Κεφάλαιο 9. Εξαγωγή Κανόνων Συσχέτισης
9.1 Ο αλγόριθμος Assosiation Rules
9.2 Δημιουργία ενός μοντέλου Association Rules
9.3 Αξιολόγηση των Itemsets και των Association Rules
9.3.1 Αξιολόγηση των Itemsets
9.3.2 Αξιολόγηση των κανόνων συσχέτισης
9.4 Ασκήσεις αξιολόγησης Κανόνων Συσχέτισης
9.5 Λύσεις Ασκήσεων αξιολόγησης Κανόνων Συσχέτισης
9.6. Βιβλιογραφία/Αναφορές
Κεφάλαιο
9. Εξαγωγή Κανόνων Συσχέτισης
Σύνοψη
Σ’ αυτό το κεφάλαιοθα μελετήσουμε τον αλγόριθμο Assosiation Rules. Ο συγκεκριμένος αλγόριθμος παράγει συσχετίσεις μεταξύ αντικειμένων και ανήκει στην οικογένεια των Apriori αλγορίθμων. Οι ομαδοποιήσεις αντικειμένων που παράγει ονομάζονται itemsets. Με βάση τα itemssets που έχουν παραχθεί δημιουργούνται οι κανόνες συσχέτισης μεταξύ των αντικειμένων. Ένας κανόνας συσχέτισης σηματοδοτεί την εξάρτηση ενός συνόλου αντικειμένων από ένα άλλο σύνολο αντικειμένων.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
9.1.
Ο αλγόριθμος Assosiation Rules
Ο αλγόριθμος Assosiation Rules (Νανόπουλος, & Μανωλόπουλος, 2008· Χαλκίδη, & Βεζυργιάννης, 2005), εκτελείται σε δύο στάδια. Στο πρώτο στάδιο, γίνονται οι υπολογισμοί για να επιλεγούν τα Itemsets (σύνολα αντικειμένων) που εμφανίζονται με τη μεγαλύτερη συχνότητα. Στο δεύτερο στάδιο, δημιουργούνται οι κανόνες συσχέτισης με βάση τις συχνότητες των itemsets.
Θα μελετήσουμε ένα παράδειγμα για την καλύτερη κατανόηση της λειτουργίας του αλγορίθμου, ο οποίος εκτελείται σε δύο στάδια. Ας υποθέσουμε ότι έχουμε τις ταινίες Α, Β και τα σύνολα {Α} και {Α, Β} σ’ έναν πίνακα μιας βάσης δεδομένων ενός Video Club.
- Στο πρώτο στάδιο, γίνονται οι υπολογισμοί, για να επιλεγούν τα itemsets που εμφανίζονται με τη μεγαλύτερη συχνότητα με την εύρεση του Support που έχουν είτε μεμονωμένα αντικείμενα είτε μετέπειτα συνδυασμοί αυτών.
- Support({A}): Το σύνολο των εγγραφών στις οποίες εμφανίζεται η ταινία Α (item {A}) στον υπό εξέταση πίνακα της βάσης δεδομένων.
- Support({A, B}): Το σύνολο των εγγραφών στις οποίες εμφανίζονται οι ταινίες Α και Β μαζί (itemset {A, B}).
Αν Support >= MINIMUM_SUPPORT,
τότε το itemset γίνεται αποδεκτό.
-
Στο δεύτερο στάδιο, δημιουργούνται οι κανόνες συσχέτισης βάσει της πιθανότητας
(probability) ή,
αλλιώς, εμπιστοσύνης (confidence). Έστω ότι ελέγχουμε αν η ταινία Β εξαρτάται από την ταινία Α. Στην περίπτωση που αυτός ο κανόνας ισχύει, τότε το Video Club θα μπορούσε να προτείνει την ταινία Β σ’ έναν πελάτη που διαλέγει την ταινία Α. Ο τύπος του probability είναι ο ακόλουθος:
Probability (A=>B) = Probability (B|A) = Support ({A, B})/Support ({A})
Αν
Probability >= MINIMUM_PROBABILITY,
ο κανόνας είναι ισχυρός.
Τονίζεται ότι ο δείκτης probability μάς βοηθά να ελέγξουμε αν ένας κανόνας είναι «ισχυρός». Όμως, ένας κανόνας μπορεί να είναι ισχυρός (να έχει υψηλό probability/confidence) και να είναι «παραπλανητικός». Δηλαδή, να υπάρχει αρνητική συσχέτιση μεταξύ των στοιχείων του κανόνα. Για τον εντοπισμό «παραπλανητικών κανόνων» υπάρχει ο δείκτης σημαντικότητας (importance) που αξιολογεί τους κανόνες συσχέτισης. Ο τύπος του importance δίνεται παρακάτω:
Importance (A=>B) = log (Probability
(Β|A)/Probability (B| not A))
Αν importance = 0, δεν υπάρχει καμία συσχέτιση μεταξύ Α
και Β.
Αν importance < 0, probability(Β) μειώνεται αν το Α
είναι αληθές.
Αν importance > 0, probability(Β) αυξάνεται αν το Α
είναι αληθές.
Τέλος, ένας εναλλακτικός
τρόπος υπολογισμού της συσχέτισης μεταξύ των στοιχείων μέσα στα itemsets
είναι o παρακάτω:
Correlation({A,B})=
Probability({A,B})/(Probability({A})*Probability({B}))
Αν Correlation = 1, οι ταινίες Α και Β
είναι ανεξάρτητες.
Αν Correlation < 1, οι ταινίες έχουν
αρνητική συσχέτιση.
Αν Correlation > 1, οι ταινίες έχουν
θετική συσχέτιση.
Τονίζεται, ότι o δείκτης correlation δεν
χρησιμοποιείται στον SQL Server αλλά μπορεί να υπολογιστεί εξωτερικά από
τον χρήστη.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
9.2.
Δημιουργία ενός μοντέλου Association Rules
Ας υποθέσουμε ότι ο ιδιοκτήτης ενός Video Club θέλει να συσχετίσει τις ταινίες που ενοικιάζονται από τους πελάτες του και να βρει την πιθανότητα να ενοικιάζει μια ταινία μαζί με κάποια άλλη. Μ’ αυτόν τον τρόπο θα μπορεί να προτείνει στους πελάτες του ταινίες σχετικές μ’ αυτήν που οι ίδιοι έχουν επιλέξει. Παρακάτω περιγράφονται αναλυτικά τα βήματα που ακολουθούμε, ώστε να δημιουργήσουμε ένα μοντέλο association rules.
Αναλυτικά Βήματα
- Στην καρτέλα Solution Explorer κάνουμε δεξί κλικ στο Mining Structures και, στη συνέχεια, επιλέγουμε New Mining Structure. Εμφανίζεται το παράθυρο καλωσορίσματος του οδηγού Data Mining Wizard, στο οποίο επιλέγουμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα. Στο παράθυρο που εμφανίζεται, όπως φαίνεται στην Εικόνα 9.1, επιλέγουμε From existing relational or data warehouse, καθώς θα χρησιμοποιήσουμε την βάση που ήδη έχουμε δημιουργήσει. Στη συνέχεια επιλέγουμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
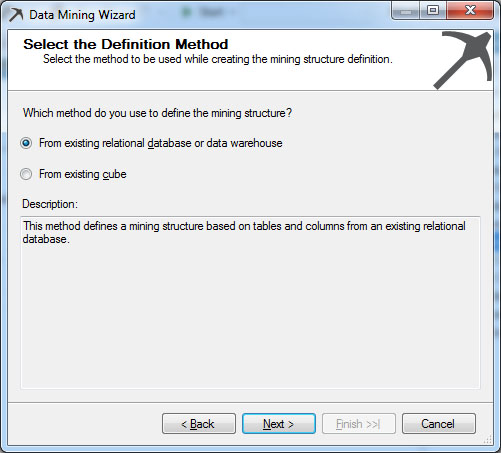
Εικόνα 9.1
-
Εμφανίζεται το παράθυρο επιλογής αλγορίθμου, όπως φαίνεται στην Εικόνα 9.2, στο οποίο επιλέγουμε Microsoft Assosiation Rules, καθώς με αυτόν τον αλγόριθμο θα ασχοληθούμε. Στη συνέχεια, επιλέγουμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
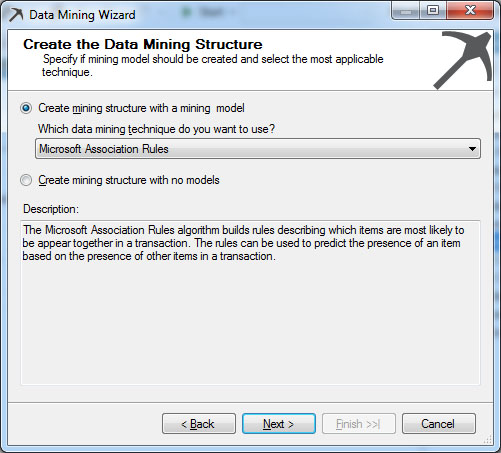
Εικόνα 9.2
-
Εμφανίζεται το παράθυρο επιλογής Data Source View, όπως φαίνεται στην Εικόνα 9.3, στο οποίο επιλέγουμε την βάση δεδομένων Movie Click. Στη συνέχεια επιλέγουμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
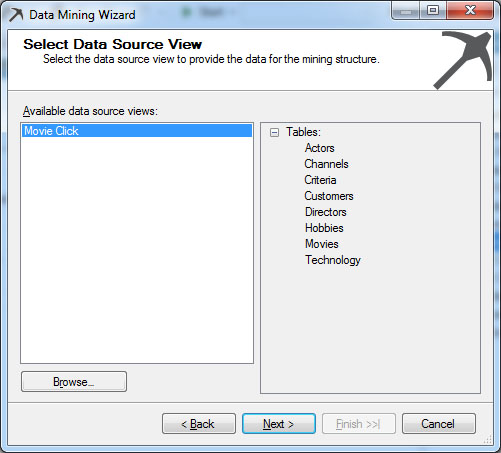
Εικόνα 9.3
-
Σ’ αυτό το στάδιο επιλέγουμε ποιος πίνακας θα είναι ο case και ποιοι πίνακες θα είναι nested. Case είναι ο πίνακας που περιέχει τα δεδομένα που θέλουμε να προβλέψουμε. Nested είναι οι πίνακες τα δεδομένα των οποίων είναι παράμετροι στον Case (ξένα κλειδιά). Στη συγκεκριμένη περίπτωση, όπως φαίνεται στην Εικόνα 9.4, επιλέγουμε τον πίνακα Customers ως Case και τον πίνακα Movies ως Nested, καθώς θέλουμε να συσχετίσουμε τις ταινίες που έχουν επιλέξει οι πελάτες. Κατόπιν, επιλέγουμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
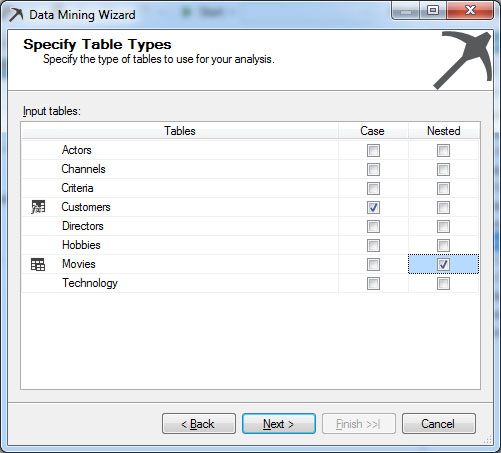
Εικόνα 9.4
-
Σ’ αυτό το στάδιο επιλέγουμε ποια από τα δεδομένα των πινάκων που επιλέξαμε στο προηγούμενο βήμα θα είναι είσοδος στο μοντέλο και για ποια δεδομένα θέλουμε να προβλέψουμε συσχετίσεις. Συγκεκριμένα, όπως φαίνεται στην Εικόνα 9.5, κάνουμε τις εξής επιλογές:
- Για κάθε πίνακα επιλέγουμε ένα κλειδί Key. Στη συγκεκριμένη περίπτωση
επιλέγουμε τα CustomerID και Movies.
- Ορίζουμε ως Input τα πεδία των πινάκων που μας ενδιαφέρουν. Στη
συγκεκριμένη περίπτωση επιλέγουμε το Movies.
- Ορίζουμε ως Predictable το πεδίο που μας ενδιαφέρει να συσχετίσουμε.
Στη συγκεκριμένη περίπτωση επιλέγουμε το Movies. Στη συνέχεια επιλέγουμε
Next> ώστε να προχωρήσουμε στο επόμενο βήμα.
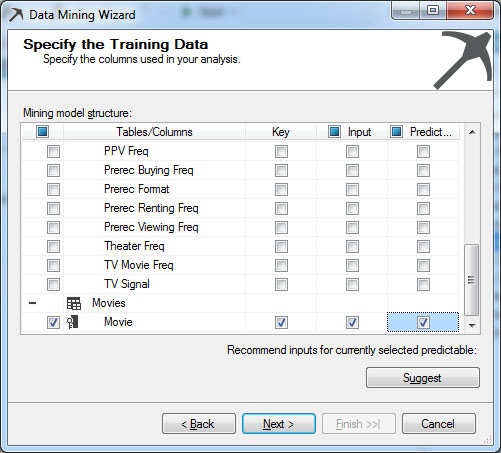
Εικόνα 9.5
-
Στο παράθυρο που εμφανίζεται, όπως φαίνεται στην Εικόνα 9.6, ορίζουμε το ποσοστό των δεδομένων που το μοντέλο θα διατηρήσει για την επαλήθευσή του. Στη συγκεκριμένη περίπτωση, επιλέγουμε την τιμή 0%. Αυτό σημαίνει ότι η αξιολόγηση του μοντέλου θα γίνει με την αισιόδοξη (optimistic) μέθοδο. Δηλαδή, θα προβλέψουμε τις εγγραφές που έχουν χρησιμοποιηθεί ως δεδομένα εκπαίδευσης. Στη συνέχεια, πατάμε Next.
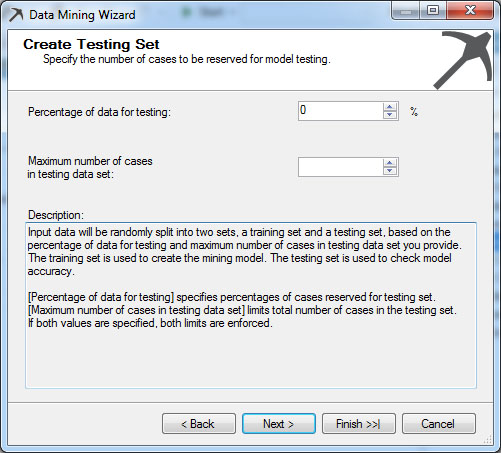
Εικόνα 9.6
-
Στη συνέχεια, ορίζουμε όνομα για το μοντέλο μας στο πεδίο Mining structure name, όπως φαίνεται στην Εικόνα 9.7. Στη συγκεκριμένη περίπτωση συμπληρώνουμε CustMovies στο πεδίο Mining structure name και CustMovieClick_AssosiationRules στο πεδίο Mining model name. Κατόπιν, επιλέγουμε Allow drill through και, στη συνέχεια, Finish, ώστε να ολοκληρωθεί η διαδικασία.
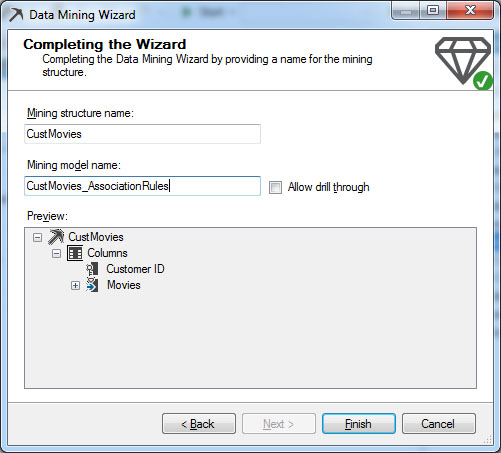
Εικόνα 9.7
-
Στη συνέχεια, όπως φαίνεται στην Εικόνα 9.8, επιλέγουμε την καρτέλα Mining Models, ώστε να καθορίσουμε τις παραμέτρους για το μοντέλο που θα μελετήσουμε. Στη συγκεκριμένη περίπτωση θέλουμε να συσχετίσουμε τις ταινίες που επιλέγουν οι πελάτες. Έτσι, ορίζουμε τα χαρακτηριστικά ως εξής:
• CustomerID: Key
• Movies: Predict
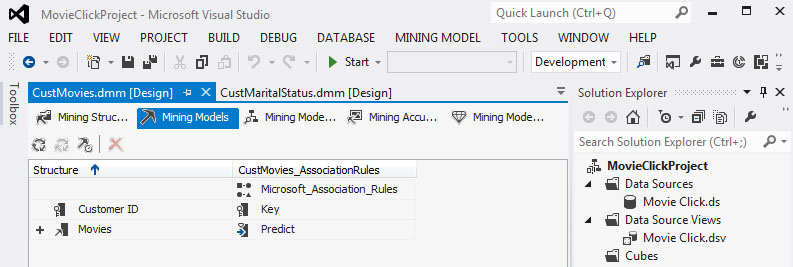
Εικόνα 9.8
-
Στη συνέχεια, θα μελετήσουμε τις παραμέτρους με τις οποίες κατασκευάζεται το μοντέλο και τις προεπιλεγμένες τιμές που παίρνουν. Στην ίδια καρτέλα, όπως φαίνεται στην Εικόνα 9.8, κάνουμε δεξί κλικ στον αλγόριθμο Microsoft_Assosiation_Rules και επιλέγουμε Set Algorithm Parameters. Εμφανίζεται το παράθυρο Algorithm Parametrs, όπως φαίνεται στην Εικόνα 9.9, στο οποίο βλέπουμε επτά παραμέτρους.
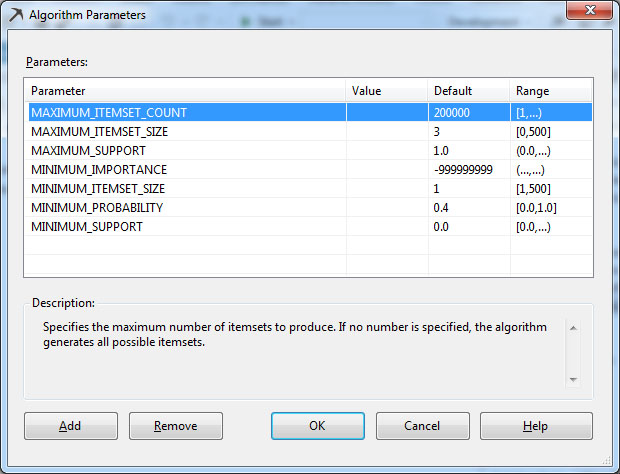
Εικόνα 9.9
Ακολουθεί η αναλυτική περιγραφή της κάθε παραμέτρου του αλγορίθμου
Association Rules:
- MAXIMUM_ITEMSET_COUNT:
Αυτή η παράμετρος προσδιορίζει το μέγιστο πλήθος των Itemsets που
παράγει ο αλγόριθμος. Στην περίπτωση που δεν προσδιορίσουμε τον ακριβή
αριθμό, ο αλγόριθμος παράγει όλα τα δυνατά itemsets. Η προεπιλεγμένη
τιμή αυτής της παραμέτρου είναι 200000.
- MAXIMUM_ITEMSET_SIZE:
Αυτή η παράμετρος προσδιορίζει το μέγιστο πλήθος των items που
επιτρέπονται σε ένα itemset. Δίνοντας στην παράμετρο την τιμή 0
ορίζουμε ότι δεν υπάρχει όριο στο πλήθος των items που επιτρέπονται στο
Itemset. Η προεπιλεγμένη τιμή της παραμέτρου αυτής είναι 3.
- MAXIMUM_SUPPORT:
Αυτή η παράμετρος προσδιορίζει τον μέγιστο αριθμό των εμφανίσεων ενός
itemset που θα εξετάζεται από τον αλγόριθμο. Αν η τιμή της παραμέτρου
είναι μικρότερη του 1 τότε αναπαριστά ένα ποσοστό επί των συνολικών
περιπτώσεων. Τιμές μεγαλύτερες του ενός αναπαριστούν τον απόλυτο αριθμό
των εμφανίσεων ενός itemset.
- MINIMUM_IMPORTANCE:
Αυτή η παράμετρος προσδιορίζει το κατώτατο όριο που πρέπει να έχει ένας
κανόνας συσχέτισης για να χαρακτηριστεί ως σημαντικός (βλέπε ενότητα
9.1). Οι κανόνες οι οποίοι έχουν τιμή μικρότερη από την τιμή που
ορίζεται φιλτράρονται και απορρίπτονται.
- MINIMUM_ITEMSET_SIZE:
Αυτή η παράμετρος προσδιορίζει το ελάχιστο αριθμό στοιχείων από τα οποία
θα πρέπει να αποτελείται ένα Itemset και λαμβάνει τιμές [1,500]. Η
προεπιλεγμένη τιμή για αυτήν την παράμετρο είναι 1.
- MINIMUM_PROPABILITY:
Αυτή η παράμετρος προσδιορίζει το ελάχιστο όριο της εμπιστοσύνης
(confidence) για να γίνει ένας κανόνας αποδεκτός (βλέπε Ενότητα 9.1). Η
προεπιλεγμένη τιμή αυτής της παραμέτρου αυτής είναι 0.4.
- MINIMUM_SUPPORT:
Αυτή η παράμετρος προσδιορίζει τον ελάχιστο αριθμό των εμφανίσεων που
πρέπει να έχει ένα itemset για να επιλεχθεί. Αν η τιμή της παραμέτρου
είναι μικρότερη του 1 τότε αναπαριστά ένα ποσοστό επί των συνολικών
περιπτώσεων. Τιμές μεγαλύτερες από 1 αναπαριστούν τον απόλυτο αριθμό των
εμφανίσεων που πρέπει ένα itemset να έχει για να γίνει αποδεκτό. Η
προεπιλεγμένη τιμής αυτής της παραμέτρου είναι 0,0.
Για να κατανοήσουμε καλύτερα την λειτουργία των παραπάνω παραμέτρων θα
περιγράψουμε συνοπτικά τον τρόπο με τον οποίο εφαρμόζεται ο αλγόριθμος
Apriori. Όπως αναφέρθηκε και στην Ενότητα 9.1, ο Apriori αλγόριθμος
εκτελείται σε δύο στάδια:
- Στο πρώτο στάδιο, γίνονται οι υπολογισμοί για να επιλεγούν τα itemsets που εμφανίζονται με τη μεγαλύτερη συχνότητα. Ο αλγόριθμος, λοιπόν, υπολογίζει το support όλων των items, του καθενός ξεχωριστά. Τα items που έχουν support μεγαλύτερo ή ίσo από το ελάχιστο όριο υποστήριξης (MINIMUM_SUPPORT) γίνονται δεκτά και συγκροτούν το σύνολο L1. Στη συνέχεια, παράγονται όλα τα δυνατά ζευγάρια των στοιχείων του συνόλου L1, δηλαδή συγκροτούνται δυάδες από items. Για κάθε ζευγάρι υπολογίζεται ξανά το support και όσα από τα ζευγάρια γίνονται δεκτά συγκροτούν το σύνολο L2. Κατόπιν,παράγονται όλα τα δυνατά ζευγάρια των στοιχείων του συνόλου L2, δηλαδή τριάδες από items. Τελικά, ο αλγόριθμος συνεχίζει να παράγει n-άδες από items, έως ότου η τιμή του n να γίνει ίση με την τιμή της παραμέτρου MAXIMUM_ITEMSET_SIZE
- Στο δεύτερο στάδιο, ο Apriori δημιουργεί τους κανόνες συσχέτισης. Από το τελευταίο σύνολο L που προκύπτει, ελέγχεται το confidence όλων των δυνατών κανόνων συσχέτισης που μπορεί να προκύψουν. Οι κανόνες που έχουν εμπιστοσύνη μεγαλύτερη από την ελάχιστη εμπιστοσύνη που έχει προσδιοριστεί (MINIMUM_PROPABILITY) γίνονται τελικά αποδεκτοί. Τέλος, οι κανόνες αυτοί ελέγχονται και ως προς τη σημαντικότητα τους, ένα στάδιο στο οποίοπρέπει να περάσουν το κατώφλι που έχει οριστεί από την παράμετρο (MINIMUM_IMPORTANCE).
9.3.
Αξιολόγηση των Itemsets και των Association Rules
Σ’ αυτήν την ενότητα θα αξιολογήσουμε την ποιότητα τόσο των Itemsets όσο και των κανόνων συσχέτισης.
9.3.1.
Αξιολόγηση των Itemsets
Για να αξιολογήσουμε τα Itemsets, επιλέγουμε την καρτέλα Mining Model Viewer και, κατόπιν, την καρτέλα Itemsets, ώστε να εμφανιστούν τα itemsets με τη μεγαλύτερη συχνότητα που έχουν δημιουργηθεί από τον αλγόριθμο association rules. Όπως φαίνεται στην Εικόνα 9.10, εμφανίζεται ένας πίνακας με τρεις στήλες.
- Η στήλη Support εμφανίζει τη συχνότητα του κάθε itemset. Η ελάχιστη τιμή που παρατηρούμε σ’ αυτήν την στήλη καθορίζεται από την τιμή της παραμέτρου MINIMUM_SUPPORT. Αν η τιμή της παραμέτρου είναι πολύ μικρή, είναι πιθανό να εμφανιστούν πολλά itemsets.
- Η στήλη Size απεικονίζει το πλήθος των αντικειμένων που συγκροτούν το itemset. Η μέγιστη τιμή εξαρτάται από την τιμή της παραμέτρου MAXIMUM_ITEMSET_SIZE. Η προεπιλεγμένη τιμή της παραμέτρου είναι 3 και, επομένως, το μέγιστο πλήθος των ταινιών που περιέχει ένα itemset δεν ξεπερνάει τις 3.
- Η στήλη Itemset περιέχει τα αντικείμενα (items) από τα οποία αποτελείται το κάθε itemset.
Επιπλέον, παρατηρούμε, όπως φαίνεται στην ίδια Εικόνα, ότι υπάρχουν διάφορα πεδία με τα οποία μπορούμε να παραμετροποιήσουμε τα αποτελέσματα. Για παράδειγμα, στη συγκεκριμένη περίπτωση:
- Στο πεδίο Minimum support
καθορίζεται ο ελάχιστος αριθμός εμφανίσεων που απαιτούμε να έχει το κάθε
itemset. H τιμή του εδώ είναι 80.
- Στο πεδίο Minimum itemset
size καθορίζεται το ελάχιστο πλήθος των items
που συγκροτούν ένα itemset.
- Στο πεδίο Maximum rows
καθορίζουμε το πλήθος των Itemsets. Η τιμή που δίνουμε εδώ ισούται με
2000 και περιορίζει την τιμή της παραμέτρου MAXIMUM_ITEMSET_COUNT.
- Στο πεδίο Filter Itemset
καθορίζουμε το item με βάση το οποίο θέλουμε να φιλτράρουμε τα itemsets.
- Στο πεδίο Show επιλέγουμε τον τρόπο με τον οποίο θα εμφανίζονται τα
itemsets (π.χ. show attribute name and value).
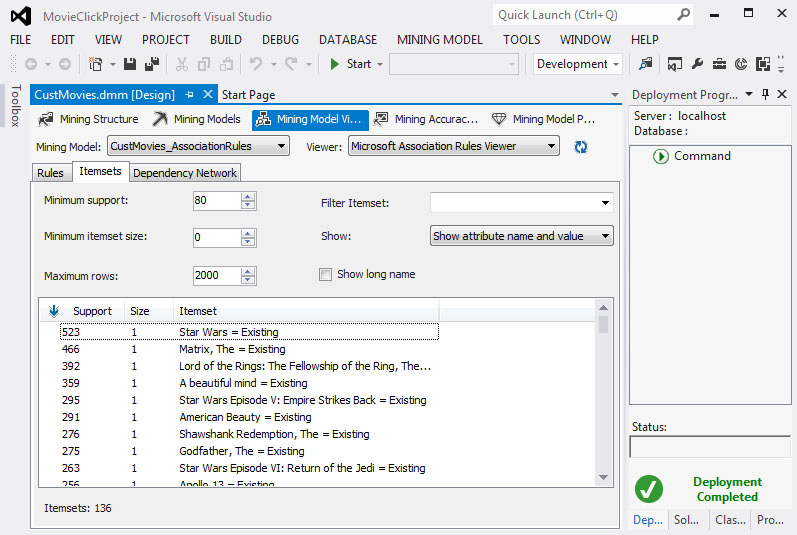
Εικόνα 9.10
Στη συνέχεια, ας υποθέσουμε ότι θέλουμε να βρούμε τα itemsets που εμπεριέχουν την ταινία Star Wars και, επίσης, να βλέπουμε μόνο τα names των attributes. Όπως φαίνεται στην Εικόνα 9.11, συμπληρώνουμε στο πεδίο Filter Itemset το όνομα της ταινίας, δηλαδή Star Wars. Επίσης, επιλέγουμε στο drop box Show την επιλογή Show attribute name only. Όπως φαίνεται στην ίδια Εικόνα, βλέπουμε πλέον αποκλειστικά itemsets που εμπεριέχουν την ταινία Star Wars.
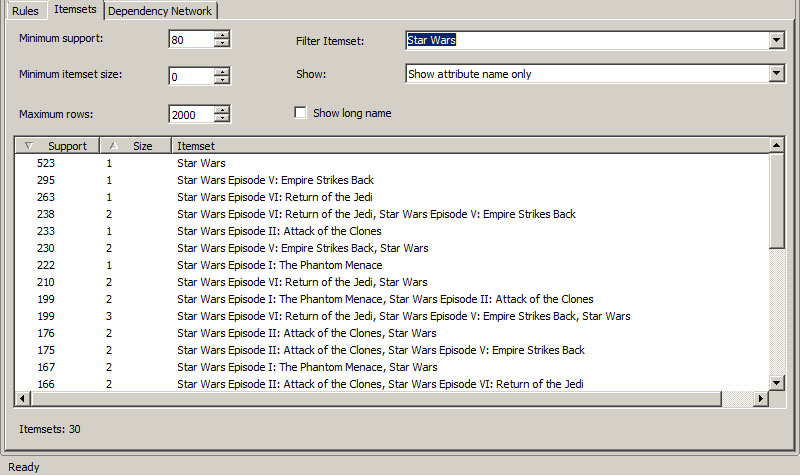
Εικόνα 9.11
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
9.3.2. Αξιολόγηση των κανόνων συσχέτισης
Για να αξιολογήσουμε τους κανόνες συσχέτισης, επιλέγουμε την καρτέλα Mining Model Viewer και, κατόπιν, την καρτέλα Rules, ώστε να εμφανιστούν οι κανόνες συσχέτισης με τη μεγαλύτερη πιθανότητα/εμπιστοσύνη (probability/confidence) και βαθμό σημαντικότητας (importance). Όπως φαίνεται σ
Στην Εικόνα 9.12 εμφανίζεται ένας πίνακας με τρεις στήλες:
- Στην στήλη Probability εμφανίζεται ο βαθμός
εμπιστοσύνης/πιθανότητας του κανόνα. Όλα τα ποσοστά που βλέπουμε είναι
πάνω από 0.4 καθώς η προεπιλεγμένη τιμή της παραμέτρου
MINIMUM_PROBABILITY είναι 0.4.
- Στην στήλη Importance εμφανίζεται ο βαθμός
σημαντικότητας του κανόνα συσχέτισης. (βλέπε Ενότητα 9.1)
- Στην στήλη Rule απεικονίζονται οι κανόνες που τελικά
παρήγαγε ο αλγόριθμος. Κάθε κανόνας αποτελείται από το αριστερό και το
δεξιό μέρος και έχει την παρακάτω μορφή:
«Σύνολο μεταβλητών που εξαρτούν τις μεταβλητές του δεξιού μέλους --> Σύνολο
μεταβλητών που εξαρτώνται από τις μεταβλητές του αριστερού μέλους»
Έτσι, η ταινία που βρίσκεται στο δεξιό μέρος του κανόνα εξαρτάται από την ταινία ή τις ταινίες που βρίσκονται στο αριστερό μέρος του. Για παράδειγμα, ένας πελάτης που επέλεξε την ταινία «The Godfather: Part 2» συνήθως επιλέγει και την ταινία «The Godfather», όπως φαίνεται στην πέμπτη σειρά από το τέλος του πίνακα της Εικόνας 9.12.
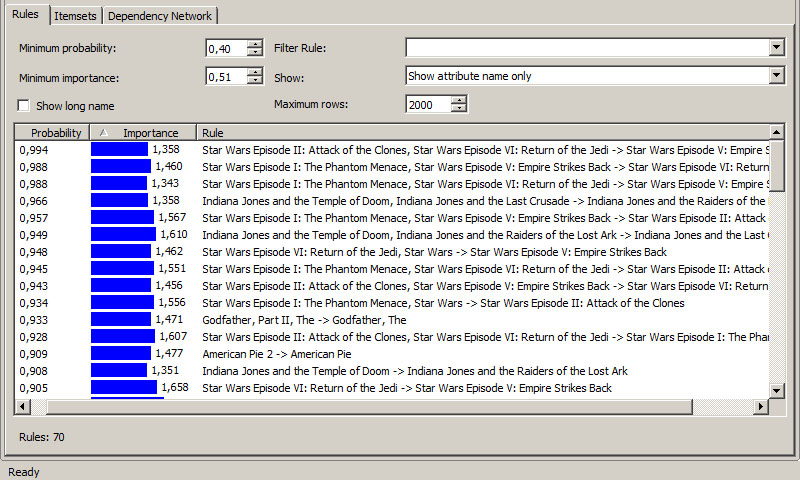
Εικόνα 9.12
Στη συνέχεια, για να δούμε καλύτερα τις συσχετίσεις που έχει βρει ο αλγόριθμος, ανοίγουμε την καρτέλα Dependency Network του Mining Model Viewer, όπως φαίνεται στην Εικόνα 9.13. Παρατηρούμε ότι:
- Κάθε κόμβος αντιπροσωπεύει ένα ξεχωριστό item.
- Δύο ή περισσότερα items που συνδέονται με μια γραμμή σχηματίζουν ένα
itemset.
- Το βέλος μεταξύ δύο items συμβολίζει την ύπαρξη κανόνα.
- Η γραμμή κύλισης στο αριστερό μέρος του παραθύρου ελέγχει τον δείκτη
importance score.
- Εάν κάνουμε κλικ σε έναν κόμβο, βλέπουμε τους υπόλοιπους κόμβους που
σχετίζονται με αυτόν. Για παράδειγμα, κάνοντας κλικ σε ένα node (π.χ.
Indiana Jones and the Temple of Doom), βλέπουμε όλους τους nodes που
σχετίζονται με αυτόν. Με διαφορετικά χρώματα βλέπουμε αυτόν που
επιλέξαμε, αυτούς τους nodes που εξαρτώνται από αυτόν και τους nodes από
τους οποίους αυτός εξαρτάται.
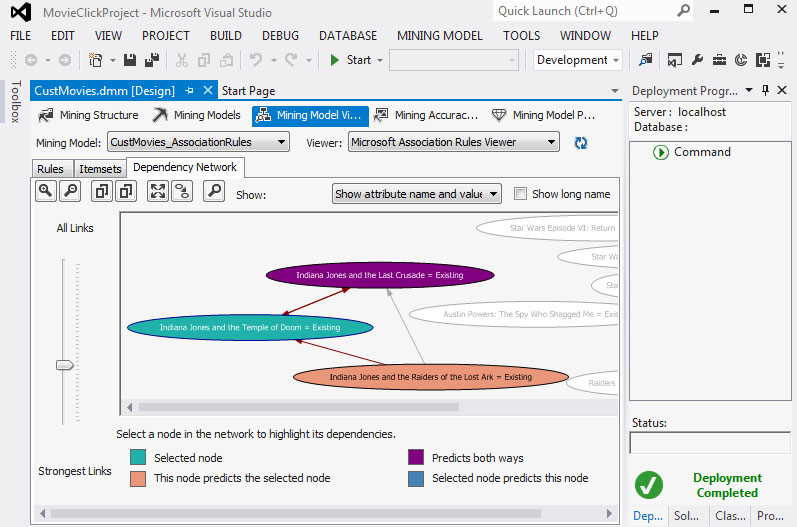
Εικόνα 9.13
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
9.4.
Ασκήσεις αξιολόγησης Κανόνων Συσχέτισης
-
Να αλλάξετε την παράμετρο (MΑΧΙΜUM_ITEMSET_SIZΕ)
του αλγορίθμου Association Rules, ώστε τα itemsets να εμπεριέχουν
το πολύ μέχρι 5 αντικείμενα (items).Nα αξιολογήσετε το νέο μοντέλο
(αξιολογώντας τις καρτέλες itemsets και rules).
-
Να αλλάξετε την παράμετρο (MINIMUM_SUPPORT) του
αλγορίθμου Association Rules, θέτοντας σε αυτή την
τιμή 0.1 .Nα αξιολογήσετε το μοντέλο (αξιολογώντας τις καρτέλες
itemsets και rules).
-
Να αλλάξετε τις παραμέτρους (MINIMUM_SUPPORT,
MINIMUM_PROBABILITY, MAXIMUM_ITEM_SIZE) του αλγορίθμου
Association Rules, θέτοντας σε αυτές τις τιμές 0.05, 0.6, και
4, αντίστοιχα. Κατόπιν, να αξιολογήσετε το νέο μοντέλο (αξιολογώντας τις
καρτέλες itemsets και rules).
-
Να αλλάξετε τις παραμέτρους (MINIMUM_SUPPORT,
MINIMUM_PROBABILITY, MAXIMUM_ITEM_SIZE, MINIMUM
IMPORTANCE) του αλγορίθμου
Association Rules, θέτοντας σε αυτές τις τιμές 0.05, 0.6, 4,
και 1.5 αντίστοιχα. Κατόπιν, να βρείτε τους δέκα κανόνες με τις μεγαλύτερες τιμές στο δείκτη probabilty.
-
Να δημιουργήσετε ένα νέο μοντέλο που να συσχετίζει τις ταινίες με την
ηλικία των πελατών. Αυτά τα δύο δεδομένα (ταινίες και ηλικία πελατών) να
χρησιμοποιηθούν ως είσοδοι (input variables) στο νέο μοντέλο, αλλά να
ζητείται και η πρόβλεψης τους (predicable variables).
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
9.5.
Λύσεις ασκήσεων αξιολόγησης Κανόνων Συσχέτισης
Άσκηση 1
Να αλλάξετε την παράμετρο (MΑΧΙΜUM_ITEMSET_SIZΕ) του αλγορίθμου Association Rules, έτσι ώστε τα itemsets να εμπεριέχουν το πολύ μέχρι 5 αντικείμενα. Να αξιολογήσετε το νέο μοντέλο (αξιολογώντας τις καρτέλες itemsets και rules).
Λύση
-
Λύση άσκησης 1:
+
1. Αλλάζουμε την τιμή της παραμέτρου του αλγορίθμου MAXIMUM_ITEMSET_SIZE, δίνοντας την τιμή πέντε. Όπως φαίνεται στην Εικόνα 9.14, έχει παραχθεί ένα itemset με μέγεθος 5 που αφορά τη σειρά ταινιών επιστημονικής φαντασίας Star Wars. To συγκεκριμένο itemset εμφανίζεται 124 φορές στη βάση δεδομένων video club. Αυτό σημαίνει ότι 124 διαφορετικοί πελάτες έχουν ενοικιάσει στο παρελθόν τις πέντε ταινίες της σειράς Star Wars.
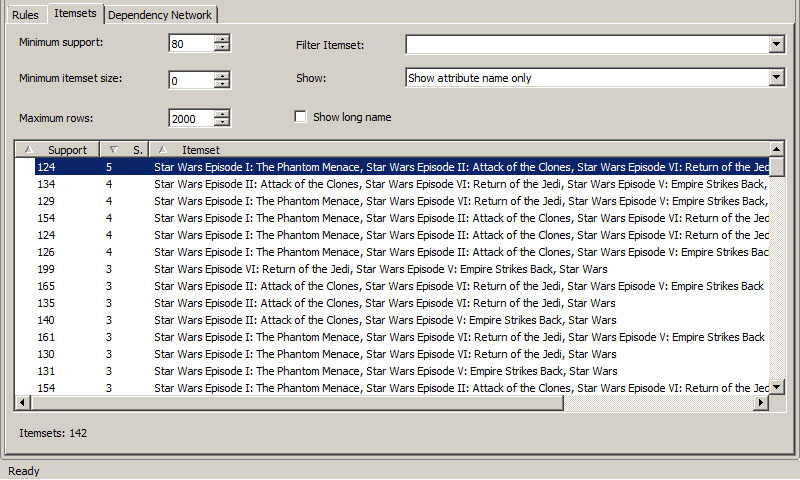
Εικόνα 9.14
2. Κάνοντας Drill Through πάνω στο συγκεκριμένο itemset, βλέπουμε το προφίλ των πελατών που τις έχουν νοικιάσει. Συγκεκριμένα, όπως φαίνεται στην Εικόνα 9.15, έχουμε δύο στήλες (Customer_ID, Movies). Παρατηρήστε ότι εμφανίζονται και άλλες ταινίες εκτός απ’ αυτές που εμπεριέχονται στο itemset.
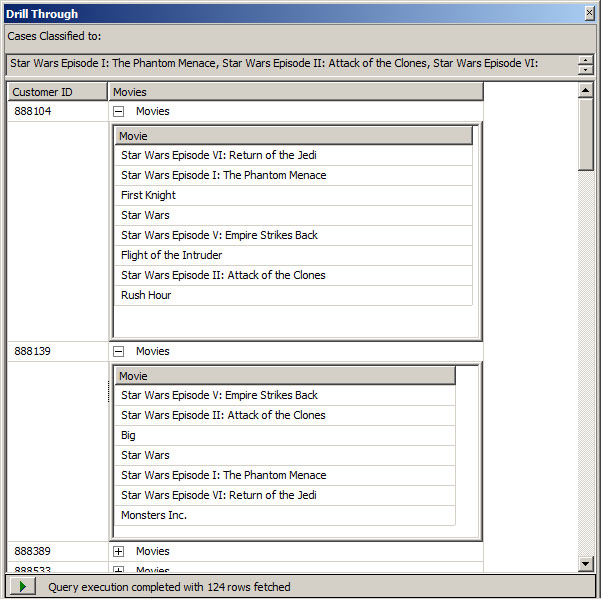
Εικόνα 9.15
- 3. Τέλος, όσον αφορά τους κανόνες συσχέτισης, ο αλγόριθμος βρήκε «ισχυρούς κανόνες» με Probability κοντά στην μονάδα. Θα πρέπει, όμως, να συνεκτιμήσουμε, σύμφωνα μ’ αυτά που περιγράφηκαν στην Ενότητα 9.1 αν οι κανόνες είναι «παραπλανητικοί», λαμβάνοντας υπόψη την τιμή της στήλης importance, όπως φαίνεται στην Εικόνα 9.16,
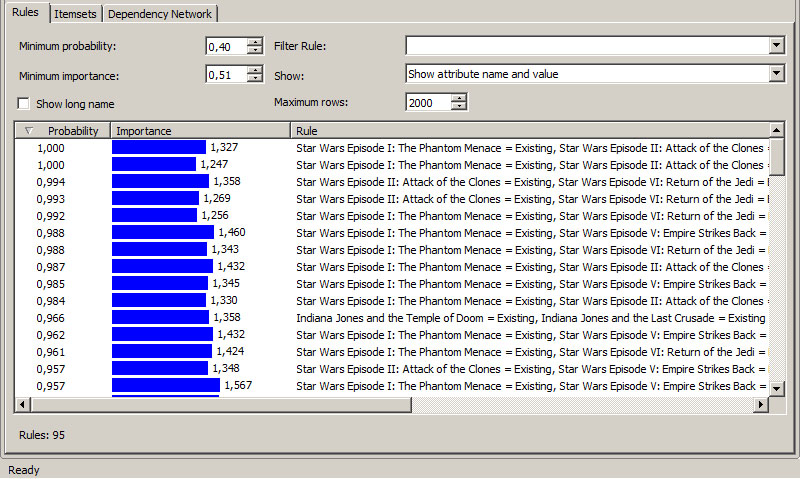
Εικόνα 9.16
Άσκηση 2
Να αλλάξετε την παράμετρο (MINIMUM_SUPPORT) του αλγορίθμου Association Rules, θέτοντας σ’ αυτήν την τιμή 0.1. Να αξιολογήσετε το μοντέλο (αξιολογώντας τις καρτέλες itemsets και rules).
-
Λύση άσκησης 2:
+
1. Στην παράμετρο MINIMUM_SUPPORT δίνουμε την τιμή 0.1, όπως φαίνεται στην Εικόνα 9.17. Η παράμετρος αυτή προσδιορίζει το ελάχιστο όριο της υποστήριξης (support) που ένα itemset χρειάζεται για να γίνει αποδεκτό στην πρώτη φάση του αλγορίθμου Association Rules. Η τιμή 0.1 σημαίνει πρακτικά ότι ένα itemset, για να γίνει αποδεκτό, πρέπει να υπάρχει στο 10% των συνολικών εγγραφών που εξετάζει ο αλγόριθμος. Επομένως, για να γίνει δεκτό ένα itemset, στο Video Club θα πρέπει να περιέχονται όλες οι ταινίες του itemset στο 10% των προτιμήσεων όλων των πελατών.
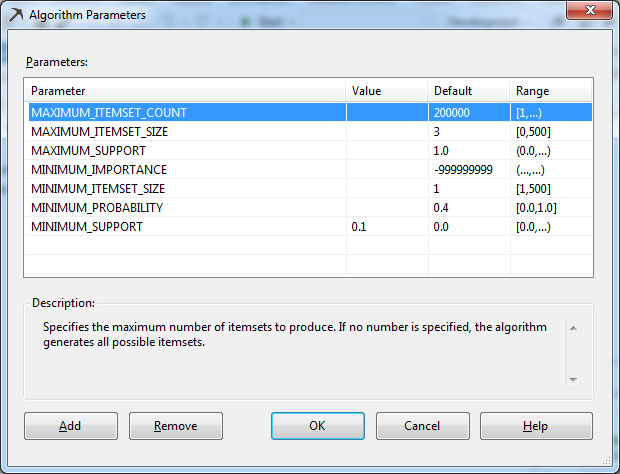
Εικόνα 9.17
>2. Όπως φαίνεται στην καρτέλα itemsets της Εικόνας 9.18, τα itemsets που πληρούν την προϋπόθεση του 0.1 Minimum Support είναι μόλις 4. Βλέπουμε ότι η παράμετρος Minimum support πάνω από το Grid έχει τιμή 359, που ισοδυναμεί με το 10% όλων των εγγραφών του πίνακα Μovies που εξετάζει ο αλγόριθμος.
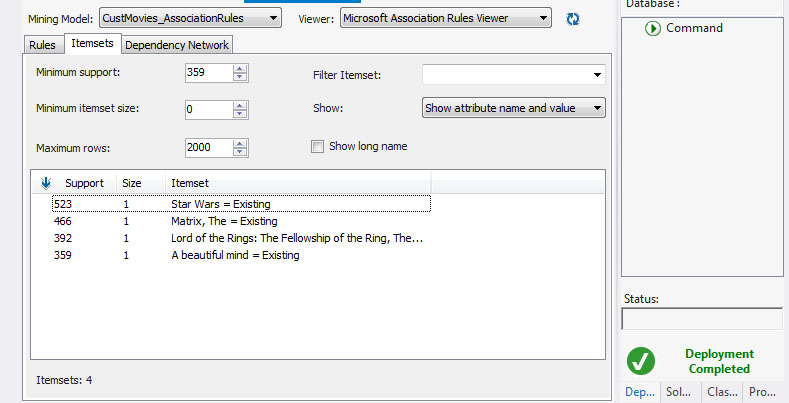
Εικόνα 9.18
- 3. Τέλος, όπως φαίνεται στην καρτέλα Rules της Εικόνας 9.19, είναι πολύ δύσκολο να προχωρήσει με επιτυχία ο αλγόριθμος στη δεύτερη φάση υλοποίησής του, δηλαδή στην παραγωγή κανόνων συσχέτισης. Αυτό συμβαίνει διότι έχει ήδη απορριφθεί η πλειοψηφία των itemsets. Συνεπώς, δεν παράγεται κανένας κανόνας συσχέτισης.
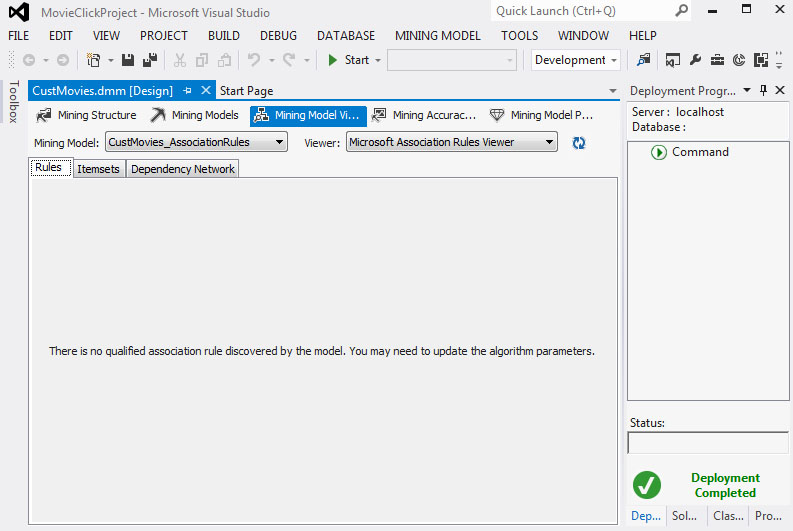
Εικόνα 9.19
Άσκηση 3
Να αλλάξετε τις παραμέτρους (MINIMUM_SUPPORT, MINIMUM_PROBABILITY, MAXIMUM_ITEM_SIZE) του αλγορίθμου Association Rules, θέτοντας σ’ αυτές τις τιμές 0.05, 0.6 και 4, αντίστοιχα. Κατόπιν, να αξιολογήσετε το νέο μοντέλο (αξιολογώντας τις καρτέλες itemsets και rules).
-
Λύση άσκησης 3:
+
1. Αλλάζουμε τις τιμές στις παραμέτρους, όπως φαίνεται στην Εικόνα 9.20.
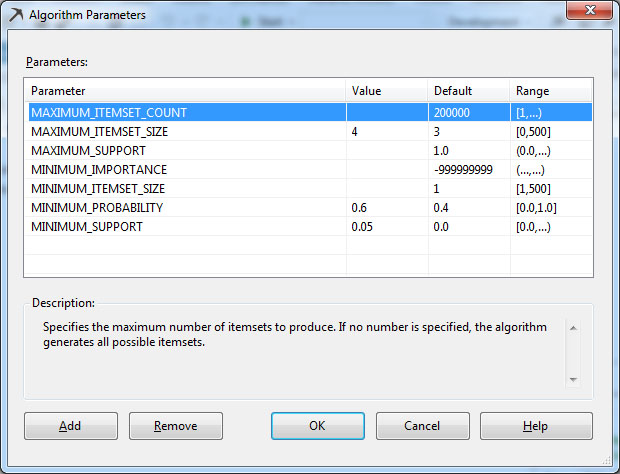
Εικόνα 9.20
2. Στην καρτέλα Itemsets, όπως φαίνεται στην Εικόνα 9.21, παρατηρήστε ότι δεν έχουν προκύψει itemsets με size 4.
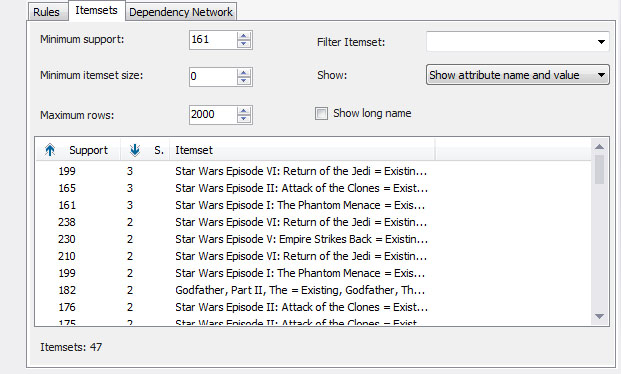
Εικόνα 9.21
3. Στην καρτέλα Rules, όπως φαίνεται στην Εικόνα 9.22, παρατηρήστε ότι το Minimum Probability έχει προσδιοριστεί σε 0.61, ενώ το Minimum Importance έχει προσδιοριστεί σε 0.79. Όπως αναμενόταν, στην πρώτη στήλη του πίνακα δεν υπάρχει κανένας κανόνας με τιμή μικρότερη από 0.6 για τον δείκτη probability. Στη δεύτερη στήλη του πίνακα οι τιμές των κανόνων για το δείκτη importance είναι πολύ παραπάνω από τη μονάδα, υποδηλώνοντας θετική συσχέτιση μεταξύ των μεταβλητών του αριστερού και του δεξιού μέρους των κανόνων (βλέπε Ενότητα 9.1).
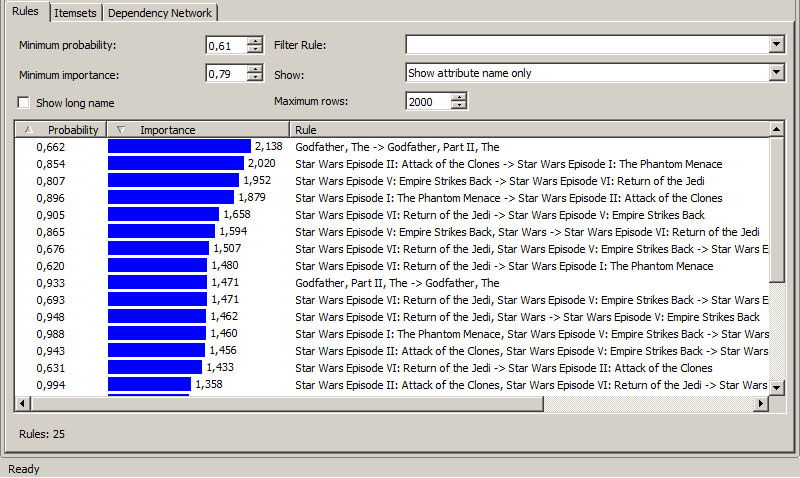
Εικόνα 9.22
Άσκηση 4
Να αλλάξετε τις παραμέτρους (MINIMUM_SUPPORT, MINIMUM_PROBABILITY, MAXIMUM_ITEM_SIZE, MINIMUM IMPORTANCE) του αλγορίθμου Association Rules, θέτοντας σ’ αυτές τις τιμές 0.05, 0.6, 4 και 1.5 αντίστοιχα. Κατόπιν, να βρείτε τους δέκα κανόνες με τις μεγαλύτερες τιμές στο δείκτη probabilty.
-
Λύση άσκησης 4:
+
>1. Συμπληρώνουμε τις τιμές στις παραμέτρους, όπως φαίνεται στην Εικόνα 9.23.
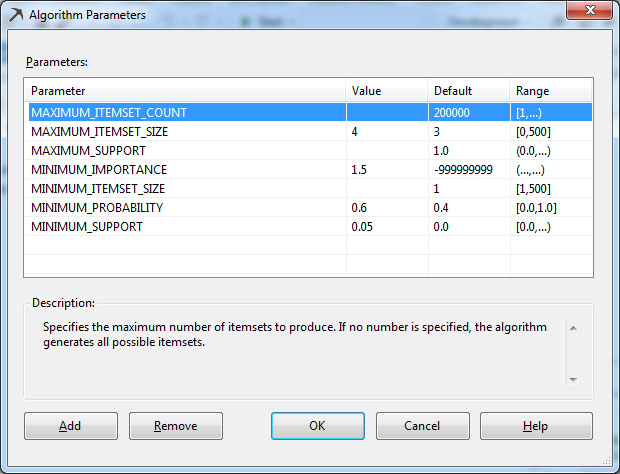
Εικόνα 9.23
2. Στην καρτέλα Rules, όπως φαίνεται στην Εικόνα 9.24, παρατηρούμε ότι υπάρχουν επτά μόνο κανόνες, τους οποίους τους ταξινομούμε ως προς τον δείκτη probability (φθίνουσα ταξινόμηση).
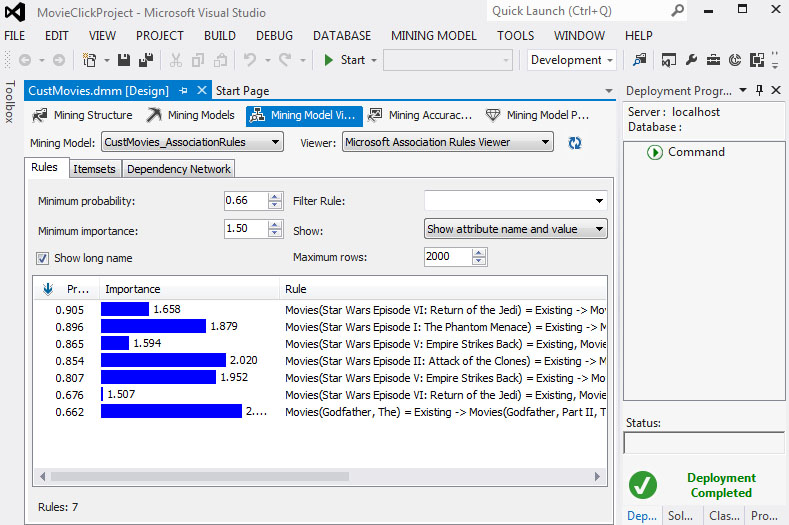
Εικόνα 9.24
Άσκηση 5
Να δημιουργήσετε ένα νέο μοντέλο που να συσχετίζει τις ταινίες με την ηλικία των πελατών. Αυτά τα δύο δεδομένα (ταινίες και ηλικία πελατών) να χρησιμοποιηθούν ως είσοδοι (input variables) στο νέο μοντέλο, αλλά να γίνεται και η πρόβλεψή τους (predicable variables).
Λύση
-
Λύση άσκησης 5:
+
1. Καταρχήν, πρέπει να εισάγουμε τις ηλικίες των πελατών στο νέο μοντέλο. Ο αλγόριθμος, όμως, δεν μπορεί να επεξεργαστεί συνεχείς τιμές, οι οποίες περιέχονται στο πεδίο Age του πίνακα Customers. Συνεπώς, θα πρέπει να μετατραπούν σε διακριτές. Γι’ αυτό, θα πρέπει να δημιουργήσουμε ένα νέο πεδίο στον πίνακα Customers. Επιλέγουμε, λοιπόν, την καρτέλα του designer της βάσης MovieClick.dsv, όπως φαίνεται στην Εικόνα 9.25. Στη συνέχεια, κάνουμε δεξί κλικ στον πίνακα Customers και επιλέγουμε New Named Calculation.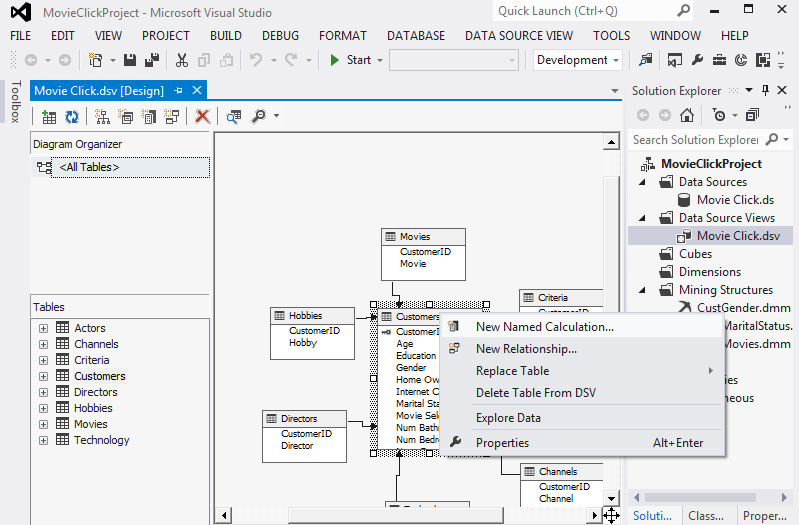
Εικόνα 9.25
2. Στο παράθυρο που εμφανίζεται, όπως φαίνεται στην Εικόνα 9.26, συμπληρώνουμε τα πεδία ως εξής:
Στο πεδίο Column name συμπληρώνουμε το όνομα του νέου πεδίου που δημιουργούμε στον πίνακα Customers. Στη συγκεκριμένη περίπτωση, συμπληρώνουμε το όνομα CategorizedAge.
- Στο πεδίο Expression συμπληρώνουμε τις εντολές με τις οποίες θα δημιουργηθεί το νέο πεδίο του πίνακα Customers:
CASE
WHEN [Age] < 20 THEN ‘Under 20’
WHEN [Age] <= 30 THEN ‘Between 20 and 30’
WHEN [Age] <= 40 THEN ‘Between 30 and 40’
ELSE ‘Over 40’
END
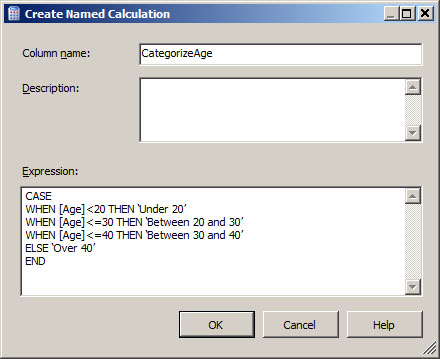
Εικόνα 9.26
3. Επιστρέφουμε στην καρτέλα Mining Structure του CustMovies.dmm, όπως φαίνεται στην Εικόνα 9.27, και κάνουμε add a Column, για να επιλέξουμε το πεδίο που μας ενδιαφέρει (CategorizeAge).
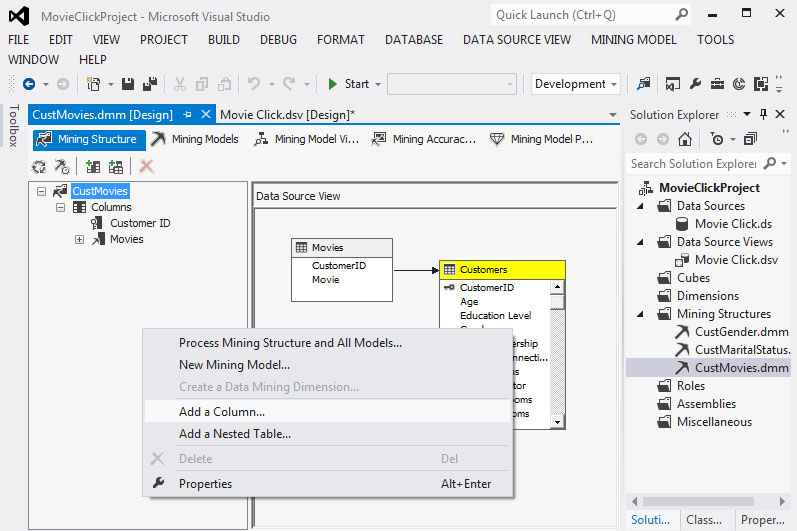
Εικόνα 9.27
4. Στην καρτέλα Mining Models, όπως φαίνεται στην Εικόνα 9.28, επιλέγουμε τα δεδομένα του πεδίου CategorizeAge να είναι Predict.
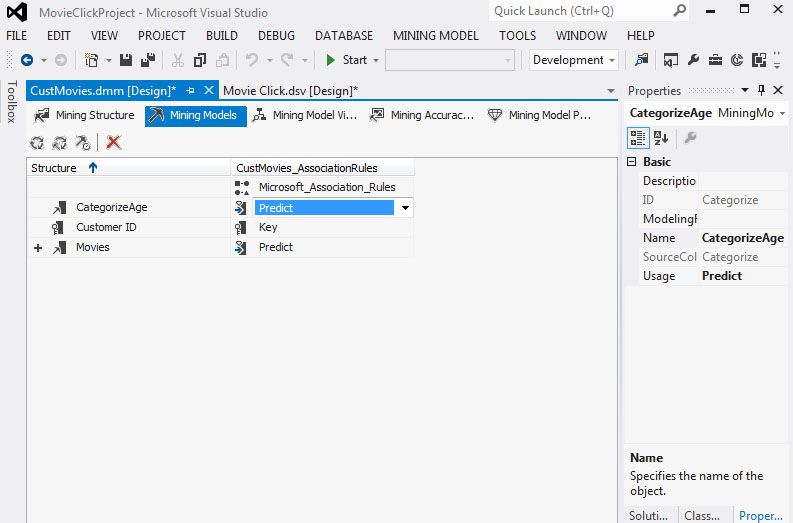
Εικόνα 9.28
5. Στo παράθυρο Set algorithms parameters, όπως φαίνεται στην Εικόνα 9.29, επαναφέρουμε τις τιμές των παραμέτρων στις αρχικές default τιμές.
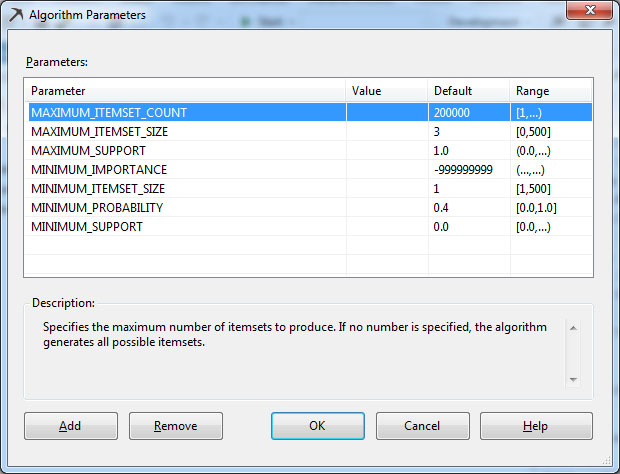
Εικόνα 9.29
6. Στην καρτέλα Itemsets, όπως φαίνεται στην Εικόνα 9.30, παρατηρούμε ότι έχουν δημιουργηθεί itemsets και για το πεδίο CategorizeAge.
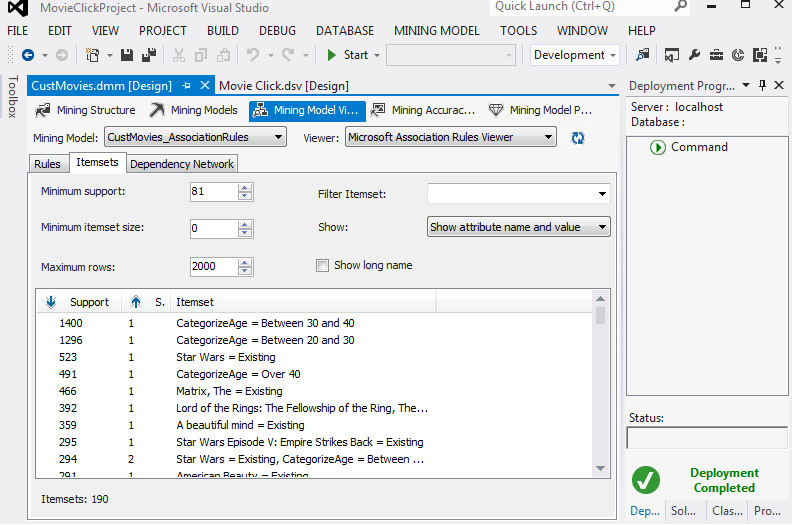
Εικόνα 9.30
7. Στην καρτέλα Rules, όπως φαίνεται στην Εικόνα 9.31, παρατηρούμε ότι έχουν δημιουργηθεί κανόνες που συσχετίζουν τις ταινίες με τις ηλικίες των πελατών. Για παράδειγμα, στην τρίτη γραμμή του πίνακα, την ταινία Fight Club την προτιμούν κυρίως πελάτες ηλικίας μεταξύ 20 και 30 ετών.
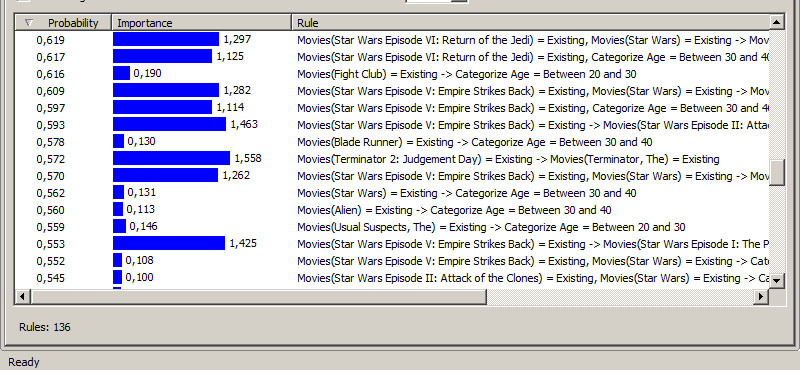
Εικόνα 9.31
8. Τέλος, στην καρτέλα Dependency Network, όπως φαίνεται στην Εικόνα 9.32, παρατηρούμε ότι τα δεδομένα μας έχουν χωριστεί κυρίως σε δύο μεγάλες ομάδες. Στη μία ομάδα ανήκουν οι ταινίες που προτιμούνται από πελάτες ηλικίας μεταξύ 30 και 40 ετών. Στην άλλη ομάδα ανήκουν οι ταινίες που σχετίζονται με πελάτες ηλικίας 20 έως 30 ετών.
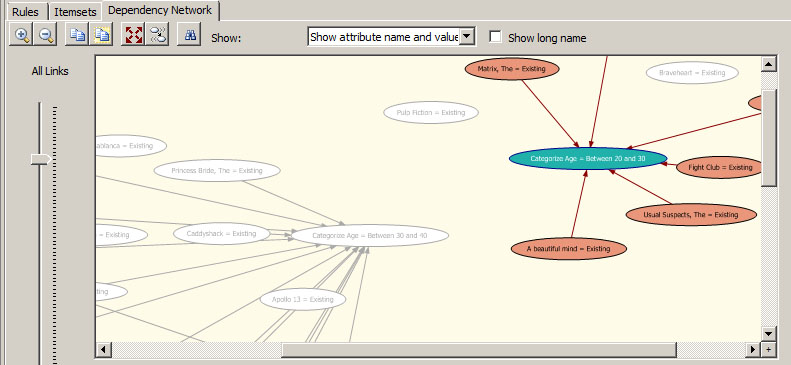
Εικόνα 9.32
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
9.6. Βιβλιογραφία/Αναφορές
Νανόπουλος, Α., & Μανωλόπουλος, Ι. (2008). Εισαγωγή στην Εξόρυξη και τις Αποθήκες Δεδομένων, Αθήνα, Εκδόσεις Νέων Τεχνολογιών.
Χαλκίδη, Μ., & Βεζυργιάννης, Μ. (2005). Εξόρυξη Γνώσης από Βάσεις Δεδομένων και τον Παγκόσμιο Ιστό, Αθήνα, Τυπωθήτω.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
Data Definition Language - DDL
Η γλώσσα ορισμού περιεχομένου χρησιμοποιείται για τον ορισμό των
πινάκων και των μεταξύ τους σχέσεων. Με τη γλώσσα αυτή δηλώνουμε τα
χαρακτηριστικά που έχει κάθε πίνακας και τους αντίστοιχους τύπους
δεδομένων του κάθε χαρακτηριστικού.
Data Manipulation Language - DML
Η γλώσσα χειρισμού δεδομένων χρησιμοποιείται για την επεξεργασία,
την ενημέρωση, την εισαγωγή και την διαγραφή δεδομένων.
Διάγραμμα οντοτήτων-συσχετίσεων (διάγραμμα E-R)
Τα Διάγραμματα οντοτήτων-συσχετίσεων παρέχουν ένα απλό και κατανοητό τρόπο περιγραφής της δομής των δεδομένων της Βάσης Δεδομένων
Ερώτημα SQL
Αποτελεί ένα δομημένο τρόπο σύνταξης ερωτοαποκρίσεων για την αναζήτηση περιεχομένου στη βάση δεδομένων μας.
create database
Ένας νέος πίνακας δημιουργείται με τη χρήση της εντολής CREATE TABLE ή σύνταξη της οποίας έχει ως εξής :
CREATE TABLE (
<όνομα πεδίου 1> <τύπος πεδίου 1>,
<όνομα πεδίου 2> <τύπος πεδίου 2>,
<όνομα πεδίου Ν> <τύπος πεδίου Ν>);
Drop Database
Μπορούμε να διαγράψουμε ολόκληρο πίνακα, μαζί με τα δεδομένα που τυχόν έχει χρησιμοποιώντας την εντολή DROP σύμφωνα με το ακόλουθο πρότυπο :
DROP TABLE <όνομα πίνακα>
ON UPDATE
H πρόταση ON UPDATE προσδιορίζει την ενέργεια που θα εκτελεστεί αν θέλουμε να αλλάξουμε την τιμή ενός πεδίου:
UPDATE <όνομα πίνακα> SET <όνομα πεδίου> <νέα τιμή πεδίου> WHERE <κριτήρια επιλογής εγγραφών>
ON DELETE
Ο σκοπός είναι πολύ απλός, διαγράφει εγγραφές από ένα πίνακα. Και πάλι έχομε την δυνατότητα να ορίσουμε ποιές εγγραφές θέλουμε να διαγραφούν (ή και όλες) π.χ.:
DELETE FROM product WHERE id=1
Καρτεσιανού γινομένου
To Καρτεσιανό γινόμενο αποτελεί την πράξη μεταξύ δύο πινάκων όπου η κάθε εγγραφή του ενός πίνακα συνδυάζεται με όλες τις εγγραφές του άλλου πίνακα
πράξη της επιλογής/selection
Η SQL εντολή μέσω της οποίας ανακτούμε πληροφορίες και συντάσσουμε ερωτήματα είναι η SELECT. Η γενική σύνταξη της SELECΤ είναι αρκετά σύνθετη, ωστόσο ένα απλό πρότυπο είναι το ακόλουθο:
SELECT <πεδίο που θέλουμε να φαίνονται>
FROM <πίνακες από τους οποίους θα αντληθούν τα δεδομένα>
WHERE <κριτήρια επιλογής των εγγραφών>
πράξης της σύνδεσης (join)
Η εντολή JOIN σημαίνει σύνδεση, δηλαδή συνδυασμός δεδομένων από δύο ή περισσότερους πίνακες.
left outer join
Περιλαμβάνει επιπρόσθετα και όλες τις εγγραφές του πίνακα που βρίσκεται στα αριστερά της πράξης της σύνδεσης (join) και δεν εμπεριέχονται στο αποτέλεσμα της πράξης της σύνδεσης.
πράξη του full outer join
Περιλαμβάνει επιπρόσθετα και όλες τις εγγραφές των πινάκων που βρίσκονται στα αριστερά και δεξιά της πράξης της σύνδεσης (join) και δεν εμπεριέχονται στο αποτέλεσμα της πράξης της σύνδεσης.
όρος distinct
Η λέξη DISTINCT αμέσως μετά την SELECT δηλώνει ότι κάθε εγγραφή του πίνακα του αποτελέσματος θα συμπεριληφθεί μία μόνο φορά. Επομένως χρησιμοποιείται όταν θέλουμε να εγγυηθούμε ότι στο αποτέλεσμα του ερωτήματος δεν θα υπάρχουν διπλοεγγραφές πρέπει να χρησιμοποιήσουμε το DISTINCT
όρος GROUP BY
H λέξη GROUP BY προσδιορίζει τις στήλες με τις οποίες θα πραγματοποιηθεί ομαδοποίηση (grouping) των δεδομένων.
όρος HAVING
Ο όρος HAVING χρησιμοποιείται για να ορίσει περιοσρισμούς που σχετίζονται με τα ήδη ομαδοποιημένα αποτελέσματα που έχουν δημιουργηθεί με την GROUP BY.
πράξη της ένωσης πινάκων/σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξη της ένωσης (UNION) συνενώνει τις εγγραφές δύο ή περισσότερων πινάκων.
Ένα παράδειγμα ένωσης δίνεται παρακάτω:
SELECT συνέδριο
FROM πρακτικά_συνεδρίου
UNION
SELECT τιτλος
FROM περιοδικό;
πράξη της τομής σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξεις αυτές υλοποιούνται στην SQL με τις εντολές UNION, EXCEPT και INTERSECΤ αντιστοίχως.
παράδειγμα τομής :
SELECT ονομα
FROM συνδρομητης
INTERSECT
SELECT ονομα
FROM συγγραφεας;
πράξη της διαφοράς σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξεις αυτές υλοποιούνται στην SQL με τις εντολές UNION, EXCEPT και INTERSECΤ αντιστοίχως.
παράδειγμα διαφοράς :
SELECT κωδικός,τίτλος
FROM άρθρο
EXCEPT
SELECT κωδικός,τίτλος
FROM άρθρο
WHERE κωδικός_περιοδικού IS NOT NULL;
Ο όρος ΙΝ
Σε περίπτωση που θέλουμε ένα πεδίο να λαμβάνει τιμές από ένα προκαθορισμένο σύνολο τιμών, τότε μπορούμε εναλλακτικά να χρησιμοποιήσουμε τον τελεστή ΙΝ.
Ο ορος Νot Ιn
Σε περίπτωση που θέλουμε ένα πεδίο να λαμβάνει τιμές από ένα προκαθορισμένο σύνολο τιμών, εξαιρώντας κάποιες τιμές τότε μπορούμε εναλλακτικά να χρησιμοποιήσουμε τον τελεστή ΝΟΤ ΙΝ.
Οι όροι all και some
H SQL προσφέρει τα κατηγορήματα SOME(ή ΑΝΥ) και ALL τα οποία αντιστοιχούν στον υπαρξιακό και καθολικό ποσοδείκτη που χρησιμοποιούμε στα μαθηματικά. Με τη χρήση των κατηγορημάτων αυτών μπορούμε να συντάξουμε πολύ χρήσιμα ερωτήματα με τη χρήση υποερωτημάτων. Πριν απο τα κατηγορήματα SOME και ALL, μπορεί να προηγείται οποιοσδήποτε τελεστής σύγκρισης (=, >, <, >=, <=, <>)
Οι όροι exists και not exists
Η τιμή που επιστρέφει το κατηγόρημα EXISTS είναι αληθής, αν το σύνολο που ακολουθεί δεν είναι κενό. Σε διαφορετική περίπτωση η τιμή που επιστρέφεται είναι ψευδής.
CREATE VIEW
Για τον ορισμό μιας όψης, η SQL παρέχει την εντολή CREATE VIEW που συντάσσεται ως εξής:
CREATE VIEW όνομα-όψης
AS
(υποερώτημα SQL);
DELETE FROM
Παρόμοια με την εντολή UPDATE λειτουργεί και η εντολή DELETE. Ο σκοπός της είναι πολύ απλός, διαγράφει εγγραφές από ένα πίνακα.
DROP TABLE
Η πλήρης διαγραφή ενός πίνακα γίνεται χρησιμοποιώντας την εντολή DROP σύμφωνα με τον ακόλουθο πρότυπο :
DROP TABLE <ονομα πίνακα>
Οι αποθηκευμένες διαδικασίες/stored procedures
O SQL Server δίνει την δυνατότητα υλοποίησης τμημάτων κώδικα τα οποία παραμένουν αποθηκευμένα μέσα στη Βάση Δεδομένων και καλούνται αποθηκευμένες διαδικασίες (stored procedures). Αυτά ενεργοποιούνται ανά τακτά χρονικά διαστήματα για την εκτέλεση μιας σημαντικής λειτουργίας.
Το εύναυσμα/trigger
Ένας σκανδαλισμός ή εύναυσμα (trigger) είναι ένα τμήμα κώδικα που εκτελείται όταν συμβεί ένα γεγονός. Τα γεγονότα που ενεργοποιούν σκανδαλισμούς είναι εισαγωγές, διαγραφές, και ενημερώσεις στα δεδομένα ενός πίνακα.
Ευρετήριο
Ένας κατάλογος (ευρετήριο) ορίζεται σε μία ή περισσότερες στήλες ενός πίνακα και στοχεύει στην αποδοτικότερη εκτέλεση των ερωτημάτων που χρησιμοποιούν τις στήλες αυτές στη συνθήκη WHERE. Η κατασκευή και κατάργηση καταλόγων πραγματοποιείται με τις εντολές CREATE INDEX και DROP INDEX αντίστοιχα.
ALTER TABLE
O ορισμός ενός πίνακα μπορεί να μεταβληθεί στην πορεία, αναλόγως με τις απαιτήσεις. H SQL προσφέρει την εντολή ALTER TABLE, με την οποία επιτρέπονται να γίνουν συγκεκριμένες αλλαγές στον πίνακα: (προσθήκη νέας στήλης, διαγραφή υπάρχουσας στήλης, αλλαγή πεδίου ορισμού μίας στήλης, εισαγωγή νέου περιορισμού, κατάργηση περιορισμού, αλλαγή της εξ ορισμού τιμής στήλης, κατάργηση αρχικής τιμής στήλης).
εντολή grant.
Με την εντολή GRANT δίνουμε δικαιώματα χρήσης της βάσης δεδομένων σε χρήστες.
εντολή revoke.
Με την εντολή REVOKE αφαιρούμε από τους χρήστες τα δικαιώματα χρήσης ενός στοιχείου (π.χ. πίνακα, όψη) μιας βάσης δεδομένων.
H παράμετρος Split method:
Αυτή η παράμετρος καθορίζει τη μέθοδο με την οποία διαχωρίζονται οι κόμβοι του δένδρου. Μπορεί να πάρει τις τιμές [1,3] όπου 1 είναι η τιμή για Binary δένδρο, 2 η τιμή για Complete (multi-way) δένδρο και 3 η τιμή και για τα δύο μαζί.
Κατηγοριοποίηση (classification)
Η κατηγοριοποίηση αποτελεί μια σημαντική λειτουργία εξόρυξης δεδομένων, όπου επιθυμούμε να προβλέψουμε σε πια κατηγορία εντάσσονται και ανήκουν κάθε φορά τα δεδομένα μας.
H παράμετρος Split method:
Αυτή η παράμετρος καθορίζει τη μέθοδο με την οποία διαχωρίζονται οι κόμβοι του δένδρου. Μπορεί να πάρει τις τιμές [1,3] όπου 1 είναι η τιμή για Binary δένδρο, 2 η τιμή για Complete (multi-way) δένδρο και 3 η τιμή και για τα δύο μαζί.
H παράμετρος Stopping Tolerance
Αυτή η παράμετρος καθορίζει τον αριθμό των περιπτώσεων που μετακινούνται μεταξύ των clusters σε κάθε πέρασμα του αλγορίθμου. Ο αλγόριθμος εφαρμόζεται επαναληπτικά στα δεδομένα και σχηματίζει τα cluster με την μορφή που εμείς τα βλέπουμε, ύστερα από ένα σύνολο επαναλήψεων. Επειδή σε κάθε επανάληψη προστίθενται διαρκώς και νέες περιπτώσεις, η τιμή της παραμέτρου μπορεί να θεωρηθεί ως ποσοστό και όχι ένας συγκεκριμένος αριθμός. Η προεπιλεγμένη τιμή της παραμέτρου είναι 10.
Η τάση (trend)
Η τάση μας δείχνει την γενική κατεύθυνση των δεδομένων μας. Για παράδειγμα, η τάση είναι αυξανόμενη στις πωλήσεις προϊόντων τις ημέρες των Χριστουγέννων.
Η περιοδικότητα (periodicity)
Η περιοδικότητα αφορά την επανεμφάνιση κάποιων τάσεων στα δεδομένα μας. Για παράδειγμα, οι πωλήσεις παγωτών αυξάνονται κάθε καλοκαίρι.
Οι ακραίες τιμές (outliers)
Κάποια δεδομένα ενδέχεται να μην είναι δυνατόν να συμπεριλφθούν σε κάποια ομάδα. Τα δεδομένα αυτά καλούνται απομακρυσμένα ή απομονωμένα (outliers) και συνήθως δημιουργούν πρόβλημα στις μεθόδους ομαδοποίησης.
ολοκληρωμένη (integrated)
Μια αποθήκη δεδομένων είναι ολοκληρωμένη διότι μπορεί και συνενώνει μέσα τις πολλές ανομοιογενείς βάσεις δεδομένων.
Μη ευμετάβλητη (non volatile)
Μια αποθήκη δεδομένων συνήθως δεν μεταβάλλεται ως προς το περιεχόμενο της. Αυτό που συμβαίνει είναι να προστίθεται μόνο καινούργιο περιεχόμενο.
Αφορά ιστορικά δεδομένα (time-variant)
Μια αποθήκη δεδομένων αφορά δεδομένα που μπορεί να έχουν βάθος δεκαετιών.
Ένα μέτρο ή αλλιώς μετρική (measure)
Είναι το μέγεθος ή τα μεγέθη που μας ενδιαφέρουν να συναθροίσουμε ή να αναλύσουμε κατά τις λειτουργίες OLAP.
διαστάσεις (dimensions)
Οι πληροφορίες που περιγράφουν τα γεγονότα, ονομάζονται διαστάσεις. Για ένα γεγονός πώλησης, διαστάσεις είναι, π.χ., το προϊόν που πωλήθηκε, το υποκατάστημα όπου έγινε η πώληση, η ημερομηνία πώλησης, κ.λπ.
Η ιεραρχία (hierarchy)
Η ιεραρχία (hierarchy) μιας διάστασης
Μια διάσταση μπορεί να αποτελείται από διαφορετικά επίπεδα ανάλυσης και να ενσωματώνει μια ιεραρχία. Για παράδειγμα, η διάσταση του χρόνου μπορεί να αναλυθεί σε μέρες, εβδομάδες, κτλ.
Το σχήμα Αστέρα (star schema)
Σύμφωνα με το μοντέλο αυτό η αποθήκη δεδομένων περιέχει ένα μεγάλο κεντρικό πίνακα που καλείται πίνακας γεγονότων (fact table) και ένα σύνολο μικρότερων πινάκων που καλούνται πίνακες διαστάσεων (fimension tables) και συνδέονται απευθείας στον fact table.
To σχήμα χιονονιφάδας (snowflake schema)
Το μοντέλο χιονιφάδας αποτελεί παραλλαγή του μοντέλου αστέρα. Διαφέρει κατά το ότι κάποιοι πίνακες διαστάσεων μπορούν να αναλυθούν περισσότερο χρησιμοποιώντας βοηθητικούς πίνακες. Η λειτουργία αυτή μοιάζει με τη διαδικασία της κανονικοποίησης στις σχεσιακές βάσεις δεδομένων.
Το σχήμα γαλαξία (galaxy schema),
Στο σχήμα γαλαξία έχουμε περισσότερους τους ενός fact tables, τους οποίους μπορούν να διαμοιράζονται περισσότερες διαστάσεις.
Η πράξη Roll-up
Η λειτουργία αυτή ομαδοποιεί τα δεδομένα του κύβου σε υψηλότερο επίπεδο ανάλυσης και μας οδηγεί σε ανώτερο επίπεδο της θεματικής ιεραρχίας, αθροίζοντας τα μετρικά στοιχεία.
Η πράξη Drill-down
Επιφέρει ακριβώς τα αντίθετα αποτελέσματα από τη λειτουργία ROLL-UP. Με τη λειτουργία DRILL-DOWN αυξάνουμε το επίπεδο λεπτομέρειας των δεδομένων μας.
Η πράξη Slice
Η λειτουργία SLICE επιλέγει τα δεδομένα του κύβου μας ως προς μία διάσταση.
Η πράξη Dice
H λειτουργία DICE επιλέγει τα δεδομένα ως προς πολλές διαστάσεις του κύβου μας, δημιουργώντας έναν μικρότερο κύβο.
Η πράξη Pivot
Η λειτουργία PIVOT πραγματοποιεί περιστροφή στις διαστάσεις του κύβου, με αποτέλεσμα τα δεδομένα να απεικονίζονται με διαφορετικό τρόπο κάθε φορά.
Συναθροιστικές συνάρτήσεις (aggregation function)
Οι συναρτήσεις συνάθροισης χρησιμοποιούνται για την εξαγωγή συγκεντρωτικών τιμών από τις τιμές μίας στήλης.
Προκειμένου να εξάγουμε έναν κανόνα συσχέτισης, πρέπει να ικανοποιούνται κάποια κατώτατα όρια τόσο για το support όσο και για τo confidence/probability. Ο κανόνας πρέπει να έχει support μεγαλύτερo από το όριο, που ονομάζεται ελάχιστη υποστήριξη (minimum_support), και η εμπιστοσύνη πρέπει να είναι μεγαλύτερη από το όριο, που ονομάζεται ελάχιστη εμπιστοσύνη (minimum_probability).
Προκειμένου να εξάγουμε έναν κανόνα συσχέτισης, πρέπει να ικανοποιούνται κάποια κατώτατα όρια τόσο για το support όσο και για τo confidence/probability. Ο κανόνας πρέπει να έχει support μεγαλύτερo από το όριο, που ονομάζεται ελάχιστη υποστήριξη (minimum_support), και η εμπιστοσύνη πρέπει να είναι μεγαλύτερη από το όριο, που ονομάζεται ελάχιστη εμπιστοσύνη (minimum_probability).
Slice
H λειτουργία Slice επιλέγει τα δεδομένα ως προς μία διάσταση του κύβου μας, δημιουργώντας μια φέτα ενός κύβου
Pivot
Η λειτουργία Pivot αλλάζει μόνο το τρόπο απεικόνισης των διαστάσεων του κύβου μα