Συγγραφή
Μηνάς Δασυγένης
Δημήτριος Σούντρης
Κριτικός Αναγνώστης
Γεώργιος Δημητρακόπουλος
Συντελεστές Έκδοσης
Τεχνική Επεξεργασία: Μηνάς Δασυγένης
Γραφιστική Επεξεργασία: Μηνάς Δασυγένης
ISBN: 978-960-603-390-2
Copyright ΣΕΑΒ, 2015
Το παρόν έργο αδειοδοτείται υπό τους όρους της άδειας Creative Commons Αναφορά Δημιουργού - Μη Εμπορική Χρήση - Όχι Παράγωγα Έργα 3.0. Για να δείτε ένα αντίγραφο της άδειας αυτής επισκεφτείτε τον ιστότοπο https://creativecommons.org/licenses/by-nc-nd/3.0/gr/
ΣΥΝΔΕΣΜΟΣ ΕΛΛΗΝΙΚΩΝ ΑΚΑΔΗΜΑΪΚΩΝ ΒΙΒΛΙΟΘΗΚΩΝ
Εθνικό Μετσόβιο Πολυτεχνείο
Ηρώων Πολυτεχνείου 9, 15780 Ζωγράφου
www.kallipos.gr
Το παρόν πόνημα γράφηκε για να χρησιμοποιηθεί ως βιβλίο θεωρίας για το μάθημα Ενσωματωμένα Συστήματα που διδάσκεται στο Τμήμα Μηχανικών Πληροφορικής και Τηλεπικοινωνιών του Πανεπιστημίου Δυτικής Μακεδονίας, από τον πρώτο συγγραφέα Μηνά Δασυγένη, και στη Σχολή Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών του Εθνικού Μετσόβιου Πολυτεχνείου, από τον δεύτερο συγγραφέα Δημήτριο Σούντρη. Μπορεί όμως, να χρησιμοποιηθεί ελεύθερα, είτε ολόκληρο, είτε τμηματικά, από οποιονδήποτε που ενδιαφέρεται να εκπαιδευτεί σε θέματα σχεδίασης Ενσωματωμένων Συστημάτων. Επειδή το βιβλίο αναφέρεται σε έναν τομέα που συνεχώς αλλάζει, θα πρέπει να υπάρχει κάποιος τρόπος ενημέρωσης των αναγνωστών. Για την καλύτερη οργάνωση και ενημέρωση, έχει δημιουργηθεί ένας ιστοχώρος υποστήριξης στη διεύθυνση http://arch.icte.uowm.gr/mdasyg/book/embedded, όπου θα τοποθετείται επιπρόσθετο υλικό, όπως παρουσιάσεις και ασκήσεις.
Επιπρόσθετα, ο πρώτος συγγραφέας έχει αναρτήσει στο κανάλι του (youtube) μια πλήρη σειρά μαγνητοσκοπημένων διαλέξεων για το μάθημα Ενσωματωμένα Συστήματα, στη διεύθυνση https://www.youtube.com/playlist?list=PLl2orJCvV3b4vwBe-6rJrcrcmQAVHoa3f, ενώ όλες οι σημειώσεις, οι παρουσιάσεις και οι εργαστηριακές ασκήσεις του μαθήματός του, είναι διαθέσιμες από το πρόγραμμα ανοικτών μαθημάτων Opencourses στη διεύθυνση http://arch.icte.uowm.gr/courses/embedded/. O ίδιος συγγραφέας έχει διαθέσει ελεύθερα το υλικό από όλα τα μαθήματα που διδάσκει, και για αυτό βραβεύτηκε από το Opencourses σε πλήθος 2500 ανοικτών μαθημάτων της Ανώτατης Εκπαίδευσης.
Η συγγραφή του παρόντος βιβλίου δεν θα ολοκληρωνόταν χωρίς τη συμπαράσταση μερικών ατόμων, που παρείχαν αμέριστη βοήθεια σε διάφορα στάδια της προσπάθειας. Αρχικά, θα ήθελα να ευχαριστήσω τον συν-συγγραφέα του βιβλίου Δημήτριο Σούντρη, που συνέβαλε τα μέγιστα για την άρτια, ποιοτική και ποσοτική, ολοκλήρωση του έργου με τις εξειδικευμένες γνώσεις του σε θέματα σχεδιασμού ενσωματωμένων συστημάτων, λόγω της συμμετοχής του σε ερευνητικά προγράμματα και των συνεργασιών με πανεπιστήμια και μεγάλες εταιρίες. Επίσης, θα ήθελα να ευχαριστήσω τον Γιώργο Δημητρακόπουλο, ο οποίος, ως κριτικός αναγνώστης, συνέβαλε στην ολοκλήρωση της συγγραφής με εύστοχες παρατηρήσεις και σχόλια.
Επιπλέον, θα ήθελα να ευχαριστώ τη Δράση «Ελληνικά Ακαδημαϊκά Ηλεκτρονικά Συγγράμματα και Βοηθήματα» (Ε.Α.Η.Σ.Β., η οποία υλοποιείται από τον Σ.Ε.Α.Β. και το Ε.Μ.Π.), που μου έδωσε τη δυνατότητα της ολοκλήρωσης και της έκδοσης του παρόντος βιβλίου.
Τέλος, περισσότερο από όλους θα ήθελα να ευχαριστήσω τον πατέρα μου Μιχάλη Δασυγένη, ο οποίος, ως ένας δεύτερος προσεκτικός αναγνώστης, με τροφοδοτούσε με σχόλια κατά τη διάρκεια της συγγραφής του βιβλίου, προκειμένου να ολοκληρωθεί με επιτυχία και εντός των αυστηρών χρονοδιαγραμμάτων η συγγραφή του.
Το παρόν πόνημα γράφηκε για να χρησιμοποιηθεί ως βιβλίο θεωρίας για το μάθημα Ενσωματωμένα Συστήματα που διδάσκεται στο Τμήμα Μηχανικών Πληροφορικής και Τηλεπικοινωνιών του Πανεπιστημίου Δυτικής Μακεδονίας, από τον πρώτο συγγραφέα Μηνά Δασυγένη, και στη Σχολή Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών του Εθνικού Μετσόβιου Πολυτεχνείου, από τον δεύτερο συγγραφέα Δημήτριο Σούντρη.
Το βιβλίο αυτό δύναται να χρησιμοποιηθεί σε συνδυασμό με το υποστηρικτικό υλικό, που βρίσκεται στη ιστοσελίδα του μαθήματος Ενσωματωμένα Συστήματα στη διεύθυνση http://arch.icte.uowm.gr/courses/embedded/ και με τις μαγνητοσκοπημένες διαλέξεις στο https://www.youtube.com/playlist?list=PLl2orJCvV3b4vwBe-6rJrcrcmQAVHoa3f.
Με το βιβλίο αυτό και με το υποστηρικτικό υλικό, επιτυγχάνονται τα παρακάτω μαθησιακά αποτελέσματα:
Στόχοι Θεωρίας: Οι φοιτητές κατανοούν:
τι είναι ενσωματωμένο σύστημα και τι ιδιαιτερότητες έχει,
τα δίκτυα επικοινωνίας στα ενσωματωμένα συστήματα,
πώς γίνεται ο συσχεδιασμός υλικού και λογισμικού,
τι είναι οι επιταχυντές υλικού και πότε χρησιμοποιούνται,
την αρχιτεκτονική δημοφιλών επεξεργαστών ενσωματωμένων συστημάτων,
τι είναι τα λειτουργικά συστήματα πραγματικού χρόνου,
τη σημασία των σκληρών και μαλακών περιορισμών,
την απόδοση των ενσωματωμένων συστημάτων.
Στόχοι Εργαστηρίου: Οι φοιτητές κατανοούν:
τον προγραμματισμό ενσωματωμένων συστημάτων, λαμβάνοντας υπόψιν τις ιδιαίτερες απαιτήσεις τους,
την ευελιξία των FPGA, ως ρεαλιστικών αρχιτεκτονικών υλοποίησης ενσωματωμένων συστημάτων.
Οι φοιτητές αποκτούν δεξιότητες στη(ν):
δημιουργία και βελτιστοποίηση προγραμμάτων ως προς τις επιδόσεις και την κατανάλωση ενέργειας,
εξοικείωση με αναπτυξιακά περιβάλλοντα της ARM και της TI,
εκτενή χρήση της VHDL για περιγραφή μονάδων ενσωματωμένων συστημάτων,
χρήση των FPGA για εφαρμογές ενσωματωμένων συστημάτων,
δημιουργία ενσωματωμένων συστημάτων με soft-cores,
δημιουργία ‘συστήματος σε ψηφίδα’ (System on Chip, SOC),
εφαρμογή της μεθοδολογίας DTSE, για βελτιστοποίηση εφαρμογών για ενσωματωμένα συστήματα,
δημιουργία και χρήση πυρήνων πνευματικής ιδιοκτησίας (IP cores),
σχεδίαση ενσωματωμένων συστημάτων λογισμικού σε C και υλικού σε VHDL.
Τις τελευταίες δεκαετίες οι αναπτυγμένες κοινωνίες βιώνουν τα οφέλη της ψηφιακής εποχής. Η ανακάλυψη του τρανζίστορ το 1947 από τους John και Walter Brattain στα εργαστήρια της AT&T [1], αποτέλεσε το εφαλτήριο για μια επανάσταση δίχως προηγούμενο. Τα χρόνια που ακολούθησαν χαρακτηρίστηκαν από ανακαλύψεις, ευρεσιτεχνίες και πρωτοποριακές σχεδιάσεις και συσκευές που επηρέασαν κάθε τομέα της καθημερινότητας. Από το 1981 που άρχισε να πωλείται ο πρώτος προσωπικός υπολογιστής της IBM (IBM Personal Computer, PC), έως και τις μέρες μας που μπορούμε να προμηθευτούμε πολυπύρηνα συστήματα στο ίδιο υπόστρωμα του ολοκληρωμένου κυκλώματος, με ασύλληπτες επιδόσεις που χρησιμοποιούν τεχνολογίες υλοποίησης των 14 nm [2], τα τεχνολογικά προϊόντα δεν σταματάνε να μας εκπλήσσουν. Το πλήθος αυτών των προϊόντων φαίνεται και από τις πολλές κατηγορίες που καλύπτουν. Η πιο πολυπληθής και αφανής κατηγορία είναι αυτή των ενσωματωμένων συστημάτων. Σε αυτό το βιβλίο παρουσιάζουμε κάθε πτυχή του σχεδιασμού αυτών των συστημάτων, παρέχοντας όσο το δυνατόν πληρέστερη γνώση γύρω από το πολύ μεγάλο εύρος αυτών των συστημάτων που τα συναντάμε από τα ξυπνητήρια, έως και σε δορυφόρους.
Οι ψηφιακοί υπολογιστές που χρησιμοποιούμε είτε φανερά, είτε χωρίς να το γνωρίζουμε (όπως τα ενσωματωμένα συστήματα), έχουν παρουσιάσει μια μεγάλη εξέλιξη τις δεκαετίες από το 1940 και ύστερα. Πριν από το 1940 είχαν παρουσιαστεί κάποιες μηχανές που χρησιμοποιούσαν μηχανικά τμήματα (και άρα δεν ήταν ψηφιακοί), και είτε είχαν κατασκευαστεί, είτε είχαν παραμείνει στα σχηματικά διαγράμματα. Οι μηχανές αυτές βασίζονταν σε πολύπλοκες κατασκευές από μοχλούς, γρανάζια, ταινίες και διακόπτες και χρησιμοποιούνταν για τον υπολογισμό κάποιων βασικών σχέσεων με πράξεις της πρόσθεσης, της αφαίρεσης, του πολλαπλασιασμού και της διαίρεσης. Κάποια από αυτά τα μηχανήματα μπορούσαν να προγραμματιστούν με τη χρήση διάτρητων καρτών, δηλαδή καρτελών που είχαν σε συγκεκριμένα σημεία οπές προσδιορίζοντας μια αλληλουχία πράξεων, σαν ένα είδος σημερινού προγράμματος. Αυτός ο προγραμματισμός χρησιμοποιήθηκε κατά κύριο λόγο σε υφαντικές μηχανές. Οι πρώτες πρωταρχικές κατασκευές που χρησιμοποιούσαν το ψηφιακό σύστημα (δηλαδή, ένα σύστημα με δυο καταστάσεις, την ανοικτή και την κλειστή), άρχισαν να εμφανίζονται προς τα τέλη της δεκαετίας του 1930, και αυτό γιατί υπήρχε μια αδήριτη ανάγκη να βελτιωθεί η υπολογιστική ικανότητα.

1.1: Η πρώτη ψηφιακή υπολογιστική μηχανή με το όνομα Colossus χρησιμοποιήθηκε με επιτυχία από τους συμμάχους για την αποκρυπτογράφηση των γερμανικών επικοινωνιών. Εικόνα από www.wikipedia.org.
Η επιτακτική ανάγκη για τη βελτίωση της τεχνολογίας ήταν ο Β’ Παγκόσμιος Πόλεμος. Όπως ισχύει και στις μέρες μας, οι μεγαλύτερες τεχνολογικές ανακαλύψεις γίνονται για να καλυφθούν στρατιωτικές ανάγκες (ακόμη και το διαδίκτυο δημιουργήθηκε από τον Αμερικάνικο Στρατό προκειμένου να αυξήσουν την αξιοπιστία των επικοινωνιών σε περίπτωση πολέμου). Επιστήμονες, μηχανικοί και φυσικοί από όλες τις αντιμαχόμενες πλευρές, δημιούργησαν μεγάλες υπολογιστικές μηχανές για την κρυπτογράφηση και αποκρυπτογράφηση μηνυμάτων, υπολογισμό τροχιάς βλημάτων ή βελτίωση των επικοινωνιών. Η πρώτη υπολογιστική μηχανή που χρησιμοποιήθηκε με επιτυχία για να δώσει ένα προβάδισμα στους συμμάχους με την αποκρυπτογράφηση των γερμανικών επικοινωνιών, είναι το Colossus (Εικόνα 1.1) 1 που κατασκευάστηκε στην Αγγλία το 1943 από μια ομάδα, με επικεφαλείς τους Alan Turing και Tommy Flowers. Οι γερμανικές επικοινωνίες χρησιμοποιούσαν την κρυπτογράφηση με το μηχάνημα Enigma (Εικόνα 1.22) (το Enigma ήταν ένα μηχάνημα με γρανάζια που δε μπορούσε να επαναπρογραμματιστεί και για αυτό δεν θεωρείται υπολογιστής).

1.2: Το μηχάνημα Enigma που χρησιμοποιήθηκε για την κρυπτογράφηση/αποκρυπτογράφηση μηνυμάτων, χρησιμοποιούσε γρανάζια. Εικόνα από wikipedia.org.
Τα επόμενα χρόνια, στην άλλη πλευρά του Ατλαντικού Ωκεανού, κατασκευάστηκε ο υπολογιστής ENIAC (Electronic Numerical Integrator And Computer) (Εικόνα 1.33), προκειμένου να χρησιμοποιηθεί από τον Στρατό για τον υπολογισμό βαλλιστικών τροχιών (ήταν τα χρόνια του ψυχρού πολέμου που υπήρχε μεγάλη έρευνα για τα βαλλιστικά όπλα). Μάλιστα, επειδή ο Colossus αποτελούσε κρατικό μυστικό και ήταν απόρρητη η ύπαρξη του έως το 2000, πολλοί θεωρούσαν ότι ο ENIAC ήταν ο πρώτος προγραμματιζόμενος υπολογιστής (σε πολλά ακαδημαϊκά συγγράμματα αναφέρεται μόνο ο ENIAC). Επιπρόσθετα, ο ENIAC χρησιμοποιούσε το δεκαδικό σύστημα σε μια μορφή που είναι γνωστή ως BCD (binary coded decimal), ενώ ο Colossus χρησιμοποιούσε το δυαδικό σύστημα. Εκτός από αυτούς τους 2 υπολογιστές, παρουσιάστηκαν και άλλοι υπολογιστές, με υποδεέστερες, όμως, δυνατότητες (π.χ. δεν ήταν προγραμματιζόμενοι ή χρησιμοποιούσαν ηλεκτρικά ρελέ).

1.3: Ο πιο γνωστός υπολογιστής πριν το 1950 ήταν ο ENIAC. Εικόνα από wikipedia.org.
Η χρονιά, όμως, που σηματοδότησε τη μεγάλη επανάσταση στη βιομηχανία των ψηφιακών συστημάτων, είναι η χρονιά που ανακαλύφθηκε το τρανζίστορ (1947), το μικροσκοπικό αυτό στοιχείο που χρησιμοποιεί 3 ακροδέκτες, από τους οποίους ο ένας (η βάση) ρυθμίζει το ρεύμα (ως ροή ηλεκτρονίων) που διέρχεται διαμέσου των δυο άλλων επαφών, και έχει τη δυνατότητα να ανοίγει ή να κλείνει τη ροή των ηλεκτρονίων. Ο πρώτος υπολογιστής που χρησιμοποίησε τα τρανζίστορ ήταν ο Transistor Computer από το Πανεπιστήμιο του Manchester (Εικόνα 1.44). Τα επόμενα χρόνια παρουσιάστηκαν πλήθος υπολογιστών από Πανεπιστήμια όπως το MIT, Cambridge, Manchester κτλ ή από εταιρίες, όπως Intel, IBM, DEC, ARM, CRAY, κτλ., με πλήθος δυνατοτήτων και χαρακτηριστικών. Λόγω των διαφορετικών τεχνολογικών και φιλοσοφιών που χρησιμοποίησαν οι μηχανικοί και επιστήμονες για τη δημιουργία των υπολογιστών, έχει καθιερωθεί να τμηματοποιείται η εξέλιξη των υπολογιστών σε 5 γενιές.

1.4: Ο πρώτος υπολογιστής που χρησιμοποίησε transistor από το Πανεπιστήμιο του Manchester το 1953. Εικόνα από SSEM Manchester museum close up by Parrot of Doom - Own work. Licensed under CC BY-SA 3.0.
Η πρώτη γενιά των υπολογιστών χρησιμοποιεί λυχνίες κενού, και για αυτό το λόγο παρουσιάζει πολύ μικρό χρόνο ανάμεσα σε σφάλματα (MTBF, mean time between failures). Χρησιμοποιεί το δεκαδικό σύστημα (BCD), και δεν υπάρχει η δυνατότητα του εύκολου προγραμματισμού σε κάποια υψηλή γλώσσα. Το μέγεθος συνήθως είναι όσο ένα μεγάλο δωμάτιο ή αποθήκη, και η ταχύτητα επεξεργασίας είναι πολύ χαμηλή. Οι υπολογιστές αυτής της γενιάς μπορούν να χρησιμοποιήσουν καλώδια (patch cables), διακόπτες και περιστροφικά γρανάζια για τον προγραμματισμό. Οι πιο γνωστοί αντιπρόσωποι αυτής της κατηγορίας είναι ο Colossus και ο ENIAC. Ο ENIAC είχε βάρος 30 τόνους και καταλάμβανε 1300 τετραγωνικά μέτρα, ενώ η ταχύτητα του περιορίζονταν στις 500 προσθέσεις το δευτερόλεπτο.
Η δεύτερη γενιά χρησιμοποιεί transistor, αλλά επειδή δεν έχουν σμικρυνθεί, είναι αρκετά ογκώδη μηχανήματα. Λόγω των τρανζίστορ, έχει βελτιωθεί αρκετά η αξιοπιστία τους, χρησιμοποιούν το δυαδικό σύστημα (αφού ταιριάζει με τις 2 καταστάσεις που έχουν τα τρανζίστορ - ανοιχτή και κλειστή), χρησιμοποιούν διάτρητες κάρτες, και εμφανίζονται και οι πρώτες γλώσσες προγραμματισμού. Το πιο γνωστό μηχάνημα αυτής της εποχής είναι ο PDP-1 της DEC (Εικόνα 1.55) που είχε μνήμη 4ΚB και συχνότητα λειτουργίας 0.2 Mhz, ενώ η αρχική του τιμή ήταν αρκετά υψηλή $100K USD. Το αξιοθαύμαστο ήταν η επεκτασιμότητα του συστήματος, αφού ο χρήστης μπορούσε να προμηθευτεί επιπρόσθετα, πληκτρολόγιο, εκτυπωτή, αποθηκευτικό χώρο, οθόνη και κάμερα.

1.5: Ο πρώτος εμπορικός υπολογιστής ήταν ο PDP-1 της DEC, που υποστήριζε πλήθος επιπρόσθετων περιφερειακών. Εικόνα από Matthew Hutchinson - http://www.flickr.com/photos/hiddenloop/307119987/. Licensed under CC BY 2.0 via Commons.
Η τρίτη γενιά έχει αυξημένη αξιοπιστία και χρησιμοποιεί λειτουργικά συστήματα που επιτρέπουν την ταυτόγχρονη εκτέλεση πολλαπλών προγραμμάτων (ψευδο-παράλληλα), αφού έχει χρονοδρομολογητή. Επιτρέπει την καλύτερη χρήση των υπολογιστικών πόρων (αφού πολλαπλοί χρήστες μοιράζονται τους πόρους ταυτόγχρονα) και χρησιμοποιεί ολοκληρωμένα κυκλώματα σε πυρίτιο, δηλαδή κυκλώματα με πολλά τρανζίστορ που κατασκευάζονται στην ίδια ψηφίδα πυριτίου με φωτολιθογραφικές μεθόδους. Στη γενιά αυτή χρησιμοποιείται και η έννοια της ιδεατής μνήμης, όπου επιτρέπει την καλύτερη εκμετάλλευση της ελάχιστης μνήμης RAM, με τη χρήση τεχνικών σελιδοποίησης και επέκτασης σε δευτερεύουσα μνήμη (σκληρό δίσκο). Το πιο αντιπροσωπευτικό παράδειγμα αυτής της κατηγορίας είναι το IBM System/360 που είχε 512KB RAM, με συχνότητα εκτέλεσης τα 4Mhz. O επεξεργαστής που χρησιμοποιούσε βασίζονταν σε καταχωρητές και είχε διασωλήνωση, ενώ χρησιμοποιούσε μικροκώδικα μέσα στους επεξεργαστές για να παρέχει συμβατότητα προς άλλα μηχανήματα. Αυτός ο υπολογιστής, που είχε μέγεθος όσο ένα μεγάλο διπλό ψυγείο, χρησιμοποιήθηκε σε μια πιο ‘ενσωματωμένη’ έκδοση (σε μέγεθος μιας βαλίτσας) για να εγκατασταθεί στο διαστημόπλοιο Apollo 11 που προσελήνωσε η NASA το 1969. Εμφανίστηκε, όμως, η ανάγκη για αύξηση της αξιοπιστίας του συστήματος και, έτσι, η IBM με 4000 μηχανικούς, σχεδίασε το ενσωματωμένο αυτό σύστημα, με μέσο χρόνο μεταξύ βλαβών στις 25000 ώρες και πυκνότητα ολοκλήρωσης 40000 στοιχείων ανά κυβικό πόδι (για τρισδιάστατη κατασκευή). Το Apollo Guidance Computer ήταν το πρώτο ενσωματωμένο σύστημα που κατασκευάστηκε (Εικόνα 1.76).

1.6: Ο πιο χαρακτηριστικός υπολογιστής της 3ης γενιάς ήταν ο IBM S/360. Εικόνα από τον Ben Franske της wikipedia.org - Licensed under CC BY 2.5 via Commons
Στη γενιά αυτή ανήκουν όλοι οι υπολογιστές από τα μέσα της δεκαετίας του 1990 και μετά. Οι υπολογιστές αυτοί έχουν πολύ μεγάλη αξιοπιστία, πολλές δυνατότητες, μεγάλη πυκνότητα ολοκλήρωσης, τα λειτουργικά συστήματα έχουν πλούσια και φιλικά περιβάλλοντα εργασίας, υποστηρίζουν πλήθος τεχνικών για την καλύτερη εκμετάλλευση των πόρων του συστήματος, όπως εικονική μνήμη, ψευδο-παραλληλισμός εργασιών, πολλαπλούς ταυτόχρονους χρήστες, πρωτόκολλα άμεσης πρόσβασης σε υλικό κτλ. Εκτός από το λογισμικό, το υλικό έχει επίσης βελτιωθεί, ενσωματώνοντας όλες τις βέλτιστες τεχνικές των τελευταίων 50 χρόνων, χρησιμοποιώντας πολύ μεγάλες πυκνότητες ολοκλήρωσης και νέους τρόπους επικοινωνίας και διασύνδεσης. Δεν υπάρχουν κάποια χαρακτηριστικά παραδείγματα αυτής της γενιάς, αφού ανήκουν όλοι οι υπολογιστές από το 2000 και μετά.

1.7: Το πρώτο ενσωματωμένο σύστημα που κατασκευάστηκε ήταν το Apollo Guidance Computer που τοποθετήθηκε στο ομώνυμο διαστημόπλοιο για το ταξίδι στη Σελήνη. Περιείχε μια μικρογραφία ενός IBM S/360. Εικόνα από commons.wikimedia.org - Public Domain.
Τα όρια ανάμεσα στην 4η και την 5η γενιά είναι δυσδιάκριτα. Για την ώρα δεν έχει εμφανιστεί αυτή η γενιά, και έτσι υπάρχουν μόνο προβλέψεις (με τον ίδιο κίνδυνο που υπάρχει σε κάθε πρόβλεψη, που είναι να μη γίνει με αυτόν τον τρόπο). Πάντως, η γενιά αυτή χαρακτηρίζεται από ακόμη πιο φιλικά λειτουργικά συστήματα, ενώ το υλικό θα έχει πολύ ωραία εμφάνιση και στυλ. Οι υπολογιστές αυτοί θα είναι ενσωματωμένοι γύρω μας (ubiquitous computing, πανταχόθεν υπολογιστική δυνατότητα) και δε θα μπορούμε να τους προσδιορίσουμε επακριβώς. Δύο χαρακτηριστικά, επομένως, είναι ότι οι υπολογιστές θα είναι αόρατοι και διασυνδεδεμένοι. Η επικοινωνία θα γίνεται με την ομιλία και όχι με πληκτρολόγιο ή ποντίκι. Δε θα υπάρχει το χάος των καλωδίων, αφού όλα θα είναι ασύρματα. Οι έξυπνες τηλεοράσεις θα είναι τόσο αναπτυγμένες, που δε θα χρειάζεται, όπως τώρα, η σύνδεση της έξυπνης τηλεόρασης με ένα mediaPC. Ο χρήστης θα έχει μια οθόνη για υπολογιστή, αλλά δε θα υπάρχει κεντρική μονάδα, αφού θα είναι ενσωματωμένη μέσα στην οθόνη. Τα αρχεία, τα προγράμματα και τα παιχνίδια θα βρίσκονται στο διαδίκτυο (‘σύννεφο’ – cloud) και θα είναι προσβάσιμα από οποιοδήποτε διασυνδεδεμένη συσκευή. Οι συσκευές του χρήστη θα είναι τερματικές συσκευές για απομακρυσμένη σύνδεση σε κεντρικούς διακομιστές του διαδικτύου. Η γενιά αυτή τώρα αρχίζει να εμφανίζεται και θα σχεδιαστεί από τη νέα γενιά μηχανικών, ίσως και από κάποιους από τους αναγνώστες αυτού του βιβλίου.
Οι περισσότεροι χρήστες μπορούν να αναγνωρίσουν ένα υπολογιστικό σύστημα, όπως ένα επιτραπέζιο υπολογιστή, ένα διακομιστή ή ένα φορητό υπολογιστή. Όμως, υπάρχει και ένας άλλος τύπος υπολογιστικών συστημάτων που είναι αθέατος για αυτούς που δε το γνωρίζουν και είναι ο κόσμος των ενσωματωμένων συστημάτων. Ο κόσμος αυτός είναι πολύ μεγαλύτερος από τον κόσμο των τυπικών υπολογιστικών συστημάτων, αφού κατασκευάζονται ετησίως δισεκατομμύρια μονάδες ενσωματωμένων συστημάτων σε σύγκριση με τις τυπικές υπολογιστικές μονάδες που κυμαίνονται σε κάποια εκατομμύρια Έχει υπολογισθεί ότι σε ένα τυπικό σύγχρονο σπίτι υπάρχουν 1-2 υπολογιστές και πάνω από 50 ενσωματωμένα συστήματα. Τι είναι όμως τα Ενσωματωμένα Συστήματα (ΕΣ);
Ένας πρώτος ορισμός για τα ΕΣ, είναι ότι σε αυτά κατηγοριοποιείται οποιαδήποτε συσκευή η οποία περιλαμβάνει έναν προγραμματιζόμενο επεξεργαστή, ο οποίος δεν είναι ένας επεξεργαστής γενικού σκοπού. Βέβαια, υπάρχουν και άλλοι ορισμοί και περισσότερες λεπτομέρειες για το πως ορίζεται ένα ΕΣ, αλλά αυτές θα αναλυθούν στη συνέχεια.
Τα ενσωματωμένα συστήματα έχουν ίδια αρχιτεκτονική με τα τυπικά υπολογιστικά συστήματα. Όπως κάθε προγραμματιζόμενο ψηφιακό σύστημα, έτσι και αυτά έχουν έναν ή περισσότερους επεξεργαστές, μια μνήμη και διεπαφές εισόδου εξόδου 1.8. Τα διαφορετικά στοιχεία των ενσωματωμένων συστημάτων είναι ότι χρησιμοποιούν άλλες κατηγορίες επεξεργαστών (συνήθως με χαμηλές δυνατότητες για αυτό και ονομάζονται και μικροεπεξεργαστές), με περισσότερες δυνατότητες διασύνδεσης εισόδου/εξόδου και πολύ λιγότερους πόρους (π.χ. μνήμη). Ένα ενσωματωμένο σύστημα, μπορεί να θεωρηθεί ως μια μικρογραφία ενός τυπικού υπολογιστικού συστήματος. Οι διαφορετικές απαιτήσεις των ΕΣ, έχουν οδηγήσει στη διαφοροποίηση από τα τυπικά υπολογιστικά συστήματα, όπως θα συζητηθεί στις επόμενες ενότητες.
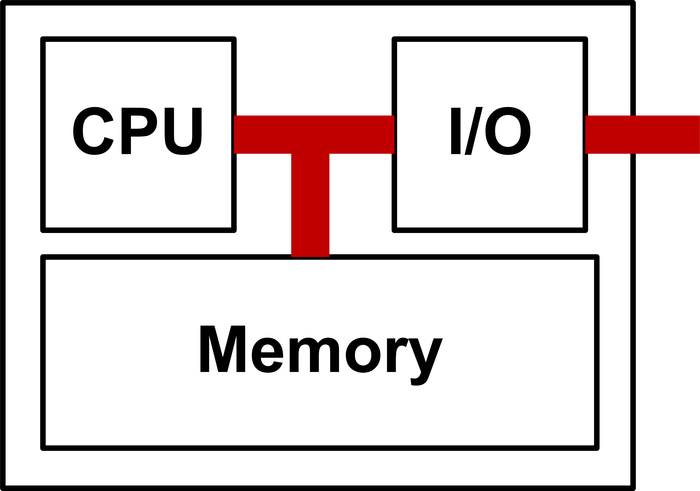
1.8: Ένα ΕΣ έχει, όπως και τα τυπικά υπολογιστικά συστήματα, έναν επεξεργαστή, μία μνήμη και τουλάχιστον έναν τρόπο επικοινωνίας με το περιβάλλον (είσοδο/έξοδο).
Κατά την τελευταία δεκαετία, τα ενσωματωμένα συστήματα, παρόλο που, αρχικά, είχαν εμφανιστεί ως συσκευές, ή προϊόντα χαμηλών επιδόσεων (όπως ρολόγια και ηλεκτρονικοί υπολογιστές τσέπης), σήμερα χρησιμοποιούνται σε αρκετά πολύπλοκες συσκευές με αυξημένες απαιτήσεις σε επιδόσεις, όπως π.χ. είναι τα φορητά τερματικά πολυμέσων, ή οι ψηφιακοί προσωπικοί βοηθοί. Έτσι, τα ενσωματωμένα συστήματα έχουν γίνει πλέον μέρος της καθημερινής ζωής των περισσότερων ανθρώπων (στις τεχνολογικά αναπτυγμένες κοινωνίες) και, μάλιστα, μερικές φορές τα χρησιμοποιούν χωρίς καν να το γνωρίζουν. Γι’ αυτό το λόγο, αρκετοί ερευνητές έχουν χαρακτηρίσει τα ενσωματωμένα συστήματα ως επανάσταση των ηλεκτρονικών συσκευών.
1.9: Τα ενσωματωμένα συστήματα βρίσκονται σχεδόν παντού.
Τα ενσωματωμένα συστήματα τα συναντάμε παντού. Αν και οι περισσότεροι από εμάς γνωρίζουμε ότι καθημερινά κατασκευάζονται εκατομμύρια υπολογιστές σε όλον τον κόσμο, αυτό που ίσως δεν ξέρουμε είναι ότι κατασκευάζονται πολλά περισσότερα (δισεκατομμύρια) ενσωματωμένα συστήματα για ένα πλήθος διαφορετικών λειτουργιών. Αυτό οφείλεται στο γεγονός ότι τα ενσωματωμένα συστήματα δεν τα βλέπουμε αφού είναι ‘ενσωματωμένα’ στις ψηφιακές συσκευές. Έχει υπολογιστεί ότι στις τεχνολογικά αναπτυγμένες κοινωνίες, αν και μόνον ένα ποσοστό 40% διαθέτει προσωπικό υπολογιστή, κάθε σπίτι έχει τουλάχιστον 30 ενσωματωμένα συστήματα.
Το Σχήμα 1.9 δείχνει κάποια τυπικά παραδείγματα από την καθημερινή μας ζωή στα οποία υπάρχουν ενσωματωμένα συστήματα. Συνήθως τα ενσωματωμένα συστήματα, σε αντίθεση με τους υπολογιστές γενικού σκοπού, χρησιμοποιούνται για εξειδικευμένες εφαρμογές και έχουν περιορισμένη χρήση. Ένας γενικός ορισμός θα μπορούσε να είναι ότι ενσωματωμένο σύστημα είναι κάθε ψηφιακό σύστημα που εκτελεί κάποια λειτουργία και δεν είναι προσωπικός υπολογιστής, φορητός υπολογιστής ή κεντρικός διακομιστής (mainframe). Η καλύτερη κατανόηση, όμως, του τι είναι ενσωματωμένο σύστημα, θα γίνει με την παρουσίαση κάποιων παραδειγμάτων. Μερικά παραδείγματα ενσωματωμένων συστημάτων είναι:
Τηλεοράσεις και βίντεο. Οι τηλεοράσεις έχουν ενσωματωμένους επεξεργαστές για να ελέγχουν την εικόνα, να ρυθμίζουν τα κανάλια, να εκτυπώνουν μηνύματα πάνω στην εικόνα, να απενεργοποιούν και να ενεργοποιούν τα κυκλώματα της τηλεόρασης.
Συσκευές τηλε-ελέγχου. Οι συσκευές τηλε-ελέγχου (telecontrol) έχουν ενσωματωμένους επεξεργαστές για να μετατρέπουν τις εντολές του χρήστη σε σήματα υπερύθρων για να ελέγχουν άλλες συσκευές.
Κινητά/Ασύρματα τηλέφωνα. Τα κινητά τηλέφωνα έχουν ενσωματωμένους επεξεργαστές για να διεκπεραιώνουν τις διαδικασίες αποκωδικοποίησης/κωδικοποίησης της φωνής, για να υλοποιούν το πρωτόκολλο επικοινωνίας και να εκτελούν τις πολύπλοκες εφαρμογές του τηλεφώνου.
Οχήματα. Όλα τα σύγχρονα αυτοκίνητα έχουν ένα πλήθος από ενσωματωμένους επεξεργαστές, είτε για την προστασία των επιβατών, είτε για βοηθητικές ενδείξεις, είτε για τη βελτίωση των συνθηκών οδήγησης.
Συσκευές νοικοκυριού. Οι σύγχρονες συσκευές νοικοκυριού (φούρνοι, πλυντήρια, ψυγεία κ.α.) έχουν ενσωματωμένους επεξεργαστές, για να προστατεύουν τα τρόφιμα ή τα ρούχα από λανθασμένες ρυθμίσεις, για να βελτιώνουν τις διαδικασίες συντήρησης ή μαγειρέματος και γενικά να αποτελούν τους βοηθούς της νοικοκυράς.
Αυτόματοι πωλητές. Οι αυτόματοι πωλητές έχουν ενσωματωμένους επεξεργαστές για να διεκπεραιώνουν τη λειτουργία της πώλησης αγαθών.
Εκτυπωτές/Φαξ. Οι συσκευές αυτές έχουν ενσωματωμένα συστήματα για τον έλεγχο της εκτύπωσης, της μετατροπής των δεδομένων σε εντολές προς τους μηχανισμούς εκτύπωσης, και της διασύνδεσης με άλλα συστήματα.
Φωτογραφικές μηχανές/Μηχανές βιντεολήψης. Και αυτές οι συσκευές έχουν ένα η παραπάνω ενσωματωμένα συστήματα για να ρυθμίζουν αυτόματα κάποια χαρακτηριστικά, ή να αποθηκεύουν με βέλτιστο τρόπο τα δεδομένα που λαμβάνουν.
Ένας λόγος που εξηγεί γιατί τα ενσωματωμένα συστήματα είναι τόσο δημοφιλή, είναι το ότι αποτελούνται από υλικό υψηλών επιδόσεων σε συνδυασμό με ένα εξειδικευμένο λογισμικό, ένας συνδυασμός που έχει πολύ μικρό χρόνο σχεδιασμού και εισόδου στην αγορά (short time to market).
Τα παραδείγματα της προηγούμενης ενότητας αποτελούν λίγα από τα πραγματικά υπαρκτά ενσωματωμένα συστημάτα. Είναι σαφές ότι υπάρχει μια δυσκολία στη διατύπωση ενός ορισμού που θα κάλυπτε όλες αυτές τις περιπτώσεις. Το πλήθος των ορισμών για τα ενσωματωμένα συστήματα είναι ίσως ανάλογο του αριθμού των σχεδιαστών που ασχολούνται με αυτά. Η λέξη ενσωματωμένο υποδηλώνει ότι το σύστημα είναι ‘ενσωματωμένο’ σε μια άλλη συσκευή και ότι η λειτουργία του δε θα τροποποιηθεί από τη στιγμή που θα γίνει διαθέσιμο στην αγορά. Αν και αυτός ο ορισμός φαίνεται σωστός, εντούτοις υπάρχουν κάποιες περιπτώσεις που προκαλούν σύγχυση. Για παράδειγμα, ένας προσωπικός υπολογιστής που εκτελεί μόνο ένα πρόγραμμα (π.χ. κιόσκι πολυμέσων) είναι ενσωματωμένο σύστημα; Ή ένας σύγχρονος προσωπικός ψηφιακός βοηθός που μπορεί να εκτελέσει ένα πλήθος προγραμμάτων αντίστοιχων με εκείνα του προσωπικού υπολογιστή (π.χ. αποστολή ηλεκτρονικής αλληλογραφίας, ηλεκτρονικός υπολογιστής, επεξεργασία κειμένου, λογιστικών φύλων, παιχνιδιών, αναπαραγωγή πολυμέσων, χρήση διαδικτύου) είναι ενσωματωμένο, αφού δεν ακολουθεί τον παραπάνω ορισμό;
Ένας πιο αυστηρός ορισμός είναι ότι τα ενσωματωμένα συστήματα είναι εξειδικευμένα συστήματα υπολογιστών, τα οποία είναι αφοσιωμένα στην εκτέλεση μιας συγκεκριμένης λειτουργίας. Είναι συνδυασμός υλικού και λογισμικού μέρους. Μάλιστα, είναι κοινή πρακτική για τα ενσωματωμένα συστήματα η τοποθέτηση πάνω στην ίδια επιφάνεια πυριτίου επεξεργαστικών πυρήνων, μνημών, περιφερειακών, διασυνδέσεων εισόδου/εξόδου και μερικές φορές αναλογικών/ψηφιακών κυκλωμάτων, καταλήγοντας σε ολόκληρα συστήματα πάνω στο ίδιο υλικό πυριτίου (System-on-Chip, SOC). Συνήθως, τα ενσωματωμένα συστήματα είναι τμήμα ενός μεγαλύτερου συστήματος ή προϊόντος.
Πάντως, υπάρχουν μερικά σαφή χαρακτηριστικά σχετικά με τα ενσωματωμένα συστήματα. Έτσι, τα ενσωματωμένα συστήματα έχουν μια συγκεκριμένη λειτουργία. Ένα ενσωματωμένο σύστημα σχεδιάζεται για μια μόνο λειτουργία και την εκτελεί αδιαλείπτως. Γι αυτό και μερικές φορές ονομάζεται και ‘αποκλειστικό’ σύστημα. Ένα ενσωματωμένο σύστημα δεν μπορεί να χρησιμοποιηθεί για λειτουργίες διαφορετικές από αυτές που έχει σχεδιαστεί να επιτελέσει. Για παράδειγμα, δε θα μπορούσαμε να χρησιμοποιήσουμε τον ενσωματωμένο επεξεργαστή ενός έξυπνου πλυντηρίου, για να αναπαράγουμε πολυμέσα. Επίσης, τα ενσωματωμένα συστήματα έχουν αυξημένους περιορισμούς. Αν και κάθε υπολογιστικό σύστημα έχει περιορισμούς στο σχεδιασμό, τα ενσωματωμένα συστήματα πρέπει να έχουν όσο το δυνατόν μικρότερο κόστος σχεδιασμού (αφού κατασκευάζονται σε μεγάλες ποσότητες και πρέπει να είναι φθηνά, ώστε να τα προτιμήσουν οι καταναλωτές), να έχουν υψηλές επιδόσεις (ώστε να ανταποκρίνονται αμέσως στις εντολές του χρήστη και να παρουσιάζουν μεγάλη διαδραστικότητα με αυτόν), να έχουν μικρό μέγεθος (αφού συχνά βρίσκονται σε φορητές συσκευές), να έχουν μικρή κατανάλωση ενέργειας (αφού από τη μια πρέπει να λειτουργούν συνέχεια και από την άλλη να μην απαιτείται κάποια μέθοδος ψύξης), και να έχουν μεγάλη αξιοπιστία (δηλαδή να έχουν απρόσκοπτη λειτουργία). Ακόμη, θα μπορούσαμε να πούμε ότι τα ενσωματωμένα συστήματα βασίζονται σε ένα πλήθος επεξεργαστών (από διάφορες εταιρείες) και αρχιτεκτονικών. Έτσι, ενώ ένας προσωπικός υπολογιστής συνήθως αποτελείται από επεξεργαστές της εταιρείας AMD, ή της INTEL, τα ενσωματωμένα συστήματα συναντώνται με ένα πλήθος επεξεργαστών. Ένα ακόμη χαρακτηριστικό των ενσωματωμένων συστημάτων είναι το λειτουργικό που έχουν, που σχεδόν πάντα είναι ένα λειτουργικό πραγματικού χρόνου (Real Time Operating System - RTOS). Σε αντίθεση με τα κλασσικά λειτουργικά συστήματα (π.χ. Windows, Linux, FreeBSD) που συναντώνται σε προσωπικούς υπολογιστές, τα λειτουργικά των ενσωματωμένων συστημάτων λαμβάνουν πάντα σοβαρά υπόψη τις προτεραιότητες των εφαρμογών, και δίνουν όλη την επεξεργαστική ισχύ τους σε εφαρμογές με υψηλή προτεραιότητα. Ο σχεδιαστής είναι υπεύθυνος για να δώσει (ή να αφαιρέσει) προτεραιότητες στις εφαρμογές του συστήματος. Αν το κάνει σωστά, τότε τα λειτουργικά συστήματα των ενσωματωμένων αποδεικνύονται πολύ πιο σταθερά και αξιόπιστα, σε σύγκριση με τα λειτουργικά των προσωπικών υπολογιστών. Μια άλλη διαφοροποίηση είναι ότι το λειτουργικό σύστημα των ενσωματωμένων συστημάτων έχει πολύ μικρό μέγεθος (μερικά KB) και για αυτό τον λόγο δεν είναι και φιλικό προς τον χρήστη (user friendly) ή τον προγραμματιστή. Τέλος, το λειτουργικό σύστημα και οι εφαρμογές των ενσωματωμένων συστημάτων βρίσκονται τοποθετημένα σε μνήμη ROM, που ονομάζεται και μνήμη εντολών. Αντιθέτως, το λειτουργικό σύστημα ενός προσωπικού υπολογιστή, ή ενός διακομιστή, βρίσκεται σε κάποια αποθηκευτική μονάδα δίσκου (λόγω του υπερβολικά μεγάλου μεγέθους που έχει) και είναι πολύ εύκολο να τροποποιηθεί. Για να αλλάξει το λογισμικό του ενσωματωμένου, πρέπει να αντικατασταθεί η μνήμη ROM με μια άλλη που έχει το καινούργιο πρόγραμμα, μια διαδικασία που απαιτεί εξειδικευμένο προσωπικό. Ασφαλώς, τα τελευταία χρόνια φαίνεται πως τροποποιείται το τοπίο ως προς τη μνήμη, και έτσι πολλά ΕΣ έχουν αντί για μνήμη ROM μνήμη FLASH ή EEPROM, η οποία επιτρέπει την εύκολη αναβάθμιση του συστήματος σε περίπτωση ανάγκης.
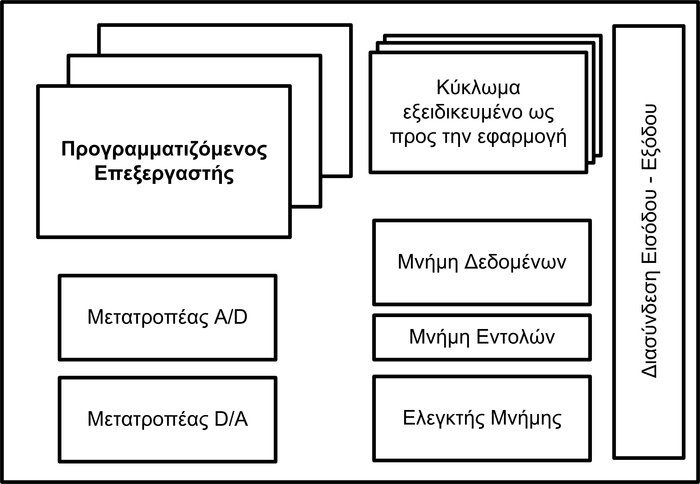
1.10: Ένα τυπικό ενσωματωμένο σύστημα αποτελείται από διακριτά δομοστοιχεία.
Ένα ενσωματωμένο σύστημα αποτελείται συχνά από πολλά τμήματα. Το σχήμα 1.10 παρουσιάζει τα δομοστοιχεία, που μαζί συνθέτουν ένα τυπικό ενσωματωμένο σύστημα. Συνήθως, ένα ενσωματωμένο σύστημα αποτελείται από έναν ή περισσότερους επεξεργαστές, από τους μετατροπείς αναλογικού σήματος σε ψηφιακό (A/D converter), από μετατροπείς ψηφιακού σήματος σε αναλογικό (D/A converter), από τη μνήμη εντολών που έχει το λογισμικό του συστήματος, τη μνήμη δεδομένων όπου αποθηκεύονται ή διαβάζονται δεδομένα, από κυκλώματα εξειδικευμένα ως προς την εφαρμογή που εκτελείται, από τον ελεγκτή της μνήμης δεδομένων και, τέλος, τη διασύνδεση εισόδου-εξόδου. Η μνήμη εντολών του επεξεργαστή βρίσκεται εκτός ολοκληρωμένου κυκλώματος, επειδή μπορεί να χρειαστεί να γίνει κάποια μικρή τροποποίηση της λειτουργίας του. Επίσης, η μνήμη δεδομένων αποτελείται συνήθως από μνήμη πάνω στο ολοκληρωμένο κύκλωμα και από κάποια παρασκηνιακή μνήμη.
Τα πιο σημαντικά δομοστοιχεία που έχει ένα ενσωματωμένο σύστημα είναι ο μικροεπεξεργαστής και η μνήμη. Η σημαντικότητά τους οφείλεται στο γεγονός ότι ο σχεδιασμός και η χρήση αυτών, επηρεάζουν σημαντικά την επίδοση και την κατανάλωση ενέργειας του συστήματος.
Ο μικροεπεξεργαστής έχει εξελιχθεί σημαντικά, και ενώ αρχικά αποτελούνταν από μερικές χιλιάδες τρανζίστορ, τώρα έχει κοντά στα 100-400 εκατομμύρια τρανζίστορ πάνω στο ίδιο ολοκληρωμένο κύκλωμα (για παράδειγμα Alpha 21364 [3], Pentium 4 [4], Athlon XP [5] και άλλοι). Η σημαντική πρόοδος που επιτελέστηκε στους επεξεργαστές, έκανε προσιτά στο καταναλωτικό κοινό (και με χαμηλό κόστος) τα ενσωματωμένα συστήματα. Η πολυπλοκότητα των παραπάνω επεξεργαστών, σε συνδυασμό με μονάδες μνήμης που περιέχουν πάνω από 256 εκατομμύρια στοιχεία στο ίδιο ολοκληρωμένο κύκλωμα, έχουν κάνει δυνατό το σχεδιασμό ολόκληρων συστημάτων ως ένα ολοκληρωμένο κύκλωμα (System On Chip, SOC). Αυτό ξεφεύγει από τον κλασσικό σχεδιασμό ASIC (Application-Specific Integrated Circuit), αφού για παράδειγμα είμαστε σε θέση να υλοποιήσουμε όλες τις λειτουργίες βασικής ζώνης ενός κινητού τηλεφώνου σε ένα μόνο ολοκληρωμένο κύκλωμα.
Σε αντίθεση με τον επεξεργαστή, το άλλο σημαντικό δομοστοιχείο ενός ενσωματωμένου συστήματος, δηλαδή η μνήμη εντός και εκτός ολοκληρωμένου κυκλώματος, δεν έχει ακολουθήσει τους ίδιους ρυθμούς ανάπτυξης. Αυτά τα δύο γεγονότα, έχουν δημιουργήσει ένα ολοένα αυξανόμενο χάσμα ανάμεσα στις συχνότητες λειτουργίας του επεξεργαστή και της μνήμης, το οποίο δημιουργεί αρκετά προβλήματα, ειδικά σε εφαρμογές που έχουν αυξημένες απαιτήσεις πρόσβασης στη μνήμη.
Όμως, μαζί με την ανάπτυξη των ενσωματωμένων συστημάτων υπήρξε και μια ανάπτυξη στην πολυπλοκότητα των εφαρμογών που εκτελούνται από αυτά. Αν και δεν είναι σαφές αν η τεχνολογία είναι αυτή που προώθησε την ανάπτυξη τόσο πολύπλοκων εφαρμογών, ή οι επεξεργαστικές απαιτήσεις των εφαρμογών πίεσαν τους μηχανικούς να σχεδιάσουν καλύτερα συστήματα· εντούτοις, έχουμε φτάσει σε μια εποχή που η επεξεργαστική πολυπλοκότητα των εφαρμογών είναι αρκετά μεγάλη. Μερικές φορές είναι αδύνατον κάποιες εφαρμογές να εκτελεστούν σε πραγματικό χρόνο με τη χρήση των σημερινών ενσωματωμένων συστημάτων.
Σε αυτή την ενότητα θα παρουσιάσουμε 3 σχεδιαστικά παραδείγματα για να γίνουν κατανοητές οι ανάγκες ελέγχου και υπολογισμών που διέπουν τα ενσωματωμένα συστήματα, με διάφορους βαθμούς πολυπλοκότητας. Ένα απλό ΕΣ που βρίσκεται σε μια επαγωγική κουζίνα, ένα μεσαίας πολυπλοκότητας ΕΣ που βρίσκεται μέσα σε ένα ψηφιακό καταγραφέα αυτοκινήτου (CAR DVR) και ένα υψηλής πολυπλοκότητας ΕΣ που βρίσκεται μέσα σε ένα αυτοκίνητο.
Σε μια σύγχρονη οικία, κάποιος μπορεί να διακρίνει ενσωματωμένα συστήματα σε πλήθος συσκευών. Μια από αυτές τις συσκευές είναι η επαγωγική εστία (Εικόνα 1.11). Στο παρελθόν χρησιμοποιούνταν κεραμικές κουζίνες με περιστροφικούς διακόπτες, οι οποίες ασφαλώς δεν ήταν ενσωματωμένα συστήματα. Η ρύθμιση της θερμοκρασίας γίνονταν με κάποιο διμεταλλικό έλασμα που μόλις ζεσταίνονταν σε κάποια θερμοκρασία, έκοβε το ρεύμα που διέρρεε από την αντίσταση. Ο περιστροφικός διακόπτης ρύθμιζε την απόσταση από το διμεταλλικό έλασμα και την επαφή στην αντίσταση. Δεν υπήρχε κάποιο πρόγραμμά ή κάποια παραπάνω ανάγκη. Προκειμένου οι κατασκευαστές να βελτιώσουν το σχεδιασμό της κουζίνας και να προσθέσουν στυλ, αλλά ταυτόγχρονα να δώσουν και παραπάνω δυνατότητες ξανασχεδίασαν το σύστημα με τη χρήση ενός ΕΣ.
Οι δυνατότητες που παρέχει το νέο ΕΣ είναι οι εξής:
Τα κουμπιά δεν είναι περιστροφικά, αλλά αισθητήρια απόστασης τα οποία κρύβονται κάτω από το γυαλί της εστίας και εκπέμπουν μια υπεριώδη ακτινοβολία, όπου ανιχνεύουν την αντανάκλαση. Ο χρήστης αρκεί να τοποθετήσει το δάκτυλο πάνω από το αισθητήριο και μέσω της αντανάκλασης στο δάχτυλο του θα ανιχνευθεί η επιλογή. Αντικαταστάθηκαν λοιπόν, οι περιστροφικοί διακόπτες με αυτούς τους οπτικούς αισθητήρες ανάκλασης (reflective optical sensors), εμείς θα τους καλούμε διακόπτες ανάκλασης ή απλώς διακόπτες.
Επιλογή του ‘ματιού’ της κουζίνας που θα θερμανθεί.
Επιλογή θερμοκρασίας μέσω κουμπιών αύξησης ή μείωσης (από 0, που είναι σβηστό, έως 9 που είναι το μέγιστο), για το συγκεκριμένο μάτι.
Ηχητική ένδειξη για κάθε επιλογή με beeper (κάθε φορά που ο χρήστης επιλέγει κάτι).
Φωτεινή ένδειξη με οθόνες 7 στοιχείων (7 segments display) για κάθε μάτι που δείχνει τον αριθμό που έχει επιλεγεί, ενώ επίσης χρησιμοποιείται η τελεία για να σηματοδοτεί το μάτι που έχει επιλεχθεί.
Ρύθμιση της θερμοκρασίας μέσω PWM (pulse width modulation, διαμόρφωση πλάτους παλμού), όπου αναλόγως της επιλογής της θερμοκρασίας, διαμορφώνεται κατάλληλα ο κύκλος ενεργοποίησης και απενεργοποίησης. Π.χ. για θερμοκρασία στο επίπεδο 1, σημαίνει ότι η αντίσταση στο μάτι θα είναι 10% ενεργοποιημένη και 90% απενεργοποιημένη, ενώ στη μέγιστη βαθμίδα 9, θα είναι 100% ενεργοποιημένη.
Κλείδωμα των επιλογών μέσω ειδικού διακόπτη, όπου απαιτείται παρατεταμένη επιλογή του κατάλληλου διακόπτη για να αρθεί το κλείδωμα. Το κλείδωμα χρησιμοποιείται για να ακυρώνει τις λειτουργίες των άλλων διακοπτών, ώστε να μη πατηθούν κατά λάθος (π.χ. αν αφήσει κάποιος κάτι στην κουζίνα).
Οι απαιτήσεις του προγράμματος δε συνοδεύονται από αυστηρούς χρονικούς περιορισμούς (δεν απαιτείται να ενεργοποιηθεί η αντίσταση μέσα σε XX ns, αν ενεργοποιηθεί λίγο αργότερα δεν υπάρχει πρόβλημα), ούτε από ενεργειακούς περιορισμούς (η εστία τροφοδοτείται από εναλλασσόμενο ρεύμα 230V, και το 99% καταναλώνεται στις αντιστάσεις των ματιών), ούτε από θέμα κόστους (το κόστος των ηλεκτρονικών στοιχείων είναι αμελητέο ως προς την υπόλοιπη κατασκευή). Γενικά, ο σχεδιασμός ενός ΕΣ για αυτό το σύστημα είναι αρκετά απλός και εύκολος. Η μόνη απαίτηση είναι ο μικροεπεξεργαστής να έχει αρκετές εισόδους/εξόδους για να καλύψει τις ανάγκες.

1.11: Μια σύγχρονη επαγωγική εστία φέρει ένα ενσωματωμένο σύστημα.
Επειδή οι ανάγκες είναι αρκετά απλές, συνήθως οι κατασκευαστές επιλέγουν τον πιο απλό επεξεργαστή, έναν 8bit στα 16Mhz (συγκρίνετε τους επεξεργαστές στους επιτραπέζιους ή φορητούς υπολογιστές που διαχειρίζονται 64bit στα 1.5 με 2 Ghz). Ο επεξεργαστής θα πρέπει να έχει εσωτερική μνήμη FLASH για να μπορεί να διατηρεί το πρόγραμμα (32ΚΒ μνήμη FLASH είναι υπεραρκετά). Η μνήμη θα μπορούσε να είναι και εξωτερική, αλλά δεν υπάρχει διαφορά στο κόστος και προτιμάται ο επεξεργαστής να έχει εσωτερική μνήμη. Η μνήμη RAM του μικροεπεξεργαστή αρκεί να είναι κάποια Byte (π.χ. 1 ή 2 KB είναι αρκετά). Ως προς τους ακροδέκτες του μικροεπεξεργαστή, κάθε οθόνη 7 στοιχείων μαζί με την τελεία, απαιτεί 8 εξόδους, το beeper απαιτεί 1 έξοδο, κάθε διακόπτης απαιτεί 1 είσοδο, και κάθε αντίσταση έχει ένα ρελέ που ελέγχει τη ροή του ρεύματος, οπότε συνολικά ο μικροεπεξεργαστής για 2 μάτια πρέπει να υποστηρίζει 2*8 + 1 +2 εξόδους και 6 εισόδους, συνολικά 23. Μάλιστα, για να μειωθούν οι απαιτήσεις σε ακροδέκτες, μπορούν να χρησιμοποιηθούν 2 των 8bit εξωτερικοί σειριακοί καταχωρητές παράλληλης εξόδου συνδεδεμένοι σε σειρά, που χρησιμοποιούν 3 ακροδέκτες από τον μικροεπεξεργαστή (και όχι 2*8), οπότε οι συνολικές ανάγκες του συστήματος είναι 3 + 1 + 2+ 6 = 12 ακροδέκτες. Εκτός από τις παραπάνω συνδέσεις, θα απαιτηθούν και οι κατάλληλες αντιστάσεις pull-up ή pull-down, o σχεδιασμός του PCB (printed circuit board, τυπωμένη πλακέτα κυκλώματος), η δρομολόγηση των ασθενών και ισχυρών ρευμάτων και η κατάλληλη θωράκιση από παρεμβολές για να είναι σύμφωνη με το πρότυπο της ηλεκτρομαγνητικής θωράκισης. Ασφαλώς δε χρειάζεται λειτουργικό σύστημα το ΕΣ, και αρκεί να γραφεί ένα πρόγραμμα είτε σε γλώσσα μηχανής, είτε στην πιο φιλική C, όπως συνηθίζεται Το πρόγραμμα θα αποτελείται από έναν αέναο βρόχο που θα κάνει διαδοχική σταθμοσκόπηση των επιλογών των διακοπτών, θα ενημερώνει κατάλληλα τις οθόνες 7 στοιχείων, θα ενεργοποιεί το beeper, και θα διαμορφώνει μέσω PWM τη θερμοκρασία.
Ο κατασκευαστής της κουζίνας μπορεί να παρέχει για την ίδια κουζίνα πολλαπλές δυνατότητες. Εκτός από το παραπάνω που είναι το βασικό μοντέλο, θα μπορούσε να προσθέσει ένα δομοστοιχείο bluetooth (που απαιτεί 2 ακροδέκτες RX/TX, για σειριακή επικοινωνία με τον μικροεπεξεργαστή), και να δίνει μια εφαρμογή για έξυπνα κινητά, ώστε η ρύθμιση της θερμοκρασίας να γίνεται με ακόμη πιο φιλικό τρόπο ή θα μπορούσε να τοποθετήσει ένα δομοστοιχείο επικοινωνίας wifi 802.11 για σύνδεση στο διαδίκτυο, ώστε να στέλνει ενημερώσεις με email ή να υπάρχει έλεγχος από κεντρικό website. Ασφαλώς, το κάθε μοντέλο επαγωγικής κουζίνας θα έχει και την ανάλογη τιμή, που συνήθως είναι πολλαπλάσια από το κόστος του υλικού (π.χ. ένα δομοστοιχείο bluetooth κοστίζει 5 ευρώ, ενώ ο κατασκευαστής της κουζίνας μπορεί να χρεώνει αυτό το μοντέλο 150 ευρώ παραπάνω από το βασικό). Βέβαια το πως διαμορφώνεται το κόστος αποτελεί μελέτη της επόμενης ενότητας.
Ένα αρκετά δημοφιλές ΕΣ είναι ο ψηφιακός καταγραφέας υψηλής ανάλυσης (High Definition DVR), ο οποίος τοποθετείται με μια βεντούζα στο παρμπρίζ του αυτοκινήτου και καταγράφει τη διαδρομή. Αυτή η καταγραφή μπορεί να χρησιμοποιηθεί ως αποδεικτικό στοιχείο σε περίπτωση τρακαρίσματος, για να καθοριστεί ο υπαίτιος. Σε σύγκριση με το προηγούμενο ΕΣ, αυτό έχει υψηλότερες απαιτήσεις, όπως φαίνονται από τη λίστα που ακολουθεί:
Αποθήκευση VIDEO σε υψηλή ανάλυση σε κάρτα Micro SD.
Συμπίεση VIDEO κατά H.234 σε πραγματικό χρόνο για μείωση των απαιτήσεων χώρου.
Χαμηλή κατανάλωση ενέργειας (έως 1 A στα 12V, όσο παρέχει η σύνδεση του εσωτερικού αναπτήρα αυτοκινήτου).
Πλήθος κουμπιών ελέγχου.
Ρολόι πραγματικού χρόνου με διατήρηση της ημερομηνίας.
Εσωτερική μπαταρία LiPO με κύκλωμα φόρτισης μέσω mini USB.
Μενού με ποικίλες ρυθμίσεις ποιότητας και διαχείρισης της κάρτας SD.
Μετατροπέας Αναλογικού σε Ψηφιακό, για την διασύνδεση με τον οπτικό αισθητήρα CMOS ή CCD.
Υποστήριξη LCD (liquid crystal display) για την εμφάνιση του video και των ρυθμίσεων.
Δημιουργία συμβατού συστήματος αρχείου FAT στην κάρτα SD, ώστε να μπορεί να διαβαστεί από ένα PC
Υποστήριξη για USB Mass Storage Device όταν συνδέεται σε ένα PC
Πολύ μικρό μέγεθος, ώστε να μην επηρεάζει το οπτικό πεδίο του χρήστη (αφού τοποθετείται στο μπροστινό παρμπρίζ).

1.12: Ένας ψηφιακός καταγραφέας αυτοκινήτου υψηλής ανάλυσης αποτελεί ένα μεσαίας πολυπλοκότητας ΕΣ.
Όπως φαίνεται από τις απαιτήσεις, το σύστημα αυτό είναι πιο πολύπλοκο από το απλό ΕΣ που χρησιμοποιείται σε μια επαγωγική κουζίνα. Η πιο σημαντική απαίτηση είναι η ύπαρξη αυστηρών περιορισμών χρόνου και συγκεκριμένα η ανάγνωση μιας εικόνας υψηλής ανάλυσης (1080p, δηλαδή 1920x1080 στα 3x8=24 bit), σε ρυθμό 25 FPS (frames per second, εικονοστοιχεία το δευτερόλεπτο), συμπίεση και αποθήκευση σε ένα μέσο αποθήκευσης. O επεξεργαστής θα πρέπει να είναι 32bit (διαφορετικά με 8bit θα υπήρχε μεγάλη καθυστέρηση) και για να επιτευχθεί η χαμηλή κατανάλωση και ο μικρός όγκος, θα πρέπει να ενσωματώνει τις περισσότερες λειτουργίες πάνω στο ίδιο ολοκληρωμένο κύκλωμα (SoC, System On Chip - σύστημα πάνω στο ίδιο chip). Θα πρέπει να χρησιμοποιηθεί είτε ένας δυνατός 32bit επεξεργαστής, συνήθως της εταιρίας ARM, ή ένας άλλος 32bit επεξεργαστής, με έναν επιταχυντή υλικού για τη λειτουργία της συμπίεσης Η.234 σε πραγματικό χρόνο. Θα πρέπει το ίδιο SoC να υποστηρίζει USB για mass storage device (υποστήριξη σύνδεσης σε υπολογιστή ως δίσκο), και να έχει έναν ελεγκτή για μνήμες SD. Για να διατηρείται η ώρα, θα πρέπει να υπάρχει ένα κύκλωμα RTC (real time clock, ρολόι πραγματικού χρόνου) στο ίδιο το SoC (ή εκτός), το οποίο θα τροφοδοτείται από συγκεκριμένο ακροδέκτη του επεξεργαστή από τη μπαταρία της συσκευής και θα συνδέεται μέσω ενός διαύλου με τον επεξεργαστή. Κάθε φορά που ο επεξεργαστής ζητάει να ενημερωθεί για την τρέχουσα ώρα (π.χ. κατά την ενεργοποίηση του συστήματος), θα δίνεται αυτή η ενημέρωση, όπως επίσης θα υπάρχει δυνατότητα της ρύθμισης του RTC σε μια συγκεκριμένη ώρα. Το SoC θα πρέπει να έχει και τον ελεγκτή για το LCD, ενώ τα κουμπιά θα πρέπει να συνδεθούν είτε κατευθείαν σε ακροδέκτες του SoC, είτε σε ένα ξεχωριστό περιφερειακό Ι/Ο, που συνδέεται με τον επεξεργαστή. Επίσης, απαιτούνται πυκνωτές και αντιστάσεις για το κύκλωμα φόρτισης και προστασίας της μπαταρίας, όπως και για τη διασύνδεση των περιφερειακών. Αυτό το ΕΣ μπορεί να υλοποιηθεί είτε αποκλειστικά σε C χωρίς λειτουργικό σύστημα, το οποίο είναι αρκετά πολύπλοκο αλλά όχι αδύνατο, αφού θα πρέπει να υλοποιήσει ο σχεδιαστής το λογισμικό οδήγησης για κάθε ελεγκτή (LCD, H.234, CCD/CMOS, κ.α.), να σχεδιάσει τη γραφική διεπαφή χρήστη και να υλοποιήσει το λογισμικό τμήμα του USB, για τη διασύνδεση με τον υπολογιστή, ώστε να φαίνεται ως μια συσκευή USB Mass Storage Device. Αυτή η σχεδίαση που ονομάζεται ‘bare metal programming’, είναι η πιο δύσκολη, αλλά έχει ως αποτέλεσμα την καλύτερη εκμετάλλευση των πόρων. Μια εναλλακτική σχεδίαση αποτελεί η χρήση ενός λειτουργικού συστήματος, π.χ. Linux, που έχει έτοιμες βιβλιοθήκες για πολλές λειτουργίες. Το μειονέκτημα με το λειτουργικό σύστημα είναι ότι ίσως απαιτηθεί πιο γρήγορος επεξεργαστής και περισσότερη μνήμη, αφού το ΛΣ θα χρησιμοποιεί κάποιους από τους πόρους του συστήματος. Η ανάπτυξη του λογισμικού όταν υπάρχει ένα ΛΣ γίνεται πολύ πιο εύκολη, αφού το ΛΣ παρέχει στον προγραμματιστή μια αφαιρετική εικόνα για το hardware, και έτσι δε χρειάζεται να γνωρίζει λεπτομέρειες σχετικά με το υλικό, αρκεί να χρησιμοποιεί τις τυπικές διεπαφές του ΛΣ.
Ένα από τα πιο σύνθετα ΕΣ βρίσκεται σε ένα σύγχρονο αυτοκίνητο. Θα πρέπει να σημειωθεί ότι σε αυτή την περίπτωση δεν υπάρχει μόνο ένα ΕΣ, αλλά πλήθος ΕΣ, που συνεργάζονται μεταξύ τους για την επίτευξη του επιθυμητού αποτελέσματος, το οποίο είναι η επίτευξη υψηλής ασφάλειας και άνεσης για τους επιβάτες. Επειδή όλα αυτά τα συστήματα συνεργάζονται μεταξύ τους, εμείς θα τα θεωρήσουμε ως ένα μεγάλο ΕΣ. Επιπρόσθετα, τα ΕΣ γνώρισαν μεγάλη ανάπτυξη κατά τη δεκαετία του 1970, όταν προέκυψε η πετρελαϊκή κρίση και έτσι οι κατασκευαστές αυτοκινήτων ερεύνησαν πως θα μπορούσαν να μειώσουν την κατανάλωση καυσίμου, και που το πέτυχαν με την τοποθέτηση ψηφιακών συστημάτων μέσα στο αυτοκίνητο που ρύθμιζε κάθε στάδιο λειτουργίας του κινητήρα και βελτιστοποιούσε την καύση.
Οι λειτουργίες του ΕΣ σε ένα σύγχρονο αυτοκίνητο είναι:
Βελτιστοποίηση της καύσης καυσίμου.
Έλεγχος οδήγησης cruise (adaptive cruise control, ACC).
Προειδοποίηση σύγκρουσης (forward collision warning, FCW).
Προειδοποίηση αποχώρησης λωρίδας (Lane Departure Warning, LDW).
Σύστημα βοήθειας στο παρκάρισμα (Park Assist System, PAM).
Σύστημα παρακολούθησης πίεσης ελαστικών (Time Pressure Monitoring System, TPMS).
Ξεκλείδωμα χωρίς κλειδί (Remote Keyless Entry).
Διασύνδεση με bluetooth, wifi, GSM.
Πλοήγηση με GPS.
Έλεγχος ραδιόφωνου (π.χ. όταν λαμβάνει μια κλήση μέσω bluetooth να μειώνεται η ένταση).
Σύστημα αντιμπλοκαρίσματος τροχών (Antilock braking system, ABS).
Έλεγχος ταχύτητας (Wheel Speed Sensor).
Κάμερα οπισθοπορείας (rear view camera).
Ηλεκτρικό Τιμόνι (electric power steering) για τη βοήθεια στο παρκάρισμα.
Έλεγχος αερόσακων (airbags).
Έλεγχος ζώνης (seatblet pretensionner).
Μπροστινό Radar για άμεση ενεργοποίηση φρένων.
Διαγνωστικά αισθητηρίων (sensor diagnostics).
Multimedia System
.....(και πολλά άλλα)
Είναι εμφανές ότι ένα τέτοιο σύστημα έχει πολλές και πολύπλοκες απαιτήσεις, άλλες που απαιτούν απόκριση σε πραγματικό χρόνο (π.χ. τo ABS), και άλλες που είναι πιο ανεκτικές ως προς τις αποκρίσεις (π.χ. GPS). Επίσης, είναι εμφανές ότι ένα τέτοιο σύστημα δε μπορεί να υποστηριχθεί από ένα μόνο επεξεργαστή, αλλά απαιτούνται πολλαπλοί επεξεργαστές, διάσπαρτοι σε διάφορα σημεία του οχήματος, οι οποίοι επικοινωνούν με ένα ή περισσότερα δίκτυα διασύνδεσης (θα αναλύσουμε τα δίκτυα διασύνδεσης σε άλλο κεφάλαιο). Το πιο δημοφιλές δίκτυο διασύνδεσης για τα οχήματα, είναι το CAN (controller area network, δίκτυο περιοχής ελεγκτών). Συνήθως, τα αυτοκίνητα έχουν ένα ή δυο δίκτυα CAN. Σε περίπτωση που έχουν δυο δίκτυα CAN, αυτά χρησιμοποιούνται ως εξής: Στο πρώτο δίκτυο CAN τοποθετούνται τα αισθητήρια και οι συσκευές δράσης που έχουν αυστηρούς περιορισμούς χρόνου (δηλαδή, από τη στιγμή που ανιχνευτεί μια δυσλειτουργία, θα πρέπει ο επεξεργαστής να τη χειριστεί άμεσα και να δώσει την κατάλληλη εντολή), όπως ABS, έλεγχος πέδησης, έλεγχος τιμονιού, έλεγχος φώτων, έλεγχος κινητήρα κ.α. Στο δεύτερο δίκτυο CAN τοποθετούνται αισθητήρια και οι συσκευές δράσεις (κυρίως ενδεικτικές λυχνίες) που έχουν πιο χαλαρούς περιορισμούς. Για παράδειγμα, το αισθητήριο των θυρών (ανοιχτές/κλειστές), της πρόσδεσης της ζώνης, του air-condition και των αισθητηρίων θερμοκρασίας κ.ο.κ. Με την πάροδο του χρόνου οι κατασκευαστές τοποθετούν όλο και περισσότερα αισθητήρια πάνω στους διαύλους CAN προκειμένου να κάνουν όσο το δυνατόν πιο φιλικά στη χρήση και στην οδήγηση, και πιο ασφαλή αυτοκίνητα, εμπλουτίζοντας τα με νέες δυνατότητες. Έτσι, ενώ στο παρελθόν τα αισθητήρια συνδέονταν άμεσα με τις ενδεικτικές λυχνίες στο ταμπλό, τώρα ενημερώνουν τον αντίστοιχο επεξεργαστή (που στην αυτοκινητοβιομηχανία ονομάζεται ECU, engine control unit- μονάδα ελέγχου μηχανής), και αυτός αποφασίζει τι θα εκτελεστεί. Για ένα τέτοιο ΕΣ απαιτείται ένα λειτουργικό σύστημα που σέβεται τις αυστηρές προθεσμίες (μια τυπική επιλογή είναι το λειτουργικό σύστημα QNX Neutrino RTOS), επεξεργαστές 32bit με γρήγορη εξυπηρέτηση διακοπών (π.χ. ARM), με μονάδα διαχείρισης μνήμης (MMU) ή μονάδα προστασίας μνήμης (MPU), αφού θα υπάρχουν αρκετές διεργασίες και θα πρέπει να είναι απομονωμένες, ώστε η μια να μη ‘μολύνει’ το χώρο μνήμης της άλλης, αρκετά μέτρα καλώδια για τα αισθητήρια, ένα λειτουργικό σύστημα για το 2ο δίκτυο (π.χ. Linux), που θα σχεδιαστούν οι γραφικές διεπαφές, και ο έλεγχος της τηλεματικής (τηλεματική είναι η αποστολή μέσω ασύρματου δικτύου δεδομένων σε απομακρυσμένη τοποθεσία· στο όχημα μπορεί να χρησιμοποιηθεί π.χ. για την αυτόματη αποστολή της θέσης στις πρώτες βοήθειες σε περίπτωση σύγκρουσης). Επίσης, θα πρέπει κάθε ηλεκτρονικό στοιχείο και αισθητήριο να υποστηρίζει αυτο-διάγνωση και ενημέρωση λειτουργίας και σε περίπτωση προβλήματος να μπορεί να μεταβεί σε μια ασφαλή κατάσταση, ώστε να μην επηρεάζει το υπόλοιπο όχημα. Σύμφωνα με τη νομοθεσία αρκετών χωρών, είναι υποχρεωτικό να ενημερώνεται ο οδηγός μέσω κατάλληλης λυχνίας MIL (malfunction indicator lamp, λυχνία ένδειξης δυσλειτουργίας) για την ύπαρξη οποιουδήποτε προβλήματος. Συστήματα άκρως απαραίτητα για την ασφάλεια, θα πρέπει να έχουν πλεονάζουσες (redundancy) επικοινωνίες, ώστε αν παρουσιάσει πρόβλημα το ένα κανάλι επικοινωνίας, να μπορεί να χρησιμοποιηθεί μια εναλλακτική διαδρομή. Το ΕΣ θα πρέπει να έχει επίσης μνήμη FLASH ή EEPROM, για να αποθηκεύει σε μη πτητικό μέσο (δηλαδή, που δε χάνει τα δεδομένα αν διακοπεί το ρεύμα), εκτός από τις ρυθμίσεις του χρήστη και το αρχείο καταγραφής βλάβης (fault log file), ώστε ο μηχανικός να μπορεί με το κατάλληλο μηχάνημα να ενημερωθεί με λεπτομέρειες για το πότε και υπό ποιες συνθήκες παρουσιάστηκε το σφάλμα. Τα αισθητήρια για το σύστημα των αυστηρά χρονικών προδιαγραφών, θα πρέπει να συνδέονται σε ξεχωριστή γραμμή διακοπής (interrupt line), ώστε να εξυπηρετούνται άμεσα αν χρειαστεί, ενώ τα αισθητήρια στο 2ο δίκτυο θα μπορούσαν να επικοινωνούν με κάποια διεργασία τύπου δαίμονα (daemon) που εκτελείται στο λειτουργικό σύστημα. Ασφαλώς, θα πρέπει να εξεταστεί ο χρόνος χείριστης εξυπηρέτησης (worst case service time), και να ελαχιστοποιηθεί, ώστε να μη διακυβεύεται η ασφάλεια. Η ανάπτυξη του λογισμικού θα πρέπει να γίνει σε μια γλώσσα υψηλού επιπέδου, εκτός από τις λειτουργίες που απαιτούν ελάχιστο χρόνο εξυπηρέτησης και μπορούν να προγραμματιστούν στη γλώσσα μηχανής του συγκεκριμένου επεξεργαστή.
Ένα σημαντικό στοιχείο για το σχεδιασμό των ΕΣ, όπως και κάθε άλλου προϊόντος, είναι το κόστος. Το συνολικό κόστος είναι το άθροισμα δυο επιμέρους κοστών: το μη επαναλαμβανόμενο κόστος μηχανικής (non recurrent engineering cost, NRE) και το κόστος μονάδας (unit cost).
Το NRE κόστος
περιέχει το κόστος που έχει δαπανήσει η εταιρία για την ανάπτυξη του συγκεκριμένου προϊόντος σε πληρωμές προσωπικού, σε σεμινάρια μηχανικών, σε αγορά ποικιλίας υλικών και δημιουργίας πρωτοτύπων, σε δοκιμές ποιότητας ή ηλεκτρομαγνητικής συμβατότητας, σε έξοδα των γραφείων (φως, νερό, θέρμανση, αναλώσιμα), σε ειδικό εξοπλισμό που απαιτήθηκε για τη δημιουργία του προϊόντος (π.χ. κάποιο εξειδικευμένο παλμογράφο), την αγορά δημοσιεύσεων ή πατεντών κ.ο.κ. Το κόστος αυτό συγκεντρώνει όλα τα παραπάνω και μόλις αποφασιστεί η μαζική κατασκευή του προϊόντος, τότε μπορεί να υπολογιστεί, ώστε να διευκρινιστεί και η τιμή πώλησης στο ράφι.
Το κόστος μονάδας είναι ένα επαναλαμβανόμενο κόστος και εμπεριέχει όλα τα επιμέρους κόστη για την αγορά των υλικών, την αποστολή στα κατάλληλα εργοστάσια, το τύπωμα των πλακετών, την συναρμολόγηση, τη δοκιμή του κάθε προϊόντος, τη μισθοδοσία όσων ασχολούνται με την κατασκευή (ή σε περίπτωση που έχει γίνει εξωτερική ανάθεση (outsourcing) το κόστος αυτής, το πακετάρισμα και την αποστολή στις κεντρικές αποθήκες. Αυτό το κόστος πληρώνεται κάθε φορά που κατασκευάζεται ένα τέτοιο προϊόν. Το κόστος αυτό μεταβάλλεται κάθε φορά ανάλογα με την ισοτιμία των νομισμάτων (αν κάποια πληρωμή γίνεται σε άλλο νόμισμα, π.χ. σε κινέζικα γουάν), ανάλογα με τον προμηθευτή (μερικές φορές επιλέγονται πιο οικονομικοί προμηθευτές για να μειώσουν το κόστος οι εταιρίες), ή ανάλογα και με την ποσότητα των μονάδων που κατασκευάζονται (άλλο κόστος έχει η κατασκευή 100 πλακετών και άλλο για
, σύμφωνα με την οικονομία κλίμακας).
Αφού υπολογισθούν αυτά τα 2 κόστη η εταιρία αποφασίζει το επιθυμητό περιθώριο κέρδους, έστω . Κάποιες εταιρίες π.χ. αρκετά εξελιγμένων τηλεφώνων που τιμολογούν τα κινητά τους πάνω από 600 ευρώ, έχουν ένα περιθώριο κέρδους περίπου 50%. Ο υπολογισμός της τιμής πώλησης του προϊόντος υπολογίζεται από την εξίσωση:
Για να μειωθεί το κόστος NRE, μια πολύ χρήσιμη τακτική είναι η επαναχρησιμοποίηση αν όχι ολόκληρου του σχεδιασμού, όσο το δυνατόν μεγαλύτερου τμήματος, ώστε το NRE κόστος να διαιρεθεί σε πολλά προϊόντα. Έτσι, είναι πολύ συχνό το φαινόμενο της ίδιας βασικής αρχιτεκτονικής, να επαναχρησιμοποιείται σε πολλά προϊόντα με μόνη διαφορά την προσθήκη 1-2 νέων στοιχείων και τη συγγραφή κατάλληλου κώδικα. Ένα παράδειγμα είναι π.χ. μια επαγωγική κουζίνα χωρίς ώρα και η ίδια επαγωγική κουζίνα με δυνατότητα εμφάνισης της ώρας σε μια οθόνη και χρονοπρογραμματισμό μαγειρέματος (η μόνη διαφορά του βασικού σχεδιασμού με αυτόν, είναι ότι έχει προστεθεί ένα σύστημα RTC με κόστος USD$1, πέντε νέες οθόνες 7-στοιχείων για την εμφάνιση της ώρας, 2-3 κουμπιά και το κατάλληλο λογισμικό· έτσι, το NRE κόστος διαιρείται σε 2 προϊόντα και άρα είναι μικρότερο ανά προϊόν.
Με τον όρο χρόνο εισαγωγής του προϊόντος στην αγορά (time-to-market), εννοούμε το χρονικό διάστημα από τη σύλληψη της ιδέας ως την τοποθέτηση του προϊόντος στο ράφι. Αυτό το χρονικό διάστημα καλύπτει όλες τις φάσεις έρευνας αγοράς, μοντελοποίησης, σχεδιασμού, κατασκευής και θα πρέπει να είναι αρκετά μικρό. Έχει υπολογιστεί ότι για τα ΕΣ θα πρέπει να είναι περίπου 6 μήνες, διαφορετικά υπάρχει σημαντική απώλεια εσόδων.
Κάθε προϊόν, έτσι και τα ΕΣ ακολουθούν συγκεκριμένες φάσεις κερδοφορίας. Το Σχήμα 1.13 παρουσιάζει αναλυτικά όλες αυτές της φάσεις. Στον κατακόρυφο άξονα υπάρχει το ποσοστό τον εσόδων και ασφαλώς, όσο πιο μεγάλη είναι αυτή η τιμή τόσο περισσότερα έσοδα έχει η εταιρία, και στον οριζόντιο άξονα βρίσκεται ο χρόνος. Τα έσοδα μπορούν να υπολογιστούν αν υπολογιστεί το εμβαδόν του σχήματος που περικλείεται από την γραμμή του ΕΣ ως τον οριζόντιο άξονα και αφαιρεθεί το εμβαδόν του σχήματος κάτω από τον άξονα. Όσο μεγαλύτερο είναι το εμβαδόν τόσο μεγαλύτερα είναι τα έσοδα.
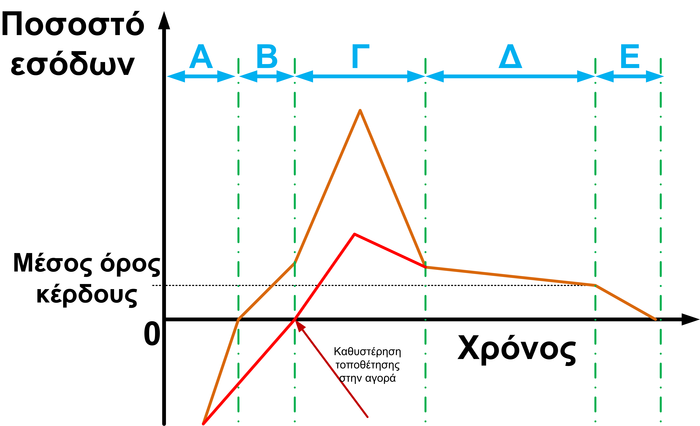
1.13: Κάθε προϊόν ακολουθεί συγκεκριμένες φάσεις κερδοφορίας. Μια καθυστέρηση τοποθέτησης στην αγορά μειώνει τα κέρδη.
Οι φάσεις που διέρχεται ένα προϊόν είναι πέντε. Μια σωστή τοποθέτηση του προϊόντος ακολουθεί την πορτοκαλί γραμμή (που έχει και τα περισσότερα έσοδα). Στην πρώτη φάση (φάση Α) δεν έχει αναπτυχθεί το προϊόν και έτσι η εταιρία δεν έχει έσοδα παρά μόνο έξοδα. Τα έξοδα αυτά κυρίως είναι τα NRE, αφού βρίσκεται στη φάση της έρευνας και ανάπτυξης. Μόλις τελειώσει αυτή η φάση, το ΕΣ τοποθετείται στα ράφια (φάση Β) και με την κατάλληλη προώθηση υπάρχουν πωλήσεις και άρα έσοδα. Αν σε αυτό το σημείο δεν υπάρχουν έσοδα σημαίνει ότι κανείς δε θέλει αυτό το προϊόν και άρα είχε γίνει λάθος εκτίμηση και πρέπει να τροποποιηθεί κατάλληλα. Στη φάση Β βρίσκονται οι καταναλωτές που ονομάζονται early adopters (πρώιμοι καταναλωτές). Όταν συγκεντρωθεί μια κρίσιμη μάζα από αυτούς τους χρήστες και πουληθεί ένας ικανοποιητικός αριθμός ΕΣ, τότε θα προωθείται αυτόματα μέσα σε φόρουμ συζήτησης και περιοδικά, και έτσι οι πωλήσεις θα εκτοξευθούν (αν είναι ενδιαφέρον και καινοτόμο). Αυτή είναι η φάση Γ. Κάποια στιγμή τα έσοδα θα αρχίσουν να μειώνονται και αυτό γιατί είτε επειδή όσοι χρειάζονταν αυτό το προϊόν το έχουν αγοράσει, είτε επειδή άλλες εταιρίες έχουν αντιγράψει και κλωνοποιήσει και έτσι υπάρχουν και άλλοι προμηθευτές. Σιγά σιγά τα έσοδα δεν θα μειώνονται με τόσο μεγάλο ρυθμό και θα πλησιάζει το μέσο όρο κέρδους των προϊόντων της κατηγορίας. Το ΕΣ θα βρίσκεται ακόμη στα ράφια, αλλά οι πωλήσεις του θα είναι σταθερές (φάση Δ). Κάποια στιγμή θα αποσυρθεί το ΕΣ από την αγορά, γιατί δε θα καλύπτει τις νέες ανάγκες, και η κατασκευάστρια εταιρία δε θα μπορεί να συντηρεί και να λειτουργεί μια γραμμή παραγωγής για ένα παρωχημένο προϊόν. Στη φάση Ε θα γίνει η απόσυρση (ονομάζεται EOL, end-of-life ή τέλος ζωής).
Αν ένα προϊόν καθυστερήσει να εισαχθεί στην αγορά (κόκκινη γραμμή), τότε είναι φανερό ότι τα έσοδα θα είναι αρκετά λιγότερα. Για αυτό θα πρέπει ο χρόνος εισαγωγής του προϊόντος στην αγορά να μη ξεπερνάει τους 6 μήνες, ενώ επίσης η τυπική διάρκεια ζωής είναι 18 μήνες.
Ως τώρα έχει γίνει κατανοητό ότι το οικοσύστημα των ΕΣ δεν είναι ομοιογενές, αφού κυμαίνεται από 8bit επεξεργαστές έως και 32bit, από διάφορες εταιρίες με πλήθος λειτουργικών συστημάτων, ή απλώς εκτέλεση σε ‘γυμνό’ υλικό, με ποικίλες απαιτήσεις. Μπορούμε όμως να σταχυολογήσουμε τα χαρακτηριστικά που συναντώνται σε ΕΣ:
Εκτέλεση μιας λειτουργίας ή αρκετά περιορισμένων σε αριθμό διεργασίες: Όλα τα ΕΣ εκτελούν σε ένα αέναο βρόχο ένα πρόγραμμα που λαμβάνει δεδομένα από αισθητήρια και επιτελεί κάποιες ενέργειες.
Περιορισμένων δυνατοτήτων: τα ΕΣ χρησιμοποιούν πολύ λιγότερους πόρους (π.χ. επεξεργαστικούς ή μνήμης) ως προς τα αντίστοιχα υπολογιστικά συστήματα των επιτραπέζιων υπολογιστών, και αυτό επειδή ο κατασκευαστής ενός ΕΣ γνωρίζει ακριβώς τους πόρους που χρειάζεται η εφαρμογή του και επιλέγει το υλικό που ταιριάζει καλύτερα.
Χαμηλή κατανάλωση ενέργειας και ισχύος: τα φορητά ΕΣ θα πρέπει να έχουν σχεδιαστεί με τέτοιο τρόπο, ώστε να έχουν χαμηλή στιγμιαία κατανάλωση ισχύος, αλλά και χαμηλό κατανάλωση ενέργειας σε μια συγκεκριμένη περίοδο. Αξίζει να σημειώσουμε τη διαφορά μεταξύ της κατανάλωσης ισχύος και της κατανάλωσης ενέργειας. Η κατανάλωση ισχύος αναφέρεται στο έργο που καταναλώνεται στη μονάδα του χρόνου, και στο σύστημα SI μετράται σε Joule / second, γνωστό και ως Watt. Η ενέργεια ομοίως που καταναλώνεται7 σε ένα σύστημα μετράται σε killowatt-hour ή Joules, και αφορά τα watt που έχουν καταναλωθεί σε όλο το χρονικό διάστημα. Για παράδειγμα, ένα ΕΣ που καταναλώνει 1 Watt ισχύ σε 100 ώρες έχει συνολική κατανάλωση ενέργειας 100 watt-hours. Ένα άλλο ΕΣ που καταναλώνει 100 Watt ισχύ σε 1 ώρα, έχει ίδια συνολική κατανάλωση ενέργειας 100 watt-hours. Όμως το προηγούμενο ΕΣ έχει χαμηλότερη κατανάλωση ισχύος, και άρα είναι καλύτερο.
Αντιδραστικά και Πραγματικού Χρόνου: Αρκετά ΕΣ χρησιμοποιούνται σε εφαρμογές που απαιτούν το σεβασμό αυστηρών χρονικών περιορισμών. Για αυτό το λόγο απαιτούνται επεξεργαστές με προβλέψιμο χρόνο εξυπηρέτησης διακοπών και ΛΣ (λειτουργικά συστήματα) που έχουν δημιουργηθεί ειδικά για ανταπόκριση σε πραγματικό χρόνο (RTOS, real time operating systems-λειτουργικά συστήματα πραγματικού χρόνου).
Αξιοπιστία: Τα ΕΣ κατασκευάζονται για να λειτουργούν χωρίς την παρέμβαση κάποιου ανθρώπινου χειριστή, που αν καταρρεύσει το ΛΣ μπορεί να πατήσει το reset και να ξεκινήσει η εκτέλεση από την αρχή. Τα ΕΣ μπορούν να τοποθετηθούν σε πολύ μεγάλα υψόμετρα (π.χ. δορυφόροι) ή σε πολύ χαμηλά (υποβρύχια αισθητήρια), που δε θα υπάρχει κάποιος κοντά. Θα πρέπει λοιπόν να λειτουργούν αξιόπιστα και αδιάκοπτα.
Μικρό κόστος: Το κόστος παραγωγής στα ΕΣ θα πρέπει να είναι ελάχιστο, αφού κατασκευάζονται σε πολύ μεγαλύτερες ποσότητες από ότι τα υπόλοιπα συστήματα. Για αυτό το λόγο στα ΕΣ, οι 8 bit επεξεργαστές καταλαμβάνουν ένα σημαντικό τμήμα της παγκόσμιας αγοράς επεξεργαστών (περίπου 25%), αν και σε όλες τις άλλες περιοχές τα 8bit συστήματα έχουν εξαφανιστεί. Ακόμη και σήμερα κατασκευάζονται και χρησιμοποιούνται ευρέως 8 bit επεξεργαστές που είχαν σχεδιαστεί το 1980 (π.χ. ο Intel 8051), και αυτό επειδή έχουν πολύ χαμηλό κόστος. Γιατί κάποιος να χρησιμοποιήσει 32 bit επεξεργαστή που έχει και μεγαλύτερη κατανάλωση ενέργειας, αν μπορεί να υλοποιήσει τις προδιαγραφές που θέλει με ένα 8 bit;
Μικρό μέγεθος και βάρος: Τα ΕΣ είναι ενσωματωμένα μέσα σε άλλα συστήματα και έτσι πρέπει να καταλαμβάνουν όσο το δυνατόν μικρότερο όγκο. Αυτό σημαίνει και λιγότερο υλικό και άρα πιο περιορισμένους πόρους.
Συνεχή λειτουργία και μεγάλη διάρκεια ζωής: Τα ΕΣ συνήθως από τη στιγμή που θα τεθούν σε λειτουργία θα λειτουργούν αδιάκοπα, και μάλιστα για πάρα πολλά χρόνια. Σε αντίθεση με έναν επιτραπέζιο υπολογιστή που έχει εκτιμώμενο χρόνο ζωής 2 με 4 χρόνια, τα ΕΣ έχουν εκτιμώμενο χρόνο ζωής πάνω από 15 χρόνια που σημαίνει ότι θα πρέπει να έχουν σχεδιαστεί κατάλληλα ώστε να ‘αντέξουν’ και να αντιμετωπίσουν με επιτυχία οποιοδήποτε πρόβλημα προκύψει.
Δυσκολία στην ενημέρωση λογισμικού: Σε αντίθεση με τους τυπικούς υπολογιστές που μπορούν και ενημερώνουν το λογισμικό μέσω διαδικτύου (update), ένα ΕΣ μόλις βγει από το εργοστάσιο δε θα μπορέσει να ανανεωθεί το λογισμικό, κατά μεγάλη πιθανότητα και έτσι δύσκολα θα μπορέσουν να διορθωθούν προβλήματα (κυρίως ασφάλειας) σε διεργασίες που εκτελούνται, και άρα είναι πιο επιρρεπείς στη μη εξουσιοδοτημένη πρόσβαση.
Ασφάλεια: Αρκετά ΕΣ τοποθετούνται σε κρίσιμες υποδομές, όπως π.χ. έλεγχο ενός πυρηνικού αντιδραστήρα. Θα πρέπει να υπάρχει μέριμνα ώστε αυτά τα ΕΣ να προστατεύονται όσο το δυνατόν καλύτερα, αφού αν αποκτήσει κάποιος κακόβουλος χρήστης πρόσβαση σε αυτά θα μπορέσει να τα απενεργοποιήσει ή να τα καταστρέψει. Πραγματικά σενάρια που είδαν το φως της δημοσιότητας αφορούν τη δημιουργία ενός ιού (STUXNET), που κατέστρεψε τα ενσωματωμένα συστήματα στους πυρηνικούς αντιδραστήρες του Ιράν [6], ή τον απομακρυσμένο έλεγχο των ΕΣ ενός οχήματος μέσω δικτύου κινητής τηλεφωνίας από κακόβουλους χρήστες [7].
Κατασκευασιμότητα (manufacturability): Ένα ΕΣ θα πρέπει να κατασκευάζεται σε μεγάλες ποσότητες και για να υπάρχει μειωμένο κόστος θα πρέπει να κατασκευάζεται αυτόματα ή σχεδόν αυτόματα. Με τον όρο κατασκευασιμότητα εννοούμε τις τεχνικές και τα στοιχεία που πρέπει να επιλεχθούν, ώστε να μπορεί εύκολα να κατασκευαστεί σε μεγάλες ποσότητες. Σε αυτό τον όρο συγκαταλέγονται εκτός από το σχεδιασμό της τυπωμένης πλακέτας και του περιβλήματος (housing) και η επιλογή των προϊόντων και των προμηθευτών (ώστε να μπορούν απροβλημάτιστα να παρέχουν τα στοιχεία που απαιτούνται και να μην παρατηρηθεί κάποια έλλειψη, ένα παράδειγμα είναι ότι ο 8051 επεξεργαστής επειδή κατασκευάζεται από πολλές διαφορετικές εταιρίες είναι ένα προϊόν που αποτελεί μια ασφαλή επιλογή για 8bit επεξεργαστή, σε σύγκριση με έναν επεξεργαστή 8bit που κατασκευάζεται από μια μονό εταιρία και μπορεί να χρεοκοπήσει).
Αυξημένη ανάγκη για μείωση του χρόνου εισαγωγής του προϊόντος στην αγορά (time-to-market): Τα ΕΣ προορίζονται κυρίως για καταναλωτικές συσκευές, οπότε θα πρέπει να έχουν ένα πολύ σύντομο χρόνο ολοκλήρωσης. Διαφορετικά, ο κατασκευαστής ενδέχεται να ζημιωθεί, όπως έχει συζητηθεί προηγουμένως.
Όπως φαίνεται από τις παραπάνω προδιαγραφές υπάρχει πολλές φορές σύγκρουση χαρακτηριστικών. Για παράδειγμα η επίτευξη της αξιοπιστίας έρχεται σε σύγκρουση με το μειωμένο χρόνο σχεδίασης. Δικαιολογημένα λοιπόν, ο σχεδιασμός των ενσωματωμένων συστημάτων θεωρείται αρκετά δύσκολος και αγχωτικός με απαίτηση ειδικών γνώσεων από πολλούς τομείς, και για αυτό οι μηχανικοί σχεδιασμού ΕΣ έχουν αρκετά παχυλούς μισθούς [8].
Σε αυτό το κεφάλαιο αναπτύχθηκε η ιστορία των υπολογιστών και έγινε κατανοητό ότι τα σημερινά συστήματα ακολουθούν μια συνεχή εξέλιξη από το 1940 έως σήμερα. Επίσης, δόθηκαν παραδείγματα προδιαγραφών και σχεδίασης ενσωματωμένων συστημάτων, ενώ αφιερώθηκε και ένα τμήμα σε βασικά στοιχεία οικονομίας των ΕΣ. Τέλος, αναφέρθηκαν τα χαρακτηριστικά και οι προκλήσεις των ΕΣ και κατέστη σαφές η δυσκολία σχεδίασης και οι αντικρουόμενες ανάγκες τέτοιων συστημάτων.
Τα επόμενα κεφάλαια διαμορφώνονται ως εξής: Στο κεφάλαιο 2, περιγράφουμε τον τρόπο σχεδιασμού των ΕΣ και την έννοια της μοντελοποίησης. Στο κεφάλαιο 3 αναπτύσσονται τα βασικά στοιχεία που φέρουν τα ΕΣ, όπως η αρχιτεκτονική, η διασωλήνωση, οικογένειες επεξεργαστών, και η κρυφή μνήμη. Στο κεφάλαιο 4 αναφέρουμε τις τεχνολογίες υλοποίησης, θέματα απόδοσης, κατανάλωσης, επαλήθευσης, ενώ στο κεφάλαιο 6 περιγράφουμε πως συνδέονται όλα τα περιφερειακά μεταξύ τους με διαύλους και δίκτυα διασύνδεσης. Σε αυτό το σημείο ολοκληρώνεται το πρώτο μέρος, που αφορούσε το υλικό. Στο δεύτερο μέρος του βιβλίου που αφορά τη βελτιστοποίηση σχεδιασμού πολύπλοκων ενσωματωμένων συστημάτων, περιγράφουμε το πρόβλημα και τη μεθοδολογία επιλογής και χρήσης ενός δυναμικού διαχειριστή μνήμης. Στο πρώτο κεφάλαιο αυτού του μέρους, αναλύουμε τις δυναμικές πολυμεσικές εφαρμογές που εκτελούνται σε ενσωματωμένα συστήματα, στο δεύτερο κεφάλαιο του Β’ μέρους σκιαγραφούμε τα χαρακτηριστικά των δυναμικών εφαρμογών, και στο τελευταίο κεφάλαιο περιγράφουμε με αρκετές λεπτομέρειες τη βελτιστοποίηση της δυναμικής μνήμης για εφαρμογές πολυμέσων.
Το βιβλίο αυτό συνοδεύεται από 3 παραρτήματα: Στο πρώτο παράρτημα, υπάρχει μια σειρά εργαστηριακών ασκήσεων για τον 8bit μικροεπεξεργαστή arduino, στο δεύτερο παράρτημα υπάρχουν ασκήσεις βελτιστοποίησης λογισμικού για τον επεξεργαστή ARM, ενώ στο τρίτο παράρτημα υπάρχουν ασκήσεις για τη χρήση επαναδιαμορφώσιμης αρχιτεκτονικής για τις εκπαιδευτικές FPGA πλακέτες Altera DE2-115.
Τέλος, στο βιβλίο αυτό υπάρχει ένας πίνακας των ακρωνυμίων και ένα αναλυτικό λεξιλόγιο μεταφράσεων αγγλικών όρων στα ελληνικά, που έχει δημιουργηθεί από τους συγγραφείς.
O σχεδιασμός ενός ενσωματωμένου συστήματος δεν είναι μια τυποποιημένη διαδικασία που καταλήγει πάντα στην ίδια υλοποίηση. Σπάνια μπορεί να βρεθεί μια βέλτιστη λύση -αν υπάρχει- ως προς κάθε απαίτηση του χρήστη ή του μηχανικού. Αντιθέτως, ο σχεδιαστής πρέπει να λαμβάνει υπόψη του όλες τις απαιτήσεις της εφαρμογής, τα χαρακτηριστικά της διαθέσιμης αρχιτεκτονικής και τους στόχους, και να προτείνει λύσεις που να ικανοποιούν όσο το δυνατόν περισσότερο τις ανάγκες του. Ο σχεδιαστής θα πρέπει διαρκώς να αναλύει και να εκτιμά τους πιθανούς συμβιβασμούς (trade-offs), ενώ ταυτόχρονα θα πρέπει να βελτιστοποιεί όσο το δυνατόν περισσότερο συγκεκριμένα χαρακτηριστικά της εφαρμογής του. Όσον αφορά το σχεδιασμό ενσωματωμένων συστημάτων, ο σχεδιαστής καλείται να μεγιστοποιεί την επίδοση του συστήματος με ταυτόχρονη ελαχιστοποίηση του κόστους. Αυτή η σύγκρουση προκαλεί και την ύπαρξη μιας πληθώρας λύσεων, οι οποίες ικανοποιούν και διαφορετικές ανάγκες. Για παράδειγμα, ένας μηχανικός που θέλει να σχεδιάσει ένα ψηφιακό ρολόι, θα προσπαθήσει να ελαχιστοποιήσει το κόστος και ταυτόχρονα να καλύψει τις ελάχιστες επεξεργαστικές και λειτουργικές απαιτήσεις. Από την άλλη πλευρά, ένας μηχανικός που θα κληθεί να σχεδιάσει έναν ψηφιακό προσωπικό βοηθό (Personal Digital Assistant), θα προσπαθήσει να μεγιστοποιήσει τις επιδόσεις της συσκευής από άλλες παρόμοιες συσκευές, ώστε να έχει καλύτερες επιδόσεις, αλλά με λιγότερη πίεση στο κόστος της συσκευής. Σε όλες λοιπόν τις περιπτώσεις ο στόχος είναι ένας: Μεγιστοποίηση της επίδοσης με όσο το δυνατόν μικρότερο κόστος. Αυτό επιτυγχάνεται με τη μοντελοποίηση.
Η ραγδαία ανάπτυξη των ενσωματωμένων συστημάτων, όπως είδαμε προηγουμένως, δεν οφείλεται μόνο στην πρόοδο που επιτελέστηκε στο υλικό μέρος (π.χ. αύξηση επιδόσεων των επεξεργαστών, αύξηση βαθμού ολοκλήρωσης), αλλά και από το λογισμικό μέρος. Το λογισμικό μέρος είναι αυτό που οργανώνει, κατευθύνει και ελέγχει το υλικό μέρος για τη σωστή και έγκυρη λειτουργία του συστήματος. Όπως τα χαρακτηριστικά του υλικού μέρους επηρεάζουν σημαντικά την ταχύτητα και την κατανάλωση ενέργειας του συστήματος (π.χ. η χρήση ενός πολύ αργού επεξεργαστή θα έχει ως συνέπεια το όλο σύστημα να λειτουργεί με μικρή ταχύτητα), έτσι και το λογισμικό μέρος παίζει έναν κυρίαρχο ρόλο στη διαμόρφωση όλων των μετρικών ενός συστήματος. Ένα λογισμικό μέρος καλά προγραμματισμένο θα βοηθήσει το υλικό μέρος να αποδώσει τα μέγιστα των δυνατοτήτων του, ενώ σε αντίθετη περίπτωση, θα κάνει και το ενσωματωμένο σύστημα με τα πιο γρήγορα υλικά μέρη να μειονεκτεί αισθητά έναντι παρόμοιων συστημάτων.
Το λογισμικό μέρος συμπληρώνει το υλικό μέρος. Η σχέση που συνδέει αυτά τα δύο μέρη είναι παρόμοια (σε ένα αρκετά υψηλό επίπεδο αφαίρεσης), με τη σχέση που έχει ένα όχημα με τον οδηγό του. Αν και το όχημα έχει όλη τη λειτουργικότητα που απαιτείται, εντούτοις περιμένουμε από τον οδηγό να το εκκινήσει, να κάνει τις κατάλληλες ενέργειες, ώστε το όχημα να μετακινηθεί και να οδηγηθεί σε κάποια τοποθεσία που είχε τεθεί ως προορισμός. Μπορεί να θεωρηθεί ότι ο οδηγός παριστάνει το λογισμικό μέρος, ενώ το υλικό μέρος συνδέεται με το όχημα. Έτσι, η συνύπαρξη και των δύο αυτών μερών αποτελεί το συνολικό σύστημα. Παρόλο που και τα δύο είναι αναπόσπαστα μέρη του συστήματος, κατά τα τελευταία χρόνια έχει δοθεί μεγαλύτερη έμφαση στο λογισμικό και, ιδιαίτερα, στους τρόπους καλύτερης μοντελοποίησης και προγραμματισμού των εφαρμογών, ειδικά για ενσωματωμένα συστήματα. Αυτό οφείλεται κυρίως στην τάση που επικρατεί να χρησιμοποιούνται τυπικά εξαρτήματα υλικού μέρους από το ράφι (off-the-shelf components), όπως για παράδειγμα επεξεργαστές των εταιρειών ARM, ή TI, ή μνήμες των εταιρειών Motorola, ή Kingston, κ.τ.λ. Όπως παρατηρείται παγκοσμίως, το πρόβλημα της ανάπτυξης ενός συστήματος, κατευθύνεται περισσότερο προς τη συγγραφή του λογισμικού μέρους, που θα ενεργοποιήσει το υλικό μέρος. Έτσι, η μερική τυποποίηση των υλικών μερών των ενσωματωμένων συστημάτων αποτελεί έναν παράγοντα που έχει μετατοπίσει το πρόβλημα της ανάπτυξης ενσωματωμένων συστημάτων προς το λογισμικό μέρος. Όμως, αυτός δεν είναι ο μόνος λόγος.
Τα τελευταία χρόνια, η ανάπτυξη των εφαρμογών των ενσωματωμένων συστημάτων έχει γίνει ο κυρίαρχος διαμορφωτής του κόστους για έναν ακόμη παράγοντα· αυτός είναι η πολυπλοκότητα των εφαρμογών. Οι πρώτες εκδόσεις των ενσωματωμένων συστημάτων είχαν ένα μικρό πρόγραμμα, το οποίο επιτελούσε κάποιες πολύ απλές λειτουργίες. Μαζί με την απαίτηση της αγοράς για ενσωματωμένα συστήματα με καλύτερες επιδόσεις στο υλικό μέρος, υπήρξε και η απαίτηση για πιο πολλές λειτουργίες, για προγράμματα φιλικά προς το χρήστη, και για εφαρμογές αρκετά απαιτητικές (όπως π.χ. η αναπαραγωγή πολυμέσων). Γι’ αυτόν το λόγο υπήρξε και υπάρχει αρκετά μεγαλύτερη έμφαση στην ανάπτυξη των εφαρμογών ενσωματωμένων συστημάτων.
Ένας τρόπος μέτρησης της ανάπτυξης των εφαρμογών αποτελεί και το μέτρο της πολυπλοκότητας των εφαρμογών. Η πολυπλοκότητα μιας εφαρμογής εξαρτάται από τον αριθμό των εντολών και συναρτήσεων που την αποτελούν, από τις λειτουργίες που αυτή κάνει, από το μέγεθος κώδικα που αποθηκεύεται στη μνήμη εντολών, και από τον αποθηκευτικό όγκο σε μνήμη δεδομένων. Αν βγάλουμε χονδρικά ένα μέσο όρο της πολυπλοκότητας των εφαρμογών θα παρατηρήσουμε ότι ακολουθεί μια εκθετική αύξηση χρονολογικά (Σχήμα 2.1). Αν στο ίδιο γράφημα τοποθετήσουμε και τις επιδόσεις των επεξεργαστών, θα δούμε ότι αυτές υστερούν, και δεν μπορούν να καλύψουν τις τρέχουσες απαιτήσεις των εφαρμογών. Βλέπουμε, λοιπόν, ότι υπάρχει ένα χάσμα ανάμεσα στο τι μπορεί να εκτελεστεί σε ένα σύστημα (επιδόσεις υλικού μέρους) και στο τι απαιτούν οι εφαρμογές για να εκτελεστούν (πολυπλοκότητα λογισμικού μέρους).
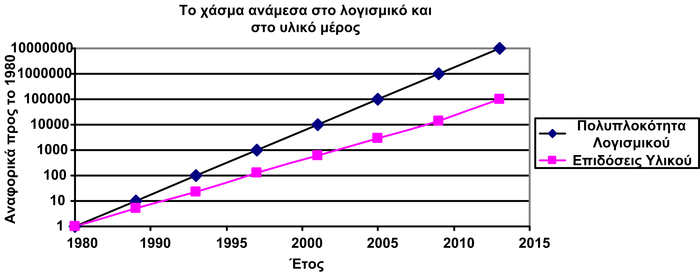
2.1: Η πολυπλοκότητα των εφαρμογών ενσωματωμένων συστημάτων αυξάνεται με πολύ μεγαλύτερο ρυθμό σε σχέση με τις επιδόσεις των επεξεργαστών.
Το πρόβλημα της δημιουργίας λογισμικού ενσωματωμένων συστημάτων είναι τόσο σημαντικό, ώστε μεγάλες εταιρείες, όπως η Microsoft και η Sun (εταιρείες που έχουν κυριαρχήσει στο λογισμικό μέρος των επιτραπέζιων συστημάτων, ή των διακομιστών), έχουν κατευθύνει μέρος του προϋπολογισμού τους στην έρευνα και ανάπτυξη εφαρμογών ενσωματωμένων συστημάτων. Για παράδειγμα, η Microsoft αναπτύσσει τα Windows Mobile, η Google to Android, και η Sun τη Java Virtual Machine, που όλα συμβάλλουν στην ανάπτυξη λογισμικού ενσωματωμένων συστημάτων.
Το λογισμικό μέρος των ενσωματωμένων συστημάτων, είναι ένας ακμάζων τομέας, και αυτό φαίνεται στα οικονομικά μεγέθη που το συνοδεύουν. Για παράδειγμα, τα στοιχεία από το Υπουργείο Άμυνας των Η.Π.Α. – ένας από τους μεγαλύτερους παγκοσμίως αγοραστές ενσωματωμένων συστημάτων – (Σχήμα 2.2), δείχνουν ότι το κόστος ανάπτυξης του λογισμικού είναι έως και 6 φορές μεγαλύτερο από το κόστος ανάπτυξης των υλικών μερών. Είναι γνωστό, ότι το λογισμικό καταλαμβάνει περισσότερο από το 70% του κόστους ανάπτυξης πολύπλοκων ενσωματωμένων συστημάτων, όπως φορητά τερματικά, ηλεκτρονικά συστήματα αυτοκινήτων, συστήματα επικοινωνιών κτλ [9], [10], [11], [12].
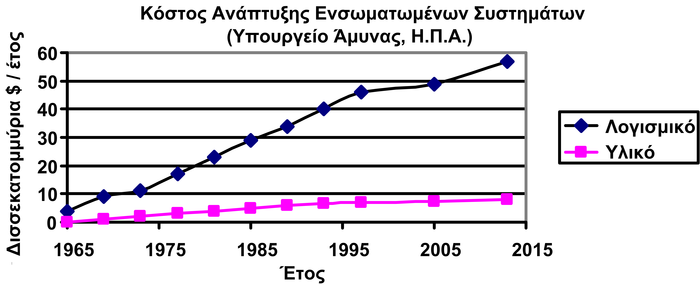
2.2: Το λογισμικό μέρος κυριαρχεί στη διαμόρφωση του κόστους ενός ενσωματωμένου συστήματος.
Τέλος, η σπουδαιότητα του λογισμικού των ενσωματωμένων συστημάτων φαίνεται καθαρά και από τα στοιχεία που αναφέρονται στην έκθεση του Υπουργείου Εμπορίου και Βιομηχανίας της Ολλανδίας, στην οποία αναφέρεται ότι ο αριθμός των ατόμων ή εταιρειών που παίρνουν συμβόλαια για ανάπτυξη κώδικα ενσωματωμένων συστημάτων θα αυξηθεί από 2 εκατομμύρια το 1994 σε 13 εκατομμύρια το 2015, ενώ ο αριθμός των κατασκευαστών υλικού ενσωματωμένων συστημάτων θα αυξηθεί από 0,6 εκατομμύρια σε 1,1 εκατομμύρια, αντιστοίχως [13].
Είναι σημαντικό λοιπόν να αναλύεται η εφαρμογή, που θα εκτελεστεί στο ενσωματωμένο σύστημα, και να γίνεται συσχεδιασμός του υλικού και του λογισμικού μέρους. Η μεθοδολογία, σχεδιασμού ΕΣ αποτελείται από στάδια που βελτιώνουν το λογισμικό μέρος και από στάδια που βελτιώνουν το υλικό μέρος. Επίσης, μια σωστή μεθοδολογία έχει εφαρμοστεί με επιτυχία σε ένα πλήθος εφαρμογών, που εκτελούνται σε ενσωματωμένα συστήματα, γεγονός που δείχνει τη γενική χρήση που μπορεί αυτή να έχει.
2.3: Η πολυπλοκότητα των εφαρμογών αυξάνεται λογαριθμικά.
Όπως έχει αναφερθεί στην εισαγωγή του βιβλίου, το κόστος έρευνας και ανάπτυξης (non recurrent engineering cost, NRE) ενός ενσωματωμένου συστήματος είναι αποφασιστικής σημασίας για τη διαμόρφωση της τιμής του τελικού προϊόντος, αφού θα πρέπει να ενσωματωθεί στην τελική τιμή. Όσο μεγαλύτερο είναι αυτό το αρχικό κόστος, τόσο πιο πολύ θα αυξηθεί η τιμή των τελικών προϊόντων και ενδεχομένως θα επηρεάσει αρνητικά τον αριθμό πωλήσεων, προκαλώντας ίσως και ζημιά στην εταιρία που το προμηθεύει στην αγορά.
Η μείωση του κόστος NRE είναι λοιπόν ζωτικής σημασίας, αφού η ίδια η βιωσιμότητα μιας εταιρίας εξαρτάται από αυτό, και θα πρέπει να είναι όσο το δυνατόν μικρότερο. Το ίδιο προϊόν μπορεί σε δυο διαφορετικές εταιρίες να συνδέονται με NRE κόστη που έχουν πολύ μεγάλη διαφορά. Το κόστος NRE για το ίδιο προϊόν σε δυο διαφορετικές εταιρίες είναι διαφορετικό. Για να ελαχιστοποιηθεί αυτό το κόστος θα πρέπει να θυμηθούμε (1ο κεφάλαιο) τους παράγοντες που το διαμορφώνουν. Ο πρώτος παράγοντας είναι το κόστος μισθοδοσίας του προσωπικού. Μια εταιρία μπορεί να έχει υψηλό μισθολογικό κόστος λόγω νοοτροπίας ή φορολογίας και ασφαλιστικού, ενώ μια εταιρία σε άλλη περιοχή του πλανήτη μπορεί να έχει υποπολλαπλάσιο κόστος. Για αυτό αρκετές εταιρίες του Δυτικού Κόσμου, προβαίνουν σε εξωτερικές αναθέσεις (outsourcing) ή ανοίγουν παραρτήματα σε χώρες με χαμηλό μισθολογικό κόστος, όπως η Ινδία ή η Κίνα. Ο επόμενος παράγοντας είναι τα πάγια έξοδα των κτιρίων. Ομοίως, αυτό μπορεί να μειωθεί σε μετεγκατάσταση της εταιρίας είτε σε κατάλληλη οικοδομική ζώνη που παρέχει σε μικρότερο κόστος κτιριακή επιφάνεια, νερό, ρεύμα και διαδίκτυο, ή σε μετεγκατάσταση σε άλλη πόλη ή χώρα. Ένας άλλος παράγοντας, είναι το κόστος των υλικών για τη δημιουργία του πρωτοτύπου. Αν και αυτό το κόστος είναι συνήθως μικρότερο από τα δυο προηγούμενα, εντούτοις διαμορφώνει και αυτό το NRE, ιδιαίτερα αν πρέπει να γίνουν πολλά και μακροχρόνια πειράματα, δοκιμάζοντας πολλά διαφορετικά σενάρια ή σχεδιασμούς. Για να μειωθεί αυτό το κόστος, εκτός από την προμήθεια των υλικών από πάροχο που έχει τις χαμηλότερες τιμές και ταυτόχρονα καλύπτει τα επίπεδα αξιοπιστίας, ποιότητας και ταχύτητας παράδοσης, θα πρέπει να ακολουθηθεί μια τεχνική που θα επιτύχει μείωση του χρόνου, μείωση των λανθασμένων σχεδιαστικών επιλογών και μείωση των προβληματικών πρωτοτύπων. Αυτή η τεχνική ονομάζεται μοντελοποίηση, και είναι πάντα το πρώτο βήμα σε οποιαδήποτε μεθοδολογία σχεδιασμού, είτε ενσωματωμένων συστημάτων είτε οποιοδήποτε άλλου προϊόντος.
Η μοντελοποίηση είναι μια τεχνική (ή για να είμαστε ακριβείς, ένα σύνολο από τεχνικές) που επιτρέπουν ένα σχεδιαστή να πετύχει το στόχο του με την πρώτη προσπάθεια. Αν και έχει μεγάλη σημασία, αρκετές φορές παραλείπεται από τα επίσημα διαγράμματα σχεδίασης, λόγω χρονικής πίεσης, αφού κάποιοι σχεδιαστές πιστεύουν ότι μπορεί να καταφέρουν το τελικό αποτέλεσμα (π.χ. την ανάπτυξη ενός ΕΣ) με τη σύνδεση των δομοστοιχείων και τη συγγραφή του κώδικα. Αν και μπορεί να το πετύχουν και να σχεδιάσουν κάτι που να λειτουργεί, εντούτοις η μεγαλύτερη πιθανότητα είναι ότι δε θα το καταφέρουν και θα χάσουν το παράθυρο εισαγωγής στην αγορά, με δυσάρεστες οικονομικές συνέπειες. Αλλά, ακόμη και να τα καταφέρουν, δε σημαίνει ότι το τελικό αποτέλεσμα θα είναι στιβαρό και θα λειτουργεί σε οποιαδήποτε συνθήκη.
Παραδείγματα που δείχνουν τη σημασία της μοντελοποίησης μπορούμε να βρούμε σε κάθε χώρο. Ένα προσωπικό απλό παράδειγμα του συγγραφέα κατά την επίβλεψη μιας εργασίας φοιτητή, ήταν όταν έπρεπε να δημιουργηθεί μια συσκευή συνδεδεμένη στο Internet που έλεγχε τέσσερα ρελέ. Ο σχεδιασμός έγινε χωρίς μοντελοποίηση και εξέταση των αναγκών από το φοιτητή. Το πρωτότυπο συνδέθηκε στην τροφοδοσία και λειτούργησε με επιτυχία για 1 συσκευή. Όταν όμως συνδέθηκε και δεύτερη συσκευή, τότε παρουσιάστηκε δυσλειτουργία με τυχαία συμπεριφορά. Το πρόβλημα ήταν ότι δεν είχε μοντελοποιηθεί η ζητούμενη απαίτηση ρεύματος σε πλήρη λειτουργία (και με τα 4 ρελέ), οπότε το τροφοδοτικό των 300 mA, ενώ επαρκούσε για τον έλεγχο ενός ρελέ, δεν επαρκούσε για την ικανοποίηση της χειρότερης κατάστασης. Ένα άλλο παράδειγμα, αφορά το σχεδιασμό ενός ιστοχώρου εξέτασης φοιτητών, όπου ενώ λειτουργούσε σωστά όταν ήταν συνδεδεμένοι 1-2 φοιτητές, σε περίπτωση που συνδέονταν και οι 100 φοιτητές, δε λειτουργούσε καθόλου επειδή ο φόρτος του διακομιστή από 1% γίνονται 3000%. Το πρόβλημα ήταν στον αριθμό των ερωτημάτων ανά σελίδα που ήταν υπερβολικά πολλά, επειδή δεν είχε μοντελοποιηθεί πως να κλιμακώνεται. Με τη βελτίωση της σελίδας και τη μείωση των ερωτημάτων, το σύστημα μπόρεσε και λειτούργησε. Σε αυτά τα παραδείγματα φάνηκε ότι ακόμη και να λειτουργεί, αν δεν έχει προηγηθεί μια ανάλυση και μοντελοποίηση, τότε μπορεί να υπάρξουν περιπτώσεις που θα αποτύχει ή απαιτείται επιπρόσθετος χρόνος σχεδίασης για να βρεθεί το πρόβλημα στο τελικό προϊόν και να διορθωθεί. Ακόμα, αν αυτό το προϊόν κατασκευαστεί και διατεθεί, και αποτύχει σε μια κρίσιμη στιγμή, μπορεί να υπάρξει και απώλεια υλικής αξίας ή ανθρώπινης ζωής.
Η μοντελοποίηση δεν ανήκει στα βήματα της μεθοδολογίας που θα ήταν καλό να γίνουν (‘nice to do’). Ανήκουν στα βήματα που πρέπει να γίνουν (‘must do’). Η σημαντικότητα αυξάνεται όσο περισσότερο αυξάνονται η πολυπλοκότητα και οι απαιτήσεις. Αν κάποιοι αποφασίσουν να κατασκευάσουν μια αποθήκη με ξύλα, αρκεί να σημειώσουν σε ένα χαρτί τις διαστάσεις των τοίχων, τα εργαλεία και τα υλικά που θα χρησιμοποιήσουν. Σε περίπτωση που δεν ταιριάζουν κάποια υλικά μεταξύ τους μπορεί να γίνουν κάποια μπαλώματα για να τα καλύψουν. Αν όμως απαιτείται η κατασκευή ενός σπιτιού με πολλούς χώρους, τότε αυξάνεται η πολυπλοκότητα και θα πρέπει να ληφθούν υπόψιν πολλά περισσότερα στοιχεία, όπως διελεύσεις των καλωδίων, των δικτύων ύδρευσης και αποχέτευσης, τα πάχη των τοίχων μαζί με τη μόνωση, τα κουφώματα και πλήθος άλλων λεπτομερειών. Αν δε γίνει αυτό, στο τέλος μπορεί να μην καλύπτονται οι προδιαγραφές κατοίκησης και να μην έχει σωστή μόνωση ή μπορεί να ξεχάσουν να βάλουν βρύσες στο μπάνιο ή ακόμη αν είναι πολυκατοικία να υπάρχει κατάρρευσή, αν δεν έχει γίνει μοντελοποίηση των στατικών φορτίων. Για αυτό είναι απαραίτητο να μοντελοποιηθεί η κατασκευή ενός τέτοιου σύνθετου σχεδιασμού και μάλιστα, όχι μόνο με μια κάτοψη. Θα πρέπει να γίνει μια θερμική μελέτη, ηλεκτρολογική μελέτη, μελέτη ύδρευσης και αποχέτευσης, στατική μελέτη και άλλα. Σε περίπτωση που υπάρξει πρόβλημα σε μια τέτοια κατασκευή μπορεί να είναι δύσκολο να διορθωθεί, με αποτέλεσμα να υπάρχει σημαντική οικονομική καταστροφή.
Αν δεν υπάρξει η μοντελοποίηση, το τελικό αποτέλεσμα βασίζεται στην τύχη και σε υπερβολική εργασία της ομάδας να διορθώσει τα προβλήματα καθώς εμφανίζονται. Στις περισσότερες περιπτώσεις όμως, δεν υπάρχει τύχη, η ομάδα ασχολείται ήδη πολλές εργατοώρες με το προϊόν και δε μπορεί να διαθέσει άλλες ή πλησιάζει κάποια κρίσιμη καταληκτική ημερομηνία, και λόγω κακού προγραμματισμού δεν υπάρχουν όλες οι πρώτες ύλες, που είναι απαραίτητες για την κατασκευή του πρωτοτύπου. Σχεδιαστικά project μεγάλων προϋπολογισμών (πάνω από 1.000.000 ευρώ) που χρηματοδοτούνται συμμετοχικά από ανώνυμους χρήστες (crowd-funding), έχουν αποτύχει λόγω έλλειψης μοντελοποίησης, όπως για παράδειγμα η εταιρία Pirate3D που μάζεψε $1.5 εκατομμύρια δολάρια για την κατασκευή οικονομικών τρισδιάστατων εκτυπωτών, αλλά τελικά το κόστος τελικών προϊόντων ήταν πολύ μεγαλύτερο από το αναμενόμενο, ή η εταιρία Ζano Drones που συγκέντρωσε $3.5 εκατομμύρια δολάρια για την ανάπτυξη μικρών τετρακόπτερων που ελέγχονται από το smartphone, αλλά μετά από μήνες έρευνας χρεοκόπησε χωρίς να κατασκευάσει τίποτα. Σίγουρα για την ολοκληρωτική αποτυχία δεν έφταιγε μόνο η έλλειψη σωστής μοντελοποίησης των προϊόντων που ήθελαν να σχεδιάσουν, αλλά μια ελλιπής μοντελοποίηση ή λάθος εκτιμήσεις οδηγούν σε αυτό το αποτέλεσμα.
Ο σχεδιασμός και η κατασκευή ενός προϊόντος δεν πρέπει να βασίζεται στην τύχη. Θα πρέπει να έχει προηγηθεί μια σειρά μοντελοποιήσεων σε διάφορα επίπεδα, ώστε να βρεθούν από πριν τα προβλήματα, τα υλικά, τα εργαλεία και το κόστος που τα συνοδεύει. Ενώ το κάθε αποτυχημένο σχεδιαστικό έργο αποτυγχάνει με ποικίλους τρόπους, όλα τα σωστά σχεδιασμένα προϊόντα έχουν ένα κοινό στοιχείο: μια προσεκτική και σε βάθος περίοδο μοντελοποίησης. Η μοντελοποίηση έχει αποδειχθεί ότι είναι απαραίτητο στοιχείο και εργαλείο των μηχανικών. Η μοντελοποίηση δεν αφορά μόνο τον κατασκευαστικό τομέα. Χρησιμοποιείται παντού: από την οικοδομική κατασκευή έως την κατασκευή νέων οχημάτων ή αεροπλάνων ή και δορυφόρων, από την κατασκευή νέων επεξεργαστών, έως και μεγάλων συστοιχιών με δεκάδες χιλιάδες επεξεργαστές, από τη μοντελοποίηση ενός τοπικού δικτύου, ως και τη μοντελοποίηση του διαδικτύου κ.ο.κ. Οποιοδήποτε σύστημα μπορεί να μοντελοποιηθεί, με πολλούς τρόπους και με πολλαπλά επίπεδα λεπτομέρειας. Μπορεί να χρησιμοποιηθεί ένα μαθηματικό μοντέλο, ένα δομικό μοντέλο, ένα ιεραρχικό μοντέλο, ένα μοντέλο συμπεριφοράς, ένα μοντέλο απεικόνισης, ένα μοντέλο επικοινωνίας κ.ο.κ. Γενικά, ένα μοντέλο είναι οτιδήποτε μπορεί να απλοποιήσει και να απεικονίσει την πραγματικότητα, και ο λόγος που τα κατασκευάζουμε είναι για την καλύτερη κατανόηση του συστήματος που σχεδιάζουμε.
Με τη χρήση των μοντέλων επιτυγχάνουμε τους παρακάτω στόχους:
Απεικονίζεται το σύστημα όπως είναι ή όπως το σκεφτόμαστε.
Προσδιορίζουμε τη δομή και την ιεραρχία ή τη συμπεριφορά.
Μας οδηγεί και μας υπενθυμίζει τα βήματα προς την ολοκλήρωση του συστήματος.
Καταγράφει λεπτομέρειες και αποφάσεις που έχουμε πάρει.
Μας επιτρέπει να δημιουργήσουμε πολλαπλά αντίγραφα του ίδιου προϊόντος.
Μας βοηθάει να επιβεβαιώσουμε τις λειτουργικές και άλλες προδιαγραφές, πριν ακόμη κατασκευαστεί.
Μας επιτρέπει να κάνουμε μια γρήγορη σχεδιαστική αναζήτηση, αν υπάρχουν πολλές εναλλακτικές.
Μας επιτρέπει να έχουμε μια κοινή εικόνα για το τελικό προϊόν σε όλα τα μέλη της ομάδας.
Όσο πιο πολύπλοκο είναι ένα σύστημα τόσο πιο σημαντική είναι η μοντελοποίηση, και αυτό γιατί υπάρχει αδυναμία να κατανοηθεί η έντονη πολυπλοκότητα και οι αλληλεξαρτήσεις από τους μηχανικούς. Ιεραρχικά και τμηματικά όμως μπορούμε να το επιτύχουμε, αφού η προσέγγιση ‘διαίρεση-και-κατάκτηση’ που είχε προτείνει ο Edsger Dijkstra [14], δηλαδή της διαίρεσης ενός σύνθετου προβλήματος σε πολλά επιμέρους βήματα, τα οποία ξεχωριστά μπορούν να επιλυθούν, δίνουν το καλύτερο αποτέλεσμα. Αν επιτευχθεί η επίλυση όλων των μικρών προβλημάτων, τότε θα επιτευχθεί και η επίλυση του μεγάλου πολύπλοκου προβλήματος. Η πρόταση του Dijkstra υλοποιείται με τη μοντελοποίηση.
Αφού έγινε κατανοητή η σημασία της μοντελοποίησης, το επόμενο βήμα είναι να βρεθεί ο σωστός τρόπος μοντελοποίησης. Κάποιοι σχεδιαστές ΕΣ, μπορούν να μοντελοποιήσουν ένα σύστημα σε ένα κομμάτι χαρτιού, στον πίνακα, σε ένα σχεδιαστικό πρόγραμμα στο κινητό τους ή ακόμη και σε μια χαρτοπετσέτα8.
Ασφαλώς, και μόνο που γίνεται η μοντελοποίηση, είναι ένα θετικό στοιχείο, αν μπορεί να το ακολουθήσει και να τον οδηγήσει σε μια σωστή υλοποίηση. Όμως, το πρόβλημα με αυτά τα αυθαίρετα μοντέλα είναι ότι τα καταλαβαίνει μόνο ο δημιουργός τους και από την άλλη υπάρχει μια δυσκολία διαμοιρασμού σε άλλους, και συνεπώς και δυσκολία επεξεργασίας και σχολιασμού από αυτούς. Οπότε, το σημείο κλειδί είναι η δημιουργία ενός μοντέλου σε προτυποποιημένη (formal) γλώσσα, που την κατανοούν και άλλοι και μπορούν να τη χρησιμοποιήσουν για τις δικές τους ανάγκες. Επομένως, θα πρέπει η σχεδιαστική ομάδα να επιλέξει μια ή παραπάνω γλώσσες μοντελοποίησης και να τις χρησιμοποιεί έως την κατασκευή του προϊόντος ή ακόμη και μετά για τη βελτιστοποίηση και αναθεώρηση.
Υπάρχουν τέσσερις βασικές αρχές στη μοντελοποίηση:
Η επιλογή του μοντέλου επιδρά στον τρόπο που αντιμετωπίζεται το πρόβλημα και στη λύση που διαμορφώνεται.
Κάθε μοντέλο μπορεί να εκφραστεί με διαφορετικά επίπεδα ακρίβειας.
Τα καλύτερα μοντέλα είναι συνδεδεμένα με την πραγματικότητα.
Δεν υπάρχει ένα μοντέλο για όλα. Υπάρχουν πολλαπλά μοντέλα, και θα πρέπει να χρησιμοποιούνται παραπάνω από ένα σε κάθε πρόβλημα.
Η πρώτη αρχή σημαίνει ότι η σχεδιαστική ομάδα θα πρέπει να γνωρίζει αρκετούς τρόπους μοντελοποίησης για να επιλέξει το κατάλληλο εργαλείο. Τα σωστά μοντέλα θα διαφωτίσουν και θα φέρουν στην επιφάνεια σχεδιαστικά θέματα που ίσως δεν θα είχαν γίνει κατανοητά, αν είχε επιλεχθεί κάποιο άλλο μοντέλο. Για παράδειγμα, αν κάποιος μοντελοποιήσει ένα προϊόν (π.χ. μια ανεμογεννήτρια) με το να κατασκευάσει μια μακέτα μικρογραφίας και να την τοποθετήσει σε ένα πειραματικό τούνελ αέρος, ενώ κάποιος άλλος το μοντελοποιήσει με μαθηματικές εξισώσεις και κάνει προσομοίωση, ο δεύτερος θα μπορέσει να κάνει και μια καλύτερη ανάλυση, αφού θα μπορεί να αλλάξει κάποιες παραμέτρους (π.χ. μήκος φτερών) για να διαπιστώσει αν έχει όφελος ή όχι η τροποποίηση. Αυτός που θα επιλέξει το μοντέλο θα πρέπει να έχει γενική γνώση και να μην είναι εξειδικευμένος σε ένα θέμα μόνο. Για παράδειγμα, ένας σχεδιαστής βάσης δεδομένων που μοντελοποιεί ένα σύστημα, μπορεί να γνωρίζει μόνο μοντέλα οντοτήτων και εξαρτήσεων, ενώ ένας προγραμματιστής αντικειμενοστραφών γλωσσών, μπορεί να γνωρίζει μόνο για μοντέλα αντικειμένων και ιδιοτήτων.
Η δεύτερη αρχή σημαίνει ότι το ίδιο στοιχείο μπορεί να εκφραστεί με πολλά επίπεδα λεπτομέρειας. Από ένα απλό εκτελέσιμο που δέχεται κάποιους εισόδους και εμφανίζει στην έξοδο κάποια αποτελέσματα, έως το επίπεδο τρανζίστορ που δείχνει πως συμπεριφέρεται κάθε πύλη. Βέβαια, όσες πιο πολλές λεπτομέρειες έχει ένα μοντέλο, τόσο πιο δύσκολη είναι η ανάπτυξη και βελτίωση του. Θα πρέπει να επιλέγεται το κατάλληλο επίπεδο λεπτομέρειας κάθε φορά. Συνήθως, ακολουθείται μια σχεδιαστική προσέγγιση top-bottom και bottom-up. Δηλαδή, όταν απαιτείται ο σχεδιασμός ενός προϊόντος, αρχικά γνωρίζουμε την υψηλού επιπέδου περιγραφή, στη συνέχεια αρχίζουμε να κατεβαίνουμε προς το επίπεδο της υλοποίησης (top-bottom) για να εξάγουμε τα βασικά δομοστοιχεία που αυτή θα αποτελείται. Μετά την εξαγωγή ακολουθούμε μια πορεία bottom-up, δηλαδή μοντελοποιούμε, κάθε δομοστοιχείο ξεχωριστά, δομοστοιχεία που έχουν μοντελοποιηθεί συνδέονται και μοντελοποιούν μεγαλύτερα, μέχρι να φτάσουμε στο ανώτερο επίπεδο που είναι το τελικό προϊόν.
Η τρίτη αρχή ερμηνεύεται ότι θα πρέπει τα μοντέλα που επιλέγονται να έχουν μεγάλη σχέση με την πραγματικότητα και να μη γίνονται αβάσιμες εκτιμήσεις λειτουργίας. Στα μοντέλα αυτά θα πρέπει να εξετάζονται και οι ακραίες συνθήκες και όχι μόνο οι τυπικές. Όλα τα μοντέλα απλοποιούν την πραγματικότητα. Θα πρέπει να προσέχουμε όμως, να μην υπερ-απλοποιούμε την πραγματικότητα καλύπτοντας σημαντικές πτυχές, που μπορεί να επηρεάσουν αρνητικά το προϊόν. Για παράδειγμα, αν μοντελοποιήσουμε ένα ΕΣ που θα σταλεί σε κάποιον δορυφόρο, με τον ίδιο τρόπο που θα μοντελοποιηθεί ένα παρόμοιο ΕΣ στη γη, τότε θα αγνοηθεί ο παράγοντας της κοσμικής ηλεκτρομαγνητικής ακτινοβολίας. Στη γη η κοσμική ακτινοβολία επηρεάζει ελάχιστα τα ΕΣ, ενώ στο διάστημα είναι πολύ έντονες οι συνέπειες της. Είναι κατανοητό, ότι κάποιος θα πρέπει να επιλέξει το μοντέλο ύστερα από έρευνα, ιδιαίτερα αν αφορά σχεδιασμό σε περιοχή που δεν έχει ασχοληθεί ξανά.
Η τέταρτη αρχή σημαίνει ότι για το ίδιο προϊόν απαιτούνται πολλά μοντέλα που δείχνουν μια διαφορετική εικόνα. Όπως σε ένα κατασκευαστικό έργο, υπάρχουν πολλά μοντέλα (ηλεκτρολογικό, στατικό, μηχανολογικό, θερμομονωτικό,...), έτσι και σε ένα έργο σχεδιασμού ενσωματωμένων συστημάτων, χρησιμοποιούνται πολλά μοντέλα που είναι ανεξάρτητα ως προς αυτό που εξετάζουν, αλλά συνδέονται με το τελικό προϊόν Τυπικά μοντέλα που συναντώνται στα ΕΣ είναι το μοντέλο καταστάσεων χρήσης (use-cases) που περιγράφει τις λειτουργικές προδιαγραφές του συστήματος, το μοντέλο σχεδιασμού που παρουσιάζει τα φυσικά και ηλεκτρονικά δομοστοιχεία του κυκλώματος και πως συνδέονται, το μοντέλο υλοποίησης που δείχνει πως θα είναι το τελικό προϊόν, το μοντέλο λειτουργικής εμφάνισης, που δείχνει στον τελικό χρήστη πως θα επικοινωνεί μαζί του, και ασφαλώς μοντέλα περιγραφής προγράμματος, σχεδιασμού, και προσομοίωσης.
Στο σχεδιασμό ενσωματωμένων συστημάτων, υπάρχουν πολλές γλώσσες μοντελοποίησης. Οι πιο σημαντικές γλώσσες ή εργαλεία μοντελοποίησης που χρησιμοποιούνται, είναι οι παρακάτω:
VHDL
Verilog
SystemC
SystemVerilog
UML
MATLAB
EDA TOOLS
Τα εργαλεία που έχει στη διάθεσή του ένας μηχανικός για να μοντελοποιήσει ένα σύστημα συνήθως δέχονται διαφόρους τρόπους για την εισαγωγή της περιγραφής. Μπορεί να είναι είτε μια ειδική μορφή κειμένου σαν μια τυπική γλώσσα προγραμματισμού, όπως για παράδειγμα η VHDL ή η Verilog, είτε μια σχηματική μορφή που μοιάζει με διάγραμμα, όπως η UML, είτε πολύπλοκα περιβάλλοντα που έχουν και γραφική είσοδο και είσοδο σε μορφή προγράμματος, όπως το Matlab.
Τον τελευταίο καιρό έχουν παρουσιαστεί και ειδικά περιβάλλοντα μοντελοποίησης που παρέχουν τη δυνατότητα στη σχεδιαστική ομάδα να δημιουργήσει ένα αφαιρετικό λειτουργικό μοντέλο πριν ακόμη σχεδιαστεί το σύστημα. Αυτά τα περιβάλλοντα είναι ιδιαίτερα χρήσιμα σε αυτούς που σχεδιάζουν σύνθετα ΕΣ με διάφορους επεξεργαστές και δομοστοιχεία από πολλούς παρόχους, οπότε πριν αποφασίσουν και επιλέξουν αυτά τα στοιχεία, επιβεβαιώνουν τη συνεργασία τους. Ο σχεδιαστής μπορεί να περιγράψει τις οντότητες σε SystemC και να ορίσει τα πρότυπα επικοινωνίας. Το εργαλείο χρησιμοποιεί συνήθως μια υψηλού επιπέδου μοντελοποίηση, όπως το μοντέλο επιπέδου συναλλαγής (transaction level modeling, TLM), στο οποίο καθορίζονται τα δεδομένα που μεταφέρονται από μια οντότητα του συστήματος στην άλλη, και επίσης παρέχει μια βιβλιοθήκη από πολλά δομικά στοιχεία, όπως συγκεκριμένους επεξεργαστές, στοιχεία μνήμης, ελεγκτές, διαύλους και άλλα. Αφού τοποθετηθούν όλα τα απαραίτητα στοιχεία με τις περιγραφές λειτουργίας και τις διασυνδέσεις, δημιουργείται ένα εκτελέσιμο πρόγραμμα, το οποίο μπορεί να επιτύχει υψηλές ταχύτητες προσομοίωσης (έχουν αναφερθεί προσομοιώσεις μεγάλης λεπτομέρειας, με ταχύτητες που προσεγγίζουν το 40% της πραγματικής εκτέλεσης του συστήματος). Αυτό το πρόγραμμα δέχεται εισόδους και δείχνει με γραφικό τρόπο τα αποτελέσματα, όπως για παράδειγμα το γράφο κλήσεων συναρτήσεων, τις πληροφορίες καθυστέρησης των συναρτήσεων, τους χρόνους εξυπηρέτησης διακοπών, την κίνηση δεδομένων στους διαύλους και άλλα. Επειδή είναι εκτελέσιμο, ο μηχανικός μπορεί να επέμβει άμεσα και να τροποποιήσει παραμέτρους σε αυτό το μοντέλο μέσω μιας διεπαφής συμβατής με το GDB (gnu debugger) ή να αποσφαλματώσει και να διορθώσει τμήματα κώδικα με πρόσβαση μέσα στο εσωτερικό των μοντέλων και των διαύλων ή να δει σχετικά συνοπτικά γραφήματα εκτέλεσης και χρονισμού, όπως ρυθμό ολοκλήρωσης αποτελεσμάτων (throughput), καθυστέρηση επικοινωνίας (latency), κατανάλωση ενέργειας (δυναμική, στατική, ρολογιού), κατανομή ενέργειας (power distribution), χρήση διαύλου, μέγιστο, ελάχιστο και μέσο όρο του εύρους ζώνης διαύλων. Όταν αποκτηθεί το πραγματικό hardware μπορεί να μεταφερθεί σε αυτό ο κώδικας που θα έχει αναπτυχθεί, αφού θα έχουν διορθωθεί τα σφάλματα του προγράμματος που βασίζονταν σε θέματα που είχαν μοντελοποιηθεί. Βέβαια, θα εμφανιστούν νέα σφάλματα τα οποία συνδέονται με το hardware, αλλά τουλάχιστον θα έχει μειωθεί σημαντικά ο χρόνος έρευνας και ανάπτυξης, αφού θα μπορεί να συνδέεται το μοντέλο με το αντίστοιχο hardware μέσω απομακρυσμένης αποσφαλμάτωσης (remote debugging) για να βρεθεί η πιθανή ασυνέπεια ή το πρόβλημα. Ένα αντιπροσωπευτικό παράδειγμα τέτοιου εργαλείου είναι το περιβάλλον εικονικής προτυποποίησης Vista Virtual Prototyping της εταιρίας Mentor (Εικόνα 2.4).
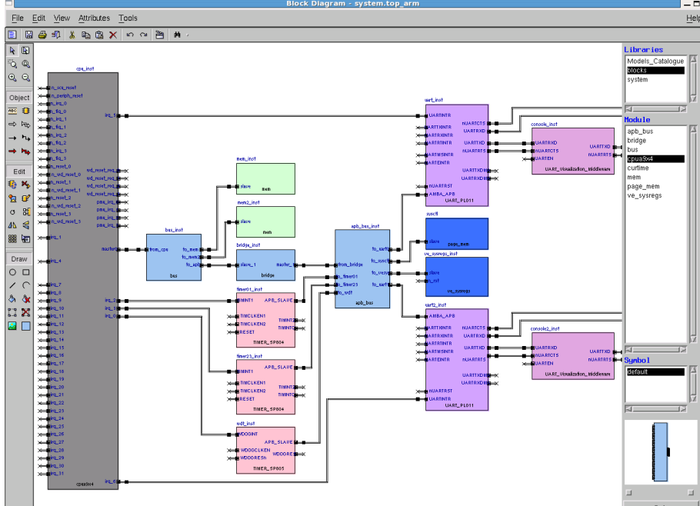
2.4: Η μοντελοποίηση μπορεί να γίνει σε ιδεατά περιβάλλοντα, χωρίς πραγματικό hardware. Μια τέτοια πλατφόρμα είναι το Vista της Mentor. Εικόνα από mentor.com.
Στις μέρες μας σχεδιάζονται σύνθετα και πολύπλοκα προϊόντα, ενώ ταυτόχρονα ο χρόνος εισαγωγής του προϊόντος στην αγορά (time-to-market) έχει μειωθεί και είναι περίπου 6 μήνες. Προκειμένου να τηρούν αυτό το μικρό χρόνο, οι σχεδιαστές πρέπει να μοντελοποιούν με διάφορους τρόπους και εργαλεία το τελικό προϊόν. Σε αυτό το κεφάλαιο περιγράψαμε τη σημαντικότητα της μοντελοποίησης του σχεδιασμού στα ενσωματωμένα συστήματα. Περιγράψαμε τις βασικές αρχές και τα επίπεδα περιγραφής, ενώ δώσαμε και μια ενδεικτική λίστα με τα εργαλεία και τις πιο σημαντικές γλώσσες μοντελοποίησης που πρέπει να γνωρίζει ένας μηχανικός που καλείται να μοντελοποιήσει ένα ενσωματωμένο σύστημα.
Ο σχεδιασμός των ΕΣ μπορεί να επιτευχθεί σε διάφορα επίπεδα, ανάλογα με τις ανάγκες και τις προδιαγραφές που συνοδεύουν το εκάστοτε σύστημα. Από τη χρήση ενός μίνι έτοιμου υπολογιστή από το ράφι, που θα μπει μέσα σε ένα μηχάνημα ATM, έως τη σχεδίαση εκ του μηδενός του επεξεργαστή και των περιφερειακών που θα χρησιμοποιηθούν. Ανάμεσα στις δυο αυτές ακραίες περιπτώσεις υπάρχουν πάρα πολλοί συνδυασμοί. Προκειμένου κάποιος μηχανικός να μπορεί να επιλέξει μια καλή υλοποίηση για το πρόβλημά του (ποτέ δεν υπάρχει απόλυτα βέλτιστη υλοποίηση, αφού υπάρχουν πάρα πολλοί συμβιβασμοί- trade-offs), θα πρέπει να γνωρίζει θέματα αρχιτεκτονικής και τεχνολογίες υλοποίησης ενσωματωμένων συστημάτων, καθώς και τις προκλήσεις, προβλήματα και οφέλη που συνοδεύουν κάθε επιλογή. Σε αυτό το κεφάλαιο καλύπτουμε την πρώτη απαίτηση και στο κεφάλαιο που ακολουθεί τη δεύτερη απαίτηση.
Όπως έχει γίνει κατανοητό από την εισαγωγή, ένα ΕΣ βασίζεται στις ίδιες αρχές αρχιτεκτονικής που διέπουν κάθε προγραμματιζόμενο σύστημα. Τα δομικά του τμήματα είναι 3: μνήμη,
επεξεργαστής και
είσοδος/έξοδος. Σε αυτό το κεφάλαιο συνοψίζουμε τις βασικές αρχές αρχιτεκτονικής, που βρίσκουν εφαρμογή στη συγκεκριμένη κατηγορία συστημάτων, περιγράφοντας βασικές γνώσεις για τα 3 δομικά τμήματα. Τα δεδομένα αποθηκεύονται ή ανακαλούνται από το
, επεξεργάζονται και μετασχηματίζονται από το
και μεταφέρονται μέσω διαύλων και δικτύων διασύνδεσης για το
. Σε αυτό το κεφάλαιο αναπτύσσουμε θέματα αρχιτεκτονικής που άπτονται της μνήμης και του επεξεργαστή, και σε επόμενο κεφάλαιο αναλύουμε την είσοδο/έξοδο.
Όλα τα ΕΣ φέρουν μια ποικιλία τεχνολογιών και ιδιοτήτων μνήμης. Ακόμη και το πιο απλό ΕΣ που βασίζεται σε ένα μικροεπεξεργαστή 8 bit, όπως το δημοφιλές ATMEGA328P, έχει διάφορες μνήμες, όπως μνήμη SRAM για τους καταχωρητές, 2KB μνήμη RAM για την εκτέλεση του προγράμματος, μνήμη FLASH για την αποθήκευση του προγράμματος, και μνήμη EEPROM 1ΚΒ για την αποθήκευση ρυθμίσεων. Στο κεφάλαιο αυτό περιγράφονται όλες αυτές οι τεχνολογίες (SRAM, EEPROM, FLASH) και πολλές άλλες που συναντάμε στα ΕΣ.
Η μνήμη χρησιμοποιείται για να διατηρεί τα δεδομένα (είτε μόνιμα είτε όσο διατηρείται η τροφοδοσία), και το πρόγραμμα εκτέλεσης του επεξεργαστή. Υπάρχει ποικιλία τεχνολογιών μνήμης, και συχνά χρησιμοποιείται ένα μίγμα μέσα σε ένα ΕΣ. Κάποιο είδος μνήμης θα διατηρήσει το περιεχόμενό της, ενώ δεν τροφοδοτείται καθόλου με ενέργεια (αυτή η κατηγορία μνήμης ονομάζεται non volatile-μη πτητική, ενώ η αντίθετη περίπτωση ονομάζεται volatile-πτητική), όμως η πρόσβαση σε αυτή θα είναι αργή. Άλλες συσκευές μνήμης θα είναι μεγάλης χωρητικότητας, όμως θα απαιτούν στοιχεία κυκλώματος πρόσθετης υποστήριξης για την ανανέωση ή τον έλεγχο και θα είναι πιο αργές στην πρόσβαση. Ακόμα άλλες συσκευές μνήμης θα θυσιάσουν την χωρητικότητα για την ταχύτητα, που παράγουν οι σχετικά μικρές συσκευές, όμως θα είναι σε θέση να αντεπεξέλθουν με το γρηγορότερο επεξεργαστή. Γενικά, υπάρχουν πολλές τεχνολογίες και κυκλώματα μνήμης, γιατί όπως ισχύει σε κάθε σχεδιασμό συστήματος, υπάρχουν πάρα πολλοί βαθμοί ελευθερίας και αναλόγως της βαρύτητας που δίνεται, προκύπτουν διαφορετικά χαρακτηριστικά. Για αυτό και έχει ειπωθεί ότι ενώ οι χρήστες θέλουν την ελευθερία της επιλογής (όπως π.χ. στα καταναλωτικά προϊόντα) οι σχεδιαστές συστημάτων την απεχθάνονται γιατί τους κάνει πολύ δύσκολο το έργο της επιλογής των κατάλληλων υποσυστημάτων.
Μια οποιαδήποτε μνήμη αποτελείται από κελιά, όπου το κάθε κελί αποθηκεύει ένα bit. Το bit αποθηκεύεται ως τάση, όπου η ύπαρξη ή απουσία τάσης καθορίζει αν θα είναι 1 ή 0. Υπάρχουν και κάποιες πιο σύνθετες υλοποιήσεις που χρησιμοποιούν πολλαπλές τάσεις στο ίδιο κελί (ονομάζονται MLC, multi-level cell ή κελί πολλαπλών επιπέδων τάσης [15]) και επιτρέπουν την αύξηση της χωρητικότητας στο ίδιο κελί δηλαδή αύξηση της χωρητικότητας στην ίδια επιφάνεια πυριτίου (συνήθως αποθηκεύονται 2 bit σε ένα κελί του 1 bit), που όμως αν και έχουν περάσει δεκαετίες από τότε που προτάθηκαν βρίσκονται σε ερευνητικό στάδιο, γιατί απαιτούνται πολύ ευαίσθητοι ανιχνευτές τάσης και είναι πολύ επιρρεπείς σε τροποποίηση και αλλοίωση των αποτελεσμάτων, ιδιαίτερα για τις πολύ μικρές τεχνολογίες υλοποίησης (π.χ. πλάτος τρανζίστορ 14nm).
Τα bit ομαδοποιούνται συνήθως σε λέξεις των 8 στοιχείων (1 Byte) ή σε κάποιες περιπτώσεις και σε άλλα μεγέθη όπως των 32 Byte. Έτσι λοιπόν, αν σε μια μνήμη υπάρχουν λέξεις των
bit η κάθε μια, συνολικά η μνήμη θα φέρει
bit. Αναφερόμαστε σε μια μνήμη ως μνήμη
(‘
-από-
’). Κάποιες μνήμες έχουν επιπρόσθετα bit για διάγνωση και επιδιόρθωση σφαλμάτων, όπως οι μνήμες με υποστήριξη ECC (error correcting code, κώδικα για διόρθωση σφαλμάτων). Οι ECC μνήμες χρησιμοποιούνται σε περιβάλλοντα ακραίων καταστάσεων λειτουργίας, όπως στο ΕΣ που θα τοποθετηθεί σε ένα δορυφόρο και θα βομβαρδίζεται συνεχώς από την κοσμική ηλεκτρομαγνητική ακτινοβολία, δημιουργώντας μαλακά σφάλματα (soft errors), δηλαδή προσωρινή αλλοίωση των τιμών των bit [16].
Μια μνήμη αποτελείται από λέξεις των
bit, οπότε θα πρέπει να μπορεί κάποιος να διευθυνσιοδοτήσει αυτές τις
λέξεις, ώστε να διαβάσει στην έξοδο δεδομένων της μνήμης, τη λέξη. Τα σήματα εισόδου διευθύνσεων
είναι απαραίτητα για να προσδιορίσουν μια συγκεκριμένη λέξη. Με άλλα λόγια, εάν μια μνήμη έχει
διευθύνσεις ως είσοδο, αυτή μπορεί να έχει μέχρι
λέξεις. Ο δίαυλος των διευθύνσεων απαιτεί
bit. Αυτά μπορεί να βρίσκονται σε
διαφορετικές γραμμές ή σε λιγότερες με τη χρήση της πολύπλεξης. Η διευθυνσιοδότηση μιας μνήμης επιτρέπει την εγγραφή ή ανάγνωση μιας λέξης. Μερικές μνήμες μπορούν μόνο να προσπελαστούν (όπως η ROM), ενώ άλλες επιτρέπουν την προσπέλαση και την εγγραφή δεδομένων (όπως η RAM). Σε αντίθεση με τη μνήμη μόνο για ανάγνωση, δεν υπάρχει μνήμη μόνο για εγγραφή (δηλαδή, δε μπορεί να γίνει ανάγνωση), και ένα φύλλο δεδομένων (data sheet) για μια υποτιθέμενη τέτοια συσκευή, αποτελεί κλασσικό ανέκδοτο των αρχιτεκτόνων της δεκαετίας του 1970 [17].
Όλες οι μνήμες μπορούν να διευθυνσιοδοτούν λέξεις. Ένα στοιχείο που διαφοροποιεί τις μνήμες, είναι πόσα bit ή Byte έχει κάθε λέξη. Συνήθως κάθε λέξη είναι 8bit, ή 32bit, και αυτό σημαίνει ότι με μια διεύθυνση μνήμης ο επεξεργαστής αποκτά πρόσβαση σε 8 bit ή 32 bit αντίστοιχα. Άρα, σε περίπτωση που χρησιμοποιούνται 8 bit απαιτούνται 4 διαδοχικές διευθύνσεις για τη μεταφορά 32 bit. Υπάρχουν όμως και ειδικοί τρόποι πρόσβασης σε κάποιες μνήμες, που στέλνεται μόνο η αρχική διεύθυνση και το συνολικό μέγεθος των Byte που απαιτούνται για την ανάγνωση (burst transfer, μεταφορά ριπής).
Τα ολοκληρωμένα τσιπ μνήμης έρχονται σε διαφορετικά μεγέθη, ως προς την οργάνωση. Παραδείγματος χάριν, ένα τσιπ DRAM (δυναμική RAM) μπορεί να περιγραφεί ως 4MBx1 (οργανωμένο σε bit), ενώ ένα τσιπ SRAM (στατική RAM) μπορεί να είναι 512KBx8 (οργανωμένο σε λέξεις). Και στις δύο περιπτώσεις, κάθε τσιπ έχει ακριβώς την ίδια ικανότητα αποθήκευσης, αλλά είναι οργανωμένο με διαφορετικούς τρόπους. Στην περίπτωση της DRAM, θα απαιτούνταν οκτώ τσιπ συνδεδεμένα όλα στις ίδιες γραμμές διευθύνσεων, όπου το πρώτο τσιπ θα έδινε το bit ελάχιστης σημαντικότητας (LSB), ενώ το τελευταίο τσιπ θα μετέφερε το μεγαλύτερης σημαντικότητας (MSB). Ασφαλώς, η πρόσβαση θα ήταν παράλληλη σε αυτά τα τσιπ και ταυτόχρονα θα τοποθετούνταν στην έξοδο και τα 8 bit μόλις αποκωδικοποιούνταν η διεύθυνση μνήμης.
Στην περίπτωση της SRAM θα απαιτούνταν μόνο ένα τσιπ. Εντούτοις, επειδή συνήθως τα τσιπ DRAM οργανώνονται παράλληλα, υποστηρίζουν ταυτόχρονη προσπέλαση και επιτυγχάνονται καλές ταχύτητες πρόσβασης. Το τελικό μέγεθος για τη DRAM είναι (4MBx1)x8 ή 32MB.
Το ακρωνύμιο RAM σημαίνει μνήμη τυχαίας πρόσβασης ή προσπέλασης (Random Access Memory). Αυτό όμως είναι ένας ατυχής χαρακτηρισμός, δεδομένου ότι σχεδόν όλη η μνήμη των υπολογιστών μπορεί να θεωρηθεί ‘τυχαίας πρόσβασης’. Βέβαια πρόσφατα, έχουν προταθεί στα ΕΣ και μνήμες ‘σειριακές’ (serial memory), όπως το Hybrid Memory Cube [18] από μια κοινοπραξία μεγάλων εταιριών (Xilinx, Altera, Microsoft, Samsung, ARM κ.α.), με το όρο ‘serial’ όμως να αφορά τον τρόπο μεταφοράς των δεδομένων προς και από αυτή τη συσκευή και όχι την εσωτερική δομή, όπου πάλι είναι τύπου RAM. Ο όρος RAM δημιουργήθηκε με τους πρώτους υπολογιστές με τρανζίστορ (δεκαετία 1960), αφού ως τότε υπήρχε ένα είδος μνήμης πυρήνα (magnetic core memory), όπως φαίνεται στην Εικόνα 3.19, και η μνήμη ήταν αρκετά αργή στην ανάγνωση και εγγραφή. Επίσης, εκείνη την εποχή, υπήρχαν μαγνητικές ταινίες αποθήκευσης ως μνήμες, που υποστήριζαν μόνο τη σειριακή εγγραφή και ανάγνωση. Η επινόηση της γρήγορης μνήμης RAM, έδωσε μια σημαντική ώθηση στους υπολογιστές.

3.1: Πριν από τη RAM χρησιμοποιούνταν μαγνητικοί δακτύλιοι μνήμης (1955-1975). Εικόνα από wikipedia.org.
Η RAM είναι η μνήμη λειτουργίας στους ηλεκτρονικούς υπολογιστές. Είναι το μέρος όπου ο επεξεργαστής μπορεί εύκολα να γράψει δεδομένα για προσωρινή αποθήκευση (όσο τροφοδοτείται η μνήμη με ρεύμα). Η RAM είναι γενικά ευμετάβλητη (πτητική), χάνοντας το περιεχόμενό της όταν χάνει το σύστημα ενέργεια (ρεύμα). Οποιεσδήποτε πληροφορίες αποθηκεύονται στη RAM και πρέπει να διατηρηθούν, πρέπει να γραφτούν σε κάποια μορφή μόνιμης αποθήκευσης πριν το σύστημα χάσει την ισχύ του. Προκειμένου να αντιμετωπιστεί το μειονέκτημα της πτητικότητας των δεδομένων, που είναι κρίσιμης σημασίας σε διακομιστές, έχουν κατασκευαστεί μνήμες RAM με εφεδρικό σύστημα τροφοδότησης ενέργειας (Εικόνες 3.2 και 3.3), ώστε αν διακοπεί η τροφοδοσία να συνεχίσουν να τροφοδοτούνται με ρεύμα για να διατηρούν τα δεδομένα.

3.2: Ένα ΕΣ (Gecko100) που φέρει μνήμη RAM με υποστήριξη τροφοδότησης από μπαταρία. Εικόνα από austexsoftware.com.

3.3: Μνήμη DRAM με ενσωματωμένη μπαταρία.
Οι μνήμες RAM διαιρούνται σε δύο οικογένειες: στατική RAM (επίσης γνωστή ως Static RAM ή SRAM) και δυναμική RAM (επίσης γνωστή ως dynamic RAM ή DRAM). Οι μνήμες SRAM χρησιμοποιούν πύλες λογικής σε συνδεσμολογία μανδαλωτών ή flip-flop, ώστε να διατηρούν κάθε bit των στοιχείων. Αυτή η κατηγορία είναι η γρηγορότερη διαθέσιμη μορφή RAM, απαιτεί ελάχιστα εξωτερικά στοιχεία κυκλώματος υποστήριξης, και έχει σχετικά μικρή κατανάλωση ενέργειας. Στα μειονεκτήματά τους συμπεριλαμβάνονται η μειωμένη χωρητικότητα (αφού συνήθως απαιτούν 6 τρανζίστορ, περίπου 6 φορές περισσότερη επιφάνεια από τις DRAM), το αυξημένο κόστος και η χαμηλότερη πυκνότητα ολοκλήρωσης. Για αυτό, χρησιμοποιούνται μόνο σε ειδικού τύπου κυκλώματα που απαιτούν μεγάλη ταχύτητα πρόσβασης (όπως οι κρυφές μνήμες-cache memorie). Η DRAM αντί για τρανζίστορ χρησιμοποιεί πυκνωτές για την αποθήκευση φορτίων, και αισθητήρια για την ανίχνευση ή όχι του φορτίου. Οι σειρές πυκνωτών θα κρατήσουν τη φόρτιση τους μόνο για μια μικρή χρονική περίοδο προτού η διαρροή εξαλείψει το φορτίο. Επομένως, η DRAM χρειάζεται μια συνεχή αναζωογόνηση-ανανέωση (refresh) όπου διαβάζεται το κελί και ξαναγράφεται, κάθε λίγα χιλιοστά του δευτερολέπτου (για παράδειγμα η μνήμη DRAM τεχνολογίας DDR απαιτεί κάθε κελί να ανανεώνεται ανά 7.8 μs). Αυτή η διαρκής ανάγκη ανανέωσης απαιτεί πρόσθετη υποστήριξη και μπορεί να καθυστερήσει την πρόσβαση σε αυτή, αν τη στιγμή που πρόκειται να γίνει μια ανάγνωση, απαιτείται ανανέωση του κελιού. Οι DRAM είναι συσκευές μνήμης υψηλής-χωρητικότητας διαθέσιμες και έρχονται σε μια ευρεία και διαφορετική ποικιλία υπό κατηγοριών. Λόγω της πολυπλοκότητας που έχουν μπορούν να διασυνδεθούν μόνο με κανονικούς επεξεργαστές, και δεν είναι πρακτική η σύνδεση με μικρούς μικροελεγκτές ΕΣ. Οι περισσότεροι επεξεργαστές με δυνατότητα διευθυνσιοδότησης μεγάλων μεγεθών μνήμης, έχουν εγγενή υποστήριξη για DRAM (ή αν δεν έχουν μπορούν να συνδεθούν σε ένα ενδιάμεσο ελεγκτή μνήμης).
Ένα σημαντικό πρόβλημα με τη χρήση της DRAM, προκύπτει από το γεγονός ότι είναι εξωτερική μνήμη (δε βρίσκεται στο ίδιο τσιπ με τον επεξεργαστή) και άρα υπάρχει αυξημένη καθυστέρηση και ενεργειακή ανάγκη για κάθε πρόσβαση. Για να θεραπευτεί κάπως αυτό το μειονέκτημα κάποιοι επεξεργαστές έχουν κρυφές (μη ορατές) μνήμες εντολών και δεδομένων πάνω στο ίδιο πυρίτιο με τον επεξεργαστή και αποθηκεύουν τις πρόσφατες προσβάσεις μνήμης. Αυτές οι μνήμες είναι (συχνά, αλλά όχι πάντα) εσωτερικές στους επεξεργαστές και υλοποιούνται με γρήγορα στοιχεία μνήμης και μεγάλης-ταχύτητας διαύλους δεδομένων. Έτσι λοιπόν δεδομένα που επαναχρησιμοποιούνται μπορούν να αποθηκευτούν προσωρινά σε αυτή τη μνήμη μόλις διαβαστούν και έτσι την επόμενη φορά που θα ζητηθούν να βρίσκονται κοντά στον επεξεργαστή. Οι κρυφές μνήμης είναι τεχνολογίας SRAM.
Οι μνήμες DRAM παρουσιάζουν μια διαρκή εξέλιξη τεχνολογίας από το 1975 που είχαν πρωτοπαρουσιασθεί, την οποία θα συνοψίσουμε σε λίγες γραμμές: Μια αύξηση των επιδόσεων επήλθε όταν η μνήμη συγχρονίστηκε με το ρολόι του διαύλου που συνέδεε τον επεξεργαστή με τη μνήμη. Βέβαια, η μνήμη θα έπρεπε να έχει αυστηρούς χρονισμούς και να υποστηρίζει παραμετροποιήσιμη καθυστέρηση (wait cycles), ώστε η όλη επικοινωνία να είναι συγχρονισμένη. Αυτή η μνήμη ονομάζονταν synchronous DRAM (SDRAM) και είχε ταχύτητες λειτουργίας (Mhz) SDRAM PC-66, SDRAM PC-100, SDRAM PC-133.
Μια βελτίωση στη SDRAM πραγματοποιήθηκε όταν άλλαξε η επικοινωνία με τη μνήμη, και από εκεί που η επικοινωνία γίνονταν με τις στάθμες της λογικής (1 και 0), στη συνέχεια γίνονταν με τις ανερχόμενες και κατερχόμενες ακμές του ρολογιού. Αυτό επέτρεψε να διπλασιαστεί ο ρυθμός επικοινωνίας με τη μνήμη (double data rate, DDR) για το ίδιο ρολόι του συστήματος. Οι ενδεικτικές ταχύτητες σε Mhz για αυτές τις μνήμες ήταν DDR-200, DDR-233, DDR-333, DDR-400. Μια ακόμη βελτίωση συντελέστηκε όταν αυξήθηκε η συχνότητα λειτουργίας, μειώθηκε η τάση τροφοδοσίας και διπλασιάστηκε η χωρητικότητα του διαύλου δεδομένων (από 128 bit σε 256 bit). Αυτές οι μνήμες ονομάστηκαν DDR2 SDRAM με συχνότητες λειτουργίας DDR2-400, DDR2-533, DDR2-667, DDR2-800 και DDR2-1066. Η επόμενη γενιά των μνημών (DDR3 SDRAM) διπλασίασε το εύρος του διαύλου σε 512 bit, και την τάση λειτουργίας στα 1.5 Volt και συχνότητα λειτουργίας DDR3-1600. Η επόμενη γενιά που ακόμη δεν έχει καθιερωθεί από την αγορά γιατί είναι στα πρώιμα στάδια (παρουσιάστηκε το 2014), είναι η DDR4, με 1.2 Volt και με συχνότητες λειτουργίας DDR4-2133 και DDR4-3200. Οι μνήμες της τελευταίας γενιάς έχουν τόσο μεγάλες ταχύτητες που μπορούν να τις εκμεταλλευτούν μόνο εφαρμογές που κάνουν εντατική χρήση της μνήμης (εφαρμογές διακομιστών), για αυτό και η αύξηση της απόδοσης σε ένα σύστημα που αναβαθμίζεται από DDR3 σε DDR4 είναι 0 έως 5%, ενώ το κόστος αγοράς της μνήμης είναι 2 με 3 φορές περισσότερο [19]. Επίσης, υπάρχουν και τροποποιήσεις των DDR, όπως οι LPDDR(Χ) (X=2,3,4) με το LP να σημαίνει low-power (χαμηλή κατανάλωση), δηλαδή μνήμες που λειτουργούν με μειωμένη τάση τροφοδοσίας και χρησιμοποιούνται σε φορητές συσκευές (π.χ. σε κινητά), GDDR(X) (X=2,3,4,5) με το G να σημαίνει graphics (γραφικά) και είναι μνήμες που χρησιμοποιούνται σε κάρτες γραφικών και φέρουν κάποιες εξειδικευμένες αρχιτεκτονικές τροποποιήσεις, Rambus RDRAM και η εξέλιξή της ως XDR SDRAM, οι οποίες είναι κλειστές τεχνολογίες με πατέντες που κατέχει η Rambus και υποστηρίζουν μεγαλύτερες συχνότητες λειτουργίας από τις αντίστοιχες DDR, αλλά με αυξημένο κόστος. Σε ερευνητικό επίπεδο (μετά τη DDR4) υπάρχει η τεχνολογία Υβριδικού Κύβου Μνήμης (Hybrid Memory Cube, HMC) που συναγωνίζεται την τεχνολογία Μνήμη Υψηλού Εύρους ζώνης (High Bandwidth Memory, HBM) ως προς το ποια θα επικρατήσει. Οι τεχνολογίες αυτές χρησιμοποιούν την τρισδιάστατη ολοκλήρωση, δηλαδή την κατακόρυφη τοποθέτηση πολλών τσιπ και την κατάλληλη σύνδεση με οπές (vias), ενώ έχουν μειώσει τις γραμμές μεταφοράς δεδομένων χρησιμοποιώντας υψηλής ταχύτητας σειριακή αποστολή και λήψη δεδομένων από τον επεξεργαστή. Όπως και σε άλλα δομικά στοιχεία, η τεχνολογία δε σταματάει να κάνει άλματα ανάπτυξης.
Η Read Only Memory (ROM), ή μνήμη μόνο για ανάγνωση, είναι μια μνήμη που μπορεί να προσπελαστεί για ανάγνωση, αλλά όχι να αποθηκεύσει δεδομένα κατά την τυπική λειτουργία. Φυσικά, υπάρχει τρόπος να γραφούν μια ή ελάχιστες φορές δεδομένα, αλλά αυτή η διαδικασία καλείται προγραμματισμός και όχι αποθήκευση. Τέτοιος προγραμματισμός γίνεται συνήθως εκτός σύνδεσης (off line), δηλαδή όταν δεν χρησιμοποιείται ενεργά η μνήμη ως μνήμη σε ένα ΕΣ. Μια ROM προγραμματίζεται συνήθως πριν τοποθετηθεί στην κατάλληλη υποδοχή του ΕΣ. Η Εικόνα 3.4 παρέχει ένα διάγραμμα δομικών στοιχείων μιας ROM.
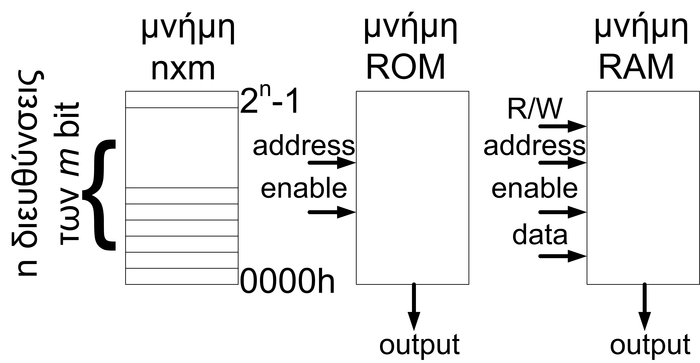
3.4: Βασικές μνήμες () λέξεις και Bits ανά λέξη, (
) διάγραμμα τμήματος ROM, (c) διάγραμμα τμήματος RAM.
Μια ROM μπορεί να χρησιμοποιηθεί για διάφορους σκοπούς σε ένα ΕΣ. Για παράδειγμα, μπορεί να αποτελεί το πρόγραμμα εκκίνησης (boot loader), δηλαδή το πρώτο πρόγραμμα που θα εκτελέσει ένα ΕΣ μόλις τροφοδοτηθεί με ρεύμα. Το πρόγραμμα αυτό μπορεί στη συνέχεια να μεταφορτώσει το υπόλοιπο πρόγραμμα ή το λειτουργικό σύστημα από κάποιο μέσο μεγαλύτερης χωρητικότητας, όπως μια μνήμη Flash. Για μικρά ΕΣ μια μνήμη ROM μπορεί να φέρει όλο το πρόγραμμα και να μην απαιτείται κάτι παραπάνω. Όμως, όπως θα δούμε παρακάτω, οι μνήμες RAM δε χρησιμοποιούνται πια, αφού έχουν κατασκευαστεί νέες οικογένειες μόνιμης αποθήκευσης με μεγαλύτερη ευελιξία. Μια ROM επίσης, μπορεί να χρησιμοποιηθεί για την υλοποίηση ενός συνδυαστικού κυκλώματος. Μπορεί να υλοποιηθεί οποιαδήποτε συνδυαστική συνάρτηση μεταβλητών με τη χρησιμοποίηση μιας 2
x 1 ROM, και μπορούν να υλοποιηθούν
λειτουργίες των ίδιων μεταβλητών
χρησιμοποιώντας μια 2
x
ROM.
Μια άλλη κοινή χρήση είναι η υλοποίηση ενός συνδυαστικού κυκλώματος. Μπορούμε να υλοποιήσουμε οποιαδήποτε συνδυαστική συνάρτηση. Προγραμματίζουμε απλά τη ROM για να υλοποιήσουμε τον πίνακα αλήθειας για την ή τις συναρτήσεις, που θέλουμε.
Η μνήμη ROM προγραμματίζεται μόνο στα εργοστάσια κατασκευής και δεν είναι δυνατός ο επαναπρογραμματισμός της. Η διαδικασία της φόρτωσης του λογισμικού σε μία ROM είναι γνωστή ως ‘κάψιμο (burn) της ROM’. Αυτός ο όρος προέρχεται από το γεγονός ότι η διαδικασία προγραμματισμού εκτελείται περνώντας ένα αρκετά μεγάλο ρεύμα μέσω των κατάλληλων διακοπτών που έχει το εσωτερικό πλέγμα της ROM για ‘να τους καταστρέψει’ ή να τους ‘κάψει’ και με αυτόν τον τρόπο δημιουργεί ένα μηδέν σε εκείνη την θέση bit. Μια συσκευή γνωστή ως ‘καυστήρας’ ή προγραμματιστής ROM μπορεί να επιτελέσει αυτή τη λειτουργία ή αν η ROM είναι ειδικού τύπου να προγραμματιστεί εντός συστήματος (In-System Programing-ISP) ή εντός κυκλώματος (In-Circuit Programming - ICP). Η απλή μνήμη ROM προγραμματίζεται μόνο μια φορά, γιατί κατά τον προγραμματισμό τροποποιείται μόνιμα το κύκλωμα. Αυτή η μνήμη χρησιμοποιείται σε ΕΣ που μόλις φύγουν από το εργοστάσιο δεν πρόκειται να μεταβληθούν (ή να ενημερωθούν).
Μια πιο ευέλικτη κατηγορία ROM, είναι η PROM (programmable ROM), η οποία μπορεί να προγραμματιστεί μια φορά από το χρήστη με ειδικό εξοπλισμό. Αυτές οι μνήμες ταιριάζουν καλύτερα για τη γρήγορη προτυποποίηση και στα ΕΣ χαμηλών απαιτήσεων.
Για να προγραμματιστεί μια συσκευή PROM, ο χρήστης παρέχει ένα αρχείο που καθορίζει το επιθυμητό περιεχόμενο για τη μνήμη. Ένα κομμάτι του εξοπλισμού αποκαλούμενο προγραμματιστής ROM (σημείωση: ο προγραμματιστής είναι εξοπλισμός υλικού, όχι ένα πρόσωπο που γράφει κώδικα λογισμικού) και έπειτα διαμορφώνει κάθε προγραμματίσημη σύνδεση σύμφωνα με το αρχείο. Μόλις προγραμματιστεί η ROM καταστρέφονται με μεγάλο ρεύμα οι κατάλληλες διασυνδέσεις, και οι εναπομείναντες διασυνδέσεις υλοποιούν το κύκλωμα. Οι συνδέσεις που καταστρέφονται δε μπορούν ποτέ να επανεγκαθιδρυθούν. Για αυτόν τον λόγο, η βασική PROM αναφέρεται συχνά ως μιας φοράς-χρονοπρογραμματίσημη συσκευή, ή OTP (One Time Programmable).
Ένας άλλος τύπος του PROM είναι μια διαγράψιμη PROM (erasable PROM, EPROM). Αυτή η συσκευή χρησιμοποιεί τρανζίστορ αιωρούμενης πύλης (floating gate), που κατά τον προγραμματισμό συνδέονται μέσω της έκχυσης ηλεκτρονίων (με υψηλότερη τάση από την κανονική για το τρανζίστορ 12V έως 25V), από το υπόλοιπο κύκλωμα. Με την κατάλληλη εφαρμογή της υψηλής τάσης επανπρογραμματίζεται στα νέα δεδομένα.
Τα OTP ROMs χρησιμοποιούνται όλο και λιγότερο στα ΕΣ, αφού δεν είναι ευέλικτα. Αν απαιτηθεί κάποια αλλαγή θα πρέπει να απομακρυνθεί και να πεταχθεί το παλαιό τσιπ και να προγραμματιστεί ένα νέο. Έτσι, η χρήση των OTP ROMS είναι μια ακριβή επιλογή ανάπτυξης ΕΣ, και προτιμούνται άλλα είδη μνήμης. Η καλύτερη επιλογή για την ανάπτυξη συστημάτων και τη διόρθωση είναι η διαγράψιμη προγραμματιζόμενη μνήμη μόνο για ανάγνωση (EPROM). Μια λάμψη υπεριώδους φωτός μέσω ενός μικρού παραθύρου στην κορυφή του τσιπ μπορεί να σβήσει το EPROM, επιτρέποντας να επαναπρογραμματιστεί και να επαναχρησιμοποιηθεί. Αυτές οι μνήμες είναι συμβατές ως προς το σήμα και τον προγραμματισμό OTP ROMs. Κατά συνέπεια, ένα EPROM μπορεί να χρησιμοποιηθεί κατά τη διάρκεια της ανάπτυξης, ενώ ένα OTP ROM μπορεί να χρησιμοποιηθεί στην παραγωγή χωρίς καμία αλλαγή στο υπόλοιπο του συστήματος.
Τα EPROM και τα ισοδύναμα συγγενικά OTP τους κυμαίνονται, ως προς την χωρητικότητα, από μερικά ΚB (υπερβολικά σπάνιο αυτές τις μέρες), ως ένα megabyte ή περισσότερο.
Η EEPROM είναι ηλεκτρικά διαγράψιμη μνήμη μόνο για ανάγνωση, επίσης γνωστή ως EEPROM (ηλεκτρικά διαγράψιμη και προγραμματίσιμη μνήμη μιας ανάγνωσης). Πολύ σπάνια, καλείται επίσης ηλεκτρικά μεταβλητή μνήμη μιας ανάγνωσης (Electrically alterable read-only memory, EAROM).
Η EEPROM μπορεί να σβηστεί και να επαναπρογραμματιστεί μέσα σε ένα κύκλωμα, σε αντίθεση με τις προηγούμενες μνήμες που απαιτείται η απομάκρυνση από το κύκλωμα και η τοποθέτηση σε ειδική συσκευή. Η χωρητικότητα τους είναι σημαντικά μικρότερη από το τυποποιημένο ROM (μόνο μερικά kilobyte), και έτσι δεν χρησιμοποιούνται για αποθήκευση κώδικα προγραμματισμού. Αντ’ αυτού, χρησιμοποιούνται, για να κρατούν τις παραμέτρους των συστημάτων και τις πληροφορίες που διατηρούνται κατά την αποσύνδεση.
Είναι κοινό για πολλούς μικροελεγκτές (όπως ATMEGA 328P), να ενσωματώνουν ένα μικρό τσιπ EEPROM για την αποθήκευση των παραμέτρων του συστήματος. Αυτό είναι ιδιαίτερα χρήσιμο στα ενσωματωμένα συστήματα και μπορεί να χρησιμοποιηθεί για την αποθήκευση των διευθύνσεων δικτύων, τοποθετήσεις διαμόρφωσης, αύξοντες αριθμούς, που συντηρούν τα αρχεία, κτλ. Για παράδειγμα, σε ΕΣ διαδικτύου που έχει σχεδιάσει ο συγγραφέας του βιβλίου, έχει τοποθετήσει κώδικα που ενεργοποιείται και διαβάζει τις εφεδρικές ρυθμίσεις λειτουργίας από την EEPROM σε περίπτωση που το ΕΣ δε μπορεί να συνδεθεί σε κάποιο διακομιστή ή να λάβει τις αυτόματες ρυθμίσεις από DHCP.
Η FLASH είναι η νεότερη τεχνολογία ROM και είναι αρκετά δημοφιλής. Συνήθως, συνυπάρχει μαζί με τη μνήμη EEPROM ή σε κάποια ΕΣ την έχει αντικαταστήσει τελείως. Η μνήμη FLASH έχει τα πλεονεκτήματα της επαναπρογραμματισημότητας εντός κυκλώματος (όπως η EEPROM) και τη μεγάλη χωρητικότητα όπως η ROM. Τα τσιπ FLASH αναφέρονται μερικές φορές ως ‘flash ROMs’ ή ‘flash RAMs’. Δεδομένου ότι δεν είναι όπως τα τυποποιημένα ROMs ή όπως η τυποποιημένη RAM, προτιμούμε ακριβώς να τα λέμε ‘FLASH’ για αποφυγή σύγχυσης.
Η FLASH οργανώνεται κανονικά όπως οι τομείς σε ένα μαγνητικό δίσκο, και έχει το πλεονέκτημα ότι οι μεμονωμένοι τομείς μπορούν να διαγραφούν και να ξαναεγγραφούν χωρίς να επηρεάζουν το περιεχόμενο του υπολοίπου της συσκευής. Συγκεκριμένα, πριν μπορέσει να γραφτεί ένας τομέας, πρέπει να διαγραφεί. Μπορεί απλά να ξαναεγγραφτεί, όπως γίνεται και με ένα RAM.
Υπάρχουν αρκετές διαφορετικές τεχνολογίες FLASH, και οι απαιτήσεις διαγραφής και προγραμματισμού των συσκευών FLASH ποικίλλουν από κατασκευαστή σε κατασκευαστή. Οι δυο βασικές τεχνολογίες FLASH είναι η NOR FLASH και η NAND FLASH. Οι μνήμες FLASH είναι ιδιαίτερα δημοφιλείς και χρησιμοποιούνται σχεδόν σε όλα τα ΕΣ για την αποθήκευση δεδομένων και προγράμματος. Το μεγάλο πλεονέκτημα είναι ότι μπορούν να ενημερωθούν από τον κατασκευαστή εν ώρα λειτουργίας, χωρίς να χρειάζεται να μετακινηθεί η συσκευή (αν υπάρχει σύνδεση με το διαδίκτυο ή δυνατότητα σύνδεσης συσκευής USB που φέρει την ενημέρωση). Η NOR FLASH επιτρέπει τυχαία πρόσβαση σε οποιοδήποτε byte αλλά έχει μεγάλους χρόνους εγγραφής και είναι ακριβό κύκλωμα. Επειδή επιτρέπει διευθυνσιοδότηση ανά byte μπορεί να αντικαταστήσει άμεσα τα υπόλοιπα είδη ROM σε οποιοδήποτε κύκλωμα (drop-in replacement), και μπορεί να περιέχει και κώδικα που θα εκτελείται άμεσα από αυτήν (π.χ. ROM). Η NAND FLASH έχει μεγαλύτερη πυκνότητα αποθήκευσης, μικρότερο κόστος, λιγότερα καλώδια και πιο γρήγορους χρόνους εγγραφής, αλλά το μειονέκτημα είναι ότι οι προσβάσεις γίνονται πάντα σε ομάδες από bits (π.χ. 4096). Έτσι δεν υπάρχει άμεση τυχαία προσπέλαση σε οποιοδήποτε σημείο, αφού μεταφέρονται όλα τα bit σε κάθε πρόσβαση. Χρησιμοποιείται μόνο για αποθήκευση και όχι για άμεση εκτέλεση όπως η NOR FLASH. Αν απαιτηθεί να εκτελεστεί ο κώδικας που περιέχει, αντιγράφεται η αντίστοιχη ομάδα στη μνήμη RAM, και εκτελείται από εκεί. Εντούτοις, επειδή είναι αρκετά φθηνή χρησιμοποιείται σε πάρα πολλά ΕΣ. Όλες οι κάρτες SD για παράδειγμα που τοποθετούνται στα κινητά τηλέφωνα ή σε ΕΣ, είναι τεχνολογίας NAND FLASH.
Αναπόσπαστο στοιχείο κάθε υπολογιστή είναι η μνήμη. Στην πληθώρα των περιπτώσεων ένας επεξεργαστής έχει μνήμη εντός (on-chip) και εκτός (off-chip) ολοκληρωμένου κυκλώματος. Στην on-chip μνήμη συγκαταλέγονται οι φανεροί και μη φανεροί καταχωρητές, η κρυφή μνήμη, και η μνήμη FLASH ή EEPROM (αν υπάρχει). Η off-chip μνήμη ομοίως μπορεί να είναι FLASH ή κάποιο είδος RAM. Τις περισσότερες περιπτώσεις η off-chip μνήμη είναι διευθυνσιοδοτούμενη ανά Byte, δηλαδή κάθε διεύθυνση μνήμης αντιστοιχεί σε μια θέση μνήμης χωρητικότητας 8 bit. Σε περίπτωση που ο επεξεργαστής χρησιμοποιεί μεγέθη αποθήκευσης δεδομένων μεγαλύτερα του 1 Byte (multi Byte), υπάρχουν δυο τρόποι αποθήκευσης στην εξωτερική μνήμη· αυτό ονομάζεται endianess (σειρά αποθήκευσης των Byte): big endian και little endian. Ο κάθε επεξεργαστής σχεδιάζεται για να υποστηρίζει τον έναν ή τον άλλο τρόπο αποθήκευσης και δεν αλλάζει. Υπάρχουν περιπτώσεις που ο επεξεργαστής έχει δυνατότητα να υποστηρίζει και τους 2 τρόπους αποθήκευσης με χρήση επιπρόσθετων κυκλωμάτων, οπότε σε αυτή την περίπτωση ονομάζεται bi-endian, και μπορεί με την κατάλληλη εντολή κώδικα μηχανής να αποφασίζεται κατά την εκτέλεση ενός προγράμματος ποιον τρόπο θα χρησιμοποιήσει, από τους ανωτέρω δυο. Η endianess αφορά την αρχιτεκτονική του επεξεργαστή και όχι της μνήμης, οπότε όλες οι μνήμες μπορούν να χρησιμοποιηθούν είτε με big είτε με little endian.
Η endianess αφορά μόνο την αποθήκευση μιας λέξης που αποτελείται από πολλά Byte. Ένα μόνο Byte θα αποθηκευτεί με τον ίδιο τρόπο είτε υπάρχει little είτε big endian. Σε περίπτωση όμως που η λέξη προς αποθήκευση αποτελείται από πολλά Byte, τότε η endianess καθορίζει τι θα αποθηκευτεί και που. Ένας big endian επεξεργαστής αποθηκεύει το σημαντικότερο Byte (Most Significant Byte, MSB) στη μικρότερη διεύθυνση και συνεχίζει να αποθηκεύει διαδοχικά τα επόμενα Byte, ως έως το χαμηλότερης σημαντικότητας Byte (Least Significant Byte, LSB), ενώ ένας little endian αρχιτεκτονικής επεξεργαστής αποθηκεύει το LSB στη μικρότερη διεύθυνση μνήμης και συνεχίζει διαδοχικά την αποθήκευση έως το MSB.
Η Εικόνα 3.5 παρουσιάζει ένα παράδειγμα αποθήκευσης μιας λέξης που αποτελείται από 1 Byte (η λέξη είναι DEh), μιας λέξης που αποτελείται από 2 Byte (η λέξη είναι ABDEh), και μιας λέξης που αποτελείται από 4 Byte (η λέξη είναι 3AF1ABDEh). Όταν η λέξη είναι 1 Byte μόνο, τότε θα αποθηκευτεί στη συγκεκριμένη διεύθυνση (π.χ. FFFFh) με τον ίδιο τρόπο και στις δυο endianess. Αν η λέξη είναι ABDEh, τότε το μεγαλύτερης σημαντικότητας Byte είναι το ABh, και το χαμηλότερης σημαντικότητας Byte είναι το DEh. Στη little endian θα αποθηκευτεί στη χαμηλότερη διεύθυνση πρώτα το DEh, και στην επόμενη διεύθυνση το ABh, ενώ στη big endian θα αποθηκευτεί στη χαμηλότερη διεύθυνση πρώτα το ABh και στην επόμενη διεύθυνση το DEh. Ομοίως, αν η λέξη είναι η 3AF1ABDEh, με MSB 3Ah και LSB DEh, και θέλουμε να το αποθηκεύσουμε στη διεύθυνση μνήμης , τότε στη little endian θα αποθηκευτεί πρώτα το LSB, δηλαδή το DEh, στην επόμενη διεύθυνση
+1 το επόμενο Byte, δηλαδή το ABh, στην επόμενη διεύθυνση
+2 το F1h και στην τελευταία
+3 το 3Ah. Στη big endian η σειρά αποθήκευσης των Byte θα είναι αντίστροφη. Πρώτα το υψηλής σημαντικότητας Byte, δηλαδή το 3Αh, και στη συνέχεια τα υπόλοιπα με φθίνουσα πορεία, δηλαδή F1h, ABh και τέλος το DEh
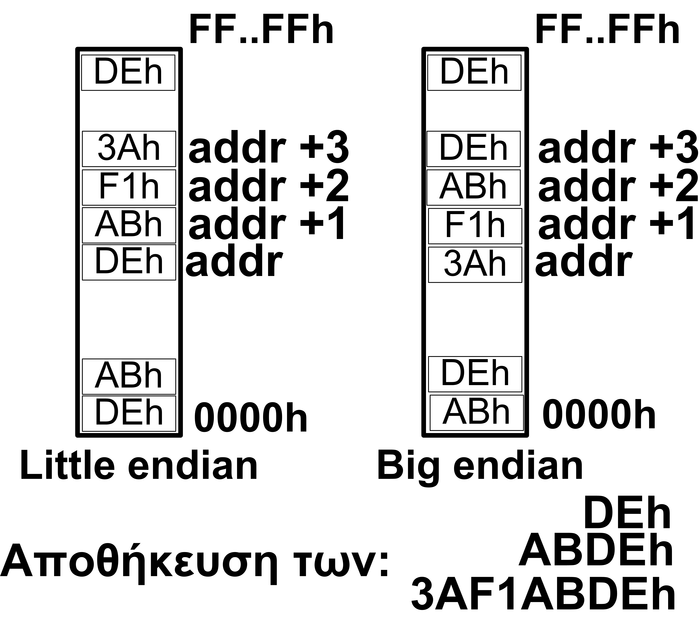
3.5: Αρχιτεκτονική Μνήμης Big endian και Little Endian.
Με τη little-endian αρχιτεκτονική, το λιγότερο σημαντικό στοιχείο μεταφέρεται πέρα από το λιγότερο σημαντικό μέρος των στοιχείων και αποθηκεύεται στη λιγότερη σημαντική θέση μνήμης. Για έναν προγραμματιστή, είναι ευκολότερο να γίνει κατανοητή η πορεία στοιχείων. Η δυσχέρεια της little endian αρχιτεκτονικής, είναι ότι το στοιχείο εμφανίζεται “προς τα πίσω” στη μνήμη του υπολογιστή και έτσι υπάρχει ένα τμήμα θέσεων που πρέπει να διαβαστεί για να καθοριστεί το μέγεθος. Η αποθήκευση της λέξης 3ΑF1ABDEh στη μνήμη οδηγεί στην αποθήκευση DEABF13Αh στη μνήμη. Σημειώστε ότι ένας επεξεργαστής με little endian αρχιτεκτονική θα διαβάσει αυτό το στοιχείο ορθά, αφού υποστηρίζει αυτόν τον τρόπο αποθήκευσης, ασχέτως του πως αποθηκεύονται τα δεδομένα στη μνήμη. Εναλλακτικά, ένας επεξεργαστής με big endian αρχιτεκτονική που αποθηκεύει την τιμή 3ΑF1ABDEh στη μνήμη καταλήγει να αποθηκεύσει τελικά την ίδια τιμή 3ΑF1ABDEh μέσα στο τσιπ μνήμης. Αυτό φαίνεται (για έναν προγραμματιστή) να έχει περισσότερο νόημα. Κανένα σχέδιο δεν έχει περισσότερο πλεονέκτημα από το άλλο, η λειτουργία τους είναι ίδια, είναι δύο διαφορετικοί τρόποι με το ίδιο αποτέλεσμα. Όταν κάνετε υψηλού επιπέδου προγραμματισμό σε ένα σύστημα, το “endian-ness” έχει λίγη διαφορά. Ο μόνος χρόνος που εκτίθεστε πραγματικά σε κάτι τέτοιο, είναι όταν εξετάζετε τα στοιχεία πολλαπλών Byte άμεσα στη μνήμη και καλείστε να τα ερμηνεύσετε. Εντούτοις, όταν αναπτύσσετε και διορθώνετε το υλικό χαμηλού επιπέδου σταθερού λογισμικού, θα τα συναντάτε πολύ συχνά και έτσι μια κατανόηση big endian και little endian αρχιτεκτονικών στο σχεδιαστή των ενσωματωμένων συστημάτων είναι απαραίτητη.
H endianess εμφανίζεται οπουδήποτε πρέπει να αποθηκευτεί ή να μεταφερθεί μια λέξη που αποτελείται από πολλαπλά Byte. Εκτός από την αποθήκευση λέξεων στη μνήμη, εμφανίζεται και στις επικοινωνίες δικτύου, δηλαδή κατά την αποστολή και λήψη δεδομένων μέσω δικτυακών πρωτοκόλλων, όπως το TCP/IP. Αυτό οφείλεται στο γεγονός, ότι μπορεί ο αποστολέας και ο παραλήπτης να έχουν διαφορετικά endianess και έτσι να ερμηνεύσουν διαφορετικά τα Byte. Για παράδειγμα, αν ένας υπολογιστής λάβει τη λέξη 3ΑF1ABDEh και είναι big endian θα ερμηνεύσει τα δεδομένα ως τον 32bit αριθμό 3ΑF1ABDEh, ενώ αν είναι little endian θα ερμηνεύσει τα δεδομένα ως DEABF13Ah. Για αυτό το λόγο, έχουν δημιουργηθεί ειδικές συναρτήσεις που πρέπει να καλούνται πριν την αποστολή και μετά τη λήψη των δεδομένων, ώστε να μετατρέπουν τα δεδομένα σε σειρά αποθήκευσης δικτύου (network byte order, NBO), να στέλνονται, και στη λήψη να μετατρέπονται από τη ΝΒΟ στην endianess του υπολογιστή. Ένα ζεύγος τέτοιων συναρτήσεων είναι οι htons()/ntohs() που υπάρχει στο πρότυπο IEEE Std 1003.1-2001 (‘POSIX.1’). Το πρόβλημα με το endianess εμφανίζεται και στην αποθήκευση δεδομένων σε αρχεία που μοιράζονται υπολογιστές με διαφορετικό endianess, και η συνηθισμένη λύση είναι η χρήση των συναρτήσεων htons()/ntohs(), ακόμη και αν δεν υπάρχουν δικτυακές επικοινωνίες.
Παραδείγματα επεξεργαστών που υποστηρίζουν big endian είναι οι Sun SPARC, Motorola 68K, η οικογένεια των PowerPC ή παλαιότερα οι IBM S/360, ενώ παραδείγματα επεξεργαστών αρχιτεκτονικής little endian είναι οι επεξεργαστές που υποστηρίζουν την οικογένεια x86, IA32 ή AMD64 εταιριών Intel, AMD και άλλων ή παλαιότερα οι DEC Vax. Η endianess είναι πολύ σημαντική στα ΕΣ, αφού σε αντίθεση με τους επιτραπέζιους υπολογιστές ή διακομιστές που όλα είναι συμβατά με x86 (little endian), υπάρχουν πολλές διαφορετικές αρχιτεκτονικές ή σχεδιασμοί νέων αρχιτεκτονικών και έτσι απαιτείται αυτή η γνώση σε ένα μηχανικό που ασχολείται με αυτά. Ως προς τα οφέλη ή προτερήματα της endianess, ισχύει ότι: H little endian μπορεί να διαβάσει την ίδια λέξη μερικές φορές σε διάφορα bit width, π.χ. το 4A 00 00 00 είτε διαβαστεί ως 8bit (4A), είτε ως 16 bit (004A) είναι το ίδιο (χρησιμοποιείται στους compilers). Από την άλλη, η big endian βοηθάει στο να βρεθεί πόσος μεγάλο είναι ο αριθμός διαβάζοντας μόνο την πρώτη θέση μνήμης (που φέρει το MSB). Τέλος η little-endian απλοποιεί το hardware σε πράξεις πολλαπλών Byte (αφού απαιτείται μια μόνο εντολή αύξησης inc για να διαβαστεί το επόμενο Byte).
Η ορολογία Endianess, bin-endian ή little-endian προέρχεται από το λογοτεχνικό βιβλίο ‘Τα ταξίδια του Γκιούλιβερ’. Μέσα στο βιβλίο περιγράφεται η διαμάχη δύο μυθικών λαών για το πως μπορεί κάποιος να σπάσει ένα βρασμένο αυγό, είτε κτυπώντας το στην μυτερή άκρη, είτε στην μέση (δηλαδή μεγάλη/big ή μικρή/little άκρη/endianess του αυγού). Στην διαμάχη αυτή (μέσα στο λογοτεχνικό έργο), όσοι υποστήριζαν την μία ή την άλλη τεχνική χαρακτηρίστηκαν ως ‘big-endians’ ή ‘little-endians’ και από εκεί η ορολογία υιοθετήθηκε στην πληροφορική.
Ένα άλλο στοιχείο που χαρακτηρίζει τους επεξεργαστές είναι η πιθανή απαίτηση των ευθυγραμμισμένων προσβάσεων (αναγνώσεων και εγγραφών) στη μνήμη. Αυτό το χαρακτηριστικό είναι παρόμοιο προς τον τρόπο αποθήκευσης των Byte (Ενότητα 3.2.6) ως προς το ότι εμφανίζεται σε λέξεις που αποτελούνται από πολλαπλά Byte. Αν η πρόσβαση αφορά μόνο 1 Byte τότε δεν υπάρχει θέμα ευθυγράμμισης. Η επίτευξη ευθυγραμμισμένων προσβάσεων μερικές φορές επιβάλλεται από τον ίδιο τον επεξεργαστή, και αν ανιχνευθεί μη ευθυγραμμισμένη πρόσβαση δημιουργείται μια προβληματική κατάσταση εξαίρεσης. Γεγονός όμως είναι, ότι οι μη ευθυγραμμισμένες προσβάσεις προκαλούν σημαντική επιβάρυνση στο χρόνο πρόσβασης (διπλασιάζεται) και για αυτό όλοι οι σύγχρονοι συμβολομεταφραστές αναδιατάσσουν τον κώδικα ή προσθέτουν στη μνήμη Byte συμπλήρωσης (memory padding) προκειμένου να ευθυγραμμιστούν οι προσβάσεις, όπως θα περιγραφεί στη συνέχεια.
Το πρόβλημα με την ευθυγράμμιση των προσβάσεων μνήμης δημιουργείται από το γεγονός ότι ο κάθε επεξεργαστής κατασκευάζεται με ένα εγγενές μήκος λέξης (native bit width, NBW) που διαχειρίζεται και μεταφέρει στις εσωτερικές και εξωτερικές μονάδες. Αυτό το μήκος λέξης χαρακτηρίζει τον επεξεργαστή: Ως σήμερα μπορεί κάποιος να χρησιμοποιήσει στα ΕΣ επεξεργαστές με 8, 16, 32 ή 64 bit. Το μήκος αυτό δηλώνει και την χωρητικότητα των εσωτερικών και εξωτερικών διαύλων του επεξεργαστή. Όταν μια μεταφορά ταυτίζεται με το NBW τότε έχει τη μέγιστη ταχύτητα εξυπηρέτησης (το μικρότερο χρόνο πρόσβασης). Για παράδειγμα, μια μεταφορά 16 bit σε έναν επεξεργαστή 16 bit είναι προτιμότερη από μια μεταφορά 8 ή 32 bit σε έναν επεξεργαστή 16 bit. Το πρόβλημα γίνεται ακόμη πιο περίπλοκο όταν υπάρχει κρυφή μνήμη, αλλά προς το παρόν θα υποθέσουμε ότι δεν υπάρχει κρυφή μνήμη.
Η βέλτιστη ταχύτητα πρόσβασης στη μνήμη επιτυγχάνεται όταν οι επεξεργαστές διαβάζουν ή γράφουν με μήκος λέξης όσο το εγγενές μήκος λέξης του επεξεργαστή. Oι επεξεργαστές ομαδοποιούν τις διευθύνσεις μνήμης σε ομάδες μεγέθους τόσων Byte, όσα τα Byte του ΝΒW. Έτσι, ένας επεξεργαστής 32 bit ομαδοποιεί τις διευθύνσεις μνήμης ανά 4 Byte· μια ομάδα φέρει τις διευθύνσεις 0h, 1h, 2h, 3h, ενώ μια άλλη τις 4h, 5h, 6h, 7h. Η ομαδοποίηση γίνεται αγνοώντας τα bit ελάχιστης σημαντικότητας που διευθυνσιοδοτούν εσωτερικά της ομάδας τα Byte. Για την περίπτωση των 32 bit, 2 bit διευθυνσιοδοτούν τα 4 Byte της ομάδας, οπότε αγνοούνται τα 2 bit ελάχιστης σημαντικότητας της διεύθυνσης μνήμης. Για 64 bit, 4 bit διευθυνσιοδοτούν τα 8 Byte της ομάδας και έτσι αγνοούνται τα 8 bit ελάχιστης σημαντικότητας της διεύθυνσης μνήμης. Για παράδειγμα, η διεύθυνση ABF1h έχει αναπαράσταση στο δυαδικό σύστημα και η ομάδα σε ένα 32 bit σύστημα είναι η
, δηλαδή από
(ABF0h) έως
(ABF3h), ενώ σε ένα 64 bit η ομάδα είναι η
, δηλαδή από
(ABF0h) έως
(ABFFh). Η μικρότερη διεύθυνση ονομάζεται βάση της ομάδας, και η μεγαλύτερη κορυφή. Μερικοί σχεδιαστές εκμεταλλεύονται την ομαδοποίηση με το να απαλείψουν τα χαμηλότερα bit από τον εξωτερικό δίαυλο διευθύνσεων (καταλήγοντας σε λιγότερα καλώδια και χαμηλότερη κατανάλωση ενέργειας), αφού θα είναι πάντα 00 (η βάση της ομάδας). Έτσι σε ένα 32bit σύστημα, αντί για 32bit χρησιμοποιούν 30bit ή μπορούν να χρησιμοποιηθούν τα ίδια bit για να διευθυνσιοδοτήσουν 4 φορές περισσότερη μνήμη (π.χ. για 32bit να διευθυνσιοδοτήσουν 34 bit).
Μια πρόσβαση πολλαπλών Byte στη μνήμη θεωρείται ευθυγραμμισμένη, όταν γίνεται στη βάση της ομάδας και όχι σε κάποια ενδιάμεση διεύθυνση της ομάδας. Στο προηγούμενο παράδειγμα, μια πρόσβαση για ανάγνωση 4 Byte σε έναν επεξεργαστή 32 bit στη διεύθυνση ABF0h (που είναι η βάση της ομάδας των Byte ABF0h - ABF3h) θεωρείται ευθυγραμμισμένη, γιατί με την ίδια μοναδική πρόσβαση θα μεταφερθούν σε μια συναλλαγή και τα 4 Byte ABF0h - ABF3h. Αν όμως η πρόσβαση γίνονταν σε μια ενδιάμεση διεύθυνση της ομάδας, όπως πρόσβαση για ανάγνωση 4 Byte στη διεύθυνση ABF1h, τότε θα ήταν μη ευθυγραμμισμένη, επειδή κάποια Byte ανήκουν σε μια ομάδα και κάποια σε άλλη, δηλαδή τα Byte ABF1h, ABF2h, ABF3h ανήκουν σε μια ομάδα και θα απαιτηθεί μια συναλλαγή, ενώ το 4o Byte (ABF4h) ανήκει στην επόμενη ομάδα και απαιτεί μια επιπρόσθετη συναλλαγή, δηλαδή έχει διπλασιαστεί ο χρόνος πρόσβασης. Τα αποτελέσματα αυτά έχουν αποδειχθεί και παρουσιαστεί στην επιστημονική κοινότητα και αποτελούν βασική γνώση για τους καλούς προγραμματιστές [20].
Προκειμένου κάποιος επεξεργαστής να υποστηρίξει μη ευθυγραμμισμένες προσβάσεις στη μνήμη θα πρέπει να έχει ειδικά κυκλώματα για να χειρίζονται αυτές τις περιπτώσεις. Συγκεκριμένα, θα πρέπει να έχει 2 προσωρινούς καταχωρητές (μη φανεροί στο χρήστη), που θα υποστηρίζουν παραμετροποιήσιμη ολίσθηση έως 3 θέσεις (για 32 bit), και ένα κύκλωμα συνένωσης των τιμών 2 καταχωρητών στο τελικό. Η Εικόνα 3.6 παρουσιάζει ένα τέτοιο παράδειγμα, όπου φαίνεται ότι η ευθυγραμμισμένη πρόσβαση γίνεται άμεσα και αποθηκεύεται η τιμή στον καταχωρητή, ενώ η μη ευθυγραμμισμένη υπόκειται σε κάποια επεξεργασία προκειμένου να ολοκληρωθεί. Η απαίτηση της επιπρόσθετης επεξεργασίας μαζί με το μειονέκτημα του διπλασιασμού του χρόνου πρόσβασης στη μνήμη, εκτός ότι καθυστερεί τον επεξεργαστή, απαιτεί και την αφοσίωση ενός αριθμού τρανζίστορ στην υλοποίηση των ειδικών κυκλωμάτων. Για αυτό το λόγο, αρκετοί επεξεργαστές δεν υποστηρίζουν μη ευθυγραμμισμένες προσβάσεις, αφού οι αρχιτέκτονες αυτών έχουν αποφασίσει να αφιερώσουν αλλού αυτόν τον αριθμό των τρανζίστορ. Παραδείγματα επεξεργαστών που δεν υποστηρίζουν ευθυγραμμισμένες προσβάσεις είναι ο Motorola 68000 (ενώ το επόμενο μοντέλο 68020 είχε τα ειδικά αυτά κυκλώματα), ο MIPS, και οι περισσότεροι επεξεργαστές ARM και RISC. Από την άλλη μεριά βρίσκονται επεξεργαστές που υποστηρίζουν μη ευθυγραμμισμένες προσβάσεις, όπως ο PowerPC και οι επεξεργαστές που είναι συμβατοί με 8086, IA-32 και AMD64/x86-64.
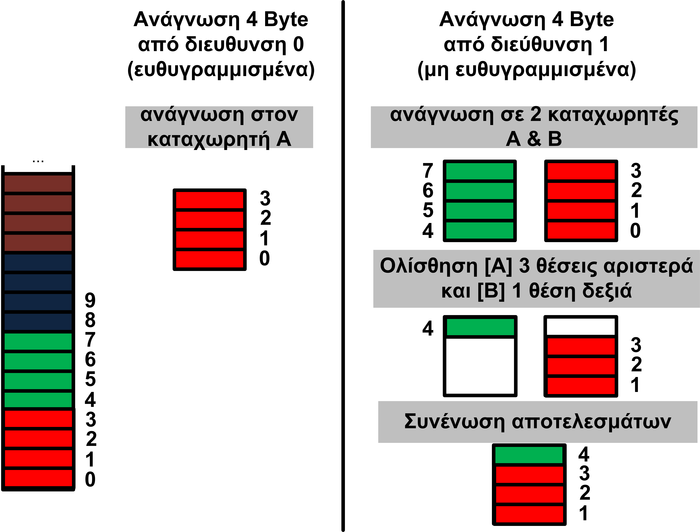
3.6: Η υποστήριξη για μη ευθυγραμμισμένες προσβάσεις στη μνήμη απαιτεί επιπρόσθετα κυκλώματα ολίσθησης και συνένωσης.
Εκτός από τη μείωση της ταχύτητας και την απαίτηση για επιπρόσθετο υλικό, η απαίτηση για υποστήριξη μη ευθυγραμμισμένων προσβάσεων δημιουργεί πρόβλημα στις ατομικές λειτουργίες συγχρονισμού. Όλοι οι σύγχρονοι επεξεργαστές που προορίζονται για πολύ-διαδιεργασιακά λειτουργικά συστήματα έχουν δομές συγχρονισμού ανάμεσα σε νήματα και διεργασίες. Αυτές οι δομές (όπως π.χ. οι σημαφόρες στο FreeBSD), απαιτούν ατομικές λειτουργίες ανάγνωσης ή εγγραφής στη μνήμη, δηλαδή λειτουργίες που θα εκτελεστούν ενιαία και αδιάσπαστα σε όσο το δυνατόν ελάχιστους κύκλους. Σε περίπτωση μη ευθυγραμμισμένης πρόσβασης, θα απαιτηθούν πολλαπλοί κύκλοι για την ολοκλήρωση και έτσι ενδέχεται η λειτουργία της ενημέρωσης της κοινής μεταβλητής συγχρονισμού να διακοπεί για να εκτελεστεί κάτι άλλο, δημιουργώντας πρόβλημα συνέπειας. Για αυτό το λόγο, υπάρχει η απαίτηση στα συστήματα που υποστηρίζουν μη ευθυγραμμισμένες προσβάσεις, τουλάχιστον οι δομές συγχρονισμού να είναι ευθυγραμμισμένες.
Ακόμη και να υποστηρίζει η αρχιτεκτονική μη ευθυγραμμισμένες προσβάσεις, θα πρέπει να αποφεύγονται. Προς αυτή την κατεύθυνση κινούνται τα τελευταία χρόνια όλοι οι συμβολομεταφραστές και μόλις ανιχνεύσουν την ύπαρξη μη ευθυγράμμισης, προσθέτουν έξτρα Byte(s), ώστε να ευθυγραμμιστούν τα δεδομένα. Για παράδειγμα, αν ο χρήστης δημιουργήσει σε ένα 32 bit σύστημα την δομή που φαίνεται στον κώδικα 3.7, τότε είναι εμφανές ότι η μεταβλητή long4Byte ξεκινάει από τη διεύθυνση 1 του struct (η μεταβλητή charA1Byte ξεκινάει από τη θέση 0 του struct) και άρα κάθε φορά που γίνεται πρόσβαση στην long4Byte θα υπάρχει πρόβλημα. Για την αντιμετώπιση αυτού του θέματος, όλοι οι συμβολομεταφραστές κάνουν τη βελτιστοποίηση padding, δηλαδή την τοποθέτηση έξτρα Byte για ευθυγράμμιση. Κάποιοι compilers επίσης, μπορούν να αναδιατάσσουν τις δομές, ώστε να μειωθούν ή να εξαλειφθούν τα επιπρόσθετα Byte· π.χ. στο προηγούμενο παράδειγμα, αν η δομή long4Byte μεταφέρονταν στην αρχή του struct, τότε δε θα υπήρχε κανένα πρόβλημα μη ευθυγράμμισης (τα Byte δε χρειάζονται ευθυγράμμιση). Αναλόγως του compiler βέβαια, ίσως θα τοποθετούνταν 2 dummy Byte στο τέλος, ώστε η επόμενη δομή να είναι ευθυγραμμισμένη.
typedef struct {
char charA1Byte;
long long4Byte;
char charB1Byte;
} Struct;typedef struct {
char charA1Byte;
char dummy0[2];
long long4Byte;
char charB1Byte;
} Struct;Εκτός από την παραπάνω ευθυγράμμιση, υπάρχει η έννοια της ευθυγράμμισης και σε μικρότερα μήκη λέξεων, όταν η διεύθυνση που απαιτείται η πρόσβαση είναι η βάση μιας υποομάδας. Με παρόμοιο σκεπτικό με την ομάδα, η υποομάδα δημιουργείται με τη διατήρηση των μεγαλύτερης σημαντικότητας ψηφίων σε μια σταθερή τιμή και την τροποποίηση μόνο των bit της χαμηλότερης σημαντικότητας. Π.χ. κάποιες ομάδες των 2 byte είναι οι διευθύνσεις (0,1), (2,3), (4,5) κ.ο.κ. αφού σε όλα διατηρούνται τα υψηλότερα bit της
λέξης σταθερά, και εναλλάσσεται μόνο το 1 bit της χαμηλότερης σημαντικότητας στις τιμές 0 και 1. Έτσι, μια πρόσβαση λέξης 16 bit στις διευθύνσεις 0 ή 1 ή 3 είναι ευθυγραμμισμένη, αφού και τα 2 Byte ανήκουν στην ίδια ομάδα, ενώ μια πρόσβαση 16 bit στις διευθύνσεις 1 ή 3 ή 5 είναι μη ευθυγραμμισμένες. Η ευθυγράμμιση προσβάσεων εμφανίζεται και στα λειτουργικά συστήματα (ΛΣ), και ιδιαίτερα στο σύστημα διαχείρισης της μνήμης κατά την αντιστοίχηση των σελίδων μνήμης σε ιδεατές ή φυσικές σελίδες.
Τέλος, σε περίπτωση που χρησιμοποιεί ο επεξεργαστής κρυφή μνήμη, τότε η ευθυγράμμιση γίνεται ως προς το μέγεθος της γραμμής της κρυφής μνήμης που συνδέεται στον επεξεργαστή (δηλαδή την κρυφή μνήμη επιπέδου 1). Για παράδειγμα, αν η κρυφή μνήμη έχει 16 Byte ανά γραμμή, τότε η ευθυγράμμιση γίνεται ανά 16 Byte και ασφαλώς ως προς τις υποομάδες που δημιουργούνται. Έτσι, μια πρόσβαση 8 Byte στις θέσεις 0 ή 8 είναι ευθυγραμμισμένη (σε όλες τις άλλες δεν είναι), μια πρόσβαση 4 Byte είναι ευθυγραμμισμένη στις θέσεις 0 ή 4 ή 8 ή 12 (σε όλες τις άλλες δεν είναι), κ.ο.κ.
Κάθε πρόσβαση στην εξωτερική μνήμη επιφέρει μια μεγαλύτερη ενεργειακή και χρονική επιβάρυνση, παρά αν θα ήταν πρόσβαση σε μνήμη εντός ολοκληρωμένου κυκλώματος. Επίσης, έχει παρατηρηθεί ότι τα περισσότερα προγράμματα παρουσιάζουν μια χρονική και χωρική τοπικότητα, που μπορεί να την εκμεταλλευτεί κάποιος προς όφελος του. Η χρονική τοπικότητα στις προσβάσεις σημαίνει ότι αν ο επεξεργαστής έχει προσπελάσει μια διεύθυνση μνήμης, τότε σε σύντομο χρονικό διάστημα υπάρχει μεγάλη πιθανότητα να απαιτηθεί πάλι η προσπέλαση της ίδιας διεύθυνσης μνήμης. Η χωρική τοπικότητα στις προσβάσεις σημαίνει ότι αν ο επεξεργαστής έχει προσπελάσει μια διεύθυνση μνήμης, τότε σε σύντομο χρονικό διάστημα υπάρχει μεγάλη πιθανότητα να απαιτηθεί η προσπέλαση των γειτονικών διευθύνσεων της μνήμης. Αν λοιπόν αντιγραφούν τα δεδομένα της εξωτερικής μνήμης (και οι γειτονικές διευθύνσεις) κατά την πρόσβαση σε κάποια εσωτερική μνήμη, τότε θα επιτευχθεί μεγάλο ενεργειακό και χρονικό κέρδος. Αν μάλιστα η μνήμη αυτή λειτουργεί κρυφά (χωρίς να φαίνεται ή να παρεμβαίνει στο πρόγραμμα και χωρίς να απαιτείται ειδική λειτουργία για να χρησιμοποιηθεί), τότε τα υπάρχοντα προγράμματα θα επωφεληθούν άμεσα. Έτσι λοιπόν, δημιουργήθηκε μια τέτοια μνήμη και ονομάζεται ‘κρυφή μνήμη’ (cache memory). Οι σημερινοί επεξεργαστές δεν έχουν μόνο μια τέτοια μνήμη, αλλά μια ιεραρχία από τέτοιες μνήμες, για λόγους που θα εξηγηθούν στη συνέχεια.
Η κρυφή μνήμη λειτουργεί ως εξής: Όταν θέλουμε ο επεξεργαστής να προσπελάσει (να διαβάσει ή εγγράψει) μια διεύθυνση κύριας μνήμης, πρώτα ελέγχουμε για την ύπαρξη αντιγράφου των δεδομένων της τοποθεσίας αυτής στην κρυφή μνήμη. Αν έχει γίνει αντιγραφή στην κρυφή μνήμη, τότε υπάρχει επιτυχία κρυφής μνήμης (cache hit) και μπορεί να ολοκληρωθεί άμεσα η πρόσβαση. Αν όμως δεν έχει γίνει αντιγραφή, τότε υπάρχει αστοχία κρυφής μνήμης (cache miss) και πρέπει πρώτα να διαβάσουμε τη διεύθυνση (και ίσως και κάποιες γειτονικές διευθύνσεις) και να μεταφέρουμε τα δεδομένα μέσα στην κρυφή μνήμη. Μόλις ολοκληρωθεί η περιγραφή, ο επεξεργαστής μπορεί να διαβάσει τα δεδομένα από την κρυφή μνήμη. Σημειώστε ότι αναφερόμαστε σε προσπελάσεις ανάγνωσης και όχι εγγραφής (δεν υπάρχει κέρδος ή νόημα να επαναχρησιμοποιούνται δεδομένα που γράφονται συνεχώς).
Η περιγραφή αυτή της λειτουργίας της κρυφής μνήμης οδηγεί σε διάφορες επιλογές σχεδιασμού κρυφής μνήμης: χαρτογράφηση κρυφής μνήμης, πολιτική αντικατάστασης της κρυφής μνήμης και τεχνικές εγγραφής στην κρυφή μνήμη. Αυτές οι επιλογές σχεδιασμού μπορεί να έχουν πολλαπλές επιδράσεις στο κόστος του συστήματος, την απόδοσή του καθώς και στην κατανάλωση ενέργειας και για αυτό θα έπρεπε να αξιολογηθούν προσεκτικά για μια δεδομένη εφαρμογή σε ένα ΕΣ.
Η χαρτογράφηση κρυφής μνήμης είναι μια μέθοδος για την εκχώρηση των διευθύνσεων της κυρίας μνήμης στον πολύ μικρότερο αριθμό διαθέσιμων διευθύνσεων της κρυφής μνήμης, και για να προσδιοριστεί αν το περιεχόμενο της συγκεκριμένης διεύθυνσης κύριας μνήμης είναι στην κρυφή μνήμη. Μια κρυφή μνήμη μπορεί να έχει π.χ. 128 διευθύνσεις οι οποίες θα πρέπει να αντιστοιχηθούν σε χιλιάδες ή εκατομμύρια διευθύνσεις της εξωτερικής μνήμης RAM. Η χαρτογράφηση της κρυφής μνήμης μπορεί να επιτευχθεί με τη χρήση μιας από τις ακόλουθες τρεις βασικές τεχνικές:
Άμεση χαρτογράφηση ή απευθείας απεικόνιση (direct mapped): Σε αυτή τη τεχνική, η διεύθυνση της κύριας μνήμης διαιρείται σε δύο περιοχές, τα bit ευρετηρίου (index) και τις ετικέτας (tag). Είναι η απλούστερη οργάνωση και για αυτό έχει και τη χαμηλότερη κατανάλωση ενέργειας λειτουργίας (αλλά και τη μικρότερη απόδοση). Το ευρετήριο αντιπροσωπεύει την διεύθυνση της κρυφής μνήμης και επομένως ο αριθμός των bits αυτού καθορίζεται από το μέγεθος της κρυφής μνήμης, με τη σχέση: μέγεθος ευρετηρίου = (μέγεθος κρυφής μνήμης). Για παράδειγμα, αν το μέγεθος της κρυφής μνήμης είναι 128 (από 0 έως 127) γραμμές, τότε ισχύει
και άρα απαιτούνται 7 bit. Τα υπόλοιπα bit της διεύθυνσης μνήμης αποτελούν την ετικέτα, αφού όπως γίνεται κατανοητό πολλές διαφορετικές διευθύνσεις κύριας μνήμης θα χαρτογραφηθούν στην ίδια γραμμή της κρυφής μνήμης. Έτσι, όταν αποθηκεύουμε το περιεχόμενο μιας διεύθυνσης κύριας μνήμης στην κρυφή μνήμη αποθηκεύουμε επίσης και την αντίστοιχη ετικέτα. Για να καθορίσουμε αν μια επιθυμητή διεύθυνση κύριας μνήμης είναι στην κρυφή μνήμη, πηγαίνουμε στη διεύθυνση της κρυφής μνήμης, που υποδεικνύεται από τον δείκτη, και έπειτα συγκρίνουμε την ετικέτα αυτή με την επιθυμητή ετικέτα.
Η κρυφή μνήμη απευθείας απεικόνισης για μέγεθος γραμμής 1 byte, φαίνεται στην Εικόνα 3.9. Συγκεκριμένα, φαίνεται ο διαχωρισμός της διεύθυνσης σε tag και index. Τα bit του index καθορίζουν τη γραμμή της κρυφής μνήμης που θα συγκριθεί το tag. Αν σε αυτή τη γραμμή το tag είναι το ίδιο με αυτό που προκύπτει από την αρχική διεύθυνση, τότε η κρυφή μνήμη φέρει έγκυρα δεδομένα για την τρέχουσα πρόσβαση και τα προωθεί στον επεξεργαστή.
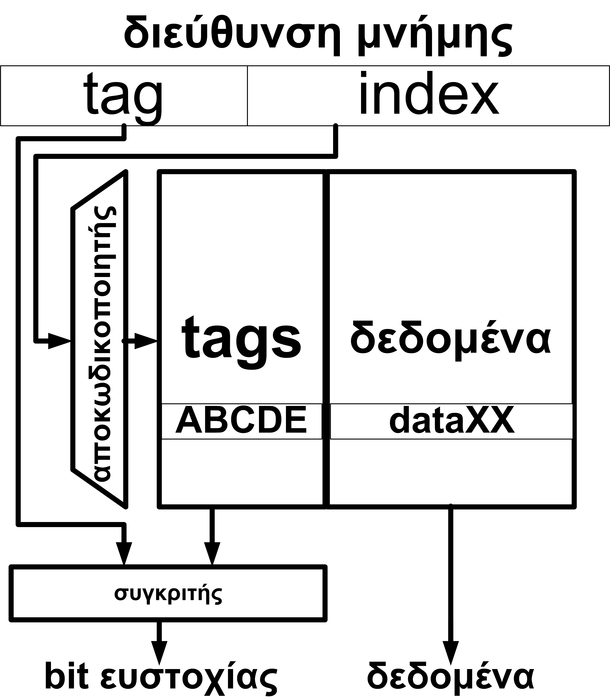
3.9: Οργάνωση της κρυφής μνήμης άμεσης απεικόνισης όπου κάθε γραμμή κρυφής μνήμης φέρει 1 Byte.
Ένα παράδειγμα χρήσης είναι το παρακάτω. Έστω ότι η κρυφή μνήμη έχει 64 Byte και γραμμές του ενός Byte. Αυτό σημαίνει ότι συνολικά υπάρχουν 64 γραμμές κρυφής μνήμης (από 0 έως 63), και άρα απαιτούνται 6 bit (). Αν τα bit της αρχικής διεύθυνσης ήταν 12 (που σημαίνει ότι το σύστημα διευθυνσιοδοτούσε συνολική εξωτερική μνήμη
Bytes, τότε το tag θα είχε 4 bit (τα πιο σημαντικά bit) και το index 6 bit (τα χαμηλότερης σημαντικότητας bit). Άρα μια διεύθυνση 10
που έχει δυαδική αναπαράσταση
θα χωρίζονταν στα tag bits
και στα index bits
. Η κρυφή μνήμη θα εξέταζε τη γραμμή
, δηλαδή τη γραμμή 47 και αν εκεί έβρισκε το tag
τότε θα υπήρχε ευστοχία και θα προωθούνταν τα δεδομένα άμεσα (μέσα σε ένα κύκλο ρολογιού) στον επεξεργαστή, διαφορετικά αν το tag ήταν διαφορετικό, τότε θα υπήρχε αστοχία.
Η παραπάνω δομή εκμεταλλεύεται τη χρονική τοπικότητα. Όμως, προκειμένου να υπάρξει καλύτερη εκμετάλλευση και της χωρικής τοπικότητας, μια κρυφή μνήμη δε φέρει μόνο 1 byte σε μια γραμμή, αλλά πολλαπλά Byte (από 2 έως 16). Αυτά τα byte έχουν το ίδιο tag και έτσι μεταφέρονται ομαδικά από τη μνήμη, κάτι που είναι εύκολο και γρήγορο, αφού όλες οι σύγχρονες μνήμες υποστηρίζουν γρήγορες μεταφορές ριπής (burst transfers). Όταν η κρυφή μνήμη έχει πολλαπλά Βyte σε μια γραμμή, θα πρέπει με κάποιον τρόπο να προσδιορίζεται το Byte που απαιτεί ο επεξεργαστης. Αυτό επιτυγχάνεται με τη μετατόπιση (offset), που καταλαμβάνει τα bit χαμηλότερης σημαντικότητας. Αναλόγως πόσα Byte φέρει η κρυφή γραμμή, τόσα επιλέγονται τα bit που μπορούν να διευθυνσιοδοτήσουν μοναδικά τα Byte. Για παράδειγμα, αν η κάθε γραμμή φέρει 4 Byte, τότε απαιτούνται 2 bit, αφού , ενώ αν φέρει 16 απαιτούνται 4 bit (
). Η Εικόνα 3.10 δείχνει την εσωτερική δομή μιας κρυφής μνήμης άμεσης απεικόνισης με πολλαπλά Byte ανά γραμμή. Στο παράδειγμα της προηγούμενης παραγράφου, αν η κρυφή μνήμη είχε 2 Byte ανά γραμμή, τότε θα είχε συνολικά
γραμμές των 2 Byte, δηλαδή 32 γραμμές, και άρα θα απαιτούνταν 5 bit (
) στο index για τη διευθυνσιοδότηση, 1 bit στο offset, και τα υπόλοιπα στο tag, δηλαδή 4 bit (αν το μήκος διεύθυνσης της μνήμης ήταν 12bit). Σε αυτή την περίπτωση, μια διεύθυνση
που έχει δυαδική αναπαράσταση
θα χωρίζονταν στα tag bits
, στα index bits
και στο offset bit
b (που είναι το LSB). Η κρυφή μνήμη θα εξέταζε τη γραμμή
, δηλαδή τη γραμμή 23 και αν εκεί έβρισκε το tag
, θα υπήρχε ευστοχία και με τον αποπλέκτη θα επιλέγονταν το Byte στη 2η θέση της γραμμής με index bit 1. Αυτό το Byte θα προωθούνταν στον επεξεργαστή. Αν το tag δεν ταίριαζε, τότε θα έπρεπε να μεταφέρει από την εξωτερική μνήμη, όλα τα Byte της γραμμής (σε αυτό το παράδειγμα 2 Byte), να ενημερώσει κατάλληλα το tag και να τα προωθήσει στον επεξεργαστή.
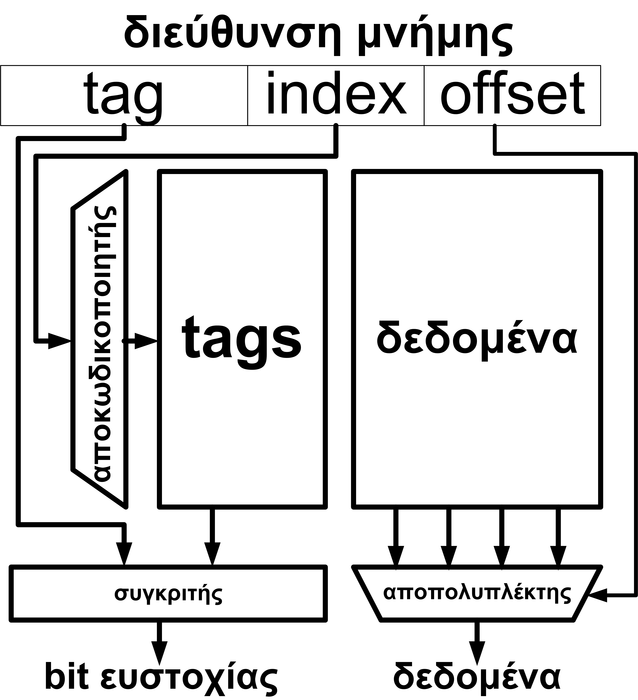
3.10: Οργάνωση της κρυφής μνήμης άμεσης απεικόνισης με πολλαπλά Byte ανά γραμμή.
Όπως φαίνεται, το πρόβλημα είναι ότι πολλαπλές διευθύνσεις της εξωτερικής μνήμης συναγωνίζονται για την ίδια γραμμή της κρυφής μνήμης, αφού η αντιστοίχηση είναι 1-προς-1. Είναι πιο απλή και γρήγορη (όταν υπάρχει ευστοχία) από τις υπόλοιπες αρχιτεκτονικές κρυφής μνήμης.
Μία τυπική κρυφή μνήμη άμεσης απεικόνισης μπορεί να αποθηκεύει 8 kilobytes δεδομένων σε γραμμές των 16 Byte. Συνεπώς, θα μπορούσαν να υπάρχουν 512 γραμμές. Μία διεύθυνση των 32 bits θα μπορούσε να έχει 4 bit για τo offset και 9 bit για το index (επιλογή γραμμής), αφήνοντας τα υπόλοιπα 19 bit για το tag, το οποίο απαιτεί μόλις λίγο πιο πάνω από ένα kilobyte για την αποθήκευση ( bit
γραμμές
bit ή 1215 Byte). Παρατηρούμε λοιπόν ότι όσο μεγαλύτερο είναι το tag, τόσο αυξάνονται και οι αποθηκευτικές ανάγκες της κρυφής μνήμης.
Xαρτογράφηση (ή απεικόνιση) πλήρους συσχέτισης (fully associative): Σε αυτή τη τεχνική, κάθε διεύθυνση κρυφής μνήμης περιέχει όχι μόνο το περιεχόμενο της διεύθυνση κύριας μνήμης αλλά και ολόκληρη τη διεύθυνση αυτής. Για να προσδιορίσουμε αν μια επιθυμητή διεύθυνση κύριας μνήμης είναι στην κρυφή μνήμη, συγκρίνουμε ταυτόχρονα (συσχετιζόμενα) όλες τις αποθηκευμένες στην κρυφή μνήμη διευθύνσεις με την επιθυμητή διεύθυνση. Σε αυτήν την περίπτωση οποιαδήποτε διεύθυνση της κρυφής μνήμης μπορεί να τοποθετηθεί σε οποιαδήποτε γραμμή της κρυφής μνήμης. Έχει πάρα πολύ αυξημένες ανάγκες σε υλικό (απαιτούνται πάρα πολλοί συγκριτές), μεγάλη κατανάλωση ενέργειας (λόγω των πολλών συγκρίσεων), αλλά πολύ καλό ποσοστό ευστοχίας. Εντούτοις, λόγω του μεγάλου κόστους δε χρησιμοποιείται. Η Εικόνα 3.11 παρουσιάζει την οργάνωση μιας τέτοιας κρυφής μνήμης.
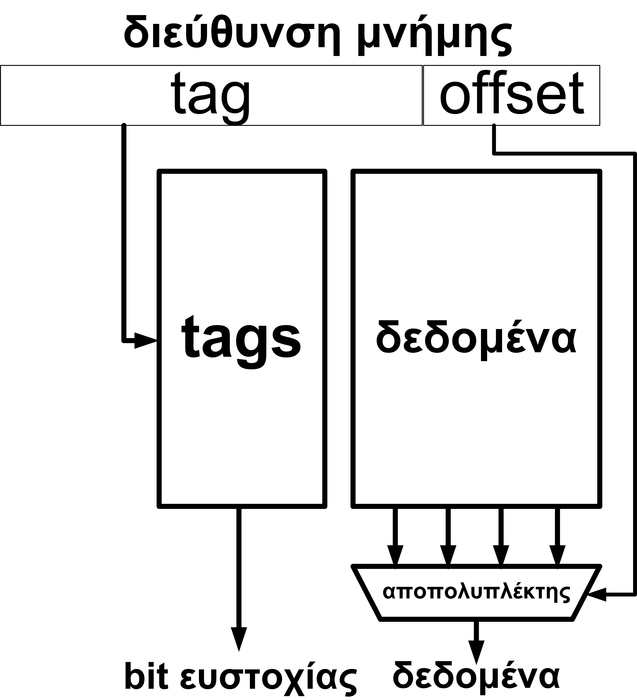
3.11: Οργάνωση της κρυφής μνήμης πλήρους συσχέτισης.
Χαρτογράφηση (ή απεικόνιση) με συσχέτιση σε ομάδες (set associative): Η τεχνική αυτή αποτελεί έναν συμβιβασμό μεταξύ των δυο παραπάνω τεχνικών. Όπως στην άμεση χαρτογράφηση, έτσι και εδώ, το index χαρτογραφεί κάθε διεύθυνση κύριας μνήμης σε μια διεύθυνση κρυφής μνήμης, αλλά τώρα κάθε διεύθυνση κρυφής μνήμης περιλαμβάνει το περιεχόμενο και τις ετικέτες δύο ή περισσότερων τοποθεσιών μνήμης, που ονομάζονται ομάδες (sets). Για να προσδιορίσουμε αν μια επιθυμητή διεύθυνση κύριας μνήμης είναι στην κρυφή μνήμη, πηγαίνουμε στη διεύθυνση της κρυφής μνήμης που υποδεικνύεται από το index, και έπειτα ταυτόχρονα (συσχετιζόμενα) συγκρίνουμε όλες τις ετικέτες στην τοποθεσία με την επιθυμητή ετικέτα. Η κρυφή μνήμη με ένα σύνολο ονομάζεται
-δρόμων ομαδικά συσχετιζόμενη κρυφή μνήμη. Τυπικές δομές κρυφής μνήμης είναι 2-δρόμων, 4-δρόμων και 8-δρόμων. Το Σχήμα 3.12 παρουσιάζει μια δομή κρυφής μνήμης δυο δρόμων. Όπως και στην κρυφή μνήμη απευθείας απεικόνισης, η διεύθυνση της εξωτερικής μνήμης χωρίζεται σε tag|index|offset. Το index σε αυτή την περίπτωση, δείχνει τη γραμμή και στα 2 σετ. Μόλις βρεθεί η γραμμή συγκρίνεται το αρχικό tag ταυτόχρονα και με τα tag από τα 2 σύνολα. Αν βρεθεί σε ένα από αυτά τότε προωθούνται τα δεδομένα προς τον επεξεργαστή από το αντίστοιχο σύνολο. Αν δε βρεθεί σε κανένα, τότε η κρυφή μνήμη θα μεταφέρει από την εξωτερική μνήμη τα δεδομένα και θα τα αποθηκεύσει σε ένα από τα δυο σύνολα. Η επιλογή θα γίνει με κάποιον αλγόριθμο, όπως θα αναφερθεί στη συνέχεια.
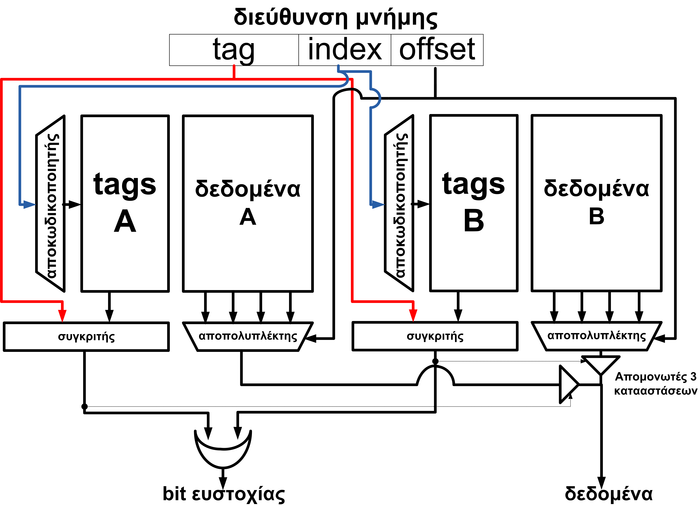
3.12: Οργάνωση της κρυφής μνήμης συσχέτισης κατά ομάδων δυο δρόμων.
Αυξάνοντας το επίπεδο της πολυπλοκότητας, η συσχέτιση κατά ομάδες στοχεύει να μειωθούν τα προβλήματα αντιστοίχησης που υπάρχουν στην απευθείας απεικόνισης μνήμη, δυνατότητα σε ένα συγκεκριμένο αντικείμενο της μνήμης να αποθηκευτεί σε περισσότερες από μια τοποθεσίες της κρυφής μνήμης. Μία διεύθυνση εξωτερικής μνήμης που παρουσιάζεται στην κρυφή μνήμη μπορεί να έχει δεδομένα σε οποιοδήποτε σύνολο. Σε περίπτωση που υπήρχε διαμάχη αντιστοίχησης (όπως συνέβαινε στην κρυφή μνήμη απευθείας απεικόνισης) από διευθύνσεις που απεικονίζονταν στην ίδια γραμμή, τώρα αυτή η διαμάχη εξαλείφεται αφού στην ίδια γραμμή υπάρχουν πολλαπλές επιλογές (σε άλλα σετ). Σε σύγκριση με το προηγούμενο παράδειγμα, μια διεύθυνση των 32 bit θα μπορούσε να έχει 4 bit για τo offset και 8 bit για το index (όχι 9 όπως στην απευθείας απεικόνιση), επειδή το ίδιο μέγεθος μνήμης διαιρείται σε 2 σετ, αφήνοντας 20 bit για το tag. Τα tag bit απαιτούν ( bit
γραμμές
bit για κάθε set, και άρα συνολικά 10240 bit ή 1280 Byte, δηλαδή λίγο πάνω από ένα ΚΒ (η ίδια μεγέθους μνήμη απευθείας απεικόνισης απαιτούσε 1215 Byte). Παρατηρούμε λοιπόν ότι όσο αυξάνεται ο βαθμός συσχέτισης, αυξάνονται και οι αποθηκευτικές ανάγκες της κρυφής μνήμης. Στην ακραία περίπτωση της πλήρης συσχέτισης, το μέγεθος για τα tags είναι
bit
γραμμές
ή 1792 Byte. Οι κρυφές μνήμες μερικής συσχέτισης, έχουν καλά ποσοστά ευστοχίας και για αυτό χρησιμοποιούνται τόσο σε ΕΣ όσο και στα υπόλοιπα υπολογιστικά συστήματα.
Ως προς το χρόνο, όσο πιο μεγάλη είναι η συσχέτιση, τόσο μεγαλύτερη καθυστέρηση έχει. Η αύξηση στο χρόνο γίνεται εξαιτίας της ανάγκης να πολλαπλασιαστούν τα δεδομένα από τα δύο σετ. Όταν ένα νέο δεδομένο τοποθετείται στην κρυφή μνήμη, πρέπει να ληφθεί μια απόφαση, σε ποιο από τα δύο σετ θα τοποθετηθεί. Η πολιτική αντικατάστασης θα περιγραφεί στην επόμενη ενότητα.
Η κρυφή μνήμη κρατάει μια εγγραφή για να ξέρει ποιο ζευγάρι ποιας τοποθεσίας είχε τοποθετηθεί τελευταία ώστε να τοποθετήσει τα νέα δεδομένα σε μια άλλη τοποθεσία. Η συσχέτιση κατά ομάδες απαιτεί τουλάχιστον δύο επιπλέον δρόμους για κάθε βαθμό συσχέτισης, αλλά πρακτικά τα πλεονεκτήματα της συσχέτισης μετά από 4 δρόμους είναι λιγότερα και δεν δίνουν βάση για περαιτέρω αύξηση της συσχέτισης.
Στην άλλη ειδική συσχέτιση, είναι πιθανόν να σχεδιαστεί μια κρυφή μνήμη συσχέτισης στην τεχνολογία VLSI. Θα ήταν βέβαια προτιμότερο να διαιρεθεί η κρυφή μνήμη άμεσης απεικόνισης σε ακόμη μικρότερα συστατικά μέρη. Τα αποθηκευμένα δεδομένα σχεδιάζονται διαφορετικά χρησιμοποιώντας την κρυφή μνήμη διευθυνσιοδοτούμενη από δεδομένα (Content Addressable Memory - CAM). Ένα δομοστοιχείο της CAM είναι παρόμοιο με αυτό της RAM με έναν ενσωματωμένο συγκριτή, έτσι ώστε η βάση δεδομένων αποθηκευμένων στοιχείων της CAM να μπορεί να εκτελέσει μια παράλληλη έρευνα για να τοποθετηθεί μια διεύθυνση σε κάθε τοποθεσία (πλήρους συσχέτισης).
Η πολιτική αντικατάστασης της κρυφής μνήμης είναι η τεχνική για την επιλογή της γραμμής της κρυφής μνήμης που θα αντικατασταθεί όταν μια συσχετιστική κρυφή μνήμη είναι πλήρης. Ασφαλώς η πολιτική αυτή δε χρειάζεται σε μια άμεσης απεικόνισης κρυφής μνήμης, αφού υπάρχει αντιστοίχηση πάντα 1 προς 1 (1 διεύθυνση εξωτερικής μνήμης πάντα αντιστοιχεί σε μια γραμμή της κρυφής μνήμης). Υπάρχουν τρεις συνηθισμένες πολιτικές αντικατάστασης. Μια πολιτική τυχαίας αντικατάστασης (random) επιλέγει τυχαία το σετ που θα αντικατασταθεί. Όσο απλή κι αν είναι στην υλοποίηση της, αυτή η πολιτική δεν κάνει τίποτα για να αποτρέψει την αντικατάσταση κάποιου στοιχείου που είναι πιθανό να χρησιμοποιηθεί σύντομα ξανά. Η πολιτική αντικατάστασης του λιγότερο χρησιμοποιούμενου στοιχείου (least recently used) αντικαθιστά το στοιχείο που δεν έχει προσπελαστεί για το μεγαλύτερο χρονικό διάστημα, υποθέτοντας βέβαια ότι αυτό σημαίνει δεν είναι πιθανό να προσπελαστεί στο άμεσο μέλλον. Η πολιτική αυτή εξασφαλίζει ένα σημαντικό λόγο ευστοχίας έναντι αστοχίας, αλλά απαιτεί ακριβό υλικό για να παρακολουθεί τους χρόνους προσπέλασης των δομικών στοιχείων. Η πολιτική κατά την οποία αυτό που είχε έρθει πρώτο, θα αποχωρήσει και πρώτο (FIFO), χρησιμοποιεί μια ουρά μεγέθους N και σπρώχνει κάθε διεύθυνση στοιχείου στην ουρά, όταν η διεύθυνση αυτή προσπελαύνεται, και έπειτα επιλέγει από την κορυφή το στοιχείο που θα αντικαταστήσει μετακινώντας τα υπόλοιπα στοιχεία της ουράς.
Όταν εγγράφουμε στην κρυφή μνήμη πρέπει να ενημερώνουμε την εξωτερική μνήμη ανά τακτά χρονικά διαστήματα. Η ενημέρωση αυτή αποτελεί ένα ζήτημα για τα δεδομένα της κρυφής μνήμης από τη στιγμή που η κρυφή μνήμη εξ ορισμού είναι μόνο για ανάγνωση. Υπάρχουν δύο τεχνικές: (i) άμεσης εγγραφής ή εγγραφής διαμέσου (write-through) και εγγραφής με καθυστέρηση (write-back).
Στην τεχνική άμεσης εγγραφής, όποτε εγγράφουμε στην κρυφή μνήμη εγγράφουμε επίσης και στην κυρία μνήμη, γεγονός που απαιτεί από τον επεξεργαστή αναμονή έως ότου η εγγραφή στην κύρια μνήμη ολοκληρωθεί. Όντας εύκολη να υλοποιηθεί, η τεχνική αυτή μπορεί να έχει ως αποτέλεσμα διάφορες περιττές εγγραφές στην κύρια μνήμη. Για παράδειγμα, υποθέτουμε ότι ένα πρόγραμμα εγγράφει σε ένα στοιχείο της κρυφής μνήμης, μετά το διαβάζει και μετά το ξαναγράφει με το δομικό στοιχείο να παραμένει στην κρυφή μνήμη κατά τη διάρκεια αυτών των τριών προσπελάσεων. Δεν θα υπήρχε ανάγκη να ανανεωθεί η κύρια μνήμη μετά την πρώτη εγγραφή, από τη στιγμή που η δεύτερη εγγραφή επικαλύπτει την πρώτη. Όμως, επειδή χρησιμοποιείται η εγγραφή διαμέσου, τότε μεταφέρεται σε κάθε εγγραφή η τιμή στην αργή εξωτερική μνήμη.
Η τεχνική της εγγραφής με καθυστέρηση μειώνει τον αριθμό των εγγραφών στην κύρια μνήμη εγγράφοντας ένα στοιχείο στην κύρια μνήμη μόνο όταν το στοιχείο αντικαθίσταται (από την πολιτική αντικατάστασης). Διαφορετικά παραμένει στη κρυφή μνήμη. Η τεχνική αυτή απαιτεί τη σύνδεση ενός επιπλέον bit, που ονομάζεται ακάθαρτο bit (dirty), σε κάθε tag. Μόλις γίνει μια εγγραφή, τότε το bit ακαθαρσίας από 0 γίνεται 1, που σημαίνει ότι αν ποτέ αυτή η γραμμή της κρυφής μνήμης απομακρυνθεί θα πρέπει να μεταφερθούν τα δεδομένα στην εξωτερική μνήμη.
Σε συστήματα που αποτελούνται από πολλούς επεξεργαστές, η τεχνική write-back εγκυμονεί κινδύνους ασυνέπειας της εικόνας που έχουν οι επεξεργαστές για κάθε διεύθυνση μνήμης, επειδή υπάρχει η δυνατότητα κάποιος επεξεργαστής να έχει τροποποιήσει κάποια διεύθυνση μνήμης και να μην έχει μεταφέρει την αλλαγή στην εξωτερική μνήμη. Αν ένας άλλος επεξεργαστής διαβάσει από την εξωτερική μνήμη, τότε θα δει άλλη τιμή. Παρόμοιο πρόβλημα εμφανίζεται και με την εγγραφή διαμέσου, αφού ένας επεξεργαστής μπορεί να έχει διαβάσει και μεταφέρει μια διεύθυνση της εξωτερικής μνήμης στην κρυφή του μνήμη, ένας άλλος επεξεργαστής να τροποποιήσει τα δεδομένα στην εξωτερική μνήμη, αλλά ο πρώτος να συνεχίζει να χρησιμοποιεί την παλαιά τιμή των δεδομένων που έχει η κρυφή μνήμη. Ασφαλώς, αυτά τα προβλήματα έχουν λυθεί στους σημερινούς πολυπύρηνους επεξεργαστές με διάφορα επιπρόσθετα πρωτόκολλα που αναλύονται στο σχετικό μάθημα των ‘Συστημάτων Παράλληλης και Κατανεμημένης Επεξεργασίας’.
Συνοψίζοντας λοιπόν, οι μνήμες αποθηκεύουν δεδομένα για να χρησιμοποιηθούν από τους επεξεργαστές. Η ROM τυπικά μόνο διαβάζεται από ένα ενσωματωμένο σύστημα. Μπορεί να προγραμματιστεί κατά τη διαδικασία της κατασκευής (προγραμματισμός με χρήση μάσκας) ή από τον χρήστη (προγραμματιζόμενη ROM ή PROM). Η PROM μπορεί να έχει δυνατότητα διαγραφής χρησιμοποιώντας ακτίνες UV (EPROM), ή ηλεκτρικά διαγράψιμη (EEPROM). Η RAM από την άλλη, είναι μνήμη που μπορεί να διαβαστεί ή να εγγραφεί από ένα ενσωματωμένο σύστημα. Η στατική RAM χρησιμοποιεί flip-flop για να αποθηκεύσει κάθε bit, ενώ η δυναμική RAM χρησιμοποιεί ένα τρανζίστορ κι ένα πυκνωτή, με αποτέλεσμα λιγότερα τρανζίστορ αλλά και με την ανάγκη ανανέωσης του φορτίου του πυκνωτή και πιο αργή απόδοση. Η ψευδοστατική RAM είναι μια δυναμική RAM (DRAM) με ενσωματωμένο ελεγκτή ανανέωσης. Οι σχεδιαστές πρέπει όχι μόνο να επιλέγουν τα κατάλληλα είδη μνημών για ένα δεδομένο ενσωματωμένο σύστημα, αλλά πρέπει και να συνδέουν συχνά τις μικρότερες μνήμες στις μεγαλύτερες, σε μια ιεραρχία μνήμης. Με τη χρήση της ιεραρχίας της μνήμης μπορούμε να βελτιώσουμε την απόδοση του συστήματος κρατώντας αντίγραφα των συχνά προσπελασμένων οδηγιών/δεδομένων σε μικρές και γρήγορες μνήμες κοντά στον επεξεργαστή. Η κρυφή μνήμη είναι μία μικρή και γρήγορη μνήμη μεταξύ ενός επεξεργαστή και της κύριας μνήμης. Αρκετά χαρακτηριστικά σχεδιασμού της κρυφής μνήμης επηρεάζουν σημαντικά την ταχύτητα και το κόστος της κρυφής μνήμης, συμπεριλαμβανομένων και της χαρτογράφησης, των πολιτικών αντικατάστασης και των τεχνικών εγγραφής.
Ένας σύγχρονος μικροεπεξεργαστής μπορεί να εκτελέσει τις εντολές με υψηλό ρυθμό. Για να εκμεταλλευτεί πλήρως αυτή τη δυνατή απόδοση ο επεξεργαστής, πρέπει να συνδεθεί με ένα σύστημα μνήμης το οποίο είναι και πολύ μεγάλο και πολύ γρήγορο. Εάν η μνήμη είναι πάρα πολύ μικρή, δε θα είναι σε θέση να κρατήσει αρκετά προγράμματα, έτσι ώστε να κρατήσει τον επεξεργαστή απασχολημένο. Εάν είναι πάρα πολύ αργή, η μνήμη δεν θα είναι σε θέση να παρέχει εντολές τόσο γρήγορα όσο ο επεξεργαστής μπορεί να τις εκτελέσει.
Δυστυχώς, όσο μεγαλύτερη είναι μια μνήμη τόσο πιο αργή είναι. Δεν είναι επομένως δυνατό, να σχεδιαστεί μια μόνο μνήμη που να είναι και αρκετά μεγάλη και αρκετά γρήγορη, για να κρατήσει απασχολημένο έναν επεξεργαστή υψηλής απόδοσης.
Εντούτοις, είναι δυνατό να κατασκευαστεί ένα σύνθετο σύστημα μνήμης που συνδυάζει μια μικρή, γρήγορη μνήμη και μια μεγάλη, αργή κύρια μνήμη για να παρουσιάσει μια εξωτερική συμπεριφορά, η οποία με τις χαρακτηριστικές στατιστικές προγράμματος εμφανίζεται να συμπεριφέρεται, τις περισσότερες φορές, όπως μια μεγάλη, γρήγορη μνήμη. Το μικρό, γρήγορο συστατικό μνήμης είναι η κρυφή μνήμη (cache), η οποία αυτόματα διατηρεί τα αντίγραφα των εντολών και των δεδομένων που ο επεξεργαστής χρησιμοποιεί πολύ συχνά.
Η αποτελεσματικότητα της κρυφής μνήμης εξαρτάται από τις ιδιότητες της χωρικής και χρονικής τοποθεσίας του προγράμματος.
Αυτή η αρχή μνήμης δύο-επιπέδων μπορεί να επεκταθεί σε μια ιεραρχία μνήμης πολλών επιπέδων, και ο σκληρός δίσκος του υπολογιστή μπορεί να αναγνωρισθεί ως τμήμα αυτής της ιεραρχίας. Με την κατάλληλη υποστήριξη διαχείρισης μνήμης, το μέγεθος ενός προγράμματος είναι περιορισμένο όχι από την κύρια μνήμη του υπολογιστή, αλλά από το μέγεθος του σκληρού δίσκου, το οποίο μπορεί να είναι πολύ μεγαλύτερο από αυτό της κύριας μνήμης.
Μία χαρακτηριστική ιεραρχία μνήμης υπολογιστών περιλαμβάνει διάφορα επίπεδα, με κάθε επίπεδο να κατέχει χαρακτηριστικό μέγεθος και ταχύτητα.
Οι καταχωρητές του επεξεργαστή μπορούν να εκληφθούν ως η κορυφή της ιεραρχίας μνήμης. Ο επεξεργαστής RISC τυπικά θα έχει περίπου τριάντα δύο 32 bit καταχωρητές. Αν έχει 32 καταχωρητές των 4 Byte θα έχει ένα σύνολο 128 bytes, με έναν χρόνο πρόσβασης μερικών νανοδευτερολέπτων (nanoseconds).
Η κρυφή μνήμη σε ένα ΕΣ πάνω στο τσιπ θα έχει χωρητικότητα από οκτώ έως 32 kbytes, με χρόνο πρόσβασης περίπου δέκα νανοδευτερόλεπτα.
Τα υψηλής απόδοσης υπολογιστικά συστήματα γραφείου μπορούν να έχουν παραπάνω από ένα επίπεδο κρυφής μνήμης. Το δεύτερο επίπεδο θα έχει χωρητικότητα μερικών εκατοντάδων kbytes και χρόνο πρόσβασης μερικών δεκάδων νανοδευτερολέπτων.
Η κύρια μνήμη θα είναι από κάποια KΒ έως δεκάδες ΜΒ δυναμικής RAM, με χρόνο πρόσβασης περίπου 100 νανοδευτερόλεπτα.
Μετά τη μνήμη RAM υπάρχει ο χώρος μόνιμης αποθήκευσης σε δίσκο ή σε μνήμη Flash. Αυτές είναι εκατοντάδες MB μέχρι μερικά GB με ένα χρόνο πρόσβασης μερικών δεκάδων χιλιοστών του δευτερολέπτου (miliseconds).
Σημειώστε ότι η διαφορά απόδοσης μεταξύ της κύριας μνήμης και του χώρου μόνιμης αποθήκευσης, είναι πολύ μεγαλύτερη από τη διαφορά μεταξύ οποιονδήποτε άλλων παρακείμενων επιπέδων, ακόμα και όταν δεν υπάρχει καμία δευτερεύουσα κρυφή μνήμη στο σύστημα. Τα δεδομένα που φυλάσσονται στους καταχωρητές είναι υπό τον άμεσο έλεγχο του μεταγλωττιστή ή του συμβολομεταφραστή, αλλά τα περιεχόμενα των υπόλοιπων επιπέδων της ιεραρχίας διαχειρίζονται συνήθως αυτόματα. Οι κρυφές μνήμες είναι αποτελεσματικά αόρατες στο πρόγραμμα εφαρμογής, με τμήματα ή σελίδες εντολών και δεδομένα που μεταναστεύουν πάνω-κάτω στην ιεραρχία, υπό τον έλεγχο του υλικού. Μερικά συστήματα έχουν διάφορες μονάδες μεταφοράς δεδομένων από το δίσκο στη μνήμη RAM και ονομάζονται σελίδες. Η σελιδοποίηση μεταξύ της κύριας μνήμης και του δίσκου ελέγχεται από το λειτουργικό σύστημα, και παραμένει διαφανής στο πρόγραμμα εφαρμογής. Καθώς η διαφορά απόδοσης μεταξύ της κύριας μνήμης και δίσκου είναι τόσο μεγάλη, απαιτούνται ακόμη πιο περίπλοκοι αλγόριθμοι για να καθορίσουν πότε πρέπει να μεταναστεύσουν δεδομένα μεταξύ των επιπέδων.
Ένα ενσωματωμένο σύστημα συνήθως δεν θα έχει ένα μεγάλο δίσκο και για αυτό σπάνια χρησιμοποιείται η σελιδοποίηση. Ωστόσο, πολλά ενσωματωμένα συστήματα ενσωματώνουν κρυφές μνήμες, και τα τσιπ των επεξεργαστών διαθέτουν μια ποικιλία οργανώσεων κρυφής μνήμης.
Η γρήγορη μνήμη είναι ακριβότερη ανά bit από την αργή μνήμη, γι’ αυτό η ιεραρχία μνήμης στοχεύει επίσης να δώσει μια απόδοση, κοντά στη γρηγορότερη μνήμη με ένα μέσο κόστος ανά bit που πλησιάζει αυτό της πιο αργής μνήμης.
Κάποια μορφή μνήμης on-chip (εντός ολοκληρωμένου κυκλώματος ή επιπλήνθια μνήμη) είναι απαραίτητη, εάν ένας μικροεπεξεργαστής απαιτεί μια εξωτερική μνήμη. Με τις σημερινές ταχύτητες ρολογιού, μόνο η on-chip μνήμη μπορεί να υποστηρίξει ταχύτητες πρόσβασης σε κατάσταση μηδενικής αναμονής (χωρίς να περιμένει ο επεξεργαστής), και θα δώσει επίσης την καλύτερη αποδοτικότητα ενέργειας και μειωμένη ηλεκτρομαγνητική παρέμβαση από την off-chip μνήμη.
On-chip RAM Σε πολλά ενσωματωμένα συστήματα προτιμάται η απλή on-chip RAM (ονομάζεται και scratch pad), έναντι της κρυφής μνήμης για διάφορα πλεονεκτήματα:
Είναι απλούστερη, φτηνότερη, και χρησιμοποιεί λιγότερη ενέργεια. Θα δούμε στα ακόλουθα τμήματα ότι η κρυφή μνήμη μεταφέρει ένα σημαντικό πλεονέκτημα στα πλαίσια της λογικής ότι είναι απαραίτητη, προκειμένου να επιτρέψει αποδοτική λειτουργία.
Υφίσταται επίσης ένα σημαντικό κόστος σχεδίασης, εάν μια κατάλληλη off-the-shelf κρυφή μνήμη δεν είναι διαθέσιμη. Ο σχεδιασμός μιας κρυφής μνήμης είναι αρκετά σύνθετος.
Έχει περισσότερη ντετερμινιστική (αιτιοκρατική) συμπεριφορά.
Οι κρυφές μνήμες έχουν σύνθετες συμπεριφορές που μπορούν να κάνουν δύσκολη την πρόβλεψη του πόσο καλά θα λειτουργήσουν κάτω από συγκεκριμένες περιστάσεις. Ειδικότερα, μπορεί να είναι δύσκολο να εγγυηθεί τη διακοπή του χρόνου απόκρισης (interrupt response time), δηλαδή το χρόνο που απαιτείται για να εξυπηρετηθεί μια διακοπή του επεξεργαστή.
Το μειονέκτημα με την on-chip RAM έναντι της κρυφής μνήμης είναι ότι απαιτεί ρητή διαχείριση από τον προγραμματιστή, ενώ η κρυφή μνήμη είναι συνήθως διαφανής στον προγραμματιστή. Όπου το μείγμα προγράμματος είναι καθορισμένο με σαφήνεια και υπό τον έλεγχο του προγραμματιστή, η on-chip RAM μπορεί αποτελεσματικά να χρησιμοποιηθεί ως μία κρυφή μνήμη ελεγχόμενη από το λογισμικό. Όπου το μείγμα εφαρμογής δεν μπορεί να προβλεφθεί αυτή η διεργασία ελέγχου γίνεται πολύ δύσκολη.
Ως εκ τούτου μια κρυφή μνήμη προτιμάται συνήθως σε οποιοδήποτε γενικού σκοπού σύστημα, όπου η εφαρμογή του μείγματος είναι άγνωστη. Στα ΕΣ όμως, που προσδιορίζονται για ειδικού σκοπού εφαρμογές, μπορεί να χρησιμοποιηθεί αυτού του είδους η μνήμη αντί για cache.
Ένα σημαντικό πλεονέκτημα της on-chip RAM είναι ότι επιτρέπει στον προγραμματιστή να διαθέσει χώρο αυτήν χρησιμοποιώντας γνώσεις μελλοντικών αναγκών, δηλαδή να μεταφέρει σε αυτή από πριν δεδομένα που θα χρησιμοποιηθούν στο μέλλον [21]. Μια κρυφή μνήμη έχει γνώση μόνο της συμπεριφοράς στο παρελθόν του προγράμματος, και δεν μπορεί επομένως ποτέ να προετοιμαστεί εκ των προτέρων για κρίσιμες μελλοντικές διεργασίες. Αυτή είναι μια διαφορά, η οποία είναι πιο πιθανό να είναι σημαντική όταν κρίσιμες διεργασίες πρέπει να συναντήσουν αυστηρούς περιορισμούς πραγματικού χρόνου.
Ο σχεδιαστής του συστήματος πρέπει να αποφασίσει ποια είναι η σωστή προσέγγιση για ένα συγκεκριμένο σύστημα, λαμβάνοντας όλους αυτούς τους παράγοντες υπόψη. Οποιαδήποτε μορφή on-chip μνήμης επιλεχθεί, πρέπει να διευκρινιστεί με μεγάλη προσοχή. Πρέπει να είναι αρκετά γρήγορη ώστε να κρατήσει τον επεξεργαστή απασχολημένο και αρκετά μεγάλη, ώστε να περιέχει κρίσιμες ρουτίνες, αλλά ούτε πολύ γρήγορη (γιατί θα καταναλώσει πάρα πολλή ενέργεια), ούτε πολύ μεγάλη (γιατί θα καταλάβει πολύ μεγάλη περιοχή του τσιπ).
Κρυφές Μνήμες
Οι πρώτοι επεξεργαστές RISC εισήχθησαν σε μία εποχή που τυποποιημένα τσιπ μνήμης ήταν γρηγορότερα από τους σύγχρονούς μικροεπεξεργαστές, αλλά αυτή η κατάσταση δεν παρέμεινε για πολύ. Επόμενες εξελίξεις στην τεχνολογία διαδικασίας ημιαγωγών, κατέστησαν μικροεπεξεργαστές γρηγορότερους, έχουν εφαρμοστεί για να βελτιώσουν τα τσιπ μνήμης. Τα τυποποιημένα μέρη DRAM έχουν γίνει λίγο γρηγορότερα, αλλά κυρίως έχουν αναπτυχθεί με στόχο να προσφέρουν μια πολύ υψηλότερη χωρητικότητα.
Ταχύτητες επεξεργαστών και μνήμης
Το 1980 ένα χαρακτηριστικό τσιπ DRAM θα μπορούσε να κρατήσει 4 Kbits δεδομένων, με τα 16 Kbit τσιπ να φτάνουν το 1981 και το 1982, αντίστοιχα. Αυτά τα μέρη θα ανακύκλωναν στα 3 ή 4 MHz για τις τυχαίες προσβάσεις, και για δύο φορές αυτό το ποσοστό για τις τοπικές προσβάσεις (στην τροποποίηση σελίδων). Οι μικροεπεξεργαστές εκείνο το καιρό μπορούσαν να ζητήσουν περίπου δύο εκατομμύρια προσβάσεις μνήμης ανά δευτερόλεπτο.
Το 2000 τα τσιπ DRAM είχαν χωρητικότητα 256 Mbits ανά τσιπ, με τις τυχαίες προσβάσεις να λειτουργούν περίπου στα 30 MHz. Οι μικροεπεξεργαστές μπορούσαν να ζητήσουν αρκετές εκατοντάδες εκατομμυρίων προσβάσεις μνήμης ανά δευτερόλεπτο. Εάν ο επεξεργαστής ήταν τόσο πολύ γρηγορότερος από τη μνήμη, μπορούσε να αποδώσει τα μέγιστα, μόνο με τη βοήθεια μιας κρυφής μνήμης. Μια κρυφή μνήμη είναι μια μικρή, πολύ γρήγορη μνήμη, που διατηρεί αντίγραφα των πρόσφατα χρησιμοποιημένων τιμών μνήμης. Λειτουργεί διαφανώς στον προγραμματιστή, αποφασίζοντας αυτόματα ποιες τιμές θα κρατήσει και ποιες θα παραγράψει. Στην εποχή μας συνήθως εφαρμόζεται πάνω στο ίδιο τσιπ με τον επεξεργαστή (στο παρελθόν ήταν σε διαφορετικά τσιπ). Οι κρυφές μνήμες λειτουργούν επειδή τα προγράμματα επιδεικνύουν κανονικά την ιδιοκτησία της τοπικότητας, το οποίο σημαίνει ότι σε οποιοδήποτε χρόνο τείνουν να εκτελούν τις ίδιες εντολές πολλές φορές (παραδείγματος χάριν σε έναν βρόχο) στις ίδιες περιοχές δεδομένων (για περίπτωση μια στοιβάδα).
Ενοποιημένες και κρυφές μνήμες του Χάρβαρντ
Οι κρυφές μνήμες μπορούν να κατασκευαστούν με πολλούς τρόπους. Στο πιο υψηλό επίπεδο ένας επεξεργαστής μπορεί να έχει μία από τις ακόλουθες δύο διατάξεις:
Μια ενοποιημένη (unified) κρυφή μνήμη. Αυτή είναι μια ενιαία κρυφή μνήμη τόσο για τις εντολές όσο και για τα δεδομένα, όπως διευκρινίζεται στο σχήμα 3.13.
Ξεχωριστές κρυφές μνήμες εντολών και δεδομένων (split). Αυτή η διάταξη καλείται μερικές φορές ως τροποποιημένη αρχιτεκτονική του Χάρβαρντ όπως παρουσιάζεται παρακάτω.
Και οι δύο αυτές οι διατάξεις είναι χρήσιμες. Η ενοποιημένη κρυφή μνήμη αυτόματα ρυθμίζει το ποσοστό της κρυφής μνήμης που χρησιμοποιείται από τις εντολές σύμφωνα με τις τρέχουσες απαιτήσεις του προγράμματος, δίνοντας καλύτερη απόδοση από ότι ένας προκαθορισμένος διαχωρισμός. Από την άλλη μεριά, οι χωριστές κρυφές μνήμες επιτρέπουν τις εντολές φόρτωσης και αποθήκευσης να εκτελεστούν μέσα σε έναν ενιαίο κύκλο ρολογιού.
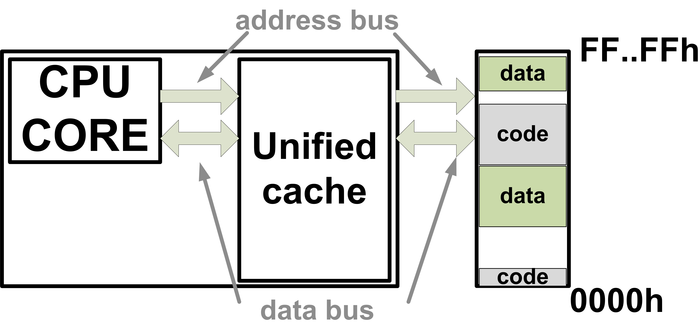
3.13: Μία ενοποιημένη κρυφή μνήμη εντολών και δεδομένων.
Μετρικές απόδοσης κρυφής μνήμης
Δεδομένου ότι ο επεξεργαστής μπορεί να λειτουργήσει στην υψηλή συχνότητα ρολογιού του μόνον όταν τα αντικείμενα μνήμης που απαιτεί διατηρούνται στην κρυφή μνήμη, η συνολική απόδοση συστήματος εξαρτάται έντονα από το ποσοστό των προσβάσεων μνήμης το οποίο δεν μπορεί να ικανοποιηθεί από την κρυφή μνήμη. Η πρόσβαση σε ένα αντικείμενο το οποίο βρίσκεται στην κρυφή μνήμη καλείται επιτυχία, και η πρόσβαση σε ένα αντικείμενο που δεν βρίσκεται στην κρυφή μνήμη καλείται αποτυχία. Το ποσοστό όλων των προσβάσεων μνήμης που ικανοποιούνται από την κρυφή μνήμη είναι το ποσοστό επιτυχιών, εκφρασμένο συνήθως ως ποσοστό, και το ποσοστό αυτών που δεν ικανοποιούνται είναι το ποσοστό αποτυχιών.
Το ποσοστό αποτυχιών, μιας καλά σχεδιασμένης κρυφής μνήμης, πρέπει να είναι μόνο μερικά τοις εκατό, εάν ένας σύγχρονος επεξεργαστής πρόκειται να εκπληρώσει τη δυνατότητά του. Το ποσοστό αποτυχίας εξαρτάται από έναν αριθμό παραμέτρων της κρυφής μνήμης, συμπεριλαμβανομένου του μεγέθους της (ο αριθμός των bytes της μνήμης μέσα στην κρυφή μνήμη) και της οργάνωσης της.
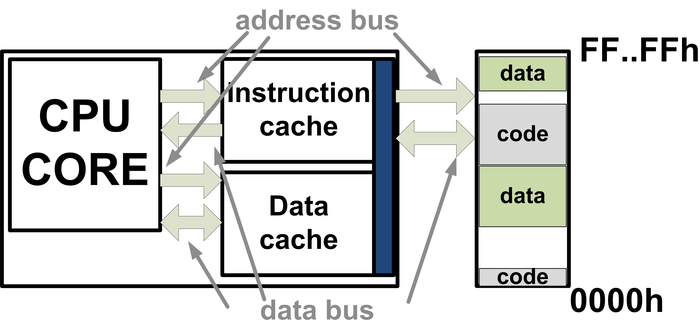
3.14: Ξεχωριστά δεδομένα και εντολές κρυφής μνήμης.
Όπως έγινε κατανοητό, ένας επεξεργαστής διαχειρίζεται τον κώδικα προγράμματος μέσα σε ένα ενσωματωμένο σύστημα μέσω των διεργασιών (αν υπάρχει λειτουργικό σύστημα, ΛΣ). Ο πυρήνας πρέπει επίσης να έχει κάποιο σύστημα φόρτωσης και εκτέλεσης διεργασιών μέσα στο σύστημα, εφόσον η CPU εκτελεί μόνο τον κώδικα της διεργασίας που είναι μέσα στην κρυφή μνήμη ή στη RAM. Με τις πολλαπλές διεργασίες να μοιράζονται τον ίδιο χώρο, ένα ΛΣ χρειάζεται ένα σύστημα με μηχανισμό προστασίας για να προστατέψει τον κώδικα της διεργασίας από άλλες ανεξάρτητες διεργασίες. Επιπλέον, εφόσον ένα ΛΣ πρέπει να τοποθετηθεί στην ίδια μνήμη με τις διεργασίες τις οποίες διαχειρίζεται, ο μηχανισμός προστασίας πρέπει να περιλαμβάνει τη διαχείριση του δικού του κώδικα στη μνήμη, και να το προστατέψει από τον κώδικα των διεργασιών που διαχειρίζεται. Αυτές οι λειτουργίες, και άλλες πολλές, είναι καθήκον του Διαχειριστή Μνήμης ενός ΛΣ. Δεν έχουν όλα τα ΕΣ ΛΣ, γιατί η ύπαρξη ενός ΛΣ επιβαρύνει το σύστημα με την εκτέλεση κώδικα που απαιτείται για το ίδιο το ΛΣ. Όμως, υπάρχουν περιπτώσεις που πρέπει να χρησιμοποιηθεί ένα ΛΣ σε ένα ΕΣ, όπως θα συζητηθεί στο σχετικό κεφάλαιο με τα ΛΣ.
Γενικά, τα καθήκοντα του διαχειριστή μνήμης πυρήνα σε ένα ΛΣ περιλαμβάνουν:
Διαχείριση της χαρτογράφησης μεταξύ της λογικής μνήμης που βλέπουν οι διεργασίες και της φυσικής μνήμης RAM, αφού κάθε διεργασία εκτελείται σε ένα δικό της απομονωμένο χώρο διευθύνσεων (που ονομάζεται λογικός χώρος διευθύνσεων).
Καθορισμό των διαδικασιών που θα φορτωθούν στο διαθέσιμο χώρο μνήμης, όπως και σε ποιες διευθύνσεις θα φορτωθούν.
Προσδιορισμός και ελευθέρωση της μνήμης για διεργασίες που αποτελούν το σύστημα.
Υποστήριξη προσδιορισμού και ελευθέρωσης μνήμης των προγραμμάτων (μέσα στη διεργασία), όπως η γλώσσα C με λειτουργίες ‘alloc’ και ‘dealloc’, ή ειδικές ρουτίνες προσδιορισμού και ελευθέρωσης προσωρινής μνήμης.
Παρακολούθηση της χρήσης μνήμης σε ένα τμήμα συστήματος, ώστε να μπορεί να το απελευθερώνει σε περίπτωση που μια διαδικασία τερματίσει.
Διαβεβαίωση για τη συνεκτικότητα της κρυφής μνήμης (για συστήματα πολλών επεξεργαστών με κρυφή μνήμη), ώστε όλοι οι επεξεργαστές να βλέπουν την ίδια εικόνα για μια διεύθυνση της εξωτερικής μνήμης.
Διαβεβαίωση προστασίας της μνήμης διεργασιών, ώστε η μια διεργασία να μη μπορεί να διαβάσει ή να καταστρέψει τα δεδομένα ή τις εντολές άλλης διεργασίας.
H φυσική μνήμη αποτελείται από δισδιάστατες σειρές φτιαγμένες από κελιά που διευθυνσιοδοτούνται από μια μοναδική γραμμή και στήλη, στην οποία κάθε κελί μπορεί να αποθηκεύσει 1 bit. Το ΛΣ συμπεριφέρεται στη μνήμη ως μια μεγάλη μονοδιάστατη σειρά, καλούμενη χάρτης μνήμης (memory map). Υπάρχει ο λογικός (ή ιδεατός) και ο φυσικός χώρος διευθύνσεων μνήμης. Οι διεργασίες βλέπουν τον ιδεατό χώρο διευθύνσεων ενώ οι φυσικές διευθύνσεις τοποθετούνται στο δίαυλο διευθύνσεων της μνήμης. Η αντιστοίχηση γίνεται είτε από το ίδιο το ΛΣ, είτε από τον επεξεργαστή, αν διαθέτει μια μονάδα διαχείρισης μνήμης (memory management unit).
Ο τρόπος με τον οποίο τα ΛΣ διαχειρίζονται το χώρο της λογικής μνήμης διαφέρει ανάμεσα στα ΛΣ. Γενικά, οι πυρήνες των ΛΣ εκτελούν κώδικα πυρήνα (kernel) σε ξεχωριστό χώρο μνήμης από τις διεργασίες που εκτελούν κώδικα υψηλότερου επιπέδου (δηλαδή κώδικα επιπέδου εφαρμογής), και ονομάζεται κώδικας χρήστη (user). Η διαφοροποίηση έγκειται στο γεγονός ότι ο κώδικας που εκτελείται σε επίπεδο πυρήνα δεν έχει κανένα περιορισμό και μπορεί να προσπελάσει οποιοδήποτε περιφερειακό ή διεύθυνση μνήμης. Αντιθέτως, ο κώδικας που εκτελείται σε επίπεδο χρήστη, έχει πολλούς περιορισμούς που υπάρχουν για την καλύτερη ασφάλεια και σταθερότητα του συστήματος. Αν ο κώδικας που εκτελείται σε επίπεδο χρήστη θελήσει κάποια ενέργεια που απαιτεί αυξημένα δικαιώματα, θα ζητήσει από τον πυρήνα να μεσολαβήσει και να δράσει εκ μέρους αυτού, επιστρέφοντας σε αυτόν τα αποτελέσματα. Κάθε ένας από αυτούς τους χώρους μνήμης ( πυρήνα, συμπεριλαμβανομένου και του κώδικα πυρήνα του ΛΣ και
χρήστη, συμπεριλαμβανομένων των διεργασιών υψηλού επιπέδου) υπόκεινται σε διαχείριση με διαφορετικό τρόπο. Στην πραγματικότητα, οι περισσότερες διεργασίες τυπικά εκτελούνται με μια από τις δύο μεθόδους: πυρήνα και χρήστη, ανάλογα με τις ρουτίνες που εκτελούνται. Οι ρουτίνες πυρήνα εκτελούνται σε μεθόδους πυρήνα (αναφερόμενες επίσης ως μέθοδοι-επόπτες -supervisors), σε διαφορετικό χώρο μνήμης και επίπεδο από ότι τα υψηλότερα επίπεδα λογισμικού, όπως οι εφαρμογές. Τυπικά, αυτά τα υψηλότερα επίπεδα λογισμικού εκτελούνται σε μεθόδους χρήστη και μπορούν μόνο να εισχωρήσουν σε οτιδήποτε εκτελείται σε μέθοδο πυρήνα μέσω κλήσεων συστήματος (operating system calls). Ο πυρήνας διαχειρίζεται τη μνήμη και για τον εαυτό του και για τις διεργασίες χρήστη.
Επειδή οι πολλαπλές διεργασίες μοιράζονται την ίδια φυσική μνήμη όταν φορτώνονται στη RAM για επεξεργασία, πρέπει επίσης να υπάρχει κάποιος μηχανισμός προστασίας, έτσι ώστε οι διεργασίες να μην μπορούν ακούσια ή εκούσια να επηρεάσουν η μια την άλλη όταν εναλλάσσονται μέσα και έξω από έναν χώρο μιας φυσικής μνήμης. Αυτά τα ζητήματα τυπικά λύνονται από το λειτουργικό σύστημα μέσω της ‘ανταλλαγής’ μνήμης, όπου τα διαμερίσματα της μνήμης ανταλλάσσονται μέσα και έξω από τη μνήμη κατά το χρόνο εκτέλεσης. Τα πιο κοινά διαμερίσματα μνήμης που χρησιμοποιούνται για ανταλλαγή είναι τα τμήματα (τεμαχισμός των διεργασιών) και οι σελίδες (τεμαχισμός της λογικής μνήμης). Η κατάτμηση και η σελιδοποίηση όχι μόνο απλοποιούν την ανταλλαγή, αλλά επιτρέπουν την επαναχρησιμοποίηση κώδικα και την προστασία μνήμης, καθώς επίσης αποτελούν τη βάση για την εικονική μνήμη. Η εικονική μνήμη είναι ένας μηχανισμός που ελέγχεται από το ΛΣ για να επιτρέψει τον περιορισμένο χώρο μνήμης μίας συσκευής να μοιραστεί από τις πολλαπλές ανταγωνιστικές διεργασίες χρήστη.
Μια διεργασία ενθυλακώνει όλες τις πληροφορίες που σχετίζονται με την εκτέλεση ενός προγράμματος, συμπεριλαμβανομένων του πηγαίου κώδικα, της στοίβας, των δεδομένων, κτλ. Όλοι οι διαφορετικοί τύποι πληροφοριών σε μια διεργασία χωρίζονται σε λογικές μονάδες μνήμης μεταβλητού μεγέθους, αποκαλούμενα τμήματα. Ένα τμήμα είναι ένα σύνολο λογικών διευθύνσεων που περιέχουν τον ίδιο τύπο πληροφοριών. Οι διευθύνσεις τμημάτων είναι λογικές διευθύνσεις που αρχίζουν από το 0, και αποτελούνται από έναν αριθμό τμήματος, που υποδεικνύει τη διεύθυνση βάσεων του τμήματος, και ένα τμήμα έναρξης που καθορίζει την πραγματική φυσική διεύθυνση μνήμης. Τα τμήματα προστατεύονται ανεξάρτητα, που σημαίνει ότι έχουν προσδιορίσει τα χαρακτηριστικά της προσβασιμότητας, όπως η κοινόχρηστη ιδιότητα (shared), όπου οι άλλες διεργασίες μπορούν να έχουν πρόσβαση σε αυτό το τμήμα, Μόνο για Ανάγνωση ή Ανάγνωση και Εγγραφή.
Τα περισσότερα ΛΣ τυπικά επιτρέπουν στις διεργασίες να χρησιμοποιούν πλήρη ή μερικό συνδυασμό των πέντε τύπων των πληροφοριών μέσα στα τμήματα: τμήμα κειμένου ή κώδικα (code / text segment), τμήμα δεδομένων (data segment), τμήμα συμβόλων bss (block starting symbol segment), και το τμήμα στοίβας (stack segment). Ένα τμήμα κειμένου είναι μια περιοχή μνήμης που περιλαμβάνει τον πηγαίο κώδικα. Ένα τμήμα δεδομένων είναι μια περιοχή μνήμης που περιλαμβάνει τις αρχικοποιημένες μεταβλητές του πηγαίου κώδικα (δεδομένα). Ένα τμήμα bbs είναι μια περιοχή μνήμης προσδιορισμένη με στατικό τρόπο, που περιλαμβάνει τις μεταβλητές του πηγαίου κώδικα που δεν έχουν αρχικοποιηθεί (δεδομένα). Τα τμήματα δεδομένων, κειμένου και bbs καθορίζονται κατά το χρόνο μετάφρασης, και είναι υπό αυτή τη μορφή στατικά τμήματα. Αυτά τα τρία τμήματα είναι αυτά που τυπικά αποτελούν τμήμα ενός εκτελέσιμου αρχείου. Τα εκτελέσιμα αρχεία μπορεί να διαφέρουν ως προς τα τμήματα από τα οποία συντίθενται, αλλά γενικά περιλαμβάνουν μια επιγραφή, και διαφορετικά κομμάτια τα οποία αναπαριστούν τους τύπους των τμημάτων, συμπεριλαμβανομένου του ονόματος, τις άδειες κτλ, όπου ένα τμήμα μπορεί να φτιαχτεί από ένα ή περισσότερα κομμάτια. Το ΛΣ δημιουργεί την εικόνα μιας διεργασίας μέσω της χαρτογράφησης μνήμης των περιεχομένων του εκτελέσιμου αρχείου, που σημαίνει τη φόρτωση και διερμηνεία των τμημάτων (περιοχών) που αντικατοπτρίζουν στην εκτελέσιμη μνήμη. Υπάρχουν διάφορα σχήματα εκτελέσιμων αρχείων που υποστηρίζονται από τα ενσωματωμένα ΛΣ, τα πιο κοινά συμπεριλαμβάνουν:
ELF (Executable and Linkable Format - εκτελέσιμο και διασυνδεδεμένο αρχείο): βασισμένο στο UNIX, περιλαμβάνει έναν συνδυασμό από κατάλληλη επικεφαλίδα (ELF), τον πίνακα επικεφαλίδας προγράμματος, τον πίνακα επικεφαλίδας τμήματος, την περιοχή ELF και το τμήμα ELF. Τα Linux, FreeBSD και τα vxWorks(WRS) είναι μερικά παραδείγματα των ΛΣ που υποστηρίζουν ELF.
Κλάση Java Byte: Ένα αρχείο κλάσης περιγράφει με λεπτομέρειες μια κλάση της Java υπό μορφή πλήθους bytes των 8 bit. Αντί για τμήματα, τα στοιχεία του αρχείου κλάσης καλούνται αντικείμενα. Η μορφοποίηση αρχείου κλάσης Java περιλαμβάνει την περιγραφή της κλάσης, όπως επίσης και το πώς αυτή η κλάση συνδέεται με τις υπόλοιπες κλάσεις. Τα κύρια περιεχόμενα ενός αρχείου κλάσης είναι ένας πίνακας συμβόλων (με σταθερές), δήλωση των πεδίων, κλήσεις μεθόδων (κώδικας) και συμβολικές αναφορές (όπου υπάρχουν άλλες αναφορές κλάσεων). Το ΛΣ Jbed RT είναι ένα παράδειγμα που υποστηρίζει τη μορφοποίηση κώδικα Java Byte.
COFF (Common Object File Format - κοινό σχήμα αρχείων αντικειμένου): Μια μορφοποίηση αρχείου κλάσης το οποίο (μεταξύ άλλων) καθορίζει ένα αρχείο εικόνας το οποίο περιλαμβάνει τις επικεφαλίδες αρχείων που περιέχουν μια υπογραφή αρχείου, επικεφαλίδα COFF, μια προαιρετική επικεφαλίδα, και επίσης αρχεία αντικειμένου που περιέχουν μόνο την επικεφαλίδα COFF. Το ΛΣ WinCE της Microsoft είναι ένα παράδειγμα ενσωματωμένου OS που υποστηρίζει τη μορφοποίηση αρχείου εκτέλεσης COFF.
Ένα τμήμα στοίβας είναι ένα τμήμα της μνήμης που είναι δομημένο ως ουρά τελευταίο μέσα, πρώτα έξω (Last In First Out - LIFO), όπου το στοιχείο είναι ‘ωθημένο’ επάνω στη στοίβα, ή ‘απωθημένο’ από την στοίβα (η ώθηση και η απώθηση είναι οι μόνες δύο διαδικασίες συνδεδεμένες με την στοίβα).
H στοίβα χρησιμοποιείται ως μια απλή και αποδοτική μέθοδος στα πλαίσια ενός προγράμματος για τη διάθεση και την απελευθέρωση της μνήμης για δεδομένα που είναι προβλέψιμα (δηλαδή τοπικές μεταβλητές, διάβαση παραμέτρων, κ.λπ.). Σε μία στοίβα, ο χρησιμοποιούμενος και ελεύθερος χώρος μνήμης βρίσκεται κατά συνέπεια μέσα στο χώρο μνήμης. Εντούτοις, δεδομένου ότι ‘η ώθηση’ και ‘η απώθηση’ είναι οι μόνες δύο διαδικασίες που συνδέονται με μία στοίβα, μία στοίβα μπορεί να έχει περιορισμένες χρήσεις.
Η καρδιά σε κάθε υπολογιστικό σύστημα είναι το δομοστοιχείο που κάνει τους υπολογισμούς. Στους υπολογιστές γενικού σκοπού δεν υπάρχει ευελιξία ως προς αυτό: υπάρχουν ένας ή περισσότεροι επεξεργαστές γενικής αρχιτεκτονικής 64 bit συμβατής με Intel x86-64, που σημαίνει ότι μπορούν να αντεπεξέλθουν σε οποιαδήποτε φόρτο εργασίας τους ζητηθεί. Αντιθέτως, στα ΕΣ υπάρχει μια μεγάλη ποικιλία υλοποιήσεων, κάποιες από τις οποίες είναι αντιδιαμέτρου αντίθετες μεταξύ τους. Για παράδειγμα τα ΕΣ μπορούν να χρησιμοποιήσουν έναν γενικής χρήσης επεξεργαστή (π.χ. Intel ATOM), ειδικούς επεξεργαστές ψηφιακής επεξεργασίας σημάτων (π.χ. Texas Instrument TIC6201), μικροεπεξεργαστές 8 bit (π.χ. AVR ATMEGA328P), σύνθετους επεξεργαστές 32 bit (π.χ. ARM Cortex Α15), απλούς επεξεργαστές 32 bit (MIPS R3000), επεξεργαστές μαλακού πυρήνα σε επαναδιαμορφώσιμη λογική FPGA (soft-cores, π.χ. Altera NIOS II) ή ακόμη και εξειδικευμένα κυκλώματα υλικού (ASIC), τα οποία δεν έχουν καν επεξεργαστή, αλλά υλοποιούν μια συγκεκριμένη λειτουργία χρησιμοποιώντας μια μηχανή πεπερασμένων καταστάσεων (finite state machine). Μάλιστα, οι επεξεργαστές δεν είναι συμβατοί μεταξύ τους, όπως στους υπολογιστές γενικού σκοπού ή στους φορητούς υπολογιστές ή στους διακομιστές (που όλοι είναι συμβατοί με τις προδιαγραφές της αρχιτεκτονικής x86-64, και έτσι ένα πρόγραμμα μπορεί να εκτελεστεί σε όλους τους συμβατούς επεξεργαστές). Το οικοσύστημα των ΕΣ φαίνεται τόσο χαοτικό σε κάποιον που μόλις τώρα το γνωρίζει, και ο σχεδιασμός ενός ΕΣ μπορεί να παρομοιαστεί με ένα δαιδαλώδες λαβύρινθο με πολλά μονοπάτια, που κάθε μονοπάτι οδηγεί σε άλλες επιλογές. Στο επόμενο κεφάλαιο, αναλύουμε τους προγραμματιζόμενους επεξεργαστές·τα επεξεργαστικά στοιχεία σε FPGA και σε ASIC αναλύονται σε άλλο κεφάλαιο.
Σε αυτή την ενότητα θα περιγράψουμε την ισχύουσα αρχιτεκτονική στα προγραμματιζόμενα υπολογιστικά συστήματα, που φέρει κοινά στοιχεία, είτε αφορά τα ΕΣ, είτε άλλα συστήματα. Η αρχιτεκτονική αυτή ονομάζεται αποθηκευμένου προγράμματος (stored-program), γιατί το πρόγραμμα βρίσκεται αποθηκευμένο σε μια μορφή μόνιμης αποθήκευσης (π.χ. σε ένα δίσκο ή σε έναν οδηγό Flash), μεταφέρεται στη μνήμη RAM, και στη συνέχεια η κάθε εντολή του προγράμματος εισέρχεται μέσα στον επεξεργαστή, ο οποίος την εκτελεί. Μόλις την εκτελέσει, τότε φέρνει την επόμενη εντολή κ.ο.κ.
Από τα παραπάνω καταλαβαίνουμε ότι ο επεξεργαστής εκτελεί συνεχώς έναν αέναο βρόχο, που αποτελείται από τα βήματα της προσκόμισης της εντολής και της εκτέλεσης. Με μια καλύτερη ανάλυση βρίσκουμε ότι ο επεξεργαστής εκτελεί συνεχώς τέσσερις λειτουργίες:
Προσκόμιση εντολής (fetch)
Αποκωδικοποίηση εντολής (decode)
Εκτέλεση εντολής (execute)
Αποθήκευση των αποτελεσμάτων (store)
Έτσι, ο επεξεργαστής προσκομίζει από την εξωτερική μνήμη, σε έναν εσωτερικό καταχωρητή που ονομάζεται καταχωρητής εντολής (Instruction Register) την εντολή που θα ξεκινήσει την εκτέλεση. Η εντολή αυτή είναι κωδικοποιημένη με ‘1’ και ’0’ σε συγκεκριμένες θέσεις.
Οι επεξεργαστές χωρίζονται σε 2 κατηγορίες ως προς το μήκος των εντολών που υποστηρίζουν (Εικόνα 3.15): οι εντολές σταθερού μήκους bit, που σημαίνει ότι όλες οι εντολές θα έχουν πάντα το ίδιο μήκος (π.χ. 32 bit) και οι εντολές μεταβλητού μήκους bit, που σημαίνει ότι άλλες εντολές θα είναι 1 Byte, άλλες εντολές 2 Byte, κ.ο.κ. (σε κάποιους επεξεργαστές έφτανε μέχρι και 31 Byte) [22]. Οι εντολές με σταθερό μήκος bit είναι πολύ πιο εύκολο να αποκωδικοποιηθούν και άρα απαιτούν λιγότερο υλικό στον επεξεργαστή για αυτή τη λειτουργία. Δεν είναι παράξενο λοιπόν, που η πλειονότητα των επεξεργαστών που χρησιμοποιούνται στα ΕΣ, έχει υιοθετήσει εντολές σταθερού μήκους. Από την άλλη, οι εντολές μεταβλητού μήκους επιτρέπουν μεγαλύτερη ευελιξία και είναι πιο φιλικές για τον προγραμματισμό, αφού επιτρέπουν συνήθως και πολύπλοκες λειτουργίες με μια εντολή (π.χ. έλεγχος σε μια περιοχή μνήμης για την ύπαρξη ενός string). Αυτές οι πολύπλοκες λειτουργίες μπορούν να υλοποιηθούν με πολλές εντολές στους υπολογιστές σταθερού μήκους. Βέβαια, η ύπαρξη πολύπλοκων εντολών συνεπάγεται και την έντονη διακύμανση στον απαιτούμενο χρόνο εκτέλεσης κάθε εντολής: κάποιες εντολές θα απαιτήσουν 1 κύκλο, κάποιες 10 κύκλους, σε αντιδιαστολή με τις εντολές σταθερού μήκους που έχουν στη συντριπτική πλειονότητα χρόνο εκτέλεσης του 1 κύκλου ρολογιού. Οι ιδιότητες αυτές (σταθερό μήκος εντολής, χρόνος εκτέλεσης εντολής ίσο με 1 κύκλο ρολογιού, λίγες εντολές και όχι πολύπλοκες, απλοποιημένη λογική αποκωδικοποίησης) χαρακτηρίζουν τους υπολογιστές RISC (reduced instruction set computing, επεξεργαστές με μειωμένο σύνολο εντολών), όπως είναι οι επεξεργαστές ARM και MIPS. Στον αντίποδα βρίσκονται οι CISC (complex instruction set computing, επεξεργαστές πολύπλοκου σετ εντολών), που είναι κυρίως οι οικογένειες ΙΑ32 και x86-64. Εκτός από τις παραπάνω σημαντικές διαφορές, υπάρχουν και άλλες όπως το ότι οι εντολές RISC απαιτούν 1 κύκλο εκτέλεσης, θα πρέπει όλοι οι παράμετροι να είναι σε καταχωρητές, σε αντίθεση με τους CISC που επιτρέπουν και εντολές με απευθείας πράξη πάνω σε δεδομένα θέσης μνήμης, και ότι τα προγράμματα RISC είναι μεγαλύτερα σε μέγεθος αφού απαιτούν πολλές απλές εντολές για να ολοκληρωθούν. Πριν από το 1970 όλοι οι υπολογιστές ήταν CISC, αλλά με την ανάπτυξη των ενσωματωμένων συστημάτων, όλοι οι νέοι επεξεργαστές είναι RISC και οι επεξεργαστές που ήταν CISC (οικογένεια επεξεργαστών Intel x86) αποκωδικοποιούνται σε μικρο-εντολές RISC. Επίσης, οι σημερινοί RISC επεξεργαστές έχουν ενισχυθεί με κάποιες παραπάνω εντολές (τύπου CISC) για τη διευκόλυνση κάποιων λειτουργιών, χωρίς να σημαίνει ότι δεν είναι RISC.
3.15: Οι εντολές των επεξεργαστών έχουν ποικίλες μορφές. Στο σχήμα εμφανίζονται οι εντολές σταθερού μήκους bit (a) και οι εντολές μεταβλητού μήκους bit (β) με τις διάφορες μορφές, ως προς τις παραμέτρους
Εκτός από το μήκος των εντολών, ένα άλλο στοιχείο είναι ο αριθμός των παραμέτρων που δέχεται μια εντολή. Για παράδειγμα μια εντολή πρόσθεσης σε έναν επεξεργαστή είναι: ΑDD ΑΧ,ΒΧ, που σημαίνει να προστεθούν οι τιμές των καταχωρητών AX και BX και το αποτέλεσμα να αποθηκευτεί στον καταχωρητή AX. Σε έναν άλλο επεξεργαστή, η εντολή πρόσθεσης είναι διαφορετική: ΑDDS R1,R2,R3, που σημαίνει να προστεθούν οι τιμές των καταχωρητών R2 και R3 και το αποτέλεσμα να αποθηκευτεί στον καταχωρητή R1. Όπως φαίνεται ο κάθε επεξεργαστής έχει τη δικιά του σύνταξη και τα δικά του ονόματα στους καταχωρητές και τις εντολές. Υπάρχουν γενικά εντολές που δε παίρνουν καμία παράμετρο, ή παίρνουν 1 ή 2 ή 3 παραμέτρους. Ο κάθε επεξεργαστής υποστηρίζει το δικό του συντακτικό (η Εικόνα 3.15 δείχνει τη δομή των εντολών για 0 ή 1 ή 2 ή 3 παραμέτρους).
Όλα τα προγράμματα που εξετάζει ένας επεξεργαστής εκφράζονται ως ψηφία 1 και 0 στη μνήμη του συστήματος. Η μνήμη αποθηκεύει μόνο 1 και 0, οπότε θα πρέπει με κάποιον τρόπο να καθορίζεται τι σημαίνει μια λέξη, π.χ. 11100011. Αυτή η λέξη θα μπορούσε να είναι εντολή προς τον επεξεργαστή (κώδικας μηχανής) ή δεδομένα (ένας χαρακτήρας ASCII ή μια ακέραια τιμή χωρίς πρόσημο ή μια ακέραια τιμή με πρόσημο ή τμήμα μιας μεγαλύτερης λέξης). Το τι σημαίνει κάθε φορά, συσχετίζεται με το που βρίσκεται η συγκεκριμένη τιμή. Αν βρίσκεται σε ένα τμήμα μνήμης που έχει σημανθεί με κατάλληλο τρόπο ως κώδικας (code), τότε θα εκτελεστεί, ενώ αν είναι σε μια περιοχή μνήμης που έχει σημανθεί ως δεδομένο θα επεξεργαστεί κατάλληλα. Σε αυτή τη λειτουργία βασίζονται κάποιοι κακόβουλοι χρήστες που τοποθετούν δεδομένα ειδικής κωδικοποίησης στη μνήμη του συστήματος και στη συνέχεια καταφέρουν να κάνουν τον επεξεργαστή να τα εκτελέσει ως κώδικα και άρα να εκτελέσει αυτά που οι ίδιοι με προσοχή έχουν τοποθετήσει.
Ο κάθε επεξεργαστής καταλαβαίνει μόνο το δικό του κώδικα μηχανής. Κάθε κώδικας μηχανής διαιρείται σε πεδία όπως opcode (κώδικας πράξης) και operand(s) (παράμετροι). Οι μηχανικοί βρίσκουν τις λίστες με κώδικες μηχανής πολύ πολύπλοκες για να τα γράψουν και ακόμα ποιο πολύπλοκες να τις καταλάβουν. Για να αντιμετωπίσουν αυτό το μεγάλο πρόβλημα, χρησιμοποιείται μια σημειολογική γλώσσα που να γεφυρώνει το χάσμα ανάμεσα σε υπολογιστή και άνθρωπο την αποκαλούμενη Συμβολική γλώσσα (Assembly). Προκειμένου να προγραμματιστεί ένας οποιοδήποτε επεξεργαστής, μπορεί να χρησιμοποιηθεί μια γλώσσα υψηλού επιπέδου, όπως η C, που θα μεταγλωττιστεί από τα κατάλληλα εργαλεία, δημιουργώντας τη συμβολική γλώσσα (assembly) που θα μεταφραστεί τον κώδικα μηχανής, και στη συνέχεια την ακολουθία των bit 0 και 1 που καταλαβαίνει ο προγραμματιστής. Εναλλακτικά, κάποιος επεξεργαστής μπορεί να προγραμματιστεί κατευθείαν με τη συμβολική γλώσσα. Αν και η μνήμη του συστήματος αποθηκεύει τιμές στο δυαδικό σύστημα, συνήθως αυτές απεικονίζονται στο δεκαεξαδικό σύστημα, ώστε να έχουν μια πιο συμπαγή μορφή. Η Εικόνα 3.16 παρουσιάζει ένα τμήμα ενός προγράμματος που έχει γραφεί σε συμβολική γλώσσα, και έχει μεταφραστεί στον αντίστοιχο κώδικα μηχανής για τον επεξεργαστή 8086. Κάθε συμβολική εντολή καταλαμβάνει κάποια Byte που τοποθετούνται σε διαδοχικές θέσεις στη μνήμη (στήλη (α)).

3.16: Ο κώδικας μηχανής που έχει προέλθει από τη συμβολική γλώσσα (γ), εκφρασμένος στο δεκαεξαδικό σύστημα (β), τοποθετείται σε διαδοχικές διευθύνσεις μνήμης (α).
Ένας επεξεργαστής υποστηρίζει (i) τις δικές του εντολές συμβολικής γλώσσας, με (ii) τη δικιά του σύνταξη και τους (iii) δικούς του κανόνες χρήσης της συμβολικής γλώσσας. Αυτά τα 3 στοιχεία καθορίζουν το σετ εντολών του επεξεργαστή (Instruction Set). Όπως φαίνεται στην Εικόνα 3.16 κάποιες εντολές απαιτούν 3 Byte, κάποιες 2 κτλ. Ο αριθμός των Byte που καταλαμβάνει μια εντολή εξαρτάται από αυτό που κάνει. Αυτό ισχύει για τους επεξεργαστές πολύπλοκου σετ εντολών (Complex Instruction Set Computing - CISC) αλλά όχι για τους επεξεργαστές ελαττωμένου σετ εντολών (Reduced Instruction Set Computing - RISC). Οι εντολές εισέρχονται στον επεξεργαστή και αποκωδικοποιούνται. Εντολές των επεξεργαστών RISC είναι απλές στην κωδικοποίηση ενώ των CISC, εμφανίζουν μεγάλη πολυπλοκότητα λόγω της διακύμανσης του μεγέθους.
Οι επεξεργαστές χρησιμοποιούν διαφορετικές συμβολικές γλώσσες. Καμία δεν είναι όμοια με κάποια άλλη Το προηγούμενο παράδειγμα γράφτηκε σε Assembly 8086. Αυτή η Assembly ισχύει μόνο στην οικογένεια 8086 των επεξεργαστών της Intel. Άλλες συμβολικές γλώσσες, επειδή είναι βασισμένες σε πολύ διαφορετικό υλικό επεξεργαστών, έχουν διαφορετική σύνταξη. Μερικά παραδείγματα των διαφορετικών εκδόσεων της ίδιας λειτουργίας δίνονται στον Πίνακα 3.1. Σε κάθε περίπτωση, ένας καταχωρητής φορτώνεται με μια τιμή 0x41. Σημειώστε επίσης τους διαφορετικούς τρόπους στη σημείωση δεκαεξαδικού.
| Επεξεργαστής | Εντολή |
|---|---|
| Intel x86 | mov al, 41h |
| Motorola 6800/68HC11 | LDAA #$41 |
| Motorola 680x0 | move.b #$41,D0 |
| PIC16xx | movlw 0x41 |
| Motorola 56000 | move #$0041,A |
| Intel 80960 | lda 0x41,r4 |
Στη συμβολική γλώσσα του κάθε επεξεργαστή, υπάρχουν εντολές που καλύπτουν διάφορες λειτουργίες που συναντώνται σε υπολογιστικά συστήματα, όπως:
ολίσθηση, περιστροφή με διάφορους τρόπους (δεξιά/αριστερή, με κρατούμενο ή χωρίς)
πρόσθεση, αφαίρεση, πολλαπλασιασμός, διαίρεση
πρόσθεση, αφαίρεση, πολλαπλασιασμός, διαίρεση , ύψωση σε δύναμη, ρίζα
πρόσβαση σε συσκευές εισόδου εξόδου
ανάγνωση ή εγγραφή στη μνήμη, λειτουργίες σε περιοχές μνήμης
διακλαδώσεις υπό συνθήκη ή χωρίς, πράξεις με σημαίες
Πράξεις διανυσματικής επεξεργασίας (vector processing)
Οι παραπάνω εντολές, αν και βρίσκονται σε επεξεργαστές γενικού τύπου, δε βρίσκονται όλες σε επεξεργαστές ΕΣ, αφού τα ΕΣ είναι εξειδικευμένα για κάποια εφαρμογή. Αν αυτή η εφαρμογή δε χρειάζεται κάποιες από τις ανωτέρω λειτουργίες, τότε δε θα υλοποιηθεί σε υλικό για να υπάρχει μειωμένο κόστος και κατανάλωση ενέργειας. Να σημειωθεί, ότι κάποιοι επεξεργαστές, όπως ο ARM, είναι τόσο πολύ παραμετροποιήσιμοι, όπου αποτελούνται από δομικά στοιχεία που προσθέτονται η αφαιρούνται κατά τη διάρκεια της κατασκευής ενός συγκεκριμένου επεξεργαστή. Αν για παράδειγμα, δεν απαιτείται μια λειτουργία πραγματικών αριθμών, δε θα τοποθετηθεί η μονάδα FPU, αν δε χρειάζεται η λειτουργία διανυσματικών πράξεων, θα παραληφθεί και η αντίστοιχη μονάδα (NEON). Για αυτό και δεν υπάρχει ένας επεξεργαστής ARM, αλλά πολλοί διαφορετικοί επεξεργαστές που προκύπτουν με συνδυασμό των ανωτέρων λειτουργιών (και ασφαλώς και άλλων δυνατοτήτων, όπως βαθμού διασωλήνωσης, όπως αναγράφεται στην επόμενη ενότητα).
Όπως είναι κατανοητό ο κώδικας μηχανής για κάθε εντολή που είναι μια αριθμητική τιμή, απαιτεί να αποκωδικοποιηθεί. Η αποκωδικοποίηση σημαίνει τη δημιουργία των κατάλληλων σημάτων ελέγχου προς τις μονάδες του επεξεργαστή προκειμένου να υλοποιήσουν την κατάλληλη λειτουργία. Για παράδειγμα, αν η εντολή προσδιορίζει ότι θα πρέπει να γίνει η πράξη της άθροισης, τότε κατά την αποκωδικοποίηση θα δημιουργηθούν σήματα προς τον πρώτο καταχωρητή πηγή και προς τον δεύτερο καταχωρητή πηγή, για να τοποθετήσουν τα δεδομένα στις κατάλληλες γραμμές, προς την αριθμητική λογική μονάδα, για να κάνει τη συγκεκριμένη πράξη από το πλήθος των πράξεων που υποστηρίζει, και προς τον καταχωρητή προορισμού, για να δεχτεί και να αποθηκεύσει το αποτέλεσμα. Η Εικόνα 3.17 παρουσιάζει τις βασικές μονάδες του επεξεργαστή, δηλαδή τη μονάδα ελέγχου (control unit), τους καταχωρητές (registers), τη μονάδα αριθμητικών και λογικών πράξεων (arithmetic & logical unit, ALU), την κρυφή μνήμη και τη διεπαφή εισόδου/εξόδου (Ι/Ο). Παρατηρήστε ότι η κρυφή μνήμη συνδέεται άμεσα με μια εξωτερική μνήμη και με τον επεξεργαστή, ενώ και η Ι/Ο (που συνήθως υπάρχουν πολλοί ελεγκτές Ι/Ο) έχει τους δικούς τις ακροδέκτες στο τσιπ. Υπάρχουν πολλοί τρόποι δημιουργίας σημάτων ελέγχου, αλλά δε θα τους αναπτύξουμε αφού αποτελούν ύλη της αρχιτεκτονικής υπολογιστών.
3.17: Στο εσωτερικό του επεξεργαστή, τα πιο σημαντικά στοιχεία είναι η μονάδα ελέγχου, η αριθμητική λογική μονάδα και οι καταχωρητές.
Όπως έχει συζητηθεί, η εκτέλεση μιας εντολής περνάει από 4 στάδια. Προκειμένου να επιτευχθεί χρόνος εκτέλεσης 1 κύκλου ανά εντολή, στους επεξεργαστές RISC έχει διαιρεθεί το τέταρτο στάδιο σε πρόσβαση μνήμης (memory access) και εγγραφή στους καταχωρητές (Write Back), δηλαδή τα 5 στάδια είναι:
Προσκόμιση εντολής (fetch)
Αποκωδικοποίηση εντολής (decode)
Εκτέλεση εντολής (execute)
Πρόσβαση στη μνήμη (εγγραφή/ανάγνωση) (memory access)
Έγγραφή στους καταχωρητές (Write Back)
Σε μια απλή σχεδίαση, όσο μια εντολή ήταν στο πρώτο στάδιο, τα υπόλοιπα στάδια δε θα έκαναν κάτι χρήσιμο (Εικόνα 3.18). Για αυτό το λόγο, αποφασίστηκε να βελτιωθεί η λειτουργία του επεξεργαστή, με παρόμοιο τρόπο όπως στην αυτοκινητοβιομηχανία, όπου το όχημα κατασκευάζεται διαδοχικά κατά τη διέλευση από τη γραμμή παραγωγής, και συνεχώς πάνω στη γραμμή παραγωγής υπάρχουν πολλαπλά οχήματα σε διαφορετικές φάσεις ολοκλήρωσης.
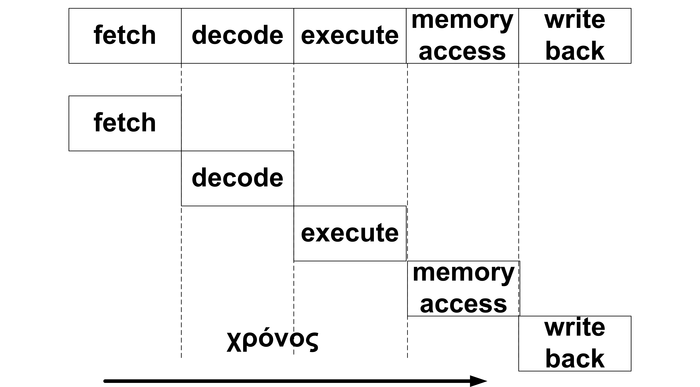
3.18: Κατά την εκτέλεση μιας εντολής σε έναν απλό επεξεργαστή, υπάρχουν μονάδες υλικού που δε χρησιμοποιούνται συνεχώς.
Η βελτίωση της απόδοσης του επεξεργαστή επιτυγχάνεται με παρόμοιο τρόπο με την αυτοκινητοβιομηχανία. Δηλαδή, με την συνεχή χρήση όλων των υπομονάδων του υπολογιστή, με την ταυτόχρονη (ή παράλληλη) ενασχόληση με πολλές εντολές, όπου η κάθε εντολή βρίσκεται σε διαφορετικό στάδιο ολοκλήρωσης. Η Εικόνα 3.19 παρουσιάζει την εξέλιξη κατά τον άξονα του χρόνου της εκτέλεσης εντολών σε ένα επεξεργαστή. Τη χρονική στιγμή 0, εισέρχεται η πρώτη εντολή στο στάδιο Fetch. Όταν αυτή η εντολή προωθηθεί στο στάδιο Decode, τότε μια άλλη εντολή θα προσκομιστεί και θα βρίσκεται στο στάδιο Fetch. Τη χρονική στιγμή t=3, η πρώτη εντολή αφού έχει περάσει από τα στάδια Fetch και Decode, θα βρεθεί στο στάδιο execute, ενώ η 2 εντολή θα βρεθεί στο στάδιο Decode μετά την επιτυχή ολοκλήρωση του σταδίου προσκόμισης. Με αυτόν τον τρόπο κάποια στιγμή και τα 5 στάδια της διασωλήνωσης θα είναι σε χρήση με 5 διαφορετικές εντολές. Οι σύγχρονοι επεξεργαστές για τα ενσωματωμένα συστήματα έχουν διάφορα επίπεδα διασωλήνωσης. Υπάρχουν επεξεργαστές με αυτά τα τυπικά 5 στάδια διασωλήνωσης (όπως ο MIPS R3000), αλλά και επεξεργαστές με 15 στάδια διασωλήνωσης όπως ο ARM Cortex A15, όπου η διαδικασία fetch έχει διαιρεθεί σε 5 στάδια, η Decode σε 7 στάδια και τα άλλα 3 αφορούν την εκτέλεση, η δε εγγραφή των αποτελεσμάτων απαιτεί 4 ακόμη κύκλους. Επιπρόσθετα, ο ίδιος ο επεξεργαστής έχει δυο διαφορετικές γραμμές διασωλήνωσης: μια γραμμή για τις πράξεις με ακέραιους αριθμούς (integer pipeline), και μια για τις πράξεις με πραγματικούς αριθμούς (floating point unit pipeline).
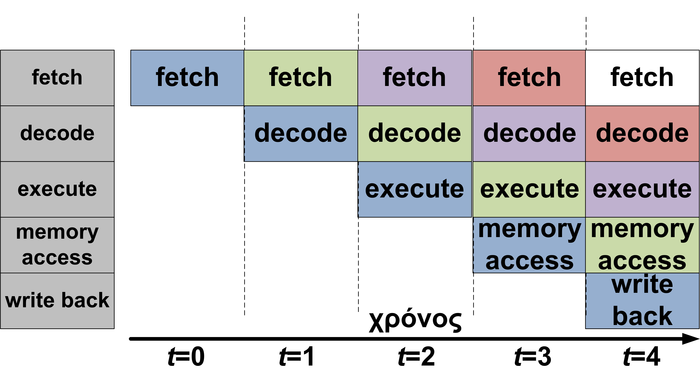
3.19: Σε ένα διασωληνωμένο επεξεργαστή, υπάρχουν ταυτόχρονα πολλές εντολές σε διαφορετικά στάδια ολοκλήρωσης.
Μια αναλυτική εικόνα της διασωλήνωσης στον πιο απλό επεξεργαστή ενσωματωμένων συστημάτων MIPS, παρουσιάζεται στην Εικόνα 3.2010. Φαίνονται τα 5 στάδια της διασωλήνωσης και για κάθε στάδιο τα βασικά στοιχεία που το συνθέτουν. Στο στάδιο Instruction Fetch, φαίνεται ο καταχωρητής που φέρει την επόμενη διεύθυνση της εντολής, η οποία διευθυνσιοδοτεί τη μνήμη εντολών (memory), ώστε να εξαχθεί η λέξη που θα προωθηθεί προς την αποκωδικοποίηση. Επίσης σε αυτό το στάδιο, έχει προστεθεί και ένας αθροιστής (adder), γιατί η κάθε διεύθυνση απέχει από την επόμενη κατά +4 (υπό κανονικές συνθήκες), αφού κάθε εντολή είναι 32 bit. Στο επόμενο στάδιο γίνεται η αποκωδικοποίηση της εντολής, όπου ενεργοποιούνται οι κατάλληλοι καταχωρητές (registers) από τη συστοιχία καταχωρητών (register file). Σε αυτό το στάδιο υπάρχει και η επέκταση πρόσημου (sign extension) σε περίπτωση που απαιτείται να γίνει μια πράξη, όπου τα μήκη των λέξεων δεν είναι ίδια. Στο στάδιο εκτέλεσης, υπάρχει η ALU όπου σε κάθε είσοδο έχει έναν πολυπλέκτη, που επιλέγει κάθε φορά την πηγή που θα τοποθετηθεί στην είσοδο της αριθμητικής λογικής μονάδας, επίσης υπάρχει και ένας συγκριτής για τον έλεγχο των συνθηκών. Στο τέταρτο στάδιο, υπάρχει ένας πολυπλέκτης και επιτυγχάνεται η πρόσβαση στη μνήμη δεδομένων, ενώ στο τελευταίο στάδιο υπάρχει η αποθήκευση των ενημερωμένων τιμών στους καταχωρητές (αν η εντολή απαιτεί κάτι τέτοιο). Η διαδρομή που ακολουθεί μια εντολή από την προσκόμιση ως και την εγγραφή, ονομάζεται διαδρομή δεδομένων (datapath) επεξεργαστή.
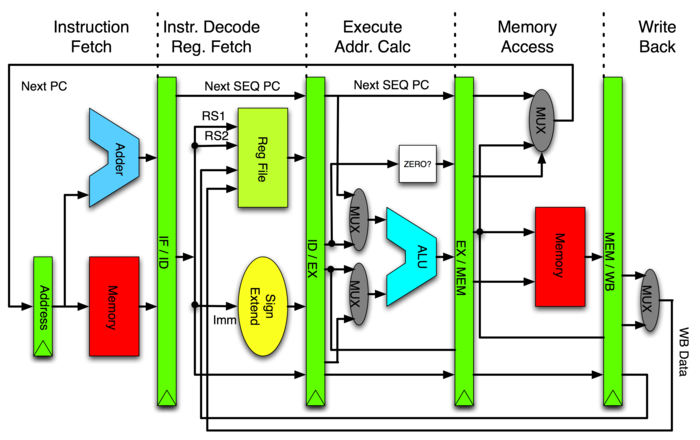
3.20: Μια αναλυτική εικόνα της αρχιτεκτονικής της διασωλήνωσης του επεξεργαστή MIPS. Εικόνα από wikipedia.org.
Εκτός από τα βασικά αυτά δομικά στοιχεία, παρατηρείται ότι κάθε στάδιο της διασωλήνωσης διαχωρίζεται από τους καταχωρητές διασωλήνωσης, οι οποίοι διαφυλάσσουν ότι το κρίσιμο μονοπάτι περιορίζεται ανάμεσα στα στοιχεία του κάθε σταδίου. Οι καταχωρητές αυτοί, εκτός από το διαχωρισμό των σταδίων μεταφέρουν και δεδομένα και σήματα ελέγχου, οπότε η καθυστέρηση είναι ενιαία για όλες τις εντολές, τα δεδομένα και τα σήματα ελέγχου. Ασφαλώς, αυτός είναι ένας απλός επεξεργαστής ΕΣ (που όμως χρησιμοποιείται σε πάρα πολλές συσκευές κυρίως δικτυακές modem/routers), και διαφορετικοί επεξεργαστές έχουν πολύ πιο σύνθετες δομές διασωλήνωσης.
Η εισαγωγή της διασωλήνωσης σε ένα σύστημα, δεν αυξάνει την ταχύτητα εκτέλεσης μιας εντολής, αφού έτσι και αλλιώς η εντολή διέρχεται από τα ίδια στάδια. Αυξάνει όμως την απόδοση του όλου συστήματος, και για στάδια διασωλήνωσης η απόδοση (ρυθμός εντολών στη μονάδα του χρόνου) αυξάνεται κατά
. Όμως, η χρήση της διασωλήνωσης αυξάνει την πολυπλοκότητα του συστήματος και δημιουργεί μια νέα εστία κινδύνων, που ονομάζονται κίνδυνοι διασωλήνωσης. Οι κυριότεροι κίνδυνοι είναι: (i) δομικοί κίνδυνοι, (ii) κίνδυνοι ελέγχου και (iii) κίνδυνοι δεδομένων. Οι δομικοί κίνδυνοι υπάρχουν όταν το ίδιο δομικό στοιχείο απαιτείται να χρησιμοποιηθεί από 2 διαφορετικά στάδια της διασωλήνωσης. Για παράδειγμα, στην Εικόνα 3.20, το αρχείο καταχωρητών μπορεί να χρησιμοποιηθεί και στο στάδιο 2 και στο στάδιο 5. Αυτός ο κίνδυνος μπορεί να εξαλειφθεί με την προσθήκη υλικού (π.χ. μιας επιπρόσθετης θύρας εγγραφής/ανάγνωσης στο αρχείο των καταχωρητών) ή με την προσθήκη καθυστέρησης στο ανάλογο στάδιο (και κατ’ επέκταση σε όλη τη διασωλήνωση, αφού αν δεν προχωρήσει ένα στάδιο στο επόμενο δε μπορεί να συνεχίσει κανένα). Οι κίνδυνοι ελέγχου δημιουργούνται όταν υπάρχει διακλάδωση ή κλήση συνάρτησης, όπου σε αυτή την περίπτωση δεν πρέπει να φορτωθεί ο καταχωρητής εντολών με την εντολή που έπεται (+4 Byte στο MIPS), αλλά με την εντολή που βρίσκεται πολλά Byte μακρυά και αφορά την πρώτη εντολή της συνάρτησης ή της εναλλακτικής διαδρομής. Αυτό μπορεί να λυθεί πάλι με την προσθήκη υλικού που θα εκτελεί μια λειτουργία πρόβλεψης επόμενης εντολής (με συνηθισμένα ποσοστά επιτυχίας 90%) ή με καθυστέρηση έως ότου υπολογιστεί η διεύθυνση της νέας εντολής στο στάδιο της εκτέλεσης. Τέλος, οι κίνδυνοι δεδομένων προκύπτουν όταν απαιτούνται δεδομένα που έχουν υπολογιστεί αλλά ακόμη δεν έχουν γραφεί (γιατί είναι στο στάδιο 4 ή 5). Ομοίως, μια λύση είναι η καθυστέρηση μέχρι να αποθηκευτούν στο αρχείο των καταχωρητών ή με την προσθήκη υλικού που θα δημιουργήσει μονοπάτια συντόμευσης, ώστε να μεταφέρουν τα δεδομένα άμεσα εκεί που χρειάζονται, παρακάμπτοντας προσωρινά την τυπική λειτουργιά.
Μερικοί επεξεργαστές για να αυξήσουν τον ρυθμό απόδοσης, έχουν ταυτόχρονα πολλές λειτουργικές μονάδες (π.χ. 3 ALU, 2 FPU κτλ). Όταν υπάρχει ανάγκη για χρήση μιας από αυτές τις μονάδες, τότε χρησιμοποιείται ένας χρονοδρομολογητής που αποφασίζει ποια μονάδα θα ασχοληθεί με κάθε συγκεκριμένη εντολή, ενώ μέχρι να ελευθερωθεί μια μονάδα που απαιτεί μια εντολή, την καθυστερεί και δεν την προωθεί. Για να προωθηθεί μια εντολή από την αναμονή στην εκτέλεση, θα πρέπει να τηρούνται οι εξής προϋποθέσεις: θα πρέπει όλες οι εξαρτήσεις εισόδου να έχουν υπολογιστεί, και η μονάδα που απαιτείται να είναι ελεύθερη προς χρήση. Συνήθως, ο χρονοδρομολογητής τοποθετεί τις εντολές σε ουρές αναμονής ανά λειτουργική μονάδα, που ονομάζονται σταθμοί αναμονής (reservation stations). Προκειμένου να επιτευχθεί η μέγιστη απόδοση, ο χρονοδρομολογητής είναι κατασκευασμένος σε υλικό και τα πάντα γίνονται και υπολογίζονται κατά το χρόνο εκτέλεσης. Αυτού του είδους οι επεξεργαστές ονομάζονται υπερβαθμωτοί (superscalar). Αρκετοί υπερβαθμωτοί επεξεργαστές επιτρέπουν την καλύτερη εκμετάλλευση των πολλαπλών λειτουργικών μονάδων με την εκτέλεση εντολών εκτός σειράς (out of order execution). Ενώ οι τυπικοί επεξεργαστές εκκινούν την εκτέλεση μιας εντολής σε κάθε κύκλο ρολογιού (single issue), οι πιο σύνθετοι επεξεργαστές μπορούν και εκκινούν έως και 4 εντολές κάθε κύκλο (multiple issue), αφού έχουν διασφαλίσει ότι επιτρέπεται από τις εξαρτήσεις δεδομένων και τη διαθεσιμότητα των λειτουργικών μονάδων. Οι επεξεργαστές εκτέλεσης εκτός σειράς, έχουν επιπρόσθετο υλικό για τη σειριοποίηση των αποτελεσμάτων στο τέλος (commitment stage) και την ολοκλήρωση της εκτέλεσης (retirement stage).
H αντιδιαμετρική αρχιτεκτονική, ως προς τους υπερβαθμωτούς επεξεργαστές, είναι οι επεξεργαστές πολύς μεγάλης λέξης εντολής (very long instruction word, VLIW). Οι επεξεργαστές αυτοί έχουν πολλαπλές λειτουργικές μονάδες, αλλά δεν έχουν υλικό για τη εύρεση των εξαρτήσεων και την εκτέλεση εκτός σειράς. Όλες οι λειτουργίες κωδικοποιούνται σε μια μεγάλη εντολή (48 bit έως και 128 bit), όπου το opcode φέρει κωδικοποιημένες τις λειτουργίες που επιτελεί η κάθε λειτουργική μονάδα. Αυτό σημαίνει ότι ο έλεγχος εξαρτήσεων γίνεται κατά το στάδιο της μεταγλώττισης και όχι κατά το χρόνο εκτέλεσης. Τα πειραματικά αποτελέσματα έχουν δείξει ότι καλύτερα αποτελέσματα υπάρχουν όταν οι αποφάσεις λαμβάνονται κατά το χρόνο της εκτέλεσης, αλλά με αυξημένο τίμημα στο υλικό και στην κατανάλωση ενέργειας.
Τα ΕΣ κυμαίνονταν σε ένα πολύ μεγάλο εύρος αρχιτεκτονικών, οπότε σε ΕΣ υψηλών επιδόσεων βρίσκονται και υπερβαθμωτοί επεξεργαστές και επεξεργαστές VLSI. Στην πλειονότητα των περιπτώσεων όμως, που απαιτείται ένα οικονομικό και μικρό σύστημα με χαμηλό ενεργειακό προφίλ, επιλέγονται απλοί επεξεργαστές χωρίς τις επιπρόσθετες αυτές δυνατότητες, που συναντώνται σε κάθε σύγχρονο επεξεργαστή υψηλών επιδόσεων όπως Intel Core I7.
Κάθε μεθοδολογία σχεδιασμού βασίζεται σε κάποια αρχιτεκτονική. Η επιλογή της αρχιτεκτονικής πρέπει να γίνει προσεκτικά, διαφορετικά μπορεί να μην είναι πρακτικά υλοποιήσιμη. Η αρχιτεκτονική θα πρέπει να έχει όσο το δυνατόν χαμηλότερο κόστος, να μπορεί να υλοποιηθεί πραγματικά (δηλαδή να μην είναι η μεθοδολογία μόνο θεωρητική), και να είναι παραμετροποιήσιμη, δηλαδή να παρέχει στο σχεδιαστή ευελιξία στο να τροποποιεί κάποια χαρακτηριστικά που ίσως ταιριάζουν καλύτερα στο πρόβλημά του. Πριν αρχίσουμε την έρευνά μας, προβήκαμε σε μια ανάλυση των αρχιτεκτονικών των ενσωματωμένων συστημάτων διαφόρων κατασκευαστών, σημειώσαμε τα κοινά χαρακτηριστικά που έχουν, τα θετικά και αρνητικά σημεία τους, και αναπτύξαμε τη δικιά μας αρχιτεκτονική.
Έτσι, λοιπόν, η μεθοδολογία σχεδιασμού ΕΣ που παρουσιάζουμε βασίζεται σε μια γενική αρχιτεκτονική, η οποία συναντάται αρκετά συχνά στα ενσωματωμένα συστήματα (Σχήμα 3.21). Όπως φαίνεται στο Σχήμα 3.21, η αρχιτεκτονική αποτελείται από δομοστοιχεία εντός και εκτός ολοκληρωμένου κυκλώματος. Η εξωτερική μνήμη δεδομένων και η μνήμη εντολών βρίσκονται εκτός ολοκληρωμένου κυκλώματος, ενώ η μνήμη δεδομένων (ή επιπλήνθια μνήμη), η μονάδα διαχείρισης μνήμης (Memory Management Unit, MMU), o ελεγκτής απευθείας πρόσβασης στη μνήμη (Direct Memory Access, DMA), η σκιώδης (ή κρυφή) μνήμη εντολών, ο επεξεργαστής και τα εξειδικευμένα στοιχεία για την εφαρμογή (IP-blocks) βρίσκονται πάνω στο ολοκληρωμένο κύκλωμα. Τα δομοστοιχεία αυτά θα τα αναπτύξουμε στη συνέχεια, μαζί με το λόγο για τον οποίον έχουν επιλεγεί. Πρέπει να σημειωθεί βέβαια ότι ο τύπος του συγκεκριμένου δομοστοιχείου, για παράδειγμα αν ο τύπος της μνήμης θα είναι SRAM ή DRAM, δεν είναι ρητά καθορισμένος, αλλά καθορίζεται από το σχεδιαστή, ή από τη διαθεσιμότητα των υλικών.
.png)
3.21: Η μεθοδολογία μας χρησιμοποιεί μια γενική αρχιτεκτονική ενσωματωμένων συστημάτων και δεν περιορίζεται σε συγκεκριμένα δομοστοιχεία.
Με τον όρο επίδοση ενός συστήματος αναφερόμαστε συνήθως σε δύο μεγέθη, ανάλογα με το επίπεδο σχεδιαστικής αφαίρεσης που βρισκόμαστε. Στο υψηλό επίπεδο συστήματος (system level) χρησιμοποιούμε το μέγεθος της επεξεργαστικής ισχύος που μετράται σε εκατομμύρια εντολών ανά δευτερόλεπτο (Millions of Instructions Per Second-MIPS). Αν και είναι ευρέως διαδεδομένο αυτό το μέγεθος ως μέτρο σύγκρισης επιδόσεων, εντούτοις δε χαρακτηρίζει όλο το σύστημα, αλλά μόνο τον επεξεργαστή του. Υπάρχουν σε ένα σύστημα αρκετοί παράγοντες που επιδρούν αρνητικά στην επίδοση, με συνέπεια να υπάρχει μια μεγάλη απόκλιση από αυτήν την ανώτερη θεωρητική τιμή. Σε πιο χαμηλό επίπεδο, δηλαδή στο επίπεδο κυκλώματος, χρησιμοποιούμε τα μεγέθη του κρίσιμου μονοπατιού (critical path) και της παροχής δεδομένων (throughput). Το πρώτο μετρικό υποδηλώνει το μέγιστο χρόνο που απαιτείται για την επεξεργασία κάποιων δεδομένων, και είναι ο χρόνος από τη στιγμή που τα δεδομένα θα εισέλθουν στο κύκλωμα μέχρι τη στιγμή που η έξοδος θα είναι διαθέσιμη στην αρτηρία δεδομένων εξόδου (output data bus). Το δεύτερο μετρικό υποδηλώνει το χρόνο που χρειάζεται το κύκλωμα για να επεξεργαστεί διαδοχικά δεδομένα. Αν το κύκλωμα είναι σχεδιασμένο με τέτοιο τρόπο ώστε, ενώ δεν έχει ολοκληρώσει ακόμη την επεξεργασία κάποιων δεδομένων, να δέχεται και άλλα (νέα) δεδομένα, τότε έχει μεγαλύτερη παροχή δεδομένων από ένα κύκλωμα που πρέπει πρώτα να επεξεργαστεί τα δεδομένα και να τα εξάγει στην αρτηρία δεδομένων, προτού δεχτεί καινούργια δεδομένα. Αν και θα μπορούσαμε να χρησιμοποιήσουμε την παροχή δεδομένων για να χαρακτηρίσουμε την επίδοση συστημάτων, εντούτοις στους βιομηχανικούς και ακαδημαϊκούς κύκλους χρησιμοποιείται το μετρικό MIPS των επεξεργαστών των συστημάτων.
Εκτός από αυτά τα μετρικά, πολύ συχνά χρησιμοποιείται και το μετρικό της συχνότητας λειτουργίας του επεξεργαστή. Η συχνότητα λειτουργίας του επεξεργαστή ορίζεται ως η συχνότητα λειτουργίας του ρολογιού με το οποίο χρονίζεται ο επεξεργαστής. Ασφαλώς, η χρήση του όρου αυτού είναι δόκιμη μόνο στην περίπτωση που έχουμε ρολόι στο σύστημά μας, δηλαδή όταν αναφερόμαστε σε ένα ‘σύγχρονο’ (synchronous) ψηφιακό σύστημα, σε αντιδιαστολή προς ένα ‘ασύγχρονο’ (asynchronous) σύστημα. Στην περίπτωση που έχουμε στο κύκλωμα παραπάνω από ένα ρολόι αναφέρουμε όλες τις συχνότητες στις οποίες λειτουργεί το σύστημα (π.χ. ρολόι πυρήνα 833 Mhz, ρολόι αρτηρίας δεδομένων 133 Mhz κτλ). Το μετρικό αυτό είναι υποκειμενικό και δεν μπορεί να χρησιμοποιηθεί για τη σύγκριση επεξεργαστών διαφορετικών οικογενειών. Αυτό οφείλεται στο γεγονός ότι ένας επεξεργαστής με χαμηλή συχνότητα μπορεί να εκτελεί περισσότερες παράλληλες εντολές (περισσότερα MIPS) από ότι ένας επεξεργαστής με υψηλότερη συχνότητα. Είναι γνωστό εξάλλου, ότι κάποιες εταιρείες που κατασκευάζουν επεξεργαστές διαφημίζουν τα προϊόντα τους με τις ισοδύναμες συχνότητες επεξεργασίας και όχι με τις πραγματικές. Για παράδειγμα, η εταιρεία Advanced Micro Devices (AMD) διαφημίζει ότι ο επεξεργαστής AMD 3200 Mhz είναι PR 4000+ Mhz, δηλαδή ότι είναι ισοδύναμος με έναν Intel Pentium συχνότητας 4000 Mhz.
Πάντως, όποιο μετρικό και να χρησιμοποιήσουμε για να συγκρίνουμε τους επεξεργαστές, που έχουν παρουσιαστεί τις τελευταίες δύο δεκαετίες, θα διαπιστώσουμε ότι η επίδοση ενός συστήματος ακολουθεί το νόμο του Moore [23]. O Moore έκανε μια πολύ σημαντική παρατήρηση και πρόβλεψη το 1965, όταν εργαζόταν ως μηχανικός στην εταιρεία Fairchild. Παρατήρησε λοιπόν ότι η πυκνότητα των ολοκληρωμένων κυκλωμάτων που υλοποιούνται στο πυρίτιο ακολουθεί μια αυξητικά εκθετική πορεία με συνέπεια κάθε 18 μήνες να διπλασιάζεται. Έτσι, ο Moore πρότεινε μια μαθηματική σχέση, η οποία έκτοτε καθιερώθηκε ως νόμος του Moore. Αν και έχουν περάσει 40 χρόνια από τότε, o νόμος του Moore ισχύει ακόμη και σήμερα. Οι εταιρείες κατασκευής ολοκληρωμένων κυκλωμάτων, όπως η AMD και η INTEL, παρουσιάζουν συνεχώς νέα μοντέλα και νέες αρχιτεκτονικές επεξεργαστών, που όμως ακολουθούν πιστά το νόμο αυτό (Σχήμα 3.22).
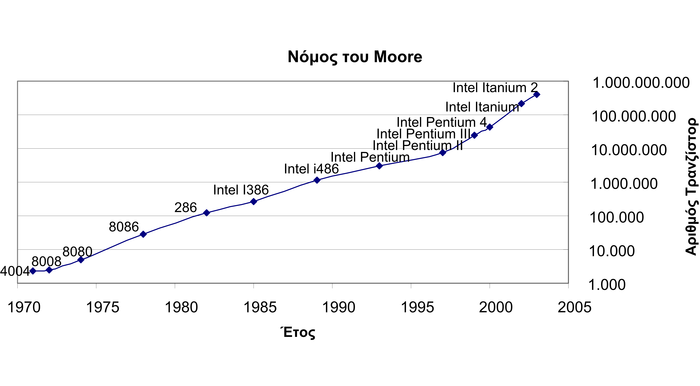
3.22: Η πρόβλεψη του Gordon Moore το 1965, για το διπλασιασμό του αριθμού των τρανζίστορ στο πυρίτιο κάθε 18 μήνες, συνεχίζει να ισχύει ακόμη και σήμερα.
Μια από τις συνέπειες του νόμου του Moore είναι ότι με την αύξηση της πυκνότητας ολοκλήρωσης επηρεάζεται θετικά και η συχνότητα λειτουργίας του επεξεργαστή και, κατ’ επέκταση, οι επιδόσεις του. Συγκεκριμένα, αν σημειώσουμε τις επιδόσεις των επεξεργαστών ως προς τη χρονιά που παρουσιάστηκαν στην αγορά, θα διαπιστώσουμε ότι ακολουθούν μια παράλληλη αυξητική πορεία με την αύξηση της πυκνότητας ολοκλήρωσης, που σημαίνει ότι οι επιδόσεις των επεξεργαστών αυξάνουν κατά 60% ετησίως (Νόμος του
Moore για τις επιδόσεις επεξεργαστών, Σχήμα 3.23). Αν και υπάρχουν ερευνητές που υποστήριξαν ότι ο νόμος αυτός δεν μπορεί να συνεχίσει να ισχύει γιατί υπάρχει ένα όριο στην τεχνολογία κατασκευής των επεξεργαστών, εντούτοις η συνεχής εκμετάλλευση της παραλληλίας σε επίπεδο εντολών επεξεργαστή (η εκτέλεση αρκετών εντολών ταυτόχρονα), οι μικρο-αρχιτεκτονικές ανακαλύψεις, η σμίκρυνση των γεωμετρικών διαστάσεων της τεχνολογίας, οι νέες αρχιτεκτονικές και οι πιο βαθιές διαδοχικές διοχετεύσεις έχουν οδηγήσει στο να έχουν οι επεξεργαστές πολύ υψηλές συχνότητες λειτουργίας. Από ότι φαίνεται μάλιστα, ο νόμος αυτός θα συνεχίσει να ισχύει για αρκετά χρόνια ακόμη· υπάρχουν προβλέψεις ότι θα ισχύει ως και τη δεύτερη δεκαετία του 2000.
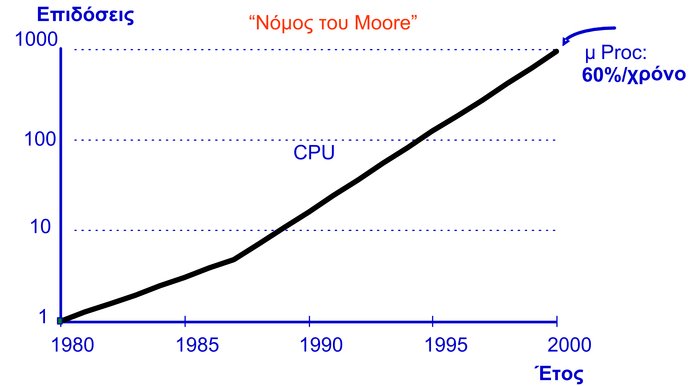
3.23: Μια διαφορετική ερμηνεία του νόμου του Moore είναι ότι η επίδοση των επεξεργαστών αυξάνει κατά 60% κάθε χρόνο.
Κοιτώντας κάποιος τα δεδομένα αυτά θα μπορούσε να συμπεράνει ότι ίσως δεν υπάρχει πρόβλημα στην επίδοση των συστημάτων, αφού οι επεξεργαστές που αποτελούν την καρδιά του συστήματος, έχουν ολοένα και μεγαλύτερες συχνότητες επεξεργασίας. Δυστυχώς όμως, ενώ οι τεχνολογικές εξελίξεις στους επεξεργαστές τους έκαναν να έχουν συχνότητες λειτουργίας που ακολουθούσαν μια εκθετική πορεία, οι συχνότητες λειτουργίας της μνήμης, ενός άλλου βασικού και αναπόσπαστου μέρους ενός συστήματος, υστέρησαν σημαντικά.
Η μνήμη είναι αναπόσπαστο στοιχείο ενός συστήματος και δε μπορεί να λειτουργήσει ένα σύστημα χωρίς καμία μορφή μνήμης. Η μνήμη χρησιμοποιείται για την αποθήκευση ή ανάκτηση δεδομένων κατά τη λειτουργία του συστήματος. Όπως κάθε κύκλωμα ή στοιχείο, έτσι και οι μνήμες ακολούθησαν μια αναπτυξιακή πορεία κατά τα τελευταία 40 χρόνια. Η βελτίωσή τους φαίνεται τόσο στο μέγεθος (η μνήμη 1 KB του παρελθόντος αντικαταστάθηκε από μνήμες 1 GB) όσο και στη συχνότητα λειτουργίας της μνήμης (η συχνότητα λειτουργίας των 8 Mhz έγινε 233 Mhz). Εντούτοις, η βελτίωση στη συχνότητα λειτουργίας δεν ακολούθησε τους ταχύτατους ρυθμούς ανάπτυξης των επεξεργαστών, με συνέπεια τη δημιουργία ενός ολοένα αυξανόμενου χάσματος ανάμεσα σε αυτήν και τον επεξεργαστή (Σχήμα 3.24). Έχει υπολογιστεί ότι ενώ οι επιδόσεις των επεξεργαστών αυξάνονται κατά 60% ετησίως, οι επιδόσεις των μνημών αυξάνονται μόνο κατά 7%, που σημαίνει ότι το χάσμα ανάμεσά τους αυξάνει κατά 50% περίπου ετησίως.
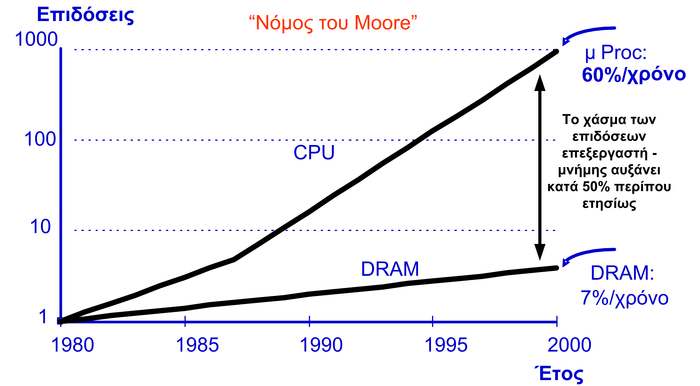
3.24: Ο διαφορετικός ρυθμός ανάπτυξης και βελτίωσης των επεξεργαστών δημιουργεί ένα ολοένα αυξανόμενο χάσμα ανάμεσα σε αυτούς και τις μνήμες.
Προκειμένου να αντιμετωπιστεί κάπως το πρόβλημα της καθυστέρησης στην πρόσβαση της μνήμης, έχει υιοθετηθεί η χρήση μνήμης πάνω στο ολοκληρωμένο κύκλωμα (on-chip memory), δηλαδή η χρήση μνήμης πάνω στο ολοκληρωμένο κύκλωμα του επεξεργαστή. Η μνήμη αυτή είναι αρκετά πιο γρήγορη από τη μνήμη παρασκηνίου (background memory), δηλαδή τη μνήμη που βρίσκεται εκτός ολοκληρωμένου κυκλώματος (εξωτερική μνήμη), αφού συνήθως λειτουργεί στη συχνότητα του επεξεργαστή. Η μνήμη αυτή, όμως, έχει πολύ μεγάλο κόστος υλοποίησης, και για αυτό το λόγο συνήθως είναι πολύ μικρή σε μέγεθος (της τάξης των μερικών εκατοντάδων KB). Έτσι, απαιτούνται πάλι προσβάσεις στην εξωτερική μνήμη, οι οποίες έχουν σημαντικό αντίκτυπο στην επίδοση, αλλά και στην κατανάλωση ισχύος, όπως θα συζητηθεί στη συνέχεια.
Οι συνέπειες του χάσματος αυτού είναι σημαντικές στην επίδοση των σημερινών συστημάτων, ιδιαίτερα όταν τα συστήματα αυτά εκτελούν εφαρμογές με έντονη χρήση της μνήμης. Έτσι, ενώ για παράδειγμα απαιτείται ένας κύκλος ρολογιού για πρόσβαση στη μνήμη καταχωρητών του επεξεργαστή και ένας με δύο κύκλους για πρόσβαση στη μνήμη εντός ολοκληρωμένου κυκλώματος, η εξωτερική μνήμη απαιτεί από 10 έως 20 κύκλους ρολογιού για πρόσβαση. Κατά τη διάρκεια που γίνεται η πρόσβαση στην εξωτερική μνήμη, ο επεξεργαστής περιμένει (stall) να αναγνωστούν ή να γραφούν τα δεδομένα. Το Σχήμα 3.25 αναπαριστά τις επιπτώσεις στο χρόνο εκτέλεσης μιας τυπικής εφαρμογής πολυμέσων (αποκωδικοποίηση MPEG4), όταν οι προσβάσεις που αυτή απαιτεί, γίνονται εξ` ολοκλήρου στη μνήμη καταχωρητών ή τη μνήμη εντός ολοκληρωμένου κυκλώματος ή την παρασκηνιακή μνήμη. Είναι φανερό, λοιπόν, ότι η αρκετά χαμηλότερη συχνότητα λειτουργίας της μνήμης ενός συστήματος αποτελεί κυρίαρχο ανασχετικό παράγοντα επίτευξης υψηλής επίδοσης. Δεν είναι υπερβολή, μάλιστα, να συμφωνήσουμε με την άποψη αρκετών ερευνητών ότι τα σημερινά συστήματα “ξοδεύουν” πάνω από το μισό του χρόνου εκτέλεσης μιας εφαρμογής περιμένοντας να ολοκληρωθούν οι προσβάσεις στην παρασκηνιακή μνήμη.
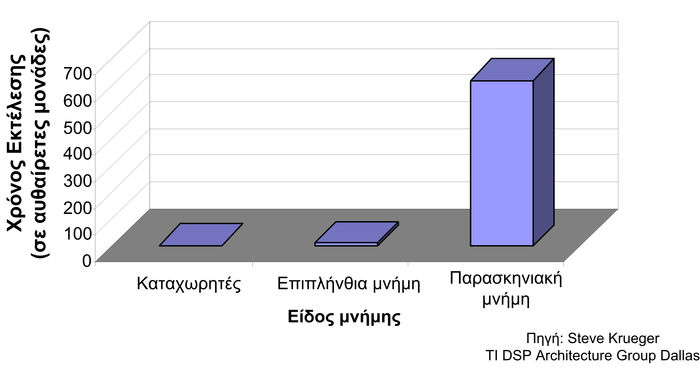
3.25: Η καθυστέρηση πρόσβασης στην παρασκηνιακή μνήμη έχει δραματικές επιπτώσεις πάνω στην επίδοση ενός συστήματος.
Όμως, το πρόβλημα δεν περιορίζεται μόνο στην επίδοση ενός συστήματος. Κατά την τελευταία δεκαετία έχει εμφανιστεί ένα ακόμη μετρικό, που χαρακτηρίζει ένα σύστημα, και αυτό είναι η καταναλισκόμενη ενέργεια. Η τεχνολογική ανάπτυξη και η δραματική βελτίωση που έχει συντελεστεί στα ολοκληρωμένα κυκλώματα έχει επηρεάσει αρνητικά την κατανάλωση ενέργειας, όπως θα αναπτυχθεί στη συνέχεια.
Μέχρι την προηγούμενη δεκαετία, οι σχεδιαστές είχαν ως στόχο τη μεγιστοποίηση της επίδοσης, με όσο το δυνατόν μικρότερο κόστος. Έτσι, σχεδόν παντού οι μηχανικοί έδιναν ιδιαίτερη έμφαση στο να παρουσιάζουν προϊόντα ολοένα και πιο ‘γρήγορα’, παραμελώντας τελείως την κατανάλωση ενέργειας. Από τα μέσα περίπου της δεκαετίας του 1990, όμως, αυτό έχει αλλάξει δραματικά. Η κατανάλωση ενέργειας αποτελεί ένα ισοδύναμο (ή και πιο σημαντικό) μετρικό χαρακτηρισμού ενός συστήματος που πρέπει να λαμβάνεται σοβαρά υπόψη σε όλα τα στάδια του σχεδιασμού του. Σήμερα, είναι αδιανόητο να μην αναφέρεται η κατανάλωση ενέργειας ενός συστήματος (ή επεξεργαστή), μαζί με τα υπόλοιπα χαρακτηριστικά, όταν αυτό παρουσιάζεται στο καταναλωτικό κοινό.
Οι λόγοι που έκαναν να αναδυθεί αυτό το μετρικό από την αφάνεια, κατά την τελευταία δεκαετία, και το έκαναν εξίσου σημαντικό με την επίδοση και το κόστος είναι πολλοί. Ο πιο σημαντικός λόγος από όλους είναι η εκτεταμένη χρήση των φορητών συσκευών. Προσωπικοί φορητοί υπολογιστές, ψηφιακοί βοηθοί, κινητά τηλέφωνα, φορητές μονάδες αναπαραγωγής βίντεο, φορητά τερματικά πολυμέσων και άλλες συσκευές έχουν υιοθετηθεί από τους περισσότερους καταναλωτές και έχουν γίνει αναπόσπαστα στοιχεία της καθημερινής τους ζωής. Η μέχρι τώρα εξέλιξή τους, μάλιστα, προδιαγράφει ένα λαμπρό μέλλον για τις φορητές συσκευές με ολοένα αυξανόμενα ποσοστά διεισδυτικότητας στην καταναλωτική αγορά. Θα αναφερθούμε περαιτέρω στις φορητές συσκευές και γενικότερα στα ενσωματωμένα συστήματα, στο δεύτερο κεφάλαιο.
Οι επιδόσεις των σημερινών επεξεργαστών, όπως είδαμε, διπλασιάζονται κάθε 18 μήνες (Σχήμα 3.23). Μια από τις συνέπειες αυτού του γεγονότος είναι ότι και η κατανάλωση ενέργειας αυτών αυξάνεται εκθετικά (Σχήμα 3.26). Αν και αρχικά οι μικροεπεξεργαστές κατανάλωναν λίγα Watt-hour, στην εποχή μας υπάρχουν επεξεργαστές που έχουν κατανάλωση ισχύος πάνω από 80 Watt. Τέτοια επίπεδα κάνουν επιτακτική τη χρήση συστημάτων ψύξης, η οποία γίνεται ολοένα πιο δύσκολη και ακριβή. Αν συνεχιστεί ο ρυθμός αυτός αύξησης της κατανάλωσης, τότε σε λίγα χρόνια θα έχουμε καταναλώσεις εκατοντάδων Watt-hour, που ασφαλώς δεν επιτρέπεται στα περισσότερα συστήματα.
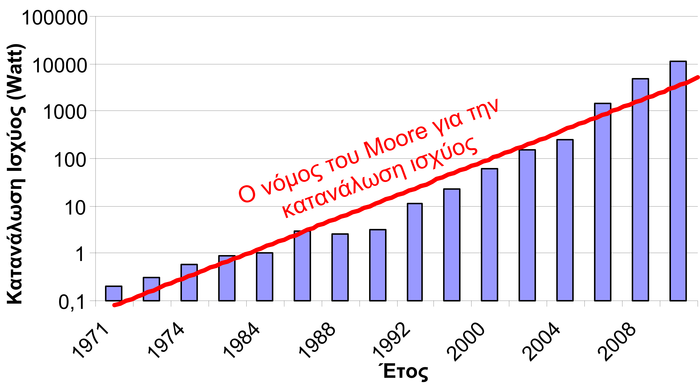
3.26: Άλλη μια ερμηνεία του νόμου του Moore είναι ότι η κατανάλωση ενέργειας των συστημάτων αυξάνει εκθετικά με το ημερολογιακό έτος.
Σχετικά με τις φορητές συσκευές, το πρόβλημα της κατανάλωσης ενέργειας είναι πολύ πιο σοβαρό από ότι στα επιτραπέζια συστήματα. Οι σημερινές μπαταρίες ιόντων λιθίου έχουν μια ενεργειακή πυκνότητα περίπου 100 Wh/Kg. Αυτό σημαίνει ότι αν θέλαμε να χρησιμοποιήσουμε έναν επεξεργαστή που έχει απαίτηση ισχύος 50 Watt, θα απαιτούνταν μια μπαταρία 2 Kg, που δεν ενδείκνυται για μια φορητή συσκευή. Προκειμένου να αντιμετωπιστεί εν μέρει, αυτό το πρόβλημα, οι εταιρείες έχουν παρουσιάσει στο καταναλωτικό κοινό επεξεργαστές χαμηλής κατανάλωσης ενέργειας, οι οποίοι όμως έχουν πολύ μικρές επιδόσεις και δεν μπορούν να αντεπεξέλθουν στην πολυπλοκότητα των σημερινών εφαρμογών.
Προφανώς, η λύση στο πρόβλημα της κατανάλωσης ισχύος με μείωση των επιδόσεων δεν είναι αποτελεσματική. Οι χρήστες των φορητών συσκευών απαιτούν την εκτέλεση των εφαρμογών τους με όσο το δυνατόν μικρότερη κατανάλωση ισχύος, και όσο γίνεται πιο γρήγορα. Όταν δεν ικανοποιούνται οι επεξεργαστικές απαιτήσεις, ο χρήστης θα έχει κάποια προβλήματα (π.χ. να σταματάει η αναπαραγωγή κάποιας ταινίας, ή να διακόπτεται η επικοινωνία, ή να υπάρχουν αρκετές καθυστερήσεις στην επεξεργασία των δεδομένων του). Οι χρήστες αυτών των φορητών συστημάτων δεν μπορούν να ανεχθούν τέτοιες προβληματικές λειτουργίες, και έτσι σύντομα αντικαθιστούν αυτές τις συσκευές με άλλες που καλύπτουν αυτές τις απαιτήσεις.
Αλλά, η μεγάλη κατανάλωση ισχύος δεν είναι το μόνο πρόβλημα στη φορητότητα. Η κατανάλωση ισχύος συνδέεται άμεσα με το κόστος ψύξης και ενσωμάτωσης της στο σύστημα. Από τη στιγμή που η θερμότητα πρέπει να αποβάλλεται στο περιβάλλον μέσω της συσκευασίας και της μονάδας ψύξης, το κόστος γίνεται ιδιαίτερα υψηλό έως και απαγορευτικό. Ένας επεξεργαστής, με μεγαλύτερη κατανάλωση ισχύος από έναν άλλο, αποβάλει περισσότερη θερμότητα στο περιβάλλον και χρειάζεται μια μεγαλύτερη μονάδα ψύξης. Εκτός από το μέγεθός της, η μεγαλύτερη μονάδα ψύξης προκαλεί και περισσότερο θόρυβο (ηχορύπανση) λόγω των μηχανικών μερών που περιλαμβάνει. Συνεπώς, υπάρχει ένα ξεκάθαρο πλεονέκτημα στη μείωση της κατανάλωσης ισχύος, τόσο για να μειωθεί το κόστος όσο και για να μειωθεί ο θόρυβος που θα παράγει η συσκευή.
Εκτός από τα παραπάνω οφέλη, υπάρχει και το θέμα της αξιοπιστίας (reliability). Τα συστήματα με μεγάλη κατανάλωση ισχύος αναπτύσσουν υψηλές θερμοκρασίες. Οι υψηλές θερμοκρασίες επιδρούν αρνητικά στα κυκλώματα πολύ μεγάλης κλίμακας ολοκλήρωσης (Very Large Scale Integration, VLSI) και οδηγούν σε διάφορες καταστάσεις αστοχίας. Μια αύξηση της θερμοκρασίας κατά C διπλασιάζει το ποσοστό αστοχίας του κυκλώματος. Επίσης, η λειτουργία ενός ολοκληρωμένου κυκλώματος σε υψηλή θερμοκρασία μειώνει και τη διάρκεια ζωής του. Έτσι, λοιπόν, η μικρή κατανάλωση ισχύος δεν αφορά μόνον τις φορητές συσκευές, αλλά κάθε υπολογιστικό σύστημα, από το πιο απλό έως το πιο πολύπλοκο.
Οι δύο σημαντικότεροι παράγοντες στη διαμόρφωση της συνολικής κατανάλωσης ισχύος ενός συστήματος είναι η κατανάλωση ισχύος του επεξεργαστή και της μνήμης. Οι προσβάσεις στην εξωτερική μνήμη εκτός του ότι είναι αργές (όπως αναφέρθηκε προηγουμένως) έχουν και αρκετά υψηλό ενεργειακό τίμημα. Ο λόγος είναι απλός: Προκειμένου να αναγνωσθεί μια εξωτερική μνήμη πρέπει να γίνει πρόσβαση στην αρτηρία δεδομένων και διευθύνσεων της μνήμης· δηλαδή, πρέπει να μεταφερθούν σήματα από μέσα από το ολοκληρωμένο κύκλωμα προς τα έξω από αυτό και αντιστρόφως. Για να γίνει αυτό, πρέπει να χρησιμοποιηθούν ενισχυτές σημάτων. Έτσι, δε μας εκπλήσσει το γεγονός που υποστηρίζουν ερευνητές ότι, δηλαδή, η κατανάλωση ενέργειας της ιεραρχίας μνήμης αποτελεί το 60% - 80% της ολικής κατανάλωσης ισχύος ενός ενσωματωμένου συστήματος, που εκτελεί εφαρμογές με εντατική χρήση της εκτός ολοκληρωμένου κυκλώματος μνήμης.
Όπως έγινε φανερό από τις προηγούμενες ενότητες, υπάρχει ένα σημαντικό πρόβλημα στο σχεδιασμό ενσωματωμένων συστημάτων ως προς την επίδοση (ταχύτητα) και την κατανάλωση ενέργειας. Το πρόβλημα εστιάζεται από τη μια μεριά στον κυρίαρχο ανασχετικό παράγοντα της μνήμης του ενσωματωμένου συστήματος και από την άλλη μεριά στην ικανοποίηση των επεξεργαστικών απαιτήσεων των σύγχρονων εφαρμογών. Το πρόβλημα αυτό έχει γίνει αντιληπτό από τους ερευνητές εδώ και χρόνια και για αυτό το λόγο έχει παρουσιαστεί μια πληθώρα μεθοδολογιών, τεχνικών, ή τρόπων για την αποτελεσματική αντιμετώπισή του. Συγκεκριμένα, η μεγάλη καθυστέρηση και το υψηλό κόστος ενέργειας της εκτός ολοκληρωμένου κυκλώματος μνήμης, έχει οδηγήσει ερευνητές να προτείνουν διάφορους τρόπους για την καλύτερη εκμετάλλευση, είτε της μνήμης δεδομένων είτε της μνήμης εντολών, ενώ οι υψηλές επεξεργαστικές απαιτήσεις αντιμετωπίζονται κυρίως με τη χρήση εξειδικευμένων κυκλωμάτων, ως προς τις λειτουργίες της εφαρμογής. Όμως, όπως φαίνεται από τη σχετική βιβλιογραφία, οι ερευνητικές εργασίες αντιμετωπίζουν μερικώς το πρόβλημα και παρουσιάζουν ελλείψεις, ή δε λαμβάνουν υπόψη χαρακτηριστικά τα οποία θα μπορούσαν να χρησιμοποιηθούν για την περαιτέρω βελτίωση του συστήματος, ή παρουσιάζουν μια βέλτιστη λύση που δεν ικανοποιεί κάθε σχεδιαστή.
Αν και η υπολογιστική ισχύς των σημερινών ενσωματωμένων πυρήνων είναι αρκετές εκατομμύρια εντολές το δευτερόλεπτο (millions instructions per second, MIPS), επιτρέποντας την εκτέλεση πολύπλοκων εφαρμογών με υψηλές επεξεργαστικές απαιτήσεις, εντούτοις η ιεραρχία μνήμης αποτελεί ανασχετικό παράγοντα στην επίτευξη υψηλών επιδόσεων, λόγω του μεγάλου χρόνου προσπέλασης σε αυτήν. Έχει αναφερθεί ότι ακόμα και οι σημερινοί επεξεργαστές ψηφιακών σημάτων εμφανίζονται αναποτελεσματικοί στην εκτέλεση συγκεκριμένων λειτουργιών των εφαρμογών MPEG. Επιπρόσθετα, έχει βρεθεί ότι το υψηλό ενεργειακό κόστος ανά πρόσβαση στη μνήμη είναι υπεύθυνο για τη μεγάλη κατανάλωση ισχύος σε εφαρμογές που κυριαρχούνται από μεταφορές δεδομένων από και προς την παρασκηνιακή μνήμη.
Το σημαντικό πρόβλημα του χάσματος επιδόσεων ανάμεσα στον επεξεργαστή και στη μνήμη έχει οδηγήσει αρκετούς ερευνητές στην προσπάθεια ανάπτυξης μεθοδολογιών για να το γεφυρώσουν. Μια προφανής λύση στο πρόβλημά μας θα μπορούσε να είναι η χρήση μνημών με πολλές θύρες. Όμως, μια τέτοια οργάνωση μνήμης αυξάνει σε απαγορευτικά όρια την ολική κατανάλωση ενέργειας, και έτσι η λύση αυτή δεν είναι πρακτική. Οι μνήμες με πολλές θύρες εισόδου / εξόδου έχουν μεγάλο κόστος επιφάνειας και κατανάλωσης ενέργειας, και συνήθως τις βρίσκουμε σε πολύ μικρά μεγέθη. Βέβαια, υπάρχουν μερικές περιπτώσεις στις οποίες είναι αναγκαία η χρήση μνημών με πολλές θύρες, επειδή διαφορετικά δε θα ικανοποιούνταν οι απαιτήσεις επεξεργασίας πραγματικού χρόνου.
Από την άλλη μεριά, προκειμένου να αντιμετωπιστούν οι προκλήσεις ως προς την κατανάλωση ενέργειας και επίδοσης των ενσωματωμένων συστημάτων, ερευνητές έχουν προτείνει τη χρήση πολυεπίπεδων αρχιτεκτονικών μνήμης. Γι’ αυτό το λόγο, σχεδόν κάθε πλατφόρμα ενσωματωμένου συστήματος, σήμερα, έχει στην ιεραρχία μνήμης δεδομένων περισσότερα από ένα επίπεδα. Η βελτίωση των χαρακτηριστικών, που επιφέρει η χρήση πολυεπίπεδων αρχιτεκτονικών, βασίζεται στο γεγονός ότι τόσο η καταναλισκόμενη ενέργεια όσο και η επίδοση εξαρτώνται από το μέγεθος της μνήμης. Έτσι, με την εκμετάλλευση της ιεραρχίας της μνήμης, μπορούν να αποκομιστούν αρκετά οφέλη με τη μετατόπιση ενός αριθμού προσβάσεων από την παρασκηνιακή μνήμη στη μνήμη εντός ολοκληρωμένου κυκλώματος. Ασφαλώς, προκειμένου να γίνει καλύτερη εκμετάλλευση της μνήμης, πρέπει να ληφθούν υπόψη οι βελτιστοποιήσεις που μπορούν να γίνουν επί-τόπου (in-place optimizations). Αν και μελλοντικά θα αναλύσουμε τον όρο αυτό, σε αυτό το σημείο θα αναφέρουμε ότι βελτιστοποιήσεις επί-τόπου σημαίνει ότι χρησιμοποιούμε την ίδια περιοχή μνήμης για δύο ή περισσότερους πίνακες που δεν έχουν επικαλυπτόμενη διάρκεια ζωής. Στις τρέχουσες υλοποιήσεις η χρήση μνήμης εντός του ολοκληρωμένου κυκλώματος βασίζεται είτε σε υλικούς ελεγκτές που δημιουργούν αντίγραφα από το ένα επίπεδο στο άλλο, βασιζόμενοι σε τοπικά χαρακτηριστικά, είτε σε αλγοριθμικούς μετασχηματισμούς που εκμεταλλεύονται τα χαρακτηριστικά επαναχρησιμοποίησης δεδομένων. Συγκεκριμένα, για τη δεύτερη κατηγορία, οι μετασχηματισμοί εισάγουν αντίγραφα δεδομένων από απομακρυσμένα επίπεδα σε επίπεδα κοντά στον επεξεργαστή. Οι τεχνικές που έχουν προταθεί μέχρι σήμερα για τους μετασχηματισμούς χρησιμοποιούν μόνο ένα μικρό μέρος των βελτιστοποιήσεων που μπορούν να επιτευχθούν και, μάλιστα, σε μερικές προσεγγίσεις κάποιες βελτιστοποιήσεις αγνοούνται τελείως. Η ιεραρχία μνήμης μπορεί να εμπεριέχει πρόχειρες (ελεγχόμενες από το πρόγραμμα) μνήμες, ή σκιώδεις μνήμες. Προκειμένου μια εφαρμογή να απεικονιστεί αποτελεσματικά, θα πρέπει να γίνει διεξοδική διερεύνηση διαφορετικών υλοποιήσεων, κάτι το οποίον είναι αρκετά χρονοβόρο, εάν γίνει χειρωνακτικά.
Όσον αφορά τις κρυφές μνήμες, κάποιες εργασίες προτείνουν τη βελτίωση των παραμέτρων των σκιωδών μνημών με αύξηση του μεγέθους ή με ρυθμίσεις του μεγέθους μπλοκ, ή με την εύρεση του καταλληλότερου βαθμού συσχετικότητας αυτών των μνημών. Επίσης, ερευνητές έχουν προτείνει τη χρήση ελεγχόμενης από το πρόγραμμα προμετάκλησης, ή τη χρήση προγραμμάτων βελτιστοποιημένων για συγκεκριμένες σκιώδεις μνήμες. Τέλος, άλλες προσεγγίσεις χρησιμοποιούν πολυνηματικές (multithreading) τεχνικές, εκτέλεση εκτός σειράς και χρήση ειδικών τρόπων λειτουργίας μνήμης. Αν και το πρόβλημα έχει σε ένα μικρό βαθμό αντιμετωπιστεί με αυτές τις τεχνικές, εντούτοις το χάσμα επιδόσεων ανάμεσα στον επεξεργαστή και στη μνήμη παραμένει.
Τα στοιχεία εκτός ολοκληρωμένου κυκλώματος είναι η εξωτερική μνήμη και η μνήμη εντολών. Επιλέξαμε μια εξωτερική μνήμη, επειδή τα υπολογιστικά συστήματα σήμερα διεκπεραιώνουν πολύπλοκες εφαρμογές, τα δεδομένα των οποίων δεν μπορούν να αποθηκευτούν στη μνήμη εντός ολοκληρωμένου κυκλώματος. Συνεπώς, είναι αναγκαίο να υπάρχει μια μεγάλη εξωτερική μνήμη για να διατηρεί τα πολυδιάστατα σήματα. Στην πραγματικότητα, η εξωτερική μνήμη δεδομένων μπορεί να αποτελείται από μονάδες διαφορετικών τύπων και χαρακτηριστικών. Για παράδειγμα, η εξωτερική μνήμη μπορεί να έχει ένα επίπεδο στο οποίο βρίσκεται η παρασκηνιακή μνήμη τύπου RAM και τεχνολογίας DRAM, και ένα ακόμη επίπεδο στο οποίο βρίσκεται ένας σκληρός δίσκος (Σχήμα 3.27). Όπως θα δούμε στην επόμενη ενότητα, και η μνήμη δεδομένων εντός ολοκληρωμένου κυκλώματος χρησιμοποιεί μια παρόμοια ιεραρχία. Έτσι, λοιπόν, το σύστημά μας έχει μια πολυεπίπεδη ιεραρχία μνήμης δεδομένων. Η παρασκηνιακή μνήμη επιλέγεται συνήθως να είναι τεχνολογίας DRAM, λόγω του χαμηλού κόστους που έχει συγκρινόμενη με τη μνήμη SRAM. Η μεθοδολογία μας επιτρέπει τη χρήση ποικίλων DRAM, αρκεί ο σχεδιαστής να μπορεί να προσδιορίσει τα χαρακτηριστικά τους (κύκλοι πρόσβασης, κατανάλωση ισχύος, κ.α.), όπως SDRAM - synchronous DRAM, RDRAM - rambus DRAM, EDO DRAM - extended data out RAM κ.α. Αναλόγως της μνήμης που θα επιλεγεί, θα πρέπει να ληφθούν υπόψη και οι τρόποι με τους οποίους αυτή μπορεί να χρησιμοποιηθεί. Για παράδειγμα, οι σύγχρονες μνήμες DRAM υποστηρίζουν ρυθμό πρόσβασης ριπής (burst), ή συστοιχίας (bank) κ.α., χαρακτηριστικά τα οποία βελτιώνουν τις επιδόσεις και την κατανάλωση ισχύος, αν χρησιμοποιηθούν σωστά. Ο σχεδιαστής απλώς πρέπει να ορίσει τα χαρακτηριστικά αυτά σε αρχεία ρυθμίσεων, τα οποία θα περιγράψουμε σε επόμενο κεφάλαιο.
Το γεγονός ότι η εξωτερική μνήμη βρίσκεται εκτός ολοκληρωμένου κυκλώματος συνεπάγεται ότι οι προσβάσεις στη μνήμη αυτή αποτελούν τον κυρίαρχο παράγοντα διαμόρφωσης της ολικής κατανάλωσης ισχύος και επίδοσης [24]. Το πρόβλημα αυτό το αντιμετωπίζουμε επιτυχώς με μια ιεραρχία μνήμης πάνω στο ολοκληρωμένο κύκλωμα, όπως θα αναλυθεί σύντομα.
Κάθε προγραμματιζόμενος επεξεργαστής συνοδεύεται από μια μνήμη εντολών (Instruction Memory), η οποία είναι τύπου μόνο ανάγνωσης (ROM-Read Only Memory
και έχει το λογισμικό του επεξεργαστή. Η μνήμη εντολών συνήθως τοποθετείται εκτός ολοκληρωμένου κυκλώματος, ώστε να είναι δυνατή η εύκολη αντικατάστασή της με μια αναβαθμισμένη έκδοση στην περίπτωση που αυτό χρειαστεί. Η αντικατάσταση γίνεται εύκολα με απομάκρυνση της μνήμης και τοποθέτηση μιας άλλης μνήμης που έχει προγραμματιστεί με την καινούργια έκδοση του προγράμματος. Τα δεδομένα που μεταφέρει η μνήμη αυτή δε χάνονται ποτέ. Αν και θα μπορούσε να χρησιμοποιηθεί επανεγγράψιμη ROM (π.χ. Electrically Erasable Programmable ROM, EEPROM), για λόγους κόστους, αξιοπιστίας και ταχύτητας πρόσβασης της μνήμης, τα πραγματικά ενσωματωμένα συστήματα χρησιμοποιούν μια μνήμη ROΜ, η οποία προγραμματίζεται μια μόνο φορά και συνήθως δεν αντικαθίσταται ποτέ.
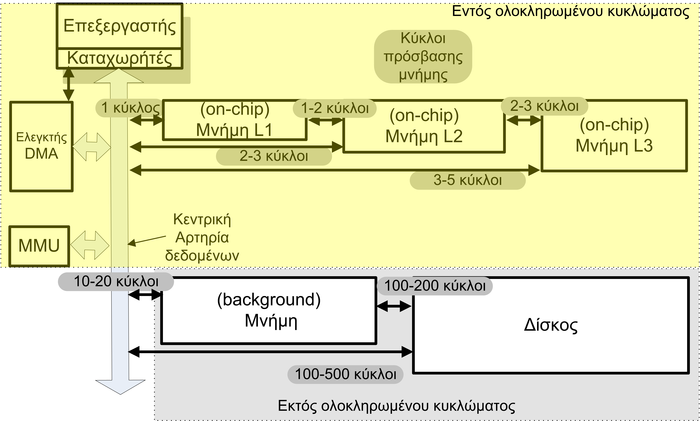
3.27: Η αρχιτεκτονική μας χρησιμοποιεί μια πολυεπίπεδη ιεραρχία μνήμης.
Επειδή η μνήμη εντολών είναι εξωτερική συνεπάγεται μια καθυστέρηση στην πρόσβαση της μνήμης από τον επεξεργαστή, αφού ως γνωστόν η πρόσβαση δομοστοιχείων εκτός ολοκληρωμένου κυκλώματος είναι αρκετά αργή και τουλάχιστον μια τάξη μεγέθους βραδύτερη από προσβάσεις σε στοιχεία εντός ολοκληρωμένου κυκλώματος. Όπως θα δούμε στην επόμενη ενότητα, αντιμετωπίζουμε το πρόβλημα αυτό με μια σκιώδη μνήμη εντολών.
Ένα από τα στοιχεία της αρχιτεκτονικής πάνω στο ολοκληρωμένο κύκλωμα είναι η μνήμη δεδομένων. Η μνήμη αυτή τις περισσότερες φορές είναι τύπου SRAM λόγω των μεγάλων ταχυτήτων πρόσβασης που προσφέρει, με τίμημα το κόστος κατασκευής της, αν και οι ερευνητές έχουν αρχίσει να τοποθετούν πάνω στο ολοκληρωμένο κύκλωμα μνήμη τύπου DRAM [25], [26]. Η μνήμη δεδομένων μπορεί να είναι είτε μια σκιώδης μνήμη, είτε μια πρόχειρη (scratchpad) μνήμη. Η σκιώδης μνήμη αποτελεί τη διασύνδεση ανάμεσα στον επεξεργαστή και στην παρασκηνιακή μνήμη, δεν έχει δικό της χώρο διευθύνσεων και δεν είναι άμεσα ελέγξιμη από το σχεδιαστή. Στην περίπτωση που χρησιμοποιείται σκιώδης μνήμη, όλες οι προσβάσεις στην παρασκηνιακή μνήμη γίνονται διαμέσου της σκιώδους μνήμης, αντικαθιστώντας δεδομένα που βρίσκονται μέσα σ’ αυτήν. Έτσι, τα δεδομένα της σκιώδους μνήμης αλλάζουν δυναμικά κατά τη λειτουργία του συστήματος. Η λειτουργία της σκιώδους μνήμης δεδομένων είναι αρκετά πολύπλοκη και, έτσι, προτείνουμε να μην τη χρησιμοποιείται σε εφαρμογές χαμηλής κατανάλωσης ενέργειας.
Η πρόχειρη μνήμη, αντιθέτως, μπορεί να ελεγχθεί άμεσα από το σχεδιαστή. Χρησιμοποιεί συγκεκριμένες διευθύνσεις μνήμης, που σημαίνει ότι ο σχεδιαστής μπορεί ρητά να τοποθετήσει δεδομένα σ’ αυτήν τη μνήμη, αποθηκεύοντας τα σε κάποια διεύθυνση μνήμης που αντιστοιχεί σ’ αυτή την πρόχειρη μνήμη. Αν και η σκιώδης μνήμη και η πρόχειρη μνήμη είναι ίδιας τεχνολογίας (SRAM), εντούτοις η πρόχειρη μνήμη εγγυάται πάντα χρόνο πρόσβασης ενός κύκλου, που δεν μπορεί να εγγυηθεί η σκιώδης μνήμη, αφού μπορεί να υπάρξει αστοχία. Συνήθως κατά τη διάρκεια της μεταγλώττισης ο σχεδιαστής ορίζει ρητά τα δεδομένα που θα τοποθετηθούν πάνω στην πρόχειρη μνήμη.
Πάντως ανεξαρτήτως της μνήμης εντός ολοκληρωμένου κυκλώματος που θα επιλέξουμε, αυτή θα τοποθετηθεί στο σύστημα τηρώντας και διασφαλίζοντας την ιεραρχία μνήμης δεδομένων (Σχήμα 3.27). Η πιο μικρή και γρήγορη μνήμη θα βρίσκεται πολύ κοντά στον επεξεργαστή (μνήμη πάνω στο ολοκληρωμένο κύκλωμα L1, ή απλώς L1) και θα μπορεί να υποστηρίξει πρόσβαση ενός κύκλου· δηλαδή, μέσα σε ένα κύκλο ο επεξεργαστής θα μπορεί είτε να διαβάσει είτε να γράψει κάποιο στοιχείο σ’ αυτήν. Στην ιεραρχία μνήμης μπορεί να έχουμε και άλλα επίπεδα (π.χ. μνήμες εντός ολοκληρωμένου κυκλώματος L2 και L3, ή απλώς L2, L3, με χρόνους πρόσβασης από τον επεξεργαστή ίσους με 2-3 κύκλους και 3-5 κύκλους, αντίστοιχα). Επίσης, η ιεραρχία μνήμης είναι πλήρως διασυνδεδεμένη, που σημαίνει ότι υπάρχουν συνδέσεις μεταξύ των γειτονικών επιπέδων, ώστε σε περίπτωση που απαιτείται να μεταφερθούν δεδομένα από γειτονικά επίπεδα να μην υπάρχει επιβάρυνση της κεντρικής αρτηρίας δεδομένων.
Πριν συνεχίσουμε την περιγραφή της επιλεγμένης αρχιτεκτονικής θα εξηγήσουμε γιατί χρησιμοποιούμε την πολυεπίπεδη ιεραρχία μνήμης δεδομένων. Ο λόγος που το κάνουμε είναι για να βελτιστοποιήσουμε την επίδοση και την κατανάλωση ισχύος του συστήματος. Έτσι, η μνήμη διαιρείται σε επίπεδα διάφορων μεγεθών. Η επίδοση και η κατανάλωση ισχύος μιας μνήμης εξαρτώνται από το μέγεθος της μνήμης. Όσο πιο μικρό μέγεθος έχει η μνήμη τόσο πιο υψηλή είναι η επίδοση και πιο μικρή η κατανάλωση ισχύος. Όσο πιο συχνά χρησιμοποιούνται κάποια δεδομένα, τόσο πιο κοντά τοποθετούνται στον επεξεργαστή και αντίστροφα. Είναι σαφές ότι η επιλογή των δεδομένων που θα τοποθετηθούν στα διάφορα επίπεδα είναι μια κρίσιμη απόφαση και επηρεάζει κάθε παράμετρο του συστήματος. Η συστηματική μεθοδολογία που παρουσιάζουμε λύνει με επιτυχία αυτό το πρόβλημα.
Ένα ακόμη δομοστοιχείο, που υπάρχει εντός ολοκληρωμένου κυκλώματος, είναι η μονάδα διαχείρισης μνήμης. Η μονάδα αυτή χρησιμοποιείται καταρχήν για να κάνει αναζωογόνηση (refresh) των δεδομένων της μνήμης, γιατί διαφορετικά αυτά θα εξασθενήσουν και θα χαθούν. Επίσης, στην περίπτωση που υπάρχουν πολλαπλοί επεξεργαστές, χρησιμοποιείται για την κοινή και συνεπή χρήση της μνήμης, καθώς και του ποιος επεξεργαστής έχει πρόσβαση σε κάποιο επίπεδο της μνήμης. Τέλος, χρησιμοποιείται για τη μετατροπή των λογικών (εικονικών) διευθύνσεων μνήμης του επεξεργαστή σε πραγματικές διευθύνσεις της μνήμης, όταν χρησιμοποιείται διευθυνσιοδότηση απεικόνισης μνήμης (memory mapped). Ως γνωστόν, όλη η ιεραρχία μνήμης δεδομένων διευθυνσιοδοτείται από ένα συνεχές πεδίο εικονικών (virtual) διευθύνσεων μνήμης (π.χ. 0-64 ΜΒ). Στις διευθύνσεις αυτές αντιστοιχούν πραγματικές διευθύνσεις εσωτερικών και εξωτερικών μνημών. Έτσι, για παράδειγμα οι διευθύνσεις 0-1 ΚΒ αντιστοιχούν στην L1, οι διευθύνσεις 1 ΚΒ - 3 ΚΒ αντιστοιχούν στην L2 κ.ο.κ. Η μονάδα MMU είναι υπεύθυνη για τη μετατροπή των εικονικών διευθύνσεων στις πραγματικές διευθύνσεις της μνήμης. Οι εικονικές διευθύνσεις 1-3 ΚΒ αντιστοιχούν σε πραγματικές διευθύνσεις X1-X2 ΚΒ, τα οποία εξαρτώνται από τη μνήμη κ.ο.κ. Η μονάδα αυτή συναντάται σήμερα σχεδόν σε κάθε ενσωματωμένο σύστημα.
Μια μονάδα, που επίσης χρησιμοποιείται στη μεταφορά δεδομένων, είναι η μονάδα απευθείας πρόσβασης στη μνήμη (DMA-Direct Memory Access). Ως γνωστόν, στα περισσότερα ενσωματωμένα συστήματα οι μεταφορές δεδομένων από (ή σε) μνήμη εκτός ολοκληρωμένου κυκλώματος μπορούν να επιτευχθούν με διάφορους τρόπους. Ο ευκολότερος και αρκετά διαδεδομένος (αλλά μη αποδοτικός) είναι όταν ο επεξεργαστής εποπτεύει, ελέγχει και διενεργεί τη μεταφορά. Το μειονέκτημα είναι ότι κατά τη διάρκεια που γίνεται η μεταφορά μ’ αυτόν τον τρόπο, ο επεξεργαστής περιμένει και δεν εκτελεί κανέναν υπολογισμό, μέχρι να ολοκληρωθεί η μεταφορά δεδομένων, η οποία συνήθως απαιτεί αρκετούς κύκλους ρολογιού. Ένας εναλλακτικός τρόπος μεταφοράς είναι η χρήση του ειδικού τρόπου λειτουργίας ‘Απευθείας Πρόσβασης στη Μνήμη’ (Direct Memory Access-DMA). Όταν χρησιμοποιείται αυτός ο τρόπος, ο επεξεργαστής δεν εποπτεύει τη μεταφορά δεδομένων, αλλά αυτό ανατίθεται σε έναν ελεγκτή ή μηχανή που ονομάζεται ελεγκτής ή μηχανή DMA (DMA Controller). H χρήση του ελεγκτή DMA συνεπάγεται ότι ο επεξεργαστής μπορεί να χρησιμοποιηθεί για την εκτέλεση άλλων λειτουργιών, εφόσον δεν υπάρχουν εξαρτήσεις δεδομένων. Συνήθως, τα ενσωματωμένα συστήματα έχουν παραπάνω από ένα κανάλι (ή προτεραιότητα) για να διενεργούν τις μεταφορές DMA. Η αρχιτεκτονική μας, λοιπόν, έχει έναν ελεγκτή DMA, ο οποίος υποστηρίζει περισσότερα από ένα κανάλια. Συνήθως, οι ελεγκτές DMA έχουν 4 κανάλια, όπως ο επεξεργαστής TI C6201 [27].
Η ‘καρδιά’ του ενσωματωμένου συστήματος είναι ο επεξεργαστής. Αν και η αρχιτεκτονική μας μπορεί εύκολα να επεκταθεί και σε πολλαπλούς επεξεργαστές, εμείς έχουμε διεξάγει τα πειράματά μας με έναν προγραμματιζόμενο επεξεργαστή. Η αξιολόγηση της συγκεκριμένης μεθοδολογίας έγινε χρησιμοποιώντας επεξεργαστές από τις εταιρείες Advanced RISC Machines (ARM) Ltd και Texas Instruments, για δύο λόγους. Πρώτον, οι δύο αυτές εταιρείες έχουν αθροιστικά το μεγαλύτερο μερίδιο στην αγορά των ενσωματωμένων συστημάτων και δεύτερον είχαμε στη διάθεση μας συμβολομεταφραστές και προσομοιωτές επιπέδου εντολών για τους επεξεργαστές τους. Πρέπει να τονίσουμε ότι η αρχιτεκτονική μας είναι αρκετά γενική, ώστε να μπορεί να χρησιμοποιηθεί οποιοσδήποτε επεξεργαστής, αρκεί να υπάρχει στη διάθεση του σχεδιαστή ο αντίστοιχος προσομοιωτής.
Ειδικότερα, από την εταιρεία ARM Ltd επιλέξαμε τον επεξεργαστή ARM7TDMI της οικογένειας ARM7 [28]. Η επιλογή μας βασίστηκε στο γεγονός ότι οι επεξεργαστές της οικογένειας ARM7 είναι αρκετά διαδεδομένοι στην αγορά των φορητών ενσωματωμένων συστημάτων, γιατί έχουν τον καλύτερο λόγο επίδοσης προς κατανάλωση ισχύος (MIPS/Watt) μαζί με τον καλύτερο λόγο επίδοσης προς κόστος (MIPS/$). Όσον αφορά τις τεχνικές λεπτομέρειες, ο επεξεργαστής αυτός είναι ένας επεξεργαστής τύπου μειωμένου συνόλου εντολών (Reduced Instruction Set Computer - RISC), δηλαδή ενός απλοποιημένου συνόλου εντολών με μέγεθος λέξης 32 bit και με 16 καταχωρητές χρήστη 32 bit σε σύνολο 37 καταχωρητών. Ο επεξεργαστής αυτός υποστηρίζει διαδοχική διοχέτευση τριών βαθμίδων και είναι αρχιτεκτονικής Von Neuman· δηλαδή, αρχιτεκτονικής με διαφορετική αρτηρία δεδομένων και διαφορετική αρτηρία εντολών. Η λέξη TDMI που βρίσκεται μετά το όνομα ARM7 είναι το ακρωνύμιο των λέξεων Thumb instruction set with Debug, Multiplier and Interrupt· δηλαδή, ότι έχει ένα σετ εντολών τύπου Thumb, υποστηρίζει εύκολη εκσφαλμάτωση, με ικανότητα εκτέλεσης γρήγορων πολλαπλασιασμών, και υποστηρίζει σημαίες διακοπτών. Η επέκταση Thumb σημαίνει ότι το σετ εντολών του επεξεργαστή έχει συμπιεστεί από 32 bit σε 16 bit, με συνέπεια να υπάρχει έως και 40% μείωση στο μέγεθος της μνήμης εντολών που χρησιμοποιεί αυτός ο επεξεργαστής. Ασφαλώς, η συμπίεση των εντολών σημαίνει ότι θα πρέπει να υπάρχει μια μονάδα αποσυμπίεσης εντολών μέσα στον επεξεργαστή, ώστε η εντολή 16 bit στη μνήμη εντολών να αποσυμπιέζεται στην εντολή 32 bit μέσα στον επεξεργαστή. Τα δεδομένα βέβαια δε συμπιέζονται και παραμένουν με μήκος 32 bit. Ο χρόνος αποσυμπίεσης είναι αμελητέος, αφού γίνεται μέσα στον πυρήνα του επεξεργαστή. Η τυπική συχνότητα λειτουργίας του επεξεργαστή είναι 33 Mhz. Ο επεξεργαστής αυτός διευθυνσιοδοτεί λέξεις 32 bit, άρα μπορεί να χειριστεί μνήμη έως 4GB. Το μήκος λέξης δεδομένων που υποστηρίζει είναι 32, ή 16, ή 8 bit. Τέλος, ο ARM7TDMI υποστηρίζει την τεχνική φόρτωσης - αποθήκευσης (load-store) που σημαίνει ότι τα δεδομένα μπορεί να υποστούν επεξεργασία μόνον όταν έχουν μεταφερθεί σε καταχωρητές και τοποθετούνται μόνο σε καταχωρητές (και στη συνέχεια στη μνήμη). Δηλαδή, δεν υπάρχει η δυνατότητα επεξεργασίας δεδομένων απευθείας στη μνήμη.
Προκειμένου να αξιολογήσουμε τον επεξεργαστή ARM7TDMI χρησιμοποιήσαμε το αναπτυξιακό πρόγραμμα ARM Software Development Toolkit [29] (Σχήμα 3.28). Το εργαλείο αυτό αποτελείται από μια σειρά προγραμμάτων μεταγλώττισης, εκσφαλμάτωσης (debugging) και προσομοίωσης προκειμένου να αξιολογηθεί η επίδοση μιας εφαρμογής σε μια αρχιτεκτονική με κάποιον επεξεργαστή ARM. Από όλους τους διαθέσιμους επεξεργαστές εμείς προτιμήσαμε τον αρκετά διαδεδομένο επεξεργαστή ARM7TDMI. Ο χρήστης μπορεί να δηλώσει μια ιεραρχία μνήμης, τους χρόνους πρόσβασης που απαιτούνται σε κάθε επίπεδό της και να μετρήσει τους κύκλους ρολογιού που απαιτήθηκαν από την εφαρμογή, καθώς και την κατανομή τους στις διάφορες συναρτήσεις της εφαρμογής. Η προσομοίωση γίνεται σε επίπεδο εντολών, οπότε η επίδοση που μετράται συμπίπτει με την πραγματική επίδοση χωρίς προσομοίωση. Το πρόγραμμα αυτό υποστηρίζει πρόχειρες μνήμες καθώς και σκιώδεις μνήμες.
3.28: Η αξιολόγηση της μεθοδολογίας μας χρησιμοποιώντας τον επεξεργαστή ARM7TDMI έγινε με τη βοήθεια του προγράμματος ARM Software Development Toolkit
Εκτός από τον επεξεργαστή της εταιρείας Advanced RISC Machines, επιλέξαμε έναν ακόμη αρκετά διαδεδομένο επεξεργαστή ενσωματωμένων συστημάτων, τον TI C6201 [27]. Οι λόγοι που τον επιλέξαμε σχετίζονται αρχικά με το γεγονός ότι για ένα μικρό χρονικό διάστημα υπήρχε στη διάθεσή μας μια αναπτυξιακή πλακέτα με δύο επεξεργαστές TI C6201, για την καλύτερη αξιολόγηση της μεθοδολογίας, και είχαμε στη διάθεση μας το αναπτυξιακό πρόγραμμα για αυτόν τον επεξεργαστή. Όσον αφορά τις τεχνικές πληροφορίες, ο επεξεργαστής αυτός χρονίζεται στα 200 Mhz, έχει 5 ns μέγιστο χρόνο εκτέλεσης εντολής, είναι επεξεργαστής 32 bit, μπορεί να δεχτεί έως και 8 εντολές ανά κύκλο και έχει 1500 MIPS. Μάλιστα, έχει 6 λειτουργικές μονάδες (4 μονάδες αριθμητικής λογικής (ALU-Arithmetical Logical Unit) και 2 μονάδες πολλαπλασιασμού) και είναι αρχιτεκτονικής φόρτωσης-αποθήκευσης, όπως και ο ARM7TDMI, που σημαίνει ότι τα δεδομένα πρέπει να έρθουν σε κάποιον καταχωρητή προτού υποστούν επεξεργασία, και δε γίνεται απευθείας επεξεργασία στη θέση μνήμης. Ο επεξεργαστής αυτός έχει πάνω στο ίδιο ολοκληρωμένο κύκλωμα και έναν ελεγκτή DMA με τέσσερα κανάλια. Υποστηρίζει δεδομένα 8, 16 και 32 bit. Έχει 32 καταχωρητές γενικής χρήσης. Ο επεξεργαστής αυτός είναι αρχιτεκτονικής πολύ-μεγάλης λέξης εντολής (Very-Long Instruction Words–VLIW), που σημαίνει ότι δέχεται μια πολύ μεγάλη εντολή (μέχρι 256 bit), η οποία συνθέτεται από εντολές 32 bit (μέχρι και 8 εντολές), οι οποίες τροφοδοτούνται στις λειτουργικές μονάδες. Δεν απαιτείται κάθε φορά να υπάρχουν και οι 8 εντολές, αλλά ο επεξεργαστής δέχεται και λιγότερες εντολές ανά κύκλο. Όπως και πριν, ο επεξεργαστής αυτός διευθυνσιοδοτεί λέξεις 32 bit, άρα μπορεί να χειριστεί μνήμη έως 4 GB. Τέλος, ο επεξεργαστής διαθέτει λογική μείωσης της κατανάλωσης ισχύος (power down logic), που σημαίνει ότι μπορεί κάποια μέρη του επεξεργαστή να τίθενται σε κατάσταση μικρής κατανάλωσης ισχύος, όταν αυτά δε χρησιμοποιούνται.
Όσον αφορά την αξιολόγηση του επεξεργαστή TI C6201, χρησιμοποιήσαμε το αναπτυξιακό πρόγραμμα Texas Instrument Code Composer Studio v2.2 [30] (Σχήμα 3.29). Το εργαλείο αυτό είναι παρόμοιο με το εργαλείο της εταιρείας ARM, αφού είναι ένα πλήρες εργαλείο μετάφρασης και προσομοίωσης εφαρμογών για επεξεργαστές της σειράς 6000 της εταιρείας TI. Ο χρήστης μπορεί να ορίσει τις διευθύνσεις μνήμης εντός και εκτός ολοκληρωμένου κυκλώματος, αλλά δεν μπορεί να καθορίσει ακριβώς τους χρόνους πρόσβασης, αφού είναι προκαθορισμένοι από την εταιρεία. Υποστηρίζονται μόνο δύο επίπεδα μνήμης (εντός και εκτός ολοκληρωμένου κυκλώματος). Το θετικό στοιχείο είναι ότι ο προσομοιωτής υποστηρίζει μεταφορές με τη χρήση του ελεγκτή DMA, αλλά ο χρήστης πρέπει να ορίσει με μια δύσκολη χειρωνακτική διαδικασία τις ακριβείς παραμέτρους. Η προσομοίωση γίνεται σε επίπεδο εντολών, συνεπώς είναι αρκετά ακριβής. Τέλος, ο χρόνος εκτέλεσης του προσομοιωτή για την ίδια εφαρμογή, συγκρινόμενος με τον προσομοιωτή του ARM7TDMI, είναι έως και 150 φορές μεγαλύτερος (5 λεπτά προσομοίωσης για μια εφαρμογή στον ARM7TDMI, αντιστοιχούν σε περίπου 12 ώρες προσομοίωση στον επεξεργαστή TI C6201).
3.29: Προσομοιώνουμε τον επεξεργαστή TI C6201 με τη χρήση του προγράμματος Code Composer Studio v2.0.
Στα δομοστοιχεία εντός του ολοκληρωμένου κυκλώματος βρίσκονται η σκιώδης μνήμη εντολών και ο επιταχυντής υλικού IP-block accelerator. Η σκιώδης μνήμη εντολών είναι μια μνήμη τεχνολογίας SRAM, η οποία βοηθάει στη μείωση της καθυστέρησης πρόσβασης στην εκτός ολοκληρωμένου κυκλώματος μνήμη εντολών του επεξεργαστή. Η μνήμη αυτή μειώνει την κατανάλωση ισχύος και αυξάνει την επίδοση του συστήματος. Ανάλογα με την εφαρμογή (και τον επεξεργαστή), η μνήμη αυτή έχει διαφορετικά χαρακτηριστικά, τα οποία πρέπει να προσδιοριστούν επακριβώς.
Τέλος, το IP-block είναι ένα εξειδικευμένο κύκλωμα για συγκεκριμένες λειτουργίες. Έχουμε αναπτύξει εργαλεία που βοηθούν το σχεδιαστή στο σχεδιασμό των μονάδων IP-block σε συνθέσιμη γλώσσα περιγραφής υλικού ολοκληρωμένων κυκλωμάτων πολύ υψηλής ταχύτητας [VHSIC (Very High Speed Integrated Circuits) Hardware Description Language (VHDL)]. Στην περίπτωση που δεν καλύπτονται οι απαιτήσεις της επίδοσης του συστήματος, ο σχεδιαστής μπορεί να υλοποιήσει κάποιες λειτουργίες (συνήθως συναρτήσεις) του μικροεπεξεργαστή, με τις οποίες ο επεξεργαστής ασχολείται σε μεγάλο βαθμό. Για κάθε συνάρτηση, μπορούμε να εξάγουμε τις πληροφορίες κατατομής (profiling) χρησιμοποιώντας τα εργαλεία προσομοίωσης για κάποιον επεξεργαστή. Εκτός του γεγονότος ότι κάποιες λειτουργίες λογισμικού γίνονται πολύ πιο γρήγορα σε υλικό, η χρήση των IP-block απελευθερώνει και τον επεξεργαστή, ο οποίος έχει τη δυνατότητα να λειτουργήσει παράλληλα με το εξειδικευμένο κύκλωμα, που επιπρόσθετα αυξάνει τις επιδόσεις. Εκτός από τις βελτιωμένες επιδόσεις, η χρήση των IP-block μειώνει και την κατανάλωση ισχύος του κυκλώματος, αφού η εφαρμογή μας ολοκληρώνει τη λειτουργία πολύ πιο γρήγορα και αφού, αντί να ενεργοποιείται ένα πλήθος κυκλωμάτων στον επεξεργαστή, όπως είναι οι καταχωρητές, η μνήμη εντολών κτλ, ενεργοποιείται ένα πολύ μικρότερο κύκλωμα που αποτελείται από πλήρεις αθροιστές και πύλες.
Σ’ αυτό το κεφάλαιο αναλύσαμε τις αρχιτεκτονικές που συναντούμε στα τυπικά ΕΣ. Αναλύθηκαν οι αρχιτεκτονικές των επεξεργαστών και οι μνήμες και έγινε μια εισαγωγή στη διαδικασία εισόδου εξόδου. Στη συνέχεια, περιγράψαμε διεξοδικά την αρχιτεκτονική που επιλέξαμε για να αναπτύξουμε και να αξιολογήσουμε τη μεθοδολογία σχεδιασμού ΕΣ, καθώς και τους λόγους που μας κατεύθυναν προς την επιλογή των δομοστοιχείων. Η αρχιτεκτονική-στόχος που παρουσιάσαμε, είναι μια γενική αρχιτεκτονική που από τη μια μεριά συναντάται σε μια πληθώρα ενσωματωμένων συστημάτων και από την άλλη μεριά παρέχει ευελιξία στο σχεδιαστή να την τροποποιήσει, ώστε να καλύπτονται καλύτερα οι σχεδιαστικές του απαιτήσεις.
Η μεγάλη ποικιλία του οικοσυστήματος των ενσωματωμένων συστημάτων, που οφείλεται στο ευρύ φάσμα των απαιτήσεων που καλούνται να χρησιμοποιηθούν, αντικατοπτρίζεται και στις πάρα πολλές δυνατότητες υλοποίησης. Σε αντίθεση με τους τυπικούς προσωπικούς ή φορητούς υπολογιστές ή και διακομιστές, που οι μόνες επιλογές περιορίζονται στον τύπο του επεξεργαστή (που όλοι ακολουθούν τη συμβατότητα με την αρχιτεκτονική Intel IA32 ή AMD64), και της κεντρικής πλακέτας συστήματος (που διαφοροποιούνται μόνο ως προς τις υποδοχές επέκτασης), τα ΕΣ μπορούν να υλοποιηθούν με πολλαπλούς τρόπους, ο καθένας από τους οποίους παρουσιάζει τα δικά του ιδιαίτερα χαρακτηριστικά και ταιριάζει καλύτερα σε συγκεκριμένες σχεδιαστικές απαιτήσεις. Σε αυτό το κεφάλαιο περιγράφονται όλοι οι διαφορετικοί τρόποι υλοποίησης, και γίνεται κατανοητό πότε και που θα χρησιμοποιηθεί μια τεχνολογία.
Η επεξεργασία μέσα στο ενσωματωμένο σύστημα μπορεί να υλοποιηθεί μέσω των διαφόρων μονάδων εξειδικευμένου υλικού. Αυτά υλοποιούνται είτε σε μη προγραμματιζόμενο υλικό (ή αλλιώς σε ολοκληρωμένα κυκλώματα εξειδικευμένης εφαρμογής), είτε σε προγραμματιζόμενο υλικό (ή αλλιώς σε επί του πεδίου προγραμματιζόμενοι συστοιχίες πυλών). Ένας επεξεργαστής ειδικού σκοπού (που αναφέρεται σε ολοκληρωμένα κυκλώματα εξειδικευμένης εφαρμογής) σε αντίθεση με έναν επεξεργαστή γενικού σκοπού είναι σχεδιασμένος σε ψηφιακό κύκλωμα, ώστε να εκτελεί μια συγκεκριμένη υπολογιστική εργασία ή εφαρμογή. Ο επεξεργαστής ειδικού σκοπού ονομάζεται αλλιώς και ως συνεπεξεργαστής (coprocessor) ή επιταχυντής υλικού (hardware accelerator). Ένας σχεδιαστής ενσωματωμένων συστημάτων μπορεί να επιτύχει διάφορα οφέλη επιλέγοντας να χρησιμοποιήσει ένα επεξεργαστή ειδικού σκοπού, ώστε να υλοποιήσει μια υπολογιστική εργασία.
Πρώτον, η απόδοση των εξειδικευμένων ενσωματωμένων επεξεργαστών είναι ταχύτερη, εξαιτίας των λιγότερων κύκλων ρολογιού, ως αποτέλεσμα ενός εξατομικευμένου μονοπατιού δεδομένων. Επιπλέον, η απόδοση αυτή είναι βελτιωμένη, λόγω των μικρότερων κύκλων ρολογιού των απλούστερων λειτουργικών μονάδων και της απλούστερης λογικής ελέγχου. Δεύτερον, το μέγεθος είναι μικρότερο, εξαιτίας του απλού μονοπατιού δεδομένων και ότι δεν απαιτείται μνήμη προγράμματος, εφόσον η υπολογιστική εργασία είναι υλοποιημένη σε ψηφιακό υλικό και υλοποιείται με συνδυαστικά ή ακολουθιακά κυκλώματα. Τρίτον, η κατανάλωση ενέργειας είναι λιγότερη, εξαιτίας του αποτελεσματικού υπολογισμού, χωρίς να υλοποιούνται περιττές συναρτήσεις.
Όμως, υπάρχουν διάφορα μειονεκτήματα όπως το κόστος που ίσως είναι υψηλότερο, λόγω του υψηλού κόστος έρευνας και ανάπτυξης (NRE). Ταυτόχρονα, ο χρόνος εισαγωγής στην αγορά είναι μεγαλύτερος και μειώνεται η ευελιξία σε σχέση με τους επεξεργαστές γενικού σκοπού.
Από την άλλη πλευρά, η τεχνολογία επί του πεδίου προγραμματιζόμενοι συστοιχίες πυλών, προσπαθεί να διατηρήσει τα οφέλη που έχουν οι επεξεργαστές ειδικού σκοπού, αλλά και να βελτιώσει το κόστος, το χρόνο εισαγωγής στην αγορά και την ευελιξία. Το κεφάλαιο ξεκινά με την περιγραφή της τεχνολογίας ολοκληρωμένων κυκλωμάτων εξειδικευμένης εφαρμογής και έπειτα επί του πεδίου προγραμματιζόμενοι συστοιχίες πυλών. Τα πλεονεκτήματα και τα μειονεκτήματα όλων των επιλογών θα αναλυθούν σε επόμενους παραγράφους.
Λίγα χρόνια μετά την ανακάλυψη του τρανζίστορ, η Texas Instruments κατασκεύασε μια σειρά διακριτών δομοστοιχείων, η οποία απαριθμούσε εκατοντάδες λογικά στοιχεία υλοποιώντας μια πληθώρα λειτουργιών. Η σειρά αυτή ήταν γνωστή ως 7400, από τον αριθμό που φέρει το πρώτο δομικό στοιχείο και αποτελείται από τέσσερις πύλες NAND (Εικόνα 4.1)11. Αυτά τα στοιχεία ονομάστηκαν TTL (transistor-transistor logic ή λογική συνδεδεμένων τρανζίστορ), είχαν τυποποιημένες συσκευασίες (standard packaging) και μπορούσαν να συνδεθούν εύκολα, ώστε να κατασκευάσουν μεγαλύτερα ψηφιακά συστήματα. Παρείχαν ένα πλήθος από λειτουργίες, όπως ψηφιακές πύλες, φλιπ-φλοπς, μετρητές, απομονωτές, αριθμητικές λογικές μονάδες κτλ. Ενδεικτικό είναι το γεγονός, ότι τα περισσότερα μικρά και μεγάλα υπολογιστικά κέντρα του 1960 και 1970 χρησιμοποίησαν αυτή την οικογένεια.
Εκτός από την οικογένεια 7400 υπήρχε και η οικογένεια διακριτών στοιχείων 5400, η οποία είχε τα ίδια ακριβώς μέλη, αλλά παρείχε προδιαγραφές για στρατιωτικές εφαρμογές (π.χ. μεγαλύτερο εύρος θερμοκρασιών λειτουργίας). Εκτός από την Texas Instruments που τα παρείχε αρχικά, και άλλες εταιρίες προσέφεραν συμβατά δομοστοιχεία με την ίδια αρίθμηση και έτσι υπήρχε μια αφθονία στοιχείων TTL. Με τον καιρό δημιουργήθηκαν και εκδόσεις που είχαν ελαφρώς διαφορετικά χαρακτηριστικά (αλλά παρείχαν τις ίδιες ψηφιακές λειτουργίες)· εκδόσεις μειωμένης κατανάλωσης ενέργειας (είχαν το γράμμα ‘L’, όπως 74L00), εκδόσεις με μειωμένες καθυστερήσεις διάδοσης χρησιμοποιώντας διόδους Schottky (είχαν το γράμμα ‘S’, όπως 74S00), εκδόσεις συνδυασμό των δυο προηγούμενων (είχαν τα γράμματα ‘LS’, όπως 74LS00), εκδόσεις μεγάλης ταχύτητας (fast και είχαν το γράμμα ‘F’, όπως 74F00), και εκδόσεις προηγμένης χαμηλής κατανάλωσης ενέργειας (advanced low power, με τα γράμματα ‘ΑL’, όπως 74ΑL00). Τα στοιχεία της TTL λογικής ονομάζονταν συσκευές διαμέσου οπής (through hole devices), γιατί οι ακροδέκτες διέρχονταν από οπές πάνω στην πλακέτα και στη συνέχεια γίνονταν η κόλληση.
Η οικογένεια TTL 7400 ή παραλλαγές αυτής, συνεχίζει να υπάρχει ύστερα από 55 χρόνια. Οι μεγαλύτεροι κατασκευαστές συνεχίζουν να προμηθεύουν τα καταστήματα ηλεκτρονικών με δομοστοιχεία, είτε διαμέσου οπής (through hole devices) ή τα πιο σύγχρονα στοιχεία επιφανειακής συγκόλλησης (surface mount). Χρησιμοποιούνται τόσο για την εκπαίδευση, αφού οι φοιτητές μπορούν να κάνουν πλήθος εργαστηριακών ασκήσεων σε μια προτυποποιημένη πλακέτα (breadboard) για να μάθουν ψηφιακή σχεδίαση, ή για τη συντήρηση παλαιών ψηφιακών συστημάτων (legacy digital systems) ή ως λογική συγκόλλησης (glue logic), προκειμένου να διασυνδεθούν και να επικοινωνήσουν δυο διαφορετικά και μη συμβατά ψηφιακά συστήματα.
Τα TTL χρησιμοποιούν διπολικά τρανζίστορ και έτσι παρουσιάζουν μια μεγάλη κατανάλωση ενέργειας. Προκειμένου να βελτιστοποιηθεί η κατανάλωση χρησιμοποιήθηκε μια εναλλακτική υλοποίηση, η οποία είναι γνωστή ως CMOS (Complementary metal–oxide–semiconductor ή Τεχνολογία Συμπληρωματικού ημιαγωγού μετάλλου- οξειδίου). Αυτή η τεχνολογία που χρησιμοποιείται ως τις μέρες μας λόγω της χαμηλής κατανάλωσης ενέργειας, αποτελείται από τρανζίστορ n-MOS και p-MOS, όπου η κάθε ψηφιακή λειτουργία υλοποιείται από ένα n και ένα p δίκτυο τρανζίστορ, ώστε το ένα να συμπληρώνει το άλλο. Μια από τις πρώτες οικογένειες της CMOS που αναπτύχθηκε την ίδια περίοδο με την 7400 ήταν η 4000 η οποία ήταν αρκετά πιο αργή από ότι η TTL και έτσι δε βρήκε μεγάλη απήχηση. Όμως, μετά από λίγα χρόνια, το 1980, κάποιοι κατασκευαστές παρουσίασαν μια νέα οικογένεια CMOS που ήταν συμβατή με τη σειρά 7400 με χαμηλότερη κατανάλωση ενέργειας, και από τότε άρχισε η ευρεία υιοθέτηση αυτής της τεχνολογίας.
Από τη στιγμή που παρουσιάστηκαν οι πρώτες τυποποιημένες συσκευές που είχαν παραπάνω από ένα τρανζίστορ, υιοθετήθηκαν κάποιοι ακρωνύμια, ώστε να προσδιορίζουν τον αριθμό των τρανζίστορ που φέρουν. Συσκευές που φέρουν από μια έως είκοσι λογικές πύλες φέρουν τον χαρακτηρισμό SSI (small scale integrated ή μικρής κλίμακας ολοκλήρωσης), ενώ συσκευασίες που περιέχουν είκοσι έως διακόσιες λογικές πύλες ονομάζονται MSI (medium scale integrated ή μεσαίας κλίμακας ολοκλήρωσης). Συσκευασίες που περιέχουν 200 έως 200.000 λογικές πύλες ονομάζονται LSI (large scale integrated ή μεγάλης κλίμακας ολοκλήρωσης) και τέλος από 200.000 λογικές πύλες και πάνω VLSI (very large scale integrated ή πολύ μεγάλης κλίμακας ολοκλήρωσης). Η ονομασία VLSI ήταν και η τελευταία (Χ)LSI που χρησιμοποιήθηκε, γιατί από τις αρχές του 1980 είχε γίνει σαφές ότι αν συνεχίζονταν η προσθήκη επιθέτων μπροστά από το LSI θα τελείωναν σε λίγα χρόνια οι προσδιορισμοί.
Όλες οι παραπάνω οικογένειες παρέχουν πλήθος ψηφιακών λειτουργιών μέσα στην ίδια συσκευασία, και μπορούν να χρησιμοποιηθούν για την υλοποίηση ενσωματωμένων συστημάτων. Για παράδειγμα συσκευασίες SSI, όπως ο δημοφιλής μετρητής 555, μπορούν να χρησιμοποιηθούν για ένα απλό ψηφιακό σύστημα ξυπνητηριού, έως και VLSI όπου ανήκουν ενσωματωμένοι επεξεργαστές υψηλής απόδοσης.
Ένα στοιχείο, επίσης, που μας ενδιαφέρει στο σχεδιασμό ΕΣ είναι η συσκευασία που περιέχει το ολοκληρωμένο κύκλωμα. Η συσκευασία περιέχει εκτός από την ίδια τη λογική και τους ακροδέκτες, το περίβλημα προστασίας, τους ενισχυτές και τους αισθητήρες για τη διασύνδεση με άλλες εξωτερικές συσκευές. Όπως και κάθε άλλη επιλογή που συνδέεται με τα ενσωματωμένα συστήματα, έτσι και εδώ υπάρχει μια μεγάλη ποικιλία, η οποία εξαρτάται από την πολυπλοκότητα ή των αριθμό των τρανζίστορ που περιέχει. Οι πιο απλές συσκευές έχουν συσκευασίες ακροδεκτών μονής γραμμής (single in-line package) (Εικόνα 4.212) ή διπλής γραμμής (dual in-line package) (Εικόνα 4.513), και επινοήθηκαν το 1964 στην εταιρία Fairchild R&D. Αυτές οι συσκευασίες είναι εύκολες στη χρήση και μπορούν να τοποθετηθούν, είτε με κόλληση πάνω στην ηλεκτρονική πλακέτα του κυκλώματος, είτε σε ειδική υποδοχή που επιτρέπει την αντικατάσταση (Εικόνα 4.5). Οι συσκευασίες είναι ορθογώνιες, απαραίτητο για τη διευκόλυνση της δρομολόγησης των αγωγών μέσα στην ψηφιακή λογική. Οι τυπικές συσκευασίες DIP (Εικόνα 4.414) περιέχουν 8 ή 14 ή 16 ακροδέκτες και φέρουν τις ονομασίες DIP8, DIP14 και DIP16 αντιστοίχως. Επίσης, υπάρχουν διαφορετικά υλικά κατασκευής (π.χ. πλαστικό ή κεραμικό) ή μικρότερες αποστάσεις ανάμεσα στους ακροδέκτες, οπότε προκύπτουν οι κατηγορίες CDIP (κεραμική συσκευασία), PDIP (πλαστική συσκευασία), SPDIP (1.778 mm απόσταση ακροδεκτών), SDIP (7.62 mm πλάτος). Τέλος, υπάρχουν και συσκευασίες που φέρουν τέσσερις γραμμές ακροδεκτών και ονομάζονται QIP (quad in-line package) (Εικόνα 4.315).

4.2: Η συσκευασία SIL αποτελείται από 1 σειρά ακροδεκτών. By I, NobbiP. Licensed under CC BY-SA 3.0 via Commons από wikipedia.org.

4.3: Εκτός από τις SIL και DIP υπάρχουν και οι συσκευασίες QIP με τέσσερις σειρές ακροδεκτών. By TheBug at the German language Wikipedia. Licensed under CC BY-SA 3.0 via Commons. Εικόνα από wikipedia.org.
Οι συσκευασίες DIP και SIL χρησιμοποιούνται για κυκλώματα που απαιτούν σχετικά λίγους ακροδέκτες (έως 64). Όμως, υπάρχουν κυκλώματα που έχουν μεγαλύτερες απαιτήσεις. Μια συνηθισμένη συσκευασία για αυτά είναι η PGA (pin grid array ή πλέγμα πίνακα ακροδεκτών)(Εικόνα 4.616). Αυτή είναι μια ορθογώνια ή τετράγωνη συσκευασία που φέρει τους ακροδέκτες από την κάτω πλευρά του ολοκληρωμένου κυκλώματος. Η τυπική απόσταση των ακροδεκτών είναι 2.54 mm και μπορεί είτε να καλύπτει όλη την επιφάνεια, είτε να αφήνει μια περιοχή στο κέντρο χωρίς ακροδέκτες (αν δεν υπάρχει ανάγκη διασύνδεσης). Τα ολοκληρωμένα κυκλώματα σε συσκευασία PGA τοποθετούνται πάνω σε ειδικές υποδοχές σε κεντρικές πλακέτες, και μπορούν να κολληθούν από βιομηχανικά ρομπότ (επειδή είναι πάρα πολλοί ακροδέκτες και απαιτείται μεγάλη ακρίβεια) πάνω στην πλακέτα.

4.4: H συσκευασία DIP αποτελείται από 2 σειρές ακροδεκτών. By Kimmo Palosaari - OpenPhoto.net. Licensed under Public Domain via Commons. Εικόνα από wikipedia.org.

4.5: Οι συσκευασίες DIP μπορούν να κολληθούν στην πλακέτα ή να τοποθετηθούν σε μια υποδοχή. Licensed under CC BY-SA 3.0 via Commons. Εικόνα από wikipedia.org.
Προκειμένου να μειωθεί το κόστος του ολοκληρωμένου κυκλώματος, να μειωθεί το μήκος των ακροδεκτών και οι παρεμβολές, επιτρέποντας με αυτόν τον τρόπο την επίτευξη υψηλότερης συχνότητας λειτουργίας, χρησιμοποιείται η συσκευασία BGA (ball grid array - σφαιρικό πλέγμα πίνακα), στην οποία οι ακροδέκτες είναι σφαίρες συγκόλλησης για την άμεση επιφανειακή κόλληση στην κεντρική πλακέτα του συστήματος (Εικόνα 4.7)17. Αυτές οι συσκευασίες χρησιμοποιούνται για όλα τα πολύπλοκα ολοκληρωμένα κυκλώματα που έχουν εκατομμύρια τρανζίστορ και απαιτούν υψηλές ταχύτητες επικοινωνίας. Με τη συγκόλληση επιτυγχάνεται και η καλύτερη επαφή του τσιπ με την πλακέτα, η οποία βοηθάει και στη θερμική απαγωγή και ψύξη του επεξεργαστή, ενώ το μειωμένο μήκος των ακροδεκτών ελαττώνει σημαντικά την ηλεκτρομαγνητική επαγωγή, η οποία είναι ένα σημαντικό χαρακτηριστικό για την αποφυγή αλλοίωσης των σημάτων, που συμβαίνει στις PGA συσκευασίες υψηλής συχνότητας. Οι συσκευασίες BGA έχουν το μειονέκτημα ότι απαιτούν εξειδικευμένο ρομποτικό εξοπλισμό ακριβείας για την τοποθέτηση πάνω στην πλακέτα, για αυτό έχουν και το υψηλότερο κόστος.

4.6: H συσκευασία PGA αποτελείται από ένα πυκνό πλέγμα ακροδεκτών. Εικόνα από το χρήστη Eric Gaba (Sting) της wikipedia.org.

4.7: Η συσκευασία BGA αποτελείται αντί για ακροδέκτες από σφαίρες κόλλησης. By Konstantin Lanzet - CPU collection Konstantin Lanzet. Licensed under CC BY-SA 3.0 via Commons. Εικόνα από wikipedia.org.
Τα ενσωματωμένα συστήματα αναλόγως της πολυπλοκότητας χρησιμοποιούν όλες τις συσκευασίες. Ο σχεδιαστής των ΕΣ θα πρέπει να γνωρίζει όλες αυτές τις συσκευασίες και να μπορεί να επιλέγει την καλύτερη συσκευασία για το πρόβλημά του. Όσο πιο πολύπλοκο είναι το ΕΣ τόσο πιο σύγχρονη συσκευασία θα πρέπει να επιλέξει. Σε περίπτωση που αποφασίζει να σχεδιάσει το δικό του επεξεργαστή για το ΕΣ, τότε ασφαλώς εμφανίζονται και άλλα θέματα σχεδιασμού, που διδάσκονται ή διερευνώνται σε μαθήματα VLSI ή CAD/CAM/CAE.
Για πέντε δεκαετίες, η αλματώδης πρόοδος της τεχνολογίας έχει βοηθήσει στην ανάπτυξη και υιοθέτηση των υπολογιστών σε όλους τους τομείς της καθημερινής μας ζωής. Έτσι, αν κοιτάξει κανείς γύρω του θα δει ότι περιτριγυρίζεται από ηλεκτρονικά συστήματα, που εμπεριέχονται για παράδειγμα στις τηλεοράσεις, στα αυτοκίνητα, στους υπολογιστές, στα κινητά τηλέφωνα, σε βομβητές κτλ. Τα περισσότερα από αυτά τα ηλεκτρονικά συστήματα έχουν κυκλώματα που ελέγχουν κάποιες ή όλες τις λειτουργίες της συσκευής.
Στα υπολογιστικά συστήματα γενικού σκοπού, ο σχεδιασμός ή η επιλογή του επεξεργαστή είναι μια ορθογώνια διαδικασία ως προς το λογισμικό και έτσι οι ομάδες είναι τελείως ανεξάρτητες ή ακριβέστερα, συνεργάζονται μόνο οι ομάδες της αρχιτεκτονικής με αυτές που κατασκευάζουν τους μεταγλωττιστές και τους συμβολομεταφραστές. Οι υπόλοιποι προγραμματιστές, απλώς χρησιμοποιούν τα αναπτυξιακά εργαλεία που τους παρέχονται.
Στα ενσωματωμένα συστήματα όμως, πάντα υπάρχει ο συ-σχεδιασμός του υλικού και του λογισμικού, το οποίο περιγράφεται λεπτομερώς και σε επόμενη παράγραφο. Αρχικά, επιλέγεται ή σχεδιάζεται ο εξειδικευμένος επεξεργαστής που καλύπτει τις απαιτήσεις, ένα αρκετά δύσκολο εγχείρημα που δεν πρέπει να υποτιμάται, μαζί με τις αρχιτεκτονικές λεπτομέρειες που το συνοδεύουν όπως οι κρυφές μνήμες, οι μηχανισμοί συνοχής ή δυνατότητα πολυεπεξεργασίας κτλ. Ο σχεδιασμός του υπόλοιπου συστήματος δεν είναι λιγότερο σημαντικός ή πιο δύσκολος. Υπάρχει αλληλεπίδραση των σχεδιαστικών αποφάσεων ανάμεσα στον επεξεργαστή και στα υπόλοιπα στοιχεία του ενσωματωμένου συστήματος. Για να σχεδιαστεί ένας απλός επεξεργαστής θα πρέπει να εργάζονται δυο ή τρεις μηχανικοί, από έξι έως εννέα μήνες, προκειμένου να δημιουργήσουν μια περιγραφή επιπέδου μεταφοράς καταχωρητών (register transfer level, RTL). Το επόμενο βήμα είναι η κατασκευή, η δοκιμή, η ανάπτυξη λογισμικού κτλ. Κάποιοι πιστεύουν ότι ο πιο δύσκολος στόχος είναι να σχεδιαστεί ένας επεξεργαστής, για αυτό υποστηρίζουν ότι ο σχεδιασμός ενός πολύπλοκου ενσωματωμένου συστήματος ολοκληρώνεται με το σχεδιασμό του επεξεργαστή. Όμως, αυτό είναι λάθος, αφού το πιο σωστό είναι ότι ο ο σχεδιασμός ενός πολύπλοκου ενσωματωμένου συστήματος ξεκινάει με το σχεδιασμό του επεξεργαστή.
Στη συνέχεια τα ηλεκτρονικά κυκλώματα σχεδιάζονταν μόνο σε ολοκληρωμένα κυκλώματα εξειδικευμένα για την εφαρμογή (Application Specific Integrated Circuit, ASIC). Τα κυκλώματα αυτά εκτός από τις υψηλές επιδόσεις είχαν και υψηλό κόστος παραγωγής. Σήμερα, το κόστος αυτό δεν έχει μειωθεί, αλλά αυξάνεται συνεχώς εκθετικά ακολουθώντας το νόμο του Moore [23]. Γι’ αυτό το λόγο, ερευνητές έχουν υποστηρίξει ότι οι συνθήκες μας οδηγούν σε μια απομάκρυνση από τα ASIC και σε εντατικοποίηση της χρήσης των προγραμματιζόμενων υλοποιήσεων[31], της άλλης εναλλακτικής πορείας υλοποίησης συστημάτων. Οι δύο αυτές εναλλακτικές πορείες υλοποίησης έχουν θετικά και αρνητικά στοιχεία. Συγκεκριμένα, τα ASIC έχουν πολύ χαμηλή ευελιξία (αφού σχεδιάζονται αποκλειστικά για μια εφαρμογή), έχουν πολύ χαμηλή κατανάλωση ενέργειας με υψηλές επιδόσεις και έχουν πολύ μεγάλο χρόνο ανάπτυξης (Σχήμα 4.8). Στην ακριβώς αντίθετη θέση βρίσκονται οι επεξεργαστές γενικού σκοπού, οι οποίοι είναι αρκετά ευέλικτοι (αφού είναι γενικού σκοπού), αλλά υστερούν στις επιδόσεις και συνοδεύονται από μεγάλη κατανάλωση ενέργειας. Ανάμεσα στις δύο αυτές ακραίες θέσεις, υπάρχουν οι ψηφιακοί επεξεργαστές σήματος, οι οποίοι έχουν μεγάλη ευελιξία, χαμηλό χρόνο ανάπτυξης (αφού είναι προγραμματιζόμενοι και εύκολα μπορεί να μεταφραστεί μια εφαρμογή σε εκτελέσιμη μορφή για τον επεξεργαστή), αλλά η κατανάλωση ενέργειας και οι επιδόσεις υστερούν συγκρινόμενες με τα ASIC. Στις ενδιάμεσες θέσεις επίσης υπάρχουν τα FPGA, τα οποία έχουν μια παρόμοια ροή σχεδιασμού με τα ASIC, αλλά αρκετά πιο γρήγορη αφού παρέχουν τη δυνατότητα του προγραμματισμού, και του χαμηλότερου κόστους, γιατί παράγονται κατά μεγάλες ποσότητες.
Έως τώρα αναφερθήκαμε για υλοποιήσεις ενσωματωμένων συστημάτων που είτε φέρουν έναν επεξεργαστή, είτε αποτελούνται από εξειδικευμένο υλικό. Ως τώρα ήταν η εισαγωγή και δεν έχει δοθεί μια λεπτομερή ταξινόμηση. Είναι όμως ευκολονόητο ότι τα ΕΣ μπορούν να υλοποιηθούν με πάρα πολλούς τρόπους, και αυτό φαίνεται και από το μεγάλο πλήθος των ακρωνυμίων υλοποίησης, όπως CPLD, FPGA, ASIC, SOC, PSOC, DSP, ASIP, ASSP, PAL, CPU, MCPU, που θα περιγράψουμε λεπτομερώς στις επόμενες ενότητες.
Το Σχήμα 4.8 παρουσιάζει ποικίλες μορφές υπολογισμού που μπορούν να υλοποιήσουν ένα ενσωματωμένο σύστημα. Η ειδίκευση αυξάνεται από τα αριστερά στα δεξιά και η ευελιξία από τα δεξιά στα αριστερά.
Μπορούμε να διαχωρίσουμε ένα ενσωματωμένο σύστημα στην επεξεργασία συστήματος, την επεξεργασία εφαρμογής, και την επιτάχυνση πυρήνων. Ανάλογα με το επιθυμητό επίπεδο κόστους/απόδοσης, μπορούμε να εφαρμόσουμε διάφορους βαθμούς προσαρμογής σε κάθε επίπεδο: γενικής χρήσης, εξαρτώμενοι από το πεδίο ή επεξεργαστές οριζόμενοι από την εφαρμογή, στα υψηλού επιπέδου συστατικά, και προγραμματίσιμη ή μη προγραμματίσιμη επιτάχυνση στους πυρήνες εντατικών υπολογισμών. Στην πραγματικότητα, ένας συνδυασμός αυτών των τεχνικών βρίσκεται συνήθως σε πολλά από τα σημερινά πολύπλοκα ενσωματωμένα συστήματα.
Εξετάζοντας αυτά τα παραδείγματα, είναι σημαντικό να τονισθεί ότι σε πολλές περιπτώσεις οι επιταχυντές υλικού κάνουν τον υπολογισμό περιφερειακά, δηλαδή εκεί που απαιτείται απομακρυσμένα από τον επεξεργαστή, π.χ. εκεί που παράγονται τα δεδομένα ή εκεί που καταναλώνονται για επεξεργασία. Αυτό επιτυγχάνει μείωση της επικοινωνίας και συνεπώς της επιβάρυνσης του δικτύου διασύνδεσης. Βέβαια, υπάρχουν και επιταχυντές που συνεργάζονται στενά με κάποιον επεξεργαστή, π.χ. για την κρυπτογράφηση ή αποκωδικοποίηση video υψηλής ποιότητας. Ασφαλώς, η ανάπτυξη τέτοιων επιταχυντών στενής συνεργασίας με τον επεξεργαστή, απαιτεί ιδιαίτερες δεξιότητες και γνώσεις. Επιπλέον, η ιστορία έχει δείξει ότι η επιτάχυνση υλικού που επιτυγχάνεται με τέτοιους βοηθητικούς πυρήνες επεξεργασίας, είναι συχνά ο πρώτος υποψήφιος για να απορροφηθεί από το λογισμικό, μόλις η ταχύτητα του πυρήνα-επεξεργαστή γίνεται επαρκής για την απαραίτητη απόδοση ή μόλις αυξηθεί ο αριθμός των επεξεργαστών και μπορεί υπολογιστικά να καλυφθούν οι απαιτήσεις. Αυτό δεν είναι παράξενο, αφού ένα λογισμικό αναπτύσσεται και αναβαθμίζεται με μεγαλύτερη ευκολία από ένα υλικό. Ένας άλλος λόγος για να χρησιμοποιηθούν επιταχυντές υλικού σε διεπαφές εισόδου/εξόδου είναι ότι αυτοί είναι ιδιαίτερα αποδοτικοί σε επεξεργασία ροής δεδομένων (data streams), που σε διαφορετική περίπτωση θα έπρεπε να αποθηκευτούν στη μνήμη αυξάνοντας το ενεργειακό ισοζύγιο, αφού οι προσβάσεις στη μνήμη είναι δαπανηρές και άρα η άλλη εναλλακτική αποθήκευσης των δεδομένων στη μνήμη (1 πρόσβαση για εγγραφή) και μετά ανάκληση των δεδομένων για επεξεργασία (1 πρόσβαση για ανάγνωση) και αποθήκευση των νέων δεδομένων στη μνήμη (1 πρόσβαση για εγγραφή), απαιτεί πολλές παραπάνω προσβάσεις, από την άμεση περιφερειακή επεξεργασία και αποθήκευση του αποτελέσματος στη μνήμη (μόνο 1 πρόσβαση για εγγραφή). Προκειμένου ο σχεδιασμός να είναι αποτελεσματικός και σύντομος, θα πρέπει οι επιταχυντές να χρησιμοποιούν προτυποποιημένους διαύλους δεδομένων, όπου έχουν σαφώς ορισμένες και επιβεβαιωμένες διεπαφές και διαγράμματα χρονισμού, ενώ πρέπει να υπάρχει και καλή υποστήριξη τόσο σε block επαναχρησιμοποιήσιμης λογικής, όσο και σε οδηγούς συσκευών. Σε ειδικές συνθήκες μπορούν να δημιουργηθούν νέοι δίαυλοι και νέα πρότυπα επικοινωνίας ανάμεσα στον επιταχυντή και τον επεξεργαστή, αλλά θα πρέπει αυτό να γίνει συνειδητά και με πλήρη επίγνωση όλων των μειονεκτημάτων και πλεονεκτημάτων της επιλογής.
Μέχρι τις αρχές της δεκαετίας του 1980, τα περισσότερα συστήματα κυκλωμάτων λογικής υλοποιούνταν σε μικρής κλίμακας τυποποιημένα ολοκληρωμένα κυκλώματα (large scale integrated LSI circuits), όπως μικροεπεξεργαστές, ελεγκτές διαύλου-Ε/Ε, χρονιστές συστημάτων κλπ. Εντούτοις, κάθε σύστημα είχε ακόμα την ανάγκη για ‘λογική συγκόλλησης’ (glue logic) για να συνδεθεί με μεγαλύτερα κυκλώματα. Για παράδειγμα, απαιτούνταν συνδέσεις πολυπλεξίας σειριακού σε παράλληλο και αντίστροφα ή τροποποίησης επιπέδων λογικής τάσης (12V, 7V, 5V, 3.3V, 1.8V). Τα εξειδικευμένα ολοκληρωμένα κυκλώματα είχαν ως σκοπό να αντικαταστήσουν τη μεγάλη ποσότητα κυκλωμάτων συγκόλλησης και συνεπώς να μειώσουν την πολυπλοκότητα συστημάτων και το κόστος παραγωγής, καθώς επίσης και να βελτιώσουν την απόδοση. Όμως, τα εξειδικευμένα ολοκληρωμένα κυκλώματα ήταν (και είναι) ακριβά για να αναπτυχθούν εκ του μηδενός, ενώ υπήρχαν και μεγάλες χρονικές καθυστερήσεις για την εισαγωγή του προϊόντος στην αγορά λόγω του απαγορευτικά μεγάλου χρόνου σχεδίασης. Επομένως, η προσέγγιση εξειδικευμένου ολοκληρωμένου κυκλώματος ήταν μόνο βιώσιμη για προϊόντα με πολύ μεγάλη ποσότητα (που χαμηλώνει την επίδραση του κόστους σχεδιασμού και ανάπτυξης, NRE). Αντιμετωπίζοντας αυτό το πρόβλημα, η νεοσύστατη εταιρεία Xilinx εισήγαγε στα μέσα της δεκαετίας του `80 (γύρω στα 1984) την τεχνολογία των προγραμματιζόμενων συστοιχιών πυλών στο πεδίο (Field Programmable Gate Arrays, FPGA), ως εναλλακτική λύση των εξειδικευμένων ολοκληρωμένων κυκλωμάτων για την υλοποίηση της λογικής συγκόλλησης. Έτσι, οι επί του πεδίου προγραμματιζόμενες συστοιχίες πυλών αποτέλεσαν μια σημαντική τεχνολογία, η οποία επέτρεψε στους σχεδιαστές των κυκλωμάτων να υλοποιούν κυκλώματα σε σχετικά μικρό χρονικό διάστημα, αφού δεν απαιτούνταν η διαδικασία της φυσικής χωροθέτησης, της δημιουργίας μασκών και της κατασκευή ολοκληρωμένων κυκλωμάτων.
4.8: Η κάθε πλατφόρμα υλοποίησης έχει διαφορετικά χαρακτηριστικά ως προς τις επιδόσεις, την κατανάλωση ενέργειας και την ευελιξία.
Το χαμηλό κόστος των επαναπρογραμματιζόμενων δομών έχουν οδηγήσει τους κατασκευαστές στην υιοθέτηση αυτών των δομών ως τις αρχιτεκτονικές υλοποίησης των ενσωματωμένων συστημάτων. Έτσι, οι σχεδιαστές επιλέγουν συνήθως αρχιτεκτονικές με προγραμματιζόμενους επεξεργαστές, ή επεξεργαστές εξειδικευμένους προς την εφαρμογή (Application Specific Instruction Set Processor - ASIP). Όμως, υπάρχουν και απλά ενσωματωμένα που μπορούν να υλοποιηθούν με 4bit ή 8bit μικροελεγκτές, όπως τον ATMEGA328P. Θα περιγράψουμε τους μικροελεγκτές, όπως και την πιο εξελιγμένη μορφής τους (μικροεπεξεργαστές) στην επόμενη παράγραφο.
Μερικές φορές ένα ενσωματωμένο σύστημα επιτελεί μια απλή λειτουργία που διαβάζει τιμές από αισθητήρες και ενεργοποιεί αντίστοιχες συσκευές δράσης. Τέτοια συστήματα δεν έχουν υψηλές υπολογιστικές απαιτήσεις και μπορούν να χρησιμοποιήσουν μικροελεγκτές ή μικροεπεξεργαστές. Ο μικροελεγκτής (microcontroller, mC) είναι ένα ολοκληρωμένο κύκλωμα που μπορεί να παρέχει αρκετά περιορισμένες υπολογιστικές ικανότητες, αφού συνήθως λειτουργεί σε ταχύτητες κάποιων Mhz και έχει κάποια KB μνήμης RAM, εντούτοις παρέχει αρκετά χαρακτηριστικά που είναι χρήσιμα σε συγκεκριμένες περιπτώσεις. Αυτό το στοιχείο είναι παρόμοιο με έναν επεξεργαστή (ή μικροεπεξεργαστή), δηλαδή έχει την ικανότητα να εκτελεί αριθμητικές και λογικές πράξεις, να μεταφέρει δεδομένα εντός και εκτός του ολοκληρωμένου κυκλώματος και να μπορεί να εκτελέσει ένα πρόγραμμα (αρχιτεκτονική αποθηκευμένου προγράμματος). Τα σημαντικότερα χαρακτηριστικά του μικροελεγκτή είναι τα παρακάτω: Ο μικροελεγκτής έχει χαμηλό κόστος, που είναι πολύ σημαντικό για ενσωματωμένα συστήματα που πρόκειται να κατασκευαστούν σε χιλιάδες ή εκατομμύρια κομμάτια. Επίσης, περιέχει έναν αριθμό από διάφορες ενσωματωμένες λειτουργικές μονάδες (ή περιφερειακές συσκευές) στο ίδιο υπόστρωμα πυριτίου με τον επεξεργαστή. Αυτές οι μονάδες παρέχουν χρήσιμες δυνατότητες για τα ΕΣ, όπως μέτρηση χρόνου με χρονιστές (timers), μέτρηση συμβάντων με μετρητές (counters), υποστήριξη διάφορων τρόπων επικοινωνίας, όπως σειριακή (RS232 ή USB) ή άλλων προτύπων, και υποστήριξη καλύτερης αξιοπιστίας με χρονομετρητές επιτηρητών (watchdog timers), οι οποίοι αν παρατηρήσουν κάποια δυσλειτουργία επανεκκινούν το σύστημα. Επιπρόσθετα, ο μικροελεγκτής περιέχει πάνω στο ίδιο chip, επαναπρογραμματιζόμενη μνήμη που φέρει το αποθηκευμένο πρόγραμμα και είναι είτε τύπου EEPROM, είτε FLASH, και έτσι δε χρειάζεται η αποθήκευση του προγράμματος σε ένα εξωτερικό μέσο όπως ένα δίσκο. Ακόμη, ο μικροελεγκτής παρέχει άμεση πρόσβαση και χειρισμό σε ακροδέκτες για ψηφιακή και αναλογική επεξεργασία ή για να οδηγήσει φορτία ή transistor ενίσχυσης ρεύματος, ενώ έχει και εξειδικευμένες εντολές χειρισμού bit. Ένα ολοκληρωμένο κύκλωμα που έχει όλα τα παραπάνω, ονομάζεται μικροελεγκτής. Η ολοκλήρωση όλων αυτών των υπομονάδων στο ίδιο τσιπ, έχει ως συνέπεια τη δυνατότητα λειτουργίας του με ελάχιστες εξωτερικές απαιτήσεις και έτσι μπορεί να τοποθετηθεί εύκολα σε ΕΣ με μικρό μέγεθος και με χαμηλή απαίτηση ενέργειας. Για παράδειγμα, ένα απλό ΕΣ που βασίζεται σε έναν επεξεργαστή ATmega328 AVR μπορεί να λειτουργήσει με την προσθήκη 2 αντιστάσεων, 2 πυκνωτών, ενός σταθεροποιητή τάσης και ενός κρυστάλλου σταθερής συχνότητας (με συνολικό κόστος υλικού για παραγγελία 1000 κομματιών στα 2$).
Πολύ σημαντικό στοιχείο είναι η ευκολία πρόσβασης στους ακροδέκτες του ολοκληρωμένου κυκλώματος, αφού μπορούν να συνδεθούν αισθητήρια ή συσκευές δράσης και να χρησιμοποιηθούν με απλές εντολές ανάγνωσης ή εγγραφής. Οι μικροελεγκτές μπορεί να παρέχουν μόνο ρεύμα λίγων mA για οδήγηση στους ακροδέκτες, αλλά με κατάλληλες διατάξεις (π.χ. τρανζίστορ που ενισχύουν την ικανότητα οδήγησης και ελέγχου), μπορούν να χειριστούν συσκευές με μεγάλες απαιτήσεις σε ρεύματα οδήγησης (όπως κινητήρες) ή με κατάλληλες αντιστάσεις να διαβάσουν αισθητήρια που λειτουργούν σε μεγαλύτερες τάσεις. Ασφαλώς, απαιτείται προσοχή στην επιλογή των κατάλληλων βοηθητικών ηλεκτρονικών στοιχείων, διαφορετικά μπορούν να καταστραφούν οι ακροδέκτες του μικροεπεξεργαστή.
Αξίζει να σημειωθεί ότι, εκτός από τους μικροελεγκτές, υπάρχουν και οι μικροεπεξεργαστές (microprocessor, mP) που έχουν παρόμοια στοιχεία, αλλά και κάποιες σημαντικές διαφορές. Οι μικροεπεξεργαστές είναι και αυτοί ολοκληρωμένα κυκλώματα στα οποία εμπεριέχονται πιο σύνθετα δομοστοιχεία από τους mC με περισσότερες λειτουργικές μονάδες και με μεγάλες υπολογιστικές ικανότητες. Για παράδειγμα μπορεί να έχουν 3 αριθμητικές λογικές μονάδες (ALU), 2 μονάδες πράξεων πραγματικών αριθμών (FPU), 2 μονάδες πράξεων διανυσματικών στοιχείων (SIMD), ελεγκτές DMA, ελεγκτές video και ήχου και πολλά άλλα. Αυτά είναι τα επεξεργαστικά στοιχεία των σημερινών προσωπικών υπολογιστών και ασφαλώς έχουν πολλαπλάσιο κόστος από τους mC. Δε μπορούν να λειτουργήσουν με προσθήκη απλών ηλεκτρονικών στοιχείων όπως οι mC, και απαιτείται μια κεντρική πλακέτα (motherboard) πάνω στην οποία τοποθετούνται αυτοί και τα παθητικά και ενεργητικά ηλεκτρονικά στοιχεία υποστήριξης.
Οι σημερινές ενσωματωμένες πολυμεσικές εφαρμογές, όπως η αποκωδικοποίηση επίγειου τηλεοπτικού σήματος υψηλής ανάλυσης (Full HD 1080p, 4Κ, 8K) που χρησιμοποιεί κωδικοποίηση MPEG4 ή Η264, απαιτούν υψηλή υπολογιστική ισχύς και πολύ συγκεκριμένη λειτουργικότητα. Οι απαιτήσεις για απόδοση, ισχύς, κόστος ή μέγεθος για διάφορες εφαρμογές δεν μπορούν να αντιμετωπιστούν αποτελεσματικά με τη χρήση μικροεπεξεργαστών 8bit. Μπορούν να χρησιμοποιηθούν επεξεργαστές ειδικού σκοπού (ASIC), αλλά έχουν υψηλό κόστος κατασκευής και δεν είναι προγραμματιζόμενοι. Μια λύση είναι να χρησιμοποιήσουμε επεξεργαστές συνόλου εντολών που είναι ειδικοί σε μια εφαρμογή ή μια συγκεκριμένη περιοχή εφαρμογών. Αυτοί οι επεξεργαστές συνόλου εντολών ονομάζονται επεξεργαστές συνόλου εντολών ειδικής εφαρμογής (application-specific instruction-set processors - ASIP), οι οποίοι μπορούν να προγραμματιστούν γράφοντας προγράμματα σε γλώσσα υψηλού επιπέδου (όπως η C). Με αυτόν τον τρόπο έχουμε ευελιξία, ενώ η απόδοση και οι άλλοι περιορισμοί ικανοποιούνται αποτελεσματικά. Ο επεξεργαστής συνόλου εντολών ειδικής εφαρμογής είναι ένας προγραμματιζόμενος επεξεργαστής, ο οποίος είναι βελτιστοποιημένος για την εκτέλεση μιας συγκεκριμένης κλάσης εφαρμογών με κοινά χαρακτηριστικά, όπως η ψηφιακή επεξεργασία σήματος, τηλεπικοινωνίες κτλ. Ένα χαρακτηριστικό αυτού του τύπου επεξεργαστή, είναι ότι ο σχεδιαστής μπορεί να βελτιστοποιήσει το μονοπάτι δεδομένων ανάλογα με τις απαιτήσεις της κλάσης εφαρμογών. Με άλλα λόγια, ο επεξεργαστής μπορεί να περιέχει καταχωρητές ειδικού σκοπού και διαύλους για την ταχεία ολοκλήρωση των υπολογισμών. Επίσης, ο σχεδιαστής μπορεί να προσθέσει λειτουργικές μονάδες ειδικού σκοπού για να εκτελέσουν ορισμένες κοινές απαιτητικές λειτουργίες σε λιγότερους κύκλους ρολογιού και να απαλείψει κάποιες άλλες μονάδες οι οποίες είναι περιττές.
Έκτος των βασικών λειτουργικών μονάδων, ο επεξεργαστής μπορεί να περιέχει μονάδες ελέγχου ειδικού σκοπού, για να εκτελέσουν κοινές και συνδυασμένες λειτουργίες σε λιγότερους κύκλους, όπως η εκτέλεση λειτουργιών πολλαπλασιασμού και πρόσθεσης σε μια μόνο εντολή. Με τη χρήση του επεξεργαστή ειδικής εφαρμογής μέσα στο ενσωματωμένο σύστημα, υπάρχουν πολλά οφέλη: Ευελιξία, γρήγορη ανάπτυξη και αποσφαλμάτωση, ενώ συγχρόνως η χρήση του συγκεκριμένου επεξεργαστή συνδέεται με πολύ καλή απόδοση για τη συγκεκριμένη κλάση εφαρμογών, μικρότερο μέγεθος από ένα γενικού τύπου επεξεργαστή και συνεπώς μικρότερη κατανάλωση με μικρότερο κόστος. Ως προς τους μηχανικούς που σχεδιάζουν και κατασκευάζουν αυτούς τους επεξεργαστές, απαιτείται μεγάλο κόστος στην έρευνα και ανάπτυξη τόσο του υλικού, όσο και του λογισμικού υποστήριξης, όπως είναι οι μεταγλωττιστές και οι συμβολομεταφραστές.
Ένα παράδειγμα επεξεργαστή, από την κλάση επεξεργαστών ASIP, είναι οι επεξεργαστές ψηφιακού σήματος (Digital Signal Processor - DSP). Ένα DSP είναι ένας επεξεργαστής σχεδιασμένος για την ψηφιακή επεξεργασία ενός μεγάλου όγκου δεδομένων. Η προέλευση αυτού του μεγάλου όγκου δεδομένων είναι σε μορφή ψηφιακού σήματος, όπως οι εικόνες από μια ψηφιακή κάμερα, ένα πλαίσιο ήχου (ή φωνής) μέσω μιας συσκευής τηλεφωνίας διαδικτύου (Voice Over Internet Protocol, VOIP), φίλτρα, δρομολογητές δικτύου κτλ.
Συνήθως, ένα DSP περιέχει πολλούς καταχωρητές, πολλαπλά τμήματα μνήμης, πολλαπλασιαστές και άλλες αριθμητικές μονάδες. Επίσης, τα DSP περιέχουν ειδικές εντολές για ψηφιακή επεξεργασία σήματος, όπως το φιλτράρισμα σήματος, μετασχηματισμούς ή συνδυασμός αυτών. Επιπλέον, ένα DSP περιέχει συχνά αριθμητικές μονάδες για την υλοποίηση απαιτητικών λειτουργιών, όπως οι πράξεις πολλαπλασιασμού και πρόσθεσης ή ολίσθησης και πρόσθεσης, οι οποίες υλοποιούνται σε υλικό και εκτελούνται πολύ ταχύτερα από μια υλοποίηση λογισμικού σε έναν μικροεπεξεργαστή. Για παράδειγμα, ο επεξεργαστής DSP περιέχει μονάδες ειδικού σκοπού, όπως μια μονάδα πολλαπλασιασμού-πρόσθεσης (multiply-accumulate unit, MAC), η οποία μπορεί να εκτελεί μια πράξη σαν τη με μια μόνο εντολή. Επίσης, ένα DSP μπορεί να επιτρέψει τη παράλληλη εκτέλεση μερικών λειτουργιών. Για παράδειγμα, επειδή τα προγράμματα DSP συχνά χειρίζονται μεγάλους πίνακες δεδομένων, ένα DSP μπορεί να περιέχει ένα εξειδικευμένο υλικό ώστε να ανακαλεί ακολουθιακές θέσεις μνήμης παράλληλα με άλλες πράξεις, έτσι ώστε να επιταχύνει ακόμα περισσότερο την εκτέλεση. Τέλος, ένα DSP μπορεί να περιέχει έναν αριθμό ενσωματωμένων περιφερειακών συσκευών, που είναι χρήσιμες για την επεξεργασία σήματος πάνω σε ένα ολοκληρωμένο κύκλωμα. Για παράδειγμα, μια συσκευή DSP πιθανώς να περιέχει μετατροπείς σήματος αναλογικό σε ψηφιακό, ψηφιακό σε αναλογικό, χρονιστές, μετρητές συμβάντων, ελεγκτές άμεσης πρόσβασης μνήμης, σειριακές θύρες επικοινωνίας κλπ.
Τα ολοκληρωμένα κυκλώματα εξειδικευμένης εφαρμογής (Application-specific integrated circuits - ASICs) αναφέρονται σε εκείνα τα ολοκληρωμένα κυκλώματα που κατασκευάζονται ειδικά για συγκεκριμένες υπολογιστικές εργασίες. Με άλλα λόγια, το κάθε ολοκληρωμένο κύκλωμα κάνει μια συγκεκριμένη εργασία γρήγορα, αλλά ενδεχόμενα είναι ακατάλληλο για άλλη δουλειά έστω και αν εκείνη έχει πάνω από 90% ομοιότητα με την πρώτη. Για παράδειγμα, ένα κύκλωμα ASIC που χρησιμοποιείται για την εξόρυξη νομισμάτων bitcoin χρησιμοποιώντας συναρτήσεις σύνοψης, είναι παντελώς ακατάλληλο για την εξόρυξη νομισμάτων σε οποιοδήποτε άλλο νόμισμα ή ακόμη και για υπολογισμό συναρτήσεων σύνοψης για άλλα θέματα. Στο ASIC οι λειτουργίες που επιτελεί κατασκευάζονται μόνιμα πάνω στο υπόστρωμα και δε μπορούν να μεταβληθούν.
Εντούτοις, υπάρχουν περιπτώσεις που προτιμάται η χρήση ενός ASIC ως προς έναν μικροεπεξεργαστή ή μικροελεγκτή, ακόμη και αν δεν παρέχει καθόλου ευελιξία. Στα πλεονεκτήματα που στηρίζουν την επιλογή του ASIC, συγκαταλέγονται τα παρακάτω: αυξανόμενη ταχύτητα, μικρή κατανάλωση ενέργειας, χαμηλό κόστος (για τη μαζική παραγωγή), καλύτερη διασφάλιση ορθής λειτουργίας, καλύτερος έλεγχος των χαρακτηριστικών Ε/Ε και περισσότερο συμπαγή σχεδιασμό πλακέτας (λιγότερο σύνθετο PCB).
Η επιλογή ενός ASIC συνδέεται και με σημαντικά μειονεκτήματα, όπως μακροχρόνια σχεδίαση, δυσκολία στη ρύθμιση της γραμμής παραγωγής του ASIC στα εργοστάσια κατασκευής (απαιτούνται αρκετές δεκάδες εβδομάδες), ακριβή διαδικασία για χαμηλού όγκου παραγωγή, πολύ υψηλό κόστος ανάπτυξης (υψηλή επένδυση στα εργαλεία CAD και σε σταθμούς εργασίας) και τέλος η λειτουργία του είναι δεσμευμένη και δε μπορεί να τροποποιηθεί.
Τα ολοκληρωμένα κυκλώματα εξειδικευμένης εφαρμογής μπορούν να ταξινομηθούν σε τρεις κατηγορίες: η πλήρους εξατομίκευση ASIC (full-custom), η ημι-εξατομίκευση ASIC (semicustom) και επί του πεδίου προγραμματιζόμενων ολοκληρωμένων κυκλωμάτων (field programmable IC), όπως φαίνεται στο Σχήμα 4.9. H τελευταία κατηγορία αναφέρεται μερικές φορές ως επί του πεδίου προγραμματιζόμενοι συστοιχίες πυλών (field programmable gate arrays, FPGA), που θα την εξετάζουμε διεξοδικά στην επόμενη ενότητα.
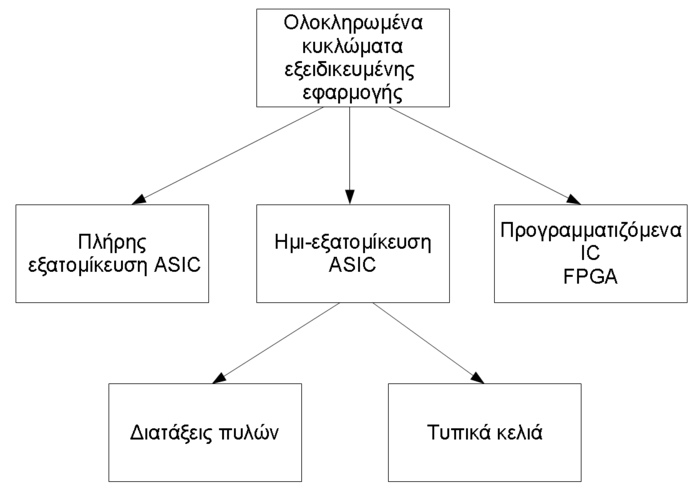
4.9: Κατηγορίες ολοκληρωμένων κυκλωμάτων εξειδικευμένης εφαρμογής.
Πριν αναλύσουμε τις παραπάνω κατηγορίες πρέπει να σημειώσουμε ότι ένα ολοκληρωμένο κύκλωμα (integrated circuit) ή αλλιώς τσιπ (chip) είναι μια συσκευή ημιαγωγών (semiconductor device) που αποτελείται από ένα σύνολο συνδεδεμένων τρανζίστορ και άλλων συσκευών. Υπάρχει ένα πλήθος διαφορετικών διαδικασιών και τεχνολογιών για να κατασκευαστούν ημιαγωγοί, η πιο δημοφιλής είναι ο συμπληρωματικός ημιαγωγός μετάλλου-οξειδίου (complementary metal oxide semiconductor - CMOS [32]). Έτσι, οι ημιαγωγοί (semiconductors) αποτελούνται από πολλά στρώματα μετάλλου, οξειδίου του πυριτίου και απλού πυριτίου, όπως φαίνεται στο Σχήμα 4.1018. Τα κατώτατα στρώματα σχηματίζουν τα τρανζίστορ. Τα μεσαία στρώματα σχηματίζουν λογικά συστατικά ή λογικές πύλες. Τα ανώτερα στρώματα συνδέουν αυτά τα λογικά συστατικά με αγωγούς. Ένας τρόπος για να δημιουργηθούν αυτά τα στρώματα είναι η τοποθέτηση φωτοευαίσθητων χημικών ουσιών στην επιφάνεια του τσιπ και έπειτα η είσοδος του φωτός μέσω των μασκών για να τροποποιηθούν οι περιοχές των χημικών ουσιών. Ένα σύνολο μασκών ονομάζεται συχνά κατάστρωση (layout).
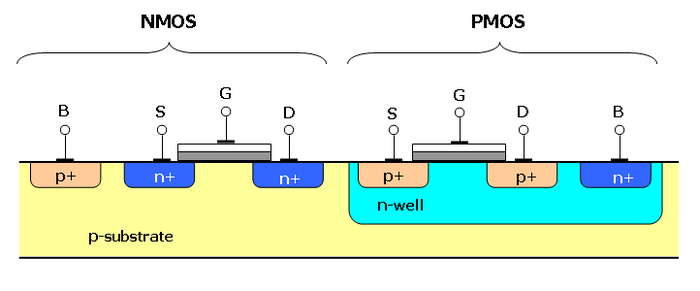
4.10: Ένα τρανζίστορ CMOS αποτελείται από πολλά στρώματα υλικού. By Reza Mirhosseini - originally uploaded to en.wikipedia. Licensed under Public Domain via Commons. Εικόνα από wikipedia.org.
Συνεπώς, για να αποκτήσουμε ένα ολοκληρωμένο κύκλωμα που υλοποιεί μια συγκεκριμένη υπολογιστική εργασία, πρέπει τελικά να κατασκευαστούν όλα τα στρώματα ή αλλιώς η κατάστρωση. Το ζητούμενο είναι ποιος κατασκευάζει κάθε στρώμα και πότε. Η απάντηση στο ερώτημα αυτό βρίσκεται στις τρεις κατηγορίες που θα αναφέρουμε παρακάτω.
Σε ένα ASIC πλήρους εξατομίκευσης, υλοποιούνται όλα τα επίπεδα στο πυρίτιο με την πλήρη δημιουργία όλων των στρωμάτων μασκών, όπως φαίνεται στο Σχήμα 4.11.
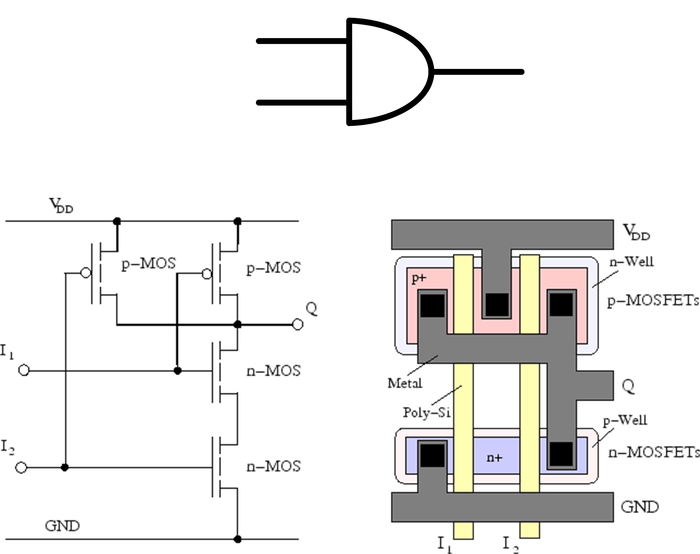
4.11: Σε μια σχεδίαση πλήρους - εξατομίκευσης πρέπει να ορίζεται κάθε στρώμα υλικού.
Έτσι, βελτιστοποιούμε όλα τα στρώματα για μια συγκεκριμένη ψηφιακή υλοποίηση του ενσωματωμένου συστήματος. Τέτοια βελτιστοποίηση περιλαμβάνει την τοποθέτηση των τρανζίστορ για να ελαχιστοποιηθούν τα μήκη διασύνδεσης, κλιμάκωση των τρανζίστορ (δηλαδή βέλτιστη επιλογή μεγέθους τρανζίστορ) για να βελτιστοποιηθούν οι μεταδόσεις σημάτων και συνδέσεις μεταξύ των τρανζίστορ μέσω καλωδίων χωρίς να τέμνονται άλλα καλώδια ή τρανζίστορ. Μόλις ολοκληρώσουμε όλες τις μάσκες ή αλλιώς δημιουργήσουμε μια πλήρη κατάστρωση, στέλνουμε τις προδιαγραφές των μασκών σε έναν προμηθευτή που κατασκευάζει τα ολοκληρωμένα κυκλώματα. Τα πλεονεκτήματα των σχεδιασμών πλήρης εξατομίκευσης περιλαμβάνουν την υψηλότερη απόδοση, την αποτελεσματική ισχύ και το μικρότερο μέγεθος ψηφίδων ή κύβων (die). Όμως, τα κύρια μειονεκτήματα είναι ο μεγαλύτερος χρόνος σχεδίασης, η υψηλότερη πολυπλοκότητα και κόστος, μαζί με τον υψηλότερο κίνδυνο αποτυχίας. Αυτή η επιλογή σχεδιασμού έχει μόνο νόημα όταν δεν είναι διαθέσιμες ούτε οι βιβλιοθήκες ούτε οι πυρήνες πνευματικής ιδιοκτησίας IP, ή όταν απαιτούνται πολύ υψηλές αποδόσεις. Επανειλημμένως, λίγα έργα είναι πραγματικά ‘πλήρης - εξατομίκευσης’ λόγω του πολύ υψηλού κόστους και του απαγορευτικού αργού χρόνου εισαγωγής στην αγορά. Οι περισσότερες από τις εργασίες πλήρης - εξατομίκευσης συσχετίζονται με την παραγωγή βιβλιοθήκης κελιών ή δευτερεύοντα μέρη ενός πλήρους σχεδιασμού. Παραδείγματα ολοκληρωμένων κυκλωμάτων πλήρους - εξατομίκευσης βρίσκονται σε συστήματα χαμηλών χρόνων απόκρισης (π.χ. αυτοκίνητα, ηλεκτρονικά συστήματα αεροσκαφών) ή ειδικών απαιτήσεων (π.χ. στρατιωτικές εφαρμογές ή διαστημικά ηλεκτρονικά). Παραδοσιακά, οι μικροεπεξεργαστές και οι μνήμες ήταν αποκλειστικά πλήρους - εξατομίκευσης, αλλά η βιομηχανία στρέφεται όλο και περισσότερο σε τεχνικές ημι-εξατομίκευσης ASIC.
Το κόστος έρευνας και ανάπτυξης για πλήρη εξατομικευμένη σχεδίαση ASIC είναι πολύ μεγάλο και έτσι χρησιμοποιείται μόνο σε περιπτώσεις που κάποιο ASIC θα πουληθεί σε εκατομμύρια κομμάτια, όπως είχαμε συζητήσει στο πρώτο κεφάλαιο. Προκειμένου να μειωθεί το υπερβολικά υψηλό κόστος της πλήρους εξατομίκευσης στα περισσότερα έργα, έχει αναπτυχθεί μια ευρεία ποικιλία προσεγγίσεων σχεδιασμού για να μειωθεί ο χρόνος σχεδίασης, να μειωθεί ο χρόνος εισαγωγής προϊόντος στην αγορά, να μειωθούν τα κόστη και να αυτοματοποιηθούν οι διαδικασίες. Αυτές οι προσεγγίσεις συνήθως καλούνται ημι-εξατομίκευση (semicustom). Οι σχεδιασμοί ημι-εξατομίκευσης υλοποιούνται σε επίπεδο λογικών πυλών. Υπό αυτήν την έννοια, χάνουν μερικώς την ευελιξία που ήταν διαθέσιμη από την πλήρους - εξατομίκευσης - δηλαδή καταβάλλεται το κόστος για μια πολύ ευκολότερη τεχνική σχεδίασης. Οι λύσεις ημι-εξατομίκευσης μπορούν να ταξινομηθούν περαιτέρω σε διατάξεις πυλών (gate arrays) και τυπικά κελιά (standard cell).
Διατάξεις Πυλών: Οι διατάξεις πυλών ASIC αποτελούνται από συνεχείς διατάξεις τρανζίστορ των τύπων και
. Ο προμηθευτής πυριτίου παρέχει προσχεδιασμένα πλακίδια βάσης (master or base wafers), τα οποία περιέχουν ένα σύνολο μασκών προκαθορισμένων πυλών και έπειτα διαμορφώνονται σύμφωνα με τις πληροφορίες διασύνδεσης που παρέχονται από τον πελάτη, δηλαδή ο σχεδιαστής συνδέει τις πύλες για να υλοποιήσει ένα συγκεκριμένο κύκλωμα. Επομένως, ο σχεδιαστής παίρνει τις εξατομικευμένες πληροφορίες που ορίζουν τις συνδέσεις μεταξύ των τρανζίστορ σε μια διάταξη πυλών. Παρόλο που μια διάταξη πυλών προτυποποιεί το τσιπ σε επίπεδο γεωμετρίας, τυπικά η αλληλεπίδραση χρήστη ακόμα υφίσταται σε λογικό επίπεδο. Η απεικόνιση, από τρανζίστορ σε πύλες, εκτελείται μέσω ενός ειδικού εργαλείου CAD (computer aided design, σχεδίαση υποβοηθούμενη από τον υπολογιστή). Η διάταξη πυλών χρησιμοποιεί μια βιβλιοθήκη συστατικών και μακροεντολών που μειώνουν το χρόνο ανάπτυξης. Δύο κύριοι τύποι διατάξεων πυλών μπορούν να αναφερθούν: με κανάλι (channeled) και χωρίς κανάλι (channelless), όπως φαίνεται στο Σχήμα 4.12.
Σε μια διάταξη πυλών με κανάλι, οι διασυνδέσεις σχεδιάζονται μέσα στα προκαθορισμένα διαστήματα (κανάλια) μεταξύ των γραμμών των λογικών κελιών. Σε μια διάταξη πυλών χωρίς κανάλι, γίνεται αντιληπτό ότι δεν υπάρχουν κανάλια σύνδεσης. Δηλαδή, οι συνδέσεις σχεδιάζονται με τα ανώτερα στρώματα μεταλλικών, στην κορυφή των λογικών κελιών. Και στις δύο περιπτώσεις, μόνο μερικά στρώματα μασκών (τα ανώτερα) πρέπει να σχεδιαστούν και να κατασκευαστούν, για τη συγκεκριμένη εφαρμογή.
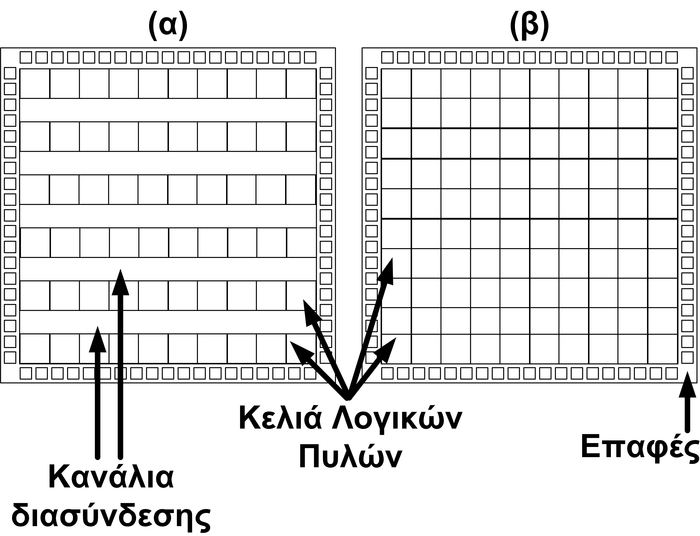
4.12: Δύο αρχιτεκτονικές διατάξεων πυλών: διατάξεις πυλών channeled και channelless.
Τυπικά Κελιά ASIC: Τα τυπικά κελιά είναι λογικά συστατικά, όπως πύλες, πολυπλέκτες, αθροιστές, flip-flops, που σχεδιάζονται προηγουμένως και αποθηκεύονται σε μια βιβλιοθήκη. Έτσι, τα τρανζίστορ μέσα σε ένα κελί είναι προσχεδιασμένα, αλλά δεν έχει προσδιοριστεί η τοποθέτηση των κελιών. Ο σχεδιαστής για να υλοποιήσει μια συγκεκριμένη εφαρμογή πρέπει να επιλέξει ποια κελιά θα χρησιμοποιήσει και στην συνέχεια ασχολείται με την τοποθέτηση και την σύνδεση τους. Για αυτό μια σχεδίαση δημιουργείται χρησιμοποιώντας τις επιλεγμένες βιβλιοθήκες κελιών ως είσοδοι σε ένα σύστημα CAD: ο κώδικας περιγραφής μιας γλώσσας περιγραφής υλικού (hardware description language - HDL) συνθέτεται και επιλέγονται τα κατάλληλα κελιά. Έπειτα, ένα εργαλείο CAD μετατρέπει αυτόματα τη σχεδίαση σε μια κατάστρωση τσιπ (δηλαδή, τοποθέτηση και σύνδεση μεταξύ των κελιών). Οι σχεδιασμοί τυπικών κελιών οργανώνονται στο τσιπ, ως γραμμές κελιών σταθερού ύψους, όπως φαίνεται στο Σχήμα 4.13. Μαζί με τα συστατικά κελιών λογικού επιπέδου, τα συστήματα τυπικών κελιών προσφέρουν συναρτήσεις υψηλού επιπέδου όπως πολλαπλασιαστές και διατάξεις μνήμης. Με αυτό τον τρόπο, επιτρέπεται η χρήση προκαθορισμένων συστατικών υψηλού επιπέδου για την ολοκλήρωση της σχεδίασης.
Τα βήματα σε μια παραδοσιακή σχεδιαστική ροή ASIC είναι:
Εισαγωγή σχεδιασμού (design entry): εισαγωγή σχεδιασμού χρησιμοποιώντας είτε μια γλώσσα περιγραφής υλικού όπως οι VHDL, Verilog ή ένα σχηματικό συντάκτη (schematic editor).
Λογική σύνθεση (logic synthesis): από την γλώσσα περιγραφής υλικού εξάγεται μια λίστα διασυνδέσεων netlist, δηλαδή μια περιγραφή των λογικών κελιών και των συνδέσεων τους.
Διαμερισμός συστήματος (system partitioning): διαιρεί ένα μεγάλο σύστημα σε τμήματα μεγέθους ASIC.
Προσομοίωση συμπεριφοράς (behavioral simulation): ελέγχει την λειτουργία των κυκλωμάτων.
Χωροθέτηση (floorplanning): τακτοποιεί τα διαφορετικά τμήματα του κυκλώματος στο τσιπ.
Τοποθέτηση (placement): τοποθετεί τις θέσεις των κελιών σε ένα τμήμα.
Διασύνδεση (routing): δημιουργεί συνδέσεις μεταξύ των κελιών και των τμημάτων.
Εξαγωγή (extraction): προσδιορίζει την αντίσταση και την χωρητικότητα των διασυνδέσεων και υπολογίζει τις καθυστερήσεις για τους σκοπούς της προσομοίωσης.
Φυσική προσομοίωση (physical simulation): ελέγχει την λειτουργία του κυκλώματος μετά την συμπερίληψη των καθυστερήσεων που δημιουργούνται από τα φορτία διασύνδεσης.
Έλεγχος κανόνων σχεδίασης (design rule check - DRC): ελέγχει ότι η κατάστρωση του κυκλώματος συμμορφώνεται με τις προδιαγραφές των κανόνων σχεδίασης. Τα εργαλεία DRC κυμαίνονται από μια απλή φυσική εξέταση χώρου μέχρι και σύνθετους ελέγχους.
Μέχρι τώρα είδαμε ολοκληρωμένα κυκλώματα εξειδικευμένης εφαρμογής που τα κυκλώματα τους είναι σταθερά και μόνιμα. Δηλαδή, κυκλώματα που εκτελούν μια συγκεκριμένη λειτουργία και μόλις κατασκευαστούν δεν μπορούν να αλλάξουν την λειτουργικότητα τους. Επίσης, το κόστος ανάπτυξης για να κατασκευάσουμε ένα ολοκληρωμένο κύκλωμα (δηλαδή, να δημιουργήσουμε μια κατάστρωση και μάσκες) μπορεί να είναι πάρα πολύ ακριβό για να γίνει απόσβεση, εάν ο αριθμός των κυκλωμάτων που εκτιμάμε πως θα πουληθούν είναι μικρός. Επιπλέον, η κατασκευή ενός ολοκληρωμένου κυκλώματος είναι ένα ρίσκο, εφόσον μετά την κατασκευή ανακαλύψουμε ότι ένα ολοκληρωμένο κύκλωμα δεν λειτουργεί σωστά στο σύστημα στόχου εξαιτίας των προβλημάτων κατασκευής ή εσφαλμένου αρχικού σχεδιασμού. Συνεπώς, θα θέλαμε μια λογική συσκευή που θα μας επιτρέψει να υλοποιήσουμε την λειτουργικότητα του συστήματος πάνω στην συσκευή αυτή και να μην απαιτείται από μας να κατασκευάσουμε το ολοκληρωμένο κύκλωμα. Γι αυτό το λόγο υπάρχουν εμπορικές προγραμματιζόμενες λογικές συσκευές, τις οποίες μπορούμε να προγραμματίζουμε επί τόπου (ή επί του πεδίου εφαρμογής) στο εργαστήριο μας. Εδώ, ο όρος πρόγραμμα δεν αναφέρεται στην συγγραφή λογισμικού το οποίο εκτελείται σε ένα μικροεπεξεργαστή, αλλά σημαίνει διαμόρφωση λογικών κυκλωμάτων και διασύνδεση διακοπτών ώστε να υλοποιήσουμε ένα συγκεκριμένο επιθυμητό κύκλωμα. Συνεπώς, οι προγραμματιζόμενες λογικές συσκευές έχουν το πλεονέκτημα ότι μπορούν να αλλάξουν την λειτουργία των κυκλωμάτων σύμφωνα με τις ανάγκες της εφαρμογής που θέλουμε να υλοποιήσουμε. Η αλλαγή ασφαλώς υλοποιείται από τον προγραμματιστή ή σχεδιαστή του υλικού, και με τη μεταφόρτωση του παραγόμενου αρχείου περιγραφής, που ονομάζεται bitstream.
Η τεχνολογία FPGA μας επιτρέπει να αγοράσουμε ένα προκατασκευασμένο ολοκληρωμένο κύκλωμα που θα περιέχει όλα τα στρώματα λογικής και διασύνδεσης, πριν ακόμα υλοποιήσουμε την λειτουργικότητα της εφαρμογής μας. Τα στρώματα υλοποιούν ένα προγραμματιζόμενο κύκλωμα, όπου ο προγραμματισμός έχει μια σημασία χαμηλού επιπέδου παρά ένα πρόγραμμα λογισμικού. Έτσι, ο προγραμματισμός που λαμβάνει χώρα, αποτελείται από τη δημιουργία ή καταστροφή συνδέσεων ανάμεσα στα καλώδια, τα οποία συνδέουν πύλες είτε καταστρέφοντας (‘καίγοντας’) μια ασφάλεια ή θέτοντας ένα bit σε ένα προγραμματιζόμενο διακόπτη ή πολυπλέκτη. Υπάρχουν μικρές συσκευές που λέγονται προγραμματιστές (programmers), όπως το USB Blaster της Altera ή το JTAG Programmer της Xilinx, οι οποίες συνδέονται με έναν υπολογιστή γραφείου και εκτελούν τον προγραμματισμό που αναφέραμε. Τέλος, υπάρχουν πολλές προγραμματιζόμενες λογικές συσκευές, αλλά η πιο δημοφιλής είναι η επί του πεδίου προγραμματιζόμενες συστοιχίες πυλών (Field Programmable Gate Arrays - FPGA). Οι συσκευές FPGAs μπορούν να υλοποιήσουν ένα οποιοδήποτε σχεδιασμό υλικού, όπως ένα ολόκληρο πυρήνα επεξεργαστή (processor core), μαζί με τα περιφερειακά εντός του ίδιου ολοκληρωμένου κυκλώματος. Επίσης, αυτές οι συσκευές είναι ειδικά κατάλληλες για ταχεία προτυποποίηση ενός τμήματος υλικού το οποίο τελικά θα υλοποιηθεί αργότερα σε ένα ASIC. Παρακάτω δίνουμε μια σύντομη ιστορική ανασκόπηση και περιγράφουμε την βασική αρχιτεκτονική των FPGA.
Ο βασικός σκοπός της τεχνολογίας FPGA είναι η επίτευξη ικανοποιητικής απόδοσης στην υλοποίηση του κυκλώματος, σε σύγκριση με τα κυκλώματα εξειδικευμένου σκοπού, ενώ παράλληλα εξακολουθούν να παρέχουν το πλεονέκτημα της ευελιξίας όπως εμφανίζουν οι επεξεργαστές γενικού σκοπού. Επίσης, σε σχέση με τα κυκλώματα εξειδικευμένου σκοπού, η τεχνολογία FPGA έχει διάφορα πλεονεκτήματα όπως: ταχύς χρόνος για την εισαγωγή προϊόντος στην αγορά, χαμηλό μη-επαναλαμβανόμενο κόστος κατασκευής, δεν απαιτείται καμία μάσκα κατασκευής, ιδανικές για προτυποποίηση και τέλος γίνονται σχεδιαστικές αλλαγές χωρίς κόστος. Έτσι, διαμορφώνοντας μια συσκευή με ένα καινούργιο κύκλωμα, τα λάθη σχεδίασης μπορούν εύκολα να διορθωθούν, να προστεθούν νέα χαρακτηριστικά ή η λειτουργία του υλικού μπορεί εύκολα να απεικονιστεί σε άλλες εφαρμογές. Φυσικά, τα ολοκληρωμένα κυκλώματα FPGA σε σχέση με τα ASICs κοστίζουν περισσότερο ανά τσιπ για να εκτελέσουν μια συγκεκριμένη λειτουργία και έτσι δεν είναι καλοί υποψήφιοι για σχεδιασμούς που στοχεύουν σε μεγάλη παραγωγή.
Επειδή οι επαναπρογραμματιζόμενες αρχιτεκτονικές, όπως τα FPGA και τα PLD (programmable logic devices, προγραμματίσιμες συσκευές λογικής) έχουν αποκτήσει ιδιαίτερη δημοτικότητα και πολλαπλές χρήσεις, ακολουθεί μια λεπτομερή περιγραφή στο επόμενο κεφάλαιο.
Όπως αναλύσαμε προηγουμένως, μια τυπική τεχνολογία υλοποίησης των ΕΣ, είναι τα ASIC. Όμως, σε μερικές περιπτώσεις (παραδείγματος χάριν, σε αυτές όπου ο αναμενόμενος όγκος προϊόντων δεν δικαιολογεί τα έξοδα πλήρους σχεδιασμού και τις δαπάνες NRE μιας τυπικής σχεδίασης ASIC), προτιμώνται άλλες τεχνολογίες, όπως τα FPGAs και τα PLDs Το κόστος μερικών συστατικών NRE (όπως τα σύνολα μασκών) αυξάνεται με αντίστροφη αναλογία ως προς τα μεγέθη χαρακτηριστικών γνωρισμάτων VLSI, και αυτά γίνονται θεμελιώδεις περιοριστές στην οικονομική βιωσιμότητα ενός συγκεκριμένου σχεδιασμού σε έναν δεδομένο όγκο συστημάτων. Αυτό σημαίνει ότι σημείο ισορροπίας για τη χρήση της εναλλακτικής τεχνολογίας (όπως η επαναδιαμορφώσιμη λογική) μετατοπίζεται, οπότε όλο και περισσότερα κυκλώματα δε δικαιολογούν μια πλήρη επένδυση σε μια γραμμή παραγωγής VLSI μικρού μεγέθους τρανζίστορ. Οι σχεδιαστές αυτών των κυκλωμάτων επιλέγουν άλλες εναλλακτικές αρχιτεκτονικές, όπως FPGA και PLD.
Τα FPGAs και PLDs (συχνά ομαδοποιούνται με τον κοινό όρο επαναδιαμορφώσιμη λογική), επιτρέπουν στους σχεδιαστές να επιτύχουν υψηλή απόδοση παρόμοια με τα τυπικά τυποποιημένα δομοστοιχεία που υπάρχουν στην αγορά.
Η επαναδιαμορφώσιμη λογική ανταλλάσσει το υψηλότερο κόστος του υλικού (και συχνά την ταχύτητα, αλλά όχι πάντα) με τις χαμηλότερες δαπάνες σχεδίου και τη γρηγορότερη είσοδο στην αγορά. Δηλαδή, το κόστος αγοράς ενός ολοκληρωμένου κυκλώματος FPGA είναι αρκετά μεγάλο, ως προς ένα IC παρόμοιου αριθμού πυλών. Πχ. ένα ολοκληρωμένο κύκλωμα FPGA με περίπου 1.2 δισεκατομμύρια τρανζίστορ XC5VFX30T-1FFG665C, FPGA Virtex-5 κοστίζει το 2015 πάνω από 1000 ευρώ, ενώ ένα αρκετά πολύπλοκο IC που έχει 1.4 δισεκατομμύρια τρανζίστορ με τον επεξεργαστή CPU INTEL CORE I7-4790K 4.00GHZ LGA1150, κοστίζει 400 ευρώ.
Αν και το κόστος ανά τρανζίστορ στα FPGA είναι σχεδόν τριπλάσιο, εντούτοις το FPGA IC είναι πολύ πιο ευέλικτο και μπορεί να προσαρμοστεί σε κάθε πρόβλημα. Από αυτή την άποψη, είναι μια καλή αντιστοιχία με τα χαμηλού όγκου πωλήσεων προϊόντα. Πιο πρόσφατα, οι σχεδιαστές είχαν αρχίσει να χρησιμοποιούν τα FPGAs και PLDs για να υλοποιήσουν δυναμικά επαναδιαμορφώσιμους πυρήνες υπολογισμού, όπου αναλόγως τις ανάγκες του προβλήματος φορτώνεται κατ’ απαίτηση η κατάλληλη διαμόρφωση, και έτσι το υπόστρωμα υλικού ανταποκρίνεται καλύτερα στο πρόβλημα. Για παράδειγμα, έστω ένας υπολογιστικός πυρήνας εκτίμησης κίνησης έχει ρυθμιστεί στο υλικό να επεξεργάζεται block 32x32 pixels. Θα μπορούσε να ζητηθεί μια καλύτερη ποιότητα στο τελικό αποτέλεσμα με το να επαναδιαμορφωθεί για να επεξεργάζεται block 16x16. Η επαναδιαμόρφωση κατά το χρόνο εκτέλεσης μπορεί να χρησιμοποιηθεί για να αλλάξει τη συμπεριφορά του κυκλώματος, είτε ως προς την απόδοση, είτε ως προς την κατανάλωση. Βέβαια, η επαναδιαμόρφωση μπορεί να γίνει μόνο σε συγκεκριμένα FPGA και μόνο για συγκεκριμένα προβλήματα, στα οποία η εφαρμογή μπορεί να τμηματοποιηθεί, οπότε να επαναδιαμορφωθεί μόνο το κατάλληλο τμήμα και όχι όλο το ολοκληρωμένο κύκλωμα. Πάντως, η χρήση των FPGA βρίσκει απήχηση και στα συστήματα που εισέρχονται πρώτα στην καταναλωτική αγορά (first batch), τα οποία συνήθως έχουν προβλήματα και ίσως δεν ανταποκρίνονται πλήρως στις προσδοκίες των χρηστών. Με την επαναδιαμορφώσιμη λογική, μπορούν να γίνονται ενημερώσεις ή τροποποιήσεις με στόχο τη βελτίωση. Επίσης, μια εταιρία όσο περιμένει την ολοκλήρωσης της παραγωγικής διαδικασίας για τα ASIC, μπορεί να χρησιμοποιεί FPGA τα οποία βασίζονται στην ίδια περιγραφή HDL, βοηθώντας την επίτευξη ενός γρήγορου ρυθμού διείσδυσης στην καταναλωτική αγορά (αν και με υψηλότερο κόστος τελικού προϊόντος αφού το FPGA IC έχει πολλαπλάσιο κόστος παραγωγής από το ASIC IC).
Για να εξεταστούν όλοι οι τύποι εφαρμογών, εξαιτίας των αυξήσεων στην πυκνότητα κυκλωμάτων μια πρόσφατη τεχνική είναι η ιδέα του συστήματος σε ένα προγραμματίσιμο τσιπ (System on a Programmable Chip, SoPC). Τα SoPCs συνδυάζουν την επαναδιαμορφώσιμη λογική με ένα σταθερό μη-επαναδιαμορφώσιμο επεξεργαστή και ένα συνδυασμό σταθερών περιφερειακών και ελεγκτών μνήμης. Αυτό συνδυάζει το καλύτερο από τους δυο κόσμους: οι μονάδες του επεξεργαστή και τα μπλοκ λογικής των περιφερειακών μπορούν να εφαρμοστούν σαν μία μακροεντολή, με τον τελευταίας τεχνολογίας σχεδιασμό ASIC, και η επαναδιαμορφώσιμη λογική μπορεί να χρησιμοποιηθεί για την υλοποίηση είτε λογικής συγκόλλησης, είτε απαιτητικών πυρήνων επεξεργασίας. Η ιδέα πίσω από το SoPC είναι να παρέχει ένα συστατικό το οποίο ταιριάζει παντού (one-size-fits-all) και να υποστηρίζει αποτελεσματικά το λογισμικό μέσα από τον παραδοσιακό πυρήνα. Την ίδια στιγμή παρέχει ένα εύκολο μονοπάτι για την περιορισμένου βαθμού ευελιξία που υπάρχει σε επεξεργαστές, χωρίς να αυξάνει το κόστος του ολοκληρωτικού σχεδιασμού ASIC.
Η πλειοψηφία των σχεδιαστών FPGA/PLD προσφέρει αυτή την στιγμή SoPC τα οποία περιλαμβάνουν δημοφιλείς πυρήνες επεξεργαστών. Για παράδειγμα η Altera προσφέρει συστατικά βασισμένα στο ARM στην γραμμή Excalibur και η Xilinx προσφέρει chips βασισμένα σε τεχνολογία PPC στην οικογένεια Virtex-II-Pro (περισσότεροι από 4 επεξεργαστές ανά FPGA). Οι τελευταίες πλακέτες της Xilinx με την αρχιτεκτονική Zynq7000 φέρουν τετραπύρηνους επεξεργαστές ARM A9 MPCore, ενώ της Altera με την αρχιτεκτονική Cyclone V SOC, φέρουν διπύρηνους επεξεργαστές ARM Cortex A9.
Σε γενικές γραμμές τα FPGA μπορούν να θεωρηθούν ως προγραμματιζόμενες συσκευές που παρέχουν μια μεγάλη πυκνότητα ολοκλήρωσης και ευελιξία. Η βασική αρχιτεκτονική των FPGA αποτελείται από τρία συστατικά, ανεξαρτήτως της εταιρίας που τα κατασκευάζει:
τη λογική μονάδα (logic block),
τη διασύνδεση (routing) και
τη μονάδα Ε/Ε (I/O block).
Τα FPGA αποτελούνται από ένα δισδιάστατο πλέγμα προγραμματιζόμενων λογικών μονάδων που μπορούν να διασυνδεθούν μεταξύ τους καθώς επίσης και με τις προγραμματιζόμενες μονάδες Ε/Ε μέσω κάποιου είδους προγραμματιζόμενης αρχιτεκτονικής διασύνδεσης. Τα τελευταία χρόνια γίνονται προσπάθειες ανάπτυξης τρισδιάστατων ολοκληρωμένων κυκλωμάτων στα FPGA, τα οποία αποτελούνται από την κατακόρυφη συσσώρευση πολλαπλών IC που συνδέονται μέσω κατακόρυφων διαμπερών οπών. Το πρώτο τρισδιάστατο FPGA, που διατέθηκε για πώληση στους καταναλωτές υψηλών απαιτήσεων, ήταν το Virtex-7 2000T που παρουσιάστηκε το 2011. Είχε 6.8 δισεκατομμύρια τρανζίστορ με συνέπεια να διαθέτει πάνω από 2 εκατομμύρια λογικά κελιά ή το ισοδύναμο 20 εκατομμυρίων λογικών πυλών. Για την κατασκευή χρησιμοποιήθηκαν 4 ολοκληρωμένα κυκλώματα FPGA Virtex, το ένα πάνω από το άλλο, με πάνω από 10.000 κατακόρυφες οπές διασύνδεσης. Εκτός από το Virtex-7 2000T, που είναι ομογενές τρισδιάστατο ολοκληρωμένο κύκλωμα, αφού και τα 4 επίπεδα φέρουν ίδια FPGA, η Xilinx παρουσίασε το 2012 μια ετερογενή αρχιτεκτονική που περιέχει 2 chip FPGA και ένα ολοκληρωμένο κύκλωμα πομποδέκτη 8 καναλιών και 28Gbps, με όνομα H580T. Όπως και τα τρισδιάστατα ολοκληρωμένα κυκλώματα ASIC, έτσι και τα FPGA έχουν πολύ υψηλό κόστος, εξαιτίας της δυσκολίας παραγωγής τους, αφού απαιτείται να ευθυγραμμιστούν χιλιάδες οπές διασύνδεσης σε όλα τα επίπεδα μεγέθους κάποιων χιλιάδων τρανζίστορ. Για αυτό και τα περισσότερα ολοκληρωμένα κυκλώματα είναι δισδιάστατα και αυτό δε φαίνεται να αλλάζει τα επόμενα χρόνια.
Όλα τα FPGA έχουν την ίδια τυπική αρχιτεκτονική, ανεξαρτήτως της εταιρίας που τα κατασκευάζει. Στο Σχήμα 4.14 φαίνεται μια γενική αρχιτεκτονική FPGA.
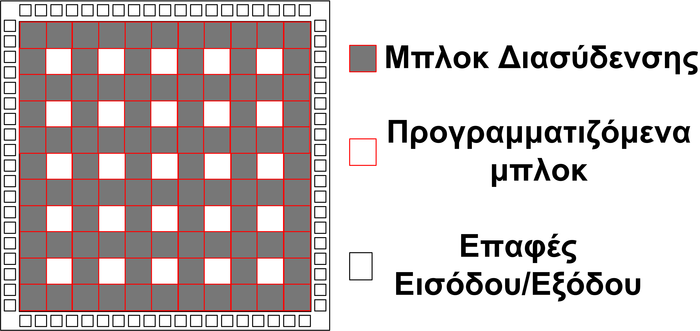
4.14: Τυπική Αρχιτεκτονική FPGA.
Για να γίνει η υλοποίηση ενός κυκλώματος σε ένα FPGA πρέπει να προγραμματιστεί η κάθε βασική λογική μονάδα του, ώστε να υλοποιεί ένα μικρό μέρος της λογικής, ενώ ταυτόχρονα κάθε μια από τις μονάδες Ε/Ε να ενεργεί είτε ως μονάδα εισόδου, είτε ως εξόδου, ανάλογα με τις απαιτήσεις του κυκλώματος. Η προγραμματιζόμενη διασύνδεση ρυθμίζεται για να υλοποιεί τις απαραίτητες συνδέσεις τόσο ανάμεσα στις βασικές λογικές μονάδες, όσο και ανάμεσα στις βασικές λογικές μονάδες και τις μονάδες Ε/Ε. Η λειτουργική πολυπλοκότητα των βασικών λογικών μονάδων μπορεί να ποικίλει από μια απλή λογική συνάρτηση 2-εισόδων έως πολύπλοκες αριθμητικές λειτουργίες πολλαπλών bit. Η επιλογή της κοκκιότητας (granularity) της βασικής λογικής μονάδας εξαρτάται από το πεδίο της κάθε εφαρμογής. Η χρησιμοποιούμενη τεχνολογία προγραμματισμού καθορίζει και τη μέθοδο αποθήκευσης της πληροφορίας προγραμματισμού. Η επιλογή της συγκεκριμένης τεχνολογίας έχει σημαντική επίδραση τόσο στην καταλαμβανόμενη επιφάνεια όσο και στην απόδοση του FPGA. Όπως αναφέρθηκε, τα FPGA είναι προγραμματιζόμενα και επαναδιαμορφούμενα πολλών χρήσεων, δηλαδή μπορούν να επανδιαμορφώνονται συνεχώς. Θα πρέπει λοιπόν να αποθηκεύεται κάπου αυτό το πρόγραμμα, και για αυτό χρησιμοποιούνται διάφορες τεχνολογίες.
Οι κυριότερες και επικρατέστερες τεχνολογίες αποθήκευσης των δεδομένων προγραμματισμού, είναι η Στατική Μνήμη Τυχαίας Προσπέλασης (SRAM), η αντι-ασφάλεια (antifuse) και η μη-πτητική (non-volatile). Η επιλογή μιας εκ των προαναφερθέντων τεχνολογιών βασίζεται κυρίως στο υπολογιστικό περιβάλλον, στο οποίο πρόκειται να χρησιμοποιηθεί το FPGA, και στις δυνατότητες του εκάστοτε ολοκληρωμένου κυκλώματος FPGA. Κάποιες τεχνολογίες επιτρέπουν τη διατήρηση του προγραμματισμού ακόμη και αν σταματήσει η παροχή και επανέλθει το ρεύμα (όπως π.χ. η Flash), ενώ κάποιες άλλες είναι πτητικές και απαιτούν σε κάθε εκκίνηση λειτουργίας τον επαναπρογραμματισμό του FPGA.
Οι προγραμματιζόμενες συσκευές FPGA που διατίθενται στην αγορά διαφέρουν στον τύπο τεχνολογίας προγραμματισμού, στην αρχιτεκτονική της βασικής λογικής μονάδας καθώς και την δομή της αρχιτεκτονικής διασύνδεσης. Στις επόμενες παραγράφους θα περιγράψουμε τα τρία συστατικά της αρχιτεκτονικής FPGA και τις τεχνολογίες προγραμματισμού.
H λογική μονάδα των FPGA είναι υπεύθυνη για την υλοποίηση σε επίπεδο πύλης της λειτουργίας που απαιτείται για κάθε εφαρμογή. Η λογική μονάδα χαρακτηρίζεται από την εσωτερική δομή και την κοκκοποίηση της. Η εσωτερική δομή καθορίζει τις διάφορες κατηγορίες λογικής τις οποίες μπορεί να υλοποιήσει, ενώ η κοκκοποίηση ορίζει το μέγεθος της συνάρτησης την οποία μπορεί να πραγματοποιήσει. Η λειτουργικότητα της λογικής μονάδας υλοποιείται ελέγχοντας τις συνδέσεις ορισμένων βασικών λογικών πυλών ή χρησιμοποιώντας πίνακες αναζήτησης (lookup-table - LUT). Η λειτουργικότητα αυτή έχει σημαντική επίπτωση καθώς αυξάνει το μέγεθος της λογικής μονάδας και είναι πιθανόν αυτό να μην αξιοποιείται πλήρως, με αποτέλεσμα να υπάρχει απώλεια τόσο στην επιφάνεια όσο και στην καταναλισκόμενη ενέργεια.
Η λογική μονάδα που χρησιμοποιείται στις FPGA μπορεί να γενικευτεί, με την κλωνοποίηση σε γειτονικές θέσεις, όπως φαίνεται στο Σχήμα 4.15.
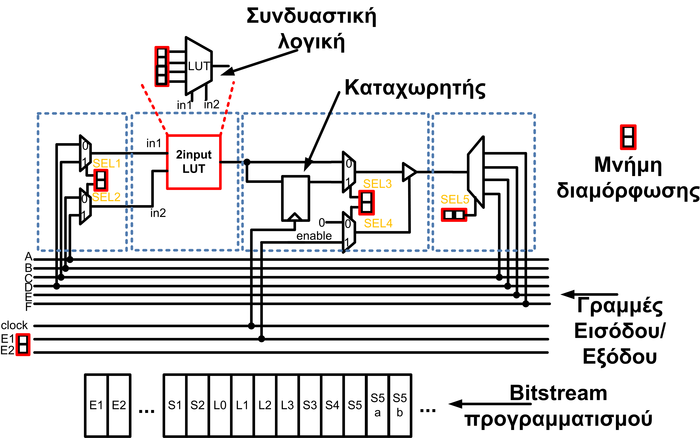
4.15: Ένα FPGA κελί αποτελείται από στοιχεία μνήμης, πολυπλέκτες και αποκωδικοποιητές.
Γενικά, το βασικό λογικό στοιχείο περιέχει κάποια μορφή μιας προγραμματιζόμενης συνδυαστικής λογικής, ένα flip-flop και κάποια γρήγορη λογική κρατουμένου για να μειώσει το χώρο και τις καθυστερήσεις. Στο γενικό μας λογικό στοιχείο, η έξοδος του στοιχείου είναι επιλέξιμη ανάμεσα στην έξοδο της συνδυαστικής λογικής ή την έξοδο του flip-flop. Επίσης, στο Σχήμα 4.15 φαίνεται κάποια μορφή προγραμματισμού ή μνήμη διαμόρφωσης για να ελέγξει την έξοδο του πολυπλέκτη, και συνεπώς την έξοδο του προγραμματίσιμου κελιού.
Όσον αφορά το τμήμα συνδυαστικής λογικής της λογικής μονάδας, έχουν χρησιμοποιηθεί διαφορετικές μέθοδοι υλοποίησης, όπως οι πίνακες αναζήτησης, οι πολυπλέκτες και οι συνδυασμοί λογικών πυλών. Έτσι, ο πιο κοινός τρόπος υλοποίησης της συνδυαστικής λογικής είναι ο πίνακας αναζήτησης (LUT). Στο Σχήμα 4.16 φαίνεται πως υλοποιείται ένας πίνακας αναζήτησης των 2 ή των 3 εισόδων.
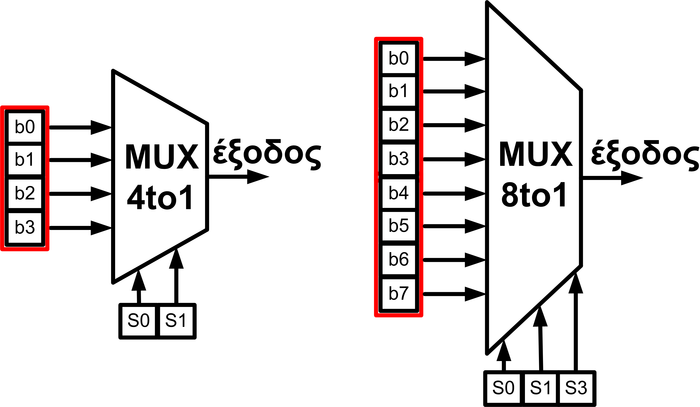
4.16: Πίνακας αναζήτησης δύο και τριών εισόδων που βρίσκεται σε ένα κελί FPGA.
Όπως φαίνεται, υπάρχει μια σειρά προγραμματιζόμενων κελιών μνήμης με έναν πολυπλέκτη, ο οποίος επιλέγει την έξοδο ενός συγκεκριμένου κελιού μνήμης. Ο πίνακας αναζήτησης λειτουργεί ως μνήμη με γραμμές διευθύνσεων και
θέσεις μνήμης. Για να υλοποιήσουμε μια συγκεκριμένη λογική συνάρτηση με την μνήμη, φορτώνεται ο πίνακας αληθείας της συνάρτησης στην μνήμη. Για παράδειγμα, σε ένα πίνακα αναζήτησης LUT αν θέσουμε
, τότε υλοποιείται μια συνάρτηση AND 3 εισόδων. Υπενθυμίζουμε ότι ο πίνακας αναζήτησης παράγει το λογικό 1 όταν όλες οι γραμμές διευθύνσεων (με ονόματα
) έχουν λογικό 1 και γι’ αυτό το κελί μνήμης της θέσης 7 (
) είναι το μόνο κελί που αποθηκεύει την τιμή 1. Οι λογικές μονάδες των οικογενειών XC3000 και XC4000 της εταιρείας Xilinx βασίζονται στους πίνακες αναζήτησης. Ένας πολυπλέκτης 3 εισόδων, μπορεί να υλοποιήσει οποιαδήποτε συνάρτηση 3 εισόδων με την τοποθέτηση της κατάλληλης σειράς bit στις εισόδους. Αν αντιγραφεί το ίδιο κύκλωμα πολλές φορές, τότε θα υπάρχει η δυνατότητα εξόδου παραπάνω από ένα bit, ώστε να δημιουργούνται στην έξοδο ολόκληρες λέξεις.
Παρόλο που οι περισσότερες προγραμματιζόμενες συσκευές FPGA χρησιμοποιούν πίνακες αναζήτησης για συνδυαστική λογική, υπάρχουν εναλλακτικές αρχιτεκτονικές βασισμένες σε πολυπλέκτες. Η βασική ιδέα του πολυπλέκτη είναι ότι για να υλοποιήσει διαφορετικές λογικές συναρτήσεις συνδέει κάθε μια από τις εισόδους της στις κατάλληλες γραμμές. Για παράδειγμα, θεωρούμε ένα πολυπλέκτη με γραμμή επιλογής εισόδου
, εισόδους
και
και έξοδο
. Θέτοντας το σήμα
σε λογικό 0, ο πολυπλέκτης μπορεί να υλοποιήσει την συνάρτηση AND
. Επίσης, θέτοντας το σήμα
σε λογικό 1, δίνει έξοδο τη συνάρτηση OR
. Έτσι, συνδέοντας ένα αριθμό από πολυπλέκτες και από βασικές λογικές πύλες, μπορεί να κατασκευαστεί ένα λογικό στοιχείο το οποίο μπορεί να υλοποιεί ένα μεγάλο αριθμό λογικών συναρτήσεων. Ένα παράδειγμα οικογένειας FPGA που στηρίζεται σε πολυπλέκτες για την υλοποίηση της λογικής μονάδας είναι αυτό της ACT3 της εταιρείας Actel.
Από την άλλη μεριά, η πολυπλοκότητα της λογικής μονάδας ποικίλει από μια πολύ μικρή μονάδα η οποία μπορεί να υλοποιήσει μια συνάρτηση 3-εισόδων, έως μια δομή η οποία είναι μια 4-bit αριθμητική λογική μονάδα (δηλαδή, πάνω από 8 εισόδους). Τόσο το μέγεθος, όσο και η πολυπλοκότητα των βασικών μονάδων, αναφέρεται συχνά ως κοκκοποίηση του τελευταίου. Με άλλα λόγια, το κριτήριο της κοκκοποίησης αναπαριστά τη μικρότερη μονάδα από την οποία αποτελείται η προγραμματιζόμενη διάταξη. Η επιλογή της κοκκοποίησης της λογικής μονάδας εξαρτάται από το πεδίο εφαρμογής στο οποίο θα χρησιμοποιηθεί το FPGA, και έχει σημαντική επίπτωση στο χρόνο που χρειάζεται για την επαναδιαμόρφωση, και είναι ιδιαίτερα κρίσιμο ειδικά για συστήματα που η διαμόρφωση γίνεται κατά την διάρκεια λειτουργίας του FPGA.
Όλες οι επαναδιαμορφούμενες πλατφόρμες διακρίνονται ανάλογα με την κοκκοποίηση τους σε λεπτόκοκκες και χοντρόκοκκες. Στις λεπτόκοκκες αρχιτεκτονικές, η βασική λογική μονάδα αποτελείται από ένα συνδυαστικό δίκτυο και μερικούς καταχωρητές. Μια διάταξη από τέτοιες λογικές μονάδες μπορεί να υλοποιήσει πολύ μικρούς υπολογισμούς και επομένως απαιτεί περισσότερα bit δεδομένων κατά την διάρκεια του προγραμματισμού. Η κοκκοποίηση αυτού του τύπου είναι περισσότερο αποδοτική για λειτουργίες ελέγχου, ενώ οι μονάδες που χαρακτηρίζονται ως χοντρόκοκκες και οι οποίες έχουν μεγαλύτερες αριθμητικές ικανότητες, είναι περισσότερο χρήσιμες για λειτουργίες μεταφοράς δεδομένων μέσω των διόδων δεδομένων (datapath).
Το Σχήμα 4.17 παρουσιάζει τη σημασία της κοκκοποίησης. Συγκεκριμένα στα σχήματα 4.17(a) και 4.17(β) εμφανίζονται δυο FPGA με μικρή και μεγάλη κοκκοποίηση, πάνω στα οποία θα απεικονιστεί μια λειτουργία, που αφαιρετικά εμφανίζεται με μια κόκκινη γραμμή. Το FPGA με τη μικρή κοκκοποίηση θα μπορέσει να αντιστοιχίσει καλύτερα αυτή τη λειτουργία σε αντίθεση με το (β) αφού στην πρώτη περίπτωση (Σχήμα4.17(γ)) θα απαιτηθούν 14/104 κελιά (ποσοστό χρήσης 14%) και στη δεύτερη περίπτωση (Σχήμα4.17(δ)) θα απαιτηθούν 9/28 κελιά (ποσοστό χρήσης 32%). Η χρήση παραπάνω κελιών, εκτός του ότι μειώνει τα διαθέσιμα επαναπρογραμματιζόμενα κελιά για άλλες λειτουργίες, έχει ως αποτέλεσμα και την αύξηση της κατανάλωσης ενέργειας. Στο παράδειγμα αυτό αρκετά αφαιρετικά παρουσιάστηκε η έννοια της κοκκοποίησης. Στην πραγματικότητα, το κάθε κελί έχει πεπερασμένα στοιχεία μνήμης και υλοποίησης λειτουργικών πράξεων, οπότε ένα κελί με διπλάσια επιφάνεια μάλλον θα έχει και διπλάσια χωρητικότητα μνήμης και υλοποίησης λογικών συναρτήσεων με παραπάνω παραμέτρους. Συνεπώς, θα χρησιμοποιούνταν αρκετά λιγότερα κελιά, οπότε στην πραγματικότητα η διαφορά δε θα είναι τόσο μεγάλη. Τέλος, όσο μικρότερη είναι η κοκκοποίηση τόσο πιο πολύπλοκη είναι η διασύνδεση των κελιών.
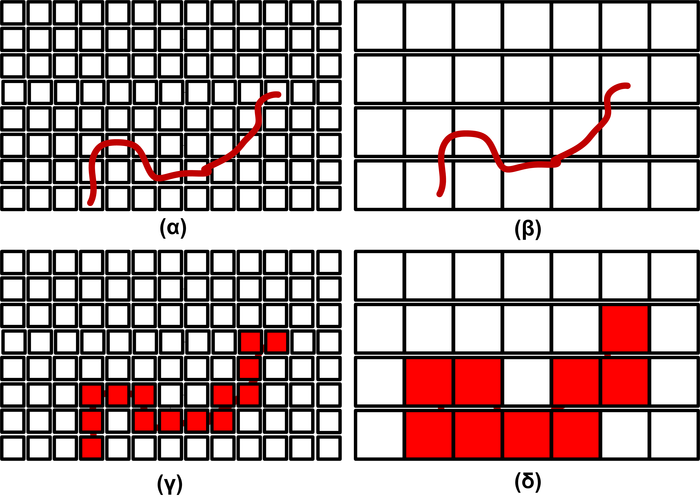
4.17: Όσο μεγαλώνει η κοκκοποίηση σε ένα FPGA, τόσο δεν αξιοποιείται πλήρως το ολοκληρωμένο κύκλωμα, με συνέπεια να υπάρχει απώλεια στην επιφάνεια και στην καταναλισκόμενη ενέργεια. Στο παράδειγμα μας, η ίδια λειτουργία (που απεικονίζεται αφαιρετικά με μια κόκκινη γραμμή), σε δυο FPGA με μικρή και μεγάλη κοκκιότητα, χρησιμοποιεί 14/104 της επιφάνειας (γ) έναντι 9/28 (δ) στο IC μεγάλης κοκκιότητας.
Η αρχιτεκτονική διασύνδεσης πραγματοποιείται χρησιμοποιώντας διακόπτες (switches), οι οποίοι προγραμματίζονται για να υλοποιούν τις συνδέσεις (δηλαδή να συνδέουν ή να αποσυνδέουν γραμμές επικοινωνίας). Η μέθοδος με την οποία δημιουργούνται οι συνδέσεις ανάμεσα στις βασικές λογικές μονάδες έχει σημαντική επίπτωση στα χαρακτηριστικά της αρχιτεκτονικής του FPGA. Με βάση την τοποθέτηση των βασικών λογικών μονάδων και των πόρων διασύνδεσης, οι διατάξεις προγραμματιζόμενων πυλών είναι δυνατόν να διακριθούν στις ακόλουθες κατηγορίες:
Αρχιτεκτονική νησίδας,
Αρχιτεκτονική βασιζόμενη σε γραμμές και
Ιεραρχική αρχιτεκτονική.
Παρακάτω παρουσιάζουμε τα βασικά χαρακτηριστικά της κάθε μιας από τις προαναφερθείσες αρχιτεκτονικές.
Η αρχιτεκτονική νησίδας αποτελείται από μια διάταξη προγραμματιζόμενων λογικών μονάδων με κατακόρυφα και οριζόντια προγραμματιζόμενα κανάλια διασύνδεσης. Η βασική ιδέα της συγκεκριμένης αρχιτεκτονικής παρουσιάζεται στο Σχήμα 4.18. Ο αριθμός των τμημάτων των καλωδίων που υπάρχουν στο εσωτερικό του καναλιού προσδιορίζει τους διαθέσιμους πόρους για τη διασύνδεση. Οι ακροδέκτες της λογικής μονάδας έχουν πρόσβαση στο κανάλι διασύνδεσης διαμέσου του κουτιού διασύνδεσης (connection box). Οι οικογένειες XC4000 και XC3000 της Xilinx είναι παραδείγματα του συγκεκριμένου τύπου αρχιτεκτονικής.
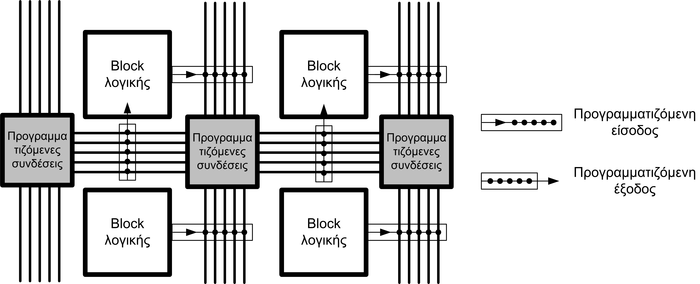
4.18: Αρχιτεκτονική FPGA τύπου νησίδας.
Όπως υποδηλώνει το όνομα, στη συγκεκριμένη αρχιτεκτονική οι λογικές μονάδες είναι τοποθετημένες σε γραμμές και διαχωρίζονται μεταξύ τους με οριζόντια κανάλια διασύνδεσης. Η αρχιτεκτονική αυτή παρουσιάζεται στο Σχήμα 4.19.
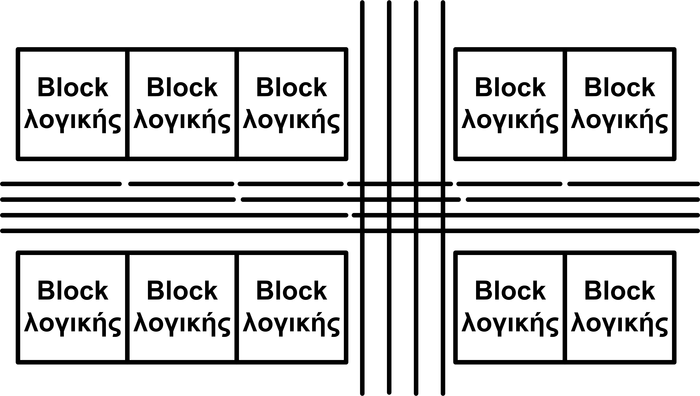
4.19: Αρχιτεκτονική FPGA βασισμένη σε γραμμές.
Τα μονοπάτια διασύνδεσης στο εσωτερικό του καναλιού χωρίζονται σε ένα ή περισσότερα τμήματα, το μήκος των οποίων μπορεί να κυμαίνεται από το πλάτος ενός ζεύγους βασικών λογικών στοιχείων, έως και ολόκληρο το μήκος του καναλιού. Τα τμήματα αυτά ενδέχεται να ενώνονται στα άκρα τους χρησιμοποιώντας προγραμματιζόμενους διακόπτες για τη δημιουργία γραμμών μεγαλύτερου μήκους. Πέρα από αυτά τα κανάλια, υπάρχουν και εκείνα που βρίσκονται τοποθετημένα κάθετα ανάμεσα στις λογικές μονάδες, τα οποία παρέχουν τις απαραίτητες συνδέσεις ανάμεσα στα οριζόντια κανάλια και τα κατακόρυφα τμήματα της διασύνδεσης. Το μήκος των συγκεκριμένων τμημάτων στα κανάλια προσδιορίζεται από τον συμβιβασμό που γίνεται ανάμεσα στον αριθμό των μονοπατιών, την αντίσταση που εμφανίζουν οι διακόπτες διασύνδεσης και τη χωρητικότητα των συγκεκριμένων τμημάτων. Ένα παράδειγμα οικογένειας FPGA που στηρίζεται στην αρχιτεκτονική βασιζόμενη σε γραμμές είναι αυτό της ACT3 που παράγει η εταιρεία Actel.
Οι πλειονότητα των λογικών σχεδιασμών παρουσιάζουν κάποια τοπικότητα στις συνδέσεις, η οποία υποδηλώνει μια ιεραρχία στην τοποθέτηση και διασύνδεση των συνδέσεων ανάμεσα στις λογικές μονάδες. Η ιεραρχική αρχιτεκτονική στα FPGA (Εικόνα 4.20) προσπαθεί να εκμεταλλευτεί το συγκεκριμένο χαρακτηριστικό, ώστε οι διατάξεις των προγραμματιζόμενων πυλών να εμφανίζουν μικρότερες καθυστερήσεις διασύνδεσης και μια πιο προβλέψιμη συμπεριφορά χρονισμού. Η συγκεκριμένη αρχιτεκτονική δημιουργείται συνδέοντας λογικές μονάδες σε συστοιχίες, οι οποίες στη συνέχεια συνδέονται αναδρομικά για τη δημιουργία μιας ιεραρχικής δομής. Ο αριθμός των διακοπτών διασύνδεσης από τους οποίους πρέπει να περάσει το σήμα καθορίζει τη ταχύτητα του δικτύου. Η ιεραρχική αρχιτεκτονική μειώνει το πλήθος των διακοπτών που απαιτούνται για τη δημιουργία μεγάλων μονοπατιών διασύνδεσης, με αποτέλεσμα η διάταξη να λειτουργεί σε μεγαλύτερη ταχύτητα.
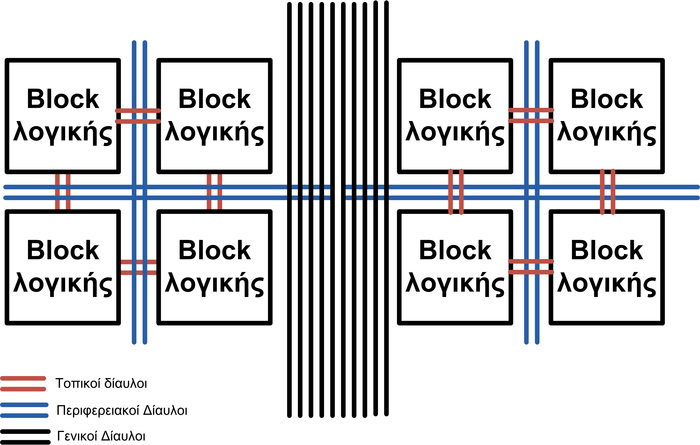
4.20: Ιεραρχική δομή FPGA, στην οποία φαίνονται τα τοπικά και τα γενικά κανάλια διασύνδεσης.
Σε σχέση με τις αρχιτεκτονικές λογικής μονάδας και διασύνδεσης, η αρχιτεκτονική Ε/Ε όπως φαίνεται στο Σχήμα 4.21 είναι παρόμοια στις περισσότερες οικογένειες FPGA. Τα τμήματα Ε/Ε έχουν τρισταθείς απομονωτές (tri-state buffers) για τις εξόδους και απομονωτές εισόδων για τις εισόδους. Το σήμα επίτρεψης τριστάθειας, το σήμα εξόδου και τα σήματα εισόδου μπορούν να καταχωριστούν ξεχωριστά μέσα στο τμήμα Ε/Ε ή να μην καταχωριστούν με βάση πως είναι προγραμματισμένο το τμήμα Ε/Ε.
Όλοι οι ακροδέκτες εισόδου/εξόδου του ολοκληρωμένου κυκλώματος μπορούν να προγραμματιστούν να είναι είτε είσοδοι, είτε έξοδοι, είτε να μη συνδέονται πουθενά. Κατά τον προγραμματισμό του FPGA, ο σχεδιαστής δηλώνει με το αρχείο περιορισμών (constraints file) ποιοι ακροδέκτες χρησιμοποιούνται και σε ποιες θύρες αντιστοιχούν στo δομοστοιχείο της σχεδιαστικής κορυφής (top level design).
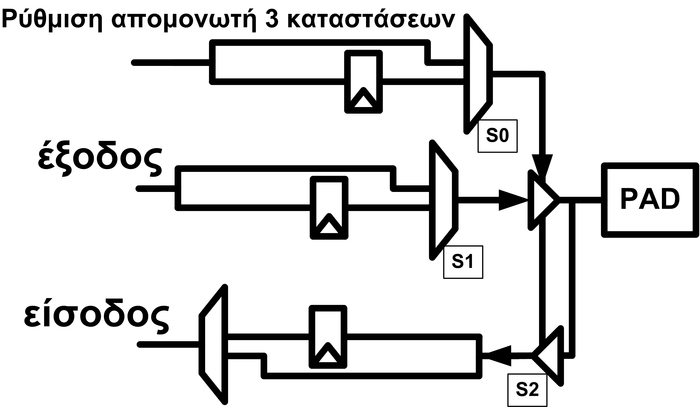
4.21: Τυπική αρχιτεκτονική εισόδου εξόδου των FPGA.
Σε σύγχρονες αρχιτεκτονικές FPGAs, μπορεί να βρεθούν μια ευρεία ποικιλία πρόσθετων χαρακτηριστικών που βελτιώνουν αλλά και περιπλέκουν σημαντικά αυτή τη βασική δομή Ε/Ε. Για παράδειγμα, τα τμήματα Ε/Ε της αρχιτεκτονικής Xilinx Virtex-4 παρέχουν τα παρακάτω χαρακτηριστικά:
περισσότερες από 50 παραλλαγές προτύπων σηματοδότησης Ε/Ε μερικές από τις οποίες περιλαμβάνουν τα χαρακτηριστικά όπως:
ψηφιακά ελεγχόμενη αντίσταση για να εξαλείψει την ανάγκη για τον τερματισμό αντιστάσεων, ώστε να αντιμετωπίζει τις επιδράσεις των γραμμών μετάδοσης και
διαφορική σηματοδότηση για να βελτιώσει την ακεραιότητα των σημάτων
διπλασιασμό του ρυθμού δεδομένων που καταχωρεί σε πολλαπλούς κόμβους για παρουσίαση και λήψη δεδομένων σε και από την εσωτερική λογική και
προγραμματιζόμενες καθυστερήσεις εισόδων.
Τόσο το μπλοκ λογικής, όσο και οι πόροι διασύνδεσης από τους οποίους αποτελείται το FPGA πρέπει να προγραμματιστούν, ώστε να υλοποιούν την απαιτούμενη συνάρτηση. Τα περιεχόμενα της λογικής μονάδας μπορούν να προγραμματιστούν για την πραγματοποίηση της λογικής συνάρτησης αυτού, ενώ οι διακόπτες διασύνδεσης προγραμματίζονται για τον έλεγχο των συνδέσεων μεταξύ των λογικών μονάδων. Υπάρχει ένα πλήθος διαφορετικών μεθόδων για την αποθήκευση της πληροφορίας προγραμματισμού, οι οποίες εκτείνονται από την ευμετάβλητη μέθοδο της SRAM, έως την μη αναστρέψιμη τεχνολογία αντι-ασφάλειας (antifuse). Το μεγαλύτερο τμήμα της επιφάνειας ενός FPGA καταλαμβάνεται κυρίως από την περιοχή των επαναδιαμορφώσιμων συστατικών. Επομένως, η επιλογή της μεθόδου προγραμματισμού επηρεάζει σημαντικά την επιφάνεια του FPGA. Ένας επιπλέον παράγοντας, ο οποίος πρέπει να λαμβάνεται υπόψη είναι το πόσες φορές απαιτείται η επαναδιαμόρφωση του FPGA. Έτσι για τα FPGA στα οποία η τεχνολογία προγραμματισμού τους βασίζεται στην αντι-ασφάλεια μπορούν να προγραμματιστούν μόνο μία φορά, ενώ αντίθετα όσα χρησιμοποιούν SRAM δεν εμφανίζουν κάποιο παρόμοιο περιορισμό, και μπορούν να προγραμματίζονται πολύ συχνά.
Στη συγκεκριμένη μέθοδο προγραμματισμού η διαμόρφωση αποθηκεύεται σε κελιά μνήμης SRAM. Στην περίπτωση που το δίκτυο διασύνδεσης υλοποιείται με τη χρήση των τρανζίστορ διέλευσης (pass-transistors), τότε τα κελιά της SRAM ελέγχουν εάν το τρανζίστορ άγει ή όχι. Επιπλέον, όταν οι λογικές μονάδες αποτελούνται από έναν πίνακα αναζήτησης τότε η λογική αποθηκεύεται στα κελιά SRAM. Η συγκεκριμένη μέθοδος προγραμματισμού παρουσιάζει το μειονέκτημα της προσωρινής αποθήκευσης της πληροφορίας. Αποτέλεσμα είναι πως η διαμόρφωση πρέπει να φορτώνεται στο FPGA κάθε φορά που το τελευταίο ανατροφοδοτείται. Όσα συστήματα βασίζονται στη τεχνολογία αυτή συχνά χρησιμοποιούν μια μόνιμη εξωτερική συσκευή αποθήκευσης των δεδομένων (π.χ. μνήμη FLASH ή EEPROM). Η χρήση της μεθόδου SRAM απαιτεί τουλάχιστον 5 τρανζίστορ ανά κελί. Λόγω του σχετικά μεγάλου μεγέθους των κελιών μνήμης, μεγάλο μέρος της επιφάνειας του FPGA καταλαμβάνεται για την αποθήκευση της διαμόρφωσης. Το βασικό πλεονέκτημα που έχει η χρήση της μεθόδου προγραμματισμού που στηρίζεται στη τεχνολογία της SRAM είναι η δυνατότητα επαναχρησιμοποίησης της συσκευής για την υλοποίηση διαφορετικών εφαρμογών, απλά φορτώνοντας κάθε φορά την κατάλληλη διαμόρφωση. Το χαρακτηριστικό αυτό έκανε τη συγκεκριμένη τεχνολογία αποθήκευσης πληροφορίας στα FPGA αρκετά δημοφιλή για την υλοποίηση επαναδιαμορφώσιμων συστημάτων, τα οποία στοχεύουν στην επίτευξη κερδών στην απόδοση προσαρμόζοντας την υλοποίηση των συναρτήσεων στις ανάγκες τις συγκεκριμένης εφαρμογής.
Στη μέθοδο προγραμματισμού που στηρίζεται στη τεχνολογία SRAM, η πληροφορία αποθηκεύεται ελέγχοντας την κατάσταση των κελιών μνήμης. Αντίθετα η τεχνολογία της αντι-ασφάλειας (antifuse) χρησιμοποιεί προγραμματιζόμενες συνδέσεις, των οποίων η αντίσταση μεταβάλλεται με την εφαρμογή υψηλής τάσης. Στη μη-προγραμματισμένη κατάσταση η αντίσταση των συνδέσεων είναι της τάξης των μερικών GΩ, επομένως μπορεί να θεωρηθεί ως ανοιχτό κύκλωμα. Με την εφαρμογή μιας σχετικά μεγάλης τιμής τάσης, συμβαίνει ένα φυσικό φαινόμενο που ονομάζεται τήξη. Το αποτέλεσμα αυτού είναι η δημιουργία μιας αντίστασης της τάξης των μερικών Ohm (Ω) κατά μήκος της συσκευής, υλοποιώντας με τον τρόπο αυτό μια σύνδεση. Το πλεονέκτημα της συγκεκριμένης μεθόδου είναι πως το μέγεθος του προγραμματιζόμενου στοιχείου είναι της τάξης του μεγέθους ενός περάσματος, με αποτέλεσμα να πετυχαίνεται σημαντική μείωση στην επιφάνεια συγκρινόμενη με τα FPGA που στηρίζονται σε SRAM. Αντίστοιχα, η αντίσταση μεταξύ των στοιχείων είναι της τάξης των μερικών Ohm (Ω) και είναι πολύ μικρότερη από την αντίσταση των τρανζίστορ μετάβασης τα οποία χρησιμοποιούνται ως διακόπτες διασύνδεσης στη μέθοδο SRAM. Η συγκεκριμένη τεχνική προγραμματισμού δεν έχει προσωρινή μορφή, και επομένως δεν απαιτεί την ύπαρξη εξωτερικής συσκευής για την αποθήκευση της πληροφορίας διαμόρφωσης κατά το διάστημα διακοπής της τροφοδοσίας. Το μειονέκτημα της τεχνολογίας αυτής, σε αντίθεση με ότι συμβαίνει στην τεχνολογία SRAM, είναι πως πιθανά λάθη που συμβαίνουν κατά το στάδιο του σχεδιασμού δεν μπορούν να διορθωθούν αφού η διαδικασία διαμόρφωσης είναι μη αναστρέψιμη.
Η κατηγορία των τεχνολογιών προγραμματισμού που εμφανίζουν μόνιμο χαρακτήρα χρησιμοποιεί τις ίδιες τεχνικές με εκείνες των EPROM, EEPROM και Flash μνημών. Η συγκεκριμένη μέθοδος βασίζεται σε ένα ειδικό τρανζίστορ με δύο πύλες, εκ των οποίων η μία είναι πλωτή πύλη, ενώ η άλλη πύλη επιλογής. Όταν κατά μήκος του τρανζίστορ διέλθει κάποιο ισχυρό ρεύμα, το φορτίο παγιδεύεται στην πλωτή πύλη αυξάνοντας τη τάση κατωφλίου του τρανζίστορ. Στη κανονική λειτουργία τα προγραμματισμένα τρανζίστορ μπορούν να θεωρηθούν ως ανοιχτά κυκλώματα, ενώ τα υπόλοιπα να ελεγχθούν χρησιμοποιώντας τις πύλες επιλογής. Η φόρτιση στην πλωτή πύλη θα παραμείνει ακόμη και κατά τη διακοπή της τροφοδοσίας. Η πλωτή φόρτιση μπορεί να απομακρυνθεί εκθέτοντας την πύλη σε υπεριώδες φως για την περίπτωση των EPROM, και σε ηλεκτρικό ρεύμα στις περιπτώσεις των EEPROM και Flash. Οι συγκεκριμένες τεχνικές καλύπτουν το κενό που υπάρχει ανάμεσα στις τεχνολογίες προγραμματισμού SRAM και αντι-ασφάλειας, παρέχοντας την ευστάθεια που εμφανίζει η αντι-ασφάλεια με τον επαναπρογραμματισμό που παρουσιάζει η SRAM. Η αντίσταση των διακοπτών διασύνδεσης είναι μεγαλύτερη από εκείνη της αντι-ασφάλειας, ενώ ο προγραμματισμός είναι περισσότερο πολύπλοκος και χρονοβόρος σε σύγκριση με αυτόν που απαιτείται για την τεχνολογία SRAM.
Η πολυπλοκότητα των FPGAs κάνει απαραίτητη την χρήση ειδικού λογισμικού για την σχεδίαση και υλοποίηση αλγορίθμων ή εφαρμογών απευθείας στο υλικό. Συνεπώς, κάθε εταιρία παρέχει το δικό της λογισμικό προγραμματισμού που μπορεί να εκμεταλλευτεί βέλτιστα τις δυνατότητες των συσκευών της. Οι Εικόνες 4.22 και 4.23 παρουσιάζουν τα εργαλεία για τις 2 πιο δημοφιλείς εταιρίες, Altera και Xilinx. Για αυτό το λόγο χρησιμοποιούμε μια σχεδιαστική ροή. Αυτή δεν είναι τίποτα άλλα από μια σειρά διαδικασιών με την χρήση εργαλείων CAD (Computer Aided Design), ώστε τελικά να έχουμε την ολοκληρωμένη σχεδίαση. Τα σημερινά εργαλεία έχουν αυτοματοποιήσει τη σχεδιαστική ροή. Ο σχεδιαστής απλώς εισάγει τις κατάλληλες πληροφορίες και το περιβάλλον ανάπτυξης εκτελεί ένα-προς-ένα όλα τα εργαλεία με την κατάλληλη σειρά, αναφέροντας τα αποτελέσματα, τις μετρήσεις, τα λάθη, τα προβλήματα, τις προειδοποιήσεις και οποιαδήποτε άλλη χρήσιμη πληροφορία.
4.22: Η εταιρία Altera παρέχει το Quartus II ως ένα ολοκληρωμένο εργαλείο ανάπτυξης για τα δικά της FPGA.
4.23: Η εταιρία Xilinx παρέχει το ISE και το Vivado ως ολοκληρωμένα εργαλεία ανάπτυξης για τα δικά της FPGA.
Τα τυπικά βήματα της σχεδιαστική ροής που βρίσκουμε σε όλα τα περιβάλλοντα που στοχεύουν τα FPGA είναι τα εξής:
Εισαγωγή σχεδιασμού (design entry): δημιουργία των αρχείων σχεδιασμού χρησιμοποιώντας ένα σχηματικό συντάκτη (schematic editor) ή γλώσσα περιγραφής υλικού (hardware description language, HDL), όπως οι γλώσσες Verilog και VHDL.
Σύνθεση σχεδιασμού (design synthesis): μια διαδικασία που μετατρέπει από ένα υψηλό επίπεδο αφαίρεσης λογικής (όπως Verilog ή VHDL) σε ένα χαμηλότερο επίπεδο αφαίρεσης λογικής χρησιμοποιώντας μια βιβλιοθήκη. Υπάρχουν πολλά εργαλεία για την σύνθεση όπως Sinplify, Synopsys, κλπ
Απεικόνιση (mapping): μια διαδικασία που απεικονίζει σε κάθε λογικό στοιχείο ένα συγκεκριμένο φυσικό στοιχείο που υλοποιεί πραγματικά τη λογική συνάρτηση σε μια διαμορφώσιμη συσκευή.
Τοποθέτηση (place) και σύνδεση (route): τοποθετεί λογικά στοιχεία σε συγκεκριμένες θέσεις του στόχου τσιπ FPGA και συνδέει λογικά στοιχεία. Αυτό το στάδιο γίνεται συνήθως με εκάστοτε εργαλεία της εταιρείας FPGA, όπως της Xilinx, Actel, Altera, κλπ
Παραγωγή προγράμματος (program generation): παράγεται ένα αρχείο bit-stream για προγραμματισμό της συσκευής.
Προγραμματισμός συσκευής (device programming): μεταφόρτωση του αρχείου bit-stream στο FPGA.
Επιβεβαίωση σχεδιασμού (design verification): χρησιμοποιείται η προσομοίωση για να ελέγξει τις λειτουργίες. Η προσομοίωση μπορεί να γίνει σε διαφορετικά επίπεδα. Η λειτουργική ή προσομοίωση συμπεριφοράς δεν λαμβάνει υπόψη τις καθυστερήσεις συστατικών ή της διασύνδεσης. Η προσομοίωση χρονισμού χρησιμοποιεί τις πληροφορίες καθυστέρησης που εξάγονται από το κύκλωμα. Επίσης, παράγονται άλλες αναφορές για να ελέγξουν άλλα αποτελέσματα εφαρμογής, όπως η μέγιστη συχνότητα, η καθυστέρηση και η χρήση των πόρων.
Τα στάδια απεικόνιση, τοποθέτηση και σύνδεσης αναφέρονται κοινά ως υλοποίηση σχεδιασμού.
Η βιομηχανία ημιαγωγών βρίσκεται σε ανθηρούς καιρούς, με παγκόσμιες πωλήσεις το έτος πάνω από 300 δισεκατομμύρια αμερικάνικα δολάρια- από τα οποία το 30% προέρχεται από τους μικροεπεξεργαστές, τα DSP, τους μικροελεγκτές, και τα περιφερειακά chips που μπορούν να προγραμματισθούν. Αναλυτικά στοιχεία υπάρχουν από την Ομοσπονδία Κατασκευαστών Ημιαγωγών19, η οποία διατηρεί ένα αρκετά ενημερωμένο αρχείο πωλήσεων τόσο ανά γεωγραφική περιοχή, όσο και συνολικά, Εκεί φαίνεται η συνεχόμενη αύξηση και από τα 261 εκατομμύρια το 1976, οι συνολικές πωλήσεις έφτασαν 300 δισεκατομμύρια το 2015. Όπως αναγράφεται στην αρχική σελίδα της Ομοσπονδίας, μόνο οι αμερικάνικες εταιρίες πούλησαν 71 εκατομμύρια ολοκληρωμένα κυκλώματα το 2014 ή 200 IC για κάθε Αμερικάνο πολίτη.
Μαζί με αυτές τις τεράστιες ευκαιρίες αγοράς, ωστόσο, έχει επέλθει και μια αύξηση στην πολυπλοκότητα του σχεδιασμού συστημάτων. Εκτιμάται ότι μέχρι το τέλος του 2015 τα αναμενόμενα ποσά τρανζίστορ για λύσεις σε τυπικά συστήματα σε chip (SoC) θα είναι πάνω από 3 τρισεκατομμύρια, με αντίστοιχες αναμενόμενες ταχύτητες ρολογιού πάνω από 100 GHz, και τις πυκνότητες τρανζίστορ να φτάνουν τα 660 εκατομμύρια τρανζίστορ/τετρ. εκατοστό. Σύμφωνα με την εταιρία VLSI Research, ο αριθμός των τρανζίστορ που κατασκευάστηκαν το 2014, έχει ξεπεράσει τα (Εικόνα 4.24), που είναι ένα αστρονομικό νούμερο (25 φορές μεγαλύτερο από το συνολικό αριθμό των αστεριών στο γαλαξία μας, και 75 φορές μεγαλύτερος από το συνολικό εκτιμώμενο αριθμό γαλαξιών στο σύμπαν). Η αύξηση του αριθμού των τρανζίστορ ακολουθεί το νόμο του Moore, του διπλασιασμού του αριθμού των τρανζίστορ στην ίδια επιφάνεια κάθε 18 μήνες.
Παράλληλα, αυτή η αύξηση στην πολυπλοκότητα προκαλεί μια αύξηση σε απώλεια ενέργειας, κόστος, και στον χρόνο ‘σχεδιασμού της αγοράς’. Στην επιστημονική κοινότητα συζητιέται ότι τα προϊόντα υπολογιστών θα εξελιχθούν τελικά από μεγάλα, γενικού σκοπού, απρόσωπα δυσκίνητα συστήματα σε φορητά, προσωπικά, ευέλικτα, στοχευμένα στην αγορά προϊόντα. Η εξατομίκευση, η ευελιξία και η γρήγορη απόκριση στην αγορά θα υπαγορεύσει μια ‘απότομη αλλαγής’ προσέγγιση σχεδιασμού. Αυτό φαίνεται και στα πιο πρόσφατα στατιστικά που δημοσίευσε τον Οκτώβριο του 2015 η Gartner στα οποία φαίνεται η πτώση κατά 9.2% των πωλήσεων των προσωπικών υπολογιστών από όλους τους κατασκευαστές και η πολλαπλάσια άνοδος πωλήσεων των κινητών τηλεφώνων. Το συμπέρασμα είναι ότι υπάρχει μια έντονη τάση της μετακίνησης της προτίμησης από μεγάλες συσκευές (π.χ. υπολογιστές γραφείου) σε μικρότερες (κινητά) και σε λίγα χρόνια σε ακόμη μικρότερες (π.χ. φορέσιμες συσκευές, όπως τα γυαλιά της google με τις κατάλληλες εφαρμογές [33], [34]). Αυτό δείχνει ότι και η ανάγκη για βέλτιστα και αποδοτικά ενσωματωμένα συστήματα συνεχώς θα αυξάνεται, όπως και θα αυξάνονται και οι πιέσεις που αφορούν τα προϊόντα, με το πιο χαρακτηριστικό το χρόνο τοποθέτησης στην αγορά.
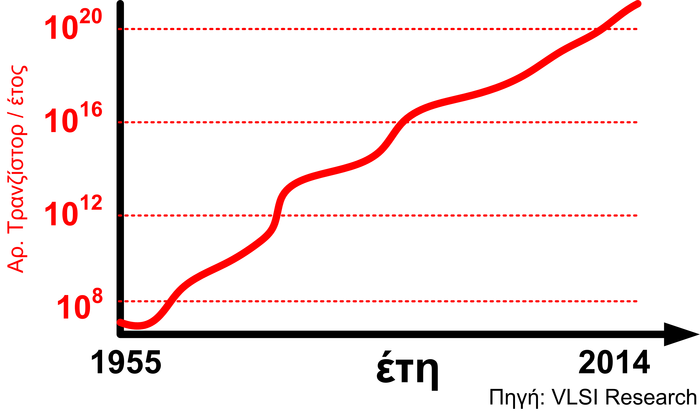
4.24: Ο συνολικός αριθμός τρανζίστορ που παράχθηκαν το 2014 είναι ένα αστρονομικό νούμερο που αν συγκριθεί με τον αριθμό των αστεριών στον γαλαξία μας τον ξεπερνάει κατά 25 φορές.
Ο χρόνος τοποθέτησης του προϊόντος στην αγορά για νέες πλατφόρμες δε θα μετριέται πλέον σε χρόνια, αλλά σε μήνες ή εβδομάδες. Ο κύκλος σχεδιασμού πρέπει να μειωθεί ή να γίνει το στενό πέρασμα για μελλοντικές εξελίξεις και να καθορίσει ποιες εταιρίες θα επιζήσουν και ποιες όχι. Οι αυστηρές απαιτήσεις στο time-to-market, ζευγαρωμένες με επιπρόσθετους περιορισμούς σχεδίασης όπως η ευελιξία σχεδίασης, το κόστος, οι απαιτήσεις πραγματικού χρόνου και ο άκαμπτος παράγοντας προτύπου (π.χ. μέγεθος, βάρος και απώλεια ενέργειας) αντιπροσωπεύουν μια αξιοσέβαστη πρόκληση που οι σχεδιαστές των υφισταμένων συστημάτων πρέπει να ξεπεράσουν. Σήμερα, η ανάγκη για μια ιδανική αλλαγή κατεύθυνσης στην μέθοδο σχεδιασμού έχει γίνει ακόμη περισσότερο απαιτητική, αλλά και δύσκολη.
Όσον αφορά τον όγκο πωλήσεων, οι ενσωματωμένοι επεξεργαστές έχουν ξεπεράσει τους επεξεργαστές Η/Υ κατά πολύ. Μια μεγάλη έκταση από εφαρμογές, ειδικά στον τομέα των ασύρματων και φορητών συσκευών, έχουν χαρακτηριστεί από μια τεράστια απαίτηση για ενσωματωμένους επεξεργαστές. Δεδομένου μιας εκτιμημένης εξέλιξης στην τεχνολογία IC σήμερα, ένα ενσωματωμένο SoC πραγματικού χρόνου θα βρει ακόμη περισσότερες κατάλληλες εφαρμογές στο μέλλον, με την επαναχρησιμοποίηση των IP να παρουσιάζεται ως μια μέθοδος για βελτίωση της παραγωγικότητας.
Τα τρέχοντα δεδομένα πυκνότητας ισχύος δείχνουν ότι η απόδοση τείνει να διπλασιάζεται κάθε 18 μήνες. Η θερμική εξαγωγή των ολοκληρωμένων κυκλωμάτων σε κάποιες περιπτώσεις μπορεί να φτάσει τα επίπεδα εκείνα της πυρηνικής ισχύος (250 watts/τετρ. εκατοστό), αν δε ακολουθηθούν οι βέλτιστες πρακτικές εξοικονόμησης ενέργειας και σχεδιασμού. Με μια τέτοια αύξηση σε απώλεια ενέργειας, τα κόστη που σχετίζονται με τις ανάγκες συσκευασίας και θερμικής εξαγωγής μπορούν να μειώσουν οποιαδήποτε πλεονάσματα επιτυγχάνονται με υψηλότερες πυκνότητες τρανζίστορ. Ο θόρυβος και τα ζητήματα σύζευξης θα λύνονται επίσης πιο δύσκολα όσο οι συχνότητες αυξάνονται. Σαν αποτέλεσμα ένα κατανεμημένο σύστημα που περιέχει αρκετούς μικρότερους, αργότερους, ενεργειακά αποδοτικούς επεξεργαστές θα γίνει μια προτιμότερη επιλογή για ένα σύστημα μεμονωμένου επεξεργαστή με πρόβλημα απώλειας ενέργειας που λύνεται δύσκολα. Ήδη έχουν προταθεί ως λύση στο πρόβλημα δημιουργίας συστοιχιών μεγάλων επεξεργαστικών δυνατοτήτων, η χρήση των επεξεργαστών ARM που μπορεί να είναι πιο αργοί από τους επεξεργαστές της Intel, αλλά είναι πιο αποδοτικοί στην ενέργεια [35], και για αυτό αποτελούν τη de-facto επιλογή στα έξυπνα κινητά τηλέφωνα.
Όσο η τεχνολογία των IC εξελίσσεται από μικρό-επίπεδα σε υποδεέστερα μικρό-επίπεδα και από αυτά σε επίπεδα στοιχειώδους δομής, το κόστος παραγωγής συνεχώς αυξάνεται εκθετικά. Μια γραμμή παραγωγής για ολοκληρωμένα κυκλώματα με μέγεθος 24nm, κοστίζει αρκετά δισεκατομμύρια δολάρια [36]. Έτσι, οι σχεδιαστές ολοκληρωμένων κυκλωμάτων θα τείνουν να παράγουν ένα chip κατάλληλο για περισσότερες από μια εφαρμογές. Αυτά θα συνδυάζονται με το γεγονός ότι η ευελιξία επίδοσης και η ευελιξία εφαρμογής είναι τόσο βασικές για την επιτυχία ενός ενσωματωμένου συστήματος, οπότε συμπεραίνουμε ότι ένα σύστημα με υψηλό βαθμό αναδιαμόρφωσης μπορεί να μην είναι ασυνήθιστο στο κοντινό μέλλον.
Ο συ-σχεδιασμός υλικού–λογισμικού αναφέρεται σε ένα παράλληλο και συνεργατικό σχεδιασμό υλικού και λογισμικού σε ένα σύστημα. Μια διαδικασία συ-σχεδιασμός συνήθως περιλαμβάνει τέσσερις κύριες εργασίες: επιλογή αρχιτεκτονικής, διαμοιρασμό HW/SW, χρονικό προγραμματισμό και σύνθεση επικοινωνίας. Η διαδικασία σχεδιασμού ρέει σε ένα μοντέλο καταρράκτη, που συχνά ξεκινά με ένα σύνολο λεπτομερειών.
Όπως επισημάνθηκε και στην εισαγωγή του βιβλίου, οικονομικοί παράγοντες στο σχεδιασμό VLSI έχουν οδηγήσει την ενσωμάτωση σε επίπεδα στα οποία κυκλώματα που προηγουμένως χρειαζόταν για να υλοποιηθούν ολόκληρες πλακέτες FPGA και πολλαπλά τσιπ, τώρα ενσωματώνονται σε έναν ενιαίο μονό ολοκληρωμένο σύστημα (chip), με την ονομασία System-on-Chip (SoC). Το σύστημα SoC παρουσιάζει αντιφατικές προδιαγραφές. Αφ’ ενός παρέχει αρκετές ευκαιρίες για ελαχιστοποίηση του κόστους, και αφετέρου συνεπάγεται έναν υψηλότερο βαθμό εξειδίκευσης ο οποίος μειώνει το συνολικό όγκο κάθε επιμέρους συστατικού. Με άλλα λόγια, ο συνδυασμός δύο γενικού σκοπού συστατικών είναι λιγότερο γενικός από κάθε συστατικό ξεχωριστά. Δεδομένου ότι ενσωματώνουμε περισσότερα συστατικά το προκύπτον κομμάτι του πυριτίου γίνεται πιο εξειδικευμένο και αναμένονται ενδεχόμενες μειώσεις του όγκου του (σχετικά με τη δυνατότητα εφαρμογής του σε διάφορα προϊόντα). Επιπλέον, με την αύξηση που προκύπτει στις δαπάνες πολυπλοκότητας και σχεδιασμού, υποδηλώνεται ότι οι σχεδιαστές πρέπει να βρουν νέους τρόπους να επαναχρησιμοποιήσουν το αποτέλεσμα στο σχεδιασμό, και ενθαρρύνεται η τακτική της επαναχρησιμοποίησης του σχεδίου και των έτοιμων προς χρήση (plug-and-play) συστατικών. Πρέπει επίσης να εξεταστούν οι ατέλειες της παραγωγικής και κατασκευαστικής διαδικασίας, θέματα που προκαλούν προβλήματα στα SoC. Μια άλλη σημαντική επίπτωση της επιλογής SoC είναι η αυξανόμενη σημασία και δυσκολία που υπάρχει, ώστε να εξασφαλιστεί η ορθότητα των συστημάτων. Αυτό περιλαμβάνει την λεπτομερή παρουσίαση, την προσομοίωση, την επικύρωση, την επαλήθευση και τη δοκιμή.
Η έλλειψη καλής τεκμηρίωσης είναι συνήθως ένα από τα μεγάλα εμπόδια στην επαναχρησιμοποίηση του πρωτοτύπου σχεδιασμού. Η επαναχρησιμοποίηση επιτυγχάνεται με τους σκληρούς και μαλακούς πυρήνες πνευματικής ιδιοκτησίας (intellectual property, IP). Η επαναχρησιμοποίηση πυρήνων, είτε σκληρών είτε μαλακών, υπονοεί ένα χαρτοφυλάκιο που περιέχει στοιχεία καθορισμένα με σαφήνεια, με τον προσεκτικό χαρακτηρισμό του συγχρονισμού, της λειτουργίας, και της στρατηγικής επαλήθευσης.
Οι μαλακοί (soft) πυρήνες είναι διαθέσιμοι είτε ως RTL (register transfer level, περιγραφή επιπέδου επικοινωνίας καταχωρητών), είτε ως τεχνολογικά ανεξάρτητες λίστες δικτύων διασύνδεσης (netlists). Εκτός από τους μαλακούς πυρήνες, υπάρχουν και οι σκληροί πυρήνες. Οι σκληροί πυρήνες έχουν ήδη τοποθετηθεί και δρομολογηθεί για μια συγκεκριμένη VLSI διαδικασία. Σήμερα, οι περισσότερες IP προσφέρονται είτε για μαλακής είτε για σκληρής μορφής πυρήνες. Η χρήση των πυρήνων βελτιώνει σε μεγάλο ποσοστό την παραγωγικότητα, όμως θέτει και σημαντικές προκλήσεις στην επικύρωση των συστημάτων, στην εφαρμογή των αλλαγών, στην προσαρμογή του πυρήνα σε διαφορετικούς διαύλους ή στις μεταδόσεις σημάτων, στην εφαρμογή μιας νέας τεχνολογικής διαδικασίας και στο συντονισμό τους με ποικίλους κατασκευαστές πυριτίου.
Η εικονική σύνθετη επαναχρησιμοποίηση είναι αυτή που εγγυάται έναν πλήρη διαχωρισμό των εξουσιοδοτημένων και των ενσωματωμένων ρόλων. Ένα εικονικό συστατικό είναι ένα πλήρως χαρακτηρισμένο, ελεγμένο, διαμορφωμένο στοιχείο. Αυτό συνεπάγεται την υιοθέτηση μιας αυστηρής προδιαγραφής των διεπαφών επικοινωνίας, μιας αυστηρά ορισμένης τεκμηρίωσης και έναν ξεκάθαρο διαχωρισμό συστημάτων. Αρχικά, αυτό λειτουργεί ενάντια στην αντιστοιχία χρόνος-αγορά και την απόδοση, και απαιτούνται αρκετές αναθεωρήσεις του σχεδιασμού, ώστε να επιτευχθεί ένα καλό αποτέλεσμα.
Σε αυτή τη παράγραφο παρουσιάζουμε ένα σύστημα SoC που χρησιμοποιείται σε εφαρμογές πολυμέσων φορητών συσκευών. Ο κόσμος των κινητών τηλεπικοινωνιών μας δίνει ένα ενδιαφέρον παράδειγμα μιας ετερογενούς SoC πλατφόρμας πολυπρογραμματισμού. Η τέταρτη γενιά (4G) των ασύρματων τεχνολογιών θα προσφέρει σύντομα σε όλους αρκετή χωρητικότητα για εφαρμογές πολυμέσων σε συσκευές κυψελωτού δικτύου, όπως βιντεοκλήση, αναγνώριση λόγου και εφαρμογές ηλεκτρονικού εμπορίου. Σε αυτό το σενάριο, η πλατφόρμα του υλικού πρέπει να προσφέρει τόσο ταχύτητα όσο και ευελιξία, δεδομένου ότι θα πρέπει να υποστηρίζει μεγάλη ποικιλία δυνητικά εξελίξιμων προτύπων και εφαρμογών. Ταυτόχρονα, τα κόστη των τερματικών συσκευών (κινητά και PDA) και η περιορισμένη ηλεκτρική ισχύς, κάνουν σαφή την ανάγκη για μια πολύ ειδικά σχεδιασμένη ενσωματωμένη λύση. Η πλατφόρμα OMAP της Texas Instruments (Σχήμα 4.2520) καλύπτει πολλές από αυτές τις απαιτήσεις, και παρέχεται με διάφορες ρυθμίσεις. Για παράδειγμα, η συσκευή OMAP1510 έχει ένα διπύρηνο SoC περιλαμβάνει ένα επεξεργαστή 200ΜHz, με πυρήνα C55x DSP (μέγιστη απόδοση 400 MIPS), και ένα 175ΜHz με πυρήνα ARM9 (μέγιστη απόδοση 210 MIPS). Μαζί με τους δυο πυρήνες το σύστημα ενσωματώνει ακόμα αρκετές τοπικές συστοιχίες μνήμης (local banks) τοπικής μνήμης (ένα 192-KB frame buffer για video, περισσότερο από 64 KB για μνήμη δεδομένων και 12 KB I-cache για το DSP, και 16 KB I-cache και 8 KB D-cache για τον ARM) και διάφορες άλλες I/O συσκευές.
Ο συνδυασμός ενός DSP και ενός πυρήνα γενικής χρήσης είναι ένας καλός συμβιβασμός κόστους, απόδοσης, αλλά και απαίτησης ρεύματος. Ο ARM διαχειρίζεται και ελέγχει τον κώδικα του συστήματος (λειτουργικό σύστημα, περιβάλλον χρήστη, χειριστές διακοπών (interrupt handlers) κ.ο.κ.). Το DSP σαφώς πολύ καλύτερο για την επεξεργασία σήματος βάσης σε πραγματικό χρόνο και σε χειρισμό πολυμέσων (όπως βίντεο). Δοκιμάζοντας να εκτελέσουμε ολόκληρη την εφαρμογή σε έναν ταχύτερο RISC επεξεργαστή θα είχαμε σημαντικά προβλήματα με την κατανάλωση ενέργειας, αλλά και με το μέγεθος του κώδικα για το σύστημα. Η εκτέλεση Λειτουργικού συστήματος και κώδικα συστήματος σε C55x DSP είναι απλά πέρα των δυνατοτήτων του.
Από την σκοπιά της ανάπτυξης εφαρμογής μια ετερογενής διπύρηνης πλατφόρμας θέτει σημαντικές προκλήσεις. Καταρχάς, όπως αναφέρθηκε, οι σχεδιαστές πρέπει να αποφασίζουν στατικά, τι θα εκτελείται σε DSP και τι σε ARM. Όταν το κατορθώσουν αυτό, για να απλοποιήσουν το σχεδιασμό, ο συνδυασμός αλυσίδας εργαλείων πρέπει να εξάγει την αρχιτεκτονική του DSP επιταχυντή και να την παρουσιάσει μέσα σε ένα φιλικό προς τον χρήστη περιβάλλον (ΑPI), έτσι ώστε η κύρια εφαρμογή να μπορεί να προγραμματιστεί ανεξάρτητα από το DSP. Αυτή η εφαρμογή γραφικού περιβάλλοντος DSP (ονομάζεται γέφυρα DSP στο περιβάλλον TI) παρέχει μηχανισμούς για να ξεκινήσει και να ελέγξει εργασίες στο DSP, να μετακινήσει δεδομένα από και προς το DSP, και να ανταλλάξει μηνύματα. Με αυτό τον τρόπο, οι λειτουργίες που εκτελούνται στον DSP είναι προσβάσιμες διαμέσου ενός περιβάλλοντος κλήσης απομακρυσμένης βοήθειας που θυμίζει τις γνωστές συναρτήσεις C.
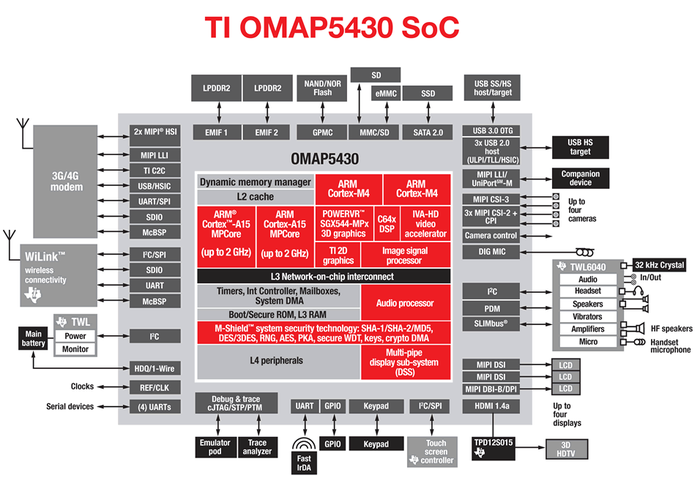
4.25: Η αρχιτεκτονική υλικού ΤΙ OMAP. To διάγραμμα δείχνει ένα παράδειγμα (τον TI OMAP 4430 SoC στο PANDA SoC Board) ένα ετερογενή DSP μικροεπεξεργαστή στο ίδιο υπόστρωμα πυριτίου. Βy pandaboard.org. Licensed under CC BY-SA 3.0 via Commons.
Από την πλευρά του DSP, οι προγραμματιστές συνήθως υλοποιούν μεμονωμένες εφαρμογές μέσα από μια ξεχωριστή συλλογή, αλυσίδας εργαλείων. Είναι ακόμη συνηθισμένο για το κατασκευαστή του συστήματος να δίνει ένα σετ από τυποποιημένες DSP βιβλιοθήκες που υλοποιούν τις πιο κοινές λειτουργίες (φίλτρα, μεταμορφώσεις, κωδικοποιητές, κ.α.), έτσι δεν απασχολεί τους προγραμματιστές εφαρμογών το καθόλου φιλικό προς τον χρήστη DSP. Ένα παράδειγμα προγράμματος του OMAP είναι η εφαρμογή ενός πρότυπου video κλήσης 3G σε ένα κινητό τερματικό. Η video κλήση περιλαμβάνει έναν αποκωδικοποιητή πολυμέσων (για να συμπιέζει τη μεταδιδόμενη φωνή και εικόνα που θα σταλεί και να αποσυμπιέζει τις εισερχόμενες ροές) και ορισμένα πρωτόκολλα μετάδοσης (εξασφαλίζουν τη μεταφορά πολυμέσων για να υπάρχει η ακολουθία των πακέτων στο κανάλι, ένα πρωτόκολλο για να διαχειρίζεται την κλήση, και ένα πρωτόκολλο ζεύξης για να περιγράψει το περιεχόμενο). Σε αυτή την περίπτωση, συμπίεση και αποσυμπίεση υλοποιούνται στον DSP (χρησιμοποιώντας κάποιες αφιερωμένες οδηγίες του C55x σύμφωνα με το codec), όπου ο ARM τρέχει τα πρωτόκολλα συμπληρωματικά στο κώδικα του συστήματος και στο περιβάλλον του χρήστη.
Τα ενσωματωμένα συστήματα υπολογισμού πρέπει να αντιμετωπίσουν τους περιορισμούς του κόστος, της κατανάλωσης ενέργειας, και της απόδοσης. Εάν επικρατούσε μία απαίτηση σχεδίου, η ζωή θα ήταν πολύ ευκολότερη για τους σχεδιαστές ενσωματωμένων συστημάτων που —θα μπορούσαν να χρησιμοποιούν σωστά τυποποιημένες αρχιτεκτονικές με εύκολα μοντέλα προγραμματισμού. Αλλά επειδή οι τρεις περιορισμοί πρέπει να αντιμετωπισθούν ταυτόχρονα, οι σχεδιαστές ενσωματωμένων συστημάτων πρέπει να προσαρμόσουν το υλικό και τις αρχιτεκτονικές λογισμικού, ώστε να ανταποκρίνεται στις ανάγκες των εφαρμογών. Το εξειδικευμένο υλικό βοηθάει ώστε να αντιμετωπισθούν οι απαιτήσεις απόδοσης για χαμηλότερη κατανάλωση ενέργειας στο λιγότερο δυνατό κόστος από ένα γενικής χρήσης σύστημα. Συνήθως, τα ενσωματωμένα συστήματα υπολογισμού είναι συχνά ετερογενείς πολυεπεξεργαστές με πολλαπλές CPUs και στοιχεία επεξεργασίας (PEs). Στο συσχεδιασμό εξειδικευμένων επεξεργαστικών μονάδων (processing elements, PE) και επεξεργαστών, τα στοιχεία επεξεργασίας PEs καλούνται γενικά επιταχυντές. Αντίθετα, ο συνεπεξεργαστής ελέγχεται από τη μονάδα εκτέλεσης μιας ΚΜΕ.
Ο συ-σχεδιασμός υλικού/λογισμικού είναι μια συλλογή των τεχνικών που οι σχεδιαστές χρησιμοποιούν για να τους βοηθήσουν τη δημιουργία αποδοτικών συστημάτων ειδικής εφαρμογής. Εάν δεν γνωρίζει κάποιος τίποτα για τα χαρακτηριστικά της εφαρμογής, είναι δύσκολο να ξέρει πώς να βελτιστοποιήσει το σχεδιασμό του συστήματος. Αλλά εάν γνωρίζει κάποιος την εφαρμογή, ως σχεδιαστής, όχι μόνο μπορεί να προσθέσει χαρακτηριστικά στο υλικό και το λογισμικό που το κάνουν να τρέχει γρηγορότερα χρησιμοποιώντας λιγότερη ενέργεια, αλλά μπορεί επίσης να αφαιρέσει στοιχεία υλικού και λογισμικού που δεν βοηθούν την εφαρμογή. Το να αφαιρούνται περιττά στοιχεία είναι συχνά τόσο σημαντικό, όσο το να προσθέτονται νέα χρήσιμα στοιχεία. Όπως το όνομα υπονοεί, ο συ-σχεδιασμός υλικού/λογισμικού σημαίνει σχεδιασμό από κοινού αρχιτεκτονικές υλικού και λογισμικού, ώστε να επιτευχθούν οι στόχοι όσον αφορά το κόστος, την ενέργεια και την απόδοση.
Ο συ-σχεδιασμός είναι μια ριζικά διαφορετική μεθοδολογία σε σχέση με τις στρωματικές αφαιρέσεις, οι οποίες έχουν χρησιμοποιηθεί στον υπολογισμό γενικής χρήσης. Επειδή ο συ-σχεδιασμός προσπαθεί να βελτιστοποιήσει πολλά διαφορετικά μέρη του συστήματος συγχρόνως, κάνει εκτενή χρήση εργαλείων για την ανάλυση, αλλά και για τη βελτιστοποίηση σχεδίου. Όλο και περισσότερο, ο συ-σχεδιασμός υλικού/λογισμικού χρησιμοποιείται και για να σχεδιάσει συστήματα. Παραδείγματος χάριν, οι κεντρικοί υπολογιστές μπορούν να βελτιωθούν με μερικές εξειδικευμένες εφαρμογές από τις λειτουργίες του σωρού του λογισμικού τους.
Τα SoCs ενσωματώνουν τα στοιχεία που προέρχονται από διάφορους προμηθευτές. Παραδείγματος χάριν, ο επεξεργαστής ήχου Cirrus Logic Maverick EP9312 (Εικόνα 4.26). Αυτό είναι ένα SoC που ενσωματώνει έναν επεξεργαστή ARM920T, μαζί με όλες τις λειτουργίες για να επιτρέψει τις εφαρμογές Jukebox-καταγραφής ψηφιακής μουσικής (εκτέλεση-καταγραφή). Το υπόλοιπο των συστατικών SoC περιλαμβάνει την ικανότητα επεξεργασίας σήματος, τις επικοινωνίες, την αποθήκευση, και τη διεπαφή με τον χρήστη. Στο συγκεκριμένο παράδειγμα, το τσιπ περιλαμβάνει τα στοιχεία για τις τυποποιημένες διασυνδέσεις, καθώς επίσης και τα ιδιόκτητα στοιχεία για τις πιο εξατομικευμένες λειτουργίες. Το τελευταίο σύνολο στοιχείων εμπεριέχει έναν προγραμματίσιμο μαθηματικό επεξεργαστή για τους ακέραιους αριθμούς, φίλτρο δεκαδικής υποδιαστολής και το συστατικό κλειδώματος τύπου Maverick για να διαχειρίζεται τις καταστάσεις ασφάλειας για την διαχείριση ψηφιακών δικαιωμάτων.
Τα SoCs είναι σύνθετα ολοκληρωμένα κυκλώματα. Παραδείγματος χάριν, το EP93121 περιλαμβάνει 5.7 εκατομμύρια τρανζίστορ σε τεχνολογία CMOS 0,25 μm, παρέχοντας υψηλή ταχύτητα (200 MHz) και χαμηλή στιγμιαία κατανάλωση ισχύος (1,5 W) συγκρινόμενος με έναν γενικής χρήσης επεξεργαστή. Μια τυπική εφαρμογή για το EP9312 είναι το οικιακό σύστημα αναπαραγωγής τραγουδιών, για το οποίο χρειάζεται να δημιουργηθούν, να διαχειριστούν, και να αποσυμπιεστούν πολλαπλές ροές συμπιεσμένων ακουστικών στοιχείων σε όλο το σπίτι για ποικίλους ψηφιακούς φορείς μουσικής (π.χ., ένας φορητός προσωπικός φορέας, ένα κέντρο ψυχαγωγίας, ένα στερεοφωνικό συγκρότημα αυτοκινήτων).
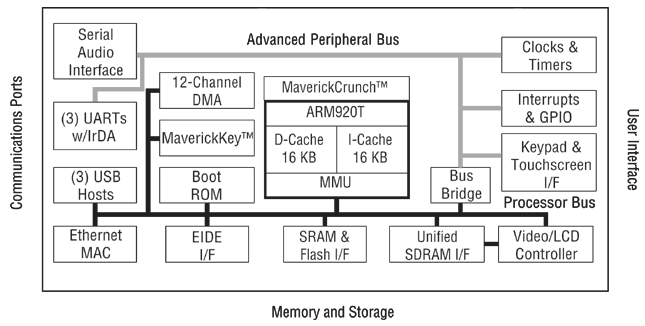
4.26: Παράδειγμα ενός εμπορικού SoC. Το διάγραμμα παρουσιάζει το SoC Cirrus Logic EP9312 chip. Αυτό περιλαμβάνει όλα τα συστατικά ενός χαρακτηριστικού SoC: ένας τριανταδυάμπιτος πυρήνας RISC (o ARM920T), τυποποιημένες περιφερειακές μονάδες (ήχος, UARTs, USB, Ethernet), μνήμη διεπαφής (SRAM, flash, SDRAM), διεπαφές βίντεο και συσκευές εισόδου, ιδιόκτητα στοιχεία IP (το τμήμα ασφάλειας κλειδώματος τύπου Maverick), και τους διαύλους διασύνδεσης.
Η μεγάλη ‘υπόσχεση’ της τεχνικής επαναχρησιμοποίησης του σχεδιασμού στην τεχνολογία SoC, είναι να καταστήσει τα τμήματα υλικού τόσο ανταλλάξιμα όσο τα παξιμάδια βίδας και τα μπουλόνια στην κατασκευή των φυσικών αγαθών. Οι εταιρείες κατασκευής μικροεπεξεργαστών και σχεδιασμού περιβάλλοντος δεν μπορούν να σχεδιάσουν από την αρχή ολοκληρωμένα SoCs για κάθε νέο προϊόν. Αυτό οδηγεί στην κεντρική ιδέα της επαναχρησιμοποίησης των συστατικών SoC, συχνά αποκαλούμενης ως στοιχεία πνευματικής ιδιοκτησίας (ή στοιχεία IP). Με τον όρο επαναχρησιμοποίηση (όρος δανεισμένος από την περιοχή της τεχνολογίας λογισμικού), η κοινότητα SoC δείχνει ότι είναι ικανή να υιοθετήσει την περιγραφή των στοιχείων του υλικού στα διάφορα σχέδια με ελάχιστες ή καθόλου αλλαγές. Τα στοιχεία IP μπορεί να είναι οτιδήποτε από τα περιφερειακά αναλογικά, και τους ελεγκτές διαύλων, ως και τις γέφυρες που υλοποιούνται από τους πυρήνες μικροεπεξεργαστών. Οι εταιρείες μικροεπεξεργαστών μιλούν πολύ για τη μέθοδο επαναχρησιμοποίησης, αλλά μέχρι τώρα αγωνίζονται ακόμα να βρουν έναν αποδοτικό τρόπο για να θέσουν τη μέθοδο σε εφαρμογή. Η χορήγηση αδειών IP από τους τρίτους προκαλεί νομικά ζητήματα και προβλήματα συμβατότητας, προσθέτοντας περισσότερες προκλήσεις στην επαναχρησιμοποίηση IP. Το σημαντικότερο πρόβλημα με την επαναχρησιμοποίηση IP σχετίζεται με την έλλειψη τυποποιημένων διεπαφών, μεθοδολογίας των συστημάτων προσομοίωσης, και κοινής στρατηγικής επικύρωσης.
Η προσωπική επαναχρησιμοποίηση είναι παραδοσιακή στις ομάδες σχεδιασμού ASIC. Στη μέθοδο αυτή τα μέρη ενός σχεδίου επαναχρησιμοποιούνται για τις διαδοχικές εκδόσεις. Το πλεονέκτημα έγκειται στον γεγονός ότι δεν απαιτείται ειδική υποδομή, εξ άλλου η δεδομένη μέθοδος δεν ανέρχεται σε κλιμακούμενη σειρά στις μεγαλύτερες ομάδες ή στα διαφορετικά σχέδια, και συνήθως υπονοεί την επαναχρησιμοποίηση της ομάδας του σχεδιασμού.
Η επαναχρησιμοποίηση πρωτοτύπου (source-πηγή) παρέχει μια υπάρχουσα περιγραφή RTL (επίπεδο μεταφοράς καταχωρητών), ή λίστα δικτύου, ή περιγραφή για την αυτοδύναμη επανεκκίνηση ενός νέου σχεδίου. Η αποτελεσματικότητά της εξαρτάται από την ποιότητα του κώδικα, της τεκμηρίωσης, της ακολουθίας ελέγχου, και της διαθεσιμότητας του αρχικού σχεδιαστή.
O συ-σχεδιασμός υλικού/λογισμικού μπορεί να χρησιμοποιηθεί για να σχεδιάσει συστήματα από την αρχή ή για να δημιουργήσει συστήματα που υλοποιούνται σε μια υπάρχουσα πλατφόρμα. Η χρήση της ΚΜΕ και μιας αρχιτεκτονικής επιταχυντών είναι μια κοινή πλατφόρμα συσχεδιασμού. Μια ποικιλία διαφορετικών CPUs μπορεί να χρησιμοποιηθεί για να φιλοξενήσει τον επιταχυντή. Ο επιταχυντής μπορεί να εφαρμόσει πολλές διαφορετικές λειτουργίες, επιπλέον μπορεί να εφαρμοστεί χρησιμοποιώντας οποιαδήποτε από τις αρκετές τεχνολογίες λογικής. Αυτές οι επιλογές επηρεάζουν το χρόνο σχεδιασμού, την κατανάλωση ενέργειας, και άλλα σημαντικά χαρακτηριστικά του συστήματος.
Η πλατφόρμα συσχεδιασμού θα μπορούσε να εφαρμοστεί σε οποιοιδήποτε από τις πολλές διαφορετικές τεχνολογίες σχεδιασμού.
Μια πιθανή υλοποίηση είναι ένα σύστημα βασισμένο σε Η/Υ με τον επιταχυντή να στεγάζεται σε μια κάρτα που συνδέεται με το PC bus (Εικόνα 4.27). Η πλακέτα αυτή μπορεί να χρησιμοποιήσει ένα συνηθισμένο τσιπ ή έναν FPGA για να υλοποιήσει τον επιταχυντή. Αυτό το είδος του συστήματος είναι σχετικά ογκώδες και συχνότερα χρησιμοποιείται για ανάπτυξη ή για πολύ χαμηλής έντασης εφαρμογές. Ένας συνηθισμένος τυπωμένος πίνακας κυκλωμάτων, χρησιμοποιεί είτε ένα FPGA, είτε ένα συνηθισμένο ενσωματωμένο κύκλωμα για τον επιταχυντή. Η κάρτα επέκτασης FPGA απαιτεί περισσότερη σχεδιαστική εργασία από ένα σύστημα βασισμένο σε Η/Υ, αλλά έχει αποτελέσματα σε ένα χαμηλότερου κόστους και αρκετά ποιο δυνατό επεξεργαστικά σύστημα.
Μια εναλλακτική και η πιο πρόσφατη υλοποίηση είναι μια πλατφόρμα FPGA που περιλαμβάνει μια ΚΜΕ και μια δομή FPGA σε ένα ενιαίο τσιπ, όπως η σειρά Zynq7000 της Xilinx (Εικόνα 4.28). Αυτά τα τσιπ είναι ακριβότερα από τα συνηθισμένα τσιπ αλλά παρέχουν μια εφαρμογή ενιαίου τσιπ με μία ή περισσότερες CPUs και μια τυπική επαναδιαμορφώσιμη λογική.

4.27: Ο επιταχυντής σε ένα Ενσωματωμένο σύστημα, μπορεί να είναι μια κάρτα FPGA που συνδέεται στο δίαυλο του συστήματος. Εδώ φαίνεται η Virtex 6 FPGA κάρτα της Xilinx με διεπαφή PCI Express. Εικόνα από xilinx.com.

4.28: Στα ενσωματωμένα συστήματα μπορεί να χρησιμοποιηθεί κάποια αρχιτεκτονική FPGA που εμπεριέχει και έναν ή περισσότερους επεξεργαστές. Εδώ φαίνεται η αναπτυξιακή πλατφόρμα Xilinx Zybo, η οποία περιέχει έναν διπύρηνο επεξεργαστή ARM Cortex-A9 στα 650 Mhz και επαναδιαμορφώσιμη FPGA με 28000 λογικά κελιά.
Ένας επιταχυντής υλικού είναι ένα συνηθισμένο ολοκληρωμένο κύκλωμα, που υλοποιεί μια εξειδικευμένη λειτουργία, με όσο το δυνατόν μικρότερη κατανάλωση ενέργειας και υψηλές επιδόσεις. Πολλά ενσωματωμένα συστήματα σε τσιπ systems-on-chips (SoC) χρησιμοποιούν επιταχυντές για διάφορες λειτουργίες.
Ο συνδυασμός μιας ΚΜΕ με έναν ή περισσότερους επιταχυντές είναι η απλούστερη μορφή ετερογενούς πλατφόρμας ενσωματωμένων συστημάτων. Η ΚΜΕ καλείται συχνά host (ξενιστής). Η ΚΜΕ επικοινωνεί με τον επιταχυντή μέσω των δεδομένων και των καταχωρητών ελέγχου που βρίσκονται μέσα σε αυτόν. Αυτοί οι καταχωρητές επιτρέπουν στην ΚΜΕ να ελέγξουν τη λειτουργία του επιταχυντή και για να του δώσουν εντολές. Η ΚΜΕ και ο επιταχυντής μπορούν επίσης να επικοινωνήσουν μέσω της κοινής μνήμης. Εάν ο επιταχυντής πρέπει να λειτουργήσει σε έναν μεγάλο όγκο δεδομένων, είναι συνήθως αποδοτικότερο να αφήσει τα στοιχεία στη μνήμη και να έχει τον επιταχυντή να διαβάζει και να γράφει μνήμη άμεσα, παρά να έχει μεταφορά των δεδομένων της ΚΜΕ από τη μνήμη στους καταχωρητές του επιταχυντή και αντίστροφα. Η ΚΜΕ και ο επιταχυντής συγχρονίζουν τις ενέργειές τους. Περισσότερες και γενικότερες πλατφόρμες είναι επίσης δυνατές. Μπορούμε να χρησιμοποιήσουμε διάφορες CPUs, σε αντίθεση με τον ενιαίο επεξεργαστή που είναι συνδεδεμένος με τους επιταχυντές. Μπορούμε να χρησιμοποιήσουμε πολλαπλούς διαύλους. Επιπλέον, μπορούμε να δημιουργήσουμε ένα πιο σύνθετο σύστημα μνήμης που να παρέχει διαφορετικούς τύπους προσβάσεων στα διαφορετικά μέρη του συστήματος. Ο συ-σχεδιασμός τέτοιων τύπων συστημάτων είναι περισσότερο δύσκολος, ιδιαίτερα όταν δεν κάνουμε τις υποθέσεις για τη δομή της πλατφόρμας.
Πολλοί σχεδιαστές, οι οποίοι είναι σχετικοί με την πληροφορική γενικού σκοπού σχετίζουν την πολυεπεξεργασία μόνο με τους διακομιστές υψηλών επιδόσεων, τις μηχανές βάσεων δεδομένων ή τους σταθμούς εργασίας για επιστημονικούς λόγους και τις διεργασίες heavy-duty ή μετατροπή σε 3D γραφικά ή πρόγνωση του καιρού. Στην πραγματικότητα η πολυεπεξεργασία στα ενσωματωμένα συστήματα είναι πολύ κοινή, παρόλο που συχνά παίρνει πολλές διαφορετικές μορφές. Η πιο επιτυχημένη μορφή της πολυεπεξεργασίας (SMP) στην οποία το σύστημα εξυπηρετεί πολλούς επεξεργαστές, είναι μέσω μια μορφής μνήμης, η οποία διαμοιράζεται (υπολογιστικά συστήματα διαμοιραζόμενης μνήμης). Στην SMP αρχιτεκτονική, οι διεργασίες χρονοδρομολογούνται ατομικά σε κάθε επεξεργαστή από το λειτουργικό σύστημα, το οποίο είναι συχνά υπεύθυνο για την μετανάστευση των διεργασιών κατά μήκος του επεξεργαστή, για να εξισορροπήσει την υπερχείλιση της μηχανής.
Στα ενσωματωμένα η πιο ευρέως υιοθετημένη μορφή πολυεπεξεργασίας είναι η ετερογενής, στην οποία κατεξοχήν διαφορετικοί επεξεργαστές βρίσκονται στο ίδιο σύστημα, αλλά ο καθένας μπορεί να θεωρηθεί ως ένα υποσύστημα (με μια ιδιωτική μνήμη ), το οποίο δεν επηρεάζεται από τα άλλα στοιχεία του προγράμματος. Με άλλα λόγια, διαφορετικά λειτουργικά συστήματα (ή microkernels) ελέγχουν τους ατομικούς επεξεργαστές ο καθένας από τους οποίους τρέχει ένα προκαθορισμένο, κατανεμημένο σύνολο διεργασιών. Η επικοινωνία μεταξύ των επεξεργαστών επιτυγχάνεται μέσα από μια καλά καθορισμένη μνήμη η οποία μοιράζεται και χειρίζεται τον συγχρονισμό των μηχανισμών, παρόμοια με τον τρόπο με τον οποίο χειριζόμαστε και άλλες μηχανές DMA. Σε αυτές τις διαμορφώσεις, είναι κοινό να ορίζουμε έναν επεξεργαστή ως τον κύριο επεξεργαστή του συστήματος. Ο κύριος αυτός επεξεργαστής ελέγχει την δραστηριότητα των διεργασιών πάνω στους άλλους επεξεργαστές (σκλάβους), στέλνοντας τις κατάλληλες εντολές ελέγχου στους microkernels οι οποίοι τρέχουν πάνω στους σκλάβους.
Μια άλλη κοινή μορφή πολυεπεξεργασίας εκμεταλλεύεται τον έμφυτο παραλληλισμό των δεδομένων στην εφαρμογή. Αν μπορούμε να γράψουμε την εφαρμογή σε μορφή SPMD (το ίδιο πρόγραμμα σε πολλά δεδομένα, single program multiple data), μπορούμε να χρησιμοποιήσουμε πολλαπλούς ίδιους επεξεργαστές με ιδιωτικές μνήμες δεδομένων για να επεξεργασθούμε ανεξάρτητα περιοχές με προσωπικά δεδομένα. Μπορούμε να βρούμε παραδείγματα από τις πολλές εφαρμογές SPMD οι οποίες χειρίζονται δισδιάστατες εικόνες. (π.χ. ιατρική απεικόνιση) ή άλλες συνηθισμένες ροές δεδομένων (τηλεπικοινωνίες, ήχο και βίντεο). Αυτή η προσέγγιση δεν είναι καινούργια, αλλά χρονολογείται στα μέσα τις δεκαετίας του 1970. Συνεχίστηκε μέχρι και στην δεκαετία του 1980 και συμπεριλάμβανε την εκπληκτική ανάπτυξη των επεξεργαστών οι οποίοι σαφέστατα κατασκευάστηκαν για να καθορίζονται παράλληλα (όπως η Inmos’s Transputers) και δοκιμάστηκαν για πολύ καιρό πριν εγκαταλειφθούν τελείως.
Μέχρι πρόσφατα το SMP ήταν ακριβό και συνήθως ήταν αποτελεσματικό για συγκεκριμένα προβλήματα, και το οποίο το έκανε απαγορευτικά ακριβό για οτιδήποτε άλλο εκτός από ακριβούς σταθμούς υψηλών προδιαγραφών και διακομιστές. Τα τελευταία χρόνια οι επεξεργαστές SMP γίνονται πιο κοινοί και αρκετοί κατασκευαστές ενσωματωμένων συστημάτων προσφέρουν πολυπύρηνα συστήματα (όπως dual ή quad cores ARMS ή MIPS ή PPC ). Με αυτό το σενάριο τα ενσωματωμένα συστήματα γίνονται εμπορεύσιμα σαν τα SMP και τα ενσωματωμένα SMP συστήματα γίνονται οικονομικά πιο βιώσιμα. Η ανάπτυξη του λογισμικού στα ενσωματωμένα πολυπύρηνα συστήματα είναι μια πρόκληση. Ήδη η βέλτιστη χρήση των παράλληλων διακομιστών που έχουν πολλούς πόρους είναι μια δύσκολη διαδικασία. Τα ΕΣ με τους πολύ λιγότερους πόρους και τις ακόμη περισσότερες απαιτήσεις κάνουν το έργο πολύ πιο δύσκολο, με λιγότερες δυνατότητες. Για παράδειγμα πολλές φορές απαιτείται η συνέπεια της μνήμης στα ΕΣ να υλοποιείται από μηχανισμούς λογισμικού ή υλικού των σχεδιαστών και όχι από κάποιο λειτουργικό σύστημα.
Εκτός από τη συμμετρική πολυεπεξεργασία, στα ΕΣ συναντάμε και την ασύμμετρη πολυεπεξεργασία ή ετερογενής πολυεπεξεργασία. Αυτή είναι η πιο κοινή μορφή πολυεπεξεργασίας στα ενσωματωμένα SoCs σήμερα. Η πρώτη ερώτηση η οποία μας έρχεται στο μυαλό είναι η εξής: δεδομένου ότι ο γενικός σκοπός των επεξεργαστών είναι διαθέσιμος, γιατί θα πρέπει να χρησιμοποιήσουμε διαφορετικούς επεξεργαστές για κάθε μια διεργασία; Οι λόγοι είναι: οι εκτιμήσεις του κόστους, της απόδοσης και της προσαρμογής. Το να χρησιμοποιηθούν διαφορετικοί επεξεργαστές για διαφορετικές διεργασίες επιτρέπει στους σχεδιαστές να επιλέξουν την πιο αποτελεσματική ως προς το κόστος εναλλακτική για κάθε στάδιο της εφαρμογής. Για παράδειγμα, το DSP και οι επεξεργαστές γενικού σκοπού έχουν ευδιάκριτα διαφορετικά σύνολα χαρακτηριστικών τα οποία τους κάνουν να ταιριάζουν καλύτερα σε διαφορετικού τύπου φόρτου εργασίας. Σε μια εφαρμογή, η οποία περιλαμβάνει και DSP και συστατικά υπολογισμού γενικού σκοπού, χωρίζοντας τις δύο διεργασίες και χρησιμοποιώντας ετερογενές σύστημα είναι πολύ αποτελεσματικότερο ως προς το κόστος από το να δοκιμάσουμε να επιβάλλουμε την ανάδραση σε ολόκληρη την εφαρμογή σε ένα παραδοσιακό γενικού σκοπού SMP (πολύ ακριβό) ή σε ένα μέρος ενός DSP (πολύ άκαμπτο).
Δυστυχώς, η ετερογενής πολυεπεξεργασία δεν είναι δωρεάν. Το μεγαλύτερο εμπόδιο έρχεται από την απουσία ενός διαισθητικού προτύπου προγραμματισμού. Οι διεργασίες θα πρέπει να είναι ρητά χωρισμένες για τους μεμονωμένους επεξεργαστές, η εσωτερική επικοινωνία και ο συγχρονισμός πρέπει να αντιμετωπιστούν χειροκίνητα, τα εργαλεία και τα δυαδικά συστήματα σύνταξης είναι διαφορετικά, και η αποσφαλμάτωση είναι αδέξια.
Παρά τις εγγενείς δυσκολίες στο πρότυπο προγραμματισμού, διάφορες τάσεις βιομηχανίας ωθούν έντονα στην κατεύθυνση της ετερογενούς πολυεπεξεργασίας. Πολλοί προμηθευτές και πρωτοβουλίες σε βιομηχανικό επίπεδο υποστηρίζουν μερικούς μικροελεγκτές και συνδυασμούς DSP που στοχεύουν σε μερικές από τις πιο ελπιδοφόρες περιοχές αγοράς. Παραδείγματος χάριν, και το PCA της Intel και οι γραμμές προϊόντων της Texas Instruments OMAP ανήκουν σε αυτήν την κατηγορία νέων πλατφορμών SoC. Μια από τις σημαντικότερες κατευθυντήριες δυνάμεις πίσω από την υιοθέτηση αυτών των μορφών αρχιτεκτονικής προέρχεται από τις αντιπαραβαλλόμενες απαιτήσεις. Εκτιμώντας ότι οι εφαρμογές και τα λειτουργικά συστήματα παίρνουν έναν μακροχρόνιο χρόνο να μεταναστεύσουν στις νέες αρχιτεκτονικές, τα νέα προϊόντα ωθούν συνεχώς το σχεδιασμό με περισσότερες απαιτήσεις και ένα γρηγορότερο ποσοστό υιοθέτησης. Ο συνδυασμός ενός συμβατικού πυρήνα μικροεπεξεργαστή (όπως ARM) με έναν αποδοτικά προσανατολισμένο στον προγραμματίσιμο επιταχυντή (όπως πολλές σύγχρονες μηχανές DSP ή FPGA), υπόσχεται να παρέχει την ευελιξία που χρειάζεται για να αντιμετωπιστούν και τα δύο σύνολα απαιτήσεων. Πρέπει όμως να περάσουν πολλά στάδια μέχρι η ετερογενής πολυεπεξεργασία να γίνει κάτι συνηθισμένο και τυπικό.
Σε αυτό το κεφάλαιο περιγράψαμε τους τρόπους υλοποίησης των ενσωματωμένων συστημάτων. Αφού έγινε μια μικρή ιστορική αναδρομή, αναφερθήκαμε στους μικροελεγκτές, στους επεξεργαστές ειδικών εφαρμογών, σε ολοκληρωμένα κυκλώματα και σε FPGA. Ιδιαίτερα περιγράψαμε τα FPGA και τα στοιχεία που αποτελούνται, αφού είναι η πιο δημοφιλής πλατφόρμα ανάπτυξης πολύπλοκων ενσωματωμένων συστημάτων. Τέλος, αναφερθήκαμε στα συστήματα πάνω στο ίδιο υπόστρωμα πυριτίου και δώσαμε μια τυπική σχεδιαστική ροή.
Όπως κάθε υπολογιστικό σύστημα, έτσι και τα ενσωματωμένα συστήματα έχουν ένα θεμελιώδη σκοπό ύπαρξης, ο οποίος είναι η επεξεργασία των δεδομένων και η λήψη αποφάσεων ή εκτέλεση ενεργειών. Αυτό επιτυγχάνεται με τους τρόπους εισόδου και εξόδου του επεξεργαστή από τα περιφερειακά, μέσω κατάλληλων θυρών. Τα δεδομένα μεταφέρονται από και προς τα περιφερειακά μέσω κατάλληλων δικτύων διασύνδεσης και διαύλων. Αν και τα ενσωματωμένα συστήματα χρησιμοποιούν τους περισσότερους προτυποποιημένους διαύλους που υπάρχουν στα τυπικά υπολογιστικά συστήματα και τους διακομιστές, εντούτοις χρησιμοποιούν και πολλούς διαύλους που τους συναντάμε μόνο σε αυτή την περιοχή, λόγω της ευρείας χρήσης τους. Σε αυτό το κεφάλαιο περιγράφουμε τους διαύλους και τη επικοινωνία και στη συνέχεια τις τυπικές λειτουργίες εισόδου εξόδου.
Στη πιο βασική μορφή του, ένας υπολογιστής περιέχει ένα επεξεργαστικό στοιχείο (processing element, PE) είτε είναι επεξεργαστής, είτε είναι επαναδιαμορφώσιμη λογική, είτε ASIC, μνήμη και έναν ή παραπάνω τρόπους επικοινωνίας με το εξωτερικό περιβάλλον. Στις μέρες μας μπορεί ένας μηχανικός ενσωματωμένων συστημάτων να προμηθευτεί έναν πλήρη υπολογιστή σε μέγεθος όσο ένα πακέτο τσιγάρα, με κόστος κάτω από 10$, με τους πιο γνωστούς αντιπρόσωπους τον υπολογιστή CHIP (κόστος 9$, με 512MB RAM, 4MB Flash, ARM7, USB, HDMI, GPIO) ή τον υπολογιστή Raspberry Pi Zero (κόστος 5$, με 512MB RAM, ARM6, USB, HDMI, GPIO). Αυτοί οι υπολογιστές, που ονομάζονται υπολογιστές μιας πλακέτας (single board computers, SBC), μπορούν να χρησιμοποιηθούν με το κατάλληλο λογισμικό σε ενσωματωμένες εφαρμογές μέτριων υπολογιστικών απαιτήσεων, χωρίς κανένα πρόβλημα. Όπως οι μεγαλύτεροι υπολογιστές, έτσι και αυτοί, αλλά και κάθε υπολογιστικό σύστημα, χρησιμοποιούν κανάλια διασύνδεσης ή διαύλους για να συνδέουν τα περιφερειακά και τα δομοστοιχεία, τόσο εντός του ολοκληρωμένου κυκλώματος όσο και εκτός. Υπάρχουν πάρα πολλοί δίαυλοι με διαφορετικά χαρακτηριστικά. Ο μηχανικός θα πρέπει να επιλέγει κάθε φορά το δίαυλο που θα χρησιμοποιήσει για την επικοινωνία, με βάση τη διαθεσιμότητα και την κάλυψη των αναγκών. Αν το ενσωματωμένο σύστημα βρίσκεται ήδη στη διάθεσή του, τότε θα πρέπει να χρησιμοποιήσει τους διαύλους που αυτό υποστηρίζει, όπως για παράδειγμα το CHIP που υποστηρίζει το δίαυλο USB ή το GPIO και για να διασυνδεθεί θα πρέπει να επιλεχθεί ένα περιφερειακό που να είναι συμβατό με το USB ή μπορεί να επικοινωνήσει μέσω του GPIO. Αν το ενσωματωμένο σύστημα βρίσκεται σε κατάσταση ανάπτυξης, τότε θα πρέπει να επιλεχθούν οι δίαυλοι που θα υποστηρίζει. Η σύνδεση του επεξεργαστή με το περιφερειακό γίνεται μέσω ενός δικτύου διασύνδεσης (Interconnection Network, IN), και περιλαμβάνει είτε αποκλειστικές γραμμές σημείο-προς-σημείο, ή διαμοιραζόμενα κανάλια πολλών συσκευών (Εικόνα 5.1).
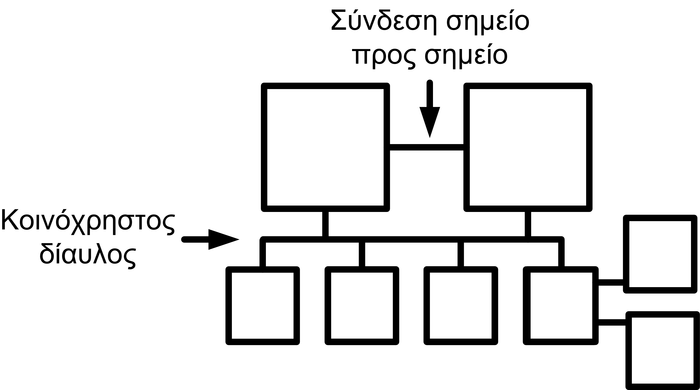
5.1: Το δίκτυο διασύνδεσης ενός συστήματος αποτελείται από κοινόχρηστους διαύλους και αποκλειστικές διασυνδέσεις σημείο-προς-σημείο.
Για να επικοινωνήσει ο επεξεργαστής με ένα περιφερειακό θα πρέπει να του στείλει πληροφορίες που ανήκουν σε 3 κατηγορίες: (α) δεδομένα, (β) διεύθυνση, και (γ) έλεγχος (Εικόνα 5.2). Τα δεδομένα είναι το ωφέλιμο φορτίο και μπορεί ο επεξεργαστής είτε να στείλει ή να ζητήσει να διαβάσει. Η διεύθυνση χρησιμοποιείται είτε στη περίπτωση που ένα περιφερειακό έχει πολλαπλές θέσεις μνήμης και ο επεξεργαστής αιτεί πρόσβαση σε μια από αυτές, είτε για να προσδιοριστεί ακριβώς το περιφερειακό, αν υπάρχουν περισσότερο από ένα, από τα οποία το καθένα έχει δικιά του μοναδική διεύθυνση. Ο έλεγχος προσδιορίζει κυρίως αν θα γίνει εγγραφή ή ανάγνωση, αλλά μπορεί να χρησιμοποιηθεί και για πιο προχωρημένες λειτουργίες όπως αίτηση για διακοπή, εξυπηρέτηση διακοπής, αίτηση για έλεγχο του διαύλου κ.α., που θα αναλύσουμε σε επόμενη ενότητα. Το κάθε περιφερειακό έχει μια διεπαφή, στην οποία υπάρχουν οι καταχωρητές ελέγχου, κατάστασης και δεδομένων. Ο καταχωρητής ελέγχου τροποποιείται από τον επεξεργαστή και καθορίζει τη λειτουργία που αιτείται, ο καταχωρητής κατάστασης δείχνει την κατάσταση της συσκευής (αν είναι αδρανής, αν έχει δεδομένα προς αποστολή, αν είναι απασχολημένη με προηγούμενη επεξεργασία).
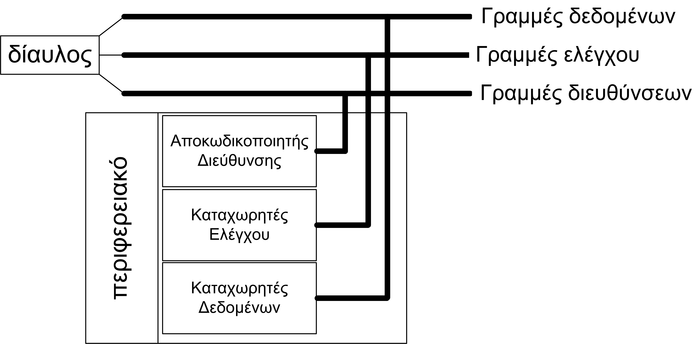
5.2: Τα περιφερειακά για να συνδεθούν στο δίαυλο χρησιμοποιούν μια διεπαφή που επεξεργάζεται τα δεδομένα, τα σήματα ελέγχου και τη διεύθυνση που έχει τοποθετήσει ο επεξεργαστής.
Η λειτουργία, η χρήση και η πρόσβαση στους προτυποποιημένους διαύλους καθορίζεται από αυστηρά πρωτόκολλα, ηλεκτρικών προδιαγραφών (π.χ. τι τάση θα πρέπει να υπάρχει και σε ποιους ακροδέκτες), χρονισμού (για πόσο χρονικό διάστημα θα πρέπει να εφαρμοστεί κάτι στο δίαυλο, Εικόνα 5.3), και καταστάσεων (ποιες είναι οι καταστάσεις που διέρχεται μια μεταφορά). Τα πρωτόκολλα διαύλων καθορίζουν πως επικοινωνούν οι συσκευές και πρέπει όλες οι συνδεδεμένες συσκευές να τα σέβονται στην εντέλεια. Προκειμένου ένα περιφερειακό να είναι συμβατό με το συγκεκριμένο δίαυλο θα πρέπει να έχει πιστοποιηθεί ότι ακολουθεί όλες τις προδιαγραφές, διαφορετικά είτε δε θα λειτουργήσει, είτε θα προκαλέσει πρόβλημα επικοινωνίας ή και καταστροφής στις υπόλοιπες συσκευές. Συνοψίζοντας, ο δίαυλος είναι ένα κοινόχρηστο μέσο μετάδοσης που αποτελείται από καλώδια και προδιαγραφές.
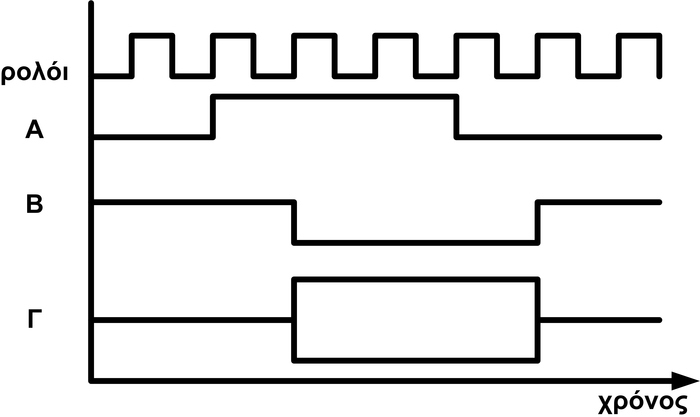
5.3: Η λειτουργία κάθε διαύλου καθορίζεται από το διάγραμμα χρονισμού. Στην εικόνα φαίνεται το ρολόι, ένα σήμα Α που από χαμηλή στάθμη εξυψώνεται 3 κύκλους ρολογιού, ένα σήμα Β που βρίσκεται σε υψηλή στάθμη και χαμηλώνει στο 0 για 3 κύκλους ρολογιού, και ένα σήμα Γ που βρίσκεται για 3 κύκλους σε μια απροσδιόριστη κατάσταση (π.χ.είτε είναι 1 είτε 0, είτε πολλαπλά διαφορετικά bit).
Το πρώτο χαρακτηριστικό των διαύλων είναι το μέγεθος της ταυτόχρονης μεταφοράς των δεδομένων. Υπάρχουν δυο βασικές κατηγορίες: (α) σειριακό και (β) παράλληλο. Στη σειριακή επικοινωνία στέλνεται το κάθε bit ξεχωριστά, και ο δέκτης έχει τους κατάλληλους καταχωρητές που επιτελούν τη μετατροπή σειριακό σε παράλληλο, αφού τα δεδομένα χρησιμοποιούνται σε λέξεις των 8 ή 16 ή 13 bit. Στην παράλληλη επικοινωνία, υπάρχουν πολλαπλοί αγωγοί μεταφοράς που χρησιμοποιούνται ταυτόχρονα. Μέχρι το τέλος της δεκαετίας του 1990, υπήρχε μια προτίμηση στους παράλληλους διαύλους για τη μεταφορά μεγάλου όγκου δεδομένων, όπως π.χ. από το σκληρό δίσκο ή την κάρτα γραφικών. Όμως, διαπιστώθηκαν αρκετά προβλήματα που εμπόδιζαν τα συστήματα να επιτύχουν μεγαλύτερες ταχύτητες επικοινωνίας και έτσι εγκαταλείφθηκαν οι παράλληλοι δίαυλοι. Το πρώτο πρόβλημα είναι ο όγκος των διαύλων. Ένας σειριακός δίαυλος καταλαμβάνει πολύ μικρότερη επιφάνεια από τον παράλληλο. Οι παράλληλοι δίαυλοι παρουσιάζουν διαφορετικές καθυστερήσεις σε κάθε αγωγό, επειδή είναι αδύνατο να κατασκευαστούν όλοι οι αγωγοί με μια ιδανική διαδικασία και να έχουν ίδιες αντιστάσεις. Η διαφορά της αντίστασης, όσο μικρή και να είναι, προκαλεί διαφορετική καθυστέρηση σε κάθε αγωγό και έτσι δημιουργείται πρόβλημα συγχρονισμού. Οι σειριακοί δίαυλοι δεν έχουν τέτοιο πρόβλημα, αφού όλα τα bit διέρχονται από τον ίδιο αγωγό και έχουν την ίδια καθυστέρηση. Οι παράλληλοι δίαυλοι δεν έχουν εγκαταλειφθεί. Χρησιμοποιούνται μέσα στα ολοκληρωμένα κυκλώματα, αν και υπάρχει μια τάση να αποσυρθούν και εκεί. Εκτός ολοκληρωμένου κυκλώματος, χρησιμοποιούνται μόνο σειριακοί δίαυλοι σε κάθε σύγχρονο ψηφιακό σύστημα. Υπάρχουν όμως και υβριδικές υλοποιήσεις, στις οποίες χρησιμοποιείται ένας σειριακός δίαυλος (όπως το PCI express) και πολλαπλές ανεξάρτητες παράλληλες κλωνοποιήσεις αυτού (όπως το PCI express x8, που αποτελείται από 8 σειριακούς διαύλους).
Το δεύτερο χαρακτηριστικό των διαύλων αφορά το μέγιστο αριθμό των συνδεδεμένων συσκευών. Αν είναι μόνο δυο συσκευές, ο δίαυλος αφορά την επικοινωνία σημείο-προς-σημείο (point-to-point), ενώ αν αφορά περισσότερες από δυο συσκευές, ο δίαυλος είναι κοινόχρηστος. Αυτό το χαρακτηριστικό είναι ανεξάρτητο ως προς το προηγούμενο. Δηλαδή, υπάρχουν σειριακοί δίαυλοι που ανήκουν στην κατηγορία σημείο-προς-σημείο (π.χ. το RS232) και άλλοι που ανήκουν στην κατηγορία του κοινόχρηστου (π.χ. το 1-wire). Επίσης, υπάρχουν παράλληλοι δίαυλοι που ανήκουν στην κατηγορία σημείο-προς-σημείο (π.χ. Accelerated Graphics Port, AGP) και παράλληλο δίαυλοι που ανήκουν στην κατηγορία της κοινόχρηστης επικοινωνίας (π.χ. PCI).
Το τρίτο χαρακτηριστικό αφορά το συγχρονισμό. Υπάρχουν σύγχρονοι και ασύγχρονοι δίαυλοι. Ο όρος σύγχρονος σημαίνει συγχρονισμένος με το ίδιο κοινό ρολόι επικοινωνίας (Εικόνα 5.3). Ο επεξεργαστής και τα περιφερειακά που συνδέονται έχουν πρόσβαση στο ίδιο ρολόι του συστήματος, το οποίο είτε παρέχεται με ξεχωριστό κανάλι διαύλου, είτε μπορεί να εξαχθεί από την κωδικοποίηση των δεδομένων από τον παραλήπτη (με όφελος λιγότερους αγωγούς). Στην περίπτωση του σύγχρονου δίαυλου, η αίτηση τοποθετείται στο κανάλι ελέγχου μαζί με τη διεύθυνση για κάποιους συγκεκριμένους κύκλους ρολογιού και μετά γίνεται η ανάγνωση των δεδομένων από το περιφερειακό ή η εγγραφή των δεδομένων. Όταν ολοκληρωθεί το έργο, απομακρύνεται ο έλεγχος και η διεύθυνση. Η αλληλουχία των καταστάσεων ορίζεται σαφώς από τον επεξεργαστή και τα περιφερειακά στις ρυθμίσεις του συστήματος, με τα wait states (καταστάσεις αναμονής).
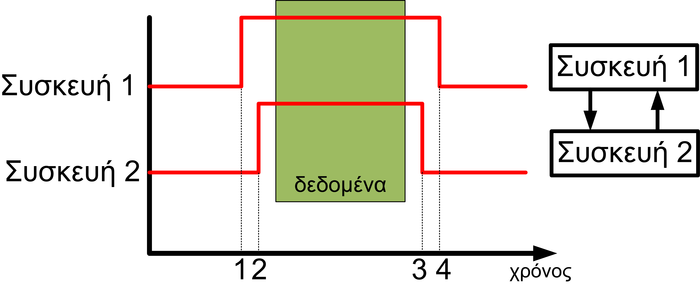
5.4: Ένα διαδεδομένο πρωτόκολλο επικοινωνίας ανάμεσα σε δυο συσκευές, είναι η χειραψία τεσσάρων φάσεων.
Στην περίπτωση του ασύγχρονου διαύλου, δεν υπάρχει κοινό ρολόι, αλλά γίνεται μια χειραψία ανάμεσα στον επεξεργαστή και στο περιφερειακό. Ο επεξεργαστής τοποθετεί ένα σήμα ελέγχου στο δίαυλο, το περιφερειακό το διαβάζει και ανταποκρίνεται με ένα άλλο σήμα, ο επεξεργαστής μπορεί να ενεργοποιεί ένα άλλο σήμα και να στέλνει τα δεδομένα κ.ο.κ. Η πιο διαδεδομένη χειραψία στην επικοινωνία με τα περιφερειακά, είναι η χειραψία τεσσάρων φάσεων κατά την οποία μια συσκευή ανυψώνει ένα σήμα σε υψηλή στάθμη, το άλλο περιφερειακό απαντάει με το να σηκώσει και αυτό ένα δεύτερο σήμα σε υψηλή στάθμη, στη συνέχεια, η 1η συσκευή στέλνει τα δεδομένα, μόλις ληφθούν αυτά με επιτυχία η 2η συσκευή απομακρύνει το σήμα, και μετά από κάποια καθυστέρηση η 1η συσκευή απομακρύνει και αυτή το δικό της σήμα (Εικόνα 5.4) Ένα παράδειγμα ασύγχρονης επικοινωνίας φαίνεται στην Εικόνα 5.5, στην οποία μια συσκευή Α τοποθετεί μια διεύθυνση και ενεργοποιεί το σήμα ανάγνωσης, και μια άλλη συσκευή Β τοποθετεί τα δεδομένα στο δίαυλο και ταυτόχρονα χρησιμοποιεί το κατάλληλο σήμα για να ενημερώσει τη συσκευή Α να τα διαβάσει. Όπως φαίνεται, οι 2 συσκευές εκτελούν συγχρονισμένα βήματα εκτέλεσης, αφού κάθε ενέργεια είναι μια απάντηση στην προηγούμενη, και επίσης οι ενέργειες δεν έχουν καμία σχέση με το ρολόι (και για αυτό παραλείπεται από το σχήμα). Η χρήση των ασύγχρονων διαύλων είναι πολύ δύσκολη, λόγω της καθυστέρησης της χειραψίας, κάτι που πρέπει να γίνεται κάθε φορά, για αυτό και δε χρησιμοποιείται.
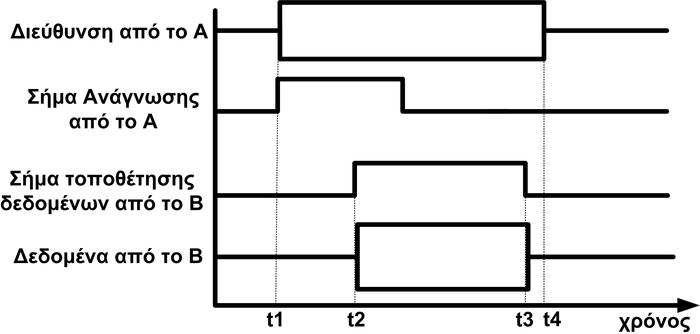
5.5: Στην ασύγχρονη επικοινωνία δε χρησιμοποιείται ρολόι, αλλά μόνο οι λογικές στάθμες των σημάτων.
Το τέταρτο χαρακτηριστικό του διαύλου αφορά την πολυπλεξία. Για λόγους εξοικονόμησης καλωδίων, ιδιαίτερα στους παράλληλους διαύλους, δεν υπάρχουν ξεχωριστοί αγωγοί για δεδομένα και διευθύνσεις, αλλά χρησιμοποιούνται οι ίδιοι ακροδέκτες άλλοτε για την ανάγνωση της διεύθυνσης και άλλες φορές για την πρόσβαση των δεδομένων. Ασφαλώς, η επίτευξη της πολυπλεξίας απαιτεί κατάλληλα σήματα ελέγχου που να προσδιορίζουν το νόημα των bit που βρίσκονται στους ακροδέκτες, αν είναι bit διεύθυνσης ή δεδομένων. Πολυπλεξία συναντάμε και στους σειριακούς διαύλους που μοιράζονται τα bit διεύθυνσης και δεδομένων, ενώ σχεδόν πάντα υπάρχουν και καλώδια ελέγχου που δεν πολυπλέκονται.
Το πέμπτο χαρακτηριστικό αφορά τη διαιτησία του διαύλου στις κοινόχρηστες επικοινωνίες. Σε αυτές τις επικοινωνίες, κάθε φορά μια συσκευή έχει τον έλεγχο, που ονομάζεται και κύριος του διαύλου (bus master). Θα πρέπει να υπάρχει ένας τρόπος να αποφασιστεί, ποιος είναι κάθε φορά ο κυρίαρχος. Σε περίπτωση που στο δίαυλο συνδέεται ένας επεξεργαστής, τότε αυτός είναι ο κύριος του διαύλου και κάθε φορά καθορίζει ποιος χειρίζεται το δίαυλο. Μπορεί όμως και να παραχωρήσει προσωρινά την κυριαρχία σε ένα βοηθητικό επεξεργαστικό στοιχείο, όπως θα δούμε στην επόμενη παράγραφο. Η διαιτησία συνδέεται με την είσοδο έξοδο και έτσι θα περιγραφεί στην επόμενη ενότητα. Η διαιτησία σε κάποια συστήματα είναι κεντρική (δηλαδή γίνεται πάντα από τον επεξεργαστή) και σε κάποια άλλα είναι κατανεμημένη, δηλαδή όλες οι συσκευές που είναι συνδεδεμένες στο δίαυλο αποφασίζουν για το ποιος θα έχει κάθε φορά το δίαυλο, είτε μέσω ενός κουπονιού (token), είτε μέσω μιας ακολουθίας.
Επίσης, κάποια άλλα χαρακτηριστικά αφορούν συγκεκριμένα περιφερειακά, όπως η υποστήριξη ρυθμού ριπής (burst) ή σελίδας, κατά την οποία ο επεξεργαστής αντί να στέλνει κάθε φορά μια διεύθυνση και δεδομένα, τοποθετεί μόνο την πρώτη διεύθυνση και το μέγεθος της μεταφοράς σε Byte, και το αντίστοιχο περιφερειακό (π.χ. η μνήμη) στέλνει σε ριπή όλα τα δεδομένα που έχει ζητήσει. Ομοίως, υπάρχουν και οι αποσυνδεδεμένες μεταφορές στις οποίες η διεύθυνση και τα δεδομένα μπορεί να έχουν μια χρονική απόσταση, και ενδιάμεσα να έχουν συμβεί άλλες συναλλαγές με το δίαυλο από άλλα περιφερειακά.
Υπάρχουν πολλά περιφερειακά που συνδέονται σε έναν επεξεργαστή. Κάποια μπορεί να λειτουργήσουν σε μεγάλες συχνότητες λειτουργίας ενώ άλλα σε αρκετά χαμηλές. Επειδή η μέγιστη συχνότητα λειτουργίας ενός διαύλου καθορίζεται από το περιφερειακό με τη χαμηλότερη συχνότητα λειτουργίας, από νωρίς αποφασίστηκε η χρήση μιας ιεραρχίας διαύλων επικοινωνίας. Επειδή τα σημερινά συστήματα έχουν πολλαπλούς διαύλους επικοινωνίας, θα πρέπει να χρησιμοποιούνται κάποια εξειδικευμένα κυκλώματα που ονομάζονται γέφυρες διαύλων. Αυτά, συνδέονται σε δυο διαφορετικούς διαύλους (π.χ. σε ένα γρήγορο και σε ένα αργό) και μπορούν και μετατρέπουν τα σήματα επικοινωνίας και τα πρωτόκολλα από το ένα είδος στο άλλο, ώστε να δίνεται η δυνατότητα της διασύνδεσης όλων των περιφερειακών του συστήματος. Στους προσωπικούς υπολογιστές, για πολλά χρόνια χρησιμοποιήθηκαν δυο γέφυρες, η γρήγορη γέφυρα (ή βόρεια γέφυρα, north bridge) διασύνδεσης του επεξεργαστή (ή των επεξεργαστών αν το σύστημα ήταν πολυπύρηνα) με τη μνήμη και την κάρτα γραφικών, και η αργή γέφυρα (ή νότια γέφυρα, south bridge) διασύνδεσης του δίσκου, πληκτρολογίου, ποντικού, γέφυρας ISA των θυρών εισόδου/εξόδου κτλ. (Εικόνα 5.6). Οι γέφυρες συνδέονταν μεταξύ τους, οπότε ο επεξεργαστής μπορούσε να έχει πρόσβαση σε οποιοδήποτε τμήμα του συστήματος. Οι γέφυρες μπορεί να είναι αρκετά εξελιγμένες και να εκτελούν και κάποια επεξεργασία γνωρίζοντας ακριβώς το πρωτόκολλο επικοινωνίας του αντίστοιχου δίαυλοι, ή μπορεί να είναι απλά μετατροπείς λογικής στάθμης χωρίς ευφυΐα
5.6: Μια τυπική ιεραρχική αρχιτεκτονική διαύλων στην οποία φαίνονται οι γέφυρες διασύνδεσης.
Η αρχιτεκτονική των σημερινών υπολογιστών (είτε σταθμών εργασίας, είτε ενσωματωμένων συστημάτων), έχει απομακρυνθεί από τη χρήση κοινόχρηστων διαύλων και έχει εξελιχθεί στη χρήση αποκλειστικών συνδέσεων σημείο-προς-σημείο. Όπως φαίνεται στην Εικόνα 5.7, η νότια γέφυρα έχει αντικατασταθεί από το PCIe συγκρότημα ρίζας (root complex) όπου και συνδέει τη μνήμη, τους επεξεργαστές, και την κάρτα γραφικών. Το συγκρότημα ρίζας συνδέεται σε ένα διαμεταγωγέα PCIe (PCIe switch), από τον οποίο ξεκινάνε συνδέσεις σημείο-προς-σημείο προς κάθε περιφερειακό ή προς άλλες γέφυρες. Στο διαμεταγωγέα PCI συνδέεται η γέφυρα PCI για το δίαυλο PCI, και οι ελεγκτές IDE, USB, E/E.
5.7: Η ιεραρχική αρχιτεκτονική διαύλων των σημερινών υπολογιστών, όπου κυριαρχούν οι συνδέσεις σημείο-προς-σημείο.
Με τον όρο είσοδο και έξοδο ενός ενσωματωμένου συστήματος, αναφερόμαστε στην τοποθέτηση δεδομένων που προέρχονται από κάποια εξωτερική συσκευή μέσα σε καταχωρητές και στην αντιγραφή των δεδομένων των καταχωρητών του επεξεργαστή, στους ακροδέκτες της συσκευασίας και στη συνέχεια, την κατάλληλη μεταφορά στο περιφερειακό δομοστοιχείο.
Το πως υλοποιείται η είσοδος/έξοδος (Ε/Ε) εξαρτάται από το συγκεκριμένο επεξεργαστή. Μικροί 8bit επεξεργαστές, μπορούν να υποστηρίζουν μόνο απλές λειτουργίες, ενώ σύνθετοι 32bit μπορούν να υποστηρίζουν περισσότερες τεχνικές. Για να υλοποιηθεί η Ε/Ε απαιτείται αφενός υποστήριξη από το υλικό, αφετέρου και προγραμματιστική υποστήριξη.
Υπάρχουν 2 δημοφιλείς τεχνικές που υποστηρίζουν τις Ε/Ε: (α) περιόδευση (polling), και (β) διακοπές (interrupts). Όπως αναφέραμε στην προηγούμενη ενότητα, υπάρχουν κατ ελάχιστον 3 καταχωρητές στο περιφερειακό. Ένας από αυτούς είναι ο καταχωρητής κατάστασης. Ο επεξεργαστής ελέγχει περιοδικά τον καταχωρητή κατάστασης κάθε περιφερειακού για να διαπιστώσει αν υπάρχουν δεδομένα που πρέπει να λάβει. Αν ο καταχωρητής σηματοδοτήσει ότι υπάρχουν δεδομένα (π.χ. από το πληκτρολόγιο), τότε διαβάζει τον καταχωρητή δεδομένων. Είναι ευκολονόητο ότι τις περισσότερες φορές δεν υπάρχουν δεδομένα και έτσι σπαταλώνται κύκλοι του επεξεργαστή. Αυτή η τεχνική είναι πολύ απλή να υλοποιηθεί και δεν απαιτεί καθόλου υποστήριξη από το υλικό. Αυτή η τεχνική μπορεί να παρομοιαστεί με κάποιον που βλέπει συνεχώς το κινητό τηλέφωνο του αν έχει λάβει SMS. Με τις διακοπές υποστηρίζεται και η διαιτησία του διαύλου. Μια συσκευή που θέλει να στείλει δεδομένα στον επεξεργαστή χρησιμοποιεί μια διακοπή για να τον ενημερώσει. Ο επεξεργαστής εξετάζει τη διακοπή και παρέχει τον έλεγχο, αφού χρησιμοποιήσει κατάλληλο σήμα.
Η δεύτερη τεχνική είναι η βελτιωμένη έκδοση Ε/Ε. Σε αυτή την τεχνική κάθε περιφερειακό συνδέεται με μια αποκλειστική γραμμή με τον επεξεργαστή, και όταν θελήσει να στείλει δεδομένα, αλλάζει τη λογική στάθμη της γραμμής, προκαλώντας μια διακοπή αίτησης εξυπηρέτησης (interrupt service request, IRQ). Ο επεξεργαστής σταματάει να εκτελεί αυτό που επεξεργάζονταν, ενημερώνει το περιφερειακό με κατάλληλο σήμα επιβεβαίωσης διακοπής (interrupt acknowledge) και αρχίζει την εκτέλεση ενός ειδικού κώδικα που ονομάζεται ρουτίνα εξυπηρέτησης διακοπής (interrupt service routine, ISR). Αυτός ο κώδικας αναλαμβάνει τη μεταφορά των δεδομένων από το περιφερειακό στον επεξεργαστή. Σε περίπτωση που ο επεξεργαστής δεν έχει τόσες πολλές γραμμές διακοπών, τότε μπορεί να χρησιμοποιηθεί μια υβριδική διασύνδεση στην οποία συνδέονται πολλές συσκευές σε μια γραμμή διακοπής. Όταν ο επεξεργαστής διαπιστώσει ότι έχει συμβεί μια διακοπή, σταματάει το έργο που εκτελεί, και ελέγχει όλες τις συσκευές που είναι συνδεδεμένες στο κοινό κανάλι με περιόδευση. Επειδή η χρήση της διακοπής, σημαίνει την παρεμπόδιση εκτέλεσης του προγράμματος που εκτελείται ήδη, θα πρέπει να έχει μικρή καθυστέρηση (latency), ώστε να μη προκαλεί πρόβλημα. Κάποιοι επεξεργαστές ενσωματωμένων συστημάτων υποστηρίζουν και πολύ γρήγορες κλήσεις εξυπηρέτησης διακοπών, όπως ο ARM που παρέχει είτε την κανονική εξυπηρέτηση, είτε τη γρήγορη εξυπηρέτηση. Η επιλογή εξαρτάται από τον προγραμματιστή και τις δυνατότητες που θέλει να χρησιμοποιήσει, αφού η γρήγορη εξυπηρέτηση παρέχει μειωμένες λειτουργίες.
Στην απλή υλοποίηση των διακοπών, ο επεξεργαστής εκτελεί κάθε φορά την ίδια συνάρτηση εξυπηρέτησης διακοπής, ανεξαρτήτου του πια συσκευή την έχει δημιουργήσει. Μια βελτιωμένη υλοποίηση υποστηρίζει διαφορετικές ρουτίνες εξυπηρέτησης διακοπής για κάθε περιφερειακό. Σε αυτή την περίπτωση, όλες οι διακοπές είναι αριθμημένες και μοναδικές. Κατά την έναρξη λειτουργίας του συστήματος καταγράφονται οι αντιστοιχήσεις της κάθε διακοπής με τη διεύθυνση που ξεκινάει η αντίστοιχη ρουτίνα εξυπηρέτησης διακοπής. Οπότε, όταν εμφανιστεί μια συγκεκριμένη διακοπή, ο επεξεργαστής εκτελεί τον κώδικα που έχει καθοριστεί. Αυτό το είδος της διακοπής ονομάζεται διανυσματική διακοπή (vectored interrupt), επειδή για κάθε διακοπή αντιστοιχεί ένα διάνυσμα που είναι μια διεύθυνση μνήμης κώδικα. Για λόγους διευκόλυνσης του επεξεργαστή, υπάρχει ένα ειδικό υλικό που ονομάζεται προγραμματιζόμενος ελεγκτής διακοπών (programmable interrupt controller, PIC), στο οποίο συνδέονται όλα τα κανάλια διακοπών, και όταν συμβεί μια διακοπή αυτό ενημερώνει τον επεξεργαστή μαζί με τη διεύθυνση του ISR. H Intel ήταν η πρώτη που πρόσθεσε αυτό το ειδικό ολοκληρωμένο κύκλωμα το 1990 και του έδωσε την ονομασία 89C59A. Μετά από 10 χρόνια παρουσιάστηκε μια βελτιωμένη έκδοση, ο ελεγκτής APIC που υποστηρίζει 255 προγραμματιζόμενες διακοπές, ταυτόγχρονη είσοδο/έξοδο, παρέχει μετρητές υψηλής ακριβείας, μεταβίβαση διακοπής στον πρώτο διαθέσιμο επεξεργαστή και βελτίωση στην απόδοση επεξεργασίας των διακοπών. Στα σημερινά συστήματα ο προγραμματιζόμενος ελεγκτής διακοπών βρίσκεται πάνω στο ίδιο chip με τον επεξεργαστή. Το APIC απαιτεί επίσης την κατάλληλη υποστήριξη από το λειτουργικό σύστημα, προκειμένου να ρυθμιστεί.
Με την εισαγωγή των πολλαπλών διακοπών, δημιουργήθηκε η απαίτηση των προτεραιοτήτων. Κάποιες διακοπές είναι πιο σημαντικές από κάποιες άλλες, όπως για παράδειγμα η διακοπή που έρχεται από το ρολόι του συστήματος, είναι πιο σημαντική από τη διακοπή που έρχεται από το πληκτρολόγιο. Τα περισσότερα σημερινά συστήματα υποστηρίζουν προτεραιότητες ως εξής: μια ρουτίνα εξυπηρέτησης διακοπής μπορεί να σταματήσει προσωρινά να εκτελείται, αν συμβεί μια διακοπή μεγαλύτερης προτεραιότητας και μόνο τότε. Δηλαδή, οι διακοπές χαμηλότερης προτεραιότητας δεν ικανοποιούνται. Για να υποστηρίζουν αυτή τη δυνατότητα, θα πρέπει οι επεξεργαστές να χρησιμοποιούν εμφωλευμένες διακοπές (nested interrupts), και επίσης να μπορούν να απενεργοποιούν προσωρινά τις διακοπές. Η δυνατότητα προσωρινής απενεργοποίησης των διακοπών χρησιμοποιείται σε περίπτωση που ο επεξεργαστής εκτελεί ένα κομμάτι κώδικα που δεν πρέπει να διακοπεί σε καμία περίπτωση, όπως π.χ. όταν γίνεται εξυπηρέτηση μιας διακοπής υψηλής προτεραιότητας Για την υλοποίηση υπάρχει μια σημαία μέσα στον επεξεργαστή, η οποία τίθεται σε ‘0’ όταν ο επεξεργαστής δε δέχεται διακοπές, και ‘1’ όταν δέχεται. Η σημαία αυτή στην αρχιτεκτονική x86 είναι η IF και με τις εντολές assembly CLI (clear interrupts) και STI (set interrupts), μπορεί να απενεργοποιήσει ή να ενεργοποιήσει το χειρισμό διακοπών. Παρομοίως, στον ARM καλείται η εντολή MSR με τα κατάλληλα ορίσματα όπου γράφει στην κατάλληλη θέση του καταχωρητή κατάστασης που αντιστοιχεί στην αποδοχή των διακοπών, είτε τη τιμή 1 είτε την τιμή 0. Όταν ο επεξεργαστής δεν εξυπηρετεί διακοπές, τότε απλώς τις αγνοεί. Το περιφερειακό που έχει ζητήσει μια διακοπή διατηρεί τη λογική στάθμη της γραμμής της διακοπής σε υψηλή τιμή, μέχρι να εξυπηρετηθεί, οπότε δεν χάνονται διακοπές. Βέβαια, αν ο επεξεργαστής διατηρεί για πολύ χρόνο απενεργοποιημένες τις διακοπές, τότε μπορεί να καθυστερήσει σημαντικά να εξυπηρετήσει μια διακοπή και να γίνει κάποια υπερχείλιση ή κάποιο άλλο μη επιθυμητό γεγονός.
Μια βελτίωση που έχει γίνει αφορά τη χρήση ενός ειδικού συνεπεξεργαστή άμεσης πρόσβασης στη μνήμη (direct memory access, DMA). Αυτός μπορεί να γίνει κυρίαρχος του διαύλου και να μεταφέρει από ή προς τη μνήμη από οποιαδήποτε συνδεδεμένη συσκευή. Ο επεξεργαστής έχει άμεση πρόσβαση και ρυθμίζει τους καταχωρητές του DMA, και συγκεκριμένα το μέγεθος της μεταφοράς, τη διεύθυνση μνήμης, τη διεύθυνση του περιφερειακού και αν είναι εγγραφή ή ανάγνωση, του παραχωρεί την κυριότητα του διαύλου και ξεκινάει αυτόνομα τη μεταφορά των δεδομένων. Ο επεξεργαστής μπορεί να συνεχίσει να εκτελεί τον ίδιο ή άλλον κώδικα προγράμματος, και όταν ολοκληρωθεί η αντιγραφή θα ενημερωθεί με διακοπή από τον ελεγκτή DMA.
Με την παραχώρηση του ελέγχου στον ελεγκτή DMA μπορεί να εμφανιστεί και ένα πρόβλημα που ονομάζεται αντιστροφή των προτεραιοτήτων. Συγκεκριμένα, μπορεί να ρυθμιστεί μια μεταφορά DMA από τον επεξεργαστή και να του δοθεί ο έλεγχος, και καθώς γίνεται η μεταφορά, να δημιουργηθεί μια διακοπή υψηλής προτεραιότητας στον επεξεργαστή, που όμως επειδή δεν έχει τον έλεγχο του διαύλου δε μπορεί να την ικανοποιήσει. Με την εισαγωγή ενός ατομικού καναλιού επικοινωνίας του επεξεργαστή με το DMA, το πρόβλημα λύνεται, αφού μπορεί να δοθεί εντολή από τον επεξεργαστή να σταματήσει τη μεταφορά.
Τα περιφερειακά που χρησιμοποιούνται για Ε/Ε, υποστηρίζουν δυο προγραμματιστικούς τρόπους πρόσβασης. Ο πρώτος τρόπος ονομάζεται προγραμματιζόμενη Ε/Ε και οι διευθύνσεις που αντιστοιχούν σε κάθε περιφερειακό βρίσκονται σε ένα ανεξάρτητο χώρο διευθύνσεων ως προς τη μνήμη. Σε περίπτωση που απαιτηθεί πρόσβαση σε μια τέτοια διεύθυνση ο επεξεργαστής χρησιμοποιεί ειδικές εντολές εισόδου και εξόδου. Για παράδειγμα, οι ενσωματωμένοι μικροεπεξεργαστές της Intel, χρησιμοποιούν τις εντολές in και out. Ο δεύτερος τρόπος πρόσβασης ονομάζεται απεικόνιση στη μνήμη, και η διεύθυνση που αντιστοιχεί στο περιφερειακό, βρίσκεται μέσα στο χώρο διευθύνσεων μαζί με τις διευθύνσεις της μνήμης. Οι επεξεργαστές της Intel, υποστηρίζουν και αυτόν τον τρόπο πρόσβασης μέσω των τυπικών εντολών πρόσβασης διευθύνσεων μνήμης mov, δηλαδή δεν υπάρχουν άλλες εντολές, είτε γίνεται πρόσβαση στη μνήμη είτε σε ένα περιφερειακό. Σχεδόν όλοι οι επεξεργαστές χρησιμοποιούν αυτόν τον τρόπο πρόσβασης, και κάποιοι και τον πρώτο. Οι MIPS και οι ARM επεξεργαστές χρησιμοποιούν μόνο αυτόν τον τρόπο.
Κατά τα 30 τελευταία χρόνια τα ενσωματωμένα συστήματα έχουν ακολουθήσει τις εξελίξεις των σταθερών υπολογιστών στην επικοινωνία και έχουν υιοθετήσει πολλές φορές διαύλους που αρχικά είχαν προταθεί για τους προσωπικούς υπολογιστές. Η πρώτη σοβαρή πρόταση προήλθε από την IBM το 1980, όπου αφορούσε τον πρότυπο δίαυλο 8bit της βιομηχανίας, ISA (Industry Standard Association). Χρησιμοποιούνταν στους πρώτους προσωπικούς υπολογιστές της IBM και στη συνέχεια από όλους τους κατασκευαστές που παρείχαν συμβατούς υπολογιστές με IBM (IBM PC compatible). Ο δίαυλος γρήγορα επεκτάθηκε σε 16bit και αργότερα σε 32bit το 1988 με την ονομασία επεκταμένος ISA (extended ISA). H IBM προσπάθησε στη συνέχεια να χρησιμοποιήσει ένα νέο δικό της δίαυλο, που δεν έδινε όμως δικαιώματα χρήσης στους άλλους το MCA (microchannel architecture). Λόγω των δικαιωμάτων χρήσης, οι υπόλοιποι κατασκευαστές παρέμειναν με το EISA και πρότειναν δυο νέες εκδόσεις: το PCI (peripheral component interconnect) και το VESA local bus. Ο Πίνακας 5.1 παρουσιάζει τους πιο δημοφιλείς διαύλους που έχουν χρησιμοποιηθεί από το 1980 έως σήμερα. Μπορεί κάποιος να παρατηρήσει ότι με την πρόοδο της τεχνολογίας αποσύρονται οι παράλληλοι δίαυλοι και χρησιμοποιούνται οι σειριακοί. Το πιο χαρακτηριστικό γεγονός είναι η αντικατάσταση των παράλληλων διαύλων IDE (αργότερα μετονομάστηκαν σε PATA, Parallel ATA) που είχαν μέγιστη ταχύτητα μεταφοράς 133 ΜΒ/sec, από τους σειριακούς διαύλους SATA (serial ATA), με μέγιστη ταχύτητα μεταφοράς περίπου 2GB/sec.
| Δίαυλος | bits | Mhz | Ταχύτητα (MB/sec) |
| 8-bit ISA | 8 | 8 | 4 |
| 16-bit ISA | 16 | 8 | 8 |
| EISA | 32 | 8.33 | 33.3 |
| 32-bit PCI | 32 | 33 | 133 |
| 64-bit PCI | 64 | 33 | 266 |
| 1x AGP | 64 | 66 | 266 |
| 8x AGP | 64 | 533 | 2100 |
| VL BUS | 33 | 50 | 132 |
| SCSI I/II | 8 | 5 | 40 |
| FAST SCSI | 8 | 10 | 80 |
| Wide SCSI | 16 | 10 | 60 |
| Ultra SCSI | 16 | 20 | 320 |
| PCIe x1 | 1 | 2500 | >500 |
| RAMBUS | 32 | 1066 | 4200 |
| IDE / PATA | 16 | 66 | 133 |
| SATA 1.0 | 1 | 1500 | 150 |
| SATA 2.0 | 1 | - | 300 |
| SATA 3.0 | 1 | - | 600 |
| SATA 3.2 | 1 | - | 1969 |
Οι δίαυλοι ISA και EISA ήταν από τους μακροβιότερους διαύλους, που οφείλονταν στην μεγάλη χρήση και ευκολία ανάπτυξης εκείνα τα χρόνια. Όμως, είχαν εγγενή προβλήματα που δεν επέτρεπαν την εύκολη χρήση τους, ιδιαίτερα από χρήστες που δε γνώριζαν εσωτερικές λεπτομέρειες. Προκειμένου να λειτουργήσει ένα περιφερειακό θα έπρεπε να αναφέρει τη γραμμή διακοπής, τη διεύθυνση επικοινωνίας και το κανάλι DMA που έπρεπε να λειτουργήσει, στοιχεία που χαρακτήριζαν μοναδικά το περιφερειακό. Αν ένα άλλο περιφερειακό τοποθετούνταν στον κοινό δίαυλο με ίδιες παραμέτρους, τότε δυσλειτουργούσε όλο το σύστημα. Επίσης, η χρήση της πολυπλεξίας διευθύνσεων και δεδομένων μείωνε το μέγιστο ρυθμό επικοινωνίας. Τέλος, η διευθυνσιοδότηση στο δίαυλο ήταν 20bit και άρα μπορούσαν να υπάρχουν διευθύνσεις από 1 έως 1ΜΒ. Αυτά τα προβλήματα ώθησαν τους σχεδιαστές να βρουν ένα νέο δίαυλο. Αυτός ήταν ο PCI.
O δίαυλος PCI προτάθηκε αρχές του 1990 με το πιο σημαντικό χαρακτηριστικό της αυτόματης ρύθμισης των παραμέτρων επικοινωνίας των περιφερειακών. Είναι ο πιο κοινός δίαυλος και βρίσκεται ακόμη στις κεντρικές πλακέτες των περισσότερων συστημάτων, αν και τείνει να αντικατασταθεί και να εξαλειφθεί από νέους διαύλους. Σε αντίθεση με το ISA που λειτουργούσε στα 8Mhz, αυτός ο 32bit δίαυλος λειτουργεί στα 33/66Mhz με υποστήριξη τάσεων 3.3V και 5V, ενώ επιτυγχάνονταν εύρος ζώνης 524MB/sec για 64bit μεταφορές. Όπως και στον ISA έτσι και εδώ υπάρχει πολυπλεξία των διευθύνσεων και των δεδομένων για εξοικονόμηση ακροδεκτών, αλλά λόγω της μεγάλης συχνότητας λειτουργίας δεν αποτελεί πρόβλημα. Κάθε συσκευή παρέχει κάποιους καταχωρητές κατάστασης και ελέγχου, όπου έχει πρόσβαση ο επεξεργαστής τόσο για να κάνει την αυτόματη ρύθμιση, όσο και για να χειριστεί το περιφερειακό.
Προκειμένου να μειωθεί το πλάτος των αγωγών ο παράλληλος δίαυλος PCI εξελίχθηκε σε ένα σειριακό υβριδικό δίαυλο με δυνατότητα παραλληλίας με την ονομασία PCIe (PCI express) (Εικόνα 5.7). Συγκεκριμένα, αυτός ο δίαυλος αποτελείται από κανάλια επικοινωνίας (ονομάζονται lanes) και είναι τύπου σημείο-προς-σημείο (δηλαδή, μια συσκευή PCIe συνδέεται σε μια άλλη PCIe και δε γίνεται να συνδεθεί και τρίτη συσκευή. Το κάθε κανάλι επιτρέπει την αμφίδρομη αποστολή και λήψη δεδομένων από δυο γραμμές, με κατάλληλη διαφορική κωδικοποίηση, δηλαδή σειριακά. Ένα περιφερειακό μπορεί να σχεδιαστεί για να χρησιμοποιήσει πολλαπλά κανάλια (π.χ. 4 κανάλια και ονομάζεται x4, με μέγιστο τα 32 κανάλια), οπότε τα κανάλια χρησιμοποιούνται παράλληλα, αλλά η πρωταρχική επικοινωνία παραμένει σειριακή. Ένα θετικό χαρακτηριστικό αυτού του διαύλου, είναι ότι περιφερειακά που χρησιμοποιούν λιγότερα κανάλια επικοινωνίας (π.χ. 4 κανάλια), μπορούν να συνδεθούν σε μεγαλύτερες υποδοχές επέκτασης πολλών καναλιών (π.χ. υποδοχή x8), και να λειτουργήσουν χωρίς κανένα πρόβλημα. Τα δεδομένα πριν σταλούν σε ένα κανάλι συσκευάζονται σε πακέτα. Οπότε, σε περίπτωση που υπάρχουν πολλαπλά κανάλια, το κάθε πακέτο προς αποστολή προωθείται σε οποιοδήποτε κανάλι είναι ελεύθερο. Συνήθως, όλα τα κανάλια από κάθε συσκευή καταλήγουν στις αντίστοιχες θύρες ενός διακόπτη μεταγωγής (switch), που συνδέεται στο κεντρικό δίκτυο (root complex), δημιουργώντας μια ιεραρχική δομή. Οι δίαυλοι PCIe είναι αρκετά διαδεδομένοι και χρησιμοποιούνται σε κάθε υπολογιστικό σύστημα. Μπορεί να χρησιμοποιηθούν και σε ενσωματωμένα συστήματα, όταν υπάρχει ανάγκη για αυξημένο εύρος ζώνης, αλλά τις περισσότερες φορές επιλέγονται άλλοι δίαυλοι πιο οικονομικοί στους οποίους μπορούν να συνδεθούν άμεσα και εξωτερικά περιφερειακά. Ο δίαυλος PCIe χρησιμοποιείται κυρίως για τα εσωτερικά περιφερειακά ενός συστήματος, δηλαδή για αυτά που βρίσκονται άμεσα συνδεδεμένα στην κεντρική πλακέτα του συστήματος.
Ένα χαρακτηριστικό του διαύλου PCI express, είναι η υποστήριξη διαφορικής σηματοδοσίας χαμηλής τάσης (low voltage differential signalling, LVDS), η οποία μπορεί να υποστηρίξει έως και 2 Gbit/s με κατανάλωση ισχύος κάποια mW. Η κωδικοποίηση LVDS αφορά το φυσικό επίπεδο, και έχει υιοθετηθεί από πολλά πρωτόκολλα διαύλων. Σε αυτή τη σηματοδοσία χρησιμοποιούνται 2 καλώδια για τη ταυτόχρονη σειριακή μετάδοση των bit, και η αποστολή των bit βασίζεται στη διαφορά δυναμικού ανάμεσα τους. Αν η διαφορά είναι μεγαλύτερη από κάποια τιμή, τότε ανιχνεύεται ως ‘1’ διαφορετικά ως ‘0’. Η διαφορική σηματοδοσία επιτρέπει την μεγάλη ανοχή στο θόρυβο, αφού αν υπάρχει κάποια ηλεκτρομαγνητική ακτινοβολία θα επηρεάσει ταυτόχρονα και τους 2 αγωγούς που έχουν παράλληλη όδευση (Εικόνα 5.8). Οι τάσεις που χρησιμοποιούνται είναι συνήθως 0.3 v και αυτό επιτρέπει την επίτευξη μεγάλης ταχύτητας αλλαγής από 0 σε 1 και 1 σε 0, με συνέπεια την επίτευξη εύρους ζώνης των Gbit.
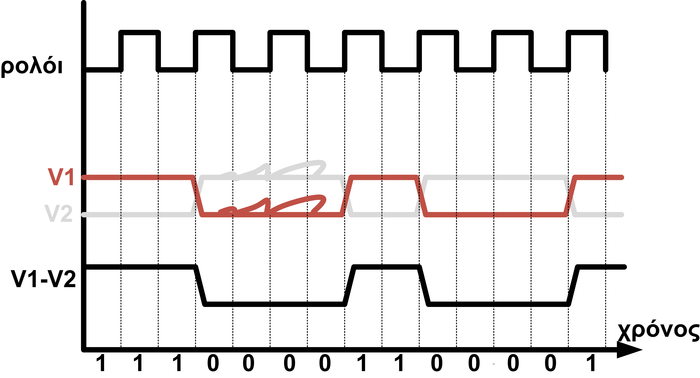
5.8: Η διαφορική σηματοδοσία LVDS, που χρησιμοποιείται στο PCIe, επιτρέπει την απροβλημάτιστη μεταφορά bit ακόμη και αν εμφανιστεί θόρυβος.
Προς τα μέσα της δεκαετίας του 1990, η εταιρία ARM εισήγαγε το δίαυλο Advanced Microcontroller Bus Architecture (AMBA), στις σχεδιάσεις εντός ολοκληρωμένου κυκλώματος για τη διασύνδεση των διαφόρων δομοστοιχείων που συνθέτουν ένα σύστημα πάνω στο chip. Ο AMBA χρησιμοποιείται σε κάθε σχεδίαση που χρησιμοποιεί τον επεξεργαστή ARM (π.χ. στο 90% των έξυπνων κινητών τηλεφώνων) και επιτρέπει πολλαπλούς επεξεργαστές και μεγάλο αριθμό περιφερειακών. Η ARM αν και κράτησε την κυριότητα, δημοσίευσε τις προδιαγραφές και έτσι υιοθετήθηκε από πολλούς κατασκευαστές και εκτός του οικοσυστήματος της ARM (π.χ. σε σχεδιασμούς ASIC). Η τρέχουσα έκδοση του AMBA είναι η 5 και παρουσιάστηκε το 2013. Θεωρείται το de facto standard για τη σχεδίαση ενσωματωμένων συστημάτων SoC, επειδή έχει πολύ καλή υποστήριξη από πολλούς παρόχους και επειδή έχει πολύ καλή τεκμηρίωση. Ο δίαυλος ΑΜΒΑ χωρίζεται σε υποκατηγορίες, αναλόγως του είδους των συσκευών που συνδέονται. Υπάρχει ο δίαυλος υψηλών ταχυτήτων AHB/ΑΜΒΑ που υποστηρίζει έως και 128bit, ο δίαυλος χαμηλών ταχυτήτων που συνδέονται περιφερειακά χαμηλών απαιτήσεων σε εύρος ζώνης, και δίαυλοι ειδικών προδιαγραφών, όπως αποσφαλμάτωσης, διατήρησης συνέπειας μνήμης κ.ο.κ. Από τις πρώτες εκδόσεις ο δίαυλος δημιουργήθηκε στοχεύοντας στην απόδοση· υποστηρίζει διασωληνωμένες μεταφορές, μεταφορές ριπής, αποδεσμευμένες μεταφορές και πολλαπλούς κυρίους των διαύλων.
Ένας αρκετά κοινός σειριακός δίαυλος που δημιουργήθηκε το 1994 από την κοινοπραξία 7 εταιριών (όπως IBM, Microsoft, και άλλες), είναι ο ενιαίος σειριακός δίαυλος επικοινωνίας (universal serial bus, USB). Στις προδιαγραφές του καθορίζονται τα καλώδια, οι συνδετήρες και τα πρωτόκολλα επικοινωνίας. Ως τώρα έχουν παρουσιαστεί αρκετές εκδόσεις, με την τελευταία να φέρει τον αριθμό 3.1 (Πίνακας 5.2). Η ιδιαιτερότητα αυτού του διαύλου και το πιο σημαντικό πλεονέκτημα που οδήγησε στην ευρεία αποδοχή του, είναι ότι εκτός από τα δεδομένα μεταφέρει και ενέργεια (από 500mA έως 3Α στα 5 Volt) από τον υπολογιστή προς τα περιφερειακά. Στο δίαυλο μπορούν να συνδεθούν πολλαπλές συσκευές μέσω ενός USB διανομέα (hub). Στα αξιοσημείωτα χαρακτηριστικά του USB είναι η τοποθέτηση και άμεση χρήση (plug and play) χωρίς να απαιτείται η ρύθμιση παραμέτρων επικοινωνίας από το χρήστη, η τοποθέτηση και απομάκρυνση του περιφερειακού, ενώ ο υπολογιστής είναι σε λειτουργία (hot pluggable), η υποστήριξη πολλών ταχυτήτων, ώστε να μπορεί να χρησιμοποιηθεί τόσο από συσκευές χαμηλού εύρους ζώνης (όπως το πληκτρολόγιο), όσο και από συσκευές υψηλού εύρους ζώνης (π.χ. σκληρός δίσκος ή κάρτα γραφικών) και η χρήση καλωδίων διαφορετικών τύπων που δεν επιτρέπουν τη λανθασμένη συνδεσμολογία περιφερειακών USB στο διανομέα USB. Ο δίαυλος USB χρησιμοποιεί την περιόδευση των περιφερειακών, και κάθε φορά μόνο ένα περιφερειακό μπορεί να επικοινωνήσει με τον υπολογιστή· έτσι, δε μπορούν να προκληθούν συγκρούσεις. Το μέγιστο μήκος σύνδεσης είναι 5m, επειδή μετά υπάρχει εξασθένηση των σημάτων ή αυξημένα επίπεδα θορύβου που αλλοιώνουν τα σήματα. Ο δίαυλος USB είναι πολύ δημοφιλής στα ενσωματωμένα συστήματα, επειδή δίνει τη δυνατότητα της διασύνδεσης με μιας πληθώρας περιφερειακών. Ακόμη και οι πιο οικονομικοί υπολογιστές μιας πλακέτας των 5$, όπως το Raspberry pi zero, διαθέτουν διεπαφή USB, αν έχουν εξαλείψει άλλους ακροδέκτες που ως τώρα θεωρούνταν σημαντικοί (όπως του δικτύου LAN).
| Έκδοση | Ημερομηνία | Ταχύτητα |
| 0.9 | Απρίλιος 1995 | 1.5 Mbit/s |
| 1.0 | Ιανουάριος 1996 | 1.5 Mbit/s και 12 Mbit/s |
| 2.0 | Απρίλιος 2000 | 480 Mbit/s |
| 3.0 | Νοέμβριος 2008 | 5 Gbit/s |
| 3.1 | Ιούλιος 2013 | 10 Gbit/s |
Ένα άλλο πρωτόκολλο που αναπτύχθηκε παράλληλα με το USB από την εταιρία Apple αρχές του 1990 είναι το Firewire, το οποίο έχει προτυποποιηθεί κατά IEEE 1394. Είναι ένα σειριακό πρωτόκολλο όπως το USB με τις παρακάτω διαφορές: (α) οι συσκευές συνδέονται στο Firewire σε αλυσίδα, δηλαδή η κάθε μια με τις διπλανές της, και μια μόνο συνδέεται στον υπολογιστή, (β) επιτρέπει τη χρήση του DMA, ώστε να μεταφέρει η μια συσκευή δεδομένα σε μια άλλη χωρίς τη διαμεσολάβηση του επεξεργαστή (όπως γίνεται στο USB), (γ) μπορεί και παρέχει πολύ περισσότερη ενέργεια στις συσκευές που διασυνδέονται (έως 30V σε 1.5Α), (δ) κάθε έκδοση Firewire έχει διαφορετικό συνδετήρα (όλες οι εκδόσεις του USB έχουν συμβατούς συνδετήρες), (ε) η ταχύτητα της τελευταίας έκδοσης Firewire 800 είναι πολύ καλύτερη από την ταχύτητα του USB 2.0, αλλά είναι πιο χαμηλή από την ταχύτητα του USB 3.0. To Firewire υποστηρίζεται κυρίως από την Apple, και η τελευταία έκδοση ονομάζεται thunderbolt, αλλά με την έλευση του USB 3.1 το μέλλον για αυτό το δίαυλο φαίνεται δυσοίωνο.
Στις τυπικές διεπαφές εισόδου εξόδου βρίσκουμε και τη σειριακή διασύνδεση RS232 με μέγιστη ταχύτητα 115200 bps σε 12V. Αυτή η διασύνδεση είναι πολύ χρήσιμη στην ανάπτυξη ενσωματωμένων συστημάτων, γιατί μπορεί να επιτευχθεί ακόμη και με 2 καλώδια αποστολής και λήψης. Χαρακτηριστικό είναι ότι κατά την ανάπτυξη προγραμμάτων σε FPGA ή σε μικροεπεξεργαστές, οι σχεδιαστές εκτυπώνουν στη σειριακή θύρα μηνύματα αποσφαλμάτωσης. Αν και οι σημερινοί σταθμοί εργασίας δεν έχουν θύρα RS232, εντούτοις υπάρχουν μετατροπείς USB-RS232 που καλύπτουν αυτή την έλλειψη. Η θύρα αυτή υπάρχει ακόμη στους διακομιστές που επιτρέπουν την εμφάνιση διαγνωστικών μηνυμάτων του βασικού συστήματος εισόδου εξόδου (Basic Input Output System, BIOS) πριν φορτωθεί το λειτουργικό σύστημα. Υπάρχουν και άλλα σειριακά πρωτόκολλα, όπως το RS422 για αποστάσεις έως 1.5 Km και χρησιμοποιείται για το βιομηχανικό αυτοματισμό, το RS485 που είναι παρόμοιο με το RS422 αλλά επιτρέπει πολλαπλούς κυρίους του διαύλου, το ps/2 που χρησιμοποιήθηκε στο παρελθόν για τη διασύνδεση πληκτρολογίων και ποντικιών, αλλά αντικαθίσταται από τη διασύνδεση USB, και η παράλληλη θύρα 25 ακίδων ΙΕΕΕ1284 στην οποία συνδέονται εκτυπωτές, αλλά με την έλευση του USB αντικαταστάθηκε από μικρούς και ευέλικτους ακροδέκτες USB.
Στα ενσωματωμένα συστήματα χρησιμοποιούνται επίσης και πιο απλοί δίαυλοι, που φέρουν ονομασίες όπως 4-wire, 3-wire, 2-wire, 1-wire ανάλογα με τον αριθμό των καλωδίων που χρησιμοποιούν για να συνδέσουν τα περιφερειακά στον επεξεργαστή. Ένας δίαυλος 4-wire είναι ο SPI (Serial Peripheral Interface, σειριακή περιφερειακή διεπαφή) και χρησιμοποιεί 4 καλώδια: ρολόι, επιλογή περιφερειακού, εγγραφή και ανάγνωση (Εικόνα 5.9). Η μέγιστη συχνότητα λειτουργίας είναι 20Mhz, ταχύτητα η οποία ικανοποιεί τις απαιτήσεις μεταφοράς τιμών αισθητήρων σε κάποιον μικροεπεξεργαστή ή τον έλεγχο κάποιων περιφερειακών. Ένας ακόμη δίαυλος 4 καλωδίων είναι ο SSI (Synchronous Serial Interface, σειριακή σύγχρονη διεπαφή), που βασίζεται στο RS-422 και χρησιμοποιεί 2 καλώδια για το ρολόι και 2 για τα δεδομένα. Μια παραλλαγή του SPI χρησιμοποιεί 3 καλώδια (3-wire) όπου υπάρχει μόνο μια γραμμή για την εγγραφή και ανάγνωση (αμφίδρομη επικοινωνία).
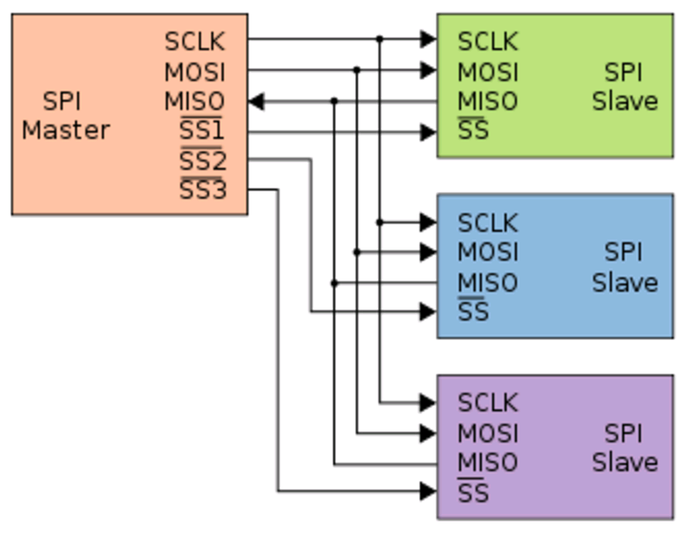
5.9: Ο δίαυλος SPI με 3 περιφερειακά. Από το χρήστη Cburnett της wikipedia.com.
Ο δίαυλος με 2 καλώδια ονομάζεται IC και υποστηρίζει πολλαπλούς κυρίους, πολλαπλά περιφερειακά, και έχει αναπτυχθεί από την εταιρία Philips. Ο δίαυλος αυτός υποστηρίζει διάφορες ταχύτητες επικοινωνίας από 100 Khz έως 5 Mhz. Χρησιμοποιεί κατάλληλες αντιστάσεις pull-up που συνδέουν την κάθε γραμμή (ρολόι και δεδομένα) με την τροφοδοσία (Εικόνα 5.10). Πάνω στις προδιαγραφές αυτού του διαύλου έχει αναπτυχθεί ο δίαυλος SMB με πολύ πιο αυστηρές οδηγίες για να επιτευχθεί σταθερότητα και αξιοπιστία. Οι σημερινοί υπολογιστές χρησιμοποιούν το SMB προκειμένου να διαβάζει ο επεξεργαστής τις τιμές από τα αισθητήρια πάνω στην κεντρική πλακέτα, όπως θερμοκρασίας και ταχύτητας ανεμιστήρα ψήκτρας. Το I
C είναι ένα αρκετά διαδεδομένο πρωτόκολλο στα ενσωματωμένα συστήματα που διαβάζουν τιμές από αισθητήρια, αφού χρησιμοποιεί ελάχιστα καλώδια και άρα έχει μειωμένο κόστος.
Ο δίαυλος με 1 καλώδιο έχει προταθεί από την Dallas Semiconductor και χρησιμοποιεί το ίδιο καλώδιο για δεδομένα χαμηλού εύρους ζώνης, σηματοδοσία και ρολόι. Η απόσταση που υποστηρίζεται είναι πολύ μεγαλύτερη από τον IC. Τα περιφερειακά του 1-wire έχουν ένα πυκνωτή που συγκεντρώνει το φορτίο και μπορεί να τα τροφοδοτεί με ενέργεια τα χρονικά διαστήματα που δεν παρέχεται ενέργεια από τη μια γραμμή. Συνήθως χρησιμοποιείται από αισθητήρια (π.χ. θερμοκρασίας ή υγρασίας) που έχουν ελάχιστες ανάγκες σε εύρος ζώνης.
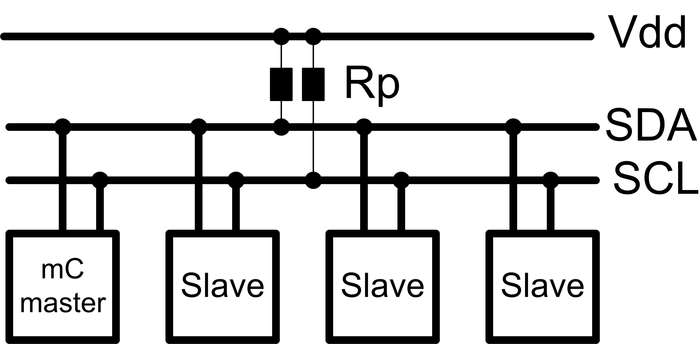
5.10: Ο δίαυλος ΙC χρησιμοποιεί μόνο 2 καλώδια για την επικοινωνία.
Ένας άλλος δίαυλος είναι ο CAN (controller area network, περιοχή δικτύου ελεγκτών), ο οποίος έχει προτυποποιηθεί και χρησιμοποιείται στην αυτοκινητοβιομηχανία. Χρησιμοποιεί μηνύματα και επιτυγχάνει καλή απόδοση λόγω χρονικής πολυπλεξίας. Η ανάπτυξη του ξεκίνησε το 1983 από τη Bosch GmbH, και χρησιμοποιήθηκε για πρώτη φορά το 1988 στη BMW 8. Είναι ένα σειριακός δίαυλος πολλαπλών κυρίων, πολλαπλών κόμβων, και υποστηρίζει από απλά περιφερειακά, έως σύνθετους σταθμούς επεξεργασίας δεδομένων. Όλοι οι κόμβοι συνδέονται με 2 καλώδια μεταξύ τους και έχουν τις κατάλληλες τερματικές αντιστάσεις των 120 Ω. Αν και δεν υπάρχει σήμα ρολογιού, εντούτοις όλοι οι κόμβοι είναι συγχρονισμένοι μεταξύ τους και έχουν ρυθμιστεί να δειγματοληπτούν τα bit όλοι, την ίδια στιγμή. Αυτός ο δίαυλος χρησιμοποιείται μόνο στα ενσωματωμένα συστήματα των οχημάτων, πλοίων ή αεροπλάνων.
Εκτός από αυτούς τους διαύλους, υπάρχουν και πρωτόκολλα ασύρματης επικοινωνίας, όπως το bluetooth, Wifi, Wi-MAX, 3G και άλλα τα οποία συνδέονται τις περισσότερες φορές μέσω USB με τον επεξεργαστή, και έτσι δεν είναι ξεχωριστοί δίαυλοι. Ιδιαίτερα, τον τελευταίο καιρό έχουν σχεδιαστεί πολύ οικονομικά περιφερειακά διασύνδεσης με το διαδίκτυο, όπως το ESP8266 που κοστίζει 5$, απαιτεί τάση 3.3 V, είναι συμβατό με 802.11b και επικοινωνεί μέσω σειριακής σύνδεσης 2 αγωγών με κάποιον επεξεργαστή. Σε παρόμοια τιμή μπορεί κάποιος να προμηθευτεί ένα περιφερειακό Bluetooth ή το περιφερειακό nRF24L01 για επικοινωνία στα 2.4 Ghz σε μεγάλες αποστάσεις χωρίς οπτική επαφή, δημιουργώντας ένα ασύρματο κατανεμημένο ενσωματωμένο σύστημα. Η προσθήκη ασύρματης επικοινωνίας στα ενσωματωμένα συστήματα, προσδίδει μια ελευθερία και ευελιξία, ιδιαίτερα όταν συνδέονται στο διαδίκτυο, κατασκευάζοντας το IoT (internet of things, διαδίκτυο των συσκευών). Όμως, η ελευθερία αυτή δεν έχει μόνο πλεονεκτήματα. Το πιο σοβαρό μειονέκτημα είναι η ασφάλεια, αφού δίνει τη δυνατότητα σε κακόβουλους χρήστες για απομακρυσμένη επίθεση στο ενσωματωμένο σύστημα. Η ασφάλεια των ενσωματωμένων συστημάτων είναι ένα πολύ σημαντικό θέμα που θα πρέπει να απασχολεί κάθε σχεδιαστή ΕΣ.
Σε αυτό το κεφάλαιο αναπτύξαμε όλα τα θέματα της διασύνδεσης των Ενσωματωμένων Συστημάτων. Περιγράψαμε τους πιο σημαντικούς διαύλους, εξηγήσαμε τους τρόπους εισόδου και εξόδου, και τις βελτιώσεις που έχουν επιτευχθεί όλα αυτά τα χρόνια από το 1980 έως σήμερα. Μετά την ανάλυση των θεμάτων διαιτησίας και διακοπών, αναφερθήκαμε στους πιο σημαντικούς διαύλους 4,3,2 και 1 καλωδίων και ολοκληρώσαμε το κεφάλαιο με τα ασύρματα δίκτυα και τους κινδύνους που ελλοχεύουν με τη σύνδεση στο διαδίκτυο.
Όπως γνωρίζουμε, ένας αυξανόμενο όγκος μετακινούμενων εφαρμογών γενικής χρήσης (π.χ. 3D παιχνίδια, video players) στα ενσωματωμένα συστήματα, παρουσιάζει την ανάγκη να αποτυπωθεί εντός μίας φθηνής αλλά και φορητής ενσωματωμένης συσκευής. Όμως τα ενσωματωμένα συστήματα δυσκολεύονται στην εκτέλεση τέτοιων περίπλοκων εφαρμογών, επειδή οι εφαρμογές προέρχονται από επιτραπέζια συστήματα, τα οποία έχουν διαφορετικούς περιορισμούς σε σχέση με τα χαρακτηριστικά της χρήσης μνήμης, και πιο συγκεκριμένα δεν ασχολούνται με την αποδοτική χρήση της δυναμικής μνήμης. Σήμερα, ένας επιτραπέζιος υπολογιστής τυπικά περιέχει τουλάχιστον 4-8 GB μνήμης RAM, εν αντιθέσει στo εύρος των 256-1024 MB που υπάρχουν στις ενσωματωμένες συσκευές χαμηλής κατανάλωσης και υψηλής τεχνολογίας. Επομένως, ένα από τα κύρια βήματα στην διαδικασία δημιουργίας συμβατότητας μεταξύ των πολυμεσικών εφαρμογών (οι οποίες ήταν αρχικά αναπτυγμένες για PC) και ενσωματωμένων συστημάτων, περιλαμβάνει την βελτίωση του υποσυστήματος δυναμικής μνήμης.
Το υπόλοιπο του παρόντος κεφαλαίου είναι οργανωμένο με την εξής σειρά: στην ενότητα 6.1 περιέχεται η ανάλυση του τομέα πολυμεσικών εφαρμογών, συμπεριλαμβανόμενων και των τυπικών χαρακτηριστικών αυτού του τύπου εφαρμογών, που προσφέρει κίνητρα για βελτιστοποιήσεις στις δυναμικές δομές δεδομένων. Έπειτα, στην ενότητα 6.2 γίνεται η παρουσίαση των δυναμικών δομών δεδομένων και των συγκεκριμένων χαρακτηριστικών τους. Στην συνέχεια, στην ενότητα 6.3, εξηγείται λεπτομερώς η ροή της μεθόδου για την ενασχόληση με τα διάφορα στάδια βελτιστοποίησης. Τέλος, στην ενότητα 6.4, εξάγονται κάποια συμπεράσματα.
Οι βελτιστοποιήσεις που παρουσιάζονται σε αυτό εδώ το βιβλίο, εκμεταλλεύονται τα χαρακτηριστικά των μοντέρνων πολυμεσικών και επικοινωνιακών ενσωματωμένων εφαρμογών. Ενώ το παραδοσιακό λογισμικό περιείχε μόνο δεδομένα γενικού τύπου ή δεδομένα δομής στοίβας, οι σύγχρονες εφαρμογές απαιτούν την χρήση δεδομένων δομής σωρού (ή αλλιώς δυναμικές δομές δεδομένων). Σε αυτήν την ενότητα, περιγράφονται οι χρήσεις των δυναμικών δομών δεδομένων στις μοντέρνες πολυμεσικές εφαρμογές, και πως χρησιμοποιούνται τα DDTs (dynamic data type, δυναμικός τύπος δεδομένων), για την διαχείριση αυτών των δεδομένων. Το σύνολο των πολυμεσικών και επικοινωνιακών εφαρμογών που αναλύονται περιέχει εφαρμογές 3D αναδόμησης εικόνας [37], [38], εφαρμογές απόδοσης βίντεο, όπως το MPEG-4 Visual Texture Coder (VTC) [39], [40], 3D παιχνίδια [41], [42], την βασισμένη σε URL εφαρμογή πλαισίου εναλλαγών, IPv4 εφαρμογές δρομολογητή [43] και τις εφαρμογές ασφάλειας [44]. Επειδή, αυτές οι εφαρμογές ασχολούνται με δεδομένα που δεν είναι μετρήσιμα σε χρόνο μεταγλώττισης προγράμματος (compile time), απαιτούνται δομές δεδομένων σωρού (ή αλλιώς δυναμικές δομές δεδομένων) για την αποθήκευση των αναγκαίων πληροφοριών για την εφαρμογή. Για παράδειγμα, στη 3D αναδόμηση εικόνας, η οποία μελετάται στην Ενότητα 6.2.1, συγκρίνονται δύο εικόνες για την εύρεση κοινών σημείων. Από την στιγμή που ο αριθμός των κοινών σημείων δεν είναι γνωστός την ώρα της μεταγλώττισης του προγράμματος, τότε απαιτείται μια δυναμική δεδομένων.
Τα προηγούμενα επιλεγμένα χαρακτηριστικά αναπαριστώνται με την χρήση μιας μοντέρνας εφαρμογής 3D αναδόμησης εικόνας [45]. Συγκεκριμένα, εστιάζουμε σε έναν από τους εσωτερικούς αλγορίθμους, ο οποίος λειτουργεί όπως η τρισδιάστατη αντίληψη των ζωντανών πλασμάτων, όπου η σχετική μετατόπιση μεταξύ ποικίλων δισδιάστατων προβολών χρησιμοποιείται για την αναδόμηση της 3D διάστασης [38]. Αυτή η μονάδα λογισμικού κάνει έντονη την χρήση μιας δυναμικής μνήμης και είναι ένας θεμελιώδης λίθος σε πολλούς σύγχρονους αλγορίθμους τρισδιάστατης όρασης εικόνας: επιλογή χαρακτηριστικού και αντιστοίχηση, οι αλγόριθμοι αυτοί περιέχουν πολλαπλές σειριακές προσπελάσεις και διεργασίες φιλτραρίσματος εισαγόμενων δεδομένων. Ο εξεταζόμενος αλγόριθμος είναι απόσπασμα του πρωτότυπου κώδικα του συστήματος 3D αναδόμησης εικόνας (βλέπε [45] για ολόκληρο τον κώδικα του αλγορίθμου 1,75 εκατομμυρίων σειρών υψηλού επιπέδου C++), και δημιουργεί την μαθηματική αφαίρεση από τα συσχετιζόμενα στιγμιότυπα, η οποία χρησιμοποιείται στον γενικό αλγόριθμο. Ο αλγόριθμος επιλέγει και αντιστοιχίζει στοιχεία (γωνίες) σε διαφορετικά ακόλουθα στιγμιότυπα, και οι σχετικές αντισταθμίσεις αυτών των χαρακτηριστικών ορίζουν την θέση τους στο χώρο (βλέπε Σχήμα 6.1). Οι διεργασίες που εκτελούνται στις εικόνες φορτώνουν μνήμη, πχ. κάθε εικόνα με ανάλυση 640x489 pixels χρησιμοποιεί περίπου 2.5 MB, και ως αποτελέσματα τυχαιοποιούνται οι προσπελάσεις του αλγορίθμου στις εικόνες. Έτσι, οι κλασικές βελτιστοποιήσεις, όπως οι κατά σειρά πρόσβαση (row-dominated), προσπελάσεων εικόνας δεν μπορούν να εφαρμοσθούν.

Έναρξη του ταιριάσματος γωνιών σε δύο εικόνες των βημάτων του αμφιθεάτρου (αρχαιολογική περιοχή): με βάση την αναζήτηση γειτονικών χωρίων. Ήδη, οι περισσότερες αντιστοιχίες φαίνονται να είναι σωστές (μερικώς λόγω της δευτερεύουσας διαφοράς μεταξύ των εικόνων, οι οποίες μπορούν να φανούν στη δεξιά κάτω γωνία). Το σημείο του κέντρου διευρύνεται.

6.2: Ροή εκτέλεσης του DDTs στην τρισδιάστατη εφαρμογή αναδημιουργίας εικόνας.
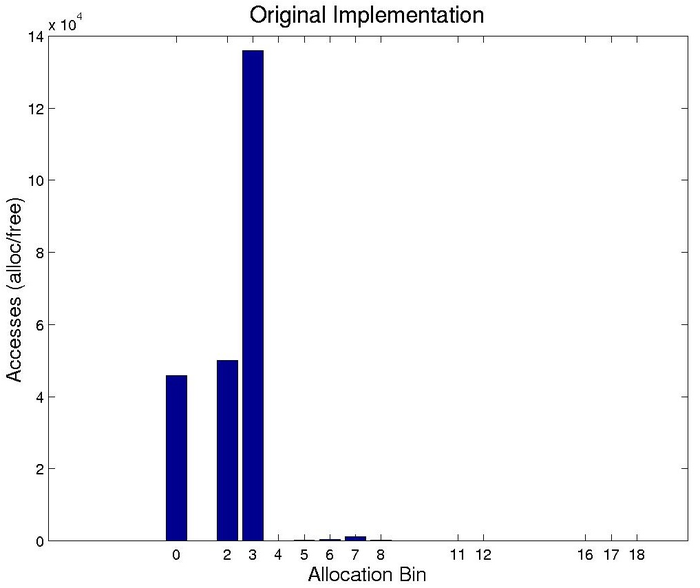
6.3: Μελέτη των δοχείων κατανομής μεγέθους blocks του διαχειριστή DM Kingsley που ζητείται από την αρχική τρισδιάστατη εφαρμογή αναδημιουργίας.
Για να δικαιολογήσουμε την μεταβαλλόμενη χρήση μνήμης, χρησιμοποιούμε καθορισμένη μνήμη για την λήψη μίας εκτίμησης της γενικής συνεισφοράς του κάθε DDT στην διάχυση ενέργειας, όπως φαίνεται στον Πίνακα 6.1. Αυτό αποδίδει πιο ακριβείς συνεισφορές στις εκτιμήσεις κόστους ενέργειας και αποφεύγει, για παράδειγμα, το DDT με πολύ μικρή ή μεγάλη διαστρέβλωση της χρήσης μνήμης, και αποκρύπτει την συνεισφορά μνήμης από τα υπόλοιπα DDT. Για την εκτίμηση ενέργειας, χρησιμοποιείται το ενσωματωμένο μοντέλο μνήμης SRAM, το οποίο περιγράφεται στο [46], έχοντας για τις εφαρμογές ιεραρχίας μνήμης υπόψη έναν κόμβο τεχνολογίας 0.13 μm. Αυτό το μοντέλο βασίζεται σε παράγοντες αποτυπωμάτων μνήμης (π.χ. μέγεθος, διαρροές ή εσωτερική δομή) και παράγοντες που προέρχονται από προσπελάσεις μνήμης (π.χ. αριθμός προσπελάσεων ή το είδος τεχνολογίας του κόμβου που χρησιμοποιήθηκε). Να σημειωθεί ότι μπορεί να χρησιμοποιηθεί οποιοδήποτε μοντέλο εκτίμησης ενέργειας, αν αντικαταστήσουμε αυτή την μονάδα στα εργαλεία.
| Μεταβλητή | Προσβάσεις DDT | Αποτύπωμα μνήμης(B) | Ενέργεια 0,13μm tech.(μJ) |
| Αντιστοιχίες εικόνας | 1.20*106 | 5.14x102 | 0.18x103 |
| Αντιστοιχίες Υποψηφίων | 8.44x105 | 2.75x105 | 3.03x103 |
| CM Στατικό Αντίγραφο | 6.24x104 | 1.08x105 | 4.48x104 |
| Πολλαπλές Αντιστοιχίες | 1.84x104 | 3.62x102 | 0.02x101 |
| Καλύτερες Αντιστοιχίες | 1.66x104 | 3.07x102 | 0.02x101 |
| Σύνολο | 2.14x106 | 3.86x105 | 4.80x104 |
Η ανάλυση των πληροφοριών που καταγράφουν τα ιδιαίτερα χαρακτηριστικά (Πίνακας 6.1) μας δείχνει πώς τα DDTs επηρεάζουν το υποσύστημα της δυναμικής μνήμης. Τα νούμερα της ενέργειας υπολογίζονται με βάση μία μνήμη που είναι αρκετά μεγάλη, ώστε να χωράει ένα DDT. Τα DDTs και οι διάφορες δυναμικές συμπεριφορές μπορούν να προέλθουν από την εσωτερική υποδιαίρεση ενός γενικού αλγορίθμου σε διάφορους υποαλγορίθμους, που έχουν περιγραφεί προηγουμένως, οι οποίοι περιέχουν διαφορετικές φάσεις διάσχισης και φιλτραρίσματος. Πρώτον, το CandidateMatches είναι το μεγαλύτερο DDT σε αυτό το σύστημα. Δεύτερον, το ImageMatches έχει συχνές προσπελάσεις. Τέλος, το CMCopyStatic είναι μία εφαρμογή δυναμικού πίνακα, η οποία έχει πολύ γρηγορότερη πρόσβαση σε συγκεκριμένα δεδομένα αποθήκευσης (και κρατάει παρά μόνο ένα αντίγραφο των περιεχόμενων του CandidateMatches), και καταναλώνει ένα σημαντικό ποσοστό της ενέργειας που χρησιμοποιείται από το σύστημα. Ο λόγος που έχει τόσο υψηλό κόστος ενέργειας, είναι ότι συγκεκριμένες προσπελάσεις προσθέτουν καινούργια στοιχεία, που επιβαρύνουν το σύστημα με το κόστος μιας μηδενικής μνήμης.
Όπως μας έδειξε αυτή η ανάλυση, τα DDTs στις πολυμεσικές εφαρμογές αλληλεπιδρούν ως τοπικές μεταβλητές (με πολύ μικρό προσδόκιμο ζωής). Αυτές αποθηκεύουν τα ενδιάμεσα δεδομένα που παράγονται ανάμεσα στους διάφορους υποαλγορίθμους. Οι υποαλγόριθμοι χρησιμοποιούνται στο τέλος για την παροχή δεδομένων εξόδου της τρέχοντος μονάδας, στις επόμενες μονάδες λογισμικού των συνολικών εφαρμογών, λόγω της μοναδικότητας στην μηχανική λογισμικού, όπως είναι ο ρόλος του BestMatches και του MultiMatches. Ένα τελευταίο χαρακτηριστικό των πολυμεσικών και επικοινωνιακών εφαρμογών είναι ο επαναλαμβανόμενος κύκλος των μοτίβων δυναμικής εκχώρησης και αποεκχώρησης τους. Πιο συγκεκριμένα, στη μονάδα 3D αναδόμησης εικόνας, αυτή η συμπεριφορά που αναλύθηκε προηγουμένως είναι παρόμοια για κάθε ζευγάρι διαδοχικών στιγμιοτύπων, και σε κάθε καινούργια έκδοση του αλγορίθμου, το παλιότερο στιγμιότυπο αντικαθίσταται από το επόμενο σύνολο στιγμιοτύπων της εισόδου και έτσι οι αλγόριθμοι εφαρμόζονται με τον ίδιο ακριβώς τρόπο.
Σ’ αυτό το βιβλίο μελετάμε ένα σημαντικό υποσύνολο του τομέα των πολυμεσικών εφαρμογών, πιο συγκεκριμένα την επεξεργασία εικόνας (ανάλυση, ερμήνευση εικόνας και αναδόμηση εικόνας), επεξεργασία βίντεο (αναδόμηση βίντεο πολλαπλών οπτικών γωνιών), όπως και την 3D αναδόμηση και απόδοση εικόνας. Γενικά, το πιο στάνταρ κομμάτι της επεξεργασίας εικόνας (φιλτράρισμα και προγραμματισμός) των εφαρμογών χειρίζεται τα στατικά δεδομένα της στοίβας [47]. Όμως, οι πιο προηγμένοι αλγόριθμοι όρασης υπολογιστή και κατανόησης εικόνας πρέπει να διαχειριστούν δυναμικούς τύπους μέσα στο σωρό [37], [48]. Οι τύποι δυναμικών δεδομένων που χρησιμοποιούνται, είτε βασίζονται σε βιβλιοθήκες, όπως η STL (Standard Template Library, Βιβλιοθήκη Στάνταρ Προτύπων) [49], [50] ή σε δικό τους κώδικα. Έτσι, μπορούμε με αυτήν την προσέγγιση να συμπεράνουμε από αυτό ότι η πλειονότητα αυτών των DDTs θα ήταν κατάλληλη για διαχείριση.
Επιπλέον, πολλοί αλγόριθμοι επεξεργασίας εικόνας και βίντεο λειτουργούν με δομές δεδομένων που είναι πολύ πολυπλοκότερες από τους δισδιάστατους πίνακες και είναι δομημένοι με δυναμικό τρόπο (π.χ. με μεγέθη που εξαρτώνται από τις καταγραφές δεδομένων) [51]. Για παράδειγμα, οι αλγόριθμοι καταμερισμού λειτουργούν με δομές δεδομένων που μπορούν να οργανωθούν ως διασυνδεδεμένες λίστες. Παρόλα αυτά, οι πιο αποδοτικοί αλγόριθμοι έχουν ως στόχο την πρόσβαση σε τέτοια δεδομένα με σύνηθες τρόπο. Ο κυρίως τομέας εφαρμογών είναι ο 3D καταμερισμός εικόνας.
Επίσης, βλέπουμε πιο λεπτομερώς τις εφαρμογές επικοινωνιακών πρωτοκόλλων για τα μετακινούμενα ενσωματωμένα συστήματα. Πιο συγκεκριμένα, στο [52] βλέπουμε πως τα πρωτόκολλα επικοινωνίας περιέχουν δομές δεδομένων δυναμικής φύσεως. Ακόμα πιο συγκεκριμένα, οι αλγόριθμοι δρομολόγησης πακέτου έχουν να κάνουν με μία ποικιλία σειρών πακέτων, οι οποίες είναι εκ φύσεως δυναμικές, αφού είναι γνωστό εκ των προτέρων πόσα πακέτα θα μπουν σε κάθε σειρά δρομολόγησης.
Για αυτούς τους δύο συγκεκριμένους τομείς, το εύρος των πιθανών εφαρμογών είναι αρχικά πολύ μεγάλο. Όμως, για τα περισσότερα ενσωματωμένα συστήματα ο αριθμός και οι τύποι των εφαρμογών πολυμεσικών και επικοινωνιακών πρωτοκόλλων, για να συμπεριληφθούν στον τελικό σχεδιασμό (τουλάχιστον σε ένα μεγάλο βαθμό) πρέπει να είναι γνωστός στο χρόνο σχεδιασμού. Έτσι, είναι δυνατό να αναλύσουμε τους τύπους των δυναμικά κατανεμημένων αντικειμένων που υπάρχουν σε κάθε εφαρμογή (π.χ. σημεία, τρίγωνα, 3D πρόσωπα, αναγνώριση ή συχνά μεγέθη πακέτων κλπ.) και για την σχεδίαση της πιο βολικής εφαρμογής DDT για κάθε μεταβλητή, όπως και της πιο βολικής DDM για την προκείμενη εφαρμογή.
Επιπλέον, η εμπειρία μας έχει δείξει, ότι σε κάθε εφαρμογή, το εύρος μεγεθών που χρησιμοποιείται από δυναμικά στοιχεία είναι πολύ περιορισμένο και μπορεί να καθοριστεί στο χρόνο σχεδιασμού: πρώτον, με μία στατική ανάλυση του πηγαίου κώδικα της εφαρμογής, και δεύτερον, με μία ανάλυση καταγραφής ιδιαίτερων χαρακτηριστικών της συγκεκριμένης εφαρμογής με ένα μειωμένο ποσό ομάδας δεδομένων εισόδου (π.χ. γενικά λιγότερο από 10 παραλλαγές). Να σημειωθεί πως το μέγεθος των δυναμικών στοιχείων είναι γνωστό εκ των προτέρων, αλλά όχι ο ίδιος ο αριθμός αυτών που θα κατανεμηθούν, και μπορεί να ποικίλει σε σημαντικό βαθμό από την μία αντιπροσωπευτική είσοδο δεδομένων στην άλλη. Έτσι, η χρήση της δυναμικά κατανεμημένης μνήμης δικαιολογείται και χρησιμοποιείται εκτενώς σε αυτούς τους τομείς εφαρμογών. Για παράδειγμα, με σκοπό να αναλύσουμε έναν MPEG-4 video player, αλλά και διάφορες ρυθμίσεις συστήματος, όπως ανάλυση οθόνης και ανάλυση οπτικοποίησης, θα πρέπει να μελετηθούν σύμφωνα με την ενσωματωμένη συσκευή για την οποία προορίζονται: smartphone, PDA (Φορητός Ψηφιακός Βοηθός), μία φορητή gaming συσκευή κλπ. Αυτό το σετ ρυθμίσεων πρέπει να εξερευνηθεί για ένα αντιπροσωπευτικό σετ στιγμιοτύπων εισόδου (πχ. με ένα διαφορετικό αριθμό αποδιδόμενων αντικειμένων και υφών), ενώ έχουμε υπόψη μας την κατανομή πιθανότητας των διάφορων τύπων εισόδου για τις τελικές συνθήκες λειτουργίας της συγκεκριμένης ενσωματωμένης συσκευής, αφού αυτά τα χαρακτηριστικά θα επηρεάσουν την τελική δυναμική δομή δεδομένων για την τελική χρήση της εφαρμογής.
Επίσης, είναι απαραίτητο να αναγνωρίσουμε τα κυρίαρχα δυναμικά κατανεμημένα στοιχεία για κάθε εφαρμογή. Στην πραγματικότητα, κάθε εφαρμογή περιέχει ένα μεγάλο αριθμό κατανεμημένων στοιχείων, αλλά στις περισσότερες εφαρμογές πολυμεσικών και επικοινωνιακών πρωτοκόλλων λίγες μεταβλητές (π.χ. μεταξύ 15 και 20), τείνουν να δικαιολογούν ένα μεγάλο ποσοστό των συνολικών προσπελάσεων μνήμης ή των αποτυπωμάτων μνήμης που χρησιμοποιούνται για δυναμική αποθήκευση μνήμης: γενικά μεταξύ 50 και 70 του ποσοστού προσπελάσεων στη μνήμη.
Όπως βλέπουμε στην Ενότητα 6.1, στις μοντέρνες εφαρμογές πολυμέσων και επικοινωνιακών πρωτοκόλλων, τα δεδομένα αποθηκεύονται σε οντότητες οι οποίες ονομάζονται DDTs ή απλώς δοχεία, όπως διανύσματα, λίστες ή δέντρα, που μπορούν δυναμικά να προσαρμοστούν στην ποσότητα μνήμης που χρησιμοποιείται από κάθε εφαρμογή [53]. Αυτά τα δοχεία υλοποιούνται στο επίπεδο αρχιτεκτονικής λογισμικού και είναι υπεύθυνα για την συγκράτηση και την οργάνωση των δεδομένων μέσα στην μνήμη, και επίσης υπηρετούν τα αιτήματα της εφαρμογής στον χρόνο εκτέλεσης. Αυτές οι υπηρεσίες απαιτούν την συμπερίληψη αφηρημένων τελεστών τύπων δεδομένων για αποθήκευση, ανάκτηση και παραποίηση των τιμών των δεδομένων, που δεν συνδέεται με μία εφαρμογή συγκεκριμένου δοχείου και που μοιράζεται μία κοινή διεπαφή (όπως στην STL [49]).
Τα δυναμικά δεδομένα συχνά αναφέρονται ως δεδομένα σωρού, ενώ τα στατικά δεδομένα, συνήθως ή κατοικούν στο τομέα γενικών δεδομένων ή στην στοίβα. Η διαφορά μεταξύ δυναμικών τύπων δεδομένων και δυναμικών δομών δεδομένων, είναι ότι το πρώτο μας παρέχει μία διεπαφή με μία καθορισμένη ομάδα διεργασιών, ενώ το δεύτερο μας παρέχει μία συγκεκριμένη εφαρμογή που υπακούει στην διεπαφή. Για παράδειγμα, η STL παρέχει ακολουθίες ως δυναμικούς τύπους δεδομένων. Με αυτή την λογική τα διανύσματα και οι λίστες, είναι δύο συγκεκριμένες δομές δεδομένων με διαφορετικούς συμβιβασμούς πολυπλοκότητας που εφαρμόζουν τον τύπο ακολουθίας δεδομένων.
Για να κατανοήσουμε την διαφορά μεταξύ δυναμικών τύπων δεδομένων και παραδοσιακών στατικών τύπων δεδομένων, είναι απαραίτητο πρώτα να κατανοήσουμε πως τα διαφορετικά στοιχεία που αποθηκεύονται σε αυτούς τους τύπους δεδομένων αποτυπώνονται στην πραγματική ιεραρχία της μνήμης. Η αποτύπωση ενός στοιχείου στην πραγματική του θέση στην μνήμη για τύπους στατικών και δυναμικών δεδομένων, αποτελούνται από δύο στρώσεις. Η πρώτη στρώση, που από εδώ και στο εξής θα αναφέρεται ως αποτύπωση στοιχείων, αποτυπώνει την τοποθεσία ενός στοιχείου σε μία συγκεκριμένη δομή δεδομένων, σε μία θέση στα block μνήμης που απασχολούνται από την δομή δεδομένων. Η δεύτερη στρώση, που από εδώ και στο εξής θα αναφέρεται ως αποτύπωση block, αποτυπώνει τα block μνήμης μιας δομής δεδομένων σε δεξαμενές δεδομένων, που μπορούν αντιπροσωπεύσουν την ιεραρχία της φυσικής μνήμης. Η παρουσία της μονάδας διαχείρισης μνήμης προσθέτει μία τρίτη στρώση, υλικού (hardware), που αποτυπώνει διευθύνσεις εικονικής μνήμης σε διευθύνσεις φυσικής μνήμης.
Η διαφορά μεταξύ δυναμικών και στατικών τύπων δεδομένων είναι πως υλοποιούνται αυτές οι αποτυπώσεις. Οι διαφορές περιγράφονται στην στρώση αποτύπωσης των στοιχείων. Μετά περιγράφονται και στην στρώση αποτύπωσης των blocks. Στην στρώση αποτύπωσης στοιχείων, η αποτύπωση είναι αμετάβλητη για τους τύπους στατικών δεδομένων. Η πιο τυπική δομή στατικών δεδομένων είναι ο πίνακας, ο οποίος ένα πολύ καλό παράδειγμα δομής. Η αντιστάθμιση μνήμης ενός στοιχείου στο block μνήμης που χρησιμοποιείται από τον πίνακα, είναι μία γραμμική αποτύπωση του ευρετηρίου του (που γίνεται με το να πολλαπλασιάζεται με το μέγεθος του στοιχείου). Αυτή η αποτύπωση είναι στατική και καθορίζεται από την δυαδική διεπαφή της εφαρμογής της πλατφόρμας (ABI) [54].
Για τους τύπους των δυναμικών δεδομένων, από την άλλη, η αποτύπωση του στοιχείου στην θέση των block μνήμης καθορίζεται από την εφαρμογή της συγκεκριμένης δομής μνήμης. Επιπλέον, μέσω των λειτουργιών που παρέχονται από τους δυναμικούς τύπους δεδομένων, αυτή η αποτύπωση μπορεί να αλλάξει κατά την διάρκεια του χρόνου εκτέλεσης. Για παράδειγμα, ένας vector, που είναι ότι πιο πλησιέστερο σε έναν πίνακα, αποτυπώνει τα στοιχεία σε ένα block μνήμης που χρησιμοποιεί, αρκετά όμοια με έναν πίνακα. Όμως, ένας vector επιτρέπει την εισαγωγή στοιχείων οπουδήποτε με χρήση ευρετηρίου. Αυτή η εισαγωγή επηρεάζει όλα αυτά τα στοιχεία μετά από το πρώτο στοιχείο που έχει εισαχθεί, και αλλάζει την τοποθεσία τους. Το γεγονός ότι οι τύποι δυναμικών δεδομένων επιτρέπουν την εισαγωγή, όπως και την αφαίρεση στοιχείων, έχει συνέπειες για την στρώση αποτύπωσης των blocks. Είναι απαραίτητο να αντικαταστήσουμε τα μικρότερα block μνήμης με όσο το δυνατόν μεγαλύτερα στοιχεία γίνεται να προστεθούν στην δομή δυναμικών δεδομένων, τα οποία αυξάνονται. Έτσι, για τους τύπους δυναμικών δεδομένων, η στρώση αποτύπωσης block είναι απαραίτητα δυναμική.
Για τους στατικούς τύπους δεδομένων, σε περίπτωση που κατανεμηθούν σε χρόνο εκτέλεσης, είναι δυνατό να έχουμε δυναμική αποτύπωση μνήμης. Όμως, επειδή δεν υπάρχει δυναμικότητα στην αποτύπωση στοιχείων, αυτή η κατανομή δεν χρειάζεται τόσο συχνά, αφού είναι απαραίτητη μόνο για την δημιουργία εντελώς καινούργιων δομών δεδομένων, αποφεύγοντας την δυναμικότητα στην αποτύπωση στοιχείων.
Η πραγματική εφαρμογή δυναμικών δομών δεδομένων κωδικοποιεί μόνο την στρώση αποτύπωσης στοιχείων. Ο δυναμισμός στην στρώση αποτύπωσης block διαχειρίζεται από τον διαχειριστή δυναμικής μνήμης (DDM), o οποίος όχι μόνο έχει να αναλάβει την εξυπηρέτηση των αιτημάτων κατανομής μνήμης, αλλά και να επιβεβαιώσει ότι αυτό γίνεται με τον βέλτιστο τρόπο.
Με τον συνδυασμό της αποτύπωσης της στρώσης ευρετηρίου και της αποτύπωσης block έχουμε ως αποτέλεσμα την αποθήκευση στοιχείων των DDTs σε δεξαμενές μνήμης. Μετά από αυτή την αποτύπωση, είναι δυνατό να αποτυπώσουμε αυτές τις δεξαμενές μνήμης, μαζί με την δεξαμενή που είναι αφιερωμένη στα γενικά δεδομένα και στα δεδομένα στοίβας, σε μία ιεραρχία πραγματικής μνήμης. Αυτό το βήμα συνδυάζει τους δυναμικούς και στατικούς τύπους δεδομένων και είναι συμβατό με την αποτύπωση της στρώσης ευρετηρίου και την αποτύπωση block. Έτσι, τα δυναμικά δεδομένα πρέπει να είναι τα πρώτα που θα επεξεργαστούμε, πριν να μπορέσουν να συνδυαστούν σε θέματα δεξαμενών μνήμης με την στατική δεξαμενή στοίβας που έχει απομείνει.
Όπως είδαμε δύο στοιχεία είναι απαραίτητα για να γίνει δυνατός ο σχεδιασμός εφαρμογών που χρησιμοποιούν δυναμικά δεδομένα. Πρώτον, η εφαρμογή τελεστών ενός DDT μπορεί να έχει σημαντικές συνέπειες στα μοτίβα αποθήκευσης και προσπέλασης. Δεύτερον, η εφαρμογή του DDM μπορεί να επηρεάσει σε ποιο σημείο της ιεραρχίας μνήμης βρίσκονται αυτές οι προσπελάσεις και η αποθήκευση τους. Αυτά περιγράφονται παρακάτω.
Ο σχεδιασμός των DDTs υποτάσσεται σε μία συγκεκριμένη διεπαφή που αποτελείται από μία ομάδα τελεστών. Οι υπάρχουσες και δημοφιλείς βιβλιοθήκες έχουν ένα ικανοποιητικό σύνολο τελεστών, που παρέχουν την ζητούμενη ελαστικότητα, χωρίς να περιορίζουν σε μεγάλο βαθμό την εφαρμογή των DDTs (π.χ. STL [49] και συλλογές Java). Πριν όμως εξετάσουμε αυτούς τους τελεστές, είναι σημαντικό να αντιληφθούμε ότι υπάρχει μια ποικιλία διάφορων DDTs. Επίσης, η επιλογή του ιδανικού DDT, συνήθως βασίζεται στην εφαρμογή για την οποία τον χρειαζόμαστε. Έτσι, υπάρχει ένα ευρύ σύνολο βιβλιοθηκών που μας δίνει διαφορετικές κλάσεις DDTs. Μερικές βιβλιοθήκες, όπως η STL [49], είναι πιο τυποποιημένες και έρχονται μαζί με τους περισσότερους μεταγλωττιστές της C++. Άλλες βιβλιοθήκες είναι πιο κατακερματισμένες, και είναι έτσι στάνταρ ad-hoc ή δημιουργημένες για συγκεκριμένους σκοπούς. Αυτές οι δύο κατηγορίες βιβλιοθηκών εξετάζονται λεπτομερώς.
Αυτή η ταξινόμηση, όπως ορίζεται από την STL, περιέχει τις ακόλουθες έννοιες υψηλού επιπέδου. Αυτή η ιεραρχία, μαζί με τις εφαρμογές παρουσιάζονται και στο Σχήμα 6.4. Τα λιγότερο διαφανή στοιχεία είναι οι διάφορες κλάσεις των DDTs, ενώ τα πιο διαφανή συγκεκριμενοποιούν κάποιες εφαρμογές, που παρέχονται από την βιβλιοθήκη STL.
To Δοχείο: είναι ένα αντικείμενο που αποθηκεύει άλλα αντικείμενα (τα στοιχεία του), και έχει μεθόδους για την προσπέλαση των στοιχείων. Συγκεκριμένα, κάθε τύπος που είναι μοντέλο Δοχείο έχει ένα συσχετισμένο τύπο επανάληψης, που μπορεί να χρησιμοποιηθεί για την επαναλαμβανόμενη διάσχιση τον στοιχείων του.
Ακολουθίες: Ένα δοχείο μεταβλητού μεγέθους, του οποίου τα στοιχεία είναι στοιχισμένα σε μία αυστηρά γραμμική ακολουθία. Υποστηρίζουν την εισαγωγή και αφαίρεση στοιχείων.
Συσχετιζόμενα Δοχεία: Ένα δοχείο μεταβλητού μεγέθους, που υποστηρίζει την αποδοτική ανάκτηση στοιχείων, η οποία είναι βασισμένη σε κλειδιά. Υποστηρίζει την εισαγωγή και αφαίρεση στοιχείων, αλλά διαφέρει από τις ακολουθίες στο ότι δεν παρέχει μηχανισμό για την εισαγωγή στοιχείου σε μία συγκεκριμένη θέση.
Πέρα από αυτές τις γενικές κατηγορίες, η STL επίσης παρέχει κάποιες συγκεκριμένες δομές δεδομένων, κυρίως για να παρέχει λειτουργικότητα στα παραπάνω είδη δοχείων, ή για τις συγκεκριμένες ανάγκες της διαχείρισης ακολουθιών χαρακτήρων (strings). Λόγω του ότι βασίζονται στα ήδη υπάρχοντα δοχεία, ή απευθύνονται σε κάποια συγκεκριμένη ανάγκη (διαχείριση string), που δεν είναι πολύ σχετική με τον τομέα τον multimedia. Αυτά δεν περιγράφονται περαιτέρω σ’ αυτό εδώ το βιβλίο.
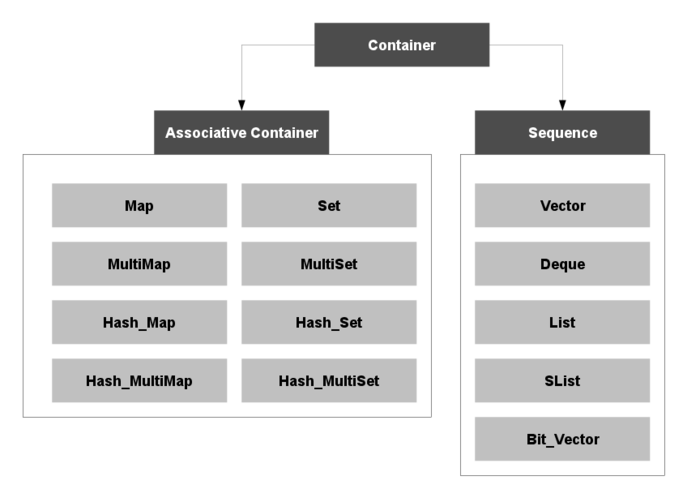
6.4: Ιεραρχία των διάφορων DDTs όπως έχουν ταξινομηθεί από την STL (σε πιο σκούρο χρώμα), μαζί με τις εφαρμογές (ανοιχτό χρώμα) που συσχετίζονται με την STL.
Σχοινιά: Αυτά είναι σχεδιασμένα για να είναι αναρριχήσιμες οι εφαρμογές μονοδιάστατων πινάκων, και είναι σχεδιασμένες ειδικά για διεργασίες που περιέχουν ολόκληρη την ακολουθία χαρακτήρων.
Bitset: Παρόμοιο μ’ ένα vector τιμών Boole, περιέχει μια συλλογή bits και παρέχει συνεχή πρόσβαση σε κάθε bit. Αντίθετα από τον vector, το bitset δεν μπορεί να αλλάξει. Έτσι αυτό το κάνει παρόμοιο και μ’ έναν πίνακα. Τα bitset δεν αναλύονται σ’ αυτό το βιβλίο, αφού δεν ορίζονται ως δοχείο STL, αφού έχουν ελλιπείς επαναλήψεις για διάσχιση.
Προσαρμογείς Δοχείων: Τεχνικά μιλώντας οι προαναφερθέντες τομείς δεν είναι δοχεία, αλλά προσαρμογείς που μπορούν να τοποθετηθούν πάνω από άλλα δοχεία για να περιορίσουν την διεπαφή.
Σχετικό είναι το γεγονός ότι οι προσπελάσεις στα δοχείο επιτυγχάνονται μέσω των επαναληπτών. Ενώ τα στατικά δεδομένα, όπως και οι πίνακες, χρησιμοποιούν δείκτες για την προσπέλαση και την πλοήγηση στα στοιχεία, αυτό είναι δυνατό μόνο και μόνο γιατί οι θέσεις μνήμης διαδοχικών χαρακτήρων είναι συνεχόμενες. Οι επαναλήπτες είναι μία γενική μορφή των δεικτών. Οι επαναλήπτες είναι τα κεντρικά στοιχεία του γενικού προγραμματισμού, γιατί είναι μια διεπαφή μεταξύ των δοχείων και των αλγόριθμων: οι αλγόριθμοι τυπικά θεωρούν τους επαναλήπτες ως ορίσματα, έτσι ένα δοχείο χρειάζεται μόνο να παρέχει ένα τρόπο προσπέλασης στοιχείων με την χρήση επαναληπτών [49]. Οι επαναλήπτες κατηγοριοποιούνται από την STL, όπως φαίνεται στο Σχήμα 6.5.
Απλός Επαναλήπτης: Ένα αντικείμενο που μπορεί να υποστεί διακοπή αναφοράς για να κατευθύνει σε ένα άλλο αντικείμενο. Το πιο απλό παράδειγμα είναι στην περίπτωση των στατικών τύπων δεδομένων, στο οποίο υπάρχει ένα δείκτης που μας οδηγεί σε έναν πίνακα.
Eπαναλήπτης Εισόδου: Ένας επαναλήπτης που μπορεί να υποστεί διακοπή αναφοράς για να κατευθύνει σε ένα άλλο αντικείμενο, και μπορεί να αυξηθεί για να μπορεί να αποκτήσει τον επόμενο επαναλήπτη σε μία ακολουθία.
Επαναλήπτης Εξόδου: Ένας επαναλήπτης που παρέχει έναν μηχανισμό για την αποθήκευση (αλλά όχι απαραίτητα την προσπέλαση) ακολουθιών τιμών.
Προωθητικός Επαναλήπτης: Ένας επαναλήπτης που ανταποκρίνεται στην διαισθητική έννοια μίας γραμμικής ακολουθίας τιμών.
Διευθυντικός Επαναλήπτης: Ένας επαναλήπτης που μπορεί να αυξηθεί και να μειωθεί.
Eπαναλήπτης Τυχαίας Προσπέλασης: Ένας επαναλήπτης που παρέχει αύξηση και μείωση και επίσης παρέχει μεθόδους συνεχούς χρόνου για την εμπρός και πίσω μετακίνηση, σε βήματα αυθαίρετου μεγέθους. Το καλύτερο παράδειγμα είναι ένας δείκτης προς κάποιον πίνακα.
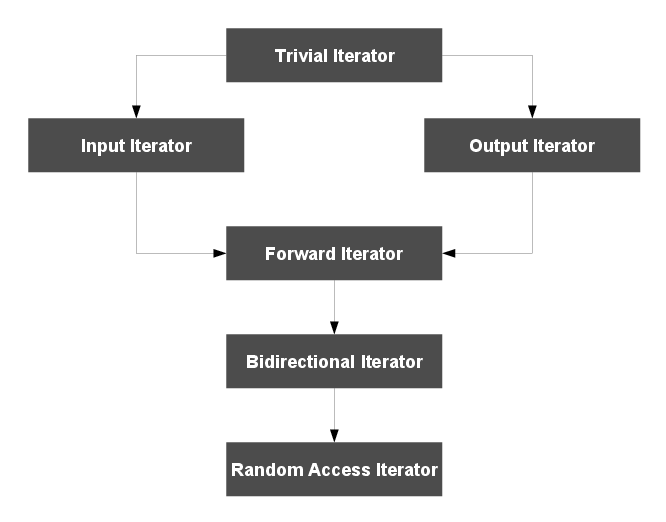
6.5: Ιεραρχία των διάφορων κλάσεων επαναληπτών που χρησιμοποιούνται για την διάσχιση και την προσπέλαση των διάφορων DDTs, όπως ορίζεται από την STL
Ο τελευταίος τρόπος με τον οποίο μπορούν να κατηγοριοποιηθούν, είναι ανάλογα με το πώς χρησιμοποιούνται στην εφαρμογή. Εδώ, διακρίνουμε τους διάφορους τρόπους με τους οποίους μπορεί να χρησιμοποιηθεί ένα DDT από μία εφαρμογή. Τα μοτίβα χρήσης βασίζονται στο πως χρησιμοποιείται ο επαναλήπτης προς το DDT. Οι περισσότερες λειτουργίες που ορίζονται στα DDTs απαιτούν έναν επαναλήπτη, αυτό όμως δεν ισχύει για όλες. Για τις ακολουθίες, θεωρούμε την λειτουργία append (τοποθέτησης στο τέλος) όπως βασίζεται σε ένα προωθητικό επαναλήπτη, ως την τοποθεσία όπου προστίθεται ένα στοιχείο που είναι ακριβώς ορισμένο. Από την άλλη, η ανάθεση σε ένα ευρετήριο για την ακολουθία ή την ανάθεση μίας τιμής σε ένα κλειδί στο συσχετιζόμενο δοχείο, θεωρείται όπως βασίζεται σε έναν τυχαίο επαναλήπτη. Έτσι είναι δυνατό να ξεχωρίσουμε δύο διαφορετικά μοτίβα χρήσης:
Ένας στατικός αριθμός επαναληπτών προελαύνει το DDT. Αυτή είναι η περίπτωση όπου ένα DDT χρησιμοποιείται ως μια ενδιάμεση μεταβλητή και χτίζεται σε μία σειρά φάσεων. Σημειώνουμε πως ο πραγματικός αριθμός σε χρόνο εκτέλεσης δεν πρέπει να είναι στατικός, αλλά περιστασιακά στατικός, με την έννοια ότι υπάρχει ένα ακριβώς ορισμένο σύνολο φωλιών βρόχων που θα μπορούσαν να παραποιήσουν το DDT. Επίσης να σημειωθεί ότι αυτή η προϋπόθεση δεν είναι τόσο περιοριστική, αφού οι ροές ελέγχου είναι κατά κύριο λόγο στατικές. Έτσι, όσο δεν υπάρχει βρόχος υψηλού επιπέδου που συνεχώς δημιουργεί έναν επαναλήπτη για την προσπέλαση του DDT, τόσο το μοτίβο χρήσης θεωρείται πως ανήκει σε αυτήν την κατηγορία.
Ένας δυναμικός αριθμός επαναληπτών προελαύνει το DDT. Αυτή είναι η περίπτωση όπου το DDT χρησιμοποιείται ως κύρια κατάσταση, και τροποποιείται ξανά και ξανά σε ένα βρόχο υψηλού επιπέδου. Ένα παράδειγμα αυτού είναι ένα ιστόγραμμα που υπολογίζεται στην διάρκεια μίας ολόκληρης εισόδου, και έτσι ένας επαναλήπτης τυχαίας προσπέλασης χρησιμοποιείται για να μεταποιήσει το DDT κάθε τιμής.
Ενώ τα DDTs λειτουργούν ως κύριες καταστάσεις, μπορούν να βελτιστοποιηθούν για να έχουν αποδοτικές λειτουργίες. Για τα DDTs που λειτουργούν ως ενδιάμεσες μεταβλητές, είναι δυνατό, δεδομένων των κατάλληλων βελτιστοποιήσεων, να αφαιρεθούν εντελώς. Αυτό περιγράφεται λεπτομερώς στην Ενότητα 6.3.3. Για όλους τους τύπους δυναμικών δεδομένων είναι δυνατό να χρησιμοποιήσουμε πληροφορίες σχετικές με την εφαρμογή, για να βελτιστοποιήσουμε λειτουργίες, αλλά και την αποτύπωση επιπέδου blocks στην ιεραρχία της μνήμης. Αυτό περιγράφεται στην Ενότητα 6.3.
Πέρα από τις Boost C++ βιβλιοθήκες [55], που παρέχουν μία επιπλέον ποικιλία λειτουργικότητας που λείπει από την C++ και την STL, υπάρχουν αρκετές βιβλιοθήκες δέντρων που είναι διαθέσιμες στο κοινό εδώ και αρκετά χρόνια [49]. Ενώ η Boost είναι ένα στάνταρ ad-hoc, οι άλλες βιβλιοθήκες είναι προσωπικές συνεισφορές από διάφορους συγγραφείς, χωρίς να έχουν οριστεί. Αυτές οι βιβλιοθήκες εστιάζονται στις κλάσεις των DDTs (όπως και σε άλλες λειτουργικότητες) που δεν υπάρχουν στην STL. Κυρίως εστιάζονται σε γραφήματα και δέντρα, συγκεκριμένα σε δομές δεδομένων που έχουν περισσότερη δομή στην διεπαφή τους. Τα δέντρα περιέχουν την έννοια γονέα και παιδιού, όπως και αδελφών, ενώ οι ακολουθίες έχουν μόνο αδερφικά στοιχεία. Τα γραφήματα προσθέτουν ακόμα περισσότερη ελαστικότητα στους συνδέσμους.
Είναι σημαντικό να σημειωθεί πως η συζήτηση που γίνεται εδώ για τα δέντρα, προορίζεται για δέντρα, των οποίων η πραγματική δομή τους έχει σημασιολογικό συσχετισμό με την εφαρμογή. Κάποια από τα συσχετιζόμενα δοχεία, για παράδειγμα το map, χρησιμοποιούν τα εσωτερικά δέντρα, αλλά από άποψη διεπαφής παρουσιάζονται ως συσχετιζόμενα δοχεία που αποτυπώνουν κλειδιά σε τιμές. Τα δέντρα που παρουσιάζονται εδώ, χρησιμοποιούνται από εφαρμογές που στηρίζονται πάνω σε μία συγκεκριμένη δομή στην σχέση παιδιού- γονέα, πέρα από αυτές που χρησιμοποιούνται καθαρά για λόγους επιδόσεων. Έτσι, τέτοιες βιβλιοθήκες έχουν πολύ λιγότερη ελαστικότητα, αναφορικά με τις εσωτερικές δομές δεδομένων που χρησιμοποιούνται για την αντιπροσώπευση αυτών των δέντρων. Από την άλλη, επειδή υπάρχουν σημασιολογίες στην φυσική διάταξη των στοιχείων, αυτές οι πληροφορίες μπορούν να εκμεταλλευτούν για χάρη διάφορων βελτιστοποιήσεων.
Παρόμοιες παρατηρήσεις ισχύουν εδώ, όπως και στην τελευταία ενότητα που είναι αφιερωμένη στην δυνατότητα για βελτιστοποιήσεις. Κατ’ αρχήν, οι ενδιάμεσες εκδόσεις αναπαραστάσεων των δεδομένων ενός δέντρου μπορούν να είναι περιττές, και έτσι είναι δυνατόν να αφαιρεθούν. Αλλά λόγω των διαφορετικών διεπαφών και της μεγαλύτερης ποικιλίας στον τρόπο που ορίζονται αυτές οι βιβλιοθήκες δέντρων, δεν υπάρχει σε αυτό το βιβλίο η ίδια η διαδικασία βελτιστοποίησης. Οι ακολουθίες STL αναφέρονται στην Ενότητα 6.3.3.
Ο ρόλος του υποσυστήματος DDM είναι να τροφοδοτεί την εφαρμογή ή τα DDTs της εφαρμογής με block μνήμης, όπου μπορούν να αποθηκευτούν τα πραγματικά δεδομένα. Αυτά τα block ζητούνται μέσω της εκχώρησης και επιστρέφονται από την εφαρμογή μέσω της αποεκχώρησης. Αυτό συμβαίνει μέσω των λειτουργιών που είναι επ ακριβώς ορισμένες [56], και περιγράφονται παρακάτω. Από τη στιγμή που το υποσύστημα DMM είναι ορισμένο σε αυτές τις δύο μόνο λειτουργίες, δεν περιορίζεται ως προς την εφαρμογή του σε οποιαδήποτε διεργασία.
Είναι δυνατόν να δοθούν μόνο μερικές εγγυήσεις: ότι η εκχώρηση ενός block μνήμης θα επιστρέψει ένα block τουλάχιστον του αιτούμενου μεγέθους. Δηλαδή ένα block που είναι κατανεμημένο δεν συμπίπτει με ένα άλλο κατανεμημένο block, έτσι το το block μνήμης δεν μεταφέρεται στην μνήμη, και κατά προτίμηση η μνήμη αποεκχώρησης θα επαναχρησιμοποιηθεί για μελλοντικές κατανομές. Οι δύο κύριες λειτουργίες που παρέχονται από το DMM είναι:
malloc (που ονομάζεται new στην C++): Μία λειτουργία που δέχεται ως είσοδο ένα απαιτούμενο μέγεθος και επιστρέφει ένα block μνήμης που είναι τόσο μεγάλο τουλάχιστον όσο το απαιτούμενο μέγεθος.
free (που ονομάζεται delete στην C++): Μία λειτουργία που ελευθερώνει ένα προηγουμένως κατανεμημένο block, επιτρέποντας έτσι την επαναχρησιμοποίηση του για μελλοντικές κατανομές.
Υπάρχουν αρκετοί μη λειτουργικοί περιορισμοί, που πρέπει να έχουμε υπόψη πριν να κρίνουμε ότι ένα DMM είναι βέλτιστο, ή ακόμα και χρησιμοποιήσιμο. Ένας από αυτούς τους παράγοντες είναι ο κατακερματισμός της μνήμης. Έχει ήδη παρουσιαστεί σε προηγούμενη ενότητα, μαζί με την διαφορά ανάμεσα σε δύο είδη κατακερματισμού μνήμης και πιο συγκεκριμένα της εσωτερικής και εξωτερικής μνήμης. Εδώ παρέχεται ένα παράδειγμα, για να διευκρινιστεί καλύτερα αυτή η έννοια.
Στην Εικόνα 6.6, έχουμε δύο παραδείγματα ενός μοτίβου εκχώρησης/αποεκχώρησης, στο πάνω και στο κάτω μέρος. Σε κάθε μοτίβο, κατανέμεται ένα block των 20 KB από την εφαρμογή, που στην συνέχεια αποεκχωρείται, και μετά εκχωρείται από την εφαρμογή ένα block των 40 KB. Και στις δύο περιπτώσεις, το υποσύστημα DMM επιστρέφει το πρώτο block μνήμης, που μπορεί να βρεθεί και ταιριάζει με το απαιτούμενο μέγεθος. Στην πρώτη περίπτωση, το υποσύστημα DMM δεν τεμαχίζει το block των 40 KB που βρίσκει. Αυτό έχει ως αποτέλεσμα, λιγότερη διαθέσιμη ελεύθερη μνήμη από ότι θα είχαμε αν επέστρεφε ένα block των 20 KB. Αυτό ονομάζεται εσωτερικός κατακερματισμός και έχει ως αποτέλεσμα αχρησιμοποίητο χώρο που δεν θα μπορεί η εφαρμογή να χρησιμοποιήσει, όσο το block των 20 KB είναι εκχωρημένο. Το υποσύστημα DMM δεν μπορεί να επιστρέψει το εναπομείναν block των 20 KB, αφού θεωρείται χρησιμοποιημένο ολόκληρο το block των 40 KΒ, και η εφαρμογή δεν μπορεί να χρησιμοποιήσει το περισσεύουν χώρο, αφού το μόνο που γνωρίζει είναι πως έκανε εκχώρηση σε ένα block που μπορεί να χωρέσει 20 KB. Στην δεύτερη περίπτωση του σχήματος 6.6, το υποσύστημα DMM αποφασίζει να τεμαχίσει το ελεύθερο block των 40 KB για να διαχειριστεί τους εσωτερικούς κατακερματισμούς. Όμως, αυτό έχει ως αποτέλεσμα, η διαδοχική αίτηση για 40 KB, να μην βρει κανένα block διαθέσιμο. Σε μία τέτοια περίπτωση το υποσύστημα DMM πρέπει να ζητήσει περισσότερη μνήμη από το Λειτουργικό Σύστημα (ΛΣ) για να μπορέσει να υπακούσει στο αίτημα της εφαρμογής (με αποτέλεσμα μία μεγαλύτερη δεξαμενή block μνήμης). Την ίδια στιγμή, η μνήμη που απασχολείται από τα ελεύθερα block μνήμης των 20 KB παραμένει αχρησιμοποίητη και έτσι χάνεται. Αυτό ονομάζεται εξωτερικός κατακερματισμός. Σε αυτό το απλό παράδειγμα, το υποσύστημα DMM θα μπορούσε να έχει διαλέξει το block των 20 KB για την αίτηση των 20 KB και θα είχε απαλείψει και τα προβλήματα κατακερματισμού. Στα πραγματικά συστήματα, η εύρεση του πιο ταιριαστού block μπορεί να αποβεί ακριβής λόγω του χρόνου που χρειάζεται για να βρεθεί αυτό το block. Το δεύτερο DMM υποσύστημα θα μπορούσε να έχει συγχωνεύσει τα δύο block 20 KB σε ένα block των 40 KB. Αυτό όμως προκαλεί συμβιβασμούς κόστους στα πραγματικά συστήματα. Επιπλέον, η συγχώνευση μπορεί να έχει ως αποτέλεσμα αργότερα τον εσωτερικό ή εξωτερικό κατακερματισμό και έτσι η συγχώνευση σε συγκεκριμένες χρονικές στιγμές μπορεί να μην είναι η βέλτιστη.
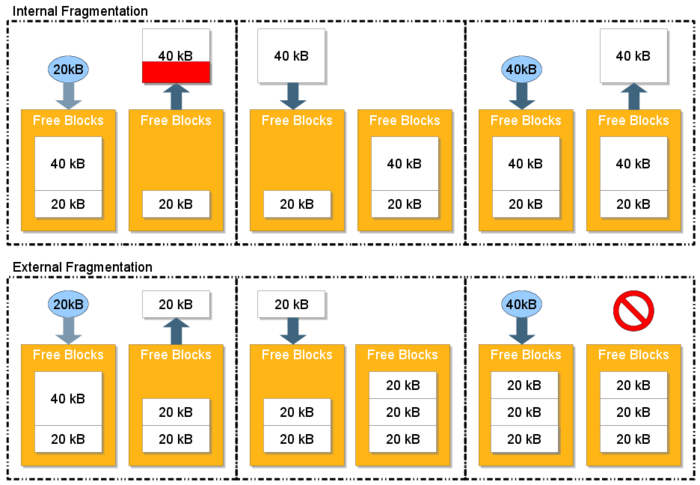
6.6: Παράδειγμα εξωτερικού και εσωτερικού κατακερματισμού.
Ενώ τα περισσότερα λειτουργικά συστήματα πάνε πακέτο με μία στάνταρ βιβλιοθήκη DMM [56], αυτές δεν βελτιστοποιούνται ποτέ για λόγους κατανάλωσης ενέργειας. Επιπλέον, δεν λαμβάνουν υπόψη τους, την συμπεριφορά της εφαρμογής σε σχέση με τις εκχωρήσεις/αποεκχωρήσεις μνήμης και των προσπελάσεων μνήμης. Στην παρουσία μίας ιεραρχίας μνήμης, σαν αυτές που βρίσκουμε στα ενσωματωμένα συστήματα, έχει συχνά ως αποτέλεσμα υποβέλτιστες επιλογές για τους εκχωρητές μνήμης [58]. Όπως ο σχεδιασμός των DDTs, ο σχεδιασμός του υποσυστήματος DMM πρέπει να λάβει υπόψη του αρκετούς παράγοντες πριν μπορέσει να θεωρηθεί χρήσιμο για κάποιο συγκεκριμένο σύστημα:
Το μοτίβο κατανομής της εφαρμογής στο πέρας του χρόνου άμεσα, αλλά και μέσω της χρήση DDT. Είναι σημαντικό το υποσύστημα DMM να είναι ικανό να εκχωρεί και να αποεκχωρεί αποδοτικά τα block που συχνά εκχωρούνται ή αποεκχωρούνται. Αυτή η αποδοτικότητα τυπικά μετριέται σχετικά και με την υπολογιστικότητα και τις προσπελάσεις μνήμης που εκτελεί κρυφά το DMM γι’ αυτές τις εφαρμογές.
Το αποτύπωμα μνήμης του συγκεκριμένου εκχωρητή μνήμης δεν καθορίζεται μόνο από τα δυναμικά δεδομένα, τα οποία είναι φυσικά ένας παράγοντας που συμβάλλει στην πολυπλοκότητα του συστήματος, αλλά και από τον κατακερματισμό της μνήμης μέσα στον διαχειριστή δυναμικής μνήμης. Αν αυτό δεν τεθεί υπό έλεγχο, τα δυναμικά δεδομένα εύκολα μπορούν να καταναλώσουν όλους τους πόρους της συγκεκριμένης πλατφόρμας, υποβιβάζοντας έτσι ή και διαλύοντας εντελώς την προσδοκώμενη συμπεριφορά της εφαρμογής Έτσι, ο κατακερματισμός της μνήμης είναι ένας σημαντικός παράγοντας για την συνολική συμπεριφορά του συστήματος, που πρέπει να ληφθεί υπόψιν.
To μοτίβο προσπέλασης της εφαρμογής στα δυναμικά δεδομένα και η δυναμική μνήμη που έχει κατανεμηθεί για χάρη του, καθορίζει την κατανάλωση ενέργειας της εφαρμογής. Με το να τοποθετούμε τα συχνά προσπελασμένα block σε τοπικές και μικρότερες μνήμες είναι δυνατό να έχουμε ένα τεράστιο κέρδος σε κατανάλωση ενέργειας.
Έχοντας αυτό το μοτίβο προσπέλασης κατά νου, το υποσύστημα DMM μπορεί να κάνει σίγουρη την χαμηλότερη κατανάλωση ενέργειας.
Όπως εξηγήσαμε στην Ενότητα 6.2 απαιτούνται διάφορες βελτιστοποιήσεις για την μείωση ενεργειακού κόστους που προκαλείται από τις δυναμικές προσπελάσεις μνήμης στην εφαρμογή. Αυτές οι βελτιστοποιήσεις δεν έχουν σκοπό μόνο τις εφαρμογές πολυμέσων που πρέπει να βελτιωθούν, αλλά και τις βιβλιοθήκες, και το υλικό και λογισμικό που χρησιμοποιούν αυτές οι εφαρμογές. Η μέθοδος για την προσέγγιση τέτοιων εφαρμογών είναι συνηθισμένη, όπως και τα βήματα που παράγουν τα συγκεκριμένα αποτελέσματα για κάθε εφαρμογή πολυμέσων. Με την μεταποίηση διάφορων κομματιών στις βιβλιοθήκες και τον χρόνο εκτέλεσης, είναι δυνατό να μειώσουμε σε σημαντικό ποσοστό τα κόστη ενεργειών της δυναμικής μνήμης σε αυτές τις εφαρμογές. Από την στιγμή που οι επιλύσεις είναι συγκεκριμένες για τις εν λόγω εφαρμογές, πρέπει να συλλεχθούν πρώτα οι πληροφορίες που έχουν σχέση με την εφαρμογή.
Θα περιγραφεί τώρα λεπτομερώς η συστηματική μεθοδολογία, η οποία εμφανίστηκε σε προηγούμενη ενότητα. Η μέθοδος που παρουσιάζεται σε αυτό το βιβλίο είναι ανεξάρτητη από την πλατφόρμα (π.χ. εξαρτάται από την περίπτωση οργάνωσης της ιεραρχίας των δεδομένων μνήμης που χρησιμοποιείται και από την πλατφόρμα, αλλά είναι ανεξάρτητη από την αρχιτεκτονική του επεξεργαστή). Εξαρτάται από τα μεγέθη μνήμης που υπάρχουν στο σύστημα, αφού έχει να κάνει με την κατανάλωση ενέργειας και της συμπεριφοράς της μνήμης. Όμως, οι συμβιβασμοί των διαφορετικών βημάτων βελτιστοποίησης δεν εξαρτώνται από τα επακριβή κόστη ενέργειας της κάθε προσπέλασης μνήμης. Έτσι μόνο τα σχετικά κόστη ενέργειας, και κατά συνέπεια τα σχετικά μεγέθη των διαφορετικών επιπέδων μνήμης (L1, L2, κύρια μνήμη) της ιεραρχίας μνήμης είναι σχετικά, και όχι οι λεπτομέρειες της εν λόγω αρχιτεκτονικής.
Ενώ τα αποτελέσματα και οι ακριβείς τελικές επιλογές σχεδιασμού είναι εξαρτημένες από την πλατφόρμα, η μέθοδος είναι γενική, και εφαρμόζεται σε όλες τις πλατφόρμες, και μόνο οι λειτουργίες κόστους, και η τελική επιλογή σχεδιασμού για ένα συγκεκριμένο σχέδιο θα είναι εξαρτημένες από την πλατφόρμα, και όχι η εφαρμοσιμότητα της ίδιας της μεθόδου.
Εκεί που στις παραδοσιακές προσεγγίσεις βελτιστοποίησης, οι πληροφορίες αφορούσαν στατικά δεδομένα, τα οποία εκδηλώνονται στο πηγαίο κώδικα, σχετικά με τα μεγέθη πινάκων και τα όρια βρόχων, η εισαγωγή δυναμικών δεδομένων αφαιρεί αυτή την πηγή πληροφοριών. Και ενώ μπορούν ακόμα να ταυτοποιηθούν οι βρόχοι παραγωγής, λόγω της προσαρμοστικότητας στο μέγεθος που διαθέτουν τα DDTs (που εξυπηρετούν και ως αποθήκη γι’ αυτά τα δυναμικά δεδομένα) σε χρόνο εκτέλεσης, δεν είναι πλέον δυνατό να ταυτοποιήσουμε τις ποσότητες των εν λόγω δεδομένων. Έτσι, οι πληροφορίες που έχουν να κάνουν με τη συμπεριφορά δυναμικών δεδομένων πρέπει να συλλεχθούν κατά το χρόνο εκτέλεσης. Αυτό έχει ως αποτέλεσμα, η μέθοδος να αρχίζει με το βήμα συλλογής μετα-δεδομένων, πριν εφαρμοστούν τα διάφορα βήματα βελτιστοποίησης, που καταλήγει σε μία μέθοδο ροής που διαχειρίζεται την δυναμική μνήμη [59].
Τώρα θα εξετάσουμε αυτή τη μέθοδο ροής, γιατί είναι δομημένη και οργανωμένη όπως είναι, και εξηγώντας τι περιέχουν τα διάφορα βήματα. Πρώτα, η συνολική μέθοδος εξηγείται στην Ενότητα 6.3.1. Μετά, το βήμα που συλλέγει τις πληροφορίες που απαιτούνται για τα διαφορετικά βήματα βελτιστοποίησης εξηγείται στην Ενότητα 6.3.2. Τελικά, τα διαφορετικά βήματα βελτιστοποίησης περιγράφονται στις Ενότητες 6.3.3 και 6.3.5.
Σ’ αυτήν την ενότητα δίνουμε μία περίληψη της μεθόδου, εξηγώντας την σειρά των διαφορετικών βημάτων και γιατί αυτή είναι η πιο λογική σειρά. Οι εξηγήσεις των διάφορων βημάτων περιγράφονται περαιτέρω στις ακόλουθες υποενότητες.
Όπως βλέπουμε στο Σχήμα 6.7, το πρώτο βήμα της μεθόδου είναι η συλλογή πληροφοριών σε σχέση με την συμπεριφορά της εφαρμογής. Αυτό που δεν είναι εμφανές στο σχήμα είναι οι βελτιστοποιήσεις υψηλού επιπέδου που είναι δυνατές στον αντικειμενοστραφή προγραμματισμό και στη γλώσσα περιγραφής υψηλού επιπέδου (π.χ. Ενοποιημένη Γλώσσα Μοντελισμού ή Unified Modelling Language, UML [60]). Αυτά πρέπει να γίνουν πρώτα, αφού μπορούν να τροποποιήσουν εντελώς το σχεδιασμό της εφαρμογής και των υπαρχόντων DDT. Μπορούν να αποσυνδεδεθούν μετά από ακόλουθα βήματα, με την εισαγωγή εκτιμητών υψηλού επιπέδου [52].
Το βήμα πληροφοριών ιδιαίτερων χαρακτηριστικών, συλλέγεται στην μορφή μετα-δεδομένων λογισμικού, περιγράφοντας την χρήση DDTS και δυναμικών δεδομένων γενικά, και σε σχέση με εκχωρήσεις και αποεκχωρήσεις, όπως και προσπελάσεις, και συνοψίζονται σε σχέση με μία ποικιλία αξόνων. Αυτό το βήμα πληροφοριών μετά κληροδοτείται σε διάφορα βήματα βελτιστοποίησης, κάνοντας τα δυνατά. Το βήμα ανάλυσης και καταγραφής ιδιαίτερων χαρακτηριστικών εξηγείται με περισσότερες πληροφορίες στην Ενότητα 6.3.2.
Μετά την συλλογή των πληροφοριών, είναι δυνατό να έχουμε μία ολιστική βελτιστοποίηση σε σχέση με την χρήση DDTs στο επίπεδο αλγόριθμου της εφαρμογής. Τυπικά, τα DDTs χρησιμοποιούνται με δύο τρόπους: ως κεντρική αποθήκη για τα στοιχεία σε έναν αλγόριθμο, εξυπηρετώντας έτσι ως η κατάσταση του αλγόριθμου, ή σαν φορτωτής για την αποσύνδεση φάσεων παραγωγής και κατανάλωσης. Στην δεύτερη περίπτωση, η οποία συχνά παρατηρείται σε εφαρμογές πολυμέσων, η χρήση DDTs έχει ως σκοπό την αποφυγή πολυπλοκότητας και τη βελτίωση της καθαριότητας. Σε τέτοιες περιπτώσεις, είναι δυνατό να βελτιστοποιήσουμε συστηματικά αυτά τα DDTs, με ένα πρωτόγνωρο βήμα βελτιστοποίησης την Αφαίρεση Ενδιαμέσου Μεταβλητής (Intermediate Variable Removal, IVR). Αυτό το βήμα κάνει δυνατό ένα συμβιβασμό μεταξύ του εύρους ζώνης υπολογισμών και μνήμης. Ανάλογα με την πλατφόρμα και τα σχετικά κόστη προσπελάσεων μνήμης και υπολογισμών, αυτό επιτρέπει βελτιστοποιήσεις που έχουν να κάνουν με κατανάλωση ενέργειας. Ένα μικρό παράδειγμα IVR παρουσιάζεται εδώ, για να δώσει μια ιδέα στον αναγνώστη, ως προς το τι περιέχει. Παραπάνω πληροφορίες για το IVR στην Ενότητα 6.3.3.
Στο πρώτο δείγμα κώδικα του Σχήματος 6.8, δημιουργείται ένα DDT στο οποίο προστίθεται μία ακολουθία στοιχείων (παραγόμενα από μια διαδικασία). Μετά αυτή η ακολουθία στοιχείων καταναλώνεται σε ένα δεύτερο βρόχο. Αν οι δύο βρόχοι είχαν γραφεί ταυτόχρονα, όπως στο δεύτερο δείγμα κώδικα στο Σχήμα 6.8, τα κόστη καταγραφής όλων αυτών των στοιχείων στη μνήμη (όπως και η κράτηση λογαριασμών στα DDT, απαραίτητα για την ανάπτυξη της ακολουθίας), όπως και η ανάγνωση από την μνήμη δεν θα ήταν απαραίτητα. Αντ’αυτού κάθε στοιχείο θα μπορούσε να είχε γραφεί στην τοπική μνήμη (ή ακόμα και σε καταχωρητή) και μετά θα είχε καταναλωθεί, έχοντας ως αποτέλεσμα πολύ μικρότερα κόστη ενέργειας, αφού οι μεγαλύτερες μνήμες απαιτούν περισσότερη ενέργεια. Επιπλέον, η κράτηση λογαριασμών DDT θα μπορούσε να έχει απαλειφθεί οριστικά. To ΙVR εστιάζει σε τέτοιες μεταποιήσεις, κάνοντας ταυτόχρονα σίγουρη την τήρηση περιορισμών σε σχέση με την οργάνωση εισόδου/εξόδου, και ασχολείται με πιο πολύπλοκους βρόχους παραγωγής και κατανάλωσης.
Μόνο όταν έχει οριστεί ποια DDTs θα παραμείνουν, είναι αποδοτικό να ξεκινήσει η βελτιστοποίηση της εφαρμογής τους σε ένα βέλτιστο Pareto21 σχεδιασμό, έχοντας υπόψιν μας την πλατφόρμα στην οποία αποτυπώνεται η εφαρμογή, όπως και η κατά συνέπεια συμπεριφορά της εφαρμογής, σχετικά με τα DDTs. Οι βελτιστοποιήσεις DDT δεν περιγράφονται περαιτέρω σε αυτό το βιβλίο. Αντ’αυτού, αναφέρονται στα [61], [52]. Για ακόμα μία φορά, εκτιμητές υψηλού επιπέδου χρησιμοποιούνται για την αποσύνδεση αυτού του βήματος από τους συγγραφείς των [52]. Παίρνοντας ξανά το παράδειγμα 6.8, αν το ενδιάμεσο DDT δεν είχε αφαιρεθεί, στην ιδανική περίπτωση θα είχε χρησιμοποιηθεί ένα DDT που μοιάζει σε λίστα, επειδή έχει οδηγήσει σε λιγότερες αντιγραφές, ενώ συνέχεια προσθέτει καινούργια στοιχεία στο τέλος του.
vector<int> a;
for (int i = 0; i < SIZE; i++) {
if (h(i))
vector.push_back(f(i));
}
for (vector<int>::iterator i = a.begin(); i != a.end(); ++i) {
g(*i);
} for (int i = 0; i < SIZE; i++) {
if (h(i))
g(f(i));
}Τέλος, όταν οι εφαρμογές των DDTs έχουν καθοριστεί, θα είναι ξεκάθαρο ποια block είναι κατανεμημένα από αυτά τα DDTs, αλλά και την ίδια την εφαρμογή. Αφού οι εφαρμογές DDT καθορίζουν τις τεχνικές εσωτερικής αποθήκης στα block μνήμης, είναι απαραίτητο να έχουμε την τελική εφαρμογή των DDTs, για να δούμε πως είναι η συμπεριφορά κατανομής της εφαρμογής. Για παράδειγμα, μία μικρή εναλλαγή, όπως η αλλαγή της ακολουθίας στυλ vector σε μία ακολουθία σε στυλ διασυνδεδεμένης λίστας, όχι μόνο αλλάζει ριζικά το μοτίβο ανακατανομής, αλλά και τους τύπους των block που κατανέμονται. Στην περίπτωση του vector, θα κατανεμηθεί ένα συνεχόμενο block μνήμης που περιέχει τα στοιχεία, με αποτέλεσμα μία μεγάλη κατανομή ή αρκετές αφού σιγά σιγά ο vector μεγαλώνει και το block μνήμης επεκτείνεται και έτσι ανακατανέμεται. Από την άλλη, αν χρησιμοποιηθεί μία διασυνδεδεμένη λίστα, πολλά μικρά block θα κατανεμηθούν, που το καθένα θα περιέχει ένα και μόνο ένα στοιχείο και τους δείκτες προς το προηγούμενο και το επόμενο block, με μία κατανομή να συμβαίνει κάθε φορά, που προστίθεται ένα στοιχείο. Έτσι, είναι ξεκάθαρο πως η εφαρμογή DDT έχει μεγάλη επιρροή στο μοτίβο κατανομής. Γι’ αυτό το βήμα βελτιστοποίησης DDM είναι μετά το βήμα βελτιστοποίησης DDT. Περισσότερες πληροφορίες σε σχέση με την βελτιστοποίηση DDM δίνονται στην Ενότητα 6.3.5.
Σημειώνουμε πως όλα τα παραπάνω βήματα έχουν να κάνουν με δυναμικά δεδομένα και την αποτύπωση τους σε δεξαμενές μνήμης. Μετά από αυτά τα βήματα, είναι δυνατό να συνδυάσουμε αυτές τις αφηρημένες δεξαμενές δεδομένων με γενικά δεδομένα και δεδομένα στοίβας. Αυτό είναι έξω από την θεματολογία αυτού του βιβλίου, αλλά δείχνει πως η προηγούμενη μέθοδος συνδέεται με την υπάρχουσα μελέτη των στατικών δεδομένων. Περισσότερες πληροφορίες στην Ενότητα 6.3.6
Για να γίνουν δυνατά τα διάφορα βήματα βελτιστοποίησης, όπως έχει ήδη εξηγηθεί στην ενότητα 6.3, είναι αναγκαίο να κατανοηθεί τι είναι η συμπεριφορά δυναμικής μνήμης της εφαρμογής. Για αυτό τον σκοπό, αφού η εν λόγω εφαρμογή είναι δυναμική, είναι αναγκαίο να καταγραφούν τα ιδιαίτερα χαρακτηριστικά της, για να μπορούμε να έχουμε μία ακριβή εικόνα τον διαφορετικών απαιτήσεων της εφαρμογής σε σχέση με τις προσπελάσεις μνήμης και τις κατανομές μνήμης. Επιπλέον, συλλέγονται πληροφορίες καταγραφής ιδιαιτέρων στοιχείων υψηλού επιπέδου αφαίρεσης, όπως η χρήση διαφόρων μεθόδων που παρέχονται από ένα DDT. Με το να χρησιμοποιήσουμε μία στάνταρ διεπαφή (π.χ. η διεπαφή ακολουθίας από το STL [49]), είναι δυνατή η μελέτη συμπεριφοράς της εφαρμογής σε σχέση με αυτήν την διεπαφή και έπειτα να βελτιστοποιήσουμε την εφαρμογή DDT βάσει πώς χρησιμοποιούνται τα DDTs. H βιβλιοθήκη καταγραφής ιδιαίτερων στοιχείων που έχει αναπτυχθεί μπορεί να συλλέξει όλες αυτές τις πληροφορίες χωρίς να απαιτεί δραστικές αλλαγές στον πηγαίο κώδικα της εφαρμογής [62].
Αφού συλλεχθούν τα ακατέργαστα δεδομένα καταγραφής ιδιαιτέρων στοιχείων, αναλύονται και συνοψίζονται σε μεταδεδομένα που περιγράφουν τη συμπεριφορά μνήμης της εφαρμογής σε υψηλό επίπεδο. Τυπικές πληροφορίες που θα εντοπισθούν εδώ, είναι πώς χρησιμοποιούνται τα διαφορετικά DDTs της εφαρμογής, ποια είναι η τυπική συμπεριφορά κατανομής της εφαρμογής, που συμβαίνουν οι περισσότερες προσπελάσεις, κλπ. Εκτελώντας αυτή την καταγραφή ιδιαιτέρων στοιχείων και την ανάλυση για μία ομάδα αντιπροσωπευτικών πληροφοριών εισόδου, είναι δυνατό να αποκτήσουμε μια πιο ξεκάθαρη εικόνα της συμπεριφοράς της εφαρμογής. Με αυτές τις πληροφορίες, μπορούμε να ταυτοποιήσουμε ενδιάμεσα DDTs που μπορούν να αφαιρεθούν, να βελτιστοποιήσουμε την εφαρμογή των εναπομεινάντων DDTs και να ορίσουμε έναν βέλτιστο εκχωρητή μνήμης για την εκάστοτε πλατφόρμα εφαρμογής και υλικού.
Πριν να οριστούν ποιες θα είναι οι εφαρμογές των διάφορων DDT στην εφαρμογή, είναι αναγκαίο να αποφασιστεί ποια DDTs απαιτούνται για την εκτέλεση του αλγορίθμου. Από άποψη σχεδιασμού, είναι καλή ιδέα να αποσυνδέσουμε τις δηλώσεις παραγωγής από τις δηλώσεις κατανάλωσης, λόγω του ξεκάθαρου διαχωρισμού που δημιουργεί με μία στάνταρ διεπαφή, πιο συγκεκριμένα τα ενδιάμεσα DDTs μεταξύ των βημάτων της εφαρμογής. Μερικά DDTs απαιτούνται από μία θεωρητική άποψη και μόνο, επειδή μπορούν να κωδικοποιήσουν στην κύρια κατάσταση ενός συγκεκριμένου κομματιού της εφαρμογής, όπου η εφαρμογή ανακυκλώνεται μέσα σε ένα βρόχο και ενημερώνει ανά τακτά διαστήματα την κατάσταση. Από την άλλη, άλλα DDTs υπάρχουν μόνο σε συγκεκριμένες φάσεις ως προσωρινοί διαμεσολαβητές μεταξύ δύο βημάτων του αλγορίθμου.
Από άποψη παραδείγματος αρθρωτού προγραμματισμού και χρήσης των τύπων αφηρημένων δεδομένων [63], [64], που όλα αυτά χρησιμοποιούνται σε όλες τις μοντέρνες γλώσσες προγραμματισμού, η λειτουργικότητα του οποιουδήποτε προγράμματος πρέπει να αποσυνδεθεί και να οριστεί ανεξάρτητα από την συγκεκριμένη εφαρμογή των δομών δεδομένων (δυναμικές ή στατικές) που χρησιμοποιούνται για την αποθήκευση των δεδομένων της εφαρμογής, όσο είναι διαθέσιμες όλες οι μέθοδοι και οι συναρτήσεις πρόσβασης που απαιτούνται από τον εφαρμοσμένο αλγόριθμο [65]. Σύμφωνα με αυτό το παράδειγμα προγραμματισμού λογισμικού, η προτεινόμενη μέθοδος βασίζεται στην υπόθεση ότι τα DDT μπορούν να ταυτοποιηθούν στον αρχικό πηγαίο κώδικα της εξεταζόμενης εφαρμογής, και ότι μπορούν να αντικατασταθούν χωρίς παράπλευρες συνέπειες που απαιτούν τροποποιήσεις της ροής ελέγχου της εφαρμογής. Με άλλα λόγια, ο πηγαίος κώδικας εισόδου της εφαρμογής πρέπει να μην περιέχει εφαρμογές DDT εκεί που εφαρμόζεται η εν λόγω μέθοδος, και πρέπει να έχει οριστεί σε μία ξεχωριστή ενότητα ή στάνταρ βιβλιοθήκη εφαρμογών DDT στην C++, όπως η STL. Ακόμα, όλος ο αλγόριθμος που χρησιμοποιεί τις εφαρμογές DDT πρέπει να αλληλεπιδράσει μ’ αυτές μόνο μέσω των στάνταρ και κοινών σετ μεθόδων [66].
Πρέπει να σημειωθεί ότι ο προαναφερθείς περιορισμός δεν περιορίζει σε μετρήσιμο βαθμό την εφαρμοσιμότητα της προτεινόμενης μεθόδου, αφού όλες οι εξεταζόμενες εφαρμογές και οι περισσότερες σύγχρονες εφαρμογές, ακολουθούν αυτή την υπόθεση. Επίσης, όπως υιοθετείται το παράδειγμα αντικειμενοστραφούς προγραμματισμού ως το κοινό στάνταρ για την εκμετάλλευση του παραδείγματος συστήματος πάνω σε chip σε επίπεδο λογισμικού, αυτή η προηγούμενη υπόθεση θα χρειαστεί να επιβληθεί περαιτέρω, λόγω της αναγκαιότητας ορισμού και χρήσης βιβλιοθηκών πολλαπλών χρήσεων, που βασίζονται σε στάνταρ διεπαφές.
Η βελτιστοποίηση IVR χρησιμοποιεί πληροφορίες από το βήμα καταγραφής ιδιαίτερων χαρακτηριστικών, για να προσδιορίσει ποια DDT χρησιμοποιούνται με τρόπο παραγωγού- καταναλωτή. Αυτός είναι ένας από τους λόγους που το βήμα καταγραφής ιδιαιτέρων στοιχείων δεν καταγράφει μόνο τη συμπεριφορά της μνήμης, αλλά και την συμπεριφορά της εφαρμογής, σε σχέση με αφηρημένες λειτουργίες DDT, όπως αυτές ορίζονται από την διεπαφή του DDT. Μόνο όταν είναι γνωστό ποια είναι τα εναπομείναντα DDT, είναι δυνατό να συνεχίσουμε στο επόμενο βήμα, την βελτιστοποίηση των DDT, η οποία δεν παρουσιάζεται με περισσότερες λεπτομέρειες σ’ αυτό το βιβλίο. Περισσότερες πληροφορίες σε σχέση με τις βελτιστοποιήσεις των DDT μπορούν να βρεθούν στο [52].
Τυπικά, υπάρχει ένας συμβιβασμός μεταξύ DDTs που κατά κύριο λόγο προσπελάζονται με τυχαίο τρόπο, και DDT που προσπελάζονται διαδοχικά. Δεν είναι δυνατή η σχεδίαση DDTs, τα οποία θα υποστηρίζουν και τους δύο τύπους εργασιών στo Ο(1). Για να κατανοήσει ο αναγνώστης το συμβιβασμό, ο Πίνακας 6.2 δίνει μερικές στάνταρ εφαρμογές που παρέχονται από τις περισσότερες γενικές βιβλιοθήκες. Πρέπει να σημειωθεί πως αυτοί οι συμβιβασμοί βρίσκονται στο ελάχιστο της πολυπλοκότητας (η οποία μεταφράζεται και σε προσπελάσεις μνήμης και σε υπολογισμούς).
| Εφαρμογή | Τυχαία προσπέλαση | Append | Prepend | Εισαγωγή | Αφαίρεση |
| Διάνυσμα | O(1) | O(1) | O(N) | O(N) | O(N) |
| Λίστα | O(N) | O(1) | O(1) | O(1) | O(1) |
| Fingertree | O(log N) | O(1) | O(1) | O(log N) | O(log N) |
Όμως, άμα θεωρήσουμε την κατανάλωση ενέργειας, πρέπει να ληφθούν υπόψιν η αποτύπωση μνήμης, όπως και άλλοι παράγοντες. Αυτοί οι παράγοντες παρουσιάζονται λεπτομερώς παρακάτω.
Η εφαρμογή των εργασιών των DDT εξαρτάται από το επιλεγμένο δοχείο και κάθε ένα από αυτά μπορεί να προτιμά συγκεκριμένο τρόπο προσπέλασης δεδομένων και των μοτίβων αποθήκευσης. Κάθε εφαρμογή μπορεί να φιλοξενήσει ένα συγκεκριμένο νούμερο διαφορετικών δοχείων σύμφωνα με το συγκεκριμένο μοτίβο προσπέλασης δεδομένων της και αποθήκευσης στον αλγόριθμο. Διαλέγοντας μια ακατάλληλη εφαρμογή δοχείου για ένα αφηρημένο τύπο δεδομένων θα έχει σημαντικές αρνητικές επιπτώσεις στο υποσύστημα δυναμικής μνήμης του ενσωματωμένου συστήματος [61], [52]. Από την μία, η ανεπαρκής προσπέλαση δεδομένων και οι ανεπαρκείς διεργασίες μνήμης μπορούν να δημιουργήσουν προβλήματα στις επιδόσεις, λόγω της επιπρόσθετης υπολογιστικής επιβάρυνσης των εσωτερικών DDT μηχανισμών. Από την άλλη, κάθε προσπέλαση των DDT στην φυσική μνήμη (όπου αποθηκεύονται τα δεδομένα) καταναλώνει ενέργεια. Οπότε, οι μη αναγκαίες προσπελάσεις μπορούν να αποτελέσουν ένα σημαντικό ποσοστό απορρόφησης ρεύματος του συστήματος [67], [68]. Στην πραγματικότητα, η κατανάλωση ενέργειας είναι ένας από τους πιο καθοριστικούς παράγοντες στο πόσο λειτουργικές μπορεί να είναι τέτοιες συσκευές, γιατί φορητοί υπολογιστές όπως τα tablets και τα notebooks στηρίζονται σε περιορισμένη μπαταρία για την λειτουργία τους. Έτσι, ο σχεδιασμός του DDT για ένα συγκεκριμένο φορητό ενσωματωμένο σύστημα και μία εφαρμογή πολυμέσων πρέπει να θεωρήσει πολλούς συνδυασμένους παράγοντες:
Ο αλγόριθμος εφαρμοσμένος σε σχέση με υψηλού επιπέδου τελεστές τους οποίους το DDT παρέχει. Αφού διαφορετικές εφαρμογές έχουν διαφορετικά κόστη για το εύρος των διεργασιών, αυτός είναι ένας από τους κύριους παράγοντες. Ενώ συγκεκριμένες εφαρμογές μπορεί να έχουν 0(1) προσπέλαση, τυπικά θα απαιτούν 0(Ν) για εισαγωγή, ενώ τον ‘Ν’ έχει το μέγεθος του DDT. Υπάρχει πληθώρα επιλογών, αλλά καμία διεργασία DDT έχει Ο(1) για όλες τις διεργασίες και έτσι υπάρχει ένας συμβιβασμός μεταξύ των διαφορετικών τελεστών. Αυτό το κόστος εκφράζεται αναφορικά με τους υπολογισμούς, αλλά και με τον αριθμό προσπελάσεων, και έχει σημαντικές επιπτώσεις στην γενική κατανάλωση ενέργειας
Η απαίτηση μνήμης των DDT εφαρμογών ποικίλει βάσει της επιλεγμένης εφαρμογής. Συγκεκριμένες εφαρμογές απαιτούν παραπάνω δείκτες για την δυνατότητα διαχείρισης της διαθέσιμης μνήμης. Άλλες δεν απαιτούν τέτοια επιβάρυνση, αλλά δεν επιτρέπουν τον διαχωρισμό μνήμης που χρησιμοποιείται από τα στοιχεία σε μικρότερα block και έτσι φθηνότερης μνήμης. Αυτοί οι συμβιβασμοί έχουν μεγάλη επιρροή και στο αποτύπωμα μνήμης και στην αποτύπωση στην ιεραρχία της μνήμης, και έμμεσα στην κατανάλωση ενέργειας.
Η συμπεριφορά προσπέλασης και μετατόπισης των στοιχείων μέσα σε ένα DDT, και πιο συγκεκριμένα η κατανάλωση δεδομένων, επίσης έχει μεγάλη επιρροή στην επιλογή σχεδιασμού ενός DDT. Όπως είδαμε, τα DDT μπορούν να καταναλωθούν με διάφορους τρόπους. Αυτό μπορεί να έχει σοβαρές συνέπειες και σε σχέση με την πολυπλοκότητα στους υπολογισμούς και στην προσπέλαση μνήμης που απαιτείται για τέτοιες μετατοπίσεις, όπως και στη συμπεριφορά αποθήκευσης στην κρυφή μνήμη του εν λόγω DDT.
Το τελικό βήμα βελτιστοποίησης για τα δυναμικά δεδομένα, είναι η βελτιστοποίηση του εκχωρητή δυναμικής μνήμης. Αυτό το βήμα έρχεται μετά από την βελτιστοποίηση των εφαρμογών του DDT, αφού αυτές θα επηρεάσουν το μοτίβο κατανομής και προσπέλασης της εφαρμογής. Στο βήμα βελτίωσης διαχειριστή μνήμης (DDMR), χρησιμοποιούνται από τα μεταδεδομένα καταχωρημένων χαρακτηριστικών, πληροφορίες για την εφαρμογή σε σχέση με τα μοτίβα κατανομής αλλά και προσπέλασης στα κατανεμημένα block. Έτσι, καθορίζεται ποιοι τύποι block μνήμης χρησιμοποιούνται λιγότερο και ποιοι περισσότερο. Με αυτές τις πληροφορίες, είναι δυνατό να καθοριστεί πως πρέπει να δομηθεί ο εκχωρητή μνήμης σε σχέση με δύο συγκεκριμένους παράγοντες.
Πρώτον, βοηθάει με την σχεδίαση της δομής του εκχωρητή μνήμης. Αν και πολλά διαφορετικά μεγέθη block χρησιμοποιηθούν από την εφαρμογή, τότε ο διαχωρισμός και ο συγκερασμός είναι σίγουρα ωφέλιμος, αφού αλλιώς ένα μεγάλο κομμάτι του αποτυπώματος μνήμης θα χαθεί λόγω κατακερματισμού. Επιπλέον, βοηθάει στο να οριστεί ποια block μνήμης είναι συχνά κατανεμημένα, έτσι επιτρέποντας την λήψη απόφασης ως προ το ποια block μνήμης θα πρέπει να έχουν τις δικές τους προσαρμοσμένες ελεύθερες λίστες για γρήγορη κατανομή αυτών των block.
Δεύτερον, βοηθάει με την τοποθέτηση block μνήμης επάνω στις δεξαμενές μνήμης. Οι δεξαμενές μνήμης τυπικά είναι μεγάλα block μνήμης τα οποία τοποθετούνται σε διαφορετικά στοιχεία της ιεραρχίας της μνήμης. Η πιο απλή προσέγγιση είναι να υπάρχει μία δεξαμενή μνήμης ανά ιεραρχικό στοιχείο block που συχνά προσπελάζονται και πρέπει μετά να τοποθετηθούν σε μικρότερες δεξαμενές μνήμης, που βρίσκονται πιο κοντά στον επεξεργαστή (CPU), ενώ block που δεν προσπελάζονται τόσο συχνά πρέπει να τοποθετούνται σε δεξαμενές μνήμης μακριά από τον επεξεργαστή. Ένα καλό μέτρο είναι ο αριθμός προσβάσεων ανά byte, από την στιγμή που δεν βγάζει νόημα το να τοποθετήσουμε ένα συχνά προσπελάσιμο block σε μία μικρότερη δεξαμενή μνήμης αν αυτό το block είναι μεγαλύτερο από δύο δεξαμενές που μαζί έχουν περισσότερες προσπελάσεις.
Για να επιτραπεί αυτό το βήμα βελτιστοποίησης, απαιτείται κάποια εξερεύνηση ώστε να βρούμε τις ακριβείς παραμέτρους που μας δίνουν τον βέλτιστο κατανομέα μνήμης. Έτσι, είναι απαραίτητη η ύπαρξη βιβλιοθήκης συνδυασμών που επιτρέπουν την κάλυψη του χώρου σχεδιασμού των εκχωρητών μνήμης. Αυτό το σύνολο συνδυασμών θα πρέπει να είναι εύκολα συναρμολογούμενο, ώστε οι εκχωρητές μνήμης οποιαδήποτε πολυπλοκότητας να μπορούν χτιστούν αντ’αυτών.
Μετά την ολοκλήρωση των προηγούμενων βημάτων που είναι ανεξάρτητα της αρχιτεκτονικής, υπάρχει μια βέλτιστη αντιστοίχηση τύπων δυναμικών δεδομένων της εφαρμογής σε δεξαμενές μνήμης. Χρησιμοποιώντας δεξαμενές μνήμης που προκύπτουν από αυτά τα δεδομένα σωρού, μαζί με την κατανάλωση μνήμης και προσπελάσεων λόγω δεδομένων στοίβας και σωρού, είναι δυνατό να αποτυπωθεί σε μία πραγματική ιεραρχία μνήμης, λαμβάνοντας υπόψιν τις αλληλεπιδράσεις διάφορων ομάδων διεργασιών. Αυτή η τελική φάση, ονομαζόμενη Μεταφορά Δεδομένων και Εξερεύνηση Μνήμης σε Εργασιακό Επίπεδο(Data Transfer and Storage Exploration, T-DTSE), αναλύεται στο [69]. Όμως το κομμάτι που καλύπτεται σε αυτό το βιβλίο, έχει σχέση με την φυσική κατανομή μνήμης και ανάθεση μνήμης και είναι συμπληρωματικό του Τ-DTSE, αφού δίνει την δυνατότητα εφαρμογής των εντολών προσπέλασης. Ταυτόχρονα, συνδυάζεται με διάφορες επιτρεπόμενες τροποποιήσεις πηγαίου κώδικα, εξαρτημένες από την αρχιτεκτονική.
Σε αυτό το κεφάλαιο είδαμε πως οι εφαρμογές πολυμέσων τελευταίας τεχνολογίας, με στόχο τα νέα φορητά ενσωματωμένα συστήματα (π.χ. 3D παιχνίδια, video-players) μοιράζονται διάφορα χαρακτηριστικά σε σχέση με την εκτέλεση πολλαπλών διεργασιών και την πολύπλοκη διαχείριση μνήμης, που τις καθιστά τις τέλειες υποψήφιες για βελτιστοποιήσεις δυναμικών δεδομένων. Αυτές οι πολύπλοκες και δυναμικές εφαρμογές προέρχονται από τα αρχικά επιτραπέζια συστήματα, τα οποία έχουν πολλή περισσότερη μνήμη και δυνατότητες. Επομένως, έχουμε αναλύσει σε αυτό το κεφάλαιο τα χαρακτηριστικά των δυναμικών δεδομένων σε αυτή την ομάδα καινούργιων εφαρμογών πολυμέσων, και έχουμε προτείνει ένα καινούργιο σχεδιασμό ροής, για να βελτιστοποιήσουμε και να εγκαθιδρύσουμε τη διαχείριση δυναμικής μνήμης στα φορητά ενσωματωμένα συστήματα.
Όπως έχει εξηγηθεί στο προηγούμενο κεφάλαιο, το πρόβλημα που αφορά τη βελτιστοποίηση του σχεδιασμού των δυναμικών ενσωματωμένων συστημάτων είναι ότι προσπαθούν να εκμεταλλευτούν όσο το δυνατόν περισσότερο τη στατική γνώση σχετικά με τις εφαρμογές (κατά το χρόνο σχεδιασμού), αλλά και να αφήσουν χώρο για τις εκτιμήσεις χρόνου εκτέλεσης που επιτρέπουν να αντιμετωπίσουν τις δυναμικές παραλλαγές, αποκλείοντας τη χειρότερη περίπτωση λύσεων. Αυτό απαιτεί τις εκτενείς πληροφορίες για τα στατικά και δυναμικά χαρακτηριστικά των εφαρμογών. Το κεφάλαιο περιγράφει τις μεθόδους σκιαγράφησης και ανάλυσης, προκειμένου να ληφθούν αυτές οι πληροφορίες και να αποτελέσουν τα μεταδεδομένα του προγράμματος. Αυτά θα καθοδηγήσουν στη βέλτιστη επιλογή του δυναμικού διαχειριστή μνήμης.
Δεν υπάρχει ένας τυποποιημένος ορισμός ή μια αναπαράσταση των μεταδεδομένων λογισμικού, για να απεικονίσει τα χαρακτηριστικά της δυναμικής συμπεριφοράς πρόσβασης στοιχείων των εφαρμογών ,υποκείμενων στις ποικίλες εισόδους. Το σχήμα 7.1 επεξηγεί πώς η χρήση μιας κοινής αποθήκης πληροφοριών (μεταδεδομένα λογισμικού), μπορεί να μειώσει τη γενική προσπάθεια που απαιτείται για να εφαρμοστούν οι διαφορετικές τεχνικές βελτιστοποίησης σε μια εφαρμογή. Χωρίς μεταδεδομένα, κάθε ομάδα βελτιστοποίησης πρέπει να μελετήσει την εφαρμογή για να εξαγάγει ανεξάρτητα τα χαρακτηριστικά που είναι σχετικά για την εργασία τους. Αν και οι πληροφορίες που απαιτούν οι περιοχές μπορούν να είναι ελαφρώς διαφορετικές για κάθε ομάδα, είναι επίσης αρκετά πιθανό να υπάρχουν και κοινές. Επομένως, ακόμα κι αν η διαδικασία εξαγωγής μεταδεδομένων μπορεί να είναι πιο σύνθετη από τις πληροφορίες που απαιτούνται για κάθε μια από τις ομάδες στην απομόνωση, η συσσωρευμένη προσπάθεια μπορεί να μειωθεί σημαντικά. Επιπλέον, μόλις εξαχθούν τα μεταδεδομένα, είναι διαθέσιμα χωρίς κανένα κόστος για οποιεσδήποτε πρόσφατες εργασίες βελτιστοποίησης. Σε αυτό το κεφάλαιο προτείνεται μια ομοιόμορφη αναπαράσταση των δυναμικών στοιχείων πρόσβασης και της συμπεριφοράς δέσμευσης των εφαρμογών, που ορίζονται ως τα μεταδεδομένα λογισμικού. Επιπλέον, αυτό το κεφάλαιο περιγράφει τις μεθόδους σκιαγράφησης και ανάλυσης για να λάβει συστηματικά αυτά τα μεταδεδομένα. Τα επιλεγμένα μεταδεδομένα παρέχουν μια ισόπεδη αναπαράσταση συστήματος της συμπεριφοράς των δυναμικών ενσωματωμένων εφαρμογών λογισμικού. Οι συνεισφορές αυτού του κεφαλαίου είναι:
Μια ομοιόμορφη αντιπροσώπευση για τα μεταδεδομένα εφαρμογής και μια μέθοδο για να τα εξαγάγουν από τις δυναμικές εφαρμογές.
Τεχνικές σκιαγράφησης και ανάλυσης που καταδεικνύουν μια συγκεκριμένη εφαρμογή αυτής της μεθόδου.
Ένα παράδειγμα για το πώς αυτά τα μεταδεδομένα μπορούν να χρησιμοποιηθούν με τις διαφορετικές μεθόδους επιπέδων συστημάτων και τη σχετικότητά τους στις στοχοθετημένες διαχειριστικές βελτιστοποιήσεις μνήμης. Το υπόλοιπο του κεφαλαίου οργανώνεται ως εξής. Στην αρχή, η αντιπροσώπευση μεταδεδομένων εισάγεται στην Ενότητα 7.2. Έπειτα, συζητείται στο τμήμα 7.3 μια συγκεκριμένη μέθοδος για να λάβουν τις πληροφορίες σχεδιασμού περιγράμματος και οι τεχνικές ανάλυσης για την μετατροπή σε επιθυμητά μεταδεδομένα. Κατόπιν στο τμήμα 7.4, παρουσιάζεται μια περιπτωσιολογία που υιοθετεί αυτά τα μεταδεδομένα για τις διάφορες βελτιστοποιήσεις που αφορούν το δυναμικό αποτύπωμα κατανάλωσης ενέργειας και μνήμης των στοιχείων. Τέλος, στο τμήμα 7.6 περιγράφονται τα συμπεράσματα και η πιθανή μελλοντική εργασία σε αυτήν την περιοχή.
Προτείνουμε να ταξινομήσουμε τις πληροφορίες για μια εφαρμογή λογισμικού σε τρία επίπεδα αυξανόμενης αφαίρεσης: Μηδενικό επίπεδο μεταδεδομένων: Εκτενής χαρακτηρισμός που λαμβάνεται γενικά μέσω της σκιαγράφησης. Πρώτο επίπεδο μεταδεδομένων: Συνολική αντιπροσώπευση των πληροφοριών στο προηγούμενο επίπεδο που δημιουργείται από τα εργαλεία ανάλυσης. Αυτές οι πληροφορίες χρησιμοποιούνται και ενημερώνονται από τα εργαλεία βελτιστοποίησης κατά τη διάρκεια του χρόνου σχεδιασμού. Δεύτερο επίπεδο μεταδεδομένων: Πληροφορίες που επεκτείνονται με την τελική εφαρμογή απαριθμώντας τις ανάγκες των πόρων της. Ο διαχειριστής χρόνου εκτέλεσης του ενσωματωμένου συστήματος μπορεί να το χρησιμοποιήσει για να προσαρμόσει την απόδοση του συστήματος στις ανάγκες των εφαρμογών που τρέχουν αυτήν την περίοδο. Αυτές οι πληροφορίες μπορούν να ολοκληρωθούν με τις παραλλαγές των διαθέσιμων πόρων κατά τη διάρκεια του χρόνου (πχ. ικανότητα μπαταριών, νέες ενότητες που είναι συνδεόμενες, κ.λπ.).
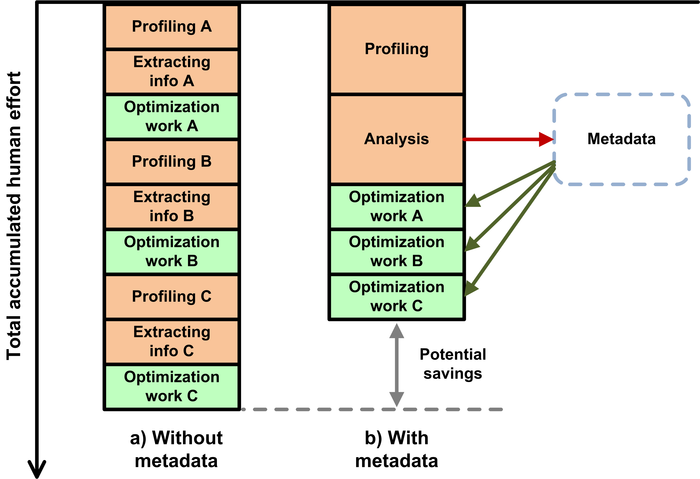
7.1: Ποιοτική σύγκριση του χρόνου που επενδύεται κατά χρησιμοποίηση της προτεινόμενης διανομής των μεταδεδομένων μιας εφαρμογής ή μιας παραδοσιακής ροής σχεδίου χωρίς, μια κοινή βάση πληροφοριών.
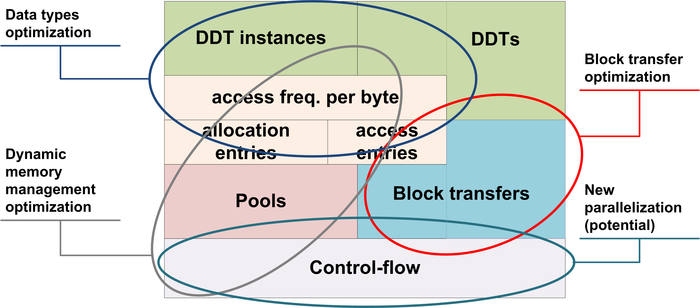
7.2: Τα διάφορα εργαλεία βελτιστοποίησης μπορούν να χρησιμοποιήσουν διαφορετικά υποσύνολα των μεταδεδομένων εφαρμογής λογισμικού.
Η εστίαση αυτού του κεφαλαίου είναι στα μεταδεδομένα στο πρώτο επίπεδο. Ως εκ τούτου, στο υπόλοιπο αυτού του κεφαλαίου, ο όρος «μεταδεδομένα» χρησιμοποιείται αναφορικά στις πληροφορίες και όχι κατά ομολογία για το ακατέργαστο αρχείο καταγραφής προσβάσεων που παράγεται από τα εργαλεία σκιαγράφησης. Η έννοια των μεταδεδομένων για το λογισμικό που τρέχει στα ενσωματωμένα συστήματα περιλαμβάνει δύο μέρη: οι μετρήσεις και οι καθορισμένες τιμές τους. Οι διαφορετικές μετρήσεις στο σύνολο πληροφοριών μεταδεδομένων μπορούν να ταξινομηθούν σύμφωνα με την κύρια χρήση τους. Αν και τα μεταδεδομένα λογισμικού καθορίζονται συνολικά, τα διαφορετικά εργαλεία βελτιστοποίησης μπορούν να υιοθετήσουν διαφορετικά, επικαλύπτοντας ενδεχομένως, υποσύνολα. Το Σχήμα 7.2 δίνει μια επισκόπηση αυτών των πιθανών επικαλύψεων. Ένα εργαλείο βελτιστοποίησης μπορεί να πάρει ως εισαγωγή τις τιμές οποιασδήποτε από τις μετρήσεις, να τις χρησιμοποιήσει για να μετασχηματίσει την εφαρμογή και να ενημερώσει τις επηρεασθείσες μετρήσεις με τις τιμές που προσδιορίζονται από τη νέα συμπεριφορά της μετασχηματισμένης εφαρμογής
Η πρώτη ερώτηση που πρέπει να απαντήσουμε καθορίζοντας την έννοια των μεταδεδομένων για τις εφαρμογές λογισμικού που τρέχουν στα ενσωματωμένα συστήματα είναι: Ποιες είναι οι παρούσες μετρήσεις στα μεταδεδομένα; Οποιεσδήποτε πληροφορίες σχετικά με τη συμπεριφορά μιας εφαρμογής που θα μπορούσε ενδεχομένως να χρησιμοποιηθεί από σχεδόν οποιοδήποτε εργαλείο βελτιστοποίησης πρέπει να συμπεριληφθεί. Για τις εφαρμογές λογισμικού αυτό αφορά κυρίως τις απαιτήσεις των πόρων τους (αποτύπωμα μνήμης, εύρος ζώνης μνήμης, προϋπολογισμός κύκλων, αφιερωμένες ανάγκες υλικού, κλπ.), αλλά και οποιεσδήποτε εφαρμόσιμες προθεσμίες, εξαρτήσεις σε άλλες ενότητες λογισμικού, γεγονότα που προκαλούν τη συγκεκριμένη συμπεριφορά, κλπ. Σε μερικές περιπτώσεις, στοιχεία που απαιτούνται από τα εργαλεία βελτιστοποίησης μπορούν να εξαχθούν από τις πληροφορίες των σχεδιασμένων περιγραμμάτων (τα ακατέργαστα στοιχεία) κατά τρόπο απλό, αλλά στις περισσότερες άλλες περιπτώσεις πρέπει να υιοθετηθούν οι πιο επιμελημένες τεχνικές εξαγωγής. Αν και οι μετρήσεις μεταδεδομένων μπορούν να καλύψουν όλες τις σχετικές πτυχές της εφαρμογής, η εστίαση αυτής της εργασίας είναι στην ανάλυση της συμπεριφοράς μνήμης των εφαρμογών.
Η Εικόνα 7.3 παρουσιάζει πλήρη άποψη της δομής των μεταδεδομένων λογισμικού για τη δυναμική συμπεριφορά μνήμης των ενσωματωμένων συστημάτων όπως προτείνεται σε αυτό το κεφάλαιο. Αυτό το σχήμα περιλαμβάνει τις σημασιολογικές διασυνδέσεις μεταξύ των διαφορετικών κατηγοριών, όπως η κληρονομιά, η σύνθεση ή η ένωση. Οι πληροφορίες μεταδεδομένων αγκαλιάζουν τις πτυχές και του αριθμού των προσβάσεων σε μια μεταβλητή ή των σχέσεων μεταξύ των πεδίων εκτέλεσης και των δυναμικών τύπων στοιχείων που προσεγγίζονται. Μερικές τεχνικές βελτιστοποίησης απαιτούν τα μεταδεδομένα καθορίζονται για κάθε δυναμικό τύπο στοιχείων (το DDT) στην εφαρμογή. Συγκεκριμένα, DDTs παρουσιάζεται στον αριθμό και ως αφηρημένες οντότητες και ως συγκεκριμένες εφαρμογές για τις ακολουθίες και τα δέντρα, αλλά θα μπορούσε να προστεθεί στο σχήμα οποιοσδήποτε άλλος δυναμικός τύπος στοιχείων.
Οι διαφορετικές μετρήσεις που περιλαμβάνονται στα μεταδεδομένα μπορούν να ταξινομηθούν σύμφωνα με την κύρια χρήση τους. Η κορυφαία οντότητα στα μεταδεδομένα είναι η ροή ελέγχου. Αυτή η οντότητα φυλάσσει τις πληροφορίες για τα δυναμικά στοιχεία (δυναμική οντότητα στοιχείων) που προσεγγίζονται σε κάθε πλαίσιο υπό μορφή μεμονωμένων μεταφορών block προσβάσεων και στοιχείων μνήμης (οντότητα μεταφοράς block). Αυτές οι προσβάσεις συμβαίνουν στις πραγματικές φυσικές θέσεις μνήμης που αντιπροσωπεύονται από την οντότητα Pool, στην οποία οι περιπτώσεις των διάφορων δυναμικών στοιχείων διατίθενται. Επιπλέον, η οντότητα ροής ελέγχου περιέχει τις αθροισμένες πληροφορίες υπό μορφή ιστογραμμάτων πρόσβασης και δέσμευσης, το ζητούμενο εύρος ζώνης και τη συχνότητα των προσβάσεων ανά διατιθέμενο byte. Η δυναμική οντότητα στοιχείων περιέχει τις συγκεκριμένες πληροφορίες για κάθε δυναμικά διατιθέμενο μεταβλητό ή δυναμικό τύπο στοιχείων, όπως ο αριθμός που καθορίζει τις αναγνώσεις, εγγραφές ή το μέγιστο αποτύπωμα μνήμης. Το είδος αυτών των πληροφοριών είναι το ίδιο για τις μεταβλητές και τους δομημένους τύπους στοιχείων (εντούτοις, οι συγκεκριμένες τιμές θα είναι διαφορετικές για κάθε περίπτωση). Η δομή μεταδεδομένων αποκαλύπτει επίσης τις ενώσεις μεταξύ των δυναμικών οντοτήτων στοιχείων και των συγκεκριμένων περιπτώσεων τους (δυναμική οντότητα περιπτώσεων ημερομηνίας). Ομοίως, η σχέση από τις οντότητες στοιχείων και από τις περιπτώσεις με τις διαδικασίες που εκτελούνται παρουσιάζεται στη δυναμική οντότητα διαδικασιών στοιχείων, εφόσον ενδείκνυται, για παράδειγμα, η μεταβλητή οντότητα δεν έχει καμία διαδικασία, ενώ οι ακολουθίες ή τα δέντρα έχουν διάφορες ξεχωριστές διαδικασίες όπως Πρόσθεση, Αφαίρεση, κ.λπ.
Οι πληροφορίες σχετικά με τις δυναμικές δομές δεδομένων και τις μεταβλητές της εφαρμογής, παρουσιάζονται σε τρία επίπεδα αφαίρεσης: αθροισμένο στα στοιχεία το επίπεδο τύπων, ρητό για κάθε συγκεκριμένη περίπτωση κάθε στοιχείου ή μεταβλητής, και συγκεκριμένος για τις διαδικασίες που εκτελούνται. Κάθε μεταβλητή ή δυναμική οντότητα στοιχείων συνδέεται σε μια Pool όπου οι συγκεκριμένες περιπτώσεις διατίθενται μέσω του δυναμικού διαχειριστή μνήμης του συστήματος. Επομένως, η οντότητα Pool αθροίζει την δέσμευση, την πρόσβαση, τη συχνότητα ανά byte και τις πληροφορίες εύρους ζώνης για όλες τις περιπτώσεις των μεταβλητών και των δυναμικών τύπων στοιχείων που δημιουργούνται μέσα. Η οντότητα Pool περιέχει, επιπλέον, τις πληροφορίες μεταδεδομένων σχετικά με τις κατανομές και τις προσβάσεις και, το πιο σημαντικό, μια περιγραφή της δομής της Pool, δηλαδή οι αλγόριθμοι και οι δομές δεδομένων που απαιτούνται για να εκτελέσουν τη λογιστική της μνήμης. Τέλος, οι πληροφορίες για τις πιθανές μεταφορές block στοιχείων (όπως το μέγεθος και ο αριθμός χρόνων που εκτελείται κάθε μεμονωμένη μεταφορά block ) είναι τοποθετημένες στην οντότητα μεταφοράς block.
H οντότητα ροής ελέγχου αντιπροσωπεύει τη ροή ελέγχου της εφαρμογής και μπορούμε να τη δούμε δουν ως σύνολο κλήσεων των διευθύνσεων κώδικα. Ο σκοπός αυτής της οντότητας είναι να ενθυλακώσει μια σημαντική μερίδα της κύριας ροής ελέγχου εφαρμογής, που επιτρέπει την εξαγωγή των πληροφοριών, όπως η δυναμική συμπεριφορά στοιχείων της εφαρμογής στις συγκεκριμένες στιγμές.
Υπάρχει μια είσοδος που είναι πάντα παρούσα και παίρνει ένα συγκεκριμένο προσδιοριστικό για να αντιπροσωπεύσει την λειτουργία main() της εφαρμογής. Οποιοσδήποτε αριθμός πρόσθετων καταχωρήσεων ροής ελέγχου μπορεί να είναι παρών στις πληροφορίες μεταδεδομένων, αρκεί να προσδιορίζεται μεμονωμένα.
Εκτός από τις πληροφορίες σχετικά με τις διαφορετικές προσβάσεις, τις κατανομές και άλλα μεταδεδομένα που εμφανίστηκαν μέσα σε ένα ιδιαίτερο τμήμα της ροής ελέγχου, κάθε είσοδος περιέχει επίσης τις πληροφορίες για τις οποίες επικαλούνται άλλες καταχωρήσεις ροής ελέγχου, δίνοντας με αυτόν τον τρόπο μια πλήρη άποψη της γραφικής παράστασης ελέγχου-ροής της εφαρμογής. Οι πληροφορίες για τη συμπεριφορά πρόσβασης δέσμευσης ή μνήμης οποιουδήποτε νήματος (μέσω όλων των διαφορετικών πεδίων που ενεργοποιούν) μπορούν να εξαχθούν εύκολα από αυτές τις πληροφορίες, εάν είναι απαραίτητο. Άλλες πληροφορίες, όπως οι προθεσμίες ή ο προϋπολογισμός κύκλων δεν συμπεριλαμβάνονται σε αυτό το κεφάλαιο.
Οι καταχωρήσεις μεταδεδομένων που εισάγονται σε αυτήν την υποενότητα είναι συγκεκριμένες για τη δυναμική συμπεριφορά πρόσβασης και δέσμευσης μνήμης των εφαρμογών. Αυτές οι πληροφορίες είναι σχετικές με την πλειοψηφία των οντοτήτων μεταδεδομένων που φαίνονται στην Εικόνα 7.3.
Η έννοια της ομάδας της δυναμικής μνήμης [56] είναι κρίσιμη για τις εφαρμογές που χρησιμοποιούν τη δυναμική διαχείριση μνήμης. Δεδομένου ότι η συμπεριφορά των εφαρμογών γίνεται περισσότερη εξαρτώμενη στην εισαγωγή, η ανάλυση του δυναμικού διαχειριστικού υποσυστήματος μνήμης κερδίζει περισσότερη σημασία. Επομένως, οι πληροφορίες σχετικά με τη συμπεριφορά των διαφορετικών ομάδων της εφαρμογής (συγκεκριμένα η οντότητα Pool) είναι ουσιαστικές στα μεταδεδομένα των εφαρμογών λογισμικού προκειμένου να επιτραπούν οι περαιτέρω τεχνικές βελτιστοποίησης (πχ. δυναμικός καθαρισμός μνήμης, δυναμική ανάθεση μνήμης στους πόρους μνήμης, πρόσβαση που σχεδιάζει, κλπ.). Είναι σημαντικό να παρατηρηθεί ότι οι πληροφορίες Pool δεν μπορούν να εξαχθούν από τη φάση ανάλυσης του αρχικού κώδικα εφαρμογής, αλλά θα δημιουργηθούν, θα χρησιμοποιηθούν και θα ενημερωθούν από τα διαφορετικά εργαλεία βελτιστοποίησης, πχ. για τη βελτιστοποίηση DMM, που θα χρησιμοποιήσουν τις πληροφορίες μεταδεδομένων για να επικοινωνήσουν και να περάσουν τους περιορισμούς μεταξύ τους. Τα αναπτυγμένα εργαλεία μπορούν να εξαγάγουν, αντίθετα, τις πληροφορίες όπως ο αριθμός κατανομών και μη-κατανομών , ο μέγιστος αριθμός αντικειμένων που διατίθενται συγχρόνως και το ιστόγραμμα των κατανομών κατά μήκος του χρόνου. Η οντότητα μεταβλητών περιέχει τις πληροφορίες σχετικές με τις προσβάσεις στις δυναμικές μεταβλητές, με μια κοκκοποίηση κάτω σε κάθε δυναμική μεταβλητή που δηλώνεται στην εφαρμογή.
Επιπλέον, είναι δυνατό να εξαχθούν οι πληροφορίες σχετικά με το μέγιστο μήκος, να σημάνουν το μήκος και τον αριθμό όλων των block των στοιχείων που εκτελούνται σε μια οντότητα ροής ελέγχου (είτε πρόκειται για ένα πεδίο ή νήμα), η οποία είναι διαφορετική από τον αριθμό μεμονωμένων προσβάσεων μνήμης. Αυτές οι πληροφορίες, που φυλάσσονται στην οντότητα block για κάθε μεμονωμένη πιθανή μεταφορά block, προσφέρουν επίσης τις λεπτομέρειες στις οποίες το στοιχείο καταγράφει τα μεταφερμένα στοιχεία εκεί που ανήκει, το μέγεθος της μεταφοράς και ο αριθμός χρόνων που εμφανίζονται τέτοιες μεταφορές στοιχείων block.
Η έννοια των πληροφοριών του DDT εμφανίζεται στο σχήμα 7.3. Εντούτοις, δεν είναι πραγματικά ένα μέρος των πληροφοριών μεταδεδομένων οποιασδήποτε εφαρμογής, είναι μια εννοιολογική διεπαφή για να τοποθετήσει τις σχετικές πληροφορίες με οποιοδήποτε δυναμικό τύπο στοιχείων όπως, μια ακολουθία (διάνυσμα), έναν κατάλογο ή ένα δέντρο. Για παράδειγμα, ο αριθμός παρουσιάζει τις πληροφορίες που θα συνδέονταν στους τύπους στοιχείων ακολουθίας και δέντρων.
Οι διαφορετικοί τύποι στοιχείων έχουν διαφορετικές σχετικές πληροφορίες που δεν παρουσιάζουμε εδώ χάριν της περιεκτικότητας. Αντίστοιχα, κάθε συγκεκριμένη περίπτωση ενός δεδομένου τύπου στοιχείων έχει συνδέσει τις πληροφορίες (για παράδειγμα, η ακολουθία και οι οντότητες περιπτώσεων δέντρων). Επιπλέον, η ακολουθία και οι οντότητες διαδικασιών δέντρων απαριθμούν όλες τις διαδικασίες για τις οποίες οι πληροφορίες μπορούν να συλλεχθούν για τέτοιους τύπους στοιχείων. Για οποιουσδήποτε άλλους τύπους στοιχείων που δεν παρουσιάζονται εδώ, κωδικοποιείται ένα νέο σύνολο πληροφοριών για τα στοιχεία σε κάθε περίπτωση. Εντούτοις, ο εννοιολογικός ρόλος που αυτές οι πληροφορίες θα έπαιρναν στη δομή μεταδεδομένων είναι ίδιος με το ρόλο των σχετικών μερών ακολουθίας ή δέντρων.
Η αφετηρία για την εξαγωγή μεταδεδομένων είναι ο πηγαίος κώδικας της εφαρμογής. Οι ακατέργαστες πληροφορίες για τη συμπεριφορά των διαφόρων στοιχείων συγκεντρώνονται μέσω μιας εκτενούς σκιαγράφησης στο δυναμικό επίπεδο τύπων στοιχείων, που προκαλεί την εφαρμογή με τα αντιπροσωπευτικά σύνολα δεδομένων εισόδου. Κατόπιν, η φάση ανάλυσης χρησιμοποιεί αυτά τα ακατέργαστα στοιχεία προκειμένου να εξαχθούν οι τιμές για τις μετρήσεις μεταδεδομένων. Μόλις καθοριστούν τα μεταδεδομένα, τα διαφορετικά εργαλεία μπορούν να συνδεθούν με έναν τρόπο σωληνώσεων, όπου χρησιμοποιούν ως εισαγωγή τα τρέχοντα μεταδεδομένα και παράγουν μια ενημερωμένη έκδοση που μπορεί να χρησιμοποιηθεί από την επόμενη. Ο προσδιορισμός των σχετικών συνόλων δεδομένων εισόδου, είναι κρίσιμο να λάβει τις σημαντικές πληροφορίες σχεδιασμού περιγράμματος, επειδή η συμπεριφορά των δυναμικών εφαρμογών επηρεάζεται έντονα από τη φύση της εισόδου. Επομένως, η αξία των μετρήσεων πρέπει να υπολογιστεί για κάθε διαφορετική περίπτωση δεδομένων εισόδου. Σε πολλές περιπτώσεις, θα είναι δυνατό να αφαιρεθεί και να γίνει ένας ενιαίος χαρακτηρισμός επειδή οι τιμές των διαφορετικών μετρικών μεταδεδομένων θα είναι οι ίδιες, αλλά σε μερικά άλλα διαφορετικά σύνολα περιπτώσεων μεταδεδομένων οι τιμές θα απαιτηθούν. Επομένως, ένας μηχανισμός που προσδιορίζει στο χρόνο εκτέλεσης τα χαρακτηριστικά της τρέχουσας περίπτωσης εισαγωγής και συνεπώς το σωστό σύνολο μεταδεδομένων (για να επιλέξει τις σωστές βελτιστοποιήσεις), όπως αυτή που παρουσιάζεται στο [70] μπορεί να χρησιμοποιηθεί εκτός από τις προτεινόμενες τεχνικές.
Το βήμα για τη σχεδίαση περιγράμματος πρέπει να συλλέξει τις πληροφορίες σχετικές με τη δυναμική συμπεριφορά στοιχείων της εφαρμογής, έτσι ώστε η πιο πρόσφατη ανάλυση μπορεί να εξάγει τα κατάλληλα μεταδεδομένα από αυτές τις πληροφορίες. Δηλαδή, το σχεδιαζόμενο περίγραμμα πρέπει να εξαγάγει τις πληροφορίες για: (α) δέσμευση και ελευθέρωση της δυναμικής μνήμης, (β) προσβάσεις μνήμης (διαβάζει και γράφει), (γ) διαδικασίες στους δυναμικούς τύπους στοιχείων, (δ) πορείες έλεγχου-ροής που οδηγούν στις θέσεις όπου αυτές οι διαδικασίες εκτελούνται και προσδιορίζονται (ε) των νημάτων που εκτελούν αυτές τις διαδικασίες.
Γενικά, η σκιαγράφηση των πληροφοριών μπορεί να ληφθεί μέσω δύο κύριων τρόπων: ερμηνεία δυαδικού κώδικα και ενοργάνωση (τροποποίηση) πηγαίου κώδικα. Οι προσεγγίσεις που λειτουργούν άμεσα στο δυαδικό κώδικα δεν απαιτούν τις τροποποιήσεις στον πηγαίο κώδικα, αλλά συνήθως οι πληροφορίες που εξάγονται δεν μπορούν να αφορούν εύκολα τις μεταβλητές και το DDTs. Σε αντίθεση, οι προσεγγίσεις βασισμένες στην τροποποίηση του πηγαίου κώδικα, είναι συνήθως ικανές να παρέχουν τις πληροφορίες που μπορούν να αφορούν τα συγκεκριμένα στοιχεία και τις θέσεις στον πηγαίο κώδικα. Σε αυτήν την δεύτερη κατηγορία, είναι πάλι δυνατό να γίνει διάκριση μεταξύ των αυτοματοποιημένων προσεγγίσεων (από το μεταγλωττιστής ή άλλο εργαλείο, που μπορεί να λειτουργήσει παρομοίως) και χειρωνακτικά (ο προγραμματιστής τροποποιεί τον πηγαίο κώδικα για να εισαγάγει την πιο συγκεκριμένη ενοργάνωση). Για αυτήν την πρόταση, έχουμε επιλέξει μια ημιαυτόματη προσέγγιση, όπως πρώτα παρουσιάστηκε στο [62]. Με αυτήν την λύση, ο σχεδιαστής πρέπει να σχολιάσει τους τύπους των μεταβλητών που είναι σχετικές, αλλά ο μεταγλωττιστής παίρνει αυτόματα την προσοχή του σχολιασμού όλων των προσβάσεων τους, μέσω του πηγαίου κώδικα. Ένα σημαντικό πλεονέκτημα αυτής της επιλογής είναι ότι ο μεταγλωττιστής εξασφαλίζει ότι καμία πρόσβαση σε οποιεσδήποτε από τις περιπτώσεις των επιλεγμένων τύπων στοιχείων δεν αγνοείται.
Σχεδιάζοντας το περίγραμμα συγκεντρώνονται οι πληροφορίες συμπεριλαμβανομένων των προσβάσεων μνήμης, των κατανομών και μη-κατανομών μνήμης, των προσβάσεων στις κλιμακωτές μεταβλητές και τις συγκεκριμένες περιπτώσεις των δυναμικών τύπων στοιχείων των εφαρμογών (που προσδιορίζονται μεμονωμένα από ένα αριθμητικό προσδιορισμό), των αλλαγών του πεδίου και των νημάτων που εκτελούν κάθε ένα από τα προηγούμενα γεγονότα. Οι αποσπασματικές ακατέργαστες πληροφορίες διατηρούν την ακολουθία, το οποίο σημαίνει ότι μπορούν να δημιουργηθούν τα συσσωρευμένα σύνολα, όπως τα ιστογράμματα των παραλλαγών αποτυπώματος μνήμης κατά μήκος του χρόνου.
Σε αυτό το τμήμα, παρουσιάζουμε μια τεχνική για τις εφαρμογές που γράφονται σε C++. Ωστόσο, οι έννοιες μεταδεδομένων είναι ανεξάρτητες από τη γλώσσα προγραμματισμού και ισχύουν ακόμα για άλλες γλώσσες, υπό τον όρο ότι είναι διαθέσιμο το αντίτιμο σχεδιασμού περιγράμματος της μεθόδου. Ο σχολιασμός τύπων εκτελείται μέσω της χρήσης των προτύπων, για να τυλίξει τους τύπους και να τους δώσει έναν νέο τύπο, και στην υπερφόρτωση, για να συλλάβει όλες τις προσβάσεις στις περιπλεγμένες μεταβλητές. Τα πρότυπα είναι χρονικά κατασκευάσματα που περιγράφουν τη γενική συμπεριφορά μιας κατηγορίας (ή της λειτουργίας) βασισμένης στις παραμέτρους τύπων, κατά συνέπεια είναι μερικές φορές γνωστοί ως «παραμετρικοί τύποι». Όταν το πρότυπο κατηγορίας αρχικοποιείται με τον επιθυμητό τύπο, ο μεταγλωττιστής παράγει τις σωστές οδηγίες για να εξετάσει εκείνο τον τύπο.
Η βιβλιοθήκη σκιαγράφησης που χρησιμοποιείται σε αυτό το κεφάλαιο αποτελείται από διάφορα πρότυπα κατηγορίας με σκοπό να είναι ορθογώνια και συναρμολογούμενα. Επιπλέον, η βιβλιοθήκη περιέχει ένα σύνολο βοηθητικών κατηγοριών για τις πληροφορίες που σχηματοποιούν και που καταγράφουν. Για να κρατήσουμε το πεδίο αυτής της εργασίας κάτω από την εστίαση, μόνο τα βασικά στοιχεία απαιτούνται για να καταλάβουμε τη δομή της βιβλιοθήκης. Το πρώτο βοηθητικό στοιχείο στη βιβλιοθήκη είναι η υποδομή. Το ακόλουθο τεμάχιο κώδικα παρουσιάζει τη βασική δομή μιας κατηγορίας αναγραφών που γράφει ένα δυαδικό αρχείο για κάθε γεγονός εφαρμογής:
class DMMLogger {
enum LogType {
LOG_VAR_READ = 0,
LOG_VAR_WRITE = 1,
...
LOG_MALLOC_END = 5,
...
};
public :
inline static void log_read ( const void * addr , const unsigned int id ,
const size_t sz) {
write_header ( LOG_VAR_READ , 4* sizeof ( unsigned int )) << id <<
addr << sz << ( unsigned long ) pthread_self ();
}
inline static void log_malloc_end ( const unsigned int id ,
const size_t sz , const void * addr ) {
write_header ( LOG_MALLOC_END , 4* sizeof ( unsigned int )) << id <<
addr << sz << ( unsigned long ) pthread_self ();
}
private :
DMMLogger & write_header ( LogType logType , unsigned short logSize ) {
unsigned short logType_s = ( unsigned short ) logType ;
if ( logFile_ != NULL ) {
fwrite (& logType_s , sizeof ( unsigned short ), 1, logFile_ );
fwrite (& logSize , sizeof ( unsigned short ), 1, logFile_ );
}
return * this ;
}
DMMLogger & operator <<( const unsigned int num ) {
if ( logFile_ != NULL )
fwrite (& num , sizeof ( unsigned int), 1, logFile_ );
return * this ;
}
DMMLogger & operator <<( const void * addr ) {
if ( logFile_ != NULL )
fwrite (& addr , sizeof ( unsigned int), 1, logFile_ );
return * this ;
}
FILE * logFile_ ; // Initialized in the constructorΟι πρόσθετες μέθοδοι, όπως το log_write, log_malloc_begin, log_free_begin, log_free_end, log_scope_begin, log_scope_end, sequence_get, sequence_add, sequence_remove, sequence_clear, map_get, map_add, map_remove ή map_clear, μπορούν να κατασκευαστούν εύκολα με έναν ανάλογο τρόπο. Το σύνολο καταχωρήσεων στο logType πρέπει να διευρυνθεί αντίστοιχα.
Επίσης, απαιτείται μια απλή κατηγορία που εξάγει τα malloc() και τα free(), με τις υπονοούμενες ικανότητες αναγραφών. Μπορεί να εφαρμοστεί εύκολα με τον παρακάτω παρόμοιο κώδικα:
template <int ID , typename Logger = DMMLogger >
class logged_allocator {
public :
inline static void * malloc ( const size_t sz) {
Logger :: log_malloc_begin (ID , sz );
void * ptr =:: malloc (sz );
Logger :: log_malloc_end (ID , sz , ptr );
return ptr ;
}
inline static void free ( void * ptr) {
Logger :: log_free_begin (ID , ptr );
:: free (ptr );
Logger :: log_free_end (ID , ptr );
}
};Κατά τη διάρκεια της πραγματικής φάσης ενοργάνωσης του πηγαίου κώδικα, ο σχεδιαστής χρησιμοποιεί τα ακόλουθα πρότυπα κατηγορίας:
«scope» Αυτό είναι το πρότυπο κατηγορίας που χρησιμοποιείται για να χαρακτηρίσει τα διαφορετικά τμήματα του ελέγχου-ροής (control-flow). Το ακόλουθο τεμάχιο κώδικα επεξηγεί την εφαρμογή του:
template <class Logger = std_scope_logger >
class scope {
public :
scope (std :: string name )
: name_ ( name )
{
Logger :: log_scope_begin ( name_ );
}
~ scope () {
Logger :: log_scope_end ( name_ );
}
private :
std:: string name_ ;
};Ο σχεδιαστής μπορεί να δηλώσει μια περίπτωση αυτού του προτύπου κατηγορίας στην αρχή οποιουδήποτε τμήματος του κώδικα και ο μεταγλωττιστής, η συνάρτηση κατασκευής και η αντίστοιχη καταστροφή της δομής θα παραγάγουν τα περίγραμμα σχεδιάζοντας τα σημεία. Μετά, τα εργαλεία ανάλυσης μπορούν να καθορίσουν ποιες περιοχές του κώδικα εκτελέσθηκαν, η ακολουθία ενεργοποιήσεων και, επιπλέον, ποια τμήματα του κώδικα ήταν αρμόδια για τα διαφορετικά περιγράμματα γεγονότων. Επιπλέον, το πρότυπο πεδίο μπορεί να συνδυαστεί με τον προσδιορισμό νημάτων για να λάβει την πλήρη γραφική παράσταση ελέγχου-ροής της εφαρμογής για ένα σύνολο εισαγωγής και να αφορά το υπόλοιπο των γεγονότων (κατανομές, προσβάσεις στους δυναμικούς τύπους στοιχείων) στις συγκεκριμένες μερίδες του κώδικα που εκτελούνται από τα συγκεκριμένα νήματα.
«Allocated» Οι περιπτώσεις κατηγορίας δημιουργούνται κανονικά και καταστρέφονται μέσω του νέου και διαγράφονται μέσω των χειριστών. Αυτό το πρότυπο κατηγορίας αυτοματοποιεί την υπερφόρτωσή τους για να παραγάγει τη σκιαγράφηση των σημείων. Χαρακτηριστικά, ο σχεδιασμός περιγράμματος των σημείων παράγεται για κάθε μια από τις διαδικασίες και τα αιτήματα διαβιβάζονται στο διαθέτη συστημάτων, μέσω του malloc και των free λειτουργιών:
template <class Allocator >
class allocated {
public :
void * operator new( const size_t sz) {
return Allocator :: malloc (sz );
}
void operator delete ( void * p) {
return Allocator :: free (p);
}
void * operator new []( const size_t sz) {
return Allocator :: malloc (sz );
}
void operator delete []( void * p) {
return Allocator :: free (p);
}
};Προκειμένου να καταγραφούν όλα τα δυναμικά γεγονότα μνήμης σχετικά με τις περιπτώσεις μιας κατηγορίας (ή δομής), ο σχεδιαστής θα το δήλωνε ως εξής:
class NewClass : public allocated < logged_allocator <1> > {
...
};Καμία άλλη γραμμή στον πηγαίο κώδικα της κατηγορίας δεν πρέπει να τροποποιηθεί.
«VAR» Αυτό το πρότυπο κατηγορίας περικλείει τη δήλωση των μεμονωμένων μεταβλητών ή των ιδιοτήτων κατηγορίας και παράγει ένα σχεδιασμό περιγράμματος σημείων για κάθε πρόσβαση μνήμης. Επιπλέον, προέρχεται από το «διατιθέμενο» πρότυπο, με αυτόν τον τρόπο δίνοντας επίσης την αναγραφή δέσμευσης και ελευθέρωσης της συσκευασμένης μεταβλητής. Παρακάτω είναι ένα απόσπασμα της εφαρμογής προτύπων:
template <typename T, // Type of the wrapped object
int ID , // Id used in the profiling tokens
class Logger = DMMLogger ,
class Allocator = logged_allocator <ID , Logger > >
class var : public allocated < typename Allocator > {
public :
T data_ ;
// Constructor
template <typename T2 >
var( const T2 & data )
: data_ ( data )
{
Logger :: log_write (&( data_ ), ID , sizeof (T));
}
// Assignment operator from basic type
template <typename T2 >
var & operator = ( const T2 & data ) {
data_ = data ;
Logger :: log_write (&( data_ ), ID , sizeof (T));
return * this ;
}
// Assignment operator from wrapped type
template <typename T2 , int ID2 >
var & operator = ( const var <T2 , ID2 > & other ) {
Logger :: log_read (&( other . data_ ), ID2 , sizeof (T2 ));
data_ = other . data_ ;
Logger :: log_write (&( data_ ), ID , sizeof (T));
return * this ;
}
};Αυτό το πρότυπο μπορεί να χρησιμοποιηθεί για να τυλίξει τις μεταβλητές οποιουδήποτε βασικού τύπου, συμπεριλαμβανομένων των δεικτών και των ιδιοτήτων κατηγορίας. Στις προσβάσεις σχεδιαγράμματος, στις ιδιότητες μιας κατηγορίας ή μιας δομής, είναι απαραίτητο να τοποθετηθεί εσωτερικά, εκεί που ταξινομούνται και συσκευάζονται οι ιδιότητες των μεταβλητών. Στη συνέχεια, εάν οποιεσδήποτε από τις ιδιότητες είναι επίσης δομές, η τεχνική μπορεί να εφαρμοστεί κατ’ επανάληψη, έως ότου επιτυγχάνονται οι βασικοί τύποι:
var <int , 1> var1 ;
var <int , 2> * pointer1 = new var <int , 2>;
struct A {
var <int , 3> foo ;
};
struct B {
A a;
var <int *, 4> bar ;
};Απαιτείται μια πρόσθετη εκτίμηση κατά το κάλυμμα των δεικτών. Στο ακόλουθο τεμάχιο κώδικα, η πρώτη δήλωση σημαίνει ότι καταγράφονται μόνο οι προσβάσεις στο δείκτη quux, αλλά όχι οι προσβάσεις στους ακέραιους αριθμούς που είναι δείκτες Εντούτοις, όταν και οι δύο προσβάσεις είναι ενδιαφέρουσες, το σχέδιο που δίνεται για τον καθορισμό του baz, είναι ένας συνδυασμός των προηγούμενων σχεδίων, πρέπει να χρησιμοποιηθεί αντ’ αυτού:
var (int , 1) * quux ;
var (var(int , 2) *, 3) baz;Χρησιμοποιώντας το πρότυπο κατηγορίας «VAR», ο σχεδιαστής δεν πρέπει να ανησυχήσει για τον προσδιορισμό όλων των θέσεων στον πηγαίο κώδικα, όπου οι μεταβλητές προσεγγίζονται, δεδομένου ότι ο μεταγλωττιστής θα εξασφαλίσει ότι καταγράφονται κατάλληλα.
«VECTOR: » Αυτό το πρότυπο κατηγορίας αντικαθιστά το διάνυσμα από το STL στο [49] προκειμένου να σχεδιαστεί περίγραμμα συμπεριφοράς χρήσης ακολουθίας στο δυναμικό επίπεδο αφαίρεσης στοιχείο-τύπων. Αυτές οι πληροφορίες μπορούν να χρησιμοποιηθούν, για παράδειγμα, για να αποφασίσουν ποια είναι η ιδανική εφαρμογή στοιχείο-τύπων, όπως φαίνεται στο [61]. Η εφαρμογή του προτύπου ταιριάζει με το STL από λογική άποψη, αλλά προσθέτει την αναγραφή στις σωστές θέσεις για να δώσει μια υψηλού επιπέδου άποψη του σχεδίου χρήσης της δομής δεδομένων (πχ. συνηθισμένες είσοδοι, γραμμικές οδεύσεις, τυχαίες προσβάσεις, κλπ.). Η δήλωση ενός διανύσματος με αυτό το πρότυπο είναι απλή:
vector <int , 1> aVector ;
Τέλος, ο σχεδιαστής μπορεί να συνδυάσει τα πρότυπα «VECTOR» και «VAR» στο σχεδιάγραμμα μαζί με τις προσβάσεις στα πραγματικά στοιχεία, μέσα στην ακολουθία.
«Allocated» «VAR» και «VECTOR» παραμετρικά πρότυπα, με ένα μοναδικό προσδιοριστικό που καταγράφεται στα σχεδιασμό περιγράμματος σημεία ως εκ τούτου, πληροφορίες σχεδιασμού περιγράμματος μπορούν εύκολα να συνδεθούν με τον αρχικό κώδικα. Το παραμετρικό πρότυπο «πεδίου» με ένα κατανοητό από τον άνθρωπο προσδιοριστικό για την ευκολότερη αναζήτηση της καλύτερης επιλογής.
Μόλις εξαχθούν οι πληροφορίες σχεδιασμού περιγράμματος από την εφαρμογή, διάφορα βήματα ανάλυσης μπορούν να εφαρμοστούν για να εξαγάγουν και να υπολογίσουν τις σχετικές μετρήσεις μεταδεδομένων, που θα χρησιμοποιηθούν από τα διάφορα εργαλεία βελτιστοποίησης για να μειώσουν την κατανάλωση ενέργειας, τις προσβάσεις μνήμης και το αποτύπωμα μνήμης. Κάθε ένα από αυτά τα εργαλεία βελτιστοποίησης θα χρησιμοποιήσει τα συγκεκριμένα μέρη των καθορισμένων μεταδεδομένων. Επομένως, οι πληροφορίες μεταδεδομένων μπορούν να αναφέρουν την κατασκευή των μεταβλητών σε διαφορετικές, ενδεχομένως με επικάλυψη, περιοχές ενδιαφέροντος. Σε αυτό το τμήμα, παρουσιάζουμε διάφορες τεχνικές που μπορούν να χρησιμοποιηθούν για να εξαγάγουν τις διαφορετικές μερίδες των πληροφοριών μεταδεδομένων. Η διαδικασία ανάλυσης είναι δομημένη ως σύνολο αντικειμένων που εκτελούν τους συγκεκριμένους στόχους ανάλυσης. Ο κύριος οδηγός διαβάζει κάθε πακέτο από το αρχείο ημερολογίου που παράγεται κατά τη διάρκεια της φάσης του σχεδιασμού περιγράμματος και επικαλείται στη συνέχεια όλα τα αντικείμενα ανάλυσης για να τα επεξεργαστεί. Λόγω του τρόπου ότι οι πληροφορίες μας συγκεντρώνονται κατά το σχεδιασμό του περιγράμματος, δεν είναι σημαντικό να υπάρξει ένα απόλυτα αποτύπωμα χρόνου, διότι ο χρόνος που απαιτεί στο σχεδιάγραμμα εξουσιάζει (έτσι, καταστρέφοντας) το χρόνο εκτέλεσης της εφαρμογής 1. Επομένως, το μέτρο συγχρονισμού καθορίζεται ως προς το ποσό σκιαγράφησης των πακέτων (ενός συγκεκριμένου τύπου, όπως τα πακέτα δέσμευσης ή πρόσβασης) που έχουν περάσει από την αρχή της εκτέλεσης. Εντούτοις, αυτό είναι ένα καλό μέτρο για τον τύπο ανάλυσης που προτείνεται εδώ, εξαιτίας του γεγονότος ότι όλες οι μετρήσεις μεταδεδομένων, καθώς επίσης και οι μέθοδοι ανάλυσης και βελτιστοποίησης, εξετάζουν τις δυναμικές προσβάσεις μνήμης και όχι με το χρόνο υπολογισμού. Κατά συνέπεια, ο συγχρονισμός είναι βασισμένος στα γεγονότα που αλλάζουν την κατάσταση της δυναμικής μνήμης (πχ. κατανομές) ή που καθορίζει τα κύρια σημεία για το υποσύστημα μνήμης (πχ. αριθμός προσβάσεων).
Ο αλγόριθμος 1 παρουσιάζει την εργασία που εκτελείται από τη συσκευή ανάλυσης των προσβάσεων στις μεταβλητές. Κάθε φορά που διαβάζεται ή γράφεται μια μεταβλητή, το γεγονός βρίσκεται στο αρχείο ημερολογίου. Χρησιμοποιώντας τη διεύθυνση της πρόσβασης μνήμης, είναι δυνατό να βρεθεί η συγκεκριμένη περίπτωση ενός δυναμικού τύπου στοιχείων. Αυτές οι πληροφορίες επιτρέπουν επίσης τον αριθμό προσβάσεων του αντίστοιχων δυναμικών τύπου και της περίπτωσης στοιχείων DDT.
// event.type is variable read or write
process(event) {
Update application reads/writes counter
Update reads/writes counters of current control -flow point
FindBlockOfAddress (event.address) =>
Update block reads/writes counter
Update DDT & DDT -instance reads/writes counter
}Ένας άλλος σημαντικός στόχος ανάλυσης είναι η συμπεριφορά δέσμευσης δεδομένου ότι τέτοιες πληροφορίες μπορούν να χρησιμοποιηθούν για να σχεδιάσουν τους ιδιαίτερα συντονισμένους οριζόμενους από εφαρμογή δυναμικούς διευθυντές μνήμης. Για να επιτρέψουμε αυτήν την βελτιστοποίηση, προσδιορίζουμε τον αριθμό κατανομών ανά μέγεθος block, τα διαφορετικά μεγέθη block και αριθμό προσβάσεων ανά μέγεθος block. Με αυτές τις πληροφορίες είναι δυνατόν να αυτοματοποιηθεί η εξερεύνηση των οριζόμενων από εφαρμογή δυναμικών διευθυντών μνήμης, όπως καταδεικνύεται στο [71]. Επιπλέον, οι προσβάσεις στις μεταβλητές που αντιμετωπίζονται μεταξύ MallocBegin και MallocEnd, ή μεταξύ FreeBegin και FreeEnd, μπορούν να χρησιμοποιηθούν για να αξιολογήσουν τα γενικά κόστη των διαφορετικών δυναμικών διευθυντών μνήμης. Τέλος, αυτά τα στοιχεία μπορούν επίσης να χρησιμοποιηθούν για να ανιχνεύσουν τις διαρροές μνήμης. Ο αλγόριθμος 2 επιδεικνύει πώς εξάγονται όλες αυτές οι πληροφορίες.
process(event) {
case event of
AllocEnd ->
Create new live -block with event.size , event.address
and the control -flow information from
activeControlFlows .get(threadId ).top()
Increase allocation count for event.size
DeallocEnd ->
FindBlockOfAddress (event.address) =>
Increase de -allocation count for event.size
Add number of accesses to accesses for block
of size event.size
Destroy live -block
VarRead or
VarWrite ->
FindBlockOfAddress (event.address) =>
Increment read or write counter for this live -block
}
finalize () {
forall block ? live -block {
Report memory leak for this block and where it was
allocated
}
}Προσδιορίζοντας τις μεταφορές block μεταξύ των μονάδων που καθορίζουν το περίγραμμα, τα γεγονότα πρόσβασης μνήμης, μας επιτρέπουν την εφαρμογή των βελτιστοποιήσεων μεταφοράς στοιχείων. Παραδείγματος χάριν, οι αφιερωμένοι πόροι υλικού (δηλαδή οι μηχανές DMA) μπορούν να χρησιμοποιηθούν για να εκτελέσουν τις μεταφορές στοιχείων που είναι μακροχρόνιες, χωρίς να επηρεαστούν οι κύκλοι υπολογισμού για τα κύρια στοιχεία επεξεργασίας. Υπάρχουν διάφορες απόψεις για τις αποφάσεις του είδους των βελτιστοποιήσεων που πρέπει να εφαρμοστούν. Για παράδειγμα, στο [72] παρουσιάζεται μια τεχνική για να εκτελεσθούν επιλεκτικά οι μεταφορές στοιχείων που χρησιμοποιούν μια ενότητα DMA στα ενσωματωμένα συστήματα. Επιλέγουμε να καθορίσουμε μια μοναδική μεταφορά στοιχείων, καθώς ένα σύνολο αυστηρά διαδοχικών προσβάσεων στοιχείων, γίνεται στα ίδια δεδομένα από ένα νήμα. Με αυτόν τον καθορισμό, χρησιμοποιούμε τον παρακάτω αλγόριθμο για να προσδιορίσουμε τις μεταφορές στοιχείων της εφαρμογής.
Μια πρόσθετη βελτιστοποίηση που επιτρέπεται από τον προσδιορισμό των σχεδίων στις προσβάσεις στα στοιχεία είναι η τοποθέτηση εκείνων των στοιχείων που προσεγγίζονται συνήθως κατά μνήμες που υποστηρίζουν ταχύτητες ριπής (πχ. DRAM), με αυτόν τον τρόπο μειώνοντας τον αριθμό ενεργοποιήσεων σελίδων και αλλαγής τρόπου στα στοιχεία μνήμης. Εμείς προτείνουμε τον παρακάτω αλγόριθμο για να προσδιορίσουμε τα σχέδια πρόσβασης στις προσβάσεις στους δυναμικούς τύπους στοιχείων.
Αυτός ο αλγόριθμος είναι αρμόδιος της οικοδόμησης ενός καταλόγου σχεδίων πρόσβασης, που εμφανίζονται κατά τη διάρκεια της εκτέλεσης της εφαρμογής. Επιπλέον, κάθε σχέδιο πρόσβασης αποσυντίθεται σε μικρότερα, πιο θεμελιώδη. Κατά αυτόν τον τρόπο ο σχεδιαστής έχει μια πλήρη άποψη με έναν τρόπο πολυ-κοκκοποίησης των σχεδίων πρόσβασης που χαρακτηρίζουν την εφαρμογή. Αυτός ο αλγόριθμος μπορεί να γίνει αποδοτικότερος με τη χρησιμοποίηση ενός μέγιστου παραθύρου που εξετάζει προηγούμενες καταστάσεις (look-back).
Μέσω του πειραματισμού έχουμε διαπιστώσει ότι, για τη δυναμική συμπεριφορά στοιχείων, ένα παράθυρο 100 στοιχείων προσδιορίζει το ίδιο σχέδιο με ένα που δεν είναι περιορισμένου παραθύρου, ενώ οι χρόνοι ανάλυσης παραμένουν οριακοί.
process(event) {
case event of
DeallocEnd ->
FindBlockOfAddress (event.address) =>
Record last active transfer for the block
Destroy block
AllocEnd ->
Create new block with event.address
VarRead or
VarWrite ->
FindBlockOfAddress (event.address) =>
if consecutive access for event.threadID and
same direction (read/write) {
Update active transfer with event.address
} else {
Record last active transfer (if any)
Create new transfer with event.address
}
}Ενώ ο προηγούμενος περιγεγραμμένος αλγόριθμος είναι πολύ ακριβής και μπορεί να δώσει μια πολύ συγκεκριμένη άποψη των σχεδίων συμπεριφοράς, στην περίπτωση των πολύ δυναμικών συμπεριφορών, δεν θα ανιχνευθούν τα ακριβή ταιριάσματα. Σε αυτήν την περίπτωση, προτείνουμε τον παρακάτω αλγόριθμο, που εξάγει τα μη-ακριβή σχέδια, που δεν παρακολουθούν τον αριθμού επαναλήψεων, και του αριθμού χρόνων στα οποία επαναλαμβάνονται τα γεγονότα. Κατά αυτόν τον τρόπο κάθε σχέδιο δεν φυλάσσει τις λεπτές πληροφορίες κοκκοποίησης σχετικά με τα σχέδια που αποτελούνται. Ένα ενδεικτικό παράδειγμα για αυτό δίνεται εδώ:
Παράδειγμα: Το ταίριασμα σχεδίων. Δεδομένου του ακόλουθου ρεύματος των γεγονότων: AAAABAAABAAABAAAB, όπου το Α σημαίνει τις προσβάσεις μέσων variable1 και Β σε variable2, τα ακόλουθα σχέδια θα συνάγονταν: Ακριβές ταίριασμα: 4*[ 3*[ Α], μη-ακριβές] ταίριασμα Β: [[Το Α], Β] αυτό φαίνεται σαφές ότι τα variable1 και variable2 προσεγγίζονται σε έναν βρόχο. Εάν, εντούτοις, ο αριθμός προσβάσεων σε variable1 ποικίλλει σε αυτόν τον βρόχο λόγω δυναμικών εξαρτώμενων στοιχείων, μπορεί να έχουν ένα ρεύμα όπως: AAAABAAAAABAAABAB. Κατόπιν, το σχέδιο που εξάγεται θα ήταν: Ακριβές ταίριασμα: [4*[ Α], Β, 5*[ Α], Β, 3*[ Α], Β, Α, μη-ακριβές] ταίριασμα Β: [[Το Α], μη-ακριβές] το σχέδιο-ταίριασμα Β μπορεί να είναι ευεργετικό για τις εφαρμογές που καταδεικνύουν τη δυναμική συμπεριφορά, ακόμα κι αν προσφέρει τις λιγότερες πληροφορίες από το ακριβές σχέδιο.
Αυτοί οι δύο αλγόριθμοι δεν περιορίζονται στις προσβάσεις μπορούν να χρησιμοποιηθούν για το ταίριασμα σχεδίων οποιαδήποτε από το σχεδιασμό περιγράμματος γεγονότα, για παράδειγμα δέσμευση ή πεδίο-γεγονότα. Συμπερασματικά, οι δύο αλγόριθμοι εξυπηρετούν τους διαφορετικούς σκοπούς: Ο ακριβής αλγόριθμος δίνει την κυρίαρχη συμπεριφορά της εφαρμογής, αλλά μπορεί να παραλείψει στα λιγότερο σταθερά σχέδια ο μη-ακριβής αλγόριθμος δίνει ένα σφαιρικό βλέμμα ποιου είδους σχέδια αναμένονταν. Η συγκέντρωση των πληροφοριών για τη στατιστική συμπεριφορά των διαφορετικών ακολουθιών στην εφαρμογή, επιτρέπει να διακριθεί ο μέσος αριθμός στοιχείων στις ακολουθίες κάθε συγκεκριμένου τύπου. Ο αλγόριθμος για να εξαγάγει αυτές τις πληροφορίες είναι απλός κατά συνέπεια, δεν παρουσιάζεται εδώ. Αυτές οι πληροφορίες και το ιστόγραμμα των διαδικασιών επικαλέσθηκαν γιατί κάθε ακολουθία είναι κρίσιμη όχι μόνο για τον προσδιορισμό των κυρίαρχων τύπων στοιχείων, αλλά και για να αποφασίσουν το είδος των δυναμικών τύπων στοιχείων που πρέπει να χρησιμοποιηθούν στο [61].
Εδώ, παρουσιάζουμε μια ολοκληρωμένη προσέγγιση στο απόσπασμα και εκμεταλλευόμαστε τα χαρακτηριστικά των εφαρμογών, που τρέχουν στα ενσωματωμένα συστήματα με τη βοήθεια του καθορισμού μεταδεδομένων ενός των κοινών λογισμικού. Επομένως, είναι σημαντικό να παρουσιαστεί επίσης ένα ενσωματωμένο παράδειγμα όπου οι διαφορετικές μέθοδοι βελτιστοποίησης εφαρμόζονται σε μια ενιαία εφαρμογή. Επιπλέον, αυτό το παράδειγμα επιδεικνύει πως τα μεταδεδομένα λογισμικού επιτρέπουν τις σχετικές βελτιστοποιήσεις με συνέπεια τα σημαντικά κέρδη στην κατανάλωση ενέργειας και στο αποτύπωμα μνήμης. Ένα δίκτυο TCP/IP όπως το σωρό συμπεριλαμβανομένου Deficit Round Robin(DRR), των εξερχόμενων πακέτων χρησιμοποιείται ως δοκιμαστική εφαρμογή για να επεξηγήσουν τη συνεργατική επίδραση που αποκτάται όταν χρησιμοποιούνται τα μεταδεδομένα λογισμικού από διάφορα εργαλεία βελτιστοποίησης στην ίδια εφαρμογή.
Type Pattern a = case Kind of
Element => a
Pattern => record {
count :: Integer ,
pattern :: List (Pattern a)
}
current :: List (Pattern a)
initialize () {
current = new List;
}
process(event) {
case event of
type -> patternize(new List(Element type ));
}
patternize(segment) {
n = segment.length;
if (n > windowsize || current.length == 0) {
current.append(segment );
}
if (current.get (-1). pattern == segment) {
// Segment fits a pattern
// Increase pattern count
current.get (-1). count = current.get (-1). count + 1;
// Create a new segment to look for
segment = new List(current.get ( -1));
current.dropLast (1);
// Start fresh with higher -order pattern
patternize(segment );
} elseif (current.range(-n, -1) == segment) {
// Segment fits another segment
// Drop the segment in current
current.dropLast(n);
// Create a new segment to look for
segment = new List(Pattern 2 segment );
// Start fresh with higher -order pattern
patternize(segment );
} else {
// Try to look for a bigger match
segment.prepend(current.get ( -1));
current.dropLast (1);
patternize(segment );
}
}Ο τελικός στόχος αυτού του παραδείγματος είναι να βελτιστοποιηθεί η εφαρμογή του συστήματος σε τρία διαφορετικά βασικά σημεία: τα δυναμικά στοιχεία δακτυλογραφούν, δυναμικές διαχείριση μνήμης και μεταφορές block των δυναμικών στοιχείων. Τα διενεργηθέντα βήματα είναι:
Type Pattern a = case Kind of
Element => a
Pattern => List (Pattern a)
current :: List (Pattern a)
initialize () {
current = new List;
}
process(event) {
case event of
type -> patternize(new List(Element type ));
}
patternize(segment) {
n = segment.length;
if (n > windowsize || current.length == 0) {
current.append(segment );
}
if (current.get (-1). pattern == segment) {
// Segment fits a pattern
// Create a new segment to look for
segment = new List(current.get ( -1));
current.dropLast (1);
// Start fresh with higher -order pattern
patternize(segment );
} elseif (current.range(-n, -1) == segment) {
// Drop the segment in current
current.dropLast(n);
// Create a new segment to look for
if (n == 1) {
// Keep current segment , namely of one item.
} else {
// Generate a pattern out of multiple items.
segment = new List(Pattern segment );
}
// Start fresh with higher -order pattern
patternize(segment );
} else{
// Try to look for a bigger match
segment.prepend(current.get ( -1));
current.dropLast (1);
patternize(segment );
}
}Εξαγωγή των μεταδεδομένων του λογισμικού από την αρχική εφαρμογή που χρησιμοποιεί τις τεχνικές σκιαγράφησης και ανάλυσης που παρουσιάζονται σε αυτό το κεφάλαιο.
Βελτιστοποίηση των δυναμικών τύπων στοιχείων, για να μειώσει τον αριθμό προσβάσεων μνήμης και το αποτύπωμα μνήμης των δυναμικών δομών δεδομένων, που χρησιμοποιούνται στην εφαρμογή (πχ. συνδεδεμένοι κατάλογοι, διπλά συνδεδεμένοι κατάλογοι).
Βελτιστοποίηση της δυναμικής διαχείρισης μνήμης για να υποστηρίξει μια αποδοτικότερη εκτέλεση των λειτουργιών malloc() και των free(). Μετά από αυτό το βήμα, ο αριθμός προσβάσεων που εκτελούνται στη μνήμη για να διαχειριστούν τη δυναμική μνήμη ελαχιστοποιείται. Αντίστοιχα, το συνολικό αποτύπωμα μνήμης που απαιτείται από το δυναμικό διαχειριστή μνήμης για να εξυπηρετήσει όλες τις απαιτήσεις των εφαρμογών ελαχιστοποιείται, δηλαδή με τη μείωση του εσωτερικού και εξωτερικού κατακερματισμού που προκαλείται από τον ίδιο το διαχειριστή στο [56].
Βελτιστοποίηση της συμπεριφοράς μεταφοράς block της εφαρμογής για να χρησιμοποιηθούν οι πόροι DMA για τις μεταφορές των block των δυναμικών στοιχείων (σε αντιδιαστολή με τη μεταφορά των στατικών σειρών ή των μεταβλητών). Το αποτέλεσμα αυτού του βήματος λαμβάνει υπόψη την επίδραση των ταυτόχρονων προσβάσεων από τον επεξεργαστή και το DMA, στον τρόπο πρόσβασης συστοιχίας των μνημών DRAM. Η συμπεριφορά μνήμης της εφαρμογής αξιολογείται μετά από κάθε βήμα, προκειμένου να συγκριθεί ο αντίκτυπος κάθε απόφασης. Στο τέλος, η εφαρμογή προσαρμόζεται για να βεβαιώσει τη συσσωρευμένη επίδραση όλων των βελτιστοποιήσεων.
Ένα TCP/IP υποσύστημα δικτύων χρησιμοποιείται σε όλο αυτό το παράδειγμα ως εφαρμογή οδηγών. Αυτό το σύστημα οργανώνεται σε διάφορα νήματα που επικοινωνούν μέσω των ασύγχρονων σειρών αναμονής FIFO: η παραγωγή ενός νήματος είναι η είσοδος για μια άλλη. Μια πιο λεπτομερής εξήγηση αυτής της εφαρμογής μπορεί να βρεθεί στο [72]. Βασικά, η εφαρμογή διαιρείται στις ακόλουθες ενότητες:
Έγχυση πακέτων. Μια συλλογή των πραγματικών (ασύρματων) ιχνών 73 δικτύων, χρησιμοποιείται για να παραγάγει τα πακέτα που τροφοδοτούνται το σύστημα.
Σχηματισμός πακέτων. Η επιγραφή TCP/IP προστίθεται στα στοιχεία προκειμένου να χτιστεί ένα πλήρες πακέτο.
Κρυπτογράφηση (DES). Αυτή η ενότητα παρακάμπτεται από τα πακέτα των συνόδων που δεν απαιτούν την κρυπτογράφηση.
Checksum TCP.
Διαχείριση σχεδίου και ποιότητα–υπηρεσιών. Ο DRR είναι ένας δίκαιος αλγόριθμος σχεδιασμού δικτύων που χρησιμοποιείται συνήθως για το σχεδιασμό σύμφωνα με το διαθέσιμο εύρος ζώνης [73]. Αυτός ο αλγόριθμος έχει εφαρμοστεί στους διάφορους δρομολογητές (πχ. στη σειρά Cisco 12000).
Αυτά τα υποσυστήματα αποτελούν τη βάση ενός απλουστευμένου σωρού δικτύων. Εξαιτίας του γεγονότος ότι χρησιμοποιούμε τα ίχνη δικτύων που συλλέγονται από τα ασύρματα σημεία πρόσβασης μιας πανεπιστημιούπολης στο [74], και όχι από τις πραγματικές συσκευές, η αναπαραγωγή των λεπτομερειών όπως η αναμετάδοση πακέτων ή ο έλεγχος εύρους ζώνης γίνεται σχεδόν αδύνατη, ως εκ τούτου παραμένουμε στην απλουστευμένη περιγραφή που παρουσιάσθηκε πριν. Δεδομένου ότι η εφαρμογή είναι πολύπλοκη, πολλά πακέτα είναι ζωντανά συγχρόνως κατά τη διάρκεια της εκτέλεσης κατά συνέπεια, οι προσβάσεις μνήμης εκτελούνται ταυτόχρονα από τα πολλαπλάσια νήματα. Πολυνηματώδης, τελικά σημαίνει ότι οι προσβάσεις μνήμης από τα διαφορετικά νήματα παρεμβάλλουν λευκές σελίδες με έναν λεπτόκοκκο τρόπο και η γενική συμπεριφορά δεν μπορεί να περιγραφεί από την ανεξάρτητη συμπεριφορά κάθε τμήματος. Επομένως, ολόκληρο το σύστημα πρέπει να βελτιστοποιηθεί αντί κάθε νήμα ανεξάρτητα. Η αρχιτεκτονική στόχων για αυτό το σύστημα αποτελείται από ένα στοιχείο επεξεργασίας που συνδέεται με μια ενότητα SRAM και με μια εξωτερική ενότητα DRAM (δείτε τον Πίνακα 7.1 για μια περιγραφή των παραμέτρων εργασίας τους), όπως παρουσιάζεται στο [72]. Μια μηχανή άμεσης πρόσβασης μνήμης (DMA), φροντίζει για τις μεταφορές στοιχείων μεταξύ της εξωτερικής μνήμης και της εσωτερικής, με αποδοτικό τρόπο, και από οποιεσδήποτε από τις μνήμες προς τις εξωτερικές συσκευές (δηλαδή απομονωτές υλικού στους προσαρμογείς δικτύων). Ο επεξεργαστής μπορεί να έχει πρόσβαση και στις δύο μνήμες άμεσα εντούτοις, η πρόσβαση στο εξωτερικό DRAM πρέπει να συντονιστεί με το DMA για να αποφύγει τις περιττές ποινικές ρήτρες ενέργειας και λανθάνουσας κατάστασης, λόγω των παρεμβάσεων στις σελίδες.
| Ενέργεια/Πρόσβαση | 3.5 nJ |
| Ενεργοποίηση Ενέργειας/Προφόρτιση | 10 nJ |
| Καθυστέρηση CAS | 2 Κύκλοι |
| Καθυστερημένη Προφόρτιση | 2 Κύκλοι |
| Ενεργό για να διαβάσει ή να γράψει | 2 Κύκλοι |
| Αποκατάσταση γραφής | 2 Κύκλοι |
| Τελευταία Δεδομένα να διαβαστούν/γραφούν εκ νέου | 1 Κύκλος |
| Μέγιστο μήκος ριπής | 1.024 λέξεις |
Η εφαρμογή οδηγών ενοργανώνεται και σχεδιάζεται το περίγραμμα, και οι αποσπασματικές πληροφορίες αναλύονται όπως εξηγούνται στο τμήμα 7.4.2. Μετά από αυτό το βήμα, εκτελέστε συνεχώς τις βελτιστοποιήσεις και τα αρχικά μεταδεδομένα λογισμικού είναι έτοιμα. Οι πληροφορίες που εξάγονται περιλαμβάνουν:
Για κάθε δυναμική δομή δεδομένων, τον αριθμό των λειτουργιών που εκτέλεσε, τον αριθμό προσβάσεων μνήμης και το συνολικό αποτύπωμα μνήμης.
Για το δυναμικό διαχειριστή μνήμης, τον αριθμό προσβάσεων μνήμης που εκτελούνται για να διαχειριστούν όλα τα ελεύθερα χρησιμοποιημένα block της δυναμικής μνήμης, και το συνολικό ποσό μνήμης που χρησιμοποιείται πραγματικά για να εξυπηρετήσει όλες τις αιτήσεις από την εφαρμογή. Η συνολική χρήση της μνήμης εξαρτάται από τον εσωτερικό και εξωτερικό κατακερματισμό τα οποία προκαλούνται από το διαχειριστή.
Τέλος, τον αριθμό των προσβάσεων σε κάθε δυναμικό αντικείμενο και το σχέδιο πρόσβασης κάθε νήματος στο σύστημα. Αυτές οι πληροφορίες επιτρέπουν τους πιο σχετικούς δυναμικούς τύπους στοιχείων στην εφαρμογή. Ο πρώτος αντιστοιχεί στα πακέτα που δημιουργούνται για να σταλούν. Ο τεράστιος αριθμός τους απαιτεί την υψηλή αποδοτικότητα από το δυναμικό διαχειριστή μνήμης. Οι επόμενες πιο σχετικές δομές δεδομένων είναι ο κατάλογος κόμβων και η σειρά αναμονής των πακέτων που χτίζονται από την ενότητα DRR. Ο κατάλογος κόμβων αντιπροσωπεύει τους οικοδεσπότες στον οποίο μια σύνδεση είναι ενεργός, δηλαδή, είναι εκεί μια είσοδος για κάθε οικοδεσπότη προορισμού για την οποία υπάρχουν τα πακέτα περιμένοντας να αποσταλλούν Κάθε είσοδος στον κατάλογο περιέχει τη σειρά αναμονής των πακέτων περιμένοντας να σταλεί προς αυτόν τον προορισμό. Και οι δύο δομές δεδομένων είναι δυναμικές επειδή ο αριθμός στοιχείων τους ποικίλλει στο χρόνο εκτέλεσης κατά συνέπεια, είναι καλοί υποψήφιοι για τις τεχνικές βελτιστοποίησης τύπων στοιχείων.
Τέλος, η τελευταία των σχετικών δυναμικών δομών δεδομένων που χρησιμοποιούνται στην εφαρμογή, είναι η ασύγχρονη σειρά αναμονής FIFO που τα νήματα χρησιμοποιούν για να περάσουν τα μηνύματα μεταξύ τους. Αυτή η δομή δεδομένων κάνει τη βαριά χρήση των πρωτόγονων συγχρονισμού, οι οποίοι είναι από το πεδίο αυτής της εργασίας. Εντούτοις, η καλύτερη εφαρμογή αυτής της δομής δεδομένων μπορεί να καθοριστεί με έναν απλό τρόπο επειδή παρουσιάζει ένα πολύ κανονικό σχέδιο πρόσβασης.
Κάθε ένα από τα επόμενα τρία βήματα βελτιστοποίησης στηρίζεται στα μεταδεδομένα λογισμικού που εξάγονται σε αυτό το σημείο και που ενημερώνονται από τα αντίστοιχα εργαλεία.
Η πρώτη βελτιστοποίηση που εφαρμόζεται σε αυτό το παράδειγμα είναι ο καθαρισμός των δυναμικών δομών δεδομένων της εφαρμογής (DDTR). Μετά από τα βήματα σκιαγράφησης και ανάλυσης, οι δυναμικοί τύποι στοιχείων οντοτήτων μεταδεδομένων, οι δυναμικές περιπτώσεις τύπων στοιχείων και οι δυναμικές διαδικασίες τύπων στοιχείων περιέχουν τις πληροφορίες για τον τύπο και τον αριθμό διαδικασιών που εκτελούνται για κάθε τύπο στοιχείων. Επιπλέον, αυτές οι πληροφορίες είναι επίσης διαθέσιμες για τις συγκεκριμένες περιπτώσεις τους, το οποίο το καθιστά πιθανό να μελετήσει και να βελτιστοποιήσει κάθε μια από τις διαδικασίες, που διενεργήθηκαν συχνότερα. Οι μέθοδοι σκιαγράφησης και ανάλυσης επιτρέπουν να διαφοροποιήσουν μεταξύ των προσβάσεων που διανέμονται στις δομές δεδομένων, και των προσβάσεων στις εσωτερικές δομές των τύπων στοιχείων εφαρμογής. Αυτή η διαφοροποίηση το καθιστά πιθανό να προσδιορίσει τους πιο σχετικούς τύπους στοιχείων για τη βελτιστοποίηση, ανεξάρτητα από την αρχική εφαρμογή τους. Επιπλέον, οι τεχνικές βελτιστοποίησης μας εστιάζουν στη βελτιστοποίηση των γενικών εξόδων που επιβάλλονται από κάθε δομή δεδομένων, αλλά δεν μπορούν να μειώσουν τον αριθμό προσβάσεων που οι αλγόριθμοι εφαρμογής εκτελούν. Προκειμένου να μειωθεί ο αριθμός προσβάσεων που διανέμονται στις δυναμικές δομές δεδομένων (σε αντίθεση με τον αριθμό προσβάσεων μνήμης που εκτελούνται πραγματικά στο υποσύστημα μνήμης), οι βελτιστοποιήσεις σε πιο υψηλό επίπεδο αφαίρεσης που είναι από το πεδίο αυτού του κεφαλαίου θα ήταν το ζητούμενο.
Οι αποσπασματικές πληροφορίες αποκαλύπτουν ότι οι δύο δυναμικές περιπτώσεις στοιχείων που συγκεντρώνουν τις περισσότερες από τις προσβάσεις εφαρμογής είναι ο κατάλογος κόμβων στον αλγόριθμο DRR (δυναμική δομή «Α») και η σειρά αναμονής των εκκρεμών πακέτων για κάθε έναν από τους κόμβους (δυναμική δομή «Β»). Χρησιμοποιώντας τις μεθόδους που εξηγούνται στο προηγούμενο κεφάλαιο, επιλέγουμε την καλύτερη επιλογή για τις αντίστοιχες εφαρμογές τους. Αν και το τρέξιμο μιας εξαντλητικής εξερεύνησης όλων των περιπτώσεων δεν απαιτείται για να πάρει τη βέλτιστη λύση, σε αυτό το πείραμα τρέξαμε ένα πλήρες σκούπισμα όλων των συνδυασμών για να εκτελέσουμε μια πρόσθετη συγκριτική δοκιμή και να επικυρώσουμε την προσέγγιση βελτιστοποίησης. Για κάθε μια από τις δυναμικές δομές δεδομένων, μια από τις ακόλουθες εφαρμογές μπορεί να επιλεχτεί (περισσότερες λεπτομέρειες σε κάθε μια από τις εφαρμογές μπορούν να βρεθούν [75]):
Σειρά δεικτών.
Σειρά αντικειμένων.
Ενιαίος συνδεομένος κατάλογος.
Διπλός συνδεομένος κατάλογος.
Ενιαίος συνδεομένος κατάλογος με το δείκτη περιπλάνησης.
Διπλός συνδεομένος κατάλογος με το δείκτη περιπλάνησης.
Ενιαίος συνδεομένος κατάλογος σειρών.
Διπλός συνδειμένος κατάλογος σειρών.
Ενιαίος συνδεδεμένος κατάλογος σειρών με το δείκτη περιπλάνησης.
Διπλός συνδεδεμένος κατάλογος σειρών με το δείκτη περιπλάνησης.
Τα δέντρα δεν αντιπροσωπεύονται σε αυτήν την ιεραρχία, αλλά μπορούν να χτιστούν χρησιμοποιώντας έναν συνδυασμό αυτών των δομών δεδομένων. Για την αποδοτικότερη εξερεύνηση των δέντρων, θα απαιτούταν μια περαιτέρω μελέτη των πιθανών διεπαφών που ένα δέντρο μπορεί να εκθέσει. Δεδομένου ότι οι περισσότερες εφαρμογές δέντρων είναι μάλλον ειδικές, και από υψηλή άποψη οι διαφορετικοί τύποι δέντρων έχουν τις διαφορετικές ιδιότητες, θα ήταν απαραίτητο να ταξινομεί αρχικά τις διαφορετικές δομές δεδομένων δέντρων, πριν καθοριστούν οι ομάδες διεπαφών. Μερικές δομές δεδομένων δέντρων, όπως τα διατεταγμένα δέντρα, συμπεριφέρονται πλήρως όπως τα σύνολα. Άλλες δομές δεδομένων δέντρων έχουν την πιο θεμελιώδη κωδικοποίηση στη δομή δεδομένων δέντρων, όπως οι ιδιότητες γονέας-παιδιών.
Στο υπόλοιπο αυτού του τμήματος, το AI-BJ αντιπροσωπεύει το συνδυασμό της εφαρμογής για το Α και της εφαρμογής j για το Β. Παραδείγματος χάριν, Α1-B3 αντιπροσωπεύει ότι μια σειρά δεικτών χρησιμοποιείται ως εφαρμογή για τον κατάλογο κόμβων στον αλγόριθμο DRR και ένας ενιαίος-συνδεδεμένος κατάλογος χρησιμοποιείται ως εφαρμογή για τη σειρά αναμονής των εκκρεμών πακέτων για κάθε κόμβο. Υπάρχουν δέκα πιθανές εφαρμογές για κάθε μια από τις δυναμικές δομές. Εξαιτίας του γεγονότος ότι θελήσαμε να κάνουμε μια πλήρη δοκιμή όλων των περιπτώσεων, χρησιμοποιήσαμε δέκα τρία εισηγμένα ίχνη ως είσοδο και εκτελέσαμε δέκα επαναλήψεις που αντιμετωπίζουν τις στατιστικές παραλλαγές, ο συνολικός αριθμός τρεξίματος συνδυασμών που ανήλθε σε 13.000. Εντούτοις, αυτός ο υψηλός αριθμός εκτελέσεων εκτελέσθηκε για να επικυρώσει ακριβώς τη βελτιστοποίηση με μια εξαντλητική δοκιμή, αλλά σε πρακτικές περιπτώσεις δεν υπάρχει καμία ανάγκη να εκτελεσθούν. Για αυτό το εκτενές πείραμα, τα μεταδεδομένα για κάθε μια από τις δυναμικές περιπτώσεις στοιχείων συλλέχθηκαν από τους δυναμικούς τύπους στοιχείων οντοτήτων μεταδεδομένων, δυναμικές περιπτώσεις τύπων στοιχείων και δυναμικές διαδικασίες τύπων στοιχείων, με τις πρόσθετες πληροφορίες στις πληροφορίες πρόσβασης (σχήμα 7.3). Δύο συμπεράσματα προέρχονται από τα αποτελέσματα των πειραμάτων. Ο πρώτος είναι η επιβεβαίωση της αποδοτικότερης δομής δεδομένων σχετικά με το συνολικό αριθμό προσβάσεων μνήμης. Ο δεύτερος είναι η ανάλυση της δομής δεδομένων που μειώνει πιο πολύ το συνολικό ποσό μνήμης (αποτύπωμα μνήμης) που απαιτείται για να εκτελέσει την εφαρμογή.
Τα πειραματικά αποτελέσματα δείχνουν ότι ο αποδοτικότερος συνδυασμός δυναμικών δομών δεδομένων είναι A3-B3, το οποίο σημαίνει ότι μια ενιαία-συνδεμένη εφαρμογή καταλόγων πρέπει να χρησιμοποιηθεί και για τον κατάλογο ενεργών κόμβων σε DRR και για τη σειρά αναμονής των πακέτων περιμένοντας να σταλεί για κάθε έναν από τους κόμβους. Αυτή η λύση είναι η βέλτιστη για 11, των 13 εισαγωγών που εξετάστηκαν. Ο πίνακας 7.2 παρουσιάζει τον αριθμό προσβάσεων που απαιτούνται από τη βέλτιστη λύση για κάθε εισαγωγή, και τον αριθμό προσβάσεων μνήμης που απαιτούνται από την επιλεγμένη λύση A3-B3. Η τελευταία στήλη παρουσιάζει διαφορά ποσοστού και μεταξύ των δύο. Είναι σχετικό να σημειωθεί ότι η μέση διαφορά από A3-B3 σε μια υποθετική «τέλεια» λύση 2 είναι τόσο μικρή όπως 0.28%.
| Είσοδος | Προσβάσεις Μνήμης Α3-Β3 | Βέλτιστη Πρόσβαση Μνήμης | Διαφορά επί % |
| 01 | 4328501556 | 4247377390 | |
| 02 | 3589773903 | 3530754848 | 1.91 |
| 03 | 8004231 | 8004231 | 1.67 |
| 04 | 1867812 | 1867812 | 0 |
| 05 | 9622944 | 9622944 | 0 |
| 06 | 25225070 | 25225070 | 0 |
| 07 | 192869416 | 192869416 | 0 |
| 08 | 183636289 | 183636289 | 0 |
| 09 | 12699747 | 12699747 | 0 |
| 10 | 45429504 | 45429504 | 0 |
| 11 | 239756665 | 239756665 | 0 |
| 12 | 19082840 | 19082840 | 0 |
| 13 | 250188588 | 250188588 | 0 |
| Μέση διαφορά | 0.28 |
Στην περίπτωση του αποτυπώματος μνήμης, μια βέλτιστη λύση Παρέτο που εξετάζει επίσης την επίδραση στον αριθμό προσβάσεων μνήμης αξιολογήθηκε. Ο Πίνακας 7.3 παρουσιάζει τα αποτελέσματα που επιτυγχάνονται από τα πειράματα. Σε αυτήν την περίπτωση, το A3-B3 είναι βέλτιστο μόνο σε μια από τις 13 εισηγμένες περιπτώσεις. Η γενική διαφορά από αυτήν την λύση στη βέλτιστη λύση αποτυπώματος μνήμης (με τις πολύ κακές ανταλλαγές πρόσβασης μνήμης) είναι μόνο 3.33%. Αυτό σημαίνει ότι, ακόμα κι αν δεν υπάρχει μια «τέλεια» λύση για να μειώσει τη μνήμη αποτυπώματος της εφαρμογής, η επιλογή της καλύτερης λύσης συμβιβασμού για να μειώσει τον αριθμό προσβάσεων δεν επιβάλλει μια σημαντική ποινική ρήτρα στο συνολικό ποσό μνήμης που απαιτείται.
| Είσοδος | Αποτύπωμα Μνήμης Α3-Β3 | Βέλτιστο Αποτύπωμα Μνήμης | Διαφορά επί % |
| 01 | 9028421 | 8992232 | 0.40 |
| 02 | 7882678 | 7872560 | 0.13 |
| 03 | 1978361 | 1809807 | 9.31 |
| 04 | 47778 | 47778 | 0 |
| 05 | 992569 | 953663 | 4.08 |
| 06 | 2178989 | 2025122 | 7.60 |
| 07 | 186441 | 185851 | 0.32 |
| 08 | 174315 | 171398 | 1.70 |
| 09 | 1589535 | 1532995 | 3.69 |
| 10 | 3316557 | 3271309 | 1.38 |
| 11 | 760281 | 716898 | 6.05 |
| 12 | 772158 | 732497 | 5.41 |
| 13 | 471254 | 456433 | 3.25 |
| Μέση Διαφορά | 3.33 |
Μόλις βελτιστοποιηθούν οι δυναμικές δομές δεδομένων της εφαρμογής και οι αντίστοιχες πληροφορίες μεταδεδομένων ενημερωθούν (δυναμικές σχετικές με τα στοιχεία οντότητες, σχήμα 7.3), εκτελείται η βελτιστοποίηση του δυναμικού διαχειριστή μνήμης, όπως περαιτέρω εκτίθεται λεπτομερώς στο επόμενο κεφάλαιο. Αναφερόμαστε στο δυναμικό διαχειριστή μνήμης ως ενσωματωμένο σύνολο συγκεκριμένων δυναμικών διαχειριστών μνήμης εφαρμογής (δηλαδή οι διαχειριστές DM επιπέδων εφαρμογής μεταγλωττίστηκαν με κάθε εφαρμογή λογισμικού). Εάν περισσότερες από μια εφαρμογές είναι παρούσες, κατόπιν κάθε ένας χρησιμοποιείται κατά τη μεταγλώττιση της εφαρμογής.
Σε κάθε περίπτωση, όλοι οι προσαρμοσμένοι διαχειριστές DM μοιράζονται τις κοινές υπηρεσίες των επιπέδων του ΛΣ για την παροχή των μεγάλων block μνήμης (πχ. sbrk() και mmap()). Οι πληροφορίες μεταδεδομένων για αυτό το βήμα περιλαμβάνουν τον αριθμό block των ποικίλων μεγεθών που διατίθενται από την εφαρμογή για τα πακέτα δικτύων (οργανισμοί στοιχείων και επιγραφές δικτύων ανεξάρτητα), τον κατάλογο κόμβων προορισμού για τον αλγόριθμο DRR και τις σειρές αναμονής των εκκρεμών πακέτων για κάθε κόμβο.
Η εκτέλεση αυτού του βήματος εφόσον έχουν βελτιστοποιηθεί οι δυναμικές δομές δεδομένων είναι σημαντική, επειδή ο αριθμός κατανομών και μη-κατανομών μνήμης δεν θα αλλάξει άλλο λόγω των τροποποιήσεων εφαρμογής. Κάθε φορά που δημιουργείται μια νέα περίπτωση οποιοιδήποτε από αυτούς τους δυναμικούς τύπους στοιχείων, ο δυναμικός διαχειριστής μνήμης πρέπει να ψάξει για έναν κατάλληλο ελεύθερο block, δηλαδή ένα block ικανοποιητικού μεγέθους που εκτείνεται πέρα από μια σειρά των διευθύνσεων μνήμης, που δεν καταλαμβάνονται αυτήν τη χρονική στιγμή από οποιοδήποτε άλλο αντικείμενο.
Αντιθέτως, όταν καταστρέφεται μια μεταβλητή, το διάστημα μνήμης που χρησιμοποιούσε πρέπει να επανενταχθεί στην ομάδα των διαθέσιμων διευθύνσεων για τις νέες περιπτώσεις. Όλες αυτές οι διαδικασίες παράγουν γενικά κόστη στο συνολικό ποσό εργασίας που το σύστημα πρέπει να κάνει. Επιπλέον, ο διαχειριστής μνήμης απαιτεί κάποια πρόσθετη μνήμη για τη λειτουργία του και ολόκληρη η λογιστική της διαδικασίας αυξάνει το συνολικό αριθμό προσβάσεων μνήμης. Επομένως, η καταλληλότητα ενός δεδομένου δυναμικού διαχειριστή μνήμης εξαρτάται από τα γενικά κόστη που επιβάλλει στο σύστημα και την πρόσθετη μνήμη που απαιτούνται λόγω της ύπαρξης του εσωτερικού και εξωτερικού τεμαχισμού στο[56].
Το μέγεθος των διατιθέμενων block μνήμης και η συχνότητα εμφάνισής τους, μαζί με το σχέδιο των κατανομών και μη-κατανομών, καθορίζουν το χαρακτηριστικό του καταλληλότερου διαθέτη μνήμης. Αυτοί οι αριθμοί καθορίζονται στα μεταδεδομένα λογισμικού της εφαρμογής (δυναμικά στοιχεία και τη Pool σχετικές με οντότητες, Εικόνα 7.3).
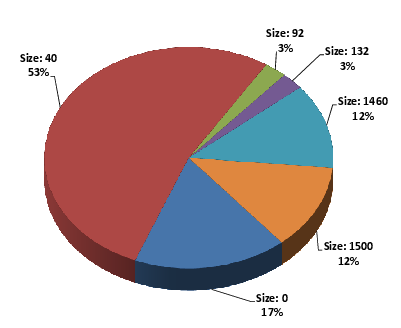
7.4: Διανομή συχνότητας των «δημοφιλών» μεγεθών κατανομής για όλες τις περιπτώσεις εισαγωγής.
Το σχήμα 7.4 παρουσιάζει τη συχνότητα της εμφάνισης κάθε μεγέθους δέσμευσης στην εφαρμογή οδηγών, για τα δημοφιλέστερα μεγέθη. Ο αριθμός το καθιστά σαφές ότι ο διαχειριστής μνήμης για αυτήν την εφαρμογή πρέπει να βελτιστοποιηθεί, για να διαθέσει τις μεγάλες ποσότητες πακέτων από ένα μικρό σύνολο μεγεθών block. Προκειμένου να μειωθεί ο αριθμός προσβάσεων μνήμης, ο διαχειριστής μνήμης πρέπει να εντοπίσει τον πιο κατάλληλο ελεύθερο block με το λιγότερο ποσό προσβάσεων μνήμης. Για αυτόν τον λόγο, ένας διαχειριστής μνήμης που παίρνει ελεύθερο χώρο από μια σφαιρική Pool αρχικά, αλλά έπειτα ελευθερώνει τα block στους καταλόγους συγκεκριμένων μεγεθών επιλέγεται. Επιπλέον, προκειμένου να μειωθεί το ποσό εσωτερικού τεμαχισμού, είναι επίσης δυνατό να δημιουργηθούν οι κατάλογοι ελεύθερων block για έναν μικρό αριθμό πρόσθετων μεγεθών που περιορίζουν το ποσό σπαταλημένης μνήμης για τα ανώμαλα μεγέθη. Η δομή του διαθέτη μνήμης κρατιέται στην είσοδο poolDescription της οντότητας Pool. (σχήμα. 7.3).
lp12cm
DMM & Περιγραφή
DMM 1 & Kingsley-όπως [126] διαχείριση μνήμης με κάδους για τα τεμάχια των 128 διαφορετικών μεγεθών, 8-16384 bytes. Αυτή η δημοφιλής διαχείριση μνήμης χρησιμοποιείται σε όλο το υπόλοιπο αυτού του τμήματος ως σημείο αναφοράς για σύγκριση με προσαρμοσμένους διαχειριστές δυναμικής μνήμης
DMM 2 & Ειδικές σωρούς με τις λίστες των ελεύθερων μπλοκ των μεγεθών 40, 1460 και 1500
DMM 3 & Προσαρμοσμένη σωρό με τις λίστες των ελεύθερων μπλοκ των μεγεθών ακριβώς 40, ακριβώς 1460, ακριβώς 1500, έως 92, έως 132, έως 256, έως 512 και έως 1024 bytes. Η συγκεκριμένη σειρά περιορισμών της “έως” και “ακριβώς” εξασφαλίζουν ότι τα πιο κοινά μεγέθη δέσμευσης απαιτούν τον ελάχιστο αριθμό προσβάσεων για να βρείτε ένα κατάλληλο μπλοκ
DMM 4 & Προσαρμοσμένη σωρό με τις λίστες των ελεύθερων μπλοκ των μεγεθών 40, 1460 και 1500 byte, συν υποστήριξη για το διαχωρισμό και συνενώνονται
DMM 5 & Ειδικές σωρούς με τις λίστες των ελεύθερων μπλοκ των μεγεθών 40, 1460, 1500, 92 και 132 byte (κατά σειρά προτεραιότητας αναζήτησης), καθώς και υποστήριξη για το διαχωρισμό και συνένωση
DMM 6 & Όπως στο DMM 2, καθώς και ειδική μεταχείριση για μπλοκ με μηδενικά bytes (εφαρμογή ειδικής βελτιστοποίησης)
DMM 7 & Όπως DMM 3, καθώς και ειδική μεταχείριση για μπλοκ με μηδενικά bytes (εφαρμογή ειδικής βελτιστοποίησης)
DMM 8 & Όπως DMM 4, καθώς και ειδική μεταχείριση για μπλοκ με μηδενικά bytes (εφαρμογή ειδικής βελτιστοποίησης)
DMM 9 & Όπως DMM 5, καθώς και ειδική μεταχείριση για μπλοκ με μηδενικά bytes (εφαρμογή ειδικής βελτιστοποίησης)
Μια σημαντική εκτίμηση είναι ότι η εξεταζόμενη εφαρμογή πραγματικά ζητά τα block μηδέν bytes στο μέγεθος. Αυτό δεν είναι ένα λάθος, αλλά μια συνέπεια της ανάγκης να σταλούν αναγνωριστικά πακέτα. Δεδομένου ότι αυτά τα TCP τμήματα 0 bytes κινούνται προς το επίπεδο IP, το σώμα τμήματος μηδέν bytes κρατιέται και μια επιγραφή 40 bytes TCP+IP προστίθενται με τις προηγούμενες εκτιμήσεις, και οι μέθοδοι που παρουσιάζονται στο επόμενο κεφάλαιο, το διάστημα σχεδίου του δυναμικού διαχειριστή μνήμης, μπορεί να στενέψουν σε μερικές επιλογές. Για την εφαρμογή οδηγών αυτού του παραδείγματος, αξιολογήσαμε τους δυναμικούς διευθυντές μνήμης που περιγράφηκαν στον πίνακα 7.4. Μετά από κάθε πείραμα, εξετάσαμε τις πληροφορίες που παράγονται στη Pool, Pool, Allocation Information, Dynamic Data, Dynamic Data Instances και Control Flow στις οντότητες μεταδεδομένων (σχήμα. 7.3) και τις συλλέξαμε για να αξιολογήσουμε την ποιότητα κάθε λύσης.
Προτεινόμενα block: Πρέπει να καθοριστούν τα «πρόσθετα» μεγέθη block μνήμης ίσα με κάθε μέγεθος πακέτων που αντιπροσωπεύει τουλάχιστον 10% των γενικών μεγεθών πακέτων. Το υπόλοιπο των προκαθορισμένων block μνήμης πρέπει να είναι μέγεθος δύναμης του δύο μέχρι το μέγεθος MTU. Στην περίπτωση IEEE 802.11b, αυτό σημαίνει ότι απαιτείται ένα πρόσθετο προκαθορισμένο block μνήμης 40 bytes και ένας πρόσθετο προκαθορισμένο block μνήμης 1.500 bytes. Το υπόλοιπο των προκαθορισμένων block μνήμης πρέπει να έχει 256, 512 και 1.024 bytes, αντίστοιχα.
Για μερικές από τις περιπτώσεις που εξετάστηκαν στα πειράματα αυτού του κεφαλαίου, προσθέσαμε δύο μικρότερα μεγέθη (92 και 132 bytes). Επομένως, τα δημοφιλέστερα αιτήματα μνήμης μπορούν ικανοποιηθούν χωρίς οποιοδήποτε εσωτερικό κατακερματισμό και η τα λιγότερο δημοφιλή αιτήματα μπορεί να ικανοποιηθούν με ένα λογικό εσωτερικό τεμαχισμό. Επιπλέον, η απόφαση σχεδίου του προκαθορισμού τα block των σταθερών μεγεθών, στον χρόνο σχεδιασμού, δίνει το πλεονέκτημα απόδοσης και έτσι δε χρειάζεται να υπολογίσει το μέγεθος block για κάθε αίτημα στο χρόνο εκτέλεσης.
Προτεινόμενη συγχώνευση και διαχωρισμός των block: Κανένας διαχωρισμός ή συγχώνευση των block μνήμης δεν πρέπει να χρησιμοποιηθεί. Δεδομένου ότι το μέγιστο ζητούμενο μέγεθος block είναι ήδη γνωστό (το MTU των πακέτων), δεν υπάρχει καμία ανάγκη να συγχωνευτεί block για να εξετάσει τον εξωτερικό τεμαχισμό. Επιπλέον, ο καθορισμός των μεγεθών block που αποτρέπουν τον μεγαλύτερο μέρος του εσωτερικού τεμαχισμού (δηλαδή ο εσωτερικός τεμαχισμός που παράγεται από τα δημοφιλή αιτήματα), μειώνει την ανάγκη να χωριστούν τα block. Επιπλέον, και οι συγχωνευμένοι μηχανισμοί είναι υπολογιστικά εντατικοί, κατά συνέπεια μπορούν να επιβραδύνουν ουσιαστικά τις διαδικασίες δέσμευσης και απελευθέρωσης και μπορούν επίσης να υποστούν έναν σημαντικό αριθμό προσβάσεων μνήμης για να μετασχηματίσουν τα παλαιά μεγέθη block στα νέα.
Προτεινόμενες δεξαμενές: Πρέπει να δημιουργηθούν διάφορες δεξαμενές ίσες με τον αριθμό των προκαθορισμένων μεγεθών block. Στην παρούσα περίπτωση, δύο πρόσθετες δεξαμενές που κρατούν τα 40 bytes και τα 1500 bytes, και μια δεξαμενή για κάθε πρόσθετο μέγεθος block που δημιουργείται.
Αυτή η αδύνατη οργάνωση Pool προτιμάται αντί πιο σύνθετων επειδή επιτρέπει μια γρηγορότερη πρόσβαση στη συγκεκριμένη Pool μνήμης, που θα συντηρήσει κάθε αίτημα: στη χειρότερη περίπτωση, ο αριθμός προσβάσεων μνήμης που θα απαιτηθεί για να βρει τη Pool που κρατά το block του κατάλληλου μεγέθους είναι της τάξεως του αριθμού Pool. Τέλος, μόλις ληφθεί η απόφαση της μη υποστήριξης της συγχώνευσης ούτε του διαχωρισμού των block, το DMM δεν πρέπει να υποστηρίξει (τις δαπανηρές στην απόδοση) μετακινήσεις των block μεταξύ των Pool.
Προτεινόμενοι κατάλληλοι αλγόριθμοι: Προκειμένου να επιλεχτεί μια Pool, προτείνονται οι κατάλληλοι αλγόριθμοι. Η ακριβής τακτοποίηση (best fit) χρησιμοποιείται μόνο για να κάνει διακρίσεις μεταξύ των πρόσθετων Pool, ενώ η πρώτη τακτοποίηση (first fit) χρησιμοποιείται μεταξύ των υπολοίπων. Μόλις επιλεχτεί μια Pool, η πρώτη μόνο τακτοποίηση χρησιμοποιείται για να επιλέξει τον κατάλληλο block. Αυτή η διαμόρφωση απαιτεί τις λιγότερες προσβάσεις προκειμένου να βρεθούν τα block μνήμης για να ικανοποιήσει ένα αίτημα μνήμης. Εάν γίνει λανθασμένος συνδυασμός μεγεθών Pool και κατάλληλων αλγορίθμων, ο αριθμός προσβάσεων μνήμης που εκτελούνται από το διαχειριστή DM μπορεί να αυξήσει σημαντικά και να οδηγήσει στους πιο μακροχρόνιους χρόνους εκτέλεσης και τις μεγαλύτερες καταναλώσεις ενέργειας. Σαν τελική εκτίμηση για να παρακινήσει τη σχετικότητα του δυναμικού διαχειριστή μνήμης για τη σφαιρική απόδοση της πλήρους εφαρμογής που χρησιμοποιείται σε αυτό το παράδειγμα, η Εικόνα 7.5 παρουσιάζει το βάρος των προσβάσεων μνήμης λόγω της δυναμικής διαχείρισης μνήμης πέρα από το συνολικό αριθμό προσβάσεων μνήμης, για κάθε έναν από τους διαχειριστές μνήμης που χρησιμοποιούνται στα πειράματά μας. Οι δυναμικοί διαχειριστές μνήμης 2, 3, 6 και 7 απαιτούν έναν σχετικά χαμηλό αριθμό προσβάσεων μνήμης για να εκτελέσουν την εργασία τους. Αντίθετα, τα DMMs 4, 5, 8 και 9 εισάγουν περισσότερα από ένα τρίτο των προσβάσεων μνήμης που απαιτούνται από την εφαρμογή για να ρυθμιστεί ακριβώς η δυναμική μνήμη. Το DMM 1 εισάγει ένα μέτριο 10% των πρόσθετων προσβάσεων.
Το Σχήμα 7.6 παρουσιάζει συνολικό ποσό προσβάσεων μνήμης που απαιτούνται για να επεξεργαστούν κάθε περίπτωση εισαγωγής με τα DMMs 1, 6 και 7. Κατόπιν, το Σχήμα 7.7 αποκαλύπτει ότι για τις εντατικές περιπτώσεις στοιχείων, όπου τα συνήθως μεγάλα πακέτα στέλνονται και η εργασία που απαιτείται για να επεξεργαστεί τα στοιχεία εκτοπίζει την εργασία που απαιτείται για να διαθέσει τα block, ο αριθμός προσβάσεων λόγω της δυναμικής διαχείρισης μνήμης αντιπροσωπεύει λιγότερο από 1% του συνόλου (είσοδοι 1 και 2 και στους δύο αριθμούς). Εντούτοις, όταν μπορεί η εισαγωγή των δυνάμεων εφαρμογής για να στείλει πολλά μικρά πακέτα (δηλαδή τα μικρά τμήματα TCP στέλνονται λόγω της ανάγκης), ο αριθμός προσβάσεων λόγω της διαχείρισης μνήμης να χρησιμοποιήσει μέχρι ένα 24% του συνόλου για την εισαγωγή. Ενδιαφέρον είναι επίσης, ότι τα γενικά κόστη των DMMs 6 και 7 είναι περίπου το μισό από αυτό, που υπογραμμίζει τη σημασία της απόδοσης του δυναμικού διαχειριστή μνήμης. Μόλις ερευνήσουμε τις βασικές παραμέτρους του διαχειριστή μνήμης και μειώσουμε το διάστημα σχεδίου για το διαχειριστή μνήμης σε ένα εύχρηστο μέγεθος, τρέξαμε διάφορες προσομοιώσεις για να αναλύσουμε την απόδοση κάθε επιλογής όσον αφορά τον αριθμό προσβάσεων μνήμης και αποτυπώματος μνήμης. Ένα μειωμένο διάστημα σχεδίου επιτρέπει μια λεπτομερή ανάλυση και τον καταλληλότερο προσαρμοσμένο δυναμικό διαχειριστή μνήμης.
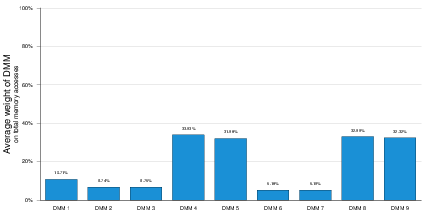
7.5: Ποσοστό των προσβάσεων διαχειριστών μνήμης πέρα από τις συνολικές προσβάσεις εφαρμογής.
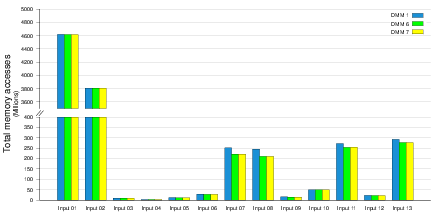
7.6: Αποτελέσματα της δυναμικής διαχείρισης μνήμης στο συνολικό αριθμό προσβάσεων μνήμης: συνολικός αριθμός προσβάσεων για κάθε εισαγωγή.
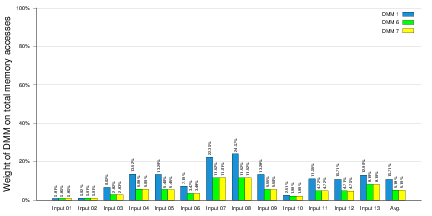
7.7: Αποτελέσματα της δυναμικής διαχείρισης μνήμης στο συνολικό αριθμό προσβάσεων μνήμης: ποσοστό πέρα από τις συνολικές προσβάσεις μνήμης που αντιστοιχούν στον διαχειριστή δυναμικής μνήμης.
Έχοντας ως στόχο την ελαχιστοποίηση των προσβάσεων μνήμης, ο δυναμικός διαχειριστής μνήμης πρέπει να είναι σε θέση να προσκομίσει τα block για τα δημοφιλέστερα μεγέθη γρήγορα. Ομοίως, η διαδικασία για τα ελεύθερα block που γίνονται αχρησιμοποίητα, πρέπει να είναι γρήγορη. Αυτό προτείνει την ειδίκευση των καταλόγων ελεύθερων block για τα δημοφιλή μεγέθη. Εντούτοις, η χρησιμοποίηση ενός υψηλού αριθμού καταλόγων αυξάνει το χρόνο αναζήτησης, και επομένως ο αριθμός καταλόγων πρέπει να μειώσει ειδικά αυτά που λαμβάνουν τις περισσότερες προσβάσεις. Ο πίνακας 7.5 παρουσιάζει τη διαφορά στον αριθμό προσβάσεων μνήμης σχετικών άμεσα με τη διαχείριση της δυναμικής μνήμης στη βέλτιστη λύση για κάθε περίπτωση εισαγωγής.
Το DMMs 6 και 7 είναι οι διαχειριστές μνήμης που υφίστανται τα χαμηλότερα γενικά κόστη, με το DMM6 να είναι καλύτερο για τις περισσότερες από τις περιπτώσεις εισαγωγής (11 από τα 13). Έναντι του DMM 1, ο δυναμικός διαχειριστής μνήμης που χρησιμοποιείται ως αναφορά για αυτήν την περιπτωσιολογική μελέτη, ενώ τα DMMs 6 και 7 λαμβάνουν μια βελτίωση μέχρι 62.35% και 62.33%, αντίστοιχα (για 5 εισόδους). Κατά μέσον όρο, και οι δύο διαχειριστές επιτρέπουν μια μείωση 45.67% και 45.62% των προσβάσεων μνήμης, λόγω της διαχείρισης της δυναμικής μνήμης, αντίστοιχα (σχήμα. 7.8).
Η μείωση του αριθμού προσβάσεων μνήμης λόγω DMM είναι σημαντική, αλλά ο τελικός στόχος είναι να μειωθεί ο συνολικός αριθμός προσβάσεων μνήμης της εφαρμογής. Ο πίνακας 7.6 παρουσιάζει τη διαφορά στο συνολικό αριθμό προσβάσεων μνήμης πότε η χρησιμοποίηση καθενός των διαχειριστών σύγκρινε με το βέλτιστο για κάθε περίπτωση εισαγωγής. Τα αποτελέσματα είναι συνεπή και, πάλι, τα DMMs 6 και 7 επιτρέπουν τη μεγαλύτερη μείωση των προσβάσεων μνήμης, με μια αμελητέα μέση απόκλιση στο βέλτιστο τρόπο για κάθε διαφορετική περίπτωση εισόδου. Με παρόμοιο τρόπο με την προηγούμενη ανάλυση, η Εικόνα 7.9 επεξηγεί τη βελτίωση που επιτυγχάνεται από αυτούς τους δύο δυναμικούς διαχειριστές μνήμης (μέχρι 14.18% για την είσοδο 08 και 5.98% κατά μέσον όρο). Για να γίνει κατανοητή η διαφορά μεταξύ των δύο λύσεων που είναι οι πιο κοντινές στο βέλτιστο για τις περισσότερες περιπτώσεις, το σχήμα 7.10 παρουσιάζει τη διαφορά μεταξύ τους για κάθε περίπτωση εισόδου. Η βελτίωση του DMM 6 ως προς το DMM 7 είναι πολύ μικρή. Αυτή η διαφορά μελετάται περαιτέρω παρακάτω.
Η χρησιμοποίηση της λιγότερης μνήμης είναι ευεργετική για μια εφαρμογή που τρέχει σε ένα ενσωματωμένο σύστημα από πολλές απόψεις. Παραδείγματος χάριν, το σύστημα μπορεί να χρησιμοποιήσει μια μικρότερη μνήμη, η οποία θα μεταφράσει σε έναν γρηγορότερο χρόνο πρόσβασης και μια πιο μικρή κατανάλωση ενέργειας. Ο διαχειριστής συστημάτων μπορεί ακόμη και να είναι σε θέση να ελαττώσει την κατανάλωση ενέργειας στις αχρησιμοποίητες ενότητες μνήμης για να μειώσει περαιτέρω τη συνολική κατανάλωση ενέργειας. Κατά συνέπεια, η μείωση του αποτυπώματος μνήμης της εφαρμογής είναι ένας σχετικός στόχος βελτιστοποίησης. Προκειμένου να μειωθεί το αποτύπωμα μνήμης της εφαρμογής, ο δυναμικός διαχειριστής μνήμης πρέπει να εξασφαλίσει ότι το ποσό μνήμης που σπαταλιέται πρέπει, λόγω του εσωτερικού ή/και εξωτερικού τεμαχισμού, να περιορίζεται στο ελάχιστο. Επομένως, μια σημαντική βελτιστοποίηση είναι να σιγουρευτεί ότι τα block με τα σωστά μεγέθη χρησιμοποιούνται για κάθε δέσμευση. Το DMM 6 χτίζει τους καταλόγους ελεύθερων block για τα δημοφιλέστερα μεγέθη (40, 1460 και 1500 bytes), για να μειώσει τον αριθμό προσβάσεων που απαιτούνται για να βρουν το σωστό block. Το DMM 7 προσθέτει μερικά λιγότερο συχνά ζητούμενα μεγέθη (92 και 132 bytes), καθώς επίσης και ενδιάμεσα (256, 512 και 1024 bytes), για να αποφύγει μια υψηλή ποινική ρήτρα για τις κατανομές των ενδιάμεσων μεγεθών. Εκτελέσαμε διάφορα πειράματα για να επικυρώσουμε τις προηγούμενες υποθέσεις βασισμένες στα αποσπασματικά μεταδεδομένα λογισμικού. Ο Πίνακας 7.7 και το σχήμα 7.11 παρουσιάζει το ποσό μνήμης που απαιτείται από την εφαρμογή για κάθε σύνολο δεδομένων εισόδου, χρησιμοποιώντας κάθε έναν από τους διαφορετικούς διαχειριστές. Για την εφαρμογή του DDTs, χρησιμοποιήσαμε τον προηγουμένως επιλεγμένο συνδυασμό: A3-B3. Ο πίνακας 7.8 παρουσιάζει την απόκλιση των διαφορετικών εφαρμογών όσον αφορά το βέλτιστο, για κάθε περίπτωση εισαγωγής. Εξετάζοντας το αποτύπωμα μνήμης, το DMM 7 είναι ο καλύτερος διαχειριστής μνήμης για τις περισσότερες από τις περιπτώσεις εισαγωγής. Εντούτοις, η διαφορά σε μια υποθετική τέλεια λύση για όλες τις περιπτώσεις είναι τώρα μεγαλύτερη, με μια μέση απόκλιση 10.02%, αλλά ένα μέγιστο λάθος 81.9% (για 10 εισόδους). Αντίθετα, η μέση διαφορά του DMM 6 ως προς το βέλτιστο είναι τώρα αρκετά υψηλότερη. Η υψηλότερη παραλλαγή των αποτελεσμάτων που επιτυγχάνονται για το αποτύπωμα μνήμης, έναντι των αποτελεσμάτων που επιτυγχάνονται για τον αριθμό προσβάσεων μνήμης, οφείλεται στο γεγονός ότι το αποτύπωμα μνήμης είναι πιο ευαίσθητο στις μικρές παραλλαγές στον αριθμό block κάθε μεγέθους που διατίθενται, ακόμα κι αν ο αριθμός προσβάσεων για να βρει τα block παραμένει ο ίδιος. Το σχήμα 7.12 παρουσιάζει τη διαφορά στο αποτύπωμα μνήμης κάθε δυναμικού διαχειριστή μνήμης στο βέλτιστο, που υπολογίζεται κατά μέσο όρο για όλες τις περιπτώσεις εισαγωγής. Το σχήμα 7.13 παρουσιάζει το συνολικό αποτύπωμα μνήμης (στις bytes) που απαιτείται από τους διαφορετικούς δυναμικούς διευθυντές μνήμης για κάθε περίπτωση εισόδου.
| Input | DMM1(%) | DMM2(%) | DMM3(%) | DMM4(%) | DMM5(%) | DMM6(%) | DMM7(%) | DMM8(%) | DMM9(%) |
| 01 | 0.01 | 0 | 0 | 40,41 | 39,26 | 0 | 0 | 40,10 | 35,82 |
| 02 | 0,01 | 0 | 0 | 20,38 | 20,20 | 0 | 0 | 20,63 | 20,36 |
| 03 | 4,11 | 0,76 | 0,73 | 20,38 | 20,74 | 0 | 0,03 | 15,46 | 16,18 |
| 04 | 9,10 | 1,84 | 1,95 | 42,34 | 41,53 | 0 | 0 | 29,76 | 29,24 |
| 05 | 9,06 | 2,43 | 2,41 | 46,09 | 47,11 | 0 | 0,07 | 35,56 | 38,13 |
| 06 | 4,05 | 1,01 | 1,02 | 30,07 | 30,19 | 0 | 0,06 | 20,81 | 21,88 |
| 07 | 13,87 | 4,03 | 4,14 | 63,55 | 63,61 | 0 | 0,11 | 68,00 | 70,74 |
| 08 | 16,53 | 4,85 | 4,85 | 65,94 | 65,99 | 0 | 0 | 65,20 | 65,41 |
| 09 | 8,93 | 2,40 | 2,42 | 45,54 | 43,53 | 0 | 0.,03 | 36,19 | 31,98 |
| 10 | 0,54 | 0 | 0 | 32,22 | 29,46 | 0 | 0 | 28,25 | 28,39 |
| 11 | 7,04 | 2,04 | 2,08 | 37,47 | 44,36 | 0 | 0,02 | 50,99 | 44,03 |
| 12 | 6,75 | 1,91 | 1,88 | 39,39 | 39,42 | 0 | 0,12 | 38,01 | 45,30 |
| 13 | 5,48 | 1,59 | 1,60 | 156,88 | 46,77 | 0 | 0.01 | 234,48 | 161,15 |
| Average | 6,57 | 1,76 | 1,78 | 49,28 | 41,09 | 0 | 0.03 | 52,57 | 46,82 |
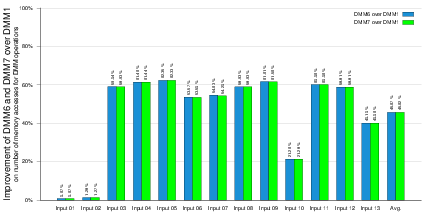
7.8: Η βελτίωση του αριθμού προσβάσεων μνήμης λόγω DMM κατά την χρησιμοποίηση του DMM 6 ή 7, αντί του DMM 1.
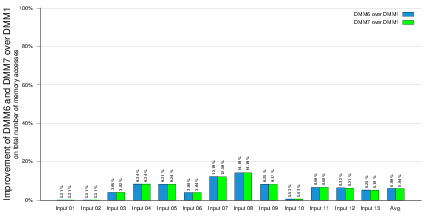
7.9: Βελτίωση στο συνολικό αριθμό προσβάσεων μνήμης λόγω των βελτιστοποιήσεων στο διαχειριστή δυναμικής μνήμης: βελτίωση DMM 6 και 7 πέρα από το διαχειριστή δυναμικής μνήμης αναφοράς (DMM 1).
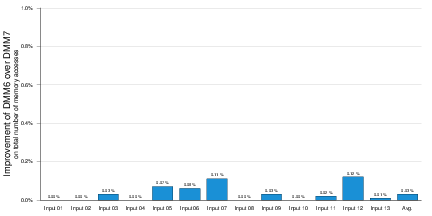
7.10: Βελτίωση στο συνολικό αριθμό προσβάσεων μνήμης λόγω των βελτιστοποιήσεων στο διαχειριστή δυναμικής μνήμης: οριακή βελτίωση DMM 6 άνω των DMM 7 για το συνολικό αριθμό προσβάσεων μνήμης
| Input set | DMM1 | DMM2 | DMM3 | DMM4 | DMM5 | DMM6 | DMM7 | DMM8 | DMM9 |
| Input 01 | 9292957 | 9158053 | 9179392 | 9990414 | 10564220 | 9158542 | 9176738 | 10071532 | 10659022 |
| Input 02 | 8261672 | 8114640 | 8146305 | 30344312 | 36688944 | 8069856 | 8100836 | 36775346 | 31719557 |
| Input 03 | 2324829 | 3101201 | 1955788 | 3138464 | 3084152 | 3191153 | 2141262 | 2508024 | 2668710 |
| Input 04 | 583720 | 1068413 | 793154 | 805870 | 848280 | 858652 | 638234 | 564347 | 618625 |
| Input 05 | 2041645 | 1541750 | 1541532 | 3707705 | 3590099 | 1240996 | 1229171 | 1346610 | 1232973 |
| Input 06 | 3657349 | 4387276 | 3302356 | 9287451 | 9497449 | 4450461 | 2957479 | 7873662 | 7400638 |
| Input 07 | 14509008 | 491348 | 488828 | 4030953 | 3985615 | 263972 | 261308 | 39644311 | 37313804 |
| Input 08 | 16552416 | 535652 | 510296 | 4077566 | 3964176 | 279673 | 249007 | 26375050 | 26260057 |
| Input 09 | 2280466 | 2576408 | 2257745 | 4787656 | 4938782 | 2135969 | 1938658 | 3025090 | 3396929 |
| Input 10 | 3441933 | 9070597 | 6375234 | 3487045 | 3944477 | 9064424 | 6260861 | 3511306 | 3510688 |
| Input 11 | 9476152 | 2228468 | 1261357 | 64222751 | 58511747 | 1946504 | 978527 | 10085511 | 13690317 |
| Input 12 | 1959322 | 2038829 | 1417485 | 6459893 | 6600368 | 2093518 | 1122728 | 1581100 | 897078 |
| Input 13 | 7667048 | 4888330 | 756467 | 2465793 | 2481203 | 4834146 | 600508 | 46420012 | 7808988 |
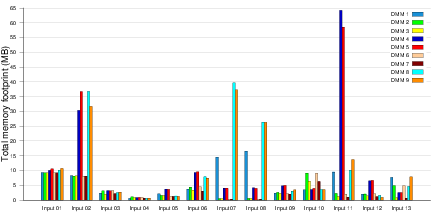
7.11: Συνολικό αποτύπωμα μνήμης που απαιτείται από κάθε έναν από τους διαχειριστές δυναμικής μνήμης για κάθε περίπτωση εισαγωγής
Η εφαρμογή απαιτεί ένα ορισμένο ποσό μνήμης, αλλά ο δυναμικός διαχειριστής μνήμης χρειάζεται κάποια πρόσθετη μνήμη για τις εσωτερικές δομές του. Επιπλέον, τα αποτελέσματα του εσωτερικού και εξωτερικού τεμαχισμού παράγουν μια σημαντική αύξηση στο πραγματικό ποσό μνήμης, που απαιτείται για να εξυπηρετήσει τις ανάγκες της εφαρμογής. Για τον καλύτερο κατάλληλο διαχειριστή μνήμης, το DMM 7, τα γενικά κόστη είναι μόνο 40.26% (έναντι 1562.44% του διαχειριστή αναφοράς, DMM 1 που είναι διαχειριστής μνήμης γενικού σκοπού). Εντούτοις, εάν ο διαχειριστής μνήμης χρησιμοποιούμενος δεν είναι μεγάλης ακρίβειας που συντονίζεται στη συμπεριφορά δέσμευσης της εφαρμογής, τα γενικά κόστη μπορούν να αυξηθούν μέχρι 2996.77% (κατά μέσον όρο, κατά τη χρησιμοποίηση του DMM 8).
| Input | DMM1(%) | DMM2(%) | DMM3(%) | DMM4(%) | DMM5(%) | DMM6(%) | DMM7(%) | DMM8(%) | DMM9(%) |
| 01 | 1.5 | 0 | 0.2 | 9.1 | 15.3 | 0.0 | 0.2 | 10.0 | 16.4 |
| 02 | 2.4 | 0.6 | 0.9 | 276.0 | 354.6 | 0.0 | 0.4 | 355.7 | 293.1 |
| 03 | 18.9 | 58.6 | 0.0 | 60.5 | 57.7 | 63.2 | 9.5 | 28.2 | 36.4 |
| 04 | 3.4 | 89.3 | 40.5 | 42.8 | 50.3 | 52.1 | 13.1 | 0.0 | 9.6 |
| 05 | 66.1 | 25.4 | 25.4 | 201.6 | 192.1 | 1.0 | 0.0 | 9.5 | 0.3 |
| 06 | 23.7 | 48.3 | 11.7 | 214.0 | 221.1 | 50.5 | 0.0 | 166.2 | 150.2 |
| 07 | 5452.4 | 88.0 | 87.1 | 1442.6 | 1425.3 | 1.0 | 0.0 | 15071.5 | 14179.6 |
| 08 | 6547.4 | 151.1 | 104.9 | 1537.5 | 1484.8 | 12.3 | 0.0 | 10492.1 | 10445.9 |
| 09 | 17.6 | 32.9 | 16.5 | 147.0 | 154.8 | 10.2 | 0.0 | 56.0 | 75.2 |
| 10 | 0 | 163.5 | 85.2 | 1.3 | 14.6 | 163.3 | 81.9 | 2.0 | 2.0 |
| 11 | 868.4 | 127.7 | 28.9 | 6463.2 | 5879.6 | 98.9 | 0.0 | 930.7 | 1299.1 |
| 12 | 118.4 | 127.3 | 58.0 | 620.1 | 635.8 | 133.4 | 25.1 | 76.2 | 0.0 |
| 13 | 1176.8 | 714.0 | 26.0 | 310.6 | 313.2 | 705.0 | 0.0 | 673.0 | 1200.4 |
| Μέση τιμή | 1099.8 | 122.4 | 37.3 | 871.3 | 830.7 | 99.3 | 10.0 | 2144.0 | 2131.4 |
Ανάλυση του αποτυπώματος μνήμης με κάθε δυναμικό διαχειριστή μνήμης: μέση διαφορά στο αποτύπωμα μνήμης κάθε διαχειριστή μνήμης στο βέλτιστο. Αν και το DMM 7 δεν είναι η καλύτερη λύση για όλες τις περιπτώσεις εισαγωγής, είναι η καλύτερη γενική λύση.
Με τα προηγούμενα αποτελέσματα, φαίνεται λογικό να υιοθετήσει κάποιος το DMM7 ως τελικό διαχειριστή μνήμης για την εφαρμογή. Εντούτοις, στο τμήμα 7.4.6, αναλύεται αυτός ανεξάρτητα από την εφαρμογή των βελτιστοποιήσεων στη μεταφορά των block των δυναμικών στοιχείων και εξετάζεται η επίδραση και των δύο δυναμικών διαχειριστών μνήμης.
Ανάλυση του αποτυπώματος μνήμης με κάθε δυναμικό διαχειριστή μνήμης: Υπερυψωμένο Μέσο αποτυπώματος μνήμης κάθε δυναμικού διαχειριστή μνήμης.
Η παραδοσιακή εφαρμογή της μεταφοράς DMA είναι να μετακινηθούν τα στοιχεία στη μνήμη (ή μεταξύ της μνήμης και των εξωτερικών συσκευών), απελευθερώνοντας τους κύκλους των επεξεργαστών. Εντούτοις, στα ενσωματωμένα συστήματα είναι επίσης κοινή πρακτική να χρησιμοποιηθεί η μεταφορά DMA για να μειώσει τη μέση λανθάνουσα κατάσταση στα στοιχεία πρόσβασης από την κύρια μνήμη (πχ. που αντιγράφει τα στοιχεία στις πιο στενές μνήμες όπως «scratchpad» προτού να τους χρειαστεί πραγματικά η ΚΜΕ στο [76]). Το DRAM είναι συνήθως η τεχνολογία μνήμης που επιλέγεται για να εφαρμόσει την κύρια μνήμη των ενσωματωμένων συστημάτων. Αυτές οι συσκευές οργανώνονται εσωτερικά στις συστοιχίες και τις σελίδες, με τον περιορισμό ότι μόνο μια σελίδα μπορεί να είναι ενεργός σε κάθε συστοιχία οποιαδήποτε στιγμή. Η αλλαγή της ενεργού σελίδας σε μια συστοιχία DRAM έχει κύκλους τους μη-αμελητέους δαπανών ως προς την κατανάλωση ενέργειας. Αυτός ο τύπος οργάνωσης ευνοεί τα διαδοχικά σχέδια πρόσβασης. Εντούτοις, όταν χρησιμοποιεί το DMA την κύρια μνήμη παράλληλα με τον επεξεργαστή, έχει πρόσβαση και από τους δύο παρεμβάλλει λευκές σελίδες με έναν ακαθόριστο τρόπο. Επομένως, δύο σχετικοί στόχοι βελτιστοποίησης για τις εφαρμογές που τρέχουν στα ενσωματωμένα συστήματα είναι ο αποδοτικός σχεδιασμός των μεταφορών στοιχείων για τα block των δυναμικών στοιχείων που χρησιμοποιούν την ενότητα DMA και η σωστή παρεμβολή λευκών σελίδων των προσβάσεων από τον επεξεργαστή και το DMA για να αποφύγουν τις περιττές ενεργοποιήσεις σειρών στις σελίδες των ενοτήτων DRAM. Σε αυτό το τμήμα, αξιολογούμε την εφαρμογή των τεχνικών βελτιστοποίησης βασισμένων στις πληροφορίες που παρέχονται από τα μεταδεδομένα λογισμικού για τη μεταφορά των δυναμικών block στοιχείων. Τα μεταδεδομένα λογισμικού περιέχουν τις πληροφορίες για τον αριθμό μεταφορών block που περιλαμβάνουν τις περιπτώσεις δυναμικών τύπων στοιχείων, μήκους, κατεύθυνσης (κύρια μνήμη) και του νήματος που τις άρχισαν (κυρίως, η οντότητα μεταφορών block από το σχήμα. 7.3). Αυτές οι πληροφορίες διευκολύνουν τη βελτίωση της χρησιμοποίησης της ενότητας DMA για την εφαρμογή οδηγών αυτού του παραδείγματος. Εάν η περίπτωση εισαγωγής παράγει τη μακροχρόνια σειρά διαδοχικών προσβάσεων (δηλαδή τα μακριά πακέτα διαδικασιών συστημάτων κυρίως), είναι καλοί υποψήφιοι που εκτελούνται από το DMA. Αντίθετα, εάν το σύστημα πρέπει να επεξεργαστεί πολλά μικρά πακέτα, τα γενικά κόστη του προγραμματισμού του DMA μπορούν να είναι υψηλότερα από τον αριθμό κύκλων που θα απαιτούταν η μεταφορά αν ήταν εκτελεσμένος άμεσα από τον επεξεργαστή. Επιπλέον, ο σχεδιασμός των προσβάσεων στους δυναμικούς τύπους στοιχείων πρέπει να εξετάσει επίσης δύο περισσότερες περιστάσεις. Κατ’ αρχάς, όταν εκτελείται μια μεταφορά block από το DMA παράλληλα με τον επεξεργαστή, οι εξωτερικές ενότητες DRAM λαμβάνουν δύο ταυτόχρονα ρεύματα των προσβάσεων που μπορούν να αναγκάσουν τις πρόσθετες ενεργοποιήσεις σειρών. Δεύτερον, η ενότητα DMA μπορεί να ωφεληθεί από τη χαμηλότερη λανθάνουσα κατάσταση των τρόπων έκρηξης DRAM ως εκ τούτου, μπορεί να είναι ενδιαφέρον να βεβαιωθεί ότι ο επεξεργαστής δεν προαγοράζει την ενότητα DMA από το δίαυλο κατά τη διάρκεια των μεταφορών. Εντούτοις, μπορεί να είναι απαραίτητο να εγγυηθεί ότι ο επεξεργαστής μπορεί να έχει πρόσβαση στη μνήμη σε έναν οριακό αριθμό κύκλων, για παράδειγμα, για να προσκομίσει τον κώδικα διακόπτει τη ρουτίνα από την κύρια μνήμη.
Λαμβάνοντας αυτές τις εκτιμήσεις υπόψη, εξετάζουμε για αυτό το πείραμα τις 3 διαφορετικές πολιτικές σχεδιασμού. Ο πρώτος εκτελεί όλες τις προσβάσεις στη δυναμική μνήμη με τον επεξεργαστή. Ο δεύτερος χρησιμοποιεί την ενότητα DMA για τα block περισσότερων από 32 bytes (οκτώ λέξεις), αλλά ο μέγιστος αριθμός κύκλων ότι η μηχανή DMA μπορεί να κρατήσει το δίαυλο κατά τη διάρκεια των συναλλαγών έκρηξης περιορίζεται σε οκτώ λέξεις (επομένως, μόλις χορηγηθεί στο DMA η πρόσβαση στο δίαυλο, μπορεί να μεταφέρει χωρίς διακοπές τουλάχιστον τόσα bytes όσο η πιο σύντομη μεταφορά). Τέλος, η τρίτη διαμόρφωση υιοθετεί την ενότητα DMA για τις μεταφορές τουλάχιστον 32 bytes, αλλά εξασφαλίζει ότι το DMA μπορεί να έχει πρόσβαση μέχρι μια ολόκληρη σελίδα DRAM σε μια ενιαία συναλλαγή έκρηξης η αποδοτικότητα επιπλέον, αυτή η τελευταία πολιτική χρησιμοποιεί τις τεχνικές που παρουσιάζονται στο [72] και στο [59] για να αποφασίσουν για να χρησιμοποιήσει το DMA ή όχι εάν το σύστημα είναι μπορεί να αναγνωρίσει την παρούσα περίπτωση εισαγωγής. Αναφερόμαστε σε αυτές τις πολιτικές ως «κανένα DMA (No DMA)» «το DMA προκαλεί πρόβλημα (DMA Bad)» και «το DMA προαιρετικό (DMA opt)», αντίστοιχα. Τα αποτελέσματα αυτής της μελέτης αποκαλύπτουν ότι η χρησιμοποίηση της ενότητας DMA μπορεί να απομακρύνει ένα μη αμελητέο ποσό κύκλων των επεξεργαστών (μέσος όρος 43% κατά τη χρησιμοποίηση της βέλτιστης διαμόρφωσης DMA με DMM7), αλλά μόνο εάν το DMA χρησιμοποιείται κατάλληλα. Διαφορετικά, μπορεί να ασκήσει σημαντική αρνητική επίδραση στην κατανάλωση ενέργειας του υποσυστήματος μνήμης, της μέσης λανθάνουσας κατάστασης μνήμης και σπαταλημένους κύκλους αναμονής επεξεργαστών, για να έχει πρόσβαση στη μνήμη.
Το σχήμα 7.14 παρουσιάζει την επίδραση ενός καλού σχεδιασμού: Με τη χρησιμοποίηση της σωστής διαμόρφωσης, μια βελτίωση μέχρι 33% επιτυγχάνεται στον αριθμό των κύκλων που ξοδεύει ένας επεξεργαστής στην πρόσβαση της μνήμης σε σύγκριση με απουσία χρησιμοποίησης DMA. Υπάρχει επίσης μια μικρή βελτίωση στην κατανάλωση ενέργειας. Επιπλέον, έναντι μιας κακής διαμόρφωσης DMA που δεν περιορίζει αρκετά τις παρεμβάσεις μεταξύ των δύο στοιχείων, ένα 24% της μέσης βελτίωσης είναι εφικτό για τον αριθμό ενεργοποιήσεων ακολουθίας προσβάσεων DRAM, 14% για τον αριθμό των κύκλων των επεξεργαστών που ξοδεύονται, πρόσβαση της μνήμης και 9% για την κατανάλωση ενέργειας.
7.14: Βελτίωση που πραγματοποιήθηκε χρησιμοποιώντας μια μεταφορά DMA για τα δυναμικά στοιχεία. Τα περισσότερα εναπομείναντα block παρουσιάζουν τις βελτιώσεις που επιτυγχάνονται με τη σωστή διαμόρφωση DMA έναντι της μη χρησιμοποίησης των σωστών βελτιώσεων block του DMA σε σύγκριση με τη λανθασμένη χρησιμοποίησης που δεν περιορίζει την παρέμβαση του DMA με τον επεξεργαστή.
Το σχήμα 7.15 επεξηγεί την επίδραση που έχουν στην απόδοση του συστήματος οι βελτιστοποιήσεις που εκτελούνται προηγουμένως στον δυναμικό διαχειριστή μνήμης, κατά τη χρησιμοποίηση μιας ενότητας DMA. Εδώ, χρησιμοποιούμε την καλύτερη διαμόρφωση DMA με τους δυναμικούς διαχειριστές μνήμης που επιλέγονται στο προηγούμενο βήμα, τα DMM 6 και 7. Κατόπιν, συγκρίνουμε τα τελικά αποτελέσματα απόδοσής τους με τα αποκτηθέντα, χρησιμοποιώντας την ίδια διαμόρφωση DMA με το διαχειριστή αναφοράς, DMM 1. Τα αποτελέσματα αυτής της σύγκρισης είναι αποκαλυπτικά: Ο συνδυασμός του DMA με οποιαδήποτε από το βελτιστοποιημένο DMMs επιτυγχάνει τις βελτιώσεις, σε σύγκριση με το συνδυασμό του DMA και της αναφοράς DMM, περίπου 6% στο μέσο αριθμό ενεργοποιήσεων σειρών DRAM, 13% στον αριθμό κύκλων που ξοδεύονται από τον επεξεργαστή που έχει πρόσβαση στη μνήμη και 9% στην κατανάλωση ενέργειας του υποσυστήματος μνήμης.
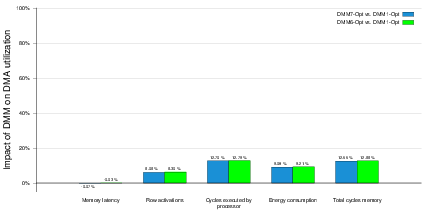
7.15: Η επιλογή ενός από τους βελτιστοποιημένους δυναμικούς διαχειριστές μνήμης που βελτιώνουν τη γενική απόδοση κατά την προσθήκη μιας ενότητας DMA.
Η έκβαση του βήματος βελτιστοποίησης δυναμικής διαχείρισης μνήμης ήταν ότι το DMM 7 είναι η καλύτερη μέση λύση όταν εξετάζεται το αποτύπωμα μνήμης, και το DMM6 κατά την εξέταση του αριθμού προσβάσεων μνήμης. Εντούτοις, η διαφορά μεταξύ των δύο κατά την εξέταση του αριθμού προσβάσεων μνήμης ήταν αμελητέα. Έτσι, κρατήσαμε και τους δύο δυναμικούς διαχειριστές μνήμης, ακριβώς χάριν της ανάλυσης του αντίκτυπού τους στην απόδοση της ενότητας DMA. Το σχήμα 7.16 δείχνει ότι και οι δύο διαχειριστές έχουν μια παρόμοια επίδραση στη συμπεριφορά ολόκληρου του υποσυστήματος μνήμης, με το μεγαλύτερο αντίκτυπο που είναι χαμηλότερο από 0.30% (για τον αριθμό ενεργοποιήσεων σειρών DRAM). Επομένως, μπορούμε τώρα να καταλήξουμε στο συμπέρασμα ακίνδυνα, ότι ο DMM7 είναι ο διαχειριστής μνήμης που πρέπει πάντα να χρησιμοποιείται σε αυτό το σύστημα. Η διαθεσιμότητα μιας κοινής αντιπροσώπευσης μεταδεδομένων λογισμικού απλοποιεί αυτόν τον τύπο ανάλυσης.
Στο σχήμα 7.17 παρουσιάζει γενικές βελτιώσεις που επιτυγχάνονται χρησιμοποιώντας το DMM7 με τη βέλτιστη διαμόρφωση DMA, έτσι ώστε τα αποτελέσματα των τεχνικών βελτιστοποίησης DMMR και DMA συνδυάζονται και αναλύονται από κοινού. Μέχρι 43% των κύκλων επεξεργαστών είναι τώρα ελεύθερα να χρησιμοποιηθούν για οποιοδήποτε σκοπό εκτός από την πρόσβαση των δυναμικών στοιχείων από την κύρια μνήμη, και είναι δυνατή μια μέση μείωση 9% στην κατανάλωση ενέργειας του υποσυστήματος μνήμης . Επιπλέον, έναντι μιας λανθασμένης διαμόρφωσης της ενότητας DMA, μια μείωση 29% στον αριθμό ενεργοποιήσεων σειρών DRAM και 18% στην ενέργεια που ξοδεύεται στις ενότητες μνήμης είναι δυνατή.
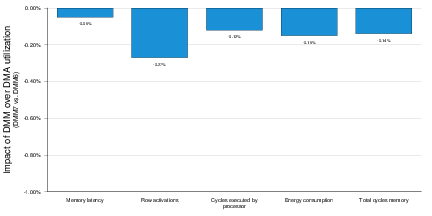
7.16: Αντίκτυπος των διαφορετικών βελτιστοποιημένων διαχειριστών μνήμης από το προηγούμενο βήμα στη χρησιμοποίηση του DMA: Τα αποτελέσματα των DMM 6 και 7 είναι σχεδόν ίδια.
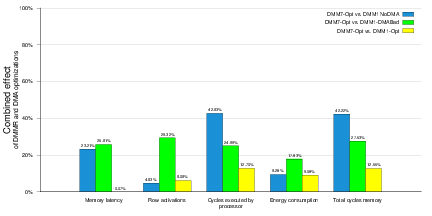
7.17: Τελική συνδυασμένη επίδραση των βελτιστοποιήσεων DMM και DMA.
Ο κύριος διαφοροποιητής σε αυτό το κεφάλαιο όσον αφορά τη σχετική εργασία είναι ότι η προσέγγισή μας στα μεταδεδομένα λογισμικού δεν στοχεύει να καθορίσει την εφαρμοσμένη μηχανική των εφαρμογών λογισμικού, ούτε για να αναλύσει ή να χαρακτηρίσει τη δομή τους. Αντ’ αυτού, προσπαθούμε να αντιπροσωπεύσουμε τα χαρακτηριστικά της συμπεριφοράς τους, όταν υπόκεινται στις συγκεκριμένες εισόδους, με έναν επαναχρησιμοποιήσιμο τρόπο. Επιπλέον, περιορίζουμε συγκεκριμένα αυτήν την εργασία στο πεδίο των εφαρμογών που εξουσιάζονται από τους δυναμικά διατιθέμενους τύπους στοιχείων που τρέχουν στα ενσωματωμένα συστήματα. Τα παραχθέντα μεταδεδομένα λογισμικού μπορούν να χρησιμοποιηθούν με τα μεταδεδομένα υλικού της πλατφόρμας για να προσαρμόσουν τη διαχείριση των πόρων και να εφαρμόσουν τις διαφορετικές τεχνικές βελτιστοποίησης. Όσον αφορά το θέμα της σκιαγράφησης, αυτό το κεφάλαιο παρουσιάζει μια μέθοδο για να σχολιάσει την εφαρμογή DDTs με τα πρότυπα έτσι ώστε όλες οι προσβάσεις στις μεταβλητές τους καταγράφονται.
Αυτή η μέθοδος απαιτεί μόνο μια μεταγλώττιση της εφαρμογής· μπορεί έπειτα να οργανωθεί με τις διαφορετικές εισόδους για να πάρει το διαφορετικό σχεδιασμό περιγράμματος στις εκτελέσεις. Το κύριο πλεονέκτημα της εξηγημένης μεθόδου υποσημειώσεων είναι ότι ο μεταγλωττιστής διαδίδει την ενοργάνωση προσβάσεων αυτόματα, που εγγυάται ότι όλες αυτές καταγράφονται. Αυτή η μέθοδος υποστηρίζει πολυνημάτωση εντούτοις, όπως συμβαίνει με την αναγραφή οποιουδήποτε πολύπλοκου κώδικα, είναι δυνατό ότι λόγω του θεωρήματος του «Heisenburg» η παρατήρηση αλλάζει ελαφρά το αποτύπωμα εκτέλεσης της εφαρμογής. Πιστεύουμε ότι αυτό δεν είναι ένα πρόβλημα για το καλά συμπεριφερόμενο λογισμικό πολυμέσων που εφαρμόζει τα κατάλληλα κλειδώματα συγχρονισμού και ασφάλειας των νημάτων. Συγκρίνοντας, με ένα εργαλείο όπως το Valgrind, που τρέχει τον κώδικα μπορεί να διατηρήσει τον κώδικα πανομοιότυπο χωρίς σκιαγράφηση. Εντούτοις, θα ήταν επίσης πιο δύσκολο να συνδεθούν οι πληροφορίες περιγράμματος με τις συγκεκριμένες γραμμές στον πηγαίο κώδικα.
Σε αυτό το κεφάλαιο έχουμε εισαγάγει την έννοια των μεταδεδομένων λογισμικού για να χαρακτηρίσουμε τη δυναμική συμπεριφορά δέσμευσης και πρόσβασης στοιχείων των εφαρμογών λογισμικού, στα ενσωματωμένα συστήματα. Έχουμε καθορίσει και την έννοια των μεταδεδομένων λογισμικού και τις σχετικές πληροφορίες για να εκτελέσουμε τις βελτιστοποιήσεις στο δυναμικό υποσύστημα μνήμης. Αυτές οι πληροφορίες μπορούν να μοιραστούν και να χρησιμοποιηθούν από τα διαφορετικά εργαλεία βελτιστοποίησης, ακόμη και από τους ανεξάρτητους παρόχους, επιτρέποντας τη βελτιστοποίηση της σύνθετης ενσωματωμένης κατανάλωσης ενέργειας συστημάτων, ως προς τις προσβάσεις μνήμης και το αποτύπωμα μνήμης. Στην πραγματικότητα, οποιοδήποτε εργαλείο μπορεί να ενημερώσει τις τιμές μεταδεδομένων για τις μετρήσεις που επηρεάζονται από τις βελτιστοποιήσεις του. Οι ενημερωμένες πληροφορίες μπορούν έπειτα να χρησιμοποιηθούν από τα επόμενα εργαλεία βελτιστοποίησης.
Η εφαρμογή αυτής της μεθοδολογίας θα μείωνε το χρόνο για το χαρακτηρισμό των εφαρμογών, επειδή οι πληροφορίες που παράγονται κατά τη διάρκεια μιας ενιαίας φάσης σκιαγράφησης και ανάλυσης θα ήταν διαθέσιμες σε όλες τις επόμενες τεχνικές βελτιστοποίησης.
Η μέθοδος για να εξαγάγει τα μεταδεδομένα των ενσωματωμένων εφαρμογών λογισμικού που έχουμε παρουσιάσει, διαιρείται σε δύο βήματα: σκιαγράφηση των εφαρμογών, η οποία παράγει τις ακατέργαστες πληροφορίες, και την ανάλυση αυτών των πληροφοριών, για να λάβει τις τελικές τιμές μεταδεδομένων.
Για το σχεδιασμό περιγράμματος βήμα, έχουμε προτείνει τη χρήση μιας εξειδικευμένης βιβλιοθήκης προτύπων. Για το βήμα ανάλυσης, έχουμε παρουσιάσει ένα σύνολο αλγορίθμων που μπορούν να χρησιμοποιηθούν για να συμπεράνει τα διαφορετικά χαρακτηριστικά των εφαρμογών.
Τέλος, έχουμε παρουσιάσει μια περιπτωσιολογική μελέτη στην οποία τα μεταδεδομένα λογισμικού επιτρέπουν να προσδιορίσουν τα πιο σχετικά χαρακτηριστικά μιας εφαρμογής και επιτρέπουν στη συνεπή χρησιμοποίηση των πολλαπλάσιων βελτιστοποιήσεων για να επιτύχουν τις βελτιώσεις στην κατανάλωση ενέργειας, τις προσβάσεις μνήμης και το αποτύπωμα μνήμης.
Όσον αφορά τις μελλοντικές επεκτάσεις, η έννοια των μεταδεδομένων μπορεί να χρησιμοποιηθεί στο χρόνο εκτέλεσης, με τη διευκόλυνση της δυναμικής επιλογής του DDTs και του DMMs που χρησιμοποιούνται για να εκτελέσει τις διαφορετικές φάσεις (με τα διαφορετικά σχέδια πρόσβασης) μιας εφαρμογής σε ένα ορισμένο ενσωματωμένο σύστημα. Αυτό θα μπορούσε να επιτευχθεί μέσω της χρήσης των σεναρίων συστημάτων και μιας βιβλιοθήκης που βρίσκεται στους συνδυασμούς απλών στοιχείων για να εφαρμόσει τα σχέδια που παρήχθησαν από τις μεθοδολογίες DDTR και DMMR. Η έννοια των σεναρίων συστημάτων είναι βασισμένη στον προσδιορισμό των σχετικών (διαφορετικών) εισαγόμενων όρων στον σχέδιο-χρόνο και τον υπολογισμό των κατάλληλων λύσεων DDTR και DMMR για κάθε μια από αυτές τις καταστάσεις. Αργότερα, μια ενότητα ελέγχου προσδιορίζει στο χρόνο εκτέλεσης το τρέχον σενάριο, έτσι ώστε το λειτουργικό σύστημα να μπορεί να εφαρμόσει τις κατάλληλες λύσεις DDTR και DMMR, που συνδυάζουν τα συστατικά από τη βιβλιοθήκη.
Όπως εισάγεται ήδη στα προηγούμενα κεφάλαια αυτού του βιβλίου, πρέπει να αναπτυχθούν νέες μεθοδολογίες διαχείρισης μνήμης επιπέδου συστήματος για τις εφαρμογές πολυμέσων, λόγω της αυξανόμενης πολυπλοκότητας και της δραστικής ανόδου στις απαιτήσεις μνήμης. Στο παρελθόν, οι περισσότερες εφαρμογές που ήταν στις ενσωματωμένες πλατφόρμες, παρέμειναν κυρίως στην κλασική περιοχή της επεξεργασίας σήματος, και απέφευγαν ενεργά τους αλγορίθμους που χρησιμοποιούν τα δυναμικά στοιχεία αποεκχώρησης στο χρόνο εκτέλεσης, που αποκαλείται επίσης και ως δυναμική μνήμη (dynamic memory, DM από εδώ και στο εξής). Πρόσφατα, τα πολυμέσα και οι ασύρματες εφαρμογές δικτύων για να μεταφερθούν στα ενσωματωμένα συστήματα έχουν δεχτεί μια πολύ γρήγορη αύξηση της ποικιλίας, πολυπλοκότητας και λειτουργίας. Αυτές οι εφαρμογές (πχ. MPEG4 ή νέα πρωτόκολλα δικτύων) εξαρτώνται, με λίγες εξαιρέσεις, από το DM για τις διαδικασίες τους, λόγω της έμφυτης προβλεψιμότητας των δεδομένων εισόδου. Ο σχεδιασμός των τελικών ενσωματωμένων συστημάτων για το (στατικό) αποτύπωμα μνήμης στη χειρότερη περίπτωση22 θα οδηγούσε να μην μπορεί να ικανοποιήσει τις απαιτήσεις αυτών των εφαρμογών. Ακόμα κι αν χρησιμοποιούνται οι μέσες τιμές των πιθανών εκτιμήσεων του αποτυπώματος μνήμης, αυτές οι στατικές λύσεις θα οδηγήσουν σε υψηλότερους αριθμούς αποτυπώματος μνήμης (δηλαδή, περίπου 25%) από τις λύσεις DM [77]. Επιπλέον, αυτές οι ενδιάμεσες στατικές λύσεις δεν λειτουργούν σε ακραίες περιπτώσεις δεδομένων εισόδου, ενώ οι υλοποιήσεις με DM μπορούν να το κάνουν, δεδομένου ότι μπορούν να κλιμακώσουν το απαραίτητο αποτύπωμα μνήμης. Κατά συνέπεια, πρέπει να χρησιμοποιηθούν στο σχεδιασμό ενσωματωμένων συστημάτων για δυναμικές εφαρμογές διαχειριστές δυναμικής μνήμης. Σήμερα, είναι πολλές οι γενικές διαθέσιμες πολιτικές διαχείρισης DM, και οι εφαρμογές τους, οι οποίες παρέχουν σχετικά καλή εκτέλεση και χαμηλό κατακερματισμό για συστήματα γενικής χρήσης [56]. Εντούτοις, για τα ενσωματωμένα συστήματα, τέτοιοι διαχειριστές πρέπει να εφαρμοστούν μέσα στο περιορισμένο λειτουργικό σύστημά τους (ΛΣ) και να λάβουν υπόψιν τους περιορισμένους διαθέσιμους πόρους. Κατά συνέπεια, τα πρόσφατα ενσωματωμένα ΛΣ (πχ. [78] ) χρησιμοποιούν τους διαχειριστές DM σύμφωνα με την βασική ιεραρχία μνήμης και το είδος εφαρμογών που θα τρέξουν σε αυτούς.
Συνήθως, οι εξατομικευμένοι διαχειριστές DM έχουν ως σκοπό να βελτιώσουν την απόδοση [79], [56], αλλά μπορούν επίσης να χρησιμοποιηθούν για να βελτιστοποιήσουν σε μεγάλο βαθμό το αποτύπωμα μνήμης έναντι των διαχειριστών γενικού σκοπού DM, το οποίο επηρεάζει την τελική κατανάλωση ενέργειας και την απόδοση στα ενσωματωμένα συστήματα, καθώς πρέπει να μοιραστούν την περιορισμένη διαθέσιμη μνήμη, εντός ολοκληρωμένου κυκλώματος με πολλές ταυτόχρονες δυναμικές εφαρμογές. Για παράδειγμα, στους τρισδιάστατους οπτικούς αλγορίθμους, ένας κατάλληλα εξατομικευμένος σχεδιασμένος διαχειριστής DM μπορεί να βελτιώσει το αποτύπωμα μνήμης κατά 45% περίπου πέρα από τους συμβατικούς γενικής χρήσης διαχειριστές DM [77]. Πόσο μάλλον, όταν χρησιμοποιούνται οι εξατομικευμένοι διαχειριστές DM, οι σχεδιασμοί των οποίων πρέπει να βελτιστοποιηθούν χειρωνακτικά από τον υπεύθυνο για την ανάπτυξη, εξετάζοντας μόνο έναν περιορισμένο αριθμό εναλλακτικών λύσεων σχεδιασμού και εφαρμογής. Αυτές καθορίζονται βασισμένες στην εμπειρία και την έμπνευση του σχεδιαστή. Αυτή η εξερεύνηση είναι περιορισμένη λόγω της έλλειψης συστηματικών μεθοδολογιών, για να ερευνήσουν με συνέπεια το χώρο σχεδιασμού της διαχείρισης DM. Κατά συνέπεια, οι σχεδιαστές πρέπει να καθορίσουν, να κατασκευάσουν και να αξιολογήσουν χειρωνακτικά τις νέες εξατομικευμένες εφαρμογές των στρατηγικών DM, οι οποίες έχουν αποδειχθεί πολύ χρονοβόρες. Ο υπεύθυνος για την ανάπτυξη βρίσκεται αντιμέτωπος ακόμα, με τον καθορισμό της δομής του διαχειριστή DM και πώς να σχεδιάσει το περίγραμμα ανά περίπτωση, ακόμα κι αν το ενσωματωμένο ΛΣ προσφέρει την ιδιαίτερη υποστήριξη για τις τυποποιημένες γλώσσες, όπως η C ή C++.
Σε αυτό το κεφάλαιο, παρουσιάζουμε μια μεθοδολογία που επιτρέπει στους υπεύθυνους για την ανάπτυξη, να σχεδιάσουν τους εξατομικευμένους μηχανισμούς DM διαχείρισης, με το μειωμένο αποτύπωμα μνήμης που απαιτείται για αυτά τα δυναμικά πολυμέσα και τις ασύρματες εφαρμογές δικτύων. Καταρχήν, αυτή η μεθοδολογία οριοθετεί το σχετικό χώρο σχεδιασμού των διαχειριστικών αποφάσεων DM για ένα ελάχιστο αποτύπωμα μνήμης, στις δυναμικές ενσωματωμένες εφαρμογές. Μετά από αυτό, έχουμε μελετήσει τη σχετική επιρροή κάθε απόφασης του χώρου σχεδιασμού για το αποτύπωμα μνήμης, και έχουμε καθορίσει μια κατάλληλη διάταξη για να προσπελάσουμε αυτό το χώρο σχεδιασμού σύμφωνα με τη συμπεριφορά DM αυτών των δυναμικών εφαρμογών. Κατά συνέπεια, οι κύριες συνεισφορές της μεθοδολογίας μας είναι διπλές: (1) ο καθορισμός μιας συνεπούς ορθογωνιοποίησης του χώρου σχεδιασμού της διαχείρισης DM για τα ενσωματωμένα συστήματα και (2) ο καθορισμός μιας κατάλληλης διάταξης των αποφάσεων σχεδιασμού, για τα δυναμικά πολυμέσα και τις ασύρματες εφαρμογές δικτύων (και οποιουδήποτε άλλου τύπου ενσωματωμένων εφαρμογών, που κατέχει τα ίδια δυναμικά χαρακτηριστικά αποεκχώρησης) για να ενισχυθούν οι σχεδιαστές και για να δημιουργήσουν προσαρμοσμένους διαχειριστές DM σύμφωνα με τη συγκεκριμένη δυναμική συμπεριφορά κάθε εφαρμογής.
Αυτό το κεφάλαιο οργανώνεται ως εξής. Στην Ενότητα 8.1, περιγράφουμε τη σχετική εργασία στα πλαίσια της διαχείρισης μνήμης για τις εφαρμογές πολυμέσων. Στην ενότητα 8.2 παρουσιάζουμε το χώρο σχεδιασμού σχετικής διαχείρισης DM των αποφάσεων, για ένα μειωμένο αποτύπωμα μνήμης στις δυναμικές εφαρμογές πολυμέσων. Στη ενότητα 8.3 καθορίζουμε τη διάταξη για να προσπελάσουμε αυτό το χώρο σχεδιασμού και να ελαχιστοποιήσουμε το αποτύπωμα μνήμης της υπό ανάλυση εφαρμογής. Στη ενότητα 8.4 περιγράφουμε τη σφαιρική ροή σχεδιασμού, που προτείνεται στην μεθοδολογία μας για να ελαχιστοποιήσει το αποτύπωμα μνήμης στις δυναμικές ενσωματωμένες εφαρμογές. Στη ενότητα 8.5 εισάγουμε τις περιπτωσιολογικές μελέτες μας και παρουσιάζουμε λεπτομερώς τα πειραματικά αποτελέσματα που επιτεύχθηκαν. Τέλος, στη ενότητα 8.6 συνάγουμε τα συμπεράσματά μας.
Οι βάσεις ήδη καθιερώνονται αρκετά στην επιστημονική κοινότητα για την αποδοτική χρήση της δυναμικής μνήμης (dynamic memory, DM). Η διαθέσιμη βιβλιογραφία είναι αρκετή για τις γενικής χρήσης εφαρμογές και τις πολιτικές διαχειριστικού λογισμικού DM[56]. Προσπαθώντας να επαναχρησιμοποιηθεί αυτή η εκτενής διαθέσιμη βιβλιογραφία, στα ενσωματωμένα συστήματα, όπου η ομάδα των εφαρμογών που εκτελούνται είναι ιδιαίτερα απαιτητικές (πχ. καταναλωτικές συσκευές) τείνουν να χρησιμοποιήσουν τις παραλλαγές DM της γνωστής κατάστασης προόδου γενικής χρήσης. Παραδείγματος χάριν, η χρήση συστημάτων βασισμένη σε linux έχει ως βάση τον Lea DM διαχειριστή [79] [56] και επίσης τα βασισμένα σε Windows συστήματα (και σε κινητά, αλλά και υπολογιστές ) περιλαμβάνουν τις ιδέες του διαχειριστή DM Kingsley [80], [81], [56]. Τέλος, κάποια ΛΣ πραγματικού χρόνου ενσωματωμένων συστημάτων (πχ. [78]) υποστηρίζουν DM αποεκχώρησης μέσω των εξατομικευμένων διαχειριστών DM που βασίζονται στους απλούς κατανεμητές περιοχών [82] με ένα λογικό επίπεδο απόδοσης, για τα συγκεκριμένα χαρακτηριστικά γνωρίσματα πλατφορμών. Όλες αυτές οι προσεγγίσεις προτείνουν τις βελτιστοποιήσεις εξετάζοντας τα συστήματα γενικής χρήσης, όπου η σειρά των εφαρμογών είναι πολύ ευρεία και απρόβλεπτη στο χρόνο σχεδιασμού. Αντίθετα, η προσέγγισή μας εκμεταλλεύεται τη πρόσθετη συμπεριφορά DM των πολυμέσων και των ασύρματων εφαρμογών δικτύων για να δημιουργηθούν οι προσαρμοσμένοι και αποδοτικοί διαχειριστές DM για τα ενσωματωμένα συστήματα.
Αργότερα, εμφανίστηκε η έρευνα για τους εξατομικευμένους διαχειριστές DM που λαμβάνουν συγκεκριμένη συμπεριφορά εφαρμογής για να βελτιώσουν την απόδοση [79], [83], [56]. Επίσης, για τη βελτίωση της ταχύτητας στα ιδιαίτερα περιορισμένα ενσωματωμένα συστήματα [84], προτείνεται να χωριστεί ο DM σε σταθερά block και να τοποθετηθεί σε έναν ενιαίο συνδεδεμένο κατάλογο με μια απλή (αλλά γρήγορη) κατάλληλη στρατηγική, πχ. την πρώτη ή επόμενη τοποθέτηση [56]. Επιπλέον, είναι διαθέσιμες κάποιες μερικώς διαμορφώσιμες βιβλιοθήκες διαχειριστών DM για να παρέχουν το χαμηλό υπερυψωμένο και υψηλό επίπεδο απόδοσης αποτυπώματος μνήμης, για τις χαρακτηριστικές συμπεριφορές μιας ορισμένης εφαρμογής (πχ. Obstacks) [56], o οποίος είναι ένας εξατομικευμένος διαχειριστής DM που βελτιστοποιείται για μια συμπεριφορά σωρού εκχώρησης/αποεκχώρησης). Ομοίως, στο [83] προτείνεται ένας διαχειριστής DM που επιτρέπεται να καθορίσει τις πολλαπλάσιες περιοχές στη μνήμη με διάφορες καθορισμένες από το χρήστη λειτουργίες, για τη μνήμη αποεκχώρησης. Επιπλέον, δεδομένου ότι η χρήση των αντικειμενοστραφών γλωσσών στο σχεδιασμό ενσωματωμένων συστημάτων με την υποστήριξη για την αυτόματη ανακύκλωση των νεκρών (μη χρησιμοποιούμενων) αντικειμένων σε DM (συνήθως αποκαλούμενο ως συλλογή απορριμάτων), όπως η Java, έχει συντελεστεί αρκετή εργασία για να προτείνει αυτόματα τα περιορισμένα γενικά έξοδα συλλογής απορριμάτων χρησιμοποιώντας έναν αλγόριθμο σχετικό με την απόδοση, η οποία μπορεί να χρησιμοποιηθεί σε πραγματικού χρόνου συστήματα [85], [86]. Σε αυτό το πλαίσιο, επίσης οι επεκτάσεις υλικού έχουν προταθεί για να εκτελέσουν αποτελεσματικότερα τη συλλογή απορριμάτων [87]. Η κύρια διαφορά αυτών των προσεγγίσεων, έναντι των δικών μας είναι ότι στοχεύουν κυρίως στις βελτιστοποιήσεις απόδοσης και προτείνουν τις ειδικές λύσεις χωρίς να καθορίζουν έναν ολοκληρωμένο χώρο σχεδίασης και εξερεύνησης σχεδιασμού για τα δυναμικά ενσωματωμένα συστήματα, όπως προτείνουμε σε αυτό το κεφάλαιο.
Επιπλέον, έχει γίνει έρευνα για να παρέχει την αποδοτική υποστήριξη υλικού για τη διαχείριση DM. Στο [88] παρουσιάζεται μια μονάδα διαχειριστικής επέκτασης αντικειμένου για να χειριστεί την αποεκχώρηση των block μνήμης στο υλικό, χρησιμοποιώντας έναν αλγόριθμο που είναι μια παραλλαγή του κλασικού δυαδικού συστήματος buddy. Στο [89] προτείνεται μια ενότητα υλικού αποκαλούμενη SoCDMMU (δηλαδή, δυναμική διαχειριστική μονάδα μνήμης σε συστήματα εντός ολοκληρωμένου κυκλώματος, System On chip Dynamic Memory Management Unit), που αντιμετωπίζει τη σφαιρική μνήμη αποεκχώρησης εντός ολοκληρωμένου κυκλώματος για να επιτύχει έναν αιτιατό τρόπο, ώστε να διαιρεθεί η μνήμη μεταξύ των στοιχείων επεξεργασίας των σχεδίων SOC. Εντούτοις, το ΛΣ εκτελεί ακόμα τη διαχείριση της μνήμης που διατίθεται σε έναν αποκλειστικό επεξεργαστή εντός ολοκληρωμένου κυκλώματος. Όλες αυτές οι προτάσεις είναι πολύ σχετικές για τα ενσωματωμένα συστήματα όπου το υλικό μπορεί ακόμα να αλλάξει, ενώ η εργασία μας θεωρείται για τις σταθερές ενσωματωμένες αρχιτεκτονικές σχεδιασμού, όπου η προσαρμογή μπορεί να γίνει μόνο στο ΛΣ ή το επίπεδο λογισμικού.
Τέλος, πολύ έρευνα έχει εκτελεσθεί στις τεχνικές βελτιστοποίησης για το αποτύπωμα μνήμης, τη κατανάλωση ενέργειας, την απόδοση και άλλους σχετικούς παράγοντες, συμπληρωματικά με την εργασία μας και για τη χρήση στα στατικά στοιχεία που συνήθως είναι επίσης παρόντα στις δυναμικές εφαρμογές που εξετάζουμε.
Στην κοινωνία λογισμικού η βιβλιογραφία που είναι διαθέσιμη είναι πολύ για τις πιθανές επιλογές σχεδιασμού για τους μηχανισμούς DM διαχείρισης [56], αλλά καμία από τις προηγούμενες εργασίες δεν παρέχει ένα πλήρες χώρο σχεδιασμού, χρήσιμο για τις συστηματικές εφαρμογές εξερεύνησης σε λογισμικό και στα ασύρματα δίκτυα για τα ενσωματωμένα συστήματα. Ως εκ τούτου, στην Ενότητα 8.2.1 απαριθμούμε αρχικά το σύνολο των σχετικών αποφάσεων στο χώρο σχεδιασμού της διαχείρισης DM, για ένα μειωμένο αποτύπωμα μνήμης στις ασύρματες εφαρμογές δικτύων και στα δυναμικά πολυμέσα. Κατόπιν, στην Ενότητα 8.2.2 συνοψίζουμε εν συντομία τις αλληλεξαρτήσεις που παρατηρούνται μέσα σε αυτό το χώρο σχεδιασμού, οι οποίες μας επιτρέπουν μερικώς να διατάξουμε αυτόν τον απέραντο χώρο σχεδιασμού των αποφάσεων. Τέλος, στην Ενότητα 8.2.3 εξηγούμε πώς να δημιουργήσουμε σφαιρικούς DM διαχειριστές για τα δυναμικά πολυμέσα και τις ασύρματες εφαρμογές δικτύων.
Η συμβατική διαχείριση DM αποτελείται βασικά από δύο χωριστούς στόχους, δηλαδή τη εκχώρηση και την αποεκχώρηση [56]. Πιο αναλυτικά, η εκχώρηση είναι ο μηχανισμός ο οποίος αναζητεί ένα block αρκετά μεγάλο για να ικανοποιήσει το αίτημα μιας δεδομένης εφαρμογής και η αποεκχώρηση είναι ο μηχανισμός που επιστρέφει αυτό το block στη διαθέσιμη μνήμη του συστήματος και επαναχρησιμοποιείται αργότερα από ένα άλλο αίτημα.
Στις πραγματικές εφαρμογές, τα block μπορούν να ζητηθούν και να επιστραφούν σε οποιαδήποτε διάταξη, δημιουργώντας κατά συνέπεια ‘τις τρύπες’ μεταξύ των χρησιμοποιημένων block. Αυτές οι τρύπες είναι γνωστές ως κατακερματισμός μνήμης. Αφ’ ενός, ο εσωτερικός κατακερματισμός εμφανίζεται όταν επιλέγεται να ικανοποιηθεί ένα μεγαλύτερο block από αυτό που απαιτεί ένα αίτημα. Απ΄την άλλη όμως, εάν η ελεύθερη μνήμη για να ικανοποιήσει ένα αίτημα μνήμης είναι διαθέσιμη, αλλά μη συνεχής (έτσι δεν μπορεί να χρησιμοποιηθεί για εκείνο το αίτημα), καλείται εξωτερικός κατακερματισμός. Επομένως, πάνω από την κατανομή μνήμης και την αποεκχώρηση, ο διαχειριστής DM πρέπει επίσης να φροντίσει τα ζητήματα τεμαχισμού. Αυτό γίνεται από τα διαιρούμενα και συνεχόμενα ελεύθερα block για να κρατήσει τον τεμαχισμό μνήμης όσο το δυνατόν μικρότερο. Τέλος, για να υποστηρίξουν όλους αυτούς τους μηχανισμούς, οι πρόσθετες δομές δεδομένων πρέπει να συνταχθούν για να παρακολουθήσουν όλα τα ελεύθερα και χρησιμοποιημένα block, και τους μηχανισμούς ανασυγκρότησης. Κατά συνέπεια, για να δημιουργήσουμε έναν αποδοτικό διαχειριστή DM, πρέπει συστηματικά να ταξινομήσουμε τις αποφάσεις σχεδιασμού που μπορούν να ληφθούν, για να χειριστούν όλους τους πιθανούς συνδυασμούς των παραγόντων που έχουν επιπτώσεις στο υποσύστημα DM (πχ. τεμαχισμός, γενικά έξοδα των πρόσθετων δομών δεδομένων, κλπ).
Έχουμε ταξινομήσει όλες τις σημαντικές επιλογές σχεδιασμού, που αποτελούν τον χώρο σχεδιασμού του διαχειριστή DM στα διαφορετικά ορθογώνια δέντρα απόφασης. Το ορθογώνιο σημαίνει ότι οποιαδήποτε απόφαση σε οποιοδήποτε δέντρο μπορεί να συνδυαστεί με οποιαδήποτε απόφαση σε ένα άλλο δέντρο, και το αποτέλεσμα πρέπει να είναι ένας ενδεχόμενος έγκυρος συνδυασμός, καλύπτοντας κατά συνέπεια ολόκληρο το πιθανό χώρο σχεδιασμού. Κατόπιν, η σχετικότητα μιας ορισμένης λύσης σε κάθε συγκεκριμένο σύστημα εξαρτάται από τους περιορισμούς σχεδιασμού της, το οποίο υπονοεί ότι μερικές λύσεις μπορούν να μην συναντήσουν όλους τους περιορισμούς συγχρονισμού και δαπανών για εκείνο το συγκεκριμένο σύστημα. Επιπλέον, οι αποφάσεις στα διαφορετικά ορθογώνια δέντρα μπορούν να διαταχτούν διαδοχικά κατά τέτοιο τρόπο ώστε τα δέντρα να μπορούν να διαβούν χωρίς επαναλήψεις, εφ’ όσον διαδίδονται οι κατάλληλοι περιορισμοί από ένα επίπεδο απόφασης σε όλα τα επόμενα επίπεδα. Βασικά, όταν ληφθεί μια απόφαση σε κάθε δέντρο, καθορίζεται ένας εξατομικευμένος διαχειριστής DM (στη σημείωση, τον ατομικό διαχειριστή DM μας) για ένα συγκεκριμένο σχεδιασμό συμπεριφοράς DM (συνήθως, μια από τις φάσεις συμπεριφοράς της εφαρμογής DM). Κατά αυτόν τον τρόπο μπορούμε να αναδημιουργήσουμε οποιουσδήποτε διαθέσιμους DM διαχειριστές γενικού σκοπού [56] ή να δημιουργήσουμε ιδιαίτερα DM διαχειριστές.
Τα δέντρα έχουν ομαδοποιηθεί στις κατηγορίες σύμφωνα με τα διαφορετικά κύρια μέρη που μπορούν να διακριθούν στη διαχείριση DM [56]. Μια επισκόπηση των σχετικών κατηγοριών αυτού του χώρου σχεδιασμού για ένα μειωμένο αποτύπωμα μνήμης παρουσιάζεται στην Εικόνα 8.1. Αυτή η προσέγγιση επιτρέπει την μείωση της πολυπλοκότητας του σφαιρικού σχεδιασμού των διαχειριστών DM στα μικρότερα υπό-προβλήματα που μπορούν να αποφασιστούν τοπικά, καθιστώντας εφικτό τον καθορισμό μιας κατάλληλης διάταξης για να προσπελαστούν Έπειτα περιγράφουμε τις πέντε κύριες κατηγορίες και τα δέντρα απόφασης που παρουσιάζονται στην Εικόνα 8.1. Για κάθε έναν από αυτούς, εστιάζουμε στα δέντρα απόφασης που είναι σημαντικά για τη δημιουργία των διαχειριστών DM, με ένα μειωμένο αποτύπωμα μνήμης.
A. Η δημιουργία των δομών block, που διαχειρίζεται τις δομές δεδομένων block δημιουργείται και χρησιμοποιείται αργότερα από τους διαχειριστές DM για να ικανοποιήσει τα αιτήματα μνήμης. Πιο συγκεκριμένα, το δέντρο δομών block καθορίζει τα διαφορετικά block του συστήματος και των δομών εσωτερικού ελέγχου. Σε αυτό το δέντρο, περιλαμβάνουμε όλους τους πιθανούς συνδυασμούς δυναμικών τύπων στοιχείων (από τώρα και στο εξής αποκαλούμενων DDTs), που απαιτούνται για να αντιπροσωπεύσουν και να κατασκευάσουν οποιαδήποτε δυναμική αντιπροσώπευση [68], [77] στοιχείων, που χρησιμοποιούνται σε έναν διαχειριστή DM. Από την άλλη, το δέντρο μεγεθών block αναφέρεται στα διαφορετικά μεγέθη των βασικών διαθέσιμων block για τη διαχείριση DM, η οποία μπορεί να καθοριστεί ή όχι. Τρίτον, οι ετικέτες block και τα καταγραμμένα δέντρα πληροφοριών διευκρινίζουν τους πρόσθετους τομείς που απαιτούνται μέσα στο block για να αποθηκεύσουν τις πληροφορίες που χρησιμοποιούνται από τον DM διαχειριστή. Τέλος, το εύκαμπτο σε μέγεθος διαχειριστικό δέντρο block αποφασίζει, εάν οι διαιρεμένοι και συγχωνευμένοι μηχανισμοί ενεργοποιούνται ή αν η πρόσθετη μνήμη ζητείται από το σύστημα. Αυτό εξαρτάται από τη διαθεσιμότητα του μεγέθους του block μνήμης που έχει ζητηθεί.
Β. Το τμήμα pool βασίζεται στο κριτήριο, το οποίο εξετάζει τον αριθμό των pool (δεξαμενές) που υπάρχουν (ή περιοχών μνήμης) στον DM διαχειριστή και τους λόγους για τους οποίους δημιουργούνται. Το δέντρο μεγέθους σημαίνει ότι τα pool μπορούν να υπάρξουν είτε περιέχοντας εσωτερικά στα block διάφορων μεγεθών, είτε αυτά μπορούν να διαιρεθούν έτσι ώστε μια pool να υπάρχει ανά διαφορετικό μέγεθος block. Επιπλέον, το δέντρο δομών pool διευκρινίζει τη σφαιρική δομή ελέγχου για τις διαφορετικές ομάδες του συστήματος. Σε αυτό το δέντρο περιλαμβάνουμε όλους τους πιθανούς συνδυασμούς DDTs που απαιτούνται για να αντιπροσωπεύσουν και να κατασκευάσουν οποιαδήποτε δυναμική αντιπροσώπευση στοιχείων των pool μνήμης [68], [77].
Γ. Κατανεμημένα block, τα οποία εξετάζουν τις πραγματικές ενέργειες που απαιτούνται σε διαχείριση DM, για να ικανοποιήσουν τα αιτήματα μνήμης και να τα συνδέσουν με έναν ελεύθερο block μνήμης. Εδώ περιλαμβάνουμε όλες τις διαθέσιμες σημαντικές επιλογές προκειμένου να επιλέξουμε ένα block από έναν κατάλογο ελεύθερων block [56]. Σημειώστε ότι μια απελευθέρωση εμποδίζει την κατηγορία με τα ίδια δέντρα, όπως αυτή η κατηγορία μπόρεσε να δημιουργηθεί, αλλά δεν την περιλαμβάνουμε στην Εικόνα 8.1 για να αποφύγουμε την πολυπλοκότητα, όχι απαραίτητα στο χώρο σχεδιασμού διαχείρισης DM. Το γεγονός είναι ότι η κατηγορία διάθεσης block κατέχει περισσότερη επιρροή για το αποτύπωμα μνήμης από την πρόσθετη κατηγορία block. Επιπλέον, αυτές οι δύο κατηγορίες συνδέονται τόσο στενά σχετικά με το αποτύπωμα μνήμης της τελικής λύσης, ώστε οι αποφάσεις να λαμβάνονται μόνον όταν ακολουθούνται σε ένα άλλο. Κατά συνέπεια, η απελευθερωμένη κατηγορία block καθορίζεται εντελώς αφού επιλέξει τις επιλογές αυτής της κατηγορίας διάθεσης block.
Δ. Συνεχή block, τα οποία συσχετίζονται με τις ενέργειες που εκτελούνται από τους DM διαχειριστές για να εξασφαλίσουν ένα χαμηλό ποσοστό της εξωτερικής μνήμης τεμαχισμού, ενώνοντας δύο μικρότερα block σε έναν μεγαλύτερο. Κατ’ αρχάς, ο αριθμός ανώτατου δέντρου μεγέθους block καθορίζει τα νέα μεγέθη block που επιτρέπονται μετά από συγχώνευση δύο διαφορετικών συνεχόμενων block. Το δέντρο καθορίζει πόσο συχνά πρέπει να εκτελεσθεί η συγχώνευση.
Ε. Διαιρεμένα block, τα οποία αναφέρονται στις ενέργειες που εκτελούνται από τους διαχειριστές DM για να εξασφαλίσουν ένα χαμηλό ποσοστό του εσωτερικού τεμαχισμού μνήμης, δηλαδή χωρίζοντας έναν μεγαλύτερο block σε δύο μικρότερα. Κατ’ αρχάς, ο αριθμός ελάχιστου δέντρου μεγέθους block, καθορίζει νέα μεγέθη block που επιτρέπονται μετά από τον διαχωρισμό ενός φραγμού σε μικρότερους. Και τότε καθορίζει το δέντρο πόσο συχνά πρέπει να εκτελεσθεί ο διαχωρισμός (αυτά τα δέντρα δεν παρουσιάζονται στο πλήρες στοιχείο στην Εικόνα 8.1, επειδή οι επιλογές είναι οι ίδιες όπως στα δύο δέντρα της συγχωνευμένης κατηγορίας).
Μετά από αυτόν τον καθορισμό των κατηγοριών και των δέντρων απόφασης, σε αυτό το τμήμα προσδιορίζουμε τις πιθανές αλληλεξαρτήσεις τους. Επιβάλλεται μια μερική διάταξη στο χαρακτηρισμό των διαχειριστών DM. Τα δέντρα απόφασης είναι ορθογώνια, αλλά μη ανεξάρτητα. Επομένως, η επιλογή ορισμένων φύλλων σε μερικά δέντρα έχει μεγάλες επιπτώσεις στις συναφείς αποφάσεις σε άλλες (δηλαδή, αλληλεξαρτήσεις), όταν σχεδιάζεται ένας ορισμένος διαχειριστής DM. Ολόκληρο το σύνολο αλληλεξαρτήσεων για το χώρο σχεδιασμού παρουσιάζεται στην Εικόνα 8.2. Αυτές οι αλληλεξαρτήσεις μπορούν να ταξινομηθούν σε δύο κύριες ομάδες. Κατ’ αρχάς, χρήση άλλων δέντρων ή κατηγοριών (που σύρονται ως πλήρη βέλη στην Εικόνα 8.2). Δεύτερον, οι αλληλεξαρτήσεις που έχουν επιπτώσεις σε άλλα δέντρα ή κατηγορίες, λόγω των συνδεόμενων σκοπών τους (που παρουσιάζονται ως βέλη στην Εικόνα 8.2). Τα βέλη δείχνουν ότι η αρχική πλευρά έχει επιπτώσεις στο λαμβάνοντα και πρέπει να αποφασιστεί πρώτα.
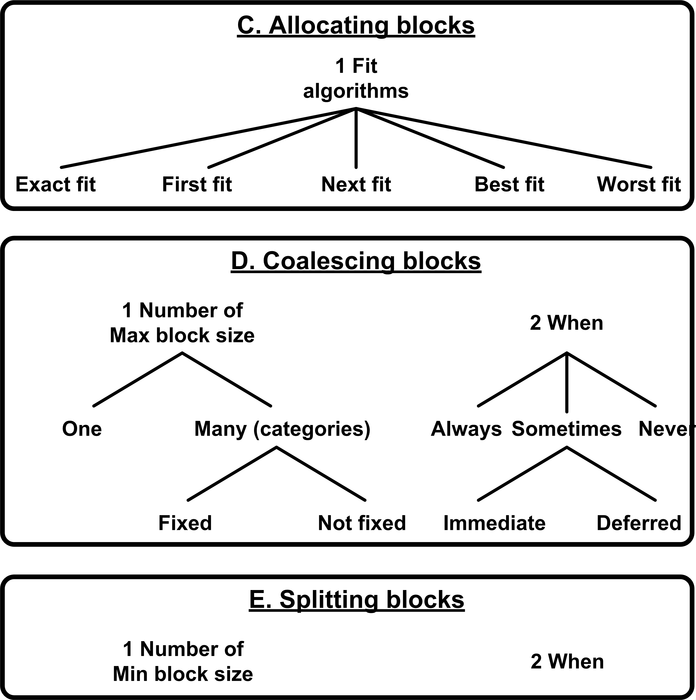
8.2: Αλληλεξαρτήσεις μεταξύ των ορθογώνιων δέντρων στο χώρο σχεδιασμού.
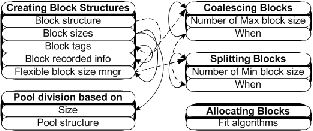
8.3: Παράδειγμα της αλληλεξάρτησης μεταξύ δύο ορθογώνιων δέντρων του διαστήματος διαχείρισης σχεδιασμού DM.
Αυτές οι αλληλεξαρτήσεις εμφανίζονται και οφείλονται στην ύπαρξη των αντίθετων φύλλων και των δέντρων στο χώρο σχεδιασμού. Απεικονίζονται στην Εικόνα 8.2 και αντιπροσωπεύονται από τα πλήρη τόξα:
Κατ’ αρχάς, μέσα στη κατηγορία δημιουργίας δομών block, εάν κανένα φύλλο από το δέντρο ετικετών block δεν επιλεχθεί, τότε το καταγεγραμμένο block του δέντρου πληροφοριών, δεν μπορεί να χρησιμοποιηθεί: δεν θα υπήρχε κανένας χώρος μνήμης για να αποθηκεύσει τις καταγεγραμμένες πληροφορίες μέσα στο block. Αυτή η αλληλεξάρτηση παρουσιάζεται γραφικά για παράδειγμα στην Εικόνα 8.3.
Το ένα φύλλο από το δέντρο μεγεθών block αποκλείει τη χρήση του δέντρου μεγέθους στο τμήμα pool που εδρεύει στην κατηγορία κριτηρίου και του εύκαμπτου δέντρου διαχειριστών μεγέθους block δημιουργώντας τη κατηγορία δομών block. Αυτό εμφανίζεται επειδή το ένα φύλλο μεγέθους block δεν επιτρέπει να καθορίσει οποιαδήποτε νέα μεγέθη.
Αυτές οι αλληλεξαρτήσεις υπάρχουν, δεδομένου ότι τα φύλλα πρέπει να συνδυαστούν για να δημιουργήσουν ολόκληρους συνεπείς σχεδιασμούς DM. Παραδείγματος χάριν, οι διαιρεμένοι και συγχωνευμένοι μηχανισμοί συσχετίζονται αρκετά και οι αποφάσεις σε μια κατηγορία πρέπει να βρουν ισοδύναμες σε άλλες κατηγορίες. Αυτές οι αλληλεξαρτήσεις αντιπροσωπεύονται με τα τόξα στην Εικόνα 8.2
Κατ’ αρχάς, το εύκαμπτο δέντρο διαχειριστών μεγέθους block επηρεάζει πολύ όλα τα δέντρα μέσα στα συγχωνευμένα block και τις διαιρεμένες κατηγορίες block. Κατά συνέπεια, σύμφωνα με το επιλεγμένο φύλλο για έναν ορισμένο ατομικό διαχειριστή DM (δηλαδή, διάσπαση ή συνεχή φύλλο), ο διαχειριστής DM πρέπει να επιλέξει μερικά φύλλα των δέντρων που περιλαμβάνονται ή δεν περιλαμβάνονται σε εκείνες τις αποφάσεις. Παραδείγματος χάριν, εάν το διασπασμένο φύλλο επιλέγεται, ο διαχειριστής DM δεν θα χρησιμοποιήσει τη συνεχή κατηγορία και τις λειτουργίες των αντίστοιχων εσωτερικών δέντρων τους, που έχει ο ατομικός διαχειριστής DM. Εντούτοις, μπορεί να χρησιμοποιηθεί σε έναν άλλο ατομικό διαχειριστή DM, σε μια διαφορετική φάση της DM εκχώρησης, κατά συνέπεια ο τελικός σφαιρικός διαχειριστής περιέχει και τους δύο (δείτε την Ενότητα 8.2.3 για περισσότερες λεπτομέρειες).
Εντούτοις, το κύριο κόστος της επιλογής που γίνεται στο εύκαμπτο δέντρο διαχειριστών μεγέθους block, χαρακτηρίζεται από το κόστος των κατηγοριών των συγχωνευμένων block όπως και των διαιρεμένων block. Αυτό σημαίνει ότι ένας λεπτομερής εκτιμητής της επιρροής δαπανών πρέπει να είναι διαθέσιμος για να πάρει την απόφαση στο προαναφερθέν εύκαμπτο δέντρο διαχειριστών μεγέθους block. Στην πραγματικότητα, αυτός ο εκτιμητής είναι απαραίτητος, εάν οι παραγόμενες αποφάσεις σε άλλες κατηγορίες έχουν μια επιρροή στο τελικό κόστος μικρότερη από την επιρροή του δέντρου που αποφασίζει να τους χρησιμοποιήσει [90]. Αυτό δεν συμβαίνει στο δέντρο το οποίο ορίζει και έτσι κανένας εκτιμητής δεν απαιτείται.
Δεύτερον, η απόφαση που λαμβάνεται στο δέντρο δομών pool έχει σημαντικές επιπτώσεις σε ολόκληρο το τμήμα pool που εδρεύει στην κατηγορία κριτηρίου. Αυτό συμβαίνει επειδή μερικές δομές δεδομένων περιορίζουν ή δεν επιτρέπουν στη pool να διαιρεθεί με τους σύνθετους τρόπους που τα κριτήρια αυτής της κατηγορίας προτείνουν.
Τρίτον, το δέντρο δομών block μέσα στη κατηγορία δομών block η οποία δημιουργείται, επηρεάζει έντονα την απόφαση στο δέντρο ετικετών block της ίδιας κατηγορίας, επειδή ορισμένες δομές δεδομένων απαιτούν τους πρόσθετους τομείς για τη συντήρησή τους. Παραδείγματος χάριν, οι ενιαίοι συνδεόμενοι κατάλογοι απαιτούν έναν επόμενο τομέα και ένας κατάλογος όπου διάφορα μεγέθη block επιτρέπονται και πρέπει να περιλάβει έναν τομέα επιγραφών και μέσα το μέγεθος κάθε ελεύθερου φραγμού. Διαφορετικά το κόστος για να διαβεί τον κατάλογο και να βρει ένα κατάλληλο block για το ζητούμενο μέγεθος κατανομής, είναι υπερβολικά μεγάλο [68].
Τέλος, τα αντίστοιχα When δέντρα από τις διαιρεμένες και συγχωνευμένες κατηγορίες block μαζί με ένα διπλό βέλος στην Εικόνα 8.3 συσχετίζονται πολύ στενά ο ένας με τον άλλον και μια διαφορετική απόφαση σε κάθε δέντρο, δεν φαίνεται να παρέχει οποιοδήποτε είδος οφέλους στην τελική λύση. Αντίθετα, σύμφωνα με τη μελέτη και τα πειραματικά αποτελέσματά μας, αυξάνει συνήθως το κόστος στο αποτύπωμα μνήμης της τελικής λύσης διαχειριστών DM. Εντούτοις, αυτό το διπλό βέλος απαιτείται επειδή δεν είναι δυνατό να αποφασιστεί ποια κατηγορία έχει περισσότερη επιρροή στην τελική λύση χωρίς μελέτη των ειδικών παραγόντων της επιρροής για ορισμένο μετρικό, για να βελτιστοποιήσει (πχ. αποτύπωμα μνήμης, κατανάλωση ενέργειας, απόδοση, κλπ). Κατά συνέπεια, η απόφαση για την οποία η κατηγορία πρέπει να αποφασιστεί, πρώτα πρέπει να αναλυθεί για κάθε ιδιαίτερη συνάρτηση κόστους ή είναι μετρικά απαραίτητο να βελτιστοποιηθεί στο σύστημα.
Τα σύγχρονα πολυμέσα και οι ασύρματες εφαρμογές δικτύων περιλαμβάνουν διαφορετικούς σχεδιασμούς συμπεριφοράς DM, τα οποία συνδέονται με τις λογικές φάσεις τους (δείτε το Τμήμα 8.5 για τα πραγματικά παραδείγματα). Συνεπώς, η μεθοδολογία μας πρέπει να εφαρμοστεί σε κάθε μια από αυτές τις διαφορετικές φάσεις προκειμένου να δημιουργηθεί χωριστά ένας εξατομικευμένος ατομικός διαχειριστής DM για κάθε μια από αυτές. Κατόπιν, ο σφαιρικός διαχειριστής DM της εφαρμογής είναι ο συνυπολογισμός όλων αυτών των ατομικών διαχειριστών DM σε ένα. Για αυτόν τον λόγο, έχουμε αναπτύξει τη βιβλιοθήκη C++ που εδρεύει στις αφηρημένες κατηγορίες ή τα πρότυπα που καλύπτουν όλες τις πιθανές αποφάσεις στο χώρο σχεδιασμού DM και μας επιτρέπουν την κατασκευή της τελικής σφαιρικής εφαρμογής των εξατομικευμένων διαχειριστών DM με έναν απλό τρόπο μέσω της σύνθεσης C++ των στρωμάτων [91].
Μόλις καθοριστεί ολόκληρος ο χώρος σχεδιασμού για τη διαχείριση DM στα δυναμικά ενσωματωμένα συστήματα και ταξινομηθεί στο προηγούμενο τμήμα, η διάταξη για τους διαφορετικούς τύπους εφαρμογών μπορεί να καθοριστεί σύμφωνα με τη συμπεριφορά και το κόστος συναρτήσεων DM που βελτιστοποιείται. Σε αυτήν την περίπτωση, το υποσύστημα DM βελτιστοποιείται για να επιτύχει τις λύσεις με ένα μειωμένο αποτύπωμα DM. Επομένως, πρώτα στην Ενότητα 8.3.1 συνοψίζουμε τους παράγοντες της επιρροής για το αποτύπωμα DM. Κατόπιν, στο Τμήμα 8.3.2 περιγράφουμε εν συντομία τα χαρακτηριστικά γνωρίσματα που επιτρέπουν σε μας να ομαδοποιήσουμε τις διαφορετικές δυναμικές εφαρμογές και να εστιάσουμε στα κοινά (και ιδιαίτερα) χαρακτηριστικά γνωρίσματα των πολυμέσων και τις ασύρματες εφαρμογές δικτύων, οι οποίες μας επιτρέπουν να συγκεντρώσουμε αυτές τις εφαρμογές και να καθορίσουμε μια κοινή διάταξη εξερεύνησης του χώρου σχεδιασμού. Τέλος, στην Ενότητα 8.3.2 παρουσιάζουμε την κατάλληλη διάταξη εξερεύνησης για αυτά τα πολυμέσα και τις ασύρματες εφαρμογές δικτύων για να επιτευχθούν οι μειωμένες λύσεις διαχείρισης αποτυπώματος μνήμης DM.
Οι κύριοι παράγοντες που έχουν επιπτώσεις στο μέγεθος μνήμης είναι δύο: η υπερυψωμένη οργάνωση και τα απόβλητα μνήμης τεμαχισμού.
Τα γενικά έξοδα οργάνωσης είναι τα γενικά έξοδα που παράγονται από τους υποβοηθούμενους τομείς και τις δομές δεδομένων, τα οποία συνοδεύουν κάθε block και pool αντίστοιχα. Αυτή η οργάνωση είναι ουσιαστική να διαθέσει, να απελευθερώσει και να χρησιμοποιήσει τα block μνήμης μέσα στις pool, και εξαρτάται από τα ακόλουθα μέρη:
Οι τομείς (πχ. επιγραφές, υποσημειώσεις, κλπ) μέσα στα block μνήμης χρησιμοποιούνται για να αποθηκεύσουν τα στοιχεία σχετικά με το συγκεκριμένο block και είναι συνήθως μερικά bytes μακριά. Η χρήση αυτών των τομέων ελέγχεται από την κατηγορία Α (που δημιουργεί τις δομές block) στο χώρο σχεδιασμού.
Οι υποστηριζόμενες δομές δεδομένων, παρέχουν την υποδομή για να οργανώσουν την pool και για να χαρακτηρίσουν τη συμπεριφορά της. Μπορούν να χρησιμοποιηθούν για να αποτρέψουν τον τεμαχισμό με τον καταναγκασμό των block, για να διατηρήσουν τη μνήμη σύμφωνα με το μέγεθός τους, χωρίς απαραίτητα να πρέπει να διαιρεθούν και να συγχωνευτούν. Η χρήση αυτών των δομών δεδομένων ελέγχεται από την κατηγορία Β (το τμήμα pool βασίζεται στο κριτήριο αυτό). Σημειώστε ότι οι ίδιες επικουρικές δομές δεδομένων βοηθούν στο να αποτρέψουν τον τεμαχισμό, αλλά σιωπηρά παράγουν κάποια γενικά έξοδα. Τα γενικά έξοδα που παράγουν μπορούν να είναι συγκρίσιμα με τον τεμαχισμό που παράγεται από τις μικρές δομές δεδομένων. Εν τούτοις αυτός ο αρνητικός παράγοντας ξεπερνιέται από τη δυνατότητά τους να αποτρέψουν τα προβλήματα τεμαχισμού, ο οποίος είναι ένας πιο σχετικός αρνητικός παράγοντας για το αποτύπωμα μνήμης [56]. Η ίδια επίδραση στην πρόληψη τεμαχισμού είναι επίσης παρούσα στο δέντρο C1. Αυτό συμβαίνει επειδή ανάλογα με τον κατάλληλο αλγόριθμο που επιλέγεται, είναι δυνατό να μειωθεί ο εσωτερικός τεμαχισμός του συστήματος. Παραδείγματος χάριν, εάν διατίθεται ένα τμήμα 12 bytes χρησιμοποιώντας έναν επόμενο κατάλληλο αλγόριθμο και ο επόμενος φραγμένος μέσα στη pool είναι 100 bytes, 88 bytes χάνονται στον εσωτερικό τεμαχισμό ενώ μια καλή εφαρμογή αλγορίθμου, πιθανώς δεν θα χρησιμοποιήσει ποτέ οποιοδήποτε block για το αίτημα. Επομένως, αποτρέποντας τον τεμαχισμό, η κατηγορία Γ είναι εξίσου σημαντική με τη Β.
Τα απόβλητα μνήμης τεμαχισμού προκαλούνται από τον εσωτερικό και εξωτερικό τεμαχισμό, που συζητήθηκε νωρίτερα σε αυτό το κεφάλαιο, το οποίο εξαρτάται από τα εξής:
Ο εσωτερικός τεμαχισμός θεραπεύεται συνήθως από την κατηγορία Ε (διαιρεμένα block). Αυτό έχει επιπτώσεις συνήθως στις μικρές δομές δεδομένων. πχ. εάν έχετε μόνο 100 bytes block μέσα στις pool σας και εσείς θέλετε να διαθέσετε 20 bytes block, θα ήταν σοφό να χωριστεί κάθε block σε 100 bytes μέσα στη pool σας, σε 5 block 20 bytes για να αποφευχθεί ένα μεγάλο μέρος εσωτερικού τεμαχισμού.
Ο εξωτερικός τεμαχισμός θεραπεύεται συνήθως από την κατηγορία Δ (συγχωνευμένα block). Έχει επιπτώσεις συνήθως στα μεγάλα αιτήματα στοιχείων. Παραδείγματος χάριν, εάν ένα block 50KB πρέπει να διατεθεί, αλλά υπάρχουν μόνο 500 bytes block μέσα στις pool, θα ήταν απαραίτητο να συγχωνευτούν 100 bytes block για να παραχθεί το ζητούμενο ποσό μνήμης.
Σημειώστε τη διάκριση μεταξύ των κατηγοριών Δ και Ε, που προσπαθούν να εξετάσουν τον τεμαχισμό, σε αντιδιαστολή με την κατηγορία Β και Γ που προσπαθούν να τον αποτρέψουν.
Τα δυναμικά πολυμέσα και οι ασύρματες ενσωματωμένες εφαρμογές δικτύου περιλαμβάνουν διάφορες μη–κατανεμημένες φάσεις (ή οι σχεδιασμοί) για τις δομές δεδομένων τους, οι οποίες αντιπροσωπεύουν συνήθως τις διαφορετικές φάσεις στη λογική της ίδιας εφαρμογής. Έχουμε ταξινομήσει αυτούς τους διαφορετικούς σχεδιασμούς εκχώρησης DM σε τρία ορθογώνια συστατικά [56], δηλαδή, το κυρίαρχο μέγεθος block κατανομής, τον κύριο σχεδιασμό και το ποσοστό των εντατικών φάσεων μνήμης αποεκχώρησης.
Όπως έχουμε παρατηρήσει εμπειρικά, χρησιμοποιώντας αυτήν την προηγούμενη ταξινόμηση βασισμένη στα συστατικά, τα δυναμικά πολυμέσα και οι ασύρματες εφαρμογές δικτύων, μοιράζονται τον κεντρικό αγωγό που χαρακτηρίζει την εκτίμηση του αποτυπώματος DM. Κατ’ αρχάς, τα κυρίαρχα μεγέθη block κατανομής είναι λίγα (όπως οι περιπτωσιολογικές μελέτες μας δείχνουν, 6 ή 7 μπορούν να αποτελέσουν 70-80 % από τα συνολικά αιτήματα κατανομής), αλλά αυτά τα μεγέθη επιδεικνύουν μια μεγάλη παραλλαγή δεδομένου ότι μερικοί απ’ αυτούς, μπορεί να είναι ακριβώς μερικά bytes, ενώ άλλες μπορούν να είναι αρκετά ΚB. Επομένως, οι κατάλληλοι διαχειριστές DM δεν είναι αρμόδιοι μόνο για τα μεγάλα ή πολύ μικρά μεγέθη, και οι συνδυασμοί λύσεων και για τους δύο τύπους κατανομών απαιτούνται σε αυτές τις εφαρμογές. Δεύτερον, το κύριο τμήμα σχεδίων, που καθορίζει το κυρίαρχο σχεδιασμό μη-κατανομής, πχ. κεκλιμένη ράμπα, αιχμές, οροπέδια, (δείτε [56] για περισσότερες λεπτομέρειες), δείχνει ότι πολύ συχνά τα δυναμικά πολυμέσα και οι ασύρματες εφαρμογές δικτύων κατέχουν τις πολύ ενεργές φάσεις, όπου λίγες δομές δεδομένων διατίθενται δυναμικά με έναν πολύ γρήγορο και μεταβλητό τρόπο (δηλαδή οξύνει), ενώ άλλες δομές δεδομένων αυξάνονται συνεχώς (δηλαδή κεκλιμένες ράμπες) και παραμένουν σταθερές σε ένα ορισμένο σημείο για μεγάλο διάστημα, προτού να ελευθερωθούν. Σύμφωνα με τις παρατηρήσεις μας, αυτές οι φάσεις δημιουργίας/καταστροφής του συνόλου των δομών δεδομένων με ορισμένα μεγέθη κατανομής επηρεάζονται συνήθως από τη λογική δομή των φάσεων που καθορίζονται από τους σχεδιαστές στον κώδικα εφαρμογής (πχ. που δίνει τις φάσεις) ή τα πρόσθετα γεγονότα (πχ. άφιξη των πακέτων στις ασύρματες εφαρμογές δικτύων). Τρίτον, το ποσοστό των εντατικών φάσεων αποεκχώρησης μνήμης καθορίζει πόσο συχνά πρέπει να αλλάξει τη δομή του διαχειριστή DM, για να εγκαταστήσει τα νέα μεγέθη αποεκχώρησης και το σχεδιασμό της δυναμικής εφαρμογής. Σε αυτήν την περίπτωση έχουμε παρατηρήσει επίσης τα πανομοιότυπα χαρακτηριστικά γνωρίσματα και στα δυναμικά πολυμέσα και στις ασύρματες εφαρμογές δικτύων, επειδή η συμπεριφορά χρόνου εκτέλεσης του συστήματος τείνει να ακολουθήσει μια προκαθορισμένη διάταξη για το πώς να χειριστεί τις διαφορετικές φάσεις και τα γεγονότα. Παραδείγματος χάριν, στα τρισδιάστατα παιχνίδια η ακολουθία για να συντηρήσει τα νέα γεγονότα, ως μετακίνηση της φωτογραφικής μηχανής από τους παίκτες (πχ. αναπροσαρμογή των ορατών αντικειμένων, απόδοση του νέου υποβάθρου, κλπ) καθορίζεται πάντα ανάλογα με τον τύπο αντικειμένου. Ομοίως, καθορίζεται και ο τρόπος να αντιμετωπιστεί η άφιξη των νέων πακέτων στις ασύρματες εφαρμογές δικτύων. Κατά συνέπεια, όλα αυτά τα προηγούμενα χαρακτηριστικά γνωρίσματα επιτρέπουν σε μας για να συγκεντρώσουμε αυτούς τους δύο αρχικά διαφορετικούς τομείς των εφαρμογών, εξετάζοντας τα κοινά χαρακτηριστικά DM τους και να καθορίσουν μια κοινή διάταξη για να προσπελαστεί ο χώρος σχεδιασμού.
Σε αυτήν την υποενότητα συζητάμε τη σφαιρική διάταξη μέσα στις ορθογώνιες κατηγορίες χώρου διαχείρισης του σχεδιασμού DM σύμφωνα με τους προαναφερθέντες παράγοντες της επιρροής για ένα μειωμένο αποτύπωμα μνήμης, για τα δυναμικά πολυμέσα και τις ασύρματες εφαρμογές δικτύων. Έχουμε καθορίσει αυτήν την σφαιρική διάταξη μετά από την εκτενή δοκιμή (δηλαδή, περισσότερο από 6 μήνες πειραμάτων, με τις διαφορετικές διαταγές και εφαρμογές των διαχειριστών DM) χρησιμοποιώντας ένα αντιπροσωπευτικό σύνολο δέκα πραγματικών δυναμικών ενσωματωμένων πολυμέσων και ασύρματων εφαρμογών δικτύων, με διαφορετικά μεγέθη κώδικα (δηλαδή, από 1000 γραμμές έως 700 χιλιάδες γραμμές C++ κώδικα), συμπεριλαμβανομένου: εξελικτική τρισδιάστατη απόδοση όπως [92] ή MPEG 4 κωδικοποιητής (VTC) [40], οι τρισδιάστατοι αλγόριθμοι [38], τρισδιάστατα παιχνίδια [41], [42] και αποθήκευση, εφαρμογές [93] αναδημιουργίας εικόνας δικτύων και δρομολόγησης.
Η εμπειρία προτείνει ότι το πλήθος των περιπτώσεων του κατακερματισμού δεν μπορεί να αποφευχθεί, μόνο με μια κατάλληλη οργάνωση pool [56]. Τα πειράματά μας δείχνουν, ότι αυτό ισχύει ιδιαίτερα για τα ενσωματωμένα δυναμικά πολυμέσα και τις ασύρματες εφαρμογές δικτύων. Επομένως, οι κατηγορίες Δ και Ε τοποθετούνται στη σειρά απόφασης πριν από τις κατηγορίες Γ και Β. Η τελική σειρά είναι η ακόλουθη: το δέντρο A2 τοποθετείται πρώτα για να καθορίσει εάν ένα ή περισσότερα μεγέθη block χρησιμοποιούνται και το A5 είναι τοποθετημένο δεύτερο, για να αποφασίσει τη σφαιρική δομή των block. Έπειτα, οι κατηγορίες που εξετάζουν τον τεμαχισμό, δηλαδή, οι κατηγορίες Δ και Ε, αποφασίζονται επειδή, όπως έχουμε προαναφέρει, είναι σημαντικότερες από τις κατηγορίες που προσπαθούν να αποτρέψουν τον τεμαχισμό (δηλαδή, Γ και Β). Κατόπιν, το υπόλοιπο των γενικών εξόδων οργάνωσης πρέπει να αποφασιστεί για αυτά τα αιτήματα block. Κατά συνέπεια, αποφασίζονται τα υπόλοιπα δέντρα στην κατηγορία A (δηλαδή, Α1, A3 και A4). Μετά, λαμβάνοντας υπόψη τις αλληλεξαρτήσεις, η τελική σφαιρική διάταξη είναι η ακόλουθη: A2->A5->E2->D2->E1->D1->B4->B1- >C1->A1->A3->A4.
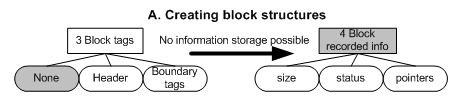
8.4: Παράδειγμα της σωστής διάταξης μεταξύ δύο ορθογώνιων δέντρων.
Εάν η διάταξη που προτείναμε πριν δεν ακολουθείται, οι περιττοί περιορισμοί διαδίδονται στα επόμενα δέντρα απόφασης. Ως εκ τούτου, οι καταλληλότερες αποφάσεις δεν μπορούν να ληφθούν στα υπόλοιπα ορθογώνια δέντρα. Ένα παράδειγμα αυτού παρουσιάζεται στην Εικόνα 8.4. Υποθέστε ότι η διάταξη ήταν A3 και έπειτα E2 και D2. Με απόφαση του σωστού φύλλου για A3, προφανής θα ήταν η επιλογή για να σώσει το αποτύπωμα μνήμης, να μην επιλεχτεί κανένα φύλλο, το οποίο δείχνει ότι δεν πρέπει να χρησιμοποιηθεί κανένας τομέας επιγραφών οποιουδήποτε τύπου. Αυτό φαίνεται λογικό εκ πρώτης όψεως επειδή οι τομείς επιγραφών, θα απαιτούσαν ένα σταθερό ποσό πρόσθετης μνήμης για κάθε block που πρόκειται να διατεθεί. Μετά από την απόφαση για κανένα φύλλο στο δέντρο A3, αποφασίζονται τα φύλλα που χρησιμοποιούνται για τα δέντρα E2 και D2. Τώρα, είμαστε υποχρεωμένοι για να επιλέξουμε το never φύλλο επειδή μετά διαδίδουμε τους περιορισμούς A3, τα block δεν μπορούν να είναι διαιρεμένα κατάλληλα ή συγχωνευμένα χωρίς αποθήκευση των πληροφοριών για το μέγεθός τους. Ως εκ τούτου, ο τελικός διαχειριστής DM χρησιμοποιεί τη λιγότερη μνήμη ανά block, αλλά δεν μπορεί να εξετάσει τον εσωτερικό ή εξωτερικό τεμαχισμό από τα διαιρεμένα ή συγχωνευμένα block. Αυτή η λύση θα μπορούσε να φανεί ως σωστή απόφαση για μια εφαρμογή όπου το κυρίαρχο μέγεθος block, καθορίζεται και έτσι κανένα σοβαρό αποτέλεσμα δεν υπάρχει λόγω του εσωτερικού ή εξωτερικού τεμαχισμού. Εντούτοις, εάν η εφαρμογή περιλάβει ένα μεταβλητό ποσό μεγεθών κατανομής (χαρακτηριστική συμπεριφορά σε πολλά δυναμικά πολυμέσα και ασύρματες εφαρμογές δικτύων), το πρόβλημα τεμαχισμού (εσωτερικό και εξωτερικό) πρόκειται να καταναλώσει περισσότερη μνήμη από τους πρόσθετους τομείς επιγραφών που απαιτούνται για τη συγχώνευση και το διαχωρισμό δεδομένου ότι τα ελευθερωμένα block δεν θα είναι σε θέση να επαναχρησιμοποιηθούν. Επομένως, είναι απαραίτητο να αποφασίσει για τα E2 και D2 δέντρα πρώτα, και να διαδοθούν έπειτα οι προκύπτοντες περιορισμοί στο δέντρο A3. Για να καταδειχτεί η ακρίβεια αυτής της εξήγησης, στις ακόλουθες παραγράφους παρουσιάζονται τα πειραματικά αποτελέσματα του αποτυπώματος μνήμης για μια εφαρμογή πολυμέσων με ένα ποικίλο κυρίαρχο μέγεθος block που χρησιμοποιεί κάθε μια από τις πιθανές διαταγές, δηλαδή ένας τρισδιάστατος αλγόριθμος με τα εξελικτικά πλέγματα [92]. Αυτός περιγράφεται αργότερα λεπτομερέστερα στις περιπτωσιολογικές μελέτες και τα πειραματικά αποτελέσματά μας 8.5. Τα αποτελέσματα που παρουσιάζονται είναι μέσες τιμές, μετά από 10 τρεξίματα για κάθε πείραμα και τις ομάδες 10 εκρήξεων. Καταρχήν, η εφαρμογή διαιρείται σε διάφορες εκρήξεις 1.000 (από)εκχωρήσεων με ένα περιορισμένο ποσό block (10 διαφορετικά μεγέθη που κυμαίνονται σε bytes από 20 μέχρι 500).
| Διαχειριστές DM | Ίχνη Μνήμης (ΚΒ) | Χρόνος Εκτέλεσης |
| (1) A3-D2/E2 | 2.392*10^2 | 7.005 |
| (2) D2/E2-A3 | 4.682*10 | 11.687 |
| Σύγκριση 2-1 | 19.56 |
Αυτός είναι ένας χαρακτηριστικός τρόπος με τον οποίο μπορεί να τρέξει μια εφαρμογή πολυμέσων με διάφορες φάσεις. Στις εφαρμογές δικτύων η σειρά των μεγεθών μπορεί να ποικίλει ακόμα περισσότερο, λόγω της αβεβαιότητας στα πακέτα φόρτου εργασίας και εισαγωγής. Έχουμε εφαρμόσει δύο διαφορετικές εκδόσεις του ίδιου διαχειριστή DM, οι οποίες περιλαμβάνουν μια ενιαία pool όπου τα ελεύθερα και χρησιμοποιημένα block συνδέονται διπλά μέσα σε έναν κατάλογο. Η μόνη διαφορά μεταξύ αυτών των δύο διαχειριστών DM είναι η προαναφερθείσα εξηγημένη διάταξη μεταξύ A3 και D2/E2.
Στην πρώτη λύση, αποφασίζεται το A3 και έπειτα D2 και E2. Ως εκ τούτου, καμία συνεχής και διαιρεμένη υπηρεσία δεν παρέχεται στο διαχειριστή DM, αλλά απαιτούνται και λιγότερο υπερυψωμένα block. Στη δεύτερη λύση αποφασίζονται πρώτα οι D2 και E2 και έπειτα καθορίζεται ο A3. Κατά συνέπεια, αυτός ο διαχειριστής DM περιλαμβάνει και τις δύο υπηρεσίες (δηλαδή, συγχώνευση και διαχωρισμό), αλλά περιλαμβάνει γενικά έξοδα 7 bytes ανά block στον κατάλογο ως πρόσθετη επιγραφή για τη συντήρηση: 2 bytes για το μέγεθος, κάθε σύνδεση 2 bytes (2 απαιτούνται) και 1 byte (δηλαδή, ένας τομέας bool) για να αποφασίσουν εάν χρησιμοποιείται. Τα αποτελέσματα που επιτυγχάνονται και στις δύο περιπτώσεις παρουσιάζονται στον Πίνακα 8.1. Παρουσιάζεται σαφώς ότι τα γενικά έξοδα των πρόσθετων επιγραφών είναι λιγότερο σημαντικά από τα γενικά έξοδα λόγω του τεμαχισμού, όπου απαιτείται, η 5 φορές λιγότερη μνήμη (δείτε τη σύγκριση 2-1 γραμμών στον Πίνακα 8.1). Επομένως, όπως προτείνουμε στη σφαιρική διάταξη εξερεύνησης μας για το μειωμένο αποτύπωμα μνήμης (δείτε το τμήμα 8.3.3 για περισσότερες λεπτομέρειες), ο δεύτερος διαχειριστής DM παράγει τα καλύτερα αποτελέσματα. Σε αυτόν τον δεύτερο διαχειριστή, πρώτα τα D2 και E2 δέντρα αποφασίζονται και έπειτα χρησιμοποιούνται οι περιορισμοί τους για να επιλέξουν το A3 φύλλο δέντρων. Επίσης σημειώστε τη διαφορά στο χρόνο εκτέλεσης: ο πρώτος διαχειριστής DM έχει έναν πολύ χαμηλό συνολικό χρόνο εκτέλεσης, επειδή δεν παρέχει τις συγχωνευμένες ή διαιρεμένες υπηρεσίες, ενώ ο δεύτερος έχει πρόσθετα γενικά έξοδα στο χρόνο εκτέλεσης 66.83%. Αυτό δείχνει ότι η απαίτηση απόδοσης του συστήματος υπό ανάπτυξη, πρέπει να λάβει υπόψη όταν αποφασίζονται οι επιλογές στο χώρο σχεδιασμού. Ως εκ τούτου, εάν ο σχεδιαστής συστημάτων απαιτεί ένα ορισμένο επίπεδο απόδοσης, το οποίο δεν επιτυγχάνεται από την ακραία μειωμένη λύση αποτυπώματος μνήμης που παρουσιάζεται στον αριθμό 2, μια άλλη λύση μπορεί να σχεδιαστεί πιο κοντά στη λύση με αριθμό 1 (αλλά με μια ισορροπημένη ανταλλαγή μεταξύ του αποτυπώματος μνήμης και της απόδοσης). Όπως έχει αναφερθεί πιο πριν, έχουμε εκτελέσει ένα μεγάλο ποσό παρόμοιων πειραμάτων για τις υπόλοιπες και παραγόμενες διαταγές απόφασης που προτίθενται. Το κύριο συμπέρασμα από τις μελέτες μας είναι ότι με την προτεινόμενη σφαιρική διάταξη, η μεθοδολογία εξερεύνησης δεν είναι απαραίτητα περιορισμένη και μόνο οι απαραίτητοι περιορισμοί διαβιβάζονται στα επόμενα δέντρα απόφασης, η οποία δεν είναι δυνατή με άλλες διατάξεις για αυτούς τους τύπους δυναμικών εφαρμογών με τον μη περιορισμό του μεγέθους αυτών.
Ο κύριος στόχος της προτεινόμενης μεθοδολογίας σχεδιασμού DM διαχείρισης, είναι να παρασχεθούν στους υπεύθυνους για την ανάπτυξη μια ροή σχεδιασμού των εξατομικευμένων διαχειριστών DM για τα δυναμικά πολυμέσα και τα ασύρματα συστήματα δικτύων. Αυτή η ροή σχεδιασμού διαιρείται σε τέσσερις κύριες φάσεις, όπως υποδεικνύεται στην Εικόνα 8.5. Η πρώτη φάση της μεθοδολογίας λαμβάνει και ταξινομεί τις αναλυτικές πληροφορίες για το DM και τον χρόνο με τον οποίο εκτελείται κάθε δυναμικό αποεκχώρησης, όπως απεικονίζεται στην πρώτη ωοειδή μορφή της Εικόνας 8.5. Αυτή η φάση είναι βασισμένη στη σκιαγράφηση της χρήσης του DM στην εξεταζόμενη εφαρμογή επειδή, σύμφωνα με την εμπειρία μας, είναι η μόνη ρεαλιστική επιλογή για τα σημερινά δυναμικά πολυμέσα και τις ασύρματες εφαρμογές [91], [77] δικτύων. Η σκιαγράφηση πραγματοποιείται ως εξής. Κατ’ αρχάς, παρεμβάλλουμε στον κώδικα της εφαρμογής υψηλού επιπέδου σχεδιάζοντας το περίγραμμα πλαισίου μας, το οποίο είναι βασισμένο στη βιβλιοθήκη C++ της σκιαγράφησης των αντικειμένων και των πρόσθετων γραφικών εργαλείων [77]. Κατόπιν, σχεδιάζουμε αυτόματα το περίγραμμα ένα αντιπροσωπευτικό σύνολο περιπτώσεων εισαγωγής της εφαρμογής, γενικά μεταξύ 10 και 15 διαφορετικών εισαγωγών, συμπεριλαμβανομένων των ακραίων περιπτώσεων min και max.
Στο αποτύπωμα μνήμης μεθοδολογίας, που αντιπροσωπεύεται ως δεύτερη ορθογώνια μορφή της Εικόνας 8.5, χαρακτηρίζεται η συμπεριφορά DM της εφαρμογής. Οι φάσεις κατανομής προσδιορίζονται και συνδέονται με τις λογικές φάσεις της εφαρμογής (πχ. ψαλίδισμα, φωτισμός, κλπ σε τρισδιάστατη εμφάνιση [94]) που χρησιμοποιούν τα εργαλεία μας, για να αναλύσουν τις πληροφορίες σχεδιασμού περιγράμματος που λαμβάνονται στην προηγούμενη φάση. Αυτά τα εργαλεία προσδιορίζουν τις κύριες παραλλαγές στις διαφορετικές γραφικές παραστάσεις και τους πίνακες και τα δυναμικά διατιθέμενα μεγέθη. Κατόπιν, το χώρο σχεδιασμού για τη διαχείριση DM και τη διάταξη εξερεύνησης για τα δυναμικά πολυμέσα και τις ασύρματες εφαρμογές δικτύων, που προτείνονται χρησιμοποιώντας στις Ενότητες 8.2 και 8.3, αντίστοιχα, κατάλληλα σύνολα υποψηφίων εξατομικευμένων διαχειριστών DM οι οποίοι επιλέγονται για κάθε αίτηση. Αυτή η δεύτερη φάση μπορεί να πάρει μέχρι μια εβδομάδα για τις πολύ σύνθετες εφαρμογές, δηλαδή με περισσότερες από 20 φάσεις εκχώρησης στην ίδια εφαρμογή. Έπειτα, στην τρίτη φάση της μεθοδολογίας διαχείρισης DM, εφαρμόζουμε τους υποψηφίους διαχειριστές DM και διερευνάμε εξαντλητικά τη συμπεριφορά χρόνου εκτέλεσής τους στην αίτηση κάτω από τη μελέτη, όπως η κατανάλωση αποτυπώματος μνήμης, τεμαχισμού, απόδοσης και ενέργειας. Για αυτόν το λόγο, όπως έχουμε εξηγήσει στο Τμήμα 8.2.3, έχουμε αναπτύξει μια βελτιστοποιημένη C++ βιβλιοθήκη, που καλύπτει όλες τις αποφάσεις στο χώρο σχεδιασμού μας και επιτρέπει την κατασκευή και τη σκιαγράφηση των εφαρμογών εξατομικευμένων διαχειριστών DM με έναν απλό τρόπο μέσω της σύνθεσης C++ των στρωμάτων [91]. Κατά συνέπεια, ολόκληρη η εξερεύνηση εφαρμογής γίνεται αυτόματα, χρησιμοποιώντας την προαναφερθείσα βιβλιοθήκη και τα πρόσθετα εργαλεία, η οποία εκτελεί τους πολλαπλάσιους χρόνους για την εφαρμογή, με τους διαφορετικούς DM διαχειριστές για να αποκτηθεί ο πλήρης χρόνος εκτέλεσης που σχεδιάζει το περίγραμμα και τις πληροφορίες. Αυτή η τρίτη φάση διαρκεί μεταξύ 3 και 4 ημερών στην περίπτωση σύνθετων εφαρμογών. Στην τέταρτη και τελική φάση της ροής σχεδιασμού διαχείρισης DM, χρησιμοποιούμε τα εργαλεία μας για να αξιολογήσουμε αυτόματα τη σκιαγράφηση που παράγεται στην προηγούμενη φάση και για να καθορίσουμε τα τελικά χαρακτηριστικά γνωρίσματα της εφαρμογής του εξατομικευμένου διαχειριστή DM για την εφαρμογή, όπως ο τελικός αριθμός ανώτατων μεγεθών block και ο αριθμός μεγεθών μνήμης εκχώρησης. Αυτή η τέταρτη φάση διαρκεί μεταξύ 2 ή 3 ημερών. Συνολικά, ολόκληρη η τυπική ροή για τους διαχειριστές DM απαιτεί μεταξύ 2 και 3 εβδομάδων για τις πραγματικές εφαρμογές.
Έχουμε εφαρμόσει την προτεινόμενη μεθοδολογία σε τρεις ρεαλιστικές περιπτωσιολογικές μελέτες που αντιπροσωπεύουν τα διαφορετικά πολυμέσα και τις περιοχές εφαρμογής δικτύων: η πρώτη περιπτωσιολογική μελέτη είναι ένα τρισδιάστατο σύστημα αναδημιουργίας εικόνας και ο τρίτος είναι ένα τρισδιάστατο δεδομένο σύστημα βασισμένο στα εξελικτικά πλέγματα. Στις ακόλουθες υποενότητες περιγράφουμε εν συντομία, τη συμπεριφορά των τριών περιπτωσιολογικών μελετών και τη προτεινόμενη μεθοδολογία που εφαρμόζεται για να σχεδιάσει τους εξατομικευμένους διαχειριστές που ελαχιστοποιούν το αποτύπωμα μνήμης. Όλα τα αποτελέσματα που παρουσιάζονται είναι οι μέσες τιμές μετά από ένα σύνολο 10 προσομοιώσεων για κάθε εφαρμογή διαχειριστών που χρησιμοποιεί 10 πρόσθετες πραγματικές εισαγωγές από αυτές που χρησιμοποιούνται στο σχεδιάγραμμα και σχεδιάζουν τους εξατομικευμένους διαχειριστές DM. Όλες οι τελικές τιμές στις προσομοιώσεις ήταν πανομοιότυπες (παραλλαγές λιγότερες από 2%).
Η πρώτη περιπτωσιολογική μελέτη που παρουσιάζεται είναι το έλλειμμα γύρω από την εφαρμογή του Robin (DRR) που λαμβάνεται από τη NetBench αξιολογώντας την ακολουθία [93]. Είναι ένας αλγόριθμος που εφαρμόζεται σε πολλούς δρομολογητές. Στην πραγματικότητα, οι παραλλαγές του DRR αλγορίθμου χρησιμοποιήθηκαν από το Cisco για τα εμπορικά προϊόντα του σημείου πρόσβασης και εν τέλει στις ευρυζωνικές συσκευές πρόσβασης. Χρησιμοποιώντας τον αλγόριθμο DRR ο δρομολογητής προσπαθεί να ολοκληρώσει μια έκθεση σχεδιάζοντας με την άδεια του ίδιου ποσού στοιχείων, για να περαστεί και να σταλεί από κάθε εσωτερική σειρά αναμονής. Στον αλγόριθμο DRR, ο χρονοπρογραμματιστής επισκέπτεται κάθε εσωτερική σειρά αναμονής με αντικείμενα, αυξάνοντας το μεταβλητό «έλλειμμα» από την αξία «κβάντο» και καθορίζει τον αριθμό bytes στο πακέτο στην κορυφή της σειράς αναμονής. Εάν το μεταβλητό «έλλειμμα» είναι λιγότερο από το μέγεθος του πακέτου στην κορυφή της σειράς αναμονής (δηλαδή, δεν έχει αρκετές πιστώσεις αυτήν τη στιγμή), ο χρονοπρογραμματιστής κινείται για να συντηρηθεί η επόμενη σειρά αναμονής. Εάν το μέγεθος του πακέτου στην κορυφή της σειράς αναμονής είναι λιγότερο ή ίσο προς το μεταβλητό «έλλειμμα», τότε εκείνη η μεταβλητή μειώνεται από τον αριθμό bytes στο πακέτο και το πακέτο διαβιβάζεται στο λιμένα παραγωγής. Ο χρονοπρογραμματιστής συνεχίζει αυτήν την διαδικασία, που αρχίζει από την πρώτη σειρά αναμονής, κάθε φορά που διαβιβάζεται ένα πακέτο. Εάν μια σειρά αναμονής δεν έχει άλλα πακέτα, καταστρέφεται. Τα πακέτα άφιξης περιμένουν στη σειρά στον κατάλληλο κόμβο, εάν κανένας τέτοιος κόμβος δεν υπάρχει, δημιουργείται. Έχουν χρησιμοποιηθεί δέκα πραγματικά ίχνη κυκλοφορίας δικτύων διαδικτύου μέχρι 10MB/sec [95] για να τρέξουν τις ρεαλιστικές προσομοιώσεις DRR.
Για να δημιουργήσουμε τον εξατομικευμένο διαχειριστή DM έχουμε ακολουθήσει βήμα προς βήμα τη μεθοδολογία μας. Κατά συνέπεια, προκειμένου να καθοριστούν οι λογικές φάσεις της εφαρμογής και του ατομικού διαχειριστή DM, σχεδιάζουμε αρχικά το περίγραμμα της συμπεριφοράς DM με τις δυναμικές δομές δεδομένων μας, που σχεδιάζουν το περίγραμμα κατά προσέγγιση [77]. Κατόπιν, εφαρμόζουμε την εξερεύνηση σχεδιασμού της διαχείρισης DM. Κατ’ αρχάς, λαμβάνουμε την απόφαση στο δέντρο A2 (μεγέθη block), να έχουμε δηλαδή πολλά μεγέθη block για να αποτρέψουμε τον εσωτερικό τεμαχισμό. Αυτό γίνεται επειδή τα block μνήμης που ζητούνται από την εφαρμογή DRR, ποικίλλουν πολύ στο μέγεθος (για να αποθηκεύσουν τα πακέτα των διαφορετικών μεγεθών) και εάν μόνο ένα μέγεθος block χρησιμοποιείται για όλα τα ζητούμενα διαφορετικά μεγέθη block, τότε o εσωτερικός θρυμματισμός θα μπορούσε να είναι μεγάλος. Κατόπιν, στο δέντρο Α5 (εύκαμπτος διαχειριστής block μεγέθους) επιλέγουμε να χωρίσουμε ή να συγχωνεύσουμε, έτσι ώστε κάθε φορά που ζητείται ένα block μνήμης με ένα μεγαλύτερο ή μικρότερο μέγεθος από τον τρέχοντα block, να επικαλούνται οι συγχωνευμένοι ή διαιρεμένοι μηχανισμοί. Στα δέντρα E2 και D2 (when) το επιλέγουμε πάντα, επιπλέον η δοκιμή ανασυγκροτείται μόλις εμφανίζεται ο τεμαχισμός. Κατόπιν, στα δέντρα E1 και D1 (αριθμός ανώτατου/ελάχιστου μεγέθους block), επιλέγουμε πολλές κατηγορίες και σταθερές, επειδή θέλουμε να πάρουμε τη μέγιστη επίδραση από τους συγχωνευμένους και διαιρεμένους μηχανισμούς με τον μη περιορισμό του μεγέθους αυτών των νέων block. Μετά από αυτό, στα δέντρα B1 (το τμήμα pool βάσει μεγέθους) και B2 (δομή pool), επιλέγεται η απλούστερη πιθανή εφαρμογή pool, η οποία είναι μια ενιαία pool, επειδή εάν δεν υπάρχει κανένα σταθερό μέγεθος block, κατόπιν καμία πραγματική χρήση δεν υπάρχει για τις σύνθετες δομές pool, για να επιτύχει ένα μειωμένο αποτύπωμα μνήμης.
Κατόπιν, στο δέντρο C1 (κατάλληλοι αλγόριθμοι), επιλέγουμε την ακριβή τακτοποίηση, για να αποφύγουμε όσο το δυνατόν περισσότερο την απώλεια της μνήμης στον εσωτερικό τεμαχισμό. Έπειτα, στο δέντρο Α1 (δομή block), επιλέγουμε το απλούστερο DDT που επιτρέπεται, το οποίο είναι ένας διπλά συνδεόμενος κατάλογος. Κατόπιν, στα δέντρα A3 (ετικέτες block) και A4 (το block που κατέγραψε τις πληροφορίες), επιλέγουμε έναν τομέα επιγραφών για να προσαρμόσουμε τις πληροφορίες για το μέγεθος και τη θέση κάθε φραγμού για να υποστηρίξουμε τους διαιρεμένους και συγχωνευμένους μηχανισμούς. Τέλος, μετά από αυτό, πρέπει να παρθούν αυτές οι αποφάσεις μετά από τη διάταξη που περιγράφεται στο τμήμα 8.3, σύμφωνα με την προτεινόμενη ροή σχεδιασμού μπορούμε να καθορίσουμε εκείνες τις αποφάσεις του τελικού εξατομικευμένου διαχειριστή DM, που εξαρτάται από την ιδιαίτερη συμπεριφορά χρόνου εκτέλεσής της στην εφαρμογή (πχ. τελικός αριθμός ανώτατων μεγεθών block) μέσω της προσομοίωσης με την εξατομικευμένη C++ βιβλιοθήκη και τα εργαλεία μας [91] (δείτε στο τμήμα 8.4 για περισσότερες λεπτομέρειες). Κατόπιν, το εφαρμόζουμε και συγκρίνουμε την εξατομικευμένη λύση με τους πολύ γνωστούς βελτιστοποιημένης κατάστασης προόδου, γενικής χρήσης διαχειριστές, δηλαδή Lea v2.7.2 [96] και Kingsley [56]. Ο διαθέτης Lea είναι ένας από τους καλύτερους γενικούς διαχειριστές (σε επίπεδο του συνδυασμού αποτυπώματος ταχύτητας και μνήμης) [79] και διάφορες παραλλαγές είναι ενσωματωμένες στις διαφορετικές διανομές του GNU Linux ΛΣ. Είναι ένας υβριδικός διαχειριστής DM, που περιλαμβάνει τις διαφορετικές συμπεριφορές για τα διαφορετικά μεγέθη αντικειμένου. Για τα μικρά αντικείμενα χρησιμοποιεί κάποιους γρήγορους καταλόγους [56], για τα μέσου μεγέθους αντικείμενα εκτελεί την κατά προσέγγιση καλή εφαρμογή κατανομής [56] και για τα μεγάλα αντικείμενα χρησιμοποιεί την αφιερωμένη μνήμη (που διατίθεται άμεσα με τη λειτουργία mmap ()). Επίσης, συγκρίνουμε την προσέγγισή μας με μια βελτιστοποιημένη έκδοση του Kingsley [56] DM διαχειριστή, που χρησιμοποιεί ακόμα τη δύναμη να διαχωρίζει δύο κατάλληλους καταλόγους [56] για να επιτύχει τις γρήγορες κατανομές, αλλά βελτιστοποιείται για αντικείμενα μεγαλύτερα από 1.024 bytes, τα οποία παίρνουν τη μνήμη τους από έναν ταξινομημένο συνδεδεμένο κατάλογο, θυσιάζοντας οριστικά την τακτοποίηση ταχύτητας. Μια παρόμοια τεχνική εφαρμογής χρησιμοποιείται αρκετά βασισμένη στα παράθυρα ΛΣ [80], [81].
Επιπλέον, έχουμε συγκρίνει την εξατομικευμένη λύση DM με μια σχεδιασμένη χειρωνακτικά εφαρμογή των σημασιολογικών περιοχών διαχειριστών [82] που μπορούν να βρεθούν σε κάποιο ενσωματωμένο ΛΣ (πχ. [78] Στην Εικόνα 8.6 παρουσιάζονται οι χρήσεις των εξατομικευμένων διαχειριστών DM με λιγότερη μνήμη από το Lea 2.7.2 (Linux ΛΣ), το Kingsley και τους διαχειριστές DM περιοχών. Αυτό οφείλεται στο γεγονός ότι ο εξατομικευμένος διαχειριστής DM δεν έχει καθορίσει τα μεγέθη και προσπαθεί να συγχωνευτεί και να χωρέσει όσο το δυνατόν περισσότερο, το οποίο είναι μια καλύτερη επιλογή στις δυναμικές εφαρμογές με τα μεγέθη και με τη μεγάλη παραλλαγή. Επιπλέον, δεν χρησιμοποιείται όταν τεράστια κομμάτια της μνήμης συγχωνεύονται, και έτσι επιστρέφονται πίσω στο σύστημα για άλλες εφαρμογές. Το Lea και το Kingsley δημιουργούν τους τεράστιους ελεύθερους καταλόγους αχρησιμοποίητων block (σε περίπτωση που επαναχρησιμοποιούνται αργότερα), συγχωνεύονται και χωρίζουν σπάνια (Lea) ή ποτέ (Kingsley) και τελικά, έχουν καθορίσει τα μεγέθη block. Αυτό μπορεί να παρατηρηθεί στην Εικόνα 8.7, όπου παρουσιάζουμε γραφικές παραστάσεις χρήσης DM των εξατομικευμένων διαχειριστών DM και Lea, και Εικόνα 8.8, όπου τα αιτήματα DM της εφαρμογής παρουσιάζονται κατά τη διάρκεια που οργανώνεται το ένα εκ των δύο. Στην περίπτωση του διαχειριστή DM περιοχών, καταναλώνεται περισσότερο αποτύπωμα μνήμης από το Lea λόγω του τεμαχισμού, δεδομένου ότι κανένας συγχωνευμένος/διαιρεμένος μηχανισμός δεν εφαρμόζεται για να επαναχρησιμοποιήσει τα block μνήμης.

8.6: Μέγιστα αποτελέσματα αποτυπώματος μνήμης στην εφαρμογή DRR.
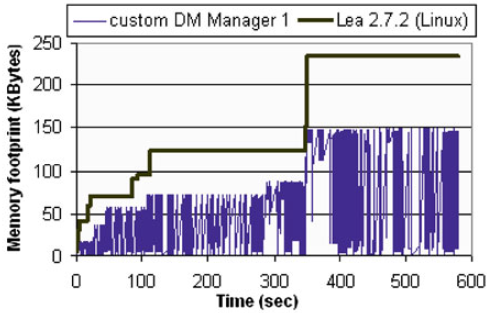
8.7: Συμπεριφορά του αποτυπώματος μνήμης του Lea διευθυντή DM έναντι του εξατομικευμένου διαχειριστή DM.
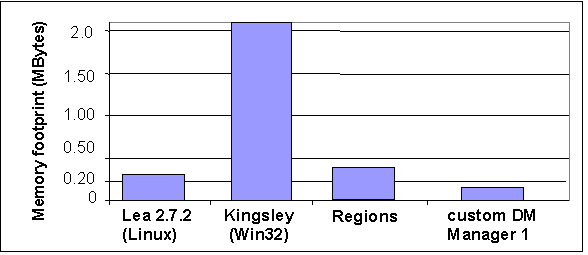
8.8: Αιτήματα εκχώρησης DM στην εφαρμογή DRR.
Σχετικά με την απόδοση των διαφόρων διαχειριστών DM (δείτε τον Πίνακα 8.2 για περαιτέρω περίληψη με τα αποτελέσματα όλων των περιπτωσιολογικών μελετών), μπορούμε να παρατηρήσουμε ότι σε όλες τις περιπτώσεις 600 το δευτερόλεπτο, είναι ο χρόνος που χρησιμοποιείται για να σχεδιάσει τα προγραμματισμένα ίχνη των 600 δευτερολέπτων στην κίνηση του διαδικτύου. Αυτό σημαίνει ότι όλοι οι διαχειριστές DM που μελετώνται ικανοποιούν σε πραγματικό χρόνο τις απαιτήσεις της εφαρμογής DRR. Επιπλέον, ο διαχειριστής DM βελτιώνει εκτενώς το αποτύπωμα μνήμης που χρησιμοποιείται από τους άλλους διαχειριστές DM, αλλά κανένα πρόσθετο χρονικό γενικό έξοδο δεν παρατηρείται, λόγω των εσωτερικών διαδικασιών συντήρησής του. Τέλος, έχουμε αξιολογήσει τη συνολική κατανάλωση ενέργειας του τελικού ενσωματωμένου συστήματος με κάθε έναν από τους μελετημένους διαχειριστές DM, χρησιμοποιώντας έναν ακριβή κυκλικό βραχίονα βασισμένο στον προσομοιωτή που περιλαμβάνει ένα πλήρες πρότυπο εκτίμησης ενέργειας–καθυστέρησης για τεχνολογία τρανζίστορ 0.13 μm [97]. Τα αποτελέσματα δείχνουν ότι ο εξατομικευμένος διαχειριστής DM επιτυγχάνει τα πολύ καλά αποτελέσματα για την ενέργεια, όταν συγκρίνεται με τους διαχειριστές DM της κατάστασης προόδου. Αυτό οφείλεται στο γεγονός ότι οι περισσότερες από τις προσβάσεις μνήμης αποδίδονται εσωτερικά από τους διαχειριστές στις σύνθετες δομές διαχείρισης και δεν απαιτούνται στον εξατομικευμένο διαχειριστή, το οποίο χρησιμοποιεί τις απλούστερες εσωτερικές δομές δεδομένων που βελτιστοποιούνται για την εφαρμογή στόχων. Κατά συνέπεια, ο διαχειριστής DM μειώνει τις τιμές κατανάλωσης ενέργειας από 12%, ενώ το Kingsley, και το Lea κατά 15% και 16% αντίστοιχα (Εικόνα 8.9). Είναι σημαντικό να αναφερθεί ότι ακόμα κι αν ο Kingsley έχει ένα μικρότερο ποσό διαχειριστικών προσβάσεων DM, δεδομένου ότι δεν εκτελεί τις διαιρεμένες ή συγχωνευμένες διαδικασίες, αυτό πάσχει από μια μεγάλη ποινική ρήτρα του αποτυπώματος μνήμης. Αυτό μεταφράζεται στις πολύ ακριβές προσβάσεις μνήμης, επειδή πρέπει να χρησιμοποιηθούν οι μεγαλύτερες μνήμες. Συνεπώς, για τις δυναμικές εφαρμογές δικτύων όπως DRR, η μεθοδολογία μας επιτρέπει να σχεδιάσουμε τους πολύ προσαρμοσμένους διαχειριστές DM που εκθέτουν το λιγότερο τεμαχισμό από το Lea, οι περιοχές ή Kingsley και απαιτούν έτσι τη λιγότερη μνήμη. Δεδομένου ότι αυτή η μείωση στο αποτύπωμα μνήμης συνδυάζεται με μια απλούστερη εσωτερική διαχείριση του DM, το τελικό σύστημα καταναλώνει λιγότερη ενέργεια.
Οι δεύτερες μορφές περιπτωσιολογικής μελέτης, όπου ένας από τους υπο-αλγορίθμους αναδημιουργίας μιας τρισδιάστατης εφαρμογής [38] που λειτουργεί όπως την τρισδιάστατη αντίληψη στα ζωντανά όντα, όπου η σχετική μετατόπιση μεταξύ διάφορων 2D προβολών χρησιμοποιείται για να αναδημιουργήσει τη 3D διάσταση. Η ενότητα λογισμικού που χρησιμοποιείται ως αίτηση των οδηγών μας, είναι μια από τις βασικές δομικές μονάδες σε πολλούς τρέχοντες τρισδιάστατους αλγορίθμους οράματος: επιλογή χαρακτηριστικών γνωρισμάτων και συσχέτιση. Έχει εξαχθεί από τον αρχικό κώδικα του τρισδιάστατου συστήματος αναδημιουργίας εικόνας (δείτε [45] για τον πλήρη κώδικα του αλγορίθμου με 1.75 εκατομμύρια γραμμές υψηλού επιπέδου C++), και δημιουργεί τη μαθηματική αφαίρεση από τα σχετικά πλαίσια που χρησιμοποιείται στο σφαιρικό αλγόριθμο. Περιλαμβάνει ακόμα 600.000 γραμμές C++ κώδικα, ο οποίος καταδεικνύει την πολυπλοκότητα των εφαρμογών που μπορούμε να εξετάσουμε την προσέγγισή μας και την ανάγκη της υποστήριξης εργαλείων για τις φάσεις παραγωγής ανάλυσης και της εξερεύνησης του κώδικα στη γενική προσέγγισή μας (δείτε την Εικόνα 8.4).
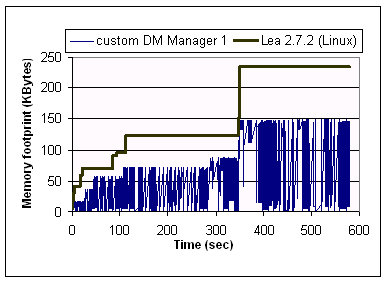
8.9: Σχετική ενεργειακή βελτίωση του εξατομικευμένου διαχειριστή DM στην εφαρμογή DRR.
Αυτή η εφαρμογή ταιριάζει με τις γωνίες [38] που ανιχνεύονται σε 2 επόμενα πλαίσια και στηρίζεται σε μεγάλο ποσοστό στο DM, λόγω της μη προβλεψιμότητας των χαρακτηριστικών γνωρισμάτων των εικόνων εισαγωγής στον χρόνο σύνταξης (πχ. ο αριθμός πιθανών γωνιών που ταιριάζουν ποικίλλει σε κάθε εικόνα). Επιπλέον, οι διαδικασίες γίνονται στις εικόνες με εντατικές ανάγκες σε μνήμη. Παραδείγματος χάριν, κάθε εικόνα με ένα μέγεθος 640 × 480 pixels πέρα από 1MB. Επομένως, τα γενικά έξοδα DM (πχ. ο εσωτερικός και εξωτερικός τεμαχισμός [56]) αυτής της εφαρμογής πρέπει να ελαχιστοποιηθούν για να είναι χρησιμοποιήσιμα για τις ενσωματωμένες συσκευές, όπου τρέχουν ταυτόχρονα περισσότερες εφαρμογές. Τέλος, σημειώστε ότι οι προσβάσεις του αλγορίθμου στις εικόνες τυχαιοποιούνται. Αυτό έχει ως συνέπεια ότι οι κλασικές βελτιστοποιήσεις πρόσβασης εικόνας δε μπορούν να μειώσουν περαιτέρω το αποτύπωμα DM. Για αυτήν την περιπτωσιολογική μελέτη, η δυναμική συμπεριφορά της δείχνει, ότι η εφαρμογή παρουσιάζει ελάχιστη ποικιλία σε δυναμικούς τύπους [77] και συγκεκριμένα 8 διαφορετικά μεγέθη κατανομής.
Επιπλέον, τα περισσότερα από αυτά τα διατιθέμενα μεγέθη είναι σχετικά μικρά (δηλαδή, μεταξύ 32 ή 16 Bytes) και μόνο πολύ λίγα block είναι πολύ μεγαλύτερα (πχ. 163KB). Επιπλέον, βλέπουμε ότι οι περισσότεροι από τους τύπους στοιχείων αλληλεπιδρούν ο ένας με τον άλλον και είναι ενεργοί σχεδόν σε όλο το χρόνο εκτέλεσης της εφαρμογής. Μέσα σε αυτό το πλαίσιο, εφαρμόζουμε τη μεθοδολογία μας και χρησιμοποιούμε τη διάταξη που παρέχεται στο Τμήμα 8.3 και προσπαθούμε να ελαχιστοποιήσουμε την απώλεια του αποτυπώματος DM (πχ. τεμαχισμός, από πάνω στις επιγραφές, κλπ) αυτής της εφαρμογής. Σαν αποτέλεσμα, λαμβάνουμε μια τελική λύση που αποτελείται από έναν εξατομικευμένο διαχειριστή DM με 4 διαχωρισμένες pool ή τις περιοχές για τα σχετικά μεγέθη στην εφαρμογή. Η πρώτη pool χρησιμοποιείται για το μικρότερο μέγεθος κατανομής που ζητείται στην εφαρμογή, δηλαδή 32 bytes. Η δεύτερη pool επιτρέπει τις κατανομές των μεγεθών μεταξύ 756 bytes και 1.024 bytes. Κατόπιν, η τρίτη pool χρησιμοποιείται για τα αιτήματα κατανομής 16.384 bytes. Τέλος, η τέταρτη pool χρησιμοποιείται για τα μεγάλα αιτήματα κατανομής (πχ. 163 ή 265KB). Η pool για το μικρότερο μέγεθος έχει έναν ενιαίο συνδεδεμένο κατάλογο, επειδή δεν πρέπει να συγχωνευτεί ή να χωρίσει, δεδομένου ότι μόνο ένα μέγεθος block μπορεί να ζητηθεί από αυτήν. Το υπόλοιπο των pool περιλαμβάνει τους διπλά συνδεόμενους καταλόγους ελεύθερων block, με τις επιγραφές που περιέχουν το μέγεθος κάθε αντίστοιχου block και της πληροφορίας για την επικρατούσα κατάστασή τους (δηλαδή, σε λειτουργία ή ελεύθερα). Αυτοί οι μηχανισμοί υποστηρίζουν αποτελεσματικά την άμεση συγχώνευση και το διαχωρισμό μέσα σε αυτές τις pool, και σχεδιάζεται με τη μεθοδολογία μας ο εσωτερικός και εξωτερικός τεμαχισμός στο εξατομικευμένο διαχειριστή DM.
Σε αυτήν την περιπτωσιακή μελέτη, έχουμε συγκρίνει τη λύση μας με τους ανά περιοχή σημασιολογικούς διαχειριστές [82], [56]. Επίσης, έχουμε εξετάσει το διαχειριστή μας με τις ίδιες βελτιστοποιημένες εκδόσεις Kingsley και Lea που χρησιμοποιούνται στο προηγούμενο παράδειγμα (δηλαδή, DRR) δεδομένου ότι αυτοί είναι οι τύποι διαχειριστών DM που βρίσκονται στα ενσωματωμένα συστήματα. Τα επιτευχθέντα αποτελέσματα αποτυπώματος μνήμης απεικονίζονται στην Εικόνα 8.10. Αυτά τα αποτελέσματα δείχνουν ότι οι τιμές που λήφθηκαν με την διαχείριση DM σχεδίασαν τη μεθοδολογία λαμβάνοντας υπόψη τις σημαντικές βελτιώσεις στο αποτύπωμα μνήμης έναντι της χειρωνακτικά σχεδιασμένης εφαρμογής ενός διαχειριστή περιοχών (28.47%), του Lea (29.46%) και της βελτιστοποιημένης έκδοσης Kingsley (33.01%). Αυτά είναι τα αποτελέσματα, επειδή ο εξατομικευμένος διαχειριστής DM, είναι σε θέση τεμαχισμού του συστήματος με δύο τρόπους. Κατ’ αρχάς, επειδή ο σχεδιασμός και η συμπεριφορά του ποικίλλουν σύμφωνα με τα ζητούμενα διαφορετικά μεγέθη block. Δεύτερον, στις pool όπου μια σειρά των αιτημάτων μεγεθών block επιτρέπεται, χρησιμοποιεί τις άμεσες συγχωνευμένες και διαιρεμένες υπηρεσίες για να μειώσει και τον εσωτερικό και εξωτερικό τεμαχισμό. Στους διαχειριστές περιοχών, τα μεγέθη block κάθε μιας διαφορετικής περιοχής καθορίζονται σε ένα μέγεθος block και όταν χρησιμοποιούνται τα block διάφορων μεγεθών, αυτό δημιουργεί τον εσωτερικό τεμαχισμό. Στο Lea, η σειρά των μεγεθών block που επιτρέπονται, δεν εγκαθιστά ακριβώς αυτά που χρησιμοποιούνται στις εφαρμογές και τα μικτά μεγέθη αποεκχώρησης λίγων μεγεθών block και έτσι παράγουν απόβλητα των καταλόγων μεγεθών που δεν χρησιμοποιούνται στο σύστημα. Επιπλέον, η συχνή χρήση των συνεχών/διαιρεμένων μηχανισμών στο Lea δημιουργεί πρόσθετα γενικά κόστη στο χρόνο εκτέλεσης έναντι του διαχειριστή περιοχών, ο οποίος έχει ρυθμίσει καλύτερα τα μεγέθη κατανομής σε εκείνους που χρησιμοποιούν την εφαρμογή. Τέλος, στο Kingsley, οι συγχωνευμένοι/διαιρεμένοι μηχανισμοί εφαρμόζονται, αλλά μια αρχική μνήμη ορίου είναι διατηρημένη και διανεμημένη μεταξύ των διαφορετικών καταλόγων για τα μεγέθη. Σε αυτήν την περίπτωση, κάποια από τα ”απόβλητα” (ή pool των DM block στο Kingsley) είναι υποαπασχολούμενα. Επιπλέον, η τελική ενσωματωμένη εφαρμογή συστημάτων που χρησιμοποιεί τον εξατομικευμένο διαχειριστή DM, επιτυγχάνει τα καλύτερα ενεργειακά αποτελέσματα από τις εφαρμογές, χρησιμοποιώντας τους διαχειριστές DM γενικού σκοπού. Σε αυτήν την περίπτωση μελέτης, ο διαχειριστής DM υιοθετεί τις λιγότερες προσβάσεις διαχείρισης στους DM και το αποτύπωμα μνήμης από οποιοδήποτε άλλον διαχειριστή. Κατά συνέπεια, ο διαχειριστής DM μας επιτρέπει τη γενική αποταμίευση κατανάλωσης ενέργειας σχετικά με τις περιοχές, 11% πέρα από Kingsley και 14% πέρα από το Lea (Εικόνα 8.11).
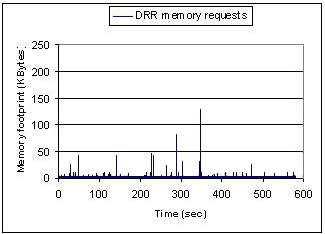
8.10: Μέγιστα αποτελέσματα αποτυπώματος μνήμης στην τρισδιάστατη εφαρμογή ανοικοδόμησης.
Η τρίτη περιπτωσιολογική μελέτη είναι η τρισδιάστατη δεδομένη ενότητα [94] μιας ολόκληρης τρισδιάστατης τηλεοπτικής εφαρμογής συστημάτων. Αυτή η ενότητα ανήκει στην κατηγορία τρισδιάστατων αλγορίθμων με τα εξελικτικά πλέγματα [92] που προσαρμόζουν την ποιότητα κάθε αντικειμένου που επιδεικνύεται στην οθόνη που αποσπά έγκαιρα την προσοχή των χρηστών (πχ. ποιότητα των συστημάτων [94] υπηρεσιών). Επομένως, τα αντικείμενα αντιπροσωπεύονται από κορυφές (ή τρίγωνα)και αντιμετωπίζουν την ανάγκη να αποθηκευτούν δυναμικά λόγω της αβεβαιότητας να συντάσσουν το χρόνο των χαρακτηριστικών γνωρισμάτων των αντικειμένων που δίνουν (δηλαδή, αριθμός και ανάλυση). Κατ’ αρχήν, εκείνες οι κορυφές που βρίσκονται στις πρώτες τρεις φάσεις ολόκληρης της διαδικασίας απεικόνισης, δηλαδή, του μετασχηματισμού model-view, φωτεινής διαδικασίας και κανονικού μετασχηματισμού [94] άποψης. Τέλος, το σύστημα επεξεργάζεται τα χαρακτηριστικά των αντικειμένων στις επόμενες τρεις φάσεις (δηλαδή, ψαλίδισμα, άποψη-και επαναπροσαρμογή [94]) της διαδικασίας απεικόνισης, για να παρουσιάσει το τελικό αντικείμενο. Σύμφωνα με τα πειράματά μας, αυτή η εφαρμογή μοιάζει πολύ με τη συμπεριφορά DM της οπτικής εφαρμογής αποκωδικοποιητών σύστασης MPEG4 (VTC) στα πρότυπα [40].
Σε αυτήν την περίπτωση, έχουμε συγκρίνει τον εξατομικευμένο διαχειριστή μας με το Lea v2.7.2, το βελτιστοποιημένο της έκδοσης Kingsley, και λόγω των ιδιαίτερων φάσεων εμπιστοσύνης της, όπου οι ενδιάμεσες τιμές χτίζονται με έναν σειριακό τρόπο και καταστρέφονται τελικά στο τέλος κάθε φάσης (για τις φάσεις που χειρίζονται τις κορυφές), έχουμε χρησιμοποιήσει επίσης Obstacks [56]. Το Obstacks είναι ένας γνωστός εξατομικευμένος διαχειριστής DM που βελτιστοποιείται με παρόμοιας με σωρό συμπεριφορά για τις εφαρμογές. Το Obstacks χρησιμοποιείται εσωτερικά από το GCC του GNU. Όπως η Εικόνα 8.12 παρουσιάζει, το Lea και ο διαχειριστής περιοχών επιτυγχάνουν τα καλύτερα αποτελέσματα στο αποτύπωμα μνήμης από το διαχειριστή DM Kingsley. Επίσης, λόγω της παρόμοιας με σωρό συμπεριφοράς της εφαρμογής στις φάσεις που χειρίζονται τα τρίγωνα, το Obstacks επιτυγχάνει ακόμα τα καλύτερα αποτελέσματα από τους διαχειριστές Lea, στο αποτύπωμα μνήμης. Εντούτοις, ο διαχειριστής που σχεδιάζεται με τη μεθοδολογία μας, βελτιώνει περαιτέρω τις τιμές αποτυπώματος μνήμης που λαμβάνονται από το Obstacks. Το γεγονός είναι ότι η βελτιστοποιημένη συμπεριφορά Obstacks δεν μπορεί να χρησιμοποιηθεί στις τελικές φάσεις της δεδομένης διαδικασίας, επειδή τα πρόσωπα όλων χρησιμοποιούνται ανεξάρτητα σε ένα διαταραγμένο σχεδιασμό και ελευθερώνονται χωριστά. Κατά συνέπεια, η Obstacks πάσχει από μια υψηλή ποινική ρήτρα στο αποτύπωμα μνήμης λόγω του κατακερματισμού, επειδή δεν έχει πάρει μια κατάλληλη δομή συντήρησης των block DM για τέτοια συμπεριφορά αποεκχώρησης.
Από μια ενεργειακή άποψη, ο εξατομικευμένος DM διαχειριστής βελτιώνει επίσης τα αποτελέσματα που επιτυγχάνονται με τους μελετημένους γενικής χρήσης διαχειριστές στο βασισμένο προσομοιωτή ARM. Οι ενεργειακοί αριθμοί του τελικού ενσωματωμένου συστήματος μεταβάλλονται από 18% σε 20%, αντίστοιχα. Στην περίπτωση Obstacks και Kingsley, παράγουν τις λιγότερες προσβάσεις μνήμης από τον εξατομικευμένο DM διαχειριστή και σε αυτό οφείλεται η βελτιστοποιημένη διαχείρισή των block DM για την απόδοση, αλλά η μεγαλύτερη κατανάλωση του αποτυπώματος μνήμης, επιτρέπει τελικά τη γενική αποταμίευση 13% και 14% στην κατανάλωση ενέργειας για το διαχειριστή DM μας, αντίστοιχα (Εικόνα 8.13).
Τέλος, για να αξιολογήσουμε τη διαδικασία σχεδιασμού με την μεθοδολογία μας, μας πήρε δύο εβδομάδες για τον προτεινόμενο σχεδιασμό και τη ροή εφαρμογής των τελικών εξατομικευμένων διαχειριστών DM για κάθε περιπτωσιολογική μελέτη. Επίσης, όπως ο πίνακας 8.2 παρουσιάζει, αυτοί οι διαχειριστές DM επιτυγχάνουν τις λιγότερες τιμές αποτυπώματος μνήμης με μόνο ένα 10% υπερυψωμένο (κατά μέσον όρο) κατά τη διάρκεια του χρόνου εκτέλεσης του γρηγορότερου γενικής χρήσης διαχειριστή DM που παρατηρείται σε αυτές τις περιπτωσιολογικές μελέτες, δηλαδή, Kingsley. Επιπλέον, η μείωση στην απόδοση δεν είναι σχετική, δεδομένου ότι οι εξατομικευμένοι διαχειριστές DM την συντηρούν σε πραγματικό χρόνο συμπεριφοράς που απαιτείται από τις εφαρμογές, και κατά συνέπεια, ο χρήστης δεν θα παρατηρήσει οποιαδήποτε διαφορά. Επιπλέον, οι προτεινόμενοι εξατομικευμένοι διαχειριστές DM , περιλαμβάνουν τις βελτιστοποιημένες εσωτερικές οργανώσεις διαχείρισης DM των block μνήμης για κάθε μελετημένη εφαρμογή, οι οποίοι παράγουν συνήθως μια μείωση στις προσβάσεις μνήμης έναντι των γενικής χρήσης διαχειριστών κατάστασης προόδου, όπως το Lea ή οι περιοχές, οι οποίοι σχεδιάζονται για ένα ευρύ φάσμα των σχεδίων συμπεριφοράς των αιτημάτων μνήμης και DM. Μόνο οι Kingsley και Obstacks παράγουν τις λιγότερες προσβάσεις μνήμης από το διαχειριστή DM συνήθειας λόγω της προσανατολισμένης απόδοσης των σχεδιασμών τους ξεπερνώντας το, αλλά σπαταλώντας ένα μεγάλο μέρος του αποτυπώματος μνήμης λόγω του τεμαχισμού. Κατά συνέπεια, αυτοί οι διαχειριστές απαιτούν τις μεγαλύτερες μνήμες εντός ολοκληρωμένου κυκλώματος για να αποθηκεύσουν τα δυναμικά στοιχεία αλλά απαιτείται περισσότερη ενέργεια ανά πρόσβαση [97], η οποία αντιδρά στις πιθανές βελτιώσεις στην κατανάλωση ενέργειας λόγω των λιγότερων προσβάσεων μνήμης. Εν περιλήψει, οι εξατομικευμένοι διαχειριστές DM μας μειώνουν επίσης κατά 15% κατά μέσον όρο τη συνολική κατανάλωση ενέργειας του τελικού ενσωματωμένου συστήματος έναντι των γενικής χρήσης διαχειριστών DM.
Αν και η μεθοδολογία μας για το σχεδιασμό των εξατομικευμένων διαχειριστών DM έχει οδηγηθεί από την ελαχιστοποίηση του αποτυπώματος μνήμης, μπορεί να αποκτήσει νέο στόχο προς την τέλεια επίτευξη των διαφορετικών ανταλλαγών μεταξύ οποιονδήποτε σχετικών παραγόντων σχεδιασμού, όπως η βελτίωση της απόδοσης ή η κατανάλωση λίγο περισσότερου αποτυπώματος μνήμης, για να επιτύχει περισσότερη ενέργεια ως αποταμίευση.
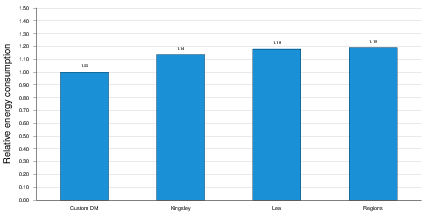
8.11: Σχετική ενεργειακή βελτίωση του εξατομικευμένου διαχειριστή DM στην τρισδιάστατη εφαρμογή ανοικοδόμησης.
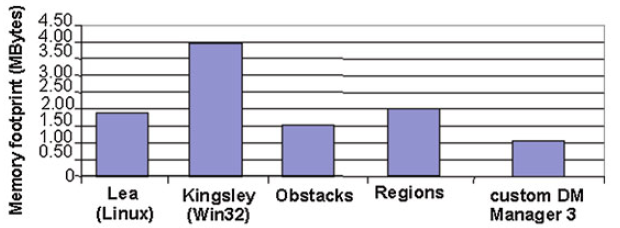
8.12: Μέγιστα αποτελέσματα αποτυπώματος μνήμης στην τρισδιάστατη απόδοση της εφαρμογής.
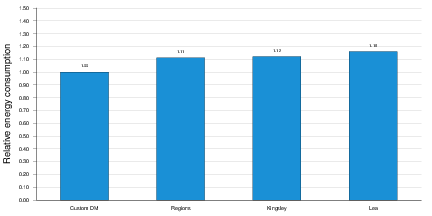
8.13: Σχετική βελτίωση του εξατομικευμένου διαχειριστή DM στην απόδοση της εφαρμογής.
Οι ικανότητες των φορητών ενσωματωμένων συσκευών έχουν βελτιωθεί τα τελευταία χρόνια και κάνουν εφικτή την διαχείριση των πολύ σύνθετων και δυναμικών εφαρμογών πολυμέσων. Τέτοιες εφαρμογές έχουν αυξήσει πρόσφατα την πολυπλοκότητα τους. Έτσι, στα καταναλωτικά ενσωματωμένα συστήματα, νέες μεθοδολογίες σχεδιασμού πρέπει να είναι διαθέσιμες για να χρησιμοποιήσουν αποτελεσματικά τη παρούσα μνήμη, σε αυτά τα πολύ περιορισμένα ενσωματωμένα συστήματα. Σε αυτό το κεφάλαιο έχουμε παρουσιάσει μια συστηματική μεθοδολογία, που καθορίζει και ερευνά το δυναμικό χώρο σχεδιασμού διαχείρισης μνήμης των σχετικών αποφάσεων, προκειμένου να σχεδιαστεί η δυναμική εξατομικευμένη μνήμη διαχειριστών με μια μείωση του αποτυπώματος μνήμης, για τις ασύρματες εφαρμογές δικτύων και δυναμικών πολυμέσων. Τα αποτελέσματά μας στις πραγματικές εφαρμογές παρουσιάζουν σημαντικές βελτιώσεις στο αποτύπωμα μνήμης, πέρα από την κατάσταση προόδου γενικής χρήσης και στους χειρωνακτικά βελτιστοποιημένους εξατομικευμένους διαχειριστές DM, που υφίστανται μόνο μικρά γενικά έξοδα στο χρόνο εκτέλεσης.
Σχεδιασμός Ενσωματωμένων Συστημάτων: Σύντομη θεωρία και υποδειγματικά λυμένη εφαρμογή πολυμέσων
Το Παράρτημα αυτό γράφτηκε με τέτοιο τρόπο, ώστε να μπορεί να αποτελέσει ένα αυτόνομο κεφάλαιο με στόχο τους διπλωματούχους μηχανικούς που θέλουν να αποκτήσουν μια σύντομη, αλλά και εμπεριστατωμένη γνώση στο αντικείμενο της διαχείρισης μνήμης πολυμεσικών εφαρμογών.
Ως ενσωματωμένο σύστημα ορίζεται κάθε συσκευή η οποία εμπεριέχει ένα προγραμματιζόμενο επεξεργαστή, αλλά δεν είναι από μόνο του ένας γενικού σκοπού υπολογιστής. Ο προγραμματισμός των ενσωματωμένων συστημάτων μπορεί να πραγματοποιηθεί σε γλώσσα μηχανής (assembly) ή σε κάποια υψηλότερη γλώσσα προγραμματισμού, αν διατίθεται ο compiler της αντίστοιχης γλώσσας για το συγκεκριμένο επεξεργαστή.
Οι εφαρμογές που σχεδιάζονται από τον προγραμματιστή δεν είναι πάντα καλογραμμένες εφαρμογές. Όταν ένας προγραμματιστής προσπαθεί να υλοποιήσει έναν αλγόριθμο, η σκέψη του επικεντρώνεται κατά κύριο λόγο στην ανάλυση της εφαρμογής και στην επίλυση του προβλήματος (δηλ. στη σωστή λογική λειτουργία της εφαρμογής) και όχι στον τρόπο με τον οποίο θα τρέχει (ή θα υλοποιηθεί) η εφαρμογή πάνω στον προγραμματιζόμενο επεξεργαστή. Το γεγονός αυτό έχει ως συνέπεια τη μη-βέλτιστη υλοποίηση μιας εφαρμογής, αφού δεν λαμβάνει υπόψη τα συγκεκριμένα χαρακτηριστικά ενός ενσωματωμένου συστήματος. Για να επιτευχθεί μια βέλτιστη υλοποίηση θα πρέπει να μειωθούν οι περιττές εκτελέσεις εντολών και οι άσκοπες προσπελάσεις στη μνήμη, οι οποίες έχουν σαν αποτέλεσμα την αργή εκτέλεση της εφαρμογής, αλλά και την υψηλή κατανάλωση ενέργειας. Ο σχεδιασμός ενσωματωμένων συστημάτων απαιτεί ελαχιστοποίηση του χρόνου εκτέλεσης της εφαρμογής, ώστε να πετύχουμε π.χ., εκτέλεση σε πραγματικό χρόνο (real-time) για εφαρμογές βίντεο. Επίσης, σε εφαρμογές που πρόκειται να χρησιμοποιηθούν σε φορητές συσκευές, η κατανάλωση ισχύος πρέπει να περιοριστεί στο ελάχιστο, ώστε να αυξηθεί η αυτονομία του συστήματος, καθώς και οι δύο παραπάνω παράγοντες πρέπει να λαμβάνονται σοβαρά υπόψη κατά τον σχεδιασμό εφαρμογών με τη χρήση ενσωματωμένων συστημάτων.
Επειδή ο προγραμματιστής κατά στην υλοποίηση αλγορίθμων σε μια γλώσσα υψηλού επιπέδου δεν λαμβάνει υπόψη του το υπολογιστικό σύστημα που θα εκτελέσει την εφαρμογή, δεν εκμεταλλεύεται τα χαρακτηριστικά του συστήματος που του προσφέρονται. Ο κύριος λόγος της αργής εκτέλεσης σε εφαρμογές πολυμέσων και δικτύων οφείλεται στον μεγάλο όγκο μεταφοράς δεδομένων από και προς τις μνήμες δεδομένων (ή κύρια μνήμη). Για τη βελτιστοποίηση αλγορίθμων με βάση την αρχιτεκτονική υλοποίησης έχει αναπτυχθεί μια Μεθοδολογία Εξερεύνησης Μεταφορών και Αποθήκευσης Δεδομένων (DTSE, Data Transfer & Storage Exploration23). Η μεθοδολογία αυτή βασίζεται σε αλγοριθμικούς μετασχηματισμούς, με στόχο τη μείωση των προσπελάσεων στην εξωτερική μνήμη. Η μείωση αυτή επιτυγχάνεται αποθηκεύοντας σε μικρού μεγέθους μνήμης προσωρινά τμήματα των δεδομένων προς επεξεργασία. Οι μικρές προσωρινές μνήμες μπορούν να τοποθετηθούν πλησιέστερα στον υπολογιστικό πυρήνα (On-chip – cache μνήμες) που έχουν μικρότερο χρόνο προσπέλασης, αλλά και χαμηλότερη κατανάλωση ενέργειας ανά προσπέλαση (Σχήμα 1).
Τα στάδια της βελτιστοποίησης μιας εφαρμογής είναι τρία. Το πρώτο στάδιο είναι ο εντοπισμός των σημείων της εφαρμογής, όπου εμφανίζονται οι μεγαλύτερες καθυστερήσεις και εκείνων των σημείων, όπου γίνονται οι περισσότερες προσπελάσεις στη μνήμη (πίνακες δεδομένων). Η ανάλυση αυτή ονομάζεται σκιαγράφηση (profiling) και σε μικρού μεγέθους εφαρμογές ο εντοπισμός μπορεί να γίνει εύκολα, αντιθέτως σε μεγάλου μεγέθους αλγορίθμους η χρήση εργαλείων είναι απαραίτητη. Ένα τέτοιο εργαλείο που βοηθά το σχεδιαστή είναι το ATOMIUM (http://www.imec.be/design/atomium) το οποίο μετρά τον αριθμό των προσπελάσεων σε κάθε πίνακα δεδομένων της εφαρμογής και κατευθύνει το σχεδιαστή να επικεντρώσει την προσπάθεια και τη βελτίωση αυτών των σημείων.
Στην συνέχεια ακολουθεί το στάδιο των μετασχηματισμών βρόχου (global loop) και το τρίτο στάδιο των μετασχηματισμών επαναχρησιμοποίησης δεδομένων (data-reuse transformations), όπως παρουσιάζονται συνοπτικά στις επόμενες παραγράφους.
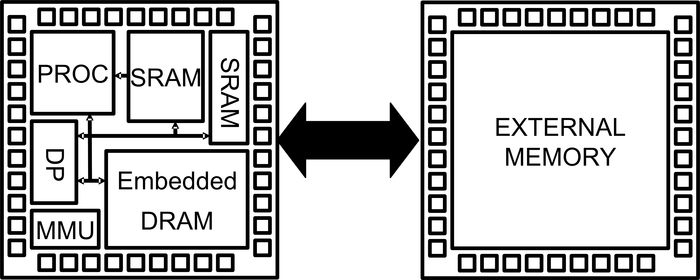
A.1: Ενσωματωμένο σύστημα με προσωρινές μνήμης αποθήκευσης πάνω στο ολοκληρωμένο κύκλωμα του επεξεργαστή (SRAM, Embedded DRAM) για την προσωρινή αποθήκευση μικρού μεγέθους μεταβλητών, μειώνοντας τον αριθμό των προσπελάσεων στην εξωτερικό μνήμη.
Οι κυριότεροι μετασχηματισμοί βρόχων (global loop) είναι οι loop unrolling, loop merging, loop tilling, loop bump, loop extend, loop body split, loop reverse, και loop interchange. Παρακάτω παρουσιάζονται όλοι οι μετασχηματισμοί με παραδείγματα για να γίνουν ευκολότερα κατανοητοί.
Στόχος της εφαρμογής των μετασχηματισμών global loop είναι να φέρουν την μορφή της εφαρμογής σε κανονική δομή. Με τον όρο κανονική δομή εννοούμε τη μορφή του παρακάτω σχήματος. Δηλαδή στην μορφή συγχωνευμένων φωλιασμένων βρόχων, κάθε βρόχος θα έχει στο εσωτερικό του ένα βρόχο που θα περιέχει ένα άλλο βρόχο εσωτερικά του και θα συνεχίζει ομοίως.
for (i=0;i<Ν;i++)
{
code into loop i
for (j=0;j<M;j++)
{
code into loop j
for (k=0;k<F;k++)
{
code into loop k
for (l=0;l<G;l++)
{
code into loop l
for (m=0;m<P;m++)
code into loop m
}
}
}
}
a) Loop unrolling: Μειώνει την πρόσθετη επιβάρυνση των βρόχων, και ενεργοποιεί άλλους μετασχηματισμούς.
lll for (i=0;i<4;i++)
a[i]=b[i]*c[i];
& & for (i=0; i<2; i++)
{
a[i*2]=b[i*2]*c[i*2];
a[i*2+1]=b[i*2+1]*c[i*2+1];
}
b) Loop merging: Μειώνει την πρόσθετη επιβάρυνση των βρόχων, και κανονικοποιεί τη δομή του αλγορίθμου. Παράλληλα μειώνει τις περιττές προσπελάσεις στη μνήμη δεδομένων.
lll for (i=0;i<Ν;i++)
a[i]=b[i]*c[i];
for (j=0;j<Ν;j++)
d[j]=c[j]*e[j];
& & for (i=0;i<Ν;i++)
{
a[i]=b[i]*c[i];
d[i]=c[i]*e[i];
}
c) Loop tilling: Χωρίζει ένα βρόχο σε δυο ή περισσότερους συγχωνευμένους βρόχους, αλλάζει την σειρά των προσπελάσεων σε κάθε πίνακα και αλλάζει τη συμπεριφορά της cache μνήμης.
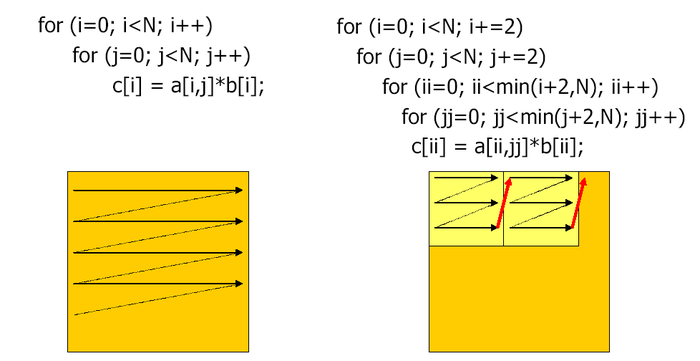
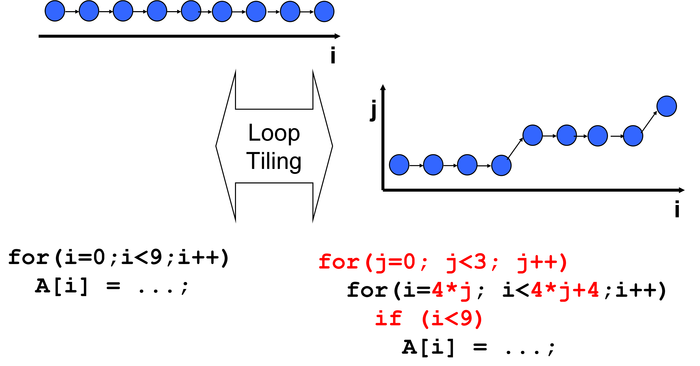
d) Loop Bump: Ενεργοποιεί το μετασχηματισμό Loop Merging
ll for (i=2; i<N; i++)
B[i] = f(A[i]);
for (i=0; i<N-2; i++)
C[i] = g(B[i+2]);
&
i+2 > i υπάρχουν εξαρτήσεις
for (i=2; i<N; i++)
B[i] = f(A[i]);
for (i=2; i<N; i++)
C[i-2] = g(B[i+2-2]);
&
i+2–2 = i merging possible
Loop Merge
& for (i=2; i<N; i++)
B[i] = f(A[i]);
C[i-2] = g(B[i]);
e) Loop Extend: Ενεργοποιεί το μετασχηματισμό Loop Merging
ll for (i=0; i<N; i++)
B[i] = f(A[i]);
for (i=2; i<N+2; i++)
C[i-2] = g(B[i]); &
for (i=0; i<N+2; i++)
if(i<N)
B[i] = f(A[i]);
for (i=0; i<N+2; i++)
if(i>=2)
C[i-2] = g(B[i); &
Loop Extend
Loop Merge
& for (i=0; i<N+2; i++)
if(i<N)
B[i] = f(A[i]);
if(i>=2)
C[i-2] = g(B[i);
f) Loop Body Split: Ενεργοποιεί άλλους μετασχηματισμούς
ll for (i=0; i<N; i++)
A[i] = f(A[i-1]);
B[i] = g(in[i]);
for (j=0; j<N; j++)
C[i] = h(B[i],A[N]); &
& for (i=0; i<N; i++)
A[i] = f(A[i-1]);
for (k=0; k<N; k++)
B[k] = g(in[k]);
for (j=0; j<N; j++)
C[j] = h(B[j],A[N]);
for (i=0; i<N; i++)
A[i] = f(A[i-1]);
for (j=0; j<N; j++)
B[j] = g(in[j]);
C[j] = h(B[j],A[N]); &
g) Loop Reverse: Απαλείφονται οι εξαρτήσεις
Υπάρχουν εξαρτήσεις μέσα στο βρόγχο.
llll &
Loop Reverse
&
& for (i=0; i<N; i++)
B[i] = f(A[i]);
C[N-i] = g(B[i]);
h) Loop Interchange: Βασικός Μετασχηματισμός
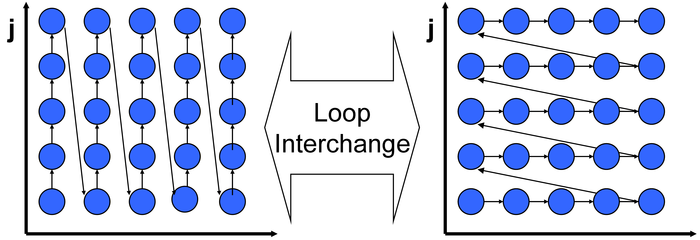
ll for(i=0; i<W; i++)
for(j=0; j<H; j++)
A[i][j] = …; & for(j=0; j<H; j++)
for(i=0; i<W; i++)
A[i][j] = …;
Η δεύτερη κατηγορία μετασχηματισμών που πρέπει να εφαρμοστούν στο αλγόριθμο είναι οι μετασχηματισμοί επαναχρησιμοποίησης δεδομένων (Data Reuse Transformations). Ο βασικός στόχος των μετασχηματισμών επαναχρησιμοποίησης δεδομένων είναι να μειώσουν τις περιττές προσπελάσεις στη μνήμη δεδομένων εισάγοντας μικρότερου μεγέθους μνήμες (για την προσωρινή αποθήκευση δεδομένων) που μπορούν να τοποθετηθούν πλησιέστερα στον επεξεργαστή. Σε αυτά τα επίπεδα θα τοποθετηθούν οι μεταβλητές οι οποίες εμφανίζουν το μεγαλύτερο αριθμό επαναχρησιμοποίησης και άρα μειώνονται οι προσπελάσεις στην εξωτερική μνήμη. Έτσι, οι μεταφορές των δεδομένων από τη μνήμη προς τον επεξεργαστή και αντίστροφα θα πραγματοποιούνται μέσω των επιπέδων που βρίσκονται κοντά στον επεξεργαστή και οι οποίες είναι πιο γρήγορες αλλά και το κόστος σε ενέργεια ανά προσπέλαση είναι μικρότερο. Έτσι μειώνεται ο χρόνος εκτέλεσης, παράλληλα όμως θα μειώνεται και η κατανάλωση της ενέργειας, αφού μειώνονται οι προσπελάσεις στην εξωτερική μνήμη. Στο σχήμα που ακολουθεί παρουσιάζεται μια αρχιτεκτονική με 3 επίπεδα μνήμης.
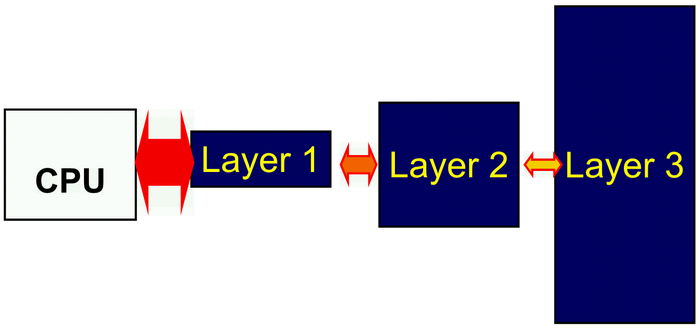
A.2: Ιεραρχία μνήμης με τρία επίπεδα.
Τα βήματα που πρέπει να ακολουθήσουμε για την εφαρμογή των μετασχηματισμών επαναχρησιμοποίησης δεδομένων είναι τα ακόλουθα:
Βήμα 1: Αναγνώριση των πινάκων δεδομένων στους οποίους μπορεί να γίνει επαναχρησιμοποίηση δεδομένων.
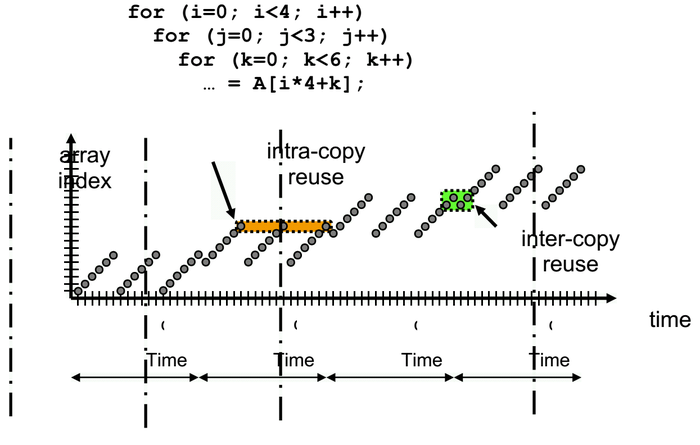
A.3: Time frame είναι η περίοδος κατά την οποία τμήμα δεδομένων από ένα μεγάλο πίνακα μπορούν να αντιγραφούν προσωρινά σε ένα μικρότερο ώστε να χρησιμοποιηθούν από το μικρό πίνακα έναντι του μεγάλου.
Βήμα 2: Καθορισμός των δυνατών συνδυασμών ιεραρχίας μνήμης
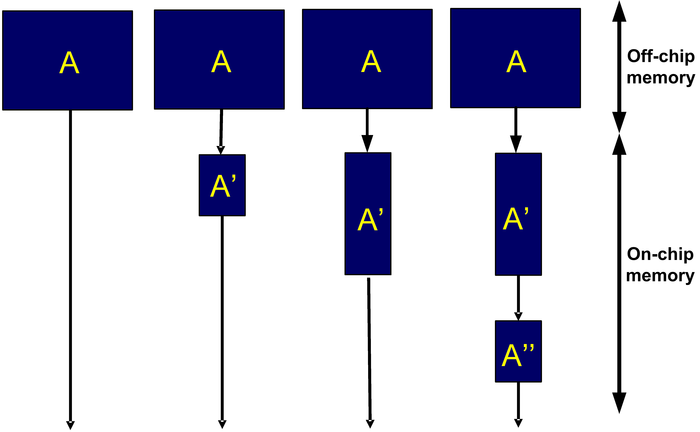
A.4: Έχοντας στην διάθεση τρία μπλοκ μνήμης (Α, Α΄, Α΄΄), δημιουργούνται τέσσερις ιεραρχίες μνήμης δεδομένων.
Σε αυτή την παράγραφο θα περιγράψουμε αναλυτικά τα στάδια για το σχεδιασμό μιας εφαρμογής πολυμέσων. Στη συνέχεια, στον αρχικό κώδικα που θα δοθεί, θα εφαρμοστούν μερικοί από τους μετασχηματισμούς με στόχο τη βελτιστοποίηση της εφαρμογής ως προς την ταχύτητα εκτέλεσης αλλά και την κατανάλωση ισχύος.
Σε αυτή την παράγραφο θα αναλυθεί ο αλγόριθμος Parallel Hierarchical One Dimensional Search (PHODS), ένας αλγόριθμος που ανήκει στην περιοχή των πολυμέσων. Ο αλγόριθμος PHODS είναι ένας αλγόριθμος εκτίμησης κίνησης (Motion Estimation), ο οποίος έχει στόχο να ανιχνεύσει τη κίνηση των αντικειμένων μεταξύ δύο διαδοχικών εικόνων (frame) του βίντεο. Οι αλγόριθμοι ανίχνευσης της κίνησης είναι καθοριστικοί για την συμπίεση βίντεο και αποτελούν τον πυρήνα κάθε εφαρμογής που περιέχει βίντεο. Ο PHODS έχει σαν είσοδο δύο διαδοχικές εικόνες από μια ακολουθία εικόνων βίντεο (διαστάσεων Μ×N), χωρίζει τις εικόνες σε block (διαστάσεων Β×B pixel) σε κάθε μια από τις εικόνες αυτές και προσπαθεί να βρει την μετατόπιση του κάθε block από τη μια εικόνα (frame) στην επόμενη (frame). Για την εύρεση της μετατόπισης κάθε μπλόκ από το ένα frame στο επόμενο frame εκτελείται σύγκριση του μπλόκ από το πρώτο frame με όλα τα μπλόκ που βρίσκονται στην γύρω περιοχή από το επόμενο frame. Βάσει ενός συγκεκριμένου κριτηρίου επιλέγεται το μπλοκ εκείνο που εμφανίζει την μικρότερη τιμή στο κριτήριο.
Ο αρχικός αλγόριθμος PHODS σε γλώσσα C παρουσιάζεται παρακάτω.
/* Parallel Hierarchical One-Dimensional Search motion estimation - Initial algorithm */
/* Used for simulation and profiling */
#include <stdio.h>
#include <math.h>
#include <string.h>
#include <stdlib.h>
#include <time.h>
#define N 144 /* frame dimension for QCIF format */
#define M 176 /* frame dimension for QCIF format */
#define B 16 /* Block size */
#define p 7 /* Search space. Restricted in a [-p,p] region around the original location of the block. */
void read_sequence(unsigned char current[N][M],unsigned char previous[N][M])
{
FILE *picture0,*picture1;
int i,j;
if((picture0=fopen(“akiyo0.y”,“rb”))==NULL)
{
printf(“previous frame doesn’t exist\n”);
exit(-1);
}
if((picture1=fopen(“akiyo1.y”,“rb”))==NULL)
{
printf(“current frame doesn’t exist\n”);
exit(-1);
}
/* Input for the previous frame */
for(i=0;i<N;i++)
for(j=0;j<M;j++)
previous[i][j]=fgetc(picture0);
/* Input for the current frame */
for(i=0;i<N;i++)
for(j=0;j<M;j++)
current[i][j]=fgetc(picture1);
fclose(picture0);
fclose(picture1);
}
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,i,j,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
for(i=0;i<N/B;i++)
for(j=0;j<M/B;j++)
{
vectors_x[i][j]=0;
vectors_y[i][j]=0;
}
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(y=0;y<M/B;y++)
{
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
}
if(distx<min1)
{
min1=distx;
bestx=i;
}
}
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
int main()
{
unsigned char current[N][M],previous[N][M];
int motion_vectors_x[N/B][M/B],motion_vectors_y[N/B][M/B];
read_sequence(current,previous);
phods_motion_estimation(current,previous,motion_vectors_x,motion_vectors_y);
}
Η μεθοδολογία βελτιστοποίησης θα εφαρμοστεί σταδιακά στο κύριο τμήμα της εφαρμογής. Εδώ πρέπει να αναφερθεί ότι δεν θα γίνουν βελτιστοποιήσεις στις συναρτήσεις εισόδου. Το τμήμα του κώδικα που αποτελεί αντικείμενο μελέτης και εφαρμογής των μετασχηματισμών είναι η συνάρτηση «phods_motion_estimation».
Στο πρώτο στάδιο θα εφαρμοστεί ο μετασχηματισμός loop merging για τους δύο βρόχους for(i=-S;i<S+1;i+=S). Επίσης στο διπλό βρόχο αρχικοποίησης των μεταβλητών vectors_x και vectors_y αλλάζουμε τις μεταβλητές των βρόχων από i, j σε x, y, ώστε να μπορεί να γίνει μετασχηματισμός συγχώνευσης με τους βρόχους που ακολουθούν. Ο μετασχηματισμός αυτός για να εφαρμοστεί θα πρέπει να μην παραβιάζονται οι εξαρτήσεις δεδομένων. Εξάρτηση δεδομένων έχουμε όταν κάποιες τιμές ενός πίνακα που δημιουργούνται και χρησιμοποιούνται στη συνέχεια του αλγορίθμου. Παραβίαση θα έχουμε όταν χρησιμοποιήσουμε μια τιμή ενός πίνακα πριν αυτή δημιουργηθεί. Στο συγκεκριμένο μετασχηματισμό δεν υπάρχει κάποια εξάρτηση, οπότε μπορούμε να τον εφαρμόσουμε. Ο αλγόριθμος μετά την εφαρμογή του μετασχηματισμού είναι ο ακόλουθος:
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
for(x=0;x<N/B;x++)
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
}
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(y=0;y<M/B;y++)
{
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
}
if(distx<min1)
{
min1=distx;
bestx=i;
}
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Στο επόμενο βήμα, με ένα δεύτερο μετασχηματισμό loop merging συγχωνεύουμε τις εντολές που περιέχουν οι βρόχοι με δείκτες k. Έτσι οι εντολές των δύο ακολουθιακών βρόχων με δείκτη k ενσωματώνονται σε ένα βρόχο που εμπεριέχει τις εντολές των δύο αρχικών.
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
for(x=0;x<N/B;x++)
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
}
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(y=0;y<M/B;y++)
{
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
{
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
}
if(distx<min1)
{
min1=distx;
bestx=i;
}
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
if(disty<min2)
{
min2=disty;
besty=i;
}
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Παρατηρώντας τον κώδικα με λεπτομέρεια στα σημεία με έντονη γραμματοσειρά βλέπουμε ότι υπάρχουν δυο βρόχοι με δείκτη l και μπορούν να συγχωνευθούν σε ένα βρόχο. Έτσι μεταφέρονται οι εντολές του δευτέρου βρόχου στο εσωτερικό του πρώτου, με συνέπεια ο αλγόριθμος να παίρνει την παρακάτω μορφή. Επίσης βλέπουμε ότι η εντολή ανάγνωσης p1=current[B*x+k][B*y+l]; εμφανίζεται δύο φορές μέσα στις εντολές του νέου βρόχου (μία φορά σε κάθε ένα από του αρχικούς) οπότε αυτόματα διαγράφεται η επανάληψη της εντολής.
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
for(x=0;x<N/B;x++)
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
}
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(y=0;y<M/B;y++)
{
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
{
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
if(distx<min1)
{
min1=distx;
bestx=i;
}
if(disty<min2)
{
min2=disty;
besty=i;
}
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Μια πιο συμπτυγμένη έκδοση του αλγορίθμου παρουσιάζεται παρακάτω.
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
distx+=abs(p1-p2);
disty+=abs(p1-q2);
}
if(distx<min1)
{
min1=distx;
bestx=i;
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Στον παραπάνω αλγόριθμο παρατηρούμε ότι για i=0 to p2 είναι ίσο με το q2 οπότε δεν είναι απαραίτητο να το υπολογίσουμε ξανά. Για να μειώσουμε τις περιττές προσπελάσεις στη μνήμη αλλά και τις περιττές εκτελέσεις εντολών εισάγουμε μια εντολή ελέγχου if(i==0) disty=distx; Οπότε αυτόματα παρακάμπτει τον υπολογισμό του disty όταν το i==0. Έτσι ο αλγόριθμος μετασχηματίζεται ως εξής:
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
if(i==0)
disty=distx;
else
{
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
}
if(distx<min1)
{
min1=distx;
bestx=i;
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Μετά την εφαρμογή των μετασχηματισμών βρόχου ο αλγόριθμος έχει πάρει την κανονικοποιημένη μορφή των συγχωνευμένων βρόχων. Το επόμενο στάδιο της μεθοδολογίας είναι η εφαρμογή των μετασχηματισμών επαναχρησιμοποίησης δεδομένων. Αυτό που θέλουμε να πετύχουμε είναι να μειωθούν οι προσπελάσεις στους πίνακες δεδομένων current και previous οι οποίοι έχουν μεγάλο μέγεθος. Η μείωση θα γίνει με την εισαγωγή μικρότερου μεγέθους πινάκων δεδομένων για την προσωρινή αποθήκευση τμημάτων των αρχικών πινάκων. Οι νέοι πίνακες θα εισαχθούν στα σημεία του αλγορίθμου μετά από κάθε βρόχο και θα αποθηκεύουν τμήμα των δεδομένων ενός από τους αρχικούς πίνακες δεδομένων, τα οποία θα χρησιμοποιηθούν στο αντίστοιχο βρόχο.
Σε κάθε εκτέλεση του βρόχου με δείκτη x, τα δεδομένα που χρησιμοποιούνται από τους δύο πίνακες δεδομένων (current και previous) μπορούν να αποθηκευθούν σε δύο buffers με διαστάσεις M×B για τον current πίνακα και τον ονομάζουμε current_line. Ενώ για τον previous πίνακα εισάγουμε έναν buffer με διαστάσεις M×(B+2*p) (όπου p=S+S/2+S/4) και τον ονομάζουμε previous_line.
Εσωτερικά που βρόχου με δείκτη y, τα δεδομένα που χρησιμοποιούνται από τους αρχικούς πίνακες δεδομένων μπορούν να αποθηκευτούν προσωρινά σε δυο buffers διαστάσεων B×B και (B+2*p×(B+2*p). Αντίστοιχα, μελετώντας τους εσωτερικότερους βρόχους δημιουργούμε μικρότερου μεγέθους buffers για την προσωρινή αποθήκευση τμημάτων δεδομένων από τους αρχικούς πίνακες. Τέλος, το μικρότερο μέγεθος buffer που μπορεί να χρησιμοποιηθεί για την προσωρινή αποθήκευση του πίνακα current είναι το block με διαστάσεις B×B. Με την ολοκλήρωση της διερεύνησης πιθανών πινάκων για την προσωρινή αποθήκευση δεδομένων σχηματίζουμε οι αλυσίδες περιγραφής των πιθανών δομών μνήμης (Σχήμα 5). Με την διερεύνηση όλων των πιθανών τρόπων χρησιμοποίησης των προσωρινών πινάκων αποθήκευσης δημιουργούνται τα δέντρα αντιγραφής και τα οποίο παρουσιάζονται στα Σχήματα 6 και 7 για το κλάδο του current και previous πίνακα αντίστοιχα.
Οι αλυσίδες αντιγραφής δεδομένων από του αρχικούς πίνακες (current και previous) δεδομένων σε μικρότερου μεγέθους πίνακες δεδομένων τους current_line, block και τους previous_line, RW αντίστοιχα.
A.6: Το δέντρο με όλους τους δυνατούς συνδυασμούς αντιγραφής δεδομένων του πίνακα current.
A.7: Το δέντρο με όλους τους δυνατούς συνδυασμούς αντιγραφής δεδομένων του πίνακα previous.
Η εφαρμογή των μετασχηματισμών επαναχρησιμοποίησης δεδομένων θα γίνει για κάθε ένα κλάδο των δένδρων αντιγραφής δεδομένων που παρουσιάζονται στα Σχήματα 6 και 7. Έτσι κάθε κλάδος αποτελεί ένα ξεχωριστό μετασχηματισμό επαναχρησιμοποίησης δεδομένων.
Αρχίζοντας τους μετασχηματισμούς από το πίνακα δεδομένων current ο πρώτος μετασχηματισμός θα εισάγει το πίνακα (buffer) current_line (Σχήμα 6). Η διαδικασία είναι η ακόλουθη, τμήμα των δεδομένων από το πίνακα current θα αντιγραφούν στο πίνακα current_line και στην εφαρμογή θα χρησιμοποιηθούν μέσω του πίνακα current_line που έχει μικρότερο μέγεθος. Ο αλγόριθμος του πρώτου μετασχηματισμού επαναχρησιμοποίησης δεδομένων θα είναι ο εξής:
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
int current_line[M][B];
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(j=0;j<M;j++) /* Copy data from current to buffer current_line */
for(i=0;i<B;i++)
current_line[i][j]=current[B*x+i][j];
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current_line[k][B*y+l]; /* Read the data from buffer current_line */
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
if(i==0)
disty=distx;
else
{
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
}
if(distx<min1)
{
min1=distx;
bestx=i;
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Ο επόμενος μετασχηματισμός επαναχρησιμοποίησης δεδομένων εισάγει το πίνακα πρόχειρης αποθήκευσης block. Ο πίνακας block θα αποθηκεύει προσωρινά τμήμα δεδομένων από το current και θα το χρησιμοποιεί ο επεξεργαστής μέσω του πίνακα buffer. Οπότε ο αλγόριθμος μετασχηματίζεται ως ακολούθως:
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
int block[Β][Β];
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(k=0;k<B;k++) /* Copy data from current to buffer block */
for(l=0;l<B;l++)
block[k][l]=current[B*x+k][B*y+l];
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=block[k][l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
if(i==0)
disty=distx;
else
{
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
}
if(distx<min1)
{
min1=distx;
bestx=i;
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Ο τρίτος μετασχηματισμός επαναχρησιμοποίησης δεδομένων εισάγει και τους δυο προηγούμενους πίνακες δεδομένων των current_line και τον block. Η διαδικασία αντιγραφής δεδομένων θα ακολουθεί την ιεραρχία μνήμης, έτσι τμήμα δεδομένων από τον πίνακα current θα αντιγράφεται στο current_line και στη συνέχεια, τμήμα από το current_line θα αντιγράφεται στο block. Μέσω του πίνακα block θα γίνεται η ανάγνωση των δεδομένων από το κριτήριο του αλγορίθμου. Ο αλγόριθμος του τρίτου μετασχηματισμού θα είναι ο παρακάτω.
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
int current_line[M][B];
int block[Β][Β];
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(j=0;j<M;j++) /* Copy data from current to buffer current_line */
for(i=0;i<B;i++)
current_line[i][j]=current[B*x+i][j];
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
S=4;
for(k=0;k<B;k++) /* Copy data from current to buffer block */
for(l=0;l<B;l++)
block[k][l]=current_line[k][B*y+l];
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current_line[k][B*y+l]; /* Read the data from buffer current_line */
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous[B*x+vectors_x[x][y]+i+k][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
if(i==0)
disty=distx;
else
{
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous[B*x+vectors_x[x][y]+k][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
}
if(distx<min1)
{
min1=distx;
bestx=i;
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Με τον ίδιο τρόπο γίνεται η εφαρμογή των μετασχηματισμών επαναχρησιμοποίησης δεδομένων με τον πίνακα δεδομένων previous. Πρώτη μας επιλογή είναι η εισαγωγή του πίνακα previous_line. Η διάσταση του πίνακα αυτού είναι M×(2*p+B), p=B+S+S/2+S/4. Η εισαγωγή του πίνακα αυτού είναι όμοια με την αντίστοιχη του current_line για τον current πίνακα. Ο αλγόριθμος μετασχηματίζεται στον ακόλουθο.
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
int previous_line[Β+2*p][Μ];
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
{
for(i=0;i<2*p+B;i++)
for(j=0;j<M;j++)
{
if(x==0)
{
if(i<p) previous_line[i][j]=0;
else previous_line[i][j]=previous[i-p][j]; /* Copy from previous array */
}
else
{
if(i<2*p) previous_line[i][j]=previous_line[i+B][j]; /* Reuse from the same array*/
else
{
if(x==N/B-1 && i>B+p) previous_line[i][j]=0;
else previous_line[i][j]=previous[B*x-p+i][j];
}
}
}
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=previous_line[vectors_x[x][y]+i+k+p][B*y+vectors_y[x][y]+l];
distx+=abs(p1-p2);
if(i==0)
disty=distx;
else
{
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2=previous_line[vectors_x[x][y]+k+p][B*y+vectors_y[x][y]+i+l];
disty+=abs(p1-q2);
}
}
if(distx<min1)
{
min1=distx;
bestx=i;
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
}
Ο μετασχηματισμός αυτός εισάγει τον πίνακα RW διαστάσεων (B+2*p)×(B+2*p) για την προσωρινή αποθήκευση τμήμα δεδομένων του πίνακας previous. Ο αρχικός αλγόριθμος PHODS μετασχηματίζεται στον παρακάτω.
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
int RW[Β+2*p][Β+2*p];
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
for(k=0;k<B+2*p;k++) /* Copy data from previous to RW */
for(l=0;l<B+2*p;l++)
{
if((B*x+k-p)<0 || (B*x+k-p)>(N-1) || (B*y+l-p)<0 || (B*y+l-p)>(M-1))
rw[k][l]=0;
else
{
if(l>2*p-1 || y==0) rw[k][l]=previous[B*x+k-p][B*y+l-p];
else rw[k][l]=rw[k][l+B];
}
}
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=rw[vectors_x[x][y]+i+k+p][vectors_y[x][y]+l+p]; /* Read from RW */
distx+=abs(p1-p2);
if(i==0)
disty=distx;
else
{
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2= rw[vectors_x[x][y]+k+p][vectors_y[x][y]+l+p+i]; /* Read from RW */
disty+=abs(p1-q2);
}
}
if(distx<min1)
{
min1=distx;
bestx=i;
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
Ο τελευταίος μετασχηματισμός επαναχρησιμοποίησης εισάγει και τους δύο πίνακες previous_line και RW στον κλάδο του πίνακα previous.
void phods_motion_estimation(int current[N][M],int previous[N][M],int vectors_x[N/B][M/B],int vectors_y[N/B][M/B])
{
int x,y,k,l,p1,p2,q2,distx=0,disty=0,S,min1,min2,bestx,besty;
int previous_line[Β+2*p][Μ];
int RW[Β+2*p][Β+2*p];
for(x=0;x<N/B;x++) /* For all blocks in the current frame */
{
for(i=0;i<2*p+B;i++)
for(j=0;j<M;j++)
{
if(x==0)
{
if(i<p) previous_line[i][j]=0;
else previous_line[i][j]=previous[i-p][j]; /* Copy from previous array */
}
else
{
if(i<2*p) previous_line[i][j]=previous_line[i+B][j]; /* Reuse from the same array*/
else
{
if(x==N/B-1 && i>B+p) previous_line[i][j]=0;
else previous_line[i][j]=previous[B*x-p+i][j];
}
}
}
for(y=0;y<M/B;y++)
{
vectors_x[x][y]=0;
vectors_y[x][y]=0;
for(k=0;k<B+2*p;k++) /* Copy data from previous_line to RW */
for(l=0;l<B+2*p;l++)
{
if((B*x+k-p)<0 || (B*x+k-p)>(N-1) || (B*y+l-p)<0 || (B*y+l-p)>(M-1))
rw[k][l]=0;
else
{
if(l>2*p-1 || y==0) rw[k][l]=previous_line[k-p][B*y+l-p];
/* Copy from previous_line array */
else rw[k][l]=rw[k][l+B]; /* Reuse from the same array*/
}
}
S=4;
while(S>0)
{
min1=255*B*B;
min2=255*B*B;
for(i=-S;i<S+1;i+=S) /* For all candidate blocks in X dimension */
{
distx=0;
disty=0;
for(k=0;k<B;k++) /* For all pixels in the block */
for(l=0;l<B;l++)
{
p1=current[B*x+k][B*y+l];
if((B*x+vectors_x[x][y]+i+k)<0 || (B*x+vectors_x[x][y]+i+k)>(N-1) || (B*y+vectors_y[x][y]+l)<0 || (B*y+vectors_y[x][y]+l)>(M-1))
p2=0;
else
p2=rw[vectors_x[x][y]+i+k+p][vectors_y[x][y]+l+p]; /* Read from RW */
distx+=abs(p1-p2);
if(i==0)
disty=distx;
else
{
if((B*x+vectors_x[x][y]+k)<0 || (B*x+vectors_x[x][y]+k)>(N-1) || (B*y+vectors_y[x][y]+i+l)<0 || (B*y+vectors_y[x][y]+i+l)>(M-1))
q2=0;
else
q2= rw[vectors_x[x][y]+k+p][vectors_y[x][y]+l+p+i]; /* Read from RW */
disty+=abs(p1-q2);
}
}
if(distx<min1)
{
min1=distx;
bestx=i;
if(disty<min2)
{
min2=disty;
besty=i;
}
}
S=S/2;
vectors_x[x][y]+=bestx;
vectors_y[x][y]+=besty;
}
}
}
}
Για να αποδείξει κανείς την επιτυχία ή όχι της εφαρμογής των μετασχηματισμών πρέπει να πραγματοποιηθούν κάποιες μετρήσεις. Οι μετρήσεις των προσπελάσεων στην μνήμη δεδομένων μπορεί να γίνει με την χρήση του εργαλείου Atomium (εφόσον είναι διαθέσιμο) ή ακόμα εισάγοντας απαριθμητές (counters) σε κάθε σημείο που έχουμε ανάγνωση από κάποιο πίνακα δεδομένων. Οι μετρήσεις για την ταχύτητα εκτέλεσης (performance) και τις εντολές που εκτελούνται μπορούν να επιτευχθούν με το προσομοιωτή ενός επεξεργαστή π.χ., ARM. Δημιουργώντας project με το εργαλείο ARMulator24 μπορούμε να κάνουμε προσομοίωση του αλγορίθμου και να δούμε τα στατιστικά αποτελέσματα, το συνολικό αριθμό των κύκλων που απαιτούνται για την ολοκλήρωση της εκτέλεσης. Επίσης, υπολογίζει τον συνολικό αριθμό των εντολών που εκτελούνται και την εκτέλεση της εφαρμογής.
Αν και οι επεξεργαστές που χρησιμοποιούνται στους τυπικούς σταθμούς εργασίας ή στους διακομιστές ή στα έξυπνα τηλέφωνα, είναι αρχιτεκτονικής 32 bit ή 64 bit, στα ενσωματωμένα συστήματα χρησιμοποιούνται αρχιτεκτονικές από 8 bit έως και 64bit. Ένας αρκετά δημοφιλής, αξιόπιστος και οικονομικός επεξεργαστής 8 bit είναι ο ATmega328P, που αποτελεί την καρδιά της αναπτυξιακής πλατφόρμας Arduino UNO. Σε αυτό το παράρτημα, θα γίνει η παρουσίαση του Arduino UNO και στη συνέχεια θα ακολουθήσουν οι ασκήσεις εμβάθυνσης σε αυτή την αρχιτεκτονική.
Στην ενότητα αυτή, παρουσιάζεται ο μικροελεγκτής Arduino που χρησιμοποιήθηκε, τα χαρακτηριστικά του και μερικά από τα διαθέσιμα εξαρτήματα που μπορούν να συνδεθούν απ’ ευθείας με αυτό. Το Arduino [98] είναι μία ανοιχτού λογισμικού πλατφόρμα πρωτοτύπων ηλεκτρονικών συσκευών που βασίζονται στην ευελιξία και στην ευκολία χρήσης υλικού και λογισμικού. Το Arduino μπορεί να αλληλεπιδρά με το περιβάλλον κάνοντας λήψη σημάτων μέσα από μια ποικιλία αισθητήρων. Το arduino μπορεί να χρησιμοποιηθεί για την ανάπτυξη διαλογικών λειτουργιών, με είσοδο από μια πληθώρα πηγών (διακόπτες, αισθητήρες,..) και έλεγχο φυσικών αντικειμένων (φώτα, κινητήρες,..). Το arduino μπορεί να είναι αυτόνομο ή να επικοινωνεί με άλλα arduino ή υπολογιστικά συστήματα Τα έργα που βασίζονται σε αυτόν τον μικροελεγκτή, μπορούν να είναι αυτόνομα ή μπορούν να επικοινωνούν με το λογισμικό που τρέχει σε έναν υπολογιστή (π.χ. Flash, Processing, MaxMSP). Το arduino είναι ένα εργαλείο που μας επιτρέπει να κατασκευάσουμε υπολογιστικά συστήματα που μπορούν να αισθανθούν και να ελέγξουν το φυσικό κόσμο πολύ πιο εύκολα από ότι αν χρησιμοποιούσαμε έναν τυπικό υπολογιστή γραφείου. Είναι μια αρχιτεκτονική που βασίζεται σε ανοιχτό κώδικα, μια πλακέτα μικρο-επεξεργαστή και ένα αναπτυξιακό περιβάλλον για τη συγγραφή προγράμματος για την πλακέτα. Η οικογένεια Arduino αποτελείται από πολλές αναπτυξιακές πλακέτες, διαφορετικών χαρακτηριστικών (Εικόνα B.1). Η πιο δημοφιλής αναπτυξιακή πλακέτα είναι η Arduino UNO (Εικόνα B.1).
| c | c | c | Arduino Leonardo & Arduino Mega & Arduino LilyPad

&

&

Arduino Fio & Arduino Ethernet & Arduino Nano

&

&

Arduino BT & Arduino Mini & Arduino Pro Mini

&

&


B.1: Η αναπτυξιακή πλατφόρμα Arduino αποτελείται από τον μικροεπεξεργαστή 8bit ATMEGA328P. Στην εικόνα φαίνεται η έκδοση UNO.
Η ευκολία σχεδίασης και χρήσης ενσωματωμένων συστημάτων που βασίζονται στην οικογένεια arduino, οφείλεται κατά μεγάλο ποσοστό στις δυνατότητες επέκτασης που παρέχονται με τη χρήση πλακετών επέκτασης (που ονομάζονται ως ‘shields’ στην αγγλική γλώσσα). Shields είναι τα εξαρτήματα που συνδέονται απευθείας με όλα τα pin του arduino. Μερικά από αυτά φαίνονται στην Εικόνα B.2.
| p0.15 | c | c | Arduino Wifi Shield &

&
Το Arduino WiFi Shield συνδέει το Arduino στο διαδίκτυο ασύρματα.
Arduino Ethernet Shield &

&
Το Arduino Ethernet Shield συνδέει το Arduino στο διαδίκτυο με ένα RJ45 καλώδιο.
Wireless SD Shield &

&
Το Wireless SD Shield επιτρέπει σε μια πλακέτα Arduino να επικοινωνεί ασύρματα με μια ασύρματη μονάδα. Η μονάδα μπορεί να επικοινωνήσει έως και 100 πόδια σε εσωτερικούς χώρους ή σε εξωτερικούς χώρους ως 300 πόδια. Η μονάδα περιλαμβάνει μια θύρα υποδοχής SD
Wireless Proto Shield &

&
Το Wireless Proto Shield επιτρέπει στο Arduino να επικοινωνεί ασύρματα με μια ασύρματη μονάδα. Η μονάδα μπορεί να επικοινωνήσει έως και 100 πόδια σε εσωτερικούς χώρους ή σε εξωτερικούς χώρους ως 300 πόδια. Η μονάδα δεν περιλαμβάνει θύρα υποδοχής SD.
Arduino Motor Shield &

&
Το Arduino Motor Shield επιτρέπει την οδήγηση δύο DC κινητήρων από την ίδια συσκευή, ελέγχοντας την ταχύτητα και την κατεύθυνση του καθενός ξεχωριστά.
Στις εργαστηριακές ασκήσεις που βρίσκονται σε αυτό το παράρτημα, χρησιμοποιείται η αναπτυξιακή πλακέτα Arduino UNO. Τα χαρακτηριστικά αυτής της πλακέτας εμφανίζονται στον Πίνακα B.3.
| Μικροελεγκτής | ATMEGA328 |
|---|---|
| Τάση λειτουργίας | 5V DC |
| Τάση εισόδου | 7-12V DC |
| Όρια τάσης εισόδου | 6-20V DC |
| Ψηφιακοί ακροδέκτες Ι/Ο | 14, (6 PWM έξοδοι) |
| Αναλογικοί ακροδέκτες εισόδου | 6 |
| Ισχύς συνεχόμενου ρεύματος ανά ακροδέκτη | 40mA |
| Ισχύς συνεχόμενου ρεύματος για ακροδέκτη τάσης 3.3V | 50mA |
| Μνήμη flash | 32KB (ATMEGA328) |
| Μνήμη SRAM | 2KB (ATMEGA328) |
| Μνήμη EEPROM | 1KB (ATMEGA328) |
| Ταχύτητα ρολογιού | 16MHz |
Το Arduino UNO μπορεί να τροφοδοτηθεί με DC ρεύμα είτε από τον υπολογιστή μέσω της σύνδεσης USB, είτε από εξωτερική τροφοδοσία που παρέχεται μέσω μιας υποδοχής φις των 2.1mm που βρίσκεται στην κάτω αριστερή γωνία. Για την αποφυγή προβλημάτων, η εξωτερική τροφοδοσία θα πρέπει να είναι από 7 ως 12V. Το Σχήμα B.2 παρουσιάζει τις εισόδους και εξόδους τροφοδοσίας του Arduino UNO.

B.2: Είσοδοι/Έξοδοι Τροφοδοσίας Arduino UNO.
Οι ακροδέκτες τροφοδοσίας είναι οι ακόλουθοι:
: Η τάση εισόδου της πλακέτας όταν χρησιμοποιεί εξωτερική πηγή ενέργειας. Η τροφοδοσία τάσης γίνεται μέσω αυτού του ακροδέκτη.
: Η τάση που χρησιμοποιείται από τα διάφορα μέρη της πλακέτας και το μικροελεγκτή είναι 5V. Η τάση αυτή, την οποία δίνει αυτός ο ακροδέκτης, είναι είτε η τάση 5V που δίνει η σύνδεση με USB, είτε η ρυθμισμένη τάση που δίνεται μέσω του Vin.
: Είσοδοι γείωσης.
Ο μικροεπεξεργαστής ATmega328 έχει τρεις ομάδες μνήμης. Διαθέτει flash memory, στην οποία αποθηκεύονται τα Arduino sketch, SRAM (static random access memory), στην οποία δημιουργείται το sketch και χρησιμοποιεί τις μεταβλητές όταν τρέχει, και EEPROM, η οποία χρησιμοποιείται από τους προγραμματιστές για την αποθήκευση μακροχρόνιων πληροφοριών. 2KΒ μνήμης SRAM: Η ωφέλιμη μνήμη που μπορούν να χρησιμοποιήσουν τα προγράμματα για να αποθηκεύουν μεταβλητές, πίνακες κλπ Η μνήμη χάνει τα δεδομένα της όταν η παροχή ρεύματος στο Arduino σταματήσει ή πατηθεί το κουμπί επανεκκίνησης. 1KΒ μνήμης EEPROM: Μπορεί να χρησιμοποιηθεί για εγγραφή ή ανάγνωση δεδομένων από τα προγράμματα. Σε αντίθεση με την SRAM, δε χάνει τα περιεχόμενά της με απώλεια τροφοδοσίας ή επανεκκίνησης. 32KΒ μνήμης Flash: 2 KΒ χρησιμοποιούνται από το firmware του Arduino που έχει εγκαταστήσει ήδη ο κατασκευαστής του. Το firmware είναι αναγκαίο για την εγκατάσταση προγραμμάτων στο μικροελεγκτή μέσω της θύρας USB. Τα υπόλοιπα 30KΒ της μνήμης Flash χρησιμοποιούνται για την αποθήκευση αυτών ακριβώς των προγραμμάτων, αφού πρώτα μεταγλωττιστούν στον υπολογιστή. Η μνήμη Flash, δε χάνει τα περιεχόμενά της με απώλεια τροφοδοσίας ή επανεκκίνησης.
Η αναπτυξιακή πλακέτα Arduino UNO έχει 14 ψηφιακούς ακροδέκτες (Σχήμα B.3).

B.3: Οι ψηφιακοί ακροδέκτες του Arduino UNO.
Όλοι οι ψηφιακοί ακροδέκτες μπορεί να χρησιμοποιηθούν για είσοδο και έξοδο ψηφιακών τιμών. Το Arduino UNO χρησιμοποιεί 5V τάση στους ακροδέκτες, οπότε αν ένας ακροδέκτης εισόδου φέρει τάση 5V διαβάζεται ως ‘1’ ενώ διαφορετικά διαβάζεται ως 0. Αντίστοιχα, ο ακροδέκτης εξόδου γράφει το λογικό ‘1’ ως τάση +5V, ενώ το ‘0’ αντιστοιχεί στη γείωση. Εκτός από τη γενική λειτουργία των ακροδεκτών εισόδου εξόδου, κάποιοι ακροδέκτες έχουν επιπρόσθετες λειτουργίες. Οι ακροδέκτες αυτοί περιγράφονται στη συνέχεια. Ακροδέκτες 0 και 1: λειτουργούν ως RX και TX της σειριακής θύρας όταν το πρόγραμμά ενεργοποιεί τη σειριακή θύρα. Έτσι, όταν το πρόγραμμά στέλνει δεδομένα στη σειριακή θύρα, αυτά προωθούνται και στη θύρα USB μέσω του ελεγκτή Serial-Over-USB, αλλά και στον ακροδέκτη 0 για να τα διαβάσει ενδεχομένως μια άλλη συσκευή. Αυτό φυσικά σημαίνει ότι αν στο πρόγραμμά ενεργοποιήσει το σειριακό interface, χάνει 2 ψηφιακές εισόδους/εξόδους η πλατφόρμα. Ακροδέκτες 2 και 3: λειτουργούν και ως εξωτερικά interrupt (interrupt 0 και 1 αντίστοιχα). Ρυθμίζονται μέσα από το πρόγραμμά ώστε να λειτουργούν αποκλειστικά ως ψηφιακές είσοδοι στις οποίες όταν συμβαίνουν συγκεκριμένες αλλαγές, η κανονική ροή του προγράμματος σταματάει άμεσα και εκτελείται μια συγκεκριμένη συνάρτηση. Τα εξωτερικά interrupt είναι ιδιαίτερα χρήσιμα σε εφαρμογές που απαιτούν συγχρονισμό μεγάλης ακρίβειας. Ακροδέκτες 3, 5, 6, 9, 10 και 11: μπορούν να λειτουργήσουν και ως ψευδό- αναλογικές έξοδοι με το σύστημα PWM (Pulse Width Modulation).

B.4: Οι αναλογικοί ακροδέκτες του Arduino UNO.
Η αναπτυξιακή πλατφόρμα Arduino UNO μπορεί να χρησιμοποιηθεί και για τη ανάγνωση αναλογικών σημάτων. Στην κάτω πλευρά του Arduino, με τη σήμανση ANALOG IN όπως φαίνεται και στο Σχήμα B.4, υπάρχει μια ακόμη σειρά από 6 pin, αριθμημένα από το 0 ως το 5. Κάθε κανάλι εισόδου μπορεί να χρησιμοποιηθεί ανεξάρτητα. Το κάθε κανάλι έχει διακριτική ικανότητα 10bit (1024 τιμές), δηλαδή διαιρείται η τάση αναφοράς σε 1024 εύρη. Η τάση αναφοράς μπορεί να ρυθμιστεί με μια εντολή (analogReference())στο 1.1V, ενώ η προεπιλογή είναι στα 5V. Επίσης, μπορεί να χρησιμοποιηθεί η τάση που εφαρμόζεται στο pin με τη σήμανση AREF που βρίσκεται στην απέναντι πλευρά της πλακέτας. Έτσι, αν τροφοδοτηθεί ο ακροδέκτης AREF με 3.3V και στη συνέχεια διαβάσει κάποιον ακροδέκτη αναλογικής εισόδου στο οποίο εφαρμόζεται τάση 1.65V, το Arduino θα επιστρέψει την τιμή 512 (γιατί, ( 1,65V/3,3V ) * 1024 = 512.
Η ανάπτυξη προγραμμάτων στην οικογένεια Arduino, γίνεται μέσω του προγράμματος Arduino IDE [99].
Το περιβάλλον ανάπτυξης Arduino περιέχει ένα πρόγραμμα επεξεργασίας κειμένου, για τη σύνταξη του κώδικα, μια περιοχή στην οποία εμφανίζονται μηνύματα, μία κονσόλα κειμένου και μια γραμμή εργαλείων υπό μορφή κουμπιών. Συνδέεται με το hardware μέρος του arduino για να φορτώσει προγράμματα και να επικοινωνεί μαζί τους. Ο κώδικας που έχει γραφεί για το Arduino ονομάζεται sketch. Στον Πίνακα B.4 παρουσιάζονται τα εργαλεία του περιβάλλοντος ανάπτυξης, υπό μορφή κουμπιών και στο Σχήμα B.5 το ίδιο το περιβάλλον.
B.5: Το ολοκληρωμένο πρόγραμμα ανάπτυξης προγραμμάτων σε Arduino.
Το Arduino IDE είναι βασισμένο σε Java και συγκεκριμένα παρέχει:
Ένα πρακτικό περιβάλλον για τη συγγραφή των προγραμμάτων, με συντακτική χρωματική σήμανση.
Μερικές έτοιμες βιβλιοθήκες για προέκταση της.
Τον compiler για τη μεταγλώττιση των sketch.
Μία σειριακή οθόνη (serial monitor) που παρακολουθεί τις επικοινωνίες της σειριακής (USB), αναλαμβάνει να στείλει αλφαριθμητικά στο Arduino μέσω αυτής και είναι ιδιαίτερα χρήσιμο για την αποσφαλμάτωση των sketch.
Την επιλογή για ανέβασμα των μεταγλωττισμένων sketch στο Arduino.
Γλώσσα Προγραμματισμού: Η γλώσσα του Arduino βασίζεται στη γλώσσα Wiring [100] μια παραλλαγή C/C++ για μικροελεγκτές αρχιτεκτονικής AVR όπως ο ATmega, και υποστηρίζει όλες τις βασικές δομές της C καθώς και μερικά χαρακτηριστικά της C++. Για compiler χρησιμοποιείται ο AVR gcc και ως βασική βιβλιοθήκη C χρησιμοποιείται η AVR libc. Λόγω της καταγωγής της από τη C, στη γλώσσα του Arduino, μπορούν να χρησιμοποιηθούν ουσιαστικά οι ίδιες βασικές εντολές και συναρτήσεις, με την ίδια σύνταξη, τους ίδιους τύπων δεδομένων και τους ίδιους τελεστές όπως και στη C. Πέρα από αυτές όμως, υπάρχουν κάποιες ειδικές εντολές, συναρτήσεις και σταθερές που βοηθούν για τη διαχείριση του ειδικού hardware του Arduino. Τα προγράμματα του Arduino διαιρούνται σε τρία μέρη: δομή (structure), τιμές (values) και συναρτήσεις (functions).
| p0.1 | p0.3 | p0.3 |

& Verify & Ελέγχει για συντακτικά λάθη στον κώδικα.

& Upload & Μεταγλωττίζει τον κώδικα και τον φορτώνει στο Arduino.

& New & Δημιουργεί ένα νέο sketch.

& Open & Παραθέτει ένα μενού με όλα τα sketch για άνοιγμα σε νέο παράθυρο.

& Save & Αποθηκεύει ένα sketch.

& Serial Monitor & Ανοίγει την σειριακή οθόνη.
Τα προγράμματα του Arduino διαιρούνται σε τρία μέρη: δομή (structure), τιμές (values) και συναρτήσεις (functions).

B.6: Η τυπική δομή των προγραμμάτων Arduino.
Ασφαλώς, σημαντικό στοιχείο της διαδικασίας συγγραφής προγραμμάτων στο Arduino, αποτελεί η αποσφαλμάτωση του συστήματος, είτε του λογισμικού (software) είτε του υλικού (hardware). Πολλές φορές θέλουμε να αποσφαλματώσουμε το κύκλωμά μας ή να επιβεβαιώσουμε ότι ένα κομμάτι του λειτουργεί σωστά. Για να το πετύχουμε αυτό, χρησιμοποιούμε τη σειριακή επικοινωνία σε συνδυασμό με εντολές εκτύπωσης στο σειριακό τερματικό.
Εμφανίζουμε τη σειριακή οθόνη, πατώντας το εικονίδιο με το μεγεθυντικό φακό στη εργαλειοθήκη με τα εικονίδια (τέρμα δεξιά).
Ρυθμίζουμε την ταχύτητα σε 9600 bps
Στο sketch του arduino στο setup() τοποθετούμε τη γραμμή Serial.begin(9600);
Στο σημείο που θέλουμε να εμφανίσουμε κάποια τιμή, δίνουμε Serial.println(value); ή Serial.print(value) (το ln κάνει και αλλαγή γραμμής).
Με αυτόν τον τρόπο μπορούμε να αποσφαλματώσουμε βήμα-προς-βήμα όλο το κύκλωμα. Εκτυπώνουμε τις τιμές από τις εισόδους, και τις τιμές που στέλνουμε στις εξόδους και έτσι προσδιορίζουμε το πρόβλημα.
Η εκπαίδευση πάνω στην ανάπτυξη εφαρμογών στο arduino γίνεται συνήθως σε κάποιο εργαστήριο. Παρακάτω παραθέτονται οι κανόνες που διέπουν το εργαστήριο του Ψηφιακών Συστημάτων και Αρχιτεκτονικής του Πανεπιστημίου Δυτικής Μακεδονίας.
Πριν χρησιμοποιήσετε οποιοδήποτε εξοπλισμό, θα πρέπει να ακουμπήσετε μια γειωμένη επιφάνεια (π.χ. το κουτί ενός υπολογιστή) για να απομακρυνθεί ο στατικός ηλεκτρισμός. Αυτό θα πρέπει να το επαναλαμβάνετε κατά τακτά χρονικά διαστήματα (π.χ. κάθε 20-30 λεπτά).
Απαγορεύεται η απομάκρυνση οποιουδήποτε εξοπλισμού από το εργαστήριο.
Να αναφέρετε αμέσως οποιοδήποτε πρόβλημα (χαμένο εξάρτημα, δυσλειτουργία εξαρτήματος) στους υπευθύνους.
Απαγορεύετε να σημειώνετε ή να τροποποιείτε μόνιμα τα εξαρτήματα.
Κατά την είσοδο στο εργαστήριο:
Ενημερώνετε τον υπεύθυνο για τον εξοπλισμό που θα χρησιμοποιήσετε.
Υπογράφετε την παραλαβή του εξοπλισμού και των εξαρτημάτων που το συνοδεύουν.
Κατά την έξοδο από το εργαστήριο:
θα πρέπει να παραδώσετε τακτοποιημένο τον εξοπλισμό (μέσα στις πλαστικές σακούλες/κουτιά), ακριβώς όπως σας παραδόθηκε.
Ο πάγκος να είναι καθαρός, η οθόνη, ο υπολογιστής, το πληκτρολόγιο και το mouse να είναι τακτοποιημένα.
Ο υπεύθυνος ελέγχει τον εξοπλισμό που του παραδίδετε και υπογράφει το φύλλο παραλαβής.
Πάντα να έχετε κλειστή την τροφοδοσία κατά τη σύνδεση ή αποσύνδεση εξαρτημάτων από μια πλακέτα.
Απαγορεύονται χυμοί, νερά, καφέδες, τρόφιμα στο εργαστήριο. Μπορείτε να τα αφήνετε έξω από το εργαστήριο.
Μην ασκείτε υπερβολική πίεση κατά τη συναρμολόγηση ενός κυκλώματος. Μπορείτε να χρησιμοποιείτε γειτονικές επαφές/connection points αν δείτε ότι ένα εξάρτημα δεν τοποθετείται χωρίς πίεση.
Κάποια εξαρτήματα, όπως η μεμβράνη πίεσης ή το ποτενσιόμετρο επαφής, είναι πολύ ευαίσθητα. Για να τα τοποθετήστε στο breadboard πρέπει να τα πιάσετε από πολύ χαμηλά (δίπλα στις επαφές).
Οι αντιστάσεις και οι δίοδοι που έχουν λυγισμένες επαφές να τις αφήνετε σε αυτή τη μορφή και να μην τις ισιώνετε, διαφορετικά υπάρχει κίνδυνος να κοπούν.
Σε περίπτωση που δεν ακολουθήσετε τις υποδείξεις ασφαλείας και προστασίας τόσο του εαυτού σας όσο και του εξοπλισμού, ή αν δεν είστε προσεκτικοί θα υπάρχουν κυρώσεις.
Ο υπεύθυνος του εργαστηρίου έχει τον τελευταίο λόγο. Οι υποδείξεις του θα πρέπει να λαμβάνονται σοβαρά υπόψιν.
Οι εργαστηριακές ασκήσεις που παρουσιάζονται σε αυτό το Παράρτημα, βασίζονται και χρησιμοποιούν ηλεκτρονικά στοιχεία που βρίσκονται στο δημοφιλές ολοκληρωμένο αναπτυξιακό κιτ της Sparkfun (SparkFun Inventor’s Kit). Στο εργαστήριο έχουμε προμηθευτεί αρκετά αναπτυξιακά κιτ της εταιρίας Sparkfun, και μπορούν να υλοποιηθούν απρόσκοπτα όλες αυτές οι ασκήσεις. Αρκετές από αυτές τις ασκήσεις βασίζονται σε πληροφορίες και ενδεικτικές εργασίες, που αναγράφονται στον ιστοχώρο της εταιρίας Sparkfun, όπως και σε φυλλάδιο που παρέχεται μαζί με το SparkFun Inventor’s Kit. O Πίνακας B.5 απαριθμεί τα εξαρτήματα που έχει το κιτ και απαιτούνται για τις ασκήσεις. Οι ενδιαφερόμενοι μπορούν είτε να προμηθευτούν το συγκεκριμένο kit είτε να προμηθευτούν ξεχωριστά από κατάλληλους προμηθευτές.
Τα LEDs (δίοδοι εκπομπής φωτός) χρησιμοποιούνται σε πάρα πολλές εφαρμογές. Αυτός είναι και ο λόγος που το πρώτο εργαστήριο χρησιμοποιεί LEDs και έχουν συμπεριληφθεί στο SparkFun Inventor’s Kit. Σκοπός της άσκησης είναι να κάνουμε ένα LED να ενεργοποιείται και να απενεργοποιείται κατ’ επανάληψη.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 15 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-01 απαιτούνται τα εξής μέρη:
1 κίτρινο LED 5mm
1 αντίσταση 330 Ohm (πορτοκαλί-πορτοκαλί-καφέ)
3 καλώδια
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.8. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.7. Συνδέστε το θετικό ακροδέκτη του LED στο 13ο pin του Arduino και μια αντίσταση στον αρνητικό ακροδέκτη, που να πηγαίνει στη γείωση. Επισημαίνεται ότι o θετικός ακροδέκτης του LED είναι αυτός με το μεγαλύτερο μήκος. Τέλος συνδέστε, στις κατάλληλες θέσεις του breadboard, ένα καλώδιο στο pin τροφοδοσίας 5V του Arduino και ένα καλώδιο σε ένα από τα τρία pin γείωσης (Gnd) που βρίσκονται πάνω στο Arduino.
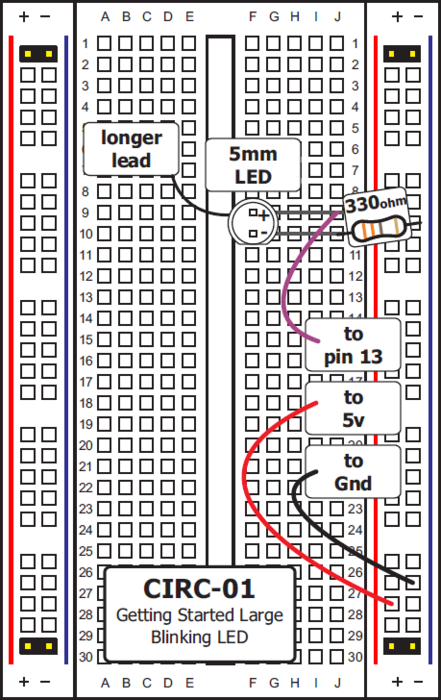
B.7: Προτεινόμενη υλοποίηση του CIRC01
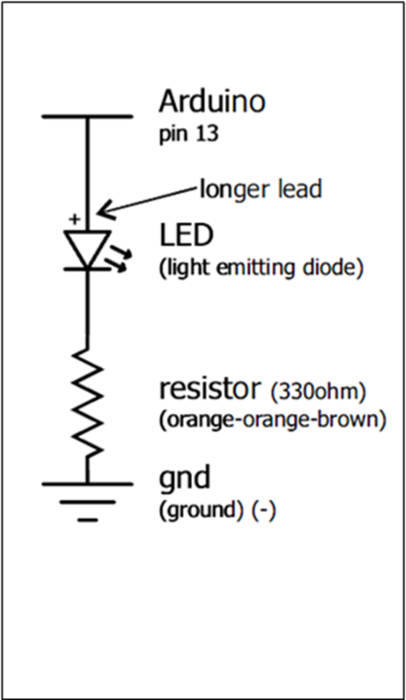
Σχηματικό Διάγραμμα του CIRC01
Συνδέστε το Arduino Uno και ανοίξτε το προγραμματιστικό περιβάλλον του. Επιβεβαιώστε ότι η επιλεγμένη σειριακή θύρα είναι η θύρα στην οποία είναι συνδεδεμένο το Arduino. Πηγαίνετε στις Ιδιότητες Υπολογιστή>Διαχείριση Συσκευών>Θύρες(COM & LPT) και συγκρίνετε την αναγραφόμενη θύρα με αυτή που είναι επιλεγμένη στο μενού Εργαλεία > Σειριακή θύρα, του προγραμματιστικού περιβάλλοντος του Arduino. Βεβαιωθείτε ότι η επιλεγμένη πλακέτα είναι το Arduino Uno Πηγαίνετε στο μενού Εργαλεία > Πλακέτα και επιλέξτε το Arduino Uno. Βεβαιωθείτε ότι ο επιλεγμένος προγραμματιστής είναι ο AVRISP mkII. Πηγαίνετε στο μενού Εργαλεία > Προγραμματιστής και επιλέξτε τον AVRISP mkII.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. (Εναλλακτικά κατεβάστε τον από (http://ardx.org/CODE01).
/*
* Blink
* Turns on an LED on for one second,
* then off for one second, repeatedly
* The circuit:
* LED connected from digital pin 13 to ground
* Note: On most Arduino boards, there is already
* an LED on the board
* connected to pin 13, so you don't need any extra
* components for this example
*Created 1 June 2005
*By David Cuartielles
*http://arduino.cc/en/Tutorial/Blink
*based on an orginal by H. Barragan
* for the Wiring i/o board
*/
int ledPin = 13; // LED connected to digital pin 13
// The setup() method runs once, when it starts
void setup(){
// initialize the digital pin as an output:
pinMode(ledPin, OUTPUT);
}
// the loop() method runs over and over again,
// as long as the Arduino has power
void loop()
{
digitalWrite(ledPin, HIGH); // set the LED on
delay(1000); // wait for a second
digitalWrite(ledPin, LOW); // set the LED off
delay(1000); // wait for a second
}Πατήστε Αποθήκευση (Ctrl+s). Θα σας ζητηθεί να δώστε όνομα φακέλου (Sketch Folder). Δώστε ‘CIRC-01’ και πατήστε ‘Αποθήκευση’. Το πρόγραμμα θα δημιουργήσει τον φάκελο CIRC-01 μέσα στον οποίο θα περιέχεται το αρχείο CIRC-01.ino με τον κώδικα που γράψατε παραπάνω. Στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα πατώντας Φόρτωση (Ctrl+u). Μόλις ολοκληρωθεί η διαδικασία φόρτωσης το πρόγραμμα θα εκτελεστεί στην πλακέτα, κάνοντας το LED του κυκλώματος και της πλακέτας να αναβοσβήνει. Σε περίπτωση που δε συμβαίνει τίποτα στο κύκλωμα, ελέγξτε την πολικότητα του LED, καθώς και την ορθότητα των παραμέτρων που περιγράφηκαν στην προηγούμενη ενότητα.
Αλλαγή του pin σύνδεσης του LED: Το LED είναι συνδεδεμένο στο pin 13, αλλά μπορούμε να το συνδέσουμε σε οποιοδήποτε από τα pins του Arduino. Για αλλάξετε το pin αφαιρέστε το καλώδιο από το pin 13 και συνδέστε το σε ένα άλλο pin της επιλογής σας (από 0 ως 13 για τα ψηφιακά ή A0 ως A5 για τα αναλογικά pins). Ταυτόχρονα αλλάξτε τη γραμμή 15 του κώδικα:
int ledPin = 13; // LED connected to digital pin 13
Δίνοντας τον αλλαγμένο αριθμό pin (από 0 ως 13 για τα ψηφιακά ή 14 ως 19 για τα αναλογικά pins). Πατήστε Αποθήκευση ως (Ctrl+Shift+s), και μεταβείτε έξω από το φάκελο του project CIRC_01 αν είστε μέσα σ αυτόν (θα πρέπει να βλέπετε το φάκελο CIRC_01). Δώστε όνομα φακέλου CIRC_01_d1 για να αποθηκεύσετε το πρόγραμμα. Στη συνέχεια, φορτώστε το στην πλακέτα (Ctrl+u). Επιβεβαιώστε την ορθή λειτουργία του κυκλώματος.
Αλλαγή της χρονικής διάρκειας on/off του LED: Το LED είναι ρυθμισμένο να αναβοσβήνει ανά 1sec (1000ms), κάτι το οποίο μπορούμε να αλλάξουμε. Αλλάξτε τις τιμές ‘1000’ στο παρακάτω τμήμα του κώδικα:
digitalWrite(ledPin, HIGH); // set the LED on
delay(1000); // wait for a second
digitalWrite(ledPin, LOW); // set the LED off
delay(1000); // wait for a secondΠατήστε Αποθήκευση ως (Ctrl+Shift+s), μεταβείτε έξω από το φάκελο του ήδη αποθηκευμένου project, αν είστε μέσα σ αυτόν, (όμοια με πριν θα πρέπει να βλέπετε τους φακέλους CIRC_01, CIRC_01_d1) και δώστε όνομα φακέλου CIRC_01_d2 για να αποθηκεύσετε το πρόγραμμα. Στη συνέχεια, φορτώστε το στην πλακέτα (Ctrl+u). Επιβεβαιώστε ότι ο χρόνος on/off έχει μεταβληθεί.
Αλλαγή της φωτεινότητας του LED: Εκτός από τον ψηφιακό (on/off) έλεγχο, το Arduino μπορεί να παρέχει έλεγχο που μοιάζει με τον αναλογικό (ενδιάμεσες καταστάσεις) σε ορισμένα pins. Αλλάξτε την τιμή του pin σε 9.
int ledPin = 9;
Προσαρμόστε κατάλληλα και το καλώδιο στο κύκλωμα. Στη συνέχεια αντικαταστήστε τον κώδικα μέσα στο loop() με τον παρακάτω κώδικα:
analogWrite(ledPin, 20);
Όπου 20 μπορείτε να δώσετε οποιαδήποτε τιμή από 0 ως 255. Πατήστε Αποθήκευση ως (Ctrl+Shift+s), μεταβείτε έξω από το φάκελο του ήδη αποθηκευμένου project (CIRC-01-d2) και δώστε όνομα φακέλου CIRC_01_d3 για να αποθηκεύσετε το πρόγραμμα. Στη συνέχεια, φορτώστε το στην πλακέτα (Ctrl+u). Επιβεβαιώστε την ορθή λειτουργία του κυκλώματος.
Ομαλή μετάβαση μεταξύ των καταστάσεων on/off του LED (Fading): Προσαρμόζοντας τον κώδικα του προηγούμενου ερωτήματος σε δύο διαδοχικές επαναλήψεις από 0 ως 255 η πρώτη, και από 254 ως 1 η δεύτερη, μπορούμε να δώσουμε όλες τις ενδιάμεσες τιμές φωτεινότητας στο LED, δημιουργώντας έτσι, ένα αποτέλεσμα ομαλής μετάβασης μεταξύ των καταστάσεων on/off. Αντικαταστήστε τον κώδικα μέσα στο loop() με τον παρακάτω κώδικα:
for(int i=0; i<=255; i++)
{
analogWrite(ledPin, i);
delay(10);
}
for(int i=254; i>=1; i--)
{
analogWrite(ledPin, i);
delay(10);
}Πατήστε Αποθήκευση ως (Ctrl+Shift+s), μεταβείτε έξω από το φάκελο του ήδη αποθηκευμένου project (CIRC-01-d3) και δώστε όνομα φακέλου CIRC_01_d4 για να αποθηκεύσετε το πρόγραμμα. Στη συνέχεια, φορτώστε το στην πλακέτα (Ctrl+u). Επιβεβαιώστε την ορθή λειτουργία του κυκλώματος. Δείτε επίσης τον κώδικα στο Αρχείο>Παραδείγματα>01.Basics>Fade που περιέχει μια διαφορετική υλοποίηση της ίδιας λειτουργίας.
Στην προηγούμενη εργαστηριακή άσκηση υλοποιήθηκε ένα κύκλωμα που ενεργοποιούσε και απενεργοποιούσε ένα LED. Σ’ αυτή την εργαστηριακή άσκηση θα υλοποιηθεί ένα κύκλωμα που εφαρμόζει την ίδια λειτουργία σε οκτώ LEDs. Θα υλοποιηθούν διάφορα LED animations και θα κατανοηθούν καλύτερα οι βασικές αρχές λειτουργίας και προγραμματισμού του Arduino, αφού θα χρησιμοποιηθούν πίνακες για ευκολότερη διαχείριση των μεταβλητών και η for() για επαναλήψεις.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 25 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-02 απαιτούνται τα εξής μέρη:
8 κίτρινο LED των 5mm
8 αντιστάσεις των 330 Ohm (πορτοκαλί-πορτοκαλί-καφέ)
10 καλώδια
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.10. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.9.
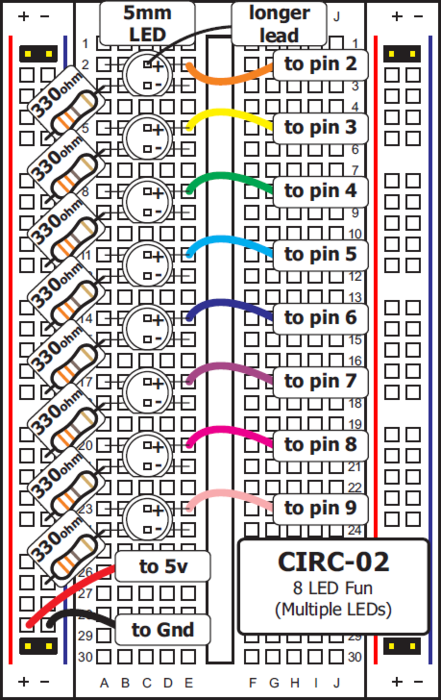
B.9: Προτεινόμενη υλοποίηση του CIRC02
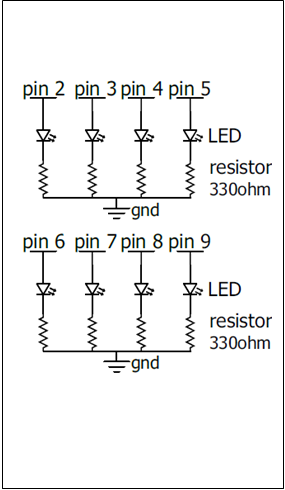
Σχηματικό Διάγραμμα του CIRC02
Συνδέστε το θετικό ακροδέκτη του LED στο στο αναγραφόμενο pin του Arduino και μια αντίσταση 330 Ohm στον κάθε αρνητικό ακροδέκτη, που να πηγαίνει στη γείωση. Επισημαίνεται ότι o θετικός ακροδέκτης του LED είναι αυτός με το μεγαλύτερο μήκος. Τέλος συνδέστε, στις κατάλληλες θέσεις του breadboard, ένα καλώδιο στο pin τροφοδοσίας 5V του Arduino και ένα σε κάποιο pin γείωσης (Gnd).
Συνδέστε το Arduino Uno και ανοίξτε το προγραμματιστικό περιβάλλον του. Επιβεβαιώστε ότι η επιλεγμένη σειριακή θύρα είναι η θύρα στην οποία είναι συνδεδεμένο το Arduino. Βεβαιωθείτε ότι η επιλεγμένη πλακέτα είναι το Arduino Uno. Βεβαιωθείτε ότι ο επιλεγμένος προγραμματιστής είναι ο AVRISP mkII. Όλα τα παραπάνω έχουν περιγραφεί αναλυτικά στην Ενότητα B.3.1 του CIRC-01.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. (Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE02)
/* ---------------------------------------------------------
* | Arduino Experimentation Kit Example Code|
* | CIRC-02 .: 8 LED Fun :. (Multiple LEDs)|
* ---------------------------------------------------------
*
* A few Simple LED animations
*
* For more information on this circuit http://tinyurl.com/d2hrud
*
*/
//LED Pin Variables
int ledPins[] = {2,3,4,5,6,7,8,9};
//An array to hold the pin each LED is connected to
//i.e. LED #0 is connected to pin 2, LED #1, 3 and so on
//to address an array use ledPins[0] this would equal 2
//and ledPins[7] would equal 9
/*
* setup() - this function runs once when you turn your Arduino on
* We the three control pins to outputs
*/
void setup()
{
//Set each pin connected to an LED to output mode
//(pulling high (on) or low (off)
for(int i = 0; i < 8; i++){ //this is a loop and will repeat eight times
pinMode(ledPins[i],OUTPUT); //we use this to set each LED pin to output
} //the code this replaces is below
/* (commented code will not run)
* these are the lines replaced by the for loop above they do exactly the
* same thing the one above just uses less typing
pinMode(ledPins[0],OUTPUT);
pinMode(ledPins[1],OUTPUT);
pinMode(ledPins[2],OUTPUT);
pinMode(ledPins[3],OUTPUT);
pinMode(ledPins[4],OUTPUT);
pinMode(ledPins[5],OUTPUT);
pinMode(ledPins[6],OUTPUT);
pinMode(ledPins[7],OUTPUT);
(end of commented code)*/
}
/*
* loop() - this function will start after setup finishes and then repeat
* we call a function called oneAfterAnother().
* if you would like a different behaviour
* uncomment (delete the two slashes) one of the other lines
*/
void loop() // run over and over again
{
//this will turn on each LED one by one then turn each off
oneAfterAnotherNoLoop();
//does the same as oneAfterAnotherNoLoop but with less typing
//oneAfterAnotherLoop();
//oneOnAtATime();
//this will turn one LED on then turn the next one
//on turning the
//former off (one LED will look like it is scrolling
//along the lin//inAndOut();
//lights the two middle LEDs then moves them out then back
//in again
}
/*
* oneAfterAnotherNoLoop() - Will light one LED then delay for delayTime
* then light the next LED until all LEDs are on it will then turn
* them off one after another
*
* this does it without using a loop which makes for a lot of typing.
* oneOnAtATimeLoop() does exactly the same thing with less typing
*/
void oneAfterAnotherNoLoop(){
int delayTime = 100; //the time (in milliseconds) to pause between LEDs
//make smaller for quicker switching and larger for slower
digitalWrite(ledPins[0], HIGH); //Turns on LED #0 (connected to pin 2 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[1], HIGH); //Turns on LED #1 (connected to pin 3 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[2], HIGH); //Turns on LED #2 (connected to pin 4 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[3], HIGH); //Turns on LED #3 (connected to pin 5 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[4], HIGH); //Turns on LED #4 (connected to pin 6 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[5], HIGH); //Turns on LED #5 (connected to pin 7 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[6], HIGH); //Turns on LED #6 (connected to pin 8 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[7], HIGH); //Turns on LED #7 (connected to pin 9 )
delay(delayTime); //waits delayTime milliseconds
//Turns Each LED Off
digitalWrite(ledPins[7], LOW); //Turns on LED #0 (connected to pin 2 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[6], LOW); //Turns on LED #1 (connected to pin 3 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[5], LOW); //Turns on LED #2 (connected to pin 4 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[4], LOW); //Turns on LED #3 (connected to pin 5 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[3], LOW); //Turns on LED #4 (connected to pin 6 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[2], LOW); //Turns on LED #5 (connected to pin 7 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[1], LOW); //Turns on LED #6 (connected to pin 8 )
delay(delayTime); //waits delayTime milliseconds
digitalWrite(ledPins[0], LOW); //Turns on LED #7 (connected to pin 9 )
delay(delayTime); //waits delayTime milliseconds
}
/*
* oneAfterAnotherLoop() - Will light one LED then delay for delayTime then light
* the next LED until all LEDs are on it will then turn them
* off one after another
* this does it using a loop which makes for a lot less typing.
* than oneOnAtATimeNoLoop() does exactly the same thing with less typing
*/
void oneAfterAnotherLoop(){
int delayTime = 100; //the time (in milliseconds) to pause between LEDs
//make smaller for quicker switching and larger for slower
//Turn Each LED on one after another
for(int i = 0; i <= 7; i++){
digitalWrite(ledPins[i], HIGH); //Turns on LED #i each time this runs i
delay(delayTime); //gets one added to it so this will repeat
} //8 times the first time i will = 0 the final
//time i will equal 7;
//Turn Each LED off one after another
for(int i = 7; i >= 0; i--){
//same as above but rather than starting at 0 and counting up
//we start at seven and count down
digitalWrite(ledPins[i], LOW); //Turns off LED #i each time this runs i
delay(delayTime); //gets one subtracted from it so this will repeat
} //8 times the first time i will = 7 the final
//time it will equal 0
}
/*
* oneOnAtATime() - Will light one LED then the next turning off all the others
*/
void oneOnAtATime(){
int delayTime = 100; //the time (in milliseconds) to pause between LEDs
//make smaller for quicker switching and larger for slower
for(int i = 0; i <= 7; i++){
int offLED = i - 1; //Calculate which LED was turned on last time through
if(i == 0) { //for i = 1 to 7 this is i minus 1 (i.e. if i = 2 we will
offLED = 7; //turn on LED 2 and off LED 1)
} //however if i = 0 we don't want to turn of led -1 (doesn't exist)
//instead we turn off LED 7, (looping around)
digitalWrite(ledPins[i], HIGH); //turn on LED #i
digitalWrite(ledPins[offLED], LOW); //turn off the LED we turned on last time
delay(delayTime);
}
}
/*
* inAndOut() - This will turn on the two middle LEDs then the next two out
* making an in and out look
*/
void inAndOut(){
int delayTime = 100; //the time (in milliseconds) to pause between LEDs
//make smaller for quicker switching and larger for slower
//runs the LEDs out from the middle
for(int i = 0; i <= 3; i++){
int offLED = i - 1; //Calculate which LED was turned on last time through
if(i == 0) { //for i = 1 to 7 this is i minus 1 (i.e. if i = 2 we will
offLED = 3; //turn on LED 2 and off LED 1)
} //however if i = 0 we don't want to turn of led -1 (doesn't exist)
//instead we turn off LED 7, (looping around)
int onLED1 = 3 - i; //this is the first LED to go on
//ie. LED #3 when i = 0 and LED #0 when i = 3
int onLED2 = 4 + i; //this is the first LED to go on
//ie. LED #4 when i = 0 and LED #7 when i = 3
int offLED1 = 3 - offLED; //turns off the LED we turned on last time
int offLED2 = 4 + offLED; //turns off the LED we turned on last time
digitalWrite(ledPins[onLED1], HIGH);
digitalWrite(ledPins[onLED2], HIGH);
digitalWrite(ledPins[offLED1], LOW);
digitalWrite(ledPins[offLED2], LOW);
delay(delayTime);
}
//runs the LEDs into the middle
for(int i = 3; i >= 0; i--){
int offLED = i + 1; //Calculate which LED was turned on last time through
if(i == 3) { //for i = 1 to 7 this is i minus 1 (i.e. if i = 2 we will
offLED = 0; //turn on LED 2 and off LED 1)
} //however if i = 0 we don't want to turn of led -1 (doesn't exist)
//instead we turn off LED 7, (looping around)
int onLED1 = 3 – I; //this is the first LED to go on
//ie. LED #3 when i = 0 and LED #0 when i = 3
int onLED2 = 4 + i; //this is the first LED to go on
//ie. LED #4 when i = 0 and LED #7 when i = 3
int offLED1 = 3 - offLED; //turns off the LED we turned on last time
int offLED2 = 4 + offLED; //turns off the LED we turned on last time
digitalWrite(ledPins[onLED1], HIGH);
digitalWrite(ledPins[onLED2], HIGH);
digitalWrite(ledPins[offLED1], LOW);
digitalWrite(ledPins[offLED2], LOW);
delay(delayTime);
}
}Πατήστε Αποθήκευση (Ctrl+s). Θα σας ζητηθεί να δώστε όνομα φακέλου (Sketch Folder). Δώστε ‘CIRC-02’ και πατήστε ‘Αποθήκευση’. Το πρόγραμμα θα δημιουργήσει τον φάκελο CIRC-02 μέσα στον οποίο θα περιέχεται το αρχείο CIRC-02.ino με τον κώδικα που γράψατε παραπάνω. Στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα πατώντας Φόρτωση (Ctrl+u). Μόλις ολοκληρωθεί η διαδικασία φόρτωσης το πρόγραμμα θα εκτελεστεί στην πλακέτα, κάνοντας το LED του κυκλώματος και της πλακέτας να αναβοσβήνει. Σε περίπτωση που κάποια LEDs δεν ανάβουν, ελέγξτε την πολικότητα τους. Αν κάποια LEDs ανάβουν εκτός της ακολουθίας που περιγράφεται στη συνάρτηση oneAfterAnotherNoLoop() ελέγξτε μήπως τα καλώδια τους έχουν τοποθετηθεί στη λάθος θύρα.
Αλλαγή συνάρτησης ελέγχου των LEDs: Στη συνάρτηση loop() υπάρχουν τέσσερεις συναρτήσεις και οι τελευταίες τρεις ξεκινούν με ‘//’. Αυτό σημαίνει ότι η γραμμή αντιμετωπίζεται ως σχόλιο και δεν εκτελείται. Για να αλλάξετε τη συνάρτηση ελέγχου των LEDs από την oneAfterAnotherNoLoop(), σε μία από τις άλλες τρεις, βάλτε σχόλιο στην oneAfterAnotherNoLoop(), και σβήστε τα από μια άλλη, όπως παρακάτω. Πατήστε Αποθήκευση ως (Ctrl+Shift+s), και μεταβείτε έξω από το φάκελο του project CIRC_02 αν είστε μέσα σ’ αυτόν. Δώστε όνομα φακέλου CIRC_02_d1 για να αποθηκεύσετε το πρόγραμμα. Στη συνέχεια, φορτώστε το στην πλακέτα (Ctrl+u). Επιβεβαιώστε την ορθή λειτουργία του κυκλώματος. (Σημείωση: Οι oneAfterAnotherNoLoop() και oneAfterAnotherLoop() έχουν την ίδια λειτουργία, απλά διαφέρουν ως προς την υλοποίηση)
Δημιουργία μιας δικιάς μας συνάρτησης για τον έλεγχο των LEDs: Στο τέλος του προγράμματος, μετά τη συνάρτηση inAndOut(), ορίστε μια συνάρτηση με όνομα my_animation() η οποία θα υλοποιεί ένα animation που θα γράψετε εσείς. Ενδεικτικά η δομή μιας συνάρτησης είναι:
void function_name()
{
variable_decleration;
commands;
}Μόλις ολοκληρώσετε τη συγγραφή της συνάρτησης, πηγαίνετε στη συνάρτηση loop() και καλέστε την γράφοντας my_animation();. Το animation που πρέπει να υλοποιήσετε είναι το animation που υπάρχει στο video http://www.youtube.com/watch?v=WxE2xWZNfOc. Θα πρέπει να χρησιμοποιήσετε τουλάχιστον ένα for-loop. Μην παραλείψετε να κάνετε σχόλια όλες τις άλλες κλήσεις συναρτήσεων που περιέχονται στην loop(). Πατήστε Αποθήκευση ως (Ctrl+Shift+s), μεταβείτε έξω από το φάκελο του ήδη αποθηκευμένου project, αν είστε μέσα σ αυτόν, (όμοια με πριν θα πρέπει να βλέπετε τους φακέλους CIRC_02, CIRC_02_d1) και δώστε όνομα φακέλου CIRC_02_d2 για να αποθηκεύσετε το πρόγραμμα. Στη συνέχεια, φορτώστε το στην πλακέτα (Ctrl+u). Επιβεβαιώστε ότι η συνάρτηση σας δουλεύει όπως θα έπρεπε.
Τα pins του Arduino είναι κατάλληλα για να ελέγχουν μικρά ηλεκτρονικά στοιχεία όπως τα LEDs, όμως όταν έχουμε να κάνουμε με μεγαλύτερα στοιχεία, όπως ένα μοτέρ, απαιτείται η χρήση εξωτερικού τρανζίστορ. Τα τρανζίστορ είναι πολύ χρήσιμα, γιατί μας επιτρέπουν να ρυθμίζουμε μεγάλης έντασης ρεύματα, χρησιμοποιώντας ρεύματα μικρότερης έντασης. Το τρανζίστορ έχει τρία pins. Για ένα NPN τρανζίστορ όπως αυτό που θα χρησιμοποιήσουμε σ’ αυτό το εργαστήριο, συνδέετε το φορτίο στο συλλέκτη, και τον εκπομπό στη γείωση. Όταν ένα μικρής έντασης ρεύμα περνάει από τη βάση στον εκπομπό, θα ελεγχθεί ένα μεγαλύτερης έντασης ρεύμα και θα κινηθεί το μοτέρ. Το τρανζίστορ που θα χρησιμοποιηθεί είναι ένα P2N2222AG, το οποίο είναι ένα σύνηθες τρανζίστορ γενικής χρήσης. Τα σημαντικά στοιχεία του, είναι η μέγιστη τάση (40 V) και το μέγιστο ρεύμα (200 mA) τα οποία είναι αρκετά υψηλά για να θέσουν σε λειτουργία το μοτέρ μας. Όσον αφορά τη δίοδο 1N4001 μπορείτε να ανατρέξετε στο σχετικό λήμμα της Wikipedia για να δείτε για ποιο λόγο χρησιμοποιείται.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 30 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-02 απαιτούνται τα εξής μέρη:
1 Τρανζίστορ P2N2222AG ( TO92 )
1 Μοτέρ DC
1x Αντίσταση 10 kOhm (Καφέ–Μαύρο–Πορτοκαλί)
8 καλώδια
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.12. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.11.
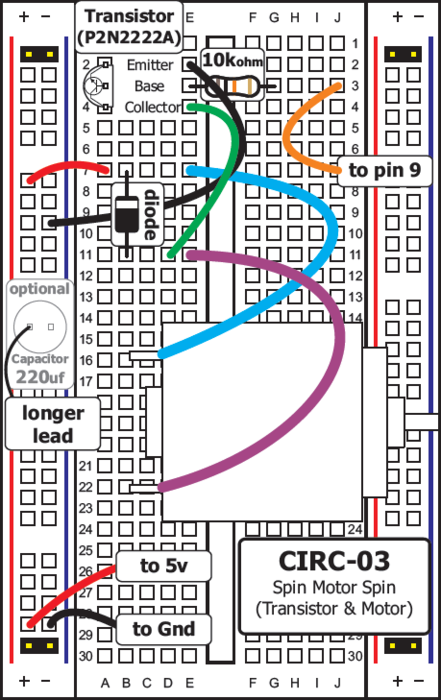
B.11: Προτεινόμενη υλοποίηση του CIRC03
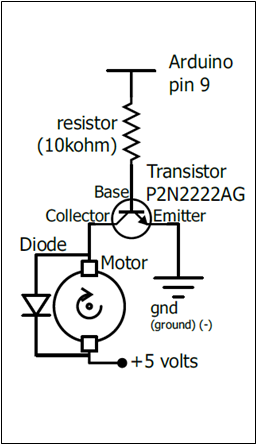
Σχηματικό Διάγραμμα του CIRC03
Συνδέστε τη βάση του τρανζίστορ με μία αντίσταση 10kOhm και στη συνέχεια συνδέστε την άλλη άκρη της αντίστασης με το pin 9 του Arduino. Ο εκπομπός του τρανζίστορ συνδέεται στη γείωση, ενώ ο συλλέκτης ακριβώς πριν τη δίοδο, όπως φαίνεται στο Σχήμα B.12. Τέλος στη δίοδο συνδέεται και το μοτέρ (το κόκκινο καλώδιο στην πλευρά που συνδέεται με την τάση +5 V, ενώ το μαύρο στην πλευρά που έχουμε συνδέσει τον συλλέκτη του τρανζίστορ). Ο πυκνωτής που φαίνεται στο Σχήμα B.11 δεν είναι απαραίτητος για τη λειτουργία του κυκλώματος και μπορεί να παραληφθεί. Η τοποθέτηση του χρειάζεται μόνο στην περίπτωση που παρατηρήσετε ότι το Arduino κάνει επανεκκίνηση μόνο του. Τέλος συνδέστε, στις κατάλληλες θέσεις του breadboard, ένα καλώδιο στο pin τροφοδοσίας 5V του Arduino και ένα καλώδιο σε ένα από τα τρία pin γείωσης (Gnd) που βρίσκονται πάνω στο Arduino.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE03.
/*-----------------------------------------------------------
*| Arduino Experimentation Kit Example Code|
*| CIRC-03 .: Spin Motor Spin :. (Transistor and Motor) |
*-----------------------------------------------------------
*
* The Arduinos pins are great for driving LEDs however if you hook
* up something that requires more power you will quickly break them.
* To control bigger items we need the help of a transistor.
* Here we will use a transistor to control a small toy motor
*
* http://tinyurl.com/d4wht7
*
*/
int motorPin = 9; // define the pin the motor is connected to
// (if you use pin 9,10,11 or 3you can also control speed)
/*
* setup() - this function runs once when you turn your Arduino on
* We set the motors pin to be an output (turning the pin high (+5v)
* or low (ground) (-))
* rather than an input (checking whether a pin is high or low)
*/
void setup()
{
pinMode(motorPin, OUTPUT);
}
/*
* loop() - this function will start after setup finishes and then repeat
* we call a function called motorOnThenOff()
*/
void loop() // run over and over again
{
motorOnThenOff();
//motorOnThenOffWithSpeed();
//motorAcceleration();
}
/*
* motorOnThenOff() - turns motor on then off
* (notice this code is identical to the code we used for
* the blinking LED)
*/
void motorOnThenOff(){
int onTime = 2500; //the number of milliseconds for the motor to turn on for
int offTime = 1000; //the number of milliseconds for the motor to turn off for
digitalWrite(motorPin, HIGH); // turns the motor On
delay(onTime); // waits for onTime milliseconds
digitalWrite(motorPin, LOW); // turns the motor Off
delay(offTime); // waits for offTime milliseconds
}
/*
* motorOnThenOffWithSpeed() - turns motor on then off but uses speed values
* (notice this code is identical to the code we used for
* the blinking LED)
*/
void motorOnThenOffWithSpeed(){
int onSpeed = 200; // a number between 0 (stopped) and 255 (full speed
int onTime = 2500; //the number of milliseconds for the motor to turn on for
int offSpeed = 50; // a number between 0 (stopped) and 255 (full speed)
int offTime = 1000; //the number of milliseconds for the motor to turn off for
analogWrite(motorPin, onSpeed); // turns the motor On
delay(onTime); // waits for onTime milliseconds
analogWrite(motorPin, offSpeed); // turns the motor Off
delay(offTime); // waits for offTime milliseconds
}
/*
* motorAcceleration() - accelerates the motor to full speed then
* back down to zero
*/
void motorAcceleration(){
int delayTime = 50; //milliseconds between each speed step
//Accelerates the motor
for(int i = 0; i < 256; i++){ //goes through each speed from 0 to 255
analogWrite(motorPin, i); //sets the new speed
delay(delayTime); // waits for delayTime milliseconds
}
//Decelerates the motor
for(int i = 255; i >= 0; i--){ //goes through each speed from 255 to 0
analogWrite(motorPin, i); //sets the new speed
delay(delayTime); // waits for delayTime milliseconds
}
}Αποθηκεύστε το ως CIRC_03 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα. Αν το μοτέρ δεν δουλεύει, ελέγξτε ξανά το κύκλωμα σας, καθώς και τις παραμέτρους του προγραμματιστικού περιβάλλοντος του Arduino (όπως έχουν περιγραφεί στο CIRC_01, Ενότητα B.3.1). Ελέγξτε επίσης αν τα τρανζίστορ είναι τα αναγραφόμενα P2N2222AG (TO92) και αν δεν είναι, ελέγξτε αν τα pins τους έχουν την ίδια λειτουργία με αυτά του P2N2222AG (TO92), από το site του κατασκευαστή (σε ορισμένα τρανζίστορ ο εκπομπός και ο συλλέκτης είναι ανάποδα). Τέλος, αν το Arduino κάνει επανεκκίνηση μόνο του, πρέπει να τοποθετήσουμε στο κύκλωμα τον πυκνωτή που αναφέρθηκε στην αρχή της άσκησης.
Αλλαγή της συνάρτησης ελέγχου του μοτέρ (Έλεγχος της ταχύτητας): Σε προηγούμενο εργαστήριο είδαμε την ικανότητα του Arduino να ελέγχει τη φωτεινότητα ενός LED. Θα χρησιμοποιήσουμε την ίδια ικανότητα για να ελέγξουμε την ταχύτητα του μοτέρ μας. Το Arduino το πετυχαίνει αυτό χρησιμοποιώντας διαμόρφωση πλάτους παλμού (PWM), μόνο που αντί να μεταβάλλει απευθείας την τάση που προέρχεται από το pin, μεταβαίνει μεταξύ των δύο καταστάσεων πολύ γρήγορα. Για παράδειγμα, εάν το Arduino διαμορφώνει το πλάτος του παλμού στο 50επειδή τα μάτια μας δεν είναι αρκετά γρήγορα για να το δουν να ανάβει και να σβήνει. Το ίδιο χαρακτηριστικό λειτουργεί και με τρανζίστορ. Στη συνάρτηση loop() υπάρχουν τρεις συναρτήσεις, δύο εκ των οποίων είναι σχόλια. Αφού διαβάσετε και κατανοήσετε τι λειτουργία έχει η κάθε συνάρτηση, αλλάξτε τη συνάρτηση ελέγχου του μοτέρ. Στη συνέχεια αποθηκεύστε και τρέξτε το πρόγραμμα για καθεμιά από τις συναρτήσεις.
Σε εφαρμογές όπου χρειάζεται μεγαλύτερος έλεγχος και ακρίβεια στην κίνηση από αυτή που μας παρέχει ένα μοτέρ, χρησιμοποιούμε Servos. Στο εσωτερικό ενός servo, υπάρχει ένα μικρό κιβώτιο ταχυτήτων (για να κάνει πιο ισχυρή την κίνηση) και μερικά ηλεκτρονικά στοιχεία (μοτέρ, ποτενσιόμετρο κτλ). Ένα τυπικό servo μπορεί να κινείται μεταξύ των 0 και 180 μοιρών. Η κίνηση ελέγχεται μέσω ενός χρονισμένου παλμού, μεταξύ 1.25 ms (0 μοίρες) και 1.75 ms (180 μοίρες). Ο χρόνος ενδέχεται να διαφέρει μεταξύ διαφορετικών κατασκευαστών. Αν ο παλμός στέλνεται μεταξύ κάθε 25 - 50 ms το servo λειτουργεί ομαλά. Το Arduino έχει μια βιβλιοθήκη η οποία δίνει τη δυνατότητα να ελέγχετε 2 servos μαζί (συνδεδεμένα στα pins 9, 10) με μόνο μια γραμμή κώδικα.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 30 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-02 απαιτούνται τα εξής μέρη:
1 3pin Header
1 Mini Servo
5 καλώδια
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.14. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.13.
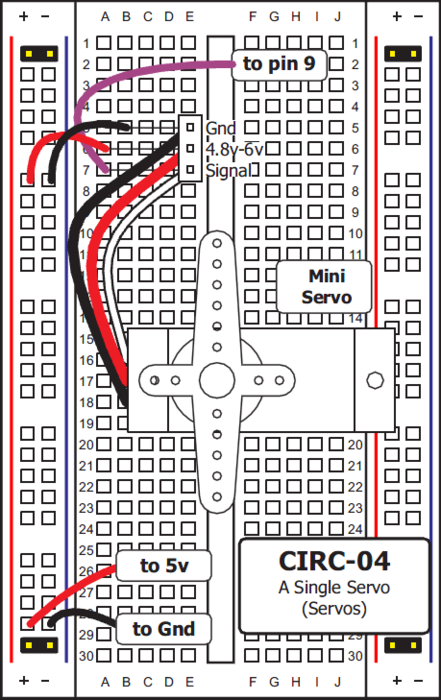
B.13: Προτεινόμενη υλοποίηση του CIRC04
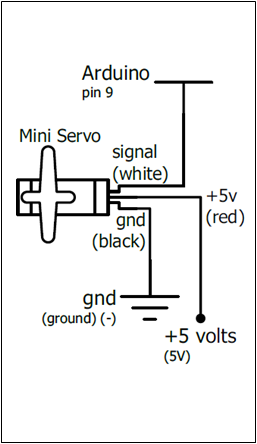
Σχηματικό Διάγραμμα του CIRC04
Συνδέστε το Servo με το 3pin Header και στη συνέχεια τοποθετήστε το στο breadboard όπως φαίνεται στο Σχήμα B.13. Συνδέστε το άσπρο καλώδιο του Servo με το pin 9 του Arduino, το κόκκινο καλώδιο στην τάση +5 V, ενώ το μαύρο στη γείωση. Τέλος συνδέστε τα +5V και Gnd στο Arduino. Στο servo τοποθετήστε το εξάρτημα που έχει μια ακμή (‘ένα δόντι’) μόνο για να μπορείτε να παρακολουθήσετε καλύτερα την μετακίνηση.
*** Προσοχή: Ενδέχεται το header pin να μη μπορεί να σταθεροποιηθεί πάνω στο breadboard. Σε αυτή την περίπτωση, αφού προγραμματίσετε το arduino θα ασκείτε ελαφριά πίεση με το δάχτυλο στο συνδετήρα για να λειτουργεί. ***
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE04.
// Sweep
// by BARRAGAN <http://barraganstudio.com>
#include <Servo.h>
Servo myservo; // create servo object to control a servo
// a maximum of eight servo objects can be created
int pos = 0; // variable to store the servo position
void setup()
{
myservo.attach(9); // attaches the servo on pin 9 to the servo object
}
void loop()
{
for(pos = 0; pos < 180; pos += 1) // goes from 0 degrees to 180 degrees
{ // in steps of 1 degree
myservo.write(pos); // tell servo to go to position in variable 'pos'
delay(15); // waits 15ms for the servo to reach the position
}
for(pos = 180; pos>=1; pos-=1) // goes from 180 degrees to 0 degrees
{
myservo.write(pos); // tell servo to go to position in variable 'pos'
delay(15); // waits 15ms for the servo to reach the position
}
}*** Προσοχή: Το servo δέχεται εντολές τοποθέτησης από 0 έως 180 μοίρες. Μη δοκιμάσετε να στείλετε τιμή μεγαλύτερη από 180 γιατί θα υπερθερμανθεί και μπορεί να καεί. ***
Αποθηκεύστε το ως CIRC_04 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα. Αν το Servo δεν περιστρέφεται, ελέγξτε μήπως τυχόν το έχετε τοποθετήσει ανάποδα. Ελέγξτε επίσης αν έχετε συνδέσει σωστά την πηγή. Αν το Servo ξεκινά να περιστρέφεται αλλά καταλήγει να κάνει σπασμωδικές κινήσεις, και υπάρχει ένα λαμπάκι πάνω στην πλακέτα arduino που αναβοσβήνει, τότε η τροφοδοσία του USB δεν είναι αρκετή και θα πρέπει να χρησιμοποιηθεί ένα εξωτερικό καλώδιο τροφοδοσίας.
Μπορείτε να προγραμματίσετε το Servo χωρίς να χρησιμοποιήσετε τις έτοιμες βιβλιοθήκες του Arduino. Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino:
int servoPin = 9;
void setup(){
pinMode(servoPin,OUTPUT); }
void loop() {
int pulseTime = 2100; //(the number of microseconds
//to pause for (1500 90 degrees
// 900 0 degrees 2100 180 degrees)
digitalWrite(servoPin, HIGH);
delayMicroseconds(pulseTime);
digitalWrite(servoPin, LOW);
delay(25);
}Τροποποιήστε τον (αν δε λειτουργεί κανονικά), ώστε να περιστρέφεται για 180ο. Στη συνέχεια, αποθηκεύστε το ως CIRC_04_c1 και φορτώστε το πρόγραμμα στο Arduino.
Μπορείτε να δείτε μερικές ενδιαφέρουσες εφαρμογές με Servos στους παρακάτω συνδέσμους:
Xmas Hit Counter ( http://tinkerlog.com/2007/12/04/arduino-xmas-hitcounter/ )
Open Source Robotic Arm ( http://www.thingiverse.com/thing:387 )
Servo Walker ( http://www.instructables.com/id/simpleWalker-4-legged-2-servo-walking-robot/ )
Ο καταχωρητής μετατόπισης είναι ένα ολοκληρωμένο κύκλωμα, το οποίο δίνει 8 πρόσθετες εξόδους (για τον έλεγχο ηλεκτρονικών στοιχείων) χρησιμοποιώντας μόνο τρία pins του Arduino. Επίσης μπορούν να συνδεθούν πολλοί καταχωρητές μετατόπισης μαζί, ώστε να έχουμε επιπρόσθετες εξόδους χρησιμοποιώντας πάλι τα ίδια pins. Για να το χρησιμοποιήσετε θέτετε το data pin σε HIGH ή LOW, δίνετε έναν παλμό στο ρολόι, και επαναλαμβάνετε μέχρι να έχετε 8 bits δεδομένων. Τότε δίνετε έναν παλμό στο latch και μεταφέρονται τα 8 bits δεδομένων στα αντίστοιχα pins του καταχωρητή μετατόπισης. Για βαθύτερη μελέτη της λειτουργίας του ανατρέξτε στο σχετικό λήμμα της Wikipedia (http://en.wikipedia.org/wiki/Shift_register).
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 45 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-05 απαιτούνται τα εξής μέρη:
8 κόκκινα LED των 5mm
8 αντιστάσεις των 330 Ohm (πορτοκαλί-πορτοκαλί-καφέ)
19 καλώδια
1 Καταχωρητής ολίσθησης 74HC595
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.16. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.15.
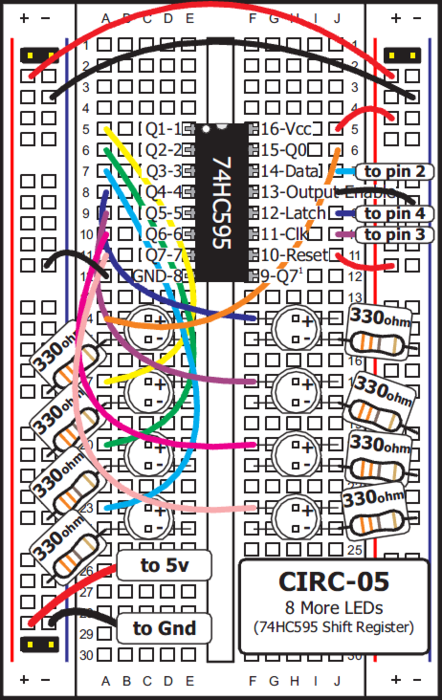
B.15: Προτεινόμενη υλοποίηση του CIRC05
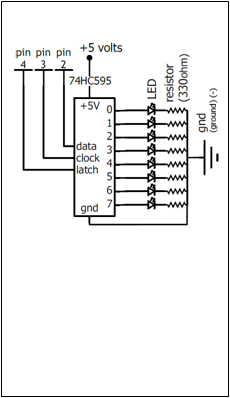
Σχηματικό Διάγραμμα του CIRC05
Τοποθετήστε τον καταχωρητή ολίσθησης στο breadboard. Η ημικυκλική εγκοπή του, θα πρέπει να είναι σύμφωνη με τη φορά του Σχήματος B.15. Συνδέστε το θετικό ακροδέκτη του κάθε LED στο αναγραφόμενο pin του καταχωρητή ολίσθησης, και μια αντίσταση 330 Ohm στον κάθε αρνητικό ακροδέκτη, που να πηγαίνει στη γείωση. Συνδέστε το 8ο και το 13ο pin του καταχωρητή ολίσθησης στη γείωση καθώς και το 10ο και 16ο στο +5 V. Συνδέστε τα pin 11, 12 και 14 του καταχωρητή ολίσθησης στα αναγραφόμενα pins του Arduino. *** Προσοχή: Αν συνδέσετε ανάποδα το IC του καταχωρητή ολίσθησης μπορεί να καταστρέψει το ολοκληρωμένο κύκλωμα. Διαβάστε το datasheet και στη συνέχεια ακολουθήστε πιστά τις οδηγίες σύνδεσης. *** Τέλος συνδέστε μεταξύ τους τις γειώσεις και τα +5 V του breadboard. Στο σημείο αυτό θα πρέπει να γνωρίζετε κάποιες βασικές πληροφορίες για τον καταχωρητή μετατόπισης (Serial to parallel converter): Διαβάστε το σχετικό λήμμα στη Wikipedia (http://en.wikipedia.org/wiki/Shift_register). Στο παρόν κύκλωμα η χρήση του καταχωρητή μετατόπισης θα μας δώσει 8 επιπλέον εξόδους για τον έλεγχο των LEDs, χρησιμοποιώντας μόνο 3 pins του Arduino.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE05.
/*---------------------------------------------------------
*| Arduino Experimentation Kit Example Code |
*| CIRC-05 .: 8 More LEDs :. (74HC595 Shift Register) |
*---------------------------------------------------------
*
*We have already controlled 8 LEDs however this does it in a slightly
*different manner. Rather than using 8 pins we will use just three
*and an additional chip.
*
*/
//Pin Definitions
//Pin Definitions
//The 74HC595 uses a serial communication
//link which has three pins
int data = 2;
int clock = 3;
int latch = 4;
//Used for single LED manipulation
int ledState = 0;
const int ON = HIGH;
const int OFF = LOW;
/*
* setup() - this function runs once when you turn your Arduino on
* We set the three control pins to outputs
*/
void setup()
{
pinMode(data, OUTPUT);
pinMode(clock, OUTPUT);
pinMode(latch, OUTPUT);
}
/*
* loop() - this function will start after setup finishes and then repeat
* we set which LEDs we want on then call a routine which sends to the 74HC595
*/
void loop() // run over and over again
{
int delayTime = 100; //the number of milliseconds to delay between LED updates
for(int i = 0; i < 256; i++){
updateLEDs(i);
delay(delayTime);
}
}
/*
*updateLEDs() - sends the LED states set in ledStates to the 74HC595
*sequence
*/
void updateLEDs(int value){
digitalWrite(latch, LOW); //Pulls the chips latch low
shiftOut(data, clock, MSBFIRST, value); //Shifts out the 8 bits to the
//shift register
digitalWrite(latch, HIGH); //Pulls the latch high displaying the data
}
/*
* updateLEDsLong() - sends the LED states set in ledStates to the 74HC595
* sequence. Same as updateLEDs except the shifting out is done in software
* so you can see what is happening.
*/
void updateLEDsLong(int value){
digitalWrite(latch, LOW); //Pulls the chips latch low
for(int i = 0; i < 8; i++){ //Will repeat 8 times (once for each bit)
int bit = value & B10000000; //We use a "bitmask" to select only the eighth
//bit in our number (the one we are addressing this time through
value = value << 1; //we move our number up one bit value
//so next time bit 7 will be
//bit 8 and we will do our math on it
if(bit == 128){digitalWrite(data, HIGH);}
//if bit 8 is set then set our data pin high
else{digitalWrite(data, LOW);} //if bit 8 is unset then set the data pin low
digitalWrite(clock, HIGH); //the next three lines pulse the clock pin
delay(1);
digitalWrite(clock, LOW);
}
digitalWrite(latch, HIGH);
//pulls the latch high shifting our data into being displayed
}
//These are used in the bitwise math that we use to change individual LEDs
//For more details http://en.wikipedia.org/wiki/Bitwise_operation
int bits[] = {B00000001, B00000010, B00000100, B00001000, B00010000,\
B00100000, B01000000, B10000000};
int masks[] = {B11111110, B11111101, B11111011, B11110111, B11101111,\
B11011111, B10111111, B01111111};
/*
* changeLED(int led, int state) - changes an individual LED
* LEDs are 0 to 7 and state is either 0 - OFF or 1 - ON
*/
void changeLED(int led, int state){
//clears ledState of the bit we are addressing
ledState = ledState & masks[led];
if(state == ON){ledState = ledState | bits[led];}
//if the bit is on we will add it to ledState
updateLEDs(ledState); //send the new LED state to the shift register
}Αποθηκεύστε το ως CIRC_05 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα. Αν το Arduino σβήνει, ελέγξτε μήπως έχετε τοποθετήσει ανάποδα τον καταχωρητή ολίσθησης.
Υλοποίηση του προγράμματος δίχως τη χρήση της έτοιμης συνάρτησης shiftOut(): Αλλάξτε στη loop() τη γραμμή updateLEDs(i); σε updateLEDsLong(i); και φορτώστε το πρόγραμμα στην πλακέτα. Παρατηρήστε ότι ενώ δεν αλλάζει κάτι στη λειτουργία του κυκλώματος, ο κώδικας, μας επιτρέπει πλέον να ‘επικοινωνούμε’ με το chip 1 bit τη φορά. Για περισσότερες λεπτομέρειες διαβάστε τα σχόλια του κώδικα της συνάρτησης updateLEDsLong() και για μεγαλύτερη εμβάθυνση μπορείτε να ανατρέξτε στο σχετικό λήμμα της Wikipedia (http://en.wikipedia.org/wiki/Serial_Peripheral_Interface_Bus).
Έλεγχος μεμονωμένων LEDs: Μπορείτε επίσης να ελέγξετε μεμονωμένα LEDs, όπως είχατε κάνει στο CIRC-02, χρησιμοποιώντας την changeLED(<αριθμός LED>,<ON/OFF>); Για παράδειγμα στη loop(), αντικαταστήστε τον υπάρχοντα κώδικα με τον παρακάτω, αποθηκεύστε το ως CIRC_05_c1 και φορτώστε το στο Arduino:
//the number of milliseconds to delay between LED updates
int delayTime = 100;
for(int i = 0; i < 8; i++){
changeLED(i,ON);
delay(delayTime);
}
for(int i = 0; i < 8; i++){
changeLED(i,OFF);
delay(delayTime);
}Υλοποίηση ενός δικού σας LED animation: Ορίστε μια δική σας συνάρτηση με όνομα my_animation(), η οποία θα υλοποιεί ένα LED animation και καλέστε την, όπως έχει περιγραφεί στο CIRC-02. Μπορείτε αν θέλετε να χρησιμοποιήσετε την ίδια συνάρτηση που είχατε υλοποιήσει στο CIRC-02, τροποποιώντας την κατάλληλα, ώστε να κάνει compile χωρίς σφάλματα (αλλαγή της digitalWrite() σε changeLED() κτλ). Αποθηκεύστε τo ως CIRC_05_c2 και φορτώστε το στο Arduino.
Το Arduino μπορεί να χρησιμοποιηθεί και για τον έλεγχο συσκευών που παράγουν ήχο, παρόλο που ο ήχος είναι αναλογικό μέγεθος. Για να το πετύχουμε αυτό θα χρησιμοποιήσουμε ένα πιεζοηλεκτρικό στοιχείο buzzer. Το πιεζοηλεκτρικό στοιχείο παράγει έναν ήχο κάθε φορά που το διαπερνά ένας παλμός ρεύματος. Αν πάλλουμε το πιεζοηλεκτρικό στοιχείο στην κατάλληλη συχνότητα οι παραγόμενοι ήχοι θα παράγουν μουσικές νότες (π.χ. 440Hz για να παραχθεί η νότα λα).
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 20 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-06 απαιτούνται τα εξής μέρη:
1 Πιεζοηλεκτρικό στοιχείο
4 Καλώδια
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.18. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.17.
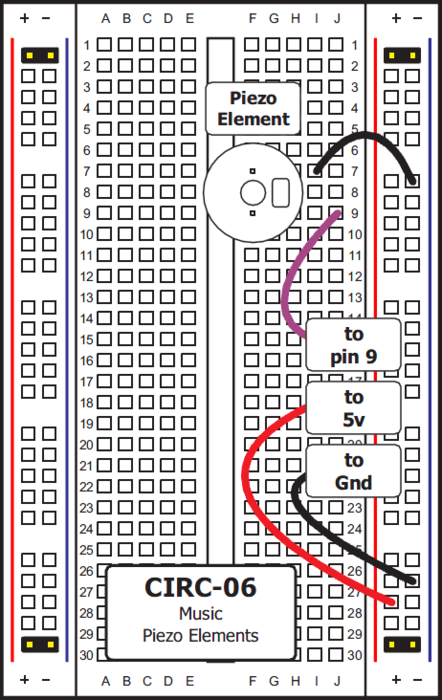
B.17: Προτεινόμενη υλοποίηση του CIRC06
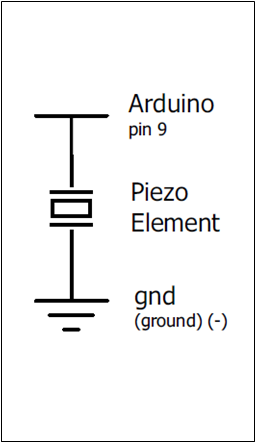
Σχηματικό Διάγραμμα του CIRC06
Συνδέστε το θετικό ακροδέκτη του πιεζοηλεκτρικού στοιχείου στο pin 9 του Arduino, και τον αρνητικό ακροδέκτη στη γείωση.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE06.
/* Melody
* (cleft) 2005 D. Cuartielles for K3
*
* This example uses a piezo speaker to play melodies. It sends
* a square wave of the appropriate frequency to the piezo, generating
* the corresponding tone.
*
* The calculation of the tones is made following the mathematical
* operation:
*
* timeHigh = period / 2 = 1 / (2 * toneFrequency)
*
* where the different tones are described as in the table:
*
*note frequency period timeHigh
* c 261 Hz 3830 1915
* d 294 Hz 3400 1700
* e 329 Hz 3038 1519
* f 349 Hz 2864 1432
* g 392 Hz 2550 1275
* a 440 Hz 2272 1136
* b 493 Hz 2028 1014
* C 523 Hz 1912 956
*
* http://www.arduino.cc/en/Tutorial/Melody
*/
int speakerPin = 9;
int length = 15; // the number of notes
// a space represents a rest
char notes[] = "ccggaagffeeddc ";
int beats[] = { 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 2, 4 };
int tempo = 300;
void playTone(int tone, int duration) {
for (long i = 0; i < duration * 1000L; i += tone * 2) {
digitalWrite(speakerPin, HIGH);
delayMicroseconds(tone);
digitalWrite(speakerPin, LOW);
delayMicroseconds(tone);
}
}
void playNote(char note, int duration) {
char names[] = { 'c', 'd', 'e', 'f', 'g', 'a', 'b', 'C' };
int tones[] = { 1915, 1700, 1519, 1432, 1275, 1136, 1014, 956 };
// play the tone corresponding to the note name
for (int i = 0; i < 8; i++) {
if (names[i] == note) {
playTone(tones[i], duration);
}
}
}
void setup() {
pinMode(speakerPin, OUTPUT);
}
void loop() {
for (int i = 0; i < length; i++){
if (notes[i] == ' '){
delay(beats[i] * tempo); // rest
} else {
playNote(notes[i], beats[i] * tempo);
}
// pause between notes
delay(tempo / 2);
}
}Αποθηκεύστε το ως CIRC_06 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα. Αν το Arduino σβήνει, ελέγξτε μήπως έχετε τοποθετήσει ανάποδα τον καταχηρητή ολίσθησης.
Ρύθμιση της ταχύτητας της μελωδίας: Η ταχύτητα της μελωδίας καθορίζεται από την τιμή της μεταβλητής tempo. Μεγαλύτερες τιμές, δίνουν γρηγορότερη εκτέλεση της μελωδίας, ενώ μικρότερες πιο αργή. Δοκιμάστε να αλλάξετε την τιμή της στο παρακάτω τμήμα του κώδικα: int tempo = 300; Στη συνέχεια, αποθηκεύστε και φορτώστε το πρόγραμμα στο Arduino ώστε να διαπιστώσετε την αλλαγή στη λειτουργία του κυκλώματος.
Έλεγχος τονικότητας κάθε νότας: Μπορείτε επίσης να αλλάξετε την τονικότητα κάθε νότας, αλλάζοντας τις τιμές του πίνακα tones[ ]. int tones[] = 1915, 1700, 1519, 1432, 1275, 1136, 1014, 956 ; Κάθε τιμή του πίνακα είναι η αντίστοιχη νότα στον πίνακα names[ ].
Σύνθεση μιας δικιάς σας μελωδίας: Το πρόγραμμα είναι ρυθμισμένο να παίζει το παιδικό τραγούδι ‘Twinkle Twinkle Little Star’, αλλά η αλλαγή του είναι απλή υπόθεση. Αλλάξτε το παρακάτω τμήμα του κώδικα:
int length = 15; // the number of notes
char notes[] = "ccggaagffeeddc "; // a space represents a rest
int beats[] = { 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 2, 4 };με αυτό
int length = 13; // the number of notes
char notes[] = "ccdcfeccdcgf "; // a space represents a rest
int beats[] = { 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 4 };Αφού το δοκιμάσετε, προσπαθήστε να συνθέσετε τη δικιά σας μελωδία και παραδώστε τον κώδικα. Αποθηκεύστε τo ως CIRC_06_c1 και φορτώστε το στο Arduino.
Το Arduino μπορεί να χρησιμοποιηθεί και για να διαβάσει δεδομένα από συσκευές εισόδου. Στο παρόν εργαστήριο θα χρησιμοποιήσουμε κουμπιά ως συσκευές εισόδου. Το Arduino ελέγχει την τιμή της τάσης στο pin που έχουμε συνδεδεμένο το κουμπί και με βάση την τιμή αυτή θέτει την τιμή σε HIGH ή LOW. Το κουμπί είναι ρυθμισμένο να ανεβάζει την τιμή LOW όταν το πατήσουμε, όμως αν το κουμπί δεν έχει πατηθεί η τιμή της τάσης μπορεί να είναι κυμαινόμενη και να προκαλεί σφάλματα στη λειτουργία του κυκλώματος. Για το λόγο αυτό χρησιμοποιούνται αντιστάσεις pull up στα κουμπιά, ώστε όταν δεν έχουν πατηθεί, το pin να παίρνει την τιμή HIGH.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 35 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-07 απαιτούνται τα εξής μέρη:
1 κόκκινο LED των 5mm
1 αντίσταση των 330 Ohm (πορτοκαλί-πορτοκαλί-καφέ)
7 καλώδια
1 Καταχωρητής ολίσθησης 74HC595
2 Αντιστάσεις 10k Ohm (Καφέ – Μαύρο – Πορτοκαλί)
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.20. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.19.
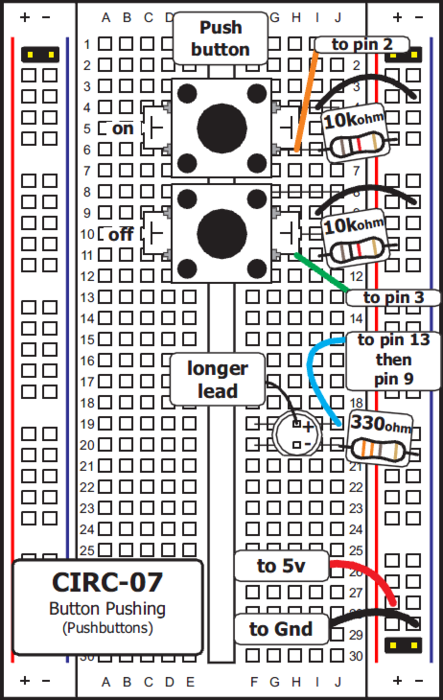
B.19: Προτεινόμενη υλοποίηση του CIRC07
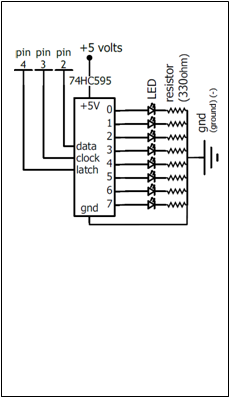
Σχηματικό Διάγραμμα του CIRC07
Συνδέστε το θετικό ακροδέκτη του LED στο pin 13 του Arduino (το pin 9 που αναγράφεται στο Σχήμα B.20, θα χρησιμοποιηθεί σε παρακάτω ερώτημα) και τον αρνητικό ακροδέκτη σε μια αντίσταση 330 Ohm, η άλλη άκρη της οποίας συνδέεται στη γείωση. Τοποθετήστε στο breadboard τα κουμπιά και συνδέστε το ένα pin στη γείωση και το άλλο με μια αντίσταση 10k Ohm, η οποία συνδέεται στα +5 V
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE07.
/*
Button: Turns on and off a light emitting diode(LED) connected to digital
pin 13, when pressing a pushbutton attached to pin 7.
The circuit:
* LED attached from pin 13 to ground
* pushbutton attached to pin 2 from +5V
* 10K resistor attached to pin 2 from ground
* Note: on most Arduinos there is already an LED on the board
attached to pin 13.
created 2005
by DojoDave <http://www.0j0.org>
modified 17 Jun 2009
by Tom Igoe
http://www.arduino.cc/en/Tutorial/Button
*/
// constants won't change. They're used here to
// set pin numbers:
const int buttonPin = 2; // the number of the pushbutton pin
const int ledPin = 13; // the number of the LED pin
// variables will change:
int buttonState = 0; // variable for reading the pushbutton status
void setup() {
// initialize the LED pin as an output:
pinMode(ledPin, OUTPUT);
// initialize the pushbutton pin as an input:
pinMode(buttonPin, INPUT);
}
void loop(){
// read the state of the pushbutton value:
buttonState = digitalRead(buttonPin);
// check if the pushbutton is pressed.
// if it is, the buttonState is HIGH:
if (buttonState == HIGH){
// turn LED on:
digitalWrite(ledPin, HIGH);
}
else {
// turn LED off:
digitalWrite(ledPin, LOW);
}
}Αποθηκεύστε το ως CIRC_07 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα.
Χρήση των κουμπιών: Δημιουργήστε ένα νέο sketch και αντιγράψτε τον παρακάτω κώδικα:
int ledPin = 13; // choose the pin for the LED
int inputPin1 = 3; // button 1
int inputPin2 = 2; // button 2
void setup() {
pinMode(ledPin, OUTPUT); // declare LED as output
pinMode(inputPin1, INPUT); // make button 1 an input
pinMode(inputPin2, INPUT); // make button 2 an input
}
void loop(){
if (digitalRead(inputPin1) == LOW) {
digitalWrite(ledPin, LOW); // turn LED OFF
}
if (digitalRead(inputPin2) == LOW) {
digitalWrite(ledPin, HIGH); // turn LED ON
}
}Στη συνέχεια, αποθηκεύστε το ως CIRC_07_c1 και φορτώστε το πρόγραμμα στο Arduino. Επιβεβαιώστε την αλλαγή στη λειτουργία του κυκλώματος.
LED fading: Μπορείτε επίσης να χρησιμοποιήσετε τα κουμπιά για να ελέγξετε αναλογικό σήμα. Στο σημείο αυτό θα χρειαστεί να αλλάξετε το καλώδιο στο θετικό pin του LED, από το pin 13 του Arduino, στο pin 9. Επίσης κάντε την αντίστοιχη αλλαγή και στον κώδικα (του CIRC_07_c1).
const int ledPin = 13;
const int ledPin = 9;
Τέλος αλλάξτε τη loop() με τον παρακάτω κώδικα:
int value = 0;
void loop(){
if (digitalRead(inputPin1) == LOW) { value--; }
else if (digitalRead(inputPin2) == LOW) { value++; }
value = constrain(value, 0, 255);
analogWrite(ledPin, value);
delay(10);
}Αποθηκεύστε το ως CIRC_07_c2 και φορτώστε το πρόγραμμα στο Arduino. Επιβεβαιώστε την αλλαγή στη λειτουργία του κυκλώματος.
Ρύθμιση της ταχύτητας του fading: Αλλάζετε την τιμή στο παρακάτω τμήμα του κώδικα CIRC_07_c2: delay(10);
Πέρα από τα ψηφιακά pins, το Arduino έχει επίσης 6 pins τα οποία μπορούν να χρησιμοποιηθούν για αναλογικές εισόδους. Αυτές οι είσοδοι δέχονται μια τιμή τάσης (μεταξύ 0 και 5 volts DC) και τη μετατρέπουν σε έναν αριθμό από 0 ως 1024 (ανάλυση 10 bit). Μια χρήσιμη συσκευή που εκμεταλλεύεται τις εισόδους αυτές είναι το ποτενσιόμετρο (μεταβλητή αντίσταση). Περιστρέφοντας τον διακόπτη του μπορούμε να μεταβάλλουμε την τιμή της τάσης στο pin εισόδου και να χρησιμοποιήσουμε τις παραγόμενες τιμές σαν μεταβλητές στο πρόγραμμά μας.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 25 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-08 απαιτούνται τα εξής μέρη:
1 κίτρινο LED των 5mm
1 αντίσταση των 330 Ohm (πορτοκαλί-πορτοκαλί-καφέ)
4 καλώδια
1 Ποτενσιόμετρο 10kOhm
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.22. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.21.
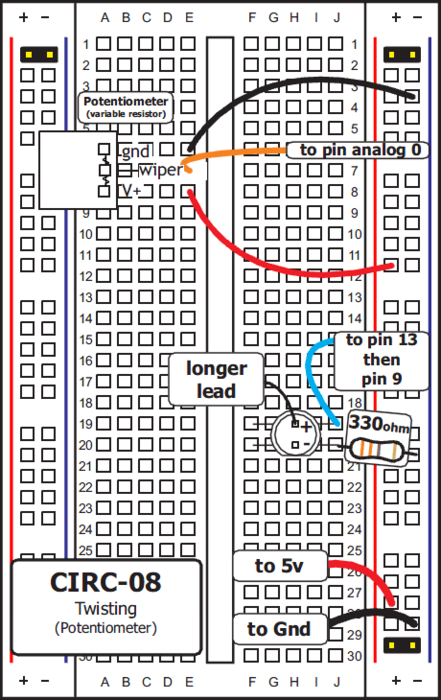
B.21: Προτεινόμενη υλοποίηση του CIRC08
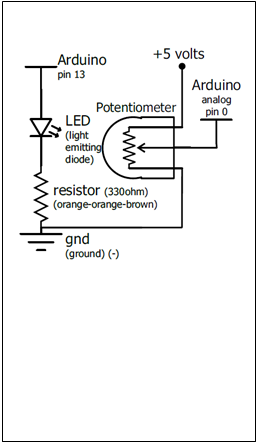
Σχηματικό Διάγραμμα του CIRC08
Συνδέστε το θετικό ακροδέκτη του LED στο pin 13 του Arduino (το pin 9 που αναγράφεται στο Σχήμα B.21, θα χρησιμοποιηθεί σε παρακάτω ερώτημα) και τον αρνητικό ακροδέκτη σε μια αντίσταση 330 Ohm, η άλλη άκρη της οποίας συνδέεται στη γείωση. Τοποθετήστε στο breadboard το ποτενσιόμετρο και συνδέστε το ένα pin στη γείωση, το μεσαίο στο αναλογικό pin 0 του Arduino και το τρίτο στα +5 V.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE08.
/*
Analog Input
Demonstrates analog input by reading an analog sensor on analog pin 0 and
turning on and off a light emitting diode(LED) connected to digital pin 13.
The amount of time the LED will be on and off depends on
the value obtained by analogRead().
The circuit:
*Potentiometer attached to analog input 0
*center pin of the potentiometer to the analog pin
*one side pin (either one) to ground
*the other side pin to +5V
*LED anode (long leg) attached to digital output 13
*LED cathode (short leg) attached to ground
*Note: because most Arduinos have a built-in LED attached
to pin 13 on the board, the LED is optional.
Created by David Cuartielles
Modified 16 Jun 2009
By Tom Igoe
http://arduino.cc/en/Tutorial/AnalogInput
*/
int sensorPin = 0; // select the input pin for the potentiometer
int ledPin = 13; // select the pin for the LED
int sensorValue = 0; // variable to store the value coming from the sensor
void setup(){
// declare the ledPin as an OUTPUT:
pinMode(ledPin, OUTPUT);
}
void loop(){
// read the value from the sensor:
sensorValue = analogRead(sensorPin);
// turn the ledPin on
digitalWrite(ledPin, HIGH);
// stop the program for <sensorValue> milliseconds:
delay(sensorValue);
// turn the ledPin off:
digitalWrite(ledPin, LOW);
// stop the program for for <sensorValue> milliseconds:
delay(sensorValue);
}Αποθηκεύστε το ως CIRC_08 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα. Σε περίπτωση που το κύκλωμα δε λειτουργεί, ελέγξτε αν έχετε συνδέσει το ποτενσιόμετρο με το αναλογικό pin 0 (A0 στο Arduino).
Ενεργοποίηση με τη χρήση τιμής - κατωφλίου: Αντικαταστήστε την loop() του CIRC_08 με την παρακάτω:
void loop() {
int threshold = 512;
if(analogRead(sensorPin) > threshold){ digitalWrite(ledPin, HIGH);}
else{ digitalWrite(ledPin, LOW);}
} Στη συνέχεια, αποθηκεύστε το ως CIRC_08_c1 και φορτώστε το πρόγραμμα στο Arduino. Όταν η τιμή της αντίστασης ξεπεράσει τα 512 Ohm που έχουμε θέσει ως κατώφλι, τότε το LED ανάβει.
Έλεγχος φωτεινότητας: Μπορείτε επίσης να χρησιμοποιήσετε το ποτενσιόμετρο για να ελέγξετε τη φωτεινότητα του LED. Στο σημείο αυτό θα χρειαστεί να αλλάξετε το καλώδιο στο θετικό pin του LED, από το pin 13 του Arduino, στο pin 9. Επίσης κάντε την αντίστοιχη αλλαγή και στον κώδικα (του CIRC_08_c1).
const int ledPin = 13;
const int ledPin = 9;
Τέλος αλλάξτε ολόκληρη τη loop() με τον παρακάτω κώδικα:
void loop() {
int value = analogRead(sensorPin) / 4;
analogWrite(ledPin, value);
}Αποθηκεύστε το ως CIRC_08_c2 και φορτώστε το πρόγραμμα στο Arduino. Επιβεβαιώστε την αλλαγή στη λειτουργία του κυκλώματος.
Έλεγχος Servo: Αντικαταστήστε το LED του παραπάνω κυκλώματος με ένα Servo. Συνδέστε το όπως στο κύκλωμα CIRC_04 (στο pin 9) και ανοίξτε το παράδειγμα που βρίσκεται στο: Αρχείο>Παραδείγματα>Servo>Knob Αλλάξτε τη γραμμή: int sensorpin = 0; σε: int sensorpin = 2; Αποθηκεύστε το ως CIRC_08_c3 και φορτώστε το πρόγραμμα στο Arduino. Επιβεβαιώστε την αλλαγή στη λειτουργία του κυκλώματος.
Χρησιμοποιώντας την ίδια βασική αρχή λειτουργίας που περιγράφηκε στην εργαστηριακή άσκηση 8 μπορούμε να χρησιμοποιήσουμε έναν φωτοαντιστάτη σαν συσκευή εισόδου. Επειδή το Arduino δε μπορεί να μετρήσει την τιμή της αντίστασης, αλλά μόνο αυτή της τάσης, χρησιμοποιείται διαιρέτης τάσης. Ο φωτοαντιστάτης επιστρέφει υψηλή τιμή όταν βρίσκεται σε συνθήκες χαμηλού φωτισμού και χαμηλή τιμή όταν βρίσκεται σε καλά φωτισμένο χώρο.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 30 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-09 απαιτούνται τα εξής μέρη:
1 κίτρινο LED των 5mm
1 αντίσταση των 330 Ohm (πορτοκαλί-πορτοκαλί-καφέ)
1 αντίσταση 10 kOhm (Καφέ – Μαύρο – Πορτοκαλί)
6 καλώδια
1 Φωτοαντιστάτης
1 Servo
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.24. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.23.
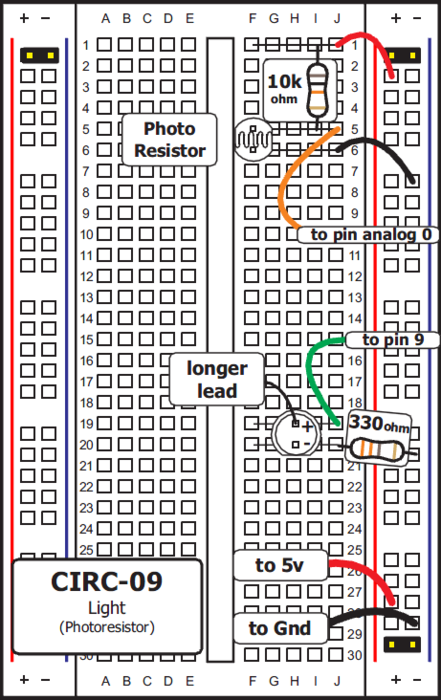
B.23: Προτεινόμενη υλοποίηση του CIRC09
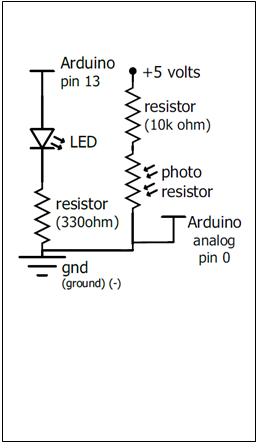
Σχηματικό Διάγραμμα του CIRC09
Συνδέστε το θετικό ακροδέκτη του LED στο pin 9 του Arduino και τον αρνητικό ακροδέκτη σε μια αντίσταση 330 Ohm, η άλλη άκρη της οποίας συνδέεται στη γείωση. Τοποθετήστε στο breadboard το φωτοαντιστάτη και συνδέστε το ένα pin στη γείωση και το άλλο σε μια αντίσταση 10k Ohm που καταλήγει στα +5V καθώς και στο αναλογικό pin 0 ταυτόχρονα.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE09.
/*
Analog Input
Demonstrates analog input by reading an analog sensor on analog pin 0 and
turning on and off a light emitting diode(LED) connected to digital pin 13.
The amount of time the LED will be on and off depends on
the value obtained by analogRead().
The circuit:
*Potentiometer attached to analog input 0
*center pin of the potentiometer to the analog pin
*one side pin (either one) to ground
*the other side pin to +5V
*LED anode (long leg) attached to digital output 13
*LED cathode (short leg) attached to ground
*Note: because most Arduinos have a built-in LED attached
to pin 13 on the board, the LED is optional.
Created by David Cuartielles
Modified 16 Jun 2009
By Tom Igoe
http://arduino.cc/en/Tutorial/AnalogInput
*/
int sensorPin = 0; // select the input pin for the potentiometer
int ledPin = 13; // select the pin for the LED
int sensorValue = 0; // variable to store the value coming from the sensor
void setup() {
// declare the ledPin as an OUTPUT:
pinMode(ledPin, OUTPUT);
}
void loop(){
// read the value from the sensor:
sensorValue = analogRead(sensorPin);
// turn the ledPin on
digitalWrite(ledPin, HIGH);
// stop the program for <sensorValue> milliseconds:
delay(sensorValue);
// turn the ledPin off:
digitalWrite(ledPin, LOW);
// stop the program for for <sensorValue> milliseconds:
delay(sensorValue);
}Αφού επιβεβαιώστε τη λειτουργία, αντικαταστήσετε το loop με: int lightPin=sensorPin;
void loop()
{
int lightLevel = analogRead(lightPin); //Read the lightlevel
lightLevel = map(lightLevel, 0, 900, 0, 255); //adjust the value 0 to 900 to
//span 0 to 255
lightLevel = constrain(lightLevel, 0, 255);//make sure the
//value is betwween
//0 and 255
analogWrite(ledPin, lightLevel); //write the value
}Αποθηκεύστε το ως CIRC_09 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα.
Αν το LED δεν ανταποκρίνεται στις διακυμάνσεις φωτός και έχετε ελέγξει το κύκλωμά σας για πιθανά λάθη (πολικότητα LED, σωστά pins στο Arduino), είναι πιθανό να φταίνε οι συνθήκες φωτισμού του εργαστηρίου. Δοκιμάστε μια πιο δυνατή πηγή φωτός κοντά στη φωτοαντίσταση (πχ φακός) και δείτε αν αυτό έχει αποτέλεσμα.
Αντιστροφή της λειτουργίας: Για να κάνετε το κύκλωμα να έχει την αντίστροφη απόκριση στις μεταβολές του φωτισμού αλλάξτε το παρακάτω τμήμα του κώδικα:
analogWrite(ledPin, lightLevel); με αυτό: analogWrite(ledPin, lightLevel); Στη συνέχεια, αποθηκεύστε το ως CIRC_09_c1 και φορτώστε το πρόγραμμα στο Arduino.
Ενεργοποίηση με χρήση τιμής - κατωφλίου: Αντικαταστήστε την loop() του CIRC_09 με την παρακάτω:
void loop(){
int threshold = 300;
if(analogRead(lightPin) > threshold){
digitalWrite(ledPin, HIGH);
}else{
digitalWrite(ledPin, LOW);
}
}Τέλος αλλάξτε ολόκληρη τη loop() με τον παρακάτω κώδικα:
void loop() {
int value = analogRead(sensorPin) / 4;
analogWrite(ledPin, value);
}Στη συνέχεια, αποθηκεύστε το ως CIRC_09_c2 και φορτώστε το πρόγραμμα στο Arduino.
Έλεγχος ενός Servo: Αντικαταστήστε το LED με ένα Servo το οποίο θα συνδέσετε όπως στο κύκλωμα CIRC_04 (στο pin 9). Επιβεβαιώστε ότι με τις διακυμάνσεις του φωτός στο φωτοαντιστάτη μπορείτε να ελέγξετε το σέρβο. Να τοποθετήσετε κατάλληλους ελέγχους, ώστε να στέλνονται τιμές από 0 (για σκοτάδι) έως 180 (μέγιστη φωτεινότητα) στο σέρβο. Στη συνέχεια ανοίξτε το παράδειγμα που βρίσκεται στο: Αρχείο>Παραδείγματα>Servo>Knob και φορτώστε το στο Arduino χωρίς αλλαγές. Επιβεβαιώστε την ορθή λειτουργία του κυκλώματος.
Στο παρόν εργαστήριο θα χρησιμοποιηθεί ένας αισθητήρας θερμοκρασίας ως συσκευή εισόδου. Έχει τρία pins, γείωση, σήμα και +5V και δίνει έξοδο 10 mV ανά μονάδα κελσίου στο pin σήματος. Η μετατροπή αυτής της εξόδου σε μονάδες μέτρησης θερμοκρασίας γίνεται με τη χρήση μαθηματικών συναρτήσεων. Στη συνέχεια για να εμφανίσουμε τις τιμές θα χρησιμοποιηθεί η Σειριακή Οθόνη του προγραμματιστικού περιβάλλοντος του Arduino.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 15 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-10 απαιτούνται τα εξής μέρη:
1 αισθητήρας θερμοκρασίας
5 καλώδια
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.26. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.25.
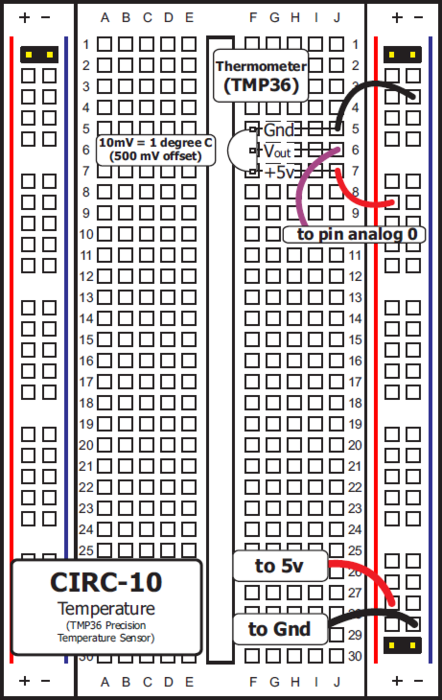
B.25: Προτεινόμενη υλοποίηση του CIRC10
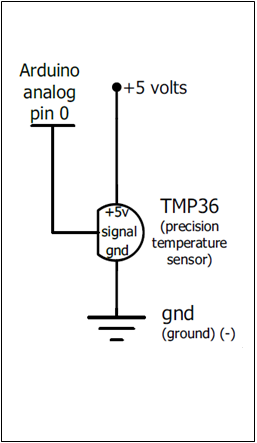
Σχηματικό Διάγραμμα του CIRC10
Τοποθετήστε τον αισθητήρα θερμοκρασίας στο breadboard όπως υποδεικνύεται στο Σχήμα B.25 και στη συνέχεια συνδέστε το ένα του άκρο στα +5V, το μεσαίο pin στο Α0 του Arduino και τέλος το άλλο του άκρο στη γείωση.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE10.
/*---------------------------------------------------------
| Arduino Experimentation Kit Example Code |
*| CIRC-10 .: Temperature :. (TMP36 Temperature Sensor) |
* ---------------------------------------------------------
*
* A simple program to output the current temperature to the IDE's debug window
*
* For more details on this circuit: http://tinyurl.com/c89tvd
*/
//TMP36 Pin Variables
//the analog pin the TMP36's Vout (sense) pin is connected to
int temperaturePin = 0;
//the resolution is 10 mV / degree centigrade
//(500 mV offset) to make negative temperatures an option
/*
* setup() - this function runs once when you turn your Arduino on
* We initialize the serial connection with the computer
*/
void setup()
{
Serial.begin(9600); //Start the serial connection with the computer
//to view the result open the serial monitor
//last button beneath the file bar (looks like a box with an antenae)
}
void loop() // run over and over again
{
//getting the voltage reading from the temperature sensor
float temperature = getVoltage(temperaturePin);
//converting from 10 mv per degree wit 500 mV offset
temperature = (temperature - .5) * 100;
//to degrees ((volatge - 500mV) times 100)
Serial.println(temperature); //printing the result
delay(1000); //waiting a second
}
/*
* getVoltage() - returns the voltage on the analog input defined by
* pin
*/
float getVoltage(int pin){
//converting from a 0 to 1023 digital range
return (analogRead(pin) * .004882814);
// to 0 to 5 volts (each 1 reading equals ~ 5 millivolts
}Αποθηκεύστε το ως CIRC_10 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα. Για να δείτε τις μετρήσεις του αισθητήρα πρέπει να μεταβείτε στο προγραμματιστικό περιβάλλον του Arduino στο μενού Εργαλεία>Σειριακή οθόνη (Ctrl+Shift+M). Θα πρέπει να σας εμφανίζονται οι μετρήσεις με χρόνο ανανέωσης 1 sec. Αν εμφανίζονται “ασυναρτησίες”, πρέπει να αλλάξετε την ταχύτητα σε 9600 baud.
Μορφοποίηση - μετατροπή των δεδομένων εξόδου: Για να μορφοποιήσετε την έξοδο τροποποιήστε το παρακάτω σημείο του κώδικα: Serial.println(temperature); σε: Serial.print(temperature);Serial.println(Deegrees centigrade); ή οποιαδήποτε άλλη πληροφορία θα θέλατε να εκτυπώνεται στην έξοδο. Η μετατροπή των δεδομένων αντίστοιχα, γίνεται με μαθηματικό τρόπο.
Για να εμφανίσουμε τις μετρήσεις σε βαθμούς Fahrenheit αλλάξουμε την παρακάτω γραμμή στον κώδικά μας: temperature = (temperature - .5) * 100; με: temperature = (((temperature - .5) * 100)*1.8) + 32; Με παρόμοιο τρόπο μπορούμε να εμφανίσουμε τις μετρήσεις σε volts, αν διαγράψουμε τη γραμμή temperature = (temperature - .5) * 100; Αποθηκεύστε ως CIRC_10_c1, CIRC_10_c2, CIRC_10_c3, για καθεμιά από τις περιπτώσεις και φορτώστε τα στο Arduino για να διαπιστώσετε τις αλλαγές στη λειτουργία του προγράμματος.
Αλλαγή στο ρυθμό μετάδοσης συμβόλων (baud rate): Αν ποτέ χρειαστεί να έχετε σαν έξοδο μεγάλο όγκο δεδομένων θα πρέπει να αυξήσετε το baud rate. Στο πρόγραμμά μας είναι 9600, αλλά είναι επιτεύξιμες και πολύ μεγαλύτερες ταχύτητες. Αλλάξτε την παρακάτω γραμμή: Serial.begin(9600); σε: Serial.begin(115200); και μεταβείτε στη σειριακή οθόνη (Ctrl+Shift+M) όπου θα αλλάξετε επίσης από 9600 σε 115200. Πλέον μπορείτε να μεταδίδετε δεδομένα 12 φορές γρηγορότερα.
Στο παρόν εργαστήριο θα ελέγξουμε ένα ρελέ. Το ρελέ είναι ένας μαγνητικά ελεγχόμενος μηχανικός διακόπτης. Περιέχει έναν ηλεκτρομαγνήτη, ο οποίος όταν ενεργοποιείται μετακινεί έναν ενσωματωμένο διακόπτη. Χρησιμοποιείται ξανά το τρανζίστορ P2N2222AG και η δίοδος 1N4001 για τους λόγους που αναλύθηκαν στο εργαστήριο 3.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 30 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-02 απαιτούνται τα εξής μέρη:
1 κίτρινο LED των 5mm
13 Καλώδια
2 Αντιστάσεις 330 Ohm (Πορτοκαλί – Πορτοκαλί – Καφέ)
1 Αντίσταση 10k Ohm (Καφέ – Μαύρο – Πορτοκαλί)
1 Ρελέ (SPDT)
1 Μοτέρ
1 κόκκινο LED
1 Τρανζίστορ P2N2222AG (TO92)
1 Δίοδος (1N4001)
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.28. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.27.
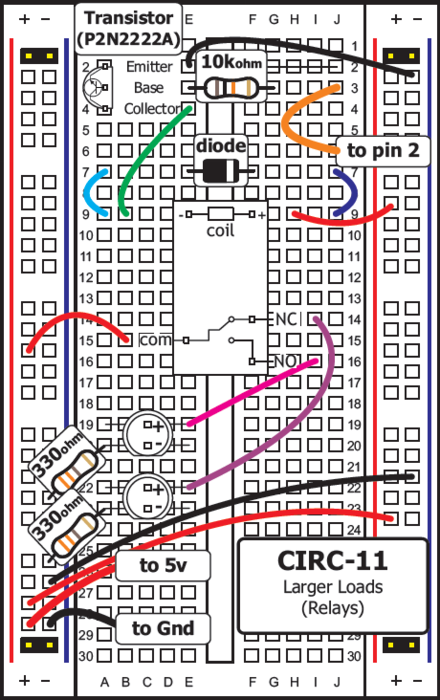
B.27: Προτεινόμενη υλοποίηση του CIRC11
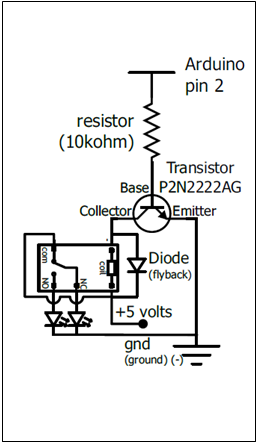
Σχηματικό Διάγραμμα του CIRC11
Τοποθετείστε το τρανζίστορ πάνω αριστερά, κατά τη φορά του Σχήματος B.27, τη δίοδο και το ρελέ, επίσης κατά τη φορά του Σχήματος B.27. Τοποθετήστε το κίτρινο LED με μία αντίσταση 330 Ohm στο αρνητικό του άκρο που να καταλήγει στη γείωση και όμοια από κάτω του το κόκκινο LED (δεν θα υπάρξει διαφορά στη λειτουργία αν τοποθετηθούν τα LED με την αντίθετη σειρά, απλά χρησιμοποιούμε αυτή τη διάταξη για να υπάρχει ένα σημείο αναφοράς στις μετέπειτα αλλαγές). Συνδέστε τον εκπομπό του τρανζίστορ στη γείωση, τη βάση με μία αντίσταση 10 kOhm της οποίας το άλλο άκρο πηγαίνει στο pin 2 του Arduino και το συλλέκτη με το αρνητικό άκρο του πηνίου του ρελέ (Σχήμα B.27). Στη συνέχεια συνδέστε το αρνητικό άκρο του πηνίου με τη δίοδο, και στη συνέχεια το άλλο άκρο της διόδου με τη θετική πλευρά του πηνίου. Συνδέστε την επαφή NC του ρελέ με το θετικό άκρο του κόκκινου LED, την επαφή NO με το θετικό άκρο του κίτρινου LED και την επαφή com του ρελέ με τα +5V. Τέλος συνδέστε μεταξύ τους τις γειώσεις και τα +5V του breadboard.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE11.
/*
Blink
Turns on an LED on for one second, then off for one second, repeatedly.
The circuit:
* LED connected from digital pin 13 to ground.
* Note: On most Arduino boards, there is already an LED on the board
connected to pin 13, so you don't need any extra components for this example.
Created 1 June 2005
By David Cuartielles
http://arduino.cc/en/Tutorial/Blink
based on an orginal by H. Barragan for the Wiring i/o board
*/
int ledPin = 2;
// Relay connected to digital pin 2 <-----Change this to pin 2
// The setup() method runs once, when the sketch starts
void setup(){
// initialize the digital pin as an output:
pinMode(ledPin, OUTPUT);
}
// the loop() method runs over and over again,
// as long as the Arduino has power
void loop()
{
digitalWrite(ledPin, HIGH); // set the LED on
delay(1000); // wait for a second
digitalWrite(ledPin, LOW); // set the LED off
delay(1000); // wait for a second
}Αποθηκεύστε το ως CIRC_11 και στη συνέχεια φορτώστε το πρόγραμμα στην πλακέτα. Σε περίπτωση που δε δουλεύει όπως θα έπρεπε ελέγξτε ξανά αν έχουν τοποθετηθεί σωστά όλα τα μέρη του κυκλώματος. Επίσης ενδέχεται τα ρελέ να μην κάνουν καλή επαφή, καθώς δεν έχουν σχεδιαστεί για χρήση με το breadboard και γι αυτό το λόγο μπορεί να χρειάζονται λίγη επιπλέον πίεση προς τα κάτω (και ίσως να πετάγονται ξανά προς τα έξω περιστασιακά).
Παρατήρησης του επαγωγικού ρεύματος: Η μεταβολή της μαγνητικής ροής στο πηνίο γεννά ένα ηλεκτρικό ρεύμα, το λεγόμενο “επαγωγικό”, που έχει αντίθετη φορά από εκείνο που παρέχεται στο πηνίο. Για να το παρατηρήσετε, αφού αποσυνδέσετε το breadboard από την πηγή ή το Arduino από την τροφοδοσία του (USB), αφαιρέστε τη δίοδο και στη θέση της τοποθετήστε ένα LED, το θετικό άκρο του οποίου να συνδέεται με το αρνητικό άκρο του πηνίου (αν το τοποθετήσετε ανάποδα το κύκλωμα δε θα δουλεύει σωστά) Αφού τοποθετήσετε το LED συνδέστε ξανά την πηγή και παρατηρήστε το να ανάβει στιγμιαία, λίγο αφότου σβήσει το κίτρινο LED που προϋπήρχε στο κύκλωμα.
Έλεγχος μοτέρ: Στο αρχικό κύκλωμα (πριν την αλλαγή της διόδου με το LED) και αφού αποσυνδέσετε το breadboard από την πηγή ή το Arduino από την τροφοδοσία του (USB), αφαιρέστε το κόκκινο LED μαζί με την αντίσταση 330 Ohm που συνδέεται στο αρνητικό του άκρο, και στη θέση του τοποθετήστε ένα μοτέρ, με το κόκκινο καλώδιο να συνδέεται στην NC και το μαύρο στη γείωση. Συνδέστε ξανά την πηγή και επιβεβαιώστε την ορθή λειτουργία του κυκλώματος.
Εκτός από τα LEDs που έχουμε δει ως τώρα, τα οποία είναι μονόχρωμα, υπάρχουν και LEDs τα οποία μπορούν να παράγουν πολλά χρώματα. Ονομάζονται RGB LEDs και είναι τυπικά τρία LEDs (κόκκινο, πράσινο και μπλε) σε ένα. Όταν ενεργοποιούνται ταυτόχρονα και τα τρία LEDs τα φώτα τους ενώνονται και προκύπτουν διάφορα χρώματα. Τα χρώματα που προκύπτουν εξαρτώνται από τη φωτεινότητα κάθε LED ξεχωριστά. Η φωτεινότητα ελέγχεται με διαμόρφωση πλάτους παλμού (PWM), η λειτουργία της οποίας έχει αναλυθεί στην εργαστηριακή άσκηση 3.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 30 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-02 απαιτούνται τα εξής μέρη:
1 RGB LED των 5mm
3 αντιστάσεις των 330 Ohm (πορτοκαλί-πορτοκαλί-καφέ)
6 καλώδια
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.30. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.29.
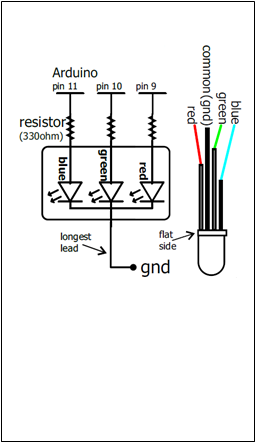
B.29: Προτεινόμενη υλοποίηση του CIRC12
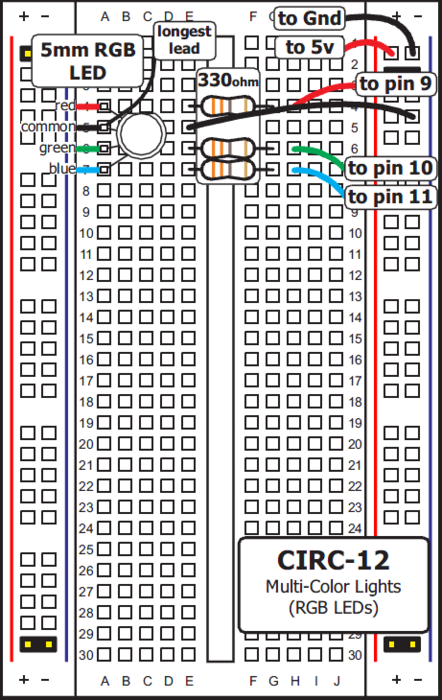
Σχηματικό Διάγραμμα του CIRC12
Τοποθετήστε το RGB LED όπως φαίνεται στο Σχήμα B.29. (Τα pins του LED αναλύονται στο Σχήμα B.30). Στη συνέχεια συνδέστε από μία αντίσταση 330 Ohm σε κάθε pin που αντιστοιχεί σε κάποιο χρώμα, και έπειτα κάθε αντίσταση με το ανάλογο pin του Arduino. Επίσης συνδέστε και το pin της γείωσης.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE12S.
/*
RGB_LED_Color_Fade_Cycle.pde
Cycles through the colors of a RGB LED
Written for SparkFun Arduino Inventor's Kit CIRC-RGB
*/
// LED leads connected to PWM pins
const int RED_LED_PIN = 9;
const int GREEN_LED_PIN = 10;
const int BLUE_LED_PIN = 11;
// Used to store the current intensity level of the individual LEDs
int redIntensity = 0;
int greenIntensity = 0;
int blueIntensity = 0;
// Length of time we spend showing each color
const int DISPLAY_TIME = 100; // In milliseconds
void setup() {
// No setup required.
}
void loop() {
// Cycle color from red through to green
// (In this loop we move from 100% red, 0% green to 0% red, 100% green)
for (greenIntensity = 0; greenIntensity <= 255; greenIntensity+=5){
redIntensity = 255-greenIntensity;
analogWrite(GREEN_LED_PIN, greenIntensity);
analogWrite(RED_LED_PIN, redIntensity);
delay(DISPLAY_TIME);
}
// Cycle color from green through to blue
// (In this loop we move from 100% green, 0% blue to 0% green, 100% blue)
for (blueIntensity = 0; blueIntensity <= 255; blueIntensity+=5){
greenIntensity = 255-blueIntensity;
analogWrite(BLUE_LED_PIN, blueIntensity);
analogWrite(GREEN_LED_PIN, greenIntensity);
delay(DISPLAY_TIME);
}
// Cycle cycle from blue through to red
// (In this loop we move from 100% blue, 0% red to 0% blue, 100% red)
for (redIntensity = 0; redIntensity <= 255; redIntensity+=5) {
blueIntensity = 255-redIntensity;
analogWrite(RED_LED_PIN, redIntensity);
analogWrite(BLUE_LED_PIN, blueIntensity);
delay(DISPLAY_TIME);
}
}Αποθηκεύστε το ως CIRC_12 και στη συνέχεια φορτώστε το πρόγραμμα στο Arduino. Σε περίπτωση που το LED δεν ανάβει, ή δείχνει λάθος χρώματα, ελέγξτε αν το κύκλωμά σας είναι σωστό.
Μείωση της υπερβολικής παρουσίας του κόκκινου χρώματος: Ενδέχεται τo κόκκινο χρώμα του LED να είναι εντονότερο από τα άλλα και αυτό να έχει ως συνέπεια τα χρώματα που προκύπτουν να μην είναι τόσο ισορροπημένα. Αν συμβαίνει κάτι τέτοιο, μπορείτε να το διορθώσετε είτε βάζοντας μια αντίσταση περισσότερων Ohm στο pin του κόκκινου χρώματος, είτε αλλάζοντας την παρακάτω γραμμή στο πρόγραμμά σας, από: analogWrite(RED_LED_PIN, redIntensity); σε: analogWrite(RED_LED_PIN, redIntensity/3); Αποθηκεύστε (Ctrl+s) και φορτώστε ξανά το πρόγραμμα στο Arduino, για να επιβεβαιώσετε ότι το πρόβλημα λύθηκε.
Χρήση δεκαεξαδικών τριάδων για την απεικόνιση των χρωμάτων: Εάν έχετε δουλέψει με HTML ή CSS, πιθανότατα θα σας βολεύει περισσότερο να χρησιμοποιείτε δεκαεξαδικούς για να καθορίσετε το χρώμα που επιθυμείτε. Σε κάθε περίπτωση πάντως μπορείτε να επισκεφθείτε το σχετικό λήμμα στη Wikipedia (http://en.wikipedia.org/wiki/Web_colors#Hex_triplet) για περισσότερες πληροφορίες. Για να μπορείτε να χρησιμοποιήσετε κι εδώ το ίδιο σύστημα, δημιουργήστε ένα καινούριο Arduino Sketch και αντιγράψτε τον παρακάτω κώδικα (Εναλλακτικά κατεβάστε τον από http://ardx.org/RGBMB)
/*
Set_RGB_Color.pde
Shows how to use HTML-style hex triplet color codes to specify RGB LED colors
Written for SparkFun Arduino Inventor's Kit CIRC-RGB
*/
// LED leads connected to PWM pins
const int RED_LED_PIN = 9;
const int GREEN_LED_PIN = 10;
const int BLUE_LED_PIN = 11;
// HTML-style hex triplet color code values from Wikipedia
const unsigned long ORANGE = 0xFF7F00;
const unsigned long TEAL = 0x008080;
const unsigned long AUBERGINE = 0x614051;
// Length of time we spend showing each color
const int DISPLAY_TIME = 2000; // In milliseconds
void setup() {
// No setup required.
}
void loop() {
// Cycle through our awesome colors
setColor(ORANGE);
delay(DISPLAY_TIME);
setColor(TEAL);
delay(DISPLAY_TIME);
setColor(AUBERGINE);
delay(DISPLAY_TIME);
}
void setColor(unsigned long color) {
/*
Sets the color of the RGB LED to the color specified by the
HTML-style hex triplet color value supplied to the function.
The color value supplied should be an unsigned long number of the form:
0xRRGGBB
e.g. 0xFF7F00 is orange
where:
0x specifies the value is a hexadecimal number
RR is a byte specifying the red intensity
GG is a byte specifying the green intensity
BB is a byte specifying the blue intensity
How it works (you don't need to understand this to use the function):
The supplied value of the form 0xRRGGBB is an unsigned long which can
store four bytes. If we view the number in bit form the bits of the
unsigned long look like this:
iiiiiiiirrrrrrrrggggggggbbbbbbbb
where:
i are bits that are ignored (because we only need three bytes for the value)
r are bits specifying the red intensity
g are bits specifying the green intensity
b are bits specifying the blue intensity
We use bit shifting and masking to extract the individual values.
Bit shifting moves the bits in a number along in one direction to produce
a new number. For example ">> n" means shift the bits n positions to the
right.
e.g. iiiiiiiirrrrrrrrggggggggbbbbbbbb >> 8 gives:
00000000iiiiiiiirrrrrrrrgggggggg
The number 0xFF represents the bit mask:
00000000000000000000000011111111
The "&" character means the two values are "and"ed together--for each bit
in the two numbers being "and"ed together the resulting bit is only set in
the result if the same bits are set in both the input numbers.
So, continuing our example:
00000000iiiiiiiirrrrrrrrgggggggg && 0xFF gives:
00000000iiiiiiiirrrrrrrrgggggggg &&
00000000000000000000000011111111 =
000000000000000000000000gggggggg
And we now have extracted only the green bits from our hex triplet.
More details on bit math can be found here:
<http://www.arduino.cc/playground/Code/BitMath>
*/
// Extract the intensity values from the hex triplet
byte redIntensity = (color >> 16) & 0xFF;
byte greenIntensity = (color >> 8) & 0xFF;
byte blueIntensity = color & 0xFF;
// Display the requested color
analogWrite(RED_LED_PIN, redIntensity);
analogWrite(GREEN_LED_PIN, greenIntensity);
analogWrite(BLUE_LED_PIN, blueIntensity);
}Εκτός από τα παραπάνω, χρησιμοποιήστε τη συνάρτηση δημιουργίας τυχαίων αριθμών για την παραγωγή τυχαίων χρωμάτων. Ορίστε μια νέα μεταβλητή: long randNumber; Αρχικοποιήστε την συνάρτηση randomSeed(analogRead(0)); και λάβετε μια τυχαία τιμή: randNumber = random(1300000); την οποία θα την εμφανίσετε με setColor();
Στη συνέχεια αποθηκεύστε το ως CIRC_12_c1 και φορτώστε το στο Arduino για να επιβεβαιώσετε την ορθή λειτουργία του. Εφόσον λειτουργεί σωστά μπορείτε να πειραματιστείτε δίνοντας τις δικές σας τιμές για τα χρώματα με έναν, ίσως, πιο γνώριμο για εσάς τρόπο.
Στην παρούσα εργαστηριακή άσκηση θα χρησιμοποιηθεί ένας αισθητήρας κάμψης σαν συσκευή εισόδου. Ο αισθητήρας κάμψης χρησιμοποιεί άνθρακα πάνω σε μία λωρίδα πλαστικό, για να λειτουργεί σαν ποτενσιόμετρο, μόνο που τώρα η αντίσταση δεν μεταβάλλεται γυρίζοντας κάποιον διακόπτη αλλά λυγίζοντας τον αισθητήρα. Χρησιμοποιείται ξανά διαιρέτης τάσης (όπως στα εργαστήρια 8 και 9) προκειμένου να ανιχνευθεί η αλλαγή στην αντίσταση από το Arduino. Ο αισθητήρας λυγίζει προς μια κατεύθυνση ( η ‘ριγέ’ πλευρά να βρίσκεται στο εξωτερικό της καμπύλης ) και όσο περισσότερο λυγίζει, τόσο μεγαλώνει η αντίσταση. Η αντίσταση κυμαίνεται από 10 KOhm μέχρι 35 KOhm. Στο κύκλωμά μας θα χρησιμοποιήσουμε τον αισθητήρα κάμψης για να ελέγξουμε την κίνηση ενός Servo.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 25 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-02 απαιτούνται τα εξής μέρη:
1 3pin Header
1 Mini Servo
1 Αντίσταση 10 kOhm (Καφέ – Μαύρο – Καφέ)
1 Αισθητήρας κάμψης
8 καλώδια
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.32. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.31.
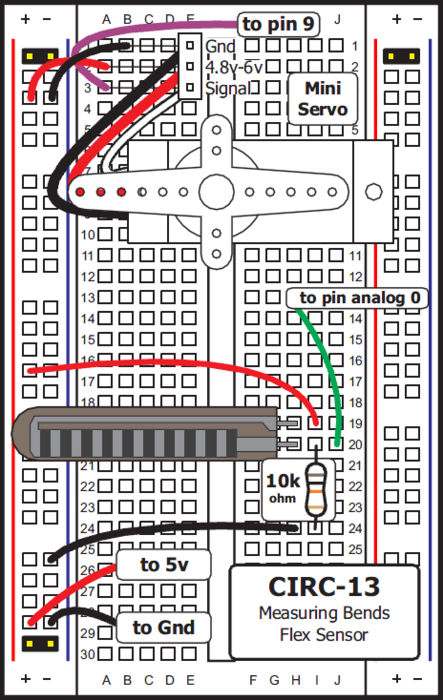
B.31: Προτεινόμενη υλοποίηση του CIRC13
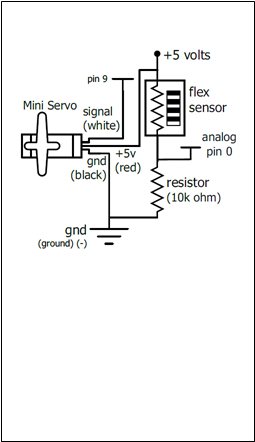
Σχηματικό Διάγραμμα του CIRC13
Τοποθετήστε το 3pin Header όπως φαίνεται στο Σχήμα B.31. Συνδέστε κάθε καλώδιο του Servo με το 3pin Header και στη συνέχεια με τρία καλώδια συνδέστε το άσπρο καλώδιο του Servo με το pin 9 του Arduino, το κόκκινο καλώδιο στην τάση +5V, ενώ το μαύρο στη γείωση. Τοποθετήστε στη συνέχεια τον αισθητήρα κάμψης στο breadboard και συνδέστε το ένα άκρο του στα +5V και το άλλο σε μία αντίσταση 10 kOhm το άλλο άκρο της οποίας πηγαίνει στη γείωση, καθώς και με το αναλογικό pin Α0 του Arduino. Τέλος συνδέστε τα +5V και Gnd στο Arduino. ΠΡΟΣΟΧΗ1: Ο αισθητήρας κάμψης πρέπει να λυγίζει από τη μέση προς την άκρη, όχι στο σημείο που είναι οι συνδετήρες. ΠΡΟΣΟΧΗ2: Ο αισθητήρας κάμψης πρέπει να λυγίζει ως 90 μοίρες όχι περισσότερο. Επίσης, να αποφεύγονται οι παραπάνω από μια κάμψεις.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE13S.
//Based on File>Examples>Servo>Knob
//Controlling a servo position using a potentiometer (variable resistor)
//by Michal Rinott <http://people.interaction-ivrea.it/m.rinott>
#include <Servo.h>
Servo myservo; //create servo object to control a servo
int potpin = 0; // analog pin used to connect the potentiometer
int val; // variable to read the value from the analog pin
void setup()
{
Serial.begin(9600);
myservo.attach(9);//attaches the servo on pin 9 to the servo object
}
void loop()
{
val=analogRead(potpin);
//reads the value of the potentiometer (value between 0 and 1023)
Serial.println(val);
val=map(val,50,300,0,179);
//scale it to use it with the servo (value between 0 and 180)
myservo.write(val);
//sets the servo position according to the scaled value
delay(15);//waits for the servo to get there
}Αποθηκεύστε το ως CIRC_13 και στη συνέχεια φορτώστε το πρόγραμμα στο Arduino. Σε περίπτωση που το Servo δεν κινείται ελέγξτε μήπως έχετε συνδέσει κάτι λάθος. Αν το Servo δεν κινείται όπως θα περιμένατε ίσως λυγίζετε τον αισθητήρα κάμψης προς τη λάθος πλευρά (ενδέχεται να λειτουργεί μόνο προς μια κατεύθυνση). Δοκιμάστε να τον λυγίσετε με τη “ριγέ” πλευρά να βρίσκεται στο εξωτερικό της καμπύλης. Τέλος, αν το Servo κινείται μόνο μια φορά θα πρέπει να βαθμονομηθεί σωστά (θα εξηγηθεί παρακάτω).
Βαθμονόμηση (Calibration): Ανεξάρτητα απ’ το αν το Servo κινείται σωστά ή όχι, πιθανότατα το εύρος τιμών που παίρνουμε από τον αισθητήρα είναι ανακριβές. Για να προσαρμόσουμε το εύρος στις σωστές του τιμές θα ακολουθήσουμε την εξής διαδικασία:
Ανοίγουμε το μενού Εργαλεία>Σειριακή οθόνη (Ctrl+Shift+M).
Παρατηρούμε την τιμή που μας επιστρέφει ο αισθητήρας άκαμπτος.
Αλλάζουμε την τιμή fromLow στη συνάρτηση map(value, fromLow, fromHigh, toLow, toHigh) από 50 στην τιμή που βρήκαμε στο βήμα 2. Αν η τιμή που βρέθηκε στο βήμα 2 είναι 50 δε χρειάζεται να προβούμε σε καμία αλλαγή.
Επιστρέφουμε στη σειριακή οθόνη.
Λυγίζουμε εντελώς τον αισθητήρα (90 μοίρες) και σημειώνουμε την τιμή που μας επιστρέφεται.
Αλλάζουμε την τιμή της fromHigh στη συνάρτηση map(value, fromLow, fromHigh, toLow, toHigh) από 300 στην τιμή που βρήκαμε στο βήμα 5. Αν η τιμή που βρέθηκε στο βήμα 5 είναι 300 δε χρειάζεται να προβούμε σε καμία αλλαγή. Αποθηκεύστε το πρόγραμμα ως CIRC_13_c1 και φορτώστε το στο Arduino. Επιβεβαιώστε την ορθή λειτουργία του κυκλώματος.
Ενδιαφέρουσες εφαρμογές: Μπορείτε να δείτε μερικές ενδιαφέρουσες εφαρμογές του αισθητήρα κάμψης στις παρακάτω ιστοσελίδες:
One player Rock Paper Scissors Glove (http://grathio.com/2010/03/rock_paper_scissors_training_glove/)
Electronic Plant Brace (http://www.flickr.com/photos/mleak/322577143/in/set-72157601527068224/)
Το ποτενσιόμετρο μεμβράνης λειτουργεί ακριβώς όπως ένα κοινό ποτενσιόμετρο, αλλά είναι επίπεδο, λεπτό ευλύγιστο και δεν έχει περιστρεφόμενο διακόπτη. Η αντίσταση του μεταβάλλεται απλά ασκώντας πίεση σε διαφορετικά σημεία της επιφάνειάς του. Η αντίσταση κυμαίνεται από 100 μέχρι 10K Ohm και η τιμή που επιστρέφεται μπορεί να χρησιμοποιηθεί για να υπολογιστεί η θέση που πιέστηκε στην επιφάνειά του. Στο παρόν κύκλωμα θα χρησιμοποιηθεί για να ελέγξουμε τα χρώματα ενός RGB LED.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 25 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-02 απαιτούνται τα εξής μέρη:
1 RGB LED
3 αντιστάσεις των 330 Ohm (πορτοκαλί-πορτοκαλί-καφέ)
9 καλώδια
1 Ποτενσιόμετρο Μεμβράνης
Κατασκευάστε το κύκλωμα, σύμφωνα με τη σχηματική αναπαράσταση του Σχήματος B.34. Μια προτεινόμενη υλοποίηση εικονίζεται στο Σχήμα B.33.
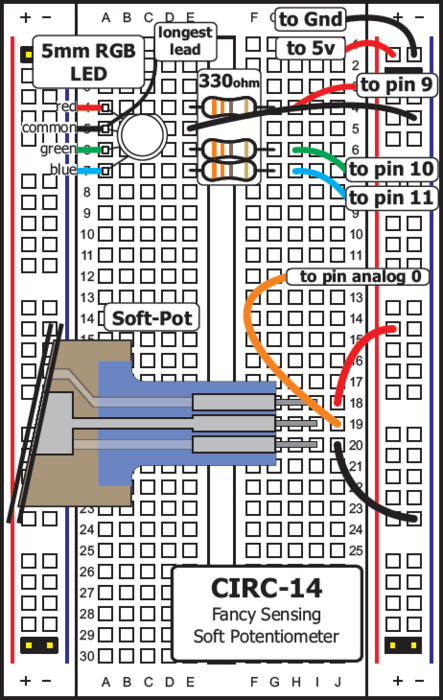
B.33: Προτεινόμενη υλοποίηση του CIRC14
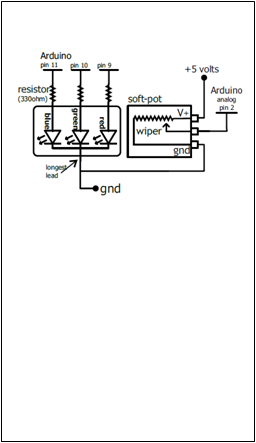
Σχηματικό Διάγραμμα του CIRC14
Τοποθετήστε το RGB LED όπως φαίνεται στο Σχήμα B.33. (Τα pins του LED αναλύονται στο Σχήμα B.34). Στη συνέχεια συνδέστε από μία αντίσταση 330 Ohm σε κάθε pin που αντιστοιχεί σε κάποιο χρώμα, και έπειτα κάθε αντίσταση με το ανάλογο pin του Arduino. Επίσης συνδέστε και το pin της γείωσης. Τέλος τοποθετήστε το ποτενσιόμετρο μεμβράνης στο breadboard και συνδέστε το μεσαίο pin στο A0 του Arduino, και τα άλλα δυο στα +5V και τη γείωση αντίστοιχα. ΠΡΟΣΟΧΗ: το ποτενσιόμετρο μεμβράνης ΔΕΝ πρέπει να λυγίζει. Με το δάχτυλο σας το ακουμπάτε σε διάφορα σημεία ελαφρά.
Αντιγράψτε τον παρακάτω κώδικα στο προγραμματιστικό περιβάλλον του Arduino. Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE14S.
/*---------------------------------------------------------
*| Experimentation Kit for Arduino Example Code|
*| CIRC-14: Fancy Sensing:(Soft Potentiometer) |
*---------------------------------------------------------
*
* Will fade an RGB LED from Red-Green-Blue in relation to the
* soft pot value
*
*/
// LED leads connected to PWM pins
const int RED_LED_PIN=9; //Red LED Pin
const int GREEN_LED_PIN=10; //Green LED Pin
const int BLUE_LED_PIN=11; //Blue LED Pin
void setup(){
//no need for any code here
}
void loop(){
int sensorValue=analogRead(0); //read the Soft Pot
int redValue=constrain(map(sensorValue,0,512,255,0),0,255);
//calculate the red Value (255-0 over the range 0-512)
int greenValue=constrain(map(sensorValue,0,512,0,255),0,255)\
-constrain(map(sensorValue,512,1023,0,255),0,255);
//calculate the green value (0-255 over 0-512 & 255-0 over 512-1023)
int blueValue=constrain(map(sensorValue,512,1023,0,255),0,255);
//calculate the blue value 0-255 over 512-1023
// Display the requested color
analogWrite(RED_LED_PIN, redValue);
analogWrite(GREEN_LED_PIN, greenValue);
analogWrite(BLUE_LED_PIN, blueValue);
}Αποθηκεύστε το ως CIRC_14 και στη συνέχεια φορτώστε το πρόγραμμα στο Arduino. Σε περίπτωση που το LED δεν ανάβει, ή δείχνει λάθος χρώματα, ελέγξτε αν το κύκλωμά σας είναι σωστό. Αν λαμβάνετε περίεργα αποτελέσματα, ίσως πιέζετε το ποτενσιόμετρο σε περισσότερες από μία θέσεις. Αυτό είναι φυσιολογικό και μπορεί να χρησιμοποιηθεί για την επίτευξη ιδιαίτερων αποτελεσμάτων.
Μείωση της υπερβολικής παρουσίας του κόκκινου χρώματος: Ενδέχεται τo κόκκινο χρώμα του LED να είναι εντονότερο από τα άλλα και αυτό να έχει ως συνέπεια τα χρώματα που προκύπτουν να μην είναι τόσο ισορροπημένα. Αν συμβαίνει κάτι τέτοιο, μπορείτε να το διορθώσετε είτε βάζοντας μια αντίσταση περισσότερων Ohm στο pin του κόκκινου χρώματος, είτε αλλάζοντας την παρακάτω γραμμή στο πρόγραμμά σας, από: analogWrite(RED_LED_PIN, redIntensity); σε: analogWrite(RED_LED_PIN, redIntensity/3); Αποθηκεύστε (Ctrl+s) και φορτώστε ξανά το πρόγραμμα στο Arduino, για να επιβεβαιώσετε ότι το πρόβλημα λύθηκε.
Χρήση HSB (Hue, Saturation & Brightness) για την απεικόνιση των χρωμάτων: Ένας εναλλακτικός τρόπος απεικόνισης των χρωμάτων πέρα από το RGB είναι το HSB. Επισκεφθείτε το σχετικό λήμμα στη Wikipedia (http://en.wikipedia.org/wiki/HSV_color_space) για περισσότερες πληροφορίες. Για να μπορείτε να χρησιμοποιήσετε κι εδώ το ίδιο σύστημα, δημιουργήστε ένα καινούριο Arduino Sketch και αντιγράψτε τον παρακάτω κώδικα (Εναλλακτικά κατεβάστε τον από http://ardx.org/CODE14MB)
//LED leads connected to PWM pins
const int RED_LED_PIN=9;
const int GREEN_LED_PIN=10;
const int BLUE_LED_PIN=11;
//http://www.kasperkamperman.com/blog/arduino/arduino-programming-hsb-to-rgb/
void getRGB(int hue, int sat, int val, int colors[3]){
/*convert hue, saturation and brightness ( HSB/HSV ) to RGB
The dim_curve is used only on brightness/value and on saturation
(inverted).
This looks the most natural.
*/
// val=dim_curve[val];
// sat=255-dim_curve[255-sat];
int r;
int g;
int b;
int base;
if (sat==0){//Acromatic color (gray).Hue doesn't mind.
colors[0]=val;
colors[1]=val;
colors[2]=val;
}else{
base=((255-sat)*val)>>8;
switch(hue/60) {
case 0:
r = val;
g = (((val-base)*hue)/60)+base;
b = base;
break;
case 1:
r = (((val-base)*(60-(hue%60)))/60)+base;
g = val;
b = base;
break;
case 2:
r = base;
g = val;
b = (((val-base)*(hue%60))/60)+base;
break;
case 3:
r = base;
g = (((val-base)*(60-(hue%60)))/60)+base;
b = val;
break;
case 4:
r = (((val-base)*(hue%60))/60)+base;
g = base;
b = val;
break;
case 5:
r = val;
g = base;
b = (((val-base)*(60-(hue%60)))/60)+base;
break;
}
colors[0]=r;
colors[1]=g;
colors[2]=b;
}
}
int rgb_colors[3];
/// ----------------
int redIntensity;
int greenIntensity;
int blueIntensity;
void setup() {
}
void loop() {
int sensorValue = analogRead(0);
getRGB(map(sensorValue, 0, 1023, 0, 255), 0xff, 0xff, rgb_colors);
redIntensity = rgb_colors[0];
greenIntensity = rgb_colors[1];
blueIntensity = rgb_colors[2];
// Display the requested color
analogWrite(RED_LED_PIN, 255-redIntensity);
analogWrite(GREEN_LED_PIN, 255-greenIntensity);
analogWrite(BLUE_LED_PIN, 255-blueIntensity);
}Στη συνέχεια αποθηκεύστε το ως CIRC_14_c1 και φορτώστε το στο Arduino για να επιβεβαιώσετε την ορθή λειτουργία του.
Προσαρμοσμένα κουμπιά: Το ποτενσιόμετρο μεμβράνης, μπορεί να χρησιμοποιηθεί για να δημιουργήσετε προσαρμοζόμενα κουμπιά. Για να το πετύχετε αυτό θα πρέπει να ορίσετε ζώνες τιμών στις οποίες θα αντιστοιχεί μία συγκεκριμένη λειτουργία. Χρησιμοποιήστε το παρακάτω ενδεικτικό κομμάτι κώδικα και τη Σειριακή οθόνη (Ctrl+Shift+M) (ανατρέξτε στον κώδικα του εργαστηρίου 10 για να θυμηθείτε πως εκτυπώνεται κάτι ως έξοδος στη σειριακή οθόνη) προκειμένου να προσδιορίσετε τις επιθυμητές τιμές για 2 ή περισσότερα κουμπιά.
if(analogRead(0)>minValue && analogRead(0)<maxValue){
analogWrite(RED_LED_PIN, YourValue);
analogWrite(GREEN_LED_PIN, YourValue);
analogWrite(BLUE_LED_PIN, YourValue); }Τροποποιήστε σχετικά τον κώδικα για δημιουργία 3 ζωνών. Κάθε ζώνη να αντιστοιχηθεί με ένα χρώμα της επιλογής σας. Στη συνέχεια αποθηκεύστε το ως CIRC_14_c2 και φορτώστε το στο Arduino για να επιβεβαιώσετε την ορθή λειτουργία του.
Εκτιμώμενος Χρόνος Υλοποίησης Εργαστηρίου: 120 λεπτά
Για την εκπόνηση του κυκλώματος CIRC-15 απαιτούνται τα εξής μέρη:
14 καλώδια
1 beeper
1 οθόνη NOKIA 5110 LCD
1 ultrasonic module
Η εργασία χωρίζεται σε δύο φάσεις: στην πρώτη, υλοποιείται το κύκλωμα του συστήματος και στη δεύτερη, γράφεται ο κώδικας που θα πραγματοποιεί τις κατάλληλες ενέργειες. Το τελικό αποτέλεσμα καλείται να εκτελεί τις παρακάτω ενέργειες: το σύστημα μέσω του ultrasonic Module να μετράει την απόσταση και όταν αυτή είναι μικρότερη των σαράντα cm (40cm) να ενεργοποιείται ο βομβητής εκπέμποντας επαναλαμβανόμενο ήχο που θα αυξάνεται ανάλογα με την απόσταση. Παράλληλα, στην οθόνη θα εμφανίζονται τα cm που απομένουν αν η απόσταση είναι μικρότερη των σαράντα cm, αλλιώς θα εμφανίζεται το μήνυμα “Hello Student XXXX (όπου ΧΧΧ είναι ο αριθμός μητρώου του φοιτητή)”. Το σύστημα, θα υλοποιηθεί στον μικροελεγκτή Arduino. Οι συσκευές που θα επικοινωνούν με το Arduino, είναι μία οθόνη NOKIA 5110LCD μαζί με έξι καλώδια σύνδεσης, ο αισθητήρας ultrasonic SDM-IO και τέσσερα καλώδια, το beeper με δύο καλώδια και δύο επιπλέον καλώδια σύνδεσης του Pin (5V) και του (GND) από το Arduino στο breadboard. Η συγγραφή του κώδικα και το Compile, μπορούν να επιτευχθούν με το πρόγραμμα Arduino IDE. ΠΡΟΣΟΧΗ!! Το καλώδιο σύνδεσης USB του Arduino με τον Η/Υ πρέπει να συνδεθεί μόνο όταν ο κώδικας δεν έχει λάθη και ΜΟΝΟ ΑΝ η σύνδεση του κυκλώματος είναι σωστή.
Αρχικά πρέπει να δοθεί ρεύμα στο breadboard όπου και θα γίνουν όλες οι συνδέσεις. Με ένα καλώδιο συνδέστε την τάση 5V του Arduino με μια υποδοχή με την ένδειξη (+) στο breadboard. Η τάση 5V βρίσκεται στην πλευρά του Arduino που βρίσκονται και οι αναλογικές θύρες (Analog IN). Κάντε το ίδιο και για τη γείωση (GND του Arduino) με το (-).
Ο βομβητής έχει δύο pins. Το (+) συνδέεται με ένα από τα digital pins του Arduino από το 2 έως το 13 και το (-) με τη γείωση. (Α1) Ποια είναι η συνάρτηση καθυστέρησης του arduino και τι παραμέτρους δέχεται; (B1) Βρείτε τμήμα κώδικα από τον ιστοχώρο Arduino Playground http://arduino.cc ώστε το beeper να ενεργοποιείται και να εκπέμπει ήχο για ένα δευτερόλεπτο. Τροποποιήστε τον κώδικα στη συνάρτηση beep() Στο Χ (της beeper) αντικαταστήστε τον αριθμό του pin σύνδεσης με το Arduino.
int beeper = Χ;
void setup(){
Serial.begin(9600);
pinMode(beeper, OUTPUT); //pin is output
}
void loop() {
beep();
delay(100);
}
void beep(){
}Αφού συμπληρώσετε τα τμήματα του κώδικα συνδέστε το καλώδιο και φορτώστε το πρόγραμμα. Βεβαιωθείτε για την ορθή λειτουργία.
Ο αισθητήρας αυτός έχει τέσσερα pins σύνδεσης. Αυτά συνδέονται με το Arduino με τον παρακάτω τρόπο:
VCC στην τάση 5V
TRIG σε ένα από τα ελεύθερα pin του Arduino
ECHO σε ένα από τα ελεύθερα pin του Arduino
GND GND (Arduino)
(A2) Βρείτε τι κάνει κάθε ένα από τα τέσσερα pins του ultrasonic module. Συμπληρώστε τον κώδικα ορίζοντας τα εξής:
#define SDM_IO_TIMEOUT 1000
int TrigPin = XX; (Β2) Συμπληρώστε τον αριθμό TrigPin.
int EchoPin = XX; (Β3) Συμπληρώστε τον αριθμό EchoPin.
unsigned long ultrasoundDuration;
int timeout;
unsigned long tStartPing = 0;
float sensorValue = 0;Στην setup() συμπληρώστε επίσης pinMode(ΧΧΧΧPin, OUTPUT); (Β4) Συμπληρώστε το σωστό Pin pinMode(ΧΧΧΧPin, INPUT); (Β5) Συμπληρώστε το σωστό Pin Στην loop() συμπληρώστε το εξής: sensorValue = read_sdm_io_range();
Δίνεται ακόμα η παρακάτω ημιτελής συνάρτηση
//SDM-IO Ultrasonic Range Sensor distance function
float read_sdm_io_range(){
unsigned char pin = 0;
unsigned int time_flag = 0;
digitalWrite(TrigPin, HIGH);
delayMicroseconds(2);
digitalWrite(TrigPin, LOW);
delayMicroseconds(10);
digitalWrite(TrigPin, HIGH);
tStartPing = micros();
timeout = 0;
pin = digitalRead(EchoPin);
while(pin) {
pin = digitalRead(EchoPin);
time_flag++;
if(time_flag>SDM_IO_TIMEOUT){
timeout = 1;
break;
}
}
ultrasoundDuration=micros()-tStartPing;(B6) Εκτυπώστε στη θυριακή οθόνη σε δεκαδική μορφή το μήνυμα «ultrasoundDuration us,» και αφήστε μια νέα γραμμή αν πολλαπλασιάσουμε με 0,017 το ultrasoundDuration το αποτέλεσμα μετατρέπεται σε cm. Κάντε το και εκτυπώστε το και αυτό στη θυριακή οθόνη.
if (timeout)
return 999;
else
return ultrasoundDuration*0.017; //result in cm
}Αφού συμπληρώσετε τα τμήματα του κώδικα συνδέστε το καλώδιο και φορτώστε το πρόγραμμα. Βεβαιωθείτε για την ορθή λειτουργία.
Σύνδεση της οθόνης: Η οθόνη έχει οχτώ pins σύνδεσης. Αυτά συνδέονται με το Arduino με τον παρακάτω τρόπο:
VCC στην τάση 3.3V (Arduino)
GND (Κενό)
SCE σε ένα από τα ελεύθερα pin του Arduino
RST σε ένα από τα ελεύθερα pin του Arduino
D/C σε ένα από τα ελεύθερα pin του Arduino
DN(MOSI) σε ένα από τα ελεύθερα pin του Arduino
SCLK σε ένα από τα ελεύθερα pin του Arduino
LED (Κενό)
(A3) Βρείτε τι κάνει κάθε ένα από τα οχτώ pins. Συμπληρώστε τον κώδικα ορίζοντας τα εξής:
//The pins to use on the arduino
#define PIN_SCE XX
#define PIN_RESET XX
#define PIN_DC XX
#define PIN_SDIN XX
#define PIN_SCLK XXΌπου ΧΧ οι αριθμοί των Pin που συνδέσατε στο Arduino. ΠΡΟΣΟΧΗ!! Υπενθυμίζουμε πως στα Pin 0 και 1 δεν πρέπει να συνδεθεί τίποτα. Στην setup() συμπληρώστε τις LcdInitialise();, LcdClear();.
Από τη διεύθυνση (http://blog.stuartlewis.com/2011/02/12/scrolling-text-with-an-arduino-and-nokia-5110-screen/) θα βρείτε τους ορισμούς των παραπάνω συναρτήσεων και άλλων που είναι απαραίτητοι για να εκτυπωθεί μήνυμα στη οθόνη. (B7) Βρείτε και τοποθετείστε στον κώδικα ότι είναι απαραίτητο για να γίνει εκτύπωση και στη συνάρτηση loop() εμφανίστε το μήνυμα “Hello Student XXXX (αριθμός μητρώου)” Αφού συμπληρώσετε τα τμήματα του κώδικα συνδέστε το καλώδιο και φορτώστε το πρόγραμμα. Βεβαιωθείτε για την ορθή λειτουργία.
Σύνδεση ultrasonic + beeper: Συνδέστε μαζί στο Arduino τον αισθητήρα ultrasonic και ρυθμίστε τη συνάρτηση beep() να ενεργοποιεί το beeper όταν η απόσταση είναι μικρότερη από 40 cm. (A4) Εξηγείστε πως ο αισθητήρας ultrasonic μετρά την απόσταση. (B8) Υλοποιείστε τον κώδικα που πραγματοποιεί την παραπάνω διαδικασία.
Σύνδεση ultrasonic + LCD: Συνδέστε μαζί στο Arduino τον αισθητήρα ultrasonic και την οθόνη LCD και Τροποποιήστε τον κώδικα ώστε στην οθόνη να εμφανίζεται η απόσταση σε cm όταν αυτή είναι μικρότερη των 40 cm, αλλιώς να εμφανίζεται το μήνυμα “Hello Student XXXX (αριθμός μητρώου)” (B9) Υλοποιείστε τον κώδικα που πραγματοποιεί την παραπάνω διαδικασία. (A5) Εξηγείστε τον τρόπο με τον οποίο εμφανίζονται τα γράμματα και οι χαρακτήρες στην οθόνη.
Σύνδεση όλων των περιφερειακών: Αφού όλα τα υλικά έχουν συνδεθεί, μένει να τα κάνουμε να αλληλεπιδρούν. (B10) Στη συνάρτηση loop() ορίστε το εξής: Αν η επιστρεφόμενη τιμή είναι μικρότερη από 40 cm να εκτυπώνεται στην οθόνη η επιστρεφόμενη τιμή και να ενεργοποιείται το beeper.. Αλλιώς το μήνυμα “Hello Student XXXX (αριθμός μητρώου)” και το beeper να σταματάει. (B11) Επεξεργαστείτε τη συνάρτηση beep(), ώστε ο ήχος που εκπέμπεται να επαναλαμβάνεται γρηγορότερα καθώς τα cm πέφτουν σε 30, 20 και 10.
Όπως έχει γίνει κατανοητό στα προηγούμενα κεφάλαια, το οικοσύστημα των ενσωματωμένων συστημάτων καλύπτει ένα πολύ μεγάλο εύρος απαιτήσεων και για αυτό το λόγο χρησιμοποιούνται πλήθος τεχνολογιών υλοποίησης. Εκτός από τους επεξεργαστές των 8bit και των 32bit, αρκετά συχνά χρησιμοποιούνται και οι επαναδιαμορφώσιμες αρχιτεκτονικές, όπως Altera και Xilinx. Οι αρχιτεκτονικές αυτές χρησιμοποιούνται τόσο στα πρώτα στάδια του σχεδιασμού για τη γρήγορη προτυποποίηση και τη δημιουργία του πρωτοτύπου, όσο και στην τελική υλοποίηση, σε προβλήματα που δε μπορούν να υλοποιηθούν οικονομικά και αξιόπιστα με άλλες επιλογές. Σε αυτό το παράρτημα, θα γίνει η παρουσίαση της αναπτυξιακής πλακέτας της Altera DE2-115 και στη συνέχεια θα ακολουθήσουν οι ασκήσεις εμβάθυνσης σε αυτή την πλατφόρμα.
Η αναπτυξιακή πλακέτα FPGA που θα χρησιμοποιήσουμε είναι η Altera DE2-115 (Εικόνα C.1), η οποία αν και είναι σχεδιασμένη κατά βάση για ακαδημαϊκούς σκοπούς (διδασκαλία και έρευνα), εντούτοις δεν υπολείπεται ως προς τη λειτουργικότητά της και μπορεί να χρησιμοποιηθεί ακόμη και σε πραγματικές εφαρμογές ενσωματωμένων συστημάτων. Εξάλλου, η διαδικασία ανάπτυξης ενός ενσωματωμένου συστήματος σε μια πλακέτα FPGA είναι η ίδια σε πλακέτες χαμηλής ή υψηλής πολυπλοκότητας ακόμη και σε διαφορετικές εταιρίες.
Η πλακέτα αυτή διαθέτει ένα ισχυρά επαναδιαμορφώσιμο ολοκληρωμένο κύκλωμα το Altera Cyclone IV και όλα τα σημαντικά της στοιχεία είναι συνδεδεμένα με τους ακροδέκτες (pins) του Cyclone, παρέχοντας τη δυνατότητα στο χρήστη να μπορεί να ρυθμίσει την σύνδεση πολλαπλών στοιχείων με τον τρόπο που επιθυμεί. Για την εύκολη διεξαγωγή πειραμάτων, η πλακέτα αυτή περιλαμβάνει έναν ικανοποιητικό αριθμό διακοπτών, φωτεινών LED, και οθόνες 7 στοιχείων (7-segment displays). Για πιο προχωρημένες εφαρμογές, περιλαμβάνει μνήμες SRAM, SDRAM και επίσης μη πτητική μνήμη FLASH που διατηρεί τα δεδομένα ή την επαναδιαμόρφωση. Για τα προβλήματα που απαιτούν προγραμματιζόμενο επεξεργαστή και συσκευές εισόδου εξόδου, μπορεί να χρησιμοποιηθεί ο επεξεργαστής μαλακού πυρήνα (soft-core) που περιγράφεται σε HDL, Nios II της Altera, ο οποίος μπορεί με τον κατάλληλο προγραμματισμό να εκμεταλλευτεί όλες τις διεπαφές της αναπτυξιακής πλακέτας. Επίσης περιλαμβάνει δυνατότητες όπως τυποποιημένους υποδοχείς για επεξεργασία σημάτων εικόνας και ήχου, καθώς και τη δυνατότητα σύνδεσης πλακετών, σχεδιασμένων από το χρήστη, μέσω δύο κεφαλών επέκτασης τα οποία όμως είναι προχωρημένα θέματα και δε θα εξεταστούν σε αυτό το παράρτημα.
Τα παρακάτω στοιχεία περιλαμβάνονται στην πλακέτα DE2-115:
FPGA
Cyclone V SoC 5CSEMA5F31 / EPCQ256 256-Mbit serial configuration device
I/O Διεπαφές
Εσωτερική USB-Blaster για την επαναδιαμόρφωση του FPGA
Είσοδος/Έξοδος γραμμής ήχου, είσοδος μικροφώνου (24-bit)
Έξοδος Video (VGA 24-bit DAC)
Είσοδος Video (NTSC/PAL/SECAM)
Θύρα υπερύθρων
Σειριακή θύρα RS232 DB9
10/100/1000 Ethernet (2 θύρες)
Δυο θύρες USB 2.0 Host (Type A/Β)
PS/2 πληκτρολόγιο και mouse
Αναμονές επέκτασης (40-pin headers)
Μνήμη
128MB SDRAM, 2MB SRAM, 8MB Flash, 32Kbit EEPROM
Υποδοχή για Micro SD κάρτα μνήμης
Απεικόνιση
8 οθόνες 7-segment
1 οθόνη LCD 2x16
Switches and LEDs
18 διακόπτες
18 LEDs
4 διακόπτες με αποκλυδωνισμό
Ρολόγια
50 MHz clock (3 ρολόγια)

C.1: Η αναπτυξιακή πλακέτα που χρησιμοποιείται στα εργαστήρια είναι η Altera DE2-115 που μπορεί να την προμηθευτεί κάποιος σε χαμηλή ακαδημαϊκή τιμή από το διαδίκτυο.
Για να αναπτυχθεί ένα ενσωματωμένο σύστημα σε οποιαδήποτε πλακέτα της Altera χρησιμοποιείται το λογισμικό Quartus. Υπάρχουν 2 εκδόσεις του προγράμματος, που μπορούν να μεταφορτωθούν δωρεάν από τον ιστοχώρο της Altera (www.altera.com). Η δωρεάν έκδοση (web), η οποία είναι μεν πλήρης άλλα φέρει κάποιους περιορισμούς ως προς τις δυνατότητες των εργαλείων (π.χ. δεν υποστηρίζεται η παράλληλη εκτέλεση, και όλα εκτελούνται σε έναν μόνο πυρήνα), και η επαγγελματική έκδοση (subscription), η οποία απαιτεί ένα αρχείο με άδειες που έχει αγοράσει κάποιος από την Altera και οι οποίες καθορίζουν ακριβώς τα εργαλεία, τα διαθέσιμα δομοστοιχεία (IP) και τις δυνατότητες που έχει στη διάθεσή του ο σχεδιαστής. Στα πλαίσια των εργαστηριακών ασκήσεων θα χρησιμοποιήσουμε τη web έκδοση, η οποία μας καλύπτει πλήρως. Η τελευταία έκδοση του Quartus (Ιούλιος 2015) είναι η 15, αλλά στα πλαίσια αυτών των ασκήσεων χρησιμοποιούμε την έκδοση 13, η οποία είναι διαθέσιμη για μεταφόρτωση και δεν έχει πολλές διαφοροποιήσεις σε σχέση με την 15. Όμως, το πιο σημαντικό στοιχείο είναι ότι αυτή είναι η τελευταία έκδοση που υποστηρίζει 32bit και 64bit συστήματα, από Windows XP και άνω, και έτσι μπορεί να χρησιμοποιηθεί σε όλους τους υπολογιστές που κατασκευάστηκαν από το 2001 και μετά. Κατά την αγορά της πλακέτας Altera DE2-115 υπάρχει το λογισμικό σε CD και έτσι δε χρειάζεται να μεταφορτωθεί από το Internet. Μαζί με το λογισμικό, υπάρχουν και αρκετά αρχεία επίδειξης των δυνατοτήτων της πλακέτας.
Όπως προαναφέρθηκε, οι δυο μεγαλύτεροι πάροχοι επαναδιαμορφώσιμων αρχιτεκτονικών Altera και Xilinx, υποστηρίζουν πλήρως τις πλακέτες που κατασκευάζουν με τα ολοκληρωμένα λογισμικά ανάπτυξης, επεξεργασίας και μεταφόρτωσης κώδικα HDL ή σχηματικού. Η βασική διαδικασία είναι η ίδια, με τη μόνη διαφορά την χρήση διαφορετικών περιβαλλόντων σχεδίασης και διαφορετικών ονομάτων στα εργαλεία. Κατά τη διαδικασία ανάπτυξης ενός ενσωματωμένου συστήματος σε μια πλακέτα FPGA, χρησιμοποιείται συνήθως μια γλώσσα περιγραφής υλικού όπως Verilog ή VHDL, η οποία αρχικά προσομοιώνεται και επιβεβαιώνεται η ορθή της λειτουργία, στη συνέχεια δημιουργείται το αρχείο περιορισμών (π.χ. χρονικών περιορισμών) και η αντιστοίχηση στους ακροδέκτες του FPGA (σύμφωνα με την αναπτυξιακή πλακέτα) και τέλος η μεταφόρτωση στην πλακέτα.
Το Altera Quartus αποτελεί ένα πλήρες περιβάλλον για τον σχεδιασμό συστήματος σε επαναπρογραμματιζόμενο chip (System-On-a-Programmable-Chip - SOPC). Περιλαμβάνει εργαλεία για όλες τις φάσεις σχεδιασμού της πλακέτας. Διαθέτει δικό του γραφικό περιβάλλον (GUI) καθώς και διεπαφή γραμμής εντολών (command-line interface) επιτρέποντας την χρήση οποιοδήποτε εργαλείου που περιέχει και με τους 2 τρόπους.
C.2: C.3: Στην περιοχή Tasks του εργαλείου Altera Quartus, ο χρήστης μπορεί να επιλέξει να εκτελέσει ξεχωριστά το εργαλείο που χρειάζεται.
Το αναπτυξιακό περιβάλλον της Altera, παρέχει σε ένα ενοποιημένο πρόγραμμα όλες τις λειτουργίες που απαιτούνται για το σχεδιασμό ενός ολοκληρωμένου κυκλώματος (Εικόνα C.2) Το Quartus περιλαμβάνει έναν αρθρωτό μεταγλωττιστή ο οποίος αποτελείται από τα εξής τμήματα (modules):
Ανάλυση & Σύνθεση (Analysis & Synthesis)
Συγχώνευση Κατατμήσεων (Partition Merge)
Εφαρμοστή FPGA (Fitter)
Συναρμολογητή (Assembler)
Αναλυτή Χρονισμού (TimeQuest)
Βοηθό Σχεδιασμού (Design Assistant)
Δημιουργία αρχείου netlist (EDA Netlist Writer)
HardCopy Netlist Writer
Για την πλήρη μεταγλώττιση, η οποία περιλαμβάνει όλα τα ανωτέρω (modules), αφού εκτελέσουμε το Quartus II, και δημιουργήσουμε όλα τα αρχεία του project μας, επιλέγουμε το ”Start Compilation” που βρίσκεται στο μενού Processing.
Σε περίπτωση που επιθυμούμε να εκτελέσουμε κάθε module ξεχωριστά, κάνουμε κλικ στο (Start) από το ίδιο μενού και επιλέγουμε το εργαλείο που θέλουμε να χρησιμοποιήσουμε. Εναλλακτικά, αυτό μπορεί να γίνει και από το παράθυρο (Tasks) από το οποίο μπορούμε επίσης να αλλάξουμε τις ρυθμίσεις ή να δούμε το αρχείο αναφοράς για το εργαλείο που μας ενδιαφέρει (Εικόνα C.3).
C.3: Στην περιοχή Tasks του εργαλείου Altera Quartus, ο χρήστης μπορεί να επιλέξει να εκτελέσει ξεχωριστά το εργαλείο που χρειάζεται.
Τα παρακάτω βήματα περιγράφουν τη βασική ροή σχεδιασμού στο Altera Quartus:
Για την δημιουργία νέου project και το καθορισμό της συσκευής ή της οικογένειας συσκευών, κάνουμε κλικ στο New Project Wizard στο μενού File.
Μπορούμε να χρησιμοποιήσουμε τον ενσωματωμένο επεξεργαστή κειμένου (Text Editor) για να δημιουργήσουμε το κύκλωμά μας σε μια γλώσσα περιγραφής υλικού (harware description language, HDL) όπως τις προτυποποιημένες (Verilog, VHDL) ή την Altera Hardware Descrition Language (AHDL).
Χρησιμοποιούμε τον επεξεργαστή block (Block Editor) για να δημιουργήσουμε ένα διάγραμμα μπλοκ με σύμβολα που αναπαριστούν άλλα αρχεία σχεδιασμού ή για να δημιουργήσουμε ένα σχηματικό (schematic).
Με το εργαλείο (MegaWizard Plug-in Manager), μπορούμε να δημιουργήσουμε δικές μας παραλλαγές από συναρτήσεις υλοποιημένες σε υλικό (megafunctions) και δομοστοιχεία IP (IP functions).
Για το σχεδιασμό συστήματος-πάνω-σε-ψηφίδα χρησιμοποιούμε το (SOPC Builder ή QSYS) ή τον DSP Builder.
Για την αντιστοίχηση του κυκλώματος πάνω σε ακροδέκτες (pin) του FPGA chip, μπορούμε να καθορίζουμε τους σχεδιαστικούς περιορισμούς (constraints) με τον Assignment Editor, ή το Pin Planner.
Μπορεί προαιρετικά να γίνει πρόωρη εκτίμηση των χρονισμών πριν τη διαδικασία υλοποίησης και σύνθεσης (fitting).
Η σύνθεση του σχεδίου γίνεται με το Αnalysis & Synthesis.
Σε περίπτωση που το σχέδιο είναι χωρισμένο σε διαμερίσματα (partitions), μπορούμε να τα συγχωνεύσουμε με το εργαλείο Partition Merge.
Προαιρετικά μπορεί να γίνει λειτουργική προσομοίωση με χρήση του προσομοιωτή Modelsim Starter που περιλαμβάνεται (και είναι ελεύθερο στη χρήση) στην εγκατάσταση.
Η τοποθέτηση και δρομολόγηση του σχεδίου μας γίνεται με το εργαλείο (Fitter).
Μπορεί να γίνει εκτίμηση και ανάλυση της κατανάλωσης με το εργαλείο (PowerPlay Power Analyzer).
Με το TimeQuest Timing Analyzer γίνεται ανάλυση των χρονισμών.
Η διόρθωση κάποιον προβλημάτων χρονισμού μπορεί να γίνει με τη συνδυασμένη χρήση των εργαλείων Chip Planner, LogicLock και Assignment Editor.
Το αρχείο προγραμματισμού του chip δημιουργείται με τον Assembler και έπειτα προγραμματίζεται με το Programmer.
Μπορεί να γίνει αποσφαλμάτωση με την παρακολούθηση των σημάτων πάνω στην πλακέτα με το εργαλείο SignalTrap II Logic Analyzer, ή έναν εξωτερικό λογικό αναλυτή.
Αξίζει να αναφερθεί ότι όλα τα εργαλεία υποστηρίζουν πλήρως τη γραμμή εντολών κάτι που βοηθάει την ομαδοποιημένη εκτέλεση λειτουργιών (batch operations).
Προκειμένου να εκμεταλλευτεί καλύτερα κάποιος τα εργαλεία, προτείνεται ο έλεγχος και η προσομοίωση του κώδικα να γίνεται σε ένα περιβάλλον όμως το modelsim (που περιλαμβάνεται στην ελεύθερη web έκδοση), και μόνο όταν επιτευχθεί η επιβεβαίωση της ορθής λειτουργίας, να χρησιμοποιείται το Quartus για τη σύνθεση. Προτείνεται λοιπόν να αποφεύγεται η σύνθεση κώδικα που δεν έχει επιβεβαιωθεί, γιατί η σύνθεση είναι μια διαδικασία αρκετά χρονοβόρα (η δωρεάν έκδοση του Quartus δεν υποστηρίζει πολλαπλούς επεξεργαστές). Όσες λιγότερες φορές επαναληφθεί λοιπόν η σύνθεση, τόσο περισσότερο χρόνο θα έχει ο σχεδιαστής για να ασχοληθεί με κάποιο άλλο θέμα. Επίσης, η συγγραφή του κώδικα μπορεί να γίνει στο Quartus όπου από το μενού EDIT, επιλογή Insert Templates, παρέχονται στο σχεδιαστή αρκετοί σκελετοί κώδικα (σε Verilog ή VHDL, κτλ) που μπορούν να τοποθετηθούν στο ανοιχτό έγγραφο άμεσα πατώντας το κουμπί Insert. Ο σχεδιαστής απλώς θα πρέπει να τροποποιήσει σε ελάχιστα σημεία τις γραμμές που τον ενδιαφέρουν και να απομακρύνει τις υπόλοιπες, γλυτώνοντας πολύ χρόνο σε σύγκριση με το να πληκτρολογούσε όλες τις γραμμές.
Σε αυτή την άσκηση γνωριμίας, θα δημιουργήσετε ένα απλό project στο Quartus και θα ακολουθήσετε όλη τη ροή σχεδιασμού έως τη μεταφορά στην πλακέτα και την επιβεβαίωση ορθής λειτουργίας.
Επιλέξτε New Project Wizard από το μενού File.
Στο παράθυρο του Wizard θα σας ζητηθούν (Εικόνα C.4):
Κατάλογος Εργασίας
Όνομα Project
Προσδιορισμός του ονόματος της top-level οντότητας.
Τον τύπο της συσκευής ή την οικογένεια συσκευών, το package type κλπ
C.4: Μόλις ξεκινήσει το New Project Wizard στο Altera Quartus, ο χρήστης ενημερώνεται για τις πληροφορίες που θα εισάγει.
Στην 1η οθόνη του οδηγού, ο χρήστης συμπληρώνει 3 πεδία, τον κατάλογο εργασίας του project, το όνομα του project και το όνομα του top-level design entity για το project, το οποίο συνήθως είναι το ίδιο με το όνομα του project και για αυτό προσυπληρώνεται από το Quartus με το όνομα του project. Το όνομα του top-level design είναι μία παράμετρος που μπορεί να τροποποιηθεί, κατά την ανάπτυξη του project. Μάλιστα, μια καλή πρακτική σε ένα project που αναπτύσσεται από την αρχή, είναι η τοποθέτηση στο όνομα του top-level design (οντότητα σχεδιαστικής κορυφής), του πρώτου component που θα αναπτυχθεί, και μόλις γίνει η σύνθεση και επιβεβαιωθεί η ορθή λειτουργία, να τροποποιηθεί στην επόμενη ιεραρχικά οντότητα που θα δημιουργηθεί, ώστε το project να ακολουθεί τη διαδικασία ανάπτυξης bottom-up, δηλαδή από τα χαμηλότερα σχεδιαστικά modules προς τα υψηλότερα.
Στη 2η οθόνη του οδηγού υπάρχει η προτροπή για την προσθήκη των αρχείων ή των βιβλιοθηκών (Εικόνα C.5). Σε αυτό το σημείο μπορούν να προστεθούν οτιδήποτε τύπου σχεδιαστικά αρχεία υποστηρίζει το Quartus, όπως αρχεία VHDL, Verilog, netlists, σχηματικά κτλ. Επίσης, σε περίπτωση που απαιτούνται κατάλογοι με υποστηρικτικές βιβλιοθήκες, μπορούν να προστεθούν από την επιλογή User Libraries.
C.5: Στη 2η οθόνη του New Project Wizard, ο χρήστης μπορεί να προσθέσει αρχεία στο project.
Η επόμενη οθόνη (οθόνη 3) επιτρέπει στο χρήστη να επιλέξει τα χαρακτηριστικά τεχνολογίας για το project του και συγκεκριμένα την οικογένεια και το FPGA chip. Για να χρησιμοποιήσει την πλακέτα Altera DE2-115, ο χρήστης θα πρέπει να επιλέξει το Device Family Cyclone IV E και να περιορίσει τα αποτελέσματα που εμφανίζονται χρησιμοποιώντας το Name filter, όπως φαίνεται στην Εικόνα C.6. To ολοκληρωμένο κύκλωμα FPGA έχει τυπωμένο το όνομα του, οπότε κάποιος μπορεί να το δει στην πλακέτα. Συνήθως, η Altera DE2-115 φέρει το EP4CE115F29C7 ή EP4CE115F29C8 (όποιο και να επιλεχθεί θα λειτουργήσει ορθά σε αυτές τις εργαστηριακές ασκήσεις, αφού είναι συμβατά ως προς τις τάσεις και τον αριθμό των στοιχείων).
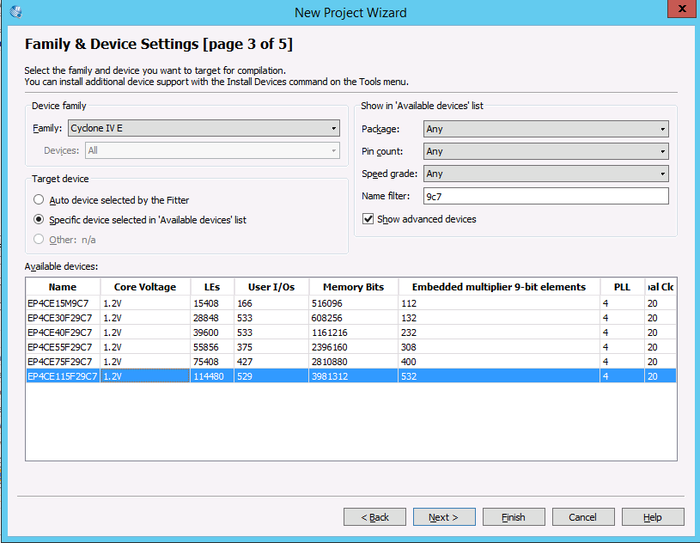
C.6: Στην 3η οθόνη του New Project Wizard, ο χρήστης επιλέγει το FPGA chip.
Στο τελευταίο βήμα (4ο) των ρυθμίσεων, ρυθμίζουμε τα εργαλεία που χρησιμοποιήσαμε ή θα χρησιμοποιήσουμε για την ανάπτυξη του project. Συνήθως, στο Simulation επιλέγουμε το ModelSim-Altera, και στο Design Entry/Synthesis, επιλέγουμε Custom/VHDL (Εικόνα C.7). Μόλις πατήσουμε NEXT, εμφανίζεται μια οθόνη σύνοψης των πληροφοριών του project (Summary) και μόλις ο χρήστης πατήσει Finish, ολοκληρώνεται η διαδικασία δημιουργίας νέου project.
C.7: Στην 4η οθόνη του New Project Wizard, ο χρήστης ρυθμίζει τα εργαλεία του project.
Μία δυνατότητα που συναντάται σε κάθε ολοκληρωμένο περιβάλλον ανάπτυξης επαναδιαμορφώσιμων αρχιτεκτονικών, είναι η δυνατότητα σύνδεσης συγκεκριμένων ακροδεκτών του FPGA chip με συγκεκριμένες διεπαφές εισόδου/εξόδου του κυκλώματος του. Για παράδειγμα, αν κάποιος θέλει να ενεργοποιηθεί ένα led όταν η λογική έξοδος του κυκλώματος του ledout λάβει την τιμή 1, θα πρέπει να συνδέσει τη λογική έξοδο ledout της HDL οντότητάς του, με το pin του FPGA που συνδέεται σε αυτό το led. Κάθε ολοκληρωμένο κύκλωμα έχει πολλούς ακροδέκτες, και για κάθε αναπτυξιακή πλακέτα υπάρχει μία αναλυτική λίστα με τις συνδέσεις όλων των ακροδεκτών. Η αντιστοίχηση των λογικών διεπαφών με τις φυσικές διεπαφές επιτυγχάνεται με τους παρακάτω τρόπους:
Με τον επεξεργαστή συνδέσεων ακροδεκτών (Pin Assignment Editor) (Εικόνα C.8)
Με την οπτική σύνδεση ακροδεκτών, όπου φαίνονται όλοι οι ακροδέκτες του chip (Εικόνα C.9)
Με την χρήση του CSV αρχείου που συνοδεύει την πλακέτα (DE2_115_pin_assignments.csv) και εισαγωγή στο project από το μενού Assignments, επιλογή Import Assignments, και στη συνέχεια χρήση των ονομάτων που φέρουν οι ακροδέκτες στο αρχείο αυτό, μέσα στο ανώτερο κύκλωμα υλοποίησης (top level design). Για παράδειγμα, μέσα σε αυτό το αρχείο υπάρχει η γραμμή CLOCK_50,Input,PIN_Y2,2,B2_N0,3.3-V LVTTL, οπότε αν στο κύκλωμα μας, χρησιμοποιήσουμε σε ένα σημείο την είσοδο CLOCK_50, τότε αυτή θα συνδεθεί άμεσα με το pin Y2 που στην Altera DE2-115 αντιστοιχεί το ρολόι των 50 Mhz.
Σε περίπτωση που ο χρήστης δώσει λάθος ακροδέκτη (π.χ. έναν ακροδέκτη που δεν υπάρχει), τότε θα εμφανιστεί κατά τη διαδικασία της τοποθέτησης και της δρομολόγησης, το μήνυμα Cannot Recognize Value Pin (Εικόνα C.11) Τέλος, να σημειωθεί ότι όταν πατηθεί ένα πλήκτρο (KEY[0] έως KEY[3]) παράγεται ένα λογικό ’0’ (και όχι ’1’ όπως θα περίμενε κάποιος), ενώ ο διακόπτης (slide switch), παράγει ’1’ όταν είναι στην άνω θέση και ’0’ όταν είναι στην κάτω.
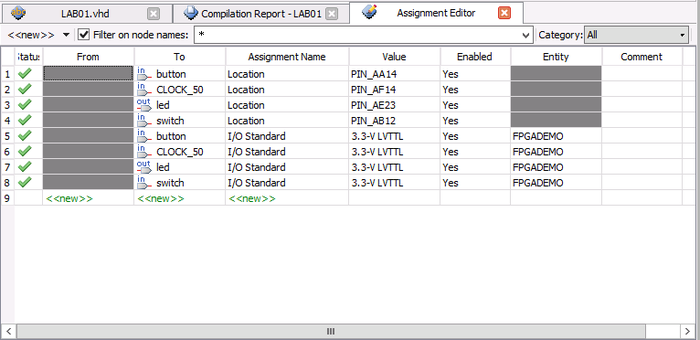
C.8: Ο επεξεργαστής συνδέσεων ακροδεκτών.
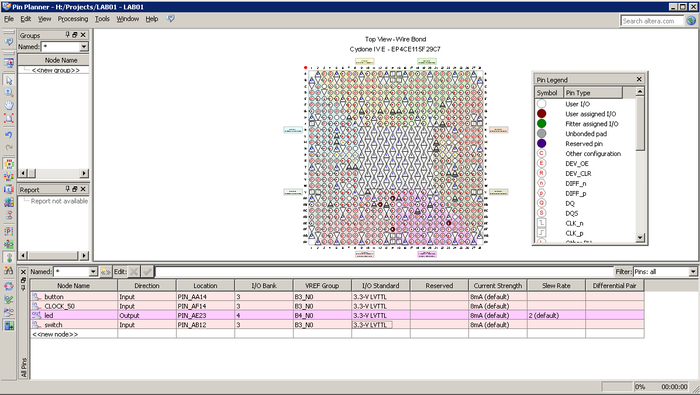
Η οπτική σύνδεση ακροδεκτών.
Αφού ολοκληρωθεί με επιτυχία η σύνθεση, τότε ο χρήστης μπορεί να επιλέξει από τις συντομεύσεις ενεργειών TASKS ή από το μενού Tools την επιλογή Programmer. Αν έχουν εγκατασταθεί οι οδηγοί της πλακέτας (κάτι που γίνεται αυτόματα κατά την εγκατάσταση του Quartus II, εφόσον ο χρήστης επιλέξει υποστήριξη για τη συγκεκριμένη πλακέτα), θα υπάρχει η συσκευή USB BLASTER, η οποία είναι το υλικό πάνω στην πλακέτα που θα δεχτεί το bitstream και θα επαναπρογραμματίστει το FPGA (Εικόνα C.12).
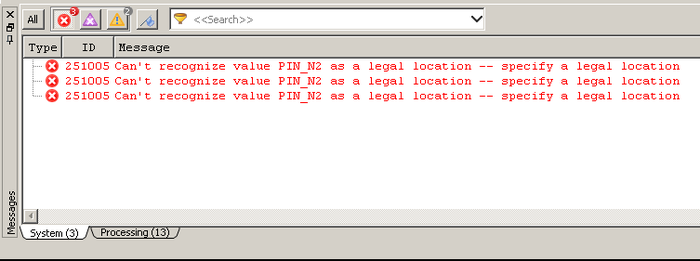
C.11: Σφάλματα κατά τη σύνδεση των ακροδεκτών.
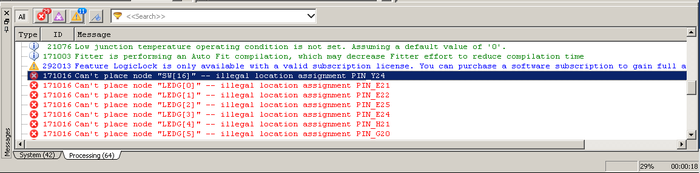
Απαιτείται προσοχή κατά τη διαδικασία της σύνδεσης των ακροδεκτών του FPGA, ώστε να μη δημιουργηθούν σφάλματα.
C.12: Στη διαδικασία του προγραμματισμού του FPGA, θα πρέπει να έχει επιλεχθεί η συσκευή USB BLASTER.
Σε αυτή την άσκηση θα γίνει μια πιο εκτενής γνωριμία με το περιβάλλον Quartus της Altera. Συγκεκριμένα, θα γίνουν ασκήσεις πάνω στα περιφερειακά της πλακέτας. Αρχικά, δημιουργήστε ένα νέο project για την Altera DE2-115 και τοποθετήστε τον κώδικα C.3 σε ένα αρχείο με όνομα book01.vhd. Στο Project Navigator, επιλέξτε το αρχείο που μόλις έχετε δημιουργήσει και πατήστε δεξί κλικ και Set as Top Level Entity, για να γίνει η σύνθεση του συγκεκριμένου component. Να σημειώσετε ότι η ονομασία του αρχείου είναι πολύ σημαντική, επειδή όταν επιλεχθεί και τεθεί ως κορυφή της ιεραρχίας σχεδίασης, το Quartus σημειώνει το όνομα του αρχείου και περιμένει να βρει ένα entity με αυτό το όνομα. Οπότε, αν το όνομα του αρχείου χωρίς την κατάληξη .vhd είναι διαφορετικό από το όνομα του entity που περιλαμβάνει, δημιουργείται ένα πρόβλημα μη εύρεσης του top level component. Το συγκεκριμένο component, όπως φαίνεται, κάνει reset όταν πατηθεί ένα κουμπί, ενώ σε διαφορετική περίπτωση μεταφέρει την τιμή του διακόπτη σε ένα led κάθε 2.62ms (επειδή ο μετρητής αυξάνεται κατά 1 με συχνότητα 50 Mhz και μετράει ως 2**17-1, οπότε ο χρόνος υπολογίζεται ως .
Για να ολοκληρωθεί η σύνθεση, θα πρέπει να γίνει η αντιστοίχηση των θυρών του ανώτερου επιπέδου σχεδιασμού στα pins του FPGA. Συγκεκριμένα, θα πρέπει να γίνει η αντιστοίχηση των pins clk, button, switch, led.
library ieee;
use ieee.std_logic_1164.all;
use ieee.numeric_std.all;
entity book01 is
port (clk: in std_logic;
button: in std_logic;
switch: in std_logic;
led: out std_logic);
end book01;
architecture behavioral of book01 is
signal counter: natural range 0 to 2**17-1; --0 every 2.62ms
begin
process(clk,button)
begin
if button='1' then
counter<=0;
elsif clk'event and clk='1' then
counter<=counter+1;
if counter=2**17-1 then
led<=switch;
counter<=0;
end if;
end if;
end process;
end behavioral;[lab01a]
Από το μενού Assignments επιλέγουμε τον Assignment Editor. Στο παράθυρο που ανοίγει ορίζουμε την αντιστοίχιση από σημείο σε σημείο και δίνουμε μία ονομασία στο σήμα μας όπως το ορίσαμε και στο αρχείο VHDL. Εναλλακτικά, η αντιστοίχηση μπορεί να γίνει δημιουργώντας ένα αρχείο qcf. Για την συγκεκριμένη άσκηση θα χρησιμοποιήσουμε ένα button για reset, ένα slide switch ως είσοδο, το ρολόι των 50Mhz, κι ένα led για έξοδο. Επιλέγουμε τα pins που θα χρησιμοποιήσουμε ως εξής: Από τα κουμπιά της πλακέτας επιλέγουμε το KEY3, από τα LED επιλέγουμε αυτό που αναγράφεται ως LEDG1, και από τους διακόπτες, επιλέγουμε τον SW11. Από το αρχείο περιορισμών της πλακέτας (DE2_115_pin_assignments.csv) βρίσκουμε τις γραμμές που μας ενδιαφέρουν, και είναι:
KEY[3],Input,PIN_R24,5,B5_N0,2.5 V,
SW[11],Input,PIN_AB24,5,B5_N2,2.5 V,
LEDG[1],Output,PIN_E22,7,B7_N0,2.5 V,
CLOCK_50,Input,PIN_Y2,2,B2_N0,3.3-V LVTTL,Από τις παραπάνω γραμμές διαπιστώνουμε τα pins που πρέπει να αντιστοιχηθούν στα ports. Αυτό μπορεί να γίνει με 2 τρόπους: (α) με επεξεργασία του αρχείου qsf (quartus settings file) που βρίσκεται στον κατάλογο του project και φέρει όλες τις ρυθμίσεις του project μας, είτε (β) με τον επεξεργαστή συσχετίσεων. Αν επιλέξουμε τον (α) τρόπο, τότε θα πρέπει να προσθέσουμε τις παρακάτω γραμμές (αφορούν μόνο την Altera DE2-115, άλλη πλακέτα έχει άλλες αντιστοιχίσεις) στο τέλος:
set_location_assignment PIN_Y2 -to CLK
set_location_assignment PIN_R24 -to BUTTON
set_location_assignment PIN_AB24 -to SWITCH
set_location_assignment PIN_E22 -to LEDΑν επιλέξουμε τον (β) τρόπο, τότε θα πρέπει να τοποθετήσουμε τις 4 αναθέσεις στο τέλος της λίστας, όπως φαίνεται στην εικόνα C.13. Επιβεβαιώστε την ορθή λειτουργία του κυκλώματος, αφού προγραμματίστε την πλακέτα.

C.13: Τοποθέτηση των συσχετίσεων των ακροδεκτών του FPGA με τις θύρες εισόδου εξόδου του Top Level Design, της πρώτης άσκησης.
Επίσης, μπορούμε να δώσουμε κάποιους σχεδιαστικούς περιορισμούς, ώστε η σύνθεση να γίνει με τρόπο που να τους ικανοποιεί. Οι σχεδιαστικοί περιορισμοί εισάγονται με το FileNew
Synopsis Design Constraints File. Στο παράθυρο που ανοίγει τοποθετούμε τη γραμμή + create_clock -period 20 [get_ports clk]+++, όπου ορίζουμε ότι το ρολόι θα πρέπει να έχει ελάχιστη περίοδο 20, και το αποθηκεύουμε στον κατάλογο του project με κατάληξη .sdc. Θα διαπιστώσουμε ότι το αρχείο μόλις αποθηκευτεί θα έχει προστεθεί στο παράθυρο project navigator στην καρτέλα Files.
Για να κάνουμε compile και synthesize το project που δημιουργήσαμε, τρέχουμε τον compiler επιλέγοντας ProcessingStart Compilation. Καθώς η διαδικασία προχωράει από στάδιο σε στάδιο, αριστερά (παράθυρο tasks), βλέπουμε την αναφορά της πορείας του κάθε χρονική στιγμή. Μετά την ολοκλήρωσή του, εμφανίζεται ένα παράθυρο που μας πληροφορεί αν το compile έγινε επιτυχώς ή όχι και αν υπήρχαν warnings ή errors. Σε περίπτωση που πήγαν όλα καλά, μπορούμε να προσομοιώσουμε το σχέδιό μας ή να περάσουμε κατευθείαν στη διαδικασία προγραμματισμού της FPGA.
Αν επιθυμούμε να κάνουμε προσομοίωση του σχεδίου μας, ανοίγουμε τον τον Waveform Editor επιλέγοντας FileNew. Κάνουμε κλικ στην καρτέλα Verification/Debugging Files, επιλέγουμε University Program VWF, πατάμε ΟΚ και σώζουμε το αρχείο με τη μορφή
project name
.vwf, στον κατάλογο του project (για να τοποθετηθεί αυτόματα στα files). Για να γίνει η προσομοίωση ορίζουμε τους χρόνους από το μενού του παραθύρου του Waveform Editor, Edit
End Time στα όρια που μας επιτρέπει. Μετά τοποθετούμε τα nodes (Edit
Insert Node or Bus) και είτε γράφουμε ένα ένα τα ονόματα των ports, είτε από το Node filter επιλέγουμε αμέσως όλες τις πόρτες. Στη συνέχεια επιλέγουμε Simulation
Functional Simulation ή Simulation
Timing Simulation, ανάλογα με την προσομοίωση που θέλουμε να γίνει, και στο τέλος μας εμφανίζονται τα αποτελέσματα σε ένα νέο παράθυρο.
Σε περίπτωση που το compile ολοκληρώθηκε επιτυχώς, μπορούμε να προγραμματίσουμε την FPGA. Η διαδικασία μεταφόρτωσης του σχεδίου μας στην FPGA καλείται FPGA Configuration. Για το configuration της Altera DE2-115 το Quartus υποστηρίζει 2 μεθόδους.
Η πρώτη καλείται Active Serial Programming και με αυτή το configuration bit stream μεταφορτώνεται στην quad serial configuration device (EPCQ256) με μη πτητικό τρόπο που σημαίνει ότι ακόμη και αν απενεργοποιηθεί και ξαναενεργοποιηθεί η FPGA, οι πληροφορίες του configuration παραμένουν.
Η δεύτερη, την οποία και θα χρησιμοποιήσουμε σ’ αυτήν την εργασία, καλείται JTAG Programming (Joined Test Action Group με βάση την τυποποίηση της IEEE) με την οποία το bit stream μεταφορτώνεται απευθείας στην FPGA και παραμένει εκεί μέχρις ότου την απενεργοποιήσουμε. Μόλις πατηθεί το reset χάνεται το configuration και επαναφορτώνεται αυτό που ήταν αποθηκευμένο στη μνήμη FLASH.
Για να γίνει το JTAG Programming ακολουθείστε τα εξής βήματα:
Ανοίξτε τον Programmer από το μενού Tools και κάντε κλικ στο Auto Detect
Επιλέξτε την εντοπισμένη συσκευή από το Hardware Setup (αν δεν είναι ήδη επιλεγμένη η USB-Blaster USB-0)
Πατήστε Start και θα μεταφερθεί αυτόματα ο κώδικας.
Μόλις ολοκληρωθεί η διαδικασία, μπορούμε να επιβεβαιώσουμε τη λειτουργία του σχεδίου μας στην FPGA. Πρέπει όταν πατάμε το switch να ανάβει το led. Όταν πατάμε το button πρέπει να κάνει reset.
Σε αυτή την άσκηση θα πρέπει να δημιουργηθεί ένας πολυπλέκτης 2-σε-1, ο οποίος θα χρησιμοποιεί 2 κουμπιά (KEY2, KEY1) για την είσοδο του πολυπλέκτη και ένα διακόπτη SW0 για την επιλογή της εισόδου. Η έξοδος θα εμφανίζεται στο LEDR0.
Το αρχείο VHDL που θα χρησιμοποιηθεί σε αυτή την άσκηση σας δίνεται στον κώδικα C.4. Αποθηκεύστε το αρχείο στον κατάλογο του project σας με όνομα mux2to1, και μόλις εμφανιστεί στα Files του Project Navigator, πατήστε δεξί κλικ στο αρχείο και Set As Top Level Entity.
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.STD_LOGIC_ARITH.ALL;
use IEEE.STD_LOGIC_UNSIGNED.ALL;
entity mux2to1 is
port ( A : in BIT;
B : in BIT;
S : in BIT;
X : out BIT);
end mux2to1;
architecture Behavioral of mux2to1 is
begin
X <= not ( (A and not S) or (B and S) );
end behavioral;[mux2to1]
Να σημειωθεί ότι σε αυτή την άσκηση, τοποθετήθηκε η πύλη not στην έξοδο, γιατί τα LED στην Altera DE2-115 ανάβουν όταν τοποθετηθεί το ’0’, οπότε με την παραπάνω τροποποίηση γίνεται καλύτερα κατανοητό πότε η έξοδος φέρει το ’1’ δηλαδή την τιμή του κουμπιού που έχει επιλεχθεί (με το S) και είναι πατημένο. Στη συνέχεια βρίσκουμε τις αντιστοιχίσεις, και κάνουμε τις απαραίτητες συσχετίσεις στο αρχείο DE2_115_pin_assignments.csv, όπως προηγουμένως:
KEY[3],Input,PIN_R24,5,B5_N0,2.5 V,
KEY[2],Input,PIN_N21,6,B6_N2,2.5 V,
SW[0],Input,PIN_AB28,5,B5_N1,2.5 V,
LEDR[0],Output,PIN_G19,7,B7_N2,2.5 V,Στην συγκεκριμένη άσκηση δεν χρειαζόμαστε το ρολόι για αυτό δεν θα δημιουργήσουμε αρχείο χρονισμών. Στη συνέχεια επιλέγουμε Start Compilation από το μενού Processing. Αν ολοκληρωθεί επιτυχώς προχωράμε στον προγραμματισμό της FPGA και επιβεβαιώνουμε την ορθή λειτουργία.
Σε αυτή την εργαστηριακή άσκηση θα δημιουργηθεί ένας μετρητής Up/Down. Συγκεκριμένα, θα χρησιμοποιείται το slide switch (SW0) το οποίο όταν είναι 1, η μέτρηση θα επιτρέπεται αλλιώς ο μετρητής θα σταματάει. Η μέτρηση θα ανανεώνεται με συχνότητα 1.49 Hz, ενώ θα χρησιμοποιείται ένα κουμπί για να κάνει reset. Η τιμή του μετρητή των 22 ψηφίων, θα εμφανίζεται στα 22 κόκκινα LED της πλακέτας. Θα χρησιμοποιηθεί ο κώδικας C.5. Δημιουργήστε ένα νέο project και τοποθετήστε τον κώδικα C.5. Θα πρέπει να εισάγεται το CSV αρχείο με τις αντιστοιχίσεις της πλακέτας, και επίσης θα πρέπει να δώστε την αντιστοίχηση για το κουμπί RST προς ένα οποιοδήποτε KEY της πλακέτας (KEY[0]/KEY[1]/KEY[2]/KEY[3]). Σημειώστε ότι δε χρειάζεται αντιστοίχηση για τη θύρα CLOCK_50, επειδή φέρει το ίδιο όνομά σε μια γραμμή του αρχείου των συσχετίσεων, δηλαδή
CLOCK_50,Input,PIN_Y2,2,B2_N0,3.3-V LVTTL,Ομοίως, δε χρειάζεται να τοποθετηθεί συσχέτιση για τις θύρες SW ή το LEDR. Αποθηκεύστε το αρχείο με όνομα counter8.vhd στον κατάλογο του project, ώστε να τοποθετηθεί αυτόματα στο Project Navigator στην καρτέλα Files, και στη συνέχεια πατήστε δεξί κλικ και ”Set as top Level Entity” και ολοκληρώστε τη σύνθεση. Σημειώστε ότι τα κουμπιά της πλακέτας παράγουν το ’0’ όταν πατηθούν, οπότε για αυτό έχουμε προσδιορίσει τον κώδικα + if RST=’0’ then+++ για να δηλώσουμε όταν πατηθεί το συγκεκριμένο κουμπί.
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.STD_LOGIC_ARITH.ALL;
use IEEE.STD_LOGIC_UNSIGNED.ALL;
entity counter8 is
port(CLOCK_50: in std_logic; --clock
RST: in std_logic; --reset
SW: in std_logic_vector(1 downto 0);
LEDR: out std_logic_vector(7 downto 0));
end counter8;
architecture behavioral of counter8 is
signal counter1Hz49: std_logic_vector(22 downto 0);--50MHz/2**23=1.49Hz
signal direction: std_logic; --0: up, 1: down
signal enable: std_logic; --counter enable
signal counter: std_logic_vector(7 downto 0);
begin
process(CLOCK_50, RST)
begin
if RST='0' then
counter1Hz49<=(others=>'0');
elsif CLOCK_50'event and CLOCK_50='1' then
counter1Hz49<=counter1Hz49+1;
end if;
end process;
process(CLOCK_50, RST)
begin
if RST='0' then
counter<=(others =>'0');
direction<='0';
elsif CLOCK_50'event and CLOCK_50='1' then
enable<=SW(0);
direction<=SW(1);
if counter1Hz49=0 and enable='1' then
if direction='0' then
counter<=counter+1;
else
counter<=counter-1;
end if;
end if;
end if;
end process;
LEDR<=counter;
end behavioral;[countercode]
Και τέλος δημιουργούμε το αρχείο timings.sdc, στον κατάλογο του project, στο οποίο ορίζουμε τη συχνότητα το ρολογιού όπως φαίνεται παρακάτω: +create_clock -period 20 [get_ports CLOCK_50]+++
Επιβεβαιώστε την ορθή λειτουργία της υλοποίησης.
Σε αυτήν την άσκηση θα γίνει εισαγωγή στον σχεδιασμό ενσωματωμένου συστήματος σε προγραμματιζόμενο chip χρησιμοποιώντας το εργαλείο Altera Qsys System Integration Tool και το Altera Program Monitor. Η διαδικασία του σχεδιασμού χωρίζεται σε δύο στάδια:
Hardware Development
Software Development
Μέχρι στιγμής έχουμε δει τον κλασσικό τρόπο σχεδιασμού ψηφιακών κυκλωμάτων. Μπορούμε να χρησιμοποιήσουμε τις ίδιες μεθόδους για να κατασκευάσουμε ένα ενσωματωμένο σύστημα. Ωστόσο, όσο η πολυπλοκότητα των συστημάτων αυξάνεται, γίνεται δύσκολο και χρονοβόρο να κατασκευάσουμε οτιδήποτε από το μηδέν. Θα εξετάσουμε μία μέθοδο που χρησιμοποιεί προσχεδιασμένα modules από την Altera για να διευκολύνουμε τον σχεδιασμό και την διαδικασία υλοποίησης. Αυτά τα προσχεδιασμένα modules είναι γνωστά ως Intellectual Property (IP) Cores. Ένα ενσωματωμένο σύστημα, γενικά αποτελείται από τον επεξεργαστή, την μνήμη και τα υποστηριζόμενα περιφερειακά.
Στην καρδιά ενός ΕΣ υπάρχει ένας (ή μπορεί και περισσότεροι) επεξεργαστής ο οποίος εποπτεύει και διαχειρίζεται τις κύριες διεργασίες που απαιτούνται. Σε αυτό το εργαστήριο θα χρησιμοποιήσουμε τον Nios II της Altera. Ο επεξεργαστής Nios II αποτελεί ιδιοκτησία της Altera και είναι ειδικά σχεδιασμένος και υλοποιημένος για τις FPGA της Altera. Ο Nios II είναι ένας soft-processor (επεξεργαστής μαλακού πυρήνα) επειδή έχει δημιουργηθεί με χρήση VHDL ή Verilog. Ο επεξεργαστής μπορεί να παραμετροποιηθεί, ώστε να πληρεί συγκεκριμένες απαιτήσεις και ανάγκες.
Ένα παράδειγμα ενσωματωμένου συστήματος παρουσιάζεται στο Σχήμα C.14, όπου εμφανίζεται ο παραμετροποιήσιμος επεξεργαστής μαλακού πυρήνα (soft core) της Altera NIOS II. Κατά το σχεδιασμό ενός ΕΣ συστήματος με NIOS II, ο σχεδιαστής μπορεί να προσθέσει ή αφαιρέσει ή τροποποιήσει πλήθος δομοστοιχείων (modules), προκειμένου να καλύψει τις σχεδιαστικές του ανάγκες. Για παράδειγμα, αν μια σχεδιαστική ανάγκη είναι να έχει χαμηλή επιφάνεια, τότε μπορεί να απομακρύνει όλα τα μη απαραίτητα δομοστοιχεία, ενώ αν υπάρχει ανάγκη για πράξεις με πραγματικούς αριθμούς μπορεί να προσθέσει μια μονάδα FPU (floating point unit).
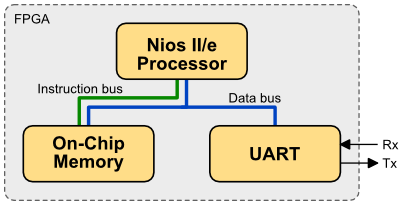
C.14: Ένα απλό ενσωματωμένο σύστημα με τον επεξεργαστή NIOS ΙΙ, τη μνήμη, και τη σειριακή διασύνδεση εισόδου εξόδου.
Το διάγραμμα μπλοκ του Nios II παρουσιάζεται στο Σχήμα C.15. Τα κύρια χαρακτηριστικά του είναι
Αρχιτεκτονική load/store 32 bit
Είσοδος/Έξοδος με απεικόνιση σε διευθύνσεις μνήμης (memory mapped)
32 επίπεδα διακοπτών
32 καταχωρητές γενικού σκοπού
Τρεις εκδόσεις με διαφορετικές δυνατότητες
Nios-II /f: fast (γρήγορος) 6 επίπεδα διασωλήνωσης, βέλτιστη απόδοση.
Nios-II /s: standard (τυπικός) 5 επίπεδα διασωλήνωσης, σχετικά καλή απόδοση.
Nios-II /e: economy (οικονομικός) 1 στάδιο διασωλήνωσης, πολύ μικρός και ελεύθερος στη χρήση (δεν απαιτείται άδεια).
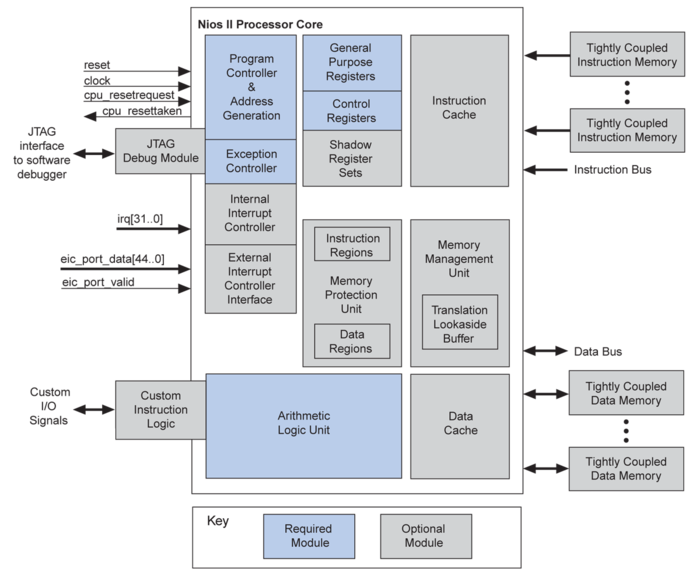
C.15: Ο μαλακός επεξεργαστής NIOS II της Altera είναι πλήρως παραμετροποιήσιμος, αφού είναι αρθρωτός.
Θα δημιουργήσουμε ένα πλήρες ΕΣ χρησιμοποιώντας το εργαλείο της Altera με όνομα ”Qsys system integration tool, QSYS” που βρίσκεται στο Quartus II. Σε αυτό το εργαστήριο, δημιουργούμε ένα βασικό ενσωματωμένο σύστημα με τον επεξεργαστή NIOS II/e, που αποτελείται από τον επεξεργαστή, μια μνήμη RAM 8KB που φέρει το πρόγραμμα, και μια σειριακή διεπαφή UART εισόδου εξόδου. Σε αυτό το εργαστήριο δεν χρησιμοποιούμε κάποιο λειτουργικό σύστημα, αλλά χρησιμοποιούμε προγραμματισμό ``γυμνού΄΄ υλικού (bare metal programming), δηλαδή δημιουργείται ο κώδικας μηχανής από το πρόγραμμά μας σε C, και ο επεξεργαστής εκτελεί άμεσα αυτόν τον κώδικα.
Τα σημαντικά βήματα αυτού του εργαστηρίου είναι:
Δημιουργία project στο Quartus.
Δημιουργία ενός NIOS II ενσωματωμένου συστήματος από το Qsys.
Δημιουργία ενός αρχείου VHDL ως σχεδιαστική κορυφή, του BSP και του προγράμματος.
Δημιουργία του συνολικού κώδικα προγραμματισμού της πλακέτας και προγραμματισμός της πλακέτας.
Το πρώτο βήμα είναι να δημιουργήσουμε ένα νέο project που αφορά την FPGA στην πλακέτα DE2-115. Δημιουργούμε ένα project για το FPGA chip που φέρει η πλακέτα μας (π.χ. EP4CE115F29C7). Στο project δεν προσθέτουμε κάποια αρχεία προς το παρόν. Θα δημιουργήσουμε την HDL περιγραφή από το πρόγραμμα QSYS, και το αρχείο της μνήμης από το SDK. Το επόμενο βήμα είναι η δημιουργία της HDL περιγραφής, το οποίο είναι απαραίτητο ώστε ο compiler να γνωρίζει τις δυνατότητες του ενσωματωμένου συστήματος. Για παράδειγμα, αν στο ενσωματωμένο σύστημα τοποθετήσουμε κάποια μονάδα FPU, τότε ο compiler θα γνωρίζει πως μπορεί να χρησιμοποιήσει εντολές FPU για πράξεις με πραγματικούς αριθμούς, και δε θα καταφύγει στην προσομοίωση με λογισμικό αυτών των δυνατοτήτων, μέσω ακέραιων πράξεων. Για αυτό, αμέσως μετά τη δημιουργία του υλικού, δημιουργείται το Board Support Package, που περιγράφει τις δυνατότητες του υλικού.
Από το μενού Tools του Quartus, επιλέγουμε το εργαλείο QSYS, που αν και δεν το αναφέρει η Altera, σημαίνει Quick System Integration, δηλαδή παρέχει έναν εύκολο τρόπο να δημιουργήσει κάποιος ένα ενσωματωμένο σύστημα με προγραμματιζόμενο επεξεργαστή. Σε αυτό το περιβάλλον, ο χρήστης επιλέγει components (κάποια είναι ελεύθερα και δωρεάν, ενώ κάποια απαιτούν ειδική άδεια) από το παράθυρο στα αριστερά με τίτλο “Component Library” και τα τοποθετεί στο παράθυρο στα δεξιά, που καταλαμβάνει το μεγαλύτερο μέρος και φέρει καρτέλες με ονόματα “System Contents”, “Address Map” κτλ. (Σχήμα C.16). Το πρώτο στοιχείο που θα προσθέσουμε είναι η onchip RAM μνήμη. Πληκτρολογήστε “On-chip memory” στο εύρεση κάτω από το component library, επιλέξτε τo δομοστοιχείο RAM or ROM, και μετά το Add ή διπλό κλικ. Στο παράθυρο ρυθμίσεων της μνήμης που θα ανοίξει αυτόματα, επιλέξτε RAM (Writable) και μέγεθος 8192. Με αυτόν τον τρόπο θα χρησιμοποιηθεί η onchip μνήμη του FPGA chip (η Altera DE2-115, έχει και 2 chip των 64 Mbytes). Στις επιλογές του Memory Initialization δε θα αλλάξουμε κάτι, επειδή δεν είναι δυνατό να δημιουργηθεί ο κώδικας μηχανής (σε μορφή hex initialization file), αφού δεν υπάρχει το board support package. Με την επιλογή Finish προστίθεται το component στο “System Contents”. Ο χρήστης μπορεί με διπλό κλικ σε ένα component να τροποποιήσει κάποια παράμετρο. Κατά την προσθήκη components, εμφανίζονται κάποια μηνύματα σφάλματος (Errors) στο κάτω παράθυρο του εργαλείου, που όμως δεν μας απασχολούν για την ώρα, αφού δεν έχει ολοκληρωθεί το σύστημα. Ως αυτό το σημείο, υπάρχουν δυο components: clk_0 και onchip_memory2_0. Τα components μπορούν με δεξί κλικ να μετονομαστούν, αλλά δεν είναι απαραίτητο.
C.16: Με το εργαλείο QSYS αυτοματοποιείται η δημιουργία ενός ενσωματωμένου συστήματος που βασίζεται σε επεξεργαστή μαλακού πυρήνα.
Το επόμενο βήμα είναι η προσθήκη του επεξεργαστή. Στο πεδίο εύρεσης components, γράψτε το nios και από τη λίστα των αποτελεσμάτων επιλέξτε το “Nios II Processor”. Ο NIOS II μπορεί να ρυθμιστεί με λίγα, ενδιάμεσα ή πολλά χαρακτηριστικά, με τις επιλογές Nios II/e, Nios II/s ή NIOS II/f αντίστοιχα. Η μόνη ελεύθερη έκδοση που δεν απαιτεί άδεια, είναι η Nios II/e, και πρέπει αυτή να επιλεγεί. Με το Finish, προστίθεται το component στην λίστα, οπότε το System Contents φέρει 3 στοιχεία: clk_0, onchip_memory2_0, nios2_qsys_0.
Το τελευταίο στοιχείο του κυκλώματος μας είναι η σειριακή διεπαφή UART. Γράψτε UART στο component library search, και επιλέξτε το UART (RS-232 Serial Port). Οι παράμετροι προεπιλογής είναι N/8/1/2 στα 115200 fixed, οπότε δεν τροποποιούνται (αν αλλάξετε κάποια από αυτές τις παραμέτρους θα πρέπει να τοποθετήσετε τις ίδιες και στο πρόγραμμα τερματικού σειριακής σύνδεσης στο τέλος της άσκησης). Επειδή θα πρέπει να συνδέσουμε αυτό το περιφερειακό σε φυσική διεπαφή, θα πρέπει να γίνει εξαγωγή ως θύρα. Επιλέξτε το external_connection του uart_0 και πατήστε στη στήλη Export (double-click to export) και θα δείτε ότι εξάγεται ως θύρα με όνομα “uart_0_external_connection”. Επίσης, θα πρέπει να συνδεθεί το interrupt request (IRQ) στον επεξεργαστή. Επιλέξτε τον επεξεργαστή, δεξί κλικ connections nios2_qsys_0.d_irq
uart_0.irq.
Σε αυτό το σημείο υπάρχουν 8 errors, επειδή δεν έχουν ολοκληρωθεί οι διασυνδέσεις. Πατήστε στη στήλη των connections σε κάθε component τη διασύνδεση με το ρολόι (clk). Με τις 3 συνδέσεις, τα λάθη έχουν μειωθεί από 8 σε 5. Ομοίως, συνδέστε το clk_reset με το αντίστοιχο reset. Με τις νέες 3 συνδέσεις τα λάθη έχουν μειωθεί σε 2. Το data_master και το instruction_master του επεξεργαστή πρέπει να συνδεθεί στη θύρα s1 της μνήμης, όπως και το s1 της uart_0 με το data_master του επεξεργαστή, και με το s1 της μνήμης. Πατήστε διπλό κλικ στον επεξεργαστή, και στη συνέχεια στο Reset Vector όπως και στο Exception Vector, επιλέξτε στο πεδίο vector memory onchip_memory2_0.s1. Πατήστε finish. Επίσης, ο επεξεργαστής μας έχει το JTAG που θα πρέπει να συνδεθεί σε κάθε περιφερειακό για την εύκολη αποσφαλμάτωση. Οπότε, συνδέστε το jtag_debug_module_reset του επεξεργαστή στις θύρες reset των στοιχείων uart_0, nios2_qsys_0 και onchip_memory2_0. Το ίδιο μπορεί να επιτευχθεί και από το μενού SystemCreate Global Reset Network. Επίσης, για λόγους αποσφαλμάτωσης θα προσθέσουμε και το περιφερειακό JTAG UART (ώστε να έχουμε εύκολη πρόσβαση εισόδου/εξόδου για την αποσφαλμάτωση του λογισμικού). Στο περιφερειακό αυτό, συνδέετε το clk και το reset, ενώ το avalon_jtag_slave συνδέεται στο δίαυλο δεδομένων (data) που καταλήγει στη θύρα s1 της μνήμης εντός ολοκληρωμένου κυκλώματος. Επίσης, στη στήλη IRQ θα πρέπει να γίνει η σύνδεση με το κανάλι IRQ του επεξεργαστή, οπότε η κατανομή των IRQ είναι η εξής: το περιφερειακό UART λαμβάνει το IRQ0, ενώ το JTAG UART λαμβάνει το IRQ1. Σε αυτό το σημείο έχουμε 4 σφάλματα, τα οποία οφείλονται σε συγκρούσεις διευθύνσεων. Κάθε στοιχείο του συστήματος θα πρέπει να βρίσκεται σε μια ξεχωριστή και μοναδική διεύθυνση. Με την επιλογή System
assign base addresses, αυτοματοποιείται η ανάθεση των πόρων. Τα σφάλματα και οι προειδοποιήσεις έχουν μειωθεί στο 0 (Σχήμα C.17).
C.17: Η τελική μορφή του απλού ενσωματωμένου συστήματος.
Αποθηκεύστε το project στο QSYS στον κατάλογο του κεντρικού project στο Quartus και στη συνέχεια αποεπιλέξτε το Generate από την καρτέλα Generation. Μετά από λίγη ώρα θα δημιουργηθεί ένα αρχείο qip στον υποκατάλογο synthesis που βρίσκεται ως υποκατάλογος σε ένα κατάλογο που φέρει το όνομα του QSYS project. Μπορείτε να κλείσετε το εργαλείο QSYS.
Το λογισμικό αλληλεπιδρά με τις συσκευές I/O μέσω των memory - mapped καταχωρητών. Σε αυτό το σχήμα, οι καταχωρητές ελέγχου και Ε/Ε μιας συσκευής απεικονίζονται στον χώρο διευθύνσεων της κύριας μνήμης. Τα Software Programs μπορούν να γραφούν σε ASSEMBLY ή σε C. Θα χρησιμοποιήσουμε τη γλώσσα C σε αυτήν την εργασία. Για να επικοινωνήσουν περιφερειακά και συσκευές στα συστήματα, θα προσπελάσουμε τους καταχωρητές τους. Από τη στιγμή που αυτοί οι καταχωρητές απεικονίζονται στον χώρο διευθύνσεων της μνήμης του συστήματος, θα γίνει εκτενής χρήση των C pointers.
Με την μέθοδο πρόσβασης χαμηλού επιπέδου, οι διευθύνσεις μνήμης που έχουν αντιστοιχηθεί στους καταχωρητές των συσκευών Ε/Ε στο Qsys Tool μπορούν να θεωρηθούν ως τιμές των pointer. Έτσι εμείς μπορούμε να χρησιμοποιήσουμε τις μεταβλητές-pointers για να χειριστούμε τους καταχωρητές. Για παράδειγμα το Σχήμα C.17 φαίνεται η βασική διεύθυνση της σειριακής θύρας είναι η 0x5000.
Οι δηλώσεις:
volatile char* uart=0x0005000;
volatile char* switches=0x0003000;
volatile char* ledg=0x0003010;ορίζουν τρεις pointers που δείχνουν σε περιοχές τύπου δεδομένων char (8 bits). Η λέξη volatile γνωστοποιεί στον μεταγλωττιστή ότι η τιμή του αντικειμένου μπορεί να τροποποιηθεί χωρίς την επέμβαση του επεξεργαστή και για αυτό δεν πρέπει να γίνουν βελτιστοποιήσεις. Εναλλακτικά, το QUARTUS δίνει τη δυνατότητα να χρησιμοποιηθούν pre-defines για τις διευθύνσεις, ώστε αν κάποια στιγμή τροποποιηθούν οι διευθύνσεις βάσης κάποιου περιφερειακού, να μη χρειάζεται να τροποποιηθεί ο κώδικας C, απλώς να γίνει ένα νέο compile. Για παράδειγμα, η διεύθυνση βάσης της σειριακής θύρας UART_0 μπορεί να χρησιμοποιηθεί ως + volatile uint32_t *uart = (volatile uint32_t*) UART_0_BASE;+++ Έτσι, αν αλλαχθεί κάποια στιγμή η διεύθυνση της σειριακής θύρας, αρκεί μια νέα μεταγλώττιση του πηγαίου προγράμματος σε C και θα λειτουργεί απρόσκοπτα. Οι διευθύνσεις αυτές δημιουργούνται κατά την παραγωγή του board support package, με το BSP Generate, όπως θα δούμε σε επόμενη παράγραφο, και τοποθετούνται στο αρχείο system.h που βρίσκεται μέσα στον υποκατάλογο του bsp, που βρίσκεται μέσα στον κατάλογο software του Project μας. Μπορείτε να ανοίξετε το system.h με έναν επεξεργαστή κειμένου και να δείτε όλα τα defines. Για να χρησιμοποιήσετε αυτά τα defines, θα πρέπει ασφαλώς να έχετε μια γραμμή + #include “system.h” +++ στο αρχείο σας.
Βασική Αρχιτεκτονική Προγράμματος σε C Η απλούστερη αρχιτεκτονική ελέγχου, όπως έχουμε δει στη θεωρία, είναι ένας ατέρμων βρόχος στον οποίο οι διεργασίες εκτελούνται ακολουθιακά. Ο κώδικας ενός βασικού προγράμματος σε C είναι:
main() {
//initialization
while (1) //infinite loop {
task_1();
task_2();
.
.
.
task_n();
}
}Το σύστημα αρχικοποιείται μία φορά στην αρχή του προγράμματος. Έπειτα, η κάθε διεργασία εκτελείται με την σειρά. Σε αυτό το παράδειγμα το πρόγραμμα δεν τερματίζεται ποτέ.
Με την επιλογή generate δημιουργείται ένα αρχείο qip (q intellectual property) στον υποκατάλογο synthesis, που βρίσκεται στον υποκατάλογο που φέρει το όνομα του QSYS project. Στο Quartus Project Navigator, περιοχή Files, προσθέστε το qip αρχείο που έχει δημιουργηθεί. Επίσης, πατήστε δεξί κλικ και Set as Top Level Entity, για να ρυθμίστε τη σχεδιαστική κορυφή.
Το επόμενο βήμα είναι να δημιουργηθεί το αρχείο περιγραφής του υλικού (board support package), ώστε να γνωρίζει ο συμβολομεταφραστής τις δυνατότητες του συστήματος. Αυτό επιτυγχάνεται από το μενού ToolsNios II Software Build Tools for Eclipse. Την πρώτη φορά που θα εκτελεστεί το εργαλείο θα σας ζητηθεί η επιλογή του workspace. Μπορείτε να το αφήσετε ως προεπιλογή, αφού δε θα χρησιμοποιηθεί.
Στο πρόγραμμα του Eclipse (Εικόνα C.18) δημιουργείται η BSP περιγραφή από το μενού FileNew
Nios II Application and BSP from Template και τοποθετήστε το SOPC file και ένα όνομα για το project. Πατήστε finish (και όχι Next) και θα δημιουργηθούν όλα τα κατάλληλα αρχεία, τόσο για την εφαρμογή όσο και το BSP (Εικόνα C.19).
Για να ρυθμίσουμε καλύτερα τις προδιαγραφές της αρχιτεκτονικής, θα επιλέξουμε το BSP με δεξί κλικ, και από το αναδυόμενο μενού θα ακολουθήσουμε το NIOS IIBSP Editor. Στο νέο παράθυρο θα απλοποιήσουμε το BSP ( επομένως και τον κώδικα που θα καταλαμβάνει το τελικό αρχείο αρχικοποίησης της μνήμης) με το να επιλέξουμε το settings και να επιβεβαιώσουμε ότι υπάρχουν tick επιλογής μόνο στις παρακάτω ρυθμίσεις:
enable_lighweight_device_driver_api
enable_reduced_device_drivers
enable_small_c_library
allow_code_at_reset
Τέλος, θα πρέπει το stderr, stdin, stdout να έχουν την επιλογή jtag_uart_0 (ή αν έχετε σειριακό καλώδιο null modem συνδεδεμένο στον υπολογιστή, την επιλογή uart_0), ώστε να εμφανίζονται τα μηνύματα σε μια συσκευή εξόδου. Πατήστε το GENERATE και μετά το EXIT.
Όπως μπορείτε να καταλάβετε, η εφαρμογή αυτή εκτυπώνει το μήνυμα Hello from NIOS II στη σειριακή θύρα, κάτι που φαίνεται στο αρχείο hello_world.c. Πατήστε ProjectBuild ALL για να δημιουργηθεί και το BSP και το πρόγραμμα Hello World. Επίσης, απαιτείται η δημιουργία του αρχείου αρχικοποίησης της μνήμης. Πατήστε δεξί κλικ στο όνομα του subproject για το hello world (όχι το subproject για το BSP), και Make Target
Build
mem_init_generate και μετά build. Αυτό θα δημιουργήσει ένα αρχείο με κατάληξη hex μέσα στον υποκατάλογο του project mem_init, το οποίο θα πρέπει να ενσωματωθεί στον κώδικα προγραμματισμού της πλακέτας.
Μεταβείτε στο Quartus, και προσθέστε στα αρχεία, το αρχείο αρχικοποίησης της μνήμης από τον κατάλογο software, υποκατάλογος mem_init μέσα στον φάκελο του project λογισμικού (όχι του BSP). Το File of type, πρέπει να έχει την επιλογή Memory Files (*.mif, *.hex).
Το επόμενο βήμα, είναι η τοποθέτηση των περιορισμών. Όπως και στα προηγούμενα εργαστήρια, δημιουργήστε ένα αρχείο sdc (Synopsis Design Constraints File) μέσα στο φάκελο του project, που να ρυθμίζει ένα ρολόι των 40Mhz με τις γραμμές:
create_clock -name {clk} -period 40.000 -waveform { 0.000 20.000 } [get_ports {clk_clk}]
derive_clock_uncertaintyΜόλις αποθηκευτεί το αρχείο .sdc στον κατάλογο του project, θα προστεθεί στη λίστα των αρχείων του project. Σε αυτό το σημείο η λίστα των αρχείων θα αποτελείται από τρεις καταχωρήσεις: Το αρχείο του επεξεργαστή, το αρχείο αρχικοποίησης μνήμης και το αρχείο των σχεδιαστικών περιορισμών. Το τελευταίο βήμα είναι η σύνδεση των ακροδεκτών.
Για να βρεθούν οι ακροδέκτες που απαιτούνται να συνδεθούν, πρέπει το Quartus να ολοκληρώσει τη διαδικασία του elaboration. Αυτό επιτυγχάνεται με ProcessingStart
Start Analysis and elaboration.
Στη συνέχεια, από το μενού AssignmentsPin Planner θα εμφανιστεί μια οθόνη με τους ακροδέκτες. Από το αρχείο csv βρίσκουμε τις γραμμές που μας αφορούν, δηλαδή τις παρακάτω γραμμές:
CLOCK_50,Input,PIN_Y2,2,B2_N0,3.3-V LVTTL,
KEY[0],Input,PIN_M23,6,B6_N2,2.5 V,
UART_RXD,Input,PIN_G12,8,B8_N1,3.3-V LVTTL,
UART_TXD,Output,PIN_G9,8,B8_N2,3.3-V LVTTL,Από το εργαλείο pin planner, γίνεται η αντιστοίχηση των λογικών ακροδεκτών του ενσωματωμένου συστήματος με τους φυσικούς ακροδέκτες της πλακέτας (Εικόνα C.20). Μόλις ολοκληρωθεί η αντιστοίχηση, από το ProcessingStart Compilation, δημιουργείται το αρχείο ρυθμίσεων της επαναδιαμορφώσιμης αρχιτεκτονικής (bitstream), το οποίο στη συνέχεια θα μεταφερθεί στην πλακέτα από το Program Device (Open Programmer).
Να σημειωθεί ότι αν γίνει κάποια αλλαγή στο QSYS, π.χ. προστεθεί κάποιο component, και γίνει πάλι generate, τότε θα πρέπει στο eclipse να ξαναδημιουργηθεί το BSP. Αυτό επιτυγχάνεται με το να επιλεχθεί το BSP subproject, και στη συνέχεια δεξί κλικ, επιλογή NIOS IIGenerate BSP. Στη συνέχεια, δεξί κλικ στο project και επιλογή Build this project. Ασφαλώς μετά θα πρέπει να γίνει build και το λογισμικό μας (build this project, αφού επιλεχθεί το project του λογισμικού), όπως και το αρχείο αρχικοποίησης της μνήμης.
C.20: Στο Pin Planner πρέπει να γίνει η αντιστοίχηση των ακροδεκτών.
Επίσης, από τη στιγμή που θα δημιουργηθεί το hardware με υποστήριξη JTAG μπορείτε μέσα από το περιβάλλον του Eclipse να μεταφορτώνετε τον κώδικα άμεσα στο FPGA, χωρίς να χρειάζεται να δημιουργήσετε ένα νέο bitstream. Αρκεί να επιλέξετε από το Eclipse το hardware και μετά Run as ή Debug as και επιλογή NIOS II Hardware. Βέβαια για να μπορεί να γίνει αυτό θα πρέπει να έχετε επιλέξει στο Run as Run Configuration το Refresh Connection για να βρεθεί το hardware και μετά να έχετε ενεργοποιημένες τις επιλογές “Ignored mismatched System ID” και “Ignored mismatched System timestamp”, γιατί απαιτούν δυνατότητες από το hardware που δεν έχουν συμπεριληφθεί.
Εκτός από το πρόγραμμα hello world, μπορείτε να χρησιμοποιήσετε και το πρόγραμμα C.6.3 στο οποίο εκτυπώνονται ταυτόχρονα και στην τυπική έξοδο του JTAG αλλά και στο παράθυρο τερματικού (Εικόνα C.21) Σε περίπτωση που χρησιμοποιήσετε σειριακό καλώδιο, θα πρέπει να γνωρίζετε ότι η θύρα της Altera DE2-115 είναι μία θύρα σειριακή τύπου DTE (data terminal equipment) σε FEMALE υποδοχή (συνήθως οι DTE χρησιμοποιούν MALE υποδοχές, οπότε δημιουργείται κάποια σύγχυση σε αυτό το σημείο), ίδιου τύπου με τη σειριακή θύρα του PC. Για να συνδεθεί μια θύρα DTE με DTE, θα πρέπει να χρησιμοποιηθεί ένα cross-over serial cable ή αλλιώς null modem cable. Αν χρησιμοποιηθεί ένα απλό καλώδιο serial Male-Female δε θα εμφανιστεί τίποτα στην οθόνη, γιατί αυτό το καλώδιο χρησιμοποιείται για σύνδεση σειριακής θύρας τύπου DTE με τύπου DCE (data computing equipment). Μπορείτε επίσης να προσθέσετε και τους ακροδέκτες CTS/RTS στο UART (από το QSYS) για να έχετε καλύτερο έλεγχο της ροής των δεδομένων (για να μη γίνει υπερχείλιση κάποιου buffer, αν μεταφέρονται πολλά δεδομένα), οπότε θα πρέπει να κάνετε και τη αντίστοιχη συσχέτιση των 2 επιπρόσθετων ακροδεκτών στο pin planner.
#include <stdio.h>
#include <stdint.h>
#include "system.h"
int main()
{
int delay;
char *str = "Hello Serial from NIOS II\n";
volatile uint32_t *uart = (volatile uint32_t*) UART_0_BASE;
printf("Start Printing to Serial Port");
while (1)
{
printf("New Iteration\n");
char *ptr = str;
while (*ptr != '\0')
{
while ((uart[2] & (1<<6)) == 0);
uart[1] = *ptr;
ptr++;
}
//add a little delay
delay=0;
while (delay<2000000)
{
delay++;
}
}
return 0;
}[alteralistingserial]
C.21: Έξοδος του προγράμματος σε ένα τερματικό σειριακής οθόνης.
Βασιζόμενοι στις δεξιότητες που αποκομίσατε από τις προηγούμενες εργαστηριακές ασκήσεις, καλείστε να υλοποιήσετε ένα ενσωματωμένο σύστημα που βασίζεται στο NIOS επεξεργαστή, και χρησιμοποιεί εκτός από τα προηγούμενα στοιχεία και το στοιχείο PIO (Parallel I/O). Θα προσθέσετε αυτό το στοιχείο 2 φορές: μία για είσοδο και μία για έξοδο ενώ θα το ρυθμίσετε στα 8 bit. Η 8 bit είσοδος θα συνδεθεί σε 8 διακόπτες SW[0] έως SW[7], ενώ η 8 bit έξοδος θα συνδεθεί σε 8 led: LEDR[0] έως LEDR[1]. Η μνήμη RAM του συστήματος θα ρυθμιστεί σε 32KB.
Σε αυτό το παράρτημα παρατίθενται για λόγους πληρότητας, τα ακρωνύμια που έχουν χρησιμοποιηθεί σε αυτό το βιβλίο.
3rd Generation Mobile Network
Antilock Breaking System
Adaptive Cruise Control
Advanced Configuration and Power Interface
Accelerated Graphics Port
Advanced High-performance Bus
Arithmetic Logic Unit
Advanced Microcontroller Bus Architecture
Advanced Micro Devices
Advanced Programmable Interrupt Controller
Acorn RISC Machine/Advanced RISC Machines
Application-Specific Integrated Circuit
Application-Specific Instruction set Processor
Application-Specific Standard Product
AVR In-System Programming
Ball Grid Array
Basic Input/Output System
bits per second
Binary Space Partitioning
Computer-Aided Design
Computer-Aided Manufacturing
Controller Area Network
Ceramic Dual-In Line Package
Complex Instruction Set Computing
Clear Interrupt
Complementary Metal-Oxide Semiconductor
Common Object File Format
Complex Programmable Device
Central Processor Unit
Cascade Voltage Switch Logic
Digital-to-Analog converter
Direct Current
Double Data Rate
Dynamic Data Types
Digital Equipment Corporation
Data Encryption Standard
Dynamic Host Configuration Protocol
Dual In Line Package
Direct Memory Access
Dynamic Memory Management
Dynamic Random-Access Memory
Deficit Round Robin
Digital-Signal Processor
Engine Control Unit
Electronic Design Automation
Electrical Erasable Programmable Read-Only Memory
Extended Industry Standard Architecture
Executable and Linkable Format
Electronic Numerical Integrator And Computer
Erasable Programmable Memory
Erasable Programmable Read-Only Memory
Forward Collision Warning
First In First Out
Field Programmable Gate Arrays
GigaByte
GNU C Compiler
GNU Debugger
General-Purpose Input/output
Global Positioning System
Global System for Mobile Communications
High Bandwidth-Memory
Hardware Description Language
High-Definition Multimedia Interface
Hue, Saturation and Brightness
Inter-Integrated Circuit
International Business Machines Corporation
Integrated Circuit
In-Circuit Programming
Integrated Drive Electronics
Institute Of Electrical and Electronics Engineers
Intellectual Property
Instruction Register
Interrupt ReQuest
Industry Standard Architecture
In-system programming
Interrupt Service Request
Intermediate Variable Removal
Join Test Action Group
Local Area Network
Liquid Crystal Display
Lane Departure Warning
Light-Emitting Diode
Last In First Out
Low Power
Low Power Double Data Rate Synchronous DRAM
Least Significant Bit
Large Scale Integrated
Look Up Table
Low-voltage differential signaling
Low Voltage Transistor Transistor Logic
MegaByte
Micro Channel Architecture
Master Controller Processor Unit
Mega Hertz
Malfunction Indication Lamp
MicroProcessor without Interlocked Pipeline Stage
Multi level cell
Memory Management Unit
Message Passing Interface
MicroProcessor Unit
Most Significant Bit
Medium Scale Integrated
Model-Specific Register
MUltipleXer
Negative-AND gate
Network Byte Order
Native Bit Width
Non Recurrent Engineering cost
Open Multimedia Application Platform
Operating System
One Time Programmable
Park Assist System
Parallel AT Attachment
Peripheral Component Interconnect eXtended
Personal Computer
Peripheral Component Interconnect
Peripheral Component Interconnect Express
Personal Digital Assistant
Dual In-line Package
Program Data Processor-1
Processing Elements
Pin Grid Array
Parallel Hierarchical One-Dimensional Search
Programmable Logic Device
P-type Metal-Oxide-Semiconductor
Power PC
Programmable Read-only Memory
Programmable System On Chip
Pulse Width Modulation
Quadruple in-line
Random-Acess Memory
Rambus Dynamic Random Access Memory
Red Green Blue
Reduced Instruction Set Computer
Read-Only Memory
Radio Sector Standard 422
Real-Time Clock
Register Transfer Level
Real-Time Operating System
Read/Write
Receiver mode/Transmission mode
Serial AT Attachment
Single Board Computer
Small Computer System Interface
Synchronous Dynamic Random Access Memory
Signal:Abort
Single Instruction Multiple Data
System Management Bus
Symmetric Multi Processing
System On Chip
System on Chip Dynamic Memory Management
Skinny Dual In Line Packaging
Single pole, double throw
Serial Peripheral Interface
Single Program Multiple Data
Static Random Access Memory
Small Scale Integrated
Synchronous Serial Interface
Set Interrupts
System on a Programmable Chip
Transmission Control Protocol/Internet Protocol
Thumb Instruction Debugger Multiplier
Transaction Level Modeling
Time Pressure Monitoring System
Transistor-Transistor Logic
Universal Asynchronous Receiver/Transmitter
Unified Modeling Language
Universal Serial Bus
VHSIC Hardware Description Language
Very High Speed Integrated Circuit
Very Long Instruction Word
Very Large Scale Integration
Voice Over Internet Protocol
Worldwide Interoperability for Microwave Access
Wireless Fidelity
eXternal Data Representation
Micro Controller
Σε αυτό το παράρτημα παρατίθενται για λόγους πληρότητας, οι αντιστοιχίες των αγγλικών όρων με τους ελληνικούς που χρησιμοποιήθηκαν (ή θα χρησιμοποιηθούν στην επόμενη έκδοση).
|p0.4||p0.6| 0,25-micron CMOS & τεχνολογία 0,25μ CMOS
10x longer & 10 φορές περισσότερο
API & προγραμματιστική διεπαφή εφαρμογής
ASIC & ολοκληρωμένα κυκλώματα ειδικού σκοπού εφαρμογών
Altera DE-series board & πλακέτα της σειράς Altera DE
Byte-lane selections & επιλογές ανά γραμμή Byte
CMOS Multidrain Logic & λογική CMOS πολλαπλών υποδοχών
Cascade Voltage Switch Logic - CVSL & διαδοχική λογική διακοπτικής τάσης
Commercially licensed IP cores & εμπορικοί πυρήνες πνευματικής ιδιοκτησίας
FLOPS & πράξεις κινητής υποδιαστολής ανά δευτερόλεπτο
FPGA & προγραμματιζόμενες συστοιχίες πυλών στο πεδίο
Finite State Machine & μηχανή πεπερασμένων καταστάσεων
Hardware Description Language & γλώσσα περιγραφής υλικού
Integrated Development Environments (IDE) & ολοκληρωμένα αναπτυξιακά περιβάλλοντα
Interrupt Descriptor Table & πίνακας περιγραφής διακοπής
Karnaugh map & χάρτης Karnaugh
LCD real estate & επιφάνεια χρήσης του LCD
MPI communicator & επικοινωνιοφορέας MPI ή αντικείμενο επικοινωνίας MPI
Maskable ROM & ROM που μπορεί να χρησιμοποιήσει μάσκα
Maverick Lock & κλείδωμα τύπου Maverik
Message Passing Protocols & πρωτόκολλα μεταβίβασης μηνυμάτων
Message passing routines & ρουτίνες μεταβίβασης μηνυμάτων
Non-reentrant code & μη επαναεισαγόμενος κώδικας
Post Metal Programming & προγραμματισμός μετά την υλοποίηση
Register Transfer Level, RTL & επίπεδο μεταφοράς καταχωρητών
Schedulability & ικανότητα χρονοπρογραμματισμού
UNIX pipe & διασωλήνωση διεργασιών UNIX
Unsynthesisable & μη συνθέσιμη
shield & πλακέτα επέκτασης [..arduino..]
a priory & εκ των προτέρων
abstract level & αφαιρετικό επίπεδο
abupt junction & απότομη επαφή
acceptor & αποδέκτης
accumulation & συσσώρευση
address register & καταχωρητής διεύθυνσης
addressable & μπορεί να διευθυνσιοδοτηθεί
allocating and deallocating & δέσμευση και αποδέσμευση
aluminum & αλουμίνιο
animation & κινησιομοίωση ή ψηφιακά κινούμενα σχέδια
annihilation gate & πύλη εξολόθρευσης
annotation method & τεχνική υποσημειώσεων
appendix & παράρτημα
application-specific & συγκεκριμένης εφαρμογής
arbiter & κριτής
arbitration & διαιτησία
area & επιφάνεια
argument & όρισμα [αν αναφερόμαστε σε προγράμματα]
arithmetic product & αριθμητικό γινόμενο
array & διάταξη
assemble & συμβολομετάφραση (για το compile)
assembler & συμβολομεταφραστής
assembly & συμβολική γλώσσα
assert & ύψωση
asynchronous resettable latch & ασύγχρονος επαναφερόμενος μανδαλωτής
atomics, atomic operations & ατομικές λειτουργίες
augmented & αυξημένο
automatic test pattern generation & αυτόματη δημιουργία διανυσμάτων δοκιμών
avalanche breakdown & χιονοστιβάδα
back annotation & επαναπροσδιορισμός παραμέτρων σχεδίασης
back-end & τελικής επεξεργασίας
back-gate coupling & σύζευξη στην πλάτης της πύλης
back-to-back & σύνδεση εξόδου σε είσοδο
backed & υποστηρίζεται από
background & υπόβαθρο
backtrace & οπίσθια ιχνηλάτιση
backwards and forwards & οπίσθια και εμπρόσθια
ball grid array & σφαιρικό πλέγμα πίνακα
bandwidth & εύρος ζώνης
bank conflict & σύγκρουση πρόσβασης συστοιχίας
barrel processor & κυλινδρικός επεξεργαστής
barrel shifter & ολισθητής τύπου “βαρελιού”
base & βάση
baseband & βασικής ζώνης
batch operation & λειτουργίες δεσμίδας
batches & δεσμίδες
battery attack & στοχεύει στη μπαταρία
become the bottleneck & λαιμόκοψη
behavioral & συμπεριφορά
behavioural level & επίπεδο συμπεριφοράς
benchmarks & μετροπρογράμματα
binary file & δυαδικό αρχείο
bind & σύνδεση
bipolar integrated injection logic & διπολική ολοκληρωμένη λογική έγχυσης
bipolar & διπολικά
bit lanes & γραμμές των bit
bit-reversals & αντιστροφές bit
blocking communication & δεσμευτική επικοινωνία
board & πλακέτα, τυπωμένο κύκλωμα
boards & πλακέτες
body effect & φαινόμενο σώματος
bond-out & ακροδέκτης
bootstrap & αρχικοποίηση
bootstrap merge & συγχώνευση αρχικοποίησης
bootstrapping & φυλακισμένο φορτίο
bounce & κλυδωνισμός
bound & δεσμευμένος
branch & διακλάδωση
breadboard & προτυποποιημένη πλακέτα
broadcast & ευρεία εκπομπή (ή ευρυεκπομπής)
broken version & προβληματική έκδοση (όχι σπασμένη)
bubble-pushing & ώθηση φούσκας
buffer & προσωρινή μνήμη, απομονωτική βαθμίδα, απομονωτής
buffered & αποθηκευμένο σε προσωρινή μνήμη
buffering & αποθηκεύεται σε προσωρινή μνήμη
bugs & σφάλματα
building block & δομικό στοιχείο
built-in & ενσωματωμένος
bulk & κύρια σώμα, μάζα
burn-in & καυτή λειτουργία.
burst transaction & μεταφορά ριπής
bursts modes & ρυθμοί ριπής
bus specifications & προδιαγραφές διαύλου
bus standards & πρότυπα διαύλων
bus systems & δίαυλοι συστήματος
bus wrappers & συσκευαστές διαύλου
bus & διάδρομος
busy wait & ενεργός αναμονή
byte-stream & ροή από Bytes
cache constant memory & κρυφή μνήμη σταθερών
cache hit & επιτυχία κρυφής μνήμης
cache line & γραμμή κρυφής μνήμης
cache miss & αστοχία κρυφής μνήμης
cached & σκιώδη αντίγραφα ή αντίγραφα στην κρυφή μνήμη
capacitance & χωρητικότητα
carrier & φορέας
carry look ahead adder & αθροιστής πρόβλεψης κρατουμένου
cell & κύτταρο
cellular & κυψελωτό , κύτταρο
charge neutrality & ουδέτερη φόρτιση
charge sharing noise & θόρυβος από κοινά φορτία
charge sharing & διαμοιρασμού φορτίου
charge sharing & διαμοιρασμός τάσης
checksum & άθροισμα ελέγχου
child & παιδί
chip & ολοκληρωμένο κύκλωμα
clock domain & περιοχή ρολογιού
clock race & συναγωνισμός ρολογιού
clocked circuits & κυκλώματα με διαφορετικές καταστάσεις ρολογιού
clocked deracer & χρονισμένος αποσυναγωνιστής
clocked transistor & χρονισμένο τρανζίστορ
clocking & ρολόι
cluster & συστοιχία
co-synthesis & συ-σχεδιασμός
coalesced & συνεχόμενες και ενιαίες
coalescing & συγχώνευση
coarse grain architecture & χρονοδροκομένη αρχιτεκτονική
coarse-grained & αδρόκοκκος / αδροκοκκιότητα
coarse & αδρά
codebase & προγραμματιστική βάση
codec & κωδικοποιητής
codesign / co-design & συσχεδιασμός
collector & συλλέκτης
column-wise accesses & προσβάσεις ανά στήλη
command prompt & προτροπή εντολών
commit history & ιστορικό τροποποιήσεων
common Mode Gain & κοινός τύπος κέρδους
common Mode Rejection Ratio & λόγος απόρριψης κοινού τύπου
compilation & συμβολομετάφραση
compiler based run-time bounds checking & έλεγχοι του μεταγλωττιστή για τα όρια, κατά το χρόνο εκτέλεσης
compiler & μεταγλωττιστής
complementary & συμπληρωματικός
completion & ολοκλήρωση
component & συστατικό
compound gates & σύνθετες πύλες
compute-accelerator & υπολογίζω-επιταγχύνω
compute-intensive & εντατικών υπολογισμών
concurrency model & μοντέλο ταυτοχρονισμού
concurrent software & ταυτόχρονα προγράμματα
conditional keeper & εξαρτώμενος διατηρητής
conductor & αγωγός
conent-addressable memories (CAMs) & διευθυνσιοδοτούμενες από το περιεχόμενο
configuration & ρυθμίσεις
conjunction & ένωση
connection stub & υποδοχή σύνδεσης
connectivity & συνδετικότητα
constant memory & μνήμη σταθερών
constant propagation & διάδοση σταθεράς
consumption & κατανάλωση
contact & επαφή
contamination delay & καθυστέρηση μόλυνσης
contamination & μόλυνση
contention current & ρεύμα συναγωνισμού
contributors & συνεισφέροντες
control logic & λογική ελέγχου
control & έλεγχος
core-dump & αποθήκευση μνήμη πυρήνα
corners & γωνίες
coupling & σύζευξη
cracker & κακόβουλος χρήστης
crash & κατάρρευση
criss-crossed & διασταυρωμένες
critical paths & κρίσιμα μονοπάτια
cross-compile & ετερομεταγλωτιστής
cross-couple & διαζευγμένο
cross-debugger & εκσφαλμάτωση σε άλλη αρχιτεκτονική, ετερο-αποσφαλματωτής
cross-hatch & διαγραμμισμένο
cross-section & διατομή, εγκάρσια τομή
cross-verify & επιβεβαίωση
crossover & διασταύρωση
crowd-funding & ανώνυμη συμμετοχική χρηματοδότηση
current-starved inverter & αντιστροφέας απορρόφησης ρεύματος
custom design & ειδική σχεδίαση
custom & ειδικής λειτουργίας
cut off & αποκοπή
cut-off region & περιοχή αποκοπής
cycle-budget & προϋπολογισμός κύκλων
daemon & δαίμονας
daemon process & διεργασία δαίμονα
datapath & χειριστής δεδομένων
datapaths & δίαυλοι δεδομένων
daytime client/server & πελάτης/διακομιστής ώρας και χρόνου
deallocation & ελευθέρωση
dedicated logic & αφοσιωμένη λογική
demand-paging & σελιδοποίηση κατά απαίτηση
depletion & αραίωση
deposition & απόθεση
deprecated & απαρχαιωμένο
descriptor & περιγραφέας
design diversity & σχεδιαστική ποικιλομορφία
design house & οίκος σχεδιασμού
design-rule checker & ελεγκτής κανόνων σχεδιασμού
developer & δημιουργός, προγραμματιστής
device switch table & πίνακας μεταγωγής συσκευών
device & συσκευή
die & ψηφίδα
differential Gain & διαφορικό κέρδος
differential inverter & διαφορικός αντιστροφέας
differential keeper & διαφορικός διατηρητής
differential & διαφορικός
diffs & διαφορές
diffusion & διάχυση
dimmer & ρεοστάτης φωτισμού
dirty & ακάθαρτo
dispatcher & αποστολέας
dissipation & κατανάλωση
distributed-processing chip-building techniques & τεχνικές κατασκευής chip κατανεμημένης επεξεργασίας
documentation & τεκμηρίωση
domain-specific & συγκεκριμένης περιοχής
domain & πεδίο
domino effect & φαινόμενο διαδοχικής επίδρασης
done signal & σήμα ετοιμασίας
donor & δότης
dopants & υλικά νόθευσης ημιαγωγού
doping & νόθευση
dotted-decimal & δεκαδικό με τελεία (ή τελείες)
downstream debugging & συρρευματική αποσφαλμάτωση
drain & υποδοχέας
drift & ολισθαίνω
dual-rail & διπλής γραμμής
dummy & εικονικός
dump & αποθήκευση, διατήρηση
dynamic Scheduling Policies & πολιτικές δυναμικού χρονοπρογραμματισμού
dynamic best effort & δυναμικός χρονοπρογραμματισμός καλύτερου φόρτου
dynamic planning based approach & προσέγγιση του καλύτερου δυναμικού σχήματος
earliest Deadline First & χρονοπρογραμματισμός της συντομότερης προθεσμίας
echo & διεργασία ηχούς
edge-triggered register & ακμοπυροδότητος καταχωρητής
edges & ακμές
effective current & ενεργό ρεύμα
effective resistance & φαινομενική αντίσταση
electric current & ηλεκτρικό ρεύμα
electro-mechanical strike plate & ηλεκτρο-μηχανικό κυπρί
electron beam lithography & λιθογραφία ηλεκτρονικής δέσμης
electrons & ηλεκτρόνια
emitter & εκπομπός
enhanced mode & εμπλουτισμένος (ή βελτιωμένος) ρυθμός
enhancement & πύκνωση
epitaxy & επίταξη
estabished & εγκαθιδρυμένη
etching & χάραξη
exascale System & συστήματα exascale
expansion headers & αναμονές επέκτασης
explicit instantiation & άμεση υλοποίηση
extraction & εξαγωγή
extrapolated & προβολή (ή εξαγωγή)
fall time & χρόνος καθόδου
falling & καθοδικές
fan-in & βαθμός εισόδου
fan-out & βαθμός οδήγησης
feedback & ανάδραση
feedthrough & διατροφοδότηση
file creation mode mask & μάσκα δικαιωμάτων κατά τη δημιουργία αρχείων
file permission mask & μάσκα δικαιωμάτων αρχείου-0
file-backed virtual memory & εικονική μνήμη που υποστηρίζεται από αρχείο αποθήκευσης
film & μεμβράνη, λεπτή στρώση
fine grain & λεπτοκομμένη
fine grained privileges & λεπτομερή δικαιώματα
firmware & σταθερολογισμικό
fixed or static priority scheduling policies & πολιτικές σταθερής ή στατικής προτεραιότητας
flat-band voltage & τάση επίπεδης ζώνης
floating gate & αιωρούμενη πύλη
floating-point & κινητής υποδιαστολής
floorplanning & χωροθέτηση
footed & με πόδι
footprint & αποτύπωμα
foreground & προσκήνιο
forks & διχάλες
formal verification & επίσημος τρόπος επιβεβαίωσης λειτουργίας
format & μορφότυπο
frame buffer & προσωρινή μνήμη πλαισίου
framework & πλαίσιο
friendly-ish front-end to the info program & φιλικό εμπρόσθιο περιβάλλον για το πρόγραμμα info
front-end & προ-επεξεργασίας
front-side bus & εμπρόσθιος δίαυλος
full custom & σχεδίαση σε επίπεδο τρανζίστορ
full feauture set & ομάδα πλήρων δυνατοτήτων
full-custom & εξατομικευμένος σχεδιασμός
fully restored logic & πλήρως αποκαταστάσιμη λογική
fully-associative & πλήρους συσχέτισης
function wrapper & συνάρτηση συσκευασίας
functional description & λειτουργική περιγραφή
fuse & ασφάλεια
gain access & επίτευξη πρόσβασης
gain factor & παράμετρος κέρδους
ganged & συνδυασμένος
gate arrays & δίκτυο πυλών
gate oxide & οξείδιο πύλης
gate-level & επίπεδο πυλών
generator & γεννήτρια
generic hardware/software co design process flow & γενικευμένο σχεδιαστικό διάγραμμα ροής υλικού/λογισμικού
generic & γενικός
glitch & ανεπιθύμητη αλλαγή κατάστασης κόμβου
glitch & μεταβασματικός ρύπος
global & καθολική
glue logic & λογική συγκόλλησης
graded junction & διαβαθμισμένη επαφή
granularity & κοκκιότητα
guard rings & δακτύλιοι φύλαξης
guts & εσωτερική δομή
hands on & πρακτική εργασία
hard links & σκληροί δεσμοί
hardware & υλικό
hardwire & συρματωμένο / καλωδιομένο
hash table & πίνακας σύνοψης
head-seek & αναζήτηση της κεφαλής
header file & αρχείο κεφαλίδας
heap-based & τύπου στοίβας
heat-manageable & διαχείριση θερμότητας
heterogeneous & ετερογενή
high-end & υψηλών επιδόσεων
high-level & υψηλού επιπέδου
histogram & ιστόγραμμα
history effect & φαινόμενο ιστορικού
hold time & χρόνου συγκράτησης
holes & οπές
home directory & προσωπικός κατάλογος χρήστη
hooks & άγκιστρο
hostname & όνομα κόμβου
hot spots & θερμές περιοχές
hot & θερμός
hotpatching & άμεση επιδιόρθωση
housekeeping tasks & περιοδικές εργασίες συντήρησης και διαχείρισης
hub & διανομέας
immunity & ανοσία
impact ionization & επίδραση ιονισμού
impedance & σύνθετη αντίσταση
implantation & εμφύτευση
implemented & υλοποιείται
impurity & πρόσμειξη
in public smart spaces & σε κοινόχρηστους ’έξυπνους’ χώρους
inconsistently & ασυνεπής
index & ευρετήριο ή κατάλογος (αναλόγως την περίπτωση)
inferred latches & υπαινισσόμενοι μανταλωτές
ingot & ράβδος
input/output values & τιμές εισόδου / εξόδου
input & είσοδος
instance & περίπτωση
instantiate & υλοποιώ
instruction cache memory & κρυφή μνήμη εντολών
insulator & μονωτής
insurgent technology & ανατρεπτική τεχνολογία
integer linear programming & μοντέλο προγραμματισμού ακεραίων
interleaving & τεχνικές πλέξης (για τη μνήμη) ή διεμπλοκή
internationalization & διεθνοποίηση
interprocess & διαδιεργασιακή
interrupt handlers & χειριστές διακοπών
intrinsic & ενδογενής
inversion & αντιστροφή
inverter & αντιστροφέας
jail functionality & λειτουργία ενφυλάκισης
jumper & διακλαδωτήρας
keeper & διατηρητής
kernel & πυρήνας
key tasks & σημαντικές εργασίες
kink effect & φαινόμενο στρέβλωσης
large scale integrated & μεγάλης κλίμακας ολοκλήρωσης
latch & μανδαλωτής
latchup & άνω μανδάλωσης
latency & καθυστέρηση
laxity & χαλαρότητα
layer & επίπεδο [π.χ. 7 OSI layers]
layer & στρώση
layout-versus-schematic & κατάστρωση προς σχηματικό πλάνο
layout & κατάστρωση, φυσικό σχέδιο, φυσική σχεδίαση
lead & συνδετήρας
leaf cells & στοιχεία φύλλου
leaker & διαρροέας
lean & ισχνή
least slack scheduling & χρονοπρογραμματισμός τoυ μικρότερου υπολείμματος
legacy & κληρονομημένα ή παλαιού τύπου
level-sensitive latch & μανδαλωτής ευαίσθητος σε στάθμη
levelized & επιπεδοποιείται
likelihood & πιθανότητα
linear & γραμμικός
linefeed & αλλαγή γραμμή
link & σύνδεση (για το compile)
live-lock & ζωντανό αδιέξοδο
loaded kernel modules & δομοστοιχεία πυρήνα προς φόρτωση
loader & φορτωτής
local memory banks & τοπικές συστοιχίες μνήμης
localization & τοπικοποίηση
lockstep & συγχρονισμένο βήμα εκτέλεσης
logic level & λογική στάθμη
logical block addressing & λογική διευθυνσιοδότηση μπλοκ
logical effort & λογικός φόρτος
loop tiling transformations & μετασχηματισμοί τεμαχισμού βρόχων
loop unrolling & ξετύλιγμα βρόγχων
low-volume & χαμηλού όγκου χρήσης
macro & σύνολο στοιχείων
macros & μακροεντολές
mainline code & βασικός κώδικας
maintainer & συντηρητής
maintainership & αρμοδιότητα συντήρησης
majority-carrier device & στοιχείο φορέων πλειονότητας
mandate & υποχρεώνει
manually & χειρωνακτικά
manuals & εγχειρίδια
manufacturability & κατασκευασιμότητα
manufacturing plant & εργοστάσιο κατασκευής
margin & περιθώριο
margins of slack for hardware & αχρησιμοποίητο περιθώριο υλικού
market-specific & εξατομικευμένες στην αγορά
mask out & απομάκρυνση με χρήση μάσκας
mask-programmed & προγραμματιζόμενο με μάσκα
mask & μάσκα
master indentifier & κυρίαρχος προσδιοριστής
master/slave & αφέντης/σκλάβος
master & κύριος
math coprocessor & μαθηματικός συνεπεξεργαστής
medium scale integrated & μεσαίας κλίμακας ολοκλήρωσης
memory fragmentation & κατακερματισμό μνήμης
memory mapped & χαρτογραφημένης μνήμης
memory padding & Byte συμπλήρωσης μνήμης
memory-intense systems & συστήματα με απαιτήσεις στη μνήμη
merged transistor logic & λογική συγχωνευμένων τρανζίστορ
meta-syntax & σύνταξη τύπου meta
metal migration & μετανάστευση μετάλλου
metal-1 & μέταλλο-1
microprobes & μικρο-εξεταστές
mirror technique & τεχνική καθρέπτης
mirror-current & καθρέπτης ρεύματος
mobility & κινητικότητα
mode & ρυθμός λειτουργίας
modularity & τμηματοποίηση
module generator & γεννήτρια μονάδων
module & δομοστοιχείο
monitor program & πρόγραμμα παρακολουθητής ή πρόγραμμα παρακολούθησης
monotonic scheduling & μονοτονική ρυθμού χρονοδρομολόγηση και χρονοδρομολόγηση μονοτονικής προθεσμίας
monotonicity & μονοτονικότητας
multiplexer & πολυπλέκτης
multitasking & πολυδιεργασιακό
multithreading & πολύμιτες
naive & απλοποιημένο
narrow bus & στενός δίαυλος
negative level-sensitive latch & μανδαλωτής ευαίσθητος σε αρνητική στάθμη
negedge & κατερχόμενη ακμή
nested interrupts & φωλιασμένες διακοπές
netlist & κομβικός κατάλογος, κατάλογος κόμβων
netlists & λίστες/κατάλογοι δικτύων
network contention & διαμάχη πρόσβασης δικτύου
network-aware & με επίγνωση του δικτύου ή με υποστήριξη δικτύου
nibble & τετράμπιτο (ή αφήνεται χωρίς μετάφραση)
node & κόμβος
noise immunity & ανοσία θορύβου
noise margin & περιθώριο θορύβου
noise tolerant precharge & προφόρτιση με ανοχή θορύβου
non-tiled & χωρίς πλακίδια
nonsaturated & μη-κορεσμένος
number-crunching languages & γλώσσες για αριθμητικές πράξεις
object-file & αρχείο αντικειμένου
objective function & αντικειμενική συνάρτηση
observability & παρατηρητικότητα
odds and ends & αρκετά, διάφορα, ποικίλα
of memory chunks & περιοχών μνήμης
off-the-shelf & από το ράφι
offset & μετατόπιση ή αντιστάθμιση
on-chip buses & δίαυλοι εντός ολοκληρωμένου κυκλώματος
on-chip & εντός ολοκληρωμένου κυκλώματος
open source hardware and software & ανοικτού κώδικα υλικού και λογισμικού
operator-level detail & λεπτομέρειες επιπέδου διαχειριστή
outlook & προοπτική
output & έξοδος
outsold & ξεπουλήθηκε
outsourcing & εξωτερική ανάθεση
overhead of a cycleaccurate simulation & επιβάρυνση της προσομοίωσης με ακρίβεια κύκλου
overhead & επιβάρυνση
overrun stack & υπέρβαση σωρού
overshoot & υπερ-ακόντιση
oxidation & οξείδωση
packaging & συσκευασία
packet-switched & Δίκτυα μεταγωγής πακέτων
packing & πακετάρισμα, συσκευασία
pad & ακροδέκτης ολοκληρωμένου,εξωτερική επαφή
page-blocked memory & μνήμη ομαδοποιημένη σε σελίδες
pane & περιοχή εργασίας
pane splitting bindings & συντομεύσεις για διαίρεση της περιοχής εργασίας
parent & γονέας
partition & διαμερισματοποίηση ή διαμέρισμα
pass gate & πύλη περάσματος
pass-gate leakage & διαρροή περάσματος πύλης
past the end of an array & μετά το τέλος του πίνακα
patching & διόρθωση
patterning & σχηματοποίηση
pay-as-you-go strategy & στρατηγική πληρωμής κατά την πορεία
peak performance & ακραίες αποδόσεις
percentage activity & ποσοστό δραστηριότητας
performance & απόδοση
periphery & περιφερειακά
persistence & επιμονή, παραμονή, μόνιμη ύπαρξη (εξαρτάται από το context)
photoresist & φωτοαντίσταση
physical level & φυσικό επίπεδο
pin & ακροδέκτης
pin grid array & πλέγμα πίνακα ακροδεκτών
pin & ακίδα ολοκληρωμένου
pinging a node & έλεγχος λειτουργίας του κόμβου
pinned memory & μνήμη κλειδωμένων σελίδων
pinout & περιγραφή ακίδων
pipeline transaction & μεταφορά διαδοχικής διοχέτευσης
pipeline & διοχέτευση
pipelining & διαδοχική διοχέτευση
place-and-route & τοποθέτηση και διασύνδεση
placement & τοποθέτηση
plastic quad flat packs & πλαστικά επίπεδα τετράγωνα πακέτα
plugin regions & περιοχές επιπρόσθετων (στοιχείων?)
polling & περιόδευση ή σταθμοσκόπηση
polysilicon & πολυπυρίτιο
pontential & δυναμικό
poor encapsulation & φτωχή ενθυλάκωση
poor logic & ελλιπή λογική
port & θύρα
porting / to port & μετατροπή σε άλλη αρχιτεκτονική
positional notation & θεσιακός συμβολισμός (ή σημειογραφία θέσης)
positive level-sensitive latch & μανδαλωτής ευαίσθητος σε θετική στάθμη
postcharge & μεταφόρτωσης
power dissipation & κατανάλωση ενέργειας
power estimation module & δομοστοιχείο εκτίμησης κατανάλωσης
pre-emption & προ-εκχώρηση
predefined computer system & προκαθορισμένο υπολογιστικό σύστημα
predicate self-resetting & κατηγορηματικές πύλες με αυτό-επαναφορά
preemption of resources & προεκχώρηση πόρων
preemptive scheme & προ-εκχωρητικό σχήμα
preliminary set-up code & προκαταρκτική αρχικοποίηση του κώδικα
preloaded & προφορτισμένα
preset & προ-τοποθέτηση
primer & πρωταρχικό
primitive [...gate...] & θεμελιώδη [..πύλη..]
process fork & διπλασιασμός της διεργασίας
process gain factor & συντελεστής κέρδους επεξεργασίας
process & διεργασία
program representations & διαφορετικές μορφές του προγράμματος
program-controlled polling & σταθμοσκόπηση ελεγχόμενη από λογισμικό
properly & ιδιότητα
property & ιδιότητα
proprietary bus documentation & έγγραφα ιδιωτικών (ή αποκλειστικών) διαύλων
prototyping & προτυποποίηση
pseudorandom & ψευδοτυχαία
pull down menu & αναδιπλούμενο μενού
pull down & χαμηλή οδήγηση, έλξη προς τη γείωση
pull up & υψηλή οδήγηση, έλξη προς την πηγή
pulse width modulation & διαμόρφωση πλάτους παλμών
pulsed latches & παλμικοί μανδαλωτές
punch-through & διάτρηση
punchthrough condition & συνθήκη διάτρησης
push thumbwheel & μοχλός πίεσης αντίχειρα
quickturn design approach & γρήγορη σχεδιαστική προσέγγιση
quiet time & χρόνος ησυχίας
race conditions & συνθήκες συναγωνισμού
race & συναγωνισμός
ramp-up & διάκλιση προς τα πάνω
range & απόσταση
rank & τάξη
ratioed circuits & κλιμακωτά κυκλώματα
ratioed & λόγος διαστάσεων
ratioing constraints & σταθερές που κυματίζουν
read burst access & πρόσβαση ανάγνωσης ριπής
real time support & υποστήριξη πραγματικού χρόνου
realize & υλοποίηση
rebind & συσχέτιση ή επανασύνδεση
reconfigurable & επαναπρογραμματιζόμενα, επαναδιαμορφώσιμα
register spill & υπερχείλιση (ή διάχυση) καταχωρητών
register & καταχωρητής
regulator & ρυθμιστής
relay & ηλεκτρονόμος [ως ρήμα: διακόπτει ηλεκτρομαγνητικά ]
request/grant interface & αίτηση/αποδοχή διασύνδεσης
reset & επαναφορά
resistance & αντίσταση
resistive & ωμικός
resistivity & ειδική αντίσταση
resistor & αντίσταση
resizable & κλιμακούμενο
resourses & πόροι
responsive system & ανταποκρινόμενο σύστημα
restore & αποκατάσταση
reverse breakdown voltage & ανάστροφη τάση κατάρρευσης
reverse engineering & αντίστροφη μηχανική
rigor later & μπορεί να προκαλέσει προβλήματα αργότερα
ripple carry adder & αθροιστής διάδοσης κρατουμένου
rise time & χρόνος ανόδου
rising & ανοδικές
roadmap & σχέδιο δράσης ή σχέδιο εκτέλεσης
rogue programs & προβληματικά προγράμματα
root complex & συγκρότημα ρίζας
root directory/folder & ριζικός κατάλογος
root & διαχειριστής (όταν αναφερόμαστε στα δικαιώματα υπερ-χρήστη στο UNIX)
round-robin & εκ περιτροπής
route & διασυνδέω
router & διασυνδετής, μονάδα διασύνδεσης
routing & διασυνδέσεις
row-nominated & επιλεγμένη γραμμή
run-time loader & φορτωτής κατά το χρόνο εκτέλεσης
runtime patching & επιδιόρθωση κατά το χρόνο εκτέλεσης
saturated load inverter & κορεσμένου φορτίου αντιστροφέας
saturated & κορεσμένος, στο κόρο
saturation & κόρος
scalar variable & βαθμωτή μεταβλητή
scale & κλιμακώνω
scaling effect & φαινόμενο κλίμακας
scan-chain insertion & εισαγωγή στην αλυσίδα ανίχνευσης σφαλμάτων
schedulable entities & οντότητες που μπορούν να χρονοδρομολογηθούν
scheduling policies & πολιτικές χρονοπρογραμματισμού
schematic & σχηματικός
scratch pad memory & πρόχειρη μνήμη
scribe & γραμμή χάραξης
script & εντολές σε δέσμη
scripting & προγραμματισμός εντολών σε δέσμη
scrutinous outlook & επιμελής προοπτική
secondary precharge devices & συσκευές δευτερεύουσας προφόρτισης
segmentation fault & σφάλμα κατάτμησης
segmented memory & κατατμημένη μνήμη
segments & τμήματα
self-aligned & αυτο-ευθυγραμμισμένος
self-biasing & αυτοπόλωση
self-bypass path & αυτό-παράκαμψης μονοπατιού
self-loading & αυτοφόρτωση
semiconductor company & εταιρία μικροεπεξεργαστών
semiconductor & ημιαγωγοί
semicustom & μερικά ειδική σχεδίαση
sense amplifier & ενίσχυση σήματος
sentinels & στοιχεία φύλαξης
sequential & ακολουθιακά
sequential design/circuit & ακολουθιακή σχεδίαση/κύκλωμα
sequential & σειριακό
session & συνεδρία
set-associative & συσχέτιση κατά ομάδες
set & θέτω
setup time & χρόνος προετοιμασίας
shared & κοινόχρηστη
shell device driver & κέλυφος οδηγού συσκευής
shifter & ολισθητής
signal flow graph & γράφος ροής σήματος
signalling & σηματοδοσία
silicide & τοποθέτηση πυριτίου
silicon planar process & επίπεδη επεξεργασία πυριτίου
silicon & πυρίτιο
simple/burst/split transaction & απλή/ριπής/διαχωρισμένη συναλλαγή
single polarity & μιας πολικότητας
single-core & μονού πυρήνα
sink & συλλέκτης
skew & στρέβλωση, χρονική απόκλιση, λόξωση
slave & σκλάβος
slider switch & διακόπτης κύλισης
small scale integrated & μικρής κλίμακας ολοκλήρωσης
sneak & κρυφά
socket aware scheduling & χρονοδρομολόγηση με γνώση των υποδοχέων (ή θυρών)
software events & λογισμικά συμβάντα
software interrupt & διακοπή λογισμικού
software & λογισμικό
source file & πηγαίος κώδικας για το αρχείο
source follower pull-up logic & λογική οδήγησης «πάνω» ακολούθου πηγής
source & πηγή
source & πηγαίο
spawn & παράγονται
specific & συγκεκριμένης
spike & αιχμή ρεύματος
ssh keys & κλειδιά ssh
stall & καθυστέρηση
standard cell & τυποποιημένο κύτταρο
state [σε διαγράμματα] & κατάσταση
status-interval & διάστημα κατάστασης
stimuli & ερέθισμα
stop bit & bit τερματισμού
stray capacitance & παρασιτική χωρητικότητα
stream & ροή ή ρεύμα
string macros & μακροεντολές συμβολοσειρών
stripe & λουρίδα
structural level & δομικό επίπεδο
substrate-bias effect & επίδραση πόλωσης υποστρώματος
substrate & υπόστρωμα
subsystem & υποσύστημα
subthreshold region & περιοχή υπο-κατωφλίου
superimpose & υπέρθεση
superuser & υπερχρήστης
surface mount & επιφανειακής συγκόλλησης
swing & ταλαντεύσεις
switched input & διακοπτόμενη είσοδος
switching noise & θόρυβος μεταγωγής
switching & μεταγωγή
synthesisable & συνθέσιμη
synthesized & έχει συνθεθεί/να συνθεθεί
system-include files & συμπεριλαμβανόμενα αρχεία του συστήματος
system-level houses & Οίκοι σχεδιασμού επιπέδου συστήματος
tag & ετικέτα
target & στόχος
task & διεργασία
taxononomy & ταξινόμηση
test & έλεγχος
testable & ελέγξιμο
testablity & ελεγξιμότητα
testing & δοκιμή
texture memory & μνήμη υφής
the bare minimum & το άκρως ελάχιστο
thread & νήμα
threshold & κατώφλι
through hole devices & συσκευές διαμέσου οπής
through-hole & οπή διαμέσου (ή διαμπερής)
tiled & σε πλακίδια (δλδ, σε δισδιάστατες ορθογώνιες επιφάνειες)
time borrowing & δανειζόμενου χρόνου
time slice & θυρίδα χρόνου
time to market cost & κόστος του χρόνου εισαγωγής του προϊόντος στην αγορά
timeouts ticking away & ενεργά όρια χρόνου
timing & χρονισμός
to compile-time & χρόνος μετάφρασης
to ship & να στείλουν
toggle & αντιστρέφεται
token & σύμβολο
toolchain & αλυσίδα εργαλείων
tools integration method & εργαλεία μεθοδολογίας ολοκλήρωσης
top-level entity & οντότητα υψηλότατου επιπέδου
trade off & συμβιβασμός, συγκερασμός
transaction & συναλλαγή / μεταφορά
transconductance & διαγωγιμότητα
transmission gate & πύλη μετάδοσης
trap SIGABRT & παγιδεύσει το σήμα SIGABRT
traversed & διασχίζει
tri-state buffer & τρίσταθμος απομονωτής
trimmer resistor & μειωτήρας αντίστασης (ή αντίσταση
triple modular redudancy & τριπλή πλεονάζουσα δομή
tristate & τρισταθής
troughput utilization of the bus & ρυθμός απόδοσης του διαύλου
tunneling & διόδευση
tutorial & οδηγός εκμάθησης
twin-tub & δίδυμος κάδος
ultraviolet light & υπεριώδης ακτινοβολία
undershoot & υπο-ακόντιση
unified cache & ενοποιημένη κρυφή μνήμη
uniprocessor & μονός επεξεργαστής
unit inverter & μοναδιαίος αντιστροφέας
unsaturated load inverter & μη-κορεσμένου φορτίου αντιστροφέας
upper and lower halves of the device driver & ανώτερο και κατώτερο μισό τμήμα
uptime & χρόνος λειτουργίας
utilities & προγράμματα
variables are accessed & οι μεταβλητές προσπελάζονται
vector variable & διανυσματική μεταβλητή
velocity saturation & κορεσμό εύρους
velocity saturation & κορεσμός ταχύτητας
vendor & προμηθευτή
very large scale integrated & πολύ μεγάλης κλίμακας ολοκλήρωσης
via & διαμέσου
volatile & πτητικός
voting systems & συστήματα πλειοψηφίας
wafer & δισκίο
watchdog timers & χρονομετρητές των επιτηρητών (ή επαγρύπνησης)
wave pipeline & διαδοχική διοχέτευση κυμάτων
waveform & κυματομορφή
weak & αδύναμος, ασθενής
well & πηγάδι
wherease & ενώ
wider paths & ευρύ μονοπάτια
wire & καλώδιο
wiring & καλωδιώσεις
working draft & σχέδιο εργασίας
working prototype & Πρωτότυπο εργασίας
worst case & δυσμενής περίπτωση
wraparound & γύρω γύρω
write-back & μεταχρονολογημένη εγγραφή ή εγγραφή με καθυστέρηση ή ετερόχρονη εγγραφή
write-through & άμεση εγγραφή
yield & απόδοση (υλικού)
zipper & φερμουάρ
100
[1] W.F. Brinkman, D.E. Haggan, and W.W. Troutman. A history of the invention of the transistor and where it will lead us. , 32(12):1858–1865, Dec 1997.
[2] Hong Jiang and Srinivas Chennupaty. Arcs001 - intel’s 14nm microarchitecture (broadwell). In Intel Developer Forum - IDF, Shenzhen, China, apr 2015.
[3] P. Bannon. Alpha EV7: A scalable single-chip smp. In Microprocessor Forum, October 1998.
[4] Hinton Glenn, Dave Sager, Mike Upton, Darren Boggs, Doug Carmean, Alan Kyker, and Patice Roussel. The microarchitecture of the pentium 4 processor. , Q1:1–10, 2001.
[5] AMD. , 25175 rev. h edition, March 2003.
[6] D. Kushner. The real story of stuxnet. , 50(3):48–53, March 2013.
[7] Charlie Miller and Chris Valasek. Remote exploitation of an unaltered passenger vehicle. BlackHat 2015 Conference, aug 2015.
[8] Lewin Edwards. . Elsevier, San Diego, CA, 2006.
[9] Tom Frazier. Software engineering economics. George Mason University (http://classweb.gmu.edu/aloerch/Frazierlec.pdf), March 2002.
[10] Philip Koopman. Embedded system engineering economics. ECE Department, Carnegie Mellon University, September 2004.
[11] Oystein Ra and Torbojorn Strom. Trends and challenges in embedded systems - CoDeVer and HiBu experiences. In Norsk Informatikkonferanse, Kongsberg, Norway, November 2002. Hogskolen Buskerud, http://www.nik.no/2002/Ra.pdf.
[12] Christina Silvano. Introduction to hw/sw co-design of embedded systems. Politechnico di Milano, 2004.
[13] Department of Trade and Industry/IDC Benelux BV. Embedded software research in the netherlands. Analysis and Results, 1997.
[14] P. GUPTA, V. AGARWAL, and M. VARSHNEY. . PHI Learning, 2012.
[15] Yaojun Zhang, Lu Zhang, Wujie Wen, Guangyu Sun, and Yiran Chen. Multi-level cell stt-ram: Is it realistic or just a dream? In Computer-Aided Design (ICCAD), 2012 IEEE/ACM International Conference on, pages 526–532, Nov 2012.
[16] D. Gomez Toro, M. Arzel, F. Seguin, and M. Jezequel. Soft error detection and correction technique for radiation hardening based on c-element and bics. , 61(12):952–956, Dec 2014.
[17] Wikipedia. Write-only memory (joke) — wikipedia, the free encyclopedia, 2015. .
[18] J. Jeddeloh and B. Keeth. Hybrid memory cube new dram architecture increases density and performance. In VLSI Technology (VLSIT), 2012 Symposium on, pages 87–88, June 2012.
[19] Chip Shots. Tests show ddr4 is useless for desktop pc users, February 2015. .
[20] Jonathan Rentzsch. Data alignment: Straighten up and fly right. IBM Bluemix Technical Topics, February 2005.
[21] M. Dasygenis, E. Brockmeyer, D. Soudris, F. Catthoor, A. Thanailakis, and G. Papakostas. Performance and energy optimization of multimedia applications using DMA combined with prefetch. , October 2003.
[22] Wikipedia. Comparison of instruction set architectures — wikipedia, the free encyclopedia, 2015. .
[23] Gordon E. Moore. Cramming more components onto integrated circuits. , 38(8):1–4, April 19 1965.
[24] F. Catthoor, S. Wuytack, E. De Greef, F. Balasa, L. Nachtergaele, and A. Vandecappelle. . Kluwer Academic Publishers, Boston, MA, 1998.
[25] B. Margolin. Embedded systems to benefit from advances in DRAM technology. , pages 76–86, 1997.
[26] R. Wilson. Graphics IC vendors take a shot at embedded DRAM. , 1(938):41–57, January 1997.
[27] Texas Instrument. , January 1997. (revised March 2004).
[28] ARM Limited. , 1999.
[29] ARM. software development toolkit v2.11. http://www.arm.com, 1996.
[30] TI. , 1999.
[31] Kurt Keutzer, Sharad Malik, and Richard Newton. From ASIC to ASIP: The next design discontinuity. , pages –, 2002.
[32] Neil H.E. Weste and David Harris. . Addison-Wesley, 3rd edition, 2004.
[33] Editorial. News [google glass is dead, but augmented reality lives on]. , 52(3):18–18, March 2015.
[34] R. Gyorodi, C. Gyorodi, G. Borha, M. Burtic, L. Pal, and J. Ferenczi. Acquaintance reminder using google glass. In Engineering of Modern Electric Systems (EMES), 2015 13th International Conference on, pages 1–4, June 2015.
[35] M.F. Cloutier, C. Paradis, and V.M. Weaver. Design and analysis of a 32-bit embedded high-performance cluster optimized for energy and performance. In Hardware-Software Co-Design for High Performance Computing (Co-HPC), 2014, pages 1–8, Nov 2014.
[36] Wikipedia. Semiconductor fabrication plant — wikipedia, the free encyclopedia, 2015. .
[37] J. Cosmas, I. Taki, D.Green, O. Zalesny, L.VanGool, M. Pollefeys, R.Degeest, M.Waelkens, K. Hraby, M. Kampel, and R. Sablatnig. 3d murale, 2002.
[38] C. Poucet, S. Mamagkakis, D. Atienza, and F. Catthoor. Systematic intermediate sequence removal for reduced memory accesses. , 2007.
[39] I. Sodagar, Hung-Ju Lee, P. Hatrack, and Ya-Qin Zhang. Scalable wavelet coding for synthetic/natural hybrid images. , 9(2):244–254, Mar 1999.
[40] Microsoft MSDN. Low fragmentation heap in XP technologies.
[41] Handheld quake.
[42] Moby games. A game documentation and review project.
[43] J. Kozubik. Freebsd and solid state devices, 2001.
[44] G. Memik, W. H. Mangione-Smith, and W. Hu. Netbench: a benchmarking suite for network processors. , 2001.
[45] Ti OMAP platform, 2004.
[46] N. Jouppi. Western research laboratory, CACTI, 2002. http://research.compaq.com/wrl/people/jouppi/CACTI.html.
[47] P. Marchal, C. Wong, A. Prayati, N. Cossement, F. Catthoor, R. Lauwereins, D. Verkest, and H. De Man. Impact of task level concurrency transformations on the mpeg4 im1 player for weakly parallel processor platform. , 2003.
[48] M. Leeman, D. Atienza, G. Deconinck, V. Florio, J.M. Mendias, C. Ykman-Couvreur, F. Catthoor, and R. Lauwereins. Methodology for refinement and optimisation of dynamic memory management for embedded systems in multimedia applications. In J. VLSI Sig. Process. Syst. 40(3), pages 383–396, 2005.
[49] Mohamed Shalan and Vincent J. Mooney. A dynamic memory management unit for embedded real-time system-on-a-chip. In Proceedings of the 2000 International Conference on Compilers, Architecture, and Synthesis for Embedded Systems, CASES ’00, pages 180–186, New York, NY, USA, 2000. ACM.
[50] S. Subha. An exclusive cache model. , pages 1715–1716, 2009.
[51] Iso/iec jtc1/sc29/wg11 mpeg-4 standard features overview.
[52] C. Baloukas, J.L. Risco-Martin, D. Atienza, C. Poucet, L. Papadopoulos, S. Mamagkakis, D. Soudris, J. Ignacio Hidalgo, F. Catthoor, and J. Lanchares. Optimization methodology of dynamic data structures based on genetic algorithms for multimedia embedded systems. In J. Syst. Softw. 82(4), pages 590–602, 2008. Special Issue: Selected papers from the 2008 IEEE Conference on Software Engineering Education and Training (CSEET08)) Engineering Education and Training (CSEET08).
[53] S. Wuytack, F. Catthoor, and H. De Man. Transforming set data types to power optimal data structures. , 1996. T IEEE Trans. Comput. Aided Des 15(6), 619-629 (1996.
[54] D. P. Bovet and M. Cesati. . O’Reilly and Associates, (1001 Morris Street), Sebastopol, 2001.
[55] boost.org. Boost C++ libraries, 2009.
[56] M. Woo and J. Neider. programming guide. , 1997.
[57] M. J. Absar and F. Catthoor. Compiler-based approach for exploiting scratch-pad in presence of irregular array access. In Design, Automation and Test in Europe, 2005. Proceedings, pages 1162–1167, March 2005.
[58] S. Mamagkakis, D. Atienza, C. Poucet, F. Catthoor, D. Soudris, and J. M. Mendias. Custom design of multi-level dynamic memory management subsystem for embedded systems. , pages 170–175, 2004.
[59] A. Bartzas, M. Peon-Quiros, S.Mamagkakis, F. Catthoor, D. Soudris, and J.M.Mendias. Enabling run-time memory data transfer optimizations at the system level with automated extraction of embedded software metadata information. In In Proceedings of ASP-DAC (IEEE Computer 73 Society Press, 2008), pages 434–439, 2008.
[60] K. Deb. . Prentice-Hall of India, 2004.
[61] David Atienza, Christos Baloukas, Lazaros Papadopoulos, Christophe Poucet, Stylianos Mamagkakis, Jose I. Hidalgo, Francky Catthoor, Dimitrios Soudris, and Juan Lanchares. Optimization of dynamic data structures in multimedia embedded systems using evolutionary computation. In Proceedingsof the 10th International Workshop on Software &Amp; Compilers for Embedded Systems, SCOPES ’07, pages 31–40, New York, NY, USA, 2007. ACM.
[62] C. Poucet, D. Atienza, and F. Catthoor. Template-based semi-automatic profiling of multimedia applications. In In Proceedings of the International Conference onMultimedia and Expo (ICME) (IEEE Computer, Signal Processing, System and Communications Society, pages 1061–1064, Toronto, Canada, 2006.
[63] A. V. Aho, R. Sethi, and J. D. Ullman. . Addison- 15 Wesley Inc, Wokingham, 1986.
[64] D. Mayhew D. Bulka. . Addison-Wesley, Wokingham, 2001.
[65] M.N. Josuttis. . Addison Wesley, Harlow, 1999.
[66] A. Alexandrescu. . Addison-Wesley Publishing Company Inc, Workingham, England, 2001.
[67] A. Bartzas, S. Mamagkakis, G. Pouiklis, D. Atienza, F. Catthoor, D. Soudris, and A. Thanailakis. Dynamic data type refinement methodology for systematic performance-energy design ex ploration of network applications. In Proceedings of the Conference on Design, pages 740–745, 2006. Automation and test in Europe (EuropeanDesign and AutomationAssociation,Leuven, 2006).
[68] E. G. Daylight, D. Atienza, A. Vandecappelle, F. Catthoor, and J.M. Mendias. Memory-access aware data structure transformations for embedded software with dynamic data accesses. In IEEE Transanctions on VLSI Systems, volume 12, pages 269–280, 2004.
[69] F. Catthoor, P. Raghavan, A. Lambrechts, M. Jayapala, A. Kritikakou, and J. Absar. . Springer, Germany, 2010.
[70] S. V. Gheorghita, M. Palkovic, J. Hamers, A. Vandecappelle, S. Mamagkakis, T. Basten, L. Eeckhout, H. Corporaal, F. Catthoor, F. Vandeputte, and K. De Bosschere. System-scenario-based design of dynamic embedded systems. In ACMTrans. Des. Automa. Electron. Syst. (TODAES) 14(1), 1-45 (2009), 2009.
[71] S. Mamagkakis, D. Atienza, C. Poucet, F. Catthoor, and D. Soudris. Energy-efficient dynamic memory allocators at themiddleware level of embedded systems. , pages 215–222, 2006.
[72] N. P. Ngoc, W. van Raemdonck, G. Lafruit, G. Deconinck, and R. Lauwereins. Qos framework for interactive 3d applications. , pages 17–325, 2002.
[73] A. Smailagic, D.P. Siewiorec, D.Anderson, C.Kasaback, T.Martin, and J. Stivoric. Benchmarking an interdisciplinary concurrent design methodology for electronic/mechanical systems. , pages 514–519, 1995.
[74] T. Henderson, D. Kotz, and I. Abyzov. The changing usage of amature campus-wide wireless network. In in Proceedings of the International Conference on Mobile Computing and Networking (MobiCom), pages 187–201, 2004.
[75] S. Mamagkakis, A. Bartzas, G. Pouiklis, D. Atienza, F. Catthoor, D. Soudris, and Antonios Thanailakis. Systematic methodology for exploration of performance-energy trade-offs in network applications using dynamic data type refinement. , 53(7):417–436, 2007.
[76] M. Dasygenis, E. Brockmeyer, B. Durinck, F. Catthoor, D. Soudris, and A. Thanailakis. A combined dma and application-specific prefetching approach for tackling the memory latency bottleneck. In IEEE Trans. Very Large Scale Integr. Syst. (TVLSI) 14(3), pages 279–291, 2006.
[77] Marc Leeman, David Atienza, Francky Catthoor, V. De Florio, G. Deconinck, J.M. Mendias, and R. Lauwereins. Power estimation approach of dynamic data storage on a hardware software boundary level. In JorgeJuan Chico and Enrico Macii, editors, Integrated Circuit and System Design. Power and Timing Modeling, Optimization and Simulation, volume 2799 of Lecture Notes in Computer Science, pages 289–298. Springer Berlin Heidelberg, 2003.
[78] University of Glasgow. Glasgow haskell compiler.
[79] K. S. McKinley E. D. Berger, B. G. Zorn. Composing high-performance memory allocators. In In Proceedings ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pages 114–124, Snowbird, Utah, 2001.
[80] Microsoft Corporation. Heap:pleasures and pains (for windows NT technologies).
[81] Microsoft Corporation. Heaps in windows CE.
[82] David Gay and Alex Aiken. Memory management with explicit regions. In Proceedings of the ACM SIGPLAN 1998 Conference on Programming Language Design and Implementation, PLDI ’98, pages 313–323, New York, NY, USA, 1998. ACM.
[83] P. Wadler. Deforestation: Transforming programs to eliminate trees. , 300:344–358, 1988.
[84] On-line application research (OAR), 2002.
[85] S. M. Blackbur and K. S. McKinley. Ulterior reference counting: Fast garbage collection without a long wait. In SIGPLAN 2003 Conference on Object-Oriented Programming,Systems,Languages and Applications, OOPSLA’03, Anaheim, California, USA, oct 2003.
[86] P. Cheng, D. F. Bacon, and V. T. Rajan. Areal-time garbage collectorwith lowoverhead and consistent utilization. In In Proceedings of SIGPLAN 2003 Symposium on Principles of Programming Languages, POPL’03, New Orleans, Lousiana, USA, 2003. (ACM SIGPLAN Notices, ACM Press).
[87] S. Steinke, N. Grunwald, L.Wehmeyer, R. Banakar, M. Balakrishnan, and P. Marwedel. Reducing energy consumption by dynamic copying of instructions onto onchipmemory. , 2002.
[88] W. Srisa-an J. Morris Chang, C.-T. Dan Lo. Omx: object management extension. In Compiler andArchitecture Support forEmbedded Systems, San Diego, 1999.
[89] M. Shreedhar and George Varghese. Efficient fair queueing using deficit round robin. , 25(4):231–242, October 1995.
[90] F. Catthoor and E. Brockmeyer. , chapter Unified Low-Power Design Flow for Data-Dominated Multi-Media and Telecom Applications. Kluwer Academic Publishers, Boston, USA, 2000.
[91] D. Atienza, S. Mamagkakis, F. Catthoor, J.M. Mendias, and D. Soudris. Modular construction and power modelling of dynamic memory managers for embedded systems. In Optimization and Simulation, volume 3254, Santorini, Greece, 2004. Springer, Heidelberg.
[92] D. Luebke, M. Reddy, J. Cohen, A. Varshney, B. Watson, and R. Huebner. . Morgan-Kaufmann Publishers, San Francisco, 2002.
[93] G. Memik, B. Mangione-Smith, and W. Hu. Netbench: a benchmarking suite for network processors. , 2001.
[94] Derick Wood. Data structures: Algorithms and performance, 1993.
[95] Lawrence Berkeley National Laboratory. The internet traffic archive, 2000.
[96] D. Lea. The lea 2.7.2 dynamic memory allocator, 2002.
[97] M. Loghi, F. Angiolini, D. Bertozzi, L. Benini, and R. Zafalon. Analyzing on-chip communication in a MPSoC environment. In Design, Automation and Test in Europe Conference and Exhibition, 2004. Proceedings, volume 2, pages 752–757, Feb 2004.
[98] Massimo Banzi, David Cuartielles, Tom Igoe, Gianluca Martino, and David Mellis. Arduino official website. (On-line) http://www.arduino.cc/, 2015.
[99] Arduino Community. Arduino official IDE website. (On-line) http://arduino.cc/en/Guide/Environment/, 2015.
[100] Hernando Barragan. Wiring : open-source programming framework for microcontrollers. (On-line) http://wiring.org.co/, 2015.
https://en.wikipedia.org/wiki/Colossus_computer↩
https://en.wikipedia.org/wiki/Enigma_machine↩
https://el.wikipedia.org/wiki/ENIAC↩
https://en.wikipedia.org/wiki/History_of_computing_hardware#/media/File:SSEM_Manchester_museum_close_up.jpg↩
https://commons.wikimedia.org/wiki/File:PDP-1.jpg#/media/File:PDP-1.jpg↩
https://commons.wikimedia.org/wiki/File:Agc_view.jpg↩
Σύμφωνα με τον πρώτο νόμο της θερμοδυναμικής, η ενέργεια ούτε καταστρέφεται, ούτε δημιουργείται σε ένα κλειστό σύστημα, απλώς τροποποιείται ή μεταφέρεται.↩
Μερικές φορές χρησιμοποιείται η φράση ‘handkerchief design’ ή ‘handkerchief idea’, που σημαίνει ιδέα ή σχεδιασμός της χαρτοπετσέτας και συμβαίνει όταν κάποιος βρίσκεται σε κάποιο γεύμα και είτε μόνος του, είτε σε συζήτηση με συναδέλφους, σκέφτεται ένα καινοτόμο προϊόν και σχεδιάζει τα βασικά του τμήματα. Επειδή, δεν υπάρχει χαρτί σημειώσεων σε ένα γεύμα, προκειμένου να μη ξεχάσει την ιδέα, βρίσκει το πρώτο υλικό πάνω στο οποίο μπορεί να γράψει και το χρησιμοποιεί. Αυτό είναι μια χαρτοπετσέτα.↩
https://commons.wikimedia.org/wiki/File:KL_Kernspeicher_Makro_1.jpg↩
https://commons.wikimedia.org/wiki/File:MIPS_Architecture_(Pipelined).svg↩
https://commons.wikimedia.org/wiki/File:7400.jpg↩
https://en.wikipedia.org/wiki/Dual_in-line_package#/media/File:SIL9_ST_TDA4601.jpg↩
https://en.wikipedia.org/wiki/Dual_in-line_package#/media/File:DIP_sockets.jpg↩
https://en.wikipedia.org/wiki/Dual_in-line_package#/media/File:Three_IC_circuit_chips.JPG↩
“R6511” by TheBug at the German language Wikipedia. Licensed under CC BY-SA 3.0 via Commons - https://commons.wikimedia.org/wiki/File:R6511.jpg#/media/File:R6511.jpg↩
https://en.wikipedia.org/wiki/Pin_grid_array#/media/File:Cyrix_IBM_CPU_6x86MX_PR200_bottom.jpg↩
https://en.wikipedia.org/wiki/Ball_grid_array#/media/File:Kl_Intel_Pentium_MMX_embedded_BGA_Bottom.jpg↩
https://en.wikipedia.org/wiki/CMOS#/media/File:Cmos_impurity_profile.PNG↩
http://www.semiconductors.org/↩
https://en.wikipedia.org/wiki/OMAP#/media/File:PandaBoard_described.png↩
Στο διάγραμμα pareto απεικονίζονται όλες οι βέλτιστες υλοποιήσεις με τους συμβιβασμούς.↩
από όλα τα στοιχεία που τοποθετούνται στη μνήμη και που μετριούνται σε bits.↩
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.10.5613&rep=rep1&type=pdf↩
http://sourceforge.net/projects/armulator/↩