Κεφάλαιο 11. Αποθήκες και κύβοι δεδομένων
11.1 Θεωρητικό υπόβαθρο για τους κύβους δεδομένων και τη πολυδιάστατη ανάλυση
11.2 Δημιουργία ενός κύβου δεδομένων
11.3 Δημιουργία ιεραρχίας σε μια διάσταση του κύβου δεδομένων
11.4 Υποβολή ερωτημάτων στον κύβο δεδομένων
11.5 Υποβολή ερωτημάτων μέσω Pivot table του Excel
11.6... Ασκήσεις για κύβους δεδομένων
11.7 Λύσεις ασκήσεων για κύβους δεδομένων
11.8. Βιβλιογραφία/Αναφορές
Κεφάλαιο
11. Αποθήκες και κύβοι δεδομένων
Σύνοψη
Σ’ αυτό το κεφάλαιο θα παρουσιάσουμε τη δημιουργία μιας αποθήκης δεδομένων ή, αλλιώς, ενός κύβου δεδομένων. Ο κύβος είναι μια πολυδιάστατη δομή δεδομένων που εμπεριέχει συναθροιστικές πληροφορίες για μία ή περισσότερες βάσεις δεδομένων. Η συνάθροιση της πληροφορίας οδηγεί σε γρήγορους χρόνους απόκρισης ερωτημάτων που τίθενται από υψηλόβαθμα στελέχη επιχειρήσεων, προκειμένου αυτά να λάβουν συνήθως στρατηγικές αποφάσεις για την επιχείρηση.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
11.1.
Θεωρητικό υπόβαθρο για τους κύβους δεδομένων και τη πολυδιάστατη ανάλυση
Τα ανώτερα στελέχη μιας επιχείρησης καλούνται συχνά να πάρουν στρατηγικές αποφάσεις (π.χ. την είσοδο της επιχείρησης σε μια νέα αγορά, τη δημιουργία ενός νέου προϊόντος κτλ.) για το μέλλον της επιχείρησης, βασιζόμενοι σ’ έναν τεράστιο όγκο δεδομένων που αφορούν την επιχείρηση και το περιβάλλον της (Νανόπουλος, & Μανωλόπουλος, 2008· Χαλκίδη, & Βεζυργιάννης, 2005). Η αποθήκη δεδομένων είναι μια πολυδιάστατη δομή, η οποία, καθώς περιέχει συναθροιστικές πληροφορίες που προέρχονται συνήθως από περισσότερες ετερογενείς βάσεις δεδομένων, βοηθά στη λήψη τέτοιων στρατηγικών αποφάσεων. Συγκεκριμένα, μια αποθήκη δεδομένων έχει τα εξής χαρακτηριστικά:
Η αποθήκη δεδομένων εστιάζει σε επιχειρηματικές διεργασίες, στις οποίες λαμβάνουν χώρα διάφορα γεγονότα (facts). Για παράδειγμα, για μία αποθήκη δεδομένων που αφορά τις πωλήσεις προϊόντων, γεγονός αποτελεί η πώληση ενός συγκεκριμένου προϊόντος σε κάποιο υποκατάστημα, μία δεδομένη χρονική στιγμή. Μία αριθμητική ποσότητα που αφορά σε ένα γεγονός, ονομάζεται μέτρο ή αλλιώς μετρική (measure). Στο γεγονός του προηγούμενου παραδείγματος, ένα μέτρο θα μπορούσε να είναι ο αριθμός των τεμαχίων του προϊόντος που πωλήθηκαν σε πελάτες. Οι πληροφορίες που περιγράφουν το γεγονός, ονομάζονται διαστάσεις (dimensions). Διαστάσεις ενός γεγονότος πώλησης, είναι, π.χ., το προϊόν που πωλήθηκε, το υποκατάστημα όπου έγινε η πώληση, η ημερομηνία πώλησης, κ.λπ. Κάθε διάσταση μπορεί να εμπεριέχει μέσα της μια ιεραρχία (hierarchy). Για παράδειγμα, η διάσταση του χρόνου μπορεί να αναλύεται στο επίπεδο της ώρας, της ημέρας, της εβδομάδας ή του μήνα μιας συναλλαγής κτλ. Η διάσταση του υποκαταστήματος μπορεί να αναλύεται στο επίπεδο της περιοχής, της πόλης, της χώρας κτλ.
Σε μια αποθήκη δεδομένων, τα γεγονότα αναπαρίστανται ως πολυδιάστατοι κύβοι δεδομένων. Κάθε άξονας του κύβου αντιστοιχεί σε μία διάσταση. Κάθε διάσταση αναπαρίσταται ως προς ένα επίπεδο της ιεραρχία της. Οι τιμές των ιδιοτήτων όλων των διαστάσεων διαμερίζουν τον κύβο σε κελιά, όπου κάθε κελί του περιέχει την αντίστοιχη τιμή του μέτρου. Ο σχεδιασμός ενός κύβου δεδομένων γίνεται συνήθως με το σχήμα αστέρα (star schema). Σε ένα σχήμα αστέρα, τα γεγονότα αναπαρίστανται στο πίνακα γεγονότων (fact table), ενώ κάθε διάσταση αναπαρίσταται με ξεχωριστό πίνακα διαστάσεων (dimension table). Το σχήμα αστέρα παίρνει την ονομασία του από τη δομή που προκύπτει, με τον πίνακα γεγονότων στο κέντρο και τις διαστάσεις τοποθετημένες ακτινωτά γύρω του. Εκτός του σχήματος αστέρα, υπάρχει το
σχήμα χιονονιφάδας (snowflake schema). Η διαφορά του με το σχήμα αστέρα βρίσκεται στο γεγονός ότι οι πίνακες διαστάσεων αποσυντίθενται σε περισσότερους από έναν πίνακες. Επίσης, υπάρχει το σχήμα γαλαξία (galaxy schema), όπου δύο ή περισσότεροι πίνακες γεγονότων διαμοιράζονται τους ίδιους πίνακες διαστάσεων.
Σ’ έναν κύβο δεδομένων μπορούμε να αλλάζουμε το επίπεδο της ιεραρχίας σε κάθε διάστασή του, προσδιορίζοντας έτσι μια διαφορετική όψη του κύβου δεδομένων. Για παράδειγμα, μπορούμε να εξετάσουμε τις πωλήσεις ανά μήνα αντί ανά ημέρα και, έτσι, να διακρίνουμε ότι τους μήνες Αύγουστο και Νοέμβριο είχαμε μειωμένες πωλήσεις σε σχέση με άλλους μήνες. Αυτές οι ενέργειες εκτελούνται με τις πράξεις OLAP (On line Analytical Processing) που βοηθούν στην εύκολη διατύπωση αναλυτικών ερωτήσεων επί κύβων δεδομένων, καθώς και στη γρήγορη εκτέλεσή τους. Οι βασικές πράξεις OLAP αναλύονται παρακάτω:
Η πράξη Rollup-up παράγει ένα κύβο δεδομένων με μειωμένο επίπεδο λεπτομέρειας και υλοποιείται όταν (α) σε κάποιες διαστάσεις επιλέγουμε ανώτερο επίπεδο στην ιεραρχία τους ή (β) αφαιρούμε κάποιες διαστάσεις. Η πράξη Drill-down παράγει ένα κύβο δεδομένων με αυξημένο επίπεδο λεπτομέρειας και υλοποιείται όταν (α) σε κάποιες διαστάσεις επιλέγουμε κατώτερο επίπεδο στην ιεραρχία τους ή (β) προσθέτουμε κάποιες διαστάσεις. Η πράξη Slice παράγει ένα κύβο δεδομένων όταν επιλέγουμε δεδομένα από μία μόνο διάσταση. Η πράξη Dice παράγει ένα κύβο δεδομένων όταν επιλέγουμε δεδομένα από μία ή περισσότερες διαστάσεις. Η πράξη Pivot παράγει ένα κύβο δεδομένων του οποίουοι διαστάσεις του έχουν αναδιαταχθεί. Τέλος, με τη βοήθεια των πράξεων OLAP είναι εύκολη η πολυδιάστατη ανάλυση ενός κύβου δεδομένων. Όμως, για την εφαρμογή τους απαιτείται ο ορισμός του τρόπου παραγωγής των κύβων-αποτελεσμάτων, μέσω μίας συναθροιστικής συνάρτησης (aggregation function) επί των τιμών των μέτρων. Οι βασικές συναθροιστικές συναρτήσεις είναι αυτές του αθροίσματος (sum), πλήθους (count), μέσου όρου (avg), μεγίστου (max), και ελαχίστου (min).
Τύποι συστημάτων OLAP
Όσον αφορά, το φυσικό επίπεδο μιας αποθήκης δεδομένων, στο περιβάλλον του SQL Server υποστηρίζονται τρεις βασικοί τύποι συστημάτων OLAP:
- Multidimensional OLAP (MOLAP)
Στα συστήματα MOLAP ο κύβος δεδομένων αποθηκεύεται σε πολυδιάστατους πίνακες. Με αυτόν τον τρόπο, επιτυγχάνεται γρήγορη εκτέλεση των πράξεων OLAP, καθώς η προσπέλαση του κύβου είναι άμεση. Ωστόσο, οι πίνακες είναι αραιοί επειδή δεν αντιστοιχεί πάντα κάθε συνδυασμός διαστάσεων σε ένα γεγονός. Για αυτόν το λόγο πολλές φορές εφαρμόζεται συμπίεση ώστε να μειωθεί ο αποθηκευτικός χώρος, κάτι το οποίο επιφέρει αύξηση του χρόνου της δημιουργίας του κύβου.
Στα συστήματα ROLAP χρησιμοποιείται ένα σχεσιακό σύστημα διαχείρισης βάσεων δεδομένων, όπου υπάρχουν ξεχωριστοί πίνακες γεγονότων και διαστάσεων. Αυτό αποτελεί και ένα από τα σπουδαιότερα πλεονεκτήματα αυτών των συστημάτων, καθώς υπάρχουν πρότυπα για να εφαρμοστεί η σχεσιακή τεχνολογία με αποτέλεσμα να παρουσιάζουν πολύ καλή κλιμάκωση στη διαχείριση μεγάλου όγκου δεδομένων. Ωστόσο η ταχύτητα εκτέλεσης αυτών των πράξεων είναι μειωμένη σε σχέση με τα MOLAP.
Τα συστήματα HOLAP είναι τα πιο διαδεδομένα, καθώς δημιουργήθηκαν με σκοπό τον συνδυασμό των πλεονεκτημάτων των παραπάνω συστημάτων. Συγκεκριμένα, δίνεται η δυνατότητα αποθήκευσης ενός τμήματος του κύβου με την μορφή MOLAP για τη γρηγορότερη εκτέλεση πράξεων OLAP, ενώ ο υπόλοιπος κύβος μπορεί να αποθηκευτεί όπως στα συστήματα ROLAP, προκειμένου να επιτευχθεί υψηλή κλιμάκωση σε μεγάλο όγκο δεδομένων.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
11.2. Δημιουργία ενός κύβου δεδομένων
Ας υποθέσουμε ότι βρισκόμαστε στην εταιρία FoodMart ως διαχειριστές της βάσης δεδομένων που έχουμε ήδη επεξεργαστεί στις ενότητες 6.2 και 6.5. Η FoodMart είναι μια μεγάλη αλυσίδα παντοπωλείων με πωλήσεις στις Ηνωμένες Πολιτείες, το Μεξικό και τον Καναδά. Το εμπορικό τμήμα της εταιρείας θέλει να αναλύσει όλες τις πωλήσεις των προϊόντων της και την αγοραστική συμπεριφορά των πελατών της που έγιναν κατά τη διάρκεια του ημερολογιακού έτους 1997. Εμείς, χρησιμοποιώντας τα στοιχεία που αποθηκεύονται στη βάση δεδομένων της επιχείρησης, θα χτίσουμε μια πολυδιάστατη δομή δεδομένων (ένα κύβο), για να επιτρέψουμε τους γρήγορους χρόνους απόκρισης της βάσης, όποτε προστρέχουν σ’ αυτήν οι εμπορικοί αναλυτές της εταιρείας. Σ’ αυτήν την ενότητα, λοιπόν, θα δημιουργήσουμε, μέσα από αναλυτικά βήματα, έναν κύβο πωλήσεων (Sales Cube) με τα εξής στοιχεία:
a. Πίνακας γεγονότων: Sales_fact_1997
b. Πίνακες διαστάσεων: Product, Product class, Time By Day, Customer,
Store
c. Μετρικά: store_sales, store_cost και unit_sales.
Αναλυτικά βήματα
- Η εισαγωγή της βάσης δεδομένων FoodMart στο περιβάλλον του Management Studio και Business Intelligence έχει γίνει ήδη στο Κεφάλαιο 6. Συγκεκριμένα, η εισαγωγή της βάσης δεδομένων FoodMart στο Management Studio περιγράφεται στην Ενότητα 6.2. Επιπλέον, η εισαγωγή της βάσης δεδομένων FoodMart στο περιβάλλον του Business Intelligence περιγράφεται στην Ενότητα 6.5, όπου το σχεσιακό σχήμα της βάσης δεδομένων περιγράφεται με την Εικόνα 6.66.
- Από τον Solution Explorer επιλέγουμε Cubes. Στη συνέχεια, επιλέγουμε με δεξί κλικ New Cube, όπως φαίνεται στην Εικόνα 11.1, προκειμένου να δημιουργήσουμε έναν νέο κύβο.
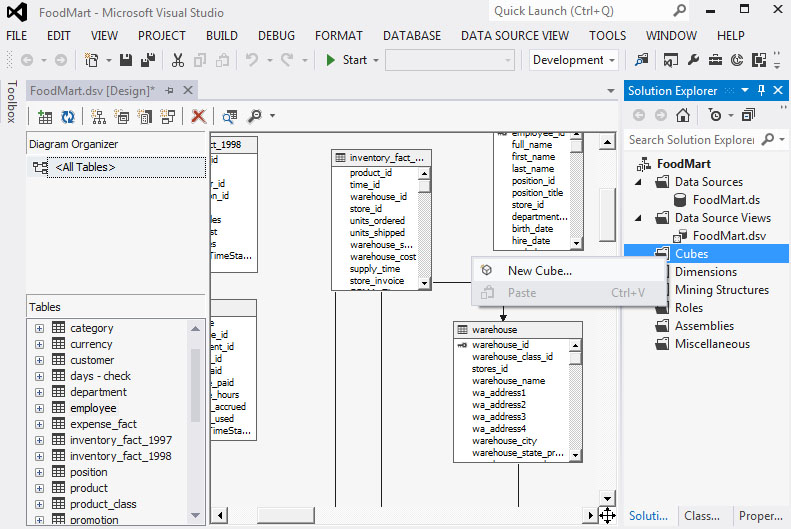
Εικόνα 11.1
-
Στο παράθυρο Cube Wizard, όπως φαίνεται στην Εικόνα 11.2, επιλέγουμε Use existing tables. Στη συνέχεια, πατάμε Next>
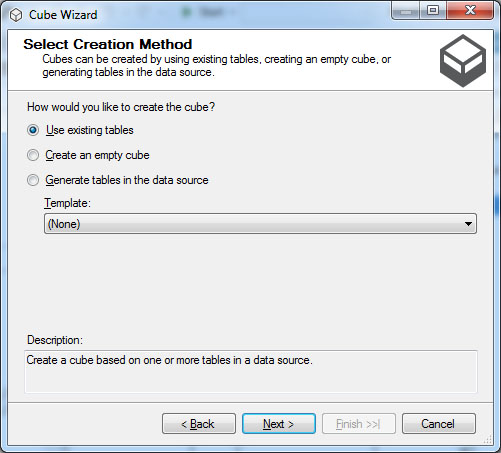
Εικόνα 11.2
-
Στο παράθυρο Select Measure Group Tables, όπως φαίνεται στην Εικόνα 11.3, επιλέγουμε τον πίνακα γεγονότων (fact table). Πιο συγκεκριμένα, επιλέγουμε τον πίνακα γεγονότων sales_fact_1997.
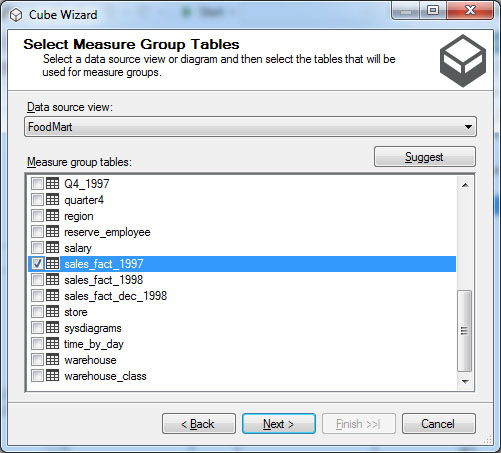
Εικόνα 11.3
-
Στο παράθυρο Select Measures επιλέγουμε τις μετρικές του κύβου μας. Πιο συγκεκριμένα, όπως φαίνεται στην Εικόνα 11.4, διατηρούμε επιλεγμένες τις μετρικές Store Sales, Store Cost και Unit Sales, ενώ αποεπιλέγουμε τη μετρική Sales Fact 1997 Count, την οποία προς το παρόν δεν χρειαζόμαστε.
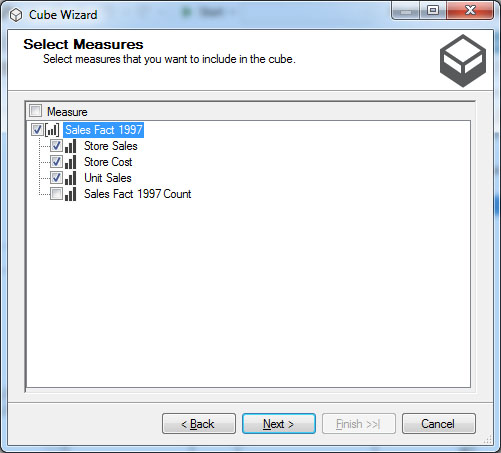
Εικόνα 11.4
-
Στο παράθυρο Select New Dimensions, όπως φαίνεται στην Εικόνα 11.5, εμφανίζονται όλοι οι πίνακες που είναι συνδεδεμένοι στον fact table. Εμείς επιλέγουμε ως πίνακες διαστάσεων τους παρακάτω πίνακες: Product, Product class, Time By Day, Customer, Store. Για τις ανάγκες του παραδείγματος μας αποεπιλέγουμε τον πίνακα Promotion.
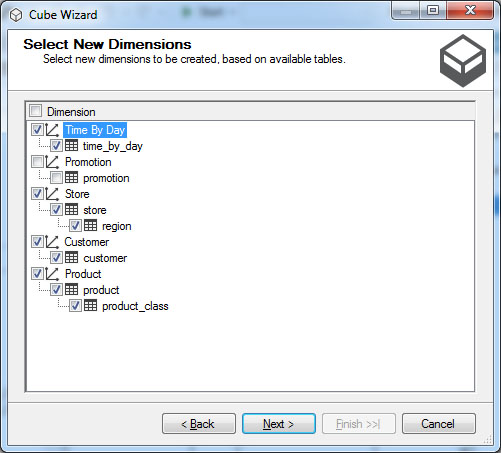
Εικόνα 11.5
-
Στο παράθυρο Completing the Wizard, όπως φαίνεται στην Εικόνα 11.6, ονομάζουμε τον κύβο μας Food_Cube. Στη συνσέχεια, πατάμε Finish.
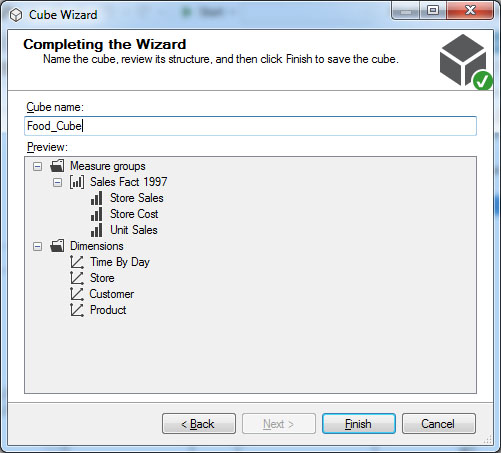
Εικόνα 11.6
-
Εμφανίζεται διαγραμματικά ο κύβος μας. Όπως φαίνεται στην Εικόνα 11.7, το σχήμα του είναι τύπου χιονονιφάδας. Τώρα, επιλέγοντας Start (το πράσινο κουμπί στην επάνω μπάρα εργαλείων), μπορούμε να κάνουμε τον Κύβο μας process.
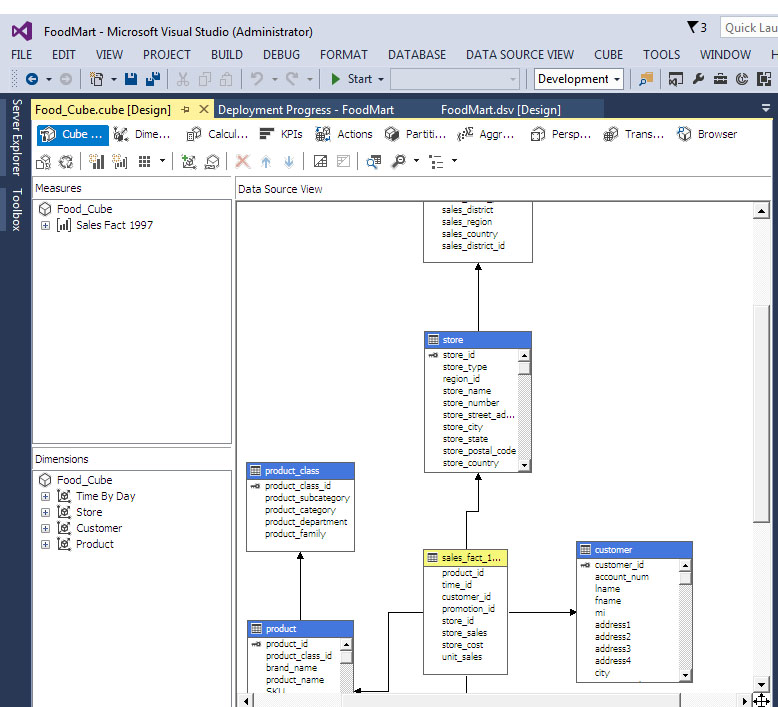
Εικόνα 11.7
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
11.3.
Δημιουργία ιεραρχίας σε μια διάσταση του κύβου δεδομένων
Στην ενότητα αυτή θα δημιουργήσουμε μια ιεραρχία μέσα σε κάθε μία από τις διαστάσεις (time, store, κτλ.) του κύβου πωλήσεων του παραδείγματος μας.
- Για να δημιουργήσουμε μια ιεραρχία σε μια διάσταση (έστω την διάσταση του χρόνου), κάνουμε δεξί κλικ πάνω στο Dimensions του Solution Explorer και, στην συνέχεια, κάνουμε κλικ στο View Designer. Θα εμφανιστεί η παρακάτω οθόνη.
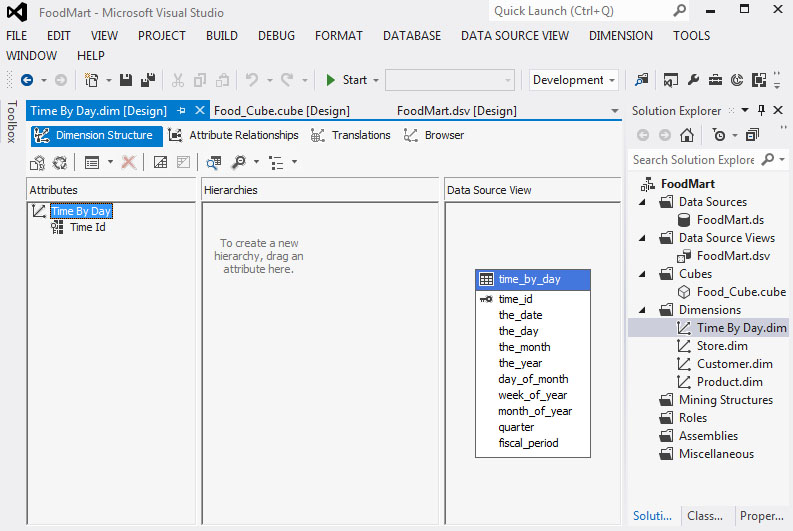
Εικόνα 11.8
-
Με drag and drop προσθέτουμε τα attributes που μας ενδιαφέρουν (The Year, Quarter, The Month, Week of Year, The Day), μεταφέροντας τα από την περιοχή Data Source View στην περιοχή attributes. Στην συνέχεια, για να δημιουργήσουμε την ιεραρχία της διάστασης Τime by Day μεταφέρουμε ξανά με drag and drop τα attributes στην περιοχή Hierarchies, όπως φαίνεται στην Εικόνα 11.9.
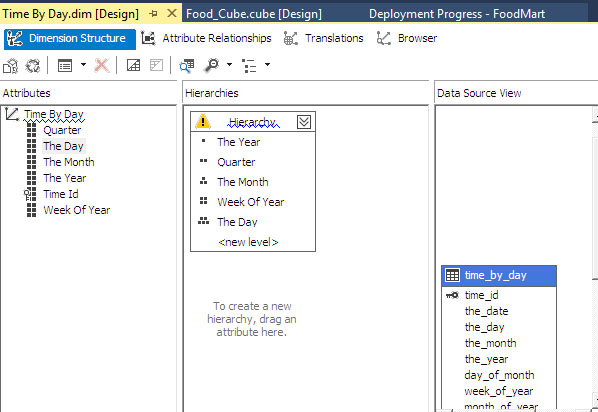
Εικόνα 11.9
-
Το ίδιο θα κάνουμε και με τις άλλες δύο διάστασεις (Store, Product). Για παράδειγμα, για τη διάσταση «Store», η ιεραρχία που θα δημιουργήσουμε φαίνεται στην Εικόνα 11.10.
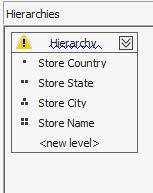
Εικόνα 11.10
-
Για να δημιουργήσουμε τη διάσταση Product, κάνουμε δεξί κλικ πάνω στο Dimensions του Solution Explorer και, στην συνέχεια, κάνουμε κλικ στο View Designer, οπότε θα εμφανιστεί η οθόνη της Εικόνας 11.12. Παρατηρούμε ότι ο πίνακας Product συνδέεται με έναν δεύτερο πίνακα, τον πίνακα product_class.
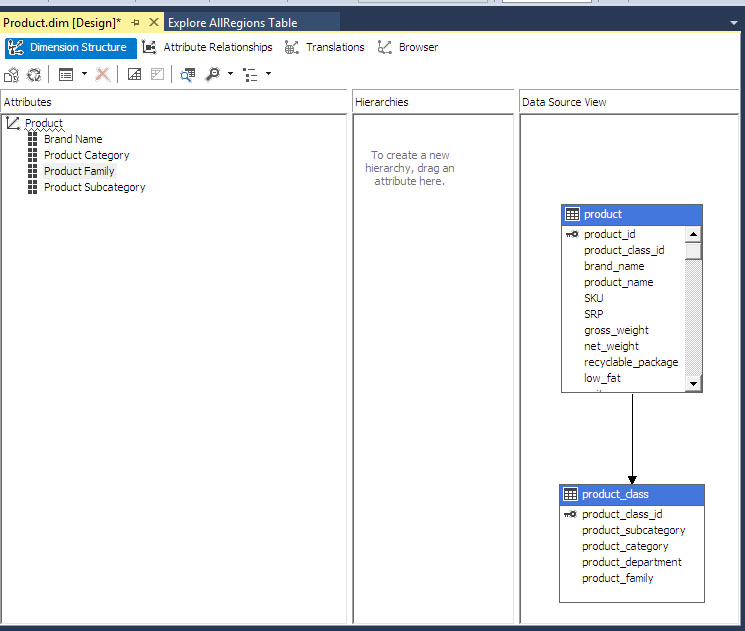
Εικόνα 11.12
-
Προκειμένου να φτιάξουμε την ιεραρχία για τη διάσταση Product, θα πάρουμε πεδία και από τους δύο συσχετιζόμενους πίνακες, όπως φαίνεται στην Εικόνα 11.13.
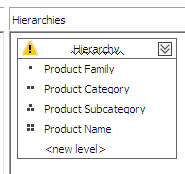
Εικόνα 11.13
Πίνακας Περιεχομένων
Περιεχόμενα Κεφαλαίου
11.4.
Υποβολή ερωτημάτων στον κύβο δεδομένων
Αφού ολοκληρώσαμε τη διαδικασία δημιουργίας ιεραρχίας για καθεμία απ’ τις διαστάσεις του κύβου, κάνουμε process τον κύβο μας, ώστε να ενημερωθεί με τις καινούργιες ιεραρχίες που δημιουργήσαμε στις διαστάσεις του χρόνου, των καταστημάτων και των προϊόντων. Πηγαίνουμε στο solution explorer, κάνουμε διπλό κλικ πάνω στο Food_Cube.cube και επιλέγουμε την καρτέλα Browser. Εμφανίζεται το παράθυρο της Εικόνας 11.14, στο οποίο με drag and drop τοποθετούμε τις διαστάσεις (product, store κτλ.) και το μετρικό (Store cost, Store sales, Unit Sales) που επιθυμούμε.
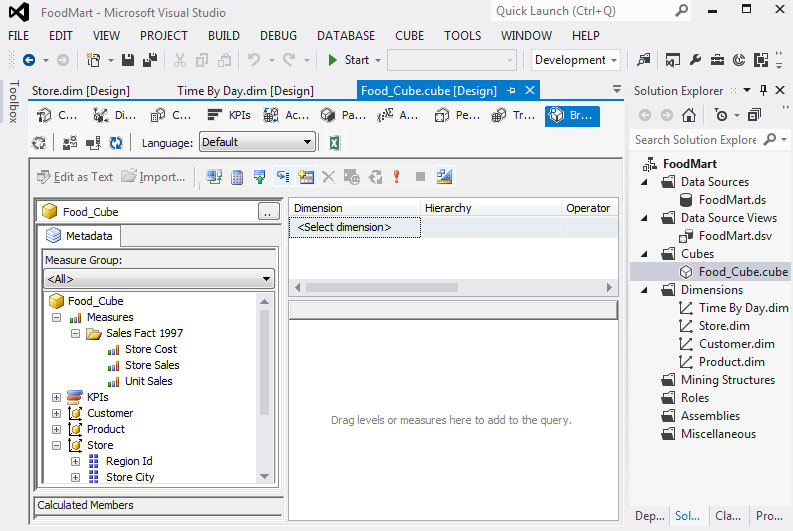
Εικόνα 11.14
Ας υποθέσουμε ότι μας ζητείται να υπολογίσουμε της ποσότητες που πουλήθηκαν στα καταστήματα της εταιρίας για το προϊόν “Big Time Ice Cream” στις πόλεις Los Angeles και San Francisco για τον μήνα Ιούλιο. Για να ικανοποιήσουμε το παραπάνω ερώτημα, τοποθετούμε το μετρικό Unit Sales με drag and drop στην περιοχή Drag levels or measures to add to the query, όπως φαίνεται στην Εικόνα 11.14. Επίσης, τοποθετούμε με drag and drop στην ίδια περιοχή το πεδίο Store City από τη διάσταση Store.
Προκειμένου να φιλτράρουμε τα δεδομένα μας μόνο για τις πόλεις Los Angeles και San Fransisco για το προϊόν “Big Time Ice Cream” για τον μήνα Ιούλιο, διαμορφώνουμε την περιοχή πάνω από το grid, που αναγράφει <Select dimension>. Συγκεκριμένα, επιλέγουμε Product Name = {Big Time Ice Cream}, Store City = {Los Angeles, San Fransisco} και The Month ={July} για τις διαστάσεις Product, Store και Time by day αντίστοιχα. Είμαστε πλέον έτοιμοι να κάνουμε τις πράξεις drill through ή roll up στον κύβο μας.
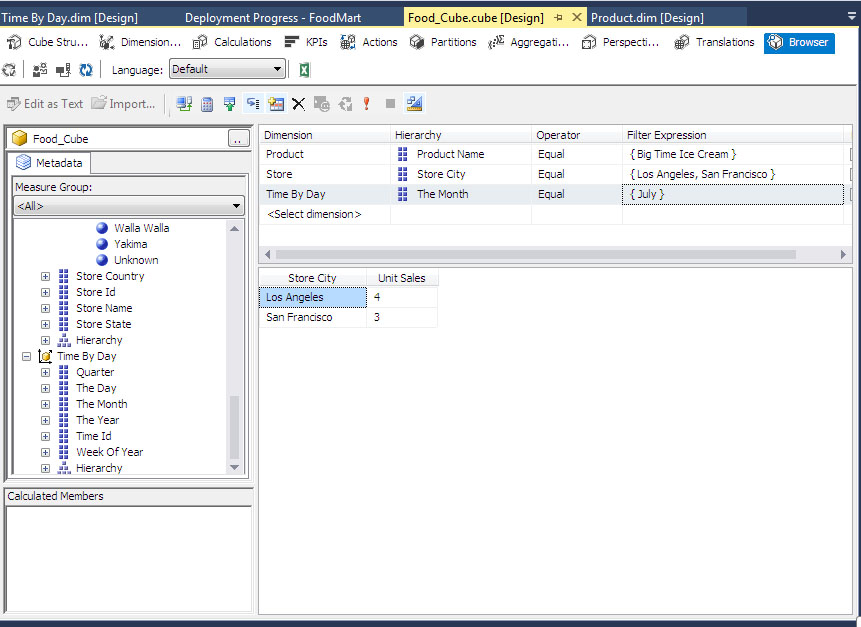
Εικόνα 11.15
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
11.5.
Υποβολή ερωτημάτων μέσω Pivot table του Excel
Ένας εναλλακτικός τρόπος υποβολής ερωτημάτων στον κύβο δεδομένων μας είναι η χρήση του Pivot table του MS Excel. Το κύριο πλεονέκτημα αυτής της επιλογής είναι ότι το Excel επιτρέπει να φτιάχνουμε διαγράμματα που περιγράφουν τα δεδομένα μας με γραφικό τρόπο. Το Visual Studio προσφέρει τη δυνατότητα της άμεσης μεταφοράς στο περιβάλλον του MS Excel (εφόσον αυτό έχει προεγκατασταθεί) σύμφωνα με τα παρακάτω βήματα:
- Επιλέγουμε το κουμπί με το λογότυπο του MS Excel (πράσινο Χ) στη μέση περίπου της οθόνης μας, όπως φαίνεται στην Eικόνα 11.16.
Εικόνα 11.16
-
Μεταφερόμαστε στο MS Excel (στο παράδειγμά μας, στην έκδοση 2007), όπου εμφανίζεται το μήνυμα της Εικόνας 11.17. Επιλέγουμε Ενεργοποίηση.
Εικόνα 11.17
-
Εμφανίζεται η οθόνη που φαίνεται στην Εικόνα 11.18. Στα πάνω αριστερά κελιά (Συγκεντρωτικός πίνακας) παρατηρούμε το pivot table. Ακόμη, στο δεξί μέρος βλέπουμε τη λίστα με τα διαθέσιμα πεδία που δημιουργήθηκαν και μεταφέρθηκαν απ’ το Visual Studio. Κάτω απ’ αυτήν τη λίστα υπάρχουν τέσσερα πεδία: Φίλτρα, Ετικέτες στήλης, Ετικέτες γραμμής, Τιμές.
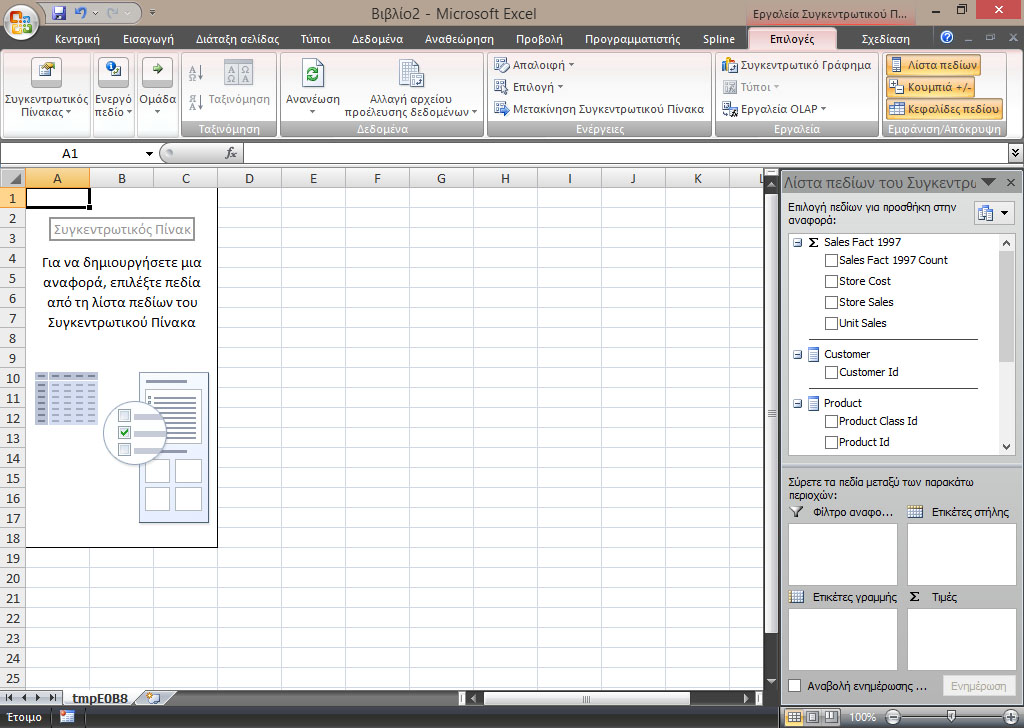
Εικόνα 11.18
4. Προκειμένου να απαντήσουμε στο ίδιο ερώτημα της Ενότητα 11.3 −
μεταφέρουμε από τη λίστα πεδίων του Συγκεντρωτικού Πίνακα, το Unit Sales
στην αριστερή περιοχή της Εικόνας 11.18. Επίσης, μεταφέρουμε την ιεραρχία
της διάστασης Store στις Ετικέτες γραμμής και εφαρμόζουμε όλα τα φίλτρα
του ερωτήματος μας (Product Name = {Big Time Ice Cream}, Store City = {Los
Angeles, San Fransisco} και The Month ={July} ) στη περιοχή πεδίων του
Συγκεντρωτικού Πίνακα.
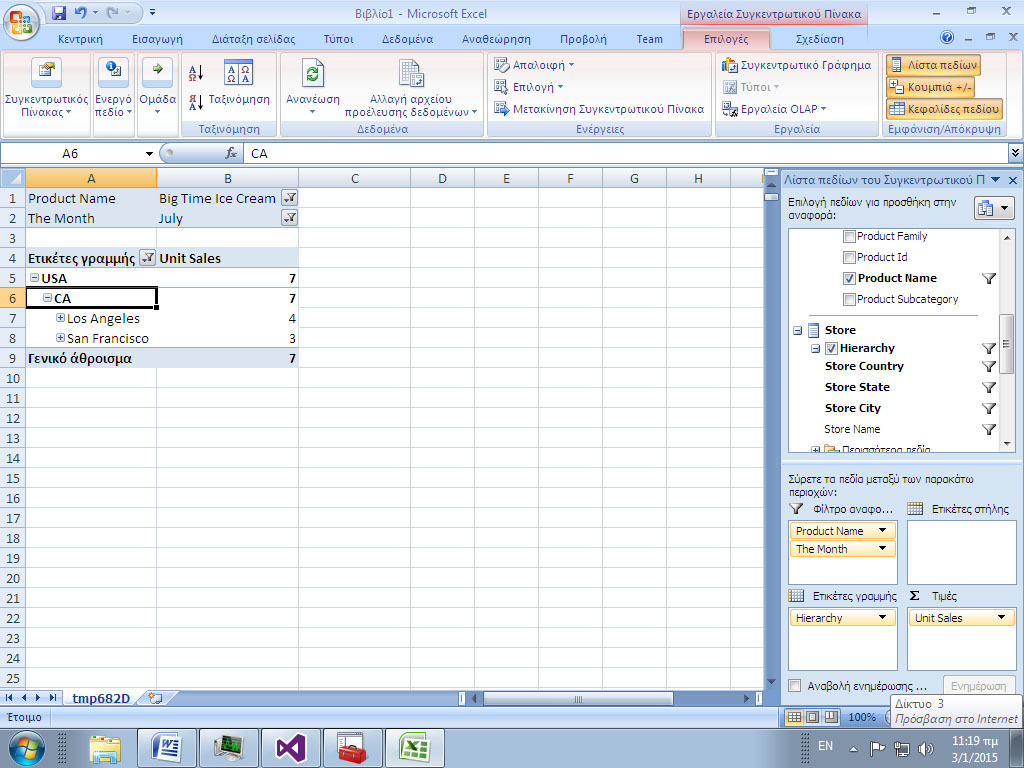
Εικόνα 11.19
-
Τέλος, όπως φαίνεται στην Εικόνα 11.20, στο excel μπορούμε να δημιουργήσουμε ενημερωτικά γραφήματα με εύκολο τρόπο.
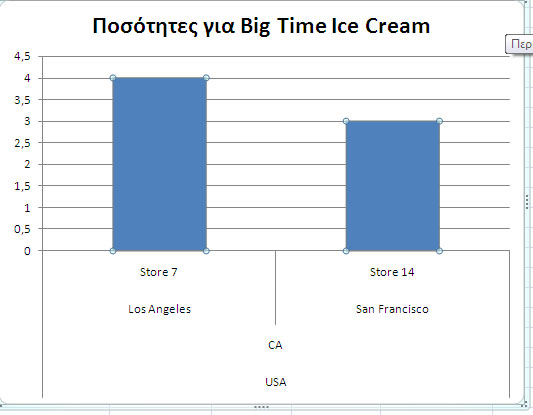
Εικόνα 11.20
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
11.6. Ασκήσεις για κύβους
δεδομένων
-
Να προσδιορίσετε τις συνολικές ποσότητες που πωλήθηκαν στην Αμερική ανά πολιτεία (California, Oregon, Washington) για κάθε τρίμηνο του έτους 1997.
-
Ποια τρία καταστήματα σημείωσαν τις μεγαλύτερες πωλήσεις για το 1997; Να φτιάξετε σχετική γραφική παράσταση στο excel.
-
Δημιουργήστε ένα γράφημα που να παρουσιάζει ποιες είναι οι έξι μεγαλύτερες ποσότητες (σε μονάδες/τεμάχια) ανά προϊόν που πωλήθηκαν τον μήνα Δεκέμβριο του 1997.
-
Δημιουργήστε ένα γράφημα που να παρουσιάζει ποια πέντε προϊόντα σημείωσαν τις μεγαλύτερες πωλήσεις (σε αξία) τον μήνα Δεκέμβριο του 1997.
-
Να προσδιορίσετε τις συνολικές πωλήσεις σε αξία των καταστημάτων για τα δύο τελευταία τρίμηνα του 1997 ανά πολιτεία των ΗΠΑ.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
11.7.
Λύσεις ασκήσεων για κύβους δεδομένων
Άσκηση 1
Να προσδιορίσετε τις συνολικές ποσότητες που πωλήθηκαν στην Αμερική ανά πολιτεία (California, Oregon, Washington) για κάθε τρίμηνο του έτους 1997.
-
Λύση άσκησης 1:
+
1. Πηγαίνουμε στη λίστα πεδίων του Συγκεντρωτικού Πίνακα στο Excel και επιλέγουμε Unit Sales, το οποίο εμφανίζεται πλέον στο κάτω δεξί παράθυρο με τις τιμές που συναθροίζονται (Σ τιμές). Στη συνέχεια, επιλέγουμε ολόκληρη την ιεραρχία της διάστασης Τime by day και την τοποθετούμε στην Ετικέτα Γραμμής, η οποία εμφανίζεται στο κάτω αριστερό παράθυρο στη λίστα πεδίων του Συγκεντρωτικού Πίνακα. Τέλος, επιλέγουμε ολόκληρη την ιεραρχία της διάστασης Store και την τοποθετούμε στην περιοχή Ετικέτες στήλης, η οποία εμφανίζεται πλέον στο πάνω δεξί παράθυρο στη λίστα πεδίων του Συγκεντρωτικού Πίνακα. Τονίζεται ότι οι Ετικέτες γραμμής είναι οι γραμμές του Pivot Table, ενώ οι Ετικέτες στήλης αποτελούν τις στήλες του Pivot table. Στη συνέχεια, επιλέγοντας τα σύμβολα + και – , μπορούμε να κάνουμε drill through/roll up τόσο στην ιεραρχία της διάστασης του χρόνου (time) όσο και στη διάσταση των καταστημάτων (stores), όπως φαίνεται στην Εικόνα 11.21.
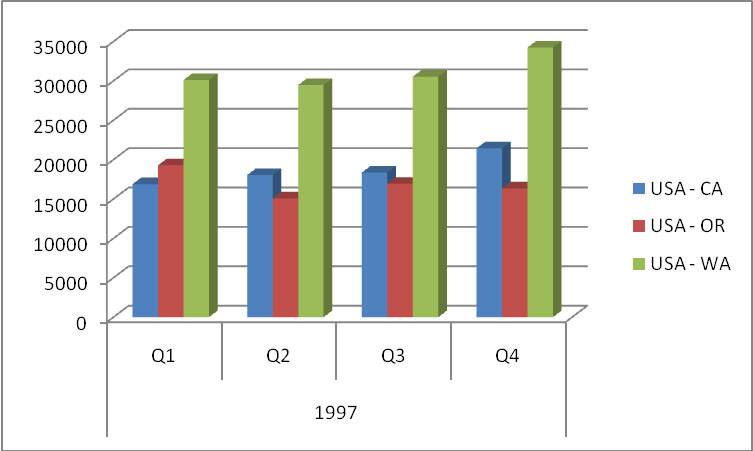
Εικόνα 11.21
2. Παρατηρούμε, όπως φαίνεται στην Εικόνα 11.22, ένα ραβδόγραμμα με την αποτίμηση των πωλήσεων ανά περιοχή και ανά τρίμηνο του 1997 για τη χώρα της Αμερικής (USA).
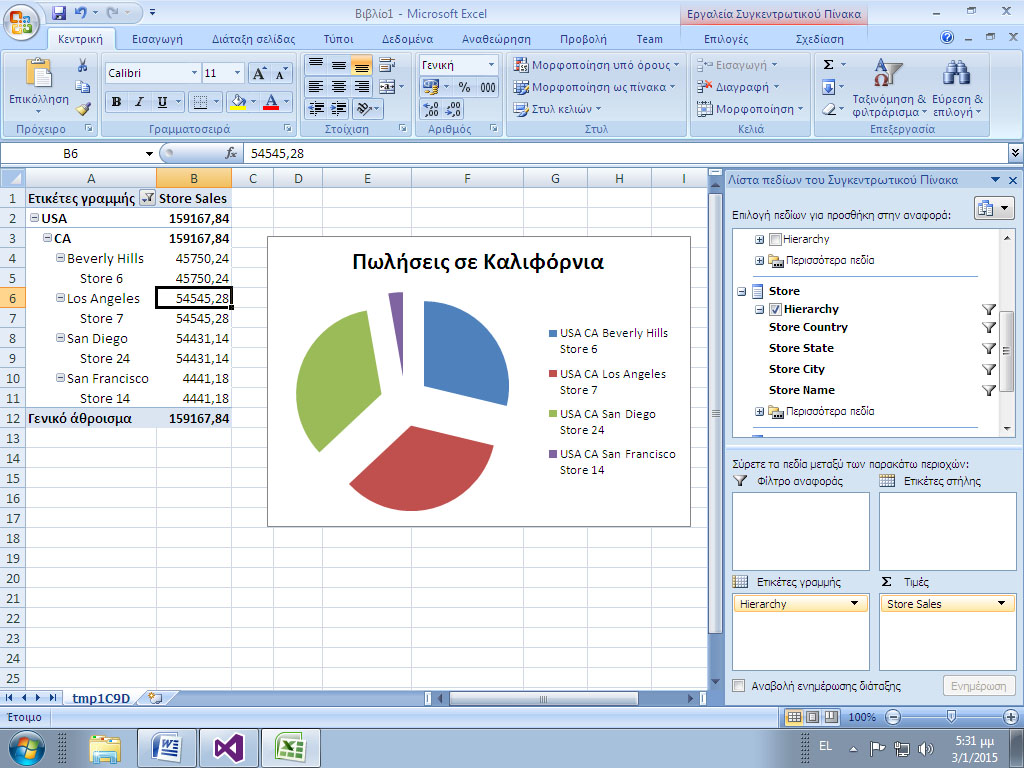
Εικόνα 11.22
Άσκηση 2
Ποιό κατάστημα σημείωσε τις μεγαλύτερες πωλήσεις για το 1997 στη πολιτεία
της Καλιφόρνια; Να φτιάξετε σχετική γραφική παράσταση στο excel που να
εμπεριέχει όλα τα καταστήματα της Καλιφόρνια.
-
Λύση άσκησης 2:
+
Στη λίστα πεδίων του Συγκεντρωτικού Πίνακα στο Excel, επιλέγουμε Store Sales, το οποίο εμφανίζεται πλέον στο κάτω δεξί παράθυρο με τις τιμές που συναθροίζονται (Σ τιμές). Στη συνέχεια, επιλέγουμε ολόκληρη την ιεραρχία της διάστασης Store και την τοποθετούμε στην περιοχή Ετικέτες Γραμμής, η οποία εμφανίζεται στο κάτω αριστερό παράθυρο στη λίστα πεδίων του Συγκεντρωτικού Πίνακα. Όπως φαίνεται στην Εικόνα 11.23, διαπιστώνουμε ότι το κατάστημα του Los Angeles είναι αυτό που έχει τις μεγαλύτερες πωλήσεις, με 54545,28 δολάρια Αμερικής. Το ίδιο αποτέλεσμα, εξάλλου, επιβεβαιώνεται και με το συγκεντρωτικό γράφημα πίτας.
Εικόνα
11.22
Άσκηση 3
Δημιουργήστε ένα γράφημα που να παρουσιάζει ποιες είναι οι έξι μεγαλύτερες ποσότητες (σε μονάδες/τεμάχια) ανά προϊόν που πωλήθηκαν τον μήνα Δεκέμβριο του 1997.
-
Λύση άσκησης 3:
+
Στο γράφημα της Εικόνας 11.24 παρουσιάζονται τα έξι προϊόντα της εταιρίας με τις μεγαλύτερες πωλήσεις για το χρονικό διάστημα αναφοράς. Τα προϊόντα αναφέρονται στο σύνολο της εμπορικής δραστηριότητας της εταιρίας και στο σύνολο της γεωγραφικής κάλυψης των προϊόντων της. Όπως φαίνεται, το προϊόν "Fast Beef Jerky" παρουσίασε τις υψηλότερες πωλήσεις στη συγκεκριμένη περίοδο.
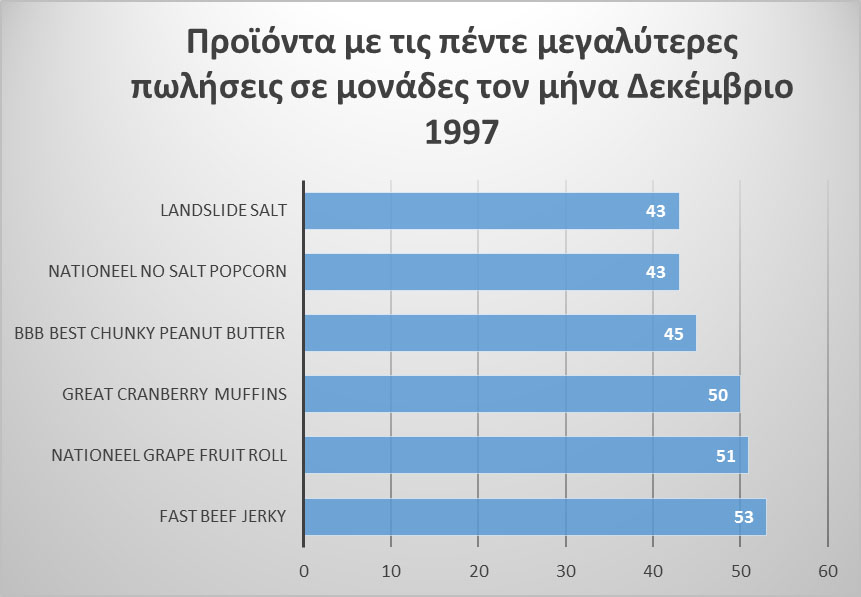 Εικόνα
11.23
Εικόνα
11.23
Άσκηση 4
Δημιουργήστε ένα γράφημα που να παρουσιάζει ποια πέντε προϊόντα σημείωσαν τις μεγαλύτερες πωλήσεις (σε αξία) το μήνα Δεκέμβριο του 1997.
-
Λύση άσκησης 4:
+
Στο γράφημα της Εικόνας 11.25 παρουσιάζεται το διάγραμμα των προϊόντων με τις πέντε μεγαλύτερες πωλήσεις σε αξία για τον μήνα Δεκέμβριο του 1997.
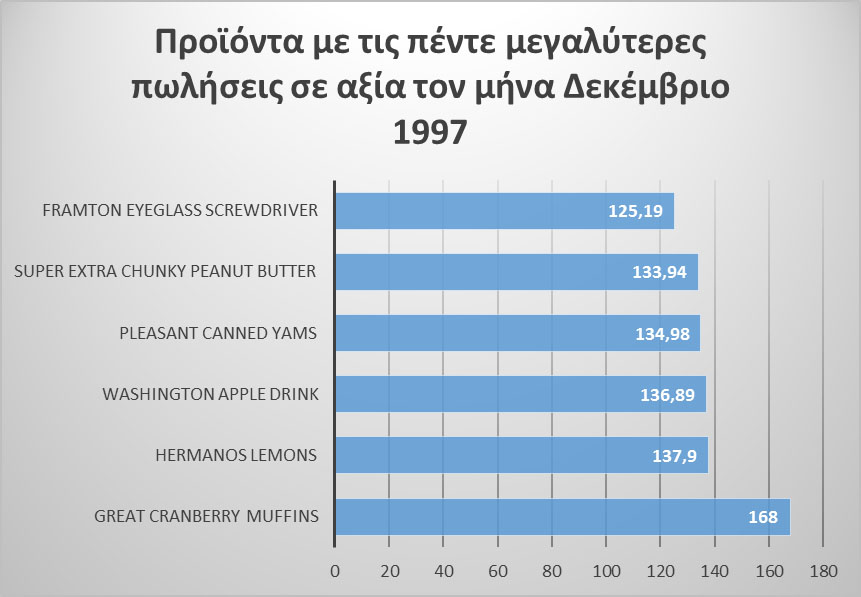 Εικόνα
11.24
Εικόνα
11.24
Άσκηση 5
Να προσδιορίσετε τις συνολικές πωλήσεις σε αξία των καταστημάτων για τα δύο τελευταία τριμήνων του 1997 ανά πολιτεία των ΗΠΑ.
-
Λύση άσκησης 5:
+
Όπως φαίνεται στην Εικόνα 11.26, υπάρχει ανοδική πορεία πωλήσεων μεταξύ του τρίτου και του τέταρτου τριμήνου στα καταστήματα που βρίσκονται στις πολιτείες CA και WA. Αντίθετα, τα καταστήματα της πολιτείας του OR φαίνεται πως έχουν μικρή μείωση των πωλήσεών τους απ’ το τρίτο στο τέταρτο τρίμηνο.
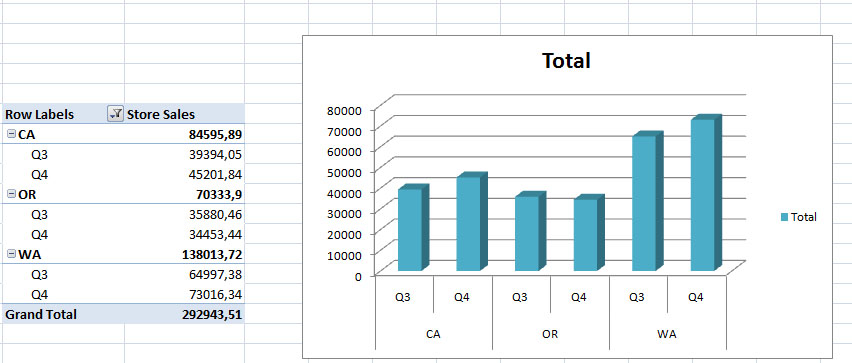 Εικόνα
11.25
Εικόνα
11.25
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
11.8. Βιβλιογραφία/Αναφορές
Νανόπουλος, Α., & Μανωλόπουλος, Ι. (2008). Εισαγωγή στην Εξόρυξη και τις Αποθήκες Δεδομένων, Αθήνα, Εκδόσεις Νέων Τεχνολογιών.
Χαλκίδη, Μ., & Βεζυργιάννης, Μ. (2005). Εξόρυξη Γνώσης από Βάσεις Δεδομένων και τον Παγκόσμιο Ιστό, Αθήνα, Τυπωθήτω.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
Data Definition Language - DDL
Η γλώσσα ορισμού περιεχομένου χρησιμοποιείται για τον ορισμό των
πινάκων και των μεταξύ τους σχέσεων. Με τη γλώσσα αυτή δηλώνουμε τα
χαρακτηριστικά που έχει κάθε πίνακας και τους αντίστοιχους τύπους
δεδομένων του κάθε χαρακτηριστικού.
Data Manipulation Language - DML
Η γλώσσα χειρισμού δεδομένων χρησιμοποιείται για την επεξεργασία,
την ενημέρωση, την εισαγωγή και την διαγραφή δεδομένων.
Διάγραμμα οντοτήτων-συσχετίσεων (διάγραμμα E-R)
Τα Διάγραμματα οντοτήτων-συσχετίσεων παρέχουν ένα απλό και κατανοητό τρόπο περιγραφής της δομής των δεδομένων της Βάσης Δεδομένων
Ερώτημα SQL
Αποτελεί ένα δομημένο τρόπο σύνταξης ερωτοαποκρίσεων για την αναζήτηση περιεχομένου στη βάση δεδομένων μας.
create database
Ένας νέος πίνακας δημιουργείται με τη χρήση της εντολής CREATE TABLE ή σύνταξη της οποίας έχει ως εξής :
CREATE TABLE (
<όνομα πεδίου 1> <τύπος πεδίου 1>,
<όνομα πεδίου 2> <τύπος πεδίου 2>,
<όνομα πεδίου Ν> <τύπος πεδίου Ν>);
Drop Database
Μπορούμε να διαγράψουμε ολόκληρο πίνακα, μαζί με τα δεδομένα που τυχόν έχει χρησιμοποιώντας την εντολή DROP σύμφωνα με το ακόλουθο πρότυπο :
DROP TABLE <όνομα πίνακα>
ON UPDATE
H πρόταση ON UPDATE προσδιορίζει την ενέργεια που θα εκτελεστεί αν θέλουμε να αλλάξουμε την τιμή ενός πεδίου:
UPDATE <όνομα πίνακα> SET <όνομα πεδίου> <νέα τιμή πεδίου> WHERE <κριτήρια επιλογής εγγραφών>
ON DELETE
Ο σκοπός είναι πολύ απλός, διαγράφει εγγραφές από ένα πίνακα. Και πάλι έχομε την δυνατότητα να ορίσουμε ποιές εγγραφές θέλουμε να διαγραφούν (ή και όλες) π.χ.:
DELETE FROM product WHERE id=1
Καρτεσιανού γινομένου
To Καρτεσιανό γινόμενο αποτελεί την πράξη μεταξύ δύο πινάκων όπου η κάθε εγγραφή του ενός πίνακα συνδυάζεται με όλες τις εγγραφές του άλλου πίνακα
πράξη της επιλογής/selection
Η SQL εντολή μέσω της οποίας ανακτούμε πληροφορίες και συντάσσουμε ερωτήματα είναι η SELECT. Η γενική σύνταξη της SELECΤ είναι αρκετά σύνθετη, ωστόσο ένα απλό πρότυπο είναι το ακόλουθο:
SELECT <πεδίο που θέλουμε να φαίνονται>
FROM <πίνακες από τους οποίους θα αντληθούν τα δεδομένα>
WHERE <κριτήρια επιλογής των εγγραφών>
πράξης της σύνδεσης (join)
Η εντολή JOIN σημαίνει σύνδεση, δηλαδή συνδυασμός δεδομένων από δύο ή περισσότερους πίνακες.
left outer join
Περιλαμβάνει επιπρόσθετα και όλες τις εγγραφές του πίνακα που βρίσκεται στα αριστερά της πράξης της σύνδεσης (join) και δεν εμπεριέχονται στο αποτέλεσμα της πράξης της σύνδεσης.
πράξη του full outer join
Περιλαμβάνει επιπρόσθετα και όλες τις εγγραφές των πινάκων που βρίσκονται στα αριστερά και δεξιά της πράξης της σύνδεσης (join) και δεν εμπεριέχονται στο αποτέλεσμα της πράξης της σύνδεσης.
όρος distinct
Η λέξη DISTINCT αμέσως μετά την SELECT δηλώνει ότι κάθε εγγραφή του πίνακα του αποτελέσματος θα συμπεριληφθεί μία μόνο φορά. Επομένως χρησιμοποιείται όταν θέλουμε να εγγυηθούμε ότι στο αποτέλεσμα του ερωτήματος δεν θα υπάρχουν διπλοεγγραφές πρέπει να χρησιμοποιήσουμε το DISTINCT
όρος GROUP BY
H λέξη GROUP BY προσδιορίζει τις στήλες με τις οποίες θα πραγματοποιηθεί ομαδοποίηση (grouping) των δεδομένων.
όρος HAVING
Ο όρος HAVING χρησιμοποιείται για να ορίσει περιοσρισμούς που σχετίζονται με τα ήδη ομαδοποιημένα αποτελέσματα που έχουν δημιουργηθεί με την GROUP BY.
πράξη της ένωσης πινάκων/σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξη της ένωσης (UNION) συνενώνει τις εγγραφές δύο ή περισσότερων πινάκων.
Ένα παράδειγμα ένωσης δίνεται παρακάτω:
SELECT συνέδριο
FROM πρακτικά_συνεδρίου
UNION
SELECT τιτλος
FROM περιοδικό;
πράξη της τομής σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξεις αυτές υλοποιούνται στην SQL με τις εντολές UNION, EXCEPT και INTERSECΤ αντιστοίχως.
παράδειγμα τομής :
SELECT ονομα
FROM συνδρομητης
INTERSECT
SELECT ονομα
FROM συγγραφεας;
πράξη της διαφοράς σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξεις αυτές υλοποιούνται στην SQL με τις εντολές UNION, EXCEPT και INTERSECΤ αντιστοίχως.
παράδειγμα διαφοράς :
SELECT κωδικός,τίτλος
FROM άρθρο
EXCEPT
SELECT κωδικός,τίτλος
FROM άρθρο
WHERE κωδικός_περιοδικού IS NOT NULL;
Ο όρος ΙΝ
Σε περίπτωση που θέλουμε ένα πεδίο να λαμβάνει τιμές από ένα προκαθορισμένο σύνολο τιμών, τότε μπορούμε εναλλακτικά να χρησιμοποιήσουμε τον τελεστή ΙΝ.
Ο ορος Νot Ιn
Σε περίπτωση που θέλουμε ένα πεδίο να λαμβάνει τιμές από ένα προκαθορισμένο σύνολο τιμών, εξαιρώντας κάποιες τιμές τότε μπορούμε εναλλακτικά να χρησιμοποιήσουμε τον τελεστή ΝΟΤ ΙΝ.
Οι όροι all και some
H SQL προσφέρει τα κατηγορήματα SOME(ή ΑΝΥ) και ALL τα οποία αντιστοιχούν στον υπαρξιακό και καθολικό ποσοδείκτη που χρησιμοποιούμε στα μαθηματικά. Με τη χρήση των κατηγορημάτων αυτών μπορούμε να συντάξουμε πολύ χρήσιμα ερωτήματα με τη χρήση υποερωτημάτων. Πριν απο τα κατηγορήματα SOME και ALL, μπορεί να προηγείται οποιοσδήποτε τελεστής σύγκρισης (=, >, <, >=, <=, <>)
Οι όροι exists και not exists
Η τιμή που επιστρέφει το κατηγόρημα EXISTS είναι αληθής, αν το σύνολο που ακολουθεί δεν είναι κενό. Σε διαφορετική περίπτωση η τιμή που επιστρέφεται είναι ψευδής.
CREATE VIEW
Για τον ορισμό μιας όψης, η SQL παρέχει την εντολή CREATE VIEW που συντάσσεται ως εξής:
CREATE VIEW όνομα-όψης
AS
(υποερώτημα SQL);
DELETE FROM
Παρόμοια με την εντολή UPDATE λειτουργεί και η εντολή DELETE. Ο σκοπός της είναι πολύ απλός, διαγράφει εγγραφές από ένα πίνακα.
DROP TABLE
Η πλήρης διαγραφή ενός πίνακα γίνεται χρησιμοποιώντας την εντολή DROP σύμφωνα με τον ακόλουθο πρότυπο :
DROP TABLE <ονομα πίνακα>
Οι αποθηκευμένες διαδικασίες/stored procedures
O SQL Server δίνει την δυνατότητα υλοποίησης τμημάτων κώδικα τα οποία παραμένουν αποθηκευμένα μέσα στη Βάση Δεδομένων και καλούνται αποθηκευμένες διαδικασίες (stored procedures). Αυτά ενεργοποιούνται ανά τακτά χρονικά διαστήματα για την εκτέλεση μιας σημαντικής λειτουργίας.
Το εύναυσμα/trigger
Ένας σκανδαλισμός ή εύναυσμα (trigger) είναι ένα τμήμα κώδικα που εκτελείται όταν συμβεί ένα γεγονός. Τα γεγονότα που ενεργοποιούν σκανδαλισμούς είναι εισαγωγές, διαγραφές, και ενημερώσεις στα δεδομένα ενός πίνακα.
Ευρετήριο
Ένας κατάλογος (ευρετήριο) ορίζεται σε μία ή περισσότερες στήλες ενός πίνακα και στοχεύει στην αποδοτικότερη εκτέλεση των ερωτημάτων που χρησιμοποιούν τις στήλες αυτές στη συνθήκη WHERE. Η κατασκευή και κατάργηση καταλόγων πραγματοποιείται με τις εντολές CREATE INDEX και DROP INDEX αντίστοιχα.
ALTER TABLE
O ορισμός ενός πίνακα μπορεί να μεταβληθεί στην πορεία, αναλόγως με τις απαιτήσεις. H SQL προσφέρει την εντολή ALTER TABLE, με την οποία επιτρέπονται να γίνουν συγκεκριμένες αλλαγές στον πίνακα: (προσθήκη νέας στήλης, διαγραφή υπάρχουσας στήλης, αλλαγή πεδίου ορισμού μίας στήλης, εισαγωγή νέου περιορισμού, κατάργηση περιορισμού, αλλαγή της εξ ορισμού τιμής στήλης, κατάργηση αρχικής τιμής στήλης).
εντολή grant.
Με την εντολή GRANT δίνουμε δικαιώματα χρήσης της βάσης δεδομένων σε χρήστες.
εντολή revoke.
Με την εντολή REVOKE αφαιρούμε από τους χρήστες τα δικαιώματα χρήσης ενός στοιχείου (π.χ. πίνακα, όψη) μιας βάσης δεδομένων.
H παράμετρος Split method:
Αυτή η παράμετρος καθορίζει τη μέθοδο με την οποία διαχωρίζονται οι κόμβοι του δένδρου. Μπορεί να πάρει τις τιμές [1,3] όπου 1 είναι η τιμή για Binary δένδρο, 2 η τιμή για Complete (multi-way) δένδρο και 3 η τιμή και για τα δύο μαζί.
Κατηγοριοποίηση (classification)
Η κατηγοριοποίηση αποτελεί μια σημαντική λειτουργία εξόρυξης δεδομένων, όπου επιθυμούμε να προβλέψουμε σε πια κατηγορία εντάσσονται και ανήκουν κάθε φορά τα δεδομένα μας.
H παράμετρος Split method:
Αυτή η παράμετρος καθορίζει τη μέθοδο με την οποία διαχωρίζονται οι κόμβοι του δένδρου. Μπορεί να πάρει τις τιμές [1,3] όπου 1 είναι η τιμή για Binary δένδρο, 2 η τιμή για Complete (multi-way) δένδρο και 3 η τιμή και για τα δύο μαζί.
H παράμετρος Stopping Tolerance
Αυτή η παράμετρος καθορίζει τον αριθμό των περιπτώσεων που μετακινούνται μεταξύ των clusters σε κάθε πέρασμα του αλγορίθμου. Ο αλγόριθμος εφαρμόζεται επαναληπτικά στα δεδομένα και σχηματίζει τα cluster με την μορφή που εμείς τα βλέπουμε, ύστερα από ένα σύνολο επαναλήψεων. Επειδή σε κάθε επανάληψη προστίθενται διαρκώς και νέες περιπτώσεις, η τιμή της παραμέτρου μπορεί να θεωρηθεί ως ποσοστό και όχι ένας συγκεκριμένος αριθμός. Η προεπιλεγμένη τιμή της παραμέτρου είναι 10.
Η τάση (trend)
Η τάση μας δείχνει την γενική κατεύθυνση των δεδομένων μας. Για παράδειγμα, η τάση είναι αυξανόμενη στις πωλήσεις προϊόντων τις ημέρες των Χριστουγέννων.
Η περιοδικότητα (periodicity)
Η περιοδικότητα αφορά την επανεμφάνιση κάποιων τάσεων στα δεδομένα μας. Για παράδειγμα, οι πωλήσεις παγωτών αυξάνονται κάθε καλοκαίρι.
Οι ακραίες τιμές (outliers)
Κάποια δεδομένα ενδέχεται να μην είναι δυνατόν να συμπεριλφθούν σε κάποια ομάδα. Τα δεδομένα αυτά καλούνται απομακρυσμένα ή απομονωμένα (outliers) και συνήθως δημιουργούν πρόβλημα στις μεθόδους ομαδοποίησης.
Oλοκληρωμένη (integrated)
Μια αποθήκη δεδομένων είναι ολοκληρωμένη διότι μπορεί και συνενώνει μέσα τις πολλές ανομοιογενείς βάσεις δεδομένων.
Μη ευμετάβλητη (non volatile)
Μια αποθήκη δεδομένων συνήθως δεν μεταβάλλεται ως προς το περιεχόμενο της. Αυτό που συμβαίνει είναι να προστίθεται μόνο καινούργιο περιεχόμενο.
Αφορά ιστορικά δεδομένα (time-variant)
Μια αποθήκη δεδομένων αφορά δεδομένα που μπορεί να έχουν βάθος δεκαετιών.
Ένα μέτρο ή αλλιώς μετρική (measure)
Είναι το μέγεθος ή τα μεγέθη που μας ενδιαφέρουν να συναθροίσουμε ή να αναλύσουμε κατά τις λειτουργίες OLAP.
διαστάσεις (dimensions)
Οι πληροφορίες που περιγράφουν τα γεγονότα, ονομάζονται διαστάσεις. Για ένα γεγονός πώλησης, διαστάσεις είναι, π.χ., το προϊόν που πωλήθηκε, το υποκατάστημα όπου έγινε η πώληση, η ημερομηνία πώλησης, κ.λπ.
Η ιεραρχία (hierarchy)
Η ιεραρχία (hierarchy) μιας διάστασης
Μια διάσταση μπορεί να αποτελείται από διαφορετικά επίπεδα ανάλυσης και να ενσωματώνει μια ιεραρχία. Για παράδειγμα, η διάσταση του χρόνου μπορεί να αναλυθεί σε μέρες, εβδομάδες, κτλ.
Το σχήμα Αστέρα (star schema)
Σύμφωνα με το μοντέλο αυτό η αποθήκη δεδομένων περιέχει ένα μεγάλο κεντρικό πίνακα που καλείται πίνακας γεγονότων (fact table) και ένα σύνολο μικρότερων πινάκων που καλούνται πίνακες διαστάσεων (fimension tables) και συνδέονται απευθείας στον fact table.
To σχήμα χιονονιφάδας (snowflake schema)
Το μοντέλο χιονιφάδας αποτελεί παραλλαγή του μοντέλου αστέρα. Διαφέρει κατά το ότι κάποιοι πίνακες διαστάσεων μπορούν να αναλυθούν περισσότερο χρησιμοποιώντας βοηθητικούς πίνακες. Η λειτουργία αυτή μοιάζει με τη διαδικασία της κανονικοποίησης στις σχεσιακές βάσεις δεδομένων.
Το σχήμα γαλαξία (galaxy schema),
Στο σχήμα γαλαξία έχουμε περισσότερους τους ενός fact tables, τους οποίους μπορούν να διαμοιράζονται περισσότερες διαστάσεις.
Η πράξη Roll-up
Η λειτουργία αυτή ομαδοποιεί τα δεδομένα του κύβου σε υψηλότερο επίπεδο ανάλυσης και μας οδηγεί σε ανώτερο επίπεδο της θεματικής ιεραρχίας, αθροίζοντας τα μετρικά στοιχεία.
Η πράξη Drill-down
Επιφέρει ακριβώς τα αντίθετα αποτελέσματα από τη λειτουργία ROLL-UP. Με τη λειτουργία DRILL-DOWN αυξάνουμε το επίπεδο λεπτομέρειας των δεδομένων μας.
Η πράξη Slice
Η λειτουργία SLICE επιλέγει τα δεδομένα του κύβου μας ως προς μία διάσταση.
Η πράξη Dice
H λειτουργία DICE επιλέγει τα δεδομένα ως προς πολλές διαστάσεις του κύβου μας, δημιουργώντας έναν μικρότερο κύβο.
Η πράξη Pivot
Η λειτουργία PIVOT πραγματοποιεί περιστροφή στις διαστάσεις του κύβου, με αποτέλεσμα τα δεδομένα να απεικονίζονται με διαφορετικό τρόπο κάθε φορά.
Συναθροιστικές συνάρτήσεις (aggregation function)
Οι συναρτήσεις συνάθροισης χρησιμοποιούνται για την εξαγωγή συγκεντρωτικών τιμών από τις τιμές μίας στήλης.
Προκειμένου να εξάγουμε έναν κανόνα συσχέτισης, πρέπει να ικανοποιούνται κάποια κατώτατα όρια τόσο για το support όσο και για τo confidence/probability. Ο κανόνας πρέπει να έχει support μεγαλύτερo από το όριο, που ονομάζεται ελάχιστη υποστήριξη (minimum_support), και η εμπιστοσύνη πρέπει να είναι μεγαλύτερη από το όριο, που ονομάζεται ελάχιστη εμπιστοσύνη (minimum_probability).
Προκειμένου να εξάγουμε έναν κανόνα συσχέτισης, πρέπει να ικανοποιούνται κάποια κατώτατα όρια τόσο για το support όσο και για τo confidence/probability. Ο κανόνας πρέπει να έχει support μεγαλύτερo από το όριο, που ονομάζεται ελάχιστη υποστήριξη (minimum_support), και η εμπιστοσύνη πρέπει να είναι μεγαλύτερη από το όριο, που ονομάζεται ελάχιστη εμπιστοσύνη (minimum_probability).
Slice
H λειτουργία Slice επιλέγει τα δεδομένα ως προς μία διάσταση του κύβου μας, δημιουργώντας μια φέτα ενός κύβου
Pivot
Η λειτουργία Pivot αλλάζει μόνο το τρόπο απεικόνισης των διαστάσεων του κύβου μας
Προσανατολισμένη σε ένα θέμα (subject-oriented)
Μια αποθήκη δεδομένων είναι προσαντολισμένη σε ένα θέμα, διότι πρέπει να εστιάζει στην αναλυτική καταγραφή πληροφοριών ενός τομέα της επιχείρησης, π.χ. ενός κύβου πωλήσεων, ενός κύβου για τις προμήθειες πρώτων υλών, κτλ.