρους της διαζευκτικής κανονικής μορφής. Για παράδειγμα, με βάση την διαζευκτική κανονική μορφή του ερωτήματος , ένα έγγραφο με διάνυσμα (1,1,1) σίγουρα θα ανήκει στην απάντηση.
3.2.2 Τελεστές Γειτονικότητας Όρων
Με τη χρήση των βασικών τελεστών AND, OR και NOT ο χρήστης μπορεί να προσδιορίσει την περιεκτικότητα ή όχι των όρων σε ολόκληρο το έγγραφο. Πολλές φορές όμως ενδιαφερόμαστε για την εμφάνιση κάποιων λέξεων που βρίσκονται συνεχόμενες ή που βρίσκονται στην ίδια πρόταση ή παράγραφο. Αν και το απλό Boolean μοντέλο δεν προσφέρει την περιγραφή τέτοιων ερωτημάτων, τα περισσότερα συστήματα που στηρίζονται στο μοντέλο αυτό υλοποιούν και μερικούς επιπλέον τελεστές αναγνωρίζοντας τις σχετικές ανάγκες των χρηστών. Οι τελεστές αυτοί αυξάνουν την εκφραστικότητα της γλώσσας ερωτημάτων και δίνουν τη δυνατότητα στους χρήστες να περιορίσουν κατά πολύ το σύνολο των εγγράφων της απάντησης.
Από τους πιο σημαντικούς τελεστές που έχουν χρησιμοποιηθεί με το Λογικό μοντέλο είναι οι εξής:
-
•
ADJ. Ο τελεστής αυτός χρησιμοποιείται για να δηλώσει ότι δύο όροι πρέπει να εμφανίζονται συνεχόμενοι μέσα στο έγγραφο της απάντησης (π.χ. πλανήτης ADJ Άρης).
-
•
NEAR/. Ο τελεστής χρησιμοποιείται για να δηλώσει την επιθυμία του χρήστη ότι δύο όροι θα πρέπει να έχουν απόσταση το πολύ μεταξύ τους, όπου είναι ο αριθμός των όρων (π.χ. πλανήτης NEAR/2 Άρης).
-
•
WITH. Με αυτόν τον τελεστή ο χρήστης μπορεί να δηλώσει ότι οι δύο όροι πρέπει να βρίσκονται στην ίδια πρόταση (π.χ. πλανήτης WITH Άρης).
-
•
SAME. Εδώ δηλώνουμε ότι οι όροι θέλουμε να βρίσκονται στην ίδια παράγραφο (π.χ. πλανήτης SAME Άρης).
Οι συμβολισμοί των τελεστών συνήθως διαφέρουν από σύστημα σε σύστημα. Για παράδειγμα, στο σύστημα WestLaw [76], που αποτελεί μία από τις μεγαλύτερες υπηρεσίες για την αναζήτηση νομικών πληροφοριών με πολύ μεγάλο αριθμό συνδρομητών, ο τελεστής WITH συμβολίζεται με /s, ο τελεστής SAME συμβολίζεται με /p ενώ ο τελεστής NEAR/ με /. Στο σύστημα CiteSeer [9], που αποτελεί έναν από τους μεγαλύτερους ιστότοπους παροχής βιβλιογραφικών πληροφοριών για την Πληροφορική επιστήμη, ο τελεστής NEAR/ συμβολίζεται με w/. Σημειώνεται ότι η προτεραιότητα των τελεστών ADJ, NEAR/, WITH και SAME είναι μεγαλύτερη από τους υπόλοιπους λογικούς τελεστές. Στον Πίνακα 3.3 δίνονται μερικά ερωτήματα χρησιμοποιώντας και τους επιπλέον τελεστές. Για κάθε ερώτημα δίνεται και το σύνολο των εγγράφων της απάντησης, με βάση τη συλλογή εγγράφων του Σχήματος 3.1.
| ερώτημα | σύνολο απάντησης |
|---|---|
| κομήτης ADJ Χάλλεϋ | { } |
| κομήτης NEAR/2 Χάλλεϋ | {, } |
| πλανήτης ADJ Άρης | {} |
| Δίας AND φυσικούς ADJ δορυφόρους | { } |
3.2.3 Επεξεργασία Ερωτημάτων
Στις προηγούμενες παραγράφους μελετήσαμε τον τρόπο έκφρασης ενός ερωτήματος στο απλό Λογικό μοντέλο. Στη συνέχεια θα εξετάσουμε τον τρόπο επεξεργασίας ενός Λογικού ερωτήματος από ένα ΣΑΠ και τον τρόπο επιστροφής των σχετικών εγγράφων στο χρήστη. Επειδή τα θέματα επεξεργασίας ερωτημάτων καλύπτονται εκτενώς σε άλλο κεφάλαιο, εδώ απλώς θα δείξουμε τη βασική μεθοδολογία που ακολουθείται για τον προσδιορισμό της απάντησης ενός Λογικού ερωτήματος.
Για τη γρήγορη επεξεργασία των ερωτημάτων θα πρέπει να υπάρχουν οι κατάλληλες μέθοδοι προσπέλασης, έτσι ώστε το σύστημα να μπορεί εύκολα να προσδιορίσει το σύνολο των εγγράφων που περιέχουν έναν όρο. Σε διαφορετική περίπτωση, θα πρέπει το σύστημα να εκτελέσει σειριακή αναζήτηση σε κάθε έγγραφο χωριστά ώστε να εντοπίσει τα έγγραφα που περιέχουν ένα συγκεκριμένο όρο. Η χρήση αυτής της μεθόδου δεν ενδείκνυται διότι οδηγεί σε πολύ μεγάλους χρόνους επεξεργασίας. Για το λόγο αυτό θα θεωρήσουμε ότι τα έγγραφα της συλλογής είναι οργανωμένα με τη βοήθεια ενός αντεστραμμένου καταλόγου, όπως έχουμε ήδη περιγράψει στο Κεφάλαιο 1.

Ένας αντεστραμμένος κατάλογος μπορεί να έχει διαφορετικές μορφές ανάλογα με τις βοηθητικές πληροφορίες που αποθηκεύει. Εδώ θα θεωρήσουμε ότι αποτελείται από το λεξιλόγιο (το σύνολο των λέξεων) και τις λίστες εμφανίσεων όπου για κάθε όρο αποθηκεύεται το έγγραφο στην οποία βρίσκεται και η αντίστοιχη θέση μέσα στο έγγραφο. Η θέση μπορεί να περιγραφεί είτε με τη θέση του πρώτου χαρακτήρα του όρου είτε με τον αύξοντα αριθμό του όρου μέσα στο έγγραφο. Για τις ανάγκες μας θα υποθέσουμε ότι καταχωρείται η θέση του πρώτου χαρακτήρα του όρου. Στο Σχήμα 3.4 παρουσιάζεται ένα τμήμα του αντεστραμμένου καταλόγου για τη συλλογή εγγράφων του Σχήματος 3.1.
Ο τρόπος χρήσης του αντεστραμμένου καταλόγου εξαρτάται από το ερώτημα. Για παράδειγμα, για ερωτήματα που προσδιορίζουν μόνο έναν όρο, το μόνο που χρειάζεται είναι να εντοπιστεί ο όρος στο λεξικό και στη συνέχεια να διαβαστεί η αντίστοιχη λίστα εμφανίσεων για το συγκεκριμένο όρο. Έστω το ερώτημα = κομήτης. Από τη λίστα εμφανίσεων του όρου κομήτης είναι προφανές ότι τα σχετικά έγγραφα ως προς το ερώτημα αυτό είναι τα , , και , επομένως η απάντηση στο ερώτημα είναι:
| (3.4) |
Μεγαλύτερο ενδιαφέρον παρουσιάζει η επεξεργασία ερωτημάτων που περιέχουν περισσότερους όρους και χρησιμοποιούν τελεστές. Έστω το ερώτημα = πλανήτης Άρης. Τα σχετικά έγγραφα ως προς το ερώτημα είναι αυτά που περιέχουν είτε τον όρο πλανήτης είτε τον όρο Άρης ή και τις δύο. Στην περίπτωση αυτή, αφού πρώτα εντοπισθούν οι λίστες εμφανίσεων των δύο λέξεων, στην συνέχεια υπολογίζεται η ένωση των συνόλων των εγγράφων. Από τον αντεστραμμένο κατάλογο έχουμε ότι τα έγγραφα που περιέχουν τον όρο πλανήτης είναι τα , , , , ενώ τα έγγραφα που περιέχουν τον όρο Άρης είναι τα , . Τα σχετικά έγγραφα ως προς το ερώτημα αντιστοιχούν στην ένωση των επιμέρους αποτελεσμάτων. Άρα, η απάντηση στο ερώτημα είναι:
| (3.5) |
Στη συνέχεια εξετάζουμε τον τρόπο επεξεργασίας ενός ερωτήματος που χρησιμοποιεί τη σύζευξη. Έστω το ερώτημα = πλανήτης Άρης. Τα σχετικά έγγραφα ως προς το ερώτημα αυτό είναι αυτά που περιέχουν και τους δύο όρους. Με βάση τις λίστες εμφανίσεων για την κάθε όρο για να υπολογίσουμε την ολοκληρωμένη απάντηση θα πρέπει να υπολογίσουμε την τομή των επιμέρους αποτελεσμάτων. Επομένως:
| (3.6) |
Στην περίπτωση της σύζευξης θα μπορούσαμε να εφαρμόσουμε και μία άλλη τεχνική αν το επιτρέπει ο τρόπος οργάνωσης του αντεστραμμένου καταλόγου. Αν μπορούμε να εκτελέσουμε τυχαία προσπέλαση (random access) σε μία λίστα εμφανίσεων, τότε ίσως μία καλύτερη λύση είναι να χρησιμοποιήσουμε τους κωδικούς των εγγράφων που εντοπίσαμε για τον όρο Άρης και να εκτελέσουμε τυχαίες προσπελάσεις στη λίστα εμφανίσεων του όρου πλανήτης. Όσα έγγραφα εντοπισθούν στη δεύτερη λίστα ανήκουν στην απάντηση του ερωτήματος. Επίσης, σε περίπτωση που το ερώτημα περιέχει περισσότερους όρους οι οποίοι συνδέονται με σύζευξη (λογικό ΚΑΙ), η εκτέλεση της πράξης της τομής αρχίζει από τις λίστες εμφανίσεων που έχουν το μικρότερο μήκος. Η εφαρμογή του κανόνα αυτού έχει ως αποτέλεσμα να απαιτούνται στη γενική πρίπτωση λιγότερες πράξεις για την εκτέλεση του ερωτήματος στο σύνολο του. Αν και η χρήση μεθόδων βελτιστοποίησης είναι πολύ σημαντική για την ταχύτητα επεξεργασίας των ερωτημάτων, δεν θα εμβαθύνουμε περισσότερο στο θέμα αυτό.
Ενώ για τις πράξεις της διάζευξης και της σύζευξης απαιτούνται μόνο οι κωδικοί των εγγράφων για τον προσδιορισμό της απάντησης, για την υποστήριξη των τελεστών ADJ, NEAR/, WITH και SAME απαιτείται ιδιαίτερη μεταχείριση των λιστών εμφάνισης. Στη συνέχεια ας εξετάσουμε ένα παράδειγμα ερωτήματος που χρησιμοποιεί τον τελεστή ADJ. Έστω το ερώτημα = πλανήτης ADJ (Άρης Δίας). Τα σχετικά έγγραφα περιέχουν τον όρο πλανήτης και συνεχόμενα τον όρο Άρης ή τον όρο Δίας. Εναλλακτικά το ερώτημα γράφεται και ως: = πλανήτης ADJ Άρης πλανήτης ADJ Δίας. Για την επεξεργασία αυτού του ερωτήματος ακολουθούμε την εξής τακτική:
-
Βήμα 1: Στο πρώτο βήμα βρίσκουμε τις λίστες εμφανίσεων των λέξεων πλανήτης, Άρης και Δίας, απευθείας από τον αντεστραμμένο κατάλογο. Οι λίστες εμφανίσεων των λέξεων αυτών έχουν ως εξής:
Λίστα_Εμφανίσεων(πλανήτης) = [, 3], [, 3], [, 51], [, 19]
Λίστα_Εμφανίσεων(Άρης) = [, 12], [, 3]
Λίστα_Εμφανίσεων(Δίας) = [, 12] -
Βήμα 2: Προσδιορίζουμε σε ποια έγγραφα οι όροι πλανήτης και Άρης εμφανίζονται μαζί. Επαναλαμβάνουμε τη διαδικασία για τους όρους πλανήτης και Δίας. Είναι εύκολο να διαπιστώσουμε ότι τα έγγραφα που περιέχουν και τους δύο όρους πλανήτης και Άρης είναι τα και . Ομοίως διαπιστώνουμε ότι το είναι το μοναδικό έγγραφο που περιέχει τους όρους πλανήτης και Δίας.
-
Βήμα 3: Με βάση την πληροφορία για τη θέση εμφάνισης του κάθε όρου μέσα στο έγγραφο, προσδιορίζουμε αν οι όροι εμφανίζονται συνεχόμενες μέσα στο έγγραφο. Εξετάζοντας τα έγγραφα που περιέχουν τους όρους πλανήτης και Άρης διαπιστώνουμε ότι το έγγραφο δεν είναι δυνατόν να ικανοποιεί τη συνθήκη πλανήτης ADJ Άρης, διότι ο όρος πλανήτης εμφανίζεται στη θέση 19. ενώ ο όρος Άρης στη θέση 3, δηλαδή πριν τον όρο πλανήτης. Επομένως, απορρίπτουμε το έγγραφο . Εξετάζοντας το έγγραφο διαπιστώνουμε ότι ικανοποιεί τη συνθήκη πλανήτης ADJ Άρης. Πράγματι, ο όρος πλανήτης εμφανίζεται στη θέση 3 ενώ ο όρος Άρης στη θέση 12. Εφόσον το πλήθος των χαρακτήρων του όρου πλανήτης είναι 8 και προσμετρώντας τον κενό χαρακτήρα, τότε δεν υπάρχει περίπτωση μεταξύ των λέξεων πλανήτης και Άρης να παρεμβάλλεται κάποιος άλλος όρος. Επομένως, το έγγραφο συμπεριλαμβάνεται στην απάντηση. Με το ίδιο σκεπτικό προσδιορίζουμε ότι το έγγραφο ανήκει στην απάντηση. Με βάση τα προηγούμενα, η απάντηση στο ερώτημα αποτελείται από τα έγγραφα και .
Από το προηγούμενο παράδειγμα διαπιστώνουμε ότι ανάλογα με τους τελεστές που υπάρχουν στο ερώτημα μπορεί να απαιτηθεί αρκετή προσπάθεια για τον προσδιορισμό της απάντησης. Αν το ερώτημα περιέχει μόνο τους βασικούς λογικούς τελεστές, τότε η απάντηση στο ερώτημα μπορεί να προσδιοριστεί χωρίς να εξετάζουμε την πληροφορία θέσης του αντεστραμμένου καταλόγου. Σε αντίθετη περίπτωση όπου υπάρχουν και τελεστές γειτνίασης, τότε οπωσδήποτε θα πρέπει να λάβουμε υπόψη τη θέση των λέξεων μέσα στα έγγραφα. Η διαδικασία επεξεργασίας μπορεί να γίνει ακόμη δυσκολότερη σε περιπτώσεις όπου το ερώτημα περιλαμβάνει περισσότερους όρους και πιο σύνθετες λογικές συνθήκες.
3.2.4 Πλεονεκτήματα και Μειονεκτήματα
Το βασικό πλεονέκτημα του απλού Λογικού μοντέλου είναι το ότι στηρίζεται στη Θεωρία Συνόλων και επομένως μπορεί να γίνει εύκολα αντιληπτό. Η απλότητα του μοντέλου ήταν και ο σημαντικότερος λόγος για την ευρεία αποδοχή του από τους κατασκευαστές συστημάτων. Ωστόσο, υπάρχουν αρκετά αδύνατα σημεία που μπορεί να δημιουργήσουν προβλήματα στη διαδικασία ανάκτησης. Μερικά από αυτά εξετάζουμε στη συνέχεια.
Ένα από τα σημαντικότερα μειονεκτήματα του μοντέλου είναι ότι δεν υποστηρίζει τη βαθμολόγηση των αποτελεσμάτων ως προς τη σχετικότητα με το ερώτημα. Αυτό σημαίνει ότι ένα έγγραφο είτε θα ανήκει στην απάντηση είτε όχι. Αυτή η ιδιότητα του μοντέλου είναι αρκετά περιοριστική καθώς έγγραφα που σχετίζονται μερικώς με το ερώτημα δεν ανακτώνται. Αν συμβολίσουμε με την ομοιότητα ενός ερωτήματος και ενός εγγράφου τότε έχουμε:
| (3.7) |
Ένα δεύτερο πρόβλημα με τη χρήση του μοντέλου είναι ότι δεν είναι εύκολο για τους χρήστες να διατυπώνουν πολύπλοκα ερωτήματα με σύνθετες λογικές εκφράσεις. Η διατύπωση μίας λογικής έκφρασης με δύο όρους και έναν τελεστή είναι μία απλή υπόθεση. Η χρήση όμως περισσότερων όρων και τελεστών δυσκολεύει τη διαδικασία της διατύπωσης του ερωτήματος.
Ένα ακόμη σημαντικό μειονέκτημα του μοντέλου είναι ότι δεν μπορεί να χειριστεί σωστά όρους που γράφονται με τον ίδιο τρόπο αλλά αναφέρονται σε διαφορετικές έννοιες. Για παράδειγμα, αν με το ερώτημα = Άρης εννοούμε την πλανήτη Άρη, το σύστημα θα μας επιστρέψει και έγγραφα που ενδεχομένως υπάρχουν αποθηκευμένα και αναφέρονται στο θεό του πολέμου.
Τέλος, ίσως το σημαντικότερο μειονέκτημα του μοντέλου είναι ότι το πλήθος των απαντήσεων είτε θα είναι πολύ μικρό είτε πολύ μεγάλο. Αυτό οφείλεται στη χρήση λογικών εκφράσεων για τη διατύπωση των ερωτημάτων και στο γεγονός ότι δεν χρησιμοποιούνται βάρη στους όρους τα οποία να δηλώνουν πόσο σημαντικός είναι ένας όρος για ένα έγγραφο. Ένας όρος είτε θα έχει βάρος 1 (υπάρχει στο έγγραφο) είτε 0 (δεν υπάρχει στο έγγραφο).
Στη συνέχεια θα μελετήσουμε μία σημαντική επέκταση του βασικού Λογικού μοντέλου που έχει ως στόχο την απαλοιφή μερικών από τα μειονεκτήματα που εμφανίζει. Σε άλλα κεφάλαια θα μελετήσουμε διαφορετικά μοντέλα που ξεφεύγουν αρκετά από την προσέγγιση αυτή.
3.3 Το Εκτεταμένο Λογικό Μοντέλο
Το εκτεταμένο Λογικό μοντέλο (extended Boolean model) προτάθηκε από τους Salton, Fox και Wu το 1983 [57] για να αντιμετωπίσει μερικά βασικά προβλήματα που εμφανίζει το απλό Λογικό μοντέλο. Σύμφωνα με την κατηγοριοποίηση των μοντέλων Ανάκτησης Πληροφορίας που περιγράφεται στο βιβλίο [3], το εκτεταμένο Λογικό μοντέλο ανήκει στην κατηγορία των εναλλακτικών συνολοθεωρητικών μοντέλων (alternative set-theoretic models). Το δεύτερο μοντέλο που συμπληρώνει την κατηγορία αυτή είναι το μοντέλο Ασαφούς λογικής (fuzzy model).
Έστω το ερώτημα = που χρησιμοποιεί τους όρους και και το λογικό τελεστή σύζευξης . Με βάση το απλό Λογικό μοντέλο, ένα έγγραφο της συλλογής χαρακτηρίζεται ως σχετικό αν και μόνο αν περιέχει και τους δύο όρους και . Σε διαφορετική περίπτωση το έγγραφο χαρακτηρίζεται μη σχετικό και επομένως ο βαθμός ομοιότητας του εγγράφου ως προς το ερώτημα θα είναι = 0. Αυτό σημαίνει ότι δεν γίνεται καμία διάκριση σε περίπτωση που το περιέχει έναν από τους δύο όρους. Άρα είτε το περιέχει μόνο έναν από τους όρους είτε δεν περιέχει κάποιον όρο, ο βαθμός ομοιότητας παραμένει 0. Αυτό το φαινόμενο παρουσιάζεται στον Πίνακα 3.4 ο οποίος συνοψίζει όλες τις δυνατές περιπτώσεις σχετικά με την εμφάνιση ή όχι των όρων στο έγγραφο. Παρατηρούμε ότι για τις τρεις τελευταίες περιπτώσεις η ομοιότητα του ως προς το είναι 0. Ωστόσο, θα περίμενε κάποιος η ομοιότητα να είναι μεγαλύτερη σε περίπτωση που ένας εκ των δύο όρων εμφανίζεται στο έγγραφο. Το φαινόμενο αυτό γίνεται εντονότερο στην περίπτωση που έχουμε περισσότερους όρους που συνδέονται με λογική σύζευξη.
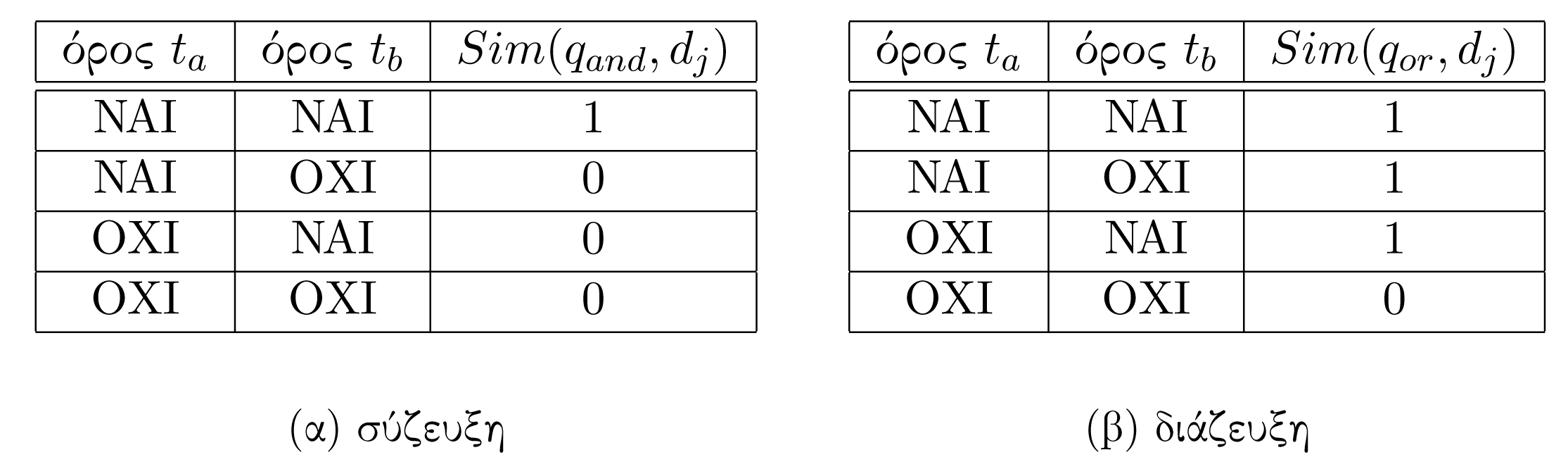
Παρόμοια παρατήρηση μπορεί να γίνει και στην περίπτωση που το ερώτημα περιέχει διάζευξη. Έστω το ερώτημα = . Σύμφωνα με το απλό Boolean μοντέλο, ένα έγγραφο είτε περιέχει έναν από τους δύο όρους είτε και τους δύο έχει βαθμό ομοιότητας = 1. Θα περίμενε κάποιος, το έγγραφο που περιέχει και τους δύο όρους να έχει μεγαλύτερο βαθμό ομοιότητας από ένα έγγραφο που περιέχει τον έναν από τους δύο όρους του ερωτήματος.
 (α) σύζευξη
(α) σύζευξη
 (β) διάζευξη
(β) διάζευξη
Σύμφωνα με το εκτεταμένο Λογικό μοντέλο, το κάθε έγγραφο αναπαρίσταται με τη βοήθεια ενός διανύσματος βαρών. Στο Σχήμα 3.5 παρουσιάζεται η αναπαράσταση δύο εγγράφων και στην περίπτωση που έχουμε δύο όρους. Αν συμβολίσουμε με και τα αντίστοιχα διανύσματα των εγγράφων, τότε έχουμε = και = , όπου και είναι οι συντεταγμένες (βάρη) του εγγράφου , και , οι συντεταγμένες του εγγράφου . Οι τιμές των βαρών φροντίζουμε να είναι κανονικοποιημένες στο διάστημα τιμών [0,1].
Το βάρος όπου ενός όρου σε ένα έγγραφο δηλώνει το πόσο σημαντικός είναι ο όρος για το έγγραφο. Υπάρχουν διάφοροι τρόποι προσδιορισμού της σημαντικότητας ενός όρου. Εδώ θα χρησιμοποιήσουμε μία από τις τεχνικές προσδιορισμού βαρών που χρησιμοποιείται και από πολλά συστήματα που βασίζονται στο Διανυσματικό μοντέλο ανάκτησης και αναλύεται σε επόμενο κεφάλαιο. Συμβολίζουμε με την κανονικοποιημένη συχνότητα εμφάνισης (normalized frequency) του όρου στο έγγραφο , που δίνεται από τον εξής μαθηματικό τύπο:
| (3.8) |
όπου είναι ο αριθμός των εμφανίσεων του όρου στο έγγραφο , ενώ είναι ο αριθμός εμφανίσεων του όρου με τις περισσότερες εμφανίσεις μέσα στο έγγραφο . Επομένως, η τιμή είναι κανονικοποιημένη στο διάστημα τιμών [0,1].
Έστω τώρα ότι συμβολίζουμε με την ανάστροφη συχνότητα εγγράφων (inverse document frequency) που μας δίνει τον αριθμό των εγγράφων που περιέχουν τον όρο . Για τον προσδιορισμό της τιμής αυτής χρησιμοποιείται ο ακόλουθος τύπος:
| (3.9) |
όπου είναι ο συνολικός αριθμός εγγράφων της συλλογής και είναι ο αριθμός εγγράφων που περιέχουν τον όρο . Η κανονικοποιημένη μορφή δίνεται από τον τύπο:
| (3.10) |
όπου είναι η μέγιστη τιμή που οφείλεται σε κάποιον όρο . Είναι προφανές ότι το παίρνει τιμές άπό το διάστημα [0,1]. Με βάση τις εξισώσεις 3.8 και 3.10 η τιμή του βάρους υπολογίζεται ως εξής [26, 60]:
| (3.11) |
Η Εξίσωση 3.11 στην ουσία αναφέρει ότι όσο περισσότερες φορές εμφανίζεται ο όρος στο έγγραφο , τόσο πιο σημαντικός γίνεται ο όρος για το έγγραφο. Ωστόσο, σε όσο περισσότερα έγγραφα εμφανίζεται ο όρος , τόσο μειώνεται η σημαντικότητά του. Για παράδειγμα, έστω ότι ο όρος ένας αναφέρεται πολλές φορές μέσα σε ένα έγγραφο. Άρα θα υπέθετε κάποιος η σημαντικότητα του όρου να είναι μεγάλη. Όμως, ο όρος αυτός βρίσκεται σχεδόν σε όλα τα έγγραφα, με αποτέλεσμα η σημαντικότητά της να μειώνεται.
Εφόσον έχουμε καθορίσει τον τρόπο αναπαράστασης του κάθε εγγράφου, στη συνέχεια περιγράφουμε τον τρόπο βαθμολόγησης του κάθε εγγράφου με βάση το ερώτημα. Αρχικά δίνεται η μέθοδος βαθμολόγησης στην περίπτωση του ερωτήματος . Ο καλύτερος βαθμός για ένα έγγραφο σύμφωνα με το ερώτημα σύζευξης αντιστοιχεί στην περίπτωση που και οι δύο όροι και περιέχονται στο έγγραφο. Σύμφωνα με το Σχήμα 3.5(α) η περίπτωση αυτή αντιστοιχεί στην επάνω-δεξιά γωνία του επιπέδου. Άρα, όσο πιο κοντά στη γωνία αυτή βρίσκεται το σημείο που αντιστοιχεί στο έγγραφο, τόσο μεγαλύτερος ο βαθμός του εγγράφου. Αν οι αποστάσεις μετρώνται χρησιμοποιώντας την Ευκλείδεια απόσταση, τότε η ομοιότητα του εγγράφου ως προς το ερώτημα δίνεται από τον ακόλουθο τύπο:
| (3.12) |
Για την περίπτωση του ερωτήματος διάζευξης , το σημείο που πρέπει να αποφύγουμε είναι η κάτω-αριστερή γωνία στο επίπεδο του Σχήματος 3.5(β). Επομένως, η ομοιότητα του εγγράφου ως προς το ερώτημα δίνεται από τον τύπο:
| (3.13) |
Παράδειγμα 3.1
Στη συνέχεια παραθέτουμε ένα παράδειγμα υπολογισμού των βαρών και της ομοιότητας στο εκτεταμένο Λογικό μοντέλο με βάση τη μικρή συλλογή του Σχήματος 3.1. Θεωρούμε ότι = κομήτης και = Χάλλεϋ. Επομένως, τα ερωτήματα και διατυπώνονται ως εξής: = κομήτης Χάλλεϋ και = κομήτης Χάλλεϋ. Αρχικά πρέπει να υπολογίσουμε τα βάρη των όρων του ερωτήματος σε σχέση με τα έγγραφα που μας ενδιαφέρουν. Έστω ότι θέλουμε να υπολογίσουμε το βαθμό ομοιότητας των εγγράφων , , και . Στο έγγραφο ο όρος κομήτης εμφανίζεται μία φορά, επομένως = 1. Η μεγαλύτερη συχνότητα εμφάνισης στο έγγραφο είναι 1, αφού κανένας όρος του εγγράφου δεν εμφανίζεται περισσότερες από μία φορά. Επομένως, με βάση την Εξίσωση 3.8 η κανονικοποιμένη συχνότητα εμφάνισης του όρου κομήτης στο έγγραφο είναι = 1. Με τη βοήθεια του τύπου 3.9 υπολογίζουμε την ανάστροφη συχνότητα εγγράφων. Ο όρος κομήτης εμφανίζεται σε = 4 έγγραφα. Εφόσον ο συνολικός αριθμός των εγγράφων της συλλογής είναι = 7, τότε σύμφωνα με την Εξίσωση 3.9 έχουμε = 0.243. Η μέγιστη ανάστροφη συχνότητα εγγράφων αντιστοιχεί στον όρο που εμφανίζεται στα λιγότερα έγγραφα της συλλογής. Υπάρχουν όροι που εμφανίζονται σε ένα μόνο έγγραφο, όπως για παράδειγμα ο όρος τροχιά. Επομένως, η μέγιστη ανάστροφη συχνότητα εγγράφων είναι 0.845. Άρα, με βάση την Εξίσωση 3.10 έχουμε = 0.243/0.845 = 0.288. Αντικαθιστώντας τις αντίστοιχες τιμές που υπολογίσαμε προηγουμένως στον τύπο 3.11, προσδιορίζουμε το βάρος του όρου κομήτης στο έγγραφο . Άρα = 1 0.288 = 0.288. Η ίδια διαδικασία εφαρμόζεται και για τα υπόλοιπα έγγραφα.
Η προηγούμενη προσέγγιση γενικεύεται εύκολα και για περιπτώσεις περισσότερων όρων στο ερώτημα. Ωστόσο, μία πιο γενική προσέγγιση που υποστηρίζει πολλές μετρικές απόστασης (και όχι μόνο την Ευκλείδεια) μελετήθηκε στις εργασίες [57, 25]. Η προσέγγιση αυτή στηρίζεται στη χρήση -νορμών (-norms) και προσφέρει μεγάλη ευελιξία στον ορισμό της ομοιότητας.
Έστω ότι ένα ερώτημα περιέχει όρους, , …, . Σύμφωνα με το μοντέλο -νόρμας, όπου , τα ερωτήματα σύζευξης και διάζευξης ορίζονται ως εξής:
| (3.14) |
| (3.15) |
όπου και είναι οι γενικευμένοι τελεστές για τη σύζευξη και τη διάζευξη αντίστοιχα με βάση το μοντέλο -νόρμας. Αν συμβολίσουμε με το βάρος του όρου στο έγγραφο τότε η ομοιότητα του εγγράφου με βάση τα ερωτήματα και προσδιορίζεται από τους εξής τύπους:
| (3.16) |
| (3.17) |
Με βάση αυτούς τους τύπους υπολογισμού της ομοιότητας εγγράφων, για διαφορετικές τιμές της μεταβλητής παίρνουμε διαφορετικές μορφές ομοιότητας. Για παράδειγμα, θέτοντας = 1 στις Εξισώσεις 3.16 και 3.17, τότε δεν υπάρχει διαχωρισμός μεταξύ του ερωτήματος σύζευξης και του ερωτήματος διάζευξης, όπως φαίνεται καθαρά από την ακόλουθη σχέση:
| (3.18) |
Αν θέσουμε = τότε η ομοιότητα ενός εγγράφου ως προς τα ερωτήματα σύζευξης και διάζευξης ταυτίζεται με την ομοιότητα όπως προσδιορίζεται από το μοντέλο Ασαφούς λογικής, δηλαδή:
| (3.19) |
Ο μαθηματικός τύπος της ομοιότητας για ένα τυχαίο ερώτημα που περιέχει πολλούς τελεστές και προσδιορίζεται εύκολα. Για παράδειγμα, έστω το ερώτημα = ( ). Παρατηρούμε ότι η πράξη προηγείται της πράξης . Η ομοιότητα ενός εγγράφου ως προς το είναι:
| (3.20) |
| (3.21) | |||||
Παρατηρούμε ότι ο τύπος εφαρμόζεται αναδρομικά με βάση τον αριθμό των πράξεων και που περιέχονται στο ερώτημα. Η παράμετρος καθορίζεται από το χρήστη, ενώ η βέλτιστη τιμή της παραμέτρου καθορίζεται πειραματικά και εξαρτάται κατά κύριο λόγο από τη συλλογή εγγράφων. Συνήθως χρησιμοποιείται μία τιμή του από το διάστημα [2,5] [31]. Επίσης, είναι δυνατή η χρήση διαφορετικών τιμών της παραμέτρου μέσα στο ίδιο ερώτημα, κάτι που προσφέρει ακόμη μεγαλύτερη ευελιξία στον τρόπο διατύπωσης των ερωτημάτων. Για παράδειγμα, ο χρήστης μπορεί να διατυπώσει ερωτήματα όπως: ( ).
3.4 Σύνοψη και Περαιτέρω Μελέτη
Το απλό Λογικό μοντέλο είναι από τα πρώτα μοντέλα ανάκτησης που έχουν χρησιμοποιηθεί, λόγω της απλότητάς του. Το μοντέλο στηρίζεται στη Θεωρία Συνόλων και τα ερωτήματα διατυπώνονται με τη βοήθεια λογικών εκφράσεων που περιέχουν όρους και τους βασικούς λογικούς τελεστές (σύζευξη), (διάζευξη) και (άρνηση). Για την αλλαγή της προτεραιότητας των τελεστών χρησιμοποιούνται παρενθέσεις.
Δύο από τα βασικά μειονεκτήματα του απλού Λογικού μοντέλου είναι η απουσία βαθμολόγησης των εγγράφων ως προς ερώτημα και το γεγονός ότι το πλήθος των εγγράφων της απάντησης είναι είτε πολύ μικρό είτε πολύ μεγάλο. Επομένως, οι ερευνητές στράφηκαν προς εναλλακτικά μοντέλα με στόχο την απαλοιφή των προβλημάτων του απλού Λογικού μοντέλου. Μία από τις σημαντικότερες επεκτάσεις οδήγησε στο εκτεταμένο Λογικό μοντέλο με χρήση -νορμών που περιγράφεται αναλυτικά στην εργασία [57] καθώς επίσης και στη διδακτορική διατριβή του Fox [25].
Ο ενδιαφερόμενος αναγνώστης μπορεί να ανατρέξει επίσης και σε ένα πλήθος άλλων ερευνητικών εργασιών στις οποίες μελετάται η συμπεριφορά του απλού και του εκτεταμένου Λογικού μοντέλου και συγκρίνεται η απόδοσή του με άλλα μοντέλα ανάκτησης. Χαρακτηριστικά αναφέρουμε την εργασία [62] όπου παρουσιάζονται οι μέθοδοι προσδιορισμού ομοιότητας εγγράφων σε συστήματα που χρησιμοποιούν Λογικά μοντέλα και την εργασία [31] όπου γίνεται μία ανασκόπηση των μοντέλων ανάκτησης που χρησιμοποιούνται στον παγκόσμιο ιστό.
3.5 Ασκήσεις
-
3.1
Ποιά είναι κατά τη γνώμη σας τα πλεονεκτήματα και τα μειονεκτήματα του απλού Λογικού μοντέλου;
-
3.2
Ποιές είναι οι επεκτάσεις που προσφέρει το εκτεταμένο Λογικό μοντέλο;
-
3.3
Να περιγράψετε τον τρόπο προσδιορισμού της ομοιότητας ενός εγγράφου με ένα ερώτημα με βάση τον τελεστή OR () και τον τελεστή AND ().
-
3.4
Να διατυπώσετε τον μαθηματικό τύπο που δίνει την ομοιότητα μεταξύ ενός εγγράφου της συλλογής και του ερωτήματος = ( ).
-
3.5
Ποιά είναι η χρησιμότητα της ανάστροφης συχνότητας εγγράφων ();
-
3.6
Για ποιό λόγο πιστεύετε ότι χρησιμοποιείται ο λογάριθμος στον ορισμό της ποσότητας ; Δεν θα μπορούσε το μοντέλο να λειτουργήσει χωρίς λογαρίθμηση;
-
3.7
Να αναφέρετε εφαρμογές όπου το απλό Λογικό μοντέλο είναι αρκετό και περιπτώσεις όπου το εκτεταμένο Λογικό μοντέλο είναι προτιμότερο.
-
3.8
Για τη συλλογή εγγράφων του Σχήματος 3.1 να κατασκευάσετε έναν αντεστραμμένο κατάλογο και να τον χρησιμοποιήσετε για την απάντηση των ερωτημάτων: (i) Χάλλεϋ OR αστρονόμος, (ii) πλανήτης AND Δίας, (iii) Άρης OR δορυφόρους. Σχολιάστε για την απόδοση στην εκτέλεση των ερωτημάτων αυτών απουσία καταλόγου.
-
3.9
Να κατασκευαστεί πρόγραμμα που να διαβάζει τη συλλογή εγγράφων CRAN και στη συνέχεια να δίνει στο χρήστη τη δυνατότητα να χρησιμοποιεί είτε το απλό Λογικό μοντέλο είτε το εκτεταμένο Λογικό μοντέλο για την επεξεργασία των ερωτημάτων. Θεωρήστε ότι δεν μας ενδιαφέρει ο κατάλογος.
-
3.10
Στο σύστημα που κατασκευάσατε στην προηγούμενη άσκηση να το χρησιμοποιήσετε για τη μελέτη της σχέσης του πλήθους των απαντήσεων ως προς τον αριθμό των όρων που υπάρχουν στο ερώτημα και συνδέονται με το λογικό τελεστή AND.
-
3.11
Δίνεται το ερώτημα . Να διατυπώσετε το ερώτημα σε διαζευκτική κανονική μορφή και να βρείτε έναν αλγόριθμο υπολογισμού της διαζευκτικής κανονικής μορφής για κάθε λογική έκφραση.
-
3.12
Να σχεδιάσετε μία δική σας συνάρτηση ομοιότητας μεταξύ ενός ερωτήματος και ενός εγγράφου που να βασίζεται στο πλήθος των κοινών όρων, και να εντοπίσετε τα πλεονεκτήματα και μειονεκτήματα σε σχέση με το απλό και το εκτεταμένο Λογικό μοντέλο.