Κεφάλαιο 2Αποτίμηση Αποτελεσματικότητας
2.1 Εισαγωγή
Στο προηγούμενο κεφάλαιο έχει αναφερθεί ότι ενώ δύο ΣΔΒΔ που διαχειρίζονται την ίδια βάση δεδομένων θα δώσουν ακριβώς την ίδια απάντηση στο ίδιο ερώτημα, κάτι τέτοιο δεν συμβαίνει πάντα στην περίπτωση των ΣΑΠ. Επομένως, τίθεται αμέσως το ζήτημα της επάρκειας των αποτελεσμάτων στα ερωτήματα των χρηστών. Η επάρκεια των αποτελεσμάτων καλείται αποτελεσματικότητα (effectiveness) του συστήματος και αποτελεί ένα σημαντικό τομέα της έρευνας που διεξάγεται στην περιοχή της Ανάκτησης Πληροφορίας.
Στόχος αυτού του κεφαλαίου είναι να παρουσιάσει τις βασικές μετρικές αποτίμησης της αποτελεσματικότητας ενός ΣΑΠ, οι οποίες έχουν προταθεί στη βιβλιογραφία. Οι μετρικές αυτές μας βοηθούν να προσδιορίσουμε πότε ένα ΣΑΠ είναι καλύτερο από κάποιο άλλο ή πότε μία μέθοδος ανάκτησης αποδίδει καλύτερα από κάποια ανταγωνιστική μέθοδο. Τα πράγματα όμως δεν είναι πάντοτε απλά. Υπάρχουν περιπτώσεις όπου σε κάποια ερωτήματα ένα ΣΑΠ είναι αποτελεσματικό και σε κάποια άλλα όχι. Η αποτελεσματικότητα του συστήματος εξαρτάται από πολλούς παράγοντες όπως: (α) τη συλλογή εγγράφων που διαχειρίζεται το σύστημα, (β) τα ερωτήματα των χρηστών, και (γ) το μοντέλο ανάκτησης που χρησιμοποιείται. Για το λόγο αυτό χρησιμοποιούνται ειδικές μέθοδοι σύγκρισης συστημάτων. Παρόμοια προσέγγιση χρησιμοποιείται και στην περιοχή των Βάσεων Δεδομένων (π.χ. TPC benchmarks), όμως όχι για τη μέτρηση της αποτελεσματικότητας αλλά της ταχύτητας στην επεξεργασία των ερωτημάτων. Αρχικά περιγράφονται αναλυτικά οι βασικές μετρικές αποτίμησης και στη συνέχεια περιγράφονται μερικές συλλογές εγγράφων που χρησιμοποιούνται ως βάση για τη διεξαγωγή πειραμάτων.
2.2 Βασικά Μέτρα Αποτελεσματικότητας
Έστω ότι έχουμε τη δυνατότητα να διαπιστώσουμε αν ένα έγγραφο που ανήκει στη συλλογή των εγγράφων είναι ή όχι σχετικό ως προς ένα ερώτημα . Θεωρούμε ότι μετά την επεξεργασία του ερωτήματος , το ΣΑΠ επέστρεψε κάποια έγγραφα που αποτελούν το σύνολο απάντησης . Έστω επίσης ότι το σύνολο περιέχει όλα τα σχετικά ως προς το ερώτημα έγγραφα της συλλογής . Τέλος με συμβολίζουμε το υποσύνολο του που περιέχει τα σχετικά ως προς το έγγραφα. Προφανώς το σύνολο είναι η τομή των συνόλων και .
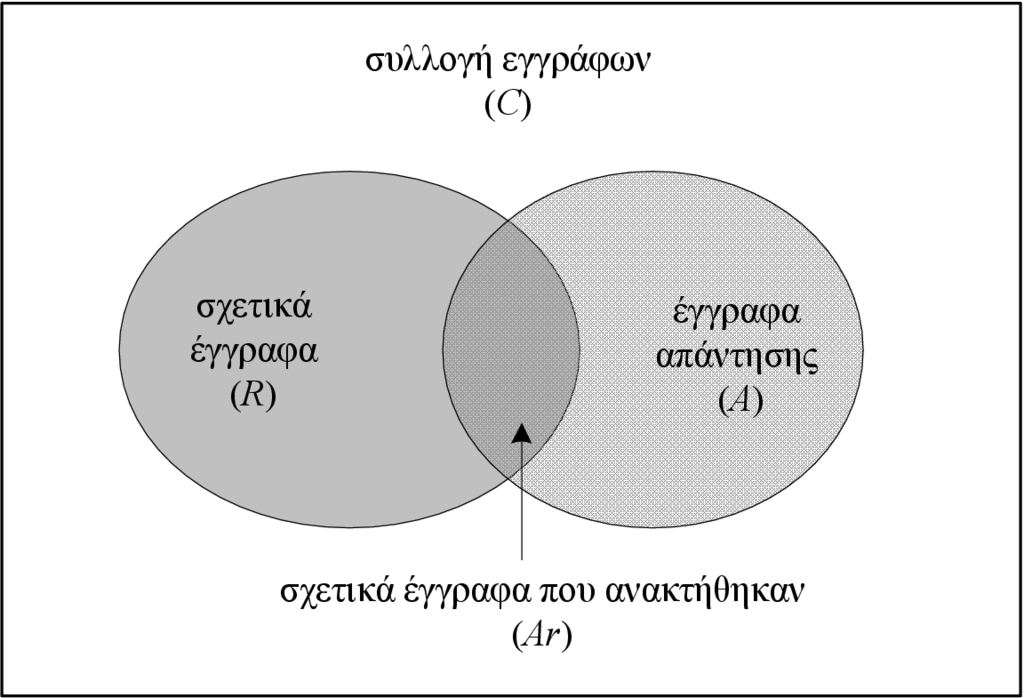

Στο Σχήμα 2.1 δίνονται τα διαφορετικά σύνολα εγγράφων με χρήση διαγραμμάτων Venn, ενώ στο Σχήμα 2.2 δίνονται οι τέσσερις δυνατοί χαρακτηρισμοί των εγγράφων ως προς ένα ερώτημα. Στην ιδανική περίπτωση, τα έγγραφα θα ανήκουν είτε στο κάτω αριστερό είτε στο επάνω δεξί τεταρτημόριο, δηλαδή όσα έγγραφα είναι σχετικά ως προς το ερώτημα έχουν ανακτηθεί, ενώ δεν έχει ανακτηθεί κάποιο μη σχετικό έγγραφο. Ωστόσο, στη γενική περίπτωση, κάποια από τα έγγραφα που έχουν ανακτηθεί δεν θα είναι σχετικά ως προς το ερώτημα, ενώ κάποια σχετικά έγγραφα δεν θα έχουν ανακτηθεί.
2.2.1 Ανάκληση, Ακρίβεια και Αστοχία
Η προσπάθεια για ποσοτικοποίηση της επάρκειας των αποτελεσμάτων που επιστρέφονται από ένα ΣΑΠ οδήγησε τους ερευνητές σε κάποια βασικά μέτρα αποτίμησης.
Ορισμός 2.1.
Η ανάκληση (recall) ορίζεται ως ο λόγος του αριθμού των σχετικών εγγράφων που ανακτήθηκαν προς το συνολικό αριθμό σχετικών εγγράφων της συλλογής:
| (2.1) |
Η ανάκληση μετρά στην ουσία το ποσοστό των σχετικών εγγράφων που το σύστημα μπόρεσε να ανακτήσει σε σχέση με όλα τα σχετικά έγγραφα που υπάρχουν στη συλλογή. Είναι προφανές ότι η τέλεια ανάκληση είναι 100%. Κάτι που η ανάκληση δεν λαμβάνει υπόψη είναι το πλήθος των εγγράφων που ανακτήθηκαν αλλά δεν είναι σχετικά ως προς το ερώτημα. Πολλές φορές εμφανίζεται το φαινόμενο να έχουν μεν ανακτηθεί όλα τα σχετικά έγγραφα, αλλά μαζί με αυτά να έχουν ανακτηθεί και πολλά μη σχετικά ως προς το ερώτημα.
Ορισμός 2.2.
Η ακρίβεια (precision) μετρά το ποσοστό των εγγράφων που είναι σχετικά μεταξύ αυτών που έχουν ανακτηθεί:
| (2.2) |
Ορισμός 2.3.
Η αστοχία (fallout) δίνει το ποσοστό των μη σχετικών εγγράφων που ανακτήθηκαν σε σχέση με το συνολικό αριθμό των μη σχετικών εγγράφων της συλλογής.
| (2.3) |
Όπως και στην περίπτωση της ανάκλησης, η καλύτερη δυνατή ακρίβεια που μπορούμε να πετύχουμε είναι 100%, ενώ η ιδανική αστοχία είναι 0%. Από τους ορισμούς της ανάκλησης και της ακρίβειας παρατηρούμε ότι αυτό που αλλάζει είναι ο παρονομαστής στις δύο αντίστοιχες σχέσεις, ενώ ο αριθμητής είναι ίδιος. Με τη βοήθεια της ανάκλησης και της ακρίβειας μπορούμε να αποτιμήσουμε κατά πόσον ένα ερώτημα απαντήθηκε ικανοποιητικά ή όχι.
Παράδειγμα 2.1
Έστω ότι η επεξεργασία ενός ερωτήματος θα πρέπει να επιστρέψει =8 σχετικά έγγραφα ως απάντηση. Υποθέστε
ότι το σύστημα επιστρέφει =12 έγγραφα, από τα οποία σχετικά είναι τα =6. Παρατηρούμε ότι από τα 8 σχετικά
έγγραφα που έπρεπε να επιστραφούν, πήραμε μόνο τα 6, επομένως = 6/8 = 0.75 (75%). Εφόσον από τα 16 έγγραφα
που πήραμε στην έξοδο σχετικά είναι μόνο τα 6, η ακρίβεια είναι = 6/12 = 0.5 (50%).
Όσο μεγαλύτερες είναι οι τιμές της ανάκλησης και της ακρίβειας, τόσο πιο αποτελεσματικό είναι το σύστημα για το συγκεκριμένο ερώτημα. Στην ιδανική περίπτωση το σύστημα θα μας επιστρέψει όλα τα σχετικά έγγραφα (100% ανάκληση) και μόνο αυτά (100% ακρίβεια). Ωστόσο, κάτι τέτοιο συμβαίνει πολύ σπάνια (αν όχι καθόλου) και αυτό οφείλεται στο γεγονός ότι το ένα μέγεθος έχει την τάση να μειώνεται όταν αυξάνεται το άλλο. Αυτό μπορούμε να το κατανοήσουμε και διαισθητικά. Όσο ζητούμε από το σύστημα να μας επιστρέψει περισσότερα σχετικά έγγραφα, τόσο αυξάνουμε και τις πιθανότητες κάποια από τα έγγραφα που επιστρέφονται να είναι μη σχετικά. Το φαινόμενο αυτό δυσκολεύει κατά πολύ την αποτίμηση της αποτελεσματικότητας.
Στο Σχήμα 2.3 παρουσιάζονται μερικοί αντιπροσωπευτικοί συνδυασμοί μεταξύ ανάκλησης και ακρίβειας. Η περίπτωση που θα πρέπει να αποφεύγεται δίνεται στο Σχήμα 2.3(α), και ανταποκρίνεται σε χαμηλή ανάκληση και χαμηλή ακρίβεια. Στη χειρότερη περίπτωση, το σύνολο των εγγράφων της απάντησης και το σύνολο των σχετικών εγγράφων δεν θα έχουν κανένα κοινό στοιχείο. Αυτό σημαίνει ότι το σύστημα δεν κατάφερε να επιστρέψει στο χρήστη κανένα σχετικό έγγραφο, κάτι που θεωρείται μεγάλη αποτυχία. Μία δεύτερη ενδιαφέρουσα περίπτωση παρουσιάζεται στο Σχήμα 2.3(β) όπου η ακρίβεια είναι στο 100% ενώ η ανάκληση είναι χαμηλή. Στην περίπτωση αυτή, το σύστημα κατάφερε να επιστρέψει πολύ καλής ποιότητας αποτελέσματα (ακρίβεια 100%), αλλά δεν κατάφερε να εντοπίσει πολλά από τα σχετικά έγγραφα (χαμηλή ανάκληση). Το αντίστροφο ισχύει για την περίπτωση του Σχήματος 2.3(γ) όπου η ανάκληση είναι πολύ υψηλή (100%) αλλά η ακρίβεια είναι χαμηλή, καθώς εκτός από τα σχετικά έγγραφα το σύστημα έχει δώσει και πολλά που δεν είναι σχετικά (χαμηλή ακρίβεια). Τέλος, στο Σχήμα 2.3(δ) δίνεται η ιδανική περίπτωση όπου τόσο η ανάκληση όσο και η ακρίβεια είναι σε πολύ υψηλά επίπεδα.
 (α) χαμηλή ανάκληση, χαμηλή ακρίβεια
(α) χαμηλή ανάκληση, χαμηλή ακρίβεια
 (β) χαμηλή ανάκληση, υψηλή ακρίβεια
(β) χαμηλή ανάκληση, υψηλή ακρίβεια
 (γ) υψηλή ανάκληση, χαμηλή ακρίβεια
(γ) υψηλή ανάκληση, χαμηλή ακρίβεια
 (δ) υψηλή ανάκληση, υψηλή ακρίβεια
(δ) υψηλή ανάκληση, υψηλή ακρίβεια
Σε μία τυπική περίπτωση, οι τιμές της ανάκλησης και της ακρίβειας θα έχουν μία σχέση που κυμαίνεται μεταξύ των περιπτώσεων (β) και (γ) του Σχήματος 2.3. Ας παρατηρήσουμε πιο προσεκτικά τη σχέση ανάκλησης-ακρίβειας με τη βοήθεια ενός παραδείγματος. Συνήθως τα έγγραφα που προσδιορίζονται από το σύστημα εξαιτίας ενός ερωτήματος επιστρέφονται στο χρήστη με φθίνουσα βαθμολογική σειρά, σύμφωνα με την εκάστοτε μέθοδο ανάκτησης και βαθμολόγησης. Για παράδειγμα, τα αποτελέσματα μίας μηχανής αναζήτησης στον παγκόσμιο ιστό εμφανίζονται στο χρήστη κατά ομάδες και όχι όλα μαζί. Με τον τρόπο αυτό, δίνεται η δυνατότητα στο χρήστη να σταματήσει την εξέταση των αποτελεσμάτων διότι από ένα σημείο και μετά τα έγγραφα είναι μεν σχετικά αλλά έχουν χαμηλό βαθμό και επομένως μικρή σχετικότητα ως προς το ερώτημα. Ας δούμε τη συμβαίνει στην περίπτωση αυτή με την ανάκληση και την ακρίβεια χρησιμοποιώντας ένα απλό παράδειγμα. Θεωρούμε ότι, ως προς ένα ερώτημα , τα σχετικά έγγραφα είναι τα , , , , και . Έστω ότι το σύστημα μας επιστρέφει τα ακόλουθα έγγραφα που δίνονται με φθίνουσα σειρά βαθμολογίας: , , , , , , , και . Συνολικά το σύστημα επέστρεψε 9 έγγραφα. Καταγράφουμε στη συνέχεια τις τιμές της ανάκλησης και της ακρίβειας για κάθε έγγραφο που παίρνουμε ως αποτέλεσμα. Οι τιμές αυτές παρουσιάζονται στον Πίνακα 2.1. Από την εξέταση του πίνακα παρατηρούμε τα εξής:
-
•
όσο αυξάνει ο αριθμός των εγγράφων που λαμβάνουμε υπόψη, η ανάκληση έχει την τάση να αυξάνεται ενώ η ακρίβεια έχει την τάση να μειώνεται,
-
•
κάθε φορά που συναντούμε ένα σχετικό έγγραφο η ανάκληση αυξάνεται, ενώ για κάθε μη σχετικό έγγραφο η ανάκληση παραμένει σταθερή και η ακρίβεια μειώνεται.
| α/α | έγγραφο | σχετικό | ανάκληση | ακρίβεια |
|---|---|---|---|---|
| 1 | ΝΑΙ | 20% | 100% | |
| 2 | ΝΑΙ | 40% | 100% | |
| 3 | ΟΧΙ | 40% | 66% | |
| 4 | ΟΧΙ | 40% | 50% | |
| 5 | ΟΧΙ | 40% | 40% | |
| 6 | ΝΑΙ | 60% | 50% | |
| 7 | ΝΑΙ | 80% | 57% | |
| 8 | ΟΧΙ | 80% | 50% | |
| 9 | ΝΑΙ | 100% | 55% |
 (α) αρχική καμπύλη
(α) αρχική καμπύλη
 (β) διαμορφωμένη καμπύλη
(β) διαμορφωμένη καμπύλη
Με βάση της τιμές της ανάκλησης και της ακρίβειας του Πίνακα 2.1 κατασκευάζουμε το γράφημα του Σχήματος 2.4(α). Η καμπύλη που σχηματίζεται καλείται καμπύλη ανάκλησης-ακρίβειας και δείχνει τον τρόπο μεταβολής της μίας μετρικής σε σχέση με την άλλη. Συνήθως, η καμπύλη ποτέ δεν χρησιμοποιείται ως έχει αλλά διαμορφώνεται κατάλληλα, χρησιμοποιώντας 11 σταθερά σημεία ανάκλησης τα οποία είναι: 0%, 10%, …, 100%. Στη συνέχεια, η καμπύλη σχηματίζεται τοποθετώντας τις αντίστοιχες τιμές της ακρίβειας για αυτές τις τιμές της ανάκλησης. Σε περιπτώσεις όπου δεν υπάρχει αντίστοιχη τιμή εφαρμόζουμε την τεχνική της παρεμβολής (interpolation) για να πάρουμε τη διαμορφωμένη καμπύλη ανάκλησης-ακρίβειας θεωρώντας τη μέγιστη τιμή της ακρίβειας που υπάρχει έως το επόμενο επίπεδο ανάκλησης. Πιο συγκεκριμένα, αν συμβολίσουμε με το -οστό επίπεδο ανάκλησης, με την πραγματική τιμή της ακρίβειας για το επίπεδο ανάκλησης και με την παρεμβαλλόμενη τιμή της ακρίβειας για το επίπεδο , τότε η τιμή υπολογίζεται ως εξής:
| (2.4) |
| α/α | ανάκληση | ακρίβεια |
|---|---|---|
| 1 | 0% | 0% |
| 2 | 10% | 100% |
| 3 | 20% | 100% |
| 4 | 30% | 100% |
| 5 | 40% | 100% |
| 6 | 50% | 50% |
| 7 | 60% | 50% |
| 8 | 70% | 57% |
| 9 | 80% | 57% |
| 10 | 90% | 55% |
| 11 | 100% | 55% |
Οι τιμές της ακρίβειας για τα 11 επίπεδα ανάκλησης δίνονται στον Πίνακα 2.2, ενώ η νέα καμπύλη (μετά την εφαρμογή της παρεμβολής) παρουσιάζεται στο Σχήμα 2.4(β). Για παράδειγμα, για το επίπεδο ανάκλησης 30% παρατηρούμε ότι δεν υπάρχει αντίστοιχη τιμή ακρίβειας στον Πίνακα 2.1, και επομένως πρέπει να εφαρμόσουμε την τεχνική της παρεμβολής. Η μέγιστη τιμή της ακρίβειας μεταξύ του επιπέδου 30% και του 40% είναι 100% και επομένως χρησιμοποιούμε αυτήν την τιμή.
Στο προηγούμενο παράδειγμα έχουμε υποθέσει την ύπαρξη ενός μόνο ερωτήματος. Επομένως, για κάθε ερώτημα μπορούμε να δημιουργήσουμε μία ξεχωριστή καμπύλη ανάκλησης-ακρίβειας. Αυτή η προσέγγιση όμως δεν είναι καθόλου πρακτική, διότι δυσκολεύει τη διαδικασία της σύγκρισης δύο διαφορετικών ΣΑΠ ή δύο διαφορετικών μεθόδων που επεξεργάζονται τα ίδια ερωτήματα στην ίδια συλλογή εγγράφων. Μία τεχνική που χρησιμοποιείται είναι η χρήση της μέσης τιμής της ακρίβειας για τα διαφορετικά επίπεδα ανάκλησης. Με τον τρόπο αυτό παράγεται μία μόνο καμπύλη και έτσι η σύγκριση μπορεί να πραγματοποιηθεί ευκολότερα. Έστω ότι έχουμε διαφορετικά ερωτήματα τα οποία έχουν εκτελεσθεί και επομένως γνωρίζουμε τις τιμές ακρίβειας για το καθένα (μετά την εφαρμογή της διαδικασίας παρεμβολής) για τα 11 επίπεδα ανάκλησης. Αν συμβολίσουμε με τη μέση τιμή της ακρίβειας για το επίπεδο ανάκλησης και με την τιμή της ακρίβειας του -οστού ερωτήματος για το επίπεδο ανάκλησης τότε η μέση ακρίβεια ορίζεται ως εξής:
| (2.5) |
 (α) σχέση ανάκλησης-ακρίβειας
(α) σχέση ανάκλησης-ακρίβειας
 (β) σύγκριση συστημάτων
(β) σύγκριση συστημάτων
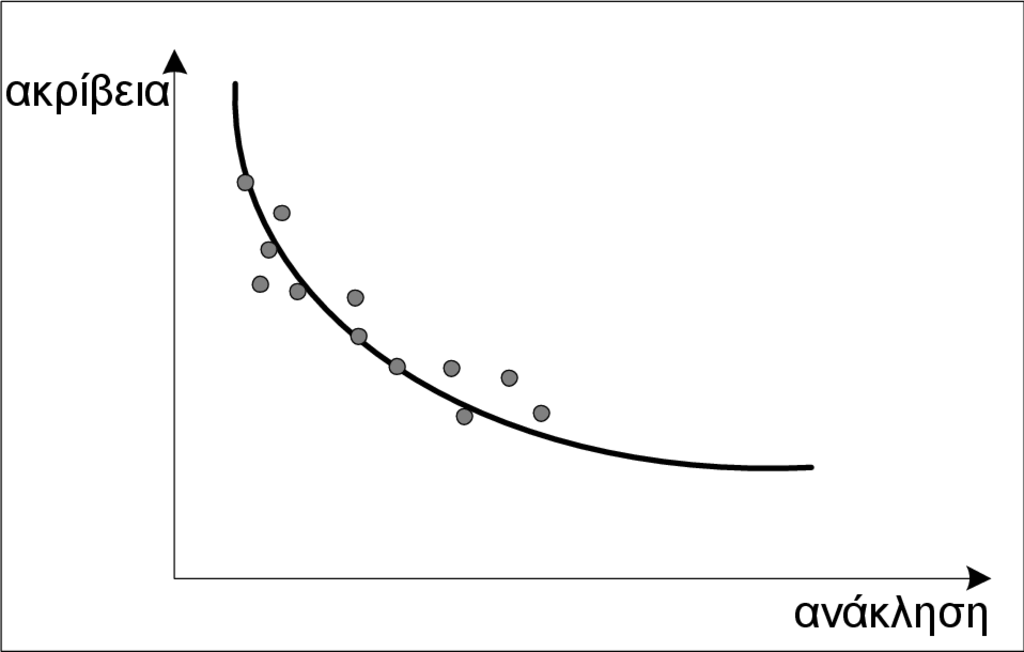
Η σχέση μεταξύ ανάκλησης και ακρίβειας έχει μελετηθεί σε βάθος από τους ερευνητές. Στη γραφική παράσταση του Σχήματος 2.5(α) η κάθε κουκίδα προσδιορίζει την ανάκληση και την ακρίβεια για ένα ερώτημα. Η καμπύλη που σχηματίζεται δείχνει τη μορφή που έχει μία τυπική γραφική παράσταση της ακρίβειας σε σχέση με την ανάκληση. Στο Σχήμα 2.5(β) δίνεται η σχέση ανάκλησης-ακρίβειας για δύο διαφορετικά ΣΑΠ. Παρατηρούμε ότι οι δύο καμπύλες μοιάζουν με αυτή του Σχήματος 2.5(α). Ωστόσο, οι δύο καμπύλες διασταυρώνονται με αποτέλεσμα να μην είναι προφανές ποιο από τα δύο συστήματα παρουσιάζει γενικώς την καλύτερη αποτελεσματικότητα. Αν και το πρώτο σύστημα εμφανίζει καλύτερη ανάκληση σε μία περιοχή της καμπύλης, εντούτοις υστερεί σε ακρίβεια, ενώ το αντίθετο συμβαίνει σε άλλη περιοχή της καμπύλης. Επομένως, η επιλογή του καλύτερου συστήματος δεν είναι καθόλου εύκολη υπόθεση και πρέπει να ληφθούν υπόψη και άλλες παράμετροι ώστε να προσδιοριστεί ο βαθμός αποτελεσματικότητας του κάθε συστήματος αλλά και ποιο σύστημα είναι πιο αποτελεσματικό από το άλλο. Για το λόγο αυτό, έχουν προταθεί εναλλακτικές μέθοδοι αποτίμησης της αποτελεσματικότητας οι οποίες παρουσιάζονται σε επόμενη ενότητα.
2.2.2 Παράγοντες Μεταβολής Ανάκλησης και Ακρίβειας
Η ανάκληση και η ακρίβεια, ως μέτρα αποτίμησης της αποτελεσματικότητας, είναι αρκετά διαδεδομένες μετρικές και χρησιμοποιούνται εκτενώς. Επομένως, είναι πολύ σημαντικό να γνωρίζουμε τους παράγοντες που επηρεάζουν τα δύο αυτά μέτρα. Η γνώση αυτών των παραγόντων μπορεί να οδηγήσει σε καλύτερα συστήματα που ανταποκρίνονται πιο αξιόπιστα στις απαιτήσεις των χρηστών.
Ένα από τα φαινόμενα που συναντούμε στα έγγραφα κειμένου είναι η συνωνυμία (synonymy) των όρων. Δύο όροι θεωρούνται ως συνώνυμοι εάν χρησιμοποιούνται εναλλακτικά για να περιγράψουν ένα αντικείμενο, μία ενέργεια, μία έννοια. Για παράδειγμα οι όροι ”αυτοκίνητο” και ”αμάξι” είναι συνώνυμοι. Το βασικό πρόβλημα της συνωνυμίας είναι ότι εάν υπάρχουν πολλοί όροι που αναφέρονται στην ίδια έννοια και ο χρήστης αναζητήσει έγγραφα σχετικά ως προς τον έναν από αυτούς τους όρους, τότε έγγραφα που δεν περιέχουν τον όρο αλλά είναι σχετικά ως προς το ερώτημα δεν θα ανακτηθούν. Αυτό σημαίνει ότι η συνωνυμία επηρεάζει αρνητικά την ανάκληση. Σχετικά με την επίδραση της συνωνυμίας στην ακρίβεια, δεν είναι εφικτή η εξαγωγή κάποιου ασφαλούς συμπεράσματος.
Το δεύτερο φαινόμενο που απαντάται συχνά στα έγγραφα κειμένου είναι η πολυσημία< (polysemy), σύμφωνα με την οποία η σημασία ενός όρου μπορεί να τελείως διαφορετική ανάλογα με το περιεχόμενο του εγγράφου.
Για παράδειγμα ο όρος ”ποντίκι” έχει διαφορετικό νόημα ανάλογα με το περιεχόμενο του εγγράφου (το ζώο ποντίκι ή το ποντίκι
που χρησιμοποιούμε για τη χρήση ηλεκτρονικού υπολογιστή).
Εάν ένας χρήστης αναζητήσει έγγραφα σχετικά με έναν όρο που έχει πολλαπλές ερμηνίες, τότε εκτός από τα έγγραφα
που σχετίζονται με την πληροφοριακή ανάγκη του χρήση θα ανακτηθούν και έγγραφα που περιέχουν μεν τον όρο, όμως
αναφέρονται σε εντελώς διαφορετικό θέμα. Είναι προφανές ότι κάτι τέτοιο θα επηρεάσει την ακρίβεια για το συγκεκριμένο
ερώτημα. Για την επίδραση της πολυσημίας στην ανάκληση δεν μπορούμε να αναφέρουμε με βεβαιότητα αν θα αυξηθεί, θα μειωθεί
η θα παραμείνει αναλοίωτη.
Παράδειγμα 2.2
Θα εξετάσουμε την επίδραση της συνωνυμίας στην ανάκληση και την ακρίβεια αντίστοιχα με ένα απλό παράδειγμα. Έστω οι όροι άστρο και αστέρας. Είναι προφανές ότι και οι δύο όροι αναφέρονται στο ίδιο ακριβώς ακτικείμενο. Υποθέτουμε ότι η συλλογή των εγγράφων αποτελείται από τα έγγραφα = . Από αυτά τα έγγραφα, θεωρήστε ότι τα , αναφέρουν τον όρο άστρο οπότε χαρακτηρίζονται ως σχετικά. Θεωρήστε επίσης ότι τα έγγραφα , και αναφέρουν τον όρο αστέρας και χαρακτηρίζονται και αυτά ως σχετικά. Αν ο χρήστης χρησιμοποιήσει τον όρο άστρο για να εκφράσει την πληροφοριακή ανάγκη, τότε στην καλύτερη περίπτωση το σύστημα θα επιστρέψει τα έγγραφα , ως σχετικά. Η αντίστοιχη ανάκληση στην περίπτωση αυτή είναι 40%. Ομοίως, αν χρησιμοποιηθεί ο όρος αστέρας τότε η ανάκληση είναι 60%. Παρατηρούμε ότι σε καμία περίπτωση η ανάκληση δεν μπορεί να φτάσει στο 100%, εκτός και αν χρησιμοποιηθούν και οι δύο όροι στο ερώτημα.
2.3 Εναλλακτικά Μέτρα Αποτελεσματικότητας
Στη βιβλιογραφία έχει διαπιστωθεί ότι η χρήση της ανάκλησης και της ακρίβειας όπως έχει περιγραφεί στις προηγούμενες παραγράφους μπορεί να δημιουργήσει προβλήματα στη μέτρηση της αποτελεσματικότητας [35, 47, 68]. Για παράδειγμα, σε πολλές περιπτώσεις η μέγιστη τιμή της ανάκλησης μπορεί να μην είναι διαθέσιμη, όπως συμβαίνει στον παγκόσμιο ιστό όπου η συλλογή εγγράφων είναι τεράστια και μεταβάλεται συνεχώς. Επιπλέον, η ανάκληση και η ακρίβεια μετρούν διαφορές πτυχές της αποτελεσματικότητας. Για τους λόγους αυτούς, οι ερευνητές μελέτησαν εναλλακτικούς τρόπους αποτίμησης της αποτελεσματικότητας, είτε χρησιμοποιώντας μία μόνο τιμή που συνοψίζει την καμπύλη ανάκλησης-ακρίβειας, είτε συνδυάζοντας την ανάκληση και την ακρίβεια με διάφορους τρόπους, δίνοντας την επιλογή στο χρήστη να δώσει περισσότερη βαρύτητα στη μία μετρική η την άλλη. Επίσης, έχουν προταθεί μετρικές που λαμβάνουν υπόψη το γεγονός ότι διαφορετικοί χρήστες αντιλαμβάνονται διαφορετικά τη σχετικότητα των εγγράφων ως προς το ερώτημα. Στη συνέχεια παρουσιάζουμε μερικές από τις πιο σημαντικές εναλλακτικές μετρικές.
2.3.1 Μονότιμες Συνόψεις
Μία μονότιμη σύνοψη (single valued summary) είναι στην ουσία μία τιμή που προκύπτει από το συνδυασμό τιμών ακρίβειας σε συγκεκριμένα επίπεδα ανάκλησης. Επειδή έχουμε μία μόνο τιμή, η σύγκριση δύο διαφορετικών αλγορίθμων ή συστημάτων είναι ευκολότερη. Ωστόσο, χρειάζεται προσοχή διότι με πολύ απλοϊκά σχήματα μπορεί να οδηγηθούμε σε εσφαλμένα συμπεράσματα. Μία μονότιμη σύνοψη που μπορούμε να χρησιμοποιήσουμε είναι η μέση τιμή της ακρίβειας για τα επίπεδα ανάκλησης όπου εμφανίζονται σχετικά έγγραφα στο αποτέλεσμα. Με βάση τις τιμές που εμφανίζονται στον Πίνακα 2.1, αν υπολογίσουμε τη μέση τιμής ακρίβειας στις περιπτώσεις που αλλάζει η ανάκληση έχουμε:
| (2.6) |
Παρατηρούμε ότι η μετρική αυτή λαμβάνει μεγαλύτερες τιμές όσο νωρίτερα το σύστημα μας δώσει τα σχετικά έγγραφα. Προφανώς, μπορεί το σύστημα να έχει καλή μέση ακρίβεια για το δεδομένο ερώτημα αλλά η ακρίβεια να μην είναι υψηλή αν λάβουμε υπόψη όλα τα επίπεδα ανάκλησης.
Μία δεύτερη μονότιμη σύνοψη που χρησιμοποιείται είναι η λεγόμενη -ακρίβεια. Αν υποθέσουμε ότι είναι το σύνολο των σχετικών εγγράφων που πρέπει να ανακτηθούν, τότε είναι το πλήθος αυτών. Η ιδέα είναι να μετρήσουμε την τιμή της ακρίβειας όταν λάβουμε ακριβώς έγγραφα στην έξοδο, ασχέτως αν αυτά είναι σχετικά ή όχι. Σύμφωνα με τις τιμές του Πίνακα 2.1 η τιμής της -ακρίβειας για το ερώτημα του παραδείγματος είναι 0.4 (40%) διότι τα σχετικά έγγραφα ως προς το ερώτημα είναι 5 και η αντίστοιχη ακρίβεια στην 5η γραμμή του πίνακα είναι 40%.
2.3.2 Αρμονικός Μέσος και -Μετρική
Μία εναλλακτική μετρική που έχει προταθεί στην εργασία [64] είναι ο αρμονικός μέσος (harmonic mean), ο οποίος δίνεται από τον ακόλουθο τύπο:
| (2.7) |
όπου το δηλώνει το -οστό έγγραφο στη διάταξη της απάντησης, είναι η τιμή της ανάκλησης όταν έχει ανακτηθεί το -οστό έγγραφο και η αντίστοιχη τιμή της ακρίβειας. Είναι προφανές ότι η τιμή του αρμονικού μέσου κυμαίνεται μεταξύ 0 και 1. Αν =0 τότε κανένα σχετικό έγγραφο δεν έχει ανακτηθεί, ενώ αν =1 τότε έχουν ανακτηθεί όλα τα σχετικά έγγραφα. Επιπλέον, αν οι τιμές ανάκλησης και ακρίβειας είναι μεγάλες, τότε και ο αρμονικός μέσος λαμβάνει μεγάλη τιμή.
Ο αρμονικός μέσος θεωρεί ότι τόσο η ανάκληση όσο και η ακρίβεια έχουν την ίδια βαρύτητα για την αποτίμηση της αποτελεσματικότητας. Ωστόσο, σε ορισμένες περιπτώσεις μπορεί η μία μετρική να θεωρηθεί περισσότερο σημαντική από την άλλη. Η -μετρική επιτρέπει τη χρήση μίας παραμέτρου που χρησιμοποιείται για να προσδιορίσει αν ενδιαφερόμαστε περισσότερο για την ανάκληση ή την ακρίβεια. Ο μαθηματικός τύπος που δίνει την -μετρική είναι ο ακόλουθος:
| (2.8) |
Όπως και στον τύπο του αρμονικού μέσου, το δηλώνει το -οστό έγγραφο στη διάταξη της απάντησης, είναι η τιμή της ανάκλησης όταν έχει ανακτηθεί το -οστό έγγραφο και η αντίστοιχη τιμή της ακρίβειας. Η παράμετρος παίρνει τιμές από το διάστημα [0,1] και καθορίζει τη σημαντικότητα της ανάκλησης ή της ακρίβειας. Αν = 0.5 τότε θεωρούμε ότι η ανάκληση και η ακρίβεια έχουν την ίδια βαρύτητα, αν τότε δίνουμε μεγαλύτερο βάρος στην ακρίβεια, ενώ αν τότε δίνουμε μεγαλύτερο βάρος στην ανάκληση. Σημειώνεται ότι όσο μικρότερη η τιμή της -μετρικής τόσο καλύτερη η αποτελεσματικότητα. Μία εναλλακτική μορφή της -μετρικής δίνεται στον ακόλουθο τύπο:
| (2.9) |
Αν = 1, τότε εύκολα διαπιστώνουμε ότι . Αν τότε δίνουμε μεγαλύτερη βαρύτητα στην ακρίβεια, ενώ αν τότε η ανάκληση θεωρείται περισσότερο σημαντική.
| ανάκληση | ακρίβεια | (=1) | (=0.2) | (=2) | |
|---|---|---|---|---|---|
| 20% | 100% | 0.33 | 0.67 | 0.13 | 0.76 |
| 40% | 100% | 0.57 | 0.43 | 0.05 | 0.55 |
| 40% | 66% | 0.50 | 0.50 | 0.36 | 0.57 |
| 40% | 50% | 0.44 | 0.56 | 0.50 | 0.58 |
| 40% | 40% | 0.40 | 0.60 | 0.60 | 0.60 |
| 60% | 50% | 0.54 | 0.46 | 0.50 | 0.42 |
| 80% | 57% | 0.67 | 0.33 | 0.42 | 0.26 |
| 80% | 50% | 0.61 | 0.39 | 0.50 | 0.29 |
| 100% | 55% | 0.71 | 0.29 | 0.44 | 0.14 |
Στον Πίνακα 2.3 δίνονται οι τιμές ανάκλησης, ακρίβειας, αρμονικού μέσου και -μετρικής για τα δεδομένα του Πίνακα 2.1. Για την -μετρική έχουμε χρησιμοποιήσει τη Σχέση 2.9, ενώ ο υπολογισμός της μετρικής πραγματοποιήθηκε για τρεις διαφορετικές τιμές της παραμέτρου (1, 0.2 και 2). Όπως είναι προφανές από τους προηγούμενους τύπους, όταν =1 η τιμή της -μετρικής είναι το συμπλήρωμα του αρμονικού μέσου. Όταν =0.2, τότε δίνουμε μεγαλύτερη βαρύτητα στην ακρίβεια και αυτό φαίνεται από τις χαμηλές τιμές που λαμβάνει η μετρική όταν έχουμε μεγάλες τιμές ακρίβειας. Κάτι αντίστοιχο παρατηρούμε και στην περίπτωση =2, όπου δίνεται μεγαλύτερη βαρύτητα στην ανάκληση, επομένως η -μετρική λαμβάνει χαμηλές τιμές για υψηλές τιμές ανάκλησης.
2.4 Συλλογές Αναφοράς και Μελέτες Αποτελεσματικότητας
Οι μετρικές που μελετήσαμε έως τώρα αποτελούν το ένα τμήμα της αποτίμησης αποτελεσματικότητας ενός συστήματος ή ενός αλγορίθμου. Το δεύτερο τμήμα που πρέπει να προσδιορισθεί είναι η συλλογή εγγράφων και το σύνολο των ερωτημάτων που θα εκτελεστούν. Βέβαια θα μπορούσε κάποιος να χρησιμοποιήσει μία οποιαδήποτε συλλογή εγγράφων και ένα οποιοδήποτε σύνολο ερωτημάτων και να προσδιορίσει τις τιμές των μετρικών. Αυτή η πρακτική δεν είναι η καλύτερη δυνατή για τους εξής λόγους:
-
•
η συλλογή εγγράφων και ο προσδιορισμός ερωτημάτων είναι χρονοβόρες διαδικασίες,
-
•
η επιλογή των εγγράφων και των ερωτημάτων ενδέχεται να οδηγήσει σε εσφαλμένα συμπεράσματα για την αποτελεσματικότητα ενός συστήματος,
-
•
η σχετικότητα ενός εγγράφου ως προς ένα ερώτημα είναι πολλές φορές υποκειμενική, με αποτέλεσμα η σύγκριση διαφορετικών μεθόδων ή συστημάτων να μην είναι επαρκής.
Τα προβλήματα αυτά έρχονται να επιλύσουν οι συλλογές αναφοράς (reference collections). Πρόκειται για συλλογές εγγράφων και ερωτημάτων που χρησιμοποιούνται από ερευνητές και από κατασκευαστές συστημάτων με στόχο την αποτίμηση της αποτελεσματικότητας. Μαζί με κάθε ερώτημα δίνονται και τα σχετικά ως προς το ερώτημα έγγραφα έτσι ώστε να είναι δυνατός ο υπολογισμός της ανάκλησης και της ακρίβειας. Η διαδικασία που εφαρμόζεται για τη διεξαγωγή των πειραμάτων και τον προσδιορισμό των μετρικών αποτελεσματικότητας παρουσιάζεται στο Σχήμα 2.6.

2.4.1 Πειράματα Cranfield
Η συλλογή Cranfield είναι η πρώτη συλλογή αναφοράς που δημιουργήθηκε για την αποτίμηση αποτελεσματικότητας. Η συλλογή άρχισε να δημιουργείται στη Μεγάλη Βρετανία στα τέλη της δεκαετίας του 1950 και αποτελείται από 1398 περιλήψεις άρθρων που έχουν δημοσιευθεί σε επιστημονικά περιοδικά αεροδυναμικής. Η συλλογή συνοδεύεται από 225 ερωτήματα για τα οποία έχουν προσδιορισθεί τα σχετικά έγγραφα κατόπιν εις βάθους μελέτης της συλλογής. Ο Cyril William Cleverdon ήταν ο πρώτος επιστήμονας που χρησιμοποίησε τις έννοιες της ανάκλησης και της ακρίβειας για την αποτίμηση της αποτελεσματικότητας των ΣΑΠ. Εκτός από Πληροφορικός, ο Cleverdon υπήρξε Βιβλιοθηκονόμος στο κολλέγιο αεροναυτικής Cranfield της Μεγάλης Βρετανίας. Τα πειράματα του Cleverdon είναι διεθνώς γνωστά ως πειράματα Cranfield.
Ένα σημαντικό τμήμα της έρευνας του Cleverdon εστιάστηκε στη μελέτη διαφορετικών μεθόδων δημιουργίας ευρετηρίων (καταλόγων) και τεχνικών ανάκτησης με στόχο την αύξηση της αποτελεσματικότητας [11]. Μελετήθηκαν 33 στρατηγικές αναζήτησης συνδυάζοντας απλά ευρετήρια, ευρετήρια φράσης, χρήση θησαυρού για τον προσδιορισμό συνωνύμων, χρήση βαρών. Ένα σημαντικό αποτέλεσμα της έρευνας ήταν το γεγονός ότι απλά σχήματα καταλόγων είχαν καλύτερη απόδοση από πιο πολύπλοκα, κάτι που θεωρήθηκε αρκετά παράξενο από άλλους ερευνητές και είχε ως συνέπεια να επικριθεί η έρευνα του Cleverdon από ορισμένους ερευνητές. Ωστόσο, ο Salton επιβεβαίωσε τα αποτελέσματα του Cleverdon με το σύστημα SMART.
2.4.2 Το Σύστημα SMART
Το σύστημα SMART (Salton’s Magic Automatic Retriever of Text) είναι ένα ΣΑΠ που αναπτύχθηκε στο Πανεπιστήμιο Cornell των Η.Π.Α. τη δεκαετία του 1960. Ο Gerard Salton ηγήθηκε της ομάδας ανάπτυξης. Το σύστημα SMART θεωρείται πολύ σημαντικό διότι ως τμήμα της έρευνας και ανάπτυξης στα πλαίσια του SMART προτάθηκαν σημαντικές τεχνικές Ανάκτησης Πληροφορίας όπως το Διανυσματικό μοντέλο και η Ανάδραση Σχετικότητας.
2.4.3 Οι Συλλογές CACM και ISI
Οι συλλογές CACM και ISI έχουν χρησιμοποιηθεί από τον Fox [24, 23]
και στη συνέχεια και από άλλους ερευνητές.
Η συλλογή εγγράφων CACM περιέχει 3204 άρθρα που έχουν δημοσιευθεί το χρονικό διάστημα 1958-1979 στο περιοδικό
Communications of the ACM. Τα άρθρα αυτά προέρχονται από διαφορετικές περιοχές της Πληροφορικής και έτσι
καλύπτεται ένα ευρύ φάσμα εννοιών. Ο συνολικός αριθμός των διαφορετικών όρων στα έγγραφα είναι 10446, ενώ
αντιστοιχούν κατά μέσο όρο 40.1 όροι ανά έγγραφο. Η συλλογή CACM συνοδεύεται από 52 ερωτήματα με 11.4 όρους το
καθένα (μέση τιμή), ενώ ο μέσος όρος των σχετικών εγγράφων ανά ερώτημα είναι 15.3. Για παράδειγμα, το 34ο ερώτημα
έχει ως εξής:
Currently interested in isolation of root of polynomial; there is an old article by Heindel, L.E. in J. ACM, Vol. 18, 533-548. I would like to find more recent material.
Η συλλογή ISI περιλαμβάνει 1460 έγγραφα που έχουν επιλεγεί από τη συλλογή που δημιούργησε ο Small στο Ινστιτούτο
Επιστημονικών Πληροφοριών (Institute of Scientific Information). Τα έγγραφα που επιλέχθηκαν για τη συλλογή
ISI είναι αυτά που έχουν το μεγαλύτερο αριθμό αναφορών. Ο συνολικός αριθμός όρων στα έγγραφα είναι 7392, ενώ
αντιστοιχούν 104.9 όροι ανά έγγραφο. Η συλλογή ISI συνοδεύεται συνολικά από 76 ερωτήματα διατυπωμένα σε φυσική
γλώσσα, ενώ για τα 35 από αυτά υπάρχουν αντίστοιχες λογικές εκφράσεις. Κάθε ερώτημα αποτελείται κατά μέσο όρο από
8.1 λέξεις, ενώ ο αριθμός των σχετικών εγγράφων ανά ερώτημα είναι κατά μέσο όρο 49.8. Στη συνέχεια δίνουμε το 4ο
ερώτημα της συλλογής ISI σε φυσική γλώσσα:
Image recognition and any other methods of automatically transforming printed text into computer-ready form.
Η αντίστοιχη λογική έκφραση για το ερώτημα αυτό έτσι όπως δίνεται στο αρχείο που περιέχει τις λογικές εκφράσεις
έχει ως εξής:
#q4= #or (#and (’image’, ’recognition’), #and ( #or (’printed’, ’text’), #or (’methods’, ’automatically’,
’transforming’, #and (’computer’, ’ready’)) ) );
2.4.4 Οι Συλλογές TREC
Το 1992 διεξήχθη το πρώτο συνέδριο TREC (Text REtrieval Conference) στο NIST (National Institute of Standards and Technology) στο Maryland των Η.Π.Α. Αφορμή για την οργάνωση του συνεδρίου ήταν η έλλειψη ενός συστηματικού τρόπου ελέγχου της απόδοσης των μεθόδων Ανάκτησης Πληροφορίας. Το συνέδριο TREC άνοιξε το δρόμο για τη δημιουργία συλλογών εγγράφων και ερωτημάτων με στόχο τη χρήση αυτών για συστηματική αποτίμηση. Αν και πριν το TREC υπήρχαν συλλογές αναφοράς (όπως έχουμε αναφέρει σε προηγούμενες παραγράφους), οι συλλογές αυτές ήταν σχετικά μικρές για να εξαχθούν ασφαλή συμπεράσματα σχετικά με την απόδοση των συστημάτων. Το συνέδριο TREC αποτελεί το κατάλληλο περιβάλλον όπου πολλοί ερευνητές μπορούν να μελετήσουν τα προβλήματα της Ανάκτησης Πληροφορίας σε πολύ μεγάλες και διαφορετικές συλλογές εγγράφων. Στον Πίνακα 2.4 παρουσιάζονται μερικά χαρακτηριστικά σύνολα δεδομένων που έχουν χρησιμοποιηθεί στα συνέδρια TREC.
| συλλογή | μέγεθος | πλήθος | μέσος αριθμός λέξεων |
|---|---|---|---|
| εγγράφων | (MBytes) | εγγράφων | ανά έγγραφο |
| Wall Street Journal 1987-1989 | 267 | 98732 | 434.0 |
| Wall Street Journal 1990-1992 | 242 | 74520 | 508.4 |
| Federal Register 1988 | 209 | 19860 | 1378.1 |
| Federal Register 1989 | 260 | 25960 | 1315.0 |
| Financial Times 1991-1994 | 564 | 210158 | 412.7 |
| Associated Press 1988 | 237 | 79919 | 468.7 |
| Associated Press 1989 | 254 | 84678 | 473.9 |
| Associated Press 1990 | 237 | 78321 | 478.4 |
Το TREC χωρίζεται σε διαφορετικές κατευθύνσεις11Ο αντίστοιχος αγγλικός όρος είναι tracks.. Η κάθε κατεύθυνση εξειδικεύεται σε μία συγκεκριμένη κατηγορία προβλημάτων ή δεδομένων. Σημειώνεται ότι δεν πραγματοποιούνται όλες οι κατευθύνσεις κάθε χρόνο. Με βάση τα στοιχεία των συνεδρίων που έχουν διεξαχθεί [69], παραθέτουμε μερικές από τις κατυεθύνσεις:
-
•
Filtering Track: Η κατεύθυνση αυτή στοχεύει στη μελέτη τεχνικών φιλτραρίσματος. Όπως έχει περιγραφεί στο Κεφάλαιο 1 το φιλτράρισμα χρησιμοποιείται όταν έχουμε ένα σύνολο ερωτημάτων που παραμένουν σταθερά και η συλλογή εγγράφων έχει τη μορφή ροής (νέα έγγραφα είναι συνεχώς διαθέσιμα). Η κατεύθυνση ενεργοποιήθηκε τελευταία φορά στο TREC 2002.
-
•
Web Track: Η κατεύθυνση αυτή ενεργοποιήθηκε τελευταία φορά στο TREC 2004 και έχει ως στόχο τη μελέτη αναζήτησης εγγράφων σε συλλογή που αποτελεί στιγμιότυπο του παγκόσμιου ιστού.
-
•
Terabyte Track: Βασικός σκοπός της κατεύθυνσης αυτής είναι η μελέτη της ικανότητας των συστημάτων ανάκτησης σχετικά με την κλιμάκωση που μπορούν να επιτύχουν ως προς το μέγεθος της συλλογής εγγράφων. Το ενδιαφέρον αυτής της κατεύθυνσης εστιάζεται σε συλλογές πολύ μεγαλύτερες από αυτές που χρησιμοποιούνται στο TREC. Η κατεύθυνση ενεργοποιήθηκε τελευταία φορά στο TREC 2006.
-
•
Question Answering Track: Αυτή η κατεύθυνση του TREC ασχολείται με τη μελέτη της απάντησης ερώτησης, με στόχο η Ανάκτηση Πληροφορίας να προχωρήσει ένα βήμα περισσότερο από την ανάκτηση εγγράφων.
-
•
Novelty Track: Η κατεύθυνση αυτή μελετά την ικανότητα των συστημάτων να εντοπίζουν νέα πληροφορία. Η τελευταία φορά που ενεργοποιήθηκε αυτή η κατεύθυνση ήταν στο συνέδριο TREC 2004.
-
•
Legal Track: Η κατεύθυνση αυτή ενεργοποιήθηκε για πρώτη φορά στο TREC 2006. Στόχος της είναι η ανάπτυξη μεθόδων αναζήτησης για την αποτελεσματική Ανάκτηση Πληροφορίας σε συλλογές νομικών εγγράφων.
-
•
SPAM Track: Στόχος της κατεύθυνσης αυτής είναι η αποτίμηση μεθόδων για φιλτράρισμα των μηνυμάτων ηλεκτρονικού ταχυδρομείου τύπου spam, που χαρακτηρίζονται ανεπιθύμητα και πολύ ενοχλητικά.
-
•
Video Track: Η κατεύθυνση αυτή στοχεύει στη μελέτη μεθόδων για αυτόματη τμηματοποίηση, τη δημιουργία μεθόδων προσπέλασης και την ανάκτηση video μα βάση το περιεχόμενο. Από το 2003 η κατεύθυνση αυτή αποκόπηκε από το TREC και είναι γνωστή με το όνομα TRECVID [70].
-
•
Genomics Track: Όπως δηλώνει και ο τίτλος της, η κατεύθυνση αυτή εστιάζει στη μελέτη μεθόδων ανάκτησης πληροφορίας σε δεδομένα γονιδίων. Σημειώνεται ότι δεν εξετάζονται μόνο ακολουθίες γονιδίων αλλά και ερευνητικές εργασίες και αναφορές.
-
•
Cross-Language Track: Η κατεύθυνση αυτή εστιάζει στην Ανάκτηση Πληροφορίας από μία συλλογή εγγράφων που είναι γραμμένα στη γλώσσα χρησιμοποιώντας ερωτήματα που δίνονται στη γλώσσα . Η κατεύθυνση ενεργοποιήθηκε τελευταία φορά στο TREC 2002. Τα θέματα που αφορούν τη διαγλωσσική Ανάκτηση Πληροφορίας μελετώνται από το CLEF (Cross-Language Evaluation Forum) [10].
Κάθε φορά προσδιορίζεται ένα σύνολο εγγράφων, ερωτημάτων και σχετικών εγγράφων για κάθε ερώτημα. Με βάση τα δεδομένα αυτά οι ερευνητές εκτελούν σειρές πειραμάτων. Στο Σχήμα 2.7 δίνεται η περιγραφή δύο ερωτημάτων (στο TREC τα ερωτήματα καλούνται topics) με κωδικούς 778 και 790 που έχουν χρησιμοποιηθεί στο Terabyte Track στο TREC 2005. Περισσότερα στοιχεία σχετικά με τις κατευθύνσεις του TREC που ενεργοποιούνται κάθε χρόνο καθώς επίσης και συλλογές εγγράφων και ερωτημάτων για τις διαφορετικές κατευθύνσεις του TREC υπάρχουν στον ιστότοπο του συνεδρίου TREC [69].
top
num Number: 778
title golden ratio
desc Description:
Golden ratio formula, description, or examples.
narr Narrative:
Documents must contain the Golden Ratio formula or a description of its development. References to works of
art, design, or architecture are acceptable. Examples of the Golden Ratio appearing in nature are acceptable.
Other terms, such as ”Golden Mean” or ”Golden Proportion”, are acceptable and can be substituted for Golden Ratio.
References to Fibonacci without specifying the Golden Ratio or its formula are not acceptable. Documents limited
to web links, bibliographies, or tables of contents (without accompanying documents) are not acceptable.
/top
top
num Number: 790
title women’s rights in Saudi Arabia
desc Description:
Provide any description of laws or restrictions affecting Saudi Arabian women’s rights.
narr Narrative:
Acceptable documents must provide a narrative description of Saudi laws or restrictions affecting Saudi women.
Relevance to women must be specifically mentioned; general laws affecting women only as a subset of the whole
Population is not acceptable. Documents that allude to women’s rights and restrictions are not acceptable unless
they give an example, however vague. References to changes in the laws, improvements, etc. are all acceptable.
The time period should be relatively current (past 50 years).
/top
2.5 Σύνοψη και Περαιτέρω Μελέτη
Στο κεφάλαιο αυτό μελετήσαμε μερικά σημαντικά ζητήματα της περιοχής της Ανάκτησης Πληροφορίας που σχετίζονται με την αποτίμηση της αποτελεσματικότητας. Σε αντίθεση με τα ΣΔΒΔ, στην περίπτωση των ΣΑΠ θα πρέπει να υπάρχουν συστηματικοί τρόποι μέτρησης της επάρκειας των αποτελεσμάτων, καθώς διαφορετικές μέθοδοι ανάκτησης ή διαφορετικά συστήματα ενδέχεται να δώσουν και διαφορετικά αποτελέσματα.
Οι δύο βασικότερες μετρικές που χρησιμοποιούνται για τη μέτρηση της αποτελεσματικότητας είναι η ανάκληση και η ακρίβεια. Λόγω της δυσκολίας να συγκρίνουμε διαφορετικές μεθόδους με βάση τις καμπύλες ανάκλησης-ακρίβειας, έχουν προταθεί και εναλλακτικές μετρικές που είτε απλά υπολογίζουν μέσες τιμές ακρίβειας σε καθορισμένα επίπεδα ανάκλησης, είτε συνδυάζουν τις τιμές ανάκλησης και ακρίβειας.
Η μέτρηση της αποτελεσματικότητας προϋποθέτει ότι εκτός από τον προσδιορισμό των μετρικών αποτίμησης πρέπει να υπάρχουν και οι κατάλληλες συλλογές εγγράφων και ερωτημάτων. Επειδή η κατασκευή νέων συλλογών είναι πολύ χρονοβόρα διαδικασία οι ερευνητές χρησιμοποιούν συλλογές που είναι διαθέσιμες και για κάθε ερώτημα το σύνολο των σχετικών εγγράφων είναι γνωστό. Μερικές από τις πιο βασικές και ευρέως χρησιμοποιούμενες συλλογές είναι οι Cranfield, CACM, ISI, και TREC.
Ο αναγνώστης που ενδιαφέρεται να εμβαθύνει στο πολύ ενδιαφέρον ζήτημα της αποτίμησης αποτελεσματικότητας μπορεί να ανατρέξει σε πλήθος επιστημονικών άρθρων που σχετίζονται με το συγκεκριμένο πρόβλημα. Μία πολύ καλή επισκόπηση της δουλειάς που έχει γίνει πάνω στο θέμα της σχετικότητας εγγράφων βρίσκεται στην εργασία [45]. Περισσότερες πληροφορίες για τις συλλογές CACM και ISI υπάρχουν στις εργασίες [24, 23], ενώ στη διδακτορική διατριβή του Fox [25] ο αναγνώστης μπορεί να βρει και άλλο χρήσιμο σχετικό υλικό.
Το σύστημα SMART είναι διαθέσιμο στη διεύθυνση [66]. Στην ίδια διεύθυνση ο ενδιαφερόμενος μπορεί να βρει και μερικές από τις συλλογές που έχουν χρησιμοποιηθεί από τους ερευνητές, μεταξύ των άλλων και τις CACM και ISI. Σχετικά με τα συνέδρια TREC ο αναγνώστης μπορεί να ξεκινήσει από τον αντίστοιχο ιστότοπο [69] και στη συνέχεια να μελετήσει τα αντίστοιχα άρθρα των συνεδρίων. Επίσης, εκτενής αναφορά σε θέματα αποτίμησης αποτελεσματικότητας γίνεται στο 3ο κεφάλαιο του βιβλίου [3] και στο 8ο κεφάλαιο του βιβλίου [41].
2.6 Ασκήσεις
-
2.1
Γιατί απαιτείται η σύγκριση συστημάτων ανάκτησης και ως προς την απόδοση και ως προς την αποτελεσματικότητα;
-
2.2
Πώς ορίζεται η ανάκληση, η ακρίβεια και η αστοχία;
-
2.3
Να σχολιάσετε τη σχέση ανάκλησης και ακρίβειας.
-
2.4
Ποιοί παράγοντες επηρεάζουν την ανάκληση ή την ακρίβεια; Να δώσετε κατατοπιστικά παραδείγματα.
-
2.5
Γιατί απαιτούνται εναλλακτικές μετρικές αποτίμησης αποτελεσματικότητας;
-
2.6
Ποιές συλλογές εγγράφων έχουν χρησιμοποιηθεί κατά καιρούς από τους ερευνητές για τη διεξαγωγή πειραμάτων;
-
2.7
Τι είναι το σύστημα SMART και για ποιό λόγο θεωρείται σημαντικό;
-
2.8
Για ποιούς λόγους θεωρείτε ότι απαιτούνται οργανωμένες συλλογές εγγράφων για τη διεξαγωγή πειραμάτων;
-
2.9
Προσπαθήστε να προσδιορίσετε εφαρμογές όπου η ανάκληση παίζει σημαντικότερο ρόλο από την ακρίβεια και το ανάποδο.
-
2.10
Ποιά είναι η καλύτερη δυνατή καμπύλη ανάκλησης-ακρίβειας που θα μπορούσαμε να έχουμε;
-
2.11
Να αποδείξετε ότι με την ένα-προς-ένα εξέταση των εγγράφων της απάντησης (α) η ανάκληση είτε αυξάνεται είτε παραμένει σταθερή και (β) η ακρίβεια μπορεί να μειωθεί, να αυξαθεί ή να παραμείνει σταθερή.
-
2.12
Δίνεται συλλογή εγγράφων που αποτελείται από έγγραφα. Για ένα συγκεκριμένο ερώτημα έστω ότι είναι το πλήθος των σχετικών εγγράφων. Αν διαλέξουμε τυχαία έγγραφα από τη συλλογή, ποιά είναι η πιθανότητα να έχουμε ανάκληση τουλάχιστον 40% και ακρίβεια τουλάχιστον 30%;
-
2.13
Αν σας ζητηθεί να εκτελέσετε ένα ερώτημα έτσι ώστε να έχουμε την καλύτερη δυνατή ανάκληση και ταυτόχρονα τη χειρότερη δυνατή ακρίβεια, πως θα προχωρούσατε;
-
2.14
Να κατασκευάσετε πρόγραμμα που εκτελεί τα ακόλουθα: (α) διαβάζει τη συλλογή εγγράφων CACM, (β) διαβάζει τα ερωτήματα που αφορούν στη συλλογή αυτή, (γ) για κάθε ερώτημα προσδιορίζει ως σχετικά τα έγγραφα που περιέχουν όλους τους όρους του ερωτήματος, (δ) τυπώνει για κάθε ερώτημα την ανάκληση και την ακρίβεια. Να επαναληφθεί η διαδικασία όταν επιλέγουμε τυχαία όρους από το ερώτημα και αναφέρουμε ως σχετικά τα έγγραφα που περιέχουν και τους όρους. Να δώσετε για όλα τα ερωτήματα τις τιμές ανάκλησης και ακρίβειας για διαφορετικές τιμές του .
-
2.15
Δίνεται μία συλλογή εγγράφων που αποτελείται από 16 έγγραφα με κωδικούς έως . Έχουμε στη διάθεσή μας δύο διαφορετικούς αλγορίθμους επεξεργασίας ενός ερωτήματος . Έστω ότι ο πρώτος αλγόριθμος αναφέρει ότι τα 5 περισσότερο σχετικά έγγραφα είναι ενώ ο δέυτερος επιστρέφει το σύνολο εγγράφων . Γνωρίζοντας ότι το σύνολο των σχετικών ως προς το ερώτημα εγγράφων είναι το : (i) να υπολογίζεται τη συνολική ανάκληση και την ακρίβεια για τις δύο μεθόδους, (ii) να υπολογίσετε την ακρίβεια κάθε φορά που αλλάζει η ανάκληση, και (iii) να συζητήσετε σχετικά με την αποτελεσματικότητα των δύο αλγορίθμων.
-
2.16
Δίνονται οι ακόλουθες δυο διατάξεις που αφορούν στην απάντηση ενός ερωτήματος από δύο μηχανές αναζήτησης:
recall: 0.17 0.17 0.33 0.5 0.67 0.83 0.83 0.83 0.83 1.0 precision: 1.0 0.5 0.67 0.75 0.8 0.83 0.71 0.63 0.56 0.6 (2.10) recall: 0.0 0.17 0.17 0.17 0.33 0.5 0.67 0.67 0.83 1.0 precision: 0.0 0.5 0.33 0.25 0.4 0.5 0.57 0.5 0.56 0.6 (2.11) Να σημειώσετε για κάθε αποτέλεσμα ποιά έγγραφα είναι σχετικά και ποιά όχι. Επίσης, να σχολιάσετε σχετικά με το ποιά μηχανή είναι πιο αποτελεσματική για την απάντηση του συγκεκριμένου ερωτήματος.