ΚΕΦΑΛΑΙΟ 4 Ανάκτηση μουσικής πληροφορίας σε εξειδικευμένα περιβάλλοντα
4.1 Δίκτυα p2p
Ο παγκόσμιος ιστός (WWW) χρησιμοποιείται, πλέον, για εμπορικούς, ψυχαγωγικούς αλλά και εκπαιδευτικούς λόγους και τείνει να γίνει το πρωτεύον μέσο διάδοσης πληροφορίας. Ένας από τους βασικούς τύπους δεδομένων που διακινούνται μέσω του παγκόσμιου ιστού είναι και η ψηφιοποιημένη μουσική. Τα ομότιμα δίκτυα (P2P) που χρησιμοποιούν τον παγκόσμιο ιστό έχουν κερδίσει ιδιαίτερη δημοτικότητα, όσο αφορά την υποδομή για τη διακίνηση των μουσικών και όχι μόνο δεδομένων. Στα προτερήματα των ομότιμων δικτύων συγκαταλέγονται ο κατά πολύ αυξημένος χώρος της βάσης που προσφέρουν, η ανεκτικότητα τους στα σφάλματα των κόμβων και η κάλυψη τους από άλλους κόμβους αλλά και η κατανομή του εργασιακού φόρτου σε ένα δίκτυο διαθέσιμων επεξεργαστών καθώς η ΑΜΠΒΠ είναι υπολογιστικά ιδιαίτερα απαιτητική. Ωστόσο, τα ίδια τα πλεονεκτήματα των ομότιμων δικτύων είναι οι παράγοντες που κάνουν την ανεύρεση πληροφορίας σε αυτά εμφανώς περισσότερο σύνθετη από ότι σε παραδοσιακά συστήματα. Η έλλειψη κεντρικού αποθηκευτικού χώρου, το αυξημένο πλήθος δεδομένων που είναι διαθέσιμα αλλά και ο δυναμικός χαρακτήρας του δικτύου εισάγουν έναν υψηλό βαθμό δυσκολίας στη διαδικασία ανεύρεσης.
Τα ομότιμα δίκτυα μπορούν να κατηγοριοποιηθούν βάσει του ελέγχου στην τοποθεσία των δεδομένων και την τοπολογία του δικτύου σε μη δομημένα, χαλαρά δομημένα και δομημένα [152]. Η απουσία δομής επιτρέπει προσαρμοστικότητα σε δυναμικά περιβάλλοντα (συμμετοχή/αποχή κόμβων), ενώ προκαλεί πιθανότητα μη εύρεσης υπαρκτών δεδομένων. Μετακινούμενα προς αυξημένη δομή, τόσο η πιθανότητα ανεύρεσης υπαρκτών δεδομένων όσο και η επιβάρυνση διαχείρισης της συμμετοχής-αποχής αυξάνουν. Επιπλέον, τα ομότιμα δίκτυα μπορούν να κατηγοριοποιηθούν βάσει του πλήθους των κεντρικών καταλόγων των αποθηκευτικών χώρων σε συγκεντρωτικά, υβριδικά και αποκεντρωμένα. Τα συγκεντρωτικά ομότιμα δίκτυα υπόκεινται στα ίδια μειονεκτήματα για τα οποία το παραδοσιακό σχήμα εξυπηρετητής-πελάτης δεν ακολουθήθηκε (ανεπάρκεια δικτύου λόγω ανεπάρκειας του κεντρικού κόμβου, μειωμένη ικανότητα κλιμάκωσης, δυσκολία διαχείρισης συμμετοχής/αποχής κόμβων, πιθανή ανεπιθύμητη κυριαρχία των διαχειριστών του κεντρικού κόμβου). Για τους λόγους αυτούς, το κεφάλαιο αυτό εστιάζει στα μη δομημένα αποκεντρωμένα ομότιμα δίκτυα, τα οποία υπερνικούν τα προαναφερθέντα μειονεκτήματα. Η απουσία δομής επιλέχθηκε για τη χαλαρότητα του ελέγχου στην τοποθεσία των δεδομένων, δηλαδή κάθε κόμβος μπορεί να μοιράζει τα δεδομένα του χωρίς να πρέπει να φιλοξενεί δεδομένα άλλων κόμβων λόγων περιορισμών τοποθεσίας.11Εδώ πρέπει να σημειωθεί ότι με το εξεταζόμενο πλαίσιο αναφερόμαστε σε εφαρμογές που υποστηρίζουν νόμιμο μοίρασμα δεδομένων στους χρήστες. Επιπλέον, παρουσιάζει ενδιαφέρον η υιοθέτηση της εν λόγω μεθοδολογίας για τον εντοπισμό παράνομης διάθεσης.
Η έρευνα για μουσικά δεδομένα βάσει περιεχομένου απαιτεί την ανάπτυξη αποδοτικών και αποτελεσματικών μεθόδων ανεύρεσης ομοιότητας, για τον τύπο των δεδομένων αυτών, οι οποίοι θα βρίσκουν μουσικά αρχεία όμοια με ένα μουσικό επερώτημα. Επιπλέον, οι ιδιαιτερότητες του αποκεντρωμένου μη δομημένου ομότιμου δικτύου πρέπει να συνυπολογιστούν ώστε να αναπτυχθούν εφικτές λύσεις. Λόγου χάριν, ο φόρτος δικτύου που προκαλούν τα επερωτήματα ανεύρεσης ομοιότητας είναι υψηλής σημασίας. Κρίσιμος παράγοντας είναι επίσης και ο όγκος επεξεργασίας που απαιτείται στους κόμβους. Για τους λόγους αυτούς, χρειάζονται (i) ένα πρότυπο το οποίο θα μπορεί να εκφράσει αποτελεσματικά την ομοιότητα μεταξύ μουσικών δεδομένων αλλά θα είναι και γρήγορο στον υπολογισμό του, και (ii) αποδοτικοί αλγόριθμοι ανεύρεσης ομοιότητας, οι οποίοι θα ελαχιστοποιήσουν το φόρτο δικτύου.
4.1.1 Σχετικές εργασίες
Σύνοψη υπαρκτών ομότιμων συστημάτων
Τα ομότιμα δίκτυα μπορούν να κατηγοριοποιηθούν βάσει του ελέγχου στην τοποθεσία των δεδομένων και την τοπολογία του δικτύου σε μη δομημένα, χαλαρά δομημένα και δομημένα [152]. Τα μη δομημένα δεν ακολουθούν κάποιο κανόνα για την τοποθεσία αποθήκευσης των δεδομένων, ενώ η τοπολογία του δικτύου είναι τυχαία (λ.χ., Gnutella). Τα χαλαρά δομημένα ομότιμα δίκτυα έχουν τόσο την τοποθεσία αποθήκευσης όσο και την τοπολογία δικτύου μη επακριβώς προσδιορισμένη (λ.χ., Freenet). Τέλος, στα δομημένα η τοποθεσία αποθήκευσης καθώς και η τοπολογία δικτύου είναι ρητά καθορισμένες (λ.χ., Chord) παράμετροι. Επιπλέον, τα ομότιμα δίκτυα μπορούν να κατηγοριοποιηθούν βάσει του πλήθους των κεντρικών καταλόγων των τοποθεσιών αποθήκευσης των δεδομένων σε συγκεντρωτικά, υβριδικά και αποκεντρωμένα. Ακολούθως, τα συγκεντρωτικά δίκτυα διατηρούν ένα κεντρικό κατάλογο σε μια και μόνο τοποθεσία (λ.χ., Napster), τα υβριδικά περιλαμβάνουν περισσότερους από ένα σε υπερ-κόμβους (λ.χ., Kazaa) με καταλόγους, ενώ στα αποκεντρωμένα (λ.χ., Chord) δεν υπάρχει κεντρικός κατάλογος. Τέλος τα ομότιμα δίκτυα μπορούν επίσης να κατηγοριοποιηθούν σε ιεραρχικά και μη, βάσει του βαθμού ιεράρχησης της υποκείμενης δομής. Είναι σύνηθες για τα αποκεντρωμένα συστήματα να μην παρουσιάζουν ιεραρχικότητα, ενώ για τα υβριδικά και τα περισσότερα συγκεντρωτικά να συμπεριλαμβάνουν κάποιου βαθμού ιεράρχηση. Τα ιεραρχικά συστήματα παρέχουν αυξημένη ικανότητα αντιμετώπισης κλιμάκωσης, ευκολία στην εκμετάλλευση της ανομοιογένειας των κόμβων και υψηλή αποδοτικότητα δρομολόγησης. Αντιδιαμετρικά, τα μη ιεραρχικά συστήματα προσφέρουν αυξημένη εξισορρόπηση φόρτου και προσαρμοστικότητα στη συμμετοχή/αποχή κόμβων.
Στην ενότητα αυτή το δίκτυο που εξετάζεται θεωρείται αποκεντρωμένο, μη δομημένο και μη ιεραρχικό. Επιπλέον, γίνεται η υπόθεση ότι το δίκτυο αποτελείται από N κόμβους, ενώ κάθε κόμβος έχει κατά προσέγγιση γειτνιάζοντες κόμβους. Η διάμετρος του δικτύου είναι το μέγιστο πλήθος κόμβων που απαιτούνται ως ενδιάμεσοι ώστε να εντοπιστεί ο κόμβος P από τον P. Ορίζεται MaxHop (μέγιστο πλήθος αλμάτων) το πλήθος των κόμβων στους οποίους ένα επερώτημα προωθείται. Το MaxHop ενός επερωτήματος έχει μια αρχική τιμή και κάθε φορά που το επερώτημα προωθείται σε ένα κόμβο, μειώνεται κατά μια μονάδα μέχρι να γίνει μηδενικό, από το οποίο σημείο και μετά το επερώτημα δεν προωθείται σε κόμβους. Η παράμετρος MaxHop εξίσου αποκαλείται και Time-To-Leave (TTL).
Μέθοδοι έρευνας σε μη δομημένα ομότιμα δίκτυα
Στην ενότητα αυτή συνοψίζονται μερικές από της ήδη διαθέσιμες προσεγγίσεις έρευνας σε αποκεντρωμένα μη δομημένα ομότιμα δίκτυα. Αρχικά εξετάζεται ο αλγόριθμος έρευνας με προτεραιότητα πλάτους (Breadth-First Search - BFS). Στην περίπτωση του BFS, ο κόμβος Q που θέτει το επερώτημα, διαβιβάζει το επερώτημα q σε όλους τους γειτονικούς κόμβους. Κάθε κόμβος P που λαμβάνει το q αρχικά ερευνά τον τοπικό χώρο αποθήκευσης για δεδομένα που ταιριάζουν με το q και στη συνέχεια το προωθεί σε όλους τους γειτονικούς του κόμβους. Στην περίπτωση που ο P έχει κάποιο ταίριασμα από τον τοπικό χώρο αποθήκευσης τότε ένα μήνυμα QueryMatch δημιουργείται περιέχοντας πληροφορίες για το ταίριασμα. Κατόπιν, τα μηνύματα QueryMatch μεταδίδονται χρησιμοποιώντας το αντίστροφο μονοπάτι που ακολούθησε το q, στον Q. Τέλος, καθώς περισσότερα από ένα μηνύματα τύπου QueryMatch παραλαμβάνονται από τον Q, μπορεί να διαλέξει τον κόμβο με τα καλύτερα χαρακτηριστικά σύνδεσης ώστε να προσκομίσει άμεσα το ταίριασμα. Είναι προφανές ότι ο η τακτική του BFS βασίζεται στη θυσία της απόδοσης και του φόρτου του δικτύου με αντίτιμο την απλότητα του αλγορίθμου και τα υψηλά ποσοστά αποτελεσμάτων. Προσπαθώντας να περιοριστεί ο φόρτος του δικτύου, εισάγεται η παράμετρος TTL (βλ. ενότητα 4.1.1). Σε μια τροποποιημένη έκδοση του αλγορίθμου αυτού, ο τυχαίος BFS (Random BFS - RBFS) [137], ο κόμβος που θέτει το επερώτημα, Q, το διαβιβάζει σε ένα ποσοστό των γειτονικών κόμβων.
Προσπαθώντας να διορθωθεί η αδυναμία του RBFS να επιλέξει το μονοπάτι του δικτύου που οδηγεί σε μεγάλα τμήματα του δικτύου, οι συγγραφείς της εργασίας [170] ανάπτυξαν τον αλγόριθμο RES. Στην προσέγγιση αυτή, ο κόμβος Q που θέτει το επερώτημα διαβιβάζει το επερώτημα q σε ένα υποσύνολο των γειτονικών του κόμβων βάσει συνολικών στατιστικών δεδομένων. Έτσι, ο Q διαβιβάζει το q σε k γειτονικούς κόμβους, οι οποίοι επέστρεψαν τα υψηλότερα ποσοστά αποτελεσμάτων κατά τα τελευταία m επερωτήματα, με τα k και m να είναι παράμετροι. Ο RES αποτελεί μια σημαντική βελτίωση σε σύγκριση με τον RBFS, ωστόσο η συμπεριφορά του είναι περισσότερο ποσοτική παρά ποιοτική, καθώς δεν επιλέγει τους γείτονες στους οποίους θα προωθήσει το επερώτημα βάσει της ομοιότητας του περιεχομένου του q των προηγουμένων επερωτημάτων.
Με στόχο την αντιμετώπιση της ποσοτικής προσέγγισης του RES, ο αλγόριθμος ISM προτάθηκε [137]. Στον ISM, για κάθε επερώτημα, κάθε κόμβος το προωθεί στους κόμβους που είναι περισσότερο πιθανόν να απαντήσουν βάσει δυο παραμέτρων: ένα σύστημα κατατομής και μια βαθμολόγηση σχετικότητας. Η κατατομή δημιουργείται και συντηρείται σε κάθε κόμβο για τους γειτονικούς του κόμβους. Οι πληροφορίες που περιλαμβάνονται στην κατατομή αυτή είναι τα t πιο πρόσφατα επερωτήματα με ταιριάσματα, τα ταιριάσματα τους αλλά και το πλήθος των ταιριασμάτων που ο γειτονικός κόμβος επέστρεψε. Η συνάρτηση βαθμολόγησης βάσει σχετικότητας (RR) υπολογίζεται συγκρίνοντας το επερώτημα q με όλα τα επερωτήματα για τα οποία υπάρχει ταίριασμα σε κάθε κατατομή. Κατά συνέπεια, για τον κόμβο που θέτει το επερώτημα, η συνάρτηση RR υπολογίζεται βάσει της ακόλουθης σχέσης:
όπου Qsim είναι η συνάρτηση ομοιότητας που χρησιμοποιείται μεταξύ των επερωτημάτων ενώ S(P,q) είναι το πλήθος των αποτελεσμάτων που επιστρέφει ο P για το επερώτημα q. Ο ISM επιτρέπει υψηλότερη βαθμολόγηση των γειτονικών κόμβων που επιστρέφουν περισσότερα αποτελέσματα με τη ρύθμιση της παραμέτρου . Εμφανώς, η καλύτερη απόδοση του ISM εμφανίζεται σε περιβάλλοντα όπου υφίσταται αυξημένος βαθμός τοπικότητας των δεδομένων.
Ανάκτηση μουσικής πληροφορίας σε ομότιμα δίκτυα
Ο χώρος συγκερασμού της ΑΜΠΒΠ και των ομότιμων δικτύων, είναι ιδιαίτερα νέος καθώς η πρώτη εργασία δημοσιεύτηκε το έτος 2002 [167]. Ωστόσο, οι λιγοστές εργασίες παρουσιάζουν ενδιαφέροντα αποτελέσματα, τα οποία σχολιάζονται στη συνέχεια.
Στην πρώτη αυτή προσέγγιση, οι συγγραφείς της εργασίας [167] παρουσίασαν τέσσερα πρότυπα ομότιμων δικτύων για ΑΜΠΒΠ. Τα πρότυπα αυτά περιλαμβάνουν όλες τις κατηγορίες βάσει του πλήθους των κεντρικών καταλόγων των αποθηκευτικών χώρων (αποκεντρωμένα, υβριδικά και συγκεντρωτικά). Η εργασία προτείνει έναν αλγόριθμο επιτάχυνσης της ανεύρεσης που βασίζεται στη διαφορά του τονικού ύψους μεταξύ δύο νοτών καθώς και μια μέθοδο διήθησης των αποτελεσμάτων βασιζόμενη σε τεχνικές αφαίρεσης των επαναλήψεων. Επιπλέον, οι συγγραφείς της [167] προτείνουν μια αρχιτεκτονική για ΑΜΠΒΠ σε ομότιμα δίκτυα, η οποία κατατάσσεται στα υβριδικά συστήματα.
Μια ακόμα έρευνα βασιζόμενη σε ένα υβριδικό σχεδιασμό παρουσιάζεται στην εργασία [166]. Στην εργασία αυτή οι συγγραφείς προτείνουν ένα σύστημα που χρησιμοποιεί μεταδεδομένα (τραγουδιστής, συλλογή, τίτλος, συνθέτης, κλπ.) αλλά και χαρακτηριστικά που εξάγονται ώστε να περιγραφεί το περιεχόμενο ενός μουσικού κομματιού. Η προτεινόμενη τοπολογία δικτύου στην εργασία [166], βασίζεται στα συστήματα DHT. Στα συστήματα αυτά, σε κάθε κόμβο ανατίθεται μια περιοχή ενός εικονικού χώρου διευθύνσεων, ενώ σε κάθε διαμοιραζόμενο δεδομένο ανατίθεται μια τιμή από το χώρο διευθύνσεων αυτό. Συνεπώς, ο εντοπισμός ενός δεδομένου απαιτεί μόνο την ανεύρεση ενός κλειδιού, του κόμβου που έχει αναλάβει το αντίστοιχο κλειδί.
Οι συγγραφείς της εργασίας [172] πρότειναν τη χρήση της μεθοδολογίας εξαγωγής χαρακτηριστικών που προτείνεται στην εργασία [190] για ΑΜΠΒΠ σε αποκεντρωμένα μη δομημένα ομότιμα δίκτυα. Η εργασία αυτή εξετάζει την περίπτωση η βάση να είναι αντιγραμμένη αλλά και τη γενικότερη περίπτωση των ομότιμων δικτύων, ενώ ειδική προσοχή δίνεται στον έλεγχο του φόρτου εργασίας που δημιουργείται στους κόμβους κατά τη διάρκεια της επερώτησης. Κάθε επερώτηση χωρίζεται σε δύο φάσεις, η πρώτη από τις οποίες περιλαμβάνει μόνο ένα μέρος του επερωτήματος, ώστε να εντοπιστούν οι κόμβοι υψηλής πιθανότητας απάντησης. Στη συνέχεια, οι κόμβοι βαθμολογούνται και το πλήρες επερώτημα διαβιβάζεται σε όλους τους κόμβους. Δεδομένου ότι ένας κόμβος διαθέτει ελεύθερους πόρους CPU, αποφασίζει εάν θα επεξεργαστεί το επερώτημα βάσει της βαθμολογίας που έλαβε για το συγκεκριμένο επερώτημα. Είναι προφανές ότι αυτή η προσέγγιση προκαλεί αυξημένο φόρτο δικτύου, καθώς το πλήρες επερώτημα διαβιβάζεται σε όλους τους κόμβους, αντί των περισσότερα υποσχόμενων.
Τέλος, παρότι προσανατολισμένο σε διαφορετικό κλάδο, η εργασία [164] αναφέρεται στην ανάκτηση ακουστικών μουσικών δεδομένων σε ομότιμα δίκτυα. Ο κεντρικός στόχος της εργασίας αυτής είναι η καταπολέμηση της μη εξουσιοδοτημένης διάθεσης μουσικών αρχείων σε ομότιμα δίκτυα. Για να επιτύχει το στόχο αυτό, οι κόμβοι χωρίζονται σε ιεραρχικές ομάδες βάσει των πόρων τους, ενώ κάθε εργασία ανατίθεται σε πολλούς κόμβους ώστε να αντιμετωπιστεί η δυναμικότητα της συμμετοχής/αποχής κόμβων.
4.1.2 Πρότυπο ομοιότητας βασισμένο στη DTW
Η αποδοτική επεξεργασία των επερωτημάτων ομοιότητας για χρονοσειρές απαιτεί την επίλυση των ακόλουθων σημαντικών ζητημάτων:
-
•
τον ορισμό ενός σημασιολογικά ορθού μέτρου αποστάσεως ώστε να εκφραστεί η ομοιότητα μεταξύ δυο χρονοσειρών και ,
-
•
την αποδοτική αναπαράσταση των χρονοσειρών, και
-
•
την εφαρμογή ενός κατάλληλου θεσμού δεικτοδότησης ώστε να αποκλειστούν γρήγορα τα αντικείμενα της βάσης δεδομένων τα οποία δεν μπορούν να συνεισφέρουν στην τελική απάντηση.
Ένα από τα κυριότερα ερευνητικά προβλήματα των χρονοσειρών είναι ο ορισμός ενός σημασιολογικά έγκυρου μέτρου για την ομοιότητα των χρονοσειρών. Για δυο χρονοσειρές και πρέπει να οριστεί ένα μέτρο απόστασης που να εκφράζει το βαθμό της ομοιότητας μεταξύ των και . Η συνηθέστερα χρησιμοποιούμενη επιλογή είναι η Ευκλείδεια απόσταση ( norm), η οποία παρουσιάζει τον περιορισμό ότι οι δυο χρονοσειρές πρέπει να έχουν ίσο μήκος. Δεδομένου ότι οι και είναι μήκους , η Ευκλείδεια του απόσταση ορίζεται ως εξής:
| (4.1) |
όπου , είναι οι τιμές των και για την -στη χρονική στιγμή. Η Ευκλείδεια απόσταση έτυχε ιδιαίτερα μεγάλης απήχησης ως μέτρο απόστασης στη βιβλιογραφία των χρονοσειρών [117], [179], [126], [146], κυρίως λόγω της απλότητας της.
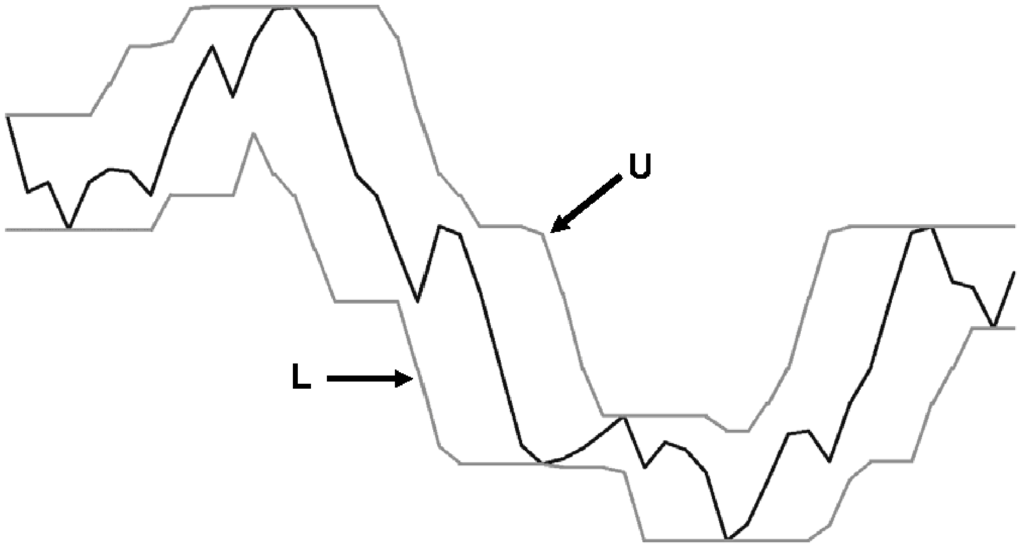
Ωστόσο, αρκετά εναλλακτικά μέτρα που να επιτρέπουν μετάφραση, περιστροφή και ανεξαρτησία κλίμακας έχουν προταθεί [118], [174], [126], [173]. Λόγου χάριν, για το παράδειγμα των χρονοσειρών του Σχήματος 4.1, παρότι οι δυο χρονοσειρές έχουν παρόμοια καμπύλη, η χρήση της Ευκλείδειας απόστασης για τη μέτρηση της ομοιότητας τους δεν θα την αποκαλύψει.
Αντιλαμβανόμενοι ότι η Ευκλείδεια απόσταση δεν καλύπτει πάντα τις απαιτήσεις των εφαρμογών, η δυναμική χρόνο-στρέβλωση (Dynamic Time Warping - DTW) προτάθηκε ως μέτρο ομοιότητας με υψηλότερη ανθεκτικότητα. Η DTW μπορεί να εκφράσει επιτυχώς την ομοιότητα χρονοσειρών ακόμα και όταν αυτές είναι εκτός φάσης στον άξονα του χρόνου ή δεν έχουν ίσο μήκος. Η απόσταση της DTW για δύο χρονοσειρές και είναι ουσιαστικά μια μέθοδος απεικόνισης της στη και τούμπαλιν. Η διαδικασία είναι επίσης γνωστή και ως ευθυγράμμιση χρονοσειρών. Για μια χρονοσειρά μήκους και μια μήκους , η απόσταση υπολογίζεται χρησιμοποιώντας την ακόλουθη μέθοδο:
-
1.
Μια μήτρα διαστάσεων κατασκευάζεται, όπου κάθε κελί στην -στη σειρά και την -στη στήλη περιέχει την απόσταση = .
-
2.
Ένα μονοπάτι στρέβλωσης ορίζεται έτσι ώστε να είναι συνεχές σύνολο κελιών της μήτρας το οποίο ορίζει μια απεικόνιση μεταξύ των στοιχείων της και των στοιχείων της .
Παρότι υφίστανται πολλά μονοπάτια στρέβλωσης τα οποία απεικονίζουν την στη , αυτό που χρειάζεται είναι να προσδιοριστεί το περισσότερο υποσχόμενο, προσπαθώντας να βελτιστοποιηθεί η αθροιστική απόσταση σε κάθε κελί του μονοπατιού στρέβλωσης. Συνεπώς, η ακόλουθη επανάληψη ορίζεται:
| (4.2) |
Το Σχήμα 4.1 δείχνει ένα παράδειγμα της ευθυγράμμισης των δύο χρονοσειρών με τη χρήση της Ευκλείδειας απόστασης (Σχήμα 4.1(a)) και με την απόσταση DTW (Σχήμα 4.1(b)). Είναι εμφανές ότι οι δυο χρονοσειρές είναι παρόμοιες παρά τη διαφορά φάσης τους. Ωστόσο, η ομοιότητά τους αυτή δεν γίνεται εμφανής με τη χρήση της Ευκλείδειας απόστασης.

Όσο αφορά τη μέθοδο DTW, το κυριότερο μειονέκτημα της είναι ότι δεν ικανοποιεί την τριγωνική ανισότητα, η οποία είναι μια ιδιαίτερα επιθυμητή ιδιότητα στο σχεδιασμό αποδοτικών θεσμών δεικτοδότησης και τη μείωση του χώρου έρευνας. Επιπλέον, ο υπολογισμός της είναι εμφανώς απαιτητικότερος επεξεργαστικά από ότι η Ευκλείδεια απόσταση . Κατά συνέπεια, μια ενδιαφέρουσα διεύθυνση για τη βελτίωση της επίδοσης της DTW είναι η χρήση ενός κάτω ορίου, με στόχο την εκμετάλλευση των θεσμών δεικτοδότησης και την αποφυγή του υπολογισμού της DTW όταν είναι δεδομένο ότι οι δυο χρονοσειρές δεν είναι όμοιες. Στην ενότητα αυτή χρησιμοποιείται το κάτω όριο που προτάθηκε στην εργασία [143]. Για μια ακολουθία , το βασίζεται στον περικλείοντα φάκελο της , ο οποίος αποτελείται από τις άνω, , και κάτω, , ακολουθίες. Για την παράμετρο (η οποία αντιπροσωπεύει την έκταση και περιορίζει το χώρο έρευνας της DTW – βλ. [143] για περισσότερες λεπτομέρειες), το -στο στοιχείο της και της ορίζονται ως εξής:
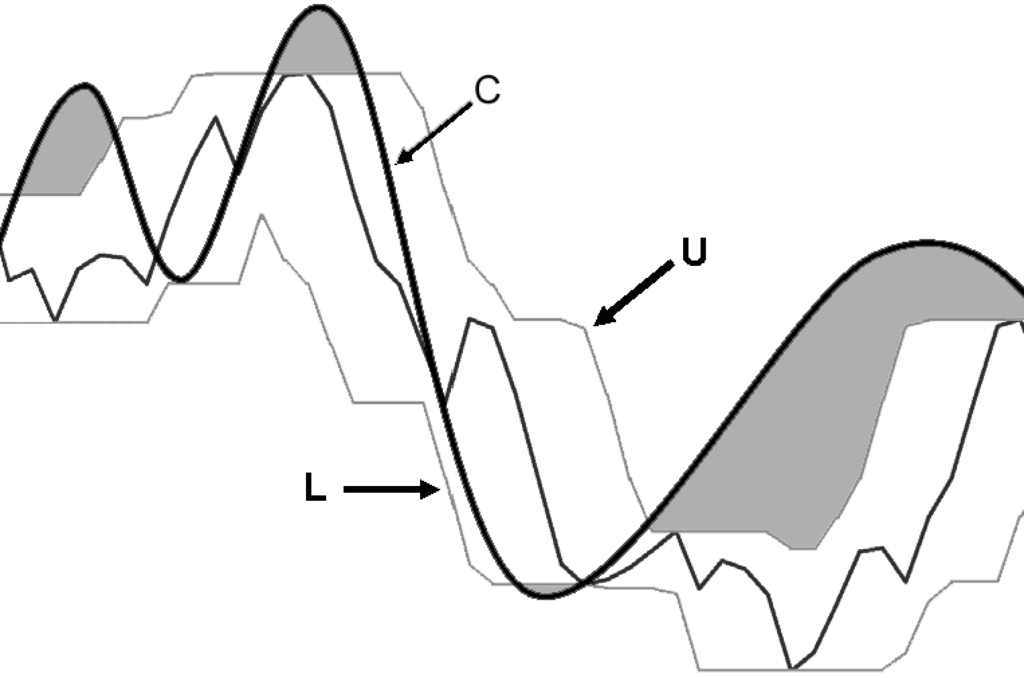
Ουσιαστικά, για κάθε , το άνω όριο βεβαιώνει ότι ενώ το κάτω ότι . Μια σχηματική απεικόνιση των και δίνεται στο Σχήμα 4.2.
Δεδομένων των και για μια ακολουθία , η τιμή του μεταξύ της και μιας ακολουθίας ορίζεται ως εξής:
| (4.3) |
Είναι προφανές ότι ο υπολογισμός του είναι γραμμικός σε σχέση με το μέγεθος των ακολουθιών αλλά και κατά πολύ γρηγορότερος από ότι ο υπολογισμός της απόστασης . Στην εργασία [143] αποδεικνύεται ότι:
και κατά συνέπεια το μπορεί να χρησιμοποιηθεί για την αφαίρεση ταιριασμάτων χωρίς να εμφανίζονται ψευδή αρνητικά αποτελέσματα. Η αποδοτικότητα του ορίου εξαρτάται από το πόσο κοντά είναι η τιμή του στην πραγματική DTW απόσταση. Ένα παράδειγμα του υπολογισμού του μεταξύ μιας ακολουθίας (αντιπροσωπεύεται από τους φακέλους και της) και μιας ακολουθίας παρουσιάζεται στο Σχήμα 4.3. Τα μέρη της τα οποία αληθώς συνεισφέρουν στο είναι εκείνα τα οποία βρίσκονται είτε πάνω από το είτε κάτω από το , και δείχνονται με γκρι χρώμα. Προφανώς, όσο περισσότερα τα μέρη αυτά, τόσο αποδοτικότερη η αφαίρεση των περιττών στοιχείων που καταφέρνει το .
4.1.3 Πλαίσιο αποτελεσματικής ανάκτησης
Επισκόπηση
Όπως ήδη αναφέρθηκε, οι αλγόριθμοι έρευνας σε ομότιμα δίκτυα βασίζονται στην ακόλουθη διαδικασία: ο κόμβος που θέτει το επερώτημα εξετάζει το δικό του περιεχόμενο και αναφέρει τα δεδομένα που ικανοποιούν το επερώτημα. Στη συνέχεια, επιλέγει ένα σύνολο των γειτονικών του κόμβων και διαδίδει το επερώτημα. Κάθε κόμβος που το λαμβάνει, με τη σειρά του εξετάζει τα τοπικά δεδομένα και προωθεί το επερώτημα σε ένα σύνολο των γειτονικών του κόμβων. Προς αποφυγή ανάμειξης απαγορευτικά μεγάλου αριθμού κόμβων, η διάδοση του επερωτήματος περιορίζεται από την παράμετρο MaxHop, η οποία καθορίζει το πλήθος των κόμβων στους οποίους το επερώτημα πρέπει να διαδοθεί.
Εξαιτίας του επιλεγμένου πρότυπου ομοιότητας, η πληροφορία που διαδίδεται μεταξύ των κόμβων αποτελείται από τις ακολουθίες και της ακολουθίας του επερωτήματος (δηλ., οι φάκελοι του επερωτήματος). Κάθε κόμβος που λαμβάνει τις ακολουθίες αυτές υπολογίζει την τιμή του LB μεταξύ των δεδομένων του και των φακέλων. Όταν η τιμή του LB είναι μικρότερη από το κατώφλι ομοιότητας που έχει θέσει ο χρήστης, τότε η πραγματική ακολουθία του επερωτήματος μεταδίδεται στον κόμβο αυτό22Το επερώτημα μπορεί να μεταδοθεί κατευθείαν από τον κόμβο που το έθεσε, εφόσον, ο τρέχων κόμβος γνωρίζει τη διεύθυνση του αρχικού. και η πραγματική DTW απόσταση υπολογίζεται μεταξύ του επερωτήματος και του αντίστοιχου δεδομένου.
Τα επερωτήματα που εξετάζονται αποτελούνται από μουσικές φράσεις, δηλαδή, τμήματα μουσικών κομματιών τα οποία αποτελούν έναν τύπο μουσικής μονάδας33Το ελάχιστου μήκους τμήμα ενός μουσικού κομματιού που είναι νοηματικά αυτόνομο και πλήρες στο μουσικό κομμάτι από το οποίο προήλθε.. Το γεγονός αυτό είναι εμφανέστερο στα επερωτήματα με σιγο-τραγούδισμα (QBH), όπου οι χρήστες τείνουν να σιγο-τραγουδούν κομμάτια τα οποία (i) είναι σχετικά μικρά, και (ii) είναι εμφανώς αναγνωρίσιμα και διαχωρισμένα σε ένα τραγούδι. Η εύρεση των μουσικών φράσεων μπορεί να γίνει χρησιμοποιώντας τη μεθοδολογία που παρουσιάζεται στην εργασία [175]. Ειδικότερα, στην [145] παρουσιάζεται ένας αλγόριθμος μετατροπής ακουστικών δεδομένων σε συμβολικά. Τα χρονικά διάκενα, τα οποία αντιστοιχούν σε φράσεις στην τονική πληροφορία, εντοπίζονται μεταξύ των στιγμών όπου εμφανίζεται σιωπή (τα αντίστοιχα διάκενα διαχωρίζουν τις φράσεις και στις ακουστικές ακολουθίες). Συνοπτικά, ενδιαφερόμαστε στην ανεύρεση μουσικών δεδομένων τα οποία περιέχουν φράσεις όμοιες με μια ακολουθία επερωτήματος. Η ομοιότητα βάσει της απόστασης DTW είναι κατάλληλη στο πλαίσιο αυτό, καθώς οι ιδιότητες της βοηθούν στην αναίρεση λαθών που το σιγο-τραγούδισμα προκαλεί.
Μια σημαντική παρατήρηση είναι ότι τα ακουστικά δεδομένα τείνουν να είναι αρκετά μεγάλα όσο αφορά τον όγκο τους σε σχέση με τα συνήθη δεδομένα των ομότιμων δικτύων. Παρότι τα επερωτήματα αποτελούνται από μουσικές φράσεις (δηλ, τμήματα των μουσικών ακολουθιών), το πλήθος των στοιχείων σε μια φράση λίγων δευτερολέπτων μπορεί να είναι της τάξης των εκατοντάδων χιλιάδων. Το μήκος των ακολουθιών και είναι ίσο με το μήκος του επερωτήματος. Κατά συνέπεια, η άμεση προσέγγιση, που απευθείας διαδίδει τις ακολουθίες και μεταξύ των κόμβων, οδηγεί σε υπερβολικά μεγάλο φόρτο δικτύου. Επιπλέον, όταν το μήκος των ακολουθιών φακέλου είναι μεγάλο, ο υπολογισμός του LB σε κάθε κόμβο μπορεί να αποβεί ιδιαίτερα δαπανηρός. Οι συνέπειες αυτές παραβιάζουν τους περιορισμούς των ομότιμων δικτύων για όσο το δυνατό λιγότερη επεξεργαστική επιβάρυνση των κόμβων. Εδώ πρέπει να σημειωθεί ότι οι προαναφερμένοι περιορισμοί δεν υφίστανται σε διαφορετικά πεδία, όπως η έρευνα όμοιων δεδομένων κειμένου σε ομότιμα δίκτυα όπου τα επερωτήματα αποτελούνται από μερικές δεκάδες στοιχεία.
Ακολούθως, παρουσιάζεται μια μέθοδος που αντιμετωπίζει τα δυο προβλήματα και επιτυγχάνει σημαντική μείωση του φόρτου του ομότιμου δικτύου κατά τη διάρκεια ενός μουσικού επερωτήματος βάσει περιεχομένου. Η μέθοδος λειτουργεί ως εξής:
-
•
Μειώνει το μήκος των ακολουθιών φακέλου εφαρμόζοντας σε αυτές δειγματοληψία. Ωστόσο, η απλή δειγματοληψία μπορεί να μην αποδειχθεί αποδοτική, καθώς οδηγεί σε υποτίμηση του LB. Κατά συνέπεια, παρουσιάζεται μια μέθοδος δειγματοληψίας με στόχο τη μείωση του μήκους των ακολουθιών χωρίς σημαντική επιρροή στον υπολογισμό του LB. Επιπλέον, η μέθοδος εστιάζει στην αποφυγή εισαγωγής ψευδών αρνητικών ταιριασμάτων εξαιτίας της χρήσης της δειγματοληψίας.
-
•
Χρησιμοποιεί (οποτεδήποτε είναι εφικτό) μια συμπιεσμένη αναπαράσταση των δειγματισμένων ακολουθιών του φακέλου. Η αναπαράσταση αυτή αποτελεί ένα είδος συμπίεσης για τις ακολουθίες, ωστόσο, δεν επιβάλλει επιπλέον εργασιακό φόρτο στους κόμβους του ομότιμου δικτύου απαιτώντας αποσυμπίεση. Όμως, εάν το φόρτος αποσυμπίεσης δεν αποτελεί κώλυμα, επιπλέον συμπίεση είναι δυνατή με τη χρήση ήδη υπαρκτών μεθόδων44Η κατεύθυνση αυτή δεν εξετάζεται καθώς δεν επηρεάζει τη σχετική απόδοση των μεθοδολογιών..
Στη συνέχεια, περιγράφονται τα προαναφερθέντα πλήρη λεπτομερειών.
Μέθοδοι δειγματοληψίας και αναπαράστασης
Έστω ότι το μήκος της εξεταζόμενης φράσης είναι . Το μήκος κάθε επερωτήματος και κατά συνέπεια των άνω () και κάτω () ακολουθιών θα είναι επίσης . Πρέπει να δειγματιστούν οι και έτσι ώστε να καταλήξουν σε δυο ακολουθίες και , κάθε μία από τις οποίες θα είναι μήκους . Αρχικά, εξετάζεται η ομοιόμορφη δειγματοληψία. Στην περίπτωση αυτή, απλά επιλέγεται κάθε φορά το -στο στοιχείο της και , όπου . Όταν υπολογίζεται το LB_Keogh μεταξύ της ακολουθίας επερωτήματος και μιας ακολουθίας δεδομένων, θεωρείται κάθε φράση μήκους στο . Κάθε φράση πρέπει να δειγματιστεί όμοια με τις και , δίνοντας τη δειγματισμένη φράση . Συνεπώς, το κάτω όριο υπολογίζεται ως εξής:
| (4.4) |
Στην εξίσωση αυτή, η τρίτη περίπτωση (δηλ., όταν ) δεν συνεισφέρει στον υπολογισμό του . Το πρόβλημα που παρουσιάζει η ομοιόμορφη δειγματοληψία είναι ότι, καθώς επιλέγει στοιχεία χωρίς κάποιο ιδιαίτερο κριτήριο, επιλέγει πολλά στοιχεία των και τα οποία οδηγούν στην τρίτη αυτή περίπτωση. Συνεπώς, το υπολογίζεται ιδιαίτερα υποτιμημένο σε σύγκριση με την περίπτωση δίχως δειγματοληψία. Η υποτίμηση της τιμής του κάτω ορίου έχει ως αποτέλεσμα την αύξηση των ψευδών ταιριασμάτων, οι οποίοι προκαλούν αυξημένο φόρτο δικτύου.
Για την αντιμετώπιση του προβλήματος αυτού, απαιτείται μια εναλλακτική μέθοδος δειγματοληψίας. Δειγματίζονται οι και ξεχωριστά. Αρχικά, ταξινομούνται τα στοιχεία της σε αύξουσα διάταξη. Για την επιλέγονται τα πρώτα στοιχεία της διάταξης αυτής. Αντίστοιχα, ταξινομείται η σε φθίνουσα διάταξη και επιλέγονται τα πρώτα στοιχεία της για την . Διαισθητικά, η επιλογή των μικρότερων τιμών της , οδηγεί στην αύξηση των εμφανίσεων της πρώτης περίπτωσης (δηλ., όταν ), εφόσον όσο μικρότερες είναι οι τιμές της , τόσο περισσότερο είναι αναμενόμενο να υφίσταται ένα μεγαλύτερο. Χρησιμοποιώντας συμβατική φρασεολογία, στόχος είναι η αύξηση της δειγματοληψίας από τις "γκρίζες" περιοχές (βλ. Σχήμα 4.3 της ενότητας 4.1.2). Ανάλογη μέθοδος εφαρμόζεται και για τη δειγματοληψία της .
Είναι, κατά συνέπεια, εμφανή τα εξής:
ΛΗΜΜΑ 4.1.
Η δειγματοληψία των και δεν προκαλεί ψευδή αρνητικά ταιριάσματα.
Απόδειξη. Υπολογίζοντας το , εξαιτίας της δειγματοληψίας, οι δυο πρώτες περιπτώσεις της Εξίσωσης 4.4 παρουσιάζονται σπανιότερα από ότι κατά τον υπολογισμό του (δηλ., χωρίς δειγματοληψία). Συνεπώς, . Εφόσον (όπου είναι η αντικειμενική απόσταση, υπολογισμένη με τη χρήση της DTW), συνεπάγεται ότι . Έτσι, δεν προκαλούνται ψευδή αρνητικά.
Η ξεχωριστή δειγματοληψία των και παρουσιάζει την αναγκαιότητα για αποθήκευση των θέσεων από τις οποίες τα στοιχεία επιλέχθηκαν για τις και . Εάν οι θέσεις αποθηκευτούν ρητά, τότε διπλασιάζεται ο όγκος της πληροφορίας που διατηρείται ( στοιχείων για την αποθήκευση των και , και επιπλέον στοιχεία για την αποθήκευση των θέσεων των επιλεγμένων στοιχείων). Καθώς οι πληροφορίες αυτές μεταδίδονται κατά το επερώτημα, αυξάνεται ο φόρτος του δικτύου, για την αποφυγή του οποίου προτείνεται μια εναλλακτική αναπαράσταση. Για την αναπαράσταση της , χρησιμοποιείται ένα πίνακας bit μήκους (ίσο με το μήκος της φράσης). Κάθε bit αντιστοιχεί σε ένα στοιχείο της . Για κάθε στοιχείο που επιλέγεται για το δειγματισμό στην , το bit του γίνεται ίσο με τη μονάδα, ενώ εναλλακτικά έχει μηδενική τιμή. Κατά συνέπεια, για την αναπαράσταση της χρησιμοποιούνται ο συνδυασμός του πίνακα bit και οι τιμές που επιλέχθηκαν για την . Όμοια μέθοδος χρησιμοποιείται και για την . Η αποδοτικότητα της αναπαράστασης γίνεται εμφανής από το χώρο που απαιτεί για την ο οποίος είναι bytes.55Κάθε στοιχείο μιας ακουστική μουσικής ακολουθίας, για την αναπαράσταση MIDI, έχει τιμή στο διάστημα 0-255, και συνεπώς απαιτεί μόνο ένα byte. Η απλοϊκή αναπαράσταση απαιτεί bytes (καθώς χρειάζεται μόνο ένα ακέραιο, δηλ., 4 bytes, για την αποθήκευση τη θέση κάθε επιλεγμένου στοιχείου). Κατά συνέπεια, η μέθοδος αυτή πλεονεκτεί όταν , δηλ., για δείγματα μεγαλύτερα από 3%.
4.1.4 Αλγόριθμοι εύρεσης ομοιότητας
Στην ενότητα αυτή παρουσιάζεται η μεθοδολογία με την οποία ήδη υπαρκτοί αλγόριθμοι αναζήτησης ομότιμων δικτύων μπορούν να χρησιμοποιηθούν στο πλαίσιο αποτελεσματικής ανάκτησης μουσικής πληροφορίας βάσει περιεχομένου. Οι υπαρκτοί αλγόριθμοι προτάθηκαν, κυρίως, για την αναζήτηση δεδομένων κειμένου όμοιων με ένα επερώτημα κειμένου. Συνεπώς, η άμεση εφαρμογή τους για την αναζήτηση μουσικών δεδομένων δεν θα εξέταζε το σημαντικά μεγαλύτερο όγκο των μουσικών δεδομένων οδηγώντας σε υπερβολικό φόρτο δικτύου. Ακολούθως, εξετάζεται η μετατροπή των αλγόριθμων BFS, RES και ISM.
Ο αλγόριθμος BFSS
Όπως ήδη περιγράφθηκε, ο απλούστερος αλγόριθμος αναζήτησης είναι βάσει της έρευνας με προτεραιότητα πλάτους. Ο προσαρμοσμένος αλγόριθμος, που χρησιμοποιεί την προαναφερθείσα δειγματοληψία και μέθοδο αναπαράστασης, ονομάζεται BFSS (Breadth-First-Search with Sampling). Ο ψευδο-κώδικας του BFSS δίνεται στο Σχήμα 4.4. Κάθε φορά, εξετάζεται ο τρέχων κόμβος . Η μεταβλητή TTL υποδηλώνει τις διαθέσιμες επανεκπομπές που διαθέτει ο , ενώ, η είναι το κατώφλι ομοιότητας που έθεσε ο χρήστης. Θεωρούμε πως οι ακολουθίες και επίσης μεταφέρουν και τους αντίστοιχους πίνακες bit.
Προφανώς, η διάδοση της πραγματικής ακολουθίας επερωτήματος από τον κόμβο που ξεκίνησε το επερώτημα στον τρέχων κόμβο, αυξάνει το φόρτο του δικτύου (καθώς το επερώτημα δεν έχει υποστεί δειγματοληψία, η ακολουθία επερωτήματος έχει πολύ μεγάλο μήκος). Για το λόγο αυτό, είναι ιδιαίτερα σημαντικό να εμφανίζεται μικρός αριθμός ψευδών ταιριασμάτων.
Είναι πιθανό ότι η έκδοση του αλγορίθμου που δεν περιλαμβάνει δειγματοληψία (ονομασμένη ως BFS) θα προκαλέσει μικρότερο αριθμό ψευδών ταιριασμάτων, ωστόσο, μεταξύ κάθε ζευγαριού κόμβων πρέπει να διαβιβαστούν οι ακολουθίες και , με μήκος ίσο της ακολουθίας επερωτήματος. Είναι λοιπόν εμφανές, ότι υφίσταται μια αντιστάθμιση μεταξύ του πλήθους των επιπλέον ψευδών ταιριασμάτων που προκαλούνται από τη δειγματοληψία και της μείωση του φόρτου δικτύου από τη μετάδοση των δειγματισμένων (δηλ., μικρότερων) φακέλων.
Ο αλγόριθμος RESS
Ο αλγόριθμος RESS προσπαθεί να μειώσει το πλήθος των μονοπατιών τα οποία εξετάζονται κατά τη διάρκεια της αναζήτησης. Αντί της τυχαίας επιλογής ενός υποσυνόλου των γειτονικών κόμβων του τρέχοντος κόμβου, διατηρεί μια κατατομή για κάθε τέτοιο κόμβο και βασίζει την επιλογή του στην κατατομή αυτή. Ειδικότερα, κάθε κόμβος διατηρεί για καθένα από τους γειτονικούς του κόμβους το πλήθος των θετικών αποτελεσμάτων που έδωσε. Στη συνέχεια, επιλέγει τους κόμβους που έδωσαν τις περισσότερες απαντήσεις κατά τη διάρκεια των τελευταίων επερωτημάτων. Οι μεταβλητές και ορίζονται από το χρήστη.
Είναι προφανές ότι ο αλγόριθμος RES μπορεί εύκολα να προσαρμοστεί στο πλαίσιο αποτελεσματικής ανάκτησης. Η ακολουθία επερωτήματος θα δειγματιστεί και θα αναπαρασταθεί σύμφωνα με την προαναφερθείσα μέθοδο. Οι δυο μεταβολές αυτές δεν επηρεάζουν τις κατατομές που διατηρεί ο RES. Η μέθοδος που προκύπτει ονομάζεται RESS (RES with sampling). Ο ψευδο-κώδικας της μεθόδου RESS δίνεται στο Σχήμα 4.5.
Καθώς μόνο ένα υποσύνολο των κόμβων εμπλέκονται στη διαδικασία, ο RESS προσπαθεί να μειώσει το φόρτο δικτύου αποφεύγοντας να χάσει μεγάλο αριθμό απαντήσεων. Ωστόσο, συγκρινόμενος με τον BFSS, ο RESS αναμένεται να εντοπίσει λιγότερες απαντήσεις.
Ο αλγόριθμος ISMS
Ο αλγόριθμος ISM έχει τον ίδιο στόχο με τον RES, δηλ., προσπαθεί να μειώσει το πλήθος των εξεταζόμενων μονοπατιών. Ωστόσο, η κατατομή που διατηρεί για κάθε κόμβο είναι διαφορετική. Ο ISM δεν βασίζει την απόφαση του μόνο στον αριθμό των απαντήσεων των προηγουμένων επερωτημάτων, αλλά επίσης εξετάζει την ομοιότητα μεταξύ των προηγούμενων επερωτημάτων και του τρέχοντος. Κατά συνέπεια, για κάθε γειτονικό κόμβο, κάθε κόμβος διατηρεί τα t πιο πρόσφατα επερωτήματα που απαντήθηκαν. Όταν ένα νέο επερώτημα διαβιβαστεί στον κόμβο, τότε υπολογίζεται η ομοιότητα του Qsim με όλα τα επερωτήματα που διατηρούνται στην κατατομή κάθε κόμβου. Ένα μέτρο βαθμολόγησης σχετικότητας δίνεται σε κάθε κόμβο , χρησιμοποιώντας τον ακόλουθο τύπο:
όπου S(P,q) είναι το πλήθος των αποτελεσμάτων που επέστρεψε ο P για το επερώτημα q. Συνεπώς, ο ISM βαθμολογεί υψηλότερα τους γειτονικούς κόμβους που επιστρέφουν περισσότερα αποτελέσματα με τη ρύθμιση της παραμέτρου . Για να γίνει η σύγκριση περισσότερο κατανοητή, ορίζεται η ίση με τη μονάδα, και κατά συνέπεια το μέτρο εστιάζει μόνο στο κριτήριο της ομοιότητας. Πρέπει επίσης να επισημανθεί ότι ο ISM είναι πιθανό να παρουσιάσει μια προδιάθεση προς τους κόμβους οι οποίοι απάντησαν επερωτήματα περίπου όμοια, στο παρελθόν, μη δίνοντας έτσι την ευκαιρία σε νέους κόμβους να εξερευνηθούν. Για το λόγο αυτό, η ακόλουθη ευρεστική μέθοδος, όπως εφαρμόζεται και στην εργασία [137], ακολουθείται: εκτός των επιλεγμένων κόμβων βάσει των προαναφερθέντων κριτηρίων, ο ISM επίσης επιλέγει τυχαία ένα επιπλέον μικρό σύνολο κόμβων (λ.χ., ένα κόμβο). Συνολικά, κόμβοι επιλέγονται, όπου η παράμετρος ορίζεται από το χρήστη. Το μήκος κάθε κατατομής (ο αριθμός των επερωτημάτων που διατηρούνται στις κατατομές) ορίζεται επίσης από το χρήστη.
Για την προσαρμογή του ISM στο πλαίσιο αποτελεσματικής ανάκτησης, πρέπει να εξετάστεί το πώς θα διατηρηθούν τα προηγούμενα επερωτήματα. Στο πλαίσιο αυτό, οι ακολουθίες επερωτημάτων αναπαρίστανται από τις δειγματισμένες ακολουθίες τους. Συνεπώς, υπολογίζεται η ομοιότητα μεταξύ του δείγματος του τρέχοντος επερωτήματος και των δειγματισμένων ακολουθιών των προηγούμενων απαντημένων επερωτημάτων. Για το λόγο αυτό, στις κατατομές των κόμβων διατηρούνται οι δειγματισμένες ακολουθίες των απαντημένων επερωτημάτων. Για την εξοικονόμηση χρόνου κατά τη διάρκεια της βαθμολόγησης, αντί για τη μέτρηση της πραγματικής ομοιότητας (με τη χρήση του μέτρου DTW), υπολογίζεται το . Ο αλγόριθμος που προκύπτει ονομάζεται ISMS (ISM with sampling), ενώ ο ψευδο-κώδικας του αλγορίθμου δίνεται στο Σχήμα 4.6.
Ο ISMS αναμένεται να έχει ελαφρά μεγαλύτερο φόρτο δικτύου από ότι ο RESS εφόσον μεταδίδει τη δειγματισμένη ακολουθία των απαντημένων επερωτημάτων σε όλους τους κόμβους που συμμετέχουν στην έρευνα (ώστε να ενημερώσουν την κατατομή τους). Ωστόσο, ελέγχοντας το περιεχόμενο των επερωτημάτων, προσπαθεί να μειώσει τον αριθμό των χαμένων απαντήσεων.
4.2 Ασύρματα δίκτυα
4.2.1 Η μουσική διάθεση υιοθετεί ένα νέο πρότυπο
Φανταστείτε να ακούτε μουσική ενώ τρέχετε ή ξεκουράζεστε σε ένα άλσος από μια υπερ-συσκευή που να χωρά στην τσέπη και να είναι πολύ ελαφριά. Μια συσκευή η οποία, εκτός της δεδομένης ικανότητας να αναπαράγει προαποθηκευμένη μουσική (τύπου MP3, WMA, WAV κλπ.) σε περιοχές όπου δεν καλύπτονται από ασύρματα τοπικά δίκτυα, μπορεί επίσης να αναζητήσει και να αποκτήσει μουσικά κομμάτια από άλλες παρεμφερείς συσκευές. Η ανταλλαγή αυτή των μουσικών δεδομένων είναι εφικτή απουσία πρόσβασης στο διαδίκτυκο μέσω της διέπαφής ασύρματης επικοινωνίας της συσκευής η οποία επιτρέπει τη συμμετοχή της σε Ασύρματα Αd-hoc66Ο όρος ad-hoc δεν έχει δόκιμο αντίστοιχο στην Ελληνική γλώσσα και για το λόγο αυτό παραμένει στην Αγγλική. Στο παρόν ενέχει σημασία "μη ρητά δομημένο". Δίκτυα (ΑΑΔ), τα οποία σχηματίζονται από όμοιες συσκευές όταν βρίσκονται σε κοντινή απόσταση. Παρότι τα προαναφερθέντα γεγονότα μπορεί να ακούγονται πιθανά μόνο στο μέλλον, στην πραγματικότητα η υλοποίηση τους είναι πολύ κοντά.
Έχοντας ήδη πλησιάσει το τέλος εποχής των παραδοσιακών μεθόδων διάθεσης της μουσικής [161], το εμπορικό πρότυπο αλλά και οι αγοραστικές συνήθειες των καταναλωτών αναμορφώθηκαν από την ανάπτυξη τεχνολογιών όπως το MP3 και τη διείσδυση του Παγκόσμιου Ιστού (WWW). Τα ομότιμα δίκτυα καθώς και η πλέον ώριμη τεχνολογία κατανεμημένης διάθεσης αρχείων, δίνουν τη δυνατότητα διάδοσης μουσικού περιεχομένου σε ψηφιακή μορφή, επιτρέποντας στους καταναλωτές μια "πανταχού παρούσα" πρόσβαση σε αποθηκευμένα μουσικά αρχεία.
Ολοκαίνουργιες ευκαιρίες για τη διάθεση της μουσικής δημιουργεί επιπλέον και η ευρύτατη διείσδυση των ασύρματων δικτύων (ασύρματα τοπικά δίκτυα, GPRS, UMTS [128]) όπως οι πρωτοπόρες εφαρμογές [163] διανομής ψηφιοποιημένων τραγουδιών σε φορητές συσκευές. Οι εφαρμογές αυτές βασίζονται στην ύπαρξη ενός κεντρικού εξυπηρετητή, ο οποίος λαμβάνει τα αιτήματα από τους ασύρματους πελάτες και τους παραδίδει μουσικά αρχεία. Ωστόσο, εκτός αυτών των ενός επιπέδου διάρθρωσης ασύρματων δικτύων, η διάθεση μουσικής μπορεί επίσης να πραγματοποιηθεί και στα αναπτυσσόμενα ΑΑΔ. Τα ΑΑΔ είναι ομότιμα, πολυεπίπεδα, κινητά, ασύρματα δίκτυα όπου τα πακέτα πληροφορίας εκπέμπονται με τη μέθοδο “store-and-forward” από τον πομπό στον αποδέκτη, μέσω ενδιάμεσων κόμβων. Τα δίκτυα αυτά αναμένονται να επιτρέψουν σε υποθέσεις όπως αυτό με το πάρκο που αναφέρθηκε στην αρχή της ενότητας αυτής. Τα κύρια χαρακτηριστικά των δικτύων αυτών, λ.χ., δυναμική τοπολογία, συνδέσεις επικοινωνίας περιορισμένου εύρους ζώνης και περιορισμένοι διαθέσιμοι πόροι εισάγουν ιδιαίτερες σχεδιαστικές προκλήσεις.
Η ενότητα αυτή εστιάζει στο ακόλουθο πρόβλημα: Έστω ένα πλήθος κινητών ξενιστών (Mobile Hosts - MH) οι οποίοι συμμετέχουν σε ένα ΑΑΔ, όπου κάθε ξενιστής μπορεί να φιλοξενεί μια πληθώρα μουσικών ακουστικών κομματιών. Έστω ότι ένας χρήστης επιθυμεί να ερευνήσει το ασύρματο δίκτυο για τραγούδια όμοια με ένα που διαθέτει. Για παράδειγμα, ο χρήστης μπορεί να δώσει ένα πολύ μικρό κομμάτι τραγουδιού (ένα απόσπασμα) και να ερευνήσει το δίκτυο για να βρει κόμβους που έχουν αποθηκευμένα όμοια μουσικά κομμάτια. Όπως θα περιγραφεί στη συνέχεια, ο ορισμός της ομοιότητας μπορεί να βασιστεί σε διάφορα χαρακτηριστικά τα οποία έχουν αναπτυχθεί για ΑΜΠΒΠ. Είναι σημαντικό να σημειωθεί ότι στο τρέχον σενάριο ο ξενιστής που θέτει το επερώτημα δεν έχει πρότερη γνώση ούτε των κατάλληλων μουσικών κομματιών που διαθέτει το δίκτυο αλλά και ούτε την τοποθεσία των ξενιστών που τα περιέχουν. Το γεγονός αυτό διαφοροποιεί το παρόν πρόβλημα από τα προβλήματα που αντιμετωπίζουν τον εντοπισμό των ξενιστών σε ένα ΑΑΔ που περιέχουν γνωστά δεδομένα. Επιπλέον, το εξεταζόμενο πρόβλημα είναι συμπληρωματικό του προβλήματος διάθεσης πολυμεσικών ροών δεδομένων σε ΑΑΔ, καθώς στην περίπτωση αυτή δεν περιέχεται αναζήτηση όμοιων μουσικών κομματιών, παρά μόνο εστιάζει στην μεταφορά των δεδομένων από τον ένα ξενιστή στον άλλο.
Απαιτήσεις που ορίζονται από το ασύρματο μέσο
Η έρευνα αυτή εστιάζει στην ανάπτυξη μεθόδων για αναζήτηση ακουστικής μουσικής βάσει περιεχομένου σε ΑΑΔ, όπου ο κόμβος που θέτει το επερώτημα λαμβάνει μουσικά αποσπάσματα τα οποία ταιριάζουν με το επερώτημα.
Η διαδικασία έρευνας μπορεί να εκμεταλλευτεί τις πρόσφατες προσεγγίσεις για ΑΜΠΒΠ σε ενσύρματα ομότιμα δίκτυα (βλ. ενότητα 4.2.2. Ωστόσο, ο συνδυασμός των χαρακτηριστικών του ασύρματου δικτύου και των ακουστικών μουσικών δεδομένων θέτουν νέες προκλητικές απαιτήσεις, οι οποίες απαιτούν και αντίστοιχες λύσεις:
-
1.
Οι μέθοδοι ΑΜΠΒΠ για ενσύρματα ομότιμα δίκτυα δεν εξετάζουν τη διαρκή μεταβολή της τοπολογίας του δικτύου, η οποία είναι εγγενής στα ΑΑΔ καθώς οι ασύρματοι ξενιστές (Mobile Hosts - MH, οι όροι MH και κόμβος είναι όμοιοι στην παρούσα ενότητα και κατά συνέπεια εναλλασσόμενοι) κινούνται εντός και εκτός του πεδίου των άλλων διαρκώς. Μια συνέπεια της κινητικότητας αυτής είναι ότι η επιλεκτική διάδοση ενός επερωτήματος σε MH, λ.χ., χρησιμοποιώντας μια δομή δεικτοδότησης όπως η DHT77Distributed Hash Tables. Στα συστήματα αυτά κάθε κόμβος αναλαμβάνει μια περιοχή σε ένα εικονικό χώρο διευθύνσεων, ενώ σε κάθε μοιραζόμενο δεδομένο ανατίθεται μια τιμή από το χώρο αυτό. [120] όπως προτείνεται από την εργασία [166] ή η διαδικασία caching88Ο όρος caching δεν έχει δόκιμο αντίστοιχο στην Ελληνική γλώσσα και για το λόγο αυτό παραμένει στο κείμενο στην Αγγλική. Στο παρόν έχει σημασία "αποθήκευσης". προηγούμενων επερωτημάτων ([137] για δεδομένα κειμένου και [140] μουσικά δεδομένα), δεν είναι δυνατή. Επιπλέον, η ανάκληση της διαδικασίας έρευνας επηρεάζεται από την πιθανότητα ανεπιτυχούς δρομολόγησης του επερωτήματος, αλλά και των απαντήσεων, λόγω της μεταβαλλόμενης τοπολογίας. Συνεπώς, απαιτείται ανάπτυξη κατάλληλων μεθόδων μετάδοσης του επερωτήματος στα ΑΑΔ.
-
2.
Μείωση του φόρτου δικτύου που βασίζεται στο μέγεθος των ακουστικών μουσικών δεδομένων (περίπου 8 mebibytes για 3 λεπτά επερωτήματος). Η μείωση αυτή είναι εφικτή αντικαθιστώντας το αρχικό επερώτημα με μια νέα αναπαράσταση η οποία χρησιμοποιεί μια καινούργια κατάλληλη μέθοδο μεταβολής μήκους του επερωτήματος. Παρότι ο φόρτος δικτύου επηρεάζει την ΑΜΠΒΠ σε ενσύρματα ομότιμα δίκτυα επίσης, το αίτημα μείωσης του φόρτου δικτύου στα ΑΑΔ είναι ιδιαίτερα πιο έντονο, καθώς η επικοινωνιακή ικανότητα περιορίζεται λόγω της συνήθως μικρότερης διαμεταγωγής των ασύρματων συνδέσεων. Στο σημείο αυτό είναι σημαντικό να αναφερθεί ότι η μείωση του φόρτου του δικτύου μειώνει επίσης και την ανάμειξη των άλλων MH, εξαιτίας περιορισμών στη χρήση των πόρων τους (λ.χ. επεξεργαστική ισχύ, αυτονομία, διαμεταγωγή).
-
3.
Στην ΑΜΠΒΠ σε ενσύρματα ομότιμα δίκτυα, μετά τον εντοπισμό ενός ταιριάσματος, μπορεί να επιστραφεί στον κόμβο που έθεσε το επερώτημα απευθείας, καθώς ο ερωτών κόμβος είναι άμεσα προσβάσιμος (μέσω της διεύθυνσης IP του). Σε αντίθεση, στα ΑΑΔ οι απαντήσεις του επερωτήματος πρέπει να μεταδοθούν στον ερωτώντα ξενιστή μέσω του δικτύου (ο κόμβος που έθεσε το επερώτημα δεν είναι άμεσα προσβάσιμος). Το αίτημα αυτό επιβαρύνει επιπλέον το φόρτο του δικτύου, απαιτώντας βελτιστοποίηση.
Τα προαναφερθέντα θέματα αντιμετωπίζονται, έως ένα βαθμό, από αλγόριθμους που προτάθηκαν για το πρόβλημα δρομολόγησης σε ΑΑΔ, παρότι δεν αντιμετωπίζουν ούτε τις ιδιαιτερότητες της έρευνας για ΑΜΠΒΠ ούτε το μέγεθος των μεταδιδόμενων δεδομένων, καθώς τα μουσικά δεδομένα είναι σημαντικά μεγαλύτερα από ότι τα συνήθη πακέτα.
Για την αντιμετώπιση των αιτημάτων που θέτει το ασύρματο μέσο, παρουσιάζονται οι ακόλουθες τεχνικές:
-
1.
Για το πρώτο αίτημα, εκτελείται μια έρευνα με προτεραιότητα πλάτους στο ΑΑΔ χρησιμοποιώντας πληροφορίες για τους γειτονικούς MH (τις πληροφορίες για τους γειτονικούς κόμβους τις αποκτά κάθε κόμβος εξετάζοντας τους γείτονες του ανά χρονικά διαστήματα). Η προσέγγιση αυτή αντιμετωπίζει επιτυχώς την κινητικότητα, διατηρεί υψηλή τελική ανάκληση και περιορίζει τα μειονεκτήματα της μεθόδου πλημμυρίσματος, λ.χ., υπερβολικός φόρτος δικτύου εξαιτίας καθολικών εκπομπών99Περιγράφεται στην ενότητα 4.2.2. (broadcast).
-
2.
Το δεύτερο αίτημα αντιμετωπίζεται με μια τεχνική που χρησιμοποιεί μια συνοπτική, βασισμένη σε χαρακτηριστικά αναπαράσταση του επερωτήματος με μειούμενο μέγεθος. Η Αναπαράσταση του Επερωτήματος με το Μειούμενο Μέγεθος (ΑΕΜΜ) μειώνει δραστικά το φόρτο του δικτύου, μειώνοντας επίσης και τον επεξεργαστικό φόρτο σε κάθε MH.
-
3.
Ο επιπλέον φόρτος δικτύου που προκαλεί το τρίτο αίτημα αντιμετωπίζεται με μια διπλή μέθοδο: (i) χρήση πολιτικών για τον περιορισμό του πλήθους των MH που αναμειγνύονται στην μετάδοση των απαντήσεων, εκμεταλλευόμενοι MH που συμμετείχαν στην διάδοση του επερωτήματος, (ii) επιτρέπεται σε τέτοιους MH να μειώσουν την μετάδοση των απαντήσεων, βασιζόμενοι σε μια ιδιότητα της προαναφερθείσας αναπαράστασης.
4.2.2 Γενικές γνώσεις και σχετικές εργασίες
Η σχετική έρευνα σε εφαρμογές ΑΜΠΒΠ σε ενσύρματα ομότιμα δίκτυα είναι αρκετά πρόσφατη και περιορισμένη όπως παρουσιάστηκε στην ενότητα 4.2.2.
Στην παρούσα ενότητα, αντιμετωπίζεται ένα ΑΑΔ όπου δυο κόμβοι επικοινωνούν μόνο όταν βρίσκονται σε φυσική εγγύτητα (εντός πεδίου). Όπως περιγράφτηκε ήδη, στα δίκτυα αυτού του τύπου οι κόμβοι συμμετέχουν τυχαία και για, συνήθως, μικρό χρονικό διάστημα λόγω της κινητικότητάς τους, ενώ όταν συμμετέχουν αλλάζουν συχνά την τοποθεσία τους. Οι παράγοντες αυτοί κάνουν τις υπαρκτές μεθόδους, λ.χ., δεικτοδότησης, να μην είναι εφαρμόσιμες.
Ανεύρεση/Παροχή πληροφορίας σε ΑΑΔ
Όπως προαναφέρθηκε, ένα κινητό ΑΔΔ (MANET) είναι μια συλλογή ασύρματων MH οι οποίοι σχηματίζουν ένα προσωρινό δίκτυο χωρίς τη βοήθεια κεντρικής διαχείρισης ή δεδομένων υπηρεσιών υποστήριξη που να είναι τακτικά διαθέσιμες στο ευρύτερο δίκτυο, στο οποίο οι ξενιστές είναι συνήθως συνδεδεμένοι. Όταν ένας κόμβος πηγή επιθυμεί να στείλει ένα μήνυμα σε ένα κόμβο προορισμό και δεν έχει ένα ισχύοντα δρόμο/μονοπάτι προς στον κόμβο προορισμό, αρχίζει μια διαδικασία ανεύρεσης μονοπατιού ώστε να εντοπίσει τον προορισμό. Εκπέμπει καθολικά αίτημα ανεύρεσης δρόμου στους γειτονικούς του κόμβους, το οποίο εκείνοι το προωθούν στους γειτονικούς τους κ.ο.κ. μέχρι ο κόμβος προορισμός ή κάποιος ενδιάμεσος κόμβος με δρόμο στον προορισμό να εντοπιστεί. Οι κόμβοι εντοπίζονται από τη διεύθυνση τους και διατηρούν μια ταυτότητα εκπομπής η οποία αυξάνεται μετά από κάθε αίτημα ανεύρεσης δρόμου που ξεκινούν. Η ταυτότητα εκπομπής συνδυασμένη με τη διεύθυνση, προσδιορίζει μοναδικά μια αίτηση ανεύρεσης δρόμου. Παρόμοια, οι αιτήσεις δεδομένων που εκπέμφθηκαν μπορούν να προσδιοριστούν.
Στα δίκτυα τύπου MANET δεν υπάρχει εκτεταμένη προηγούμενη ερευνητική εργασία για ΑΜΠΒΠ, παρότι υφίσταται μια πληθώρα αλγορίθμων δρομολόγησης, εκτός των [138], [141] στις και οποίες βασίζεται η παρούσα ενότητα.
Οι αλγόριθμοι δρομολόγησης για τα δίκτυα MANET είναι ριζικά διαφορετικοί από ότι στα παραδοσιακά πρωτόκολλα δρομολόγησης (λ.χ., προτεραιότητα συντομότερου ανοικτού μονοπατιού) και τα πρωτόκολλα εύρεσης πληροφορίας (λ.χ., κατανεμημένους πίνακες κατακερματισμού) που χρησιμοποιούνται σε ενσύρματα δίκτυα, εξαιτίας της απουσίας σταθερής υποδομής (εξυπηρετητές, σημεία πρόσβασης, δρομολογητές και καλώδια) στα MANET αλλά και της κινητικότητας των κόμβων. Για τα ΑΑΔ, προτάθηκαν [116] αρκετά πρωτόκολλα δρομολόγησης/ανεύρεσης που κατά προσέγγιση εμπίπτουν στις ακόλουθες κατηγορίες: α) βάσει πίνακα, β) κατά απαίτηση που ξεκινούν από την πηγή και γ) υβριδικά. Εκτός των πρώτων, τα οποία απαιτούν συνεπή ενημέρωση των δρόμων από κάθε κόμβο σε κάθε άλλο κόμβο του δικτύου, συνεπώς, καθιστώντας τα μη πραγματοποιήσιμα για μεγάλης κλίμακας δυναμικά MANET, οι υπόλοιπες δύο οικογένειες πρωτοκόλλων βασίζονται σε κάποια μορφή καθολικής εκπομπής. Η καθολική εκπομπή είναι η βέλτιστη λύση σε περιπτώσεις όπου πακέτα πληροφορίας μεταδίδονται σε πολλαπλούς ξενιστές στο δίκτυο. Η μέθοδος πλημμυρίσματος είναι η απλούστερη μορφή καθολικής εκπομπής, όπου κάθε κόμβος στο δίκτυο προωθεί το πακέτο πληροφορίας μια φορά ακριβώς. Το πλημμύρισμα εξασφαλίζει την πλήρη κάλυψη του MANET, εφόσον δεν υφίστανται κατατμήσεις του δικτύου, παρότι προκαλεί πολλές πλεονάζουσες εκπομπές, προκαλώντας το πρόβλημα της καταιγίδας καθολικών εκπομπών [157].
Πολλοί αλγόριθμοι προτάθηκαν [153] για την αντιμετώπιση του προαναφερθέντος προβλήματος. Οι λύσεις αυτές κατηγοριοποιούνται ως εξής: α) πιθανολογικές προσεγγίσεις (βασισμένες σε μετρητές, απόσταση και τοποθεσία) και β) αιτιοκρατικές προσεγγίσεις (καθολικές, φαινομενικά καθολικές, φαινομενικά τοπικές, τοπικές). Οι πρώτες μέθοδοι δεν εγγυώνται την πλήρη κάλυψη του δικτύου, ενώ οι τελευταίες την εγγυώνται, και κατά συνέπεια είναι προτιμώμενες.
Οι αιτιοκρατικές προσεγγίσεις παρέχουν πλήρη κάλυψη του δικτύου για τη λειτουργία καθολικής εκπομπής, επιλέγοντας μόνο ένα υποσύνολο των κόμβων για την μετάδοση των πακέτων (κόμβοι προώθησης), ενώ οι υπόλοιποι κόμβοι παραμένουν γειτονικοί στους κόμβους που προωθούν το πακέτο. Η επιλογή των κόμβων γίνεται χρησιμοποιώντας πληροφορίες "κατάστασης", όπως την τοπολογία δικτύου και την κατάσταση καθολικής εκπομπής (δηλ., τον επόμενο κόμβο που επιλέχθηκε να μεταδώσει το πακέτο, τους κόμβους που δέχτηκαν επίσκεψη πρόσφατα και το σύνολο των γειτονικών τους κόμβων). Όλες οι κατηγορίες των αιτιοκρατικών αλγορίθμων, εκτός των τοπικών αλγορίθμων, απαιτούν (πλήρεις ή μερικές) πληροφορίες καθολικής κατάστασης, κατά συνέπεια είναι μη πρακτικοί. Οι τοπικοί ή καταδεικτικοί γειτόνων αλγόριθμοι διατηρούν μερικές πληροφορίες τοπικής κατάστασης, δηλ., πληροφορία για την πρώτου επιπέδου γειτονιά μέσω ανταλλαγής μηνυμάτων τύπου ‘HELLO’, μια μέθοδος που είναι εφικτή και μη δαπανηρή. Στις μεθόδους κατάδειξης γειτόνων, η κατάσταση προώθησης ενός κόμβου εξαρτάται από τους γείτονες του. Στην πραγματικότητα, ο κόμβος πηγή επιλέγει ένα υποσύνολο των γειτόνων των κόμβων πρώτου επιπέδου του ως κόμβους προώθησης ώστε να καλύψει τους γείτονες δεύτερου επιπέδου του. Ο κατάλογος κόμβων προώθησης αυτός ενσωματώνεται στο πακέτο που εκπέμπεται. Κάθε κόμβος προώθησης με τη σειρά του καταδεικνύει το δικό του κατάλογο κόμβων προώθησης.
Αμυδρά σχετικό με το θέμα της παρούσας ενότητας είναι το ζήτημα της multicasting ροής δεδομένων (ήχος/κινούμενη εικόνα) σε MANET (λ.χ., [129]) ή της unicasting ήχου σε συσκευές 3G UMTS [163]. Ωστόσο, οι εργασίες αυτές υποθέτουν την ύπαρξη ενός κεντρικού εξυπηρετητή (παροχέας), ο οποίος παρέχει τους κινητούς πελάτες με πολυμεσικά δεδομένα και κατά συνέπεια δεν εμπίπτουν στο πλαίσιο του σεναρίου που πραγματεύεται η παρούσα ενότητα.
4.2.3 Επισκόπηση της διαδικασίας ανεύρεσης
Το πρόβλημα ανεύρεσης όμοιων μουσικών ακολουθιών σε MANET απαιτεί μια διαδικασία ανεύρεσης, η οποία θα εντοπίζει MH στο MANET οι οποίοι θα έχουν όμοιες ακολουθίες, θα βρίσκει τις ακολουθίες αυτές στον MH και θα τις επιστρέφει στον ερωτώντα κόμβο. Οι απαιτήσεις του ασύρματου πλαισίου που έχουν ήδη περιγραφεί στην ενότητα 4.2.1 καθορίζουν την εξεταζόμενη διαδικασία ανεύρεσης ως εξής:
-
i)
Δεν υφίσταται πρότερη γνώση των δεδομένων που έχει ο κάθε MH αποθηκευμένα, ενώ επίσης, ο κόμβος που θέτει το επερώτημα δεν γνωρίζει τις τοποθεσίες των απαιτούμενων δεδομένων.
-
ii)
Η πρόσβαση στους MH που καλύπτουν τα κριτήρια της αναζήτησης πρέπει να γίνει με τρόπο που να αντιμετωπίζει την κινητικότητα τους και επίσης να ελαχιστοποιεί το φόρτο του δικτύου. Εξαιτίας των σχετικών τους θέσεων και της προτιμώμενης ανεκτικότητας τους σε φόρτο δικτύου (βλ. στην συνέχεια), είναι πιθανό ότι όλοι κόμβοι δεν θα είναι προσπελάσιμοι.
-
iii)
Σε κάθε MH, οι ακολουθίες που καλύπτουν τα κριτήρια τις αναζήτησης πρέπει να εντοπιστούν χρησιμοποιώντας τον MH όσο το δυνατό λιγότερο, όσο αφορά τους διαθέσιμούς τους πόρους.
-
iv)
Κάθε ακολουθία που καλύπτει τα κριτήρια της αναζήτησης πρέπει να επιστρέψει στον κόμβο που έθεσε το επερώτημα με τρόπο που να προκαλεί ελάχιστο φόρτο δικτύου. Ας σημειωθεί ότι οι απαντήσεις ίσως πρέπει να δρομολογηθούν πίσω στον κόμβο που έθεσε το επερώτημα ακολουθώντας μονοπάτια διαφορετικά από αυτά που εντοπίστηκαν οι MH με τις εν λόγω ακολουθίες, καθώς οι ενδιάμεσοι MH ίσως άλλαξαν τοποθεσία και είναι εκτός εμβέλειας. Εξαιτίας αυτού, κάθε απάντηση που εντοπίστηκε ίσως να μη μπορέσει να επιστρέψει στον κόμβο που έθεσε το επερώτημα.
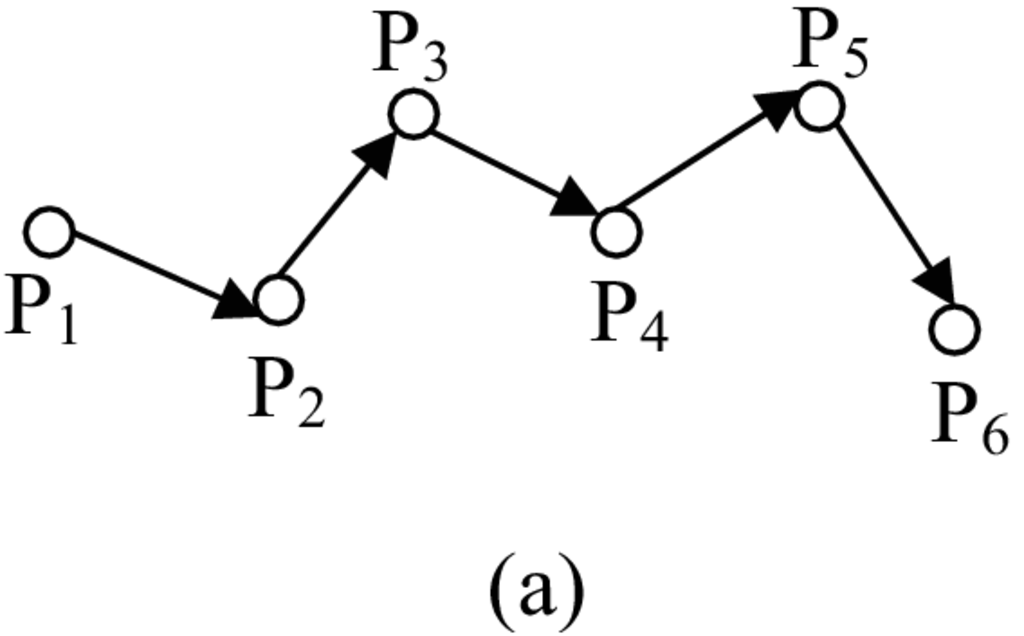
Ένα παράδειγμα παρουσιάζεται στο Σχήμα 4.7. Ο κόμβος που θέτει το επερώτημα είναι ο MH . Κατά τη διάρκεια της φάσης προώθησης του επερωτήματος (Σχήμα 4.7a), το επερώτημα λαμβάνουν οι MH και . Κατά τη διάρκεια της επιστροφής των αποτελεσμάτων (Σχήμα 4.7b), οι απαντήσεις μπορούν να επιστρέψουν κατευθείαν από τον (ο οποίος είναι ακόμα στην εμβέλεια του ). Εξαιτίας της σχετικής κίνησης όμως, ο είναι, τώρα, εκτός εμβέλειας. Συνεπώς, οι απαντήσεις του δρομολογούνται μέσω του (ο οποίος πρωτύτερα ήταν εκτός εμβέλειας του ).

Η διαδικασία ανεύρεσης αρχίζει από τον κόμβο που θέτει το επερώτημα, στοχεύοντας στον εντοπισμό ακολουθιών σε άλλους MH, οι οποίες να περιέχουν αποσπάσματα των οποίων η ομοιότητα με το επερώτημα να είναι εντός των ορίων που έθεσε ο χρήστης, το κατώφλι . Ο ορισμός του μέτρου απόστασης δίνεται αναλυτικά στον ενότητα 4.2.4. Ως το σημείο αυτό, μπορεί το μέτρο απόστασης διαισθητικά να θεωρηθεί ως το "πόσο ανόμοιες οι ακολουθίες είναι". Το μήκος των αποσπασμάτων που εντοπίστηκαν είναι ίσο με το μήκος του επερωτήματος .
Για την αντιμετώπιση της ελαχιστοποίησης του φόρτου δικτύου, το πρέπει να μετασχηματιστεί βάσει μιας αναπαράστασης σε μια μορφή , μέσω της οποίας οι ακολουθίες που καλύπτουν τα κριτήρια της αναζήτησης θα εντοπιστούν.
Εξαιτίας του μετασχηματισμού αυτού, είναι πιθανό να εμφανιστούν ψευδή θετικά αποτελέσματα. Ένα ψευδές θετικό αποτέλεσμα είναι το αποτέλεσμα το εμφανίζεται για αληθινό συγκρινόμενο με τη μετασχηματισμένη αναπαράσταση, ενώ υπό τη μη μετασχηματισμένη δεν είναι αληθές αποτέλεσμα. Επιπλέον, η πρέπει να μην εμφανίζει ψευδή αρνητικά αποτελέσματα (αληθινά αποτελέσματα τα οποία δεν βρέθηκαν λόγω του μετασχηματισμού). Ωστόσο, η συγκεκριμένη υλοποίηση καθορίζει εάν θα είναι πιθανό να εμφανιστούν ψευδή θετικά αποτελέσματα. Στηριζόμενοι στα προαναφερθέντα, ένα θεωρητικό σχέδιο για την περιγραφή όλης της διαδικασίας ανεύρεσης αποτελείται από τα εξής βήματα:
-
1.
Ο χρήστης θέτει την επερώτηση ,
-
2.
Η μετασχηματίζεται στην αναπαράσταση ,
-
3.
Η αποστέλλεται σε όλους τους MH εντός εμβέλειας,
-
4.
Τα αποτελέσματα (θετικά και ψευδή αποτελέσματα) κάθε MH αποτελούν το σύνολο ταιριασμάτων απάντησης,
-
5.
Κάθε σύνολο ταιριασμάτων απάντησης επιστρέφεται πίσω στον ερωτών κόμβο,
-
6.
Επίλυση των ψευδώς θετικών αποτελεσμάτων (μπορεί να γίνει στους MH που βρήκαν τα ταιριάσματα, στον ερωτών ή τους ενδιάμεσους κόμβους),
-
7.
Αποστολή των αληθών ταιριασμάτων στον ερωτών κόμβο.
Τα βήματα αυτά συνοψίζονται στα εξής τέσσερα γεγονότα:
- Αρχικοποίηση επερωτήματος
-
Βήματα 1,2,3
- Λήψη της
-
Βήματα 4,5
- Λήψη συνόλου απαντήσεων
-
Βήματα 5,6
- Σύνολο απαντήσεων στον κόμβο επερώτησης
-
Βήματα 7
Για την αποφυγή διπλής προσπάθειας, η διαδικασία προσαρτεί στην ένα αναγνωριστικό (βλ. ενότητα 4.2.2). Με τον τρόπο αυτό, οι MH που την έχουν ήδη λάβει δεν εκτελούν καμία πρόσθετη διαδικασία. Επιπλέον, η διάδοση της στους γειτονικούς MH ελέγχεται βάσει μιας παραμέτρου , η οποία αποτελεί απαριθμητή που μειώνεται σε κάθε MH που τη λαμβάνει (δείχνει τον αριθμό των διαθέσιμων μεταδόσεων). Η αρχική της τιμή, στον κόμβο που θέτει το επερώτημα, είναι ίση με το . Η τιμή αυτή αντιστοιχεί στην προτιμώμενη ανεκτικότητα σε φόρτο δικτύου και κάλυψη δικτύου. Η μετάδοση των συνόλων απαντήσεων (που προέρχονται από το βήμα 5) αντιμετωπίζεται παρόμοια.
Όπως ήδη περιγράφτηκε, η διαδικασία ανεύρεσης αποτελείται από τις φάσεις προώθησης και επιστροφής. Κατά την διάρκεια της πρώτης, η μεταδίδεται και κατά τη διάρκεια της δεύτερης οι απαντήσεις δρομολογούνται στον κόμβο που έθεσε το επερώτημα. Οι δύο φάσεις αλληλο-παρεμβάλλονται, καθώς κατά την διάδοση του από μερικούς MH, άλλοι MH επιστρέφουν αποτελέσματα. Ο όγκος της φάσης επιστροφής εξαρτάται κυρίως από την ύπαρξη απαντήσεων και το πλήθος των ψευδών ταιριασμάτων. Στην φάση προώθησης ο διακινούμενος όγκος εξαρτάται από το μέγεθος , την επιθυμητή κάλυψη όπως και τη συνδεσιμότητα του δικτύου. Γενικότερα, ο όγκος πληροφορίας που διακινείται κατά την φάση επιστροφής είναι μεγαλύτερος από ότι της φάσης προώθησης.
Έχοντας σκιαγραφήσει την διαδικασία ανεύρεσης, στις ακόλουθες ενότητες περιγράφεται λεπτομερώς κάθε μέρος της. Αρχικά, περιγράφονται τα χαρακτηριστικά που επιλέγονται για τη δημιουργία της . Στη συνέχεια, παρουσιάζεται η μέθοδος επιτάχυνσης της διαδικασίας ανεύρεσης εντός των MH χρησιμοποιώντας δεικτοδότηση. Ακολούθως, περιγράφονται δύο αλγόριθμοι ανεύρεσης, οι οποίοι κάνουν διαφορετικές επιλογές όσο αφορά το σχηματισμό της . Τέλος, παρουσιάζονται μέθοδοι για την βελτιστοποίηση της φάσης επιστροφής.
4.2.4 Χαρακτηριστικά και δεικτοδότηση
Χαρακτηριστικά για ΑΜΠΒΠ
Μια από τις κυριότερες προκλήσεις στην ΑΜΠ είναι η επιλογή της αναπαράστασης της μουσικής πληροφορίας εντός των υπολογιστικών συστημάτων. Καθώς τα ακουστικά μουσικά δεδομένα τείνουν να είναι πολύ μεγάλα σε μέγεθος, περιγράφονται, συνήθως, από ένα σύνολο χαρακτηριστικών τους. Μια πληθώρα απόψεων υφίστανται όσο αφορά τα χαρακτηριστικά που πρέπει να επιλεχθούν [188]. Η επιλογή των κατάλληλων χαρακτηριστικών θεωρείται πολύ σημαντική στην ΑΜΠ [134]. Τα σημασιολογικά πλούσια χαρακτηριστικά υποβοηθούν στην αποδοτική αναπαράσταση των δεδομένων και επιτρέπουν τη χρήση καταλόγων για την αποδοτική επεξεργασία των επερωτημάτων.
Τα συνήθη χρησιμοποιούμενα χαρακτηριστικά για την αναπαράσταση ακουστικών δεδομένων παράγονται από ανάλυση στο πεδίο του χρόνου [182], [183], φασματική ανάλυση [182], [183], [181] και ανάλυση wavelet [187].
Η παρούσα ενότητα δεν επικεντρώνεται στη δημιουργία νέων χαρακτηριστικών. Αντ’ αυτού, επιδεικνύωει ενδιαφέρον στη μεθοδολογία της διαδικασίας ανεύρεσης καθώς η μέθοδος που παρουσιάζεται είναι σε θέση να συμπεριλάβει κάθε διαδικασία εξαγωγής χαρακτηριστικών υψηλής απόδοσης. Κατά συνέπεια, εφαρμόζεται μια μέθοδος εξαγωγής χαρακτηριστικών που βασίζεται στο μετασχηματισμό wavelet. Ο μετασχηματισμός wavelet παρέχει μια απλή και ταυτόχρονα αποδοτική αναπαράσταση των ακουστικών δεδομένων χρησιμοποιώντας τόσο την μη ομοιόμορφη ανάλυση συχνότητας όσο και τα ωστικά χαρακτηριστικά των δεδομένων αυτών, όπως δείχνουν οι εργασίες [124], [150], [151].
Ο μετασχηματισμός wavelet έχει επιτυχώς χρησιμοποιηθεί σε επεξεργασία εικόνων και σήματος, ενώ η χρήση του στους τομείς ανάκτησης πληροφορίας και εξόρυξης δεδομένων υπήρξε εκτενέστατη [154]. Μια πλήρης έρευνα στην εφαρμογή του μετασχηματισμού wavelet στην εξόρυξη δεδομένων δίνεται στην εργασία [150]. Γενικότερα, ο μετασχηματισμός wavelet είναι ένα εργαλείο που παρέχει ποιοτική ανάλυση χρονική και συχνότητας, ενώ διαιρεί τα δεδομένα σε διαφορετικά μέρη βάσει της συχνότητάς τους και επιτρέπει τη μελέτη κάθε μέρους με ανάλυση που ταιριάζει στην κλίμακά του [150], [127], [136].
Τα wavelets (προϊόντα του ομώνυμου μετασχηματισμού) παρουσιάζουν μια πληθώρα επιθυμητών ιδιοτήτων σε σχέση με άλλους τύπους ανάλυσης. Μεταξύ αυτών βρίσκονται και η αποδοτική πολυπλοκότητα υπολογισμού, οι εξαφανιζόμενες στιγμές που υποστηρίζουν την αφαίρεση θορύβου και μείωση των διαστάσεων ενώ παράλληλα εστιάζουν στη σημαντικότερη πληροφορία, την υποστήριξη συμπίεσης που εγγυάται την τοπικότητα του wavelet, τους μη συσχετισμένους συντελεστές που επιτρέπουν τη μείωση των πολύπλοκων διαδικασιών του χρονικού πεδίου σε απλουστέρα και την υποστήριξη του θεωρήματος του Parseval. Επιπλέον, τα wavelets παρουσιάζουν την ιδιότητα της πολλαπλής ανάλυσης η οποία οδηγεί σε ιεραρχική αναπαράσταση και χειρισμό των αντικειμένων που εξετάζουν.
Τα προαναφερθέντα προτερήματα του μετασχηματισμού wavelet, ενισχύουν τη χρήση των wavelets σε μουσικά δεδομένα. Η μειωμένη υπολογιστική πολυπλοκότητα βοηθά την ήδη βεβαρημένη επεξεργασία λόγω του μεγάλου μεγέθους των ακουστικών μουσικών δεδομένων. Οι εξαφανιζόμενες στιγμές και η ιδιότητα τους να μειώνουν το θόρυβο αντιμετωπίζουν το θόρυβο που εισάγεται στις μουσικές καταγραφές από τους ήχους του περιβάλλοντος, κατά τη διάρκεια της ηχογράφησης. Η υποστήριξη συμπίεσης επιτρέπει στα τοπικά αλλοιωμένα κομμάτια να διατηρήσουν την συνολική τους ομοιότητα, ενώ οι πολλαπλές αναλύσεις ταιριάζουν με το πρότυπο ακοής, σύμφωνα με το οποίο, η αντίληψη μεγάλων ποσοτήτων μικρής κλίμακας βασίζεται στην ικανότητα πολλαπλής ανάλυσης του αυτιού [124].
Ειδικότερα, προτείνεται ο μετασχηματισμός Haar wavelet λόγω του απλού σταδιακού υπολογισμού του, την ικανότητα του όσο αφορά τη σύλληψη των χρονικά εξαρτώμενων χαρακτηριστικών των δεδομένων και την συνολική δυνατότητά του πολλαπλής ανάλυση σημάτων [144]. Ωστόσο, η μέθοδος μπορεί εύκολα να συμπεριλάβει και άλλους τύπους μετασχηματισμών wavelet.
Δεικτοδότηση στους κόμβους
Για την βελτιστοποίηση της έρευνας στους κόμβους, χρησιμοποιείται η ακόλουθη διαδικασία. Σε έναν κόμβο, κάθε αρχική μουσική ακολουθία μετασχηματίζεται σε πολυδιάστατα σημεία. Με ένα ολισθαίνον παράθυρο μήκους επί της ακολουθίας και εφαρμόζεται ο μετασχηματισμός wavelet (Discrete Wavelet Transform - DWT) στα περιεχόμενα του κάθε παραθύρου, παράγοντας συντελεστές ανά παράθυρο. Ένα παράδειγμα δίνεται στο Σχήμα 4.8a. Συνεπώς, κάθε ακουστική ακολουθία παράγει ένα σύνολο -διάστατων σημείων στο χώρο μετασχηματισμού. Καθώς ο αριθμός εξαρτάται στο μήκος του επερωτήματος και κατά συνέπεια έχει σχετικά μεγάλες τιμές (λ.χ., 64 K) ώστε να τα δεικτοδοτήσει στο χώρο μετασχηματισμού, προτείνεται η χρήση μόνο των πρώτων διαστάσεων από κάθε σημείο (στα πειράματά της εργασίας [138] χρησιμοποιήθηκε ). Η διαδικασία αυτή μειώνει δραστικά τόσο το μέγεθος του καταλόγου όσο και το πλήθος των διαστάσεων χωρίς να επηρεάζει ιδιαίτερα την ποιότητα του καταλόγου. Το γεγονός αυτό οφείλεται στο προτέρημα του DWT να συγκεντρώνει την ενέργεια της ακολουθίας στους πρώτους μερικούς συντελεστές. Ωστόσο, τα ψευδή θετικά αποτελέσματα παραμένουν πιθανά, και κατά συνέπεια απαιτούν επίλυση.
Είναι ιδιαίτερης σημασίας ότι αποδείχτηκε στην εργασία [126] ότι δεν υπάρχει πιθανότητα λανθασμένης απόρριψης ορθών αποτελεσμάτων χρησιμοποιώντας μόνο τους συντελεστές (εξαιτίας του θεωρήματος του Parseval). Στο σημείο αυτό πρέπει να αναφερθεί ότι η ιδιότητα αυτή αποδεικνύεται στην [126] για την Ευκλείδεια απόσταση. Παρότι το μέτρο απόστασης αυτό είναι απλό, είναι γνωστό για διάφορα προτερήματα του, όπως παρουσιάζονται στην εργασία [142]. Ωστόσο, η παρούσα μεθοδολογία δεν στηρίζεται αποκλειστικά στα συγκεκριμένα χαρακτηριστικά και μέτρο απόστασης, τα οποία χρησιμοποιούνται εδώ χάριν απλότητας και περιορισμένων επεξεργαστικών απαιτήσεων.
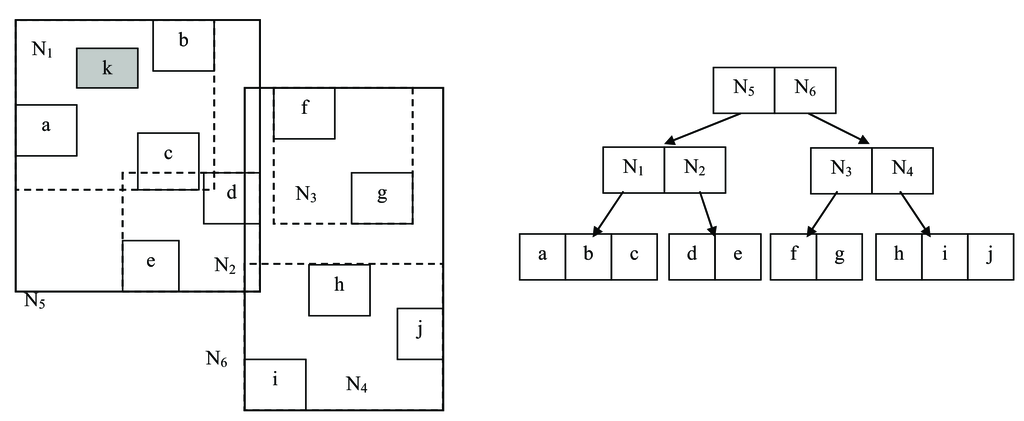
Για την αύξηση της ταχύτητας της ανάκτησης, για κάθε ακολουθία, το σύνολο των -διάστατων σημείων που προκύπτουν οργανώνονται σε ελάχιστα περικλείοντα ορθογώνια (Minimum Bounding Rectangles - MBR), τα οποία, στη συνέχεια, αποθηκεύονται σε ένα R-δένδρο [176]. Για την απάντηση ενός επερωτήματος, αρχικά εντοπίζεται η ρίζα της δενδρικής δομής και μόνο οι καταχωρίσεις της που διασταυρώνονται με το επερώτημα εξετάζονται περαιτέρω επαναληπτικά μέχρι να φτάσει η έρευνα σε φύλλο. Όλοι οι κόμβοι που δεν διασταυρώνονται δεν συμπεριλαμβάνονται στην έρευνα. Ένα παράδειγμα δίνεται στο Σχήμα 4.8b. Ακολούθως, κατά την έρευνα για όμοιες υποακολουθίες, αρχικά εντοπίζονται υποψήφιες από το R-δένδρο. Οι υποψήφιες κατατάσσονται ώστε να εξεταστούν οι περισσότερο υποσχόμενες πρώτες (με τη μέθοδο αυτή εξοικονομούμε πόρους και χρόνο επεξεργασίας) και στη συνέχεια, οι υποψήφιες υποακολουθίες εξετάζονται σε σχέση με τη δοθείσα αναπαράσταση του επερώτηματος. Όταν η αναπαράσταση αυτή μειωθεί (όπως στην περίπτωση της μειούμενης αναπαράστασης η οποία θα εξηγηθεί στην συνέχεια), τα ψευδή θετικά παραμένουν πιθανά. Ωστόσο, το πλήθος τους μειώνεται σημαντικά. Περισσότερες λεπτομέρειες σχετικά με τη δεικτοδότηση μπορούν να βρεθούν στην εργασία [180].
 (a)
(a)
 (b)
(b)
4.2.5 Αλγόριθμοι ανεύρεσης
Στην ενότητα αυτή περιγράφονται οι δύο αλγόριθμοι που αποτελούν την διαδικασία έρευνας. Ο πρώτος βασίζεται σε απλές επιλογές όσο αφορά την αναπαράσταση της ακολουθίας επερωτήματος και της διάδοσης της κατά τις φάσεις προώθησης και επιστροφής. Ο δεύτερος βασίζεται σε περισσότερο εξελιγμένες επιλογές όσο αφορά τα προαναφερθέντα ζητήματα.
Αλγόριθμος μέγιστης αναπαράστασης του επερωτήματος
Μια απλοϊκή προσέγγιση για την αναπαράσταση αποτελεί το να είναι όμοια με την ακολουθία επερωτήματος. Το κύριο πλεονέκτημα της περίπτωσης αυτής είναι ότι δεν θα προκύπτουν ψευδή θετικά αποτελέσματα, εφόσον, όταν ένα πιθανό αποτέλεσμα βρεθεί ερευνώντας τον κατάλογο, μπορεί άμεσα να εξεταστεί σε σχέση με το επερώτημα (δηλ., ). Συνεπώς, δεν θα υπάρχουν ψευδή θετικά αποτελέσματα, τα οποία επηρεάζουν αρνητικά το φόρτο δικτύου της φάσης επιστροφής καθώς θα επιστρέφονταν στον κόμβο που έθεσε το επερώτημα μόνο για να εξακριβωθούν ότι δεν είναι αληθινά ταιριάσματα. Πρέπει να σημειωθεί ότι, για να κάνουμε έρευνα του καταλόγου (δηλ., να αποφευχθεί η σειριακή έρευνα σε κάθε MH), ένας μικρός αριθμός συντελεστών DWT πρέπει να επίσης περιλαμβάνονται στην . Ωστόσο, το μέγεθός τους είναι αμελητέο σε σχέση με το μέγεθος της ακολουθίας επερωτήματος.
Ο αλγόριθμος με αυτά τα χαρακτηριστικά ονομάζεται ML (full Maximum representation with Local resolution at MHs - πλήρης αναπαράσταση με τοπική επίλυση στους κόμβους). Ο ML συνοψίζεται στο Σχήμα 4.9 σύμφωνα με το πώς δρα σε κάθε εμφανιζόμενο γεγονός όπως αυτά συνοψίστηκαν για τη διαδικασία ανεύρεσης, στην ενότητα 4.2.3.
-
•
Αρχικοποίηση επερωτήματος Ο κόμβος που θέτει το επερώτημα αναθέτει στην την πλήρη ακολουθία επερωτήματος (και επιπλέον τους μερικούς συντελεστές του επερωτήματος) και το μεταδίδει σε όλους του τους γείτονες.
-
•
Λήψη της R Στη λήψη της , κάθε MH ερευνά τους καταλόγους του, επιλύει τα ψευδή θετικά αποτελέσματα και συντάσσει ένα πίνακα αποτελεσμάτων (μόνο αληθινά θετικά αποτελέσματα). Το σύνολο των απαντήσεων επιστρέφεται στον κόμβο που έθεσε το επερώτημα, μεταδίδοντας το σε όλους τους γείτονες του (φάση επιστροφής). Ακολούθως, εφόσον υπάρχει διαθέσιμο , η μεταδίδεται σε όλους τους γειτονικούς MH του (φάση προώθησης).
-
•
Λήψη συνόλου απαντήσεων Κάθε MH , ο οποίος δεν είναι ο κόμβος που έθεσε το επερώτημα, λαμβάνοντας ένα σύνολο απαντήσεων, συνεχίζει την μετάδοση (φάση επιστροφής) σε όλους τους γειτονικούς του κόμβους εφόσον υπάρχει διαθέσιμο .
-
•
Ένα σύνολο απαντήσεων φθάνει στον κόμβο επερώτησης Όταν ένα σύνολο απαντήσεων φθάνει στον κόμβο που έθεσε το επερώτημα, τότε τα αποτελέσματα παρουσιάζονται αμέσως στο χρήστη.
Παρότι ο ML καταφέρνει να κρατήσει ελεγχόμενο το φόρτο δικτύου κατά τη φάση επιστροφής (εξαιτίας της απομάκρυνσης των ψευδών θετικών αποτελεσμάτων), ο έλεγχος αυτός επιβαρύνει υπερβολικά το φόρτο δικτύου κατά τη φάση προώθησης. Το γεγονός αυτό οφείλεται στο ότι η αναπαράσταση , η οποία μεταδίδεται κατά την φάση προώθησης, είναι ίση με το πλήρες επερώτημα. Για μεγάλες ακολουθίες επερωτήματος αυτό προκαλεί απαγορευτικό φόρτο δικτύου. Προφανώς, προκύπτει ένα θέμα συμβιβασμού μεταξύ των δύο φάσεων. Ακολούθως, απαιτείται μια μέθοδος η οποία θα εξισορροπεί το φόρτο δικτύου μεταξύ των δύο φάσεων, στοχεύοντας στη συνολική βελτίωση.
Ένα ακόμα ζήτημα στο οποίο ο ML λαμβάνει απλοϊκή απόφαση είναι η επιλογή των γειτονικών κόμβων στους οποίους το σύνολο των απαντήσεων προωθείται κατά τη φάση της επιστροφής. Αντιμετωπίζοντας τα γεγονότα δεύτερου και τρίτου τύπου, ο ML επιλέγει όλους τους γειτονικούς κόμβους για το σκοπό αυτό, καταφεύγοντας σε μέθοδο "πλημμυρίσματος". Η απλοϊκή επιλογή αυτή μπορεί να επηρεάσει σημαντικά το φόρτο δικτύου της φάσης επιστροφής. Για την αντιμετώπιση του προβλήματος αυτού απαιτείται η ανάπτυξη πολιτικών για την επιλεκτική δρομολόγηση των συνόλων απαντήσεων. Δηλαδή, πρέπει να επιλεγούν μόνο οι κόμβοι εκείνοι που είναι περισσότερο υποσχόμενοι να ικανοποιήσουν τη λήψη αποτελεσμάτων, συνεπώς μειώνοντας σημαντικά το φόρτο δικτύου στη φάση επιστροφής, χωρίς να μειώνεται η πιθανότητα του συνόλου απαντήσεων να επιστραφεί στον κόμβο που έθεσε το επερώτημα.
Αλγόριθμος μειούμενης αναπαράστασης επερωτήματος
Στην ενότητα 4.2.5 έγινε προφανές ότι δημιουργείται ένας συμβιβασμός όσο αφορά το φόρτο δικτύου μεταξύ της φάσης προώθησης και επιστροφής. Ο αλγόριθμος ML εστιάζει μόνο στη βελτίωση του φόρτου δικτύου της φάσης επιστροφής, προκαλώντας υψηλό φόρτο δικτύου στη φάση προώθησης. Στην ενότητα αυτή παρουσιάζεται ένας άλλος αλγόριθμος με δύο στόχους. Πρωτίστως, ο νέος αλγόριθμος παράγει μια αναπαράσταση η οποία επιτυγχάνει ισορροπία μεταξύ των δύο φάσεων και ελαχιστοποιεί το συνολικό φόρτο δικτύου. Ο δεύτερος στόχος είναι η ανάπτυξη μιας επιλεκτικής πολιτικής δρομολόγησης για την προώθηση των συνόλων απαντήσεων, οδηγώντας σε σημαντική μείωση το φόρτου δικτύου της φάσης επιστροφής.
Ο πρώτος στόχος αντιμετωπίζεται επιλέγοντας την αναπαράσταση μεταξύ των δύο ακρέων περιπτώσεων: (i) τη μικρότερη δυνατή αναπαράσταση με μόνο συντελεστές DWT που απατούνται για την τοπική έρευνα του καταλόγου (ελαχιστοποίηση του φόρτου δικτύου της φάσης προώθησης) και (ii) τη μέγιστη δυνατή αναπαράσταση με όλα τα στοιχεία της ακολουθίας επερωτήματος (εξαφανίζοντας την επιβάρυνση των ψευδών θετικών όσο αφορά το υπολογιστικό κόστος και το φόρτο δικτύου της φάσης επιστροφής). Συνεπώς, μεταξύ των δύο αυτών άκρων, η αναπαράσταση μπορεί να αποτελείται από τους μεγαλύτερους συντελεστές DWT, όπου . Εδώ πρέπει να σημειωθεί ότι ο τύπος αναπαράστασης αυτός, γενικεύει τις δύο ακραίες περιπτώσεις: θέτοντας , η γίνεται ίση με την πρώτη (i) περίπτωση, ενώ αντίθετα, θέτοντας , η γίνεται ίση με τη δεύτερη (ii) περίπτωση, καθώς οι συντελεστές DWT είναι ισότιμοι με τα στοιχεία της ακολουθίας επερωτήματος (εξαιτίας του θεωρήματος του Parseval)1010Στην περίπτωση του ML μπορεί να γίνει η υπόθεση ότι η αποτελείται από όλους τους συντελεστές DWT. Ωστόσο, επιλέγονται τα στοιχεία της ακολουθίας στο πεδίο του χρόνου για να αποφευχθεί ο υπολογισμός του αντίστροφου μετασχηματισμού DWT, εφόσον, στην περίπτωση αυτή το πεδίο του χρόνου εμφανίζει μικρότερες απαιτήσεις αποθήκευσης μιας και οι τιμές των δεδομένων είναι στο διάστημα 0-255.. Όπως ήδη περιγράφτηκε στην ενότητα 4.2.4, ένα πλήθος , των μεγαλύτερων συντελεστών DWT, μπορεί να συλλάβει την ενέργεια της μουσικής ακολουθίας αποδοτικά και να μειώσει τον αριθμό των ψευδών θετικών αποτελεσμάτων. Συμπερασματικά, σε σχέση με την δεύτερη (ii) περίπτωση, ο φόρτος δικτύου της φάσης προώθησης αναμένεται να είναι μικρότερος, εφόσον . Σε σχέση με την πρώτη (i) περίπτωση, ο φόρτος δικτύου της φάσης επιστροφής επίσης αναμένεται να είναι μικρότερος, καθώς το πλήθος των ψευδών θετικών αποτελεσμάτων θα έχει σημαντικά μειωθεί, εφόσον .
Ωστόσο, η ρύθμιση του , είναι δύσκολη, καθώς εξαρτάται από πολλούς παράγοντες, όπως λ.χ. η τοπολογία του MANET, οι οποίοι είναι μεταβαλλόμενοι. Για το λόγο αυτό, προτείνεται μια διαφορετική προσέγγιση. Αρχικά, στο δίνεται μια αρκετά μεγάλη τιμή και η τιμή αυτή μειώνεται μονοτονικά κατά την διάδοση της στην φάση προώθησης. Η μεθοδολογία αυτή αποτελεί τη μειούμενη αναπαράσταση (transcoding), καθώς εμπλέκει ακολουθίες με μεταβλητό αριθμό συντελεστών DWT οι οποίες αντιστοιχούν σε διάφορες προσεγγίσεις της αρχικής ακολουθίας επερωτήματος. Η μεθοδολογία transcoding:
-
•
Διατηρεί το φόρτο δικτύου κατά τη φάση προώθησης χαμηλό, καθώς το μέγεθος της μειώνεται κατά τη διάδοσή της στην φάση προώθησης.
-
•
Μειώνει το φόρτο δικτύου κατά τη φάση επιστροφής επιτρέποντας στους MH που εμπλέκονται στη φάση προώθησης να αποθηκεύσουν την μειωμένη αναπαράσταση και κατά τη φάση επιστροφής, να τη χρησιμοποιήσουν για πρώιμη επίλυση των ψευδών θετικών αποτελεσμάτων, πριν αυτά φθάσουν στον κόμβο που έθεσε το επερώτημα. Το πρόβλημα της αποθήκευσης εξαρτάται από πολλές παραμέτρους του δικτύου και είναι ανεξάρτητο από τη μέθοδο αυτή, ενώ αποδοτικές λύσεις μπορούν να βρεθούν στην εργασία [131]. Στα πειράματα της εργασίας [141], εντοπίστηκε ότι αποθηκεύοντας τις αναπαραστάσεις για ένα μικρό, σταθερό χρονικό διάστημα είναι επαρκές για αυξημένη επίδοση.
-
•
Μειώνει το χρόνο επεξεργασίας σε κάθε MH, καθώς το κόστος επίλυσης των ψευδών θετικών αποτελεσμάτων σε κάθε MH εξαρτάται από το μέγεθος της .
Η μείωση επιτυγχάνεται διατηρώντας τιμές σύμφωνα με μια αντίστροφη σιγμοειδή συνάρτηση 4.10b. Εξαιτίας του σχήματος της συνάρτησης αυτής, η άμεση γειτονιά του MH που έθεσε το επερώτημα, η οποία μπορεί να δώσει αποτελέσματα συντομότερα, λαμβάνει μεγαλύτερη , ενώ το βάρος που τίθεται στους MH που είναι μακριά είναι σημαντικά μικρότερο. Επιπλέον, με τη μέθοδο αυτή, ελέγχεται η εκθετική αύξηση του φόρτου δικτύου που προκαλείται από την απλή καθολική εκπομπή της πλήρους αναπαράστασης. Ένα παράδειγμα δίνεται στο Σχήμα 4.10a. Ο είναι κόμβος που θέτει το επερώτημα και ο είναι κόμβος που ξεκινά την προώθηση του συνόλου αποτελεσμάτων. Οι MH στο μονοπάτι από τον στον δείχνονται σκιασμένοι και επισημειώνονται με το μέγεθος της το οποίο έλαβαν ( ξεκινά με 10 K συντελεστές DWT). Το Σχήμα 4.10b δείχνει πως τα μεγέθη αυτά μειώνονται ακολουθώντας την αντίστροφη σιγμοειδή συνάρτηση. Κατά την φάση επιστροφής, ξεκινώντας από τον , οι MH και είναι προσβάσιμοι (δείχνονται με διακεκομμένα βέλη). Η αποθηκευμένη αναπαράσταση στον μπορεί να βοηθήσει στην επίλυση ψευδών θετικών αποτελεσμάτων στο σύνολο απαντήσεων. Το γεγονός αυτό οφείλεται στο ότι στον τα ψευδή θετικά εξετάστηκαν με μικρότερη από ότι στον . Αντίθετα, ο δεν βρέθηκε στο μονοπάτι, και κατά συνέπεια δεν μπόρεσε να επιλύσει ψευδή θετικά αποτελέσματα.
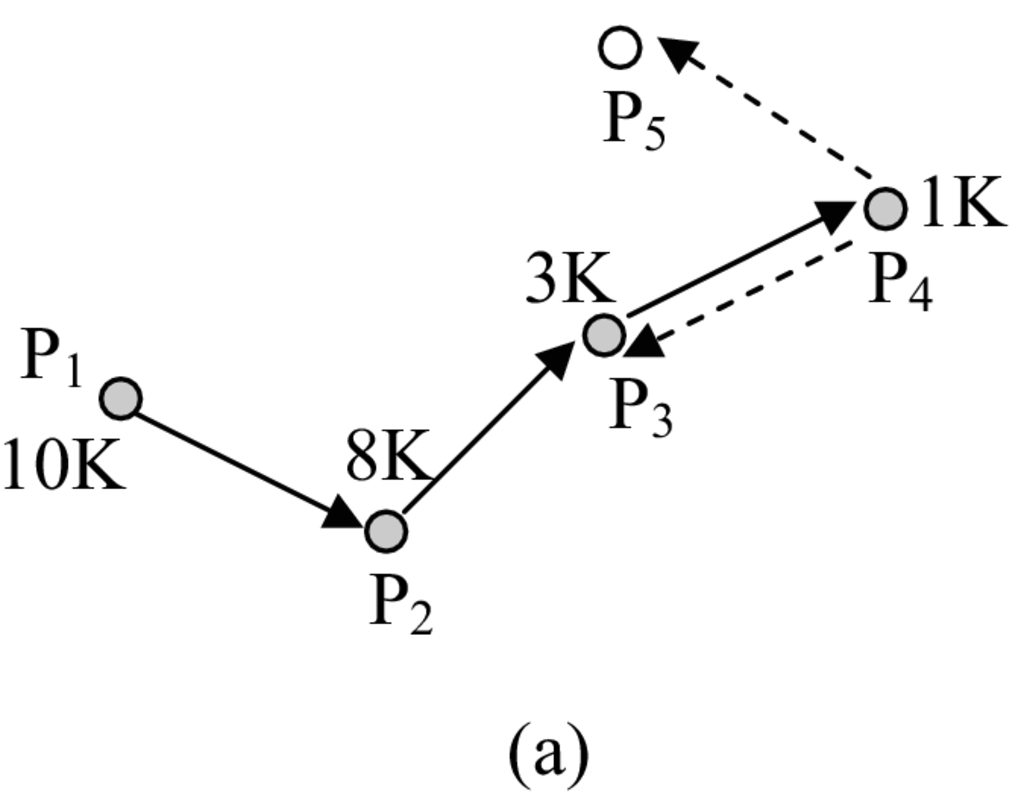
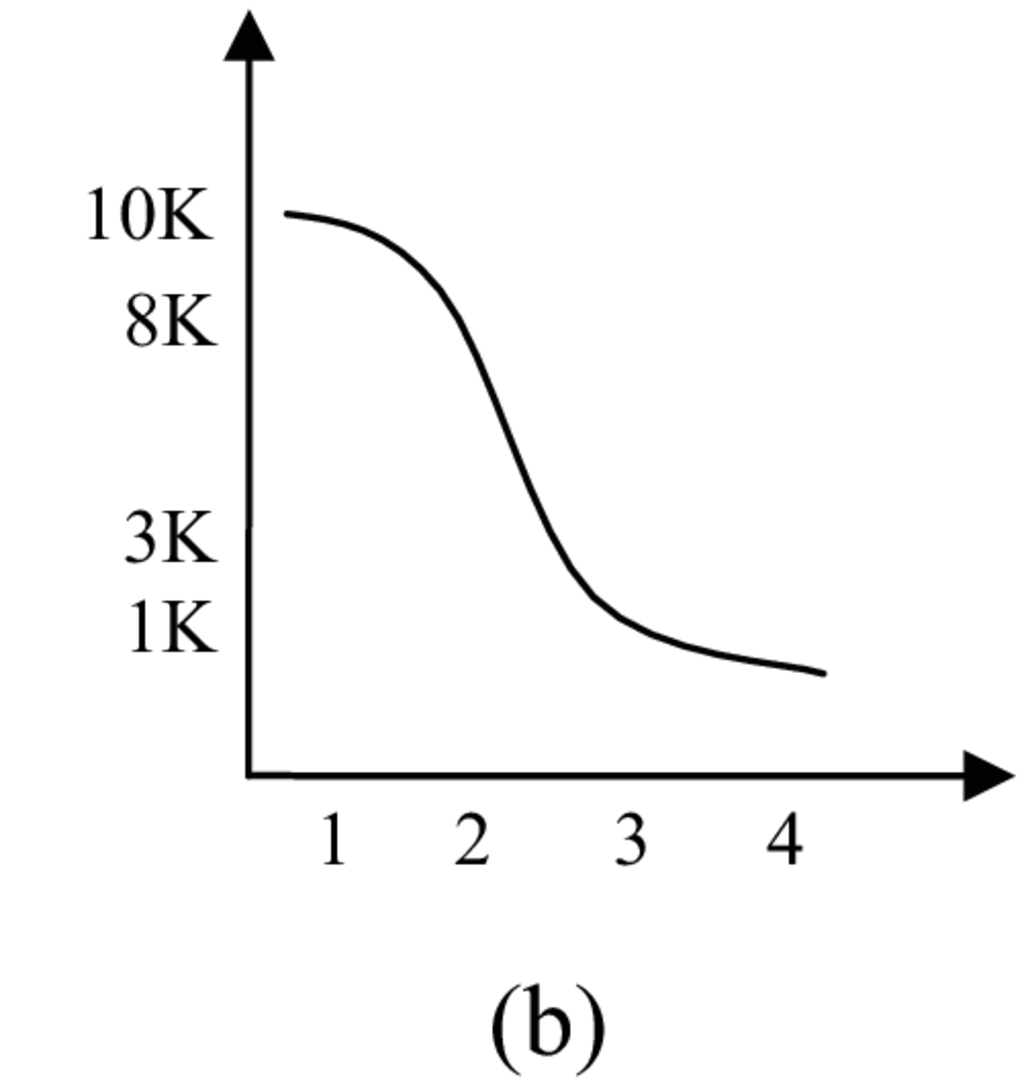
Εφεξής, το μέγεθος της αρχικής αναπαράστασης επερωτήματος, , δίνεται ως συντελεστής του μεγέθους του πλήρους επερωτήματος, ενώ η κλίση της αντίστροφης σιγμοειδούς συνάρτησης ελέγχεται από την παράμετρο (μεγαλύτερες τιμές της προκαλούν μεγαλύτερες κλίσεις).
Όσο αφορά το δεύτερο στόχο, δεν ακολουθείται η απλοϊκή προσέγγιση του αλγορίθμου ML, ο οποίος διαδίδει τα σύνολα απαντήσεων σε όλους του κόμβους. Αντίθετα, κατά την φάση προώθησης, όπως είναι σύνηθες σε όλα τα πρωτόκολλα δρομολόγησης δυναμικών πηγών [135], κάθε MH που λαμβάνει την , επιπλέον λαμβάνει και το αναγνωριστικό όλων των MH στο μονοπάτι το οποίο ακολουθήθηκε από τον κόμβο που έθεσε το επερώτημα. Τα αναγνωριστικά αυτά μπορούν να συμπεριληφθούν στην με ελάχιστο κόστος (μόνο μερικά bytes). Όταν ένας MH ξεκινά την διάδοση των συνόλων απαντήσεων, επιλέγει τους γειτονικούς κόμβους στους οποίους θα μεταδώσει τα σύνολα απαντήσεων, και δεν τα μεταδίδει σε όλους. Για την επιλογή αυτή, εφαρμόζει μια πολιτική η οποία εστιάζει στους γείτονες που περιλαμβάνονται στο μονοπάτι από τον κόμβο επερώτησης. Καθώς αρκετές τέτοιες πολιτικές μπορούν να αναπτυχθούν, στην ακόλουθη ενότητα υπάρχει λεπτομερής αναφορά σε αυτές. Όλες οι πολιτικές, παρά τις διαφορές τους, στοχεύουν στην επιλογή γειτονικών MH οι οποίοι περιλαμβάνονται στο μονοπάτι, εξαιτίας της αποθηκευμένης αναπαράστασης που διατηρούν, με τη χρήση της οποίας μπορούν να επιλύσουν ψευδή θετικά αποτελέσματα. Περισσότερες λεπτομέρειες δίνονται στην ενότητα 4.2.6.
Ο αλγόριθμος που συνδυάζει όλα τα προαναφερθέντα χαρακτηριστικά ονομάζεται RT (querying by Reduced representation with Transcoding - επερώτηση με χρήση μειωμένης και μειούμενης αναπαράστασης) και παρουσιάζεται στο Σχήμα 4.11.
-
•
Αρχικοποίηση επερωτήματος Ο κόμβος επερώτησης θέτει την ίση με ένα δείγμα με αρχικό μέγεθος (δίνεται από παράμετρο) και επιπλέον, συμπεριλαμβάνει τους συντελεστές του επερωτήματος και στην συνέχεια εκπέμπει το επερώτημα σε όλους του τους γείτονες.
-
•
Λήψη της Στη λήψη της , κάθε MH ερευνά τους καταλόγους του, επιλύει όσα περισσότερο δυνατά ψευδή θετικά αποτελέσματα βάσει του δείγματος της που έχει λάβει και συντάσσει ένα πίνακα αποτελεσμάτων. Το σύνολο των απαντήσεων επιστρέφεται στον κόμβο που έθεσε το επερώτημα, ακολουθώντας μια πολιτική για την φάση επιστροφής. Ακολούθως, εφόσον υπάρχει διαθέσιμο , το μέγεθος της μειώνεται, και η μειωμένη μεταδίδεται σε όλους τους γειτονικούς MH του (φάση προώθησης).
-
•
Λήψη συνόλου απαντήσεων Όταν ένας MH λάβει μια ένα σύνολο απαντήσεων, ελέγχει εάν μπορεί να επιλύσει μερικά από τα ψευδή θετικά αποτελέσματα. Αυτό είναι εφικτό μόνο εάν έχει λάβει μια αναπαράσταση μεγαλύτερη από την αναπαράσταση με την οποία οι ακολουθίες στο σύνολο απαντήσεων εξετάστηκαν πρωτύτερα (δηλ., στον MH που έστειλε το σύνολο απαντήσεων). Κατόπιν κάθε δυνατής αφαίρεσης, εφόσον υπάρχει διαθέσιμο , το σύνολο απαντήσεων δρομολογείται ακολουθώντας μια πολιτική (φάση επιστροφής).
-
•
Ένα σύνολο απαντήσεων φθάνει στον κόμβο επερώτησης Όταν ένα σύνολο απαντήσεων φθάνει στον κόμβο που έθεσε το επερώτημα, αρχικά όποια ψευδή θετικά αποτελέσματα εξακολουθούν να υφίστανται επιλύονται και τα αποτελέσματα παρουσιάζονται στο χρήστη.
4.2.6 Πολιτικές δρομολόγησης για τη φάση επιστροφής
Στην ενότητα αυτή, περιγράφονται τρεις πολιτικές δρομολόγησης των συνόλων απαντήσεων κατά τη φάση επιστροφής. Οι δύο πρώτες πολιτικές (καθολικός και τοπικός απαριθμητής) βασίζονται στην εργασία [125], ενώ η τρίτη (κρίσιμη μάζα) βασίζεται στην εργασία [138]. Όπως ήδη αναφέρθηκε, όλες οι πολιτικές προσπαθούν να επιλέξουν κόμβους που περιλαμβάνονται στο μονοπάτι κατά τη φάση προώθησης. Ωστόσο, η φάση επιστροφής δεν μπορεί να βασιστεί μόνο στους κόμβους αυτούς. Εξαιτίας της κινητικότητας των MH, ίσως είναι αδύνατο να προσεγγιστεί ο κόμβος επερώτησης, εκτός εάν κόμβοι, που δεν περιλαμβάνονται στο μονοπάτι, εμπλακούν επιπλέον. Ο στόχος των πολιτικών είναι ο έλεγχος του πλήθους των κόμβων που εμπλέκονται, ώστε να μειωθεί ο φόρτος δικτύου της φάσης επιστροφής. Οι πολιτικές αυτές αποτελούν μια υβριδική προσέγγιση μεταξύ της πιθανολογικής καθολικής εκπομπής, όπου η επιλογή εκπομπής είναι εντελώς τοπική σε κάθε κόμβο και της αιτιοκρατικής καθολικής εκπομπής, η οποία βασίζεται στην ανακάλυψη κάποιας μορφής κυρίαρχου συνδεδεμένου συνόλου [153].
Πολιτικές καθολικού και τοπικού απαριθμητή
Για την ευκρινέστερη παρουσίαση των δυο πρώτων πολιτικών, δίνεται το παράδειγμα του Σχήματος 4.12a, όπου παρουσιάζεται το μονοπάτι από τον MH στον MH , το οποίο ακολουθήθηκε κατά την φάση προώθησης. Το Σχήμα 4.12b δείχνει τη δρομολόγηση των συνόλων απαντήσεων από τον προς τον . Συγκρίνοντας τις δυο φάσεις, αρκετοί MH άλλαξαν τη θέση τους, ενώ άλλοι απενεργοποιήθηκαν και τέλος μερικοί έγιναν μη προσβάσιμοι. Οι MH που παρουσιάζονται σκιασμένοι είναι αυτοί που περιλαμβάνονται και στο μονοπάτι της φάσης προώθησης, ενώ οι υπόλοιποι είναι νέοι κόμβοι που εμπλέκονται μόνο στη φάση επιστροφής.
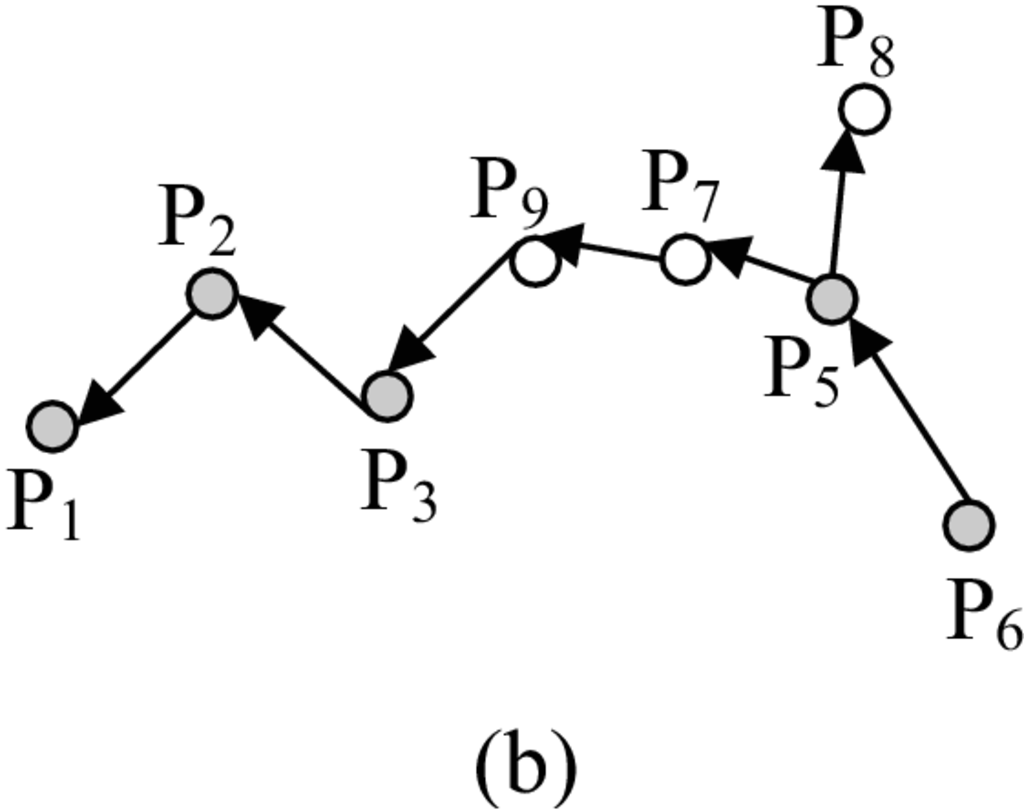
Με την πολιτική καθολικού απαριθμητή (Global-Counter - GC), όταν ένας MH ( στο προκείμενο) ξεκινά τη διάδοση ενός συνόλου απαντήσεων, αναθέτει σε κάθε διαθέσιμη τιμή άλματος (μετάδοσης), , τιμή ίση με το μονοπάτι της φάσης προώθησης και επιπλέον μια τιμή . Στο παράδειγμα, το μήκος (πλήθος ακμών) είναι ίσο με 5. Έστω και . Ο GC προσπαθεί να βρει μεταξύ των γειτονικών κόμβων, εκείνον που ήταν ο προηγούμενος του στο μονοπάτι. Στο παράδειγμα, στον , ο GC προσπαθεί να βρει τον . Εάν ο MH αυτός είναι προσβάσιμος, τότε είναι και ο μόνος στον οποίο μεταδίδεται το σύνολο απαντήσεων, και το μειώνεται κατά μια μονάδα. Η ίδια διαδικασία ακολουθείται επαναλαμβανόμενα. Στον , ο GC προσπαθεί να εντοπίσει τον . Εάν ο δεν είναι προσβάσιμος, όπως στην περίπτωση του παραδείγματος, τότε ο GC μεταδίδει το σύνολο απαντήσεων σε όλους τους γειτονικούς MH (καθολική εκπομπή στους και ) και καθένας λαμβάνει τιμή του μειωμένη κατά μια μονάδα. Στην συνέχεια, εκτός εάν βρεθεί κόμβος που περιλαμβάνεται στο μονοπάτι προώθησης, ο GC συνεχίζει την καθολική εκπομπή σε όλους τους γείτονες. Σε κάθε εκπομπή του συνόλου απαντήσεων, το μειώνεται κατά μια μονάδα, και κατά συνέπεια δρα ως καθολικός απαριθμητής. Εάν ένας MH από το μονοπάτι προώθησης εντοπιστεί σε οποιοδήποτε σημείο, τότε, όπως και προηγουμένως, ο GC προσπαθεί να βρει τον προηγούμενο του στο μονοπάτι προώθησης. Στο παράδειγμα, ο είναι ένας κόμβος από το μονοπάτι προώθησης, ο οποίος προσεγγίστηκε με ίσο με 2. Ο προηγούμενος του είναι ο , ο οποίος στη συνέχεια μεταδίδει (καθώς το είναι 1) το σύνολο απαντήσεων στον και η διαδικασία τερματίζεται.
Συνοψίζοντας, όταν επιλέγει MH για τη δρομολόγηση των συνόλων απαντήσεων, ο GC προσπαθεί να ακολουθήσει τους MH που περιλαμβάνονται στο μονοπάτι προώθησης. Ωστόσο, για να υπερνικήσει προβλήματα από τη μεταβολή του ΜΑΝΕΤ (όπως η απενεργοποίηση του στο παράδειγμα), επιτρέπει ένα ποσοστό ανακολουθίας της πολιτικής του, χρησιμοποιώντας καθολική εκπομπή. Για τον έλεγχο της ανακολουθίας, και κατά συνέπεια του φόρτου δικτύου της φάσης επιστροφής, χρησιμοποιεί την μεταβλητή . Στο σημείο αυτό πρέπει να σημειωθεί ότι για πολύ μεγάλο , ο GC καταφεύγει στην καθολική εκπομπή για πάρα πολλές φορές και συνεπώς γίνεται παρόμοιος με την απλοϊκή πολιτική του αλγορίθμου ML. Αντίθετα, για πολύ μικρό , ο κόμβος επερώτησης ίσως να μη είναι δυνατό να προσεγγιστεί, ειδικότερα όταν το MANET μεταβάλλεται πολύ γρήγορα.
Μια παραλλαγή του GC έχει ως εξής. Κατόπιν μιας ανακολουθίας, όταν ένας MH από το μονοπάτι εντοπιστεί, το επαναφέρεται στην αρχική του τιμή. Στο προηγούμενο παράδειγμα, όταν ο προσεγγίζεται, το διαθέσιμο επαναφέρεται στην αρχική τιμή 6. Συνεπώς, το δρα ως μειούμενος τοπικός απαριθμητής, εφόσον, επαναφέρεται στην αρχική του τιμή σε διάφορους MH, ανεξάρτητα. Για το λόγο αυτό, η πολιτική αυτή ονομάζεται τοπικού απαριθμητή (Local-Counter - LC). Ο στόχος της είναι η αύξηση της πιθανότητας προσέγγισης του κόμβου επερώτησης, επιβραβεύοντας τον εντοπισμό κόμβων που περιλαμβάνονται στο μονοπάτι προώθησης. Ωστόσο, η πολιτική αυτή μπορεί να προκαλέσει αύξηση του φόρτου δικτύου στη φάση επιστροφής.
Πολιτική κρίσιμης μάζας
Στην πολιτική κρίσιμης μάζας (Critical-Mass - CM), εάν τουλάχιστο ένας αριθμός, ονομάζεται παράγοντας κρίσιμης μάζας (Critical-Mass Factor - CMF), των ισχύων γειτόνων ήταν στο μονοπάτι προώθησης, επιλέγονται μόνο αυτοί για τη μετάδοση του συνόλου απαντήσεων. Εάν το πλήθος τους είναι μικρότερο από τον CMF, τότε επιπλέον τυχαία επιλέγονται μερικοί από τους τρέχοντες κόμβους (παρότι δεν υπήρξαν στο μονοπάτι προώθησης) ώστε να μεταδοθεί σε τουλάχιστο CMF MH το σύνολο απαντήσεων. Αντίθετα, εάν ο αριθμός τους είναι μεγαλύτερος από τον CMF, τότε επιλέγονται όλοι. Για παράδειγμα, έστω η περίπτωση του Σχήματος 4.13. Το Σχήμα 4.13a δείχνει τη φάση προώθησης, ενώ το Σχήμα 4.13b παρουσιάζει τη φάση επιστροφής. Κατά τη φάση επιστροφής μερικοί MH άλλαξαν τη θέση τους. Έστω ότι ο CMF είναι 2. Όταν ο ξεκινήσει τη μετάδοση του συνόλου απαντήσεων, αρχικά επιλέγει τον , καθώς ήταν στο μονοπάτι προώθησης. Εφόσον αυτός είναι και ο μόνος MH του μονοπατιού προώθησης και ο CMF είναι 2, επιπλέον επιλέγει τυχαία τον μεταξύ των άλλων προσβάσιμων MH.

Οι κόμβοι που επιλέχθηκαν τυχαία ώστε να ικανοποιήσουν τον παράγοντα CMF, λαμβάνουν το μονοπάτι του MH που εκκίνησε την επιστροφή του συνόλου αποτελεσμάτων (στο προηγούμενο παράδειγμα, ο που επιλέχθηκε από τον , θα λάβει επίσης και το μονοπάτι από τον στον ). Με τη γνώση αυτή, εξαιτίας της κινητικότητας, είναι πιθανό ότι μερικοί κόμβοι κατά τη διάρκεια της φάσης επιστροφής θα εντοπίσουν γείτονες που υπάρχουν στο μονοπάτι προώθησης (στο ίδιο παράδειγμα, ο εντοπίζει τον ο οποίος περιλαμβάνεται στο μονοπάτι προώθησης). Συνεπώς, ο αντίκτυπος αυτών των τυχαία επιλεγμένων κόμβων στην προτεινόμενη πολιτική διατηρείται σε μέτρια επίπεδα.
Η πολιτική CM διαφέρει από τις GC και LC στα ακόλουθα ζητήματα: (i) Δεν ερευνά για τον προηγούμενο κόμβο του μονοπατιού, μόνο εντοπίζει MH που περιλαμβάνονται στο μονοπάτι προώθησης ανεξαρτήτως της σειράς τους. Η τακτική αυτή επιτρέπει στον CM περισσότερη προσαρμοστικότητα στις μεταβολές του MANET. (ii) Δεν καταφεύγει σε καμία περίπτωση σε καθολική εκπομπή στους γειτονικούς κόμβους. Στη χειρότερη περίπτωση, το πλήθος των τυχαία επιλεγμένων κόμβων είναι ίσο με τον παράγοντα CMF. Έτσι επιτυγχάνεται καλύτερος έλεγχος του φόρτου δικτύου επιστροφής. Εξαιτίας των προαναφερθέντων χαρακτηριστικών, ο CM αποδίδει καλύτερα από τους GC και LC.
4.3 Ροές πληροφορίας
4.3.1 Εισαγωγή
Στις μέρες μας το διαδίκτυο έχει εξελιχθεί σε πρωτεύουσα μεθοδολογία διάχυσης της πληροφορίας ακόμα κι για καθημερινές δραστηριότητες. Οι περισσότερες των "παλαιών" μορφών πληροφορίας μετατρέπονται στις γνωστές μορφές του διαδικτυωμένου περιβάλλοντος ενώ σε κάποιες περιπτώσεις οι τεχνολογικές εξελίξεις εισαγάγουν νέες μορφές διάχυσης πληροφορίας. Έτσι, καθώς ο όγκος και η χρήση της εν λόγω πληροφορίας αυξάνει με ραγδαίους ρυθμούς, η διαχείρησή τους εξελίσσεται σε μεγάλης σημασίας δραστηριότητα, ειδικότερα για τις νέες μορφές που εισαγάγουν και νέες απαιτήσεις.
Η μετάδοση τύπου broadcasting μουσικής μέσω διαδικτύου εμπίπτει και στις δύο προαναφερθείσες κατηγορίες. Από τη μια πλευρά, όμοια με την υπηρεσία παραδοσιακού ραδιοφώνου, τα διαδικτυακά αντίστοιχά τους αποστέλλουν μουσικό πρόγραμμα μέσω του διαδικτύου σε εικοσιτετράωρη βάση, 365 ημέρες το χρόνο. Ακολούθως, αποτελούν ένα μέσο διάχυσης συνεχόμενης ροής μουσικής πληροφορίας κάνοντας χρήση μιας ήδη υπαρκτής μεθόδου, το webcasting. Παρόμοια και πάλι με το παραδοσιακό ραδιόφωνο, οι ακροατές δεν έχουν έλεγχο όσο αφορά το μεταδιδόμενο περιεχόμενο.
Από την άλλη πλευρά, η δραστηριότητα του podcasting [156] αναφέρεται στη διάθεση μιας ψηφιακής ηχογράφησης μιας ραδιοφωνικής μετάδοσης ή παρεμφερούς προγράμματος στο διαδίκτυο για ακρόαση μέσω μεταφόρτωσης. Η αρχική χρήση του podcasting στόχευε στο να δώσει την ευκαιρία στο ευρύ κοινό να διαμοιράσουν τη δική τους "μουσική εκπομπή" με τη χρήση ήδη υπαρκτών μεθόδων διαδικτυακής σύνδεσης. Τα podcasts μπορούν να δημιουργηθούν, να αναρτηθούν και να περιέχουν πλήθος μουσικών κομματιών κατά βούληση των δημιουργών τους. Πληθώρα διαδικτυακών κόμβων υφίστανται που φιλοξενούν αρκετές δεκάδες χιλιάδες τέτοιες πηγές [162], [165] διαδικτυακών ραδιοφωνικών σταθμών καθώς επίσης και πολλές δεκάδες χιλιάδες podcasts [121] (εφεξής ο όρος "πηγή" αναφέρεται τόσο στους διαδικτυακούς ραδιοφωνικούς σταθμούς όσο και στα podcasts).
Επιπλέον, βασικό χαρακτηριστικό των ραδιοφωνικών σταθμών είναι η ροή της πληροφορίας τους που δεν έχει όψιμο τέλος αλλά επίσης αποτελείται από μουσικό περιεχόμενο και μη μουσικό περιεχόμενο όπως διαφημίσεις και ομιλία εκφωνητών. Για το διαχωρισμό των μουσικών από τα μη μουσικά μέρη της πληροφορίας των πηγών, υπάρχουν αρκετές υψηλής απόδοσης μεθοδολογίες [119].
Εδώ πρέπει να σημειωθεί πως στην τρέχουσα ενότητα τα μεταδιδόμενα δεδομένα θεωρούνται ως δεδομένα ροής πληροφορίας, δηλαδή χρονοσειρές από μια πηγή. Άμεση συνέπεια της προαναφεθείσας θεώρησης είναι η μοντελοποίηση των δεδομένων όχι ως στατικά (persistent) δεδομένα αλλά ως παροδικές (transient) ροές πληροφορίας. Ακολούθως, η μεταδιδόμενη μουσική έχει ιδιαίτερες ομοιότητες με τις ροές δεδομένων όπως η ταξινομημένη φύση των δεδομένων σε πακέτα με μη γνωστό ρυθμό άφιξης για τα οποία η αποθήκευση / επεξεργασία για μεγάλο χρονικό διάστημα δεν είναι δυνατή ή επιθυμητέα αλλά είναι απαραίτητη η "σε πραγματικό χρόνο" επεξεργασία τους. Έτσι, οι μέθοδοι ΑΜΠΒΠ που εφαρμόζονται στις πηγές αυτού του είδους πρέπει να είναι τμηματικές ή αυξητικές (incremental) ώστε να μπορούν να αντεπεξέλθουν σε περιορισμούς μνήμης αλλά και απαιτήσεις εύρους χρονικής απόκρισης. Επιπλέον, μέθοδοι ροών δεδομένων απαιτούνται για την υποστήριξη μεθόδων συνεχούς επερώτησης (continuous querying) όπως παρουσιάζεται στο σενάριο - παράδειγμα που ακολουθεί. Οι παραδοσιακές μέθοδοι ΑΜΠΒΠ για στατικά δεδομένα δεν απαιτούν τεχνικές εύρεσης των ορίων των μουσικών δεδομένων καθώς τα όρια αυτά προσδιορίζονται ρητά από το αρχείο περιέκτη. Συνεπώς, η εφαρμογή των παραδοσιακών μεθόδων ΑΜΠΒΠ σε ροές δεδομένων οδηγεί σε είτε μη εφαρμοστέες είτε μη αποδοτικές λύσεις καθώς η έρευνα για ομοιότητα δεν μπορεί να τερματιστεί όταν έχει υπερβεί το κατώφλι επιθυμητής απόστασης μιας και δεν υπάρχει μέθοδος για τον προσδιορισμό του τέλους του μουσικού δεδομένου.
Ένα από τα βασικά σενάρια χρήσης της ιδέας που παρουσιάζεται εδώ περιλαμβάνει μια διαδικτυακή υπηρεσία που διαχειρίζεται περισσότερες της μίας πηγές μουσικής πληροφορίας καθώς και χρήστες που ενδιαφέρονται για το περιεχόμενο των εν λόγω πηγών. Οι χρήστες δηλώνουν στην υπηρεσία τις αρέσκειές τους όσο αφορά μουσικό περιεχόμενο και στη συνέχεια η υπηρεσία θα μπορεί σε "πραγματικό χρόνο" να επιλέξει την πηγή που για την τρέχουσά της μετάδοση ταιριάζει καλύτερα στον εκάστοτε χρήστη βάσει των προτιμήσεών του. Κατά τη διάρκεια της ακρόασης της πηγής από το χρήστη, η υπηρεσία εξακολουθεί να παρατηρεί τις πηγές ώστε να μπορεί να προσδιορίσει αν υπάρχει κάποια άλλη πηγή που να ταιριάζει καλύτερα στις προτιμήσεις του χρήστη και φυσικά να τον ενημερώσει.
Στην ενότητα αυτή θα εξεταστεί η αυξητική μέθοδος εξαγωγής χαρακτηριστικών που θα επιτρέψει τον ουσιώδη περιορισμό του υπολογιστικού κόστους της υπηρεσίας του σεναρίου αλλά και μια μεθοδολογία υπολογισμού των ορίων των μουσικών δεδομένων που επιτρέπει τον περαιτέρω περιορισμό του υπολογιστικού κόστους της διαδικασίας υπολογισμού της ομοιότητας των μουσικών δεδομένων αλλά και της εξαγωγής πλήρους συνόλου χαρακτηριστικών.
4.3.2 Σχετικές εργασίες & προαπαιτούμενες γνώσεις
Ανάκτηση μουσικής πληροφορίας βάσει περιεχόμενου
Στην παρούσα ενότητα ενδιαφερόμαστε για την αυξητική εξαγωγή χαρακτηριστικών ώστε να πληρούνται οι περιορισμοί που θέτει η ροή πληροφορίας στο εξεταζόμενο σενάριο. Ακολούθως θα παρουσιαστεί μια διαδικασία εξαγωγής μουσικών χαρακτηριστικών με τρόπο αυξητικό βασισμένη στην μέθοδο Single Gaussian Combined (G1C) της εργασίας [158] που κατατέθηκε στο διαγωνισμό MIREX 2006 [155] και κατέλαβε την πρώτη θέση.
Αρχικά, για κάθε μουσικό κομμάτι υπολογίζονται οι συντελεστές Mel Frequency Cepstrum Coefficients (MFCC), η κατανομή των οποίων μπορεί να περιγραφεί συνοπτικά με μια κατανομή Gaussian (G1) και έναν πίνακα πλήρους συνδιακύμανσης (full covariance matrix). Η απόσταση μεταξύ δύο τέτοιων κατανομών υπολογίζεται με χρήση της συμμετρικής έκδοσης της απόκλισης (Kullback Leibler divergence). Στη συνέχεια, υπολογίζονται τα πρότυπα διακύμανσης (fluctuation patterns - FPs) για κάθε τραγούδι. Ένα FP περιγράφει τη διαμόρφωση του πλάτους της έντασης ανά ζώνες συχνοτήτων, ενώ σε κάποιο βαθμό μπορεί να περιγράψει και περιοδικούς παλμούς (beats) του τραγουδιού. Όλα τα FPs που υπολογίζονται για κάθε πλαίσιο συνδυάζονται υπολογίζοντας το μέσο (median) πρότυπο. Κατά συνέπεια, για κάθε τραγούδι εξάγονται δύο χαρακτηριστικά από το FP, η βαρύτητα (FP.G) που είναι το κέντρο βάρους του FP κατά μήκος της διάστασης διαμόρφωσης συχνότητας και το μπάσο (FP.B) που είναι η ένταση της διακύμανσης των χαμηλότερων ομάδων συχνότητας στις υψηλότερες συχνότητες διαμόρφωσης. Βάσει των τεσσάρων τιμών αυτών (G1, FP, FP.B and FP.G) υπολογίζεται η ομοιότητα 2 τραγουδιών ως γραμμικός συνδυασμός βαρών (κανονικοποιημένος στο εύρος [0,1]), όπως περιγράφεται λεπτομερώς στην εργασία [158].
Ροές πληροφορίας & συνεχούς επερώτησης
Στις μέρες, μια πληθώρα εφαρμογών, όπως θα ήταν αναμενόμενο, δημιουργεί ροές πληροφορίας εν αντιθέσει με τα στατικά δεδομένα: οικονομικά στοιχεία, παρακολούθηση δικτύων, έξοδοι αισθητήτων, κλπ. Στα πλαίσια της τρέχουσας ενότητας διερευνώνται οι περιπτώσεις όπου υφίσταται ευκαιρία χρήσης συνεχόμενων επερωτήσεων. Σύνηθες παράδειγμα τέτοιας περίπτωσης είναι οι χρηματιστηριακές εφαρμογές όπου οι συνεχείς επερωτήσεις χρησιμοποιούνται για την παρακολούθηση της τιμής μετοχών αλλά και για τον εντοπισμό ομοιότητας σε μεταβολές και τάσεις τιμής μετοχών.
Οι μέθοδοι που ήδη έχουν αναπτυχθεί για την ανάκτηση πληροφορίας βάσει περιεχομένου σε ροές πληροφορίας είναι κατά κανόνα εξειδικευμένες για τον τύπο των δεδομένων που διαχειρίζονται και κατά συνέπεια δεν είναι ιδιαίτερα χρήσιμες για γενικευμένη χρήση. Ένα βασικό χαρακτηριστικό είναι η χρήση μετρικών ομοιότητας που εκμεταλλεύονται την τριγωνική ανισότητα για τον έγκαιρο περιορισμό του χώρου αναζήτησης με άμεση συνέπεια τη μείωση των μη απαραίτητων μετρήσεων απόστασης δεδομένων [132], [133], [148]. Συνήθεις τέτοιες μετρικές είναι η Ευκλείδεια και η Manhattan απόσταση, που δεν είναι κατάλληλες για τον υπολογισμό ομοιότητας μουσικών δεδομένων [123].
4.3.3 Η μέθοδος CQiSM
Αρχιτεκτονική
Αναλύοντας περαιτέρω το προαναφερθέν σενάριο χρήσης της ενότητας 4.3.1, μετά τον ορισμό των προτιμήσεων του χρήστη βάσει των οποίων προσδιορίζεται η αρέσκειά του για κάθε ροή και τον υπολογισμό των χαρακτηριστικών του, η υπηρεσία πρέπει να εξάγει τους συντελεστές MFCCs για κάθε μια πηγή, να εντοπίσει τα μέρη της που περιέχουν μουσική πληροφορία, να εξάγει χαρακτηριστικά των μερών αυτών, να υπολογίσει την ομοιότητα με τα προτιμητέα τραγούδια και τέλος να βαθμολογήσει κάθε πηγή βάσει του τρέχοντος τραγουδιού. Οι βαθμολογία τότε παρουσιάζεται στον χρήστη ενώ μετά την αρχική βαθμολόγηση, η υπηρεσία πρέπει να συνεχίσει να παρακολουθεί τις πηγές και να εφαρμόσει όλα τα προαναφερθέντα βήματα ώστε να μπορεί να προσδιορίσει αν η βαθμολογία αλλάζει κατά τη διάρκεια μετάδοσης της κάθε πηγής. Ακολούθως, θα περιγραφεί η μέθοδος CQiSM - Continuous Querying in Streaming Music ή συνεχείς επερωτήσεις σε ροές μουσικής πληροφορίας, όπως παρουσιάζεται στην έργασία [147]. Η αρχιτεκτονική της μεθόδου CQiSM παρουσιάζεται στο Σχήμα 4.14.

Ακολούθως, η μέθοδος CQiSM μπορεί να τεμαχιστεί σε τρία μέρη: την αυξητική εξαγωγή χαρακτηριστικών, τον εντοπισμό ορίων των τραγουδιών και την συνολική αξιολόγηση των πηγών. Οι επόμενες ενότητες δίνουν λεπτομερή περιγραφή των τριών μερών αυτών.
Αυξητική εξαγωγή χαρακτηριστικών
Ένα από τα εκ των ων ουκ άνευ χαρακτηριστικά των δεδομένων ροών είναι πως για να είναι διαχειρίσιμος ο ρυθμός ροής της πληροφορίας της πηγής όλες οι διαδικασίες που εφαρμόζονται στα δεδομένα πρέπει να είναι όσο το δυνατό περισσότερο βελτιστοποιημένες. Με άλλα λόγια, τα αποτελέσματα των ήδη εκτελεσμένων υπολογισμών πρέπει να χρησιμοποιούνται για την αφαίρεση υπολογιστικού φόρτου από τους επόμενους υπολογισμούς. Ακολούθως, καθώς ένας από τους πιο χρονοβόρους υπολογισμούς της μεθόδου CQiSM είναι η εξαγωγή χαρακτηριστικών, η ενότητα αυτή περιγράφει μια αυξητική έκδοση της μεθόδου G1C του Pampalk [158]. Εδώ πρέπει να σημειωθεί πως η αυξητική έκδοση του G1C στο προκείμενο αναφέρεται μόνο για τον υπολογισμό των συντελεστών MFCC.
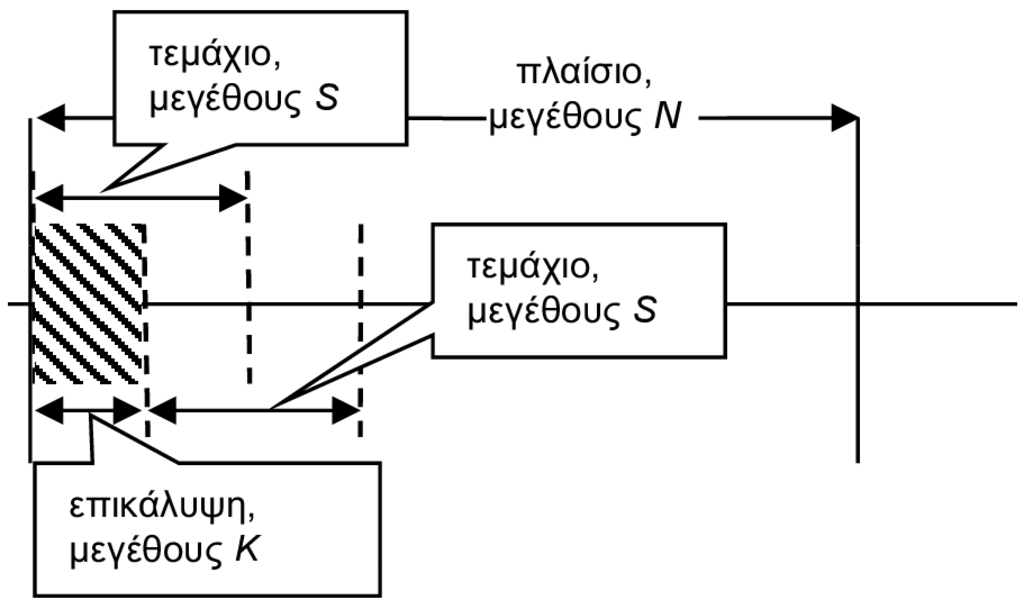
Κάθε τραγούδι τεμαχίζεται σε πλαίσια με στοιχεία καθένα, ενώ κάθε πλαίσιο τεμαχίζεται με τη σειρά του σε τμήματα μήκους στοιχεία με επικάλυψη (hop) στοιχείων μεταξύ τους (βλ. Σχήμα 4.15).
Κάθε τιμές που λαμβάνονται από μια πηγή ορίζονται ως ένα νέο τεμάχιο (το πρώτο τεμάχιο του κάθε πλαισίου δε συμμετέχει στους υπολογισμούς. Το τεμάχιο αυτό το ονομάζουμε χάριν ευκολίας εφεξής ως ενημέρωση. Για κάθε νέο τεμάχιο, εξάγονται οι συντελεστές MFCC του ώστε να είναι δυνατός ο υπολογισμός του ορίου του. Ο υπολογισμός των MFCC του νέου τεμαχίου απαιτεί την εφαρμογή ενός πλαισίου Hann στις τιμές του τεμαχίου, τον υπολογισμό του μετασχηματισμού Fast Fourier καθώς πλήθος άλλων στατικών υπολογισμών. Στη συνέχεια, τα αποτελέσματα των προαναφερθέντων υπολογισμών πολλαπλασιάζονται με τριγωνικά φίλτρα (Mel-filters) ώστε να μετασχηματιστεί η ενέργεια του φάσματος σε κλίμακα Melscale με χρήση 34 (Mel-spaced) τμημάτων συχνότητας.
Με δεδομένη την υπόθεση ότι η μέθοδος CQiSM εφαρμόζεται σε πλήρες πλαίσιο (μη αυξητική έκδοση), τα φίλτρα Mel-filters και τα προηγούμενα αποτελέσματα των υπολογισμών είναι διδιάστατοι πίνακες. Θυμίζοντας εδώ πως ο πολλαπλασιασμός πινάκων και δίνει ως αποτέλεσμα ένα πίνακα , παρατηρείται πως κάθε στήλη του πίνακα είναι αποτέλεσμα συνδυασμού όλων των στοιχείων του πίνακα με τα στοιχεία της στήλης του πίνακα . Στην αυξητική έκδοση, το αποτέλεσμα που λαμβάνεται είναι ένας μονοδιάστατος πίνακας καθώς προέρχεται από ένα τεμάχιο μόνο.
Τέλος, γίνονται και κάποιοι επιπλέον υπολογισμοί για την εξαγωγή των συντελεστών MFCC κάθε νέου τμήματος που στη συνέχεια συνδυάζονται με τους συντελεστές MFCC των προηγούμενων τεμαχίων του τρέχοντος πλαισίου για τον υπολογισμό των χαρακτηριστικών G1, FPs, FP.G και FP.B. Ακολούθως, όταν εμφανιστεί μια ενημέρωση τότε υπολογίζονται μόνο οι MFCC του και συνδυάζονται με τους MFCC των προηγούμενων τεμαχίων για να δώσουν τους MFCC του πλήρους πλαισίου κι έτσι να υλοποιηθεί η μέθοδος C1G με αυξητικό τρόπο.
Εντοπισμός ορίων τραγουδιών
Η θεώρηση των μουσικών δεδομένων ως συνεχή ροή πληροφορίας τα οποία επίσης εναλλάσσονται με μη μουσικό περιεχόμενο εισαγάγει ένα διπλό πρόβλημα προς αντιμετώπιση: τον προσδιορισμό των ορίων του κάθε τραγουδιού αλλά και τον διαχωρισμό μουσικής από ομιλία. Το δεύτερο πρόβλημα απαιτείται για τον περιορισμό των μη απαραίτητων και ιδιαίτερα κοστοβόρων υπολογισμών σε τμήματα της ροής που δε θα συνεισφέρουν στην αξιολόγηση της πηγής. Η έρευνα του διαχωρισμού μουσικής από ομιλία είναι μια ερευνητική κατεύθυνση αφ’ εαυτού της, με πλήθος εναλλακτικών προσεγγίσεων [119], η ανάλυση της οποίας υπερβαίνει το ενδιαφέρον της τρέχουσας ενότητας. Καθώς η αποδοτικότητα των μεθόδων διαχωρισμού μουσικής από ομιλία θα επηρεάσει παρόμοια όλες τις μεθόδους ανάκτησης πληροφορίας σε ροές δεδομένων, για απλοποίηση, στο προκείμενο ο διαχωρισμός θεωρείται εκ προοιμίου γνωστός.
Από την άλλη πλευρά, ο προσδιορισμός των ορίων ενός τραγουδιού αναφέρεται στον εντοπισμό του τέλους ενός τραγουδιού που ακολουθείται αμέσως από ένα άλλο χωρίς κάποια άλλη πληροφορία μεταξύ τους. Στις περιπτώσεις αυτές, όταν ένα νέο τραγούδι μιας πηγής εντοπιστεί, τότε συγκρίνεται με τις προτιμήσεις του χρήστη και καμία άλλη δραστηριότητα μέτρησης ομοιότητας δεν γίνεται εφόσον το όριο με το επόμενο τραγούδι είναι αναγνωρίσιμο. Ακολούθως, μόνο μια ελάχιστη εξαγωγή χαρακτηριστικών συνεχίζει ώστε να εντοπιστεί η αλλαγή του τραγουδιού ενώ τόσο η πλήρης εξαγωγή χαρακτηριστικών όσο και η μέτρηση ομοιότητας αποφεύγονται.
Για την απόφαση αλλαγής τραγουδιού, η μέθοδος CQiSM παρακολουθεί την πρόοδο των τιμών των συντελεστών MFCC και αναζητά μεγάλες αλλαγές. Καθώς τα τραγούδια τελειώνουν, η συνολική τους ενέργεια τείνει να μειώνεται. Το φαινόμενο αυτό είναι ιδιαίτερα προφανές στους πρώτους από τους συντελεστές MFCC που συσχετίζονται άμεσα με την ενέργεια του σήματος της ηχογράφησης. Συνεπώς, καθώς το επόμενο τραγούδι ξεκινά η ενέργεια του σήματός του είναι σημαντικά υψηλότερη και κατ’ αντιστοιχία οι πρώτοι συντελεστές MFCC του είναι ιδιαίτερα αυξημένοι. Για τον υπολογισμό λοιπόν της μεταβολής των MFCC μπορεί να χρησιμοποιηθεί οποιαδήποτε μετρική ομοιότητας. Στο προκείμενο χρησιμοποιείται η Ευκλείδεια απόσταση λόγω απλότητας και δημοφιλίας. Μετά τον υπολογισμό της αρχής ενός νέου τραγουδιού, η μέθοδος CQiSM εκτελεί μόνο μια ελαχιστοποιημένη εξαγωγή χαρακτηριστικών που βασίζεται στους συντελεστές MFCC και όχι τα χαρακτηριστικά G1, FPs & FP.G που εισαγάγουν αυξημένο υπολογιστικό φόρτο.
Συνολική αξιολόγηση πηγών
Καθώς οι μέθοδοι εξαγωγής χαρακτηριστικών και μέτρησης ομοιότητας που χρησιμοποιεί η μέθοδος CQiSM είναι σχεδιασμένες για δίνουν αποτελέσματα μονοσήμαντα (ένα αριθμό) για κάθε δύο τραγούδια χωρίς κάποια άλλη γνώση, για την αξιολόγηση της επιλογής των πηγών από τη μέθοδο CQiSM υπάρχουν δύο κύριες εναλλακτικές μεθοδολογίες. Αρχικά, ακολουθώντας μια ποσοτική αντιμετώπιση, αξιολογείται η διάχυση και το εύρος της ομοιότητας σε ένα πλήθος τραγουδιών ενώ δε δίνεται σημασία στην υπολογισμένη ομοιότητα. Ωστόσο, καθώς οι πηγές πιθανώς περιέχουν διαφορετικό πλήθος τραγουδιών ανά μονάδα χρόνου απαιτείται κανονικοποίηση όσο αφορά το πλήθος των τραγουδιών για το οποίο τα αποτελέσματα αναφέρονται. Η συνολική αξιολόγηση με την ποσοτική αντιμετώπιση δίνεται από την εξίσωση 4.5 στην οποία για κάθε νέο τραγούδι σε μια πηγή μπορούν να εντοπιστούν αποτελέσματα βάσει των προτιμήσεων των χρηστών με βαθμό ομοιότητας . Για κάθε και αθροίζεται η αντίστοιχη ομοιότητα και διαιρείται με το πλήθος των τραγουδιών που περιέχει η πηγή.
| (4.5) |
Εναλλακτικά, η ποιοτική αντιμετώπιση ενδιαφέρεται για το βέλτιστο αποτέλεσμα κάθε προτίμησης ενός χρήση αδιαφορώντας για τα υπόλοιπα αποτελέσματα. Και πάλι, για να αντιμετωπιστεί το διαφορετικό πλήθος τραγουδιών ανά μονάδα χρονικής εξέτασης για το οποίο τα αποτελέσματα προέκυψαν μεταξύ πηγών, απαιτείται κανονικοποίηση (βλ. Εξίσωση 4.6). Στην περίπτωση αυτή για κάθε νέο τραγούδι μόνο το εγγύτερο αποτέλεσμα χρησιμοποιείται για την αξιολόγηση κάθε πηγής.
| (4.6) |