 |
Γιάννης Κοντογιάννης
Σταύρος Τουμπής
ΣΤΟΙΧΕΙΑ ΠΙΘΑΝΟΤΗΤΩΝ
ΜΕ ΕΦΑΡΜΟΓΕΣ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ
ΚΑΙ ΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ
Συγγραφείς: Γιάννης Κοντογιάννης, Σταύρος Τουμπής
Γλωσσική επιμέλεια: Θεόφιλος Τραμπούλης
Τεχνική επιμέλεια: Σάββας Γκιτζένης
Κριτικός αναγνώστης: Πέτρος Δελλαπόρτας
Έκδοση: Νοέμβριος 2015
ISBN: 978-960-603-182-3
Το παρόν έργο αδειοδοτείται υπό τους όρους της άδειας Creative Commons Αναφορά Δημιουργού – Μη Εμπορική Χρήση – Παρόμοια Διανομή 3.0
Copyright © ΣΥΝΔΕΣΜΟΣ ΕΛΛΗΝΙΚΩΝ ΑΚΑΔΗΜΑΪΚΩΝ ΒΙΒΛΙΟΘΗΚΩΝ – ΣΕΑΒ, 2015
Εθνικό Μετσόβιο Πολυτεχνείο
Ηρώων Πολυτεχνείου 9, 15780 Ζωγράφου
Περιεχόμενα
- 1 Εισαγωγή
- 2 Χώρος πιθανότητας και ενδεχόμενα
- 3 Μέτρο πιθανότητας
- 4 Πιθανότητες και συνδυαστική
- 5 Ανεξαρτησία και δεσμευμένη πιθανότητα
- 6 Διακριτές τυχαίες μεταβλητές
- 7 Διακριτές κατανομές
- 8 Παραδείγματα πιθανοκρατικής ανάλυσης αλγορίθμων
- 9 Ανισότητες, από κοινού κατανομή, Ν.Μ.Α.
- 10 Συνεχείς τυχαίες μεταβλητές
- 11 Συνεχείς κατανομές, ανισότητες και ο Ν.Μ.Α.
- 12 Το Κεντρικό Οριακό Θεώρημα
- 13 Κ.Ο.Θ.: Λίγη θεωρία και αποδείξεις
- 14 Παραδείγματα εφαρμογών στη στατιστική
- 15 Συνεχής από κοινού κατανομή
- A
Παράρτημα
- A.1 Διπλά ολοκληρώματα: Συνοπτική επισκόπηση
- A.2 Ασκήσεις Κεφαλαίου 2
- A.3 Ασκήσεις Κεφαλαίου 3
- A.4 Ασκήσεις Κεφαλαίου 4
- A.5 Ασκήσεις Κεφαλαίου 5
- A.6 Ασκήσεις Κεφαλαίου 6
- A.7 Ασκήσεις Κεφαλαίου 7
- A.8 Ασκήσεις Κεφαλαίου 8
- A.9 Ασκήσεις Κεφαλαίου 9
- A.10 Ασκήσεις Κεφαλαίου 10
- A.11 Ασκήσεις Κεφαλαίου 11
- A.12 Ασκήσεις Κεφαλαίου 12
- A.13 Ασκήσεις Κεφαλαίου 13
- A.14 Ασκήσεις Κεφαλαίου 14
- A.15 Ασκήσεις Κεφαλαίου 15
Πρόλογος
Η θεωρία πιθανοτήτων και οι εφαρμογές της αποτελούν, εδώ και σχεδόν έναν αιώνα, ακέραιο μέρος των μαθηματικών. Επιπλέον, τις τελευταίες δεκαετίες οι πιθανότητες έχουν αποκτήσει κεντρικό ρόλο σε μια πλειάδα σύγχρονων επιστημονικών και τεχνολογικών περιοχών, από τη γενετική και τα χρηματοοικονομικά μέχρι τη θεμελίωση της στατιστικής, και από τη μαθηματική περιγραφή της έννοιας της πληροφορίας ως τις ψηφιακές επικοινωνίες, την πληροφορική, ακόμη και τη μελέτη του ανθρώπινου εγκεφάλου μέσω της νευροεπιστήμης.
Βασικός σκοπός του βιβλίου αυτού είναι να προσφέρει μια εισαγωγή στα στοιχειώδη εργαλεία της κλασικής θεωρίας πιθανοτήτων, από μια σύγχρονη σκοπιά που να επισημαίνει και να συνδέει τη μαθηματική αυτή θεωρία με ενδιαφέρουσες εφαρμογές της σε διάφορα πεδία. Οι κεντρικές έννοιες των πιθανοτήτων και της τυχαιότητας αναπτύσσονται παράλληλα με τη μαθηματική θεωρία που τις περιβάλλει, με έμφαση σε τρεις βασικούς άξονες:
-
1.
Μαθηματική περιγραφή: Έχουμε καταβάλει σημαντική προσπάθεια ώστε η θεωρία να παρουσιαστεί μεν με μαθηματικά αυστηρό τρόπο, χωρίς όμως να είναι απαραίτητη η γνώση προχωρημένων και πιο εξειδικευμένων μαθηματικών εργαλείων και τεχνικών.
-
2.
Σύγχρονα παραδείγματα: Μαζί με τη θεωρητική ανάπτυξη του αντικειμένου, εξίσου σημαντικός στόχος μας είναι η παρουσίαση, έστω και επιγραμματικά, των πρακτικών εφαρμογών της θεωρίας των πιθανοτήτων. Γι’ αυτόν το λόγο, έχουμε συμπεριλάβει ένα πλήθος παραδειγμάτων και ασκήσεων, με σκοπό την ανάδειξη της στενής σχέσης των πιθανοτήτων με σύγχρονες εφαρμογές τους.
-
3.
Πληροφορική και στατιστική: Αν και έχουμε προσπαθήσει να αναδείξουμε με παραδείγματα τη σχέση των πιθανοτήτων με όλο το φάσμα των εφαρμογών – από κλασικά καθημερινά προβλήματα, όπως η ρίψη ενός νομίσματος ή μια εκλογική δημοσκόπηση, μέχρι την ανάλυση κάποιων εξειδικευμένων σύγχρονων αλγορίθμων στην επιστήμη υπολογιστών – έχει δοθεί μεγαλύτερη έμφαση στην πληροφορική και τη στατιστική. Ελπίζουμε αυτό το βιβλίο να μπορέσει να κεντρίσει το ενδιαφέρον κάποιων από τους αναγνώστες του προς αυτές τις κατευθύνσεις και να αποτελέσει έναν προθάλαμο που θα τους οδηγήσει στη βαθύτερη μελέτη των αντίστοιχων περιοχών.
Ειδικά για το σημείο πρέπει να επισημάνουμε πως έχουμε συνειδητά αποφύγει να αναπτύξουμε εκτενώς τη θεωρία μέτρου, η οποία αποτελεί το φυσικό και θεμελιώδες μαθηματικό πλαίσιο της θεωρίας των πιθανοτήτων. Παρ’ όλα αυτά, στο Κεφάλαιο 3 δίνουμε τον αυστηρό μαθηματικό ορισμό του μέτρου πιθανότητας, και στα Κεφάλαια 5 έως 9 παρουσιάζουμε τη θεωρία των διακριτών τυχαίων μεταβλητών και των ιδιοτήτων τους χωρίς την παραμικρή μαθηματική παράλειψη ή αναφορά στη βαθύτερη θεωρία μέτρου.
Αν και αυτό το βιβλίο προέκυψε από τη διδασκαλία δύο προπτυχιακών μαθημάτων στο τμήμα Πληροφορικής του Οικονομικού Πανεπιστημίου Αθηνών («Πιθανότητες» και «Εφαρμοσμένες πιθανότητες και προσομοίωση», κατά τη δεκαετία 2005-2015), ευελπιστούμε πως θα μπορέσει να χρησιμοποιηθεί στη διδασκαλία εισαγωγικών μαθημάτων πιθανοτήτων σε οποιοδήποτε τμήμα θετικών επιστημών ή πολυτεχνικών σχολών. Κατά συνέπεια, το κύριο ακροατήριο στο οποίο απευθυνόμαστε είναι προπτυχιακοί φοιτητές τέτοιων τμημάτων, και γι’ αυτόν τον λόγο έχουμε φροντίσει οι μαθηματικές γνώσεις που απαιτούνται να μην ξεπερνούν κατά πολύ την ύλη μαθηματικών του Λυκείου (αν την ξεπερνούν).
Η έμφασή μας στη σχέση των πιθανοτήτων με την πληροφορική και τη στατιστική εξηγείται από τα προσωπικά επιστημονικά ενδιαφέροντα των συγγραφέων, από το γεγονός ότι τα μαθήματα που σε πρώτη φάση μάς οδήγησαν στη συγγραφή του βιβλίου διδάσκονταν σε τμήμα πληροφορικής, αλλά και από την εκτίμησή μας πως οι περιοχές της επιστήμης υπολογιστών και της στατιστικής προσφέρουν σημαντικότατο πεδίο επιστημονικής μελέτης για τα σύγχρονα εφαρμοσμένα μαθηματικά εν γένει.
Η ύλη η οποία περιέχεται σε αυτό το βιβλίο καλύπτει πλήρως το περιεχόμενο του εισαγωγικού μαθήματος «Πιθανότητες» και περίπου το ενα έκτο του πιο προχωρημένου μαθήματος «Εφαρμοσμένες πιθανότητες και προσομοίωση», τα οποία προαναφέραμε. Επιπλέον, κατά τη συγγραφή του βιβλίου ενσωματώσαμε και τα ακόλουθα στοιχεία:
-
1.
Κάποια πιο προχωρημένα μέρη της ύλης του μαθήματος των «Πιθανοτήτων», τα οποία δεν παρουσιάζονταν στις διαλέξεις κάθε χρόνο ή διδάσκονταν προαιρετικά.
-
2.
Αποδείξεις κάποιων θεωρημάτων που δεν παρουσιάζονταν στα μαθήματα και παρατίθενται εδώ για λόγους πληρότητας (σημειωμένες με ).
-
3.
Κάποιες παραγράφους (επίσης σημειωμένες με ) που περιλαμβάνουν προχωρημένο υλικό. Όσοι αναγνώστες θέλουν να εμβαθύνουν στις αντίστοιχες περιοχές θα βρουν αυτές τις παραγράφους τις πιο ενδιαφέρουσες.
-
4.
Πολλές ασκήσεις μαζί με τις αναλυτικές τους λύσεις στο τέλος του κειμένου, οι πιο δύσκολες εκ των οποίων είναι και αυτές σημειωμένες με
Υπογραμμίζουμε πως οι ασκήσεις και οι λύσεις τους αποτελούν σημαντικό και ακέραιο μέρος του βιβλίου. Στις ασκήσεις έχουμε συμπεριλάβει και κάποια σημαντικά αποτελέσματα, τα οποία άλλοτε δεν εντάσσονταν φυσικά στη ροή της ύλης του αντίστοιχου κεφαλαίου και άλλοτε κρίναμε πως αφορούσαν ερωτήματα τα οποία θα ήταν πιο χρήσιμο για τον αναγνώστη να έχει την ευκαιρία να τα εξετάσει μόνος του πριν του δοθούν οι απαντήσεις. Επιπλέον, η ίδια η φύση του αντικειμένου απαιτεί συστηματική εξοικείωση – με χαρτί και μολύβι – με τις έννοιες και τις τεχνικές που σταδιακά εισάγονται, και ίσως ο πιο αποτελεσματικός τρόπος να το επιτύχει κανείς αυτό είναι να αναπτύξει τις απαραίτητες δεξιότητες λύνοντας μια σειρά σχετικών ασκήσεων.
Είναι βέβαια μάλλον αυτονόητο, αλλά τονίζουμε πως δεν συνιστάται στους φοιτητές να χρησιμοποιήσουν το παρόν βιβλίο ως υποκατάστατο της παρακολούθησης των διαλέξεων.
Κλείνοντας, έχουμε τη χαρά να ευχαριστήσουμε τις δέκα περίπου «γενιές» φοιτητών που παρακολούθησαν τα μαθήματά μας για τη βοήθειά τους στη διαμόρφωση και την τροποποίηση της ύλης και για τις πολλές και χρήσιμες υποδείξεις τους.
Τέλος, ο πρώτος συγγραφέας αφιερώνει αυτό το βιβλίο στον ομορφότερο άνθρωπο που είχε την τύχη να γνωρίσει ποτέ στη ζωή του, τον γιο του Γιώργο. Ο δεύτερος συγγραφέας το αφιερώνει στην τριφυλλάρα
Γιάννης Κοντογιάννης, Σταύρος Τουμπής
Αθήνα, Σεπτέμβριος 2015
Κεφάλαιο 1 Εισαγωγή
[Επιστροφή στα περιεχόμενα]
1.1 Οι πιθανότητες ως μέρος των μαθηματικών
Ιστορικά, έχουν υπάρξει δύο βασικές κινητήριες δυνάμεις για την ανάπτυξη νέων μαθηματικών: Η ανθρώπινη πνευματική περιέργεια και η ευρύτερη επιστημονική ή κοινωνική αναγκαιότητα της κάθε εποχής. Για παράδειγμα, οι πρακτικές ανάγκες της μέτρησης εδαφών και αποστάσεων στην αρχαιότητα αποτέλεσαν σημαντικό κίνητρο για την ανάπτυξη της επίπεδης (Ευκλείδειας) γεωμετρίας. Παρομοίως, η ανάγκη για την κατανόηση και την πρόβλεψη της κίνησης των στερεών σωμάτων – όπως, π.χ., των πλανητών ή των βλημάτων που χρησιμοποιούνταν σε πολεμικές μάχες – ήταν ένα απ’ τα βασικότερα κίνητρα για την ανάπτυξη του διαφορικού λογισμού από τον Νεύτωνα και τον Leibniz.
Ένα πιο πρόσφατο, και ίσως πιο οικείο, παράδειγμα είναι η ανάπτυξη μιας νέας μαθηματικής θεωρίας για την περιγραφή και την ακριβή μέτρηση της «πληροφορίας». Στην εποχή μας, η έννοια της πληροφορίας βρίσκεται παντού – από τις πληροφορίες που μεταφέρονται ως δεδομένα μέσω του διαδικτύου και των κινητών τηλεφώνων, μέχρι τη μελέτη των πληροφοριών που είναι αποθηκευμένες στον ανθρώπινο εγκέφαλο και στο DNA. Πώς μετριέται και περιγράφεται η πληροφορία, ως φυσικό μέγεθος, στην καθεμία από τις πιο πάνω περιπτώσεις; Το επιστημονικό πεδίο της θεωρίας πληροφορίας δίνει κάποιες πρώτες απαντήσεις σε αυτά τα ερωτήματα.
Μάλλον το σημαντικότερο (και αρχαιότερο) κίνητρο για την ανάπτυξη των πιθανοτήτων – δηλαδή μιας μαθηματικά αυστηρής θεωρίας για την κατανόηση τυχαίων φαινομένων και, γενικότερα, καταστάσεων στις οποίες υπάρχει ένα σημαντικό μέρος αβεβαιότητας – ήταν το ανθρώπινο πάθος για τον τζόγο. Γύρω στα μέσα και προς τα τέλη του 19ου αιώνα, είχε ωριμάσει αρκετά η συστηματική μελέτη των σχετικά απλών φυσικών φαινομένων, όπως για παράδειγμα η μελέτη της κίνησης δύο απομονωμένων πλανητών κάτω από την επίδραση της αμοιβαίας βαρυτικής τους έλξης, και είχε ξεκινήσει να αναπτύσσεται έντονο επιστημονικό ενδιαφέρον για τη μελέτη «πολύπλοκων» συστημάτων.
Για παράδειγμα, ένα δωμάτιο περιέχει περίπου μόρια αέρα. Ακόμα κι αν γνωρίζουμε με ακρίβεια τους νόμους που διέπουν την κίνησή τους, είναι πρακτικά αδύνατο να λύσουμε ένα σύστημα διαφορικών εξισώσεων, ώστε να προβλέψουμε, π.χ., τη θερμοκρασία του αέρα στο δωμάτιο! Μια αποτελεσματικότερη προσέγγιση είναι να θεωρήσουμε τις θέσεις και τις ταχύτητες των μορίων τυχαίες και να αποπειραθούμε να κάνουμε μια στατιστική ανάλυση. Αυτή η προσέγγιση, η οποία αποτέλεσε την αφετηρία της σημαντικής νέας περιοχής της στατιστικής φυσικής, έδωσε την τελική ώθηση που απαιτούνταν ώστε οι πιθανότητες να αναπτυχθούν ως μια πλήρης μαθηματική θεωρία στο πρώτο μισό του 20ού αιώνα.
1.2 Ιστορική ανάπτυξη
Η αφετηρία της συστηματικής μελέτης των Πιθανοτήτων ως επιστημονικού πεδίου τοποθετείται στα μέσα του 17ου αιώνα, και συγκεκριμένα στην αλληλογραφία μεταξύ δύο σημαντικών μαθηματικών της εποχής, του Pascal και του Fermat, με αντικείμενο την κατανόηση ενός τυχερού παιχνιδιού.
 |
 |
αποτελούν κοινό κτήμα και διέπονται από το καθεστώς υλικού που ανήκει στο public domain.
Τα πρωτότυπα αρχεία βρίσκονται στις τοποθεσίες των συνδέσμων Pascal
και Fermat.]
Μετά τη θεμελίωση των βασικών εννοιών από τους Pascal-Fermat, η σκυτάλη πέρασε σε έναν από τους σημαντικότερους μαθηματικούς όλων των εποχών, τον Gauss. Στα χέρια του Gauss, οι πιθανότητες έπαψαν να αποτελούν ένα συνονθύλευμα μεμονωμένων παραδειγμάτων και απλών τεχνικών. Ο Gauss διατύπωσε και απέδειξε μια σειρά από θεμελιώδη αποτελέσματα, τα οποία αποτελούν τη βάση ολόκληρης της σύγχρονης θεωρίας πιθανοτήτων – αλλά και της στατιστικής – έως και σήμερα. Το σημαντικότερο από αυτά τα αποτελέσματα είναι το Κεντρικό Οριακό Θεώρημα (Κ.Ο.Θ.), του οποίου η μελέτη και η χρήση αποτελούν κεντρικούς στόχους αυτού του βιβλίου.

Με απλά λόγια, το Κ.Ο.Θ. μας λέει δύο πράγματα: Πρώτον, πως μέσα από την πλήρη αταξία μερικές φορές γεννιέται τάξη. Για παράδειγμα, αν στρίψουμε ένα νόμισμα δυο-τρεις φορές, είναι απολύτως αδύνατο να προβλέψουμε τι θα συμβεί· αν, ας πούμε, θα φέρουμε πρώτα Γράμματα και μετά Κορώνα ή το αντίστροφο. Αλλά, αν στρίψουμε το νόμισμα χίλιες ή δέκα χιλιάδες φορές, τότε είναι σχεδόν βέβαιο ότι το ποσοστό των φορών που φέραμε Κορώνα θα είναι μεταξύ 49% και 51%. Επιπλέον, το Κ.Ο.Θ. μάς επιτρέπει να υπολογίσουμε, κατά προσέγγιση, πόσο μικρή είναι η πιθανότητα το ποσοστό από Κορώνες να μην είναι μεταξύ 49% και 51%.
Έτσι, από τις πολλές επαναλήψεις του τυχαίου και απρόβλεπτου, προκύπτει τάξη και προβλεψιμότητα. Όπως θα δούμε σε επόμενα κεφάλαια, η βασική ιδιότητα πάνω στην οποία στηρίζεται αυτή η συμπεριφορά, είναι η ανεξαρτησία, δηλαδή το γεγονός ότι τα αποτελέσματα των διαδοχικών ρίψεων του νομίσματος είναι ανεξάρτητα το ένα από το άλλο.
Ως την εποχή του Gauss και μέχρι μερικές δεκαετίες αργότερα, η μελέτη των πιθανοτήτων βασιζόταν σχεδόν εξολοκλήρου στην υπόθεση της ανεξαρτησίας. Για παράδειγμα, σε μια ιατρική μελέτη, είναι λογικό να υποθέσουμε ότι το πόσο αποτελεσματικά δρα ένα φάρμακο έχει διακυμάνσεις από ασθενή σε ασθενή, αλλά είναι εξίσου λογικό να υποθέσουμε ότι η αποτελεσματικότητα του φαρμάκου είναι ανεξάρτητη από τον εκάστοτε ασθενή. Παρομοίως, αν κάνουμε μια δημοσκόπηση διαλέγοντας τυχαία μέλη ενός πληθυσμού, είναι λογικό να υποθέσουμε πως το να επιλέξουμε έναν συγκεκριμένο άνθρωπο για τη δημοσκόπηση δεν θα επηρεάσει τις πολιτικές προτιμήσεις κάποιου άλλου. Και στις δύο αυτές περιπτώσεις μπορούμε, λοιπόν, να υποθέσουμε πως διαδοχικά δείγματα – μετρήσεις της ανταπόκρισης των ασθενών σε ένα φάρμακο και προτιμήσεις ψηφοφόρων – είναι στατιστικά ανεξάρτητα.
Αλλά σε πιο πολύπλοκα φαινόμενα η υπόθεση της ανεξαρτησίας δεν είναι ρεαλιστική. Για παράδειγμα, ας πούμε πως έχουμε έναν αλγόριθμο επεξεργασίας κειμένου και θέλουμε να αναλύσουμε τη συνήθη συμπεριφορά του. Μια που δεν ξέρουμε εκ των προτέρων πάνω σε ποιο κείμενο θα εφαρμοστεί, λογικά θα καταφύγουμε στο να εξετάσουμε πώς συμπεριφέρεται σε κάποιο «τυχαίο» κείμενο. Αν όμως περιγράψουμε ένα τυχαίο κείμενο ως μια ακολουθία τυχαίων γραμμάτων, τότε σίγουρα δεν μπορούμε να θεωρήσουμε πως τα διαδοχικά γράμματα είναι ανεξάρτητα μεταξύ τους – εκτός κι αν είμαστε προετοιμασμένοι να δεχθούμε ως «κείμενο» μια ακολουθία γραμμάτων όπως η:
 |
 |
αποτελούν κοινό κτήμα και διέπονται από το καθεστώς υλικού που ανήκει στο public domain.
Τα πρωτότυπα αρχεία βρίσκονται στις τοποθεσίες των συνδέσμων Markov και Kolmogorov.]
Ο πρώτος ερευνητής που μελέτησε συστηματικά τις τυχαίες ακολουθίες που αποτελούνται από όχι ανεξάρτητα αλλά συσχετισμένα μεταξύ τους δείγματα, ήταν ο Markov. Στην απλούστερη μορφή τους, οι ακολουθίες τέτοιων συσχετισμένων δειγμάτων ονομάζονται «αλυσίδες Markov», και η μελέτη τους αποτελεί κεντρικό μέρος πολλών ερευνητικών περιοχών της σύγχρονης επιστήμης και τεχνολογίας. Είναι αξιοσημείωτο πως ένα από τα βασικά κίνητρα του Markov ήταν η περιγραφή κειμένων φυσικής γλώσσας μέσω των πιθανοτήτων. Ακόμη και στη σημερινή εποχή του Internet, του Google και του YouTube, πολλοί από τους πιο δημοφιλείς αλγορίθμους που χρησιμοποιούνται καθημερινά από εκατομμύρια ανθρώπους καθώς «σερφάρουν» στο διαδίκτυο, είναι βασισμένοι σε μοντέλα που περιγράφουν το περιεχόμενο των σελίδων του WWW μέσω των αλυσίδων Markov.
Ο πιο πρόσφατος μεγάλος σταθμός στην ιστορία των πιθανοτήτων είναι το 1933. Μέχρι τότε, παρά τη μεγάλη ώθηση που είχε πάρει η μελέτη τυχαίων φαινομένων στη φυσική και στο πρωτοεμφανιζόμενο τότε πεδίο της στατιστικής, οι πιθανότητες παρέμεναν μια μαθηματικά κακόφημη επιστημονική περιοχή. Ο λόγος ήταν πως δεν είχαν ακόμα ενταχθεί, με την αυστηρή έννοια, στο κεντρικό κομμάτι των μαθηματικών. Δεν είχαν, δηλαδή, θεμελιωθεί αξιωματικά, όπως η γεωμετρία, η ανάλυση, η θεωρία συνόλων και όλες οι υπόλοιπες βασικές περιοχές των μαθηματικών. Αυτήν τη θεμελίωση κατάφερε το 1933 ο σπουδαίος Ρώσος μαθηματικός A.N. Kolmogorov, του οποίου η τεράστια επιρροή στην επιστημονική εξέλιξη του 20ού αιώνα είναι εξαιρετικά έντονα αισθητή ως τις μέρες μας.
1.3 Πιθανότητες και πληροφορική
Όπως αναφέρουν στην εισαγωγή του πρόσφατου βιβλίου τους Probability and Computing οι Mitzenmacher (Harvard) και Upfal (Brown):
Τις τελευταίες δύο δεκαετίες, η χρήση της θεωρίας πιθανοτήτων στην πληροφορική έχει ενταθεί σε πάρα πολύ μεγάλο βαθμό. Προχωρημένες και πολύπλοκες τεχνικές από τις πιθανότητες αναπτύσσονται και βρίσκουν εφαρμογή σε όλο και πιο ευρείες και δύσκολες περιοχές της επιστήμης υπολογιστών.
Συγκεκριμένα, τεχνικές και βασικές έννοιες των πιθανοτήτων παίζουν κεντρικό ρόλο, μεταξύ άλλων, στις εξής περιοχές:
-
•
Περιγραφή και προσομοίωση πολύπλοκων συστημάτων. Π.χ., ένα μεγάλο δίκτυο που αποτελείται από πολλούς υπολογιστές (όπως το internet), ή ένα δίκτυο κινητής τηλεφωνίας, είναι αδύνατον να περιγραφεί με απόλυτη ακρίβεια. Νέοι υπολογιστές προστίθενται στο δίκτυο, κάποιοι αποσυνδέονται, ενώ και η συνδεσμολογία διαρκώς αλλάζει καθώς δημιουργούνται νέες συνδέσεις ή κάποιες υπάρχουσες παύουν να λειτουργούν. Επιπλέον, οι απαιτήσεις για τη μεταφορά δεδομένων αλλάζουν κάθε στιγμή με απρόβλεπτο τρόπο. Έτσι αναγκαστικά καταφεύγουμε σε μια πιθανοκρατική περιγραφή του δικτύου.
-
•
Πιθανοκρατική ανάλυση αλγορίθμων. Συχνά παρατηρούμε ένας αλγόριθμος να έχει θεωρητικά απαγορευτικά μεγάλη πολυπλοκότητα, αλλά στην πράξη να είναι πολύ αποτελεσματικός. Αυτό συμβαίνει γιατί, ενώ η παραδοσιακή έννοια της πολυπλοκότητας βασίζεται στην ανάλυση της συμπεριφοράς του αλγορίθμου στη χειρότερη περίπτωση (σύμφωνα με τη λεγόμενη worst case analysis), στη μεγάλη πλειονότητα των περιπτώσεων μπορεί να είναι πολύ αποτελεσματικός. Η λεγόμενη πιθανοκρατική (ή average case) ανάλυση δίνει μια εξήγηση γι’ αυτό το φαινόμενο: Αν θεωρήσουμε τα δεδομένα εισόδου τυχαία, τότε σε πολλές περιπτώσεις μπορούμε να δείξουμε ότι, με πιθανότητα πολύ κοντά στο 100%, η πολυπλοκότητα του αλγορίθμου είναι πολύ σημαντικά μικρότερη από αυτήν της χειρότερης περίπτωσης.
-
•
Randomized αλγόριθμοι. Υπάρχει μια κατηγορία αλγορίθμων, οι λεγόμενοι randomized ή τυχαιοκρατικοί αλγόριθμοι, οι οποίοι σε κάποια βήματα κατά την εκτέλεσή τους κάνουν «τυχαίες» επιλογές. Για παράδειγμα, το πρωτόκολλο επικοινωνίας του ethernet χρησιμοποιεί τυχαίους αριθμούς για να αποφασίσει πότε θα ξαναζητήσει πρόσβαση στο δίκτυο. Η χρήση της τυχαιότητας – σε αυτόν και πολλούς άλλους σημαντικούς αλγορίθμους – όχι μόνο απλοποιεί τη δομή του αλγορίθμου, αλλά επιτυγχάνει σημαντικά καλύτερη συμπεριφορά του συστήματος. Το τίμημα που επιφέρει είναι πως πάντα υπάρχει μια μικρή πιθανότητα δυσλειτουργίας. Βάσει σωστού σχεδιασμού και προσεκτικής μαθηματικής ανάλυσης, αυτή η πιθανότητα μπορεί να καταστεί τόσο μικρή, ώστε το κέρδος από την άποψη της πολυπλοκότητας και της ευκολίας να είναι πολύ μεγαλύτερο.
Κλείνοντας, αναφέρουμε πως άλλες περιοχές της πληροφορικής στις οποίες χρησιμοποιούνται συστηματικά μέθοδοι των πιθανοτήτων περιλαμβάνουν, μεταξύ άλλων:
-
•
το σχεδιασμό αλγορίθμων επεξεργασίας πολυμεσικών (multimedia) δεδομένων, π.χ., για τη συμπίεση ήχου, βίντεο και εικόνας,
-
•
την ανάπτυξη μεθόδων μηχανικής μάθησης και ανάκτησης πληροφοριών,
-
•
την κρυπτογραφία,
-
•
τη θεωρητική θεμελίωση των βασικών εννοιών πολυπλοκότητας και υπολογισιμότητας (μηχανές Turing, NP-complete και NP-hard προβλήματα, κλπ.).
Κεφάλαιο 2 Χώρος πιθανότητας και ενδεχόμενα
[Επιστροφή στα περιεχόμενα]
2.1 Προκαταρκτικά
Έστω ότι κάποιος μας προτείνει να του δώσουμε δυόμισι ευρώ για να παίξουμε το εξής παιχνίδι: Θα στρίβουμε ένα νόμισμα μέχρι την πρώτη φορά που θα φέρουμε Κορώνα (Κ), κι όσο πιο αργά συμβεί αυτό, δηλαδή όσο πιο πολλές συνεχόμενες φορές φέρουμε Γράμματα (Γ) στην αρχή, τόσο πιο μεγάλο θα είναι το κέρδος μας: Αν το νόμισμα έρθει Κ στην πρώτη ρίψη, θα μας δώσει ένα ευρώ. Αν έρθει Γ και μετά Κ, θα μας δώσει δύο ευρώ. Γενικά, αν έρθει φορές Γ και τη φορά έρθει Κ, θα πάρουμε ευρώ.
Αμέσως γεννιούνται μερικά προφανή ερωτήματα:
-
•
Μας συμφέρει να παίξουμε;
-
•
Πόσο πιθανό είναι να κερδίσουμε πιο πολλά χρήματα από όσα δώσαμε για να παίξουμε;
-
•
Αν παίξουμε πολλές φορές, τελικά τι είναι πιο πιθανό, να βγούμε κερδισμένοι ή χαμένοι;
-
•
Είναι «δίκαιη» η τιμή των 2.5 ευρώ;
-
•
Τι θα πει ακριβώς «δίκαιη» τιμή;
Όλα αυτά τα ερωτήματα θα απαντηθούν με συστηματικό τρόπο στα επόμενα κεφάλαια. Προς το παρόν, αυτό που παρατηρούμε είναι η αναγκαιότητα να δώσουμε μια μαθηματική περιγραφή στο πιο πάνω παιχνίδι. Να ορίσουμε, πρώτα από όλα, τι θα πει «πιθανότητα» και να βρούμε τρόπους να υπολογίζουμε ποσοτικά και με ακρίβεια τις απαντήσεις σε ερωτήματα όπως τα πιο πάνω. Αυτό στα μαθηματικά είναι η διαδικασία κατά την οποία περιγράφουμε ένα πραγματικό φαινόμενο μέσω ενός μαθηματικού «μοντέλου». Σε κάποιες περιπτώσεις, αυτή η διαδικασία μάς είναι τόσο οικεία που ούτε καν της δίνουμε σημασία – για παράδειγμα, όταν βλέπουμε σε ένα χάρτη μια ευθεία γραμμή να αναπαριστά ένα δρόμο, δεν σκεφτόμαστε «Α, βέβαια, εδώ επικαλούμαι την προσεγγιστική αναπαράσταση ενός μέρους της επιφάνειας του πλανήτη Γη μέσω του μοντέλου της επίπεδης γεωμετρίας»!
Η μοντελοποίηση φαινομένων που περιέχουν στοιχεία τυχαιότητας, και η εξοικείωση με αυτήν τη διαδικασία αποτελούν δύο από τους κεντρικούς μας στόχους.
Αν και δεν είναι ο μόνος, μάλλον ο πιο συνηθισμένος τρόπος για να προσεγγίσουμε κατ’ αρχήν διαισθητικά την έννοια της πιθανότητας είναι μέσω της έννοιας της «συχνότητας». Π.χ., αν στρίψουμε ένα «δίκαιο» νόμισμα φορές και φέρουμε φορές Κορώνα (Κ), για μεγάλα συχνά παρατηρούμε ότι,
Και όσο μεγαλώνει το πλήθος των ρίψεων, αντιστοίχως μεγαλώνει και το πλήθος των φορών που φέραμε Κ, έτσι ώστε, μακροπρόθεσμα,
Υπό αυτή την έννοια, λέμε ότι «η πιθανότητα το νόμισμα να έρθει Κ είναι 1/2».
2.2 Σύνολα
Ένα μεγάλο μέρος του μαθηματικού λεξιλογίου που θα χρησιμοποιήσουμε βασίζεται στα βασικά στοιχεία της θεωρίας συνόλων. Ξεκινάμε υπενθυμίζοντας κάποιος γνωστούς ορισμούς:
-
1.
Ένα σύνολο είναι μια συλλογή στοιχείων. Για παράδειγμα, τα οι ακέραιοι αριθμοί, οι πραγματικοί αριθμοί, είναι όλα σύνολα.
-
2.
Όταν κάποιο στοιχείο ανήκει σε κάποιο σύνολο γράφουμε Αν το δεν ανήκει στο γράφουμε Π.χ., πιο πάνω έχουμε, αλλά,
-
3.
Το είναι υποσύνολο του αν κάθε στοιχείο του ανήκει και στο οπότε γράφουμε ή
-
4.
Το κενό σύνολο ή έχει την ιδιότητα ότι δεν περιέχει κανένα στοιχείο, δηλαδή για οποιοδήποτε
Στις πιθανότητες, ανάλογα με το πρόβλημα που θα εξετάζουμε, όλα τα σύνολα που μας ενδιαφέρουν θα είναι υποσύνολα ενός βασικού συνόλου, το οποίο συνήθως συμβολίζεται ως
-
5.
Η ένωση δύο συνόλων είναι το σύνολο που αποτελείται από όλα τα στοιχεία που ανήκουν στο ή στο (ή και στα δύο). Γενικότερα, η ένωση ενός πεπερασμένου πλήθους συνόλων συμβολίζεται ως,
και περιέχει όλα τα στοιχεία του τα στοιχεία του κλπ. Βλ. Σχήμα 2.1.
-
6.
Η τομή δύο συνόλων είναι το σύνολο που αποτελείται από όλα τα στοιχεία που ανήκουν και στο και στο Γενικότερα, η τομή ενός πεπερασμένου πλήθους συνόλων συμβολίζεται ως,
και αποτελείται από τα στοιχεία που περιέχονται σε όλα τα Βλ. Σχήμα 2.1.
-
7.
Το συμπλήρωμα ενός συνόλου που είναι υποσύνολο του βασικού συνόλου αποτελείται από όλα τα στοιχεία του που δεν ανήκουν στο Βλ. Σχήμα 2.1.
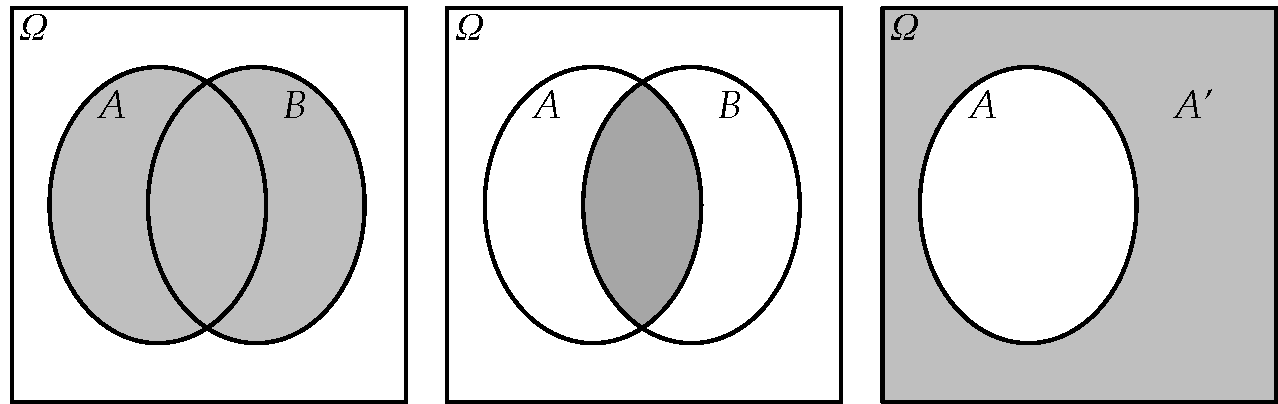
Παράδειγμα 2.1
Έστω το σύνολο όλων των δυνατών αποτελεσμάτων από τη ρίψη δύο νομισμάτων, δηλαδή,
Η περίπτωση του να φέρουμε Κ την πρώτη φορά μπορεί να περιγραφεί ως το σύνολο,
το οποίο είναι ένα υποσύνολο του Παρατηρούμε ότι το μπορεί και να εκφραστεί ως,
Παράδειγμα 2.2
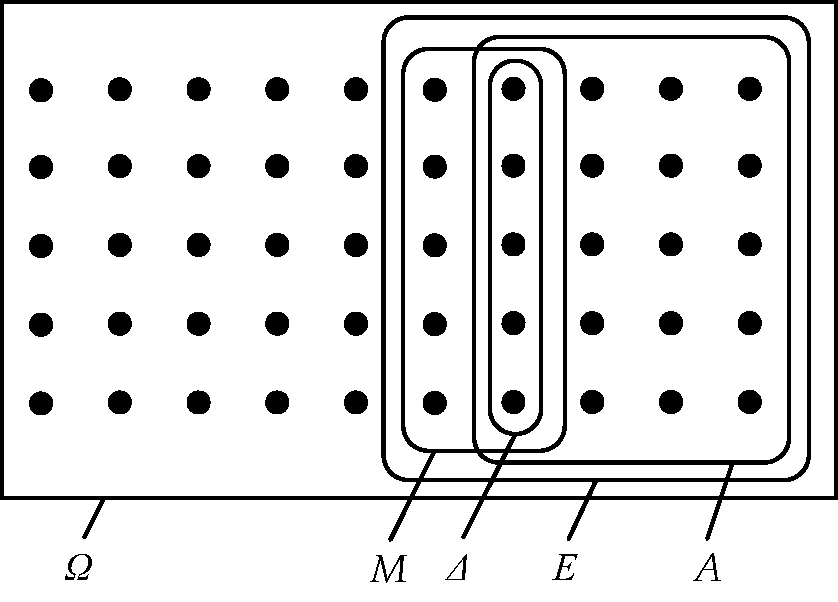
Από 50 φοιτητές που βρίσκονται σε μια αίθουσα, οι 20 έχουν αυτοκίνητο, οι 10 έχουν μοτοσυκλέτα, και οι 25 δεν έχουν κανένα από τα δύο. Επιλέγουμε έναν φοιτητή στην τύχη.
Εδώ μπορούμε να ορίσουμε τα εξής σύνολα. Βλ. Σχήμα 2.2.
| Όλοι οι 50 φοιτητές | ||||
| Όσοι έχουν αυτοκίνητο | ||||
| Όσοι έχουν μοτοσυκλέτα | ||||
| Όσοι έχουν τουλάχιστον το ένα από τα δύο μέσα | ||||
Θα απαντήσουμε στα εξής απλά ερωτήματα:
-
(α’)
Πόσοι φοιτητές είναι στο ;
-
(β’)
Πόσοι φοιτητές είναι στο ;
-
(γ’)
Ποια είναι η πιθανότητα ο επιλεγμένος φοιτητής να έχει αυτοκίνητο;
Για το (α’), εφόσον είναι 50 συνολικά οι φοιτητές, δηλαδή το πλήθος των στοιχείων του ισούται με 50, και αφού μας δίνεται ότι 25 φοιτητές δεν έχουν ούτε αυτοκίνητο ούτε μοτοσυκλέτα, εύκολα υπολογίζουμε ότι,
όπου πιο πάνω και σε ολόκληρο το βιβλίο, χρησιμοποιούμε τον συμβολισμό για το πλήθος των στοιχείων ενός οποιουδήποτε συνόλου
Για το (β’), από τη γραφική αναπαράσταση στο Σχήμα 2.2, παρατηρούμε πως,
όπου αφαιρούμε τα στοιχεία του συνόλου για να μη μετρηθούν δύο φορές. Παρατηρούμε επίσης ότι και από το (α’), ενώ μας δίνεται και ότι και άρα,
[Παρένθεση. Αν και δεν έχουμε ακόμα ορίσει την έννοια της πιθανότητας, μπορούμε να προσεγγίσουμε το ερώτημα (γ’) διαισθητικά. Εφόσον η επιλογή του φοιτητή είναι τυχαία, η ζητούμενη πιθανότητα «ο επιλεγμένος φοιτητής να έχει αυτοκίνητο», δηλαδή η πιθανότητα να επιλέξουμε από όλο το έναν φοιτητή που να είναι στο σύνολο λογικά μπορεί να υπολογιστεί ως η πιθανότητα του «ο επιλεγμένος φοιτητής να ανήκει στο », δηλαδή, ]
Παράδειγμα 2.3
Ρίχνουμε ένα «δίκαιο» νόμισμα 2 φορές. Εδώ το σύνολο όλων των δυνατών αποτελεσμάτων είναι το,
Έστω το ενδεχόμενο του να έρθει Κ την πρώτη φορά, και το ενδεχόμενο να έρθει το ίδιο αποτέλεσμα δύο φορές, δηλαδή,
[Παρένθεση. Και πάλι, αν και δεν έχουμε ακόμα ορίσει την έννοια της πιθανότητας, διαισθητικά μπορούμε να κάνουμε κάποιους απλούς υπολογισμούς. Παρατηρούμε ότι, εφόσον το νόμισμα είναι δίκαιο, είναι λογικό να υποθέσουμε ότι καθένα από τα τέσσερα δυνατά αποτελέσματα (που αντιστοιχούν στα 4 στοιχεία του ) έχουν την ίδια πιθανότητα, δηλαδή 1/4. Άρα υπολογίζουμε εύκολα τις πιθανότητες, για παράδειγμα, των εξής ενδεχομένων:
και παρομοίως, η πιθανότητα να φέρουμε δύο φορές Γ είναι κι αυτή 1/4.]
2.3 Χώρος πιθανότητας και ενδεχόμενα
Ορισμός 2.2
(Χώρος πιθανότητας και ενδεχόμενα)
-
1.
O χώρος πιθανότητας ή δειγματικός χώρος είναι το σύνολο όλων των δυνατών αποτελεσμάτων ενός τυχαίου πειράματος.
-
2.
Οποιοδήποτε υποσύνολο του χώρου πιθανότητας ονομάζεται ενδεχόμενο.
-
3.
Τα ενδεχόμενα που αποτελούνται από ένα μόνο στοιχείο, δηλαδή τα υποσύνολα της μορφής για κάποιο λέγονται στοιχειώδη ενδεχόμενα.
-
4.
Δύο ενδεχόμενα είναι ξένα όταν δεν έχουν κανένα κοινό στοιχείο, δηλαδή αν και μόνο αν, Διαισθητικά, τα είναι ξένα αν είναι αδύνατον να συμβούν συγχρόνως.
Παρατηρήσεις:
-
1.
Ο χώρος πιθανότητας μπορεί πάντα να εκφραστεί ως η ένωση τόσων στοιχειωδών ενδεχομένων όσα τα στοιχεία που περιέχει. Π.χ., αν τότε,
Και γενικότερα, κάθε ενδεχόμενο μπορεί να εκφραστεί ως ένωση τόσων στοιχειωδών ενδεχομένων όσα τα στοιχεία που περιέχει. Επίσης σημειώνουμε πως δύο οποιαδήποτε στοιχειώδη ενδεχόμενα και είναι ξένα μεταξύ τους – αρκεί, βεβαίως, να μην είναι τα ίδια, δηλαδή το στοιχείο να είναι διαφορετικό απ’ το
-
2.
Στο πιο πάνω παράδειγμα της ρίψης δύο δίκαιων νομισμάτων, ο χώρος πιθανότητας ήταν και εξετάσαμε τα ενδεχόμενα και τα οποία μπορούν να εκφραστούν ως ενώσεις στοιχειωδών ενδεχομένων:
Παρατηρούμε ότι έχουμε τις πιθανότητες (όπως υπολογίστηκαν πιο πάνω), και Άρα έχουμε τις «παράλληλες» σχέσεις:
Αργότερα θα δούμε πως, όταν κάποιο ενδεχόμενο μπορεί να εκφραστεί ως ένωση δύο άλλων ενδεχομένων η μόνη περίπτωση κατά την οποία μπορούμε να είμαστε βέβαιοι ότι θα ισχύει και η αντίστοιχη σχέση για τις πιθανότητες, είναι όταν τα είναι ξένα.
-
3.
Όταν ένα ενδεχόμενο περιγράφει την περίπτωση να συμβεί κάποιο γεγονός που μας ενδιαφέρει (π.χ. αν το είναι το ενδεχόμενο του να φέρουμε την πρώτη φορά Κ ρίχνοντας ένα νόμισμα), τότε το συμπλήρωμά του περιγράφει το αντίθετο γεγονός, δηλαδή την περίπτωση να μη συμβεί το (π.χ, πιο πάνω το αντιστοιχεί στο να φέρουμε την πρώτη φορά Γ).
Παρομοίως, η ένωση δύο ενδεχομένων είναι το ενδεχόμενο του να συμβεί το ή το Β, και η τομή τους περιγράφει το ενδεχόμενο του να συμβούν και τα δύο.
Τέλος, παραθέτουμε κάποιες βασικές σχέσεις που ικανοποιούν οι πράξεις της ένωσης, της τομής και του συμπληρώματος συνόλων. Για οποιαδήποτε υποσύνολα του έχουμε:
-
1.
-
2.
-
3.
-
4.
-
5.
-
6.
-
7.
Κλείνουμε αυτό το κεφάλαιο με ένα ενδιαφέρον παράδειγμα το οποίο, αν και απλό, αν δεν το έχετε ξαναδεί, ίσως σας κινήσει ιδιαίτερα το ενδιαφέρον.
Παράδειγμα 2.4 (Παιχνίδι Monty Hall)
Σε ένα τηλεπαιχνίδι ο διαγωνιζόμενος επιλέγει μία από τρεις κουρτίνες, αφού του πουν πως μία από αυτές κρύβει ένα δώρο και οι άλλες δύο δεν κρύβουν τίποτα (χωρίς, φυσικά, να του πουν πού είναι το δώρο). Αφού διαλέξει, ο παρουσιαστής τού ανοίγει μία από τις άλλες δύο κουρτίνες, του δείχνει ότι εκεί δεν υπάρχει τίποτα, και δίνει στον διαγωνιζόμενο τη δυνατότητα να κρατήσει την αρχική του κουρτίνα ή να διαλέξει την άλλη κουρτίνα της οποίας το περιεχόμενο παραμένει κρυφό. Ο διαγωνιζόμενος επιλέγει, και το παιχνίδι τελειώνει, είτε με νίκη του διαγωνιζόμενου (αν το δώρο βρίσκεται πίσω από την κουρτίνα της τελικής του επιλογής), είτε με ήττα του διαγωνιζόμενου (αν το δώρο δεν βρίσκεται πίσω από την κουρτίνα που επέλεξε).
Πώς μπορούμε να περιγράψουμε το χώρο πιθανότητας; Υπάρχουν διάφοροι τρόποι να περιγραφούν όλες οι δυνατές εκβάσεις του παιχνιδιού. Μια επιλογή είναι η ακόλουθη. Έστω πως ονομάζουμε κουρτίνα την κουρτίνα όπου βρίσκεται το δώρο, και κουρτίνες τις άλλες δύο. Μπορούμε να περιγράψουμε τα αποτελέσματα ως τριάδες της μορφής όπου τα παίρνουν τιμές ή και το πρώτο στοιχείο δείχνει την επιλογή του διαγωνιζόμενου, το δεύτερο την κουρτίνα που αποκαλύφθηκε, και το τρίτο την κουρτίνα που επέλεξε τελικά ο διαγωνιζόμενος.
Προφανώς υπάρχουν 3 επιλογές για το πρώτο στοιχείο. Αλλά για το δεύτερο στοιχείο υπάρχουν 2 επιλογές αν ο διαγωνιζόμενος έχει αρχικά επιλέξει την κουρτίνα με το δώρο, ενώ υπάρχει μόνο μία αν ο διαγωνιζόμενος έχει επιλέξει κενή κουρτίνα. Για το τρίτο στοιχείο, υπάρχουν πάντα δύο επιλογές. Ο αντίστοιχος χώρος πιθανότητας περιέχει τις 8 δυνατές τριάδες και έχει σχεδιαστεί στο Σχήμα 2.4.
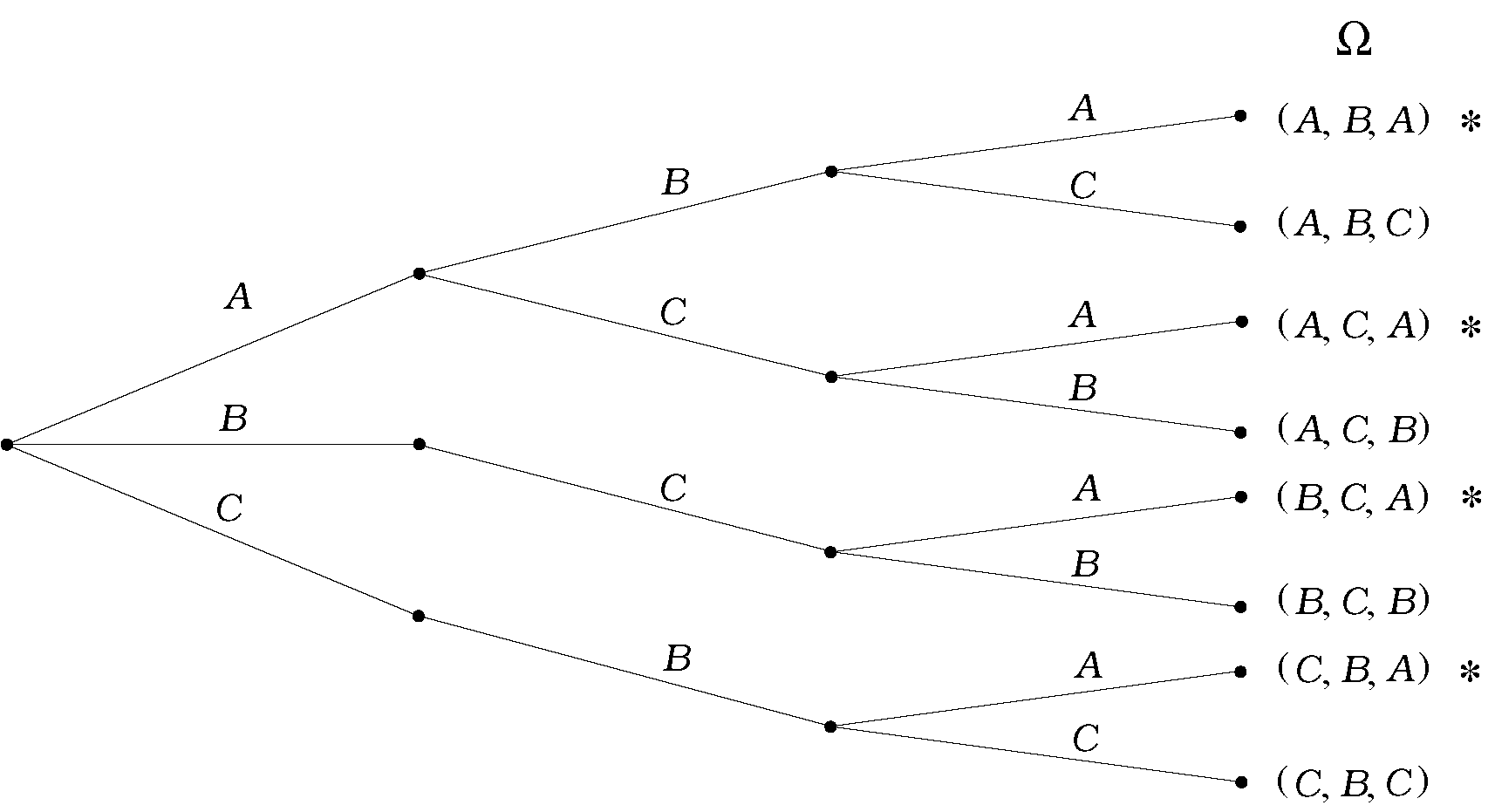
Αν θέλουμε τώρα να ορίσουμε, π.χ., το ενδεχόμενο «ο παίκτης κέρδισε το δώρο», παρατηρούμε πως τα αποτελέσματα που καταλήγουν σε νίκη για τον διαγωνιζόμενο είναι εκείνα που έχουν τελευταίο στοιχείο το δηλαδή,
Σημείωση. Αυτό το παιχνίδι ήταν επί χρόνια τηλεπαιχνίδι στην Αμερική, γνωστό με το όνομα «Monty Hall». Τα βασικό ερώτημα, το οποίο θα εξετάσουμε αργότερα, είναι, «Ποια είναι η πιο συμφέρουσα στρατηγική για τον παίκτη – να κρατήσει την αρχική του κουρτίνα ή να αλλάξει;»
2.4 Ασκήσεις
-
1.
Τυχαία παιδιά. Έστω πως εκτελείται το ακόλουθο πείραμα: Ένα ζευγάρι κάνει παιδιά, καθένα εκ των οποίων μπορεί να είναι αγόρι ή κορίτσι. Περιγράψτε το χώρο πιθανότητας αυτού του πειράματος.
-
2.
Κι άλλα τυχαία παιδιά. Έστω πως εκτελείται το ακόλουθο πείραμα: Ένα ζευγάρι κάνει παιδιά επ’ άπειρο, μέχρι να κάνει το πρώτο κορίτσι, και μετά σταματάει. Περιγράψτε το χώρο πιθανότητας αυτού του πειράματος.
-
3.
Δύο διαδοχικές ζαριές. Ρίχνουμε ένα ζάρι φορές και καταγράφουμε τα δύο αποτελέσματα με τη σειρά που ήρθαν.
-
(α’)
Ποιος είναι ο χώρος πιθανότητας
-
(β’)
Περιγράψτε τα ακόλουθα ενδεχόμενα ως υποσύνολα του :
- i.
«Ζάρι 1 = Ζάρι 2» (δηλαδή διπλές)
- ii.
«Άθροισμα »
- iii.
«Πρώτο ζάρι »
- iv.
«Άθροισμα »
- v.
«Δεύτερο ζάρι »
- i.
-
(α’)
-
4.
Υπάρχουν και περίεργοι χώροι πιθανότητας. Έστω πως ρίχνουμε ένα βελάκι σε ένα στόχο με σχήμα κύκλου, και ακτίνα Αν πετύχουμε το στόχο το βελάκι μένει καρφωμένο, και αν αστοχήσουμε το βελάκι πέφτει στο πάτωμα και το κλέβει ο σκύλος μας. Ορίστε το χώρο πιθανότητας ώστε να περιγράφει όλα τα δυνατά αποτελέσματα, δηλαδή όλες τις θέσεις στις οποίες μπορεί να καταλήξει το βελάκι μας, συμπεριλαμβανομένου του στόματος του σκύλου!
-
5.
Δύο ταυτόχρονες ζαριές. Λύστε την Άσκηση 3, υποθέτοντας πως τα ζάρια ρίχνονται ταυτόχρονα, και δεν είμαστε σε θέση να τα ξεχωρίζουμε μεταξύ τους.
-
6.
Τρία νομίσματα. Ρίχνουμε τρία νομίσματα. Περιγράψτε το χώρο πιθανότητας του πειράματος και τα ενδεχόμενα «τρεις φορές το ίδιο αποτέλεσμα», «τις πρώτες δύο φορές Γράμματα», «περισσότερες Κορώνες από Γράμματα», ως υποσύνολα του
-
7.
Άσπρες και μαύρες μπάλες. Ένα κουτί περιέχει μία άσπρη μπάλα και 3 πανομοιότυπες μαύρες μπάλες.
-
(α’)
Επιλέγουμε μια μπάλα στην τύχη και χωρίς να την ξαναβάλουμε στο κουτί επιλέγουμε άλλη μία (δηλαδή έχουμε επιλογή χωρίς επανατοποθέτηση). Περιγράψτε το χώρο πιθανότητας αυτού του πειράματος.
-
(β’)
Αν η επιλογή άσπρης μπάλας μάς δίνει κέρδος 10 ευρώ και η επιλογή μαύρης μπάλας μάς δίνει κέρδος 5 ευρώ, περιγράψτε το ενδεχόμενο συνολικά στις δύο επιλογές να κερδίσουμε 10 ευρώ.
-
(γ’)
Αν, αφού επιλέξουμε την πρώτη μπάλα, την ξαναβάλουμε στο κουτί πριν επιλέξουμε τη δεύτερη, έχουμε επιλογή με επανατοποθέτηση, και προκύπτει ένα διαφορετικό πείραμα. Περιγράψτε το χώρο πιθανότητας αυτού του πειράματος, και το ενδεχόμενο συνολικά στις δύο επιλογές να κερδίσουμε 15 ευρώ.
-
(α’)
-
8.
Λειτουργία δικτύου. Έστω τα ενδεχόμενα «Σήμερα θα πέσει το δίκτυο», «Σήμερα είναι εργάσιμη μέρα», «Σήμερα ο τεχνικός είναι στο εργαστήριο». Να εκφραστούν τα πιο κάτω ενδεχόμενα ως σύνολα, συναρτήσει των συνόλων :
-
(α’)
«Σήμερα θα πέσει το δίκτυο και είναι εργάσιμη μέρα»
-
(β’)
«Σήμερα είναι αργία και θα πέσει το δίκτυο»
-
(γ’)
«Σήμερα θα πέσει το δίκτυο, είναι εργάσιμη, και ο τεχνικός δεν είναι στο εργαστήριο»
-
(δ’)
«Σήμερα ή θα πέσει το δίκτυο και είναι αργία, ή θα πέσει το δίκτυο και ο τεχνικός είναι στο εργαστήριο, ή δεν θα πέσει το δίκτυο»
-
(α’)
-
9.
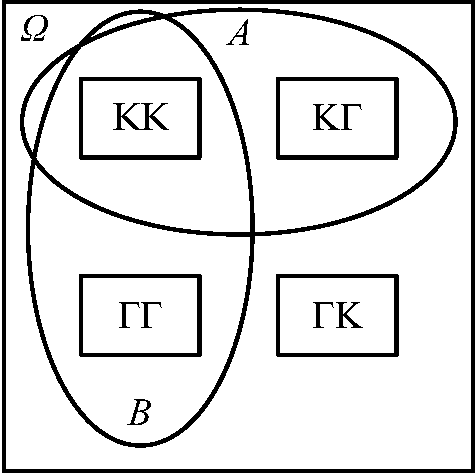
Απλά διαγράμματα ενδεχομένων. Στα τρία διαγράμματα του Σχήματος 2.5, να σκιαστούν (αντιστοίχως) τα τρία ενδεχόμενα
Σχήμα 2.5: Άσκηση 9. -
10.
Τρεις ζαριές. Ρίχνουμε ένα ζάρι φορές. Περιγράψτε το χώρο πιθανότητας και τα ενδεχόμενα: «Την και φορά ήρθε 6», «την φορά ήρθε και τη και φορά ήρθε το ίδιο αποτέλεσμα» και «τρεις φορές ήρθε το ίδιο ζυγό αποτέλεσμα».
-
11.
Σταθερά και κινητά τηλέφωνα. Ένα δίκτυο τηλεφωνίας αποτελείται από σταθερά τηλέφωνα και κινητά. Επιλέγουμε δύο τηλέφωνα στην τύχη, όπου στην επιλογή δεν επιτρέπουμε να επιλεγεί το ίδιο τηλέφωνο με την :
Περιγράψτε το χώρο πιθανότητας. Επιπλέον, αν η επιλογή σταθερού τηλεφώνου έχει κόστος ευρώ και η επιλογή κινητού ευρώ, περιγράψτε τα ενδεχόμενα Α =«συνολικά οι επιλογές κόστισαν ευρώ» και B =«συνολικά οι επιλογές κόστισαν ευρώ».
-
12.
Το πρόβλημα των τριών φυλακισμένων. Σε μια φυλακή, ο διευθυντής αποφασίζει να απονείμει χάρη σε έναν από τους τρεις φυλακισμένους (η φυλακή είναι μικρή!) και να εκτελέσει τους άλλους δύο. Ένας από τους τρεις φυλακισμένους ζητά από τον δεσμοφύλακα να του αποκαλύψει ποιος από τους άλλους δύο κρατούμενους θα εκτελεστεί, με τη λογική ότι υπάρχει πάντοτε κάποιος τέτοιος. Ο δεσμοφύλακας το κάνει, και κατόπιν του παρέχει τη δυνατότητα να αλλάξει θέση με αυτόν του οποίου την τύχη δεν αποκάλυψε. Ο φυλακισμένος έχει την επιλογή να δεχθεί ή να αρνηθεί. Να περιγράψετε το χώρο πιθανότητας αυτού του τυχαίου πειράματος.
-
13.
Monty Hall 2. Επαναλάβετε το Παράδειγμα 2.4 με την ακόλουθη τροποποίηση: Οι κουρτίνες έχουν πάρει το όνομά τους πριν τοποθετηθεί το δώρο, και έτσι τα αποτελέσματα είναι τετράδες, αντί για τριάδες.
-
14.
Monty Hall 3. Επαναλάβετε το Παράδειγμα 2.4 με την ακόλουθη τροποποίηση: Ο διαγωνιζόμενος δεν αλλάζει ποτέ κουρτίνα.
-
15.
Monty Hall 4. Επαναλάβετε το Παράδειγμα 2.4 με την ακόλουθη τροποποίηση: Ο διαγωνιζόμενος αλλάζει πάντα κουρτίνα.
Κεφάλαιο 3 Μέτρο πιθανότητας
[Επιστροφή στα περιεχόμενα]
3.1 Ορισμός, παραδείγματα και ιδιότητες
Σ’ αυτό το σύντομο κεφάλαιο θα δώσουμε, για πρώτη φορά, έναν αυστηρά μαθηματικό ορισμό της έννοιας της πιθανότητας. Αν και, εκ πρώτης όψεως, ο ορισμός φαίνεται δυσνόητος και πολύ απομακρυσμένος από αυτό που διαισθητικά ονομάζουμε «πιθανότητα», όπως θα δούμε στα παραδείγματα που ακολουθούν, στην πράξη είναι πολύ απλός και εύχρηστος.
Έστω ένας χώρος πιθανότητας και έστω το δυναμοσύνολο του δηλαδή το σύνολο που έχει ως στοιχεία όλα τα ενδεχόμενα (συμπεριλαμβανομένου και του κενού συνόλου ). Ένα μέτρο πιθανότητας είναι μια συνάρτηση η οποία ικανοποιεί τις παρακάτω ιδιότητες:
-
1.
Για οποιοδήποτε ενδεχόμενο έχουμε:
-
2.
Πάντοτε έχουμε:
-
3.
Αν δύο ενδεχόμενα είναι ξένα (δηλαδή ), τότε,
Και γενικότερα, αν είναι μια οποιαδήποτε (πεπερασμένη ή όχι) ακολουθία ξένων ενδεχομένων (δηλαδή για κάθε ), τότε,
Πριν εξετάσουμε τις συνέπειες του ορισμού, ας δούμε πώς ορίζεται το μέτρο πιθανότητας σε ένα πολύ απλό παράδειγμα.
Παράδειγμα 3.1
Ρίχνουμε ένα δίκαιο ζάρι. Όλα τα δυνατά αποτελέσματα περιγράφονται από τα στοιχεία του αντίστοιχου χώρου πιθανότητας Ορίζουμε τα ενδεχόμενα,
και τα έξι στοιχειώδη ενδεχόμενα για κάθε Εφόσον το ζάρι είναι δίκαιο, απαιτούμε το αντίστοιχο μέτρο πιθανότητας που περιγράφει αυτό το πείραμα να δίνει την ίδια πιθανότητα, δηλαδή σε κάθε δυνατό αποτέλεσμα, δηλαδή να ικανοποιεί για κάθε
Για να υπολογίσουμε την πιθανότητα του ενδεχομένου (η οποία διαισθητικά είναι προφανώς ίση με 1/2), παρατηρούμε όπως νωρίτερα πως το μπορεί να εκφραστεί ως ένωση στοιχειωδών ενδεχομένων, δηλαδή,
και πως όλα τα στοιχειώδη ενδεχόμενα είναι ξένα μεταξύ τους. Άρα από την τρίτη ιδιότητα του ορισμού ενός μέτρου πιθανότητας έχουμε,
Παρομοίως υπολογίζουμε την πιθανότητα του μονού αποτελέσματος,
Παρατηρήσεις:
-
1.
Το πιο πάνω παράδειγμα ανήκει σε μια ευρεία κατηγορία προβλημάτων όπου έχουμε ισοπίθανα στοιχειώδη ενδεχόμενα, και η οποία θα εξετασθεί πιο αναλυτικά στο επόμενο κεφάλαιο.
-
2.
Τα στοιχειώδη ενδεχόμενα είναι πάντα ξένα μεταξύ τους. Κατά συνέπεια, αν το είναι πεπερασμένο, για να οριστεί το μέτρο πιθανότητας για όλα τα ενδεχόμενα αρκεί να οριστεί για τα στοιχειώδη ενδεχόμενα. Ο λόγος είναι απλός. Έστω ένα οποιοδήποτε ενδεχόμενο το οποίο αποτελείται από τα στοιχεία Εκφράζοντας το ως την ένωση των ξένων ενδεχομένων,
και χρησιμοποιώντας την τρίτη ιδιότητα του ορισμού του μέτρου πιθανότητας, μπορούμε να υπολογίσουμε την πιθανότητα του από τις πιθανότητες των στοιχειωδών ενδεχομένων ως,
-
3.
Όταν δύο ενδεχόμενα δεν είναι ξένα, τότε η πιθανότητα της ένωσής τους γενικά δεν ισούται με το άθροισμα των επιμέρους πιθανοτήτων. Π.χ., στο πιο πάνω παράδειγμα έχουμε ότι το αλλά φυσικά αφού !
Παράδειγμα 3.2
Σε ένα εργαστήριο πληροφορικής λειτουργούν τρία δίκτυα, από τα οποία, κατά τις τελευταίες 200 μέρες:
-
•
30% των ημερών, τουλάχιστον ένα δίκτυο δεν λειτουργεί,
-
•
10% των ημερών, ακριβώς δύο δεν λειτουργούν,
-
•
5% των ημερών, δεν λειτουργεί κανένα δίκτυο.
Εξετάζουμε το τι συμβαίνει μια «τυχαία» μέρα. Έστω το σύνολο όλων των διακοσίων ημερών, και έστω το ενδεχόμενο του να λειτουργούν ακριβώς από τα τρία δίκτυα, για Για παράδειγμα, το είναι το σύνολο των ημερών εκείνων κατά τις οποίες δύο δίκτυα λειτουργούν κι ένα όχι.
Από τις υποθέσεις μας έχουμε ότι και Επιπλέον, η πρώτη υπόθεση μας λέει ότι (γιατί;). Αλλά ποιες είναι οι πιθανότητες των και
Για το παρατηρούμε ότι, εφόσον το «λειτουργούν και τα τρία δίκτυα» είναι το αντίθετο του «τουλάχιστον ένα δεν λειτουργεί», διαισθητικά περιμένουμε να ισχύει ότι,
δηλαδή ότι,
Πράγματι, αυτή η διαισθητική υπόθεση είναι σωστή, όπως θα δούμε αμέσως μετά το παράδειγμα.
Για το τώρα, παρατηρούμε ότι το ενδεχόμενο του να μην λειτουργεί τουλάχιστον ένα δίκτυο μπορεί να εκφραστεί ως ένωση,
όπου τα και είναι εξ ορισμού ξένα. Άρα,
οπότε βρίσκουμε πως ή 15%.
Λήμμα 3.1
Για οποιοδήποτε ενδεχόμενο και οποιοδήποτε μέτρο πιθανότητας έχουμε:
| (3.1) |
Απόδειξη:
Έστω ότι το είναι υποσύνολο του χώρου πιθανότητας όπου, από τη δεύτερη ιδιότητα του ορισμού ενός μέτρου πιθανότητας, έχουμε
Προφανώς μπορούμε να εκφράσουμε το ως την ένωση όπου εξ ορισμού τα και είναι ξένα. Άρα, από την τρίτη ιδιότητα του ορισμού του μέτρου πιθανότητας, που αποδεικνύει τη ζητούμενη σχέση (3.1).
Παράδειγμα 3.3
Ρίχνουμε ένα δίκαιο ζάρι 2 φορές, οπότε ο χώρος πιθανότητας αποτελείται από τα 36 δυνατά αποτελέσματα:
Όπως και στο Παράδειγμα 3.1, εφόσον το ζάρι είναι δίκαιο, λογικά υποθέτουμε ότι το καθένα από τα 36 στοιχειώδη ενδεχόμενα έχει την ίδια πιθανότητα, δηλαδή 1/36. Θα υπολογίσουμε την πιθανότητα των εξής ενδεχομένων:
Για το έχουμε, από τις πιο πάνω υποθέσεις,
όπου και πάλι χρησιμοποιήσαμε το γεγονός ότι τα στοιχειώδη ενδεχόμενα είναι πάντοτε ξένα μεταξύ τους. Για το απλώς έχουμε, άρα υπάρχει διπλάσια πιθανότητα να φέρουμε ασόδυο από το να φέρουμε εξάρες.
Με την ίδια λογική, για το έχουμε,
δηλαδή μόλις αποδείξαμε το διαισθητικά προφανές – ότι η πιθανότητα του να φέρουμε 6 την πρώτη φορά είναι 1/6. Και ακολουθώντας πάλι την ίδια λογική, εύκολα υπολογίζουμε ότι, εφόσον το αποτελείται από 5 στοιχεία και όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα, Αυτή η παρατήρηση ισχύει πιο γενικά, όπως διατυπώνεται στο πιο κάτω λήμμα.
Λήμμα 3.2
Αν όλα τα στοιχειώδη ενδεχόμενα ενός (πεπερασμένου) χώρου πιθανότητας είναι ισοπίθανα, τότε η πιθανότητα ενός οποιουδήποτε ενδεχομένου είναι ίση με:
Απόδειξη:
Έστω ότι ο χώρος πιθανότητας αποτελείται από τα στοιχεία για έστω το μέτρο πιθανότητας, και έστω η πιθανότητα ενός οποιουδήποτε στοιχειώδους ενδεχομένου, δηλαδή για κάθε Από τις ιδιότητες του ορισμού του μέτρου πιθανότητας έχουμε,
άρα έχουμε
Έστω τώρα ένα οποιοδήποτε ενδεχόμενο που αποτελείται από στοιχεία. Τότε έχουμε,
3.2 Πέντε «κανόνες πιθανότητας»
Από τον ορισμό του μέτρου πιθανότητας και τα δύο λήμματα που αποδείξαμε πιο πάνω, προκύπτουν κάποιες βασικές ιδιότητες τις οποίες θα χρησιμοποιούμε συχνά. Για να αναφερόμαστε σε αυτές πιο εύκολα, τις παραθέτουμε περιληπτικά στην επόμενη σελίδα.
Απόδειξη:
Έστω δύο ενδεχόμενα Το μπορεί να εκφραστεί ως όπου το αποτελείται από τα στοιχεία του που δεν περιέχονται στο Άρα τα και είναι ξένα, και συνεπώς, από την τρίτη ιδιότητα του ορισμού του μέτρου πιθανότητας, αλλά αφού όλες οι πιθανότητες είναι εξ ορισμού μεγαλύτερες ή ίσες του μηδενός, αυτό συνεπάγεται ότι και μας δίνει την Ιδιότητα 2.
Εφόσον εξ ορισμού τα και είναι ξένα, από τον ορισμό του μέτρου πιθανότητας έχουμε,
άρα Και εφόσον για κάθε από την Ιδιότητα 2, Παρομοίως, οποιοδήποτε είναι υποσύνολο του άρα, και έχουμε αποδείξει την Ιδιότητα 1.
Η Ιδιότητα 3 είναι μέρος του ορισμού, και οι Ιδιότητες 4 και 5 προκύπτουν από το Λήμμα 3.1 και το Λήμμα 3.2 αντίστοιχα.
Για οποιοδήποτε μέτρο πιθανότητας :
-
1.
και για κάθε ενδεχόμενο
-
2.
Αν τότε
-
3.
Αν τα ενδεχόμενα είναι ξένα (δηλαδή για κάθε ), τότε:
-
4.
για κάθε ενδεχόμενο
- 5.
Αν όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα, τότε για κάθε ενδεχόμενο :
3.3 Γενικός ορισμός του μέτρου πιθανότητας
Αν ο χώρος πιθανότητας είναι διακριτός (δηλαδή είτε πεπερασμένος είτε άπειρος αλλά αριθμήσιμος), τότε ο ορισμός που δώσαμε για το μέτρο πιθανότητας σε αυτό το κεφάλαιο είναι μαθηματικά πλήρης και απολύτως επαρκής για όλες τις αντίστοιχες εφαρμογές. Αλλά για την περίπτωση άπειρων και μη αριθμήσιμων χώρων πιθανότητας, ο ορισμός αυτός είναι απαραίτητο να τροποποιηθεί. Ο λόγος μπορεί να εξηγηθεί από το εξής παράδειγμα.
Έστω ότι θέλουμε να ορίσουμε την έννοια ενός «τυχαίου πραγματικού αριθμού» στο διάστημα Σε αυτή την περίπτωση κάθε ενδεχόμενο είναι ένα υποσύνολο του διαστήματος και το περιγράφει το ενδεχόμενο ο τυχαίος αυτός αριθμός να ανήκει στο Για παράδειγμα, αν το λογικά θα θέλαμε να ορίσουμε ένα μέτρο πιθανότητας που να μας λέει ότι η πιθανότητα ένας τυχαίος πραγματικός αριθμός μεταξύ και να είναι μικρότερος ή ίσος με ισούται με Με άλλα λόγια, να έχει Γενικά, θα θέλαμε για κάθε υποδιάστημα του η τιμή του μέτρου πιθανότητας να ισούται με το μήκος αυτού του διαστήματος.
Εδώ συμβαίνει κάτι πραγματικά αξιοσημείωτο και μάλλον απροσδόκητο. Μπορεί να αποδειχθεί πως είναι ΑΔΥΝΑΤΟΝ να οριστεί ένα μέτρο πιθανότητας στο το οποίο να ικανοποιεί τις τρεις συνθήκες του ορισμού μας και επίσης να δίνει, για κάθε υποδιάστημα
Η βαθύτερη αιτία της δυσκολίας είναι η ύπαρξη κάποιων πολύ πολύπλοκων, κατά κάποιον τρόπο παθολογικών, υποσυνόλων του
Η λύση σε αυτό το πρόβλημα είναι να περιορίσουμε τα υποσύνολα του χώρου πιθανότητας στα οποία απαιτούμε να ορίζεται το μέτρο πιθανότητας. Αυτή η παρατήρηση αποτελεί την αφετηρία μιας μεγάλης υποπεριοχής της μαθηματικής ανάλυσης, η οποία ονομάζεται θεωρία μέτρου, αλλά με την οποία δεν θα ασχοληθούμε περαιτέρω επί του παρόντος και γενικά σε αυτό το βιβλίο. Αρκεί να θυμάστε πως, όταν ο χώρος πιθανότητας δεν είναι αριθμήσιμος, υπάρχουν κάποια σπανιότατα παθολογικά ενδεχόμενα για τα οποία δεν μπορούμε να ορίσουμε την πιθανότητά τους.
Περισσότερες (πολύ περισσότερες) πληροφορίες γι’ αυτό το ζήτημα και για τη θεωρία μέτρου εν γένει μπορείτε να βρείτε σε πιο προχωρημένα βιβλία μαθηματικής ανάλυσης ή πιθανοτήτων.
3.4 Ασκήσεις
-
1.
Η πιθανότητα της διαφοράς. Να δείξετε, χρησιμοποιώντας τους κανόνες πιθανότητας αυτού του κεφαλαίου, ότι για οποιαδήποτε δύο ενδεχόμενα :
Σημείωση. Το σύνολο περιλαμβάνει όλα τα στοιχεία του αν αφαιρέσουμε τα στοιχεία του γι’ αυτό συχνά καλείται η διαφορά του από το , και συμβολίζεται
-
2.
Περίεργα ζάρια. Έστω ένα (όχι απαραίτητα δίκαιο) ζάρι για το οποίο γνωρίζουμε ότι η πιθανότητα να έρθει ή είναι ενώ η πιθανότητα να έρθει ή είναι επίσης Ποια είναι η μέγιστη δυνατή και η ελάχιστη δυνατή τιμή για την πιθανότητα να έρθει Δώστε από ένα συγκεκριμένο παράδειγμα ενός μέτρου πιθανότητας για την καθεμία από τις ακραίες δυνατές τιμές αυτής της πιθανότητας.
-
3.
Τυχαία συνάντηση. Ο Σταύρος και ο Γιάννης έχουν ορίσει να συναντηθούν σε ένα μπαρ. Ο Σταύρος έχει έρθει στην ώρα του, αλλά για τον Γιάννη γνωρίζουμε ότι μπορεί να εμφανιστεί οποιαδήποτε στιγμή μέσα στις επόμενες δύο ώρες, χωρίς προτίμηση σε κάποια στιγμή ή διάστημα. Ορίζουμε τα ακόλουθα ενδεχόμενα: =«Ο Γιάννης έρχεται εντός της πρώτης ώρας», =«Ο Γιάννης έρχεται εντός του τελευταίου μισάωρου», =«Ο Γιάννης έρχεται με τουλάχιστον μισή ώρα καθυστέρηση».
-
(α’)
Ορίστε έναν κατάλληλο χώρο πιθανότητας και ένα μέτρο πιθανότητας, και υπολογίστε τις πιθανότητες των ενδεχόμενων
-
(β’)
Υπολογίστε τις πιθανότητες των ενδεχόμενων
-
(α’)
-
4.
Ένωση τριών ενδεχόμενων. Να δείξετε ότι, για οποιαδήποτε τρία ενδεχόμενα και
(3.2) -
5.
Ένας χώρος πιθανότητας με 3 στοιχεία. Ένα τυχαίο πείραμα έχει χώρο πιθανότητας το σύνολο Έστω πως κάποιο μέτρο πιθανότητας ικανοποιεί τις σχέσεις, και Χρησιμοποιήστε τους κανόνες πιθανότητας αυτού του κεφαλαίου για να υπολογίσετε τις πιθανότητες όλων των στοιχειωδών ενδεχομένων.
-
6.
Τι λένε οι πιθανοθεωρίστες στα παιδιά τους. Στην Αττική, το των εγκλημάτων συμβαίνει τη νύχτα, και το συμβαίνει μέσα στην Αθήνα. Αν μόνο των εγκλημάτων συμβαίνουν μέρα στην Αθήνα, τι ποσοστό συμβαίνει νύχτα στην Αθήνα; Τι ποσοστό συμβαίνει νύχτα έξω από την Αθήνα;
-
7.
Διαιρέτες. Επιλέγουμε έναν τυχαίο αριθμό από το σύνολο Ποια η πιθανότητα να:
-
(α’)
διαιρείται με το
-
(β’)
διαιρείται με το
-
(γ’)
διαιρείται και με το και με το
-
(δ’)
διαιρείται με τουλάχιστον ένα από τα δύο;
-
(ε’)
διαιρείται με το αλλά όχι με το
-
(α’)
-
8.
Άλλη μια τυχαία συνάντηση. Ο Σταύρος και ο Γιάννης έχουν δώσει ραντεβού σε ένα μπαρ, και έχουν συμφωνήσει να συναντηθούν εντός μίας συγκεκριμένης ώρας. Καθένας όμως μπορεί να έρθει οποιαδήποτε χρονική στιγμή μέσα σε αυτή την ώρα, χωρίς να δείχνει κάποια προτίμηση σε κάποια στιγμή ή εύρος στιγμών, και χωρίς να επηρεάζεται από το τι θα κάνει ο άλλος. Μοντελοποιήστε το χώρο πιθανότητας αυτού του πειράματος, ορίστε κάποιο μέτρο πιθανότητας που να συμφωνεί με το πραγματικό πρόβλημα, και ακολούθως χρησιμοποιήστε αυτό το μέτρο για να υπολογίσετε ποια είναι η πιθανότητα να μην περιμένει ο πρώτος που θα έρθει τον δεύτερο για περισσότερο από ένα τέταρτο της ώρας. [Υπόδειξη. Μελετήστε το τετράγωνο ]
-
9.
Το μέτρο πιθανότητας είναι συνεχής συνάρτηση.
-
(α’)
Έστω μια οποιαδήποτε ακολουθία ενδεχόμενων σε κάποιο χώρο πιθανότητας Έστω, επιπλέον, ότι τα «μεγαλώνουν», δηλαδή Ορίζουμε ως την (άπειρη) ένωσή τους, δηλαδή το σύνολο που αποτελείται από τα στοιχεία που ανήκουν σε τουλάχιστον ένα από τα Το συμβολίζεται ως:
Να δείξετε ότι, για οποιοδήποτε μέτρο πιθανότητας
-
(β’)
Έστω μια ακολουθία ενδεχόμενων που μικραίνουν, δηλαδή και έστω η άπειρη τομή τους, δηλαδή το σύνολο αποτελείται από όλα τα στοιχεία που ανήκουν σε όλα τα Το συμβολίζεται ως:
Να δείξετε ότι, για οποιοδήποτε μέτρο πιθανότητας
Παρατηρήστε ότι οι πιο πάνω ιδιότητες δείχνουν ότι το όριο στο αριστερό σκέλος υπάρχει, και ότι μπορούμε να αλλάξουμε τη σειρά του ορίου και της πιθανότητας, εφόσον βέβαια ορίζεται το όριο των συνόλων. Αυτή είναι μια ιδιότητα που χαρακτηρίζει τις συνεχείς συναρτήσεις και τα συνήθη όρια, αλλά η έννοια της συνέχειας μπορεί να γενικευτεί στο μέτρο πιθανότητας και τα πιο πάνω αποτελέσματα δείχνουν ότι η συνάρτηση είναι πράγματι «συνεχής».
Υπόδειξη. Για το πρώτο σκέλος, παρατηρήστε πως,
δηλαδή το σύνολο μπορεί να γραφεί σαν την ένωση ξένων μεταξύ τους ενδεχόμενων. Για το δεύτερο σκέλος, χρησιμοποιήστε το πρώτο.
-
(α’)
Κεφάλαιο 4 Πιθανότητες και συνδυαστική
[Επιστροφή στα περιεχόμενα]
Όπως είδαμε σε κάποια παραδείγματα των προηγουμένων κεφαλαίων, συχνά συναντάμε καταστάσεις όπου όλες οι δυνατές εκφάνσεις ενός τυχαίου πειράματος έχουν την ίδια πιθανότητα. Αυτά αποτελούν μια επιμέρους αλλά σημαντική κατηγορία προβλημάτων, και σε αυτό το κεφάλαιο θα δούμε πώς μπορούν να επιλυθούν εύκολα με τη χρήση κάποιων απλών αποτελεσμάτων της συνδυαστικής. Η αφετηρία μας είναι ο κανόνας πιθανότητας τον οποίο είδαμε στο προηγούμενο κεφάλαιο:
Αν όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα, τότε, για κάθε ενδεχόμενο :
Για να εφαρμοστεί αυτός ο κανόνας, προφανώς πρέπει να είμαστε σε θέση να υπολογίσουμε το πλήθος των στοιχείων που περιέχονται σε διάφορα σύνολα – συγκεκριμένα στο χώρο πιθανότητας και στο ενδεχόμενο το οποίο μας ενδιαφέρει σε κάθε περίπτωση. Η συνδυαστική είναι ο μαθηματικός τομέας που μας προσφέρει ακριβώς τα εργαλεία που χρειαζόμαστε για αυτούς τους υπολογισμούς. Πιο κάτω θα δούμε μια σειρά από σχετικά απλά αποτελέσματα της συνδυαστικής, και μέσα από παραδείγματα θα δείξουμε με ποιους τρόπους αυτά τα αποτελέσματα χρησιμοποιούνται για την απάντηση ερωτημάτων σε προβλήματα πιθανοτήτων.
4.1 Διατάξεις, συνδυασμοί, επιλογές και πιθανότητες
Ξεκινάμε υπενθυμίζοντας μια πολύ απλή ιδιότητα:
και το πλήθος των στοιχείων του προφανώς ικανοποιεί:
Παράδειγμα 4.1
(α’) Εφόσον η ρίψη ενός ζαριού έχει 6 δυνατά αποτελέσματα, οι δύο διαδοχικές ρίψεις έχουν δυνατά αποτελέσματα, οι τρεις διαδοχικές ρίψεις έχουν δυνατά αποτελέσματα, και γενικά οι διαδοχικές ρίψεις έχουν δυνατά αποτελέσματα.
(β’) Επιλέγουμε έναν από τους 5 υπολογιστές ενός εργαστηρίου (5 δυνατά αποτελέσματα) και αποφασίζουμε να του εγκαταστήσουμε λειτουργικό σύστημα windows ή linux (2 δυνατά αποτελέσματα). Συνολικά υπάρχουν δυνατά αποτελέσματα.
Παράδειγμα 4.2
Τρία άτομα, ας τους πούμε Α, Β και Γ, τρέχουν σε έναν αγώνα 100 μέτρων. Υποθέτουμε ότι η τελική κατάταξη είναι εντελώς τυχαία. Ποια είναι η πιθανότητα να κερδίσει ο Β;
Κατ’ αρχάς παρατηρούμε ότι ο χώρος πιθανότητας είναι το σύνολο όλων των δυνατών διατάξεων των Α, Β και Γ:
όπου, για παράδειγμα, το 132 μας λέει πως ο Α βγήκε πρώτος, ο Β τρίτος και ο Γ δεύτερος. Το ενδεχόμενο που μας ενδιαφέρει, δηλαδή το να κερδίσει ο Β, αντιστοιχεί στο σύνολο Εφόσον «η τελική κατάταξη είναι εντελώς τυχαία», υποθέτουμε ότι όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα, και από τον κανόνα πιθανότητας έχουμε,
όπως είναι και διαισθητικά προφανές.
Εδώ απλώς απαριθμήσαμε όλες τις δυνατές κατατάξεις για τα 3 άτομα. Αλλά αν, αντί για τρεις, συμμετείχαν στον αγώνα 100 άνθρωποι, πόσες δυνατές κατατάξεις θα υπήρχαν; Μπορούμε να σκεφτούμε την τελική κατάταξη ως το αποτέλεσμα του συνδυασμού 100 επιμέρους «πειραμάτων»: Για την πρώτη θέση έχουμε 100 επιλογές. Έχοντας αποφασίσει ποιος είναι πρώτος, για τη δεύτερη θέση έχουμε 99 επιλογές, κ.ο.κ. Έτσι, εφαρμόζοντας διαδοχικά την Ιδιότητα 4.1, για την τελική κατάταξη έχουμε,
δυνατές κατατάξεις, δηλαδή δυνατούς τρόπους που μπορούν να διαταχθούν 100 άτομα. Με το ίδιο ακριβώς σκεπτικό καταλήγουμε στο εξής συμπέρασμα:
Ιδιότητα 4.2
Υπάρχουν δυνατές διατάξεις αντικειμένων.
Παρατήρηση: Θυμίζουμε πως για κάθε ακέραιο αριθμό το «Ν παραγοντικό» συμβολίζεται ως και ορίζεται ως το γινόμενο Επίσης, για λόγους ευκολίας ορίζουμε συμβατικά το
Παράδειγμα 4.3
Έστω ότι στις βουλευτικές εκλογές συμμετέχουν 42 κόμματα. Άρα υπάρχουν δυνατές κατατάξεις, αλλά πόσες δυνατές κατατάξεις έχουμε για τα 3 πρώτα κόμματα; Μπορούμε να σκεφτούμε το τελικό αποτέλεσμα ως το συνδυασμό τριών επιμέρους «πειραμάτων»: Για την πρώτη θέση έχουμε 42 επιλογές. Έχοντας αποφασίσει ποιο κόμμα είναι πρώτο, για τη δεύτερη θέση έχουμε 41, και παρομοίως για την τρίτη 40 επιλογές. Εφαρμόζοντας διαδοχικά την Ιδιότητα 4.1, το πλήθος των τελικών κατατάξεων για τα τρία πρώτα κόμματα είναι,
Γενικά, μπορούμε να ρωτήσουμε πόσες διαφορετικές διατάξεις μπορούμε να πετύχουμε, επιλέγοντας από αντικείμενα. Με το ίδιο σκεπτικό, έχουμε επιλογές για το πρώτο, για το δεύτερο, κ.ο.κ., μέχρι το αντικείμενο για το οποίο έχουμε επιλογές. Άρα, από την Ιδιότητα 4.1, βρίσκουμε πως το πλήθος των τελικών διατάξεων είναι:
Έχουμε έτσι αποδείξει το εξής:
Παράδειγμα 4.4
Έστω ότι έχουμε μια συνηθισμένη τράπουλα 52 φύλλων. Από την Ιδιότητα 4.2 υπάρχουν δυνατές διατάξεις για τα φύλλα της τράπουλας!
Αν επιλέξουμε 3 φύλλα στην τύχη, πόσες δυνατές (διατεταγμένες) τριάδες υπάρχουν; Από την Ιδιότητα 4.3, το πλήθος τους είναι,
Αν υποθέσουμε τώρα ότι η επιλογή των τριών φύλλων είναι εντελώς τυχαία, ποια είναι η πιθανότητα του ενδεχομένου να επιλέξουμε τρεις άσους; Εδώ ο χώρος πιθανότητας αποτελείται από όλες τις δυνατές τριάδες φύλλων, που, όπως υπολογίσαμε, είναι και εφόσον η επιλογή είναι εντελώς τυχαία υποθέτουμε ότι όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα. Ως υποσύνολο του το ενδεχόμενο αποτελείται από όλες τις δυνατές τριάδες άσων. Η Ιδιότητα 4.3 λοιπόν μας λέει ότι, εφόσον εξετάζουμε τις διατάξεις φύλλων που μπορούν να επιλεχθούν από (δηλαδή από τους τέσσερις άσους), έχουμε Άρα, από τον κανόνα πιθανότητας έχουμε,
Παράδειγμα 4.5
Αν επιλέξουμε 5 άτομα από μια ομάδα 100 ατόμων, η Ιδιότητα 4.3 μας λέει πως υπάρχουν,
Αλλά αν δεν μας ενδιαφέρει η διάταξη, δηλαδή η σειρά με την οποία επιλέγουμε τα 5 άτομα, πόσες διαφορετικές πεντάδες υπάρχουν; Γενικά, πόσες ομάδες αντικειμένων μπορούν να προκύψουν, όταν αυτά επιλέγονται από αντικείμενα; Έστω ότι το πλήθος τους είναι δηλαδή υπάρχουν μη διατεταγμένες ομάδες αντικειμένων. Από την Ιδιότητα 4.2, κάθε τέτοια ομάδα μπορεί να διαταχθεί με τρόπους. Άρα, το συνολικό πλήθος των διατεταγμένων ομάδων είναι Αλλά, από την Ιδιότητα 4.3, αυτό ισούται με Άρα έχουμε,
Έχουμε λοιπόν αποδείξει:
Ιδιότητα 4.4
Το πλήθος όλων των δυνατών συνδυασμών (ή μη διατεταγμένων επιλογών) αντικειμένων που επιλέγονται από αντικείμενα ισούται με,
όπου το είναι ο συνήθης διωνυμικός συντελεστής.
Παράδειγμα 4.6
Όπως στο Παράδειγμα 4.5, επιλέγουμε 5 άτομα από 100. Αν δεν μας ενδιαφέρει η σειρά επιλογής, υπάρχουν,
δυνατές πεντάδες που μπορούμε να επιλέξουμε.
Έστω τώρα ότι τα 100 άτομα αποτελούνται από 40 άνδρες και 60 γυναίκες, και ότι η επιλογή μας είναι εντελώς τυχαία. Θα εξετάσουμε τα εξής ερωτήματα:
-
•
Πόσες πεντάδες μπορούν να σχηματιστούν με 2 άνδρες και 3 γυναίκες;
-
•
Ποια η πιθανότητα να επιλέξουμε μόνο μία γυναίκα;
-
•
Ποια η πιθανότητα να μην επιλέξουμε καμία γυναίκα;
Για το πρώτο ερώτημα παρατηρούμε ότι το πείραμα μπορεί να χωριστεί σε δύο μέρη. Βάσει της Ιδιότητας 4.4 μπορούμε να επιλέξουμε 2 άνδρες από τους 40 με τρόπους, και 3 γυναίκες από τις 60 με τρόπους. Άρα, ο συνδυασμός αυτών των δύο επιλογών, βάσει της Ιδιότητας 4.1, έχει,
δυνατά αποτελέσματα.
Για τα άλλα δύο ερωτήματα, ορίζουμε το χώρο πιθανότητας ως το σύνολο όλων των δυνατών (μη διατεταγμένων) επιλογών 5 ατόμων από 100 (εφόσον σε αυτό το πρόβλημα δεν μας απασχολεί η σειρά με την οποία επιλέγονται), οπότε βάσει της Ιδιότητας 4.4 βρίσκουμε όπως παραπάνω ότι Ορίζουμε επίσης και τα δύο ενδεχόμενα,
Με την ίδια συλλογιστική που χρησιμοποιήσαμε για το πρώτο ερώτημα έχουμε, από τις Ιδιότητες 4.4 και 4.1, ότι,
[Παρατηρήστε πως στον υπολογισμό του δεν συμπεριλάβαμε την επιλογή της «καμίας γυναίκας από τις 60», αλλά αυτό δεν επηρεάζει το αποτέλεσμα διότι το πλήθος των τρόπων με τους οποίους μπορεί να γίνει αυτή η επιλογή ισούται με ]
Αφού θεωρούμε ότι η επιλογή γίνεται «εντελώς τυχαία», μπορούμε να εφαρμόσουμε τον πέμπτο κανόνα πιθανότητας, έτσι ώστε,
Παράδειγμα 4.7
Επιλέγουμε τυχαία 3 βιβλία από 10, που αποτελούνται από 5 συγγράμματα μαθημάτων και 5 εγχειρίδια (manual) υπολογιστών. Ποια η πιθανότητα να είναι όλα εγχειρίδια; Να είναι δύο εγχειρίδια κι ένα σύγγραμμα;
Ακριβώς όπως και στο προηγούμενο παράδειγμα, εφόσον δεν μας ενδιαφέρει η σειρά με την οποία επιλέγονται τα βιβλία, ορίζουμε,
και υπολογίζουμε,
οπότε έχουμε τις πιθανότητες,
Παράδειγμα 4.8
Σε κάποιες εκλογές είναι υποψήφιοι 3 φοιτητές και 7 καθηγητές. Εκλέγονται τυχαία τρεις και ζητάμε την πιθανότητα να εκλεγούν τουλάχιστον ένας φοιτητής και τουλάχιστον ένας καθηγητής. Πάλι με την ίδια συλλογιστική όπως στα δύο παραπάνω παραδείγματα, εφόσον δεν μας ενδιαφέρει η διάταξη των τριών ατόμων, υπολογίζουμε τη ζητούμενη πιθανότητα ως,
επειδή τα δύο ενδεχόμενα στη δεύτερη γραμμή παραπάνω είναι ξένα. Άρα, τελικά έχουμε,
Ας υποθέσουμε τώρα πως, ανάλογα με τη σειρά εκλογής, αυτοί που εκλέγονται παίρνουν διαφορετικούς ρόλους σε μια επιτροπή – ο πρώτος γίνεται πρόεδρος, ο δεύτερος γραμματέας και ο τρίτος ταμίας. Ποια είναι η πιθανότητα να εκλεγεί φοιτητής πρόεδρος, και καθηγητές γραμματέας και ταμίας; Εφόσον εδώ μας απασχολεί και η σειρά με την οποία επιλέγονται τα «αντικείμενα» (δηλαδή τα μέλη της επιτροπής), υπολογίζουμε αυτή την πιθανότητα βάσει του χώρου πιθανότητας ο οποίος περιέχει όλες τις διατεταγμένες τριάδες, δηλαδή περιέχει στοιχεία. Άρα, η πιθανότητα του ενδεχομένου που μας ενδιαφέρει, βάσει της Ιδιότητα 4.3 ισούται με:
Παράδειγμα 4.9
Σε 3 επεξεργαστές πρέπει να κατανεμηθούν 12 διεργασίες, δίνοντας 4 διεργασίες στον κάθε επεξεργαστή. Με πόσους τρόπους μπορεί να γίνει αυτός ο καταμερισμός;
Για να απαντήσουμε, χωρίζουμε το πρόβλημα σε τρία μέρη. Αρχικά επιλέγουμε 4 διεργασίες από τις 12 για τον πρώτο επεξεργαστή, πράγμα που (βάσει της Ιδιότητας 4.4) μπορεί να γίνει με τρόπους. Κατόπιν, επιλέγουμε 4 διεργασίες από τις υπόλοιπες 8 για τον δεύτερο επεξεργαστή, πράγμα που μπορεί να γίνει με τρόπους. Και τέλος οι 4 διεργασίες που απομένουν πηγαίνουν στον τρίτο επεξεργαστή. Χρησιμοποιώντας την Ιδιότητα 4.1, συνολικά αυτός ο καταμερισμός μπορεί να γίνει με:
Στη γενική του μορφή, ακριβώς ο ίδιος συλλογισμός μάς δίνει:
Ιδιότητα 4.5
Για να μοιραστούν αντικείμενα σε ομάδες, όπου η πρώτη αποτελείται από αντικείμενα, η δεύτερη από αντικείμενα κ.ο.κ. ως την ομάδα η οποία αποτελείται από αντικείμενα, υπάρχουν,
όπου το είναι ο πολυωνυμικός συντελεστής. [Δεδομένου φυσικά ότι το άθροισμα ].
Παρατήρηση: Αν έχουμε μόνο ομάδες και αντικείμενα, τότε για αναγκαστικά θα έχουμε και η Ιδιότητα 4.5 λέει πως υπάρχουν τρόποι να μοιράσουμε αντικείμενα σε δύο ομάδες των και αντίστοιχα. Αυτό είναι ταυτόσημο με το περιεχόμενο της Ιδιότητας 4.4, άρα η Ιδιότητα 4.5 αποτελεί γενίκευση της 4.4.
Παράδειγμα 4.10
Έχουμε 20 υπολογιστές, που αποτελούνται από 10 PC και 10 Apple, και τους μοιράζουμε τυχαία σε τρία clusters, που αποτελούνται από 10, 5 και 5 υπολογιστές αντίστοιχα. Ποιες είναι οι πιθανότητες των ενδεχομένων και πιο κάτω;
Ο χώρος πιθανότητας που περιγράφει αυτό το πείραμα, αποτελείται από όλους τους δυνατούς τρόπους με τους οποίους 20 αντικείμενα μπορούν να χωριστούν σε τρεις ομάδες των 10, 5 και 5 αντικειμένων. Άρα, από την Ιδιότητα 4.5, έχουμε,
Επιπλέον, οι υπολογιστές κατατάσσονται σε clusters τυχαία, οπότε υποθέτουμε ότι όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα και θα χρησιμοποιήσουμε και πάλι τον πέμπτο κανόνα πιθανότητας για να υπολογίσουμε την πιθανότητα του και του
Για το παρατηρούμε πως «όλα τα PC στο ίδιο cluster» είναι ακριβώς ισοδύναμο με το «όλα τα PC στο πρώτο cluster». Άρα, το πλήθος των στοιχείων του ισούται με το πλήθος των τρόπων που μπορούν τα 10 Apple να μοιραστούν σε δύο clusters με 5 το καθένα, δηλαδή Συνεπώς,
Τέλος, για το έχουμε όλους τους δυνατούς τρόπους με τους οποίους τα 10 PC μπορούν να μοιραστούν σε 3 clusters με αναλογία 4-3-3, σε συνδυασμό με όλους τους τρόπους με τους οποίους τα 10 Apple μπορούν να μοιραστούν σε 3 clusters με αναλογία 6-2-2. Άρα:
4.2 Πέντε «κανόνες αρίθμησης»
Στο κεφάλαιο αυτό ως τώρα διατυπώσαμε κάποιες βασικές ιδιότητες της συνδυαστικής τις οποίες θα χρησιμοποιούμε συχνά. Για να αναφερόμαστε σε αυτές πιο εύκολα, τις παραθέτουμε περιληπτικά πιο κάτω.
-
1.
Αν ένα πείραμα έχει δυνατά αποτελέσματα και ένα άλλο δυνατά αποτελέσματα, τότε ο συνδυασμός τους έχει δυνατά αποτελέσματα.
-
2.
Υπάρχουν δυνατές διατάξεις αντικειμένων.
-
3.
Υπάρχουν
δυνατές διατάξεις αντικειμένων που επιλέγονται από
-
4.
Υπάρχουν
δυνατοί συνδυασμοί (ή μη διατεταγμένες επιλογές) αντικειμένων που επιλέγονται από αντικείμενα.
-
5.
Υπάρχουν
δυνατοί συνδυασμοί βάσει των οποίων μπορούν να μοιραστούν αντικείμενα σε ομάδες, όπου η πρώτη αποτελείται από αντικείμενα, η δεύτερη από αντικείμενα κ.ο.κ. ως την ομάδα η οποία αποτελείται από αντικείμενα [για ].
4.3 Ασκήσεις
-
1.
Μέτρημα. Πόσες δυνατές εκδοχές υπάρχουν στο καθένα από τα παρακάτω πειράματα;
-
(α’)
Επιλέγουμε με τη σειρά από αντικείμενα, χωρίς επανατοποθέτηση.
-
(β’)
Στρίβουμε ένα νόμισμα φορές.
-
(γ’)
Επιλέγουμε από άτομα για μια δημοσκόπηση, χωρίς επανατοποθέτηση.
-
(δ’)
Ρίχνουμε ένα ζάρι φορές.
-
(ε’)
Βάζουμε ανθρώπους να κάτσουν σε μια σειρά.
-
(στ’)
Μοιράζουμε με τη σειρά φύλλα από μια συνηθισμένη τράπουλα φύλλων.
-
(ζ’)
Ρίχνουμε ένα νόμισμα φορές και ένα ζάρι φορές.
-
(α’)
-
2.
Επιλογές με επανατοποθέτηση. Ο κανόνας αρίθμησης λέει πως, αν επιλέξουμε αντικείμενα από χωρίς επανατοποθέτηση, υπάρχουν ομάδες αντικειμένων που μπορούμε να επιλέξουμε. Τι θα γινόταν αν επιλέγαμε αντικείμενα ανάμεσα σε επιτρέποντας την επανατοποθέτηση (και χωρίς να έχει σημασία η σειρά επιλογής); Μερικά παραδείγματα:
-
(α’)
Για να φτιάξουμε μια πίτσα, επιλέγουμε υλικά από διαθέσιμα, χωρίς όμως να μας νοιάζει ποιο θα μπει πρώτο, και επιτρέπεται να βάλουμε πολλές δόσεις από κάτι, μπορούμε, για παράδειγμα, να βάλουμε διπλό τυρί.
-
(β’)
Πρέπει να αγοράσουμε 15 αρκουδάκια επιλέγοντας από 5 διαφορετικά είδη, και μπορούμε να αγοράσουμε πολλές φορές το ίδιο είδος.
-
(α’)
-
3.
1-2-Χ. Η ομάδα μας παίζει στην έδρα της διαδοχικά παιχνίδια με αντίπαλες ομάδες. Με πόσους τρόπους μπορούμε να έχουμε νίκες (δηλαδή «1»), ισοπαλίες (δηλαδή «Χ»), και ήττες (δηλαδή «2»);
-
4.
Τράπουλα. Μοιράζουμε στην τύχη φύλλα από μια συνηθισμένη τράπουλα φύλλων. Ποια η πιθανότητα να περιέχει η μοιρασιά:
-
(α’)
κανέναν άσο;
-
(β’)
το πολύ τρεις άσους;
-
(α’)
-
5.
Poker. Ένας παίκτης του πόκερ παίρνει φύλλα από μια κανονική τράπουλα 52 φύλλων. Ποια είναι η πιθανότητα να έχει:
-
(α’)
καρέ (δηλαδή 4 ίδια φύλλα, για παράδειγμα άσους ή ντάμες);
-
(β’)
φουλ (δηλαδή ένα ζευγάρι και μία τριάδα, για παράδειγμα άσους και ρηγάδες);
-
(γ’)
χρώμα (δηλαδή όλα κούπες ή όλα σπαθιά ή όλα μπαστούνια ή όλα καρό);
-
(α’)
-
6.
Ξενοδοχείο Ακρόπολις. Έξι φίλοι συμφωνούν να συναντηθούν στο ξενοδοχείο Ακρόπολις των Αθηνών. Συμβαίνει όμως να υπάρχουν ξενοδοχεία με το ίδιο όνομα. Κάθε ένας από τους φίλους διαλέγει στην τύχη να πάει σε ένα από αυτά.
-
(α’)
Ποιος είναι εδώ ο χώρος πιθανότητας; Πόσα στοιχεία περιλαμβάνει;
-
(β’)
Ποια είναι η πιθανότητα να συναντηθούν ανά ζεύγη (εννοείται σε τρία διαφορετικά ξενοδοχεία);
-
(γ’)
Ποια είναι η πιθανότητα να βρεθούν δύο μόνοι τους και άλλοι τέσσερις σε δύο ζεύγη;
-
(α’)
-
7.
Superleague. H Superleague έχει 16 ομάδες και όλες πρέπει να παίξουν με όλες, ακριβώς δύο φορές, μία φορά σε κάθε έδρα. Πόσοι αγώνες πρέπει να γίνουν συνολικά;
-
8.
Λόττο. Για να κερδίσουμε το Λόττο πρέπει να προβλέψουμε αριθμούς ανάμεσα στους χωρίς διάταξη και χωρίς επανατοποθέτηση. Ποια είναι η πιθανότητα να κερδίσουμε παίζοντας μόνο μία στήλη;
-
9.
Εύκολες και δύσκολες ασκήσεις. Σε ένα μάθημα οι φοιτητές χωρίζονται σε τρεις ομάδες, και στην κάθε ομάδα δίνονται ασκήσεις οι οποίες επιλέγονται τυχαία, και χωρίς επανατοποθέτηση, από ένα σύνολο ασκήσεων. Αν, από τις ασκήσεις, οι είναι εύκολες και οι δύσκολες, ποια είναι η πιθανότητα και οι τρεις ομάδες να έχουν από μία εύκολη άσκηση;
-
10.
Μέτρημα αποτελεσμάτων.
-
(α’)
Πόσοι διαφορετικοί αναγραμματισμοί μπορούν να γίνουν με τα γράμματα της λέξης ΚΥΠΡΟΣ; Αντίστοιχα, πόσοι για τη λέξη ΣΤΑΥΡΟΣ; Για τη λέξη ΣΙΣΙΝΙ; (Οι αναγραμματισμοί δεν χρειάζεται να υπάρχουν στο λεξικό!)
-
(β’)
Μια ομάδα χορού περιλαμβάνει 12 γυναίκες και 7 άντρες. Με πόσους διαφορετικούς τρόπους μπορούμε να σχηματίσουμε 3 ζευγάρια, καθένα αποτελούμενο από μία γυναίκα και έναν άντρα;
-
(γ’)
Με την παραγγελία μιας πίτσας μπορούμε να επιλέξουμε από υλικά. Πόσοι συνδυασμοί υπάρχουν αν τα υλικά μπορούν να επαναλαμβάνονται; Πόσοι συνδυασμοί υπάρχουν αν δεν επαναλαμβάνονται; [Και στις δυο περιπτώσεις, δεν έχει σημασία η σειρά επιλογής των υλικών.]
-
(α’)
Κεφάλαιο 5 Ανεξαρτησία και δεσμευμένη πιθανότητα
[Επιστροφή στα περιεχόμενα]
Ας πούμε πως ένας μετεωρολόγος μάς πληροφορεί ότι, με βάση τα ιστορικά στατιστικά στοιχεία του καιρού στην Αθήνα, βρέχει μία στις 9 μέρες. Αν για κάποιο λόγο μάς ενδιαφέρει τι καιρό κάνει τις Κυριακές (γιατί, π.χ., τις Κυριακές κάνουμε πικ-νικ στην Πάρνηθα), λογικά θα υποθέσουμε ότι μία στις 9 Κυριακές βρέχει. Αυτός ο συλλογισμός ισχύει γιατί έχουμε, έμμεσα, υποθέσει πως το αν βρέχει ή όχι σήμερα είναι ανεξάρτητο από το ποια μέρα της εβδομάδας είναι.
Αντίθετα, αν μας ενδιαφέρει ακριβώς τι καιρό κάνει τις μέρες που έχει συννεφιά, θα ήταν λάθος να υποθέσουμε ότι μία στις 9 συννεφιασμένες μέρες βρέχει – το ποσοστό θα είναι προφανώς μεγαλύτερο, γιατί η συννεφιά δεν είναι ανεξάρτητη από τη βροχή.
Το κεντρικό αντικείμενο αυτού του κεφαλαίου είναι η μαθηματική περιγραφή του πότε δύο ενδεχόμενα είναι ανεξάρτητα, και η μελέτη του πώς επηρεάζονται οι πιθανότητες δύο ενδεχομένων από το εάν αυτά είναι ή δεν είναι ανεξάρτητα. Παράλληλα, θα διατυπώσουμε και κάποιους ακόμα κανόνες πιθανότητας, οι οποίοι συμπληρώνουν εκείνους που είδαμε στο Κεφάλαιο 3.
5.1 Ανεξάρτητα ενδεχόμενα και δεσμευμένη πιθανότητα
Παράδειγμα 5.1
Ρίχνουμε ένα δίκαιο ζάρι 2 φορές. Όπως στο Παράδειγμα 3.3, ο χώρος πιθανότητας αποτελείται από τα 36 δυνατά αποτελέσματα των δύο ρίψεων και όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα. Ορίζουμε όπως πριν τα ενδεχόμενα,
και επιπλέον το ενδεχόμενο όπου παρατηρούμε ότι το μπορεί να εκφραστεί ως
Για τις πιθανότητες αυτών των ενδεχομένων, χρησιμοποιώντας τον πέμπτο κανόνα πιθανότητας, εύκολα υπολογίζουμε:
Από αυτό το αποτέλεσμα προκύπτει η σχέση,
δηλαδή Αυτή είναι μια πολύ σημαντική παρατήρηση, αλλά εξίσου σημαντικό είναι να παρατηρήσουμε πως αυτή η σχέση δεν ισχύει για οποιαδήποτε δύο ενδεχόμενα. Για παράδειγμα,
Ορισμός 5.1 (Ανεξάρτητα
ενδεχόμενα)
Δύο ενδεχόμενα και είναι στατιστικά ανεξάρτητα, ή απλά, ανεξάρτητα, αν και μόνο αν:
Ο κάθε κανόνας πιθανότητας και ο κάθε κανόνας αρίθμησης που έχουμε δει ως τώρα αντιστοιχούν σε κάποιο συγκεκριμένο μαθηματικό αποτέλεσμα (και το ίδιο ισχύει για τους κανόνες πιθανότητας 7–10, που θα δούμε στη συνέχεια). Αντίθετα, ο κανόνας πιθανότητας που θα διατυπώσουμε τώρα, μας παρέχει έναν τρόπο για να «μοντελοποιούμε» κάποια προβλήματα, δηλαδή μας δίνει μια γέφυρα μεταξύ της διαισθητικής περιγραφής ενός παραδείγματος και της αντίστοιχης αυστηρά μαθηματικής διατύπωσής του.
Παράδειγμα 5.2
Ένα δίκτυο κινητής τηλεφωνίας εξυπηρετεί 30 συνδρομητές στο κέντρο μιας πόλης και 20 συνδρομητές στην περιφέρεια. Από τους 30 του κέντρου, οι 3 έχουν συσκευές Nokia και οι 27 Ericsson, ενώ στην περιφέρεια υπάρχουν 15 Nokia και 5 Ericsson. Επιλέγουμε τυχαία έναν συνδρομητή από την κάθε περιοχή, και εξετάζουμε τα ενδεχόμενα:
Εφόσον τα δύο ενδεχόμενα αντιστοιχούν σε δύο διαφορετικές επιλογές, είναι φυσικό να υποθέσουμε πως είναι λογικά ανεξάρτητα. Σε αυτό το απλό παράδειγμα, η ανεξαρτησία τους μπορεί εύκολα και να επιβεβαιωθεί μαθηματικά, χωρίς να χρειαστούμε τον κανόνα πιθανότητας 6.
Μια που οι επιλογές είναι τυχαίες, τα στοιχειώδη ενδεχόμενα που αντιστοιχούν σε αυτά τα δύο «πειράματα» είναι ισοπίθανα, οπότε, από τον κανόνα πιθανότητας 5, έχουμε,
Αν όμως εξετάσουμε τις δύο επιλογές ως ένα πείραμα, τότε υπάρχουν συνολικά δυνατές επιλογές, ενώ το ενδεχόμενο δηλαδή να επιλέξουμε συσκευή Nokia και τις δύο φορές, περιέχει στοιχεία. Άρα,
και συνεπώς τα είναι πράγματι ανεξάρτητα.
Παράδειγμα 5.3
Έστω ότι στρίβουμε 4 φορές ένα νόμισμα, το οποίο έρχεται Κορώνα με πιθανότητα για κάποιο (γνωστό σε μας) Εδώ ο χώρος πιθανότητας αποτελείται από τα δυνατά αποτελέσματα (π.χ., ΚΓΚΚ ή ΓΓΓΚ κ.ο.κ.) των τεσσάρων ρίψεων. Αλλά, αν το νόμισμα δεν είναι δίκαιο (δηλαδή αν το ) τα στοιχειώδη ενδεχόμενα δεν είναι ισοπίθανα, οπότε δεν μπορούμε να χρησιμοποιήσουμε τον κανόνα πιθανότητας 5 για τους υπολογισμούς πιθανοτήτων.
Από την άλλη, λογικά μπορούμε να θεωρήσουμε ότι οι διαδοχικές ρίψεις είναι ανεξάρτητες μεταξύ τους, άρα μπορούμε να υπολογίσουμε την πιθανότητα ενός στοιχειώδους ενδεχομένου, όπως π.χ. του εφαρμόζοντας τον κανόνα πιθανότητας ως,
όπου θεωρούμε ότι τα τέσσερα παραπάνω ενδεχόμενα είναι (λογικά, και συνεπώς στατιστικά) ανεξάρτητα.
Υπενθυμίζουμε την Παρατήρηση 2 που ακολουθούσε το Παράδειγμα 3.1 στην αρχή του Κεφαλαίου 3, βάσει της οποίας (σε έναν διακριτό χώρο πιθανότητας), για να υπολογίσουμε την πιθανότητα οποιουδήποτε ενδεχομένου της μορφής αρκεί να γνωρίζουμε την πιθανότητα των στοιχειωδών ενδεχομένων οπότε:
Συνδυάζοντας αυτή την παρατήρηση με το γεγονός ότι, στο παράδειγμά μας, η ανεξαρτησία μάς επιτρέπει να υπολογίσουμε την πιθανότητα για κάθε στοιχειώδες ενδεχόμενο, καταλήγουμε στο ότι μπορούμε να υπολογίσουμε την πιθανότητα οποιουδήποτε ενδεχομένου.
Για παράδειγμα, αν «τέσσερις φορές το ίδιο αποτέλεσμα», τότε έχουμε:
Με τον ίδιο τρόπο θα προσεγγίσουμε και το επόμενο παράδειγμα.
Παράδειγμα 5.4
Έστω ότι υπάρχουν τρεις συνδέσεις σε ένα δίκτυο, και η καθεμία ενεργοποιείται, ανεξάρτητα από τις άλλες δύο, με πιθανότητα Εξετάζουμε ποιες συνδέσεις είναι ενεργές μία δεδομένη στιγμή, οπότε ο χώρος πιθανότητας αποτελείται από τα 8 στοιχεία που περιγράφουν τις αντίστοιχες 8 δυνατές καταστάσεις. Για παράδειγμα, το στοιχείο του περιγράφει την κατάσταση όπου οι δύο πρώτες συνδέσεις είναι ενεργές και η τρίτη ανενεργή.
Ποια είναι η πιθανότητα του ενδεχομένου «ακριβώς μία σύνδεση είναι ενεργή»; Εφόσον τα στοιχειώδη ενδεχόμενα εδώ δεν είναι ισοπίθανα, θα ακολουθήσουμε την ίδια λογική όπως και στο προηγούμενο παράδειγμα:
Και δεδομένου ότι η κάθε σύνδεση είναι ενεργή (με πιθ. 1/4) ή ανενεργή (με πιθ. 3/4) ανεξάρτητα από τις άλλες, έχουμε,
Παρατήρηση: Όταν δύο ενδεχόμενα είναι ανεξάρτητα, η ανεξαρτησία τους μας επιτρέπει να εκφράσουμε την πιθανότητα της τομής τους ως το γινόμενο των επιμέρους πιθανοτήτων τους, Στη γενική περίπτωση όπου τα μπορεί να μην είναι ανεξάρτητα, η αντίστοιχη ιδιότητα εκφράζεται με τη χρήση της δεσμευμένης πιθανότητας:
Ορισμός 5.2
(Δεσμευμένη πιθανότητα)
Για οποιαδήποτε δύο ενδεχόμενα έχουμε,
όπου η δεσμευμένη πιθανότητα του δεδομένου του ορίζεται αντιστοίχως ως
όποτε το ενδεχόμενο έχει μη μηδενική πιθανότητα.
Παρατηρήσεις:
-
1.
Αφού προφανώς για κάθε από τον ορισμό προκύπτει πως πάντοτε έχουμε:
(5.1) Όπως θα δούμε σε αρκετά απ’ τα πιο κάτω παραδείγματα, η σχέση (5.1) θα μας φανεί πολύ συχνά χρήσιμη. Γι’ αυτόν το λόγο καταγράφεται στην περίληψη στο τέλος του κεφαλαίου ως «κανόνας πιθανότητας ».
-
2.
Τα ενδεχόμενα είναι εξ ορισμού ανεξάρτητα αν και μόνο αν Αλλά από τη σχέση (5.1) βλέπουμε πως αυτό ισχύει αν και μόνο ή, ισοδύναμα, αν και μόνο αν
-
3.
Γενικά όπως, λόγου χάρη, στο αμέσως επόμενο παράδειγμα.
Παράδειγμα 5.5
Μια εταιρία πληροφορικής απασχολεί 40 Έλληνες και 30 αλλοδαπούς εργαζόμενους, εκ των οποίων κάποιοι είναι τεχνικοί και κάποιοι προγραμματιστές:
| Έλληνες | αλλοδαποί | |
|---|---|---|
| τεχνικοί | 22 | 25 |
| προγραμματιστές | 18 | 5 |
Επιλέγουμε τυχαία έναν από τους 70 εργαζομένους, και εξετάζουμε τα ενδεχόμενα:
Εφόσον η επιλογή είναι τυχαία, από τον κανόνα πιθανότητας 5 έχουμε,
Παρομοίως, η πιθανότητα να επιλέξουμε έναν Έλληνα τεχνικό είναι,
το οποίο προφανώς δεν ισούται με άρα τα ενδεχόμενα και δεν είναι ανεξάρτητα.
Έστω τώρα πως γνωρίζουμε ότι το άτομο που επελέγη είναι τεχνικός. Ποια η πιθανότητα να είναι Έλληνας; Από τον ορισμό της δεσμευμένης πιθανότητας, αυτό ισούται με:
Σε αυτό το παράδειγμα μπορούμε να ελέγξουμε αν το αποτέλεσμα συμφωνεί με τη διαίσθησή μας για το τι θα πει «πιθανότητα ενός ενδεχομένου δεδομένου ενός άλλου» ως εξής: Εφόσον γνωρίζουμε πως το επιλεγμένο άτομο είναι τεχνικός, διαισθητικά το πείραμά μας είναι ισοδύναμο με μια τυχαία επιλογή μεταξύ των τεχνικών. Και εφόσον από αυτούς τους 47 οι 22 είναι Έλληνες, λογικά θα περιμέναμε η πιθανότητα του να επιλέξουμε έναν Έλληνα να ισούται με 22/47, το οποίο πράγματι επιβεβαιώνεται από τον προηγούμενό μας υπολογισμό, ο οποίος έγινε βάσει του ορισμού.
Τέλος, μπορούμε να εξετάσουμε την «αντίστροφη» περίπτωση: Ποια είναι η πιθανότητα να επιλέξαμε τεχνικό δεδομένου ότι επιλέξαμε κάποιον Έλληνα; Όπως και πριν, από τον ορισμό της δεσμευμένης πιθανότητας βρίσκουμε,
Στο επόμενο λήμμα καταγράφουμε μια απλή ιδιότητα της δεσμευμένης πιθανότητας, η οποία είναι ανάλογη του κανόνα πιθανότητας για τις απλές πιθανότητες που είδαμε στο Κεφάλαιο 3.
Λήμμα 5.1
Για οποιαδήποτε δύο ενδεχόμενα έχουμε:
Απόδειξη:
Ξεκινώντας από τον ορισμό της δεσμευμένης πιθανότητας, βρίσκουμε,
όπου στο πρώτο βήμα εφαρμόσαμε τον Ορισμό 5.2, στο τρίτο βήμα χρησιμοποιήσαμε τον κανόνα πιθανότητας 3, στο τελευταίο βήμα εφαρμόσαμε τον Ορισμό 5.2, και στο τέταρτο βήμα χρησιμοποιήσαμε την προφανή ιδιότητα ότι το ενδεχόμενο μπορεί να εκφραστεί ως «τα στοιχεία του που ανήκουν στο μαζί με τα στοιχεία του που δεν ανήκουν στο », δηλαδή, και το γεγονός ότι τα ενδεχόμενα και είναι εξ ορισμού ξένα.
Παράδειγμα 5.6
11Στην πρώτη του ανάγνωση, αυτό το παράδειγμα ίσως φαίνεται δυσκολότερο και πιο πολύπλοκο από τα προηγούμενα. Όπως θα δούμε πιο κάτω σε αυτό το κεφάλαιο, αποτελεί ειδική περίπτωση της χρήσης ενός πολύ σημαντικού αποτελέσματος που θα διατυπώσουμε λεπτομερώς στον κανόνα πιθανότητας 10, τον λεγόμενο «κανόνα του Bayes».Έστω πως, σε έναν πληθυσμό 10 εκατομμυρίων ανθρώπων, 20,000 άτομα είναι φορείς του ιού HIV. Επιλέγεται ένα άτομο τυχαία και του γίνεται μια εξέταση για HIV, η οποία έχει ποσοστό σφάλματος 5%, δηλαδή,
H σημαντική ερώτηση εδώ για τον εξεταζόμενο είναι: Αν το αποτέλεσμα της εξέτασης είναι θετικό (δηλαδή υποστηρίζει πως ο εξεταζόμενος είναι φορέας του ιού), ποια είναι η πιθανότητα ο εξεταζόμενος να είναι πράγματι φορέας;
Ίσως φαίνεται εκ πρώτης όψεως «προφανές» πως η απάντηση είναι 95%, αλλά, όπως θα δούμε, η σωστή απάντηση είναι πολύ διαφορετική.
Για να προσεγγίσουμε το πρόβλημα συστηματικά, ορίζουμε τα ενδεχόμενα,
και καταγράφουμε τα δεδομένα του προβλήματος:
| (5.2) |
Η ζητούμενη πιθανότητα είναι η
Ξεκινάμε υπολογίζοντας την πιθανότητα του ενδεχομένου δηλαδή του να βγει θετικό το αποτέλεσμα της εξέτασης ενός τυχαία επιλεγμένου ατόμου. Εκφράζοντας το ως την ένωση δύο ξένων ενδεχομένων, έχουμε,
και χρησιμοποιώντας τη σχέση (5.1), που προέκυψε από τον ορισμό της δεσμευμένης πιθανότητας,
όπου στο δεύτερο βήμα χρησιμοποιήσαμε το Λήμμα 5.1 και τον κανόνα πιθανότητας 4. Αντικαθιστώντας τις τιμές των πιθανοτήτων (5.2),
| (5.3) |
Τώρα είμαστε σε θέση να απαντήσουμε το βασικό μας ερώτημα: Δεδομένου ότι η εξέταση βγήκε θετική, ποια η πιθανότητα να είναι φορέας του HIV ο εξεταζόμενος; Από τον ορισμό της δεσμευμένης πιθανότητας και τη σχέση (5.1), με τον ίδιο συλλογισμό όπως προηγουμένως βρίσκουμε:
Τέλος, αντικαθιστώντας τις τιμές των πιθανοτήτων από τα δεδομένα (5.2) και τον υπολογισμό (5.3), έχουμε,
Βλέπουμε, λοιπόν, πως η πιθανότητα ο εξεταζόμενος να είναι φορέας του HIV δεδομένου πως το αποτέλεσμα της εξέτασης είναι θετικό, είναι σημαντικά μικρότερη από την πρώτη μας διαισθητική απάντηση που ήταν βασισμένη στο σκεπτικό ότι για το 95% των περιπτώσεων η εξέταση δίνει το σωστό αποτέλεσμα! Η διαφορά αυτή προκύπτει από το ότι αρχικά δεν λάβαμε υπόψη μας πως ο εξεταζόμενος επιλέχθηκε τυχαία από έναν πληθυσμό στον οποίο πολύ σπάνια συναντάμε έναν φορέα του HIV. Η αρχική πιθανότητα (2 στους χίλιους) να είναι φορέας φυσικά αυξάνεται (στο 3.76%) λόγω του θετικού αποτελέσματος της εξέτασης, αλλά δεν φτάνει ως το 95% όπως αρχικά φανταζόμασταν.
5.2 Περαιτέρω ιδιότητες
Παράδειγμα 5.7
Σε ένα εργαστήριο υπάρχουν 150 PC, εκ των οποίων τα 120 είναι συνδεδεμένα στο internet, τα 45 είναι συνδεδεμένα με ένα δίκτυο εκτυπωτών, και 30 είναι και στα δύο δίκτυα. Επιλέγουμε ένα PC στην τύχη:
-
(i)
Αν διαπιστώσουμε ότι είναι συνδεδεμένο με το δίκτυο εκτυπωτών, ποια η πιθανότητα να είναι και στο internet;
-
(ii)
Ποια η πιθανότητα να είναι συνδεδεμένο σε τουλάχιστον ένα από τα δύο δίκτυα;
Εδώ ο χώρος πιθανότητας αποτελείται από τα 150 PC, και τα ενδεχόμενα που μας ενδιαφέρουν για το πρώτο ερώτημα είναι τα =«το επιλεγμένο PC είναι στο internet» και =«το επιλεγμένο PC είναι στο δίκτυο εκτυπωτών». Εφόσον η επιλογή είναι τυχαία, εφαρμόζοντας τον κανόνα πιθανότητας 5 βρίσκουμε τις πιθανότητες και
Για το πρώτο ερώτημα, από τον ορισμό της δεσμευμένης πιθανότητας έχουμε:
[Σε αυτό το απλό παράδειγμα, να ελέγξουμε την απάντηση και διαισθητικά: Εφόσον η επιλογή μας γίνεται «δεδομένου ότι το PC έχει εκτυπωτή», είναι σαν να ζητάμε την πιθανότητα να επιλέξουμε, από τα 45 PC που έχουν εκτυπωτή, ένα από εκείνα τα 30 που είναι και στο internet, συνεπώς η ζητούμενη πιθανότητα θα ισούται με ]
Για το ερώτημα (ii), έχουμε,
Για να υπολογίσουμε το πλήθος των στοιχείων του συνόλου παρατηρούμε πως ισχύει ότι,
δηλαδή προσθέτοντας τα στοιχεία του και του έχουμε τα στοιχεία της ένωσής τους, αλλά τα στοιχεία που ανήκουν και στα δύο σύνολα (δηλαδή στην τομή τους) συμπεριλαμβάνονται δύο φορές στο γι’ αυτόν το λόγο τα προσθέτουμε άλλη μία φορά στο δεξί μέρος της πιο πάνω σχέσης. Άρα έχουμε,
Παρατηρούμε πως ο πιο πάνω υπολογισμός αποδεικνύει και τη σχέση,
η οποία ισχύει και γενικά:
| (5.4) |
Απόδειξη:
Αρκεί απλά να εφαρμόσουμε δύο φορές τον κανόνα πιθανότητας 3: Η ένωση μπορεί να εκφραστεί ως η ένωση των δύο ξένων ενδεχομένων οπότε,
και αφού εξ ορισμού τα και είναι ξένα,
που μας δίνει την (5.4).
Παρατήρηση: Αν τα ενδεχόμενα είναι ξένα, τότε και αφού εξ ορισμού η σχέση (5.4) γίνεται, Άρα μπορούμε να θεωρήσουμε τον κανόνα πιθανότητας 8 ως μια γενίκευση του κανόνα πιθανότητας 3, τον οποίο είδαμε στο Κεφάλαιο 3.
Παράδειγμα 5.8
Από ένα στοκ 200 routers, μεταξύ των οποίων 3 είναι ελαττωματικοί, επιλέγουμε τυχαία 20 για ένα δίκτυο. Ποια είναι η πιθανότητα να επιλέξαμε ακριβώς έναν ελαττωματικό;
Έστω το ενδεχόμενο που περιγράφει την πιο πάνω περίπτωση. Το είναι υποσύνολο του χώρου πιθανότητας ο οποίος αποτελείται από όλες τις (μη διατεταγμένες) εικοσάδες routers τις οποίες μπορούμε να διαλέξουμε από τους 200. Από τον κανόνα αρίθμησης 4 έχουμε και συνδυάζοντας τους κανόνες αρίθμησης 1 και 4 βρίσκουμε Όπως στο Κεφάλαιο 4, χρησιμοποιώντας τον κανόνα πιθανότητας 5 και αντικαθιστώντας τις πιο πάνω τιμές, έχουμε,
Τώρα ας υποθέσουμε ότι παρατηρούμε το δίκτυο να λειτουργεί προβληματικά (άρα έχουμε επιλέξει τουλάχιστον έναν ελαττωματικό router). Ποια είναι η πιθανότητα να έχουμε επιλέξει ακριβώς έναν ελαττωματικό router; Αν ορίσουμε το ενδεχόμενο,
τότε η ζητούμενη πιθανότητα είναι,
αφού το (γιατί;). Η υπολογίστηκε πιο πάνω, και παρομοίως έχουμε,
συνεπώς,
Σημείωση. Ο κανόνας πιθανότητας 3 του Κεφαλαίου 3 μάς επιτρέπει να υπολογίσουμε την πιθανότητα για δύο ξένα ενδεχόμενα και ο κανόνας πιθανότητας 8, που είδαμε πιο πάνω, μάς δίνει ένα γενικότερο αποτέλεσμα που ισχύει και όταν τα δεν είναι ξένα. Το επόμενό μας αποτέλεσμα είναι μια σχετική ανισότητα, η οποία είναι πολύ χρήσιμη και επίσης ισχύει γενικά. Για παραδείγματα εφαρμογών του δείτε την Ενότητα 8.3 του Κεφαλαίου 8 και τις αντίστοιχες εκεί ασκήσεις.
Για οποιαδήποτε ενδεχόμενα (είτε είναι ξένα, είτε όχι) ισχύει η ανισότητα:
Απόδειξη:
Παρατηρούμε ότι η περίπτωση προκύπτει άμεσα από τον κανόνα πιθανότητας 8: Εφόσον όλες οι πιθανότητες είναι μεγαλύτερες ή ίσες του μηδενός,
Για την περίπτωση χρησιμοποιούμε την περίπτωση δύο φορές:
Η γενική περίπτωση αποδεικνύεται με τον ίδιο τρόπο, επαγωγικά.
Παράδειγμα 5.9
Έστω ότι έχουμε δύο νομίσματα· ένα δίκαιο με και ένα που έχει πιθανότητα 2/3 να έρθει Κορώνα. Επιλέγουμε ένα από τα δύο στην τύχη και το στρίβουμε δύο φορές:
-
1.
Ποια η πιθανότητα να φέρουμε την πρώτη φορά;
-
2.
Ποια η πιθανότητα να φέρουμε ;
-
3.
Δεδομένου ότι φέραμε , ποια η πιθανότητα να έχουμε επιλέξει το δίκαιο νόμισμα;
Για το πρώτο ερώτημα, παρατηρούμε ότι δεν μπορεί να υπολογιστεί άμεσα η ζητούμενη πιθανότητα αν δεν γνωρίζουμε ποιο νόμισμα έχει επιλεγεί. Ορίζουμε λοιπόν τα ενδεχόμενα:
Από το πρόβλημα μας δίνεται ότι και Για να υπολογίσουμε τη ζητούμενη πιθανότητα εκφράζουμε το ως την ένωση δύο ξένων ενδεχομένων, οπότε,
| (5.5) | |||||
Με τον ίδιο ακριβώς τρόπο βρίσκουμε πως και και, για το δεύτερο ερώτημα, παρομοίως έχουμε,
[Παρενθετικά αναφέρουμε την εξής ενδιαφέρουσα παρατήρηση: Αν γνωρίζουμε την πιθανότητα με την οποία ένα νόμισμα έρχεται Κορώνα, τότε τα αποτελέσματα διαδοχικών ρίψεων είναι ανεξάρτητα. Αλλά αν δεν γνωρίζουμε την η ανεξαρτησία δεν ισχύει! Π.χ., με το τυχαία επιλεγμένο νόμισμα αυτού του παραδείγματος, η πιθανότητα να φέρουμε Γράμματα είναι αλλά η πιθανότητα να φέρουμε δύο φορές Γράμματα είναι το οποίο δεν ισούται με Ο λόγος είναι πως, όταν δεν γνωρίζουμε τα στατιστικά χαρακτηριστικά του νομίσματος, κάθε ρίψη μάς δίνει κάποια πληροφορία για το νόμισμα, η οποία επηρεάζει την πρόβλεψή μας για τα αποτελέσματα των μελλοντικών ρίψεων.]
Πριν εξετάσουμε το τρίτο ερώτημα, σημειώνουμε πως, για οποιαδήποτε δύο ενδεχόμενα εκφράζοντας το ως όπως στην (5.5), και εφαρμόζοντας τον κανόνα πιθανότητας 3 σε συνδυασμό με τον ορισμό της δεσμευμένης πιθανότητας, όπως πιο πάνω, βρίσκουμε:
Για οποιαδήποτε ενδεχόμενα :
Γενικότερα, αν τα ενδεχόμενα είναι ξένα (δηλ., για κάθε ) και καλύπτουν όλο το (δηλ., ), τότε:
[Άσκηση. Αποδείξτε την τελευταία παραπάνω γενική περίπτωση.]
Παράδειγμα 5.9, συνέχεια Το τρίτο ερώτημα του παραδείγματος ρωτά, δεδομένου ότι φέραμε ποια είναι η πιθανότητα να έχουμε επιλέξει το δίκαιο νόμισμα; Χρησιμοποιώντας τον ορισμό της δεσμευμένης πιθανότητας δύο φορές, βλέπουμε πως η ζητούμενη πιθανότητα μπορεί να εκφραστεί ως προς τη γνωστή πιθανότητα :
| (5.6) |
Αρχικά η πιθανότητα να επιλέξουμε το δίκαιο νόμισμα είναι 1/2. Αλλά, δεδομένου ότι το νόμισμα που επιλέξαμε έφερε 2 φορές Γράμματα, είναι λιγότερο πιθανό να επιλέξαμε το νόμισμα που 2 στις 3 φορές φέρνει Κορώνα και πιθανότερο να επιλέξαμε το δίκαιο. Ο υπολογισμός (5.6) μάς λέει ακριβώς πόσο πιο πιθανό είναι να έχουμε επιλέξει το δίκαιο νόμισμα.
Η γενίκευση αυτού του παραδείγματος είναι το αντικείμενο της επόμενης ενότητας, αλλά, πριν το εξετάσουμε αναλυτικά, επανερχόμαστε στο Παράδειγμα 2.4 του τηλεπαιχνιδιού Monty Hall από το Κεφάλαιο 2.
Παράδειγμα 5.10 (Παιχνίδι Monty Hall, συνέχεια)
Θυμηθείτε το πρόβλημα του τηλεπαιχνιδιού Monty Hall, που είδαμε στο Παράδειγμα 2.4 του Κεφαλαίου 2. Εδώ θα εξετάσουμε το βασικό ερώτημα που προκύπτει: Τι είναι πιο συμφέρον για τον παίκτη, να αλλάξει κουρτίνα ή να διατηρήσει την αρχική του επιλογή; Με άλλα λόγια, ποια από τις δύο στρατηγικές τού δίνει μεγαλύτερη πιθανότητα να κερδίσει το δώρο;
Αν και, διαισθητικά, θα φανταζόμασταν ίσως πως δεν υπάρχει διαφορά ανάμεσα στις δύο περιπτώσεις, η απάντηση ενδεχομένως να σας εκπλήξει.
Όπως στο Παράδειγμα 2.4, θεωρούμε πως υπάρχουν τρεις κουρτίνες, οι και και πως τα αποτελέσματα του παιχνιδιού (δηλαδή τα στοιχεία του χώρου πιθανότητας ) είναι της μορφής όπου το πρώτο συμβολίζει την κουρτίνα που επιλέγει αρχικά ο παίκτης, το δεύτερο την κουρτίνα που αποκαλύπτεται, και το τρίτο την κουρτίνα που επιλέγει ο παίκτης στο τέλος. Υποθέτουμε ότι το δώρο είναι πίσω από την κουρτίνα και επίσης πως η αρχική επιλογή του παίκτη είναι τυχαία, δηλαδή πως τα ενδεχόμενα «ο παίκτης πρώτα επιλέγει την », «ο παίκτης πρώτα επιλέγει την » και «ο παίκτης πρώτα επιλέγει την » έχουν πιθανότητα 1/3 το καθένα.
Στρατηγική 1. Έστω πως ο παίκτης αλλάζει πάντα κουρτίνα. Τότε θα κερδίσει αν και μόνο αν αρχικά επιλέξει την κουρτίνα ή Επειδή τα αντίστοιχα ενδεχόμενα είναι ξένα, η πιθανότητα να κερδίσει είναι Βλ. Σχήμα 5.1.
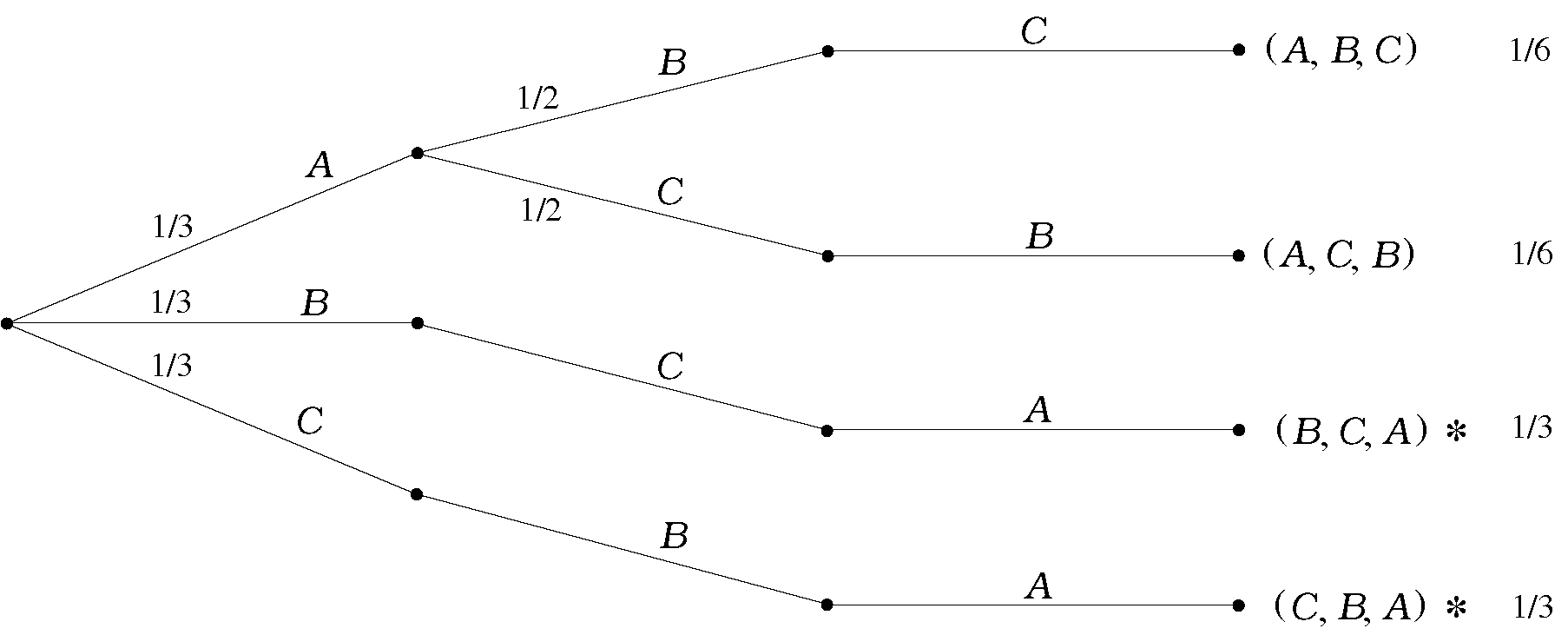
Στρατηγική 2. Ο παίκτης δεν αλλάζει ποτέ κουρτίνα. Τότε κερδίζει αν και μόνο αν επιλέξει αρχικά την κουρτίνα δηλαδή με πιθανότητα μόνο ! Βλ. Σχήμα 5.2.
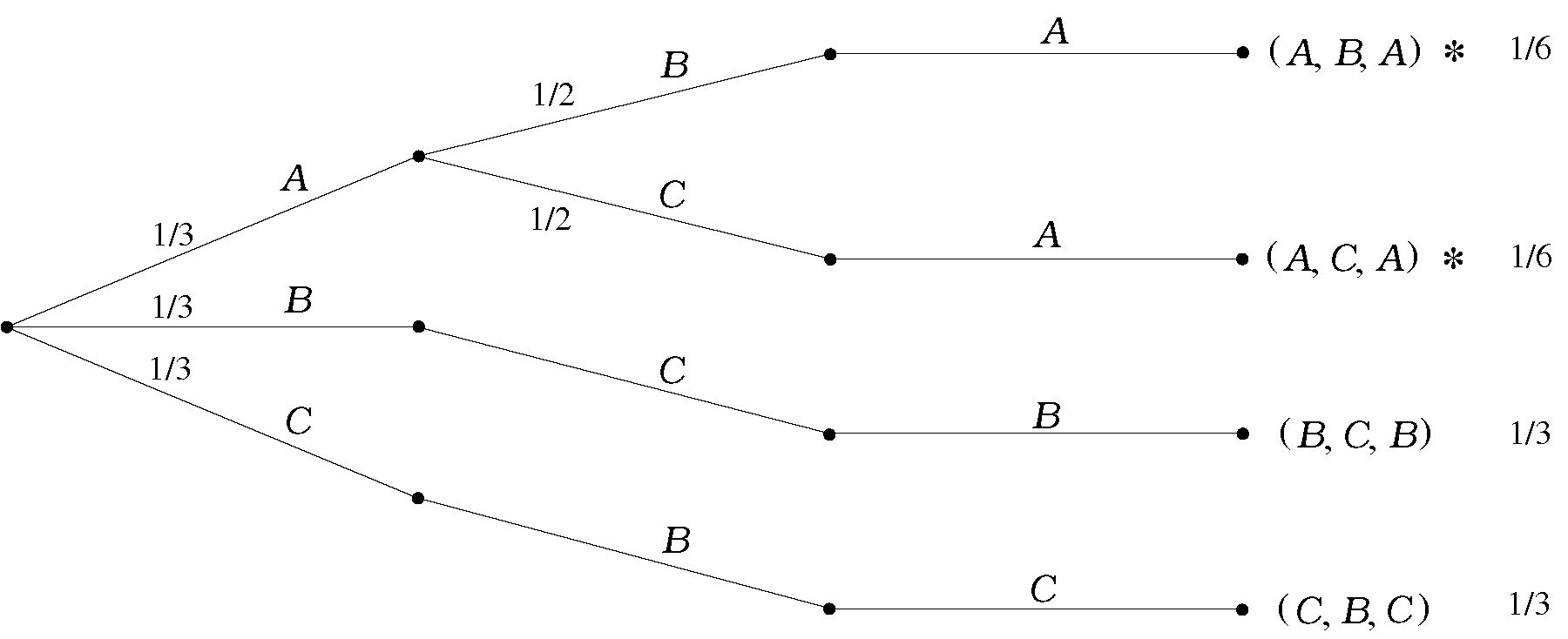
5.3 Ο κανόνας του Bayes
Σε πολλά επιστημονικά αλλά και καθημερινά προβλήματα, συχνά προκύπτει το εξής ερώτημα: Αν γνωρίζουμε την τιμή μιας δεσμευμένης πιθανότητας πώς μπορούμε να υπολογίσουμε την πιθανότητα όπου οι ρόλοι των ενδεχομένων και έχουν αντιστραφεί; Φερειπείν, στο Παράδειγμα 5.9 πιο πάνω, ήταν προφανές ότι η πιθανότητα να φέρουμε δύο φορές «Γ», δεδομένου ότι έχουμε ένα δίκαιο νόμισμα, είναι 25%, αλλά το ζητούμενο ήταν να εκτιμήσουμε πόσο πιθανό ήταν να είχαμε επιλέξει το δίκαιο νόμισμα δεδομένου ότι φέραμε δύο φορές «Γ».
Ο κανόνας του Bayes αποτελεί το βασικό εργαλείο για την επίλυση τέτοιου είδους προβλημάτων. Μια από τις σημαντικότερες και πιο συνηθισμένες τέτοιες περιπτώσεις αφορούν, όπως στο Παράδειγμα 5.6, προβλήματα που σχετίζονται με τεστ διαγνωστικών εξετάσεων. Εκεί, κατά κανόνα γνωρίζουμε τη στατιστική συμπεριφορά του τεστ κάτω από ελεγχόμενες συνθήκες, π.χ., ξέρουμε την πιθανότητα ένα τεστ εγκυμοσύνης να έχει θετικό αποτέλεσμα δεδομένου ότι η εξεταζόμενη είναι έγκυος. Αλλά για εκείνην που κάνει το τεστ το σημαντικό ερώτημα είναι «δεδομένου ότι το τεστ είναι θετικό, πόσο πιθανό είναι να είμαι έγκυος»; Παρομοίως, σε δικαστικές διαμάχες, συχνά παρουσιάζονται στοιχεία της εξής μορφής: Αν ο κατηγορούμενος ήταν αθώος, η πιθανότητα να βρισκόταν το DNA του στο σημείο του εγκλήματος είναι μικρή. Στην πραγματικότητα όμως το δικαστήριο το ενδιαφέρει η «αντίστροφη» πιθανότητα: Δεδομένου ότι η αστυνομία εντόπισε το DNA του εκεί, ποια η πιθανότητα να είναι αθώος;
Χρησιμοποιώντας τον ορισμό της δεσμευμένης πιθανότητας, όπως στη σχέση (5.6), και εφαρμόζοντας κατόπιν τον κανόνα συνολικής πιθανότητας, προκύπτει το εξής γενικό αποτέλεσμα:
Γενικότερα, αν τα ενδεχόμενα είναι ξένα (δηλ., για κάθε ) και καλύπτουν όλο το (δηλ., ), τότε:
Παρενθετικά αναφέρουμε ότι ο κανόνας του Bayes αποτελεί την αφετηρία μιας πολύ σημαντικής επιστημονικής περιοχής, της στατιστικής κατά Bayes, η οποία είναι εξαιρετικά ενεργή ερευνητικά, και η οποία τα τελευταία 20 περίπου χρόνια έχει βρει εφαρμογές σε κεντρικά θέματα σχεδόν ολόκληρου του φάσματος της επιστήμης και της τεχνολογίας.
Παράδειγμα 5.11
Σε κάποιον πληθυσμό, 2% των ανθρώπων πάσχει από μια ασθένεια. Ένας τυχαία επιλεγμένος άνθρωπος κάνει ένα διαγνωστικό τεστ γι’ αυτή την ασθένεια, όπου οι πιθανότητες σφάλματος του τεστ είναι:
Δεδομένου ότι το τεστ είναι αρνητικό, ποια η πιθανότητα παρ’ όλα αυτά να έχει την ασθένεια;
Ορίζουμε τα ενδεχόμενα,
οπότε τα δεδομένα του προβλήματος είναι,
και η ζητούμενη πιθανότητα είναι η Από τον κανόνα του Bayes έχουμε,
όπου στο δεύτερο βήμα χρησιμοποιήσαμε τον κανόνα πιθανότητας 4 και το Λήμμα 5.1. Αντικαθιστώντας τώρα τις τιμές των πιο πάνω πιθανοτήτων από τα δεδομένα μας, εύκολα υπολογίζουμε,
Παράδειγμα 5.12
Ανακοινώνεται από την εταιρία Dell ότι, από τα PC ενός συγκεκριμένου μοντέλου που κυκλοφορούν στην αγορά:
– το 25% είναι ελλατωματικά,
– το 25% έχουν σημαντικό ρίσκο να παρουσιάσουν πρόβλημα,
– το 50% δεν έχουν κανένα πρόβλημα από τα δύο.
Διανέμεται από την εταιρία ένα πρόγραμμα διάγνωσης των προβλημάτων, το οποίο είναι 99% ακριβές, δηλαδή,
όπου τα ενδεχόμενα ορίζονται ως,
Κάνουμε στο PC μας αυτό το διαγνωστικό τεστ και βγαίνει αρνητικό. Ποια η πιθανότητα ο υπολογιστής μας πράγματι να μην έχει κανένα από τα δύο προβλήματα;
Εδώ ο κανόνας του Bayes μάς δίνει,
όπου παρατηρούμε ότι τα είναι ξένα και η ένωσή τους ισούται με ολόκληρο το χώρο πιθανότητας Αντικαθιστώντας, όπως και στο προηγούμενο παράδειγμα, τις τιμές από τα δεδομένα του προβλήματος υπολογίζουμε,
Άρα, σε κάποιες (πολύ ειδικές) περιπτώσεις, μπορεί να έχουμε και όπως εδώ έχουμε
Παράδειγμα 5.13
Έστω ότι έχουμε τρία ζάρια, όπου το πρώτο είναι δίκαιο, το δεύτερο δεν έρχεται ποτέ 6, και το τρίτο έχει Επιλέγουμε ένα στην τύχη, το ρίχνουμε δύο φορές και φέρνουμε 66. Ποια η πιθανότητα να επιλέξαμε το δίκαιο ζάρι;
Ορίζουμε τα ενδεχόμενα ως «επιλέξαμε το δίκαιο ζάρι», «επιλέξαμε το δεύτερο ζάρι» και «επιλέξαμε το τρίτο ζάρι», αντίστοιχα. Επιπλέον ορίζουμε το ενδεχόμενο =«φέραμε 66». Βάσει του κανόνα του Bayes,
πράγμα το οποίο συμφωνεί με τη διαίσθησή μας: Εφόσον φέραμε 2 φορές «6», είναι πολύ πιθανότερο να επιλέξαμε ένα ζάρι το οποίο έχει πιθανότητα να φέρει «6», παρά ένα δίκαιο ζάρι.
5.4 Ακόμα πέντε «κανόνες πιθανότητας»
Σ’ αυτό το κεφάλαιο διατυπώσαμε ακόμα 5 κανόνες πιθανότητας, οι οποίοι συμπληρώνουν εκείνους του Κεφαλαίου 3. Για ευκολότερη αναφορά και χρήση, τους παραθέτουμε περιληπτικά πιο κάτω.
Για οποιαδήποτε δύο ενδεχόμενα :
-
6.
Εάν τα ενδεχόμενα είναι «λογικά ανεξάρτητα», τότε θεωρούμε πως είναι και (στατιστικά) ανεξάρτητα, δηλαδή:
-
7.
όπου η δεσμευμένη πιθανότητα ορίζεται ως,
-
8.
-
9.
Κανόνας συνολικής πιθανότητας:
-
10.
Κανόνας του Bayes:
5.5 Ασκήσεις
-
1.
Ένωση τριών ενδεχόμενων. Να δείξετε ότι, για οποιαδήποτε τρία ενδεχόμενα και η πιθανότητα της ένωσης ισούται με:
-
2.
Πιθανότητα ακριβώς ενός ενδεχομένου. Δείξτε ότι η πιθανότητα να πραγματοποιηθεί ακριβώς ένα από τα ενδεχόμενα είναι ίση με:
-
3.
Τράπουλα. Μοιράζουμε στην τύχη φύλλα από μια συνηθισμένη τράπουλα φύλλων. Ποια η πιθανότητα η μοιρασιά να περιέχει τουλάχιστον έναν άσο και τουλάχιστον μία φιγούρα (δηλαδή βαλέ, ντάμα ή ρήγα);
-
4.
Ιδιότητες δεσμευμένης πιθανότητας. Έστω τρία οποιαδήποτε ενδεχόμενα και
-
(α’)
Να δείξετε ότι
-
(β’)
Να βρεθεί η δεσμευμένη πιθανότητα αν αν και αν
-
(γ’)
Να δείξετε ότι αν και μόνο αν
Βεβαιωθείτε ότι κατανοείτε διαισθητικά γιατί ισχύουν τα παραπάνω.
-
(α’)
-
5.
Ρίψεις ζαριού. Ρίχνουμε ένα δίκαιο ζάρι δύο φορές. Υποθέτουμε ότι οι ρίψεις είναι ανεξάρτητες μεταξύ τους. Έστω τα ακόλουθα ενδεχόμενα:
-
(α’)
«το άθροισμα είναι ζυγό»,
-
(β’)
«το άθροισμα είναι μονό»,
-
(γ’)
«το άθροισμα είναι ίσο με »,
-
(δ’)
«φέραμε δύο φορές το ίδιο»,
-
(ε’)
«η πρώτη ζαριά ήρθε »,
-
(στ’)
«το πρώτο ζάρι είναι »,
-
(ζ’)
«το άθροισμα είναι ίσο με ».
Είναι ή όχι τα πιο κάτω ζεύγη ενδεχόμενων ανεξάρτητα;
(α’) (β’) (γ’) (δ’) (ε’)
-
(α’)
-
6.
Δύο δοχεία. Έστω δύο διαφορετικά τμήματα, εκ των οποίων το πρώτο αποτελείται από φοιτητές και φοιτήτριες, ενώ το δεύτερο αποτελείται από φοιτητές και φοιτήτριες. Επιλέγουμε ένα τμήμα στην τύχη, χωρίς κάποια προτίμηση, και εκ των υστέρων επιλέγουμε τυχαία ένα άτομο από αυτό το τμήμα. Έστω το ενδεχόμενο να επιλέξουμε το πρώτο τμήμα, και έστω το ενδεχόμενο να επιλέξουμε φοιτητή.
Ποια είναι η σχέση που πρέπει να ικανοποιούν τα ώστε να είναι ανεξάρτητα τα ενδεχόμενα και
-
7.
Poker με δεσμευμένες πιθανότητες. Όπως στην Άσκηση 5 του Κεφαλαίου 4, ένας παίκτης του πόκερ παίρνει φύλλα από μια κανονική τράπουλα 52 φύλλων. Χρησιμοποιώντας δεσμευμένες πιθανότητες και όχι τους κανόνες αρίθμησης του Κεφαλαίου 4, υπολογίστε τις πιθανότητες να έχει:
-
(α’)
καρέ (δηλαδή 4 ίδια φύλλα, για παράδειγμα άσους ή ντάμες);
-
(β’)
φουλ (δηλαδή ένα ζευγάρι και μία τριάδα, για παράδειγμα άσους και ρηγάδες);
-
(γ’)
χρώμα (δηλαδή όλα κούπες ή όλα σπαθιά ή όλα μπαστούνια ή όλα καρό);
-
(α’)
-
8.
Τεστ πολλαπλών απαντήσεων. Ένας μαθητής απαντά μια ερώτηση πολλαπλών απαντήσεων, με δυνατές απαντήσεις. Αν ο μαθητής δεν ξέρει την απάντηση, επιλέγει μία από τις δυνατές απαντήσεις στην τύχη, χωρίς κάποια προτίμηση. Αν η πιθανότητα να ξέρει την απάντηση είναι ποια είναι η δεσμευμένη πιθανότητα να ήξερε την απάντηση δεδομένου ότι απάντησε σωστά;
-
9.
Δεσμευμένο μέτρο πιθανότητας. Έστω ενδεχόμενο σε κάποιο χώρο πιθανότητας με Να δείξετε ότι η συνάρτηση η οποία ορίζεται ως για κάθε ενδεχόμενο είναι ένα μέτρο πιθανότητας, δηλαδή ικανοποιεί τις συνθήκες:
-
(α’)
για κάθε ενδεχόμενο
-
(β’)
-
(γ’)
Αν τα είναι ξένα ενδεχόμενα, τότε:
-
(α’)
-
10.
Συνέπειες ανεξαρτησίας. Να δείξετε ότι, αν τα και είναι ανεξάρτητα ενδεχόμενα, τότε τα ζεύγη και και και και είναι επίσης ανεξάρτητα. Μπορείτε να ερμηνεύσετε διαισθητικά το αποτέλεσμα; Υπόδειξη. Όπως στον κανόνα συνολικής πιθανότητας, το ενδεχόμενο μπορεί να εκφραστεί ως ένωση δύο ξένων ενδεχομένων,
-
11.
Ανεξαρτησία και δέσμευση. Έστω τρία οποιαδήποτε ενδεχόμενα και
-
(α’)
Να δείξετε ότι
-
(β’)
Να δείξετε ότι, αν το ενδεχόμενο είναι ανεξάρτητο από τον εαυτό του, τότε αναγκαστικά θα έχουμε είτε ή
-
(γ’)
Να δείξετε ότι αν ή τότε το είναι ανεξάρτητο του για οποιοδήποτε ενδεχόμενο
-
(α’)
-
12.
Κι άλλη τράπουλα. Επιλέγουμε χαρτιά (ανεξαρτήτως της σειράς) στην τύχη από μια συνηθισμένη τράπουλα.
-
(α’)
Ποια η πιθανότητα να επιλέξαμε άσους και μία φιγούρα;
-
(β’)
Ποια η πιθανότητα, δεδομένου ότι επιλέξαμε ακριβώς μία φιγούρα, τα άλλα φύλλα να είναι άσοι;
-
(γ’)
Ποια η πιθανότητα να επιλέξαμε φιγούρες και έναν άσο;
-
(δ’)
Είναι ή όχι τα ενδεχόμενα στο (α’) και στο (γ’) ανεξάρτητα; Αποδείξτε την απάντησή σας.
-
(α’)
-
13.
Κανόνας δεσμευμένης συνολικής πιθανότητας. Να δείξετε πως, για τρία οποιαδήποτε ενδεχόμενα και έχουμε:
-
14.
Μεσογειακή αναιμία. Σε κάποιο πληθυσμό, το των ατόμων έχει το στίγμα της μεσογειακής αναιμίας. Έστω ότι ένα τυχαία επιλεγμένο άτομο κάνει μια εξέταση για να διαπιστώσει αν έχει το στίγμα ή όχι. Η εξέταση δεν είναι απόλυτα ακριβής, και η πιθανότητα το αποτέλεσμα να βγει θετικό, ενώ δεν υπάρχει στίγμα, είναι Επιπλέον, η πιθανότητα να βγει το αποτέλεσμα αρνητικό, ενώ υπάρχει στίγμα, είναι
-
(α’)
Ποια η πιθανότητα να έχει στίγμα κάποιος που κάνει την εξέταση και προκύπτει θετικό αποτέλεσμα;
-
(β’)
Ποια είναι η αντίστοιχη πιθανότητα για κάποιον που κάνει την εξέταση δύο ανεξάρτητες φορές, και προκύπτει θετικό αποτέλεσμα την πρώτη φορά και αρνητικό αποτέλεσμα τη δεύτερη;
-
(α’)
-
15.
Ανεπιθύμητες εγκυμοσύνες. Από το σύνολο των γυναικών που κάνουν ένα τεστ εγκυμοσύνης, μόνο το είναι έγκυες. Έστω ότι το τεστ έχει τις εξής πιθανότητες σφάλματος: (θετικό όχι έγκυος) = και (αρνητικό έγκυος) =
-
(α’)
Ποια η πιθανότητα να είναι έγκυος μια γυναίκα η οποία κάνει το τεστ και βγαίνει θετικό;
-
(β’)
Ποια είναι η αντίστοιχη πιθανότητα για μια γυναίκα που κάνει το τεστ ανεξάρτητες φορές και βγει την πρώτη θετικό και τη δεύτερη αρνητικό;
-
(α’)
-
16.
Απάτη. Έστω ότι υποπτευόμαστε πως κάποιος χρησιμοποιεί ένα κάλπικο ζάρι, το οποίο δεν φέρνει ποτέ «6» και μάλιστα στην πλευρά του «6» έχει σημειωμένο το «1». Αλλά δεν είμαστε σίγουροι, οπότε θεωρούμε ότι υπάρχουν ίσες πιθανότητες να χρησιμοποιεί είτε ένα τέτοιο κάλπικο ζάρι είτε ένα δίκαιο. Όταν τον κατηγορούμε ότι σε έξι συνεχόμενες ζαριές έφερε τα αποτελέσματα 1,5,2,1,1,2, τα οποία δεν περιέχουν ούτε ένα «6», εκείνος διατείνεται ότι «Σιγά! Αυτό μια χαρά μπορεί να συμβεί και με το δίκαιο ζάρι!». Εμείς όμως τον αποστομώνουμε υπολογίζοντας πως η πιθανότητα να είναι δίκαιο το ζάρι δεδομένων αυτών των αποτελεσμάτων είναι μόλις μία στις εννιά! Αποδείξτε ότι έχουμε δίκιο.
Κεφάλαιο 6 Διακριτές τυχαίες μεταβλητές
[Επιστροφή στα περιεχόμενα]
Σε σύνθετα προβλήματα των πιθανοτήτων, όπως π.χ. σε προβλήματα ανάλυσης πολύπλοκων δικτύων ή στη στατιστική ανάλυση μεγάλων δεδομένων, η λεπτομερής, στοιχείο-προς-στοιχείο περιγραφή του πλήρους χώρου πιθανότητας είναι εξαιρετικά χρονοβόρα, και συχνά είναι και περιττή. Όπως θα δούμε σε αυτό το κεφάλαιο, η έννοια της τυχαίας μεταβλητής μάς επιτρέπει να παρακάμψουμε την πιο πάνω διαδικασία.22Ορισμένα από τα αποτελέσματα που θα δούμε απαιτούν κάποιες επιπλέον τεχνικές υποθέσεις, οι οποίες όμως δεν επηρεάζουν την ουσία τους. Περαιτέρω λεπτομέρειες δίνονται στην Ενότητα 6.3.
Παράδειγμα 6.1
Ρίχνουμε ένα δίκαιο νόμισμα φορές, και ορίζουμε τις εξής τυχαίες ποσότητες: Για κάθε έστω:
Τα είναι τυχαίες μεταβλητές, και το κάθε περιγράφει το αποτέλεσμα της ρίψης
Παρομοίως, αν ορίσουμε την ποσότητα ως το πλήθος από Κορώνες στις ρίψεις, τότε το είναι μια άλλη τυχαία μεταβλητή η οποία μπορεί και να εκφραστεί ως,
6.1 Ορισμός και βασικές ιδιότητες
Ορισμός 6.1
(Τυχαία μεταβλητή)
-
1.
(Διαισθητικά) Μια τυχαία μεταβλητή (Τ.Μ.) είναι μια οποιαδήποτε ποσότητα που εξαρτάται από την έκβαση ενός τυχαίου πειράματος.
-
2.
(Μαθηματικά) Μια τυχαία μεταβλητή (Τ.Μ.) είναι μια οποιαδήποτε συνάρτηση για κάποιο χώρο πιθανότητας
Παράδειγμα 6.2
Στο Παράδειγμα 6.1, ο χώρος πιθανότητας αποτελείται από όλες τις δυνατές -άδες αποτελεσμάτων για τις ρίψεις. Π.χ., το στοιχείο ( φορές) αντιστοιχεί στο να φέρουμε φορές Κορώνα.
Αν θέλαμε να ορίσουμε τις τυχαίες μεταβλητές απολύτως σχολαστικά, θα λέγαμε ότι, για κάθε
Με την ίδια λογική, η Τ.Μ. που περιγράφει το πλήθος από Κορώνες στις ρίψεις θα μπορούσε να οριστεί σαν συνάρτηση στο ως ή, εναλλακτικά, όπως πριν,
Ορισμός 6.2
-
1.
Το σύνολο όλων των δυνατών (πραγματικών) τιμών που μπορεί να πάρει μια τυχαία μεταβλητή είναι το σύνολο τιμών της και συμβολίζεται ή απλά
-
2.
Μια τυχαία μεταβλητή είναι διακριτή αν το σύνολο τιμών της είναι είτε πεπερασμένο είτε άπειρο αλλά αριθμήσιμο.
-
3.
Η πυκνότητα (ή διακριτή συνάρτηση πυκνότητας πιθανότητας) μια διακριτής Τ.Μ. με σύνολο τιμών είναι η συνάρτηση που ορίζεται ως:33Σημειώνουμε ότι, σε μεγάλο μέρος της βιβλιογραφίας, η συνάρτηση την οποία εδώ ονομάζουμε πυκνότητα μιας διακριτής Τ.Μ., συχνά λέγεται μάζα της
Παρατήρηση: Από αυστηρά μαθηματική σκοπιά, μια τυχαία μεταβλητή που ορίζεται ως συνάρτηση σε κάποιο χώρο πιθανότητας έχει σύνολο τιμών το πεδίο τιμών της συνάρτησης δηλαδή το σύνολο Τότε, δεδομένου κάποιου μέτρου πιθανότητας στο η πυκνότητα της ορίζεται ως,
Παράδειγμα 6.3
Στο Παράδειγμα 6.1 όλες οι Τ.Μ. έχουν σύνολο τιμών και όλες έχουν την ίδια πυκνότητα που είναι: και Η Τ.Μ. έχει σύνολο τιμών το και αποτελεί ειδική περίπτωση μιας σημαντικής ομάδας τυχαίων μεταβλητών – των τυχαίων μεταβλητών με «διωνυμική κατανομή» – τις οποίες θα εξετάσουμε αναλυτικά στο επόμενο κεφάλαιο.
Η πυκνότητα της μπορεί να υπολογιστεί σχετικά εύκολα μέσω των κανόνων αρίθμησης και πιθανότητας των προηγούμενων κεφαλαίων. Για παράδειγμα (θεωρώντας πως τα ενδεχόμενα που αφορούν τα αποτελέσματα των διαδοχικών ρίψεων είναι ανεξάρτητα) έχουμε,
Στο Κεφάλαιο 7 θα δούμε αναλυτικά τον λεπτομερή υπολογισμό των υπόλοιπων τιμών της πυκνότητας της Τ.Μ.
-
1.
για κάθε
-
2.
-
3.
για οποιοδήποτε
Απόδειξη:
Εφόσον κάθε είναι μια πιθανότητα, η πρώτη ιδιότητα είναι προφανής.
Η τρίτη ιδιότητα είναι συνέπεια του κανόνα πιθανότητας 3 του Κεφαλαίου 3. Εφόσον τα ενδεχόμενα για διαφορετικά είναι ξένα μεταξύ τους, έχουμε:
Τέλος η δεύτερη ιδιότητα είναι ειδική περίπτωση της τρίτης: Αν θέσουμε η τρίτη ιδιότητα μας δίνει,
το οποίο ισούται με 1, από τον ορισμό του συνόλου τιμών.
Ορισμός 6.3
Η συνάρτηση κατανομής μιας Τ.Μ. είναι η συνάρτηση που ορίζεται ως,
για κάθε
Παρατηρήσεις:
-
1.
Από τον ορισμό της συνάρτησης κατανομής και την τρίτη ιδιότητα της πυκνότητας πιο πάνω, βλέπουμε πως η συνάρτηση κατανομής μιας διακριτής Τ.Μ. μπορεί εύκολα να υπολογιστεί από την πυκνότητά της μέσω της σχέσης,
(6.1) -
2.
Παρατηρούμε ότι, αν τότε και από τον κανόνα πιθανότητας 2,
άρα η είναι αύξουσα συνάρτηση.
Επίσης, αφού προφανώς έχουμε Παρομοίως, αφού προφανώς έχουμε Για την αυστηρή τεκμηρίωση αυτών των δύο ορίων δείτε την Άσκηση 2 στο τέλος του Κεφαλαίου.
Παράδειγμα 6.4
Στρίβουμε ένα νόμισμα με για κάποιο σε συνεχόμενες, ανεξάρτητες ρίψεις. Όπως και στα προηγούμενα παραδείγματα, για κάθε ορίζουμε τις Τ.Μ.,
όπου κάθε περιγράφει το αποτέλεσμα της ρίψης Όπως πριν, όλες οι έχουν το ίδιο σύνολο τιμών και την ίδια πυκνότητα που ικανοποιεί, και Στο Σχήμα 6.1 βλέπουμε τη γραφική αναπαράσταση της συνάρτησης κατανομής των Εφόσον η παίρνει μόνο τις τιμές και για η πιθανότητα ισούται με μηδέν, και για έχουμε Τέλος αν το ανήκει στο διάστημα τότε,
Ορίζουμε επίσης την Τ.Μ. «πρώτη φορά που θα έρθει Κ», δηλαδή, έχουμε αν η πρώτη φορά που φέραμε Κ είναι στη ρίψη :
Η έχει σύνολο τιμών όλους τους φυσικούς αριθμούς, και η πυκνότητά της, είναι,
και γενικά, για κάθε
| (6.2) |
όπου φυσικά έχουμε χρησιμοποιήσει το γεγονός ότι τα αποτελέσματα των διαδοχικών ρίψεων είναι ανεξάρτητα. Η συνάρτηση κατανομής της μπορεί εύκολα να υπολογιστεί όπως πιο πάνω για τις Αφού η παίρνει μόνο τις τιμές για έχουμε και για οποιοδήποτε
όπου το συμβολίζει το ακέραιο μέρος ενός πραγματικού αριθμού Συνεπώς, η ισούται με και παρατηρούμε ότι το να έχουμε για κάποιο είναι ισοδύναμο με τον να φέραμε φορές Γ στις πρώτες ρίψεις. Άρα, τελικά έχουμε,
Οι γραφικές αναπαραστάσεις της πυκνότητας και της συνάρτησης κατανομής δίνονται στο Σχήμα 6.2.
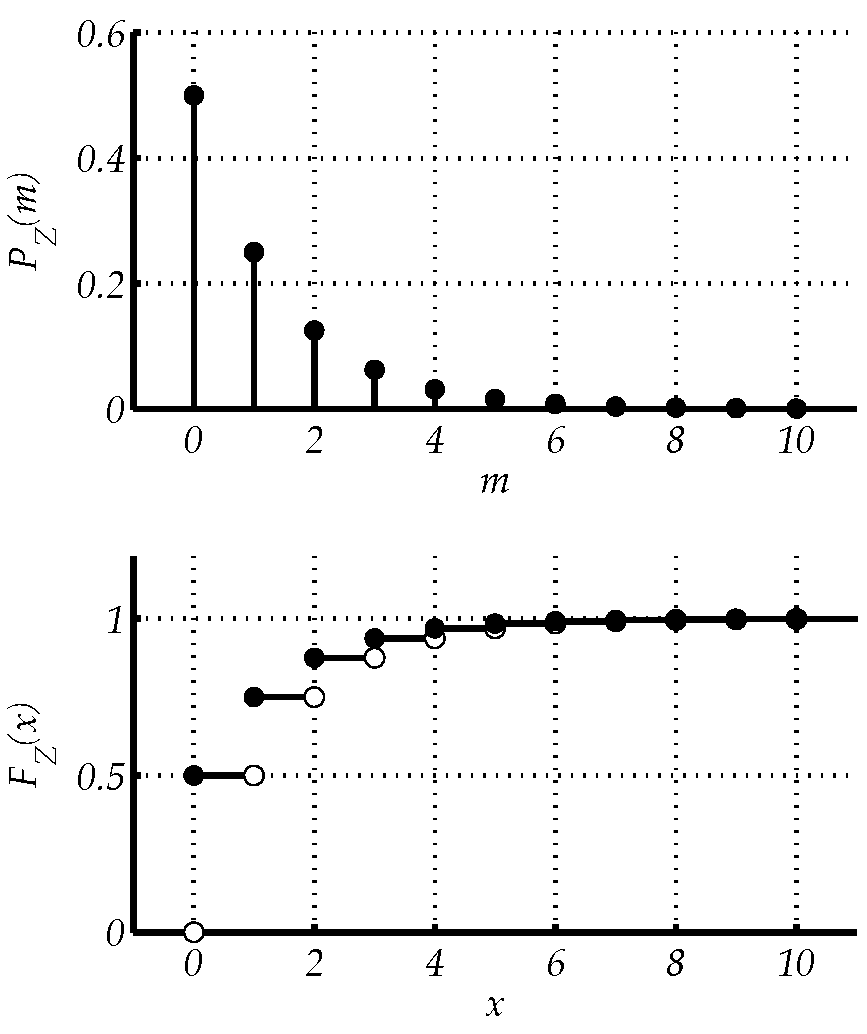
για οποιοδήποτε και το δεξί μέρος πιο πάνω τείνει στο μηδέν καθώς Άρα, αναγκαστικά έχουμε και κατά συνέπεια μπορούμε ασφαλώς να παραλείψουμε αυτό το ενδεχόμενο από το σύνολο τιμών της
Παράδειγμα 6.5
Συνεχίζοντας το Παράδειγμα 6.4, έστω τώρα πως το νόμισμα είναι δίκαιο (), και πως κάποιος μας προτείνει να παίξουμε το εξής παιχνίδι: Θα του δώσουμε 2.50 ευρώ και θα στρίψουμε το νόμισμα μέχρι την πρώτη φορά που θα φέρουμε Κ. Αν φέρουμε Κ με την πρώτη, θα μας δώσει ένα ευρώ. Αν φέρουμε Γ και μετά Κ, θα μας δώσει δύο ευρώ. Και, γενικά, αν φέρουμε φορές Γ και για πρώτη φορά φέρουμε Κ τη φορά θα μας δώσει ευρώ (βλ. Ενότητα 2.1).
Είναι ή όχι δίκαιη η αμοιβή των δυόμισι ευρώ; Ποια θα ήταν μια δίκαιη αμοιβή; Πώς θα μπορούσαμε να την υπολογίσουμε;
Πριν απαντήσουμε, παρατηρούμε πως, γνωρίζοντας την πυκνότητα της από το προηγούμενο παράδειγμα, μπορούμε εύκολα να υπολογίσουμε κάποιες απλές πιθανότητες. Για παράδειγμα, η πιθανότητα να πάρουμε σ’ αυτό το παιχνίδι μεταξύ 2 και 5 ευρώ είναι,
Επιστρέφοντας στο θέμα της δίκαιης αμοιβής, μια λογική σκέψη είναι η ακόλουθη. Ας φανταστούμε ότι παίζουμε το ίδιο παιχνίδι πολλές φορές συνεχόμενα. Αφού το αποτέλεσμα εξαρτάται από τις (τυχαίες) ρίψεις του νομίσματος, κάθε φορά θα παίρνουμε ένα διαφορετικό ποσό. Μακροπρόθεσμα, μια «δίκαιη» αμοιβή θα μπορούσε να θεωρηθεί ο μέσος όρος του ποσού που παίρνουμε ανά παιχνίδι.
Μεταφράζοντας την πιο πάνω σκέψη με λίγο μεγαλύτερη μαθηματική ακρίβεια, κατ’ αρχάς παρατηρούμε πως το ποσό που θα πάρουμε σ’ αυτό το τυχερό παιχνίδι ισούται με την Τ.Μ. του προηγούμενου παραδείγματος. Εκεί υπολογίσαμε την πυκνότητά της στη σχέση (6.2), οπότε θέτοντας έχουμε,
Διαισθητικά, τη φράση «με πιθανότητα 1/2 θα πάρουμε 1 ευρώ» μπορούμε να την ερμηνεύσουμε ως «μακροπρόθεσμα, τις μισές φορές θα πάρουμε 1 ευρώ» παρομοίως, για κάθε περιμένουμε πως, μακροπρόθεσμα, το ποσοστό των φορών που θα πάρουμε ευρώ θα είναι Άρα, το κατά-μέσο-όρο-μακροπρόθεσμο ποσό που θα πάρουμε θα ισούται με,
| (6.3) |
Αφού το άθροισμα της πιο πάνω σειράς είναι ίσο με 2, συμπεραίνουμε πως τα 2 ευρώ θα ήταν μια δίκαιη αμοιβή.44Για τον λεπτομερή υπολογισμό των σειρών , , και για άλλα σχετικά αποτελέσματα, βλ. την Ενότητα 7.3 του επόμενου κεφαλαίου.
Ο συλλογισμός που μας οδήγησε στον υπολογισμό (6.3) μας οδηγεί και στον πιο κάτω γενικό ορισμό.
6.2 Μέση τιμή, διασπορά, ανεξαρτησία
Ορισμός 6.4
Η μέση τιμή (ή αναμενόμενη τιμή, ή προσδοκώμενη τιμή) μιας διακριτής Τ.Μ. με σύνολο τιμών το και πυκνότητα ορίζεται ως:
| (6.4) |
Γενικότερα, για οποιαδήποτε συνάρτηση η μέση τιμή της νέας Τ.Μ. ορίζεται ως:
| (6.5) |
[Στην Άσκηση 1 στο τέλος του κεφαλαίου θα δείξετε πως ο δεύτερος ορισμός είναι στην πραγματικότητα συνέπεια του πρώτου.]
Παράδειγμα 6.6
Όπως υπολογίσαμε στο Παράδειγμα 6.5, η μέση τιμή της Τ.Μ. είναι,
Αν, τώρα, το ποσό που παίρναμε στο τέλος του παιχνιδιού ήταν και όχι τότε θα μπορούσαμε να υπολογίσουμε τη δίκαιη αμοιβή για το νέο παιχνίδι από τη μέση τιμή του
Ορισμός 6.5
Η διασπορά μιας διακριτής Τ.Μ. με μέση τιμή είναι:
| (6.6) |
Η τυπική απόκλιση της είναι:
Παρατηρήσεις:
-
1.
Διαισθητικά, η μέση τιμή μιας Τ.Μ. μας λέει ότι οι τιμές της «τείνουν να κυμαίνονται» γύρω από την τιμή Παρομοίως, η διασπορά της δίνει μια ποσοτική ένδειξη του πόσο μεγάλες τείνουν να είναι αυτές οι διακυμάνσεις. Συγκεκριμένα, από τον ορισμό βλέπουμε ότι η διασπορά είναι η «μέση τετραγωνική απόκλιση» της από το δηλαδή η μέση τιμή του τετραγώνου της απόστασης της τυχαίας τιμής από τη μέση τιμή της.
- 2.
-
3.
Από την έκφραση (6.7) αμέσως προκύπτει πως η διασπορά πάντοτε είναι Επιπλέον, η μόνη περίπτωση η διασπορά να ισούται με μηδέν είναι αν όλοι οι όροι του αθροίσματος, είναι μηδενικοί, πράγμα που μπορεί να συμβεί μόνο αν η T.M. ισούται με τη σταθερά με πιθανότητα ένα! Στην Άσκηση 3 στο τέλος του κεφαλαίου θα δούμε μια ενδιαφέρουσα ιδιότητα τέτοιου είδους τετριμμένων «ντετερμινιστικών» Τ.Μ.
-
4.
Ξεκινώντας από τη σχέση (6.7), έχουμε ότι η διασπορά μπορεί να εκφραστεί ως,
Το πρώτο άθροισμα εδώ ισούται με από την (6.5), το δεύτερο άθροισμα ισούται με εξ ορισμού, και το τρίτο άθροισμα ισούται με 1 από την αντίστοιχη ιδιότητα της πυκνότητας. Συνεπώς, και άρα έχουμε αποδείξει πως η διασπορά μιας οποιασδήποτε διακριτής Τ.Μ. με μέση τιμή μπορεί εναλλακτικά να εκφραστεί:
(6.8)
Παράδειγμα 6.7
Έστω μια Τ.Μ. με την ίδια πυκνότητα όπως οι Τ.Μ. του Παραδείγματος 6.4, δηλαδή ή 0, με πιθανότητα ή αντίστοιχα. Η έχει σύνολο τιμών το και πυκνότητα για κάποιο δεδομένο
Η μέση τιμή και η διασπορά της εύκολα υπολογίζονται ως,
όπου για τη διασπορά χρησιμοποιήσαμε την έκφραση (6.8).
Παρατηρούμε ότι τα αποτελέσματα αυτά συμφωνούν με τη διαίσθησή μας πως, όσο μεγαλώνει η πιθανότητα με την οποία έχουμε τόσο πιο πολύ τείνει η Τ.Μ. να παίρνει τη μεγαλύτερη από τις δύο τιμές της, και αντιστοίχως μεγαλώνει και η μέση τιμή της Παρομοίως, στο Σχήμα 6.3 όπου δίνεται η γραφική αναπαράσταση της διασποράς της ως συνάρτηση της παραμέτρου βλέπουμε πως η διασπορά είναι μεγαλύτερη όσο πιο κοντά είναι το στο άρα έχουμε μεγάλη διασπορά όταν οι τιμές της Τ.Μ. είναι πιο «τυχαίες» ή λιγότερο «προβλέψιμες».
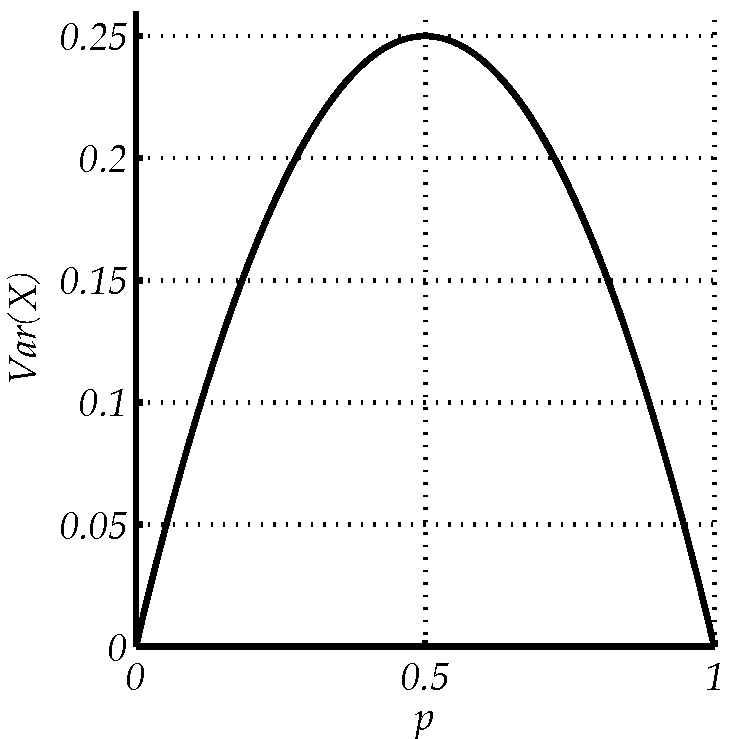
Παράδειγμα 6.8
Παράδειγμα 6.9
Σε ένα τυχερό παιχνίδι, το κέρδος μας, έστω ισούται με 1 ευρώ ή με ευρώ, με πιθανότητες 2/3 και 1/3 αντίστοιχα. Άρα η μέση τιμή του κέρδους μας είναι,
και συμπεραίνουμε πως, αν παίξουμε αυτό το παιχνίδι πολλές φορές, μακροπρόθεσμα θα βγούμε χαμένοι. Επιπλέον, από τον τύπο (6.8), το έχει διασπορά,
και τυπική απόκλιση
Στο Θεώρημα 6.1 θα εξετάσουμε τη μέση τιμή και τη διασπορά του αθροίσματος δύο τυχαίων μεταβλητών. Για τη διατύπωση των σχετικών ιδιοτήτων θα χρειαστούμε την εξής γενίκευση της έννοιας της ανεξαρτησίας:
-
1.
Δύο διακριτές Τ.Μ. και με σύνολα τιμών αντίστοιχα είναι ανεξάρτητες αν, για κάθε τα ενδεχόμενα και είναι ανεξάρτητα. Ισοδύναμα, οι είναι ανεξάρτητες αν και μόνο αν,
για κάθε όπου, χάριν συντομίας, συμβολίζουμε ως την πιθανότητα του ενδεχομένου
-
2.
Οι διακριτές Τ.Μ. είναι ανεξάρτητες αν και μόνο αν,
για κάθε -άδα τιμών όπου είναι το σύνολο τιμών της κάθε
-
3.
Οι διακριτές Τ.Μ. σε μια άπειρη ακολουθία είναι ανεξάρτητες, αν οι Τ.Μ. είναι ανεξάρτητες για κάθε
Οι παρακάτω ιδιότητες αποτελούν κάποια από τα βασικότερα εργαλεία των πιθανοτήτων.
-
1.
-
2.
Αν οι Τ.Μ. είναι ανεξάρτητες, τότε:
-
3.
-
4.
-
5.
για οποιαδήποτε υποσύνολα
Παρατήρηση: Η πρώτη ιδιότητα του θεωρήματος εύκολα επεκτείνεται και για οποιοδήποτε (πεπερασμένο) πλήθος τυχαίων μεταβλητών. Για παράδειγμα, για χρησιμοποιώντας την Ιδιότητα 1 δύο φορές βρίσκουμε,
Παρομοίως, έχουμε τη γενική περίπτωση,
[Στο ίδιο πλαίσιο, μια χρήσιμη άσκηση είναι η εξής: Διατυπώστε και αποδείξτε την προφανή γενίκευση της Ιδιότητας 4 για τυχαίες μεταβλητές.]
Πριν δώσουμε την απόδειξη, θα δούμε ένα παράδειγμα της χρήσης κάποιων από αυτές τις ιδιότητες και ένα χρήσιμο τεχνικό αποτέλεσμα.
Παράδειγμα 6.10
Παίζουμε 5 φορές «Κορώνα-Γράμματα» με ένα δίκαιο νόμισμα, όπου κερδίζουμε 1 ευρώ κάθε φορά που έρχεται Κ και χάνουμε 1 ευρώ όποτε έρχεται Γ. Έστω οι Τ.Μ. όπου κάθε με πιθανότητα 1/2. Εξετάζουμε 2 παραλλαγές του παιχνιδιού:
A. Παίζουμε 5 φορές κανονικά το παιχνίδι, με συνολικό κέρδος
B. Παίζουμε μόνο μία φορά, αλλά κερδίζοντας ή χάνοντας 5 ευρώ αντί για ένα, οπότε έχουμε συνολικό κέρδος
Από τον ορισμό των έχουμε, για κάθε
Χρησιμοποιώντας την πρώτη ιδιότητα του θεωρήματος, μπορούμε να υπολογίσουμε το «προσδοκώμενο» κέρδος,
άρα και στις δύο περιπτώσεις το μέσο κέρδος είναι μηδενικό.
Για τις διασπορές των δύο παιχνιδιών, από τις Ιδιότητες 2 και 4 βρίσκουμε, αντίστοιχα,
και Παρατηρούμε λοιπόν πως, αν και τα δύο παιχνίδια έχουν την ίδια αναμενόμενη απόδοση, το δεύτερο έχει πολύ μεγαλύτερες διακυμάνσεις, συνεπώς και πολύ μεγαλύτερο ρίσκο.
Λήμμα 6.1
Για οποιεσδήποτε δύο διακριτές Τ.Μ. και για κάθε έχουμε,
όπου, πάλι χάριν συντομίας, συμβολίζουμε την πιθανότητα του ενδεχομένου ως
Απόδειξη του Λήμματος 6.1:
Η απόδειξη είναι παρόμοια με εκείνη του κανόνα συνολικής πιθανότητας στο Κεφάλαιο 5. Έστω ένα δεδομένο στοιχείο Για κάθε ορίζουμε το ενδεχόμενο,
και παρατηρούμε πως,
Εφόσον τα είναι όλα ξένα μεταξύ τους, το αποτέλεσμα προκύπτει από τον κανόνα πιθανότητας 3.
Απόδειξη του Θεωρήματος 6.1:
1. Για να υπολογίσουμε τη μέση τιμή του παρατηρούμε ότι η νέα διακριτή Τ.Μ. έχει σύνολο τιμών,
και παίρνει κάθε τιμή στο με αντίστοιχη πιθανότητα, Άρα,
όπου στο βήμα χρησιμοποιήσαμε το Λήμμα 6.1.
2. Εφαρμόζοντας τη σχέση (6.8) στην Τ.Μ. έχουμε,
όπου στο βήμα εφαρμόσαμε την Ιδιότητα 1 στον δεύτερο όρο του αθροίσματος, στο βήμα εφαρμόσαμε την Ιδιότητα 1 στον πρώτο όρο, και στο βήμα χρησιμοποιήσαμε πάλι τη σχέση (6.8).
Έστω τώρα ότι οι είναι ανεξάρτητες.
3. Με το ίδιο σκεπτικό όπως στην απόδειξη της πρώτης ιδιότητας, υπολογίζουμε τη μέση τιμή της Τ.Μ. ως,
όπου στο βήμα χρησιμοποιήσαμε τον ορισμό της ανεξαρτησίας δύο τυχαίων μεταβλητών.
4. Εφαρμόζοντας τη σχέση (6.8) στην Τ.Μ. έχουμε,
και από την Ιδιότητα 1,
όπου χρησιμοποιήσαμε στο βήμα την Ιδιότητα 3 και στο βήμα τη σχέση (6.8).
5. Ο υπολογισμός για την απόδειξη της τελευταίας ιδιότητας είναι παρόμοιος με εκείνον στην Ιδιότητα 3. Παρατηρώντας ότι τα ενδεχόμενα που αντιστοιχούν σε διαφορετικά ζεύγη τιμών είναι ξένα και χρησιμοποιώντας τον ορισμό της ανεξαρτησίας,
ολοκληρώνουμε την απόδειξη.
6.3 Μετρησιμότητα και άπειρες τιμές
Κλείνουμε αυτό το κεφάλαιο με ορισμένες επιπλέον λεπτομέρειες, από τη σκοπιά της αυστηρής μαθηματικής προσέγγισης, για κάποιους από του ορισμούς και τα αποτελέσματα που είδαμε.
6.3.1 Ορισμός τυχαίας μεταβλητής
Στην Ενότητα 3.3 του τρίτου κεφαλαίου σημειώσαμε πως, σε κάποιες περιπτώσεις που ο χώρος πιθανότητας δεν είναι πεπερασμένος ή αριθμήσιμος, το μέτρο πιθανότητας δεν μπορεί να οριστεί για όλα τα υποσύνολα του Ένα αντίστοιχο φαινόμενα εμφανίζεται και στις τυχαίες μεταβλητές. Σε περιπτώσεις που ο χώρος πιθανότητας είναι μη αριθμήσιμος, μπορεί να υπάρχουν συναρτήσεις για τις οποίες κάποιες πιθανότητες της μορφής να μην μπορούν να ορισθούν. Αυτό συμβαίνει διότι κάποια από τα αντίστοιχα ενδεχόμενα,
μπορεί να είναι παθολογικά (με την έννοια που περιγράψαμε στην Ενότητα 3.3), ή μη μετρήσιμα όπως λέγονται στα μαθηματικά. Τέτοιου είδους παθολογικές συναρτήσεις ονομάζονται «μη μετρήσιμες» και δεν τις θεωρούμε τυχαίες μεταβλητές.
Η γενική λύση σε αυτό το πρόβλημα είναι να περιορίσουμε τις συναρτήσεις τις οποίες χρησιμοποιούμε ως τυχαίες μεταβλητές. Ο ακριβής προσδιορισμός αυτών των «καλών» συναρτήσεων αποτελεί μέρος της περιοχής της μαθηματικής ανάλυσης που ονομάζεται θεωρία μέτρου, με την οποία δεν θα ασχοληθούμε περαιτέρω. Περισσότερες πληροφορίες για αυτά τα ζητήματα μπορείτε να βρείτε σε πιο προχωρημένα βιβλία μαθηματικής ανάλυσης ή πιθανοτήτων.
Ο τρόπος με τον οποίο εμείς θα αποφύγουμε τέτοιου είδους παθολογίες είναι ορίζοντας τις Τ.Μ. που θέλουμε να χρησιμοποιήσουμε μέσω της πυκνότητάς τους. Έστω, για παράδειγμα, πως θέλουμε να χρησιμοποιήσουμε μια Τ.Μ. η οποία να παίρνει τις τιμές,
δηλαδή να έχει σύνολο τιμών και πυκνότητα με Πώς μπορεί να οριστεί μια τέτοια Τ.Μ. ως συνάρτηση σε κάποιο χώρο πιθανότητας Απλά θέτοντας ορίζοντας για κάθε και ορίζοντας ένα μέτρο πιθανότητας που για τα στοιχειώδη ενδεχόμενα θα έχει,
Τότε, για καθεμία από τις τιμές της
όπως και ήταν το ζητούμενο.
Γενικά, μια οποιαδήποτε διακριτή Τ.Μ. με δεδομένη πυκνότητα σε κάποιο σύνολο τιμών μπορεί να οριστεί ως συνάρτηση σε κάποιον διακριτό χώρο πιθανότητας με τον ίδιο τρόπο. Θέτουμε ορίζουμε το μέτρο πιθανότητας για όλα τα στοιχειώδη ενδεχόμενα ως,
και τέλος θέτουμε Έτσι, η πράγματι παίρνει την κάθε τιμή με πιθανότητα :
6.3.2 Ορισμοί και επιπλέον συνθήκες
Έστω μια διακριτή Τ.Μ. με πυκνότητα σε κάποιο σύνολο τιμών Αν το δεν είναι πεπερασμένο (όπως π.χ. για την Τ.Μ. του Παραδείγματος 6.5), τότε η μέση τιμή της δίνεται από ένα άπειρο άθροισμα, το οποίο όμως, όπως γνωρίζουμε από τα βασικά αποτελέσματα του διαφορικού λογισμού, μπορεί να παίρνει τις τιμές ή και να μην ορίζεται καν. (Για ένα παράδειγμα μιας διακριτής Τ.Μ. με άπειρη μέση τιμή δείτε την Άσκηση 4 στο τέλος του κεφαλαίου.) Για να αποφύγουμε τεχνικά ζητήματα τα οποία ξεφεύγουν κατά πολύ από τα ζητούμενα του παρόντος βιβλίου, υιοθετούμε τις πιο κάτω συμβατικές υποθέσεις, οι οποίες θα παραμείνουν εν ισχύ σε όλα τα υπόλοιπα κεφάλαια.
Συμβάσεις
-
•
Πάντοτε, όταν λέμε πως «η διακριτή Τ.Μ. έχει μέση τιμή », εμμέσως υποθέτουμε ότι το άθροισμα της σειράς που δίνει την ορίζεται, και ότι η τιμή του είναι πεπερασμένη.
-
•
Πάντοτε, όταν λέμε ότι «η διακριτή Τ.Μ. έχει διασπορά », εμμέσως υποθέτουμε ότι η μέση τιμή ορίζεται και είναι πεπερασμένη, και πως το άθροισμα της σειράς που δίνει την ορίζεται και δίνει πεπερασμένο αποτέλεσμα.
-
•
Όποτε διατυπώνεται μια ιδιότητα για τη μέση τιμή (ή τη διασπορά), εμμέσως υποθέτουμε πως η αντίστοιχη μέση τιμή (αντίστοιχα, διασπορά) ορίζεται και είναι πεπερασμένη.
Για παράδειγμα, η εναλλακτική έκφραση για τη διασπορά που δώσαμε στη σχέση (6.8) ισχύει εφόσον η μέση τιμή και η διασπορά ορίζονται και είναι πεπερασμένες. Παρομοίως, η πρώτη ιδιότητα του Θεωρήματος 6.1 ισχύει εφόσον οι μέσες τιμές και ορίζονται και είναι πεπερασμένες. Αντίστοιχες υποθέσεις καλύπτουν και τις Ιδιότητες 2, 3 και 4.
Τέλος, σημειώνουμε πως η θεωρία μέτρου επιτρέπει τον ορισμό της μέσης τιμής και της διασποράς κάτω από πιο γενικές συνθήκες, και παρέχει μαθηματικά εργαλεία τα οποία μας επιτρέπουν να διατυπώσουμε γενικότερες μορφές των αντίστοιχων ιδιοτήτων. Αλλά αυτές οι γενικεύσεις αφορούν λεπτά μαθηματικά ζητήματα και επιπλέον δεν μας είναι απαραίτητες. Κατά συνέπεια, δεν θα επεκταθούμε προς αυτή την κατεύθυνση.
6.4 Ασκήσεις
-
1.
Μέση τιμή συναρτήσεων Τ.Μ. Στον Ορισμό 6.4 ορίσαμε τη μέση τιμή της μέσω του τύπου (6.5). Αλλά η είναι και η ίδια μια τυχαία μεταβλητή, με τη δική της πυκνότητα, έστω και το δικό της σύνολο τιμών, έστω Δείξτε πως, αν εφαρμόσουμε τον τύπο του ορισμού (6.4) για τη μέση τιμή της το αποτέλεσμα ισούται με εκείνο του γενικότερου τύπου (6.5) για τη μέση τιμή της
- 2.
-
3.
Ντετερμινιστικές Τ.Μ. Στην τρίτη παρατήρηση της Ενότητας 6.2 είδαμε πως μια Τ.Μ. έχει διασπορά αν και μόνο αν παίρνει μία και μόνο μία τιμή, με πιθανότητα 1. Τέτοιες τετριμμένες περιπτώσεις Τ.Μ. ονομάζονται ντετερμινιστικές. Αποδείξτε πως μια ντετερμινιστική Τ.Μ. είναι ανεξάρτητη από οποιαδήποτε άλλη διακριτή Τ.Μ.
-
4.
Άπειρη μέση τιμή. Έστω μια Τ.Μ. με σύνολο τιμών το και πυκνότητα,
-
(α’)
Υπολογίστε την τιμή της σταθεράς Υπόδειξη.
-
(β’)
Αποδείξτε πως η μέση τιμή
-
(α’)
-
5.
Ανεξαρτησία και μέση τιμή. Δώστε ένα παράδειγμα δύο διακριτών Τ.Μ. για τις οποίες ισχύει ότι,
αλλά δεν είναι ανεξάρτητες. [Σημείωση. Αυτή η άσκηση ίσως σας φανεί σημαντικά ευκολότερη αφού διαβάσετε το Κεφάλαιο 9.]
-
6.
Ανεξαρτησία και διασπορά. Δώστε ένα παράδειγμα δύο διακριτών Τ.Μ. με διασπορές που να ικανοποιούν αλλά τέτοιες ώστε να έχουμε
-
7.
Δύο ζάρια. Ρίχνουμε διαδοχικά δύο δίκαια ζάρια, και, όπως συνήθως, περιγράφουμε το αποτέλεσμα ως ένα από τα 36 στοιχεία του χώρου πιθανότητας:
Έστω και τα αποτελέσματα των δύο ρίψεων, όπου υποθέτουμε ότι οι ρίψεις είναι ανεξάρτητες μεταξύ τους. Επιπλέον, ορίζουμε τις τυχαίες μεταβλητές και Για καθεμία από τις Τ.Μ. :
-
(α’)
Βρείτε το σύνολο τιμών.
-
(β’)
Περιγράψτε, για καθεμία από τις τιμές που μπορεί να πάρει η Τ.Μ., το αντίστοιχο ενδεχόμενο (π.χ. το ) ως υποσύνολο του χώρου πιθανότητας.
-
(γ’)
Υπολογίστε την πυκνότητα και τη συνάρτηση κατανομής της.
-
(δ’)
Υπολογίστε τη μέση τιμή και τη διασπορά της.
-
(α’)
-
8.
Πού να βρω γυναίκα να σου μοιάζει. Σε κάποιο πάρτυ πηγαίνουν ανδρόγυνα και χωρίζονται σε δύο διαφορετικά δωμάτια άντρες-γυναίκες. Φεύγοντας, οι γυναίκες πια έχουν μεθύσει, και η καθεμία παίρνει στην τύχη έναν από τους άντρες και πηγαίνει σπίτι της. Έστω το πλήθος των σωστών ζευγαριών που φεύγουν από το πάρτυ. Να βρεθούν η μέση τιμή και η διασπορά της [Υπόδειξη. Ίσως σας φανεί βολικό να χρησιμοποιήσετε τις βοηθητικές τυχαίες μεταβλητές όπου αν η γυναίκα πάρει τον δικό της άντρα, και στην αντίθετη περίπτωση.]
-
9.
Συνέλιξη. Έστω δύο ανεξάρτητες διακριτές T.M. που παίρνουν ακέραιες τιμές και έχουν πυκνότητες αντίστοιχα. Να δειχθεί ότι η νέα Τ.Μ. έχει πυκνότητα:
[Παρατήρηση. Η πιο πάνω έκφραση είναι γνωστή ως η συνέλιξη των δύο πυκνοτήτων και και εμφανίζεται συχνά στα μαθηματικά. Στο Κεφάλαιο 15 θα δούμε και τη συνεχή εκδοχή της.]
-
10.
Άλλα δύο ζάρια. Ρίχνουμε διαδοχικά δύο δίκαια ζάρια. Έστω και τα αποτελέσματα των δύο ρίψεων, οι οποίες υποθέτουμε πως είναι ανεξάρτητες. Έστω επίσης οι τυχαίες μεταβλητές και
Για τις :
-
(α’)
Βρείτε το σύνολο τιμών.
-
(β’)
Περιγράψτε, για καθεμία από τις τιμές που μπορεί να πάρει η Τ.Μ., το αντίστοιχο ενδεχόμενο (π.χ. το ) ως υποσύνολο του χώρου πιθανότητας.
-
(γ’)
Υπολογίστε την πυκνότητα και τη συνάρτηση κατανομής της.
-
(δ’)
Υπολογίστε τη μέση τιμή και τη διασπορά της, χωρίς να χρησιμοποιήσετε το Θεώρημα 6.1.
-
(α’)
-
11.
Δέκα μπάλες. Έστω πως από 10 μπάλες, οι οποίες είναι αριθμημένες από το έως το επιλέγουμε τυχαία χωρίς επανατοποθέτηση. Έστω ο μέγιστος αριθμός από τις τρεις μπάλες που επιλέξαμε, και ο ελάχιστος. Να προσδιορίσετε την πυκνότητα και τη συνάρτηση κατανομής των και
-
12.
Περιορισμοί στις παραμέτρους. Μια Τ.Μ. παίρνει τις τιμές και Η πυκνότητά της είναι:
-
(α’)
Ποιες είναι οι επιτρεπτές τιμές του και του Ποια σχέση πρέπει να ικανοποιείται μεταξύ των και
-
(β’)
Ποιο ζευγάρι τιμών μεγιστοποιεί τη μέση τιμή της
-
(γ’)
Υπολογίστε τη διασπορά της αν
-
(α’)
-
13.
Επιζώντα ζευγάρια. Έστω μια πόλη με ζεύγη ανδρών-γυναικών (δηλαδή με συνολικό πληθυσμό ατόμων.) Αν υποθέσουμε ότι τυχαία άτομα πεθαίνουν, να υπολογιστεί η μέση τιμή του πλήθους των ζευγαριών που παραμένουν. [Σημείωση. Το πρόβλημα αυτό διατυπώθηκε για πρώτη φορά από τον Daniel Bernoulli, το 1768. Υπόδειξη. Όπως και στην Άσκηση 8, ίσως σας φανεί βολικό να χρησιμοποιήσετε κάποιες βοηθητικές τυχαίες μεταβλητές.]
-
14.
Τρία ζάρια. Υπολογίσετε την πυκνότητα και τη συνάρτηση κατανομής του αθροίσματος των αποτελεσμάτων τριών (ανεξάρτητων) δίκαιων ζαριών.
-
15.
Παιχνίδι. Σε ένα παιχνίδι, ο παίκτης έχει τυχαίο κέρδος ή ευρώ, με αντίστοιχες πιθανότητες
-
(α’)
Υπολογίστε τη μέση τιμή και τη διασπορά του κέρδους του σε μία παρτίδα.
-
(β’)
Υπολογίστε τη μέση τιμή και τη διασπορά του συνολικού του κέρδους σε τρεις ανεξάρτητες παρτίδες.
-
(α’)
-
16.
Η μέθοδος της δεύτερης ροπής. Έστω μια Τ.Μ. με σύνολο τιμών το με μέση τιμή και διασπορά Δείξτε πως, αν η τυπική απόκλιση της είναι σημαντικά μικρότερη από τη μέση τιμή τότε η πιθανότητα το να ισούται με μηδέν είναι μικρή.
Συγκεκριμένα, αποδείξτε πως,
-
17.
Εναλλακτική έκφραση της Έστω μια διακριτή τυχαία μεταβλητή με σύνολο τιμών το και (πεπερασμένη) μέση τιμή Αποδείξτε πως η μπορεί εναλλακτικά να εκφραστεί ως,
-
18.
Αποστάσεις μεταξύ πυκνοτήτων. Έστω δύο πυκνότητες και στο ίδιο πεπερασμένο σύνολο H -απόσταση μεταξύ της και της ορίζεται ως,
και η -απόσταση της από την ορίζεται ως,
-
(α’)
Παρατηρήστε ότι και για τις δύο αυτές αποστάσεις πάντοτε έχουμε και Επιπλέον, παρατηρήστε ότι αν και μόνο αν δηλαδή αν για κάθε και ότι το ίδιο ισχύει και για την
-
(β’)
Έστω μια Τ.Μ. με πυκνότητα στο και έστω η συνάρτηση Εξετάζοντας τη διασπορά της Τ.Μ. αποδείξτε ότι η -απόσταση είναι πιο «ισχυρή» από την -απόσταση, υπό την έννοια ότι, για οποιεσδήποτε δύο πυκνότητες και έχουμε,
-
(α’)
Κεφάλαιο 7 Διακριτές κατανομές
[Επιστροφή στα περιεχόμενα]
Στο προηγούμενο κεφάλαιο είδαμε πως η έννοια της τυχαίας μεταβλητής (Τ.Μ.), δηλαδή μιας τυχαίας ποσότητας που προσδιορίζεται από το σύνολο τιμών της και την πυκνότητά της μας επιτρέπει να περιγράφουμε προβλήματα που μας ενδιαφέρουν με πιο σύντομο και σαφή τρόπο, χωρίς να αναγκαζόμαστε κάθε φορά να ορίζουμε σχολαστικά τον πλήρη χώρο πιθανότητας και το αντίστοιχο μέτρο πιθανότητας Το επόμενο βήμα σε αυτήν τη διαδικασία της πιο αφαιρετικής περιγραφής, είναι η καταγραφή κάποιων σημαντικών τύπων τυχαίων μεταβλητών, ιδιαίτερα χρήσιμων στην πράξη, οι οποίοι εμφανίζονται συχνά σε βασικά προβλήματα των πιθανοτήτων.
Σ’ αυτό το κεφάλαιο θα εντοπίσουμε πέντε τέτοιες κατηγορίες τυχαίων μεταβλητών και θα δείξουμε με παραδείγματα κάποιες από τις συνήθεις περιπτώσεις όπου χρησιμοποιούνται. Επιπλέον θα αποδείξουμε ορισμένες ιδιότητές τους (π.χ., θα υπολογίσουμε τη μέση τιμή και τη διασπορά τους), έτσι ώστε να μπορούμε να τις χρησιμοποιούμε χωρίς να απαιτείται η επανάληψη των ίδιων υπολογισμών σε κάθε επιμέρους πρόβλημα.
7.1 Κατανομές Bernoulli, διωνυμική και γεωμετρική
Η πιο απλή τυχαία μεταβλητή είναι εκείνη που παίρνει μόνο δύο τιμές, οι οποίες, στην απλούστερη περίπτωση είναι το «0» και το «1»:
Ορισμός 7.1
Μια διακριτή Τ.Μ. λέμε πως έχει κατανομή Bernoulli με παράμετρο , για κάποιο αν έχει σύνολο τιμών το και πυκνότητα με τιμές και Για συντομία, αυτό συμβολίζεται:
Παρατηρήσεις:
-
1.
Ο πιο πάνω ορισμός απλά λέει πως μια Τ.Μ. έχει κατανομή Bernoulli όταν παίρνει μόνο τις τιμές 0 και 1, και η παράμετρος της κατανομής είναι η πιθανότητα το να ισούται με 1, δηλαδή
-
2.
Οι πιο συχνές χρήσεις τυχαίων μεταβλητών με κατανομή Bernoulli είναι είτε για την περιγραφή δυαδικών δεδομένων (bits), είτε ως «δείκτες» που προσδιορίζουν αν κάποιο σημαντικό γεγονός έχει συμβεί ή όχι. Για παράδειγμα, μια Τ.Μ. μπορεί να παίρνει την τιμή 1 αν κάποιο σύστημα παρουσιάζει σφάλμα, αν ο αλγόριθμός μας εκτελέστηκε κανονικά, αν μια κλήση σε ένα δίκτυο τηλεφωνίας ολοκληρώθηκε, αν κάποιος ασθενής θεραπεύτηκε, αν μια άλλη Τ.Μ. πάρει τιμή κ.ο.κ., και στην αντίθετη περίπτωση να παίρνει την τιμή 0. Σε αρκετά παραδείγματα του προηγούμενου κεφαλαίου, π.χ, είδαμε τέτοιες Τ.Μ. να περιγράφουν τα αποτελέσματα διαδοχικών ρίψεων ενός νομίσματος. Στις Ασκήσεις 2 και 3 στο τέλος του κεφαλαίου θα δούμε κάποιες απλές ιδιότητες για τέτοιες δείκτριες, όπως συχνά ονομάζονται, τυχαίες μεταβλητές.
- 3.
-
4.
Αν και ο αυστηρός ορισμός που δώσαμε πιο πάνω περιορίζει τις δυνατές τιμές της παραμέτρου στο διάστημα θα μπορούσαμε να επιτρέψουμε και τις ακραίες τιμές και Σε αυτές τις τετριμμένες περιπτώσεις, προφανώς η είναι απλά μια σταθερά: με πιθανότητα 1 όταν και με πιθανότητα 1 όταν
Παράδειγμα 7.1
Έστω πως στρίβουμε φορές ένα νόμισμα με για κάποιο Όπως στο Παράδειγμα 6.4, μπορούμε να περιγράψουμε τα αποτελέσματα των διαδοχικών ρίψεων ορίζοντας ανεξάρτητες Τ.Μ. όπου η κάθε και αν φέραμε Κ τη φορά ενώ αν φέραμε Γ.
Όπως στο Παράδειγμα 6.3, παρατηρούμε πως το πλήθος των φορών που φέραμε Κορώνα στις ρίψεις, έστω μπορεί να εκφραστεί ως:
Η Τ.Μ. έχει σύνολο τιμών Για να υπολογίσουμε την πυκνότητά της, εξετάζουμε το χώρο πιθανότητας του πειράματος, ο οποίος αποτελείται από στοιχεία της μορφής,
που περιγράφουν τα αποτελέσματα των ρίψεων. Π.χ., το πιο πάνω περιγράφει το αποτέλεσμα όπου φέραμε Γ την πρώτη φορά και Κ τις επόμενες φορές.
Εφόσον το νόμισμα δεν είναι απαραίτητα δίκαιο (δηλαδή δεν μας δίνεται ότι ), δεν μπορούμε να θεωρήσουμε ότι όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα. Για τον υπολογισμό των τιμών της πυκνότητας της θα χρησιμοποιήσουμε το γεγονός ότι οι διαδοχικές ρίψεις (δηλαδή οι Τ.Μ. ) είναι ανεξάρτητες. Όπως έχουμε ήδη παρατηρήσει, για να ορίσουμε ένα μέτρο πιθανότητας σε έναν πεπερασμένο χώρο πιθανότητας αρκεί να ορίσουμε το για κάθε στοιχειώδες ενδεχόμενο Για παράδειγμα, για το στοιχειώδες ενδεχόμενο που αντιστοιχεί στο όπως πιο πάνω, έχουμε,
όπου στο τρίτο βήμα χρησιμοποιήσαμε την ανεξαρτησία των Παρομοίως, έστω το υποσύνολο του που αποτελείται από όλα τα που περιέχουν φορές Κ και φορές Γ. Τότε έχουμε, με το ίδιο σκεπτικό όπως πριν,
και αυτό ισχύει για κάθε δυνατή τιμή του
Έχοντας τώρα ορίσει το μέτρο πιθανότητας για όλα τα στοιχειώδη ενδεχόμενα, υπολογίζουμε την πυκνότητα της ως εξής. Για
και αφού τα στοιχειώδη ενδεχόμενα είναι πάντα ξένα μεταξύ τους, και για κάθε
Τέλος, παρατηρούμε ότι, από τον κανόνα αρίθμησης υπάρχουν τρόποι να διατάξουμε Κορώνες και Γράμματα, άρα και συνεπώς:
Ορισμός 7.2
Μια διακριτή Τ.Μ. λέμε πως έχει διωνυμική κατανομή με παραμέτρους και , για κάποια και αν έχει σύνολο τιμών το και πυκνότητα:
Για συντομία, αυτό συμβολίζεται:
Παρατηρήσεις:
-
1.
Μια Τ.Μ. με διωνυμική κατανομή με παραμέτρους και περιγράφει το πλήθος των «επιτυχιών» σε διαδοχικά, ανεξάρτητα, όμοια πειράματα, όπου σε κάθε πείραμα η πιθανότητα επιτυχίας ισούται με Εδώ, βέβαια, «επιτυχία» θεωρείται το γεγονός που μας ενδιαφέρει στο εκάστοτε πρόβλημα – π.χ. το να φέρουμε Κ με κάποιο νόμισμα, την εμφάνιση σφάλματος σε κάποιο σύστημα, την ορθή εκτέλεση ενός αλγόριθμου κλπ.
-
2.
Όπως είδαμε στο Παράδειγμα 7.1, μια Τ.Μ. μπορεί πάντα να εκφραστεί ως το άθροισμα ανεξάρτητων Τ.Μ. Συνεπώς, χρησιμοποιώντας την Ιδιότητα 1 του Θεωρήματος 6.1, το έχει μέση τιμή,
και, αφού κάθε Bernoulli Τ.Μ. με παράμετρο έχει μέση τιμή έχουμε,
Παρομοίως, εφόσον τα είναι ανεξάρτητα μπορούμε να εφαρμόσουμε την Ιδιότητα 4 του Θεωρήματος 6.1, σε συνδυασμό με το γεγονός ότι κάθε έχει για να υπολογίσουμε τη διασπορά του ως,
-
3.
Όταν το προφανώς η είναι απλά μια Τ.Μ. με κατανομή Και όπως στην περίπτωση της κατανομής Bernoulli, αν το πάρει μία από τις δύο ακραίες τιμές ή 1, τότε με πιθανότητα 1 έχουμε ή αντίστοιχα.
Μία από τις πιο συνηθισμένες περιπτώσεις χρήσης της διωνυμικής κατανομής είναι σε προβλήματα «επιλογών με επανατοποθέτηση» όπως το ακόλουθο.
Παράδειγμα 7.2
Ένα mailbox περιέχει μηνύματα email, εκ των οποίων τα έχουν κάποιο ιό. Από τα μηνύματα επιλέγουμε με επανατοποθέτηση. Έστω το (τυχαίο) πλήθος των μηνυμάτων από αυτά που επιλέξαμε τα οποία έχουν τον ιό. Εδώ η εκφράζει το πλήθος των «επιτυχιών» (όπου επιτυχία εδώ θεωρούμε την επιλογή ενός μηνύματος με τον ιό) ανάμεσα σε διαδοχικά πειράματα, τα οποία είναι εξ ορισμού ανεξάρτητα, και το καθένα έχει πιθανότητα επιτυχίας ίση με Άρα η Μπορούμε λοιπόν να κάνουμε μερικούς απλούς υπολογισμούς.
Ποια είναι η πιθανότητα να κολλήσουμε τον ιό από τα επιλεγμένα μηνύματα; Είναι η πιθανότητα να έχουμε επιλέξει τουλάχιστον ένα «μολυσμένο» μήνυμα, δηλαδή να έχουμε
όπου χρησιμοποιήσαμε τον τύπο της πυκνότητας μιας διωνυμικής Τ.Μ. Παρομοίως, εφαρμόζοντας τον αντίστοιχο τύπο για τη μέση τιμή έχουμε,
το οποίο παρατηρούμε πως δεν εξαρτάται από το συνολικό πλήθος των μηνυμάτων. Τέλος, αν έχουμε μολυσμένα μηνύματα ανάμεσα σε τότε, με και η πιθανότητα να έχουμε επιλέξει το πολύ δύο που να έχουν τον ιό είναι,
Παράδειγμα 7.3
Όπως στο Παράδειγμα 6.4, στρίβουμε ένα νόμισμα με για κάποιο σε συνεχόμενες, ανεξάρτητες ρίψεις, και για κάθε ορίζουμε τις ανεξάρτητες Τ.Μ.,
όπου η κάθε Έστω η πρώτη χρονική στιγμή που φέρνουμε Κ, δηλαδή το μικρότερο τέτοιο ώστε Στο Παράδειγμα 6.4 είδαμε πως η έχει σύνολο τιμών το και πυκνότητα για κάθε ακέραιο
Ορισμός 7.3
Μια διακριτή Τ.Μ. λέμε πως έχει γεωμετρική κατανομή με παράμετρο , για κάποιο αν έχει σύνολο τιμών το και πυκνότητα:
Για συντομία, αυτό συμβολίζεται:
Παρατήρηση: Μια Τ.Μ. με γεωμετρική κατανομή με παράμετρο περιγράφει τη χρονική στιγμή της πρώτης επιτυχίας σε μια σειρά από διαδοχικά, ανεξάρτητα, όμοια πειράματα, όπου σε κάθε πείραμα η πιθανότητα επιτυχίας ισούται με Αν τα αποτελέσματα των πειραμάτων περιγράφονται από μια σειρά ανεξάρτητων τυχαίων μεταβλητών (όπου αν έχουμε επιτυχία τη φορά ), τότε η μπορεί να εκφραστεί ως:
Παράδειγμα 7.4
Κάθε πακέτο δεδομένων που περνάει από έναν συγκεκριμένο κόμβο κάποιου δικτύου, «χάνεται» με πιθανότητα ανεξάρτητα από την τύχη των υπόλοιπων πακέτων. Έστω το πρώτο πακέτο που χάνεται (ή, πιο σχολαστικά, ο αύξων αριθμός του πρώτου πακέτου που χάνεται), έτσι ώστε Για να διευκολυνθούμε στον παρακάτω υπολογισμό, ορίζουμε τις ανεξάρτητες Τ.Μ. όπου κάθε περιγράφει αν το πακέτο χάθηκε () ή όχι ().
Ποια είναι η πιθανότητα το πρώτο πακέτο που χάθηκε να είναι μετά τα 10,000 πρώτα; Χρησιμοποιώντας την ανεξαρτησία των :
-
1.
Ουρά: Για κάθε ακέραιο :
-
2.
Συνάρτηση κατανομής: για και:
-
3.
Ιδιότητα έλλειψης μνήμης: Για κάθε ζευγάρι ακεραίων :
Δηλαδή, η πιθανότητα είναι ανεξάρτητη του και ίση με εκείνη που αντιστοιχεί στο δηλαδή,
-
4.
Μέση τιμή:
-
5.
Διασπορά:
Απόδειξη:
Όπως στο Παράδειγμα 7.4, ορίζουμε τις ανεξάρτητες Τ.Μ. και θέτουμε το ίσο με το μικρότερο τέτοιο ώστε
Για την πρώτη ιδιότητα, παρατηρούμε πως το είναι μεγαλύτερο από αν και μόνο αν τα πρώτα από τα είναι όλα ίσα με 0, οπότε,
Η συνάρτηση κατανομής, ακριβώς όπως στην Ιδιότητα 2, έχει ήδη υπολογιστεί στο Παράδειγμα 6.4.
Για την Ιδιότητα 3, χρησιμοποιούμε τον ορισμό της δεσμευμένης πιθανότητας σε συνδυασμό με την Ιδιότητα 1:
Για τον υπολογισμό της μέσης τιμής θα χρησιμοποιήσουμε τον τύπο για την έκφραση μιας σειράς που σχετίζεται με μια άπειρη γεωμετρική πρόοδο. Λεπτομέρειες δίνονται στην Ενότητα 7.3. Συγκεκριμένα, εφαρμόζοντας τον τύπο (7.8) με βρίσκουμε:
Παρομοίως, εφαρμόζοντας τον τύπο (7.9) με βρίσκουμε,
και, τέλος, υπολογίζουμε,
η οποία μας δίνει τη διασπορά της ολοκληρώνοντας την απόδειξη.
Παράδειγμα 7.5
Ένας φάκελος αρχείων σε κάποιο PC περιέχει 100 αρχεία, εκ των οποίων τα 70 είναι αρχεία pdf και τα 30 είναι mp3. Επιλέγουμε 3 στην τύχη με επανατοποθέτηση. Παρατηρούμε πως το πλήθος των αρχείων pdf που επιλέξαμε έχει κατανομή Συνεπώς, η πιθανότητα να επιλέξαμε τουλάχιστον 2 αρχεία pdf είναι,
Παρομοίως, το μέσο πλήθος αρχείων pdf που επιλέξαμε είναι,
Τέλος, αν συνεχίζαμε να επιλέγουμε αρχεία (πάλι με επανατοποθέτηση) μέχρι την πρώτη φορά που θα είχαμε ένα pdf, τότε το συνολικό πλήθος, έστω των επιλεγμένων αρχείων θα είχε κατανομή και βάσει της παραπάνω ιδιότητας έλλειψης μνήμης θα μπορούσαμε να υπολογίσουμε,
όπου χρησιμοποιήσαμε και την πρώτη ιδιότητα του Θεωρήματος 7.1.
Κλείνουμε αυτή την ενότητα με ένα διάσημο παράδειγμα.
Έστω Τ.Μ. όπου αν το άτομο έχει τα ίδια γενέθλια με εμένα, αλλιώς για κάθε (θεωρώντας ότι εγώ είμαι ο τριακοστός). Υποθέτουμε πως τα είναι ανεξάρτητες Τ.Μ., προφανώς με κατανομή Bernoulli, και με παράμετρο,
Άρα,
Ας εξετάσουμε τώρα μια απλή παραλλαγή αυτού του προβλήματος ρωτώντας ποια είναι η πιθανότητα, ανάμεσα στα 30 άτομα, να υπάρχουν τουλάχιστον δύο που θα έχουνε γενέθλια την ίδια μέρα; Αν υποθέσουμε και πάλι πως τα γενέθλια των διαφορετικών ατόμων είναι ανεξάρτητα μεταξύ τους και πως η κάθε ημερομηνία έχει την ίδια πιθανότητα, δηλαδή βρίσκουμε πως,
Δηλαδή, με μόλις 30 άτομα σε ένα δωμάτιο, το πιθανότερο είναι να υπάρχουν τουλάχιστον δύο με τα ίδια γενέθλια! (Δοκιμάστε το την επόμενη φορά που θα βρεθείτε με μια αρκετά μεγάλη παρέα, είναι μια καλή ευκαιρία να κερδίσετε ένα γενναίο στοίχημα.)
Παρατήρηση: Το πρώτο ερώτημα του πιο πάνω παραδείγματος θα μπορούσαμε να το σκεφτούμε σαν ένα πρόβλημα επιλογής με επανατοποθέτηση: Βάζουμε τις 365 μέρες του χρόνου σε μια σακούλα, επιλέγουμε μία από τις 365 για τα γενέθλια του πρώτου ατόμου, μετά επιλέγουμε μία ημερομηνία για τον δεύτερο πάλι από όλες τις 365 κ.ο.κ.
Αντίθετα, ο υπολογισμός βάσει του οποίου απαντήθηκε το δεύτερο ερώτημα θυμίζει επιλογή χωρίς επανατοποθέτηση: Επιλέγουμε μία από τις 365 ημέρες του χρόνου για τα γενέθλια του πρώτου ατόμου, κατόπιν επιλέγουμε μία από τις υπόλοιπες 364 για τον δεύτερο, μετά μία από τις 363 που απομένουν για τον τρίτο, κλπ.
Όπως αναφέραμε πιο πάνω, στα προβλήματα επιλογής με επανατοποθέτηση συχνά μας είναι χρήσιμη η διωνυμική κατανομή. Στην επόμενη ενότητα θα δούμε την αντίστοιχη κατανομή – την υπεργεωμετρική – η οποία προκύπτει σε προβλήματα επιλογής χωρίς επανατοποθέτηση.
7.2 Υπεργεωμετρική και Poisson κατανομή
Παράδειγμα 7.7
Ξεκινάμε εξετάζοντας μια γενική μορφή του προβλήματος των τυχαίων επιλογών χωρίς επανατοποθέτηση. Έστω πως,
επιλέγουμε τυχαία χωρίς επανατοποθέτηση. [Υποθέτουμε ότι ] Έστω η Τ.Μ.,
η οποία περιγράφει την ποσότητα που μας ενδιαφέρει εδώ. Η έχει, εξ ορισμού, σύνολο τιμών το και η πυκνότητά της είναι εύκολο να υπολογιστεί:
Για οποιοδήποτε η είναι η πιθανότητα του ενδεχομένου «επιλέξαμε αντικείμενα τύπου Ι και τύπου ΙΙ». Από τους κανόνες αρίθμησης του Κεφαλαίου 4 σε συνδυασμό με τον κανόνα πιθανότητας έχουμε,
Ορισμός 7.4
Μια διακριτή Τ.Μ. λέμε πως έχει υπεργεωμετρική κατανομή με παραμέτρους και , για ακεραίους αν έχει σύνολο τιμών το και πυκνότητα:
Για συντομία, αυτό συμβολίζεται:
Παράδειγμα 7.8
Έστω πως επιλέγουμε τυχαία τρία φύλλα από μια συνηθισμένη τράπουλα. Ποια είναι η πιθανότητα να επιλέξαμε ακριβώς μία φιγούρα;
Αν ορίσουμε την Τ.Μ. ως το πλήθος από φιγούρες που επιλέξαμε, τότε (αφού η τράπουλα περιέχει 12 φιγούρες) η έχει κατανομή και η ζητούμενη πιθανότητα ισούται με,
Παρατήρηση: Αν στο Παράδειγμα 7.7 επιλέγαμε τυχαία αντικείμενα με επανατοποθέτηση, τότε η θα είχε κατανομή αλλά, εφόσον εδώ δεν έχουμε επανατοποθέτηση, η έχει κατανομή
Ακολουθώντας κάποια από τα ίδια βήματα της μεθοδολογίας με την οποία εξετάσαμε ορισμένες από τις ιδιότητες της διωνυμικής κατανομής, μπορούμε να ορίσουμε κι εδώ τυχαίες μεταβλητές Bernoulli, οι οποίες να εκφράζουν τα αποτελέσματα των διαδοχικών επιλογών: Έστω, για κάθε :
Τότε, όπως και στην περίπτωση της διωνυμικής κατανομής, η μπορεί να εκφραστεί,
Κατ’ αρχάς παρατηρούμε πως, σε αντίθεση με την περίπτωση της διωνυμικής κατανομής, οι Τ.Μ. δεν είναι ανεξάρτητες. Για παράδειγμα, εύκολα υπολογίζουμε πως,
| (7.1) |
Από την άλλη μεριά, λόγω της συμμετρίας του προβλήματος, όλες οι Bernoulli Τ.Μ. έχουν την ίδια παράμετρο. Ένας τρόπος για να πεισθούμε γι’ αυτό είναι να σκεφτούμε πως, αντί να επιλέξουμε αντικείμενα χωρίς επανατοποθέτηση το ένα μετά το άλλο, ισοδύναμα πραγματοποιούμε το εξής πείραμα. Διατάσσουμε με τυχαίο τρόπο τα αντικείμενα και μετά επιλέγουμε τα πρώτα. Προφανώς, η πιθανότητα σε καθεμία από τις πρώτες θέσεις να έχουμε αντικείμενο τύπου Ι είναι άρα, η παράμετρος της κάθε είναι ίδια:
Εφαρμόζοντας τώρα την πρώτη ιδιότητα του Θεωρήματος 6.1, βρίσκουμε την εξής έκφραση για τη μέση τιμή μιας Τ.Μ. :
| (7.2) |
Ένας παρόμοιος αλλά λίγο πιο πολύπλοκος υπολογισμός μάς επιτρέπει να υπολογίσουμε και τη διασπορά της :
| (7.3) |
Λεπτομέρειες για την απόδειξη της (7.3) δίνονται στην Άσκηση 18 στο τέλος του κεφαλαίου.
Παράδειγμα 7.9
Παράδειγμα 7.10
Έστω πως, από τα 10 εκατομμύρια άτομα ενός πληθυσμού, οι 100 χιλιάδες έχουν στο σπίτι τους σύνδεση internet μέσω γραμμής ADSL. Από αυτό τον πληθυσμό επιλέγουμε τυχαία, για μια έρευνα αγοράς, 150 άτομα, χωρίς επανατοποθέτηση. Τότε, το πλήθος, έστω των ανθρώπων με σύνδεση ADSL ανάμεσα στους επιλεγμένους έχει κατανομή
Αν, αντίθετα, η επιλογή των ατόμων γίνει με επανατοποθέτηση, τότε το πλήθος των ανθρώπων με ADSL που θα επιλέξουμε θα έχει κατανομή αφού η πιθανότητα να επιλεγεί κάποιος με ADSL είναι Παρότι η πυκνότητα της μας είναι γνωστή, ο υπολογισμός των τιμών της πυκνότητας αυτής είναι αριθμητικά δύσκολος διότι απαιτεί τη χρήση τιμών της μορφής για μεγάλα Π.χ.,
όπου, για παράδειγμα, το είναι μια ποσότητα της τάξης του
Προκειμένου να αποφύγουμε τέτοιου είδους υπολογισμούς με αστρονομικά μεγέθη (οι οποίοι συχνά οδηγούν σε μεγάλα αριθμητικά σφάλματα στην πράξη), θα χρησιμοποιήσουμε την πιο κάτω προσέγγιση για το όταν το παίρνει μεγάλες τιμές. Η απόδειξή της δίνεται στην Ενότητα 7.4.
Πιο συγκεκριμένα, έχουμε,
Σημείωση. Αν και δεν θα μας χρειαστεί, η τιμή της σταθεράς στο Λήμμα 7.1 μπορεί να υπολογιστεί ακριβώς με κάποιο επιπλέον κόπο, και είναι
Παράδειγμα 7.11
Έστω πως σε ένα χρονικό διάστημα δευτερολέπτων, όπου θεωρούμε πως το είναι «μεγάλο», συμβαίνει ένα τυχαίο πλήθος γεγονότων, και κατά μέσο όρο συμβαίνουν τέτοια γεγονότα. Πιο συγκεκριμένα, θεωρούμε πως για κάθε δευτερόλεπτο είτε συμβαίνει ένα γεγονός είτε όχι, και αυτά είναι ανεξάρτητα μεταξύ τους. Ορίζουμε λοιπόν ανεξάρτητες Τ.Μ. όπου η κάθε αν έχουμε γεγονός το δευτερόλεπτο αλλιώς Τότε, το συνολικό πλήθος ισούται με το άθροισμα των και συνεπώς
Εφόσον υποθέτουμε πως αλλά μια διωνυμική Τ.Μ. έχει θα πρέπει να θέσουμε την πιθανότητα Όπως παρατηρήσαμε στο τελευταίο παράδειγμα, η διωνυμική κατανομή είναι δύσχρηστη για μεγάλα Το ακόλουθο θεώρημα μας λέει πως, σε αυτή την περίπτωση, μπορεί να προσεγγιστεί αποτελεσματικά από μια άλλη, πολύ πιο εύχρηστη, κατανομή.
Καθώς το οι τιμές της πυκνότητας συγκλίνουν στις αντίστοιχες τιμές της πυκνότητας μιας Τ.Μ. με κατανομή Poisson με παράμετρο , δηλαδή με σύνολο τιμών το και πυκνότητα,
Με άλλα λόγια, για κάθε έχουμε,
| (7.4) |
καθώς το
Σημείωση. Για συντομία, το ότι μια Τ.Μ. έχει κατανομή Poisson με παράμετρο συμβολίζεται ως εξής: Η κατανομή Poisson έχει δύο συνηθισμένες χρήσεις. Η μία είναι για να περιγράψει το πλήθος των γεγονότων που συμβαίνουν σε μια δεδομένη χρονική περίοδο, όταν αυτά συμβαίνουν με τον «πιο τυχαίο δυνατό τρόπο» και το μόνο που είναι γνωστό είναι το μέσο πλήθος τους. Η δεύτερη είναι προσέγγιση της διωνυμικής κατανομής. Οι ακριβείς συνθήκες κάτω από τις οποίες η κατανομή Poisson μάς δίνει πράγματι μια καλή προσέγγιση για τη διωνυμική δίνονται επιγραμματικά στο πιο κάτω πόρισμα, το οποίο είναι άμεση απόρροια του Θεωρήματος 7.2.
-
•
το είναι αρκετά «μεγάλο», δηλαδή
-
•
το είναι αρκετά «μικρό», δηλαδή
-
•
το γινόμενό είναι της τάξεως του 1.
Τότε η κατανομή της μπορεί να προσεγγιστεί από την κατανομή μιας Τ.Μ. με υπό την έννοια ότι:
Για την απόδειξη του Θεωρήματος 7.2 θα χρησιμοποιήσουμε τις πιο κάτω εκφράσεις για την εκθετική συνάρτηση Η πρώτη μπορεί να ληφθεί ως ο ορισμός της και τη θεωρούμε γνωστή. Λεπτομέρειες για την απόδειξη της τρίτης έκφρασης, η οποία είναι μια ισχυρότερη μορφή της δεύτερης, δίνονται στην Άσκηση 19 στο τέλος του κεφαλαίου.
-
1.
Η σειρά:
-
2.
Το όριο:
Επιπλέον, για μια οποιαδήποτε ακολουθία πραγματικών αριθμών που τείνουν στο καθώς το έχουμε:
| (7.5) |
() Απόδειξη του Θεωρήματος 7.2:
Έστω και δεδομένα. Η ιδέα της απόδειξης είναι απλή: Θα εφαρμόσουμε τον τύπο του Stirling στην πυκνότητα της διωνυμικής κατανομής. Θυμίζουμε ότι, όπως στο Λήμμα 7.1, η ακριβής διατύπωση του τύπου του Stirling μάς λέει πως υπάρχει μια σταθερά και μια ακολουθία πραγματικών αριθμών που τείνει στο ένα, τέτοια ώστε, για κάθε Αντικαθιστώντας αυτή την έκφραση στα παραγοντικά και που εμφανίζονται στην
| (7.6) | |||||
Θέτοντας παρατηρώντας ότι καθώς και απλοποιώντας, βρίσκουμε,
Το τελευταίο παραπάνω γινόμενο αποτελείται από έξι όρους. Καθώς το οι δύο πρώτοι είναι σταθεροί, και ο τέταρτος και ο έκτος τείνουν στο 1. Παρομοίως, ο πέμπτος όρος τείνει στο Για τον βασικότερο όρο, τον τρίτο, χρησιμοποιώντας την τρίτη έκφραση (7.5) από το Λήμμα 7.2, με και παρατηρώντας πως τα τείνουν στο καθώς το έχουμε,
Τέλος, συνδυάζοντας όλα τα παραπάνω, καθώς το
και έχουμε αποδείξει τη ζητούμενη σχέση (7.4).
Παρατήρηση: Το μόνο σημείο στην παραπάνω απόδειξη όπου εφαρμόστηκε ο τύπος του Stirling ήταν για να δεχθεί, στην έκφραση (7.6), ότι ο όρος τείνει στο 1 καθώς το Αλλά αυτό μπορεί εύκολα να αποδειχθεί και απευθείας, παρατηρώντας ότι,
το οποίο είναι ο λόγος δύο πολυωνύμων (ως προς ) βαθμού με πρώτο όρο και στα δύο, και συνεπώς τείνει στο 1 καθώς το
Παράδειγμα 7.12
Στο επόμενό μας αποτέλεσμα υπολογίζονται η μέση τιμή και η διασπορά μιας Τ.Μ. με κατανομή Poisson.
Θεώρημα 7.3
Αν τότε:
Απόδειξη:
Για τη μέση τιμή έχουμε,
Το άθροισμα της πιο πάνω σειράς υπολογίζεται στην επόμενη ενότητα, και δίνεται από τον τύπο (7.10). Εφαρμόζοντάς τον, με βρίσκουμε,
Παρομοίως υπολογίζεται και η μέση τιμή της ως,
και, εφαρμόζοντας τον αντίστοιχο τύπο (7.11) με προκύπτει πως,
Συνεπώς, η διασπορά της είναι ίση με,
ολοκληρώνοντας την απόδειξη.
Κλείνουμε αυτή την ενότητα με ένα ακόμα παράδειγμα.
Παράδειγμα 7.13
Έστω πως σε καθένα από αντικείμενα δίνουμε τυχαία έναν αριθμό από το 1 ως το 1000 (επιτρέποντας σε δύο αντικείμενα να έχουν τον ίδιο αριθμό), και μας ενδιαφέρει το (τυχαίο) πλήθος των αντικειμένων που έχουν τον αριθμό 1. Τότε, το έχει κατανομή με παραμέτρους και Εφόσον το γινόμενο βάσει του Πορίσματος 7.1, η κατανομή του μπορεί να προσεγγιστεί από την με
Συνεπώς, μπορούμε, π.χ., να υπολογίσουμε (ή, πιο σωστά, να προσεγγίσουμε) την πιθανότητα να έχουν 2 ή 3 αντικείμενα τον αριθμό 1 ως,
7.3 Η γεωμετρική και συναφείς σειρές
Εδώ συγκεντρώνουμε μερικά απλά αποτελέσματα που συχνά φαίνονται χρήσιμα σε προβλήματα που σχετίζονται με Τ.Μ. με γεωμετρική κατανομή.
Ξεκινάμε από την απλή παρατήρηση ότι, για κάθε και κάθε
[Αν αυτή η σχέση δεν σας είναι προφανής, αποδείξτε την με επαγωγή.] Υποθέτοντας ότι και διαιρώντας και τα δύο μέρη με το έχουμε τον γνωστό τύπο για το άθροισμα των όρων μιας γεωμετρικής προόδου:
Αν περιοριστούμε τώρα σε τιμές του με τότε προφανώς το καθώς το άρα, περνώντας στο όριο, προκύπτει ο τύπος του αθροίσματος μιας γεωμετρικής σειράς,
| (7.7) |
Από τον ορισμό της συνάρτησης στον τύπο (7.7) έχουμε δύο διαφορετικές εκφράσεις για την μία ως σειρά και μία ως το Μπορούμε επομένως να υπολογίσουμε την παράγωγο με δύο τρόπους: Αφού η παράγωγος ενός αθροίσματος ισούται με το άθροισμα των παραγώγων,
αλλά και,
Εξισώνοντας τις δύο παραπάνω εκφράσεις και πολλαπλασιάζοντας και τα δύο μέρη με το προκύπτει το αποτέλεσμα:
| (7.8) |
Επαναλαμβάνοντας την ίδια διαδικασία, μπορούμε να υπολογίσουμε την παράγωγο της νέας συνάρτησης με δύο τρόπους ως,
Εξισώνοντας όπως πριν τις δύο εκφράσεις για την παράγωγο και πολλαπλασιάζοντας και τα δύο μέρη με το προκύπτει:
| (7.9) |
7.4 Η συνάρτηση δυναμοσειρές, τύπος του Stirling
Σε αυτή την ενότητα θα υπολογίσουμε τις τιμές δύο σειρών που σχετίζονται με την κατανομή Poisson, και θα αποδείξουμε τον τύπο του Stirling όπως περιγράφεται στο Λήμμα 7.1.
Ξεκινάμε θυμίζοντας, όπως στο Λήμμα 7.2, ότι, για κάθε πραγματικό αριθμό η εκθετική συνάρτηση μπορεί να εκφραστεί μέσω του αναπτύγματος του Taylor ως μια δυναμοσειρά:
Εφόσον για την εκθετική συνάρτηση ισχύει πως παίρνοντας την παράγωγο ως προς και στα δύο μέρη της πιο πάνω σχέσης έχουμε,
όπου χρησιμοποιήσαμε τη γνωστή ιδιότητα πως η παράγωγος ενός αθροίσματος ισούται με το άθροισμα των παραγώγων. Άρα έχουμε αποδείξει πως, για κάθε
| (7.10) |
Επαναλαμβάνοντας την ίδια διαδικασία ακόμη μία φορά, παίρνοντας παραγώγους έχουμε,
και συνεπώς,
ή, απλοποιώντας,
| (7.11) |
()
Απόδειξη του Λήμματος 7.1:
Κατ’ αρχάς παρατηρούμε πως, παίρνοντας λογαρίθμους, αρκεί να αποδείξουμε πως, για κάποια σταθερά
| (7.12) |
όπου με συμβολίζουμε τον φυσικό λογάριθμο με βάση το (ο οποίος μερικές φορές συμβολίζεται και ως ).
Για κάθε ορίζουμε το ολοκλήρωμα,
και επίσης (για ) ορίζουμε τις ακολουθίες,
Από τον ορισμό των δύο ακολουθιών, η διαφορά τους ισούται με,
οπότε, αθροίζοντας τις διαφορές,
έχουμε,
Τώρα προσθέτοντας και αφαιρώντας το ολοκλήρωμα βρίσκουμε,
Συνεπώς, για να αποδείξουμε τη ζητούμενη σχέση (7.12), αρκεί να δείξουμε πως το αριστερό μέρος της παραπάνω σχέσης, δηλαδή το τείνει σε κάποιο (πεπερασμένο) όριο καθώς το
Παρατηρούμε πως, μετά από μια απλή αλλαγή μεταβλητών, οι ακολουθίες και μπορούν να εκφραστούν ως,
απ’ όπου εύκολα προκύπτει πως καθώς και πως η διαφορά τους,
Άρα, για να ολοκληρώσουμε την απόδειξη, αρκεί να δείξουμε πως η σειρά (των θετικών όρων ) συγκλίνει σε κάποιο πεπερασμένο άθροισμα.
Από την απλή ανισότητα (βλ. Λήμμα 7.3 πιο κάτω) έχουμε,
και εφόσον η συνάρτηση είναι αύξουσα ως προς (γιατί;), για τις τιμές του στο σχετικό ολοκλήρωμα έχουμε και,
όπου η τελευταία στοιχειώδης ανισότητα ισχύει για κάθε Τελικά, λοιπόν, βρίσκουμε πως,
και αφού η σειρά τότε συγκλίνει και η ζητούμενη σειρά, ολοκληρώνοντας την απόδειξη.
Κλείνουμε αυτό το κεφάλαιο με μια στοιχειώδη ανισότητα την οποία χρησιμοποιήσαμε ήδη πιο πάνω και η οποία θα μας φανεί χρήσιμη και αργότερα.
Λήμμα 7.3
Για κάθε πραγματικό αριθμό έχουμε ή, ισοδύναμα:
| (7.13) |
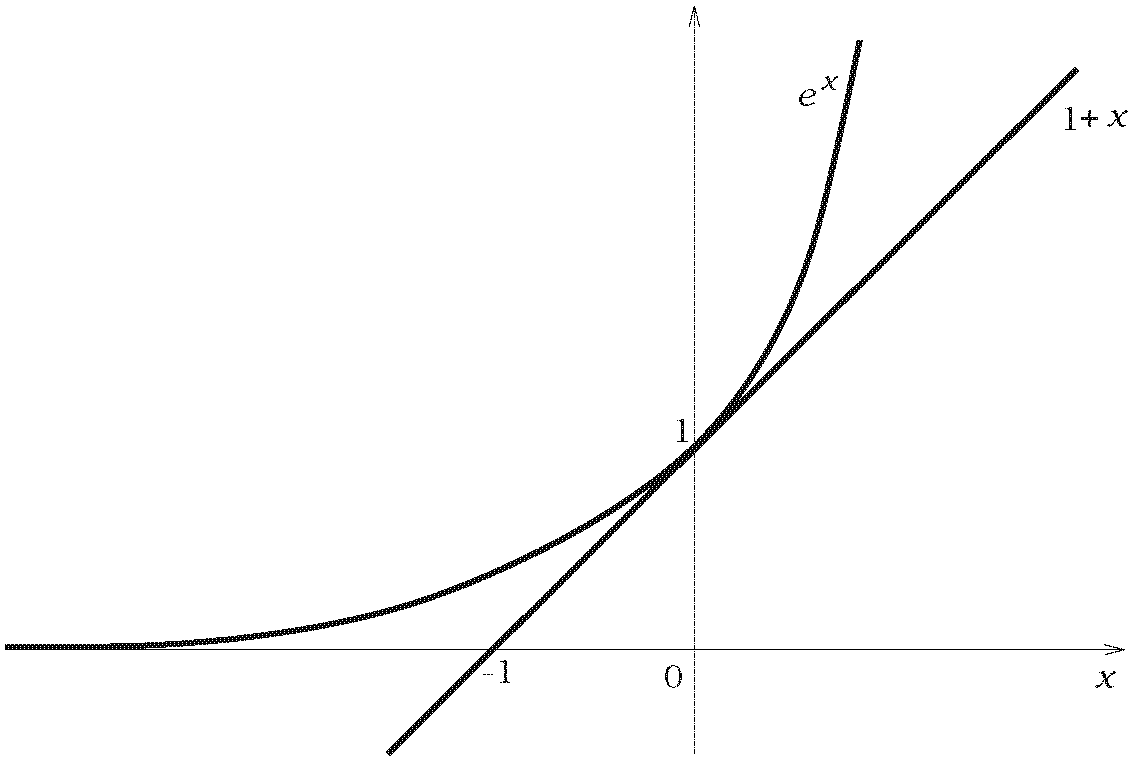
Απόδειξη:
7.5 Ασκήσεις
-
1.
Overbooking. Ένα αεροπλάνο έχει θέσεις, και έχουν γίνει κρατήσεις από επιβάτες. Η πιθανότητα καθένας από αυτούς να έρθει στο αεροδρόμιο είναι 90%, ανεξάρτητα από τους υπόλοιπους. Ποια είναι η πιθανότητα κάποιοι επιβάτες που θα φθάσουν στο αεροδρόμιο να είναι υπεράριθμοι;
-
2.
Δείκτριες τυχαίες μεταβλητές.
-
(α’)
Έστω ένα οποιοδήποτε ενδεχόμενο με πιθανότητα και έστω η «δείκτρια» Τ.Μ. που παίρνει την τιμή όταν συμβαίνει το και όταν δεν συμβαίνει. Ποια είναι η κατανομή του
-
(β’)
Έστω μια οποιαδήποτε Τ.Μ. με συνάρτηση κατανομής Για δεδομένο η δείκτρια συνάρτηση ορίζεται ως,
Δείξτε πως
-
(α’)
-
3.
Η ουρά της μέσης τιμής. Έστω μια διακριτή Τ.Μ. η οποία παίρνει πάντα τιμές μεγαλύτερες ή ίσες του μηδενός και έχει πεπερασμένη μέση τιμή Δείξτε πως, καθώς το
όπου είναι οι δείκτριες συναρτήσεις που ορίσαμε στην Άσκηση 2. Ερμηνεύστε διαισθητικά αυτό το αποτέλεσμα.
-
4.
Ελάχιστο δύο γεωμετρικών τυχαίων μεταβλητών. Έστω και δύο ανεξάρτητες τυχαίες μεταβλητές, με παραμέτρους και αντίστοιχα. Υπολογίστε την πυκνότητα της τυχαίας μεταβλητής Μπορείτε να ερμηνεύσετε διαισθητικά το αποτέλεσμα; Υπόδειξη. Ίσως σας βοηθήσει να υπολογίσετε πρώτα την πιθανότητα
-
5.
Άθροισμα Poisson. Αν οι τυχαίες μεταβλητές και είναι ανεξάρτητες, με κατανομή Poisson και Poisson αντίστοιχα, να δείξετε ότι η τυχαία μεταβλητή έχει κατανομή Poisson Υπόδειξη. Το διωνυμικό θεώρημα λέει πως
-
6.
Ταυτότητα Vandermonde. Αποδείξτε την ταυτότητα Vandermonde,
(7.14) όπου Χρησιμοποιήστε επιχειρήματα που βασίζονται αποκλειστικά στη συνδυαστική. Υπενθυμίζεται πως, κατά σύμβαση, θέτουμε για κάθε και για κάθε
-
7.
Άθροισμα διωνυμικών Τ.Μ. Χρησιμοποιήστε την ταυτότητα Vandermonde της Άσκησης 6, προκειμένου να δείξετε ότι το άθροισμα δύο διωνυμικών Τ.Μ. με παραμέτρους και αντίστοιχα, ανεξάρτητων μεταξύ τους, έχει κατανομή.
Επίσης εξηγήστε πως θα μπορούσαμε να αποδείξουμε το ίδιο αποτέλεσμα χωρίς να χρειαστεί να κάνουμε υπολογισμούς.
-
8.
Διάφορες κατανομές. Παρακάτω ορίζονται κάποιες τυχαίες μεταβλητές. Περιγράψτε την κατανομή και τις αντίστοιχες παραμέτρους καθεμίας από αυτές.
-
(α’)
Ρίχνουμε διαδοχικές (ανεξάρτητες) ζαριές με δύο ζάρια, μέχρι την φορά που θα φέρουμε διπλή. Έστω συνολικό πλήθος από ζαριές που ρίξαμε.
-
(β’)
Επιλέγουμε στην τύχη, με επανατοποθέτηση, φύλλα από μια τράπουλα. Έστω το πλήθος από κούπες που επιλέξαμε.
-
(γ’)
Όπως στο (β’), αλλά χωρίς επανατοποθέτηση.
-
(δ’)
Ρίχνουμε φορές ένα νόμισμα με (Κορώνα) Έστω το πλήθος των φορών που φέραμε Γράμματα.
-
(α’)
-
9.
Ουρά στην τράπεζα. Σε μια τράπεζα, κάθε πεντάλεπτο υπάρχει πιθανότητα να έρθει ένας νέος πελάτης. Υποθέτουμε πως οι αφίξεις πελατών σε διαφορετικά πεντάλεπτα είναι ανεξάρτητες, πως ποτέ δεν έρχονται δύο ή παραπάνω πελάτες σε ένα δεδομένο πεντάλεπτο, και ορίζουμε:
πλήθος πελατών που έφτασαν τις πρώτες ώρες,
το πρώτο λεπτo κατά το οποίο έφτασε πελάτης.
-
(α’)
Ποια είναι η κατανομή του
-
(β’)
Βρείτε την πιθανότητα να έρθουν ακριβώς πελάτες τις πρώτες δύο ώρες.
-
(γ’)
Ποια είναι η κατανομή του
-
(δ’)
Κατά μέσο όρο πόσα λεπτά θα περιμένουν οι υπάλληλοι μέχρι την άφιξη του πρώτου πελάτη;
-
(ε’)
Δεδομένου ότι δεν ήρθε κανείς τις πρώτες ώρες, ποια είναι η πιθανότητα να μην έρθει κανείς και κατά την επόμενη μισή ώρα;
-
(α’)
-
10.
Επιθέσεις μηνυμάτων spam. Κάποιος διαφημιστής στέλνει ένα email στους 10 χιλιάδες λογαριασμούς του domain aueb.gr ζητώντας τον αριθμό της πιστωτικής κάρτας του παραλήπτη. Από προηγούμενες προσπάθειές του γνωρίζει ότι οι διαφορετικοί χρήστες ανταποκρίνονται ανεξάρτητα ο ένας από τον άλλον, και η πιθανότητα να απαντήσει κάποιος με τα ζητούμενα στοιχεία είναι Ποια είναι η πιθανότητα να του απαντήσουν τουλάχιστον τρεις χρήστες;
-
11.
Τα «ν» του Βαρουφάκη. Ως γνωστόν, ο πρώην υπουργός Οικονομικών κύριος Γιάνης Βαρουφάκης αρέσκεται στο να γράφει το μικρό του όνομα με ένα «ν» αντί για δύο. Στα κείμενα που ανεβαίνουν σε ένα δημοσιογραφικό σάιτ, με πιθανότητα 0.3% ο διορθωτής κάνει λάθος και γράφει το όνομά του με δύο «ν», ανεξάρτητα από φορά σε φορά. Αν σε έναν μήνα το όνομα του κ. Βαρουφάκη αναφέρθηκε 800 φορές:
-
(α’)
Εκφράστε το συνολικό πλήθος από «ν» που χρησιμοποιήθηκαν για όλες τις φορές που γράφτηκε το όνομά του, ως το άθροισμα μιας σταθεράς και μιας Τ.Μ. με γνωστή κατανομή. Ποια είναι αυτή η κατανομή;
-
(β’)
Υπολογίστε μια προσέγγιση για την πιθανότητα το συνολικό πλήθος από «ν» που χρησιμοποιήθηκαν να είναι ίσο με 810.
-
(α’)
-
12.
Άσχετος φοιτητής. Σε ένα διαγώνισμα υπάρχουν 250 ερωτήσεις πολλαπλής επιλογής. Ο εξεταζόμενος έχει παρανοήσει εντελώς το αντικείμενο του μαθήματος, και η πιθανότητα να απαντήσει σωστά είναι (πολύ χειρότερη από το να απαντούσε τυχαία!) μόνο 0.5% για την κάθε ερώτηση, ανεξαρτήτως των υπολοίπων ερωτήσεων. Βρείτε μια προσέγγιση της πιθανότητας ο εξεταζόμενος να απαντήσει σωστά σε ακριβώς τρεις ερωτήσεις.
-
13.
Δύο διαφορετικές δημοσκοπήσεις. Σε κάποιον πληθυσμό ψηφοφόρων, άτομα, δηλαδή το 30%, είναι ψηφοφόροι κάποιου συγκεκριμένου κόμματος. Για να προβλέψει το ποσοστό αυτού του κόμματος στις εκλογές, μια εταιρία δημοσκοπήσεων διαλέγει τυχαία, ομοιόμορφα και με επανατοποθέτηση άτομα από τον πληθυσμό, και καταγράφει το πλήθος εκείνων που δήλωσαν ψηφοφόροι του. Ως πρόβλεψη του εκλογικού αποτελέσματος του κόμματος, δίνει το ποσοστό των ψηφοφόρων του στο τυχαίο δείγμα της.
-
(α’)
Ποια είναι η κατανομή του Ποια είναι η μέση τιμή και η διασπορά της πρόβλεψης του ποσοστού
-
(β’)
Επαναλάβετε το προηγούμενο ερώτημα στην περίπτωση που η επιλογή γίνεται χωρίς επανατοποθέτηση. Συγκρίνετε με τα προηγούμενα αποτελέσματα. Ποια μέθοδος είναι πιο συμφέρουσα;
-
(α’)
-
14.
Βελάκια. Ρίχνουμε δέκα βελάκια σε ένα στόχο, με κλειστά μάτια. Οι διαδοχικές ρίψεις είναι ανεξάρτητες, και η πιθανότητα να πετύχουμε τον στόχο είναι μόνο 1%.
-
(α’)
Ποια η πιθανότητα ακριβώς 2 βελάκια να πέτυχαν τον στόχο;
-
(β’)
Αν αντί για 10, ρίχναμε 140 βελάκια, βρείτε μια προσέγγιση της ίδιας πιθανότητας.
-
(α’)
-
15.
Γινόμενο Bernoulli. Έστω ανεξάρτητες τυχαίες μεταβλητές, όπου η κάθε και έστω το γινόμενό τους. Παρατηρήστε πως το γινόμενο έχει επίσης κατανομή Bernoulli και υπολογίστε την παράμετρό της:
-
16.
Χρηματιστήριο. Στο χρηματιστήριο, κάθε μέρα η τιμή μιας μετοχής αυξάνεται κατά ευρώ με πιθανότητα αλλιώς μένει σταθερή, και οι αλλαγές αυτές είναι ανεξάρτητες από τη μία μέρα στην άλλη. Έστω ότι το πρωί της μέρας η τιμή είναι ευρώ, και έστω η μεταβολή της τιμής κατά την μέρα, η μεταβολή της τιμής κατά τη μέρα, και γενικά η μεταβολή της τιμής κατά τη μέρα
-
(α’)
Ποια είναι η κατανομή των τυχαίων μεταβλητών
-
(β’)
Έστω η συνολική διαφορά της τιμής μετά από ένα μήνα (δηλαδή 30 ημέρες). Ποια είναι η κατανομή της τυχαίας μεταβλητής
-
(γ’)
Ποια είναι η πιθανότητα του ενδεχόμενου ότι μετά από ένα μήνα η τιμή θα είναι μεταξύ και ευρώ (συμπεριλαμβανομένων);
-
(δ’)
Αν είναι η τιμή μετά από μέρες, να βρεθεί η μέση τιμή και η διασπορά της.
-
(ε’)
Αν αντί για ευρώ, η τιμή αυξανόταν κατά δύο ευρώ ή έμενε σταθερή (με τις ίδιες πιθανότητες), να βρεθεί η μέση τιμή και η διασπορά της τιμής της μετοχής μετά από δύο μήνες.
-
(α’)
-
17.
XOR Bernoulli. Έστω και δύο ανεξάρτητες Τ.Μ. οι οποίες περιγράφουν δύο τυχαία bits στην εκτέλεση ενός προγράμματος. Έστω ότι η η και έστω μια νέα Τ.Μ. η
-
(α’)
Η είναι δυαδική Τ.Μ. άρα έχει κατανομή Βernoulli. Να βρεθεί η παράμετρός της.
-
(β’)
Είναι η ανεξάρτητη από τη ή όχι; Αποδείξτε την απάντησή σας.
-
(α’)
-
18.
Διασπορά υπεργεωμετρικής κατανομής. Στην παρατήρηση που ακολουθεί το Παράδειγμα 7.8 είδαμε πως μια Τ.Μ. μπορεί να εκφραστεί ως το άθροισμα Τ.Μ. οι οποίες έχουν όλες κατανομή αλλά δεν είναι ανεξάρτητες. Εδώ θα αποδείξουμε τον τύπο (7.3) για τη διασπορά της
-
(α’)
Δείξτε πως:
-
(β’)
Εξηγήστε γιατί, με βάση τον συλλογισμό που χρησιμοποιήσαμε για τον υπολογισμό της μέσης τιμής, όλοι οι όροι στο παραπάνω άθροισμα ικανοποιούν:
-
(γ’)
Υπολογίστε την παράμετρο της Bernoulli τυχαίας μεταβλητής
-
(δ’)
Χρησιμοποιώντας τα τρία πιο πάνω βήματα, δείξτε πως:
-
(ε’)
Χρησιμοποιώντας το αποτέλεσμα του βήματος (δ’), αποδείξτε τον τύπο (7.3) για τη διασπορά της
-
(α’)
-
19.
Αναπαράσταση της Η τρίτη ιδιότητα του Λήμματος 7.2 λέει ότι, για οποιαδήποτε πραγματική ακολουθία που τείνει στο καθώς το ισχύει η σχέση (7.5):
Στα τρία πιο κάτω βήματα θα δούμε την απόδειξή της.
-
(α’)
Χρησιμοποιώντας το ανάπτυγμα Taylor, δείξτε ότι για οποιοδήποτε έχουμε,
για κάποιο τέτοιο ώστε
-
(β’)
Χρησιμοποιήστε το προηγούμενο σκέλος για να δείξετε ότι υπάρχει κάποιο και μια φραγμένη ακολουθία τέτοια ώστε:
-
(γ’)
Εξηγήστε πως το πιο πάνω αποτέλεσμα συνεπάγεται ότι ισχύει η (7.5).
-
(α’)
ΠΟΛΥΜΕΣΙΚΟ ΥΛΙΚΟ ΚΕΦΑΛΑΙΟΥ
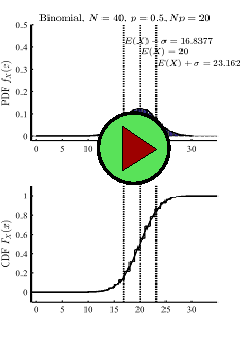






Κεφάλαιο 8 Παραδείγματα πιθανοκρατικής ανάλυσης αλγορίθμων
[Επιστροφή στα περιεχόμενα]
Σ’ αυτό το κεφάλαιο θα αναπτύξουμε κάποια πιο ρεαλιστικά παραδείγματα εφαρμογών των πιθανοτήτων στην πληροφορική. Σε μια πρώτη ανάγνωση του βιβλίου, ο αναγνώστης που θέλει απλά να εξοικειωθεί με τις βασικές ιδέες και τεχνικές των πιθανοτήτων, μπορεί ασφαλώς να το προσπεράσει.
Στις Ενότητες 8.1 και 8.2 θα εξετάσουμε δύο κλασικά προβλήματα της επιστήμης υπολογιστών, και θα δούμε πως για το καθένα από αυτά υπάρχει μια μέθοδος να λυθεί χρησιμοποιώντας έναν «randomized» (ή τυχαιοκρατικό) αλγόριθμο. Όπως αναφέραμε στο εισαγωγικό Κεφάλαιο 1, υπάρχουν αρκετά προβλήματα τα οποία επιλύονται πολύ πιο αποτελεσματικά αν επιτρέψουμε στον αλγόριθμο που χρησιμοποιούμε να πραγματοποιεί ορισμένα τυχαία βήματα κατά την εκτέλεσή του. Με προσεκτικό σχεδιασμό, αυτή η μέθοδος μπορεί να μειώσει σημαντικά την πολυπλοκότητα του αλγορίθμου. Το τίμημα αυτής της επιτάχυνσης είναι πως, λόγω της τυχαιότητας, υπάρχει πάντα κάποια πιθανότητα το αποτέλεσμα να είναι εσφαλμένο. Και πάλι με προσεκτικό σχεδιασμό ωστόσο, μπορούμε να εγγυηθούμε ότι η πιθανότητα αυτή θα είναι αποδεκτά μικρή, όπως θα δούμε λεπτομερώς παρακάτω.
Κατόπιν, στις Ενότητες 8.3 και 8.4 θα δούμε δύο παραδείγματα πιθανοκρατικής ανάλυσης αλγορίθμων. Συγκεκριμένα, θα παρουσιάσουμε δύο σχετικά απλούς, γνωστούς αλγορίθμους, και θα παρατηρήσουμε πως η κλασική τους πολυπλοκότητα (δηλαδή η πολυπλοκότητά τους για τη χειρότερη περίπτωση των δεδομένων εισόδου) είναι σχετικά μεγάλη. Αντίθετα, η συμπεριφορά τους πάνω σε τυχαία δεδομένα είναι πολύ διαφορετική: Η πολυπλοκότητά τους είναι σημαντικά μικρότερη με πιθανότητα πολύ κοντά στο 100%. Αυτό το φαινόμενο – ένας αλγόριθμος να είναι σχεδόν πάντα πολύ αποτελεσματικότερος από ό,τι στη χειρότερη δυνατή περίπτωση – είναι αρκετά συχνό και παίζει ιδιαίτερα σημαντικό ρόλο σε πολλές πρακτικές εφαρμογές.
Είναι επίσης αξιοσημείωτο πως, παρότι τα αποτελέσματα που θα αποδείξουμε είναι ισχυρά και έχουν ουσιαστικό πρακτικό ενδιαφέρον στο πλαίσιο σύγχρονων προβλημάτων της πληροφορικής, η μαθηματική τους ανάλυση είναι σχετική απλή και δεν απαιτεί τίποτα παραπάνω από κάποιες από τις απλούστερες τεχνικές των πιθανοτήτων τις οποίες έχουμε συναντήσει στα Κεφάλαια 2 έως 6.
Κάποιες ενδιαφέρουσες επεκτάσεις και γενικεύσεις των τεσσάρων αυτών παραδειγμάτων δίνονται στις ασκήσεις στο τέλος του κεφαλαίου.
8.1 Eπαλήθευση ισότητας πολυωνύμων
Εδώ εξετάζουμε το πρόβλημα της επαλήθευσης ισότητας πολυωνύμων. Τα δεδομένα μας είναι δύο πολυώνυμα βαθμού
και το ζητούμενο είναι να προσδιορίσουμε αν είναι τα ίδια, δηλαδή αν για κάθε ή όχι. Αν και δεν θα επεκταθούμε περαιτέρω, απλά σημειώνουμε πως αυτό το πρόβλημα και οι διάφορες προσεγγίσεις που έχουν αναπτυχθεί για τη λύση του έχουν μεγάλο εύρος πρακτικών εφαρμογών.
Θα δούμε τρεις μεθόδους, εκ των οποίων η τρίτη είναι ένας απλός randomized αλγόριθμος, και θα εκτιμήσουμε την πολυπλοκότητά τους. Για να απλοποιήσουμε την ανάλυση, η πολυπλοκότητα θα υπολογιστεί βάσει του πλήθους των πολλαπλασιασμών που απαιτεί η κάθε μέθοδος, δηλαδή θα αγνοήσουμε τις προσθέσεις και τις πράξεις που απαιτούνται για να υψώσουμε κάποιο πραγματικό αριθμό σε μια ακέραια δύναμη (βλ. την Άσκηση 3 στο τέλος του κεφαλαίου για μια πιο λεπτομερή ανάλυση).
1. Σύγκριση συντελεστών. Η πιο προφανής μέθοδος είναι να αναπτύξουμε το γινόμενο στην περιγραφή του ώστε να έρθει στην ίδια μορφή με το και να συγκρίνουμε τους αντίστοιχους συντελεστές.
Ο πολλαπλασιασμός των δύο πρώτων όρων απαιτεί έναν πολλαπλασιασμό για να βρούμε το Στη συνέχεια, ο πολλαπλασιασμός του αποτελέσματος,
με τον επόμενο όρο δίνει το και απαιτεί 2 επιπλέον πολλαπλασιασμούς.
Γενικά, στο βήμα πολλαπλασιάζουμε το αποτέλεσμα του προηγούμενου βήματος (που είναι ένα πολυώνυμο βαθμού ) με τον επόμενο όρο πράγμα που απαιτεί επιπλέον πολλαπλασιασμούς (για να βρούμε το γινόμενο του με τον καθένα από τους συντελεστές του προηγούμενου πολυωνύμου). Συνολικά, το πλήθος των πολλαπλασιασμών που απαιτούνται είναι,
Άρα, για μεγάλα η πολυπλοκότητα της μεθόδου αυτής είναι δηλαδή «της τάξης του » ή «τετραγωνική».55Εδώ χρησιμοποιήσαμε τον τύπο για το άθροισμα των όρων μιας αριθμητικής προόδου Η Άσκηση 2 στο τέλος του κεφαλαίου δίνει κάποιες λεπτομέρειες για την απόδειξή του.
2. Σύγκριση ριζών. Η αναπαράσταση του μάς λέει πως έχει πραγματικές ρίζες, τις Εφόσον ένα άλλο πολυώνυμο βαθμού θα είναι ίσο με το αν και μόνο αν έχουν τις ίδιες ρίζες, μπορούμε να υπολογίσουμε τις τιμές για κάθε Αν όλες είναι ίσες με το μηδέν, τότε τα δύο πολυώνυμα θα είναι τα ίδια, ενώ αν για κάποιο θα είναι διαφορετικά.
Ο υπολογισμός του κάθε απαιτεί πολλαπλασιασμούς, και η επανάληψη για όλα τα απαιτεί συνολικά πολλαπλασιασμούς. Και πάλι λοιπόν έχουμε έναν αλγόριθμο με πολυπλοκότητα της τάξης του
3. Ένας randomized αλγόριθμος. Έστω τώρα πως επιλέγουμε έναν τυχαίο ακέραιο μεταξύ του και του Δηλαδή το είναι μια τυχαία μεταβλητή με σύνολο τιμών το και πυκνότητα για κάθε Υπολογίζουμε τις τιμές και και αν είναι ίσες δηλώνουμε πως τα δύο πολυώνυμα είναι τα ίδια, ενώ αν δηλώνουμε πως είναι διαφορετικά.
Πριν εξετάσουμε την πιθανότητα να δώσουμε λάθος αποτέλεσμα, παρατηρούμε ότι η πολυπλοκότητα αυτού του randomized αλγορίθμου είναι μόλις δηλαδή γραμμική ως προς το και άρα σημαντικά μικρότερη από εκείνη των δύο προηγουμένων μεθόδων.
Έστω τώρα η πιθανότητα σφάλματος του αλγορίθμου. Εξετάζουμε δύο περιπτώσεις. Αν τα και είναι ίσα, τότε θα έχουμε πάντοτε και ο αλγόριθμος θα δίνει τη σωστή απάντηση, άρα Αν τα και είναι διαφορετικά, τότε η διαφορά τους είναι ένα πολυώνυμο βαθμού το πολύ Κατά συνέπεια θα έχει το πολύ πραγματικές ρίζες, τις οποίες συμβολίζουμε ως για κάποιον ακέραιο Στην περίπτωση, λοιπόν, που τα και είναι διαφορετικά, μπορούμε να εκφράσουμε την πιθανότητα σφάλματος ως εξής:
Αν κάποιο είναι ακέραιος μεταξύ 1 και τότε και αν όχι τότε Σε κάθε περίπτωση, οπότε,
όπου στο δεύτερο βήμα χρησιμοποιήσαμε το γεγονός ότι το είναι το πολύ και το προφανές φράγμα
Συνεπώς, με τη χρήση τυχαιότητας στο σχεδιασμό του αλγορίθμου, πετύχαμε και μεγάλη μείωση της πολυπλοκότητας και μικρή πιθανότητα σφάλματος. Συγκεκριμένα, όταν το αποτέλεσμα του αλγορίθμου είναι «», είμαστε βέβαιοι ότι είναι σωστό. Ενώ, όταν το αποτέλεσμα είναι «», ξέρουμε ότι η πιθανότητα να είναι πράγματι ίσα τα δύο πολυώνυμα είναι τουλάχιστον
8.2 Εύρεση ελαχιστιαίου cut set σε γράφους
Σκεφτείτε ένα δίκτυο υπολογιστών όπου ο κάθε υπολογιστής είναι συνδεδεμένος με κάποιους, αλλά όχι απαραίτητα όλους, από τους υπόλοιπους. Ένα παράδειγμα ενός τέτοιου δικτύου υπολογιστών δίνεται στο Σχήμα 8.1, όπου έχουμε συμβολίσει τον κάθε υπολογιστή με τον αντίστοιχο κόμβο για και δύο υπολογιστές είναι συνδεδεμένοι αν και μόνο αν οι αντίστοιχοι κόμβοι στον γράφο συνδέονται με την ακμή
Δύο υπολογιστές στο πιο πάνω δίκτυο μπορούν να επικοινωνήσουν αν είναι άμεσα συνδεδεμένοι, αν δηλαδή η αντίστοιχη ακμή περιέχεται στον γράφο, ή αν υπάρχει ένα μονοπάτι ακμών που να ξεκινάει από τον και να καταλήγει στον Για παράδειγμα, οι κόμβοι 1 και 2 επικοινωνούν άμεσα, ενώ οι 2 και 5 επικοινωνούν μέσω του μονοπατιού
Σε πολλών ειδών πραγματικά επικοινωνιακά δίκτυα (φυσικά, πολύ μεγαλύτερα και πιο πολύπλοκα από το παραπάνω απλοϊκό παράδειγμα), μας ενδιαφέρει να μπορούν όλοι οι κόμβοι να επικοινωνήσουν μεταξύ τους, δηλαδή, στον γράφο που τα αναπαριστά να υπάρχει τουλάχιστον ένα μονοπάτι ακμών που να συνδέει οποιουσδήποτε δύο κόμβους. Όταν αυτό συμβαίνει, λέμε ότι ο γράφος είναι συνδεδεμένος ή συνεκτικός.
Έστω λοιπόν ένας (μη κατευθυνόμενος) γράφος όπου το είναι το σύνολο των κόμβων του και είναι το σύνολο των ακμών του, και όπου η ακμή που συνδέει τους κόμβους και συμβολίζεται ως Ας υποθέσουμε ότι ο γράφος είναι συνδεδεμένος. Αν, π.χ., αυτός ο γράφος περιγράφει ένα επικοινωνιακό δίκτυο, μας ενδιαφέρει να γνωρίζουμε πόσο ευαίσθητο είναι το δίκτυο σε δυσλειτουργίες ή βλάβες κάποιων από τις συνδέσεις του. Για παράδειγμα, ποιο είναι το μικρότερο πλήθος συνδέσεων που, αν πάψουν να λειτουργούν, θα υπάρχουν κάποιοι κόμβοι που δε θα μπορούν να επικοινωνήσουν μεταξύ τους; Με άλλα λόγια, ποιο είναι το μέγεθος του μικρότερου υποσυνόλου τέτοιο ώστε, αν αφαιρέσουμε τις ακμές που περιέχονται στο ο νέος γράφος δεν θα είναι πια συνδεδεμένος;
Στα διακριτά μαθηματικά κάθε τέτοιο σύνολο ονομάζεται cut set (ή «σύνολο αποκοπτουσών ακμών»). Εάν επιπλέον ένα cut set έχει την ιδιότητα να έχει μέγεθος μικρότερο ή ίσο με εκείνο οποιουδήποτε άλλου cut set, τότε ονομάζεται «ελαχιστιαίο cut set» ή πιο απλά min-cut. Για παράδειγμα, στο γράφο του Σχήματος 8.1 παρατηρούμε πως τα και είναι cut sets και πως τα και είναι min-cuts.
Πέραν των εφαρμογών που αναφέραμε παραπάνω, το πρόβλημα της εύρεσης ενός min-cut σε ένα γράφο είναι και θεωρητικά ενδιαφέρον. Για παράδειγμα, δεν υπάρχει κάποιος προφανής τρόπος να βρούμε σχετικά εύκολα ένα min-cut, παρά μόνο να εξετάσουμε όλα τα δυνατά cut sets και να επιλέξουμε το μικρότερο. Αλλά το πλήθος των cut sets ενός γράφου με κόμβους είναι το οποίο είναι προφανώς απαγορευτικά (εκθετικά) μεγάλο για ρεαλιστικές τιμές του
Για δούμε ότι πράγματι υπάρχουν υποψήφια cut sets, παρατηρούμε πως κάθε cut set αντιστοιχεί σε ένα διαχωρισμό των κόμβων του γράφου σε δύο (ξένα) υποσύνολα και τέτοια ώστε κανένας κόμβος στο να μην επικοινωνεί με οποιονδήποτε κόμβο στο και η ένωσή τους να μας δίνει όλους τους κόμβους, δηλαδή Κάθε τέτοιος διαχωρισμός αντιστοιχεί ακριβώς σε ένα cut set, το οποίο αποτελείται από τις ακμές που συνδέουν κάποιο στοιχείο του με κάποιο στοιχείο του Άρα, κάθε cut set μπορεί να περιγραφεί από την επιλογή ενός υποσυνόλου του όπου φυσικά υπάρχουν υποψήφια υποσύνολα (μια που δεν συμπεριλαμβάνουμε το κενό σύνολο και ολόκληρο το ). Αλλά επειδή οι ρόλοι των και είναι συμμετρικοί, κάθε cut set μπορεί να περιγραφεί μέσω δύο διαχωρισμών, απλά αντιστρέφοντας τους ρόλους του και του Συνεπώς, το πλήθος όλων των δυνατών διαχωρισμών, δηλαδή το πλήθος όλων των υποψήφιων cut sets, είναι πράγματι
Ο παρακάτω randomized αλγόριθμος μάς δίνει μια απλή και σχετικά χαμηλής πολυπλοκότητας μέθοδο για την εύρεση ενός min-cut σε έναν οποιονδήποτε γράφο, με μεγάλη πιθανότητα. Η κεντρική ιδέα του αλγορίθμου είναι η έννοια της συνένωσης δύο κόμβων.
-
•
Επιλέγουμε τυχαία και ομοιόμορφα μία από τις ακμές του γράφου, και συνενώνουμε τους δύο κόμβους και σε έναν. Συμβολίζουμε τον νέο κόμβο αφαιρούμε την ακμή και διατηρούμε όλες τις υπόλοιπες.
-
•
Π.χ., ξεκινώντας από τον γράφο στο πρώτο διάγραμμα του Σχήματος 8.2, αν επιλέξουμε την ακμή 34 όπως φαίνεται στο δεύτερο διάγραμμα, καταλήγουμε στον γράφο του τρίτου διαγράμματος.
-
•
Παρατηρούμε τώρα ότι ένας κόμβος του νέου γράφου θα συμβολίζεται με δύο αριθμούς αντί για έναν, και ότι κάποιοι κόμβοι μπορεί να συνδέονται με παραπάνω από μία ακμές.
-
•
Συνεχίζουμε επαγωγικά: Επιλέγουμε τυχαία και ομοιόμορφα μία από τις υπάρχουσες ακμές του νέου γράφου και επαναλαμβάνουμε την ίδια διαδικασία: Συνενώνουμε τους δύο κόμβους που συνδέει η επιλεγμένη ακμή, συμβολίζουμε τον νέο κόμβο με το σύνολο των συμβόλων που περιέγραφαν τους δύο κόμβους, αφαιρούμε τις ακμές που τους συνέδεαν μεταξύ τους και διατηρούμε όλες τις υπόλοιπες.
-
•
Π.χ., ξεκινώντας από το γράφο στο τρίτο διάγραμμα του Σχήματος 8.2, αν επιλέξουμε την ακμή 14 όπως φαίνεται στο τέταρτο διάγραμμα, καταλήγουμε στο γράφο του πέμπτου διαγράμματος.
- •
Η ίδια διαδικασία επαναλαμβάνεται για ακριβώς βήματα, οπότε και θα έχουμε αναγκαστικά καταλήξει σε ένα γράφο με ακριβώς δύο κόμβους.
 |
 |
 |
|---|---|---|
 |
 |
 |
 |
- 1.
Το αποτέλεσμα του αλγορίθμου του Karger είναι ο διαχωρισμός όλων των κόμβων του αρχικού γράφου σε δύο ομάδες που συνδέονται μεταξύ τους μέσω όλων των ακμών του αρχικού γράφου οι οποίες συνέδεαν κάποιον κόμβο της πρώτης ομάδας με κάποιον της δεύτερης. Συνεπώς, το σύνολο των ακμών στο οποίο καταλήγει ο αλγόριθμος πάντοτε αντιστοιχεί σε ένα cut set. Για παράδειγμα, στο Σχήμα 8.3 καταλήγουμε στο cut set , το οποίο εύκολα βλέπουμε πως είναι και min-cut για αυτόν το γράφο.
-
2.
Στο Σχήμα 8.3 βλέπουμε μια διαφορετική πιθανή έκβαση του αλγορίθμου του Karger, όπου καταλήγουμε σε ένα διαφορετικό cut set, το , το οποίο προφανώς δεν είναι min-cut. Άρα παρατηρούμε πως ο αλγόριθμος δεν μας δίνει πάντα ένα min-cut ως αποτέλεσμα.
 |
 |
 |
 |
 |
 |
 |
Το επόμενο θεώρημα μάς δίνει πολύ ακριβείς πληροφορίες για το πώς ακριβώς και πόσο αποτελεσματικά μπορεί να εφαρμοστεί ο πιο πάνω αλγόριθμος στην πράξη.
Θεώρημα 8.1
Έστω ένας οποιοσδήποτε μη κατευθυνόμενος, συνδεδεμένος γράφος με κόμβους.
-
1.
Αν εφαρμόσουμε τον αλγόριθμο του Karger, η πιθανότητα το cut set στο οποίο θα καταλήξουμε να είναι και min-cut για αυτόν το γράφο δεν μπορεί να είναι αυθαίρετα μικρή· συγκεκριμένα,
- 2.
Αν εφαρμόσουμε τον αλγόριθμο του Karger σε ανεξάρτητες επαναλήψεις, και ως αποτέλεσμα πάρουμε το μικρότερο από όλα τα cut sets στα οποία θα καταλήξουμε, η πιθανότητα το τελικό αποτέλεσμα να μην είναι min-cut είναι μικρή· συγκεκριμένα,66Θυμίζουμε πως με συμβολίζουμε τον φυσικό λογάριθμο με βάση το ο οποίος μερικές φορές συμβολίζεται και ως
Πριν την απόδειξη, παραθέτουμε κάποιες σημαντικές παρατηρήσεις σχετικά με το παραπάνω αποτέλεσμα και με το γενικό πρόβλημα της εύρεσης min-cuts σε γράφους.
Παρατηρήσεις:
-
1.
Ο πιο απλός τρόπος να κατασκευάσουμε ένα cut set είναι να επιλέξουμε όλες τις ακμές ενός συγκεκριμένου κόμβου· προφανώς, αν τις αφαιρέσουμε, τότε ο γράφος χωρίζεται σε δύο μέρη (τον συγκεκριμένο κόμβο και όλους τους υπόλοιπους) τα οποία δεν συνδέονται μεταξύ τους. Κατά συνέπεια, το πλήθος των στοιχείων που περιέχει ένα min-cut θα είναι πάντα μικρότερο ή ίσο του πλήθους των ακμών που συνδέονται με οποιονδήποτε κόμβο. Ή, αντίστροφα, αν υπάρχει κάποιο min-cut το οποίο περιέχει στοιχεία, τότε ο κάθε κόμβος του γράφου θα έχει τουλάχιστον ακμές.
-
2.
Εφόσον κάθε επανάληψη του αλγορίθμου του Karger απαιτεί βήματα, ο αλγόριθμος που περιγράφεται στο δεύτερο μέρος του θεωρήματος απαιτεί βήματα, και άρα η πολυπλοκότητα του είναι της τάξης . Επιπλέον, για πρακτικά ρεαλιστικές τιμές του η πιθανότητα σφάλματος είναι αμελητέα· π.χ., για , η πιθανότητα σφάλματος είναι το πολύ 0.01%.
-
3.
Υπάρχει μια τροποποίηση της μεθόδου που είδαμε στο θεώρημα, ο αλγόριθμος Karger-Stein, ο οποίος επιτρέπει την εύρεση ενός min-cut με μεγάλη πιθανότητα και με πολυπλοκότητα της τάξης για κάποιο .
Από την άλλη μεριά, παρατηρούμε πως υπάρχουν γράφοι με πλήθος ακμών (όπως για παράδειγμα ο πλήρης γράφος σε κόμβους) και πως για να βρούμε κάποιο min-cut πρέπει να εξετάσουμε την κάθε ακμή τουλάχιστον μία φορά (για να διαπιστώσουμε αν ο γράφος που προκύπτει είναι συνδεδεμένος). Συνεπώς, η μικρότερη δυνατή πολυπλοκότητα οποιουδήποτε ντετερμινιστικού αλγορίθμου για την εύρεση κάποιου min-cut είναι τουλάχιστον της τάξης των βημάτων.
Ο καλύτερος γνωστός ως σήμερα ντετερμινιστικός αλγόριθμος γι’ αυτό το πρόβλημα, απαιτεί βήματα, όπου είναι το πλήθος των ακμών του αρχικού γράφου.
-
4.
Χρησιμοποιώντας κάποιους από τους υπολογισμούς που θα κάνουμε στην απόδειξη του θεωρήματος πιο κάτω, στην Άσκηση 5 στο τέλος του κεφαλαίου θα δείξετε το ακόλουθο ενδιαφέρον πόρισμα: Για οποιονδήποτε γράφο με κόμβους, υπάρχουν το πολύ min-cuts.
-
5.
Έχοντας δει το αποτέλεσμα του θεωρήματος, μια εύλογη ερώτηση είναι η εξής: Δεν θα ήταν ευκολότερο, αντί να χρησιμοποιήσουμε τον αλγόριθμο του Karger, απλά να επιλέξουμε στην τύχη ένα οποιοδήποτε cut set πολλές φορές και να πάρουμε ως αποτέλεσμα ενός υποψηφίου min-cut το μικρότερο από αυτά; Όπως θα δείξετε στην Άσκηση 6 στο τέλος του κεφαλαίου, αυτή η μέθοδος δεν είναι αποτελεσματική, γιατί η πιθανότητα ένα τυχαία επιλεγμένο cut set να είναι και min-cut είναι σημαντικά μικρότερη από την αντίστοιχη πιθανότητα του αλγορίθμου του Karger.
Απόδειξη του Θεωρήματος 8.1:
Όπως έχουμε ήδη παρατηρήσει, σε κάποιον γράφο μπορούν να υπάρχουν περισσότερα από ένα min-cuts. Έστω ένα συγκεκριμένο από αυτά τα min-cuts, και έστω το πλήθος των στοιχείων του. Όπως αναφέραμε στην πρώτη από τις παραπάνω παρατηρήσεις, ο κάθε κόμβος του γράφου θα έχει τουλάχιστον ακμές, άρα το συνολικό πλήθος των ακμών του θα είναι τουλάχιστον
Κατ’ αρχάς θα υπολογίσουμε ένα φράγμα για την πιθανότητα του ενδεχομένου:
Ορίζουμε για κάθε τα ενδεχόμενα,
και παρατηρούμε πως το θα είναι το αποτέλεσμα του αλγορίθμου αν και μόνο αν σε κανένα βήμα δεν επιλεγεί κάποια ακμή του, δηλαδή,
Οπότε, από τον ορισμό της δεσμευμένης πιθανότητας (και τη γενίκευσή του στην Άσκηση 4 του Κεφαλαίου 5) έχουμε:
| (8.1) |
Για την πρώτη πιθανότητα, εφόσον η επιλογή στο πρώτο βήμα γίνεται ομοιόμορφα ανάμεσα σε όλες τις ακμές του γράφου, έχουμε πως,
| (8.2) |
όπου χρησιμοποιήσαμε την παραπάνω παρατήρηση πως
Τώρα, δεδομένου ότι στα πρώτα βήματα δεν έχει επιλεχθεί καμία ακμή του , έχουμε έναν νέο γράφο ο οποίος περιέχει κόμβους και επίσης ακόμα περιέχει το min-cut , που έχει στοιχεία. Άρα, ο νέος γράφος έχει τουλάχιστον ακμές, και για καθεμία από τις υπόλοιπες πιθανότητες στο γινόμενο της σχέσης (8.1), με τον ίδιο συλλογισμό όπως πριν βρίσκουμε,
| (8.3) | |||||
Αντικαθιστώντας τα φράγματα των σχέσεων (8.2) και (8.3) στην (8.1), έχουμε,
όπου σχεδόν όλοι οι όροι απλοποιούνται (εκτός από τους δύο πρώτους παρονομαστές και τους δύο τελευταίους αριθμητές) ώστε,
Τέλος, παρατηρούμε πως το ενδεχόμενο είναι υποσύνολο του ενδεχομένου «success», μια που έχουμε επιτυχία του αλγορίθμου αν καταλήξει στο ή σε οποιοδήποτε άλλο min-cut. Οπότε, από τον δεύτερο κανόνα πιθανότητας, τελικά βρίσκουμε,
κι έτσι έχουμε αποδείξει το πρώτο μέρος του θεωρήματος.
Για το δεύτερο μέρος, ορίζουμε για κάθε τα ενδεχόμενα,
όπου είναι το πλήθος των επαναλήψεων, και παρατηρούμε πως, για κάθε , από το πρώτο μέρος έχουμε,
| (8.4) |
Συνεπώς, εφόσον έχουμε «error» αν και μόνο αν σε καθεμία από τις ανεξάρτητες επαναλήψεις δεν καταλήξει ο αλγόριθμος σε min-cut, βρίσκουμε ότι,77Στον υπολογισμό της πιθανότητας εμμέσως υποθέτουμε ότι το πλήθος των επαναλήψεων είναι ακέραιος αριθμός. Άσκηση. Αν το δεν είναι ακέραιος, δείξτε πως μπορούμε να επαναλάβουμε τα ίδια ακριβώς βήματα για και να καταλήξουμε στο ίδιο ακριβώς αποτέλεσμα.
το οποίο είναι και το ζητούμενο αποτέλεσμα. Στον πιο πάνω υπολογισμό, στο βήμα χρησιμοποιήσαμε το γεγονός ότι οι επαναλήψεις είναι ανεξάρτητες μεταξύ τους, στο εφαρμόσαμε το φράγμα της σχέσης (8.4), και στο χρησιμοποιήσαμε την απλή ανισότητα του Λήμματος 7.3, με .
8.3 String matching
Πολλοί αλγόριθμοι επεξεργασίας σήματος, συμπίεσης, κλπ., οι οποίοι δρουν σε ακολουθίες ψηφιακών δεδομένων, εκτελούν κάποιο είδος «string matching» (ή ταίριασμα ακολουθιών), δηλαδή ανιχνεύουν συγκεκριμένα μοτίβα στα δεδομένα τα οποία κατόπιν εκμεταλλεύονται για την πιο αποτελεσματική επεξεργασία τους. Σε αυτή την ενότητα θα εξετάσουμε ένα πολύ απλό τέτοιο παράδειγμα.
Έστω ότι ένας αλγόριθμος εκτελείται με δεδομένα εισόδου μια ακολουθία από bits , και ο χρόνος εκτέλεσής του ισούται με το μήκος της μεγαλύτερης ακολουθίας συνεχόμενων «1» μεταξύ των .
Προφανώς η πολυπλοκότητα αυτού του αλγορίθμου ισούται με , αφού στη χειρότερη περίπτωση θα έχουμε . Θα δείξουμε πως, αν τα δεδομένα εισόδου είναι τυχαία, δηλαδή προκύπτουν από μια ακολουθία ανεξάρτητων Bern(1/2) τυχαίων μεταβλητών , τότε, για μεγάλα , η πολυπλοκότητα του αλγορίθμου δεν ξεπερνά το , με μεγάλη πιθανότητα. Συγκεκριμένα, ορίζοντας μια νέα τυχαία μεταβλητή,
τότε,
| (8.5) |
Πριν αποδείξουμε την (8.5) παρατηρούμε πως υπάρχει δραματικά μεγάλη διαφορά μεταξύ του και του για ρεαλιστικές τιμές του . Για παράδειγμα, αν έχουμε ένα εκατομμύριο bits, δηλαδή 125 KB, τότε το είναι λίγο μικρότερο από 40, και η πιθανότητα να έχουμε πολυπλοκότητα μεγαλύτερη από 40 είναι το πολύ !
Θα αποδείξουμε την εξής σχέση, η οποία είναι ισοδύναμη (από τον κανόνα πιθανότητας του Κεφαλαίου 3) με την (8.5):
| (8.6) |
Θέτουμε , και για κάθε , ορίζουμε τα ενδεχόμενα,
| « συνεχόμενα “1” ξεκινώντας από τη θέση » | ||||
Παρατηρούμε πως θα υπάρχει στα μια ακολουθία από «1» με μήκος τουλάχιστον αν και μόνο αν σε κάποια θέση ξεκινάει μια ακολουθία από «1» μήκους . Συνεπώς,
Εφαρμόζοντας τώρα το φράγμα ένωσης του Λήμματος 5.2,
όπου η πιθανότητα του κάθε ενδεχομένου είναι,
άρα,
Τέλος, χρησιμοποιώντας το προφανές φράγμα , αντικαθιστώντας την τιμή του και απλοποιώντας την πιο πάνω έκφραση, βρίσκουμε,
το οποίο είναι ακριβώς το ζητούμενο φράγμα (8.6).88Όπως και στην απόδειξη του Θεωρήματος 8.1, στον πιο πάνω υπολογισμό έχουμε εμμέσως υποθέσει ότι το είναι ακέραιος. Άσκηση. Αν το δεν είναι ακέραιος αριθμός, δείξτε πως μπορούμε να επαναλάβουμε τα ίδια ακριβώς βήματα για και να καταλήξουμε στο ίδιο ακριβώς φράγμα.
8.4 Γρήγορη ταξινόμηση δεδομένων
Το πρόβλημα ταξινόμησης είναι ένα από τα πιο θεμελιώδη προβλήματα της πληροφορικής. Δεδομένης μιας λίστας , που περιέχει στοιχεία , το ζητούμενο είναι, με τον πιο αποτελεσματικό και γρήγορο τρόπο, να ταξινομηθεί η λίστα δηλαδή να αναδιαταχθούν τα στοιχεία της με βάση κάποιο συγκεκριμένο κριτήριο. Για παράδειγμα, αν τα είναι πραγματικοί αριθμοί μπορεί να τους διατάξουμε από τον μικρότερο προς τον μεγαλύτερο, ή, αν είναι λέξεις ενός κειμένου, μπορούμε να τις ταξινομήσουμε αλφαβητικά. Η μορφή των δεδομένων και το συγκεκριμένο κριτήριο δεν έχουν σημασία, αρκεί να καθορίζεται σαφώς, για κάθε ζευγάρι στοιχείων και , ποιο είναι «μεγαλύτερο» και ποιο «μικρότερο», δηλαδή ποιο από τα δύο πρέπει να τοποθετηθεί νωρίτερα στη νέα λίστα. Για να αποφύγουμε τεχνικές λεπτομέρειες που δεν παρουσιάζουν κανένα ενδιαφέρον, από εδώ και στο εξής θα θεωρούμε πάντα πως τα στοιχεία της λίστας είναι όλα διαφορετικά μεταξύ τους.
Μια μέθοδος θεωρούμε πως είναι «αποτελεσματική και γρήγορη» όπως είπαμε πιο πάνω, αν το πλήθος από ζευγάρια στοιχείων τα οποία απαιτεί να συγκριθούν είναι σχετικά μικρό. Για παράδειγμα, η προφανής, απλοϊκή μέθοδος ταξινόμησης είναι να συγκρίνουμε το κάθε με όλα τα υπόλοιπα. Αυτό απαιτεί συγκρίσεις και άρα έχει πολυπλοκότητα της τάξης του .
Εδώ θα παρουσιάσουμε τον αλγόριθμο quicksort (ή «γρήγορη ταξινόμηση») και θα αναλύσουμε τη συμπεριφορά του. Αν και έχει και αυτός πολυπλοκότητα στη χειρότερη περίπτωση, όπως θα δούμε αυτή η περίπτωση είναι μάλλον σπάνια. Κατά μέσο όρο, ο quicksort απαιτεί μόνο συγκρίσεις για να ταξινομήσει στοιχεία, και στην πράξη έχει παρατηρηθεί πως συχνά είναι γρηγορότερος από άλλους αλγορίθμους με πολυπλοκότητα . Για αυτόν το λόγο έχει υιοθετηθεί ευρύτατα ως η κύρια μέθοδος ταξινόμησης σε πολλά συστήματα υπολογιστών (π.χ. το λειτουργικό σύστημα Unix), και στις βιβλιοθήκες πολλών γλωσσών προγραμματισμού, όπως η C/C++ και η Java, στις οποίες είναι υλοποιημένος στη συνάρτηση qsort.
Δεδομένης μιας λίστας που περιέχει διαφορετικά στοιχεία, επαναλαμβάνουμε τα πιο κάτω βήματα αναδρομικά:
-
1.
Αν η λίστα που εξετάζουμε είναι κενή ή περιέχει μόνο ένα στοιχείο, την επιστρέφουμε ως έχει.
-
2.
Αν η λίστα που εξετάζουμε έχει δύο ή περισσότερα στοιχεία, επιλέγουμε ένα από αυτά, έστω ως «οδηγό», συγκρίνουμε όλα τα υπόλοιπα στοιχεία της με τον οδηγό, και κατασκευάζουμε δύο νέες λίστες:
-
–
Στη λίστα τοποθετούμε όλα τα στοιχεία που είναι μικρότερα του
-
–
Στη λίστα τοποθετούμε όλα τα στοιχεία που είναι μεγαλύτερα του
-
–
-
3.
Για καθεμία από τις δύο λίστες και επαναλαμβάνουμε τα βήματα (1.) και (2.).
-
4.
Επιστρέφουμε τη νέα λίστα με τη διάταξη
Παρατηρήσεις:
-
1.
Η περιγραφή του αλγορίθμου αφήνει ανοιχτό το θέμα του πώς επιλέγουμε ένα στοιχείο της κάθε λίστας ως οδηγό. Μια και θέλουμε να σχεδιάσουμε έναν αλγόριθμο ο οποίος να έχει καλή συμπεριφορά κάτω από γενικές συνθήκες, δεν μπορούμε να θεωρήσουμε πως έχουμε κάποια εκ των προτέρων γνώση για τη δομή και τη φύση των δεδομένων. Άρα, εφόσον δεν μπορούμε να προϋποθέσουμε τίποτα για την αρχική διάταξη των , λογικά φαίνεται αδιάφορο το πώς θα επιλέξουμε τους οδηγούς. Γι’ αυτόν το λόγο, και για λόγους απλότητας στην περιγραφή και την υλοποίηση του αλγορίθμου, υιοθετούμε τη σύμβαση ότι, για κάθε λίστα, ως οδηγός θα επιλέγεται πάντα το πρώτο στοιχείο της.
Μια εξαίρεση σε αυτό το πρωτόκολλο αποτελεί η περίπτωση της randomized μορφής του quicksort. Στο Θεώρημα 8.3 στο τέλος αυτής της ενότητας θα δούμε πως, και στην περίπτωση που επιλέξουμε τους οδηγούς τυχαία, η συμπεριφορά του αλγορίθμου δεν αλλάζει ουσιαστικά.
-
2.
Για να είναι απολύτως πλήρης η περιγραφή του αλγορίθμου υιοθετούμε και την επιπλέον σύμβαση ότι, μετά την επιλογή του οδηγού, η σχετική θέση που έχουν τα υπόλοιπα στοιχεία στις δύο νέες λίστες είναι η ίδια με την αρχική σχετική τους θέση. Έτσι, αν, για παράδειγμα, εκτελέσουμε ένα βήμα του quicksort στην λίστα και επιλέξουμε το πρώτο στοιχείο, δηλαδή το 2, ως οδηγό, τότε το αποτέλεσμα είναι η τριάδα: .
-
3.
Η εκτέλεση του αλγορίθμου σε μια απλή περίπτωση περιγράφεται αναλυτικά στο Παράδειγμα 8.1. Όπως αναφέραμε και στην αρχή, στη χειρότερη περίπτωση η πολυπλοκότητα του quicksort είναι της τάξης των συγκρίσεων· στο Παράδειγμα 8.2 θα δούμε ένα απλό σενάριο στο οποίο πράγματι συμβαίνει αυτό. Αλλά το βασικό μας αποτέλεσμα, όπως προκύπτει από τη λεπτομερή πιθανοκρατική ανάλυση του Θεωρήματος 8.2, είναι το εξής: Για τυχαία δεδομένα, το μέσο πλήθος συγκρίσεων που απαιτεί η εκτέλεση του quicksort είναι κατά προσέγγιση , το οποίο είναι σημαντικά μικρότερο του για μεγάλα .
Παράδειγμα 8.1
Έστω πως ξεκινάμε με τη λίστα,
Στο πρώτο βήμα, επιλέγοντας ως οδηγό το 5, δημιουργούμε τις δύο νέες λίστες και και καταλήγουμε στο αποτέλεσμα:
Στο επόμενο βήμα επαναλαμβάνουμε την ίδια διαδικασία, μία φορά για την καθεμία από τις δύο παραπάνω λίστες. Επιλέγοντας ως οδηγούς το 3 και το 6, αντίστοιχα, έχουμε το αποτέλεσμα:
Τέλος, παρατηρούμε ότι, από τις τέσσερις λίστες που προέκυψαν, μόνο η πρώτη περιέχει περισσότερα από ένα στοιχεία. Επιλέγοντας για αυτήν το 2 ως οδηγό, φτάνουμε στο τελικό αποτέλεσμα της ταξινομημένης λίστας:
Παράδειγμα 8.2
Έστω τώρα πως η αρχική μας λίστα είναι η Επιλέγοντας το στοιχείο ως οδηγό, μετά από συγκρίσεις η πρώτη νέα λίστα που δημιουργούμε είναι η και η δεύτερη είναι κενή. Έτσι καταλήγουμε στο αποτέλεσμα Επαναλαμβάνοντας την ίδια διαδικασία, μετά από συγκρίσεις έχουμε το αποτέλεσμα και συνεχίζοντας με αυτό τον τρόπο, μετά από βήματα καταλήγουμε στην πλήρως ταξινομημένη λίστα Συνολικά, το πλήθος των συγκρίσεων που πραγματοποιήσαμε είναι,
το οποίο είναι της τάξης του και όπου χρησιμοποιήσαμε και πάλι τον τύπο για το άθροισμα μιας αριθμητικής προόδου όπως στην Ενότητα 8.1.
Έστω πως ο quicksort εκτελείται σε μια λίστα διαφορετικών στοιχείων όπου ως οδηγό επιλέγουμε πάντα το πρώτο στοιχείο της κάθε λίστας.
Αν τα δεδομένα είναι τυχαία, δηλαδή αν η αρχική διάταξη των είναι επιλεγμένη ανάμεσα σε όλες τις δυνατές διατάξεις τους τυχαία και ομοιόμορφα (δηλαδή καθεμία από τις διατάξεις έχει πιθανότητα ), τότε η μέση τιμή του πλήθους συγκρίσεων που απαιτεί η εκτέλεση του quicksort ισούται με:
Απόδειξη:
Έστω η ταξινομημένη μορφή της λίστας . Για κάθε τέτοια ώστε , ορίζουμε μια Τ.Μ. ως:
Η κάθε είναι μια Τ.Μ. με κατανομή , της οποίας η παράμετρος είναι ίση με την πιθανότητα το και το να συγκριθούν κάποια στιγμή κατά τη διάρκεια της εκτέλεσης του αλγορίθμου. Η σημαντική παρατήρηση εδώ είναι πως αυτό συμβαίνει αν και μόνο αν, κατά την εκτέλεση του quicksort, το πρώτο στοιχείο μεταξύ των το οποίο επιλέγεται ως οδηγός είναι το ή το .
Γιατί ισχύει αυτή η ισοδυναμία; Κατ’ αρχάς παρατηρούμε δύο πράγματα. Πρώτον ότι, εφόσον πάντα καταλήγουμε σε λίστες με ένα ή κανένα στοιχείο, αποκλείεται καθ’ όλη τη διάρκεια εκτέλεσης του αλγορίθμου να μην επιλεγεί κανένα από τα ως οδηγός. Δεύτερον, ότι τα στοιχεία μιας οποιασδήποτε λίστας μόνο με οδηγούς συγκρίνονται. Οπότε, αν κάποιο στοιχείο , διαφορετικό από τα και , επιλεγεί πρώτο ως οδηγός, τότε τα και σίγουρα θα καταλήξουν σε διαφορετικές υπο-λίστες και ποτέ δεν θα συγκριθούν μεταξύ τους. Τέλος, αν το πρώτο στοιχείο μεταξύ των που επιλεγεί ως οδηγός είναι, π.χ., το , τότε σίγουρα ως εκείνη την ώρα τα και θα έχουν παραμείνει στην ίδια υπο-λίστα, και αναγκαστικά το θα συγκριθεί με τον οδηγό . Παρομοίως και για την περίπτωση που το πρώτο στοιχείο μεταξύ των που επιλεγεί ως οδηγός είναι το .
Επιπλέον, λόγω της συμμετρίας του προβλήματος, αφού δηλαδή η αρχική διάταξη των δεδομένων είναι εντελώς τυχαία, η πιθανότητα να επιλεγεί οποιοδήποτε από τα στοιχεία πρώτο ως οδηγός, είναι η ίδια. Συνεπώς,
και τώρα είμαστε έτοιμοι να υπολογίσουμε τη ζητούμενη ποσότητα.
Έστω η Τ.Μ. που περιγράφει το συνολικό πλήθος συγκρίσεων που απαιτεί η εκτέλεση του quicksort. Τότε:
όπου χρησιμοποιήσαμε την πρώτη ιδιότητα της μέσης τιμής από το Θεώρημα 6.1, και το γεγονός ότι η μέση τιμή μιας Τ.Μ. ισούται με . Συνεπώς,
όπου στο βήμα κάναμε την αλλαγή μεταβλητής του πρώτου αθροίσματος από σε , και στο βήμα παρατηρήσαμε πως οι όροι του διπλού αθροίσματος δεν εξαρτώνται απ’ το , και πως κάθε όρος στο διπλό άθροισμα εμφανίζεται φορές. Τώρα, ορίζοντας ως το άθροισμα των πρώτων όρων της αρμονικής σειράς όπως στο Λήμμα 8.1 πιο κάτω, έχουμε,
και χρησιμοποιώντας το Λήμμα 8.1 παίρνουμε το ζητούμενο αποτέλεσμα ότι, πράγματι, το μέσο πλήθος συγκρίσεων .
Λήμμα 8.1
Έστω το άθροισμα των πρώτων όρων της αρμονικής σειράς,
Για κάθε η τιμή του είναι πολύ κοντά στην τιμή του :
Συνεπώς, για μεγάλα έχουμε
Απόδειξη:
Η περίπτωση είναι τετριμμένη, αφού,
οπότε θεωρούμε πως . Χρησιμοποιώντας τον συνήθη συμβολισμό (αντίστοιχα ) για τον μικρότερο ακέραιο ο οποίος είναι (αντίστοιχα, για τον μεγαλύτερο ακέραιο ο οποίος είναι ), έχουμε,
Συνεπώς, ή, ισοδύναμα, . Παρομοίως, για το άνω φράγμα βρίσκουμε,
το οποίο μας δίνει το ζητούμενο .
Κλείνοντας, αναφέρουμε πως υπάρχει και μια σχετικά προφανής randomized μορφή του quicksort. Όπως περιγράφουμε στο τελευταίο μας αποτέλεσμα (το οποίο θα αποδείξετε στην Άσκηση 12), κατά μέσο όρο ο randomized quicksort έχει και αυτός πολυπλοκότητα της τάξης των συγκρίσεων.
Έστω πως ο quicksort εκτελείται σε μια αυθαίρετη λίστα διαφορετικών στοιχείων όπου σε κάθε υπο-λίστα ως οδηγό επιλέγουμε τυχαία και ομοιόμορφα ένα από τα στοιχεία της.
Τότε, και πάλι η μέση τιμή του πλήθους συγκρίσεων που απαιτεί η εκτέλεση του quicksort ισούται με:
8.5 Ασκήσεις
-
1.
Ένας άλλος randomized αλγόριθμος. Έστω πως έχουμε αποθηκευμένες σε έναν πίνακα τις τιμές κάποιας συνάρτησης , αλλά ξέρουμε πως το 1/5 των τιμών που περιέχει ο πίνακας είναι λάθος. Επίσης όμως ξέρουμε ότι η έχει την εξής ιδιότητα: , για κάθε και . Περιγράψτε έναν απλό randomized αλγόριθμο ο οποίος να υπολογίζει την τιμή και να μπορεί να μας εγγυηθεί πως η πιθανότητα η τιμή που υπολογίζει να είναι σωστή, είναι τουλάχιστον 50%. Ο αλγόριθμός σας πρέπει να λειτουργεί με αυτό τον τρόπο για κάθε , και χωρίς να ξέρουμε ποιες από τις τιμές του πίνακα είναι λάθος.
-
2.
Αθροίσματα. Έστω ένας άρτιος ακέραιος . Το άθροισμα των ακεραίων από το 1 έως το μπορεί να γραφτεί ως,
και παρατηρούμε (όπως παρατήρησε και ο Gauss στην τρίτη δημοτικού) ότι το άθροισμα κάθε στήλης είναι . Εφόσον υπάρχουν στήλες, το συνολικό άθροισμα πρέπει λοιπόν να ισούται με .
-
(α’)
Δείξτε το ίδιο αποτέλεσμα για περιττά .
-
(β’)
Δείξτε πως για κάθε και ,
-
(α’)
-
3.
Μέτρηση πράξεων. Στην Ενότητα 8.1 είδαμε τρεις μεθόδους επίλυσης του προβλήματος επαλήθευσης ισότητας πολυωνύμων, εκ των οποίων η τρίτη μέθοδος ήταν ένας απλός randomized αλγόριθμος. Μετρήσαμε και για τις τρεις μεθόδους το πλήθος των πολλαπλασιασμών που απαιτούνταν. Εδώ μας ενδιαφέρει το συνολικό πλήθος των «πράξεων» που απαιτεί η καθεμία από τις τρεις μεθόδους, όπου αγνοούμε τις προσθέσεις όπως πριν, κάθε πολλαπλασιασμός μετράει για μία πράξη, και για να υψώσουμε έναν αριθμό σε κάποιον εκθέτη χρειάζονται πράξεις. Για καθεμία από τις τρεις μεθόδους, υπολογίστε το πλήθος των πράξεων που χρειάζονται, όταν ο βαθμός των πολυωνύμων είναι μεγάλος. Συγκρίνετε τις τρεις μεθόδους μεταξύ τους.
Σημειώσεις. (1.) Μπορείτε να χρησιμοποιήσετε τον τύπο του Stirling, όπως στο Λήμμα 7.1: Για μεγάλα , έχουμε την προσέγγιση, , για κάποια σταθερά . (2.) Στην πράξη, η πρόσθεση είναι πράγματι σημαντικά πιο απλή από τον πολλαπλασιασμό, και ο πιο συνηθισμένος αλγόριθμος για τον υπολογισμό της ύψωσης στη δύναμη πράγματι απαιτεί κατά προσέγγιση πολλαπλασιασμούς.
-
4.
Μικρότερη πιθανότητα σφάλματος. Στην Ενότητα 8.1 δείξαμε ότι η πιθανότητα σφάλματος ενός απλού randomized αλγορίθμου για το πρόβλημα επαλήθευσης ισότητας δύο πολυωνύμων και , είναι το πολύ 0.01. Έστω τώρα ότι αυτό το ποσοστό δεν μας είναι ικανοποιητικό και θέλουμε να μειώσουμε την πιθανότητα σφάλματος σε κάποιο δεδομένο . Περιγράψτε δύο απλούς τρόπους με τους οποίους μπορούμε να τροποποιήσουμε τον αλγόριθμο, οι οποίοι θα έχουν πιθανότητα σφάλματος το πολύ .
-
5.
Πόσα min-cuts υπάρχουν; Έστω ότι για κάποιον συγκεκριμένο (μη κατευθυνόμενο, συνδεδεμένο) γράφο με κόμβους, υπάρχουν ακριβώς min-cuts, τα . Στην απόδειξη του Θεωρήματος 8.1 είδαμε πως, για κάθε ένα από αυτά, η πιθανότητα του ενδεχομένου είναι τουλάχιστον , για κάθε .
Χρησιμοποιώντας αυτό το αποτέλεσμα, αποδείξτε πως το πλήθος των min-cuts δεν μπορεί να είναι μεγαλύτερο από .
-
6.
Τυχαία cut sets. Εδώ θα απαντήσετε στην ερώτηση που θέσαμε στην Παρατήρηση 5 της Ενότητας 8.2.
Δεδομένου ενός (μη κατευθυνόμενου, συνδεδεμένου) γράφου με κόμβους, επιλέγουμε ένα τυχαίο υποσύνολο των ακμών του ως εξής. Κατ’ αρχάς επιλέγουμε ένα τυχαίο σύνολο κόμβων , όπου κάθε κόμβος συμπεριλαμβάνεται στο με πιθανότητα 1/2, ανεξαρτήτως των υπόλοιπων κόμβων (αν καταλήξουμε με το να είναι το κενό σύνολο ή ολόκληρο το , το απορρίπτουμε και επαναλαμβάνουμε τη διαδικασία). Δεδομένου του , ορίζουμε το σύνολο ως το σύνολο που περιέχει όλες τις ακμές οι οποίες συνδέουν κάποιον κόμβο του με κάποιον κόμβο εκτός του .
-
(α’)
Εξηγήστε γιατί το σύνολο είναι πάντα cut set.
-
(β’)
Αποδείξτε πως το είναι ομοιόμορφα κατανεμημένο, δηλαδή πως η πιθανότητα το να ισούται με οποιοδήποτε cut set είναι πάντα η ίδια.
-
(γ’)
Αποδείξτε πως η πιθανότητα το τυχαίο cut set να είναι min-cut είναι πάντα εκθετικά μικρή, και συγκεκριμένα ότι,
[Υπόδειξη. Ίσως σας φανούν χρήσιμα το αποτέλεσμα της Άσκησης 5, και η παρατήρηση πριν από την περιγραφή του αλγορίθμου του Karger πως το πλήθος όλων των cut sets του γράφου ισούται με .]
Άρα, πράγματι αυτή η μέθοδος είναι πολύ λιγότερο αποτελεσματική από τον αλγόριθμο του Karger, μια που η πιθανότητα να επιλέξουμε ένα min-cut είναι εκθετικά μικρή, ενώ η πιθανότητα του Θεωρήματος 8.1 είναι τουλάχιστον της τάξης του .
-
(α’)
-
7.
Φράγμα τομής. Εδώ θα δείξετε πως, αν καθένα από τα ενδεχόμενα έχει πιθανότητα κοντά στο 100% να συμβεί, τότε και η πιθανότητα του να συμβούν όλα μαζί είναι κοντά στο 100%. Χρησιμοποιήστε το φράγμα ένωσης του Κεφαλαίου 5 για να αποδείξετε πως:
Άρα, αν για όλα τα , και η πιθανότητα της τομής τους θα είναι .
-
8.
Μια γενικότερη πιθανοκρατική ανάλυση. Στην Ενότητα 8.3 αναλύσαμε το κόστος εκτέλεσης ενός αλγορίθμου που δρα σε μια ακολουθία τυχαίων bits, , όπου το ισούται με το μήκος της μακρύτερης ακολουθίας συνεχόμενων «1» ανάμεσα στα . Υποθέτοντας ότι τα είναι ανεξάρτητες Bern(1/2) τυχαίες μεταβλητές, αποδείξαμε ότι η πιθανότητα το να είναι μεγαλύτερο από τείνει στο μηδέν.
Υποθέτοντας τώρα ότι τα είναι ανεξάρτητες Bern() τυχαίες μεταβλητές (για κάποιο μεταξύ 0 και 1), αποδείξτε πως, για οποιοδήποτε , η πιθανότητα το να είναι μεγαλύτερο από,
τείνει στο μηδέν καθώς το . Δικαιολογήστε όλα τα βήματα στον υπολογισμό σας. Πώς μεταβάλλεται ο συντελεστής του για διαφορετικές τιμές του ; Σχολιάστε.
-
9.
Προσομοίωση. Στην προηγούμενη άσκηση δείξατε ότι, για κάθε ,
για μεγάλα . Εδώ θα εξετάσουμε μέσω προσομοίωσης αν αυτό το φράγμα είναι ακριβές καθώς το , δηλαδή αν . Χρησιμοποιήστε το scilab, το matlab ή όποιο άλλο προγραμματιστικό περιβάλλον σάς βολεύει για τα παρακάτω ερωτήματα.
-
(α’)
Επιλέξτε ένα αυθαίρετο στο διάστημα . Αυτή η τιμή του θα μείνει σταθερή σε όλα τα υποερωτήματα.
-
(β’)
Γράψτε ένα πρόγραμμα που να προσομοιώνει τις τιμές ανεξάρτητων Bern τυχαίων μεταβλητών , και να υπολογίζει την τιμή του για .
-
(γ’)
Κάντε ένα γράφημα που να παρουσιάζει την τιμή του ως συνάρτηση του για τις πιο πάνω τιμές του . Καθώς το μεγαλώνει, παρατηρείτε να συγκλίνει η τιμή του στην τιμή ή όχι;
-
(α’)
-
10.
Μεγάλοι χρόνοι αναμονής. Έστω μια ακολουθία τυχαίων bits δηλαδή τα είναι ανεξάρτητες Bern T.M. Για κάθε ορίζουμε μια νέα Τ.Μ., την , η οποία περιγράφει την πρώτη χρονική στιγμή κατά την οποία εμφανίζεται το μοτίβο μήκους (δηλαδή πρώτα «0» και μετά «1») στα τυχαία bits. Συγκεκριμένα, το είναι η πρώτη θέση από την οποία ξεκινά και εμφανίζεται αυτό το μοτίβο. Π.χ. αν και,
τότε . Αποδείξτε πως, για μεγάλα , ο χρόνος αναμονής θα είναι εκθετικά μεγάλος με πιθανότητα πολύ κοντά στο 1. Συγκεκριμένα, δείξτε ότι,
-
11.
Τυχαίες διατάξεις. Υπάρχουν διαφορετικές διατάξεις των στοιχείων του συνόλου . Έστω μια τυχαία διάταξη, επιλεγμένη ομοιόμορφα από όλες τις δυνατές διατάξεις, δηλαδή, με όλες τις δυνατές επιλογές να έχουν την ίδια πιθανότητα.
-
(α’)
Εξηγήστε γιατί, όταν ταξινομούμε τη λίστα , το κάθε στοιχείο μετακινείται κατά θέσεις από την αρχική του θέση μέχρι τη θέση του στην ταξινομημένη λίστα.
-
(β’)
Εξηγήστε γιατί η κάθε Τ.Μ. έχει ομοιόμορφη κατανομή στο , δηλαδή έχει σύνολο τιμών το και πυκνότητα , για κάθε .
-
(γ’)
Υπολογίστε τη μέση τιμή της συνολικής απόστασης που τα στοιχεία της λίστας μετακινούνται μέχρι την τελική τους ταξινόμηση, δηλαδή την:
Υπόδειξη. Ίσως χρειαστείτε τον τύπο για το άθροισμα μιας αριθμητικής προόδου όπως στην Άσκηση 2 παραπάνω, και τον αντίστοιχο τύπο για το άθροισμα διαδοχικών τετραγώνων:
(8.7)
-
(α’)
- 12.
Κεφάλαιο 9 Ανισότητες, από κοινού κατανομή, Νόμος των Μεγάλων Αριθμών
[Επιστροφή
στα περιεχόμενα]
9.1 Ανισότητες Markov και Chebychev
Ξεκινάμε αυτό το κεφάλαιο με δύο σημαντικά αποτελέσματα τα οποία, πέραν της μεγάλης χρησιμότητάς τους, δίνουν και μια πιο σαφή χρηστική σημασία στην έννοια της μέσης τιμής και της διασποράς.
Το πρώτο λέει πως, αν μια τυχαία μεταβλητή έχει μικρή μέση τιμή, τότε δεν μπορεί να παίρνει μεγάλες τιμές με μεγάλη πιθανότητα:
Έστω μια διακριτή Τ.Μ. που παίρνει πάντα τιμές μεγαλύτερες ή ίσες του μηδενός και έχει μέση τιμή Τότε:
Απόδειξη:
Έστω το σύνολο τιμών της . Ξεκινώντας από τον ορισμό της μέσης τιμής, έχουμε,
όπου χωρίσαμε το άθροισμα σε δύο μέρη, αυτό που αντιστοιχεί σε τιμές μικρότερες του , και τις τιμές . Εφόσον όλες οι τιμές της είναι μεγαλύτερες ή ίσες του μηδενός, το παραπάνω τελευταίο άθροισμα είναι κι αυτό μεγαλύτερο ή ίσο του μηδενός, συνεπώς,
όπου χρησιμοποιήσαμε το γεγονός ότι στο παραπάνω άθροισμα όλα τα είναι μεγαλύτερα ή ίσα του . Παρατηρώντας, τέλος, πως από την τρίτη βασική ιδιότητα της πυκνότητας (βλ. Κεφάλαιο 6), το παραπάνω τελευταίο άθροισμα ισούται με , έχουμε,
που είναι η ζητούμενη ανισότητα.
Παράδειγμα 9.1
Όπως θα δούμε πιο κάτω – ειδικά στην απόδειξη του Νόμου των Μεγάλων Αριθμών – το φράγμα που δίνει η ανισότητα Markov συχνά είναι εξαιρετικά χρήσιμο. Αλλά σε κάποιες περιπτώσεις, όπως σε αυτό το παράδειγμα, μπορεί να είναι και σχετικά ασθενές.
Έστω μια Τ.Μ. με κατανομή οπότε η έχει μέση τιμή Από την ανισότητα Markov έχουμε πως,
ενώ στην πραγματικότητα (χρησιμοποιώντας την πρώτη ιδιότητα της γεωμετρικής κατανομής από το Θεώρημα 7.1) η πιο πάνω πιθανότητα είναι,
η οποία είναι σημαντικά μικρότερη.
Αν και, πράγματι, το πιο πάνω φράγμα είναι αρκετά ασθενές, η ισχύς του έγκειται κυρίως στο γεγονός ότι δεν χρησιμοποιεί την πληροφορία πως η έχει γεωμετρική κατανομή, και ισχύει για οποιαδήποτε τυχαία μεταβλητή με
Το επόμενο αποτέλεσμα (το οποίο προκύπτει από μια σχετικά απλή εφαρμογή της ανισότητας του Markov) λέει πως, αν μια τυχαία μεταβλητή έχει μικρή διασπορά, τότε δεν μπορεί να έχει μεγάλες διακυμάνσεις, υπό την έννοια ότι δεν μπορεί να παίρνει τιμές μακρά από τη μέση τιμή της με μεγάλη πιθανότητα:
Θεώρημα 9.2 (Ανισότητα του Chebychev)
Έστω μια διακριτή Τ.Μ. με μέση τιμή και διασπορά Τότε:
Απόδειξη:
Έστω μια νέα τυχαία μεταβλητή η οποία, εξ ορισμού, έχει πάντα . Από τον ορισμό της διασποράς, παρατηρούμε πως . Εφαρμόζοντας την ανισότητα του Markov για την Τ.Μ. βρίσκουμε,
Παράδειγμα 9.2
Έστω μια Τ.Μ. με κατανομή Από τις γνωστές ιδιότητες της υπεργεωμετρικής κατανομής στο Κεφάλαιο 7, η έχει μέση τιμή και διασπορά,
Έστω τώρα πως θέλουμε να υπολογίσουμε την δηλαδή την πιθανότητα το να ισούται με 0 ή με 1 ή με 8 ή με 9 κ.ο.κ. Εφόσον γνωρίζουμε την πυκνότητα της μπορούμε να υπολογίσουμε αυτή την πιθανότητα ως Αλλά λόγω της πολυπλοκότητας του τύπου της πυκνότητας και επιπλέον επειδή απαιτεί τον υπολογισμό παραγοντικών για μεγάλα – πράγμα το οποίο, όπως παρατηρήσαμε στο Κεφάλαιο 7, μπορεί να οδηγήσει σε σημαντικά αριθμητικά σφάλματα – είναι πολύ πιο εύκολο να χρησιμοποιήσουμε την ανισότητα Chebychev για να βρούμε ένα φράγμα για τη ζητούμενη πιθανότητα:
Παράδειγμα 9.3
Από εμπειρικές μετρήσεις γνωρίζουμε πως ο χρόνος απόκλισης (σε δευτερόλεπτα) ενός συστήματος έχει μέση τιμή και τυπική απόκλιση δευτερόλεπτα. Θέλουμε να βρούμε μια τιμή τέτοια ώστε να μπορούμε να εγγυηθούμε ότι, με πιθανότητα τουλάχιστον 99%, η χρονική απόκλιση του συστήματος δεν θα ξεπερνά τα δευτερόλεπτα. Δηλαδή, θέλουμε ή, ισοδύναμα,
| (9.1) |
Αλλά από την ανισότητα Chebychev έχουμε πως,
Συνεπώς, για να ισχύει το ζητούμενο (9.1), αρκεί να διαλέξουμε το έτσι ώστε να έχουμε για το οποίο αρκεί να διαλέξουμε δευτερόλεπτα. Με άλλα λόγια, μπορούμε να εγγυηθούμε πως, με πιθανότητα τουλάχιστον 99%, ο χρόνος απόκλισης του συστήματος δεν θα ξεπερνά το ένα λεπτό.
9.2 Από κοινού κατανομή και συνδιακύμανση
Όταν δύο Τ.Μ. με αντίστοιχες πυκνότητες και είναι ανεξάρτητες, η πιθανότητα να πάρουν ένα ζευγάρι τιμών μπορεί να υπολογιστεί απλά ως το γινόμενο,
όπως μας λέει ο ορισμός της ανεξαρτησίας τυχαίων μεταβλητών στο Κεφάλαιο 6. Για ζευγάρια Τ.Μ. που ενδεχομένως δεν είναι ανεξάρτητες, οι αντίστοιχες πιθανότητες περιγράφονται από την από κοινού πυκνότητά τους, την οποία θα ορίσουμε αμέσως μετά το παρακάτω παράδειγμα.
Παράδειγμα 9.4
Δύο διαφορετικά προγράμματα κατανέμονται τυχαία σε τρεις υπολογιστές. Έστω «πλήθος προγραμμάτων που κατέληξαν στον υπολογιστή », για κάθε οπότε Προφανώς αυτές οι Τ.Μ. δεν είναι ανεξάρτητες – διαισθητικά τουλάχιστον: Αν ξέρουμε, π.χ., πως τότε και τα δύο προγράμματα κατέληξαν στον πρώτο υπολογιστή, συνεπώς
Ας εξετάσουμε τώρα τις δύο μεταβλητές Εφόσον υποθέτουμε πως η κατανομή έγινε τυχαία, το κάθε πρόγραμμα έχει, ανεξάρτητα από το άλλο, πιθανότητα να πάει στον κάθε έναν από τους τρεις υπολογιστές. Οπότε, για παράδειγμα η πιθανότητα να έχουμε και είναι η πιθανότητα του δηλαδή και τα δύο προγράμματα να πήγαν στον τρίτο υπολογιστή:
Παρομοίως, η πιθανότητα να έχουμε και είναι η πιθανότητα το πρώτο πρόγραμμα να πήγε στον υπολογιστή 2 και το δεύτερο στον 3, ή αντίστροφα, δηλαδή,
Όλες οι πιθανότητες της μορφής μπορούν να υπολογιστούν με τον ίδιο τρόπο, όπως συνοψίζεται στον πιο κάτω πίνακα:
| 0 | 1 | 2 | |
| 0 | 1/9 | 2/9 | 1/9 |
| 1 | 2/9 | 2/9 | 0 |
| 2 | 1/9 | 0 | 0 |
Ορισμός 9.1
-
1.
Η από κοινού πυκνότητα (ή διακριτή συνάρτηση από κοινού πυκνότητας πιθανότητας) δύο διακριτών Τ.Μ. με αντίστοιχα σύνολα τιμών είναι η συνάρτηση που ορίζεται ως,
-
2.
Η από κοινού πυκνότητα (ή διακριτή συνάρτηση από κοινού πυκνότητας πιθανότητας) ενός πεπερασμένου πλήθους διακριτών Τ.Μ. όπου η κάθε έχει σύνολο τιμών είναι η συνάρτηση,
για κάθε -άδα τιμών
Παράδειγμα 9.5
Για τις Τ.Μ. του Παραδείγματος 9.4, οι τιμές της από κοινού πυκνότητας συνοψίζονται στον εκεί πίνακα. Έστω, τώρα, πως θέλουμε να υπολογίσουμε από αυτές τις τιμές την πιθανότητα Χρησιμοποιώντας τον κανόνα συνολικής πιθανότητας έχουμε,
Άρα, για να βρούμε την αθροίσαμε όλες τις τιμές του πίνακα που αντιστοιχούσαν στην στήλη :
| 0 | 1 | 2 | ||
| 0 | 1/9 | 2/9 | 1/9 | 4/9 |
| 1 | 2/9 | 2/9 | 0 | 4/9 |
| 2 | 1/9 | 0 | 0 | 1/9 |
| 4/9 | 4/9 | 1/9 |
Με παρόμοιο τρόπο, αθροίζοντας τις τιμές στις στήλες και βρίσκουμε τις και και αντίστοιχα, αθροίζοντας τις τιμές που βρίσκονται στην κάθε γραμμή του πίνακα, βρίσκουμε τις πιθανότητες
Λόγω του ότι οι τιμές των πιθανοτήτων που αφορούν μόνο μία από τις δύο Τ.Μ. μπορούν να γραφτούν, όπως πιο πάνω, στο περιθώριο του πίνακα της από κοινού πυκνότητας, οι επιμέρους πυκνότητές τους συχνά ονομάζονται περιθώριες πυκνότητες. Πριν δώσουμε τον ακριβή τους ορισμό, παρατηρούμε πως είναι τώρα εύκολο να διαπιστώσουμε και μαθηματικά ότι οι δεν είναι ανεξάρτητες. Με τη βοήθεια του πίνακα βλέπουμε πως:
Ορισμός 9.2
Η περιθώρια πυκνότητα της είναι η πυκνότητα μίας από διακριτές τυχαίες μεταβλητές οι οποίες έχουν από κοινού πυκνότητα
-
1.
-
2.
- 3.
Οι είναι ανεξάρτητες αν και μόνο αν,
Στην Άσκηση 3 στο τέλος του κεφαλαίου σάς ζητείται να διατυπώσετε και να αποδείξετε τις φυσικές γενικεύσεις των πιο πάνω ιδιοτήτων για ένα οποιοδήποτε πεπερασμένο πλήθος τυχαίων μεταβλητών .
Απόδειξη:
Εφόσον για διαφορετικά ζεύγη τιμών τα ενδεχόμενα είναι ξένα μεταξύ τους, και προφανώς η ένωσή τους καλύπτει όλο το , από τον κανόνα συνολικής πιθανότητας έχουμε,
που αποδεικνύει την πρώτη ιδιότητα. Παρότι η δεύτερη ιδιότητα έχει ήδη αποδειχθεί στο Λήμμα 6.1 του Κεφαλαίου 6, θυμίζουμε πως, για κάθε , τα ενδεχόμενα είναι ξένα μεταξύ τους και η ένωσή τους για διαφορετικά ισούται με το ενδεχόμενο . Άρα, πάλι από τον κανόνα συνολικής πιθανότητας, έχουμε:
Η αντίστοιχη σχέση για την αποδεικνύεται με τον ίδιο τρόπο. Τέλος, η τρίτη ιδιότητα είναι απλώς αναδιατυπωμένος ο ορισμός της ανεξαρτησίας διακριτών τυχαίων μεταβλητών.
Παράδειγμα 9.6
Μερικές φορές το πλήθος των τιμών που παίρνει μια Τ.Μ. είναι απαγορευτικά μεγάλο για να αναπαραστήσουμε σε πίνακα την από κοινού πυκνότητά της με μια άλλη Τ.Μ. Έστω, για παράδειγμα, πως η ορίζεται ως,
και πως, δεδομένου ότι η παίρνει την τιμή η έχει κατανομή. Συνεπώς, τα αντίστοιχα σύνολα τιμών είναι και όπου το προφανώς είναι άπειρο.
Η από κοινού πυκνότητα των μπορεί εύκολα να υπολογιστεί από τον ορισμό της δεσμευμένης πιθανότητας: Για και
όπου χρησιμοποιήσαμε τον τύπο της πυκνότητας της κατανομής.
Η περιθώρια πυκνότητα της μας είναι εξ ορισμού γνωστή και, από τη δεύτερη ιδιότητα της από κοινού πυκνότητας, μπορούμε εύκολα να υπολογίσουμε και τις τιμές της περιθώριας πυκνότητας της Για παράδειγμα,
Από τον ορισμό της γνωρίζουμε πως η πιθανότητα Αλλά δεδομένου ότι το ποια θα ήταν η πιθανότητα να έχουμε Το αντιστοιχεί στο να έχει το γεωμετρική κατανομή με παράμετρο 1/4, δηλαδή με πιθανότητα επιτυχίας που είναι η μικρότερη από τις τρεις δυνατές περιπτώσεις (1/2, 1/3 ή 1/4). Άρα θεωρούμε ότι είναι μάλλον απίθανο να έχουμε δεδομένου ότι είχαμε δηλαδή επιτυχία από το πρώτο κιόλας πείραμα. Με άλλα λόγια, περιμένουμε πως η δεσμευμένη πιθανότητα θα είναι μικρότερη από την αρχική Πράγματι, από τον ορισμό της δεσμευμένης πιθανότητας βρίσκουμε,
όπως αναμενόταν.
Παράδειγμα 9.7
Έστω δύο διακριτές Τ.Μ. με από κοινού πυκνότητα όπως στον πιο κάτω πίνακα:
| 0 | 1 | 2 | ||
| 0 | 1/6 | 0 | 1/4 | 5/12 |
| 1 | 0 | 1/6 | 0 | 1/6 |
| 2 | 1/4 | 0 | 1/6 | 1/9 |
| 5/12 | 1/6 | 5/12 |
Όπως και στο Παράδειγμα 9.5, οι περιθώριες πυκνότητες και εύκολα υπολογίζονται στον πίνακα βάσει της δεύτερης ιδιότητας της από κοινού πυκνότητας. Και όπως και νωρίτερα, διαπιστώνουμε πως και εδώ οι δεν είναι ανεξάρτητες, εφόσον:
Η συνδιακύμανση μεταξύ δύο Τ.Μ. είναι μια ποσοτική έκφραση του «πόσο μη ανεξάρτητες» είναι:
Ορισμός 9.3
Η συνδιακύμανση μεταξύ δύο τυχαίων μεταβλητών ορίζεται ως:
Παράδειγμα 9.8
Για τις Τ.Μ. του Παραδείγματος 9.5 έχουμε,
και παρομοίως Από τον ορισμό της συνδιακύμανσης και την από κοινού πυκνότητά των εύκολα υπολογίζουμε,
όπου στον υπολογισμό παραλείψαμε τα τρία ζεύγη τιμών με μηδενική πιθανότητα.
Παράδειγμα 9.9
Για μια οποιαδήποτε Τ.Μ. μπορούμε να υπολογίσουμε τη συνδιακύμανση της με τον εαυτό της. Από τους ορισμούς βρίσκουμε,
άρα η συνδιακύμανση μιας οποιασδήποτε Τ.Μ. με τον εαυτό της είναι πάντα θετική. [Εκτός, βέβαια, από την τετριμμένη περίπτωση που η έχει μηδενική διασπορά, δηλαδή ισούται με κάποια σταθερά με πιθανότητα 1, οπότε η διασπορά της είναι μηδέν.] Παρομοίως, η συνδιακύμανση μεταξύ της και της ισούται με,
η οποία είναι πάντοτε αρνητική.
Παρατήρηση: Μια πρώτη διαισθητική ερμηνεία της συνδιακύμανσης είναι πως, όταν έχουμε , τότε οι δύο Τ.Μ. τείνουν να παίρνουν και οι δύο μεγάλες τιμές, ή και οι δύο μικρές τιμές. Αντίστοιχα, όταν , τότε όταν η μία Τ.Μ. παίρνει μεγάλες τιμές η άλλη τείνει να παίρνει μικρές τιμές.
Αυτό το φαινόμενο στην ακραία του μορφή φαίνεται στο Παράδειγμα 9.9 πιο πάνω, όπου είδαμε πως, για οποιαδήποτε Τ.Μ. , η συνδιακύμανση είναι πάντοτε θετική, ενώ η συνδιακύμανση είναι πάντοτε αρνητική.
-
1.
Η συνδιακύμανση εναλλακτικά ισούται με:
(9.2) -
2.
Αν οι είναι ανεξάρτητες, τότε η συνδιακύμανσή τους ισούται με μηδέν, δηλαδή,
-
3.
Αν η συνδιακύμανσή ισούται με μηδέν, αυτό δεν συνεπάγεται απαραίτητα πως οι είναι ανεξάρτητες.
-
4.
Πάντοτε έχουμε:
-
5.
Αν οι είναι ανεξάρτητες, τότε:
Παρατηρήσεις:
-
1.
Την Ιδιότητα 5 την έχουμε ήδη συναντήσει στο Θεώρημα 6.1. Εδώ θα δούμε πώς προκύπτει, εναλλακτικά, ως ειδική περίπτωση της παραπάνω Ιδιότητας 4.
-
2.
Αν και ίσως δεν συνδέεται άμεσα με την ύλη που έχουμε συναντήσει ως τώρα σε αυτό το κεφάλαιο, παραθέτουμε εδώ μία σημαντική ισοδύναμη συνθήκη για την ανεξαρτησία δύο Τ.Μ., η οποία θα μας φανεί πολύ χρήσιμη στη μετέπειτα ανάπτυξη των αποτελεσμάτων μας. Η απόδειξή της δίνεται στην Άσκηση 6 στο τέλος του κεφαλαίου.
Δύο διακριτές Τ.Μ. είναι ανεξάρτητες αν και μόνο αν, για οποιεσδήποτε συναρτήσεις και οι νέες Τ.Μ. και είναι ανεξάρτητες.
Απόδειξη:
Για την πρώτη ιδιότητα, από τον ορισμό της συνδιακύμανσης και την πρώτη ιδιότητα του Θεωρήματος 6.1, έχουμε:
Ιδιότητα 2: Αν οι είναι ανεξάρτητες, τότε από την Ιδιότητα 3 του Θεωρήματος 6.1 έχουμε , και αντικαθιστώντας στην (9.2) η συνδιακύμανση πράγματι ισούται με μηδέν,
Για την τρίτη ιδιότητα αρκεί να δώσουμε ένα παράδειγμα δύο Τ.Μ. με μηδενική συνδιακύμανση, οι οποίες δεν είναι ανεξάρτητες: Έστω δύο διακριτές Τ.Μ. με από κοινού πυκνότητα όπως στον παρακάτω πίνακα:
| -1 | 0 | 1 | ||
| -1 | 0 | 1/4 | 0 | 1/4 |
| 0 | 1/4 | 0 | 1/4 | 1/2 |
| 1 | 0 | 1/4 | 0 | 1/4 |
| 1/4 | 1/2 | 1/4 |
Οι περιθώριες πυκνότητες έχουν επίσης υπολογιστεί στον πίνακα βάσει της Ιδιότητας 2 της από κοινού πυκνότητας. Οι δεν είναι ανεξάρτητες, αφού:
Για τη συνδιακύμανσή τους, πρώτα υπολογίζουμε,
και παρομοίως αφού οι και έχουν την ίδια πυκνότητα. Επιπλέον παρατηρούμε πως,
διότι όλοι οι όροι του πιο πάνω αθροίσματος είναι μηδενικοί. [Ή ή ή , για όλα τα δυνατά ζεύγη τιμών .] Άρα,
[Παρατηρήστε πως αυτό το παράδειγμα είναι το ίδιο με εκείνο που δόθηκε για τη λύση της Άσκησης 5 του Κεφαλαίου 6.]
Για την τέταρτη ιδιότητα, ξεκινώντας από τον ορισμό της διασποράς και εφαρμόζοντας την Ιδιότητα 1 του Θεωρήματος 6.1, έχουμε,
Τέλος, η πέμπτη ιδιότητα είναι άμεση συνέπεια του συνδυασμού των Ιδιοτήτων 4 και 2.
Παράδειγμα 9.10
Έστω τρεις ανεξάρτητες Τ.Μ. που έχουν όλες την ίδια πυκνότητα, και, κατά συνέπεια, την ίδια μέση τιμή Ορίζουμε δύο νέες Τ.Μ., τις και Εφόσον και οι δύο εξαρτώνται από την περιμένουμε πως δεν θα είναι ανεξάρτητες, και πως πιθανότατα η συνδιακύμανσή τους δεν θα είναι μηδενική. Χρησιμοποιώντας την εναλλακτική έκφραση για τη συνδιακύμανση στη σχέση (9.2), έχουμε,
όπου στο τελευταίο βήμα χρησιμοποιήσαμε την Ιδιότητα 1 του Θεωρήματος 6.1. Από το ίδιο θεώρημα επίσης γνωρίζουμε πως, λόγω της ανεξαρτησίας των έχουμε Συνεπώς, οι παραπάνω έξι όροι εκτός του πρώτου και του τέταρτου απλοποιούνται, διότι είναι όλοι ίσοι με και χρησιμοποιώντας την εναλλακτική έκφραση της διασποράς βρίσκουμε πως
Άρα, η συνδιακύμανση μεταξύ και όχι μόνο είναι μη μηδενική (όπως περιμέναμε), αλλά επιπλέον ισούται ακριβώς με τη «διακύμανση» (δηλαδή τη διασπορά) της Τ.Μ. η οποία συνδέει τις και
Παράδειγμα 9.11
Παρομοίως με το προηγούμενο παράδειγμα, έστω ότι από τρεις ανεξάρτητες τυχαίες μεταβλητές και ορίζουμε δύο νέες Τ.Μ., την και την Όπως είδαμε στην Άσκηση 5 του Κεφαλαίου 7, το άθροισμα δύο ανεξάρτητων Τ.Μ. με κατανομή Poisson έχει κι αυτό κατανομή Poisson, και η παράμετρός του ισούται με το άθροισμα των δύο αρχικών παραμέτρων. Άρα εδώ έχουμε και
Ακολουθώντας τα ίδια βήματα όπως στο προηγούμενο παράδειγμα, υπολογίζουμε τη συνδιακύμανση μεταξύ και
Παρατηρούμε πως, παρότι οι τρεις Τ.Μ. εδώ, σε αντίθεση με το προηγούμενο παράδειγμα, δεν έχουν ακριβώς την ίδια κατανομή (γιατί έχουν διαφορετικές παραμέτρους), καταλήγουμε στο ίδιο αποτέλεσμα: Η συνδιακύμανση μεταξύ και είναι ίση με τη διασπορά της Τ.Μ. η οποία συνδέει τις και
9.3 Ο Νόμος των Μεγάλων Αριθμών
Σε αυτό το σημείο έχουμε πλέον αναπτύξει αρκετά μαθηματικά εργαλεία ώστε να είμαστε σε θέση να διατυπώσουμε και να αποδείξουμε ίσως το πιο θεμελιώδες αποτέλεσμα της θεωρίας των πιθανοτήτων, το Νόμο των Μεγάλων Αριθμών (ή Ν.Μ.Α., για συντομία). Χωρίς να μπούμε ακόμα σε μαθηματικές λεπτομέρειες, ο Ν.Μ.Α. λέει το εξής:
Ν.Μ.Α.: Έστω πως έχουμε ένα μεγάλο πλήθος από ανεξάρτητες τυχαίες μεταβλητές οι οποίες έχουν όλες την ίδια «κατανομή», δηλαδή την ίδια πυκνότητα και, κατά συνέπεια, και την ίδια μέση τιμή Τότε, με μεγάλη πιθανότητα, ο εμπειρικός μέσος όρος τους θα ισούται με τη μέση τιμή τους, δηλαδή:
Πριν δώσουμε την ακριβή μαθηματική διατύπωση του Ν.Μ.Α., ας δούμε μερικά απλά αλλά πολύ σημαντικά παραδείγματα.
Παράδειγμα 9.12 (Τι θα πει «πιθανότητα»;)
Έστω πως μας ενδιαφέρει η πιθανότητα του να συμβεί ένα συγκεκριμένο ενδεχόμενο Λόγου χάρη, το θα μπορούσε να αντιστοιχεί στο «η θεραπεία του ασθενή ήταν επιτυχής» ή «το δίκτυο παρουσίασε σφάλμα» ή «η εκτέλεση του αλγορίθμου ολοκληρώθηκε κανονικά» ή «ανέβηκε σήμερα στο χρηματιστήριο η τιμή της μετοχής τάδε» κλπ. Ένας τρόπος για να δώσουμε ένα φυσικό νόημα στην πιθανότητα είναι να φανταστούμε πως επαναλαμβάνεται το ίδιο ακριβώς πείραμα πάρα πολλές, ανεξάρτητες φορές, έτσι ώστε, τουλάχιστον στο διαισθητικό επίπεδο, η πιθανότητα να αντιστοιχεί στο το ποσοστό των φορών, μακροπρόθεσμα, που συμβαίνει το . Ο Ν.Μ.Α. είναι ακριβώς το αποτέλεσμα εκείνο που τεκμηριώνει αυτόν τον συλλογισμό μαθηματικά.
Συγκεκριμένα, το πιο πάνω φανταστικό σενάριο μπορεί να περιγραφεί ως εξής. Έστω πως έχουμε ένα μεγάλο πλήθος ανεξάρτητων επαναλήψεων του ίδιου πειράματος, και ας ορίσουμε, για την κάθε επανάληψη μια Τ.Μ. που να ισούται με 1 αν το συνέβη τη φορά αλλιώς να ισούται με 0. Τότε,
και ο Ν.Μ.Α. μας λέει πως, με πιθανότητα αυτό θα ισούται με τη μέση τιμή των Εφόσον τα είναι Bernoulli τυχαίες μεταβλητές, η μέση τιμή είναι απλά η πιθανότητα του να έχουμε δηλαδή του να συμβεί το Με άλλα λόγια:
Η πιθανότητα του να συμβεί ένα οποιοδήποτε ενδεχόμενο ισούται με τη συχνότητα με την οποία θα συμβεί, μακροπρόθεσμα, το σε πολλές ανεξάρτητες επαναλήψεις του ίδιου πειράματος.
Παράδειγμα 9.13 (Γιατί γίνονται δημοσκοπήσεις;)
Έστω πως σε έναν πληθυσμό ατόμων οι είναι ψηφοφόροι κάποιου κόμματος, δηλαδή το κόμμα αυτό στις εκλογές θα πάρει ποσοστό 25%. Μια δημοσκόπηση επιλέγει στην τύχη ένα σχετικά μεγάλο πλήθος ατόμων (με επανατοποθέτηση) και τα ρωτά αν θα ψηφίσουν το κόμμα αυτό. [Σε τυπικές δημοσκοπήσεις έχουμε μεταξύ 1000 και 5000 ερωτηθέντων σε έναν πληθυσμό μεταξύ 500 χιλιάδων και πολλών εκατομμυρίων ατόμων.]
Έστω μια Τ.Μ. που ισούται με 1 αν το άτομο που ρωτάται είναι ψηφοφόρος του κόμματος, και 0 αν όχι, οπότε οι είναι ανεξάρτητες Τ.Μ. με κατανομή Εδώ ο Ν.Μ.Α. μας λέει πως, αν το μέγεθος του δείγματος είναι αρκετά μεγάλο, τότε, με πιθανότητα :
Άρα, από ένα αρκετά μεγάλο (τυχαίο) δείγμα, μπορούμε να εκτιμήσουμε το πραγματικό ποσοστό ψήφων που αυτό το κόμμα θα πάρει στις εκλογές.
Παράδειγμα 9.14 (Εκτίμηση μέσω δειγματοληψίας)
Έστω πως θέλουμε να υπολογίσουμε το μέσο ύψος (σε εκατοστά) ενός κοριτσιού ηλικίας 18 μηνών, μεταξύ των κοριτσιών ενός πληθυσμού αυτής της ηλικίας. Αν είναι το ύψος του κοριτσιού θέλουμε να εκτιμήσουμε το,Αντί να εξετάσουμε ολόκληρο τον πληθυσμό, επιλέγουμε τυχαία, με επανατοποθέτηση, μέλη του πληθυσμού, όπου το μέγεθος του δείγματός μας είναι μεν σχετικά μεγάλο, αλλά είναι σημαντικά μικρότερο του συνολικού μεγέθους του πληθυσμού (όπως και στο προηγούμενο παράδειγμα).
Ορίζουμε τις εξής Τ.Μ.: Έστω «ύψος του κοριτσιού » που επιλέξαμε. Τότε τα είναι ανεξάρτητα, και το κάθε έχει σύνολο τιμών και πυκνότητα,
Άρα τα έχουν μέση τιμή,
Αν εκτιμήσουμε λοιπόν το ως τον μέσο όρο από τα ύψη των κοριτσιών που επιλέξαμε, ο Ν.Μ.Α. είναι αυτός που μας διαβεβαιώνει πως, αν το μέγεθος του δείγματός μας είναι αρκετά μεγάλο, τότε η εκτίμησή μας θα είναι ακριβής με πιθανότητα κοντά στο 100%:
Για να διατυπώσουμε τον Ν.Μ.Α. μαθηματικά με ακρίβεια, θα χρειαστούμε την έννοια της «σύγκλισης κατά πιθανότητα». Όταν η ακολουθία που μας ενδιαφέρει αποτελείται από τυχαίες μεταβλητές , και όχι απλά από πραγματικούς αριθμούς, πρέπει να ορίσουμε εκ νέου τι εννοούμε λέγοντας ότι «η ακολουθία συγκλίνει».
Έστω μια ακολουθία τυχαίων μεταβλητών μια σταθερά και μια άλλη Τ.Μ.
-
1.
H ακολουθία τυχαίων μεταβλητών συγκλίνει κατά πιθανότητα στη σταθερά αν για κάθε :
-
2.
Γενικότερα, η ακολουθία τυχαίων μεταβλητών συγκλίνει κατά πιθανότητα στην Τ.Μ. αν για κάθε :
Θεώρημα 9.3 (Ο Νόμος των Μεγάλων Αριθμών)
Έστω μια ακολουθία από ανεξάρτητες διακριτές τυχαίες μεταβλητές όπου έχουν όλες την ίδια κατανομή, δηλαδή την ίδια πυκνότητα, και κατά συνέπεια την ίδια μέση τιμή και την ίδια διασπορά Τότε:
-
1.
[Διαισθητικά] Για μεγάλα ο εμπειρικός μέσος όρος των
- 2.
[Μαθηματικά] Καθώς το ο εμπειρικός μέσος όρος τείνει στη μέση τιμή κατά πιθανότητα, δηλαδή, για κάθε :
Απόδειξη:
Η απόδειξη είναι μια απλή εφαρμογή της ανισότητας Chebychev. Χρησιμοποιώντας την πρώτη ιδιότητα του Θεωρήματος 6.1, η μέση τιμή της Τ.Μ. είναι,
Παρομοίως, χρησιμοποιώντας τις Ιδιότητες 2 και 4 του Θεωρήματος 6.1, και το γεγονός ότι τα είναι ανεξάρτητα, η διασπορά της Τ.Μ. είναι,
Τέλος, δεδομένου , από την ανισότητα Chebychev έχουμε,
Άρα,
το οποίο προφανώς τείνει στο 1, καθώς το .
Παρατηρήσεις:
-
1.
Το αποτέλεσμα του Θεωρήματος 9.3 συχνά αναφέρεται στη βιβλιογραφία ως ο «Ασθενής» Νόμος των Μεγάλων Αριθμών. Ο λόγος είναι ότι υπάρχει ένα πράγματι ισχυρότερο αποτέλεσμα, ο λεγόμενος «Ισχυρός» Νόμος των Μεγάλων Αριθμών, που μας λέει πως, κάτω από τις ίδιες συνθήκες, ο εμπειρικός μέσος όρος συγκλίνει στη μέση τιμή με πιθανότητα 1, όχι μόνο κατά πιθανότητα.
Αυτή η μορφή σύγκλισης λέει το εξής: Ας εξετάσουμε τις Τ.Μ. στην πιο βασική τους μορφή, δηλαδή ως συναρτήσεις σε κάποιο χώρο πιθανότητας . Για οποιοδήποτε συγκεκριμένο , η ακολουθία είναι απλά μια ακολουθία πραγματικών αριθμών. Μπορούμε λοιπόν να εξετάσουμε το ενδεχόμενο,
Λέμε ότι τα συγκλίνουν στο με πιθανότητα 1, αν το ενδεχόμενο έχει πιθανότητα . Δεν είναι ιδιαίτερα δύσκολο να δειχθεί (βλ. Άσκηση 14 στο τέλος του κεφαλαίου) ότι η σύγκλιση με πιθανότητα 1 συνεπάγεται και τη σύγκλιση κατά πιθανότητα, πράγμα που εξηγεί τις σχετικές ονομασίες των δύο αυτών αποτελεσμάτων.
-
2.
Αν και στη διατύπωση του Ν.Μ.Α. στο Θεώρημα 9.3 υποθέσαμε πως οι Τ.Μ. έχουν πεπερασμένη διασπορά , σημειώνουμε πως αυτή η συνθήκη δεν είναι απαραίτητη και, αν ήμασταν διατεθειμένοι να υποστούμε μια κάπως πιο σύνθετη και μακροσκελή απόδειξη, θα μπορούσαμε να την αντικαταστήσουμε με την ασθενέσθερη υπόθεση ότι η μέση τιμή είναι πεπερασμένη.
-
3.
Κλείνουμε με μια ακόμη παρατήρηση η οποία, αν και τεχνικής φύσεως, όπως θα δούμε σε επόμενα κεφάλαια είναι θεμελιώδους σημασίας για τις περισσότερες στατιστικές εφαρμογές των πιθανοτήτων.
Δύο βασικά και μάλλον προφανή ερωτήματα που γεννιούνται από τον Ν.Μ.Α. είναι τα εξής:
-
(α’)
Πόσο μεγάλο πρέπει να είναι το πλήθος των δειγμάτων, ώστε να έχουμε κάποια σχετική βεβαιότητα πως ο εμπειρικός μέσος όρος θα είναι αρκετά κοντά στη μέση τιμή ;
-
(β’)
Αντίστοιχα, δεδομένου του πλήθους , πόσο μικρή είναι η πιθανότητα το να απέχει κατά πολύ από το ;
Αν εξετάσουμε προσεκτικά την παραπάνω απόδειξη θα δούμε πως, πέρα από το ασυμπτωτικό αποτέλεσμα του θεωρήματος (το οποίο ισχύει μόνο καθώς το ), περιέχει και κάποιες πρώτες απαντήσεις στα πιο πάνω ερωτήματα. Συγκεκριμένα, δείξαμε πως η μέση τιμή και η διασπορά του είναι, αντίστοιχα,
Επιπλέον βρήκαμε ένα ακριβές ποσοτικό φράγμα για την πιθανότητα ο εμπειρικός μέσος όρος να απέχει από τη μέση τιμή κατά τουλάχιστον :
(9.3) Αν και μαθηματικά σωστό, το πιο πάνω φράγμα στις περισσότερες περιπτώσεις δεν είναι αρκετά ακριβές ώστε να είναι χρήσιμο στην πράξη. Με άλλα λόγια, η ζητούμενη πιθανότητα στη σχέση (9.3) είναι συνήθως σημαντικά μικρότερη από το φράγμα .
Το δεύτερο θεμελιώδες αποτέλεσμα των πιθανοτήτων, το Κεντρικό Οριακό Θεώρημα (ή Κ.Ο.Θ.), το οποίο αποτελεί το αντικείμενο του Κεφαλαίου 12, είναι αυτό που μας δίνει μια ακριβή προσέγγιση της πιθανότητας . Συγκεκριμένα, το Κ.Ο.Θ. λέει πως, κάτω από ορισμένες συνθήκες, η κατανομή του εμπειρικού μέσου όρου μπορεί να προσεγγιστεί με μεγάλη ακρίβεια από την κανονική κατανομή.
Η κανονική (ή γκαουσιανή) κατανομή αντιστοιχεί σε μια κατηγορία τυχαίων μεταβλητών οι οποίες έχουν ως σύνολο τιμών ολόκληρο το . Συνεπώς, πριν μπορέσουμε να διατυπώσουμε με ακρίβεια το Κ.Ο.Θ., θα πρέπει να μελετήσουμε τις συνεχείς τυχαίες μεταβλητές. Αυτό είναι το αντικείμενο του Κεφαλαίου 10 που ακολουθεί.
-
(α’)
9.4 Ασκήσεις
-
1.
Αφρικανικό χελιδόνι. Ένας βιολόγος ισχυρίζεται το εξής: «Το μέσο βάρος του αφρικανικού χελιδονιού είναι 100 γραμμάρια, ενώ το των αφρικανικών χελιδονιών έχει βάρος άνω των 200 γραμμαρίων». Είναι δυνατόν αυτός ο ισχυρισμός να ευσταθεί; Εξηγήστε.
-
2.
Απόσταση Τ.Μ. από τη μέση τιμή της. Για μια τυχαία μεταβλητή με μέση τιμή και άγνωστη κατανομή, κάποιος στατιστικολόγος ισχυρίζεται ότι η πιθανότητα η τιμή της να απέχει από τη μέση τιμή της κατά παραπάνω από είναι μικρή. Υποστηρίζει αυτό το συμπέρασμα διότι γνωρίζει πως, στη συγκεκριμένη περίπτωση, η διασπορά της είναι αρκετά μικρότερη από τη μέση τιμή στο τετράγωνο (δηλαδή από το ). Έχει δίκιο στον ισχυρισμό του ή όχι; Αποδείξτε την απάντησή σας.
-
3.
Ιδιότητες από κοινού πυκνότητας. Αν, αντί για δύο διακριτές Τ.Μ. , είχαμε ένα πεπερασμένο πλήθος , διατυπώστε και αποδείξτε τις φυσικές γενικεύσεις των τριών ιδιοτήτων της από κοινού πυκνότητας που ακολουθούν τον Ορισμό 9.2.
-
4.
Χρόνος εκτέλεσης αλγορίθμου. Ένας αλγόριθμος έχει ως δεδομένα εισόδου έναν ακέραιο αριθμό και μια σειρά από bits, . Ο χρόνος εκτέλεσης του αλγορίθμου είναι:
Αν υποθέσουμε ότι τα είναι ανεξάρτητες τυχαίες μεταβλητές όπου τα και το παίρνει τις τιμές και με πιθανότητα 1/4 για την καθεμία:
-
(α’)
Να υπολογίσετε τον μέσο χρόνο εκτέλεσης.
-
(β’)
Να δείξετε ότι η πιθανότητα ο χρόνος εκτέλεσης να ξεπερνά τα δευτερόλεπτα είναι το πολύ,
[Συνεπώς, για μεγάλα αυτή η πιθανότητα είναι το πολύ .]
-
(γ’)
Υπολογίστε τη συνδιακύμανση μεταξύ των Τ.Μ. και . Πώς εξαρτάται το αποτέλεσμα από το ; Εξηγήστε.
-
(α’)
-
5.
Μέγιστο και ελάχιστο δύο ζαριών. Ρίχνουμε ένα ζάρι δύο φορές. Έστω και τα αποτελέσματα των δύο ρίψεων.
-
(α’)
Ποια είναι η από κοινού πυκνότητα του ζεύγους , υποθέτοντας ότι οι ρίψεις είναι ανεξάρτητες και το ζάρι είναι δίκαιο;
-
(β’)
Έστω , . Βρείτε την από κοινού πυκνότητα των .
- (γ’)
-
(α’)
-
6.
Συναρτήσεις τυχαίων μεταβλητών. Έστω , δύο διακριτές τυχαίες μεταβλητές με σύνολο τιμών .
-
(α’)
Δείξτε πως, αν τα , είναι ανεξάρτητα, τότε και τα και είναι ανεξάρτητα.
-
(β’)
Βρείτε μια από κοινού πυκνότητα για την οποία τα , δεν είναι ανεξάρτητα, αλλά τα , είναι.
-
(γ’)
Γενικεύοντας το πρώτο ερώτημα, εδώ θα αποδείξετε μια σημαντική παρατήρηση που κάναμε στην Ενότητα 9.2: Έστω οποιεσδήποτε δύο διακριτές Τ.Μ. με σύνολα τιμών . Δείξτε πως οι είναι ανεξάρτητες αν και μόνο αν, για οποιεσδήποτε συναρτήσεις και , οι είναι ανεξάρτητες.
Γιατί αυτό το αποτέλεσμα δεν αντικρούει το προηγούμενο ερώτημα;
-
(α’)
-
7.
Το φράγμα του Chernoff. Έστω πως, για μια διακριτή Τ.Μ. , θέλουμε να βρούμε ένα ακριβέστερο φράγμα από αυτό της ανισότητας Markov για την πιθανότητα η να παίρνει τιμές μεγαλύτερες από κάποια σταθερά .
-
(α’)
Αποδείξτε πως, για οποιοδήποτε , έχουμε το φράγμα:
(9.4) Παρατηρήστε πως ενώ το αριστερό μέρος δεν εξαρτάται από το , το δεξί μέρος ισχύει για κάθε θετικό .
-
(β’)
Έστω τώρα πως η έχει κατανομή . Χρησιμοποιώντας τη σχέση (9.4), δείξτε πως, για οποιοδήποτε , έχουμε:
(9.5) -
(γ’)
Έστω πάλι πως . Για και :
- i.
Υπολογίστε την τιμή του που μας δίνει το καλύτερο (δηλαδή το μικρότερο) δυνατό φράγμα στη σχέση (9.5), καθώς και το αντίστοιχο φράγμα γι’ αυτήν τη βέλτιστη τιμή του .
- ii.
Υπολογίστε το αντίστοιχο φράγμα που μας δίνει η ανισότητα του Markov. Παρατηρήστε ότι είναι ασθενέστερο.
- iii.
Υπολογίστε ακριβώς την πιθανότητα και συγκρίνετε την πραγματική τιμή της με τα δύο παραπάνω φράγματα.
- i.
-
(α’)
-
8.
Συμπλήρωση πίνακα. Οι διακριτές τυχαίες μεταβλητές και έχουν από κοινού κατανομή που δίνεται από τον παρακάτω πίνακα:
-
(α’)
Συμπληρώστε τις τιμές που λείπουν.
-
(β’)
Είναι οι ανεξάρτητες ή όχι; Αποδείξτε την απάντησή σας.
-
(γ’)
Υπολογίστε την .
-
(α’)
-
9.
Ενεργοποιημένες συνδέσεις. Το πλήθος των ενεργοποιημένων συνδέσεων σε ένα δίκτυο είναι , όπου η έχει κάποια άγνωστη κατανομή με μέση τιμή και τυπική απόκλιση . Αν κάποια στιγμή το πλήθος των συνδέσεων αποκλίνει από το μέσο πλήθος κατά περισσότερο από , τότε το δίκτυο «πέφτει». Βρείτε μια τιμή για το ώστε το ενδεχόμενο να πέσει το δίκτυο να έχει πιθανότητα το πολύ .
-
10.
Συντελεστής συσχέτισης. Ο συντελεστής συσχέτισης μεταξύ δύο τυχαίων μεταβλητών , ορίζεται ως:
Να δείξετε ότι, αν , όπου η σταθερά , τότε ο συντελεστής συσχέτισης των , ισούται με ή με . Πότε ισούται με και πότε με ;
-
11.
Ασυσχέτιστες αλλά όχι ανεξάρτητες Τ.Μ. Εδώ θα δούμε ένα παράδειγμα, διαφορετικό από εκείνο της απόδειξης της τρίτης ιδιότητας της συνδιακύμανσης, δύο τυχαίων μεταβλητών που έχουν μηδενική συνδιακύμανση αλλά δεν είναι ανεξάρτητες.
Έστω , , ανεξάρτητες τυχαίες μεταβλητές Bernoulli με παράμετρο . Να δείξετε ότι οι τυχαίες μεταβλητές και δεν είναι ανεξάρτητες, αλλά έχουν μηδενική συνδιακύμανση.
-
12.
Σύγκλιση κατά πιθανότητα.
-
(α’)
Έστω μια ακολουθία ανεξάρτητων Τ.Μ. όπου η κάθε έχει κατανομή . Δείξτε πως οι συγκλίνουν στο μηδέν κατά πιθανότητα, καθώς το .
-
(β’)
Εξηγήστε γιατί το αποτέλεσμα του παραπάνω ερωτήματος εξακολουθεί να ισχύει ακόμα και αν οι Τ.Μ. δεν είναι ανεξάρτητες.
-
(γ’)
Μπορούμε με το ίδιο σκεπτικό να συμπεράνουμε ότι και ο Ν.Μ.Α. ισχύει αν οι Τ.Μ. δεν είναι ανεξάρτητες; Αν ναι, αποδείξτε το. Αν όχι, εξηγήστε γιατί.
-
(α’)
-
13.
Εκτίμηση με θόρυβο.
-
(α’)
Έστω πως θέλουμε να εκτιμήσουμε τη μέση τιμή κάποιας Τ.Μ. , χρησιμοποιώντας τις τιμές ανεξάρτητων Τ.Μ. όλες με την ίδια κατανομή με την . Αλλά αντί για τα τα ίδια, το μόνο που έχουμε διαθέσιμο είναι τα δείγματα , για , όπου το κάθε είναι μια τυχαία μέτρηση του αντίστοιχου συν κάποιο τυχαίο «θόρυβο» . Υποθέτουμε ότι τα είναι ανεξάρτητα από τα , και επίσης ότι είναι ανεξάρτητα μεταξύ τους και όλα έχουν την ίδια κατανομή, με κάποια γνωστή μέση τιμή .
Περιγράψτε μια μέθοδο εκτίμησης της μέσης τιμής , και αποδείξτε ότι συγκλίνει στο ζητούμενο κατά πιθανότητα, καθώς το πλήθος των δειγμάτων .
-
(β’)
Έστω τώρα πως θέλουμε να εκτιμήσουμε όχι κάποια σταθερά όπως πιο πάνω, αλλά την τυχαία τιμή κάποιας Τ.Μ. , χρησιμοποιώντας τις τιμές δειγμάτων , για , όπου τα είναι ανεξάρτητα από το , είναι ανεξάρτητα μεταξύ τους και όλα έχουν την ίδια κατανομή, με γνωστή μέση τιμή .
Περιγράψτε μια μέθοδο εκτίμησης της και αποδείξτε ότι συγκλίνει στην κατά πιθανότητα, καθώς .
-
(α’)
-
14.
Σύγκλιση με πιθανότητα 1. Έστω μια ακολουθία Τ.Μ. σε κάποιο χώρο πιθανότητας με αντίστοιχο μέτρο πιθανότητας . Υποθέτουμε ότι οι τείνουν με πιθανότητα 1 σε κάποια T.M. η οποία είναι επίσης ορισμένη στον , δηλαδή ότι το ενδεχόμενο,
έχει πιθανότητα . Ακολουθώντας τα πιο κάτω βήματα θα δείξουμε ότι οι τείνουν στη και κατά πιθανότητα. Έστω αυθαίρετο.
-
(α’)
Για κάθε ακέραιο , ορίζουμε τα ενδεχόμενα,
Εξηγήστε γιατί η ακολουθία των ενδεχομένων είναι αύξουσα, δηλαδή , και γιατί έχουμε,
(9.6) - (β’)
-
(γ’)
Εξηγήστε πώς τα πιο πάνω συνεπάγονται ότι οι τείνουν στη κατά πιθανότητα.
-
(α’)
ΠΟΛΥΜΕΣΙΚΟ ΥΛΙΚΟ ΚΕΦΑΛΑΙΟΥ


Κεφάλαιο 10 Συνεχείς τυχαίες μεταβλητές
[Επιστροφή στα περιεχόμενα]
Σε αυτό το κεφάλαιο θα εξετάσουμε τις ιδιότητες που έχουν οι συνεχείς τυχαίες μεταβλητές. Εκείνες οι Τ.Μ. δηλαδή, των οποίων το σύνολο τιμών δεν είναι διακριτό, όπως για παράδειγμα αν έχουμε , , , κλπ.99Ο ακριβής ορισμός του όρου «συνεχής τυχαία μεταβλητή» δίνεται στην επόμενη ενότητα. Όπως και στο Κεφάλαιο 6, έτσι και εδώ ορισμένα από τα αποτελέσματα που θα δούμε απαιτούν κάποιες επιπλέον τεχνικές υποθέσεις, οι οποίες όμως δεν επηρεάζουν την ουσία τους. Κάποιες περαιτέρω λεπτομέρειες δίνονται στην Ενότητα 10.3.
Δύο βασικοί λόγοι κινούν το ενδιαφέρον μας για τις συνεχείς Τ.Μ. Ο ένας είναι προφανής: Πολλές ποσότητες που είναι σημαντικές στην πράξη, είναι από τη φύση τους συνεχείς – π.χ., ο χρόνος που διαρκεί η εκτέλεση ενός αλγορίθμου, η θερμοκρασία ενός επεξεργαστή, η απόσταση μεταξύ ενός κινητού τηλεφώνου και της κοντινότερης κεραίας με την οποία επικοινωνεί κ.ο.κ.
Ο δεύτερος λόγος είναι πιο λεπτός και σχετίζεται με το Νόμο των Μεγάλων Αριθμών, που είδαμε στον προηγούμενο κεφάλαιο. Ο Ν.Μ.Α. περιγράφει τη συμπεριφορά του εμπειρικού μέσου όρου,
όταν οι Τ.Μ. είναι ανεξάρτητες και έχουν όλες την ίδια κατανομή. Μία από τις ισοδύναμες διατυπώσεις του Θεωρήματος 9.3 είναι πως, αν το πλήθος των είναι μεγάλο, τότε η πιθανότητα ο εμπειρικός μέσος όρος τους να απέχει σημαντικά από τη μέση τιμή τους είναι μικρή. Συγκεκριμένα, για κάθε , έχουμε,
| (10.1) |
Για να χρησιμοποιήσουμε αυτό το αποτέλεσμα στην πράξη, όπως έχουμε ήδη αναφέρει, μια προφανής βασική ερώτηση που γεννιέται είναι «πόσο μικρή είναι η πιθανότητα απόκλισης στη σχέση (10.1);». Όπως θα δούμε λεπτομερώς στο Κεφάλαιο 12, η απάντηση (την οποία μας δίνει το Κεντρικό Οριακό Θεώρημα) είναι πως, κάτω από αρκετά γενικές συνθήκες, η κατανομή του εμπειρικού μέσου μπορεί να προσεγγιστεί μέσω της κατανομής μιας συνεχούς τυχαίας μεταβλητής κατανομής, συγκεκριμένα μιας Τ.Μ. που ακολουθεί τη λεγόμενη κανονική κατανομή.
Πριν αναπτύξουμε τη θεωρία που απαιτείται για να μελετήσουμε τις συνεχείς Τ.Μ. συστηματικά, ας δούμε ένα απλό παράδειγμα.
Παράδειγμα 10.1
Έστω πως ο χρόνος (σε δευτερόλεπτα) που απαιτείται για την εκκίνηση της λειτουργίας ενός δικτύου είναι πάντοτε μεταξύ 10 και 20 δευτερολέπτων και, κατά τα άλλα, είναι «εντελώς τυχαίος». Για να περιγράψουμε το χρόνο ως μια Τ.Μ., θα θέλαμε να έχει σύνολο τιμών και η πιθανότητα του να πάρει οποιαδήποτε τιμή σε αυτό το διάστημα να είναι κατά κάποιον τρόπο ομοιόμορφη. Π.χ., θα θέλαμε η πιθανότητα το να είναι μεταξύ 10 και 11 δευτερολέπτων να είναι η ίδια με την πιθανότητα να έχουμε Επιπλέον, αφού ο χρόνος είναι «εντελώς τυχαίος», θα περιμέναμε λογικά πως θα ικανοποιεί,
| (10.2) |
δηλαδή πως θα είναι το ίδιο πιθανό η εκκίνηση να γίνει τα πρώτα 5 ή τα τελευταία 5 δευτερόλεπτα.
Στην επόμενη ενότητα θα περιγράψουμε τον συστηματικό τρόπο με τον οποίο μπορούν να οριστούν τέτοιου είδους Τ.Μ., και στην Ενότητα 11.1 του επόμενου κεφαλαίου θα δούμε πως η Τ.Μ. αυτού του παραδείγματος ανήκει σε μια συνηθισμένη και χρήσιμη οικογένεια τυχαίων μεταβλητών, αυτών που έχουν ομοιόμορφη κατανομή.
10.1 Συνεχείς Τ.Μ. και συνεχής πυκνότητα
Ορισμός 10.1
Μια τυχαία μεταβλητή είναι συνεχής με πυκνότητα , αν η Τ.Μ. και η συνάρτηση ικανοποιούν τις εξής ιδιότητες:
-
1.
Η πυκνότητα είναι μια συνάρτηση τέτοια ώστε,
dx = 1. - 2.
Το σύνολο τιμών της μπορεί να εκφραστεί ως ένωση ενός πεπερασμένου πλήθους (μη τετριμμένων) διαστημάτων πραγματικών αριθμών, και επιπλέον το αποτελείται από εκείνα τα για τα οποία η πυκνότητα δεν είναι μηδενική, δηλαδή:
- 3.
Για οποιαδήποτε η πιθανότητα η Τ.Μ. να πάρει κάποια τιμή στο διάστημα μπορεί να εκφραστεί ως προς την πυκνότητα μέσω της σχέσης,
,
(10.3) όπως αναπαρίσταται στο Σχήμα 10.1.
-
1.
Ο λόγος για τον οποίο στον ορισμό απαιτούμε τα διαστήματα που απαρτίζουν το σύνολο τιμών της να είναι μη τετριμμένα, δηλαδή να μην είναι της μορφής , είναι διότι τέτοια διαστήματα αποτελούνται από μόνο ένα στοιχείο, . Αν η είχε, για παράδειγμα, σύνολο τιμών το,
τότε προφανώς θα ήταν διακριτή και όχι συνεχής.
-
2.
Θυμίζουμε πως, από τον Ορισμό 6.3 του Κεφαλαίου 6, η συνάρτηση κατανομής μιας οποιασδήποτε τυχαίας μεταβλητής είναι η , για . Αν, τώρα, η είναι συνεχής με πυκνότητα , τότε η συνάρτηση κατανομής υπολογίζεται εύκολα ως,
, για οποιοδήποτε x ,
(10.4) βάσει της δεύτερης βασικής ιδιότητας που διατυπώνεται αμέσως μετά, στη σχέση (10.6). Περαιτέρω ιδιότητες της συνάρτησης κατανομής μιας συνεχούς Τ.Μ. δίνονται μετά το Παράδειγμα 10.2.
- 3.
Αν και η τιμή της πυκνότητας μιας συνεχούς Τ.Μ. δεν αντιστοιχεί ακριβώς σε κάποια πιθανότητα, παρατηρούμε ότι η είναι πιο πιθανό να πάρει τιμές κοντά σε κάποιο όπου η τιμή της είναι σχετικά μεγάλη. Για παράδειγμα, αν η είναι συνεχής στο , τότε για μικρά κατά προσέγγιση έχουμε,
-
≈ δ f(x0). -
Άρα είναι μεγαλύτερη η πιθανότητα το να πάρει τιμές κοντά στο αν η τιμή της πυκνότητας είναι μεγάλη, ενώ είναι λιγότερο πιθανό να πάρει τιμές κοντά σε κάποιο όπου η είναι κοντά στο μηδέν.
-
1.
Για κάθε τιμή η πιθανότητα η να ισούται ακριβώς με το είναι μηδενική:
-
2.
Για κάθε
και όλες οι πιο πάνω πιθανότητες είναι ίσες με
- 3.
Η σχέση (10.3) ισχύει ακόμη και στην περίπτωση που το ή το ή και τα δύο παίρνουν άπειρες τιμές. Δηλαδή, για κάθε και
(10.5)
,
(10.6) και, προφανώς,
dx = 1.
Απόδειξη:
Η πρώτη ιδιότητα είναι άμεση συνέπεια του Ορισμού 10.1: Εφόσον το ολοκλήρωμα οποιασδήποτε συνάρτησης από το ως το είναι ίσο με μηδέν (σχηματικά, το αντίστοιχο εμβαδόν είναι προφανώς μηδενικό), έχουμε:
| dx = 0. |
Για το πρώτο σκέλος της δεύτερης ιδιότητας, εξετάζοντας τα ξένα ενδεχόμενα και , βρίσκουμε πως,
και χρησιμοποιώντας την πρώτη ιδιότητα έχουμε, Παρομοίως αποδεικνύονται και οι ισότητες των άλλων δύο περιπτώσεων.
και παρατηρούμε πως και πως το όριό τους,
Συνεπώς, η συνέχεια του μέτρου πιθανότητας συνεπάγεται το ότι η πιθανότητα,
που αποδεικνύει τη σχέση (10.5). Παρομοίως αποδεικνύονται και τα αποτελέσματα των άλλων δύο περιπτώσεων.
Για
να υπολογίσουμε την τιμή της σταθεράς
παρατηρούμε πως, από την πρώτη παραπάνω ιδιότητα, το
ολοκλήρωμα της
για όλα τα
πρέπει να ισούται με 1, άρα,
συνεπώς το βλ. Σχήμα 10.2.
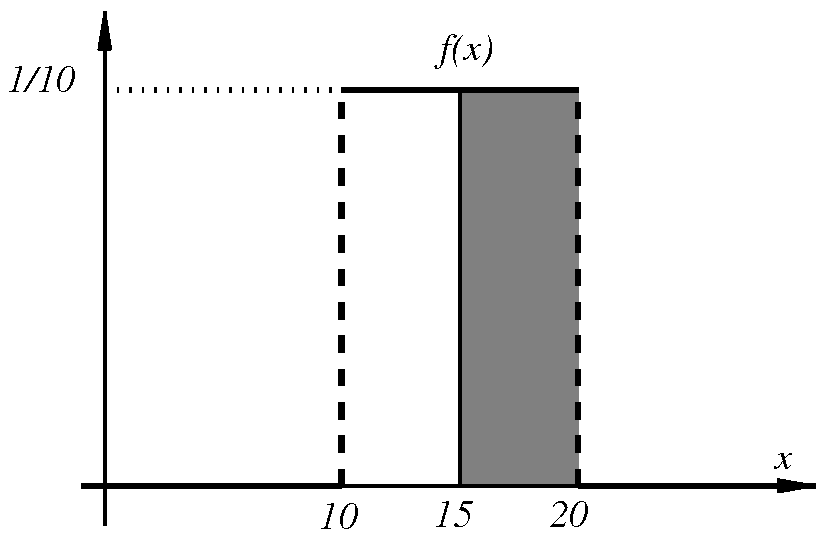
βλ. Σχήμα 10.2, και παρομοίως βρίσκουμε πως και η πιθανότητα ισούται με 1/2. Συνεπώς η σχέση (10.2), την οποία διατυπώσαμε διαισθητικά, επαληθεύεται και μαθηματικά.
-
1.
Από το θεμελιώδες θεώρημα του διαφορικού λογισμού, αμέσως προκύπτει πως ισχύει και η αντίστροφη σχέση της (10.4), δηλαδή,
(10.7) για όλα τα για τα οποία υπάρχει η παράγωγος
- 2.
- 3.
Υπενθυμίζουμε (βλ. Κεφάλαιο 6) πως η συνάρτηση κατανομής μιας οποιασδήποτε (διακριτής ή συνεχούς) τυχαίας μεταβλητής ικανοποιεί:
Παράδειγμα 10.3
Για την Τ.Μ. του Παραδείγματος 10.2 μπορούμε να υπολογίσουμε τη συνάρτηση κατανομής ως εξής: Κατ’ αρχάς, εφόσον η παίρνει τιμές μόνο στο διάστημα είναι αδύνατον να έχουμε όταν το είναι μικρότερο από 10, συνεπώς έχουμε για Παρομοίως, αν το είναι μεγαλύτερο του 20, τότε Τέλος, για βρίσκουμε,
οπότε, συνοψίζοντας:
Η γραφική της αναπαράσταση δίνεται στο Σχήμα 10.3.
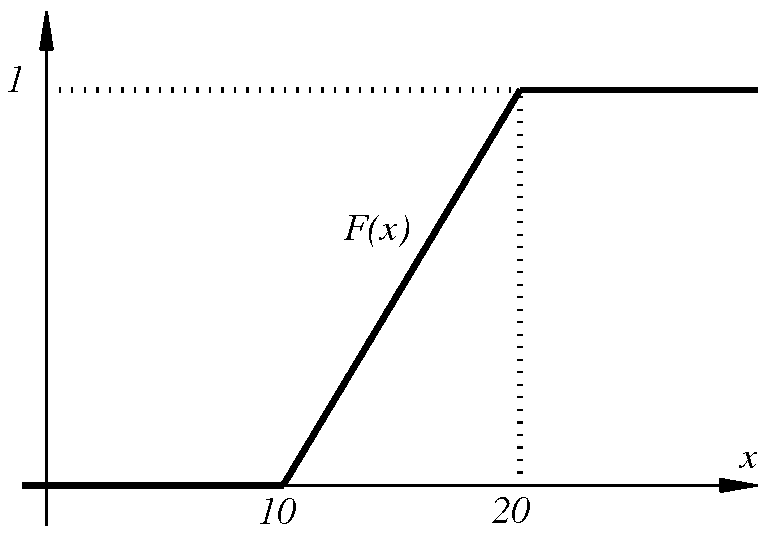
Παράδειγμα 10.4
Έστω πως η διάρκεια ζωής σε χρόνια, μιας οθόνης υπολογιστή είναι μια συνεχής Τ.Μ. με σύνολο τιμών και πυκνότητα,
Η γραφική της αναπαράσταση δίνεται στο Σχήμα 10.4.
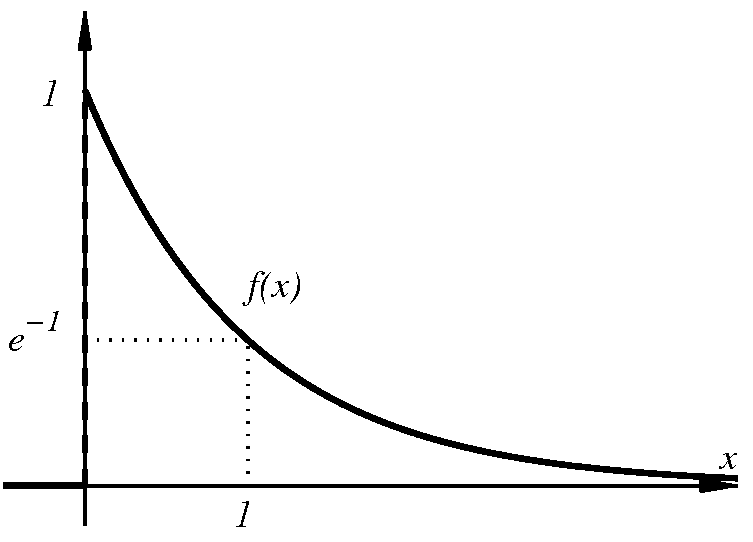
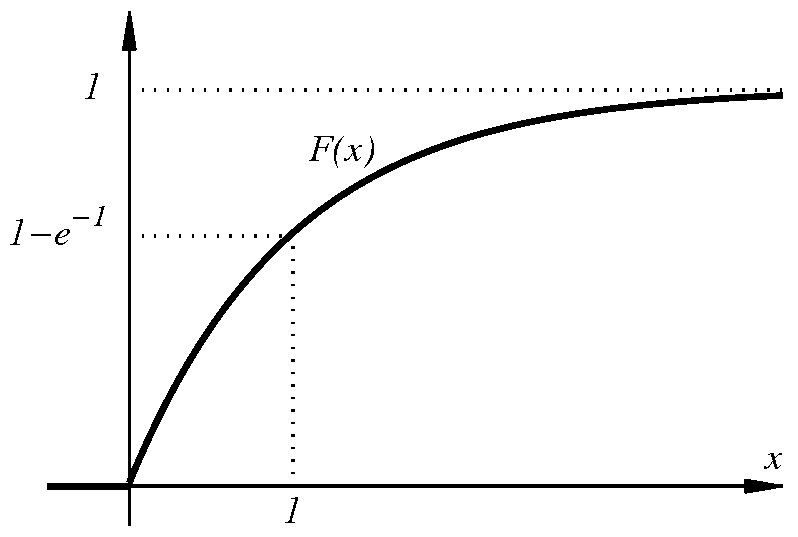
Συνεπώς, η συνάρτηση κατανομής της θα ισούται με για ενώ για
Η γραφική της αναπαράσταση δίνεται στο Σχήμα 10.4.
Όπως παρατηρήσαμε πιο πάνω, το ότι γνωρίζουμε τη συνάρτηση κατανομής διευκολύνει σημαντικά τον υπολογισμό πιθανοτήτων σχετικά με τη Για παράδειγμα, η μπορεί να υπολογιστεί απευθείας από την πυκνότητα ως,
ή, εναλλακτικά (και ευκολότερα), μέσω της συνάρτησης κατανομής,
Παρομοίως μπορούμε να υπολογίσουμε και δεσμευμένες πιθανότητες για τη όπως π.χ.,
όπου στο βήμα χρησιμοποιήσαμε τη δεύτερη βασική ιδιότητα της πυκνότητας και στο βήμα εφαρμόσαμε τη σχέση (10.8).
10.2 Μέση τιμή και διασπορά
Η μέση τιμή και η διασπορά για μια συνεχή Τ.Μ. ορίζονται κατά τρόπο ανάλογο με εκείνον που είδαμε στην περίπτωση διακριτών τυχαίων μεταβλητών. Το ρόλο της (διακριτής) πυκνότητας εδώ παίζει η (συνεχής) πυκνότητα , και τα αθροίσματα αντικαθίστανται από τα αντίστοιχα ολοκληρώματα.
Ορισμός 10.2
Η μέση τιμή (ή αναμενόμενη τιμή, ή προσδοκώμενη τιμή) μιας συνεχούς Τ.Μ. με σύνολο τιμών και πυκνότητα ορίζεται ως:
| (10.9) |
Γενικότερα, για οποιαδήποτε συνάρτηση η μέση τιμή της νέας Τ.Μ. ορίζεται ως:
| (10.10) |
Ορισμός 10.3
Για μια συνεχή Τ.Μ. με μέση τιμή η διασπορά της ορίζεται, ακριβώς όπως και στη διακριτή περίπτωση, ως,
| (10.11) |
και η τυπική απόκλιση της είναι:
Παρατηρήσεις:
-
1.
Όπως και για τις διακριτές Τ.Μ., διαισθητικά η μέση τιμή μας λέει πως η τείνει να κυμαίνεται γύρω από την τιμή . Παρομοίως, η διασπορά της είναι η μέση τετραγωνική απόκλιση της από το , δηλαδή η μέση τιμή του τετραγώνου της απόστασης της τυχαίας τιμής από τη μέση τιμή της.
-
2.
Οι δύο παραπάνω ορισμοί (10.9) και (10.10) της μέσης τιμής μιας συνεχούς Τ.Μ. είναι ακριβώς ανάλογοι των αντίστοιχων ορισμών (6.4) και (6.5) που είδαμε στο Κεφάλαιο 6 για διακριτές Τ.Μ. Επιπλέον, εφόσον κάθε συνάρτηση μιας διακριτής Τ.Μ. είναι αναγκαστικά κι αυτή μια διακριτή Τ.Μ., στην Άσκηση 1 του Κεφαλαίου 6 δείξαμε πως ο δεύτερος ορισμός είναι στην πραγματικότητα συνέπεια του πρώτου.
Στη συνεχή περίπτωση, η αντιστοιχία είναι τεχνικά πιο σύνθετη, αλλά η ουσιαστική σχέση παραμένει η ίδια: Ο δεύτερος ορισμός (10.10) είναι και πάλι συνέπεια του πρώτου (10.9), αλλά η απόδειξη είναι αρκετά πιο πολύπλοκη και βασίζεται σε τεχνικά αποτελέσματα του τομέα της πραγματικής ανάλυσης, τα οποία αφενός ξεπερνούν τους στόχους του παρόντος βιβλίου, και αφετέρου δεν σχετίζονται άμεσα με τις ιδέες και τις τεχνικές της θεωρίας πιθανοτήτων. Μια πρώτη ένδειξη της μεγαλύτερης πολυπλοκότητας που προκύπτει στην περίπτωση ακόμα και μιας απλής συνάρτησης μιας συνεχούς Τ.Μ. θα δούμε στην Άσκηση 4 στο τέλος του κεφαλαίου, όπου θα εξετάσουμε ένα παράδειγμα στο οποίο η είναι διακριτή Τ.Μ. παρότι η είναι συνεχής.
Κατά συνέπεια, χάριν ευκολίας, επιλέγουμε να δεχτούμε τον τύπο (10.10) για τη μέση τιμή της συνάρτησης μιας συνεχούς Τ.Μ. ως δεδομένο και παραλείπουμε την απόδειξή του.
- 3.
-
4.
Και πάλι όπως στη διακριτή περίπτωση, η διασπορά μπορεί εναλλακτικά να εκφραστεί ως:
(10.13) Ξεκινώντας από τη σχέση (10.12), έχουμε:
Το πρώτο ολοκλήρωμα πιο πάνω ισούται με από την (10.10), το δεύτερο ολοκλήρωμα ισούται με εξ ορισμού, και το τρίτο ολοκλήρωμα ισούται με 1 από την αντίστοιχη ιδιότητα της πυκνότητας. Συνεπώς, , και άρα έχουμε αποδείξει τη σχέση (10.13).
Παράδειγμα 10.5
Για την Τ.Μ. του Παραδείγματος 10.4, η μέση τιμή της υπολογίζεται εύκολα ολοκληρώνοντας κατά παράγοντες:
όπου στο βήμα θέσαμε και έτσι ώστε και Άρα, ο μέσος όρος ζωής μιας οθόνης είναι ένας χρόνος.
Με παρόμοιο τρόπο υπολογίζουμε και τη μέση τιμή του
όπου στο βήμα θέσαμε και έτσι ώστε και Συνεπώς, από την εναλλακτική έκφραση για τη διασπορά (10.13), βρίσκουμε πως η διασπορά του ισούται με:
Παράδειγμα 10.6
Έστω μια συνεχής Τ.Μ. με πυκνότητα,
Όπως στο Παράδειγμα 10.2, η τιμή της μπορεί να υπολογιστεί από τον ορισμό της πυκνότητας, ο οποίος μας λέει πως το ολοκλήρωμα της για όλα τα πρέπει να ισούται με 1,
και συνεπώς έχουμε βλ. Σχήμα 10.5.
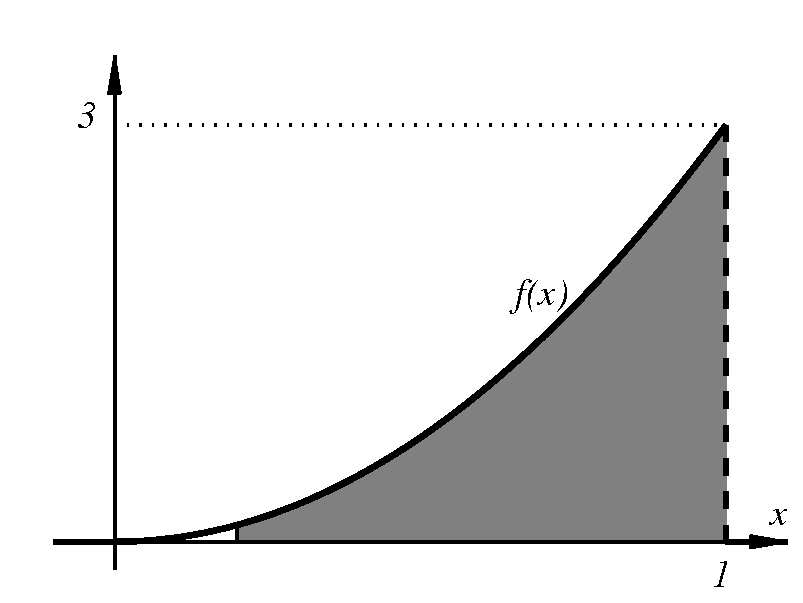 |
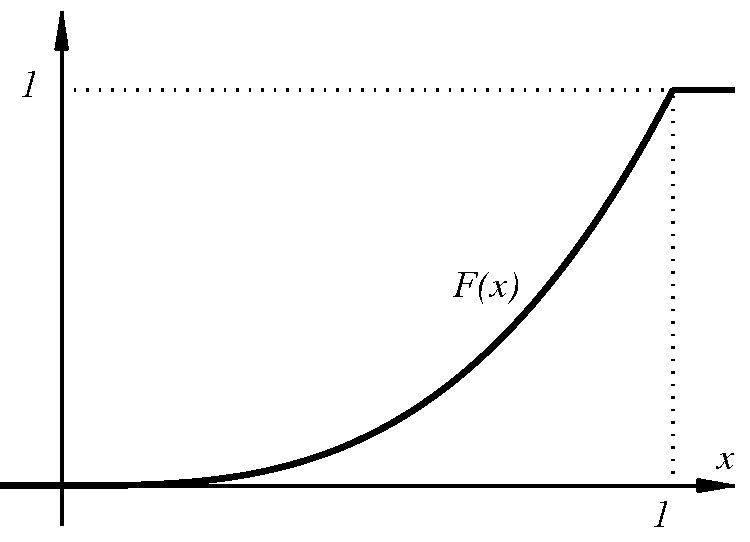 |
Έχοντας την πυκνότητα, μπορούμε να υπολογίσουμε πιθανότητες για τις τιμές της όπως, π.χ.,
Ένας παρόμοιος υπολογισμός μάς δίνει και τη συνάρτηση κατανομής της Προφανώς έχουμε για και όταν ενώ για
οπότε,
βλ. Σχήμα 10.5. Η πιθανότητα που υπολογίσαμε πιο πάνω μπορεί εναλλακτικά να υπολογιστεί και απευθείας από την ως,
Επίσης από την πυκνότητα μπορούμε να υπολογίσουμε τη μέση τιμή της και την τιμή του
οπότε η διασπορά της είναι:
Παράδειγμα 10.7
 |
 |
Για να απαντήσουμε, κατ’ αρχάς υπολογίζουμε την πυκνότητα της μέσω της σχέσης (10.7),
βλ. Σχήμα 10.6. Συνεπώς,
Χρησιμοποιώντας τη συνάρτηση κατανομής, μπορούμε τώρα να υπολογίσουμε πιθανότητες για τη όπως λ.χ. την,
το οποίο ισούται με ή, παρομοίως, δεσμευμένες πιθανότητες όπως η :
10.3 Μετρησιμότητα και άπειρες τιμές
10.3.1 Ορισμός μιας συνεχούς Τ.Μ.
Όπως αναφέραμε στην Ενότητα 6.3 του Κεφαλαίου 6, όταν ο χώρος πιθανότητας ή το σύνολο τιμών μιας Τ.Μ. είναι ένα άπειρο και μη αριθμήσιμο σύνολο, τότε απαιτείται ιδιαίτερη προσοχή στο πώς ορίζονται οι Τ.Μ. που χρησιμοποιούμε έτσι ώστε να μην μας οδηγούν σε «μη μετρήσιμα» υποσύνολα του . Σε αυτό και τα επόμενα κεφάλαια, ο τρόπος με τον οποίο αποφεύγουμε τέτοιες ενδεχόμενες παθολογίες στην περίπτωση που θέλουμε να εξετάσουμε μια συνεχή Τ.Μ. (της οποίας πάντοτε το σύνολο τιμών είναι, εξ ορισμού, άπειρο και μη αριθμήσιμο), είναι εισάγοντας τους εξής περιορισμούς:
(1.) Τα μόνα σύνολα τιμών που επιτρέπουμε για μια συνεχή Τ.Μ. είναι εκείνα που μπορούν να εκφραστούν ως ένωση ενός πεπερασμένου πλήθους διαστημάτων στο .
(2.) Μια συνεχής τυχαία μεταβλητή ορίζεται πάντοτε σε συνδυασμό με την πυκνότητά της , της οποίας το ολοκλήρωμα ορίζεται σε οποιοδήποτε διάστημα .
(3.) Τα μόνα ενδεχόμενα των οποίων υπολογίζουμε τις πιθανότητες (ή τις δεσμευμένες πιθανότητες) είναι της μορφής για σύνολα τα οποία μπορούν να εκφραστούν ως ένωση ενός πεπερασμένου πλήθους διαστημάτων στο .
Αν και, από αυστηρά μαθηματική σκοπιά, αυτοί οι περιορισμοί δεν είναι απαραίτητοι (υπάρχουν και πιο γενικές συνθήκες κάτω από τις οποίες μπορεί να οριστεί η έννοια της συνεχούς τυχαίας μεταβλητής), οι συνθήκες (1.)–(3.) αφενός είναι αρκετά γενικές ώστε να συμπεριλαμβάνουν όλες τις σημαντικές για εμάς εφαρμογές, και αφετέρου μας επιτρέπουν, δεδομένης οποιασδήποτε πυκνότητας , όπως στον Ορισμό 10.1, να κατασκευάσουμε ένα χώρο πιθανότητας και μια συνάρτηση έτσι ώστε η να είναι μια (μετρήσιμη) συνεχής Τ.Μ. με πυκνότητα . Η κατασκευή αυτή είναι η εξής:
Έστω πως έχουμε μια συνάρτηση που ικανοποιεί τις συνθήκες του Ορισμού 10.1. Θέτουμε , και ορίζουμε τη συνάρτηση ως . Επιπλέον, έστω ένα οποιοδήποτε σύνολο που μπορεί να εκφραστεί ως ένωση ενός πεπερασμένου πλήθους διαστημάτων (που δεν αλληλοεπικαλύπτονται), και ας πούμε πως τα άκρα αυτών των διαστημάτων είναι για . Ορίζουμε ένα μέτρο πιθανότητας τέτοιο ώστε, για κάθε σύνολο αυτής της μορφής,
| (10.14) |
Ένα από τα μεγάλα επιτεύγματα της θεωρίας μέτρου είναι η απόδειξη του ακόλουθου αποτελέσματος: Κάτω από τις πιο πάνω υποθέσεις, υπάρχει μια οικογένεια υποσυνόλων του με τις πιο κάτω ιδιότητες:
-
•
Το κενό σύνολο και το ανήκουν στην : .
-
•
Όλα τα υποσύνολα του τα οποία μπορούν να εκφραστούν ως ένωση ενός πεπερασμένου πλήθους διαστημάτων ανήκουν στην .
-
•
Υπάρχει ένα μέτρο πιθανότητας το οποίο ορίζεται για κάθε στοιχείο , και το οποίο ικανοποιεί τη σχέση (10.14).
Τώρα μπορούμε εύκολα να ελέγξουμε πως η συνάρτηση που έχουμε ορίσει είναι «μια συνεχής τυχαία μεταβλητή με πυκνότητα », υπό την έννοια του Ορισμού 10.1, δηλαδή, να επιβεβαιώσουμε πως ισχύει η τρίτη συνθήκη του ορισμού αυτού: Για ,
και εφόσον , πράγματι προκύπτει πως ισχύει η ζητούμενη σχέση,
όπου στο τελευταίο βήμα εφαρμόσαμε τη (10.14) στην ειδική περίπτωση ενός μόνο διαστήματος.
10.3.2 Ορισμοί και επιπλέον συνθήκες
Για μια οποιαδήποτε συνεχή Τ.Μ. με πυκνότητα , η μέση τιμή δίνεται από ένα καταχρηστικό ολοκλήρωμα, ένα ολοκλήρωμα, δηλαδή, του οποίου τα όρια είναι . Όπως γνωρίζουμε από τα βασικά αποτελέσματα του διαφορικού λογισμού, τέτοια ολοκληρώματα μπορεί να παίρνουν άπειρες τιμές, ή ακόμα και να μην ορίζονται. (Ένα παράδειγμα μιας συνεχούς Τ.Μ. με άπειρη μέση τιμή δίνεται στην Άσκηση 5 στο τέλος του κεφαλαίου.)
Για να αποφύγουμε τεχνικές λεπτομέρειες που ξεφεύγουν από τα ζητούμενα του παρόντος βιβλίου, υιοθετούμε τις πιο κάτω συμβατικές υποθέσεις (ανάλογες εκείνων του Κεφαλαίου 6 για διακριτές Τ.Μ.), οι οποίες θα παραμείνουν εν ισχύ σε όλα τα υπόλοιπα κεφάλαια.
Συμβάσεις
-
•
Πάντοτε, όταν λέμε πως «η συνεχής Τ.Μ. έχει μέση τιμή », εμμέσως υποθέτουμε ότι το ολοκλήρωμα που δίνει την ορίζεται και ότι η τιμή του είναι πεπερασμένη.
-
•
Πάντοτε, όταν λέμε ότι «η συνεχής Τ.Μ. έχει διασπορά », εμμέσως υποθέτουμε ότι η μέση τιμή ορίζεται και είναι πεπερασμένη και πως το ολοκλήρωμα που δίνει την ορίζεται και δίνει πεπερασμένο αποτέλεσμα.
-
•
Όποτε διατυπώνεται μια ιδιότητα για τη μέση τιμή (ή τη διασπορά), εμμέσως υποθέτουμε πως η αντίστοιχη μέση τιμή (αντίστοιχα, διασπορά) ορίζεται και είναι πεπερασμένη.
10.4 Ασκήσεις
-
1.
Κυκλικός δίσκος. Έστω ότι επιλέγεται εντελώς τυχαία ένα σημείο του κυκλικού δίσκου με κέντρο την αρχή των αξόνων και ακτίνα 1, δηλαδή χωρίς κάποια προτίμηση σε κάποια περιοχή του δίσκου. Έστω η απόσταση του σημείου από την αρχή των αξόνων.
Βρείτε το σύνολο τιμών της Τ.Μ. , και υπολογίστε τη συνάρτηση κατανομής και την πυκνότητά της.
-
2.
Προσδιορισμός παραμέτρων. H συνάρτηση κατανομής μιας συνεχούς Τ.Μ. δίνεται από τον τύπο:
-
(α’)
Να βρεθούν οι τιμές των και .
-
(β’)
Να υπολογιστεί η πυκνότητα της και να γίνει η γραφική της παράσταση.
-
(γ’)
Βρείτε την πιθανότητα το να είναι μικρότερο του , δεδομένου ότι είναι μικρότερο του .
-
(α’)
-
3.
Μια απλή πυκνότητα. Έστω μια συνεχής Τ.Μ. με πυκνότητα:
-
(α’)
Σχεδιάστε το γράφημα της και βρείτε την τιμή της σταθεράς .
-
(β’)
Βρείτε την πιθανότητα το να είναι μεγαλύτερο από ή μικρότερο από .
-
(γ’)
Υπολογίστε τη μέση τιμή της .
-
(α’)
-
4.
Μέση τιμή συναρτήσεων Τ.Μ. Στον Ορισμό 10.2, η μέση τιμή μιας συνάρτησης της Τ.Μ. ορίστηκε μέσω του τύπου (10.10). Αλλά η είναι και η ίδια μια τυχαία μεταβλητή, με τη δική της (ενδεχομένως συνεχή ή διακριτή) πυκνότητα, οπότε, αν εφαρμόσουμε τον τύπο του αντίστοιχου ορισμού (6.4) ή (10.9) για τη μέση τιμή της , το αποτέλεσμα θα ισούται με εκείνο του γενικότερου τύπου (10.10) για την . Εδώ θα αποδείξετε μια ειδική περίπτωση αυτής της γενικής ιδιότητας.
Έστω μια Τ.Μ. με πυκνότητα όπως εκείνη του Παραδείγματος 10.4, και έστω η συνάρτηση ,
-
5.
Άπειρη μέση τιμή. Έστω μια συνεχής Τ.Μ. με σύνολο τιμών το και πυκνότητα για .
-
(α’)
Υπολογίστε την τιμή της σταθεράς .
-
(β’)
Αποδείξτε πως η μέση τιμή .
-
(α’)
-
6.
Κατανομή Βήτα. Μια συνεχής τυχαία μεταβλητή έχει πυκνότητα:
-
(α’)
Υπολογίστε την τιμή της σταθεράς .
-
(β’)
Υπολογίστε την πιθανότητα .
-
(γ’)
Βρείτε τη συνάρτηση κατανομής .
-
(α’)
-
7.
Υποψήφιες πυκνότητες. Για καθεμία από τις παρακάτω συναρτήσεις σχεδιάστε το γράφημά της και αποφασίστε αν είναι πυκνότητα ή όχι. Δικαιολογήστε τις απαντήσεις σας. Για όσες είναι πυκνότητες, προσδιορίστε τη μέση τιμή, τη διασπορά, και την πιθανότητα να είναι η αντίστοιχη Τ.Μ. μεγαλύτερη από τη μέση τιμή της.
-
(α’)
-
(β’)
-
(γ’)
-
(δ’)
-
(α’)
-
8.
Μια απλή πυκνότητα στο Έστω πως μια συνεχής Τ.Μ. έχει πυκνότητα,
όπου η είναι μια άγνωστη θετική παράμετρος.
-
(α’)
Ποια είναι η τιμή της ;
-
(β’)
Πόση είναι η μέση τιμή ;
-
(γ’)
Πόση είναι η διασπορά ;
-
(δ’)
Υπολογίστε την πιθανότητα .
-
(α’)
-
9.
Βαρουφάκης εναντίον Merkel. Πριν από κάθε συνεδρίαση του Eurogroup την άνοιξη του 2015, ο (τότε) υπουργός Οικονομικών Γιάνης Βαρουφάκης βρισκόταν σε μία από δύο πιθανές ψυχικές διαθέσεις. Με πιθανότητα 1/2 ήταν σοβαρός, οπότε συζητούσε κανονικά με την καγκελάριο Merkel για ένα τυχαίο διάστημα μέχρι τρεις ώρες. Αντίθετα, με πιθανότητα 1/2 ήταν σε διάθεση χαβαλέ, οπότε τρόλαρε την καγκελάριο Merkel για το πολύ ένα τέταρτο και διαλυόταν νωρίς το Eurogroup. Έστω η τυχαία διάρκεια του Eurogroup στη δεύτερη περίπτωση.
Αν η Τ.Μ. έχει πυκνότητα για και για , ενώ η έχει την πυκνότητα του Παραδείγματος 10.7, υπολογίστε την πιθανότητα ένα τυχαίο Eurogroup να διήρκεσε το πολύ 10 λεπτά.
-
10.
Συνεχείς και διακριτές τυχαίες μεταβλητές. Έστω μια διακριτή Τ.Μ. , η οποία παίρνει τις τιμές 1, 2 και 3, με πιθανότητα 1/3 για την καθεμία. Δεδομένου ότι , ορίζουμε δύο συνεχείς Τ.Μ. και , οι οποίες είναι ανεξάρτητες και έχουν την ίδια πυκνότητα , όπου για , και για .
-
(α’)
Υπολογίστε την πιθανότητα του ενδεχομένου .
-
(β’)
Υπολογίστε την πυκνότητα του . Βεβαιωθείτε πως η που βρήκατε πράγματι είναι η πυκνότητα του .
-
(γ’)
Υπολογίστε τη (δεσμευμένη) πιθανότητα του ενδεχομένου , δεδομένου ότι .
-
(δ’)
Αντίστροφα, υπολογίστε τη δεσμευμένη πιθανότητα του ενδεχομένου , δεδομένου ότι και .
-
(α’)
-
11.
Απόσταση Στην Άσκηση 18 του Κεφαλαίου 6 ορίσαμε την -απόσταση μεταξύ δύο διακριτών πυκνοτήτων. Για δύο συνεχείς πυκνότητες με κοινό σύνολο τιμών το παρομοίως ορίζουμε την -απόσταση της από την ως:
-
(α’)
Δείξτε ότι η μπορεί εναλλακτικά να εκφραστεί ως:
-
(β’)
Διατυπώστε και αποδείξτε το αντίστοιχο αποτέλεσμα στην περίπτωση διακριτών πυκνοτήτων.
-
(α’)
Κεφάλαιο 11 Συνεχείς κατανομές, ανισότητες και ο Ν.Μ.Α.
[Επιστροφή στα περιεχόμενα]
Στο προηγούμενο κεφάλαιο ορίσαμε την έννοια της συνεχούς τυχαίας μεταβλητής, και είδαμε τις βασικές της ιδιότητες. Εδώ θα περιγράψουμε κάποιους ιδιαίτερους τύπους τυχαίων μεταβλητών, οι οποίες είναι χρήσιμες στην πράξη και εμφανίζονται συχνά σε βασικά προβλήματα των πιθανοτήτων. Συγκεκριμένα, θα ορίσουμε δύο οικογένειες κατανομών για συνεχείς Τ.Μ., και θα αποδείξουμε ορισμένες ιδιότητές τους. Τέλος, στις Ενότητες 11.2 και 11.3 θα διατυπώσουμε τις φυσικές γενικεύσεις στη συνεχή περίπτωση κάποιων σημαντικών αποτελεσμάτων που είδαμε σε προηγούμενα κεφάλαια.
11.1 Ομοιόμορφη και εκθετική κατανομή
Η πιο απλή περίπτωση μιας συνεχούς Τ.Μ. είναι εκείνη που παίρνει «ομοιόμορφα τυχαίες» τιμές σε κάποιο διάστημα στο .
Ορισμός 11.1
Μια συνεχής T.M. έχει ομοιόμορφη κατανομή στο διάστημα , για κάποια αν έχει σύνολο τιμών το και πυκνότητα,
βλ. Σχήμα 11.1. Για συντομία, αυτό συμβολίζεται:
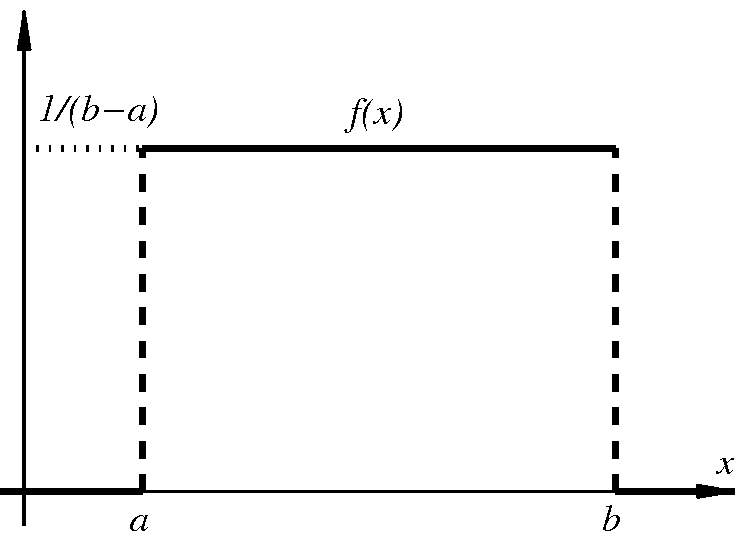 |
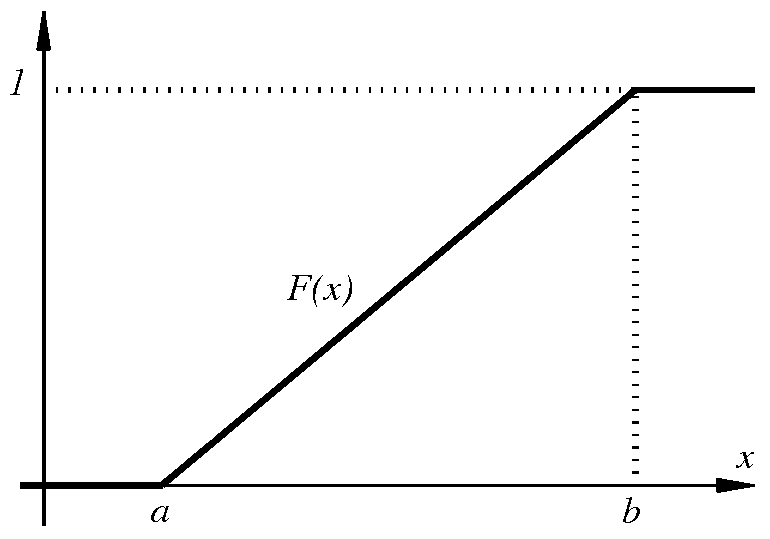 |
Παρατηρήσεις:
- 1.
- 2.
-
3.
Η μέση τιμή μιας Τ.Μ. επίσης υπολογίζεται εύκολα:
Παρομοίως υπολογίζουμε και τη μέση τιμή της ,
οπότε, η διασπορά της από την έκφραση (10.13) ισούται με,
Συνοψίζοντας, μια Τ.Μ. έχει μέση τιμή που ισούται με το μέσο του και διασπορά η οποία εξαρτάται μόνο από το μήκος του διαστήματος όπου η παίρνει τιμές, και όχι από τη θέση του:
Μια άλλη σημαντική οικογένεια τυχαίων μεταβλητών είναι εκείνες που έχουν εκθετική κατανομή. Μια ειδική περίπτωση αυτής της κατανομής συναντήσαμε ήδη στο Παράδειγμα 10.4 του προηγούμενου κεφαλαίου.
Ορισμός 11.2
Μια συνεχής Τ.Μ. έχει εκθετική κατανομή με παράμετρο , αν έχει σύνολο τιμών το και πυκνότητα,
βλ. Σχήμα 11.2. Για συντομία, αυτό συμβολίζεται:
Ένας λόγος για τον οποίο θεωρούμε την εκθετική και τη γεωμετρική συγγενείς κατανομές είναι διότι μοιράζονται αρκετές από τις θεμελιώδεις ιδιότητές τους, όπως βλέπουμε συγκρίνοντας τα αποτελέσματα του Θεωρήματος 7.1 με εκείνα του Θεωρήματος 11.1 που ακολουθεί. Ένας πιο φορμαλιστικός τρόπος για να διαπιστώσουμε την ομοιότητά τους είναι το γεγονός πως η πυκνότητα μιας τυχαίας μεταβλητής είναι μαθηματικά πανομοιότυπη με την πυκνότητα μιας Τ.Μ. με κατανομή.
Συγκεκριμένα, στη συνεχή περίπτωση, για η πυκνότητα είναι της μορφής,
| (11.1) |
όπου ορίσαμε τις σταθερές και . Αντίστοιχα, στη διακριτή περίπτωση, για η πυκνότητα μπορεί να εκφραστεί ως,
| (11.2) |
όπου τώρα έχουμε τις σταθερές και . Η ομοιότητα μεταξύ των δύο εκφράσεων στις σχέσεις (11.1) και (11.2) είναι εμφανής.
- 1.
Μέση τιμή:
-
2.
Διασπορά:
-
3.
Συνάρτηση κατανομής: για και για Η γραφική της αναπαράσταση δίνεται στο Σχήμα 11.3.
-
4.
Ιδιότητα έλλειψης μνήμης: Για κάθε :
Η πιθανότητα είναι ανεξάρτητη του και ίση με εκείνη που αντιστοιχεί στο δηλαδή,
Απόδειξη:
Από τον ορισμό της μέσης τιμής μιας συνεχούς Τ.Μ. και την πυκνότητα της εκθετικής κατανομής, βρίσκουμε,
όπου στο βήμα κάναμε την αντικατάσταση , και στο βήμα ολοκληρώσαμε κατά παράγοντες, θέτοντας και , έτσι ώστε και . Άρα έχουμε , αποδεικνύοντας την πρώτη ιδιότητα.
Για τη δεύτερη ιδιότητα, παρομοίως υπολογίζουμε τη μέση τιμή της ,
όπου στο βήμα κάναμε πάλι την αντικατάσταση , και στο βήμα ολοκληρώσαμε κατά παράγοντες, θέτοντας και , έτσι ώστε και . Τώρα παρατηρούμε πως ο πρώτος όρος στην τελευταία παραπάνω έκφραση είναι μηδενικός και πως το τελευταίο ολοκλήρωμα ισούται με τη μέση τιμή μιας Τ.Μ. με κατανομή , άρα, από την πρώτη ιδιότητα, είναι ίσο με 1. Συνεπώς έχουμε και η διασπορά της είναι,
οπότε έχουμε αποδείξει και τη δεύτερη ιδιότητα.
Για την Ιδιότητα 3 παρατηρούμε πως, εφόσον το σύνολο τιμών της είναι το , προφανώς για έχουμε, . Για , βρίσκουμε,
Τέλος, για την Ιδιότητα 4, χρησιμοποιούμε τον ορισμό της δεσμευμένης πιθανότητας σε συνδυασμό με την Ιδιότητα 3:
Παράδειγμα
11.1
Έστω πως ο χρόνος σε μήνες, μέχρι την πρώτη φορά που ένας σκληρός δίσκος θα παρουσιάσει κάποιο σφάλμα, έχει εκθετική κατανομή με μέσο όρο 30 μήνες. Συνεπώς, από την πρώτη ιδιότητα του Θεωρήματος 11.1, η
Η πιθανότητα το πρώτο σφάλμα να εμφανιστεί μετά τους πρώτους 30 μήνες, είναι,
Και η πιθανότητα ο δίσκος να μην παρουσιάσει σφάλμα για τους επόμενους 30 μήνες, δεδομένου ότι ήδη λειτουργεί 30 μήνες χωρίς πρόβλημα, είναι και πάλι,
όπου χρησιμοποιήσαμε την ιδιότητα έλλειψης μνήμης. Τέλος, η πιθανότητα το πρώτο σφάλμα να εμφανιστεί μετά τον δέκατο μήνα αλλά πριν τον εικοστό είναι,
όπου εδώ χρησιμοποιήσαμε τη γενική ιδιότητα (10.8).
11.2 Μετασχηματισμοί
Σε πολλές περιπτώσεις, όπως έχουμε δει σε παραδείγματα προηγούμενων κεφαλαίων, μπορεί να μας ενδιαφέρει περισσότερο κάποια συνάρτηση μιας τυχαίας μεταβλητής παρά η ίδια η τιμή της.
Παράδειγμα 11.2
Έστω μια συνεχής Τ.Μ. με πυκνότητα μέση τιμή και διασπορά Ποια είναι η μέση τιμή και η διασπορά της νέας Τ.Μ. για κάποιες σταθερές
Από τον γενικό ορισμό της μέσης τιμής, έχουμε,
Παρομοίως για τη διασπορά της βρίσκουμε,
Τα δύο παραπάνω αποτελέσματα, μαζί με ένα ακόμα συνοψίζονται στο θεώρημα που ακολουθεί.
-
1.
Η έχει μέση τιμή
-
2.
Η έχει διασπορά
-
3.
Αν η σταθερά είναι θετική, τότε η πυκνότητα της δίνεται από τη σχέση:
Η περίπτωση εξετάζεται στην Άσκηση 6 στο τέλος του κεφαλαίου.
Απόδειξη:
Οι δύο πρώτες ιδιότητες έχουν ήδη αποδειχθεί στο Παράδειγμα 11.2. Για την τρίτη ιδιότητα εξετάζουμε αρχικά τις συναρτήσεις κατανομής, έστω και των τυχαίων μεταβλητών , αντίστοιχα. Για την έχουμε,
Άρα, από τη σχέση (10.7), μπορούμε εύκολα να υπολογίσουμε την πυκνότητα της ως την παράγωγο της συνάρτησης κατανομής της,
που είναι ακριβώς η ζητούμενη σχέση.
Εφαρμόζοντας το παραπάνω αποτέλεσμα, έχουμε το εξής σημαντικό πόρισμα, το οποίο θα αποδείξετε στην Άσκηση 7 στο τέλος του κεφαλαίου.
Πόρισμα 11.1
Για μια οποιαδήποτε (συνεχή ή διακριτή) τυχαία μεταβλητή με μέση τιμή και διασπορά η κανονικοποιημένη τυχαία μεταβλητή,
Όπως είδαμε στην απόδειξη της τρίτης ιδιότητας του Θεωρήματος 11.2, για να υπολογίσουμε την πυκνότητα μιας συνάρτησης μιας συνεχούς Τ.Μ. συχνά είναι απλούστερο να εξετάσουμε πρώτα τη συνάρτηση κατανομής της. Ένα λίγο πιο πολύπλοκο παράδειγμα είναι το ακόλουθο.
Παράδειγμα 11.3
Έστω μια Τ.Μ. με κατανομή και έστω μια νέα Τ.Μ. Εφόσον η έχει σύνολο τιμών το και η θα έχει προφανώς το ίδιο σύνολο τιμών, άρα η πυκνότητα της θα ισούται με 0 για
Έστω, τώρα, και η πυκνότητα και η συνάρτηση κατανομής της αντίστοιχα. Για να υπολογίσουμε την πυκνότητα της για πρώτα εξετάζουμε τη συνάρτηση κατανομής της, έστω :
οπότε η πυκνότητα της για προκύπτει από τη σχέση (10.7) ως,
Και εφόσον γνωρίζουμε, εξ ορισμού, πως για η πυκνότητα ισούται με αντικαθιστώντας,
Η γραφική της αναπαράσταση δίνεται στο Σχήμα 11.4.
11.3 Ανεξαρτησία, ανισότητες και ο Ν.Μ.Α.
Όπως είδαμε στο Κεφάλαιο 9, η μέση τιμή και η διασπορά ικανοποιούν δύο σημαντικές ανισότητες, εκείνες του Markov και του Chebychev, οι οποίες, πέραν της μεγάλης χρησιμότητάς τους σε εφαρμογές, δίνουν και μια σαφή χρηστική σημασία στις έννοιες αυτές. Ξεκινάμε αυτή την ενότητα με τις γενικεύσεις αυτών των δύο σημαντικών αποτελεσμάτων για συνεχείς τυχαίες μεταβλητές.
Η ανισότητα του Markov λέει πως, αν μια τυχαία μεταβλητή έχει μικρή μέση τιμή, τότε δεν μπορεί να παίρνει μεγάλες τιμές με μεγάλη πιθανότητα. Η απόδειξη είναι παρόμοια με εκείνη που είδαμε στην περίπτωση διακριτών τυχαίων μεταβλητών (βλ. Άσκηση 11 στο τέλος του κεφαλαίου).
Συνεχίζοντας όπως στο Κεφάλαιο 9, μια απλή εφαρμογή της ανισότητας του Markov μάς δίνει την ανισότητα του Chebychev, η οποία λέει το εξής: Αν μια τυχαία μεταβλητή έχει «μικρή» διασπορά, τότε δεν μπορεί να παίρνει τιμές μακριά από τη μέση τιμή της με μεγάλη πιθανότητα. Η απόδειξη παραλείπεται μια και είναι ακριβώς η ίδια με εκείνη του Θεωρήματος 9.2.
Το τελευταίο μεγάλο αποτέλεσμα αυτού του κεφαλαίου είναι ο Νόμος των Μεγάλων Αριθμών (Ν.Μ.Α.) για συνεχείς Τ.Μ., στο Θεώρημα 11.6. Για τη διατύπωσή του χρειαζόμαστε τη γενίκευση της έννοιας της ανεξαρτησίας για συνεχείς τυχαίες μεταβλητές.
Ορισμός 11.3
-
1.
Δύο συνεχείς τυχαίες μεταβλητές είναι ανεξάρτητες αν, για κάθε τα ενδεχόμενα και είναι ανεξάρτητα. Ισοδύναμα, οι είναι ανεξάρτητες αν και μόνο αν,
για κάθε
-
2.
Οι συνεχείς Τ.Μ. είναι ανεξάρτητες αν,
για κάθε -άδα ζευγαριών τιμών
-
3.
Οι συνεχείς Τ.Μ. σε μια άπειρη ακολουθία είναι ανεξάρτητες αν οι Τ.Μ. είναι ανεξάρτητες για κάθε
Όπως και στο Κεφάλαιο 9, η απόδειξη του Ν.Μ.Α. στο Θεώρημα 11.6 βασίζεται στον υπολογισμό της μέσης τιμής και της διασποράς ενός αθροίσματος ανεξάρτητων τυχαίων μεταβλητών. Γι’ αυτόν τον υπολογισμό θα χρειαστούμε τις παρακάτω ιδιότητες, τις οποίες θα αποδείξουμε στο Κεφάλαιο 15, βλ. Πρόταση 15.3 και Θεώρημα 15.1.
Θεώρημα 11.5
(Μέση τιμή και διασπορά αθροίσματος)
-
1.
Για οποιεσδήποτε συνεχείς Τ.Μ. και σταθερές :
-
2.
Αν οι Τ.Μ. είναι ανεξάρτητες, τότε:
Παρατήρηση: Όπως και στη διακριτή περίπτωση, και οι δύο ιδιότητες του Θεωρήματος 11.5 εύκολα επεκτείνονται και για οποιοδήποτε (πεπερασμένο) πλήθος τυχαίων μεταβλητών. Με άλλα λόγια, για οποιεσδήποτε (συνεχείς ή διακριτές) τυχαίες μεταβλητές , και οποιεσδήποτε σταθερές ,
| (11.3) |
Και αν, επιπλέον, οι είναι ανεξάρτητες, τότε,
| (11.4) |
Πριν δούμε το κεντρικό αποτέλεσμα του κεφαλαίου, τον Ν.Μ.Α. για συνεχείς Τ.Μ., θα αποδείξουμε μια ανισότητα που αποτελεί ένα εξαιρετικά σημαντικό εργαλείο στις πιθανότητες. Ξεκινάμε παρατηρώντας πως, από το προφανές γεγονός ότι η διασπορά μιας Τ.Μ. είναι πάντα μεγαλύτερη ή ίση του μηδενός, έχουμε ότι,
από το οποίο προκύπτει πως,
για οποιαδήποτε Τ.Μ. . Η ανισότητα Cauchy-Schwarz, την οποία αποδεικνύουμε αμέσως μετά, μπορεί να θεωρηθεί μια γενίκευση αυτού του αποτελέσματος για την περίπτωση του γινομένου δύο τυχαίων μεταβλητών.
Πρόταση 11.1 (Ανισότητα Cauchy-Schwarz) Για δύο οποιεσδήποτε (συνεχείς ή διακριτές) Τ.Μ. έχουμε:
Απόδειξη:
Η απόδειξη είναι πολύ χαριτωμένη και εντυπωσιακά απλή. Για οποιοδήποτε , η Τ.Μ. παίρνει πάντα τιμές μεγαλύτερες ή ίσες του μηδενός, άρα και η μέση τιμή της θα είναι . Οπότε, αναπτύσσοντας το τετράγωνο και χρησιμοποιώντας την πρώτη ιδιότητα της μέσης τιμής από τα Θεωρήματα 6.1 και 11.2,
Έχουμε λοιπόν ένα τριώνυμο της μορφής , το οποίο είναι μεγαλύτερο ή ίσο του μηδενός για όλες τις τιμές του , δηλαδή ή δεν έχει καμία ρίζα ή έχει μία διπλή. Συνεπώς η διακρίνουσά του πρέπει να είναι , δηλαδή πρέπει να έχουμε,
η οποία είναι ακριβώς η ζητούμενη ανισότητα.
Κλείνουμε αυτό το κεφάλαιο με τη διατύπωση του Ν.Μ.Α. για συνεχείς Τ.Μ. Η απόδειξή του είναι ακριβώς ίδια με εκείνη του Θεωρήματος 9.3 στη διακριτή περίπτωση, και γι’ αυτόν τον λόγο παραλείπεται.
-
1.
[Διαισθητικά] Για μεγάλα ο εμπειρικός μέσος όρος των
-
2.
[Μαθηματικά] Καθώς το ο εμπειρικός μέσος όρος τείνει στη μέση τιμή κατά πιθανότητα, δηλαδή: Για κάθε έχουμε,
Τέλος, όπως αναφέραμε και στο Κεφάλαιο 9, σημειώνουμε πως, παρότι στην παραπάνω διατύπωση του Ν.Μ.Α. στο Θεώρημα 11.6 υποθέσαμε πως οι συνεχείς Τ.Μ. έχουν πεπερασμένη διασπορά , αυτή η υπόθεση δεν είναι απαραίτητη και μπορεί να αντικατασταθεί από την ασθενέσθερη υπόθεση ότι η μέση τιμή είναι πεπερασμένη. Βέβαια, σε αυτήν την περίπτωση απαιτείται μια διαφορετική απόδειξη, αρκετά πιο μακροσκελής και απαιτητική από μαθηματική άποψη.
11.4 Ασκήσεις
-
1.
Από την ομοιόμορφη στην εκθετική κατανομή. Έστω μια Τ.Μ. ομοιόμορφα κατανεμημένη στο . Αν , δείξτε πως η νέα Τ.Μ. έχει κατανομή .
-
2.
Χρόνος μετάδοσης. Ο χρόνος που μεσολαβεί από την αποστολή μέχρι την παράδοση ενός email μεγέθους από ένα διακομιστή σε έναν άλλο είναι λεπτά. Αν το έχει εκθετική κατανομή με μέση τιμή , να βρεθεί:
-
(α’)
Η μέση τιμή του χρόνου .
-
(β’)
Η πιθανότητα ο χρόνος εκτέλεσης να ξεπεράσει τα λεπτά.
-
(α’)
-
3.
Μηνυματάκια! Η διάρκεια αποστολής ενός SMS σε δευτερόλεπτα έχει ομοιόμορφη κατανομή στο διάστημα , και η διάρκεια αποστολής ενός MMS έχει εκθετική κατανομή με μέση τιμή τα δευτερόλεπτα. Στέλνουμε, σε τρεις ανεξάρτητες αποστολές, SMS και ένα MMS.
-
(α’)
Ποια είναι η μέση τιμή της συνολικής διάρκειας αποστολής;
-
(β’)
Ποια είναι η πιθανότητα και τα SMS να έχουν διάρκεια πάνω από δευτερόλεπτα το καθένα;
-
(γ’)
Ποια είναι η πιθανότητα το MMS να έχει διάρκεια μεγαλύτερη από τη μέση τιμή της συνολικής διάρκειας των SMS;
-
(δ’)
Δεδομένου ότι το MMS έχει διάρκεια πάνω από δευτερόλεπτα, ποια η πιθανότητα να διαρκέσει μεταξύ και δευτερόλεπτα;
-
(α’)
-
4.
Ελάχιστο και μέγιστο δύο Τ.Μ. Έστω οι ανεξάρτητες Τ.Μ. με συναρτήσεις κατανομής, αντίστοιχα, , . Έστω επίσης οι τυχαίες μεταβλητές και .
-
(α’)
Να υπολογίσετε τις συναρτήσεις κατανομής και των και , συναρτήσει των , .
- (β’)
-
(α’)
-
5.
Ελάχιστο Τ.Μ. Έστω ανεξάρτητες Τ.Μ. , όλες με την ίδια συνάρτηση κατανομής και έστω .
-
(α’)
Βρείτε τη συνάρτηση κατανομής της συναρτήσει της .
-
(β’)
Στην ειδική περίπτωση που όλες οι έχουν κατανομή , ποια είναι η κατανομή της ;
-
(α’)
-
6.
Γραμμικός μετασχηματισμός. Διατυπώστε και αποδείξτε την Ιδιότητα 3 του Θεωρήματος 11.2 στην περίπτωση που η σταθερά είναι αρνητική.
-
7.
Κανονικοποίηση. Αποδείξτε το Πόρισμα 11.1: (α’) για την περίπτωση που η Τ.Μ. είναι διακριτή, και (β’) για την περίπτωση που είναι συνεχής.
-
8.
Το φράγμα του Chernoff για συνεχείς Τ.Μ. Όπως στην Άσκηση 7 του Κεφαλαίου 9, εδώ θα δούμε ένα φράγμα για την πιθανότητα μια συνεχής Τ.Μ. να παίρνει τιμές μεγαλύτερες από κάποια σταθερά , ακριβέστερο απ’ αυτό που μας δίνει η ανισότητα του Markov.
-
(α’)
Αποδείξτε πως, για οποιοδήποτε , έχουμε το φράγμα:
(11.5) Παρατηρήστε πως, ενώ το αριστερό μέρος δεν εξαρτάται από το , το δεξί μέρος ισχύει για κάθε .
-
(β’)
Έστω τώρα πως η έχει κατανομή . Υπολογίστε τη μέση τιμή , όπου η είναι μια σταθερά με , και χρησιμοποιώντας τη σχέση (11.5) δείξτε πως, για οποιοδήποτε και , έχουμε:
(11.6) -
(γ’)
Έστω πάλι πως . Για και :
- i.
Υπολογίστε την τιμή του που μας δίνει το καλύτερο (δηλαδή το μικρότερο) δυνατό φράγμα στη σχέση (11.6), καθώς και το αντίστοιχο φράγμα γι’ αυτήν τη βέλτιστη τιμή του .
- ii.
Υπολογίστε το αντίστοιχο φράγμα που μας δίνει η ανισότητα του Markov. Παρατηρήστε ότι είναι ασθενέστερο.
- iii.
Υπολογίστε ακριβώς την πιθανότητα και συγκρίνετε την πραγματική τιμή της με τα δύο παραπάνω φράγματα.
- i.
-
(α’)
-
9.
Γραμμικοί συνδυασμοί. Οι τυχαίες μεταβλητές και είναι ανεξάρτητες και έχουν εκθετική κατανομή με μέση τιμή . Έστω δύο νέες τυχαίες μεταβλητές και . Να βρεθούν τα ακόλουθα: , , , , .
-
10.
Συνάρτηση μιας εκθετικής Τ.Μ. Το κόστος συντήρησης ενός δικτύου κινητής τηλεφωνίας με συνολική έκταση είναι χιλιάδες ευρώ. Αν η Τ.Μ. έχει εκθετική κατανομή με παράμετρο , να βρεθεί η πυκνότητα του .
-
11.
Ανισότητα Markov. Να αποδείξετε την ανισότητα Markov του Θεωρήματος 11.3 στην περίπτωση που το σύνολο τιμών της τυχαίας μεταβλητής είναι το .
[Παρατήρηση. Η υπόθεση γίνεται απλώς για να σας διευκολύνει. Η απόδειξη της γενικής περίπτωσης όπου το είναι κάποιο υποσύνολο του είναι ακριβώς η ίδια, απλά απαιτεί μεγαλύτερη προσοχή στο συμβολισμό. Υπόδειξη. Ακολουθήστε τα ίδια βήματα όπως στην απόδειξη της ανισότητας Markov για διακριτές Τ.Μ. στο Θεώρημα 9.1 του Κεφαλαίου 9.]
-
12.
Ανισότητα Chebychev. Για μια διακριτή Τ.Μ. αποδείξαμε την ανισότητα Chebychev στο Θεώρημα 9.2. Εξηγήστε με ποιο τρόπο τεκμηριώνονται τα βήματα της απόδειξης στην περίπτωση που η Τ.Μ. είναι συνεχής.
-
13.
Πόσο ακριβής είναι η ανισότητα Chebychev; Συγκρίνετε το φράγμα που δίνει η ανισότητα Chebychev για την πιθανότητα του ενδεχόμενου με την ακριβή πιθανότητα, στην περίπτωση που η είναι ομοιόμορφα κατανεμημένη στο διάστημα . Σχολιάστε πόσο ακριβές είναι το φράγμα, δηλαδή πόσο κοντά είναι στην πραγματική τιμή της πιθανότητας.
-
14.
Απόδειξη του Ν.Μ.Α. Για μια ακολουθία διακριτών Τ.Μ. αποδείξαμε τον Ν.Μ.Α. στο Θεώρημα 9.3. Εξηγήστε με ποιόν τρόπο τεκμηριώνονται τα βήματα της απόδειξης στην περίπτωση που οι Τ.Μ. είναι συνεχείς.
-
15.
Συνεχείς και διακριτές Τ.Μ. Θυμηθείτε τις συνεχείς Τ.Μ. και τις οποίες ορίσαμε στην Άσκηση 10 του προηγούμενου κεφαλαίου. Είναι ή όχι οι ανεξάρτητες; Αποδείξτε την απάντησή σας και εξηγήστε τη διαισθητικά.
-
16.
Άλλος ένας γραμμικός μετασχηματισμός. Έστω μια Τ.Μ. με ομοιόμορφη κατανομή στο , και έστω η νέα T.M. . Ποια είναι η συνάρτηση κατανομής της ;
-
17.
Συνδιακύμανση και συσχέτιση. Έστω δύο οποιεσδήποτε διακριτές T.M. και .
-
(α’)
Αποδείξτε πως για τη συνδιακύμανσή τους έχουμε:
- (β’)
-
(α’)
ΠΟΛΥΜΕΣΙΚΟ ΥΛΙΚΟ ΚΕΦΑΛΑΙΟΥ



Κεφάλαιο 12 Το Κεντρικό Οριακό Θεώρημα
[Επιστροφή στα περιεχόμενα]
Όπως περιγράψαμε λεπτομερώς στο Κεφάλαιο 9, ο Νόμος των Μεγάλων Αριθμών είναι ένα από τα πιο θεμελιώδη αποτελέσματα της θεωρίας των πιθανοτήτων (βλ. τα Θεωρήματα 9.3 και 11.6 για τη διατύπωση του Ν.Μ.Α. για διακριτές και συνεχείς τυχαίες μεταβλητές αντίστοιχα). Συγκεκριμένα, αν είναι μια ακολουθία από ανεξάρτητες (συνεχείς ή διακριτές) Τ.Μ. που έχουν όλες την ίδια κατανομή, τότε ο Ν.Μ.Α. μας λέει πως, για μεγάλα , ο εμπειρικός μέσος όρος των πρώτων απ’ τα θα ισούται κατά προσέγγιση με την μέση τιμή τους , με μεγάλη πιθανότητα.
Για παράδειγμα, έστω πως έχουμε ανεξάρτητα, τυχαία δείγματα , όπου το κάθε αντιστοιχεί στο αποτέλεσμα της μέτρησης της θερμοκρασίας μιας μεγάλης δεξαμενής. Αν θέλουμε να εκτιμήσουμε την (άγνωστη σε μας) μέση θερμοκρασία, έστω , του υγρού που περιέχει η δεξαμενή, τότε ο Ν.Μ.Α. μας διαβεβαιώνει πως ο εμπειρικός μέσος όρος των δειγμάτων ,
θα μας δώσει μια καλή εκτίμηση για τη , εφόσον το πλήθος των δειγμάτων είναι αρκετά μεγάλο. Φυσικά για να είναι πρακτικά χρήσιμο αυτό το αποτέλεσμα είναι απαραίτητο να δώσουμε μια ακριβέστερη ποσοτική περιγραφή του τι θα πει «καλή εκτίμηση» και πόσο «αρκετά μεγάλο» πρέπει να είναι το πλήθος των δειγμάτων. Αυτό είναι το αντικείμενο του παρόντος κεφαλαίου.
Από μαθηματική άποψη, ο Ν.Μ.Α. μας λέει πως ο εμπειρικός μέσος όρος τείνει στη μέση τιμή , καθώς το τείνει στο άπειρο. Το Κεντρικό Οριακό Θεώρημα (Κ.Ο.Θ.) που θα δούμε στην Ενότητα 12.2 είναι μια ακριβέστερη μορφή αυτού του αποτελέσματος: Λέει πως, για μεγάλα , η κατανομή του εμπειρικού μέσου όρου μπορεί να προσεγγιστεί από τη λεγόμενη «κανονική κατανομή με παραμέτρους και », όπου είναι η διασπορά των .
Συνεπώς, γνωρίζοντας (κατά προσέγγιση) την κατανομή του , μπορούμε να υπολογίσουμε την πιθανότητα το να είναι σχετικά κοντά ή μακριά από την τιμή στην οποία τείνει. Λόγου χάρη, στο πιο πάνω παράδειγμα, ποια είναι η πιθανότητα η εκτίμησή μας για τη μέση θερμοκρασία , να απέχει από την πραγματική τιμή κατά το πολύ έναν βαθμό; Αν ορίσουμε μια Τ.Μ. με την κατανομή που μας δίνει το Κ.Ο.Θ., θα έχουμε την προσέγγιση,
όπου η τελευταία πιθανότητα μπορεί εύκολα να υπολογιστεί, αφού η Τ.Μ. έχει γνωστή κατανομή.
Στην Ενότητα 12.1 θα ορίσουμε την οικογένεια των τυχαίων μεταβλητών με κανονική κατανομή και θα εξετάσουμε τις βασικές τους ιδιότητες. Στη συνέχεια, στην Ενότητα 12.2 θα διατυπώσουμε το Κ.Ο.Θ. και στην 12.3 θα δούμε αρκετά παραδείγματα του πώς χρησιμοποιείται στην πράξη. Στο Κεφάλαιο 13 θα δούμε κάποια θεωρητικά αποτελέσματα που σχετίζονται με το Κ.Ο.Θ., συμπεριλαμβανομένων των βασικών στοιχείων της απόδειξής του, και τέλος στο Κεφάλαιο 14 θα παρουσιάσουμε τις κεντρικές ιδέες του τρόπου με τον οποίο το Κ.Ο.Θ. εφαρμόζεται σε κάποια από τα θεμελιώδη προβλήματα της στατιστικής.
12.1 Κανονική κατανομή
Ορισμός 12.1
Μια συνεχής Τ.Μ. έχει κανονική κατανομή (ή γκαουσιανή κατανομή) με παραμέτρους και , αν έχει σύνολο τιμών το και πυκνότητα,
| (12.1) |
βλ. Σχήμα 12.1. Για συντομία, αυτό συμβολίζεται:
-
1.
Αν και, εκ πρώτης όψεως, η πολύπλοκη μορφή της πυκνότητας (12.1) ίσως μας ξενίζει, είναι σημαντικό να σημειώσουμε πως η κανονική κατανομή αντλεί τη σημασία της από το Κεντρικό Οριακό Θεώρημα, το οποίο μας λέει πως η κανονική κατανομή είναι, κατά κάποιον τρόπο, αναπόφευκτη! Όταν εξετάζουμε τον εμπειρικό μέσο όρο ενός σχετικά μεγάλου πλήθους τυχαίων μεταβλητών , η κατανομή του τείνει πάντοτε στην κανονική κατανομή, ανεξάρτητα του ποια κατανομή έχουν τα μεμονωμένα .
-
2.
Για να βεβαιωθούμε πως ο παραπάνω ορισμός είναι μαθηματικά ορθός σύμφωνα με τον Ορισμό 10.1, θα έπρεπε να ελέγξουμε ότι το ολοκλήρωμα (από το ως το ) της πυκνότητας στη σχέση (12.1) ισούται με 1, για κάθε ζευγάρι τιμών των παραμέτρων και . Αυτό φυσικά πράγματι ισχύει, αλλά ο σχετικός υπολογισμός, τον οποίο δίνουμε στην Ενότητα 13.1 του επόμενου κεφαλαίου, είναι κάπως τεχνικός και μακροσκελής.
-
3.
Έστω πως, για μια Τ.Μ. με κατανομή , θέλουμε να υπολογίσουμε την πιθανότητα . Αν και μπορεί να εκφραστεί ως το ολοκλήρωμα της πυκνότητας στη σχέση (12.1),
αυτό το ολοκλήρωμα δεν μπορεί να εκφραστεί σε κλειστή μορφή. Γι’ αυτόν τον λόγο, θα δείξουμε στις πιο κάτω ιδιότητες πως οποιαδήποτε πιθανότητα που αφορά μια κατανομή μπορεί να εκφραστεί ως μια αντίστοιχη πιθανότητα για τη λεγόμενη «τυπική κανονική κατανομή» . Βλ. τη «γενική μέθοδο» που δίνεται μετά το Θεώρημα 12.1 και τα παραδείγματα που ακολουθούν.
-
1.
Μέση τιμή:
-
2.
Διασπορά:
Το γεγονός πως οι παράμετροι και αντιστοιχούν στη μέση τιμή και τη διασπορά της κατανομής αναπαρίσταται και γραφικά στο Σχήμα 12.1.
-
3.
Κανονικοποίηση: Η Τ.Μ. έχει κατανομή
-
4.
Γραμμικός συνδυασμός: Αν οι τυχαίες μεταβλητές και είναι ανεξάρτητες, τότε η Τ.Μ. έχει κατανομή
- 5.
Συμβολισμός: Αν η έχει και δηλαδή τότε λέμε πως έχει τυπική κανονική κατανομή και συμβολίζουμε την πυκνότητα της και τη συνάρτηση κατανομής της αντίστοιχα ως,
(12.2) Η γραφική αναπαράσταση της πυκνότητας και της συνάρτησης κατανομής της τυπικής κανονικής κατανομής δίνονται στο Σχήμα 12.2.
 |
 |
Απόδειξη:
Η μέση τιμή της υπολογίζεται απλά μέσω του ορισμού. Αρχικά έχουμε,
αλλά παρατηρούμε πως η συνάρτηση του τελευταίου ολοκληρώματος σχετίζεται με την παράγωγο της πυκνότητας,
οπότε αντικαθιστώντας βρίσκουμε,
αποδεικνύοντας την πρώτη ιδιότητα. Για τη δεύτερη ιδιότητα, χρησιμοποιώντας και πάλι την έκφραση για την παράγωγο της ,
όπου στο βήμα ολοκληρώσαμε κατά παράγοντες, θέτοντας και , έτσι ώστε και .
Για την τρίτη ιδιότητα, έστω η πυκνότητα της όπως στην (12.1). Εφόσον , τότε από την τρίτη ιδιότητα του Θεωρήματος 11.2 με και , η έχει πυκνότητα,
η οποία είναι πράγματι η πυκνότητα της κατανομής.
Η τέταρτη ιδιότητα θα αποδειχθεί στο Πόρισμα 15.1 του Κεφαλαίου 15. Για την ειδική περίπτωση όπου η είναι απλά μια σταθερά, δείτε την Άσκηση 7 στο τέλος του κεφαλαίου.
-
1.
Ορίζουμε μια νέα Τ.Μ. και εκφράζουμε τη ζητούμενη πιθανότητα ως,
Π.χ., αν η ζητούμενη πιθανότητα ήταν για την τότε,
- 2.
- 3.
Τέλος, αντικαθιστούμε τις τιμές και από τους πίνακες τιμών της τυπικής κανονικής συνάρτησης κατανομής που δίνονται στο τέλος του κεφαλαίου. Η κάθε γραμμή περιέχει το ακέραιο μέρος και το πρώτο δεκαδικό ψηφίο του και η κάθε στήλη το δεύτερο δεκαδικό του ψηφίο.
Παραδείγματος χάρη, για να βρούμε την τιμή πάμε στον Πίνακα 12.1 που περιέχει τις τιμές της για αρνητικά και κοιτάζουμε στην γραμμή, που αντιστοιχεί στα και στην ένατη στήλη, που περιέχει την τιμή της Παρομοίως, από την τρίτη γραμμή και τελευταία στήλη του Πίνακα 12.2 βρίσκουμε την τιμή της Οπότε τελικά έχουμε,
Παράδειγμα 12.1
Έστω πως το ρολόι (clock) ενός επεξεργαστή αποκλίνει κατά δευτερόλεπτα μετά από ένα χρόνο συνεχούς λειτουργίας, όπου Ποια η πιθανότητα μετά από ένα χρόνο:
-
1.
το ρολόι να πηγαίνει «πίσω», δηλαδή να έχει αρνητική απόκλιση;
-
2.
η απόκλιση να είναι μεγαλύτερη από δευτερόλεπτα;
-
3.
η απόκλιση να είναι μικρότερη από δευτερόλεπτα;
Χρησιμοποιώντας τη γενική παραπάνω μέθοδο με και και ορίζοντας μια τυπική κανονική Τ.Μ. για το πρώτο ερώτημα εύκολα βρίσκουμε,
και, αντικαθιστώντας την από τον Πίνακα 12.1 έχουμε · βλ. Σχήμα 12.3.
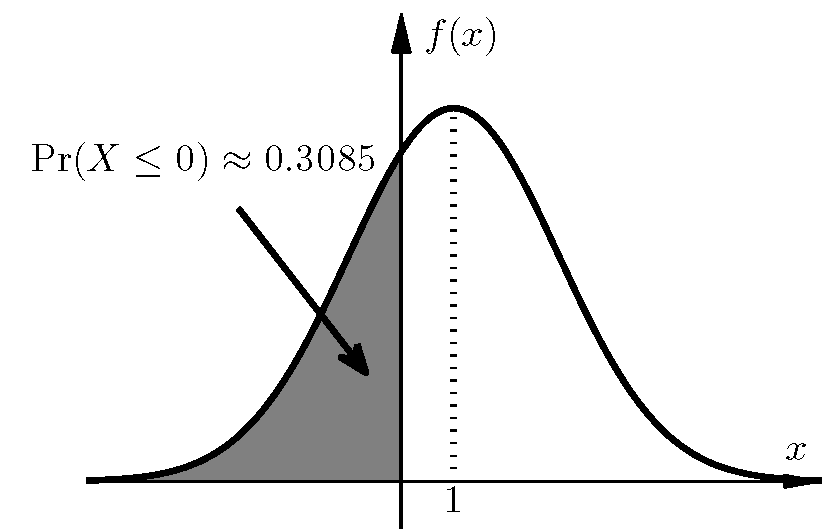
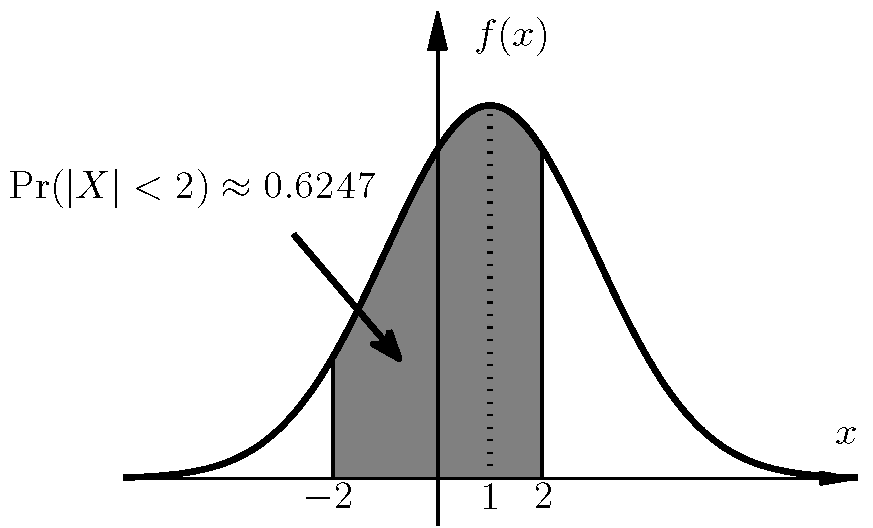
Παράδειγμα 12.2
Έστω πως η ένταση του ηλεκτρομαγνητικού θορύβου σε ένα κύκλωμα έχει κατανομή Ποια η πιθανότητα το να μην ξεπερνάει το 1 σε απόλυτη τιμή;
Όπως και στο προηγούμενο παράδειγμα, εφαρμόζοντας τη γενική παραπάνω μέθοδο με και και ορίζοντας μια τυπική κανονική Τ.Μ. βρίσκουμε,
όπου αντικαταστήσαμε τις τιμές και από τον Πίνακα 12.2.
12.2 Το Κεντρικό Οριακό Θεώρημα
Όπως αναφέραμε στην αρχή του κεφαλαίου, πέραν του ότι ο εμπειρικός μέσος όρος,
ανεξάρτητων Τ.Μ. τείνει στη μέση τιμή τους σύμφωνα με τον Ν.Μ.Α, για να εφαρμόσουμε αυτό το αποτέλεσμα στην πράξη είναι απαραίτητο να γνωρίζουμε και ποσοτικά πόσο ακριβής είναι η προσέγγιση « με μεγάλη πιθανότητα».
Το Κεντρικό Οριακό Θεώρημα (Κ.Ο.Θ.) απαντά σε αυτό ακριβώς το ερώτημα: Μας λέει πως ο εμπειρικός μέσος όρος έχει κατά προσέγγιση κανονική κατανομή. Ισοδύναμα, από την τρίτη ιδιότητα του Θεωρήματος 12.1, η Τ.Μ.,
| (12.3) |
έχει κατά προσέγγιση κανονική κατανομή.
Επιπλέον, το Κ.Ο.Θ. δεν είναι μόνο στο διαισθητικό επίπεδο μια ακριβέστερη μορφή του Ν.Μ.Α., αλλά όπως θα δούμε στην Ενότητα 13.2, μπορούμε και να αποδείξουμε τον Ν.Μ.Α. από το Κ.Ο.Θ.
Για να διατυπώσουμε το Κ.Ο.Θ. με μαθηματική ακρίβεια, θα χρειαστούμε μια διαφορετική έννοια για τη σύγκλιση μιας ακολουθίας τυχαίων μεταβλητών , διαφορετική από τη σύγκλιση κατά πιθανότητα, την οποία συναντήσαμε στο Κεφάλαιο 9.
Ορισμός 12.2
Έστω μια ακολουθία Τ.Μ. και έστω μια άλλη Τ.Μ. με συνάρτηση κατανομής H ακολουθία συγκλίνει κατά κατανομή στη αν,
για όλα τα στα οποία η είναι συνεχής.
-
[Διαισθητικά-1] Για μεγάλα ο εμπειρικός μέσος όρος,
-
[Διαισθητικά-2] Για μεγάλα το κανονικοποιημένο άθροισμα,
-
[Μαθηματικά] Καθώς το το κανονικοποιημένο άθροισμα συγκλίνει κατά κατανομή στην τυπική κανονική κατανομή, δηλαδή: Για κάθε έχουμε,
(12.4) όπου είναι η συνάρτηση κατανομής της κατανομής.
Η πλήρης απόδειξη του Κ.Ο.Θ. είναι αρκετά τεχνική, και μάλλον ξεφεύγει από τους στόχους του παρόντος βιβλίου. Παρ’ όλα αυτά, στο Κεφάλαιο 13 θα δώσουμε μια σειρά από σχετικά αποτελέσματα, συμπεριλαμβανομένης και μιας ολοκληρωμένης απόδειξης του Κ.Ο.Θ. Προς το παρόν σημειώνουμε μόνο πως, σε αντίθεση με τις υποθέσεις του Ν.Μ.Α. στα Θεωρήματα 9.3 και 11.6, εδώ η υπόθεση πως η διασπορά των είναι πεπερασμένη είναι απαραίτητη και δεν μπορεί να παραλειφθεί.
Όπως θα δούμε στα παραδείγματα που ακολουθούν, η βασική χρήση του Κ.Ο.Θ. είναι μέσω της προσέγγισης,
| (12.5) |
όπου, προφανώς, η Τ.Μ. έχει τυπική κανονική κατανομή. Κάποιες πιο ρεαλιστικές και σύγχρονες εφαρμογές του Κ.Ο.Θ. θα εξετάσουμε λεπτομερώς στο Κεφάλαιο 14.
12.3 Παραδείγματα και απλές εφαρμογές
Παράδειγμα 12.3
Έστω πως είναι η θερμοκρασία ενός επεξεργαστή την ημέρα όπου θεωρούμε πως τα είναι ανεξάρτητες Τ.Μ. με κατανομή Ποια η πιθανότητα η μέση θερμοκρασία του επεξεργαστή σε μια περίοδο 3 μηνών (δηλαδή 90 ημερών) να ξεπερνά τους 31 βαθμούς;
Για να εφαρμόσουμε το Κ.Ο.Θ. αρχικά υπολογίζουμε τη μέση τιμή και τη διασπορά των οι οποίες, από τις ιδιότητες της ομοιόμορφης κατανομής, είναι,
αντίστοιχα. Άρα, η ζητούμενη πιθανότητα μπορεί να εκφραστεί ως προς το κανονικοποιημένο άθροισμα του Κ.Ο.Θ. ως εξής,
με Άρα, από το Κ.Ο.Θ., όπως ακριβώς στην περίπτωση της προσέγγισης που δώσαμε στη σχέση (12.5), η ζητούμενη πιθανότητα μπορεί να προσεγγιστεί ως,
όπου η έχει κατανομή Αντικαθιστώντας την τιμή από τον Πίνακα 12.2, τελικά βρίσκουμε πως η ζητούμενη πιθανότητα είναι
Παράδειγμα 12.4
Από εμπειρικές μετρήσεις γνωρίζουμε πως η διάρκεια εκτέλεσης ενός αλγορίθμου είναι κατά μέσο όρο 17.5 δευτερόλεπτα, με τυπική απόκλιση δευτερόλεπτα. Ποια είναι η πιθανότητα, σε 400 διαδοχικές, ανεξάρτητες χρήσεις του αλγορίθμου, ο συνολικός χρόνος εκτέλεσης να μην ξεπερνά τις δύο ώρες;
Έστω ο χρόνος εκτέλεσης του αλγορίθμου τη φορά για Από τα δεδομένα του προβλήματος έχουμε πως τα είναι ανεξάρτητες Τ.Μ. με μέση τιμή δευτερόλεπτα και τυπική απόκλιση δευτερόλεπτα. Συνεπώς, η ζητούμενη πιθανότητα μπορεί να εκφραστεί ως προς το κανονικοποιημένο άθροισμα του Κ.Ο.Θ.,
όπου Και πάλι εφαρμόσαμε το Κ.Ο.Θ. όπως στην προσέγγιση (12.5). Άρα η ζητούμενη πιθανότητα είναι,
με την τιμή να έχει αντικατασταθεί από τον Πίνακα 12.2.
-
1.
Μια καίρια παρατήρηση για το τελευταίο από τα παραπάνω παραδείγματα, είναι πως υπολογίσαμε την πιθανότητα ο μέσος χρόνος εκτέλεσης σε πολλές επαναλήψεις να μην ξεπερνά τις δύο ώρες, χωρίς να γνωρίζουμε την κατανομή του χρόνου μίας εκτέλεσης. Αυτό το φαινόμενο είναι συχνό και πολύ σημαντικό: Το Κ.Ο.Θ. μας επιτρέπει να προσεγγίσουμε την κατανομή του εμπειρικού μέσου όρου ενός μεγάλου πλήθος δειγμάτων, ακόμα κι αν δεν γνωρίζουμε την κατανομή των ίδιων των δειγμάτων. Υπό αυτή την έννοια, η κανονική κατανομή είναι «καθολική», μια και προκύπτει φυσικά και κατά κάποιον τρόπο αναπόφευκτα για τυχαία δείγματα οποιασδήποτε προέλευσης, από την αστρονομία μέχρι την ιατρική.
-
2.
Και στα δύο παραπάνω παραδείγματα οι Τ.Μ. ήταν συνεχείς και χρησιμοποιήσαμε το Κ.Ο.Θ. για να προσεγγίσουμε τη (συνεχή) κατανομή του αθροίσματός τους μέσω της (επίσης συνεχούς) κανονικής κατανομής. Όταν οι Τ.Μ. είναι διακριτές, μπορούμε και πάλι να χρησιμοποιήσουμε το Κ.Ο.Θ., αλλά εφόσον προσεγγίζουμε μια διακριτή κατανομή (αυτή του αθροίσματος των ή του εμπειρικού μέσου όρου τους) με μια συνεχή κατανομή (την κανονική), η εφαρμογή του Κ.Ο.Θ. απαιτεί λίγη περισσότερη προσοχή, όπως θα δούμε στα επόμενα παραδείγματα.
Παράδειγμα 12.5
Έστω πως στρίβουμε ανεξάρτητες φορές ένα νόμισμα με πιθανότητα να φέρει Κορώνα ίση με κάποιο γνωστό Ορίζοντας τις ανεξάρτητες Τ.Μ. όπου η κάθε περιγράφει το αποτέλεσμα της ρίψης τη φορά (δηλαδή αν φέραμε Κορώνα, και αν φέραμε Γράμματα), από τον Ν.Μ.Α. έχουμε πως, αν το πλήθος των ρίψεων είναι μεγάλο, τότε:
Το Κ.Ο.Θ. μας επιτρέπει να ποσοτικοποιήσουμε το παραπάνω αποτέλεσμα. Συγκεκριμένα, για κάθε ζευγάρι ακεραίων μπορούμε να προσεγγίσουμε την πιθανότητα το συνολικό πλήθος από Κ να είναι μεταξύ και
Εφόσον τα και η Τ.Μ. παίρνουν όλα μόνο ακέραιες τιμές, οι δύο πιθανότητες είναι ίσες. Ο λόγος για τον οποίο προσθέτουμε ή αφαιρούμε από τα είναι διότι, εφόσον θα προσεγγίσουμε την κατανομή του αθροίσματος αυτού με μια συνεχή κατανομή (την κανονική), λογικό είναι να μοιράσουμε την απόσταση ανάμεσα στις διαδοχικές τιμές και και αντίστοιχα για τις και
Σημειώνοντας ότι τα έχουν και μπορούμε τώρα να εφαρμόσουμε το Κ.Ο.Θ. ως εξής,
όπου, χρησιμοποιώντας την προσέγγιση που δώσαμε στη σχέση (12.5), η ζητούμενη πιθανότητα μπορεί να προσεγγιστεί ως,
Πόρισμα 12.1
(Κανονική προσέγγιση στη διωνυμική κατανομή)
- •
το είναι αρκετά «μεγάλο», δηλαδή,
-
•
το δεν είναι πολύ «μικρό», ώστε το γινόμενό είναι της τάξεως του 1,
τότε η κατανομή της μπορεί να προσεγγιστεί από την κανονική κατανομή υπό την έννοια ότι, για κάθε ζευγάρι ακεραίων τιμών
Στη συνέχεια, θα ξαναδούμε τα τρία θεμελιώδη παραδείγματα του Ν.Μ.Α. από την Ενότητα 9.3 του Κεφαλαίου 9, και θα τα επανεξετάσουμε κάτω από το πολύ πιο ακριβές πρίσμα του Κ.Ο.Θ.
Παράδειγμα 12.6 (Τι θα πει «πιθανότητα»;)
Επιστρέφοντας στο Παράδειγμα 9.12 του Κεφαλαίου 9, όπου μας ενδιαφέρει η πιθανότητα του να συμβεί ένα συγκεκριμένο ενδεχόμενο θυμίζουμε πως ο Ν.Μ.Α. μάς εγγυάται ότι, αν επαναλάβουμε το ίδιο ακριβώς πείραμα πάρα πολλές, ανεξάρτητες φορές, σε διαισθητικό επίπεδο: «η πιθανότητα είναι το ποσοστό των φορών, μακροπρόθεσμα, που συμβαίνει το ».
Μαθηματικά, αυτό το σενάριο περιγράφεται ακριβώς όπως στο Παράδειγμα 12.5: Σε επαναλήψεις του πειράματος, τις οποίες περιγράφουμε με την ακολουθία των ανεξάρτητων Τ.Μ. για η συχνότητα με την οποία σημειώθηκε επιτυχία στο πείραμα, δηλαδή ο εμπειρικός μέσος όρος των θα συγκλίνει κατά πιθανότητα στο σύμφωνα με τον Ν.Μ.Α. Το Κ.Ο.Θ. μάς δίνει τη δυνατότητα να υπολογίσουμε με μεγαλύτερη ακρίβεια τον τρόπο με τον οποίο το συγκλίνει στο Στο διαισθητικό επίπεδο, μας λέει πως, για μεγάλα η κατανομή του είναι κατά προσέγγιση
Για να διατυπώσουμε αυτή την προσέγγιση με μεγαλύτερη μαθηματική ακρίβεια, ορίζουμε το συνολικό πλήθος των επιτυχιών, Τότε η έχει κατανομή και μπορούμε να χρησιμοποιήσουμε τον υπολογισμό του Παραδείγματος 12.5, όπως διατυπώνεται στο Πόρισμα 12.1. Συγκεκριμένα, για οποιουσδήποτε δύο ακεραίους η πιθανότητα η συχνότητα των επιτυχιών να είναι μεταξύ και μπορεί να προσεγγιστεί ως:
Ας δούμε ένα αριθμητικό παράδειγμα αυτού του υπολογισμού: Σε ανεξάρτητες επαναλήψεις ενός πειράματος με πιθανότητα επιτυχίας ποια είναι η πιθανότητα το ποσοστό των επιτυχιών να είναι μεταξύ 60% και 70%; Ορίζοντας και πάλι την Τ.Μ. η ζητούμενη πιθανότητα είναι,
η οποία προσεγγίζεται ως,
όπου αντικαταστήσαμε την τιμή από τον Πίνακα 12.2, και χρησιμοποιήσαμε το γεγονός πως για κάθε το οποίο επίσης προκύπτει από τον Πίνακα 12.2.
Παράδειγμα 12.7 (Γιατί γίνονται δημοσκοπήσεις;)
Όπως στο Παράδειγμα 9.13 του Κεφαλαίου 9, εξετάζουμε έναν πληθυσμό ατόμων, το 25% των οποίων (δηλαδή άτομα) είναι ψηφοφόροι κάποιου κόμματος. Για τη διεξαγωγή μιας δημοσκόπησης επιλέγονται τυχαία άτομα (με επανατοποθέτηση), και ρωτώνται αν θα ψηφίσουν αυτό το κόμμα. Όπως πριν, ορίζοντας τις ανεξάρτητες Τ.Μ. για (όπου αν το άτομο είναι ψηφοφόρος του κόμματος, και 0 αν όχι), ο Ν.Μ.Α. μας λέει πως, αν το μέγεθος του δείγματος είναι αρκετά μεγάλο, τότε το αποτέλεσμα της δημοσκόπησης, δηλαδή ο εμπειρικός μέσος όρος θα είναι κοντά στο 25% με μεγάλη πιθανότητα.
Έστω τώρα πως έχουμε ένα δείγμα ατόμων, πράγμα συνηθισμένο σε πραγματικές πολιτικές δημοσκοπήσεις. Ποια είναι η πιθανότητα το αποτέλεσμά μας να πέσει έξω κατά περισσότερο από 2%; Δηλαδή, ποια είναι η,
Ορίζοντας και πάλι την Τ.Μ.,
η οποία έχει κατανομή, η πιθανότητα που μας ενδιαφέρει μπορεί να εκφραστεί ως και από το Πόρισμα 12.1 με και έχουμε την προσέγγιση,
Συνεπώς, με ένα τυχαίο δείγμα 1000 ατόμων, η πιθανότητα η δημοσκόπηση να πέσει έξω κατά περισσότερο από 2% είναι μόλις 13%. Παρατηρήστε ότι το αποτέλεσμα αυτό δεν εξαρτάται από το μέγεθος του πληθυσμού, αλλά μόνο από το μέγεθος του δείγματος και το ποσοστό των ψηφοφόρων. Στο τελευταίο παράδειγμα αυτής της ενότητας θα δούμε μια ρεαλιστική περίπτωση δημοσκόπησης, με πραγματικά δεδομένα από το δημοψήφισμα που έγινε στην Ελλάδα τον Ιούλιο του 2015.
Παράδειγμα 12.8 (Εκτίμηση μέσω δειγματοληψίας)
Συνεχίζοντας όπως στο Παράδειγμα 9.14 του Κεφαλαίου 9, έστω πως θέλουμε να υπολογίσουμε το μέσο ύψος ενός κοριτσιού, μεταξύ των κοριτσιών ενός πληθυσμού, όπου είναι το ύψος του κοριτσιού Αντί να εξετάσουμε ολόκληρο τον πληθυσμό, επιλέγουμε τυχαία, με επανατοποθέτηση, μέλη του πληθυσμού, όπου το μέγεθος του δείγματός είναι σχετικά μεγάλο αλλά σημαντικά μικρότερο του συνολικού μεγέθους του πληθυσμού.
Όπως και πριν, ορίζουμε τις ανεξάρτητες Τ.Μ. «ύψος του κοριτσιού που επιλέξαμε», για οι οποίες έχουν σύνολο τιμών το και πυκνότητα για κάθε και κάθε Όπως υπολογίσαμε στο Παράδειγμα 9.14, τα έχουν μέση τιμή, και παρομοίως υπολογίζουμε πως η διασπορά τους ισούται με,
Αν εκτιμήσουμε λοιπόν το μέσω του εμπειρικού μέσου όρου από τα ύψη των κοριτσιών που επιλέξαμε, ο Ν.Μ.Α. μάς διαβεβαιώνει πως, για μεγάλα μεγέθη δειγμάτων θα έχουμε μια καλή εκτίμηση, δηλαδή με μεγάλη πιθανότητα. Επιπλέον, το Κ.Ο.Θ. μας δίνει την ακριβέστερη πληροφορία πως η κατανομή της εκτίμησής μας θα είναι κατά προσέγγιση κανονική, με μέση τιμή τη ζητούμενη ποσότητα και διασπορά ίση με
Κλείνουμε αυτή την ενότητα με τρία ακόμα απλά παραδείγματα εφαρμογής του Κ.Ο.Θ.
Παράδειγμα 12.9
Έστω πως η διάρκεια κάθε τηλεφωνικής κλήσης σε ένα δίκτυο έχει εκθετική κατανομή με μέση διάρκεια 85 δευτερόλεπτα, και έστω πως οι διάρκειες διαδοχικών κλήσεων είναι ανεξάρτητες. Ποια είναι η πιθανότητα η μέση διάρκεια μιας κλήσης ανάμεσα στις που έγιναν μέσα σε μία μέρα να είναι μεγαλύτερη από 90 δευτερόλεπτα;
Ορίζουμε τις ανεξάρτητες Τ.Μ. όπου η κάθε Από τις ιδιότητες της εκθετικής κατανομής ξέρουμε πως οι έχουν μέση τιμή και τυπική απόκλιση Οπότε η ζητούμενη πιθανότητα όπου είναι ο εμπειρικός μέσος όρος των μπορεί να εκφραστεί ως,
και, εφαρμόζοντας το Κ.Ο.Θ., έχουμε,
όπου αντικαταστήσαμε την τιμή από τον Πίνακα 12.2.
Παράδειγμα 12.10
Κάθε φορά που ένας προγραμματιστής γράφει ένα καινούργιο κομμάτι κώδικα σε κάποιο πρόγραμμα, διαπιστώνει πως έχει κάνει λάθη (δηλαδή βρίσκει bugs στον κώδικά του), όπου το είναι μια Τ.Μ. με σύνολο τιμών το και πυκνότητα:
Επιπλέον, τα λάθη που κάνει σε διαφορετικά μέρη του κώδικα είναι ανεξάρτητα μεταξύ τους. Ποια είναι η πιθανότητα σε 100 νέα μέρη του κώδικα να κάνει συνολικά τουλάχιστον 210 λάθη;
Έστω ανεξάρτητες Τ.Μ. όπου η κάθε έχει την ίδια πυκνότητα όπως πιο πάνω και συμβολίζει το πλήθος των λαθών στο μέρος του κώδικα. Αν ορίσουμε μια νέα διακριτή Τ.Μ. ως το άθροισμα όλων των τότε η πιθανότητα που μας ενδιαφέρει είναι η και, για να την προσεγγίσουμε μέσω του Κ.Ο.Θ., χρειαζόμαστε τη μέση τιμή και τη διασπορά των
Από τον ορισμό των και και την εναλλακτική έκφραση της διασποράς μιας διακριτής Τ.Μ., εύκολα υπολογίζουμε:
Συνεπώς, η πιθανότητα που μας ενδιαφέρει μπορεί να εκφραστεί ως,
Παρατηρήστε πως, εφόσον η Τ.Μ. είναι διακριτή αλλά θα προσεγγίσουμε την κατανομή της με την κανονική η οποία είναι συνεχής, έχουμε αφαιρέσει και πάλι 1/2 από την ποσότητα στο δεξί μέρος της τελευταίας από τις παραπάνω πιθανότητες με βάση το ίδιο σκεπτικό όπως στο Παράδειγμα 12.5.
Εφαρμόζοντας τώρα το Κ.Ο.Θ., βρίσκουμε πως η ζητούμενη πιθανότητα,
όπου αντικαταστήσαμε την τιμή από τον Πίνακα 12.2.
Αξίζει να σημειώσουμε πως, με τη βοήθεια του υπολογιστή, η ζητούμενη πιθανότητα μπορεί να υπολογιστεί ακριβώς και ισούται με Συνεπώς, η προσέγγιση που μας έδωσε το Κ.Ο.Θ. είναι πολύ ικανοποιητική. Επιπλέον, αν είχαμε κάνει τον πιο πάνω υπολογισμό μέσω του Κ.Ο.Θ. χωρίς να αφαιρέσουμε το επιπλέον 1/2, το αποτέλεσμα θα ήταν το οποίο είναι σημαντικά χειρότερο από αυτό που υπολογίσαμε.
Παράδειγμα 12.11 (Δημοψήφισμα 2015: Ποιος δουλεύει ποιον;)
Στις 5 Ιουλίου του 2015 πραγματοποιήθηκε στην Ελλάδα δημοψήφισμα σε σχέση με μια ενδεχόμενη συμφωνία δανεισμού της χώρας από την Ευρωπαϊκή Ένωση, το Διεθνές Νομισματικό Ταμείο και την Κεντρική Ευρωπαϊκή Τράπεζα. Στα αποτελέσματα σχετικής δημοσκόπησης που έκανε μία από τις μεγαλύτερες και πιο έγκυρες εταιρίες δημοσκοπήσεων, ανακοινώθηκε η πρόβλεψη πως η επιλογή του «ΟΧΙ στη συμφωνία» θα έπαιρνε ποσοστό 49,8%, με «στατιστικό σφάλμα» Επιπλέον, όπως ανακοίνωσε η ίδια η εταιρία, η έρευνα έγινε σε δείγμα ατόμων κατά το διάστημα 2-3 Ιουλίου.Το εκλογικό αποτέλεσμα τους διέψευσε οικτρά: Η επιλογή του ΟΧΙ πήρε 61.31%. Εδώ θα εξετάσουμε πόσο πιστευτό είναι αυτό το αποτέλεσμα. Συγκεκριμένα, με δεδομένα τα πραγματικά αποτελέσματα, θα υπολογίσουμε πόσο πιθανό είναι η δημοσκόπηση να είχε πράγματι οδηγήσει στην πρόβλεψη που δόθηκε από την εταιρία στα ΜΜΕ. Για να είμαστε όσο πιο επιεικείς γίνεται, ας θεωρήσουμε πως η πρόβλεψη της εταιρίας ήταν πως το ΟΧΙ θα έπαιρνε δηλαδή 52.5%, και πως η επιλογή του δείγματος έγινε με επανατοποθέτηση1010Στην πράξη δεν έχει σχεδόν καμία διαφορά η επιλογή με ή χωρίς επανατοποθέτηση, μια που εύκολα υπολογίζεται (Άσκηση. Υπολογίστε το.) πως αν η επιλογή ατόμων μεταξύ των εγγεγραμμένων ψηφοφόρων γίνει με επανατοποθέτηση, η πιθανότητα να μην επιλεχθεί κανείς δύο φορές – δηλαδή το αποτέλεσμα να είναι το ίδιο με το να μην είχαμε επανατοποθέτηση – είναι μεγαλύτερη από 0.999., οπότε βρισκόμαστε ακριβώς στο σενάριο του Παραδείγματος 12.7, με δείγματα σε έναν πληθυσμό ψηφοφόρων, όπου το ποσοστό που θέλουμε να προβλέψουμε είναι το
-
1.
Πόσο πιστευτή είναι η πρόβλεψη των δημοσκόπων βάσει του Κ.Ο.Θ.; Πρώτα θα υπολογίσουμε, με τα παραπάνω δεδομένα, την πιθανότητα να πέσει τόσο έξω η πρόβλεψη. Ποια είναι η πιθανότητα η δημοσκόπηση να δώσει αποτέλεσμα 52.5% ή μικρότερο;
Ακολουθώντας ακριβώς τα ίδια βήματα όπως στο Παράδειγμα 12.7, η ζητούμενη πιθανότητα είναι η . Κατ’ αρχάς παρατηρούμε πως εδώ,
άρα δεν είναι απαραίτητη η διόρθωση του «ακέραιου αποτελέσματος» προσθέτοντας ή αφαιρώντας 1/2. Οπότε, προσεγγίζουμε κανονικά τη ζητούμενη πιθανότητα μέσω του Κ.Ο.Θ.,
όπου η εξαιρετικά μικρή αυτή τιμή δεν συμπεριλαμβάνεται στους πίνακές μας, αλλά εύκολα μπορεί να βρεθεί με τη χρήση υπολογιστή.
-
2.
Ακριβώς πόσο πιστευτή είναι η πρόβλεψη των δημοσκόπων; Η πιθανότητα που βρήκαμε πιο πάνω, , είναι αστρονομικά μικρή. Για να έχουμε ένα μέτρο σύγκρισης, είναι παρόμοια με την πιθανότητα να κρύψουμε έναν συγκεκριμένο κόκκο άμμου σε μια παραλία και κάποιος που διαλέγει στην τύχη έναν κόκκο άμμου από ολόκληρη την παραλία να τον πετύχει! Αλλά είναι σημαντικό να θυμόμαστε πως ο υπολογισμός που μας οδήγησε σε αυτή την πιθανότητα ήταν προσεγγιστικός. Για τόσο μικρές τιμές, το σφάλμα που αναπόφευκτα εισάγεται από την προσέγγιση μπορεί να επηρεάζει σημαντικά το αποτέλεσμα.
Επανεξετάζουμε λοιπόν την πιθανότητα του να πέσει τόσο έξω η πρόβλεψη της εταιρίας, η οποία ήδη είδαμε πως μπορεί να εκφραστεί ως, , όπου η Τ.Μ. έχει κατανομή . Άρα, μπορούμε με τη χρήση του υπολογιστή να την υπολογίσουμε ακριβώς, χωρίς καμία προσέγγιση:
Συμπεραίνουμε λοιπόν πως, αν η μεθοδολογία που χρησιμοποιήθηκε είναι αυτή η οποία δηλώνεται, με βάση τα πραγματικά δεδομένα στην καλύτερη περίπτωση τα αποτελέσματα που παρουσιάστηκαν από την εταιρία είναι μαθηματικώς ανεξήγητα.
-
3.
Χωρίς επανατοποθέτηση; Τέλος, εξετάζουμε το ενδεχόμενο του να έχει επηρεαστεί σημαντικά ο υπολογισμός μας από την υπόθεση ότι η επιλογή των δειγμάτων γινόταν με επανατοποθέτηση. Στην περίπτωση που η επιλογή έγινε χωρίς επανατοποθέτηση, τότε η ζητούμενη πιθανότητα είναι και πάλι η , αλλά τώρα η Τ.Μ. έχει κατανομή , όπου είναι το συνολικό πλήθος των ψηφοφόρων, είναι το πλήθος εκείνων που σκόπευαν πράγματι να ψηφίσουν ΟΧΙ και είναι το μέγεθος του δείγματος.
Όπως πιο πάνω, μπορούμε να υπολογίσουμε,
το οποίο, αντικαθιστώντας τον τύπο της πυκνότητας της υπεργεωμετρικής κατανομής, και με τη χρήση υπολογιστή, μας δίνει
Άρα και εδώ συμπεραίνουμε πως, αν η μεθοδολογία της εταιρίας είναι πράγματι αυτή την οποία περιγράφει, είναι μαθηματικά αδικαιολόγητα τα αποτελέσματα της δημοσκόπησης.
-
4.
Η δημοσκόπηση είναι εύκολη δουλειά. Εδώ θα δούμε πως, παρά τις ατελείωτες αναλύσεις «ειδικών» στα ΜΜΕ, είναι μάλλον απλή υπόθεση η σχετικά ασφαλής πρόβλεψη του αποτελέσματος ενός δημοψηφίσματος: Έστω πως θέλαμε να προβλέψουμε το πραγματικό ποσοστό , ακολουθώντας την απλούστερη δυνατή μεθοδολογία, επιλέγοντας, λ.χ., μόνο ανεξάρτητα δείγματα από τον πληθυσμό των ψηφοφόρων (λιγότερα από τα μισά από όσα συμμετείχαν στην έρευνα της εταιρίας πιο πάνω), με επανατοποθέτηση. Τότε, η πιθανότητα το αποτέλεσμα της πρόβλεψής μας να απείχε από την πραγματικότητα περισσότερο από (όπου εδώ είμαστε πιο αυστηροί γιατί μετράμε το ενδεχόμενο λάθος και προς τα «πάνω» και προς τα «κάτω»), μπορεί εύκολα και με ακρίβεια να προσεγγιστεί μέσω του Κ.Ο.Θ. όπως και πριν. Αρχικά γράφουμε,
και από το Κ.Ο.Θ. βρίσκουμε,
Άρα, με αυτή την πολύ απλοϊκή μεθοδολογία, και με πολύ λιγότερα δείγματα, είμαστε βέβαιοι με πιθανότητα ότι θα πετύχουμε το σωστό εκλογικό αποτέλεσμα με σφάλμα μικρότερο από .
12.4 Πίνακες τιμών της τυπικής κανονικής κατανομής
Ο Πίνακας 12.1 περιέχει τιμές της συνάρτησης κατανομής,
της τυπικής κανονικής κατανομής για αρνητικές τιμές του .
Παρομοίως, ο Πίνακας 12.2 περιέχει τιμές της συνάρτησης κατανομής της τυπικής κανονικής κατανομής για θετικές τιμές του . Οι σχετικοί υπολογισμοί αναπαρίστανται γραφικά στο Σχήμα 12.4.
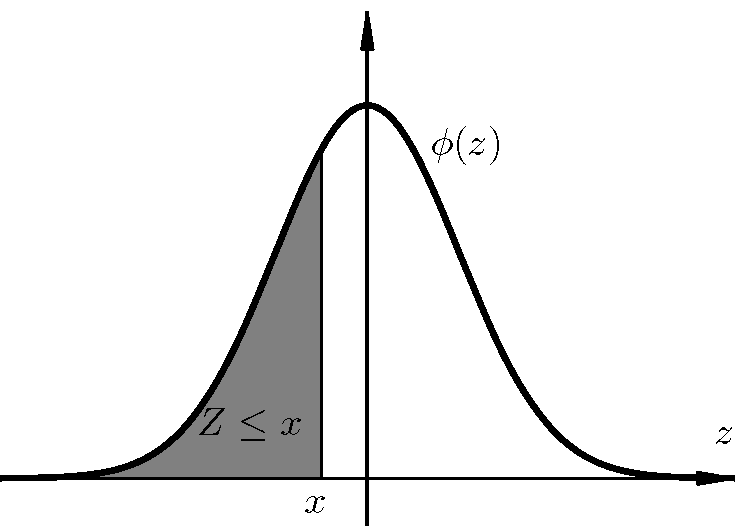 |
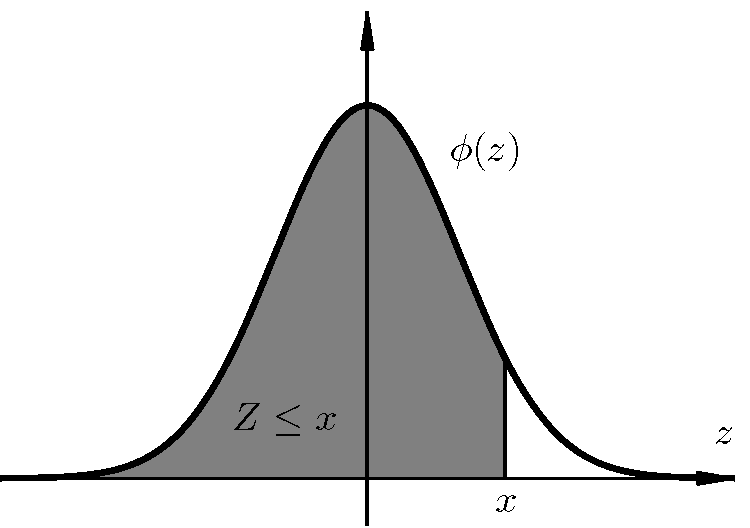 |
Είναι, φυσικά, προφανές πως ο δεύτερος πίνακας είναι περιττός: Λόγω της συμμετρίας της τυπικής κανονικής πυκνότητας , για οποιαδήποτε θετική τιμή του η μπορεί εύκολα να υπολογιστεί ως .
| 0.00 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.06 | 0.07 | 0.08 | 0.09 | |
|---|---|---|---|---|---|---|---|---|---|---|
| -3.9 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| -3.8 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| -3.7 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| -3.6 | 0.0002 | 0.0002 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| -3.5 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 |
| -3.4 | 0.0003 | 0.0003 | 0.0003 | 0.0003 | 0.0003 | 0.0003 | 0.0003 | 0.0003 | 0.0003 | 0.0002 |
| -3.3 | 0.0005 | 0.0005 | 0.0005 | 0.0004 | 0.0004 | 0.0004 | 0.0004 | 0.0004 | 0.0004 | 0.0003 |
| -3.2 | 0.0007 | 0.0007 | 0.0006 | 0.0006 | 0.0006 | 0.0006 | 0.0006 | 0.0005 | 0.0005 | 0.0005 |
| -3.1 | 0.0010 | 0.0009 | 0.0009 | 0.0009 | 0.0008 | 0.0008 | 0.0008 | 0.0008 | 0.0007 | 0.0007 |
| -3.0 | 0.0013 | 0.0013 | 0.0013 | 0.0012 | 0.0012 | 0.0011 | 0.0011 | 0.0011 | 0.0010 | 0.0010 |
| -2.9 | 0.0019 | 0.0018 | 0.0018 | 0.0017 | 0.0016 | 0.0016 | 0.0015 | 0.0015 | 0.0014 | 0.0014 |
| -2.8 | 0.0026 | 0.0025 | 0.0024 | 0.0023 | 0.0023 | 0.0022 | 0.0021 | 0.0021 | 0.0020 | 0.0019 |
| -2.7 | 0.0035 | 0.0034 | 0.0033 | 0.0032 | 0.0031 | 0.0030 | 0.0029 | 0.0028 | 0.0027 | 0.0026 |
| -2.6 | 0.0047 | 0.0045 | 0.0044 | 0.0043 | 0.0041 | 0.0040 | 0.0039 | 0.0038 | 0.0037 | 0.0036 |
| -2.5 | 0.0062 | 0.0060 | 0.0059 | 0.0057 | 0.0055 | 0.0054 | 0.0052 | 0.0051 | 0.0049 | 0.0048 |
| -2.4 | 0.0082 | 0.0080 | 0.0078 | 0.0075 | 0.0073 | 0.0071 | 0.0069 | 0.0068 | 0.0066 | 0.0064 |
| -2.3 | 0.0107 | 0.0104 | 0.0102 | 0.0099 | 0.0096 | 0.0094 | 0.0091 | 0.0089 | 0.0087 | 0.0084 |
| -2.2 | 0.0139 | 0.0136 | 0.0132 | 0.0129 | 0.0125 | 0.0122 | 0.0119 | 0.0116 | 0.0113 | 0.0110 |
| -2.1 | 0.0179 | 0.0174 | 0.0170 | 0.0166 | 0.0162 | 0.0158 | 0.0154 | 0.0150 | 0.0146 | 0.0143 |
| -2.0 | 0.0228 | 0.0222 | 0.0217 | 0.0212 | 0.0207 | 0.0202 | 0.0197 | 0.0192 | 0.0188 | 0.0183 |
| -1.9 | 0.0287 | 0.0281 | 0.0274 | 0.0268 | 0.0262 | 0.0256 | 0.0250 | 0.0244 | 0.0239 | 0.0233 |
| -1.8 | 0.0359 | 0.0351 | 0.0344 | 0.0336 | 0.0329 | 0.0322 | 0.0314 | 0.0307 | 0.0301 | 0.0294 |
| -1.7 | 0.0446 | 0.0436 | 0.0427 | 0.0418 | 0.0409 | 0.0401 | 0.0392 | 0.0384 | 0.0375 | 0.0367 |
| -1.6 | 0.0548 | 0.0537 | 0.0526 | 0.0516 | 0.0505 | 0.0495 | 0.0485 | 0.0475 | 0.0465 | 0.0455 |
| -1.5 | 0.0668 | 0.0655 | 0.0643 | 0.0630 | 0.0618 | 0.0606 | 0.0594 | 0.0582 | 0.0571 | 0.0559 |
| -1.4 | 0.0808 | 0.0793 | 0.0778 | 0.0764 | 0.0749 | 0.0735 | 0.0721 | 0.0708 | 0.0694 | 0.0681 |
| -1.3 | 0.0968 | 0.0951 | 0.0934 | 0.0918 | 0.0901 | 0.0885 | 0.0869 | 0.0853 | 0.0838 | 0.0823 |
| -1.2 | 0.1151 | 0.1131 | 0.1112 | 0.1093 | 0.1075 | 0.1056 | 0.1038 | 0.1020 | 0.1003 | 0.0985 |
| -1.1 | 0.1357 | 0.1335 | 0.1314 | 0.1292 | 0.1271 | 0.1251 | 0.1230 | 0.1210 | 0.1190 | 0.1170 |
| -1.0 | 0.1587 | 0.1562 | 0.1539 | 0.1515 | 0.1492 | 0.1469 | 0.1446 | 0.1423 | 0.1401 | 0.1379 |
| -0.9 | 0.1841 | 0.1814 | 0.1788 | 0.1762 | 0.1736 | 0.1711 | 0.1685 | 0.1660 | 0.1635 | 0.1611 |
| -0.8 | 0.2119 | 0.2090 | 0.2061 | 0.2033 | 0.2005 | 0.1977 | 0.1949 | 0.1922 | 0.1894 | 0.1867 |
| -0.7 | 0.2420 | 0.2389 | 0.2358 | 0.2327 | 0.2296 | 0.2266 | 0.2236 | 0.2206 | 0.2177 | 0.2148 |
| -0.6 | 0.2743 | 0.2709 | 0.2676 | 0.2643 | 0.2611 | 0.2578 | 0.2546 | 0.2514 | 0.2483 | 0.2451 |
| -0.5 | 0.3085 | 0.3050 | 0.3015 | 0.2981 | 0.2946 | 0.2912 | 0.2877 | 0.2843 | 0.2810 | 0.2776 |
| -0.4 | 0.3446 | 0.3409 | 0.3372 | 0.3336 | 0.3300 | 0.3264 | 0.3228 | 0.3192 | 0.3156 | 0.3121 |
| -0.3 | 0.3821 | 0.3783 | 0.3745 | 0.3707 | 0.3669 | 0.3632 | 0.3594 | 0.3557 | 0.3520 | 0.3483 |
| -0.2 | 0.4207 | 0.4168 | 0.4129 | 0.4090 | 0.4052 | 0.4013 | 0.3974 | 0.3936 | 0.3897 | 0.3859 |
| -0.1 | 0.4602 | 0.4562 | 0.4522 | 0.4483 | 0.4443 | 0.4404 | 0.4364 | 0.4325 | 0.4286 | 0.4247 |
| 0.0 | 0.5000 | 0.4960 | 0.4920 | 0.4880 | 0.4840 | 0.4801 | 0.4761 | 0.4721 | 0.4681 | 0.4641 |
Πίνακας 12.2: Τιμές της τυπικής κανονικής συνάρτησης κατανομής για θετικά
| 0.00 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.06 | 0.07 | 0.08 | 0.09 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 0.5000 | 0.5040 | 0.5080 | 0.5120 | 0.5160 | 0.5199 | 0.5239 | 0.5279 | 0.5319 | 0.5359 |
| 0.1 | 0.5398 | 0.5438 | 0.5478 | 0.5517 | 0.5557 | 0.5596 | 0.5636 | 0.5675 | 0.5714 | 0.5753 |
| 0.2 | 0.5793 | 0.5832 | 0.5871 | 0.5910 | 0.5948 | 0.5987 | 0.6026 | 0.6064 | 0.6103 | 0.6141 |
| 0.3 | 0.6179 | 0.6217 | 0.6255 | 0.6293 | 0.6331 | 0.6368 | 0.6406 | 0.6443 | 0.6480 | 0.6517 |
| 0.4 | 0.6554 | 0.6591 | 0.6628 | 0.6664 | 0.6700 | 0.6736 | 0.6772 | 0.6808 | 0.6844 | 0.6879 |
| 0.5 | 0.6915 | 0.6950 | 0.6985 | 0.7019 | 0.7054 | 0.7088 | 0.7123 | 0.7157 | 0.7190 | 0.7224 |
| 0.6 | 0.7257 | 0.7291 | 0.7324 | 0.7357 | 0.7389 | 0.7422 | 0.7454 | 0.7486 | 0.7517 | 0.7549 |
| 0.7 | 0.7580 | 0.7611 | 0.7642 | 0.7673 | 0.7704 | 0.7734 | 0.7764 | 0.7794 | 0.7823 | 0.7852 |
| 0.8 | 0.7881 | 0.7910 | 0.7939 | 0.7967 | 0.7995 | 0.8023 | 0.8051 | 0.8078 | 0.8106 | 0.8133 |
| 0.9 | 0.8159 | 0.8186 | 0.8212 | 0.8238 | 0.8264 | 0.8289 | 0.8315 | 0.8340 | 0.8365 | 0.8389 |
| 1.0 | 0.8413 | 0.8438 | 0.8461 | 0.8485 | 0.8508 | 0.8531 | 0.8554 | 0.8577 | 0.8599 | 0.8621 |
| 1.1 | 0.8643 | 0.8665 | 0.8686 | 0.8708 | 0.8729 | 0.8749 | 0.8770 | 0.8790 | 0.8810 | 0.8830 |
| 1.2 | 0.8849 | 0.8869 | 0.8888 | 0.8907 | 0.8925 | 0.8944 | 0.8962 | 0.8980 | 0.8997 | 0.9015 |
| 1.3 | 0.9032 | 0.9049 | 0.9066 | 0.9082 | 0.9099 | 0.9115 | 0.9131 | 0.9147 | 0.9162 | 0.9177 |
| 1.4 | 0.9192 | 0.9207 | 0.9222 | 0.9236 | 0.9251 | 0.9265 | 0.9279 | 0.9292 | 0.9306 | 0.9319 |
| 1.5 | 0.9332 | 0.9345 | 0.9357 | 0.9370 | 0.9382 | 0.9394 | 0.9406 | 0.9418 | 0.9429 | 0.9441 |
| 1.6 | 0.9452 | 0.9463 | 0.9474 | 0.9484 | 0.9495 | 0.9505 | 0.9515 | 0.9525 | 0.9535 | 0.9545 |
| 1.7 | 0.9554 | 0.9564 | 0.9573 | 0.9582 | 0.9591 | 0.9599 | 0.9608 | 0.9616 | 0.9625 | 0.9633 |
| 1.8 | 0.9641 | 0.9649 | 0.9656 | 0.9664 | 0.9671 | 0.9678 | 0.9686 | 0.9693 | 0.9699 | 0.9706 |
| 1.9 | 0.9713 | 0.9719 | 0.9726 | 0.9732 | 0.9738 | 0.9744 | 0.9750 | 0.9756 | 0.9761 | 0.9767 |
| 2.0 | 0.9772 | 0.9778 | 0.9783 | 0.9788 | 0.9793 | 0.9798 | 0.9803 | 0.9808 | 0.9812 | 0.9817 |
| 2.1 | 0.9821 | 0.9826 | 0.9830 | 0.9834 | 0.9838 | 0.9842 | 0.9846 | 0.9850 | 0.9854 | 0.9857 |
| 2.2 | 0.9861 | 0.9864 | 0.9868 | 0.9871 | 0.9875 | 0.9878 | 0.9881 | 0.9884 | 0.9887 | 0.9890 |
| 2.3 | 0.9893 | 0.9896 | 0.9898 | 0.9901 | 0.9904 | 0.9906 | 0.9909 | 0.9911 | 0.9913 | 0.9916 |
| 2.4 | 0.9918 | 0.9920 | 0.9922 | 0.9925 | 0.9927 | 0.9929 | 0.9931 | 0.9932 | 0.9934 | 0.9936 |
| 2.5 | 0.9938 | 0.9940 | 0.9941 | 0.9943 | 0.9945 | 0.9946 | 0.9948 | 0.9949 | 0.9951 | 0.9952 |
| 2.6 | 0.9953 | 0.9955 | 0.9956 | 0.9957 | 0.9959 | 0.9960 | 0.9961 | 0.9962 | 0.9963 | 0.9964 |
| 2.7 | 0.9965 | 0.9966 | 0.9967 | 0.9968 | 0.9969 | 0.9970 | 0.9971 | 0.9972 | 0.9973 | 0.9974 |
| 2.8 | 0.9974 | 0.9975 | 0.9976 | 0.9977 | 0.9977 | 0.9978 | 0.9979 | 0.9979 | 0.9980 | 0.9981 |
| 2.9 | 0.9981 | 0.9982 | 0.9982 | 0.9983 | 0.9984 | 0.9984 | 0.9985 | 0.9985 | 0.9986 | 0.9986 |
| 3.0 | 0.9987 | 0.9987 | 0.9987 | 0.9988 | 0.9988 | 0.9989 | 0.9989 | 0.9989 | 0.9990 | 0.9990 |
| 3.1 | 0.9990 | 0.9991 | 0.9991 | 0.9991 | 0.9992 | 0.9992 | 0.9992 | 0.9992 | 0.9993 | 0.9993 |
| 3.2 | 0.9993 | 0.9993 | 0.9994 | 0.9994 | 0.9994 | 0.9994 | 0.9994 | 0.9995 | 0.9995 | 0.9995 |
| 3.3 | 0.9995 | 0.9995 | 0.9995 | 0.9996 | 0.9996 | 0.9996 | 0.9996 | 0.9996 | 0.9996 | 0.9997 |
| 3.4 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 0.9998 |
| 3.5 | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 0.9998 |
| 3.6 | 0.9998 | 0.9998 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 3.7 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 3.8 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 3.9 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
12.5 Ασκήσεις
-
1.
Τυχαία επιλογή Τ.Μ. Η Τ.Μ. έχει ομοιόμορφη κατανομή στο διάστημα , και η Τ.Μ. έχει κανονική κατανομή με μέση τιμή και διασπορά . Ρίχνουμε ένα δίκαιο νόμισμα, και αν έρθει Κορώνα καταγράφουμε την τιμή του , ενώ αν έρθει Γράμματα καταγράφουμε την τιμή του . Αν υποθέσουμε ότι η τιμή που καταγράψαμε είναι μεγαλύτερη του , ποια είναι η πιθανότητα να είχαμε επιλέξει τη ;
-
2.
Ύψη μαθητών. Το ύψος των μαθητών ενός σχολείου ακολουθεί κανονική κατανομή με μέση τιμή για τα αγόρια και για τα κορίτσια, και με διασπορά κοινή για αγόρια και κορίτσια. Αν υποθέσουμε ότι το πλήθος των αγοριών και των κοριτσιών σε αυτό το σχολείο είναι ακριβώς ίδιο, υπολογίστε την πιθανότητα το ύψος ενός μαθητή που επιλέγεται στην τύχη να ξεπερνά το .
-
3.
Αριθμητικοί υπολογισμοί με την κανονική κατανομή. Έστω μια τυχαία μεταβλητή με κανονική κατανομή .
-
(α’)
Αν και , να βρεθούν οι και .
-
(β’)
Αν και , να βρεθούν οι και ή .
-
(γ’)
Αν και , να βρεθεί η ή .
-
(δ’)
Αν και , να βρεθούν οι και .
-
(ε’)
Αν και , να βρεθεί η μέση τιμή των και .
-
(στ’)
Αν , να βρεθεί η τιμή της διασποράς για την οποία .
-
(α’)
-
4.
Τετράγωνο κανονικής Τ.Μ. Έστω μια Τ.Μ. και μια σταθερά . Να βρεθούν η συνάρτηση κατανομής και η πυκνότητα της .
-
5.
Η κατανομή Έστω ανεξάρτητες Τ.Μ. με κάθε , και έστω η Τ.Μ. . Η κατανομή της ονομάζεται κατανομή με βαθμούς ελευθερίας, και συμβολίζεται, .
-
(α’)
Υπολογίστε την .
-
(β’)
Υπολογίστε τη μέση τιμή της κατανομής .
-
(γ’)
Βρείτε τη διασπορά, την πυκνότητα και τη συνάρτηση κατανομής της για .
-
(α’)
-
6.
Λογαριθμοκανονική κατανομή. Να βρεθούν η πυκνότητα και η συνάρτηση κατανομής της συναρτήσει της πυκνότητας και της συνάρτησης κατανομής της συνεχούς Τ.Μ. . Προσδιορίστε τις , στην ειδική περίπτωση που η έχει κανονική κατανομή .
-
7.
Γραμμικός μετασχηματισμός. Αποδείξτε πως, αν η , τότε η έχει κατανομή .
-
8.
Όλα στο 13! Σε ένα καζίνο, αν ποντάρουμε στη ρουλέτα ευρώ σε κάποιο νούμερο από το ως το και έρθει αυτό το νούμερο (πράγμα που συμβαίνει με πιθανότητα στις ) παίρνουμε ευρώ (το αρχικό μας στοίχημα συν ευρώ). Αν έρθει κάποιο άλλο νούμερο, χάνουμε το ευρώ. Ένας παίκτης ξεκινάει με ευρώ και τα ποντάρει όλα μαζί στο «», κι ένας άλλος ξεκινάει με ευρώ και ποντάρει ευρώ στο «» σε διαδοχικά (ανεξάρτητα) παιχνίδια της ρουλέτας.
-
(α’)
Δείξτε ότι και στις δύο περιπτώσεις, τα αναμενόμενα χρήματα που θα έχουν απομείνει στους παίκτες μετά το παιχνίδι είναι τα ίδια.
-
(β’)
Και για τις δύο περιπτώσεις, υπολογίστε τη διασπορά των χρημάτων των παικτών. Σχολιάστε.
-
(γ’)
Και για τις δύο περιπτώσεις, υπολογίστε την πιθανότητα ο παίκτης στο τέλος να έχει παραπάνω από ευρώ. Σχολιάστε.
-
(α’)
-
9.
Κόκκινο-μαύρο. Ένας συντηρητικός παίκτης της ρουλέτας ποντάρει σε κάθε γύρο ένα ευρώ στο κόκκινο. Αν έρθει κόκκινο, πράγμα το οποίο συμβαίνει με πιθανότητα , κερδίζει ένα ευρώ, ενώ αν έρθει μαύρο ή «0», με πιθανότητα , χάνει το ευρώ που είχε ποντάρει. Υπολογίστε μια καλή προσέγγιση για την πιθανότητα μετά από 150 γύρους να μην έχει βγει χαμένος.
-
10.
Online game. Σε ένα online παιχνίδι, όποτε ένα τανκ εκτελεί μια βολή, η βολή: είναι άστοχη με πιθανότητα , οπότε και προκαλείται στον αντίπαλο ζημιά 0 μονάδων ζωής, ή είναι απλώς επιτυχημένη με πιθανότητα , οπότε προκαλείται στον αντίπαλο ζημιά μονάδων ζωής, ή είναι εξαιρετικά επιτυχημένη (critical hit) με πιθανότητα , οπότε προκαλείται ζημιά μονάδων.
-
(α’)
Έστω η Τ.Μ. που περιγράφει τις μονάδες ζωής της ζημιάς που προκαλείται από μία βολή. Να υπολογίσετε τη μέση τιμή και τη διασπορά της.
-
(β’)
Ποια είναι η πιθανότητα, μετά από βολές, το άθροισμα όλων των ζημιών να υπερβαίνει τις μονάδες;
-
(α’)
-
11.
Χαμένος χρόνος. Κάθε πρωί, ο χρόνος που περιμένω μέχρι να έρθει το λεωφορείο για να πάω στο γραφείο μου έχει μέση τιμή 20 λεπτά και είναι εκθετικά κατανεμημένος. Στις 259 εργάσιμες μέρες που έχει ένας χρόνος, ποια είναι η πιθανότητα να έχω χάσει πάνω από τέσσερις ολόκληρες μέρες της ζωής μου περιμένοντας το λεωφορείο;
-
12.
Ζυγοβίστι Αρκαδίας. Η ετήσια βροχόπτωση στο Ζυγοβίστι Αρκαδίας περιγράφεται από μια συνεχή Τ.Μ. (σε εκατοστά), με πυκνότητα:
-
(α’)
Κατά μέσο όρο, πόσα εκατοστά βροχής πέφτουν κάθε χρόνο στο Ζυγοβίστι; Ποια είναι η διασπορά τους;
-
(β’)
Έχει παρατηρηθεί ότι η ποσότητα των καρυδιών που παράγει κάθε χρόνο το Ζυγοβίστι, σε τόνους, περιγράφεται από την Τ.Μ. . Κατά μέσο όρο, πόσους τόνους καρύδια παράγει το Ζυγοβίστι κάθε χρόνο;
-
(γ’)
Για να πετύχει η δενδροφύτευση σπάνιων κέδρων την οποία αποφάσισε η κοινότητα, απαιτείται για τα επόμενα χρόνια να πέσουν λιγότερα από εκατοστά βροχής. Ποια είναι η πιθανότητα να επιτύχει η δενδροφύτευση;
-
(α’)
-
13.
Αποσυγχρονισμός. Έστω πως βλέπω ένα streaming βίντεο στον υπολογιστή μου, και παρατηρώ ότι, κάθε φορά που αποφασίζω να το πάω πιο μπροστά ή πιο πίσω, αποσυγχρονίζεται ο ήχος με την εικόνα κατά δέκατα του δευτερολέπτου (ανεξάρτητα από τη μία φορά στην άλλη), όπου η έχει την πυκνότητα που είδαμε στην Άσκηση 8 του Κεφαλαίου 10.
Αν μετακινήσω το σημείο που βλέπω στο βίντεο 200 φορές, ποια είναι η πιθανότητα να έχει αποσυγχρονιστεί συνολικά ο ήχος κατά περισσότερα από δευτερόλεπτο;
-
14.
Τηλεφωνικές κλήσεις. Όπως στο Παράδειγμα 12.9, ας υποθέσουμε πως η διάρκεια κάθε κλήσης (σε δευτερόλεπτα) σε ένα δίκτυο έχει κατανομή και οι διάρκειες διαδοχικών κλήσεων είναι ανεξάρτητες. Μια κλήση θεωρείται «σύντομη» αν διαρκέσει λιγότερο από ένα λεπτό. Ποια είναι η πιθανότητα, το πλήθος των σύντομων κλήσεων ανάμεσα στις 250 που έγιναν σε μία μέρα να είναι μικρότερο από 120;
-
15.
Εκτίμηση με θόρυβο. Έστω πως θέλουμε να εκτιμήσουμε την άγνωστη μέση τιμή κάποιας Τ.Μ. , χρησιμοποιώντας τις τιμές ανεξάρτητων Τ.Μ. , όλες με την ίδια κατανομή με τη . Έστω επίσης πως γνωρίζουμε ότι οι έχουν διασπορά .
-
(α’)
Αν για την εκτίμηση του χρησιμοποιήσουμε τον εμπειρικό μέσο όρο , υπολογίστε κατά προσέγγιση πόσο μεγάλο πρέπει να είναι το μέγεθος του δείγματός μας, ώστε με πιθανότητα τουλάχιστον 95% η εκτίμιση να μην απέχει από την πραγματική τιμή κατά περισσότερο από 0.2, δηλαδή να έχουμε .
-
(β’)
Έστω τώρα ότι (όπως στην Άσκηση 13 του Κεφαλαίου 9) αντί για τα τα ίδια, το μόνο που έχουμε διαθέσιμο είναι τα δείγματα , για , όπου το κάθε είναι μια τυχαία μέτρηση του αντίστοιχου συν κάποιο τυχαίο «θόρυβο» . Υποθέτουμε ότι τα είναι ανεξάρτητα από τα , ότι είναι ανεξάρτητα μεταξύ τους, και ότι όλα έχουν την ίδια κατανομή, με κάποια γνωστή μέση τιμή και γνωστή διασπορά .
Περιγράψτε μια μέθοδο εκτίμησης της μέσης τιμής και πάλι υπολογίστε κατά προσέγγιση πόσο μεγάλο πρέπει να είναι το , ώστε με πιθανότητα τουλάχιστον 95% η εκτίμιση να μην απέχει από την πραγματική τιμή κατά περισσότερο από 0.2.
-
ΠΟΛΥΜΕΣΙΚΟ ΥΛΙΚΟ ΚΕΦΑΛΑΙΟΥ
-
(α’)




Κεφάλαιο 13 Κ.Ο.Θ.: Λίγη θεωρία και αποδείξεις
[Επιστροφή στα περιεχόμενα]
Σε αυτό το κεφάλαιο θα δούμε τέσσερις αποδείξεις αποτελεσμάτων που σχετίζονται με την κανονική κατανομή και το Κ.Ο.Θ., οι οποίες είναι αρκετά πιο απαιτητικές, από μαθηματική άποψη, από τις περισσότερες αποδείξεις που έχουμε συναντήσει ως τώρα. Στην Ενότητα 13.1 θα δώσουμε την απόδειξη, την οποία παραλείψαμε νωρίτερα, ενός απλού αποτελέσματος από την Ενότητα 12.1: Το ολοκλήρωμα της πυκνότητας οποιασδήποτε κανονικής Τ.Μ. ισούται με ένα. Κατόπιν, στην Ενότητα 13.2 θα δούμε πως το Κ.Ο.Θ., κάτω από πολύ γενικές συνθήκες, μπορεί να χρησιμοποιηθεί για να αποδειχθεί ο Ν.Μ.Α. Κατά συνέπεια είναι, ως μαθηματικό αποτέλεσμα, αυστηρά ισχυρότερο από τον Ν.Μ.Α.
Όπως αναφέραμε στο προηγούμενο κεφάλαιο, η απόδειξη του Κ.Ο.Θ. είναι τεχνικής φύσεως και ξεπερνά τους στόχους του παρόντος βιβλίου. Παρ’ όλα αυτά, στις Ενότητες 13.3 και 13.4 θα δούμε κάποιες ενδιαφέρουσες πτυχές αυτού του θέματος. Συγκεκριμένα, στην Ενότητα 13.3 θα αποδείξουμε μια ισχυρή μορφή του Κ.Ο.Θ., το λεγόμενο «θεώρημα de Moivre-Laplace», για την απλή περίπτωση που οι Τ.Μ. έχουν κατανομή Bernoulli. Η απόδειξη αυτή (όπως κι εκείνη της επόμενης ενότητας) είναι κάπως μακροσκελής, και η αλήθεια είναι πως υπάρχουν πολύ πιο σύντομες αποδείξεις του Κ.Ο.Θ. κάτω από πιο γενικές συνθήκες. Αυτές όμως απαιτούν τη χρήση εργαλείων της ανάλυσης Fourier ή άλλων αρκετά πιο προχωρημένων μαθηματικών περιοχών.
Τέλος, στην Ενότητα 13.4, θα δώσουμε μια όμορφη απόδειξη, εκείνη του Lindeberg, για τη γενική περίπτωση του Κ.Ο.Θ. όπως διατυπώθηκε στο Κεφάλαιο 12. Σε αντίθεση με την απόδειξη του θεωρήματος de Moivre-Laplace, η οποία βασίζεται σε μια σειρά από στοιχειώδεις υπολογισμούς, η κεντρική ιδέα της απόδειξης του Lindeberg είναι μια έξυπνη χρήση κάποιων πολύ απλών αποτελεσμάτων του διαφορικού λογισμού.
13.1 Το γκαουσιανό ολοκλήρωμα
Εδώ θα δείξουμε πως η πυκνότητα,
μιας Τ.Μ. με κατανομή έχει πράγματι ολοκλήρωμα ίσο με ένα, δηλαδή,
| (13.1) |
Ξεκινάμε με την αντικατάσταση , οπότε , και,
Άρα, για να δείξουμε το ζητούμενο αποτέλεσμα της σχέσης (13.1) αρκεί να αποδείξουμε πως το πιο κάτω ολοκλήρωμα ισούται με :
| (13.2) |
Εφόσον η είναι άρτια συνάρτηση του , έχουμε,
και παίρνοντας το τετράγωνο αυτής της σχέσης,
δηλαδή,
Τώρα, για κάθε συγκεκριμένο , στο εσωτερικό ολοκλήρωμα κάνουμε την αντικατάσταση , οπότε και,
όπου στο τελευταίο βήμα αλλάξαμε τη σειρά των δύο ολοκληρωμάτων (βλ. θεώρημα του Fubini στο Κεφάλαιο 15). Παρατηρούμε πως,
άρα το εσωτερικό ολοκλήρωμα παραπάνω μπορεί να επιλυθεί ακριβώς,
Τέλος, θυμίζουμε πως η παράγωγος της συνάρτησης είναι η , οπότε καταλήγουμε στη σχέση,
η οποία μας δίνει το ζητούμενο αποτέλεσμα, , αποδεικνύοντας την (13.2) και, κατά συνέπεια, το αρχικό μας ζητούμενο αποτέλεσμα (13.1).
13.2 Κ.Ο.Θ. Ν.Μ.Α.: Απόδειξη
Έστω οι ανεξάρτητες (συνεχείς ή διακριτές) Τ.Μ. , οι οποίες έχουν όλες την ίδια κατανομή, και άρα έχουν την ίδια μέση τιμή και την ίδια διασπορά .
Ο Ν.Μ.Α. μάς λέει πως, για μεγάλα , ο εμπειρικός τους μέσος όρος,
θα είναι κοντά στη μέση τιμή τους , με μεγάλη πιθανότητα. Επιπλέον, όπως είδαμε στο προηγούμενο κεφάλαιο, το Κ.Ο.Θ. μάς δίνει μια πιο λεπτομερή ποσοτική περιγραφή του : Για μεγάλα , ο εμπειρικός μέσος όρος έχει κατά προσέγγιση κατανομή.
Σε αυτή την ενότητα θα δείξουμε πως το Κ.Ο.Θ. είναι πράγματι πιο ισχυρό αποτέλεσμα, με την αυστηρά μαθηματική έννοια, από τον Ν.Μ.Α. Είναι μάλιστα αξιοσημείωτο πως για να αποδείξουμε τον Ν.Μ.Α. δεν χρειάζεται να κάνουμε οποιαδήποτε άλλη υπόθεση για τις Τ.Μ. (λόγου χάρη, δεν είναι απαραίτητο να θεωρήσουμε καν ότι είναι ανεξάρτητες) πέραν του ότι ικανοποιούν το Κ.Ο.Θ.
Πρόταση 13.2 Έστω μια οποιαδήποτε ακολουθία τυχαίων μεταβλητών, και σταθερές για τις οποίες ισχύει το Κ.Ο.Θ. όπως διατυπώνεται στη σχέση (12.4) του Θεωρήματος 12.2. Τότε, για τις ισχύει και ο Ν.Μ.Α.: Ο εμπειρικός τους μέσος όρος τείνει στη σταθερά κατά πιθανότητα καθώς το
Υπενθύμιση: και Ως γνωστόν, μια ακολουθία πραγματικών αριθμών δεν είναι απαραίτητο να έχει κάποιο όριο καθώς το . Αλλά μπορούμε πάντα να ορίσουμε,
όπου τα δύο παραπάνω όρια πάντοτε υπάρχουν και ικανοποιούν (γιατί;). Στην απόδειξη που ακολουθεί και σε κάποια άλλα σημεία του κεφαλαίου θα χρειαστούμε αυτές τις έννοιες, όπως και την απλή παρατήρηση ότι το όριο της υπάρχει και ισούται με , αν και μόνο αν έχουμε .
Απόδειξη της Πρότασης 13.2:
Έστω αυθαίρετο . Για τον Ν.Μ.Α. πρέπει να αποδείξουμε πως,
για το οποίο αρκεί να δείξουμε πως για κάθε ,
| (13.3) |
Έστω λοιπόν αυθαίρετο. Εφόσον η τυπική κανονική συνάρτηση κατανομής καθώς το , και καθώς το , μπορούμε να διαλέξουμε ένα αρκετά μεγάλο ώστε να έχουμε,
| (13.4) |
Παρατηρούμε πως η πιθανότητα που μας ενδιαφέρει ισούται με,
| (13.5) | |||||
όπου είναι το κανονικοποιημένο άθροισμα όπως στο Κ.Ο.Θ. Από τον δεύτερο κανόνα πιθανότητας, ξέρουμε πως η πρώτη πιθανότητα στην έκφραση (13.5) είναι αύξουσα συνάρτηση του και η δεύτερη φθίνουσα. Άρα, για κάθε , έχουμε,
και παίρνοντας το όριο , από το Κ.Ο.Θ. συμπεραίνουμε πως,
όπου η δεύτερη ανισότητα προκύπτει από τον τρόπο που επιλέξαμε το στη σχέση (13.4). Άρα έχουμε αποδείξει πως, για κάθε ισχύει η (13.3), αποδεικνύοντας έτσι τον Ν.Μ.Α.
13.3 Το θεώρημα de Moivre-Laplace
Σκοπός αυτής της παραγράφου είναι η παρουσίαση της απόδειξης μιας ισχυρής μορφής του Κ.Ο.Θ. στην περίπτωση που οι είναι τυχαίες μεταβλητές. Σε αυτή την ειδική περίπτωση το Κ.Ο.Θ. ονομάζεται «θεώρημα de Moivre-Laplace»1111Το θεώρημα αυτό πρωτοδημοσιεύτηκε το 1738 από τον Abraham de Moivre στη δεύτερη έκδοση του βιβλίου του, The Doctrine of Chances. Η πρώτη έκδοσή του, το 1718, ήταν το πρώτο βιβλίο που γράφτηκε ποτέ με αντικείμενο εξ ολοκλήρου τις πιθανότητες. Ο de Moivre ήταν Γάλλος Ουγενότος, και έγραψε το βιβλίο στα αγγλικά ενώ ζούσε αυτοεξόριστος στην Αγγλία, προκειμένου να γλιτώσει τις διώξεις στις οποίες υπόκεινταν οι Ουγενότοι στη Γαλλία. και μπορεί να αποδειχθεί με στοιχειώδεις υπολογισμούς. Όπως θα δούμε, το θεώρημα de Moivre-Laplace μάς δίνει μια ακριβή προσέγγιση για την πυκνότητα του εμπειρικού μέσου όρου των ή, ισοδύναμα, για την πυκνότητα του αθροίσματός τους .
Συμβολισμός και Θυμίζουμε πως δύο ακολουθίες πραγματικών αριθμών και λέμε ότι είναι ασυμπτωτικά ισοδύναμες, το οποίο συμβολίζεται με , όταν ο λόγος τους τείνει στο 1, . Επίσης, ο συμβολισμός σημαίνει πως τα τείνουν να είναι σημαντικά μικρότερα από τα , δηλαδή, . Για παράδειγμα, αν , τότε η ακολουθία τείνει στο μηδέν καθώς το , ενώ αν τότε .
Για κάθε καθώς έχουμε την εξής προσέγγιση για την πυκνότητα του :
| (13.6) |
Παρατηρήσεις:
-
1.
Αν και το αποτέλεσμα του θεωρήματος έχει διαφορετική μορφή από εκείνη της γενικής περίπτωσης του Κ.Ο.Θ. στο Κεφάλαιο 12, η οποία αφορούσε το κανονικοποιημένο άθροισμα,
σημειώνουμε πως η έκφραση (13.6) είναι ισχυρότερη από τη σύγκλιση των αντίστοιχων συναρτήσεων κατανομής όπως στο Θεώρημα 12.2. Συγκεκριμένα, ένας απλός (αλλά αρκετά τεχνικός και άνευ ιδιαιτέρου ενδιαφέροντος) υπολογισμός βασισμένος στις απλές ιδιότητες του ορισμού του ολοκληρώματος Riemann, αποδεικνύει πως πράγματι η (13.6) συνεπάγεται ότι η συνάρτηση κατανομής των τείνει στην .
Το βασικό περίγραμμα αυτού του υπολογισμού έχει ως εξής. Ξεκινάμε παρατηρώντας ότι, για οποιοδήποτε ,
Αντικαθιστώντας τώρα την ασυμπτωτική έκφραση της πυκνότητας του από την (13.6), και εξετάζοντας με λίγη προσοχή το πιο πάνω άθροισμα, εύκολα διαπιστώνουμε ότι, για μεγάλα , κατά προσέγγιση ισούται με,
όπου στο παραπάνω άθροισμα τα διαδοχικά που αθροίζονται έχουν μεταξύ τους απόσταση , άρα κάθε όρος του αθροίσματος ισούται με το μήκος ενός διαστήματος επί την τιμή της συνάρτησης σε εκείνο το διάστημα. Συνεπώς η τελική προσέγγιση προκύπτει από τον ορισμό του ολοκληρώματος Riemann.
-
2.
Για την απόδειξη του θεωρήματος θα χρειαστούμε την ακριβή μορφή του τύπου του Stirling, όπως δίνεται στη σημείωση που ακολουθεί το Λήμμα 7.1. Καθώς το :
(13.7)
Απόδειξη:
Η βασική ιδέα της απόδειξης είναι απλή: Θα εφαρμόσουμε τον τύπο του Stirling στην πυκνότητα της διωνυμικής κατανομής. Κατ’ αρχάς, λοιπόν, παρατηρούμε πως . Για λόγους ευκολίας, γράφουμε , και ορίζουμε μια ακολουθία ακεραίων , για κάθε , όπου τα είναι τέτοια ώστε η ακολουθία να είναι φραγμένη.
Χρησιμοποιώντας τον τύπο της πυκνότητας της διωνυμικής κατανομής έχουμε,
εφαρμόζοντας την ακριβέστερη μορφή του τύπου του Stirling όπως δίνεται στη (13.7) βρίσκουμε,
και απλοποιώντας,
Στη συνέχεια θα απλοποιήσουμε περαιτέρω την έκφραση που βρίσκεται στον εκθέτη της τελευταίας παραπάνω έκφρασης. Χρησιμοποιώντας το απλό αποτέλεσμα που δίνεται στη σχέση (13.9) του Λήμματος 13.1 παρακάτω, ο εκθέτης αυτός ισούται με,
όπου παρατηρούμε πως, από την υπόθεσή μας ότι η ακολουθία είναι φραγμένη, προκύπτει πως το άθροισμα των τεσσάρων όρων της μορφής παραπάνω ισούται με έναν όρο που τείνει στο μηδέν. Άρα, ο εκθέτης που εξετάζουμε τελικά ισούται με,
και, αντικαθιστώντας στην προηγούμενη έκφραση για την πυκνότητα του , έχουμε,
| (13.8) | |||||
Τώρα μπορούμε να εφαρμόσουμε την πιο πάνω σχέση στην περίπτωση όπου το είναι της μορφής για κάποια σταθερά , το οποίο είναι προφανώς της μορφής που έχουμε υποθέσει. Σε αυτή την περίπτωση, η (13.8) μας δίνει,
αποδεικνύοντας το θεώρημα.
Λήμμα 13.1
Καθώς
και, κατά συνέπεια, για οποιαδήποτε ακολουθία που τείνει στο άπειρο παρομοίως έχουμε,
| (13.9) |
Απόδειξη:
Η σχέση (13.9) είναι προφανής συνέπεια της πρώτης πρότασης του λήμματος, οπότε αρκεί να δείξουμε ότι:
Σε αυτό το όριο εμφανίζεται απροσδιοριστία της μορφής , η οποία μπορεί να αφαιρεθεί αν κάνουμε χρήση του κανόνα του L’Hôpital. Πράγματι, τότε έχουμε,
άρα αποδείξαμε το ζητούμενο.
13.4 To θεώρημα του Lindeberg
Στην τελευταία αυτή ενότητα του κεφαλαίου, θα δώσουμε μια πλήρη απόδειξη του Κ.Ο.Θ., και μάλιστα κάτω από γενικές συνθήκες. Ακολουθώντας τις βασικές γραμμές μιας απόδειξης του Lindeberg (1922), θα αποδείξουμε τη γενική μορφή του Κ.Ο.Θ. όπως ακριβώς είναι διατυπωμένο στο Θεώρημα 12.2 του Κεφαλαίου 12. Όπως αναφέραμε πιο πάνω, αν και η απόδειξη είναι μακροσκελής, δεν απαιτεί τη χρήση ιδιαίτερων μαθηματικών εργαλείων πέρα από κάποια απλά αποτελέσματα του διαφορικού λογισμού για συναρτήσεις μίας μεταβλητής. Επιπλέον, έχει το πλεονέκτημα ότι εύκολα γενικεύεται σε πολλές περιπτώσεις ακολουθιών τυχαίων μεταβλητών οι οποίες δεν ικανοποιούν τις παρούσες συνθήκες. Τέτοια θέματα, όμως, δεν θα μας απασχολήσουν εδώ περαιτέρω.
Απόδειξη του Lindeberg για το Κ.Ο.Θ.:
Χωρίζουμε την απόδειξη σε έξι βήματα, χάριν ευκολίας στην ανάγνωση και την κατανόησή της. Όπως θα καταστεί σαφές, το σημαντικότερο και πιο πρωτότυπο βήμα είναι το πέμπτο.
Θυμίζουμε τις υποθέσεις του Θεωρήματος 12.2: Οι τυχαίες μεταβλητές είναι ανεξάρτητες, έχουν όλες την ίδια κατανομή και, κατά συνέπεια, έχουν κοινή μέση τιμή και διασπορά , για κάθε . Ο στόχος μας είναι να δείξουμε ότι, για κάθε ,
| (13.10) |
Βημα 1. Ισχυριζόμαστε πως αρκεί να δείξουμε τη (13.10) για την περίπτωση και : Έστω ότι, για οποιαδήποτε ακολουθία ανεξάρτητων Τ.Μ. με μέση τιμή μηδέν και διασπορά ίση με ένα, γνωρίζουμε πως,
| (13.11) |
Δεδομένης της ακολουθίας που μας ενδιαφέρει, αν ορίσουμε τις νέες Τ.Μ. , για , τότε (βλ. Παρατήρηση 2 στην Ενότητα 9.2 και Θεώρημα 15.1 στο Κεφάλαιο 15) οι είναι ανεξάρτητες, και, από τις ιδιότητες των Θεωρημάτων 6.1 και 11.2, επίσης έχουμε,
Μπορούμε άρα να εφαρμόσουμε τη (13.11) στις , η οποία αμέσως μας δίνει τη (13.10).
Βημα 2. Έστω οι ανεξάρτητες Τ.Μ. , όλες με την ίδια κατανομή και με και για κάθε . Συμβολίζουμε με το κανονικοποιημένο άθροισμά τους,
και με τη συνάρτηση κατανομής του . Τότε η ζητούμενη σχέση (13.11) γίνεται,
| (13.12) |
Έστω τώρα με συνάρτηση κατανομής . Όπως στην Άσκηση 2 του Κεφαλαίου 7, ορίζουμε, για κάθε , τις δείκτριες συναρτήσεις, ως,
| (13.13) |
και παρατηρούμε πως οι και μπορούν να εκφραστούν, αντίστοιχα, ως,
Άρα, το ζητούμενό μας είναι να αποδείξουμε πως,
| (13.14) |
για κάθε δείκτρια συνάρτηση της μορφής (13.13).
Βημα 3. Εδώ ισχυριζόμαστε πως, αντί να αποδείξουμε τη σύγκλιση της σχέσης (13.14) για κάθε δείκτρια συνάρτηση , αρκεί να αποδείξουμε πως,
| (13.15) |
για όλες τις συναρτήσεις οι οποίες ικανοποιούν: Η τρίτη παράγωγος υπάρχει για όλα τα και (2.) Για κάποιο , η για όλα τα . Το ότι η (13.15) πράγματι ισχύει είναι το πιο ενδιαφέρον μέρος της απόδειξης και θα το δείξουμε στο πέμπτο βήμα. Το ότι η (13.15) για όλες αυτές τις συναρτήσεις είναι αρκετή για να αποδειχθεί η ζητούμενη σύγκλιση (13.14) για κάθε είναι το λιγότερο ενδιαφέρον μέρος της απόδειξης, και θα δειχθεί στο τελευταίο βήμα.
Παρατηρούμε πως, αν η ικανοποιεί τις δύο παραπάνω συνθήκες, τότε και η και οι τρεις πρώτοι παράγωγοί της είναι φραγμένες συναρτήσεις. Επιπλέον, από το ανάπτυγμα Taylor έχουμε ότι, για κάθε ,
για κάποιο μεταξύ των τιμών και . Το ότι η είναι φραγμένη σημαίνει πως υπάρχει κάποια σταθερά τέτοια ώστε για όλα τα . Οπότε, δεδομένου αυθαίρετου , αν θέσουμε , το παραπάνω ανάπτυγμα μας δίνει,
| (13.16) | |||||
όπου η σταθερά , με το φράγμα που έχουμε από το γεγονός ότι η ικανοποιεί τη δεύτερη από τις παραπάνω συνθήκες, και όπου η είναι δείκτρια συνάρτηση της μορφής που ορίσαμε στη (13.13).
Βημα 4. Πριν προχωρήσουμε στο πέμπτο και σημαντικότερο βήμα, θυμίζουμε μια απλή ιδιότητα που είδαμε, στην περίπτωση των διακριτών Τ.Μ., στην Άσκηση 3 του Κεφαλαίου 7: Έστω μια οποιαδήποτε διακριτή Τ.Μ. τέτοια ώστε . Δεδομένης μιας δείκτριας συνάρτησης όπως στα προηγούμενα δύο βήματα, για οποιοδήποτε δεδομένο , ορίζουμε επίσης τη συμπληρωματική δείκτρια συνάρτηση,
| (13.17) |
Από το αποτέλεσμα της Άσκησης 3 του Κεφαλαίου 7, με , έχουμε,
Επιπλέον, στην Άσκηση 4 στο τέλος αυτού του κεφαλαίου θα δείξουμε ότι το ίδιο ισχύει αν η είναι συνεχής. Και μια και το ίδιο ακριβώς αποτέλεσμα μπορεί να εφαρμοστεί στη , αν θεωρήσουμε ότι ικανοποιεί , έχουμε παρομοίως ότι, για οποιαδήποτε (συνεχή ή διακριτή) Τ.Μ. με ,
| (13.18) |
γεγονός το οποίο θα χρησιμοποιήσουμε παρακάτω.
Βημα 5. Σε αυτό το βήμα θα δούμε το συλλογισμό που βρίσκεται στην καρδιά της απόδειξης του Lindeberg. Θα αποδείξουμε τη σχέση (13.15) όπως απαιτείται από το τρίτο βήμα. Έστω λοιπόν μια αυθαίρετη συνάρτηση που ικανοποιεί τις δύο συνθήκες του τρίτου βήματος. Επιπλέον, ορίζουμε τις ανεξάρτητες Τ.Μ. με κάθε .
Από την τέταρτη ιδιότητα του Θεωρήματος 12.1, ξέρουμε ότι το κανονικοποιημένο άθροισμα των έχει κατανομή . Άρα, το ζητούμενό μας είναι να δείξουμε πως, καθώς ,
ή, θέτοντας, για ευκολία, και , ότι, καθώς ,
| (13.19) |
Η κεντρική ιδέα της απόδειξης είναι η πιο κάτω έξυπνη αναπαράσταση, όπου αντικαθιστούμε έναν-έναν τους όρους του αθροίσματος με τις αντίστοιχες κανονικές Τ.Μ.:
Δεδομένου αυθαίρετου , χρησιμοποιώντας δύο φορές το φράγμα που βρήκαμε στη σχέση (13.16) από το ανάπτυγμα Taylor, ο κάθε όρος στο τελευταίο πιο πάνω άθροισμα μπορεί να εκφραστεί ως,
| (13.20) |
όπου οι όροι των «υπολοίπων» και που προέρχονται από το ανάπτυγμα Taylor ικανοποιούν,
με τη συμπληρωματική δείκτρια συνάρτηση που ορίσαμε στην (13.17).
Η κρίσιμη παρατήρηση σε αυτό το σημείο είναι πως, λόγω της ανεξαρτησίας των Τ.Μ. και , και επειδή όλες αυτές οι Τ.Μ. έχουν μέση τιμή μηδέν και ίδια διασπορά , οι δύο πρώτες μέσες τιμές στην έκφραση (13.20) είναι ίσες με μηδέν. Οπότε, αντικαθιστώντας,
όπου για την ισότητα αντικαταστήσαμε τους ορισμούς των , για την χρησιμοποιήσαμε το γεγονός ότι όλες αυτές οι Τ.Μ. έχουν μέση τιμή μηδέν και διασπορά ένα και την παρατήρηση πως, εξ ορισμού, , και για την χρησιμοποιήσαμε το ότι όλοι οι όροι του τελευταίου αθροίσματος είναι ίδιοι για κάθε .
Εφαρμόζοντας τώρα το αποτέλεσμα (13.18) του τέταρτου βήματος πιο πάνω, έχουμε πως,
και, αφού το ήταν αυθαίρετο, έχουμε τελικά αποδείξει το ζητούμενο αποτέλεσμα της σχέσης (13.19): .
Βημα 6. Το μόνο που απομένει να κάνουμε είναι να τεκμηριώσουμε τον ισχυρισμό του βήματος 3, δηλαδή ότι αν,
για όλες τις συναρτήσεις για τις οποίες η τρίτη παράγωγος υπάρχει για όλα τα , και για όλα τα , για κάποιο , τότε έχουμε και ότι,
| (13.21) |
για κάθε δείκτρια συνάρτηση της μορφής (13.13).
Η απόδειξη αυτού του ισχυρισμού είναι κυρίως τεχνική και ελάχιστα σχετίζεται με ιδέες και εργαλεία των πιθανοτήτων. Δεν θα παρεξηγήσουμε λοιπόν τους αναγνώστες που θα τη δεχτούν χωρίς να τη διαβάσουν, και συνεχίζουμε μόνο για τους πιο φανατικούς της μαθηματικής ανάλυσης.
Έστω μια δείκτρια συνάρτηση για κάποιο δεδομένο . Θα προσεγγίσουμε την μέσω της ακολουθίας συναρτήσεων , όπου, για ,
και η σταθερά . Από τον ορισμό της είναι εύκολο να διαπιστώσουμε ότι, για μεγάλα η προσεγγίζει όλο και περισσότερο την : Καθώς το μεγαλώνει, αφενός το διάστημα στο οποίο η προσεγγίζει όλο και περισσότερο το αντίστοιχο διάστημα όπου η , και αφετέρου, τα διαστήματα όπου παίρνει τιμές αυστηρά μεταξύ 0 και 1 γίνονται όλο και μικρότερα ώσπου στο όριο εξαφανίζονται. Ένα παράδειγμα αυτής της συμπεριφοράς φαίνεται στο Σχήμα 13.1, όπου, για την περίπτωση , έχουμε σχεδιάσει τα γραφήματα των συναρτήσεων για και .
Από τον ορισμό της προφανώς έχουμε για και εύκολα μπορούμε να διαπιστώσουμε ότι η τρίτη της παράγωγος υπάρχει για κάθε . Άρα για κάθε δεδομένο , από το προηγούμενο βήμα έχουμε ότι,
| (13.22) |
Επιπλέον, έχουμε για κάθε και κάθε , αλλά αφού για όλα τα , έχουμε και ότι , οπότε,
Άρα, δεδομένου αυθαίρετου , αφού η είναι συνεχής και , μπορούμε να επιλέξουμε αρκετά μεγάλο ώστε να έχουμε για όλα τα . Συνδυάζοντας τις παραπάνω παρατηρήσεις, προκύπτει ότι,
για κάθε . Και εφόσον το ήταν αυθαίρετο, έχουμε ότι,
| (13.23) |
Τέλος (επιτέλους!), για να δείξουμε το αντίστοιχο άνω φράγμα, παρατηρούμε ότι, για κάθε και , , οπότε,
Για τον τελευταίο όρο, χρησιμοποιώντας το γεγονός ότι το έχει μέση τιμή μηδέν και διασπορά ίση με ένα, και εφαρμόζοντας ανισότητα Chebychev, έχουμε,
οπότε, αντικαθιστώντας,
Παίρνοντας το όριο , από το αποτέλεσμα (13.22) του τρίτου βήματος,
και εφόσον αυτή η σχέση ισχύει για κάθε και κάθε , αντικαθιστώντας το με το ,
Άρα, δεδομένου αυθαίρετου , από το γεγονός ότι η είναι συνεχής συνάρτηση, μπορούμε να επιλέξουμε αρκετά μεγάλο ώστε και , για κάθε . Τότε,
και επειδή το ήταν αυθαίρετο, έχουμε τελικά αποδείξει ότι,
| (13.24) |
Ο συνδυασμός των αποτελεσμάτων (13.23) και (13.24) συνεπάγεται ότι,
το οποίο αποδεικνύει τον ισχυρισμό του τρίτου βήματος και ολοκληρώνει την απόδειξη.
13.5 Ασκήσεις
-
1.
Σύγκλιση κατά πιθανότητα σύγκλιση κατά κατανομή. Αποδείξτε πως, αν οι Τ.Μ. τείνουν κατά πιθανότητα σε κάποια Τ.Μ. , τότε τείνουν στη και κατά κατανομή.
-
2.
Σύγκλιση κατά κατανομή σύγκλιση κατά πιθανότητα. Εδώ θα δούμε πως η αντίστροφη πρόταση εκείνης που αποδείξαμε στην προηγούμενη άσκηση δεν ισχύει πάντα. Έστω δύο ανεξάρτητες Τ.Μ. . Ορίζουμε την ακολουθία Τ.Μ. , για κάθε . Αποδείξτε πως οι :
-
(α’)
Συγκλίνουν κατά κατανομή στην .
-
(β’)
Συγκλίνουν κατά κατανομή στη .
-
(γ’)
Συγκλίνουν κατά πιθανότητα στην .
-
(δ’)
Δεν συγκλίνουν κατά πιθανότητα στη .
Άρα έχουμε κατά κατανομή αλλά όχι κατά πιθανότητα.
-
(α’)
-
3.
Σύγκλιση κατά κατανομή και κατά πιθανότητα σε σταθερά. Αντίθετα με τη γενική περίπτωση της προηγούμενης άσκησης, εδώ θα δείξετε πως, στην ειδική περίπτωση που μια ακολουθία τυχαίων μεταβλητών συγκλίνει κατά κατανομή σε μια σταθερά , τότε οι συγκλίνουν και κατά πιθανότητα στην .
-
4.
Η ουρά της μέσης τιμής μιας συνεχούς Τ.Μ. Έστω μια συνεχής Τ.Μ. η οποία παίρνει πάντα τιμές μεγαλύτερες ή ίσες του μηδενός και έχει πεπερασμένη μέση τιμή . Όπως είδαμε και στην Άσκηση 3 του Κεφαλαίου 7 για διακριτές Τ.Μ., δείξτε και εδώ πως, καθώς το ,
όπου είναι οι συμπληρωματικές δείκτριες συναρτήσεις τις οποίες ορίσαμε στη σχέση (13.17).
-
5.
Σύγκλιση ως προς την απόσταση Στην Άσκηση 18 του Κεφαλαίου 6, για δύο οποιεσδήποτε διακριτές πυκνότητες και στο ίδιο πεπερασμένο σύνολο , ορίσαμε τη -απόσταση της από την ως,
Έστω μια ακολουθία διακριτών Τ.Μ. όπου το κάθε έχει πυκνότητα στο πεπερασμένο σύνολο τιμών , και έστω μια άλλη Τ.Μ. με πυκνότητα στο .
Αποδείξτε πως αν, καθώς , οι αποστάσεις , τότε και οι Τ.Μ. τείνουν στη κατά κατανομή.
-
6.
Σύγκλιση της διωνυμικής στην Poisson. Στο Πόρισμα 7.1 του Κεφαλαίου 7 δείξαμε πως, αν για κάθε η είναι η πυκνότητα μιας Τ.Μ. με κατανομή και είναι η πυκνότητα της , τότε οι Τ.Μ. τείνουν στη υπό την έννοια ότι οι πυκνότητες συγκλίνουν στην P:
(13.25) -
(α’)
Δείξτε ότι οι τείνουν στη και κατά κατανομή.
-
(β’)
Γενικότερα, έστω μια οποιαδήποτε ακολουθία Τ.Μ. με αντίστοιχες πυκνότητες και σύνολο τιμών . Δείξτε πως, αν οι πυκνότητες συγκλίνουν όπως στη (13.25) στην πυκνότητα κάποιας Τ.Μ. με το ίδιο σύνολο τιμών , τότε οι τείνουν στη και κατά κατανομή.
-
(α’)
Κεφάλαιο 14 Παραδείγματα εφαρμογών στη στατιστική
[Επιστροφή στα περιεχόμενα]
Η στατιστική επιστήμη είναι μία από τις σημαντικότερες περιοχές στις οποίες εφαρμόζονται οι ιδέες και τα μαθηματικά αποτελέσματα των πιθανοτήτων. Στη στατιστική, οι πιθανότητες δεν χρησιμοποιούνται απλά ως μια συλλογή τεχνικών εργαλείων για την επίλυση προβλημάτων, αλλά αποτελούν αναπόσπαστο στοιχείο της ίδιας της θεμελίωσής της: Όπως, γενικώς, λέμε πως τα μαθηματικά αποτελούν τη γλώσσα των θετικών επιστημών, έτσι και η θεωρία πιθανοτήτων είναι η γλώσσα της στατιστικής.
Σε αυτό το κεφάλαιο έχουμε δύο στόχους. Ο πρώτος είναι να αναδείξουμε τη σύνδεση των πιθανοτήτων με κάποιους από τους βασικούς πυλώνες της στατιστικής, και ο δεύτερος είναι να παρουσιάσουμε, κυρίως μέσω επιλεγμένων παραδειγμάτων, μια συνοπτική εισαγωγή στον στατιστικό τρόπο σκέψης.
Σε καθεμία από τις Ενότητες 14.1, 14.2 και 14.3, θα παρουσιάσουμε ένα θέμα της κλασικής στατιστικής και θα δείξουμε τον κεντρικό ρόλο που παίζουν στην ανάλυσή του κάποια από τα αποτελέσματα και τις μεθόδους που έχουμε ήδη συναντήσει σε προηγούμενα κεφάλαια. Ιδιαίτερα στις Ενότητες 14.1 (διαστήματα εμπιστοσύνης) και 14.2 (έλεγχοι υποθέσεων), θα εξετάσουμε προβλήματα των οποίων η περιγραφή, η ανάλυση και η λύση θα αναπτυχθούν με τέτοιον τρόπο ώστε η κύρια έμφαση να είναι στο ευρύτερο πλαίσιο και στη γενική μεθοδολογία με την οποία αντιμετωπίζονται τα περισσότερα ερωτήματα που προκύπτουν στις αντίστοιχες περιοχές.
Η στατιστική είναι, δυστυχώς, μια πολύ – και πολύ άδικα – δυσφημισμένη επιστήμη. Αν και το παρόν βιβλίο μάλλον δεν είναι το καταλληλότερο βήμα, δεν μπορούμε να αντισταθούμε στον πειρασμό να υπενθυμίσουμε τον τεράστιο βαθμό στον οποίο η στατιστική επηρεάζει την καθημερινότητα όλων μας: Από τις κλινικές μελέτες της ιατρικής που μας έχουν διπλασιάσει τον μέσο όρο ζωής, μέχρι τις μεγαλύτερες πολιτικές αποφάσεις, οι οποίες σχεδόν πάντα βασίζονται, εν μέρει τουλάχιστον, σε στατιστικά συμπεράσματα οικονομικών προβλέψεων.
Είναι σχεδόν αδύνατον να διαβάσει κανείς τους κύριους τίτλους ενός ενημερωτικού σάιτ, να δει ειδήσεις στην τηλεόραση ή να ξεφυλλίσει μια εφημερίδα, χωρίς να συναντήσει όχι μόνο μία, αλλά αρκετές αναφορές σε στατιστικά δεδομένα της Eurostat, αποτελέσματα δημοσκοπήσεων, εντυπωσιακές ανακαλύψεις κλινικών ερευνών για καινούργια φάρμακα και ούτω καθεξής. Από αυτήν τη σκοπιά θα μπορούσε να πει κανείς πως μια έστω στοιχειώδης κατανόηση των βασικών στατιστικών εννοιών είναι απαραίτητη ώστε να μπορεί οποιοσδήποτε να λειτουργήσει ως κανονικός πολίτης στη σημερινή κοινωνία.
Αυτό ήταν, σε γενικές γραμμές, το σκεπτικό μιας επιτροπής διασήμων επιστημόνων οι οποίοι, όταν κλήθηκαν πριν 15 περίπου χρόνια να συμβουλέψουν το αμερικανικό κογκρέσο για το περιεχόμενο της ύλης των μαθηματικών που θα έπρεπε να διδάσκεται στα σχολεία, πρότειναν, στην πέμπτη δημοτικού, αμέσως μετά τα κλάσματα και πριν από οτιδήποτε άλλο, να μαθαίνουν τα παιδιά στατιστική. Αυτό το σκεπτικό έχει επηρεάσει και τη δομή των αποτελεσμάτων που θα δούμε σε αυτό το κεφάλαιο. Αφενός θέλουμε να παρουσιάσουμε μια σειρά από ενδιαφέρουσες εφαρμογές ώστε να εμπλουτιστεί η κατανόησή μας για το αντικείμενο των πιθανοτήτων, και αφετέρου ελπίζουμε η επιλογή και ο τρόπος με τον οποίο θα αναπτυχθούν αυτές οι εφαρμογές να αναδείξει τη σημασία και το ευρύτερο, ενδογενές επιστημονικό ενδιαφέρον της στατιστικής.
Ως «απεριτίφ» για το τι θα ακολουθήσει, και ως προειδοποίηση για το πόσο συχνά προκύπτουν λεπτά ζητήματα στατιστικής φύσης στην πράξη, περιγράφουμε συνοπτικά ένα απλό παράδειγμα στο οποίο θα επανέλθουμε πιο διεξοδικά στην Ενότητα 14.2.
Παράδειγμα 14.1 (Καινούργιο φάρμακο)
Για να ελεγχθεί η αποτελεσματικότητα ενός νέου φαρμάκου, η φαρμακευτική εταιρία που το παρασκευάζει πραγματοποιεί μια προκαταρκτική κλινική μελέτη με 40 ασθενείς. Σε 20 από αυτούς χορηγείται το πραγματικό φάρμακο, και στους υπόλοιπους 20 χορηγείται εικονικό φάρμακο, το λεγόμενο placebo. Μετά από ένα εύλογο χρονικό διάστημα παρατηρούμε ότι το 60% εκείνων που παίρνουν το φάρμακο σημειώνουν βελτίωση, ενώ το αντίστοιχο ποσοστό για εκείνους που παίρνουν το placebo είναι μόνο 40%. Πόσο αξιόπιστη ένδειξη της επιτυχίας του φαρμάκου μπορεί να θεωρηθεί το παραπάνω αποτέλεσμα; Μπορείτε να βρείτε και να τεκμηριώσετε μια ποσοτική απάντηση σε αυτό το ερώτημα;
14.1 Διαστήματα εμπιστοσύνης
Στα Κεφάλαια 9 και 12 είδαμε πολλά παραδείγματα όπου, προκειμένου να εκτιμήσουμε μια άγνωστη ποσότητα, χρησιμοποιήσαμε τον εμπειρικό μέσο όρο,
ανεξάρτητων τυχαίων δειγμάτων . Για παράδειγμα:
-
•
Δημοσκόπηση. Αν σε μια δημοσκόπηση το κάθε περιγράφει την απάντηση ενός ψηφοφόρου για κάποιο συγκεκριμένο κόμμα ( αν σκοπεύει να το ψηφίσει, αν όχι), τότε ο εμπειρικός μέσος όρος μας δίνει μια εκτίμηση για το ποσοστό των ψήφων που θα πάρει αυτό το κόμμα στις εκλογές.
-
•
Εκτίμηση πιθανότητας. Γενικότερα, αν τα είναι «δείκτριες» Τ.Μ., δηλαδή το κάθε ισούται με όποτε κάποιο ενδεχόμενο συμβαίνει και με όποτε όχι, τότε το μας δίνει μια εκτίμηση της πιθανότητας με την οποία συμβαίνει το .
-
•
Δημογραφική δειγματοληψία. Όταν επιλέγονται άτομα από έναν πληθυσμό τυχαία και το κάθε αναπαριστά την τιμή κάποιου χαρακτηριστικού που μας ενδιαφέρει – π.χ., το εισόδημα, την ηλικία ή το πλήθος των μελών της οικογένειας του ατόμου – τότε το δίνει μια εκτίμηση της μέσης τιμής του αντίστοιχου χαρακτηριστικού του πληθυσμού, δηλαδή του μέσου εισοδήματος, της μέσης ηλικίας, του μέσου μεγέθους της οικογένειας, κλπ.
-
•
Εμπειρικές μετρήσεις. Σε περιπτώσεις που το ζητούμενο είναι να εκτιμηθεί η μέση τιμή κάποιας ποσότητας, όπως για παράδειγμα η μέση διάρκεια μιας τηλεφωνικής κλήσης σε κάποιο δίκτυο, η μέση ατμοσφαιρική θερμοκρασία στην ανταρκτική, η μέση τιμή πώλησης ενός χρηματιστηριακού προϊόντος ή η μέση περιεκτικότητα του νερού της ΕΥΔΑΠ σε μόλυβδο, τότε ο εμπειρικός μέσος όρος από μετρήσεις της αντίστοιχης ποσότητας μας δίνει μια εκτίμηση της άγνωστης μέσης τιμής .
Σε καθένα από τα παραπάνω παραδείγματα, αν τα είναι επιλεγμένα έτσι ώστε να είναι ανεξάρτητα και να έχουν όλα την ίδια κατανομή, ο Ν.Μ.Α. μάς διαβεβαιώνει πως, για μεγάλα μεγέθη δειγμάτων :
Εδώ , η κοινή μέση τιμή των , είναι η ποσότητα που θέλουμε να εκτιμήσουμε. Επιπλέον, στην απόδειξη του Ν.Μ.Α. στο Κεφάλαιο 9 είδαμε πως η εκτίμηση έχει,
| (14.1) |
όπου είναι η κοινή διασπορά των . Και σύμφωνα με το Κ.Ο.Θ. του Κεφαλαίου 12, το έχει κατά προσέγγιση κανονική κατανομή. Για μεγάλα :
| μ |
(14.2) |
Το κύριο αντικείμενο αυτής της ενότητας είναι να εξετασθεί το πώς μπορεί να διατυπωθεί με ακρίβεια το ενδεχόμενο μέγεθος και η πιθανότητα του «στατιστικού σφάλματος» σε τέτοιου είδους εκτιμήσεις.
Παράδειγμα 14.2 (Μια απλή δημοσκόπηση)
Στις εθνικές εκλογές του Ιανουαρίου του 2015, το κόμμα της Νέας Δημοκρατίας (ΝΔ) έλαβε ποσοστό 27.81% επί των (έγκυρων) ψηφοδελτίων. Λίγο πριν τις εκλογές η γνωστή εταιρία δημοσκοπήσεων alco, βασισμένη σε ένα τυχαίο δείγμα ψηφοφόρων, ανακοίνωσε, μεταξύ άλλων αποτελεσμάτων, την πρόβλεψη πως το ποσοστό της ΝΔ θα ήταν 30.5% με «στατιστικό σφάλμα» και «διάστημα βεβαιότητας» 95%. Τι ακριβώς σημαίνει στατιστικό σφάλμα και διάστημα βεβαιότητας;
Ας μπούμε για λίγο στην θέση των δημοσκόπων. Έστω το πραγματικό ποσοστό των ψηφοφόρων της ΝΔ, και έστω οι απαντήσεις ατόμων, όπου κάθε αν το άτομο είναι ψηφοφόρος της ΝΔ, και αν όχι. Λογικά θεωρούμε ότι τα είναι ανεξάρτητες Τ.Μ. και η πρόβλεψή μας βάσει αυτών των στοιχείων είναι ο εμπειρικός μέσος Για να είμαστε, τώρα, σε θέση να ανακοινώσουμε τα αποτελέσματά μας στα ΜΜΕ, αναρωτιόμαστε πώς θα μπορούσαμε να βρούμε ένα διάστημα τιμών της μορφής τέτοιο ώστε η πιθανότητα να περιέχει το πραγματικό αποτέλεσμα να είναι τουλάχιστον 95%. Με άλλα λόγια, πόσο μεγάλο «στατιστικό σφάλμα » πρέπει να δεχθούμε ώστε το «διάστημα εμπιστοσύνης» να έχει πιθανότητα τουλάχιστον 95%;
Σε αυτό το (ομολογουμένως, υπεραπλουστευμένο) παράδειγμα, όπου ξέρουμε το πραγματικό αποτέλεσμα μπορούμε εύκολα να απαντήσουμε, με μια απλή εφαρμογή του Κ.Ο.Θ. [Δείτε την Άσκηση 4 στο τέλος του κεφαλαίου για την πιο ρεαλιστική περίπτωση όπου δεν ξέρουμε εκ των προτέρων το ] Έστω το πλήθος των ψηφοφόρων της ΝΔ στην έρευνά μας, οπότε η Από το Πόρισμα 12.1, έχουμε ότι η πιθανότητα που μας ενδιαφέρει,
κατά προσέγγιση ισούται με,
το οποίο, για να ισούται με 95%, πρέπει να έχουμε,
όπου χρησιμοποιήσαμε τους πίνακες τιμών της τυπικής κανονικής κατανομής από το Κεφάλαιο 12 για να βρούμε την τιμή για την οποία η είναι όσο το δυνατόν πιο κοντά στο 0.975. Λύνοντας ως προς βρίσκουμε,
Οπότε καταλήγουμε στο εξής συμπέρασμα:
H πρόβλεψή μας είναι πως η ΝΔ θα λάβει ποσοστό , με διάστημα εμπιστοσύνης , ή , το οποίο έχει επίπεδο εμπιστοσύνης 95%.
Παρατήρηση: Όπως είδαμε στις σχέσεις (14.1) και (14.2) παραπάνω, η ακρίβεια της εκτίμησης για τη μέση τιμή των περιγράφεται πρωτίστως από τη διασπορά , η οποία εξαρτάται από τη διασπορά των και το μέγεθος του δείγματος. Άρα, προκειμένου να είναι σχετικά ακριβής η εκτίμηση , θα πρέπει είτε το μέγεθος του δείγματος να είναι σχετικά μεγάλο, είτε η διασπορά να είναι αντίστοιχα μικρή. Στην Ενότητα 14.3 θα δούμε μια απλή μέθοδο μείωσης της διασποράς, η οποία χρησιμοποιείται κυρίως σε περιπτώσεις προσομοιωμένων δειγμάτων . Στο ακόλουθο παράδειγμα θα δούμε με ποιον τρόπο ο υπολογισμός του διαστήματος εμπιστοσύνης σχετίζεται με την επιλογή του μεγέθους του δείγματος.
Παράδειγμα 14.3
Για να μετρηθεί η δυσκολία μιας άσκησης, καταγράφηκαν οι χρόνοι σε λεπτά, που χρειάστηκαν πρωτοετείς φοιτητές για να τη λύσουν (). Υποθέτοντας ότι η τυπική απόκλιση λεπτά του τυχαίου χρόνου που απαιτεί η λύση της άσκησης είναι γνωστή, εκτιμήσαμε τον μέσο χρόνο λύσης μέσω του εμπειρικού μέσου των ο οποίος βρέθηκε να είναι λεπτά.
Έστω πως θέλουμε να δώσουμε ένα διάστημα εμπιστοσύνης της μορφής για την εκτίμησή με επίπεδο εμπιστοσύνης δηλαδή θέλουμε να ισχύει ότι,1212Επιλέγουμε το συμβολισμό για το στατιστικό σφάλμα από το αρχικό γράμμα της αγγλικής λέξης «error», δηλαδή «σφάλμα», και το συμβολισμό για την πιθανότητα του διαστήματος εμπιστοσύνης από την αγγλική λέξη «confidence» που σημαίνει «εμπιστοσύνη».
| (14.3) |
Βάσει του Κ.Ο.Θ., αυτή η πιθανότητα μπορεί να προσεγγιστεί ως,
όπου η έχει τυπική κανονική κατανομή και χρησιμοποιήσαμε και πάλι την παρατήρηση ότι το κανονικοποιημένο άθροισμα των μπορεί να εκφραστεί (βλ. (12.3) στο Κεφάλαιο 12) ως,
Άρα, για να ισχύει η (14.3) πρέπει να έχουμε, ή, ισοδύναμα,
| (14.4) |
όπου είναι η αντίστροφη συνάρτηση της τυπικής κανονικής συνάρτησης κατανομής (δηλαδή, αν και μόνο αν ). Με τα δεδομένα του προβλήματος, και η (14.4) μας δίνει,
όπου από τον πίνακα τιμών της τυπικής κανονικής συνάρτησης κατανομής στην Ενότητα 12.4 επιλέξαμε την τιμή ως μια καλή προσέγγιση στην μια που και Άρα, συμπεραίνουμε πως ο μέσος χρόνος για τη λύση της συγκεκριμένης άσκησης είναι λεπτά, με «στατιστικό σφάλμα» λεπτά και «επίπεδο εμπιστοσύνης» 90%.
Έστω όμως πως δεν είμαστε ικανοποιημένοι με αυτό το αποτέλεσμα και θέλουμε οπωσδήποτε ένα μικρότερο διάστημα εμπιστοσύνης με απόκλιση μισό λεπτό. Προκειμένου να είναι ακριβέστερη η εκτίμηση, πόσο μεγαλύτερο μέγεθος δείγματος είναι απαραίτητο; Αν θέσουμε καταφεύγοντας στη γενική έκφραση (14.4), μπορούμε να λύσουμε ως προς :
Συνεπώς, προκειμένου να είμαστε σε θέση να δώσουμε ένα διάστημα εμπιστοσύνης της μορφής με επίπεδο εμπιστοσύνης 90%, απαιτούνται τουλάχιστον 390 δείγματα
Παρατήρηση: Αν και ο υπολογισμός που οδήγησε στη σχέση (14.4) έγινε με αφορμή το Παράδειγμα 14.3, υπογραμμίζουμε ότι μέχρι εκείνο το σημείο δεν είχε χρησιμοποιηθεί κανένα από τα δεδομένα του συγκεκριμένου προβλήματος. Άρα η συσχέτιση του στατιστικού σφάλματος με το επίπεδο εμπιστοσύνης και το μέγεθος του δείγματος , όπως εκφράζεται από τη (14.4), ισχύει κάτω από γενικές συνθήκες. Οι γενικές συνέπειες αυτής της σχέσης παρατίθενται επιγραμματικά παρακάτω.
- 1.
Για το επιθυμητό επίπεδο εμπιστοσύνης βρίσκουμε την τιμή (Στο Σχήμα 14.1 δίνονται οι πιο συνηθισμένες τιμές του )
-
2.
Αν το μέγεθος του δείγματος είναι δεδομένο, τότε από τη σχέση (14.4) υπολογίζουμε το μέγεθος του στατιστικού σφάλματος
(14.5) και δίνουμε ως διάστημα εμπιστοσύνης με επίπεδο εμπιστοσύνης ή, πιο απλά, ως -διάστημα εμπιστοσύνης, το
-
3.
Αν το ζητούμενο είναι να επιτευχθεί κάποιο επιθυμητό στατιστικό σφάλμα από τη σχέση (14.4) υπολογίζουμε το απαραίτητο μέγεθος του δείγματος
(14.6) ώστε το διάστημα εμπιστοσύνης να έχει επίπεδο εμπιστοσύνης
Παρατήρηση: Σε ρεαλιστικά προβλήματα όπου η τυπική απόκλιση των δειγμάτων συχνά είναι άγνωστη, η «ορθόδοξη» στατιστική πρακτική είναι να εκτιμήσουμε πρώτα τη και κατόπιν να υπολογίσουμε το σχετικό διάστημα εμπιστοσύνης βάσει του κανονικοποιημένου αθροίσματος,
όπου είναι η εκτίμησή μας για την τυπική απόκλιση των . Αλλά, σε αντίθεση με το , για το οποίο το Κ.Ο.Θ. μάς λέει πως έχει κατά προσέγγιση κανονική κατανομή, η κατανομή του νέου κανονικοποιημένου αθροίσματος είναι διαφορετική. Αν και δεν θα επεκταθούμε περαιτέρω σε αυτή την κατεύθυνση, θα δούμε έναν πιο απλό (αλλά λιγότερο ακριβή) τρόπο με τον οποίο μπορεί να αντιμετωπιστεί το πρόβλημα της άγνωστης διασποράς σε ορισμένες περιπτώσεις.
Παράδειγμα 14.4
Η αμερικανική περιοδική έκδοση Student Monitor διανέμει ερωτηματολόγια σε φοιτητές 100 διαφορετικών πανεπιστημίων των Η.Π.Α. δύο φορές το χρόνο, προκειμένου να καταγράψει τις νέες τάσεις στον τρόπο ζωής τους. Πρόσφατα ανακοίνωσε την εκτίμηση ότι κατά μέσο όρο οι φοιτητές περνούν 15.1 ώρες την εβδομάδα «σερφάροντας» στο διαδίκτυο. Εδώ, αν η τυπική απόκλιση του τυχαίου χρόνου που περνά στο διαδίκτυο ο κάθε φοιτητής ήταν γνωστή, θα μπορούσαμε υπολογίσουμε το στατιστικό σφάλμα με επίπεδο εμπιστοσύνης για την εκτίμηση από την έκφραση (14.5) παραπάνω,
Ας υποθέσουμε πως, αν και άγνωστη, η διασπορά είναι μεταξύ 4 και 7.5, δηλαδή η αντίστοιχη τυπική απόκλιση είναι Τότε, από τον παραπάνω υπολογισμό έχουμε ότι το στατιστικό σφάλμα είναι μεταξύ και και, προκειμένου να είμαστε σίγουροι για το αποτέλεσμά μας, υιοθετούμε τη χειρότερη περίπτωση, λέγοντας πως η εκτίμηση έχει στατιστικό σφάλμα το πολύ ωρών, με επίπεδο εμπιστοσύνης 95%.
Η ίδια λογική οδηγεί και στην παρακάτω γενική μέθοδο.
- 1.
Από τα δεδομένα του προβλήματος υπολογίζουμε ένα άνω φράγμα για την τυπική απόκλιση των
-
2.
Για το επιθυμητό επίπεδο εμπιστοσύνης βρίσκουμε την τιμή
-
3.
Αν το μέγεθος του δείγματος είναι δεδομένο, τότε μπορούμε να υπολογίσουμε ένα άνω φράγμα για το μέγεθος του στατιστικού σφάλματος
(14.7) και να πούμε πως έχουμε -διάστημα εμπιστοσύνης (ή διάστημα εμπιστοσύνης με επίπεδο εμπιστοσύνης ) όχι μεγαλύτερο από το
-
4.
Αν το ζητούμενο είναι να επιτευχθεί κάποιο επιθυμητό στατιστικό σφάλμα τότε μπορούμε να υπολογίσουμε ένα άνω φράγμα για το απαραίτητο μέγεθος του δείγματος
(14.8) ώστε το διάστημα εμπιστοσύνης να έχει επίπεδο εμπιστοσύνης
Οι ασκήσεις στο τέλος του κεφαλαίου περιέχουν αρκετά ακόμα ενδιαφέροντα παραδείγματα διαστημάτων εμπιστοσύνης. Κλείνουμε αυτή την ενότητα με ένα παράδειγμα διαφορετικού τύπου.
Παράδειγμα 14.5
Για μια συγκεκριμένη μετοχή στο χρηματιστήριο, θέλουμε να προβλέψουμε αν η τιμής της την επόμενη μέρα θα ανέβει ή θα πέσει. Έστω αν η τιμή ανέβηκε τη μέρα και αν έπεσε. (Για ευκολία υποθέτουμε ότι η τιμή δεν μένει ποτέ σταθερή από μέρα σε μέρα· παρότι αυτό δεν είναι απολύτως ακριβές, δεν επηρεάζει την ουσία του προβλήματος.) Σε πολλά εμπειρικά δεδομένα έχει παρατηρηθεί ότι τα στατιστικά χαρακτηριστικά τέτοιων είναι σχεδόν ίδια με αυτά μιας ακολουθίας ανεξάρτητων Τ.Μ., και γι’ αυτόν το λόγο θεωρείται σχεδόν αδύνατη η πρόβλεψή τους.
Έστω, τώρα, πως κάποιος χρηματιστής ισχυρίζεται ότι μπορεί να προβλέψει τα με ακρίβεια μεγαλύτερη από 50%. Κάτι τέτοιο θα συνεπαγόταν πολύ μεγάλα χρηματικά κέρδη, οπότε θέλουμε να βρούμε έναν τρόπο να ελέγξουμε τον ισχυρισμό του. Του ζητάμε λοιπόν να προβλέψει, για συνεχόμενες μέρες, αν η τιμή της μετοχής θα ανέβει ή θα πέσει και καταγράφουμε τα αποτελέσματα όπου αν τη μέρα η πρόβλεψή του ήταν σωστή και αν όχι. Υπάρχει κάποιος τρόπος, βάσει των να επιβεβαιώσουμε ή να απορρίψουμε τον ισχυρισμό του χρηματιστή; Για παράδειγμα, αν μεταξύ ημερών κατάφερε να προβλέψει σωστά τις 71 (δηλαδή τα 71 από τα είναι 1 και μόνο τα 49 είναι 0), μπορούμε να πούμε πως πράγματι η φαινομενική επιτυχία της πρόβλεψής του δεν δικαιολογείται από τις τυχαίες διακυμάνσεις των τιμών της μετοχής;
Για τέτοιες περιπτώσεις στατιστικών προβλημάτων, στις οποίες η ζητούμενη απάντηση δεν είναι ποσοτική (όπως τα διαστήματα εμπιστοσύνης) αλλά της μορφής ΝΑΙ/ΟΧΙ, απαιτείται η ανάπτυξη μιας διαφορετικής μεθοδολογίας, αυτή των ελέγχων υποθέσεων.
14.2 Έλεγχοι υποθέσεων
Παράδειγμα 14.6 (Καινούργιο φάρμακο)
Επανερχόμαστε στο ερώτημα του Παραδείγματος 14.1. Σε 20 ασθενείς χορηγείται ένα νέο φάρμακο, σε άλλους 20 χορηγείται εικονικό φάρμακο (placebo), και παρατηρούμε ότι 60% εκείνων που παίρνουν το φάρμακο σημειώνουν βελτίωση ενώ το αντίστοιχο ποσοστό για εκείνους που παίρνουν το placebo είναι μόνο 40%. Θέλουμε να εξετάσουμε κατά πόσο αυτή η ένδειξη για την αποτελεσματικότητα του φαρμάκου είναι στατιστικά αξιόπιστη. Με άλλα λόγια, αναρωτιόμαστε αν, ακόμα και στην περίπτωση που το φάρμακο δεν έχει καμία επίπτωση στην πορεία της συγκεκριμένης ασθένειας, το αποτέλεσμα δικαιολογείται από απλές τυχαίες διακυμάνσεις.
Σε αυτό το απλό παράδειγμα μπορεί να δοθεί μια ακριβής απάντηση σχετικά εύκολα. Ας υποθέσουμε ότι η πιθανότητα να βελτιωθεί η υγεία ενός οποιουδήποτε ασθενή είναι και ότι το φάρμακο δεν επηρεάζει καθόλου την πορεία της ασθένειας. Ορίζοντας για κάθε μια Τ.Μ. η οποία ισούται με 1 αν ο ασθενής παρουσίασε βελτίωση και αν όχι, οι παραπάνω υποθέσεις μάς λένε πως οι με είναι ανεξάρτητες T.M. Επιπλέον, θεωρούμε ότι οι ασθενείς έως 20 πήραν το φάρμακο ενώ οι έως 40 πήραν το placebo, και θέτουμε,
έτσι ώστε οι Τ.Μ. και είναι ανεξάρτητες και έχουν κατανομή. Με αυτόν το συμβολισμό το αποτέλεσμα που παρατηρήθηκε είναι ότι και και το αρχικό ερώτημα γίνεται: Δεδομένης της υπόθεσης ότι το φάρμακο δεν έχει καμία επίδραση, είναι το αποτέλεσμα « και » αρκετά «απίθανο» ώστε να απορρίψουμε αυτή την υπόθεση; Η απόκλιση των τιμών και των δύο ομάδων ασθενών είναι στατιστικά σημαντική ή όχι;
Για να απαντήσουμε, υπολογίζουμε την πιθανότητα να παρατηρηθεί εντελώς τυχαία μια τόσο μεγάλη ή ακόμα μεγαλύτερη απόκλιση, δηλαδή την,
όπου χρησιμοποιήσαμε τον κανόνα συνολικής πιθανότητας και την ανεξαρτησία των Εφόσον όλες οι πιθανότητες και μας είναι γνωστές από τον τύπο της πυκνότητας, κάνοντας τον σχετικό (μακροσκελή αλλά απλό) υπολογισμό βρίσκουμε ότι,
Συνεπώς: Υπάρχει πιθανότητα μεγαλύτερη από μία στις τέσσερις να παρουσιαστεί από καθαρή τυχαιότητα απόκλιση στις τιμές των δύο ομάδων ασθενών τόσο μεγάλη όσο αυτή που παρατηρήσαμε. Έτσι, συμπεραίνουμε πως το αποτέλεσμα αυτής της προκαταρκτικής μελέτης μπορεί να αποδοθεί σε τυχαίο γεγονός με μη αμελητέα πιθανότητα.
Αν και η παραπάνω απάντηση είναι απολύτως ικανοποιητική, η εφαρμογή της μεθόδου με την οποία προσεγγίσαμε το ερώτημα είναι σαφώς περιορισμένη στο συγκεκριμένο πρόβλημα. Παρακάτω, στην Ενότητα 14.2.2, θα δούμε ποια είναι η συνηθισμένη «ορθόδοξη» προσέγγιση για γενικά προβλήματα αυτής της μορφής.
Παράδειγμα 14.7 (Δίκαιο ή κάλπικο νόμισμα;)
Πριν παίξουμε με κάποιον Κορώνα-Γράμματα, θέλουμε να ελέγξουμε αν το νόμισμα είναι δίκαιο ή όχι. Το στρίβουμε 210 φορές και φέρνουμε 111 Κ και 99 Γ. Τι μπορούμε να συμπεράνουμε;Πριν απαντήσουμε, παρατηρούμε ότι η μορφή αυτού του ερωτήματος είναι μαθηματικά ακριβώς ίδια με το πρόβλημα του χρηματιστή στο Παράδειγμα 14.5, όπως και με πολλά άλλα προβλήματα που εμφανίζονται συχνά στην πράξη. Για παράδειγμα, κάποιος ισχυρίζεται ότι είναι μέντιουμ και μπορεί να προβλέψει τα αποτελέσματα ενός δίκαιου νομίσματος με πιθανότητα μεγαλύτερη από 50%. Τον προκαλούμε να μας κάνει μια επίδειξη, και πανηγυρίζει μαντεύοντας σωστά τις 111 από τις 210 φορές. Είναι πράγματι μέντιουμ ή όχι;
Σε όλες αυτές τις περιπτώσεις, έχουμε ανεξάρτητες Τ.Μ. και αφού παρατηρήσουμε τις τιμές τους καλούμαστε να απαντήσουμε το ερώτημα, «είναι το ή όχι;». Μια πρώτη προσέγγιση του προβλήματος είναι μέσω των διαστημάτων εμπιστοσύνης. Ο εμπειρικός μέσος των ρίψεων ισούται με και, προκειμένου να αποφασίσουμε πόσο πιστευτό είναι το ενδεχόμενο να έχουμε βρίσκουμε ένα 95%-διάστημα εμπιστοσύνης για την εκτίμηση Από τη γενική μέθοδο της προηγούμενης παραγράφου, για βρίσκουμε την τιμή και υπολογίζουμε το στατιστικό σφάλμα από τη σχέση όπου για την τιμή της τυπικής απόκλισης επιλέγουμε τη μέγιστη δυνατή τιμή της, η οποία αντιστοιχεί στην περίπτωση Έτσι, βρίσκουμε ότι και καταλήγουμε στο 95%-διάστημα εμπιστοσύνης
Τι μπορούμε να συμπεράνουμε από τον παραπάνω υπολογισμό; Η απάντηση αγγίζει ένα από τα πιο λεπτά ζητήματα της στατιστικής. Εφόσον το είναι εντός του 95%-διαστήματος εμπιστοσύνης ένα σαφές πρώτο συμπέρασμα είναι ότι δεν μπορούμε να απορρίψουμε την περίπτωση το νόμισμα να είναι δίκαιο. Αυτό που ίσως εκ πρώτης όψεως να μην είναι προφανές, είναι πως το παραπάνω είναι το μόνο συμπέρασμα που μπορούμε να συνάγουμε από τις παρατηρήσεις μας. Συγκεκριμένα, δεν μπορούμε να πούμε ότι «επιβεβαιώσαμε» ή ότι «αποδεχόμαστε» την υπόθεση ότι τα δεδομένα είναι ανεξάρτητα με κατανομή Το μόνο στατιστικά ασφαλώς τεκμηριωμένο συμπέρασμα εδώ είναι ότι: Βάσει των παρατηρήσεων σε επίπεδο σημαντικότητας 5% δεν μπορούμε να απορρίψουμε την υπόθεση
Όπως και στο προηγούμενο παράδειγμα, η απάντηση που δόθηκε εδώ είναι πλήρης από τη στατιστική σκοπιά, αλλά η μέθοδος με την οποία βρέθηκε είναι περιορισμένη στο συγκεκριμένο πρόβλημα. Στις επόμενες δύο παραγράφους θα αναπτύξουμε μια γενική μεθοδολογία για την επίλυση προβλημάτων ελέγχου υποθέσεων.
14.2.1 Έλεγχος παραμέτρου Bernoulli
Εδώ θα δώσουμε μια πιο συστηματική απάντηση στη γενική μορφή του ερωτήματος που είδαμε στο παραπάνω παράδειγμα. Ξεκινάμε από τα δεδομένα , όπου το κάθε ή 1, και θεωρούμε πως προήλθαν από ανεξάρτητες Τ.Μ. . Η κατανομή αυτή είναι το μοντέλο μας για τα δεδομένα και η είναι μια άγνωστη παράμετρος.
Θα εξετάσουμε δύο υποθέσεις. Για κάποιο συγκεκριμένο :
-
•
Μηδενική υπόθεση .
-
•
Εναλλακτική υπόθεση .
Είναι δυνατόν, βάσει των παρατηρήσεων , να απορρίψουμε τη μηδενική υπόθεση με κάποιο επιθυμητό επίπεδο «στατιστικής σημαντικότητας»; Για να απαντήσουμε με οργανωμένο τρόπο, θα ορίσουμε την εμπειρική κατανομή των δεδομένων και θα εξετάσουμε πόσο κοντά ή μακριά είναι από την κατανομή. Υπολογίζουμε τον εμπειρικό μέσο και ορίζουμε την πυκνότητα με τιμές και . Η εμπειρική κατανομή των δεδομένων είναι η , με πυκνότητα .
Υπενθύμιση: Απόσταση και κατανομή
- 1.
- 2.
Προκειμένου να συγκρίνουμε την εμπειρική κατανομή με την κατανομή της μηδενικής υπόθεσης, ορίζουμε τη στατιστική συνάρτηση ως φορές τη -απόστασή τους,
η οποία μπορεί να εκφραστεί ως μια απλή συνάρτηση του εμπειρικού μέσου :
| (14.9) |
Το παρακάτω θεώρημα (που θα αποδειχθεί στο τέλος αυτής της ενότητας) μας λέει πως, κάτω από τη μηδενική υπόθεση, η κατανομή του είναι κατά προσέγγιση .
Θεώρημα 14.1
Κάτω από τη μηδενική υπόθεση δηλαδή για δεδομένα ανεξάρτητα και με κατανομή η στατιστική συνάρτηση,
συγκλίνει κατά κατανομή στη Για κάθε :
Είμαστε τώρα σε θέση να περιγράψουμε τη γενική μέθοδο του -ελέγχου υπόθεσης.
- 1.
Από τα δεδομένα υπολογίζουμε τον εμπειρικό μέσο και την τιμή της στατιστικής συνάρτησης,
-
2.
Επιλέγουμε το επιθυμητό επίπεδο σημαντικότητας
-
3.
Υπολογίζουμε την -τιμή, δηλαδή την πιθανότητα, κάτω από τη μηδενική υπόθεση η να είναι τόση ή μεγαλύτερη από την τιμή που υπολογίσαμε. Από το Θεώρημα 14.1:
-
4.
Αν η -τιμή η απορρίπτεται σε επίπεδο σημαντικότητας .
Αν η -τιμή η δεν απορρίπτεται σε επίπεδο σημαντικότητας .
Παρατηρήσεις:
-
1.
Υπογραμμίζουμε και πάλι πως τα μόνα δύο δυνατά συμπεράσματα του ελέγχου υπόθεσης είναι, με κάποιο προαποφασισμένο επίπεδο σημαντικότητας : Είτε να απορρίψουμε τη μηδενική υπόθεση (αν η απόσταση της εμπειρικής κατανομής των δεδομένων από την κατανομή της μηδενικής υπόθεσης είναι αρκετά μεγάλη ώστε η -τιμή να είναι αντίστοιχα μικρή), είτε να μην απορρίψουμε τη μηδενική υπόθεση . Σε καμία περίπτωση δεν καταλήγουμε στο συμπέρασμα ότι «αποδεχόμαστε» την .
-
2.
Σημειώνουμε πως η μηδενική υπόθεση είναι ειδική περίπτωση της εναλλακτικής υπόθεσης . Αν και εκ πρώτης όψεως αυτό μπορεί να μοιάζει παράξενο, είναι πολύ συνηθισμένο και δεν δημιουργεί κανένα πρόβλημα στην ανάλυσή μας. Αφενός διότι σχεδόν όλοι μας οι υπολογισμοί γίνονται κάτω από την , και αφετέρου γιατί, όπως παρατηρούμε από την παραπάνω συζήτηση, το μόνο σημαντικό σημείο είναι να βεβαιωθούμε πως όλες οι ενδεχόμενες εμπειρικές κατανομές τις οποίες συγκρίνουμε με την ανήκουν πράγματι στην , το οποίο φυσικά συμβαίνει εδώ.
Παράδειγμα 14.8
Με το νόμισμα του Παραδείγματος 14.7 φέραμε 111 Κ σε ρίψεις, οπότε ο εμπειρικός μέσος Για να ελέγξουμε αν είναι δίκαιο, δηλαδή αν επιλέγουμε το επίπεδο σημαντικότητας υπολογίζουμε τη στατιστική συνάρτηση και για την -τιμή από τους πίνακες του Κεφαλαίου 12 βρίσκουμε ότι ισούται με Εφόσον η -τιμή είναι (πολύ!) μεγαλύτερη του καταλήγουμε και πάλι στο συμπέρασμα ότι, βάσει των δεδομένων δεν μπορούμε να απορρίψουμε την μηδενική υπόθεση σε επίπεδο σημαντικότητας
Παρομοίως, ο χρηματιστής του Παραδείγματος 14.5 προέβλεψε σωστά την πορεία της μετοχής σε 71 από τις μέρες, οπότε Για να ελέγξουμε τον ισχυρισμό του ότι προβλέπει τα με ακρίβεια σημαντικά μεγαλύτερη από 50%, με και με επίπεδο σημαντικότητας υπολογίζουμε τη στατιστική συνάρτηση Η αντίστοιχη -τιμή εδώ είναι που είναι (οριακά) μικρότερο από το οπότε συμπεραίνουμε πως η απορρίπτεται σε επίπεδο σημαντικότητας δηλαδή ότι ο χρηματιστής πράγματι απέδειξε τον ισχυρισμό του.
Ένα ακόμα σχετικό παράδειγμα όπου θα δούμε στην Άσκηση 6 στο τέλος του κεφαλαίου.
Απόδειξη του Θεωρήματος 14.1:
14.2.2 Έλεγχος ανεξαρτησίας
Έστω πώς έχουμε μια ακολουθία από δεδομένα της μορφής,
όπου τα και τα παίρνουν τις τιμές 0 και 1. Υποθέτοντας ότι, βάσει της κατανομής τους, τα ζεύγη είναι ανεξάρτητα μεταξύ τους για διαφορετικά , ο στόχος μας είναι να ελέγξουμε αν και τα είναι ανεξάρτητα από τα .
Υιοθετούμε το εξής γενικό μοντέλο. Θεωρούμε ότι τα προέρχονται από ανεξάρτητες T.M. για κάποιο ενδεχομένως άγνωστο και πως, δεδομένης της τιμής του κάθε , το αντίστοιχο αν , ενώ αν . Με αυτόν το συμβολισμό, η υπόθεση της ανεξαρτησίας των από τα αντιστοιχεί στην περίπτωση όπου , δηλαδή η κατανομή των είναι ανεξάρτητη από τις τιμές των . Οι και είναι οι τρεις άγνωστες παράμετροι του μοντέλου.
Π.χ., στην περίπτωση της κλινικής μελέτης του Παραδείγματος 14.6 μπορούμε να θέσουμε αν στον ασθενή χορηγείται το κανονικό φάρμακο και αν του χορηγείται το placebo, όπου υποθέτουμε πως η επιλογή εκείνων που θα πάρουν το φάρμακο γίνεται τυχαία, με κάποια πιθανότητα . Επιπλέον, θέτοντας,
το ζητούμενο είναι να ελέγξουμε αν η πορεία της υγείας του ασθενή είναι ανεξάρτητη ή όχι από το αν πήρε το φάρμακο, δηλαδή αν .
Επιγραμματικά, οι δύο υποθέσεις που εξετάζουμε είναι:
-
•
Μηδενική υπόθεση (ανεξαρτησία) : .
-
•
Εναλλακτική υπόθεση : αυθαίρετα.
Όπως και στην προηγούμενη ενότητα, το βασικό ερώτημα είναι αν είναι δυνατόν, βάσει των παρατηρήσεων να απορρίψουμε τη μηδενική υπόθεση σε κάποιο επιθυμητό επίπεδο στατιστικής σημαντικότητας. Προκειμένου να απαντήσουμε, θα συγκρίνουμε την εμπειρική κατανομή των δεδομένων με την κατανομή που θα είχαν αν τα και τα ήταν ανεξάρτητα. Συγκεκριμένα, γράφοντας για τους εμπειρικούς μέσους των και των , ορίζουμε τις πυκνότητες ως αυτές των κατανομών και αντίστοιχα. Επιπλέον, ορίζουμε την από κοινού εμπειρική κατανομή,
για κάθε και .
Τέλος, ορίζουμε τη στατιστική συνάρτηση ως φορές την -απόσταση μεταξύ της από κοινού εμπειρικής πυκνότητας και της από κοινού πυκνότητας που θα είχαν τα αν ήταν ανεξάρτητα:
Το ακόλουθο θεώρημα περιγράφει την κατανομή της κάτω από τη μηδενική υπόθεση , για μεγάλα . Η απόδειξή του βασίζεται σε έναν πανομοιότυπο (αλλά πολύ πιο μακροσκελή) υπολογισμό με εκείνον που είδαμε στην απόδειξη του Θεωρήματος 14.1, και δεν παρουσιάζει ιδιαίτερο ενδιαφέρον· γι’ αυτόν το λόγο παραλείπεται.
Θεώρημα 14.2
Κάτω από τη μηδενική υπόθεση δηλαδή για ανεξάρτητα ζεύγη δεδομένων τέτοια ώστε τα να είναι ανεξάρτητα από τα η στατιστική συνάρτηση,
συγκλίνει κατά κατανομή στη Για κάθε :
Η μεθοδολογία του -ελέγχου ανεξαρτησίας βασίζεται στο αποτέλεσμα του Θεωρήματος 14.2 με τον ίδιο τρόπο που ο -έλεγχος παραμέτρου Bernoulli προέκυψε από το Θεώρημα 14.1. Η βασική ιδέα είναι να υπολογιστεί η απόσταση της εμπειρικής κατανομής των δεδομένων από την κατανομή που θα είχαν αν τα ήταν ανεξάρτητα, και αν βρεθεί να είναι αρκετά μεγάλη ώστε η σχετική -τιμή να είναι αντίστοιχα μικρή, τότε να απορρίψουμε τη μηδενική υπόθεση .
- 1.
Από τα δεδομένα υπολογίζουμε τις εμπειρικές πυκνότητες και και την τιμή της στατιστικής συνάρτησης,
-
2.
Επιλέγουμε το επιθυμητό επίπεδο σημαντικότητας
-
3.
Υπολογίζουμε την -τιμή, δηλαδή την πιθανότητα, κάτω από τη μηδενική υπόθεση η να είναι τόση ή μεγαλύτερη από την τιμή που υπολογίσαμε. Από το Θεώρημα 14.2:
-
4.
Αν η -τιμή η απορρίπτεται σε επίπεδο σημαντικότητας .
Αν η -τιμή η δεν απορρίπτεται σε επίπεδο σημαντικότητας .
Παρατήρηση: Όπως και στην περίπτωση του ελέγχου παραμέτρου Bernoulli στο Θεώρημα 14.2, η ασυμπτωτική κατανομή της στατιστικής συνάρτησης είναι η . Ένα παράδειγμα ελέγχου υπόθεσης στο οποίο η ασυμπτωτική κατανομή είναι διαφορετική παρουσιάζεται στην Άσκηση 8 στο τέλος του κεφαλαίου.
Παράδειγμα 14.9 (Κλινική μελέτη με πολλούς ασθενείς)
Στο Παράδειγμα 14.6, από τα κλινικά αποτελέσματα σε ασθενείς καταλήξαμε στο συμπέρασμα πως δεν μπορεί να απορριφθεί η υπόθεση ότι η λήψη του φαρμάκου είναι ανεξάρτητη από την εξέλιξη της ασθένειας. Εδώ εξετάζουμε ποιο θα ήταν το αντίστοιχο συμπέρασμα για μια κλινική μελέτη με τα ίδια ποσοστά αποτελεσμάτων αλλά με σημαντικά μεγαλύτερο μέγεθος δείγματος
Έστω πως, από ασθενείς, επιλέχθηκαν τυχαία (με ) 185 ασθενείς στους οποίους χορηγήθηκε το φάρμακο, και στους υπόλοιπους 195 χορηγήθηκε placebo. Παρατηρούμε ότι το 60% από τους πρώτους, δηλαδή 111, σημείωσαν βελτίωση, ενώ το αντίστοιχο ποσοστό για τους δεύτερους ήταν μόνο 40%, δηλαδή 78. Από αυτά τα στοιχεία εύκολα υπολογίζουμε τις σχετικές εμπειρικές πυκνότητες. Έχουμε ότι η είναι η πυκνότητα της κατανομής και η είναι η πυκνότητα της κατανομής Bernoulli με παράμετρο Παρομοίως, για τις τιμές της από κοινού εμπειρικής πυκνότητας βρίσκουμε:
Άρα η τιμή της στατιστικής συνάρτησης είναι,
το οποίο μας δίνει
Εφόσον το δείγμα είναι σχετικά μεγάλο, επιλέγουμε για το επίπεδο στατιστικής σημαντικότητας και υπολογίζουμε την -τιμή η οποία είναι προφανώς πολύ μικρότερη του Άρα, σε αντίθεση με το Παράδειγμα 14.6, εδώ συμπεραίνουμε πως η μηδενική υπόθεση – ότι η δράση του φαρμάκου είναι ανεξάρτητη από την πορεία της ασθένειας – απορρίπτεται με επίπεδο σημαντικότητας
Παρατηρήσεις:
-
1.
Στο παραπάνω παράδειγμα ίσως να μπαίναμε στον πειρασμό να πούμε ότι, αφού η -τιμή είναι μόλις , μπορούμε να απορρίψουμε την μηδενική υπόθεση με πολύ «υψηλότερο» επίπεδο σημαντικότητας, π.χ., . Αυτός ο συλλογισμός αγγίζει ένα λεπτό θέμα στατιστικής μεθοδολογίας στο οποίο δεν θα επεκταθούμε εδώ, πέραν του να υπογραμμίσουμε ότι η ορθή διαδικασία είναι πάντοτε να επιλέγεται πρώτα το επιθυμητό επίπεδο στατιστικής σημαντικότητας και μετά να συγκρίνεται με την -τιμή.
-
2.
Από το τελευταίο παραπάνω παράδειγμα και από την περιγραφή του μοντέλου στην αρχή αυτής της ενότητας ίσως να δίνεται η εντύπωση ότι περιοριζόμαστε σε περιπτώσεις όπου οι τιμές των είναι επιλεγμένες τυχαία βάσει κάποιου αρχικού σχεδιασμού. Αυτό δεν ισχύει· στην πραγματικότητα οι υποθέσεις μας απλά απαιτούν τα να είναι ανεξάρτητες Bernoulli Τ.Μ. όλες με την ίδια παράμετρο. Ένα τέτοιο παράδειγμα όπου οι τιμές των είναι εντελώς εκτός του ελέγχου μας είναι το ακόλουθο.
Παράδειγμα 14.10 (Μορφωτικό επίπεδο και εισόδημα)
Ένα πολυσυζητημένο θέμα είναι ο βαθμός στον οποίο υπάρχει (ή δεν υπάρχει) στατιστική συσχέτιση μεταξύ του μορφωτικού επιπέδου και του εισοδήματός. Μια από τις μελέτες του αμερικανικού Bureau of Labor Statistics αναφέρει τα εξής αποτελέσματα. Από ένα τυχαίο δείγμα ατόμων κάποιου πληθυσμού, καταγράφονται, για κάθε άτομο τα εξής: αν το ετήσιο εισόδημά του είναι υψηλό (δηλαδή μεγαλύτερο από ), αν όχι, και αν το μορφωτικό του επίπεδο είναι υψηλό (δηλαδή αν είναι κάτοχος πτυχίου πανεπιστημίου), αν όχι.
Παρατηρούμε ότι από τους 304 που έχουν υψηλό μορφωτικό επίπεδο οι 187 έχουν υψηλό εισόδημα, ενώ από τους υπόλοιπους 115 οι 43 έχουν υψηλό εισόδημα. Μπορούμε, βάσει αυτών των παρατηρήσεων, να αποδείξουμε ότι υπάρχει «στατιστικά σημαντική» συσχέτιση μεταξύ του μορφωτικού επιπέδου και του εισοδήματος; Με άλλα λόγια, μπορούμε από αυτά τα δεδομένα να απορρίψουμε τη μηδενική υπόθεση (της ανεξαρτησίας εισοδήματος-μορφωτικού επιπέδου) με επίπεδο σημαντικότητας, ας πούμε,
Όπως στο προηγούμενο παράδειγμα, από τα δεδομένα υπολογίζουμε τις εμπειρικές κατανομές,
από τις οποίες βρίσκουμε την τιμή της στατιστικής συνάρτησης,
δηλαδή Άρα η αντίστοιχη -τιμή είναι και συμπεραίνουμε ότι μπορούμε να απορρίψουμε (με μάλλον «πανηγυρικό» τρόπο) τη μηδενική υπόθεση της ανεξαρτησίας μεταξύ του εισοδήματος και του μορφωτικού επιπέδου, με επίπεδο εμπιστοσύνης
14.3 Μείωση διασποράς
Παράδειγμα 14.11
Έστω πως θέλουμε να υπολογίσουμε το ολοκλήρωμα της συνάρτησης στο διάστημα
το οποίο υποθέτουμε (σωστά) πως δεν μπορεί να εκφραστεί σε κλειστή μορφή. Παρατηρούμε όμως πως μπορεί να εκφραστεί σαν μια μέση τιμή ως προς την πυκνότητα της κατανομής,
όπου Άρα για να εκτιμήσουμε το αρχικό ολοκλήρωμα αρκεί να εκτιμήσουμε τη μέση τιμή,
Γι’ αυτόν το σκοπό παίρνουμε μέσω του υπολογιστή ένα μεγάλο πλήθος ανεξάρτητων δειγμάτων και υπολογίζουμε τον εμπειρικό μέσο όρο,
Ο Ν.Μ.Α. μάς διαβεβαιώνει ότι θα έχουμε κατά πιθανότητα, καθώς το αλλά με δείγματα παρατηρούμε πως η εκτίμηση φαίνεται να μην έχει ακόμα συγκλίνει στη ζητούμενη τιμή Στο Σχήμα 14.2 βλέπουμε το αποτέλεσμα ενός τέτοιου πειράματος.
Εφόσον γνωρίζουμε πως οι Τ.Μ. έχουν μέση τιμή μια ενδιαφέρουσα παρατήρηση είναι πως, για οποιαδήποτε σταθερά οι τυχαίες μεταβλητές έχουν κι αυτές μέση τιμή ίση με
άρα για κάθε μπορούμε να ορίσουμε μια νέα εκτιμήτρια:
Και πάλι ο Ν.Μ.Α. εγγυάται ότι κατά πιθανότητα, καθώς το και εύλογα διερωτόμαστε αν, με μια κατάλληλη τιμή για το η θα μπορούσε να συγκλίνει στο πιο «γρήγορα». Στο Σχήμα 14.3 βλέπουμε πειραματικά αποτελέσματα στα οποία συγκρίνεται η συμπεριφορά των δύο εκτιμητριών και για διαφορετικές τιμές του Είναι εμφανές ότι για η μοιάζει να συγκλίνει ταχύτερα και να έχει μικρότερη διασπορά από τη γεγονός το οποίο επιβεβαιώνουμε εμπειρικά και με δύο ακόμα προσομοιώσεις στο Σχήμα 14.4.
Μια και το παραπάνω σενάριο εμφανίζεται αρκετά συχνά σε προβλήματα εκτίμησης, ιδιαίτερα σε περιπτώσεις προσομοιωμένων δεδομένων, παρακάτω περιγράφουμε τη γενική του μορφή και εξετάζουμε με ποιον τρόπο μπορεί να γίνει συστηματικά η επιλογή μιας αποτελεσματικής τιμής για τη σταθερά
Μέθοδος μεταβλητών ελέγχου. Έστω πως έχουμε ανεξάρτητα δείγματα από μια ενδεχομένως άγνωστη κατανομή, και θέλουμε να εκτιμήσουμε τη μέση τιμή μιας συνάρτησης , όπου η έχει την ίδια κατανομή με τα . Αν υποθέσουμε πως γνωρίζουμε τη μέση τιμή μιας διαφορετικής συνάρτησης , εκτός από τον εμπειρικό μέσο,
μπορούμε να ορίσουμε, για οποιοδήποτε , και τη νέα εκτιμήτρια,
Από τον Ν.Μ.Α. έχουμε πως και οι δύο εκτιμήτριες συγκλίνουν κατά πιθανότητα στο καθώς , μια και,
Το παρακάτω αποτέλεσμα μας λέει πως, αν οι Τ.Μ. και δεν έχουν μηδενική συνδιακύμανση , τότε πάντοτε υπάρχει κάποιο για το οποίο η είναι πιο αποτελεσματική από τον κλασικό εμπειρικό μέσο .
Θεώρημα 14.3
Έστω πως οι τυχαίες μεταβλητές και έχουν μη μηδενική συνδιακύμανση και η έχει μη μηδενική διασπορά. Τότε, για κάθε η διασπορά της εκτιμήτριας ελαχιστοποιείται από την τιμή,
| (14.10) |
οπότε και είναι αυστηρά αποτελεσματικότερη από τον εμπειρικό μέσο:
| (14.11) |
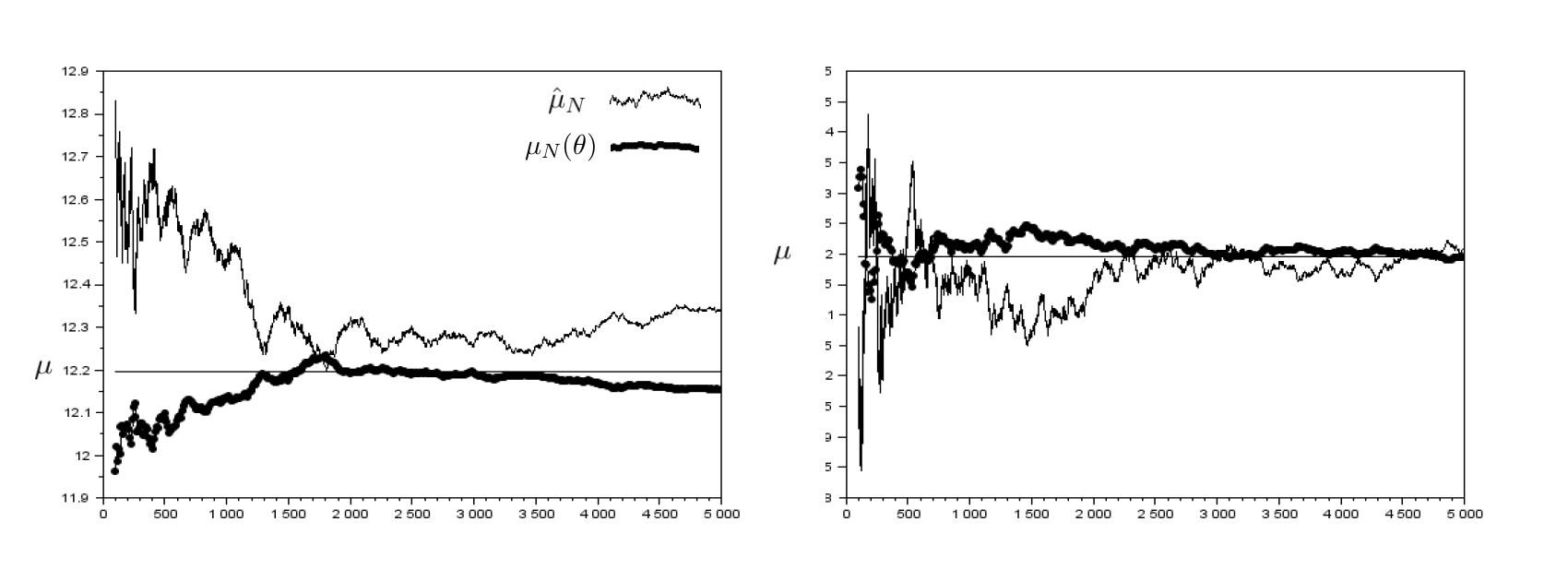
Παρατήρηση: Αν και ως τώρα έχουμε ορίσει τη συνδιακύμανση μόνο για διακριτές Τ.Μ., όπως θα δούμε στο επόμενο κεφάλαιο ο ορισμός παραμένει ακριβώς ίδιος και στην περίπτωση Τ.Μ. με συνεχή κατανομή: , για οποιεσδήποτε .
Απόδειξη:
Όπως έχουμε παρατηρήσει αρκετές φορές από την αρχή του κεφαλαίου (βλ., για παράδειγμα, (14.1)), για τη διασπορά ενός εμπειρικού μέσου όπως η έχουμε,
Άρα, για να ελαχιστοποιήσουμε τη αρκεί να βρούμε το που ελαχιστοποιεί την παραπάνω διασπορά, η οποία μπορεί να αναπτυχθεί ως,
| Var | ||||
| (14.12) |
όπου χρησιμοποιήσαμε μόνο τους ορισμούς και τις βασικές ιδιότητες της μέσης τιμής από τα Θεωρήματα 6.1 και 11.5. Συνεπώς η ελαχιστοποιείται για το εκείνο που ελαχιστοποιεί το απλό τριώνυμο στη (14.12), δηλαδή ακριβώς για την τιμή της (14.10).
Τέλος, το ότι έχουμε αυστηρή ανισότητα στη σχέση (14.11) προκύπτει από το γεγονός ότι κάτω από τις παρούσες συνθήκες το , άρα,
αφού εξ ορισμού .
Το παραπάνω θεώρημα μας διαβεβαιώνει πως, κάτω από γενικές συνθήκες, η χρήση μιας «μεταβλητής ελέγχου» με γνωστή μέση τιμή είναι αποτελεσματική για την ακριβέστερη εκτίμηση του . Παρατηρούμε όμως πως το αποτέλεσμα του θεωρήματος δεν μπορεί να εφαρμοστεί απευθείας στην πράξη, διότι το όπως στη (14.10) είναι αδύνατον να υπολογιστεί αναλυτικά – ακόμα και η απλή τιμή του μέσου μάς είναι άγνωστη. Η συνήθης πρακτική είναι να πρώτα να υπολογίσουμε μια εκτίμηση για τη βέλτιστη τιμή και μετά να χρησιμοποιήσουμε την εκτιμήτρια . Συγκεκριμένα, εφόσον,
| (14.13) |
παίρνοντας τον εμπειρικό μέσο ως μια πρώτη εκτίμηση για το , εκτιμούμε την παραπάνω συνδιακύμανση ως,
| (14.14) |
και τη διασπορά της ως,
| (14.15) |
Άρα, βάσει της (14.13), μια λογική εκτίμηση για τη είναι η . Χρησιμοποιώντας αυτό το , ορίζουμε την προσαρμοστική εκτιμήτρια με μεταβλητή ελέγχου :
| (14.16) |
Παράδειγμα 14.12
Επιστρέφουμε στο Παράδειγμα 14.11, όπου το ζητούμενο είναι να υπολογιστεί η για τη συνάρτηση μιας Τ.Μ. και όπου έχουμε τη μεταβλητή ελέγχου για την οποία
Στο Σχήμα 14.5 δίνονται τα αποτελέσματα δύο προσομοιώσεων όπου συγκρίνεται η προσαρμοστική εκτιμήτρια με τον κλασικό εμπειρικό μέσο Για μεγάλο πλήθος δειγμάτων η εκτίμηση συγκλίνει στη βέλτιστη τιμή και βρίσκουμε ότι το οποίο είναι αρκετά κοντά στην τιμή την οποία είχαμε νωρίτερα επιλέξει πειραματικά.
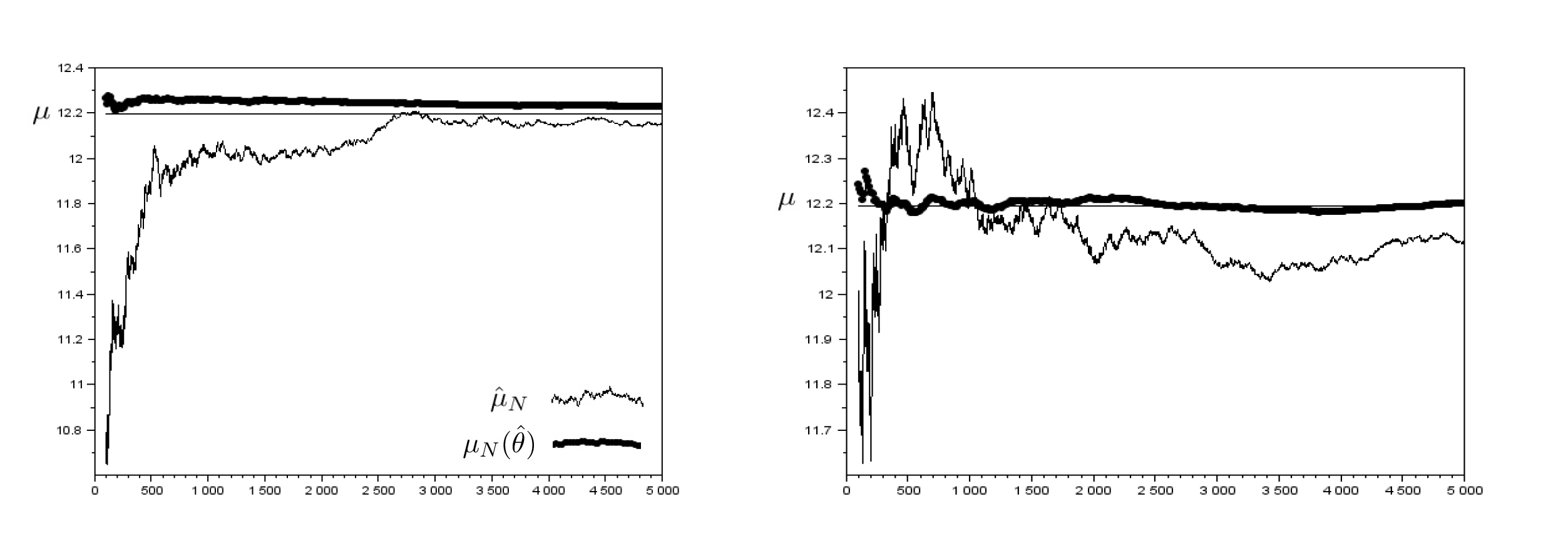
Κλείνουμε με ένα πιο ρεαλιστικό παράδειγμα από τα χρηματοοικονομικά, μία από τις πιο συνηθισμένες περιοχές όπου χρησιμοποιείται ευρέως η μέθοδος των μεταβλητών ελέγχου.
Παράδειγμα 14.13 (Τιμολόγηση δικαιώματος αγοράς)
Ένα από τα πιο κοινά χρηματιστηριακά παράγωγα είναι το λεγόμενο «δικαίωμα αγοράς». Για μια συγκεκριμένη μετοχή, μπορούμε να αγοράσουμε το δικαίωμα να πουλήσουμε τη μετοχή κάποια μελλοντική στιγμή στην τιμή άσκησης όπου τα και είναι προσυμφωνημένα. Συμβολίζοντας με την τιμή της μετοχής την κάθε χρονική στιγμή αν η είναι μεγαλύτερη από θα αγοράσουμε τη μετοχή στη φθηνότερη τιμή κερδίζοντας ευρώ, αλλιώς δεν θα εξασκήσουμε το δικαίωμά μας. Συνεπώς, η απόδοση αυτού του δικαιώματος είναι ευρώ, και σε μια αγορά με σταθερό επιτόκιο η προεξοφλημένη απόδοσή του ισούται με,
| (14.17) |
Το ζητούμενο της τράπεζας που πουλάει αυτό το δικαίωμα είναι να το τιμολογήσει, δηλαδή να αποφασίσει σε ποια τιμή θα το πουλάει, και γι’ αυτόν το λόγο θέλει να ξέρει ποια είναι μέση προεξοφλημένη απόδοση
Μια από τις βασικές υποθέσεις των χρηματοοικονομικών είναι η απουσία «arbitrage» ή «επιτηδειότητας», δηλαδή ότι δεν υπάρχει στην αγορά κάποια επένδυση η οποία μπορεί να επιφέρει κέρδη με 100% βεβαιότητα. Ο τρόπος με τον οποίο αυτή η υπόθεση αντανακλάται στα σχετικά μαθηματικά μοντέλα είναι μέσω της χρήσης ενός μέτρου πιθανότητας που λέγεται «μέτρο αδιάφορο κινδύνου». Στη δική μας περίπτωση, αυτή η υπόθεση συνεπάγεται ότι η μέση προεξοφλημένη τιμή της μετοχής μετά από οποιοδήποτε χρονικό διάστημα ισούται με τη σημερινή τιμή της η οποία μας είναι γνωστή, δηλαδή, Άρα, αν ορίσουμε τότε ξέρουμε τη μέση τιμή,
Η πιο απλή υπόθεση για την τιμή της μετοχής τη χρονική στιγμή είναι αυτή του μοντέλου «γεωμετρικής κίνησης Brown», το οποίο εδώ αντιστοιχεί στο να θεωρήσουμε ότι,
| (14.18) |
όπου η και η παράμετρος είναι η μεταβλητότητα της μετοχής. (Στην Άσκηση 11 θα δούμε ότι ο παραπάνω ορισμός (14.18) πράγματι συνεπάγεται ότι )
Κάτω από αυτές τις υποθέσεις, προκειμένου να εκτιμήσουμε τη μέση προεξοφλημένη απόδοση μπορούμε να πάρουμε ανεξάρτητα δείγματα και από αυτά να υπολογίσουμε, για κάθε τη μελλοντική τιμή της μετοχής από τη σχέση (14.18) και την τιμή της αντίστοιχης προεξοφλημένης απόδοσης του δικαιώματος από τη (14.17). Έτσι, έχουμε τα και τις αντίστοιχες τιμές της μεταβλητής ελέγχου οπότε μπορούμε να ορίσουμε την κλασική εκτιμήτρια,
και την προσαρμοστική εκτιμήτρια,
ακολουθώντας τη γενική μέθοδο που δώσαμε στους τύπους (14.14), (14.15) και (14.16). Επιλέγοντας για τις παραμέτρους τις (ρεαλιστικές) τιμές και και ξεκινώντας από προσομοιωμένα δείγματα τα αποτελέσματα των δύο εκτιμητριών και σε δύο διαφορετικά πειράματα δίνονται στο Σχήμα 14.6.
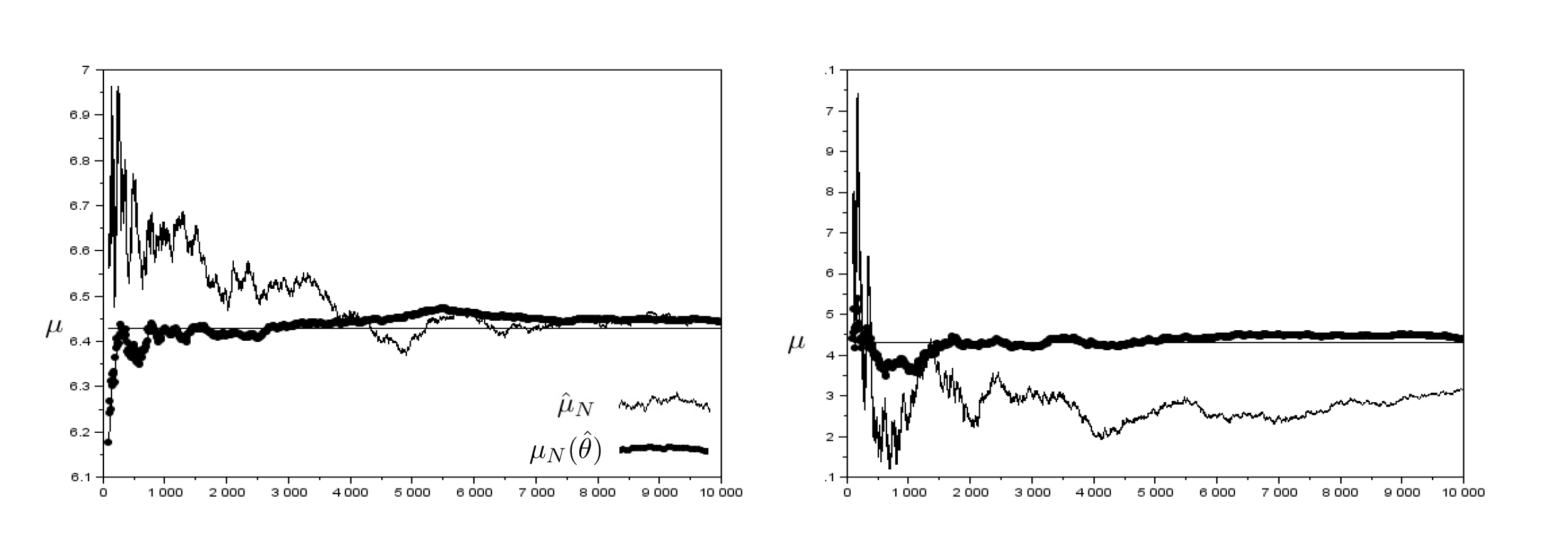
14.4 Ασκήσεις
-
1.
Διάρκειες τραγουδιών. Τον Ιούλιο του 2015, η εταιρία διαχείρισης πνευματικών δικαιωμάτων Κορδατέας Α.Ε. πραγματοποίησε δειγματοληπτικές μετρήσεις της διάρκειας τραγουδιών που παίζονταν στο ραδιόφωνο. Με δείγματα, η έρευνα κατέληξε στην εκτίμηση ότι η μέση διάρκεια των τραγουδιών ήταν 3.12 λεπτά.
-
(α’)
Αν η τυπική απόκλιση της τυχαίας διάρκειας ενός τραγουδιού είναι 54 δευτερόλεπτα, υπολογίστε ένα διάστημα εμπιστοσύνης για την παραπάνω εκτίμηση, με επίπεδο εμπιστοσύνης .
-
(β’)
Πόσα δείγματα θα χρειάζονταν ώστε να μπορεί η εταιρία να δώσει ένα -διάστημα εμπιστοσύνης με στατιστικό σφάλμα μόλις δευτερόλεπτα;
-
(α’)
-
2.
Ελέφαντες. Προκειμένου να εκτιμήσουμε το μέσο μέγεθος μιας αγέλης ελεφάντων, καταγράφουμε τα μεγέθη από αγέλες που συναντάμε, και εκτιμούμε το μέσω του εμπειρικού μέσου όρου, ο οποίος υπολογίζουμε πως είναι .
Αν η τυπική απόκλιση των τυχαίων είναι μεταξύ 5 και 7, βρείτε ένα 90%-διάστημα εμπιστοσύνης για αυτή την εκτίμηση.
-
3.
Ναύτες. Θέλουμε να εκτιμήσουμε το μέσο ύψος μεταξύ των 4000 νεοσύλλεκτων σε ένα στρατόπεδο του Ναυτικού. Επιλέγουμε από αυτούς τυχαία (χωρίς επανατοποθέτηση) και εκτιμούμε ότι το είναι κατά προσέγγιση μέτρα. Επιπλέον, θεωρούμε ότι η τυπική απόκλιση του ύψους των 4000 ναυτών είναι 3 με 9 εκατοστά.
-
(α’)
Υπολογίστε ένα διάστημα εμπιστοσύνης για την εκτίμηση , με επίπεδο εμπιστοσύνης 98%.
-
(β’)
Μπορούμε να συμπεράνουμε από το παραπάνω αποτέλεσμα ότι το ύψος του 98% των ναυτών στο στρατόπεδο είναι μεταξύ και ; Τεκμηριώστε την απάντησή σας.
-
(γ’)
Αν θέλουμε ένα 99%-διάστημα εμπιστοσύνης γι’ αυτή την εκτίμηση, πόσο μεγάλο μέγεθος δείγματος απαιτείται;
-
(δ’)
Ο διοικητής του στρατοπέδου Αρχιπλοίαρχος Παν. Τζίφας επιμένει ότι θέλει αποτελέσματα με στατιστικό σφάλμα το πολύ εκατοστό, και δεν μας επιτρέπει να πάρουμε επιπλέον δείγματα από τα που είχαμε στην αρχή. Ποιο είναι το καλύτερο αποτέλεσμα που μπορούμε να του δώσουμε;
-
(α’)
-
4.
Μια πιο ρεαλιστική δημοσκόπηση. Όπως στο Παράδειγμα 14.2, από ένα τυχαίο δείγμα ψηφοφόρων θέλουμε να εκτιμήσουμε το ποσοστό που θα πάρει η ΝΔ στις εκλογές και βρίσκουμε πως .
-
(α’)
Βρείτε ένα 95%-διάστημα εμπιστοσύνης για την εκτίμηση όταν το πραγματικό ποσοστό των ψηφοφόρων της ΝΔ μας είναι εντελώς άγνωστο.
-
(β’)
Βρείτε ένα αντίστοιχο διάστημα εμπιστοσύνης στην περίπτωση που (εύλογα) υποθέτουμε πως το πραγματικό ποσοστό είναι μεταξύ 20% και 35%. Σχολιάστε τη διαφορά του αποτελέσματός σας με αυτό του προηγούμενου σκέλους.
-
(α’)
-
5.
Εκτίμηση διασποράς. Έστω ανεξάρτητες τυχαίες μεταβλητές, όλες με την ίδια (άγνωστη) κατανομή και με (επίσης άγνωστες) μέση τιμή και διασπορά . Η πιο συνηθισμένη εκτιμήτρια για τη μέση τιμή τους είναι ο εμπειρικός μέσος όρος, , αλλά στη στατιστική βιβλιογραφία συναντάμε δύο διαφορετικές εκτιμήτριες για τη διασπορά:
-
(α’)
Υπολογίστε τη μέση τιμή .
-
(β’)
Υπολογίστε τη μέση τιμή και των δύο παραπάνω εκτιμητριών.
-
(γ’)
Μπορείτε να βρείτε κάποιο συγκριτικό πλεονέκτημα της κάθε εκτιμήτριας ως προς την άλλη;
-
(α’)
-
6.
Τυχαίο; Νομίζω. Όλοι έχουμε έναν φίλο ο οποίος ισχυρίζεται ότι φέρνει πολύ συχνά διπλές στο τάβλι. Για να ελέγξουμε τις «δυνατότητες» ενός τέτοιου ταβλαδόρου, μετράμε ότι έφερε 62 φορές διπλές στις 275 ζαριές που έριξε παίζοντας πέντε διαδοχικές παρτίδες. Αυτός θεωρεί ότι μας απέδειξε τον ισχυρισμό του διότι, λέει, «62 στις 275 είναι πολύ περισσότερες από μία στις έξι». Εμείς τι μπορούμε να του απαντήσουμε;
-
7.
Στυτική δυσλειτουργία. Εξετάζοντας τα ερωτηματολόγια της κλινικής μελέτης ενός νέου αντικαταθλιπτικού φαρμάκου παρατηρούμε ότι, από τους 66 (τυχαία επιλεγμένους, άντρες) ασθενείς που παίρνουν το φάρμακο, οι 36 παρουσίασαν συμπτώματα στυτικής δυσλειτουργίας, ενώ από τους 59 που παίρνουν το placebo μόνο οι 28 αντιμετώπισαν αντίστοιχα προβλήματα. Μπορούμε να συμπεράνουμε με επίπεδο σημαντικότητας 5% ότι η λήψη του φαρμάκου σχετίζεται με το πρόβλημα, ή όχι;
-
8.
Γιωργάκη, θα πουντιάσεις! Έχουν γίνει πολλές μελέτες με σκοπό να ελεγχθεί ο στερεότυπος ισχυρισμός του γονιού που λέει στο παιδί του ότι θα αρρωστήσει αν βγει στο κρύο με βρεγμένα μαλλιά.
Έστω πως πραγματοποιείται μια τέτοια μελέτη με άτομα ηλικίας 18-25 ετών. Αφού βρέξουν τα μαλλιά τους με κρύο νερό, για τον καθένα επιλέγεται τυχαία, με κάποια πιθανότητα , αν (1) θα κάτσει για μία ώρα δίπλα στο τζάκι σε ένα ζεστό δωμάτιο, ή (2) θα βγει για μία ώρα έξω σε θερμοκρασία C, με πολύ ελαφρύ ντύσιμο. Επιπλέον, για κάθε άτομο καταγράφουμε δύο μεταβλητές: Την η οποία ισούται με 1 ή 0 αν κάθισε στο ζεστό δωμάτιο ή βγήκε έξω αντίστοιχα, και την η οποία παίρνει τις τιμές και +1 ανάλογα με το αν η κατάσταση της υγείας του μετά από 48 ώρες έχει χειροτερέψει, έχει μείνει σταθερή ή έχει καλυτερέψει.
-
(α’)
Ορίστε ένα μοντέλο για την κατανομή των δεδομένων .
-
(β’)
Θεωρώντας πως το ζητούμενο είναι να ελεγχθεί αν η θερμοκρασία του περιβάλλοντος επηρεάζει το αν κάποιος πρόκειται να αρρωστήσει ή όχι, περιγράψτε λεπτομερώς τις παραμέτρους του μοντέλου, τη μηδενική υπόθεση και την εναλλακτική υπόθεση.
- (γ’)
-
(δ’)
Μπορεί να αποδειχθεί ότι, κάτω από τη μηδενική υπόθεση, η συγκλίνει κατά κατανομή στην , καθώς το . Περιγράψτε μια μέθοδο ελέγχου ανεξαρτησίας για τις παραπάνω υποθέσεις, βασισμένη στη του προηγούμενου ερωτήματος. Πώς υπολογίζεται η -τιμή εδώ; [Υπόδειξη. Η Άσκηση 2 του Κεφαλαίου 15 δίνει κάποιες πληροφορίες για την κατανομή .]
-
(ε’)
Τα δεδομένα από την παραπάνω μελέτη συνοψίζονται στον πίνακα:
πληθος ατομων χειρότερα το ίδιο καλύτερα ανα περιπτωση () () () τζάκι () 6 65 8 κρύο () 13 71 10 Εφαρμόστε τη μέθοδο ελέγχου του προηγούμενου ερωτήματος σε αυτές τις παρατηρήσεις. Τι μπορείτε να συμπεράνετε; Έχει δίκιο η περιβόητη Ελληνίδα μάνα;
-
(α’)
- 9.
-
10.
Διαφορετική μεταβλητή ελέγχου. Αν στο πρόβλημα του Παραδείγματος 14.12 αντί για τη μεταβλητή ελέγχου θέλουμε να χρησιμοποιήσουμε την , πώς εφαρμόζεται η γενική μέθοδος που περιγράφεται στην Ενότητα 14.3; Χρησιμοποιώντας και πάλι όποιο προγραμματιστικό περιβάλλον σάς βολεύει, υλοποιήστε το αντίστοιχο πείραμα και συγκρίνετε τα αποτελέσματα που δίνει η προσαρμοστική εκτιμήτρια για την κάθε μια από τις δύο μεταβλητές ελέγχου. Ποια σας φαίνεται πιο αποτελεσματική;
-
11.
Προεξοφλημένη τιμή μετοχής. Αποδείξετε απευθείας από τη σχέση (14.18) ότι η προεξοφλημένη τιμή της μετοχής πράγματι ισούται με τη σημερινή τιμή της .
Κεφάλαιο 15 Συνεχής από κοινού κατανομή
[Επιστροφή στα περιεχόμενα]
Στα Κεφάλαια 9 έως 12 συναντήσαμε μια σειρά ιδιοτήτων της από κοινού κατανομής δύο ή περισσοτέρων διακριτών Τ.Μ. Εδώ θα αναπτύξουμε τις αντίστοιχες ιδιότητες για συνεχείς Τ.Μ. Θα ορίσουμε την από κοινού πυκνότητα ενός πεπερασμένου πλήθους Τ.Μ. με συνεχή κατανομή, και θα αποδείξουμε τις βασικές ιδιότητες της από κοινού πυκνότητας, της μέσης τιμής και της διασποράς τους. Μια τεχνική διαφορά που προκύπτει είναι ότι συχνά σε υπολογισμούς πιθανοτήτων εμφανίζονται διπλά ή πολλαπλά ολοκληρώματα. Κατά συνέπεια, ο μαθηματικός χειρισμός που απαιτείται βασίζεται στα εργαλεία της αρκετά πιο σύνθετης περιοχής του απειροστικού λογισμού συναρτήσεων πολλών μεταβλητών, και αυτό το κεφάλαιο είναι μάλλον πιο τεχνικό από τα περισσότερα προηγούμενα. Παρ’ όλα αυτά θα προσπαθήσουμε να διατηρήσουμε τις μαθηματικές μας απαιτήσεις στο ελάχιστο. Γι’ αυτόν το λόγο επικεντρωνόμαστε κυρίως στη μελέτη της από κοινού κατανομής δύο μόνο Τ.Μ., και στο Παράρτημα A.1 συμπεριλαμβάνουμε μια σύντομη επισκόπηση κάποιων από τις απλούστερες τεχνικές υπολογισμού διπλών ολοκληρωμάτων.
15.1 Από κοινού πυκνότητα
Ορισμός 15.1
-
1.
Δύο τυχαίες μεταβλητές και είναι από κοινού συνεχείς όταν υπάρχει μια συνάρτηση η από κοινού πυκνότητα των τέτοια ώστε, για οποιαδήποτε και να ισχύει ότι,
(15.1) και γενικότερα, για οποιοδήποτε σύνολο στο επίπεδο, :
(15.2)
- 2.
Οι τυχαίες μεταβλητές είναι από κοινού συνεχείς όταν υπάρχει μια συνάρτηση η από κοινού πυκνότητα των τέτοια ώστε, για οποιαδήποτε να ισχύει ότι,
και γενικότερα, για οποιοδήποτε :
(15.3)
Παράδειγμα 15.1
Ως μια από τις απλούστερες δυνατές περιπτώσεις, εξετάζουμε δύο Τ.Μ. «ομοιόμορφα» κατανεμημένες στο δηλαδή με από κοινού πυκνότητα που ισούται με 1 αν και και για όλα τα υπόλοιπα Εδώ πολύ εύκολα μπορούμε, π.χ., να υπολογίσουμε την πιθανότητα,
και παρομοίως βρίσκουμε,
Παρατηρήσεις:
-
1.
Όπως στον υπολογισμό της πρώτης πιθανότητας στο παραπάνω παράδειγμα, η πιο απλή (και αρκετά συνηθισμένη) περίπτωση υπολογισμού μιας από κοινού πιθανότητας για δύο συνεχείς Τ.Μ. είναι αυτή που είδαμε στην πρώτη περίπτωση του ορισμού, στη σχέση (15.1): Για και , η πιθανότητα,
(15.4) μπορεί ισοδύναμα να εκφραστεί ως,
όπου το γεγονός πως οι δύο τελευταίες εκφράσεις είναι ίδιες και ίσες με τον ορισμό, προκύπτει από το θεώρημα του Fubini. (Βλ. Παράρτημα A.1.)
-
2.
Όταν κάποια πιθανότητα που μας ενδιαφέρει δεν είναι της παραπάνω απλής μορφής, υπάρχει μια γεωμετρική περιγραφή που ορισμένες φορές διευκολύνει τον υπολογισμό της. Όπως είδαμε στο Κεφάλαιο 10, οι πιθανότητες που αφορούν μια συνεχή Τ.Μ. υπολογίζονται μέσω απλών ολοκληρωμάτων της πυκνότητάς της και μπορούν να ερμηνευτούν γραφικά ως εμβαδά. Παρομοίως, όταν έχουμε ή περισσότερες συνεχείς Τ.Μ., οι πιθανότητες υπολογίζονται μέσω πολλαπλών ολοκληρωμάτων και επομένως γεωμετρικά αντιστοιχούν σε -διάστατους όγκους. Έστω, για παράδειγμα, δύο Τ.Μ. με από κοινού πυκνότητα όπως στο Σχήμα 15.1. Η πιθανότητα το να παίρνει τιμές στο σύνολο ισούται με τον όγκο του στερεού που οριοθετείται από το και το γράφημα της συνάρτησης· βλ. Σχήμα 15.1. Ένας απλός τέτοιος υπολογισμός δίνεται στο αμέσως επόμενο παράδειγμα.
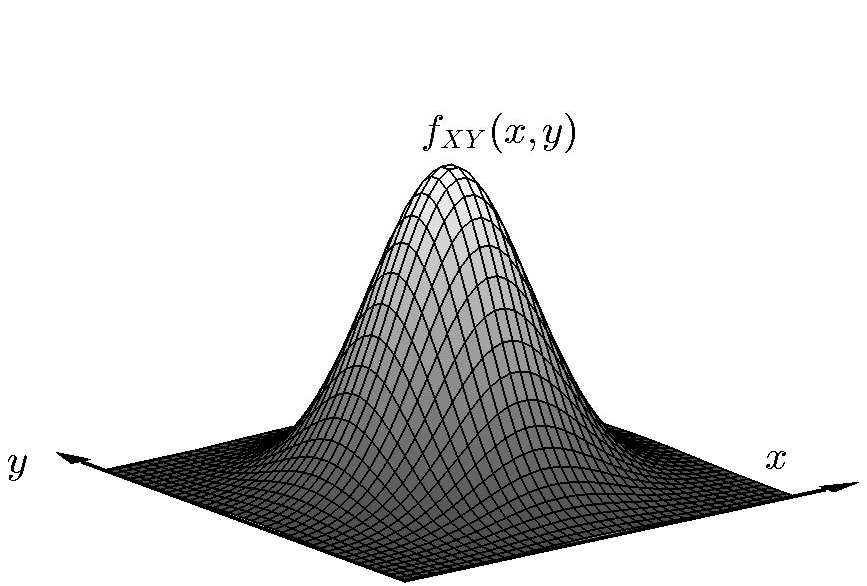
Σχήμα 15.1: Παράδειγμα μιας από κοινού πυκνότητας (αριστερά). Η πιθανότητα τα να πάρουν τιμές στο δίνεται από τον όγκο του σκιασμένου στερεού που βρίσκεται ανάμεσα στο γράφημα της και το (δεξιά). -
3.
Διαισθητικά, η τιμή της από κοινού πυκνότητας δύο Τ.Μ. στο σημείο , εκφράζει τη σχετική πιθανότητα οι Τ.Μ. να πάρουν τιμές «κοντά» στο . Πράγματι, έστω πως η είναι συνεχής στο . Τότε, από το θεμελιώδες θεώρημα του ολοκληρωτικού λογισμού,
όπως αναπαρίσταται και στο Σχήμα 15.2. Συνεπώς, όσο πιο μεγάλη είναι η τιμή της πυκνότητας, τόσο πιο πιθανό είναι τα να βρεθούν κοντά στο .
Σχήμα 15.2: Καθώς τα το στερεό που δημιουργείται ανάμεσα στο γράφημα της και το ορθογώνιο προσεγγίζει ένα ορθογώνιο παραλληλεπίπεδο, του οποίου ο όγκος του ισούται με -
4.
Στο Κεφάλαιο 10, ο ορισμός της πυκνότητας μιας συνεχούς Τ.Μ. διατυπώθηκε μέσω του ορισμού της πιθανότητας για ενδεχόμενα μόνο της απλής μορφής . Αντίθετα, στον Ορισμό 15.1 της από κοινού πυκνότητας, εκτός από τα απλά ενδεχόμενα συμπεριλάβαμε στις σχέσεις (15.3) και (15.3) την περίπτωση υπολογισμού της πιθανότητας των πιο γενικών ενδεχομένων , για αυθαίρετα σύνολα . Αν και εκ πρώτης όψεως ο Ορισμός 15.1 φαίνεται πιο γενικός, κάτω από τους περιορισμούς που θέτουμε στις Ενότητες 10.3 και 15.4 μπορεί να δειχθεί πως οι δύο ορισμοί είναι ισοδύναμοι. Κάποιες περαιτέρω λεπτομέρειες δίνονται στην Ενότητα 15.4.
Παράδειγμα 15.2
Έστω πως οι Τ.Μ είναι συνεχείς, παίρνουν τιμές στο δίσκο με ακτίνα 1, και έχουν από κοινού πυκνότητα,
Το γράφημα της είναι απλά η επιφάνεια του «βόρειου ημισφαίριου» της σφαίρας με ακτίνα 1 και κέντρο το κέντρο των αξόνων.
Έστω πως θέλουμε να υπολογίσουμε την πιθανότητα Από τη δεύτερη παρατήρηση παραπάνω, αυτή ισούται με τον όγκο που αντιστοιχεί στο μέρος της σφαίρας το οποίο αποτελείται από σημεία με θετικές συντεταγμένες, δηλαδή, στο 1/8 της πλήρους σφαίρας. Και αφού, ως γνωστόν, η σφαίρα με ακτίνα 1 έχει συνολικό όγκο η πιθανότητα ισούται με
Συγκεντρώνουμε πιο κάτω κάποιες από τις απλούστερες ιδιότητες της από κοινού πυκνότητας. Οι αποδείξεις, εκτός από εκείνη της τέταρτης ιδιότητας, παραλείπονται, μια και είναι ακριβώς ίδιες με εκείνες των αντίστοιχων αποτελεσμάτων που συναντήσαμε στα Κεφάλαια 9 έως 12
Ορισμός 15.2
Η περιθώρια πυκνότητα της είναι η πυκνότητα μίας από συνεχείς τυχαίες μεταβλητές με από κοινού πυκνότητα
-
1.
-
2.
Για οποιοδήποτε μεμονωμένο σημείο η πιθανότητα,
και αντίστοιχα η πιθανότητα η -άδα Τ.Μ. να πάρει μια οποιαδήποτε συγκεκριμένη τιμή ισούται με μηδέν.
Κατά συνέπεια, αν αλλάξουμε τις τιμές της από κοινού πυκνότητας σε ένα, δύο ή οποιοδήποτε πεπερασμένο πλήθος σημείων, δεν αλλάζει καμία από τις πιθανότητες που προκύπτουν για τις αντίστοιχες Τ.Μ.
-
3.
Για οποιαδήποτε και η πιθανότητα παραμένει η ίδια αν ένα ή περισσότερα από τα «» αντικατασταθούν με «», και ισούται με καθεμία από τις εναλλακτικές εκφράσεις που δώσαμε στην πρώτη παρατήρηση παραπάνω, ανεξάρτητα από το αν και πόσα από τα οριακά σημεία του ορθογωνίου περιέχονται ή όχι στον υπολογισμό της πιθανότητας. [Άσκηση. Διατυπώστε και τεκμηριώστε την προφανή γενίκευση αυτής της ιδιότητας για συνεχείς Τ.Μ.]
-
4.
Η και η είναι συνεχείς Τ.Μ. με περιθώριες πυκνότητες, αντίστοιχα,
και στη γενική περίπτωση, η κάθε είναι συνεχής, με περιθώρια πυκνότητα,
Θα αποδείξουμε μόνο την πρώτη από τις παραπάνω σχέσεις· οι αποδείξεις των υπολοίπων είναι πανομοιότυπες. Παρατηρούμε πως, για οποιαδήποτε , η μπορεί να εκφραστεί,
άρα, η συνάρτηση όπως ορίζεται πιο πάνω, ικανοποιεί τον ορισμό της πυκνότητας μιας συνεχούς Τ.Μ. , όπως δίνεται στο Κεφάλαιο 10.
Παράδειγμα 15.3
Έστω δύο συνεχείς Τ.Μ. με από κοινού πυκνότητα,
η οποία απεικονίζεται στο Σχήμα 15.3. Το ολοκλήρωμά της σε ολόκληρο το είναι,
το οποίο εύκολα υπολογίζεται,
και φυσικά ισούται με 1 όπως προβλέπει η πρώτη ιδιότητα της από κοινού πυκνότητας.
Θα υπολογίσουμε δύο απλές πιθανότητες. Από τον ορισμό της από κοινού πυκνότητας εύκολα βρίσκουμε πως η ισούται με,
όπου τα δύο παραπάνω ολοκληρώματα υπολογίζονται ως,
Το στερεό του οποίου τον όγκο υπολογίσαμε έχει σχεδιαστεί στο Σχήμα 15.4.
 |
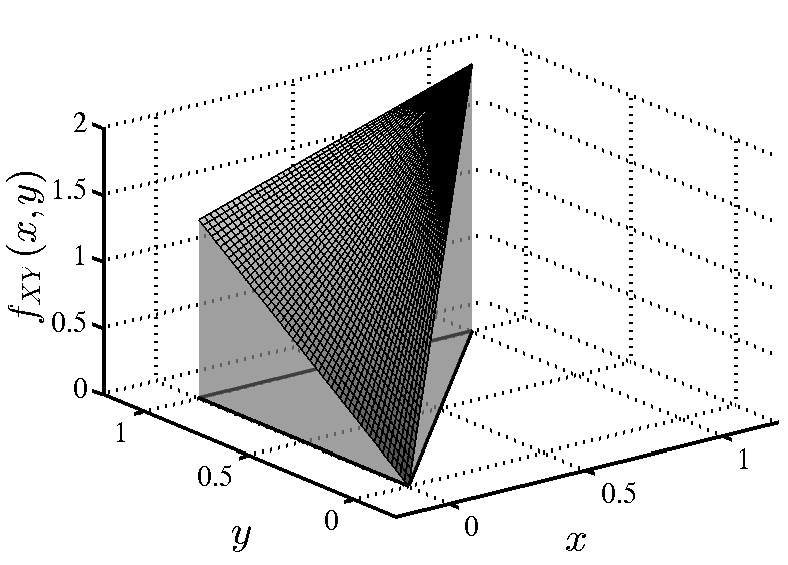 |
Παρομοίως υπολογίζουμε και την πιθανότητα ως:
όπου, και εδώ, το στερεό του οποίου τον όγκο υπολογίσαμε φαίνεται σκιασμένο στο Σχήμα 15.4.
Τέλος, θα βρούμε τις περιθώριες πυκνότητες των βάσει της τέταρτης από τις παραπάνω ιδιότητες. Για να υπολογίσουμε την παρατηρούμε πως, για ή η ισούται με το ολοκλήρωμα μιας συνάρτησης που είναι παντού δηλαδή έχουμε Ενώ για
Εξίσου εύκολα βρίσκουμε και πως,
Παράδειγμα 15.4
Έστω δύο συνεχείς Τ.Μ. με από κοινού πυκνότητα την,
η οποία έχει σχεδιαστεί στο Σχήμα 15.5. Όπως και στο προηγούμενο παράδειγμα, θα υπολογίσουμε τις πιθανότητες και και θα βρούμε τις περιθώριες πυκνότητες των και
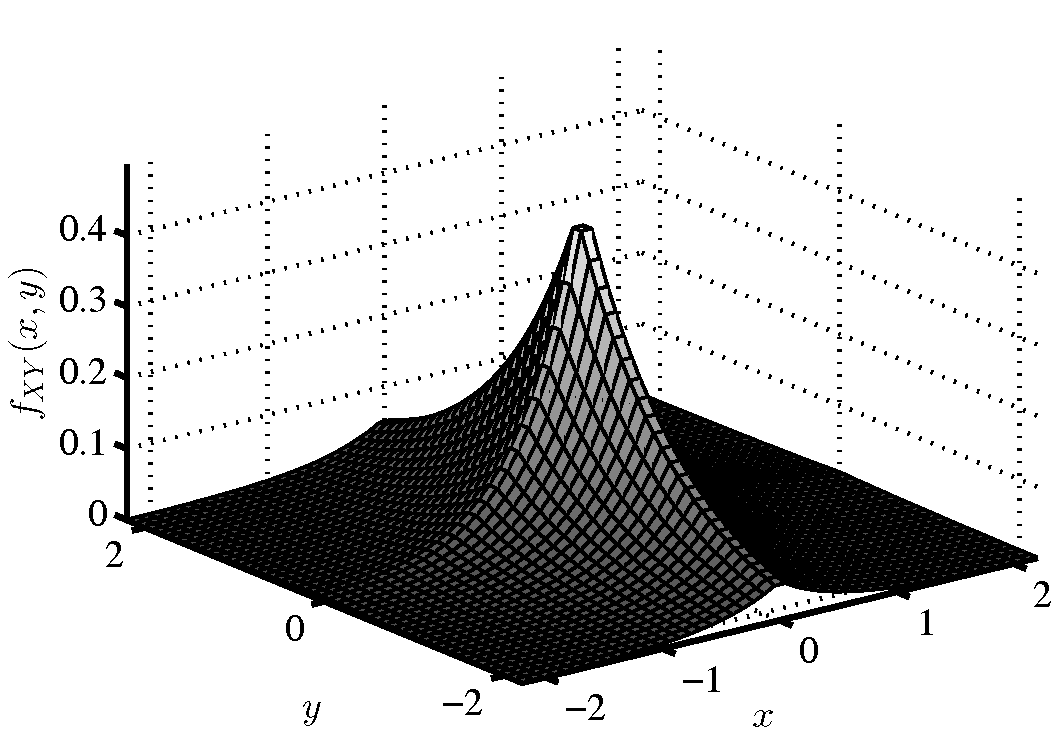
Για την πρώτη πιθανότητα έχουμε:
Το στερεό του οποίου τον όγκο υπολογίσαμε έχει σχεδιαστεί στο Σχήμα 15.6. Παρομοίως, για τη δεύτερη πιθανότητα βρίσκουμε:
Και πάλι το στερεό του οποίου τον όγκο υπολογίσαμε φαίνεται σκιασμένο στο Σχήμα 15.6.
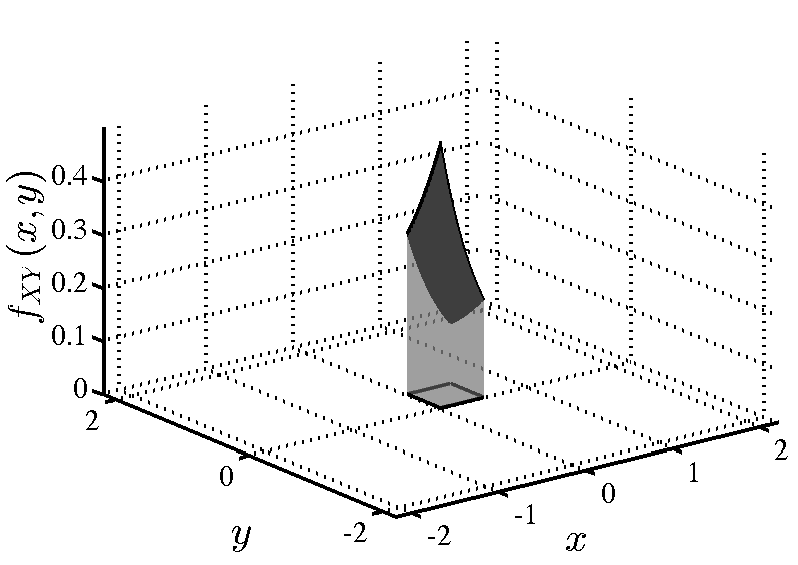
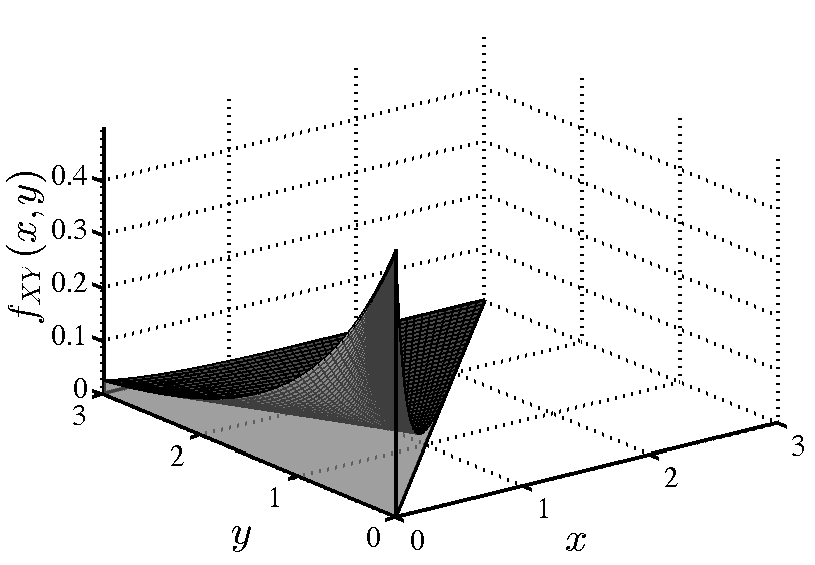
Τέλος, υπολογίζουμε τις περιθώριες πυκνότητες, χρησιμοποιώντας την τέταρτη ιδιότητα της από κοινού πυκνότητας,
για κάθε
15.2 Μέση τιμή, διασπορά και συνδιακύμανση
Πριν ορίσουμε τη συνδιακύμανση μεταξύ δύο Τ.Μ. και με συνεχή από κοινού κατανομή, παραθέτουμε την πιο κάτω βασική ιδιότητα:
| (15.5) |
και παρομοίως η μέση τιμή μιας συνάρτησης των Τ.Μ. με από κοινού πυκνότητα υπολογίζεται ως,
Όπως παρατηρήσαμε στην Ενότητα 10.2, η αντίστοιχη σχέση (10.10) για τον υπολογισμό της μέσης τιμής της συνάρτησης μιας συνεχούς Τ.Μ. , είναι συνέπεια του βασικού ορισμού της μέσης τιμής. Αλλά λόγω του ότι η απόδειξη της (10.10) από τον ορισμό είναι τεχνικής φύσεως και ξεφεύγει από τους παρόντες στόχους μας, χάριν ευκολίας επιλέξαμε να δεχθούμε τον τύπο (10.10) ως δεδομένο, παραλείποντας την απόδειξή του. Για τους ίδιους λόγους, και στη γενικότερη περίπτωση της Ιδιότητας 15.1 θα δεχτούμε τη σχέση (15.5) ως δεδομένη, παραλείποντας και πάλι την απόδειξή της.
Τώρα είμαστε σε θέση να αποδείξουμε το πρώτο σκέλος του Θεωρήματος 11.5, το οποίο διατυπώθηκε στο Κεφάλαιο 11 χωρίς απόδειξη. Η Πρόταση 15.3 που ακολουθεί δίνει μια γενικότερη μορφή του αποτελέσματος, για οποιοδήποτε πεπερασμένο πλήθος Τ.Μ.
Απόδειξη:
Έστω η από κοινού πυκνότητα των . Εφαρμόζοντας την Ιδιότητα 15.1,
όπου, από την τέταρτη βασική ιδιότητα της από κοινού πυκνότητας, η τελευταία έκφραση εντός της παραπάνω παρένθεσης ισούται με την περιθώρια πυκνότητα της . Συνεπώς,
που είναι ακριβώς το ζητούμενο αποτέλεσμα.
Παράδειγμα 15.5
Για τις Τ.Μ. του Παραδείγματος 15.3, μπορούμε να υπολογίσουμε τη μέση τιμή του γινομένου τους ως,
Ορισμός 15.3
Για δύο συνεχείς Τ.Μ. η συνδιακύμανση μεταξύ τους ορίζεται, ακριβώς όπως και στην διακριτή περίπτωση, ως:
Παρατήρηση: Όπως και για την περίπτωση διακριτών Τ.Μ., η διαισθητική ερμηνεία της συνδιακύμανσης είναι πως, όταν , τότε οι δύο Τ.Μ. τείνουν να παίρνουν και οι δύο ταυτόχρονα μεγάλες τιμές, ή και οι δύο ταυτόχρονα μικρές τιμές. Αντίστοιχα, όταν , τότε, όταν η μία Τ.Μ. παίρνει μεγάλες τιμές, η άλλη τείνει να παίρνει μικρές τιμές. Άρα η συνδιακύμανση μάς παρέχει μια πρώτη ένδειξη για το είδος της συσχέτισης μεταξύ της και της .
Οι αποδείξεις των παρακάτω απλών ιδιοτήτων της συνδιακύμανσης παραλείπονται, μια και είναι ακριβώς ίδιες με εκείνες που είδαμε στη διακριτή περίπτωση στο Κεφάλαιο 9, και συγκεκριμένα στο Παράδειγμα 9.9 και στις Ιδιότητες 1 και 4 της Ενότητας 9.2.
Πρόταση
15.4 Για
οποιεσδήποτε δύο συνεχείς Τ.Μ.
και
έχουμε:
15.3 Ανεξαρτησία
Όπως είδαμε στον Ορισμό 11.3 του Κεφαλαίου 11, δύο συνεχείς τυχαίες μεταβλητές είναι ανεξάρτητες αν και μόνο αν, για κάθε , ,
| (15.6) |
Στο επόμενο αποτέλεσμα δείχνουμε πως η ανεξαρτησία μπορεί να εκφραστεί και ως ιδιότητα της από κοινού πυκνότητας των .
| (15.7) |
Απόδειξη:
Έστω πως η από κοινού πυκνότητα των ικανοποιεί τη σχέση (15.7). Τότε, για οποιαδήποτε , , έχουμε,
και άρα οι και είναι ανεξάρτητες.
Αντίστροφα, έστω πως οι είναι ανεξάρτητες με περιθώριες πυκνότητες , αντίστοιχα. Από τον ορισμό της ανεξαρτησίας έχουμε, για οποιαδήποτε , ,
άρα η συνθήκη (15.1) στον ορισμό της από κοινού πυκνότητας ικανοποιείται από τη συνάρτηση , και συνεπώς για την από κοινού πυκνότητα των μπορούμε να θέσουμε .
Στο ακόλουθο θεώρημα αποδεικνύονται κάποιες βασικές συνέπειες της ανεξαρτησίας, τις οποίες έχουμε ήδη συναντήσει σε προηγούμενα κεφάλαια.
-
1.
-
2.
-
3.
-
4.
Για οποιεσδήποτε συναρτήσεις οι τυχαίες μεταβλητές και είναι ανεξάρτητες.
Πριν δώσουμε την απόδειξη παρατηρούμε πως, για την περίπτωση διακριτών Τ.Μ. : την Ιδιότητα 1 πιο πάνω την έχουμε συναντήσει ήδη ως μέρος της πρώτης ιδιότητας της συνδιακύμανσης στο Κεφάλαιο 9· η Ιδιότητα 2 αντιστοιχεί στην Ιδιότητα 2 της Ενότητας 9.2· η Ιδιότητα 3 είναι ακριβώς η πέμπτη ιδιότητα της συνδιακύμανσης στο Κεφάλαιο 9· και η Ιδιότητα 4 δίνεται στην Παρατήρηση 2 της Ενότητας 9.2. Επίσης σημειώνουμε ότι η τρίτη ιδιότητα έχει ήδη διατυπωθεί στη συνεχή περίπτωση, χωρίς απόδειξη, στο δεύτερο σκέλος του Θεωρήματος 11.5 στο Κεφάλαιο 11.
Απόδειξη:
Ξεκινάμε αποδεικνύοντας την τέταρτη (και σημαντικότερη) ιδιότητα. Έστω δύο οποιεσδήποτε συναρτήσεις , και δύο αυθαίρετα υποσύνολα του . Αν ορίσουμε τα «αντίστροφα» σύνολα,
τότε απλά από τους ορισμούς έχουμε,
και από την ανεξαρτησία των ,
Εφόσον η παραπάνω σχέση ισχύει για αυθαίρετα , οι και είναι πράγματι ανεξάρτητες Τ.Μ.
Για την πρώτη ιδιότητα, αφού οι είναι ανεξάρτητες, το κριτήριο (15.7) μας λέει πως μπορούμε να θεωρήσουμε ότι η από κοινού πυκνότητά τους είναι της μορφής . Οπότε βρίσκουμε ότι,
Η δεύτερη ιδιότητα είναι άμεση συνέπεια της πρώτης σε συνδυασμό με το αποτέλεσμα του τρίτου σκέλους της Πρότασης 15.4, και η τρίτη ιδιότητα παρομοίως προκύπτει από το συνδυασμό της δεύτερης με το αποτέλεσμα του τέταρτου σκέλους της Πρότασης 15.4.
Παράδειγμα 15.7
Για τις Τ.Μ. του Παραδείγματος 15.3 υπολογίσαμε στο Παράδειγμα 15.6 πως έχουν μη μηδενική συνδιακύμανση, άρα, βάσει του δεύτερου σκέλους του Θεωρήματος 15.1, δεν είναι ανεξάρτητες. Εναλλακτικά, θα μπορούσαμε να καταφύγουμε απευθείας στον ορισμό της ανεξαρτησίας. Για παράδειγμα, χρησιμοποιώντας τις περιθώριες πυκνότητες των που βρήκαμε στο Παράδειγμα 15.3, υπολογίζουμε τις πιθανότητες,
και παρατηρούμε πως,
όπου η τιμή της πιθανότητας έχει επίσης ήδη υπολογιστεί στο Παράδειγμα 15.3. Άρα, και από τον ορισμό της ανεξαρτησίας προκύπτει ότι οι δεν είναι ανεξάρτητες.
Τα τελευταία δύο αποτελέσματα αυτού του κεφαλαίου μάς λένε με ποιον τρόπο μπορεί να υπολογιστεί η πυκνότητα του αθροίσματος δύο ανεξάρτητων Τ.Μ., και ότι το άθροισμα ανεξάρτητων, κανονικών Τ.Μ. έχει κι αυτό πάντα κανονική κατανομή.
Παρατηρήσεις:
- 1.
-
2.
Πριν δούμε την απόδειξη του θεωρήματος, θα διατυπώσουμε μια σημαντική και χρήσιμη συνέπειά του, την οποία ήδη χρησιμοποιήσαμε στην απόδειξη του θεωρήματος του Lindeberg στο Κεφάλαιο 13.
| . |
Απόδειξη του Θεωρήματος 15.2:
Για να βρούμε την πυκνότητα του , κατ’ αρχάς παρατηρούμε πως η από κοινού πυκνότητα των μπορεί να εκφραστεί ως και εξετάζουμε τη συνάρτηση κατανομής του . Για δεδομένο , αν ορίσουμε το τρίγωνο , τότε έχουμε,
και, συμβολίζοντας τη συνάρτηση κατανομής του ,
Τέλος, παίρνοντας την παράγωγο ως προς και στα δύο παραπάνω μέρη,
το οποίο φυσικά ισούται με , ολοκληρώνοντας την απόδειξη.
Απόδειξη του Πορίσματος 15.1:
Κατ’ αρχάς παρατηρούμε πως η γενική περίπτωση μπορεί να αποδειχθεί με επαγωγική εφαρμογή του αποτελέσματος για Τ.Μ., οπότε αρκεί να δείξουμε ότι, αν οι και είναι ανεξάρτητες, τότε η έχει κατανομή
Ξεκινάμε με την ειδική περίπτωση της , όπου οι , είναι ανεξάρτητες. Εφαρμόζοντας τον τύπο της συνέλιξης από το Θεώρημα 15.2 και αντικαθιστώντας τις αντίστοιχες πυκνότητες της κανονικής κατανομής, η πυκνότητα της είναι,
και θέτοντας και απλοποιώντας βρίσκουμε,
Παρατηρούμε τώρα πως το τελευταίο από τα παραπάνω ολοκληρώματα είναι το ολοκλήρωμα της πυκνότητας της κατανομής σε όλο το , άρα ισούται με 1, και πως η έκφραση πριν το ολοκλήρωμα είναι ακριβώς η πυκνότητα της κατανομής . Άρα, έχουμε ότι η .
Επιστρέφοντας τώρα στη γενική περίπτωση, έστω και ανεξάρτητες, με . Αν ορίσουμε και , τότε, από την απλή ιδιότητα των γραμμικών μετασχηματισμών για κανονικές Τ.Μ. (βλ. Άσκηση 7 του Κεφαλαίου 12), έχουμε , και, από το Θεώρημα 15.1, οι είναι ανεξάρτητες. Επιπλέον, από την ειδική περίπτωση πιο πάνω, έχουμε ότι η , αλλά από τους ορισμούς,
οπότε η Τ.Μ.,
και εφαρμόζοντας και πάλι την ιδιότητα του γραμμικού μετασχηματισμού προκύπτει πως,
το οποίο είναι και το ζητούμενο αποτέλεσμα.
15.4 Μετρησιμότητα και άπειρες τιμές
Στις Ενότητες 6.3 και 10.3 ήδη συζητήσαμε κάποιες μαθηματικές πτυχές των τεχνικής φύσεως προβλημάτων που προκύπτουν όταν ο χώρος πιθανότητας στον οποίο ορίζονται οι Τ.Μ. που εξετάζουμε δεν είναι πεπερασμένος. Δεδομένου ότι οποτεδήποτε οι Τ.Μ. είναι συνεχείς, ο χώρος πιθανότητας στον οποίο θα οριστούν είναι απαραίτητα άπειρος και μη αριθμήσιμος, προκειμένου να αποφευχθούν ενδεχόμενες παθολογίες, εισάγουμε τρεις απλούς περιορισμούς παρόμοιους με εκείνους που είδαμε στο Κεφάλαιο 10:
(1.) Τα μόνα σύνολα τιμών που επιτρέπουμε για συνεχείς Τ.Μ. είναι εκείνα που μπορούν να εκφραστούν ως ενώσεις ενός πεπερασμένου πλήθους διαστημάτων στο .
(2.) Κάθε -άδα από συνεχείς Τ.Μ. ορίζεται πάντοτε σε συνδυασμό με την από κοινού πυκνότητά τους, .
(3.) Τα μόνα ενδεχόμενα των οποίων υπολογίζουμε τις πιθανότητες (ή τις δεσμευμένες πιθανότητες) είναι της μορφής για σύνολα τα οποία είτε (α’) μπορούν να εκφραστούν ως ενώσεις ενός πεπερασμένου πλήθους ορθογωνίων της μορφής,
είτε (β’) είναι χωρία όπως αυτά που περιγράφονται στο Θεώρημα του Fubini. (Βλ. Θεώρημα A.2 του Παραρτήματος A.1.)
Παρότι οι πιο πάνω υποθέσεις είναι πιο περιοριστικές από όσο είναι απαραίτητο για να αναπτυχθεί η σχετική θεωρία, είναι εύκολο να διατυπωθούν και να ελεγχθούν στην πράξη και είναι αρκετά γενικές ώστε να συμπεριλαμβάνουν όλες τις σημαντικές εφαρμογές που μας ενδιαφέρουν. Συγκεκριμένα, κάτω από αυτές τις συνθήκες, για οποιαδήποτε δεδομένη από κοινού πυκνότητα , είναι εύκολο να κατασκευαστεί ένας χώρος πιθανότητας και να οριστούν συναρτήσεις , για και ένα μέτρο πιθανότητας στο , έτσι ώστε οι να έχουν από κοινού πυκνότητα την . Η βασική ιδέα είναι αντίστοιχη της κατασκευής που είδαμε στην Ενότητα 10.3, και δεν θα δώσουμε εδώ περαιτέρω λεπτομέρειες. Αναφέρουμε μόνο πως το δύσκολο και μαθηματικά ενδιαφέρον βήμα είναι η περιγραφή μιας αρκετά πλούσιας ομάδας υποσυνόλων του στην οποία μπορεί να οριστεί το μέτρο πιθανότητας , και η απόδειξη του ότι το πράγματι έχει τις απαιτούμενες ιδιότητες.
Τέλος, για να αποφύγουμε τεχνικές λεπτομέρειες που ξεφεύγουν από τα ζητούμενα του παρόντος βιβλίου, υιοθετούμε τις ίδιες συμβατικές υποθέσεις όπως κάναμε στο Κεφάλαιο 10: Συνοπτικά, υποθέτουμε εμμέσως πως όλα τα ολοκληρώματα που εμφανίζονται σε υπολογισμούς πιθανοτήτων, μέσων τιμών και πυκνοτήτων υπάρχουν και η τιμή τους είναι πεπερασμένη.
15.5 Ασκήσεις
- 1.
- 2.
-
3.
Ασυσχέτιστες αλλά όχι ανεξάρτητες συνεχείς Τ.Μ. Έστω πως οι Τ.Μ είναι «ομοιόμορφα» κατανεμημένες στο δίσκο , δηλαδή έχουν από κοινού πυκνότητα,
-
(α’)
Βρείτε τις περιθώριες πυκνότητες των και .
-
(β’)
Δείξτε πως η συνδιακύμανση , αλλά οι δεν είναι ανεξάρτητες.
-
(α’)
-
4.
Χρόνοι διεργασιών. Δύο διεργασίες που πραγματοποιούνται σε ένα δίκτυο επεξεργαστών είναι προγραμματισμένες έτσι ώστε να τελειώσουν ταυτόχρονα και σε μια συγκεκριμένη ώρα. Έστω , οι χρόνοι καθυστέρησης του τερματισμού τους, σε δευτερόλεπτα, όπου οι Τ.Μ. , είναι ανεξάρτητες και ομοιόμορφα κατανεμημένες από το ως το .
-
(α’)
Ποια είναι η πιθανότητα η διαφορά στους χρόνους τερματισμού, δηλαδή το , να είναι λιγότερο από μισό δευτερόλεπτο;
-
(β’)
Ποια είναι η μέση τιμή της διαφοράς των χρόνων τερματισμού;
-
(γ’)
Η καθυστέρηση στον τερματισμό των διεργασιών έχει κόστος ευρώ. Ποιο είναι το μέσο κόστος που προκύπτει κάθε φορά που εκτελούνται;
-
(δ’)
Ποια είναι η πιθανότητα το κόστος να ξεπερνά τα ευρώ;
-
(ε’)
Υπολογίστε τη συνδιακύμανση .
-
(α’)
-
5.
Θεραπείες. Σε κάποιον ασθενή χορηγούνται δύο θεραπείες, με ποσοστά επιτυχίας και αντίστοιχα, για τα οποία γνωρίζουμε ότι η από κοινού πυκνότητα τους είναι:
-
(α’)
Βρείτε την τιμή της σταθεράς .
-
(β’)
Ποιες είναι οι περιθώριες πυκνότητες των , ;
-
(γ’)
Υπολογίστε τη συνδιακύμανση και δείξτε αν οι Τ.Μ. είναι ανεξάρτητες ή όχι.
-
(δ’)
Ποια είναι η πιθανότητα η δεύτερη θεραπεία να είναι αποτελεσματικότερη από την πρώτη;
-
(α’)
-
6.
Εναλλακτικές θεραπείες. Όπως στην Άσκηση 5, θεωρούμε πως σε κάποιον ασθενή χορηγούνται δύο θεραπείες με ποσοστά επιτυχίας και αντίστοιχα, οι οποίες έχουν ελαφρώς διαφορετική πυκνότητα από πριν:
-
(α’)
Ποια είναι η τιμή της σταθεράς ;
-
(β’)
Ποιες είναι οι περιθώριες πυκνότητες των , ;
-
(γ’)
Υπολογίστε τη συνδιακύμανση και δείξτε αν οι Τ.Μ. είναι ανεξάρτητες ή όχι.
-
(α’)
-
7.
Τριπλά ολοκληρώματα. Έστω πως τρεις συνεχείς Τ.Μ. έχουν από κοινού πυκνότητα:
-
(α’)
Βρείτε την τιμή της σταθεράς .
-
(β’)
Υπολογίστε τη μέση τιμή .
-
(γ’)
Υπολογίστε την πιθανότητα .
-
(α’)
-
8.
Περιθώρια και από κοινού πυκνότητα. Έστω τρεις συνεχείς Τ.Μ. και με από κοινού πυκνότητα . Βρείτε έναν τρόπο να εκφράσετε την από κοινού πυκνότητα μόνο δύο εκ των τριών Τ.Μ., συναρτήσει της . Αποδείξτε ότι το αποτέλεσμά σας ισχύει.
-
9.
Μίξη πυκνοτήτων. Έστω τρεις ανεξάρτητες Τ.Μ. με κατανομές, , και αντίστοιχα. Βρείτε την πυκνότητα της Τ.Μ.,
και εξηγήστε διαισθητικά τι περιγράφει η .
-
10.
Φτου φτου φτου. Η madame Depy Sisini – η διασημότερη επαγγελματίας ξεματιάστρα Καλλιθέας και περιχώρων – έχει διαπιστώσει ότι το επίπεδο ικανοποίησης του κάθε πελάτη της, έστω , εξαρτάται από τις τιμές δύο άλλων Τ.Μ.: Του χρόνου (σε λεπτά) που διαρκούν τα χασμουρητά της ενώ τον ξεματιάζει, και του συνολικού χρόνου (επίσης σε λεπτά) που διαρκεί η διαδικασία του ξεματιάσματος.
Έστω πως οι έχουν από κοινού πυκνότητα:
-
(α’)
Βρείτε την περιθώρια πυκνότητα και τη μέση τιμή του χρόνου των χασμουρητών.
-
(β’)
Δεδομένου ότι σε κάποιο ξεμάτιασμα η madame Depy χασμουρήθηκε για λιγότερο από ένα λεπτό, ποια η πιθανότητα το όλο ξεμάτιασμα να διήρκεσε το πολύ 10 λεπτά;
-
(α’)
-
11.
Συσχέτιση, συνδιακύμανση, διασπορά. [Εδώ θα δούμε τις προφανείς επεκτάσεις κάποιων αποτελεσμάτων που αποδείχθηκαν για διακριτές Τ.Μ. στην Άσκηση 10 του Κεφαλαίου 9 και στην Άσκηση 17 του Κεφαλαίου 11.] Για δύο συνεχείς Τ.Μ. , ο συντελεστής συσχέτισης μεταξύ τους ορίζεται ακριβώς όπως και στη διακριτή περίπτωση:
-
(α’)
Αποδείξτε ότι, αν , όπου η σταθερά , τότε το ισούται με ή με . Πότε ισούται με και πότε με ;
-
(β’)
Δείξτε ότι για τη συνδιακύμανση μεταξύ των και έχουμε:
-
(γ’)
Αποδείξτε πως ο συντελεστής συσχέτισης πάντα ικανοποιεί .
-
(α’)
-
12.
Η διμεταβλητή κανονική κατανομή. Δύο Τ.Μ. λέμε πως έχουν διμεταβλητή κανονική κατανομή με αντίστοιχους μέσους , διασπορές , και συνδιακύμανση , αν έχουν από κοινού πυκνότητα,
(15.8) για κάθε , όπου , και η συνδιακύμανσή τους ικανοποιεί . Δύο παραδείγματα αυτής της πυκνότητας για διαφορετικές τιμές των παραμέτρων απεικονίζονται στο Σχήμα 15.7.
Σχήμα 15.7: Παραδείγματα της διμεταβλητής κανονικής πυκνότητας (15.8) με μέσους Στην πρώτη περίπτωση οι διασπορές είναι και η συνδιακύμανση (αριστερά) και στην δεύτερη περίπτωση έχουμε (δεξιά). Εδώ θα δούμε έναν απλό τρόπο για να κατασκευάσουμε δύο Τ.Μ. με τις πιο πάνω ιδιότητες. Έστω δύο ανεξάρτητες Τ.Μ. με τυπική κανονική κατανομή . Ορίζουμε τις δύο νέες Τ.Μ.,
-
(α’)
Δείξτε πως οι έχουν τις επιθυμητές περιθώριες κατανομές, και .
-
(β’)
Υπολογίστε πως η συνδιακύμανσή τους πράγματι ισούται με .
-
(γ’)
Εξηγήστε γιατί πάντοτε έχουμε και σχολιάστε τον περιορισμό .
-
(δ’)
Αποδείξτε ότι οι έχουν από κοινού πυκνότητα την παραπάνω .
-
(α’)
-
13.
Το Κ.Ο.Θ. χωρίς το «Ο». Έστω πως οι Τ.Μ. στο Κ.Ο.Θ. (Θεώρημα 12.2) έχουν όλες κατανομή . Εξηγήστε γιατί σε αυτή την ειδική περίπτωση δεν χρειάζεται καν να πάρουμε το όριο για να δείξουμε ότι τα κανονικοποιημένα αθροίσματα συγκλίνουν κατά κατανομή στην τυπική κανονική κατανομή.
ΠΟΛΥΜΕΣΙΚΟ ΥΛΙΚΟ ΚΕΦΑΛΑΙΟΥ




Παράρτημα A
A.1 Διπλά ολοκληρώματα: Συνοπτική επισκόπηση
[Επιστροφή στα περιεχόμενα]
Για μια οποιαδήποτε συνάρτηση δύο μεταβλητών, το ολοκλήρωμα της στο υποσύνολο , συμβολίζεται ως,
Αν η παίρνει θετικές τιμές, η γεωμετρική ερμηνεία του διπλού ολοκληρώματος είναι πως η τιμή του ισούται με τον όγκο του στερεού που περικλείεται μεταξύ του συνόλου στο επίπεδο - και του γραφήματος . Γενικά, η τιμή του διπλού ολοκληρώματος ισούται με τον όγκο του στερεού μεταξύ του και της όπου αυτή είναι θετική, μείον τον όγκο μεταξύ του και της όπου αυτή είναι αρνητική. Για παράδειγμα, το διπλό ολοκλήρωμα της συνάρτησης στο είναι ο όγκος του στερεού που βρίσκεται μεταξύ του , όπου η συνάρτηση είναι θετική, και του γραφήματος της , μείον τον όγκο του στερεού που βρίσκεται μεταξύ του , όπου η συνάρτηση είναι αρνητική, και του γραφήματος της , όπως απεικονίζεται στο Σχήμα 1.1.
Στο ακόλουθο θεώρημα συγκεντρώνουμε κάποιες από τις απλούστερες ιδιότητες των διπλών ολοκληρωμάτων. Επίσης σημειώνουμε πως, για να αποφύγουμε τεχνικές δυσκολίες που ξεπερνούν τους στόχους αυτού του βιβλίου, εμμέσως υποθέτουμε πως υπάρχουν όλα τα ολοκληρώματα που εμφανίζονται.
Θεώρημα A.1
Για κάθε ζεύγος συναρτήσεων και στο για οποιεσδήποτε σταθερές και για οποιαδήποτε υποσύνολα έχουμε:
-
1.
Το ολοκλήρωμα είναι γραμμικό:
-
2.
Αν για κάθε τότε:
-
3.
Αν η για κάθε και το είναι υποσύνολο του τότε:
-
4.
Αν τα και είναι ξένα, τότε για οποιαδήποτε συνάρτηση :
-
5.
Για οποιοδήποτε :
-
6.
Αν το έχει εμβαδόν ίσο με μηδέν, τότε για οποιαδήποτε συνάρτηση :
Το επόμενο αποτέλεσμα αποτελεί ένα πολύ χρήσιμο και βασικό εργαλείο για τον υπολογισμό διπλών ολοκληρωμάτων. Αμέσως μετά θα δούμε δύο παραδείγματα όπου εφαρμόζονται οι πιο πάνω ιδιότητες και το θεώρημα του Fubini.
-
1.
Έστω ένα υποσύνολο στο επίπεδο, το οποίο μπορεί να εκφραστεί ως,
(A.1) για κάποιες σταθερές και κάποιες συνεχείς συναρτήσεις τέτοιες ώστε για κάθε (Ένα τέτοιο απεικονίζεται στο Σχήμα 1.2.) Αν η είναι συνεχής στο τότε το διπλό ολοκλήρωμά της στο υπάρχει και μπορεί να υπολογιστεί ως,
-
2.
Παρομοίως, έστω ένα υποσύνολο στο επίπεδο, το οποίο μπορεί να εκφραστεί ως,
(A.2) για κάποιες σταθερές και κάποιες συνεχείς συναρτήσεις τέτοιες ώστε για κάθε (Ένα τέτοιο απεικονίζεται στο Σχήμα 1.2.) Αν η είναι συνεχής στο τότε το διπλό ολοκλήρωμά της στο υπάρχει και μπορεί να υπολογιστεί ως,
-
3.
Στην ειδική περίπτωση που το είναι ένα ορθογώνιο, έχουμε:
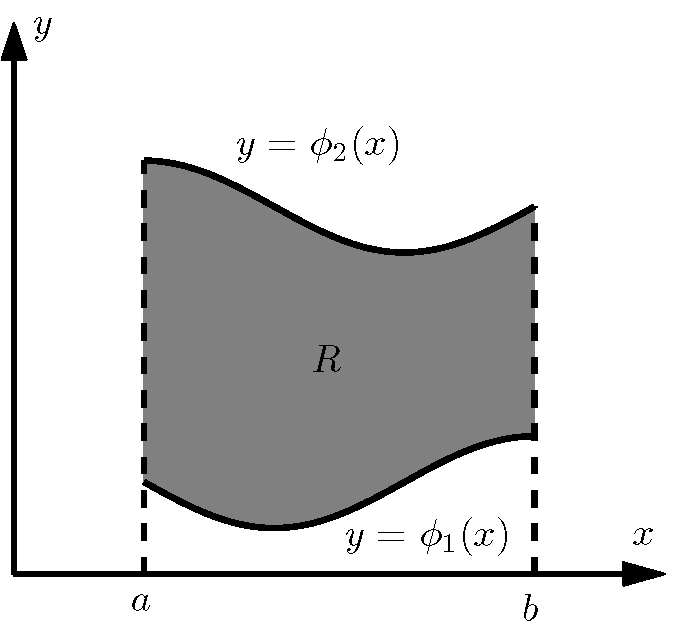 |
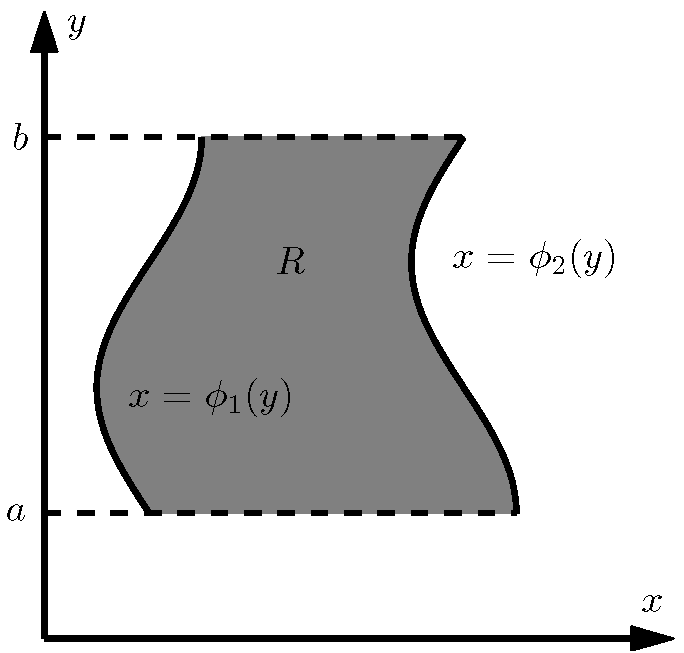 |
Παράδειγμα A.1
Θα υπολογίσουμε το διπλό ολοκλήρωμα της συνάρτησης σε τρία διαφορετικά χωρία
-
1.
Το ορθογώνιο με γωνίες τα σημεία , , , και .
-
2.
Το τρίγωνο με γωνίες τα σημεία , , και .
-
3.
Το χωρίο που περικλείεται από τις ευθείες , , και την καμπύλη .
Σε κάθε περίπτωση, το πιο σημαντικό βήμα είναι η έκφραση του αντίστοιχου σε μία από τις μορφές (A.1) ή (A.2), όπως απαιτεί η εφαρμογή του Θεωρήματος A.2. Έχουμε:
-
1.
Το μπορεί να γραφεί ως άρα,
To και ο όγκος του στερεού που μόλις υπολογίσαμε απεικονίζονται στο Σχήμα 1.3.
-
2.
Για το , παρατηρούμε πως μπορεί να εκφραστεί ως , οπότε,
Όπως πριν, το και ο όγκος του στερεού που μόλις υπολογίσαμε απεικονίζονται στο Σχήμα 1.3.
-
3.
Στην τελευταία περίπτωση, όπως φαίνεται και στο Σχήμα 1.3, έχουμε,
και εφαρμόζοντας και πάλι το θεώρημα του Fubini,
Το Θεώρημα A.2 μπορεί να εφαρμοστεί ακόμη και αν το διπλό ολοκλήρωμα είναι καταχρηστικό, δηλαδή σε περιπτώσεις που είτε το δεν είναι πεπερασμένο, είτε η συνάρτηση δεν είναι φραγμένη. Ακολουθεί ένα τέτοιο παράδειγμα.
Παράδειγμα A.2
Θα υπολογίσουμε το ολοκλήρωμα της στο τρίγωνο που περικλείεται μεταξύ των ευθειών και Το και το αντίστοιχο στερεό που δημιουργείται έχουν σχεδιαστεί στο Σχήμα 1.4.
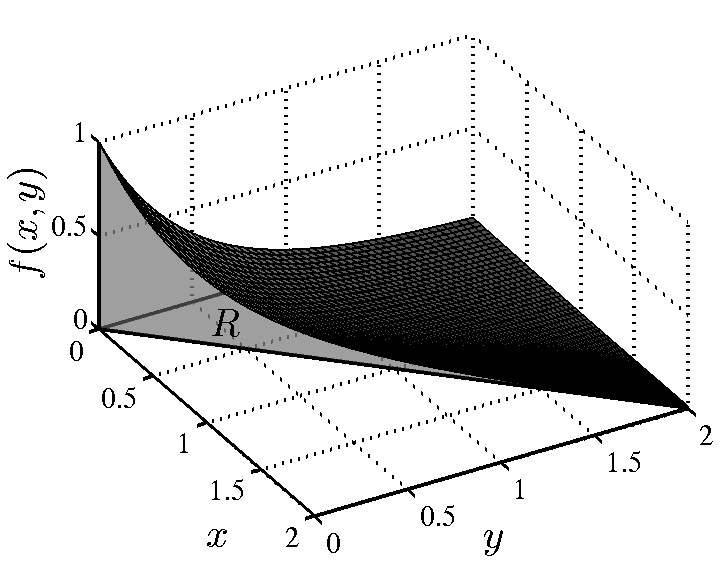
Αρχικά παρατηρούμε πως,
και, χρησιμοποιώντας τη δεύτερη περίπτωση του θεωρήματος του Fubini, έχουμε,
A.2 Ασκήσεις Κεφαλαίου 2
[Επιστροφή στα περιεχόμενα]
-
1.
Τυχαία παιδιά. Ο χώρος πιθανότητας είναι το σύνολο που αποτελείται από όλες τις δυνατές -άδες της μορφής , όπου ή . Άρα περιέχει τέτοια στοιχεία. Π.χ., το στοιχείο περιγράφει την περίπτωση όπου το ζευγάρι έκανε πρώτα ένα κορίτσι και μετά αγόρια.
-
2.
Κι άλλα τυχαία παιδιά. Ο χώρος πιθανότητας εδώ περιέχει δύο ειδών στοιχεία: Εκείνα που αντιστοιχούν σε αποτελέσματα πεπερασμένου μήκους , , , κ.ο.κ., και ένα που αντιστοιχεί στην περίπτωση όπου το ζευγάρι κάνει άπειρα αγόρια, το . Δηλαδή,
Μια εναλλακτική, ισοδύναμη περιγραφή του αποτελέσματος αυτού του πειράματος μπορεί να δοθεί με το να καταγράψουμε απλώς το πόσα παιδιά συνολικά έκανε το ζευγάρι. Τότε, ο αντίστοιχος χώρος πιθανότητας θα μπορούσε να οριστεί ως . Η αντιστοιχία των δύο χώρων πιθανότητας και είναι προφανής.
-
3.
Δύο διαδοχικές ζαριές. Ο χώρος πιθανότητας και όλα τα ζητούμενα ενδεχόμενα έχουν σχεδιαστεί στο Σχήμα 1.5.
Σχήμα 1.5: Λύση Άσκησης 3. -
4.
Υπάρχουν και περίεργοι χώροι πιθανότητας. Εδώ ο χώρος πιθανότητας μπορεί να περιγραφεί ως το ακόλουθο σύνολο:
-
5.
Δύο ταυτόχρονες ζαριές. Ο χώρος πιθανότητας και όλα τα ζητούμενα ενδεχόμενα εμφανίζονται στο Σχήμα 1.6. Σε αυτή την περίπτωση, οι αριθμοί που προκύπτουν δεν είναι διατεταγμένες δυάδες, και συνεπώς δεν έχει νόημα να υπάρχουν στο χώρο πιθανότητας ταυτόχρονα οι δυάδες και , και κ.ο.κ.
Σχήμα 1.6: Λύση Άσκησης 5. -
6.
Τρία νομίσματα. Έστω ΚΚΚ το αποτέλεσμα να έρθουν τρεις Κορώνες, ΚΚΓ να έρθουν δύο Κορώνες και κατόπιν Γράμματα κλπ. Ο χώρος πιθανότητας είναι το,
και τα ζητούμενα ενδεχόμενα είναι τα,
-
7.
Άσπρες και μαύρες μπάλες.
-
(α’)
Ο χώρος πιθανότητας του πειράματος είναι ο . Εφόσον υποθέσαμε ότι οι μαύρες είναι πανομοιότυπες, δεν μπορούμε να διακρίνουμε μεταξύ τους. Αν μπορούσαμε να τις διακρίνουμε, τότε ο χώρος πιθανότητας θα ήταν το σύνολο:
-
(β’)
Το ενδεχόμενο να κερδίσουμε συνολικά 10 ευρώ είναι προφανώς το .
-
(γ’)
Ο νέος χώρος πιθανότητας είναι ο,
και το ζητούμενο ενδεχόμενο είναι το .
-
(α’)
-
8.
Λειτουργία δικτύου. Θυμηθείτε την Παρατήρηση 2 του Κεφαλαίου 2. Κατά συνέπεια, έχουμε: , , , .
-
9.
Απλά διαγράμματα ενδεχομένων. Τα ζητούμενα ενδεχόμενα εμφανίζονται σκιασμένα στο Σχήμα 1.7.
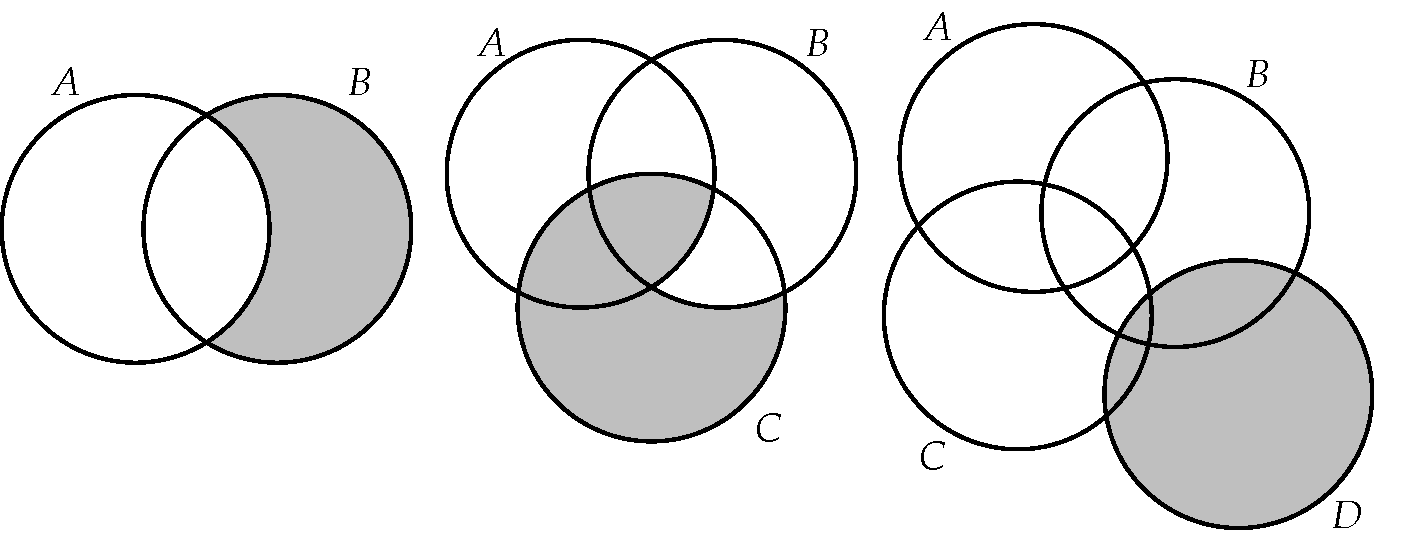
Σχήμα 1.7: Λύση Άσκησης 9. -
10.
Τρεις ζαριές. Ο χώρος πιθανότητας είναι το σύνολο που περιέχει όλες τις τριάδες που αποτελούνται από τα στοιχεία 1,2,3,4,5,6:
Τα ζητούμενα ενδεχόμενα είναι τα:
-
11.
Σταθερά και κινητά τηλέφωνα. Για το χώρο πιθανότητας έχουμε,
Για το πρώτο ζητούμενο ενδεχόμενο,
«επιλέξαμε ένα σταθερό και ένα κινητό»
δηλαδή το αποτελείται από όλα τα μη διατεταγμένα ζεύγη ακεραίων που έχουν και .
Τέλος, Β, γιατί δεν υπάρχει συνδυασμός τηλεφώνων που να δίνει αυτό το κόστος.
-
12.
Το πρόβλημα των τριών φυλακισμένων. Το πρόβλημα αυτό είναι εντελώς ανάλογο του προβλήματος Monty Hall στο Παράδειγμα 2.4, όπου στη θέση του δώρου έχουμε την απονομή χάριτος, στη θέση του διαγωνιζόμενου τον φυλακισμένο, και στη θέση του παρουσιαστή τον δεσμοφύλακα. Μπορούμε και πάλι να περιγράψουμε το χώρο πιθανότητας με χρήση του Σχήματος 2.4, εφόσον ορίσουμε ως τον φυλακισμένο που θα ελευθερωθεί και ως τους άλλους δύο. Εδώ, το πρώτο στοιχείο της τριάδας είναι το όνομα του φυλακισμένου που ρωτά, το δεύτερο στοιχείο της τριάδας είναι το όνομα του φυλακισμένου που ο δεσμοφύλακας αποκαλύπτει ότι δεν θα πάρει χάρη, και το τρίτο στοιχείο είναι το όνομα του φυλακισμένου του οποίου θα πάρει τη θέση ο φυλακισμένος που ρωτά.
-
13.
Monty Hall 2. Ο νέος χώρος πιθανότητας και τα αποτελέσματα που οδηγούν σε νίκη εμφανίζονται στο Σχήμα 1.8. Παρατηρήστε ότι ο νέος χώρος πιθανότητας έχει τη μορφή δέντρου με τρεις αρχικούς κλάδους, ο καθένας εν των οποίων είναι ακριβώς ίδιος με το χώρο πιθανότητας του Παραδείγματος 2.4.

Σχήμα 1.8: Ο χώρος πιθανότητας της Άσκησης 13. Στο πρώτο βήμα επιλέγεται η κουρτίνα στην οποία θα τοποθετηθεί το δώρο, στο δεύτερο ο διαγωνιζόμενος επιλέγει μια κουρτίνα, στο τρίτο ο παρουσιαστής ανοίγει μία από τις άλλες δύο, και στο τέταρτο ο διαγωνιζόμενος αλλάζει αν θέλει την επιλογή του. Τα αποτελέσματα που αντιστοιχούν σε «νίκη» είναι σημειωμένα με -
14.
Monty Hall 3. Ο νέος χώρος πιθανότητας και τα αποτελέσματα που οδηγούν σε νίκη εμφανίζονται στο Σχήμα 1.9. Παρατηρήστε ότι ο νέος χώρος πιθανότητας έχει μόλις 4 στοιχεία.
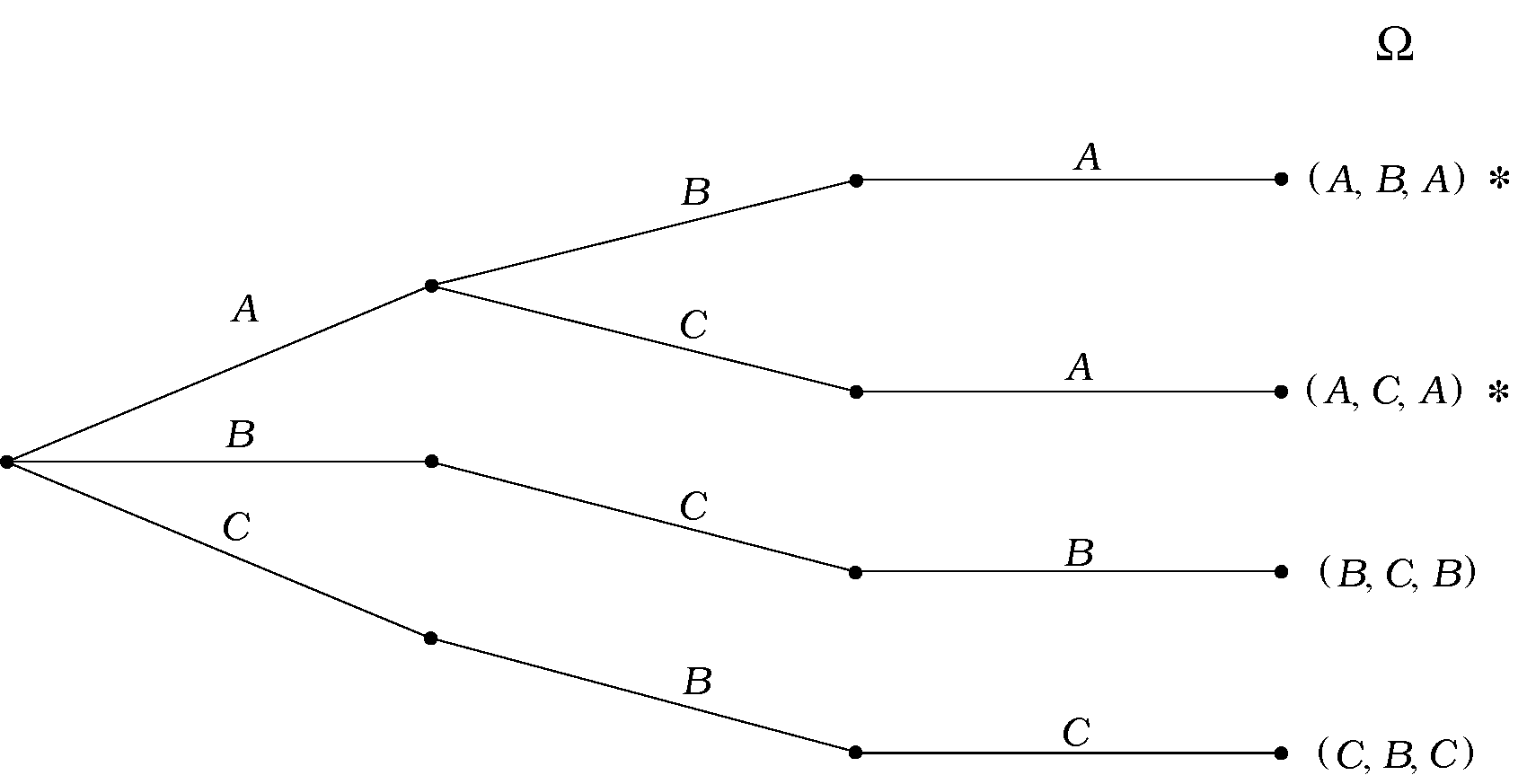
Σχήμα 1.9: Ο χώρος πιθανότητας της Άσκησης 14. Στο πρώτο βήμα ο διαγωνιζόμενος επιλέγει μια κουρτίνα, στο δεύτερο ο παρουσιαστής ανοίγει μία από τις άλλες δύο, και στο τρίτο ο διαγωνιζόμενος διατηρεί την αρχική επιλογή του. Τα αποτελέσματα που αντιστοιχούν σε «νίκη» είναι σημειωμένα με -
15.
Monty Hall 4. Ο νέος χώρος πιθανότητας και τα αποτελέσματα που οδηγούν σε νίκη εμφανίζονται στο Σχήμα 1.10. Παρατηρήστε ότι και αυτός ο χώρος πιθανότητας έχει μόνο 4 στοιχεία.
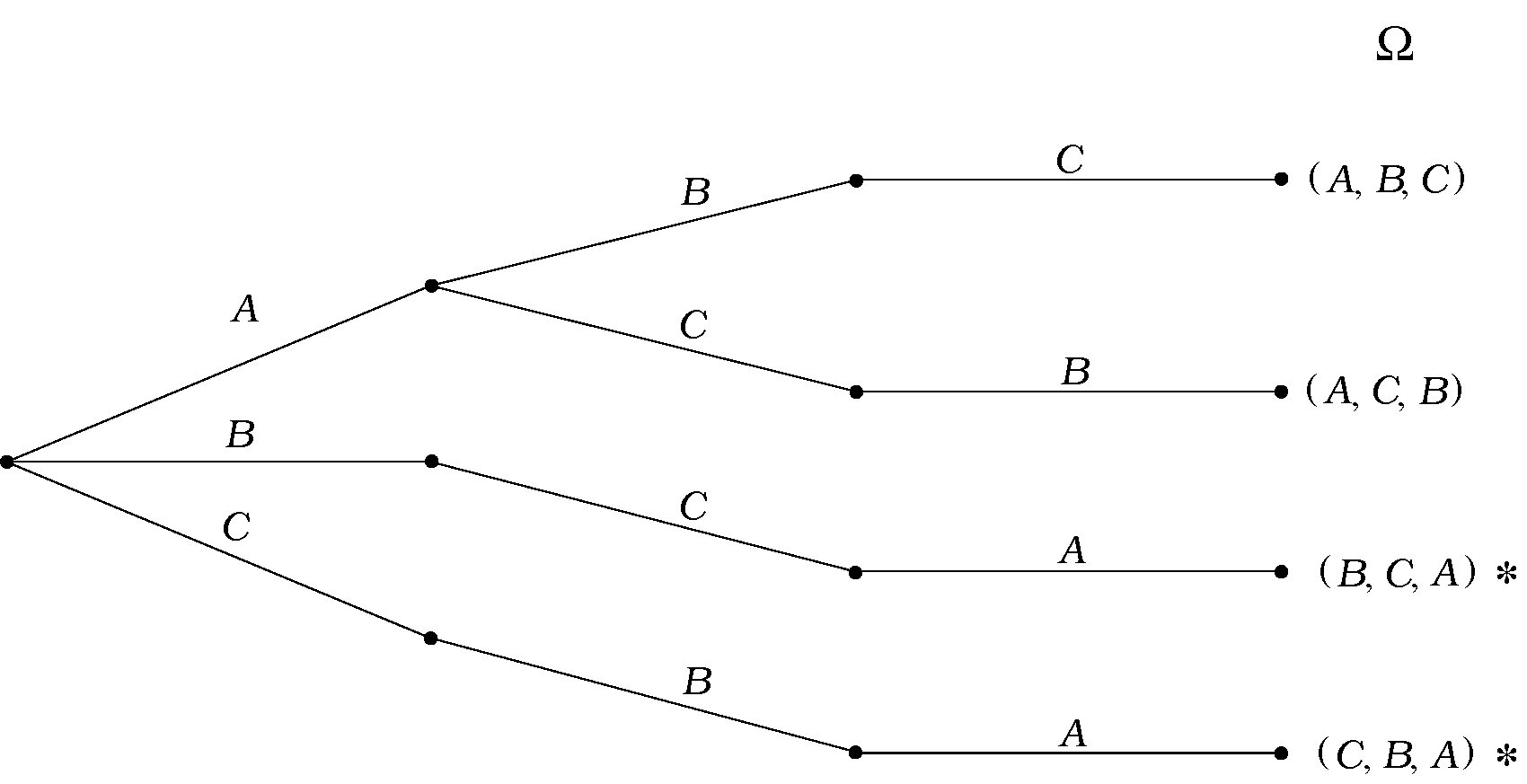
Σχήμα 1.10: Ο χώρος πιθανότητας της Άσκησης 15. Στο πρώτο βήμα ο διαγωνιζόμενος επιλέγει μια κουρτίνα, στο δεύτερο ο παρουσιαστής ανοίγει μία από τις άλλες δύο, και στο τρίτο ο διαγωνιζόμενος αλλάζει την αρχική επιλογή του. Τα αποτελέσματα που αντιστοιχούν σε «νίκη» είναι σημειωμένα με
A.3 Ασκήσεις Κεφαλαίου 3
[Επιστροφή στα περιεχόμενα]
-
1.
Η πιθανότητα της διαφοράς. Έστω ο χώρος πιθανότητας όπου ορίζονται τα ενδεχόμενα και . Έχουμε κατ’ αρχάς ότι,
Όμως τα ενδεχόμενα και είναι ξένα, συνεπώς, από τον κανόνα πιθανότητας ,
που μας δίνει ακριβώς τη ζητούμενη σχέση. Δείτε το διάγραμμα του Σχήματος 1.11.
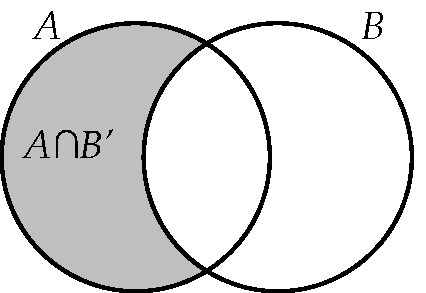
Σχήμα 1.11: Διάγραμμα για την Άσκηση 1. -
2.
Περίεργα ζάρια. Έστω ο χώρος πιθανότητας και τα στοιχειώδη ενδεχόμενα , για Έστω το μέτρο πιθανότητας που περιγράφει τις πιθανότητες αυτού του ζαριού. Μας έχει δοθεί ότι:
Για το κάτω φράγμα, προφανώς έχουμε , και η τιμή είναι εφικτή αν επιλέξουμε, για παράδειγμα, ως μέτρο πιθανότητας το ακόλουθο,
το οποίο είναι συμβατό με τα δεδομένα του προβλήματος.
Για το άνω φράγμα, παρατηρούμε ότι θα πρέπει η πιθανότητα του , δηλαδή του να έρθει , να είναι το πολύ ίση με την πιθανότητα του ενδεχόμενου να έρθει ή , η οποία είναι ίση με . (Αυτό προκύπτει από τον κανόνα πιθανότητας ). Αυτό το άνω φράγμα είναι εφικτό και επιτυγχάνεται, για παράδειγμα, για το ακόλουθο μέτρο πιθανότητας:
Παρατηρήστε ότι τα παραπάνω μέτρα πιθανότητας ικανοποιούν όλα τα αξιώματα πιθανοτήτων, και επομένως είναι αποδεκτά. Το κατά πόσο θα είναι χρήσιμα, εξαρτάται από το πόσο ανταποκρίνονται στην πραγματικότητα, και μπορούμε συνεπώς να τα χρησιμοποιήσουμε ως μοντέλα. [Από αυτή την άποψη, στις περισσότερες περιπτώσεις δεν είναι αποδεκτά, καθώς τα περισσότερα ζάρια ανταποκρίνονται στις συνθήκες για κάθε .]
-
3.
Τυχαία συνάντηση.
-
(α’)
Μπορούμε να χρησιμοποιήσουμε ως χώρο πιθανότητας το διάστημα . Επειδή ο Γιάννης δεν έχει προτίμηση σε κάποιο διάστημα, είναι λογικό να υποθέσουμε ότι η πιθανότητα ενός οποιουδήποτε διαστήματος είναι ανάλογη του μήκους του . Προκειμένου να είναι η πιθανότητα όλου του χώρου πιθανότητας ίση με τη μονάδα, προκύπτει ότι πρέπει Άρα, έχουμε ότι:
-
(β’)
Χρησιμοποιώντας τον κανόνα πιθανότητας , βρίσκουμε,
Όλα τα πιο πάνω ενδεχόμενα εμφανίζονται στο Σχήμα 1.12.
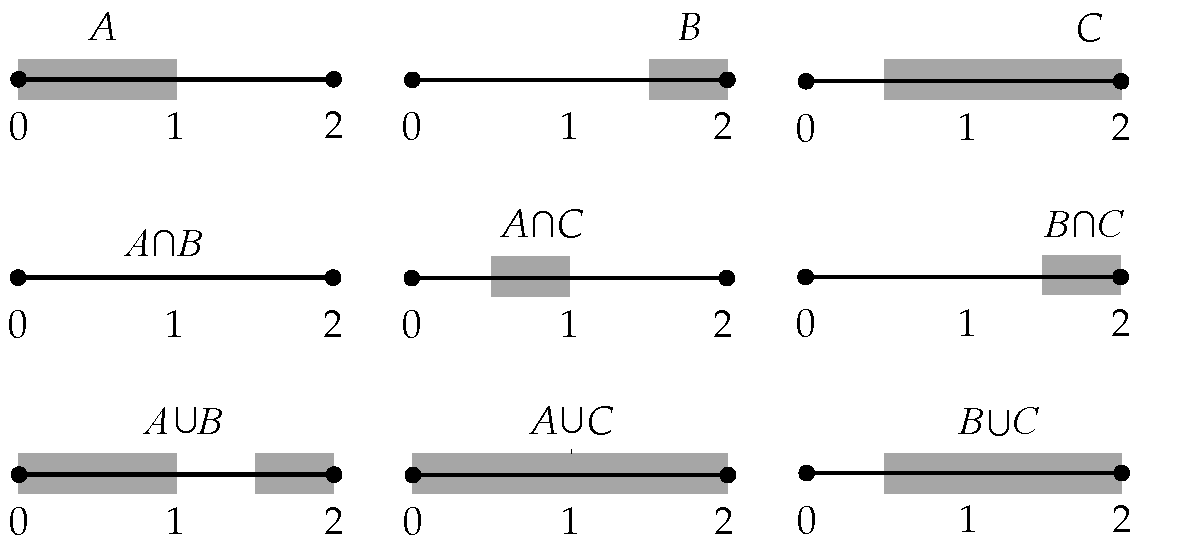
Σχήμα 1.12: Ο χώρος πιθανότητας και τα ενδεχόμενα της Άσκησης 3. -
(α’)
-
4.
Ένωση τριών ενδεχόμενων. Παρατηρήστε κατ’ αρχάς πως το είναι ίσο με την ένωση των τριών συνόλων , , και , δηλαδή
[Αν θέλουμε να είμαστε σχολαστικοί, αυτό μπορεί να αποδειχθεί με τη συνήθη μέθοδο, δηλαδή δείχνοντας ότι κάθε στοιχείο που ανήκει στο θα ανήκει και στην ένωση, και αντιστρόφως. Πράγματι, έστω ένα στοιχείο που ανήκει στο . Τότε, αν ανήκει στο , ανήκει και στην ένωση. Αν όχι, τότε, αν ανήκει στο , θα ανήκει στο άρα και στην ένωση, ενώ, αν δεν ανήκει ούτε στο ούτε στο , τότε σίγουρα θα ανήκει στο , οπότε και στο , άρα και στην ένωση. Αντιστρόφως, αν ένα στοιχείο ανήκει στην ένωση, τότε είτε θα ανήκει στο , είτε στο , άρα και στο , είτε θα ανήκει στο , άρα και στο . Άρα, θα ανήκει στο .]
Επιπλέον, τα τρία σύνολα της ένωσης στη σχέση (3.2) είναι ξένα μεταξύ τους, όπως είναι εύκολο να δειχτεί, παίρνοντας τις τομές ανά δύο. Άρα, η πιθανότητα της ένωσής τους , θα ισούται με το άθροισμα των πιθανοτήτων τους από τον κανόνα πιθανότητας , και έτσι προκύπτει το ζητούμενο. Τα τρία ξένα σύνολα έχουν σχεδιαστεί στο Σχήμα 1.13.
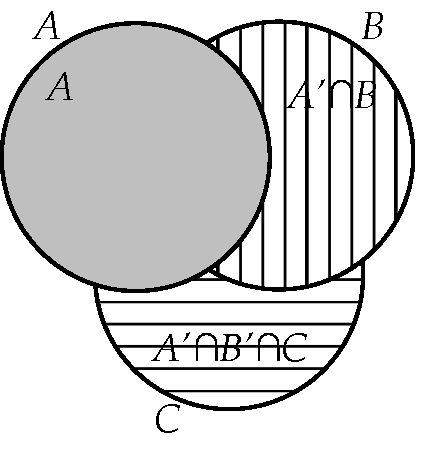
Σχήμα 1.13: Διάγραμμα για την Άσκηση 4. -
5.
Ένας χώρος πιθανότητας με 3 στοιχεία. Τα στοιχειώδη ενδεχόμενα είναι ξένα μεταξύ τους, συνεπώς η πιθανότητα της ένωσής τους ισούται με το άθροισμα των πιθανοτήτων τους:
(A.3) Ομοίως προκύπτει και ότι:
(A.4) Τέλος, ο χώρος πιθανότητας έχει , συνεπώς έχουμε:
(A.5) Οι εξισώσεις (A.3), (A.4) και (A.5) είναι ένα απλό σύστημα τριών εξισώσεων με τρεις αγνώστους, το οποίο εύκολα υπολογίζουμε ότι έχει μόνη λύση τις τιμές:
-
6.
Τι λένε οι πιθανοθεωρίστες στα παιδιά τους. Έστω ότι συμβαίνει ένα τυχαίο έγκλημα κάπου στην Αττική. Ορίζουμε ως το ενδεχόμενο το έγκλημα να έγινε στην Αθήνα, και ως το ενδεχόμενο το έγκλημα να έγινε νύχτα. Μας δίνεται ότι , και , και ζητούνται οι πιθανότητες και .
Παρατηρούμε ότι,
καθώς τα ενδεχόμενα και είναι ξένα. Συνεπώς,
Παρομοίως, έχουμε,
και άρα,
-
7.
Διαιρέτες. Εφόσον η επιλογή είναι τυχαία, όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα και συνεπώς οι υπολογισμοί των πιθανοτήτων θα βασιστούν στον κανόνα πιθανότητας .
-
(α’)
Έστω το σύνολο των αριθμών στο που διαιρούνται με το . Έχουμε , συνεπώς η ζητούμενη πιθανότητα είναι .
-
(β’)
Έστω το σύνολο των αριθμών στο που διαιρούνται με το . Έχουμε , συνεπώς η ζητούμενη πιθανότητα είναι .
-
(γ’)
Οι αριθμοί που διαιρούνται και με το και με το είναι ακριβώς αυτοί που διαιρούνται με το . Έστω το σύνολο των αριθμών στο που διαιρούνται με το . Έχουμε , συνεπώς η ζητούμενη πιθανότητα είναι .
-
(δ’)
Έστω το σύνολο των στοιχείων του που διαιρούνται με τουλάχιστον έναν από τους αριθμούς. Έχουμε,
Συνεπώς η ζητούμενη πιθανότητα είναι .
-
(ε’)
Έστω το σύνολο των στοιχείων που διαιρούνται με το αλλά όχι με το . Παρατηρήστε ότι , και ότι . Συνεπώς , άρα,
-
(α’)
-
8.
Άλλη μία τυχαία συνάντηση. Ο χώρος πιθανότητας αποτελείται από ζεύγη της μορφής , όπου είναι οι χρονικές στιγμές κατά τις οποίες καταφθάνουν στο μπαρ ο Σταύρος και ο Γιάννης αντίστοιχα. Δηλαδή το είναι το τετράγωνο του επιπέδου μεταξύ 0 και 1: .
Η υπόθεσή μας ότι οι φίλοι δεν έχουν προτίμηση στη στιγμή που θα έρθουν, εντός της ώρας, μεταφράζεται στο ότι όλα τα ζεύγη τιμών έχουν την ίδια πιθανότητα. [Παρατηρήστε ότι αναγκαστικά αυτό σημαίνει ότι όλα τα ζεύγη τιμών έχουν πιθανότητα ακριβώς , αλλιώς έχουμε άτοπο, γιατί το άθροισμα των πιθανοτήτων όλων των αποτελεσμάτων θα είναι άπειρο και όχι .]
Για να μπορέσουμε να λύσουμε την άσκηση, κάνουμε και την επιπλέον υπόθεση ότι ένα σύνολο σημείων έχει πιθανότητα να προκύψει ίση με το εμβαδόν του. Πράγματι, αυτός ο κανόνας δίνει στο τετράγωνο πιθανότητα , και ικανοποιεί και τη διαίσθησή μας σχετικά με το ότι όλα τα ζεύγη τιμών προτιμώνται εξίσου από τους δύο φίλους. Με αυτή την υπόθεση, εύκολα προκύπτει ότι η πιθανότητα του ενδεχομένου,
ισούται με το σκιασμένο εμβαδόν του Σχήματος 1.14, το οποίο είναι ίσο (γιατί;) με,
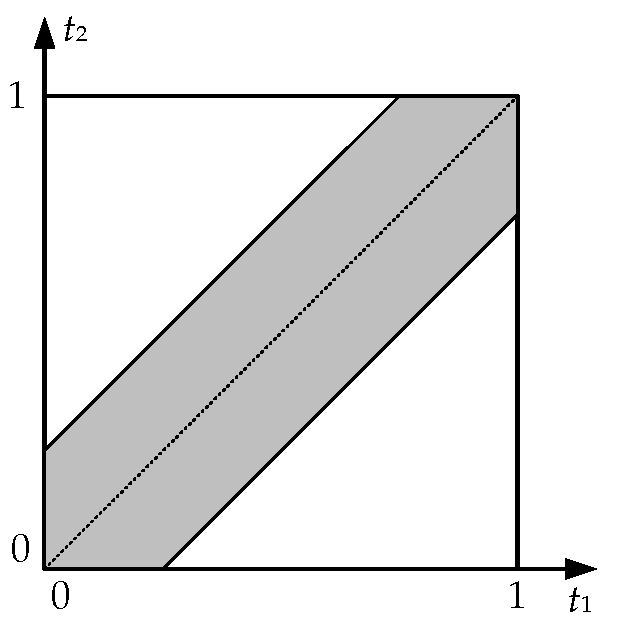
Σχήμα 1.14: Άσκηση 8: Ο χώρος πιθανότητας είναι το τετράγωνο και το ενδεχόμενο είναι το σκιασμένο υποσύνολο του -
9.
Το μέτρο πιθανότητας είναι συνεχής συνάρτηση.
-
(α’)
Έχουμε,
όπου η πρώτη ισότητα προκύπτει από την υπόδειξη της άσκησης, η δεύτερη από τον κανόνα πιθανότητας , η τρίτη από το αποτέλεσμα της Άσκησης 1, και η τελευταία από το γεγονός ότι η εκεί σειρά είναι «τηλεσκοπική» δηλαδή ο κάθε όρος εμφανίζεται αρχικά με θετικό πρόσημο και αμέσως μετά με αρνητικό.
-
(β’)
Παρατηρήστε ότι αν τα μικραίνουν, τότε τα μεγαλώνουν, και μπορούμε να εφαρμόσουμε το πρώτο σκέλος γι’ αυτά. Επιπλέον, παρατηρήστε πως, από τις στοιχειώδεις ιδιότητες των πράξεων συνόλων και τον ορισμό του , έχουμε,
Άρα,
-
(α’)
A.4 Ασκήσεις Κεφαλαίου 4
[Επιστροφή στα περιεχόμενα]
-
1.
Μέτρημα.
-
(α’)
Έχουμε 12 δυνατά αποτελέσματα για την πρώτη επιλογή, 11 για τη δεύτερη, και 10 για την τρίτη. Άρα υπάρχουν δυνατές εκδοχές. Πιο συστηματικά, από τον κανόνα αρίθμησης , το πλήθος των διατεταγμένων 3άδων είναι:
-
(β’)
Καθεμία από τις ρίψεις μπορεί να καταλήξει σε αποτελέσματα, άρα, από τον κανόνα αρίθμησης , το πλήθος των δυνατών αποτελεσμάτων είναι:
-
(γ’)
Εφόσον δεν μας ενδιαφέρει η σειρά επιλογής, το πλήθος των μη διατεταγμένων 20άδων, από τον κανόνα αρίθμησης , είναι:
-
(δ’)
Κάθε ζαριά έχει δυνατά αποτελέσματα, συνεπώς από τον κανόνα αρίθμησης έχουμε δυνατές εκδοχές.
-
(ε’)
Έχουμε επιλογές για τον πρώτο που θα επιλέξουμε, επιλογές για τον δεύτερο κ.ο.κ. Συνεπώς έχουμε συνολικά επιλογές. Το ίδιο αποτέλεσμα προκύπτει και απευθείας από τον κανόνα αρίθμησης .
-
(στ’)
Παρατηρήστε ότι τα φύλλα μοιράζονται με τη σειρά, συνεπώς ψάχνουμε για διατεταγμένες οκτάδες. Έχουμε επιλογές για το πρώτο χαρτί, επιλογές για το δεύτερο χαρτί κ.ο.κ., συνεπώς, από τον κανόνα αρίθμησης , το πλήθος από διαφορετικές οκτάδες είναι .
-
(ζ’)
Κάθε νόμισμα έχει δυνατά αποτελέσματα και κάθε ζάρι δυνατά αποτελέσματα, άρα από τον κανόνα αρίθμησης έχουμε δυνατές εκδοχές.
-
(α’)
-
2.
Επιλογές με επανατοποθέτηση. Ένας βολικός τρόπος να αναπαραστήσουμε μια οποιαδήποτε επιλογή, είναι με μια ακολουθία από ακριβώς καθέτους (/) και ακριβώς αστεράκια (*), σε αυθαίρετη σειρά. Ο αριθμός των φορών που επιλέξαμε το αντικείμενο ισούται με τον αριθμό από αστεράκια ανάμεσα στην κάθετο και την κάθετο . Ειδικά για το πρώτο αντικείμενο, μετράμε τα αστεράκια πριν την πρώτη κάθετο, και για το τελευταίο αντικείμενο μετράμε τα αστεράκια μετά την τελευταία κάθετο. Για παράδειγμα, στην περίπτωση του πρώτου παραδείγματος, η ακολουθία **////*/*/* σημαίνει ότι επιλέξαμε δύο φορές το πρώτο υλικό, μία φορά το πέμπτο, μία το έκτο, και μία το έβδομο. Όμως, ο αριθμός των διαφορετικών ακολουθιών αυτού του τύπου είναι ίσος με τον αριθμό των τρόπων που μπορούμε να τοποθετήσουμε αστερίσκους σε θέσεις, οπότε ο ζητούμενος αριθμός από συνδυασμούς αυτού του τύπου είναι ίσος με:
-
3.
1-2-Χ. Εδώ απλά θέλουμε να μοιράσουμε 9 «αντικείμενα» (τα 9 ματς) σε τρεις κατηγορίες των τεσσάρων, τριών και δύο. Συνεπώς, υπάρχουν,
-
4.
Τράπουλα. Κατ’ αρχάς παρατηρούμε ότι ο χώρος πιθανότητας του προβλήματος περιλαμβάνει όλες τις δυνατές (μη διατεταγμένες) δεκάδες φύλλων που μπορούν να επιλεγούν από φύλλα, οπότε, .
-
(α’)
Έστω το ενδεχόμενο να μην επιλεγεί κανένας άσος. Υπάρχουν τρόποι με τους οποίους μπορεί να σχηματισθεί το , ένας για καθεμία επιλογή των φύλλων από τα υπόλοιπα . Συνεπώς, από τον κανόνα πιθανότητας , .
-
(β’)
Έστω το ενδεχόμενο να πάρουμε το πολύ τρεις άσους. Το ενδεχόμενο περιέχει όλες τις μοιρασιές στις οποίες πήραμε και τους άσους, και ο υπολογισμός της πιθανότητάς του είναι απλούστερος. Πράγματι, υπάρχουν τρόποι να επιλέξουμε τους άσους και τρόποι να επιλέξουμε τα υπόλοιπα φύλλα. Συνεπώς, από τον κανόνα πιθανότητας ,
-
(α’)
-
5.
Poker. Σε αυτό το παράδειγμα, ο χώρος πιθανότητας αποτελείται από όλες τις δυνατές πεντάδες φύλλων που μπορεί να έχει ο παίκτης, όπως προκύπτει από τον κανόνα αρίθμησης .
-
(α’)
Έστω το σύνολο των 5άδων που περιέχουν καρέ. Κατ’ αρχάς παρατηρούμε πως υπάρχουν διαφορετικές πεντάδες με καρέ του άσου, μία για κάθε ένα από τα φύλλα με τα οποία συμπληρώνουμε την πεντάδα. Υπάρχουν άλλες πεντάδες με καρέ του ρήγα κ.ο.κ. Και εφόσον υπάρχουν διαφορετικά καρέ, το συνολικό πλήθος των στοιχείων του είναι . Άρα, από τον κανόνα πιθανότητας , η ζητούμενη πιθανότητα είναι:
-
(β’)
Έστω το σύνολο των 5άδων που αντιστοιχούν σε φουλ. Κατ’ αρχάς, πόσες πεντάδες αντιστοιχούν σε φουλ του άσου με ρηγάδες; Υπάρχουν τρόποι να επιλέξουμε 3 άσους και τρόποι να επιλέξουμε 2 ρηγάδες. Άρα υπάρχουν πεντάδες που περιέχουν φουλ του άσου με ρηγάδες. Επιπλέον, υπάρχουν διαφορετικά είδη φουλ: Φουλ του άσου με ρηγάδες, φουλ του άσου με ντάμες κ.ο.κ. Άρα, το πλήθος όλων των δυνατών 5άδων που αντιστοιχούν σε φουλ είναι και, από τον κανόνα πιθανότητας , η πιθανότητα για φουλ είναι:
-
(γ’)
Τέλος, έστω το σύνολο των 5άδων που αντιστοιχούν σε χρώμα. Υπάρχουν πεντάδες από κούπες, και το ίδιο πλήθος για τα μπαστούνια, σπαθιά και καρό, άρα, . Οπότε, από τον κανόνα πιθανότητας , η πιθανότητα του χρώματος είναι:
-
(α’)
-
6.
Ξενοδοχείο Ακρόπολις.
-
(α’)
Έστω πως δίνουμε έναν αριθμό από το ως το στα διαφορετικά ξενοδοχεία. Το τυχαίο πείραμα εδώ συνίσταται στην τυχαία επιλογή του ξενοδοχείου μετάβασης για καθέναν από τους φίλους. Το σύνολο των δυνατών αποτελεσμάτων θα αποτελείται από όλες τις διατεταγμένες εξάδες ξενοδοχείων (όπου το κάθε ή ). Π.χ. το στοιχείο αντιστοιχεί στο ενδεχόμενο ο πρώτος και ο τρίτος να πήγαν στο ο ξενοδοχείο, ο δεύτερος στο ο, ο τέταρτος στο ο, και οι πέμπτος και έκτος στο ο. Ο χώρος πιθανότητας επομένως θα αποτελείται από όλες τις τέτοιες εξάδες.
-
(β’)
Έστω το ενδεχόμενο να καταλήξουν οι φίλοι σε τρία ζεύγη. Παρατηρήστε ότι, πριν σκεφτούμε σε ποια ξενοδοχεία θα πάνε, υπάρχουν τρόποι να μοιραστούν 6 άνθρωποι σε 3 ζεύγη, αν μας ενδιαφέρει η σειρά σχηματισμού. [Εναλλακτικά, από τον κανόνα πιθανότητας , υπάρχουν τρόποι, το οποίο μας δίνει το ίδιο αποτέλεσμα.] Συνεπώς υπάρχουν αν, όπως στην προκειμένη περίπτωση, δεν μας ενδιαφέρει η σειρά σχηματισμού. [Θυμηθείτε το συλλογισμό που μας οδήγησε από τον κανόνα πιθανότητας στον .]
Αφού έχουμε τα τρία ζευγάρια, υπάρχουν τρόποι να μοιραστούν σε ξενοδοχεία (4 επιλογές για το πρώτο, 3 για το δεύτερο, 2 για το τρίτο). Άρα, το πλήθος των στοιχείων του είναι , και, από τον κανόνα πιθανότητας , η ζητούμενη πιθανότητα ισούται με,
-
(γ’)
Έστω το ενδεχόμενο να βρεθούν δύο μόνοι τους και άλλοι τέσσερις σε δύο ζεύγη. Παρατηρήστε ότι υπάρχουν τρόποι να σχηματιστούν τα δύο ζεύγη αν μας ενδιαφέρει η σειρά σχηματισμού, και αν δεν μας ενδιαφέρει. Οπότε υπάρχουν τρόποι να μοιραστούν οι τέσσερις ομάδες (δύο ζεύγη και δύο άτομα μόνα) σε ξενοδοχεία (4 επιλογές για το πρώτο, 3 για το δεύτερο, 2 για το τρίτο). Άρα, από τον κανόνα πιθανότητας , η ζητούμενη πιθανότητα ισούται με:
-
(α’)
-
7.
Superleague. Υπάρχουν δύο τρόποι να λύσουμε την άσκηση. Πρώτον, παρατηρήστε πως υπάρχουν συνολικά ζεύγη ομάδων, και άρα πρέπει να γίνουν αγώνες. Εναλλακτικά, παρατηρήστε πως καθεμία από τις 16 ομάδες θα υποδεχτεί καθεμία από τις άλλες 15 στο γήπεδό της, άρα θα γίνουν αγώνες.
-
8.
Λόττο. Υπάρχουν δυνατοί συνδυασμοί, όλοι τους ισοπίθανοι. Συνεπώς, από τον κανόνα πιθανότητας , η πιθανότητα να κερδίσουμε με έναν μόνο λαχνό είναι,
δηλαδή μικρότερη από μία στα 10 εκατομμύρια.
-
9.
Εύκολες και δύσκολες ασκήσεις. Εδώ ο χώρος πιθανότητας αποτελείται από όλα τα δυνατά αποτελέσματα της μοιρασιάς. Εφόσον οι ασκήσεις μοιράζονται τυχαία, θα χρησιμοποιήσουμε τον κανόνα πιθανότητας .
Έστω το ενδεχόμενο να έχει ακριβώς μία εύκολη άσκηση κάθε ομάδα. Το πλήθος όλων των δυνατών συνδυασμών με τους οποίους οι ομάδες μπορούν να πάρουν από μία εύκολη άσκηση είναι , και οι συνδυασμοί με τους οποίους μπορούν να πάρουν τις δύσκολες ασκήσεις είναι . Άρα, τελικά έχουμε:
-
10.
Μέτρημα αποτελεσμάτων.
-
(α’)
Στη λέξη ΚΥΠΡΟΣ υπάρχουν γράμματα, όλα διαφορετικά μεταξύ τους. Έχουμε επιλογές για το ποιο γράμμα θα μπει πρώτο, επιλογές για το ποιο γράμμα θα μπει δεύτερο κ.ο.κ. Συνεπώς, συνολικά έχουμε αναγραμματισμούς. Στη λέξη ΣΤΑΥΡΟΣ υπάρχουν γράμματα, που ομοίως μπορούν να παρατεθούν με τρόπους. Δύο από αυτά όμως (τα Σ), είναι όμοια, συνεπώς μπορούμε να αλλάξουμε τη σειρά τους, χωρίς να αλλάξει ο αναγραμματισμός. Επειδή τα δυο Σ μπορούν να τοποθετηθούν με δύο διαφορετικούς τρόπους, έχουμε συνολικά διαφορετικούς αναγραμματισμούς. Για τη λέξη ΣΙΣΙΝΙ, με παρόμοια συλλογιστική, βρίσκουμε ότι υπάρχουν διαφορετικοί αναγραμματισμοί.
-
(β’)
Μπορούμε να επιλέξουμε τις γυναίκες με διαφορετικούς τρόπους και τους άντρες με διαφορετικούς τρόπους. Από τις επιλεγμένες γυναίκες, η πρώτη μπορεί να επιλέξει τον καβαλιέρο της με τρόπους, η δεύτερη με τρόπους, και η τελευταία με έναν τρόπο. Συνοψίζοντας, τα ζεύγη μπορούν να σχηματιστούν με τρόπους.
-
(γ’)
Στην περίπτωση που τα υλικά επαναλαμβάνονται, είμαστε στην περίπτωση της Άσκησης 2, άρα υπάρχουν συνδυασμοί. Στην περίπτωση που τα υλικά δεν επαναλαμβάνονται, από τον κανόνα αρίθμησης έχουμε συνδυασμούς.
-
(α’)
A.5 Ασκήσεις Κεφαλαίου 5
[Επιστροφή στα περιεχόμενα]
-
1.
Ένωση τριών ενδεχόμενων. Έχουμε:
Η δεύτερη και η τέταρτη ισότητα προκύπτουν από τον κανόνα πιθανότητας , και η τρίτη ισότητα προκύπτει από τον ίδιο κανόνα πιθανότητας και την ιδιότητα 4 για τις σχέσεις συνόλων στην τελευταία ενότητα του Κεφαλαίου 2.
Μια διαισθητική ερμηνεία του αποτελέσματος μπορεί να προκύψει κοιτάζοντας Σχήμα 1.15: Η πιθανότητα της ένωσης ισούται με το άθροισμα των πιθανοτήτων των επιμέρους ενδεχομένων, εφόσον βέβαια αφαιρέσουμε τις πιθανότητες των κομματιών αυτών των ενδεχομένων που προστέθηκαν πάνω από μία φορά. Αν αφαιρέσουμε την ποσότητα , τότε οι πιθανότητες αυτών των κομματιών θα έχουν αφαιρεθεί σωστά με εξαίρεση την πιθανότητα του , η οποία αφαιρέθηκε μία φορά παραπάνω από όσες έπρεπε, και συνεπώς πρέπει να προστεθεί στην τελική έκφραση.
Σχήμα 1.15: Διάγραμμα για την Άσκηση 1. -
2.
Πιθανότητα ακριβώς ενός ενδεχομένου. Το ενδεχόμενο να πραγματοποιηθεί ακριβώς ένα από τα ενδεχόμενα , , είναι το να πραγματοποιηθεί το και όχι το , ή να πραγματοποιηθεί το και όχι το , δηλαδή, . Κατ’ αρχάς παρατηρούμε ότι και (γιατί;). Συνεπώς, από τον κανόνα πιθανότητας ,
(A.6) Επιπλέον, από τον κανόνα πιθανότητας ,
(A.7) Συνδυάζοντας τις (A.6), (A.7), προκύπτει το ζητούμενο. Το αποτέλεσμα εύκολα μπορεί να αιτιολογηθεί και διαισθητικά, με χρήση του Σχήματος 1.16.
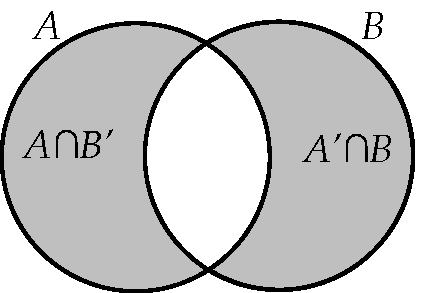
Σχήμα 1.16: Διάγραμμα για την Άσκηση 2. -
3.
Τράπουλα. Έστω το ενδεχόμενο να πάρουμε τουλάχιστον έναν άσο, και το ενδεχόμενο να πάρουμε τουλάχιστον μία φιγούρα. Ζητείται η πιθανότητα του ενδεχόμενου . Εδώ ο χώρος πιθανότητας αποτελείται από όλες τις δυνατές (μη διατεταγμένες) δεκάδες φύλλων που έχουν να επιλεγούν από φύλλα, και εφόσον η επιλογή είναι τυχαία, όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα.
Χρησιμοποιώντας τον κανόνα πιθανότητας και μετά τον κανόνα πιθανότητας , έχουμε,
όπου η καθεμία από τις πιο πάνω πιθανότητες μπορεί να υπολογιστεί από τον κανόνα πιθανότητας σε συνδυασμό και με κάποιους από τους κανόνες αρίθμησης του Κεφαλαίου 4. Συγκεκριμένα έχουμε , , και , οπότε:
-
4.
Ιδιότητες δεσμευμένης πιθανότητας.
-
(α’)
Χρησιμοποιώντας απλώς τον ορισμό της δεσμευμένης πιθανότητας, έχουμε:
[Μπορείτε να γενικεύσετε την παραπάνω σχέση σε αντί για μόνο 3 ενδεχόμενα;]
-
(β’)
Και πάλι θα χρησιμοποιήσουμε μόνο τον ορισμό της δεσμευμένης πιθανότητας. Αν , τότε τα και είναι αδύνατον να συμβούν μαζί, οπότε, διαισθητικά, δεδομένου ότι έχει συμβεί το είναι αδύνατον να συμβεί και το . Πράγματι,
Αν , τότε:
Αν , τότε, δεδομένου ότι έχει συμβεί το , σίγουρα θα έχει συμβεί κάποιο από τα αποτελέσματα που ανήκουν και στο . Πράγματι,
-
(γ’)
Χρησιμοποιώντας τον ορισμό της δεσμευμένης πιθανότητας, έχουμε,
Άρα, το αριστερό μέλος είναι , δηλαδή έχουμε , αν και μόνο αν και το δεξί μέλος είναι , δηλαδή .
-
(α’)
-
5.
Ρίψεις ζαριού. Ο χώρος πιθανότητας αποτελείται από αποτελέσματα, και συγκεκριμένα από τις διατεταγμένες δυάδες της μορφής , όπου . Χρησιμοποιώντας το γεγονός ότι το ζάρι είναι δίκαιο και οι ρίψεις ανεξάρτητες, προκύπτει ότι όλα τα στοιχειώδη ενδεχόμενα έχουν την ίδια πιθανότητα, προφανώς . Πράγματι, για παράδειγμα,
όπου η δεύτερη ισότητα προκύπτει από την ανεξαρτησία και η τρίτη λόγω του ότι το ζάρι είναι δίκαιο. Βάσει των παραπάνω, μπορούμε να υπολογίσουμε την πιθανότητα οποιουδήποτε ενδεχόμενου απλά μετρώντας το πλήθος των στοιχείων του. Άρα, αφού υπάρχουν μονά και ζυγά αποτελέσματα, . Επιπλέον,
ενώ προφανώς, .
Για να αποφανθούμε για την ανεξαρτησία των ζητούμενων ζευγαριών, χρειαζόμαστε την πιθανότητα της τομής τους, Εύκολα βρίσκουμε, αν μετρήσουμε τα αποτελέσματα που ανήκουν σε κάθε τομή, ότι:
Έτσι, συγκρίνοντας την πιθανότητα της τομής με το γινόμενο των επιμέρους πιθανοτήτων σε κάθε περίπτωση, παρατηρούμε ότι τα δύο ζεύγη και , και είναι ανεξάρτητα, ενώ όλα τα άλλα όχι.
-
6.
Δύο δοχεία. Εφόσον υποθέτουμε πως , από τον κανόνα συνολικής πιθανότητας,
Επιπλέον, από τον ορισμό της δεσμευμένης πιθανότητας,
Άρα, για να έχουμε ανεξαρτησία των ενδεχόμενων και , εξ ορισμού απαιτείται να ισχύει ότι, , δηλαδή,
ή, ισοδύναμα, απλοποιώντας την πιο πάνω σχέση,
Η απάντηση αυτή είναι διαισθητικά αναμενόμενη: Για να είναι η επιλογή του τμήματος ανεξάρτητη από την επιλογή του φύλου, πρέπει η αναλογία φοιτητριών/φοιτητών στα δύο τμήματα να είναι η ίδια.
-
7.
Poker με δεσμευμένες πιθανότητες.
-
(α’)
Φανταστείτε πως μας αποκαλύπτονται τα φύλλα όχι ταυτόχρονα, όπως σε λύσεις που βασίζονται σε συνδυαστική, αλλά διαδοχικά. Παρατηρήστε ότι το ενδεχόμενο του καρέ μπορεί να γραφεί ως ένωση πέντε ξένων ενδεχόμενων , όπου το είναι το «παράταιρο» φύλλο να είναι το -οστό που θα μας αποκαλυφθεί. Λόγω συμμετρίας, η ζητούμενη πιθανότητα είναι ίση με (γιατί;).
Για να υπολογίσουμε το , σκεφτόμαστε ως εξής: Έστω πως έχουμε τραβήξει το πρώτο χαρτί. Η πιθανότητα να κάνουμε τελικά καρέ είναι η πιθανότητα η αξία (δηλαδή το «νούμερο», άσος, 2, 3 κλπ.) του δεύτερου φύλλου να είναι διαφορετική από του πρώτου (), επί την πιθανότητα το τρίτο να έχει την ίδια αξία με το δεύτερο (), επί την πιθανότητα το τέταρτο να είναι ίδιο με το δεύτερο (), επί την πιθανότητα το τελευταίο να είναι ίδιο με το δεύτερο ().
Αν θέλουμε να είμαστε πιο σχολαστικοί, ορίζουμε τα ακόλουθα ενδεχόμενα:
Τότε, έχουμε, από τον ορισμό της δεσμευμένη πιθανότητας (δείτε και το πρώτο σκέλος της Άσκησης 4):
Άρα, η πιθανότητα να έρθει καρέ είναι ίση με:
-
(β’)
Για να υπολογίσουμε την πιθανότητα φουλ, θα υπολογίσουμε πρώτα την πιθανότητα του ενδεχόμενου να σηκώσουμε φύλλα από ακριβώς δύο αξίες. Παρατηρήστε ότι θα έχουμε φύλλα με ακριβώς δύο διαφορετικές αξίες αν και μόνο αν έχουμε καρέ ή φουλ, οπότε το ενδεχόμενο μπορεί να εκφραστεί ως ένωση δύο ξένων ενδεχομένων, , όπου =«έχουμε φουλ» και =«έχουμε καρέ». Την πιθανότητα του την υπολογίσαμε ήδη, άρα για να βρούμε τη ζητούμενη πιθανότητα,
αρκεί να υπολογίσουμε την πιθανότητα του .
Γι’ αυτόν το σκοπό θα εκφράσουμε το ως την ένωση των ξένων ενδεχομένων,
όπου το είναι το υποσύνολο του όπου η δεύτερη από τις δύο αξίες της πεντάδας εμφανίζεται για πρώτη φορά στο φύλλο . Παρατηρήστε πως:
Άρα, τελικά, η ζητούμενη πιθανότητα ισούται με:
-
(γ’)
Έστω ότι έχουμε τραβήξει το πρώτο χαρτί. Η πιθανότητα το δεύτερο να είναι του ίδιου χρώματος είναι , γιατί έχουν μείνει φύλλα προς επιλογή, εκ των οποίων είναι του ίδιου χρώματος. Με δεδομένο ότι το δεύτερο φύλλο έχει το ίδιο χρώμα με το πρώτο, το τρίτο φύλλο θα είναι επίσης του ίδιου χρώματος με πιθανότητα κ.ο.κ.
Πιο συστηματικά, ορίζοντας τα ενδεχόμενα,
έχουμε, παρομοίως με το πρώτο σκέλος της άσκησης,
Ένα ηθικό δίδαγμα αυτής της άσκησης είναι ότι πολλά προβλήματα μπορούν να αντιμετωπιστούν είτε με την εφαρμογή κανόνων της συνδυαστικής, είτε με χρήση της δεσμευμένης πιθανότητας, αλλά πολύ συχνά η μία μέθοδος είναι σαφώς ευκολότερη.
-
(α’)
-
8.
Τεστ πολλαπλών απαντήσεων. Ορίζουμε τα ενδεχόμενα «Ο μαθητής απαντά σωστά» και «Ο μαθητής γνωρίζει την απάντηση», οπότε η ζητούμενη πιθανότητα είναι η . Από τον κανόνα του Bayes:
-
9.
Δεσμευμένο μέτρο πιθανότητας.
-
(α’)
Από τον πρώτο κανόνα πιθανότητας έχουμε ότι , και υποθέτουμε ότι . Συνεπώς, από τον ορισμό της δεσμευμένης πιθανότητας:
-
(β’)
Απλά εφαρμόζοντας τον ορισμό του μέτρου πιθανότητας και τον ορισμό της δεσμευμένης πιθανότητας:
-
(γ’)
Για την τελευταία ιδιότητα έχουμε,
όπου η πρώτη και η τελευταία ισότητα προκύπτουν από τον ορισμό του , η δεύτερη και η πέμπτη από τον ορισμό της δεσμευμένης πιθανότητας, η τρίτη από την αντίστοιχη σχέση πράξεων συνόλων, και η τέταρτη από τον κανόνα πιθανότητας (διότι τα είναι προφανώς ξένα ενδεχόμενα).
-
(α’)
-
10.
Συνέπειες ανεξαρτησίας.
-
(α’)
Το ότι τα και είναι ανεξάρτητα σημαίνει πως . Από την ανεξαρτησία και τον κανόνα πιθανότητας , έχουμε,
Επίσης, από την υπόδειξη της άσκησης έχουμε,
και συνδυάζοντας τις πιο πάνω σχέσεις έχουμε,
συνεπώς τα και είναι ανεξάρτητα.
-
(β’)
Η ανεξαρτησία των και προκύπτει όμοια με το προηγούμενο σκέλος.
-
(γ’)
Αφού τα και είναι ανεξάρτητα, θα είναι και τα και , από το δεύτερο σκέλος. Εφαρμόζοντας τώρα το πρώτο σκέλος για τα και , προκύπτει ότι θα είναι ανεξάρτητα και τα και .
Όλα τα αποτελέσματα έχουν διαισθητική εξήγηση. Για παράδειγμα, σχετικά με το πρώτο αποτέλεσμα, αν τα είναι ανεξάρτητα, τότε, αν μάθουμε ότι έγινε το , δεν αλλάζει η πιθανότητα να έχει συμβεί το . Άρα, αν μάθουμε ότι έγινε το , δηλαδή ότι δεν έγινε το , πάλι δεν θα αλλάξει η πιθανότητα του .
-
(α’)
-
11.
Ανεξαρτησία και δέσμευση.
- (α’)
-
(β’)
Αν το είναι ανεξάρτητο από τον εαυτό του, τότε η πιθανότητά του ικανοποιεί,
και οι μόνοι πραγματικοί αριθμοί τέτοιοι ώστε είναι το 0 και το 1.
-
(γ’)
Έστω ένα οποιοδήποτε ενδεχόμενο . Αν , τότε, εφόσον , από τον κανόνα πιθανότητας έχουμε , συνεπώς . Άρα τα δύο ενδεχόμενα είναι ανεξάρτητα:
Παρομοίως, αν , τότε , και άρα τα και είναι ανεξάρτητα, οπότε, από το αποτέλεσμα της Άσκησης 10, τα και είναι επίσης ανεξάρτητα.
-
12.
Κι άλλη τράπουλα.
-
(α’)
Όπως στους ανάλογους υπολογισμούς σε προβλήματα του Κεφαλαίου 4, εφαρμόζοντας τον κανόνα πιθανότητας σε συνδυασμό με τους κανόνες αρίθμησης και ,
-
(β’)
Έστω τα ενδεχόμενα και . Από τον ορισμό της δεσμευμένης πιθανότητας παρομοίως έχουμε:
-
(γ’)
Αν ορίσουμε τον ενδεχόμενο , όπως και στο σκέλος (α’) βρίσκουμε,
-
(δ’)
Τα ενδεχόμενα δεν είναι ανεξάρτητα γιατί είναι αδύνατον να συμβούν μαζί, ενώ το καθένα έχει θετική πιθανότητα. Συγκεκριμένα,
-
(α’)
-
13.
Κανόνας δεσμευμένης συνολικής πιθανότητας. Με συνεχόμενες χρήσεις του ορισμού της δεσμευμένης πιθανότητας, έχουμε,
όπου η πρώτη και η τελευταία ισότητα προκύπτουν από τον ορισμό της δεσμευμένης πιθανότητας και η τρίτη από τον κανόνα πιθανότητας , αφού τα ενδεχόμενα και είναι ξένα.
-
14.
Μεσογειακή αναιμία.
-
(α’)
Έστω το ενδεχόμενο να βγει το αποτέλεσμα θετικό, και να έχει το άτομο το στίγμα. Δίνεται ότι , και . Από τον κανόνα πιθανότητας , έχουμε επίσης , και, από το Λήμμα 5.1, ότι .
Από τον κανόνα του Bayes, η ζητούμενη πιθανότητα είναι:
-
(β’)
Έστω το ενδεχόμενο να βγει το αποτέλεσμα θετικό στην πρώτη εξέταση, και το ενδεχόμενο να βγει το αποτέλεσμα θετικό στη δεύτερη εξέταση. Με εφαρμογή του κανόνα του Bayes και της υπόθεσης της ανεξαρτησίας, έχουμε:
-
(α’)
-
15.
Ανεπιθύμητες εγκυμοσύνες. Ορίζουμε τα ενδεχόμενα: =«Υπάρχει εγκυμοσύνη» και =«Το τεστ είναι θετικό». Από τα δεδομένα του προβλήματος έχουμε , και . Από τον κανόνα πιθανότητας έχουμε ότι, , και από το Λήμμα 5.1,
-
(α’)
Από τον κανόνα του Bayes και τα πιο πάνω δεδομένα:
-
(β’)
Έστω το ενδεχόμενο να βγει το αποτέλεσμα θετικό στην πρώτη ή στη δεύτερη εξέταση, αντίστοιχα. Από τον κανόνα του Bayes και την υπόθεση της ανεξαρτησίας, έχουμε:
-
(α’)
-
16.
Απάτη. Έστω τα ενδεχόμενα: =«το ζάρι είναι δίκαιο» και =«φέραμε 1,5,2,1,1,2». Γνωρίζουμε ότι , και επίσης ότι για το δίκαιο ζάρι έχουμε,
ενώ για το κάλπικο ζάρι, , , και για τα .
Χρησιμοποιώντας αυτά τα δεδομένα μαζί με τον κανόνα του Bayes:
A.6 Ασκήσεις Κεφαλαίου 6
[Επιστροφή στα περιεχόμενα]
-
1.
Μέση τιμή συναρτήσεων Τ.Μ. Έστω μια Τ.Μ. με πυκνότητα στο σύνολο τιμών , και έστω μια συνάρτηση . Τότε η νέα Τ.Μ. έχει σύνολο τιμών το και η πυκνότητά της, έστω , έχει την εξής ιδιότητα: Για κάθε υπάρχει ένα ή περισσότερα τέτοια ώστε . Έστω το σύνολο αυτών των :
Τα σύνολα είναι ξένα μεταξύ τους, και ικανοποιούν,
Συνεπώς, η πυκνότητα μπορεί να εκφραστεί ως,
-
2.
Η συνάρτηση κατανομής στο Έστω πως η Τ.Μ. έχει συνάρτηση κατανομής και είναι ορισμένη στο χώρο πιθανότητας , στον οποίο έχουμε επίσης ορισμένο το μέτρο πιθανότητας .
Ορίζουμε τα ενδεχόμενα για και παρατηρούμε ότι για κάθε και ότι, φυσικά, . Επιπλέον, χρησιμοποιώντας την ορολογία του ορίου μιας ακολουθίας συνόλων όπως στην Άσκηση 9 του Κεφαλαίου 3, η ένωση των ισούται με,
Η τελευταία ισότητα προκύπτει αμέσως από τον ορισμό μιας Τ.Μ. και η προτελευταία είναι συνέπεια του ορισμού των . Οπότε, από το αποτέλεσμα του πρώτου σκέλους της Άσκησης 9 του Κεφαλαίου 3, έχουμε ότι,
δηλαδή,
(A.8) Τέλος παρατηρούμε ότι, εφόσον η είναι αύξουσα και άνω φραγμένη, , το όριό της καθώς το υπάρχει και ισούται με το όριό της κατά μήκος οποιασδήποτε ακολουθίας πραγματικών αριθμών που τείνουν στο . Αυτό, σε συνδυασμό με το αποτέλεσμα (A.8), συνεπάγεται το πρώτο αποτέλεσμα της άσκησης: .
Η απόδειξη του δεύτερου ορίου, καθώς το , είναι ακριβώς ανάλογη. Ορίζουμε τώρα τα ενδεχόμενα για , παρατηρούμε ότι για κάθε και ότι . Οπότε,
όπου η τελευταία ισότητα προκύπτει από το συλλογισμό πως, αν κάποιο , τότε θα πρέπει να έχουμε για κάθε , πράγμα αδύνατο. Συνεπώς, από το αποτέλεσμα του δεύτερου σκέλους της Άσκησης 9 του Κεφαλαίου 3, έχουμε ότι,
(A.9) Τέλος, παρατηρούμε ότι, εφόσον η είναι αύξουσα και κάτω φραγμένη, , το όριό της καθώς το υπάρχει και ισούται με το όριό της κατά μήκος οποιασδήποτε πραγματικής ακολουθίας που τείνει στο . Αυτό, σε συνδυασμό με το αποτέλεσμα (A.9), συνεπάγεται το δεύτερο αποτέλεσμα της άσκησης: .
-
3.
Ντετερμινιστικές Τ.Μ. Έστω μια ντετερμινιστική Τ.Μ. με σύνολο τιμών , οπότε , και μια οποιαδήποτε διακριτή Τ.Μ. με σύνολο τιμών . Η επιβεβαίωση του ότι ικανοποιείται ο ορισμός της ανεξαρτησίας για τις είναι τετριμμένη διότι, προφανώς, το ενδεχόμενο ισούται με το για οποιοδήποτε . Άρα, πράγματι:
-
4.
Άπειρη μέση τιμή.
-
(α’)
Από τη δεύτερη βασική ιδιότητα της πυκνότητας ξέρουμε πως το άθροισμα όλων των τιμών της πρέπει να ισούται με 1, συνεπώς, πρέπει να έχουμε,
και άρα
-
(β’)
Η μέση τιμή της είναι,
το οποίο ισούται με αφού, ως γνωστόν, η αρμονική σειρά αποκλίνει.
-
(α’)
-
5.
Ανεξαρτησία και μέση τιμή. Έστω πως οι τυχαίες μεταβλητές παίρνουν καθένα από τα 4 ζευγάρια τιμών με πιθανότητα 1/4. Τότε η έχει σύνολο τιμών το και η πυκνότητά της παίρνει τις εξής τιμές:
Λόγω της συμμετρίας του προβλήματος, η έχει το ίδιο σύνολο τιμών και την ίδια πυκνότητα με τη . Αλλά οι δεν είναι ανεξάρτητες, αφού,
Για τις μέσες τιμές έχουμε,
και επίσης,
άρα, παρότι οι δεν είναι ανεξάρτητες, έχουμε .
-
6.
Ανεξαρτησία και διασπορά. Έστω μια Τ.Μ. η οποία παίρνει τις τιμές 0 και 1 με πιθανότητα και έστω , οπότε και η έχει το ίδιο σύνολο τιμών και την ίδια πυκνότητα με τη . Όπως είδαμε στο Παράδειγμα 6.7, η διασπορά τους ικανοποιεί,
Αλλά, εφόσον εξ ορισμού η είναι απλώς μια σταθερά, έχουμε , το οποίο φυσικά δεν ισούται με το άθροισμα των διασπορών !
-
7.
Δύο ζάρια. Κατ’ αρχάς παρατηρούμε το εξής: Το γεγονός ότι οι δύο ζαριές είναι ανεξάρτητες και τα ζάρια δίκαια, είναι προφανώς ισοδύναμο με το να υποθέσουμε ότι όλα τα στοιχειώδη ενδεχόμενα είναι ισοπίθανα.
-
(α’)
Και οι τέσσερις Τ.Μ. έχουν, εξ ορισμού, το ίδιο σύνολο τιμών .
-
(β’)
Στα Σχήματα 1.17 και 1.18, έχουμε σχεδιάσει τα ενδεχόμενα που αντιστοιχούν σε καθεμία από τις δυνατές τιμές της , της , της και της , αντίστοιχα.

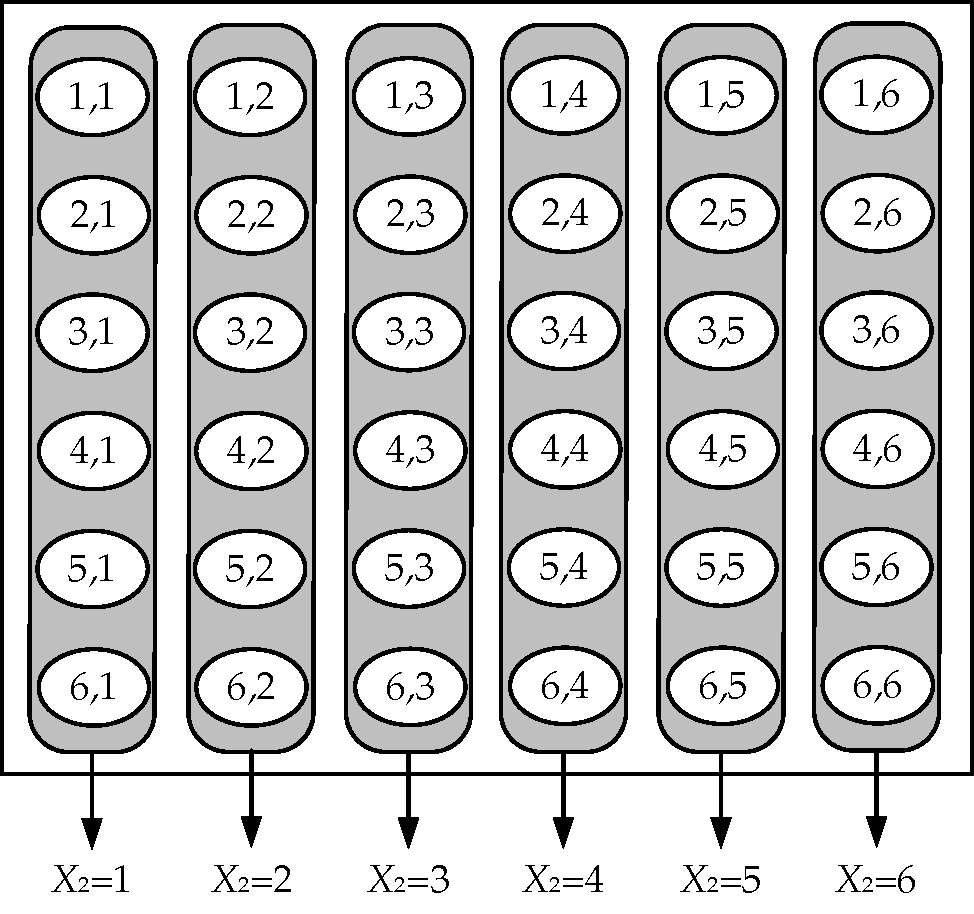
Σχήμα 1.17: Ο χώρος πιθανότητας τα ενδεχόμενα που αντιστοιχούν στην καθεμία από τις δυνατές τιμές της Τ.Μ. (αριστερά), και τα ενδεχόμενα που αντιστοιχούν στην καθεμία από τις δυνατές τιμές της Τ.Μ. (δεξιά) στην Άσκηση 7. 

Σχήμα 1.18: Ο χώρος πιθανότητας τα ενδεχόμενα που αντιστοιχούν στην καθεμία από τις δυνατές τιμές της Τ.Μ. (αριστερά), και τα ενδεχόμενα που αντιστοιχούν στην καθεμία από τις δυνατές τιμές της Τ.Μ. (δεξιά) στην Άσκηση 7. -
(γ’)
Για κάθε δυνατή τιμή της , υπάρχουν 6 στοιχεία του που αντιστοιχούν σε αυτή την τιμή, και άρα η πιθανότητα του ενδεχομένου , από τον κανόνα πιθανότητας , είναι . Συνεπώς, η πυκνότητα της είναι,
Η συνάρτηση κατανομής της εύκολα μπορεί να υπολογιστεί από τη σχέση (6.1):
Η πυκνότητα και η συνάρτηση κατανομής της έχουν σχεδιαστεί στο Σχήμα 1.19.
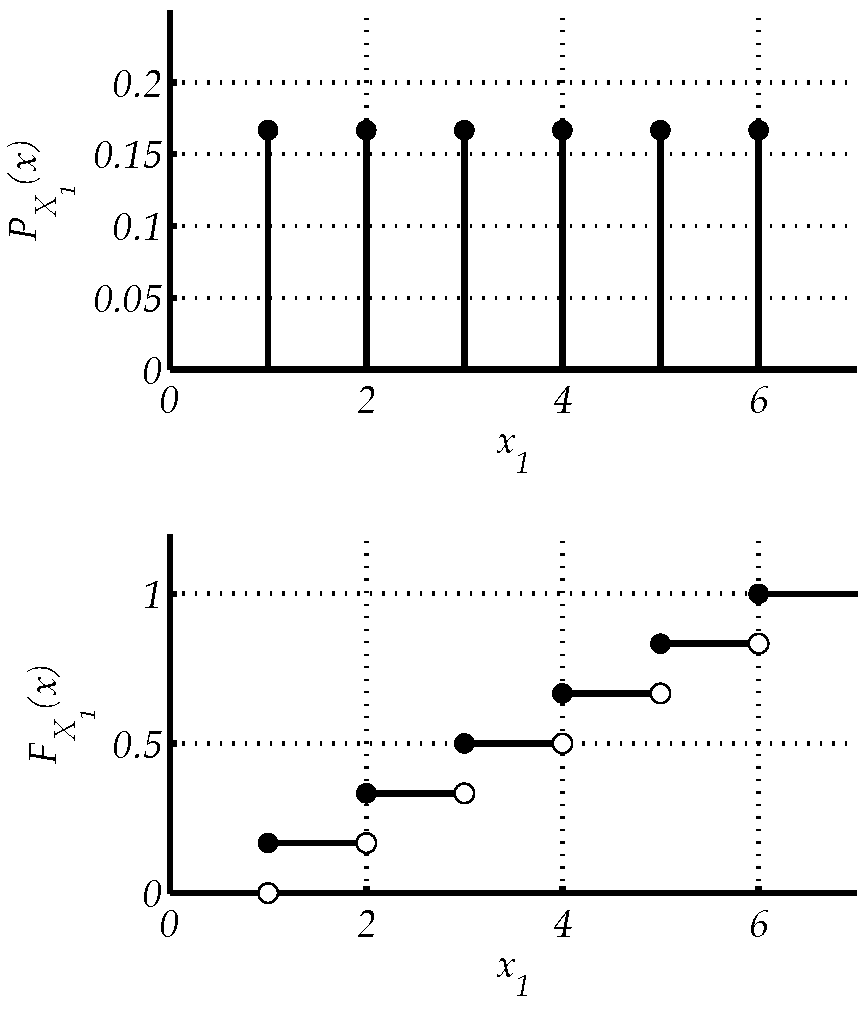
Σχήμα 1.19: Η πυκνότητα και η συνάρτηση κατανομής της Τ.Μ. στην Άσκηση 7. Με ακριβώς τον ίδιο τρόπο βρίσκουμε πως η έχει την ίδια πυκνότητα και την ίδια συνάρτηση κατανομής με τη .
Η πυκνότητα της υπολογίζεται εύκολα από τον κανόνα πιθανότητας , μέσω της σχέσης,
Με τη βοήθεια του Σχήματος 1.18 βρίσκουμε:
ενώ η συνάρτηση κατανομής προκύπτει από τη σχέση (6.1) όπως και για τη . Στο Σχήμα 1.20 έχουμε σχεδιάσει και τις δύο.
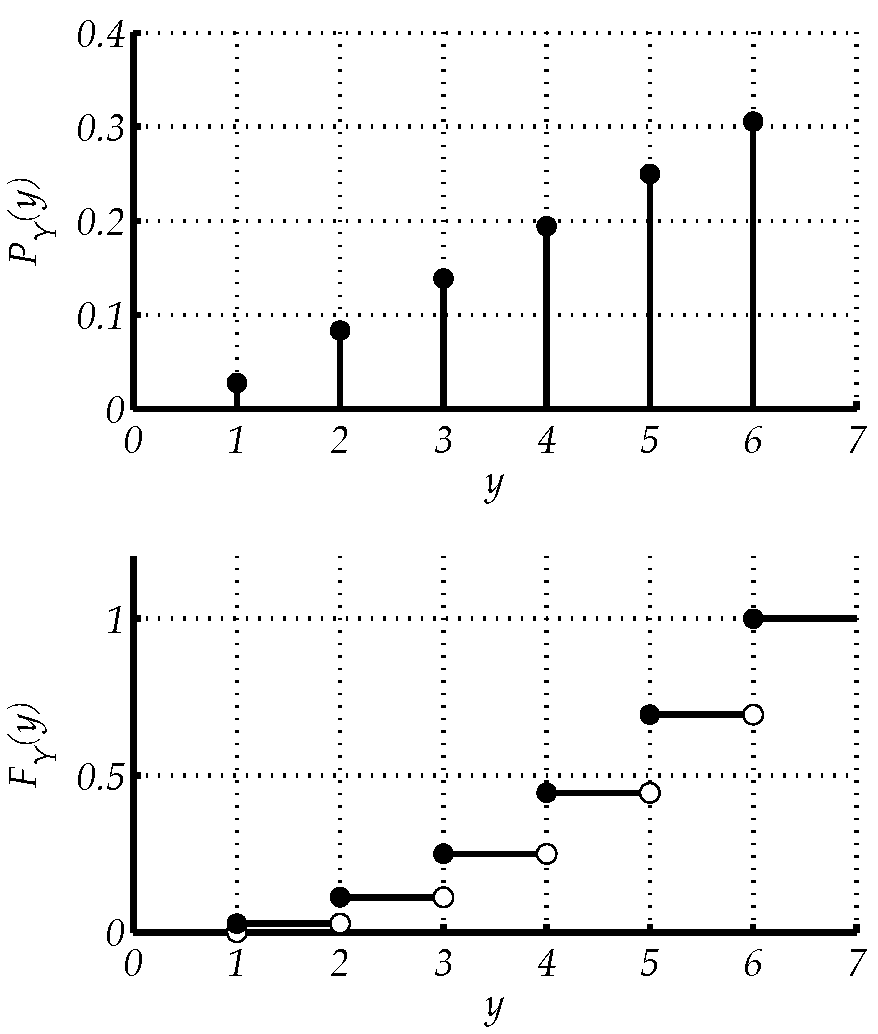
Σχήμα 1.20: Η πυκνότητα και η συνάρτηση κατανομής της Τ.Μ. στην Άσκηση 7. Παρομοίως υπολογίζεται και η πυκνότητα της , από τον κανόνα πιθανότητας και τη σχέση,
Με τη βοήθεια του Σχήματος 1.18 βρίσκουμε,
Στο Σχήμα 1.21 έχουν σχεδιαστεί η και η .
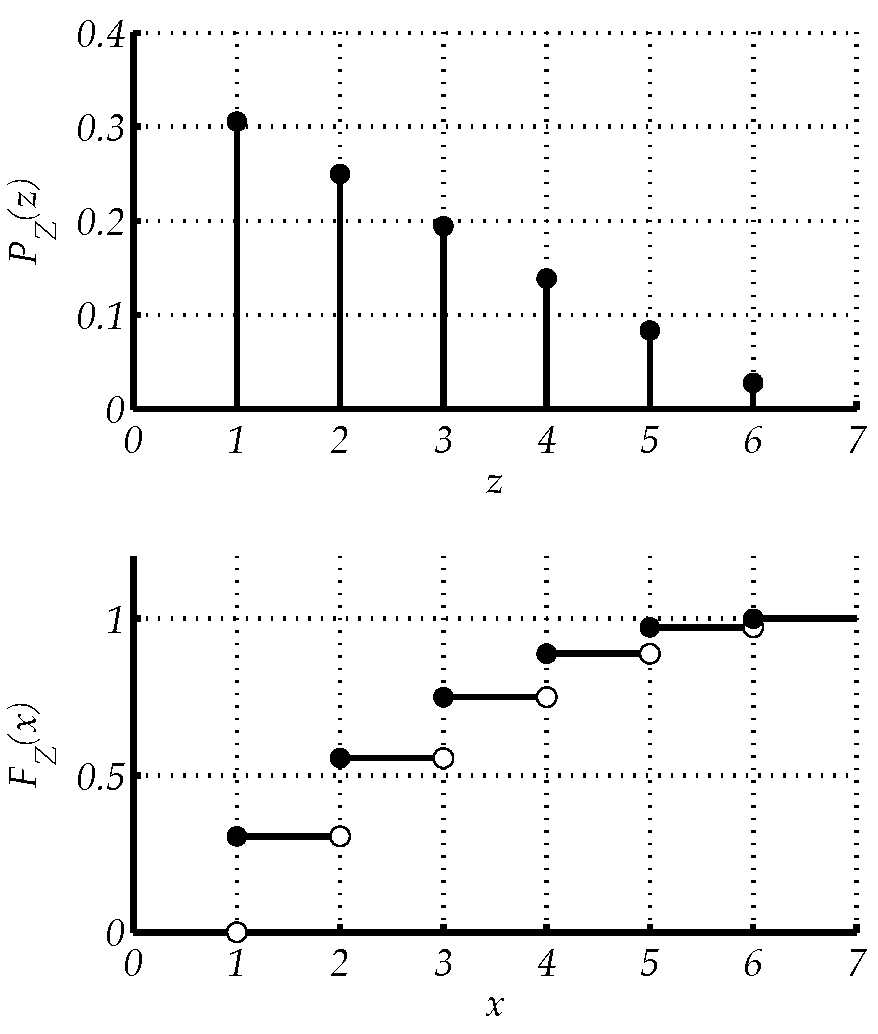
Σχήμα 1.21: Άσκηση 7: H πυκνότητά και η συνάρτηση κατανομής της Τ.Μ. -
(δ’)
Από τον ορισμό της μέσης τιμής, για τη έχουμε,
Για τη διασπορά θα χρησιμοποιήσουμε την εναλλακτική έκφραση (6.8), οπότε υπολογίζουμε πρώτα τη μέση τιμή της ,
βρίσκουμε πως,
Εφόσον η έχει την ίδια πυκνότητα με την , προφανώς έχει την ίδια μέση τιμή και την ίδια διασπορά.
Με τον ίδιο τρόπο, για τη μέση τιμή της και της έχουμε,
οπότε η διασπορά της είναι,
Τέλος, παρομοίως υπολογίζονται η μέση τιμή και η διασπορά της :
Παρατηρήστε πως, παρότι η και η έχουν διαφορετική μέση τιμή, και επιπλέον , έχουν την ίδια διασπορά. Μπορείτε να το εξηγήσετε διαισθητικά;
-
(α’)
-
8.
Πού να βρω γυναίκα να σου μοιάζει. Χρησιμοποιώντας τις τυχαίες μεταβλητές της υπόδειξης έχουμε ότι . Επιπλέον, λόγω της συμμετρίας του προβλήματος, ισχυριζόμαστε πως η πιθανότητα οποιαδήποτε γυναίκα να επιλέξει τον άντρα της είναι . Για την πρώτη γυναίκα αυτό είναι προφανές. Γιατί ισχύει και για τις υπόλοιπες; Ένας τρόπος να πεισθούμε γι’ αυτό είναι να σκεφτούμε πως, αντί με τη σειρά οι γυναίκες να επιλέγουν, η μία μετά την άλλη, έναν άντρα, ισοδύναμα βάζουμε τους άντρες σε μια τυχαία διάταξη απέναντι από τις γυναίκες και η καθεμία παίρνει αυτόν που είναι μπροστά της. Προφανώς, για την κάθε γυναίκα , η πιθανότητα απέναντί της να είναι ο άντρας της είναι ίση με .
Συνεπώς, όπως στο Παράδειγμα 6.7, η μέση τιμή της κάθε είναι,
και από την πρώτη ιδιότητα του Θεωρήματος 6.1,
Άρα, κατά μέσο όρο, μόνο ένα σωστό ζευγάρι θα φύγει από το πάρτυ!
Για να υπολογίσουμε τη διασπορά παρατηρούμε κατ’ αρχάς πως, εφόσον οι είναι δυαδικές Τ.Μ., πάντοτε έχουμε και συνεπώς, Επιπλέον, από τον ορισμό της δεσμευμένης πιθανότητας,
Ισχυριζόμαστε πως το ίδιο ισχύει για οποιαδήποτε :
Αν σκεφτούμε, όπως πριν, ότι οι άντρες τοποθετούνται σε μια τυχαία διάταξη απέναντι από τις γυναίκες και η καθεμία παίρνει αυτόν που είναι μπροστά της, τότε η πιθανότητα οι γυναίκες και να έχουν απέναντί τους τους άντρες τους είναι . Οπότε,
Τώρα είμαστε έτοιμοι να υπολογίσουμε τη διασπορά της . Για τη μέση τιμή της παρατηρούμε πως,
όπου και πάλι χρησιμοποιήσαμε την πρώτη ιδιότητα του Θεωρήματος 6.1. Στο τελευταίο παραπάνω διπλό άθροισμα υπάρχουν όροι της μορφής και όροι της μορφής για . Άρα, χρησιμοποιώντας τα αποτελέσματα που βρήκαμε πιο πάνω,
και από την έκφραση (6.8) για τη διασπορά έχουμε,
Σημείωση. Οι πιο πάνω υπολογισμοί μπορούν να θεωρηθούν ειδικές περιπτώσεις των αντίστοιχων υπολογισμών που θα κάνουμε στο επόμενο κεφάλαιο, και συγκεκριμένα στην Ενότητα 7.2, για τη μέση τιμή και τη διασπορά της λεγόμενης υπεργεωμετρικής κατανομής.
-
9.
Συνέλιξη. Παρατηρούμε πως, για οποιοδήποτε τιμή , η ισούται με αν και μόνο αν η και η για κάποιο . Συνεπώς:
Η πρώτη και η τελευταία ισότητα προκύπτουν από τον ορισμό της πυκνότητας, η δεύτερη προκύπτει γράφοντας το ενδεχόμενο σαν ένωση ξένων ενδεχόμενων, η τρίτη προκύπτει ακριβώς επειδή τα ενδεχόμενα είναι ξένα, ενώ η τέταρτη λόγω της ανεξαρτησίας των .
-
10.
Άλλα δύο ζάρια. Για τη , αρχικά παρατηρούμε πως το σύνολο τιμών της είναι το ενώ τα ενδεχόμενα στα οποία αντιστοιχεί η κάθε τιμή φαίνονται στο Σχήμα 1.22.

Σχήμα 1.22: Ο χώρος πιθανότητας και τα ενδεχόμενα που αντιστοιχούν στην καθεμία από τις δυνατές τιμές της Τ.Μ. στην Άσκηση 10. Όπως και στην Άσκηση 7, λαμβάνοντας υπόψη ότι τα αποτελέσματα είναι ισοπίθανα, εύκολα προκύπτει πως:
Επιπλέον, η συνάρτηση κατανομής προκύπτει εύκολα από την πυκνότητα, μέσω της σχέσης (6.1). Και οι δύο έχουν σχεδιαστεί στο Σχήμα 1.23.
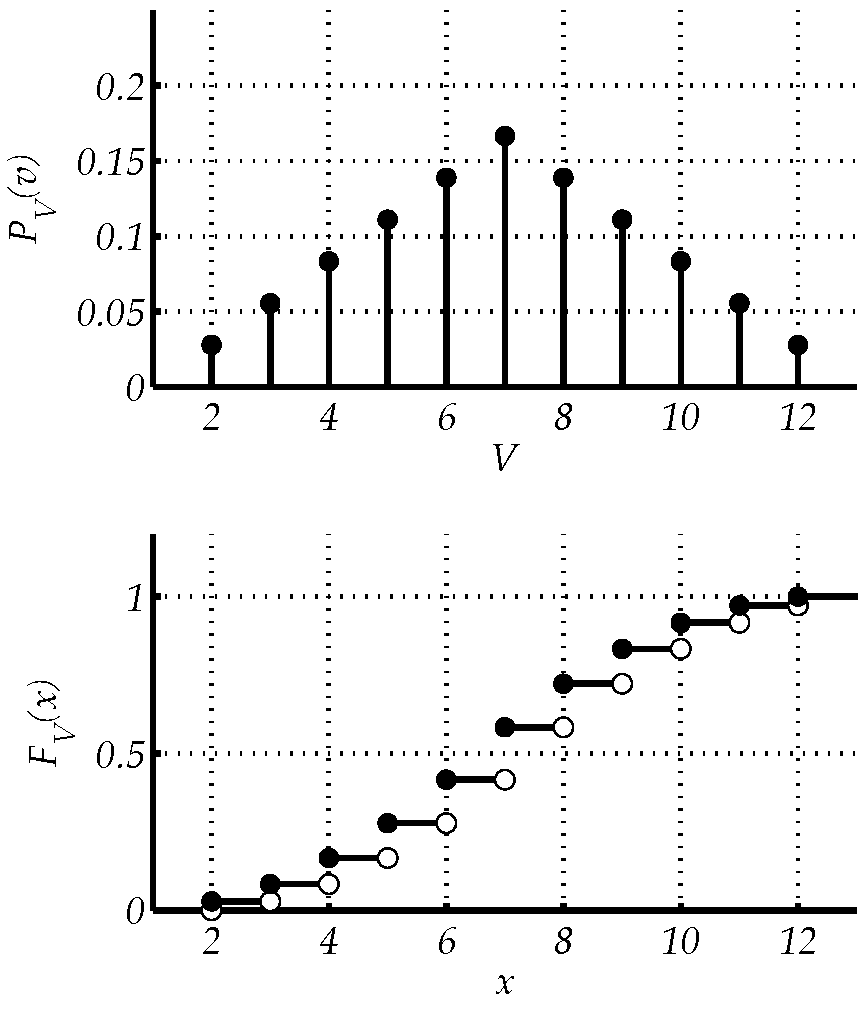
Σχήμα 1.23: Η πυκνότητα και η συνάρτηση κατανομής της Τ.Μ. στην Άσκηση 10. Παρομοίως εξετάζουμε και την Τ.Μ. : Παρατηρούμε κατ’ αρχάς πως το σύνολο τιμών της είναι το και τα ενδεχόμενα που αντιστοιχούν στην κάθε τιμή φαίνονται στο Σχήμα 1.24.
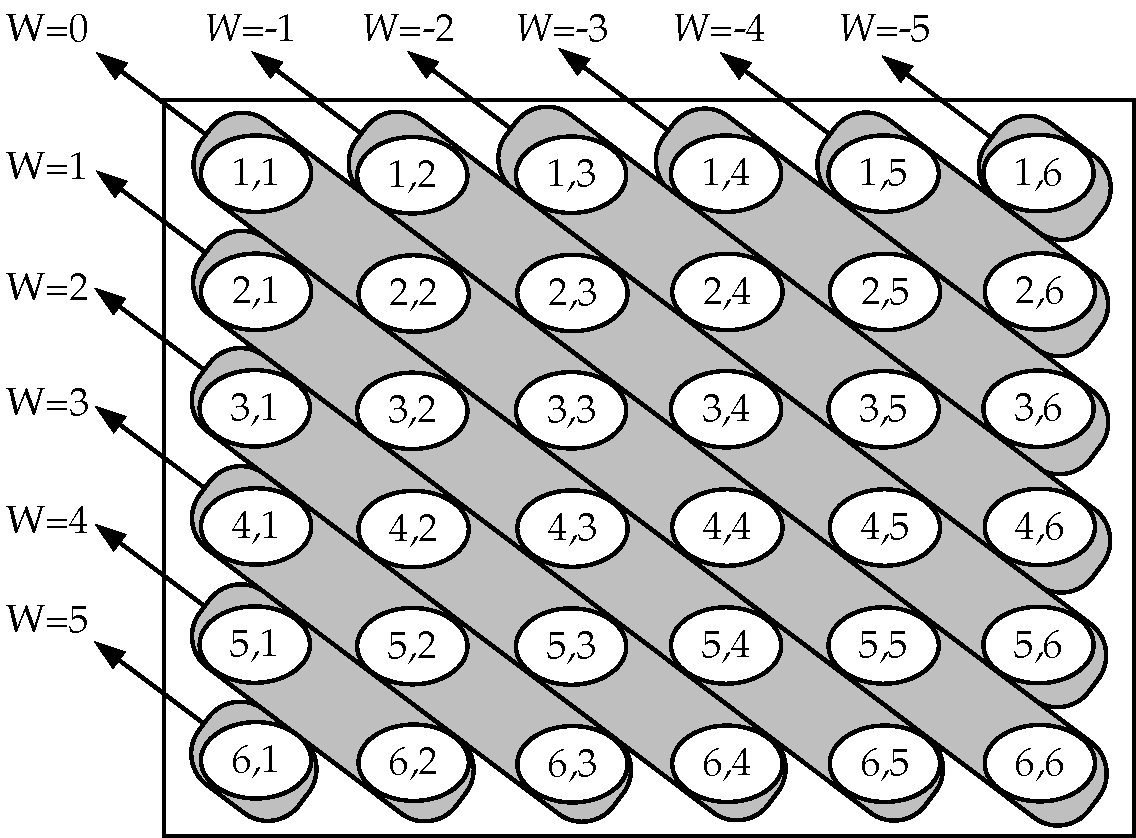
Σχήμα 1.24: Ο χώρος πιθανότητας και τα ενδεχόμενα που αντιστοιχούν στην καθεμία από τις δυνατές τιμές της Τ.Μ. στην Άσκηση 10. Σημειώνοντας και πάλι πως όλα αποτελέσματα είναι ισοπίθανα, εύκολα βρίσκουμε:
Όπως και για τη , η συνάρτηση κατανομής της προκύπτει εύκολα από την πυκνότητα, μέσω της σχέσης (6.1). Και οι δύο έχουν σχεδιαστεί στο Σχήμα 1.25.
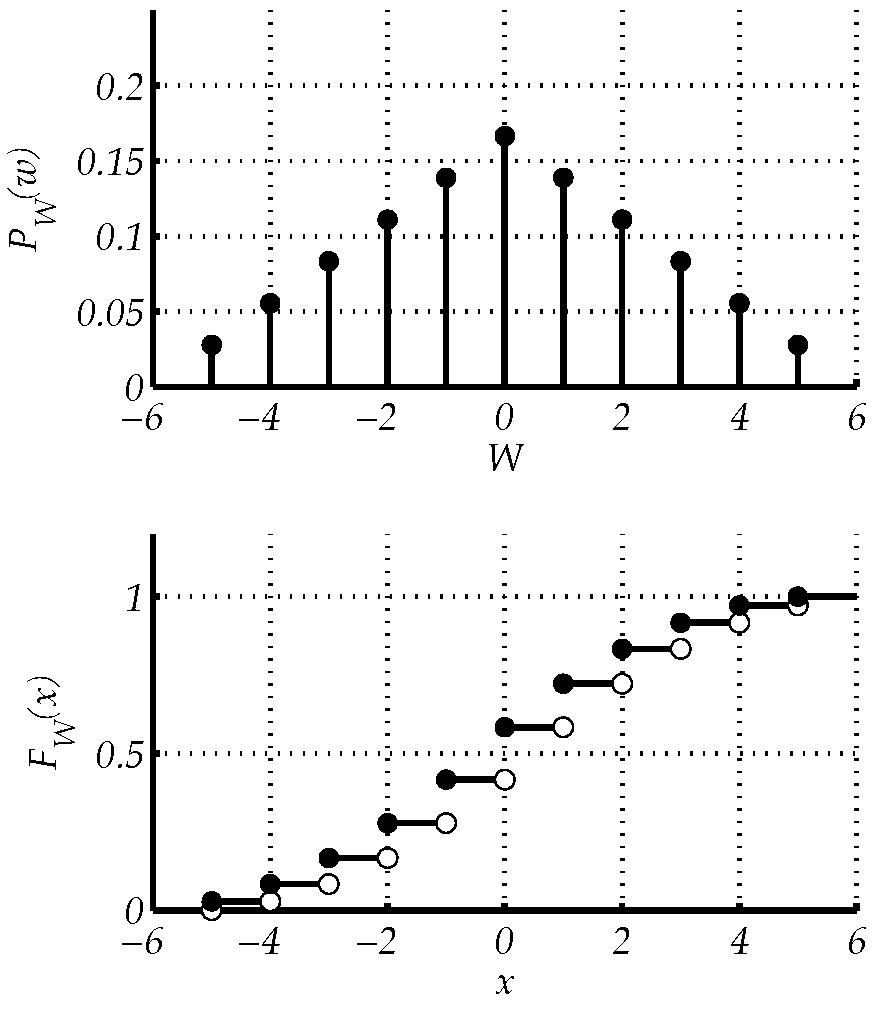
Σχήμα 1.25: Άσκηση 10: Η πυκνότητα και η συνάρτηση κατανομής της Τ.Μ. Τέλος, για τη μέση τιμή και τη διασπορά της , από τον ορισμό της μέσης τιμής και την εναλλακτική έκφραση (6.8) για τη διασπορά, έχουμε,
και παρομοίως,
-
11.
Δέκα μπάλες. Συνολικά υπάρχουν δυνατές επιλογές, άρα ο χώρος πιθανότητας αποτελείται από στοιχεία και τα αντίστοιχα στοιχειώδη ενδεχόμενα είναι ισοπίθανα.
Για το , παρατηρούμε αρχικά πως η μικρότερη δυνατή τιμή του είναι , και συνεπώς έχει σύνολο τιμών το . Τώρα, για κάθε , οι επιλογές που αντιστοιχούν σε είναι εκείνες κατά τις οποίες επιλέγουμε την μπάλα και δύο ακόμα από τις . Αυτό μπορεί να γίνει με τρόπους, και από τον κανόνα πιθανότητας προκύπτει πως η πυκνότητα της δίνεται από την έκφραση,
Η συνάρτηση κατανομής μπορεί εύκολα να προσδιοριστεί από την πυκνότητα, μέσω της σχέσης (6.1). Η πυκνότητα και η συνάρτηση κατανομής έχουν σχεδιαστεί στο Σχήμα 1.26.
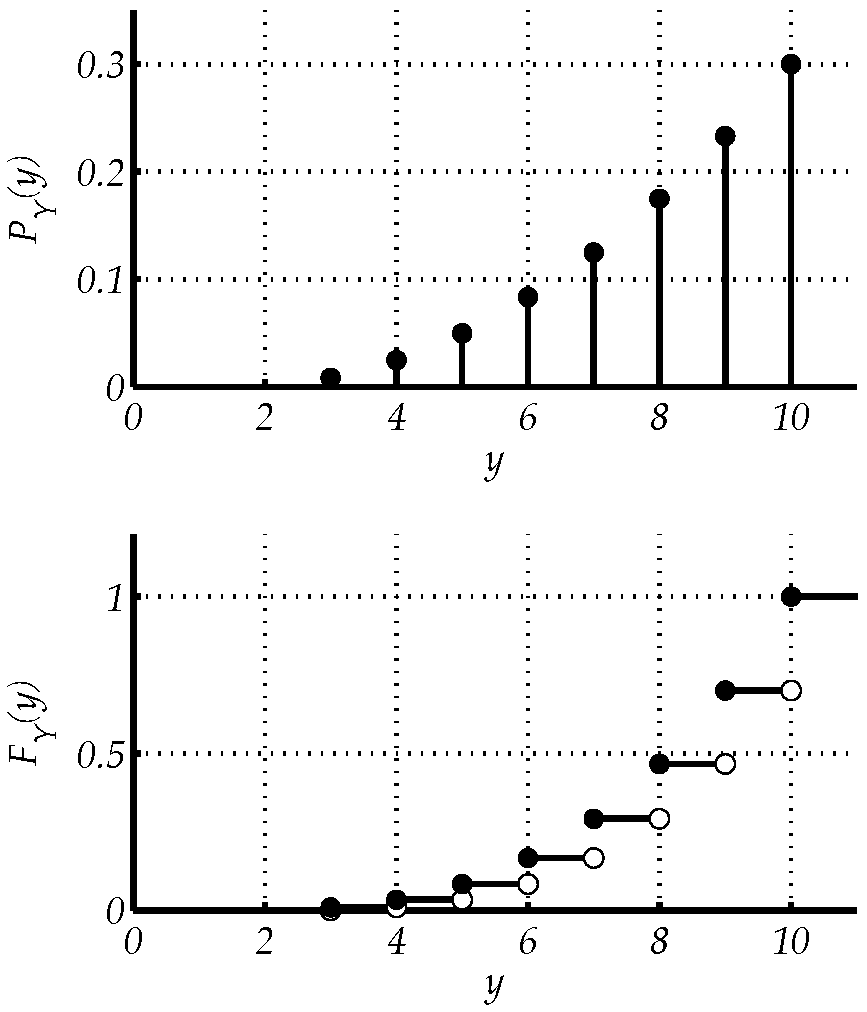
Σχήμα 1.26: Άσκηση 11: Η πυκνότητα και η συνάρτηση κατανομής της Τ.Μ. Σχετικά με τη , παρομοίως παρατηρούμε πως η μεγαλύτερη δυνατή τιμή της είναι , και συνεπώς έχει σύνολο τιμών το . Για κάθε , οι επιλογές που αντιστοιχούν σε είναι εκείνες κατά τις οποίες επιλέγουμε την μπάλα και δύο ακόμα από τις . Αυτό μπορεί να γίνει με τρόπους, και από τον κανόνα πιθανότητας προκύπτει πως η πυκνότητα της δίνεται από την έκφραση,
Η συνάρτηση κατανομής της μπορεί εύκολα να προσδιοριστεί από την πυκνότητα, μέσω της σχέσης (6.1), και οι δύο συναρτήσεις έχουν σχεδιαστεί στο Σχήμα 1.27.
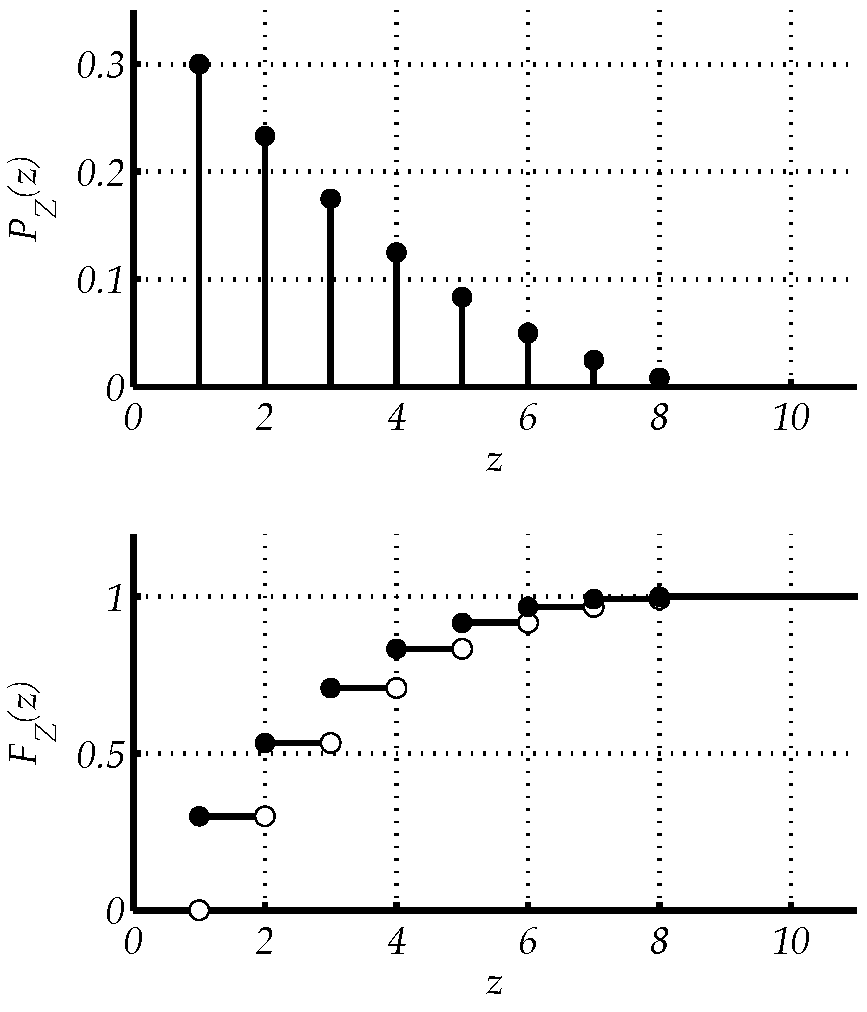
Σχήμα 1.27: Άσκηση 11: Η πυκνότητα και η συνάρτηση κατανομής της Τ.Μ. -
12.
Περιορισμοί στις παραμέτρους.
-
(α’)
Από τη βασική ιδιότητα της πυκνότητας πρέπει να έχουμε,
και, επομένως, , ή, ισοδύναμα,
Άρα, θα πρέπει να έχουμε , και .
-
(β’)
Η μέση τιμή της είναι,
η οποία παρατηρούμε ότι είναι ανεξάρτητη των και (γιατί;).
-
(γ’)
Όταν , απαραίτητα έχουμε ότι , από το πρώτο σκέλος, και επομένως η διασπορά της είναι:
-
(α’)
-
13.
Επιζώντα ζευγάρια. Έστω οι τυχαίες μεταβλητές , , όπου, για κάθε , έχουμε (ή 0) αν ο -οστός άνδρας επιβιώσει (ή πεθάνει), και αντιστοίχως (ή 0) αν η -οστή γυναίκα επιβιώσει (ή πεθάνει). Επιπλέον, ορίζουμε τις Τ.Μ. , οι οποίες παίρνουν την τιμή 1 αν το ζευγάρι παραμείνει, αλλιώς , και παρατηρούμε πως για κάθε (γιατί;).
Το συνολικό πλήθος, έστω , των ζευγαριών που παραμένουν, μπορεί να εκφραστεί ως,
και για τον υπολογισμό της ζητούμενης μέσης τιμής αρκεί να υπολογίσουμε την της κάθε . Παρατηρούμε ότι, από τον ορισμό της μέσης τιμής και τον ορισμό της δεσμευμένης πιθανότητας, έχουμε,
Ακολουθώντας ένα συλλογισμό αντίστοιχο με εκείνον της Άσκησης 8, βλέπουμε πως και , για κάθε . Συνοπτικά, η πιθανότητα του να επιβιώσει ο άντρας είναι, όπως και για οποιοδήποτε άλλο μέλος του πληθυσμού, ίση με ένα μείον την πιθανότητα να πεθάνει, δηλαδή,
Παρομοίως, αν γνωρίζουμε ότι επιβίωσε ο άνδρας , μένουν άτομα εκ των οποίων θα επιβιώσουν οι .
Τέλος, συνδυάζοντας τα πιο πάνω με την πρώτη ιδιότητα του Θεωρήματος 6.1, βρίσκουμε τη ζητούμενη μέση τιμή:
(A.10) -
14.
Τρία ζάρια. Έστω πως τα αποτελέσματα των τριών ρίψεων. Παρατηρούμε ότι η έχει σύνολο τιμών το , και από το αποτέλεσμα της Άσκησης 9 για τα , έχουμε ότι η πυκνότητα της , ικανοποιεί,
όπου συμβολίζουμε με , και τις πυκνότητες των , και αντίστοιχα. Συνεχίζοντας με αυτό τον τρόπο προκύπτουν και οι υπόλοιπες τιμές της πυκνότητας του :
Η συνάρτηση κατανομής της εύκολα υπολογίζεται από τη σχέση (6.1). Η πυκνότητα και η συνάρτηση κατανομής της έχουν σχεδιαστεί στο Σχήμα 1.28.
Σχήμα 1.28: Οι πυκνότητες και οι συναρτήσεις κατανομής της Άσκησης 14. Τώρα, για να υπολογίσουμε την πυκνότητα της , εφαρμόζουμε το αποτέλεσμα της Άσκησης 9 για τις τυχαίες μεταβλητές και . Αρχικά παρατηρούμε ότι η έχει σύνολο τιμών το , και η πυκνότητά της ικανοποιεί,
-
15.
Παιχνίδι.
-
(α’)
Η μέση τιμή της σε μία παρτίδα είναι:
Η διασπορά της είναι:
- (β’)
-
(α’)
-
16.
Η μέθοδος της δεύτερης ροπής. Έστω , για , η πυκνότητα της . Από τον ορισμό της διασποράς έχουμε,
και, εφόσον όλοι οι όροι του πιο πάνω αθροίσματος είναι μεγαλύτεροι ή ίσοι του μηδενός, ολόκληρο το άθροισμα θα είναι μεγαλύτερο ή ίσο του όρου ,
που είναι ακριβώς η ζητούμενη ανισότητα.
-
17.
Εναλλακτική έκφραση της Ξεκινάμε από τη ζητούμενη έκφραση και χρησιμοποιούμε την τρίτη βασική ιδιότητα της πυκνότητας:
Παρατηρούμε πως οι όροι του αθροίσματος δεν εξαρτώνται από το , και πως ο κάθε όρος αθροίζεται ακριβώς φορές. Συνεπώς,
που είναι ακριβώς η ζητούμενη έκφραση.
-
18.
Αποστάσεις μεταξύ πυκνοτήτων. Οι παρατηρήσεις του πρώτου σκέλους είναι άμεσες συνέπειες των ορισμών. Για το δεύτερο σκέλος παρατηρούμε ότι, προφανώς, από τον ορισμό της, οποιαδήποτε διασπορά είναι μεγαλύτερη ή ίση του μηδενός. Άρα, έχουμε,
το οποίο μας δίνει ακριβώς τη ζητούμενη ανισότητα. Στο βήμα πιο πάνω χρησιμοποιήσαμε την εναλλακτική έκφραση της διασποράς (6.8), και στο βήμα τον γενικό τύπο (6.5) για τη μέση τιμή κάποιας συνάρτησης μιας Τ.Μ.
A.7 Ασκήσεις Κεφαλαίου 7
[Επιστροφή στα περιεχόμενα]
-
1.
Overbooking. Το πλήθος, έστω , των επιβατών που θα προσέλθουν ακολουθεί διωνυμική κατανομή με παραμέτρους το πλήθος των ανεξάρτητων πειραμάτων , και πιθανότητα επιτυχίας . Θα έχουμε πρόβλημα υπεράριθμων επιβατών αν προσέλθουν με επιβάτες, δηλαδή αν . Η πιθανότητα αυτή μπορεί εύκολα να υπολογιστεί από τον τύπο της πυκνότητας της διωνυμικής κατανομής:
-
2.
Δείκτριες τυχαίες μεταβλητές.
-
(α’)
Εφόσον η παίρνει μόνο τις τιμές 0 και 1, προφανώς έχει κατανομή, όπου η παράμετρός της .
-
(β’)
Και πάλι, εφόσον η συνάρτηση παίρνει μόνο τις τιμές 0 και 1, η Τ.Μ. έχει κατανομή Bernoulli με παράμετρο .
-
(α’)
-
3.
Η ουρά της μέσης τιμής. Έστω πως η Τ.Μ. έχει πυκνότητα και σύνολο τιμών το , όπου όλα τα και για ευκολία θεωρούμε ότι . Κατ’ αρχάς, από τον ορισμό της , παρατηρούμε πως η νέα Τ.Μ. ισούται με την όταν η , αλλιώς ισούται με μηδέν. Άρα, για μεγάλες τιμές του , διαισθητικά περιμένουμε ότι η θα είναι μη μηδενική με πολύ μικρή πιθανότητα. Με αυτό το σκεπτικό, το ζητούμενο αποτέλεσμα δεν μας εκπλήσσει.
Πιο αναλυτικά τώρα, η μέση τιμή που μας ενδιαφέρει, από τον ορισμό της μέσης τιμής μιας συνάρτησης κάποιας Τ.Μ., είναι,
Αν το είναι πεπερασμένο με μέγιστο στοιχείο ίσο με , ή αν είναι άπειρο και όλα του τα στοιχεία είναι , για κάποια σταθερά , το αποτέλεσμα είναι τετριμμένο: Για κάθε , όλες οι τιμές είναι ίσες με μηδέν, οπότε το άθροισμα προφανώς τείνει στο μηδέν καθώς το .
Τέλος, αν το είναι άπειρο και όχι φραγμένο ως σύνολο, τότε για κάθε υπάρχει κάποιο τέτοιο ώστε να έχουμε αν και μόνο αν . Και επιπλέον θα έχουμε ότι καθώς το . Με αυτόν το συμβολισμό έχουμε,
αλλά επίσης ξέρουμε πως ολόκληρη η σειρά,
συγκλίνει σε ένα πεπερασμένο άθροισμα. Άρα απαραίτητα η «ουρά» της σειράς θα τείνει στο μηδέν,
αφού το καθώς το .
-
4.
Ελάχιστο δύο γεωμετρικών τυχαίων μεταβλητών. Ακολουθώντας την υπόδειξη, παρατηρούμε ότι το ελάχιστο είναι τουλάχιστον , αν και μόνο αν και οι δύο Τ.Μ. παίρνουν τιμές τουλάχιστον . Οπότε, για κάθε ,
όπου η τρίτη ισότητα ισχύει λόγω της πέμπτης ιδιότητας της ανεξαρτησίας στο Θεώρημα 6.1, και η τέταρτη από την πρώτη ιδιότητα της γεωμετρικής κατανομής στο Θεώρημα 7.1.
Αν τώρα ορίσουμε , εφόσον,
έχουμε,
Συνεπώς, και η έχει γεωμετρική κατανομή, αλλά με παράμετρο .
Αυτό εξηγείται εύκολα: Αν διεξάγουμε ταυτόχρονα δύο ακολουθίες ανεξάρτητων πειραμάτων, μπορούμε να ορίσουμε ένα ολικό πείραμα στο οποίο θα έχουμε επιτυχία την πρώτη φορά που θα έχει επιτυχία ένα από τα δύο πειράματα. Σε αυτή την περίπτωση, το πλήθος των επαναλήψεων που απαιτούνται για την πρώτη επιτυχία του ολικού πειράματος είναι όπου , είναι το πλήθος επαναλήψεων μέχρι την πρώτη επιτυχία στο πρώτο και το δεύτερο πείραμα, αντίστοιχα. Το ολικό πείραμα αποτυγχάνει όταν αποτύχουν και τα δύο επί μέρους, δηλαδή με πιθανότητα , άρα η πιθανότητα επιτυχίας είναι . Συνεπώς, το πλήθος των προσπαθειών του ολικού πειράματος μέχρι την πρώτη επιτυχία ακολουθεί γεωμετρική κατανομή με παράμετρο .
-
5.
Άθροισμα Poisson. Έστω και οι πυκνότητες των και αντίστοιχα. Παρατηρούμε (όπως και στην Άσκηση 9 του Κεφαλαίου 6) πως η ισούται με αν και μόνο αν για κάποιο έχουμε και . Αν είναι η πυκνότητα της , τότε έχουμε,
όπου η τελευταία ισότητα προκύπτει από το διωνυμικό θεώρημα. Συνεπώς, η τυχαία μεταβλητή .
-
6.
Ταυτότητα Vandermonde. Πρώτα εξετάζουμε την περίπτωση και . Θα δείξουμε ότι τα δυο μέρη της σχέσης (7.14) εκφράζουν το ίδιο πλήθος συνδυασμών. Έστω πως έχουμε άντρες και γυναίκες. Το πλήθος των τρόπων με τους οποίους μπορούμε να δημιουργήσουμε μια επιτροπή με από αυτά τα άτομα είναι προφανώς . Συγχρόνως όμως, για κάθε , υπάρχουν τρόποι να δημιουργήσουμε μια επιτροπή που να αποτελείται από άντρες και γυναίκες. Οπότε το αριστερό σκέλος είναι το άθροισμα του πλήθους των τρόπων με τους οποίους μπορούμε να φτιάξουμε μια επιτροπή ατόμων, απλώς ομαδοποιώντας τους συνδυασμούς ανάλογα με το πόσους άνδρες θα έχει η επιτροπή.
Αν το είναι μεγαλύτερο του , τότε και τα δύο σκέλη είναι ίσα με μηδέν.
Τέλος, αν το είναι μικρότερο ή ίσο του , αλλά μεγαλύτερο του ή του , τότε κάποιοι από τους όρους του αριστερού σκέλους είναι ίσοι με μηδέν, αλλά η πιο πάνω απόδειξη εξακολουθεί να ισχύει για τους όρους που απομένουν. Για παράδειγμα, αν , , , τότε θα πρέπει να ισχύει:
-
7.
Άθροισμα διωνυμικών Τ.Μ. Έστω και οι πυκνότητες των και , αντίστοιχα. Παρατηρούμε ότι η έχει σύνολο τιμών το . Επιπλέον, από το αποτέλεσμα της Άσκησης 9 του Κεφαλαίου 6 (βλ. και την παρόμοια λύση της παραπάνω Άσκησης 5), για κάθε έχουμε,
όπου στην τελευταία ισότητα χρησιμοποιήσαμε την ταυτότητα του Vandermonde. Συνεπώς η πυκνότητα της είναι αυτή της κατανομής.
Εναλλακτικά, θα μπορούσαμε να εκφράσουμε τις Τ.Μ. ως,
όπου οι είναι ανεξάρτητες Τ.Μ. Άρα, το άθροισμά τους μπορεί και αυτό να εκφραστεί ως το άθροισμα ανεξάρτητων Τ.Μ., και συνεπώς έχει κατανομή.
Τέλος, παρατηρούμε πως το αποτέλεσμα αυτό ισχύει μόνο αν η παράμετρος και των αρχικών τυχαίων μεταβλητών είναι η ίδια.
-
8.
Διάφορες κατανομές.
-
(α’)
Η ακολουθεί γεωμετρική κατανομή με παράμετρο αφού η πιθανότητα να φέρουμε διπλή είναι (γιατί;), και τα πειράματα (δηλαδή οι διαδοχικές ζαριές) είναι ανεξάρτητα μεταξύ τους.
-
(β’)
Η ακολουθεί διωνυμική κατανομή με παραμέτρους και , αφού έχουμε το πλήθος επιτυχιών σε όμοια, ανεξάρτητα πειράματα με πιθανότητα επιτυχίας .
-
(γ’)
H ακολουθεί υπεργεωμετρική κατανομή με παραμέτρους αφού επιλέγουμε χωρίς επανατοποθέτηση φύλλα από τα που έχει συνολικά μια τράπουλα, εκ των οποίων τα είναι κούπες.
-
(δ’)
Η ακολουθεί διωνυμική κατανομή με παραμέτρους και , αφού έχουμε το πλήθος επιτυχιών σε όμοια, ανεξάρτητα πειράματα με πιθανότητα επιτυχίας .
-
(α’)
-
9.
Ουρά στην τράπεζα.
-
(α’)
Οι ώρες έχουν πεντάλεπτα, κι εφόσον η πιθανότητα επιτυχίας, δηλαδή του να έρθει ένας νέος πελάτης, είναι , η κατανομή της είναι Διων.
-
(β’)
Εφόσον πλήθος πελατών που έφτασαν τις πρώτες ώρες, η πιθανότητα να έρθουν ακριβώς πελάτες τις πρώτες δύο ώρες, από τον τύπο της πυκνότητας της διωνυμικής κατανομής είναι,
-
(γ’)
H περιγράφει τη χρονική στιγμή της πρώτης επιτυχίας, άρα έχει γεωμετρική κατανομή με παράμετρο : Γεωμ(0.05).
-
(δ’)
Τα λεπτά που θα περιμένουν οι υπάλληλοι μέχρι την άφιξη του πρώτου πελάτη κατά μέσο όρο είναι πέντε φορές η μέση τιμή της . Έχουμε πεντάλεπτα, άρα ο αναμενόμενος χρόνος μέχρι τον πρώτο πελάτη είναι λεπτά.
-
(ε’)
Παρατηρήστε ότι οι 2 ώρες έχουν 24 πεντάλεπτα και οι 2.5 ώρες έχουν 30 πεντάλεπτα. Λόγω της ιδιότητας έλλειψης μνήμης έχουμε:
-
(α’)
-
10.
Επιθέσεις μηνυμάτων spam. Έστω το πλήθος των χρηστών που ανταποκρίνονται στο email. Το εκφράζει το πλήθος των επιτυχιών σε χιλιάδες όμοια, ανεξάρτητα πειράματα, που το καθένα έχει πιθανότητα επιτυχίας . Συνεπώς .
Εφόσον είναι «της τάξεως του 1», προφανώς ικανοποιούνται όλες οι συνθήκες του Πορίσματος 7.1, και μπορούμε να προσεγγίσουμε την κατανομή της μέσω της , με . Από τον τύπο της πυκνότητας της κατανομής Poisson έχουμε,
[Δεδομένου του μηδαμινού κόστους της αποστολής των μηνυμάτων, η πρόβλεψη για τον διαφημιστή δεν είναι κι άσχημη!]
-
11.
Τα «ν» του Βαρουφάκη.
-
(α’)
Έστω οι ανεξάρτητες Τ.Μ. με κατανομή για κάθε . Αν και , μπορούμε να θεωρήσουμε πως αν και μόνο αν τη φορά ο διορθωτής έκανε λάθος και έγραψε το όνομα «Γιάννης» αντί για «Γιάνης».
Άρα, αν ορίσουμε ως την Τ.Μ. , τότε η και το συνολικό πλήθος από «ν» που χρησιμοποιήθηκαν θα είναι .
-
(β’)
Εφόσον , και , προφανώς ικανοποιούνται οι συνθήκες του Πορίσματος 7.1, άρα μπορούμε να πούμε πως η έχει, κατά προσέγγιση, ίδια κατανομή με μια Τ.Μ. , οπότε έχουμε,
το οποίο ισούται με,
-
(α’)
-
12.
Άσχετος φοιτητής. Ορίζουμε τις ανεξάρτητες Τ.Μ. , όλες με την ίδια κατανομή για κάθε , όπου , και θεωρούμε πως αν και μόνο αν ο εξεταζόμενος απάντησε σωστά στην ερώτηση .
Τότε το πλήθος των σωστών απαντήσεών του έχει κατανομή και, εφόσον , και , βλέπουμε πως ικανοποιούνται οι συνθήκες του Πορίσματος 7.1. Συνεπώς, η κατανομή της είναι, κατά προσέγγιση, , και άρα:
-
13.
Δύο διαφορετικές δημοσκοπήσεις.
-
(α’)
Όπως περιγράψαμε στο Παράδειγμα 7.2, το συνολικό πλήθος επιτυχιών σε προβλήματα επιλογής με επανατοποθέτηση κατά κανόνα έχει διωνυμική κατανομή. Εδώ, αν ορίσουμε τις ανεξάρτητες Τ.Μ. , όπου το κάθε αν το άτομο στο δείγμα είναι ψηφοφόρος του κόμματος και αν όχι, τότε μπορούμε να εκφράσουμε την ως το άθροισμα των , οπότε , όπου η παράμετρος ισούται με την πιθανότητα ένα τυχαία επιλεγμένο άτομο να είναι ψηφοφόρος του κόμματος, δηλαδή . Συνεπώς, για τη μέση τιμή και τη διασπορά της πρόβλεψης, έχουμε,
όπου χρησιμοποιήσαμε τον τύπο για τη μέση τιμή και τη διασπορά της διωνυμικής κατανομής, και τις πρώτες δύο ιδιότητες του Θεωρήματος 6.1.
Πριν προχωρήσουμε αξίζει να κάνουμε ορισμένες παρατηρήσεις. Πρώτον, η μέση τιμή της εκτίμησης του εκλογικού αποτελέσματος είναι ίση με το πραγματικό αποτέλεσμα. Δεύτερον, η διασπορά της εκτίμησης μικραίνει, και συνεπώς η εκτίμηση γίνεται ακριβέστερη, καθώς το μέγεθος του δείγματός μας μεγαλώνει. Και τρίτον, η μέση τιμή και η διασπορά της εκτίμησης δεν εξαρτώνται από το μέγεθος του πληθυσμού.
-
(β’)
Από το Παράδειγμα 7.7 και τον ορισμό της υπεργεωμετρικής κατανομής, άμεσα έπεται πως εδώ η , οπότε από τις σχέσεις (7.2) και (7.3), αντικαθιστώντας τις γνωστές τιμές του προβλήματος, βρίσκουμε,
όπου και πάλι χρησιμοποιήσαμε τις πρώτες δύο ιδιότητες του Θεωρήματος 6.1.
Από τα πιο πάνω αποτελέσματα παρατηρούμε τα εξής. Πρώτον, και πάλι η μέση τιμή της εκτίμησης του εκλογικού αποτελέσματος είναι ίση με το πραγματικό αποτέλεσμα. Δεύτερον, και πάλι η διασπορά μικραίνει καθώς το μέγεθος του δείγματός μεγαλώνει, αλλά αυτήν τη φορά εξαρτάται και από το μέγεθος του πληθυσμού.
Συγκεκριμένα, η διασπορά εδώ είναι μικρότερη από την περίπτωση δειγματοληψίας με επανατοποθέτηση, άρα, υπ’ αυτήν την έννοια, είναι προτιμότερη η επιλογή δειγμάτων χωρίς επανατοποθέτηση, πράγμα και διαισθητικά αναμενόμενο, μια που σ’ αυτή την περίπτωση είμαστε βέβαιοι ότι έχουμε εξετάσει διαφορετικά άτομα χωρίς επαναλήψεις. Τέλος, παρατηρούμε ότι η διαφορά της εδώ διασποράς σε σχέση με το προηγούμενο ερώτημα είναι μεγάλη όταν το μέγεθος του δείγματος είναι σχετικά μεγάλο σε σχέση με τον συνολικό πληθυσμό. Αντίθετα, όταν το είναι σημαντικά μικρότερο του , καθώς το μέγεθος του πληθυσμού αυξάνει, η διασπορά επίσης αυξάνεται και τείνει σ’ εκείνη που είχαμε στην περίπτωση επιλογής με επανατοποθέτηση.
-
(α’)
-
14.
Βελάκια. Έστω το πλήθος από βελάκια που πέτυχαν το στόχο.
-
(α’)
Εδώ το εκφράζει το πλήθος των επιτυχιών σε όμοια, ανεξάρτητα πειράματα, που το καθένα έχει πιθανότητα επιτυχίας . Συνεπώς , και από τον τύπο της πυκνότητάς της,
-
(β’)
Παρομοίως, εδώ . Εφόσον , προφανώς ικανοποιούνται όλες οι συνθήκες του Πορίσματος 7.1, και μπορούμε να προσεγγίσουμε την κατανομή της μέσω της , με . Από τον τύπο της πυκνότητας της κατανομής Poisson έχουμε,
-
(α’)
-
15.
Γινόμενο Bernoulli. Κατ’ αρχάς παρατηρούμε πως το γινόμενο μπορεί να πάρει μόνο δύο τιμές, την και την , επομένως έχει κατανομή Bernoulli. Έστω η ζητούμενη παράμετρος. Θα δώσουμε δύο λύσεις:
Πρώτα παρατηρούμε πως η παράμετρος μιας Τ.Μ. Bernoulli είναι ίση με τη μέση τιμή της. Χρησιμοποιώντας την τρίτη ιδιότητα του Θεωρήματος 6.1 (λόγω της ανεξαρτησίας των ), βρίσκουμε,
Εναλλακτικά, παρατηρούμε πως,
όπου η τρίτη ισότητα προκύπτει λόγω της ανεξαρτησίας των .
-
16.
Χρηματιστήριο.
-
(α’)
Η κάθε ορίζεται ως,
άρα, η κάθε έχει κατανομή Bernoulli με παράμετρο . Επιπλέον, από την εκφώνηση του προβλήματος έχουμε υποθέσει ότι οι είναι ανεξάρτητες μεταξύ τους.
-
(β’)
Η ισούται με το άθροισμα 30 ανεξάρτητων τυχαίων μεταβλητών Bernoulli,
κι άρα η κατανομή της είναι διωνυμική, με παραμέτρους και .
-
(γ’)
Από τον τύπο της πυκνότητας της διωνυμικής κατανομής,
-
(δ’)
Η τιμή της μετοχής μετά από μέρες μπορεί να εκφραστεί ως,
όπου το άθροισμα των έχει κατανομή με παραμέτρους και . Επομένως, από την πρώτη ιδιότητα του Θεωρήματος 6.1 και τον τύπο της μέσης τιμής της διωνυμικής κατανομής,
Παρομοίως, από τη δεύτερη ιδιότητα του Θεωρήματος 6.1 και τον τύπο της διασποράς της διωνυμικής κατανομής,
-
(ε’)
Σε αυτή την περίπτωση έχουμε,
όπου το άθροισμα των έχει όπως πριν κατανομή. Επομένως, εφαρμόζοντας τις ίδιες ιδιότητες, βρίσκουμε,
και για τη διασπορά,
-
(α’)
-
17.
XOR Bernoulli.
-
(α’)
Για να υπολογίσουμε την παράμετρο, έστω , της χρησιμοποιούμε την ανεξαρτησία των :
-
(β’)
Θα δείξουμε πως, παρότι εκ πρώτης όψεως μοιάζουν να σχετίζονται, οι και είναι ανεξάρτητες. Αυτό μπορεί να αποδειχθεί μέσω του ορισμού της ανεξαρτησίας, δείχνοντας πως,
και για τα 4 δυνατά ζευγάρια τιμών . Πράγματι, έχουμε,
ενώ και,
Παρομοίως,
ενώ και,
Επίσης,
ενώ και,
Και, τέλος,
ενώ και,
Άρα οι είναι ανεξάρτητες.
-
(α’)
-
18.
Διασπορά υπεργεωμετρικής κατανομής.
-
(α’)
Αυτό το βήμα προκύπτει από έναν απλό υπολογισμό, σε συνδυασμό με την πρώτη ιδιότητα του Θεωρήματος 6.1:
-
(β’)
Με βάση το συλλογισμό που χρησιμοποιήσαμε για τον υπολογισμό της μέσης τιμής (στην παρατήρηση που ακολουθεί το Παράδειγμα 7.8) όλα τα έχουν την ίδια κατανομή, συνεπώς . Επιπλέον, αφού τα παίρνουν μόνο τις τιμές 0 και 1, προφανώς πάντοτε έχουμε και άρα .
Με την ίδια λογική της εναλλακτικής περιγραφής του προβλήματος, οι πιθανότητες όλων των δυνατών αποτελεσμάτων για δύο από όλες τις Τ.Μ. , είναι ίδιες ανεξαρτήτως των , και συνεπώς για κάθε .
- (γ’)
-
(δ’)
Χρησιμοποιώντας τα τρία πιο πάνω βήματα βρίσκουμε,
-
(ε’)
Από το προηγούμενο βήμα, σε συνδυασμό με τη γνωστή μέση τιμή , έχουμε,
όπως ακριβώς και στη ζητούμενη σχέση (7.3).
-
(α’)
-
19.
Αναπαράσταση της
-
(α’)
Για ορίζουμε τη συνάρτηση , η οποία έχει παραγώγους,
Συνεπώς, από ανάπτυγμα Taylor έχουμε πως, για κάποιο με ,
-
(β’)
Εφόσον η ακολουθία συγκλίνει, θα είναι υποχρεωτικά φραγμένη, άρα θα έχουμε για κάθε μεγαλύτερο ή ίσο με κάποιο . Εφαρμόζοντας το προηγούμενο αποτέλεσμα με , για ,
όπου τα ικανοποιούν . Θέτοντας και πολλαπλασιάζοντας την πιο πάνω σχέση με βρίσκουμε, για ,
όπου η ακολουθία είναι εξ ορισμού φραγμένη.
-
(γ’)
Τέλος, παίρνοντας το όριο καθώς στο αποτέλεσμα του προηγούμενου σκέλους, έχουμε,
το οποίο είναι προφανώς ισοδύναμο με το ζητούμενο αποτέλεσμα της σχέσης (7.5).
-
(α’)
A.8 Ασκήσεις Κεφαλαίου 8
[Επιστροφή στα περιεχόμενα]
-
1.
Ένας άλλος randomized αλγόριθμος. Έστω ότι μας ζητείται να υπολογίσουμε την τιμή για κάποιο συγκεκριμένο . Επιλέγουμε τυχαία έναν ακέραιο στο σύνολο και παρατηρούμε ότι το είναι επίσης ομοιόμορφα κατανεμημένο στο . Από τον πίνακα χρησιμοποιούμε τις τιμές των και και, εφόσον η συνάρτηση πάντα ικανοποιεί τη σχέση , ως απάντηση για το δίνουμε το .
Ποια είναι η πιθανότητα να έχουμε κάνει λάθος;
Η μόνη περίπτωση να δώσουμε λάθος απάντηση είναι αν η τιμή του είναι λάθος στον πίνακα ή αν η τιμή του είναι λάθος στον πίνακα. Άρα,
όπου η δεύτερη ανισότητα προκύπτει από το φράγμα ένωσης της Ενότητας 5.2, και οι δύο πιθανότητες ίσες με 1/5 γιατί το και το είναι ομοιόμορφα κατανεμημένα στο .
Παρατηρούμε πως, αν απλώς δίναμε την για απάντηση, θα κάναμε λάθος μόνο 20% του χρόνου, οπότε γιατί να μπούμε στον κόπο του πιο πολύπλοκου randomized αλγορίθμου; Η διαφορά είναι ότι, αν δεν κάναμε τίποτα, τότε για τα τα οποία έχουν λάθος τιμές στον πίνακα θα κάναμε πάντοτε λάθος. Το πλεονέκτημα του randomized αλγορίθμου είναι πως, ακόμα και για τις τιμές που είναι λάθος στον πίνακα, τουλάχιστον 60% του χρόνου μάς δίνει τη σωστή απάντηση!
-
2.
Αθροίσματα.
-
(α’)
Έστω πως για κάθε άρτιο , και έστω όπου το είναι άρτιο. Τότε προφανώς έχουμε,
Εναλλακτικά, θα μπορούσαμε να τροποποιήσουμε την αρχική μέθοδο, προσθέτοντας, ανά ζεύγη, τους αριθμούς, , , κ.ο.κ., έως το , παίρνοντας το αποτέλεσμα -φορές-το-, δηλαδή, , και τέλος προσθέτοντας σε αυτό τον μεσαίο όρο , καταλήγοντας στο ίδιο αποτέλεσμα.
-
(β’)
Για οποιαδήποτε και , χρησιμοποιώντας το πιο πάνω αποτέλεσμα βρίσκουμε,
-
(α’)
-
3.
Μέτρηση πράξεων. Η πρώτη μέθοδος δεν απαιτεί καμία ύψωση σε δύναμη, οπότε η πολυπλοκότητά της για μεγάλα παραμένει,
Η δεύτερη μέθοδος απαιτεί τον υπολογισμό των για καθεμία από τις ρίζες , οπότε το επιπλέον κόστος ισούται με
όπου χρησιμοποιήσαμε την προσέγγιση , που προκύπτει από τον τύπο του Stirling. Άρα το συνολικό κόστος αυτής της μεθόδου, για μεγάλα είναι της τάξης του , δηλαδή της τάξης του .
Παρομοίως, το συνολικό κόστος του randomized αλγορίθμου είναι,
Συμπεραίνουμε λοιπόν πως, και με αυτή την ακριβέστερη έννοια, η πολυπλοκότητα του randomized αλγορίθμου είναι σημαντικά μικρότερη από εκείνη των δύο κλασικών μεθόδων.
-
4.
Μικρότερη πιθανότητα σφάλματος. Οι δύο τρόποι είναι μάλλον προφανείς: Μπορούμε να αυξήσουμε το πλήθος των δυνατών τιμών της τυχαίας μεταβλητής που χρησιμοποιούμε, ή μπορούμε να χρησιμοποιήσουμε την ίδια μέθοδο πολλές φορές.
Στην πρώτη περίπτωση, αν αντί για δυνατές τιμές επιλέξουμε μια Τ.Μ. με δυνατές τιμές, τότε αν το ικανοποιεί , ο ίδιος υπολογισμός όπως πριν δείχνει πως η πιθανότητα σφάλματος είναι το πολύ .
Στην δεύτερη περίπτωση, επαναλαμβάνουμε το ίδιο πείραμα φορές, χρησιμοποιώντας ανεξάρτητες Τ.Μ. με την ίδια κατανομή όπως πριν. Υπολογίζουμε τις τιμές και , και αν για κάθε , δηλώνουμε πως τα δύο πολυώνυμα είναι τα ίδια· αν για τουλάχιστον ένα , δηλώνουμε πως είναι διαφορετικά. Και πάλι, η μόνη περίπτωση σφάλματος είναι αν τα και είναι διαφορετικά, οπότε έχουμε,
όπου στο βήμα χρησιμοποιήσαμε την ανεξαρτησία των , στο το γεγονός ότι όλα τα έχουν την ίδια κατανομή, και στο αντικαταστήσαμε το ήδη γνωστό φράγμα για την πιθανότητα σφάλματος από την απλή περίπτωση μίας μόνο τυχαίας μεταβλητής. Από αυτό το αποτέλεσμα είναι προφανές ότι, επιλέγοντας ένα επαρκώς μεγάλο , μπορούμε να καταστήσουμε το φράγμα όσο κοντά στο μηδέν επιθυμούμε.
-
5.
Πόσα min-cuts υπάρχουν; Έστω το τυχαίο cut set το οποίο μας δίνει ο αλγόριθμος του Karger. Εφόσον κάθε πιθανότητα είναι μικρότερη ή ίση του 1, έχουμε ότι,
διότι τα ενδεχόμενα είναι ξένα μεταξύ τους. Χρησιμοποιώντας τώρα την ανισότητα που μας υπενθύμισε η εκφώνηση, συνεχίζουμε τον πιο πάνω υπολογισμό και βρίσκουμε,
δηλαδή,
-
6.
Τυχαία cut sets.
-
(α’)
Θυμίζουμε το συλλογισμό που κάναμε πριν την περιγραφή του αλγορίθμου του Karger, σύμφωνα με τον οποίο κάθε cut set αντιστοιχεί σε ένα διαχωρισμό των κόμβων του γράφου σε δύο (όχι κενά) υποσύνολα και . Όπως αναφέρουμε εκεί, για οποιονδήποτε τέτοιο διαχωρισμό, προφανώς το σύνολο των ακμών που συνδέουν κόμβους του με κόμβους στο είναι cut set.
-
(β’)
Πιο συγκεκριμένα, ο παραπάνω συλλογισμός μάς λέει πως τα ζευγάρια (όχι κενών) υποσυνόλων του τέτοια ώστε , είναι σε 1-1 αντιστοιχία με τα cut sets του γράφου, όπου οι ρόλοι των είναι αντιστρέψιμοι. Για να αποδείξουμε ότι το τυχαίο είναι ομοιόμορφα κατανεμημένο, αρκεί να αποδείξουμε πως το αντίστοιχο τυχαίο σύνολο κόμβων είναι ομοιόμορφα κατανεμημένο, δηλαδή πως κάθε επιλέγεται με την ίδια πιθανότητα. Αλλά αυτό είναι και πάλι προφανές από την κατασκευή του: Η επιλογή οποιουδήποτε συνόλου όπως περιγράφει η άσκηση έχει την ίδια πιθανότητα, δηλαδή , και, αφού αποκλείουμε το κενό σύνολο και το , η επιλογή οποιουδήποτε στο οποίο καταλήγουμε έχει πιθανότητα .
-
(γ’)
Έστω το σύνολο όλων των cut sets και το σύνολο όλων των min-cuts. Από τον συλλογισμό που αναφέραμε πιο πάνω υπολογίσαμε πως το πλήθος των cut sets είναι , και από την προηγούμενη άσκηση ξέρουμε πως το πλήθος των min-cuts ικανοποιεί . Άρα, αφού στο σκέλος (β’) δείξαμε πως το είναι τυχαία και ομοιόμορφα επιλεγμένο ανάμεσα σε όλα τα cut sets, έχουμε ότι:
-
(α’)
-
7.
Φράγμα τομής. Χρησιμοποιώντας το φράγμα ένωσης, έχουμε,
όπου τα βήματα (a) και (c) προκύπτουν από τον κανόνα πιθανότητας 4 και το βήμα (b) από το φράγμα ένωσης (Λήμμα 5.2).
-
8.
Μια γενικότερη πιθανοκρατική ανάλυση. Για οποιοδήποτε (αυθαίρετο) , θέτουμε . Θα αποδείξουμε κάτω από τις παρούσες συνθήκες πως,
(A.11) το οποίο πράγματι τείνει στο μηδέν καθώς το . Ορίζουμε τα ενδεχόμενα ακριβώς όπως πριν. Με τον ίδιο ακριβώς συλλογισμό και χρησιμοποιώντας το φράγμα ένωσης του Λήμματος 5.2, έχουμε,
όπου εδώ η πιθανότητα του κάθε ενδεχομένου είναι,
οπότε,
Τέλος, χρησιμοποιώντας το προφανές φράγμα , γράφοντας , και αντικαθιστώντας την τιμή του ,
και έχουμε ακριβώς το ζητούμενο φράγμα (A.11).
Το αποτέλεσμα αυτό μας λέει πως, για μεγάλα , η τιμή του είναι μικρότερη από,
Παρατηρούμε πως ο συντελεστής του είναι αύξουσα συνάρτηση του , άρα όσο μεγαλώνει το , δηλαδή όσο μεγαλώνει η πιθανότητα του «1» στην ακολουθία των , τόσο μεγαλώνει και το φράγμα μας για το μήκος της μεγαλύτερης ακολουθίας συνεχόμενων «1» ανάμεσα στα , το οποίο είναι διαισθητικά απολύτως λογικό.
-
9.
Προσομοίωση. Και τα τρία ερωτήματα είναι καθαρά προγραμματιστικά. Για το τελευταίο μέρος του (γ’), σημειώνουμε πως μπορεί να αποδειχθεί ότι, πράγματι,
αλλά αυτή η σύγκλιση συμβαίνει με πολύ αργό ρυθμό, δηλαδή για πολύ μεγάλες τιμές του . Γι’ αυτόν το λόγο, ίσως να μην είναι προφανής από τα αποτελέσματα βάσει των τιμών που δίνονται στην άσκηση.
-
10.
Μεγάλοι χρόνοι αναμονής. Έχουμε ανεξάρτητες Bern T.M., και η Τ.Μ. περιγράφει την πρώτη χρονική στιγμή κατά την οποία εμφανίζεται το μοτίβο μήκους στα . Θα αποδείξουμε την (ισοδύναμη με το ζητούμενο του προβλήματος) σχέση:
(A.12) Για να φράξουμε την πιθανότητα , ορίζουμε για κάθε τα ενδεχόμενα,
Έχουμε,
και χρησιμοποιώντας το φράγμα ένωσης του Κεφαλαίου 5,
Εφόσον οι Τ.Μ. είναι ανεξάρτητες, για κάθε ενδεχόμενο βρίσκουμε,
οπότε,
το οποίο αποδεικνύει την (A.12).
-
11.
Τυχαίες διατάξεις.
-
(α’)
Το στοιχείο αρχικά βρίσκεται στη θέση . Αλλά το είναι απλά ένας από τους αριθμούς 1 έως , οπότε μετά την ταξινόμηση θα βρίσκεται στη θέση . Άρα θα έχει μετακινηθεί κατά θέσεις.
-
(β’)
Το ότι κάθε έχει ομοιόμορφη κατανομή στο είναι προφανές λόγω της συμμετρίας του προβλήματος. Για να το αποδείξουμε και αυστηρά μαθηματικά παρατηρούμε ότι προφανώς έχει σύνολο τιμών το και ότι η είναι η πιθανότητα του να επιλέξουμε μια διάταξη η οποία στη θέση να έχει στο στοιχείο . Το πλήθος αυτών των διατάξεων ισούται με το πλήθος των τρόπων με τους οποίους μπορούμε να διατάξουμε τα υπόλοιπα στοιχεία στις υπόλοιπες θέσεις, δηλαδή . Και εφόσον υπάρχουν συνολικά δυνατές διατάξεις η ζητούμενη πιθανότητα είναι, όπως περιμένουμε, ίση με .
-
(γ’)
Για να υπολογίσουμε τη ζητούμενη μέση τιμή, κατ’ αρχάς χρησιμοποιώντας τον ορισμό της μέσης τιμής μιας συνάρτησης μιας Τ.Μ., θα υπολογίσουμε τη μέση τιμή,
όπου χρησιμοποιήσαμε τον τύπο για το άθροισμα μιας αριθμητικής προόδου όπως στην Άσκηση 2 πιο πάνω. Οπότε, εφαρμόζοντας την πρώτη ιδιότητα από το Θεώρημα 6.1, βρίσκουμε,
όπου χρησιμοποιήσαμε και πάλι τον τύπο για το άθροισμα μιας αριθμητικής προόδου, και τον τύπο (8.7) για το άθροισμα τετραγώνων που δίνεται στην εκφώνηση. [Άσκηση. Αποδείξτε τη σχέση (8.7) με επαγωγή.]
-
(α’)
-
12.
Ο randomized quicksort. Η απόδειξη του Θεωρήματος 8.3 είναι ακριβώς η ίδια με εκείνη του Θεωρήματος 8.2, με μόνη απαραίτητη τροποποίηση την τεκμηρίωσή του γιατί και εδώ η πιθανότητα είναι ίση με . Όπως και στο Θεώρημα 8.2, λόγω της συμμετρίας του προβλήματος, αφού η επιλογή των οδηγών είναι τυχαία και ομοιόμορφη, και πάλι συμπεραίνουμε πως η πιθανότητα να επιλεγεί οποιοδήποτε από τα στοιχεία πρώτο ως οδηγός, είναι η ίδια. Συνεπώς, όπως και πριν, .
A.9 Ασκήσεις Κεφαλαίου 9
[Επιστροφή στα περιεχόμενα]
-
1.
Αφρικανικό χελιδόνι. Διαισθητικά, ο ισχυρισμός δεν μπορεί να ευσταθεί, γιατί ακόμα και αν το των χελιδονιών είχε βάρος ακριβώς γραμμάρια, και το υπόλοιπο ακριβώς μηδέν (!) τότε το μέσο βάρος θα ήταν γραμμάρια, ενώ σε όλες τις άλλες περιπτώσεις το μέσο βάρος θα ήταν ακόμα μεγαλύτερο.
Στην γλώσσα των πιθανοτήτων, παραβιάζεται η ανισότητα του Markov: Αν είναι το βάρος ενός τυχαίου χελιδονιού, θα πρέπει να έχουμε,
που δεν συμφωνεί με τον ισχυρισμό του βιολόγου ότι αυτή η πιθανότητα είναι ίση με 60%.
-
2.
Απόσταση Τ.Μ. από τη μέση τιμή της. Αφού έχουμε (δηλαδή η διασπορά της είναι «πολύ μικρότερη» από τη μέση τιμή στο τετράγωνο), από την ανισότητα του Chebychev προκύπτει πως:
Επομένως, ο στατιστικολόγος έχει δίκιο.
-
3.
Ιδιότητες από κοινού πυκνότητας. Έστω διακριτές τυχαίες μεταβλητές με σύνολα τιμών και πυκνότητες αντίστοιχα.
Η γενική μορφή των ιδιοτήτων της από κοινού πυκνότητάς τους είναι ως εξής:
-
(α’)
.
-
(β’)
Για κάθε :
-
(γ’)
Οι είναι ανεξάρτητες αν και μόνο αν,
για κάθε -άδα τιμών .
Οι αποδείξεις είναι παρόμοιες με εκείνες που είδαμε για την περίπτωση των Τ.Μ.
Εφόσον για διαφορετικές -άδες τιμών τα ενδεχόμενα,
είναι ξένα μεταξύ τους, και προφανώς η ένωσή τους ισούται με όλο το , από τον κανόνα συνολικής πιθανότητας έχουμε,
που αποδεικνύει την πρώτη ιδιότητα.
Παρομοίως, για κάθε δεδομένο , τα ενδεχόμενα είναι ξένα μεταξύ τους, και η ένωσή τους για διαφορετικά ισούται με το ενδεχόμενο . Άρα, πάλι από τον κανόνα συνολικής πιθανότητας, έχουμε τη δεύτερη ιδιότητα: H ισούται με:
Τέλος, η τρίτη ιδιότητα είναι απλά αναδιατυπωμένος ο ορισμός της ανεξαρτησίας διακριτών τυχαίων μεταβλητών.
-
(α’)
-
4.
Χρόνος εκτέλεσης αλγορίθμου.
- (α’)
-
(β’)
Από το προηγούμενο ερώτημα και την ανισότητα Markov έχουμε,
-
(γ’)
Ήδη γνωρίζουμε πως , πως , και παρομοίως μπορούμε να υπολογίσουμε ότι,
Επιπλέον έχουμε και . Οπότε, εφαρμόζοντας την εναλλακτική έκφραση για τη συνδιακύμανση (9.2),
όπου στο βήμα εφαρμόσαμε την πρώτη ιδιότητα του Θεωρήματος 6.1 και στο βήμα την τρίτη ιδιότητα, αφού οι Τ.Μ. και είναι ανεξάρτητες. Αντικαθιστώντας τις γνωστές τιμές στην παραπάνω έκφραση,
Παρατηρούμε κατ’ αρχάς ότι η συνδιακύμανση είναι θετική, γεγονός που δεν μας εκπλήσσει λόγω του ορισμού του ως « + κάτι ανεξάρτητο». Άρα, όταν μεγαλώνει ή μικραίνει το , αντιστοίχως θα τείνει να μεγαλώνει ή να μικραίνει και το . Επίσης παρατηρούμε πως το αποτέλεσμα δεν εξαρτάται από το , πράγμα που και πάλι βρίσκουμε λογικό: Εφόσον η συσχέτιση μεταξύ του και του δεν περιλαμβάνει άμεσα κάποιον όρο που να εξαρτάται από το , αναμενόμενο είναι και η συνδιακύμανση μεταξύ τους να είναι ανεξάρτητη του .
-
5.
Μέγιστο και ελάχιστο δύο ζαριών.
-
(α’)
Η τιμές της από κοινού πυκνότητας των εύκολα υπολογίζονται μέσω της ανεξαρτησίας: Για κάθε :
Η δεύτερη ισότητα προέκυψε λόγω ανεξαρτησίας, και η τρίτη λόγω του ότι το ζάρι είναι δίκαιο.
-
(β’)
Έχουμε ένα πείραμα με διαφορετικά αποτελέσματα. Επιπλέον, η από κοινού πυκνότητα των πρέπει να υπολογιστεί για ζεύγη τιμών . Αρχικά παρατηρούμε πως κάποια από αυτά είναι αδύνατον να εμφανιστούν, π.χ., δεν μπορεί το ελάχιστο από τις δύο ζαριές να είναι 5 και το μέγιστο 2. Συνεπώς, , και γενικά αν .
Για να υπολογίσουμε καθεμία από τις υπόλοιπες τιμές πρέπει να βρούμε τα αποτελέσματα που της αντιστοιχούν. Για παράδειγμα,
Συνεχίζοντας με τον ίδιο τρόπο, συμπληρώνουμε τις τιμές της στον ακόλουθο πίνακα:
-
(γ’)
Οι περιθώριες πυκνότητες και υπολογίζονται στο περιθώριο του πιο πάνω πίνακα, αθροίζοντας τις τιμές της από κοινού πυκνότητας στην αντίστοιχη στήλη ή γραμμή, όπως μας λέει η δεύτερη βασική ιδιότητα της από κοινού πυκνότητας. Προφανώς, όλες μας οι απαντήσεις, παρότι υπολογισμένες με διαφορετικό τρόπο, συμπίπτουν ακριβώς με τα αντίστοιχα αποτελέσματα στην Άσκηση 7 του Κεφαλαίου 6.
-
(α’)
-
6.
Συναρτήσεις τυχαίων μεταβλητών.
-
(α’)
Έστω πως είναι ανεξάρτητες. Και οι δύο Τ.Μ. έχουν σύνολο τιμών το . Για οποιαδήποτε , από την ανεξαρτησία των και τον κανόνα συνολικής πιθανότητας έχουμε πως η πιθανότητα ισούται με,
δηλαδή, για και ,
Με παρόμοιο τρόπο προκύπτει πως το ίδιο ισχύει και αν το ένα από τα δύο (ή και τα δύο) είναι ίσο με μηδέν. Συνεπώς οι είναι ανεξάρτητες Τ.Μ.
-
(β’)
Μία από τις πολλές δυνατές επιλογές είναι η ακόλουθη από κοινού κατανομή των ,
από την οποία εύκολα βρίσκουμε και την από κοινού κατανομή των :
Παρατηρούμε πως,
άρα οι δεν είναι ανεξάρτητες. Απ’ την άλλη μεριά, χρησιμοποιώντας τις τιμές του δεύτερου πίνακα εύκολα μπορούμε να επιβεβαιώσουμε πως ισχύει,
για κάθε ζευγάρι τιμών με 0 ή 1, και κατά συνέπεια πως τα είναι ανεξάρτητα.
-
(γ’)
Το αντίστροφο μέρος του ερωτήματος είναι προφανές: Αν οι και είναι ανεξάρτητες για οποιεσδήποτε συναρτήσεις και , τότε επιλέγοντας και , συμπεραίνουμε πως και οι είναι ανεξάρτητες.
Για το ορθό μέρος, έστω μια Τ.Μ. με πυκνότητα στο σύνολο τιμών , και έστω μια συνάρτηση . Τότε η νέα Τ.Μ. έχει σύνολο τιμών το και η πυκνότητά της έχει την εξής ιδιότητα: Για κάθε υπάρχει ένα ή περισσότερα τέτοια ώστε . Έστω το σύνολο αυτών των :
Τώρα η πυκνότητα μπορεί να εκφραστεί ως,
(A.13) Με ακριβώς το ίδιο σκεπτικό, η έχει σύνολο τιμών το και πυκνότητα τέτοια ώστε,
(A.14) όπου τα σύνολα ορίζονται ως,
Η ανεξαρτησία των επιβεβαιώνεται εύκολα ως εξής: Για οποιεσδήποτε τιμές ,
όπου η ισότητα προκύπτει από την Ιδιότητα 5 του Θεωρήματος 6.1, και η από τις σχέσεις (A.13) και (A.14) πιο πάνω. Συνεπώς οι τυχαίες μεταβλητές είναι πράγματι ανεξάρτητες.
Αυτό το αποτέλεσμα εκ πρώτης όψεως φαίνεται να αντικρούει το αποτέλεσμα του προηγούμενου σκέλους: Αφού οι και είναι ανεξάρτητες, δεν θα έπρεπε και οι να είναι ανεξάρτητες; Η απάντηση είναι «όχι απαραίτητα»: Όταν τα παίρνουν και θετικές και αρνητικές τιμές, το δεν είναι απαραίτητα συνάρτηση του (και αντίστοιχα για το ), μια που γνωρίζοντας, π.χ., ότι , το μόνο που μπορούμε να συμπεράνουμε είναι ότι το ισούται με ή με , αλλά δεν ξέρουμε απαραίτητα ποια είναι η τιμή του.
-
(α’)
-
7.
Το φράγμα του Chernoff.
-
(α’)
Κατ’ αρχάς, εφόσον το είναι θετικό, έχουμε,
όπου έχουμε ορίσει τη νέα T.M. . Εφόσον η παίρνει πάντα τιμές , χρησιμοποιώντας την ανισότητα του Markov για την , έχουμε:
που είναι ακριβώς η ζητούμενη σχέση.
-
(β’)
Έστω τώρα πως . Τότε, όπως είδαμε στην Ενότητα 7.1, η μπορεί να εκφραστεί ως το άθροισμα , όπου οι είναι ανεξάρτητες Τ.Μ. Άρα, εφαρμόζοντας τη σχέση (9.4) του προηγούμενου σκέλους στη , με τη σταθερά στη θέση της , βρίσκουμε πως,
Από το τρίτο σκέλος της Άσκησης 6 παραπάνω γνωρίζουμε πως, εφόσον οι Τ.Μ. είναι ανεξάρτητες, θα είναι και οι Τ.Μ. ανεξάρτητες. Συνεπώς, χρησιμοποιώντας την Ιδιότητα 3 του Θεωρήματος 6.1, έχουμε,
Επιπλέον, αφού όλα τα έχουν την ίδια κατανομή, όλοι οι όροι του πιο πάνω γινομένου είναι ίσοι μεταξύ τους και όλοι ίσοι με . Άρα,
-
(γ’)
Έστω τώρα πως .
- i.
Για , το φράγμα (9.5) που μόλις αποδείξαμε μας δίνει,
Για να βρούμε το καλύτερο δυνατό φράγμα αρκεί να υπολογίσουμε την τιμή του που ελαχιστοποιεί το δεξί μέρος της παραπάνω σχέσης. Για να βρούμε αυτή την τιμή, αρκεί να ελαχιστοποιήσουμε τη συνάρτηση ως προς . Παίρνοντας παραγώγους, εύκολα βρίσκουμε πως,
το οποίο ισούται με μηδέν αν και μόνο αν , δηλαδή για την τιμή,
Επιπλέον, η δεύτερη παράγωγος ισούται με
το οποίο είναι προφανώς πάντα θετικό, άρα η τιμή πράγματι ελαχιστοποιεί την . Αντικαθιστώντας αυτή την τιμή στο φράγμα μας,
- ii.
Η Τ.Μ. έχει μέση τιμή , όποτε η ανισότητα του Markov μάς δίνει,
το οποίο είναι σαφώς σημαντικά ασθενέστερο.
- iii.
Τέλος, η ζητούμενη πιθανότητα μπορεί εύκολα να υπολογιστεί ακριβώς. Εφόσον το έχει σύνολο τιμών το , από τον τύπο της πυκνότητας της διωνυμικής κατανομής έχουμε,
το οποίο ισούται με, Προφανώς το φράγμα του Chernoff εδώ μας δίνει ένα αποτέλεσμα πολύ πιο ισχυρό και πιο κοντά στην πραγματική τιμή από ό,τι η ανισότητα του Markov.
- i.
-
(α’)
-
8.
Συμπλήρωση πίνακα.
-
(α’)
Από τις απλές ιδιότητες της από κοινού κατανομής που είδαμε στην Ενότητα 9.2, εύκολα βρίσκουμε:
-
(β’)
Χρησιμοποιώντας τις σχετικές τιμές του πίνακα διαπιστώνουμε πως,
άρα οι , δεν είναι ανεξάρτητες.
-
(γ’)
Από τον ορισμό της δεσμευμένης πιθανότητας και τις τιμές του παραπάνω πίνακα, έχουμε,
-
(α’)
-
9.
Ενεργοποιημένες συνδέσεις. Σύμφωνα με την ανισότητα του Chebychev έχουμε ότι:
Θέλουμε να βρούμε μια τιμή για το ώστε το ενδεχόμενο να πέσει το δίκτυο να έχει πιθανότητα το πολύ , δηλαδή θέλουμε
Επομένως, θέτοντας πετυχαίνουμε το επιθυμητό αποτέλεσμα, και η ζητούμενη τιμή του είναι,
δηλαδή .
-
10.
Συντελεστής συσχέτισης. Κατ’ αρχάς, από την εναλλακτική έκφραση για τη συνδιακύμανση (9.2), έχουμε,
όπου χρησιμοποιήσαμε την πρώτη ιδιότητα του Θεωρήματος 6.1, και την εναλλακτική έκφραση για τη διασπορά (6.8). Επίσης, πάλι από το Θεώρημα 6.1, έχουμε,
συνεπώς,
το οποίο φυσικά ισούται με +1 αν το και με αν το .
-
11.
Ασυσχέτιστες αλλά όχι ανεξάρτητες Τ.Μ. Η Τ.Μ. έχει σύνολο τιμών το και η έχει σύνολο τιμών το . Αρχικά υπολογίζουμε τις τιμές της κοινού πυκνότητας των :
Καθώς είναι αδύνατον να έχουμε , , η πιθανότητα , και παρομοίως, .
Έχοντας υπολογίσει τις τιμές της από κοινού πυκνότητας, μπορούμε να υπολογίσουμε και τις περιθώριες πυκνότητες:
Από τα παραπάνω εύκολα προκύπτει πως οι δεν είναι ανεξάρτητες. Για παράδειγμα,
Τέλος, για να δείξουμε ότι έχουν μηδενική συνδιακύμανση, υπολογίζουμε τις μέσες τιμές,
Και από την εναλλακτική έκφραση (9.2) βρίσκουμε πως η συνδιακύμανση,
είναι πράγματι ίση με μηδέν.
-
12.
Σύγκλιση κατά πιθανότητα.
-
(α’)
Εφόσον η κάθε , για αυθαίρετο έχουμε,
Αν το , τότε η πιθανότητα είναι ίση με 1 για κάθε , ενώ αν τότε,
το οποίο προφανώς τείνει στο 1 καθώς το . Άρα, έχουμε κατά πιθανότητα καθώς .
-
(β’)
Εδώ έχουμε μια σημαντική παρατήρηση: Ο ορισμός της σύγκλισης κατά πιθανότητα σε μια σταθερά εξαρτάται μόνο από πιθανότητες της μορφής , οι οποίες αφορούν μόνο μία μεταβλητή και συνεπώς εξαρτώνται μόνο από τις περιθώριες κατανομές των . Άρα, το πιο πάνω αποτέλεσμα ισχύει ανεξαρτήτως του αν οι Τ.Μ. είναι ανεξάρτητες ή όχι.
-
(γ’)
Αντίθετα με το προηγούμενο ερώτημα, για το αποτέλεσμα του Ν.Μ.Α. είναι πολύ σημαντική η υπόθεση ότι οι είναι ανεξάρτητες, και δεν μπορεί να παραλειφθεί εντελώς. Για παράδειγμα, έστω ότι τα έχουν όλα κατανομή . Αν είναι ανεξάρτητα, τότε ο εμπειρικός τους μέσος όρος τείνει στο 1/2 κατά πιθανότητα, όπως μας λέει ο Ν.Μ.Α. Αντίθετα, αν όλα τα είναι ίσα με το , τότε και ο εμπειρικός τους μέσος όρος είναι ίσος με το για κάθε , το οποίο προφανώς δεν συγκλίνει στο 1/2!
Ο λόγος για τον οποίο η ανεξαρτησία εδώ είναι καίρια, είναι διότι, αν αλλάξει η από κοινού κατανομή των , τότε αλλάζει και η περιθώρια κατανομή του εμπειρικού μέσου όρου .
-
(α’)
-
13.
Εκτίμηση με θόρυβο.
-
(α’)
Εφόσον τα έχουν μέση τιμή , η κάθε Τ.Μ. έχει μέση τιμή μηδέν. Και επιπλέον, αφού όλες οι Τ.Μ. είναι ανεξάρτητες, τότε και οι νέες τυχαίες μεταβλητές σχηματίζουν μια ακολουθία ανεξάρτητων Τ.Μ. όπου όλες έχουν την ίδια κατανομή και συνεπώς την ίδια μέση τιμή,
Άρα, αν αποφασίσουμε να εκτιμήσουμε το μέσω του εμπειρικού μέσου όρου,
ο Ν.Μ.Α. μάς εγγυάται πως θα έχουμε κατά πιθανότητα, καθώς .
-
(β’)
Παρομοίως και εδώ ορίζουμε τις νέες Τ.Μ. , και ως εκτιμήτρια του χρησιμοποιούμε τον εμπειρικό τους μέσο όρο,
(A.15) Εφόσον οι Τ.Μ. είναι ανεξάρτητες, έχουν την ίδια κατανομή και έχουν μέση τιμή ίση με μηδέν, ο Ν.Μ.Α. μάς λέει πως ο δεύτερος όρος στο δεξί μέρος της (A.15) τείνει στο μηδέν, κατά πιθανότητα. Άρα διαισθητικά περιμένουμε πως θα έχουμε και κατά πιθανότητα, καθώς . Πράγματι, για αυθαίρετο ,
όπου η τελευταία πιθανότητα πιο πάνω τείνει στο 1 καθώς , από τον Ν.Μ.Α. για τον εμπειρικό μέσο όρο των Τ.Μ. . Άρα, πράγματι η εκτίμησή μας είναι «ασυμπτωτικά συνεπής», δηλαδή κατά πιθανότητα, καθώς .
-
(α’)
-
14.
Σύγκλιση με πιθανότητα 1.
-
(α’)
Αν για κάποιο ισχύει ότι για όλα τα , προφανώς το ίδιο θα ισχύει και για όλα τα . Άρα κάθε που ανήκει στο , ανήκει και στο , συνεπώς η ακολουθία των ενδεχομένων είναι αύξουσα.
Επιπλέον, αν για κάποιο συγκεκριμένο έχουμε , τότε από τον κλασικό ορισμό του ορίου, για κάθε υπάρχει κάποιο τέτοιο ώστε για όλα τα . Με άλλα λόγια, αν κάποιο ανήκει στο , τότε σίγουρα θα ανήκει και σε κάποιο από τα . Άρα έχουμε ότι ισχύει η ζητούμενη σχέση (9.6).
-
(β’)
Από τον δεύτερο κανόνα πιθανότητας και τη σχέση (9.6) έχουμε πως,
όπου το γεγονός ότι προκύπτει από την υπόθεση ότι οι συγκλίνουν στη με πιθανότητα 1. Άρα η πιθανότητα της παραπάνω ένωσης ισούται κι αυτή με 1, και, δεδομένου του προηγούμενου σκέλους, από την Άσκηση 9 (α’) του Κεφαλαίου 3 συμπεραίνουμε πως,
-
(γ’)
Τέλος, παρατηρούμε πως, για κάθε ,
άρα, χρησιμοποιώντας τον δεύτερο κανόνα πιθανότητας στο αποτέλεσμα του πιο πάνω ερωτήματος έχουμε,
δηλαδή,
Και αφού το που επιλέξαμε στην αρχή ήταν αυθαίρετο, έχουμε πράγματι αποδείξει ότι οι τείνουν στη κατά πιθανότητα.
-
(α’)
A.10 Ασκήσεις Κεφαλαίου 10
[Επιστροφή στα περιεχόμενα]
-
1.
Κυκλικός δίσκος. Προφανώς οι δυνατές τιμές για το ανήκουν στο διάστημα , οπότε . Για τη συνάρτηση κατανομής, θα έχουμε αν και μόνο αν το επιλεγμένο σημείο είναι εντός του κυκλικού δίσκου με ακτίνα που εμφανίζεται σκιασμένος στο Σχήμα 1.29.
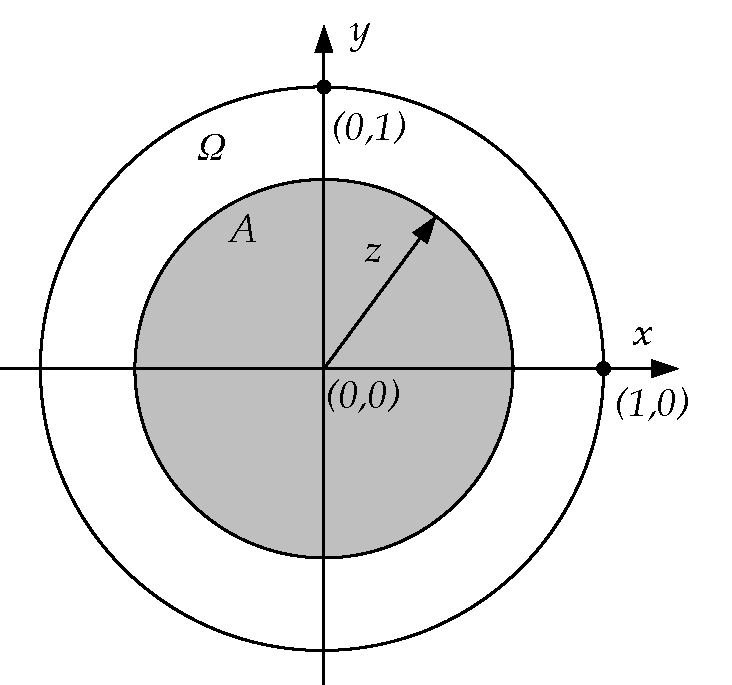
Σχήμα 1.29: Το ενδεχόμενο στην Άσκηση 1. Εφόσον το σημείο επιλέγεται ομοιόμορφα ανάμεσα σε όλα τα σημεία του , η πιθανότητα να έχουμε ισούται με το εμβαδόν του σκιασμένου δίσκου προς το εμβαδόν όλου του . Άρα, για , έχουμε,
και γενικά,
Τέλος για την πυκνότητα, από τη σχέση (10.7) έχουμε,
Οι , , έχουν σχεδιαστεί στο Σχήμα 1.30.
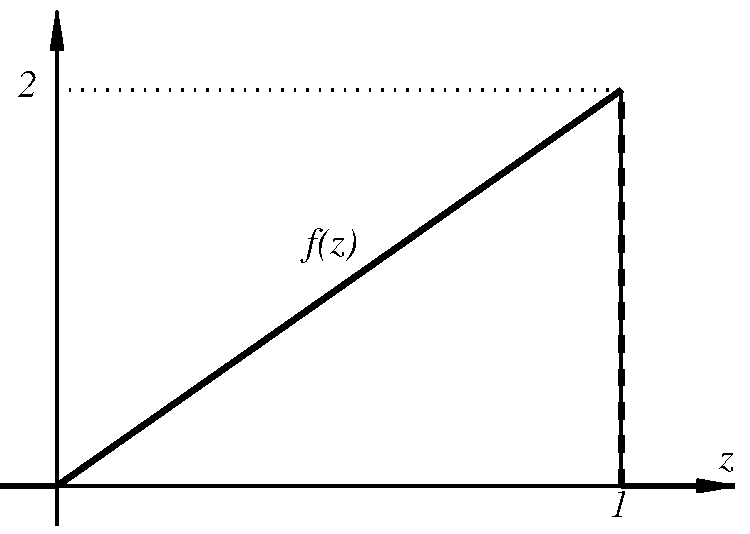
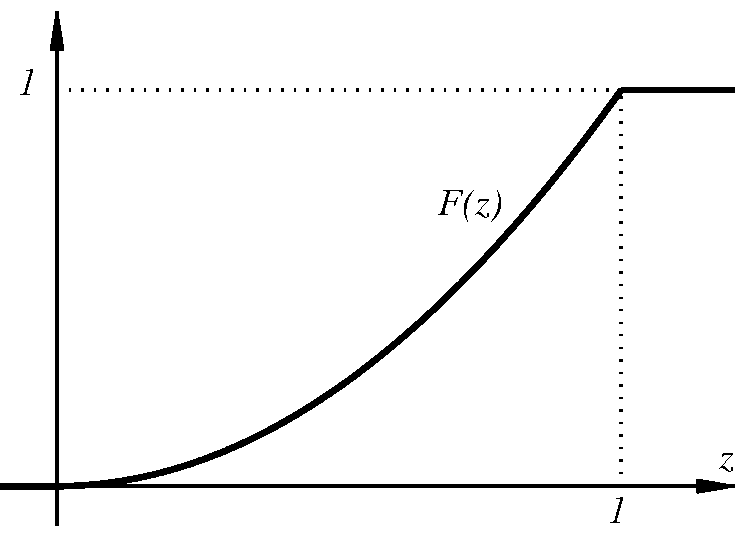
Σχήμα 1.30: Η πυκνότητα και η συνάρτηση κατανομής της Τ.Μ. στην Άσκηση 1. -
2.
Προσδιορισμός παραμέτρων.
-
(α’)
Από την τρίτη ιδιότητα της συνάρτησης κατανομής, θα πρέπει , οπότε θα πρέπει η να ισούται με μηδέν γιατί διαφορετικά . Άρα, για , , και το όριο της καθώς το είναι, Συνεπώς πρέπει να έχουμε και , δηλαδή,
-
(β’)
Για την πυκνότητα, από τη σχέση (10.7) βρίσκουμε,
Η γραφική αναπαράσταση των και δίνεται στο Σχήμα 1.31.
Σχήμα 1.31: Γραφική αναπαράσταση της πυκνότητας και της συνάρτησης κατανομής στην Άσκηση 2. -
(γ’)
Από τον ορισμό της δεσμευμένης πιθανότητας, και χρησιμοποιώντας τη συνάρτηση κατανομής ,
-
(α’)
-
3.
Μια απλή πυκνότητα.
-
(α’)
Το ολοκλήρωμα της πυκνότητας από το ως το πρέπει να ισούται με 1, αλλά,
οπότε πρέπει να έχουμε . Άρα η πυκνότητα , όπως αναπαρίσταται και στο Σχήμα 1.32, είναι:
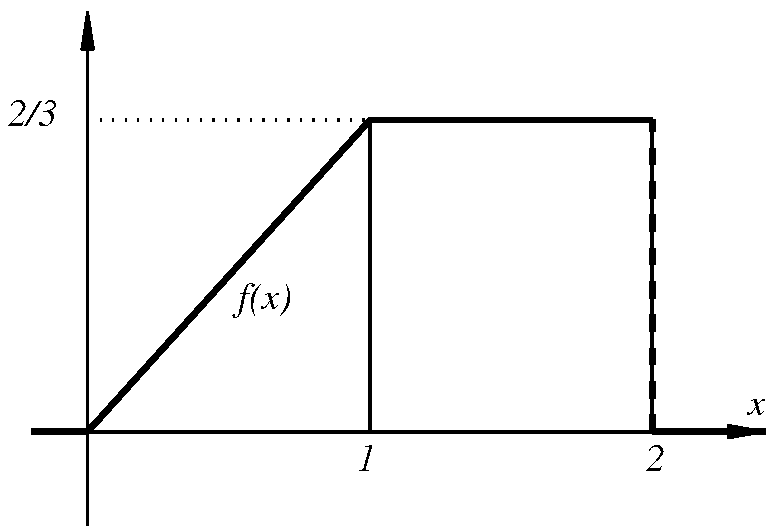
Σχήμα 1.32: Η πυκνότητα στην Άσκηση 3. -
(β’)
Η ζητούμενη πιθανότητα εύκολα υπολογίζεται από την πυκνότητα,
-
(γ’)
Από τον ορισμό της μέσης τιμής εύκολα βρίσκουμε,
-
(α’)
-
4.
Μέση τιμή συναρτήσεων Τ.Μ.
-
(α’)
Από τον τύπο (10.10) έχουμε,
-
(β’)
Η διακριτή Τ.Μ. έχει σύνολο τιμών και οι τιμές της πυκνότητάς της υπολογίζονται εύκολα ως εξής,
και παρομοίως,
και,
Εφαρμόζοντας τώρα τον ορισμό της μέσης τιμής μιας διακριτής Τ.Μ., βρίσκουμε,
το οποίο φυσικά ισούται ακριβώς με την τιμή της που υπολογίσαμε παραπάνω.
-
(α’)
-
5.
Άπειρη μέση τιμή.
-
(α’)
Από τον Ορισμό 10.1 γνωρίζουμε πως το ολοκλήρωμα της πυκνότητας για όλα τα πρέπει να ισούται με 1, συνεπώς,
άρα έχουμε .
-
(β’)
Από τον ορισμό της μέσης τιμής,
μια που, ως γνωστόν, το καταχρηστικό ολοκλήρωμα για κάθε :
-
(α’)
-
6.
Κατανομή Βήτα.
-
(α’)
Η σταθερά πρέπει να έχει τιμή τέτοια ώστε το ολοκλήρωμα της πυκνότητας να ισούται με τη μονάδα,
Συνεπώς . Η πυκνότητα έχει σχεδιαστεί στο Σχήμα 1.33.
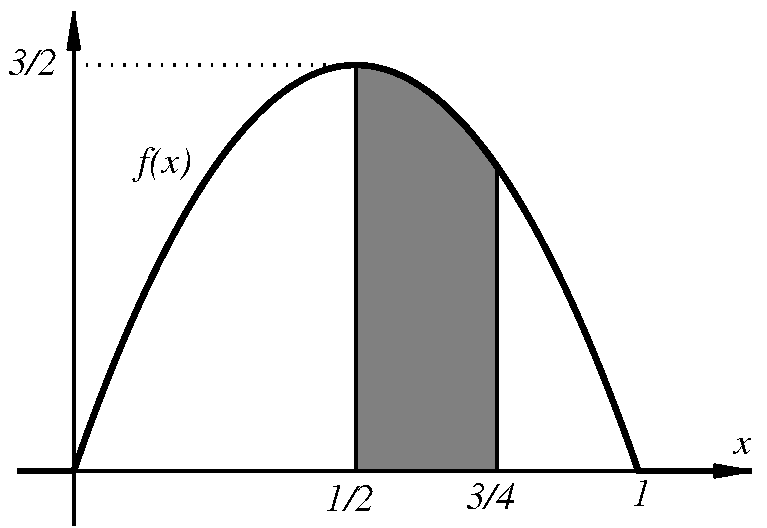
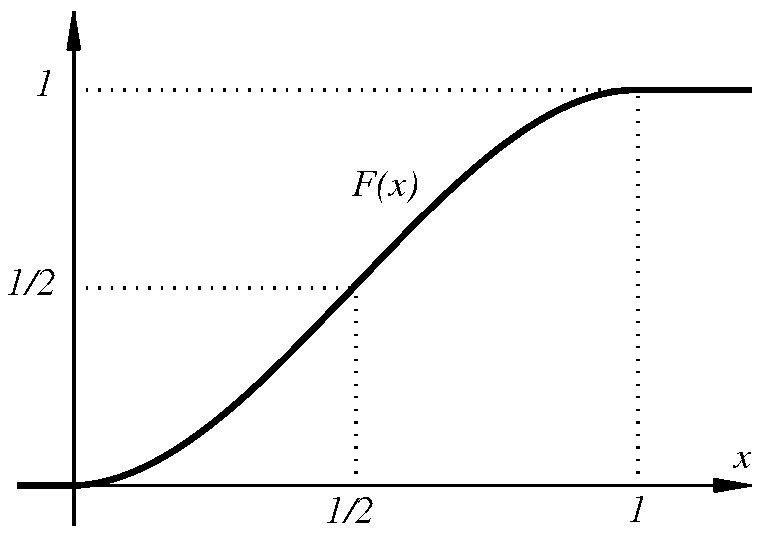
Σχήμα 1.33: Η πυκνότητα και η συνάρτηση κατανομής της τυχαίας μεταβλητής στην Άσκηση 6. -
(β’)
Παρομοίως, η ζητούμενη πιθανότητα είναι,
Το αντίστοιχο εμβαδόν εμφανίζεται σκιασμένο στο Σχήμα 1.33.
-
(γ’)
Προφανώς για έχουμε , και για έχουμε . Για την περίπτωση , βρίσκουμε:
Συνεπώς:
Η συνάρτηση κατανομής έχει σχεδιαστεί στο Σχήμα 1.33.
-
(α’)
-
7.
Υποψήφιες πυκνότητες. Σε καθεμία από τις παρακάτω περιπτώσεις, για να είναι η πυκνότητα, θα πρέπει να ισχύει ότι για όλα τα και . Επομένως έχουμε:
-
(α’)
Για τη συνάρτηση ,
Επιπλέον, προφανώς για κάθε . Άρα η είναι πυκνότητα. Το γράφημά της δίνεται στο Σχήμα 1.34.
Σχετικά με τη μέση τιμή και τη διασπορά, έχουμε:
Το ότι η μέση τιμή είναι είναι αναμενόμενο, λόγω του ότι η πυκνότητα είναι συμμετρική γύρω από το . Και για τη ζητούμενη πιθανότητα,
όπου και αυτό είναι αναμενόμενο λόγω της συμμετρίας της . Bλ. Σχήμα 1.34.
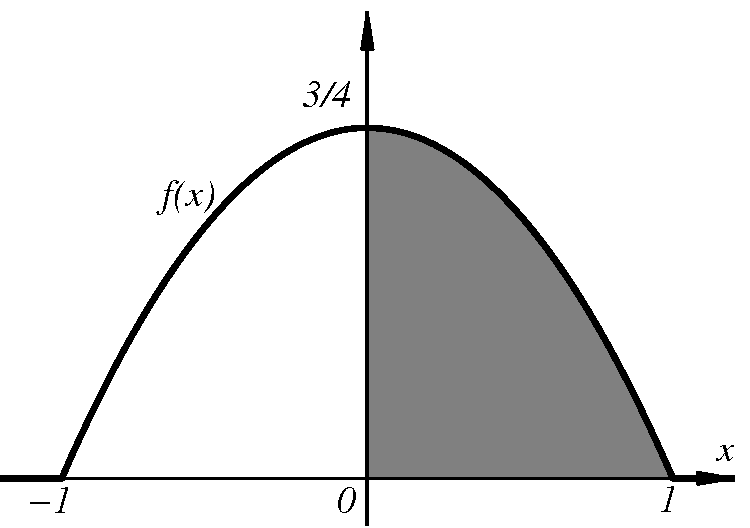
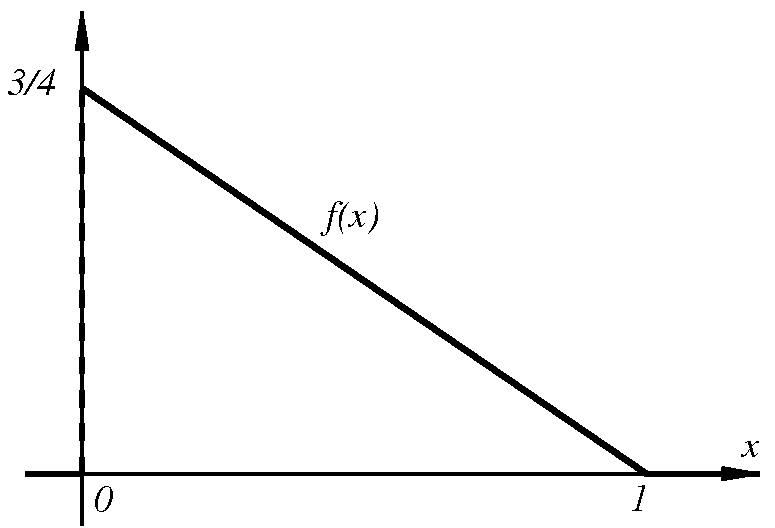
Σχήμα 1.34: Αριστερά, η πυκνότητα της Άσκησης α’, και το εμβαδόν που αντιστοιχεί στην πιθανότητα Δεξιά, η συνάρτηση στην Άσκηση β’. -
(β’)
Για τη συνάρτηση αυτού του υποερωτήματος,
Άρα η δεν είναι πυκνότητα. Το γράφημά της φαίνεται στο Σχήμα 1.34.
-
(γ’)
Εδώ, το ολοκλήρωμα της είναι,
και άρα, αφού επιπλέον παντού, η είναι πυκνότητα. Το γράφημά της δίνεται στο Σχήμα 1.35. Σχετικά με τη μέση τιμή και τη διασπορά, βρίσκουμε:
Και για τη ζητούμενη πιθανότητα,
Παρατηρούμε ότι η πιθανότητα δεν ισούται με . Το αντίστοιχο εμβαδόν εμφανίζεται σκιασμένο στο Σχήμα 1.35.
-
(δ’)
Η εδώ δεν είναι πυκνότητα, διότι παίρνει αρνητικές τιμές όταν το είναι μεγαλύτερο από . Το γράφημά της φαίνεται στο Σχήμα 1.35.
-
(α’)
-
8.
Μια απλή πυκνότητα στο
-
(α’)
Η τιμή της θα προσδιοριστεί χρησιμοποιώντας τη βασική ιδιότητα της πυκνότητας που μας λέει πως το ολοκλήρωμά της στο πρέπει να ισούται με τη μονάδα. Υπολογίζουμε, λοιπόν,
όπου το βήμα προκύπτει από την αλλαγή μεταβλητής . Συνεπώς θα πρέπει να έχουμε .
-
(β’)
Από τον ορισμό της , εύκολα υπολογίζουμε,
όπου το βήμα προκύπτει από την αλλαγή μεταβλητής .
-
(γ’)
Παρομοίως με το προηγούμενο ερώτημα, από τον ορισμό της διασποράς βρίσκουμε,
όπου η ισότητα προκύπτει με αλλαγή μεταβλητής , και τα όρια που εμφανίζονται στα παραπάνω καταχρηστικά ολοκληρώματα είναι όλα ίσα με μηδέν, όπως προκύπτει με απλή εφαρμογή του κανόνα του L’Hôpital.
-
(δ’)
Τέλος, από τον ορισμό της πυκνότητας, εύκολα βρίσκουμε πως,
όπου η τρίτη ισότητα και πάλι προκύπτει από την αλλαγή μεταβλητής .
-
(α’)
-
9.
Βαρουφάκης εναντίον Merkel. Έστω η συνολική διάρκεια του Eurogroup, οπότε ή , με πιθανότητα 1/2 και για τις δύο περιπτώσεις.
Για τη ζητούμενη πιθανότητα, από τον κανόνα συνολικής πιθανότητας έχουμε,
-
10.
Συνεχείς και διακριτές τυχαίες μεταβλητές.
-
(α’)
Για την χρησιμοποιούμε τον κανόνα συνολικής πιθανότητας:
-
(β’)
Από τον Ορισμό 10.1, μια συνάρτηση για να είναι η πυκνότητα του πρέπει να ικανοποιεί τη σχέση, , για οποιοδήποτε διάστημα . Με τον ίδιο συλλογισμό όπως στο πρώτο ερώτημα, η πιο πάνω πιθανότητα είναι:
Συνεπώς, η συνάρτηση,
είναι η πυκνότητα του , αφού προφανώς ικανοποιεί και τις δύο άλλες συνθήκες του ορισμού, δηλαδή, για κάθε , και . Βλ. Σχήμα 1.36.
Επιπλέον, παρατηρούμε ότι προφανώς και η έχει την ίδια πυκνότητα.
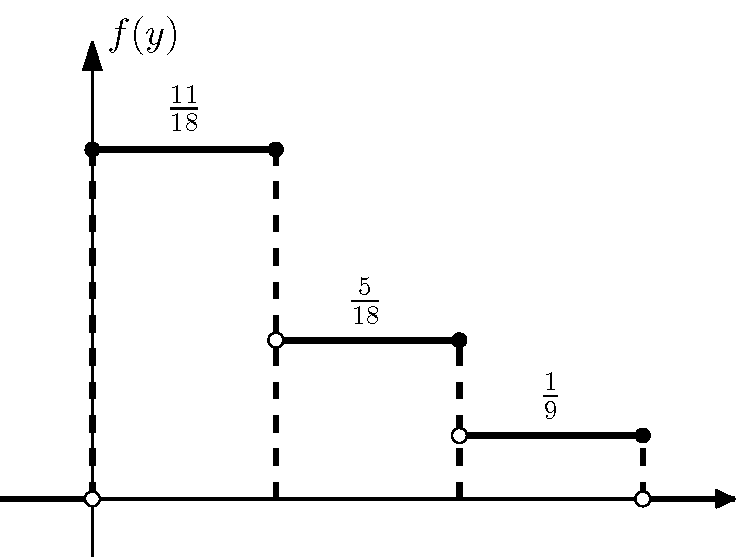
Σχήμα 1.36: Η πυκνότητα της Άσκησης 10. -
(γ’)
Αφού, δεδομένης της τιμής του , τα και είναι ανεξάρτητα, έχουμε,
όπου οι δύο παραπάνω πιθανότητες είναι και οι δύο ίσες με , οπότε,
-
(δ’)
Για την τελευταία πιθανότητα, χρησιμοποιώντας τον κανόνα του Bayes βρίσκουμε ότι η ισούται με,
Υπολογίζοντας αρχικά τους τρεις όρους του παρονομαστή όπως πριν,
και αντικαθιστώντας, βρίσκουμε τελικά:
-
(α’)
-
11.
Απόσταση
-
(α’)
Αναπτύσσοντας το τετράγωνο στο ορισμό της βρίσκουμε,
όπου χρησιμοποιήσαμε τη βασική ιδιότητα του ορισμού μιας συνεχούς πυκνότητας που μας λέει πως το ολοκλήρωμά της σε ολόκληρο το (ή, ισοδύναμα, σε ολόκληρο το σύνολο τιμών της) ισούται με 1.
-
(β’)
Παρομοίως, για δύο διακριτές πυκνότητες και στο ίδιο σύνολο τιμών , έχουμε,
άρα,
όπου παραπάνω χρησιμοποιήσαμε την αντίστοιχη ιδιότητα μιας διακριτής πυκνότητας, δηλαδή το ότι το άθροισμα όλων των τιμών της ισούται με 1.
-
(α’)
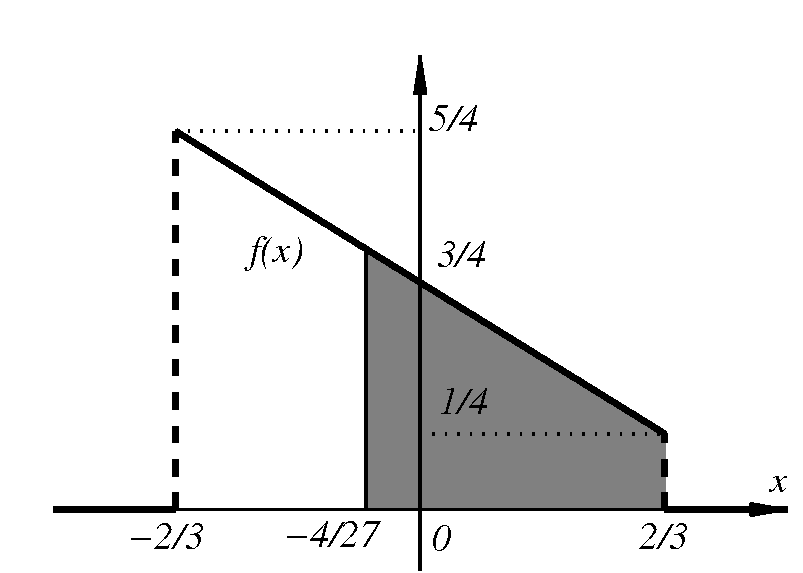
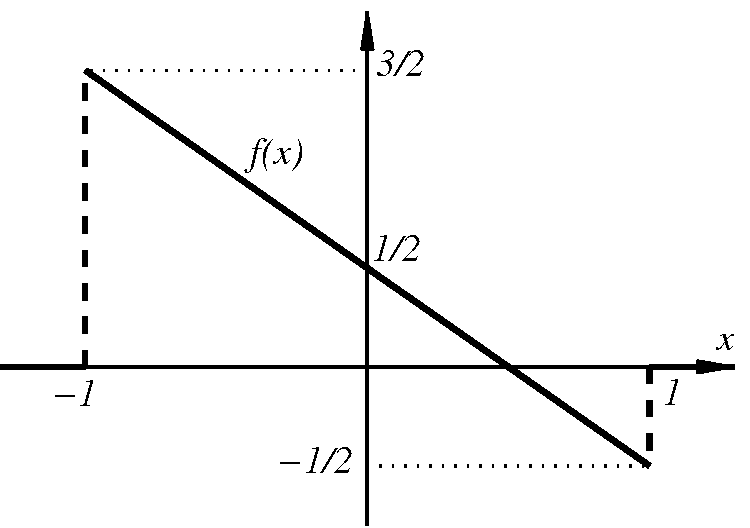
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A.11 Ασκήσεις Κεφαλαίου 11
[Επιστροφή στα περιεχόμενα]
-
1.
Από την ομοιόμορφη στην εκθετική κατανομή. Θα υπολογίσουμε τη συνάρτηση κατανομής της Κατ’ αρχάς, παρατηρούμε ότι, εξ ορισμού, η έχει σύνολο τιμών το , άρα για . Για ,
Συνεπώς, η έχει συνάρτηση κατανομής εκείνη της κατανομής, βλ. Θεώρημα 11.1, άρα έχουμε .
-
2.
Χρόνος μετάδοσης.
- (α’)
-
(β’)
Η πιθανότητα ο χρόνος εκτέλεσης να ξεπεράσει τα λεπτά, δηλαδή είναι,
Αλλά το τριώνυμο παραγοντοποιείται ως , και εφόσον η Τ.Μ. παίρνει μόνο θετικές τιμές, το πιο πάνω τριώνυμο είναι θετικό αν και μόνο αν το είναι μεγαλύτερο από τη θετική του ρίζα. Συνεπώς,
όπου στο βήμα αντικαταστήσαμε τον τύπο της συνάρτησης κατανομής μιας εκθετικής Τ.Μ. από το Θεώρημα 11.1.
-
3.
Μηνυματάκια! Έστω οι ακόλουθες τυχαίες μεταβλητές:
οπότε, .
-
(α’)
Για τη μέση τιμή της συνολικής διάρκειας αποστολής, από την πρώτη ιδιότητα του Θεωρήματος 11.5,
αφού οι , έχουν ομοιόμορφη κατανομή στο διάστημα και η έχει εκθετική κατανομή με μέση τιμή .
-
(β’)
Εφόσον οι τρεις αποστολές είναι ανεξάρτητες μεταξύ τους, η πιθανότητα και τα SMS να έχουν διάρκεια πάνω από δευτερόλεπτα το καθένα είναι:
-
(γ’)
H πιθανότητα το MMS να έχει διάρκεια μεγαλύτερη από τη μέση τιμή της συνολικής διάρκειας των SMS είναι,
όπου χρησιμοποιήσαμε τον τύπο της συνάρτησης κατανομής μιας εκθετικής Τ.Μ. από το Θεώρημα 11.1.
-
(δ’)
Από τον ορισμό της δεσμευμένης πιθανότητας και τον τύπο της συνάρτησης κατανομής της εκθετικής Τ.Μ. (βλ. Θεώρημα 11.1), η ζητούμενη δεσμευμένη πιθανότητα ισούται με:
-
(α’)
-
4.
Ελάχιστο και μέγιστο δύο Τ.Μ.
-
(α’)
Για τη συνάρτηση κατανομής της , χρησιμοποιώντας το γεγονός ότι οι είναι ανεξάρτητες και παρατηρώντας πως το μέγιστο μεταξύ δύο αριθμών είναι μικρό αν και μόνο αν και οι δύο αριθμοί είναι μικροί, έχουμε,
Παρομοίως, για να βρούμε τη συνάρτηση κατανομής της , παρατηρώντας πως το ελάχιστο μεταξύ δύο αριθμών είναι μεγάλο αν και μόνο αν και οι δύο αριθμοί είναι μεγάλοι, υπολογίζουμε,
-
(β’)
Εφόσον οι και έχουν σύνολο τιμών το , και η θα έχει το ίδιο σύνολο τιμών, συνεπώς για . Και για , χρησιμοποιώντας το αποτέλεσμα του προηγούμενου ερωτήματος και τον τύπο για την εκθετική συνάρτηση κατανομής από το Θεώρημα 11.1,
άρα και η έχει εκθετική κατανομή, με παράμετρο, .
-
(α’)
-
5.
Ελάχιστο Τ.Μ.
-
(α’)
Όπως και στην προηγούμενη άσκηση, παρατηρούμε πως το ελάχιστο μεταξύ αριθμών είναι μεγάλο αν και μόνο αν και οι αριθμοί είναι μεγάλοι. Άρα, χρησιμοποιώντας την ανεξαρτησία των ,
-
(β’)
Στην ειδική περίπτωση που η είναι εκθετική με παράμετρο , δηλαδή
τότε από το προηγούμενο ερώτημα προκύπτει πως,
δηλαδή η είναι επίσης εκθετικά κατανεμημένη, με παράμετρο .
-
(α’)
-
6.
Γραμμικός μετασχηματισμός. Επαναλαμβάνουμε την ίδια απόδειξη όπως για την Ιδιότητα 3 του Θεωρήματος 11.2, αυτήν τη φορά όμως υποθέτοντας πως η σταθερά είναι αρνητική. Εξετάζουμε αρχικά τις συναρτήσεις κατανομής, έστω και των τυχαίων μεταβλητών αντίστοιχα. Για την έχουμε,
όπου η ανισότητα αντιστρέφεται όταν πολλαπλασιάζουμε με την αρνητική ποσότητα Και τώρα υπολογίζουμε την πυκνότητα της ως την παράγωγο της συνάρτησης κατανομής της, από τη σχέση (10.7),
άρα, όταν η είναι αρνητική, η έχει πυκνότητα,
Παρατηρήστε πως μπορούμε να εκφράσουμε και τις δύο περιπτώσεις ( και ) με ενιαίο τρόπο ως,
-
7.
Κανονικοποίηση. (α’) Στην περίπτωση που η είναι συνεχής, χρησιμοποιώντας την πρώτη ιδιότητα του Θεωρήματος 11.2,
και παρομοίως, εφαρμόζοντας τη δεύτερη ιδιότητα του Θεωρήματος 11.2,
(β’) Η απόδειξη στη διακριτή περίπτωση είναι ακριβώς η ίδια, με τη μόνη διαφορά ότι αντί για την πρώτη και τη δεύτερη ιδιότητα του Θεωρήματος 11.2, επικαλούμαστε τις δύο πρώτες ιδιότητες του Θεωρήματος 6.1 αντίστοιχα.
-
8.
Το φράγμα του Chernoff για συνεχείς Τ.Μ.
- (α’)
-
(β’)
Έστω τώρα πως . Από τον γενικό ορισμό της μέσης τιμής μιας συνάρτησης Τ.Μ., μαζί με τον ορισμό της πυκνότητας της εκθετικής κατανομής,
όπου παρατηρούμε πως το παραπάνω καταχρηστικό ολοκλήρωμα υπάρχει, επειδή το όριο,
υπάρχει και ισούται με μηδέν, κι αυτό λόγω του περιορισμού που έχουμε θέσει ότι .
Αντικαθιστώντας αυτό το αποτέλεσμα στη σχέση 11.5, έχουμε,
-
(γ’)
Έστω τώρα πως .
- i.
Για , το φράγμα (11.6), που μόλις αποδείξαμε, μας δίνει,
Για να βρούμε το καλύτερο δυνατό φράγμα αρκεί να υπολογίσουμε την τιμή του που ελαχιστοποιεί το δεξί μέρος της παραπάνω σχέσης. Για να βρούμε αυτή την τιμή θα ελαχιστοποιήσουμε τη συνάρτηση ως προς . Παίρνοντας παραγώγους, εύκολα βρίσκουμε πως,
το οποίο ισούται με μηδέν αν και μόνο αν , δηλαδή για την τιμή,
Επιπλέον, η δεύτερη παράγωγος ισούται με,
το οποίο είναι προφανώς πάντα θετικό για και , άρα η τιμή πράγματι ελαχιστοποιεί την . Αντικαθιστώντας αυτή την τιμή στο φράγμα μας,
- ii.
Η Τ.Μ. έχει μέση τιμή , όποτε η ανισότητα του Markov μάς δίνει,
το οποίο είναι προφανώς εξαιρετικά ασθενέστερο.
- iii.
Τέλος, η ζητούμενη πιθανότητα μπορεί εύκολα να υπολογιστεί ακριβώς. Εφόσον το , γνωρίζουμε από το Θεώρημα 11.1 πως,
Προφανώς, λοιπόν, και πάλι το φράγμα του Chernoff μάς δίνει ένα αποτέλεσμα πολύ πιο ισχυρό και πιο κοντά στην πραγματική τιμή από ό,τι η ανισότητα του Markov.
- i.
- 9.
-
10.
Συνάρτηση μιας εκθετικής Τ.Μ. Εφόσον η έχει σύνολο τιμών το , η προφανώς έχει σύνολο τιμών το . Αν, τώρα, και είναι η συνάρτηση κατανομής και η πυκνότητα του αντίστοιχα, και , είναι η συνάρτηση κατανομής και η πυκνότητα του αντίστοιχα, τότε για έχουμε , ενώ για ,
οπότε,
Άρα η πυκνότητα της θα είναι,
-
11.
Ανισότητα Markov. Ξεκινώντας από τον ορισμό της μέσης τιμής,
Εφόσον όλες οι τιμές στο πρώτο ολοκλήρωμα είναι μεγαλύτερες ή ίσες του μηδενός, το ολοκλήρωμα είναι κι αυτό μεγαλύτερο ή ίσο του μηδενός, συνεπώς,
όπου χρησιμοποιήσαμε το γεγονός ότι στο πρώτο από τα παραπάνω ολοκληρώματα όλα τα εκεί είναι μεγαλύτερα ή ίσα του . Παρατηρώντας, τέλος, πως από τον ορισμό της πυκνότητας το τελευταίο από τα παραπάνω ολοκληρώματα ισούται με , έχουμε,
που είναι η ζητούμενη ανισότητα.
-
12.
Ανισότητα Chebychev. Η απόδειξη της ανισότητας Chebychev στη συνεχή περίπτωση είναι ακριβώς η ίδια με την απόδειξη του αντίστοιχου αποτελέσματος για μια διακριτή Τ.Μ. στο Θεώρημα 9.2, με τη μόνη διαφορά ότι, αντί για τη διακριτή ανισότητα Markov στο Θεώρημα 9.1, επικαλούμαστε το ανάλογο συνεχές αποτέλεσμα, δηλαδή την ανισότητα Markov του Θεωρήματος 11.3.
-
13.
Πόσο ακριβής είναι η ανισότητα Chebychev; Αν η είναι ομοιόμορφα κατανεμημένη στο , τότε και Άρα η ανισότητα Chebychev μας δίνει,
ενώ στην πραγματικότητα η παραπάνω πιθανότητα είναι,
όπως προκύπτει απλά ολοκληρώνοντας την πυκνότητα της . Παρατηρούμε ότι, καθώς αυξάνει to , το φράγμα τείνει στο σχετικά αργά, ενώ στην πραγματικότητα η πιθανότητα γίνεται ακριβώς για .
-
14.
Απόδειξη του Ν.Μ.Α. Στη συνεχή περίπτωση η απόδειξη του Ν.Μ.Α. είναι ακριβώς η ίδια με την απόδειξη του αντίστοιχου αποτελέσματος για διακριτές Τ.Μ. στο Θεώρημα 9.3, με τις ακόλουθες διαφορές:
- –
- –
- –
- –
-
15.
Συνεχείς και διακριτές Τ.Μ. Θυμίζουμε πως στην Άσκηση 10 του Κεφαλαίου 10 δείξαμε ότι και επίσης υπολογίσαμε πως,
Εφόσον , έχουμε ότι,
άρα οι και δεν είναι ανεξάρτητες.
Ο λόγος είναι απλός: Δεδομένης της τιμής της , όταν δηλαδή γνωρίζουμε την κατανομή των , τότε είναι πράγματι ανεξάρτητες. Αλλά όταν δεν ξέρουμε το , τότε βλέποντας την τιμή της αποκτάμε κάποια ένδειξη για το και άρα και για τις πιθανές τιμές της . Π.χ., αν η , ξέρουμε σίγουρα ότι το και ξέρουμε με βεβαιότητα την κατανομή της . Ενώ αν η , έχουμε πολύ μεγαλύτερη αβεβαιότητα για την κατανομή της .
-
16.
Άλλος ένας γραμμικός μετασχηματισμός. Έστω και οι συναρτήσεις κατανομής των και αντίστοιχα. Παρατηρούμε πως, από τον ορισμό της ,
Όμως, η είναι η:
Ακολούθως, παίρνουμε περιπτώσεις:
Αν το , τότε και άρα Αν το , τότε οπότε . Τέλος, αν , τότε και επομένως . Συνεπώς,
δηλαδή η έχει ομοιόμορφη κατανομή στο διάστημα .
-
17.
Συνδιακύμανση και συσχέτιση.
-
(α’)
Αν εφαρμόσουμε την ανισότητα Cauchy-Schwarz της Πρότασης 11.1 στις τυχαίες μεταβλητές και , βρίσκουμε πως,
ή, ισοδύναμα, αντικαθιστώντας τους ορισμούς της συνδιακύμανσης και της διασποράς,
(A.16) το οποίο προφανώς συνεπάγεται και το ζητούμενο αποτέλεσμα.
-
(β’)
Επιπλέον, αν για κάποια Τ.Μ. με μη μηδενική διασπορά θέσουμε , τότε και,
οπότε έχουμε,
Παρομοίως, αν θέσουμε , θα έχουμε .
-
(α’)
A.12 Ασκήσεις Κεφαλαίου 12
[Επιστροφή στα περιεχόμενα]
-
1.
Τυχαία επιλογή Τ.Μ. Ορίζουμε την Τ.Μ. η οποία παίρνει την τιμή αν φέρουμε κορώνα και την τιμή αν φέρουμε Γράμματα. Επιπλέον, έστω η τιμή που καταγράψαμε. Χρησιμοποιώντας τον κανόνα του Bayes, ή επαναλαμβάνοντας τα ίδια βήματα, η ζητούμενη πιθανότητα ισούται με:
όπου στο βήμα χρησιμοποιήσαμε την ανεξαρτησία των Τ.Μ. , στο τέλος εφαρμόσαμε τη γενική μέθοδο υπολογισμού πιθανοτήτων για την κανονική κατανομή που είδαμε στην Ενότητα 12.1, και αντικαταστήσαμε την τιμή από τον Πίνακα 12.2.
-
2.
Ύψη μαθητών. Ορίζουμε τις Τ.Μ.,
έτσι ώστε και . Επίσης ορίζουμε τα σχετικά ενδεχόμενα «Ο μαθητής είναι αγόρι» και «ο μαθητής είναι πάνω από ». Τότε, από τον κανόνα συνολικής πιθανότητας,
και, χρησιμοποιώντας τη γενική μέθοδο υπολογισμού πιθανοτήτων για την κανονική κατανομή που είδαμε στην Ενότητα 12.1, έχουμε,
όπου η Τ.Μ. και αντικαταστήσαμε τις σχετικές τιμές της από τον Πίνακα 12.2.
-
3.
Αριθμητικοί υπολογισμοί με την κανονική κατανομή. Σε πολλά από τα παρακάτω ερωτήματα θα χρησιμοποιήσουμε τη γενική μέθοδο υπολογισμού πιθανοτήτων για την κανονική κατανομή που είδαμε στην Ενότητα 12.1. Έστω .
- (α’)
-
(β’)
Παρομοίως έχουμε,
και,
-
(γ’)
Όπως και στο προηγούμενο ερώτημα,
-
(δ’)
Εδώ έχουμε,
και,
οπότε,
-
(ε’)
Εφόσον για οποιαδήποτε Τ.Μ. έχουμε ,
και για τη έχουμε,
όπου είναι μια Τ.Μ. με κατανομή . Αν συμβολίσουμε την πυκνότητα της με ,
και παρατηρούμε ότι έχουμε το ολοκλήρωμα από το ως το της περιττής συνάρτησης [δηλαδή η ικανοποιεί ], άρα το ολοκλήρωμα ισούται με μηδέν!
-
(στ’)
Κατ’ αρχάς έχουμε,
και από τον Πίνακα 12.2 βρίσκουμε πως η τιμή για την οποία το είναι όσο το δυνατόν πιο κοντά στο 1/3, είναι το . Άρα για να ισχύει η ζητούμενη σχέση πρέπει να έχουμε, , δηλαδή,
-
4.
Τετράγωνο κανονικής Τ.Μ. Υπολογίζουμε πρώτα τη συνάρτηση κατανομής. Για την περίπτωση , προφανώς , ενώ για ,
όπου η Τ.Μ. , άρα τελικά,
(A.17) Τώρα η πυκνότητα μπορεί εύκολα να υπολογιστεί παίρνοντας παραγώγους. Για έχουμε , ενώ για ,
όπου χρησιμοποιήσαμε τη βασική ιδιότητα της πυκνότητας ως παράγωγο της συνάρτησης κατανομής, δηλαδή για την τυπική κανονική κατανομή, και τον τύπο της πυκνότητας . Τελικά, λοιπόν, προκύπτει ότι,
(A.18) -
5.
Η κατανομή
-
(α’)
Έστω η πυκνότητα της για την οποία, όπως παρατηρήσαμε στην απόδειξη του Θεωρήματος 12.1, ισχύει ότι . Για τη ζητούμενη μέση τιμή, ολοκληρώνοντας κατά παράγοντες βρίσκουμε,
όπου θέσαμε και , έτσι ώστε και . Και συνεχίζοντας τον παραπάνω υπολογισμό, έχουμε,
-
(β’)
Χρησιμοποιώντας το γεγονός ότι για κάθε και εφαρμόζοντας το Θεώρημα 11.5, η μέση τιμή της είναι,
- (γ’)
-
(α’)
-
6.
Λογαριθμοκανονική κατανομή. Και πάλι θα ξεκινήσουμε από τη συνάρτηση κατανομής. Προφανώς για έχουμε , ενώ για ,
Και παίρνοντας παραγώγους βρίσκουμε ότι, για ,
ενώ προφανώς έχουμε όταν .
Με αντικατάσταση της κανονικής συνάρτησης κατανομής και πυκνότητας στις παραπάνω εκφράσεις, προκύπτει ότι,
Παρατηρήστε ότι η πυκνότητα καθώς το .
-
7.
Γραμμικός μετασχηματισμός. Έστω ότι η έχει κατανομή με πυκνότητα . Ο ευκολότερος τρόπος να βρούμε την κατανομή της είναι παρατηρώντας, από το Θεώρημα 11.2 και την Άσκηση 6 του Κεφαλαίου 11, ότι (για ), η πυκνότητα της είναι,
την οποία αναγνωρίζουμε φυσικά ως την πυκνότητα της κατανομής .
Η περίπτωση είναι, προφανώς, τετριμμένη. (Γιατί;)
-
8.
Όλα στο 13! Κατ’ αρχάς ορίζουμε τις εξής Τ.Μ.:
-
(α’)
Η παίρνει τις τιμές και , με αντίστοιχες πιθανότητες και , άρα,
Η ισούται με το άθροισμα των , όπου η κάθε παίρνει τις τιμές και με αντίστοιχες πιθανότητες και , οπότε,
συνεπώς η μέση τιμή της είναι,
η οποία είναι ακριβώς ίδια με την .
-
(β’)
Παρομοίως υπολογίζουμε και τις αντίστοιχες διασπορές. Για τον πρώτο παίκτη,
Για κάθε γύρο του παιχνιδιού του δεύτερου παίκτη έχουμε,
και επειδή τα διαδοχικά του παιχνίδια είναι ανεξάρτητα,
Παρατηρούμε πως, παρότι οι δύο παίκτες έχουν το ίδιο αναμενόμενο κέρδος, η διασπορά των χρημάτων του πρώτου παίκτη είναι φορές μεγαλύτερη από του δεύτερου! Αυτό είναι αναμενόμενο, μια και ο πρώτος παίκτης ή τα χάνει όλα ή έχει τεράστιο κέρδος, ενώ για τον δεύτερό υπάρχουν και πολλά «ενδιάμεσα» ενδεχόμενα.
-
(γ’)
H παίρνει μόνο τιμές, με πιθανότητα , και με πιθανότητα . Επομένως,
Η , από την άλλη, ισούται με το άθροισμα ανεξάρτητων τυχαίων μεταβλητών με ίδια κατανομή, άρα μπορούμε να προσεγγίσουμε την κατανομή της με βάση το Κ.Ο.Θ. Κατ’ αρχάς έχουμε,
και σημειώνοντας πως πιο πάνω βρήκαμε για τις Τ.Μ. ότι και , κανονικοποιώντας το πιο πάνω άθροισμα και χρησιμοποιώντας το Κ.Ο.Θ.:
Άρα, ο πρώτος παίκτης που τα ποντάρει όλα μαζί σε ένα παιχνίδι είναι πολύ πιο απίθανο να βγει «λίγο χαμένος», κατά μόνο 20 ευρώ, από τον πιο συντηρητικό δεύτερο παίκτη, ο οποίος ποντάρει σιγά σιγά και γι’ αυτόν τον λόγο τα χρήματά του έχουν μικρότερες τυχαίες διακυμάνσεις.
-
(α’)
-
9.
Κόκκινο-μαύρο. Έστω ανεξάρτητες Τ.Μ. όπου η κάθε ισούται με με πιθανότητα 16/33, ή με με πιθανότητα 17/33. Έτσι, αν ορίσουμε την Τ.Μ. , η περιγράφει το κέρδος του παίκτη μετά από γύρους, και ο παίκτης τελικά δεν θα έχει βγει χαμένος αν .
Θα προσεγγίσουμε την κατανομή του μέσω του Κ.Ο.Θ., οπότε θα χρειαστούμε τη μέση τιμή και τη διασπορά των ,
όπου χρησιμοποιήσαμε το γεγονός ότι πάντοτε . Τώρα μπορούμε εύκολα να εφαρμόσουμε το Κ.Ο.Θ. με , για να υπολογίσουμε τη ζητούμενη πιθανότητα,
όπου είναι ο εμπειρικός μέσος όρος των , και όπως έχουμε εξηγήσει, επειδή η Τ.Μ. παίρνει μόνο ακέραιες τιμές, προσθέσαμε ένα επιπλέον 1/2. Συνεχίζοντας τον παραπάνω υπολογισμό, η ισούται με,
άρα τελικά από το Κ.Ο.Θ. παίρνουμε την προσέγγιση,
-
10.
Online game.
-
(α’)
Από τον ορισμό και τις απλές ιδιότητες της μέσης τιμής και της διασποράς, εύκολα βρίσκουμε ότι:
-
(β’)
Έστω ανεξάρτητες Τ.Μ. , όπου η κάθε ισούται με τις μονάδες ζωής που αφαιρεί η βολή και έχει την ίδια κατανομή με την του προηγούμενου σκέλους. Θέλουμε να υπολογίσουμε την πιθανότητα το άθροισμα όλων των να ξεπερνάει το 1700. Θα την προσεγγίσουμε χρησιμοποιώντας το Κ.Ο.Θ.: Εφόσον οι έχουν μέση τιμή και τυπική απόκλιση ,
-
(α’)
-
11.
Χαμένος χρόνος. Έστω ανεξάρτητες Τ.Μ. όπου η κάθε έχει κατανομή, και περιγράφει πόσα λεπτά περίμενα το λεωφορείο τη μέρα Αν ορίσουμε την Τ.Μ. , τότε η περιγράφει συνολικά πόσο χρόνο περίμενα το λεωφορείο (σε λεπτά) σε ένα χρόνο. Μας ενδιαφέρει η πιθανότητα το να είναι μεγαλύτερο από λεπτά.
Εφόσον η κάθε έχει γνωστή μέση τιμή και τυπική απόκλιση , χρησιμοποιώντας για ακόμα μια φορά το Κ.Ο.Θ.:
-
12.
Ζυγοβίστι Αρκαδίας.
-
(α’)
Παρατηρούμε ότι η έχει ομοιόμορφη κατανομή στο διάστημα , επομένως, από τις γνωστές ιδιότητες της ομοιόμορφης κατανομής, έχουμε:
-
(β’)
Από το Θεώρημα 11.5 απλώς έχουμε,
-
(γ’)
Θα χρησιμοποιήσουμε το Κ.Ο.Θ. Έστω , , η βροχόπτωση για κάθε ένα από τα χρόνια. Η πιθανότητα να πετύχει η δενδροφύτευση ισούται με:
-
(α’)
-
13.
Αποσυγχρονισμός. Για κάθε , έστω η Τ.Μ. που περιγράφει κατά πόσα δέκατα του δευτερολέπτου αποσυγχρονίστηκε το βίντεο τη φορά που το μετακίνησα. Ξέρουμε ότι οι Τ.Μ. είναι ανεξάρτητες, και από την Άσκηση 8 του Κεφαλαίου 10 επίσης γνωρίζουμε ότι έχουν μέση τιμή και διασπορά .
Μας ενδιαφέρει η πιθανότητα το άθροισμα των να ξεπερνά σε απόλυτη τιμή το ένα δευτερόλεπτο. Χρησιμοποιώντας το Κ.Ο.Θ. μπορούμε εύκολα να την εκτιμήσουμε ως,
-
14.
Τηλεφωνικές κλήσεις. Έστω μια Τ.Μ. . Η πιθανότητα μια κλήση να είναι σύντομη είναι,
Έστω, τώρα, ανεξάρτητες Τ.Μ. , όπου η κάθε αν η κλήση είναι σύντομη. Η ζητούμενη πιθανότητα είναι,
όπου είναι η μέση τιμή των , είναι το πλήθος τους, και αφαιρέσαμε 1/2 με ακριβώς το ίδιο σκεπτικό όπως στο Παράδειγμα 12.5 και το Πόρισμα 12.1. Εφόσον τα έχουν διασπορά , χρησιμοποιώντας το Κ.Ο.Θ. η παραπάνω πιθανότητα μπορεί να εκφραστεί ως,
-
15.
Εκτίμηση με θόρυβο.
-
(α’)
Εφαρμόζοντας όπως και στις προηγούμενες περιπτώσεις το Κ.Ο.Θ., για οποιοδήποτε μέγεθος δείγματος έχουμε ότι η πιθανότητα που μας ενδιαφέρει μπορεί να προσεγγιστεί ως,
όπου η , και χρησιμοποιήσαμε το γεγονός ότι η πυκνότητα της τυπικής κανονικής κατανομής είναι συμμετρική γύρω από το μηδέν, και άρα, για οποιοδήποτε , .
Για να ισούται αυτή η πιθανότητα με 0.95, θα πρέπει να έχουμε , δηλαδή , το οποίο, από τους πίνακες τιμών της , συμβαίνει για , δηλαδή για .
-
(β’)
Όπως στη λύση της Άσκησης 13 του Κεφαλαίου 9, ορίζουμε τις νέες (ανεξάρτητες) Τ.Μ. , για , και εκτιμούμε το μέσω του εμπειρικού μέσου όρου,
Όπως είδαμε εκεί, ο εμπειρικός μέσος όρος πράγματι συγκλίνει κατά πιθανότητα στη ζητούμενη τιμή .
Για να επιλέξουμε το μέγεθος του δείγματος , κατ’ αρχάς εύκολα υπολογίζουμε,
όπου χρησιμοποιήσαμε τις βασικές ιδιότητες της μέσης τιμής και της διασποράς. Οπότε, τώρα μπορούμε να επαναλάβουμε ακριβώς τα ίδια βήματα όπως στο προηγούμενο ερώτημα, αντικαθιστώντας το με το , και το κανονικοποιημένο άθροισμα με το αντίστοιχο,
Έτσι, παρομοίως βρίσκουμε,
Και πάλι, για να είναι η πιθανότητα αυτή κατά προσέγγιση ίση με , θα πρέπει να έχουμε , το οποίο, από τους πίνακες τιμών της , συμβαίνει για , δηλαδή για .
Παρατηρούμε πως, αφού τετραπλασιάστηκε η διασπορά των δειγμάτων μας (αρχικά ενώ ), επίσης τετραπλασιάστηκε και το απαιτούμενο μέγεθος του δείγματος ώστε η εκτίμησή μας να διατηρήσει την ίδια ακρίβεια.
-
(α’)
A.13 Ασκήσεις Κεφαλαίου 13
[Επιστροφή στα περιεχόμενα]
-
1.
Σύγκλιση κατά πιθανότητα σύγκλιση κατά κατανομή. Για κάθε , συμβολίζουμε με τη συνάρτηση κατανομής της και αντίστοιχα με τη συνάρτηση κατανομής της . Έστω ένα οποιοδήποτε στο οποίο η είναι συνεχής. Θα δείξουμε το ζητούμενο αποτέλεσμα σε δύο βήματα.
Πρώτα, για οποιοδήποτε και κάθε , έχουμε,
όπου στο βήμα χρησιμοποιήσαμε τον κανόνα συνολικής πιθανότητας, στο το προφανές γεγονός ότι η τομή δύο ενδεχομένων είναι υποσύνολο του καθενός από τα δύο, σε συνδυασμό με τον δεύτερο κανόνα πιθανότητας, και στο πάλι εφαρμόσαμε τον δεύτερο κανόνα πιθανότητας, αφού, για οποιοδήποτε με , .
Τώρα, παίρνοντας το όριο στην παραπάνω ανισότητα, εφόσον από την υπόθεση ότι τα συγκλίνουν κατά πιθανότητα, έχουμε ότι για κάθε :
Και παίρνοντας το όριο , από τη συνέχεια της στο συμπεραίνουμε πως,
(A.19) Παρομοίως, για οποιοδήποτε και κάθε , προς την αντίθετη κατεύθυνση έχουμε,
όπου το βήμα προκύπτει από τον δεύτερο κανόνα πιθανότητας, αφού, για οποιοδήποτε με , . Παίρνοντας το όριο , αμέσως προκύπτει πως,
για κάθε , και παίρνοντας τώρα το όριο , από τη συνέχεια της στο , έχουμε,
(A.20) Ο συνδυασμός των (A.19) και (A.20) συνεπάγεται πως , και άρα οι συγκλίνουν στη κατά κατανομή.
-
2.
Σύγκλιση κατά κατανομή σύγκλιση κατά πιθανότητα. Θα ξεκινήσουμε αποδεικνύοντας το (γ’). Έχουμε, για αυθαίρετο ,
το οποίο όχι απλώς τείνει στο 1, αλλά είναι ίσο με 1 για κάθε . Συνεπώς οι τείνουν στην κατά πιθανότητα, αποδεικνύοντας το ζητούμενο του (γ’). Αυτό, σε συνδυασμό με το αποτέλεσμα της προηγούμενης άσκησης, επίσης συνεπάγεται ότι οι τείνουν στην κατά κατανομή, αποδεικνύοντας το (α’).
Για το (β’), παρατηρούμε πως η συνάρτηση κατανομής της είναι η
και πως η κάθε παίρνει τέσσερις δυνατές τιμές, τις με πιθανότητα 1/4 για την καθεμία, συνεπώς η συνάρτηση κατανομής της είναι,
Θα δείξουμε, για κάθε στο οποίο η είναι συνεχής, δηλαδή για κάθε πραγματικό , ότι καθώς . Για , η σύγκλιση είναι προφανής και τετριμμένη αφού για κάθε . Όταν , για όλα τα που είναι αρκετά μεγάλα ώστε να έχουμε , , η οποία προφανώς συγκλίνει στην . Τέλος, όταν το , για κάθε έχουμε . Άρα έχουμε αποδείξει ότι καθώς , για όλα τα , συνεπώς οι συγκλίνουν στη κατά κατανομή, αποδεικνύοντας το (β’).
Για να αποδείξουμε το (δ’), παρατηρούμε ότι η Τ.Μ. παίρνει τέσσερις δυνατές τιμές, τις με πιθανότητα 1/4 για την καθεμία. Συνεπώς, για οποιοδήποτε και για κάθε , η πιθανότητα,
το οποίο φυσικά δεν τείνει στο 1, άρα οι δεν τείνουν στη κατά πιθανότητα.
-
3.
Σύγκλιση κατά κατανομή και κατά πιθανότητα σε σταθερά. Έστω η συνάρτηση κατανομής της , για κάθε . Η σταθερά , ως τυχαία μεταβλητή, έχει συνάρτηση κατανομής,
Εφόσον οι τείνουν στην κατά κατανομή, έχουμε ότι για κάθε ,
Για να αποδείξουμε ότι η σύγκλιση ισχύει και κατά πιθανότητα, παρατηρούμε ότι, για αυθαίρετο ,
όπου η ανισότητα προκύπτει από τον δεύτερο κανόνα πιθανότητας. Εφόσον, τώρα, καθώς το ,
συμπεραίνουμε πως και οι πιθανότητες , άρα οι συγκλίνουν στην και κατά πιθανότητα.
-
4.
Η ουρά της μέσης τιμής μιας συνεχούς Τ.Μ. Έστω πως η Τ.Μ. έχει πυκνότητα και σύνολο τιμών κάποιο . Η απόδειξη σε αυτή την περίπτωση είναι απολύτως ανάλογη με εκείνη που είδαμε στην Άσκηση 3 του Κεφαλαίου 7 για διακριτές Τ.Μ.
Εδώ, η μέση τιμή που μας ενδιαφέρει, από τον ορισμό της μέσης τιμής μιας συνάρτησης κάποιας Τ.Μ., είναι,
και παρατηρώντας πως αν και μόνο αν , έχουμε,
Αλλά, εφόσον μας δίνεται πως το καταχρηστικό ολοκλήρωμα είναι πεπερασμένο, απαραίτητα η «ουρά» του ολοκληρώματος θα τείνει στο μηδέν, δηλαδή,
καθώς το , που είναι ακριβώς το ζητούμενο αποτέλεσμα.
-
5.
Σύγκλιση ως προς την απόσταση Έστω πως οι αποστάσεις καθώς . Από το αποτέλεσμα της Άσκησης 18 του Κεφαλαίου 6, έχουμε πως, καθώς ,
το οποίο συνεπάγεται πως,
Αν η κάθε έχει συνάρτηση κατανομής , και η έχει συνάρτηση κατανομής , τότε, για οποιοδήποτε , χρησιμοποιώντας τη σύγκλιση όλων των τιμών των πυκνοτήτων , έχουμε, καθώς ,
το οποίο μας λέει ακριβώς ότι οι τείνουν στη κατά κατανομή.
-
6.
Σύγκλιση της διωνυμικής στην Poisson. Παρατηρούμε κατ’ αρχάς πως αρκεί να αποδείξουμε απευθείας το ερώτημα (β’). Έστω λοιπόν μια ακολουθία Τ.Μ. με αντίστοιχες πυκνότητες , συναρτήσεις κατανομής , και σύνολο τιμών . Και έστω μια άλλη Τ.Μ. με το ίδιο σύνολο τιμών , πυκνότητα και συνάρτηση κατανομής . Υποθέτουμε ότι οι συγκλίνουν στην όπως στην σχέση (13.25).
Για έχουμε, εξ ορισμού, , ενώ για οποιοδήποτε η μπορεί να εκφραστεί ως,
Αλλά από την (13.25) ξέρουμε πως ο κάθε όρος σε αυτό το πεπερασμένο άθροισμα τείνει, καθώς το , στο αντίστοιχο , και συνεπώς,
άρα οι τείνουν στη κατά κατανομή.
Παρατηρούμε, τέλος, πως σ’ αυτήν την περίπτωση η πιο πάνω σύγκλιση ισχύει για όλα τα , όχι μόνο για εκείνα στα οποία η είναι συνεχής.
A.14 Ασκήσεις Κεφαλαίου 14
[Επιστροφή στα περιεχόμενα]
-
1.
Διάρκειες τραγουδιών. Έστω οι διάρκειες των τραγουδιών στην έρευνα της εταιρίας, όπου υποθέτουμε ότι οι Τ.Μ. είναι ανεξάρτητες, με άγνωστο μέσο και τυπική απόκλιση λεπτά.
-
(α’)
Ακολουθούμε τη γενική μέθοδο της Ενότητας 14.1 στην περίπτωση γνωστής διασποράς. Έχοντας ήδη την τιμή του εμπειρικού μέσου , για το επίπεδο εμπιστοσύνης βρίσκουμε την τιμή του , και από τη σχέση (14.5) υπολογίζουμε το μέγεθος του στατιστικού σφάλματος λεπτά ή δευτερόλεπτα. Άρα, έχουμε το διάστημα εμπιστοσύνης με επίπεδο εμπιστοσύνης .
-
(β’)
Ακολουθώντας την ίδια μεθοδολογία, από τη σχέση (14.6) βρίσκουμε πως το ελάχιστο πλήθος δειγμάτων που απαιτούνται ώστε να έχουμε στατιστικό σφάλμα δευτερόλεπτα, δηλαδή λεπτά, είναι δείγματα.
-
(α’)
-
2.
Ελέφαντες. Έχουμε τον εμπειρικό μέσο των ανεξάρτητων Τ.Μ. , οι οποίες έχουν άγνωστη μέση τιμή και τυπική απόκλιση μεταξύ .
-
3.
Ναύτες. Έστω τα ύψη των ναυτών στο στρατόπεδο, και έστω το ύψος του ναύτη στην τυχαία επιλογή μας, για . Η κάθε έχει μέση τιμή,
και διασπορά,
Θέλουμε να εκτιμήσουμε τον άγνωστο μέσο , ενώ υποθέτουμε ότι η τυπική απόκλιση των είναι μεταξύ .
- (α’)
-
(β’)
Το διάστημα εμπιστοσύνης βασίζεται στο γεγονός ότι, από το Κ.Ο.Θ., γνωρίζουμε κατά προσέγγιση την κατανομή του εμπειρικού μέσου . Βάσει αυτής της προσέγγισης, υπολογίζουμε την πιθανότητα του διαστήματος εμπιστοσύνης:
Αυτή η πιθανότητα προφανώς δεν είναι η ίδια με το ποσοστό των ναυτών που έχουν ύψος εντός του διαστήματος εμπιστοσύνης, το οποίο ποσοστό ισούται με:
H διαφορά μεταξύ αυτών των δύο πιθανοτήτων μπορεί να παρατηρηθεί πιο ανάγλυφα στο εξής παράδειγμα. Έστω πως 500 ναύτες έχουν ύψος 1.60, 3000 έχουν ύψος 1.77 και 250 έχουν ύψος 1.94. Τότε το μέσο ύψος είναι,
και η διασπορά,
οπότε η τυπική απόκλιση . Αυτές οι τιμές συμφωνούν με τα δεδομένα του προβλήματος, και η εκτίμηση είναι επίσης απολύτως λογική. Αλλά παρότι έχουμε το 98%-διάστημα εμπιστοσύνης , βλέπουμε πως μόνο το 75% των ναυτών έχει ύψος εντός αυτού του διαστήματος.
-
(γ’)
Ακολουθώντας την ίδια γενική μέθοδο όπως στο πρώτο σκέλος, για το επίπεδο εμπιστοσύνης έχουμε , και το επιθυμητό στατιστικό σφάλμα είναι . Άρα, το μέγεθος του στατιστικού δείγματος που απαιτείται ώστε να έχουμε επίπεδο εμπιστοσύνης , από τη σχέση (14.8) είναι
-
(δ’)
Με δείγματα και στατιστικό σφάλμα , το μόνο που μπορούμε να μεταβάλουμε είναι το επίπεδο εμπιστοσύνης του διαστήματος . Επιστρέφοντας στη βασική σχέση (14.4), έχουμε,
όπου και πάλι λάβαμε υπόψη μας την χειρότερη δυνατή περίπτωση της τυπικής απόκλισης, και αντικαταστήσαμε την τιμή του από τον σχετικό πίνακα της Ενότητας 12.4. Λύνοντας ως προς βρίσκουμε , άρα το καλύτερο αποτέλεσμα που μπορούμε να δώσουμε στον Αρχιπλοίαρχο κ. Τζίφα είναι ότι το διάστημα έχει επίπεδο εμπιστοσύνης .
-
4.
Μια πιο ρεαλιστική δημοσκόπηση. Έστω ανεξάρτητες T.M., όπου το μέγεθος του δείγματος και θέλουμε να εκτιμήσουμε την παράμετρο .
-
(α’)
Η διασπορά των μάς είναι άγνωστη, αλλά παρατηρούμε ότι είναι μέγιστη στην περίπτωση , οπότε έχουμε ότι η τυπική απόκλιση .
Θα εφαρμόσουμε και εδώ τη γενική μέθοδο της Ενότητας 14.1 στην περίπτωση άγνωστης διασποράς. Έχοντας ήδη την εκτίμηση , για το επίπεδο εμπιστοσύνης βρίσκουμε , και από τη σχέση (14.7) υπολογίζουμε ότι το στατιστικό σφάλμα . Άρα, έχουμε -διάστημα εμπιστοσύνης όχι μεγαλύτερο από το 27.4% έως 33.6%.
Παρατηρήστε πως το αποτέλεσμα που υπολογίσαμε εδώ είναι ακριβώς ίδιο με αυτό που ανακοίνωσε η εταιρία alco βασισμένη στα ίδια δεδομένα!
-
(β’)
Υποθέτοντας τώρα ότι το είναι μεταξύ 0.2 και 0.35, η μέγιστη τιμή που μπορεί να πάρει η διασπορά αντιστοιχεί στο , οπότε έχουμε,
Επαναλαμβάνοντας τον υπολογισμό του προηγούμενου σκέλους με τη νέα τιμή , το στατιστικό σφάλμα είναι , και συνεπώς μπορούμε να δώσουμε ένα λίγο μικρότερο -διάστημα εμπιστοσύνης, το .
-
(α’)
-
5.
Εκτίμηση διασποράς.
-
(α’)
Εφόσον ορίσαμε το , χρησιμοποιώντας τις βασικές ιδιότητες της μέσης τιμής (Ιδιότητα 1 του Θεωρήματος 6.1 και Ιδιότητα 1 του Θεωρήματος 11.5) υπολογίζουμε,
το οποίο μας δίνει,
(A.21) Το παραπάνω διπλό άθροισμα έχει όρους, αυτούς που αντιστοιχούν στα ζεύγη , της μορφής,
(A.22)
όπου χρησιμοποιήσαμε την ανεξαρτησία των , την Ιδιότητα 3 του Θεωρήματος 6.1, την αντίστοιχη ιδιότητα για συνεχείς Τ.Μ. η οποία θα αποδειχθεί στο Θεώρημα 15.1 του Κεφαλαίου 15, και την εναλλακτική έκφραση για τη διασπορά από τις εκφράσεις (6.8) και (10.13). Εφαρμόζοντας πάλι τις ίδιες ιδιότητες, βρίσκουμε ότι οι υπόλοιποι όροι του διπλού αθροίσματος στην έκφραση (A.21), οι οποίοι αντιστοιχούν στα ζεύγη , είναι της μορφής,
(A.23) Οπότε, αντικαθιστώντας τα αποτελέσματα (A.22) και (A.23) στη σχέση (A.21), τελικά βρίσκουμε,
-
(β’)
Εδώ κατ’ αρχάς παρατηρούμε πως, λόγω της συμμετρίας του προβλήματος, το αποτέλεσμα του προηγούμενου σκέλους παραμένει το ίδιο με οποιαδήποτε Τ.Μ. στη θέση της , δηλαδή,
για κάθε . Χρησιμοποιώντας αυτή την έκφραση (και εφαρμόζοντας και πάλι την Ιδιότητα 1 του Θεωρήματος 6.1 και την αντίστοιχη Ιδιότητα 1 του Θεωρήματος 11.5), έχουμε,
και παρομοίως,
-
(γ’)
Ο ορισμός της είναι εκ πρώτης όψεως πιο φυσικός, υπό την έννοια ότι βασίζεται στον εμπειρικό μέσο όρο των οπότε αντιστοιχεί ακριβώς στον ορισμό της διασποράς.
Από την άλλη μεριά, η έχει την επιθυμητή ιδιότητα η μέση τιμή της να είναι ίση με τη ζητούμενη ποσότητα . Τέτοιου είδους εκτιμήτριες ονομάζονται «αμερόληπτες» και παίζουν σημαντικό ρόλο στην κλασική στατιστική.
-
(α’)
-
6.
Τυχαίο; Νομίζω. Εδώ έχουμε ένα παράδειγμα ελέγχου υπόθεσης παραμέτρου Bernoulli όπως στην Ενότητα 14.2.1, με που είναι η πιθανότητα να έρθουν διπλές σε μία ζαριά. Ακολουθώντας την εκεί γενική μεθοδολογία, υπολογίζουμε τον εμπειρικό μέσο όρο των παρατηρήσεων και, για να είμαστε αρκετά επιεικείς, επιλέγουμε το επίπεδο σημαντικότητας . Η τιμή της στατιστικής συνάρτησης εδώ ισούται με , και για την -τιμή από τους πίνακες του Κεφαλαίου 12 βρίσκουμε ότι ισούται με Εφόσον η -τιμή είναι μεγαλύτερη του , απαντάμε στο φίλο μας ότι, βάσει της επίδοσής του, δεν μπορούμε να απορρίψουμε την υπόθεση ότι η τύχη του είναι ίδια με την τύχη όλων μας, σε επίπεδο σημαντικότητας !
-
7.
Στυτική δυσλειτουργία. Το πρόβλημα είναι της ίδιας ακριβώς μορφής με αυτό του Παραδείγματος 14.10. Με για το συνολικό πλήθος των ασθενών, ή 0 ανάλογα με το αν ο ασθενής αντιμετώπισε ή όχι στυτικά προβλήματα, και ή 0 αν πήρε το φάρμακο ή το placebo αντίστοιχα, για τις εμπειρικές κατανομές έχουμε,
από τις οποίες βρίσκουμε ότι την τιμή της στατιστικής συνάρτησης ισούται με,
δηλαδή . Άρα η αντίστοιχη -τιμή είναι , και συμπεραίνουμε ότι δεν μπορούμε να απορρίψουμε τη μηδενική υπόθεση (δηλαδή το ενδεχόμενο τα προβλήματα που παρουσιάστηκαν στους ασθενείς να είναι ανεξάρτητα του φαρμάκου) με επίπεδο εμπιστοσύνης .
-
8.
Γιωργάκη, θα πουντιάσεις!
-
(α’)
Από την περιγραφή του προβλήματος έχουμε πως οι προήλθαν από μια ακολουθία ανεξάρτητων Τ.Μ. Επιπλέον θεωρούμε πως, για κάθε , δεδομένης της τιμής του , η αντίστοιχη έχει κατανομή με αυθαίρετη πυκνότητα ή όταν η ισούται με 0 ή 1 αντίστοιχα.
-
(β’)
Αν συμβολίσουμε τις τιμές των δύο παραπάνω πυκνοτήτων , , , και , , , τότε το μοντέλο έχει παραμέτρους τις τιμές και , οι οποίες όλες ανήκουν στο και ικανοποιούν τους περιορισμούς και . Η μηδενική υπόθεση , η οποία περιγράφει την περίπτωση ανεξαρτησίας των από τα , αντιστοιχεί στη συνθήκη και . Για την εναλλακτική υπόθεση έχουμε ότι οι τιμές είναι αυθαίρετες.
-
(γ’)
Όπως στην πιο απλή περίπτωση του ελέγχου ανεξαρτησίας στην Ενότητα 14.2.2, προκειμένου να απαντήσουμε στο αν οι και οι είναι ανεξάρτητες, θα συγκρίνουμε την εμπειρική κατανομή των δεδομένων με την κατανομή που θα είχαν αν τα και τα ήταν ανεξάρτητα. Στη γενικότερη αυτή περίπτωση ορίζουμε τις εμπειρικές πυκνότητες,
για κάθε και . Και τώρα μπορούμε να ορίσουμε τη στατιστική συνάρτηση ως φορές την -απόσταση μεταξύ της από κοινού εμπειρικής πυκνότητας και της από κοινού πυκνότητας που θα είχαν τα αν ήταν ανεξάρτητα:
-
(δ’)
Μας δίνεται πως, κάτω από τη μηδενική υπόθεση , η στατιστική συνάρτηση, συγκλίνει κατά κατανομή στη καθώς Επιπλέον, από το αποτέλεσμα της Άσκηση2 2 του Κεφαλαίου 15 έχουμε ότι η κατανομή είναι η , οπότε, καθώς ,
Βάσει αυτού, προτείνουμε την εξής μέθοδο -ελέγχου ανεξαρτησίας για το εδώ σενάριο:
- i.
Από τα δεδομένα , υπολογίζουμε τις εμπειρικές πυκνότητες και , και την τιμή της στατιστικής συνάρτησης όπως ορίστηκαν παραπάνω.
- ii.
Επιλέγουμε το επιθυμητό επίπεδο σημαντικότητας .
- iii.
Υπολογίζουμε την -τιμή, δηλαδή την πιθανότητα, κάτω από τη μηδενική υπόθεση , η να είναι τόση ή μεγαλύτερη από την τιμή που υπολογίσαμε. Από το παραπάνω αποτέλεσμα:
- iv.
Αν η -τιμή , η απορρίπτεται σε επίπεδο σημαντικότητας .
Αν η -τιμή , η δεν απορρίπτεται σε επίπεδο σημαντικότητας .
- i.
-
(ε’)
Από τον πίνακα της εκφώνησης εύκολα υπολογίζουμε τις τιμές της από κοινού εμπειρικής πυκνότητας:
Απο κοινου εμπειρικη
κατανομη 0 +1 6/173 65/173 8/173 13/173 71/173 10/173 Και για τις εμπειρικές κατανομές των και αντίστοιχα έχουμε:
Αντικαθιστώντας αυτές τις τιμές στον ορισμό της , η τιμή της στατιστικής συνάρτησης εδώ είναι,
που μας δίνει , οπότε για την -τιμή βρίσκουμε . Για ακόμα μια φορά, λοιπόν, η Ελληνίδα μάνα διαψεύδεται!
-
(α’)
-
9.
Μεταβλητές ελέγχου. Η άσκηση είναι καθαρά προγραμματιστική. Στα Σχήματα 1.37 και 1.38 δίνουμε δύο ακόμα αποτελέσματα προσομοίωσης για καθένα από τα δύο προβλήματα.
Σχήμα 1.37: Οι τιμές των εκτιμητριών (έντονη γραμμή) και (απλή γραμμή), σε δύο ακόμα πειράματα προσομοίωσης για τον υπολογισμό ενός ολοκληρώματος όπως στο Παράδειγμα 14.12. Παρατηρούμε ότι η προσαρμοστική εκτιμήτρια είναι σημαντικά αποτελεσματικότερη από τον εμπειρικό μέσο 
Σχήμα 1.38: Οι τιμές των εκτιμητριών (έντονη γραμμή) και (απλή γραμμή), σε δύο ακόμα πειράματα προσομοίωσης για το πρόβλημα τιμολόγησης ενός παραγώγου όπως στο Παράδειγμα 14.13. Και εδώ βλέπουμε ότι η προσαρμοστική εκτιμήτρια είναι σημαντικά αποτελεσματικότερη από τον εμπειρικό μέσο -
10.
Διαφορετική μεταβλητή ελέγχου. Η μεθοδολογία που ακολουθούμε είναι ακριβώς ίδια με του Παραδείγματος 14.12, όπου χρησιμοποιούμε τους γενικούς τύπους (14.14), (14.15) και (14.16) για τον ορισμό της προσαρμοστικής εκτιμήτριας , με τη μόνη διαφορά ότι τώρα έχουμε και (γιατί;).
Στο Σχήμα 1.39 δίνονται τα αποτελέσματα τεσσάρων πειραμάτων για τις τρεις εκτιμήτριες , με , και με . Είναι εμφανές ότι η προσαρμοστική εκτιμήτρια με την μεταβλητή ελέγχου είναι πιο αποτελεσματική από τον εμπειρικό μέσο, αλλά δεν συγκλίνει τόσο γρήγορα όσο στην περίπτωση της .
Σχήμα 1.39: Αποτελέσματα πειραμάτων προσομοίωσης του προβλήματος στο Παράδειγμα 14.12 με δείγματα. Η τιμές του εμπειρικού μέσου εμφανίζονται ως μια απλή γραμμή, της προσαρμοστικής εκτιμήτριας με μεταβλητή ελέγχου την αναπαρίστανται ως έντονες κουκκίδες, και της με μεταβλητή ελέγχου την ως Για λόγους ευκρίνειας, οι τιμές των δύο τελευταίων εκτιμητριών σχεδιάστηκαν μόνο κάθε 100 βήματα. -
11.
Προεξοφλημένη τιμή μετοχής. Για τη ζητούμενη μέση τιμή, από τη σχέση (14.18) έχουμε,
(A.24)
όπου η έχει τυπική κανονική κατανομή με πυκνότητα . Οπότε η τελευταία μέση τιμή παραπάνω ισούται με,
όπου αναγνωρίζουμε το τελευταίο παραπάνω ολοκλήρωμα ως το ολοκλήρωμα της πυκνότητας της κατανομής σε όλο το , το οποίο φυσικά ισούται με 1. Συνεπώς,
και αντικαθιστώντας αυτή την έκφραση στη (A.24) προκύπτει ακριβώς το ζητούμενο αποτέλεσμα.
A.15 Ασκήσεις Κεφαλαίου 15
[Επιστροφή στα περιεχόμενα]
-
1.
Παραδείγματα ανεξαρτησίας.
-
(α’)
Οι Τ.Μ. του Παραδείγματος 15.1 έχουν από κοινού πυκνότητα για και για . Από την τέταρτη βασική ιδιότητα της από κοινού πυκνότητας εύκολα υπολογίζουμε πως η περιθώρια πυκνότητα του είναι,
και παρομοίως ότι η είναι της ίδιας ακριβώς μορφής, δηλαδή πως όταν και όταν όχι. Είναι προφανές από τις παραπάνω εκφράσεις ότι έχουμε για κάθε , άρα από το κριτήριο (15.7) προκύπτει ότι οι και είναι ανεξάρτητες Τ.Μ. Επιπλέον παρατηρούμε ότι και οι δύο έχουν κατανομή .
-
(β’)
Εδώ μπορούμε εύκολα να δείξουμε ότι οι Τ.Μ. του Παραδείγματος 15.2 δεν είναι ανεξάρτητες, χωρίς να χρειαστεί να κάνουμε λεπτομερείς υπολογισμούς. Από την τέταρτη ιδιότητα της από κοινού πυκνότητας και τον ορισμό της , αμέσως βλέπουμε πως οι περιθώριες πυκνότητες και παίρνουν αυστηρά θετικές τιμές για όλα τα , οπότε και οι πιθανότητες,
είναι θετικές. Αλλά το ορθογώνιο είναι ξένο ως προς το σύνολο τιμών του ζευγαριού , άρα η πιθανότητα,
και συνεπώς δεν ισούται με το γινόμενο των και . Οπότε από τον ορισμό (15.6), οι δεν είναι ανεξάρτητες.
-
(α’)
-
2.
Περισσότερα για την κατανομή Όπως στην Άσκηση 5 του Κεφαλαίου 12, για τις ανεξάρτητες Τ.Μ. όπου κάθε , ορίζουμε την τυχαία μεταβλητή Επίσης θυμίζουμε πως, εκεί, δείξαμε ότι η μέση τιμή της κατανομής είναι , και ότι για κάθε .
- (α’)
-
(β’)
Για , η πυκνότητα της κατανομής είναι η πυκνότητα της Τ.Μ. , για την οποία, από το αποτέλεσμα της Άσκησης 4 του Κεφαλαίου 12, έχουμε,
Για , η πυκνότητα της είναι η πυκνότητα της , όπου οι είναι ανεξάρτητες (από την τέταρτη ιδιότητα του Θεωρήματος 15.1) και έχουν κοινή πυκνότητα την . Άρα, για η , ενώ για σύμφωνα με το Θεώρημα 15.2 η δίνεται από τη συνέλιξη,
Και κάνοντας στο τελευταίο παραπάνω ολοκλήρωμα διαδοχικά τις αντικαταστάσεις , , και , βρίσκουμε πως,
την οποία αναγνωρίζουμε ως την πυκνότητα της κατανομής! Άρα η είναι η ίδια κατανομή με την .
Παρομοίως, για , η πυκνότητα της είναι η πυκνότητα της Τ.Μ. , όπου η έχει πυκνότητα και είναι ανεξάρτητη από τη η οποία έχει πυκνότητα . Άρα, για η , και για σύμφωνα με το Θεώρημα 15.2 η μπορεί να υπολογιστεί ως η συνέλιξη,
Κάνοντας τις ίδιες διαδοχικές αντικαταστάσεις όπως για την , έχουμε,
οπότε, τελικά βρίσκουμε,
-
3.
Ασυσχέτιστες αλλά όχι ανεξάρτητες συνεχείς Τ.Μ.
-
(α’)
Από την τέταρτη ιδιότητα της από κοινού πυκνότητας, η περιθώρια πυκνότητα της είναι για , και για ,
Λόγω συμμετρίας, η περιθώρια πυκνότητα του είναι ακριβώς ίδια, , για όλα τα .
-
(β’)
Οι συναρτήσεις και είναι άρτιες, οπότε οι αντίστοιχες συναρτήσεις και είναι περιττές, άρα τα ολοκληρώματά τους σε όλο το , τα οποία είναι ίσα με τις μέσες τιμές τους και , είναι ίσα με μηδέν. Επιπλέον, η μέση τιμή είναι και αυτή ίση με μηδέν όπως εύκολα διαπιστώνουμε λόγω της συμμετρίας του προβλήματος ή υπολογίζοντας αναλυτικά το διπλό ολοκλήρωμα,
το οποίο ισούται με μηδέν αφού στο εσωτερικό ολοκλήρωμα (ως προς ) ολοκληρώνουμε μια περιττή συνάρτηση. Συνεπώς η συνδιακύμανση,
Το γεγονός ότι οι δεν είναι ανεξάρτητες προκύπτει με το ίδιο ακριβώς επιχείρημα όπως στο δεύτερο σκέλος της Άσκησης 1.
-
(α’)
-
4.
Χρόνοι διεργασιών. Εφόσον οι Τ.Μ. , είναι ανεξάρτητες με κοινή κατανομή , σύμφωνα με το κριτήριο (15.7) μπορούμε να θέσουμε για την από κοινού πυκνότητά τους για , και αλλού. [Παρατηρήστε ότι η από κοινού κατανομή των είναι ίδια με αυτή του Παραδείγματος 15.1 και της Άσκησης 1.]
-
(α’)
Η πιθανότητα ισούται με το ολοκλήρωμα της από κοινού πυκνότητας στο σύνολο , δηλαδή με τον όγκο του στερεού που περικλείεται ανάμεσα στο και το γράφημα της . Αλλά αφού η πυκνότητα ισούται με 1 σε όλα τα σημεία του , η ζητούμενη πιθανότητα είναι ίση με το εμβαδόν του το οποίο, όπως βλέπουμε και από το Σχήμα 1.40, ισούται με 3/4. Άρα, .
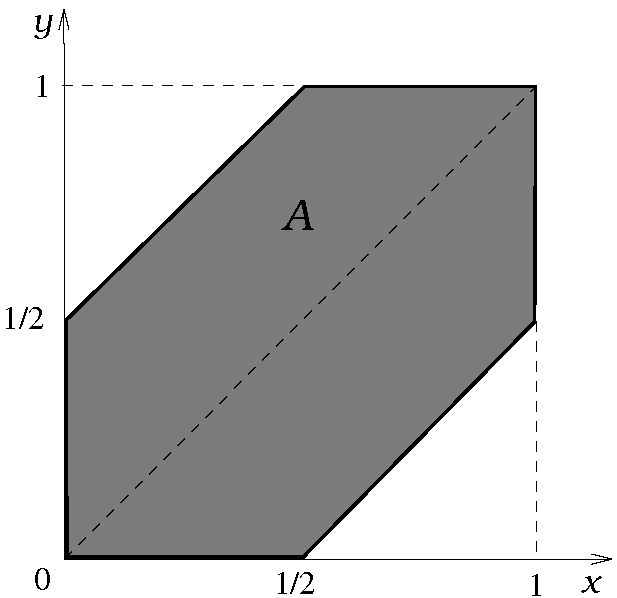
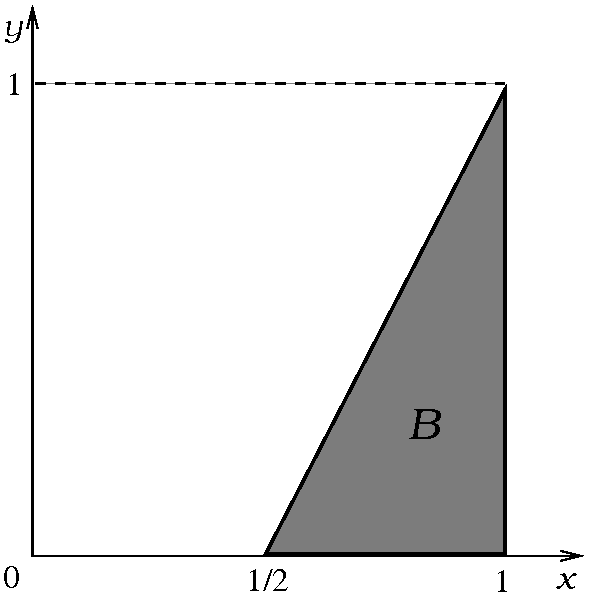
Σχήμα 1.40: Άσκηση 4: Η από κοινού πυκνότητα είναι ίση με τη μονάδα εντός του τετραγώνου και μηδενική εκτός. -
(β’)
Η ζητούμενη μέση τιμή μπορεί να εκφραστεί ως το διπλό ολοκλήρωμα,
όπου το πρώτο πιο πάνω ολοκλήρωμα υπολογίζεται απλά ως,
Το δεύτερο ολοκλήρωμα μπορεί να υπολογιστεί με τον ίδιο τρόπο ή, εναλλακτικά, παρατηρώντας πως λόγω συμμετρίας πρέπει να ισούται με το πρώτο. Άρα, τελικά,
-
(γ’)
Η μέση τιμή του κόστους είναι εύκολο να υπολογιστεί, βάσει της Πρότασης 15.3, και των ιδιοτήτων της ομοιόμορφης κατανομής:
-
(δ’)
Για τη ζητούμενη πιθανότητα κατ’ αρχάς παρατηρούμε πως,
όπου το σύνολο ορίζεται ως,
και έχει σχεδιαστεί στο Σχήμα 1.40. Με το ίδιο σκεπτικό όπως στο πρώτο σκέλος της άσκησης, παρατηρούμε πως η ζητούμενη πιθανότητα ισούται με το εμβαδόν του το οποίο, όπως βλέπουμε και από το Σχήμα 1.40, ισούται με 1/4, συνεπώς έχουμε, .
-
(ε’)
Αφού οι είναι ανεξάρτητες, από το Θεώρημα 15.1 γνωρίζουμε πως η συνδιακύμανση .
-
(α’)
-
5.
Θεραπείες.
-
(α’)
Από την πρώτη ιδιότητα της από κοινού πυκνότητας γνωρίζουμε ότι το ολοκλήρωμα της σε όλο το πρέπει να ισούται με τη μονάδα:
συνεπώς πρέπει να έχουμε . Η πυκνότητα έχει σχεδιαστεί στο Σχήμα 1.41.
Σχήμα 1.41: Η πυκνότητα της Άσκησης 5. -
(β’)
Θα χρησιμοποιήσουμε την τέταρτη ιδιότητα της από κοινού πυκνότητας. Προφανώς για ή , η περιθώρια πυκνότητα , ενώ για , έχουμε:
Παρομοίως, η περιθώρια πυκνότητα της είναι όταν , ενώ για :
- (γ’)
-
(δ’)
Τέλος, υπολογίζουμε τη ζητούμενη πιθανότητα:
Στο Σχήμα 1.42 έχουμε σχεδιάσει το στερεό του οποίου ο όγκος αντιστοιχεί στην παραπάνω πιθανότητα.
Σχήμα 1.42: Ο όγκος του στερεού ισούται με την της Άσκησης 5.
-
(α’)
-
6.
Εναλλακτικές θεραπείες.
-
(α’)
Και πάλι, πρέπει το ολοκλήρωμα της στο να ισούται με τη μονάδα:
Άρα, . Η πυκνότητα έχει σχεδιαστεί στο Σχήμα 1.43.
Σχήμα 1.43: Η πυκνότητα της Άσκησης 6. -
(β’)
Από την τέταρτη ιδιότητα της από κοινού πυκνότητας, όταν η , ενώ για ,
Παρομοίως, αν τότε , ενώ αν ,
Οπότε, συγκεντρωτικά,
-
(γ’)
Για τη συνδιακύμανση, υπολογίζουμε τη μέση τιμή των ,
όπου για τη μέση τιμή του πραγματοποιήσαμε την αντικατάσταση , και τη μέση τιμή του γινομένου τους,
Οπότε τελικά,
Και εφόσον η συνδιακύμανση είναι μη μηδενική, από το Θεώρημα 15.1 έχουμε ότι οι δεν είναι ανεξάρτητες.
-
(α’)
-
7.
Τριπλά ολοκληρώματα. Καταρχάς ορίζουμε το σύνολο τιμών των ως το σύνολο όπου η από κοινού πυκνότητα παίρνει θετικές τιμές.
-
(α’)
Θα υπολογίσουμε τη σταθερά απαιτώντας το ολοκλήρωμα της σε όλο το να είναι ίσο με 1. Γι’ αυτό τον υπολογισμό (και όλους τους παρακάτω σε αυτήν την άσκηση), χρησιμοποιούμε την τρισδιάστατη εκδοχή του θεωρήματος του Fubini:
όπου έχουμε παραλείψει τον λεπτομερή υπολογισμό των τελευταίων τριών απλών ολοκληρωμάτων. Επομένως, .
-
(β’)
Με παρόμοιο τρόπο θα υπολογίσουμε και τη μέση τιμή , ως,
όπου και πάλι έχουμε παραλείψει τον λεπτομερή υπολογισμό των τελευταίων εννέα ολοκληρωμάτων.
-
(γ’)
Τέλος, ορίζοντας το σύνολο, , έχουμε,
Το εσωτερικό ολοκλήρωμα ως προς είναι,
και αντικαθιστώντας την παραπάνω έκφραση στο δεύτερο ολοκλήρωμα ως προς έχουμε ότι ισούται με,
οπότε αντικαθιστώντας αυτή την έκφραση στο τρίτο ολοκλήρωμα ως προς , βρίσκουμε,
-
(α’)
-
8.
Περιθώρια και από κοινού πυκνότητα. Η απόδειξη είναι παρόμοια με εκείνη της τέταρτης βασικής ιδιότητας της από κοινού πυκνότητας: Για οποιαδήποτε και , η πιθανότητα μπορεί να εκφραστεί ως,
άρα, αν ορίσουμε τη συνάρτηση,
τότε ικανοποιεί τον ορισμό της από κοινού πυκνότητας 15.1 για δύο συνεχείς Τ.Μ. .
-
9.
Μίξη πυκνοτήτων. Όταν η η , ενώ όταν η η . Άρα μπορούμε να σκεφτούμε την ως μια τυχαία επιλογή, με πιθανότητα 1/2 για τα δύο αποτελέσματα, μεταξύ της και της .
Για να βρούμε την πυκνότητα της εφαρμόζουμε τον κανόνα συνολικής πιθανότητας: Για αυθαίρετα,
Άρα, αντικαθιστώντας τις τιμές των πυκνοτήτων και , αν ορίσουμε τη συνάρτηση,
τότε η ικανοποιεί τον ορισμό της πυκνότητας της συνεχούς Τ.Μ. όπως δίνεται στο Κεφάλαιο 10.
-
10.
Φτου φτου φτου.
-
(α’)
Η περιθώρια πυκνότητα του , από την τέταρτη ιδιότητα της από κοινού πυκνότητας είναι για , ενώ για έχουμε,
όπου παρατηρούμε ότι το εσωτερικό ολοκλήρωμα ως προς είναι το ολοκλήρωμα της πυκνότητας της κατανομής σε όλο το , άρα ισούται με 1. Οπότε βρίσκουμε,
δηλαδή η περιθώρια κατανομή του χρόνου των χασμουρητών είναι . Συνεπώς, η madame Depy χασμουριέται κατά μέσο όρο για δύο λεπτά ανά ξεμάτιασμα.
-
(β’)
Από τον ορισμό της δεσμευμένης πιθανότητας, η ζητούμενη πιθανότητα είναι,
(A.25) όπου, από το πρώτο σκέλος, ήδη ξέρουμε πως , άρα, ο παρονομαστής είναι, . Για τον αριθμητή παρατηρούμε ότι, από τους περιορισμούς των τιμών της πυκνότητας, η μόνη περίπτωση να έχουμε και είναι αν το . Οπότε,
και προχωρώντας όπως και στο προηγούμενο ερώτημα, το παραπάνω τριπλό ολοκλήρωμα μπορεί να υπολογιστεί ως,
όπου το εσωτερικό ολοκλήρωμα ως προς ισούται με ένα. Συνεπώς,
Τέλος, αντικαθιστώντας στη σχέση (A.25), βρίσκουμε,
-
(α’)
-
11.
Συσχέτιση, συνδιακύμανση, διασπορά. Οι αποδείξεις είναι ακριβώς ίδιες με εκείνες που είδαμε στη διακριτή περίπτωση, στις λύσεις της Άσκησης 10 του Κεφαλαίου 9 και της Άσκησης 17 του Κεφαλαίου 11. Η μόνη διαφορά είναι ότι χρησιμοποιούμε τις αντίστοιχες ιδιότητες της μέσης τιμής, της διασποράς και της συνδιακύμανσης για συνεχείς αντί για διακριτές Τ.Μ. Συγκεκριμένα:
- –
- –
- –
-
12.
Η διμεταβλητή κανονική κατανομή.
- (α’)
-
(β’)
Χρησιμοποιώντας τις τιμές των και που μόλις υπολογίσαμε, από τον ορισμό της συνδιακύμανσης και τους ορισμούς των , βρίσκουμε ότι,
όπου στο βήμα χρησιμοποιήσαμε τη βασική ιδιότητα της μέσης τιμής από την Πρόταση 15.3, στο αντικαταστήσαμε την και χρησιμοποιήσαμε την Ιδιότητα 1 από το Θεώρημα 15.1 επειδή οι είναι ανεξάρτητες, και στο βήμα απλά χρησιμοποιήσαμε το γεγονός ότι .
-
(γ’)
Ο επιπλέον περιορισμός απλώς αποκλείει την τετριμμένη περίπτωση όπου η μπορεί απλά να εκφραστεί ως γραμμικός μετασχηματισμός της . Για παράδειγμα, αν , τότε,
και κατά συνέπεια,
[Η περίπτωση είναι παρόμοια.]
-
(δ’)
Αν και απαιτεί μακροσκελείς υπολογισμούς, η βασική ιδέα της απόδειξης του τελευταίου ερωτήματος είναι απλή: Θα εξετάσουμε την πιθανότητα και θα δείξουμε, μέσω απλών μετασχηματισμών, ότι μπορεί να εκφραστεί ως το διπλό ολοκλήρωμα της που ορίστηκε από την (15.8) στο ορθογώνιο .
Κατ’ αρχάς, αντικαθιστώντας του ορισμούς των Τ.Μ. , η ζητούμενη πιθανότητα είναι,
και εκφράζοντάς την ως προς τις αντί για τις γίνεται,
Τώρα, εφόσον οι είναι ανεξάρτητες, το κριτήριο (15.7) μας λέει πως έχουν από κοινού πυκνότητα , όπου είναι η πυκνότητα της τυπικής κανονικής κατανομής. Άρα, από το θεώρημα του Fubini, η πιο πάνω πιθανότητα ισούται με το διπλό ολοκλήρωμα,
και κάνοντας στο εσωτερικό ολοκλήρωμα την αντικατάσταση,
έτσι ώστε,
έχουμε,
Τέλος, πραγματοποιώντας την αντικατάσταση , έτσι ώστε και , βρίσκουμε,
άρα, σύμφωνα με τον Ορισμό 15.1, η είναι πράγματι η από κοινού πυκνότητα των .
-
13.
Το Κ.Ο.Θ. χωρίς το «Ο». Έστω πως οι Τ.Μ. είναι ανεξάρτητες με κοινή κατανομή . Τότε, από την Ιδιότητα 3 του Θεωρήματος 12.1, η κάθε έχει κατανομή , και από το Πόρισμα 15.1 το άθροισμα,
Οπότε, εφαρμόζοντας και πάλι την Ιδιότητα 3 του Θεωρήματος 12.1, το κανονικοποιημένο άθροισμα,
έχει τυπική κανονική κατανομή για κάθε , όχι μόνο κατά προσέγγιση για μεγάλα όπως μας λέει το Κ.Ο.Θ.
Βιβλιογραφία
Παραθέτουμε έναν συνοπτικό κατάλογο βιβλίων, στα ελληνικά και τα αγγλικά, που μπορούν να χρησιμοποιηθούν για περαιτέρω ή ταυτόχρονη μελέτη.
-
1.
Εισαγωγη στις πιθανοτητεσ
-
(α’)
Εισαγωγή στις πιθανότητες, D.P. Bertsekas, J.N. Tsitsiklis. Εκδόσεις Τζιόλα, 2010. [Πρωτότυπο στα αγγλικά: Introduction to Probability, D.P. Bertsekas, J.N. Tsitsikli. 2η έκδοση, Athena Scientific, 2008.]
-
(β’)
Εισαγωγή στη θεωρία πιθανοτήτων, P. Hoel, S. Port, C. Stone. Πανεπιστημιακές Εκδόσεις Κρήτης, 2001. [Πρωτότυπο στα αγγλικά: Introduction to Probability Theory, P.G. Hoel, S.C. Port, C.J. Stone. Brooks Cole, 2009.]
-
(γ’)
Βασικές αρχές θεωρίας πιθανοτήτων, S. Ross. Εκδόσεις Κλειδάριθμος, 2012. [Πρωτότυπο στα αγγλικά: First Course in Probability, S. Ross. 8η έκδοση, Prentice Hall, 2009.]
-
(α’)
-
2.
Περαιτερω θεωρια και εφαρμογες των πιθανοτητων
-
(α’)
Πιθανότητες, τυχαίες μεταβλητές και στοχαστικές διαδικασίες, A. Papoulis, S.U. Pillai. 4η έκδοση, Εκδόσεις Τζιόλα, 2007. [Πρωτότυπο στα αγγλικά: Probability, Random Variables and Stochastic Processes, A. Papoulis, S.U. Pillai. 4η έκδοση, McGraw Hill, 2002.]
-
(β’)
Introduction to Probability Models, S. Ross. 10η έκδοση, Academic Press, 2010.
-
(γ’)
Stochastic Processes, S. Ross. 2η έκδοση, Wiley, 1995.
-
(α’)
-
3.
Εφαρμογες των πιθανοτητων στην πληροφορικη
-
(α’)
Probability and Computing: Randomized Algorithms and Probabilistic Analysis, M. Mitzenmacher, E. Upfal. Cambridge University Press, 2005.
-
(β’)
Randomized Algorithms, R. Motwani, P. Raghavan. Cambridge University Press, 1995.
-
(γ’)
Average Case Analysis of Algorithms on Sequences, W. Szpankowski. Wiley Series in Discrete Mathematics and Optimization, 2011.
-
(δ’)
Probability and Algorithms, J.M. Steele, D. Aldous, D.J. Bertsimas, E.G. Coffman, D. Hochbaum, M. Hofri, J.C. Lagarias, S.T. Weidman. U.S. National Research Council, 1992. Διαθέσιμο online:
-
(α’)
- 4.
Στατιστικη και προσομοιωση
-
(α’)
Introduction to the Practice of Statistics, D.S. Moore, G.P. McCabe, B.A. Craig. W.H. Freeman, 2014.
-
(β’)
Statistical Inference, G. Casella, R.L. Berger. Duxbury Press, 2001.
-
(γ’)
Monte Carlo Statistical Methods, C.P. Robert, G. Casella. Springer, 2004.
-
(δ’)
Monte Carlo Methods in Financial Engineering, P. Glasserman. Springer, 2003.
-
(α’)
-
5.
Θεωρια πιθανοτητων βασει της θεωριας μετρου
-
(α’)
An Introduction to Probability Theory and Its Applications, volumes I-II, W. Feller. 3η έκδοση, Wiley, 1968.
-
(β’)
Probability and Measure, P. Billingsley. 3η έκδοση, Wiley, 1995.
-
(γ’)
Probability: Theory and Examples, R. Durrett. 4η έκδοση, Cambridge University Press, 2010.
-
(α’)
-
6.
Μαθηματικος λογισμος
-
(α’)
Διαφορικός και ολοκληρωτικός λογισμός, τόμοι Ι-ΙΙ, T.M. Apostol. 1η έκδοση, Εκδόσεις Ατλαντίς, 1962. [Πρωτότυπο στα αγγλικά: Calculus, volumes I-II, T.M. Apostol. 2η έκδοση, Wiley, 1967.]
-
(β’)
Διαφορικός και ολοκληρωτικός λογισμός, M. Spivak. 2η έκδοση, Πανεπιστημιακές Εκδόσεις Κρήτης, 2010. [Πρωτότυπο στα αγγλικά: Calculus, M. Spivak. 4η έκδοση, Publish or Perish, 2009.]
-
(γ’)
Απειροστικός λογισμός (ενιαίος τόμος), R.L. Finney, F.R. Giordano, M.D. Weir. Πανεπιστημιακές Εκδόσεις Κρήτης, 2012. [Πρωτότυπο στα αγγλικά: Thomas’ Calculus, R.L. Finney, F.R. Giordano, M.D. Weir. Addison Wesley Longman, 2001.]
-
(α’)
Ευρετήριο
- Bayes, κανόνας 5.3, 5.4, Παράδειγμα 5.6, 5.3
- Bernoulli
- Daniel 13.
- κατανομή Ορισμός 7.1
- Cauchy-Schwarz, ανισότητα Proposition 1
- Chebychev, ανισότητα 12., Θεώρημα 11.4, 13.4, Θεώρημα 9.2
- Chernoff, φράγμα 8., 7.
- Fermat, Pierre de 1.2
- Fourier, ανάλυση Κεφάλαιο 13
- Fubini, θεώρημα Θεώρημα A.2, 1.
- Gauss, Johann Carl Frederich 1.2, 2.
- Kolmogorov, Andrei N. 1.2
- Lindeberg, θεώρημα Κεφάλαιο 13, 13.4
- Markov
- Andrei A. 1.2
- αλυσίδα 1.2
- ανισότητα 11., Θεώρημα 11.3, Θεώρημα 9.1
- Merkel, Angela 9.
- Monty Hall, παιχνίδι 13., Παράδειγμα 2.4, Παράδειγμα 5.10
- Pascal, Blaise 1.2
- Poisson
- κατανομή Θεώρημα 7.2
- προσέγγιση στη διωνυμική Παράδειγμα 12.5, 6., Πόρισμα 7.1
- Stirling, τύπος 2., 13.3, 7.4, Λήμμα 7.1, 3.
- Taylor, ανάπτυγμα (α’), 13.4, (α’), 7.4
- cut set 6., 8.2
- de Moivre
- Abraham 13.3
- de Moivre-Laplace, θεώρημα Κεφάλαιο 13, 13.3
- min-cut 5., 8.2
- string matching 9., 8.3
- quicksort αλγόριθμος 12., 8.4
- randomized αλγόριθμος 1.3, Κεφάλαιο 8, 1., 12., 8.1, Θεώρημα 8.3, 8.2
- string matching 9., 8.3
- Ζυγοβίστι Αρκαδίας 12.
- Κεντρικό Οριακό Θεώρημα (Κ.Ο.Θ.) 1.2, Κεφάλαιο 10, Κεφάλαιο 12, 12.2, Θεώρημα 12.2, Κεφάλαιο 13, 13.2, 13.3, 13.4, 14.1, 13., 3., Proposition 2
- Κορδατέας Α.Ε. 1.
- Νόμος των Μεγάλων Αριθμών (Ν.Μ.Α.) Κεφάλαιο 11, 14., 11.3, Θεώρημα 11.6, Κεφάλαιο 12, Κεφάλαιο 13, 13.2, 14.1, Κεφάλαιο 9, 1., 9.3, Θεώρημα 9.3
- Τζίφας, Παν., Αρχιπλοίαρχος (δ’)
- άθροισμα ανεξάρτητων κανονικών Τ.Μ. Πόρισμα 15.1
- αλγόριθμος του Karger 8.2
- αλυσίδα Markov 1.2
- ανάλυση Fourier Κεφάλαιο 13
- ανάπτυγμα Taylor (α’), 13.4, (α’), 7.4
- ανεξαρτησία 1.2, 15.3, Θεώρημα 15.1, 5.1, Ορισμός 5.1, Ορισμός 6.6, 2.
- ανεξάρτητα ενδεχόμενα 1., 5.1, Ορισμός 5.1, Ορισμός 6.6, 5.4
- ανεξάρτητες
Τ.Μ.
- διακριτές Κεφάλαιο 12, 12.2, Θεώρημα 12.2, 13.2, Ορισμός 6.6, Θεώρημα 6.1, 2., 9.3, Θεώρημα 9.3, 9.2, 9.2
- συνεχείς Ορισμός 11.3, Θεώρημα 11.5, Θεώρημα 11.6, Κεφάλαιο 12, 12.2, Θεώρημα 12.2, 13.2, 15.3, Πόρισμα 15.1, Θεώρημα 15.1, Θεώρημα 15.2
- ανισότητα Cauchy-Schwarz Proposition 1
- ανισότητα του Chebychev 12., Θεώρημα 11.4, 13.4, Θεώρημα 9.2
- ανισότητα του Markov 11., Θεώρημα 11.3, Θεώρημα 9.1
- από κοινού κατανομή
- διακριτή 9.2
- συνεχής Κεφάλαιο 15
- από κοινού πυκνότητα
- απόσταση 18.
- απόσταση 11., 5., 18.
- αρμονική σειρά Λήμμα 8.1
- γεωμετρική
κατανομή
Ορισμός
7.3
- ιδιότητες Θεώρημα 7.1
- γεωμετρική σειρά 7.3
- γκαουσιανή κατανομή 12.1
- δείκτρια συνάρτηση 4., 13.4, 13.4, 2., 3.
- δείκτρια Τ.Μ. 14.1, 2., 2., 3.
- δεσμευμένη πιθανότητα 4., 5.1, 5.4, Ορισμός 5.2, Λήμμα 5.1, 5.2, 5.3
- δεσμευμένο μέτρο πιθανότητας 9.
- δημοσκόπηση Παράδειγμα 12.11, Παράδειγμα 12.7, 14.1, 4., Παράδειγμα 14.2, 13., Παράδειγμα 9.13
- δημοψήφισμα Παράδειγμα 12.11
- διακριτή Τ.Μ. 2.
- διασπορά
- διακριτής Τ.Μ. Ορισμός 6.5
- εκτίμηση 5.
- συνεχούς Τ.Μ. Ορισμός 10.3
- διάστημα εμπιστοσύνης Κεφάλαιο 14, 1., 3., 14.1, 14.1, 14.1
- διατάξεις Ιδιότητα 4.3, Ιδιότητα 4.4, Ιδιότητα 4.5
- διμεταβλητή κανονική κατανομή 12.
- διπλό
ολοκλήρωμα
A.1,
1.
- ιδιότητες Θεώρημα A.1
- διωνυμική κατανομή Παράδειγμα 12.5, 6., 13.3, 7.1, Πόρισμα 7.1, Ορισμός 7.2, Θεώρημα 7.2
- δυναμοσειρές 7.4
- εκθετική
κατανομή
Ορισμός
11.2
- ιδιότητες Θεώρημα 11.1
- εκθετική συνάρτηση 19., 7.4, Λήμμα 7.2
- έλεγχος ανεξαρτησίας 6., 14.2.2
- έλεγχος παραμέτρου Bernoulli 6., 14.2.1
- έλεγχος υπόθεσης Κεφάλαιο 14, 6., 14.2, 14.2.1, 14.2.2
- εμπειρική κατανομή 14.2.1
- εμπειρικός μέσος όρος Κεφάλαιο 10, 1., Κεφάλαιο 12, Θεώρημα 12.2, 12.2, 1., 9., 3., 14.1, 14.2.1, 14.2.2, 14.2.2, 14.3, 14.3, Παράδειγμα 14.11, 1., 9.3, 14.1, 14.1, 14.2.1, Proposition 2
- ενδεχόμενο 2., 2.1, 3.1, 3.2, Κεφάλαιο 4, Κεφάλαιο 5, Ορισμός 5.1, 2.2
- επαλήθευση ισότητας πολυωνύμων 8.1
- επιλογές Ιδιότητα 4.3, Ιδιότητα 4.4, Ιδιότητα 4.5
- επιλογή με επανατοποθέτηση 7.1, 7.1
- επιλογή χωρίς επανατοποθέτηση 7.2
- επίπεδο εμπιστοσύνης 1., 3., 14.1, 14.1
- επίπεδο σημαντικότητας 6., 14.2.2, 14.2.1
- εύρεση ελαχιστιαίου cut set 8.2
- θεώρημα de Moivre-Laplace Κεφάλαιο 13, 13.3
- θεώρημα του Fubini Θεώρημα A.2, 1.
- θεώρημα του Lindeberg Κεφάλαιο 13, 13.4
- ιδιότητα έλλειψης μνήμης
- ιδιότητες
- ανεξαρτησίας Θεώρημα 15.1
- γεωμετρικής κατανομής Θεώρημα 7.1
- διακριτής από κοινού πυκνότητας 3., 9.2
- διακριτής πυκνότητας 6.1
- διπλού ολοκληρώματος Θεώρημα A.1
- εκθετικής κατανομής Θεώρημα 11.1
- κανονικής κατανομής Θεώρημα 12.1
- μέσης τιμής και διασποράς Θεώρημα 11.5, Θεώρημα 6.1
- συνδιακύμανσης 9.2, Proposition 4
- συνεχούς από κοινού πυκνότητας 15.1
- συνεχούς πυκνότητας 10.1
- συνεχούς συνάρτησης κατανομής 10.1
- ισοπίθανα στοιχειώδη ενδεχόμενα 3.2, Λήμμα 3.2, 4.2, Κεφάλαιο 4
- κανόνας δεσμευμένης συνολικής πιθανότητας 13.
- κανόνας συνολικής πιθανότητας 5.4, 5.2
- κανόνας του Bayes 5.3, 5.4, Παράδειγμα 5.6, 5.3
- κανόνες αρίθμησης 4.2
- κανόνες πιθανότητας 1–5 3.2
- κανόνες πιθανότητας 6–10 5.4
- κανονική κατανομή Κεφάλαιο 10, Θεώρημα
12.2, 12.1,
Πόρισμα
12.1, Κεφάλαιο 13,
13.2,
13.4,
12.,
13.,
Θεώρημα
15.2, 3.,
12.1
- διμεταβλητή 12.
- ιδιότητες Θεώρημα 12.1
- κανονική προσέγγιση στη διωνυμική Πόρισμα 12.1
- κανονικοποιημένο άθροισμα Θεώρημα 12.2, 1., 14.1, Παράδειγμα 14.3
- κανονικοποίηση 7., Πόρισμα 11.1, 3., Θεώρημα 12.2
- κατανομή
- Bernoulli Ορισμός 7.1
- Poisson Θεώρημα 7.2
- Βήτα 6.
- γεωμετρική Ορισμός 7.3
- γκαουσιανή 12.1
- διμεταβλητή κανονική 12.
- διωνυμική Ορισμός 7.2
- εκθετική Ορισμός 11.2
- κανονική 12.1
- λογαριθμοκανονική 6.
- ομοιόμορφη Ορισμός 11.1
- τυπική κανονική 5.
- υπεργεωμετρική Ορισμός 7.4
- 5., 2.
- κριτήριο ανεξαρτησίας 4., 15.3, 2.
- λογαριθμοκανονική κατανομή 6.
- μέθοδος της δεύτερης ροπής 16.
- μείωση διασποράς 14.3, 14.3, 14.3
- μέση
τιμή
- διακριτής Τ.Μ. 17., Ορισμός 6.4
- συνάρτησης διακριτής Τ.Μ. 1., Ορισμός 6.4
- συνάρτησης πολλαπλών Τ.Μ. Ιδιότητα 15.1, Proposition 3
- συνάρτησης συνεχούς Τ.Μ. Ορισμός 10.2
- συνεχούς Τ.Μ. Ορισμός 10.2
- μεταβλητές ελέγχου 9., 14.3, 14.3, 14.3
- μετασχηματισμός
- γραμμικός 16., 6., Θεώρημα 11.2, 7.
- συνεχούς Τ.Μ. 11.2
- μετρησιμότητα 10.3, 15.4, 6.3
- μέτρο πιθανότητας Κεφάλαιο 3, 3.3
- ξεμάτιασμα 10.
- ξένα ενδεχόμενα 4., 3., 3.2, 5.2, 5.3
- ομοιόμορφη κατανομή Ορισμός 11.1
- παιχνίδι Monty Hall 13., Παράδειγμα 2.4, Παράδειγμα 5.10
- περιθώρια
πυκνότητα
- διακριτής Τ.Μ. Ορισμός 9.2
- συνεχούς Τ.Μ. Ορισμός 15.2
- πιθανοκρατική ανάλυση 1.3, Κεφάλαιο 8, 8., 8.3, Θεώρημα 8.2
- πράξεις συνόλων 2.3, Ορισμός 2.1
- πρόβλημα γενεθλίων Παράδειγμα 7.6
- πρόβλημα ταξινόμησης 8.4
- προσαρμοστική εκτιμήτρια 9., 14.3
- προσέγγιση Poisson στη διωνυμική Παράδειγμα 12.5, 6., Πόρισμα 7.1
- προσομοίωση 9., 14.3, 14.3, Παράδειγμα 14.13, 9.
- πυκνότητα
- από κοινού, διακριτή 1.
- από κοινού, συνεχής Ορισμός 15.1
- διακριτής Τ.Μ. 3.
- διακριτής Τ.Μ., περιθώρια Ορισμός 9.2
- συνεχούς Τ.Μ. 1.
- συνεχούς Τ.Μ., περιθώρια Ορισμός 15.2
- στατιστική συνάρτηση 6., 14.2.1, 14.2.2, 14.2.2, 14.2.1
- στατιστικό σφάλμα 1., 3., 14.1, 14.1
- στοιχειώδες ενδεχόμενο 3.
- σύγκλιση κατά κατανομή Ορισμός 12.2, 1., 6.
- σύγκλιση κατά πιθανότητα 1., 12., Ορισμός 9.4, Proposition 2
- σύγκλιση με πιθανότητα 1 1., 14.
- σύγκλιση ως προς την απόσταση 5.
- συνάρτηση
κατανομής
Ορισμός
12.2, Θεώρημα
12.2, 1.,
2.,
Ορισμός
6.3
- συνεχής, ιδιότητες 10.1
- συνδιακύμανση 17.,
14.3,
14.3,
11.,
Ορισμός
15.3, 10.,
11.,
Ορισμός
9.3
- ιδιότητες 9.2, Proposition 4
- συνδυασμοί Ιδιότητα 4.1, Ιδιότητα 4.2, Ιδιότητα 4.4, Ιδιότητα 4.5
- συνέλιξη
- συνεχής Τ.Μ. 10.1
- σύνολα 2.2
- σύνολο τιμών τυχαίας μεταβλητής 1.
- συντελεστής συσχέτισης 17., 11., 10.
- ταυτότητα Vandermonde 6.
- τιμολόγηση δικαιώματος αγοράς Παράδειγμα 14.13
- τυπική
απόκλιση
- διακριτής Τ.Μ. Ορισμός 6.5
- συνεχούς Τ.Μ. Ορισμός 10.3
- τυπική κανονική κατανομή 3.,
5.,
Ορισμός
12.2, 13.4,
13.,
12.1
- τιμές συνάρτησης κατανομής Table 12.1, Table 12.2
- τύπος του Stirling 2., 13.3, 7.4, Λήμμα 7.1, 3.
- τυχαία μεταβλητή (T.M.) Ορισμός 6.1
- τυχαία μεταβλητή (Τ.Μ.)
- υπεργεωμετρική κατανομή 18., Ορισμός 7.4
- φράγμα ένωσης Λήμμα 5.2, 7., 8.3
- φράγμα τομής 7.
- φράγμα του Chernoff 8., 7.
- χώρος πιθανότητας Κεφάλαιο 2, 1.
Απόδοση αγγλικών όρων
- •
average case analysis: πιθανοκρατική ανάλυση
-
•
bits: δυαδικά δεδομένα, δυαδικά ψηφία
-
•
cut set: σύνολο αποκοπτουσών ακμών
-
•
divide and conquer: διαίρει και βασίλευε
-
•
min-cut: ελαχιστιαίο σύνολο αποκοπτουσών ακμών
-
•
quicksort algorithm: αλγόριθμος γρήγορης ταξινόμησης
-
•
randomized algorithm: τυχαιοκρατικός αλγόριθμος
-
•
string matching: ταίριασμα ακολουθιών
-
•
worst case analysis: ανάλυση χειρότερης περίπτωσης
Αρκτικόλεξα
-
Κ.Ο.Θ.: Κεντρικό Οριακό Θεώρημα
-
Ν.Μ.Α.: Νόμος των Μεγάλων Αριθμών
-
Τ.Μ.: Τυχαία Μεταβλητή