Κεφάλαιο 10. Χρονοσειρές
10.1 Θεωρητικό υπόβαθρο των αλγορίθμων χρονοσειρών (time series) του SQL Server
10.2 Δημιουργία ενός μοντέλου πρόβλεψης χρονοσειρών
10.3 Τροποποίηση και παραμετροποίηση του μοντέλου Time Series
10.4 Αξιολόγηση του μοντέλου Time Series.
10.4.1 Καρτέλα Charts
10.4.2 Καρτέλα Model
10.5 Ασκήσεις αξιολόγησης μοντέλου Time Series
10.6 Λύσεις ασκήσεων αξιολόγησης μοντέλου Time Series
10.7. Βιβλιογραφία/Αναφορές
Κεφάλαιο
10. Χρονοσειρές
Σύνοψη
Σ’ αυτό το κεφάλαιο θα παρουσιάσουμε τη δημιουργία ενός μοντέλου χρονοσειρών (time series). Συγκεκριμένα, θα μάθουμε τον τρόπο με τον οποίο δημιουργείται και χρησιμοποιείται ένα μοντέλο χρονοσειρών για την AdventureWorks. Η Adventure Works, μια βάση δεδομένων που παρουσιάστηκε στις Eνότητες 6.3. και 6.6., αφορά μια πολυεθνική εταιρία που εμπορεύεται ποδήλατα σε διάφορες ηπείρους/χώρες. Το τμήμα πωλήσεων της εταιρίας επιθυμεί να προβλέψει τις μελλοντικές πωλήσεις ανά μοντέλο ποδηλάτου βάσει των πωλήσεων που σημειώθηκαν στο παρελθόν.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.1.
Θεωρητικό υπόβαθρο των αλγορίθμων χρονοσειρών (time series) του SQL Server
Μια χρονοσειρά είναι το σύνολο διαδοχικών τιμών ενός χαρακτηριστικού για ένα χρονικό διάστημα. Πιο συγκεκριμένα, δοθέντος ενός χαρακτηριστικού A, μια χρονοσειρά είναι το σύνολο Ν παρατηρηθέντων ζευγών: {(t1, a1), (t2, a2), … , (tn, an)}, όπου T = {1, 2, … , n} είναι μια αλληλουχία διαδοχικών χρονικών στιγμών (π.χ. ημέρα, μήνας κτλ.), ενώ an είναι μια παρατηρηθείσα τιμή επί του χαρακτηριστικού Α για τη χρονική στιγμή n ως παρατήρηση στο χρόνο αυτό (Aggarwal, 2015· Dunham, 2003· Han, & Kamber, 2001). Για παράδειγμα, η συλλογή των ημερήσιων τιμών κλεισίματος του χρηματιστηρίου Αθηνών για ένα έτος αποτελεί μια ακολουθία χρονοσειράς. Η ανάλυση μιας χρονοσειράς έχει ποικίλες εφαρμογές σε πολλούς επιστημονικούς τομείς, με σκοπό τη δημιουργία μοντέλων που θα προβλέπουν επαρκώς τις μελλοντικές τιμές ενός υπό εξέταση χαρακτηριστικού. Για παράδειγμα, ένας αλγόριθμος χρονοσειρών (time series) θα επέτρεπε την πρόβλεψη των μελλοντικών τιμών κλεισίματος των μετοχών εταιριών στο χρηματιστήριο Αθηνών.
Μερικά βασικά χαρακτηριστικά των χρονοσειρών είναι:
- Η τάση (trend) . Είναι η συστηματική μεταβολή (γραμμική ή μη) των τιμών ενός χαρακτηριστικού στη μονάδα του χρόνου. Στον SQL Server, μπορούμε να δούμε την τάση μιας χρονοσειράς σε ένα διάγραμμα παρατηρώντας την καμπύλη πρόβλεψης, η οποία είτε αυξάνεται, είτε μειώνεται, είτε παραμένει σταθερή στη μονάδα του χρόνου.
- Η περιοδικότητα (periodicity) .Είναι ένα επαναλαμβανόμενο μοτίβο είτε υψηλών είτε χαμηλών παρατηρηθεισών τιμών ενός χαρακτηριστικού, το οποίο σχετίζεται με συγκεκριμένες χρονικές στιγμές (π.χ., κάθε φορά τα Χριστούγεννα αυξάνονται οι πωλήσεις). Στον αλγόριθμο χρονοσειρών του SQL Server, μπορούμε να εντοπίσουμε ή να ορίσουμε την περιοδικότητα μέσα από τις παραμέτρους AUTO_DETECT_PERIODICITY και PERIODICITY_HINT, αντίστοιχα.
- Οι ακραίες τιμές (outliers). Είναι κάποιες παρατηρηθείσες τιμές ενός χαρακτηριστικού, οι οποίες διαφέρουν σημαντικά από τη μέση τιμή των υπολοίπων τιμών του. Αυτές οι ακραίες τιμές συνήθως επηρεάζουν αρνητικά το μοντέλο πρόβλεψης και καλό είναι να εντοπίζονται και να απομακρύνονται από τα δεδομένα εκπαίδευσης. Στον αλγόριθμο χρονοσειρών του SQL Server, μπορούμε να ορίσουμε ακρότατα με τις παραμέτρους MAXIMUM_SERIES_VALUE και MINIMUM_SERIES_VALUE.
O SQL Server διαθέτει δύο αλγορίθμους χρονοσειρών, τον ΑRIMA και τον ARTXP. Περιγράφουμε συνοπτικά τα πιο βασικά χαρακτηριστικά τους:
- Ο αλγόριθμος ARIMA (ΑutoRegressive Ιntegrated Μoving Αverage) χρησιμοποιείται κυρίως για μακροπρόθεσμες (long-term) προβλέψεις των τιμών ενός χαρακτηριστικού μιας χρονοσειράς. Η αυτοπαλινδρόμηση (autoregression) προβλέπει μελλοντικές τιμές μιας χρονοσειράς λαμβάνοντας υπόψη τις παλαιότερες παρατηρηθείσες τιμές της. Ο ARIMA υποθέτει ότι υπάρχει μια εξάρτηση μεταξύ των παρελθοντικών και μελλοντικών τιμών μιας χρονοσειράς, γνωστή ως μεταβαλλόμενη μέση τιμή (moving average). H μεταβαλλόμενη μέση τιμή θεωρεί την υπό εξέταση χρονοσειρά ως μη στατική (non-stationary). Αυτό σημαίνει ότι οι μελλοντικές τιμές της χρονοσειράς προκύπτουν από ένα μοντέλο μεταβαλλόμενης μέσης τιμής επί των παρελθοντικών τιμών της. Επιπροσθέτως, ο ARIMA είναι μονοπαραγοντικός (univariate). Αυτό σημαίνει ότι για τις προβλέψεις του δεν λαμβάνει υπόψη άλλα χαρακτηριστικά ως δεδομένα εισόδου παρά μόνο το υπό εξέταση χαρακτηριστικό της χρονοσειράς.
- Ο αλγόριθμος ARTXP (AutoRegressive Tree XP model) χρησιμοποιείται κυρίως για βραχυπρόθεσμες (short-term) και πολυπαραγοντικές (multivariate) προβλέψεις. Με τον όρο βραχυπρόθεσμες εννοούμε ότι ο ARTXP προβλέπει καλύτερα τις πιο άμεσες (πιο κοντινές) μελλοντικές τιμές ενός χαρακτηριστικού. Επίσης, είναι πολυπαραγοντικός και υποστηρίζει το λεγόμενο cross-prediction, επειδή λαμβάνει υπόψη και άλλα χαρακτηριστικά ως δεδομένα εισόδου για τη δημιουργία του μοντέλου χρονοσειράς. Ας υποθέσουμε, για παράδειγμα, ότι έχουμε μια βάση δεδομένων με πολλά χαρακτηριστικά για την οικονομία (ΑΕΠ, πληθωρισμό, επιτόκια καταθέσεων κτλ.). Ένας αλγόριθμος που υποστηρίζει το cross-prediction θα στηριχθεί στην εξελικτική πορεία όλων των παραπάνω διαθέσιμων χαρακτηριστικών, για να προβλέψει τις επόμενες τιμές τού υπό εξέταση χαρακτηριστικού (π.χ. του ΑΕΠ).
Στο περιβάλλον του SQL Server χρησιμοποιείται εξ ορισμού ένα μείγμα (mixed) των δύο παραπάνω αλγορίθμων (mixed model). Στην περίπτωση που ο χρήστης δεν επιθυμεί τη χρήση του μεικτού μοντέλου, η παράμετρος FORECAST_METHOD επιτρέπει την επιλογή μόνο ενός από τους δύο αλγορίθμους. Αντίστοιχα, η παράμετρος PREDICTION_SMOOTHING δίνει τη δυνατότητα να αποδώσουμε διαφορετική βαρύτητα στους δυο αλγορίθμους. Τονίζεται ότι στην Ενότητα 10.2. θα περιγραφούν οι υπόλοιπες παράμετροι του αλγορίθμου χρονοσειρών του SQL Server.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.2. Δημιουργία ενός μοντέλου πρόβλεψης χρονοσειρών
Ας υποθέσουμε ότι έχει ζητηθεί απ’ το τμήμα πωλήσεων να προβλέψουμε τις μελλοντικές πωλήσεις ανά κωδικό προϊόντος για το επόμενο έτος. Συγκεκριμένα, ζητήθηκε να βρούμε τις περιόδους αιχμής πώλησης ποδηλάτων και να μάθουμε πού αυξάνονται και πού υστερούν οι πωλήσεις σε σχέση με την κάθε περιοχή/ χώρα πώλησης. Επιπλέον, ζητήθηκε να καθορίσουμε αν οι πωλήσεις των προϊόντων διαφοροποιούνται ανάλογα με την εποχή του έτους. Τα στοιχεία της εταιρείας θα μελετηθούν σε μηνιαίο επίπεδο και θα αφορούν τις πωλήσεις για τρεις περιοχές: Ευρώπη, Βόρεια Αμερική και Ειρηνικό.
Αναλυτικά Βήματα
- Αρχικά, όπως φαίνεται στην Εικόνα 10.1, δημιουργούμε ένα New Data Source View σύμφωνα με τα βήματα που προαναφέρθηκαν στην ενότητα 6.6. Κατόπιν, εισάγουμε τον πίνακα vTimeSeries (dbo).
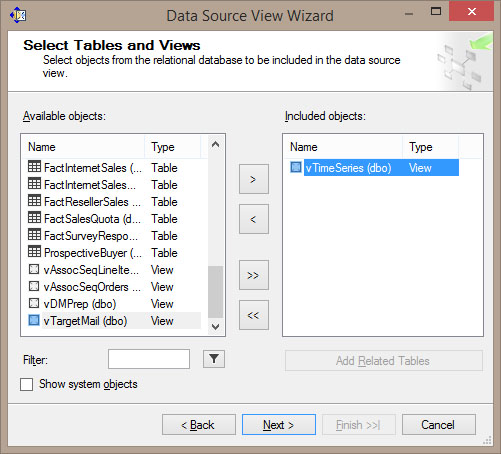
Εικόνα 10.1
-
Στη συνέχεια, δίνουμε στο Data Source View το όνομα SalesByRegion, όπως φαίνεται στην Εικόνα 10.2.
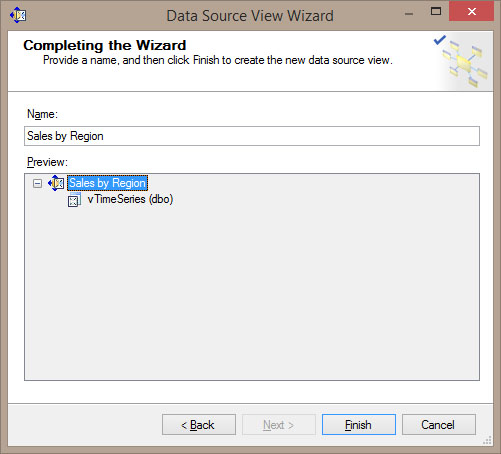
Εικόνα 10.2
-
Στη συνέχεια, όπως φαίνεται στην Εικόνα 10.3, εμφανίζεται το παράθυρο που περιέχει το σχεδιάγραμμα με τον πίνακα vTimeSeries.
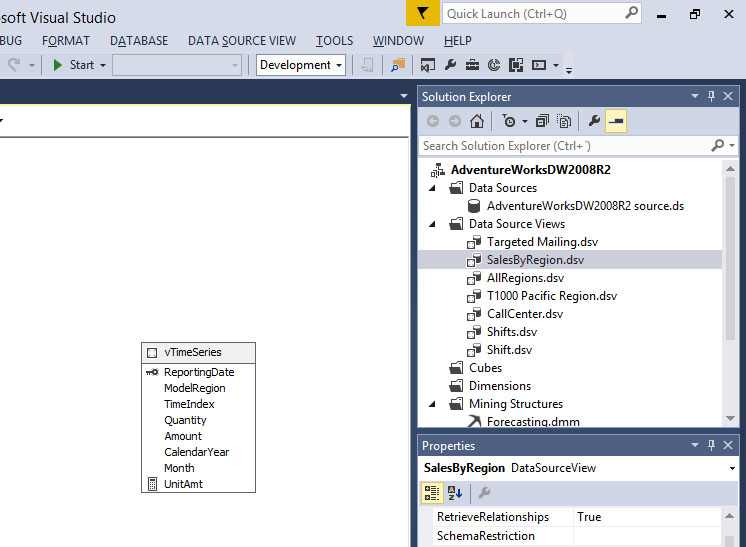
Εικόνα 10.3
-
Για να προσδιορίσουμε τον χρονικό ορίζοντα των δεδομένων του πίνακα vTimeSeries, θα πρέπει, όπως φαίνεται στην Εικόνα 10.4, να πάμε στο data source view του SalesByRegion, να κάνουμε δεξί κλικ στον πίνακα vTimeSeries και να επιλέξουμε Explore Data.
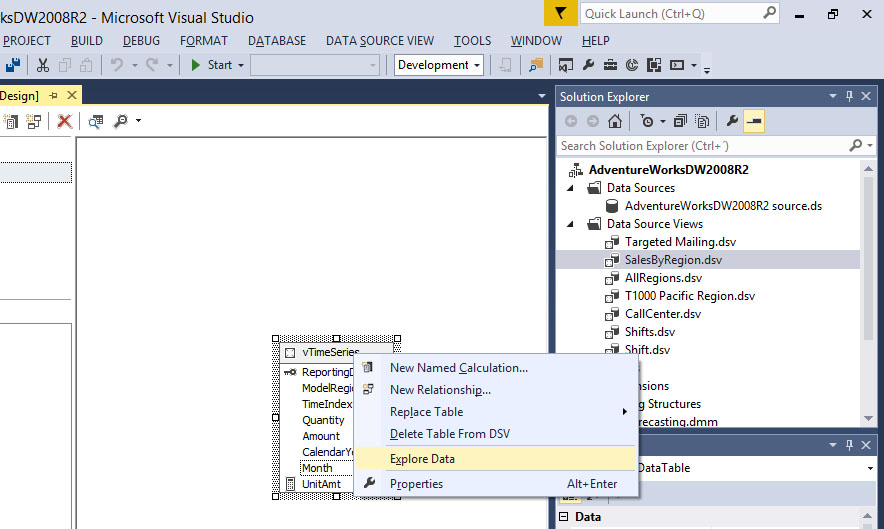
Εικόνα 10.4
-
Η νέα καρτέλα που εμφανίζεται, όπως φαίνεται στην Εικόνα 10.5, περιέχει τον πίνακα vTimeSeries με διάφορες δυνατότητες επιλογής. Για παράδειγμα, μπορούμε να δούμε ότι δεν υπάρχουν δεδομένα για τα ποδήλατα με κωδικό “Τ1000 Europe” πριν από τον Ιούλιο του 2007, ενώ σε όλους τους λοιπούς κωδικούς ποδηλάτων υπάρχουν δεδομένα από τον Ιούλιο του 2005. Τονίζεται ότι αυτό δεν συνιστά πρόβλημα, καθώς όλοι οι κωδικοί προϊόντος έχουν δεδομένα μέχρι τον Ιούνιο του 2008.
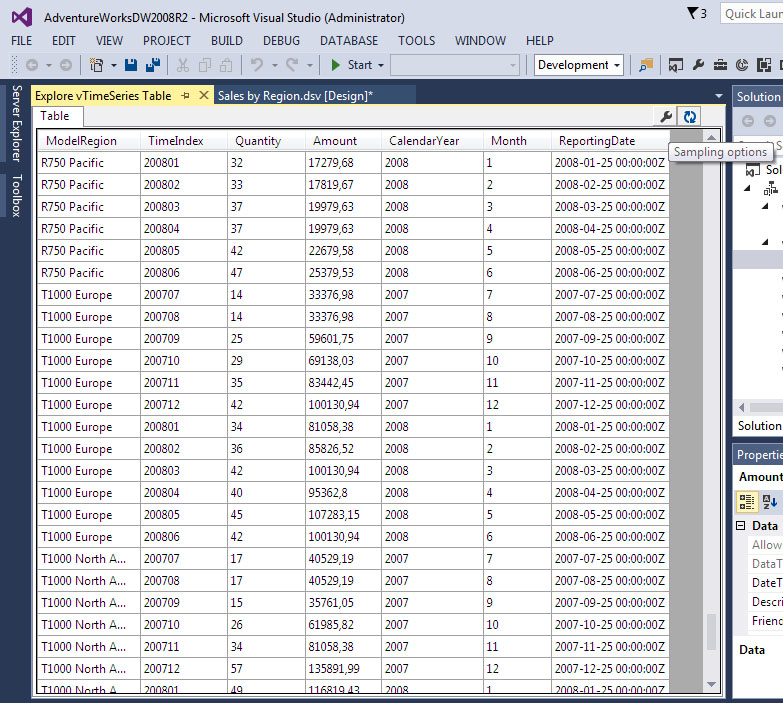
Εικόνα 10.5
-
Προκειμένου η επεξεργασία των δεδομένων να γίνει με τυχαία δειγματοληψία, κάνουμε κλικ στο κλειδί (υδραυλικό κλειδί) που βρίσκεται επάνω δεξιά στην Εικόνα 10.5, με αποτέλεσμα να εμφανίζεται η καρτέλα Data Exploration Options. Στο Sampling methods αυτής της καρτέλας της Εικόνας 10.6, όπως φαίνεται στην Εικόνα 10.6, φροντίζουμε να αποεπιλέξουμε το πεδίο Top count και να επιλέξουμε το πεδίο Random sample. Επίσης, στο Sample count ορίζουμε την τιμή 1000. Στη συνέχεια, πατάμε OK.
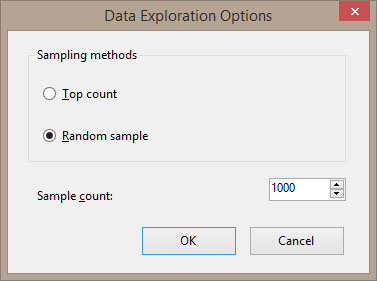
Εικόνα 10.6
-
Στη συνέχεια, επιλέγουμε το Reporting Date, για να το ορίσουμε ως Set Logical Primary Key, όπως φαίνεται στην Εικόνα 10.7.
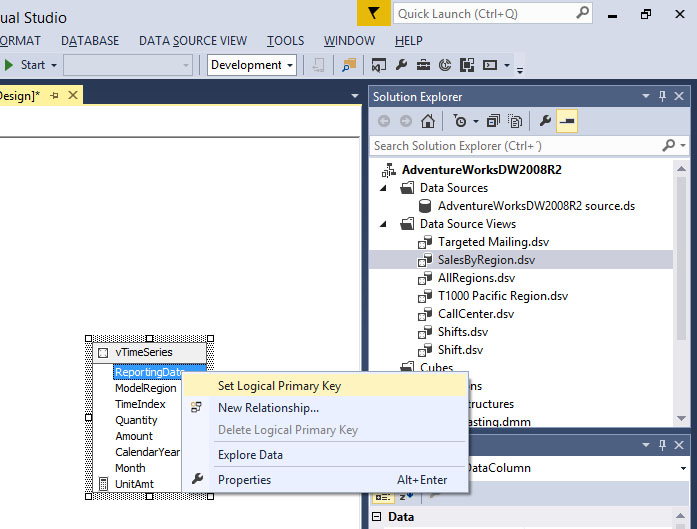
Εικόνα 10.7
-
Στη συνέχεια, για να δημιουργήσουμε ένα mining structure, θα πρέπει να επιλέξουμε την καρτέλα Solution Explorer, να κάνουμε δεξί κλικ στο Mining Structure και να επιλέξουμε New Mining Structure, όπως φαίνεται στην Εικόνα 10.8.
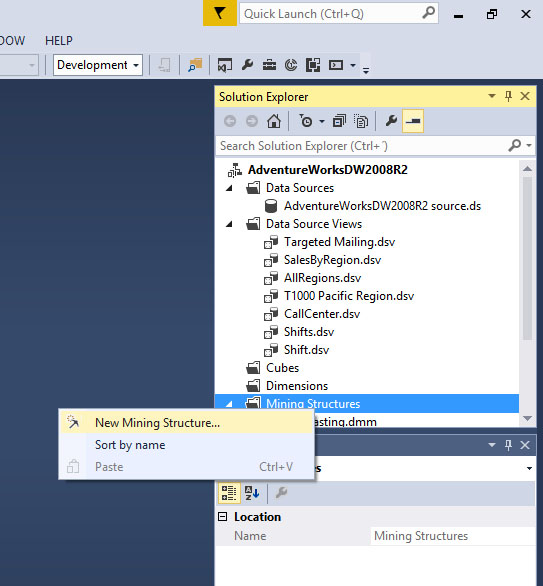
Εικόνα 10.8
-
Στο παράθυρο καλωσορίσματος του οδηγού Data Mining Wizard, όπως φαίνεται στην Εικόνα 10.9, επιλέγουμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
Εικόνα 10.9
-
Στο νέο παράθυρο, όπως φαίνεται στην Εικόνα 10.10, επιλέγουμε From existing relational database or data warehouse, καθώς τα δεδομένα μας θα εισαχθούν από την σχεσιακή βάση που εισάγαμε στην Ενότητα 6.3. Στη συνέχεια, πατάμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
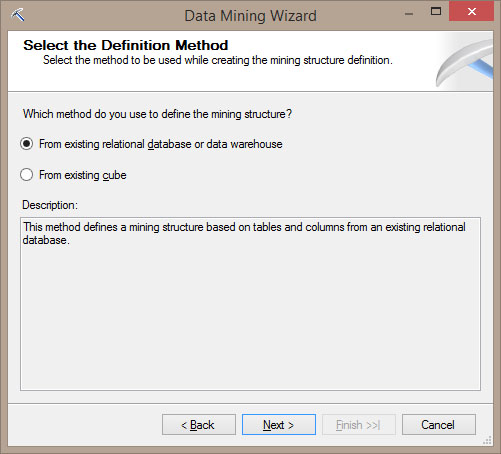
Εικόνα 10.10
-
Στο νέο παράθυρο, όπως φαίνεται στην Εικόνα 10.11, επιλέγουμε τον αλγόριθμο με τον οποίο θα επεξεργαστούμε τα δεδομένα. Στη συγκεκριμένη περίπτωση, επιλέγουμε τον Microsoft Time Series. Πατάμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
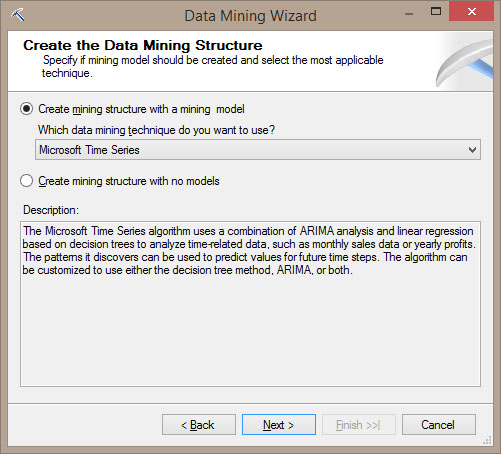
Εικόνα 10.11
-
Στη συνέχεια, εμφανίζεται το παράθυρο με τα διαθέσιμα data source views του project μας. Επιλέγουμε, όπως φαίνεται στην Εικόνα 10.12, το Sales By Region. Στη συνέχεια, πατάμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
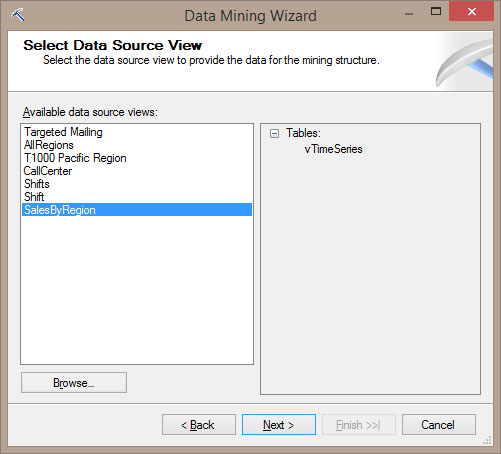
Εικόνα 10.12
-
Σ’ αυτό το βήμα θα επιλέξουμε ποιος πίνακας θα οριστεί ως case και ποιοι πίνακες θα είναι nested. Στη συγκεκριμένη περίπτωση, όπως φαίνεται στην Εικόνα 10.13, δεν θα ορίσουμε nested πίνακες. Επιλέγουμε ως Case τον πίνακα vTimeSeries table και επιλέγουμε Next.
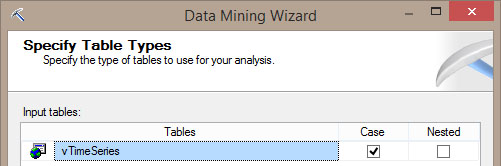
Εικόνα 10.13
-
Σ’ αυτό το βήμα θα επιλέξουμε ποια δεδομένα που ορίσαμε στο προηγούμενο βήμα θα είναι είσοδος στη χρονοσειρά και ποια δεδομένα θέλουμε να προβλέψουμε.
Συγκεκριμένα, όπως φαίνεται στην Εικόνα 10.14, κάνουμε τις εξής επιλογές:
- Επιλέγουμε ως κλειδιά (Keys) τα ModelRegion και ReportingDate της όψης vTimeSeries.
- Ορίζουμε ως Input το πεδίο Quantity.
- Ορίζουμε ως Predictable ξανά το πεδίο Quantity.
- Στη συνέχεια, πατάμε Next >, ώστε να προχωρήσουμε στο επόμενο βήμα.
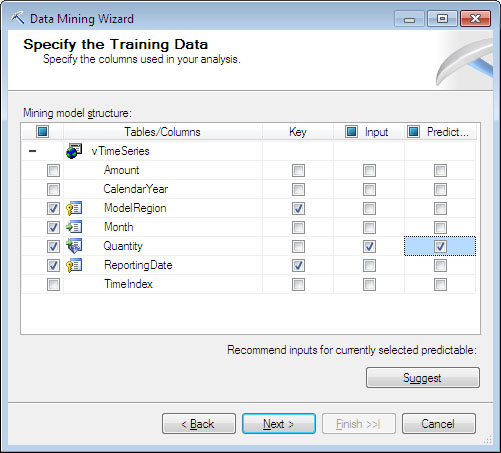
Εικόνα 10.14
-
Εμφανίζεται μια σύνοψη - επιβεβαίωση του περιεχομένου του Mining Structure, όπως φαίνεται στην Εικόνα 10.15. Κατόπιν, επιλέγουμε Next>, ώστε να προχωρήσουμε στο επόμενο βήμα.
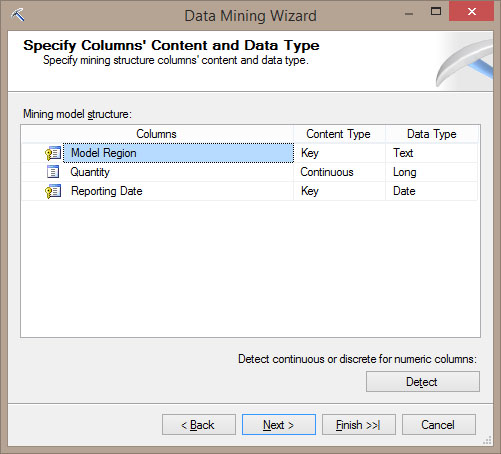
Εικόνα 10.15
-
Στο νέο παράθυρο θα ορίσουμε όνομα για το Mining Structure και το Mining Model. Στη συγκεκριμένη περίπτωση, συμπληρώνουμε Forecasting και στα δύο πεδία, όπως φαίνεται στην Εικόνα 10.16. Τέλος, επιλέγουμε Finish, για να ολοκληρωθεί η διαδικασία.
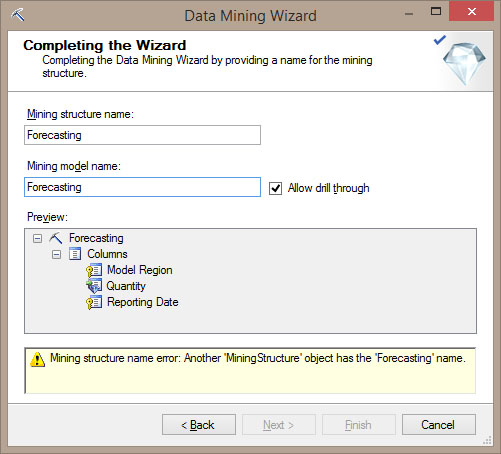
Εικόνα 10.16
-
Στην εικόνα 10.17, εμφανίζεται το παράθυρο του Data Mining
Designer όπου στην καρτέλα Mining Structure
βλέπουμε το μοντέλο Forecasting.dmm που δημιουργήσαμε. Στη συνέχεια
μπορούμε να κάνουμε κλικ στο Start για να κάνουμε employment στο μοντέλο
μας.
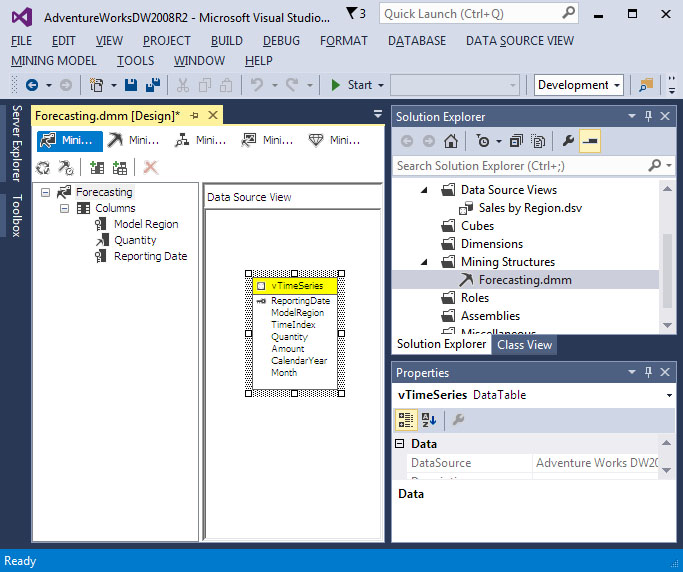
Εικόνα 10.17
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.3.
Τροποποίηση και παραμετροποίηση του μοντέλου Time Series
Μπορούμε να αλλάξουμε τη δομή του μοντέλου μας χρησιμοποιώντας την καρτέλα Mining Structure από το Data Mining Designer. Όταν δημιουργήθηκε το μοντέλο με τον Data Mining Wizard, χρησιμοποιήθηκαν τρία πεδία: ReportingDate, ModelRegion και Quantity. Ωστόσο, η υπό εξέταση όψη vTimeSeries περιέχει, επίσης, το πεδίο Amount, με το οποίο μπορούμε να προβλέψουμε τα εκάστοτε ποσά των πωλήσεών μας. Με τη χρήση της καρτέλας Mining Structure, μπορούμε να προσθέσουμε αυτήν τη στήλη από το data source view του mining structure.
- Για να προστεθεί το Amount στο mining structure Forecasting, θα πρέπει να επιλέξουμε το Amount από τον πίνακα vTimeSeries και να το σύρουμε (με drag & drop) στη λίστα του Forecasting structure, όπως φαίνεται στην Εικόνα 10.18.
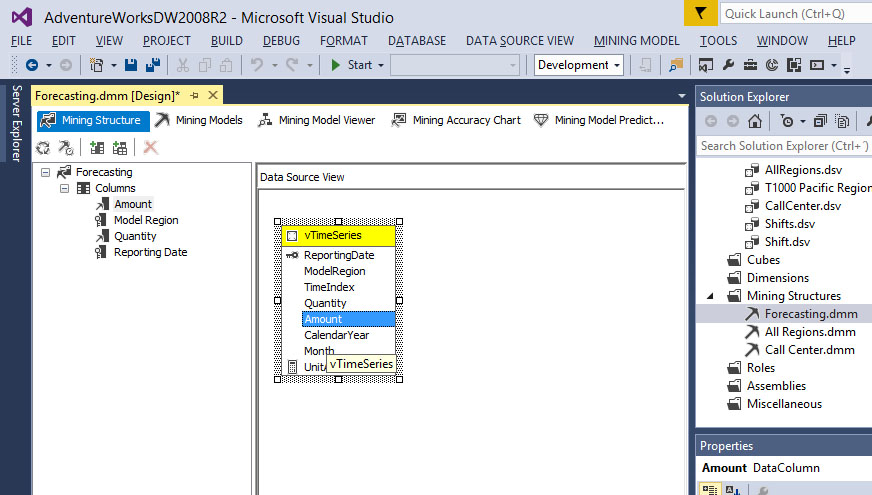
Εικόνα 10.18
-
Στο μοντέλο Forecasting, η στήλη Amount μπορεί να χρησιμοποιηθεί ως πεδίο πρόβλεψης. Ως εκ τούτου, πηγαίνουμε στην καρτέλα Mining Models του Forecasting, όπως φαίνεται στην Εικόνα 10.19, και επιλέγουμε στο κελί του Amount το Predict.
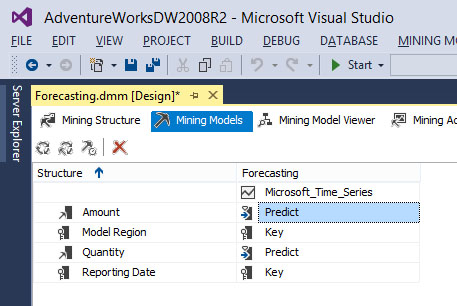
Εικόνα 10.19
-
Στη συνέχεια θα μελετήσουμε πώς επηρεάζονται η αποτελεσματικότητα και η συμπεριφορά του αλγορίθμου Time Series, αλλάζοντας μερικές απ’ τις τιμές των παραμέτρων του . Όπως φαίνεται στην Εικόνα 10.20, κάνουμε δεξί κλικ στον τίτλο Microsoft Time Series και επιλέγουμε Set Algorithm Parameters.
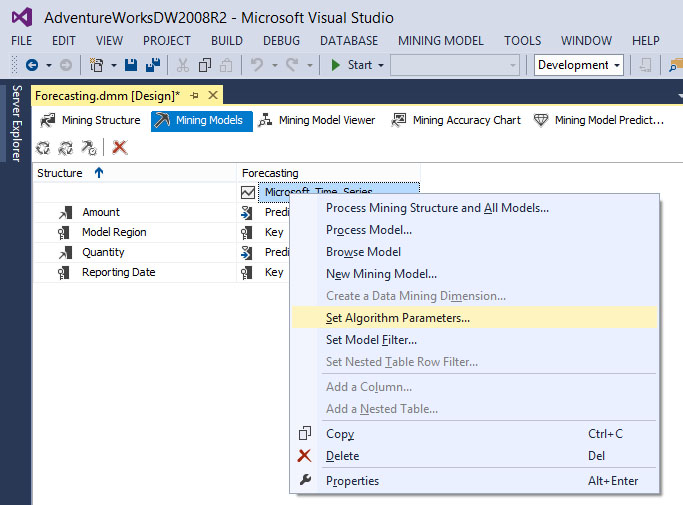
Εικόνα 10.20
-
Όσον αφορά την παραμετροποίηση του αλγορίθμου Time Series, αυτός παρέχει δώδεκα διαφορετικές παραμέτρους, όπως φαίνεται στην Εικόνα 10.21, που επηρεάζουν το πώς ένα μοντέλο δημιουργείται και το πώς τα δεδομένα του χρόνου αναλύονται κάθε φορά.
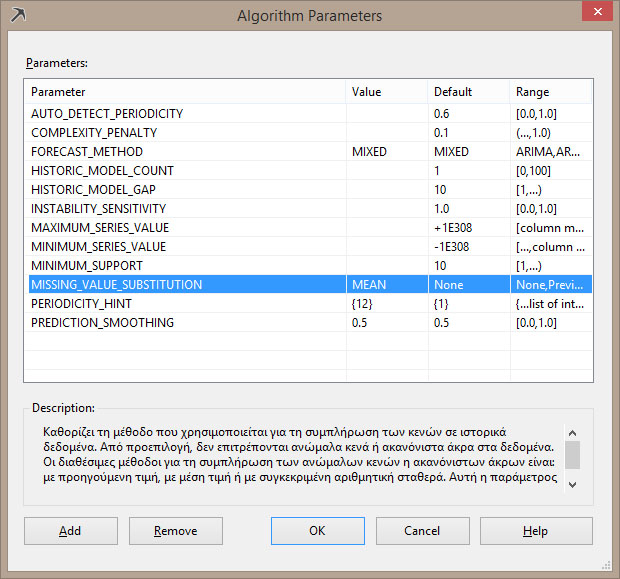
Εικόνα 10.21
Ακολουθεί η αναλυτική περιγραφή της κάθε παραμέτρου του αλγορίθμου Time Series:
- AUTO_DETECT_PERIODICITY: Παίρνει τιμές μεταξύ 0 και 1 (default 0.6). Χρησιμοποιείται για την ανίχνευση περιοδικότητας. Όσο η τιμή τείνει στη μονάδα, ευνοείται η ανακάλυψη περισσότερων μοτίβων.
- COMPLEXITY_PENALTY: Ελέγχει την ανάπτυξη του δέντρου, οι κόμβοι του οποίου καθορίζουν την ύπαρξη διαφορετικής συμπεριφοράς ανά χρονική περίοδο στα δεδομένα της χρονοσειράς μας (default 0.1). Μείωση της τιμής της παραμέτρου επιφέρει αύξηση της πιθανότητας διαχωρισμού (split) στο δέντρο.
- FORECAST_METHOD: Καθορίζει τον αλγόριθμο που θα χρησιμοποιηθεί. Οι αλγόριθμοι είναι τρείς: ARTXP, ARIMA και MIXED (default τιμή: MIXED).
- HISTORIC_MODEL_COUNT: Καθορίζει τον αριθμό των μοντέλων που θα δημιουργηθούν (default τιμή: 1).
- HISTORICAL_MODEL_GAP: Καθορίζει τη χρονική καθυστέρηση ανάμεσα σε δύο διαδοχικά μοντέλα (default τιμή: 10). Ο αριθμός αντιστοιχεί σε χρονικές μονάδες βάσει του εκάστοτε μοντέλου.
- INSTABILITY_SENSITIVITY: Η συγκεκριμένη παράμετρος ελέγχει αν η διακύμανση των προβλέψεων ξεπερνά ένα κατώφλι που έχει οριστεί. Αφορά μόνο τον αλγόριθμο ARTPX (default τιμή: 1) και δεν χρησιμοποιείται για τον ARIMA. Όταν μια προβλεπόμενη τιμή ξεπεράσει το όριο που έχει οριστεί, ο ARTPX επιστρέφει NULL τιμές και σταματάει η διαδικασία. MAXIMUM_SERIES_VALUE: Η παράμετρος επιβάλλει έναν περιορισμό στην ανώτατη τιμή που μπορεί να δοθεί σε μια πρόβλεψη. Χρησιμοποιείται για να θέσουμε ένα μέγιστο όριο στις τιμές των προβλέψεών μας.
- MINIMUM_SERIES_VALUE: Η παράμετρος επιβάλλει έναν περιορισμό στην κατώτατη τιμή που μπορεί να δοθεί σε μία πρόβλεψη. Χρησιμοποιείται για να θέσουμε ένα ελάχιστο όριο στις τιμές των προβλέψεών μας.
- MINIMUM_SUPPORT: Με αυτή την παράμετροορίζουμε τον ελάχιστο αριθμό περιπτώσεων (cases) που απαιτούνται για τη δημιουργία ενός κόμβου στο δέντρο που εκφράζει τα δεδομένα της χρονοσειράς μας (default τιμή: 10).
- MISSING_VALUE_SUBSTITUTION: Η παράμετρος καθορίζει τη μέθοδο συμπλήρωσης κενών στα δεδομένα της χρονοσειράς μας. Οι πιθανές τιμές που μπορεί να πάρει είναι: Previous (επανάληψη τιμής που σημειώθηκε την προηγούμενη χρονική στιγμή), Mean (μέσος), Numeric constant (μία σταθερή τιμή) και None (κενή τιμή).
- PERIODICITY_HINT: Η παράμετρος προσδιορίζει την ύπαρξη περιοδικότητας στα δεδομένα μας. Για παράδειγμα, αν οι πωλήσεις ποικίλλουν ανά έτος και οι μονάδες μέτρησης της χρονοσειράς είναι ανά μήνα, τότε η περιοδικότητα είναι {12}.
- PREDICTION_SMOOTHING: Η παράμετρος χρησιμοποιείται μόνο εφόσον έχει επιλεχθεί η τιμή MIXED στην παράμετρο FORECAST_METHOD. Η παράμετρος καθορίζει το ποσοστό συμμετοχής του κάθε αλγορίθμου (ARTXP και ΑRΙΜΑ).
- Όσον αφορά την περιοδικότητα των δεδομένων (πόσο συχνά επαναλαμβάνεται ένα pattern στα δεδομένα), μπορούμε να ρυθμίσουμε την τιμή της παραμέτρου PERIODICITY_HINT, όπως φαίνεται στην Εικόνα 10.21. Τα δεδομένα της όψης vTimeSeries είναι διαμορφωμένα σε μηνιαία βάση και η περιοδικότητά τους ορίζεται σε ετήσιο επίπεδο. Ως εκ τούτου, θα ορίσουμε την παράμετρο PERIODICITY_HINT ίση με την τιμή {12}.
Όπως ήδη αναφέρθηκε στην Ενότητα 10.1., η παράμετρος FORECAST_METHOD ρυθμίζει ποιος αλγόριθμος θα χρησιμοποιείται κάθε φορά (δηλαδή, αν θα χρησιμοποιηθεί ο αλγόριθμος ARTXP, για βραχυπρόθεσμες προβλέψεις ή ο αλγόριθμος ΑRIMA για μακροπρόθεσμες προβλέψεις). Βέβαια, η συγκεκριμένη παράμετρος έχει τεθεί εξ ορισμού σε MIXED, που σημαίνει ότι χρησιμοποιούνται και οι δύο αλγόριθμοι. Η παράμετρος PREDICTION_SMOOTHING είναι αυτή που ρυθμίζει το ποσοστό συμμετοχής του κάθε αλγορίθμου. Στην περίπτωσή μας, η παράμετρος αυτή ορίζεται στην τιμή 0.5, επειδή παρέχει, γενικά, την καλύτερη ισορροπία μεταξύ βραχυπρόθεσμων και μακροπρόθεσμων προβλέψεων.
Τέλος, η ύπαρξη κενών τιμών είναι ένα ακόμη πρόβλημα που μπορεί να παρουσιαστεί στα δεδομένα πωλήσεων. Για παράδειγμα, όπως φαίνεται στην Εικόνα 10.5, δεν υπάρχουν δεδομένα πωλήσεων για τα ποδήλατα με κωδικό Τ1000 Europe πριν από τον Ιούλιο του 2007. Για να αποφύγουμε την περίπτωση εμφάνισης κάποιου σφάλματος απ’ το σύστημα, μπορούμε να καθορίσουμε στην παράμετρο MISSING_VALUE_SUBSTITUTION την τιμή MEAN, όπως φαίνεται στην Εικόνα 10.21, ώστε η μέση τιμή πώλησης της συνολικής χρονικής περιόδου πωλήσεων να καταχωρηθεί στις κενές τιμές.
- Σε περίπτωση που δεν έχουν αποθηκευτεί οι αλλαγές που έχουμε κάνει, θα εμφανιστεί μήνυμα, όπως φαίνεται στην Εικόνα 10.22, στο οποίο επιλέγουμε Yes.
Εικόνα 10.22
-
Στη συνέχεια, εμφανίζεται ένα νέο παράθυρο, όπως φαίνεται στην Εικόνα 10.23, στο οποίο βρίσκονται συγκεντρωμένες οι επιλογές μας. Επιλέγουμε Run, ώστε να δημιουργηθεί το μοντέλο και να γίνει deployment.
Εικόνα
10.23
-
Στη συνέχεια, εμφανίζεται ένα νέο παράθυρο, όπως φαίνεται στην Εικόνα 10.24, που παρουσιάζει τις ενέργειες που έγιναν για τη δημιουργία της πρόβλεψης. Παράλληλα, μας πληροφορεί αν αυτές οι ενέργειες ολοκληρώθηκαν με επιτυχία. Επιλέγουμε Close, ώστε να ολοκληρωθεί η διαδικασία.
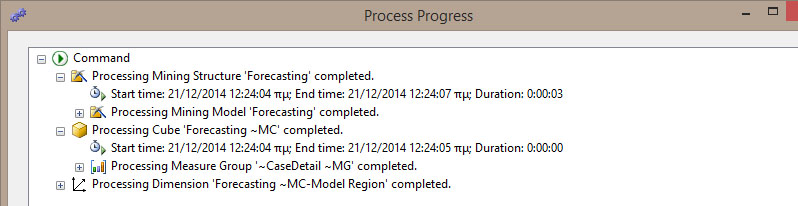
Εικόνα 10.24
-
Αν το employment είναι επιτυχημένο, τότε θα εμφανιστεί το παράθυρο της Εικόνας 10.25.
Εικόνα 10.25
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.4.
Αξιολόγηση του μοντέλου Time Series.
Το μοντέλο πρόβλεψης που δημιουργήθηκε στην προηγούμενη ενότητα προβλέπει, όπως αναφέραμε, μελλοντικές πωλήσεις βάσει των πωλήσεων ποδηλάτων που έγιναν σε τρεις διαφορετικές περιοχές (Europe, North America και Pacific) για τα έτη 2005 - 2008. Μετά την επιτυχή δημιουργία του μοντέλου πρόβλεψης, μπορούμε να εξερευνήσουμε τα αποτελέσματα απ’ την καρτέλα του Mining Model Viewer, η οποία περιέχει τις δύο καρτέλες Charts και Model.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.4.1.
Καρτέλα Charts
Η καρτέλα Charts εμφανίζει με γραφικό τρόπο μελλοντικές προβλέψεις για τα πεδία amount και/ή quantity με βάση το προϊόν και την εκάστοτε περιοχής πώλησής του. Όπως φαίνεται στην Εικόνα 10.26, το γράφημα εμφανίζει τόσο ιστορικά δεδομένα όσο και δεδομένα μελλοντικής πρόβλεψης. Συγκεκριμένα, το διάγραμμα εμφανίζει στοιχεία για το ποδήλατο με κωδικό προϊόντος Μ200 για τις περιοχές Europe, North America και Pacific, τόσο για το πεδίο amount όσο και για το πεδίο quantity. Οι καμπύλες τάσης δείχνουν ότι οι συνολικές πωλήσεις για όλες τις περιοχές γενικά (εκτός της περιοχής του Ειρηνικού) αυξάνονται κάθε 12 μήνες, και συγκεκριμένα τον μήνα Δεκέμβριο. Αυξάνοντας την επιλογή Prediction Steps, μπορούμε να αυξήσουμε τον χρονικό ορίζοντα των προβλέψεών μας.
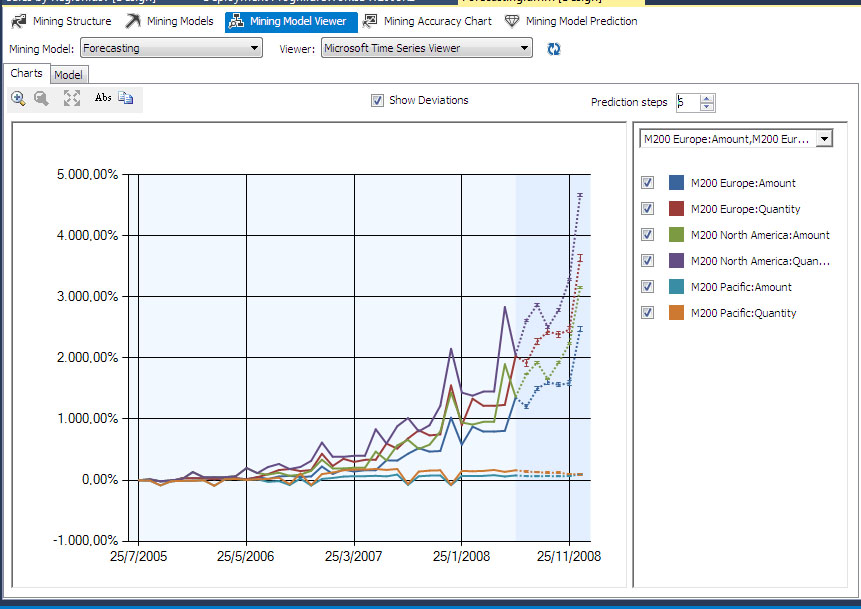
Εικόνα 10.26
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.4.2
Καρτέλα Model
Η καρτέλα Model εμφανίζει το μοντέλο πρόβλεψης με τη μορφή ενός δέντρου απόφασης. Συγκεκριμένα, εμφανίζεταιένα δέντρο για κάθε δυνατό συνδυασμό των τριών παραγόντων που υπάρχουν στα δεδομένα μας (κωδικός προϊόντος, περιοχή πώλησης και χαρακτηριστικό πρόβλεψης). Καθώς έχουμε ως δεδομένα τους τέσσερεις κωδικούς προϊόντων (Μ200, Τ1000, R250 και R750), τις τρεις περιοχές πώλησης (Europe, North America και Pacific) και τα δύο χαρακτηριστικά πρόβλεψης (Amount και Quantity), δημιουργούνται συνολικά 24 δέντρα απόφασης (4*3*2=24).
Τονίζεται ότι όταν ένα δέντρο απόφασης αποτελείται μόνο από έναν κόμβο, αυτό σημαίνει ότι η τάση των δεδομένων είναι ομοιογενής στη μονάδα του χρόνου και η χρονοσειρά μπορεί να εκφραστεί απλά με μία μόνο γραμμική εξίσωση. Από την άλλη, όταν ένα δέντρο απόφασης αποτελείται από πολλούς κόμβους και διακλαδώσεις, αυτό σημαίνει ότι η χρονοσειρά δεν είναι γραμμική και κάθε κλαδί του δέντρου πρέπει να εκφραστεί με μια διαφορετική εξίσωση.
- Στην περίπτωση μας, επιλέγουμε την καρτέλα Model στο Mining Model Viewer και διαλέγουμε το M200 North America: Amount, όπως φαίνεται στην Εικόνα 10.27. Αυτό εμφανίζει έναν μόνο κόμβο. Αφήνοντας τον κέρσορα πάνω στον κόμβο, βλέπουμε πληροφορίες, όπως είναι ο αριθμός των περιπτώσεων που υπάρχουν στη χρονοσειρά και η εξίσωση χρονοσειράς που προκύπτει από την ανάλυση αυτών των δεδομένων.
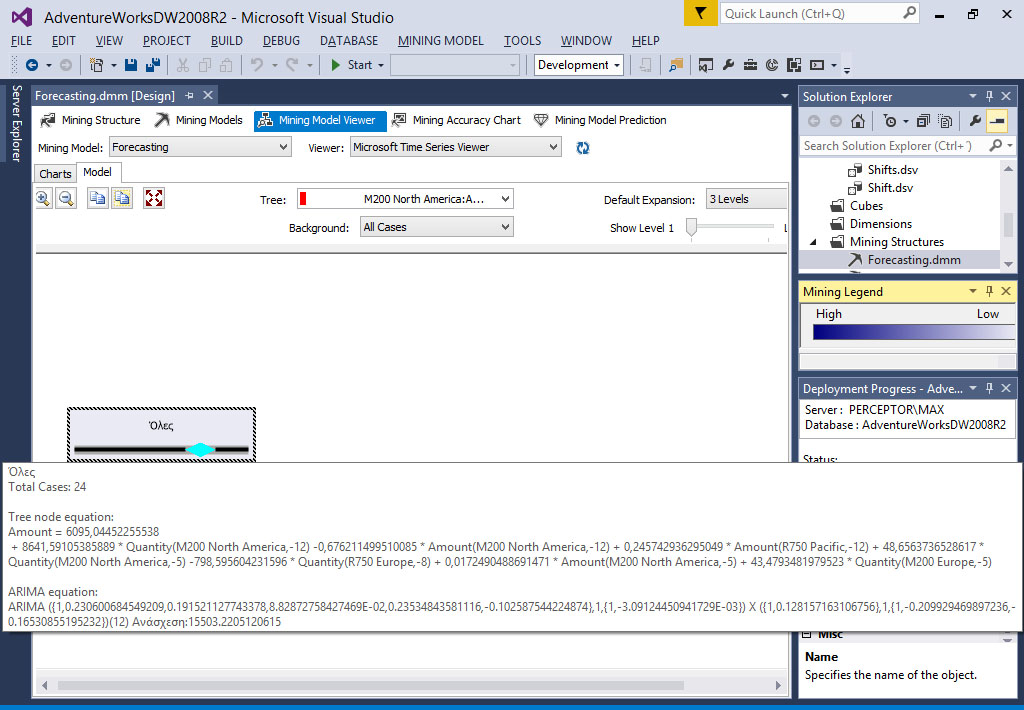
Εικόνα 10.27
-
Κάνουμε δεξί κλικ στον κόμβο και επιλέγουμε Mining Legend. Το Mining Legend, όπως φαίνεται στην Εικόνα 10.28, περιλαμβάνει πληροφορίες για τις ανεξάρτητες μεταβλητές και τους συντελεστές που συμμετέχουν στην εξίσωση πρόβλεψης της χρονοσειράς για το M200 North America: Amount. Επιπλέον, το Mining Legend περιέχει ένα ιστόγραμμα που αφορά τις μεταβλητές που παίρνουν διακριτές τιμές και δείχνει την κατανομή των τιμών τους μέσα στο κόμβο..
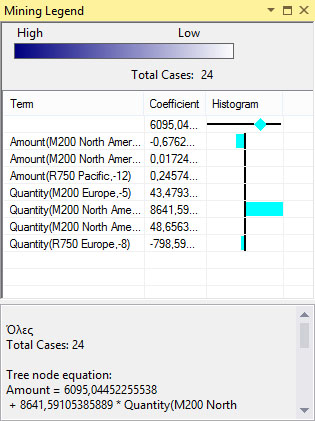
Εικόνα 10.28
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.5.
Ασκήσεις αξιολόγησης μοντέλου Time Series
-
Να αξιολογήσετε τις τάσεις πωλήσεων που προκύπτουν απ’ το μοντέλο πρόβλεψης Time Series για τη χρονοσειρά που αφορά το προϊόν R250 στην περιοχή πώλησης Europe όσον αφορά το ποσό των πωλήσεων (amount).
-
Να δημιουργήσετε ένα
ερώτημα SQL που να προβλέπει το ποσό των πωλήσεων σε δολάρια και τις ποσότητες των ποδηλάτων που θα πωληθούν κατά το διάστημα 25/7/2008 έως 25/11/2008, δηλαδή τους 5 μήνες που έπονται των δεδομένων της χρονοσειράς μας. Η πρόβλεψη να γίνει για κάθε δυνατό συνδυασμό ενός τύπου προϊόντος (Μ200, Τ1000, R250 και R750) και μιας περιοχής πώλησης (Europe, North America και Pacific).
-
Να συγκρίνετε τις τάσεις πωλήσεων μεταξύ των ποδηλάτων με κωδικό προϊόντος M200 και να προσδιορίσετε πιθανά προβλήματα.
-
Να δημιουργήσετε ένα γενικό μοντέλο πρόβλεψης που να μην αφορά μια μεμονωμένη περιοχή πώλησης (Europe, North America και Pacific) και ένα συγκεκριμένο κωδικό ποδηλάτου (Μ200, Τ1000, R250, R750) Αντιθέτως, να προβλέπει συγκεντρωτικά και σε παγκόσμιο επίπεδο τα συνολικά ποσά πωλήσεων, καθώς και τις συνολικές ποσότητες ποδηλάτων που θα πωληθούν παγκοσμίως.
-
Eστω ότι εργάζεστε για την AdventureWorks, μια πολυεθνική εταιρία που εμπορεύεται τέσσερις τύπους ποδηλάτων (Μ200, R250, R750 και Τ1000) σε τρεις περιοχές (Ευρώπη, Βόρεια Αμερική και Ειρηνικό). Το τμήμα πωλήσεων επιθυμεί να προβλέψει τις πωλήσεις του επόμενου εξαμήνου (Ιανουάριος 2008 έως Ιούνιος 2008) για το μοντέλο ποδηλάτου R750 στις τρεις παραπάνω περιοχές, λαμβάνοντας υπόψη τις πωλήσεις που σημειώθηκαν στο προγενέστερο διάστημα (Ιούλιος 2005 έως Δεκέμβριος του 2007). Δημιουργήστε, λοιπόν, ένα μοντέλo χρονοσειράς που θα έχει ως input και predictable το πεδίο amount, θέτοντας τις παραμέτρους του αλγορίθμου ως εξής: PERIODICITY_HINT = {12} και FORECAST_METHOD=MIXED. Τονίζεται ότι θα πρέπει να δημιουργήσετε ένα νέο ερώτημα (Data Source View & New named query) που θα επιλέγει δεδομένα μόνο μέχρι τις 31-12-2007. Ακόμη, τονίζεται ότι πρέπει να τρέξετε τον αλγόριθμο time series μόνο στο συγκεκριμένο χρονικό διάστημα τιμών.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.6.Λύσεις ασκήσεων αξιολόγησης μοντέλου Time Series
Άσκηση 1
Να αξιολογήσετε τις τάσεις πωλήσεων που προκύπτουν από το μοντέλο
πρόβλεψης Time Series για την χρονοσειρά που αφορά το προϊόν R250
στην περιοχή πώλησης Europe όσον
αφορά το ποσό των πωλήσεων (ammount).
-
Λύση άσκησης 1:
+
Βρισκόμαστε στην καρτέλα Model του Mining Model Viewer. Επιλέγουμε τον συνδυασμό προϊόντος και περιοχής R250 Europe: Amount. Αυτή η ενέργεια εμφανίζει έναν κόμβο που σε κάποια χρονική στιγμή διασπάται σε δύο, κάτι που σημαίνει ότι έχει υπάρξει μια δραστική αλλαγή στη χρονοσειρά. Όπως φαίνεται στην Εικόνα 10.29, η ημερομηνία 22/8/2007 έχει προσδιοριστεί ως ορόσημο για μια σημαντική αλλαγή στα δεδομένα της χρονοσειράς.
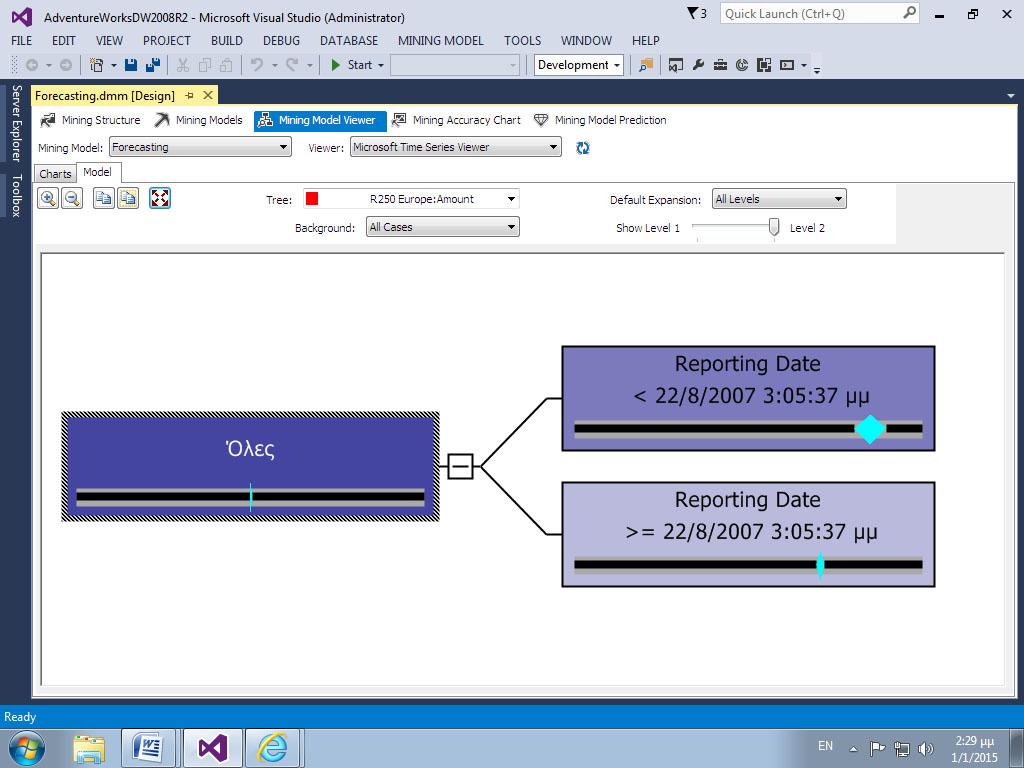
Εικόνα 10.29
Βρισκόμαστε στην καρτέλα Charts του Mining Model Viewer. Επιλέγουμε το προϊόν R250 για την περιοχή Europe και προβλέπουμε το χαρακτηριστικό amount. Όπως φαίνεται στην Εικόνα 10.30, στις 25/8/2007 οι πωλήσεις του προϊόντος R250 έπεσαν δραματικά: από 127054 $ στα 46423 $. Δηλαδή, σημειώθηκε μια πτώση των πωλήσεων κατά τρείς φορές σε σχέση με την προτεραία κατάσταση. Ασφαλώς, ένα τέτοιο συμβάν θα πρέπει να αντιμετωπιστεί από το τμήμα πωλήσεων!
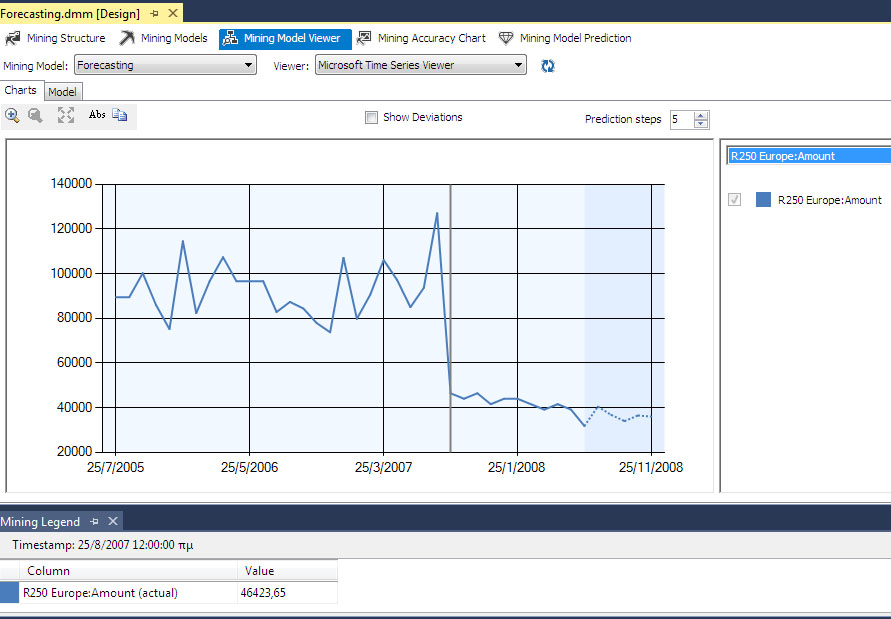 Εικόνα 10.
Εικόνα 10.
Άσκηση 2
Να δημιουργήσετε ένα ερώτημα SQL που να προβλέπει το ποσό των πωλήσεων σε δολάρια και τις ποσότητες των ποδηλάτων που θα πωληθούν κατά το διάστημα 25/7/2008 έως 25/11/2008, δηλαδή τους 5 μήνες που έπονται των δεδομένων της χρονοσειράς μας. Η πρόβλεψη να γίνει για κάθε δυνατό συνδυασμό ενός τύπου προϊόντος (Μ200, Τ1000, R250 και R750) και μιας περιοχής πώλησης (Europe, North America και Pacific).
-
Λύση άσκησης 2:
+
Για να δημιουργήσουμε το ερώτημα, ανοίγουμε την καρτέλα Mining Model Prediction, όπως φαίνεται στην Εικόνα 10.31. Στο Mining Model κάνουμε κλικ στο Select Model και επιλέγουμε το Forecasting. Στη συνέχεια, πατάμε OK.
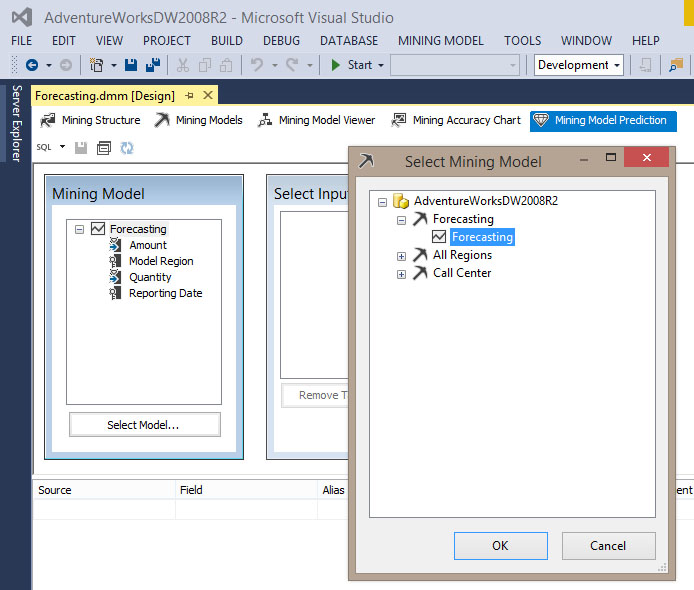
Εικόνα 10.31
-
Όπως φαίνεται στην Εικόνα 10.32, αγνοούμε το παράθυρο Select Input Table, διότι δεν έχουμε να εισάγουμε δεδομένα από άλλους συσχετιζόμενους πίνακες. Αντίθετα, ενδιαφερόμαστε για τον πίνακα με τις κενές γραμμές που βρίσκεται στην κάτω περιοχή του παραθύρου..
>Ξεκινάμε από την πρώτη γραμμή του πίνακα. Στη στήλη Source κάνουμε κλικ και επιλέγουμε Forecasting, επειδή αυτό είναι το μοντέλο για την πρόβλεψή μας. Στη στήλη Field επιλέγουμε Model Region, προκειμένου να ομαδοποιούνται τα δεδομένα μας ανά κωδικό προϊόντος και περιοχή πώλησης.
Συνεχίζουμε στη δεύτερη γραμμή του πίνακα. Στη στήλη Source επιλέγουμε Prediction Function, στη στήλη Field επιλέγουμε PredictTimeSeries (μια ενσωματωμένη συνάρτηση του SQL Server) και στη στήλη Alias πληκτρολογούμε PredictAmount, που θα είναι το όνομα του πεδίου που θα προβλέπουμε. Στη στήλη Criteria/Arguments γράφουμε “[Forecasting].[Amount], 5”, προκειμένου να προβλέψουμε το ποσό των πωλήσεων σε δολάρια για τους επόμενους 5 μήνες (25/7/2008 έως 25/11/2008) που έπονται των δεδομένων της χρονοσειράς μας.
Συμπληρώνουμε, τέλος, την τρίτη γραμμή του πίνακα. Στη στήλη Source επιλέγουμε Prediction Function, στη στήλη Field επιλέγουμε PredictTimeSeries και στη στήλη Alias πληκτρολογούμε PredictQuantity, που θα είναι το όνομα του πεδίου που θα προβλέπουμε. Στη στήλη Criteria/Arguments γράφουμε “[Forecasting].[Quantity], 5”, προκειμένου να προβλέψουμε τις ποσότητες των ποδηλάτων που θα πωληθούν τους επόμενους 5 μήνες (25/7/2008 έως 25/11/2008) που έπονται των δεδομένων της χρονοσειράς μας. Τέλος, κάνουμε κλικ στο Switch to query result view (το κουμπί πάνω αριστερά στην Εικόνα 10.32), για να εμφανιστούν τα αποτελέσματα του ερωτήματος.
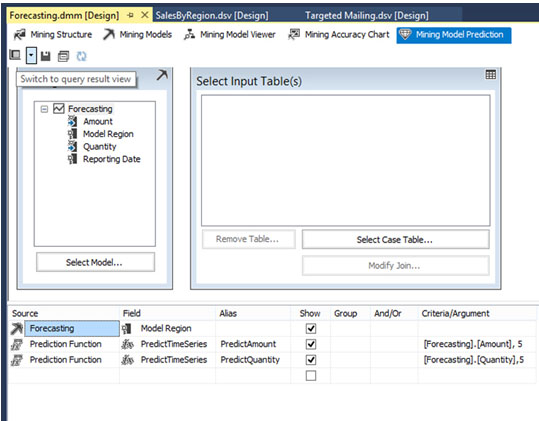
Εικόνα 10.32
-
Όπως φαίνεται στην Εικόνα 10.33, τα αποτελέσματα του ερωτήματός μας περιέχονται σε τρεις ξεχωριστές στήλες. Η πρώτη στήλη περιέχει όλους τους δυνατούς συνδυασμούς των προϊόντων και της περιοχής πώλησης. Η δεύτερη στήλη περιέχει τις πέντε προβλεπόμενες τιμές ποσών πωλήσεων ανά κωδικό προϊόντος και περιοχή πώλησης. Τέλος, η τρίτη στήλη περιέχει τις πέντε προβλεπόμενες ποσότητες ποδηλάτων ανά κωδικό προϊόντος και περιοχή πώλησης. Τελικά, στην Εικόνα 10.33 παρουσιάζονται οι αναλυτικές προβλέψεις μας για το προϊόν 200 Europe.
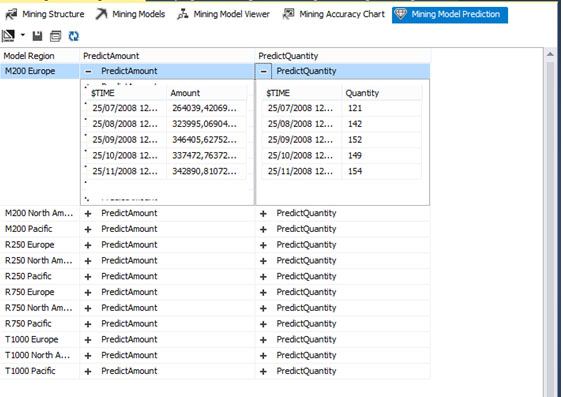
Εικόνα 10.33
Άσκηση 3
Να συγκρίνετε τις τάσεις πωλήσεων μεταξύ των ποδηλάτων με κωδικό προϊόντος
M200 και να προσδιορίσετε πιθανά προβλήματα.
-
Λύση άσκησης 3:
+
Στην Εικόνα 10.34 εμφανίζονται οι τάσεις πωλήσεων του ποδηλάτου Μ200 στις τρεις περιοχές πώλησης. Οι καμπύλες πρόβλεψης πωλήσεων για το μοντέλο M200 στις περιοχές της Ευρώπης και της Βόρειας Αμερικής είναι σταθερά αυξανόμενες. Αντιθέτως, η καμπύλη πρόβλεψης των πωλήσεων για το Μ200 στην περιοχή του Ειρηνικού είναι χαμηλή και σχετικά επίπεδη. Προφανώς, το τμήμα πωλήσεων θα πρέπει να προσέξει ιδιαίτερα το μεγάλο χάσμα που εμφανίζεται στις προβλέψεις πωλήσεων μεταξύ των τριών περιοχών στο ίδιο μοντέλο ποδηλάτου.
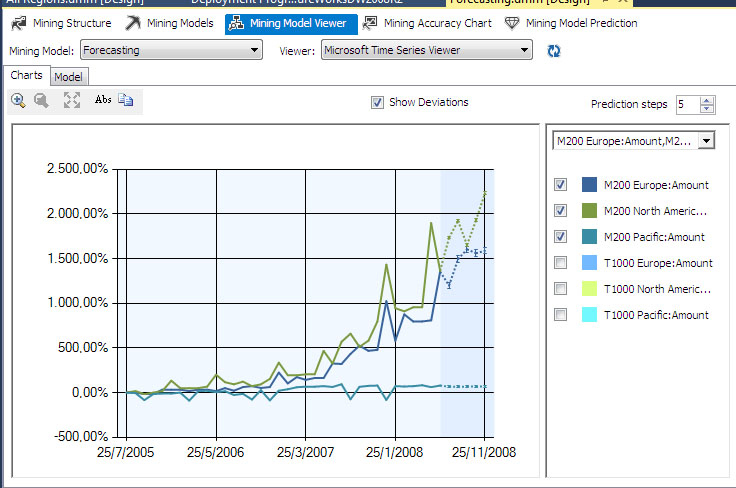 Εικόνα
10.34
Εικόνα
10.34
Άσκηση 4
Να δημιουργήσετε ένα γενικό μοντέλο πρόβλεψης που να μην αφορά μια μεμονωμένη περιοχή πώλησης (Europe, North America και Pacific) και ένα συγκεκριμένο κωδικό ποδηλάτου (Μ200, Τ1000, R250, R750) Αντιθέτως, να προβλέπει συγκεντρωτικά και σε παγκόσμιο επίπεδο τα συνολικά ποσά πωλήσεων, καθώς και τις συνολικές ποσότητες ποδηλάτων που θα πωληθούν.
-
Λύση άσκησης 4:
+
Το πρώτο βήμα για τη δημιουργία του γενικευμένου μοντέλου είναι η συγκέντρωση των στοιχείων για τις πωλήσεις σ’ όλον τον κόσμο. Μπορούμε να το κάνουμε αυτό, δημιουργώντας μια νέα προβολή προέλευσης δεδομένων (data source view) που θα εκτελέσει συγκεντρωτικούς υπολογισμούς (sums ή averages) πάνω στα πεδία ammount και quantity.
Για να δημιουργήσουμε μια vέα προβολή προέλευσης δεδομένων, στο Solution Explorer επιλέγουμε με δεξί κλικ New Data Source View. Στην επιλογή Select Tables and Views κάνουμε κλικ στο Next χωρίς να επιλέξουμε κάποιον πίνακα. Το Data Source View το ονομάζουμε AllRegions.
>Μετά τη δημιουργία του, κάνουμε δεξί κλικ στην κενή προβολή δεδομένων σχεδίασης, όπως φαίνεται στην Εικόνα 10.35, και επιλέγουμε New Named Query.
Εικόνα 10.35
Στο παράθυρο Create Named Query, όπως φαίνεται στην Εικόνα 10.36, γράφουμε AllRegions στο πεδίο Name. Στη συνέχεια, γράφουμε Sum and average of sales for all models and regions στο πεδίο Description. Τέλος, στο SQL query editor (στο κάτω μέρος του παραθύρου) γράφουμε τo παρακάτω ερώτημα ομαδοποίησης:
SELECT ReportingDate,
SUM([Quantity]) as SumQty, AVG([Quantity]) as AvgQty,
SUM([Amount]) AS SumAmt, AVG([Amount]) AS AvgAmt,
'All Regions' as [Region]
FROM dbo.vTimeSeries
GROUP BY ReportingDate
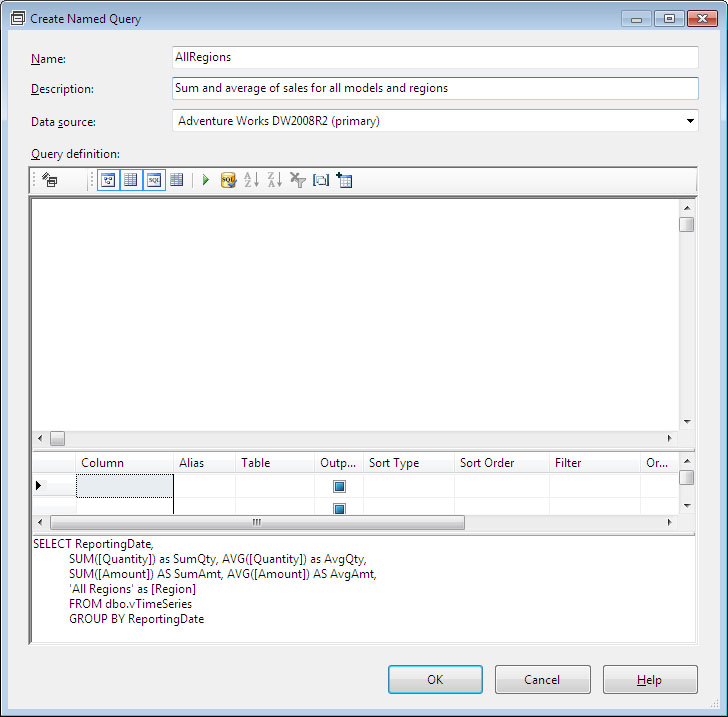
Εικόνα 10.36
-
4. Στο παραπάνω παράθυρο πατάμε OK, οπότε δημιουργείται το Data Source View, όπως φαίνεται στην Εικόνα 10.37.
Εικόνα 10.37
Στη συνέχεια, κάνουμε δεξί κλικ στην όψη AllRegions και επιλέγουμε Explore Data. Όπως φαίνεται στην Εικόνα 10.38, η νέα προβολή προέλευσης δεδομένων περιέχει συγκεντρωτικά αθροίσματα και μέσες τιμές για τις συνολικές πωλήσεις και τη συνολική ποσότητα ποδηλάτων που πουλήθηκε, για όλες τις περιοχές (Στήλες SumQty, AvgQty, SumAmt, AvgAmt) ανά χρονική περίοδο.
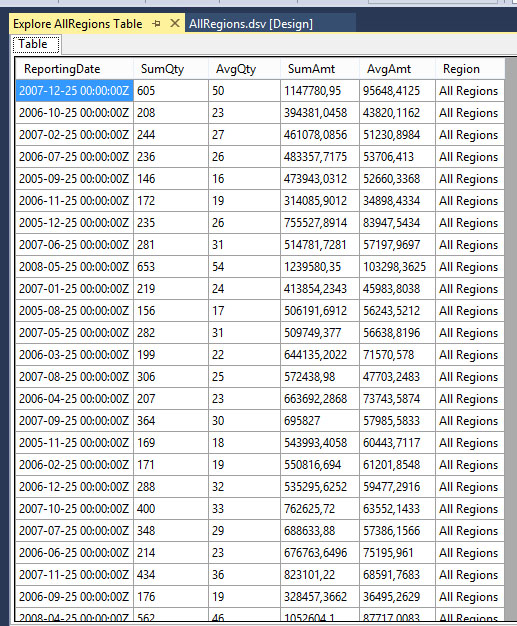
Εικόνα 10.38
-
Για να δημιουργήσουμε ένα μοντέλο πρόβλεψης για τα νέα συγκεντρωτικά στοιχεία, θα πρέπει να δημιουργήσουμε ένα New Mining Structure, όπως προαναφέρθηκε. Στο Data Mining Wizard επιλέγουμε τον αλγόριθμο Microsoft Time Series, στο Data source view το AllRegion, και επιλέγουμε το AllRegions για Case. Επίσης, όπως φαίνεται στην Εικόνα 10.39, επιλέγουμε ως κλειδί (key) το ReportingDate, και ως Input και Predict τα πεδία AvgAmt, AvgQty, SumAmt, και SumQty. Κατόπιν, πατάμε Next.
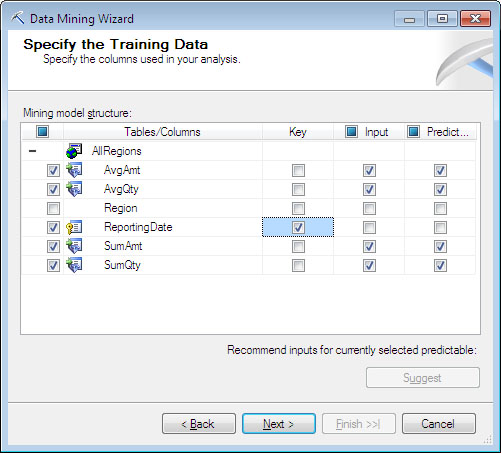
Εικόνα 10.39
-
Στη συνέχεια, θα ονομάσουμε All Regions τόσο το Mining structure name όσο και το Mining model name.
-
Κατόπιν, κάνουμε Process the structure and the model και εμφανίζεται ο πίνακας της Εικόνας 10.40.
Εικόνα 10.40
-
Στη συνέχεια, πηγαίνουμε στην καρτέλα Charts, όπως φαίνεται στο διάγραμμα της Εικόνας 10.41. Βλέπουμε σ’ αυτό τις προβλέψεις του αλγόριθμου Time Series για τα συγκεντρωτικά δεδομένα. Συγκεκριμένα, οι τέσσερις καμπύλες δείχνουν τις μέσες τιμές ποσών πώλησης και ποσοτήτων ποδηλάτων, καθώς επίσης και τα συνολικά εκτιμώμενα ποσά πωλήσεων και ποσότητες ποδηλάτων.
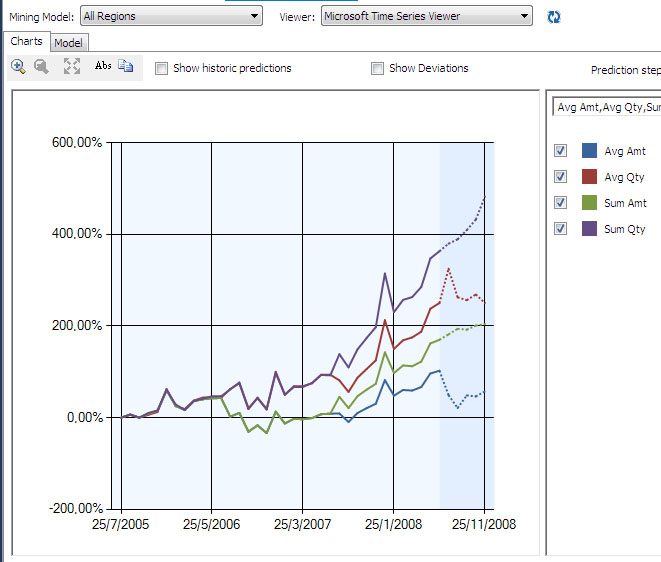
Εικόνα 10.41
Άσκηση 5
Έστω ότι εργάζεστε για την AdventureWorks, μια πολυεθνική εταιρία που εμπορεύεται τέσσερις τύπους ποδηλάτων (Μ200, R250, R750 και Τ1000) σε τρεις περιοχές (Ευρώπη, Βόρεια Αμερική και Ειρηνικό). Το τμήμα πωλήσεων επιθυμεί να προβλέψει τις πωλήσεις του επόμενου εξαμήνου (Ιανουάριος 2008 έως Ιούνιος 2008) για το μοντέλο ποδηλάτου R750 στις τρεις παραπάνω περιοχές, λαμβάνοντας υπόψη τις πωλήσεις που σημειώθηκαν στο προγενέστερο διάστημα (Ιούλιος 2005 έως Δεκέμβριος του 2007). Δημιουργήστε, λοιπόν, ένα μοντέλo χρονοσειράς που θα έχει ως input και predictable το πεδίο amount, θέτοντας τις παραμέτρους του αλγορίθμου ως εξής: PERIODICITY_HINT = {12} και FORECAST_METHOD=MIXED. Τονίζεται ότι θα πρέπει να δημιουργήσετε ένα νέο ερώτημα (Data Source View & New named query) που θα επιλέγει δεδομένα μόνο μέχρι τις 31-12-2007. Ακόμη, τονίζεται ότι πρέπει να τρέξετε τον αλγόριθμο time series μόνο στο συγκεκριμένο χρονικό διάστημα τιμών.
-
Λύση άσκησης 5:
+
Στην Εικόνα 10.42 παρουσιάζεται ένα διάγραμμα με την πρόβλεψη των πωλήσεων του ποδηλάτου R750 στην Ευρώπη, τη Βόρεια Αμερική και τον Ειρηνικό Ωκεανό για το χρονικό διάστημα Ιανουάριος – Ιούνιος 2008. Οι διακεκομμένες γραμμές αντιστοιχούν στις προβλέψεις του μοντέλου χρονοσειρών Mixed. Για την πρόβλεψη αυτών χρησιμοποιήθηκαν δεδομένα για το συγκεκριμένο ποδήλατο μέχρι και τον Δεκέμβριο του 2007.
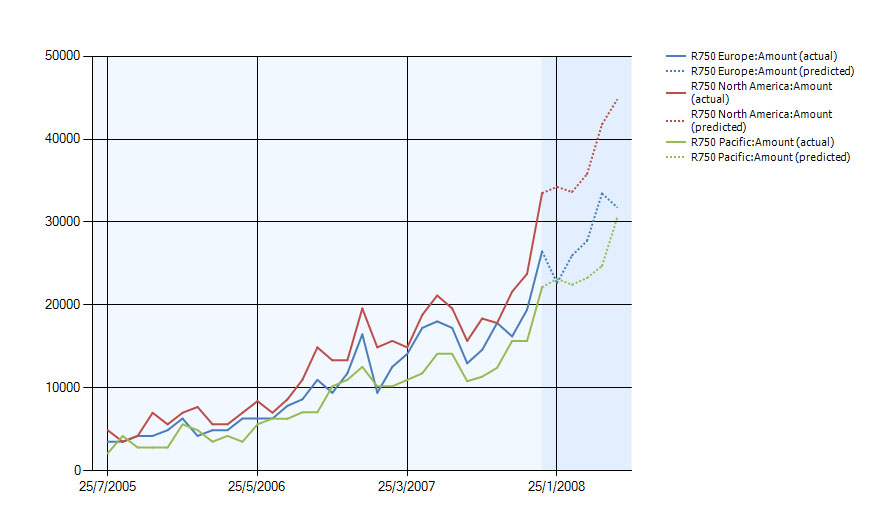
Εικόνα 10.42
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
10.7. Βιβλιογραφία/Αναφορές
Aggarwal, C. C. (2015). Data Mining: The Textbook, Springer.
Dunham, M. H. (2003). Data Mining: Introductory and Advanced Topics, New Jersey, Prentice Hall.
Han, J., & Kamber, M. (2001). Data Mining: Concepts and Techniques, Academic Press.
Πίνακας Περιεχομένων /
Περιεχόμενα Κεφαλαίου
Data Definition Language - DDL
Η γλώσσα ορισμού περιεχομένου χρησιμοποιείται για τον ορισμό των
πινάκων και των μεταξύ τους σχέσεων. Με τη γλώσσα αυτή δηλώνουμε τα
χαρακτηριστικά που έχει κάθε πίνακας και τους αντίστοιχους τύπους
δεδομένων του κάθε χαρακτηριστικού.
Data Manipulation Language - DML
Η γλώσσα χειρισμού δεδομένων χρησιμοποιείται για την επεξεργασία,
την ενημέρωση, την εισαγωγή και την διαγραφή δεδομένων.
Διάγραμμα οντοτήτων-συσχετίσεων (διάγραμμα E-R)
Τα Διάγραμματα οντοτήτων-συσχετίσεων παρέχουν ένα απλό και κατανοητό τρόπο περιγραφής της δομής των δεδομένων της Βάσης Δεδομένων
Ερώτημα SQL
Αποτελεί ένα δομημένο τρόπο σύνταξης ερωτοαποκρίσεων για την αναζήτηση περιεχομένου στη βάση δεδομένων μας.
create database
Ένας νέος πίνακας δημιουργείται με τη χρήση της εντολής CREATE TABLE ή σύνταξη της οποίας έχει ως εξής :
CREATE TABLE (
<όνομα πεδίου 1> <τύπος πεδίου 1>,
<όνομα πεδίου 2> <τύπος πεδίου 2>,
<όνομα πεδίου Ν> <τύπος πεδίου Ν>);
Drop Database
Μπορούμε να διαγράψουμε ολόκληρο πίνακα, μαζί με τα δεδομένα που τυχόν έχει χρησιμοποιώντας την εντολή DROP σύμφωνα με το ακόλουθο πρότυπο :
DROP TABLE <όνομα πίνακα>
ON UPDATE
H πρόταση ON UPDATE προσδιορίζει την ενέργεια που θα εκτελεστεί αν θέλουμε να αλλάξουμε την τιμή ενός πεδίου:
UPDATE <όνομα πίνακα> SET <όνομα πεδίου> <νέα τιμή πεδίου> WHERE <κριτήρια επιλογής εγγραφών>
ON DELETE
Ο σκοπός είναι πολύ απλός, διαγράφει εγγραφές από ένα πίνακα. Και πάλι έχομε την δυνατότητα να ορίσουμε ποιές εγγραφές θέλουμε να διαγραφούν (ή και όλες) π.χ.:
DELETE FROM product WHERE id=1
Καρτεσιανού γινομένου
To Καρτεσιανό γινόμενο αποτελεί την πράξη μεταξύ δύο πινάκων όπου η κάθε εγγραφή του ενός πίνακα συνδυάζεται με όλες τις εγγραφές του άλλου πίνακα
πράξη της επιλογής/selection
Η SQL εντολή μέσω της οποίας ανακτούμε πληροφορίες και συντάσσουμε ερωτήματα είναι η SELECT. Η γενική σύνταξη της SELECΤ είναι αρκετά σύνθετη, ωστόσο ένα απλό πρότυπο είναι το ακόλουθο:
SELECT <πεδίο που θέλουμε να φαίνονται>
FROM <πίνακες από τους οποίους θα αντληθούν τα δεδομένα>
WHERE <κριτήρια επιλογής των εγγραφών>
πράξης της σύνδεσης (join)
Η εντολή JOIN σημαίνει σύνδεση, δηλαδή συνδυασμός δεδομένων από δύο ή περισσότερους πίνακες.
left outer join
Περιλαμβάνει επιπρόσθετα και όλες τις εγγραφές του πίνακα που βρίσκεται στα αριστερά της πράξης της σύνδεσης (join) και δεν εμπεριέχονται στο αποτέλεσμα της πράξης της σύνδεσης.
πράξη του full outer join
Περιλαμβάνει επιπρόσθετα και όλες τις εγγραφές των πινάκων που βρίσκονται στα αριστερά και δεξιά της πράξης της σύνδεσης (join) και δεν εμπεριέχονται στο αποτέλεσμα της πράξης της σύνδεσης.
όρος distinct
Η λέξη DISTINCT αμέσως μετά την SELECT δηλώνει ότι κάθε εγγραφή του πίνακα του αποτελέσματος θα συμπεριληφθεί μία μόνο φορά. Επομένως χρησιμοποιείται όταν θέλουμε να εγγυηθούμε ότι στο αποτέλεσμα του ερωτήματος δεν θα υπάρχουν διπλοεγγραφές πρέπει να χρησιμοποιήσουμε το DISTINCT
όρος GROUP BY
H λέξη GROUP BY προσδιορίζει τις στήλες με τις οποίες θα πραγματοποιηθεί ομαδοποίηση (grouping) των δεδομένων.
όρος HAVING
Ο όρος HAVING χρησιμοποιείται για να ορίσει περιοσρισμούς που σχετίζονται με τα ήδη ομαδοποιημένα αποτελέσματα που έχουν δημιουργηθεί με την GROUP BY.
πράξη της ένωσης πινάκων/σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξη της ένωσης (UNION) συνενώνει τις εγγραφές δύο ή περισσότερων πινάκων.
Ένα παράδειγμα ένωσης δίνεται παρακάτω:
SELECT συνέδριο
FROM πρακτικά_συνεδρίου
UNION
SELECT τιτλος
FROM περιοδικό;
πράξη της τομής σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξεις αυτές υλοποιούνται στην SQL με τις εντολές UNION, EXCEPT και INTERSECΤ αντιστοίχως.
παράδειγμα τομής :
SELECT ονομα
FROM συνδρομητης
INTERSECT
SELECT ονομα
FROM συγγραφεας;
πράξη της διαφοράς σχέσεων
H SQL παρέχει ειδικές εντολές για την υποστήριξη των πράξεων της σχεσιακής άλγεβρας που αναφέρονται στην ένωση, διαφορά και τομή πινάκων. Οι πράξεις αυτές υλοποιούνται στην SQL με τις εντολές UNION, EXCEPT και INTERSECΤ αντιστοίχως.
παράδειγμα διαφοράς :
SELECT κωδικός,τίτλος
FROM άρθρο
EXCEPT
SELECT κωδικός,τίτλος
FROM άρθρο
WHERE κωδικός_περιοδικού IS NOT NULL;
Ο όρος ΙΝ
Σε περίπτωση που θέλουμε ένα πεδίο να λαμβάνει τιμές από ένα προκαθορισμένο σύνολο τιμών, τότε μπορούμε εναλλακτικά να χρησιμοποιήσουμε τον τελεστή ΙΝ.
Ο ορος Νot Ιn
Σε περίπτωση που θέλουμε ένα πεδίο να λαμβάνει τιμές από ένα προκαθορισμένο σύνολο τιμών, εξαιρώντας κάποιες τιμές τότε μπορούμε εναλλακτικά να χρησιμοποιήσουμε τον τελεστή ΝΟΤ ΙΝ.
Οι όροι all και some
H SQL προσφέρει τα κατηγορήματα SOME(ή ΑΝΥ) και ALL τα οποία αντιστοιχούν στον υπαρξιακό και καθολικό ποσοδείκτη που χρησιμοποιούμε στα μαθηματικά. Με τη χρήση των κατηγορημάτων αυτών μπορούμε να συντάξουμε πολύ χρήσιμα ερωτήματα με τη χρήση υποερωτημάτων. Πριν απο τα κατηγορήματα SOME και ALL, μπορεί να προηγείται οποιοσδήποτε τελεστής σύγκρισης (=, >, <, >=, <=, <>)
Οι όροι exists και not exists
Η τιμή που επιστρέφει το κατηγόρημα EXISTS είναι αληθής, αν το σύνολο που ακολουθεί δεν είναι κενό. Σε διαφορετική περίπτωση η τιμή που επιστρέφεται είναι ψευδής.
CREATE VIEW
Για τον ορισμό μιας όψης, η SQL παρέχει την εντολή CREATE VIEW που συντάσσεται ως εξής:
CREATE VIEW όνομα-όψης
AS
(υποερώτημα SQL);
DELETE FROM
Παρόμοια με την εντολή UPDATE λειτουργεί και η εντολή DELETE. Ο σκοπός της είναι πολύ απλός, διαγράφει εγγραφές από ένα πίνακα.
DROP TABLE
Η πλήρης διαγραφή ενός πίνακα γίνεται χρησιμοποιώντας την εντολή DROP σύμφωνα με τον ακόλουθο πρότυπο :
DROP TABLE <ονομα πίνακα>
Οι αποθηκευμένες διαδικασίες/stored procedures
O SQL Server δίνει την δυνατότητα υλοποίησης τμημάτων κώδικα τα οποία παραμένουν αποθηκευμένα μέσα στη Βάση Δεδομένων και καλούνται αποθηκευμένες διαδικασίες (stored procedures). Αυτά ενεργοποιούνται ανά τακτά χρονικά διαστήματα για την εκτέλεση μιας σημαντικής λειτουργίας.
Το εύναυσμα/trigger
Ένας σκανδαλισμός ή εύναυσμα (trigger) είναι ένα τμήμα κώδικα που εκτελείται όταν συμβεί ένα γεγονός. Τα γεγονότα που ενεργοποιούν σκανδαλισμούς είναι εισαγωγές, διαγραφές, και ενημερώσεις στα δεδομένα ενός πίνακα.
Ευρετήριο
Ένας κατάλογος (ευρετήριο) ορίζεται σε μία ή περισσότερες στήλες ενός πίνακα και στοχεύει στην αποδοτικότερη εκτέλεση των ερωτημάτων που χρησιμοποιούν τις στήλες αυτές στη συνθήκη WHERE. Η κατασκευή και κατάργηση καταλόγων πραγματοποιείται με τις εντολές CREATE INDEX και DROP INDEX αντίστοιχα.
ALTER TABLE
O ορισμός ενός πίνακα μπορεί να μεταβληθεί στην πορεία, αναλόγως με τις απαιτήσεις. H SQL προσφέρει την εντολή ALTER TABLE, με την οποία επιτρέπονται να γίνουν συγκεκριμένες αλλαγές στον πίνακα: (προσθήκη νέας στήλης, διαγραφή υπάρχουσας στήλης, αλλαγή πεδίου ορισμού μίας στήλης, εισαγωγή νέου περιορισμού, κατάργηση περιορισμού, αλλαγή της εξ ορισμού τιμής στήλης, κατάργηση αρχικής τιμής στήλης).
εντολή grant.
Με την εντολή GRANT δίνουμε δικαιώματα χρήσης της βάσης δεδομένων σε χρήστες.
εντολή revoke.
Με την εντολή REVOKE αφαιρούμε από τους χρήστες τα δικαιώματα χρήσης ενός στοιχείου (π.χ. πίνακα, όψη) μιας βάσης δεδομένων.
H παράμετρος Split method:
Αυτή η παράμετρος καθορίζει τη μέθοδο με την οποία διαχωρίζονται οι κόμβοι του δένδρου. Μπορεί να πάρει τις τιμές [1,3] όπου 1 είναι η τιμή για Binary δένδρο, 2 η τιμή για Complete (multi-way) δένδρο και 3 η τιμή και για τα δύο μαζί.
Κατηγοριοποίηση (classification)
Η κατηγοριοποίηση αποτελεί μια σημαντική λειτουργία εξόρυξης δεδομένων, όπου επιθυμούμε να προβλέψουμε σε πια κατηγορία εντάσσονται και ανήκουν κάθε φορά τα δεδομένα μας.
H παράμετρος Split method:
Αυτή η παράμετρος καθορίζει τη μέθοδο με την οποία διαχωρίζονται οι κόμβοι του δένδρου. Μπορεί να πάρει τις τιμές [1,3] όπου 1 είναι η τιμή για Binary δένδρο, 2 η τιμή για Complete (multi-way) δένδρο και 3 η τιμή και για τα δύο μαζί.
H παράμετρος Stopping Tolerance
Αυτή η παράμετρος καθορίζει τον αριθμό των περιπτώσεων που μετακινούνται μεταξύ των clusters σε κάθε πέρασμα του αλγορίθμου. Ο αλγόριθμος εφαρμόζεται επαναληπτικά στα δεδομένα και σχηματίζει τα cluster με την μορφή που εμείς τα βλέπουμε, ύστερα από ένα σύνολο επαναλήψεων. Επειδή σε κάθε επανάληψη προστίθενται διαρκώς και νέες περιπτώσεις, η τιμή της παραμέτρου μπορεί να θεωρηθεί ως ποσοστό και όχι ένας συγκεκριμένος αριθμός. Η προεπιλεγμένη τιμή της παραμέτρου είναι 10.
Η τάση (trend)
Η τάση μας δείχνει την γενική κατεύθυνση των δεδομένων μας. Για παράδειγμα, η τάση είναι αυξανόμενη στις πωλήσεις προϊόντων τις ημέρες των Χριστουγέννων.
Η περιοδικότητα (periodicity)
Η περιοδικότητα αφορά την επανεμφάνιση κάποιων τάσεων στα δεδομένα μας. Για παράδειγμα, οι πωλήσεις παγωτών αυξάνονται κάθε καλοκαίρι.
Οι ακραίες τιμές (outliers)
Κάποια δεδομένα ενδέχεται να μην είναι δυνατόν να συμπεριλφθούν σε κάποια ομάδα. Τα δεδομένα αυτά καλούνται απομακρυσμένα ή απομονωμένα (outliers) και συνήθως δημιουργούν πρόβλημα στις μεθόδους ομαδοποίησης.
ολοκληρωμένη (integrated)
Μια αποθήκη δεδομένων είναι ολοκληρωμένη διότι μπορεί και συνενώνει μέσα τις πολλές ανομοιογενείς βάσεις δεδομένων.
Μη ευμετάβλητη (non volatile)
Μια αποθήκη δεδομένων συνήθως δεν μεταβάλλεται ως προς το περιεχόμενο της. Αυτό που συμβαίνει είναι να προστίθεται μόνο καινούργιο περιεχόμενο.
Αφορά ιστορικά δεδομένα (time-variant)
Μια αποθήκη δεδομένων αφορά δεδομένα που μπορεί να έχουν βάθος δεκαετιών.
Ένα μέτρο ή αλλιώς μετρική (measure)
Είναι το μέγεθος ή τα μεγέθη που μας ενδιαφέρουν να συναθροίσουμε ή να αναλύσουμε κατά τις λειτουργίες OLAP.
διαστάσεις (dimensions)
Οι πληροφορίες που περιγράφουν τα γεγονότα, ονομάζονται διαστάσεις. Για ένα γεγονός πώλησης, διαστάσεις είναι, π.χ., το προϊόν που πωλήθηκε, το υποκατάστημα όπου έγινε η πώληση, η ημερομηνία πώλησης, κ.λπ.
Η ιεραρχία (hierarchy)
Η ιεραρχία (hierarchy) μιας διάστασης
Μια διάσταση μπορεί να αποτελείται από διαφορετικά επίπεδα ανάλυσης και να ενσωματώνει μια ιεραρχία. Για παράδειγμα, η διάσταση του χρόνου μπορεί να αναλυθεί σε μέρες, εβδομάδες, κτλ.
Το σχήμα Αστέρα (star schema)
Σύμφωνα με το μοντέλο αυτό η αποθήκη δεδομένων περιέχει ένα μεγάλο κεντρικό πίνακα που καλείται πίνακας γεγονότων (fact table) και ένα σύνολο μικρότερων πινάκων που καλούνται πίνακες διαστάσεων (fimension tables) και συνδέονται απευθείας στον fact table.
To σχήμα χιονονιφάδας (snowflake schema)
Το μοντέλο χιονιφάδας αποτελεί παραλλαγή του μοντέλου αστέρα. Διαφέρει κατά το ότι κάποιοι πίνακες διαστάσεων μπορούν να αναλυθούν περισσότερο χρησιμοποιώντας βοηθητικούς πίνακες. Η λειτουργία αυτή μοιάζει με τη διαδικασία της κανονικοποίησης στις σχεσιακές βάσεις δεδομένων.
Το σχήμα γαλαξία (galaxy schema),
Στο σχήμα γαλαξία έχουμε περισσότερους τους ενός fact tables, τους οποίους μπορούν να διαμοιράζονται περισσότερες διαστάσεις.
Η πράξη Roll-up
Η λειτουργία αυτή ομαδοποιεί τα δεδομένα του κύβου σε υψηλότερο επίπεδο ανάλυσης και μας οδηγεί σε ανώτερο επίπεδο της θεματικής ιεραρχίας, αθροίζοντας τα μετρικά στοιχεία.
Η πράξη Drill-down
Επιφέρει ακριβώς τα αντίθετα αποτελέσματα από τη λειτουργία ROLL-UP. Με τη λειτουργία DRILL-DOWN αυξάνουμε το επίπεδο λεπτομέρειας των δεδομένων μας.
Η πράξη Slice
Η λειτουργία SLICE επιλέγει τα δεδομένα του κύβου μας ως προς μία διάσταση.
Η πράξη Dice
H λειτουργία DICE επιλέγει τα δεδομένα ως προς πολλές διαστάσεις του κύβου μας, δημιουργώντας έναν μικρότερο κύβο.
Η πράξη Pivot
Η λειτουργία PIVOT πραγματοποιεί περιστροφή στις διαστάσεις του κύβου, με αποτέλεσμα τα δεδομένα να απεικονίζονται με διαφορετικό τρόπο κάθε φορά.
Συναθροιστικές συνάρτήσεις (aggregation function)
Οι συναρτήσεις συνάθροισης χρησιμοποιούνται για την εξαγωγή συγκεντρωτικών τιμών από τις τιμές μίας στήλης.
Προκειμένου να εξάγουμε έναν κανόνα συσχέτισης, πρέπει να ικανοποιούνται κάποια κατώτατα όρια τόσο για το support όσο και για τo confidence/probability. Ο κανόνας πρέπει να έχει support μεγαλύτερo από το όριο, που ονομάζεται ελάχιστη υποστήριξη (minimum_support), και η εμπιστοσύνη πρέπει να είναι μεγαλύτερη από το όριο, που ονομάζεται ελάχιστη εμπιστοσύνη (minimum_probability).
Προκειμένου να εξάγουμε έναν κανόνα συσχέτισης, πρέπει να ικανοποιούνται κάποια κατώτατα όρια τόσο για το support όσο και για τo confidence/probability. Ο κανόνας πρέπει να έχει support μεγαλύτερo από το όριο, που ονομάζεται ελάχιστη υποστήριξη (minimum_support), και η εμπιστοσύνη πρέπει να είναι μεγαλύτερη από το όριο, που ονομάζεται ελάχιστη εμπιστοσύνη (minimum_probability).
Slice
H λειτουργία Slice επιλέγει τα δεδομένα ως προς μία διάσταση του κύβου μας, δημιουργώντας μια φέτα ενός κύβου
Pivot
Η λειτουργία Pivot αλλάζει μόνο το τρόπο απεικόνισης των διαστάσεων του κύβου μα