Κεφάλαιο 1Εισαγωγή στην Ανάκτηση Πληροφορίας
1.1 Εισαγωγή
Η Ανάκτηση Πληροφορίας (Information Retrieval) είναι η επιστημονική περιοχή που μελετά τα προβλήματα που σχετίζονται με την αναπαράσταση, την οργάνωση και την επεξεργασία στοιχείων πληροφορίας, με στόχο την αποτελεσματική και αποδοτική πρόσβαση των χρηστών σε αυτά. Αν και η γνωστική περιοχή της Ανάκτησης Πληροφορίας ξεκίνησε με τη μελέτη εγγράφων κειμένου (text), στη συνέχεια επεκτάθηκε και στη μελέτη άλλων τύπων δεδομένων, κάτι που επιβλήθηκε από τις ανάγκες των σύγχρονων εφαρμογών. Έτσι, σήμερα μπορούμε να χρησιμοποιούμε μεθόδους ανάκτησης για την πρόσβαση σε πολυμεσικά δεδομένα (όπως: εικόνα, ήχο, βίντεο) καθώς και σε δεδομένα διαθέσιμα μέσω του παγκόσμιου ιστού (world wide web). Λόγω της ποικιλομορφίας των τύπων δεδομένων στα οποία μπορεί να έχει ταυτόχρονα πρόσβαση ο χρήστης, θεωρούμε στη συνέχεια ότι η κάθε είδους πληροφορία είναι γενικώς αποθηκευμένη με τη μορφή εγγράφων (documents). Θα θεωρήσουμε ότι ο όρος έγγραφο είναι ισοδύναμος με τον όρο έγγραφο κειμένου (text document). Ο ενδιαφερόμενος αναγνώστης μπορεί να ανατρέξει στη διεθνή βιβλιογραφία σχετικά με την ανάκτηση άλλων τύπων δεδομένων, όπως εικόνα, ήχο και βίντεο.
Στο κεφάλαιο αυτό θα προσπαθήσουμε να δώσουμε μία γενική εικόνα της γνωστικής περιοχής της Ανάκτησης Πληροφορίας περιγράφοντας τις βασικές έννοιες και δίνοντας συνοπτικά τα θέματα που διαπραγματευόμαστε στη συνέχεια του βιβλίου σε μεγαλύτερο βάθος.
| κωδικός | όνομα | διάμετρος (χλμ) | δορυφόροι |
|---|---|---|---|
| 1 | Ερμής | 4880 | 0 |
| 2 | Αφροδίτη | 12103.6 | 0 |
| 3 | Γη | 12756.3 | 1 |
| 4 | Άρης | 6794 | 2 |
| 5 | Δίας | 142984 | 63 |
| 6 | Κρόνος | 120536 | 34 |
| 7 | Ουρανός | 51118 | 21 |
| 8 | Ποσειδώνας | 49532 | 13 |
| 9 | Πλούτωνας | 2274 | 3 |
Έστω ότι έχουμε στη διάθεσή μας ένα Σύστημα Ανάκτησης Πληροφορίας (ΣΑΠ) που διαχειρίζεται αρχεία με έγγραφα κειμένου σχετικά με το διάστημα και ένα Σύστημα Διαχείρισης Βάσεων Δεδομένων (ΣΔΒΔ) που επίσης αποθηκεύει δεδομένα σχετικά με το διάστημα. Οι δυνατότητες που έχει το ΣΑΠ είναι εντελώς διαφορετικές από αυτές του ΣΔΒΔ (αν και υπάρχουν ήδη υλοποιήσεις που χρησιμοποιούν τεχνικές και από τις δύο περιοχές με στόχο την καλύτερη εξυπηρέτηση των χρηστών). Ας θεωρήσουμε το ακόλουθο ερώτημα: Να βρεθούν οι πλανήτες του ηλιακού μας
συστήματος που έχουν κανέναν, έναν ή δύο φυσικούς δορυφόρους. Το βασικό χαρακτηριστικό του ερωτήματος αυτού
είναι ότι είναι σαφές, και επομένως θα θέλαμε από το σύστημα μια σαφή απάντηση που να καλύπτει πλήρως το ερώτημα
του χρήστη. Το ερώτημα αυτό μπορεί να απαντηθεί πολύ εύκολα από ένα ΣΔΒΔ, αρκεί να υπάρχει η πληροφορία σχετικά
με τον αριθμό των δορυφόρων που έχει ο κάθε πλανήτης. Για παράδειγμα, αν υπάρχουν στο σύστημα τα δεδομένα του
Πίνακα 1.1, τότε μπορούμε να διατυπώσουμε το προηγούμενο ερώτημα με το εξής ερώτημα SQL:
SELECT όνομα
FROM πλανήτες
WHERE δορυφόροι = 0 OR δορυφόροι = 1 OR δορυφόροι = 2
| : | Ο κομήτης του Χάλλεϋ μας επισκέπτεται περίπου κάθε εβδομήντα έξι χρόνια. |
|---|---|
| : | Ο κομήτης του Χάλλεϋ ανακαλύφθηκε από τον αστρονόμο Έντμοντ Χάλλεϋ. |
| : | Ένας κομήτης διαγράφει ελλειπτική τροχιά. |
| : | Ο πλανήτης Άρης έχει δύο φυσικούς δορυφόρους, το Δείμο και το Φόβο. |
| : | Ο πλανήτης Δίας έχει εξήντα τρεις γνωστούς φυσικούς δορυφόρους. |
| : | Ο Ήλιος είναι ένας αστέρας. |
| : | Ο Άρης είναι ένας πλανήτης του ηλιακού μας συστήματος. |
Ας εξετάσουμε τώρα ένα άλλο ερώτημα που δεν είναι και τόσο σαφές όσο το προηγούμενο: Να βρεθούν πληροφορίες σχετικές με τον κομήτη του Χάλλεϋ. Το ερώτημα αυτό δεν προσδιορίζει κάποια συγκεκριμένη πληροφορία που πρέπει να επιστραφεί στο χρήστη. Σε αντίθεση με το προηγούμενο ερώτημα, το ερώτημα αυτό είναι λιγότερο σαφές ως προς το αποτέλεσμα. Ένα τέτοιο ερώτημα δεν μπορεί να απαντηθεί από ένα τυπικό ΣΔΒΔ και επομένως, απαιτούνται διαφορετικοί μηχανισμοί οργάνωσης και επεξεργασίας των δεδομένων με στόχο την αποτελεσματική και αποδοτική επεξεργασία των ερωτημάτων των χρηστών. Έστω ότι υπάρχουν επτά διαφορετικά έγγραφα, με κωδικούς , , , , , και τα περιεχόμενα των οποίων δίνονται στο Σχήμα 1.1. Με βάση τα περιεχόμενα των εγγράφων, αναγνωρίζουμε ότι τα έγγραφα και είναι αυτά που σχετίζονται περισσότερο με το ερώτημα, ενώ το σχετίζεται λιγότερο γιατί αναφέρεται μεν σε κομήτες αλλά όχι στον κομήτη του Χάλλεϋ. Τέλος, το έγγραφο δεν σχετίζεται καθόλου με το ερώτημα, καθώς αναφέρεται στον πλανήτη Άρη και στους δορυφόρους του.
Ένα ΣΑΠ είναι καταλληλότερο για την επεξεργασία του δεύτερου ερωτήματος, ενώ ένα ΣΔΒΔ είναι πιο κατάλληλο για την επεξεργασία του πρώτου. Αν και υπάρχουν συστήματα που λειτουργούν ταυτόχρονα και ως ΣΔΒΔ και ως ΣΑΠ, θα θεωρήσουμε ότι οι δύο κατηγορίες συστημάτων είναι διακριτές. Πράγματι, τα γνωστικά αντικείμενα των Βάσεων Δεδομένων και της Ανάκτησης Πληροφορίας αναπτύχθηκαν παράλληλα, κυρίως λόγω των διαφορών στα δεδομένα: ενώ τα ΣΔΒΔ διαχειρίζονται πλήρως δομημένα δεδομένα (structured data) με τη μορφή εγγραφών, τα ΣΑΠ διαχειρίζονται αδόμητα δεδομένα (unstructured data) ή ημι-δομημένα δεδομένα (semi-structured data). Η βασική αυτή διαφοροποίηση οδήγησε τους ερευνητές των δύο κατευθύνσεων να μελετήσουν διαφορετικά προβλήματα που οφείλονται στην αναπαράσταση, οργάνωση και επεξεργασία των δεδομένων. Στον Πίνακα 1.2 παρουσιάζονται μερικές από τις βασικότερες διαφορές μεταξύ ενός ΣΔΒΔ και ενός ΣΑΠ. Ας εξετάσουμε τις διαφορές αυτές πιο προσεκτικά:
| χαρακτηριστικό | ΣΔΒΔ | ΣΑΠ |
|---|---|---|
| είδος δεδομένων | απολύτως δομημένα | αδόμητα, ημι-δομημένα |
| τύπος δεδομένων | αριθμητικά, αλφαριθμητικά | έγγραφα |
| γλώσσα ερωτημάτων | SQL,QBE | λέξεις-κλειδιά ή φυσική γλώσσα |
| ερώτημα | σαφές | ασαφές |
| ταύτιση απάντησης | επακριβής | μερική |
| αποτελέσματα | χωρίς βαθμολόγηση | βαθμολογημένα |
-
•
Ένα ΣΔΒΔ διαχειρίζεται δεδομένα που είναι αποθηκευμένα σε εγγραφές (records). Για παράδειγμα, ένας πλανήτης μπορεί να αναπαρασταθεί με μία εγγραφή τη μορφής όνομα, διάμετρος, αρ_δορυφόρων . Τα στοιχεία όνομα, διάμετρος και αρ_δορυφόρων καλούνται πεδία της εγγραφής. Επομένως, όλα τα δεδομένα που είναι αποθηκευμένα στη βάση θα πρέπει να έχουν την ίδια μορφή. Βέβαια, σε ένα ΣΔΒΔ σπάνια τα δεδομένα είναι αποθηκευμένα σε ένα μόνο πίνακα. Στην πραγματικότητα υπάρχει ένα σύνολο πινάκων που ορίζει τα δεδομένα και τις σχέσεις μεταξύ τους. Είναι προφανές, ότι τα δεδομένα ενός ΣΔΒΔ έχουν μία συγκεκριμένη μορφή (δομή). Αντιθέτως, σε ένα ΣΑΠ δεν είναι απαραίτητη η ύπαρξη δομής στα δεδομένα. Τα δεδομένα είναι αποθηκευμένα με τη μορφή εγγράφων που περιέχουν ελέυθερο κείμενο και επομένως δεν χαρακτηρίζονται από συγκεκριμένη δομή.
-
•
Σε ένα ΣΔΒΔ, σε ένα πεδίο μίας εγγραφής αποθηκεύεται μία αριθμητική ή αλφαριθμητική τιμή, που έχει συνήθως περιορισμένο μήκος. Αντιθέτως, το μέγεθος του κάθε εγγράφου δεν περιορίζεται, ενώ το περιεχόμενό του μπορεί να είναι διαφορετικό ανάλογα με την εφαρμογή. Αξίζει να σημειωθεί ότι τα περισσότερα ΣΔΒΔ υποστηρίζουν τη δυνατότητα αποθήκευσης μεγάλων αντικειμένων, οπότε θα μπορούσαν να χρησιμοποιηθούν για τη διαχείριση εγγράφων. Ωστόσο, η δυνατότητα αποθήκευσης εγγράφων είναι ένα μόνο από τα χαρακτηριστικά ενός ΣΑΠ.
-
•
Προηγουμένως, είδαμε ότι διαφορετικά διατυπώνεται ένα ερώτημα σε ένα ΣΔΒΔ και διαφορετικά σε ένα ΣΑΠ. Στην πρώτη περίπτωση ο χρήστης επικοινωνεί με το ΣΔΒΔ είτε διατυπώνοντας ένα ερώτημα σε μία γλώσσα ερωτημάτων όπως είναι η SQL, είτε συμπληρώνει κάποια φόρμα ενώ στη συνέχεια το ερώτημα μετατρέπεται σε SQL χωρίς την παρέμβαση του χρήστη. Αντίθετα, για τη διατύπωση ενός ερωτήματος σε ένα ΣΑΠ χρησιμοποιείται φυσική γλώσσα. Στην πιο απλή μορφή του ένα ερώτημα απαρτίζεται από ένα μικρό σύνολο όρων που εκφράζουν την πληροφοριακή ανάγκη του χρήστη (π.χ. ο πλανήτης Δίας).
-
•
Η διατύπωση ενός ερωτήματος με μία γλώσσα ερωτημάτων όπως η SQL περιορίζεται από τους κανόνες της γλώσσας, ενώ τα ερωτήματα που απευθύνονται σε ένα ΣΔΒΔ χαρακτηρίζονται από σαφήνεια. Για παράδειγμα, το ερώτημα SQL που είδαμε προηγουμένως αναφέρεται με σαφήνει για το ποια αποτελέσματα επιθυμεί ο χρήστης στην έξοδο (συνθήκη WHERE). Στην περίπτωση ενός ΣΑΠ, η απλή περάθεση μερικών όρων ή μίας παραγράφου δεν είναι ικανή να προσδιορίσει με ακρίβεια την πληροφοριακή ανάγκη του χρήστη. Βέβαια, υπάρχουν μοντέλα ανάκτησης στα οποία δηλώνεται με ακρίβεια το είδος της απάντησης (π.χ. το λογικό μοντέλο) όμως τα περισσότερα μοντέλα προσπαθούν να προσδιορίσουν το βαθμό ομοιότητας των εγγράφων με το ερώτημα. Αυτό σημαίνει ότι η ταύτιση του εγγράφου με το ερώτημα μπορεί να είναι μερική (partial match). Για παράδειγμα, έστω ότι ένας χρήστης εκφράζει την πληροφοριακή του ανάγκη χρησιμοποιώντας τους όρους Δίας, Κρόνος. Αν το ΣΑΠ διαχειρίζεται τη συλλογή εγγράφων του Σχήματος 1.1 τότε προφανώς δεν υπάρχει κάποιο έγγραφο που να περιέχει και τους δύο όρους του ερωτήματος. Στην περίπτωση αυτή θα μπορούσε να τερματιστεί η αναζήτηση χωρίς καθόλου αποτελέσματα. Όμως, αν και δεν υπάρχουν αποτελέσματα για τον πλανήτη Κρόνο, υπάρχουν έγγραφα σχετικά με τον πλανήτη Δία. Παρατηρούμε ότι σε αντίθεση με ένα ερώτημα σε ένα ΣΔΒΔ το ερώτημα προς ένα ΣΑΠ χαρακτηρίζεται από ασάφεια σχετικά με την εμφάνιση των όρων στα έγγραφα.
-
•
Τα αποτελέσματα που αφορούν ένα ερώτημα SQL αποτελούν ένα σύνολο εγγραφών για τα οποία δεν ορίζεται κάποια βαθμολόγηση. Εξαίρεση αποτελούν τα ερωτήματα που περιέχουν την έκφραση ORDER BY και τα οποία εμφανίζουν τα αποτελέσματα ταξινομημένα κατά αύξουσα ή φθίνουσα διάταξη με βάση κάποιο πεδίο (ή πεδία). Ωστόσο, δεν μπορούμε να προσδιορίσουμε κάποια εγγραφή που να είναι περισσότερο σχετική ως προς το ερώτημα σε σχέση με κάποια άλλη. Για την ακρίβεια, μία εγγραφή είτε θα ικανοποιεί τις συνθήκες του ερωτήματος είτε όχι. Σε ένα ΣΑΠ ωστόσο, μπορούμε να προσδιορίσουμε το βαθμό ομοιότητας ενός εγγράφου ως προς το ερώτημα. Άρα, τα αποτελέσματα ενός ερωτήματος μπορούν να εμφανιστούν στο χρήστη με φθίνουσα διάταξη ως προς το βαθμό ομοιότητας.
Η σχετικότητα ενός εγγράφου ως προς τα ενδιαφέροντα ενός χρήστη μπορεί να διαπιστωθεί σχετικά εύκολα αν ο χρήστης διαβάσει προσεκτικά το έγγραφο. Ο ανθρώπινος εγκέφαλος μπορεί γρήγορα να αποφανθεί αν ένα έγγραφο είναι σχετικό ή όχι. Για την περίπτωση της μικρής συλλογής εγγράφων του Σχήματος 1.1, η μελέτη όλων των εγγράφων είναι εύκολη υπόθεση τόσο γιατί τα έγγραφα είναι λίγα όσο και γιατί το κάθε έγγραφο αποτελείται από πολύ λίγες λέξεις. Με ποιόν τρόπο όμως θα μπορέσουμε να διακρίνουμε τα σχετικά έγγραφα ανάμεσα σε αρκετές χιλιάδες εγγράφων που μπορεί να αποτελούνται από πολλές χιλιάδες λέξεις το καθένα; Δυστυχώς η τεράστια ποσότητα πληροφορίας είναι ο κανόνας και όχι η εξαίρεση. Για παράδειγμα, με τη βοήθεια του παγκόσμιου ιστού έχουμε πρόσβαση σε μεγάλες ποσότητες πληροφορίας και χωρίς τα κατάλληλα εργαλεία, η πληροφορία αυτή παραμένει ανεκμετάλλευτη. Επίσης, υπάρχουν μεγάλες ποσότητες πληροφορίες αποθηκευμένες σε ηλεκτρονικές βιβλιοθήκες. Χωρίς τους κατάλληλους μηχανισμούς ανάκτησης, το μόνο που θα μπορούσαμε να εφαρμόσουμε είναι η σειριακή εξέταση των εγγράφων με σκοπό τον προσδιορισμό των σχετικών εγγράφων ως προς τα ενδιαφέροντα του χρήστη. Όπως είναι προφανές, κάτι τέτοιο δεν είναι εφικτό. Στο σημείο αυτό έρχεται να βοηθήσει η Ανάκτηση Πληροφορίας που προσφέρει αποδοτικές και αποτελεσματικές μεθόδους οργάνωσης δεδομένων και επεξεργασίας ερωτημάτων με στόχο τον αυτοματοποιημένο και συστηματικό προσδιορισμό της σχετικής πληροφορίας ως προς τις πληροφοριακές ανάγκες των χρηστών.
Πριν προχωρήσουμε σε περισσότερες λεπτομέρειες κρίνεται σκόπιμη μία συνοπτική παρουσίαση μερικών εκ των σημαντικότερων γεγονότων στο χώρο της Ανάκτησης Πληροφορίας:
-
[1890] Χρήση καρτών Hollerith από το Γραφείο Πληθυσμιακής Απογραφής των ΗΠΑ (US Census Bureau).
-
[1950] Πρωτοεμφανίζεται ο όρος Ανάκτηση Πληροφορίας.
-
[1960] Η δημοσίευση της εργασίας των Maron και Kuhns [42] σχετικά με τη χρήση πιθανοτήτων στην Ανάκτηση Πληροφορίας.
-
[1962] Δημοσιεύονται οι πρώτες μελέτες του William Cleverdon σχετικά με τα πειράματα Cranfield.
-
[1968] Δημοσιεύεται το βιβλίο του Gerand Salton με τίτλο Automatic Information Organization and Retrieval.
-
[1969] Δημοσιεύεται η εργασία του John W. Sammon Jr. [61] που αποτέλεσε την πρώτη πρόταση για τη χρήση οπτικοποιημένης διεπαφής με συστήματα ανάκτησης.
-
[1971] Εκδίδεται το βιβλίο του Gerand Salton για το σύστημα SMART [59].
-
[1975] Δημοσιεύεται η εργασία [58] από την ομάδα του Salton σχετικά με το Διανυσματκό μοντέλο ανάκτησης.
-
[1978] Διοργανώνεται το πρώτο συνέδριο SIGIR (Rochester, New York).
-
[1979] Εκδίδεται το βιβλίο του Van Rijsbergen με τίτλο Information Retrieval [75].
-
[1983] Δημοσιεύεται η εργασία των Salton, Fox και Wu [57] σχετικά με την επέκταση του Λογικού μοντέλου.
-
[1989] Δημιουργία του Παρκόσμιου Ιστού από τον Sir Tim Berners-Lee.
-
[1992] Διοργανώνεται το πρώτο συνέδριο TREC (Gaithersburg, Maryland).
-
[1993] Κατασκευή του φυλλομετρητή Mosaic.
-
[1994] Κατασκευάζονται οι μηχανές αναζήτησης Lycos, Infoseek και AltaVista και δημιουργείται ο φυλλομετρητής Netscape Navigator.
-
[1995] Ιδρύεται η εταιρία Yahoo!.
-
[1998] Ιδρύεται η εταιρία Google Inc.
-
[1999] Ο Sir Tim Berners-Lee εισάγει την έννοια του σημασιολογικού ιστού (semantic web).
-
[2008] Η Yahoo! ανακοινώνει ότι υιοθετεί μερικές από τις τεχνολογικές εξελίξεις του σημασιολογικού ιστού.
Στη συνέχεια παρουσιάζονται τα βασικότερα θέματα που αφορούν στη διαδικασία της Ανάκτησης Πληροφορίας, περιγράφεται η γενική αρχιτεκτονική ενός ΣΑΠ και συζητούνται θέματα που αφορούν σε προχωρημένες τεχνικές και σύγχρονες ερευνητικές τάσεις.
1.2 Η Διαδικασία της Ανάκτησης Πληροφορίας
Ένα ΣΑΠ έχει δύο βασικούς στόχους. Ο πρώτος έχει να κάνει με την ποιότητα και επάρκεια των αποτελεσμάτων, δηλαδή την αποτελεσματικότητα (effectiveness), ενώ ο δεύτερος σχετίζεται με την ταχύτητα ανάκτησης της ζητούμενης πληροφορίας, δηλαδή την απόδοση (efficiency). Αν και υπάρχουν περιπτώσεις όπου η αποτελεσματικότητα ή η απόδοση παίζει μεγαλύτερο ρόλο, μας ενδιαφέρει η ανάπτυξη ενός ΣΑΠ που να είναι δυνατό και στα δύο αυτά χαρακτηριστικά. Εδώ παρατηρούμε για άλλη μια φορά τη διαφορά μεταξύ ΣΑΠ και ΣΔΒΔ. Για ένα ΣΔΒΔ δεν τίθεται θέμα αποτελεσματικότητας διότι θεωρούμε εκ των προτέρων ότι τα αποτελέσματα προσδιορίζονται με μοναδικό τρόπο. Με άλλα λόγια, δύο ΣΔΒΔ που περιέχουν ακριβώς τα ίδια δεδομένα θα δώσουν τα ίδια αποτελέσματα για το ίδιο ερώτημα (στη γενική περίπτωση σε διαφορετικό χρόνο). Κάτι τέτοιο όμως δεν ισχύει στην περίπτωση των ΣΑΠ. Δύο διαφορετικά ΣΑΠ ενδέχεται να δώσουν διαφορετικά αποτελέσματα για το ίδιο ερώτημα. Θεωρήστε ως παράδειγμα δύο δημοφιλείς μηχανές αναζήτησης στον παγκόσμιο ιστό, τη μηχανή Yahoo! και τη μηχανή Google. Αν δοκιμάσουμε να δώσουμε το ίδιο ερώτημα στις μηχανές αυτές θα πάρουμε διαφορετικά αποτελέσματα. Η αποτίμηση των αποτελεσμάτων της διαδικασίας ανάκτησης είναι ένα από τα βασικά προβλήματα της γνωστικής περιοχής. Ωστόσο, θα πρέπει να τονιστεί ότι ειδικά για την περίπτωση του Web, η διαφορετικότητα των απαντήσεων μπορεί επίσης να οφείλεται και στο γεγονός ότι οι δύο μηχανές μπορεί να μην έχουν συλλέξει το ίδιο σύνολο ιστοσελίδων.
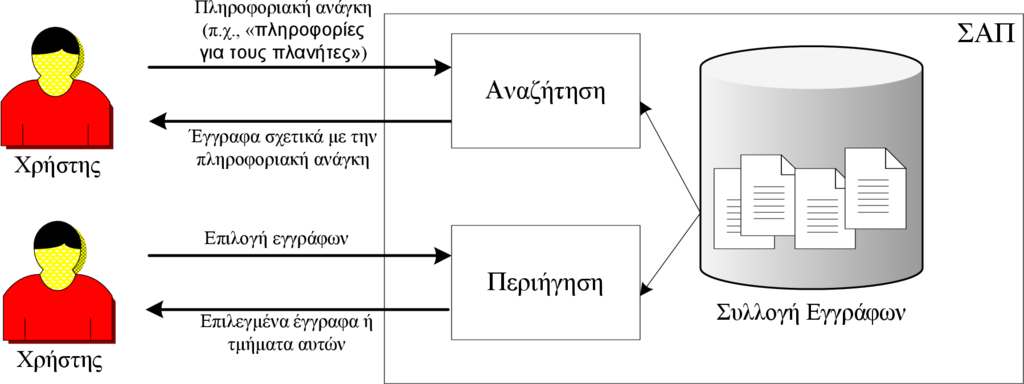
Ένα ΣΑΠ δέχεται ένα ερώτημα από κάποιον χρήστη, το οποίο εκφράζει την ανάγκη για πληροφορία σχετικά με κάποιο θέμα (όπως για παράδειγμα το ερώτημα που έχουμε αναφέρει προηγουμένως σχετικά με τον κομήτη του Χάλλεϋ). Στη συνέχεια, το σύστημα προσδιορίζει τη ζητούμενη πληροφορία και την επιστρέφει στο χρήστη. Η διαδικασία αυτή παρουσιάζεται στο Σχήμα 1.2 όπου φαίνεται ο τρόπος επικοινωνίας ενός χρήστη με ένα σύστημα Ανάκτησης ΠΛηροφορίας. Τα έγγραφα που απαρτίζουν την απάντηση είναι συνήθως ταξινομημένα σε φθίνουσα διάταξη ως προς το βαθμό ομοιότητας με το ερώτημα. Ο προσδιορισμός των σχετικών ως προς το ερώτημα εγγράφων είναι μία πολύπλοκη διαδικασία η οποία καλείται αναζήτηση (searching) και θα πρέπει να εκτελείται γρήγορα. Μία δεύτερη βασική λειτουργία που επιτρέπει την αλληλεπίδραση μεταξύ χρήση και ΣΑΠ είναι η περιήγηση (browsing), κατά την οποία ο χρήστης μπορεί να εξερευνήσει τα έγγραφα της συλλογής ένα προς ένα, ανά θεματική ενότητα ή να χρησιμοποιήσει τους πιθανούς συνδέσμους μεταξύ των εγγράφων, όπως για παράδειγμα στη διαχείριση εγγράφων τύπου HTML, ώστε να μεταβεί από το ένα έγγραφο στο άλλο. Η αναζήτηση και η περιήγηση πολλές φορές λειτουργούν συνεργατικά, καθώς μπορεί ο χρήστης να χρησιμοποιήσει την αναζήτηση για να εντοπίσει ένα υποσύνολο των εγγράφων της συλλογής και στη συνέχεια να συνεχίσει χρησιμοποιώντας την περιήγηση για τη μελέτη των αποτελεσμάτων.
1.2.1 Βασικές Λειτουργίες
Τα τμήματα της διαδικασίας της Ανάκτησης Πληροφορίας παρουσιάζονται διαγραμματικά στο Σχήμα 1.3 και θα αναλυθούν συνοπτικά στη συνέχεια, ενώ στα επόμενα κεφάλαια θα μελετήσουμε διεξοδικά τις λειτουργίες που αυτά εκτελούν.
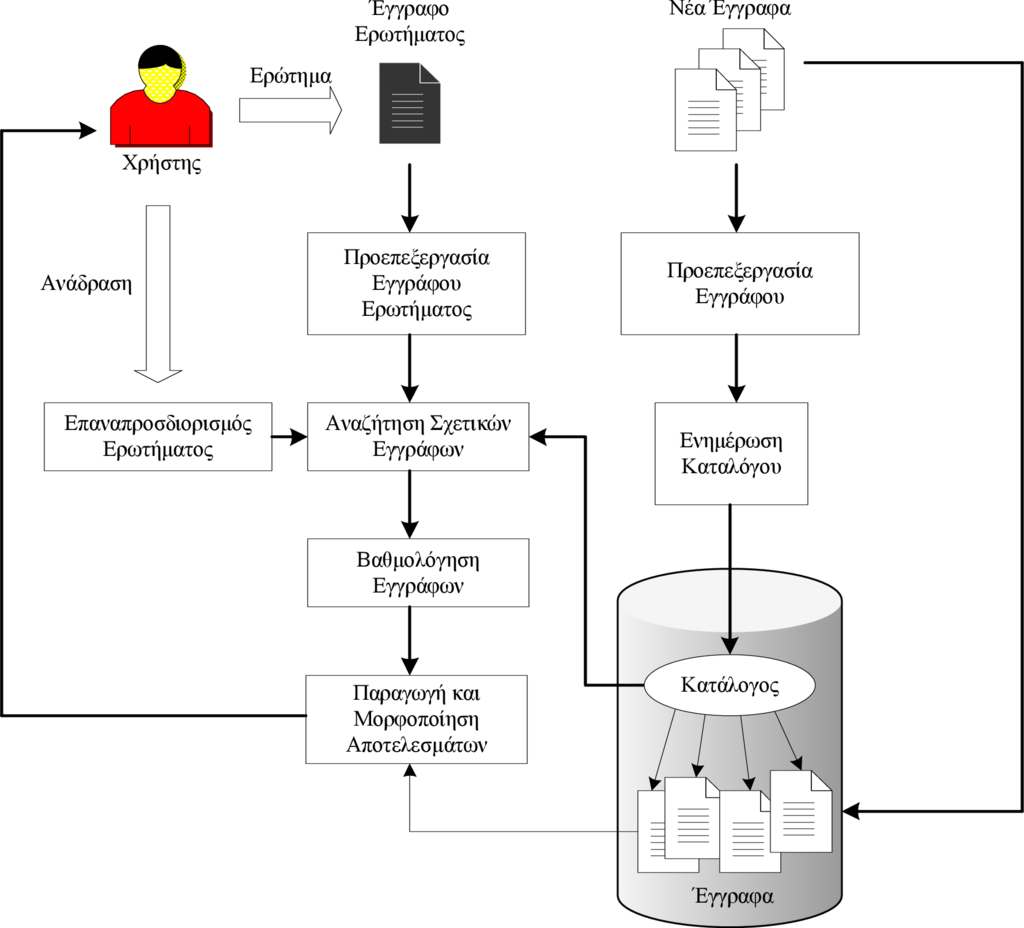
Ο κάθε χρήστης του ΣΑΠ επικοινωνεί με το σύστημα με τη βοήθεια κάποιας διεπαφής. Για παράδειγμα, στην περίπτωση μίας μηχανής αναζήτησης, η διεπαφή είναι ο φυλλομετρητής (browser) του χρήστη, ο οποίος συνδέεται με το ΣΑΠ μέσω του πρωτοκόλλου HTTP. Επίσης, η διεπαφή μπορεί να εξαρτάται από το σύστημα, όπως για παράδειγμα αν πρόκειται για μία εφαρμογή client-server, η οποία επιβάλει την εγκατάσταση ειδικού λογισμικού στο τερματικό του χρήστη. Οποιαδήποτε και αν είναι η διεπαφή, μέσω αυτής ο χρήστης έχει τη δυνατότητα να χρησιμοποιεί το ΣΑΠ σε συνάρτηση με τα δικαιώματα χρήσης που αυτός έχει.
Δύο είναι οι βασικές λειτουργίες στις οποίες ένας χρήστης μπορεί να έχει πρόσβαση: (α) η υποβολή ενός ερωτήματος (ανάγκη για πληροφορία), και (β) η υποβολή ενός νέου εγγράφου προς αποθήκευση. Προφανώς, για τη δεύτερη λειτουργία θα πρέπει ο χρήστης να έχει και ανάλογα δικαιώματα. Συνήθως, δικαίωμα καταχώρισης νέων εγγράφων έχουν μόνο εξουσιοδοτημένοι χρήστες που είναι υπεύθυνοι για τα περιεχόμενα του ΣΑΠ. Σε περίπτωση που ο χρήστης επιθυμεί να καταχωρίσει ένα νέο έγγραφο, τότε το έγγραφο αυτό υποβάλλεται στη διαδικασία της προεπεξεργασίας ώστε να μετατραπεί σε μία μορφή κατάλληλη για την εσωτερική του αναπαράσταση στο ΣΑΠ. Όπως θα μελετήσουμε στη συνέχεια, η προεπεξεργασία αυτή μπορεί να αφορά στην απαλοιφή κάποιων λέξεων που δεν μεταφέρουν σημαντική ποσότητα πληροφορίας (π.χ. άρθρα). Αν καταχωριστεί ένα νέο έγγραφο, τότε θα πρέπει να ενημερωθεί ένα ζωτικό μέρος του ΣΑΠ που καλείται κατάλογος (catalogue) ή ευρετήριο (index) και το οποίο είναι υπεύθυνο για τη γρήγορη αναζήτηση λέξεων με στόχο τον προσδιορισμό των σχετικών ως προς το ερώτημα εγγράφων. Επειδή τα περιεχόμενα του καταλόγου είναι σε άμεση συνάρτηση με τα περιεχόμενα των εγγράφων, κάθε φορά που μεταβάλλονται τα περιεχόμενα των εγγράφων (π.χ. εισαγωγή νέου εγγράφου) θα πρέπει να υπάρχει αντίστοιχη ενημέρωση του καταλόγου.
Έστω τώρα ότι ο χρήστης υποβάλει κάποιο ερώτημα προς το ΣΑΠ. Το ερώτημα ενός χρήστη συνήθως εκφράζεται με τον
προσδιορισμό μερικών λέξεων, και ίσως με κάποιους τελεστές. Στο προηγούμενο παράδειγμα, η αναζήτηση εγγράφων
σχετικών με τον κομήτη του Χάλλεϋ θα μπορούσε να εκφραστεί ως:
= κομήτης,Χάλλεϋ
Αυτή είναι η πιο γενική μορφή ενός ερωτήματος και ως απάντηση δεχόμαστε έγγραφα που περιέχουν και τις δύο ή μία
από τις δύο λέξεις. Επομένως, στην περίπτωση αυτή υπονοείται η χρήση του λογικού τελεστή OR μεταξύ των
λέξεων του ερωτήματος. Σε μερικές περιπτώσεις μπορεί να θέλουμε να χρησιμοποιήσουμε τον τελεστή AND μεταξύ
των λέξεων. Για παράδειγμα, αν στην απάντηση θέλουμε μόνο έγγραφα που περιέχουν και τις δύο λέξεις, τότε το
ερώτημα θα μπορούσε να εκφραστεί ως:
= κομήτης AND Χάλλεϋ
Σε περίπτωση που στο ερώτημα υπάρχουν πολλές λέξεις, τότε μπορεί να γίνει η χρήση των λογικών τελεστών AND,
OR και NOT (μαζί με παρενθέσεις) για τη διατύπωση πιο πολύπλοκων ερωτημάτων. Στη συνέχεια του
βιβλίου θα μελετήσουμε μηχανισμούς ανάκτησης που επιτρέπουν τη διατύπωση τέτοιων ερωτημάτων. Επίσης, ο μηχανισμός
ανάκτησης είναι αυτός που καθορίζει και τον τρόπο αναπαράστασης των εγγράφων. Συνήθως χρησιμοποιούνται ειδικές
αναπαραστάσεις των εγγράφων με στόχο την αποτελεσματική και αποδοτική επεξεργασία των ερωτημάτων. Από τους
μηχανισμούς ανάκτησης που έχουν προταθεί στη βιβλιογραφία, στα επόμενα κεφάλαια θα εστιάσουμε στους εξής:
Λογικό Μοντέλο, Διανυσματικό Μοντέλο, Πιθανοτική Ανάκτηση Πληροφορίας, και LSI (Latent Semantic Indexing).
Το ερώτημα του χρήστη θα υποστεί και αυτό κάποια προεπεξεργασία που εξαρτάται και από την προεπεξεργασία που εφαρμόζεται στα αποθηκευμένα έγγραφα. Για παράδειγμα, αν δεν λαμβάνουμε υπόψη τα άρθρα τότε θα πρέπει αυτά να διαγραφούν από το ερώτημα του χρήστη. Το προεπεξεργασμένο ερώτημα οδηγείται προς εκτέλεση με στόχο την εύρεση των σχετικών εγγράφων ως προς αυτό. Στη φάση αυτή ο κατάλογος παίζει πολύ σημαντικό ρόλο, καθώς μας βοηθά στον προσδιορισμό των εγγράφων που περιέχουν τους όρους του ερωτήματος. Χωρίς τη χρήση του καταλόγου, θα έπρεπε να αναζητήσουμε τους όρους του εγγράφου σε όλα τα αποθηκευμένα έγγραφα με σειριακό τρόπο. Επομένως, η χρήση του καταλόγου οδηγεί σε πιο αποδοτική αναζήτηση. Ο κατάλογος που χρησιμοποιείται συνήθως στα συστήματα Ανάκτησης Πληροφορίας είναι ο αντεστραμμένος κατάλογος (inverted index), ο οποίος αντιστοιχεί σε κάθε λέξη τα έγγραφα που την περιέχουν, και τις θέσεις μέσα στο έγγραφο όπου αυτές εμφανίζονται.

Στο Σχήμα 1.4 δίνεται ένα μέρος του αντεστραμμένου καταλόγου που αντιστοιχεί στα έγγραφα που εμφανίζονται στο Σχήμα 1.1. Ο αντεστραμμένος κατάλογος αποτελείται από δύο τμήματα, το λεξικό (lexicon) , το οποίο αποτελείται από όλες τις λέξεις που εμφανίζονται στα έγγραφα και τις λίστες εμφανίσεων (occurrence lists ή posting lists) , οι οποίες περιέχουν την πληροφορία εμφάνισης των λέξεων στα έγγραφα. Για παράδειγμα, η λέξη κομήτης εμφανίζεται στο έγγραφο στη θέση 3, στο έγγραφο στη θέση 29 και στο έγγραφο στη θέση 3 (θεωρώντας ότι η αρίθμηση των θέσεων στο έγγραφο αρχίζει από το 1 και κάθε χαρακτήρας καταλαμβάνει μία θέση στο έγγραφο). Η κάθε λίστα εμφανίσεων είναι ένα σύνολο από εμφανίσεις λέξεων. Το σύμβολο [, ] σημαίνει ότι η λέξη βρίσκεται στη θέση του εγγράφου . Μερικές υλοποιήσεις αντεστραμένων καταλόγων μπορεί να περιέχουν και άλλες σημαντικές πληροφορίες, όπως για παράδειγμα τη συχνότητα εμφάνισης (frequency of occurrence) κάθε λέξης στα έγγραφα της συλλογής. Στην πιο απλή του μορφή, ο αντεστραμμένος κατάλογος περιέχει για κάθε όρο το πλήθος των εγγράφων που αυτός περιέχεται και τους κωδικούς αριθμούς των εγγράφων αυτών.
Ο αντεστραμμένος κατάλογος θα πρέπει να υλοποιηθεί με κατάλληλο τρόπο ώστε η αναζήτηση των λέξεων στα έγγραφα να γίνεται αποδοτικά. Για το λόγο αυτό χρησιμοποιούνται ειδικές τεχνικές για την οργάνωση του λεξικού και τη συμπίεση των λιστών εμφανίσεων. Για παράδειγμα, το λεξικό μπορεί να οργανωθεί με τη χρήση ενός B-δένδρου ή με τη χρήση πίνακα κατακερματισμού, ώστε να έχουμε γρήγορη πρόσβαση στη λίστα εμφανίσεων κάποιας λέξης. Μορφές οργάνωσης του λεξιλογίου καθώς επίσης και μεθόδους οργάνωσης των λιστών εμφανίσεων θα μελετήσουμε σε επόμενα κεφάλαια. Επίσης, θα μελετήσουμε και άλλες μεθόδους οργάνωσης και αναζήτησης, όπως για παράδειγμα καταλόγους που βασίζονται στη χρήση υπογραφών (signatures).
Μετά τον προσδιορισμό των σχετικών εγγράφων με τη βοήθεια του καταλόγου, ακολουθεί η διαδικασία της βαθμολόγησης και της ταξινόμησης των εγγράφων. Η βαθμολόγηση των εγγράφων έχει ως στόχο τον προσδιορισμό μίας τιμής για κάθε έγγραφο, η οποία δηλώνει τη σχετικότητα του εγγράφου ως προς το ερώτημα του χρήστη. Ο βαθμός σχετικότητας συνήθως είναι μία τιμή μεταξύ του 0 και του 1, ή εκφράζεται με ποσοστό. Έτσι, ένα έγγραφο με βαθμό σχετικότητας 100% ταιριάζει ακριβώς με το ερώτημα του χρήστη. Η μέθοδος βαθμολόγησης εξαρτάται από το μοντέλο ανάκτησης που χρησιμοποιεί το σύστημα. Υπάρχουν μοντέλα που επιτρέπουν τον προσδιορισμό του βαθμού σχετικότητας, ενώ κάποια άλλα δεν έχουν αυτή τη δυνατότητα. Τα βαθμολογημένα έγγραφα επιστρέφονται στο χρήστη συνήθως με φθίνουσα διάταξη. Άρα, το πρώτο έγγραφο είναι το περισσότερο σχετικό, ενώ το τελευταίο σχετίζεται λιγότερο με την ανάγκη πληροφορίας του χρήστη.
Πολλές φορές παρατηρείται το φαινόμενο, κάποια από τα έγγραφα που επέστρεψε το ΣΑΠ να μην είναι τόσο σχετικά με το ερώτημα του χρήστη. Μία από τις μεθόδους που χρησιμοποιούνται για την ενίσχυση της ποιότητας των αποτελεσμάτων είναι η ανάδραση σχετικότητας (relevance feedback). Με τη μέθοδο αυτή, ο χρήστης έχει τη δυνατότητα να επιλέξει κάποια από τα έγγραφα της απάντησης ως περισσότερο σχετικά από τα υπόλοιπα και το σύστημα να επαναπροσδιορίσει την απάντηση με βάση την επιλογή του χρήστη. Η μέθοδος της ανάδρασης σχετικότητας θα μελετηθεί σε βάθος σε επόμενο κεφάλαιο.
Στις προηγούμενες παραγράφους προσπαθήσαμε να δώσουμε τις βασικότερες έννοιες που αφορούν στη γνωστική περιοχή της Ανάκτησης Πληροφορίας, περιγράφοντας συνοπτικά τα βασικότερα τμήματα ενός ΣΑΠ. Τα κεφάλαια που ακολουθούν μελετούν σε βάθος τις έννοιες που παρουσιάσαμε εδώ.
1.2.2 Περιστασιακή Αναζήτηση και Φιλτράρισμα Εγγράφων
Ένα ερώτημα μπορεί να ανήκει σε μία από δύο κατηγορίες. Η πρώτη κατηγορία αφορά σε ερωτήματα που εκτελούνται μία φορά, ενώ η δεύτερη κατηγορία αφορά σε ερωτήματα που εκτελούνται συνεχώς για κάποιο χρονικό διάστημα που συνήθως προσδιορίζεται από το χρήστη. Η πρώτη κατηγορία αναζήτησης καλείται περιστασιακή ή εξειδικευμένη (ad-hoc), ενώ η συνεχής επεξεργασία ενός ερωτήματος καλείται και φιλτράρισμα (filtering) ή δρομολόγηση (routing) των εγγράφων. Έστω ότι ένας χρήστης επιθυμεί να λάβει πληροφορίες σχετικά με τον πλανήτη Άρη, και υποβάλει στο ΣΑΠ το ερώτημα = {πλανήτης,Άρης} δηλώνοντας ότι επιθυμεί και τους δύο όρους στα έγγραφα της απάντησης. Με βάση τα έγγραφα του Σχήματος 1.1 το ΣΑΠ θα προσδιορίσει ότι το είναι το μοναδικό σχετικό έγγραφο ως προς το ερώτημα και θα το επιστρέψει στο χρήστη. Στο σημείο αυτό ολοκληρώνεται η επεξεργασία του ερωτήματος. Σε περίπτωση που ο χρήστης μετά από κάποιο χρονικό διάστημα επιθυμεί να εκτελέσει πάλι το ίδιο ερώτημα, θα πρέπει εκ νέου να το υποβάλει στο ΣΑΠ. Αυτός ο τρόπος επεξεργασίας είναι και αυτός που υπονοείται συνήθως από τους χρήστες.
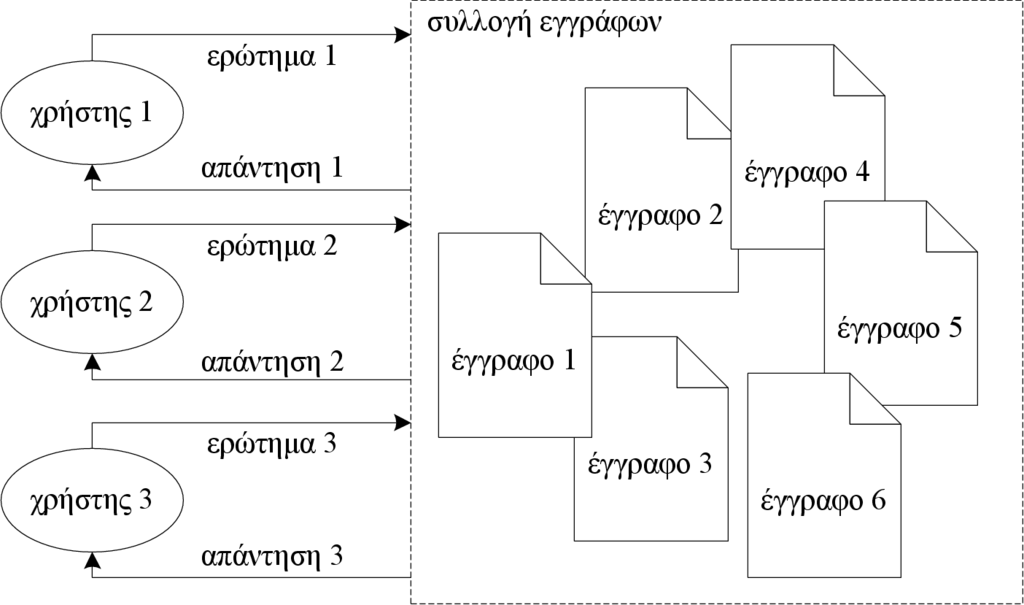
Ας υποθέσουμε τώρα ότι η συλλογή των εγγράφων αλλάζει με σχετικά γρήγορους ρυθμούς (όπως συμβαίνει για παράδειγμα στον παγκόσμιο ιστό). Ένας χρήστης που ενδιαφέρεται για πληροφορίες σχετικά με ένα θέμα θα πρέπει σε τακτά χρονικά διαστήματα να υποβάλει το ίδιο ερώτημα, έτσι ώστε να εντοπίσει νέα έγγραφα που είναι διαθέσιμα. Θα ήταν πιο εύκολο για το χρήστη να υποβάλει το ερώτημα μία μόνο φορά, δηλώνοντας ταυτόχρονα την επιθυμία του για ενημέρωση όταν γίνει διαθέσιμο ένα νέο έγγραφο που είναι σχετικό ως προς ερώτημα. Στην περίπτωση αυτή, το ΣΑΠ θα πρέπει να καταχωρίσει το ερώτημα του χρήστη και να ελέγχει κάθε νέο έγγραφο αν είναι ή όχι σχετικό με το ερώτημα. Επίσης, ο χρήστης μπορεί να ορίσει και ένα κατώφλι σχετικότητας, το οποίο ορίζει ότι είναι ενδιαφέρον κάθε νέο έγγραφο που έχει βαθμό σχετικότητας μεγαλύτερο από το κατώφλι. Το χρονικό διάστημα για το οποίο το ερώτημα παραμένει ενεργό προσδιορίζεται πάλι από το χρήστη. Με αυτόν τον τύπο επεξεργασίας ερωτημάτων μπορούμε να υποστηρίξουμε τη συνεχή εκτέλεση ερωτημάτων πολλών χρηστών, αποδεσμεύοντας τους χρήστες από την επαναλαμβανόμενη υποβολή του ίδιου ερωτήματος σε τακτά χρονικά διαστήματα.

Στο Σχήμα 1.5 δίνεται ένα παράδειγμα περιστασιακής αναζήτησης. Παρουσιάζονται τα ερωτήματα τριών χρηστών και οι απαντήσεις του συστήματος. Τονίζεται ότι το κάθε ερώτημα εκτελείται μία μόνο φορά. Στο Σχήμα 1.6 δίνεται ένα παράδειγμα φιλτραρίσματος εγγράφων. Το σύνολο των ερωτημάτων που έχει υποβάλει ο κάθε χρήστης προσδιορίζει το προφίλ του. Σε αντίθεση με την περιστασιακή εκτέλεση ερωτημάτων, τα ερωτήματα εκτελούνται συνεχώς, και κάθε νέο έγγραφο ελέγχεται ως προς τη σχετικότητά του με τα ενεργά προφίλ. Αν βρεθεί κάποιο προφίλ για το οποίο το νέο έγγραφο είναι σχετικό, τότε η ταυτότητα του νέου εγγράφου προστίθεται στα σχετικά έγγραφα και ενημερώνεται ο αντίστοιχος χρήστης. Στο παράδειγμα του σχήματος, το νέο έγγραφο (Έγγραφο 7) είναι σχετικό ως τα προφίλ των χρηστών 2 και 3.
Τονίζεται ότι το φιλτράρισμα εγγράφων αποκτά ιδιαίτερο ενδιαφέρον στις μέρες μας και κυρίως λόγω του παγκόσμιου ιστού, όπου η διαθεσιμότητα νέων ιστοσελίδων και περιεχομένου πραγματοποιείται με γρήγορους ρυθμούς, και επομένως η ανάγκη για αυτόματη ή ημι-αυτόματη ενημέρωση των αποτελεσμάτων είναι μεγαλύτερη και ιδιαίτερα χρήσιμη για τους χρήστες. Χαρακτηριστικό παράδειγμα αποτελούν να δεδομένα που βρίσκονται σε BLOGs ή RSS feeds τα οποία αλλάζουν με γρήγορους ρυθμούς.
1.2.3 Προχωρημένα Θέματα Ανάκτησης Πληροφορίας
Με βάση τα όσα έχουν αναφερθεί έως τώρα μπορεί κάποιος να υποθέσει ότι η Ανάκτηση Πληροφορίας ασχολείται μόνο με την αναζήτηση σχετικών εγγράφων ως προς κάποιο ερώτημα. Αν και ένα μεγάλο τμήμα της έρευνας στην περιοχή μελετά αυτό ακριβώς το πρόβλημα, υπάρχουν και άλλες κατευθύνσεις προς έρευνα και ανάπτυξη που έχουν εξαιρετικό ενδιαφέρον και θέτουν νέα προβλήματα προς επίλυση. Μερικές από τις κατευθύνσεις αυτές περιγράφονται στη συνέχεια:
- Δια-γλωσσιακή Ανάκτηση Πληροφορίας
-
(Cross-Language IR). Η περιοχή αυτή αναφέρεται στη μελέτη της αποτελεσματικής και αποδοτικής αναζήτησης εγγράφων στη περίπτωση όπου η γλώσσα διατύπωσης των ερωτημάτων είναι διαφορετική από αυτήν των εγγράφων. Το πρόβλημα αυτό έχει μεγάλη πρακτική σημασία λαμβάνοντας υπόψη τον αριθμό των διαφορετικών γλωσσών και τη δυνατότητα που δίνει ο παγκόσμιος ιστός για εύκολη πρόσβαση σε τεράστιες ποσότητες πληροφορίας .
- Εξόρυξη Δεδομένων από Έγγραφα Κειμένου
-
(Text Mining). Η εξόρυξη δεδομένων είναι ένα από τα στάδια της διαδικασίας που καλείται ανάκάλυψη γνώσης (knowledge discovery). Στην περίπτωση των εγγράφων κειμένου εστιάζει σε θέματα ομαδοποίησης εγγράφων (clustering), κατηγοριοπίησης (categorization), εξαγωγής πληροφορίας (information extraction), και κανόνες συσχέτισης (association rules). Οι μέθοδοι εξόρυξης εφαρμόζονται όχι μόνο στο σύνολο των εγγράφων της συλλογής, αλλά και στα αποτελέσματα ενός ερωτήματος, ιδιαίτερα σε περιπτώσεις όπου το πλήθος των εγγράφων που ικανοποιούν τις συνθήκες του ερωτήματος είναι μεγάλο και επομένως δυσκολεύεται η σειριακή εξέτασή τους από το χρήστη .
- Συστήματα Απάντησης Ερώτησης
-
(Question Answering Systems). Τα Συστήματα Απάντησης Ερωτήσεων χαρακτηρίζονται από δυνατότητες να απαντούν σε ερωτήσεις των χρηστών. Σε αντίθεση με ένα απλό ΣΑΠ που υποστηρίζει ανάκτηση εγγράφων ένα Σύστημα Απάντησης Ερώτησης δέχεται μία ερώτηση διατυπωμένη σε φυσική γλώσσα και προσπαθεί να προσδιορίσει την απάντηση στην ερώτηση αυτή. Τα πρώτα συστήματα αυτού του είδους εμφανίστηκαν τη δεκαετία του 1960 και αποτελούσαν κυρίως διεπαφές φυσικής γλώσσας με έμπειρα συστήματα (expert systems) .
- Συστήματα Συστάσεων
-
(Recommendation Systems). Τα συστήματα συστάσεων προτείνουν στο χρήστη αντικείμενα (π.χ., έγγραφα, τίτλους ταινιών, τίτλους βιβλίων) με βάση τις προτιμήσεις άλλων χρηστών και με βάση κάποιες από τις προτιμήσεις του ίδιου του χρήστη. Οι μέθοδοι σύστασης στηρίζονται στην ομοιότητα μεταξύ χρηστών ως προς τις προτιμήσεις τους (user-based) ή στην ομοιότητα μεταξύ των αντκειμένων με βάση τις προτιμήσεις των χρηστών (item-based). Επίσης, υπάρχουν και υβριδικές τεχνικές.
1.3 Σύγχρονες Τάσεις
Η γνωστική περιοχή της Ανάκτησης Πληροφορίας έχει σημειώσει σημαντικά επιτεύγματα στον τομέα της αναζήτησης σχετικής πληροφορίας σε έγγραφα. Ωστόσο, οι σύγχρονες εφαρμογές σε συνδυασμό με τις μεγαλύτερες ανάγκες των χρηστών για πιο αποτελεσματική και αποδοτική αναζήτηση, συντελέσαν στο σχεδιασμό και ανάπτυξη νέων μεθόδων. Στη συνέχεια περιγράφουμε συνοπτικά μερικές από τις σύγχρονες τάσεις που ώθησαν σημαντικά την έρευνα στον τομέα της Ανάκτησης Πληροφορίας.
-
Παγκόσμιος Ιστός. Ο παγκόσμιος ιστός είναι η μεγαλύτερη και πλουσιότερη πηγή πληροφοριών. Εκατομμύρια ιστότοποι (Web sites) σε όλον τον πλανήτη προσφέρουν πληροφορίες προσβάσιμες από την πλειοψηφία των χρηστών του διαδικτύου. Βασικό χαρακτηριστικό των πληροφοριών αυτών είναι ότι είναι δομημένες με τη βοήθεια των ιστοσελίδων, ενώ από μία ιστοσελίδα ένας χρήστης μπορεί να μεταβεί σε πολλές άλλες ακολουθώντας τους συνδέσμους (hyperlinks). Τόσο οι μεγάλες ποσότητες πληροφοριών, όσο και η μεταξύ τους σύνδεση οδήγησε στην ανάπτυξη εξειδικευμένων μεθόδων Ανάκτησης Πληροφορίας με στόχο τη βοήθεια των χρηστών στην εύρεση σχετικής πληροφορίας στον παγκόσμιο ιστό. Μεγάλες εταιρείες όπως η Yahoo και η Google βρίσκονται στην κορυφή καθώς έχουν αναπτύξει μηχανές αναζήτησης που είναι τόσο αποτελεσματικές όσο και αποδοτικές και βοηθούν τους χρήστες στην αναζήτηση χρήσιμης πληροφορίας στον παγκόσμιο ιστό.
-
Γεωγραφική Πληροφορία. Η γεωγραφική πληροφορία αποτελεί σημαντικό τμήμα της πληροφορίας που είναι διαθέσιμη. Πολλές φορές, σε ένα ερώτημα δίνονται λέξεις που αναφέρονται σε συγκεκριμένη τοποθεσία, και επομένως η γεωγραφική διάσταση θα πρέπει να ληφθεί υπόψη κατά την επεξεργασία του ερωτήματος. Η ερευνητική περιοχή της γεωγραφικής Ανάκτησης Πληροφορίας εστιάζει στην αποτελεσματική αναζήτηση πληροφορίας με γεωγραφικούς περιορισμούς. Νέες τεχνικές είναι απαραίτητες ώστε η γεωγραφική πληροφορία να χρησιμοποιηθεί κατά την διαδικασία της αναζήτησης με στόχο την επιστροφή σχετικής πληροφορίας στο χρήστη.
-
Πολυμεσικά Δεδομένα. Οι σύγχρονες εφαρμογές χαρακτηρίζονται εκτός των άλλων και από πολύπλοκους τύπους δεδομένων, οι οποίοι απαιτούν διαφορετική οργάνωση και διαχείριση από τους παραδοσιακούς αλφαριθμητικούς τύπους. Για παράδειγμα, ένα σύστημα ταυτοποίησης με βάση τα δακτυλικά αποτυπώματα απαιτεί αλγορίθμους επεξεργασίας και ανάλυσης εικόνων καθώς επίσης και μέτρα ομοιότητας μεταξύ διαφορετικών αποτυπωμάτων. Επίσης, ένα σύστημα αποθήκευσης και οργάνωσης μουσικών αρχείων επιβάλλει τη χρήση εξελιγμένων τεχνικών αναζήτησης με δυνατότητα αναζήτησης μουσικής με βάση το περιεχόμενο (content based information retrieval) και όχι με βάση τα μεταδεδομένα. Ένα τέτοιο σύστημα μπορεί να υποστηρίξει ερωτήματα της μορφής: Να βρεθούν τα 10 μουσικά αρχεία που μοιάζουν περισσότερο με το τραγούδι Bright Eyes των Blind Guardian. Οι παραδοσιακές μέθοδοι Ανάκτησης Πληροφορίας που εστιάζουν στην ανάκτηση εγγράφων με αλφαριθμητικά δεδομένα δεν επαρκούν για την αναζήτηση σε πολυμεσικά δεδομένα όπως βάσεις εικόνων, συλλογές μουσικών κομματιών και συλλογές βίντεο. Απαιτούνται σημαντικές αλλαγές και προσθήκες σε όλα τα τμήματα ενός ΣΑΠ έτσι ώστε να προσφέρουν ικανοποιητική ταχύτητα ανάκτησης και ταυτόχρονα τα αποτελέσματα να είναι όσο το δυνατό πλησιέστερα στις πληροφοριακές ανάγκες των χρηστών.
-
Ολοκλήρωση Τεχνικών Ανάκτησης και Βάσεων Δεδομένων. Οι ομοιότητες των ερευνητικών περιοχών της Ανάκτησης Πληροφορίας και των Βάσεων Δεδομένων οδήγησαν τους ερευνητές στην ανάπτυξη τεχνικών με στόχο την ανάπτυξη πιο δυνατών συστημάτων που να καλύπτουν τόσο της ανάγκες ανάκτησης δεδομένων όσο και τις ανάγκες Ανάκτησης Πληροφορίας. Τα περισσότερα σύγχρονα ΣΔΒΔ έχουν ενσωματωμένες δυνατότητες υποστήριξης ανάκτησης. Για παράδειγμα, με τη χρήση του τύπου δεδομένων TEXT ή CLOB μπορούμε να αποθηκεύουμε ολόκληρα κείμενα σε μία στήλη ενός πίνακα βάσης δεδομένων και στη συνέχεια να απαντούμε ερωτήματα που αφορούν την αναζήτηση λέξεων μέσα στα έγγραφα. Ωστόσο, απαιτούνται περισσότερα εργαλεία έτσι ώστε η ανάκτηση σχετικής πληροφορίας να μπορεί να εκμεταλλευθεί το σχήμα της βάσης δεδομένων με στόχο την εύρεση σχετικής πληροφορίας χωρίς την απαίτηση προσδιορισμού μίας συγκεκριμένης στήλης κάποιου πίνακα.
-
Ομότιμα Συστήματα. Ένα σύστημα ομοτίμων (peer-to-peer, P2P) χαρακτηρίζεται από την ύπαρξη αυτόνομων υπολογιστικών συστημάτων που διασυνδέονται μεταξύ τους και έχουν τη δυνατότητα διαμοιρασμού πληροφορίας. Στην πιο απλή του μορφή, σε ένα σύστημα P2P δεν υπάρχει κεντρική διαχείριση, και επομένως κάθε κόμβος του δικτύου δρα ανεξάρτητα από τους υπόλοιπους. Επίσης, ένας κόμβος έχει τη δυνατότητα αποσύνδεσης ή επανασύνδεσης στο δίκτυο κατά βούληση. Τέτοια συστήματα είναι πολύ δημοφιλή καθώς χρησιμοποιούνται ευρύτατα για το διαμοιρασμό αρχείων (π.χ., Kazaa, Limewire, Emule). Τα συστήματα αυτά υποστηρίζουν αναζήτηση πληροφορίας με βάση τα μεταδεδομένα των αρχείων. Οι ερευνητές έχουν ήδη στραφεί στην ενίσχυση των συστημάτων αυτών με δυνατότητα ανάκτησης με βάση το περιεχόμενο. Οι κλασικές μέθοδοι ανάκτησης δεν επαρκούν και νέες τεχνικές έχουν προταθεί πρόσφατα.
1.4 Σύνοψη και Περαιτέρω Μελέτη
Η Ανάκτηση Πληροφορίας είναι μία ενεργός γνωστική περιοχή με βασικό στόχο την αποτελεσματική και αποδοτική αναζήτηση πληροφορίας σχετικής προς τις ανάγκες των χρηστών. Η ανάγκη πληροφορίας συνήθως προσδιορίζεται με την παράθεση μερικών όρων, οπότε το σύστημα θα πρέπει να επιστρέψει στο χρήστη τα έγγραφα που σχετίζονται (μοιάζουν) περισσότερο με αυτούς. Το πρώτο βασικό ζήτημα που πρέπει να αντιμετωπιστεί είναι ο προσδιορισμός της ομοιότητας μεταξύ του ερωτήματος και των εγγράφων, ενώ το δεύτερο είναι ο τρόπος επεξεργασίας του ερωτήματος έτσι ώστε το σύστημα να απαντήσει γρήγορα και με ακρίβεια. Στα επόμενα κεφάλαια θα εστιάσουμε στα τμήματα ενός ΣΑΠ όπως αυτά έχουν περιγραφεί προηγουμένως με στόχο την πληρέστερη περιγραφή τους, θα μελετήσουμε διαφορετικά μοντέλα ανάκτησης, θέματα αποτελεσματικότητας και ζητήματα απόδοσης.
Στη βιβλιογραφία υπάρχουν πολλά συγγράμματα και επιστημονικές εργασίες που μπορούν να βοηθήσουν σημαντικά τον αναγνώστη στη μελέτη της περιοχής. Τα βιβλία [3, 26, 35, 41, 77, 75] αποτελούν πολύ καλές πηγές για το αντικείμενο. Επίσης, τα άρθρα [22, 31, 30] εισάγουν τον αναγνώστη στην περιοχή και δίνουν μία συνοπτική περιγραφή των ζητημάτων και των μεθόδων που χρησιμοποιούνται.
Υπάρχει μία πληθώρα διεθνών συνεδρίων που επικεντρώνονται στην περιοχή της Ανάκτησης Πληροφορίας. Συγκεκριμένα αναφέρουμε τα συνέδρια: Text Retrieval Conference (TREC), ACM Special Interest Group on Information Retrieval (SIGIR) Conference, European Conference on Information Retrieval (ECIR), European Conference on Research and Advanced Technology for Digital Libraries (ECDL), Joint Conference on Digital Libraries (JCDL), αλλά και τα εξειδικευμένα: ACM International Workshop on Multimedia Information Retrieval (MIR), International Symposium on Music Information Retrieval (ISMIR) και άλλα. Ακόμη, πολλά από τα μεγάλα συνέδρια που αναφέρονται στη διαχείριση δεδομένων έχουν ειδικές συνεδρίες για την Ανάκτηση Πληροφορίας. Χαρακτηριστικά αναφέρουμε τα συνέδρια: ACM Conference on Information and Knowledge Management (CIKM), ACM Special Interest Group on Management of Data (SIGMOD) Conference, International Conference on Very Large Databases (VLDB). Τέλος, αναφέρουμε και επιστημονικά περιοδικά που εστιάζουν στην περιοχή: ACM Transactions on Information Systems, Information Retrieval, Information Processing and Management, Information Systems, International Journal on Digital Libraries και άλλα.
Ο ενδιαφερόμενος αναγνώστης μπορεί επίσης να ανατρέξει σε πληθώρα ιστότοπων που περιέχουν χρήσιμο υλικό για την Ανάκτηση Πληροφορίας. Χαρακτηριστικά αναφέρουμε τη σελίδα http://www-csli.stanford.edu/ hinrich/information-retrieval.html η οποία περιέχει συνδέσμους σε βιβλία, πανεπιστημιακά ιδρύματα, ερευνητικά κέντρα και σε άλλα θέματα σχετικά με το χώρο. Η σελίδα αποτελεί μία πολύ καλή πηγή για τη διερεύνηση του χώρου.
1.5 Ασκήσεις
-
1.1
Ποιές βασικές διαφορές εντοπίζονται μεταξύ ενός ΣΔΒΔ και ενός ΣΑΠ;
-
1.2
Για ποιούς λόγους θα μπορούσε ένα έγγραφο να είναι πιο σχετικό από ένα έγγραφο ως προς κάποιο ερώτημα ;
-
1.3
Προσδιορίστε και περιγράψτε σύνοπτικά τις δύο βασικές λειτουρίες Ανάκτησης Πληροφορίας.
-
1.4
Θα μπορούσαμε να έχουμε δύο διαφορετικά ΣΔΒΔ που να δώσουν διαφορετικά αποτελέσματα για το ίδιο ερώτημα και στα ίδια δεδομένα; Να αιτιολογήσετε την απάντησή σας.
-
1.5
Ποιά τμήματα απαρτίζουν ένα ΣΑΠ; Να περιγράψετε συνοπτικά τις βασικές λειτουργίες του καθενός.
-
1.6
Ποιές οι διαφορές μεταξύ της περιστασιακής αναζήτησης (ad-hoc) και του φιλτραρίσματος (δρομολόγησης) εγγράφων; Να δώσετε ένα παράδειγμα για τον τρόπο λειτουργίας τους.
-
1.7
Για ποιούς λόγους πιστεύετε ότι ο παγκόσμιος ιστός δημιουργεί νέες περιοχές έρευνας για την επιστήμη της Ανάκτησης Πληροφορίας;
-
1.8
Για τα ερωτήματα πλανήτης OR κομήτης και πλανήτης AND κομήτης να προσδιορίσετε τα σχετικά έγγραφα με βάση τη συλλογή εγγράφων του Σχήματος 1.1.
-
1.9
Εκτός από την απλή παράθεση των σχετικών εγγράφων σε μία λίστα, ποιούς άλλους τρόπους παρουσίασης των αποτελεσμάτων προτείνετε;
-
1.10
Προσπαθήστε να διατυπώσετε μία δική σας συνάρτηση ομοιότητας μεταξύ ενός ερωτήματος και ενός εγγράφου . Η συνάρτηση ομοιότητας θα πρέπει να στηρίζεται στους όρους και θα πρέπει να λαμβάνεί μία τιμή μεταξύ 0 και 1, όπου όσο μικρότερη η ομοιότητα η τιμή να είναι κοντά στο 0 ενώ όσο μεγαλύτερη η ομοιότητα η τιμή να είναι κοντά στο 1. Να δώσετε μερικά παραδείγματα χρησιμοποιώντας τη μετρική σας και τη συλλογή εγγράφων του Σχήματος 1.1.