Κεφάλαιο 5Το Πιθανοκρατικό Μοντέλο
5.1 Εισαγωγή
Στο κεφάλαιο αυτό, εξετάζουμε το τρίτο μοντέλο ανάκτησης της κατηγορίας των Κλασικών μοντέλων το οποίο χαρακτηρίζεται από τη μαθηματική του θεμελίωση με τη βοήθεια της Θεωρίας Πιθανοτήτων. Αυτός είναι και ο βασικός λόγος για τον οποίο καλείται Πιθανοκρατικό (probabilistic) μοντέλο ανάκτησης. Είναι το πρώτο προτεινόμενο μοντέλο ανάκτησης που στηρίζεται σε πιθανότητες. Η χρήση της Θεωρίας Πιθανοτήτων στην ανάκτηση πληροφορίας προτάθηκε για πρώτη φορά από τους Maron και Kuhns το 1960 [42], ενώ η εργασία των Robertson και Sparck Jones [50] θεωρείται σταθμός για την πιθανοκρατική ανάκτηση πληροφορίας (probabilistic information retrieval).
Το κίνητρο για την εφαρμογή πιθανοτήτων είναι το γεγονός ότι η διαδικασία της ανάκτησης χαρακτηρίζεται από ασάφεια (uncertainty). Ένα τμήμα της ασάφειας οφείλεται στο ότι με βάση το ερώτημα του χρήστη δεν είναι δυνατόν να προσδιορίσουμε επακριβώς την πληροφοριακή του ανάγκη. Το άλλο τμήμα της ασάφειας οφείλεται στον προσδιορισμό της ομοιότητας μεταξύ της αναπαράστασης ενός ερωτήματος και ενός εγγράφου της συλλογής. Το Πιθανοκρατικό μοντέλο προσπαθεί να ποσοτικοποιήσει την ασάφεια, υπολογίζοντας πόσο πιθανό είναι το γεγονός ένα έγγραφο να είναι σχετικό ως προς το ερώτημα του χρήστη.
Το βασικό εργαλείο που διαθέτουμε για τον χαρακτηρισμό ενός εγγράφου ως σχετικού ή μη σχετικού ως προς ένα ερώτημα είναι η συνάρτηση ομοιότητας. Για παράδειγμα, μπορούμε να ορίσουμε κάποιο κατώφλι στο βαθμό ομοιότητας έτσι ώστε τα έγγραφα που παρουσιάζουν ομοιότητα (ως προς τη συνάρτηση ομοιότητας) μεγαλύτερη από το κατώφλι να χαρακτηρίζονται ως σχετικά, ενώ τα υπόλοιπα μη σχετικά. Μία εναλλακτική μέθοδος διαχωρισμού των εγγράφων είναι να θεωρήσουμε ότι τα έγγραφα με το μεγαλύτερο βαθμό ομοιότητας είναι τα σχετικά, ενώ τα υπόλοιπα είναι μη σχετικά. Η επιλογή της συνάρτησης ομοιότητας πραγματοποιείται κυρίως με βάση πειραματικές μετρήσεις. Σε περίπτωση που η συνάρτηση ομοιότητας προσφέρει υψηλές τιμές ανάκλησης και ακρίβειας τότε επιλέγεται. Αυτός ο τρόπος επιλογής της συνάρτησης ωστόσο δε στηρίζεται σε κάποιο φορμαλισμό και μπορεί να θεωρηθεί αυθαίρετη. Με τη χρήση του Πιθανοκρατικού μοντέλου ανάκτησης, η επιλογή της συνάρτησης ομοιότητας βασίζεται σε μία διαδικασία σύγκλισης, με σκοπό τον προσδιορισμό των τιμών των παραμέτρων του μοντέλου. Επομένως, η επιλογή της συνάρτησης ομοιότητας πραγματοποιείται με πιο φυσικό τρόπο που σίγουρα δεν είναι αυθαίρετος.
Θα ξεκινήσουμε με το απλού Πιθανοκρατικό μοντέλο, ενώ στη συνέχεια θα καλύψουμε δύο ακόμη μοντέλα που χρησιμοποιούν πιθανότητες για τον προσδιορισμό της ομοιότητας των εγγράφων και στηρίζονται στα δίκτυα Bayes.
5.2 Βασικές Έννοιες Θεωρίας Πιθανοτήτων
Στο σημείο αυτό θεωρείται σκόπιμο να παρατεθεί μία συνοπτική παρουσίαση των βασικών αρχών της Θεωρίας Πιθανοτήτων, οι οποίες θα χρησιμοποιηθούν για την περιγραφή του Πιθανοκρατικού μοντέλου. Αν είναι κάποιο γεγονός, τότε η πιθανότητα να συμβεί το γεγονός αυτό συμβολίζεται με . Με βάση τη Θεωρία Πιθανοτήτων ισχύει: . Ακολουθούν δύο σημαντικοί ορισμοί:
Ορισμός 5.1.
(ανεξάρτητα γεγονότα)
Δύο γεγονότα θεωρούνται ανεξάρτητα όταν η εμφάνιση του ενός δεν επηρεάζεται από την εμφάνιση
ή μη εμφάνιση του άλλου.
Ορισμός 5.2.
(υπό συνθήκη πιθανότητα)
Η υπό συνθήκη πιθανότητα του γεγονότος ως προς το γεγονός συμβολίζεται με και εκφράζει
την πιθανότητα να συμβεί το γεγονός δεδομένου ότι έχει συμβεί το γεγονός .
Θεώρημα 5.1.
Δύο γεγονότα και είναι ανεξάρτητα αν και μόνο αν = .
Θεώρημα 5.2.
Τα γεγονότα , , …, είναι υπο συνθήκη ανεξάρτητα αν και μόνο αν , = .
Παράδειγμα 5.1
Στο Σχήμα 5.1 δίνονται τα γεγονότα και . Με και συμβολίζονται οι αρνήσεις των γεγονότων αυτών. Προφανώς ισχύει ότι = 1 - και = 1 - . Έστω , , και τα γεγονότα που σχηματίζονται όπως φαίνεται στο Σχήμα 5.1. Αν συμβολίσουμε με το πλήθος των στοιχείων που ικανοποιούν το γεγονός και ο συνολικός αριθμός των στοιχείων, τότε έχουμε: = , = . Είναι προφανές ότι τα γεγονότα και δεν είναι ανεξάτητα. Για να το δούμε αυτό θα υπολογίσουμε την υπό συνθήκη πιθανότητα να συμβεί το γεγονός δεδομένου ότι έχει συμβεί το γεγονός . Σύμφωνα με την προηγούμενη συζήτηση, η ποσότητα αυτή συμβολίζεται με . Είναι προφανές ότι: . Από την τελευταία σχέση έχουμε: και επομένως ισχύει ότι = .

Παράδειγμα 5.2
Έστω ότι έχουμε στη διάθεσή μας δύο δίκαια ζάρια (η πιθανότητα να φέρουμε ένα από τα 6 νούμερα είναι ίδια). Είναι προφανές, ότι αν ρίξουμε διαδόχικά τα ζάρια, η τιμή του δεύτερου ζαριού δεν εξαρτάται από την τιμή του πρώτου. Για παράδειγμα, αν συμβολίσουμε τα ζάρια με και τότε η πιθανότητα το δεύτερο ζάρι να φέρει 6 δεδομένου ότι το πρώτο ζάρι έφερε 4 είναι = = 1/6, εφόσον τα δύο γεγονότα είναι ανεξάρτητα. Έστω τώρα το άθροισμα των τιμών των δύο ζαριών. Η πιθανότητα το άθροισμα των τιμών να είναι 6 δεδομένου ότι το πρώτο ζάρι έχει φέρει 4 είναι = 1/6, αφού για να πάρουμε το επιθυμητό άθροισμα θα πρέπει το δεύτερο ζάρι να φέρει 2. Ομοίως έχουμε = 1/6 ενώ = 0.
Θεώρημα 5.3.
Έστω και δύο γεγονότα. Τότε οι ποσότητες , , και συνδέονται με την ακόλουθη σχέση που είναι γνωστή και ως νόμος ή κανόνας του Bayes:
| (5.1) |
Σε περίπτωση που ο χώρος γεγονότων μπορεί να διαμεριστεί στα γεγονότα , , …, τότε ο κανόνας του Bayes παίρνει την ακόλουθη μορφή:
| (5.2) |
5.3 Υπολογισμός Σχετικότητας Εγγράφων
Η βαθμολόγηση των εγγράφων με βάση το Πιθανοκρατικό μοντέλο ανάκτησης βασίζεται στην Αρχή Πιθανοκρατικής Βαθμολόγησης (probability ranking principle)33Θεωρουμε σκόπιμο να δώσουμε και τον αρχικό ορισμό της αρχής, όπως παρουσιάζεται στην εργασία [52], και η οποία αποδίδεται στον W.S. Cooper αν και έχει διατυπωθεί νωρίτερα από τον Maron [43]. Η αρχή αναφέρει ότι: ”If a reference retrieval system’s response to each request is a ranking of the documents in the collection in order of decreasing probability of relevance to the user who submitted the request, where the probabilities are estimated as accurately as possible on the basis of whatever data have been made available to the system for this purpose, the overall effectiveness of the system to its user will be the best that is obtainable on the basis of those data”. η οποία αναφέρει ότι: εάν η απάντηση ενός συστήματος ανάκτησης σε κάθε ερώτημα είναι μία λίστα εγγράφων ταξινομημένη με φθίνουσα διάταξη ως προς την πιθανότητα σχετικότητας του κάθε εγγράφου ως προς το χρήστη, όπου οι πιθανότητες υπολογίζονται όσο γίνεται ακριβέστερα με βάση τα δεδομένα που είναι διαθέσιμα, η συνολική αποτελεσματικότητα του συστήματος θα είναι η καλύτερη δυνατή.
Δοθέντος ενός ερωτήματος , η μέθοδος επεξεγασίας του ερωτήματος προσπαθεί να εντοπίσει έγγραφα που είναι σχετικά ως προς το και να αγνοήσει τα υπόλοιπα. Συμβολίζουμε με το σύνολο των σχετικών εγγράφων ως προς κάποιο ερώτημα και με το σύνολο των μη σχετικών εγγράφων. Βασικός στόχος του Πιθανοκρατικού μοντέλου είναι ο προσδιορισμός της πιθανότητας ένα έγγραφο να ανήκει στο σύνολο των σχετικών εγγράφων . Την πιθανότητα αυτή μπορούμε να την εκφράσουμε ως που δηλώνει την πιθανότητα το έγγραφο να ανήκει στο σύνολο των σχετικών εγγράφων. Ομοίως ορίζεται η πιθανότητα . Προφανώς ισχύει ότι . Στη συνέχεια, αναφέρουμε μερικές παραδοχές που απαιτούνται για τη λειτουργία του Πιθανοκρατικού μοντέλου:
-
•
Η πιθανότητα ένα έγγραφο να είναι σχετικό ως προς το ερώτημα θεωρείται ότι εξαρτάται μόνο από τους όρους που περιέχονται στο έγγραφο και από τους όρους που περιέχονται στο ερώτημα.
-
•
Η σχετικότητα ενός εγγράφου ως προς το ερώτημα δεν εξαρτάται από τη σχετικότητα άλλων εγγράφων της συλλογής.
-
•
Για κάποιο ερώτημα το σύνολο των σχετικών εγγράφων είναι το ιδανικό σύνολο που μπορούμε να έχουμε ως απάντηση.
Στη συνέχεια, παρουσιάζεται ο τρόπος με τον οποίο μπορούμε να εκφράσουμε την ομοιότητα μεταξύ ενός ερωτήματος και ενός εγγράφου της συλλογής, καθώς επίσης και ο τρόπος που μπορούμε να υπολογίσουμε την ομοιότητα αυτή με βάση τις αρχές του Πιθανοκρατικού μοντέλου ανάκτησης. Ο Πίνακας 5.1 περιέχει τα βασικότερα σύμβολα και τις αντίστοιχες περιγραφές τους.
| σύμβολο | περιγραφή |
|---|---|
| πλήθος εγγράφων της συλλογής | |
| σύνολο σχετικών εγγράφων ως προς το ερώτημα | |
| πλήθος σχετικών εγγράφων () | |
| , | ο όρος , ο -οστός όρος () |
| , | το έγγραφο , το -οστό έγγραφο της συλλογής () |
| έγγραφο ερωτήματος | |
| πλήθος σχετικών εγγράφων που περιέχουν τον όρο | |
| πλήθος εγγράφων που περιέχουν τον όρο | |
| αριθμός εμφανίσεων του όρου στο έγγραφο | |
| αριθμός εμφανίσεων του όρου στο ερώτημα | |
| πιθανότητα να συμβεί το γεγονός | |
| πιθανότητα να συμβεί το δεδομένου του | |
| πιθανότητα το έγγραφο να είναι σχετικό | |
| πιθανότητα το έγγραφο να μην είναι σχετικό | |
| πιθανότητα τυχαίας επιλογής του από το σύνολο | |
| πιθανότητα τυχαίας επιλογής του από το σύνολο | |
| , | μήκος ερωτήματος και εγγράφου της συλλογής |
| , , , , | σταθερές |
| συνάρτηση ομοιότητας απλού πιθανοκρατικού μοντέλου | |
| συνάρτηση ομοιότητας κατά BM25 | |
| συνάρτηση ομοιότητας μοντέλου δικτύου συμπερασμάτων | |
| συνάρτηση ομοιότητας μοντέλου δικτύου πίστης |
5.3.1 Μέτρο Ομοιότητας
Ο βαθμός ομοιότητας μεταξύ ενός εγγράφου και ενός ερωτήματος ορίζεται ως ο λόγος των πιθανοτήτων το να είναι σχετικό προς την πιθανότητα το να μην είναι σχετικό. Ο λόγος χρησιμοποιείται για να αμβλύνει τα αποτελέσματα κάποιας λανθασμένης πρόβλεψης [27, 75]. Πιο συγκεκριμένα, αν συμβολίσουμε με τη συνάρτηση που επιστρέφει την ομοιότητα μεταξύ και τότε:
| (5.3) |
Με εφαρμογή του θεωρήματος του Bayes στον αριθμητή και παρονομαστή του κλάσματος της παραπάνω σχέσης, η συνάρτηση ομοιότητας γράφεται ως εξής:
| (5.4) |
όπου είναι η πιθανότητα να διαλέξουμε τυχαία το μέσα από το σύνολο των σχετικών εγγράφων . Με μία προσεκτική ματιά στην εξίσωση 5.4 παρατηρούμε ότι το κλάσμα έχει τιμή σταθερή για κάθε ερώτημα, και εφόσον δεν επηρεάζει την τελική κατάταξη των εγγράφων δεν είναι απαραίτητο να υπολογιστεί. Επομένως, η συνάρτηση ομοιότητας επαναπροσδιορίζεται ως εξής:
| (5.5) |
Αρχικά το Πιθανοκρατικό μοντέλο βασίστηκε στο συνδυασμό της Αρχής Πιθανοκρατικής Βαθμολόγησης και της Ανάκτησης Δυαδικής Ανεξαρτησίας (binary independence retrieval). Η δεύτερη αναφέρει ότι τα βάρη των όρων είναι δυαδικά και ότι οι όροι είναι ανεξάρτητοι μεταξύ τους (η παρουσία ή μη κάποιου όρου δεν επηρεάζει τους υπόλοιπους). Στην ουσία, αυτός είναι και ο τρόπος θεώρησης του απλού Λογικού μοντέλου. Το βάρος ενός όρου σε ένα έγγραφο είναι είτε 1 (αν ο όρος περιέχεται στο έγγραφο) είτε 0 (σε διαφορετική περίπτωση). Επομένως, ένα έγγραφο μπορεί να εκφραστεί ως διάνυσμα βαρών, όπου η κάθε συνιστώσα αναφέρεται στην παρουσία ή απουσία του όρου στο έγγραφο. Έτσι, αν συμβολίσουμε με το διάνυσμα των βαρών του εγγράφου , με το πλήθος των μοναδικών όρων της συλλογής εγγράφων και με το βάρος του όρου στο έγγραφο , τότε έχουμε:
| (5.6) |
Το διάνυσμα μπορεί να χρησιμοποιηθεί ως προσέγγιση της πληροφορίας που περιέχεται στο έγγραφο και προσφέρει ένα βολικό τρόπο για να εκτιμήσουμε την ποσότητα με χρήση της ποσότητας . Από τη σχέση 5.7 έχουμε:
| (5.7) |
Λαμβάνοντας υπόψη την ανεξαρτησία των όρων ισχύει ότι = , …, . Ο τύπος υπολογισμού της ομοιότητας γίνεται:
| (5.8) |
Διαχωρίζουμε τους όρους από έως σε δύο κατηγορίες, αυτούς που περιέχονται στο έγγραφο και σε αυτούς που δεν περιέχονται στο έγγραφο . Αντικαθιστώντας στην εξίσωση 5.8 παίρνουμε:
| (5.9) |
Υποθέτουμε ότι οι όροι που δεν εμφανίζονται στο ερώτημα έχουν την ίδια πιθανότητα να βρίσκονται ή όχι στα έγγραφα του (σχετικά έγγραφα). Χρησιμοποιώντας την υπόθεση αυτή το μέτρο ομοιότητας γίνεται:
| (5.10) |
Για να απλούστευση της συνάρτησης ομοιότητας πραγματοποιούνται οι αντικαταστάσεις = και = , οπότε η συνάρτηση ομοιότητας παίρνει την ακόλουθη μορφή:
| (5.11) |
Από το δεύτερο γινόμενο διαγράφουμε τους όρους που δε βρίσκονται στο έγγραφο ενώ βρίσκονται στο ερώτημα . Αν γίνει αυτό, τότε στο γινόμενο θα συμμετέχουν κλάσματα της μορφής και για τους όρους που περιέχονται στο έγγραφο και για τους όρους που δεν περιέχονται. Επειδή όμως το πρώτο γινόμενο περιλαμβάνει τις περιπτώσεις που οι όροι εμφανίζονται στο έγγραφο, θα πρέπει να μεταβληθεί το πρώτο γινόμενο όπως φαίνεται στην παρακάτω σχέση:
| (5.12) |
Από την προηγούμενη σχέση παρατηρούμε ότι το δεύτερο γινόμενο εξαρτάται μόνο από το εκάστοτε ερώτημα, καθώς αναφέρεται μόνο στους όρους που περιέχονται στο ερώτημα. Επομένως, μπορούμε να αγνοήσουμε το γινόμενο αυτό και να προχωρήσουμε με τον υπολογισμό του πρώτου γινομένου. Συνήθως, το γινόμενο των πιθανοτήτων είναι ένας πολύ μικρός πραγματικός αριθμός. Για να αποφύγουμε πολύ μικρές τιμές χρησιμοποιείται λογαρίθμηση:
| (5.13) |
| (5.14) |
Το άθροισμα της σχέσης 5.14 αφορά σε όλους τους όρους που εμφανίζονται και στο έγγραφο και στο ερώτημα. Αν συμβολίσουμε με το σύνολο των μοναδικών όρων του εγγράφου , με το σύνολο των μοναδικών όρων του ερωτήματος και με την τομή των δύο συνόλων, τότε παίρνουμε την παρακάτω σχέση όπου είναι το βάρος του όρου :
| (5.15) |
5.3.2 Υπολογισμός της Ομοιότητας
Το βασικό πρόβλημα που πρέπει να λυθεί είναι ο υπολογισμός των πιθανοτήτων και . Οι πιθανότητες αυτές δεν είναι γνωστές, αφού δεν γνωρίζουμε εκ των προτέρων πιο είναι το σύνολο των σχετικών ως προς ερώτημα εγγράφων. Επομένως, θα πρέπει να εκτιμήσουμε αρχικά με κάποιον τρόπο αυτές τις πιθανότητες και στην συνέχεια να τις προσδιορίσουμε καλύτερα.
| πλήθος σχετικών | πλήθος μη σχετικών | σύνολο | |
| εγγράφων | εγγράφων | ||
| πλήθος εγγράφων που | |||
| περιέχουν τον όρο | |||
| πλήθος εγγράφων που δεν | |||
| περιέχουν τον όρο | |||
| σύνολο |
Ο Πίνακας 5.2 περιέχει όλες τις δυνατές περιπτώσεις σχετικά με το αν ένα έγγραφο είναι σχετικό ή μή σχετικό, και αν το έγγραφο περιέχει ή όχι το συγκεκριμένο όρο . Με συμβολίζουμε το πλήθος των εγγράφων της συλλογής, είναι το πλήθος των σχετικών ως προς το ερώτημα εγγράφων ( = ), είναι το πλήθος των σχετικών εγγράφων που περιέχουν τον όρο , και είναι το πλήθος των συνολικών εγγράφων (σχετικών και μή σχετικών) που περιέχουν τον όρο . Με βάση τον Πίνακα 5.2 μπορούμε να εκτιμήσουμε τις ποσότητες και ως εξής: = και = . Οι δύο αυτές σχέσεις προϋποθέτουν ότι [56]: (α) η κατανομή των όρων στα έγγραφα που έχουν ανακτηθεί είναι ίδια με την κατανομή των όρων στο σύνολο των σχετικών εγγράφων, και (β) όλα τα έγγραφα που δεν έχουν ανακτηθεί θεωρούνται μή σχετικά ως προς το ερώτημα. Με αντικατάσταση των τιμών και στη σχέση που δίνει το έχουμε:
| (5.16) |
Παρατηρήστε ότι η σχέση 5.16 είναι προβληματική σε ορισμένες περιπτώσεις, π.χ., όταν = όπου έχουμε μηδενισμό του παρονομαστή. Για την αποφυγή των παθολογικών καταστάσεων έχει προταθεί ή χρήση κάποιας σταθεράς η οποία προστίθεται [50]. Η τιμή αυτή είναι συνήθως το 0.5 ή το . Με την προσθήκη της σταθεράς η σχέση υπολογισμού της ποσότητας γίνεται:
| (5.17) |
Σύμφωνα με αυτά που έχουμε αναφέρει, η βαθμολόγηση των εγγράφων θα ήταν απλή υπόθεση αν γνωρίζαμε το σύνολο των σχετικών εγγράφων . Κάτι τέτοιο όμως δε συμβαίνει, επομένως θα πρέπει να χρησιμοποιήσουμε μία μεθοδολογία προσδιορισμού του συνόλου . Αρχικά, πραγματοποιείται ανάκτηση των εγγράφων που περιέχουν τους όρους του ερωτήματος. Στη συνέχεια, χρησιμοποιούμε τη συνάρτηση ομοιότητας 5.15 για να βαθμολογήσουμε τα έγγραφα που έχουν ανακτηθεί, θέτοντας = 0.5 και = ως αρχικές εκτιμήσεις. Στη συνέχεια, από το σύνολο των εγγράφων που έχουν ανακτηθεί και βαθμολογηθεί επιλέγουμε ένα υποσύνολο αυτών (για παράδειγμα τα έγγραφα των οποίων ο βαθμός ομοιότητας είναι πάνω από κάποιο κατώφλι ή τα έγγραφα με το μεγαλύτερο βαθμό). Στο σημείο αυτό θα μπορούσε να βοηθήσει και ο χρήστης στη διαδικασία επιλογής των εγγράφων. Μετά από αυτό το βήμα, μπορεί να γίνει μία νέα εκτίμηση των ποσοτήτων και και επομένως της ποσότητας με βάση τον τύπο 5.17. Η διαδικασία αυτή εκτελείται είτε για ένα σταθερό αριθμό επαναλήψεων, είτε μέχρι η μεταβολή των αποτελεσμάτων να μην είναι σημαντική.
5.3.3 Μέθοδος Okapi ΒΜ25
Το Okapi είναι ένα σύστημα ανάκτησης πληροφορίας που αναπτύχθηκε στο Πανεπιστήμιο City του Λονδίνου από τον Robertson και τους συνεργάτες του και που έχει χρησιμοποιηθεί ως πλατφόρμα για τη μελέτη της αποτελεσματικότητας διαφόρων μεθόδων προσδιορισμού της ομοιότητας. Μία από τις πιο αποτελεσματικές μεθόδους υπολογισμού της ομοιότητας που έδωσε πολύ καλά αποτελέσματα στις συλλογές εγγράφων TREC είναι η μέθοδος BM25 44Το BM προκύπτει από τις λέξεις Best Match. που μελετάται στην εργασία [49]. Στην ουσία, πρόκειται για συνδυασμό των συναρτήσεων ομοιότητας BM11 και BM15 που είχαν μελετηθεί στην εργασία [51]. Ακολουθεί μία συνοπτική περιγραφή της μεθόδου BM25.
Η μέθοδος BM25 στηρίζεται στη χρήση δύο κατανομών Poisson. Σύμφωνα με αυτήν, ένα έγγραφο θεωρείται ως μία τυχαία ροή εμφανίσεων όρων. Κάθε εμφάνιση ενός όρου θεωρείται ένα γεγονός που αφορά στον όρο . Θεωρούμε ότι ο επόμενος όρος του εγγράφου θα είναι ο όρος με πιθανότητα (επομένως 1- είναι η πιθανότητα ο επόμενος όρος του εγγράφου να είναι διαφορετικός του ). Αν συμβολίσουμε με την τυχαία μεταβλητή που μας δίνει τον αριθμό των εμφανίσεων του όρου στο έγγραφο, τότε η πιθανότητα να συμβούν εμφανίσεις του όρου σε ένα έγγραφο που αποτελείται από όρους προσδιορίζεται από την διωνυμική κατανομή, σύμφωνα με τον τύπο:
| (5.18) |
Για πολύ μικρές τιμές της πιθανότητας και πολύ μεγάλες τιμές του , η διωνυμική κατανομή προσεγγίζεται με ικανοποιητική ακρίβεια από την κατανομή Poisson. Αν είναι η μέση τιμή της τυχαίας μεταβλητής , τότε έχουμε:
| (5.19) |
Για τη χρήση της συχνότητας εμφάνισης των όρων στα έγγραφα γίνεται η υπόθεση ότι η συχνότητα εμφάνισης ενός όρου ακολουθεί επίσης την κατανομή Poisson. Τα έγγραφα που περιέχουν τον όρο διαχωρίζονται σε δύο κατηγορίες: στα έγγραφα που θεωρούνται εκλεκτά ως προς τον όρο (δηλαδή αναφέρονται στο θέμα στο οποίο αναφέρεται και ο ) και στα έγγραφα που θεωρούνται μη εκλεκτά ως προς τον όρο . Υποθέτουμε λοιπόν ότι η συχνότητα εμφάνισης του όρου στις δύο κατηγορίες εγγράφων ακολουθεί την κατανομή Poisson αλλά με διαφορετικές μέσες τιμές για την κάθε περίπτωση. Έστω η τυχαία μεταβλητή που μας δίνει τη συχνότητα εμφάνισης του όρου . Τότε έχουμε:
| (5.20) |
| (5.21) |
όπου και είναι η μέση τιμή της πιθανότητας για την περίπτωση των εκλεκτών και μή εκλεκτών εγγράφων αντίστοιχα. Με βάση τη μελέτη της εργασίας [49], δίνουμε στη συνέχεια τη συνάρτηση που υπολογίζει το βαθμό ομοιότητας μεταξύ ενός ερωτήματος και ενός εγγράφου της συλλογής .
| (5.22) |
| (5.23) |
Στον παραπάνω τύπο, οι , , και είναι σταθερές ρύθμισης. Η σταθερά ισούται με = , όπου είναι μία άλλη ρυθμιστική σταθερά. Επίσης, είναι το μήκος του εγγράφου και είναι το μέσο μήκος των εγγράφων της συλλογής. Παρατηρήστε ότι η συνάρτηση ομοιότητας περιέχει αρκετές ρυθμιστικές σταθερές. Για τον τρόπο παραγωγής της μεθόδου BM25 καθώς και για τις τιμές των σταθερών που έχουν μελετηθεί παραπέμπουμε τον αναγνώστη στις εργασίες [51, 49] όπου υπάρχουν όλες οι σχετικές πληροφορίες, καθώς και πειραματικά αποτελέσματα αποτελεσματικότητας συγκριτικά με παλαιότερες προσεγγίσεις.
5.4 Ανάκτηση με Χρήση Δικτύων Bayes
Η χρήση των δικτύων Bayes (Bayesian networks) στην ανάκτηση πληροφορίας προτάθηκε για πρώτη φορά από τους Turtle και Croft το 1990 [74]. Σύμφωνα με το μοντέλο αυτό, οι όροι, τα έγγραφα της συλλογής και τα ερωτήματα χαρακτηρίζονται ως γεγονότα και αναπαριστώνται ως κόμβοι ενός δικτύου Bayes. Το μοντέλο αυτό καλείται μοντέλο δικτύου συμπερασμάτων (inference network model), και σύμφωνα με τα πειραματικά αποτελέσματα έχει καλύτερη επίδοση από άλλα πιθανοκρατικά μοντέλα ανάκτησης. Αργότερα, οι Ribeiro-Neto και Muntz [48] γενίκευσαν την προσέγγιση των Turtle και Croft με αποτέλεσμα να προκύψει ένα νέο μοντέλο, το οποίο καλείται μοντέλο δικτύου πίστης (belief network model). Τα δύο αυτά μοντέλα βασίζονται στη θεωρία των δικτύων Bayes η οποία περιγράφεται συνοπτικά στη συνέχεια.
Ένα δίκτυο Bayes είναι ένας κατευθυνόμενος άκυκλος γράφος (directed acyclic graph - DAG) όπου οι κόμβοι είναι τυχαίες μεταβλητές ενώ οι ακμές δηλώνουν εξάρτηση μεταξύ των τυχαίων μεταβλητών. Κάθε ακμή του γράφου έχει ένα βάρος που πρισδιορίζει το βαθμό εξάρτησης της μίας τυχαίας μεταβλητής από την άλλη. Εφόσον ο γράφος είναι κατευθυνόμενος και χωρίς κύκλους, δημιουργείται μία ιεραρχία από κόμβους. Υπάρχουν κόμβοι που δεν έχουν κανένα πρόγονο (άρα οι αντίστοιχες τυχαίες μεταβλητές δεν εξαρτώνται από άλλες) και κόμβοι που έχουν έναν ή περισσότερους προγόνους.
Ορισμός 5.3.
Έστω και δύο κόμβοι ενός δικτύου Bayes. Αν υπάρχει ακμή από τον στον τότε ο καλείται άμεσος πρόγονος του , ενώ ο καλείται άμεσος απόγονος του .
Έστω το σύνολο των άμεσων προγόνων του κόμβου . Η επίδραση των κόμβων στον κόμβο μπορεί να προσδιοριστεί χρησιμοποιώντας μία συνάρτηση η οποία έχει τις ακόλουθες ιδιότητες:
| (5.24) |
| (5.25) |
Αν έχουμε τυχαίες μεταβλητές, τότε η κοινή συνάρτηση πυκνότητας πιθανότητας δίνεται από τον ακόλουθο τύπο:
| (5.26) |
Παράδειγμα 5.3
Στο Σχήμα 5.2 παρουσιάζεται ένα δίκτυο Bayes που αποτελείται από έξι τυχαίες μεταβλητές. Παρατηρούμε ότι ο γράφος είναι κατευθυνόμενος και άκυκλος και αποτελείται από έξι κόμβους και έξι ακμές. Η συνάρτηση της κοινής πυκνότητας πιθανότητας είναι:
| (5.27) |
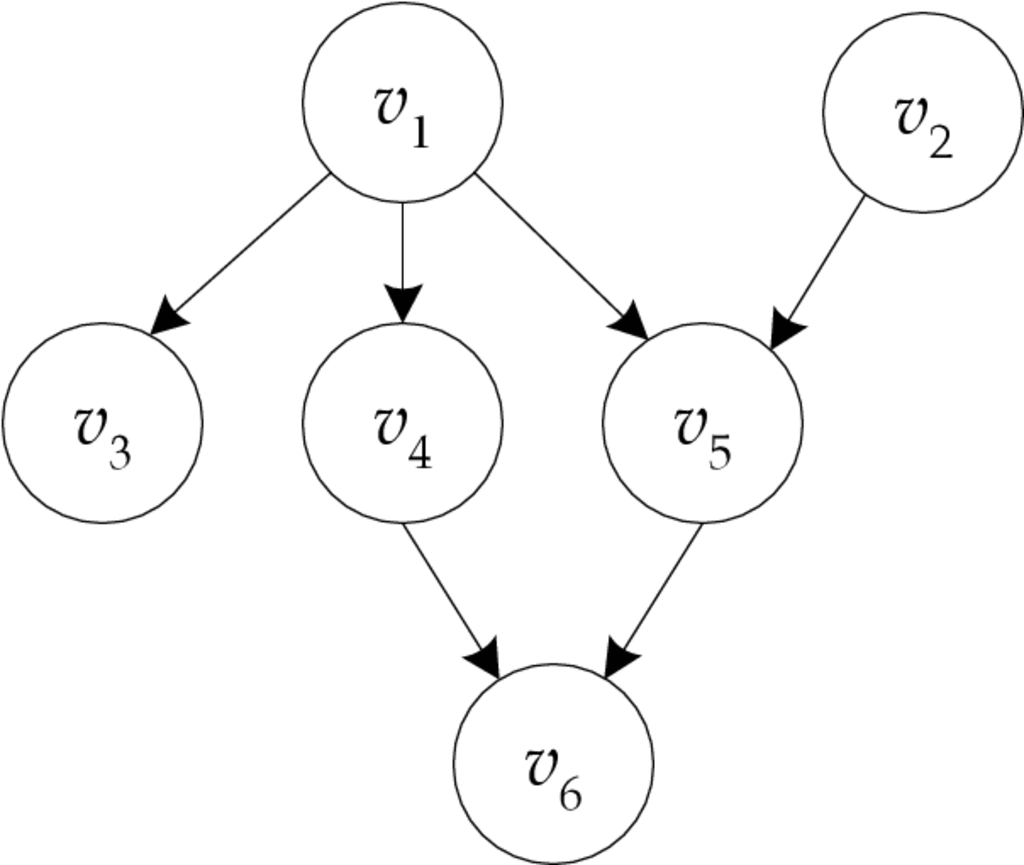
Στις επόμενες παραγράφους περιγράφονται συνοπτικά οι δύο προσεγγίσεις για την εφαρμογή των δικτύων Bayes στην ανάκτηση πληροφορίας, το μοντέλο δικτύου συμπερασμάτων και το μοντέλο δικτύου πίστης.
5.4.1 Μοντέλο Δικτύου Συμπερασμάτων
Το μοντέλο δικτύου συμπερασμάτων είναι ένα δίκτυο Bayes, οι κόμβοι του οποίου σχηματίζονται από τα έγγραφα της συλλογής, του όρους και τα ερωτήματα, και διαχωρίζεται σε δύο υποδίκτυα, το υποδίκτυο εγγράφων και το υποδίκτυο ερωτημάτων. Το υποδίκτυο των εγγράφων αναπαριστά τη συλλογή των εγγράφων χρησιμοποιώντας ποικίλες αναπαραστάσεις και κατασκευάζεται μία φορά για την κάθε συλλογή. Η δομή του υποδικτύου δε μεταβάλεται κατά την επεξεργασία ενός ερωτήματος. Αντιθέτως, το υποδίκτυο ερωτήματος κατασκευάζεται για κάθε διαφορετικό ερώτημα και αποτελείται από έναν κόμβο που δηλώνει την πληροφοριακή ανάγκη του χρήστη και ένα σύνολο κόμβων που αναπαριστούν το ερώτημα. Τα δύο υποδίκτυα συνδέονται με ακμές μεταξύ των εννοιών αναπαράστασης των εγγράφων και των εννοιών του ερωτήματος.
Στο Σχήμα 5.3 δίνεται ένα παράδειγμα ενός απλοποιημένου δικτύου συμπερασμάτων. Σύμφωνα με τον Turtle [73] το δίκτυο συμπερασμάτων περιέχει περισσότερες κατηγορίες κόμβων, ωστόσο χρησιμοποιείται συνηθέστερα στην απλοποιημένη του μορφή. Οι κόμβοι έως αναφέρονται στα έγγραφα της συλλογής, ενώ οι κόμβοι έως στους όρους που χρησιμοποιούνται για την αναπαράσταση των εγγράφων. Ο κόμβος προσδιορίζει την πληροφοριακή ανάγκη του χρήστη, η αναπαράσταση της οποίας πραγματοποιείται με τη χρήση του ερωτήματος . Συνήθως, ο κόμβος του ερωτήματος είναι ένας, αλλά αν υπάρχουν πολλές αναπαραστάσεις τότε μπορούν να χρησιμοποιηθούν και αυτές.

Ο κάθε κόμβος του δικτύου αναπαριστά μία τυχαία μεταβλητή. Η τυχαία μεταβλητή που σχετίζεται με ένα έγγραφο αναπαριστά το γεγονός ότι παρατηρούμε το συγκεκριμένο έγγραφο (το μοντέλο θεωρεί ότι τα έγγραφα παρατηρούνται κατά την αναζήτηση των σχετικών εγγράφων). Η παρατήρηση ενός εγγράφου θέτει ένα βαθμό εμπιστοσύνης στις τυχαίες μεταβλητές που σχετίζονται με τους όρους που περιέχονται στο έγγραφο. Επομένως, η παρατήρηση του εγγράφου είναι το αίτιο για αύξηση της εμπιστοσύνης στις τυχαίες μεταβλητές που σχετίζονται με τους όρους. Όπως παρατηρούμε στο Σχήμα 5.3, οι ακμές κατευθύνονται από τους κόμβους των εγγράφων προς τους κόμβους των όρων. Μία τυχαία μεταβλητή που σχετίζεται με ένα ερώτημα αναπαριστά το γεγονός ότι η πληροφοριακή ανάγκη του χρήστη έχει ικανοποιηθεί. Η εμπιστοσύνη του κόμβου του ερωτήματος είναι συνάρτηση της εμπιστοσύνης των όρων που περιέχονται στο ερώτημα. Οι ακμές κατευθύνονται από κόμβους όρων προς τον κόμβο του ερωτήματος.
Μία βασική υπόθεση που γίνεται είναι ότι όλες οι τυχαίες μεταβλητές του μοντέλου είναι δυαδικές, λαμβάνουν δηλαδή είτε την τιμή 0 (false) είτε την τιμή 1 (true). Αν και η υπόθεση αυτή είναι αυθαίρετη, βοηθάει σημαντικά στην απλοποίηση του μοντέλου ενώ ταυτόχρονα φαίνεται να μην βλάπτει τη διαδικασία της ανάκτησης.
Στη συνέχεια, εξετάζουμε συνοπτικά τον τρόπο χρήσης ενός δικτύου συμπερασμάτων. Βασικός στόχος είναι η βαθμολόγηση των εγγράφων της συλλογής ως προς το βαθμό ικανοποίησης της πληροφοριακής ανάγκης του χρήστη. Για την επίτευξη του στόχου αυτού θα πρέπει να δώσουμε τιμές στις πιθανότητες που σχετίζονται με τα έγγραφα και στις υπό συνθήκη πιθανότητες του δικτύου. Εάν κάποια στιγμή η τιμή μίας τυχαίας μεταβλητής γίνει γνωστή, τότε μπορούμε να υπολογίσουμε εκ νέου το βαθμό των εγγράφων λαμβάνοντας υπόψη τα νέα δεδομένα. Έστω ότι έχουμε ένα ερώτημα που αναπαριστά την πληροφοριακή ανάγκη ενός χρήστη. Αρχικά, προσδιορίζεται ο βαθμός εμπιστοσύνης του κάθε κόμβου του υποδικτύου ερωτήματος. Η αρχική τιμή του κόμβου είναι η πιθανότητα ικανοποίησης της πληροφοριακής ανάγκης δεδομένου ότι κανένα από τα έγγραφα δεν έχει παρατηρηθεί και όλα τα έγγραφα είναι ισοπίθανα. Εάν τώρα παρατηρήσουμε ένα έγγραφο και θέσουμε την τιμή του αντίστοιχου κόμβου σε 1 (true), ενώ οι τιμές των άλλων εγγράφων είναι 0 (false), μπορούμε να υπολογίσουμε μία νέα τιμή για κάθε κόμβο γνωρίζοντας ότι = true. Πιο συγκεκριμένα, μπορούμε να υπολογίσουμε την πιθανότητα να ικανοποιείται η πληροφοριακή ανάγκη δεδομένου ότι το έγγραφο έχει παρατηρηθεί. Στη συνέχεια, διαλέγουμε κάποιο άλλο έγγραφο και επαναλαμβάνεται η ίδια διαδικασία, έως ότου βαθμολογηθούν όλα τα έγγραφα. Για να αποφύγουμε τον έλεγχο όλων των εγγράφων, θα μπορούσαμε να χρησιμοποιήσουμε ένα υποσύνολο των εγγράφων που μεγιστοποιούν την πιθανότητα ικανοποίησης της πληροφοριακής ανάγκης. Επειδή το πρόβλημα έχει μεγάλη πολυπλοκότητα, στη βιβλιογραφία έχουν προταθεί ευριστικές μέθοδοι για το σκοπό αυτό. Εδώ θεωρούμε ότι δε χρησιμοποιείται κάποια τέτοια τεχνική.
Ορισμός 5.4.
Έστω ένα διάνυσμα με συνιστώσες, όπου = . Η κάθε συνιστώσα 55Χρησιμοποιούμε το ίδιο σύμβολο για να δηλώσουμε τον όρο και την τυχαία μεταβλητή που σχετίζεται με αυτόν. Το ίδιο θεωρούμε για τα έγγραφα και τα ερωτήματα. Από τα συμφραζόμενα θα γίνεται κατανοητό αν αναφερόμαστε στο αντικείμενο η στην τυχαία μεταβλητή που σχετίζεται με αυτό. αναπαριστά μία δυαδική τυχαία μεταβλητή (). Οι τυχαίες μεταβλητές ορίζουν τις διαφορετικές καταστάσεις του διανύσματος . H -οστή θέση του διανύσματος συμβολίζεται με .
Ορισμός 5.5.
Στο μοντέλου δικτύου συμπερασμάτων η συνάρτηση ομοιότητας ενός εγγράφου και ενός ερωτήματος συμβολίζεται με και προσδιορίζεται με την πιθανότητα του γεγονότος , δηλαδή την πιθανότητα η τυχαία μεταβλητή να είναι 1 και η τυχαία μεταβλητή να είναι επίσης 1. Η πιθανότητα αυτή συμβολίζεται με .
Η πιθανότητα υπολογίζεται ως εξής:
| (5.28) | |||||
Έστω ότι ενεργοποιούμε τον κόμβο που αναφέρεται σε ένα έγγραφο της συλλογής. Αυτό ισοδυναμεί με την παρατήρηση (εξέταση) του συγκεκριμένου εγγράφου. Η παρατήρηση του έχει ως αποτέλεσμα την ανεξαρτησία των όρων που σχετίζονται με το . Επομένως, ο βαθμός εμπιστοσύνης που προσφέρει η παρατήρηση του εγγράφου σε κάθε όρο μπορεί να υπολογιστεί για κάθε όρο ξεχωριστά (λόγω της ανεξαρτησίας). Άρα, η ποσότητα μπορεί να υπολογιστεί ως εξής:
| (5.29) |
Από τις δύο προηγούμενες σχέσεις έχουμε:
| (5.30) |
Είναι προφανές ότι για τον υπολογισμό της πιθανότητας θα πρέπει να δώσουμε κατάλληλες τιμές στις πιθανότητες , και . Χρησιμοποιώντας διαφορετικούς τρόπους υπολογισμού των παραπάνω ποσοτήτων παίρνουμε και διαφορετικές εκφράσεις για τον προσδιορισμό του βαθμού ομοιότητας του εγγράφου ως προς το ερώτημα . Επειδή οι κόμβοι των εγγράφων στο δίκτυο συμπερασμάτων δεν έχουν εισερχόμενες ακμές, μπορούμε να ορίσουμε αυθαίρετα την πιθανότητα για κάθε έγγραφο . Επειδή δεν έχουμε προηγούμενη πληροφορία σχετικά με την πιθανότητα παρατήρησης του κάθε εγγράφου, συνήθως χρησιμοποιείται η ομοιόμορφη κατανομή , όπου είναι το πλήθος των εγγράφων της συλλογής. Ωστόσο, είναι σημαντικό να θέσουμε τις πιθανότητες με τέτοιο τρόπο έτσι ώστε να εκμεταλλευτούμε την οποιαδήποτε εκ των προτέρων γνώση υπάρχει σχετικά με την συγκεκριμένη εφαρμογή.
Στη συνέχεια, περιγράφουμε τον τρόπο προσδιορισμού των πιθανοτήτων με σκοπό το δίκτυο συμπερασμάτων να χρησιμοποιηθεί για τη βαθμολόγηση των εγγράφων ως προς το Λογικό μοντέλο ανάκτησης. Θεωρούμε ότι η πιθανότητα υπολογίζεται με βάση την ομοιόμορφη κατανομή:
| (5.31) |
Για τον υπολογισμό της υπό συνθήκης πιθανότητας έχουμε:
| (5.32) |
| (5.33) |
Ο τρόπος ορισμού της πιθανότητας δηλώνει ότι η παρατήρηση ενός εγγράφου έχει ως αποτέλεσμα την ενεργοποίηση των κόμβων του δικτύου που σχετίζονται με τους όρους που περιέχονται στο . Στη συνέχεια, δίνεται ο τρόπος υπολογισμού της πιθανότητας που δηλώνει το κατά πόσον οι όροι που περιέχονται στο υπό παρατήρηση έγγραφο ικανοποιούν την πληροφοριακή ανάγκη του χρήστη:
| (5.34) |
| (5.35) |
Αντικαθιστώντας τις τιμές για τις ποσότητες , και στην εξίσωση 5.30 παίρνουμε μία συνάρτηση υπολογισμού ομοιότητας των εγγράφων ως προς το ερώτημα που είναι ή ίδια με αυτήν του Λογικού μοντέλου. Υπενθυμίζεται ότι είναι η διαζευκτική κανονική μορφή (disjunctive normal form) του ερωτήματος ενώ είναι μία συζευκτική συνιστώσα (conjunctive component) της διαζευκτικής κανονικής μορφής. Οι έννοιες αυτές έχουν περιγραφεί στο Κεφάλαιο 3. Το μοντέλο δικτύου συμπερασμάτων αν και μπορεί να παραμετροποιηθεί έτσι ώστε να χρησιμοποιεί συναρτήσεις βαθμολόγησης τύπου TF-IDF, δεν μπορεί να προσαρμοστεί ώστε να πραγματοποιεί βαθμολόγηση εγγράφων ακριβώς όπως το Διανυσματικό μοντέλο.
5.4.2 Μοντέλο Δικτύου Πίστης
Το μοντέλο δικτύου πίστης αποτελεί γενίκευση του μοντέλου δικτύου συμπερασμάτων και επομένως μπορεί να καλύψει περισσότερες περιπτώσεις. Το μοντέλο αυτό στηρίζεται στις ίδιες βασικές αρχές των δικτύων Bayes, όμως είναι αρκετά πιο ευέλικτο σε σχέση με το μοντέλο δικτύου συμπερασμάτων.
Το κάθε έγγραφο αναπαρίσταται από ένα σύνολο όρων. Ο κάθε όρος θεωρείται ως βασική, ενώ το σύνολο = όλων των όρων που χρησιμοποιούνται για την αναπαράσταση των εγγράφων αποτελεί το δειγματοχώρο (sample space) και χαρακτηρίζεται ως χώρος εννοιών (concept space). Ένα υποσύνολο του συνόλου είναι μία έννοια (concept) που μπορεί να αναπαριστά ένα έγγραφο της συλλογής ή κάποιο ερώτημα. Σε κάθε όρο αντιστοιχεί μία δυαδική τυχαία μεταβλητή . Εάν = 1 τότε θεωρούμε ότι ο αντίστοιχος όρος ανήκει στην έννοια . Συμβολίζουμε με την τιμή της τυχαίας μεταβλητής σε σχέση με την παρουσία ή απουσία του όρου στην έννοια . Αν είναι το πλήθος των όρων ( = ) τότε υπάρχουν έννοιες (υποσύνολα του ).
Τα έγγραφα της συλλογής και τα ερωτήματα μπορούν να θεωρηθούν ως έννοιες (υποσύνολα όρων) που ορίζονται στο χώρο εννοιών. Ένα έγγραφο αναπαρίσταται ως μία έννοια (χρησιμοποιούμε το ίδιο σύμβολο ) που ορίζεται ως = , όπου το αναφέρεται στην τυχαία μεταβλητή που σχετίζεται με τον όρο o οποίος σχετίζεται με το έγγραφο . Ομοίως, ένα ερώτημα αναπαρίσταται ως μία έννοια (συμβολίζεται με ), που στην ουσία πρόκειται για ένα υποσύνολο των όρων. Εάν ένας όρος χρησιμοποιείται για την περιγραφή του εγγράφου τότε προφανώς = 1 ενώ αν περιγράφει ένα ερώτημα τότε = 1. Εφόσον στόχος της διαδικασίας ανάκτησης είναι ο προσδιορισμός των πιο σχετικών εγγράφων ως προς την πληροφοριακή ανάγκη του χρήστη, για να επιτευχθεί ο στόχος αυτός θα πρέπει να βρεθεί μία μέθοδος συνδυασμού των εννοιών που αναφέρονται στα έγγραφα της συλλογής και και των εννοιών που αναφέρονται στα ερωτήματα.
Ορίζουμε μία συνάρτηση πυκνότητας πιθανότητας στο χώρο ως εξής. Έστω μία έννοια του χώρου που αναπαριστά ένα έγγραφο ή ένα ερώτημα. Τότε έχουμε:
| (5.36) |
| (5.37) |
Οι πιθανότητα εκφράζει το βαθμό κάλυψης του χώρου από την έννοια . Η κάλυψη αυτή υπολογίζεται με τη βοήθεια των υπό συνθήκη πιθανοτήτων για κάθε έννοια . Εφόσον αρχικά το σύστημα δεν μπορεί να γνωρίζει την πιθανότητα εμφάνισης μίας έννοιας, υποθέτουμε ότι κάθε έννοια έχει την ίδια πιθανότητα εμφάνισης. Αφού το συνολικό πλήθος των εννοιών είναι , η πιθανότητα εμφάνισης της κάθε έννοιας είναι .
Με βάση τη συζήτηση που προηγήθηκε, στο μοντέλο δικτύου πίστης τα έγγραφα της συλλογής και τα ερωτήματα μοντελοποιούνται ως υποσύνολα των όρων. Επομένως, για κάθε έγγραφο ή ερώτημα προκύπτει μία μόνο αναπαράσταση. Στο Σχήμα 5.4 παρουσιάζεται η τοπολογία ενός δικτύου πίστης. Παρατηρήστε τη διαφορά σε σχέση με το δίκτυο συμπερασμάτων του Σχήματος 5.3. Τα βέλη που συνδέουν τους κόμβους των όρων με τους κόμβους των εγγράφων έχουν αντίστροφη κατεύθυνση. Η διαφορά αυτή, αν και μικρή φαινομενικά, επιφέρει σημαντικές αλλαγές στον τρόπο προσδιορισμού των σχετικών εγγράφων όπως θα δούμε στη συνέχεια.

Ορισμός 5.6.
Στο μοντέλο δικτύου πίστης η συνάρτηση ομοιότητας ενός εγγράφου σε σχέση με ένα ερώτημα συμβολίζεται με και ορίζεται ως η πιθανότητα .
Με εφαρμογή του κανόνα του Bayes, έχουμε ότι = . Η τιμή είναι ανεξάρτητη από τα έγγραφα της συλλογής, οπότε ο βαθμός ομοιότητας του εγγράφου ως προς το ερώτημα είναι ανάλογος της ποσότητας , και γράφουμε . Με εφαρμογή του τύπου 5.36 για την πιθανότητα παίρνουμε:
| (5.38) |
Χρησιμοποιώντας την ιδιότητα της ανεξαρτησίας των κόμβων των εγγράφων και των κόμβων των ερωτημάτων, έχουμε:
| (5.39) |
Εάν στον τύπο 5.39 θέσουμε τις τιμές των πιθανοτήτων και τότε μπορούμε να προσδιορίσουμε το βαθμό ομοιότητας του εγγράφου ως προς το ερώτημα . Προσδιορίζοντας με διαφορετικό τρόπο τις πιθανότητες αυτές υποστηρίζεται μία πληθώρα διαφορετικών μεθόδων βαθμολόγησης των εγγράφων. Ως παράδειγμα, θα μελετηθεί ο τρόπος υπολογισμού των πιθανοτήτων ώστε το μοντέλο δικτύου πίστης να προσομοιώσει το Διανυσματικό μοντέλο.
5.5 Σύνοψη και Περαιτέρω Μελέτη
Στο κεφάλαιο αυτό μελετήσαμε μεθόδους χρήσης της Θεωρίας Πιθανοτήτων για τον προσδιορισμό της ομοιότητας μεταξύ ενός ερωτήματος και των εγγράφων της συλλογής. Αρχικά μελετήθηκε το απλό Πιθανοκρατικό μοντέλο ανάκτησης ενώ στη συνέχεια αναλύθηκαν τα βασικά συστατικά δύο μοντέλων που στηρίζονται στα δίκτυα Bayes, το μοντέλο δικτύου συμπερασμάτων και το μοντέλο δικτύου πίστης.
Τα μοντέλα ανάκτησης που βασίζονται σε πιθανοκρατική θεώρηση εγγράφων, όρων και ερωτημάτων έχουν μελετηθεί διεξοδικά στη βιβλιογραφία. Παραπέμπουμε τον αναγνώστη που θέλει να εμβαθύνει περισσότερο στο χώρο στο βιβλίο του Rijbergen [75] που αποτελεί ένα πολύ βασικό σύγγραμα, στο βιβλίο των Baeza-Yates και Ribeiro-Neto [3] και στο πιο σύγχρονο βιβλίο των Manning, Raghavan και Schutze [41]. Περισσότερες λεπτομέρειες σχετικά με το απλό Πιθανοκρατικό μοντέλο υπάρχουν στις ερευνητικές εργασίες [27, 42, 43, 50, 56] ενώ στις εργασίες [51, 49] αναλύεται ο τρόπος προσδιορισμού της ομοιότητας που χρησιμοποιείται στο σύστημα Okapi. Επίσης, εξαιρετικό ενδιαφέρον παρουσιάζουν η εργασία των Turtle και Croft [74] που αναλύει το μοντέλο δικτύου συμπερασμάτων και η εργασία των Ribeiro-Neto και Muntz [48] που εστιάζει στο μοντέλο δικύου πίστης.
5.6 Ασκήσεις
-
5.1
Να δώσετε τον κανόνα του Bayes και να σχολιάσετε το τι ακριβώς αναφέρει.
-
5.2
Από ποιόν μαθηματικό τύπο δίνεται ο βαθμός ομοιότητας μεταξύ ενός ερωτήματος και ενός εγγράφου ;
-
5.3
Να διατυπώσετε την Αρχή Πιθανοκρατικής Βαθμολόγησης και την Αρχή της Ανάκτησης Δυαδικής Ανεξαρτησίας.
-
5.4
Ποιά κατά τη γνώμη σας πιστεύετε ότι είναι τα βασικά μειονεκτήματα του απλόυ Πιθανοκρατικού μοντέλου;
-
5.5
Να περιγράψετε τα βασικά χαρακτηριστικά ενός δικτύου συμπερασμάτων και ενός δικτύου πίστης. Ποιές είναι οι βασικές τους διαφορές;