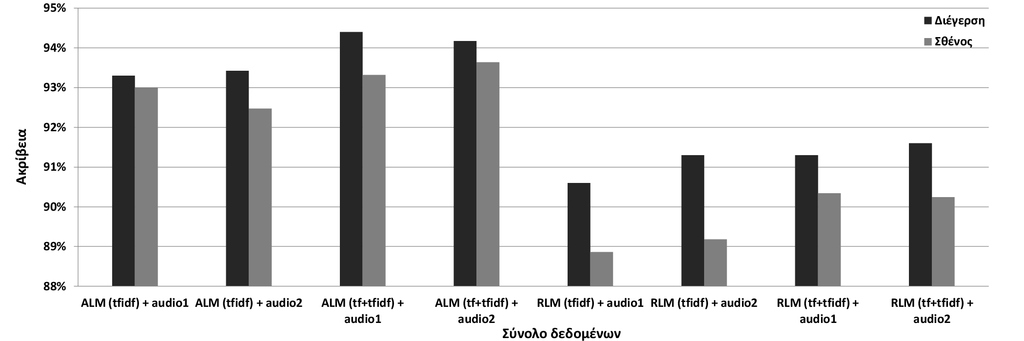ΚΕΦΑΛΑΙΟ 3 Εξόρυξη γνώσης από μουσική πληροφορία
3.1 Επαναλαμβανόμενα πρότυπα
3.1.1 Εισαγωγή
Ένας χαρακτηριστικός τύπος αναπαράστασης μουσικών δεδομένων βασίζεται στη χρήση επαναλαμβανόμενων προτύπων (ΕΠ) που ενυπάρχουν στα μουσικά δεδομένα, δηλαδή, τμήματα του μουσικού αντικειμένου, τα οποία επαναλαμβάνονται. Στην αναπαράσταση αυτή, ένα επαναλαμβανόμενο πρότυπο αντιστοιχεί σε ένα μοτίβο, δηλαδή σε ένα ελάχιστου μήκους πρότυπο που είναι νοηματικά ανεξάρτητο και πλήρες σε ένα μουσικό αντικείμενο. Τα επαναλαμβανόμενα πρότυπα αποτελούν μια χρήσιμη αναπαράσταση ενός μουσικού αντικειμένου. Η χρήση τους (με την έννοια των μοτίβων) υπήρξε εκτεταμένη στο ρου της ιστορίας της μουσικής [63] αλλά και στη σύγχρονη μουσική έρευνα [62], καθώς αποτελούν μια συμπυκνωμένη μορφή για τη δεικτοδότηση των αρχικών μορφών (λ.χ., ασυμπίεστο ακουστικό σήμα, αρχεία τύπου MIDI, κτλ.). Το γεγονός αυτό οφείλεται στο ότι το συνολικό μέγεθος όλων των επαναλαμβανόμενων προτύπων είναι μικρότερο από ότι το μέγεθος του μουσικού αντικειμένου. Συνεπώς, τα επαναλαμβανόμενα πρότυπα ικανοποιούν τα αιτήματα σημασιολογίας και απόδοσης που απαιτεί η ανάκτηση μουσικής πληροφορίας βάσει περιεχόμενου [71], [106]. Εξαιτίας των προαναφερθέντων, τα επαναλαμβανόμενα πρότυπα έχουν ήδη χρησιμοποιηθεί για τη δεικτοδότηση μουσικών ακολουθιών στην ανάκτηση μουσικής πληροφορίας [71]. Επιπλέον, τα πρότυπα αυτά παρέχουν ένα σημείο αναφοράς για την ανεύρεση των μουσικών θεμάτων [88], [105]. Ένα μουσικό θέμα (ιδιαιτέρως στην κλασική δυτικού τύπου μουσική) είναι το τμήμα εκείνο της μελωδίας, το οποίο ο συνθέτης χρησιμοποιεί ως εναρκτήριο σημείο για περαιτέρω ανάπτυξη, και το οποίο πιθανώς επαναλαμβάνεται με τη μορφή παραλλαγών11Ο βαθμός της μεταβολής καθώς και η συχνότητα επανάληψης ενός θέματος παρουσιάζουν διακυμάνσεις μεταξύ των συνθετών και των ειδών της μουσικής (λ.χ., μεταξύ της κλασικής και σύγχρονης δημοφιλούς μουσικής). [105]. Τέλος, τα επαναλαμβανόμενα πρότυπα έχουν θεωρηθεί ως χαρακτηριστικές υπογραφές των μουσικών αντικειμένων, με την έννοια ποσοτικών μέτρων για τη διαπίστωση της μουσικής ομοιότητας [69].
Για το πρόβλημα της αποδοτικής ανεύρεσης επαναλαμβανόμενων προτύπων, στη σύγχρονη βιβλιογραφία παρουσιάζονται διάφορες τεχνικές εξόρυξης δεδομένων [71], [79], [88], [105]. Καθώς η άμεση χρήση των επαναλαμβανόμενων προτύπων εμφανίζει πολλαπλές δυσκολίες, πρωτίστως λόγω του αυξημένου πλήθους τους, το επίκεντρο έχει εστιαστεί στα λεγόμενα μη-τετριμμένα επαναλαμβανόμενα πρότυπα [71], [88], [77]. Μολοντούτο, το πλήθος των μη-τετριμμένων επαναλαμβανόμενων προτύπων μπορεί επίσης να είναι αρκετά μεγάλο ώστε να δυσκολεύει τη εξέταση τους δια χειρός από αναλυτές. Για παράδειγμα, μουσικά αντικείμενα με μέγεθος παραπλήσιο των 1000 νοτών μπορούν να περιέχουν αρκετές δεκάδες μη-τετριμμένων επαναλαμβανόμενων προτύπων [71], ενώ οι αριθμοί αυτοί αυξάνουν για μεγαλύτερα μουσικά κομμάτια. Το γεγονός αυτό μπορεί έχει επιπτώσεις και στην ικανότητα των μη-τετριμμένων επαναλαμβανόμενων προτύπων να καταδεικνύουν τα μουσικά θέματα, καθώς αρκετά από τα πρότυπα είναι πιθανώς ψεύτικα και άσχετα με τα μουσικά θέματα. Κατά συνέπεια, η τρέχουσα έρευνα αναγνώρισε ότι μεταξύ των μη-τετριμμένων επαναλαμβανόμενων προτύπων, τα μέγιστα σε μήκος είναι τα πρότυπα που μπορούν να χαρακτηριστούν ως χαρακτηριστικές συμβολοσειρές μελωδίας και είναι αυτά που συνήθως οδηγούν στα μουσικά θέματα [88]. Το εύρημα αυτό εξετάζεται περαιτέρω στην [71], όπου εμφανίζονται ενδείξεις ότι τα Μεγίστου Μήκους Επαναλαμβανόμενα Πρότυπα (ΜΜΕΠ) (περιορισμένα από μια μέγιστη τιμή μήκους, λ.χ. 30) είναι τα πρότυπα, όπου συνήθως βασίζονται τα μουσικά θέματα. Στην ίδια ερευνητική κατεύθυνση, οι συγγραφείς της [105] προτείνουν μια μέθοδο ανεύρεσης των μουσικών θεμάτων, η οποία βασίζεται σε μια αρχικά υπολογισμένη συλλογή των μέγιστου μήκους επαναλαμβανόμενων προτύπων. 22Χρήζει μνείας το γεγονός ότι τα ΜΜΕΠ που ανακαλύπτονται οφείλουν να εξετάζονται περαιτέρω βάσει αρκετών χαρακτηριστικών (λ.χ., συχνότητα, διάρκεια, ρυθμική συνέπεια, θέση) [94] ώστε να οδηγήσουν ουσιαστικά στα μουσικά θέματα. Παρόλα αυτά, όπως και στην [71], το Κεφάλαιο αυτό εστιάζει στη διαδικασία ανεύρεσης των ΜΜΕΠ. Κατά συνέπεια, η εξέταση τέτοιων ιδιαίτερων χαρακτηριστικών είναι εκτός του στόχου του παρόντος.
Μια απλοϊκή μέθοδος για την ανεύρεση των ΜΜΕΠ θα μπορούσε να αποτελείται από την επιλογή τους σε ένα βήμα επεξεργασίας μετά την εξόρυξη όλων των μη-τετριμμένων επαναλαμβανόμενων προτύπων. Ωστόσο, το μήκος των ΜΜΕΠ συνήθως τείνει να είναι μεγάλο (πειραματικά δεδομένα [71], [79] έδειξαν ότι μπορεί να είναι μέχρι και αρκετές δεκάδες). Επίσης, η άμεση μέθοδος αποδεικνύεται ιδιαιτέρως μη αποδοτική, καθώς το πλήθος των ενδιάμεσων επαναλαμβανόμενων προτύπων (δηλ. αυτών που δεν είναι μεγίστου μήκους) πρέπει να εξεταστεί πριν βρεθούν τα μεγίστου μήκους. Συνεπώς απαιτήθηκε η ανάπτυξη νέων αλγορίθμων [77] για την αποδοτική ανεύρεση των ΜΜΕΠ, οι οποίοι δεν απαιτούν την ανεύρεση των ενδιάμεσων επαναλαμβανόμενων προτύπων.
Όπως ήδη αναφέρθηκε, καθώς το πλήθος των προτύπων αυτών μπορεί να φθάσει ακόμα και τις αρκετές δεκάδες, για λόγους απόδοσης πρέπει να αποφευχθούν οι δαπανηροί υπολογισμοί κατά τη διάρκεια της ανεύρεσης, εξετάζοντας όσο το δυνατό λιγότερα ενδιάμεσα πρότυπα ώστε να εντοπιστεί γρήγορα το σύνολο των ΜΜΕΠ. Στο σημείο αυτό χρήζει μνείας η ανάλογη αιτιολόγηση που έχει χρησιμοποιηθεί σε άλλους τομείς της εξόρυξης δεδομένων, λ.χ. στην εξόρυξη των μεγάλων στοιχειοσυνόλων [65], [87], [114]. Μολαταύτα, υπάρχουν σημαντικές διαφορές (που αναλύονται εκτενώς στην Ενότητα 3.1.2) μεταξύ του προβλήματος αυτού και της εξόρυξης των ΜΜΕΠ. Περιληπτικά, οι βασικές διαφορές εντοπίζονται στο γεγονός ότι οι μέθοδοι για τα μεγάλα στοιχειοσύνολα εστιάζουν σε μεγάλες και εγκατεστημένες σε δίσκους βάσεις στοιχειοσυνόλων, ενώ για την ανεύρεση των ΜΜΕΠ οι μουσικές ακολουθίες βρίσκονται στη μνήμη και οι αλγόριθμοι δίνουν προτεραιότητα στην επίτευξη καλύτερων χρόνων εκτέλεσης. Επιπλέον, στο πρόβλημα της ανεύρεσης των ΜΜΕΠ, οι αλγόριθμοι έχουν κατώφλι συχνότητας των επαναλαμβανόμενων προτύπων ίσο με τη μονάδα, ενώ στην εξόρυξη των στοιχειοσυνόλων αλγόριθμοι με τέτοια προϋπόθεση θα προκαλούσαν αυξημένη επιβάρυνση.
Τέλος, οι αλγόριθμοι που προτείνονται οφείλουν να αντιμετωπίζουν τα ιδιαίτερα χαρακτηριστικά του υπό εξέταση προβλήματος, όπως η διάταξη των νοτών στις μουσικές ακολουθίες, παράγοντες που δεν εμφανίζονται σε παρόμοιους τομείς όπως η ανεύρεση των επαναλαμβανόμενων στοιχειοσυνόλων.
3.1.2 Σχετικές εργασίες
Εξόρυξη επαναλαμβανόμενων προτύπων και ανεύρεση μουσικών θεμάτων
Η διαδικασία εξόρυξης ΕΠ παρουσιάζεται στις εργασίες [71], [88], όπου δυο αλγόριθμοι προτείνονται για την ανεύρεση των μη-τετριμμένων ΕΠ και της χαρακτηριστικής μελωδικής συμβολοσειράς. Ο πρώτος αλγόριθμος χρησιμοποιεί μια αμοιβαία συσχετιζόμενη μήτρα για την εξαγωγή των ΕΠ, ενώ ο δεύτερος βασίζεται σε μια επαναλαμβανόμενη λειτουργία ένωσης συμβολοσειρών. Πειραματικά αποτελέσματα των εργασιών [71], [88] υποδεικνύουν την υπεροχή του δεύτερου αλγόριθμου σε σχέση με τη μέθοδο με την αμοιβαία συσχετιζόμενη μήτρα. Περισσότερες πληροφορίες για τη μέθοδο με την ένωση συμβολοσειρών δίνονται στην Ενότητα 3.1.3. Οι Koh και Yu [79] παρουσίασαν μια μέθοδο εξόρυξης των ΜΜΕΠ από τη μελωδία ενός μουσικού δεδομένου χρησιμοποιώντας μια ακολουθία bit index όπως επίσης και μια επέκταση για την εξαγωγή των συχνών ακολουθιών νοτών από ένα σύνολο μουσικών αντικειμένων. Στη μέθοδο που προτείνεται στην εργασία [79], όλα τα ΕΠ βρίσκονται και επιβεβαιώνονται υπολογίζοντας τη συχνότητα εμφάνισής τους, ενώ ο έλεγχος πλεονασμού εκτελείται σε επόμενο στάδιο δημιουργώντας το σύνολο ΜΜΕΠ με μη αποδοτικό τρόπο. Οι Rolland και Ganascia [101], πρότειναν μια μέθοδο για την κατά προσέγγιση εξαγωγή των σειριακών προτύπων σε μουσικά δεδομένα, η οποία εξετάζει ένα πλήθος ιδιαιτεροτήτων των μουσικών δεδομένων και βασίζεται στον ορισμό μιας συνάρτησης ομοιότητας.
Όσον αφορά στη συμμετοχή των ΕΠ στην ανεύρεση των μουσικών θεμάτων, οι Smith και Medina [105] πρότειναν μια τεχνική ταιριάσματος προτύπων, η οποία καταλήγει στα μουσικά θέματα και βασίζεται σε πρότερη συλλογή των ΜΜΕΠ. Οι Meek και Birmingham στην εργασία [94] προσδιόρισαν μια πληθώρα χαρακτηριστικών, που απαιτείται να εξαχθούν από τα μουσικά δεδομένα για την ανεύρεση των μουσικών θεμάτων. Μεταξύ αυτών, θεωρούν ως σημαντικότερο τη θέση του θέματος (προτιμώντας τα θέματα που εμφανίζονται νωρίτερα στο μουσικό δεδομένο). Καθώς τέτοια χαρακτηριστικά, που προκύπτουν από ΕΠ, μπορούν να χρησιμοποιηθούν για την ανεύρεση των μουσικών θεμάτων, οι εργασίες [94], [105] μπορούν να θεωρηθούν συμπληρωματικές στο πρόβλημα που αντιμετωπίζει το παρόν κεφάλαιο. Επιπλέον, ένα ενδιαφέρον σύστημα για την ανεύρεση μουσικών θεμάτων βασισμένο στον παγκόσμιο ιστό παρουσιάζεται στην [80].
Τα πρότυπα είναι πιθανό να μη βρίσκονται μόνο σε μια φωνή (στην περίπτωση της πολυφωνικής μουσικής), καθώς ένα πρότυπο μπορεί να είναι κατανεμημένο σε αρκετές παράλληλα ηχούσες φωνές. Οι συγγραφείς των [75], [76] παρουσίασαν αλγόριθμους για την ανεύρεση κατανεμημένων προτύπων μεταξύ των οποίων και για το ταίριασμα κατανεμημένων προτύπων με το μέγιστο διαφορές (εξέλιξη μοτίβου).
Οι προαναφερθείσες εργασίες πρωτίστως εξετάζουν στο πρόβλημα της ανεύρεσης όλων των ΕΠ και τη σχέση τους με το σύνολο των μουσικών θεμάτων. Το εστιακό ενδιαφέρον του παρόντος κεφαλίου βρίσκεται στην ανεύρεση όλων των ΜΜΕΠ. Στο σημείο "πολλά ΕΠ (τουλάχιστο τα μεγίστου μήκους) ενός πραγματικού μουσικού αντικειμένου είναι εκ-προθέσεως κατασκευασμένα από το συνθέτη" [88]. Ακολούθως, η ύπαρξη των ΜΜΕΠ είναι βάσει πρόθεσης του συνθέτη. Συνεπώς, η αναγκαιότητα της ανεύρεσης τους είναι προφανής, εφόσον αποδίδουν πληροφορίες για την πρόθεση του συνθέτη.
Επιπλέον, όπως ήδη αναφέρθηκε, τα ΜΜΕΠ είναι επαναλαμβανόμενα πρότυπα και “περιέχουν” όλα τα ΕΠ που παράγονται ως υποακολουθίες τους. Κατά συνέπεια, τα ΜΜΕΠ εκ φύσεως μεταφέρουν τη σημασιολογική αξία των αντίστοιχων ΕΠ (των ιδίων ΜΜΕΠ αλλά και των ΕΠ που είναι υποακολουθίες τους). Η σημασιολογική αξία των ΕΠ περιγράφεται περαιτέρω στις [88], [68], [71], [79]. Ειδικότερα, τα πειραματικά αποτελέσματα στην εργασία [88] παρουσιάζουν ποσοστό ανάκλησης 100% στην εξαγωγή μουσικών μοτίβων από ΕΠ (δηλ. όλα τα μοτίβα πρέπει να είναι ΕΠ). Επίσης, οι εργασίες [71], [88] καταλήγουν ότι η ομαδοποίηση των μουσικών αντικειμένων μπορεί να γίνει αποδοτικά βάσει ΕΠ. Ωστόσο, πρέπει να καταστεί σαφές ότι τα ΜΜΕΠ είναι πρότυπα που αποκαλύπτουν μια διαφορετική, νέα όψη των μουσικών δεδομένων.
Εξόρυξη μεγάλων στοιχειοσυνόλων
Στον τομέα της εξόρυξης στοιχειοσυνόλων, τελευταία προτάθηκαν διάφορες μέθοδοι για την ανεύρεση των μεγίστου μήκους συχνών στοιχειοσυνόλων [65], [87], [114]. Οι εργασίες αυτές εστιάζουν στην αποφυγή εξέτασης όλων των συχνών στοιχειοσυνόλων, μεταφέροντας την έρευνα προς τη γρήγορη ανεύρεση των στοιχειοσυνόλων που έχουν μέγιστο μήκος ή αυτών που είναι maximal33Καθώς δεν υπάρχει δόκιμος όρος στην Ελληνική, στο κεφάλαιο αυτό παραμένει στην Αγγλική και έχει την εξής μαθηματική έννοια: Ένα maximal στοιχείο ενός υποσυνόλου ενός μερικώς ταξινομημένου συνόλου, είναι το στοιχείο του το οποίο δεν είναι μικρότερο από κανένα άλλο στοιχείο στο (δηλ. δεν έχουν υπερσύνολο που να είναι επίσης συχνό). Εμφανώς, υπάρχει μια ευδιάκριτη αναλογία μεταξύ του προβλήματος που εξετάζουν οι εργασίες [65], [87], [114] και του προβλήματος της ανεύρεσης των ΜΜΕΠ. Ωστόσο, η διαδικασία εξόρυξης των ΜΜΕΠ παρουσιάζει σημαντικές διαφορές εξαιτίας των οποίων, οι προαναφερθείσες μέθοδοι, δεν μπορούν να εφαρμοστούν άμεσα.
Πρωτίστως, η κύρια διαφορά των μεθόδων για μεγάλα στοιχειοσύνολα είναι η εστίαση τους σε ογκώδεις, εγκατεστημένες σε δίσκο βάσεις στοιχειοσυνόλων. Ακολούθως, οι τεχνικές που χρησιμοποιούνται στις εργασίες [65], [87], [114] μειώνουν τον αριθμό προσβάσεων στη βάση με τη χρήση δομών βελτιστοποιημένων για μεγάλο όγκο δεδομένων. Αντιθέτως, για την εξόρυξη μουσικών ΕΠ και ΜΜΕΠ, η μουσική ακολουθία βρίσκεται στην κύρια μνήμη και οι εμπλεκόμενες δομές και τεχνικές έχουν κύριο στόχο την ταχύτητα εκτέλεσης. Συνεπώς, η εφαρμογή υπαρκτών μεθόδων για μεγάλα στοιχειοσύνολα θα ήταν ιδιαίτερα μη αποδοτική, καθώς οι βελτιστοποιήσεις τους αφορούν στο κόστος εισόδου/εξόδου. Για το λόγο αυτό, οι συγγραφείς της εργασίας [71] δεν προσπάθησαν την άμεση εφαρμογή μιας μεθόδου εξόρυξης για βάσεις ακολουθιών, όπως επίσης και στην εργασία [60] για το πρόβλημα της εξόρυξης ΕΠ σε μουσικές ακολουθίες. Επιπλέον, στο πεδίο της εξόρυξης ΕΠ και ΜΜΕΠ, μια υποακολουθία της μουσικής ακολουθίας είναι ΕΠ εάν η συχνότητα εμφάνισης της είναι μεγαλύτερη της μονάδας. Αντίθετα, οι αλγόριθμοι εξόρυξης μεγάλων στοιχειοσυνόλων θεωρούν αρκετά μεγαλύτερο κατώφλι για τη συχνότητα εμφάνισης των προτύπων44Ακόμα και μικρά ποσοστά κατωφλιού εμφάνισης, λ.χ., 0.1%, αντιστοιχούν σε πολύ μεγαλύτερες τιμές απ’ ότι η απόλυτη τιμή της μονάδας., οπότε είναι αναπόφευκτο να έχουν αυξημένη επιβάρυνση στην περίπτωση που θεωρήσουν κατώφλι συχνότητας εμφάνισης ίσο με τη μονάδα.
Ακολούθως, το κεφάλαιο εξετάσει μια μέθοδο που εστιάζει στις απαιτήσεις της συγκεκριμένης εφαρμογής, δηλαδή, θεωρεί βελτιστοποιήσεις για μουσικές ακολουθίες που βρίσκονται στην κύρια μνήμη και για πρότυπα που εμφανίζονται τουλάχιστο δύο φορές στην ακολουθία (κατώφλι εμφάνισης ίσο με τη μονάδα), βάσει των αποτελεσμάτων της εργασίας [77].
3.1.3 Υπόβαθρο και κίνητρα
Ορισμοί
Θεωρούμε τη μουσική ακολουθία να είναι μια ακολουθία χαρακτήρων από ένα αλφάβητο διακριτών στοιχείων. Γενικά, η μουσική περιγράφεται από αρκετά χαρακτηριστικά. Μεταξύ αυτών το τονικό ύψος, ο ρυθμός, η χροιά και η δυναμική θεωρούνται τα πιο σημασιολογικά αξιόλογα [66]. Ειδικότερα, για τη μουσική δυτικού τύπου, το τονικό ύψος έχει το μεγαλύτερη πληροφοριακή βαρύτητα [66]. Παρότι, το χαρακτηριστικό του ρυθμού δεν μπορεί να αγνοηθεί, χάριν ευκολότερης αναπαράστασης, εστιάζουμε στην πληροφορία που περιέχεται στο τονικό ύψος. Παρόμοια υπόθεση έχει γίνει και σε πολλές σχετικές εργασίες που αντιμετωπίζουν την ανεύρεση ΕΠ [71], [79], [105]. Ωστόσο, είναι ευνόητο ότι η προτεινόμενη μεθοδολογία μπορεί εύκολα να εφαρμοστεί σε ακολουθίες χαρακτηριστικών ρυθμού. Στην κατεύθυνση αυτή, θα ήταν ενδιαφέρουσα η διερεύνηση του συνδυασμού των δύο σημαντικών χαρακτηριστικών (δηλ., τονικό ύψος και ρυθμός) στα πρότυπα που βρέθηκαν. Όμως στην περίπτωση αυτή ελάχιστες παραλλαγές των θεμάτων θα οδηγούσαν σε διαφοροποιημένες συνδυαστικές ακολουθίες. Έτσι, θα χρειάζονταν ανάπτυξη μεθόδων που δεν θα ήταν ευαίσθητες σε μικρές παραλλαγές ώστε να μη χάνονται αρκετά ΕΠ.
ΟΡΙΣΜΟΣ 3.1 (Επαναλαμβανόμενο Πρότυπο (ΕΠ) [71]).
Δεδομένης μιας μουσικής ακολουθίας , ένα επαναλαμβανόμενο πρότυπο είναι μια υποακολουθία συνεχόμενων στοιχείων της , η οποία εμφανίζεται τουλάχιστο δυο φορές στην .
Εδώ πρέπει να αναφερθεί ότι για την αναπαράσταση που ακολουθείται από το πρωτόκολλο MIDI, το μέγεθος του αλφάβητου (πλήθος διακριτών στοιχείων) είναι ίσο με 128. Η συχνότητα επανάληψης (εφεξής συχνότητα) ενός ΕΠ ορίζεται ως ο αριθμός των εμφανίσεων του στην . Το μήκος ενός ΕΠ είναι το πλήθος των νοτών στο .
ΟΡΙΣΜΟΣ 3.2 (Maximal ΕΠ [79]).
Ένα ΕΠ είναι maximal ΕΠ σε μια μουσική ακολουθία , εάν το είναι ΕΠ στην και δεν υπάρχει άλλο ΕΠ στην τέτοιο ώστε: (i) το να είναι υποακολουθία του , και (ii) η .
ΟΡΙΣΜΟΣ 3.3 (Μεγίστου Μήκους Επαναλαμβανόμενο Πρότυπο (ΜΜΕΠ)).
Ένα ΕΠ είναι ΜΜΕΠ σε μια μουσική ακολουθία εάν: (i) το είναι maximal ΕΠ της , και (ii) δεν υπάρχει άλλο ΕΠ στην τέτοιο ώστε .
Ο ανωτέρω ορισμός αρχικά απαιτεί ένα ΕΠ , για να είναι ΜΜΕΠ, να μην είναι υποακολουθία άλλου ΕΠ , με το οποίο να έχουν ίδια συχνότητα, στην οποία περίπτωση το είναι το maximal. Επιπλέον, ο ορισμός απαιτεί το να έχει το μέγιστο μήκος από κάθε ΕΠ . Παραδείγματος χάριν, στην ακολουθία Α = εαβγδεβγαβγδβγα, υπάρχουν 13 ΕΠ, που παρουσιάζονται στον Πίνακα 3.1 με τις αντίστοιχες συχνότητες εμφάνισης.
| α | β | γ | δ | ε | αβ | βγ | γα | γδ | αβγ | βγα | βγδ | αβγδ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 4 | 4 | 2 | 2 | 2 | 4 | 4 | 2 | 2 | 2 | 2 | 2 |
Εκ των 13 αυτών ΕΠ, το είναι ΜΜΕΠ (καθώς είναι το maximal και δεν υπάρχει άλλο ΕΠ στην τέτοιο ώστε ), τα είναι maximal, ενώ τα υπόλοιπα είναι τετριμμένα.
Τέλος, ο ορισμός του υπό εξέταση προβλήματος στο παρόν κεφάλαιο είναι ο εξής: δεδομένης μιας μουσικής ακολουθίας , να βρεθούν όλα τα ΜΜΕΠ, εφόσον υπάρχουν.
Ο αλγόριθμος HLC
Όπως έχει ήδη σχολιαστεί στην Ενότητα 3.1.2, ο Hsu και οι συνεργάτες του στην εργασία [71] πρότειναν δυο διαφορετικές τεχνικές για την ανεύρεση των μη-τετριμμένων ΕΠ. Εδώ, εστιάζουμε στον αλγόριθμο με την ένωση συμβολοσειρών, στον οποίο αναφερόμαστε ως HLC (από τα αρχικά των συγγραφέων). Ο HLC θα παρουσιαστεί επιγραμματικά (με τη βοήθεια ενός παραδείγματος), ώστε να περιγραφεί η καταλληλότητα του ως βασικού αλγορίθμου για την εξαγωγή των ΜΜΕΠ (βλ. Ενότητα 3.1.3).
Ο HLC χρησιμοποιεί την τριάδα για να αναπαραστήσει το κάθε ΕΠ που βρέθηκε σε
μια μουσική ακολουθία , όπου είναι το ΕΠ, είναι η
συχνότητα εμφάνισης του και κάθε , είναι το σημείο εκκίνησης του στην . Σύμφωνα με
την [71] η διαδικασία ένωσης συμβολοσειρών ορίζεται ως
εξής: Υποθέτουμε ότι οι τριάδες:
και
είναι δυο ΕΠ της συμβολοσειράς χαρακτηριστικών του μουσικού
αντικειμένου. Ορίζεται η -τάξης ένωση συμβολοσειρών των δυο ΕΠ ως εξής:
όπου
-
•
, , ,
-
•
για , για ,
-
•
, όπου και 55Η προϋπόθεση αυτή αναφέρεται στη συσχέτιση των στοιχείων στην ακολουθία με τις θέσεις εμφάνισης των ακολουθιών και .,
-
•
, για ,
-
•
if , , για .
Ο HLC εξελίσσεται σε 2 στάδια: Στο πρώτο εντοπίζονται τα ΕΠ μήκους (αρχικά, ), ενώ τα ΕΠ μήκους συνθέτονται εφαρμόζοντας ενώσεις ΕΠ μήκους . Η έρευνα, κατά τη διάρκεια του πρώτου σταδίου, συνεχίζει μέχρι να βρεθεί μία τιμή του , έστω , για την οποία δεν υπάρχουν ΕΠ. Στο σημείο αυτό, ο HLC πρέπει να καθορίσει το μήκος του μέγιστου σε μήκους ΕΠ, το οποίο δεν είναι γνωστό εκ προοιμίου. Ωστόσο, το μήκος του μέγιστου ΕΠ είναι γνωστό ότι είναι μεταξύ . Επομένως, ο HLC εκτελεί δυαδική αναζήτηση για πρότυπα τα μήκη των οποίων είναι στο διάστημα . Στο τέλος του πρώτου σταδίου, ο HLC έχει προσδιορίσει το και τα αντίστοιχα ΜΜΕΠ. Με το δεύτερο στάδιο, επιβεβαιώνει ότι όλα τα πρότυπα που βρέθηκαν στο προηγούμενο στάδιο είναι μη-τετριμμένα με τη βοήθεια μιας δενδρικής δομής που ονομάζεται RP-δένδρο, της οποίας κάθε κόμβος αποτελεί ένα από τα ΕΠ που βρέθηκαν. Μετά την αφαίρεση των τετριμμένων ΕΠ, μια πιο λεπτομερής διαδικασία εντοπίζει ΕΠ με μήκος που δεν είναι δύναμη του δυο, εφόσον υπάρχουν. Τα ΕΠ που προκύπτουν μετά την τελευταία αυτή διαδικασία εισάγονται στο RP-δένδρο. Τέλος, όλα τα τετριμμένα πρότυπα διαγράφονται, αφήνοντας το RP-δένδρο να περιέχει μόνο τα ΜΜΕΠ και τα μικρότερα μη-τετριμμένα ΕΠ, ολοκληρώνοντας το δεύτερο στάδιο του HLC.
Για να γίνει περισσότερο κατανοητή η λειτουργία του HLC, παραθέτουμε ένα παράδειγμα της εκτέλεσης του σε μια υποθετική μουσική ακολουθία (το παράδειγμα αυτό θα αποτελέσει και το τρέχον παράδειγμα στο κεφάλαιο αυτό). Έστω μια μουσική ακολουθία , όπου S = EBCDEHGABFJDEHGJEBCDEABFJ. Ακολουθώντας τα προαναφερθέντα, τα ΕΠ μήκους 1, 2, 4 υφίστανται, παρότι το , όπου το ΕΠ[χ] ενέχει την έννοια του συνόλου των ΕΠ με μήκος . Για να προσδιοριστεί το (και τα αντίστοιχα ΜΜΕΠ), θεωρούμε ότι , εφόσον ; ενώ , εφόσον και ΕΠ[4] είναι το τελευταίο μήκος για το οποίο υφίστανται ΕΠ. Ακολούθως, ο αλγόριθμος ψάχνει τις ενδιάμεσες τιμές μήκους 5, 6 και 7 ανακαλύπτοντας το ΕΠ[5]={EBCDE,2,(1,8)} και . Κατά συνέπεια, = 5 και το σύνολο των ΜΜΕΠ είναι το ΕΠ[5]={EBCDE,2,(1,8)} (δηλ., το ΕΠ[5] περιέχει μόνο ένα ΜΜΕΠ). Το αποτέλεσμα του πρώτου σταδίου του HLC παρουσιάζεται στο Σχήμα 3.1, όπου το ΜΜΕΠ βρίσκεται στη ρίζα. (Στο Σχήμα 3.1, τα μη-τετριμμένα ΕΠ εμφανίζονται με τονισμένες γραμμές). Το επόμενο στάδιο του HLC δεν παρουσιάζει ενδιαφέρον για το παρόν καφάλαιο καθώς εστιάζει στα ΜΜΕΠ (που βρέθηκαν στο πρώτο στάδιο), κατά συνέπεια τα βήματα του HLC που εκτελούνται στο δεύτερο στάδιο παραλείπονται.
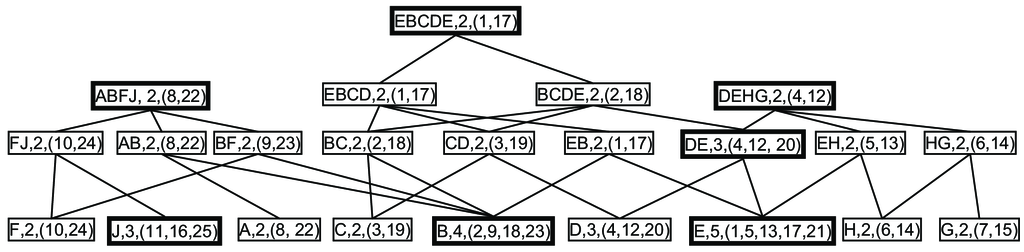
Κίνητρα
Βασιζόμενοι στα προαναφερθέντα, πρέπει να διευκρινιστεί πως μεταξύ των μη-τετριμμένων ΕΠ, ο HLC ανακαλύπτει το σύνολο των ΜΜΕΠ. Εμφανώς, αυτό γίνεται με πολύ αποδοτικό τρόπο λόγω των ακόλουθων: (i) Απαιτείται να βρεθεί μόνο ένα λογαριθμικό πλήθος ενδιάμεσων μηκών για την ανεύρεση των ΜΜΕΠ (τα μήκη τύπου εξετάζονται μέχρι να βρεθεί ένα και τότε χρησιμοποιείται δυαδική αναζήτηση στο διάστημα ), ενώ μια απλοϊκή μέθοδος θα εξέταζε όλα τα πιθανά μήκη μεταξύ 1 και . (ii) Πειραματικές μετρήσεις μπορούν να δείξουν ότι το απαιτητικότερο στάδιο σε χρόνο εκτέλεσης του HLC είναι το δεύτερο στάδιο, όπου δημιουργείται το RP-δένδρο και απαλείφονται τα τετριμμένα πρότυπα. Σε περίπτωση που το ενδιαφέρον εστιάζεται στην ανεύρεση των ΜΜΕΠ και μόνο, τότε το δεύτερο στάδιο μπορεί να παραληφθεί πλήρως.
Για τους λόγους αυτούς, μια τροποποιημένη εκδοχή του HLC (η οποία περιλαμβάνει μόνο το πρώτο του στάδιο) μπορεί να θεωρηθεί ως ένας καλός βασικός αλγόριθμος για εύρεση των ΜΜΕΠ, καθώς σαφώς υπερνικά την απλοϊκή μέθοδο. Ωστόσο, πρέπει να αναφερθεί ότι ο HLC δεν σχεδιάστηκε εξαρχής μονάχα για την ανεύρεση των ΜΜΕΠ. Παρότι εντοπίζει το σύνολο των ΜΜΕΠ χρησιμοποιώντας μόνο λογαριθμικό πλήθος ενδιάμεσων βημάτων, σε κάθε ένα από τα βήματα αυτά πρέπει να εντοπίσει όλα τα ΕΠ του βήματος. Καθώς το μέγιστο μήκος μπορεί να είναι της τάξης των μερικών εκατοντάδων, ο HLC πρέπει να εκτελέσει ενώσεις και να υπολογίσει τη συχνότητα μεγάλου αριθμού ΕΠ. Το γεγονός αυτό είναι ιδιαιτέρως εμφανές στα αρχικά βήματα, όταν το πλήθος των ΕΠ με σχετικά μικρό μήκος είναι κατά πολύ αυξημένο, εξαιτίας της μη-μονοτονικής ιδιότητας66Σύμφωνα με την ιδιότητα της μη-μονοτονίας, μια υποακολουθία της δεν μπορεί να είναι ΕΠ εκτός εάν όλες οι υποακολουθίες της είναι επίσης ΕΠ (εδώ δεν ενδιαφερόμαστε για τη διαφοροποίηση μεταξύ τετριμμένων και μη, καθώς τα ΜΜΕΠ είναι εξ ορισμού μη-τετριμμένα).. Συνεπώς, απαιτείται μια άλλη μέθοδος που θα αποφεύγει όσο το δυνατό περισσότερο το κόστος εξέτασης (δηλ., τον υπολογισμό της συχνότητα εμφάνισης) των ενδιάμεσων προτύπων.
Τέλος, πρέπει να γίνει μνεία στην εργασία των Koh και Yu [79] όπου προτείνουν μια διαφορετική προσέγγιση για την ανεύρεση των ΕΠ. Η μέθοδος τους χρησιμοποιεί ένα πίνακα bit-index και εντοπίζει όλα τα ΕΠ με μοναδιαία αύξηση μήκους. Συνεπώς, η μέθοδος αυτή προσεγγίζει το επίπεδο των ΜΜΕΠ εξετάζοντας όλα τα ενδιάμεσα μήκη και όχι μόνο ένα λογαριθμικό πλήθος όπως ο HLC. Επιπλέον, παρόμοια με τον HLC, σε κάθε εξεταζόμενο επίπεδο, η μέθοδος της εργασίας [79], ελέγχει όλα τα ΕΠ. Πειραματικά αποτελέσματα στην [79] καταδεικνύουν μια βελτίωση του συνολικού χρόνου εκτέλεσης σε σύγκριση με τον HLC. Ωστόσο, τα αποτελέσματα αυτά αναφέρονται στη διαδικασία ανεύρεσης όλων των ΕΠ, όπου ο HLC περιλάμβανε την εκτέλεση του δαπανηρού δεύτερου σταδίου του. Κατά συνέπεια, ο τροποποιημένος HLC θεωρείται αποδοτικότερος από τη μέθοδο των Koh & Yu, όσον αφορά στο πρόβλημα της ανεύρεσης μόνο των ΜΜΕΠ.
3.1.4 Ο αλγόριθμος MP
Περίγραμμα της μεθόδου
Στην ενότητα αυτή περιγράφεται ο αλγόριθμος που MP (Mining Maximum-length Patterns, Εξόρυξη μεγίστου μήκους προτύπων) βάσει των αποτελεσμάτων της εργασίας [77]. Ο αλγόριθμος MP εξελίσσεται ως εξής: Έστω μια μουσική ακολουθία μήκους . Υποθέτουμε ότι έχουν εντοπιστεί όλα τα ΕΠ μήκους δύο, ΕΠ[2] = . Τα στοιχεία της και του ΕΠ[2] σχηματίζουν ένα κατευθυνόμενο γράφο , όπου το σύνολο των κόμβων αντιστοιχεί στο σύνολο όλων των στοιχείων της και το σύνολο όλων των ακμών στο σύνολο όλων των στοιχείων του ΕΠ[2] (δηλ., μια κατευθυνόμενη ακμή στο γράφο αντιστοιχεί στο μέλος του ΕΠ[2]).
Κάθε μονοπάτι στο μπορεί να θεωρηθεί ως πιθανό ΕΠ, καθώς όλα τα υπομονοπάτια του μήκους δύο (δηλ., οι κατευθυνόμενες ακμές) είναι ΕΠ. Συνεπώς, το σύνολο όλων των πιθανών μονοπατιών του σχηματίζουν το χώρο έρευνας του εξεταζόμενου προβλήματος, καθώς τα ΜΜΕΠ είναι επίσης ΕΠ και αντιστοιχούν σε μονοπάτια του . Μια απλοϊκή προσέγγιση θα εξέταζε τον πλήρη γράφο, όπου κάθε πιθανό ζεύγος στοιχείων της θα αποτελούσε μια ακμή. Ωστόσο, η μέθοδος αυτή οδηγεί σε έναν υπέρμετρο αριθμό πιθανών μονοπατιών, ενώ (εξαιτίας της μη-μονοτονικής ιδιότητας) το πλήθος αυτό περικόπτεται δραστικά χάρις στο γεγονός ότι οι ακμές αντιστοιχούν μόνο σε μέλη του ΕΠ[2].
Ο αντικειμενικός σκοπός του MP είναι να εντοπίσει στον προαναφερθέντα χώρο έρευνας τα μονοπάτια εκείνα που έχουν το μέγιστο μήκος και αντιστοιχούν σε ΕΠ. Για να το κατορθώσει αυτό, ο MP διασχίζει το ερευνώντας τα μονοπάτια που πηγάζουν από οποιονδήποτε από τους κόμβους του. Καθώς συναντά μονοπάτια, ο MP ασχολείται μόνο με εκείνα που είναι υποψήφια να είναι ΜΜΕΠ (δηλ., όχι μόνο ΕΠ). Κατά τη διάρκεια της διάσχισης, κρατά αναφορά του μονοπατιού που έχει ήδη επισκεφτεί και: (i) έχει το μέγιστο μήκος μέχρι του σημείου αυτού, και (ii) αντιστοιχεί σε ΕΠ (δηλ., η συχνότητα του έχει υπολογιστεί και βρεθεί να είναι μεγαλύτερη του δυο)77Αρχικά, κάθε ακμή του μπορεί να να επιλεχθεί ως τέτοιο μονοπάτι.. Ο περιορισμός του χώρου έρευνας επιτυγχάνεται απορρίπτοντας τις προεκτάσεις (δηλ., προσαρτήματα κόμβων και ακμών κατά τη διάσχιση) μονοπατιών των οποίων η συχνότητα μετρήθηκε και δεν επαρκούσε ώστε να θεωρηθούν ΕΠ, καθώς καμία από τις προεκτάσεις τους δεν οδηγούσε σε ΜΜΕΠ (εξαιτίας της ιδιότητας της μη μονοτονικότητας, μιας και ένα ΜΜΕΠ είναι ΕΠ). Συνεπώς, κατά την πρόοδο της διάσχισης του , τρεις περιπτώσεις χρήζουν μνείας:
- 1η Περίπτωση:
-
Εάν το τρέχον μονοπάτι που έχει επισκεφτεί ο αλγόριθμος έχει μήκος μικρότερο από , τότε η μέτρηση της συχνότητας του μπορεί να αποφευχθεί (καθώς δεν είναι ΜΜΕΠ με βεβαιότητα).
- 2η Περίπτωση:
-
Εάν , τότε υπολογίζεται η συχνότητα του αντίστοιχου προτύπου στην και εάν βρεθεί το πρότυπο να είναι επαναλαμβανόμενο, τότε το εξισώνεται με το . Εναλλακτικά, εάν δεν είναι ΕΠ, τότε (όπως έχει ήδη περιγραφεί) η διάσχιση δεν συνεχίζει σε κανένα μονοπάτι που να περιέχει το .
- 3η Περίπτωση:
-
Τέλος, εάν το μήκος του είναι ίσο με το μήκος του , τότε ο υπολογισμός της συχνότητας αποφεύγεται στο σημείο αυτό και διατηρούμε ένα πίνακα και τον συνδέουμε με το . Εάν μετά το τέλος της διάσχισης του δεν έχουν βρεθεί άλλα ΕΠ με μήκος μεγαλύτερο του , όλα τα μονοπάτια που έχουν συνδεθεί με το είναι επίσης υποψήφια να είναι ΕΠ (το έχει επιβεβαιωθεί ως ΜΜΕΠ, εφόσον ήταν το πρώτο μονοπάτι το μήκος του οποίου εξετάσθηκε κατά τη διάσχιση, άρα και η συχνότητα του έχει υπολογιστεί εξαιτίας της πρώτης περίπτωσης.
Βάσει των προηγουμένων, ο MP υπολογίζει τη συχνότητα ενός μονοπατιού μόνο εάν το μήκος είναι τέτοιο ώστε είναι πιθανό να είναι ΜΜΕΠ. Για το λόγο αυτό, αναβάλλει όσο το δυνατό περισσότερο τη δαπανηρή διαδικασία μέτρησης της συχνότητας, στοχεύοντας στην εύρεση νέων υποψηφίων με μεγαλύτερο μήκος. Το αποτέλεσμα είναι ότι ο MP, αντίθετα με τον HLC, αποφεύγει τη μέτρηση της συχνότητας όλων των μονοπατιών ενός συγκεκριμένου μήκους. Αντίθετα, προσδιορίζει τη συχνότητα μονοπατιών συγκεκριμένου μήκους μόνο, έως ότου βρεθεί το πρώτο μονοπάτι που αντιστοιχεί σε ΕΠ. Τέλος, όταν τελειώσει η διάσχιση, εξετάζονται όλα τα συνδεδεμένα μονοπάτια που είναι συνδεδεμένα με το αρχικό ΜΜΕΠ (δηλ., εκείνα τα μονοπάτια με μήκος ίσο με το μέγιστο μήκος που βρέθηκε για το ), ώστε να βρεθούν όλα τα ΜΜΕΠ, καθώς μπορεί να υπάρχουν περισσότερα από ένα. Οφείλουμε να σημειώσουμε ότι η μέτρηση της συχνότητας στον MP εκτελείται χρησιμοποιώντας αλγόριθμο ταιριάσματος συμβολοσειρών88Χάριν απλότητας, θα μπορούσε να χρησιμοποιηθεί και ο αλγόριθμο Knuth-Morris-Pratt., καθώς η συχνότητα ενός μονοπατιού είναι ίση με το πλήθος των εμφανίσεων του (δηλ., της υποακολουθίας που αντιστοιχεί στο ) στην .
Περιγραφή του αλγορίθμου MP
Στην ενότητα αυτή περιγράφεται η αλγοριθμική μορφή του MP, όπως παρουσιάζεται στο Σχήμα 3.2. Το δεδομένο εισόδου του MP είναι η μουσική ακολουθία. Αρχικά, ο MP υπολογίζει όλα τα ΕΠ μήκους δύο και τα αποθηκεύει στο σύνολο ΕΠ[2]. Η διαδικασία αυτή αποτελεί μέρος της αρχικοποίησης και εκτελείται με τη βοήθεια μιας διδιάστατης μήτρας , το μέγεθος της οποίας για την αναπαράσταση MIDI είναι 128128. Ο γράφος κατασκευάζεται βάσει του πίνακα γειτνίασης του . Κατόπιν, ο MP εκτελεί τη διάσχιση του κατά τη διάρκεια της οποίας εξετάζει τα μονοπάτια που πηγάζουν από τους κόμβους του (η διάσχιση επισκέπτεται τους κόμβους με προτεραιότητα κατά βάθος).
Στη διαδικασία διάσχισης του γράφου, το μήκος του τρέχοντος μονοπατιού συγκρίνεται με το μήκος του τρέχοντος μέγιστου μονοπατιού (Current Maximum Length - CML), το οποίο αρχικά είναι ίσο με δυο, καθώς ο MP έχει ήδη προσδιορίσει το σύνολο ΕΠ[2]. Εάν το μήκος του είναι μεγαλύτερο από το CML, τότε ο MP υπολογίζει τη συχνότητα του και σε περίπτωση που είναι μεγαλύτερη του δύο, το αποθηκεύεται (ως το μόνο στοιχείο) στην ουρά μέγιστου μήκους (Maximum Length Queue - MLQ), ενώ το CML γίνεται ίσο με το μήκος του . Αντίθετα, όταν το μήκος του είναι ίσο με το CML, τότε το προστίθεται στην MLQ χωρίς να γίνει υπολογισμός της συχνότητάς του. Τέλος, εάν δεν έχει περικοπεί η έρευνα για μονοπάτια που περιέχουν το (περικοπές συμβαίνουν όταν η συχνότητα του υπολογιστεί και βρεθεί μικρότερη του δύο), η διάσχιση συνεχίζει επισκεπτόμενη γειτονικούς κόμβους του .
Μετά το πέρας της διάσχισης του , ο MP έχει προσδιορίσει (εφόσον υπάρχει) ένα ΜΜΕΠ (το πρώτο στοιχείο της MLQ). Ακολούθως, συνεχίζει υπολογίζοντας τη συχνότητα των όλων των υπόλοιπων στοιχείων της MLQ, ώστε να συγκεντρώσει το σύνολο όλων των ΜΜΕΠ.
Η ορθότητα του MP μπορεί εύκολα να αποδειχθεί ως εξής: Υποθέτουμε ότι το είναι ένα ΜΜΕΠ με μήκος , ενώ τα στοιχεία του είναι . Εφόσον το είναι ΜΜΕΠ, η συχνότητα του είναι μεγαλύτερη ή ίση με δύο. Συνεπώς, κάθε διαδοχικό ζευγάρι των στοιχείων του ανήκει στο ΕΠ[2] και έχει μια αντίστοιχη ακμή στο . Ακολούθως, το θα εξεταστεί από τον MP κατά τη διάρκεια της διάσχισης του , ακολουθώντας τις ακμές για . Εάν το είναι το πρώτο μονοπάτι με μήκος που θα εξεταστεί, τότε θα υπολογιστεί η συχνότητα του και το θα αποτελεί το πρώτο στοιχείο της MLQ (διαγράφοντας όποιες παλαιότερες εγγραφές που αντιστοιχούσαν σε υποψήφια μονοπάτια μικρότερου μήκους). Αλλιώς, εάν έχουν ήδη συμπεριληφθεί άλλα μονοπάτια με μήκος στην MLQ, καθώς δεν υπάρχει άλλο ΕΠ με , το θα εξεταστεί στο βήμα μετά το τέλος της διάσχισης, όταν θα υπολογίζονται οι συχνότητες όλων των στοιχείων της MLQ. Κατά συνέπεια, σε κάθε περίπτωση το θα ενσωματωθεί στην MLQ και θα περιλαμβάνεται στην έξοδο του MP.
Παράδειγμα
Για να αποσαφηνιστεί η περιγραφή του MP, στην ενότητα αυτή παρουσιάζεται ένα παράδειγμα της εκτέλεσής του ακολουθώντας το τρέχον παράδειγμα του κεφαλαίου αυτού. Στο παράδειγμα αυτό, η ακολουθία = EBCDEHGABFJDEHGJEBCDEABFJ, έχει σύνολο ΕΠ[2] και ο αντίστοιχος γράφος παρουσιάζεται στο Σχήμα 3.3. Υποθέτουμε (χωρίς απώλεια της γενικότητας) ότι ο MP ξεκινά τη διάσχιση από τα μονοπάτια που πηγάζουν από τον κόμβο και την ακμή , ειδικότερα. Αρχικά, επισκέπτεται το μονοπάτι ABC (Σχήμα 3.4a). Καθώς το μήκος του είναι , η συχνότητα του υπολογίζεται και βρίσκουμε ότι είναι μηδενική. Έτσι, ο MP δεν συνεχίζει τη διάσχιση στο μονοπάτι ABC. Κατόπιν, συνεχίζει εξετάζοντας το ABF, του οποίου η συχνότητα υπολογίζεται ίση με δύο. Συνεπώς, το CML γίνεται ίσο με τρία και το ABF εισάγεται στην MLQ. Η διάσχιση συνεχίζει περαιτέρω με το μονοπάτι αυτό προχωρώντας στο ABFJ, του οποίου η συχνότητα υπολογίζεται ίση με δύο. Ομοίως, το CML γίνεται τέσσερα και η MLQ={ABFJ}. Συνεχίζοντας, εξετάζεται το μονοπάτι ABFJH, όμως η συχνότητα του είναι μηδενική. Συνεπώς, αποφεύγεται η εξέταση μονοπατιών που το περιέχουν.
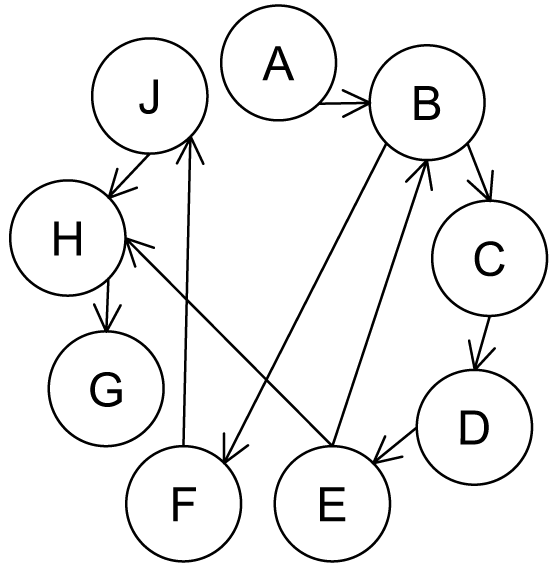
Στη συνέχεια, η διάσχιση προχωρά στον κόμβο (Σχήμα 3.4b) και την ακμή BC. Αρχικά εξετάζεται το μονοπάτι BCD, το μήκος του οποίου είναι μικρότερο του CML, και ακολούθως η συχνότητα του δεν υπολογίζεται. Ωστόσο, η διάσχιση συνεχίζει σε μονοπάτια που περιέχουν το BCD, καθώς δεν μπορεί να απορριφθεί ως μη ΕΠ (δηλ., δεν έχει υπολογιστεί η συχνότητα του). Συνεπώς, το μονοπάτι BCDE ακολουθεί προς εξέταση, το μήκος του οποίου είναι ίσο με το CML. Έτσι, το BCDE προστίθεται στην MLQ που γίνεται ίση με {ABFJ,BCDE}.

Ομοίως, τα μονοπάτια που πηγάζουν από τον κόμβο C (Σχήμα 3.4c) δεν επηρεάζουν το CML ή την MLQ, ενώ τα μονοπάτια που απορρέουν από τον κόμβο D (Σχήμα 3.4d) προσθέτουν το DEHG στην MLQ (εφόσον , η συχνότητα του δεν υπολογίζεται), ενώ η MLQ γίνεται {ABFJ,BCDE,DEHG}. Συνεχίζοντας με τον κόμβο (Σχήμα 3.4e), το μονοπάτι EBCD προστίθεται στην MLQ (MLQ={ABFJ,BCDE,DEHG,EBCD}). Κατόπιν, εξετάζεται το EBCDE και η συχνότητα του υπολογίζεται ίση με δύο (εφόσον το μήκος του είναι μεγαλύτερο από το CML). Ακολούθως, το CML γίνεται ίσο με πέντε, ενώ τα τρέχοντα στοιχεία της MLQ διαγράφονται και το EBCDE προστίθεται (εφόσον βρέθηκε μεγαλύτερη τιμή CML). Τέλος, όλοι οι υπόλοιποι κόμβοι (, , και ) δεν επιφέρουν καμία αλλαγή. Συνεπώς, εφόσον δεν υπάρχουν άλλα υποψήφια μονοπάτια στην MLQ το σύνολο των ΜΜΕΠ που βρέθηκαν είναι .
Αναπτύσσοντας βελτιστοποιήσεις
Η αποδοτικότητα του αλγόριθμου MP βασίζεται στα κεντρικά χαρακτηριστικά του, την ικανότητα του, όπως έχει ήδη περιγραφεί, να αποφεύγει τον υπολογισμό της συχνότητας εμφάνισης των υποψηφίων (εκτός του πρώτου που βρεθεί για κάθε μήκος) το μήκος των οποίων είναι ίσο με το CML, και τη δυνατότητα του να αποφεύγει εντελώς κάθε μέτρηση που σχετίζεται με υποψήφιους με μήκος μικρότερο του CML. Για την περαιτέρω βελτιστοποίηση της απόδοσής του, στην ενότητα αυτή περιγράφονται δυο τεχνικές ώστε να βελτιωθεί επιπλέον η βασική μορφή του MP.
Όπως περιγράφεται στην εργασία [71], το πλήθος των ΕΠ με μικρό μήκος είναι κατά πολύ μεγαλύτερο από το πλήθος των ΕΠ με μεγάλο μήκος. Για το λόγο αυτό, θα ήταν επιθυμητό ο MP (κατά τη διάρκεια της διάσχισης) να μειώσει τον αριθμό των εξεταζόμενων μονοπατιών με μικρό μήκος. Κάτι τέτοιο είναι εφικτό σε ένα βήμα προεργασίας. Έστω το μήκος των ΕΠ των οποίων επιθυμούμε να μειωθεί το πλήθος. Ο MP διαβάζει τη μουσική ακολουθία και κατακερματίζει τις υποακουλουθίες μήκους σε ένα πίνακα κατακερματισμού, του οποίου τα περιεχόμενα είναι ακέραιοι μετρητές (αρχικά ίσοι με μηδέν). Κατά τη διάρκεια της διάσχισης, όταν εξετάζεται ένα μονοπάτι μήκους , ο MP ελέγχει τον αντίστοιχο μετρητή και εάν αυτός είναι μικρότερος του δύο, τότε σταματά τη διάσχιση για προεκτάσεις του , καθώς το δεν μπορεί να είναι ΕΠ. Ωστόσο, εάν η τιμή του μετρητή είναι μεγαλύτερη ή ίση του δύο, το είναι πιθανό να μη είναι ΕΠ, εξαιτίας πιθανών συγκρούσεων στον πίνακα κατακερματισμού. Ακολούθως, ο κατακερματισμός μπορεί μόνο να προσφέρει ένα διηθητήρα ώστε να μειωθεί το πλήθος των εξεταζόμενων μονοπατιών μήκους . Εδώ πρέπει να αναφερθεί ότι σχετική τεχνική κατακερματισμού έχει χρησιμοποιηθεί σε εξόρυξη στοιχειοσυνόλων [99]. Καθώς η τεχνική αυτή αποδίδει ικανοποιητικά μόνο για μονοπάτια μικρού μήκους, στις υλοποιήσεις προτείνεται να εξετάζονται τιμές μικρές (λ.χ. ίσες με τρία και τέσσερα) αλλά και διακριτοί πίνακες κατακερματισμού για τις τιμές του .
Η δεύτερη τεχνική αντιμετωπίζει την επίδραση των κύκλων στο γράφο . Εμφανώς, τα στοιχειά των ΕΠ και ΜΜΕΠ δεν απαιτείται να είναι διακριτά, συνεπώς, κόμβοι και/ή ακμές του είναι πιθανό να περιέχονται περισσότερες από μια φορές για το τρέχον εξεταζόμενο μονοπάτι (κατά τη διάρκεια της διάσχισης). Ας υποθέσουμε ότι ένα μονοπάτι είναι ΕΠ αλλά το μήκος του είναι μικρότερο από το CML. Στην περίπτωση αυτή, εάν το περιέχει κύκλο, χρησιμοποιώντας τους κόμβους και τις ακμές στον κύκλο για κατάλληλο αριθμό φορών (δηλ., αρκεί να ακολουθηθεί ο κύκλος όσες φορές απαιτείται), το μπορεί να επεκταθεί ώστε το μήκος του να γίνει ίσο με το CML. Επιπλέον, εξαιτίας της Περίπτωσης 3 (όπως αυτή περιγράφεται στην Ενότητα 3.1.4), ένα μεγάλο πλήθος μονοπατιών μπορούν να προστεθούν στην MLQ. Για το λόγο αυτό, προτείνεται η βελτίωση της αρχικής μορφής του MP ώστε να μπορεί να εντοπίσει την ύπαρξη κύκλων στο τρέχον εξεταζόμενο μονοπάτι και όταν ισχύει η Περίπτωση 3 για μονοπάτι με κύκλο, να υπολογίζεται πρώτα η συχνότητα του και να ακολουθεί η προσθήκη του στην MLQ. Παρά το γεγονός ότι η τεχνική αυτή αυξάνει το πλήθος των ενδιάμεσων μονοπατιών των οποίων εξετάζεται η συχνότητα, εντούτοις περιορίζει την υπέρμετρη αύξηση των μελών της MLQ (η συχνότητα των οποίων θα πρέπει να υπολογιστεί στο τέλος της διάσχισης).
Οι δύο προαναφερθείσες βελτιστοποιήσεις έχουν βρεθεί να προσφέρουν ουσιαστική βελτίωση στην απόδοση του MP. Για το λόγο αυτό, ενσωματώθηκαν στην αρχική μορφή του, όπως αυτή περιγράφηκε προηγουμένως.
3.2 Κατηγοριοποίηση
3.2.1 Κατά γένος
Τα μουσικά γένη (genres) είναι κατηγορίες μουσικών κομματιών που έχουν κοινή μορφή (style). Παρότι η μουσική μπορεί επίσης να χαρακτηριστεί κι από μη μουσικά κριτήρια, όπως η γεωγραφική τοποθεσία της παραγωγής, η "βασική μουσική γλώσσα" μου χρησιμοποιούν τα μέλη του γένους αλλά και ο χαρακτηρισμός που της αποδίδουν τα μέλη της κοινότητας των ακροατών της είναι ιδιαίτερα σημαντική [109]. Είναι η εξειδικευμένη κοινότητα των δημιουργών, κριτικών και της μουσικής βιομηχανίας που δημιουργεί και εγκαθιδρύει τις ταξινομίες αυτές.
Ακολούθως, μια από τις αναγκαιότητες που παρουσιάζονται στην ΕΜΠ είναι η κατηγοριοποίηση κατά γένος. Εκτός της προφανούς σημασίας σε πληθώρα επαγγελματιών (πωλητές, βιβλιοθηκονόμοι, μουσικολόγοι, κλπ) ως μέσο οργάνωσης της μουσικής, η κατηγοριοποίηση κατά γένος είναι εξίσου σημαντική καθώς η έρευνα [97] δείχνει πως η αρέσκεια σε ένα μουσικό κομμάτι μπορεί να έχει υψηλή συσχέτιση με τη μορφή της εκτέλεσης και όχι στο ίδιο το περιεχόμενο του κομματιού μετατρέποντας το γένος σε ψηλής σημασίας χαρακτηριστικό για την ΕΜΠ. Καθώς τα μεταδεδομένα στη μουσική απαιτούν ρητή ανάθεση η οποία δεν συμβαίνει πάντα και η χειρωνακτική τους ανάθεση παρουσιάζει δυσκολίες και πιθανώς ασυνέπεια [98], η αναγκαιότητα για αποδοτικές αυτοματοποιημένες τεχνικές κατηγοριοποίησης της μουσικής είναι προφανής, ειδικότερα καθώς οι μουσικές συλλογές αυξάνουν σε πλήθος, μέγεθος με ταχύ ρυθμό. Επιπλέον, η κατηγοριοποίηση κατά γένος μουσικής έχει πολλαπλά οφέλη για το ευρύ κοινό καθώς διευκολύνει την πρόσβαση προσφέροντας ευκολία.
Παρότι η ΕΜΠ και ειδικότερα η έρευνα βάσει περιεχομένου είναι ακόμα σε φάση ανάπτυξης, η τρέχουσα έρευνα εστιάζει σε ακουστικά δεδομένα, γεγονός που μπορεί εύκολα να εξηγηθεί από την δημοφιλία των ακουστικών καταγραφών. Τα μουσικά δεδομένα σε συμβολική μορφή, όπως προαναφέρθηκε, έχουν την έννοια της πρόθεσης από το δημιουργό προς τον εκτελεστή. Ακολούθως, η συμβολική αναπαράσταση εμπεριέχει πλούτο πληροφορίας, η οποία δεν είναι πάντα προφανής στο αντίστοιχή ακουστική αναπαράσταση. Επιπλέον, τα ακουστικά μουσικά δεδομένα εμπεριέχουν περαιτέρω άσχετη πληροφορία με τη μορφή του θορύβου, δυσχεραίνοντας έτσι την επεξεργασία τους. Για να μπορέσει να γίνει επεξεργασία της συνολικής πληροφορίας που περιέχεται στα μουστικά δεδομένα διάφορες μέθοδοι έχουν προταθεί [92], [64], [108] που εκμεταλλεύονται χαρακτηριστικά της μουσικής όπως το τονικό ύψος, ο ρυθμός, το ηχόχρωμα κλπ για την κατηγοριοποίηση της μουσικής κατά γένος. Στην ενότητα αυτή εστιάζουμε στο τονικό ύψος και τη χρονική διάρκεια των νοτών της μουσικής πληροφορίας σε συμβολική αναπαράσταση.
Ένα από τα κυριότερα θέματα που αντιμετωπίζει η έρευνα κατηγοριοποίησης μουσικής πληροφορίας κατά γένος, ειδικότερα καθώς οι ταξινομίες εξελίσσονται σε λεπτότερου διαχωρισμού γένη και υπογένη, είναι η υποκειμενικότητα και επιβεβαίωση του ορισμού των γενών. Επιπλέον, τα νέο-αναδυόμενα γένη και τα μουσικά έργα που ανήκουν σε περισσότερα του ενός γένη, αυξάνουν σημαντικά τη δυσκολία της κατηγοριοποίησης κατά γένος.
Σχετικές εργασίες
Η κατηγοριοποίηση κατά γένος είναι μια από τις βασικές περιοχές της ΕΜΠ για την οποία η έρευνα είναι ιδιαίτερα ανθηρή. Παρότι, όπως προαναφέρθηκε, η κατηγοριοποίηση κατά γένος εστιάζει κυρίως στα ακουστικά δεδομένα, οι αντίστοιχες μέθοδοι για συμβολικά δεδομένα έχουν να παρουσιάσουν ενδιαφέροντα αποτελέσματα.
Στην εργασία [108], οι συγγραφείς εισήγαγαν τα ιστογράμματα τονικού ύψους (ΙΤΥ) ως μέθοδο για την αναπαράσταση του του περιεχόμενου τονικού ύψους στα μουσικά ακουστικά και συμβολικά σήματα. Αρχεία τύπου MIDI χρησιμοποιήθηκαν για την εξαγωγή του τονικού ύψους, η συχνότητα εμφάνισης των οποίων προσδιορίζει το ΙΤΥ. Καθώς οι προδιαγραφές των αρχείων MIDI επιτρέπουν μόνο 128 διακριτές νότες, κάθε ΙΤΥ είναι ένας πίνακας 128 τιμών καταλογοποιημένος κατά το αναγνωριστικό της νότας, που αναπαριστά τη συχνότητα εμφάνισης της αντίστοιχης νότας.
Στην ίδια εργασία εξετάζονται δύο εκδόσεις ΙΤΥ ανάλογα με το αν λαμβάνουν κατά νου την πληροφορία οκτάβας των νοτών. Η αιτιολογία για τη χρήση ή όχι της πληροφορίας οκτάβας βασίζεται στο ότι μεν τα εκτεταμένα ΙΤΥ εμπεριέχουν την πλούσια πληροφορία του τονικού ύψους συμπεριλαμβανόμενης της οκτάβας ενώ τα συμπτυγμένα ΙΤΥ είναι ανεξάρτητα οκτάβας και ο μετασχηματισμός σε κύκλο πέμπτων βελτιώνει την έκφραση της τονικής μουσικής.
Ακολούθως, η εκτεταμένη έκδοση συνυπολογίζει την πληροφορία οκτάβας του τονικού ύψους μεταξύ δύο νότες Do που απέχουν μια οκτάβα και τις θεωρεί ως διαφορετικές νότες. Στην συμπτυγμένη έκδοση, όλα τα τονικά ύψη μεταφέρονται σε μια και μόνο οκτάβα, δηλαδή οι δύο νότες Do που προαναφέρθηκαν θεωρούνται ως η ίδια νότα και στη συνέχεια μετασχηματίζονται σε ένα κύκλο πέμπτων, ώστε οι γειτνιάζοντες κάδοι του ιστογράμματος να είναι σε απόσταση πέμπτου αντί ημιτόνιου.
Για την ελαχιστοποίηση του χώρου αναζήτησης, τέσσερα μονοδιάστατα χαρακτηριστικά εξάγονται από τα το εκτεταμένο και το συμπτυγμένο ΙΤΥ, τα PITCH-Fold, AMPL-Fold, PITCH-Unfold & DIST-Fold. Το πρώτο είναι ο αριθμός κάδου της μέγιστης κορυφής του συμπτυγμένου ΙΤΥ ενώ το δεύτερο είναι το πλάτος της μέγιστης κορυφής του συμπτυγμένου ΙΤΥ. Το PITCH-Unfold είναι η περίοδος της της μέγιστης κορυφής του εκτεταμένου ΙΤΥ και το DIST-Fold είναι το διάστημα (σε πλήθος κάδων) μεταξύ των δύο υψηλότερων κορυφών του συμπτυγμένου ΙΤΥ.
Βασισμένοι στα χαρακτηριστικά αυτά οι συγγραφείς της [108] πέτυχαν 50% ακρίβεια (accuracy) για πέντε γένη.
Στην εργασία [92] παρουσιάζεται ένα σύστημα που εξάγει 109 μουσικά χαρακτηριστικά από συμβολικά μουσικά και τα χρησιμοποιεί για την κατηγοριοποίησή τους κατά γένος. Τα χαρακτηριστικά βασίζονται στην ενορχήστρωση, την υφή, το ρυθμό, τη δυναμική, στατιστικά γνωρίσματα του τονικού ύψους, τη μελωδία και της συγχορδίες. Το ίδιο σύστημα απαιτεί εκπαίδευση για τον προσδιορισμό του αποδοτικότερου υποσυνόλου χαρακτηριστικών, ένα κόστος που εξισορροπεί την γενικότητα της λύσης με την απαιτούμενη προ-επεξεργασία της επιλογής του υποσυνόλου. Η ακρίβειά του κατά την κατηγοριοποίηση κατά γένος αναφέρεται 90% για υπό-γένη και 98% για γένη.
Τέλος, οι συγγραφείς της [64] παρουσίασαν τη χρήση πέντε χαρακτηριστικά που βασίζονται στη μελωδία, το ηχόχρωμα, το ρυθμό για την κατηγοριοποίηση κατά γένος συμβολικής μουσικής πληροφορίας. Στην έρευνά τους γίνεται σύγκριση διαφορετικών μεθόδων μηχανικής μάθησης (μεταξύ των οποίων τις decision-tree, Bayesian και rule-based ομαδοποιητές).
Τα επαναλαμβανόμενα πρότυπα (ΕΠ), όπως παρουσιάστηκαν στην Ενότητα 3.1 έχουν χρησιμοποιηθεί εκτενώς στην ΕΜΠ ενώ μια από τις χρήσεις υπήρξε και η κατηγοριοποίηση μουσικών δεδομένων κατά γένος. Οι συγγραφείς της εργασίας [86] χρησιμοποίησαν ΕΠ για το χαρακτηρισμό μουσικών κατηγοριών. Στην εργασία εκείνη, για κάθε πρότυπο που ανακαλύπτεται για μια ομάδα μουσικών δεδομένων, χρησιμοποιείται ένα σύνολο από μετρήσεις ώστε να προσδιοριστεί η χρησιμότητα του προτύπου για την κατηγοριοποίηση της ομάδας των δεδομένων. Ακολούθως, βάσει των ΕΠ που περιέχει ένα κομμάτι, προσδιορίζουν την κλάση στην οποία πρέπει να ανήκει.
Η μέθοδος που χρησιμοποιείται στην εργασία [86] μπορεί να θεωρηθεί ως συμπληρωματική της μεθόδου που παρουσιάζει η Ενότητα 3.2.1. Οι συγγραφείς της [86] συλλογικά χαρακτηρίζουν ένα μουσικό γένος από τα ΕΠ που είναι κοινά στο γένος. Συνεπώς, κάθε νέο, ακόμα μη κατηγοριοποιημένο κομμάτι κρίνεται από την ομοιότητα των ΕΠ του με τα ΕΠ του γένους. Κατά τη μέθοδο που παρουσιάζεται εδώ, τα ΕΠ προσδιορίζουν τα μουσικά μέρη που περιέχουν ουσιώδη πληροφορία, ενώ τα υπόλοιπα μέρη θεωρούνται επουσιώδη και δεν εξετάζονται. Ακολούθως, τα ΕΠ ενός μουσικού κομματιού συνεισφέρουν στη συλλογή του συνόλου χαρακτηριστικών του κομματιού και κάθε νέο, ακόμα μη κατηγοριοποιημένο κομμάτι κρίνεται από την ομοιότητα των χαρακτηριστικών χρησιμοποιώντας τη μέθοδο -NN.
Προσθέτοντας τη διάρκεια
Στην ενότητα αυτή παρουσιάζεται η προσθήκη πληροφορίας της χρονικής διάρκειας με τη χρήση ιστογραμμάτων διάρκειας νοτών (ΙΔΝ) για την κατηγοριοποίηση μουσικών δεδομένων κατά γένος. Ακολούθως, προτείνονται τρία χαρακτηριστικά που βασίζονται στη διάσταση της διάρκειας των νοτών ενός μουσικού κομματιού καθώς και μια διαφοροποιημένη, σε σχέση με την εργασία [108], μέθοδος για την εξαγωγή χαρακτηριστικών από την πληροφορία τονικού ύψους ενός κομματιού.
Ένα ΙΔΥ είναι ένας πίνακας 25 ακεραίων τιμών (οι 8 συνήθεις διάρκειες, οι παρεστιγμένες και δις παρεστιγμένες επαυξήσεις τους και η κομμένη ή breve διάρκεια) καταλογοποιημένες βάσει του μεγέθους της διάρκειάς τους, που αναπαριστούν τη συχνότητα εμφάνισης κάθε διάρκειας νότας σε ένα μουσικό κομμάτι. Διαισθητικά, τα ΙΔΝ προσφέρουν μια μέθοδο για να αιχμαλωτιστεί η δομή και το ρυθμικό μέρος ενός κομματιού, κάτι που είναι επιπλέον εμφανές στα κλασσικά μουσικά κομμάτια όπου τα γένη δημιουργήθηκαν εξελίχθηκαν βασισμένα σε κανόνες. Παράδειγμα αποτελούν οι φούγκες (fugues) όπου είναι σύνηθες να υπάρχουν πολλά μέρη όπου οι διάρκειες των νοτών είναι μικρότερες από ότι στα άλλα μέρη με στόχο να μεταδώσουν ένα αίσθημα έντασης καθώς το αρχικό θέμα τους ήταν η απόδραση. Αντίθετα, οι σονάτες (sonatas) είναι γνωστές για τη δομή τους που είναι συνήθως αργή, ειδικότερα στα δεύτερα μέρη τους.
Όπως έχει ήδη σχολιαστεί, η επιλογή των χαρακτηριστικών είναι ιδιαίτερης σημασίας για όλες τις δράσεις ανάκτησης πληροφορίας. Στην προκείμενη περίπτωση η επιλογή των χαρακτηριστικών είναι επιπλέον σημαντική καθώς η απόδοση του κατηγοριοποιητή εξαρτάται κυρίως από τη διακριτική ικανότητα των χαρακτηριστικών να αποβάλουν στατιστικές ιδιότητες των ιστογραμμάτων ενώ θα διατηρούν πληροφορία που περιγράφει τις διαφορές των γενών και κατά συνέπεια υποστηρίζουν τη δράση κατηγοριοποίησης. Ακολούθως, στην ενότητα αυτή γίνεται χρήση 3 μονοδιάστατων χαρακτηριστικών από τα ΙΔΝ, η διάρκεια που έχει τη μεγαλύτερη συχνότητα εμφάνισης, το πλήθος των εμφανίσεων της διάρκειας με τη μεγαλύτερη συχνότητα εμφάνισης αλλά και την απόσταση μεταξύ των δύο υψηλότερων κορυφών συχνότητας εμφάνισης διάρκειας σε απεικόνιση σχετικής χρονικής διάρκειας.
Η επιλογή των προτεινόμενων χαρακτηριστικών βασίζεται στα ιδιαίτερα χαρακτηριστικά που απαιτείται να διατηρούν, όπως η διάρκεια της πρώτης και δεύτερης νότας που εμφανίζεται συχνότερα (έμμεσα μέσω της απόστασής τους) αλλά και το πλήθος των εμφανίσεων της συχνότερης διάρκειας. Επιπλέον, χαρακτηριστικά παρόμοιας μορφής αλλά σε διαφορετική πληροφορίας της μουσικής χρησιμοποιήθηκαν επιτυχώς στη βιβλιογραφία για την κατηγοριοποίηση συμβολικών μουσικών δεδομένων κατά γένος.
Τα προτεινόμενα χαρακτηριστικά είναι τα εξής:
- Συμπτυγμένο τονικό ύψος
-
Στα χαρακτηριστικά συμπτυγμένου τονικού ύψους, η πληροφορία της οκτάβας δεν λαμβάνεται κατά νου. Ακολούθως, τα τέσσερα μονοδιάστατα χαρακτηριστικά της εργασίας [108] εξάγονται από τα εκτεταμένα ΙΤΥ. Αυτό γίνεται για να προσδιοριστεί η συνέπεια της πληροφορίας της οκτάβας στα κλασσικά μουσικά έργα αλλά και για λόγους σύγκρισης.
- Διάρκεια
-
Στα χαρακτηριστικά διάρκειας, όλα τα χαρακτηριστικά όπως προαναφέρθηκαν στην ίδια Ενότητα εξάγονται μόνο από ΙΔΝ ώστε να παρουσιαστεί η διακριτική ικανότητα της πληροφορίας της διάρκειας των νοτών, όπως παράγονται από τα ΙΔΝ.
- Τονικό ύψος & διάρκεια
-
Το χαρακτηριστικό αυτό παράγεται από το συνδυασμό των χαρακτηριστικών του τονικού ύψους και της διάρκειας. Ακολούθως, κάθε μουσικό κομμάτι αναπαρίσταται από 7 χαρακτηριστικά, 4 από το ΙΤΥ και 3 από το ΙΔΝ. Καθώς τα χαρακτηριστικά τονικού ύψους μπορούν να είναι σε έκδοση εκτεταμένη ή συμπτυγμένη, όμοια και το συνδυαστικό χαρακτηριστικό αυτό μπορεί να εξαχθεί για τις ίδιες εκδόσεις.
- Σταθμισμένο τονικό ύψος & διάρκεια
-
Το τελευταίο χαρακτηριστικό που προτείνεται είναι μια μεταλλαγμένη έκδοση του συνδυασμού τονικού ύψους και διάρκειας. Η μετάλλαξη συνίσταται στη χρήση στάθμισης ώστε ένα από τα δύο χαρακτηριστικά να συμμετέχει με μεγαλύτερο βάρος ώστε και να επηρεάζει την κατηγοριοποίηση γένους και αντίστοιχα να μπορεί να προσδιοριστεί η συμμετοχή των χαρακτηριστικών στην απόδοση του κατηγοριοποιητή.
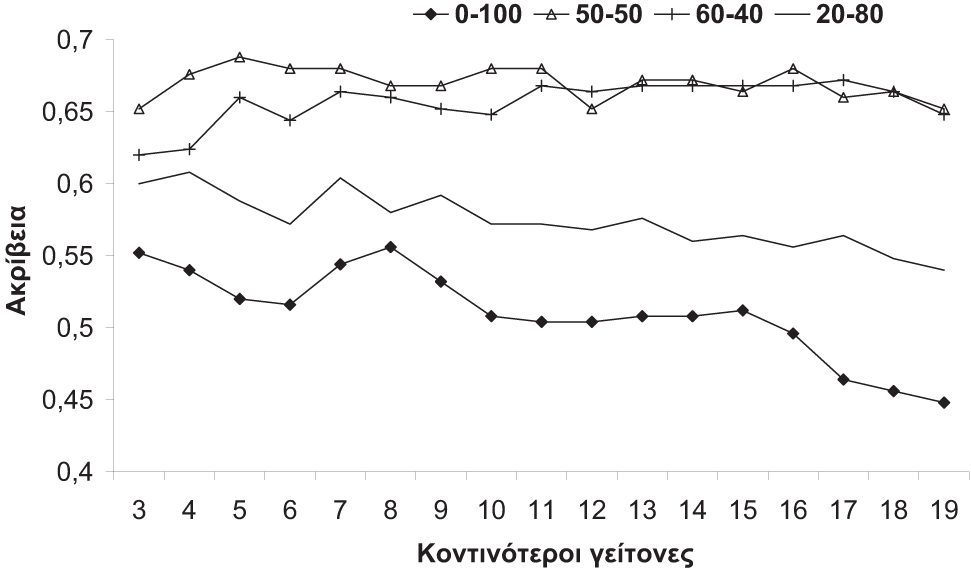
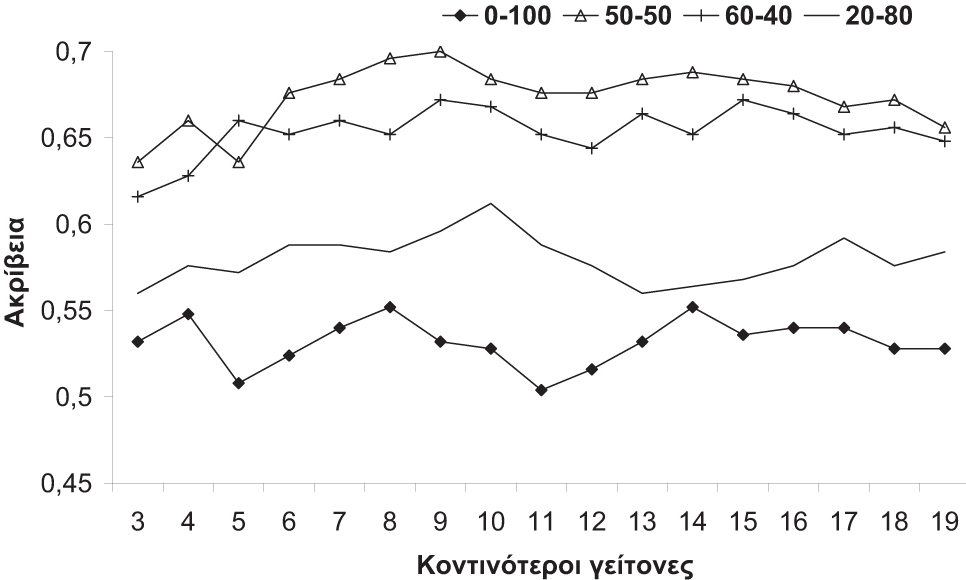
Ακολούθως, έγινε πειραματική αξιολόγηση στα χαρακτηριστικά τονικού ύψους, διάρκειας και συνδυασμού τους, τόσο για εκτεταμένα όσο και συμπτυγμένα ΙΤΥ. Μετά την εξαγωγή των χαρακτηριστικών, η διακριτική ικανότητά τους αξιολογήθηκε με τη χρήση του αλγόριθμου k-NN και χρήση της μεθόδου “leave one out”. Κατά τη μέθοδο αυτή ένα μουσικό κομμάτι της βάσης δεδομένων προς εξέταση θεωρείται ως μη γνωστού γένους και τα υπόλοιπα ως δεδομένα εκπαίδευσης. Από τα γένη των k κοντινότερων γειτόνων του άγνωστου κομματιού το γένος με τις περισσότερες εμφανίσεις θεωρείται πως είναι το γένος του άγνωστου κομματιού. Η διαδικασία επαναλαμβάνεται για όλα τα κομμάτια της βάσης δεδομένων προς εξέτασης οδηγώντας στην ακρίβεια των χαρακτηριστικών. Η επιτευχθείσα ακρίβεια παρουσιάζεται στα Σχήματα 3.5a και 3.5b.
 (a)
(a)
 (b)
(b)
Παρότι το τονικό ύψος και η διάρκεια παρουσιάζουν παρουσιάζουν παρόμοιες αποδόσεις, η διάρκεια εμφανίζεται να έχει μικρή βελτίωση στην απόδοση, ενώ ο συνδυασμός τους ξεπερνά τη μεμονωμένη χρήση των δύο χαρακτηριστικών. Επιπλέον, η διαφορά των συμπτυγμένων και εκτεταμένων ΙΨΥ παρουσιάζεται να είναι ελάχιστη.
Το δεύτερο πείραμα κάνει χρήση του σταθμισμένου τονικού ύψους & διάρκειας. Τα Σχήματα 3.6a και Figure 3.6b, παρουσιάζουν τέσσερις από τις χαρακτηριστικότερες επιλογές στάθμισης για συμπτυγμένα και εκτεταμένα ΙΨΥ. Οι ετικέτες παρουσιάζουν το ποσοστό διάρκειας - τονικού ύψους που συμμετείχε.
 (a)
(a)
 (b)
(b)
Προσθέτοντας τα επαναλαμβανόμενα πρότυπα
Στην τρέχουσα Ενότητα παρουσιάζεται η χρήση χαρακτηριστικών που εξάγονται από στατιστική πληροφορία τονικού ύψους όπως προκύπτει από Επαναλαμβανόμενα Πρότυπα με στόχο την κατηγοριοποίηση συμβολικών μουσικών δεδομένων κατά γένος.
Εξαγωγή στατιστικών χαρακτηριστικών
Η εξαγωγή των στατιστικών χαρακτηριστικών από τα ΕΠ συμβολικών δεδομένων προ-απαιτεί τον προσδιορισμό των μη τετριμμένων ΕΠ στο μουσικό κομμάτι. Εδώ, τα ΕΠ προσδιορίζονται με τη μέθοδο της εργασίας [71], δηλαδή με τη χρήση επαναλαμβανόμενων δράσεων ένωσης αλφαριθμητικών (string-join operations).
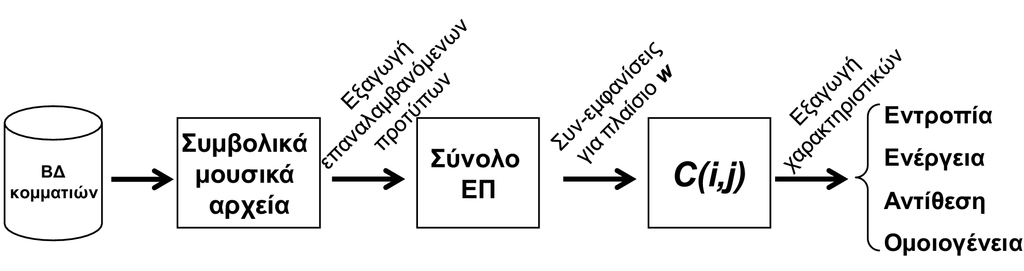
Έχοντας προσδιορίσει το σύνολο των ΕΠ για κάθε τραγούδι της βάσης δεδομένων προς εξέταση, υπολογίζεται ο πίνακας συν-εμφάνισης “co-occurrence matrix” των διακριτών τονικών υψών που εμφανίζονται στα ΕΠ. Ένα κελί του αντιπροσωπεύει το συνολικό πλήθος εμφανίσεων των i και j, στο ίδιο πλαίσιο σε όλα τα ΕΠ ενός τραγουδιού (δηλαδή, κάθε τραγούδι έχει ένα πίνακα συν-εμφάνισης που απαρτίζεται από τα ζεύγη όλων των ΕΠ του). Στη συνέχεια, τα στοιχεία του πίνακα συν-εμφάνισης κανονικοποιούνται ώστε να προσδιορισθεί η αληθής συνεισφορά τους σε κάθε τιμή , καθώς οι πίνακες συν-εμφάνισης είναι συνήθως ιδιαίτερα αραιοί. Η δραστηριότητα κανονικοποίησης γίνεται ανάλογα με το πλήθος των ζευγαριών ΕΠ που συμμετείχε στη δημιουργία του. Για τον έλεγχο της κανονικοποίησης χρησιμοποιείται η παράμετρος ως εκθέτης του (). Η χρήση της κανονικοποίησης για τον υπολογισμό σχετικών τιμών του πίνακα συν-εμφάνισης είναι απαραίτητη καθώς τα μεγαλύτερα κομμάτια τείνουν να έχουν περισσότερα ΕΠ, τα οποία συνεισφέρουν περισσότερο στον πίνακα.
Ακολούθως, τα τέσσερα προτεινόμενα χαρακτηριστικά είναι η εντροπία, η ενέργεια, η αντίθεση και η ομοιογένεια που υπολογίζονται από τον πίνακας συν-εμφάνισης κάθε τραγουδιού, με τους ακόλουθους μαθηματικούς τύπους :
| (3.1) | |||
| (3.2) | |||
| (3.3) | |||
| (3.4) |
Εδώ πρέπει να γίνει μνεία στο ότι πολλά εναλλακτικά χαρακτηριστικά που ήδη υπάρχουν στη σχετική βιβλιογραφία θα μπορούσαν να εξαχθούν από τον πίνακα συν-εμφάνισης (λ.χ. μέσο άθροισμα, διακύμανση, μέγιστη πιθανότητα, συσχέτιση, ανάστροφο σημείο διαφοράς, τάση ομαδοποίησης, κλπ) ωστόσο τα προτεινόμενα βρέθηκαν να είναι το βέλτιστο σε απόδοση υποσύνολο.
Το Σχήμα 3.7 παρουσιάζει μια σχηματική αναπαράσταση της συνολικής διαδικασίας εξαγωγής των στατιστικών χαρακτηριστικών για κάθε τραγούδι.
Χαρακτηριστικά διάρκειας
Επιπλέον, γίνεται χρήση των χαρακτηριστικών διάρκειας όπως αυτά περιγράφηκαν στην Ενότητα 3.2.1.
Υβριδική στάθμιση
Τα δύο σύνολα χαρακτηριστικών που περιγράφτηκαν στις δύο προηγούμενες Ενότητες μπορούν να συνδυαστούν ώστε να δημιουργηθεί ένα σύνολο από χαρακτηριστικά που θα αναπαριστούν κάθε τραγούδι ώστε η συνάρτηση μέτρησης ομοιότητας να σχεδιαστεί και λειτουργήσει για αυτό.
Αρχικά, εξετάστηκε η χρήση και των επτά (τέσσερα από τα ΕΠ και τρία από τα ΙΔΝ), αναπαριστώντας λοιπόν κάθε τραγούδι με επτά μονοδιάσταστα χαρακτηριστικά. Παρά τα ααποτελέσματα υψηλής απόδοσης που επιτεύχθηκαν από την αναπαράσταση αυτή (όπως παρουσιάζεται στο Σχήμα 3.8b), η συνεισφορά κάθε τύπου χαρακτηριστικών υπήρξε ιδιαίτερα δύσκολο να αποσαφηνιστεί.
Ακολούθως, χρησιμοποιήθηκε μια μέθοδος στάθμισης που επέτρεψε τα αποτελέσματα κατηγοριοποίησης κατά γένος να είναι περισσότερο ή λιγότερο επηρεασμένα από τα δύο υποσύνολα χαρακτηριστικών. Η τεχνική αυτή επιτρέπει την ανάθεση βαρών σε κάθε υποσύνολο ώστε να αυξήσει τη συμμετοχή του στη διαδικασία κατηγοριοποίησης. Όπως παρουσιάζεται στη συνέχεια (Ενότητα 3.7 ) η διαίσθηση της αναγκαιότητας για διερεύνηση της επίπτωσης των υποσυνόλων χαρακτηριστικών στην τελική απόδοση της κατηγοριοποίησης κατά γένος ήταν ορθή και απαιτούσε διερεύνηση.
Απόδοση
Το πρώτο (Σχήμα 3.8a) παρουσιάζει τη συνέπεια απουσίας της πληροφορίας των ΕΠ αλλά και την τις δευτέρου επιπέδου εξαρτήσεις στον υπολογισμό των χαρακτηριστικών (το πλαίσιο είναι ίσο με τη μονάδα), όσο αφορά την ακρίβεια. Με άλλα λόγια, από τα συμβολικά δεδομένα δεν εξάγονται τα ΕΠ, ενώ η χρήση κυλιόμενου πλαισίου γίνεται στην πληροφορία του τονικού ύψους. Επιπλέον, εξάγονται τα ΕΠ αλλά δεν συμπεριλαμβάνονται οι δευτέρου επιπέδου εξαρτήσεις των τονικών υψών στα ΕΠ. Τα βήματα αυτά γίνονται ώστε να προσδιορισμό της συμμετοχής της της εξάρτησης της πληροφορίας τονικού ύψους στα ΕΠ και να επιβεβαιώσει την επιλογή των ΕΠ ως ουσιώδη τμήματα του μουσικού κομματιού. Το Σχήμα 3.8a παρουσιάζει 21% αύξηση στην απόδοση εξαιτίας της χρήσης των ΕΠ και των δευτέρου επιπέδου εξαρτήσεων.

3.2.2 Κατά διάθεση
Κατά τη δεκαετία 2005-2015, το παράδειγμα της διάθεσης μουσικής πληροφορίας μετακινήθηκε από την φυσική διάθεση στην εικονική υπό την αιγίδα της ψηφιακά κωδικοποιημένης, υψηλής ποιότητας και φορητότητας μουσικής πληροφορίας [81]. Ακολούθως, οι ανά τον κόσμο λάτρεις της μουσικής άρχισαν να συσσωρεύουν μουσικό περιεχόμενο μεγάλης διάστασης το οποίο απαιτεί αποδοτική διαχείριση ώστε να επιτρέπει "φυσική και διαφοροποιημένη πρόσβαση" [73].
Η μουσική, όντας καλλιτεχνική έκφραση, είναι ένα πολυδιάστατο φαινόμενο. Το γεγονός αυτό είναι ιδιαίτερης σημασίας για την ΕΜΠ και ακολούθως, τα συναισθήματα που προκαλεί η μουσική αλλά και η κατηγοριοποίησή της κατά διάθεση αποτελούν σημαντικούς παράγοντες. Αυτό μπορεί να αποδοθεί εν μέρει στην ογκώδη πληροφορία συναφούς πλαισίου που κρύβεται μέσα στις συναισθηματικές εκφράσεις που περιγράφουν τη διάθεση, καθώς τέτοιου είδους πληροφορίες έχει υποστηριχθεί ότι είναι το βασικό στοιχείο σε οποιαδήποτε ανθρώπινη διαδικασία σχετικά με τη μουσική [67].
Παρά τον πολύ υποκειμενικό χαρακτήρα της αντίληψης της διάθεσης που δημιουργείται σε έναν ακροατή με ένα μουσικό κομμάτι [104], η οργάνωση που παράγεται από την ανάθεση ετικετών διάθεσης σε ένα κομμάτι μπορεί να είναι σημαντικής σημασίας για μια πληθώρα ΕΜΠ εργασίες όπως οι αυτόματες ετικέτες, δημιουργία σύστασης και playlist, μεταξύ άλλων. Ειδικότερα, το έργο της αυτοματοποιημένης δημιουργίας playlist, τόσο στις διαδικτυακές όσο και αυτόνομες εφαρμογές, έλαβε πρόσφατα αυξανόμενη προσοχή από τους χρήστες, προγραμματιστές και ερευνητές, καθώς οι ακροατές έχουν την τάση να ακούν μια σειρά σχετικών μουσικών κομματιών αντί για ένα και μοναδικό τραγούδι [91]. Η κατηγοριοποίηση κατά διάθεση μπορεί όχι μόνο να ελαφρύνει το βάρος της δημιουργίας τέτοιων playlist με βάση τη συναισθηματική έκφραση των δεδομένων εισόδου, αλλά μπορεί επίσης να βοηθήσει τους χρήστες να εντοπίζουν τα μουσικά κομμάτια της συλλογής τους, που δεν αποτελούν μέρος των συνήθως επιλέξιμων τραγουδιών και έτσι, κατά μία έννοια, ξεχασμένων [110].
Αναγνώριση διάθεσης αντιμετωπίζεται στη βιβλιογραφία ως πρόβλημα κατηγοριοποίησης ή παλινδρόμησης, όπου σε ένα ολόκληρο τραγούδι ή μέρος ενός τραγουδιού ανατίθεται ετικέτα με τιμή διάθεσης. Η ετικέτα μπορεί να είναι δυαδική (που δηλώνει την παρουσία ή απουσία ενός συναισθήματος), κατηγορηματική (που δηλώνει το είδος του συναισθήματος που ανήκει το τραγούδι), αριθμητική (μια εκτίμηση πιθανότητας ή μια τιμή κλίμακα τύπου Likert που έχει εκχωρηθεί σε κάθε τραγούδι), μονοδιάστατη (υπάρχει μία μόνο κατηγορία συναισθήματος), πολυδιάστατη (το συναίσθημα θεωρείται ως μια πολυδιάστατη οντότητα που ορίζεται από διανύσματα όπως το σθένους, διέγερση και ένταση) ή μια χρονοσειρά των διανυσμάτων (όπου η συναισθηματική αξία ενός τραγουδιού παρακολουθείται καθ ’όλη τη διάρκειά του) [78].
Τα χαρακτηριστικά που έχει δείξει η έρευνα πως επηρεάζουν τη διάθεση που δημιουργεί ένα τραγούδι ποικίλουν από το ακουστικό περιεχόμενο του κομματιού, μέχρι τα γλωσσολογικά γνωρίσματά του (τα χαρακτηριστικά στίχων αντιπροσωπεύουν κυρίως την κατανομή των λέξεων στο τραγούδι), τα μορφολογικά (αντιπροσωπεύουν την κατανομή της στίξης, επιφωνημάτων και του μεγέθους των λέξεων & στροφών του κομματιού) αλλά και αυτά που βασίζονται στην ανάθεση ετικετών από τους χρήστες. Πλήθος ακουστικών χαρακτηριστικών έχουν αποτελέσει αντικείμενο πειραματισμού συμπεριλαμβανομένων χαρακτηριστικών για ηχόχρωμα, ρυθμό, ένταση, τέμπο και τονικό ύψος. Σχετικά με τα χαρακτηριστικά των στίχων, η τρέχουσα έρευνα τα αντιμετώπισε την εξαγωγή τους με μεθόδους μοντέλου bag-of-words, μοντέλων διαφοράς γλώσσας αλλά και λανθάνοντα σημασιολογικά μοντέλα.
Σχετική έρευνα
Η έρευνα για τον προσδιορισμό της αίσθησης διάθεσης που προκαλεί ένα τραγούδι αλλά και της κατηγοριοποίησης κατά τη διάθεση αυτή έχει λάβει ιδιαίτερο ενδιαφέρον, ενώ από το 2007 και μετά ο διαγωνισμός αξιολόγησης MIREX [155], [72] επιπλέον φιλοξενεί τη δράση "Κατηγοριοποίηση ακουστικής μουσικής κατά διάθεση" (“Audio Music Mood Classification”). Ακολούθως, η τρέχουσα Ενότητα παρουσιάζει μερικές από τις βασικές μεθόδους για την κατηγοριοποίηση μουσικής πληροφορίας κατά διάθεση.
Ταξινομίες διάθεσης
Για να είναι σε θέση να γίνει κατηγοριοποίηση τραγουδιών κατά τη διάθεση, συγκίνηση τους, ή αλλιώς, χρειάζεται αρχικά να προσδιοριστεί η διάθεση. Ο Hevner [70] είχε αρχικά προτείνει ομάδες διάθεσης βάσει επιθέτων ενώ διάφορα άλλα μοντέλα της διάθεσης βάσει ομάδων επιθέτων έχουν προταθεί έκτοτε [115], [72]. Το δημοφιλέστερο μοντέλο διάθεσης, που χρησιμοποιείται εκτενώς [110], [93] στην αυτόματη κατηγοριοποίηση τραγουδιών κατά διάθεση, και αποτελεί τη βάση της παρούσας Ενότητας, είναι το μοντέλο του Thayer [107]. Στο μοντέλο αυτό, η διάθεση προσδιορίζεται σε δύο άξονες, το σθένος και την εγρήγορση, χωρίζοντας έτσι το χώρο διάθεσης σε τέσσερα μέρη έχοντας θετική/υψηλή και αρνητική/χαμηλή τιμή αντίστοιχα. Στο πλαίσιο αυτό, το σθένος και η εγρήγορση συνδέονται με την ενέργεια και την ένταση, αντίστοιχα. Υψηλού σθένους (γεμάτη ενέργεια) διάθεση δηλώνει κατάσταση που περιγράφονται από επίθετα όπως"ενθουσιασμένος", "ξετρελαμένος", κλπ, ενώ χαμηλού σθένους (κενή ενέργειας) διάθεση αντιστοιχεί σε καταστάσεις όπως "υπνηλίας". Η θετική εγρήγορση δείχνει συναισθήματα όπως "ικανοποιημένος" και "χαρούμενος", ενώ παραδείγματα συναισθημάτων χαμηλού σθένους είναι τα "νευρικός" και "λυπημένος". Για πιο λεπτομερή αναπαράσταση των συναισθημάτων, ο διαχωρισμός κάθε άξονα σε τέσσερα διακριτά μέρη προτάθηκε, δηλ. η διέγερση και το σθένος κατηγοριοποιούνται σε τέσσερις κλάσεις [110], η οποία είναι και η αντιμετώπιση που υιοθετείται στην τρέχουσα Ενότητα.
Κατηγοριοποίηση κατά διάθεση με χρήση των στίχων
Τα γλωσσολογικά χαρακτηριστικά που εξάγονται από το κείμενο των στίχων, για εφαρμογές όπως η κατηγοριοποίηση κατά διάθεση, συνήθως περιλαμβάνουν συλλογές τύπου bag-of-words [74], [85], [100], δηλ. το κείμενο αντιμετωπίζεται λες και είναι μια συλλογή από μη-ταξινομημένες λέξεις που συνοδεύονται από τη συχνότητα εμφάνισής τους (term frequency - tf). Στοχεύοντας σε ένα μέτρο που να είναι περισσότερο καταδεικτικό της διακριτικής ικανότητας του τύπου μεταξύ διάφορων κειμένου, το tfidf υπολογίζει όχι μόνο τη συχνότητα ενός όρου/λέξης σε ένα τραγούδι αλλά και τη συνολική του συχνότητα στους στίχους όλων των τραγουδιών της συλλογής. Οι συγγραφείς της [110] αντιμετώπισαν τους στίχους που ανήκαν σε ένα είδος διάθεσης ως ένα κείμενο και υπολόγισαν το tfidf των λέξεων από 10,000 τυχαία επιλεγμένα τραγούδια και στη συνέχεια εφάρμοσαν τη μέθοδο κοντινότερου γείτονα για την κατηγοριοποίηση των τραγουδιών σε 4 ή 16 κλάσεις διάθεσης.
Το μεγάλο μέγεθος του πιθανού λεξιλογίου, σε συνδυασμό με την αραιότητα των δεδομένων του μοντέλου bag-of-words κάνει τη διαδικασία διαχωρισμού μεταξύ των λέξεων ιδιαίτερα δύσκολη. Επιπλέον, οι στίχοι στο μοντέλο bag-of-words οδηγούν σε μέτρια απόδοση [85], εκτός της περίπτωσης που άπλετη ποσότητα δεδομένων είναι διαθέσιμη [110]. Για να αντιμετωπιστεί η δυσκολία αυτή, διάφορες προτάσεις έχουν γίνει που πειραματίζονται είτε με τη μείωση των διαστάσεων ή τη μοντελοποίηση της γλώσσας.
Όσο αφορά τη μείωση των διαστάσεων, οι Yang και Lee [112] χρησιμοποίησαν το εργαλείο Harvard General Inquirer ώστε να μετασχηματίσουν τις λέξεις σε ένα περιορισμένου εύρους σύνολο ψυχολογικών χαρακτηριστικών και στη συνέχεια εφάρμοσαν μια μέθοδο με δενδρική μάθηση στον παραγόμενο πίνακα συχνότητας. Άλλες, λιγότερο απαιτητικές για γνώση, μέθοδοι πέτυχαν μείωση διαστάσεων εφαρμόζοντας λανθάνουσα σημασιολογική ανάλυση (Latent Semantic Analysis - LSA) στο κείμενο των στίχων. Οι συγγραφείς της εργασίας [85] εφάρμοσαν επίσης LSA στους στίχους των τραγουδιών της διαδικτυακής πηγής last.fm και στη συνέχεια εκτέλεσαν δυαδική κατηγοριοποίηση σε 4 κλάσεις διάθεσης και στις αρνητικές ομόλογές τους (λ.χ. e.g. "θυμωμένος" - "μη θυμωμένος").
Η μοντελοποίηση γλώσσας αναφέρεται στον προσδιορισμό στατιστικών ιδιοτήτων του κειμένου κάθε κλάσης διάθεσης. Οι συγγραφείς της εργασίας [85] εξόρυξαν τους 100 συχνότερους όρους κάθε κλάσης διάθεσης και τους 100 συχνότερους όρους της αρνητικής ομόλογης κλάσης σε μια προσπάθεια να προσδιορίσουν την διακριτική ικανότητα των όρων μεταξύ δύο κλάσεων. Οι όροι με τη μεγαλύτερη διακριτική ικανότητα αποτέλεσαν τα χαρακτηριστικά στίχων στα πειράματά τους. Τα αποτελέσματα ήταν σημαντικά καλύτερα από ότι στην περίπτωση χρήσης του μοντέλου bag-of-words.
Κατηγοριοποίηση κατά διάθεση με χρήση μορφολογίας
Στην εργασία [61] παρουσιάζεται η αυξημένη συνεισφορά των μορφολογικών χαρακτήρων στη μορφολογική ανάλυση. Οι μορφολογικοί χαρακτήρες περιλαμβάνουν επιφωνήματα, σημεία στίξης (λ.χ. το θαυμαστικό), και στατιστικά στοιχεία κειμένου (όπως η λεξιλογική ποικιλία, ο ρυθμός επανάληψης, το μήκος λέξης και πρότασης, κλπ.). Στον τομέα της μουσικής, τα μορφολογικά χαρακτηριστικά έχουν χρησιμοποιηθεί στην κατηγοριοποίηση κατά γένος[100], ενώ ένα προτεινόμενο σύνολο μορφολογικών χαρακτηριστικών παρουσιάζεται στην εργασία [73].
Κατηγοριοποίηση κατά διάθεση με χρήση ακουστικής πληροφορίας & στίχων
Οι μέθοδοι που χρησιμοποιούν τόσο στην ακουστική πληροφορία όσο και στο περιεχόμενο των στίχων για τον προσδιορισμό του αισθήματος διάθεσης, βασίζονται στην υπόθεση πως η συμπληρωματικότητα των δύο πληροφοριών αυτών πηγάζει από την συνήθη προσπάθεια των τραγουδοποιών για αλληλένδετους ήχους με στίχους σε ένα τραγούδι [85], [73], [93], [111], [113]. Πληθώρα μεθόδων έχουν προταθεί για το συνδυασμό των δύο τύπων πληροφορίας, όπως: η δημιουργία διαφορετικών προβλέψεων διάθεσης για κάθε τύπο και ο συνδυασμός τους στη συνέχει μέσω στάθμισης [85] ή γραμμικού συνδυασμού [113], η εκπαίδευση διαφορετικών μοντέλων από κάθε τύπο πληροφορίας για κάθε κατηγορία διάθεσης (λ.χ. χρήση στίχων για το σθένος και ακουστικής πληροφορίας για τη διέγερση) και στη συνέχεια η ενοποίηση των αποτελεσμάτων [113], η συνάθροιση όλων των χαρακτηριστικών στον ίδιο χώρο χαρακτηριστικών και η χρήση επαυξημένων διανυσμάτων χαρακτηριστικών[85]. Οι συγγραφείς της [85] συμπεραίνουν πως ο συνδυασμός της ακουστικής και στίχων πληροφορίας προσφέρει βελτίωση στη συνολική απόδοση της δράσης κατηγοριοποίησης για τις κατηγορίες που του μοντέλου Russell [102] που εξέτασαν.
Οι Yang και Lee [111], σε μια από τις πρώτες εργασίες του χώρου, πρότειναν το συνδυασμό της πληροφορίας των στίχων με μια πληθώρα ακουστικών χαρακτηριστικών ώστε να επιτευχθεί μεγιστοποίηση της ακρίβειας της κατηγοριοποίησης και ελαχιστοποίηση του μέσου σφάλματος. Ωστόσο, το ιδιαίτερα μικρό μέγεθος δεδομένων πειραματισμού (145 τραγούδια με στίχους) κρίθηκε πως δεν είναι επαρκές για να μπορεί να καταλήξει η εργασία σε συμπεράσματα. Οι συγγραφείς της [93] εξερεύνησαν παράγοντες τόσο στην ακουστική όσο και στην πληροφορία στίχων που ταυτόχρονα επηρεάζουν τη διάθεση που προκαλεί ένα τραγούδι.
Στο πλαίσιο μείωσης διαστάσεων, οι συγγραφείς της εργασίας [113] εξήγαγαν πλήθος από χαμηλού επιπέδου ακουστικά χαρακτηριστικά από 30-δευτερόλεπτα τραγουδιών αλλά και χαρακτηριστικά στίχων, δημιούργησαν μοντέλα bag-of-words με μια ή δύο λέξεις, καθώς επίσης εφάρμοσαν και τυχαιοκρατική μέθοδο LSA. Ακολούθως, κατηγοριοποίησαν τα τραγούδια σε τέσσερις κλάσεις ακολουθώντας το μοντέλο Russell [102] για να καταλήξουν στο ότι η χρήση των χαρακτηριστικών κείμενο προσφέρει ιδιαίτερα αυξημένη ακρίβεια στις μεθόδους που πειραματίστηκαν. Σύμφωνα με το προαναφερθέν μοντέλο, το συναίσθημα αναπαρίσταται σε ένα διδιάστατο χώρο, όπου η μια διάσταση είναι η μεταφορά της θετικής/αρνητικής πόλωσης (ευχαρίστηση/δυσαρέσκεια) ενώ η δεύτερη είναι η παρουσία/απουσία ενέργειας (διέγερση/υπνηλία). Όλα τα συναισθήματα μπορούν να αναπαρασταθούν στο διδιάστατο χώρο αυτό ως συνδυασμοί τιμών των προαναφερθέντων διαστάσεων. Χρησιμοποιώντας παρόμοια μεθοδολογία, αλλά με διαφορετικό πλαίσιο εφαρμογής, οι συγγραφείς της εργασίας [89] συνδύασαν την τυχαιοκρατική μέθοδο LSA σε πληροφορία στίχων και ακουστική για την ανεύρεση ομοιότητας μεταξύ καλλιτεχνών.
Εκτός των στίχων ενός τραγουδιού, υπάρχουν κι άλλες πηγές γλωσσικής πληροφορίας που έχουν χρησιμοποιηθεί στην ΕΜΠ, όπως οι ετικέτες από εικονικές κοινωνικές δράσεις [96]. Οι Hu και Downie [73], παρουσίασαν μια διαφοροποιημένη προσέγγιση όσο αφορά την ανάθεση ετικετών διάθεσης, εξερευνώντας τις κοινωνικές ετικέτες που ανατέθηκαν σε τραγούδια, καταλήγοντας στον ορισμό 18 κλάσεων διάθεσης. Ακλολούθως, τα δεδομένα τους είναι σημαντικά ογκοδέστερα από ότι τις προηγούμενες εργασίες (5296 τραγούδια). Τέλος, ο Lamere [82] παρουσίασε μια αναλυτική περιγραφή της χρήσης των κοινωνικών ετικετών στις δράσεις της ΕΜΠ.
Εξαγωγή χαρακτηριστικών
Οι μέθοδοι ΕΜΠ που βασίζονται στο περιεχόμενο υποθέτουν πως τα δεδομένα αναπαριστούνται από χαρακτηριστικά που εξάγονται από τα μουσικά δεδομένα. Καθώς οι δράσεις της ΕΜΠ βασίζονται σημαντικά στην ποιότητα των αναπαραστάσεων, η απόδοση της αυτόματης κατηγοριοποίησης εξαρτάται ιδιαίτερα από την την ποιότητα των χαρακτηριστικών. Στην τρέχουσα Ενότητα, η έννοια του περιεχομένου επεκτείνεται από την ακουστική πληροφορία και στην πληροφορία των στίχων.
Ακουστικά χαρακτηριστικά
Στην Ενότητα αυτή δύο σύνολα ακουστικών χαρακτηριστικών χρησιμοποιούνται. Το πρώτο, audio1, δημιουργήθηκε με χρήση της εφαρμογής jAudio [90] που εξάγει ένα σύνολο από γενικευμένα για τους στόχους της ΕΜΠ χαρακτηριστικά. Το audio1 αποτελείται από τα εξής χαρακτηριστικά: Spectral Centroid, Spectral Rolloff Point, Spectral Flux, Compactness, Spectral Variability, Root Mean Square, Fraction of Low Energy Windows, Zero Crossings, Strongest Beat, Beat Sum, Strength of Strongest Beat, 13 συντελεστές MFCC, 9 συντελεστές LPC και 5 συντελεστές Method of Moments.
Το δεύτερο σύνολο, audio2, δημιουργήθηκε με την εφαρμογή MIRtoolbox [84] και τη συνάρτησή του “mirfeatures”. Η συνάρτηση αυτή υπολογίζει ένα μεγάλο πλήθος από υψηλού επιπέδου χαρακτηριστικά που είναι οργανωμένα βάσει των αξόνων της μουσικής σε δυναμική, ρυθμό, ηχόχρωμα και τονικότητα. Λεπτομερέστερα, τα χαρακτηριστικά περιλαμβάνουν τις μέσες τιμές του RMS ανά πλαίσιο, την περίληψη διακύμανσης με την υψηλότερη κορυφή και το κέντρο βάρους της, μια προσέγγιση του tempo βάσει πλαισίων, οι χρόνοι ήχησης κάθε νότας και την καμπύλη του φακέλου που χρησιμοποιείται για τον υπολογισμό του χρόνου ήχησης, και πλήθος φασματικών χαρακτηριστικών (λ.χ. κέντρο βάρους, κύρτωση, εντροπία, ρυθμός μηδενισμού, ροή κλπ).
Χαρακτηριστικά στίχων
Το κείμενο των στίχων, ειδικότερα σε περιπτώσεις όπου το σύνολο δεδομένων περιέχει πληθώρα διαφορετικών κλάσεων (λ.χ. γένους rock, ethnic και παραδοσιακά τραγούδια), είναι εγγενές προβληματικό καθώς περιλαμβάνει συχνά γλωσσικά σφάλματα, γλωσσική δυσχέρεια, ασυνήθιστες λέξεις, αποκοπές κλπ., που για να αντιμετωπιστούν απαιτούν προ-επεξεργασία:
-
•
αφαίρεση σημείων στίξης, συμβόλων, επιφωνημάτων, αποστρόφων και κόμμα,
-
•
χειρωνακτική αντιμετώπιση περικομμένων λέξεων (λ.χ. "μου είπες" γραμμένο ως "μου ’πες"), διαχωρισμός λέξεων που λανθασμένα ενώθηκαν (λ.χ. "εγώ πήγα" να εμφανίζεται ως "εγώπήγα" και κατ’ αντιστοιχία να θεωρείται ως μια νέα λέξη), περίεργες, αρχαϊκές δημοφιλείς ή ποιητικές εκφράσεις, λέξεις που κάποια από τα γράμματά τους είναι γραμμένα σε άλλα αλφάβητα που είναι οπτικά ίδια,
-
•
αφαίρεση λειτουργικών λέξεων, δηλ. λέξεων που φέρουν ελάχιστο νόημα αλλά λειτουργούν χρηστικά στη γλώσσα (λ.χ. άρθρα, αντωνυμίες, προθέσεις), και συνεπώς δεν συνεισφέρουν στη δράση διάκρισης της διάθεσης,
-
•
δράση προσδιορισμού ρίζας λέξεων (stemming)99Στην παρούσα Ενότητα η δράση stemming έγινε με το λογισμικό της εργασίας [103].
- Μοντέλο Bag-of-words
-
Για την εξαγωγή των χαρακτηριστικών στίχων, οι στίχοι κάθε τραγουδιού αναπαραστάθηκαν ως ένα σύνολο από τις 20 συχνότερα εμφανιζόμενες λέξεις (ρίζες) στο τραγούδι (κατόπιν της αφαίρεσης των λειτουργικών λέξεων). Αντίθετα με άλλες εργασίες, η χρησιμοποιούμενη εδώ μέθοδος αντιμετωπίζει το πρόβλημα της αραιότητας των δεδομένων. Περίπου 3% των τραγουδιών είχαν λεξιλόγιο μικρότερο των 20 διακριτών λέξεων συνολικά και λιγότερο από το 1% των τραγουδιών είχαν αντίστοιχο λεξιλόγιο μικρότερο των 15 λέξεων. Κάθε λέξη συνοδεύεται από τη συχνότητα εμφάνισής τους και το tfidf της. Ακολούθως, ο συνολικός αριθμός γλωσσικών χαρακτηριστικών είναι 60.
- Γλωσσικό μοντέλο
-
Αντίθετα με την εργασία [85], το χρησιμοποιούμενο εδώ γλωσσικό μοντέλο στοχεύει στην διάκριση μεταξύ διαφορετικών κλάσεων διάθεσης και όχι μεταξύ θετικής και αρνητικής έκδοσης κάθε κλάσης. Ακολούθως, οι 50 συχνότερα εμφανιζόμενες λέξεις στους στίχους μιας κλάσης υπολογίζονται οδηγώντας σε ένα σύνολο 218 διακριτών λέξεων words για οκτώ κλάσεις διάθεσης (τέσσερις για σθένος και τέσσερις για διέγερση). Αυτό αποτελεί το απόλυτο γλωσσικό μοντέλο (absolute language model - ALM) σε αντίθεση με την προσέγγιση αποστάσεων γλωσσικών μοντέλων της εργασίας [85]. Κάθε ένας από τους όρους αυτούς αποτελεί ένα χαρακτηριστικό γλωσσικής μάθησης και η τιμή του είναι αυτή του tfidf για έναν όρο στο κάθε τραγούδι (ALM tfidf). Ακολουθώντας την αιτιολόγηση της εργασίας [110], που αναφέρει πως το tf είναι επαρκής προσέγγισης όταν το idf έχει πολύ μικρή τιμή, ένα δεύτερο σύνολο δεδομένων ALM απαρτίζεται εκτός από τις τιμές tfidf και από τις τις τιμές tf (ALM tf+tfidf), δηλ. έχει διπλάσιο πλήθος γλωσσικών χαρακτηριστικών.
- Μοντέλο LSA
-
Η Λανθάνουσα Σημασιολογική Ανάλυση (LSA) [83] είναι μια μέθοδος singular value decomposition (SVD) για πίνακες, που αρχικά προτάθηκε για τη μείωση των διαστάσεων του πίνακα όρων-κειμένων (term-document matrix) στις δράσεις ανάκτησης πληροφορίας. Η μέθοδος SVD αποδομεί τον αρχικό πίνακα όρων-κειμένων σε ένα γινόμενο τριών πινάκων και "μεταφέρει" τον σε ένα νέο σημασιολογικό χώρο:
(3.5) όπου ο είναι πίνακας με γραμμές τους λεξικούς όρους και στήλες τις διαστάσεις του νέου σημασιολογικού χώρου. Οι στήλες του αναπαριστούν τα αρχικά κείμενα και οι γραμμές του τις νέες διαστάσεις, ενώ ο είναι ένας διαγώνιος πίνακες που περιέχει τις μοναδιαίες τιμές του . Ο πολλαπλασιασμός των τριών πινάκων επαναδομεί τον αρχικό πίνακα. Το γινόμενο μπορεί να υπολογιστεί έτσι ώστε οι μοναδιαίες τιμές να είναι τοποθετημένες στον σε φθίνουσα ταξινόμηση. Όσο μικρότερη η κάθε μοναδιαία τιμή, τόσο λιγότερο επηρεάζει το γινόμενο. Ακολούθως, διατηρώντας μόνο τις πρώτες λίγες () μοναδιαίες τιμές και θέτοντας τις άλλες ίσες με μηδέν, ο υπολογισμός του γινομένου οδηγεί σε μια χαμηλής τάξης προσέγγιση του αρχικού πίνακα η οποία μπορεί να υπολογιστεί με χρήση της μεθόδου least-squares best fit. Ο μειωμένος αριθμός διαστάσεων του νέου πίνακα είναι ίσος με τον αριθμό των επιλεγμένων μοναδιαίων τιμών.
Μια ενδιαφέρουσα παρενέργεια της μεθόδου αυτής είναι πως η μείωση των διαστάσεων μεταβάλει τη συχνότητα εμφάνισης λέξεων σε διάφορα κείμενα ή ακόμα πιθανώς θέτει το πλήθος εμφανίσεων μιας λέξης που δεν εμφανίζεται σε ένα κείμενο με τιμή μεγαλύτερη του μηδενός. Ακολούθως, σημασιολογικές σχέσεις μεταξύ των λέξεων και των κειμένων εμφανίζονται εκεί που αρχικά δεν ήταν προφανείς (latent).
Μορφολογικά χαρακτηριστικά
Τα 15 μορφολογικά χαρακτηριστικά που χρησιμοποιούνται στην παρούσα Ενότητα βασίζονται στο σύνολο χαρακτηριστικών που προτείνουν οι Hu και Downie στην [73]. Οι συγγραφείς της καταλήγουν σε χαρακτηριστικά που περιλαμβάνουν: τον αριθμό των παρεμβολών στο κείμενο του τραγουδιού, το μέγεθος των στίχων του τραγουδιού, τον αριθμό των μοναδικών λέξεων, το λόγο λέξεων που επαναλαμβάνονται, το μέσο μήκος των λέξεων, τον αριθμό των γραμμών στίχων, τον αριθμό των μοναδικών γραμμών στίχων, τον αριθμό των κενών γραμμών στίχων, το λόγο των κενών γραμμών στίχων σε σχέση με τις γραμμές που έχουν κείμενο, το μέσο μήκος της γραμμής, την τυπική απόκλιση του μήκους της γραμμής, τον αριθμό των μοναδικών λέξεων ανά γραμμή, το λόγο επανάληψης γραμμών στίχων, τη μέση αναλογία επανάληψης λέξης ανά γραμμή και την τυπική απόκλιση του λόγου επανάληψης λέξης ανά γραμμή.
Πειραματικά αποτελέσματα
Τα Σχήματα 3.9 και 3.10 παρουσιάζουν τα αποτελέσματα των προαναφερθέντων μεθόδων με χρήση των συνόλων δεδομένων που διαθέτουν δύο (γλωσσικά και ακουστικά χαρακτηριστικά) και τρεις τύπους πληροφορίας (γλωσσικά, ακουστικά και μορφολογικά χαρακτηριστικά). Είναι προφανές, πως παρά το αυξημένο πλήθος διαθέσιμων χαρακτηριστικών, σε πολλές περιπτώσεις η ακρίβεια της κατηγοριοποίησης είναι υψηλότερη για τα δεδομένα με τους τρεις τύπους πληροφορίας από ότι στις αντίστοιχες περιπτώσεις με δύο τύπους πληροφορίας. Ακολούθως, η συνεισφορά και σημασία χρήσης των μορφολογικών χαρακτηριστικών είναι ιδιαίτερα σημαντική.