Κεφάλαιο 9Ανάκτηση Πληροφορίας στον Παγκόσμιο Ιστό
9.1 Εισαγωγή
Ο παγκόσμιος ιστός (World Wide Web) αποτελεί πραγματική πρόκληση για πολλές εφαρμογές, διότι διαθέτει μία σειρά από χαρακτηριστικά που φέρνουν στα όρια τη σύγχρονη τεχνολογία (για παράδειγμα το τεράστιο πλήθος των εγγράφων που είναι διαθέσιμα). Στην πράξη ο Παγκόσμιος Ιστός αποτελείται από ένα τεράστιο πλήθος σελίδων που συνδέονται μεταξύ τους με συνδέσμους (links). Στο κεφάλαιο αυτό θα μελετήσουμε τεχνικές Ανάκτησης Πληροφορίας που στοχεύουν στην αποδοτικότερη και αποτελεσματικότερη διαχείριση δεδομένων στον παγκόσμιο ιστό. Πιο συγκεκριμένα, θα εστιάσουμε στη λειτουργία των μηχανών αναζήτησης και των μεθόδων βαθμολόγησης των ιστοσελίδων. Θα εξηγήσουμε την ιστορία των μηχανών αναζήτησης και των τεχνικών που έχουν χρησιμοποιηθεί για τη βελτίωση της ποιότητας των αποτελεσμάτων.
9.2 Παγκόσμιος Ιστός και Μηχανές Αναζήτησης
Ο παγκόσμιος ιστός αποτελείται από ένα τεράστιο σύνολο ιστοσελίδων (web pages) οι οποίες διασυνδέονται μεταξύ τους. Η κάθε ιστοσελίδα συνήθως είναι γραμμένη σε γλώσσα HTML (hypertext markup language). Ωστόσο, υπάρχουν και δυναμικές σελίδες των οποίων το περιεχόμενο διαμορφώνεται δυναμικά (για παράδειγμα, σελίδες που είναι γραμμένες σε php ή jsp). Μία ιστοσελίδα αποτελείται κυρίως από περιεχόμενο κειμέμου (text) αλλά μπορεί να περιέχει πιο πολύπλοκα δεδομένα όπως εικόνες, ήχο και βίντεο. Στο κεφάλαιο αυτό μας ενδιαφέρει η δομή του παγκόσμιου ιστού, και για το λόγο αυτό θα εστιάσουμε κυρίως στους συνδέσμους μεταξύ των σελίδων υποθέτοντας ότι το περιεχόμενο είναι απλό κείμενο. Η κάθε ιστοσελίδα προσδιορίζεται μοναδικά από το URL (uniform resource locator) που μπορούμε να πούμε ότι χρησιμοποιείται και ως κλειδί για την ιστοσελίδα.
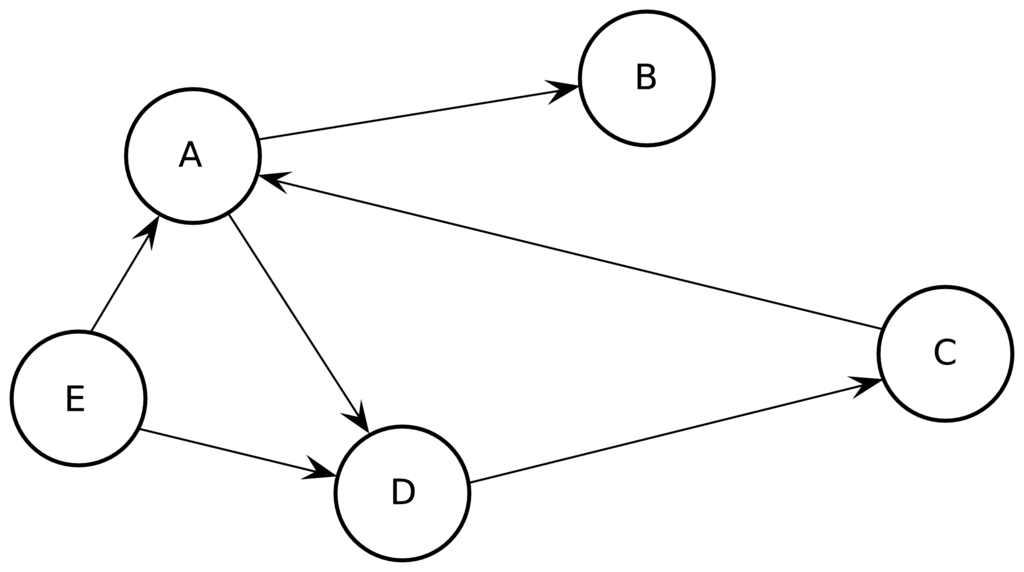
Ο παγκόσμιος ιστός μπορεί να αναπαρασταθεί απλοϊκά με ένα κατευθυνόμενο γράφημα (directed graph), όπως παρουσιάζεται στο Σχήμα 9.1. Στο παράδειγμα αυτό υπάρχουν 4 ιστοσελίδες Α, B, C και D. Παρατηρούμε ότι κάποιες σελίδες μπορεί να έχουν μόνο εισερχόμενους συνδέσμους (incoming links), κάποιες άλλες μόνο εξερχόμενους συνδέσμους (outgoing links) και κάποιες άλλες να έχουν και τους δύο τύπους συνδέσμων. Το πλήθος των συνδέσμων μπορεί να είναι πολύ διαφορετικό από ιστοσελίδα σε ιστοσελίδα και έχει παρατηρηθεί ότι ακολουθεί κατανομή power law.
Μία μηχανή αναζήτησης παγκόσμιου ιστού (web search engine) αποτελείται από ένα σύνολο τμημάτων λογισμικού και υλικού που έχει ως στόχο την εξυπηρέτηση των πληροφοριακών αναγκών των χρηστών στον παγκόσμιο ιστό. Οι μηχανές αναζήτησης χρησιμοποιούνται κυρίως στον παγκόσμιο ιστό όπου υπάρχουν και εκτενείς ανάγκες από την πλευρά των χρηστών. Επιπλέον, ο όγκος της πληροφορίας που βρίσκεται στον παγκόσμιο ιστό είναι τεράστιος που σε συνδυασμό με την ετερογένεια της πληροφορίας δημιουργεί πολύ σημαντικές προκλήσεις. Ωστόσο, υπάρχουν και μηχανές αναζήτησης ειδικού σκοπού, όπου το πεδίο εφαρμογής είναι περιορισμένο (π.χ., μηχανές αναζήτησης σε προσωπικούς υπολογιστές, μηχανές αναζήτησης για ιατρικά δεδομένα). Στην περίπτωση αυτή οι απαιτήσεις είναι διαφορετικές από την περίπτωση των μηχανών αναζήτησης γενικού σκοπού. Οι σημαντικότερες σύγχρονες μηχανές αναζήτησης είναι αυτές της Google, της Yahoo! και της Microsoft.
9.2.1 Οι Προκλήσεις του Παγκόσμιου Ιστού
Οι προκλήσεις που έχει να αντιμετωπίσει μία μηχανή αναζήτησης στον παγκόσμιο ιστό είναι οι εξής:
-
•
Η ποσότητα της πληροφορίας είναι από τα σημαντικότερα προβλήματα καθώς επηρεάζει άμεσα όλα τα τμήματα της μηχανής. Ο μεγάλος αριθμός ιστοσελίδων επηρεάζει το σαρωτή (έχει περισσότερες σελίδες να επισκεφθεί), το δεικτοδοτητή (όσο περισσότερες σελίδες υπάρχουν τόσο πιο αργή είναι η διαδικασία της δεικτοδότησης) και τον επεξεργαστή ερωτημάτων (ο χρόνος επεξεργασίας εξαρτάται άμεσα από το μέγεθος του καταλόγου).
-
•
Τα δεδομένα στον παγκόσμιο ιστό είναι διασκορπισμένα σε πολλούς υπολογιστές που βρίσκονται και σε διαφορετικές γεωγραφικές περιοχές. Το χαρακτηριστικό αυτό επιφέρει επιπλέον προβλήματα καθώς θα πρέπει η σάρωση του παγκόσμιου ιστού να γίνεται γρήγορα ώστε ο κατάλογος να είναι ενημερωμένος. Επίσης, η κατανομή των δεδομένων χωρίς κεντρικό έλεγχο μπορεί να επιφέρει επιπλέον δυσκολίες λόγω της επανάληψης των δεδομένων σε διαφορετικούς ιστότοπους (διαφορετικές ιστοσελίδες με ίδιο περιεχόμενο).
-
•
Ο παγκόσμιος ιστός χαρακτηρίζεται από μεγάλη δυναμικότητα που έχει ως αποτέλεσμα τη δημιουργία νέων ιστοσελίδων και την αλλαγή του περιεχομένου των υπαρχόντων. Το χαρακτηριστικό αυτό επηρεάζει όλα τα τμήματα της μηχανής αναζήτησης.
-
•
Τα δεδομένα που είναι αποθηκευμένα στον παγκόσμιο ιστό χαρακτηρίζονται από μεγάλη ετερογένεια και ως προς τη δομή αλλά και το περιεχόμενο. Για παράδειγμα, υπάρχουν δεδομένα που είναι σε πολλές διαφορετικές μορφές όπως κέιμενο, εικόνα, ήχος, βίντεο. Επίσης, υπάρχουν δεδομένα πλήρως δομημένα που είναι αποθηκευμένα σε βάσεις δεδομένων, ημι-δομημένα που είναι σε μορφή XML και εντελώς αδόμητα (ελεύθερο κείμενο). Επομένως, η μηχανή αναζήτησης θα πρέπει να λάβει υπόψη τις ιδιαιτερότητες αυτές ώστε να περέχει υπηρεσίες ανεξάρτητα από την ετερογένεια των δεδομένων.
-
•
Ένα από τα μεγαλύτερα προβλήματα που έχει να αντιμετωπίσει μία μηχανή αναζήτησης είναι ο εντοπισμός και η επιστροφή στο χρήστη των ιστοσελίδων με το ποιοτικότερο περιεχόμενο. Εξαιτίας της ελευθερίας λόγου στον παγκόσμιο ιστό κυκλοφορούν ιστοσελίδες που μπορεί περιέχουν και ψευδείς πληροφορίες ή σελίδες που το περιεχόμενό τους δεν χαρακτηρίζεται ποιοτικό. Η μηχανή αναζήτησης θα πρέπει να προστατεύει τους χρήστες από το περιεχόμενο αυτό επιστρέφοντας ιστοσελίδες με υψηλή ποιότητα. Επομένως, για κάθε ιστοσελίδα η μηχανή πρέπει να γνωρίζει το βαθμό ποιότητας. Ο υπολογισμός του βαθμού ποιότητας αποτελεί μία ακόμη πρόκληση λαμβάνοντας υπόψη τη συχνή μεταβολή του περιεχομένου των ιστοσελίδων.
9.2.2 Δομή μίας Μηχανής Αναζήτησης
Μία μηχανή αναζήτησης αποτελείται από τρία βασικά τμήματα, που περιγράφονται συνοπτικά παρακάτω και παρουσιάζονται στο Σχήμα 9.2:
-
•
Ο σαρωτής (crawler) είναι το τμήμα λογισμικού που είναι υπεύθυνο για τη σάρωση του παγκόσμιου ιστού και την εύρεση των ιστοσελίδων. Ο σαρωτής συλλέγει τους συνδέσμους που υπάρχουν στην τρέχουσα ιστοσελίδα που εξετάζει και στη συνέχεια τις επισκέπτεται με κάποια σειρά. Το πλήθος των σαρωτών είναι πολύ μεγάλο έτσι ώστε ο χρόνος που απαιτείται για τη σάρωση του συνόλου του παγκόσμιου ιστού να είναι σχετικά μικρό.
-
•
Ο δεικτοδοτητής (indexer) είναι το λογισμικό που λαμβάνει τις ιστοσελίδες από το σαρωτή και στη συνέχεια οργανώνει το περιεχόμενο με τέτοιον τρόπο που να επιτρέπει τη γρήγορη αναζήτηση. Η μέθοδος οργάνωσης που χρησιμοποιείται συνήθως είναι η δομή του αντεστραμμένου καταλόγου που έχουμε μελετήσει σε προηγούμενο κεφάλαιο. Ο δεικτοδοτητής είναι υπεύθυνος για την ενημέρωση του καταλόγου με νέο περιεχόμενο και τις αλλαγές που πρέπει να γίνουν σε περίπτωση που υπάρχει μεταβολή του περιεχομένου μίας ιστοσελίδας. Το κλειδί που χρησιμοποιείται για το διαχωρισμό των ιστοσελίδων είναι συνήθως το URL.
-
•
Ο επεγεργαστής ερωτημάτων (query processor) λαμβάνει μία πληροφοριακή ανάγκη (ένα ερώτημα που αποτελείται από λέξεις-κλειδιά), και σε συνεργασία με τον αντεστραμμένο κατάλογο επιστρέφει τις ιστοσελίδες που θεωρούνται σχετικά ως προς το ερώτημα του χρήστη.

9.2.3 Πρώιμες Μηχανές Αναζήτησης
Πριν από τη μηχανή αναζήτησης της Google, υπήρχαν αρκετές μηχανές αναζήτησης. Η βασική δουλειά τους ήταν να διαβάζουν τις ιστοσελίδες μέσω του σαρωτή, να προσδιορίζουν τους όρους (λέξεις) και να ενημερώνουν τον αντεστραμμένο κατάλογο μέσω του δεικτοδοτητή.
Όταν η μηχανή δεχόταν ένα ερώτημα αναζήτησης (μία λίστα με όρους), εξαγόταν από τον αντεστραμμένο κατάλογο οι αντίστοιχες σελίδες που περιείχαν τους όρους και στη συνέχεια ακολουθούσε η βαθμολόγηση που βασιζόταν στην εμφάνιση των όρων μέσα στη σελίδα. Επομένως, η εμφάνιση του όρου στην επικεφαλίδα της σελίδας έκανε τη σελίδα περισσότερο σχετική σε σχέση με την εμφάνιση του όρου στο κυρίως κείμενο της σελίδας. Επιπλέον, το πλήθος των εμφανίσεων των όρων στη σελίδα είχε ως αποτέλεσμα την αύξηση της σχετικότητας της σελίδας για το συγκεκριμένο ερώτημα. Ωστόσο, η τεχνική αυτή όπως θα δούμε στη συνέχεια δε λειτουργούσε πάντοτε σωστά.
Καθώς η χρήση των μηχανών αναζήτησης γινόταν όλο και συχνότερη, κάποιοι βρήκαν τη δυνατότητα να ξεγελάσουν τις μηχανές έτσι ώστε να οδηγούν τους χρήστες στη δική τους σελίδα. Για παράδειγμα, εάν η δουλειά κάποιου είναι να πουλά ηλεκτρονικούς υπολογιστές στον παγκόσμιο ιστό, τότε το μόνο ενδιαφέρον του είναι η σελίδα του να έχει μεγάλη επισκεψιμότητα, ανεξαρτήτως από τις πληροφοριακές ανάγκες του χρηστών. Για να ξεγελάσει κάποιος τη μηχανή, θα μπορούσε να προσθέσει πολλές φορές τον όρο “βιβλίο” στη σελίδα του, έτσι ώστε η μηχανή να νομίζει ότι η σελίδα είναι πολύ σημαντική πηγή για βιβλία. Στην περίπτωση αυτή, εάν ένας χρήστης συμπεριλάβει τον όρο “βιβλίο” στο ερώτημα, η συγκεκριμένη σελίδα θα εμφανισθεί πρώτη στα αποτελέσματα της μηχανής αναζήτησης.
Η ικανότητα των κακόβουλων χρηστών να αλλοιώνουν τα αποτελέσματα της αναζήτησης τόσο εύκολα, ήταν η βασική αιτία ώστε οι πρώτες μηχανές αναζήτησης να καταστούν γρήγορα μη χρήσιμες, αφού δεν μπορούσαν στην πραγματικότητα να καλύψουν με ακρίβεια τις πληροφοριακές ανάγκες των χρηστών. Το γεγονός αυτό έδωσε την ώθηση στους ερευνητές να αναζητήσουν καλύτερες και πιο εύρωστες μεθόδους ποσοτικοποίησης της σημαντικότητας μίας ιστοσελίδας, που δε βασίζεται μόνο στην ύπαρξη των όρων (δηλαδή στο περιχόμενο) αλλά και σε άλλα χαρακτηριστικά, όπως είναι για παράδειγμα ο τρόπος διασύνδεσης των ιστοσελίδων μεταξύ τους.
9.2.4 Σύγχρονες Μηχανές Αναζήτησης
Όπως θα παρατηρήσει η αναγνώστης, οι βασικές λειτουργίες μίας μηχανής αναζήτησης παγκόσμιου ιστού δεν έχουν μεγάλες διαφορές σε σχέση με τις λειτουργίες ενός ΣΑΠ. Βασικός στόχος της μηχανής αναζήτησης παραμένει η ανάκτηση ιστοσελίδων με περιεχόμενο που σχετίζεται άμεσα με τις πληροφοριακές ανάγκες των χρηστών. Ωστόσο, στον παγκόσμιο ιστό αντιμετωπίζουμε πολλές δυσκολίες στον προσδιορισμό της ποιότητας των ιστοσελίδων. Οι σύγχρονες μηχανές αναζήτησης άλλαξαν δραστικά τις μεθόδους προσδιορισμού της ποιότητας εξαιτίας της ύπαρξης των κακόβουλων χρηστών, όπως έχουμε δει στην προηγούμενη ενότητα.
Την πρωτοπορεία στο χώρο έφερε η μηχανή αναζήτησης της Google, η οποία χρησιμοποιεί τους συνδέσμους μεταξύ των ιστοσελίδων για τον προσδιορισμό της ποιότητας αυτών. Ο πιο απλός τρόπος να γίνει αυτό είναι απλά να πούμε ότι ιστοσελίδες που έχουν μεγάλο αριθμό εισερχόμενων συνδέσμων είναι και οι πιο ποιοτικές. Ωστόσο, αυτός ο τρόπος δε λειτουργεί στην πράξη διότι είναι πολύ εύκολο για έναν κακόβουλο χρήστη να κατασκευάσει πολλές ιστοσελίδες που να έχουν εξερχόμενους συνδέσμους προς τη σελίδα της οποίας θέλουμε να αυξηθεί ο βαθμός της ποιότητας. Στην επόμενη ενότητα θα μελετήσουμε πιο αποτελεσματικές τεχνικές για τον προσδιορισμό του βαθμού ποιότητας που δε λαμβάνει υπόψη μόνο το πλήθος των εισερχόμενων σελίδων.
Στη συνέχεια θα μελετήσουμε δύο από τις βασικότερες τεχνικές προσδιορισμού του βαθμού ποιότητας μίας ιστοσελίδας. Συγκεκριμένα, θα εξετάσουμε τον τρόπο λειτουργίας του αλγορίθμου HITS (hyperlink-induced topic search) που έχει χρησιμοποιηθεί στη μηχανή αναζήτησης Ask (http://www.ask.com) και του αλγορίθμου PageRank στον οποίο βασίστηκε η μηχανή της Google (http://www.google.com).
9.3 Ο Αλγόριθμος HITS
Το κεντρικό θέμα στο οποίο στηρίζεται ο αλγόριθμος HITS είναι η διύλιση ευρέων θεμάτων αναζήτησης μέσω της εύρεσης των αξιόπιστων πηγών πληροφορίας (authorities) για αυτά τα θέματα. Μία ιστοσελίδα χαρακτηρίζεται ως authority εάν έχει πολλούς εισερχόμενους συνδέσμους από άλλες αξιόπιστες ιστοσελίδες. Ο αλγόριθμος HITS εκτός από τις αξιόπιστες ιστοσελίδες βρίσκει επίσης και ιστοσελίδες που χαρακτησίζονται ως κομβικές ιστοσελίδες (hubs). Συνοπτικά, ο αλγόριθμος HITS συσχετίζει κάθε ιστοσελίδα με δύο τιμές και που ποσοτικοποιούν την ποιότητα της ιστοσελίδας σχετικά με το πόσο αξιόπιστη είναι (authority score) και πόσο κομβική είναι (hab score).
Το βασικό χαρακτηριστικό του αλγορίθμου HITS είναι ότι οι βαθμοί και που δίνει σε μία σελίδα εξαρτώνται από το θέμα για το οποίο ενδιαφέρεται ο χρήστης. Είναι προφανές ότι μία ιστοσελίδα που θεωρείται αξιόπιστη σχετικά με το θέμα ”C++” μπορεί να μη θεωρείται αξιόπιστη για το θέμα ”Java”. Επομένως, ο αλγόριθμος χαρακτηρίζεται ως ευαίσθητος ως προς το θέμα (topic sensitive) και θα πρέπει να εκτελείται εξαρχής εάν αλλάξει το θέμα για το οποίο ενδιαφέρεται ο χρήστης.
Έστω το γράφημα που αναπαριστά τον παγκόσμιο ιστό, όπου είναι το σύνολο των κορυφών (ιστοσελίδων) και το σύνολο των ακμών (συνδέσμων). Η εκτέλεση του αλγορίθμου HITS αρχίζει με τον προσδιορισμό ενός υποσυνόλου ιστοσελίδων που θεωρούνται σχετικές ως προς κάποιο συγκεκριμένο θέμα που περιγράφεται από τις πληροφοριακές ανάγκες του χρήστη (π.χ., ”C++”). Το σύνολο χαρακτηρίζεται και ως βασικό σύνολο ιστοσελίδων. Το σύνολο επαυξάνεται ώστε να δημιουργηθεί το σύνολο το οποίο περιλαμβάνει όλες τις ιστοσελίδες που ανήκουν στο (άρα ) και επιπλέον περιλαμβάνει όλες τις ιστοσελίδες που έχουν εισερχόμενους συνδέσμους από ιστοσελίδες του και εξερχόμενους συνδέσμους προς ιστοσελίδες του . Η συσχέτιση μεταξύ των συνόλων και απεικονίζεται στο Σχήμα 9.3 στο οποίο οι σύνδεσμοι διαφορετικού τύπου απεικονίζονται με διαφορετικές μορφές (π.χ., τα διακεκομμένα βέλη δηλώνουν συνδέσμους από ιστοσελίδες εκτός του συνόλου προς ιστοσελίδες του συνόλου ).
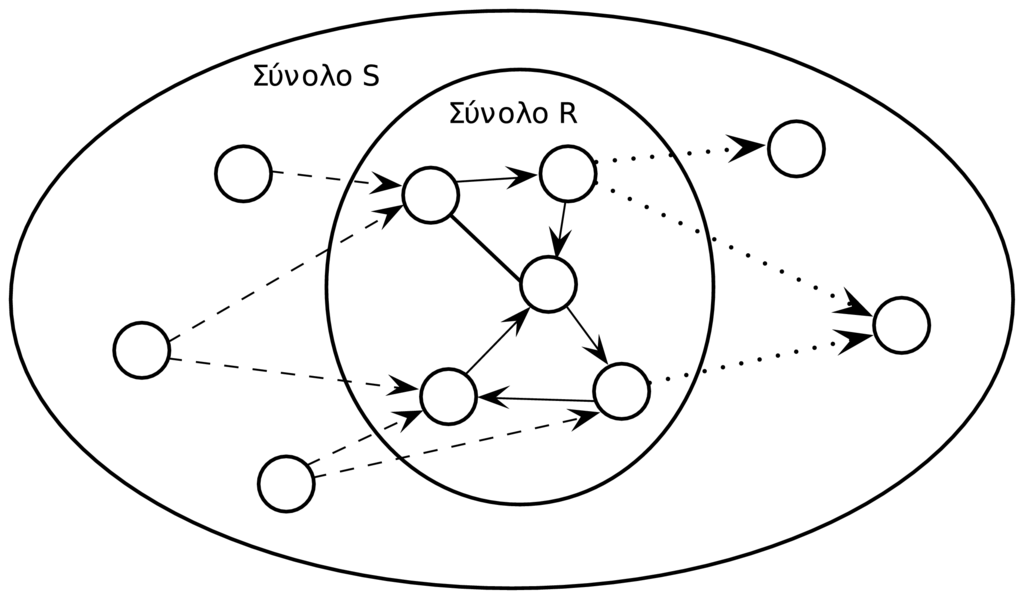
Αξίζει να σημειωθεί ότι το βασικό σύνολο ιστοσελίδων εξαρτάται από το θέμα/ερώτημα του χρήστη. Επομένως, σε πρώτη φάση θα πρέπει να υπάρχει ένας εύχρηστος τρόπος προσδιορισμού του . Στην πράξη το σύνολο δημιουργείται χρησιμοποιώντας μία μηχανή αναζήτησης. Πιο συγκεκριμένα, η μηχανή αναζήτησης δέχεται ως είσοδο το ερώτημα και δίνει στην έξοδο ένα σύνολο από ιστοσελίδες. Από το σύνολο επιλέγονται οι ιστοσελίδες (π.χ., =200) που σύμφωνα με τη μηχανή αναζήτησης είναι οι πιο σχετικές με το ερώτημα. Με βάση τον τρόπο κατασκευής των συνόλων και , το σύνολο ικανοποιεί τις ακόλουθες απαιτήσεις:
-
•
είναι σχετικά μικρό σε σχέση με το σύνολο των ιστοσελίδων του παγκόσμιου ιστού,
-
•
περιέχει ιστοσελίδες που είναι σχετικές με το , και
-
•
περιέχει πολλές αξιόπιστες ιστοσελίδες (authorities) για το ερώτημα .
Με την υπόθεση ότι το σύνολο είναι διαθέσιμο, ο αλγόριθμος HITS λειτουργεί ως εξής. Αρχικά, για κάθε σελίδα αρχικοποιεί τις τιμές (authority score) και (hub score) στην μονάδα. Στη συνέχεια ακολουθεί κανονικοποίηση των scores έτσι ώστε και . Ας υποθέσουμε ότι ο συμβολισμός δηλώνει ότι η ιστοσελίδα έχει έναν σύνδεσμο προς την ιστοσελίδα . Στη συνέχεια, ο αλγόριθμος HITS εκτελεί μία σειρά από επαναλήψεις και σε κάθε επανάληψη επαναπροσδιορίζονται οι τιμές και , . Ο επαναπροσδιορισμός αυτός πραγματοποιείται σύμφωνα με τους ακόλουθους τύπους:
| (9.1) |
και
| (9.2) |
Η φυσική ερμηνεία των παραπάνω τύπων είναι ότι μία ιστοσελίδα αυξάνει την αξιοπιστία της όταν έχει εισερχόμενους συνδέσμους από κομβικές ιστοσελίδες (hubs) που έχουν υψηλό βαθμό κομβικότητας. Ομοίως, μία ιστοσελίδα αυξάνει το βαθμό κομβικότητας όταν έχει εξερχόμενους συνδέσμους σε ιστοσελίδες με υψηλό βαθμό αξιοπιστίας.
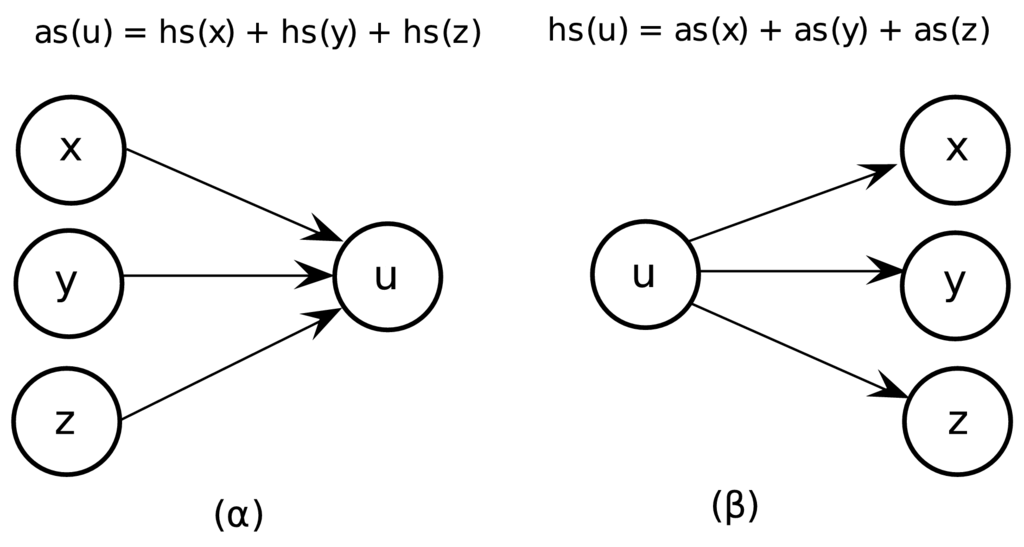
Στο Σχήμα 9.4 δίνεται ένα παράδειγμα επαναπροσδιορισμού των βαθμών αξιοπιστίας και κομβικότητας. Για τον επαναπροσδιορισμό του βαθμού αξιοπιστίας μίας ιστοσελίδας απαιτείται να γνωρίζουμε τους βαθμούς κομβικότητας για όλες τις σελίδες όπως παρουσιάζεται στο Σχήμα 9.4(α). Στο παράδειγμα του σχήματος, η ιστοσελίδα έχει εισερχόμενους συνδέσμους από τις ιστοσελίδες , και . Επομένως, ο βαθμός αξιοπιστίας της θα είναι: . Αντίστοιχα, στο Σχήμα 9.4(β) δίνεται ο τρόπος υπολογισμού του τρέχοντος βαθμού κομβικότητας της ιστοσελίδας : .
Στο Σχήμα 9.5 δίνεται ο ψευδοκώδικας του αλγορίθμου HITS που συνοψίζει τη διαδικασία που περιγράφηκε προηγουμένως. Παρατηρήστε ότι αλγόριθμος είναι επαναληπτικός και εκτελείται για επαναλήψεις. Σε κάθε επανάληψη, γίνεται ένας ακριβέστερος προσδιορισμός των βαρών. Με βάση αποτελέσματα από τη Γραμμική Άλγεβρα δεν είναι δύσκολο να αποδειχθεί ότι μετά από έναν ικανοποιητικό αριθμό επαναλήψεων το διάνυσμα που περιέχει τους βαθμούς αξιοπιστίας συγκλίνει στο σημαντικότερο ιδιοδιάνυσμα του πίνακα ενώ το διάνυσμα που περιέχει τους βαθμούς κομβικότητας συγκλίνει στο σημαντικότερο ιδιοδιάνυσμα του πίνακα . Σημειώνεται ότι είναι ο πίνακας γειτνίασης, ο οποίος έχει διαστάσεις και αποτελείται από άσσους και μηδενικά. Αν το στοιχείο που βρίσκεται στη γραμμή και τη στήλη είναι 1, σημαίνει ότι υπάρχει ένας σύνδεσμος από την -οστή ιστοσελίδα προς την -οστή σελίδα. Επίσης, είναι ο ανάστροφος πίνακας του . Επομένως, οι βαθμοί αξιοπίστίας και κομβικότητας θα μπορούσαν να υπολογιστούν χρησιμοποιώντας αποτελέσματα της Γραμμικής Άλγεβρας (π.χ., λύνοντας συστήματα εξισώσεων). Ωστόσο, στην πράξη προτιμάται ο επαναληπτικός αλγόριθμος διότι τις περισσότερες φορές δεν απαιτείται πλήρης σύγκλιση ώστε να προσδιοριστούν οι βαθμοί ακριβώς. Επειδή μπορεί να υπάρχει ανοχή σε μικρές διαφοροποιήσεις, συνήθως το πλήθος των επαναλήψεων που ρυθμίζεται από την παράμετρο είναι σχετικά μικρό (π.χ., στην πράξη 20-30 επαναλήψεις είναι αρκετές για να έχουμε μία πολύ καλή προσέγγιση).
Το αποτέλεσμα του αλγορίθμου HITS είναι τα διανύσματα και που περιέχουν τους βαθμούς αξιοπιστίας και κομβικότητας αντίστοιχα. Στη συνέχεια, θα πρέπει να επιλεγούν οι ιστοσελίδες που έχουν το μεγαλύτερο βαθμό αξιοπιστίας ως απάντηση στο ερώτημα . Επομένως, από τις ιστοσελίδες, επιλέγονται οι πρώτες ως προς το βαθμό αξιοπιστίας και επιστρέφονται στο χρήστη.
9.4 Ο Αλγόριθμος PageRank
Το 1998 οι Brin και Page (ιδρυτές της Google) χρησιμοποίησαν μία διαφορετική τεχνική για τη βαθμολογία των ιστοσελίδων, η οποία είναι γνωστή στη βιβλιογραφία ως PageRank. Σε αντίθεση με τον αλγόριθμο HITS, ο αλγόριθμος PageRank δίνει σε κάθε ιστοσελίδα δίνεται έναν μόνο βαθμό που ποσοτικοποιεί το βαθμό αξιοπιστίας της ιστοσελίδας . Επιπλέον, σε αντίθεση με τον αλγόριθμο HITS, ο αλγόριθμος PageRank εφαρμόζεται στο σύνολο του παγκόσμιου ιστού και όχι μόνο σε ένα υποσύνολο αυτού. Ωστόσο, ο βαθμός αξιοπιστίας μίας ιστοσελίδας δεν εξαρτάται από κάποιο συγκεκριμένο ερώτημα καθώς λαμβάνονται υπόψη μόνο οι σύνδεσμοι μεταξύ των ιστοσελίδων.
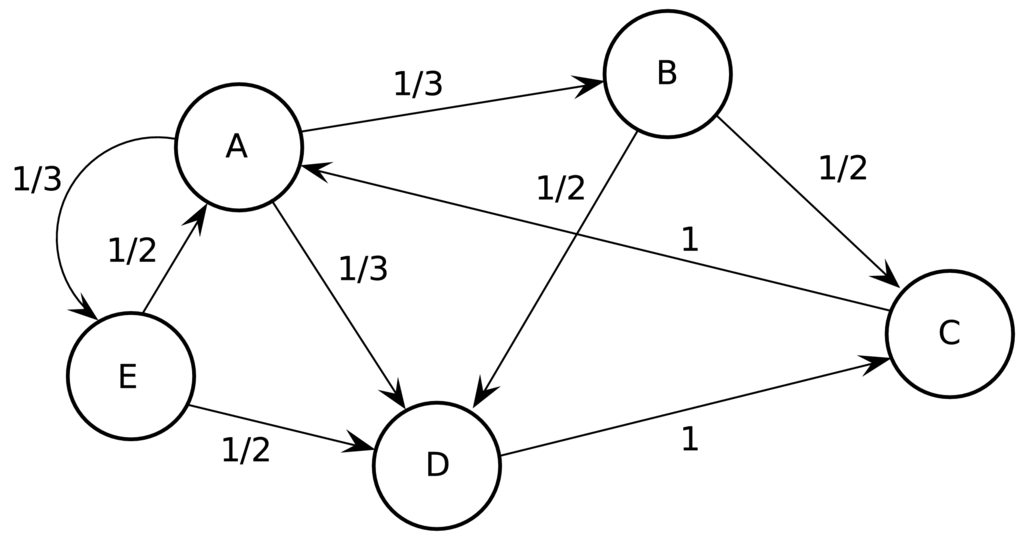
Ο αλγόριθμος PageRank αποτελεί προσομοίωση ενός τυχαίου περιπάτου (random walk) στο γράφημα που αναπαριστά τον παγκόσμιο ιστό. Στο Σχήμα 9.6 παρουσιάζεται τμήμα του παγκόσμιου ιστού που αποτελείται από πέντε ιστοσελίδες. Η τιμή που υπάρχει δίπλα σε κάθε σύνδεσμο αναπαριστά την πιθανότητα μετάβασης (transition probability). Έστω ότι ένας τυχαίος περιηγητής βρίσκεται στην ιστοσελίδα Α. Η ιστοσελίδα A έχει τρεις εξερχόμενους συνδέσμους που οδηγούν στις σελίδες B, D και E. Εφόσον ο περιηγητής θεωρείται τυχαίος, αυτό σημαίνει ότι δεν υπάρχει κάποια ιδιαίτερη προτίμηση σχετικά με την ιστοσελίδα που θα επισκεφθεί στη συνέχεια. Επομένως, η επιλογή είναι εντελώς τυχαία, και η τυχαιότητα αυτή δηλώνεται με την πιθανότητα επίσκεψης της κάθε ιστοσελίδας. Έτσι λοιπόν, από την ιστοσελίδα A ή ιστοσελίδα B έχει πιθανότητα επίσκεψης 1/3 και το ίδιο ισχύει για τις ιστοσελίδες D και E. Έστω τώρα ότι ο περιοηγητής βρίσκεται στην ιστοσελίδα C. Επειδή η C έχει μόνο έναν εξερχόμενο σύνδεσμο προς την ιστοσελίδα A, η πιθανότητα να επισκευθεί την A είναι 1, καθώς δεν υπάρχει άλλη επιλογή.
Οι πιθανότητες μετάβασης μπορούν να αναπαρασταθούν χρησιμοποιώντας τον πίνακα μεταβάσεων (transition matrix). Για το γράφημα του Σχήματος 9.6 ο πίνακας μεταβάσεων είναι ο ακόλουθος:
| (9.3) |
Στον πίνακα αυτόν, η σειρά των ιστοσελίδων είναι A, B, C, D και E. Επομένως, η πρώτη στήλη δείχνει ότι ένας περιηγητής που βρίσκεται στη ιστοσελίδα A στο επόμενο βήμα θα βρεθεί σε μία από τις ιστοσελίδες B, D ή E με την ίδια πιθανότητα 1/3. Η δεύτερη στήλη δείχνει ότι ένας περιηγητής που βρίσκεται στην ιστοσελίδα μπορεί να μεταβεί μόνο στην ιστοσελίδα C με πιθανότητα 1. Η τρίτη στήλη δείχνει ότι αν ο περιηγητής βρίσκεται στην ιστοσελίδα C θα βρεθεί στη σελίδα με πιθανότητα 1. Η τέταρτη στήλη αναφέρει ότι αν ο περιηγητής βρίσκεται στην ιστοσελίδα D θα μεταβεί είτε στη σελίδα C πιθανότητα 1. Τέλος, η πέμπτη στήλη αναφέρει ότι αν ο περιηγητής βρίσκεται στην ιστοσελίδα E τότε μπορεί να μεταβεί είτε στην ιστοσελίδα A ή D με την ίδια πιθανότητα 1/2. Παρατηρήστε ότι το άθροισμα των τιμών κάθε στήλης ισούται με 1.
Η κατανομή της πιθανότητας για τη ιστοσελίδα όπου θα βρεθεί ένας τυχαίος περιηγητής περιγράφεται με ένα διάνυσμα-στήλη, του οποίου το στοιχείο στη θέση είναι η πιθανότητα ο περιηγητής να βρεθεί στη -οστή ιστοσελίδα. Η πιθανότητα αυτή είναι η τιμή της συνάρτησης που υλοποιεί ο αλγόριθμος PageRank. Έστω ότι ο περιηγητής ξεκινά την περιήγηση από μία οποιαδήποτε από τις ιστοσελίδες με την ίδια πιθανότητα. Τότε, το αρχικό διάνυσμα θα έχει την τιμή 1/ σε όλες τις θέσεις. Εάν είναι ο πίνακας μεταβάσεων, τότε μετά από ένα βήμα η κατανομή της πιθανότητας γίνεται , μετά από δύο βήματα η κατανομή θα είναι κ.λ.π. Γενικά, πολλαπλασιάζοντας το αρχικό διάνυσμα με τον πίνακα συνολικά φορές, παίρνουμε την κατανομή μετά από βήματα.
Ας δούμε στη συνέχεια για ποιό λόγο πολλαπλασιάζοντας το διάνυσμα με τον πίνακα παίρνουμε την κατανομή του επόμενου βήματος. Η πιθανότητα ένας περιηγητής να βρεθεί στην ιστοσελίδα στο επόμενο βήμα είναι , όπου είναι η πιθανότητα ο περιηγητής που βρίσκεται στην ιστοσελίδα να μεταβεί στο επόμενο βήμα στην ιστοσελίδα και είναι η πιθανότητα ο περιηγητής να βρίσκεται στην ιστοσελίδα στο προηγούμενο βήμα.
Η συμπεριφορά αυτή αποτελεί ένα παράδειγμα εφαρμογής της θεωρίας των διεργασιών Markov. Είναι γνωστό ότι η κατανομή πιθανότητας για έναν περιηγητής προσεγγίζει την οριακή κατανομή που ικανοποιεί τη σχέση , με την προϋπόθεση ότι ικανοποιούνται οι ακόλουθες απαιτήσεις:
-
•
ο γράφος είναι ισχυρά συνεκτικός, που σημαίνει ότι για κάθε ζεύγος ιστοσελίδων μπορούμε να μεταβούμε από την στην .
-
•
δεν υπάρχουν ιστοσελίδες χωρίς εξερχόμενους συνδέσμους.
Παρατηρήστε ότι το γράφημα του Σχήματος 9.6 ικανοποιεί και τις δύο συνθήκες.
Η οριακή κατάσταση επιτυγχάνεται όταν δεν έχουμε αλλαγή στην κατανομή μετά από πολλαπλασιασμό με τον πίνακα . Με άλλα λόγια, το διάνυσμα που περιγράφει την κατανομή στην οριακή κατάσταση είναι ένα ιδιοδιάνυσμα του πίνακα (ένα ιδιοδιάνυσμα του ικανοποιεί τη σχέση για κάποια τιμή που ονομάζεται ιδιοτιμή). Επειδή ο πίνακας είναι στοχαστικός, που σημαίνει ότι το άθροισμα των τιμών της κάθε στήλης είναι 1, το διάνυσμα είναι το κύριο ιδιοδιάνυσμα (αντιστοιχεί δηλαδή στη μεγαλύτερη ιδιοτιμή του πίνακα). Επίσης, λόγω της στοχαστικότητας του , γνωρίζουμε ότι η ιδιοτιμή που αντιστοιχεί στο κύριο ιδιοδιάνυσμα είναι 1.
Το κύριο ιδιοδιάνυσμα του καταγράφει την πιθανότητα ο περιηγητής να βρεθεί σε κάθε ιστοσελίδα μετά από ένα αρκετά μεγάλο χρονικό διάστημα. Σημειώνεται ότι διαίσθηση πίσω από τη μέθοδο PageRank είναι ότι όσο πιθανότερο είναι ο περιηγητής να βρεθεί σε μία ιστοσελίδα, τόσο σημαντικότερη θεωρείται η ιστοσελίδα αυτή. Ο υπολογισμός του κύριου ιδιοδιανύσματος μπορεί να γίνει με διαδοχικούς πολλαπλασιασμούς του διανύσματος με τον πίνακα . Η διαδικασία τερματίζεται όταν η διαφορά του επόμενου από το προηγούμενο διάνυσμα είναι πολύ μικρή. Στην πράξη, για την περίπτωση του παγκόσμιου ιστού, 50-100 επαναλήψεις είναι αρκετές για να συγκλίνει ο αλγόριθμος.
Θα εφαρμόσουμε την προηγούμενη διαδικασία για το γράφημα του Σχήματος 9.6. Το αρχικό διάνυσμα βαθμών περιέχει σε όλες τις θέσεις την τιμή 1/5. Το αποτέλεσμα των διαδοχικών πολλαπλασιασμών με τον πίνακα μεταβάσεων έχει ως εξής:
| (9.4) |
Ο αναγνώστης μπορεί να παρατηρήσει τη μεταβολή των τιμών και την τάση για σύγκλιση. Φυσικά ο αριθμός των επαναλήψεων που απαιτούνται εξαρτάται άμεσα από την ακρίβεια που χρησιμοποιούμε. Στην πράξη, η πλήρης σύγκλιση επιτυχγάνεται όταν δεν υπάρχει μεταβολή των τιμών λαμβάνοντας υπόψη την ακρίβεια των πραγματικών αριθμών διπλής ακρίβειας. Στο παράδειγμα αυτό χρησιμοποιήθηκαν τέσσερα ψηφία μετά την υποδιαστολή.
9.4.1 Αδιέξοδα και Παγίδες
Έσως τώρα έχουμε υποθέσει ότι δεν υπάρχουν ιστοσελίδες χωρίς εξερχόμενους συνδέσμους και επιπλέον, για κάθε ζεύγος ιστοσελίδων , υπάρχει τουλάχιστον ένα μονοπάτι που να οδηγεί από τη στη και από τη στη . Ωστόσο, στην πράξη οι συνθήκες αυτές μπορεί να μην ικανοποιούνται. Πράγματι, η δομή του παγκόσμιου ιστού δεν ικανοποιεί τις συνθήκες αυτές.
Δύο είναι τα βασικά προβλήματα που πρέπει να αποφευχθούν. Το πρώτο αφορά στην ύπαρξη των αδιεξόδων, δηλαδή των ιστοσελίδων που δεν έχουν εξερχόμενους συνδέσμους. Οι περιηγητές που επισκέπτονται μία τέτοια ιστοσελίδα χάνονται, και το αποτέλεσμα είναι ότι στο όριο, καμία σελίδα που οδηγεί σε αδιέξοδο δεν μπορεί να έχει μη μηδενική τιμή PageRank. Το δεύτερο πρόβλημα δημιουργείται από ομάδες ιστοσελίδων που ενώ έχουν συνδέσμους προς άλλες ιστοσελίδες, οι σύνδεσμοι οδηγούν σε ιστοσελίδες εντός της ομάδας. Οι ομάδες αυτές καλούνται παγίδες (spider traps). Τα δύο αυτά προβλήματα επιλύονται με τη μέθοδο της “φορολόγησης”, σύμφωνα με την οποία ένας τυχαίος περιηγητής έχει μία πεπερασμένη πιθανότητα να εγκαταλείψει την περιήγηση σε οποιοδήποτε βήμα, ενώ νέοι περιηγητές ξεκινούν την περιήγησή τους. Ο τρόπος εφαρμογής της μεθόδου θα εξεταστεί με λεπτομέρεια στη συνέχεια.
Υπενθυμίζεται ότι μία ιστοσελίδα που δε διαθέτει εξερχόμενους συνδέσμους καλείται αδιέξοδο. Εάν υπάρχουν αδιέξοδα στο γράφημα, τότε ο πίνακας μεταβάσεων του παγκόσμιου ιστού δεν μπορεί να είναι στοχαστικός, αφού κάποιες στήλες θα έχουν άθροισμα 0 και όχι 1. Ο πίνακας του οποίου οι στήλες έχουν άθροισμα το πολύ 1 καλείται υποστοχαστικός. Εάν υπολογίσουμε την ποσότητα θα παρατηρήσουμε ότι μηδενίζονται κάποιες ή όλες οι συνιστώσες του διανύσματος βαθμών. Αυτό έχει ως αποτέλεσμα ο βαθμός αξιοπιστίας των ιστοσελίδων να μην είναι διαθέσιμος. Η καταπολέμηση των αδιεξόδων μπορεί να γίνει με δύο τρόπους:
-
•
με διαγραφή των ιστοσελίδων που αποτελούν αδιέξοδα, διαγράφοντας στη συνέχεια και τα νέα αδιέξοδα που μπορεί να παραχθούν,
-
•
με μεταβολή της διαδικασίας μοντελοποίησης της συμπεριφοράς των τυχαίων περιηγητών στον παγκόσμιο ιστό, με την οποία μπορούμε να λύσουμε και το πρόβλημα των παγίδων, όπως θα δούμε στη συνέχεια.
Ας δούμε τώρα πως μπορούμε να χειριστούμε την υπαρξη παγίδων. Μία παγίδα αποτελείται από ένα σύνολο ιστοσελίδων χωρίς αδιέξοδα, αλλά και χωρίς εξερχόμενους συνδέσμους προς σελίδες εκτός του συνόλου. Οι δομές αυτές μπορούν να εμφανίζονται από τύχη ή επίτηδες στον παγκόσμιο ιστό και προκαλούν διάφορα προβλήματα στον υπολογισμό της τιμής του PageRank. Στο Σχήμα 9.7 παρουσιέζεται ένα παράδειγμα αδιεξόδου και ένα παράδειγμα παγίδας. Στο Σχήμα 9.7(α) η ιστοσελίδα B αποτελεί αδιέξοδο, αφού δεν έχει εξερχόμενους συνδέσμους. Αυτό έχει ως αποτέλεσμα, ένας τυχαίος περιηγητής που θα βρεθεί στην ιστοσελίδα B δε θα μπορέσει να ξεφύγει. Ομοίως, στο Σχήμα 9.7(β) οι ιστοσελίδες B και C αποτελούν παγίδα. Αν ο τυχαίος περιηγητής βρεθεί σε μία από τις δύο αυτές ιστοσελίδες το μόνο που μπορεί να κάνει είναι να πηγαίνει από τη B στη C και από τη C στη Β.

Για να αποφύγουμε το πρόβλημα των αδιεξόδων και των παγίδων, τροποποιούμε τη μέθοδο υπολογισμού του βαθμού σημαντικότητας, επιτρέποντας σε κάθε τυχαίο περιηγητή να μεταβεί σε κάποια τυχαία ιστοσελίδα με μία μικρή πιθανότητα, αντί να ακολουθήσει έναν εξερχόμενο σύνδεσμο από την τρέχουσα ιστοσελίδα. Ο υπολογισμός του νέου διανύσματος με βάση το τρέχον διάνυσμα και τον πίνακα μεταβάσεων γίνεται ως εξής:
| (9.5) |
όπου είναι μία σταθερά, συνήθως μεταξύ των τιμών 0,8 και 0,9, είναι ένα διάνυσμα που έχει άσσους σε όλες τις θέσεις, και είναι το πλήθος των ιστοσελίδων. Ο όρος αναπαριστά την περίπτωση, όπου με πιθανότητα ο τυχαίος περιηγητής αποφασίζει να ακολουθήσει έναν εξερχόμενο σύνδεσμο από την ιστοσελίδα όπου βρίσκεται. Ο όρος είναι ένα διάνυσμα με συνιστώσες και αναπαριστά την εμφάνιση ενός νέου περιηγητή με πιθανότητα σε μία τυχαία ιστοσελίδα.
Σημειώστε ότι αν στο γράφημα δεν υπάρχουν αδιέξοδα, τότε η πιθανότητα της εμφάνισης ενός νέου περιηγητή είναι ακριβώς ίδια με την πιθανότητα ένας τυχαίος περιηγητής να αποφασίσει να μην ακολουθήσει κάποιον εξερχόμενο σύνδεσμο από τη ιστοσελίδα όπου βρίσκεται. Στην περίπτωση αυτή, είναι λογικό να υποθέσουμε ότι ο τυχαίος περιηγητής είτε θα ακολουθήσει κάποιον εξερχόμενο σύνδεσμο είτε θα “τηλεμεταφερθεί” σε μία τυχαία ιστοσελίδα. Αν όμως υπάρχουν αδιέξοδα, τότε υπάρχει και τρίτη περίπτωση κατά την οποία ο τυχαίος περιηγητής δεν μπορεί να μεταβεί πουθενά. Εφόσον ο όρος δεν εξαρτάται από το άθροισμα των συνιστωσών του διανύσματος , πάντα θα υπάρχουν κάποιοι τυχαίοι περιηγητές στον παγκόσμιο ιστό. Με άλλα λόγια, το άθροισμα των συνιστωσών του μπορεί να είναι μικρότερο της μονάδας αλλά ποτέ δεν θα είναι μηδέν.
Ας δούμε πως μπορούμε να υπολογίσουμε τους βαθμούς PageRank για το γράφημα του Σχήματος 9.7(β). Για το παράδειγμα θέτουμε =0,8. Άρα, η εξίσωση που προκύπτει είναι:
| (9.6) |
Παρατηρήστε ότι έχουμε χρησιμοποιήσει τον παράγοντα πολλαπλασιάζοντας κάθε στοιχείο του πίνακα με 4/5. Οι συνιστώσες του διανύσματος είναι 1/20, επειδή και =5. Τα βασικά βήματα του αλγορίθμου PageRank παρουσιάζονται στο Σχήμα 9.8. Σημειώνεται ότι είναι το γράφημα που αναπαριστά τον παγκόσμιο ιστό, όπου είναι το σύνολο των ιστοσελίδων και το σύνολο των συνδέσμων. Επίσης, και είναι το πλήθος των ιστοσελίδων με εξερχόμενους συνδέσμους προς την ιστοσελίδα .
Έχοντας μελετήσει τον τρόπο υπολογισμού του διανύσματος με τις τιμές PageRank για το τμήμα του παγκόσμιου ιστού που έχει διαβασθεί από το μηχανισμό σάρωσης, εξηγούμε στη συνέχεια πως η πληροφορία αυτή χρησιμοποιείται στην πράξη. Η κάθε μηχανή αναζήτησης διαθέτει ένα μυστικό μηχανισμό βάσει του οποίου γίνεται η τελική επιλογή για τη σειρά εμφάνισης των αποτελεσμάτων ως αντίδραση σε κάποιο ερώτημα με έναν ή περισσότερους όρους (λέξεις). Εικάζεται, ότι η Google χρησιμοποιεί περί τις 250 διαφορετικές ιδιότητες των σελίδων από όπου προκύπτει μία διάταξη των σελίδων.
Αρχικά, θα πρέπει η σελίδα να περιέχει τουλάχιστον έναν από τους όρους του ερωτήματος για να εισαχθεί στη διαδικασία της βαθμολόγησης. Συνήθως, αν η σελίδα δεν περιέχει όλους τους όρους του ερωτήματος έχει λίγες πιθανότητες να είναι στις πρώτες θέσεις των αποτελεσμάτων. Για όλες τις υποψήφιες σελίδες υπολογίζεται ένας βαθμός, και ένα σημαντικό μέρος του βαθμού είναι και η τιμή PageRank της σελίδας. Άλλα χαρακτηριστικά που λαμβάνονται υπόψη είναι η παρουσία ή απουσία όρων σε σημαντικά τμήματα, όπως επικεφαλίδες ή σύνδεσμοι προς την ίδια σελίδα.
9.5 Σύνοψη και Περαιτέρω Μελέτη
Στο κεφάλαιο αυτό μελετήσαμε θέματα που αφορούν στην αναζήτηση πληροφορίας στον παγκόσμιο ιστό. Συγκεκριμένα, εξετάσαμε τις προκλήσεις που επιφέρει ο παγκόσμιος ιστός στην Ανάκτηση Πληροφορίας και μελετήσαμε αναλυτικά τους αλγορίθμους προσδιορισμού του βαθμού αξιοπιστίας των ιστοσελίδων HITS και PageRank. Ο ενδιαφερόμενος αναγνώστης μπορεί να μελετήσει την εργασία του Kleinberg στην οποία μελετήθηκε για πρώτη φορά ο αλγόριθμος HITS [34].Επίσης, αξίζει να μελετηθούν και οι εργασίες [5] και [46] όπου αναλύεται ο αλγόριθμος PageRank και τα βασικά τμήματα της μηχανής αναζήτησης της Google. Επίσης, τα βιβλία [6, 8] αποτελούν πολύ σημαντικά βοηθήματα για την Ανάκτηση Πληροφορίας στον παγκόσμιο ιστό και τις μηχανές αναζήτησης.
9.6 Ασκήσεις
-
9.1
Ποιές είναι οι βασικές προκλήσεις που επιφέρει ο παγκόσμιος ιστός στη λειτουργία των μηχανών αναζήτησης;
-
9.2
Ποιά είναι τα βασικά τμήματα από τα οποία αποτελείται μία μηχανή αναζήτησης;
-
9.3
Να εξηγήσετε τους λόγους για τους οποίους οι πρώιμες μηχανές αναζήτησης δεν επαρκούσαν για τις πληροφοριακές ανάγκες των χρηστών.
-
9.4
Πως λειτουργεί ο αλγόριθμος HITS και ποιά η χρησιμότητά του;
-
9.6
Πως λειτουργει ο αλγόριθμος PageRank;
-
9.7
Ποιές οι βασικές διαφορές των αλγορίθμων HITS και PageRank;
-
9.8
Να κατασκευάσετε ένα γράφημα με τέσσερις κορυφές και με ένα αδιέξοδο και να υπολογίσετε το διάνυσμα των βαθμών σύμφωνα με τον αλγόριθμο PageRank. Ποιές είναι οι παρατηρήσεις σας;
-
9.9
Να υλοποιήσετε τον αλγόριθμο PageRank σε μία γλώσσα προγραμματισμού και να τον δοκιμάσετε για διαφορετικές τιμές της παραμέτρου σε γραφήματα που θα βρείτε στον ιστότοπο http://snap.stanford.edu.
-
9.10
Να σχεδιάσετε μία μέθοδο η οποία θα μπορεί να ”ξεγελάσει” τον αλγόριθμο PageRank και θα δίνει με τεχνητό τρόπο μεγαλύτερο βαθμό σε συγκεκριμένες ιστοσελίδες.